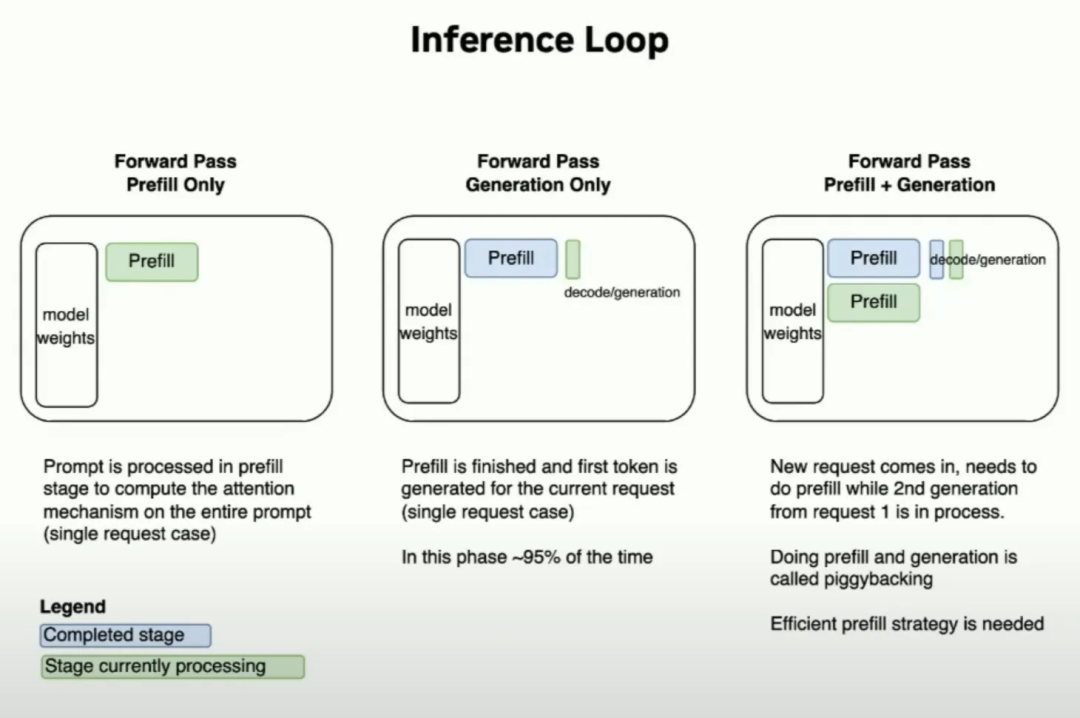
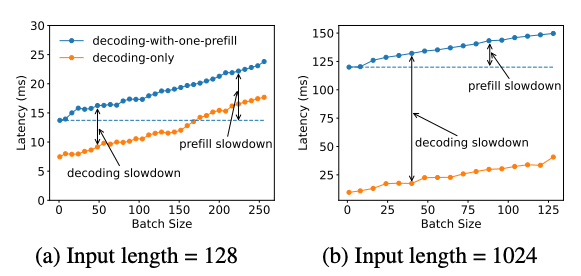
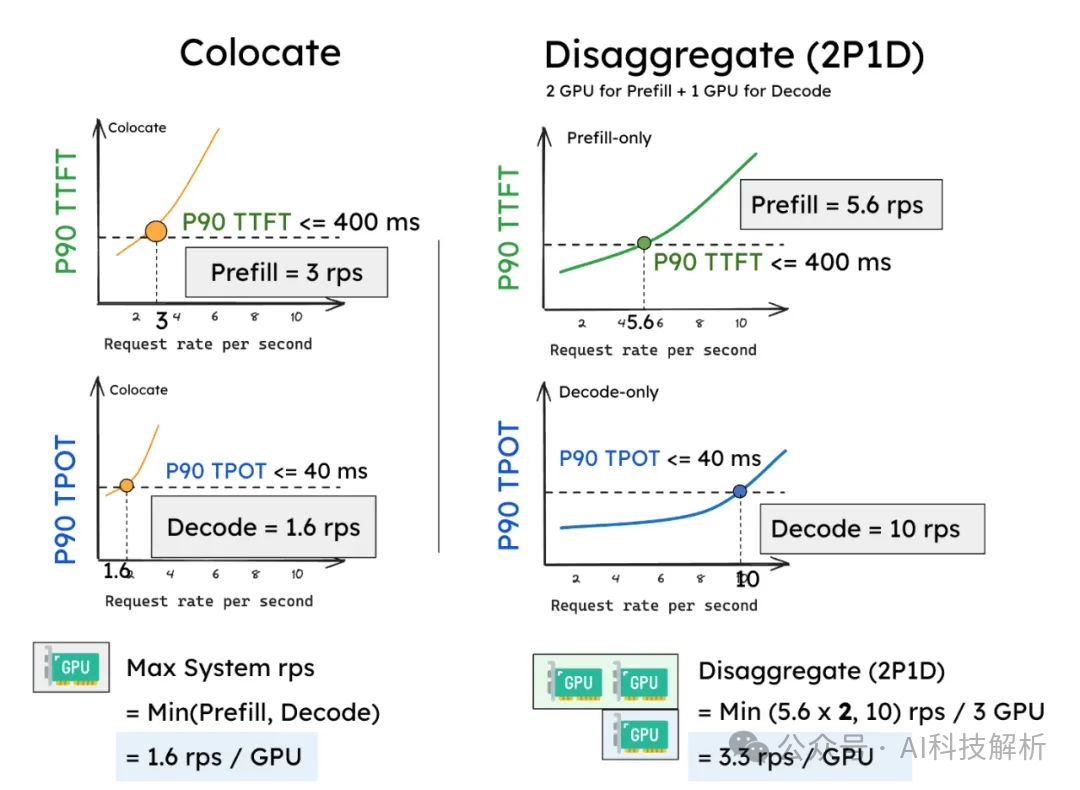
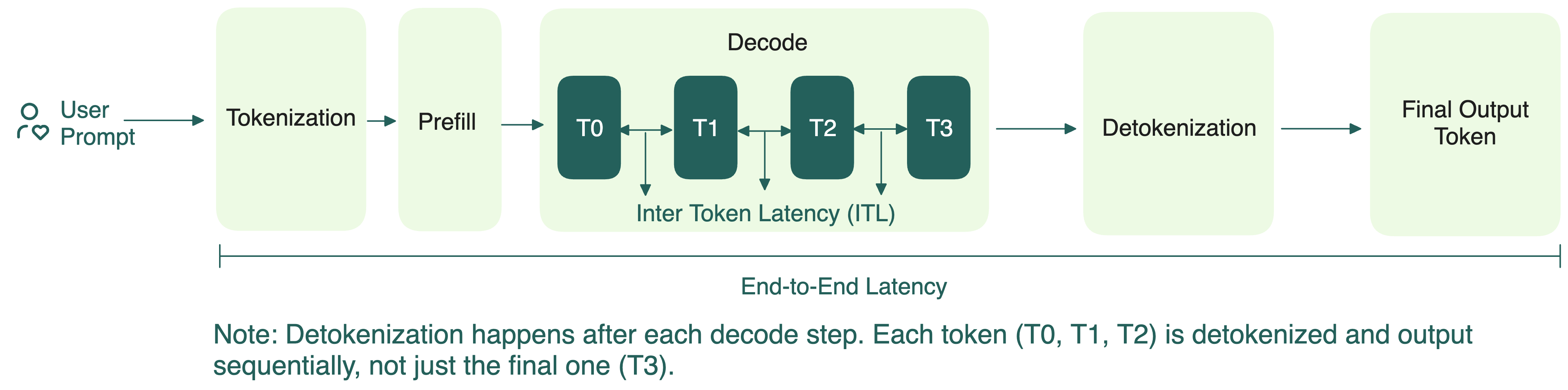
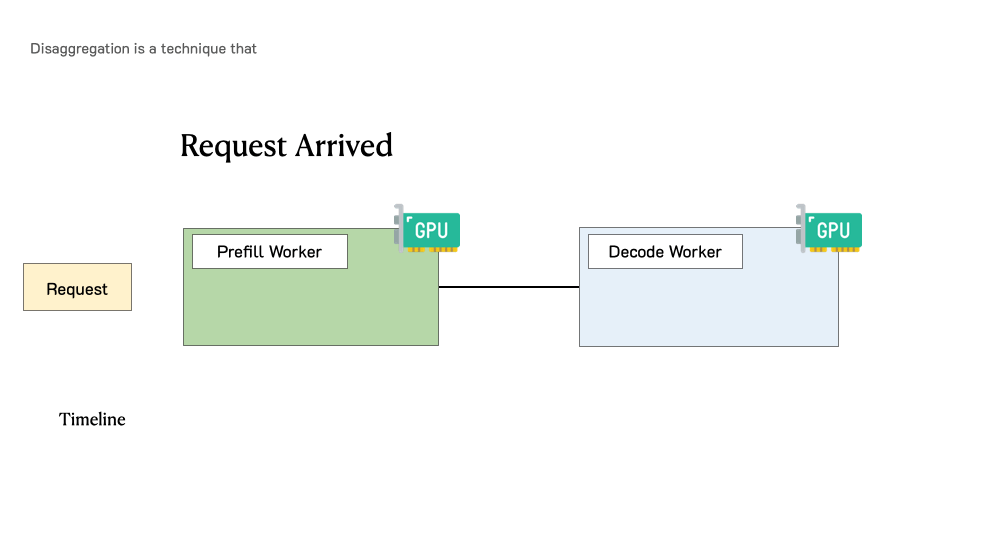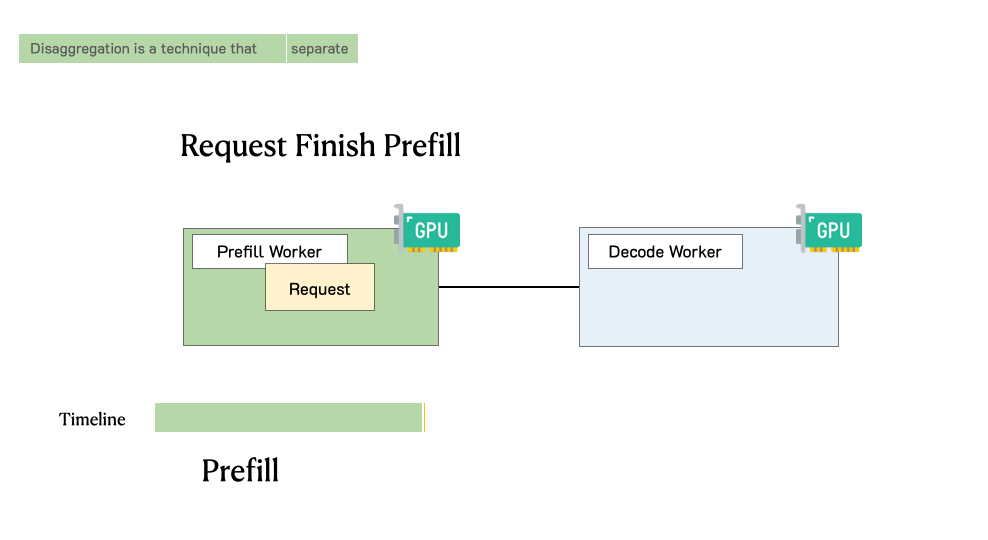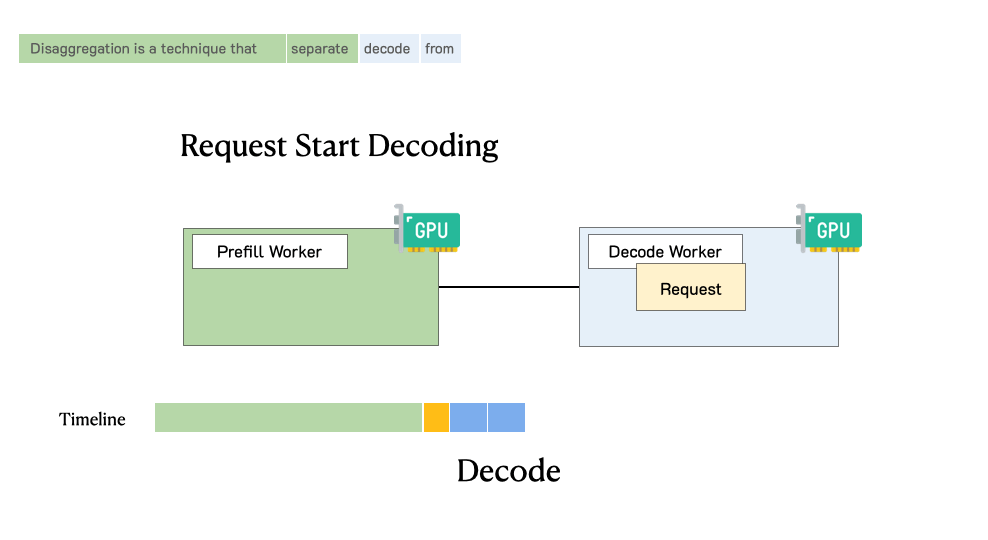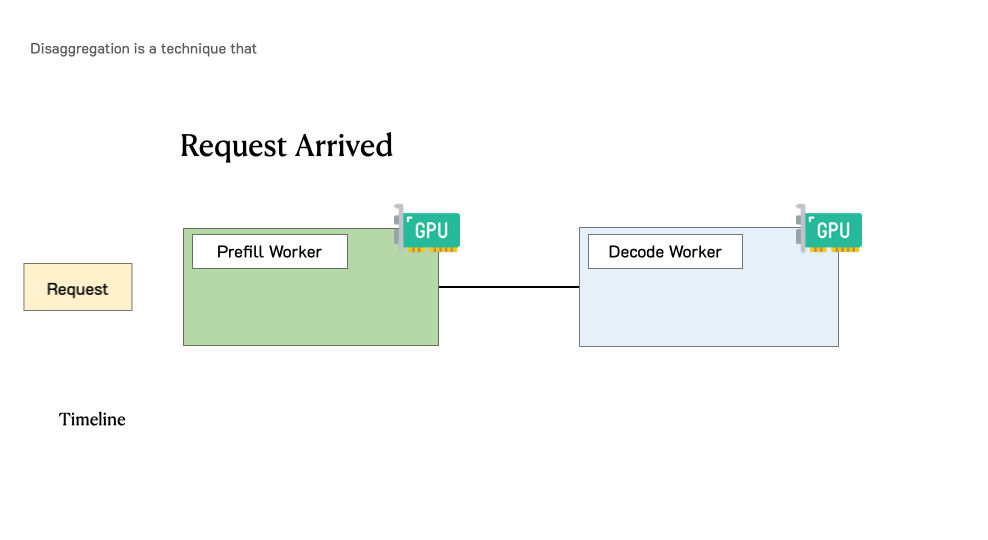
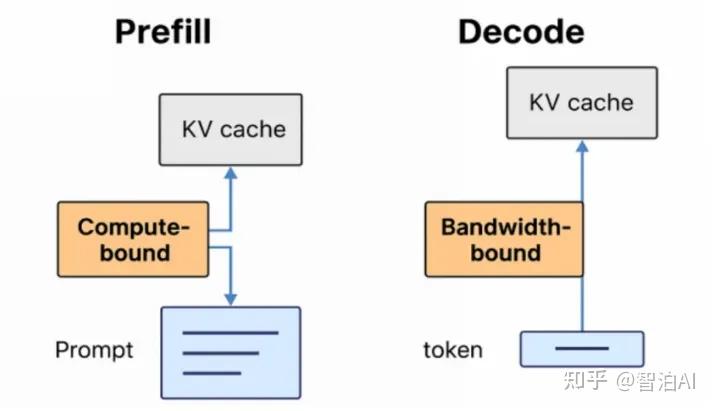
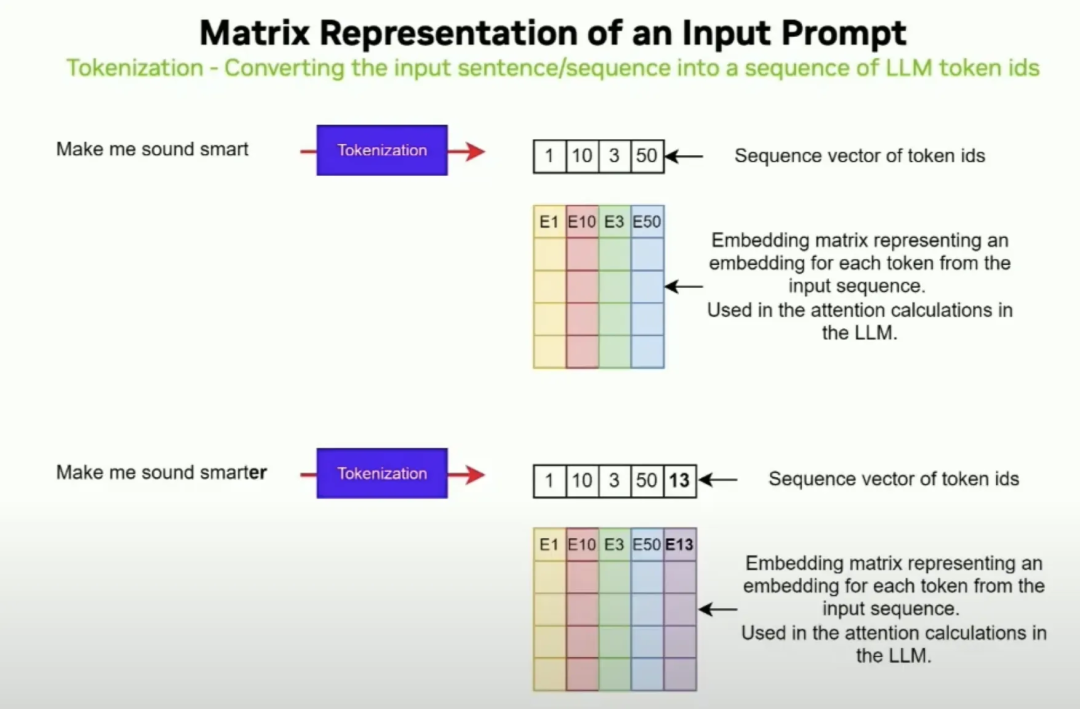
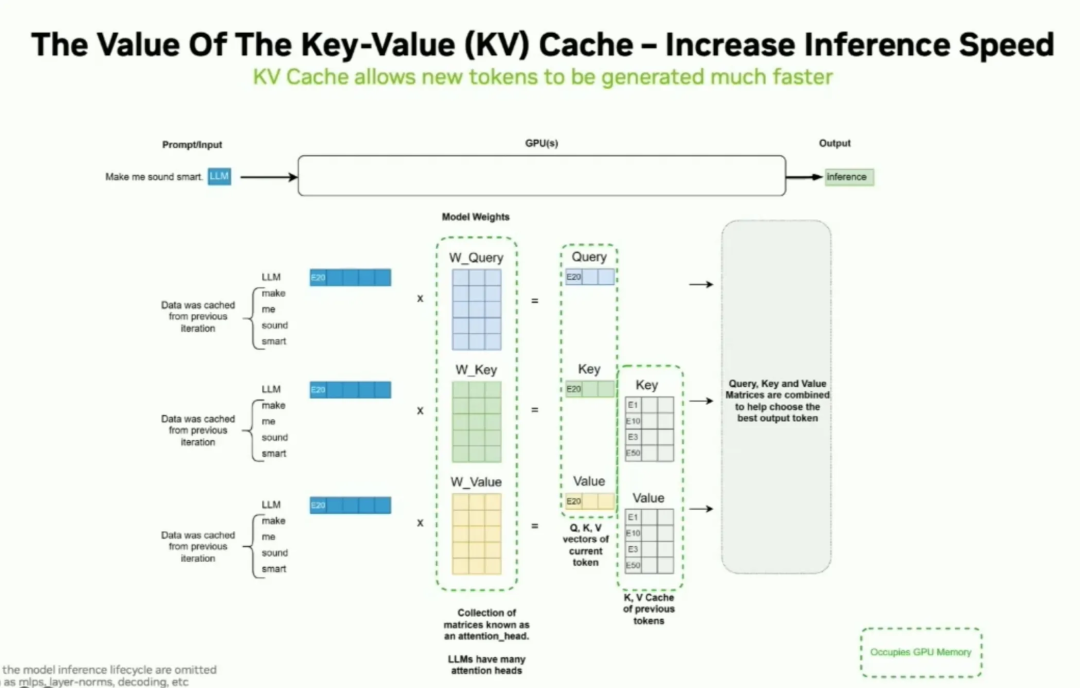
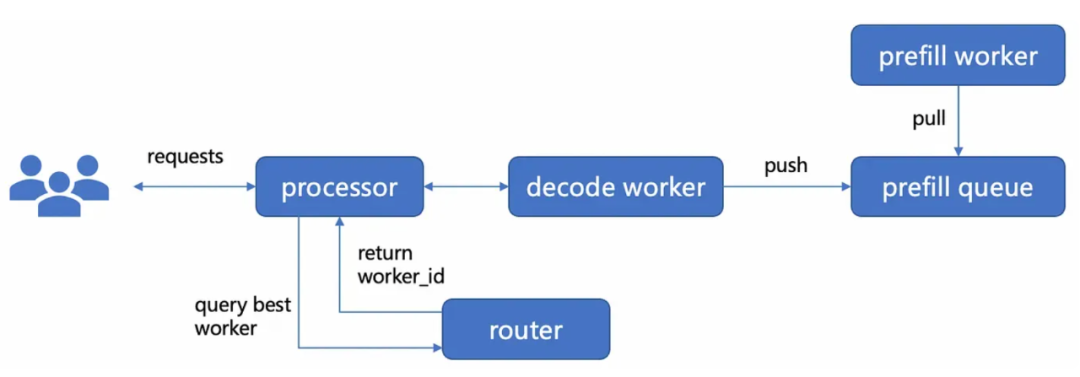
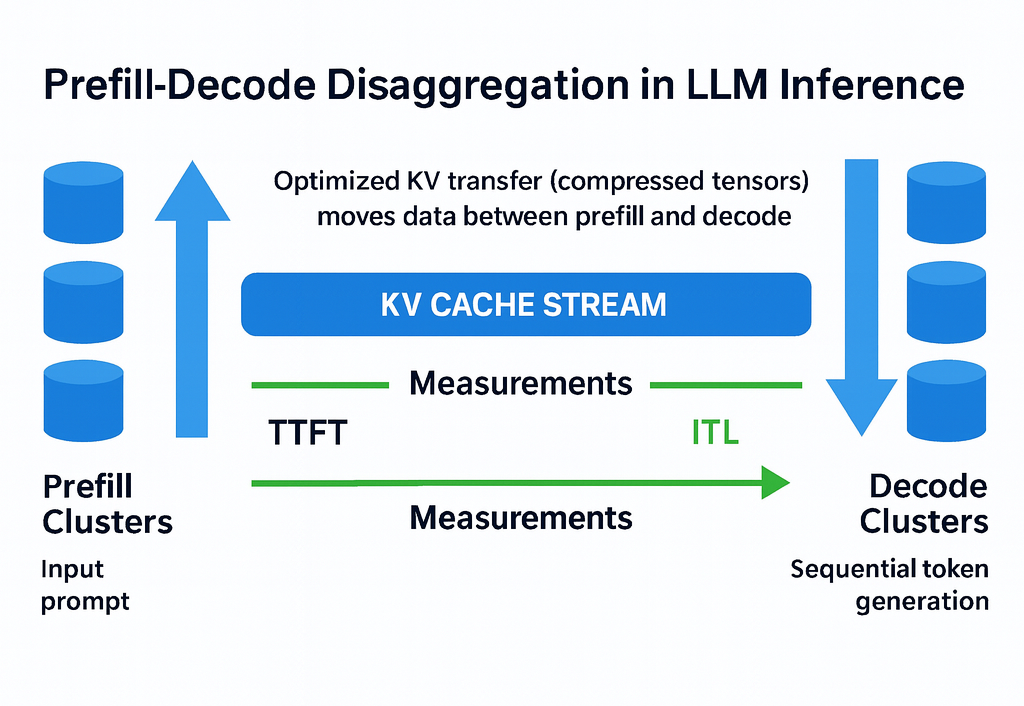
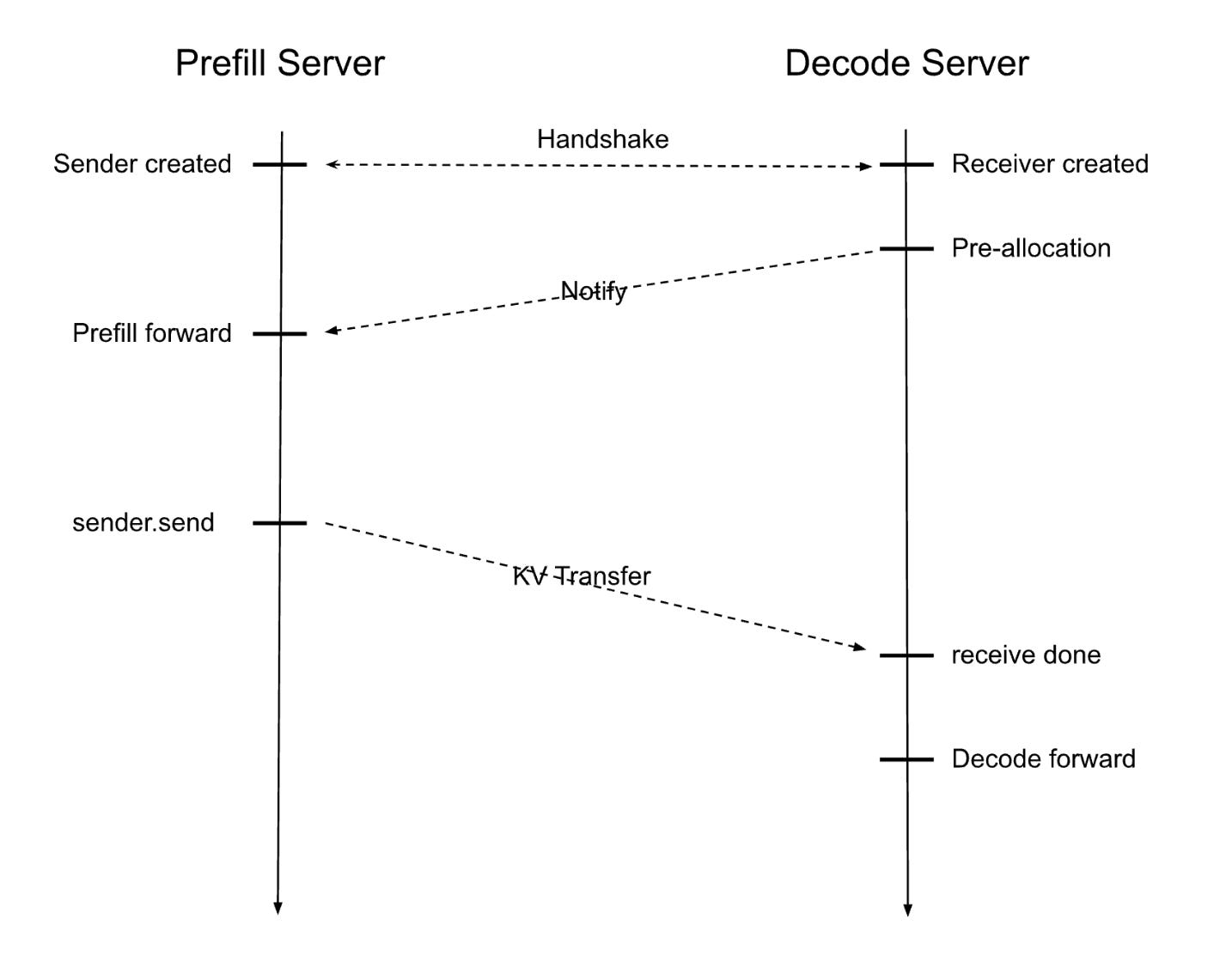
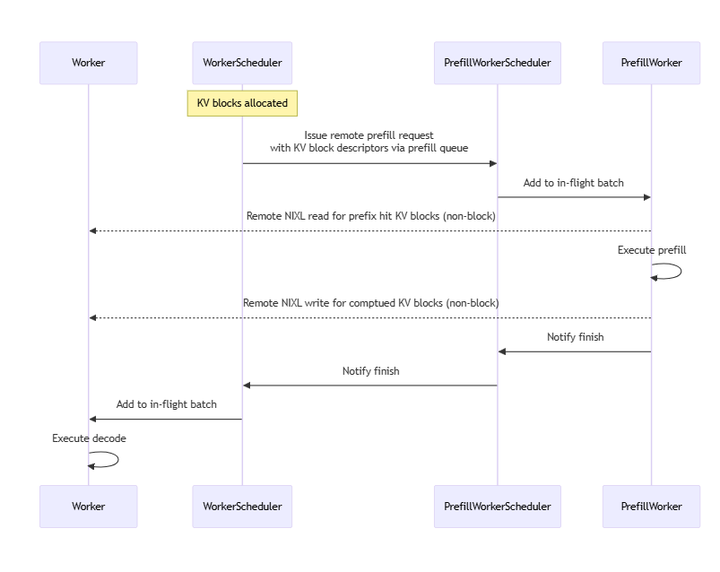
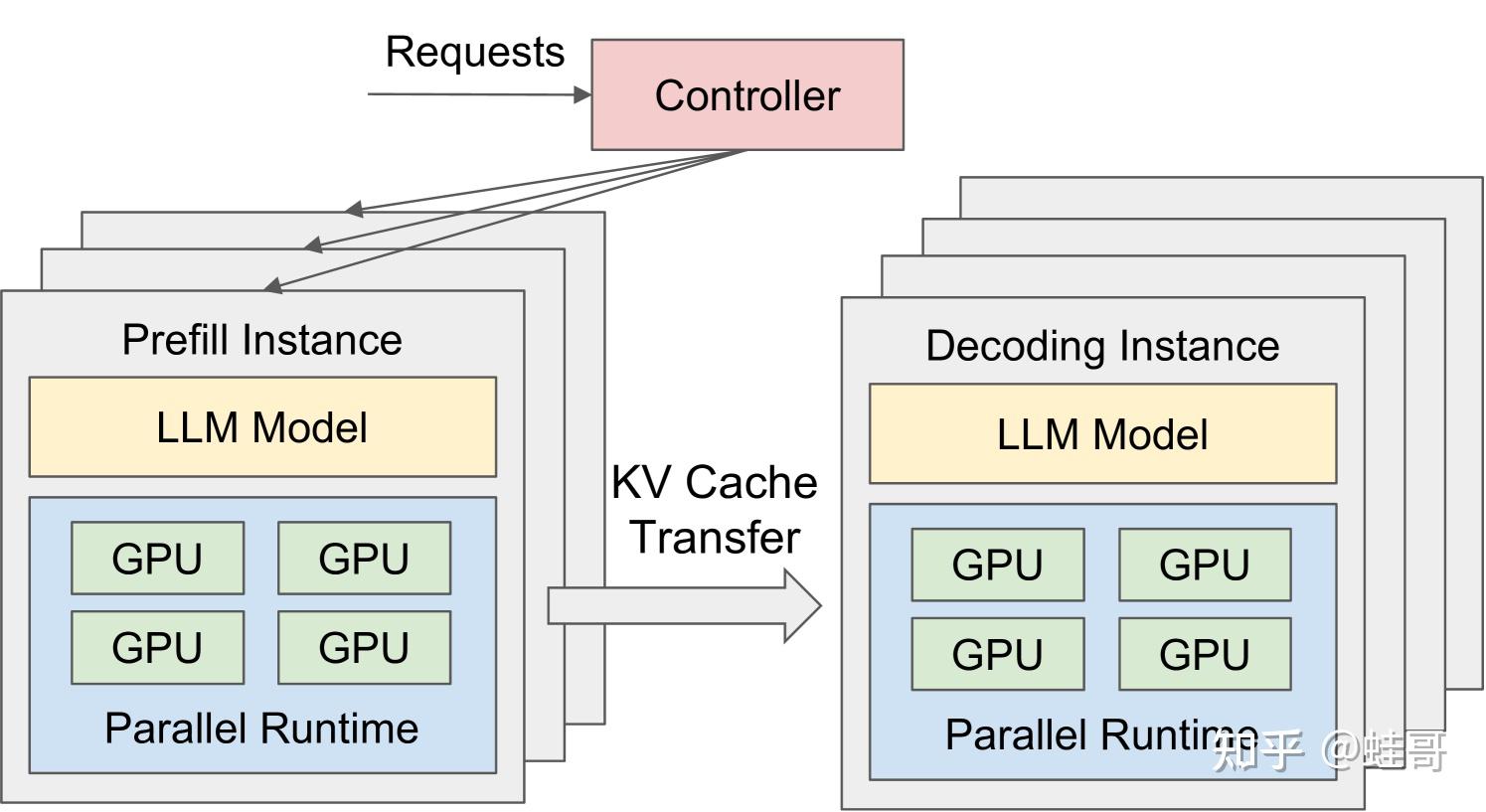
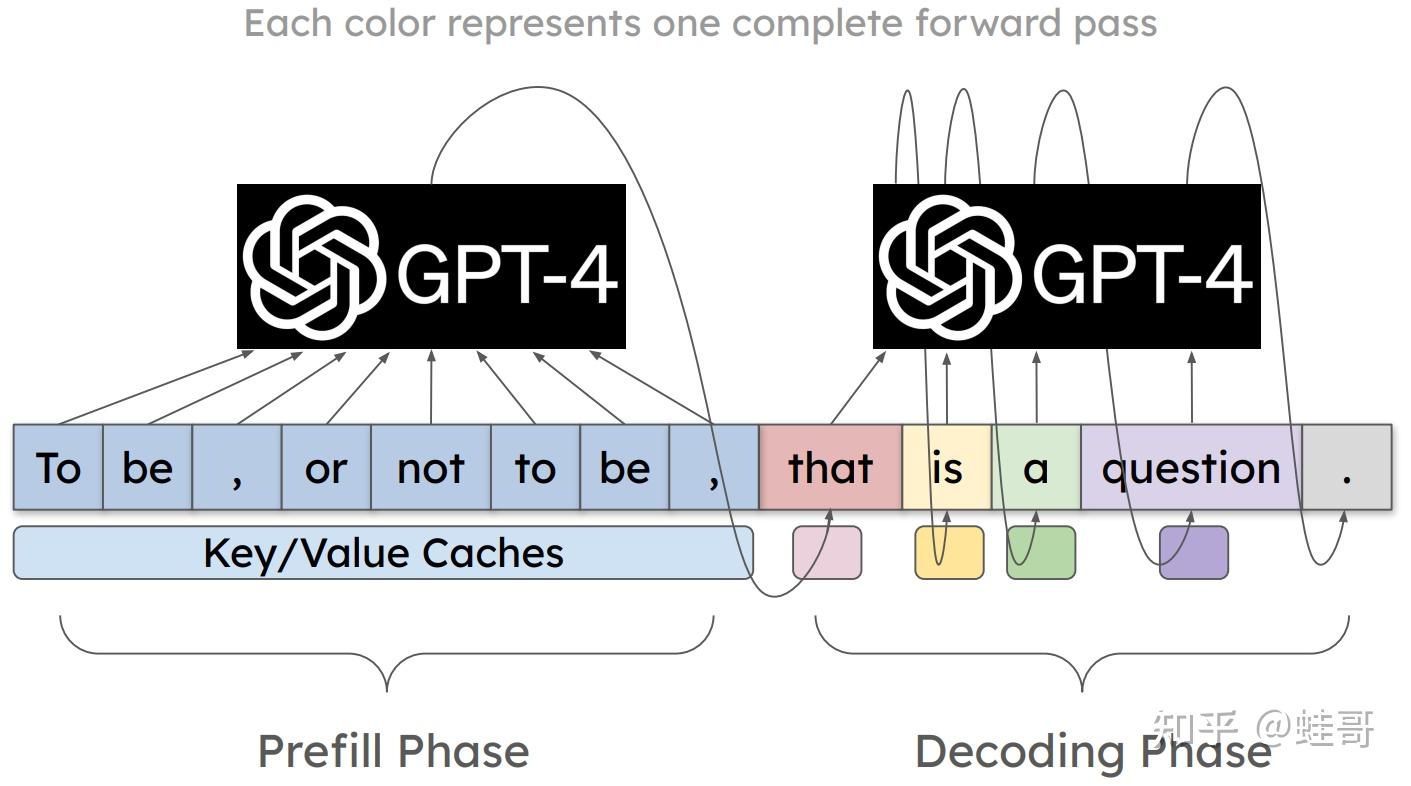
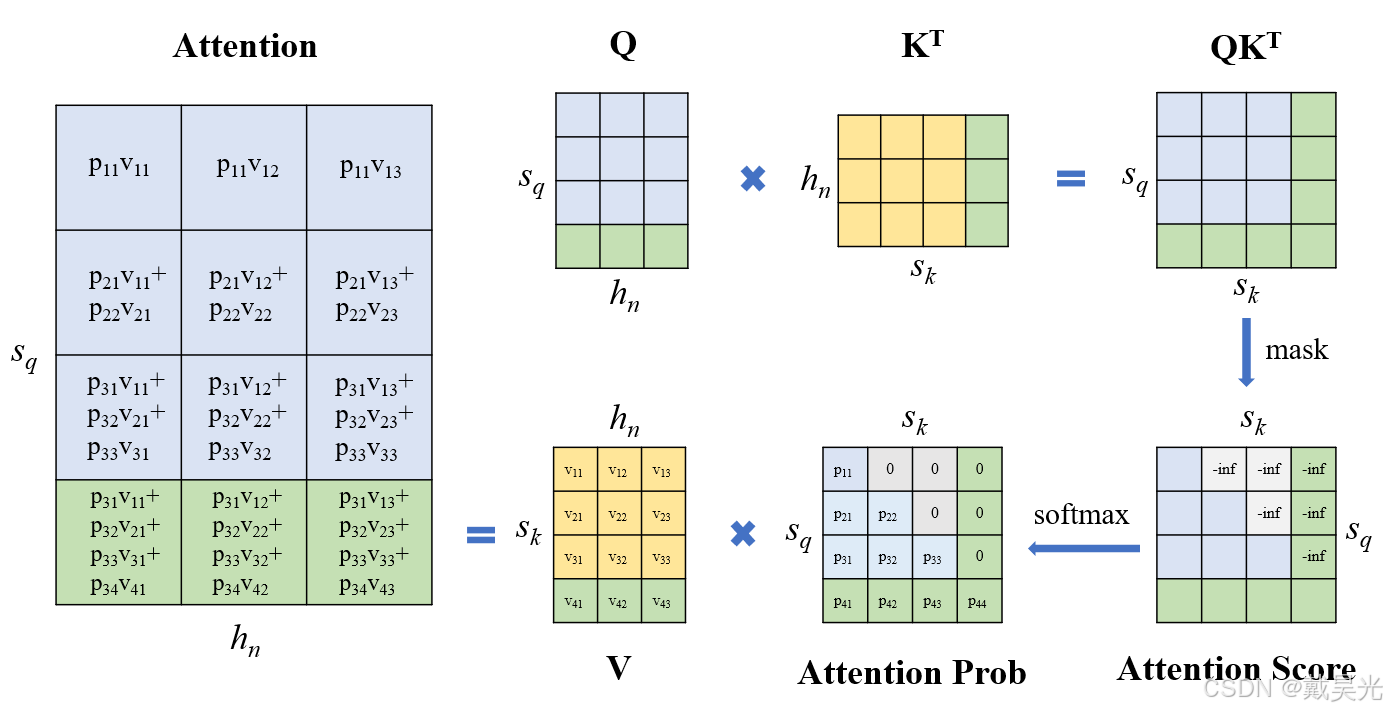
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
大模型推理优化Prefill 和 Decoding 分离原理详解-CSDN博客
DistServe: Disaggregating Prefill and Decoding for Goodput-optimized ...
Review-Distserve: Disaggregating Prefill and Decoding for Goodput ...
Decoding Games Printable
Recognizing and Decoding Transformations: General Form Guide - Studocu
DistServe: disaggregating prefill and decoding for goodput-optimized ...
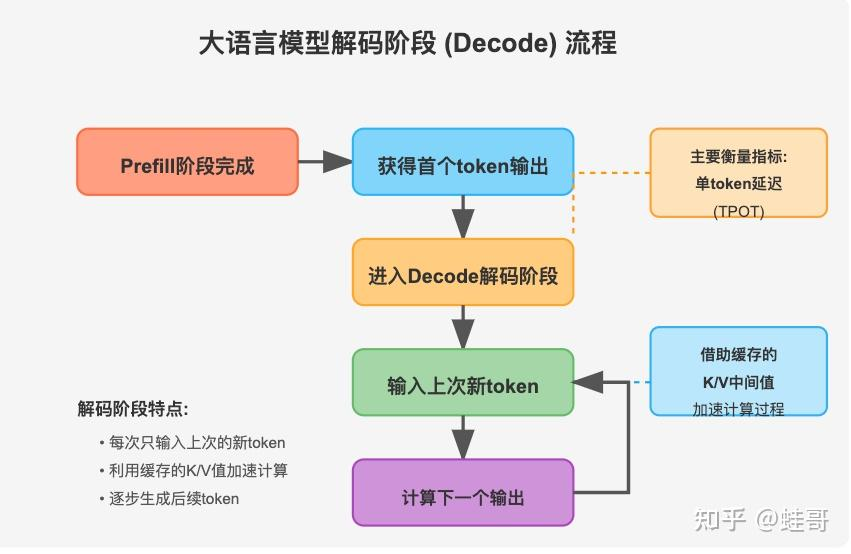
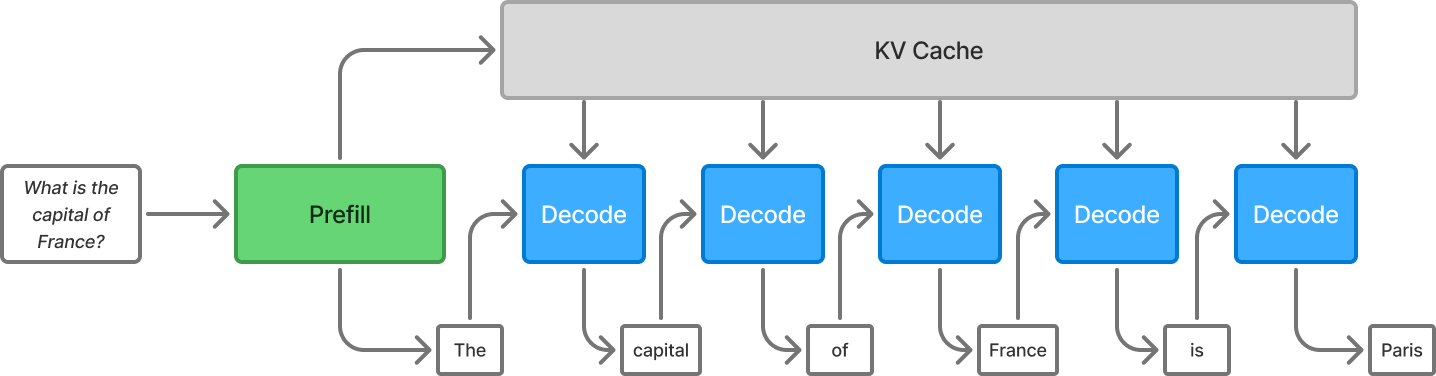
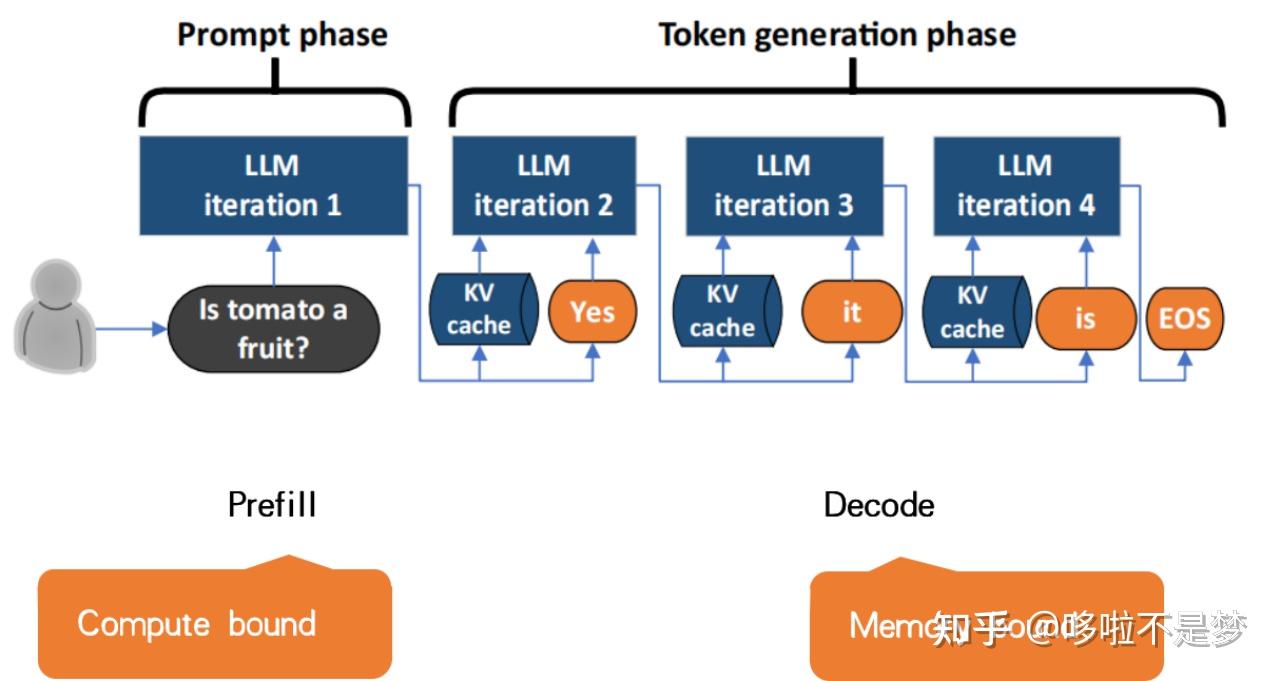
Understanding the Two Key Stages of LLM Inference: Prefill and Decode ...
LLM大模型系列(十):深度解析 Prefill-Decode 分离式部署架构_prefill和decode-CSDN博客
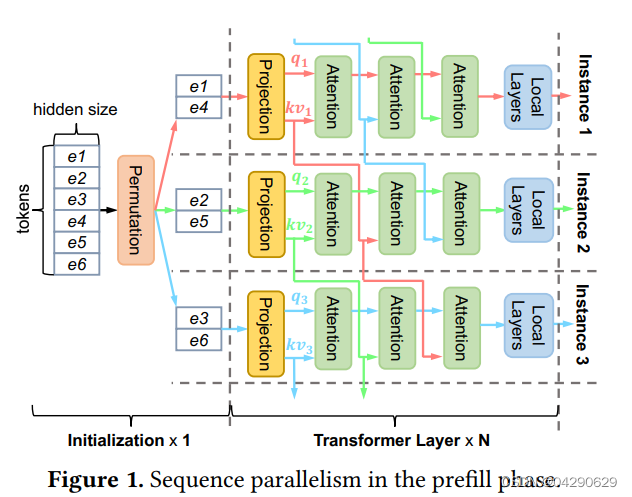
LoongServe 论文解读:prefill/decode 分离、弹性并行、零 KV Cache 迁移开销 - 知乎
深入浅出,一文理解LLM的推理流程_chunked prefill-CSDN博客
LLM推理优化 - Prefill-Decode分离式推理架构 - 知乎
GLM-4 (6) - KV Cache / Prefill & Decode_prefill和decode-CSDN博客
Runtime and memory required for LLMs Training. | Medium
Prefill and Decode for Concurrent Requests - Optimizing LLM Performance
The Shift to Distributed LLM Inference: 3 Key Technologies Breaking ...
全!新!LLM推理加速调研_prefilling decoding-CSDN博客
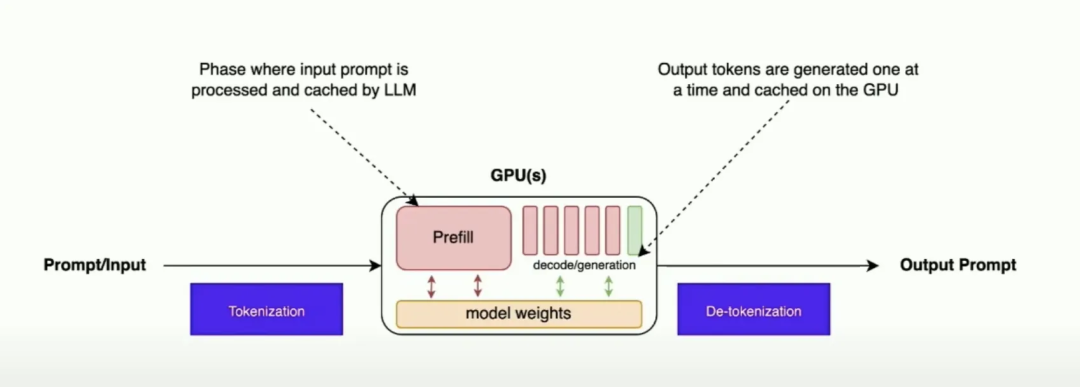
How does LLM inference work? | LLM Inference Handbook
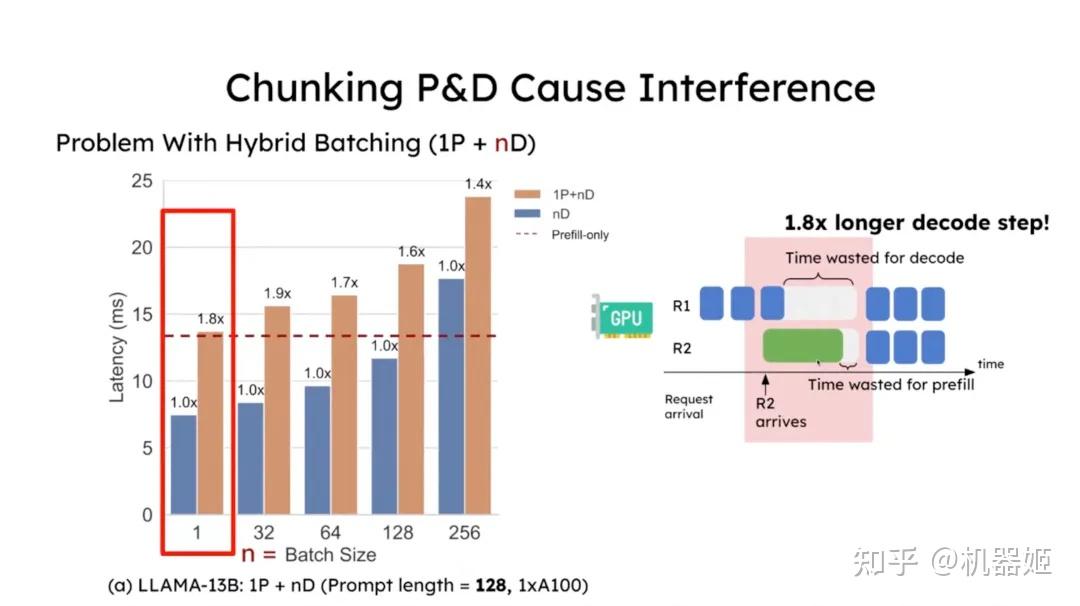
[PDF] SARATHI: Efficient LLM Inference by Piggybacking Decodes with ...
A Guide to LLM Inference (Part 1): Foundations – Stephen Carmody
(PDF) Prefill-Decode Aggregation or Disaggregation? Unifying Both for ...
Streamlining AI Inference Performance and Deployment with NVIDIA ...
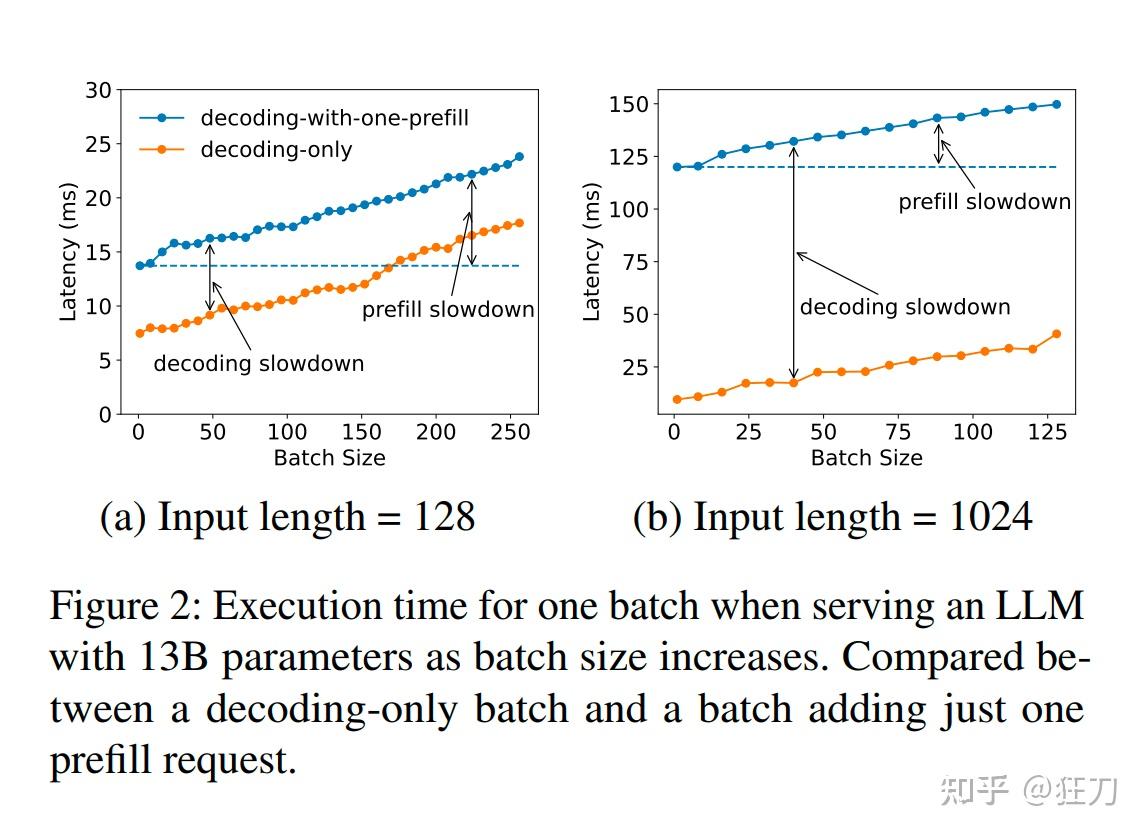
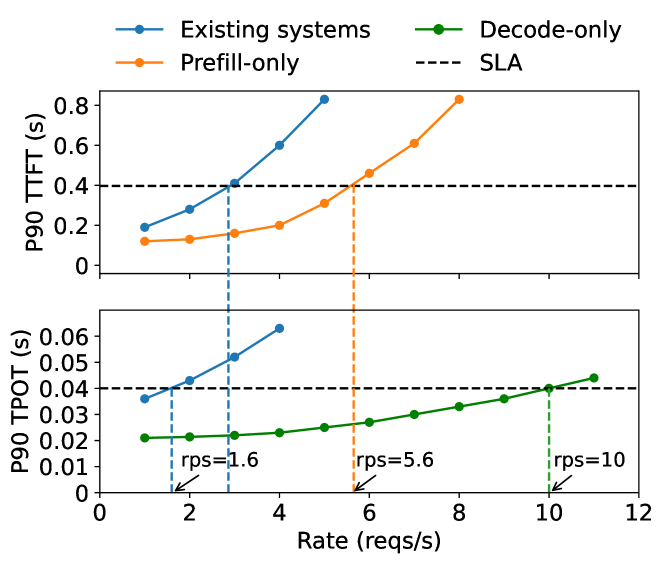
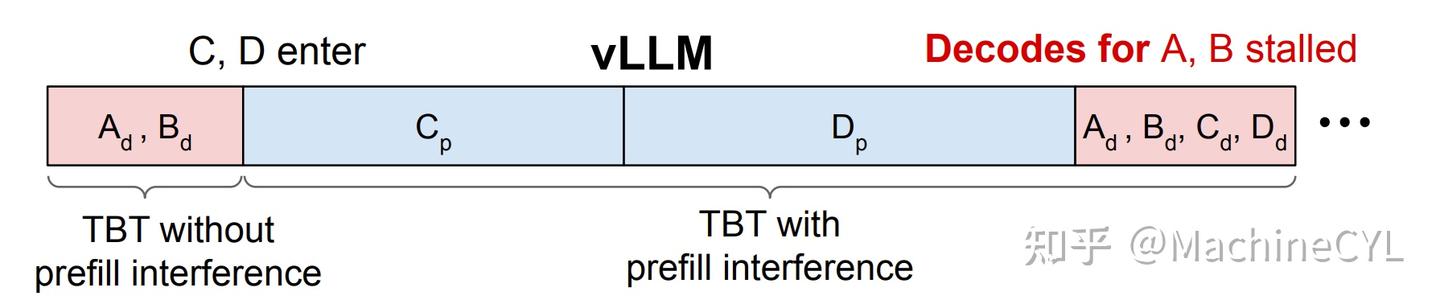
Throughput is Not All You Need: Maximizing Goodput in LLM Serving using ...
Must-Know Facts Before Studying LLM Serving | by Avacodo | Medium
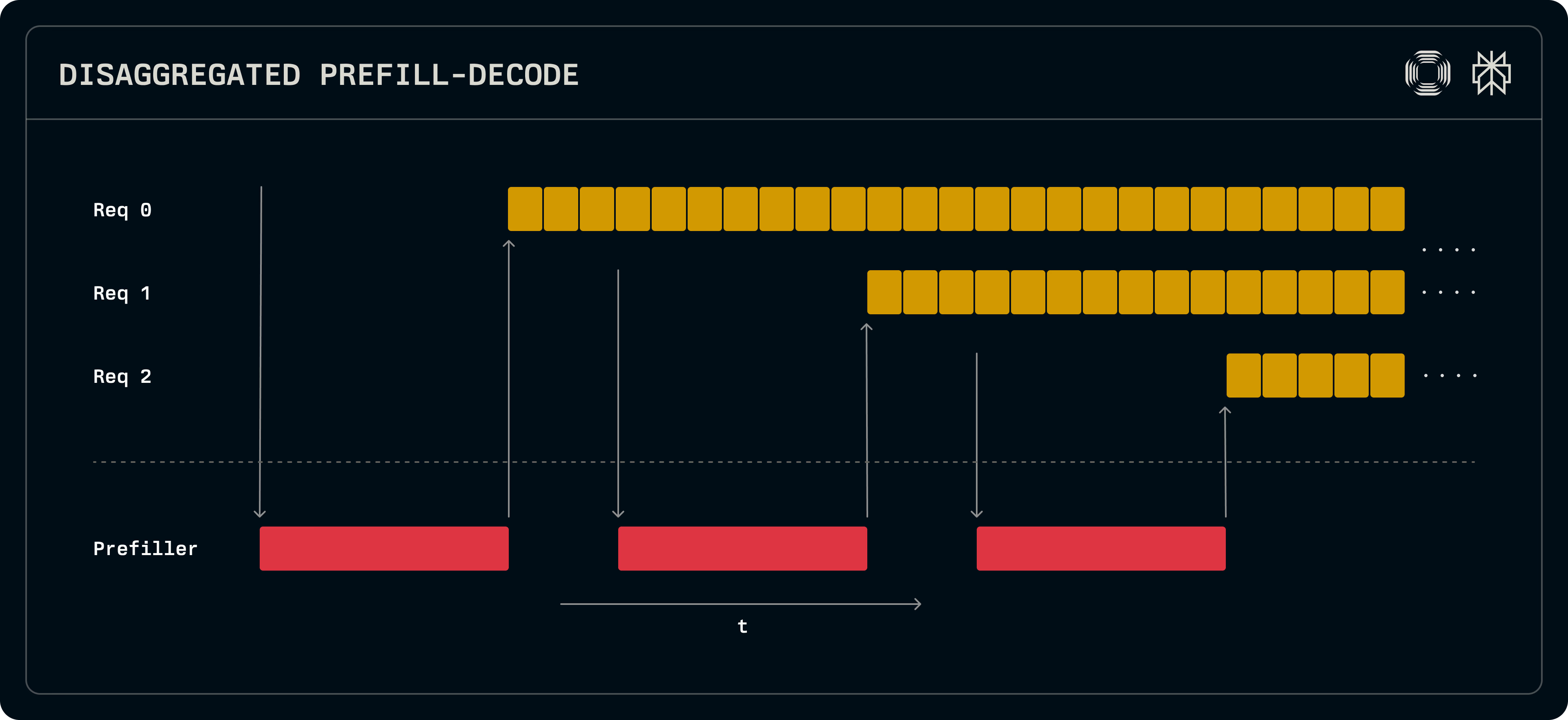
[LLM 推理服务优化] DistServe速读——Prefill & Decode解耦、模型并行策略&GPU资源分配解耦 - 知乎
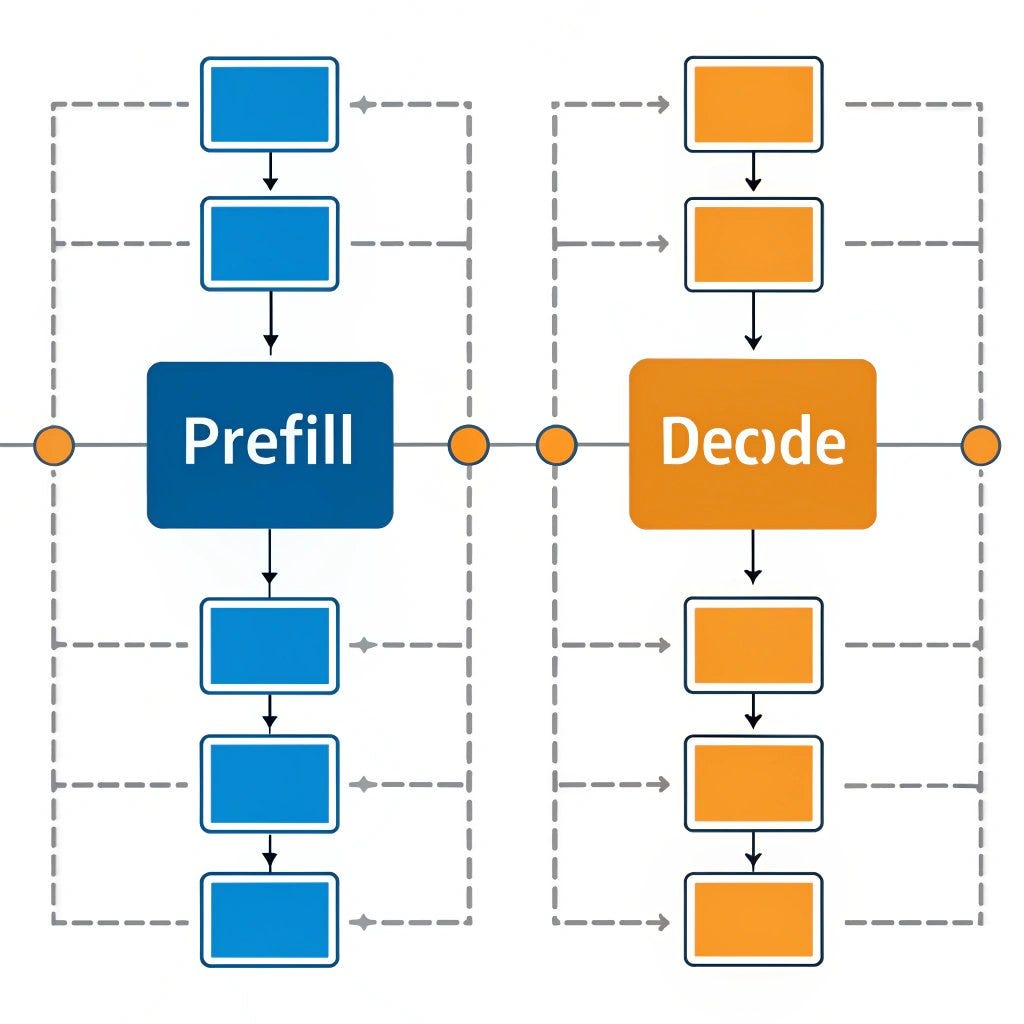
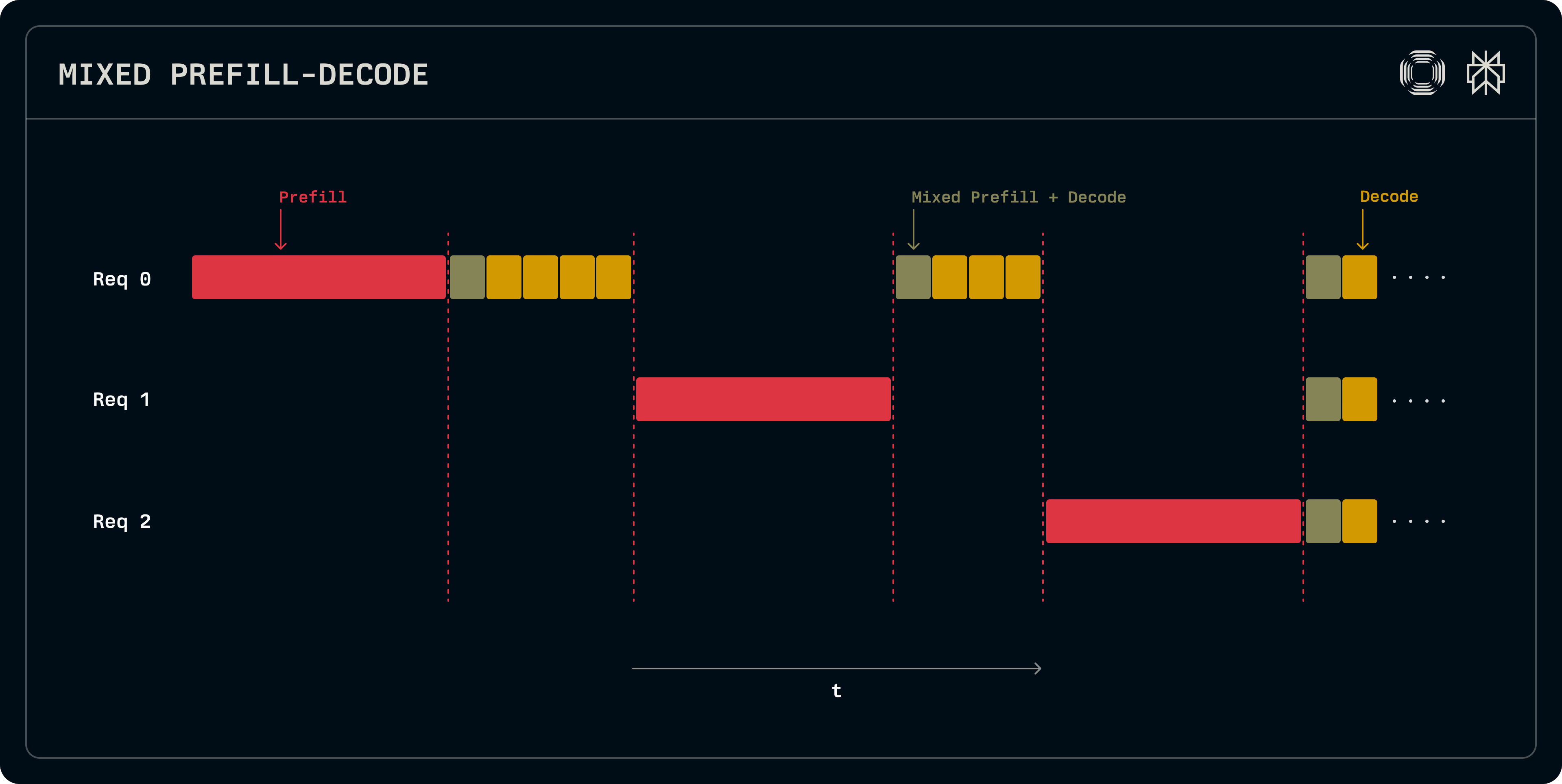
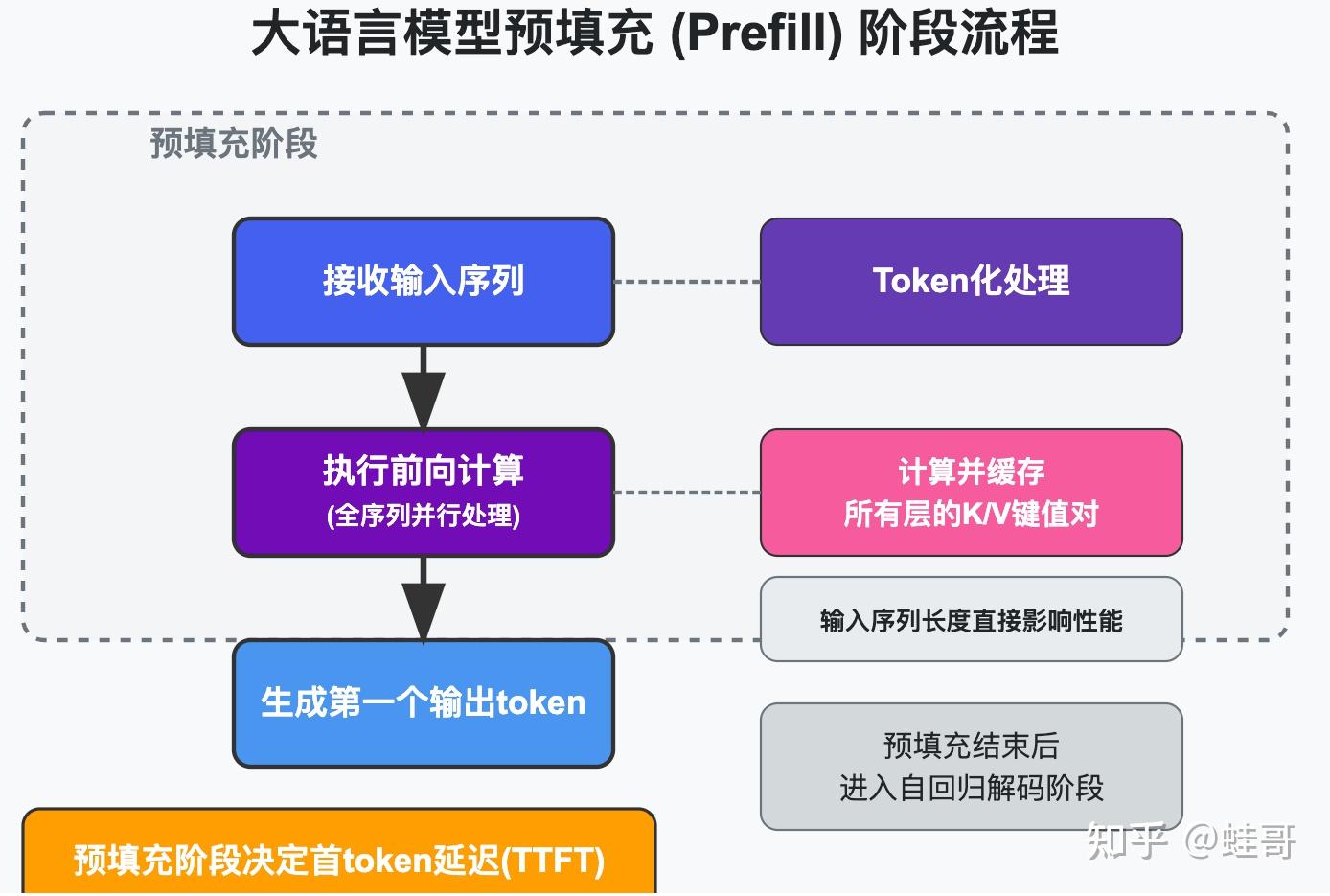
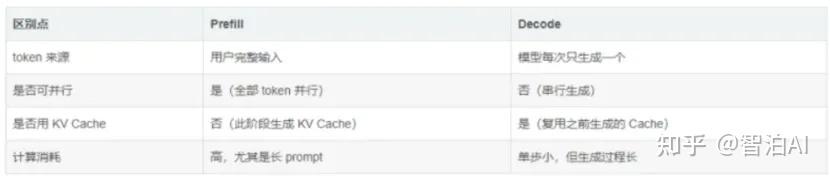
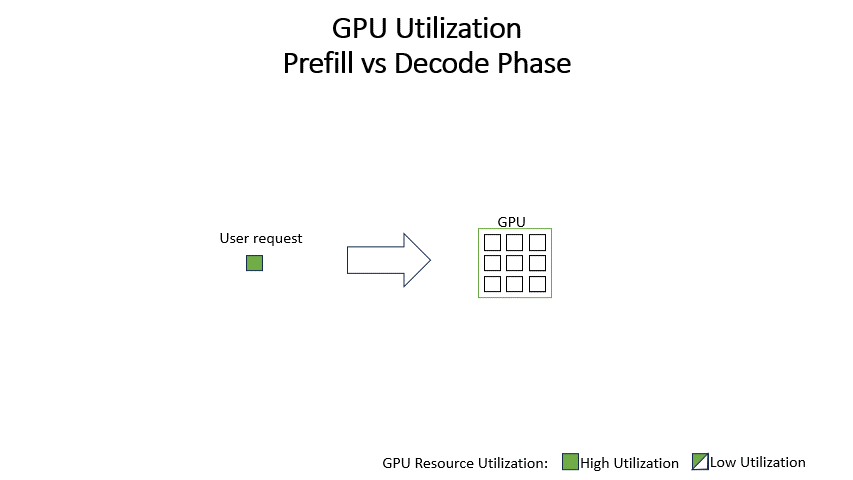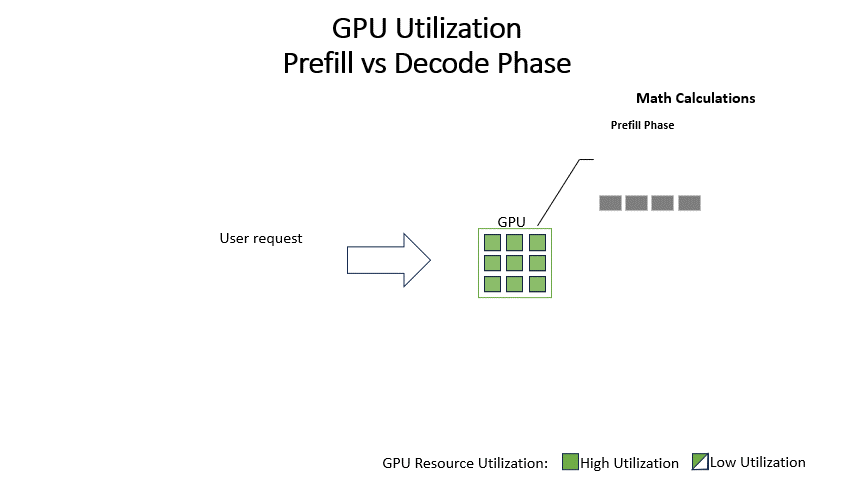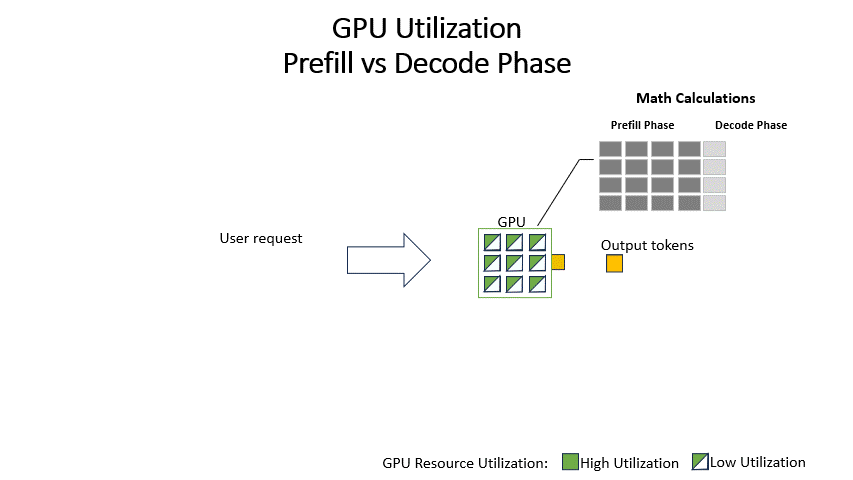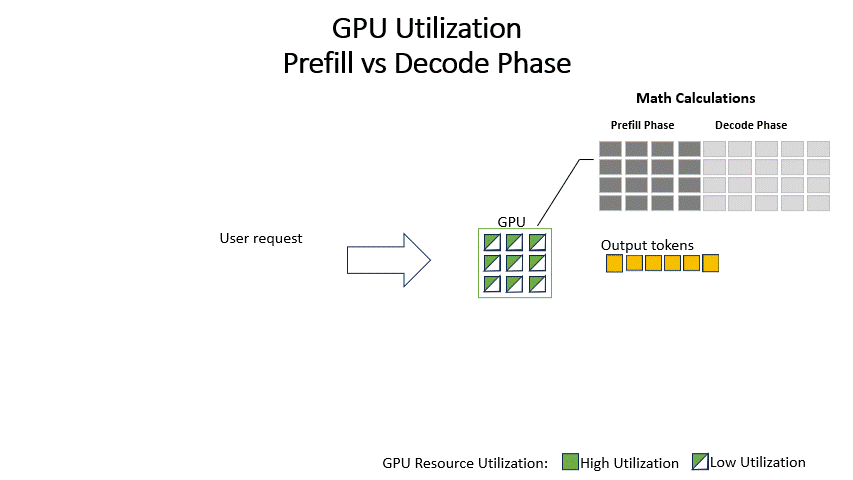
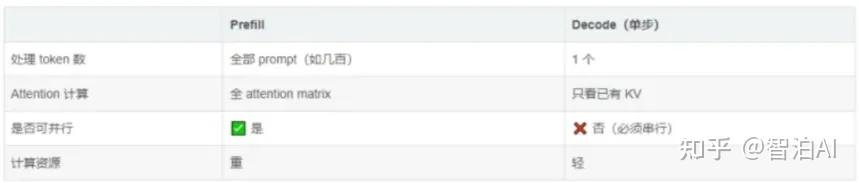
为什么LLM推理要分成Prefill和Decode两个阶段? - 知乎
LLM Serving有效吞吐量的最大化实现 - 智源社区
VoltanaLLM: Feedback-Driven Frequency Control and Routing for Energy ...
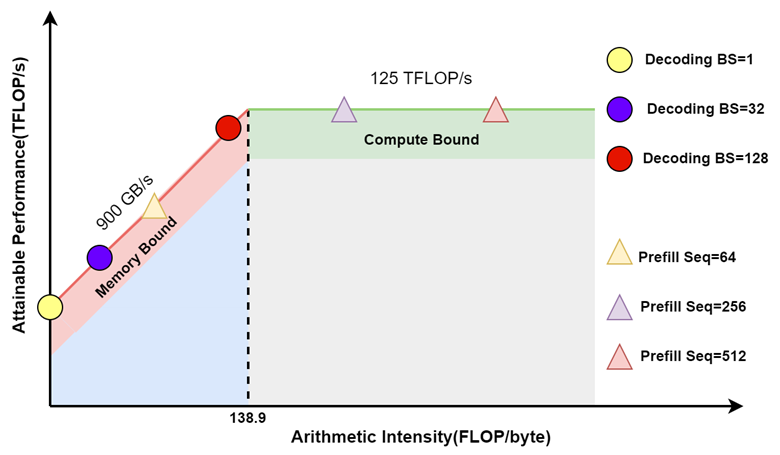
LLM Inference - Hw-Sw Optimizations
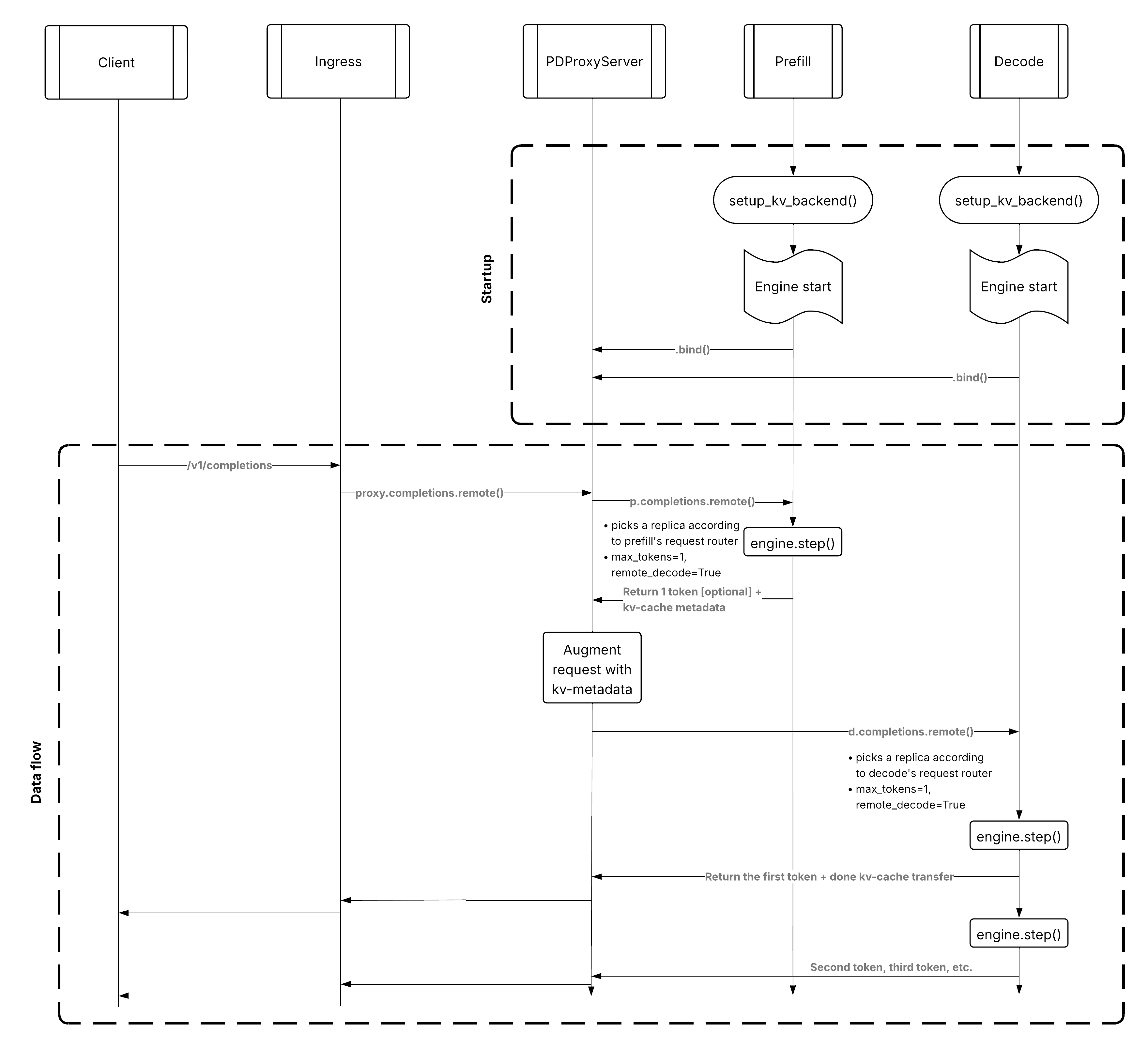
Understanding Prefill & Decode Disaggregation in LLM Serving | by ...
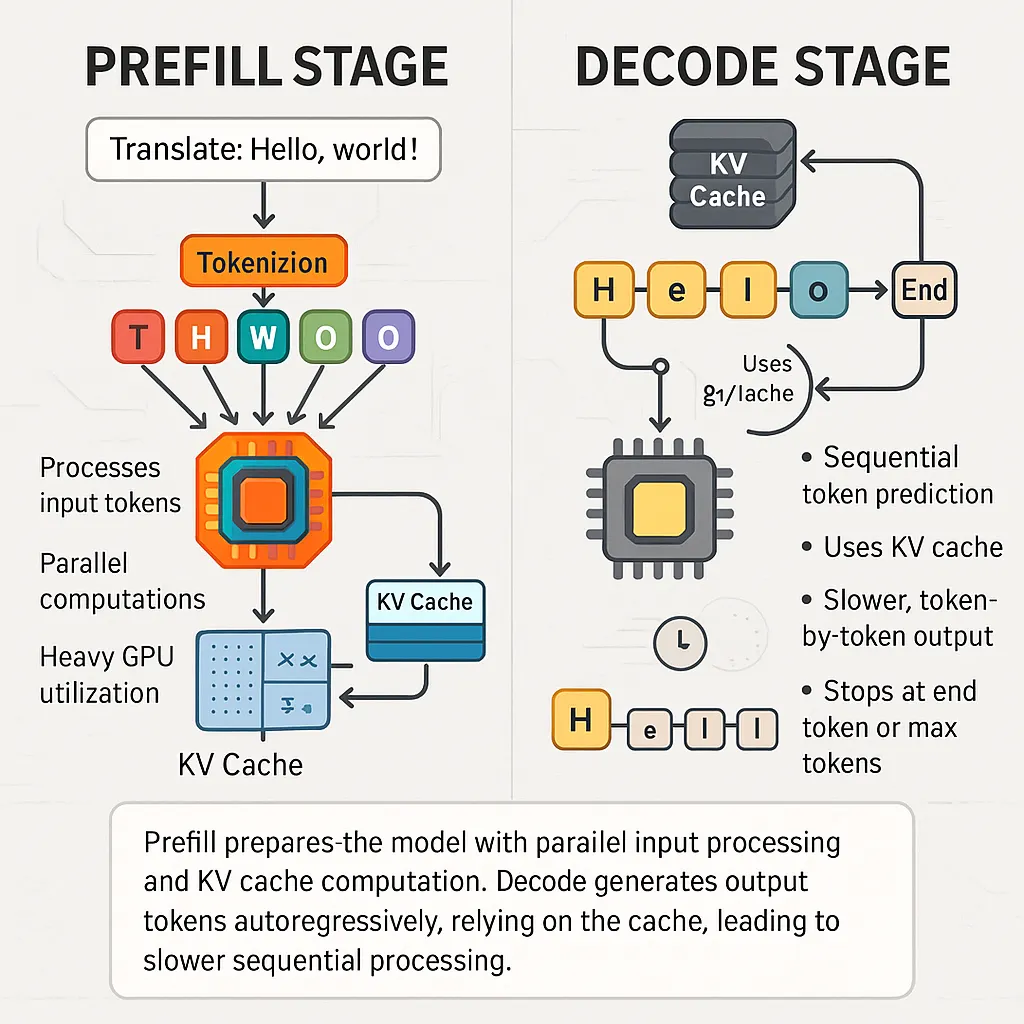
Understanding LLM Inference Basics: Prefill and Decode, TTFT, and ITL ...
AI Optimization Lecture 01 - Prefill vs Decode - Mastering LLM ...
一文搞懂LLM推理加速:Prefill-Decode分离技术深度解析_disaggregated prefill-decode-CSDN博客
Aikipedia: Prefill–Decode Disaggregation – Champaign Magazine
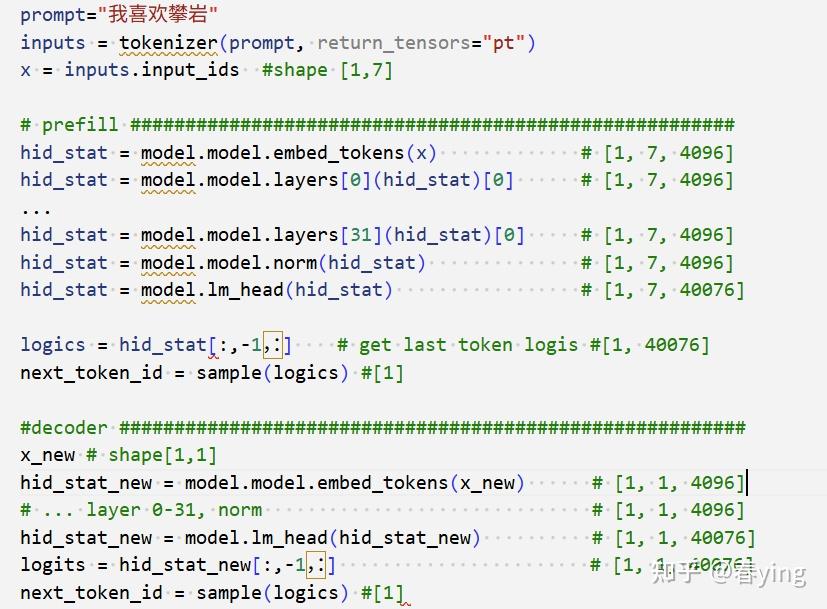
LLM 推理过程 · LLMpedia
deepseek大模型推理prefill/decode阶段研究分析_deepseek prefill-CSDN博客
打破算力瓶颈:LLM推理中Prefill/Decode分离架构深度解析-腾讯云开发者社区-腾讯云
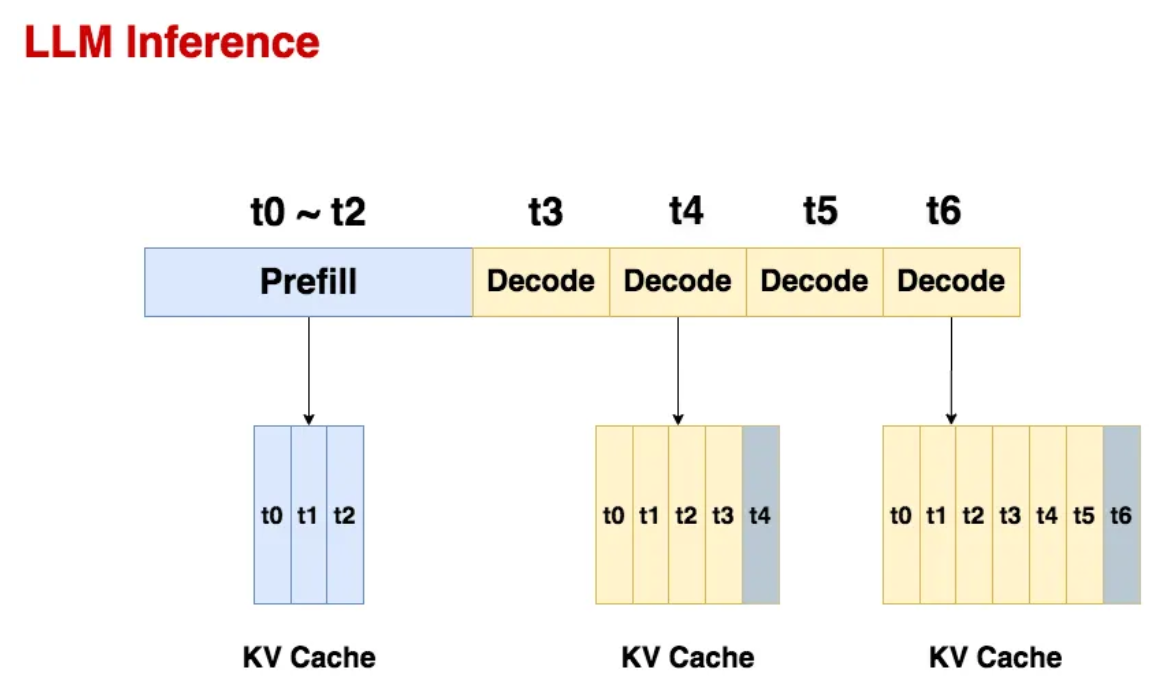
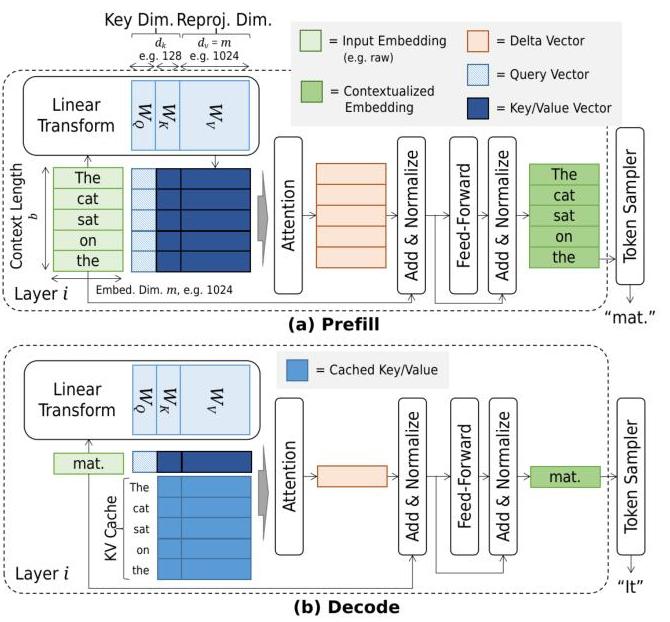
LLM Inference Series: 4. KV caching, a deeper look | by Pierre Lienhart ...
LoongServe论文解读:prefill/decode分离、弹性并行、零KV Cache迁移_prefill decode-CSDN博客
GitHub - chen-ace/LLM-Prefill-Decode-Benchmark: 通过实验对比LLM推理中Prefill和 ...
Splitting LLM inference across different hardware platforms | Gimlet Blog
LLM大模型系列(十):深度解析 Prefill-Decode 分离式部署架构_mob64ca14095513的技术博客_51CTO博客
打造高性能大模型推理平台之Prefill、Decode分离系列(一):微软新作SplitWise,通过将PD分离提高GPU的利用率 _ 同行 ...
🌸万字解析:大规模语言模型(LLM)推理中的Prefill与Decode分离方案 - 技术栈
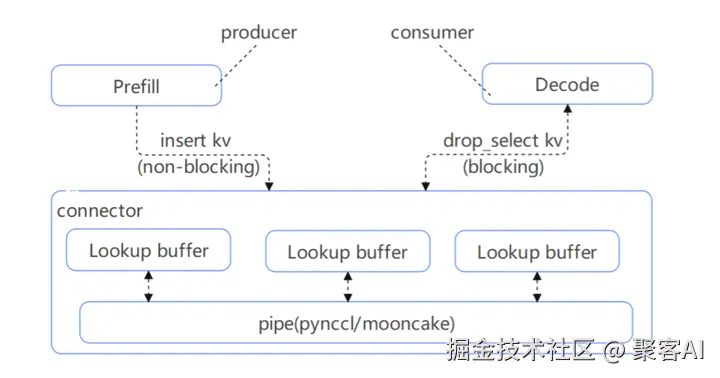
分离部署多个prefill实例与多个decode实例支持问题 · Issue #27 · LLMServe/DistServe · GitHub
大模型系列:深度解析 Prefill-Decode 分离式部署架构 - 知乎
Prefill and Decode in 2 Minutes: AI Inference Explained in Simple Words ...
A Survey of LLM Inference Systems | alphaXiv
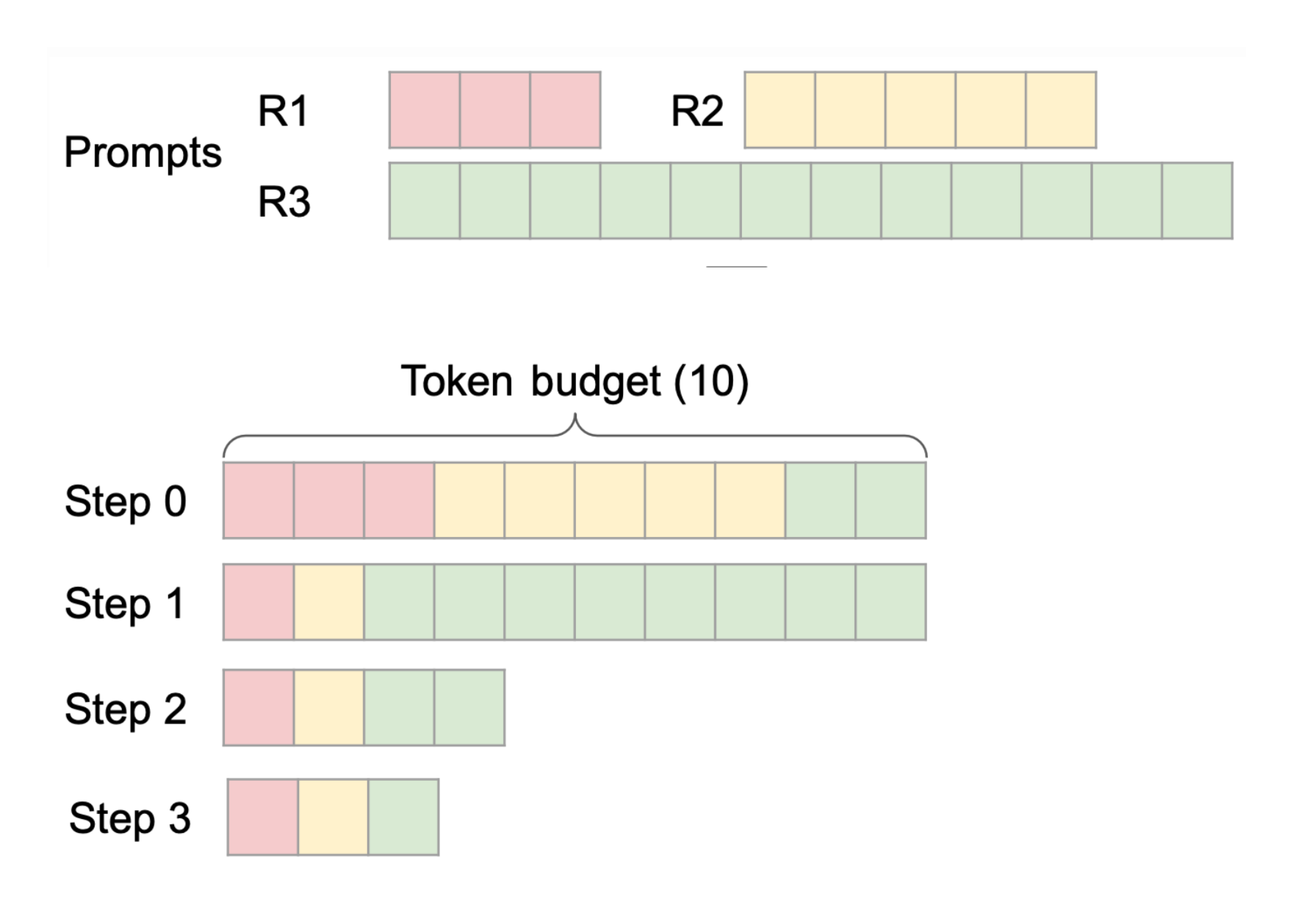
Chunked-Prefills 分块预填充机制详解 - 知乎
大模型推理优化-Prefill/Decoding分离 - 知乎
Demystifying AI Inference Deployments for Trillion Parameter Large ...
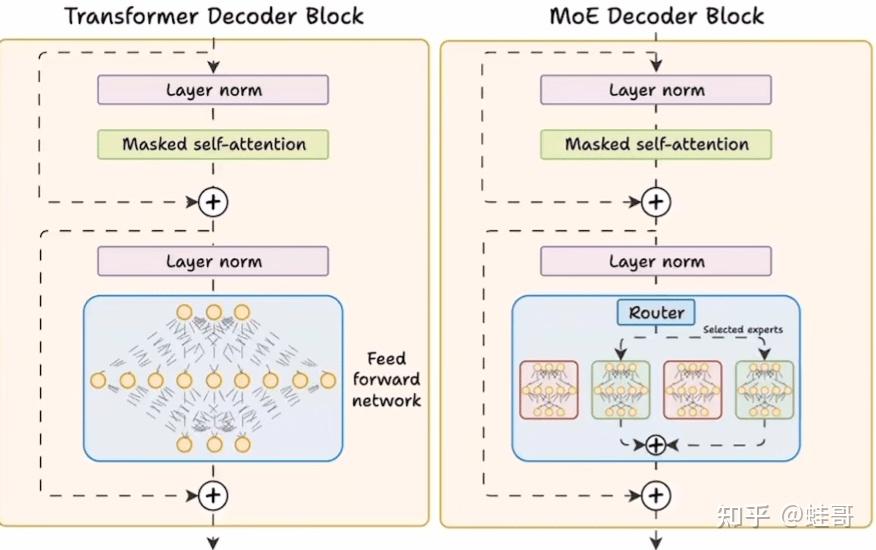
MoE Inference Economics from First Principles
基于 chunked prefill 理解 prefill 和 decode 的计算特性 - 知乎
vllm chunked-prefill性能评估_chunked prefill-CSDN博客
vLLM V1: Accelerating multimodal inference for large language models ...
Prefill-decode disaggregation | LLM Inference Handbook
大模型Prefill-Decode分离式推理架构解读 - 知乎
vllm chunked-prefill性能评估 - 知乎
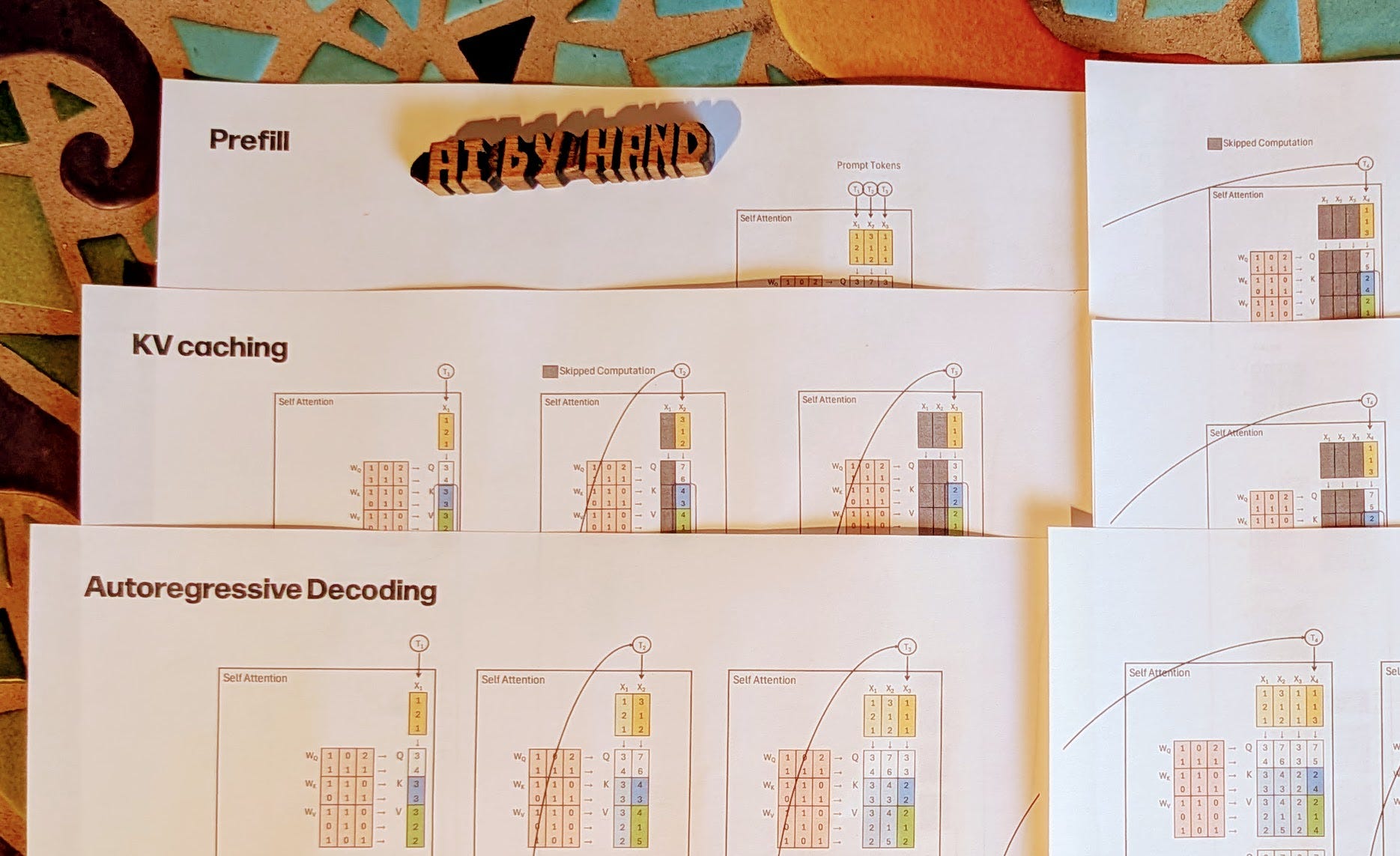
7. KV Cache, Prefill, Decode - by Prof. Tom Yeh
【有啥问啥】大模型效率部署之Prefill-Decode分离_prefill decode-CSDN博客
Understanding the Prefill-decode Disaggregation in LLM Inference ...
全面解析 LLM 推理性能的关键因素_llm prefill-CSDN博客
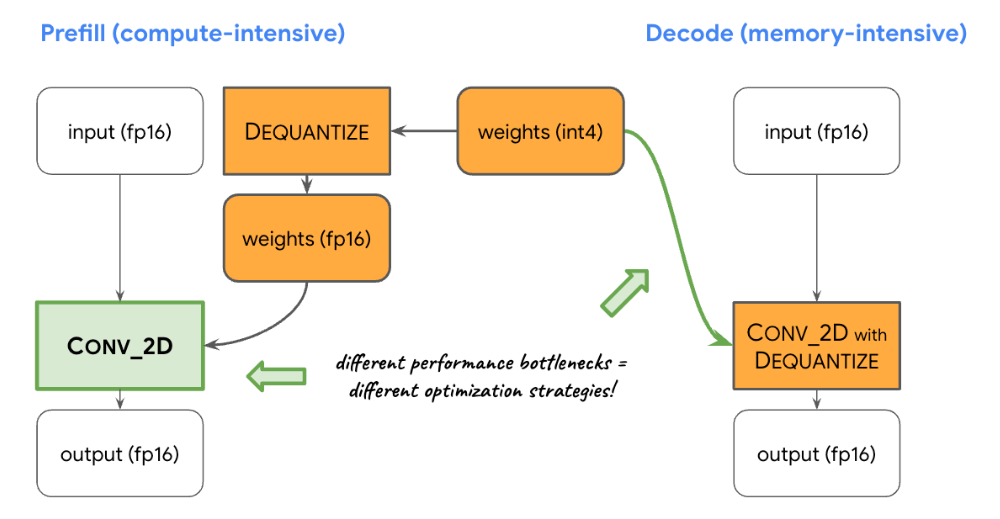
Large Language Models On-Device with MediaPipe and TensorFlow Lite ...
为什么现在的LLM都是Decoder-only的架构? - 知乎
跑一个大模型入门LLM(part2) - 知乎
打造高性能大模型推理平台之Prefill、Decode分离系列(一):微软新作SplitWise,通过将PD分离提高GPU的利用率哆啦不是梦 ...
Prefill-decode disaggregation — Ray 2.54.0
Benchmarking Prefill–Decode ratios: fixed vs dynamic - dstack