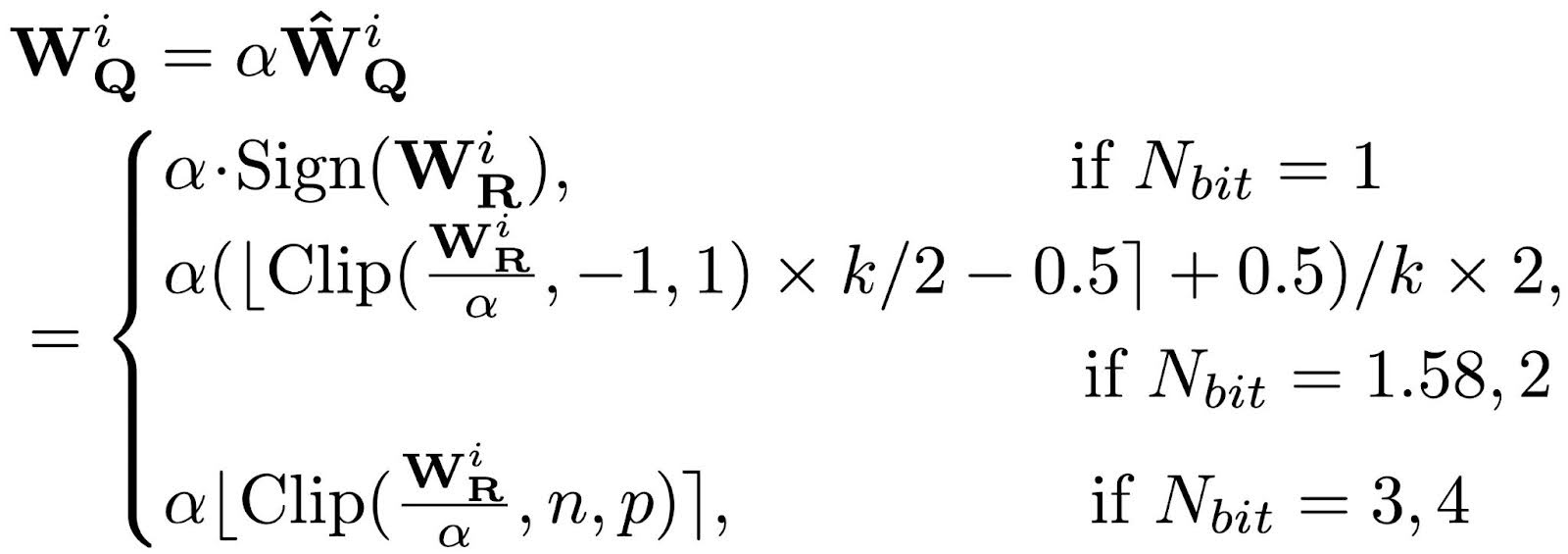Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
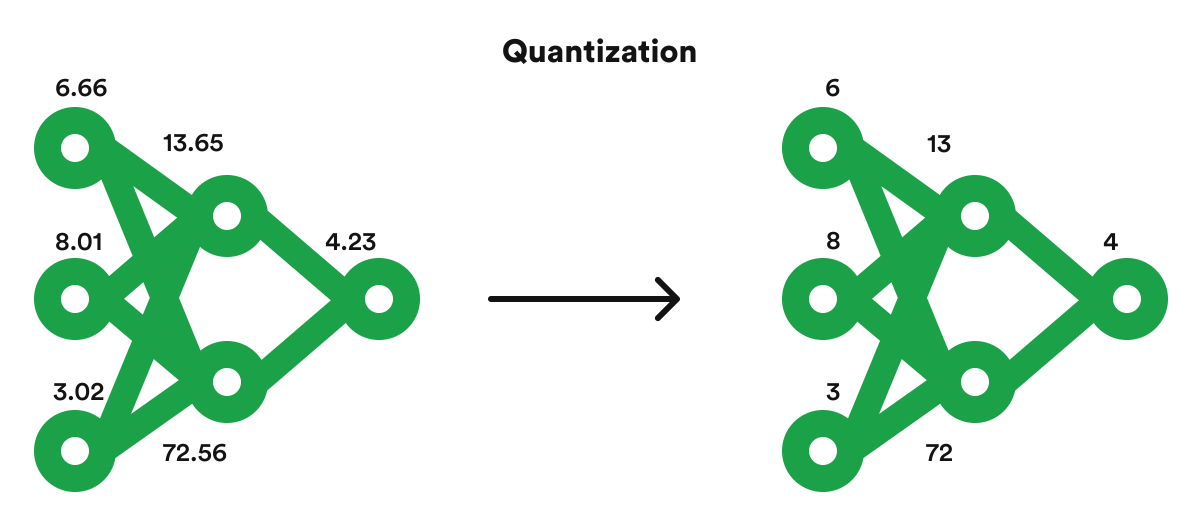
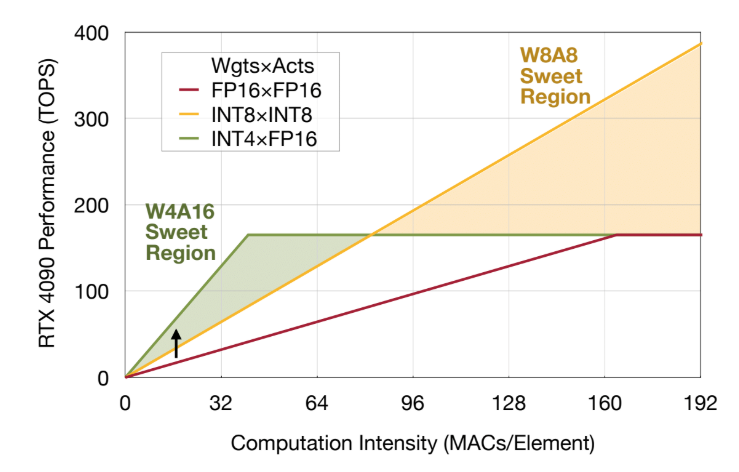
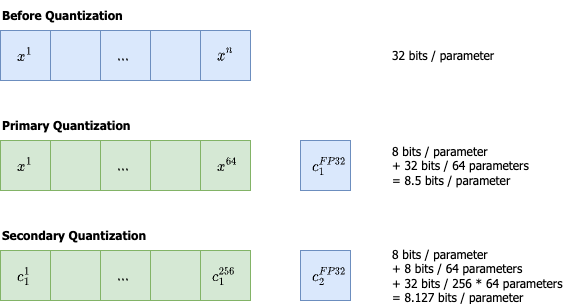
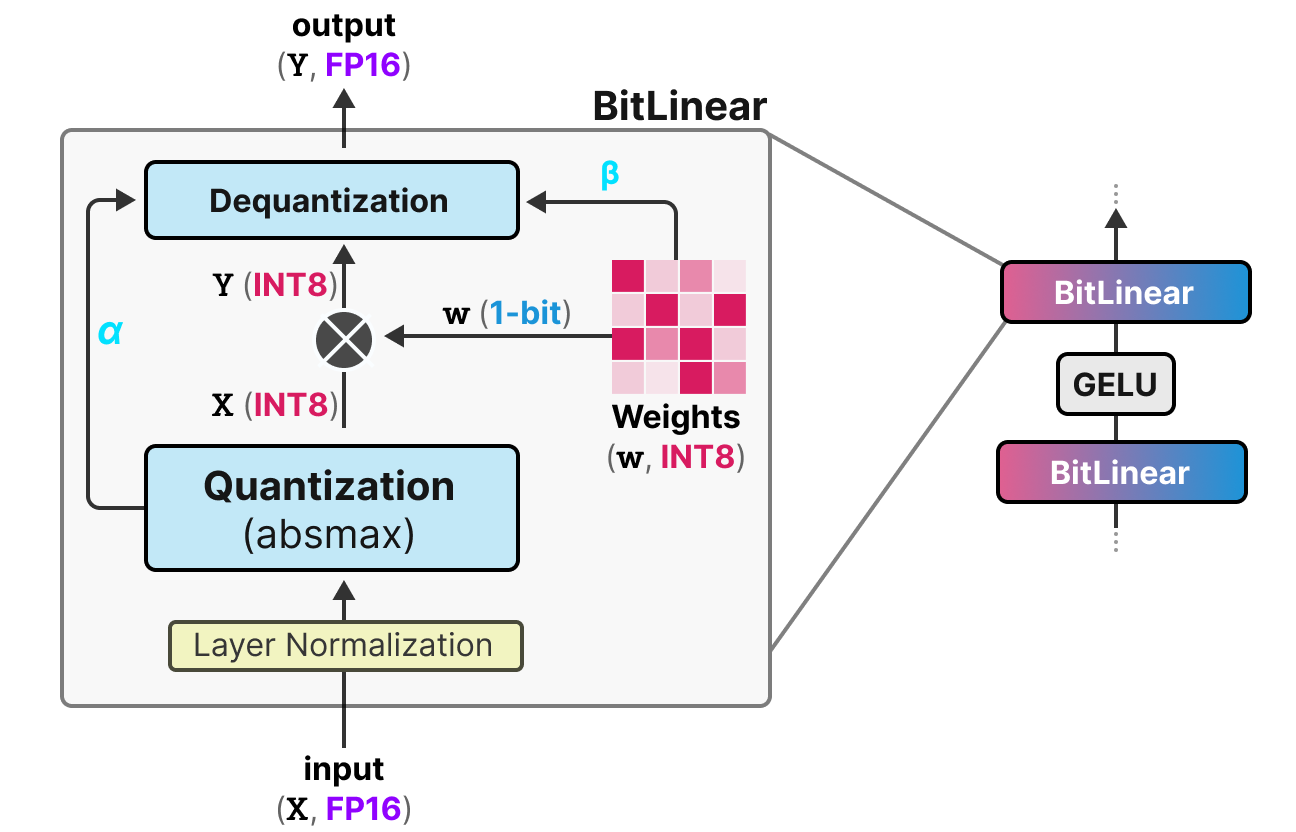
5 Essential LLM Quantization Techniques Explained
1-Bit LLM and the 1.58 Bit LLM- The Magic of Model Quantization | by Dr ...
Companding characteristics of 5 bit logarithmic quantization ...
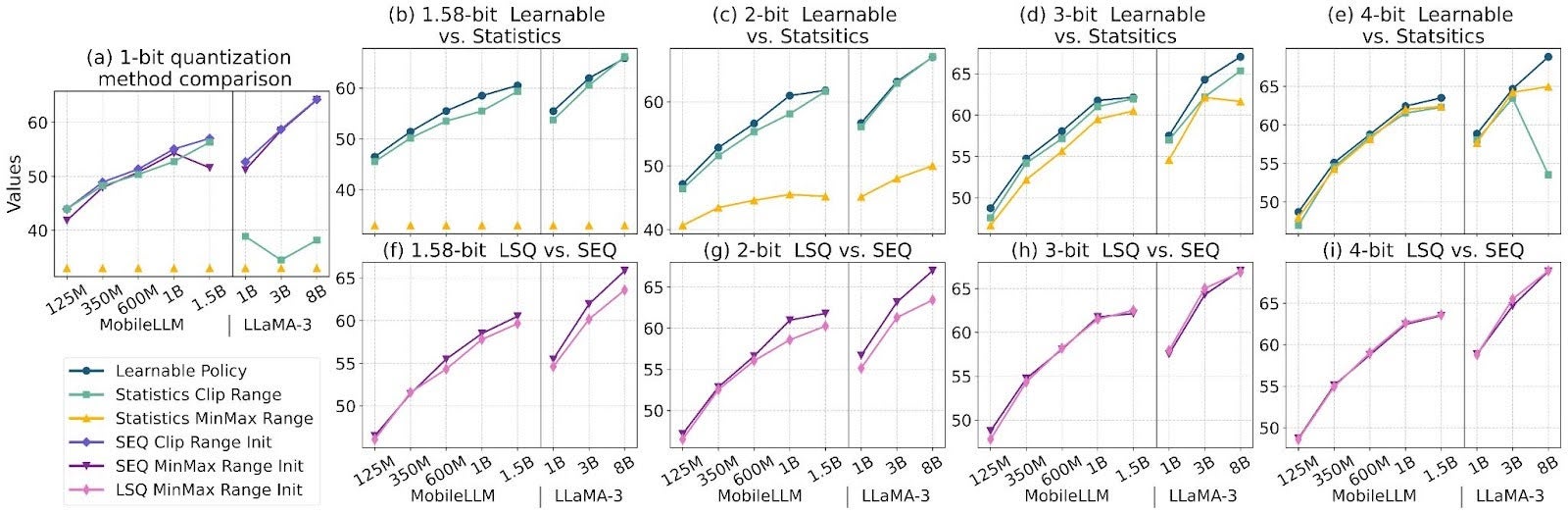
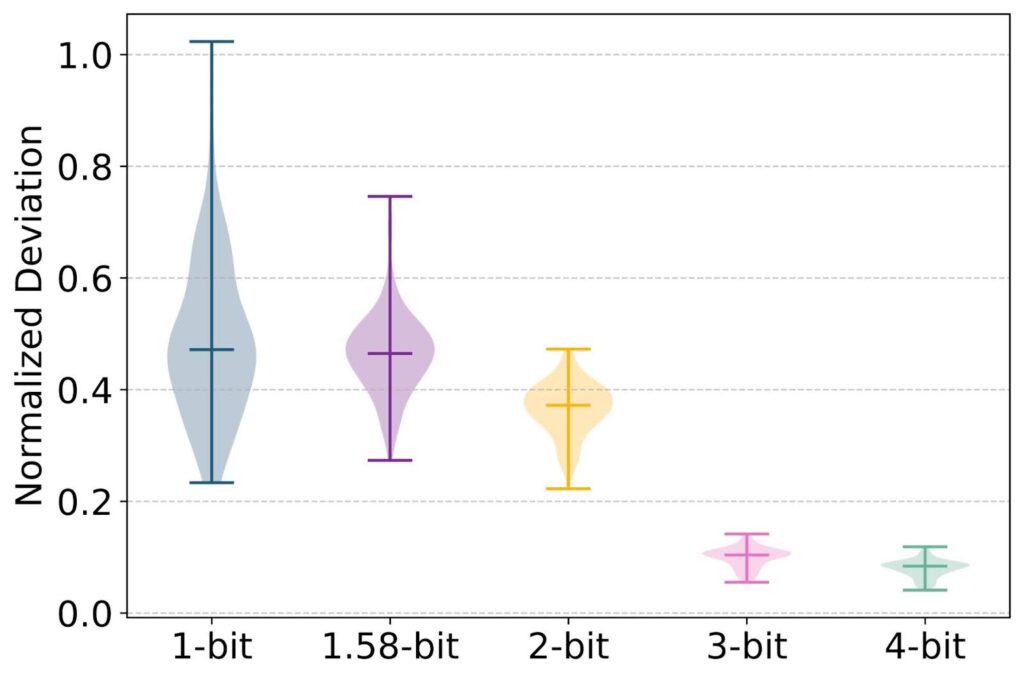
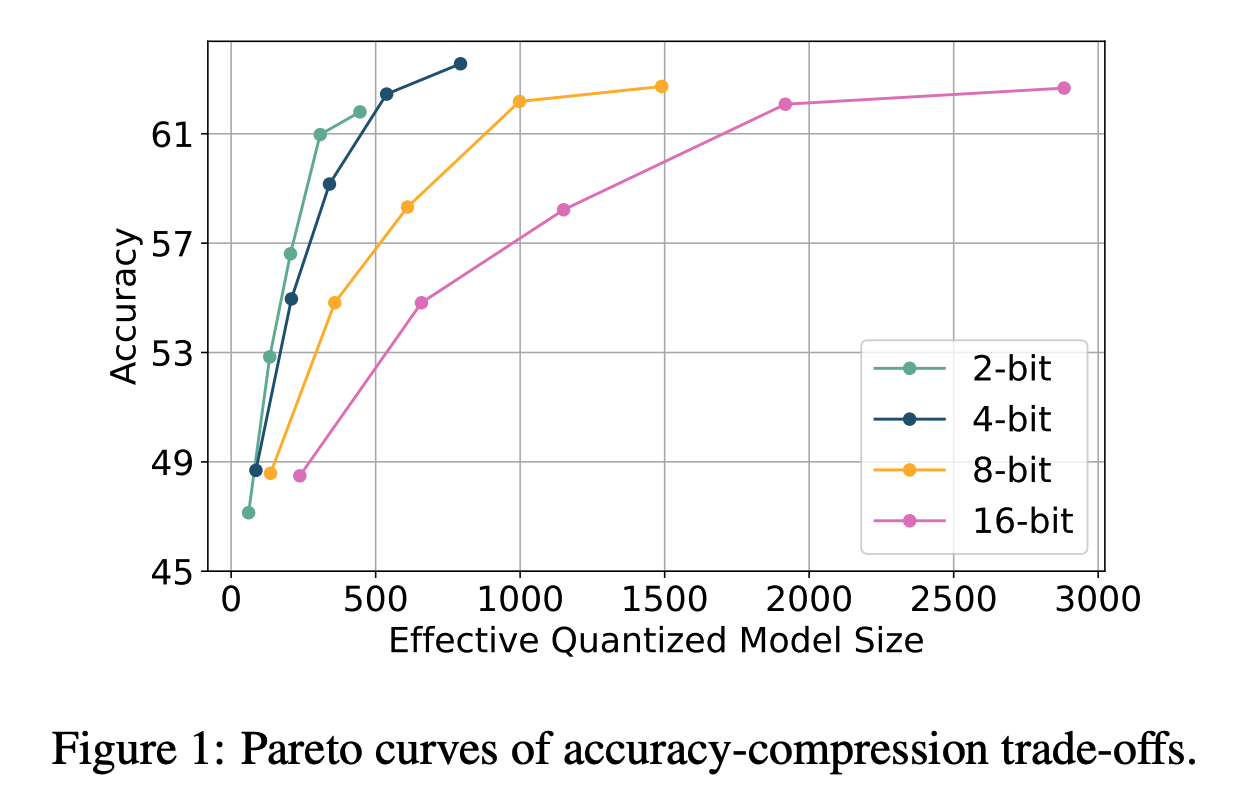
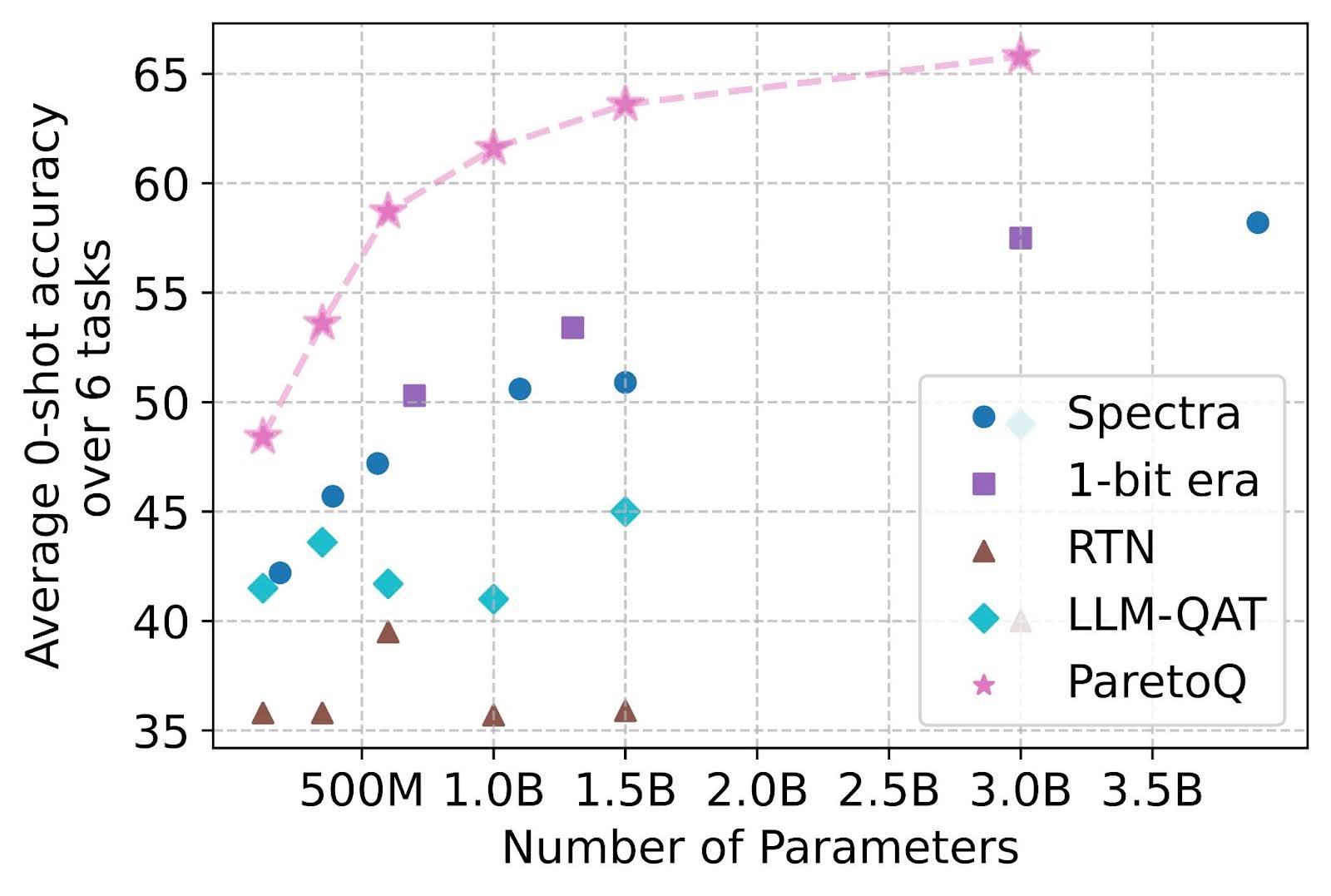
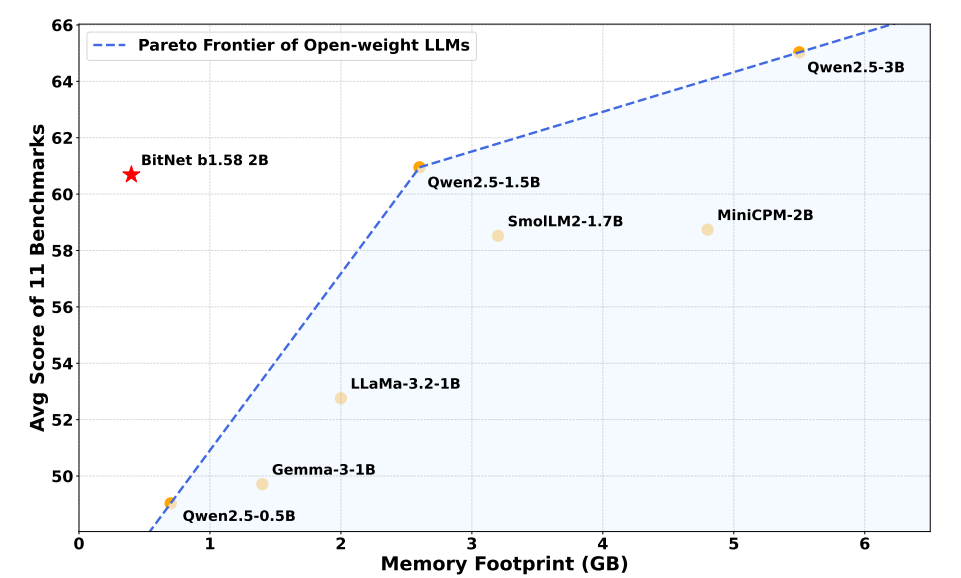
ParetoQ: Scaling Laws in Extremely Low-bit LLM Quantization – PyTorch
The Ultimate Handbook for LLM Quantization | Towards Data Science
A Visual Guide to LLM Quantization by Maarten Grootendorst | Shivanand ...
ParetoQ: Scaling Laws in Extremely Low-bit LLM Quantization | Zechun Liu
Top LLM Quantization Methods and Their Impact on Model Quality
Figure 1 from Atom: Low-bit Quantization for Efficient and Accurate LLM ...
LLM Series - Quantization Overview | by Abonia Sojasingarayar | Medium
Practical Guide to LLM Quantization Methods - Cast AI
The Complete Guide to LLM Quantization with vLLM: Benchmarks & Best ...
Optimizing LLM Model using Quantization
LLM By Examples — Use GGUF Quantization | by MB20261 | Medium
A Comprehensive Guide on LLM Quantization and Use Cases
ParetoQ: Scaling Laws in Extremely Low-bit LLM Quantization | Hung-Yueh ...
What is LLM Quantization and How to Use Them?
The Complete Guide to LLM Quantization | LocalLLM.in
Overview of LLM Quantization Techniques & Where to Learn Each of Them ...
LLM Quantization Made Easy: Essential Tips for Success
Democratizing LLMs: 4-bit Quantization for Optimal LLM Inference ...
Improving LLM Inference Latency on CPUs with Model Quantization ...
An Introduction to LLM Quantization - TextMine
A Beginner's Guide to LLM Quantization
LLM Quantization Techniques- GPTQ | Towards AI
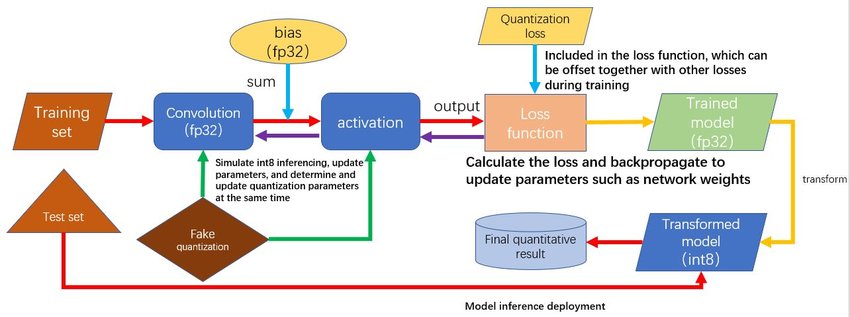
4-bit LLM training and Primer on Precision, data types & Quantization
ICQuant: Index Coding enables Low-bit LLM Quantization | AI Research ...
Making LLMs Lighter: A deep dive into LLM quantization with Code | by ...
[PDF] SpinQuant: LLM quantization with learned rotations | Semantic Scholar
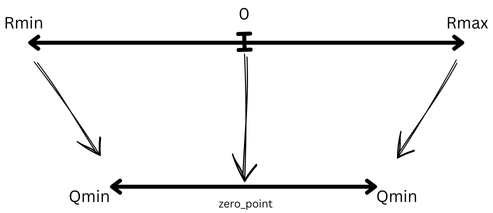
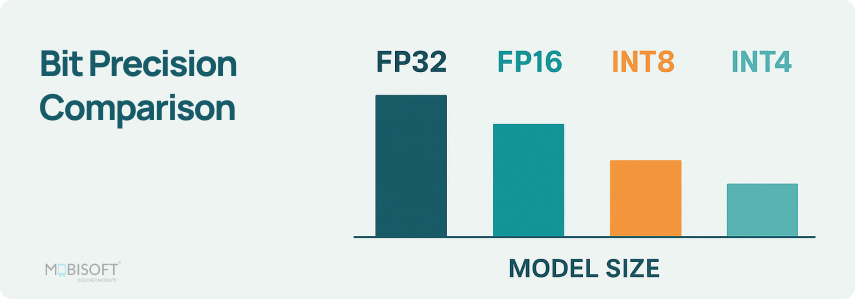
Data Types in LLM Quantization
LLM Quantization in depth. WHAT is Quantization? | by Abhinaykrishna ...
12 LLM Quantization Choices: Speed, Cost & Quality | by Modexa | Medium
(PDF) Exploiting LLM Quantization
New Method For LLM Quantization | ml-news – Weights & Biases
(PDF) BCQ: Block Clustered Quantization for 4-bit (W4A4) LLM Inference
[논문 리뷰] ButterflyQuant: Ultra-low-bit LLM Quantization through ...
A Practical Guide to LLM Quantization (int8/int4) | Hivenet
LLM Quantization-Build and Optimize AI Models Efficiently
Honey, I shrunk the LLM! A beginner's guide to quantization • The Register
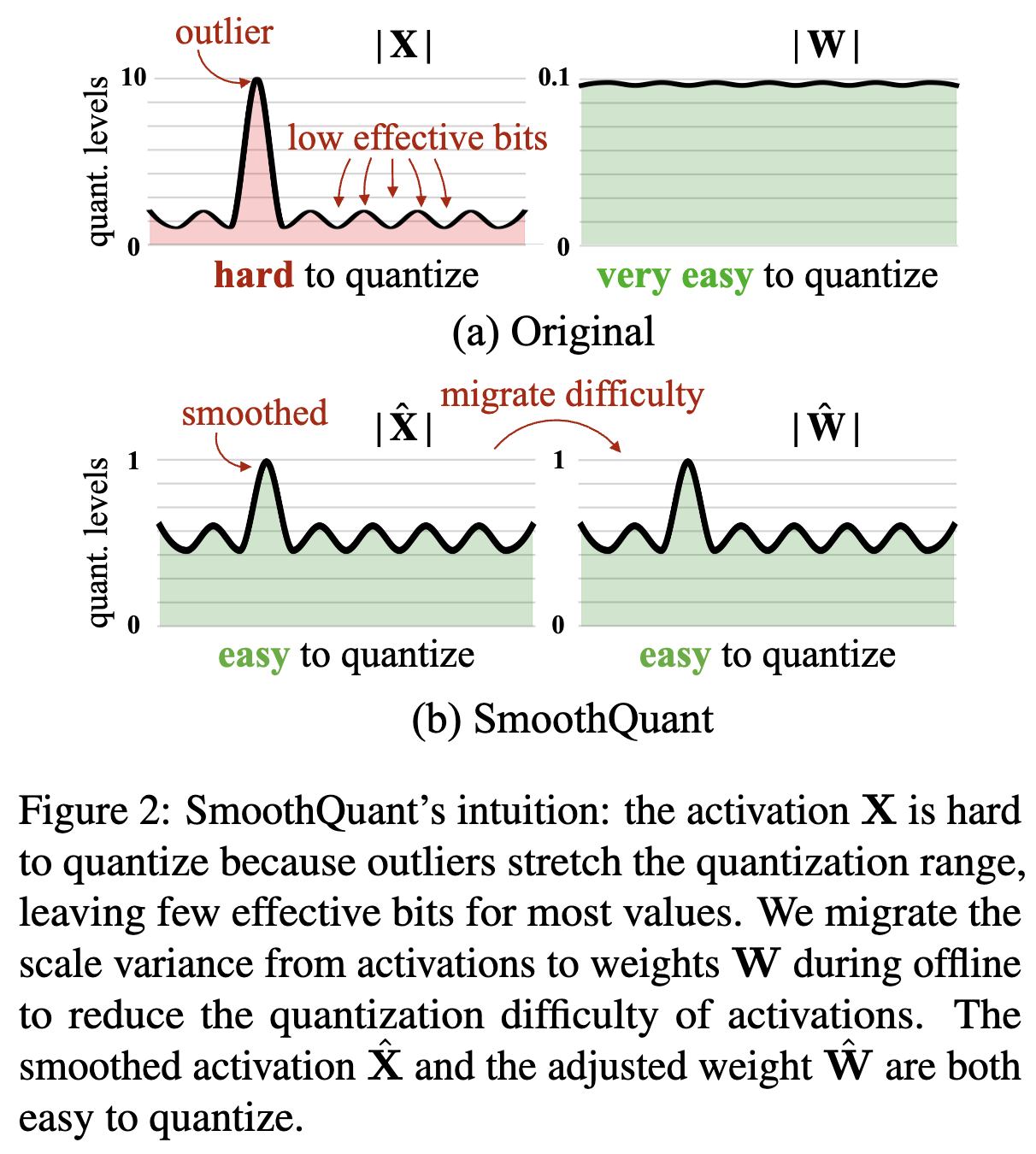
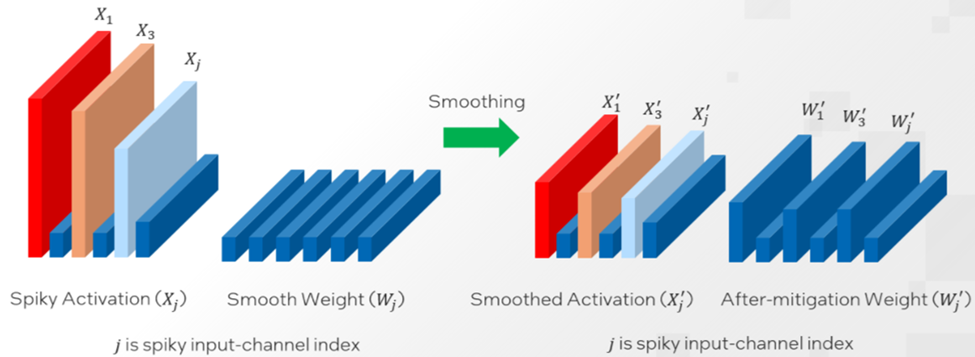
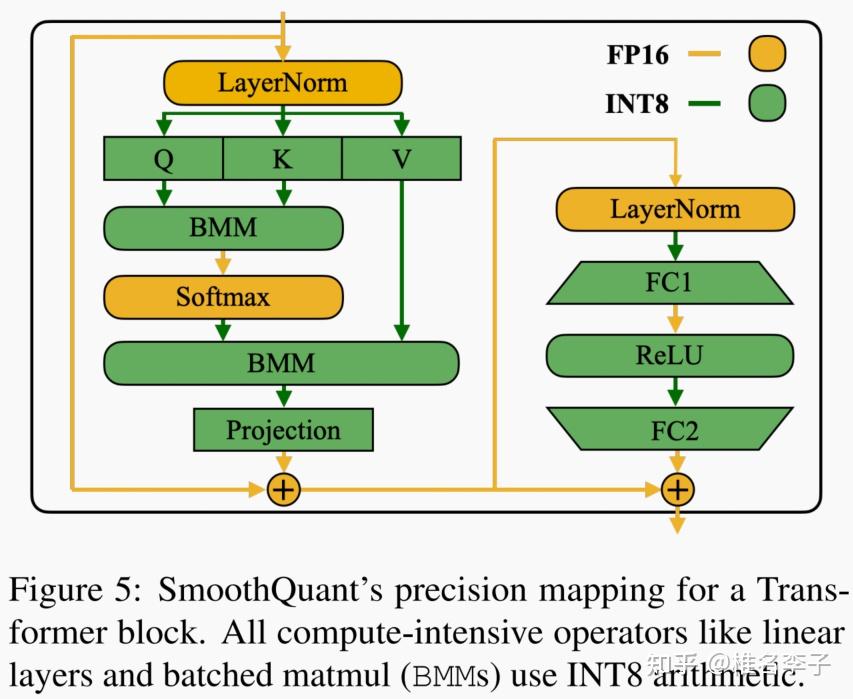
[LLM] SmoothQuant: Accurate and Efficient Post-Training Quantization ...
Data processing of 5-bit quantization for the codes simplification ...
PB-LLM: a cutting-edge technique for extreme low-bit quantization in ...
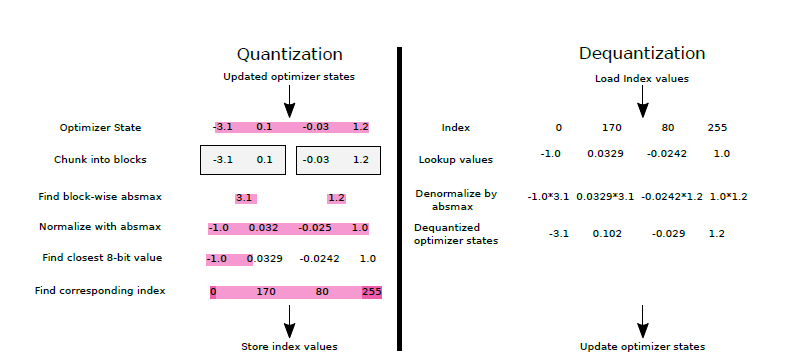
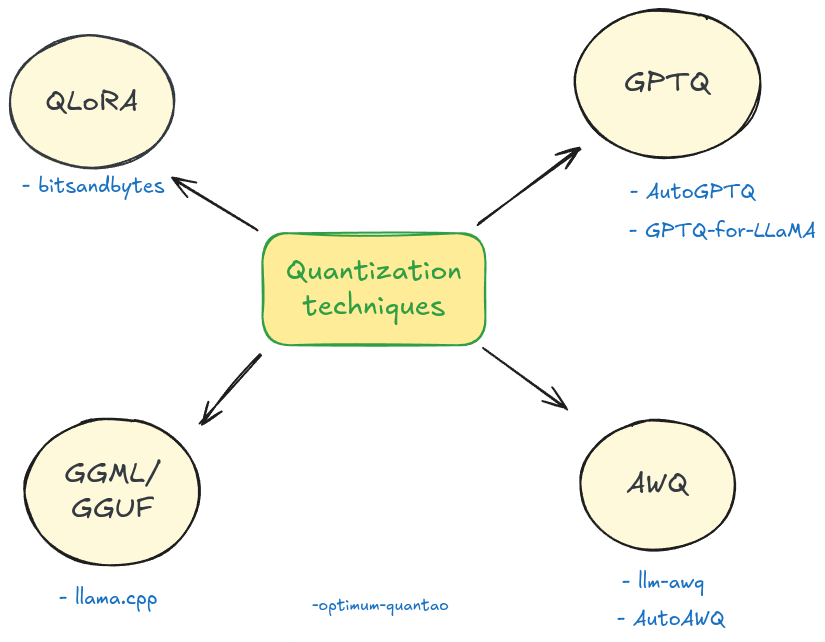
LLM Quantization: Quantize Model with GPTQ, AWQ, and Bitsandbytes ...
Advances to low-bit quantization enable LLMs on edge devices ...
LLM Quantization: Making models faster and smaller | MatterAI Blog
Quantized 8-bit LLM training and inference using bitsandbytes on AMD ...
Introduction to Weight Quantization | Towards Data Science
LLM Quantization: Weight-Only? Static? Dynamic? | by hebiao064 | Medium
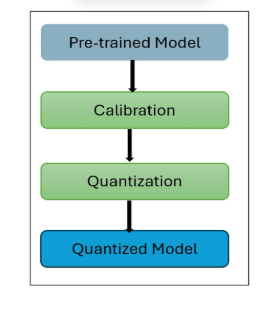
What is Quantization in LLM? A Complete Guide to Optimizing AI
Exploring Model Quantization for LLMs | by Snehal | Medium
Optimize Your LLM with Quantization: Save Memory and Boost Performance ...
Effective Post-Training Quantization for Large Language Models | by ...
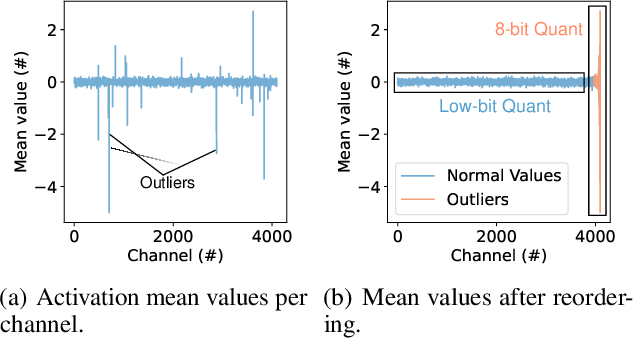
(PDF) Why Do Some Inputs Break Low-Bit LLM Quantization?
What is LLM quantization? - YouTube
Microsoft AI Researchers Introduce Advanced Low-Bit Quantization ...
Shrinking Giants: The Quantization Mathematics Making LLMs Accessible
Compressing LLMs with AWQ: Activation-Aware Quantization Explained | by ...
Lets Finetune LLM - Speaker Deck
What is Quantization in LLM. Large Language Models comes in all… | by ...
WTH is LLM quantization? 4bit GPTQ? | by Dharani J | Medium
Low-bit Quantized Open LLM Leaderboard - a Hugging Face Space by Intel ...
Quantization in LLMs: Why Does It Matter?
A Guide to Quantization in LLMs | Symbl.ai
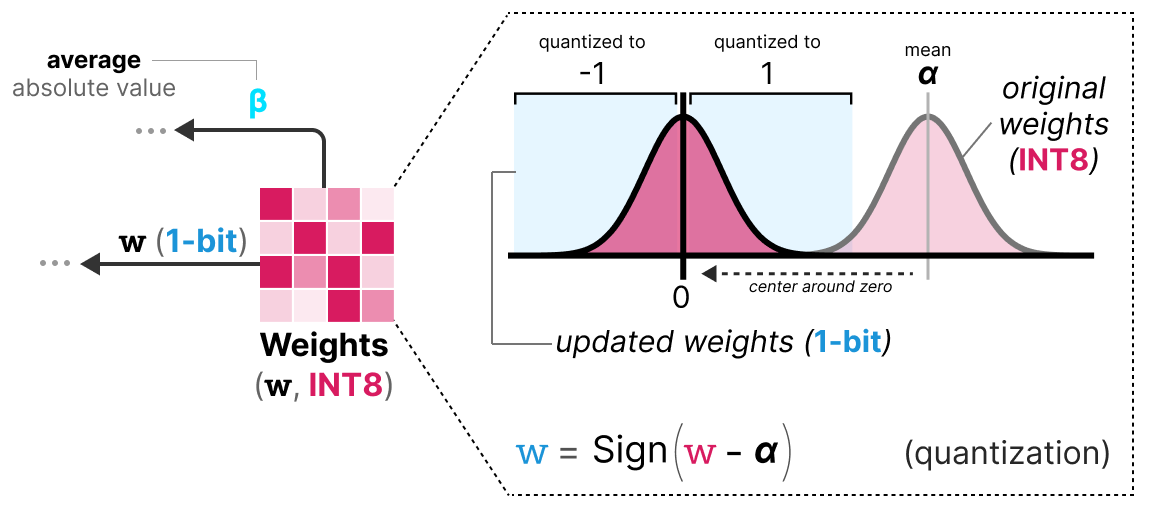
Microsoft’s 1-bit LLM Is Making AI Work on Any Device: Thanks to ...
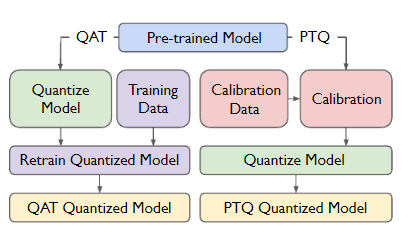
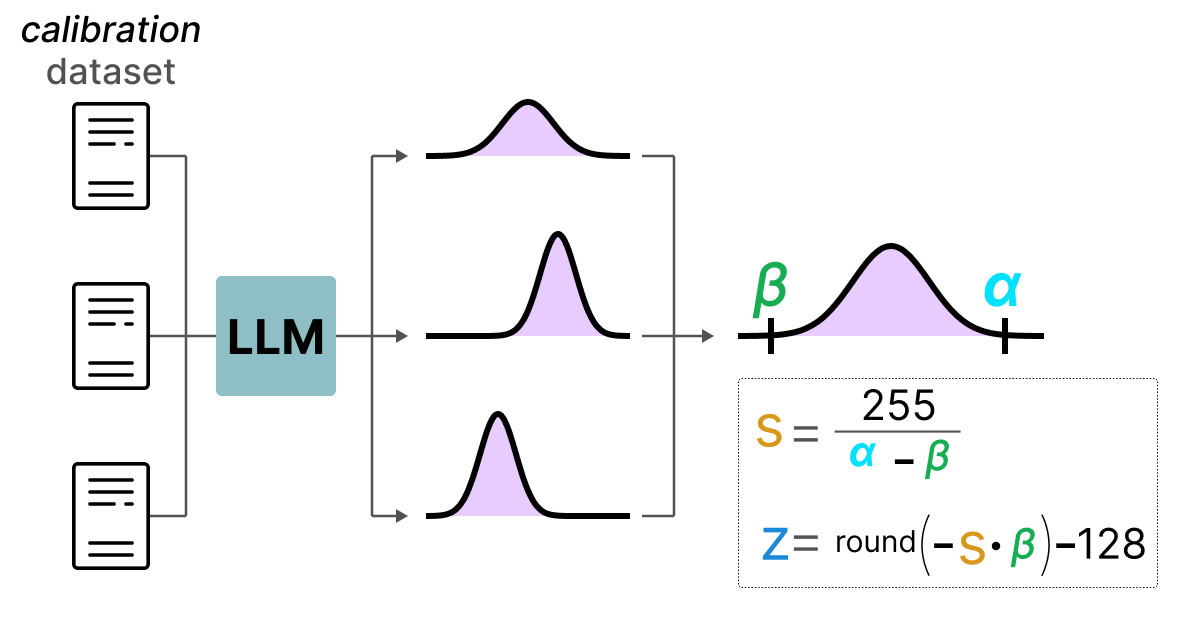
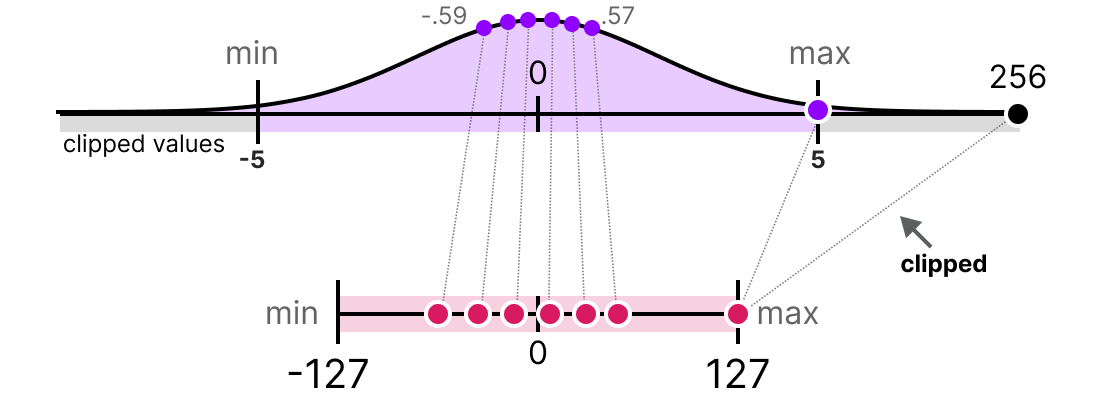
LLMs之Quantization:LLM中量化技术的可视化指南之量化技术的简介、常用数据类型、校准权重和激活值的量化方法(PTQ/QAT ...
模型量化-llm量化 - 知乎
What are Quantized LLMs?
Introduction to llm-finetuning and Quantization. Refining Generative ...
Maximizing Business Potential with Large Language Models (LLMs)
ABQ-LLM: Arbitrary-Bit Quantized Inference Acceleration for Large ...
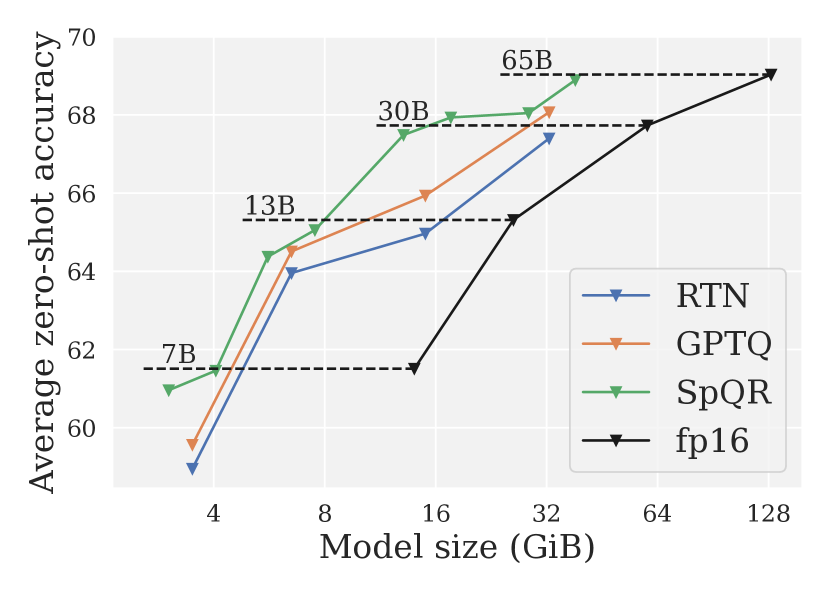
[2306.03078] SpQR: A Sparse-Quantized Representation for Near-Lossless ...
How to run LLMs on CPU-based systems | UnfoldAI
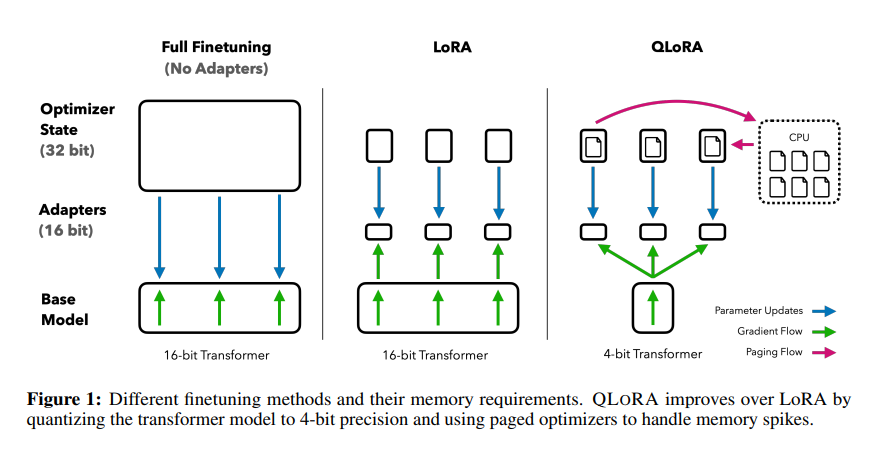
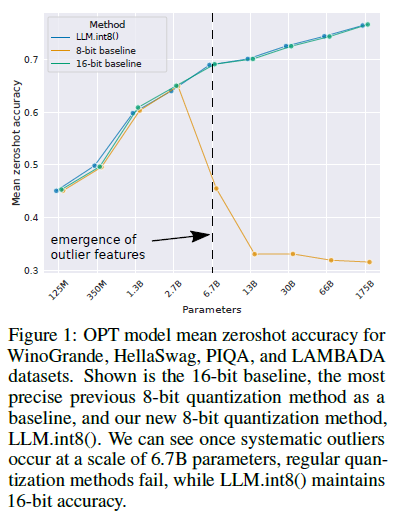
[vLLM — Quantization] bitsandbytes: 8-bit Optimizers, LLM.int8(), QLoRA ...