Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
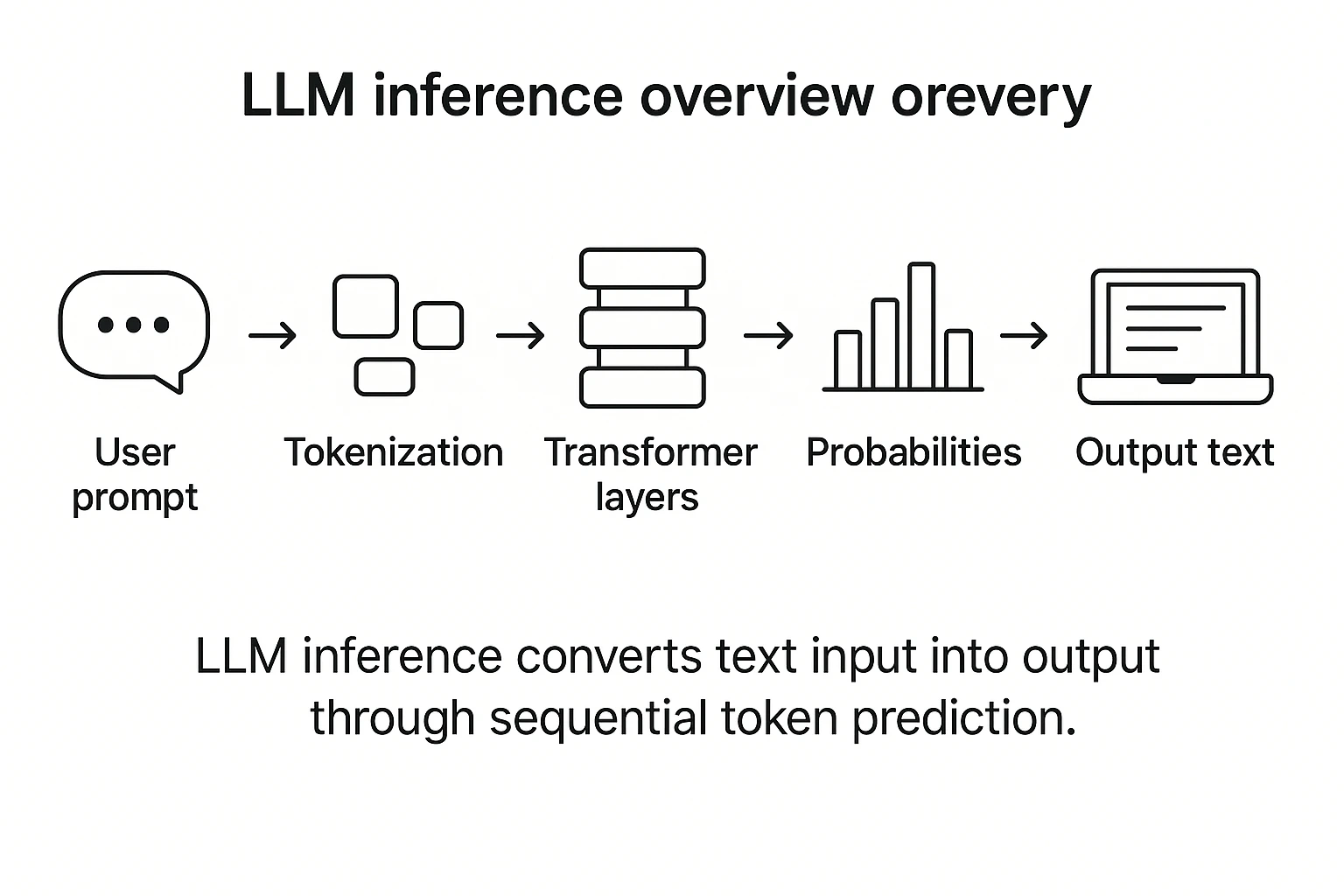
What Is LLM Inference? Process, Latency & Examples Explained (2026)
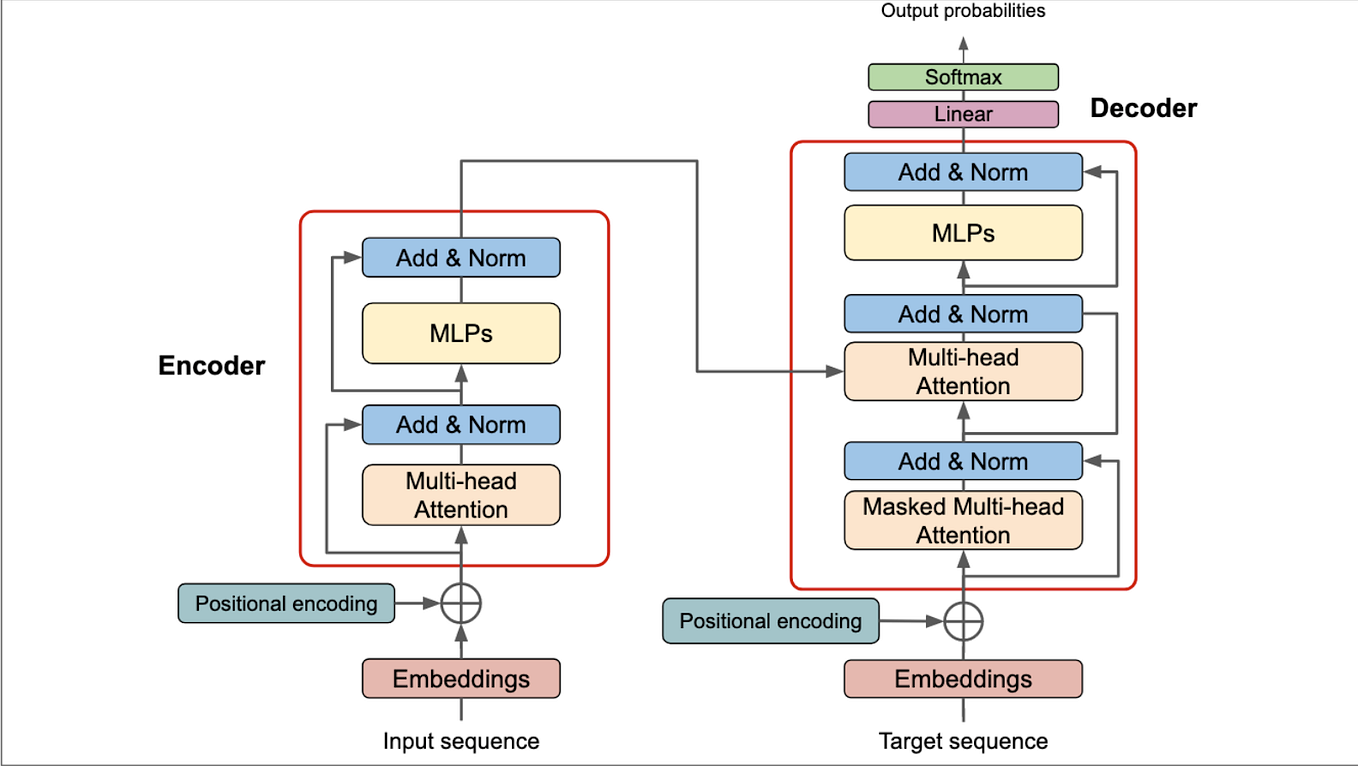
LLM Inference — A Detailed Breakdown of Transformer Architecture and ...
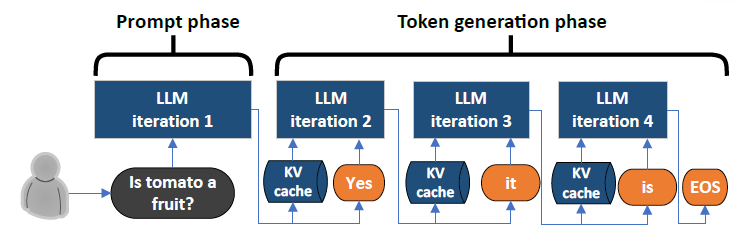
LLM Inference Series: 2. The two-phase process behind LLMs’ responses ...
LLM Inference - Hw-Sw Optimizations
How continuous batching enables 23x throughput in LLM inference ...
LLM (Large Language Models) Inference and Serving – Ranjan Kumar
LLM Inference Optimization Techniques: A Comprehensive Analysis | by ...
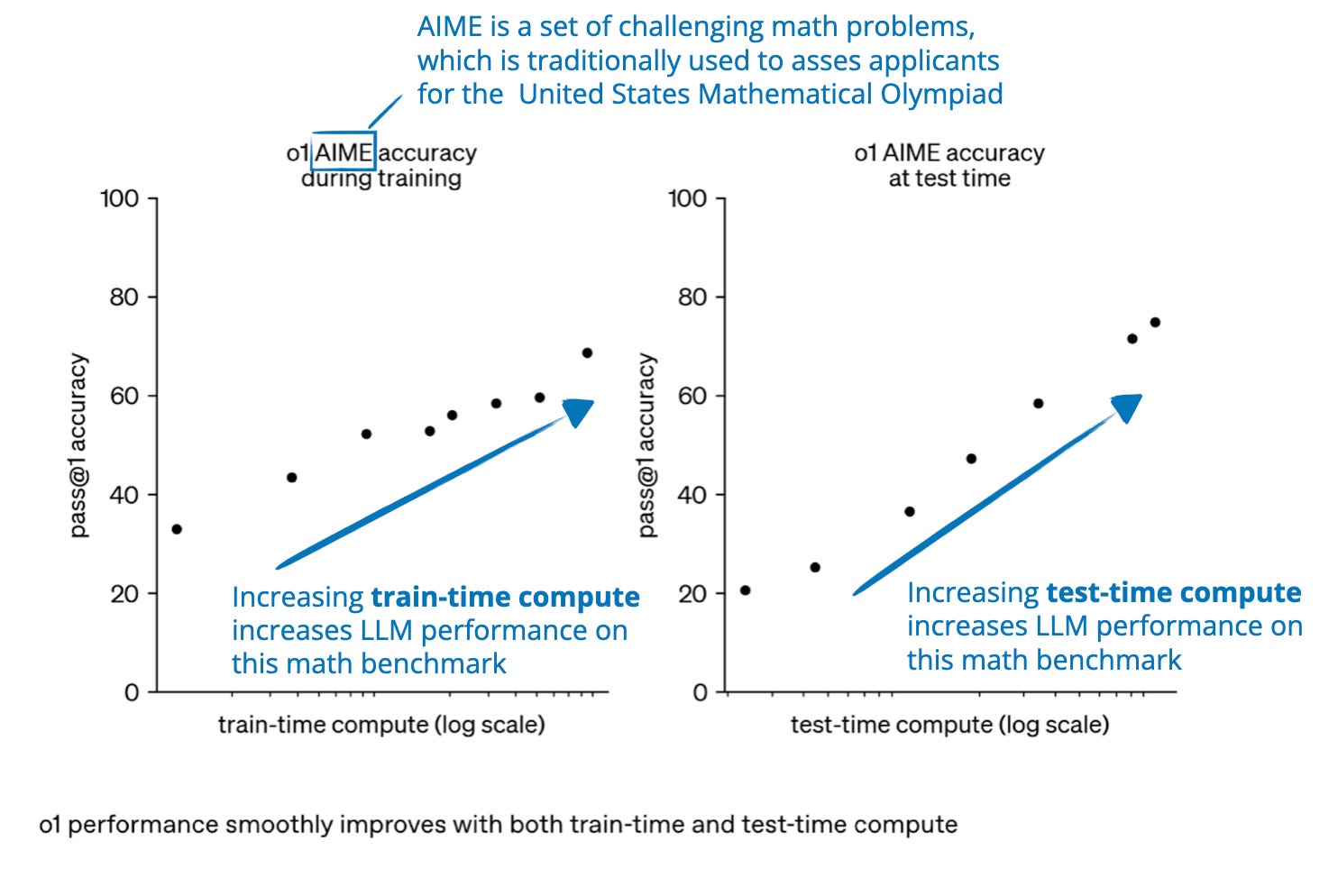
The State of LLM Reasoning Models
LLM Inference Series: 5. Dissecting model performance | by Pierre ...
Mastering LLM Techniques: Inference Optimization
What is LLM Inference? • luminary.blog
What is LLM Model Inference?
LLM Inference Arithmetics: the Theory behind Model Serving - Speaker Deck
How To Build LLM (Large Language Models): A Definitive Guide
Exploring large language models: a guide to llm architectures – large ...
LLM Inference Archives | Uplatz Blog
LLM Inference Series: 1. Introduction | by Pierre Lienhart | Medium
(PDF) Enabling Efficient Serverless Inference Serving for LLM (Large ...
LLM Inference Stages Diagram | Stable Diffusion Online
llm inference bench inference benchmarking of large language models on ...
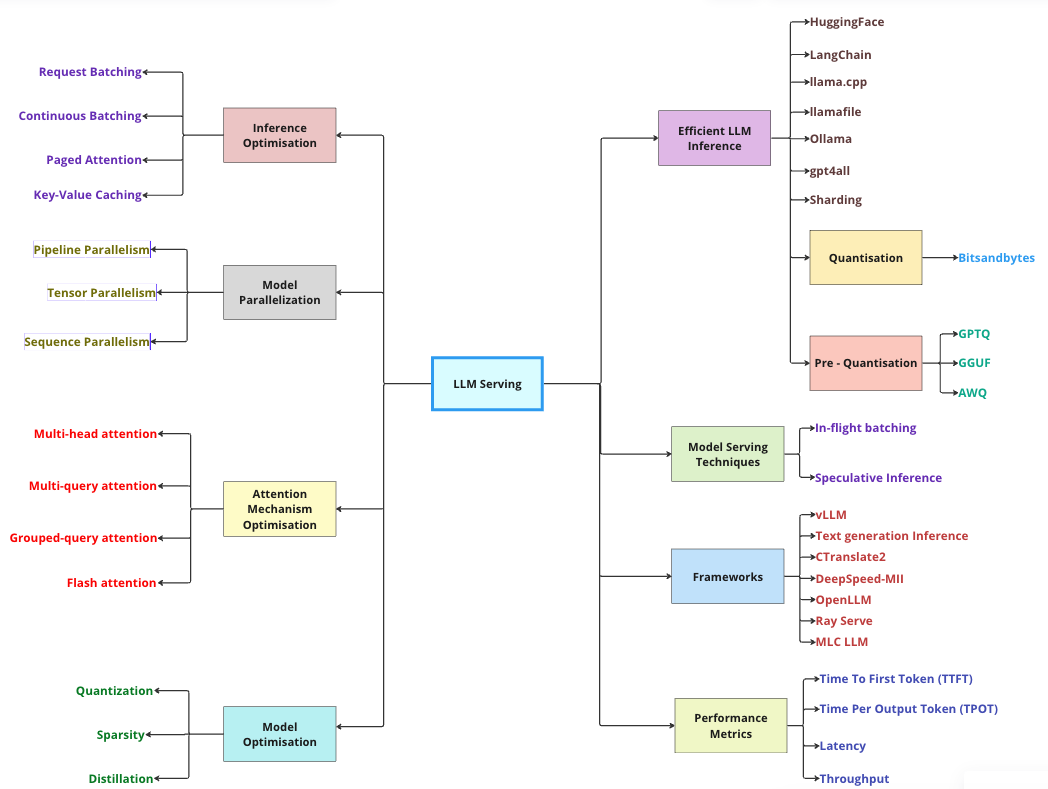
LLM inference techniques
Understanding LLM Inference - by Alex Razvant
Understanding the LLM Inference Workload: Key Insights
LLM Inference
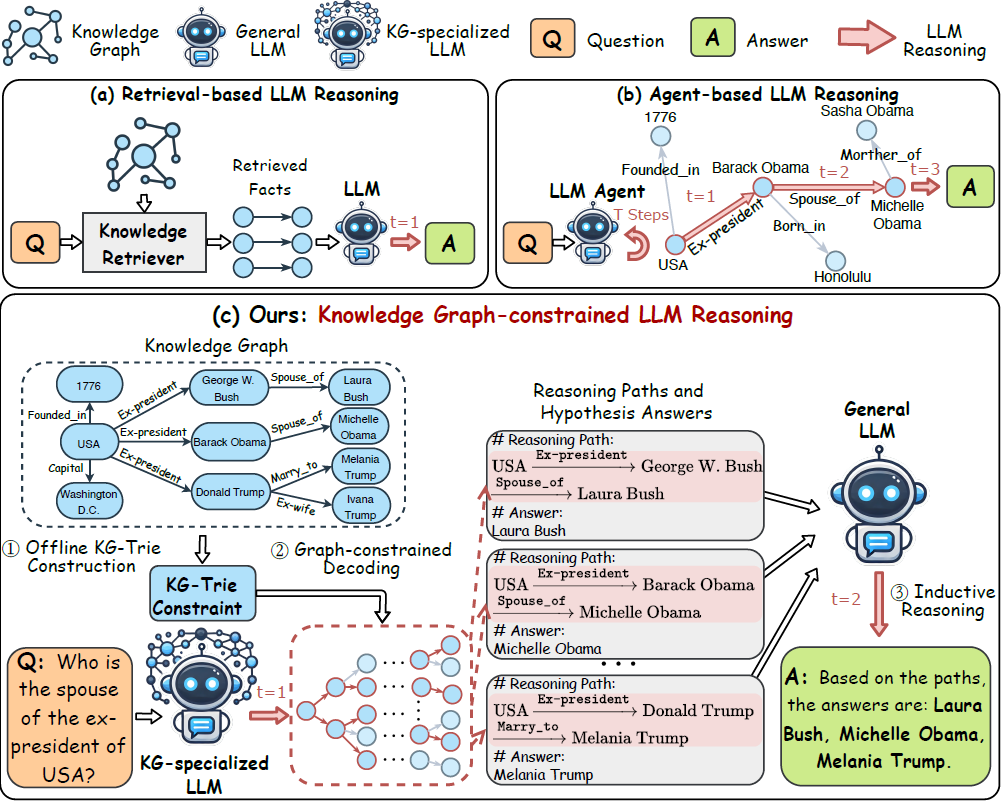
Illustration of the proposed method. (a) LLM inference comprises two ...
Ways to Optimize LLM Inference: Boost Response Time, Amplify Throughput ...
Optimizing AI Performance: A Guide to Efficient LLM Deployment
Choosing the right inference framework | LLM Inference Handbook
The State of LLM Reasoning Model Inference
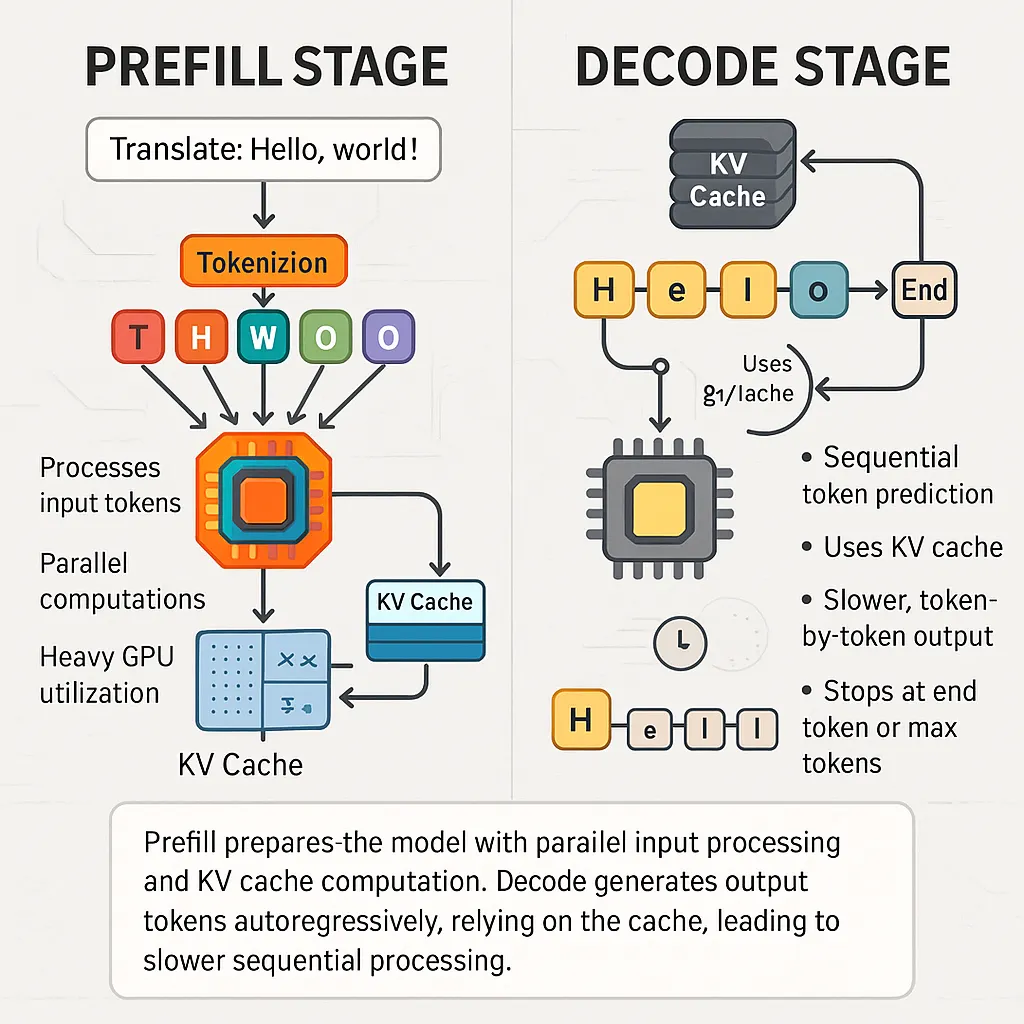
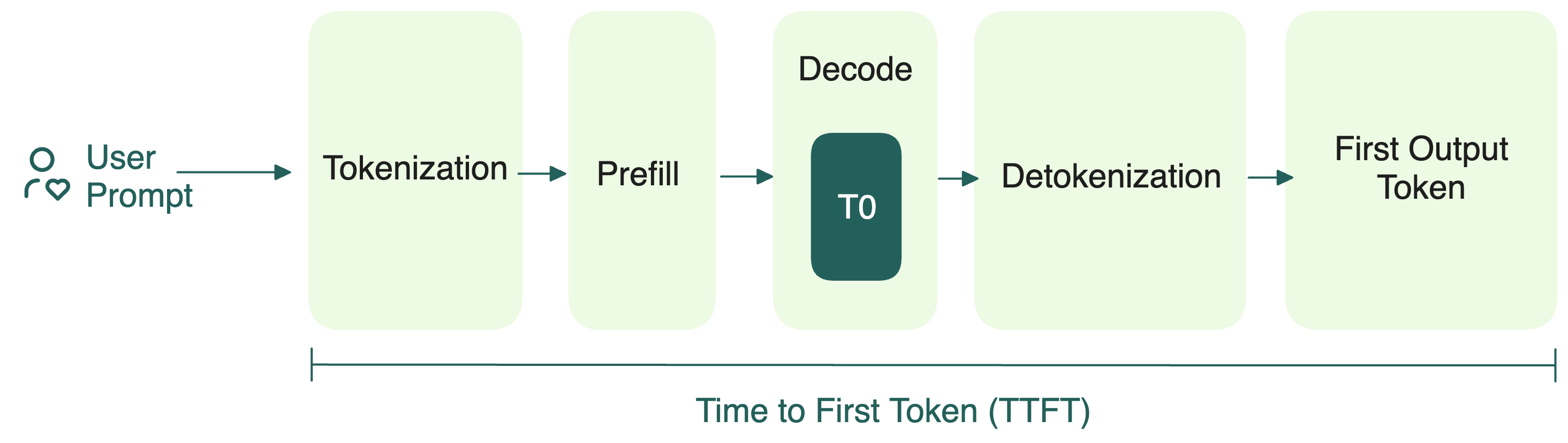
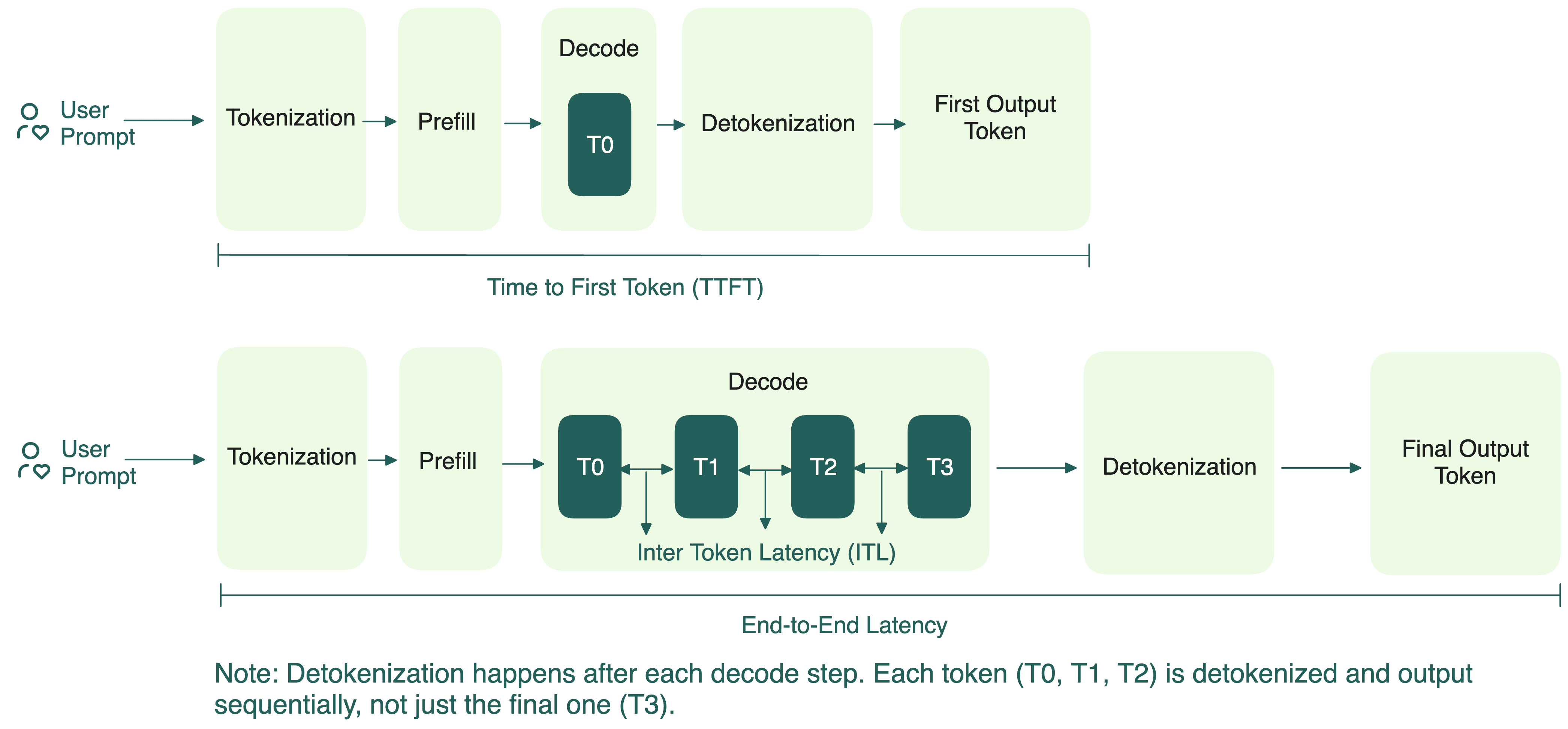
Understanding the Two Key Stages of LLM Inference: Prefill and Decode ...
Achieve 23x LLM Inference Throughput & Reduce p50 Latency
LLM in a flash: Efficient Large Language Model Inference with Limited ...
LLM Inference Parameters Explained Visually
Microsoft Research Propose LLMA: An LLM Accelerator To Losslessly Speed ...
LLM Inference: Techniques for Optimized Deployment in 2025 | Label Your ...
What Is LLM Inference? Batch Inference In LLM Inference
LLM Inference Optimization Overview - From Data to System Architecture
LLM inference optimization: Model Quantization and Distillation - YouTube
Introduction to LLM Inference Benchmarking | Yu-Chen Cheng's Blog
Choosing The Right Inference Framework - LLM Inference Handbook | PDF ...
LLM Inference Hardware: Emerging from Nvidia's Shadow
LLM Inference CookBook(持续更新) - 知乎
Illustration of the privacy-preserving LLM inference. The LLM inference ...
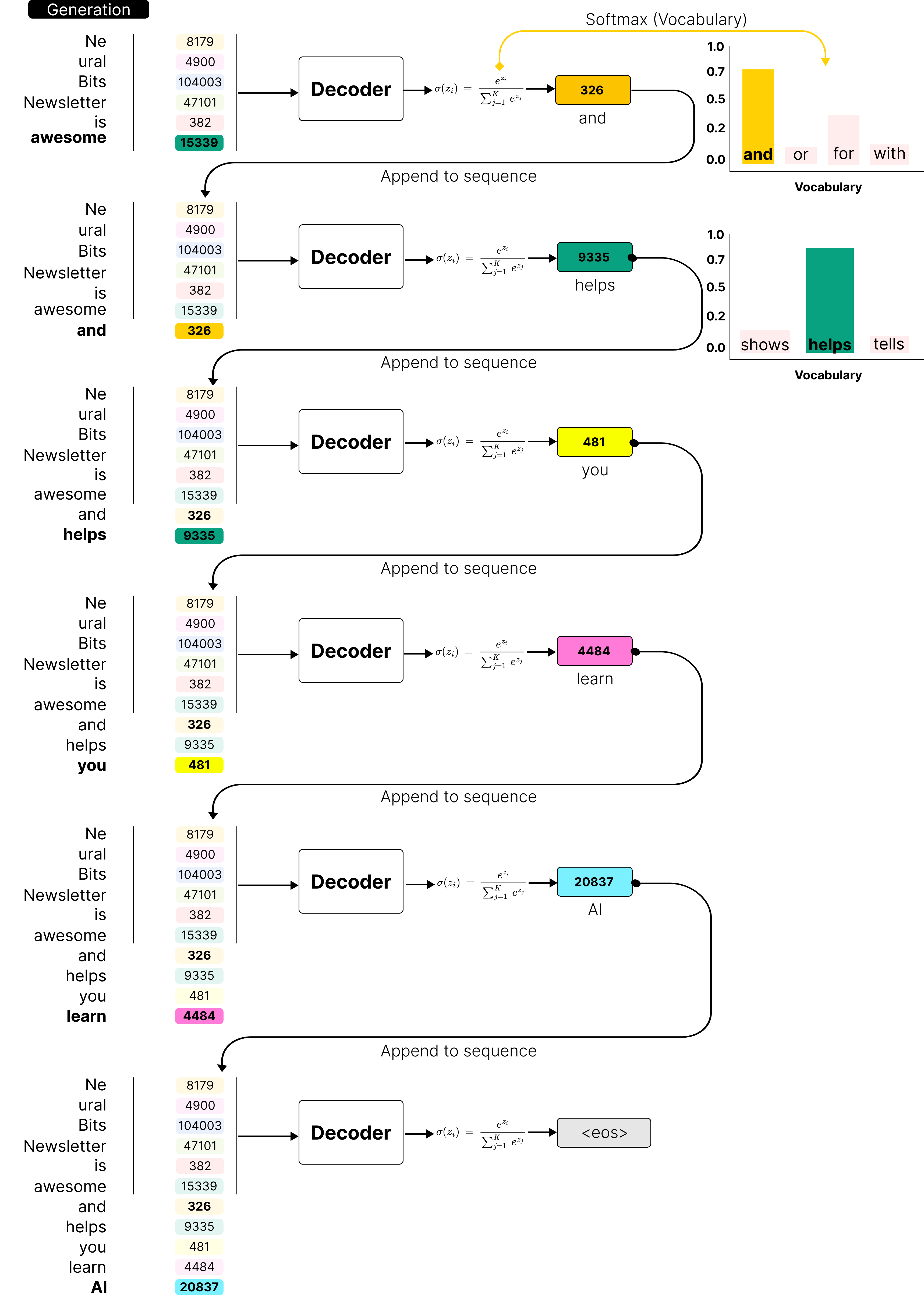
LLM Inference Series: 3. KV caching explained | by Pierre Lienhart | Medium
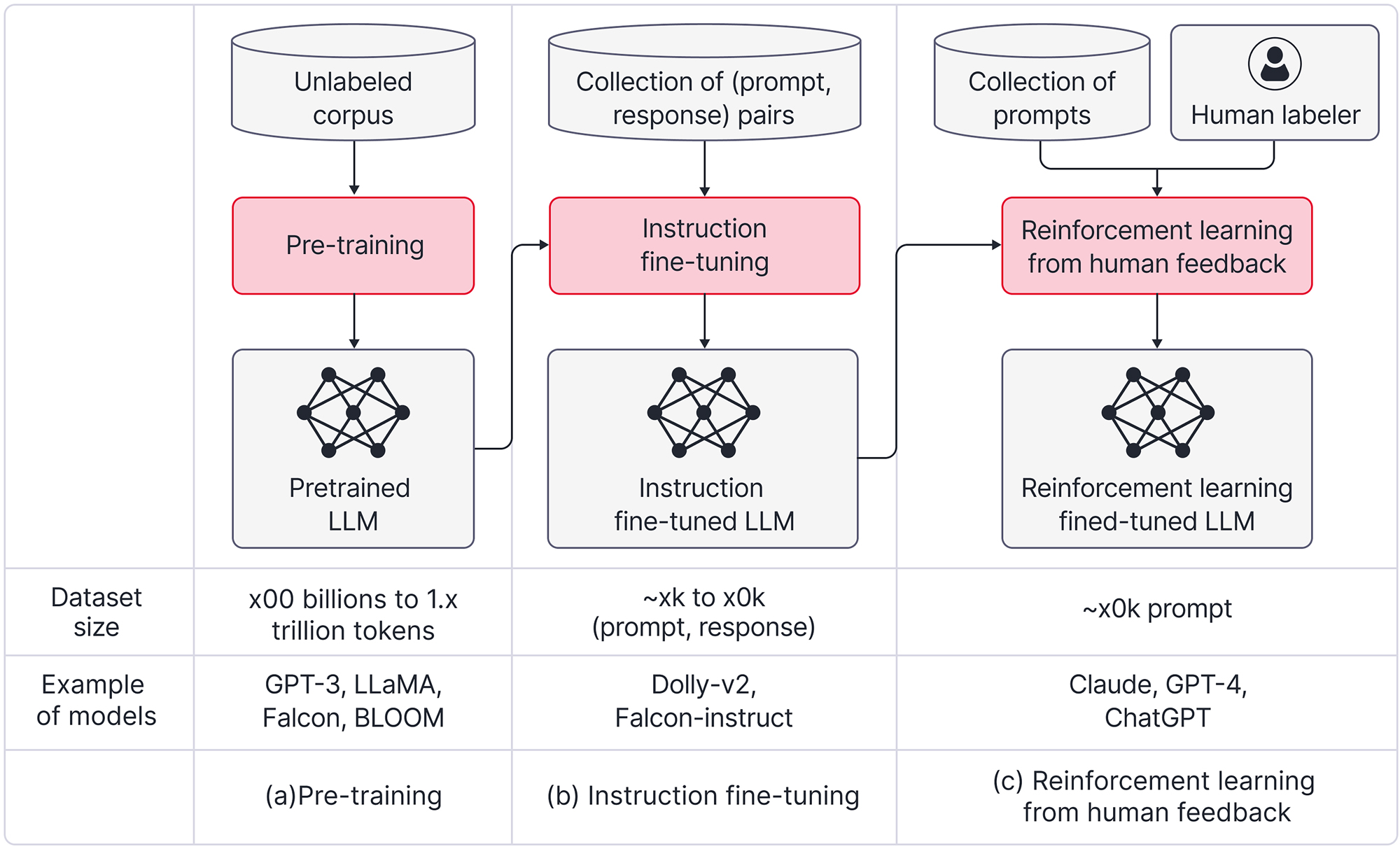
How LLM really works: From Training to Talking – The Power of Inference
Training gets all the attention. But inference is where your LLM either ...
A Survey of LLM Inference Systems | alphaXiv
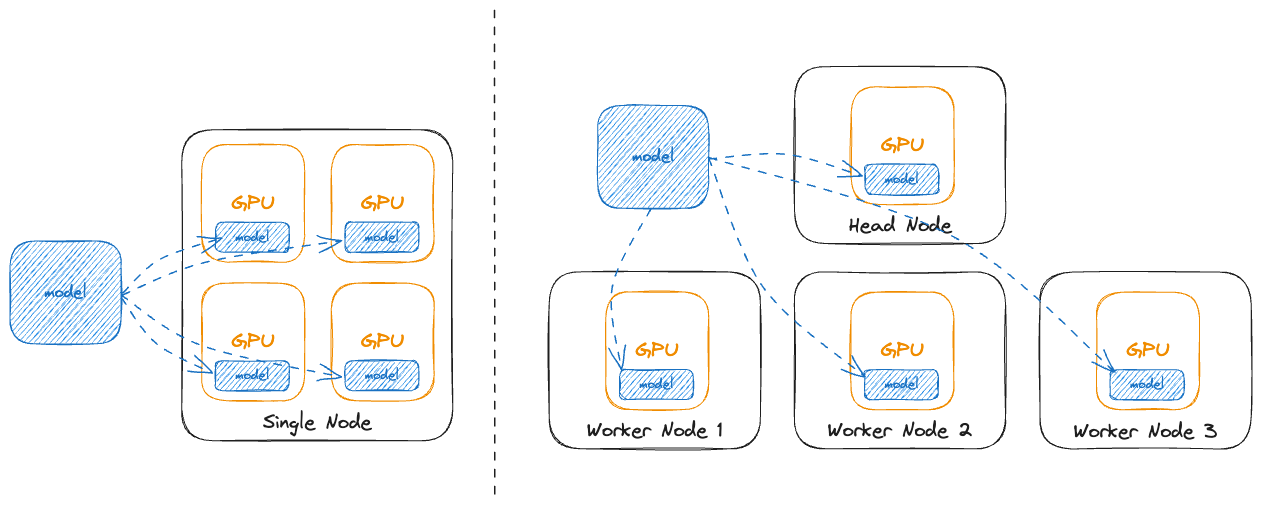
The Shift to Distributed LLM Inference: 3 Key Technologies Breaking ...
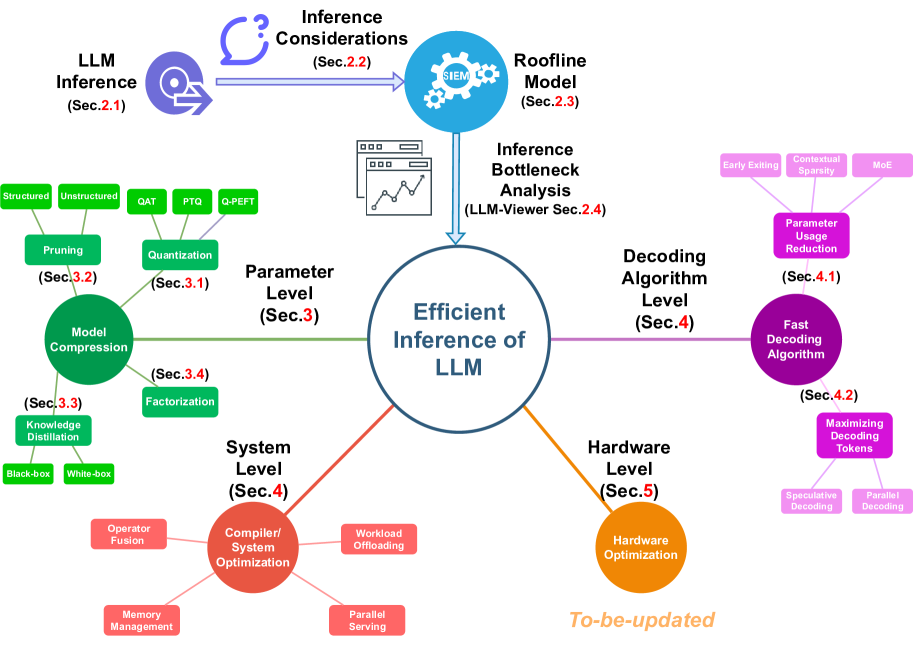
LLM Inference Unveiled: Survey and Roofline Model Insights - 知乎
Deterministic vs. Standard LLM Inference: The Strategic Choice Now on ...
Vidur: A Large-Scale Simulation Framework for LLM Inference Performance ...
How to Scale LLM Inference - by Damien Benveniste
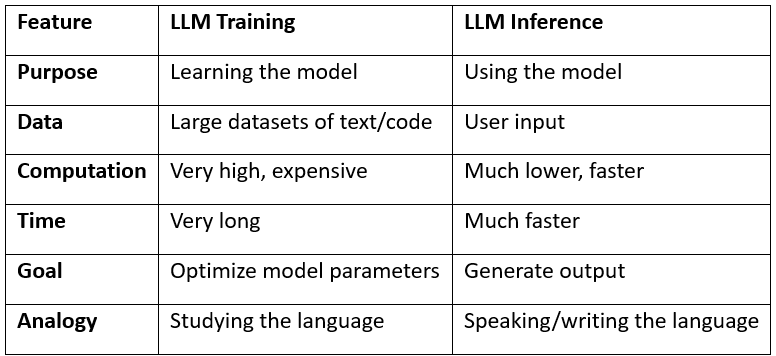
LLM Inference v_s Fine-Tuning | PDF | Cognitive Science | Computational ...
LLM Inference ( vLLM , TGI, TensorRT ) | by Pratik | Medium
A Guide to LLM Inference Performance Monitoring | Symbl.ai
Efficient LLM Inference With Limited Memory (Apple) - Data Intelligence
Rethinking LLM inference: Why developer AI needs a different approach
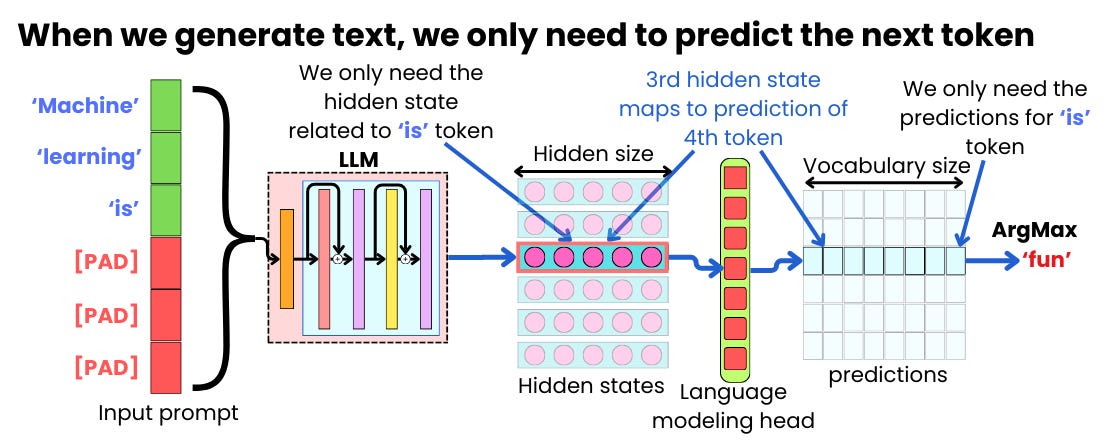
Understanding LLM Inference: How AI Generates Words | DataCamp
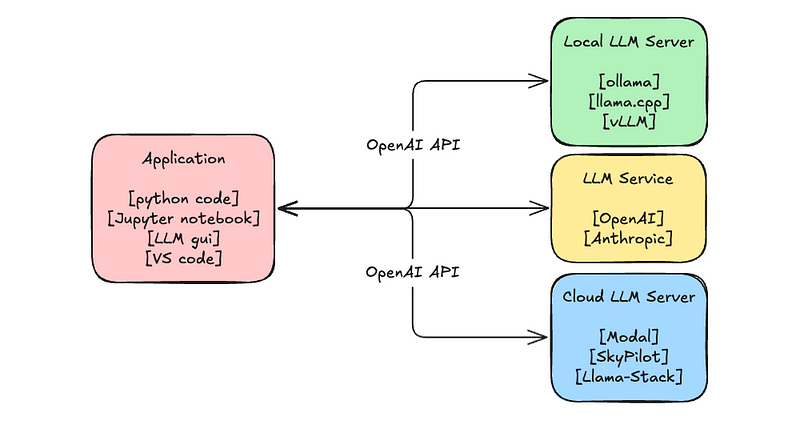
Best LLM Inference Engines and Servers to Deploy LLMs in Production - Koyeb
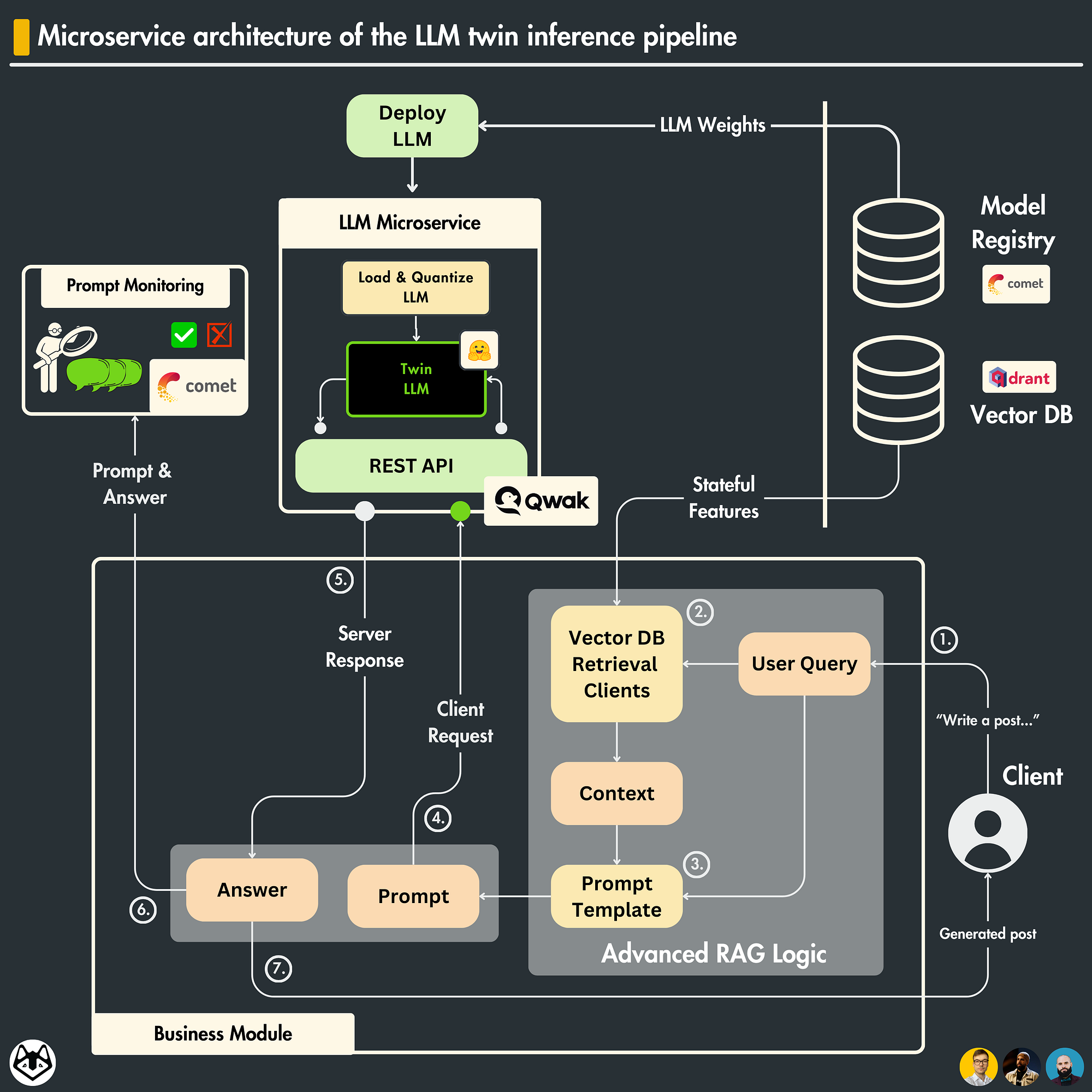
How to Architect Scalable LLM & RAG Inference Pipelines
LLM Inference Optimization 101 | DigitalOcean
How does LLM inference work? | LLM Inference Handbook
Understanding LLM Batch Inference | Adaline
(PDF) Improving the inference performance of LLM with code
Overview of an Example LLM Inference Setup - YouTube
LLM Series - Quantization Overview | by Abonia Sojasingarayar | Medium
[2402.16363] LLM Inference Unveiled: Survey and Roofline Model Insights
Topic 23: What is LLM Inference, it's challenges and solutions for it
LLM Inference Hardware: An Enterprise Guide to Key Players | IntuitionLabs
LLM Inference Series: 4. KV caching, a deeper look | by Pierre Lienhart ...
(PDF) LLM Inference Serving: Survey of Recent Advances and Opportunities
LLM Inference: how different it is from traditional ML?
LLM Inference - EcoLogits
Learn LLM Inference Optimization with #TowardsAI | Towards AI, Inc ...
MLSys @ WukLab - Efficient Augmented LLM Serving With InferCept
LLM Inference Benchmarking: How Much Does Your LLM Inference Cost ...
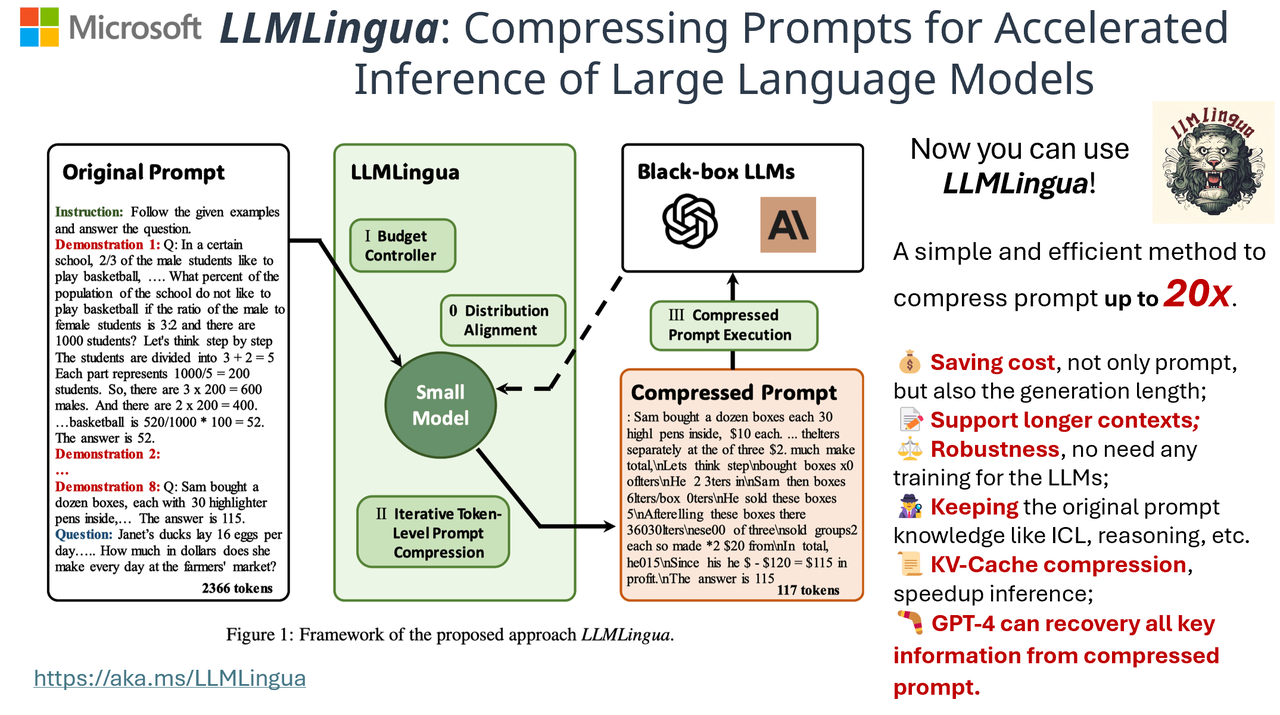
Primer on Large Language Model (LLM) Inference Optimizations: 3. Model ...
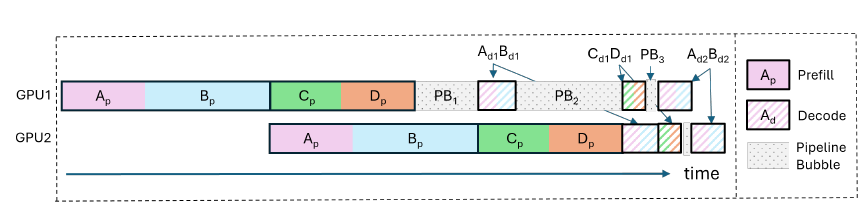
Large Language Models LLMs Distributed Inference Serving System ...
The Future of Serverless Inference for Large Language Models – Unite.AI
optimizing Large Language Model Inference: A Performance Engineering ...
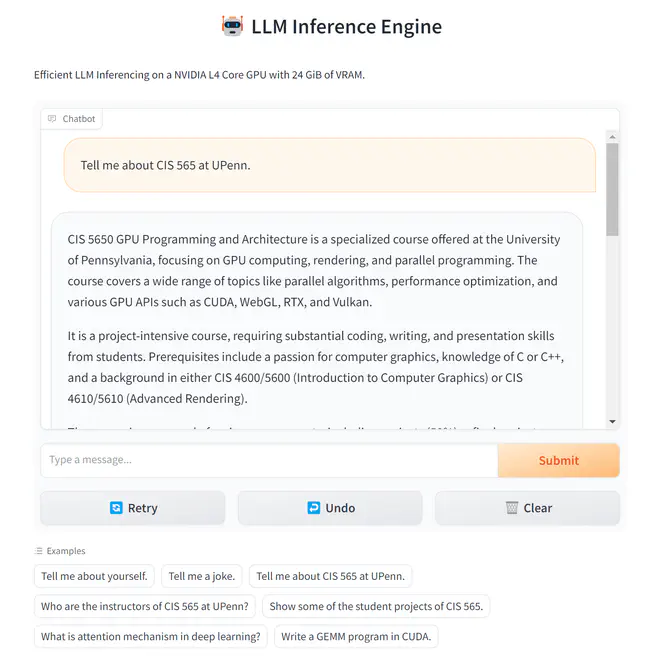
Deploying a Large Language Model (LLM) with TensorRT-LLM on Triton ...
Ithy - Understanding and Optimizing Large Language Model Inference
Maximizing Efficiency: A Comprehensive Guide to GPU and Memory ...
A High-level Overview of Large Language Models - Borealis AI
GitHub - aniketmaurya/llm-inference: Large Language Model (LLM ...
Optimizing Large Language Model Inference: A Deep Dive into Continuous
Facebook AI Researchers Open-Source 'LLM.int8()' Tool To Perform ...
Optimizing Inference on Large Language Models with NVIDIA TensorRT-LLM ...
TensorRT-LLM For All: A deep dive into getting started with NVidia’s ...
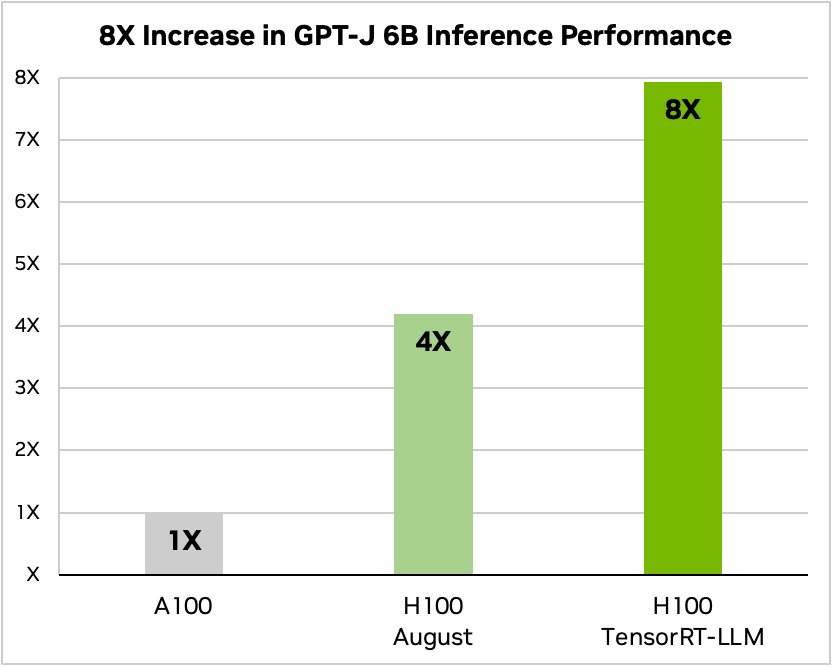
NVIDIA's Groundbreaking TensorRT-LLM Can Double Inference Performance ...
(PDF) LLM-Inference-Bench: Inference Benchmarking of Large Language ...
Efficient Large Language Model Inference · @toytag.net
GitHub - UranusSeven/Effective-LLM-Inference-Evaluation: A project ...
Comprehensive Analysis and Selection Guide for Large Language Model ...
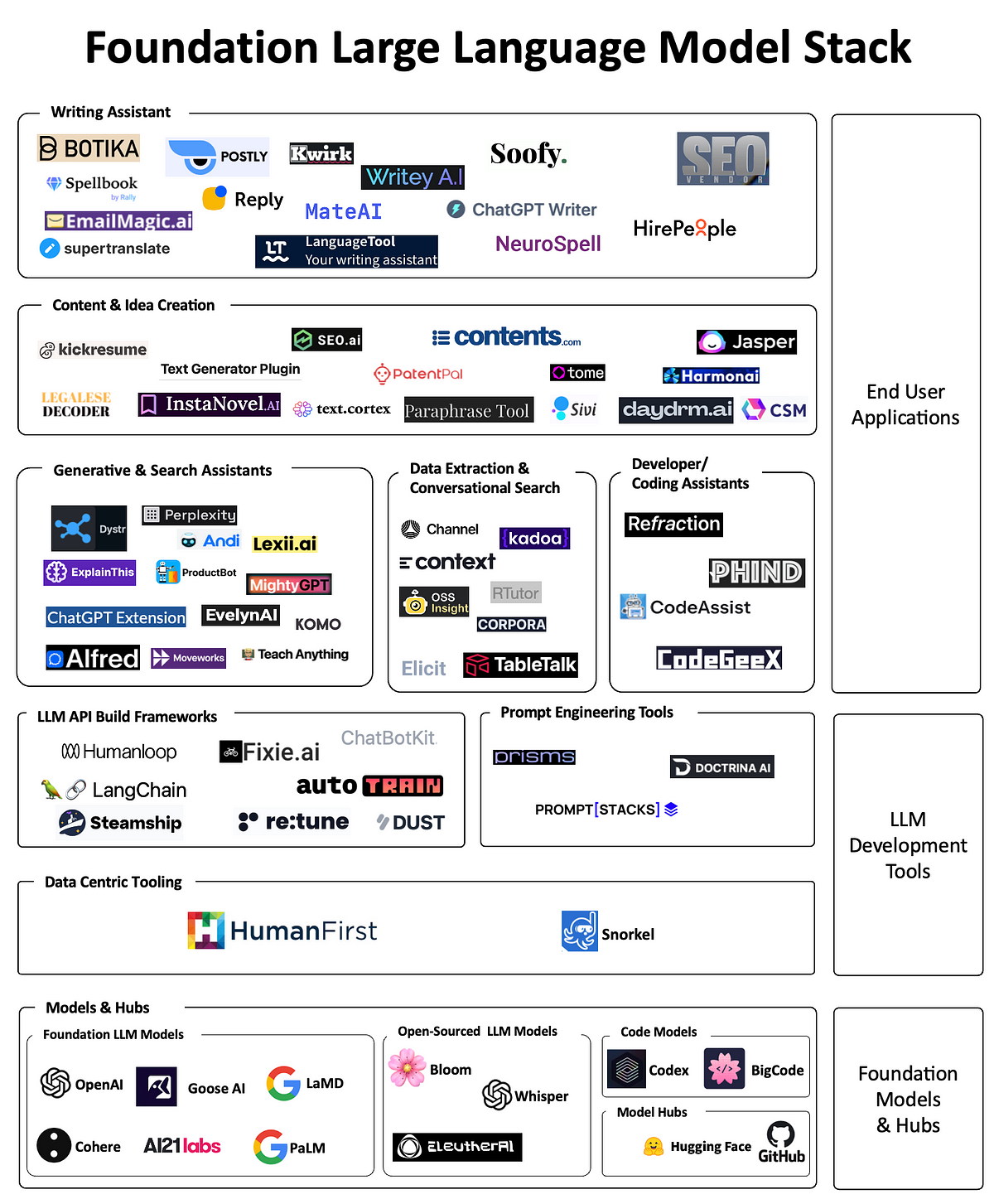
The Foundation Large Language Model (LLM) & Tooling Landscape | by ...
Ten Effective Strategies to Lower Large Language Model (LLM) Inference ...
VERSES Genius Active Inference vs LLMs and ML
Announcing SteerLM: A Simple and Practical Technique to Customize LLMs ...
Efficient Inference Archives - PyImageSearch
llm-d: Kubernetes-native distributed inferencing | Red Hat Developer
Awesome-LLM-Inference学习资料汇总 - 大语言模型推理优化必备参考 - 懂AI








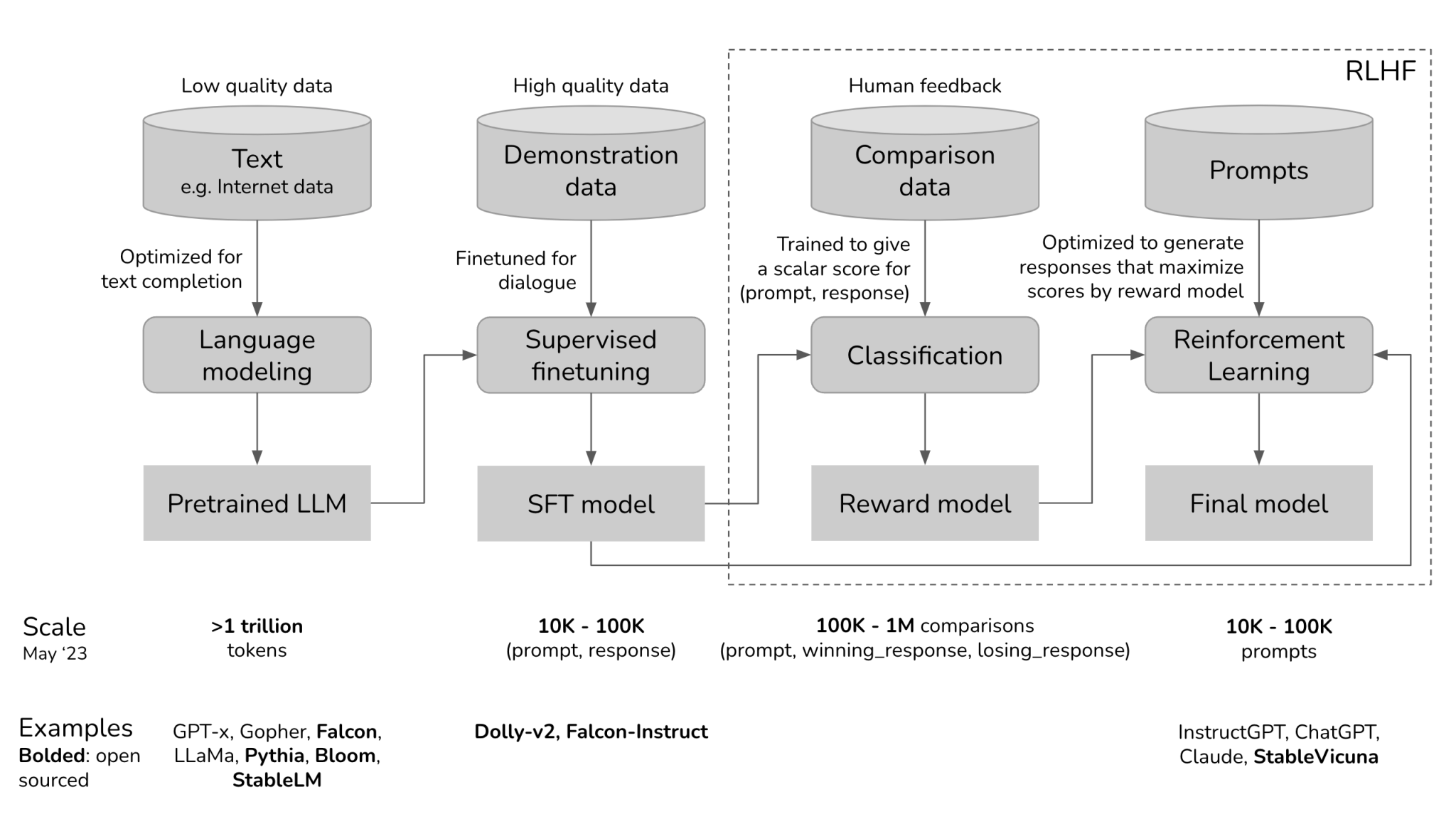





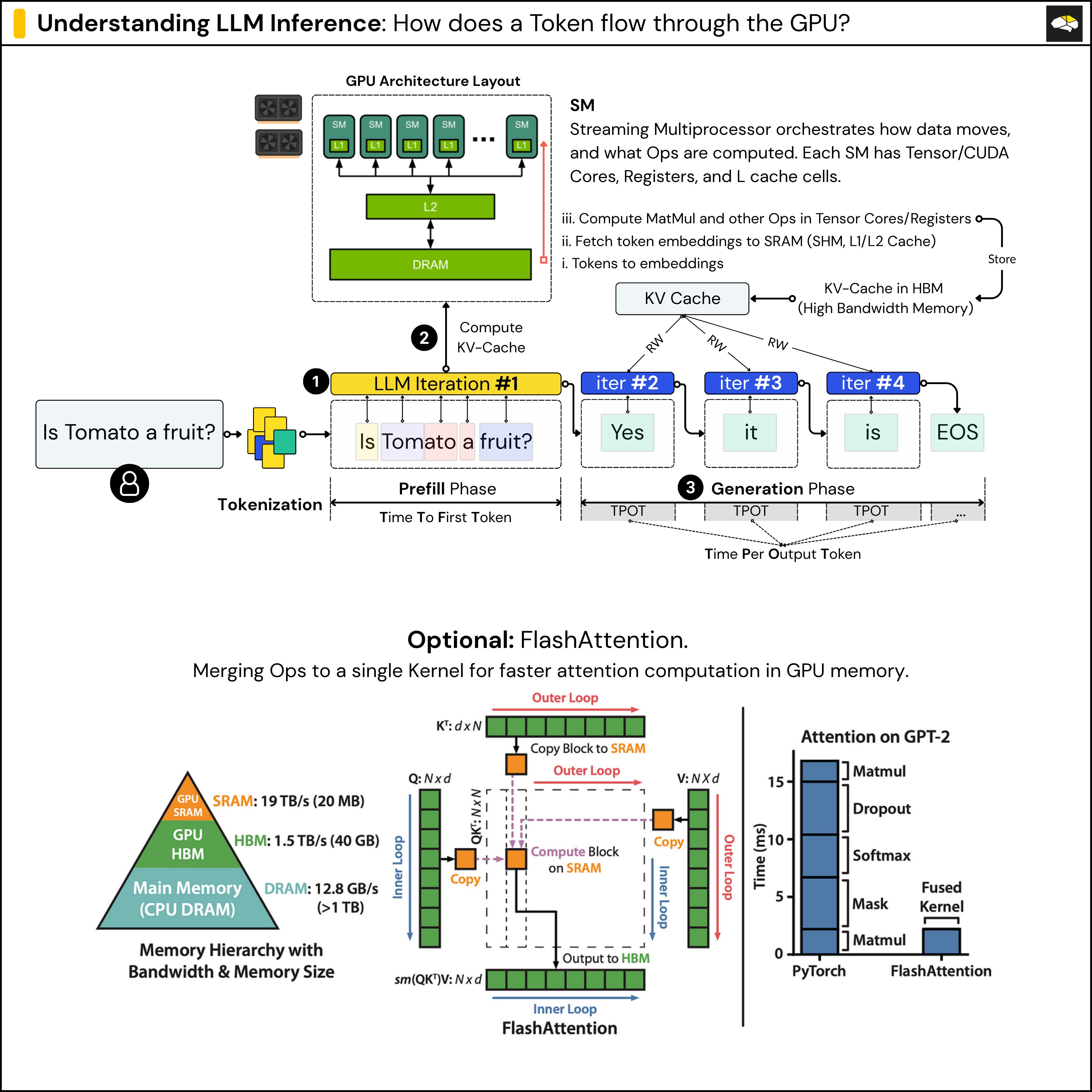


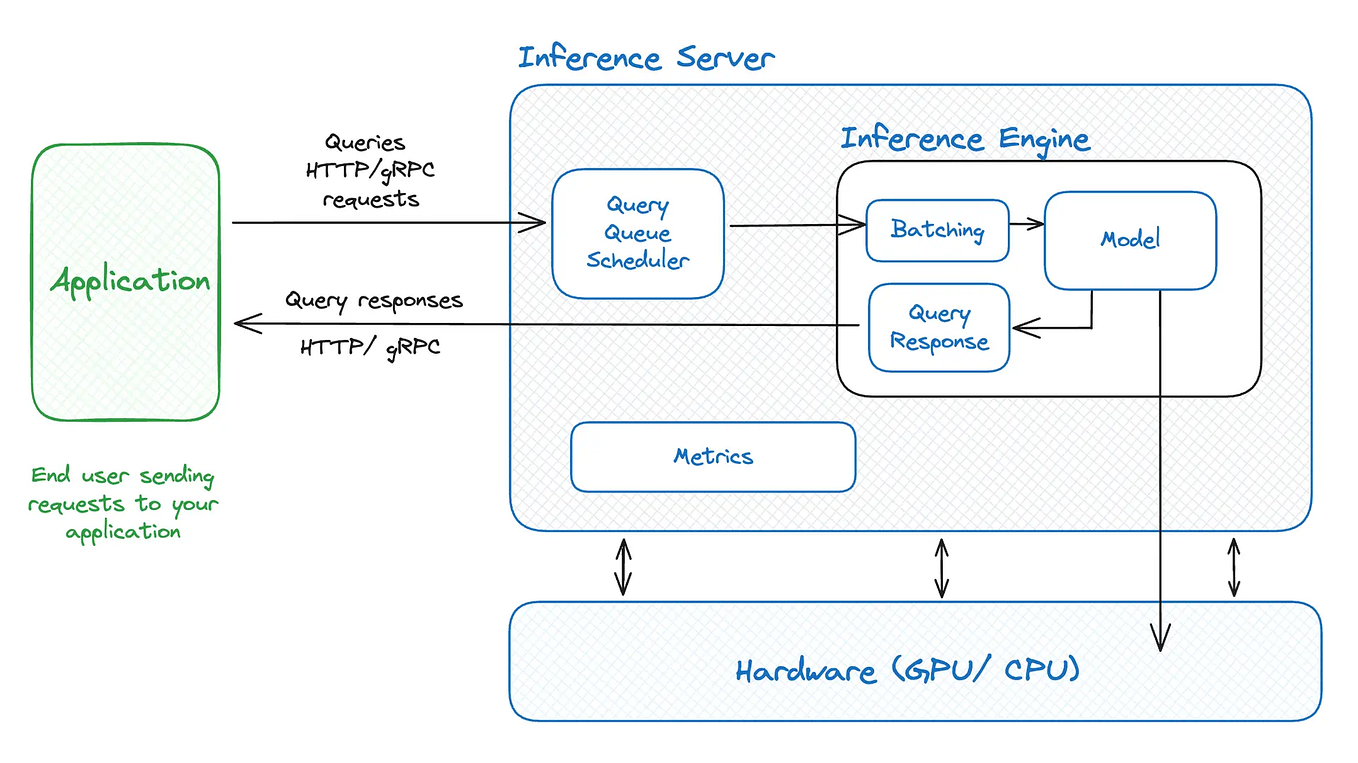


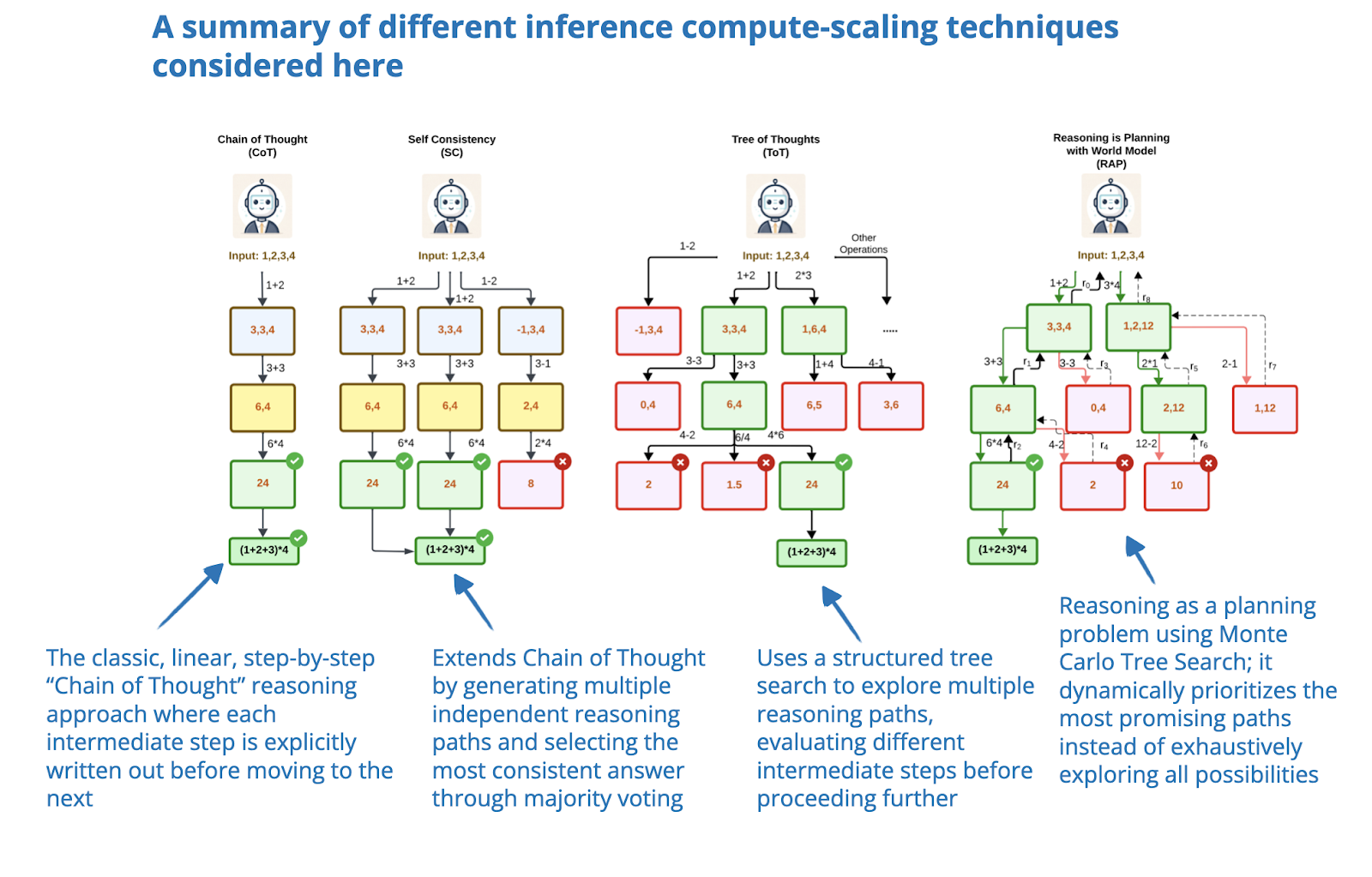

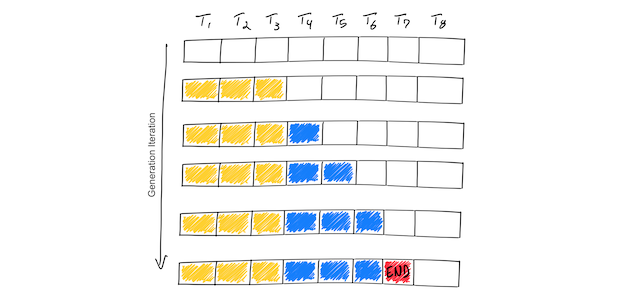
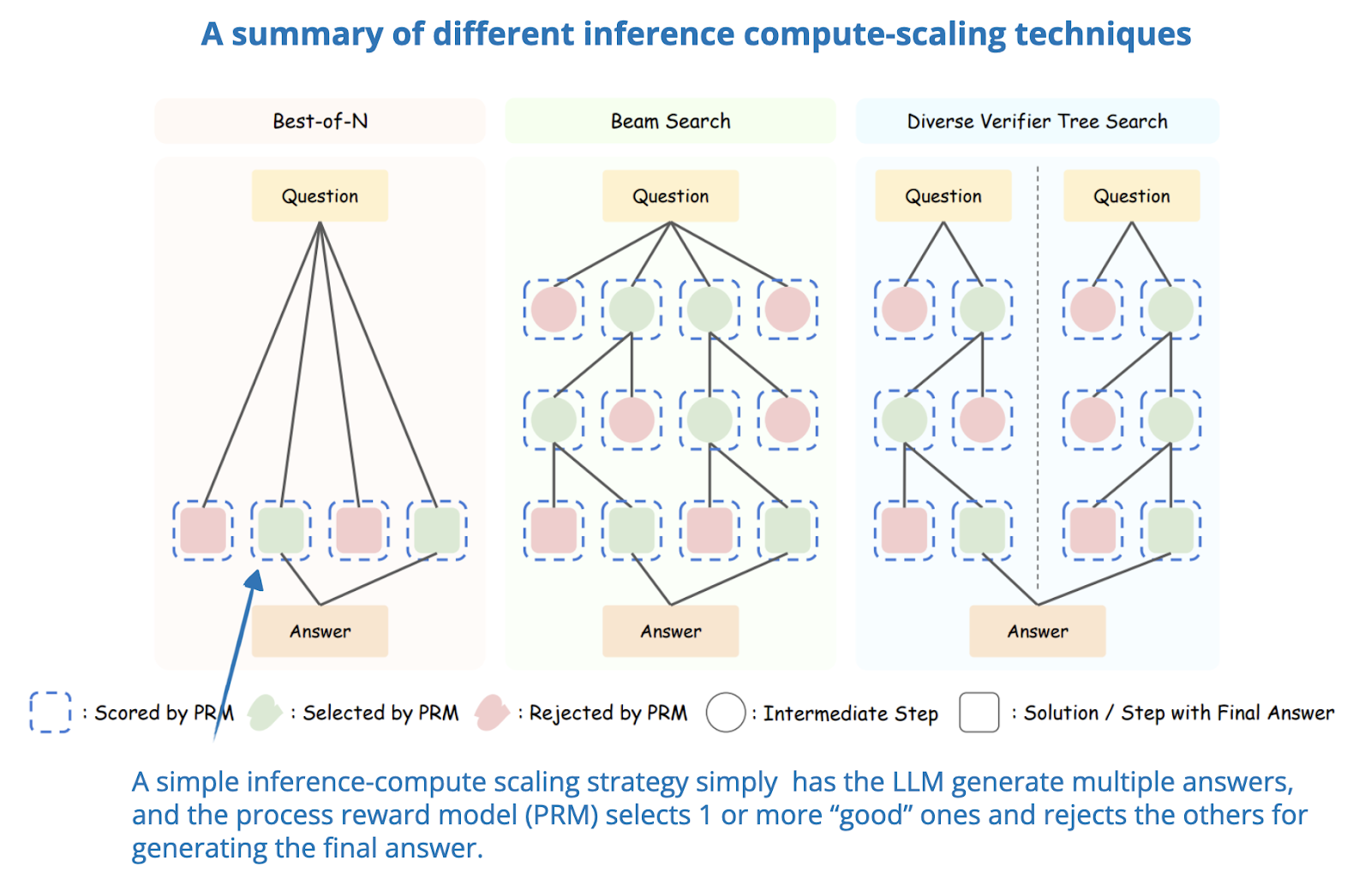






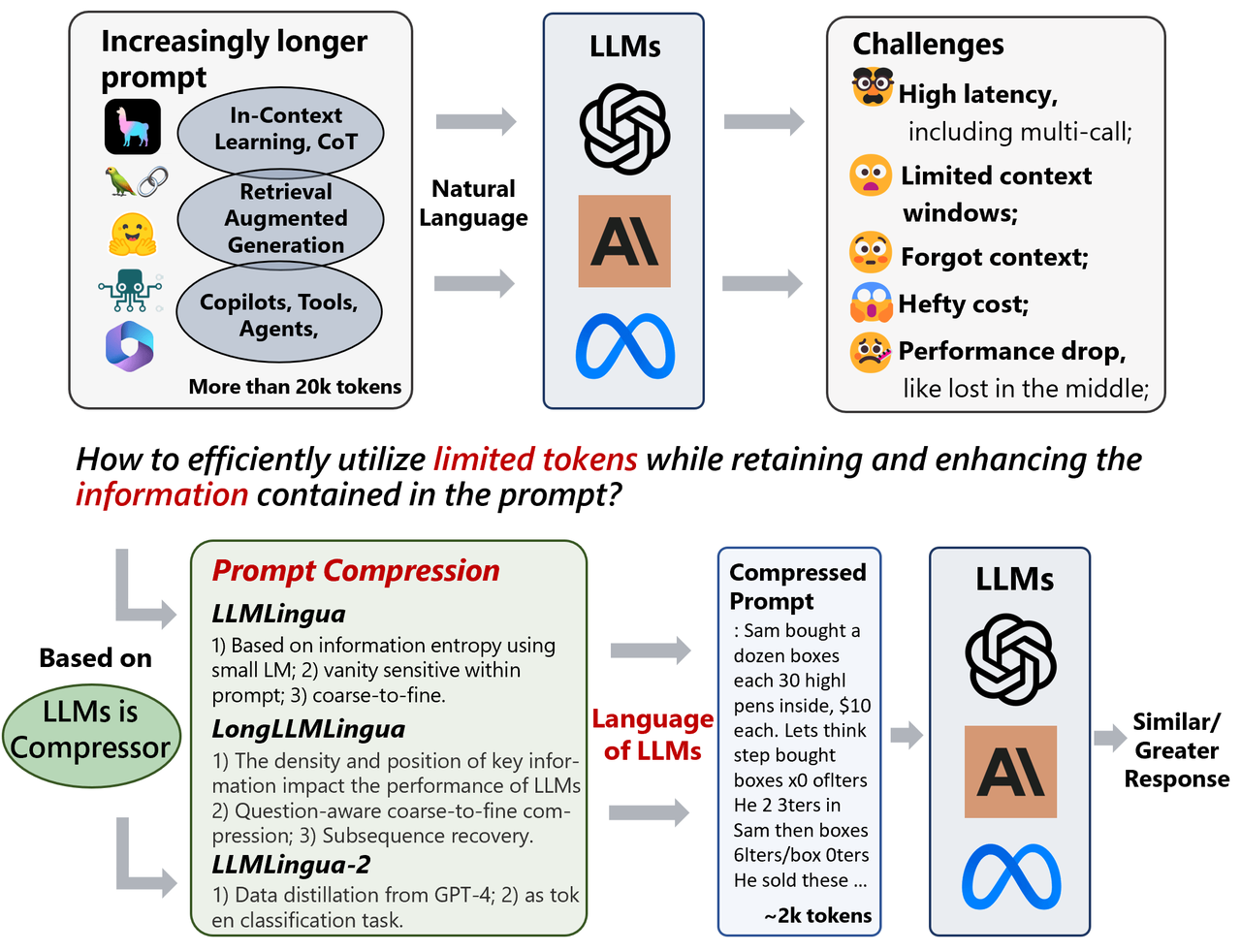

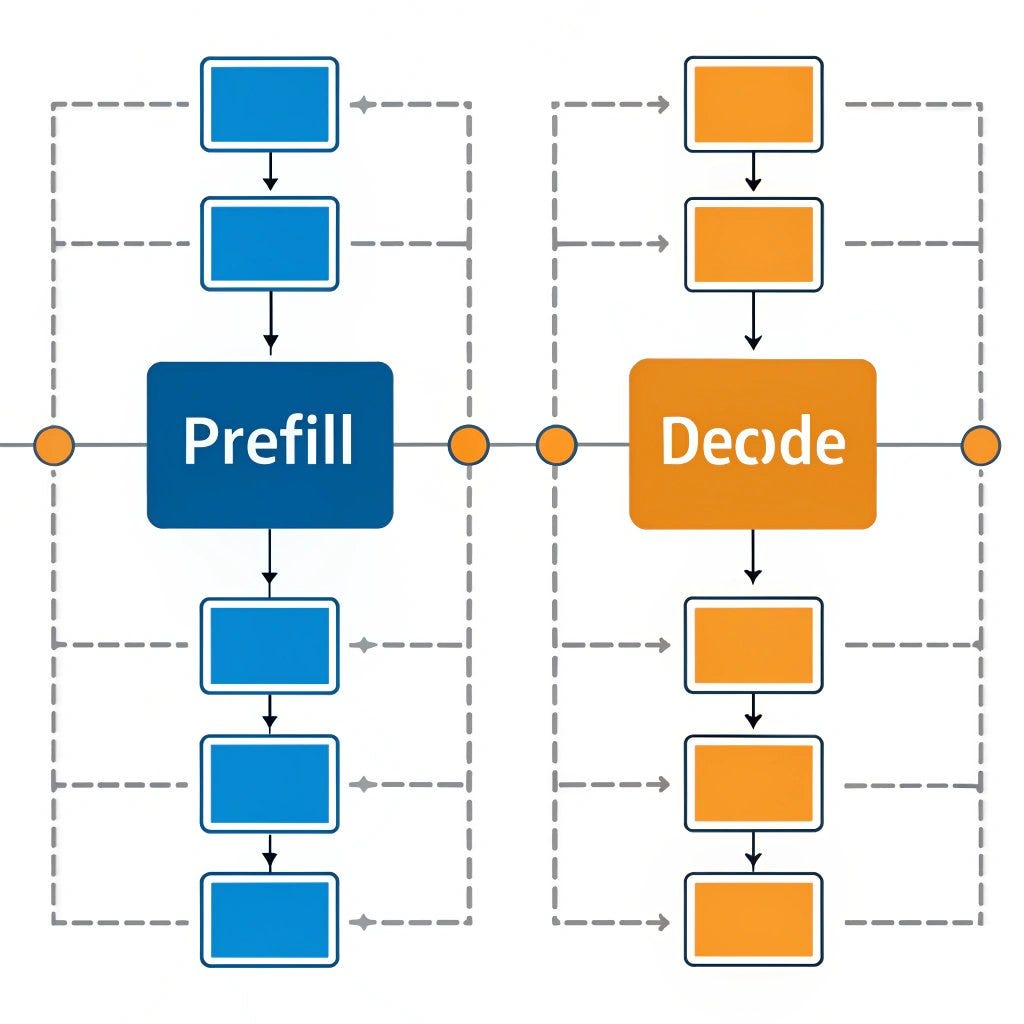


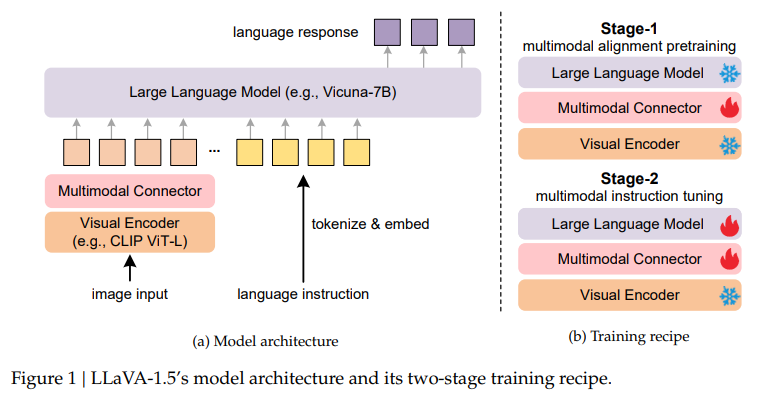


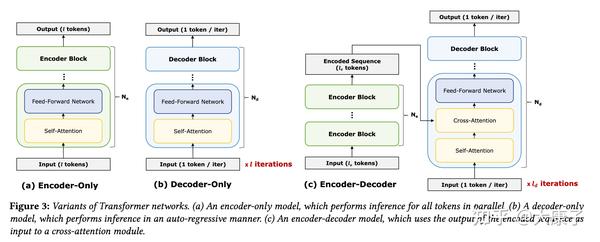

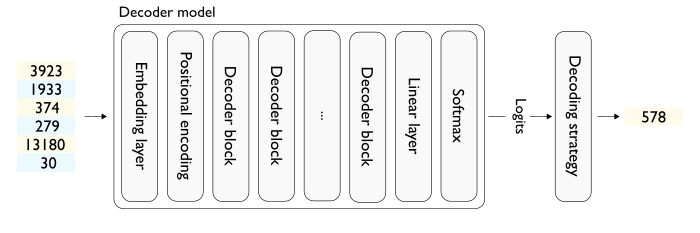




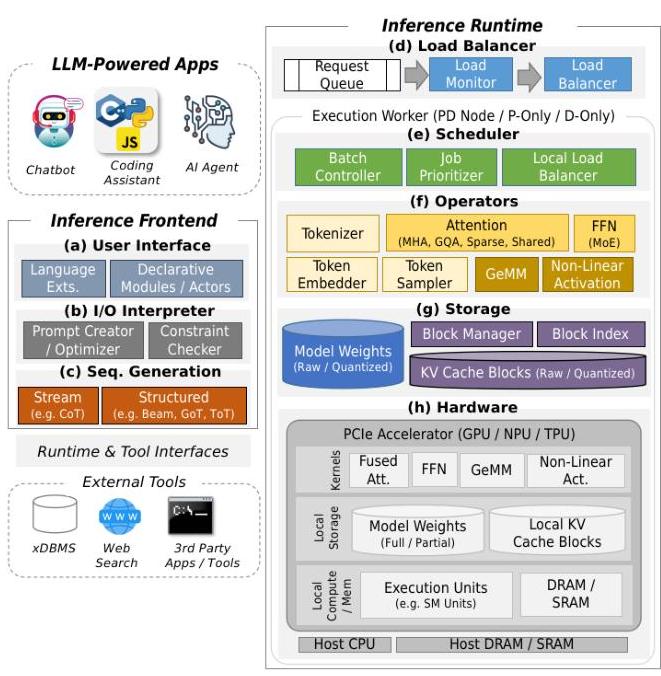
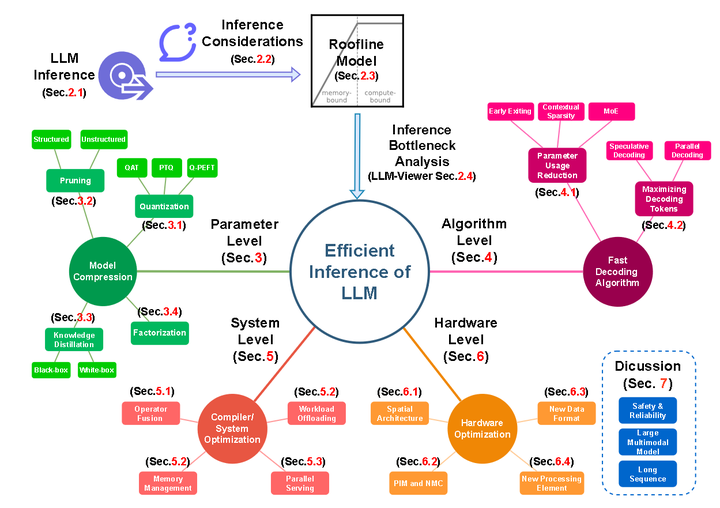





.png)

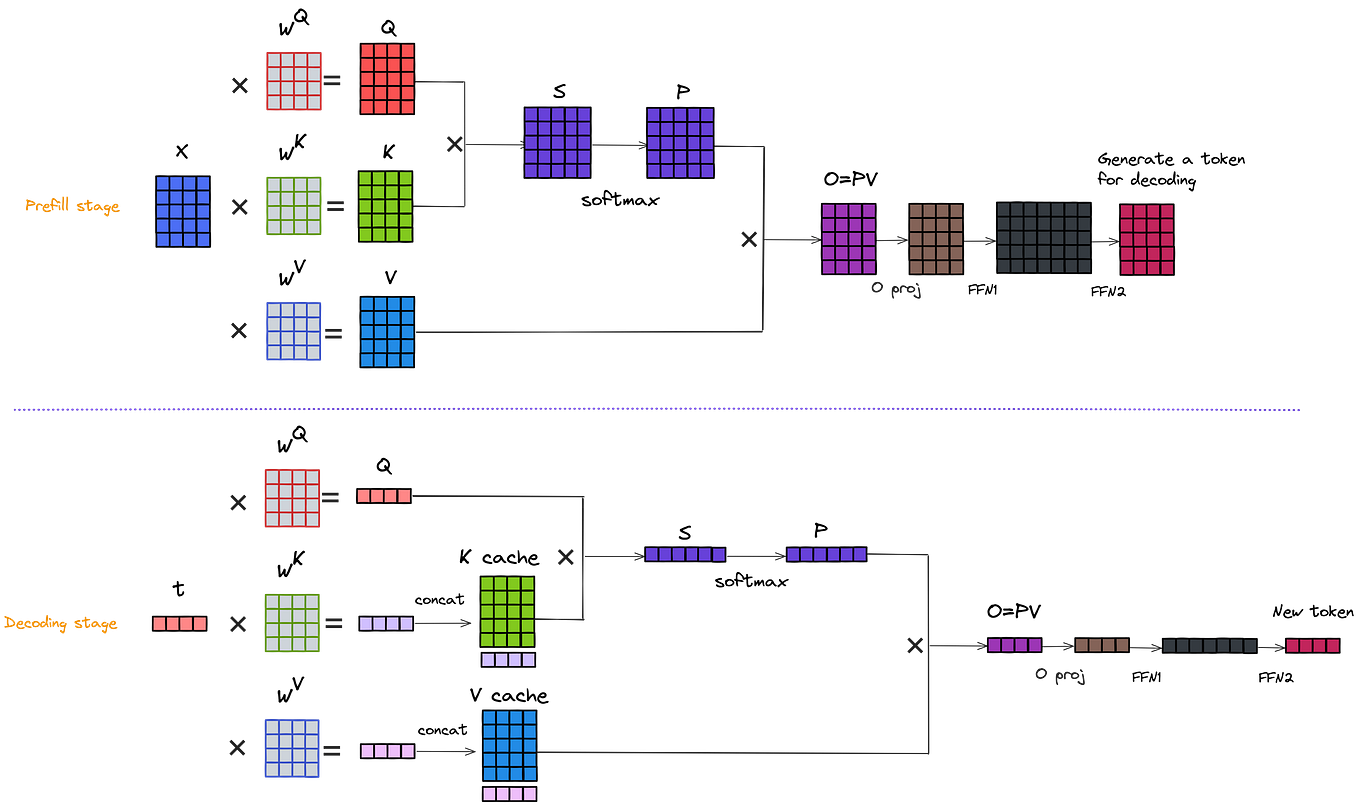

























.png)
