Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
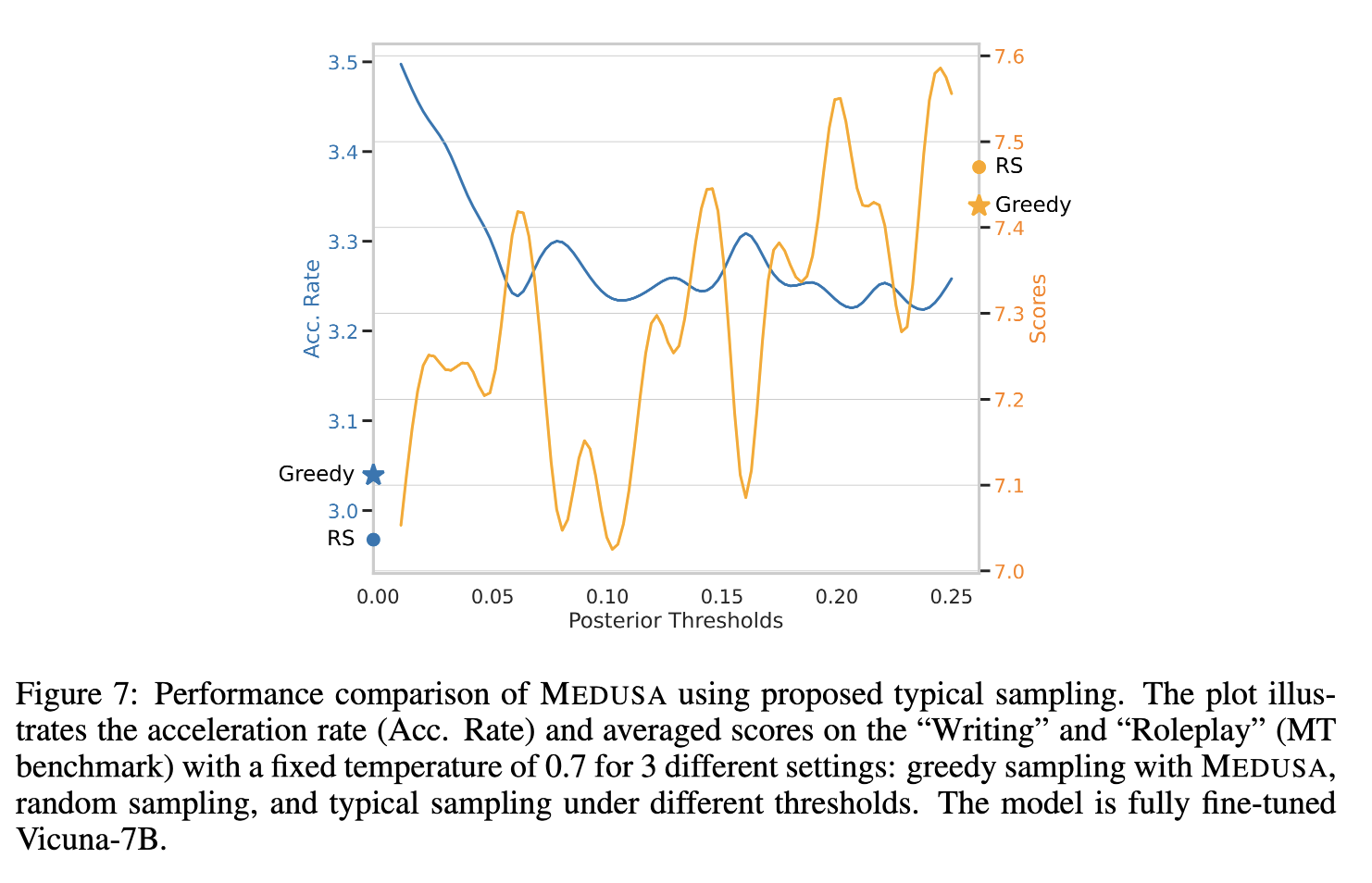
Medusa: Simple LLM Inference Acceleration Framework with Multiple ...
[Paper Review] Medusa: Simple LLM Inference Acceleration Framework with ...
M: Simple LLM Inference Acceleration Framework With Multiple Decoding ...
[paper review] MEDUSA: Simple LLM Inference Acceleration Framework with ...
[IDSL Seminar'25] MEDUSA: Simple LLM Inference Acceleration Framework ...
[Paper Reading] Medusa: Simple LLM Inference Acceleration Framework ...
Complete Guide to llama.cpp: Local LLM Inference Made Simple | by Huda ...
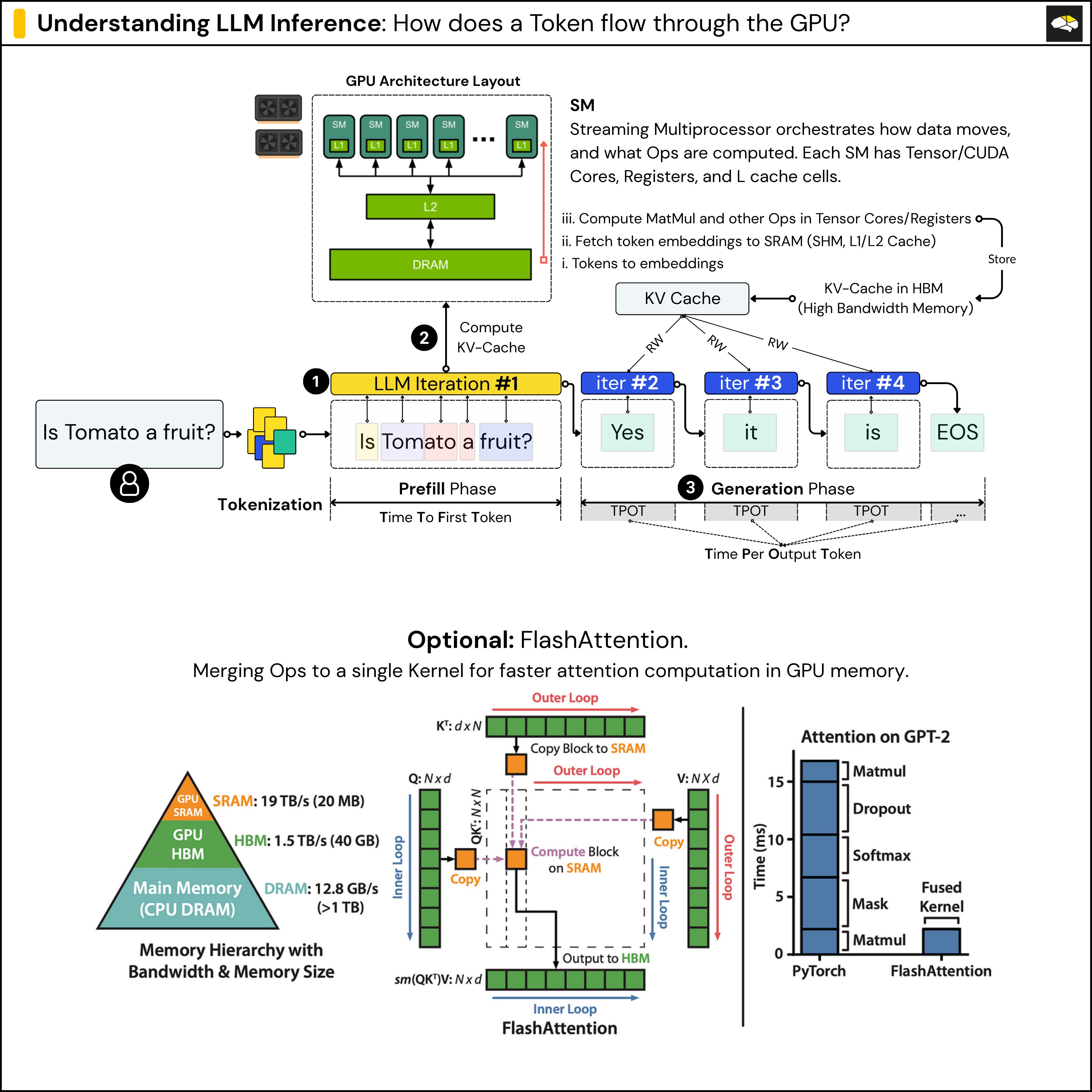
Understanding LLM Inference - by Alex Razvant
LLM Inference - Hw-Sw Optimizations
LLM Inference — A Detailed Breakdown of Transformer Architecture and ...
LLM Inference Stages Diagram | Stable Diffusion Online
The State of LLM Reasoning Model Inference
Illustration of the proposed method. (a) LLM inference comprises two ...
How continuous batching enables 23x throughput in LLM inference ...
How does LLM inference work? | LLM Inference Handbook
LLM by Examples: Inference with TinyLlama 1.1B | by MB20261 | Medium
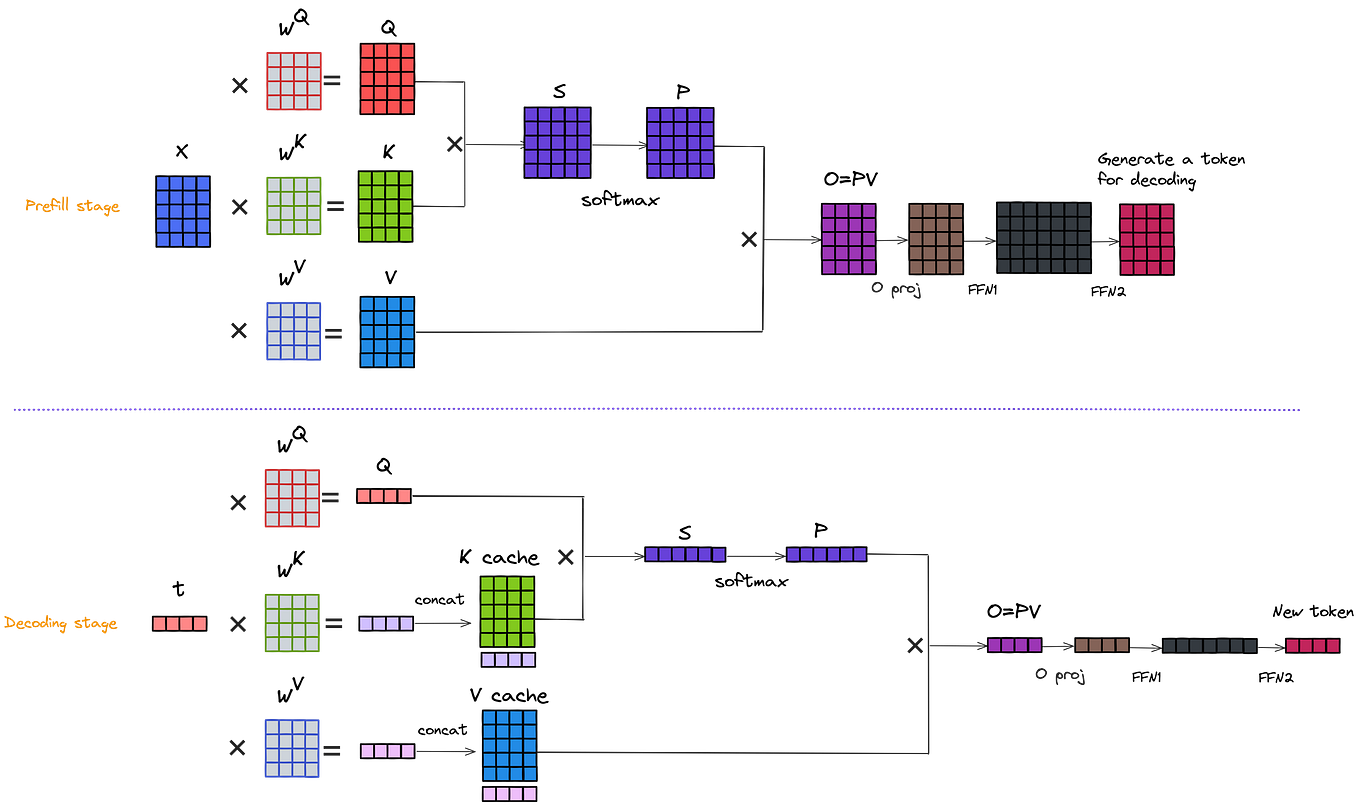
LLM Inference Series: 4. KV caching, a deeper look | by Pierre Lienhart ...
Training gets all the attention. But inference is where your LLM either ...
LLM Inference Series: 1. Introduction | by Pierre Lienhart | Medium
Achieve 23x LLM Inference Throughput & Reduce p50 Latency
LLM Inference v_s Fine-Tuning | PDF | Cognitive Science | Computational ...
Deep Dive: Optimizing LLM inference - YouTube
LLM Inference
(PDF) Improving the inference performance of LLM with code
Efficient LLM Inference and Serving with vLLM
LLM inference techniques
Just simple AI-business // LLM inference/FT | by evoailabs | Medium
A guide to LLM inference and performance | Baseten Blog
A Guide to LLM Inference Performance Monitoring | Symbl.ai
LLM Inference Series: 5. Dissecting model performance | by Pierre ...
AI/ML Infra Meetup | A Faster and More Cost Efficient LLM Inference ...
Introducing Simple, Fast, and Scalable Batch LLM Inference on ...
LLM Inference Parameters Explained Visually
LLM Inference Optimization Overview - From Data to System Architecture
Choosing The Right Inference Framework - LLM Inference Handbook | PDF ...
LLM Inference on Edge: A Fun and Easy Guide to run LLMs via React ...
LLM Inference Serving: Recent Advances | PDF | Cache (Computing) | Cpu ...
LLM inference optimization: Model Quantization and Distillation - YouTube
Want to build a fast LLM inference engine from scratch? | Karn Singh
A Survey of LLM Inference Systems | alphaXiv
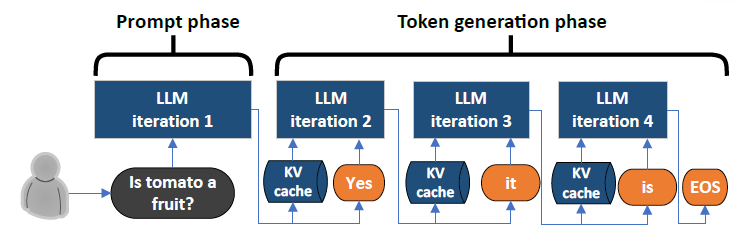
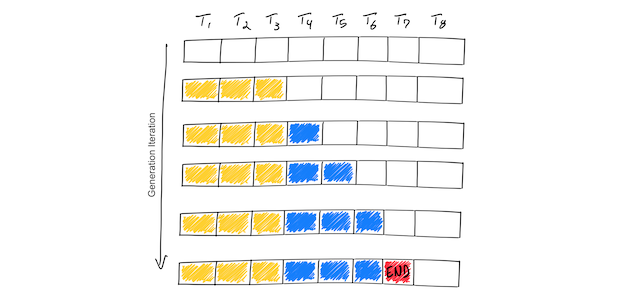
LLM Inference Series: 2. The two-phase process behind LLMs’ responses ...
Illustration of the privacy-preserving LLM inference. The LLM inference ...
[2402.16363] LLM Inference Unveiled: Survey and Roofline Model Insights
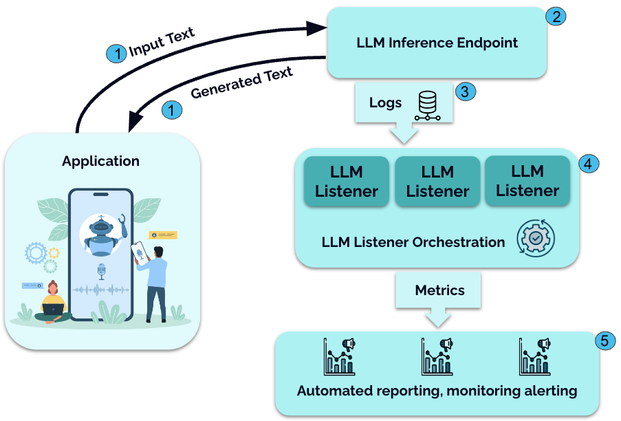
Monitoring LLM Inference Endpoints with LLM Listeners | Microsoft ...
LLM Inference Optimization for NLP Applications
A guide to open-source LLM inference and performance - Bens Bites
LLM Inference Essentials
What Is LLM Inference? Batch Inference In LLM Inference
Overview of an Example LLM Inference Setup - YouTube
LLM Inference ( vLLM , TGI, TensorRT ) | by Pratik | Medium
(PDF) Scalable Inference Systems for Real-Time LLM Integration
LLM Inference Archives | Uplatz Blog
LLM Inference Hardware: An Enterprise Guide to Key Players | IntuitionLabs
LLM Inference - EcoLogits
LLM Inference - a andreapie Collection
LLM Inference Unveiled: Survey and Roofline Model Insights
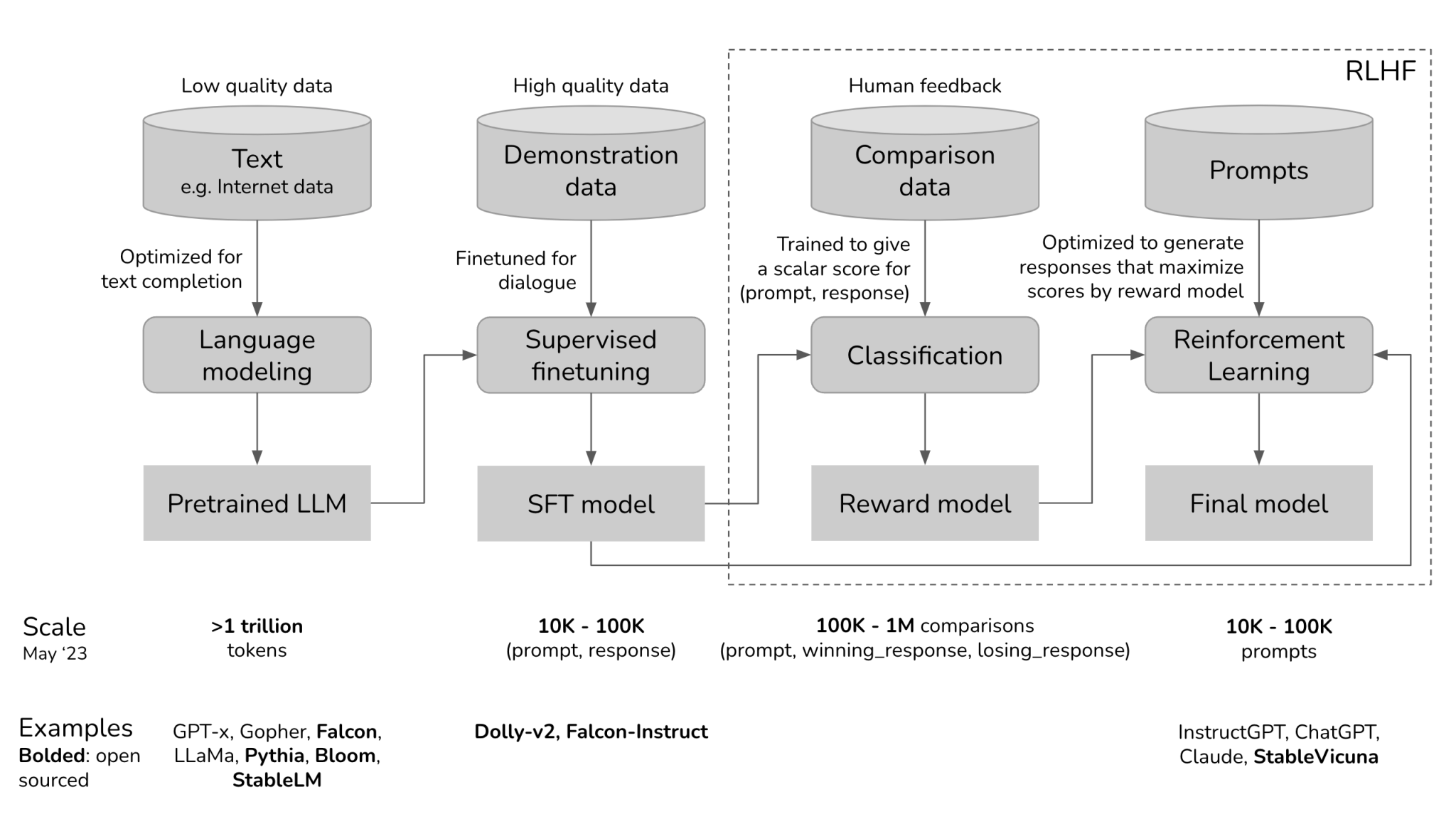
How LLM really works: From Training to Talking – The Power of Inference
How to Scale LLM Inference - by Damien Benveniste
How to Architect Scalable LLM & RAG Inference Pipelines
Understanding the LLM Inference Workload: Key Insights
Strategies for Reducing LLM Inference Latency and making tradeoffs ...
LLM Inference Hardware: Emerging from Nvidia's Shadow
LLM inference optimization: Tutorial & Best Practices | LaunchDarkly
LLM Inference Optimization Techniques: A Comprehensive Analysis | by ...
Fast, Secure and Reliable: Enterprise-grade LLM Inference | Databricks Blog
What Is LLM Inference? Process, Latency & Examples Explained (2026)
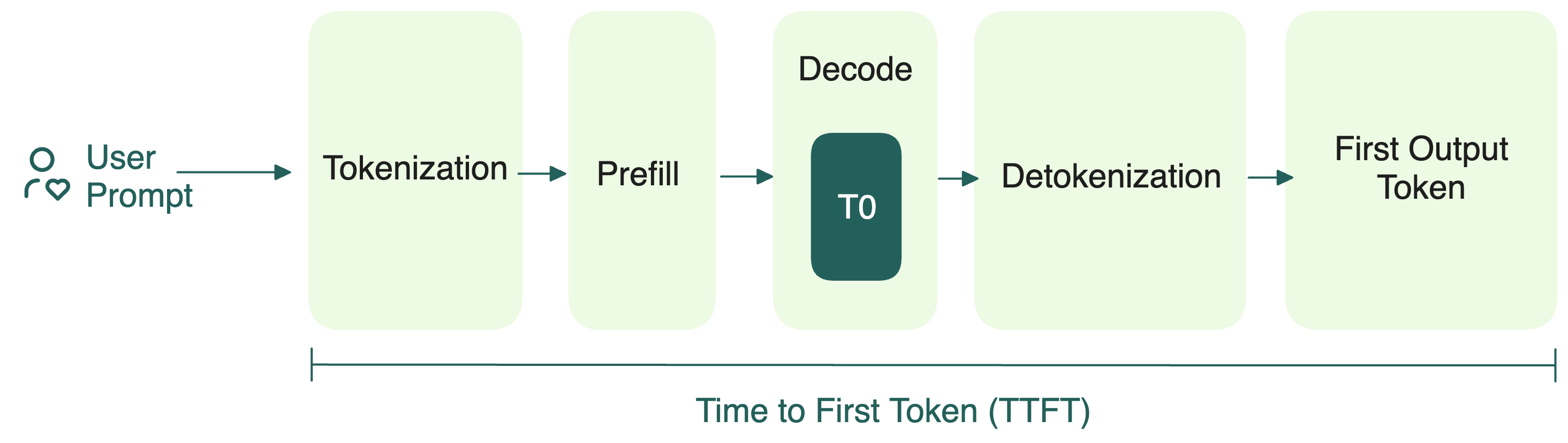
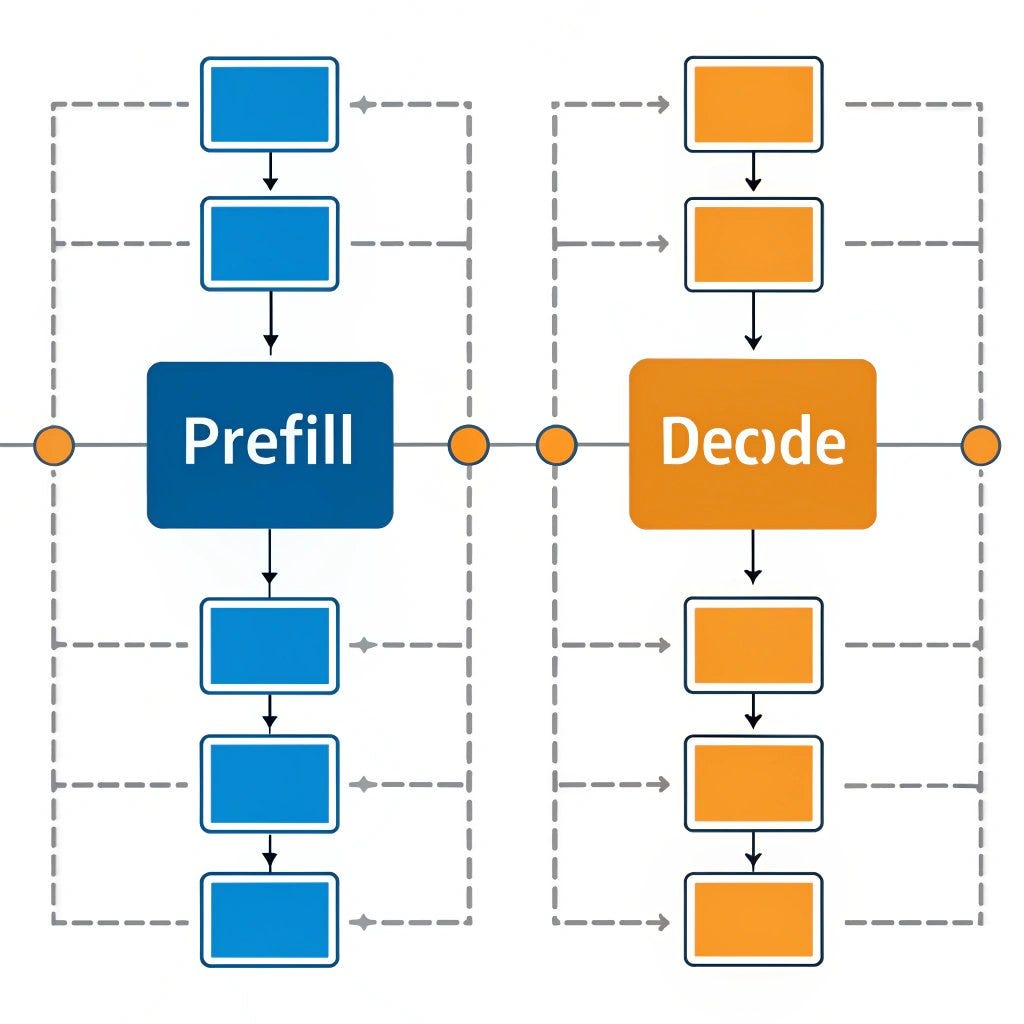
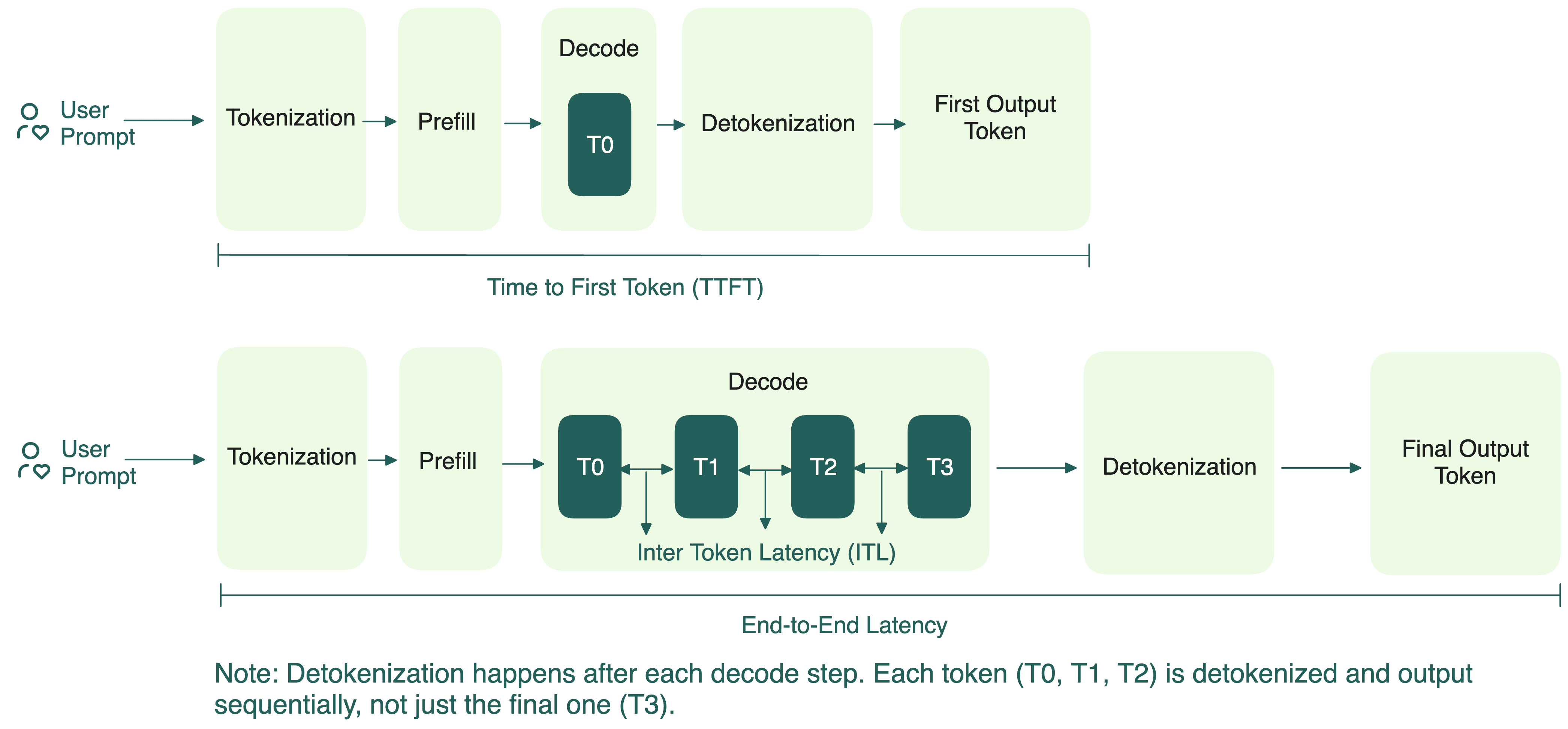
Understanding the Two Key Stages of LLM Inference: Prefill and Decode ...
Topic 23: What is LLM Inference, it's challenges and solutions for it
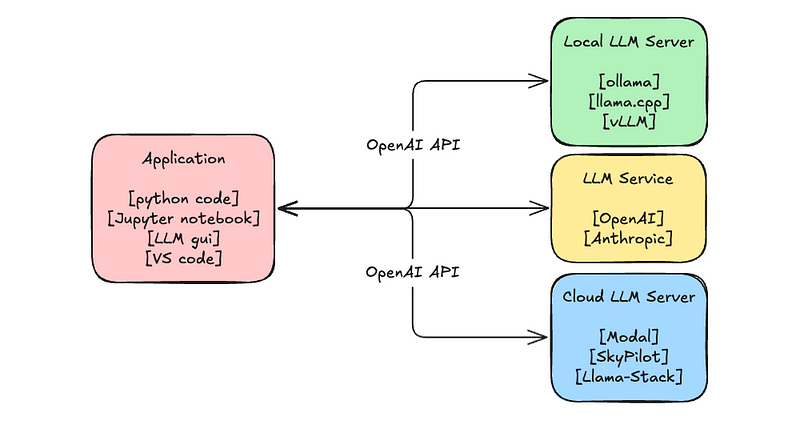
The Emerging LLM Stack: A Comprehensive Guide for Developers - Helicone
A Guide to Efficient LLM Deployment | Datadance
The Shift to Distributed LLM Inference: 3 Key Technologies Breaking ...
What is LLM Inference? • luminary.blog
What is LLM Model Inference?
LLM Inference: Techniques for Optimized Deployment in 2025 | Label Your ...
The Best NVIDIA GPUs for LLM Inference: A Comprehensive Guide | by ...
How To Build LLM (Large Language Models): A Definitive Guide
Optimizing LLM Inference. Optimization begins where architectures… | by ...
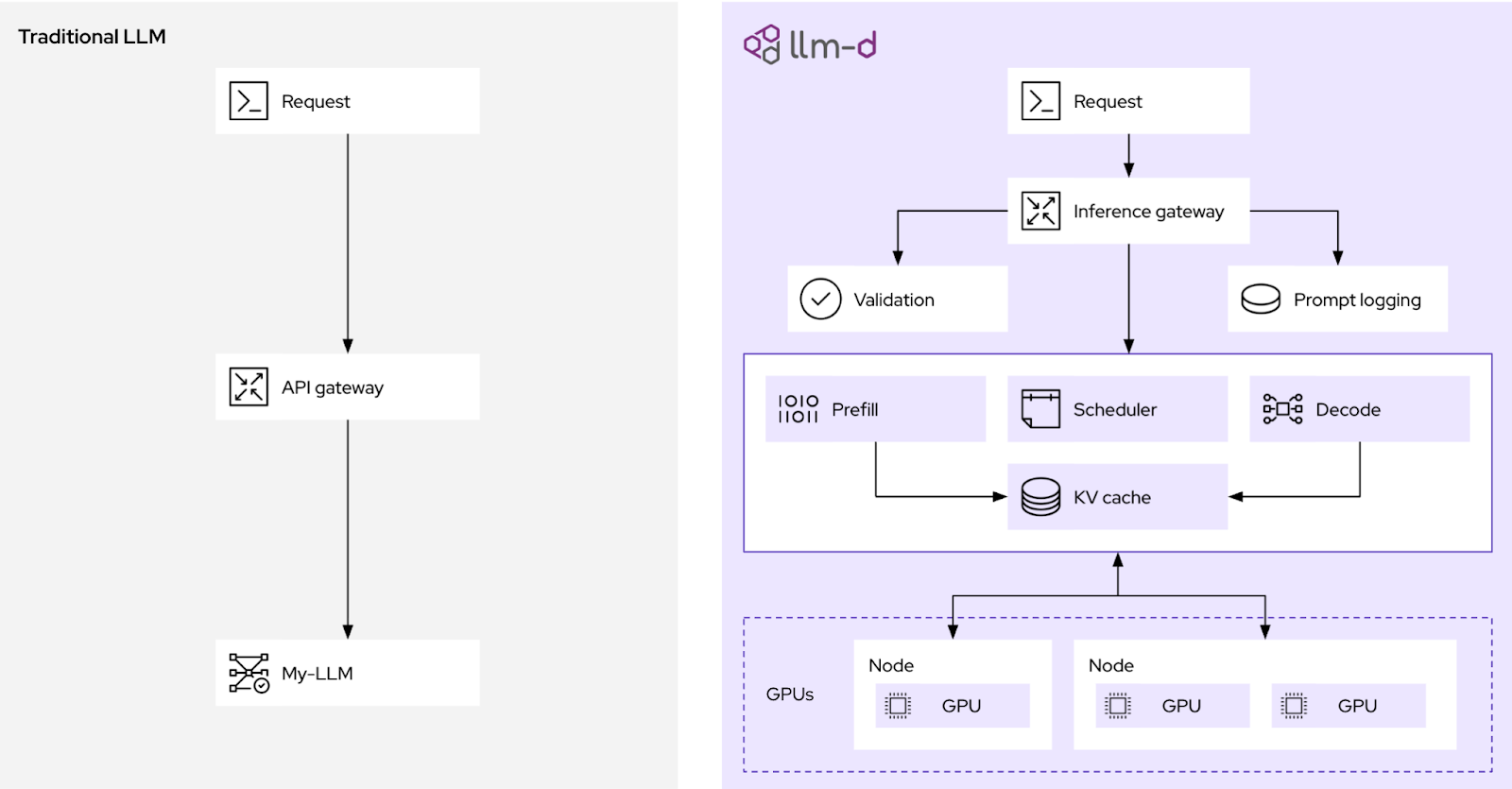
Introduction to distributed inference with llm-d | Red Hat Developer
LUT-LLM: Efficient Large Language Model Inference with Memory-based ...
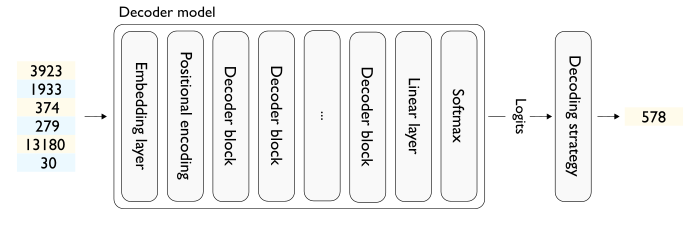
Understanding LLM Inference: How AI Generates Words | DataCamp
Deploy LLMs with Hugging Face Inference Endpoints
LLM — Inference. What are the configuration parameters… | by Pelin ...
Large Language Models LLMs Distributed Inference Serving System ...
llm-d: Kubernetes-native distributed inferencing | Red Hat Developer
GenAI-and-Simple-LLM-Inference-on-CPU-and-fine-tuning-of-LLM-Model-to ...
GitHub - Dheenathsunder/Introductio-Simple-LLM-Inference-on-CPU-and ...
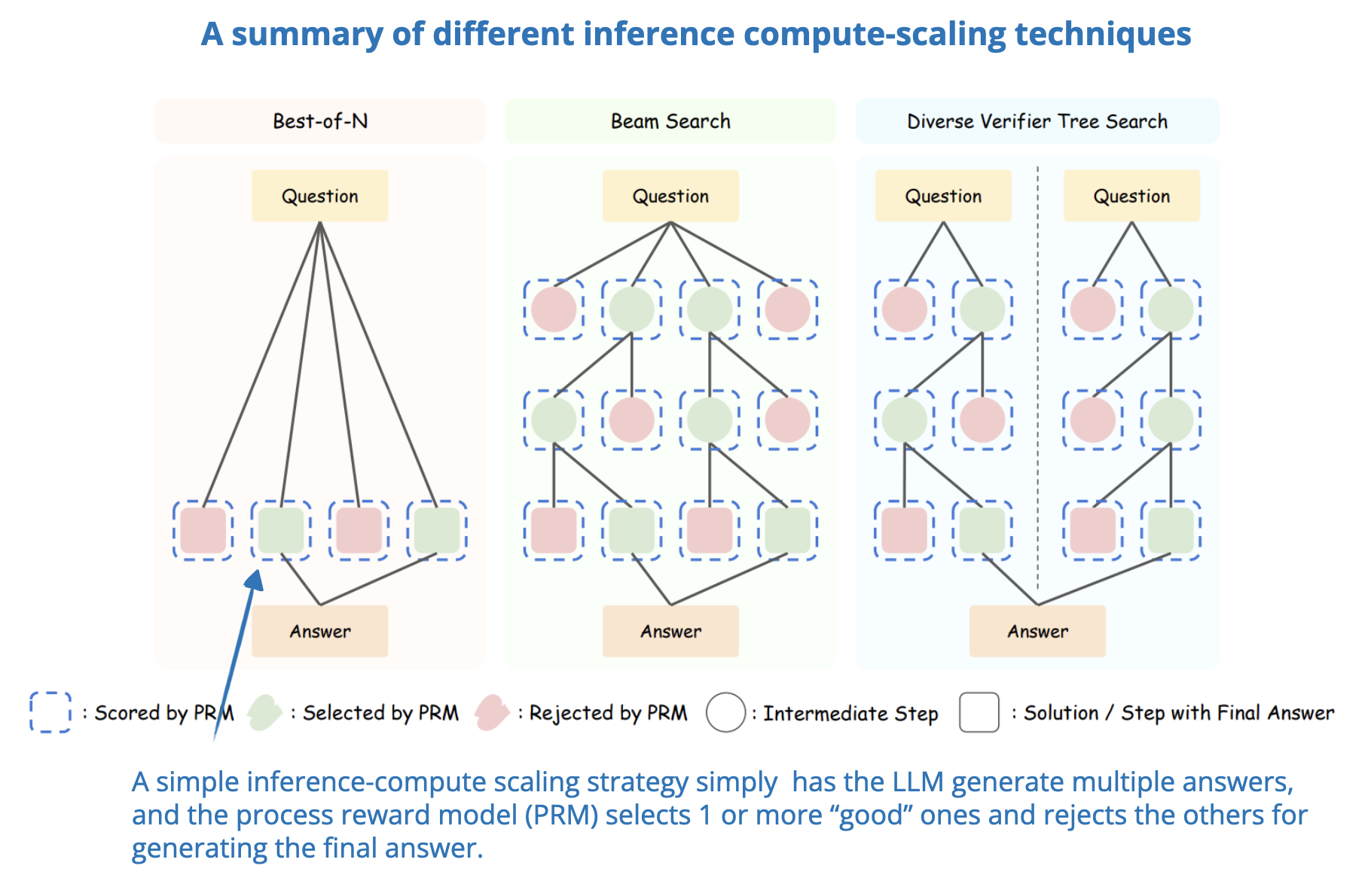
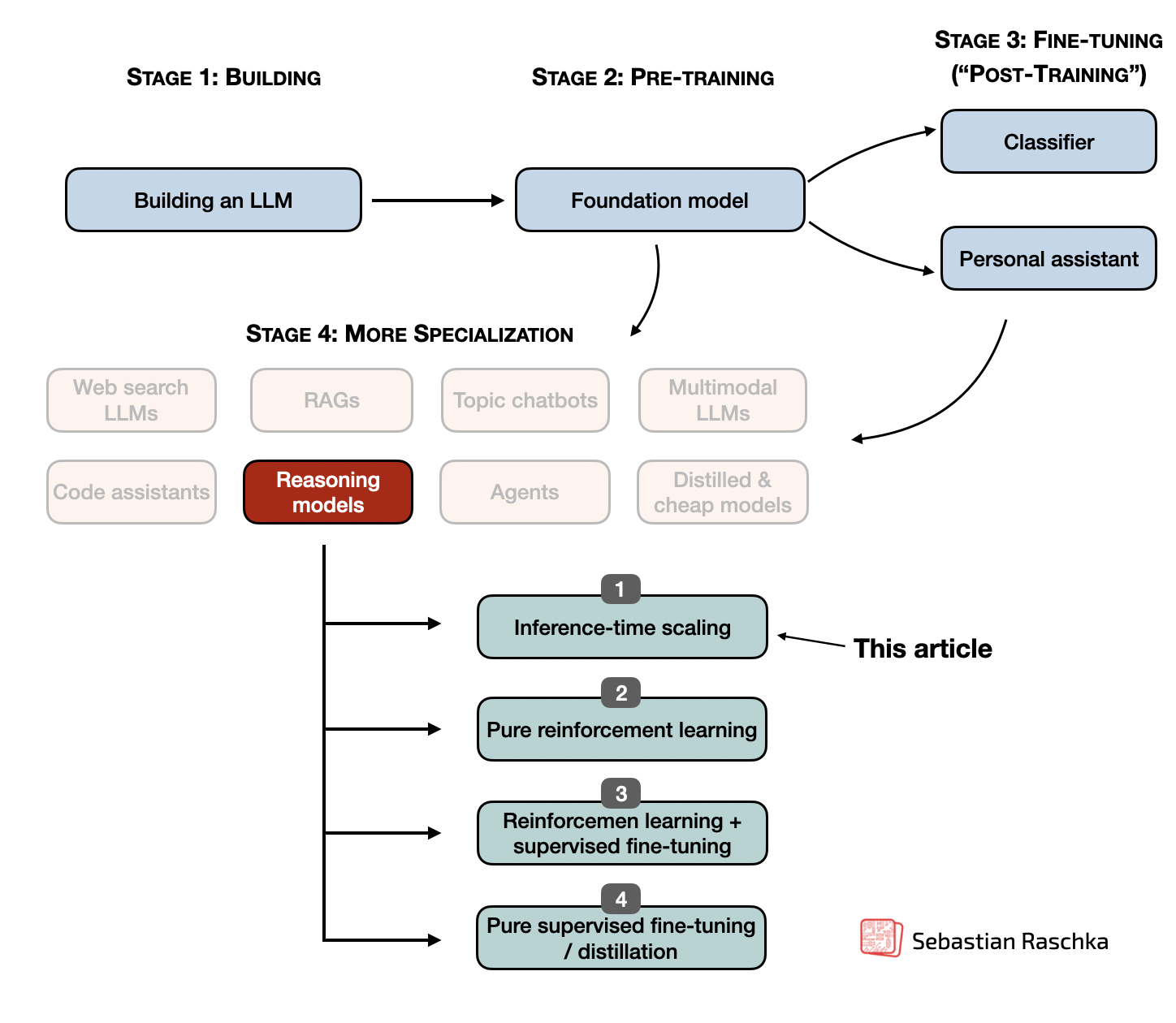
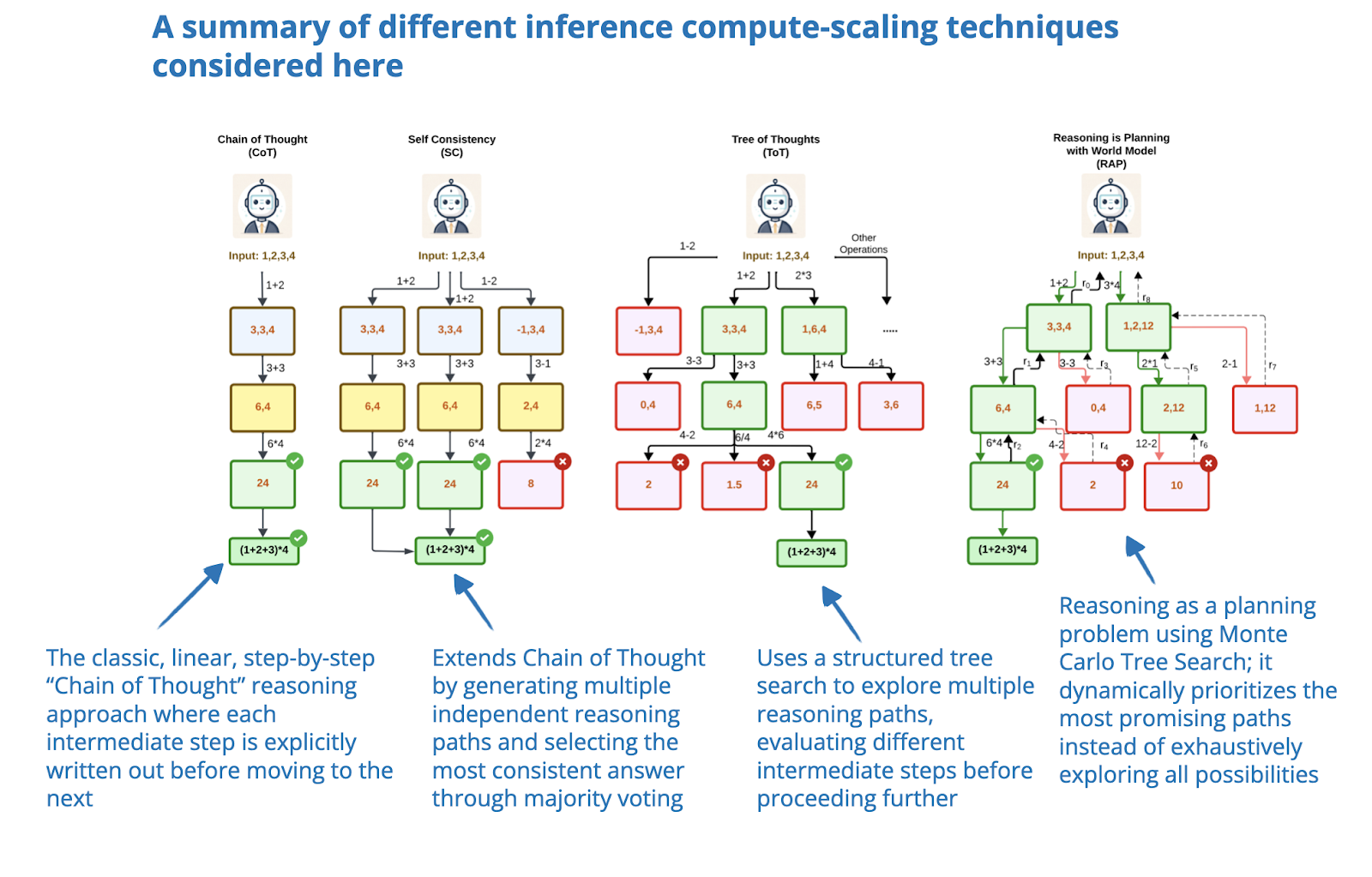
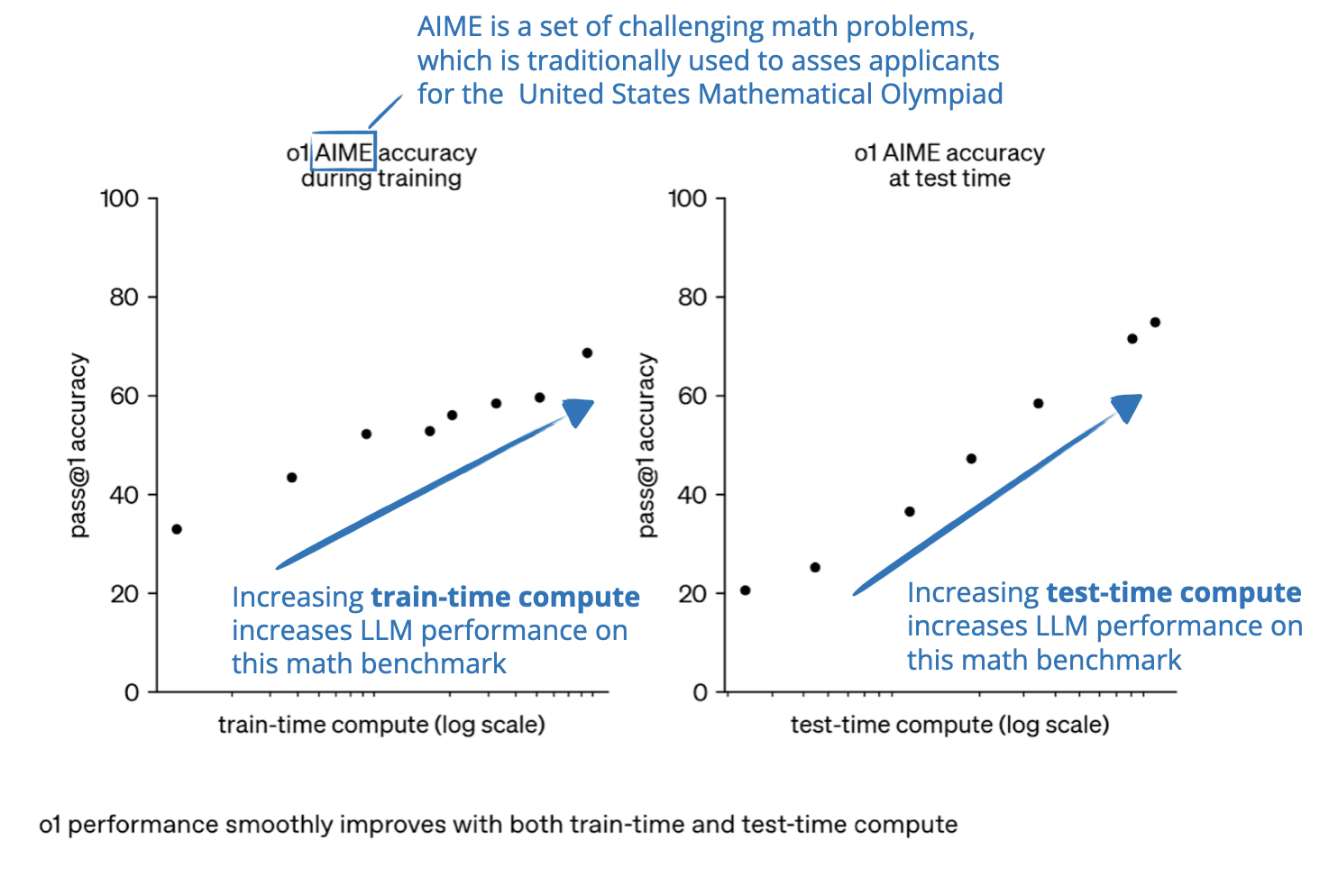
Inference-Time Compute Scaling Methods to Improve Reasoning Models ...
Multi-view Intent Learning and Alignment with Large Language Models for ...
GitHub - modelize-ai/LLM-Inference-Deployment-Tutorial: Tutorial for ...
What is a Large Language Model (LLM) - GeeksforGeeks
Deploying a Large Language Model (LLM) with TensorRT-LLM on Triton ...
llm-inference · PyPI
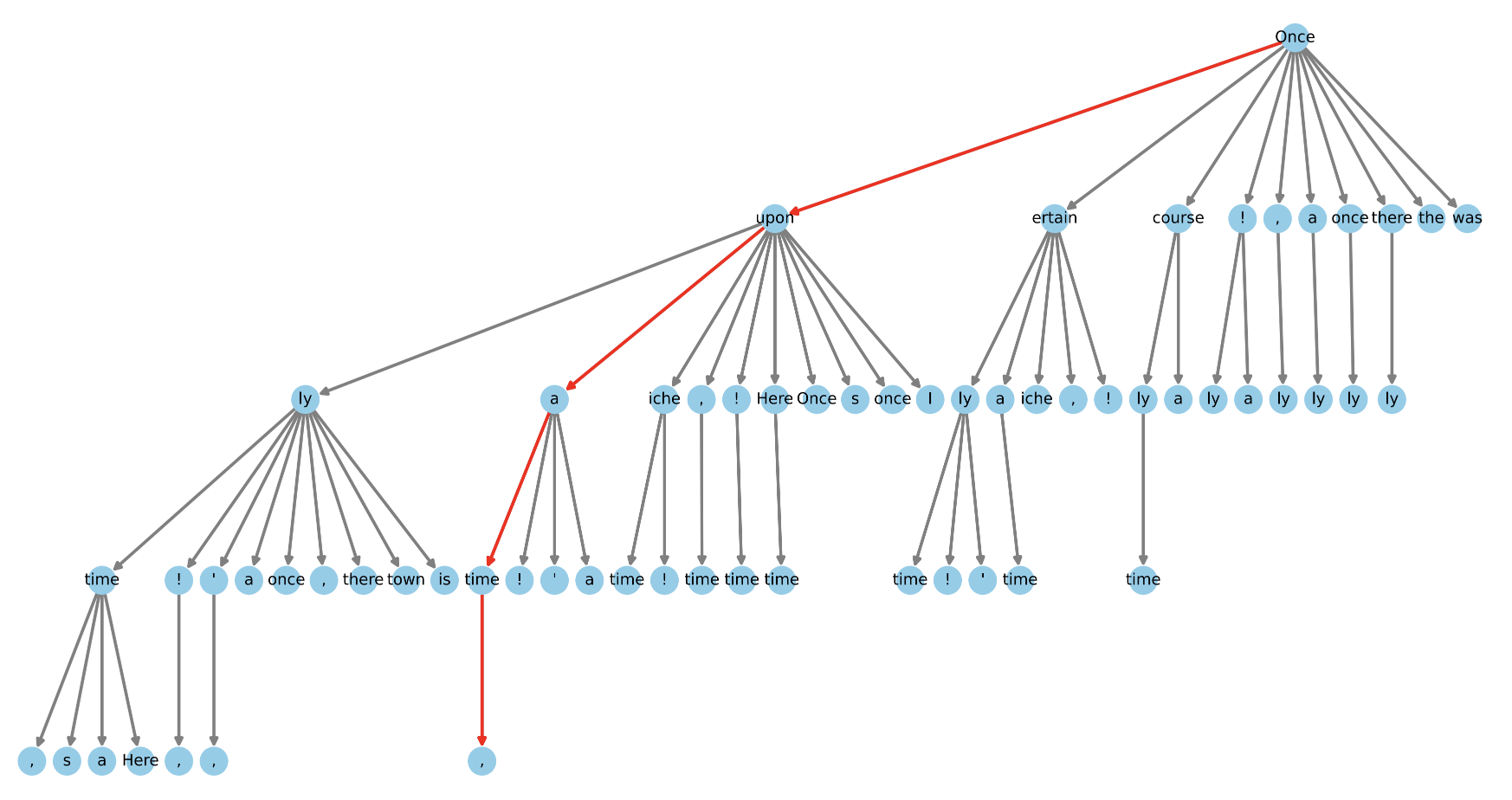
GitHub - Yiyi-philosophy/LLM-inference: LLM-inference code

































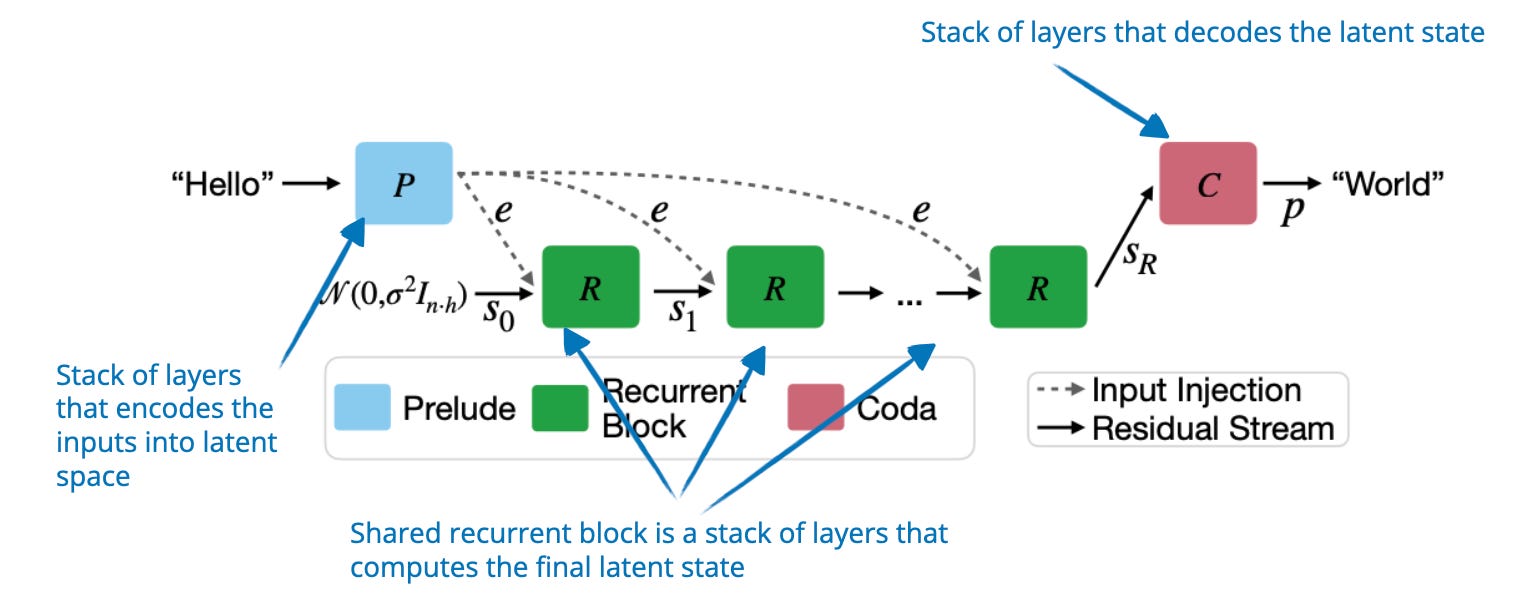

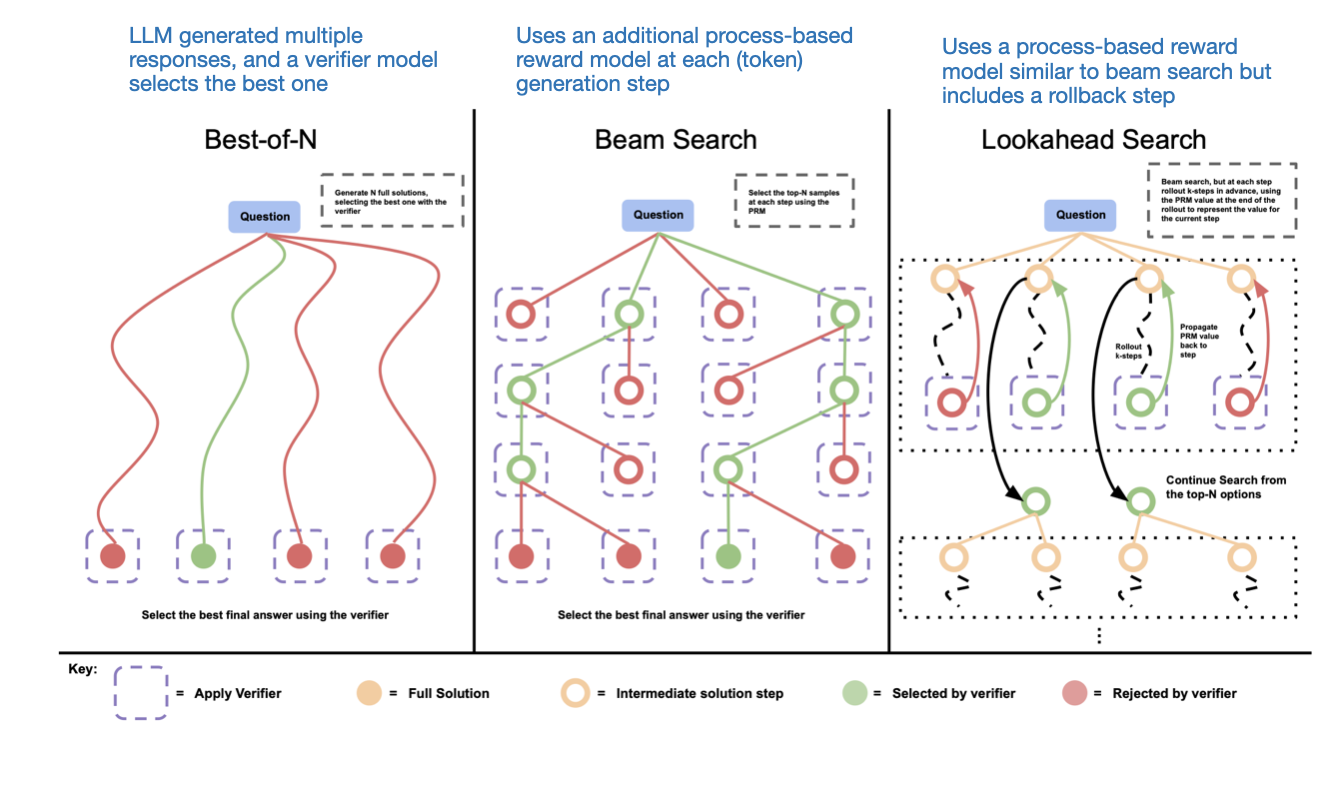
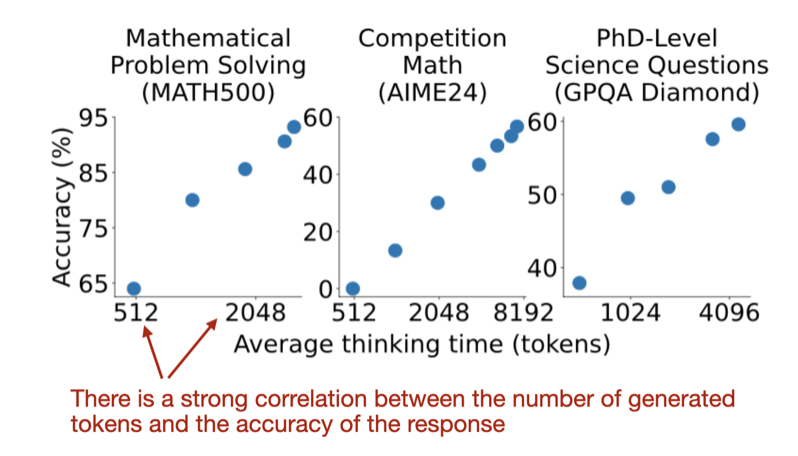
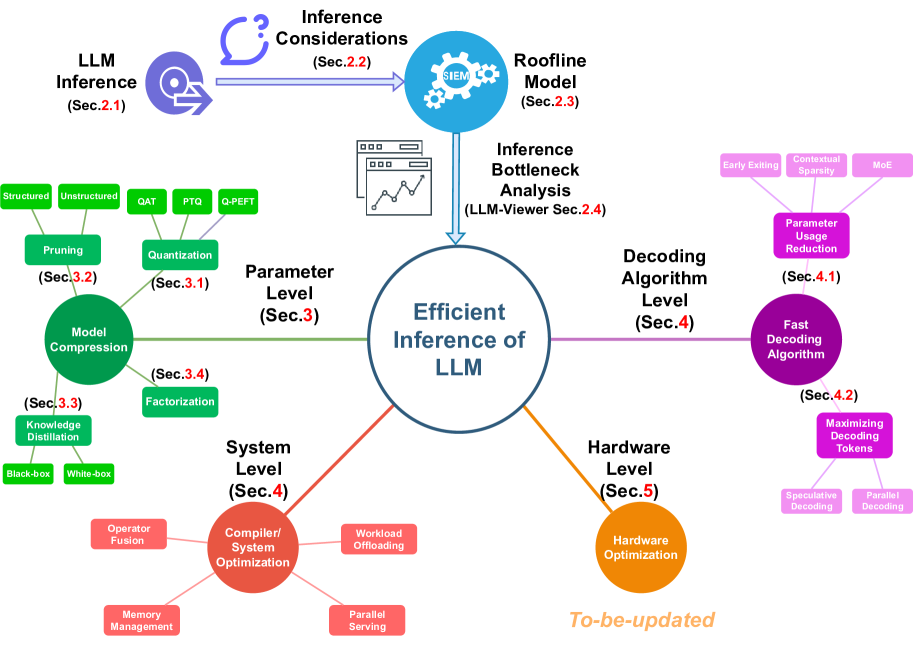


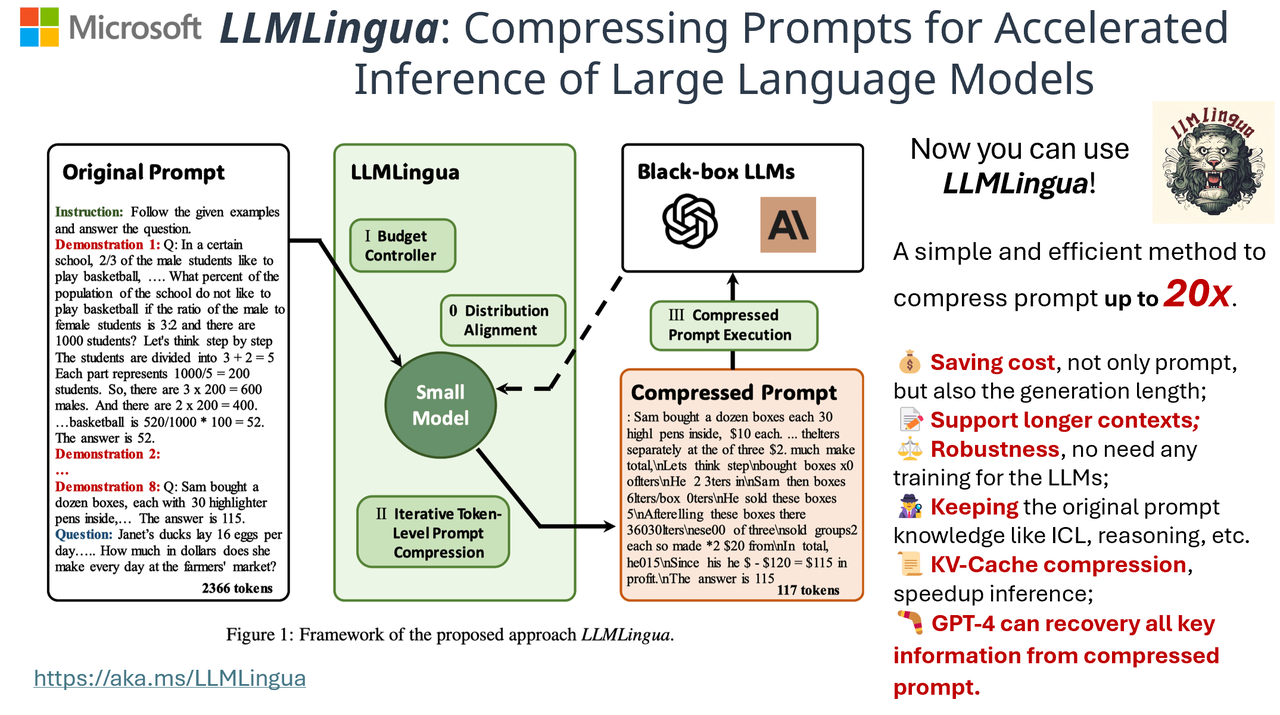

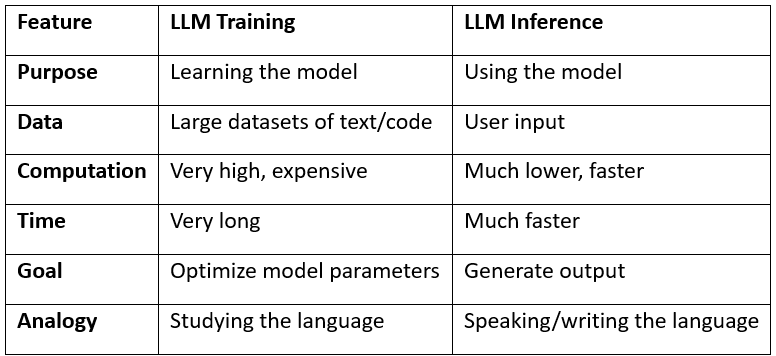









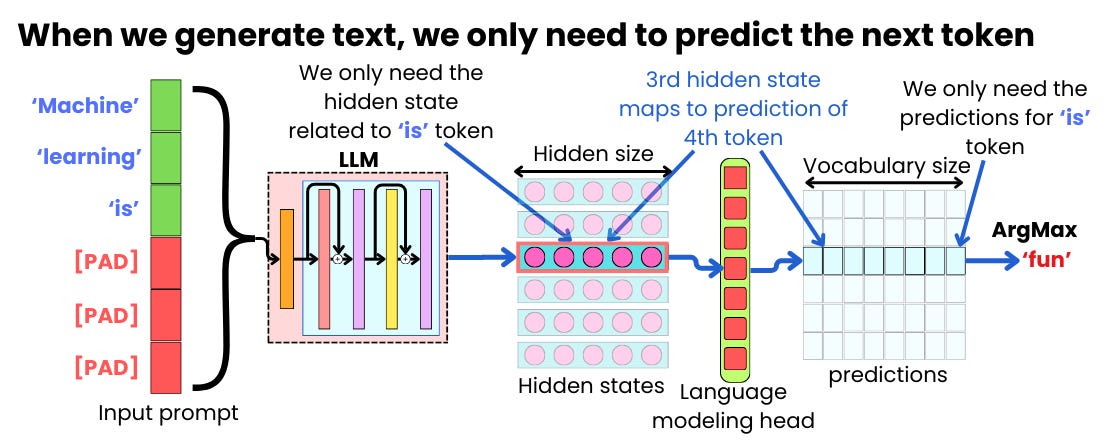
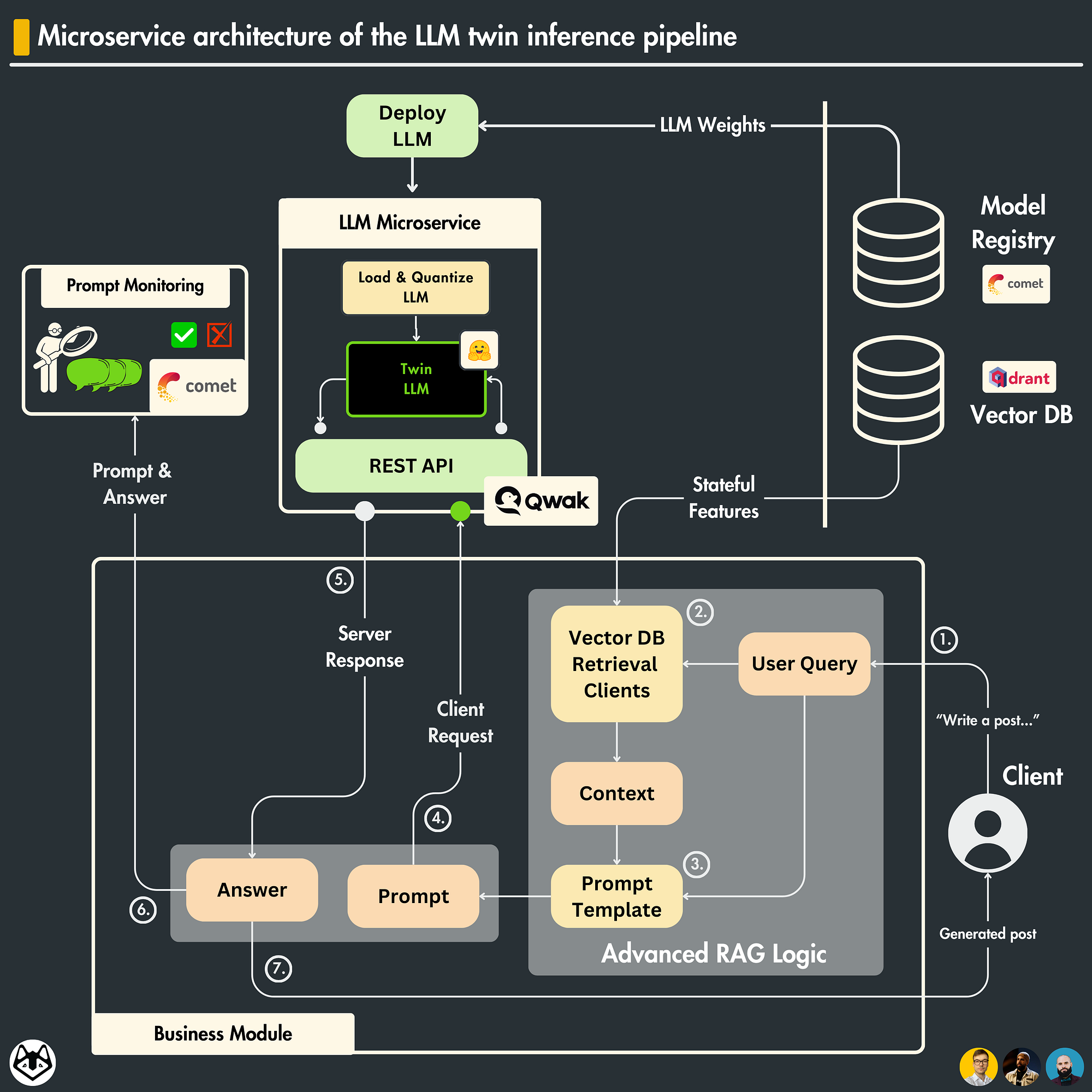

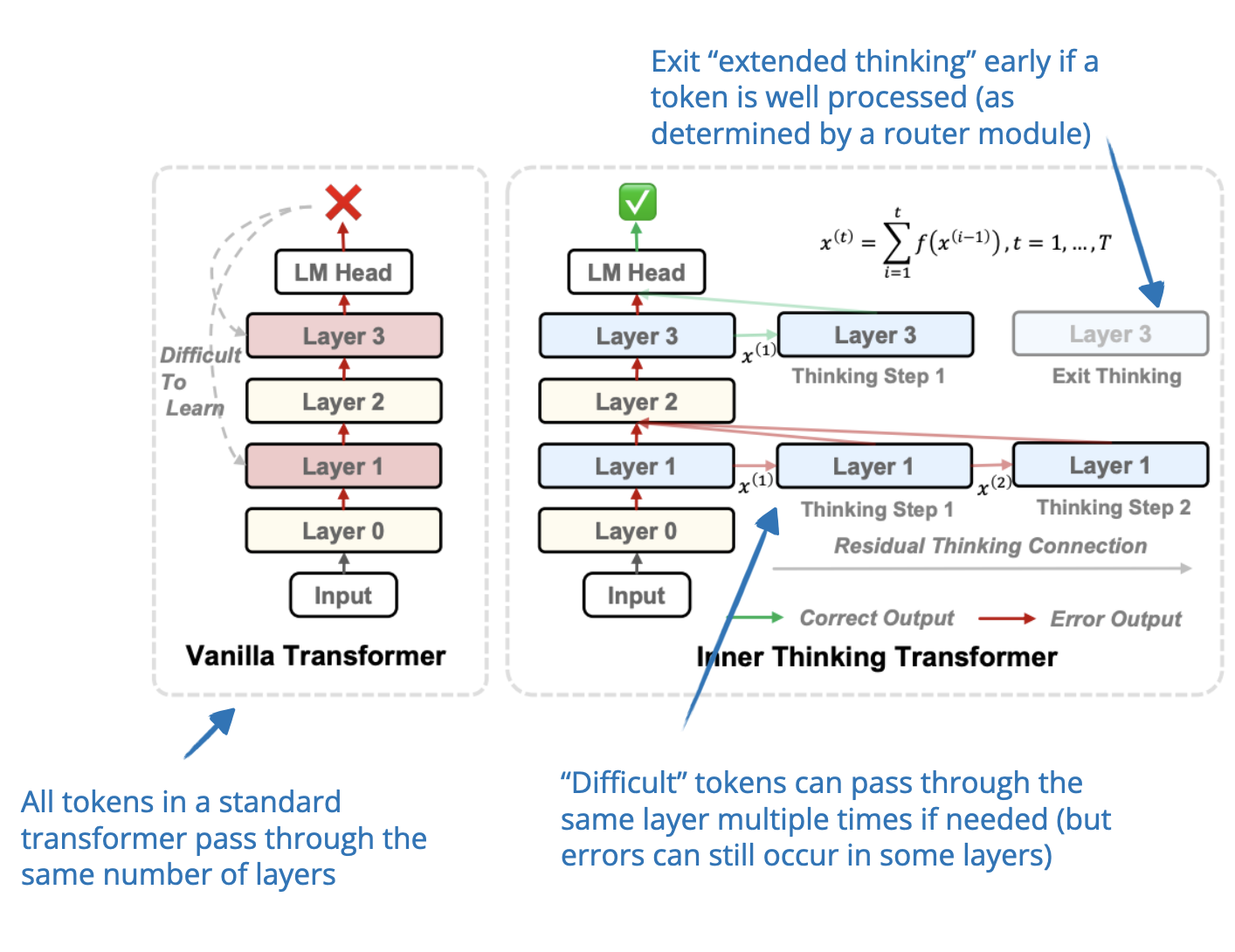



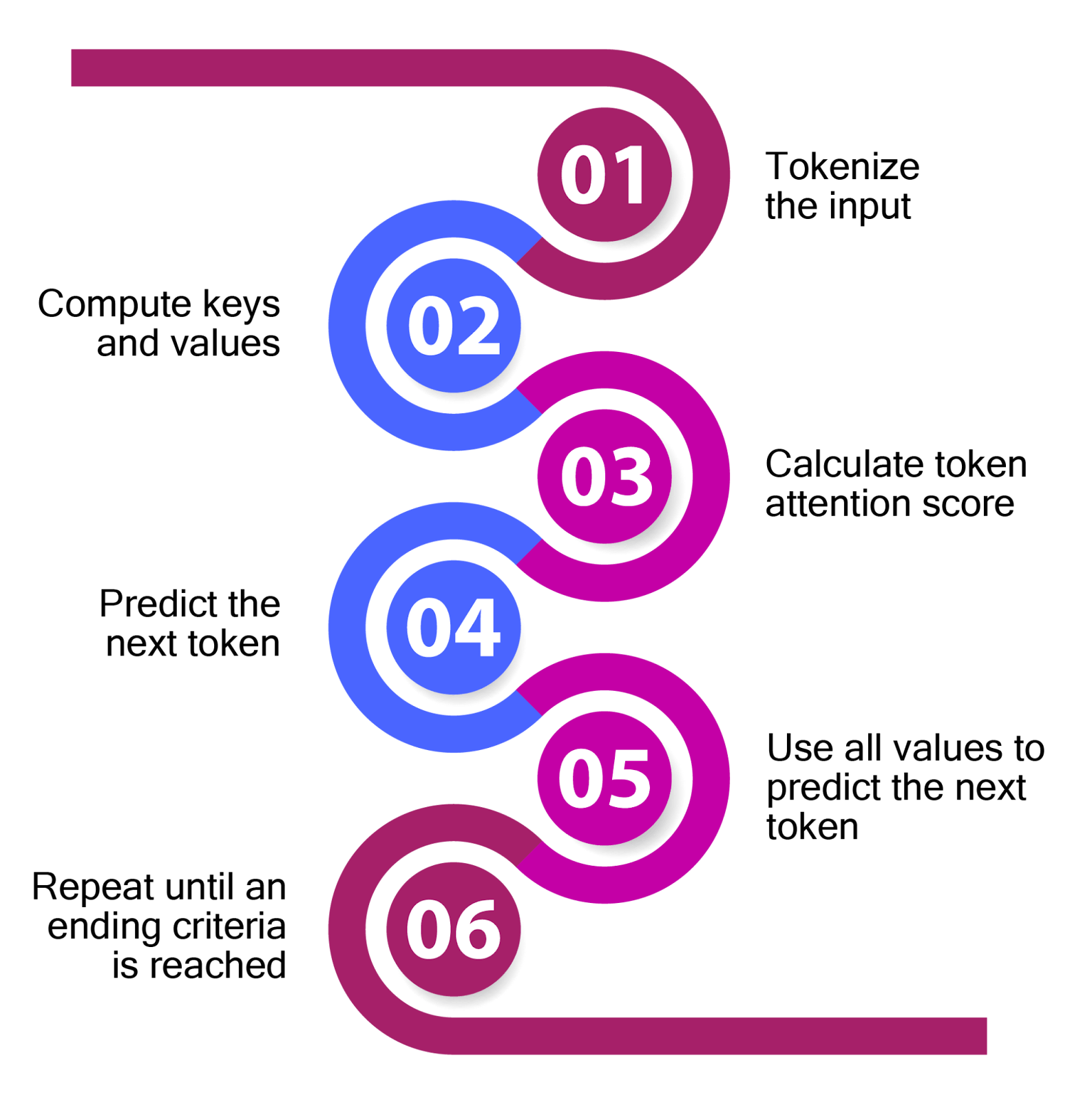
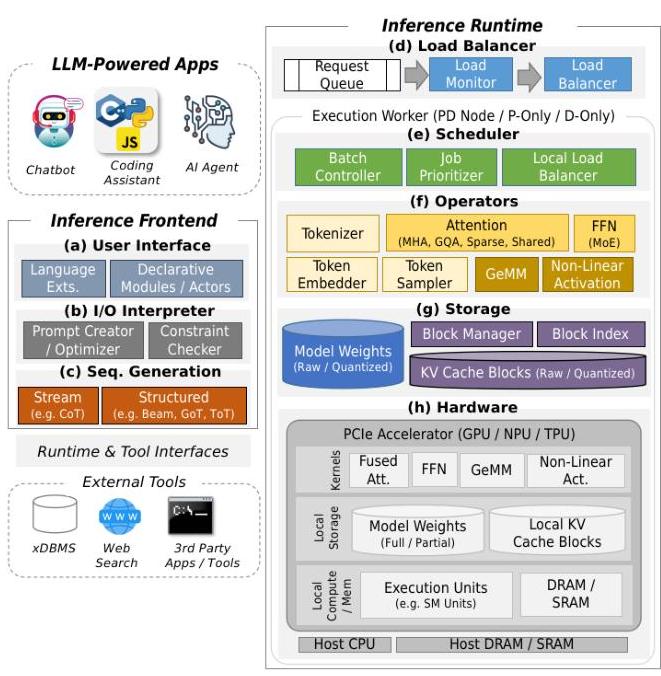

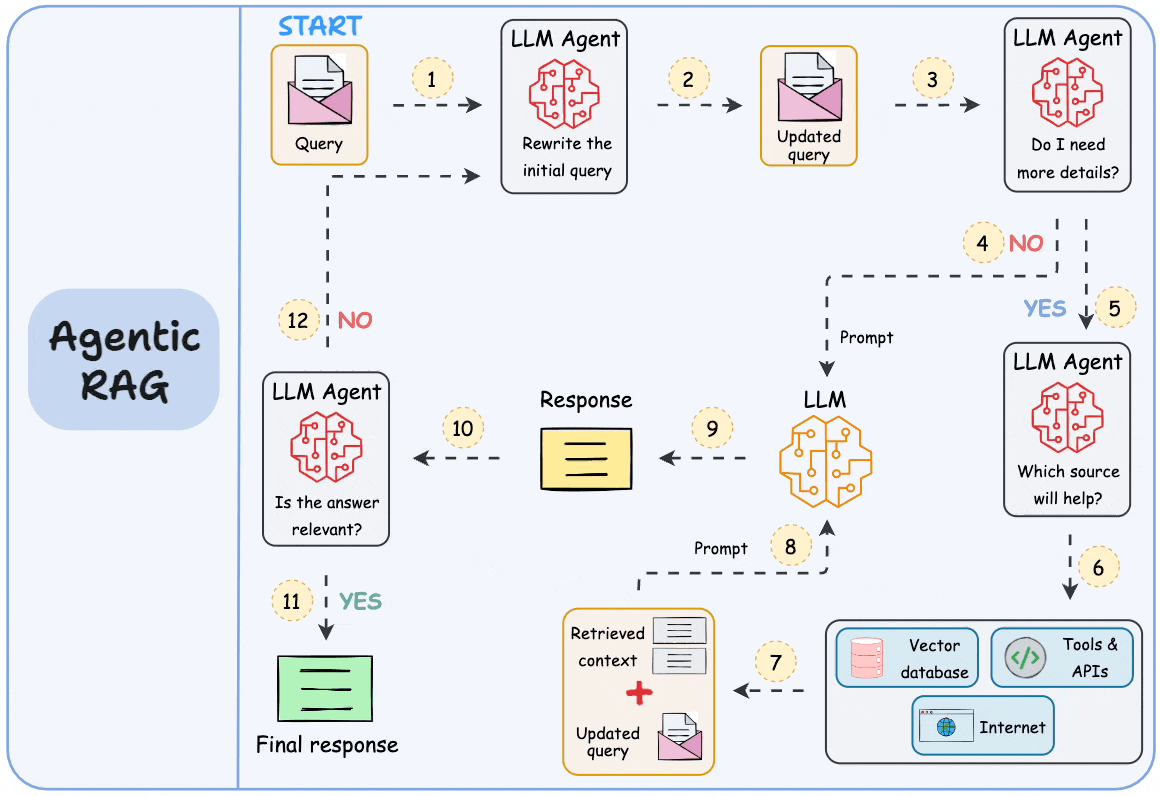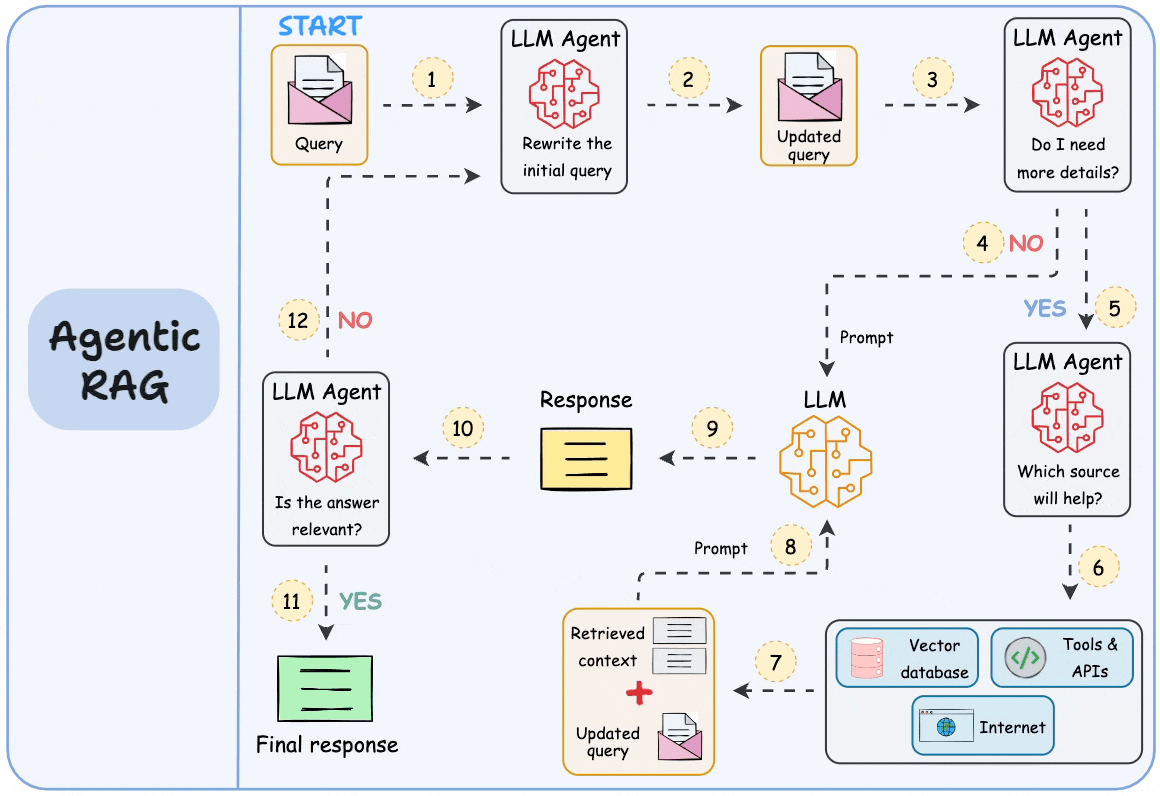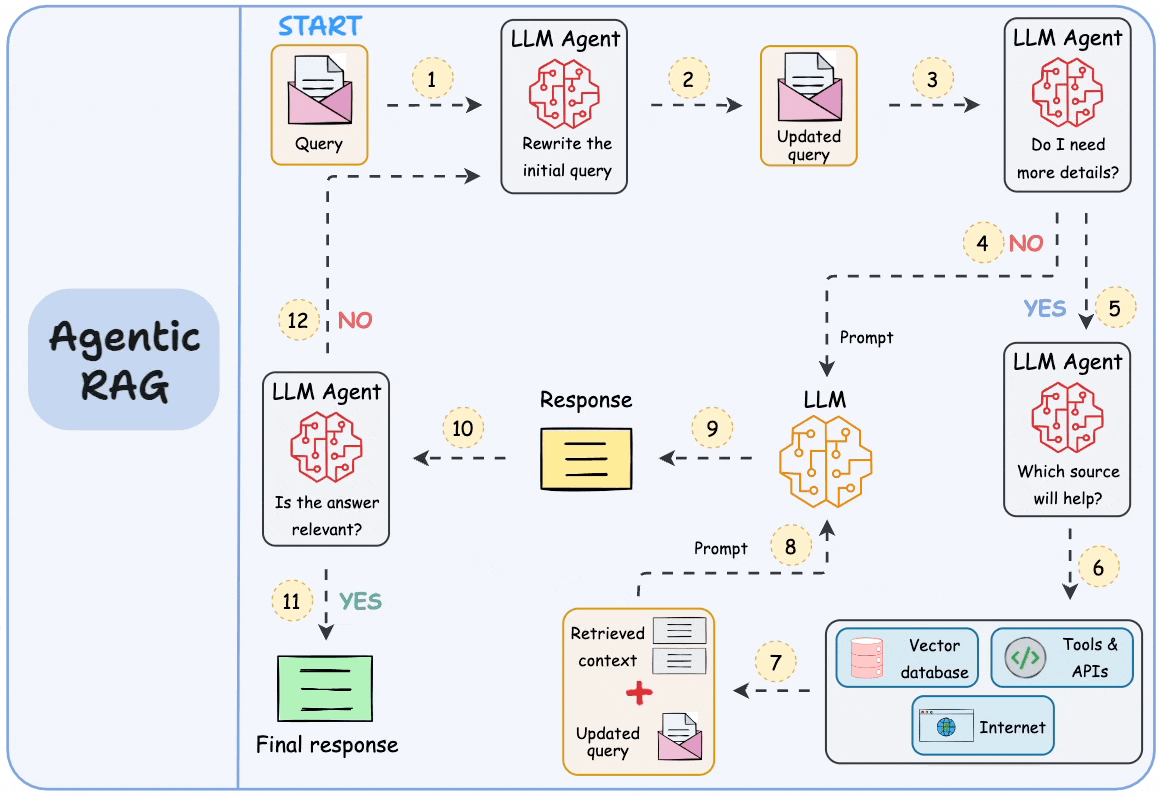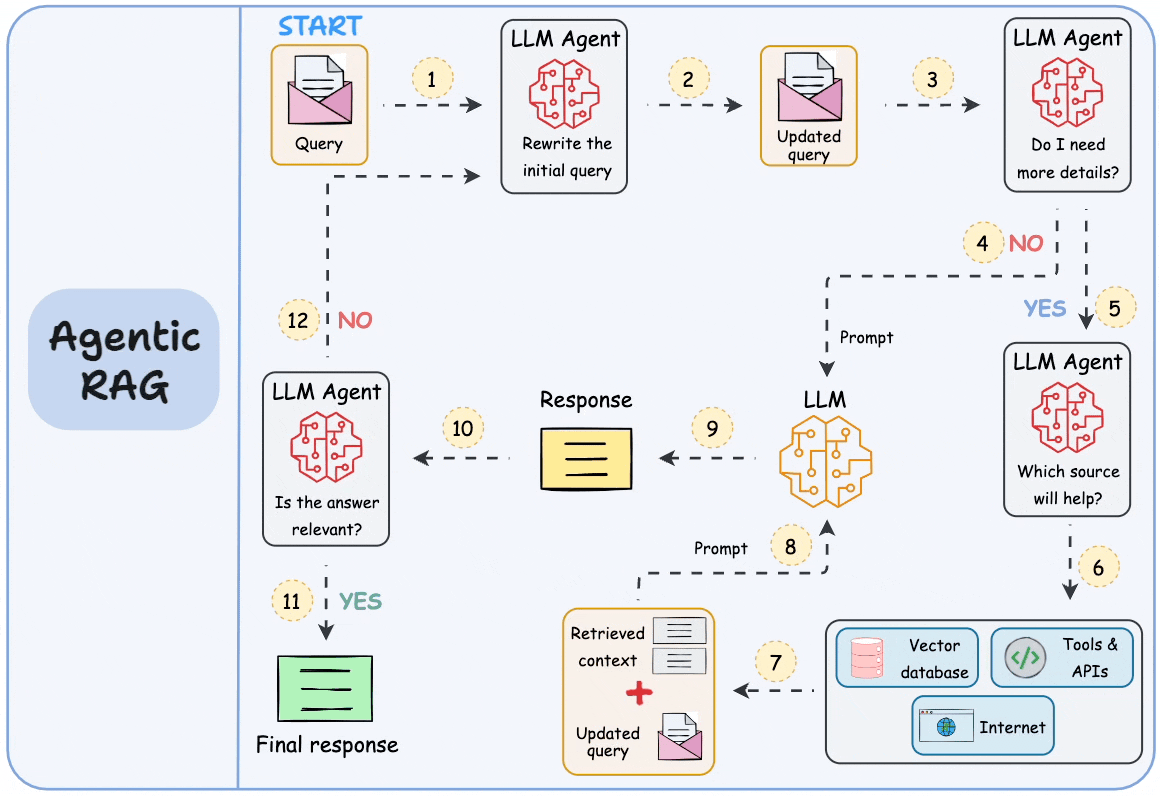
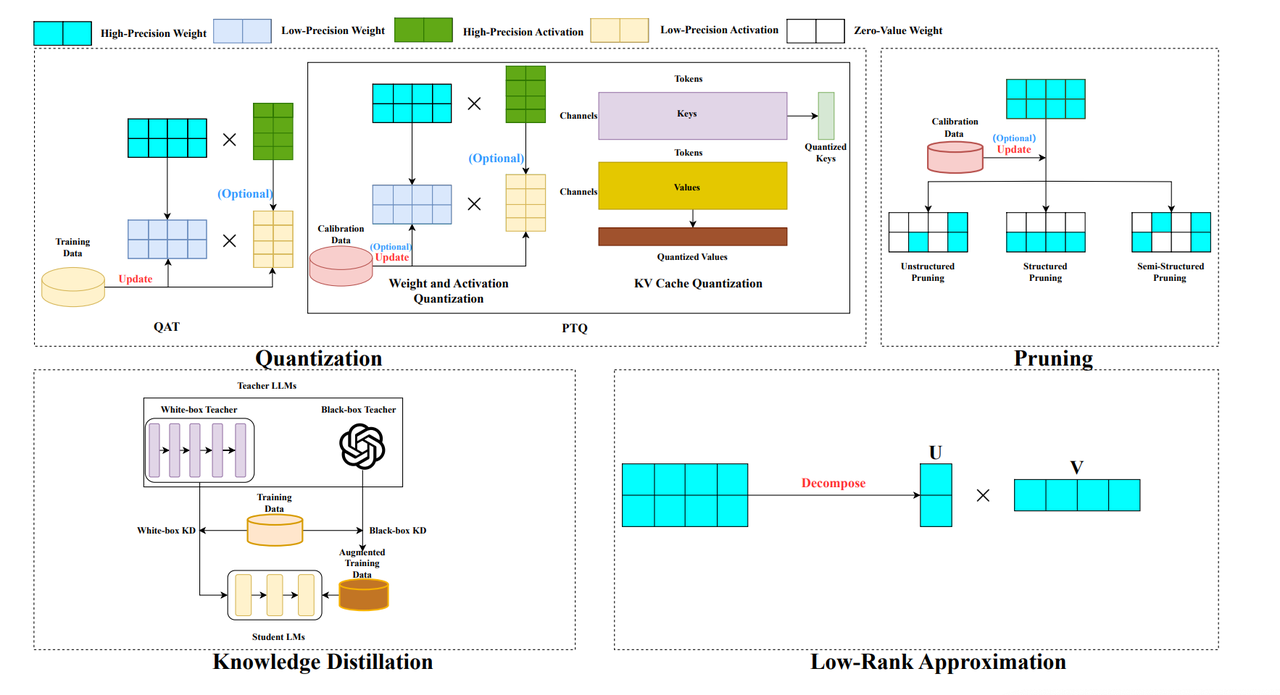

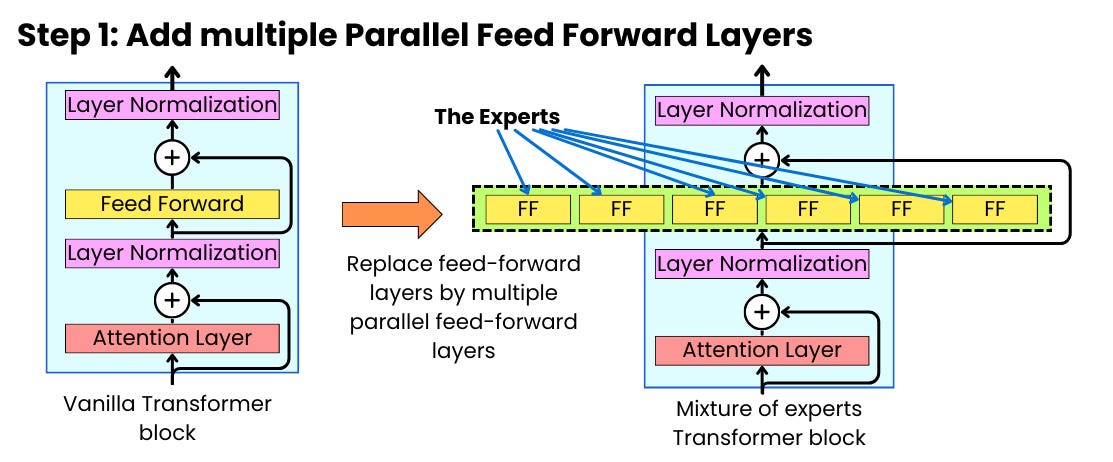
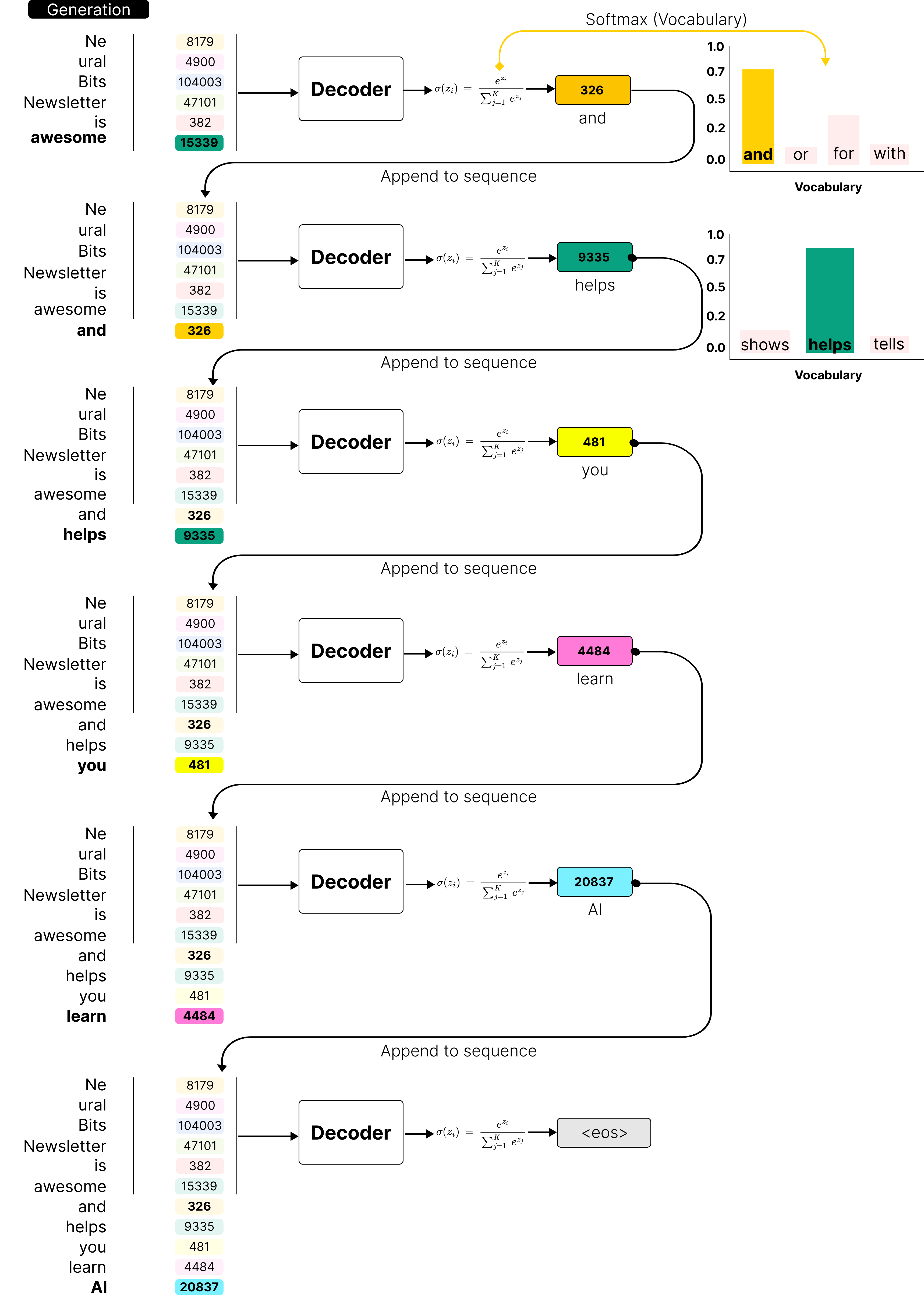
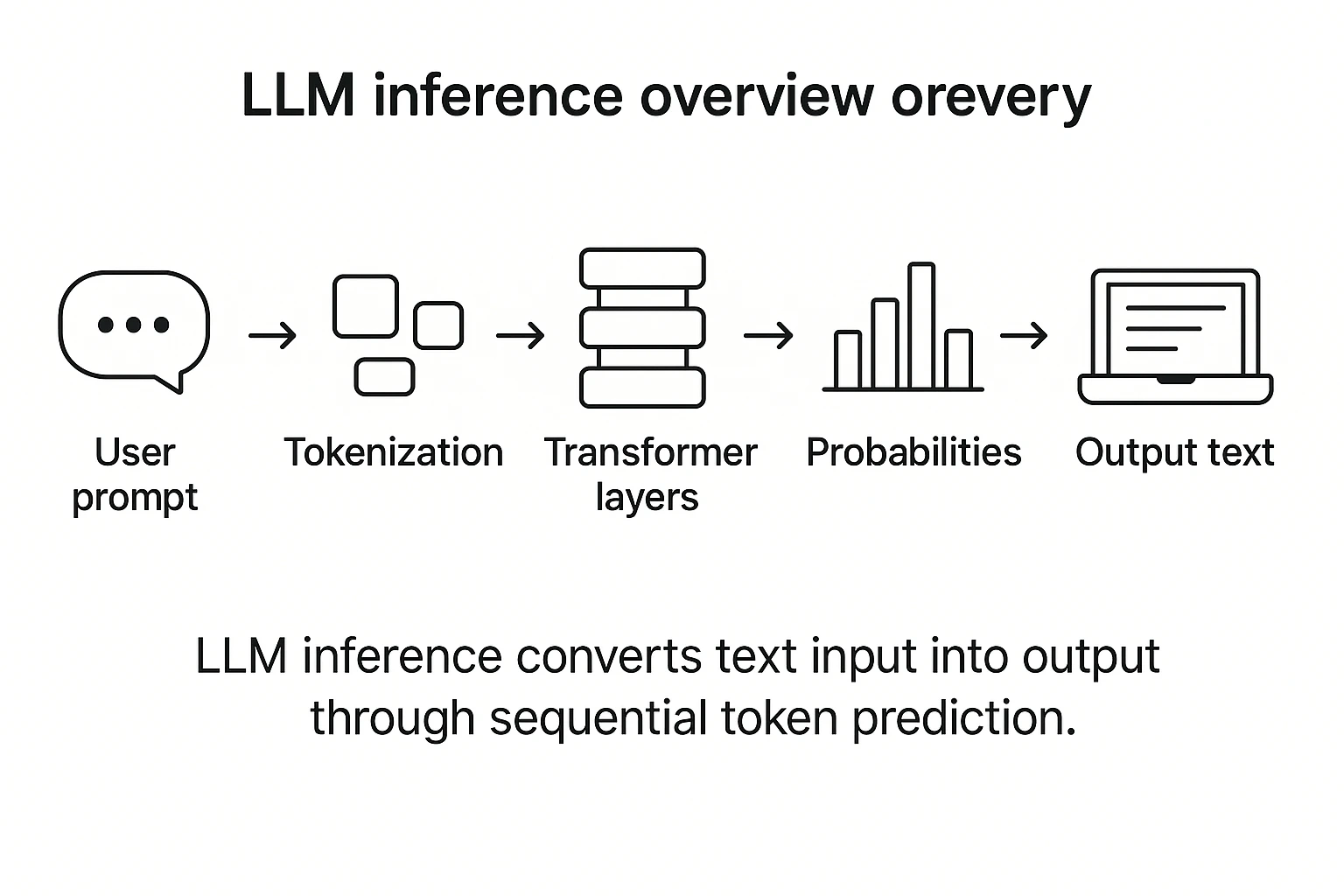


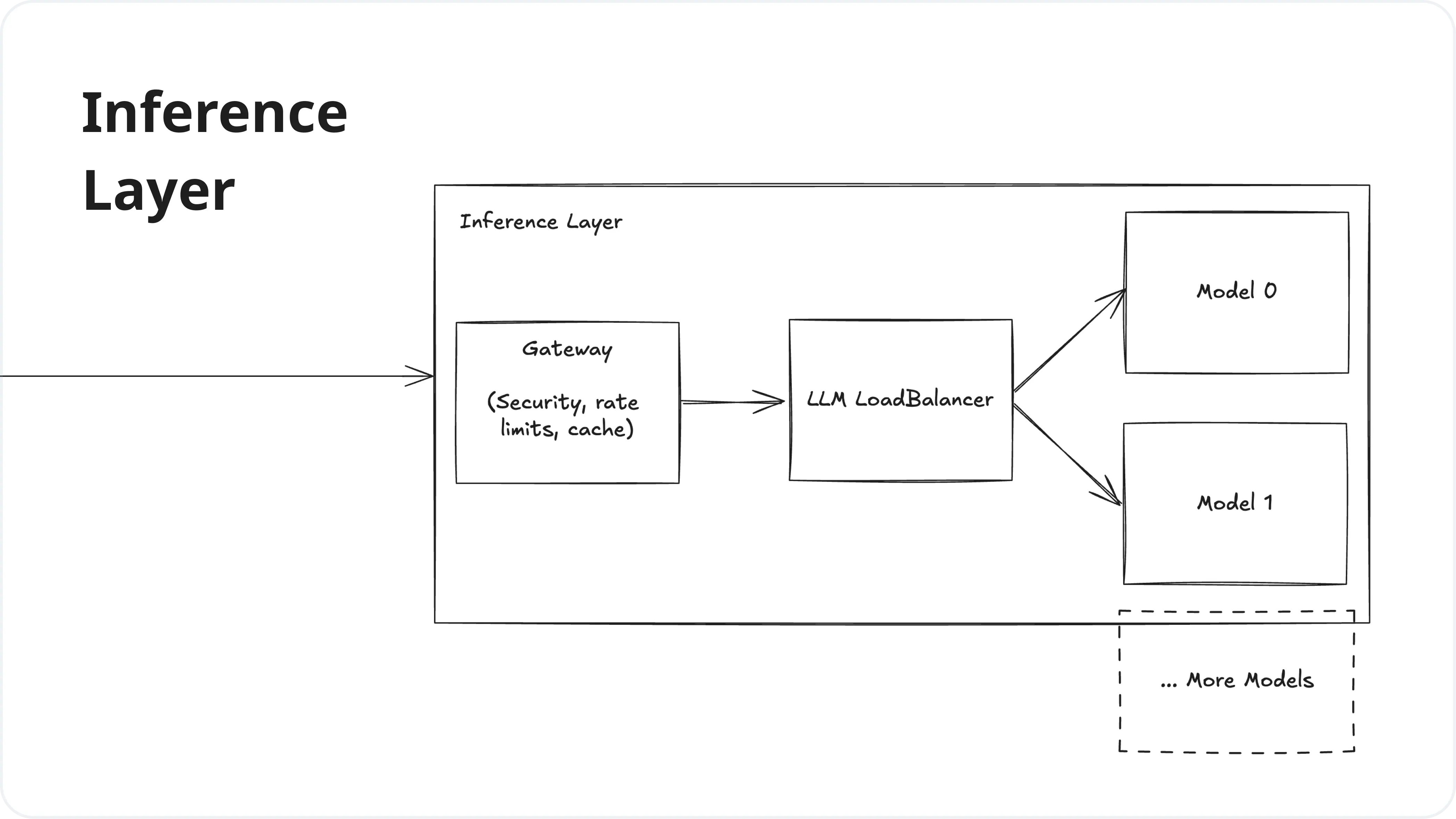












.png)