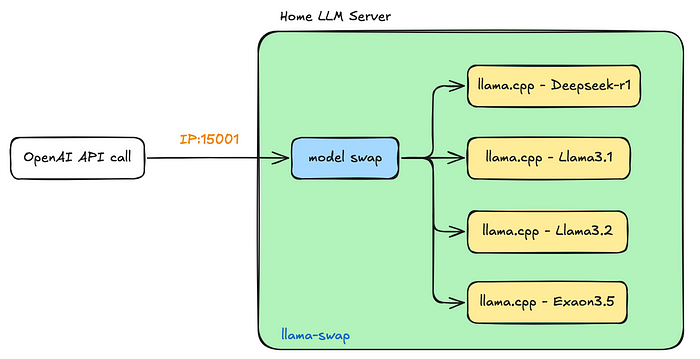
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
LLM Pre-Training and Inference - Kyle’s Tech Blog
LLM in a flash: Efficient LLM Inference with Limited Memory | by Anuj ...
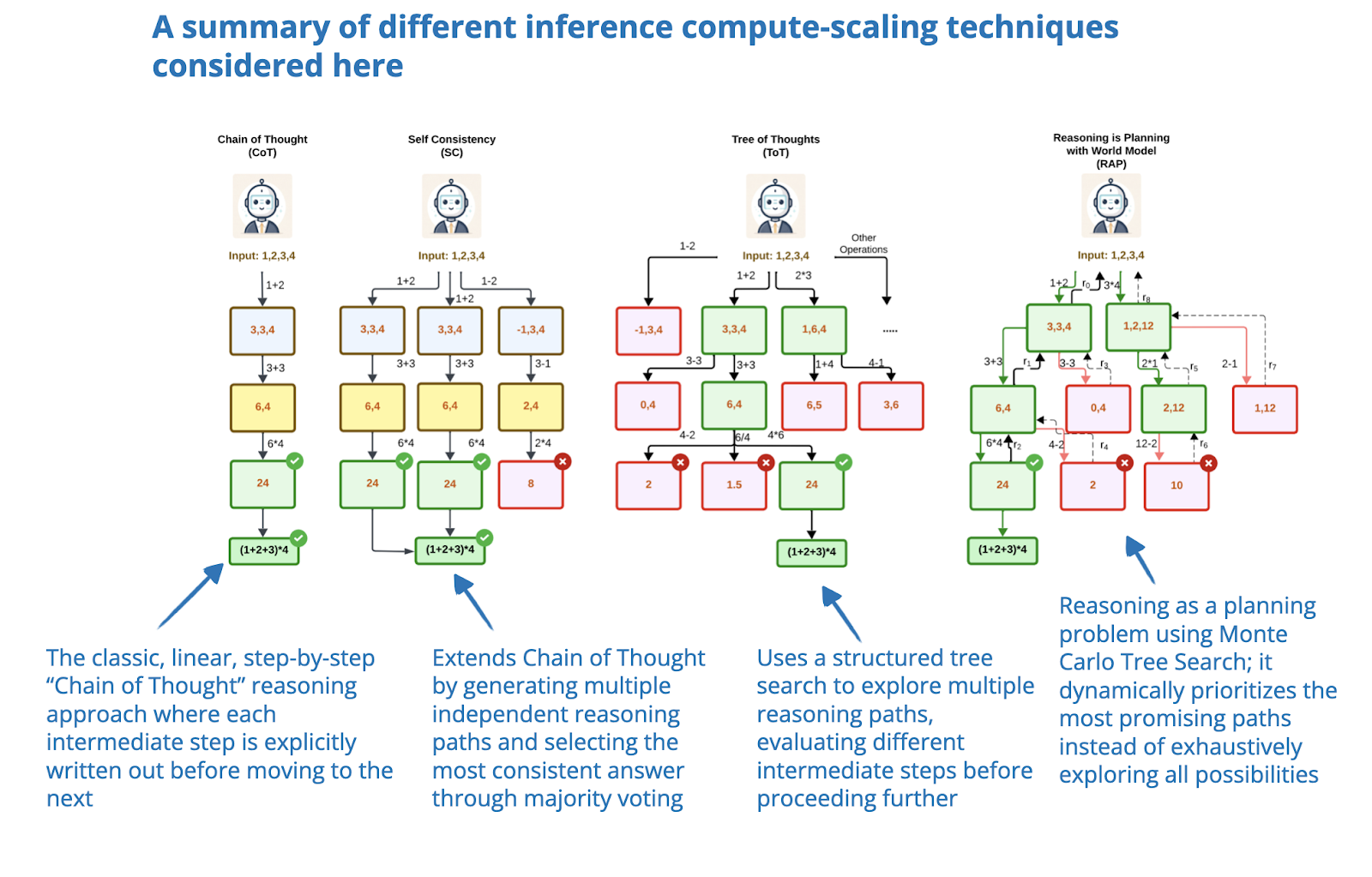
The State of LLM Reasoning Model Inference
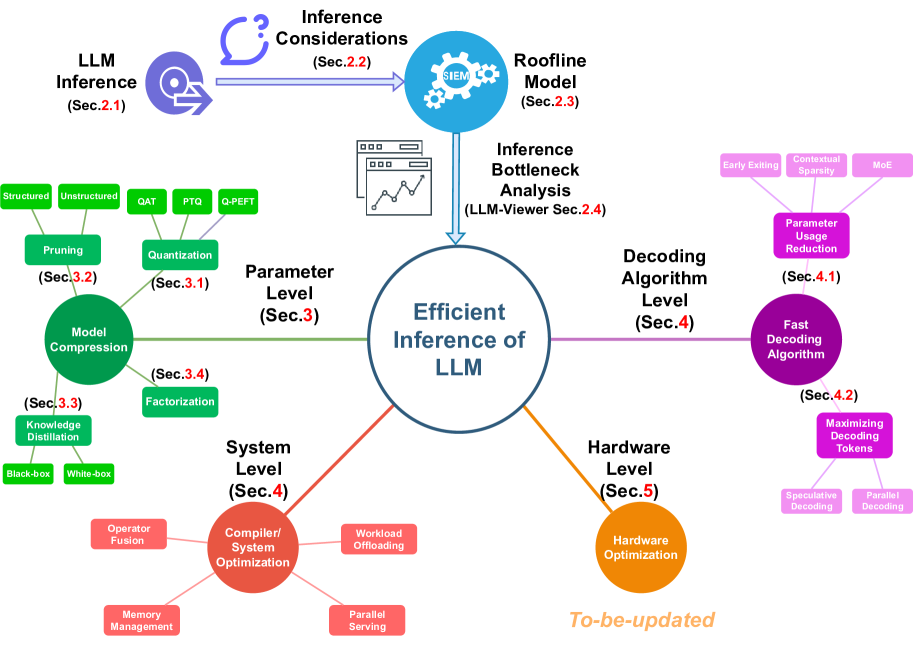
[2402.16363] LLM Inference Unveiled: Survey and Roofline Model Insights
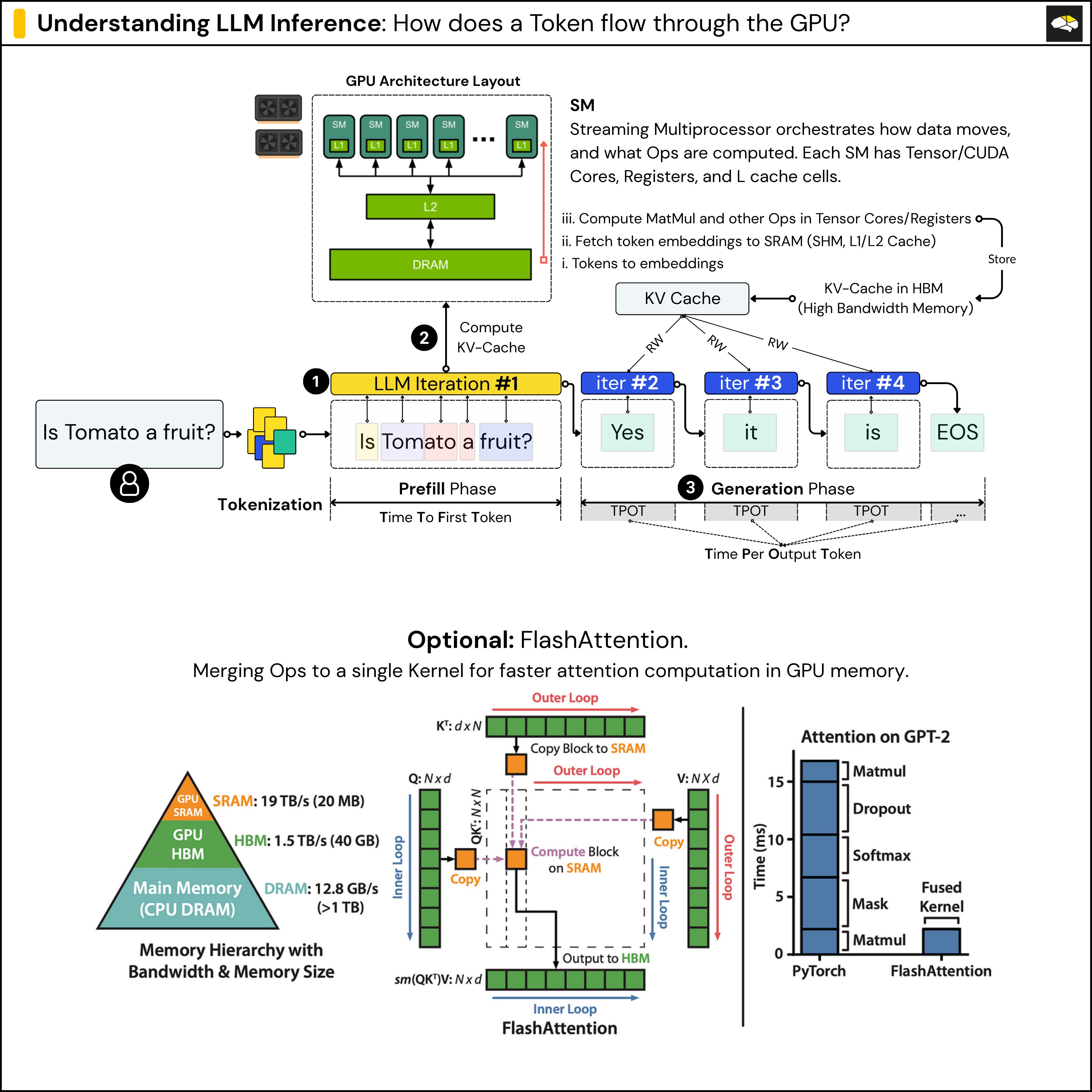
Understanding LLM Inference - by Alex Razvant
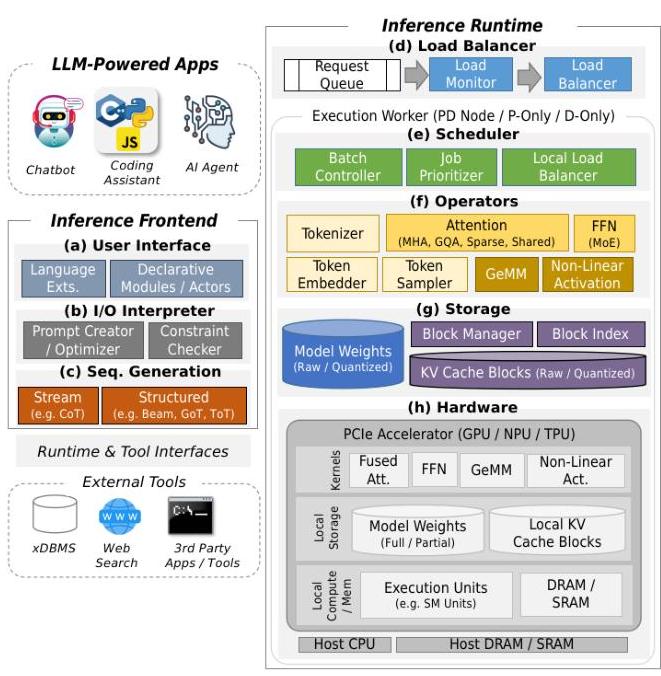
A Survey of LLM Inference Systems | alphaXiv
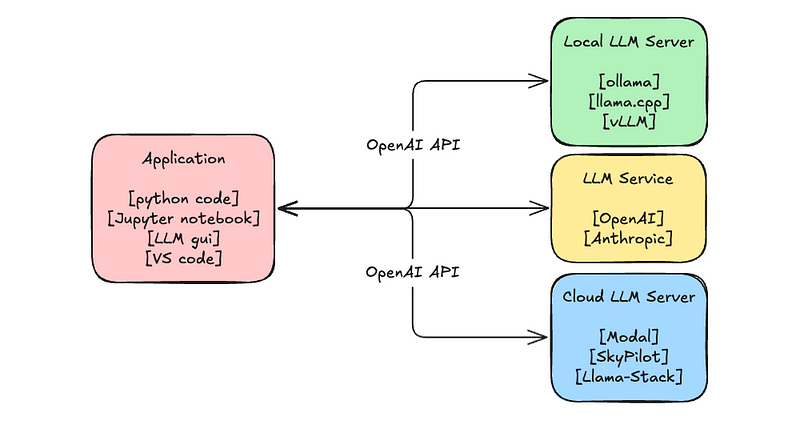
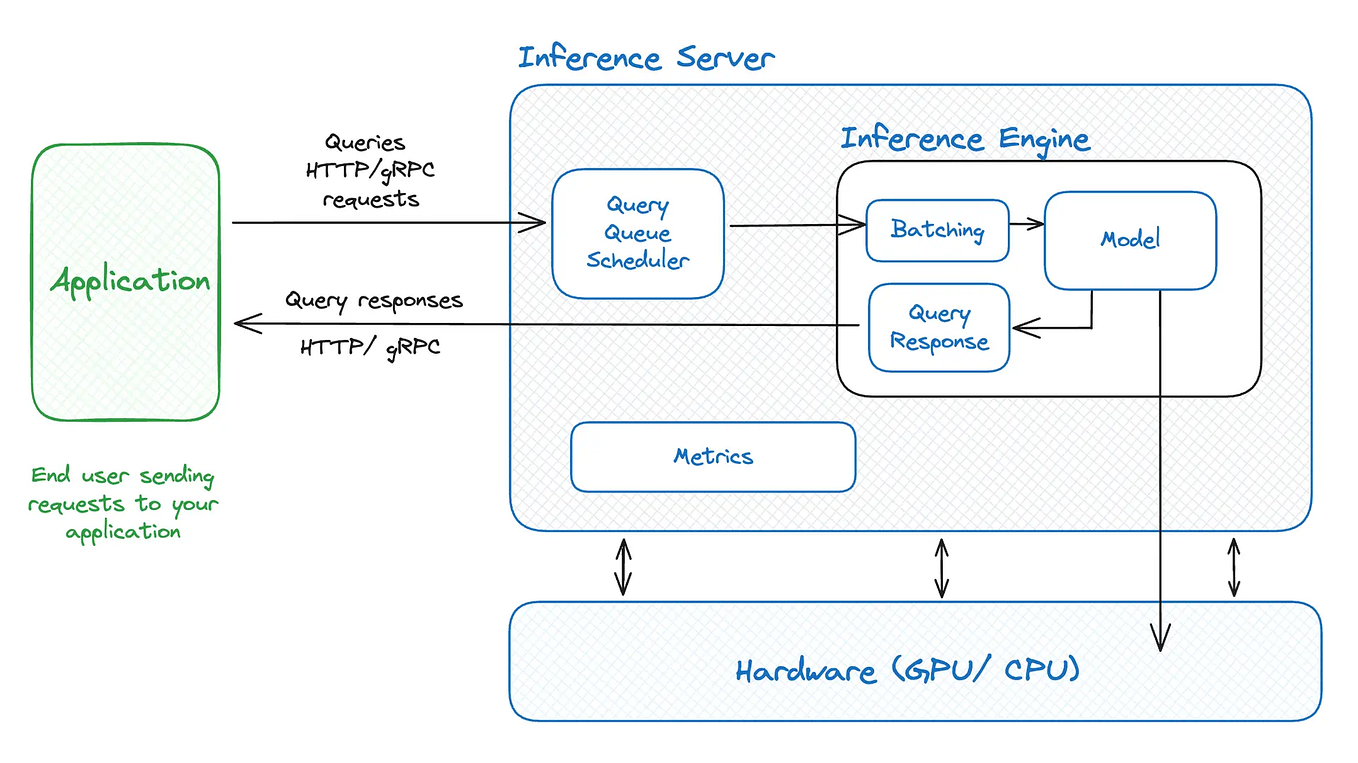
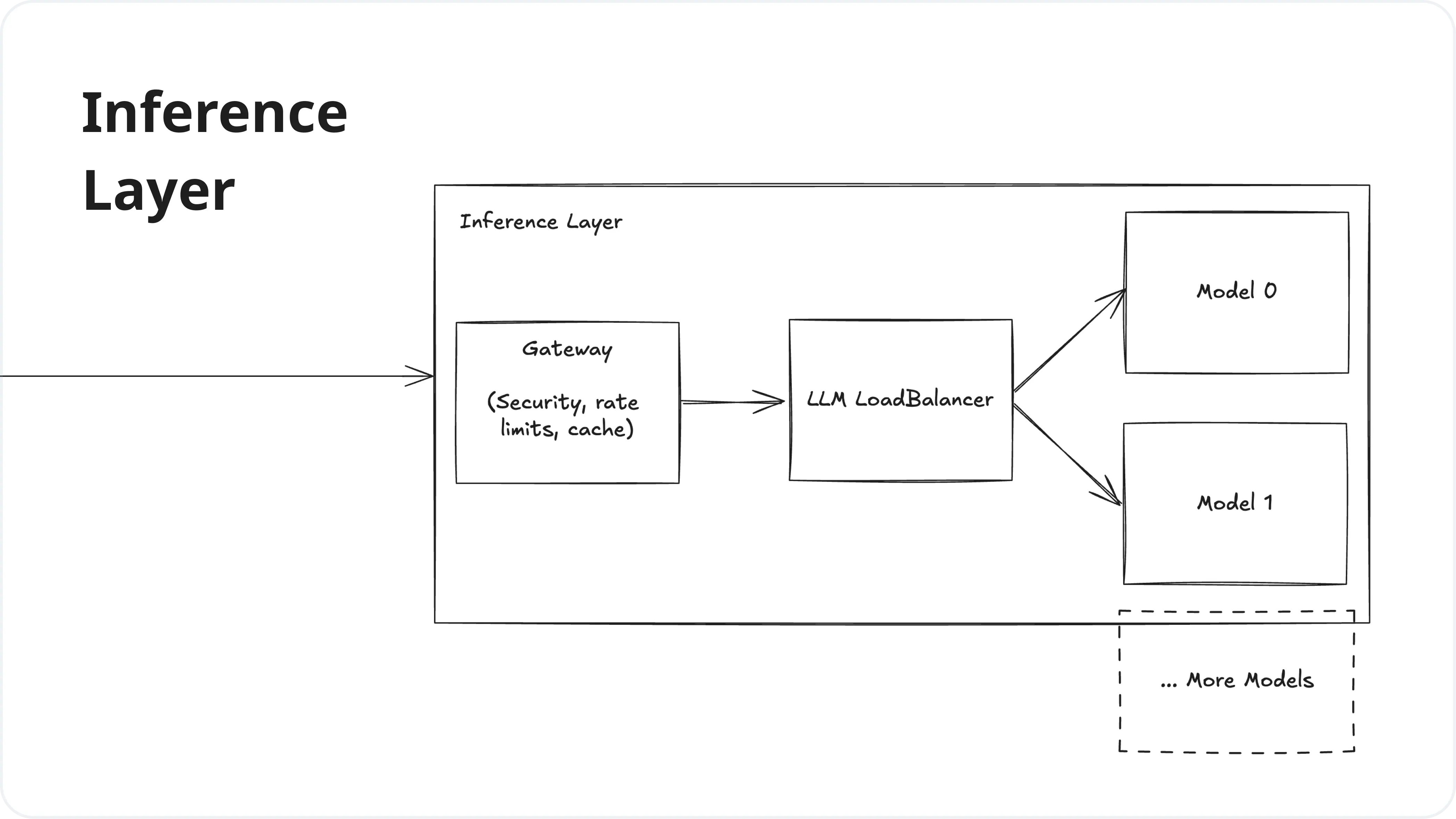
Popular LLM Inference Stacks and Setups
LLM Inference Hardware: Emerging from Nvidia's Shadow
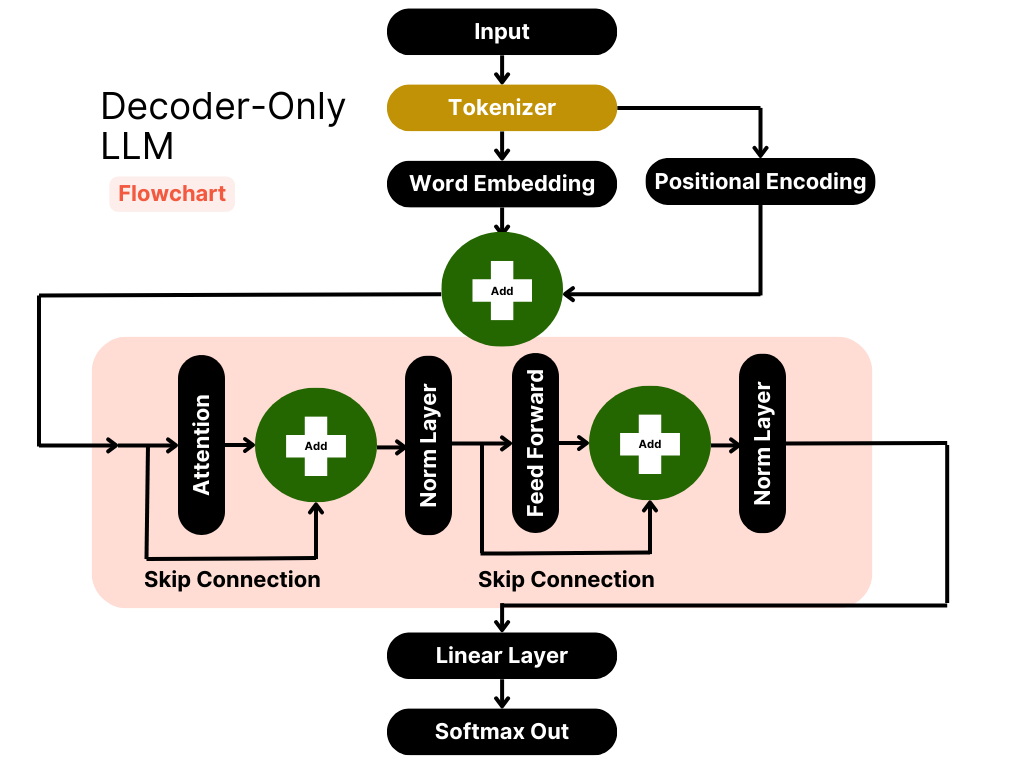
LLM Inference — A Detailed Breakdown of Transformer Architecture and ...
LLM Inference Stages Diagram | Stable Diffusion Online
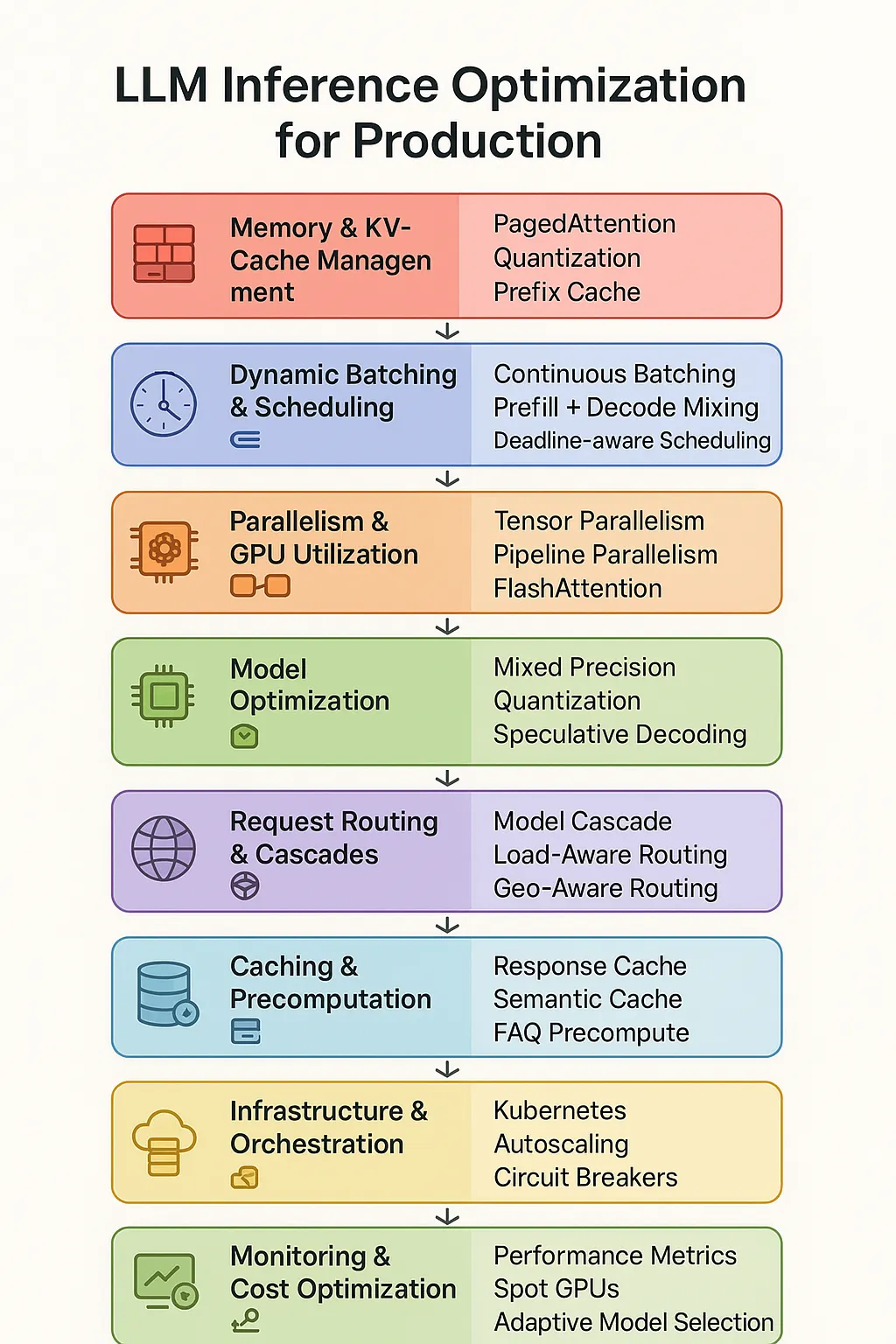
LLM Inference Optimization Overview - From Data to System Architecture
LLM Inference Essentials
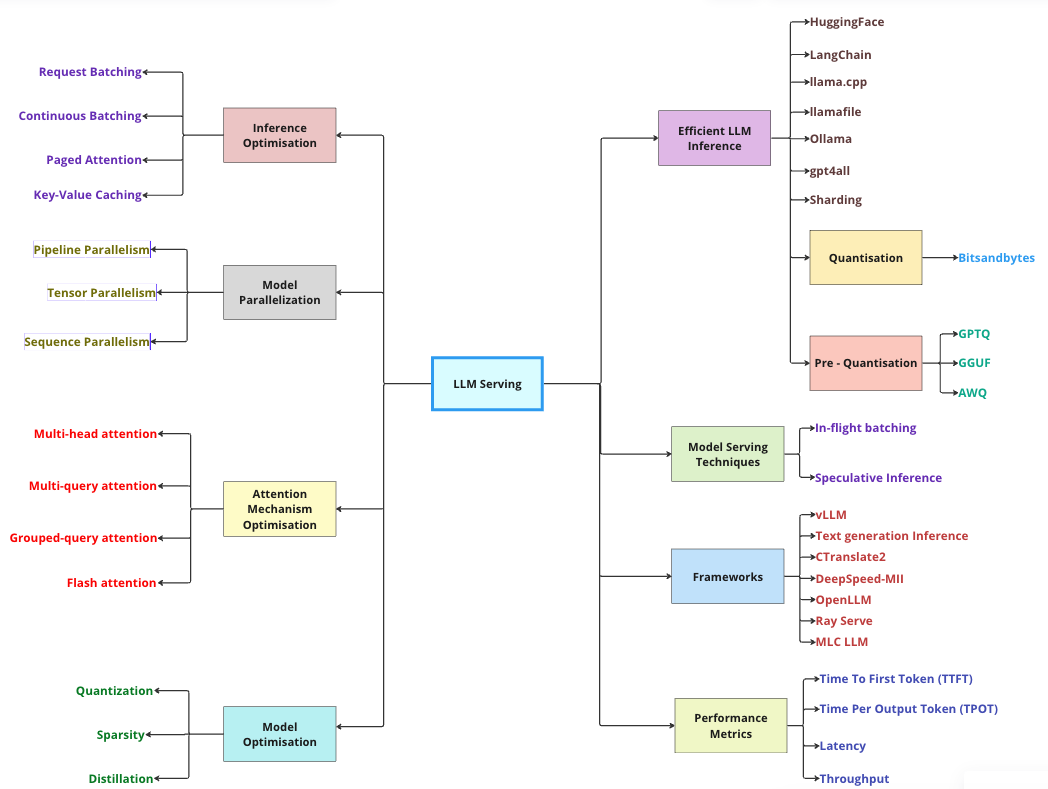
LLM Inference Optimization Techniques: A Comprehensive Analysis | by ...
On-device LLM inference | Technology Radar | Thoughtworks India
LLM Inference Hardware: An Enterprise Guide to Key Players | IntuitionLabs
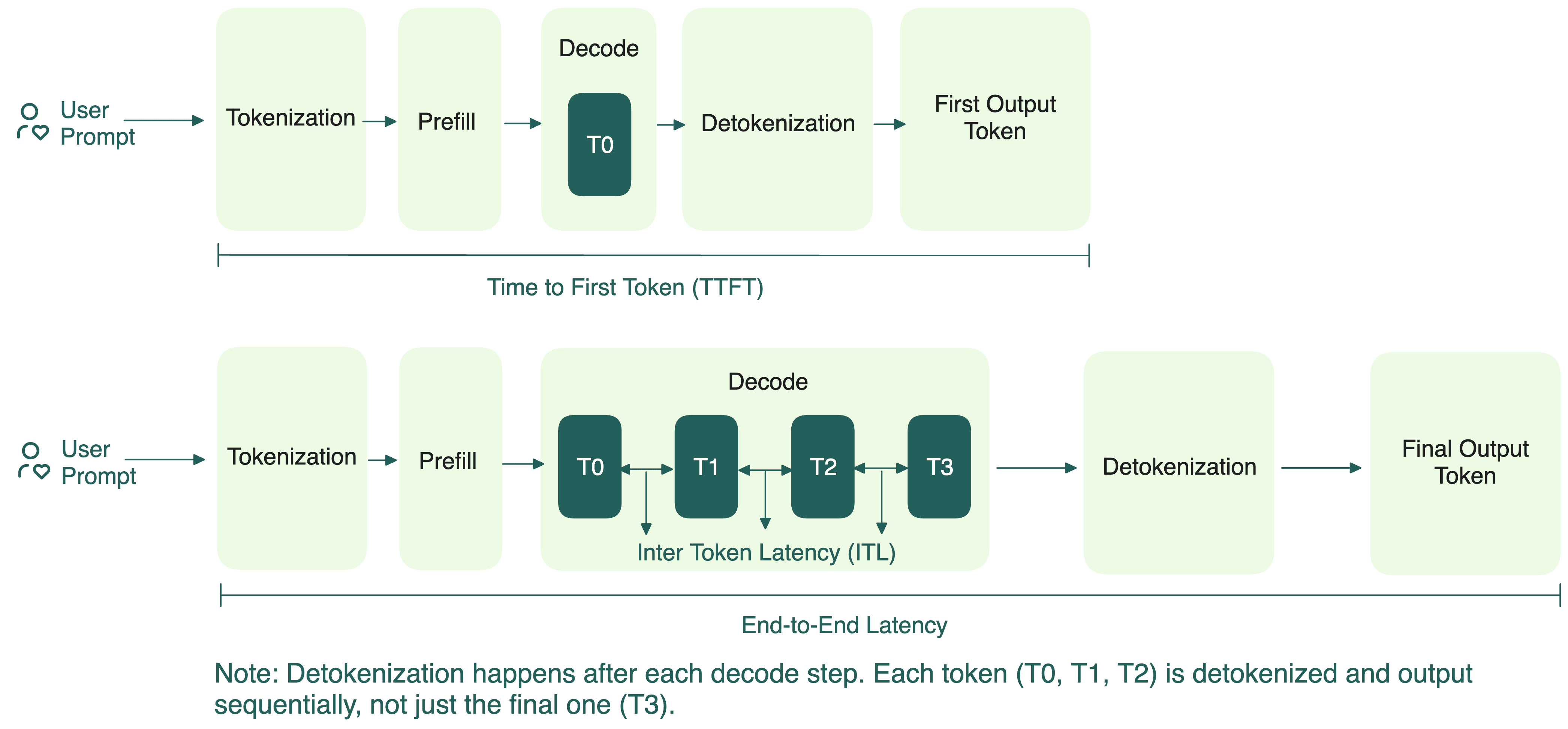
Measuring LLM Inference Efficiency: Four Core Metrics Explained
LLM Inference Series: 2. The two-phase process behind LLMs’ responses ...
LLM Inference Benchmarking: Performance Tuning with TensorRT-LLM ...
LLM Inference Optimization Techniques: Speed & Cost Guide 2026 | Hakia
An AI Engineer's complete LLM Inference Frameworks landscape 👇 First ...
InferenceOps and Management - LLM Inference Handbook | PDF ...
Vidur: A Large-Scale Simulation Framework for LLM Inference Performance ...
LLM Multi-GPU Batch Inference With Accelerate | by Victor May | Medium
AI/ML Infra Meetup | A Faster and More Cost Efficient LLM Inference ...
LLM Inference v_s Fine-Tuning | PDF | Cognitive Science | Computational ...
Overview of an Example LLM Inference Setup - YouTube
Demystifying the LLM Tech Stack (Part III: The Application Layer ...
llama.cpp: The Ultimate Guide to Efficient LLM Inference and ...
The Inference Router: A Critical Component in the LLM Ecosystem
Modern LLM inference isn’t just about spinning up containers, it’s ...
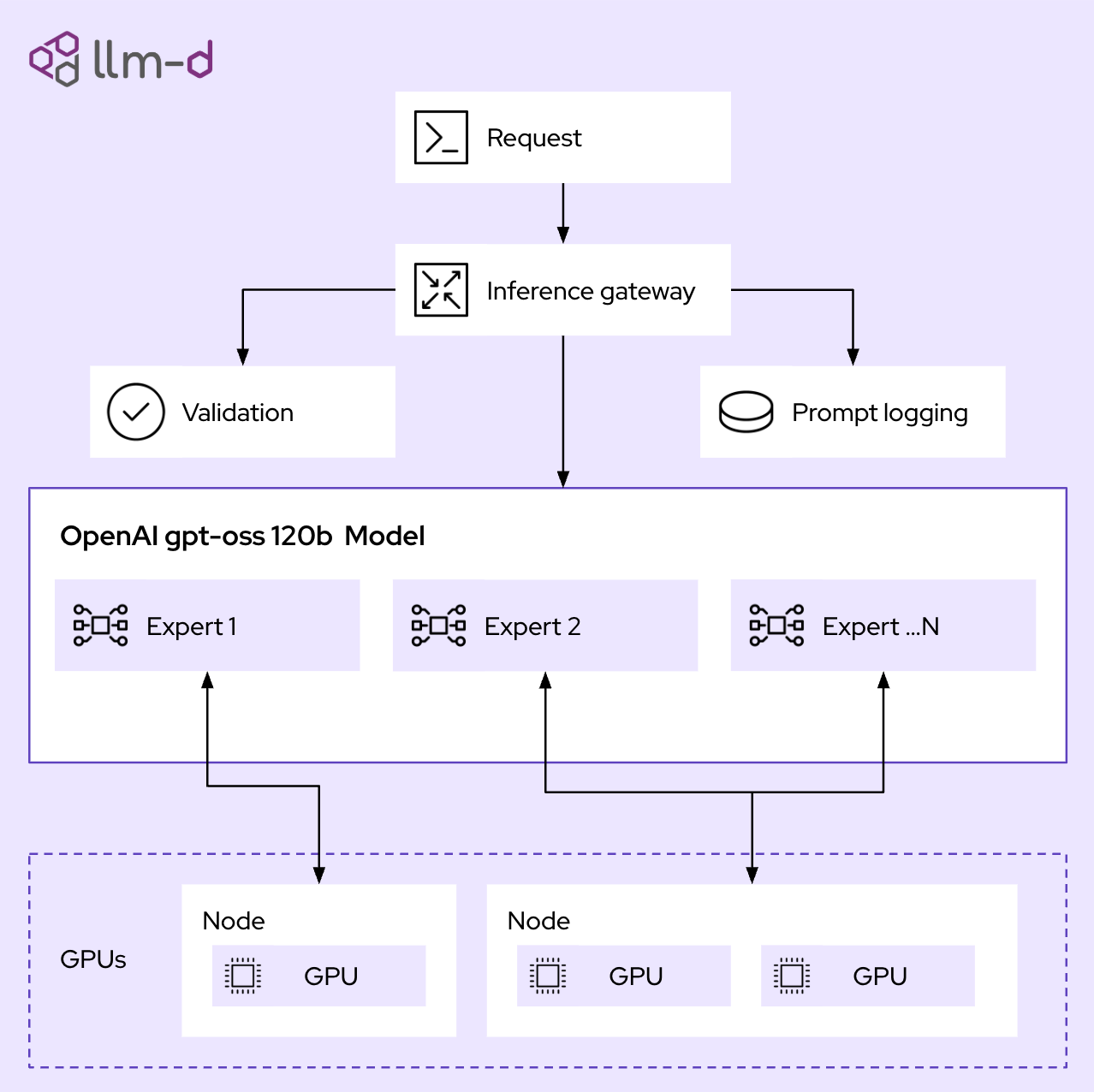
Scaling LLM Inference with llm-d and NeuReality Inference Serving Stack ...
LLM Inference Benchmarking: Fundamental Concepts | NVIDIA Technical Blog
Mastering LLM Techniques: Inference Optimization | NVIDIA Technical ...
Learn LLM Inference Optimization with #TowardsAI | Towards AI, Inc ...
LLM Inference on-premise infrastructure to Host AI Models | Upwork
Understanding LLM Inference | NVIDIA Experts Deconstruct How AI Works ...
Understanding the LLM Inference Workload: Key Insights
How to benchmark and optimize LLM inference performance (for data ...
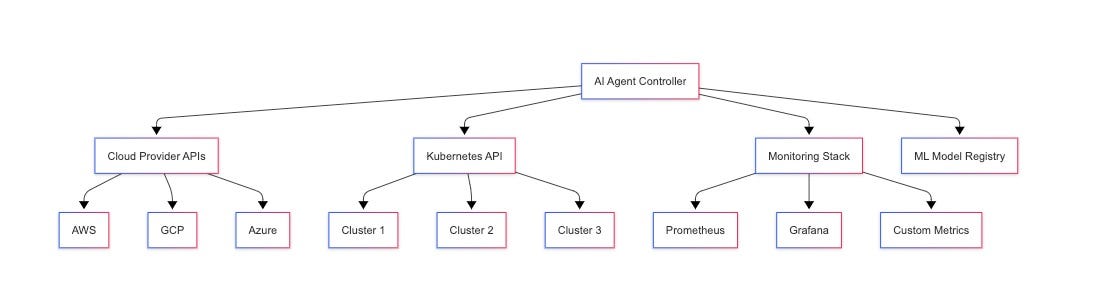
Kubernetes-Based LLM Inference Architectures: An Overview | Yuchen ...
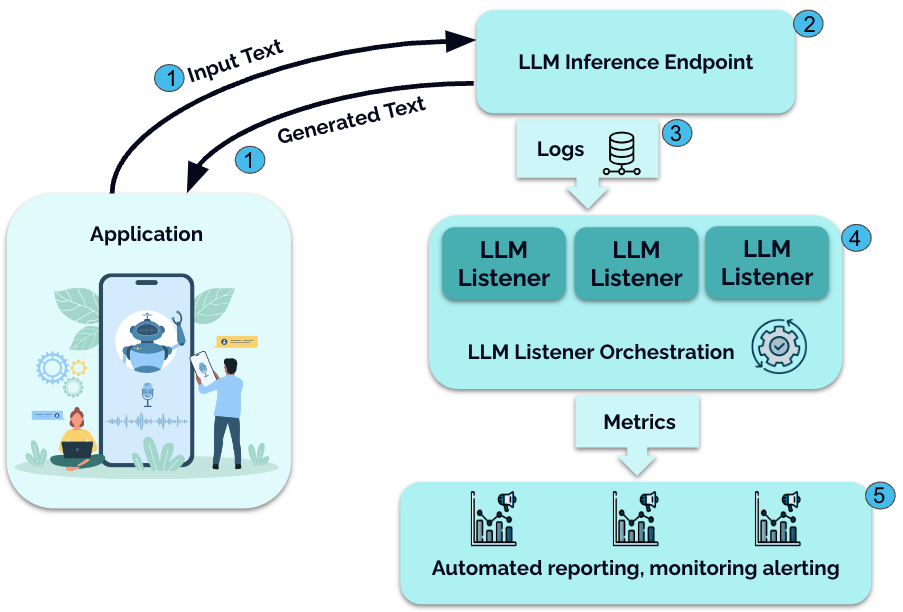
Monitoring LLM Inference Endpoints with LLM Listeners | Microsoft ...
Llm Inference Deployment - Top AI tools
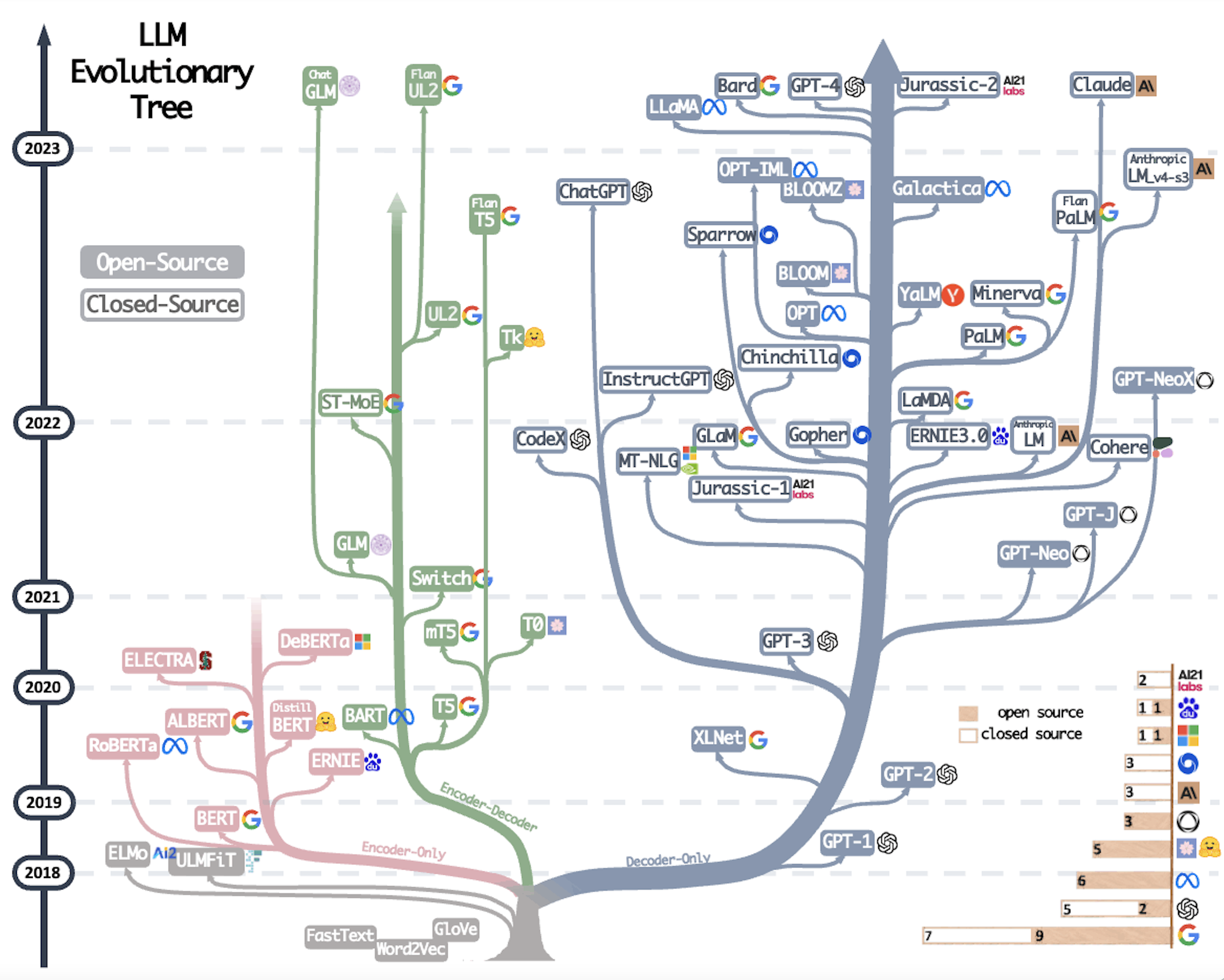
LLM Evolutionary Tree. LLM Proliferation. – blog.biocomm.ai
🔍 From Accessibility Trees to Semantic Web Intelligence: Optimizing LLM ...
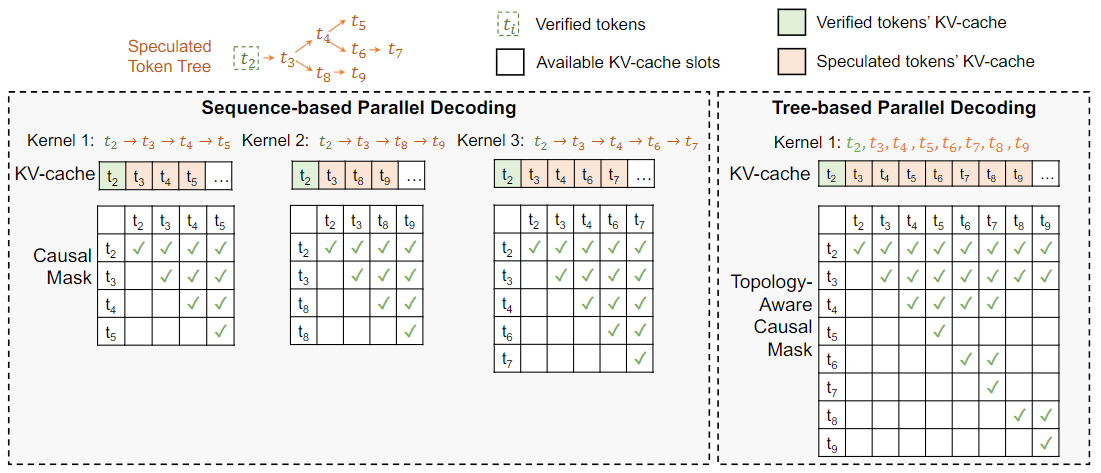
SpecInfer: Accelerating Generative LLM Serving with Speculative ...
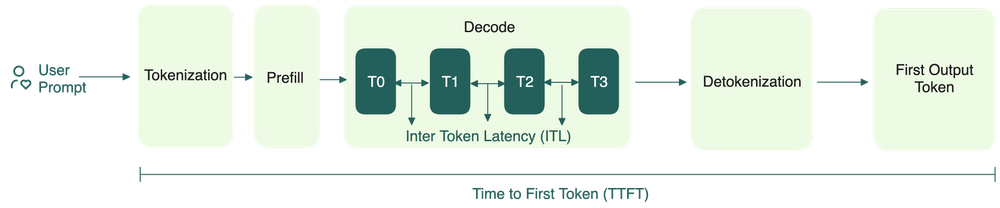
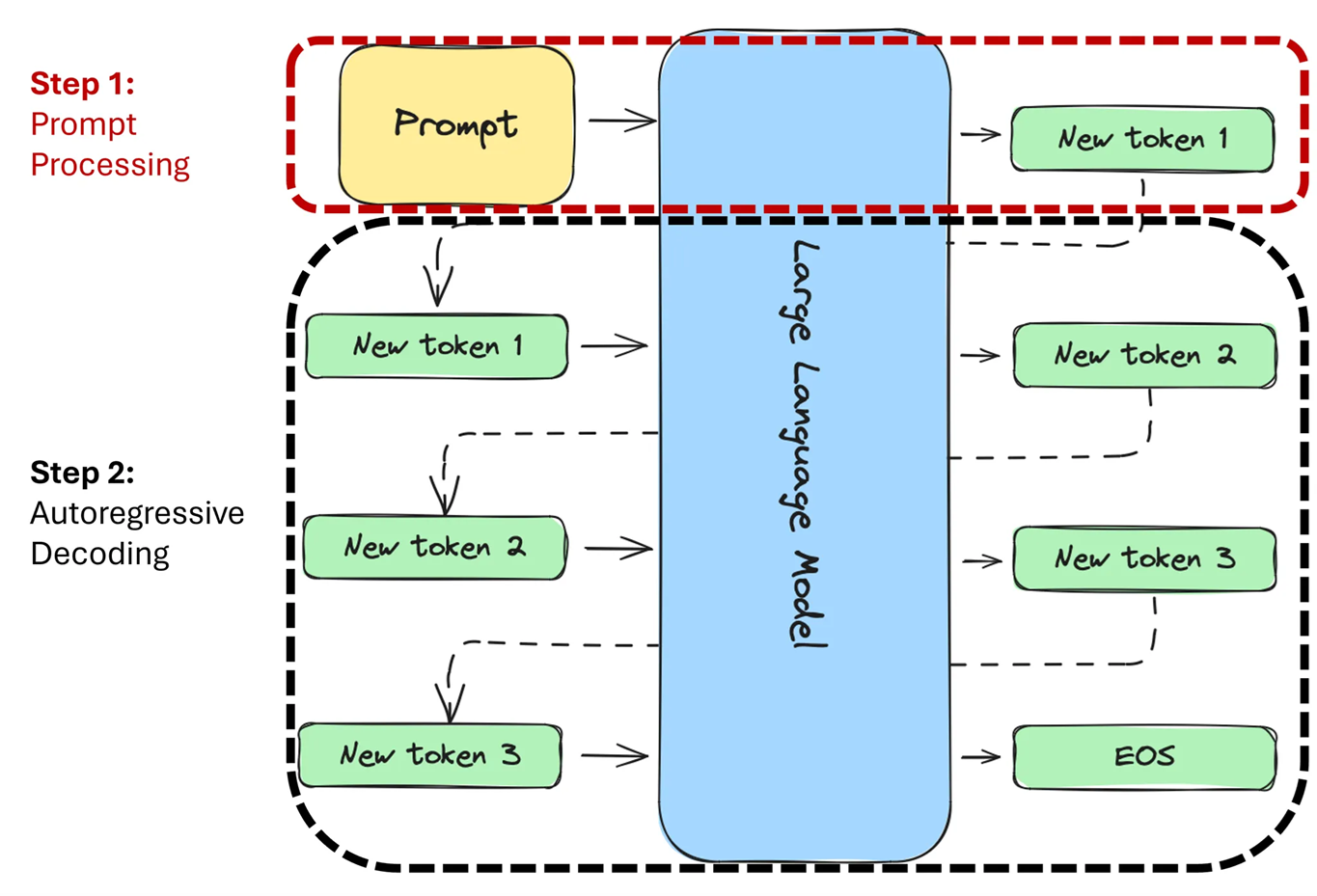
Understanding the Two Key Stages of LLM Inference: Prefill and Decode ...
[논문 리뷰] Wider or Deeper? Scaling LLM Inference-Time Compute with ...
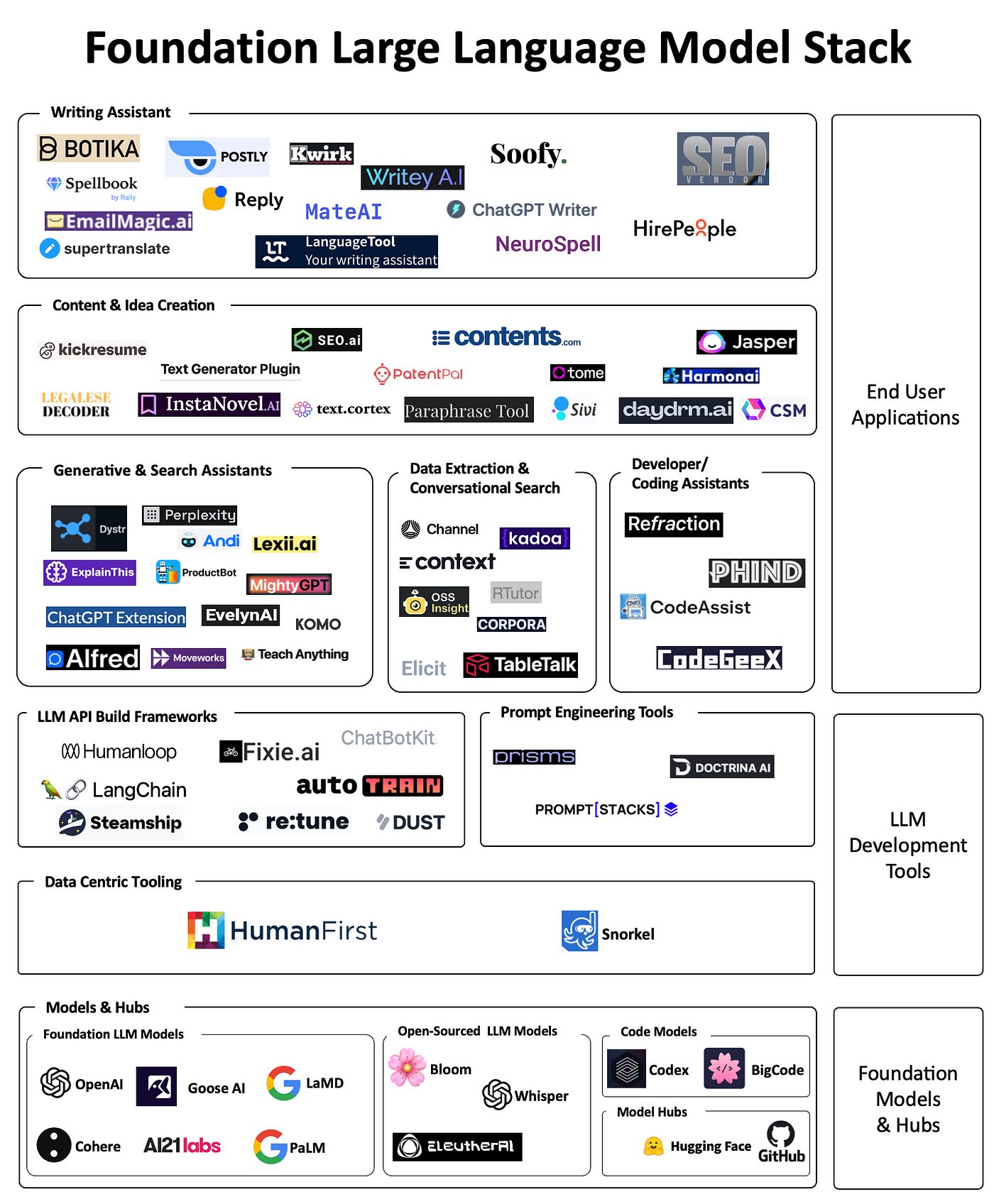
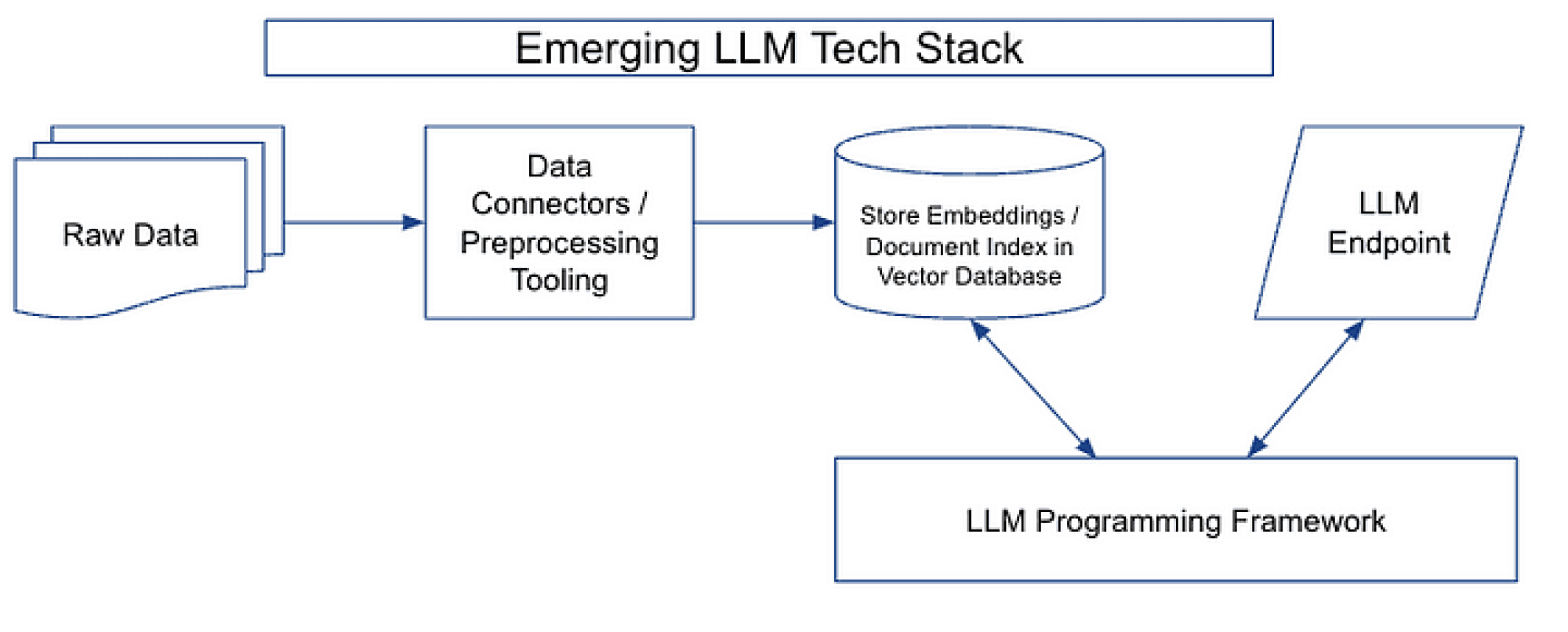
LLMs and the Emerging ML Tech Stack – Unstructured
The Emerging LLM Stack: A Comprehensive Guide for Developers - Helicone
Introduction to distributed inference with llm-d | Red Hat Developer
Optimizing AI Performance: A Guide to Efficient LLM Deployment
LLM Inference: Techniques for Optimized Deployment in 2025 | Label Your ...
4 LLM Prompt Patterns That Turned My AI From Basic Assistant to Expert ...
The Shift to Distributed LLM Inference: 3 Key Technologies Breaking ...
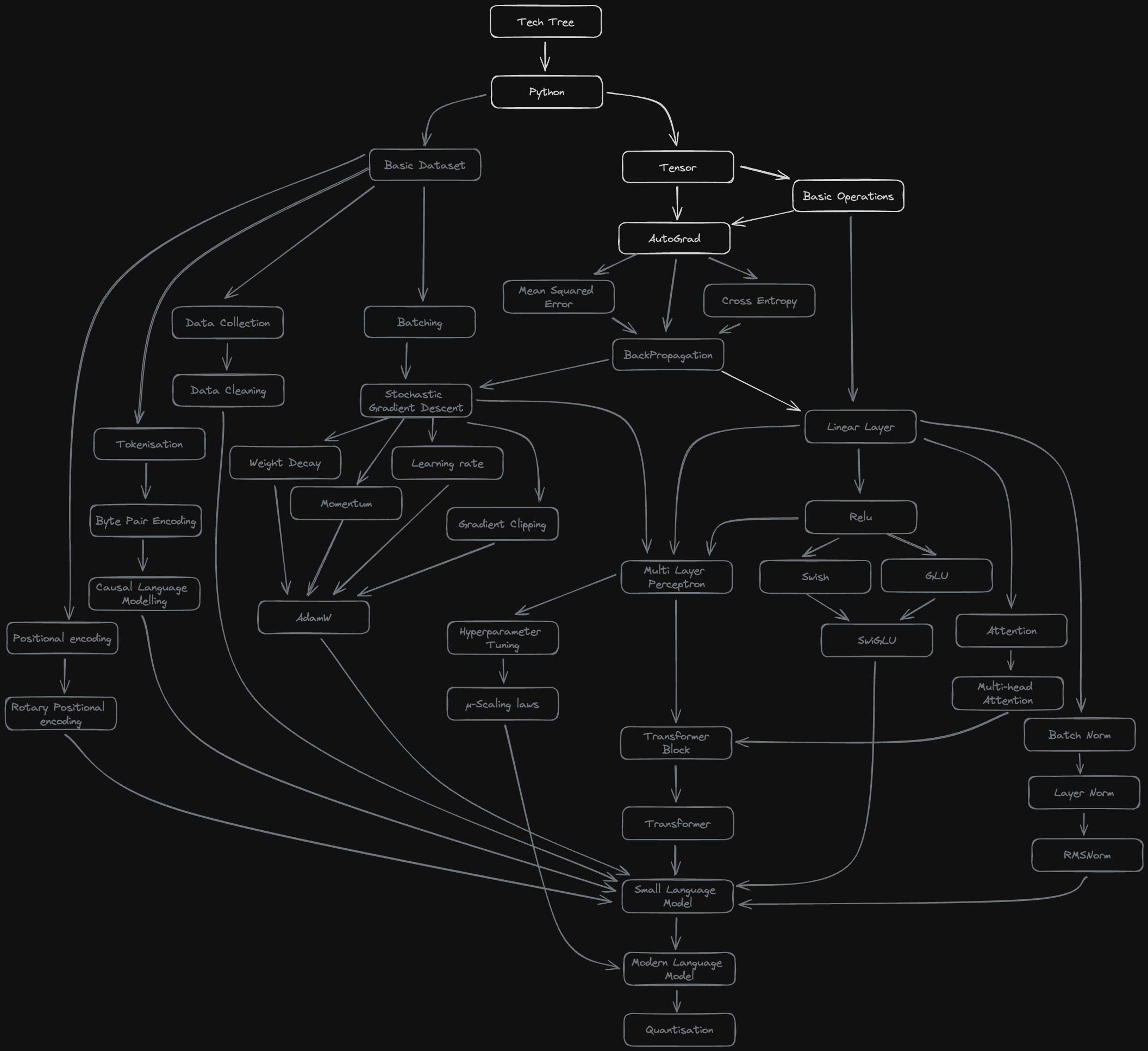
Gradient Descent into Madness - Building an LLM from scratch
High-Performance LLM Training at 1000 GPU Scale With Alpa & Ray
(PDF) SpecInfer: Accelerating Generative LLM Serving with Speculative ...
SpecInfer: Accelerating Generative LLM Serving with Tree-based ...
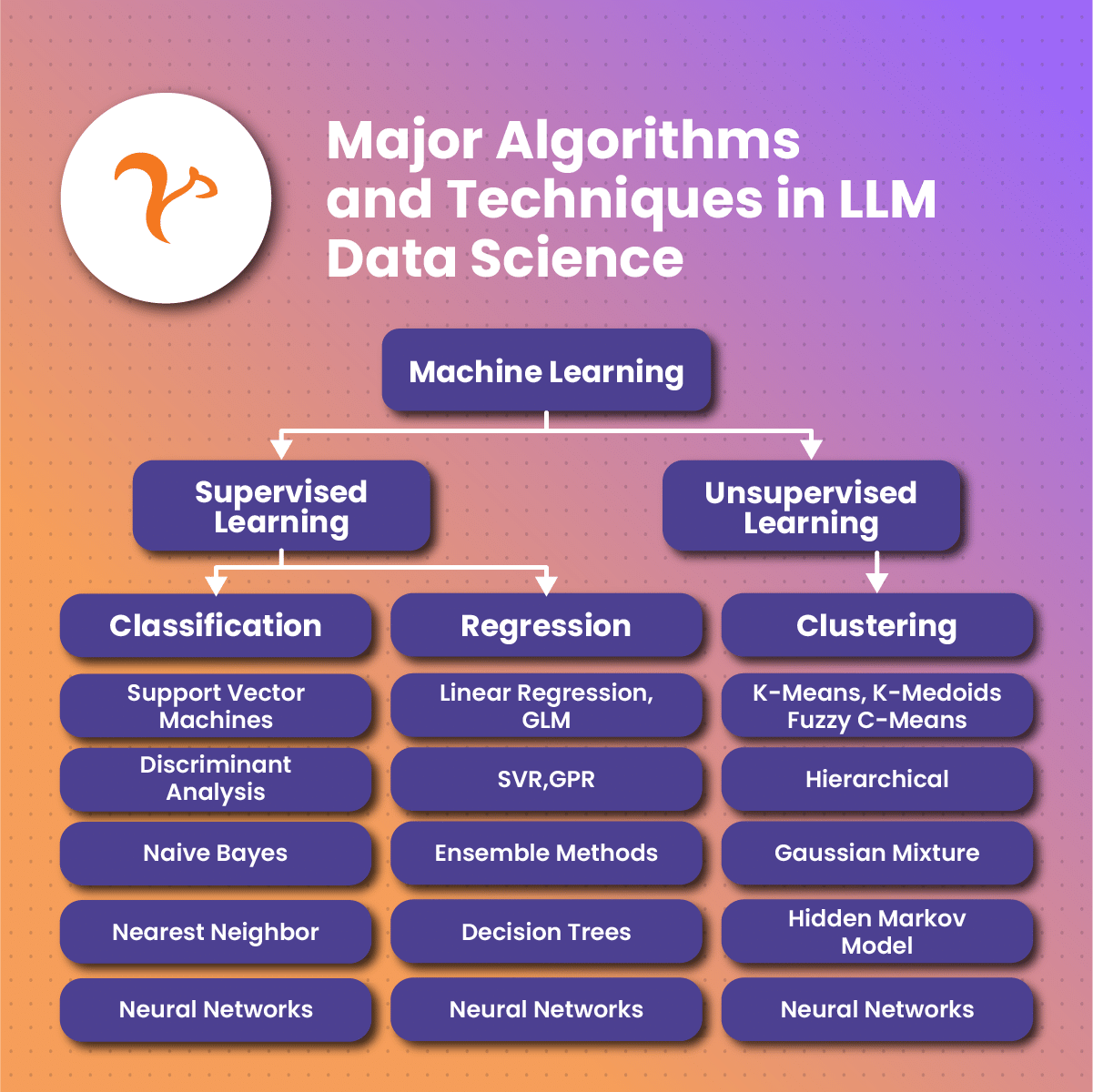
What is LLM Data Science? Basics and Functions | Netnut
Effective prompt engineering based on understanding of LLM algorith ...
Implementing Tree-of-Thoughts with LLM using Langchain | by Meenakshi ...
Wider or Deeper? Scaling LLM Inference-Time Compute with Adaptive ...
LLM-BRAIn: AI-driven Fast Generation of Robot Behaviour Tree based on ...
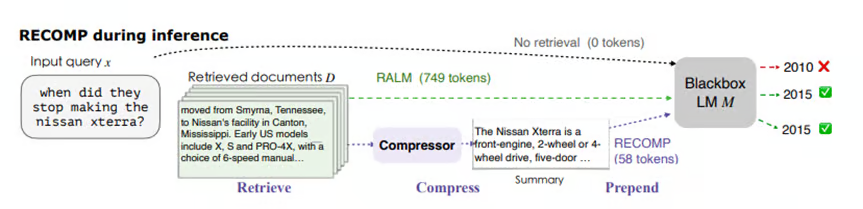
PyramidInfer: Allowing Efficient KV Cache Compression for Scalable LLM ...
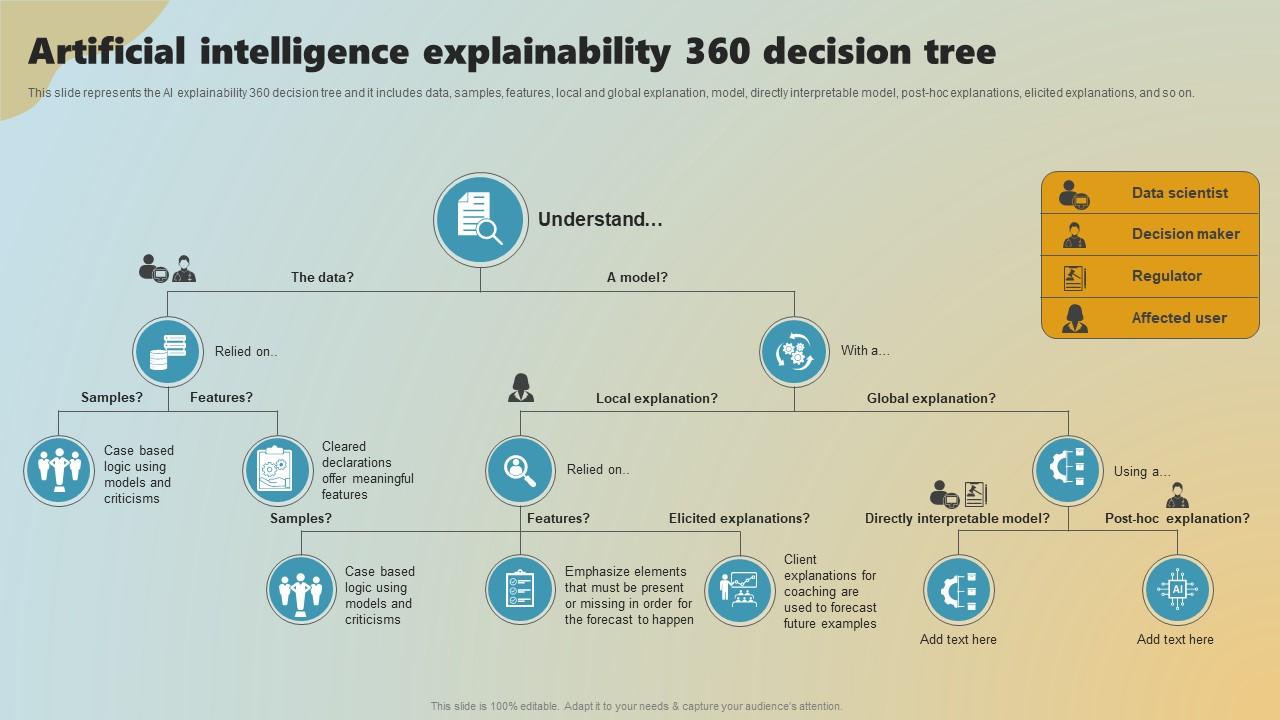
Decision Tree In Artificial Intelligence With Example at John Mcfadden blog
Understanding LLM Inference: How AI Generates Words | DataCamp
Rethinking LLM inference: Why developer AI needs a different approach
LLM Architecture: From Training to Deployment (Technical Deep Dive ...
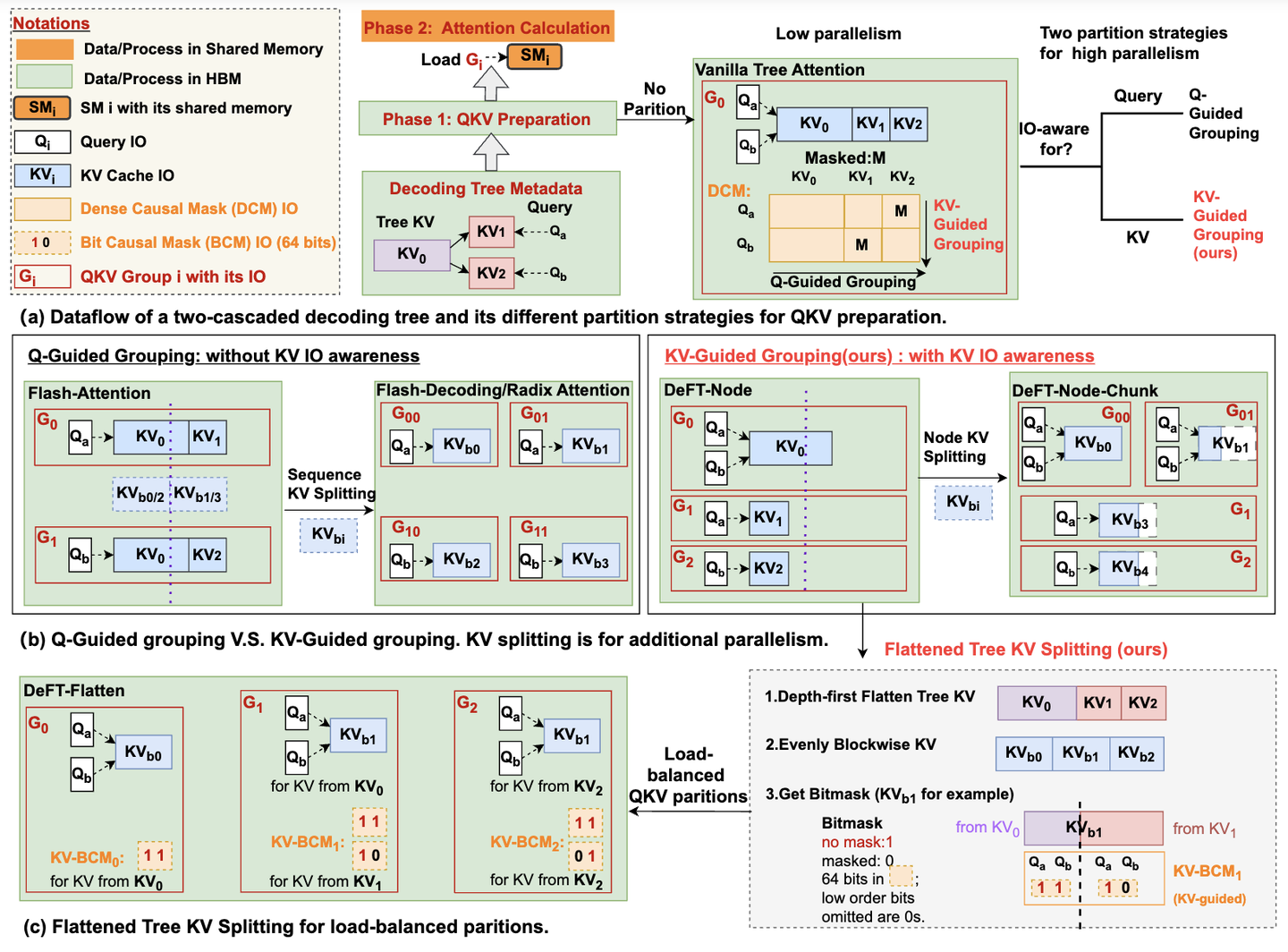
DeFT: Decoding with Flash Tree-attention for Efficient Tree-structured ...
Deploying a Large Language Model (LLM) with TensorRT-LLM on Triton ...
图文详解LLM inference:LLM模型架构详解 - 知乎
Apple Researchers Propose LazyLLM: A Novel AI Technique for Efficient ...
GitHub - waterhorse1/LLM_Tree_Search: The official implementation of ...
Open-Source-LLM-Development-Landscape解读 | 之梦
(PDF) Towards Efficient Multi-LLM Inference: Characterization and ...
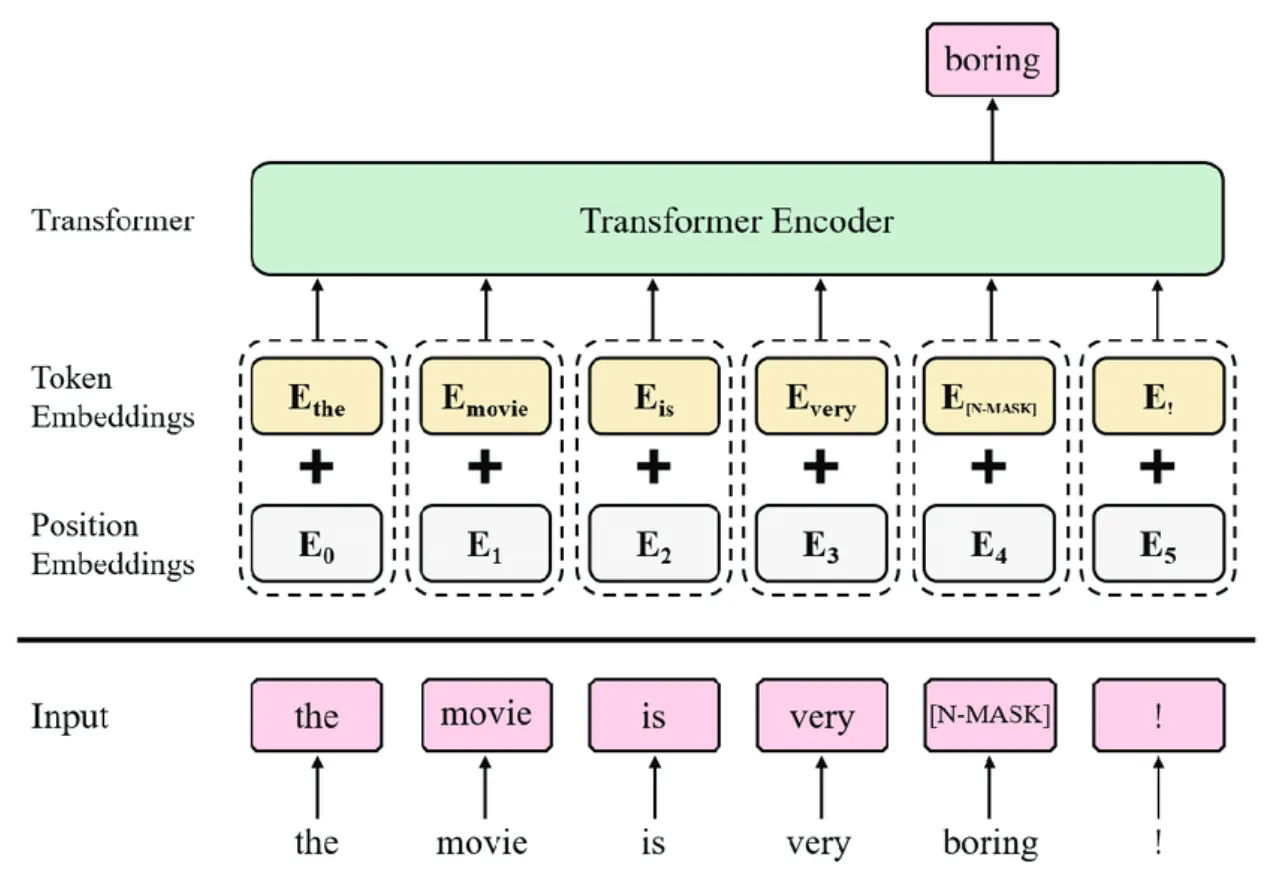
What are Large Language Models (LLMs)? | Definition from TechTarget
Understanding Decision Trees: A Complete Guide | by Noor Fatima | Medium
GitHub - OpenCSGs/llm-inference: llm-inference is a platform for ...
How to Use Tree-Based Prompting for Data Extraction with LLMs | by ...
Reading on Artificial Intelligence: #9 | by Adam Bouras | Medium
GitHub - graphcore-research/llm-inference-research: An experimentation ...
Understanding Large Language Models -- A Transformative Reading List
llm-inference · PyPI
GitHub - modelize-ai/LLM-Inference-Deployment-Tutorial: Tutorial for ...
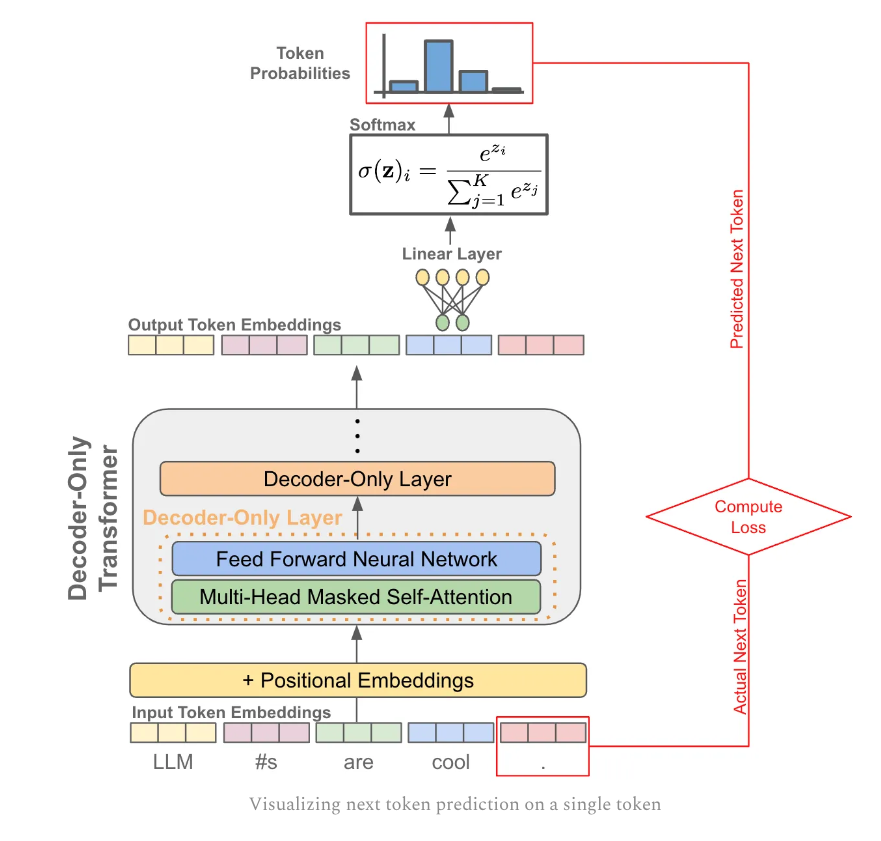
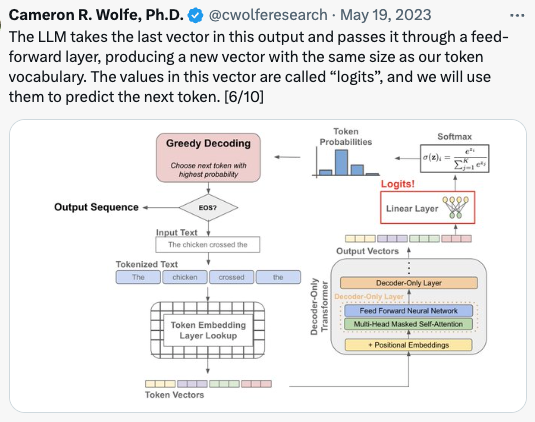
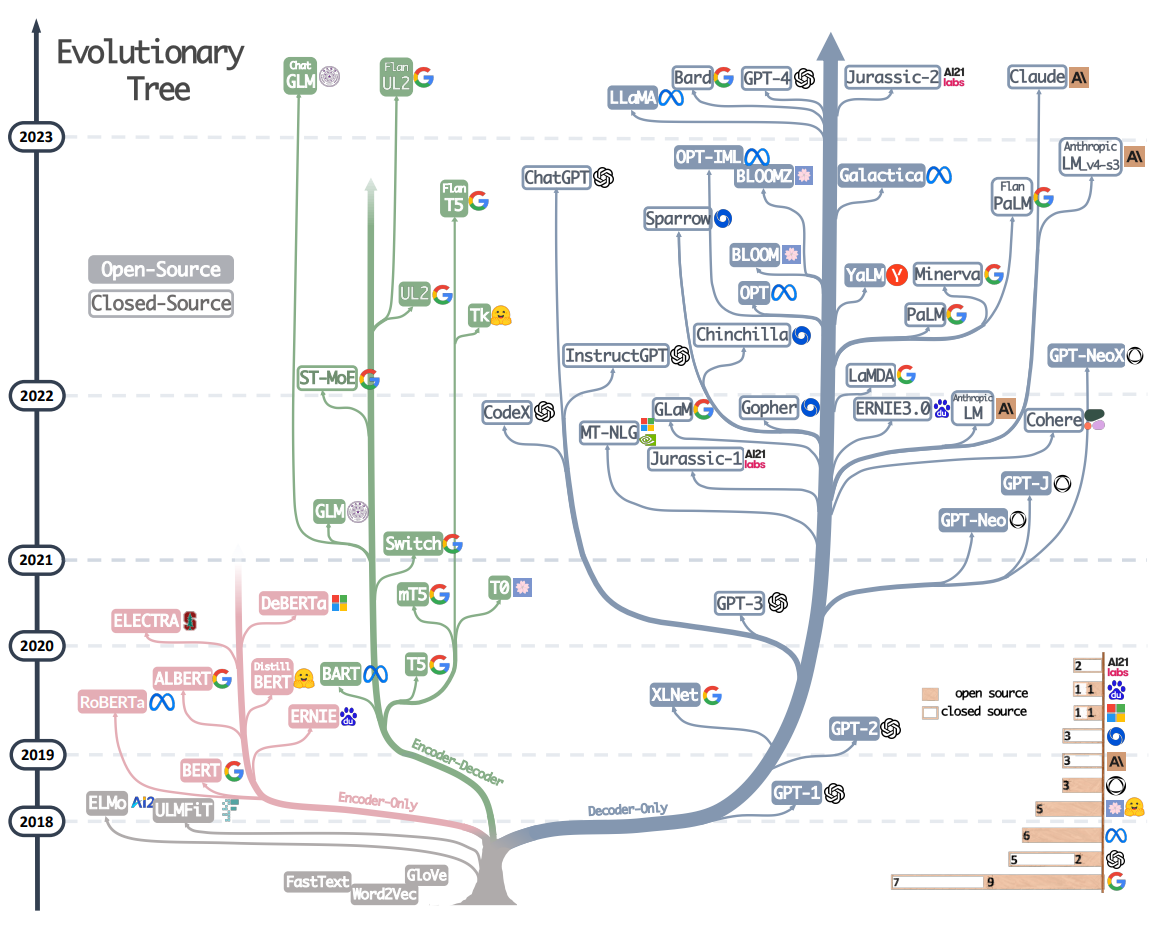
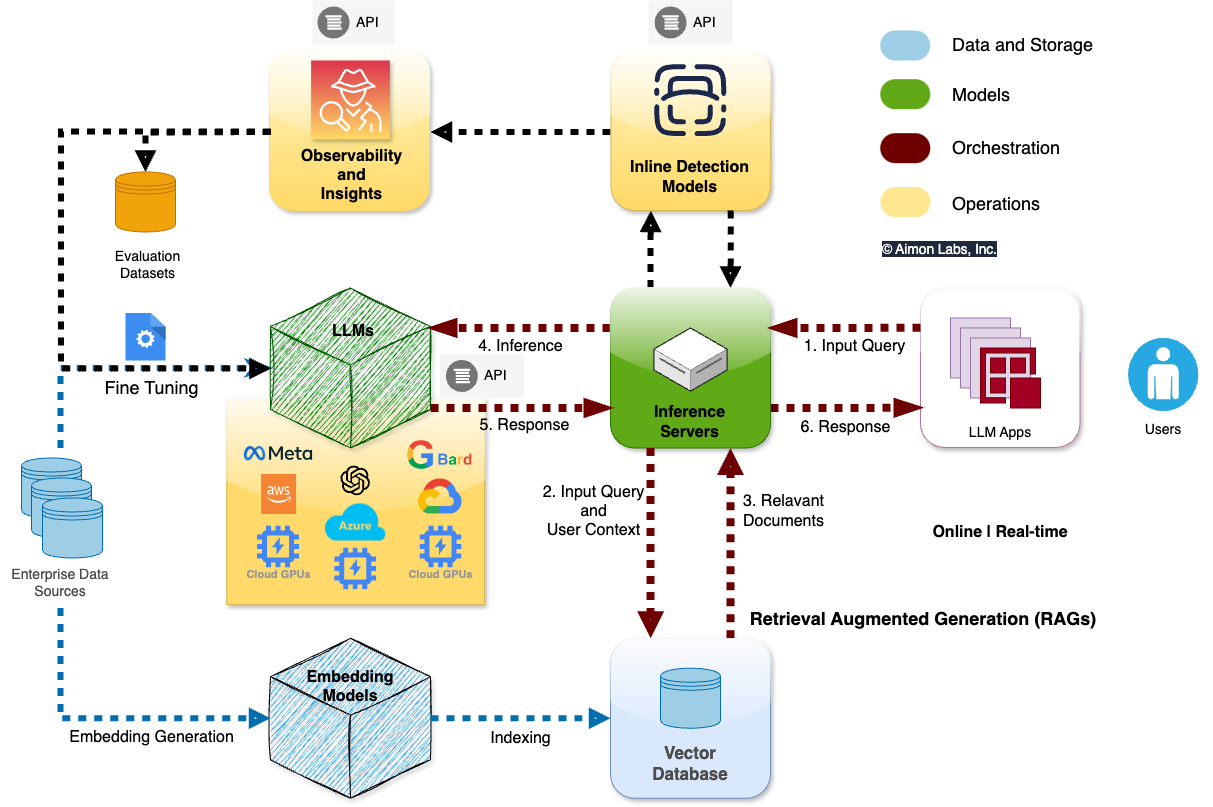

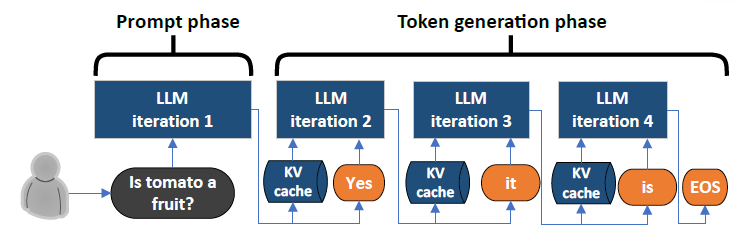
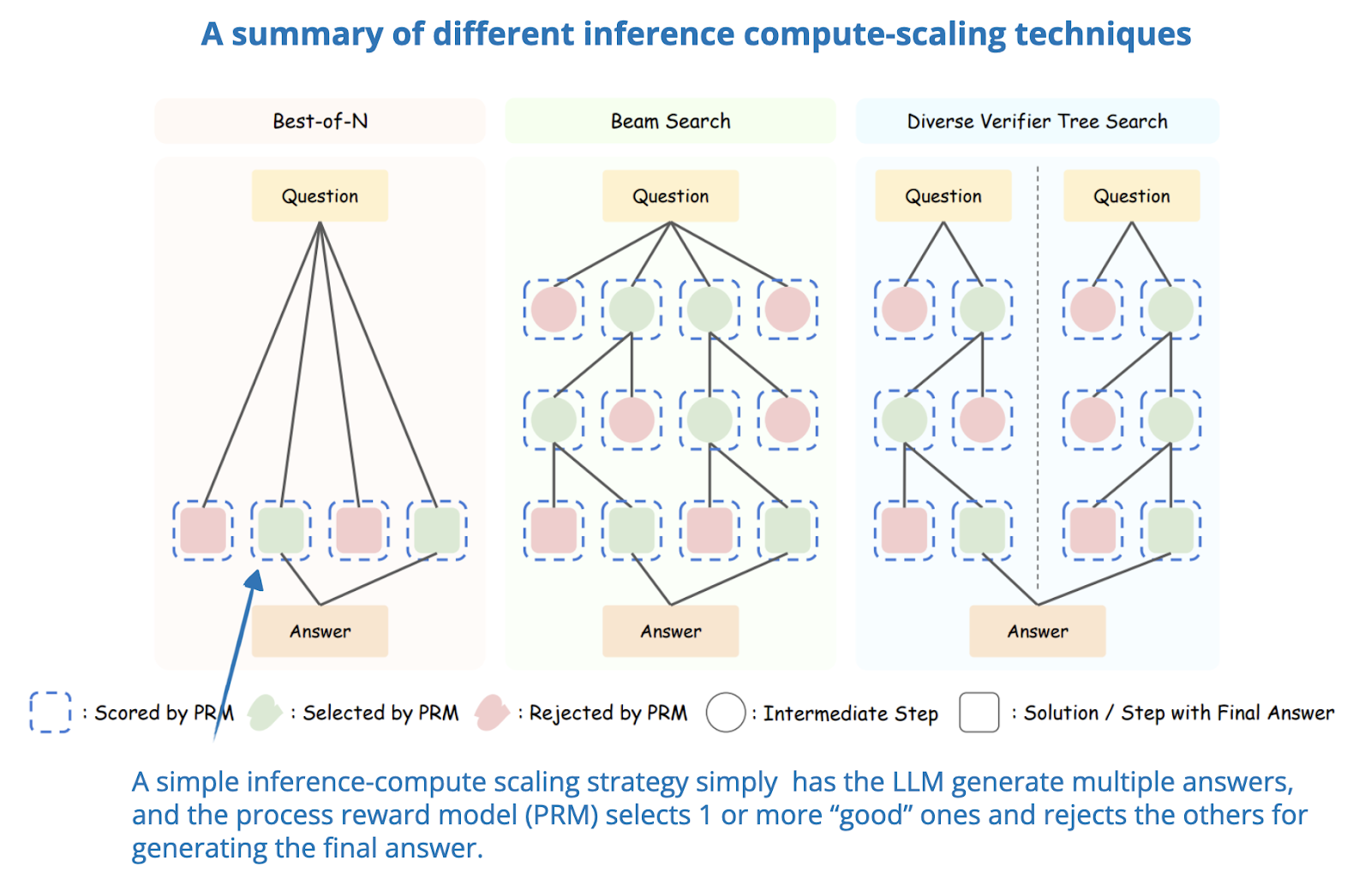
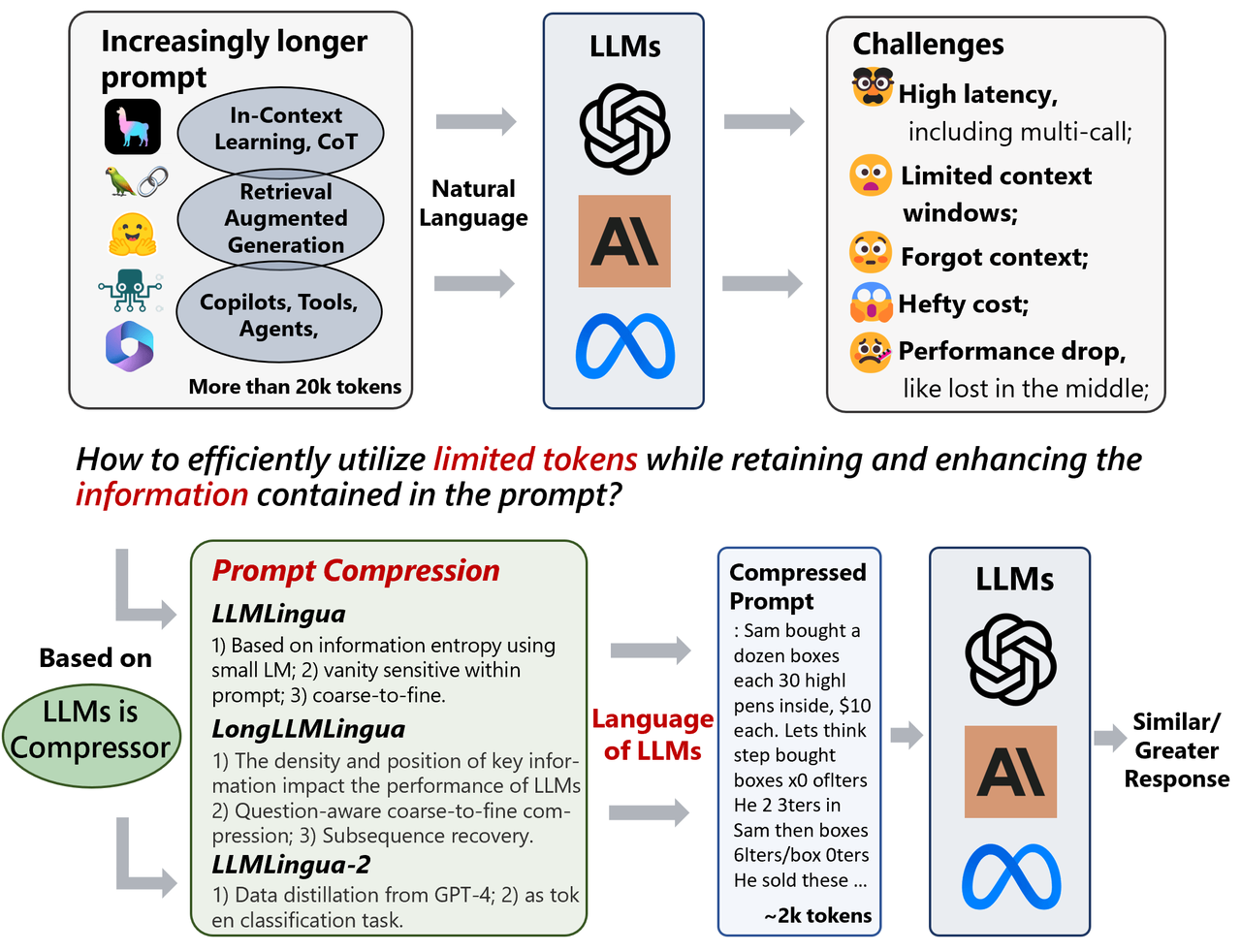
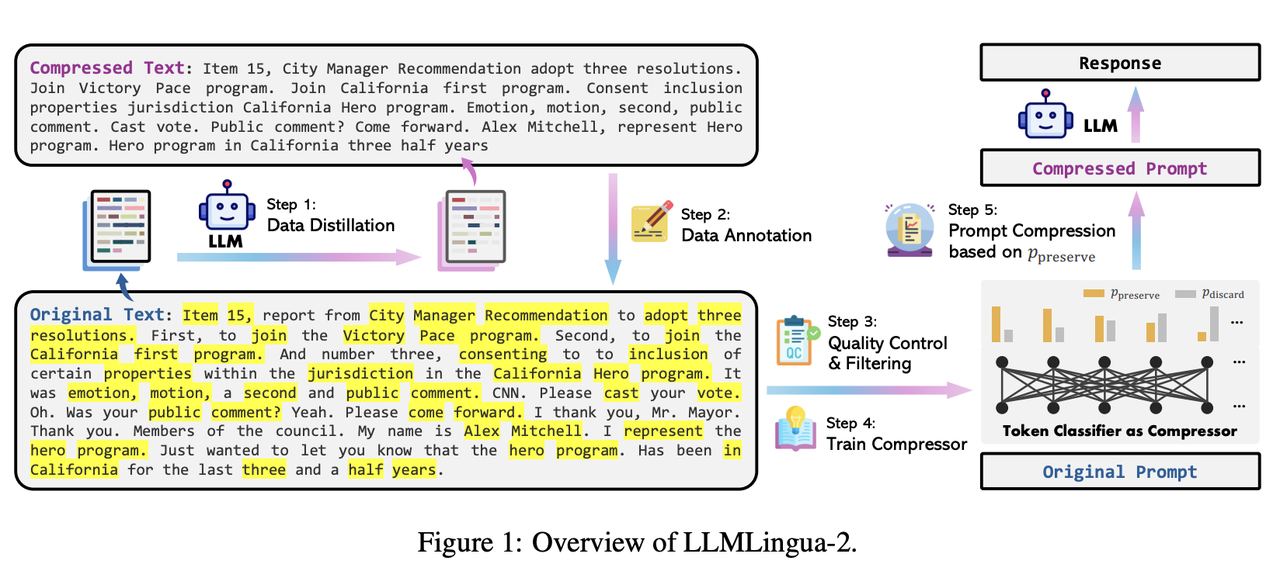
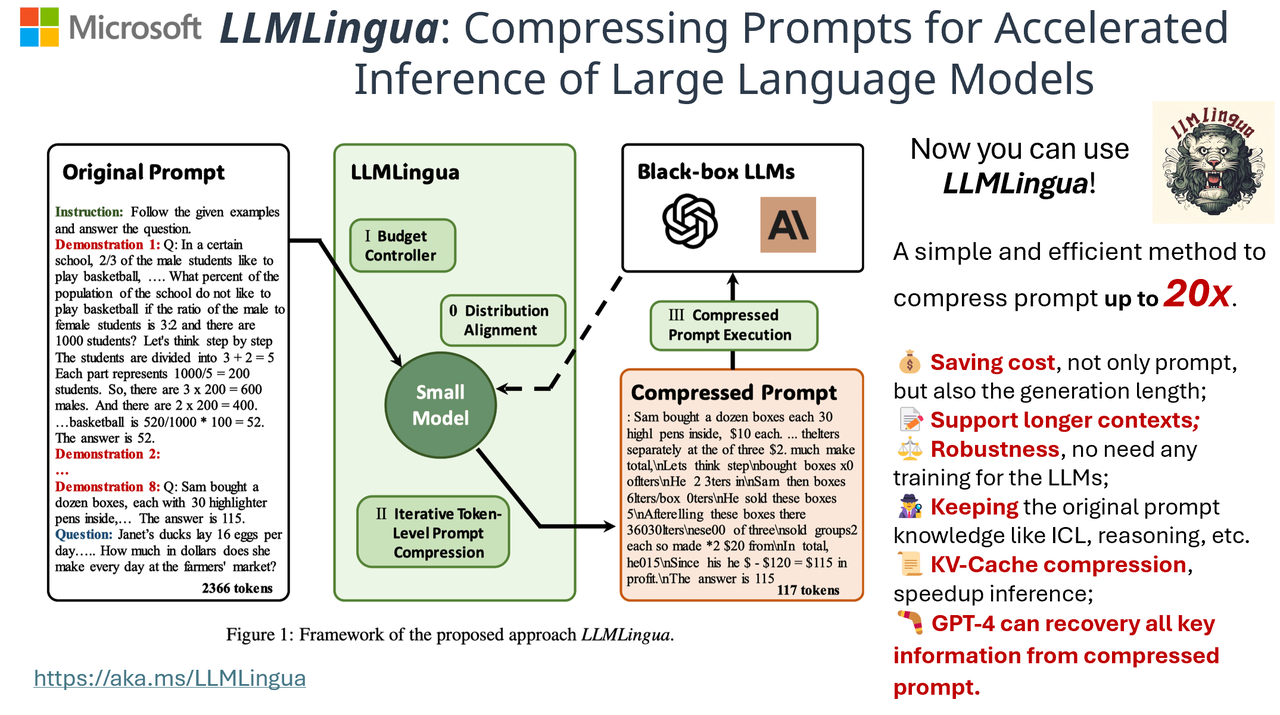
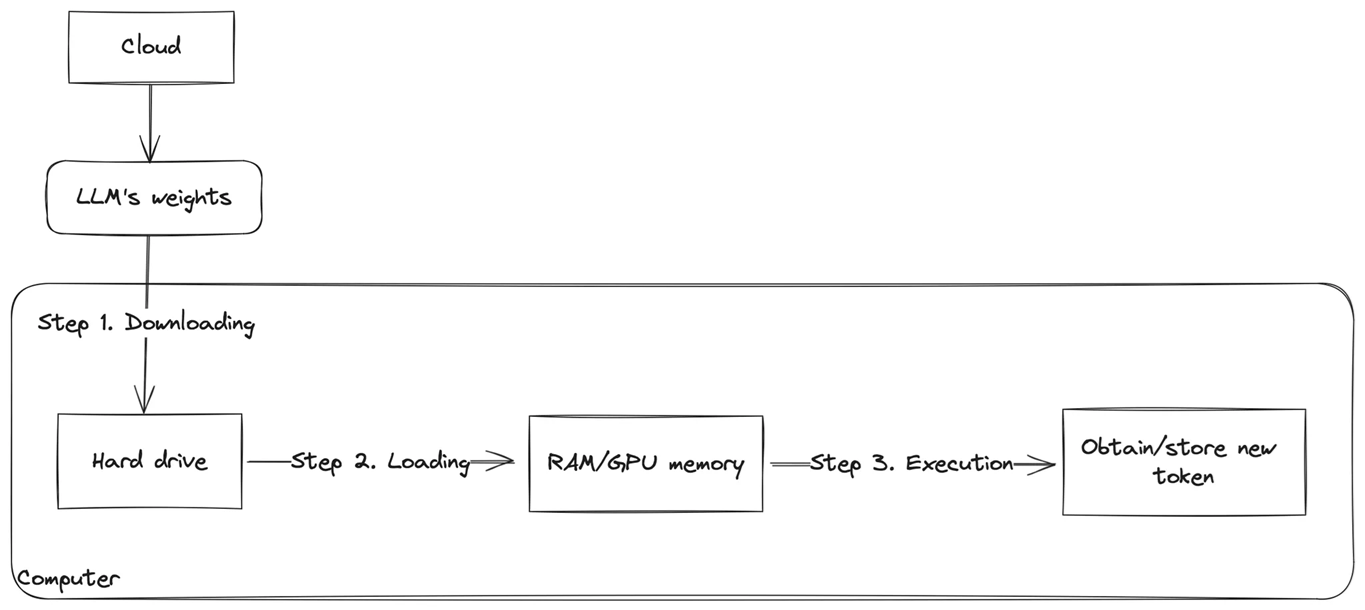






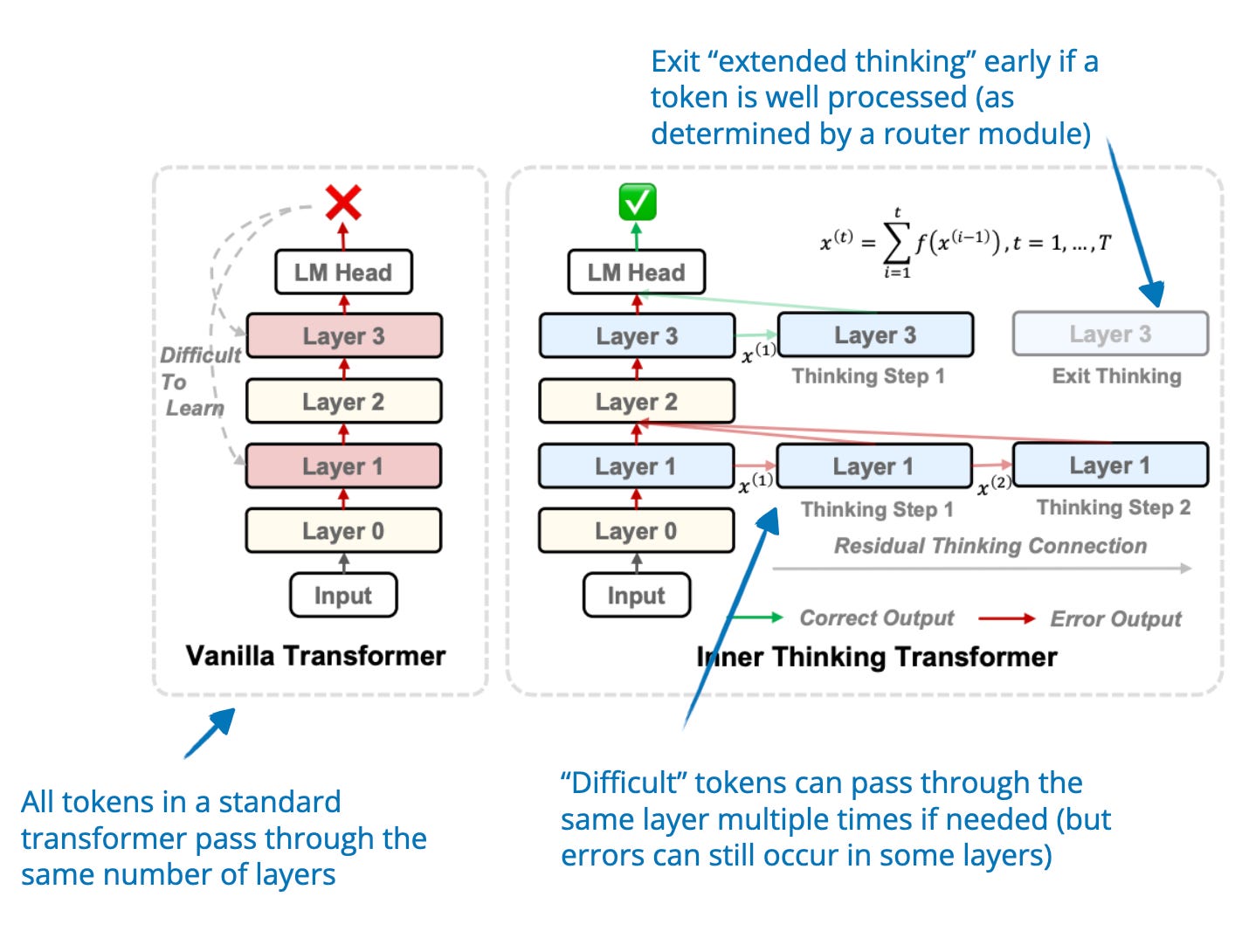


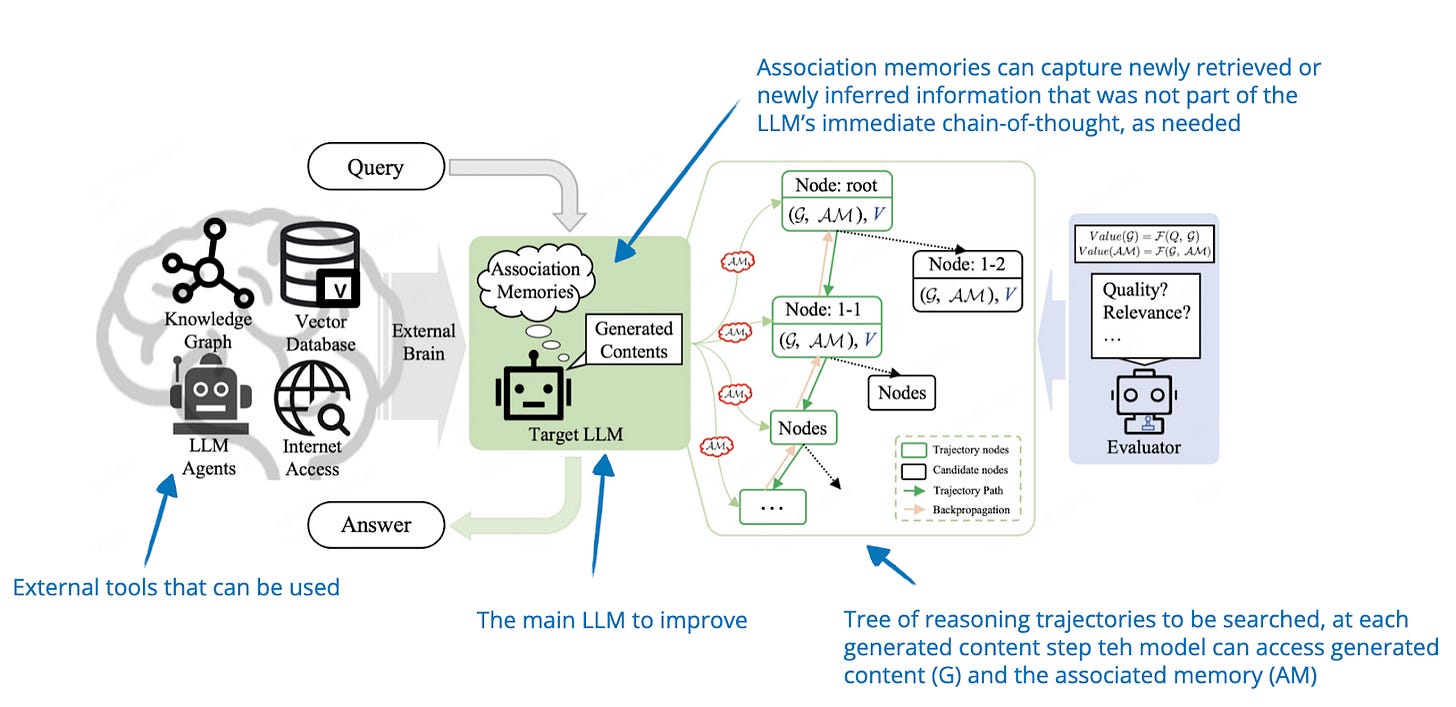
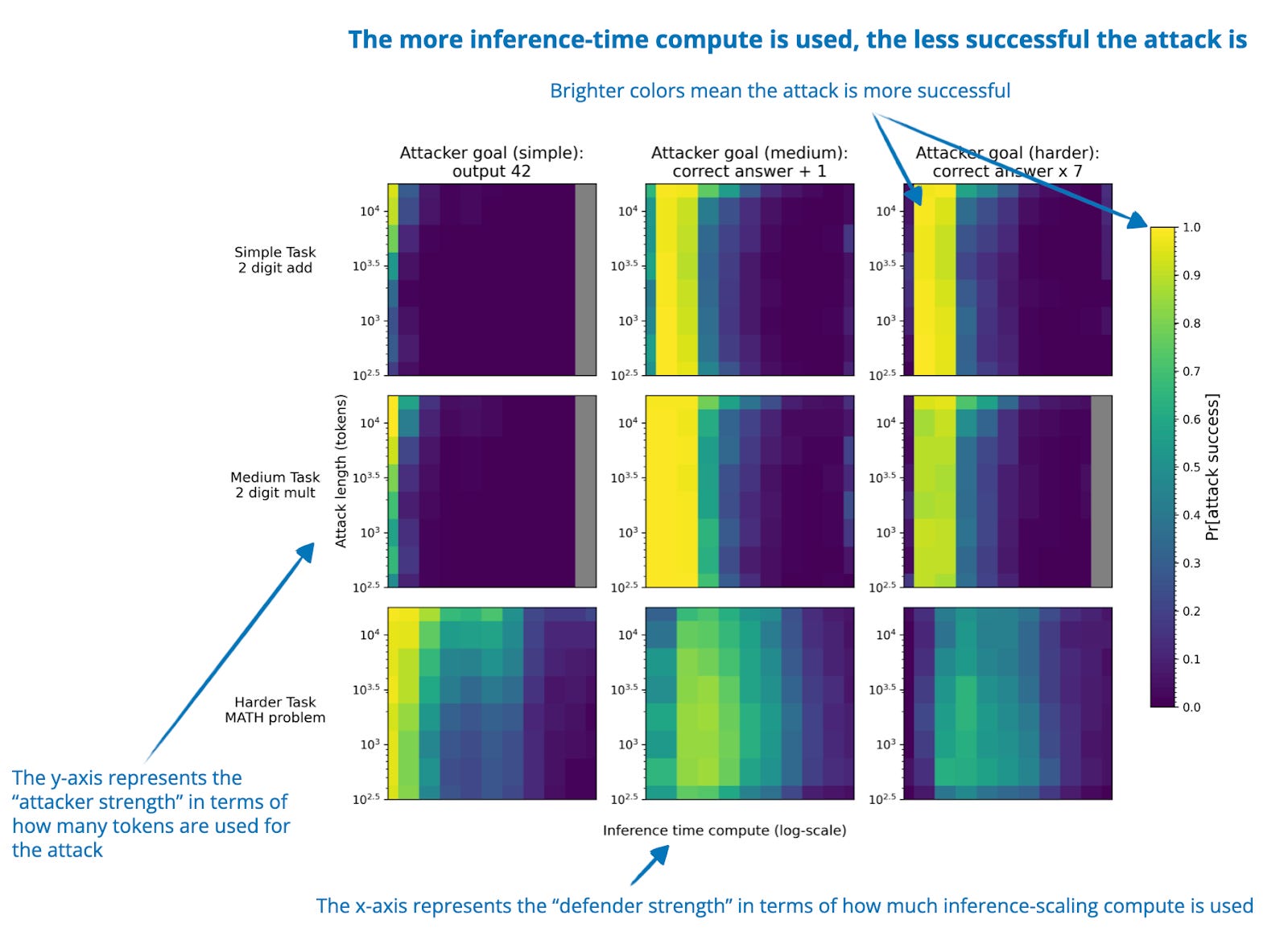
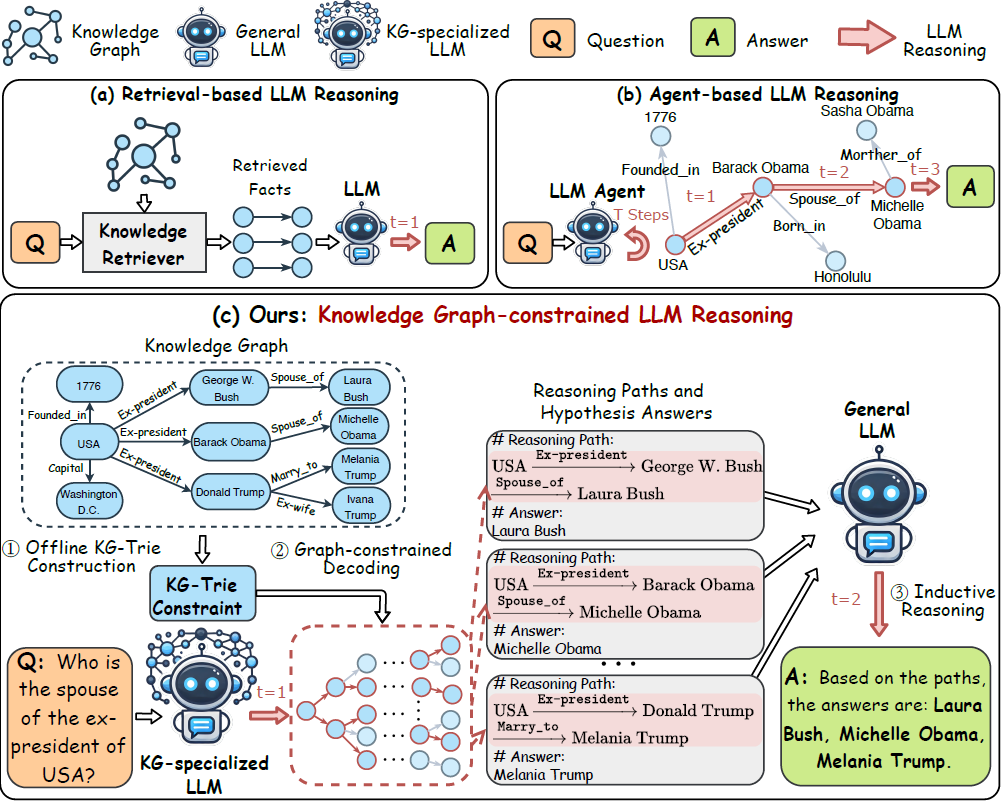





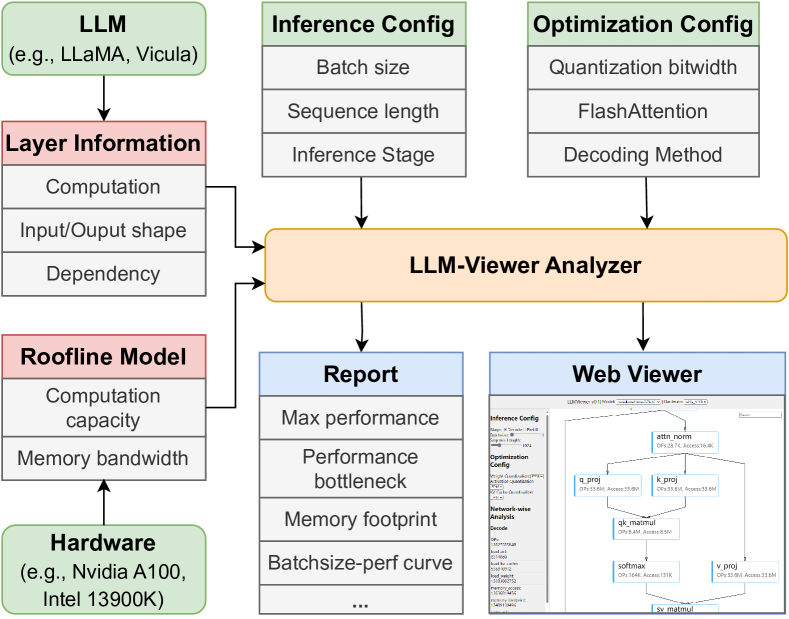
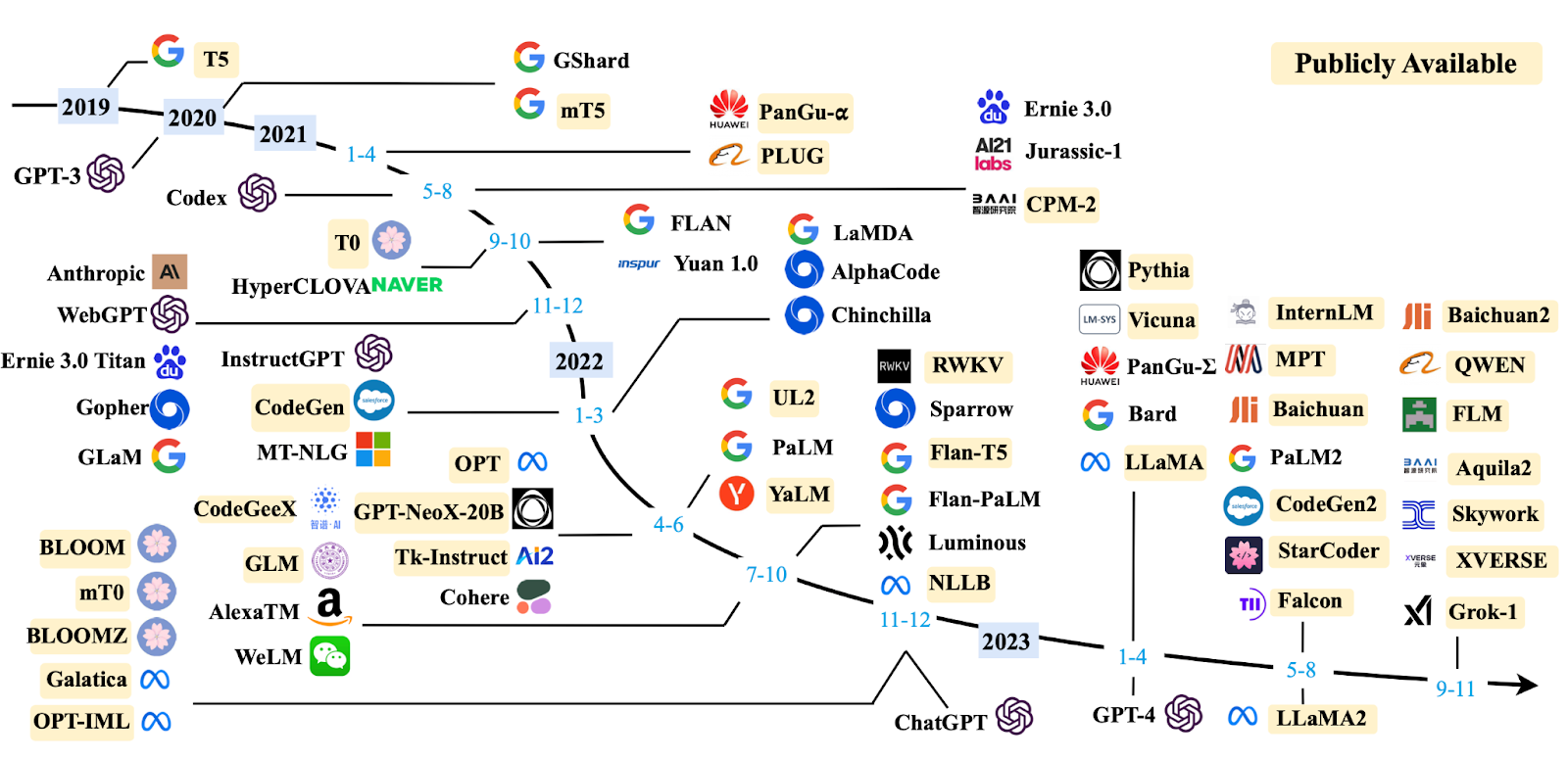




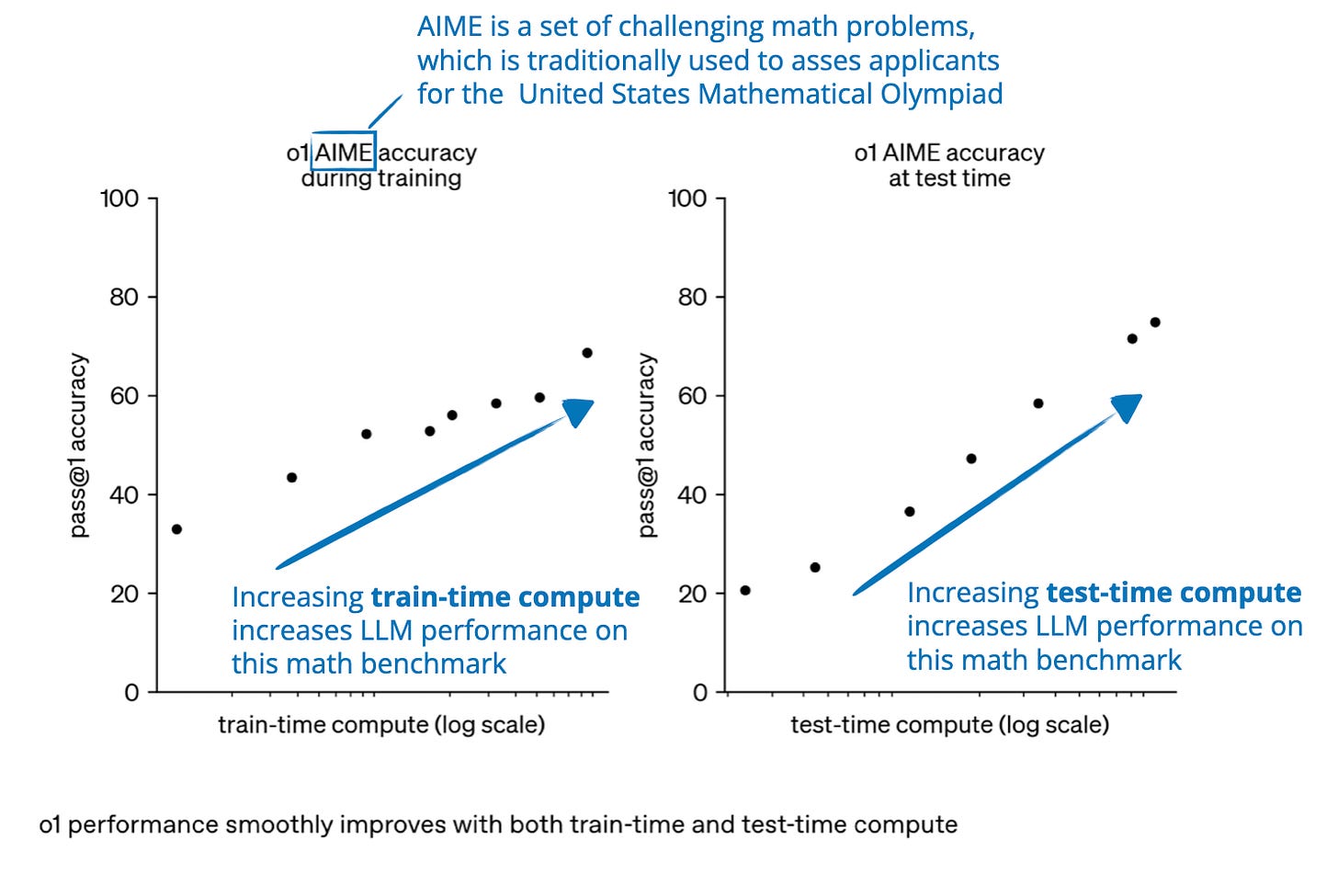

























.png)