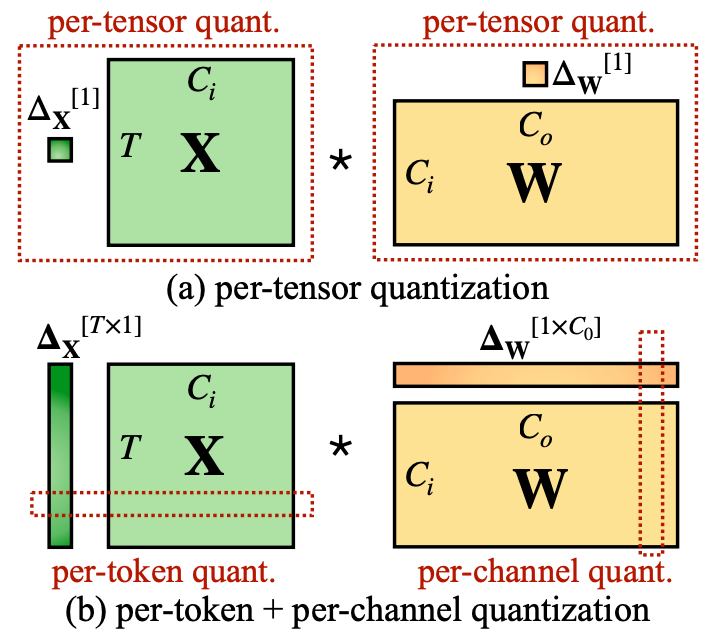
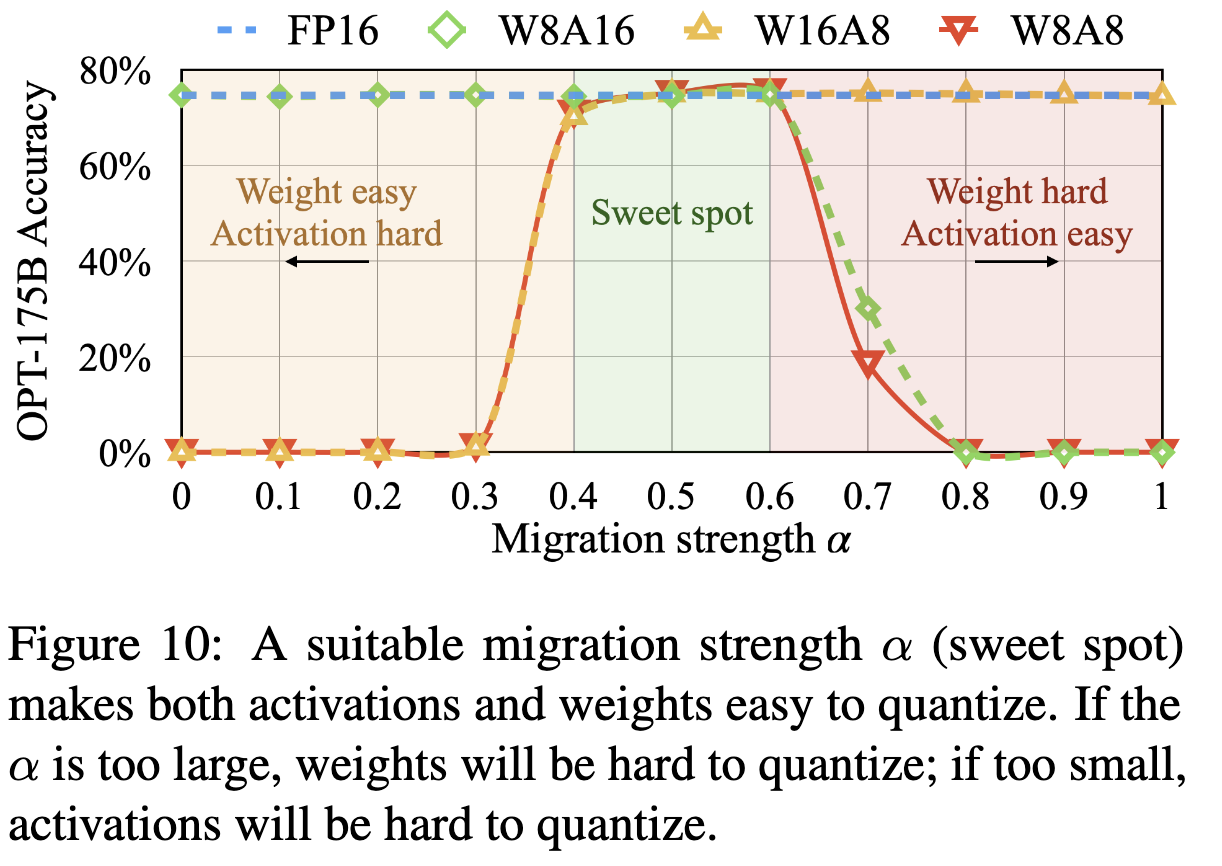
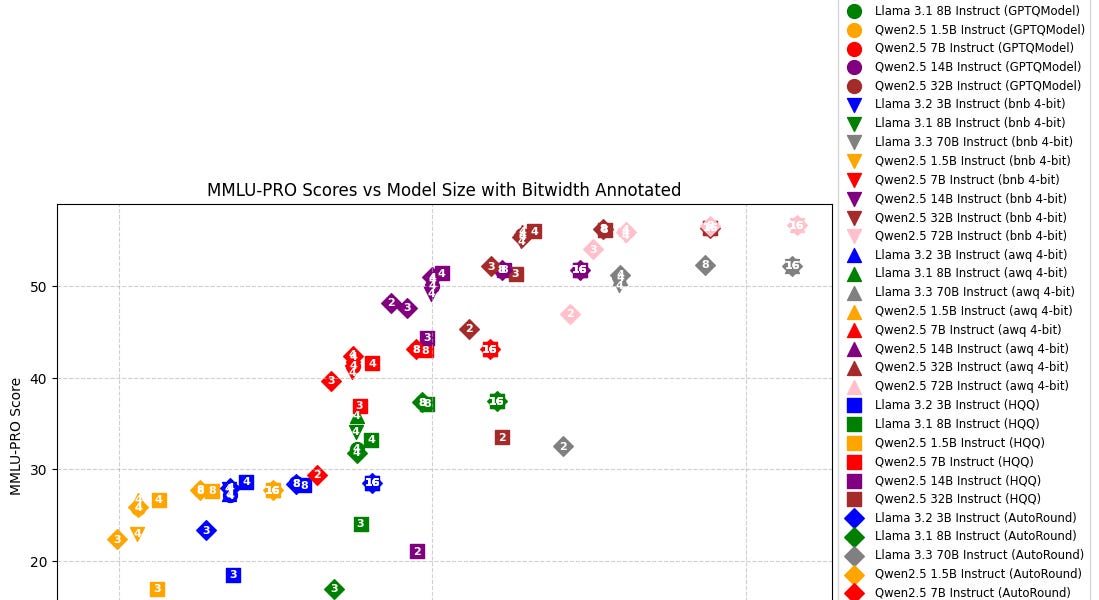
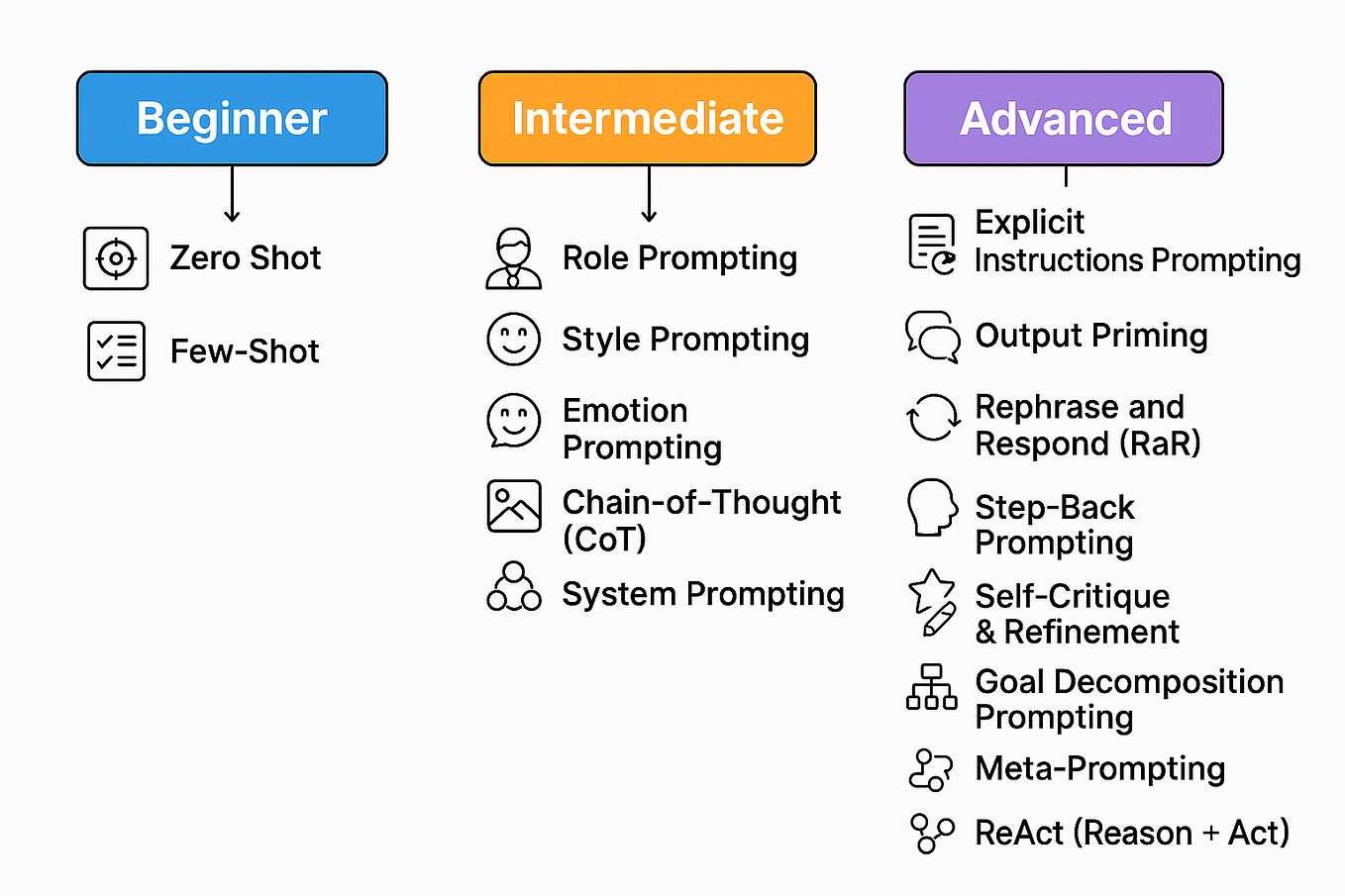
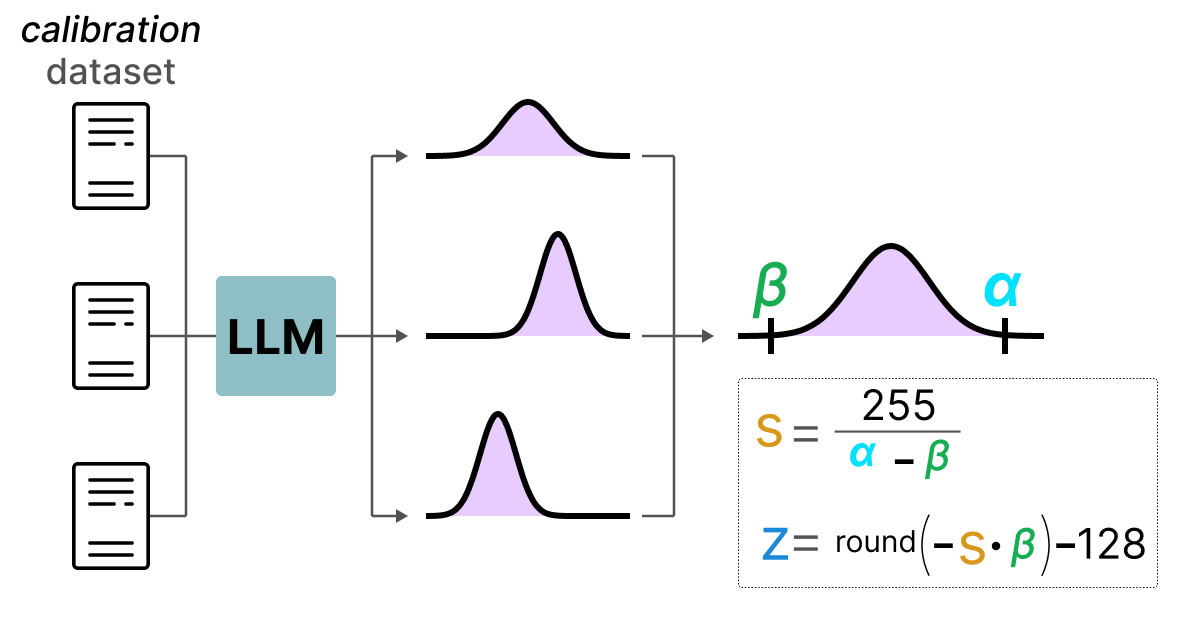
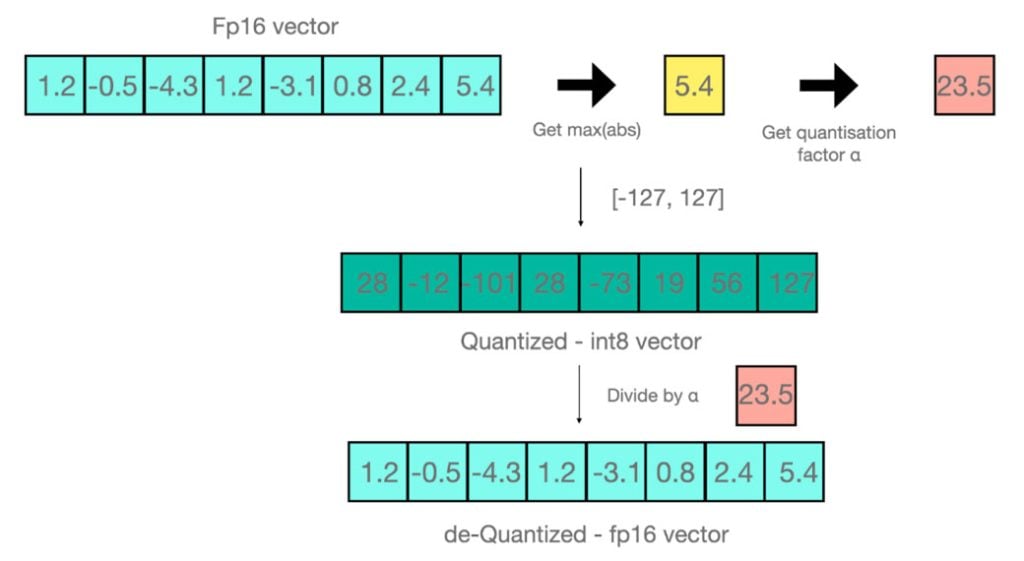
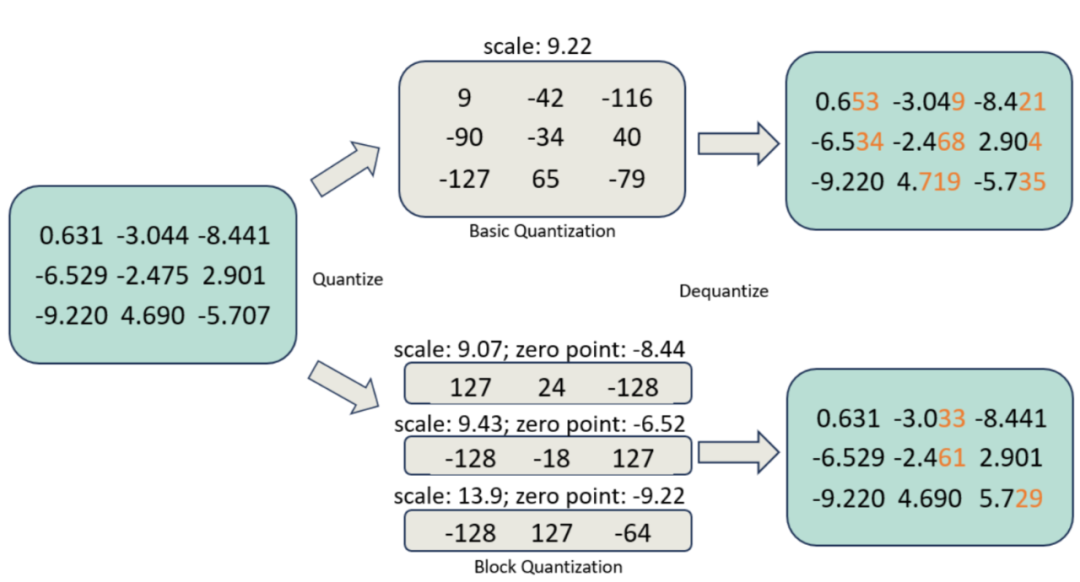
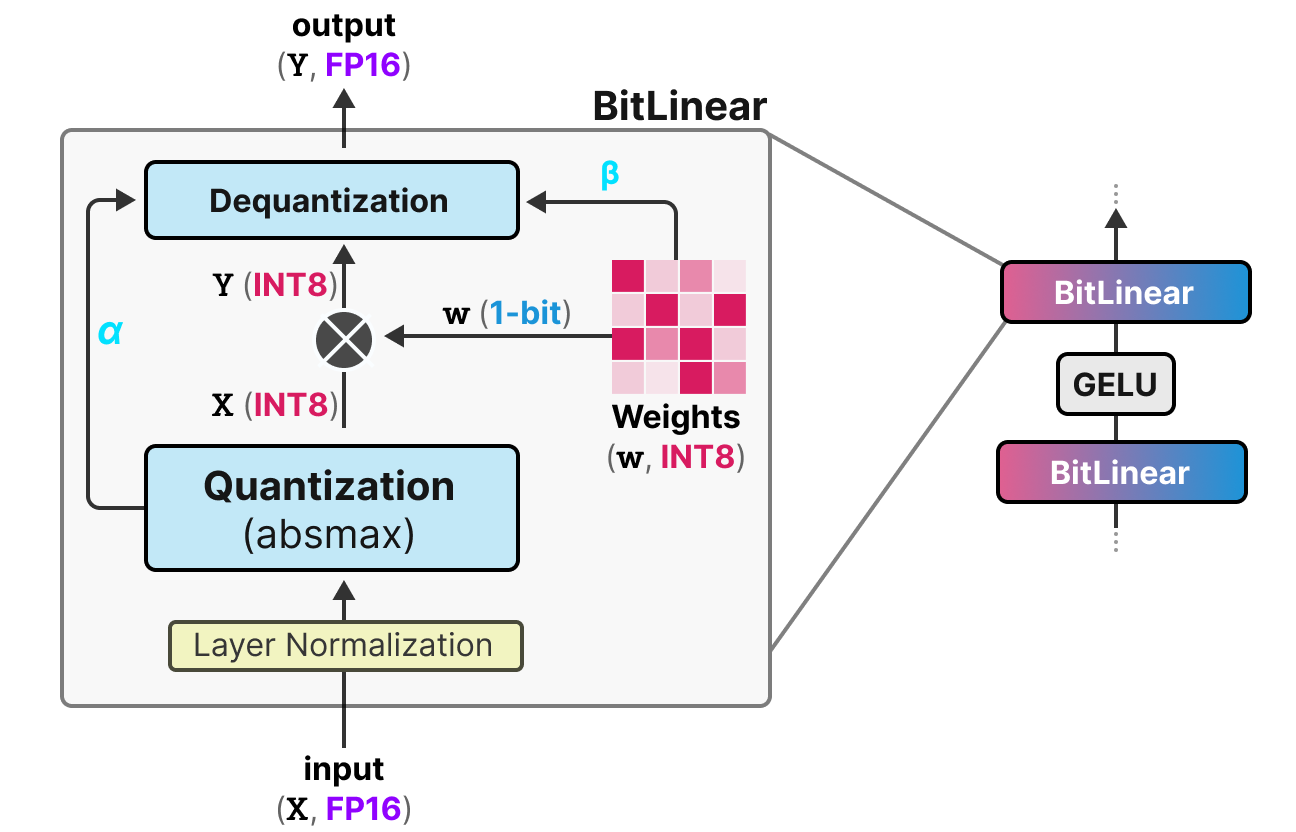
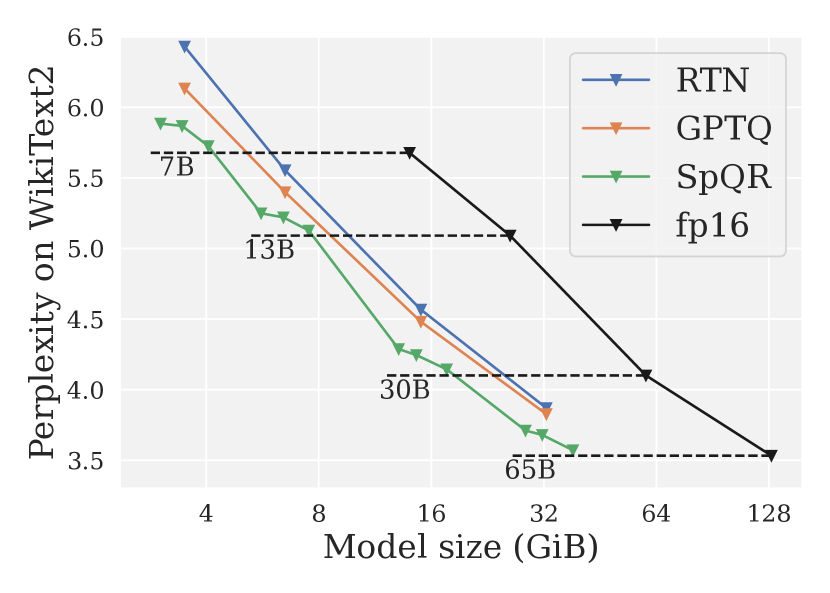
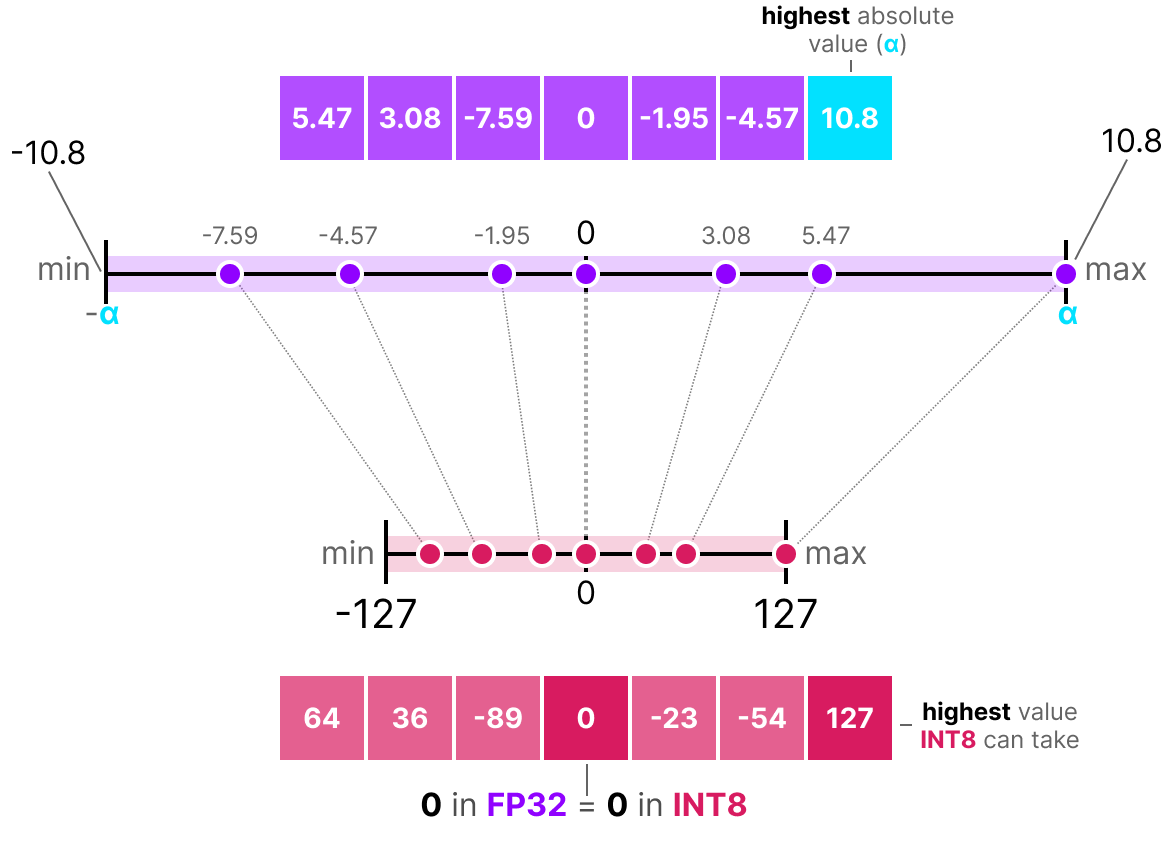
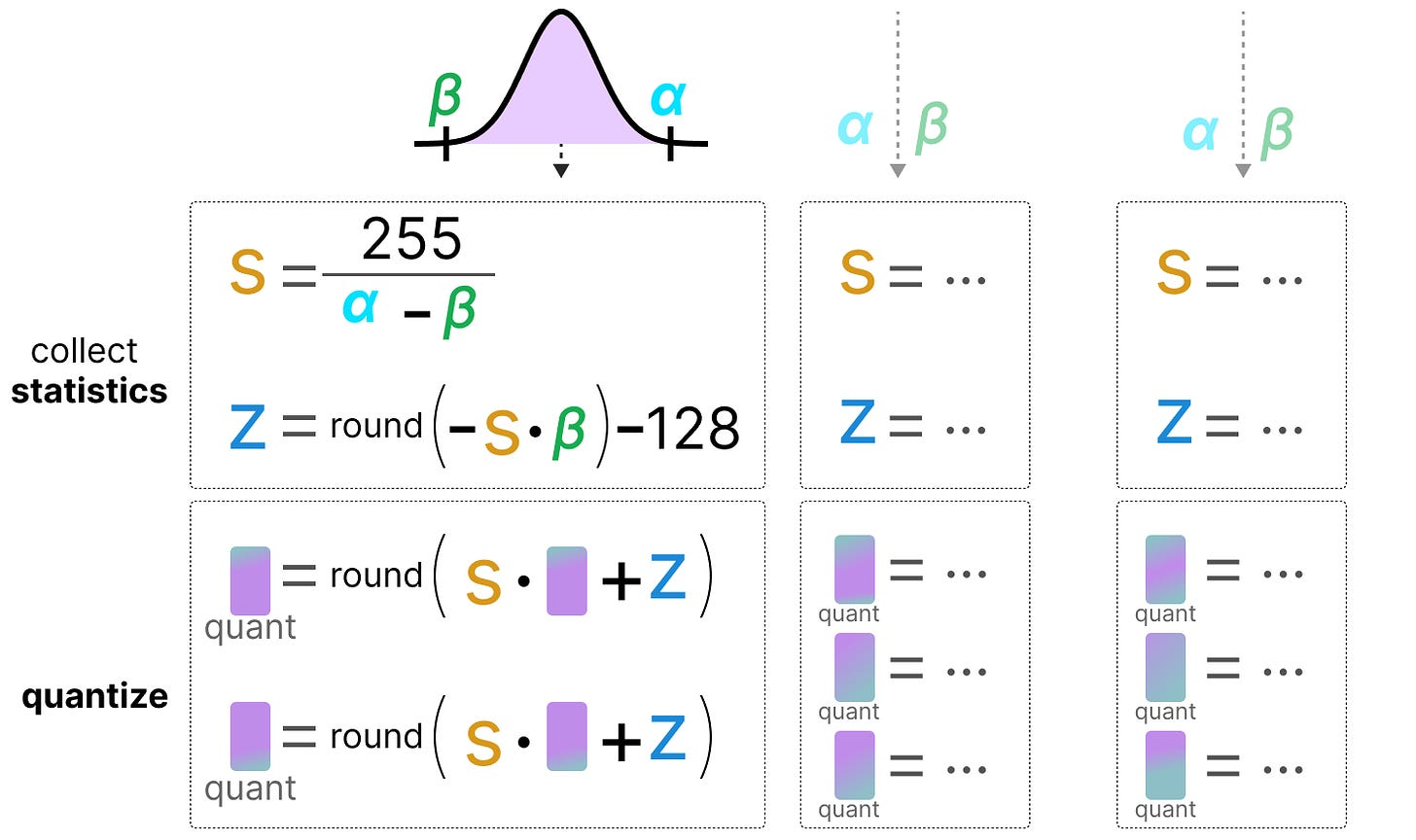
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
Free Video: LLM Quantization Performance Testing - Ollama and LM Studio ...
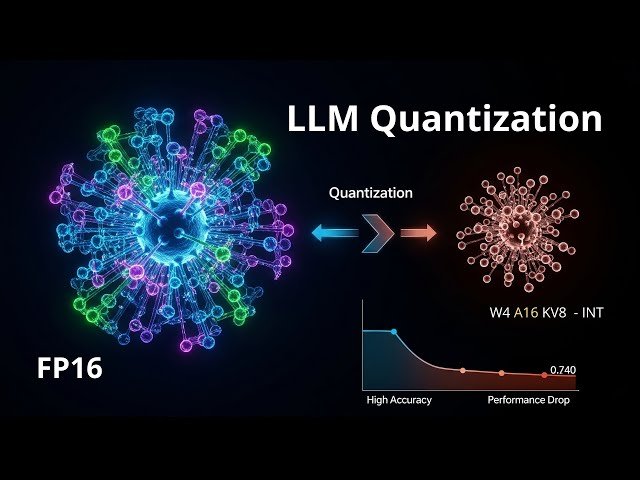
Analyzing Accuracy vs Performance in LLM Quantization
Exploring the Impact of Quantization on LLM Performance | by Olga Zem ...
LLM Quantization with Quark on AMD GPUs: Accuracy and Performance ...
LLM Quantization Performance. Deploying large language models in… | by ...
The Ultimate Handbook for LLM Quantization | Towards Data Science
A Comprehensive Guide on LLM Quantization and Use Cases
Practical Guide to LLM Quantization Methods - Cast AI
Top LLM Quantization Methods and Their Impact on Model Quality
LLM Quantization Made Easy: Essential Tips for Success
LLM Series - Quantization Overview | by Abonia Sojasingarayar | Medium
Quantization Techniques to Reduce LLM Model Size and Memory: A Complete ...
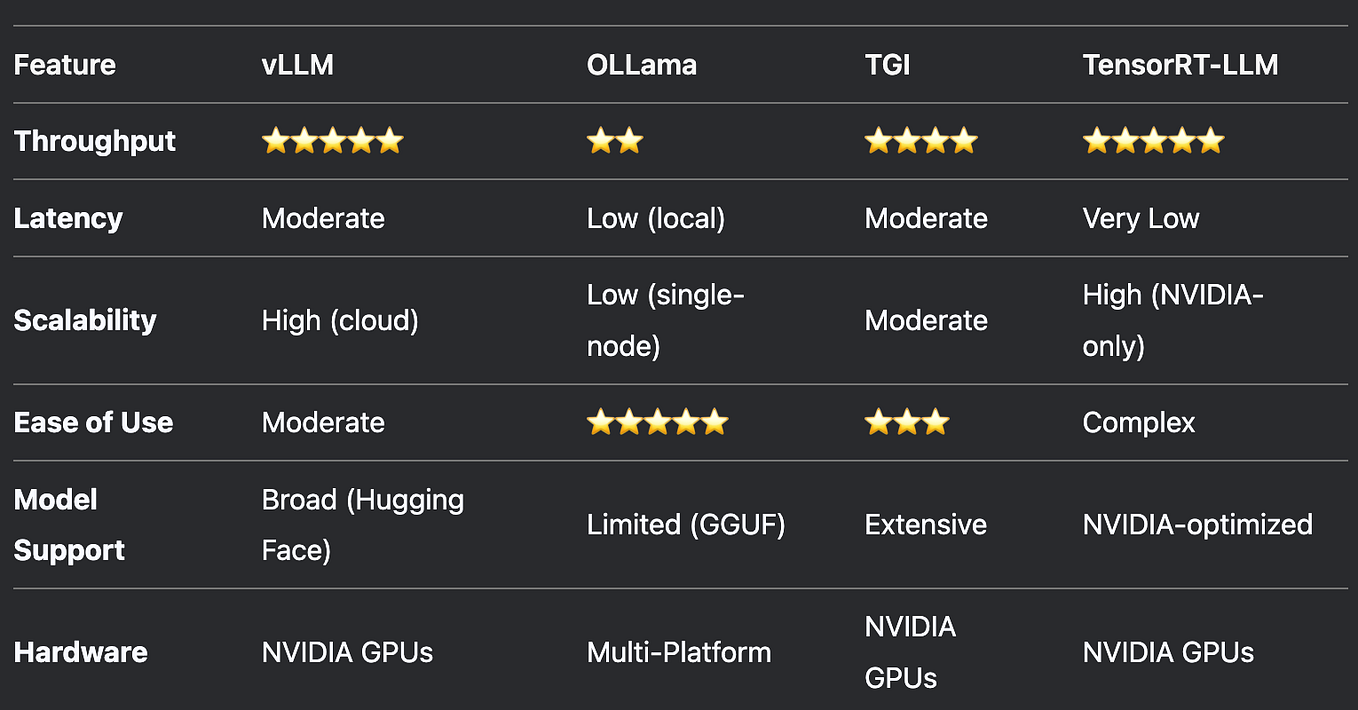
LLM Quantization Comparison
Evaluating Quantized LLM Performance and Accuracy
Simplify LLM Quantization Process for Success | by Novita AI | Jul ...
The Complete Guide to LLM Quantization | LocalLLM.in
Optimize Your LLM with Quantization: Save Memory and Boost Performance ...
An Introduction to LLM Quantization - TextMine
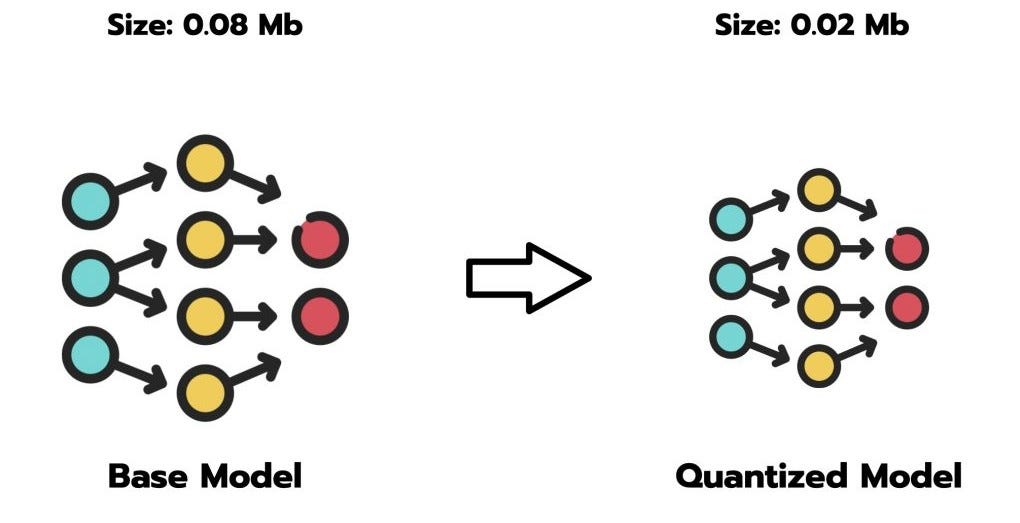
What is LLM Quantization and How to Use Them?
Optimizing LLM Model using Quantization
A Beginner's Guide to LLM Quantization
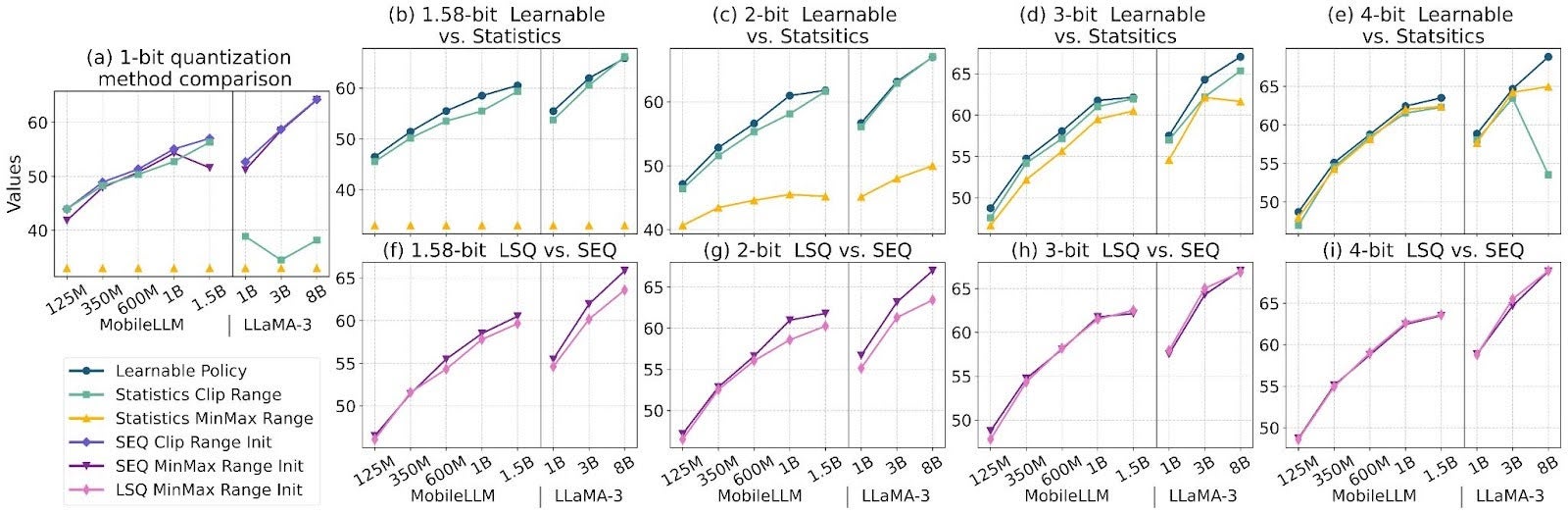
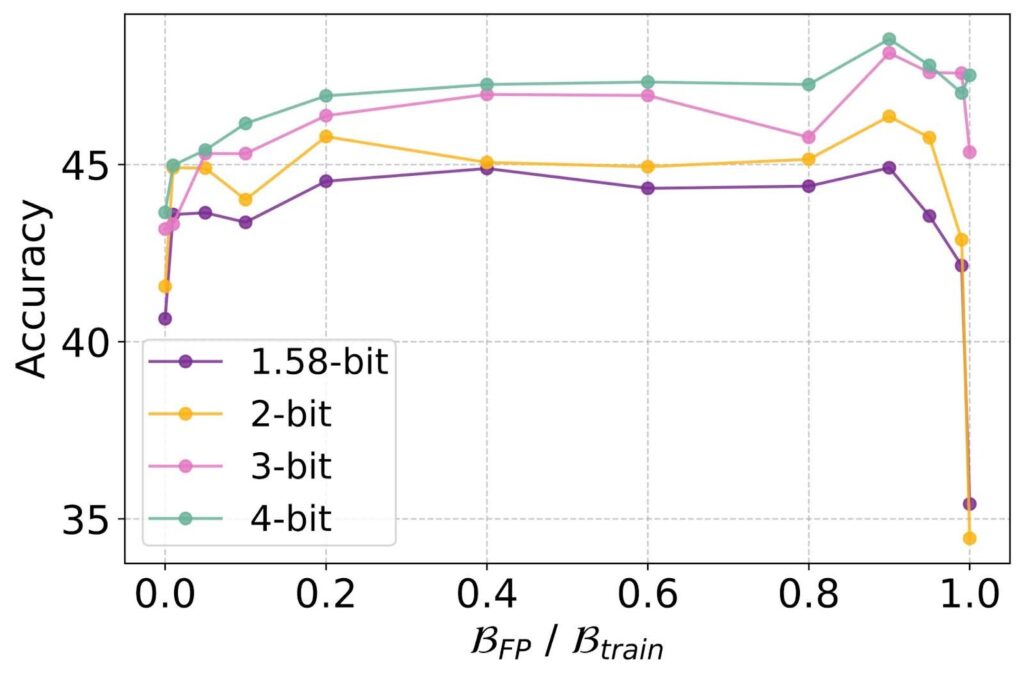
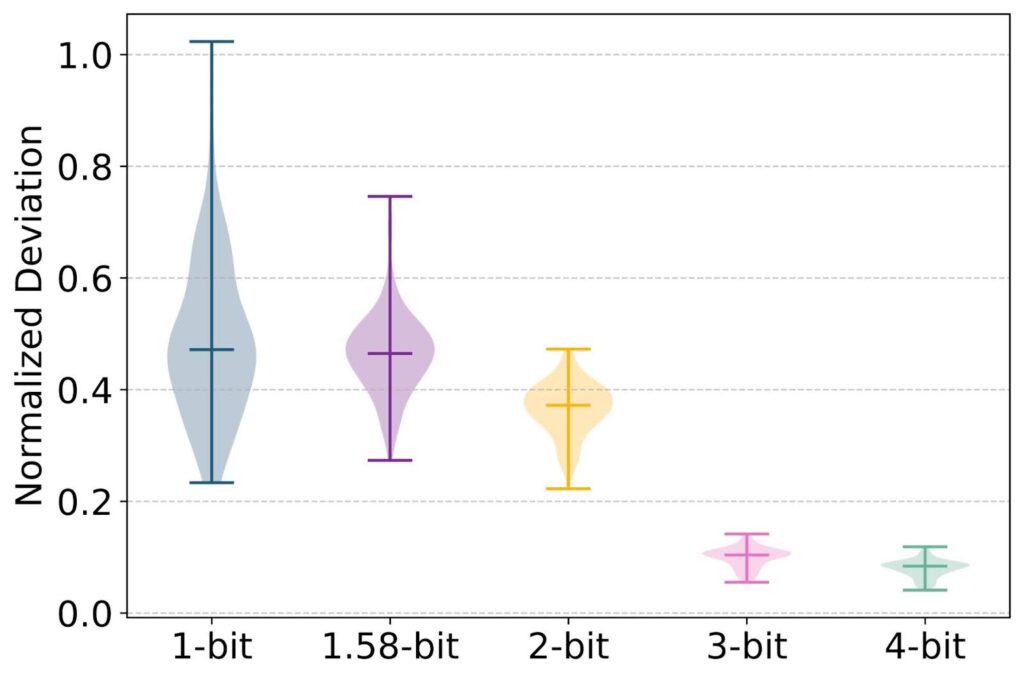
ParetoQ: Scaling Laws in Extremely Low-bit LLM Quantization – PyTorch
Overview of LLM Quantization Techniques & Where to Learn Each of Them ...
How to benchmark and optimize LLM inference performance (for data ...
LLM Quantization Techniques Explained - GPTQ, AWQ, GGUF, BitNet - YouTube
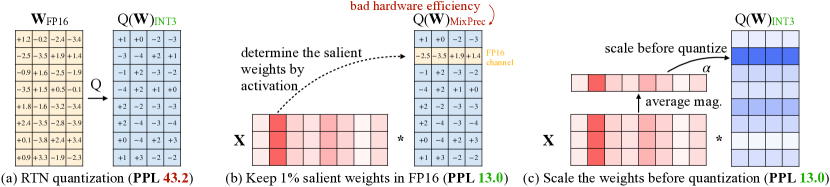
[2306.00978] AWQ: Activation-aware Weight Quantization for LLM ...
The Newbie’s Handbook on LLM Quantization and Model Compression | by ...
Performance Evaluation of A Quantized LLM On Smartphones | PDF ...
How to compute LLM embeddings 3X faster with model quantization | by ...
Paper page - SpinQuant: LLM quantization with learned rotations
LLM By Examples — Use GGUF Quantization | by MB20261 | Medium
LLM By Examples — Maximizing Inference Performance with Bitsandbytes ...
[PDF] SpinQuant: LLM quantization with learned rotations | Semantic Scholar
Fine-Tuning gpt-oss for Accuracy and Performance with Quantization ...
[vLLM — Quantization] AWQ: Activation-aware Weight Quantization for LLM ...
Paper page - AWQ: Activation-aware Weight Quantization for LLM ...
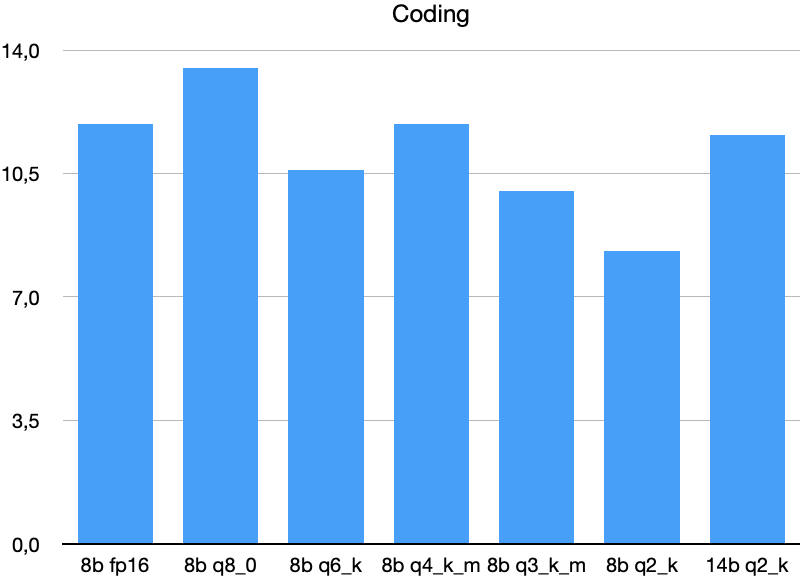
Demystifying LLM Quantization Suffixes: What Q4_K_M, Q8_0, and Q6_K ...
Paper page - MixLLM: LLM Quantization with Global Mixed-precision ...
Understanding Quantization for LLMs | by LM Po | Medium
What is Quantization in LLM? A Complete Guide to Optimizing AI
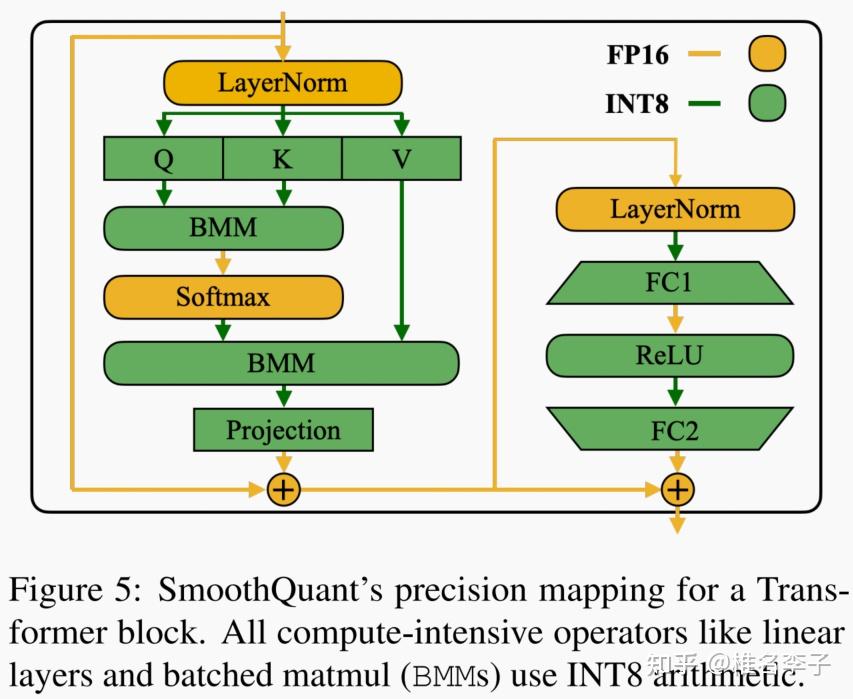
SmoothQuant: Accurate and Efficient Post-Training Quantization for ...
SliM-LLM: Salience-Driven Mixed-Precision Quantization for Large ...
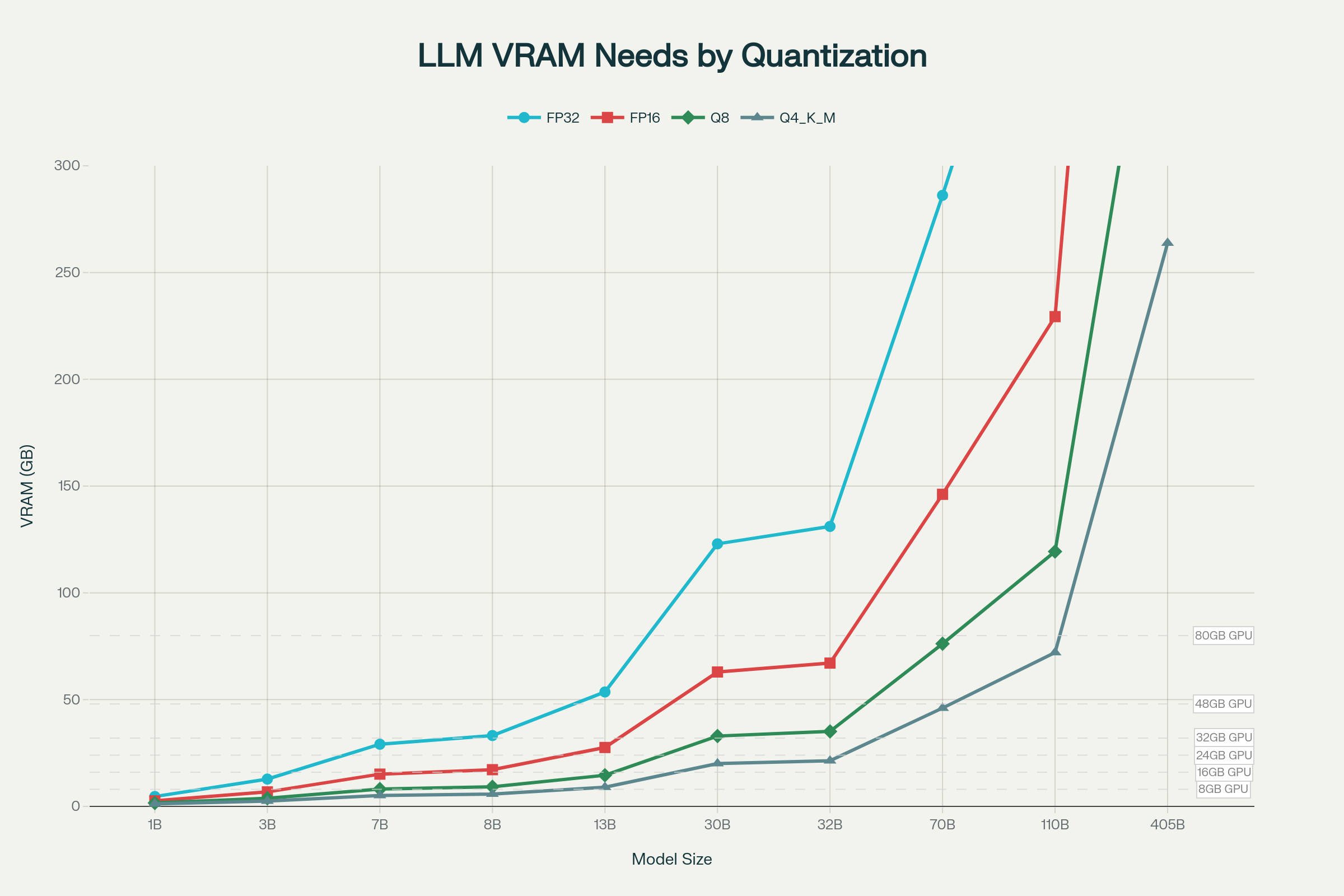
The Best GPUs for Local LLM Inference in 2025 | LocalLLM.in
LLM Compression Techniques to Build Faster and Cheaper LLMs
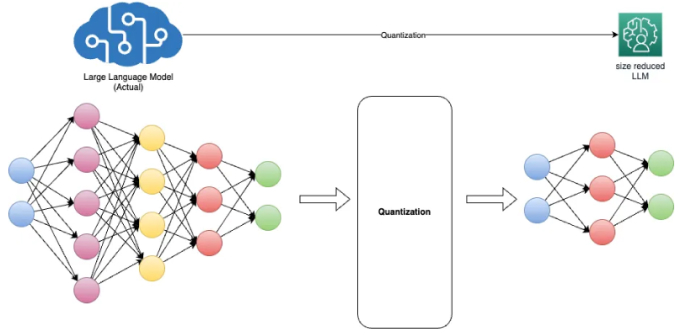
LLM Quantization-Build and Optimize AI Models Efficiently
Quantized 8-bit LLM training and inference using bitsandbytes on AMD ...
[论文评述] VQ-LLM: High-performance Code Generation for Vector Quantization ...
LLM Quantization: Making models faster and smaller | MatterAI Blog
LLM's Weight Quantization Explained - YouTube
Compressing LLMs with AWQ: Activation-Aware Quantization Explained | by ...
Quantization of Large Language Models (LLMs) - A Deep Dive
What is LLM quantization? - YouTube
Mastering LLM Techniques: Inference Optimization – GIXtools
LLM Tutorial 21 — Model Compression Techniques: Quantization, Pruning ...
[LLM] SmoothQuant: Accurate and Efficient Post-Training Quantization ...
Free Video: LLM Quantization: Why Size Matters from The Machine ...
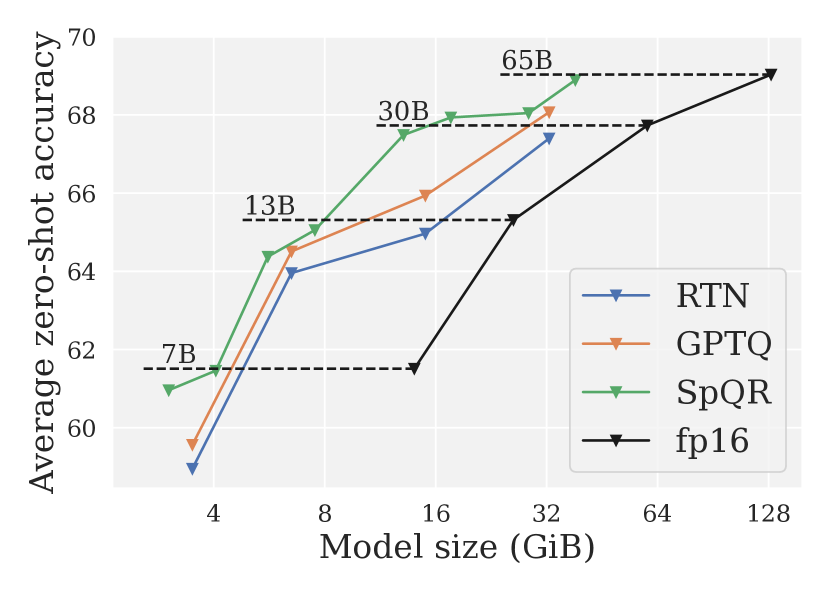
[R] SpQR: A Sparse-Quantized Representation for Near-Lossless LLM ...
LLM Compressor 0.9.0: Attention quantization, MXFP4 support, and more ...
LLM Quantization: Quantize Model with GPTQ, AWQ, and Bitsandbytes ...
Faster and More Efficient 4-bit quantized LLM Model Inference | by ...
Toward Efficient LLM Inference: A Quantitative Evaluation of ...
Practical Guide of LLM Quantization: GPTQ, AWQ, BitsandBytes, and ...
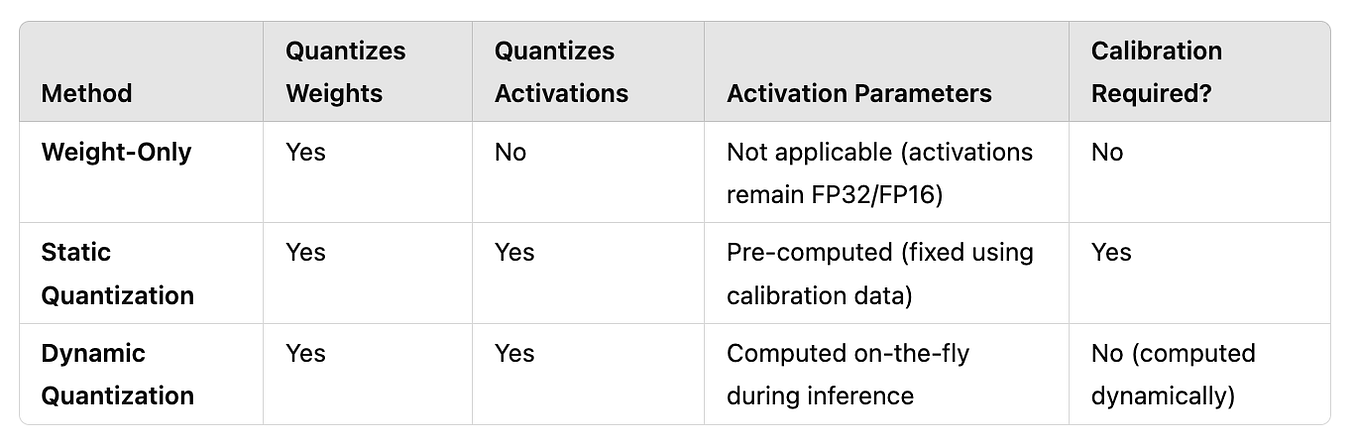
Quantization for Local LLMs: How It Works and Which Formats Fit Your Setup
Maximize LLM Performance: GGUF Optimizations and Best Practices for ...
Understanding LLM Quantization. With the surge in applications using ...
A Comparison of 5 Quantization Methods for LLMs: GPTQ, AWQ ...
Optimizing LLMs for Performance and Accuracy with Post-Training ...
Intel Releases a Low-bit Quantized Open LLM Leaderboard for Evaluating ...
Quantization, Distillation & Pruning of LLM
What is LLM quantization? Simply explained. - Blog by Simon Frey
Demystifying LLM Quantization: GPTQ, AWQ, and GGUF Explained
MSU AI Club
How to run LLMs on CPU-based systems | UnfoldAI
[2306.03078] SpQR: A Sparse-Quantized Representation for Near-Lossless ...
模型量化-llm量化 - 知乎
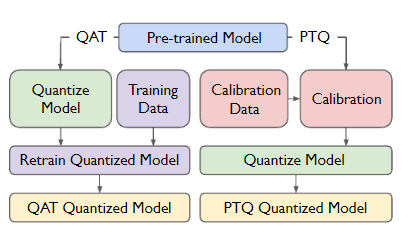
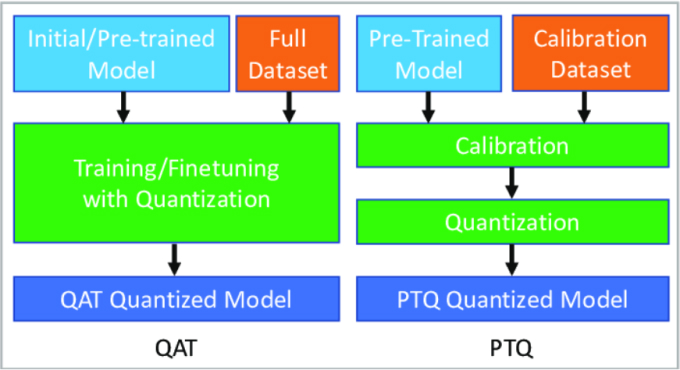
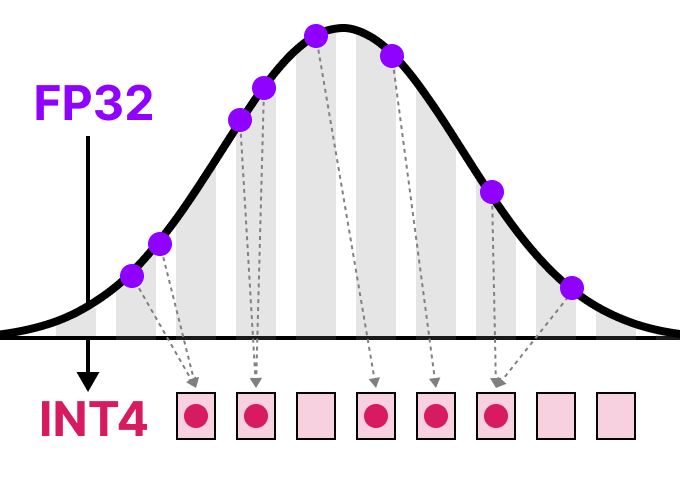
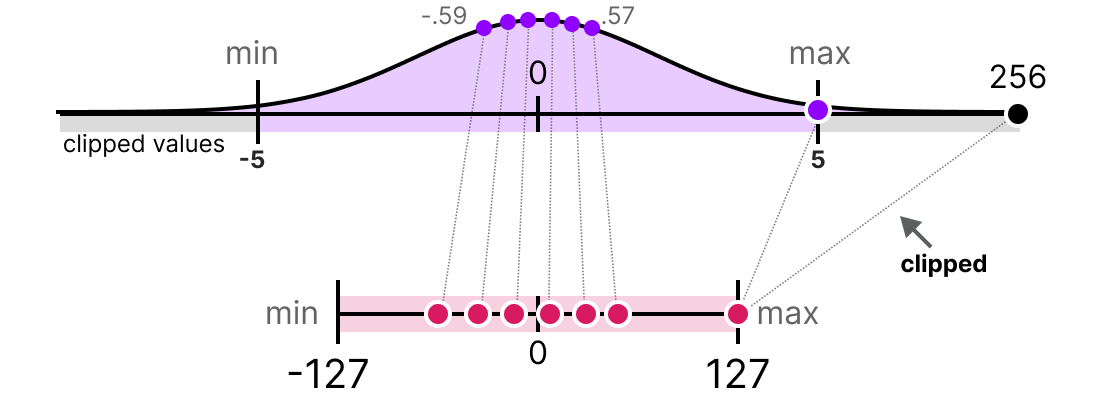
LLMs之Quantization:LLM中量化技术的可视化指南之量化技术的简介、常用数据类型、校准权重和激活值的量化方法(PTQ/QAT ...
What are Quantized LLMs?
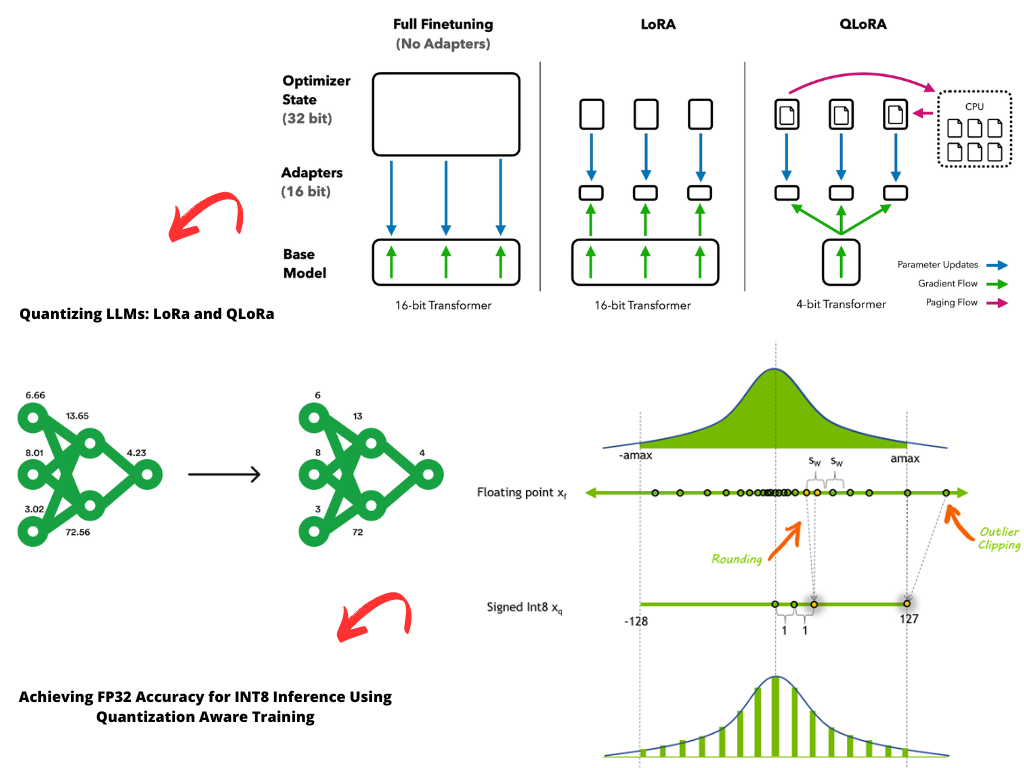
Introduction to llm-finetuning and Quantization. Refining Generative ...
Maximizing Business Potential with Large Language Models (LLMs)
一文搞懂LLM量化之GPTQ算法! - 知乎
LLMs量化系列|LLM量化方法小结 - 知乎