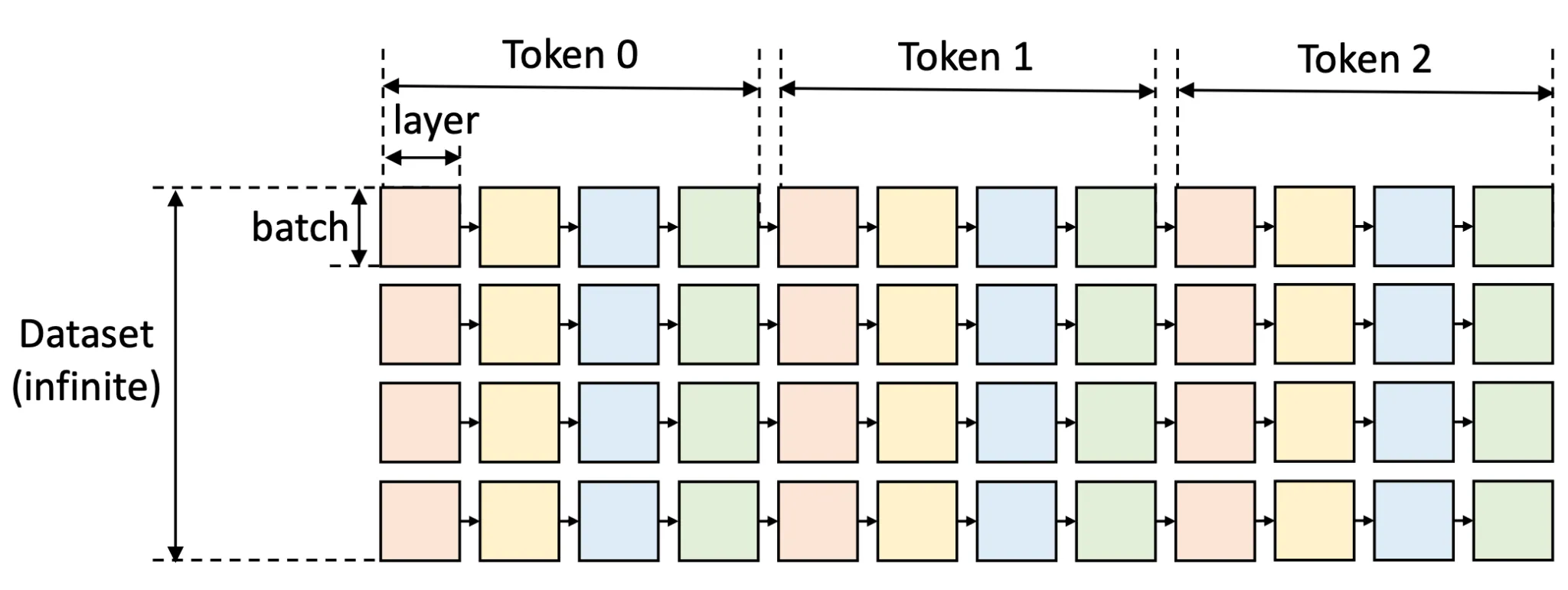
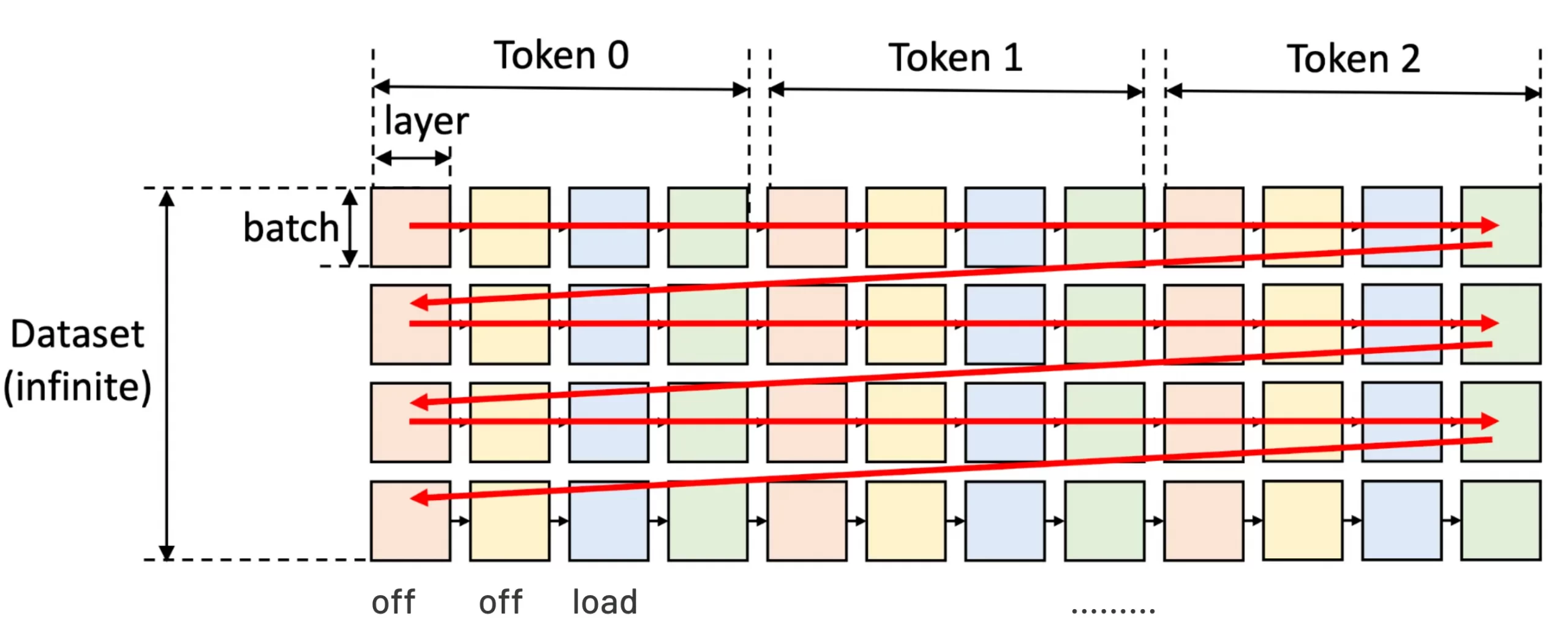
Showing 119 of 119on this page. Filters & sort apply to loaded results; URL updates for sharing.119 of 119 on this page
Fastest LLM Inference with FREE Groq API ⚡️ - YouTube
Cerebras Now The Fastest LLM Inference Processor; Its Not Even Close
Enhance Efficiency: Fastest LLM API for Developers - Novita
Getting Started with Groq API : Fastest Ever Inference Endpoint
Top 10 AI Inference Platforms in 2025: Comparing LLM API Providers
The FASTEST LLM Inference Endpoint Ever - YouTube
Build an API for LLM Inference using Rust: Super Fast on CPU - YouTube
OpenRouter - Use The LLM Inference API with the Lowest Cost - YouTube
Fastest LLM API Implementations: Boost Efficiency Now
Google's MediaPipe unveils experimental LLM inference API
Is the new Cerebras API the fastest LLM service provider? | benchmark ...
Introducing LMCache: Fastest LLM Inference Engine | Yuvraj Singh posted ...
The fastest open-source LLM #inference stack just landed. | Predibase
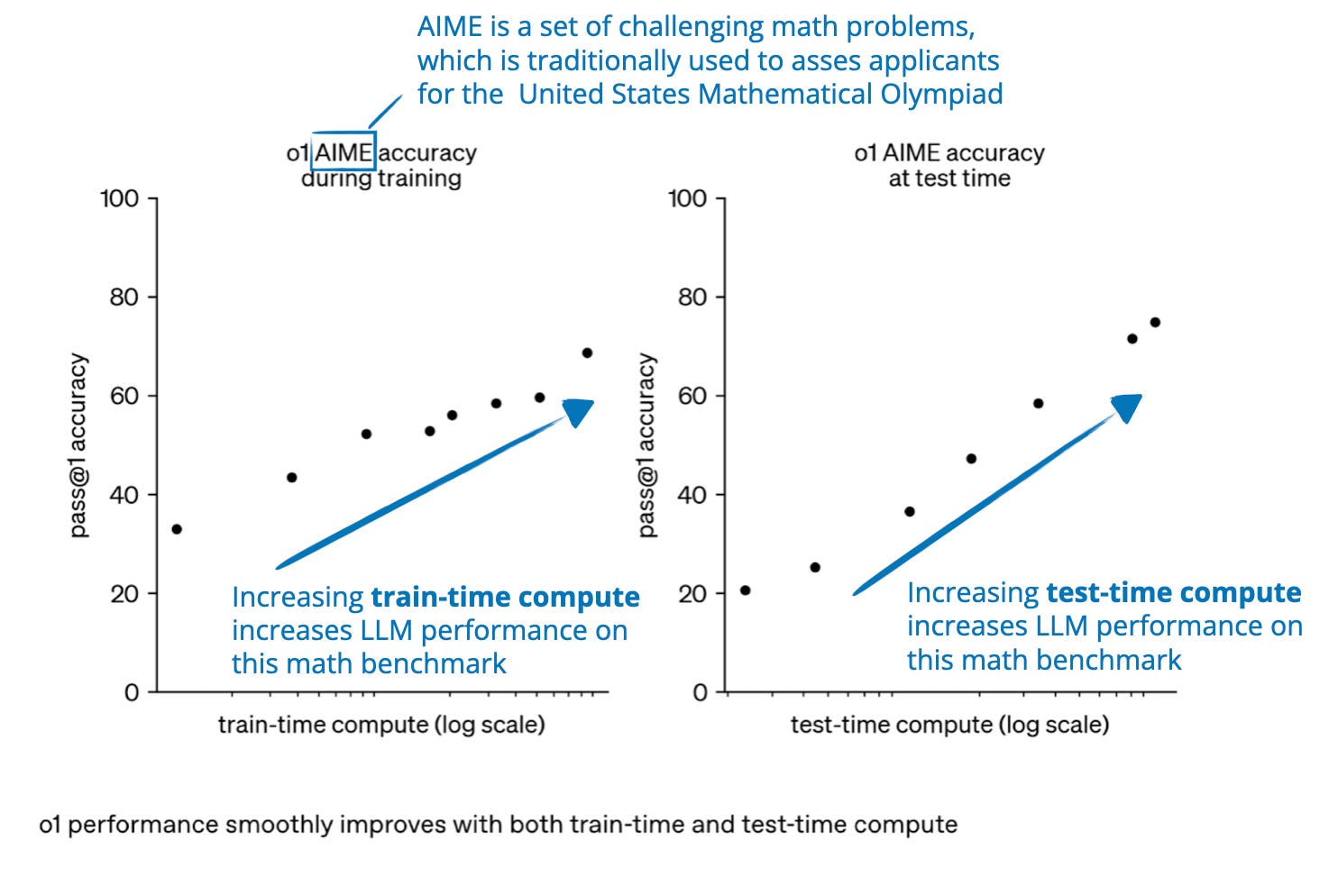
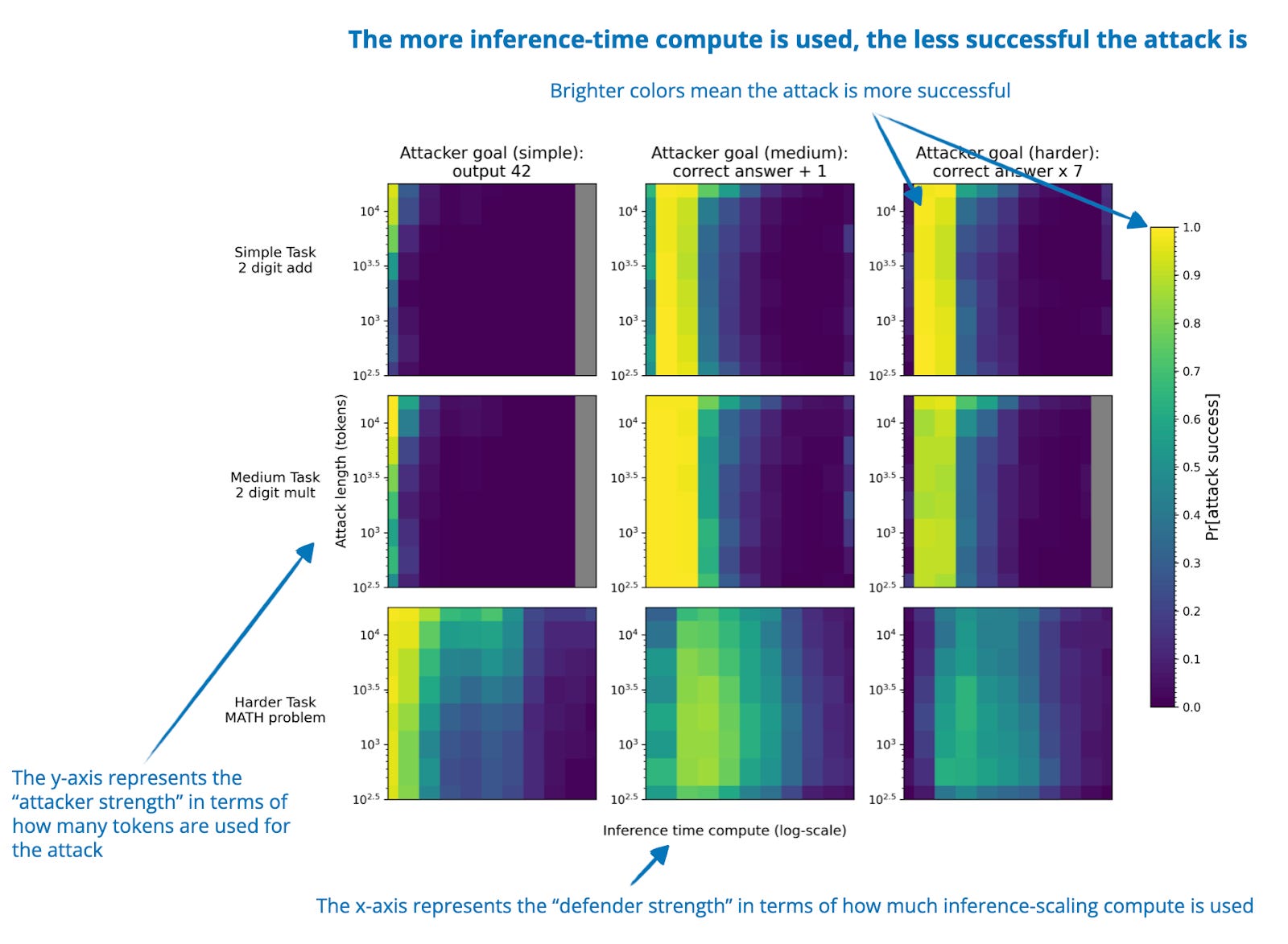
The State of LLM Reasoning Model Inference
A recipe for 50x faster local LLM inference | AI & ML Monthly - YouTube
Best LLM Inference Engines and Servers to Deploy LLMs in Production - Koyeb
The World’s Fastest LLM Inference: 3x Faster Than vLLM and TGI | by ...
LLM Inference Stages Diagram | Stable Diffusion Online
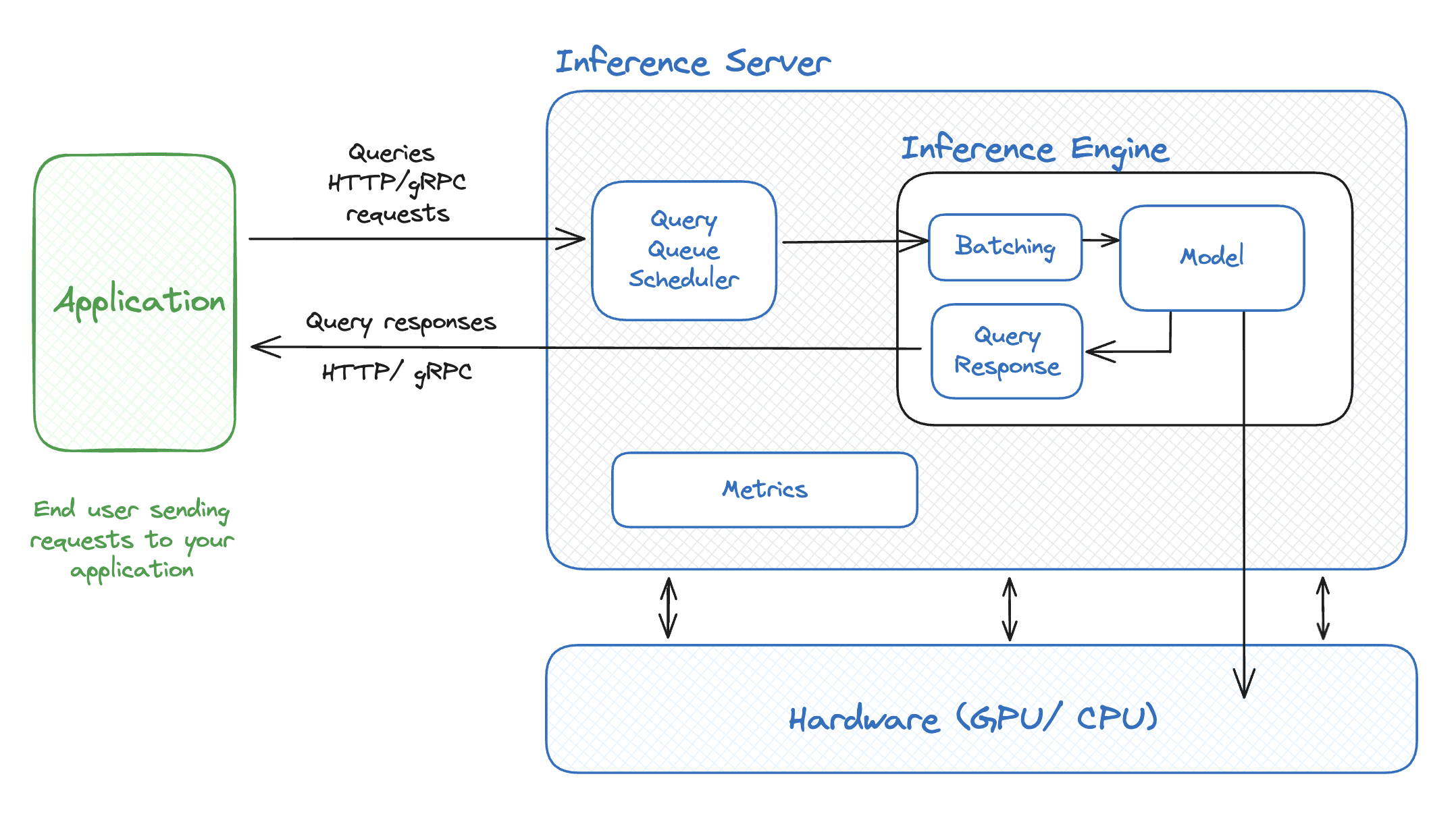
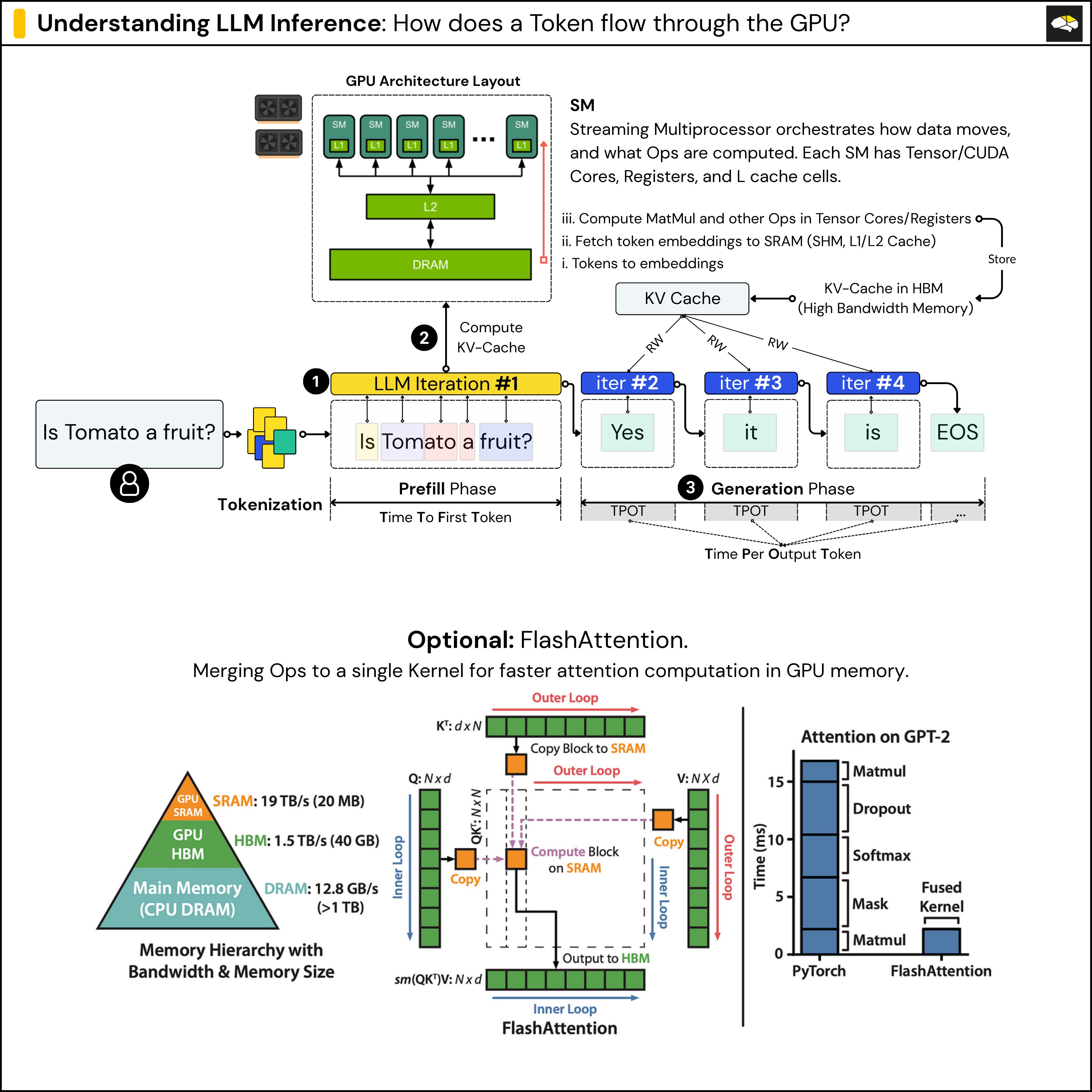
Understanding LLM Inference - by Alex Razvant
Illustration of the proposed method. (a) LLM inference comprises two ...
Mistral.rs: A Lightning-Fast LLM Inference Platform with Device Support ...
How to stream LLM responses using AWS API Gateway Websocket and Lambda
Mistral.rs: A Fast LLM Inference Platform Supporting Inference on a ...
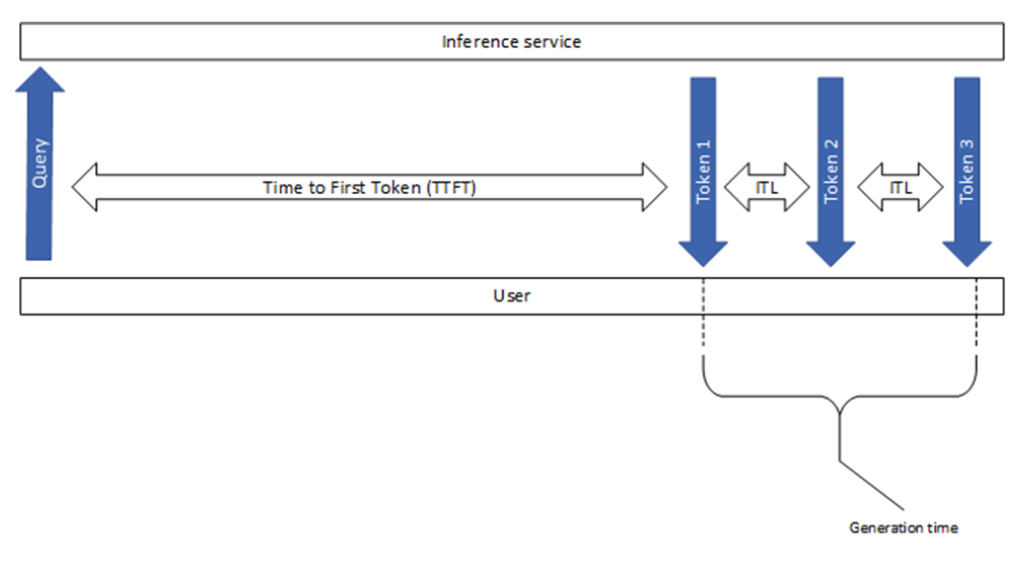
Key metrics for LLM inference | LLM Inference Handbook
WebLLM - High-Performance In-Browser LLM Inference Engine
A guide to LLM inference and performance | Baseten Blog
Top 10 AI Inferencing Platforms in 2024: Comparing the Best LLM API ...
Practical LLM inference in modern Java.pptx
LLM performance benchmarks | LLM Inference Handbook
11 Best LLM API Providers: Compare Inferencing Performance & Pricing
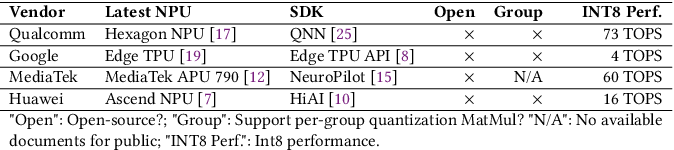
Table 2 from Fast On-device LLM Inference with NPUs | Semantic Scholar
LLM Inference Optimization 101 | DigitalOcean
Fast, Secure and Reliable: Enterprise-grade LLM Inference | Databricks Blog
LLM inference optimization: Tutorial & Best Practices | LaunchDarkly
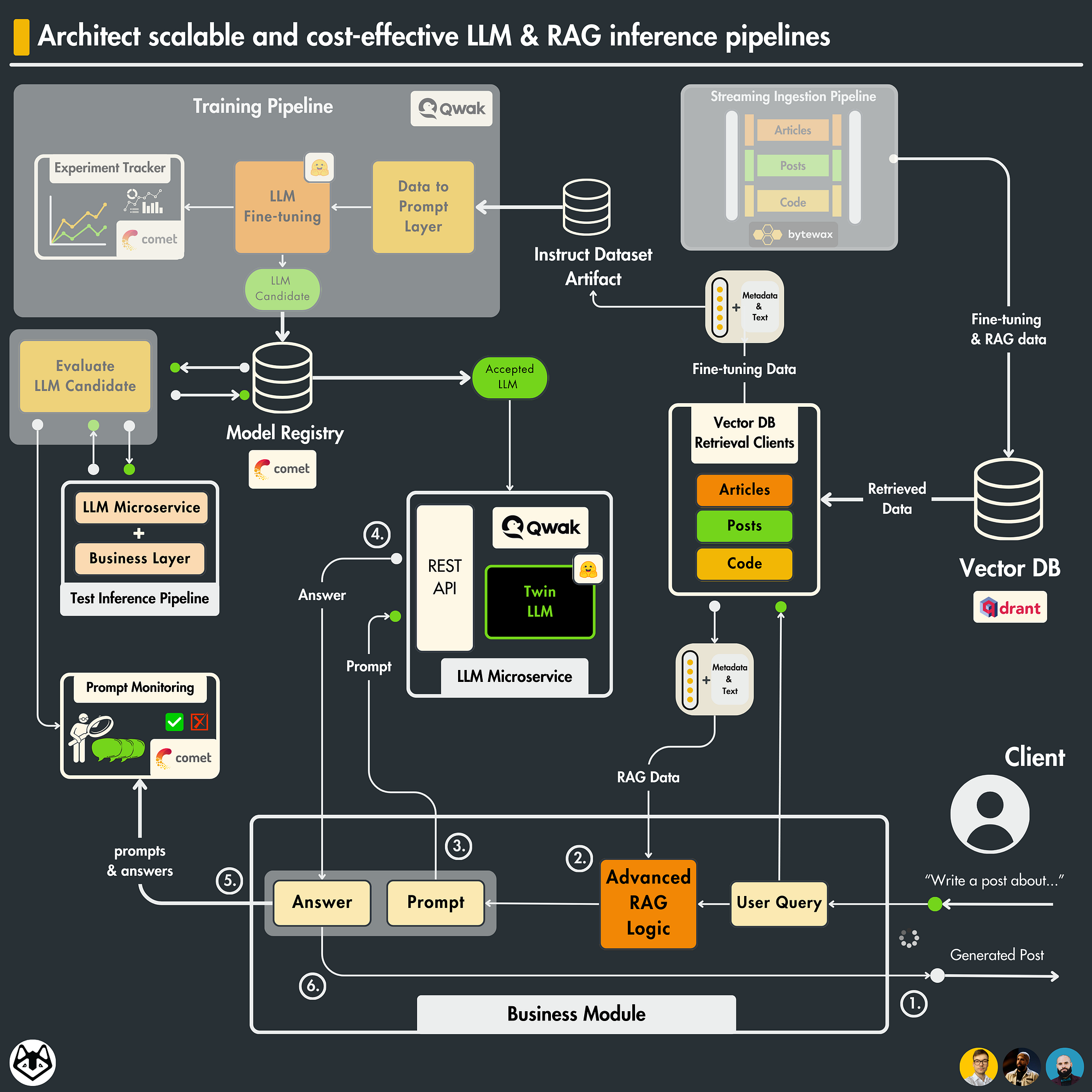
How to Architect Scalable LLM & RAG Inference Pipelines
LLM API Providers 2026: Top 12 (ShareAI Guide)
Table 1 from Fast On-device LLM Inference with NPUs | Semantic Scholar
Benchmarking Quantized LLM Inference Speed
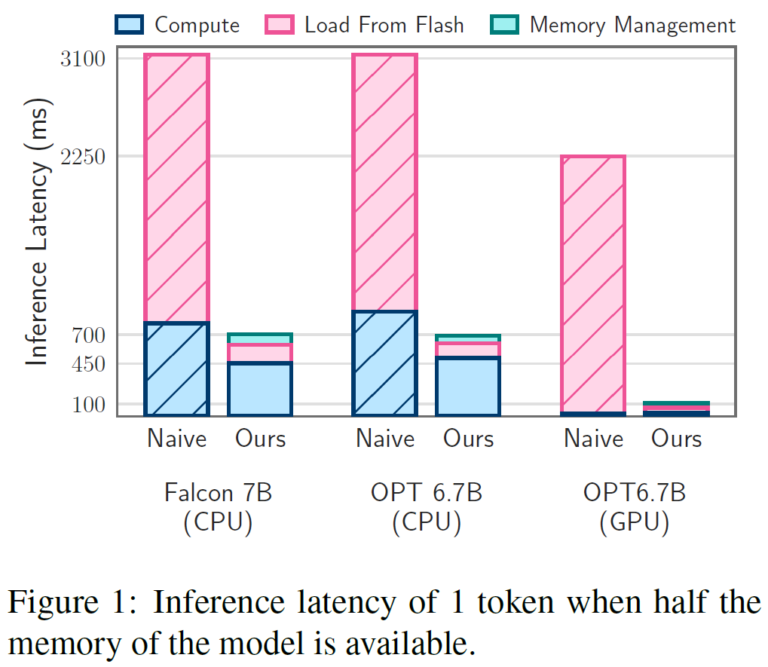
LLM in a flash: Efficient LLM Inference with Limited Memory
GitHub - ccs96307/fast-llm-inference: Accelerating LLM inference with ...
LLM Inference Optimization Techniques: A Comprehensive Analysis | by ...
Want to build a fast LLM inference engine from scratch? | Karn Singh
Benchmarking LLM Inference Backends
Modern LLM inference isn’t just about spinning up containers, it’s ...
Announcing Together Inference Engine – the fastest inference available
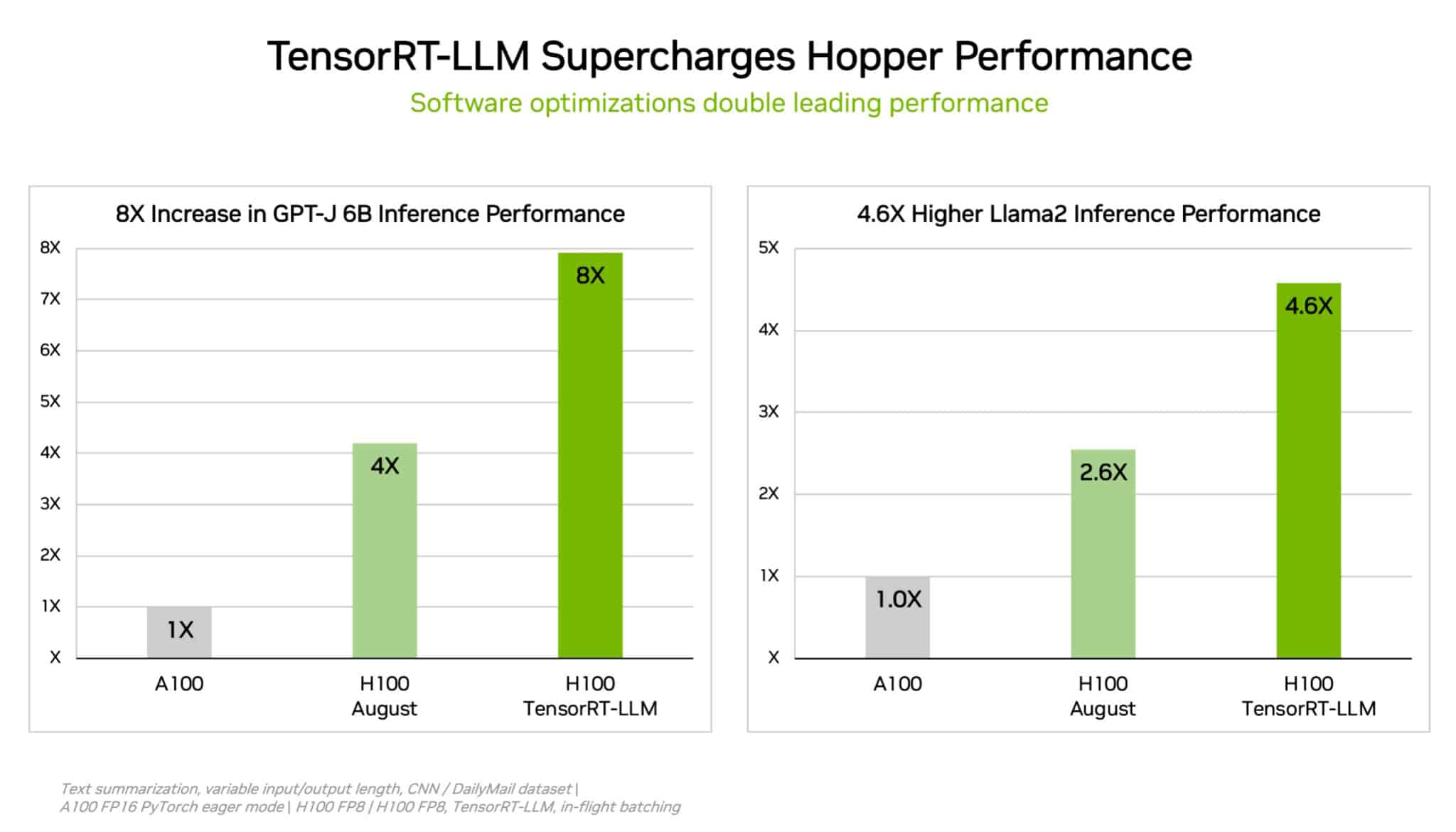
LLM Inference Benchmarking: Performance Tuning with TensorRT-LLM ...
LLM By Examples — Maximizing Inference Performance with Bitsandbytes ...
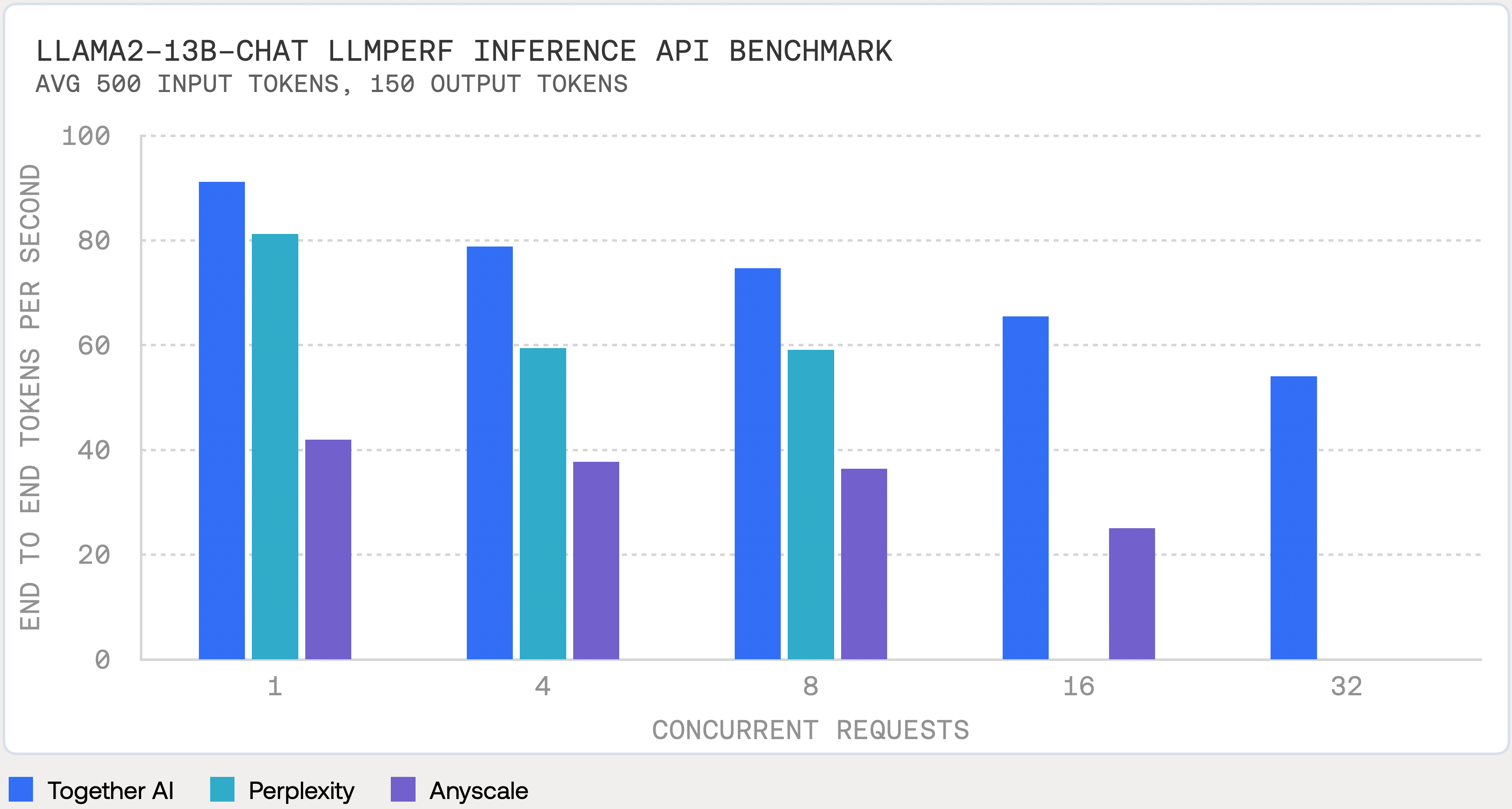
Together AI delivers fastest inference for the top open-source models
LLM Inference Optimization Overview - From Data to System Architecture
LLM Inference Speed Revolutionized by New Architecture - Pureinsights
How to Scale LLM Inference - by Damien Benveniste
LLM Online Inference You Can Count On
(PDF) Improving the inference performance of LLM with code
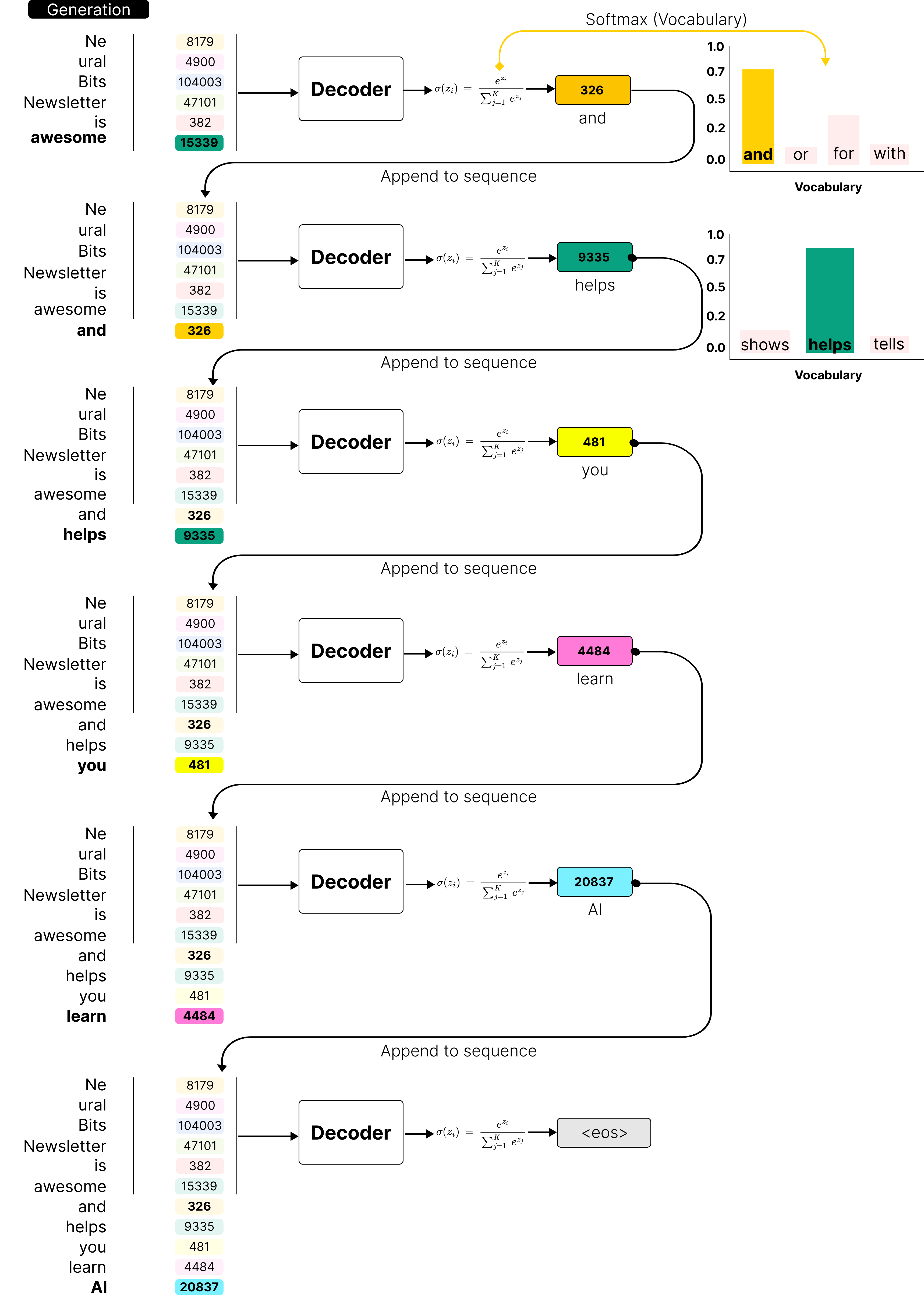
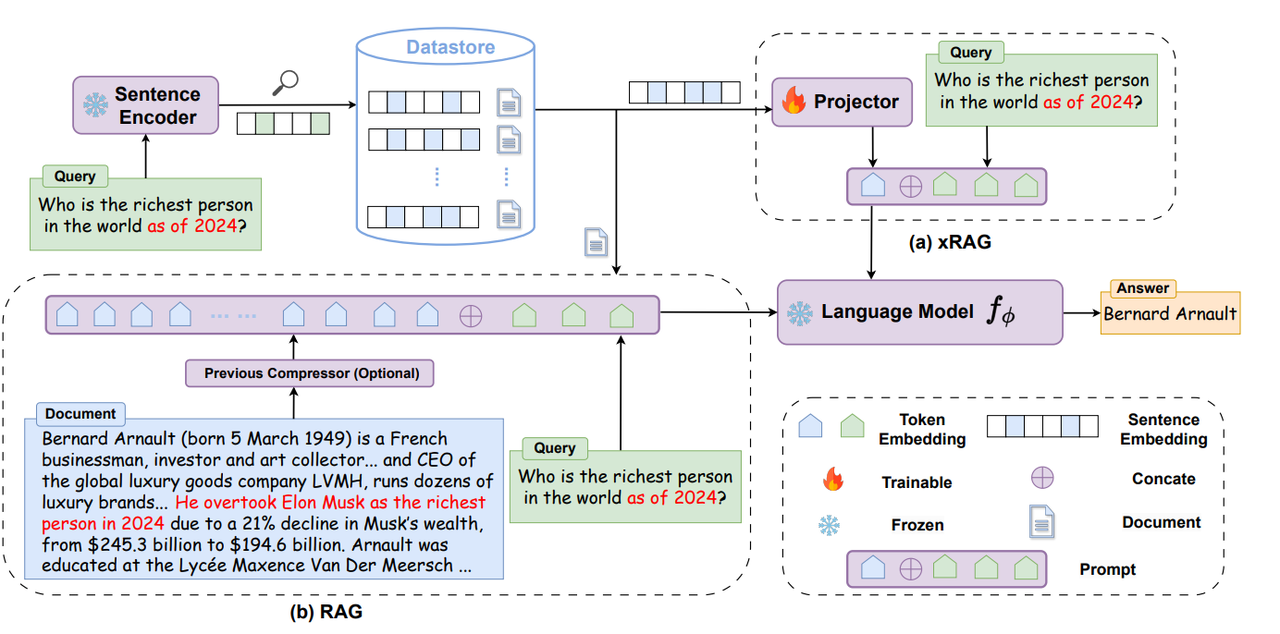
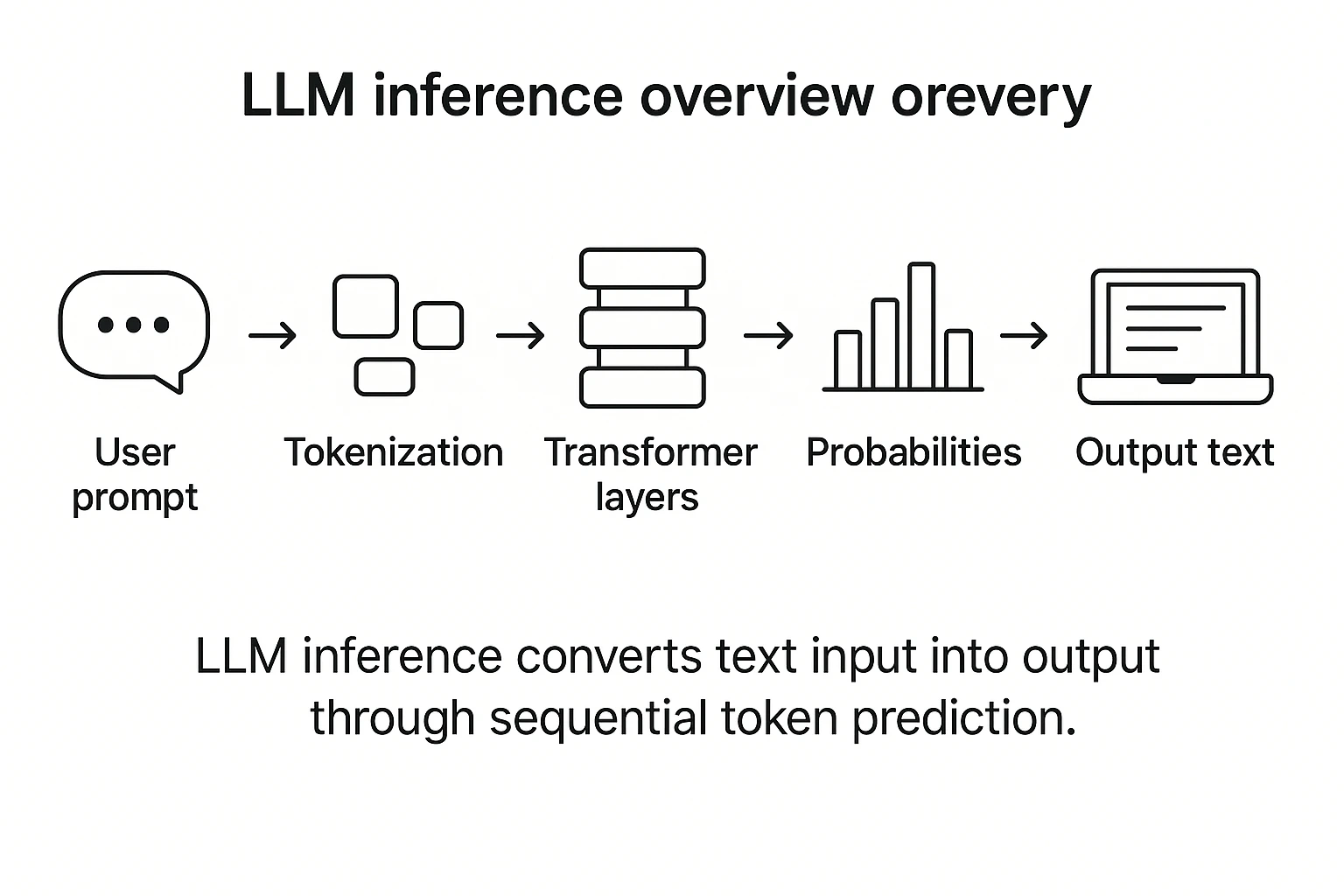
The LLM Inference Pipeline: From Text to Embeddings and the Power of RAG
A guide to open-source LLM inference and performance - Bens Bites
Table 1 from Speculative Streaming: Fast LLM Inference without ...
Running LLM Inference on Android - Speaker Deck
LLM Inference Hardware: Emerging from Nvidia's Shadow
How to benchmark and optimize LLM inference performance (for data ...
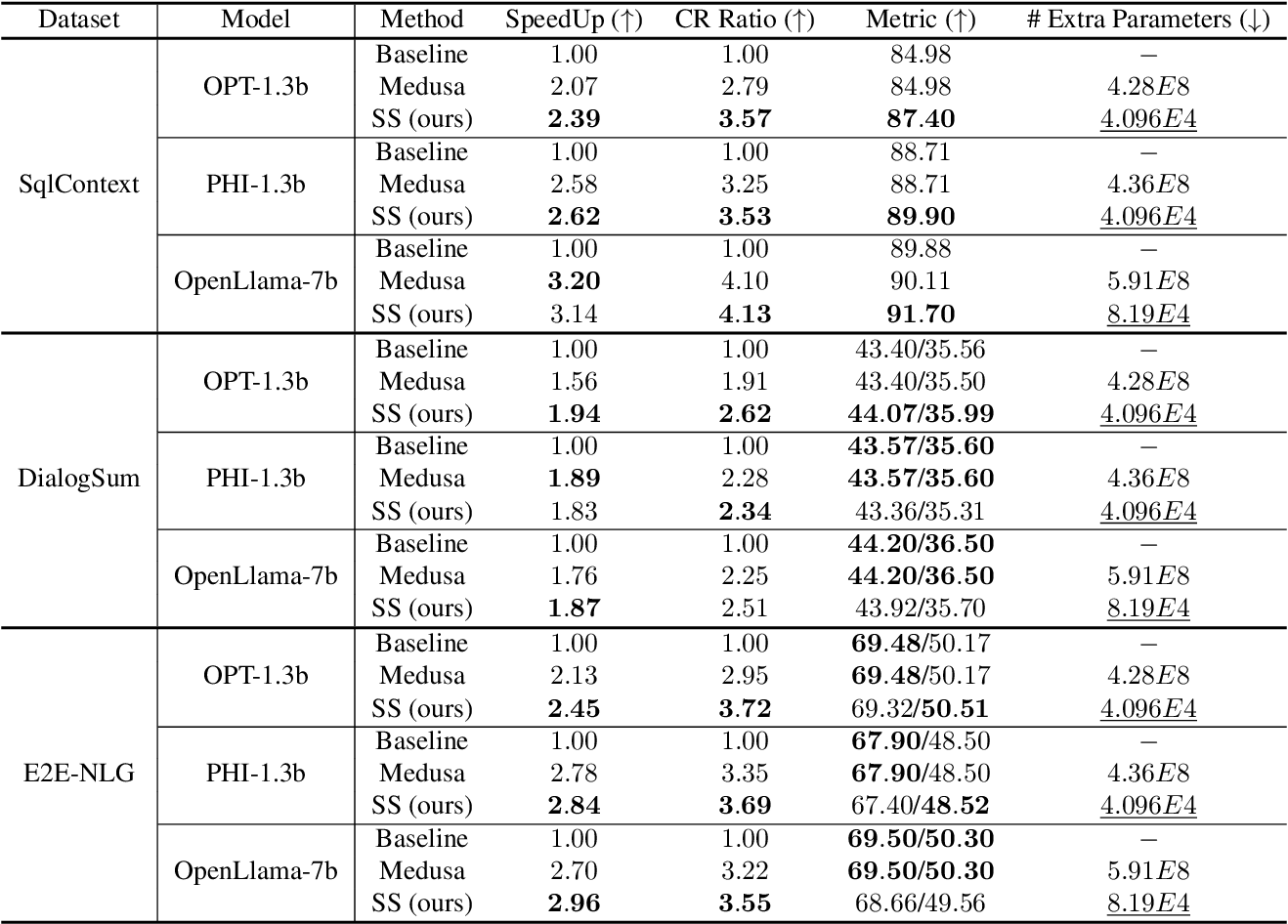
(PDF) FIRP: Faster LLM inference via future intermediate representation ...
Accelerate Deep Learning and LLM Inference with Apache Spark in the ...
Optimizing AI Performance: A Guide to Efficient LLM Deployment
Nvidia claims first place in MLCommon's first benchmarks for LLM ...
What Is LLM Inference? Process, Latency & Examples Explained (2026)
Serving Inference for LLMs: A Case Study | CoreWeave
Introducing Red Hat AI Inference Server: High-performance, optimized ...
LLM Benchmarking: Fundamental Concepts - Edge AI and Vision Alliance
The Emerging LLM Stack: A Comprehensive Guide for Developers - Helicone
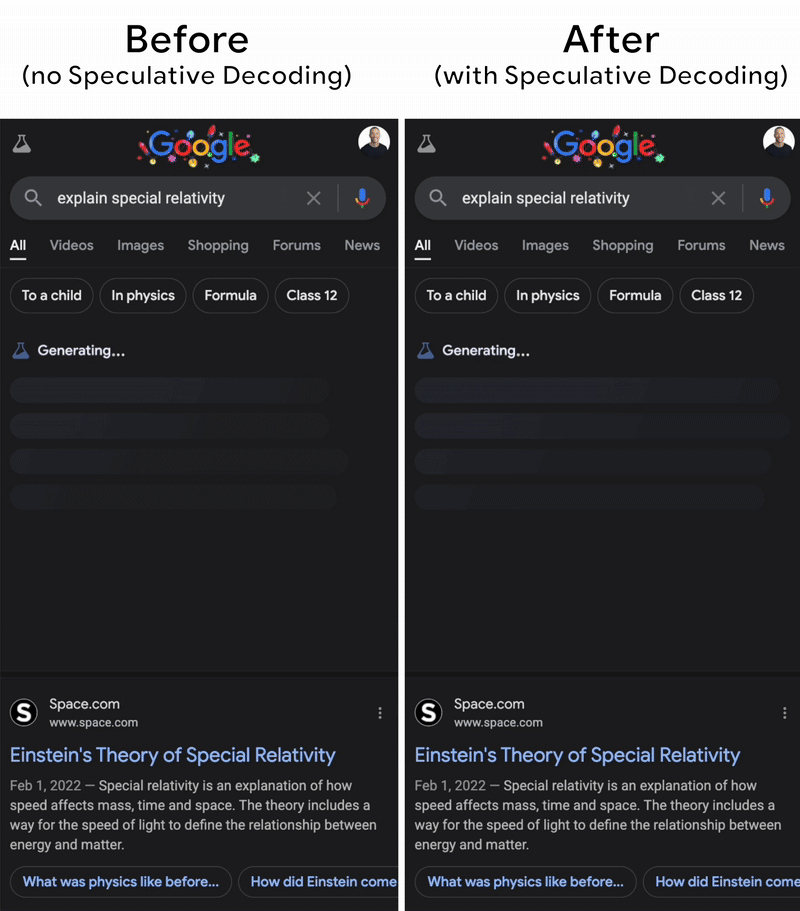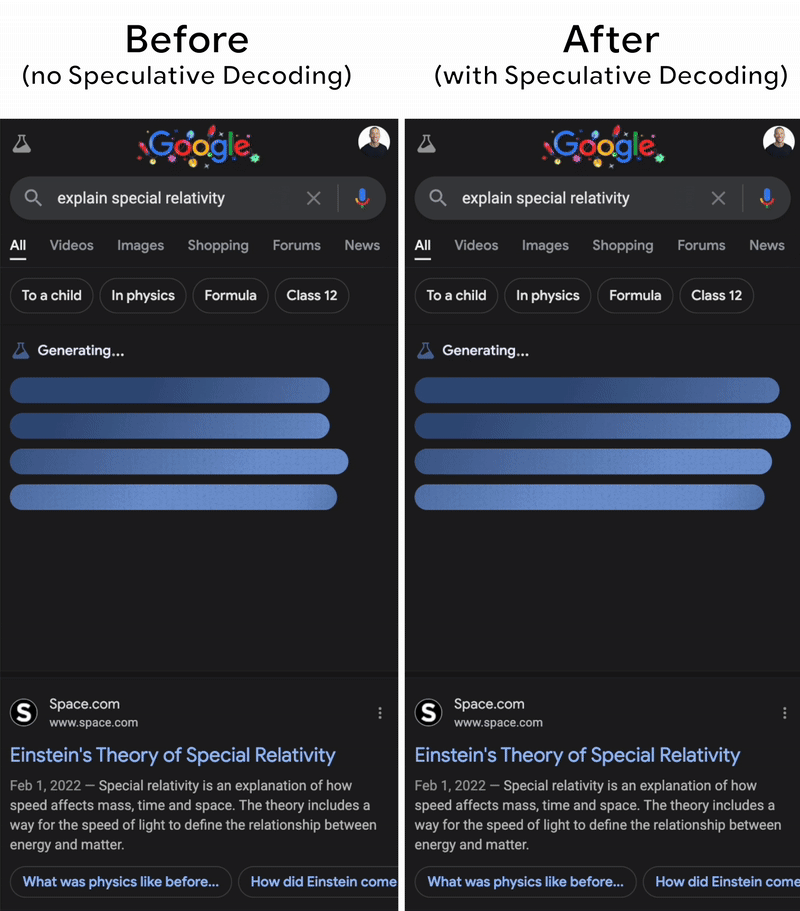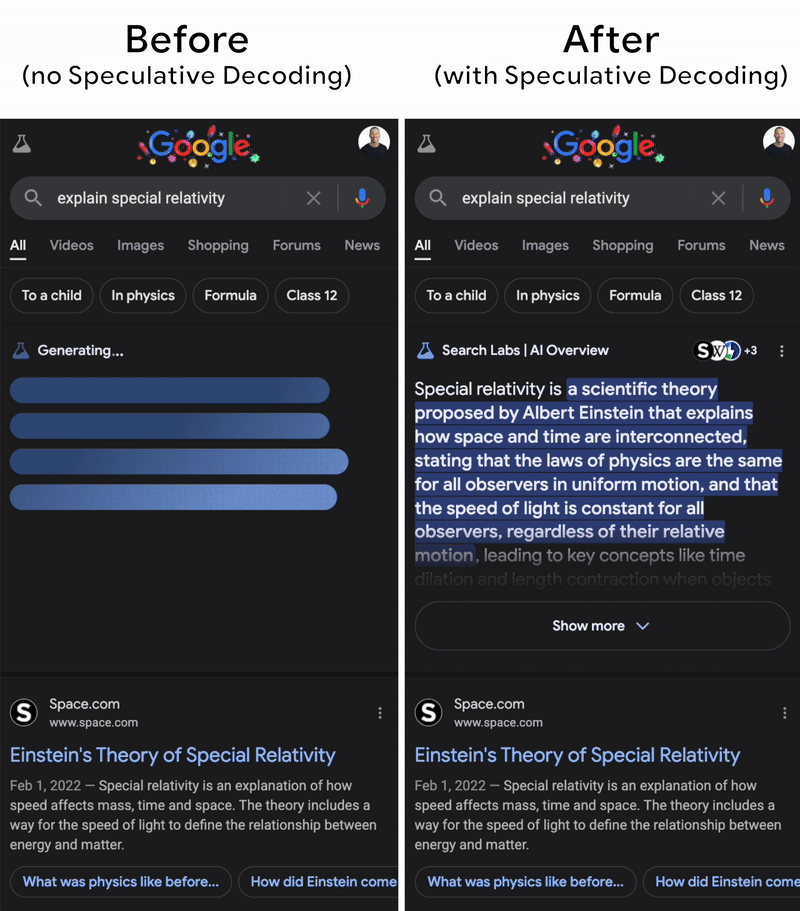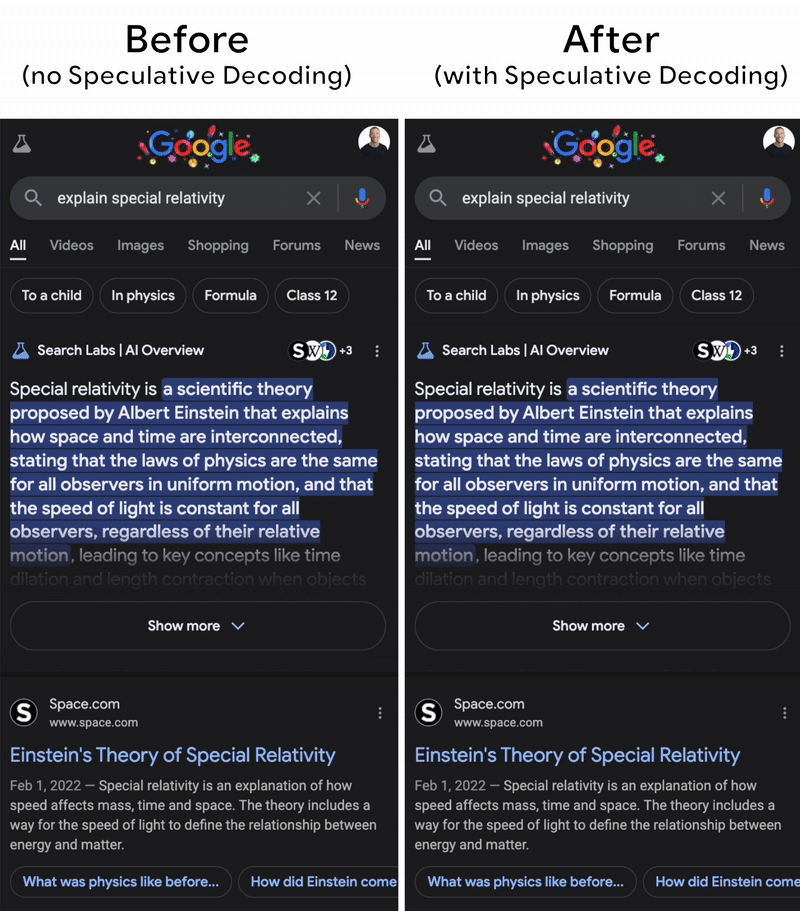
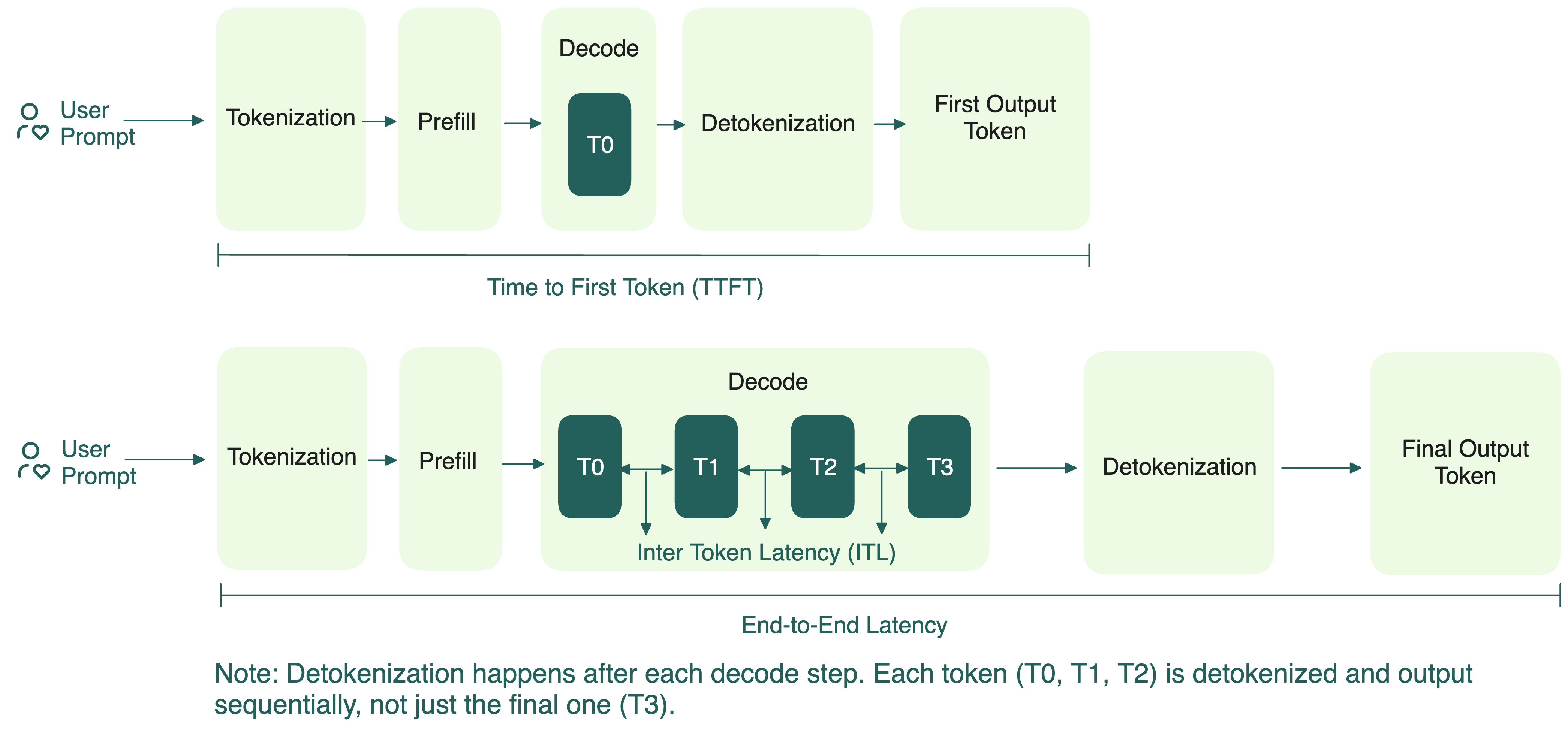
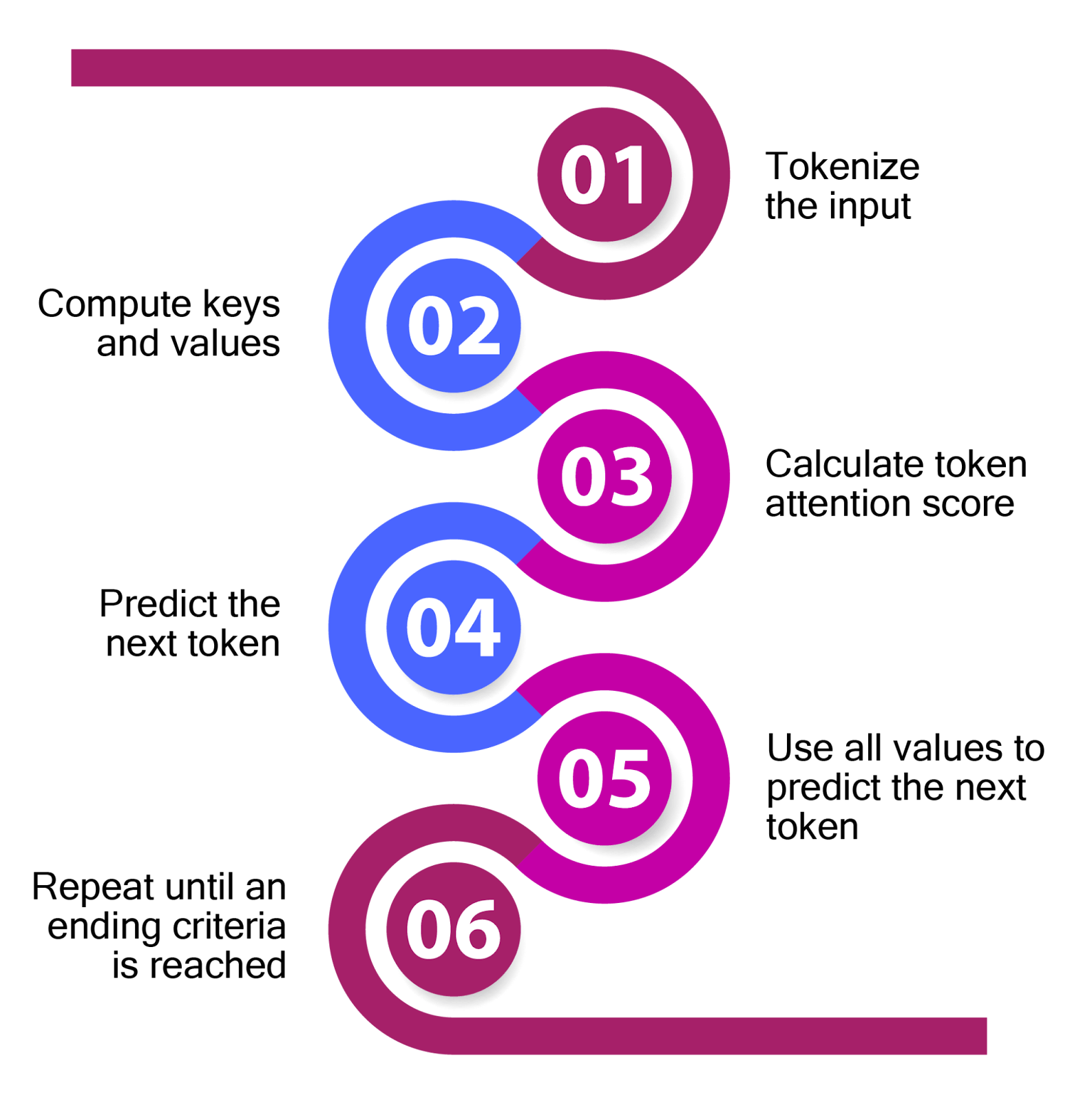
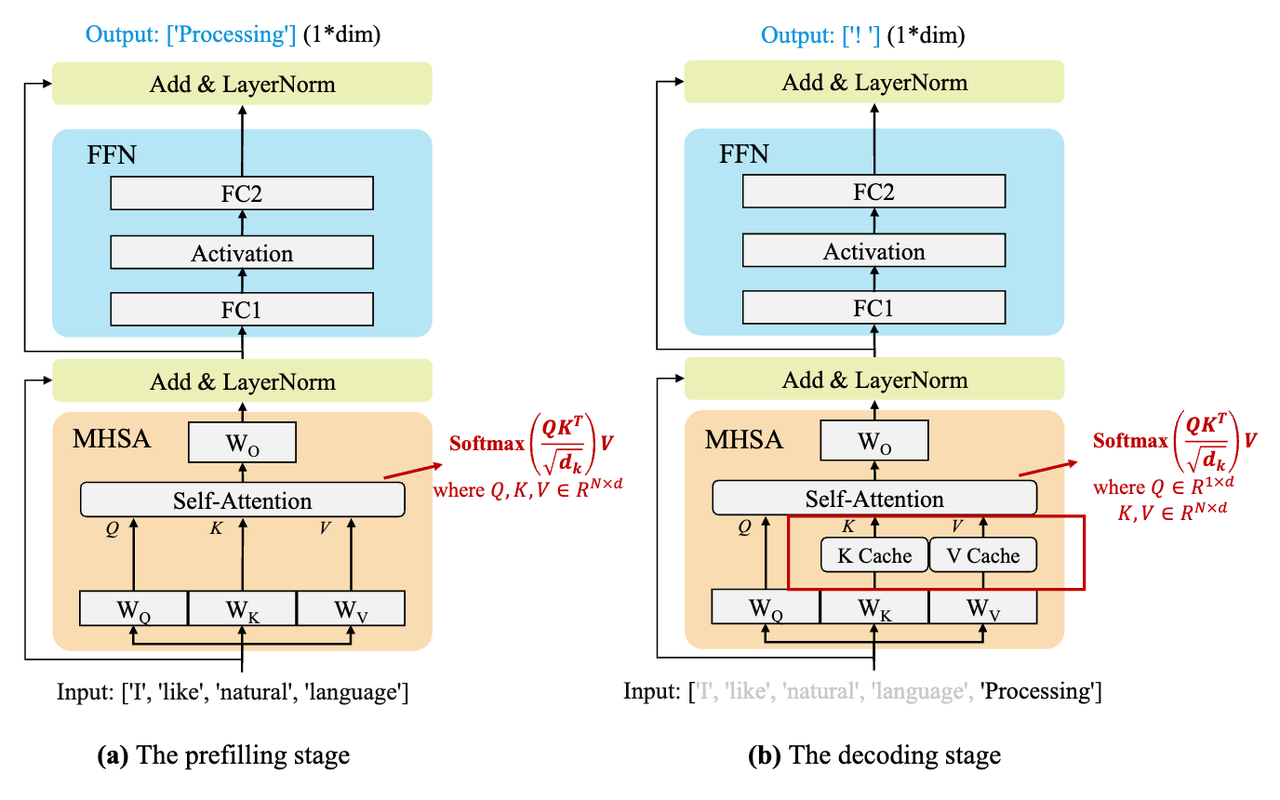
Understanding the Two Key Stages of LLM Inference: Prefill and Decode ...
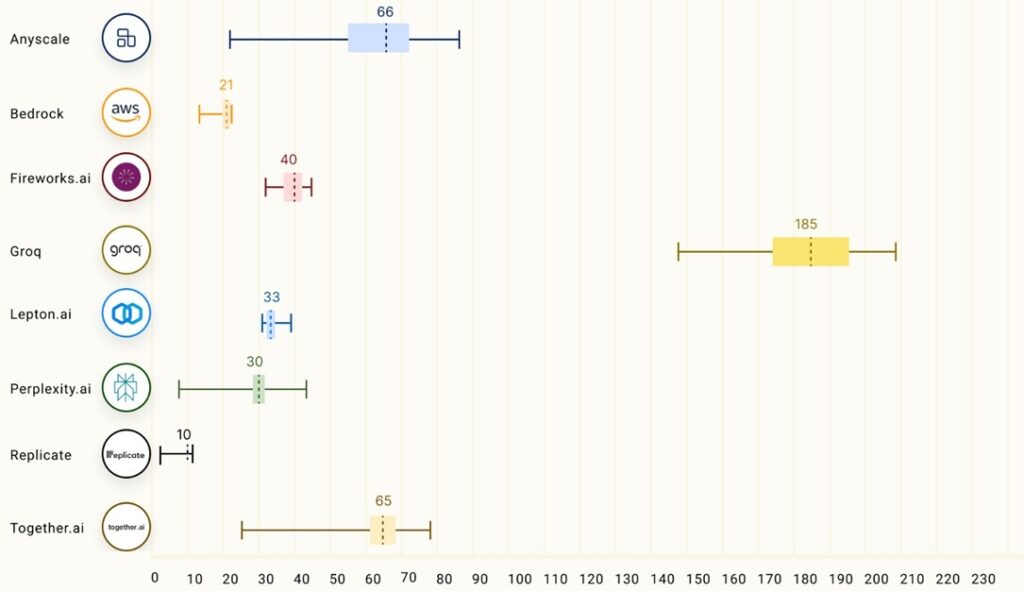
Which is the fastest LLM? A comprehensive benchmark. - Workorb Blog
Faster LLMs with Quantization - How to get faster inference times with ...
How to Select the Best GPU for LLM Inference: Benchmarking Insights ...
The Art of LLM Inference: Fast, Fit, and Free (PART 2)
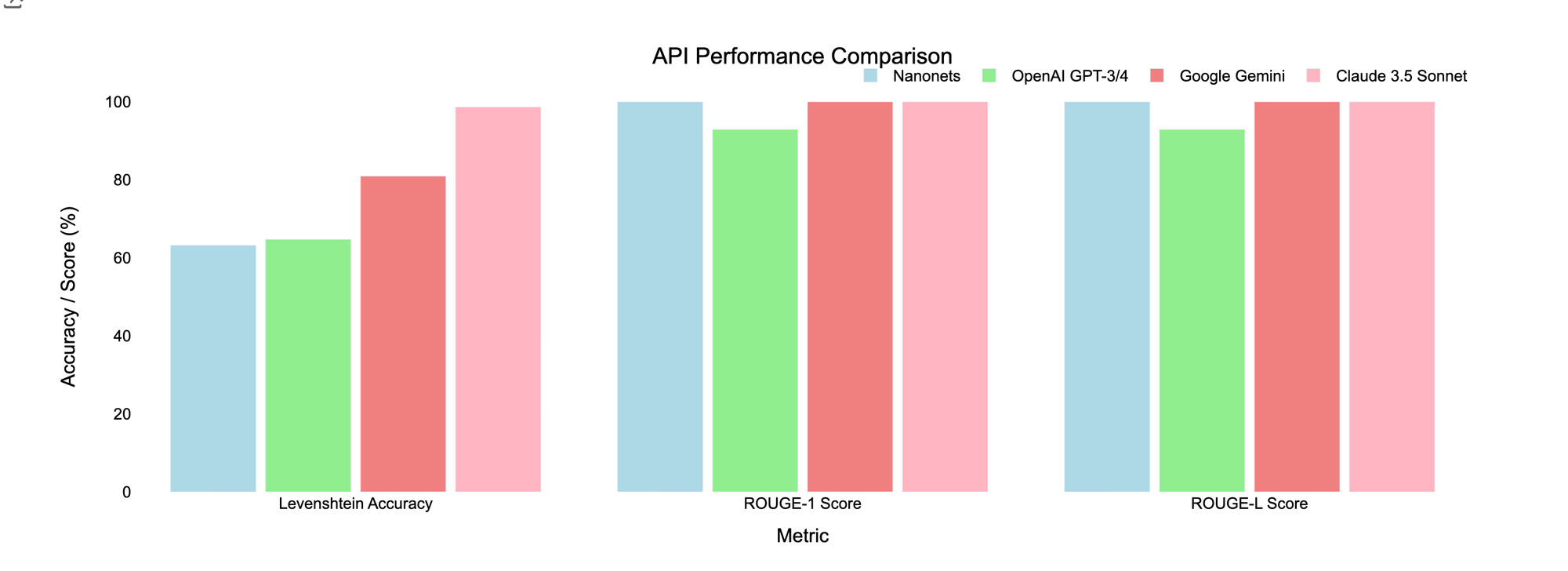
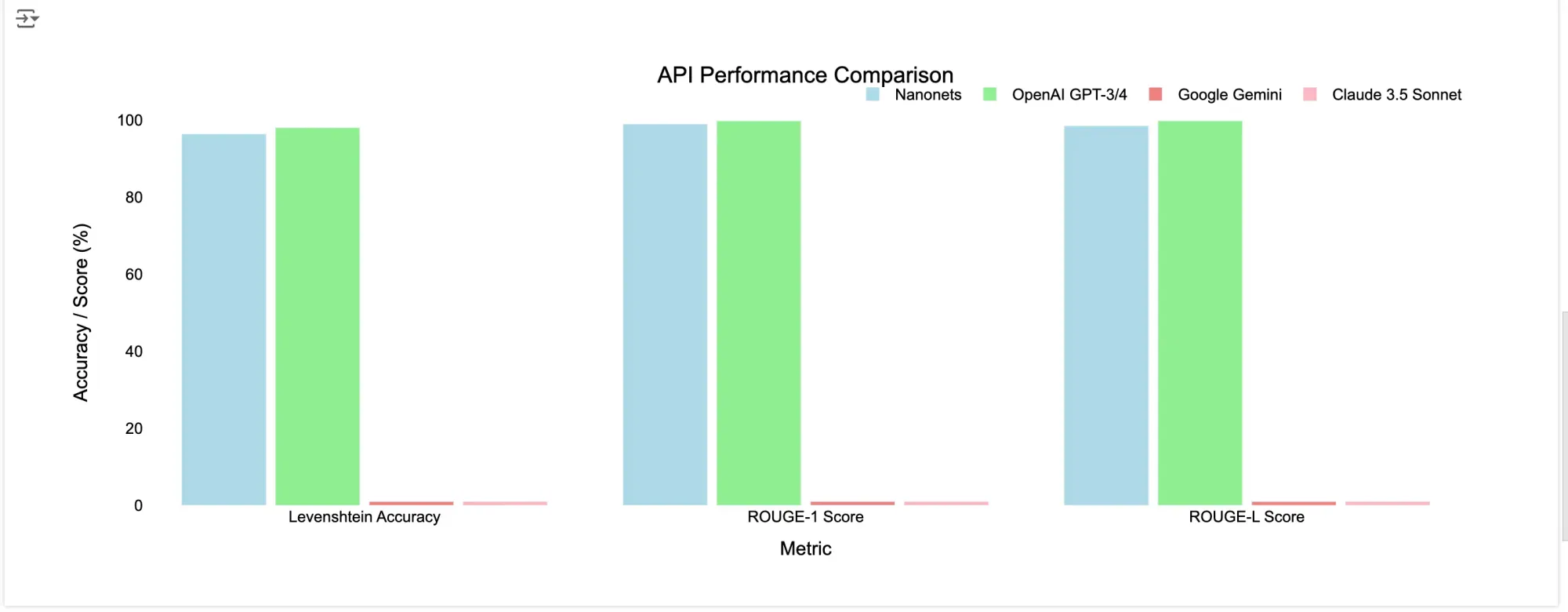
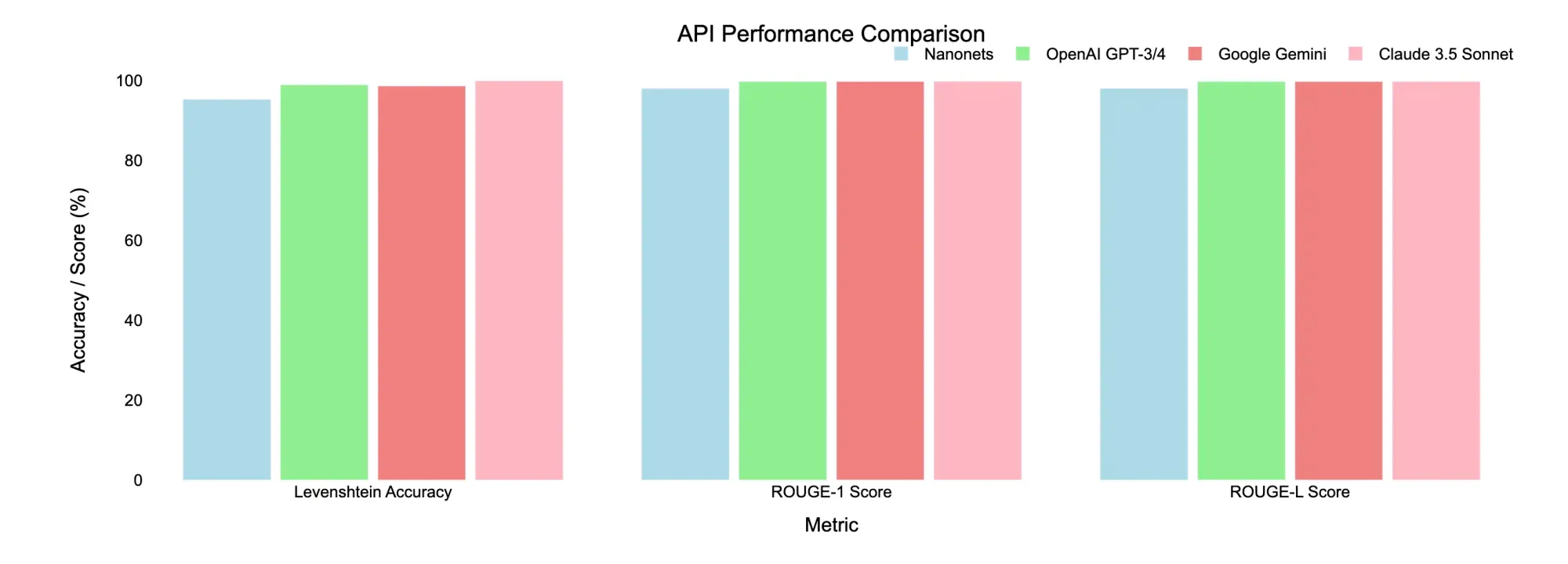
Best LLM APIs for Data Extraction
LLM APIs: Use Cases,Tools, & Best Practices for 2025 | Generative AI ...
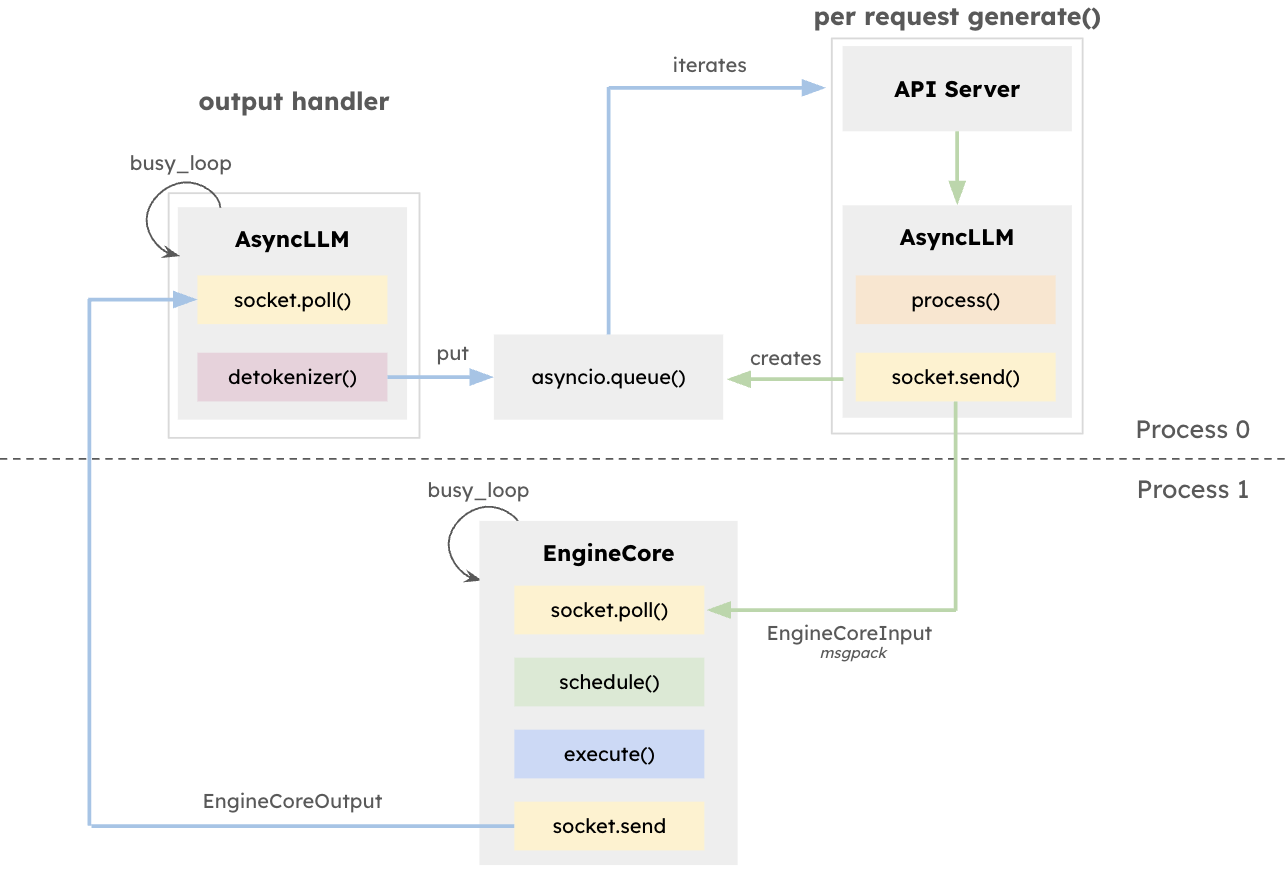
Beyond Traditional Frameworks: The Evolution of LLM Serving
Comparing LLM performance: Introducing the Open Source Leaderboard for ...
Best LLM APIs for Document Data Extraction
LLM Inference: Techniques for Optimized Deployment in 2025 | Label Your ...
The Future of Serverless Inference for Large Language Models | AI ...
Optimizing LLM Inference. Optimization begins where architectures… | by ...
Exploring LLM Visualization: Techniques, Tools, and Insights | by ...
The Art of LLM Inference: Fast, Fit, and Free (PART 1)
Deepgram & Groq : Test du “Fastest LLM Inference” et du “Fastest Text ...
Backend.AI Meets Tool LLMs : Revolutionizing AI Interaction with Tools ...
llm-inference · PyPI
Peking University Researchers Introduce FastServe: A Distributed ...









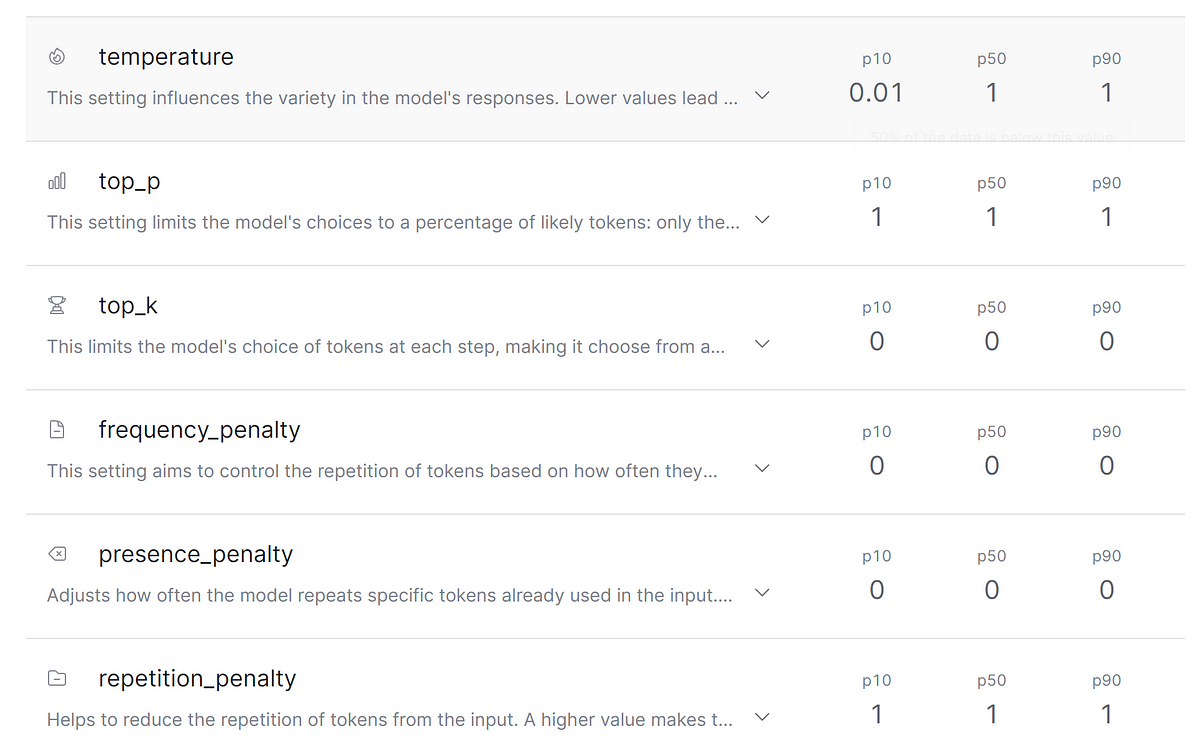


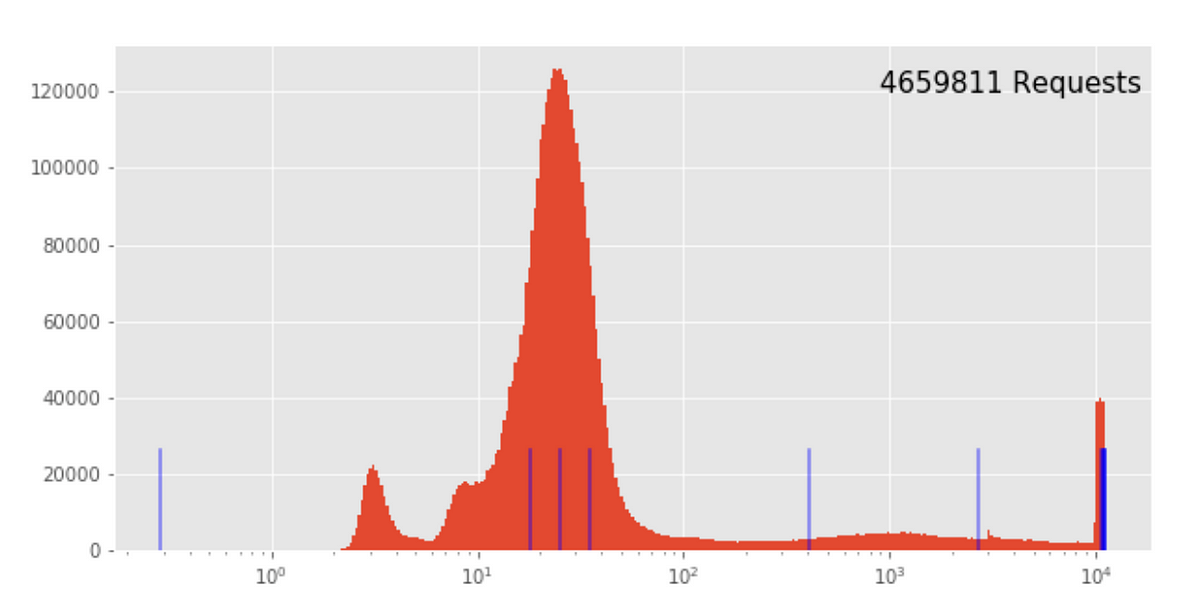
















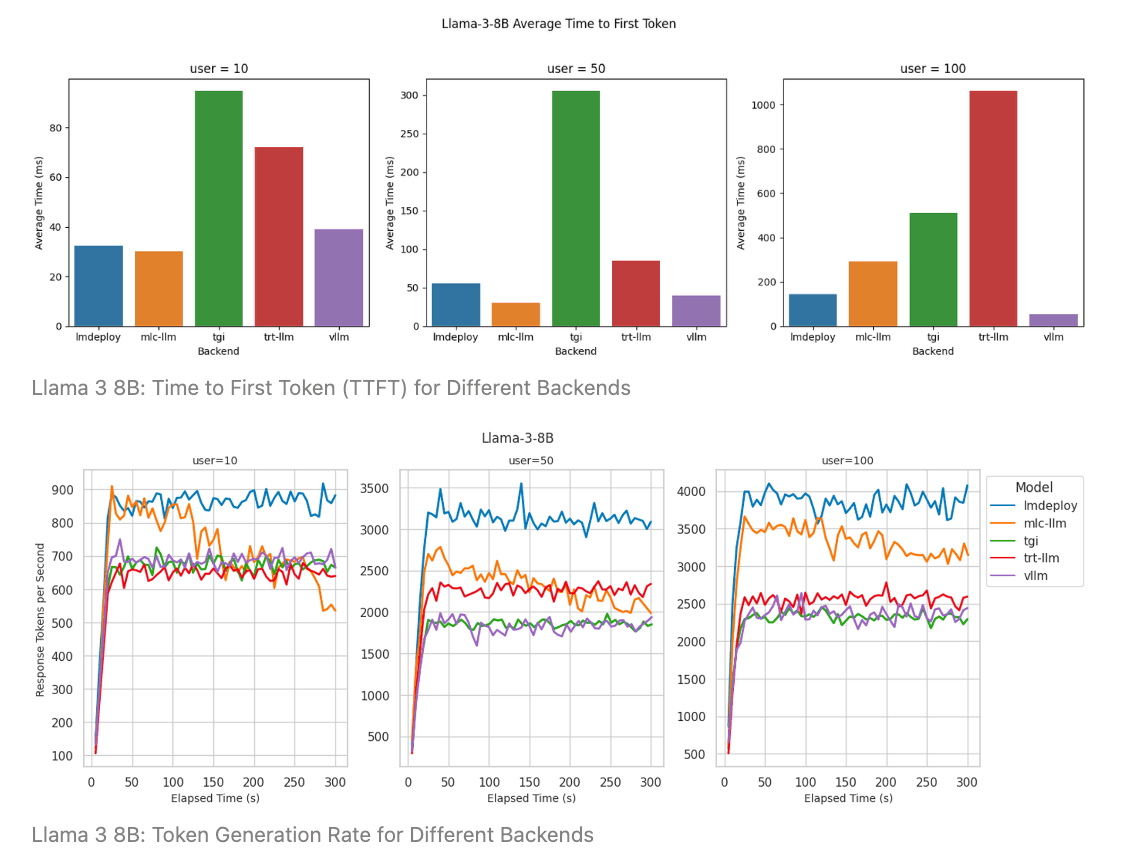



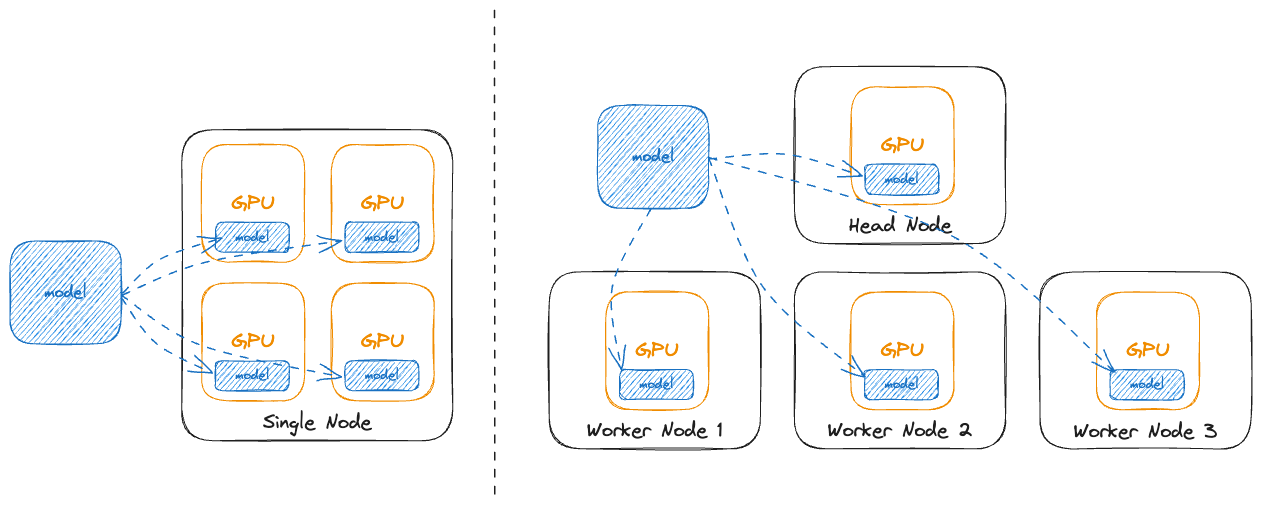

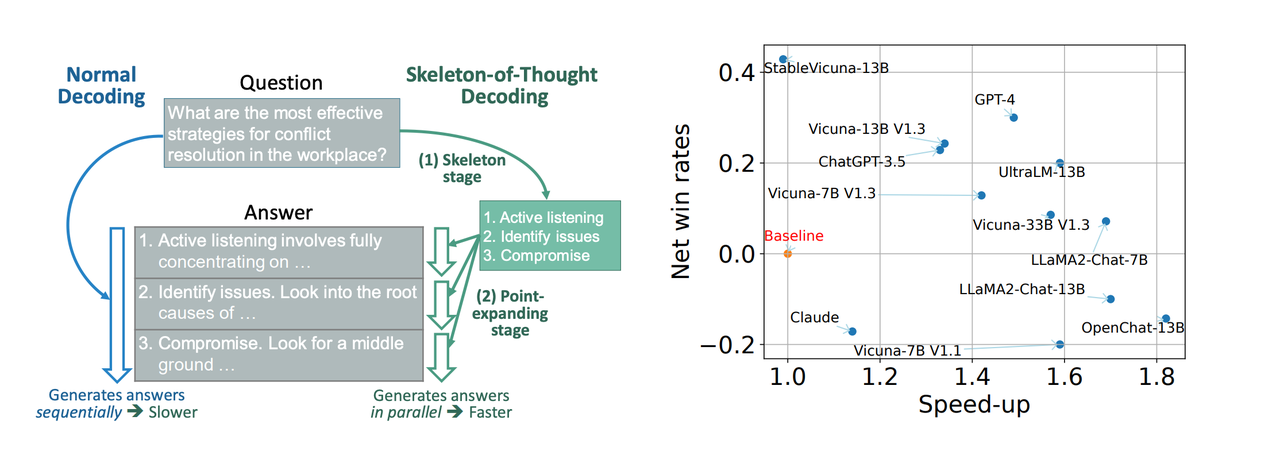
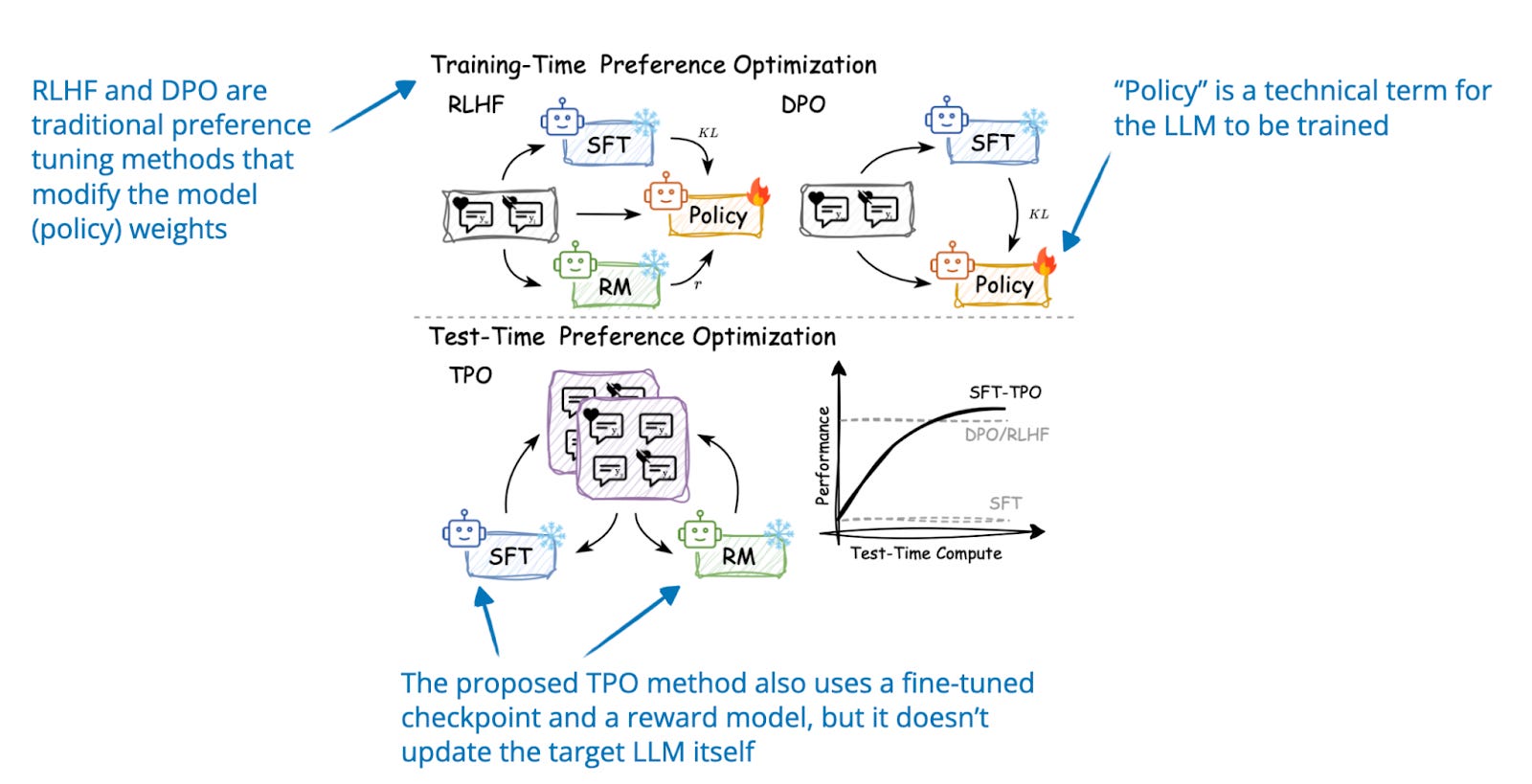
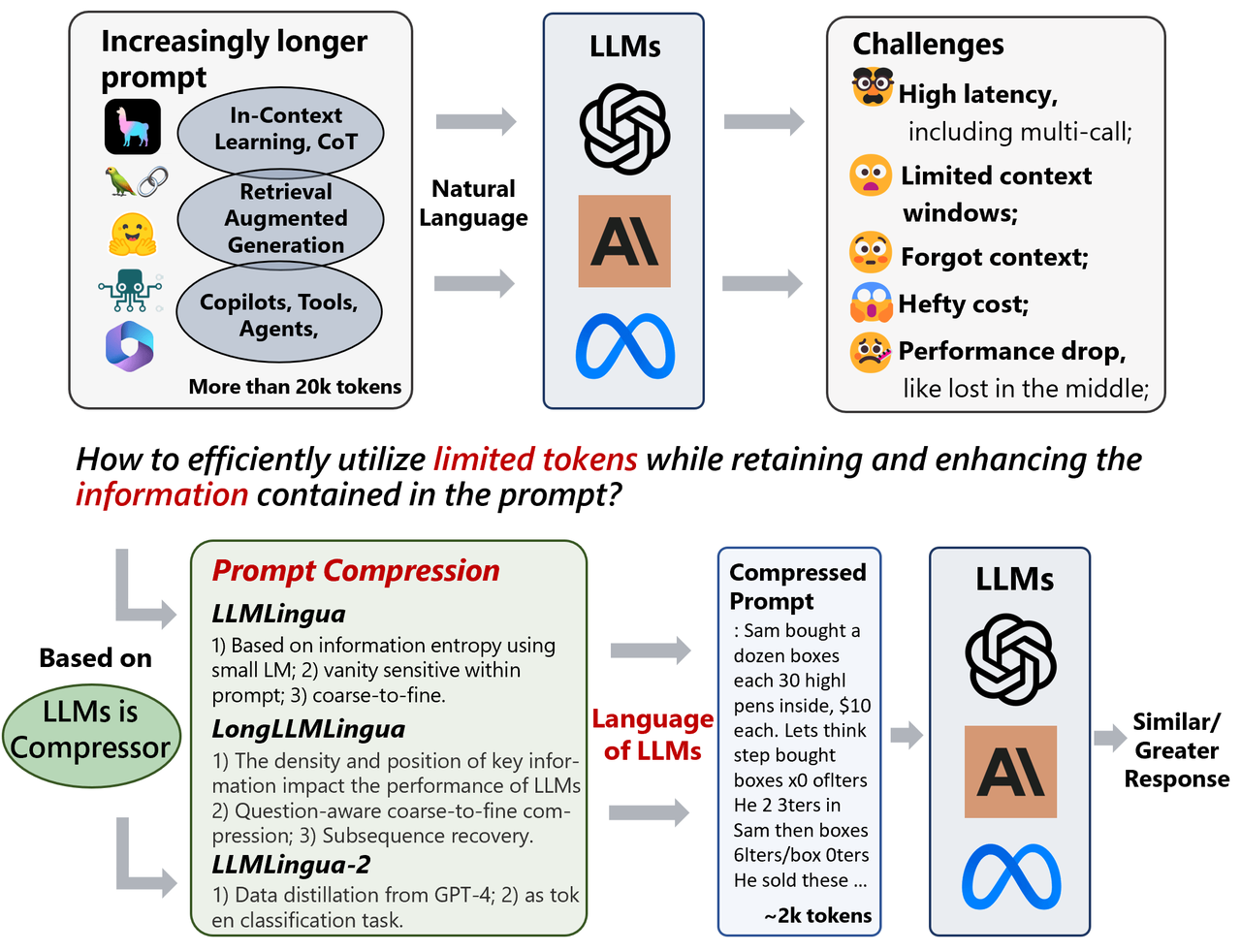

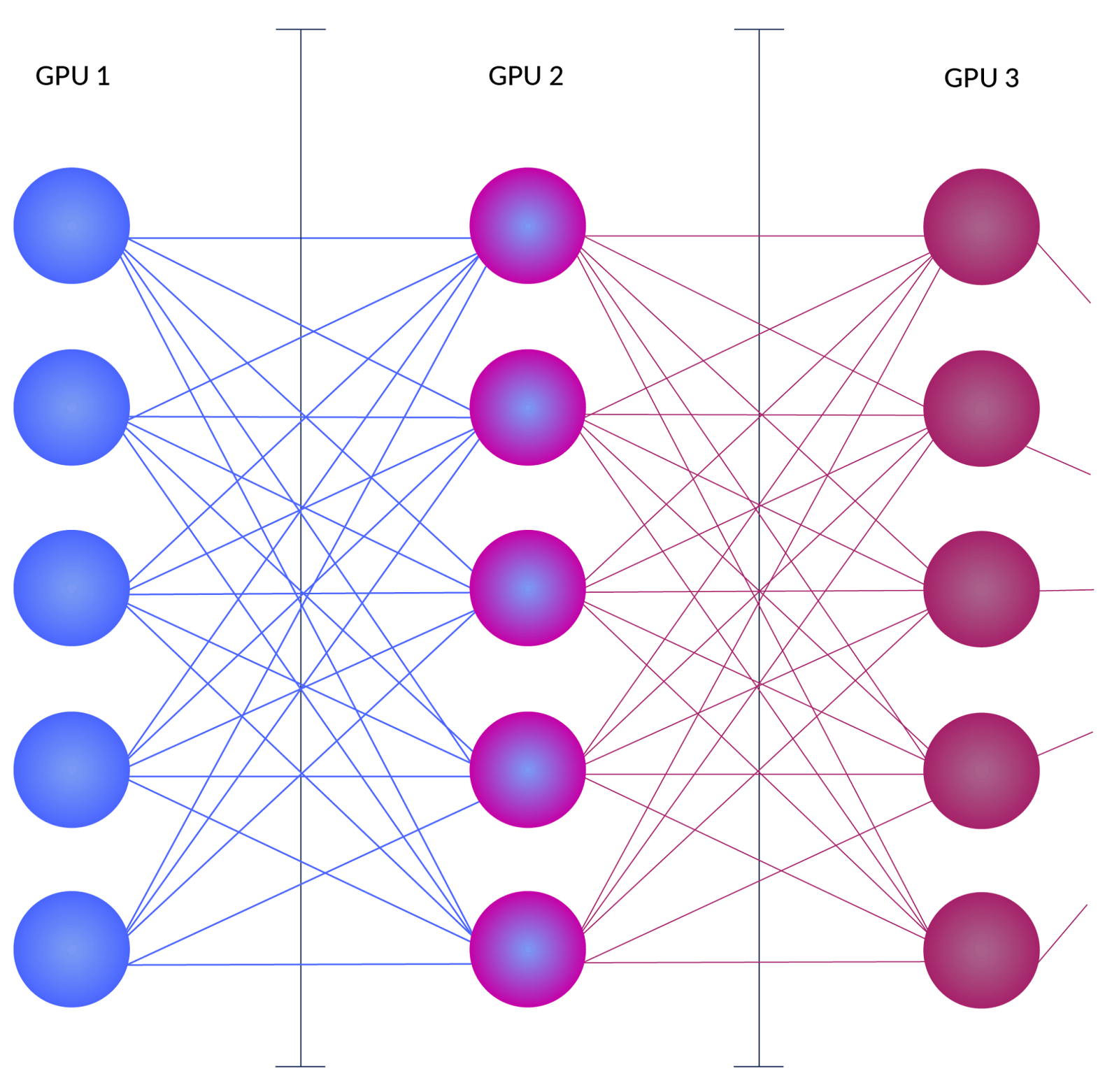
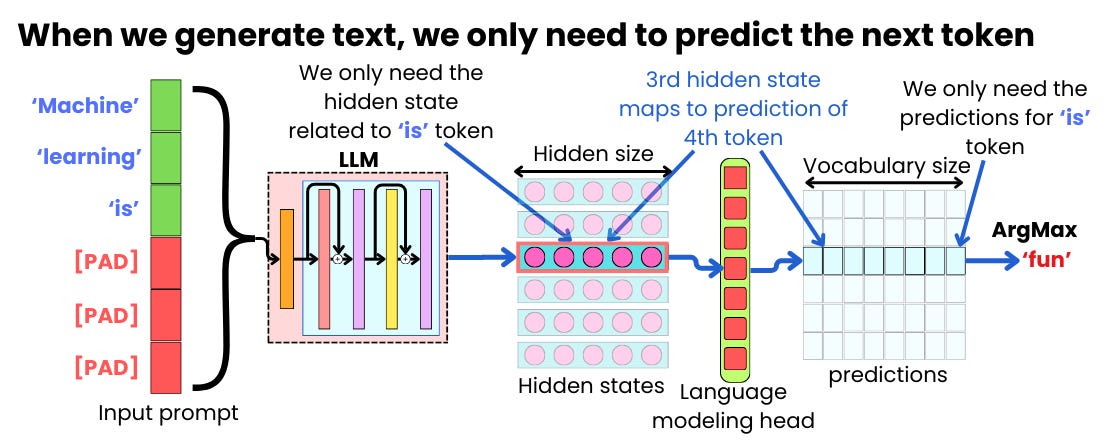

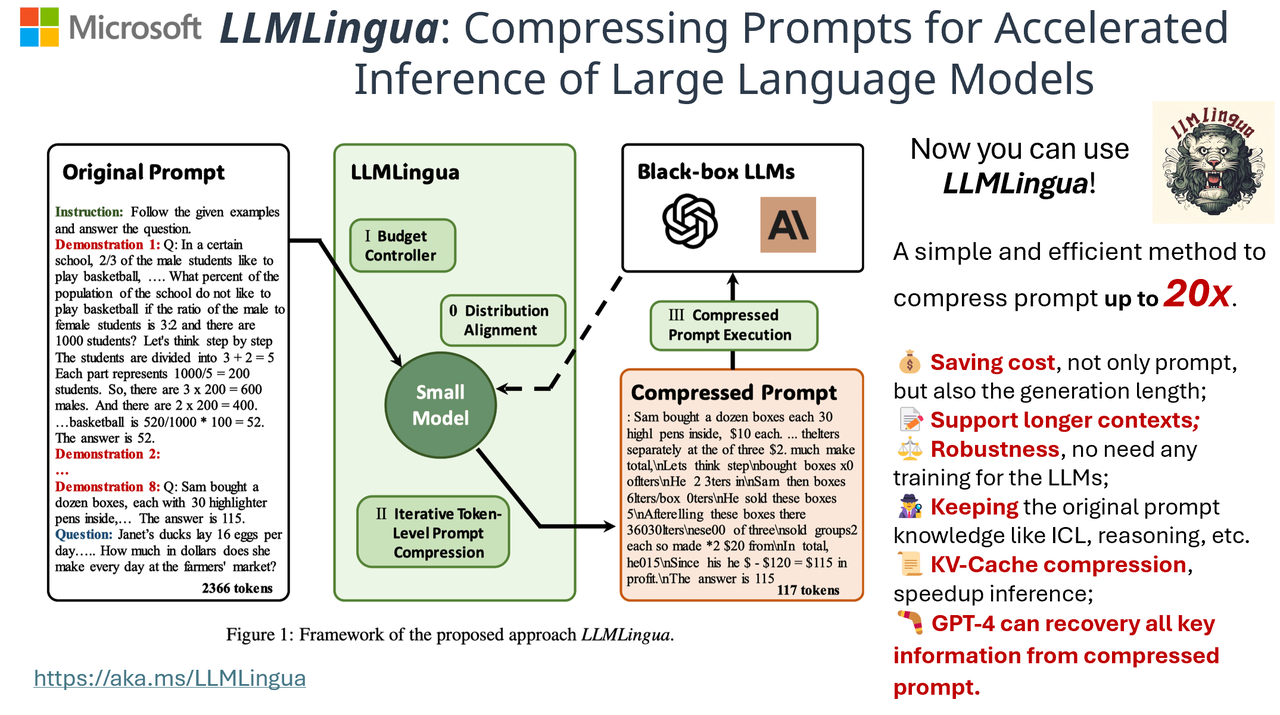




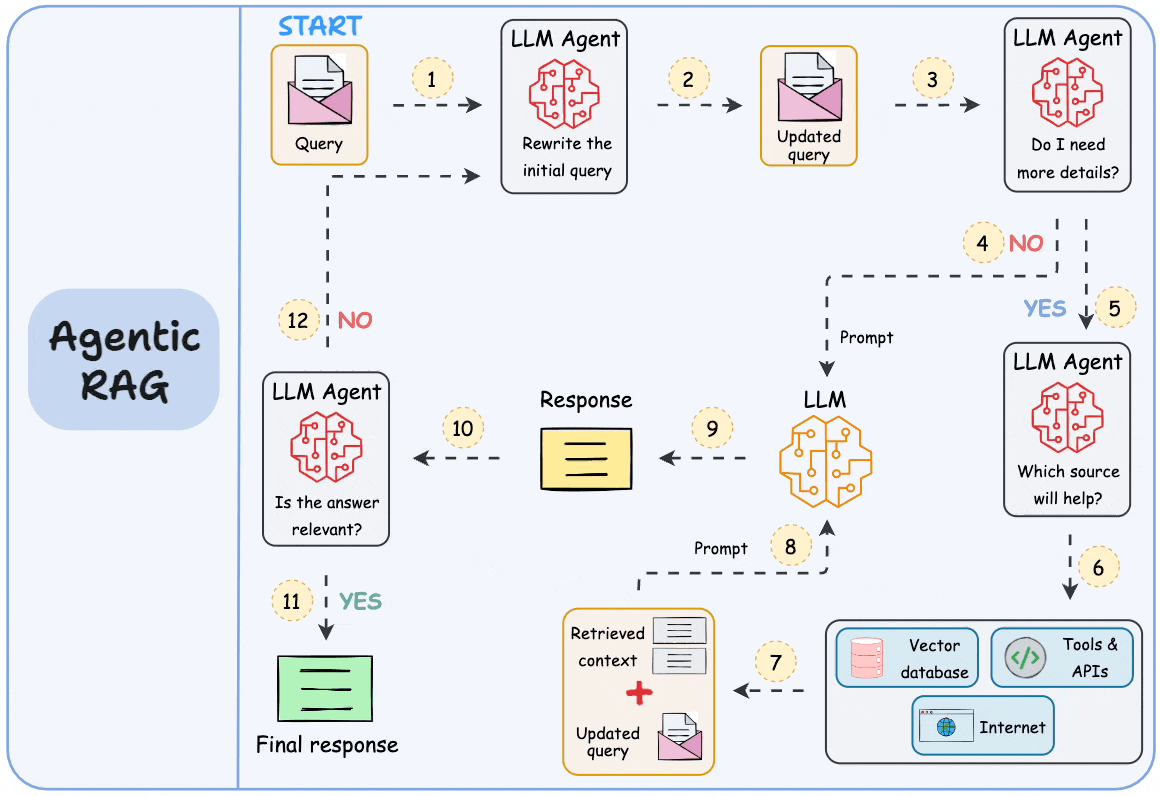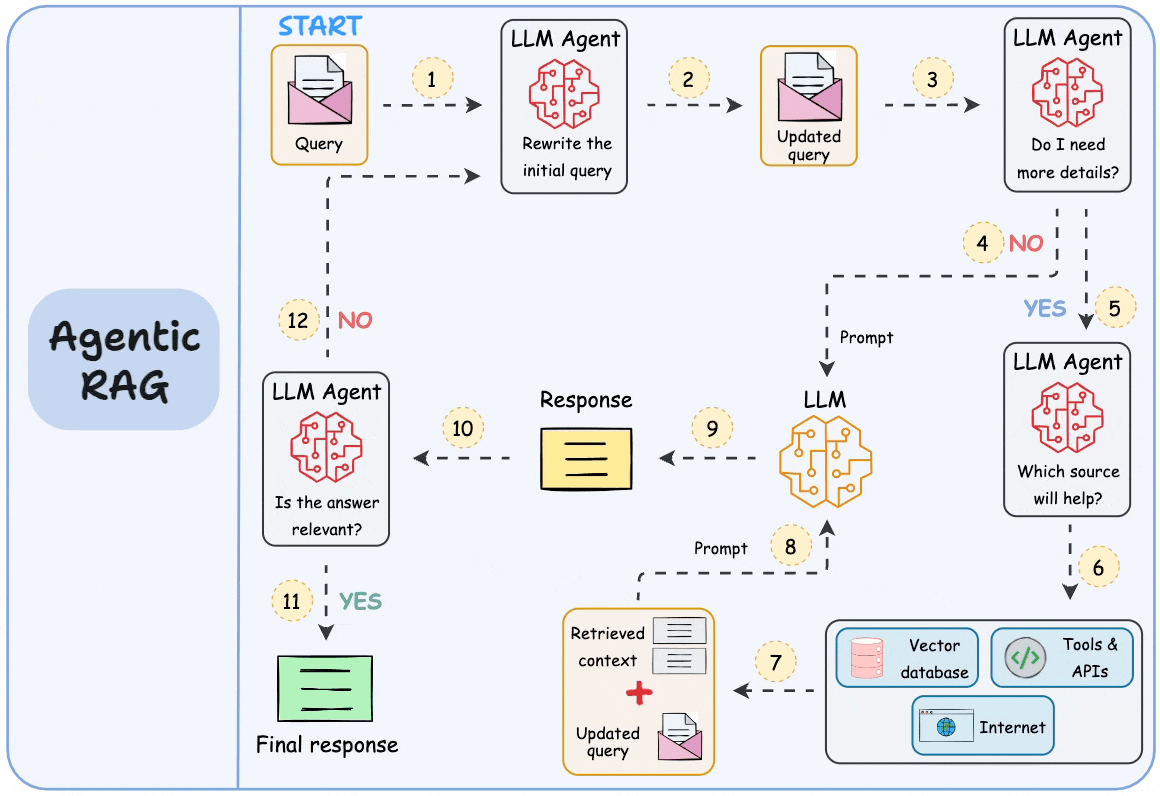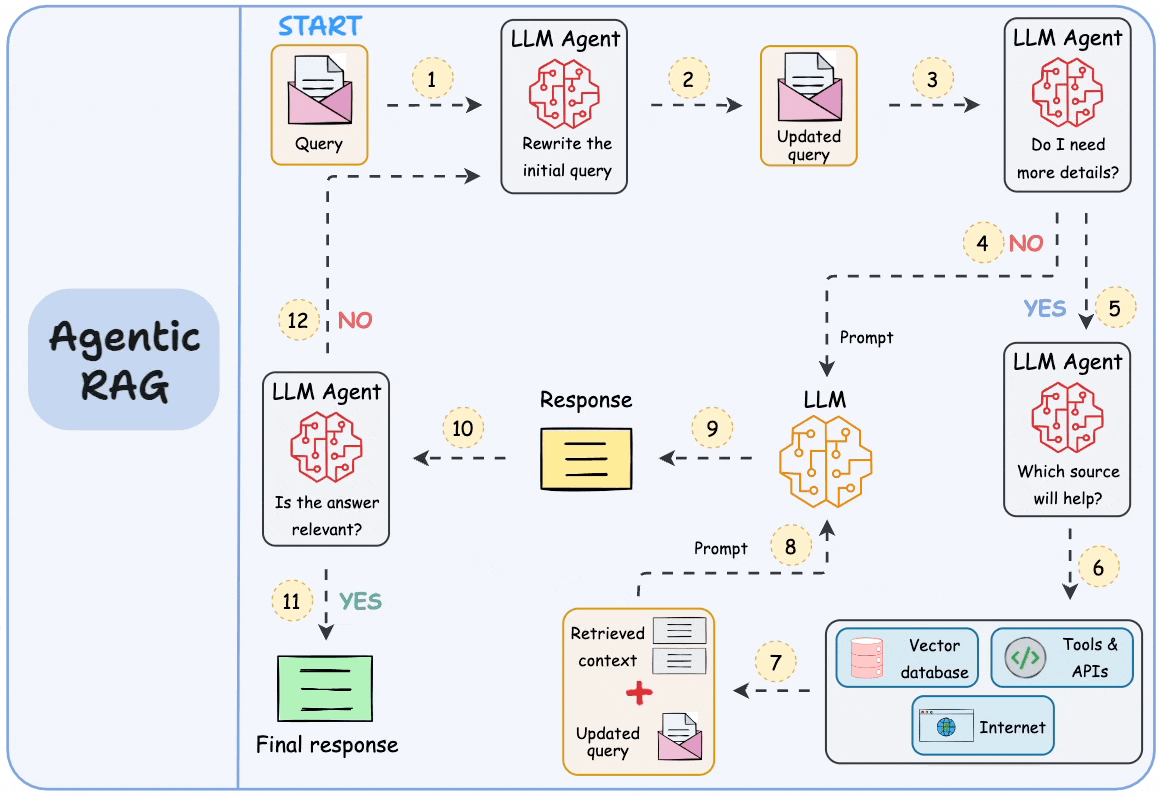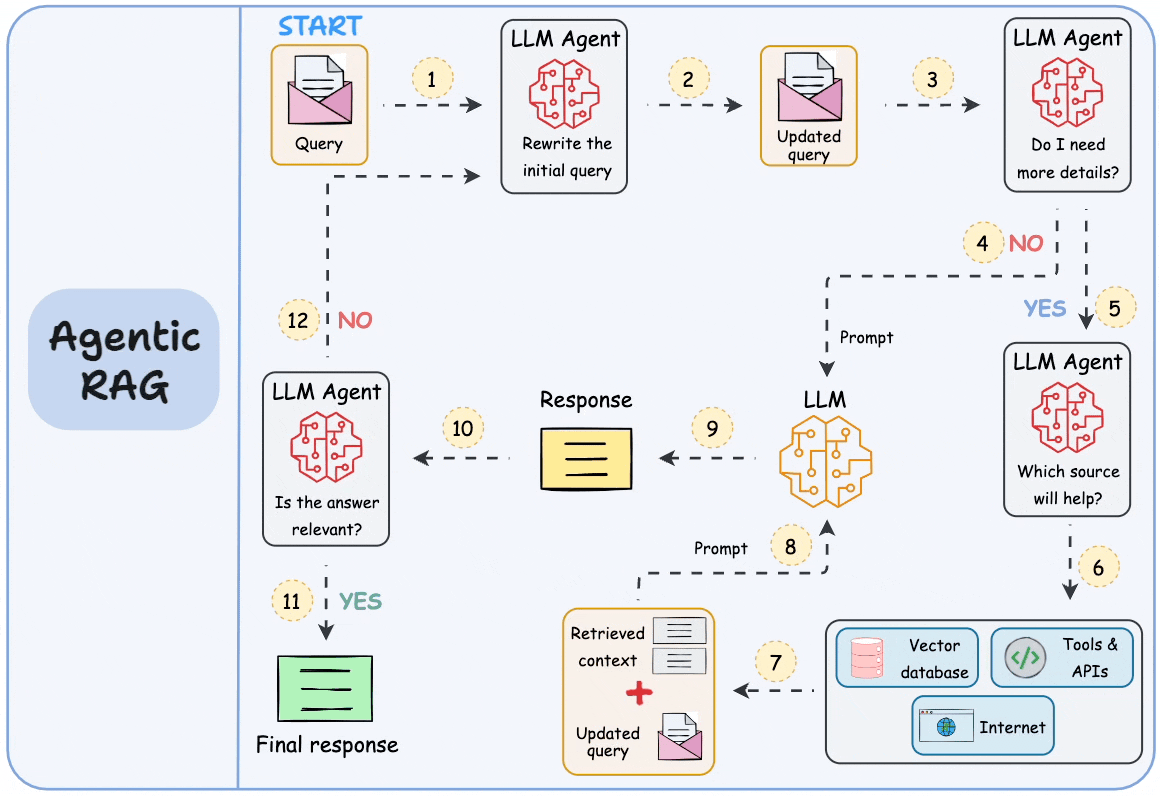




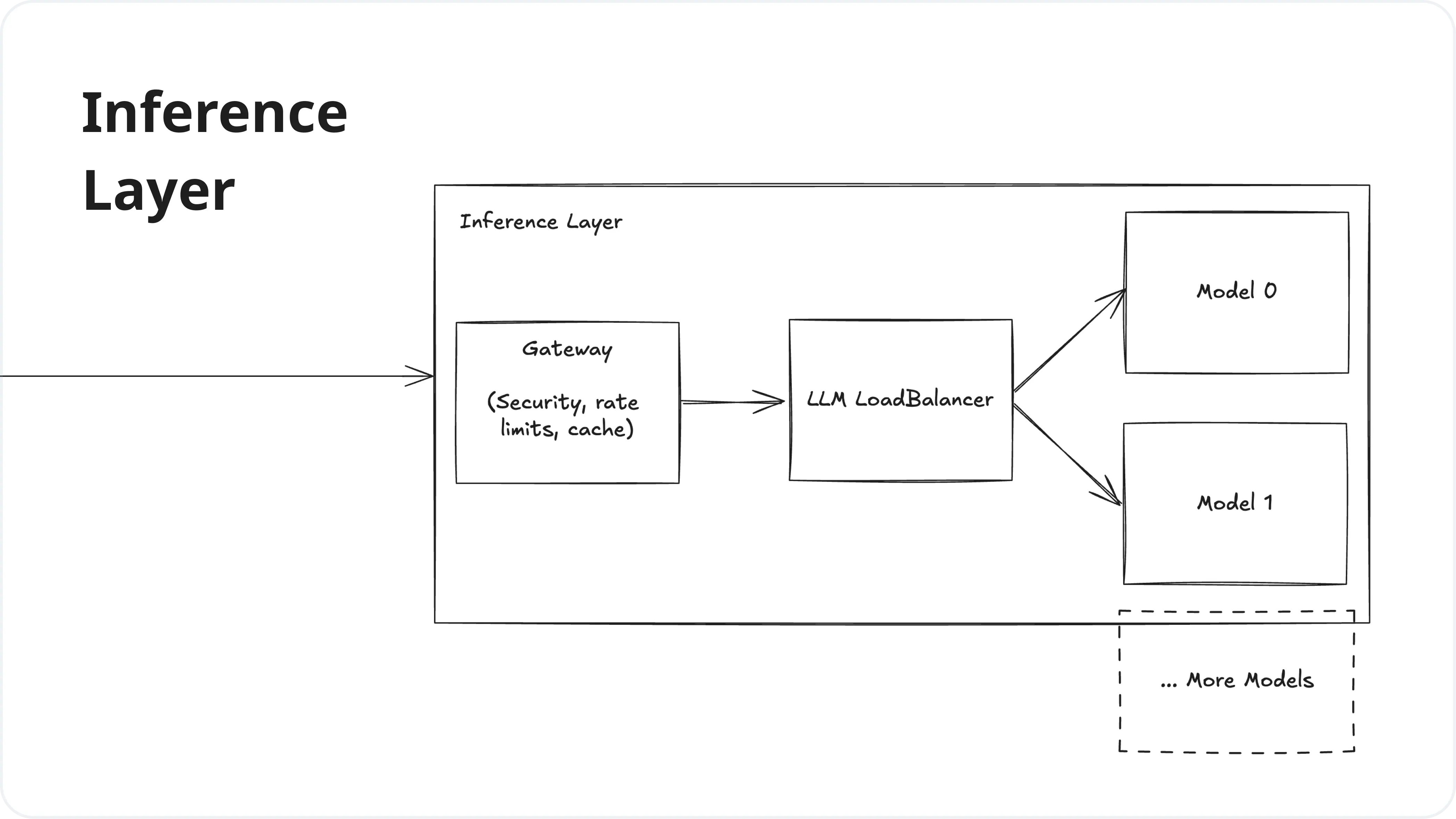

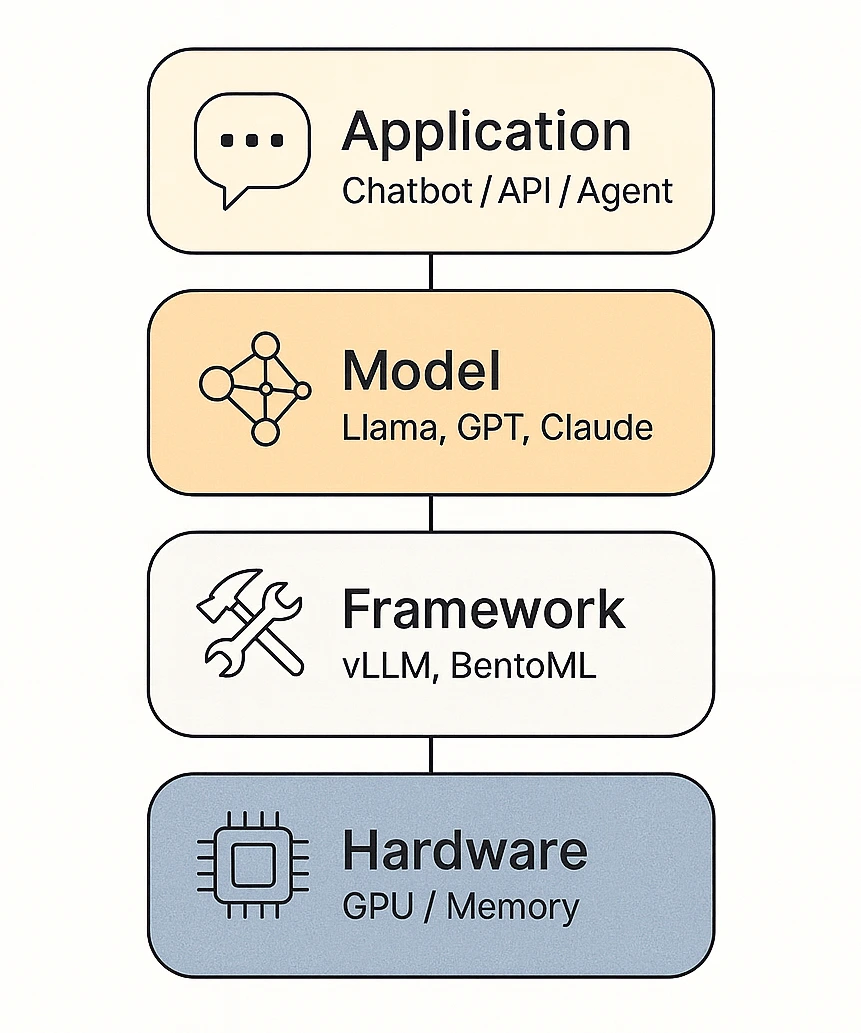
.jpg)