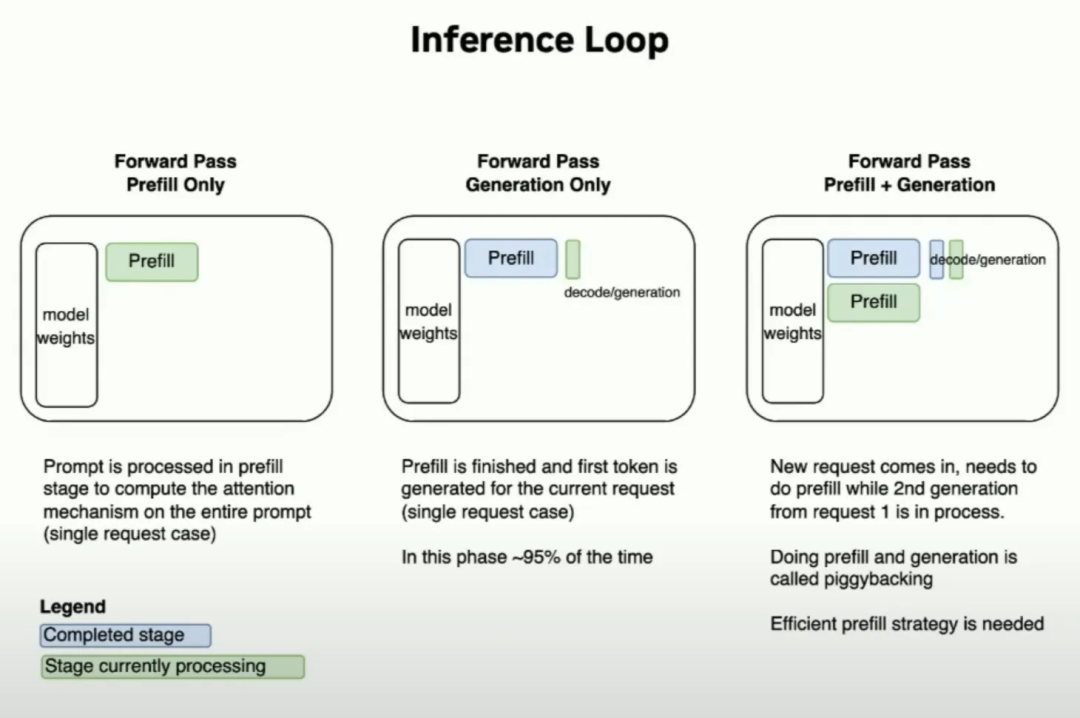
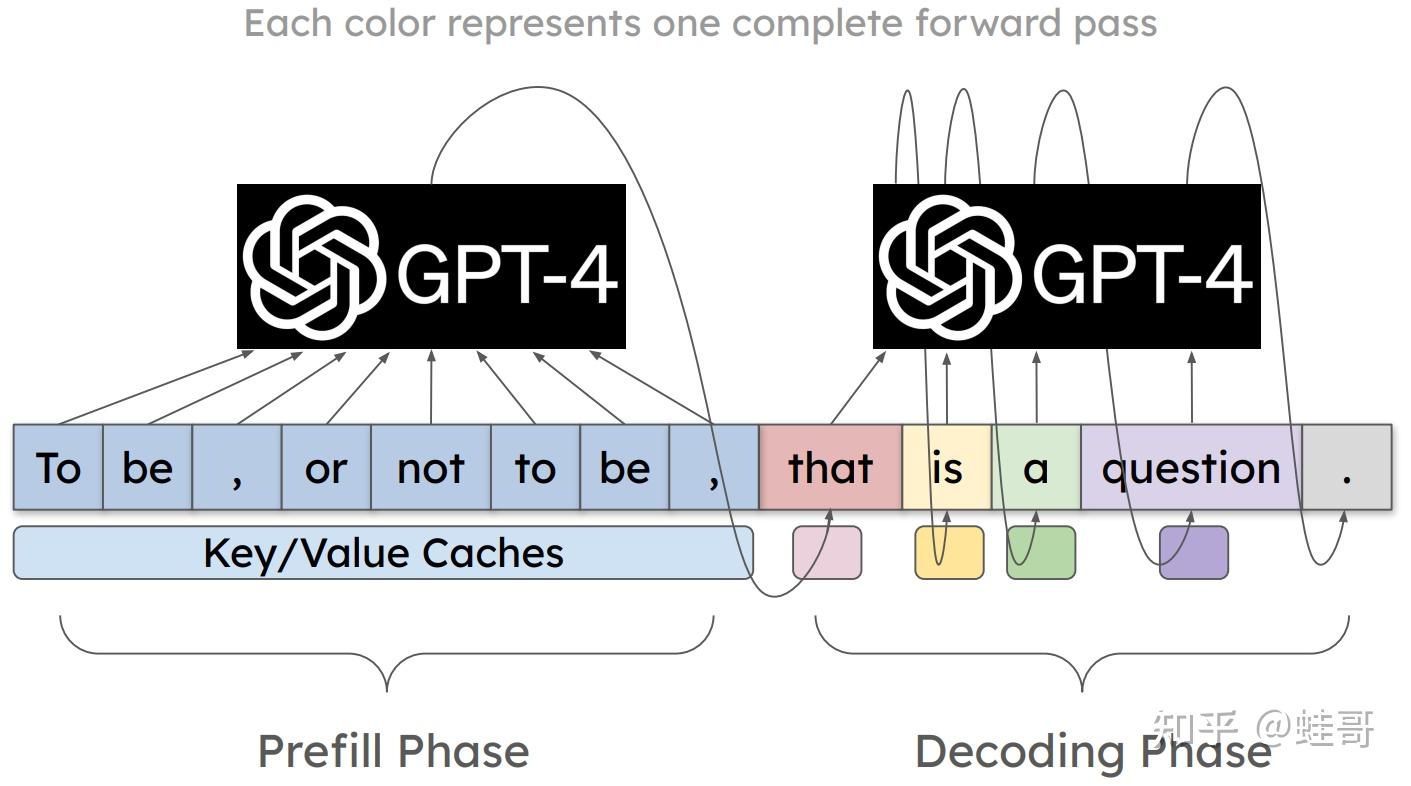
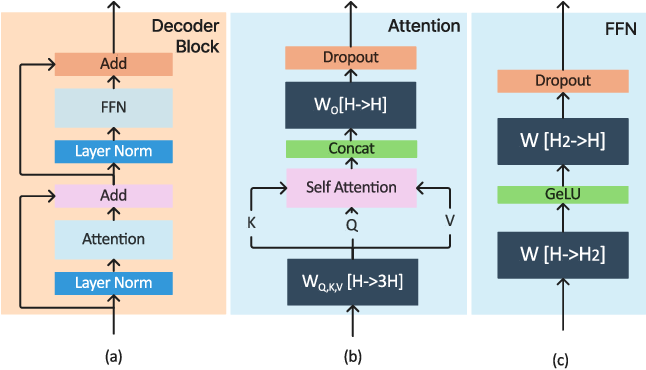
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
Decoding Data Relationships Using Cluster Diagrams LCT SS PPT Example
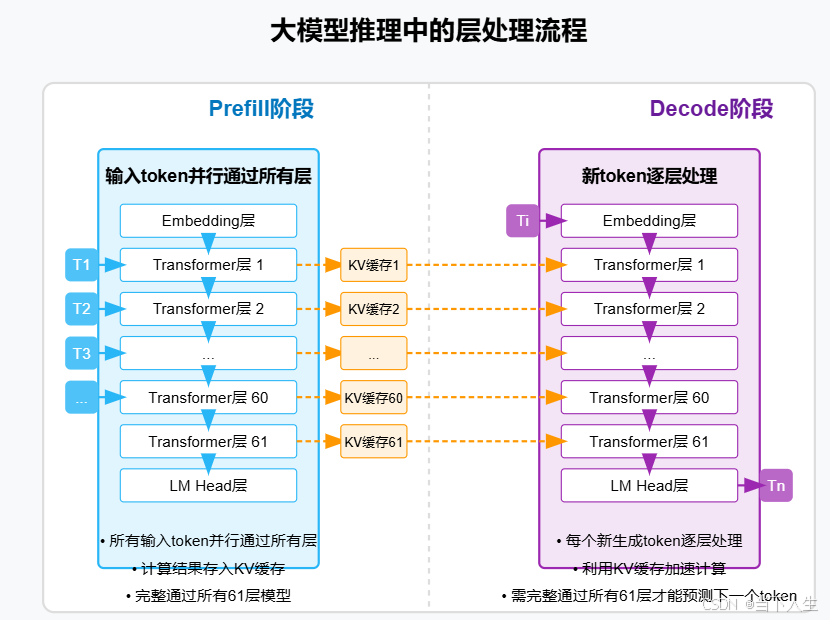
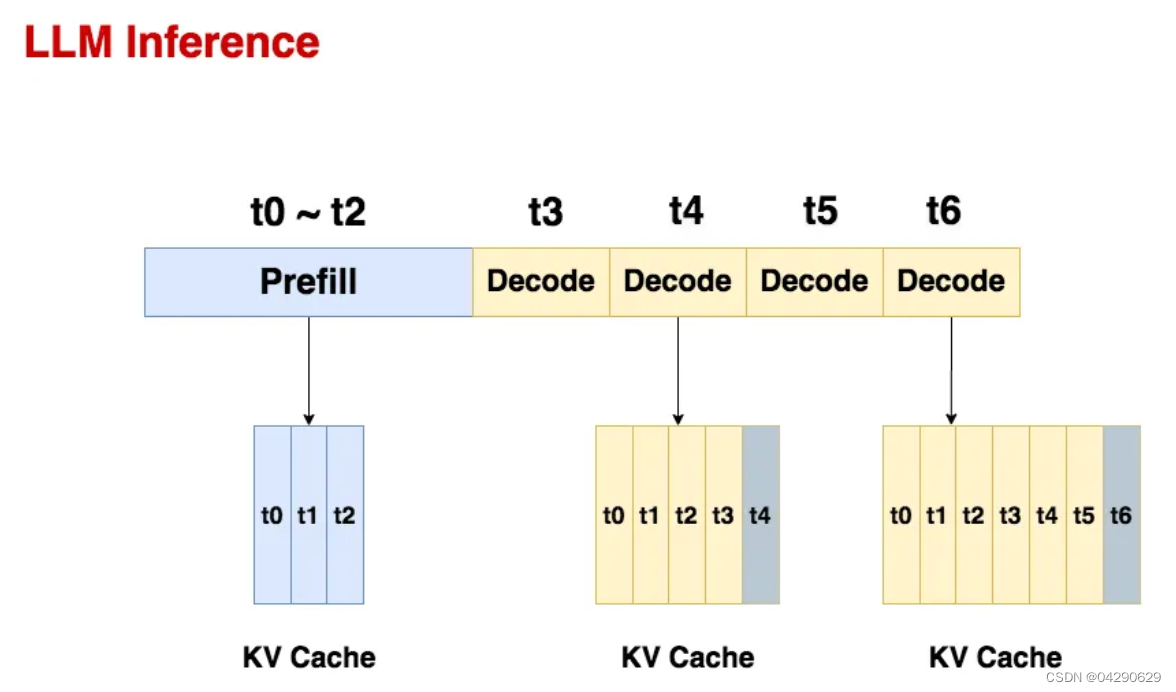
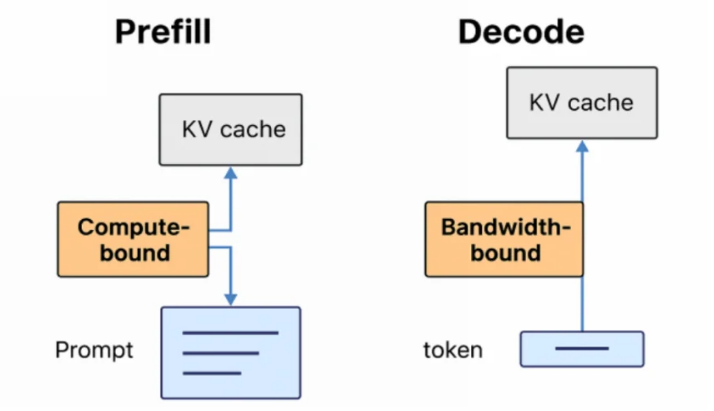
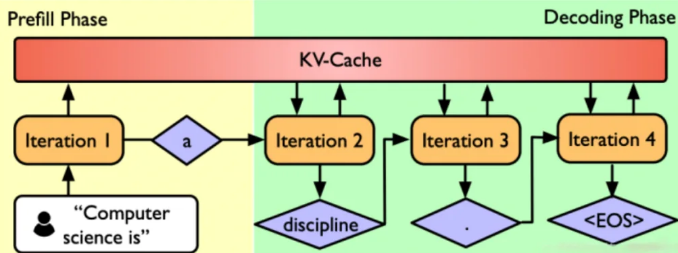
大模型推理优化Prefill 和 Decoding 分离原理详解-CSDN博客
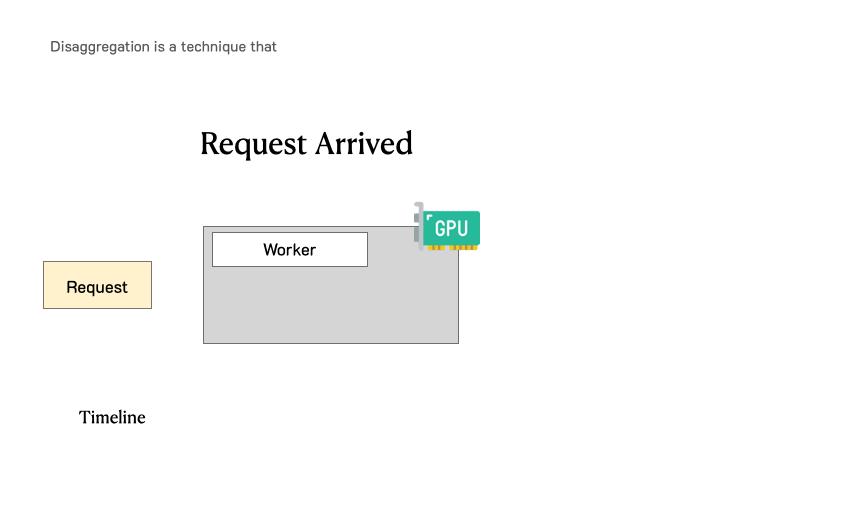
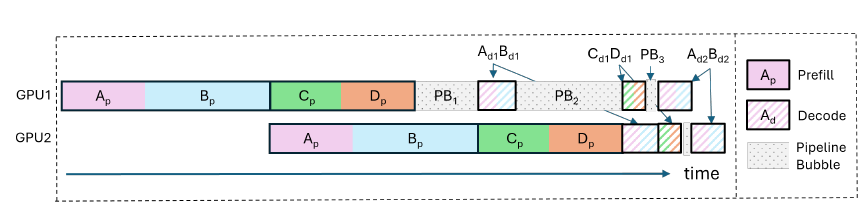
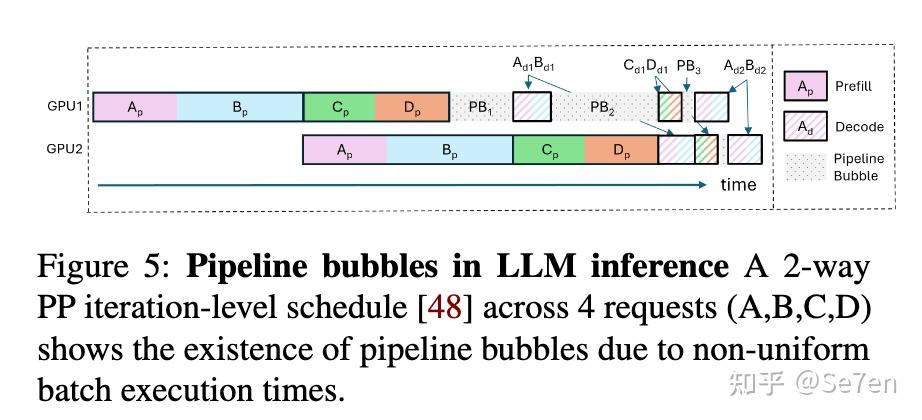
Figure 1 from DistServe: Disaggregating Prefill and Decoding for ...
【论文解读】DistServe:Disaggregating Prefill and Decoding for Goodput ...
Beginning Blends & Clusters Decoding Assessment (Project Read) | TPT
Review-Distserve: Disaggregating Prefill and Decoding for Goodput ...
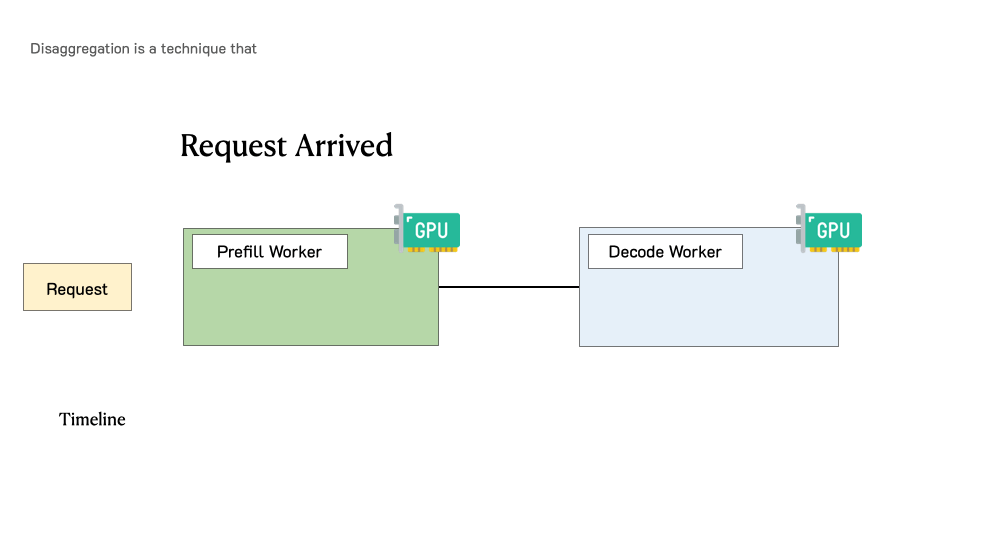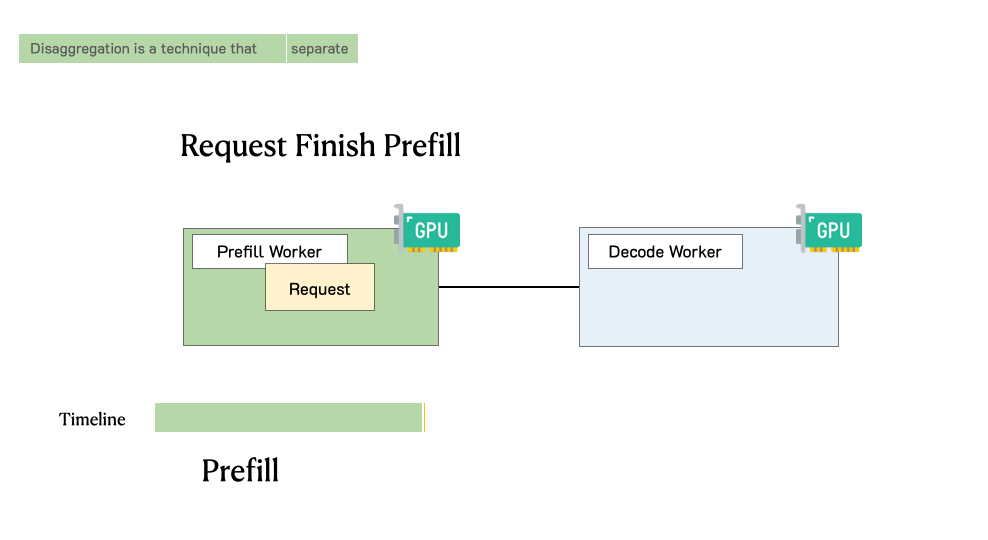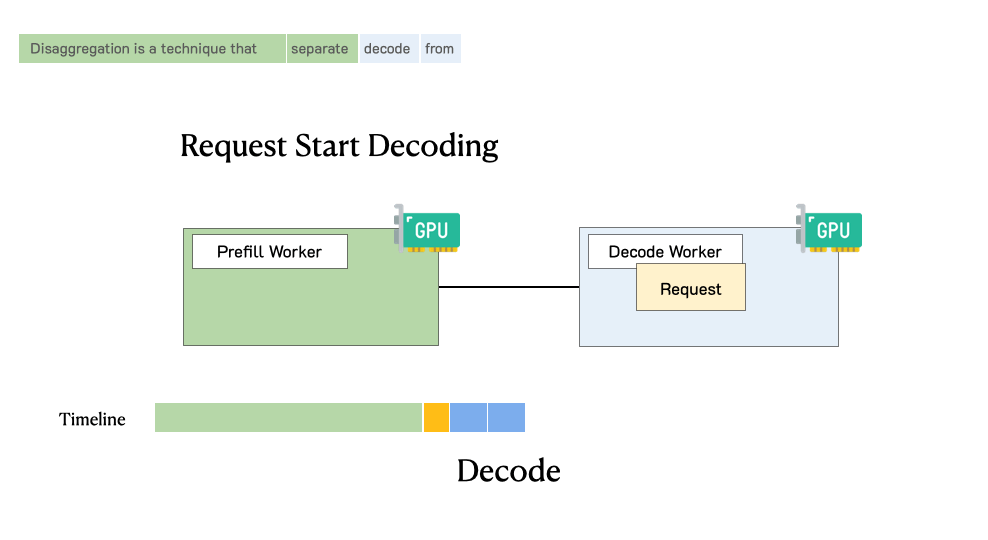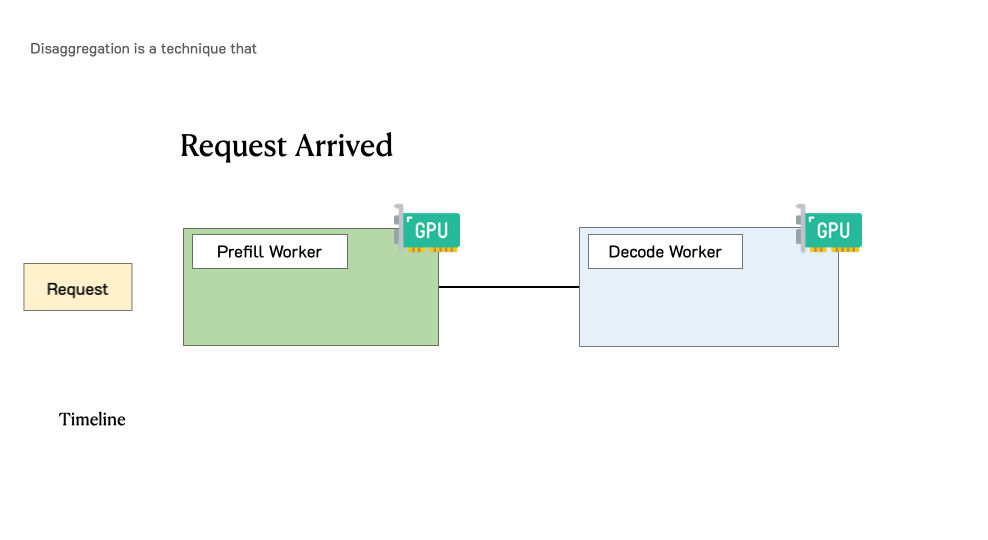
Aikipedia: Prefill–Decode Disaggregation – Champaign Magazine
LLM大模型系列(十):深度解析 Prefill-Decode 分离式部署架构_prefill和decode-CSDN博客
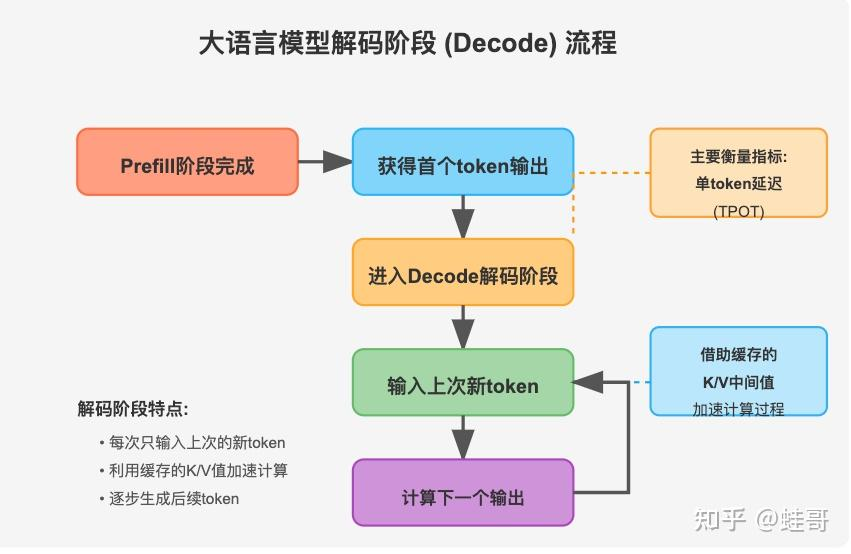
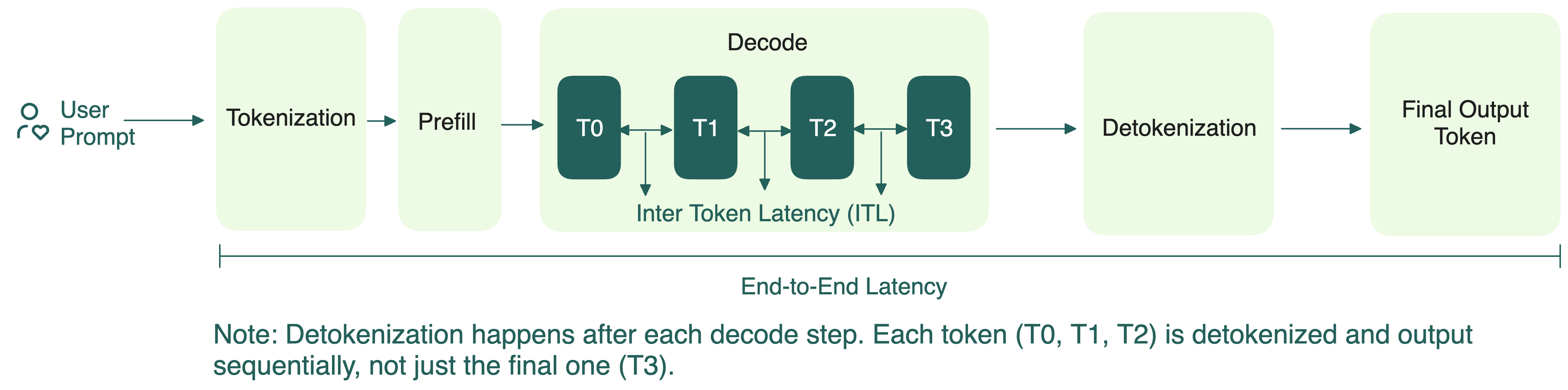
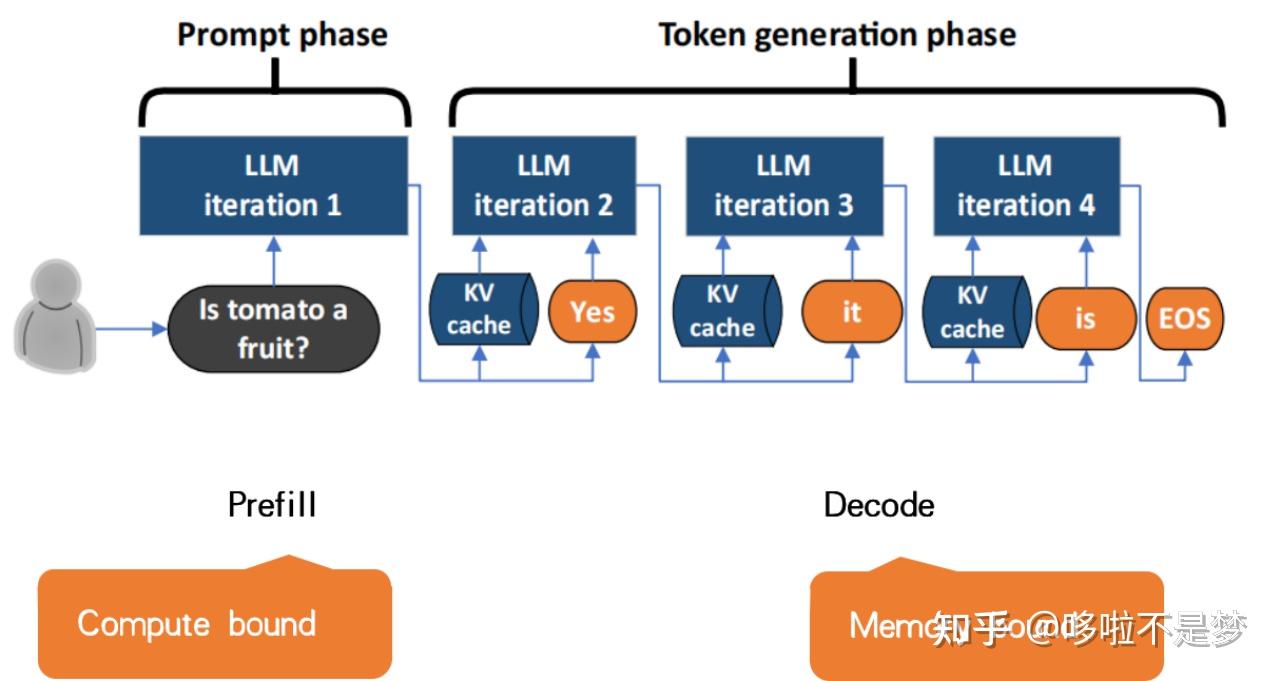
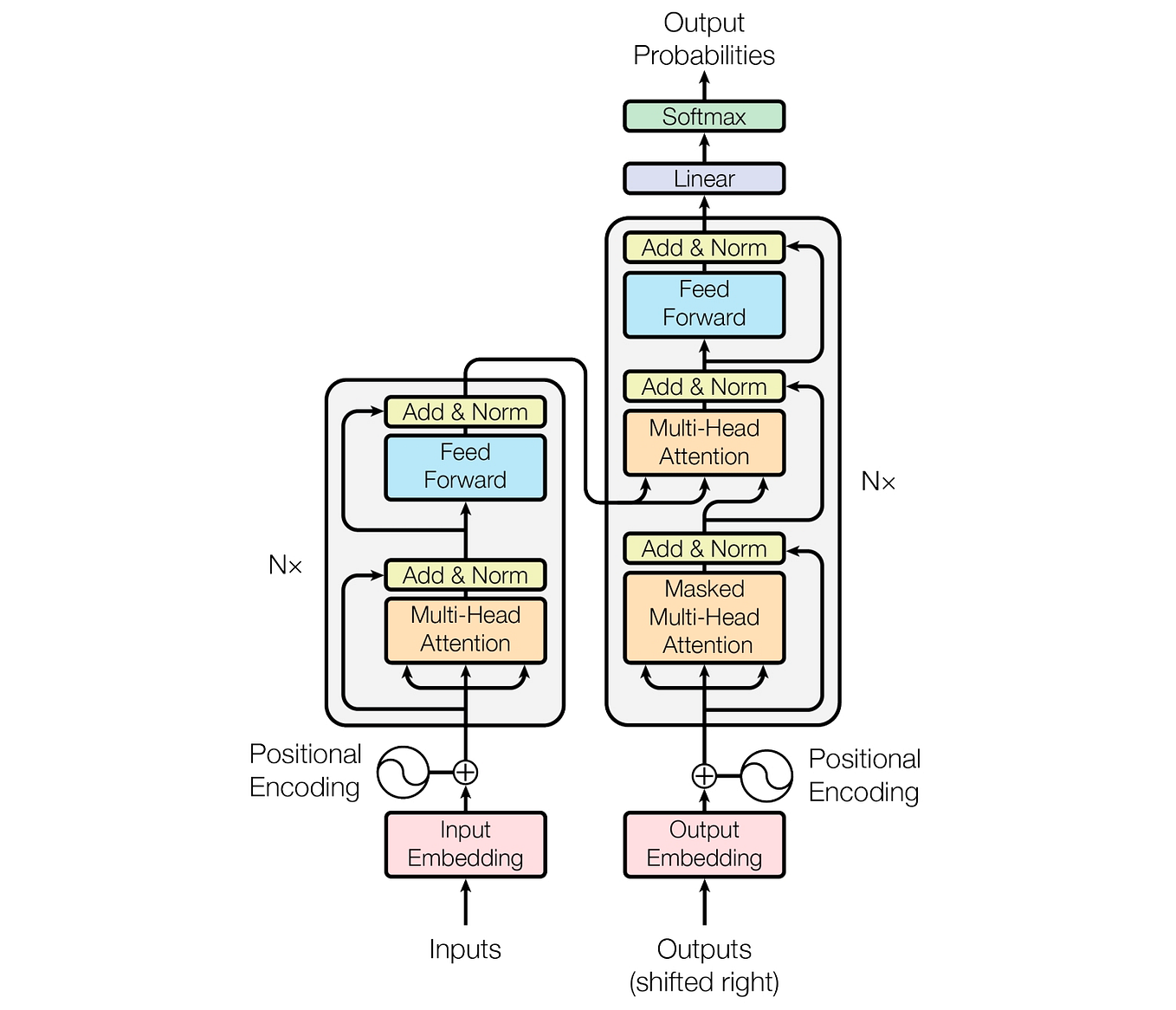
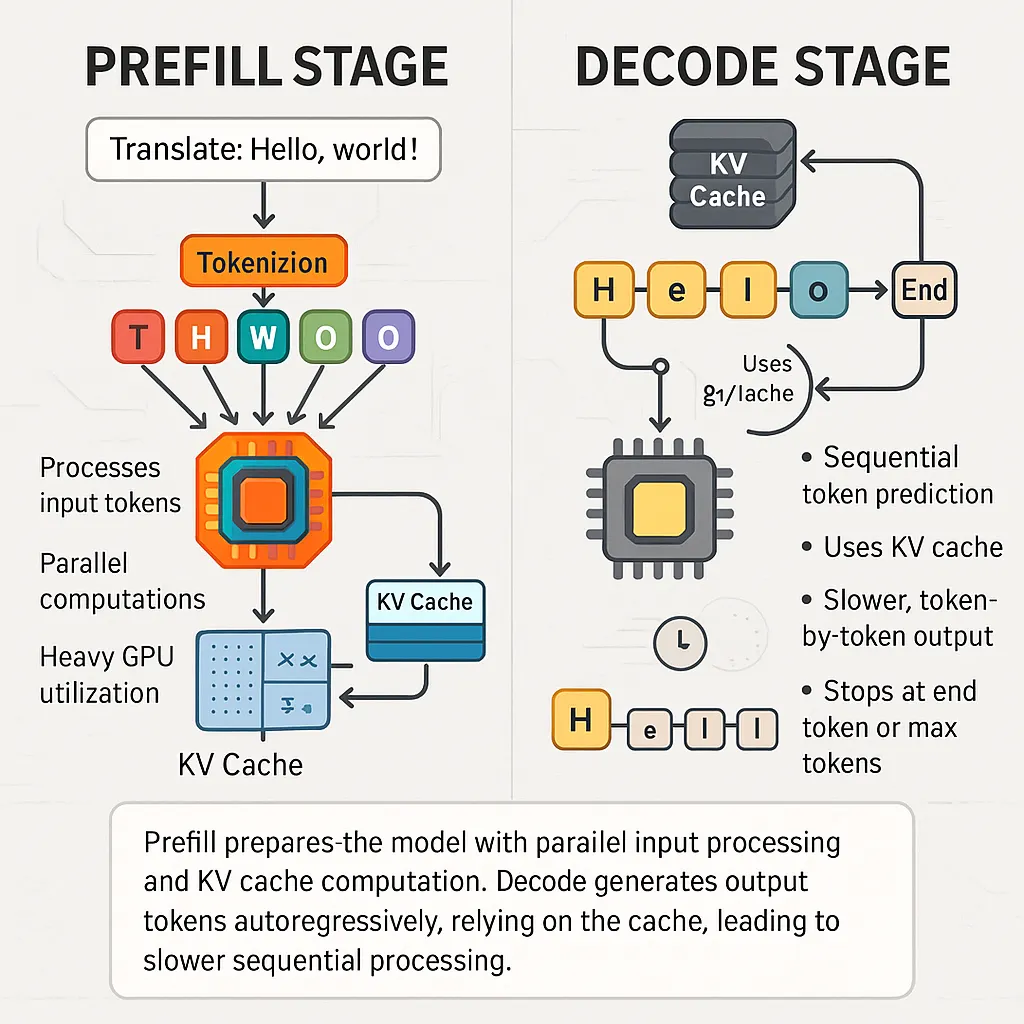
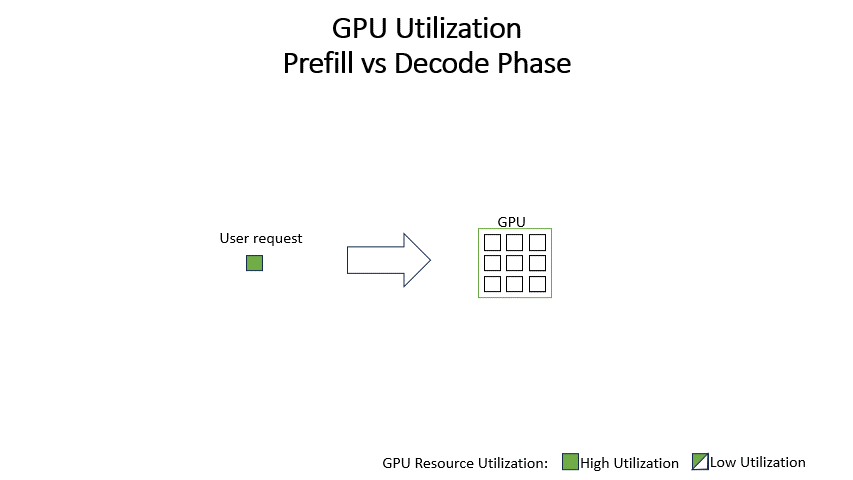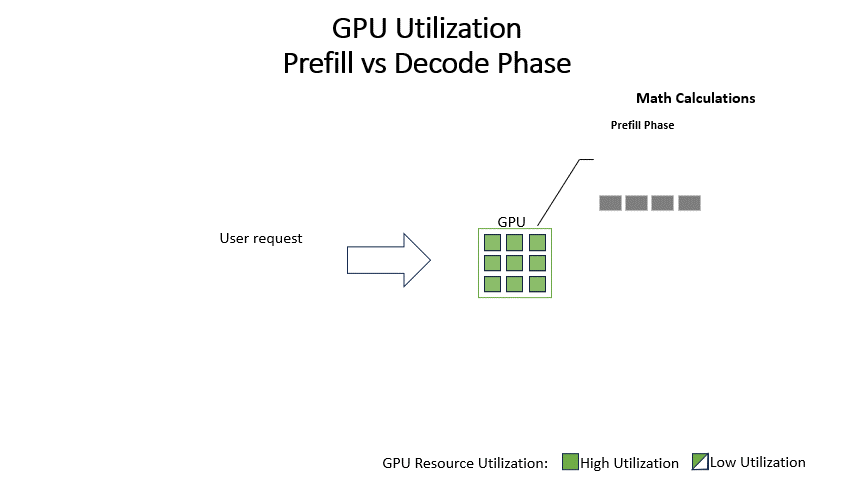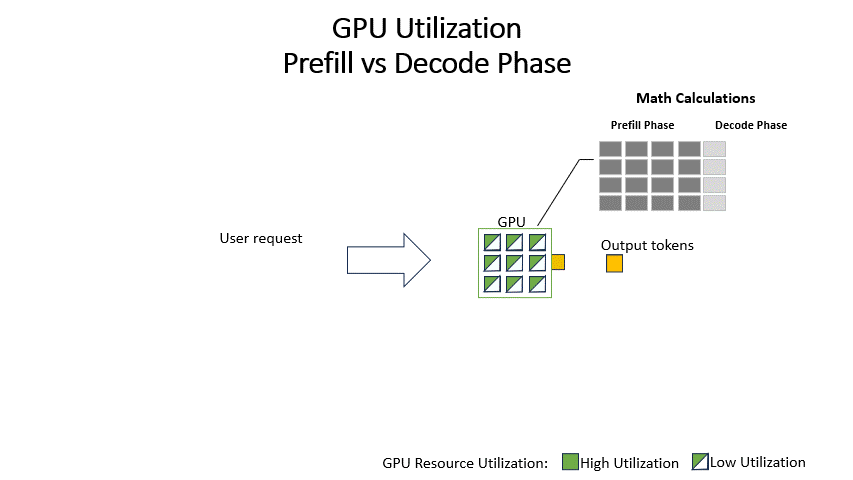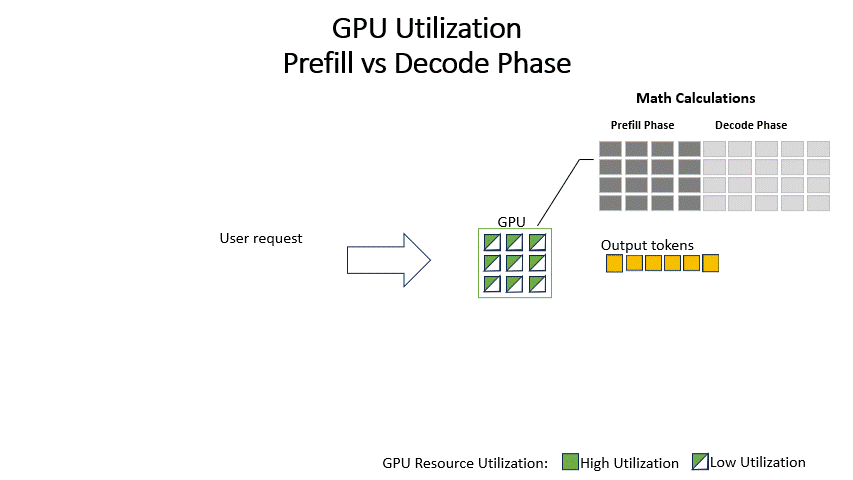
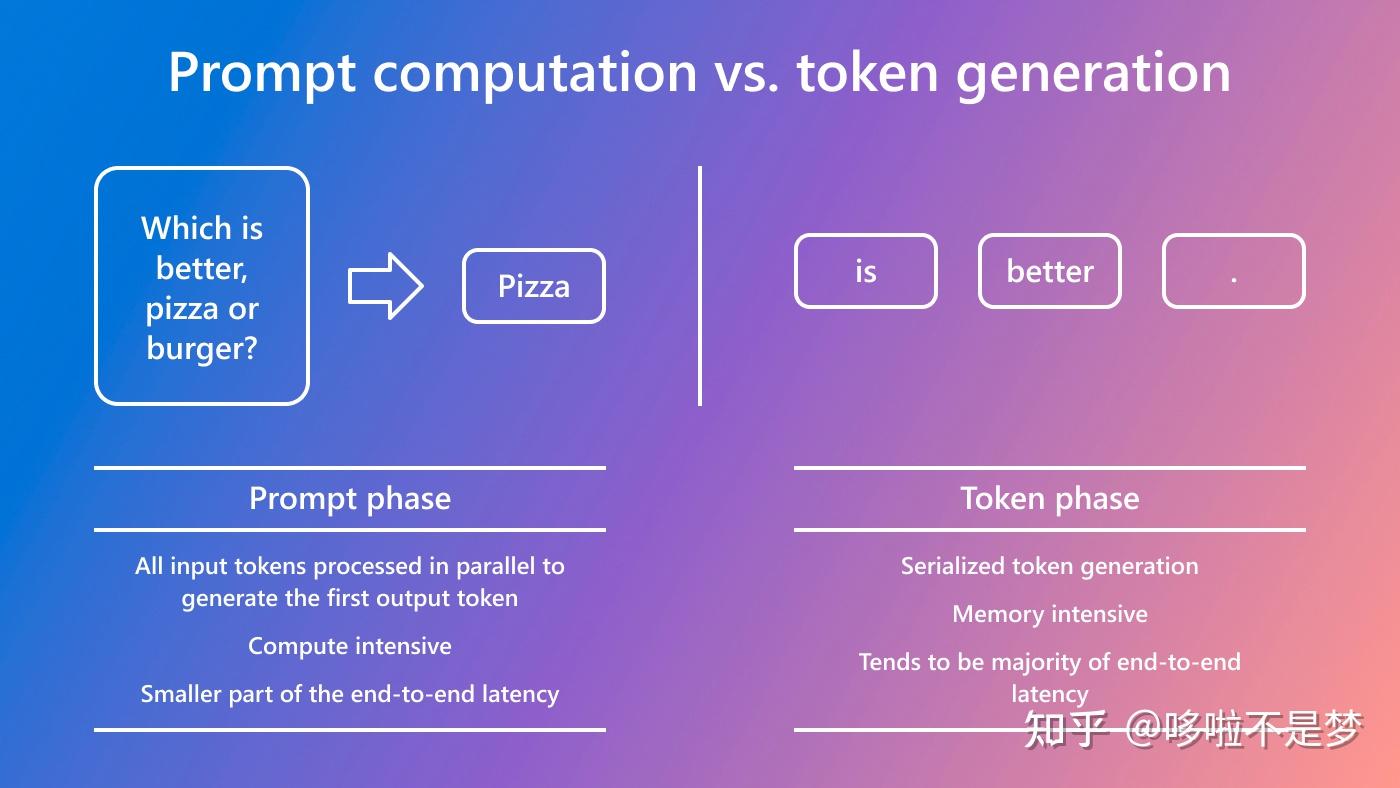
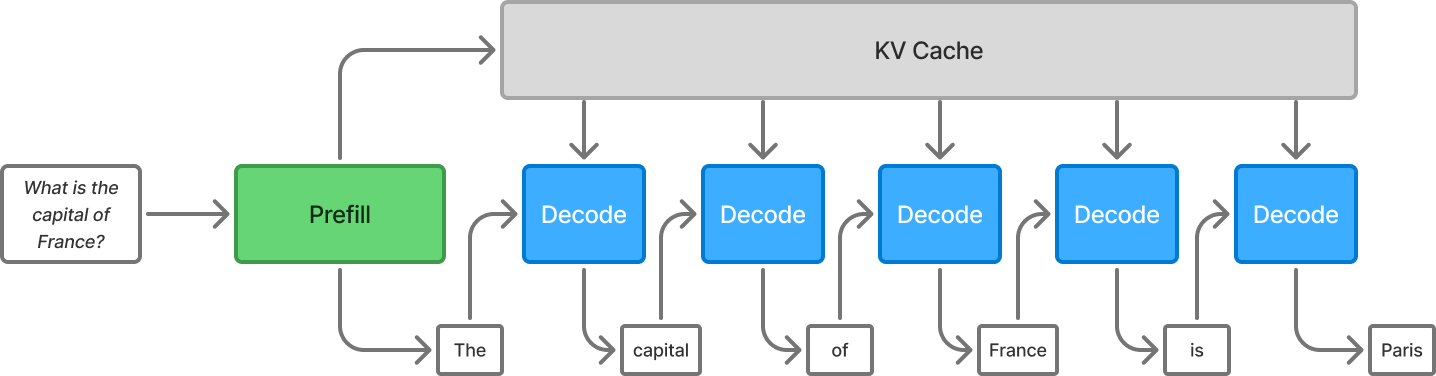
Understanding the Two Key Stages of LLM Inference: Prefill and Decode ...
deepseek大模型推理prefill/decode阶段研究分析_deepseek prefill-CSDN博客
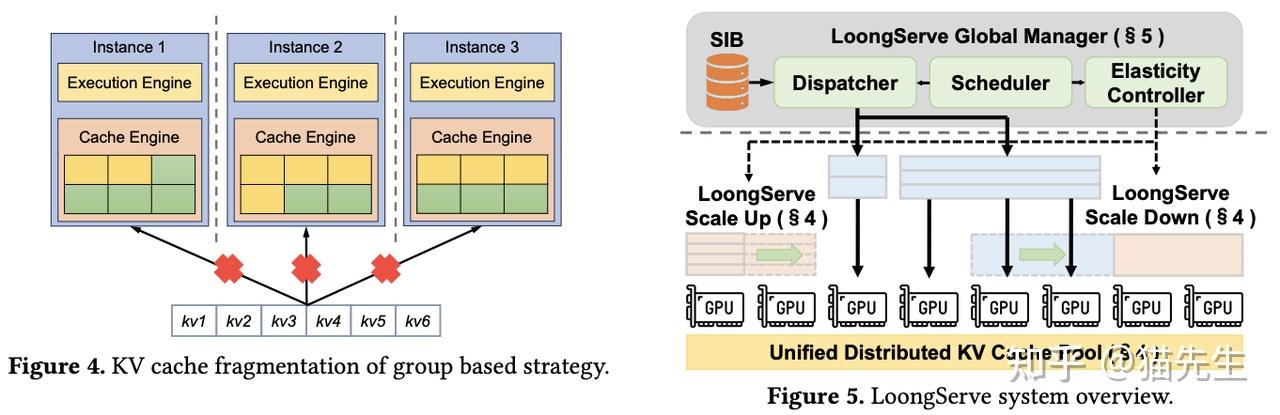
LoongServe论文解读:prefill/decode分离、弹性并行、零KV Cache迁移_prefill decode-CSDN博客
GLM-4 (6) - KV Cache / Prefill & Decode_prefill和decode-CSDN博客
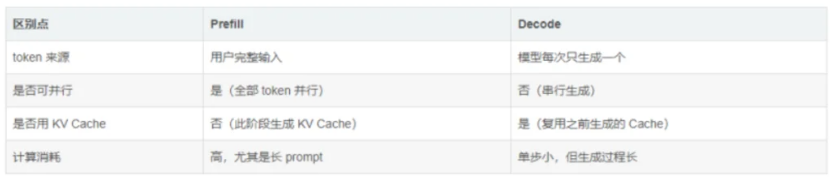
一文搞懂大模型推理:Prefill与Decode的分工、原理与性能优化!_prefill和decode-CSDN博客
Streamlining AI Inference Performance and Deployment with NVIDIA ...
打破算力瓶颈:LLM推理中Prefill/Decode分离架构深度解析-腾讯云开发者社区-腾讯云
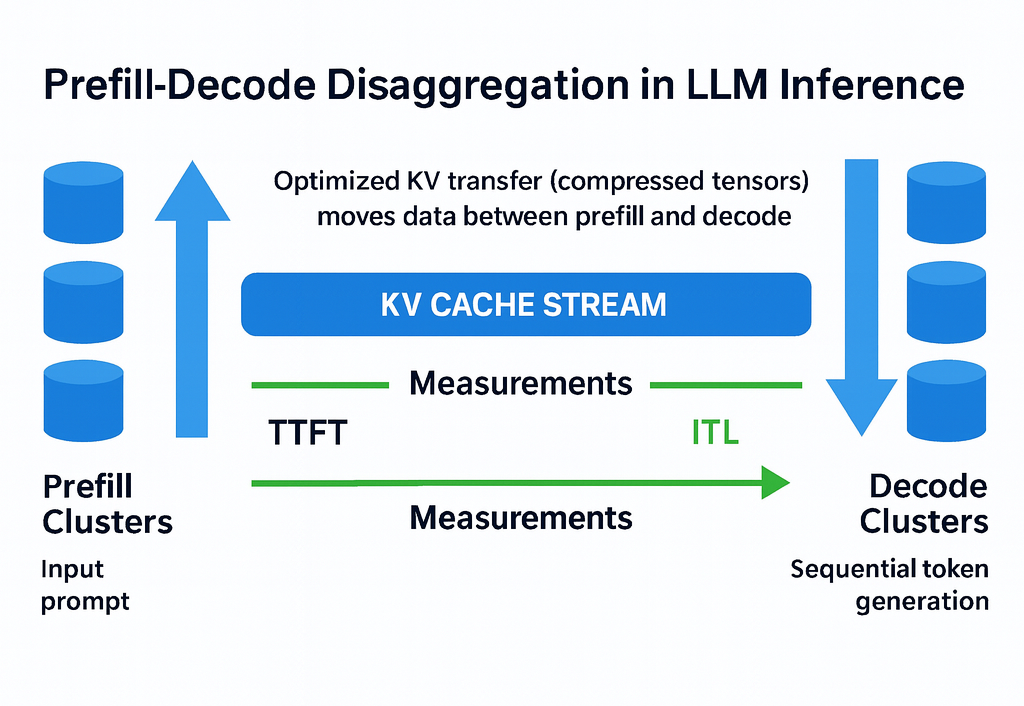
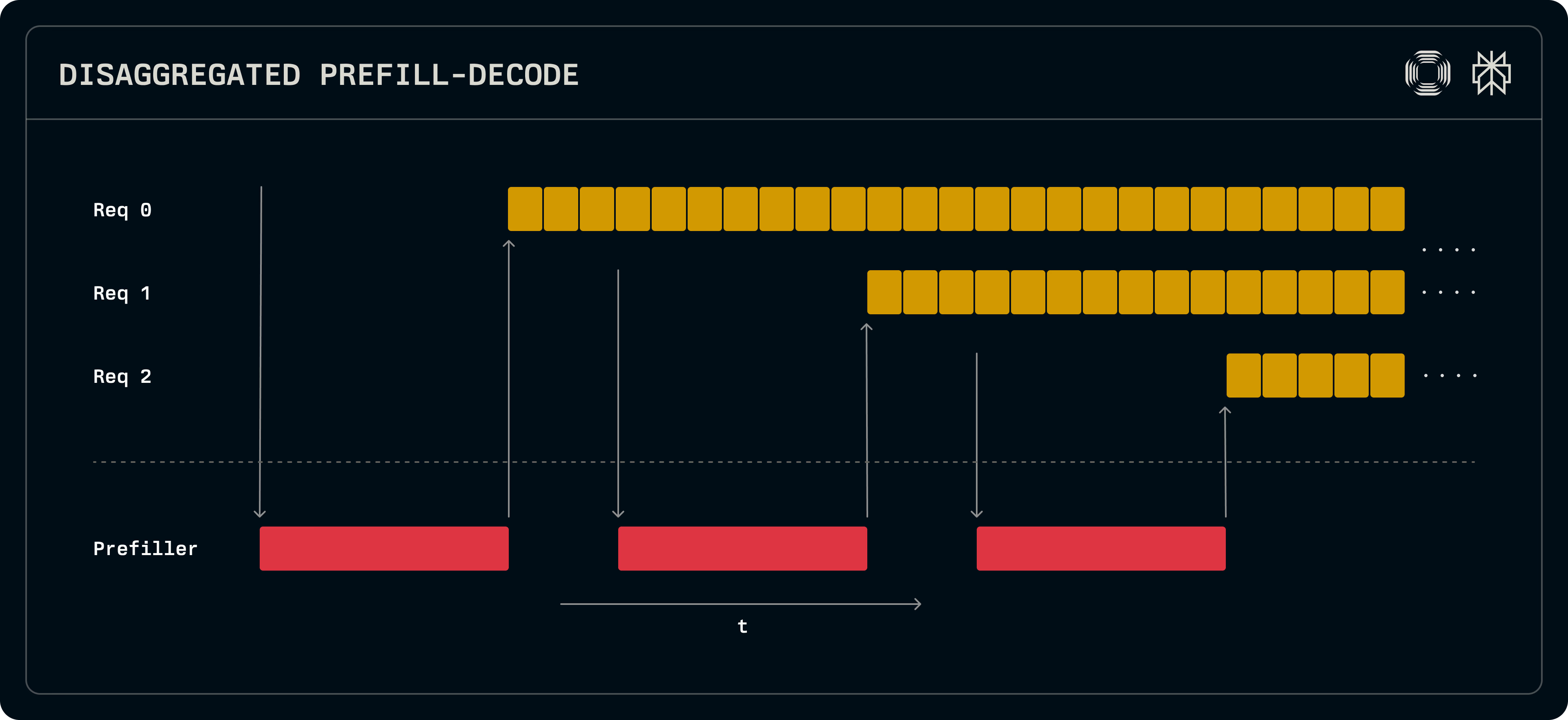
Prefill-decode disaggregation | LLM Inference Handbook
Prefill and Decode for Concurrent Requests - Optimizing LLM Performance
深入浅出,一文理解LLM的推理流程_chunked prefill-CSDN博客
大模型推理优化-Prefill/Decoding分离 - 知乎
打造高性能大模型推理平台之Prefill、Decode分离系列(一):微软新作SplitWise,通过将PD分离提高GPU的利用率 _ 同行 ...
What’s the difference between Inference Compute Clusters and Training ...
Prefill and Decode for Concurrent Requests | BARD AI
MoE Inference Economics from First Principles
Prefill and Decode in 2 Minutes: AI Inference Explained in Simple Words ...
为什么大语言模型推理要分成 Prefill 和 Decode?深入理解这两个阶段的真正意义_prefill和decode-CSDN博客
LLM Inference - Hw-Sw Optimizations
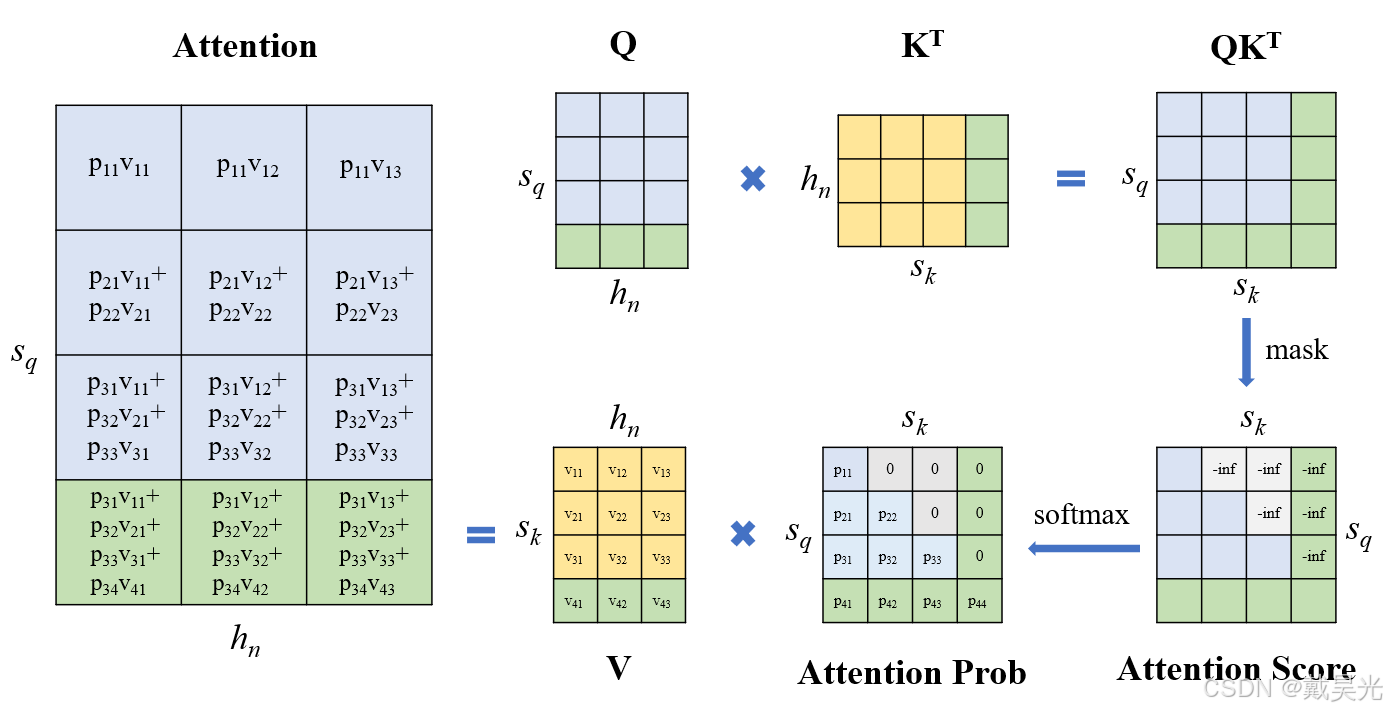
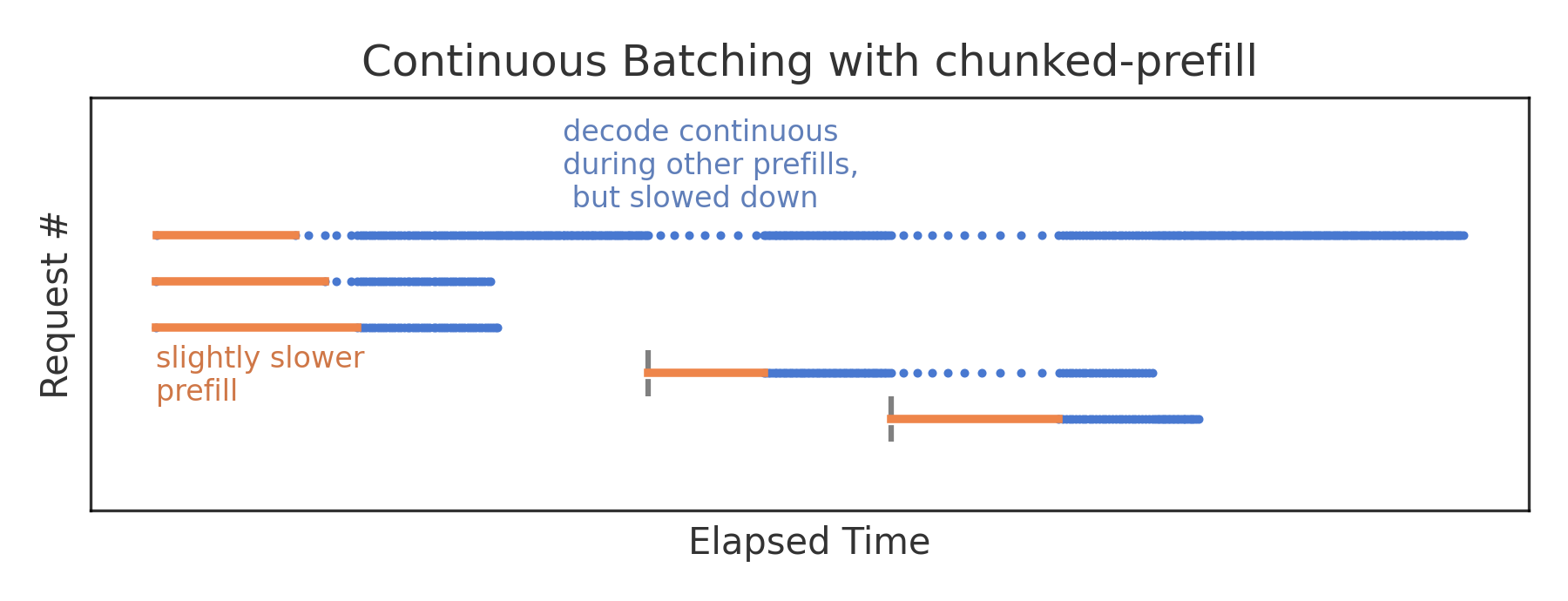
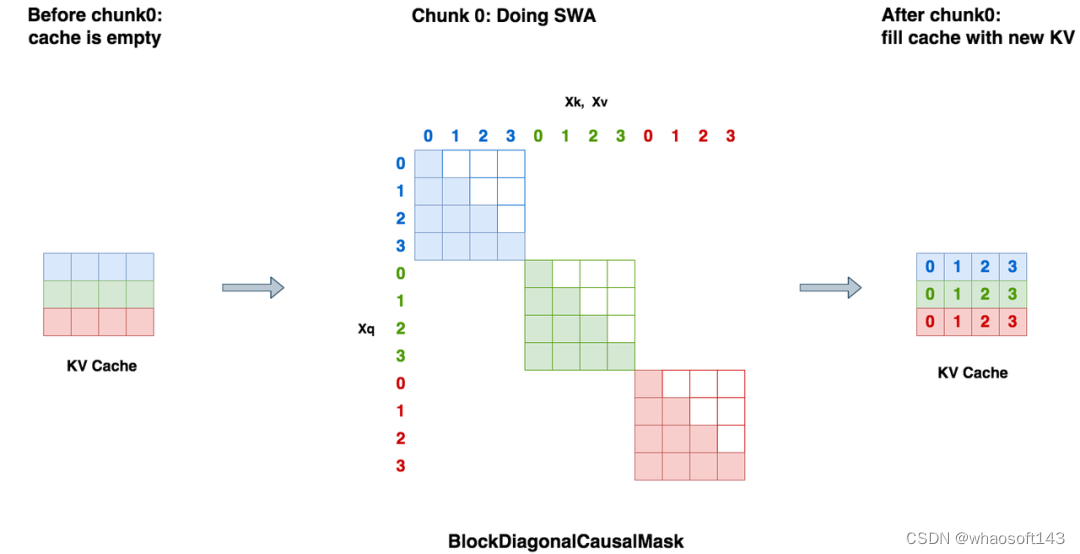
Chunked-Prefills 分块预填充机制详解_chunk prefill-CSDN博客
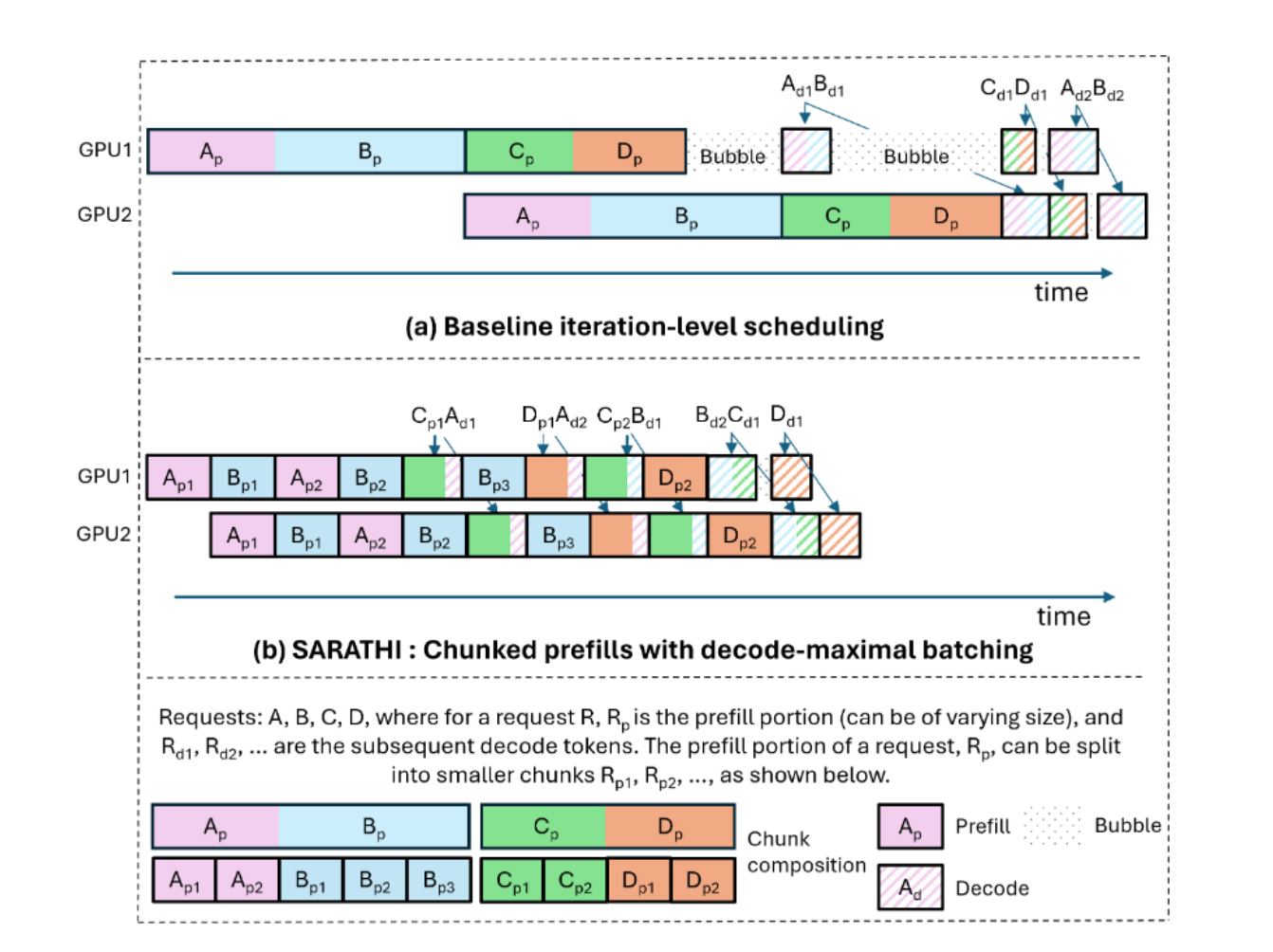
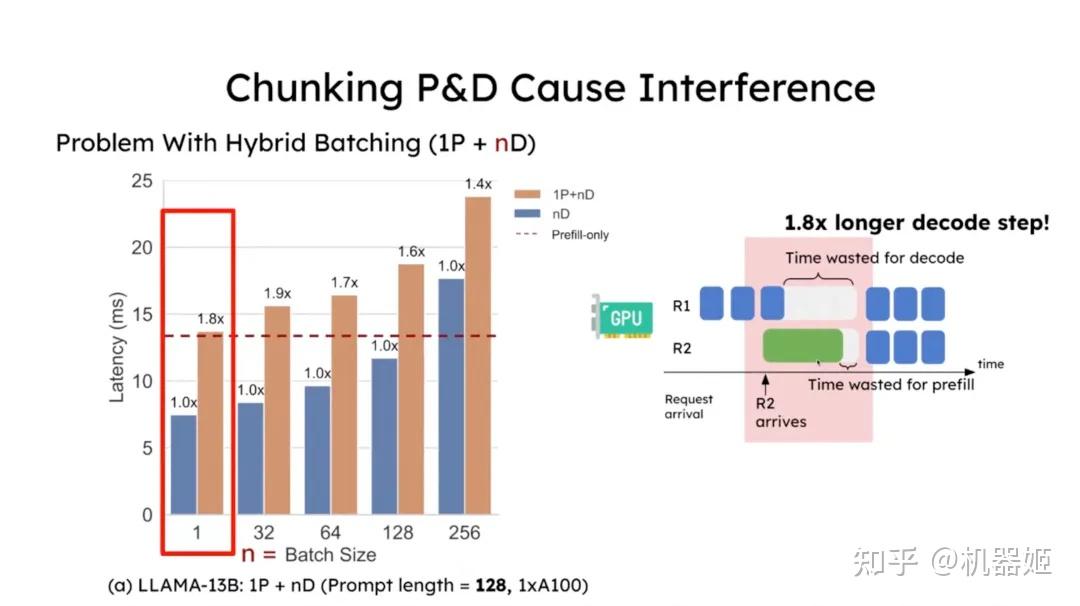
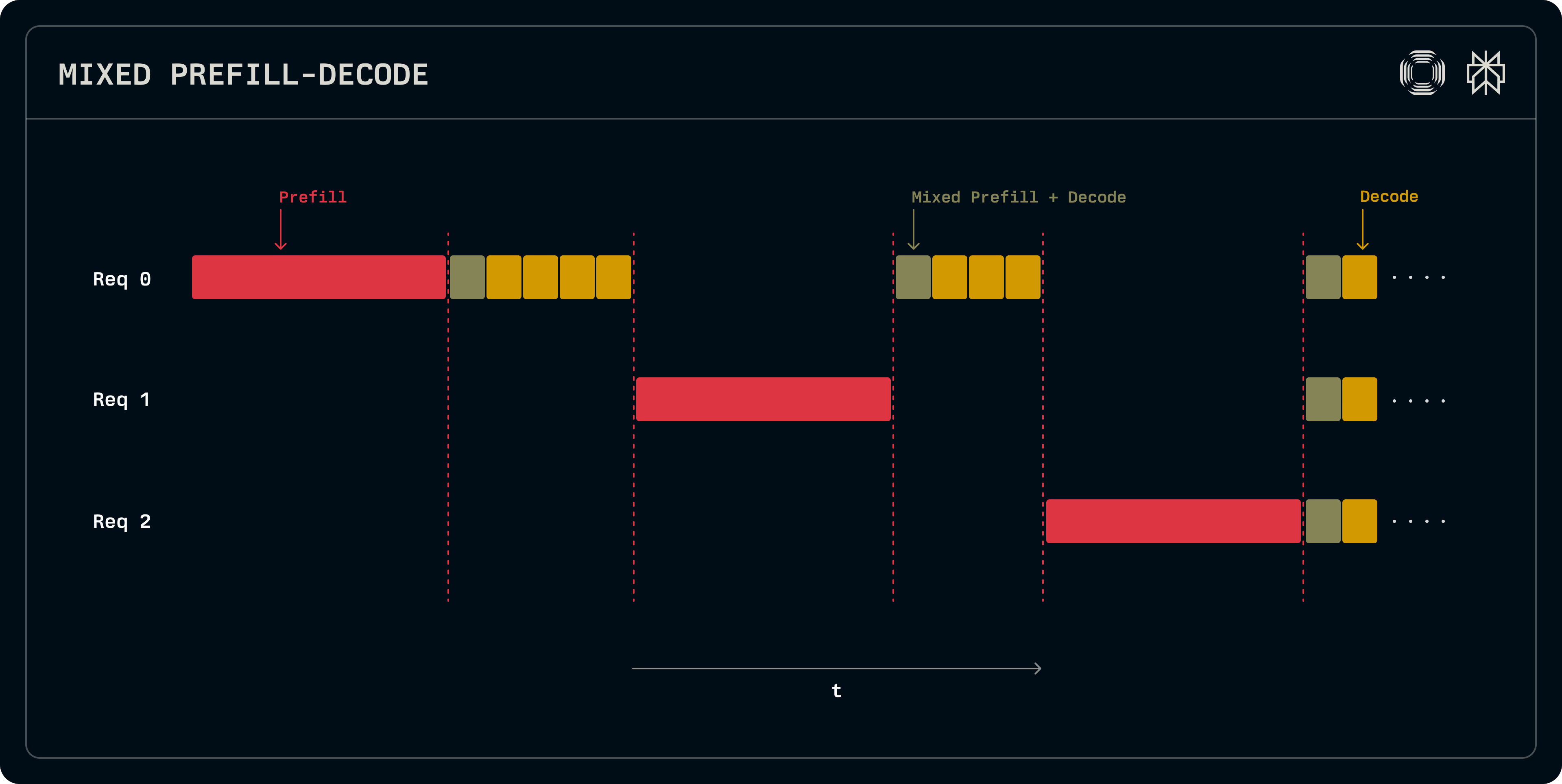
SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked ...
Demystifying AI Inference Deployments for Trillion Parameter Large ...
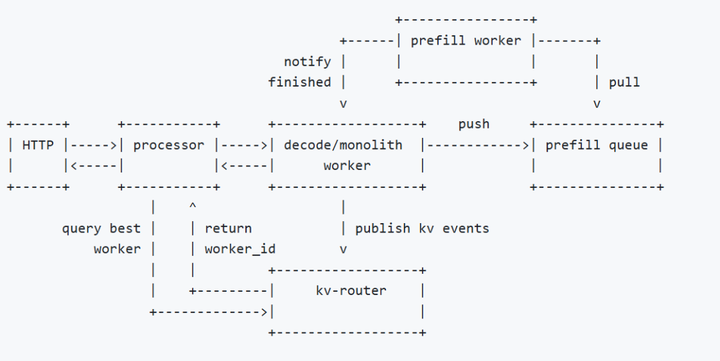
llm-d: Kubernetes-native distributed inferencing | Red Hat Developer
[LLM 推理服务优化] DistServe速读——Prefill & Decode解耦、模型并行策略&GPU资源分配解耦 - 知乎
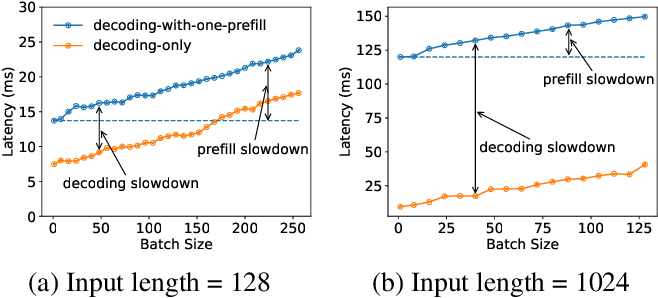
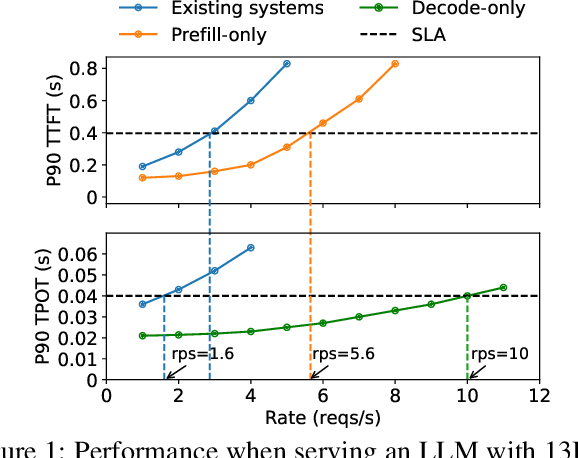
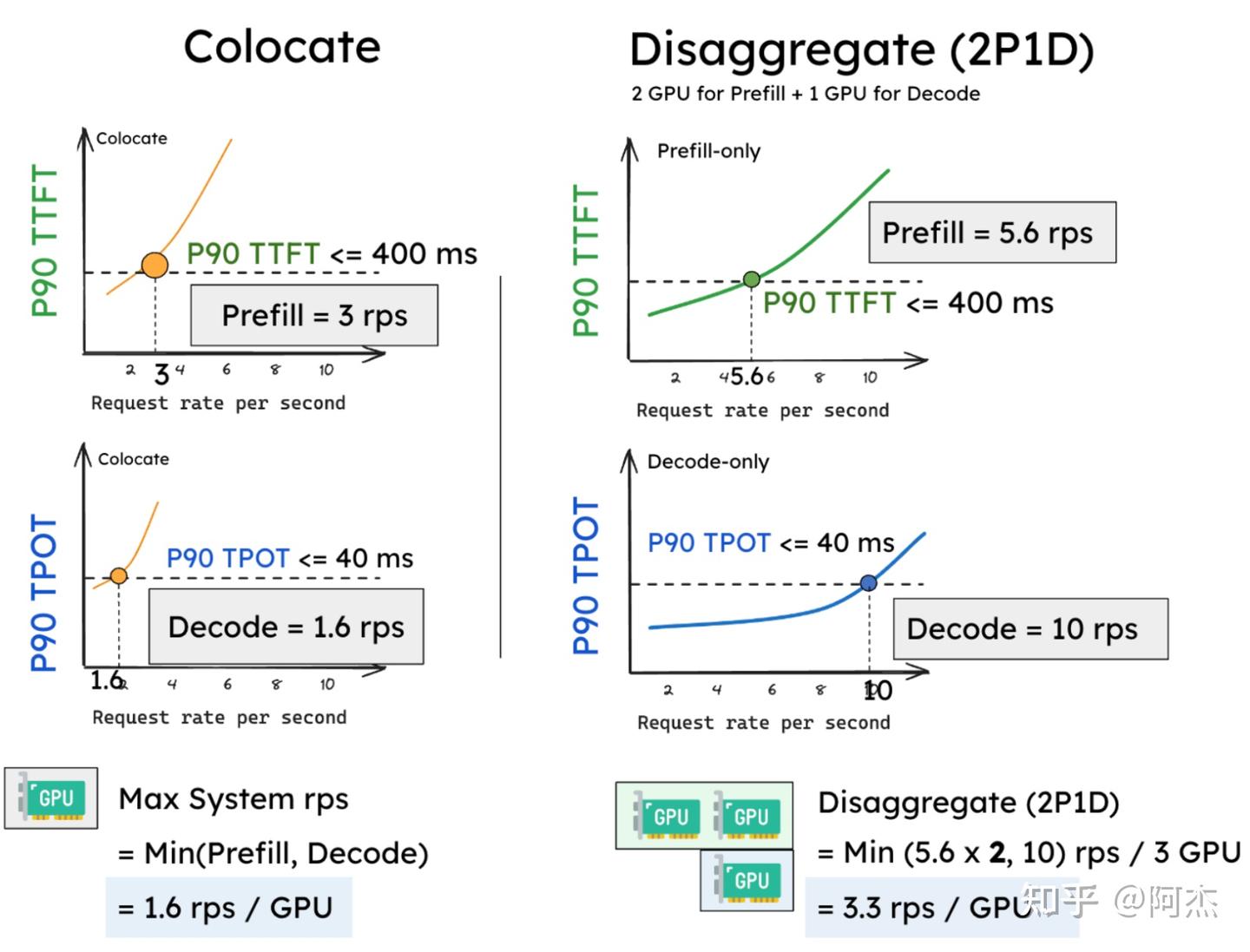
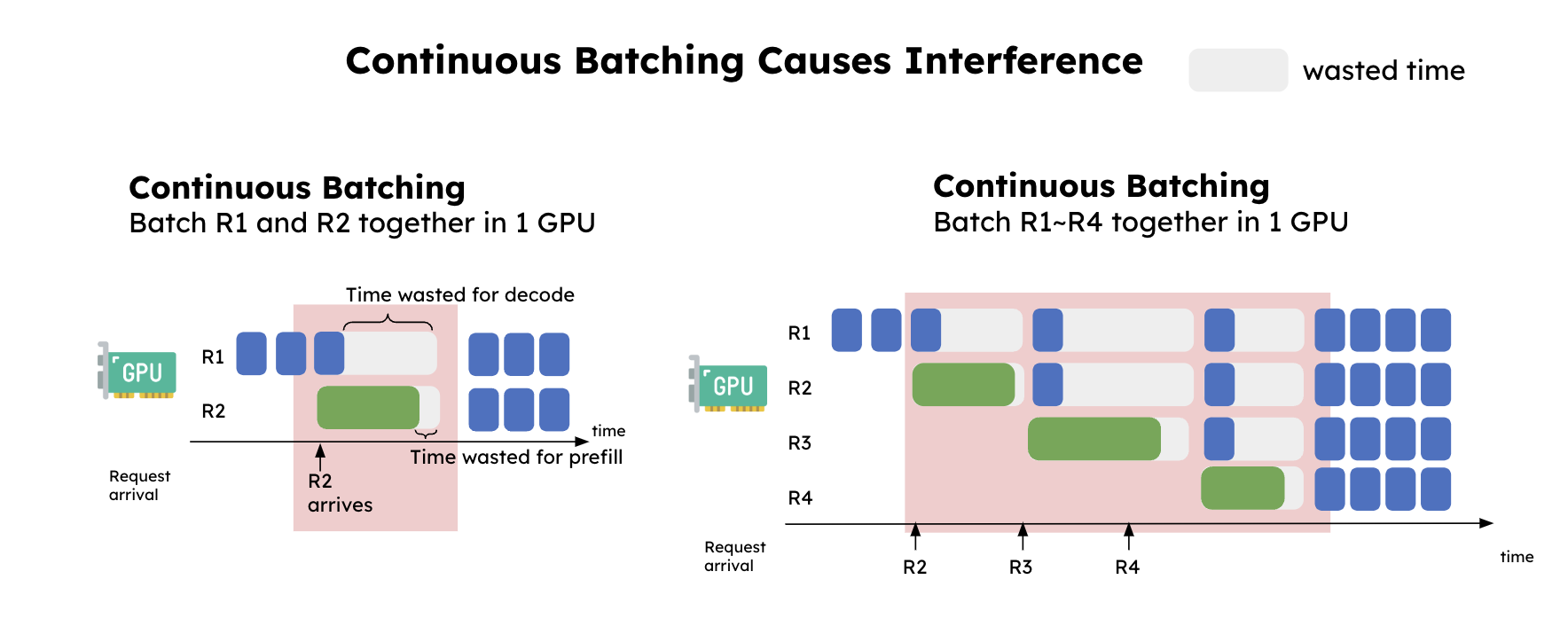
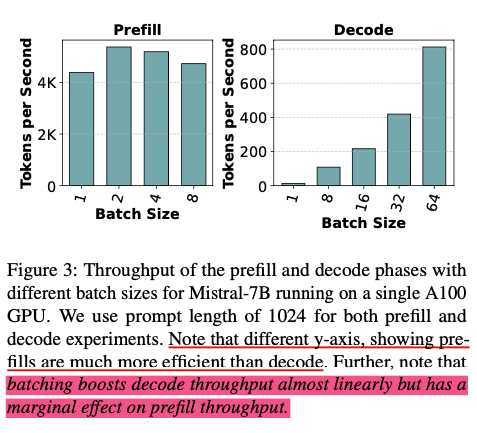
Throughput is Not All You Need: Maximizing Goodput in LLM Serving using ...
Chunked-Prefills 分块预填充机制详解_Se7en_InfoQ写作社区
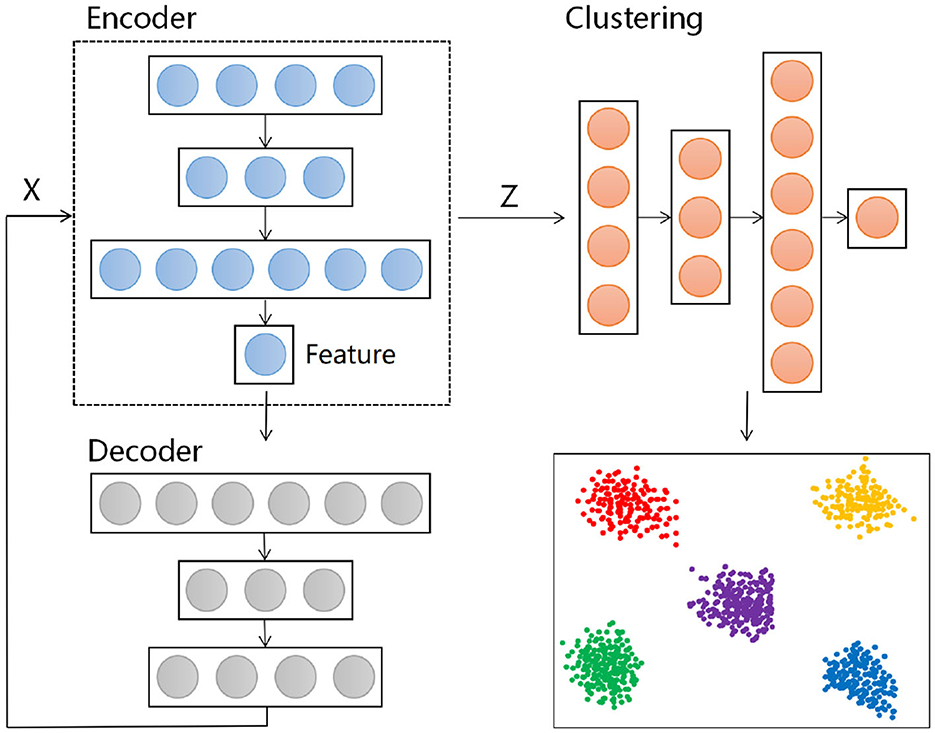
Frontiers | Text clustering based on pre-trained models and autoencoders
LoongServe 论文解读:prefill/decode 分离、弹性并行、零 KV Cache 迁移开销 - 知乎
vllm chunked-prefill性能评估_chunked prefill-CSDN博客
AI Optimization Lecture 01 - Prefill vs Decode - Mastering LLM ...
LLM推理优化 - Prefill-Decode分离式推理架构 - 知乎
第二章:推理加速核心:预填充(Prefill)与解码(Decode)的深度解析与实现-CSDN博客
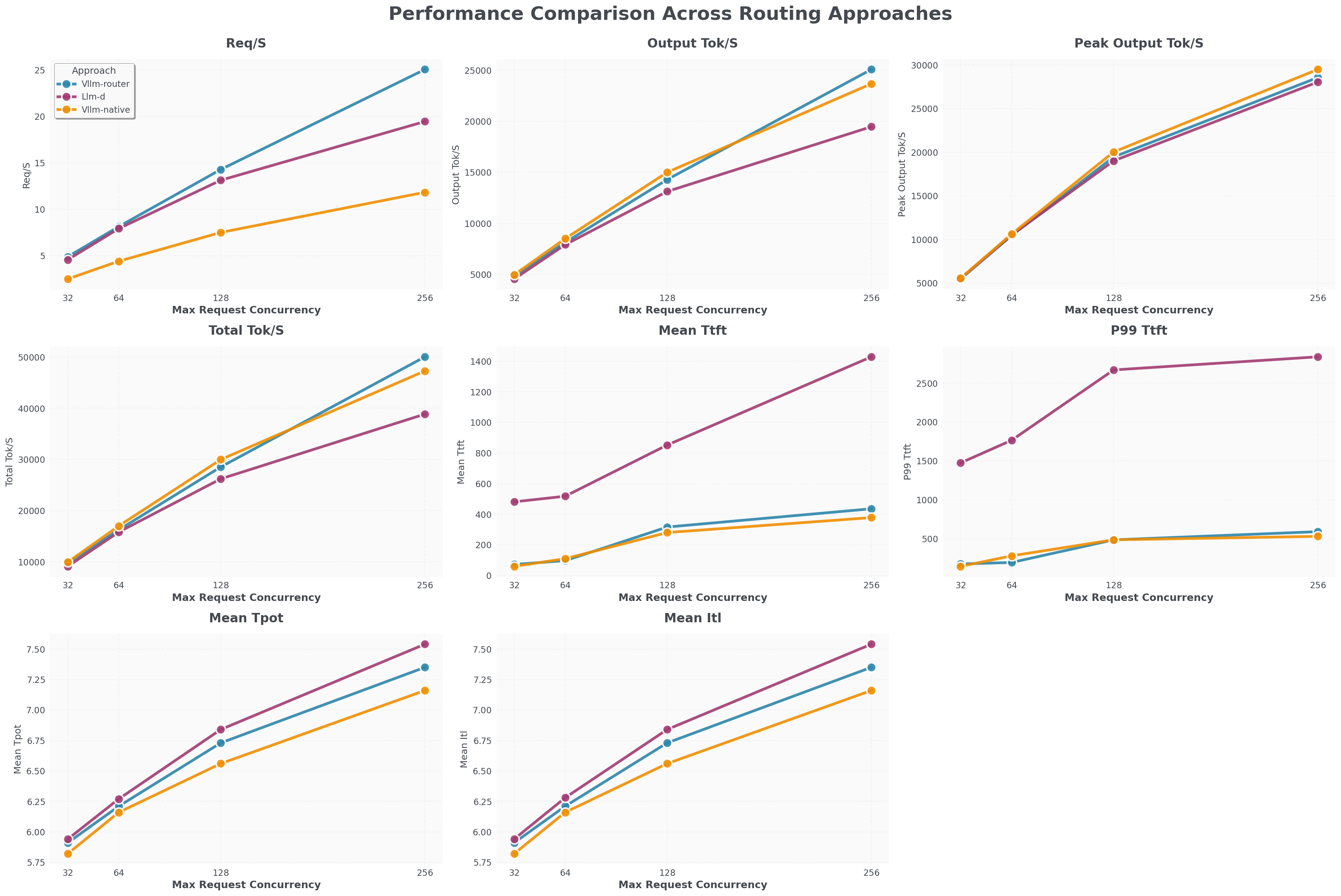
vLLM Router: A High-Performance and Prefill/Decode Aware Load Balancer ...
【有啥问啥】大模型效率部署之Prefill-Decode分离_prefill decode-CSDN博客
vLLM V1: Accelerating multimodal inference for large language models ...
Benchmarking Text Generation Inference
LLM大模型系列(十):深度解析 Prefill-Decode 分离式部署架构_mob64ca14095513的技术博客_51CTO博客
Disaggregated Inference [BETA] — AWS Neuron Documentation
Splitting LLM inference across different hardware platforms | Gimlet Blog
大模型Prefill-Decode分离式推理架构解读 - 知乎
Disaggregated Prefill-Decode: The Architecture Behind Meta's LLM ...
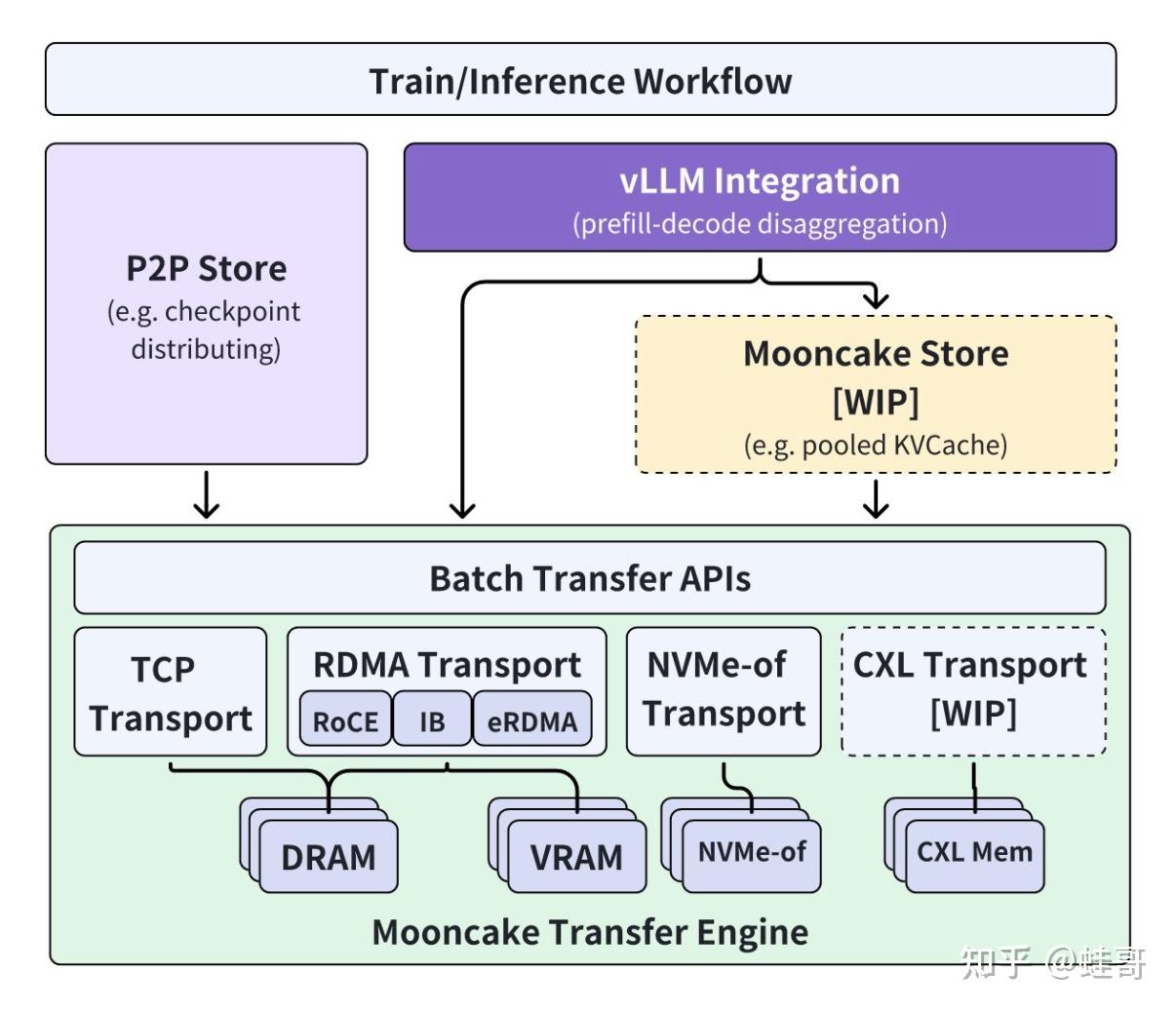
Mooncake | 开源LLM推理架构 - 知乎
打造高性能大模型推理平台之Prefill、Decode分离系列(一):微软新作SplitWise,通过将PD分离提高GPU的利用率哆啦不是梦 ...
大模型系列:深度解析 Prefill-Decode 分离式部署架构 - 知乎
Disaggregated Prefill-Decode Architecture | vllm-project/vllm-ascend ...
隆重推出 NVIDIA Dynamo:用于扩展推理AI模型的低延迟分布式推理框架 - NVIDIA 技术博客
基于 chunked prefill 理解 prefill 和 decode 的计算特性 - 知乎
Understanding Prefill & Decode Disaggregation in LLM Serving | by ...
vllm chunked-prefill性能评估 - 知乎
vllm调度笔记:chunked prefill调度策略 - 知乎
🌸万字解析:大规模语言模型(LLM)推理中的Prefill与Decode分离方案 - 技术栈
LLM Inference Optimization — Splitwise | by Don Moon | Sep, 2024 ...
Prefill/Decode Disaggregation and the New Economics of Heterogeneous AI ...
[Feature] Prefill/Decoding disaggregation substantially boosts ...
Chunked-Prefills 分块预填充机制详解 - 知乎
Understanding the Prefill-decode Disaggregation in LLM Inference ...
prefill和decode | 格物致知
Benchmarking Prefill–Decode ratios: fixed vs dynamic - dstack
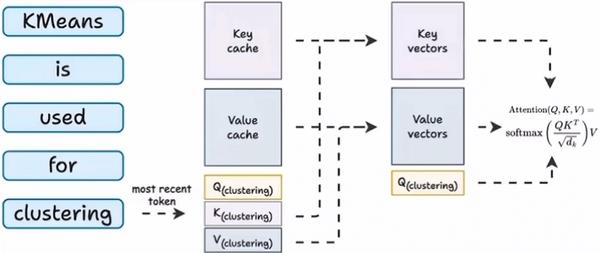
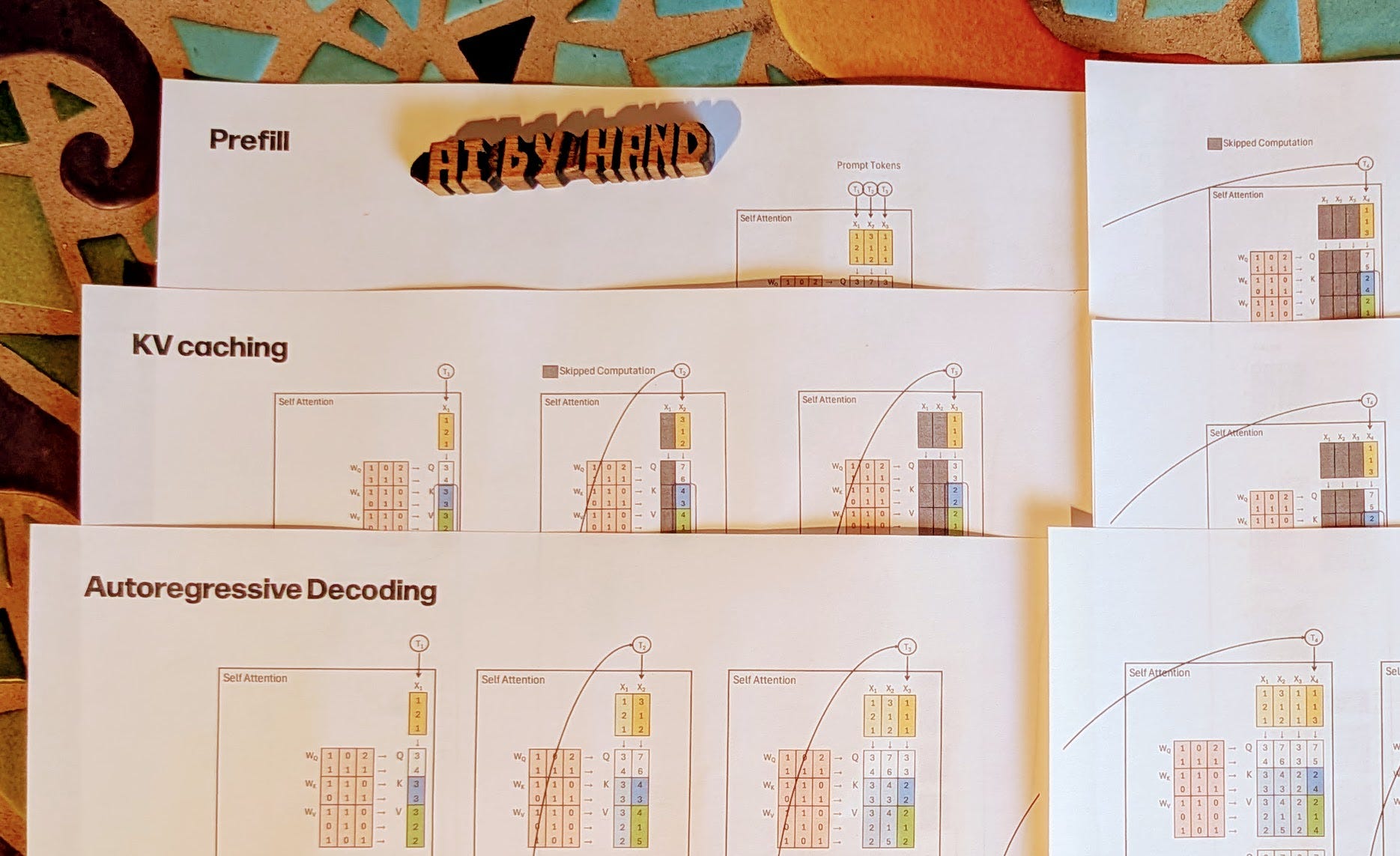
7. KV Cache, Prefill, Decode - by Prof. Tom Yeh
Mixtral 8 * 7b~推理优化原理_prefill decode-CSDN博客