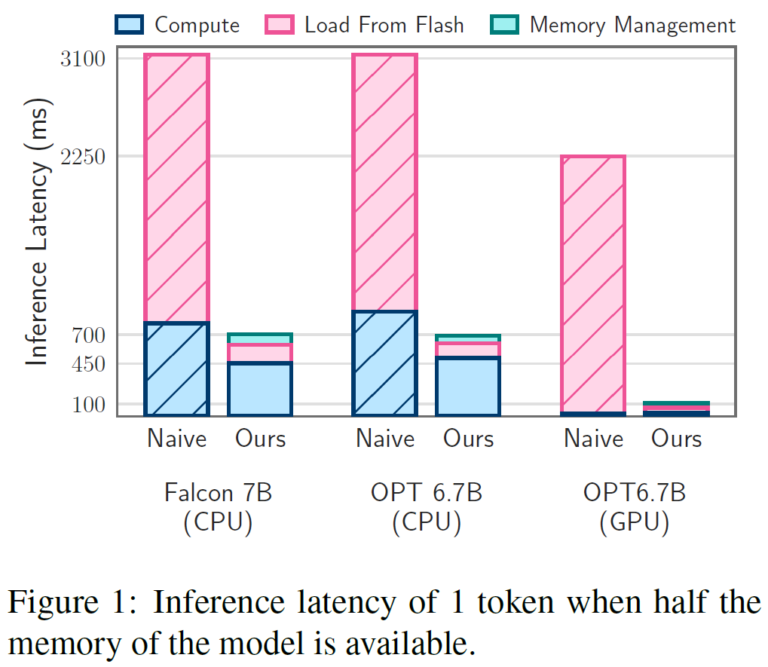
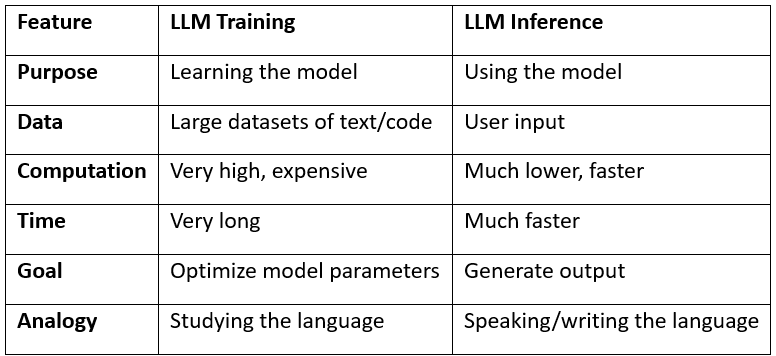
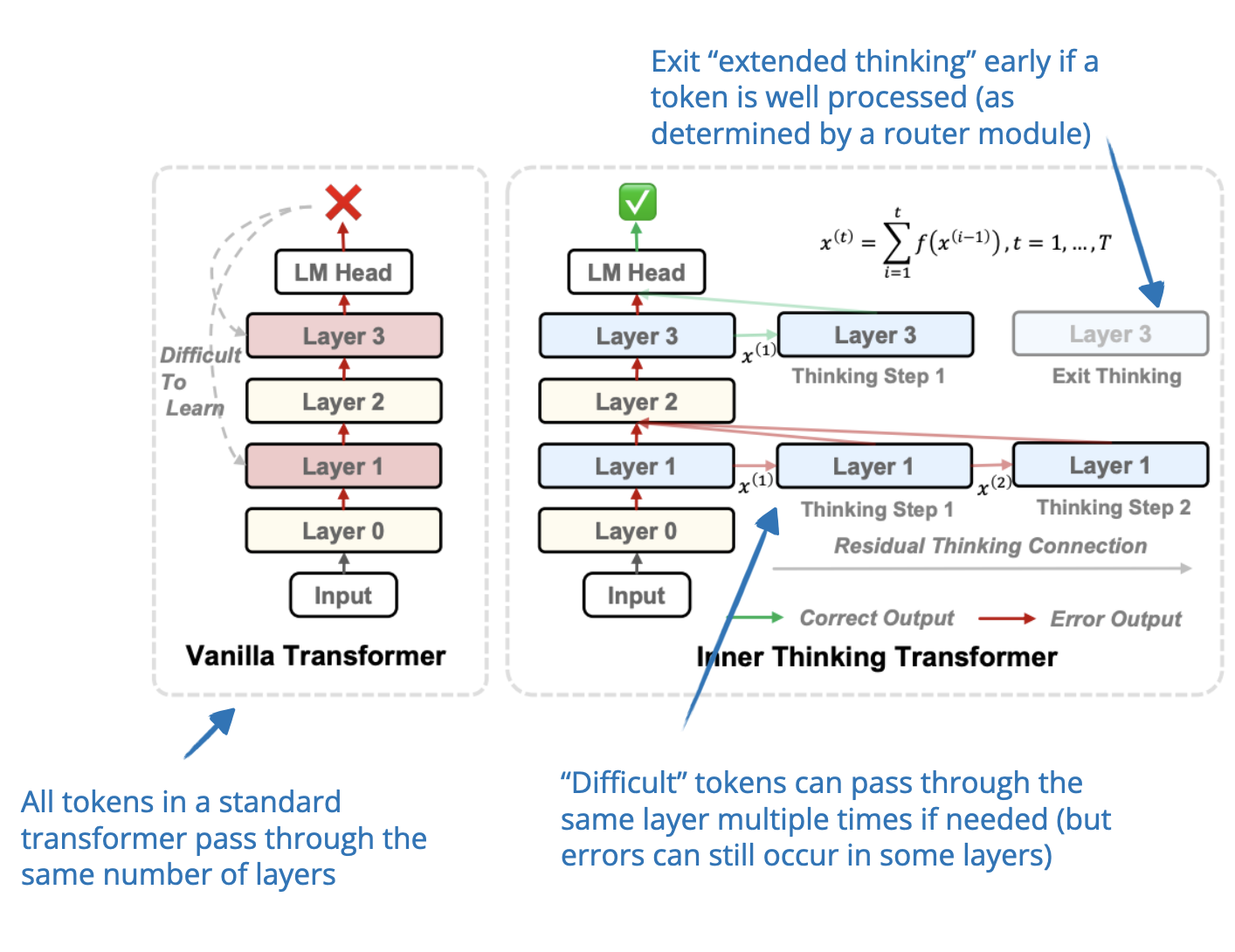
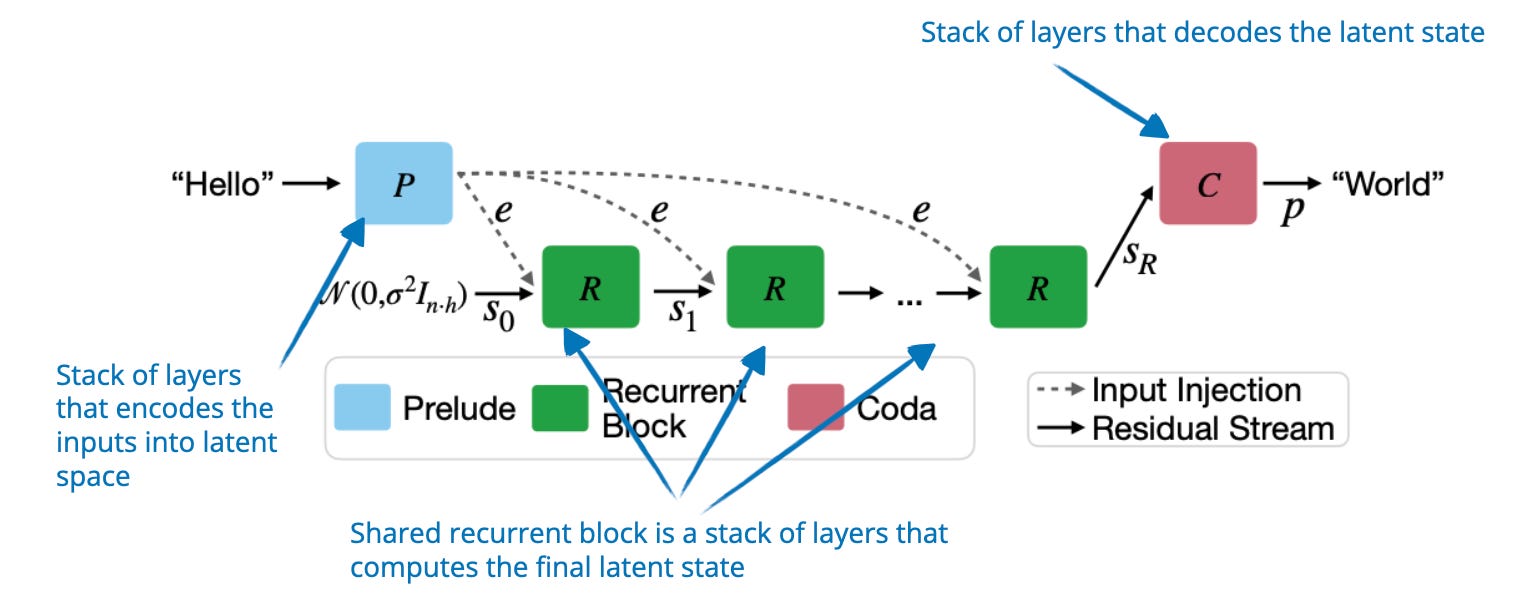
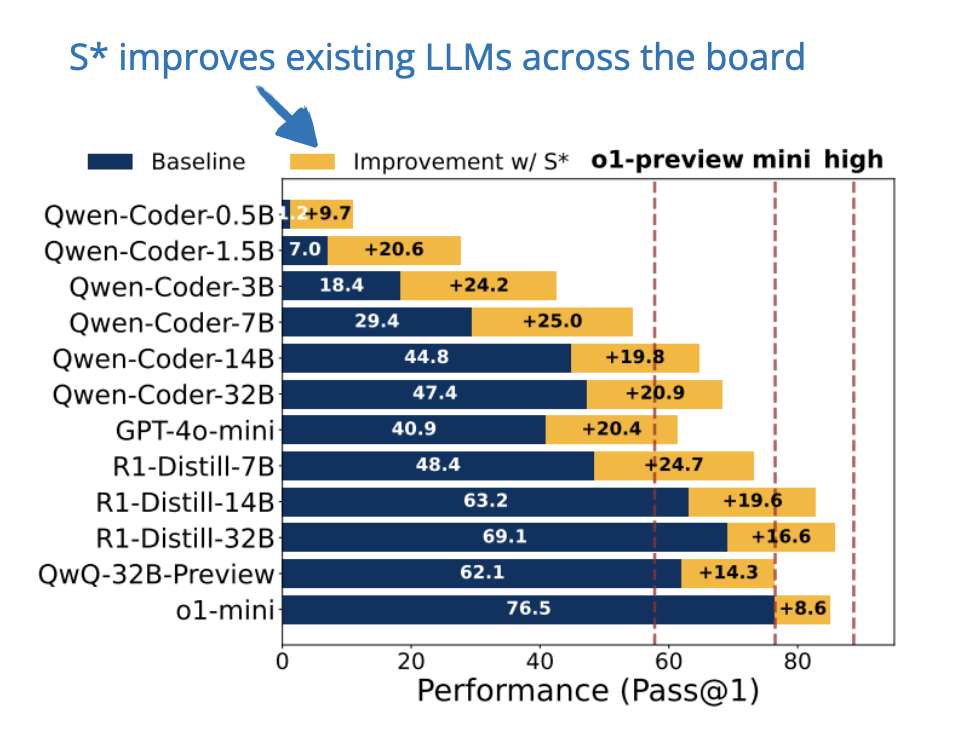
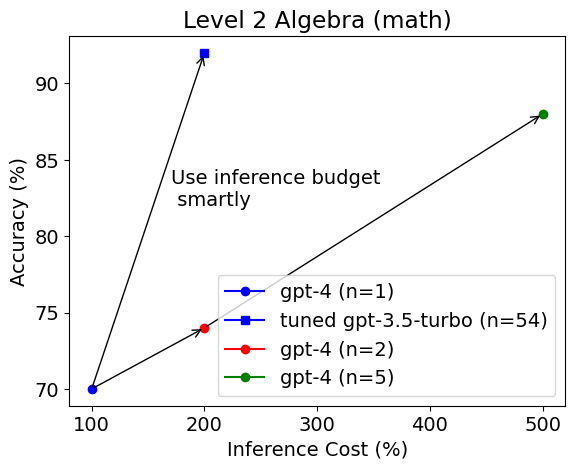
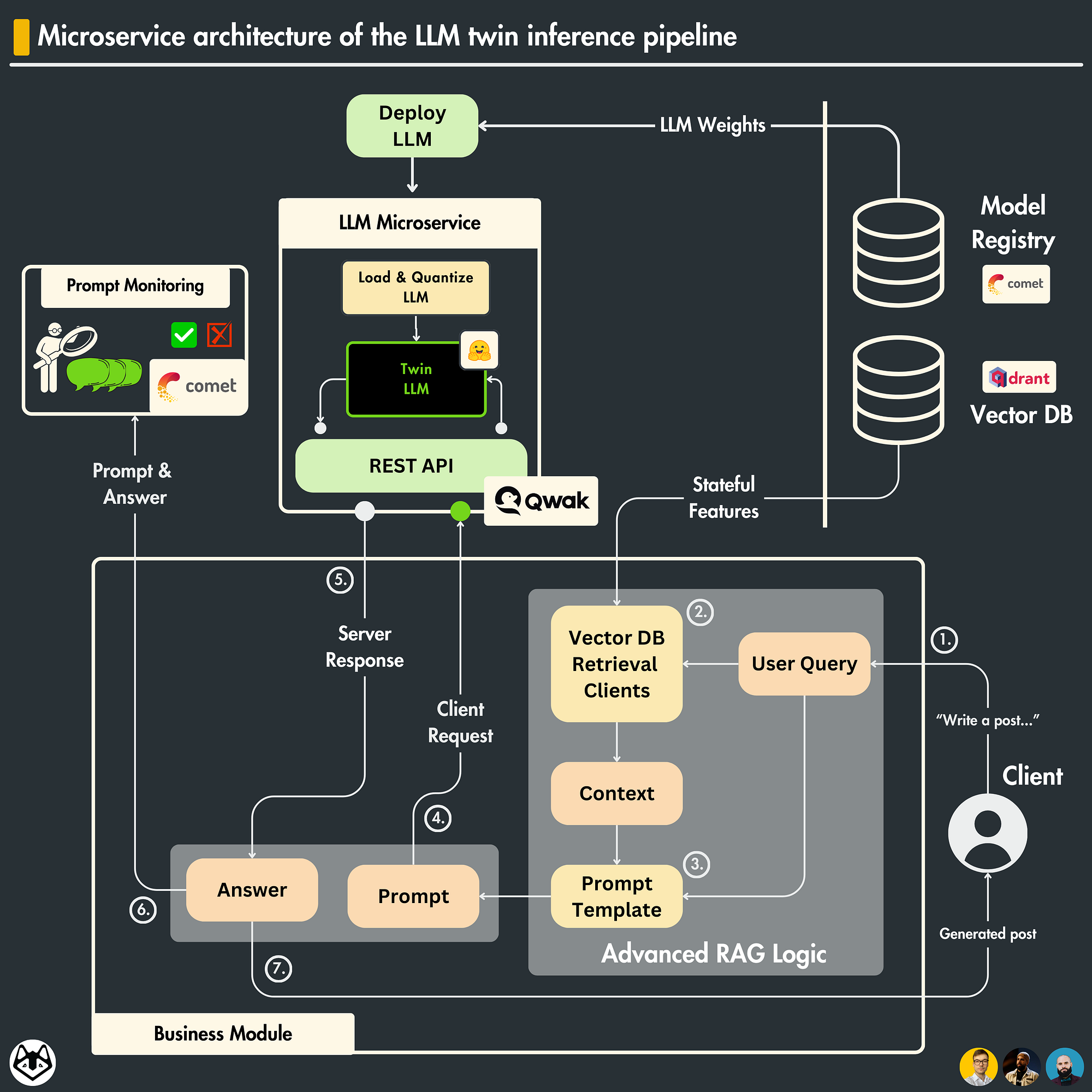
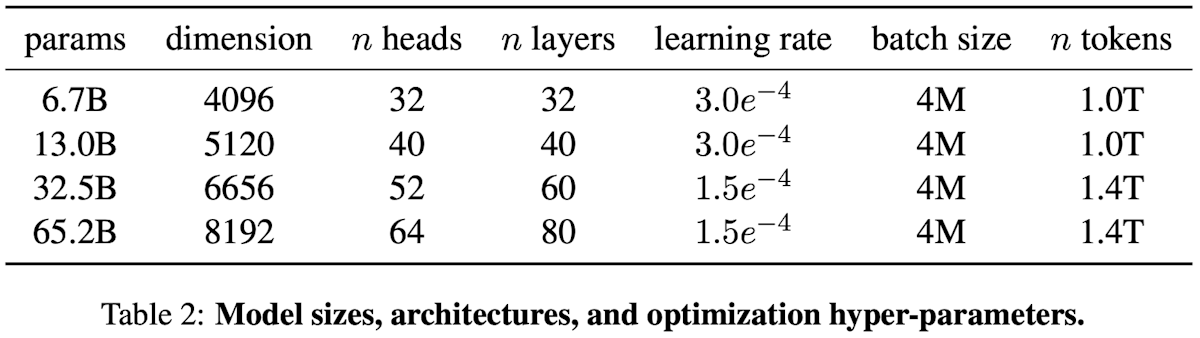
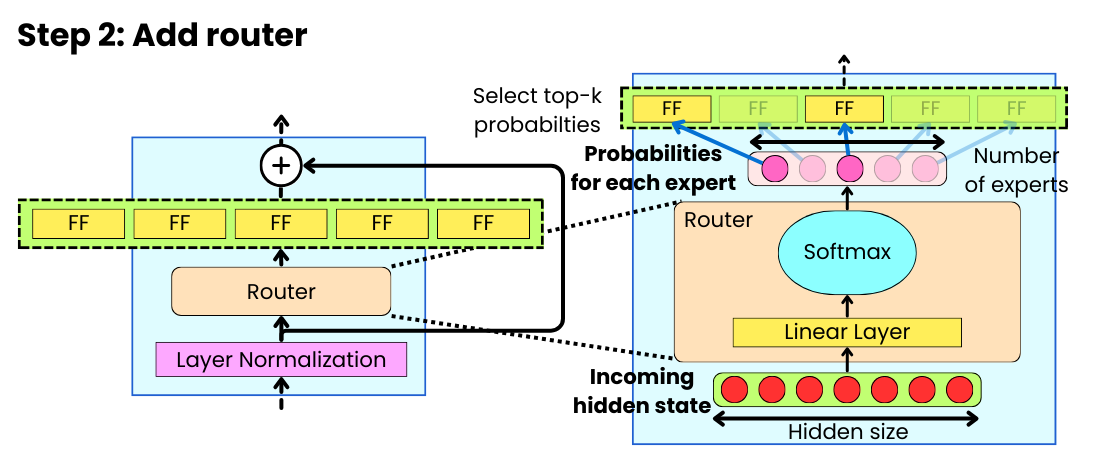
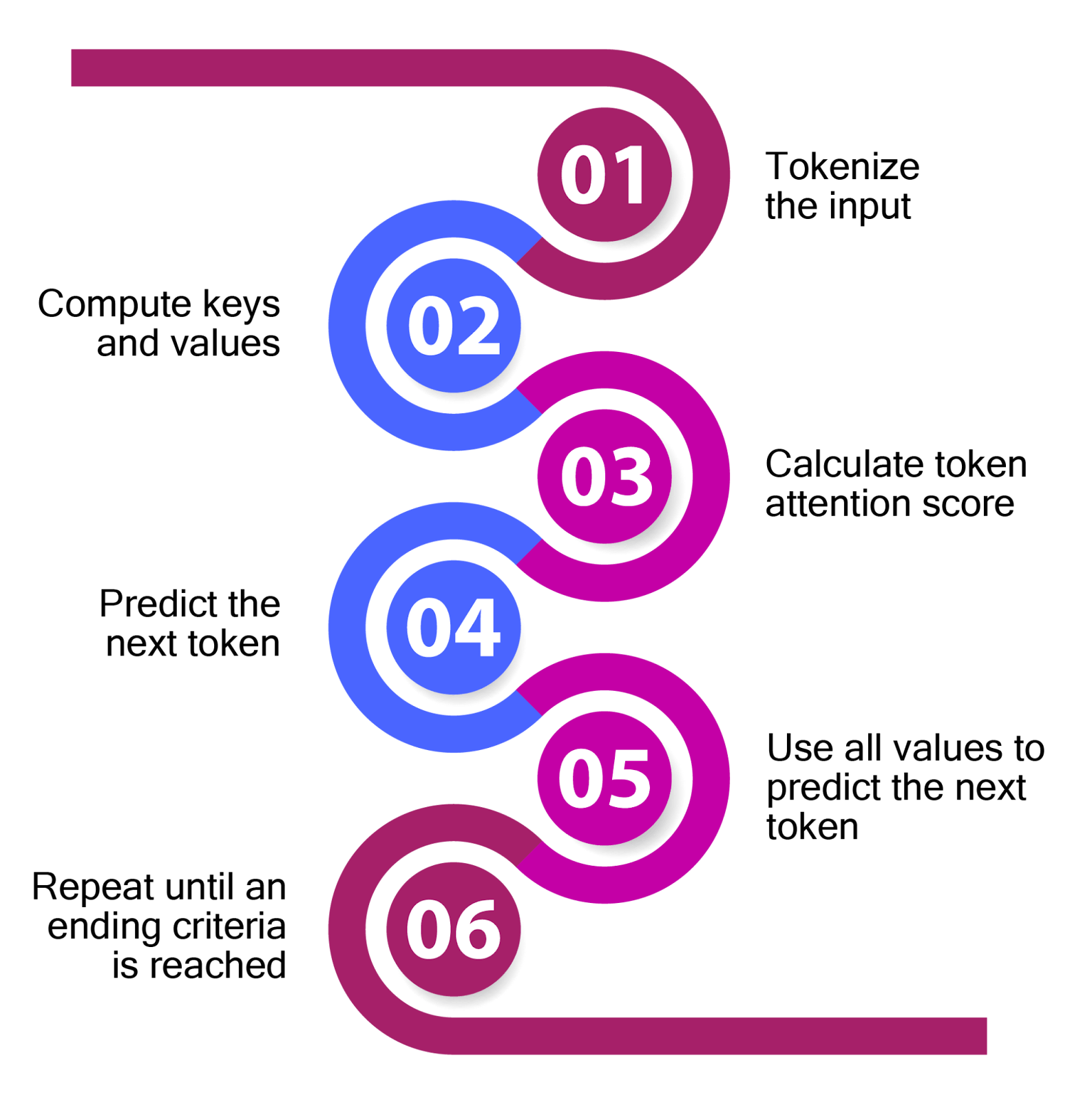
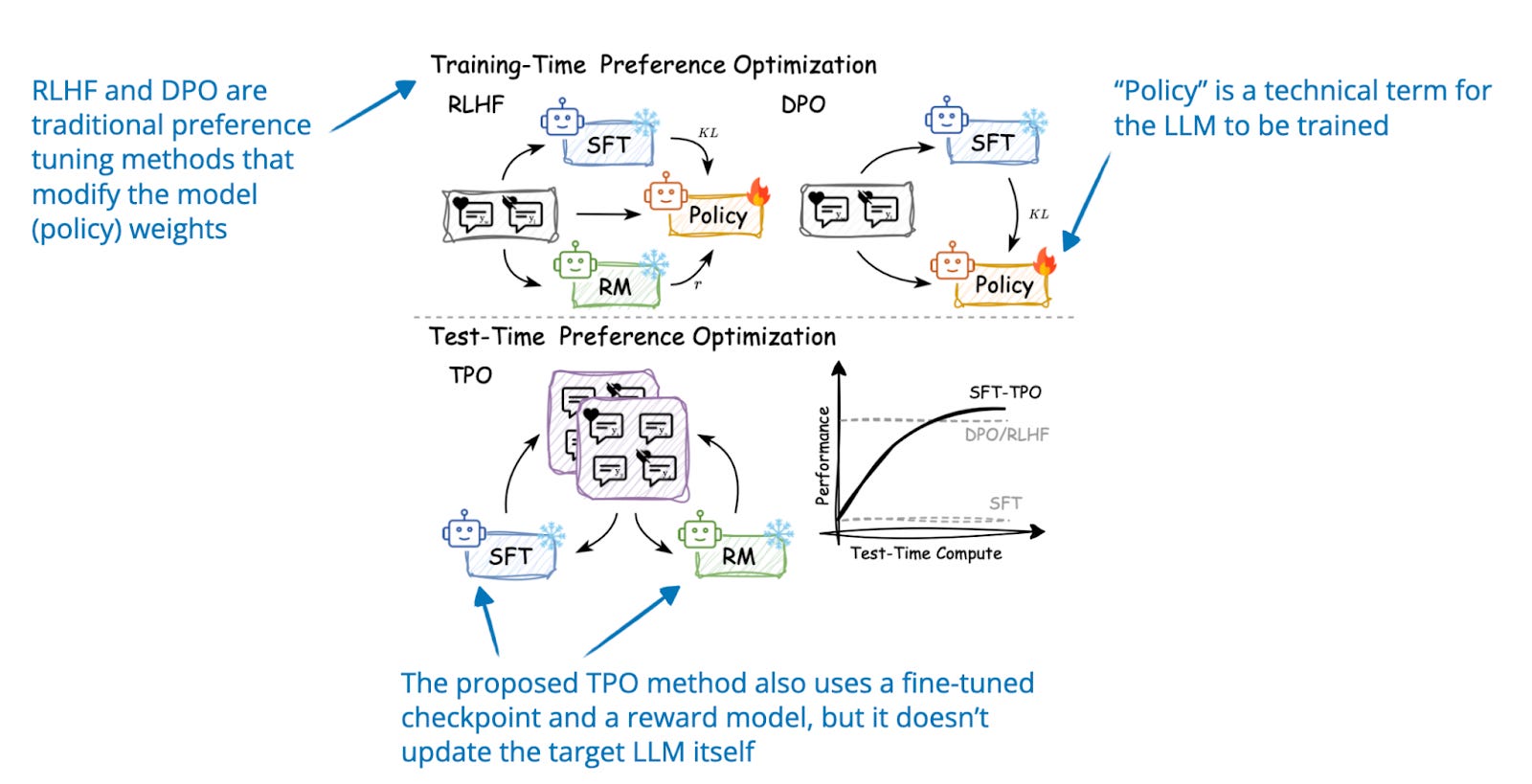
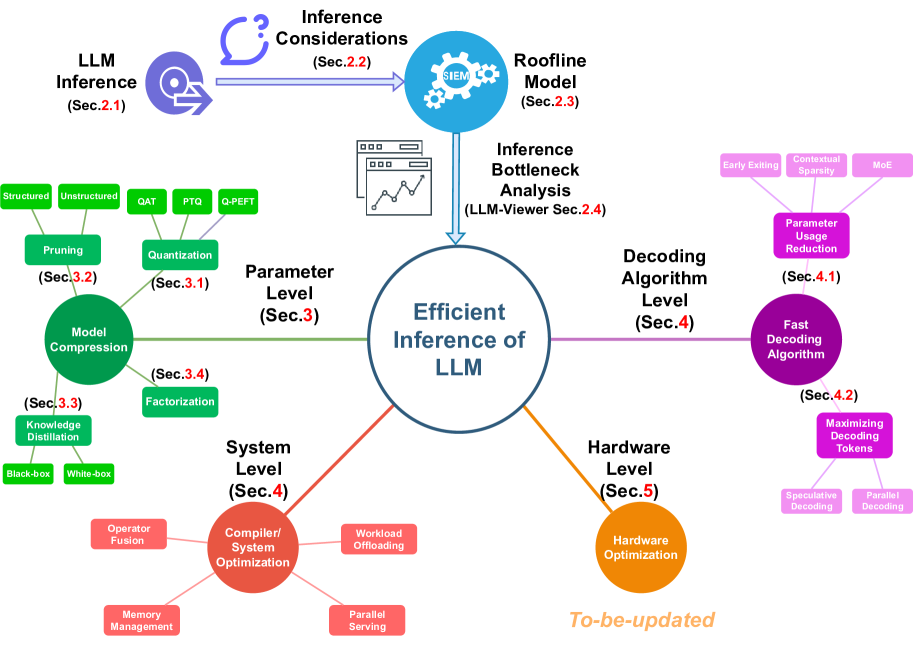
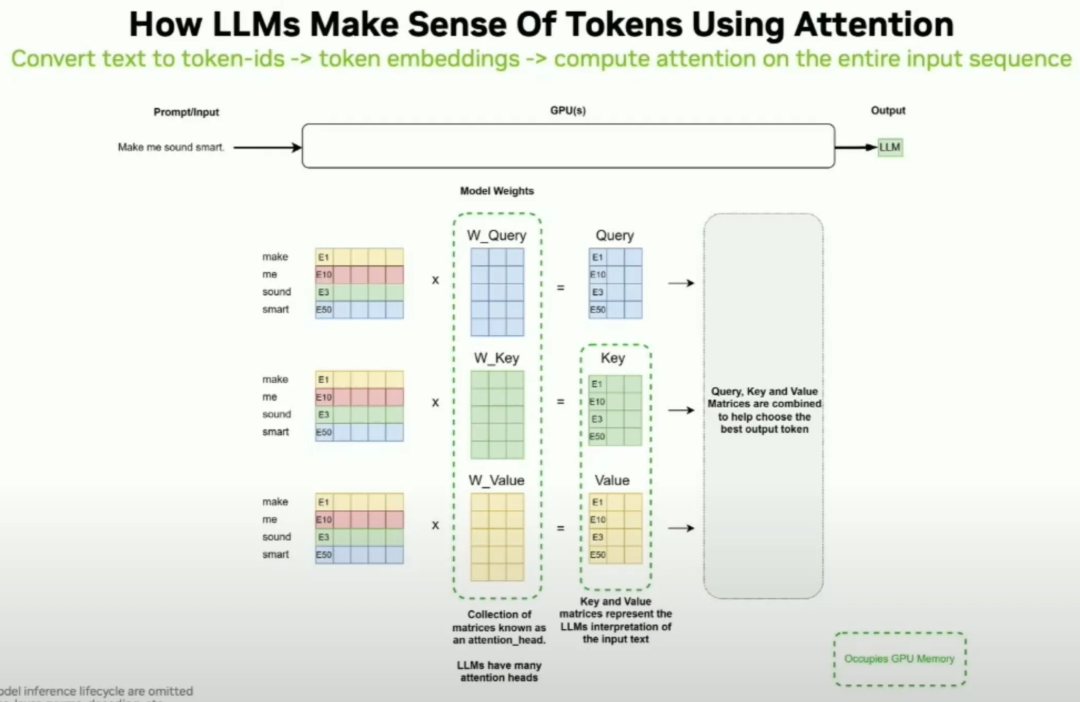
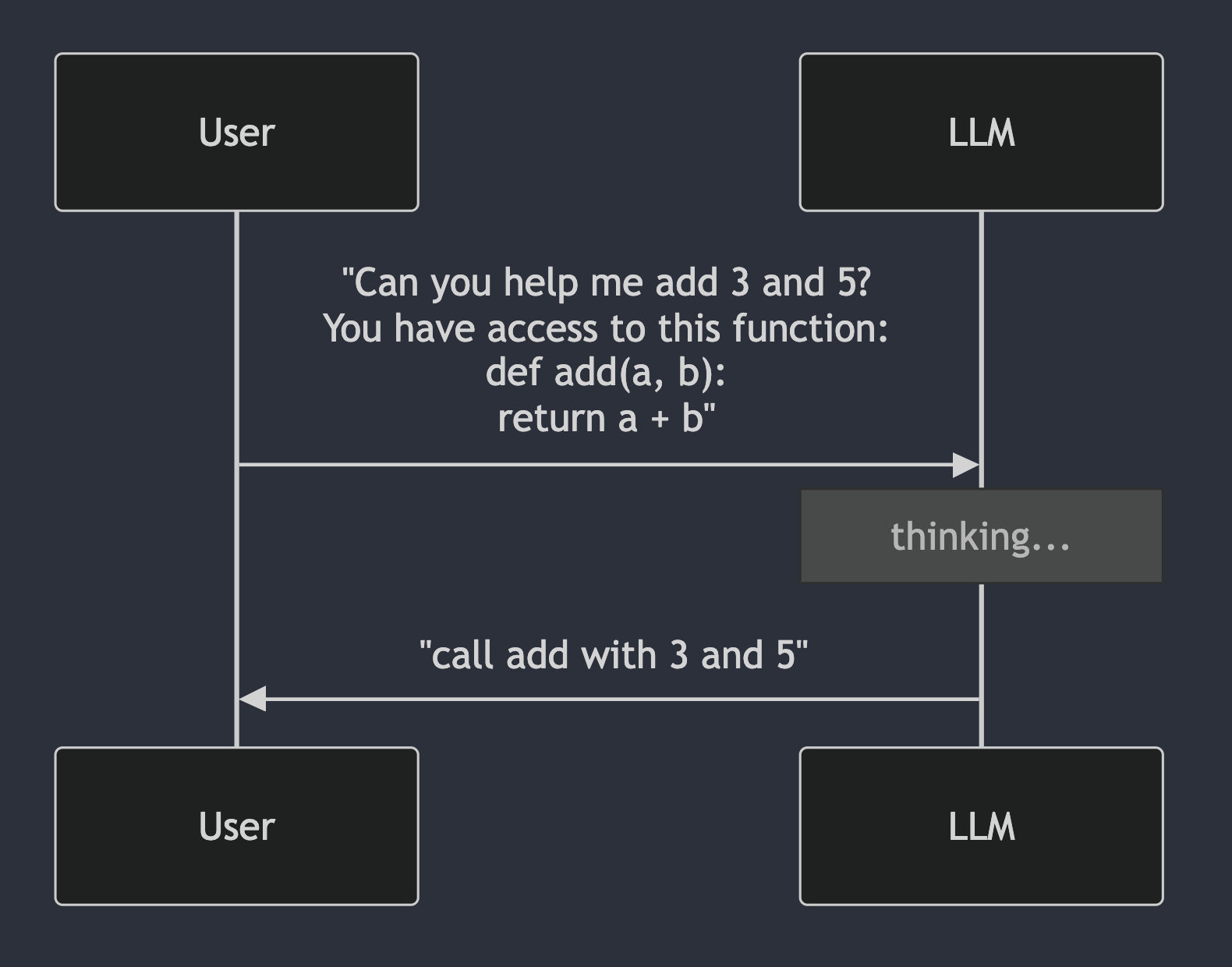
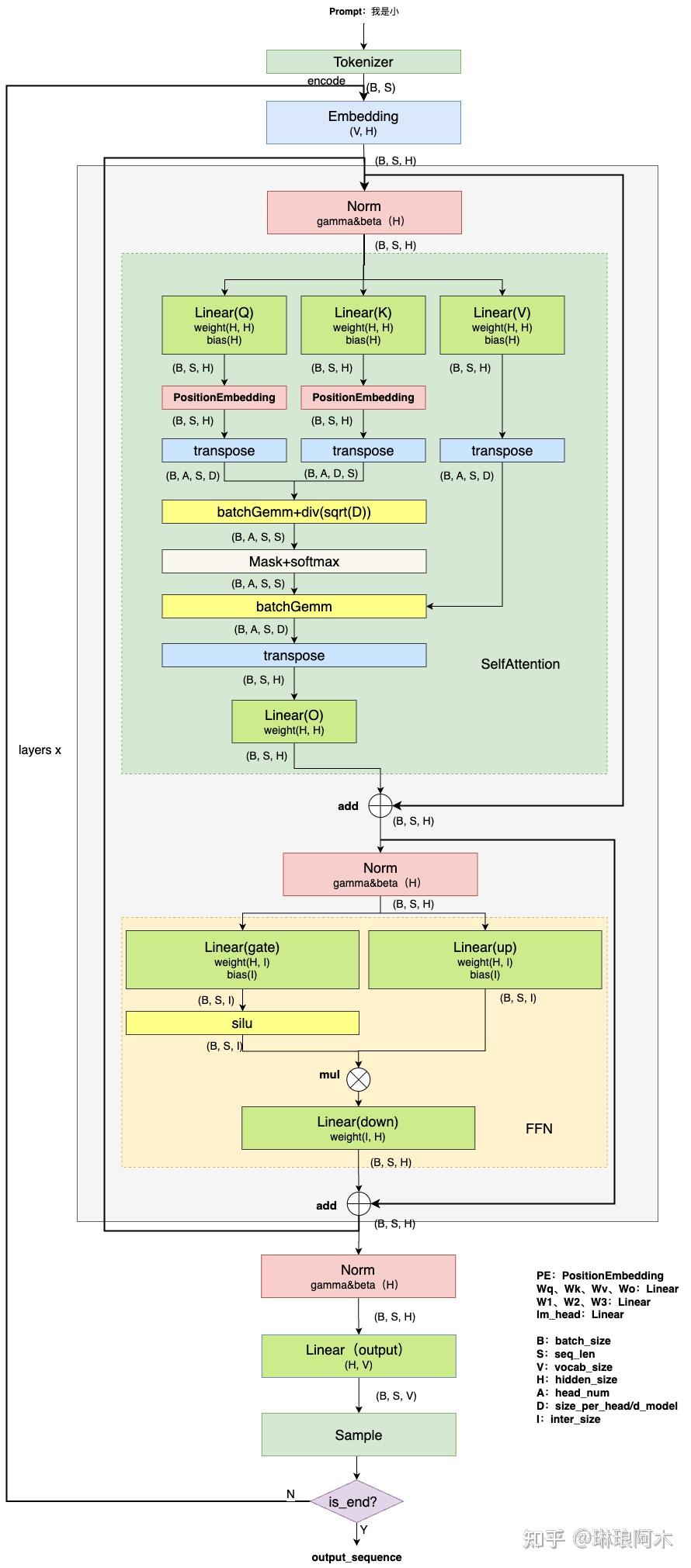
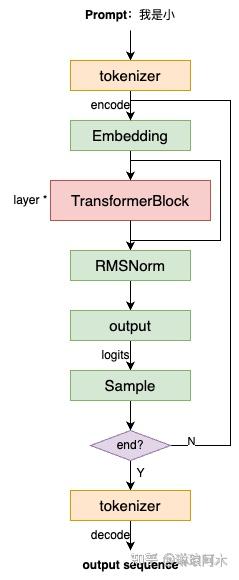
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
Function Calling - LLM Inference Handbook | PDF
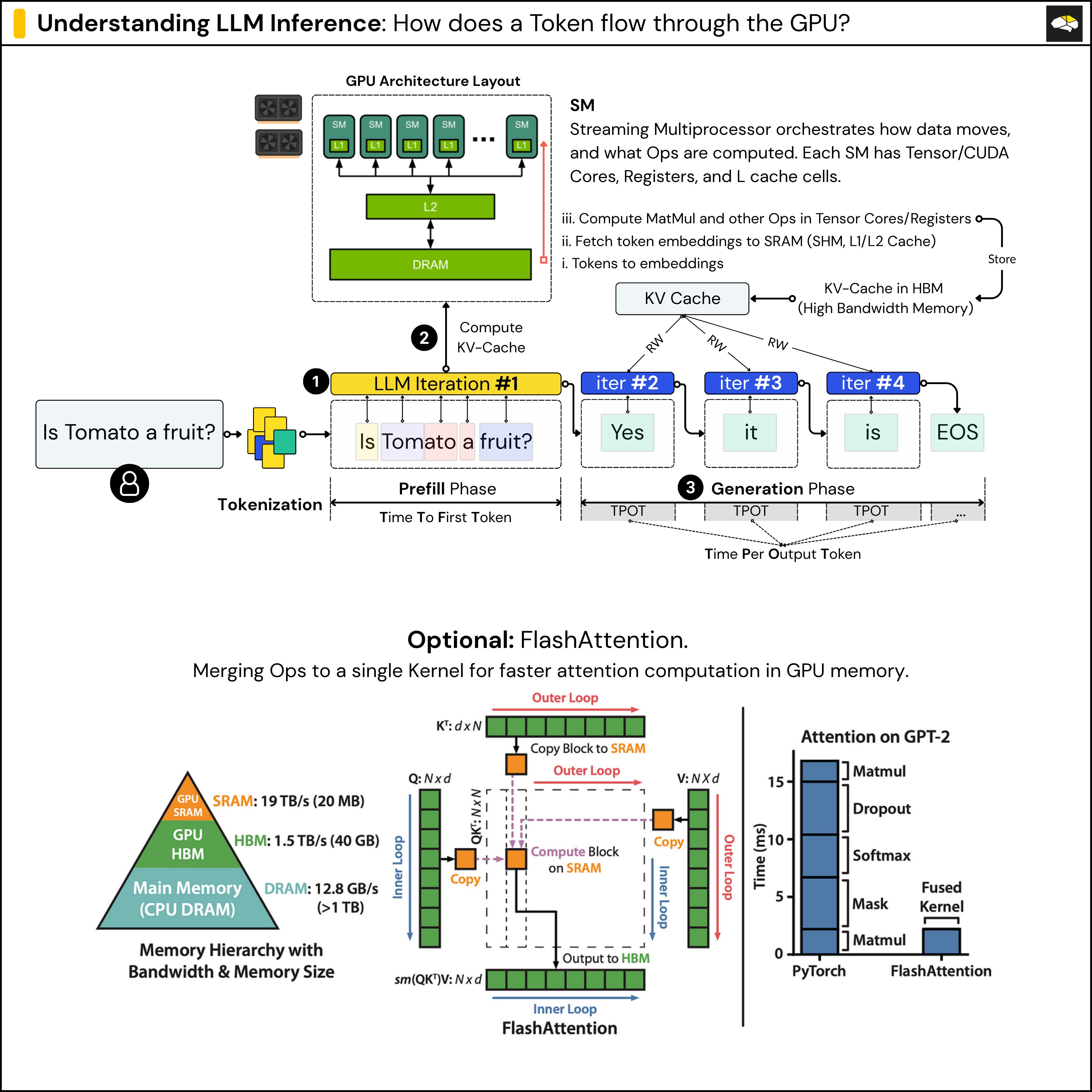
Understanding LLM Inference - by Alex Razvant
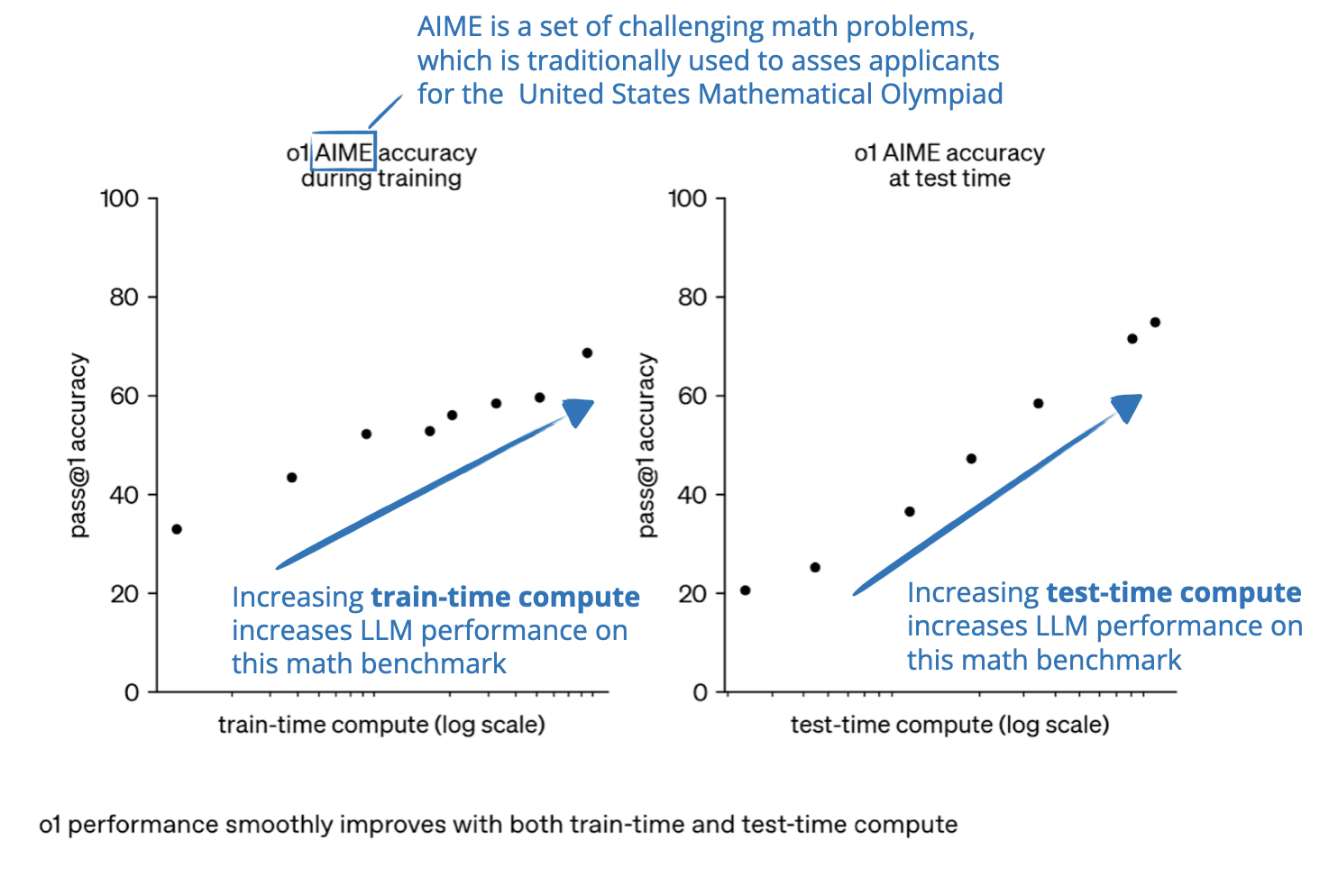
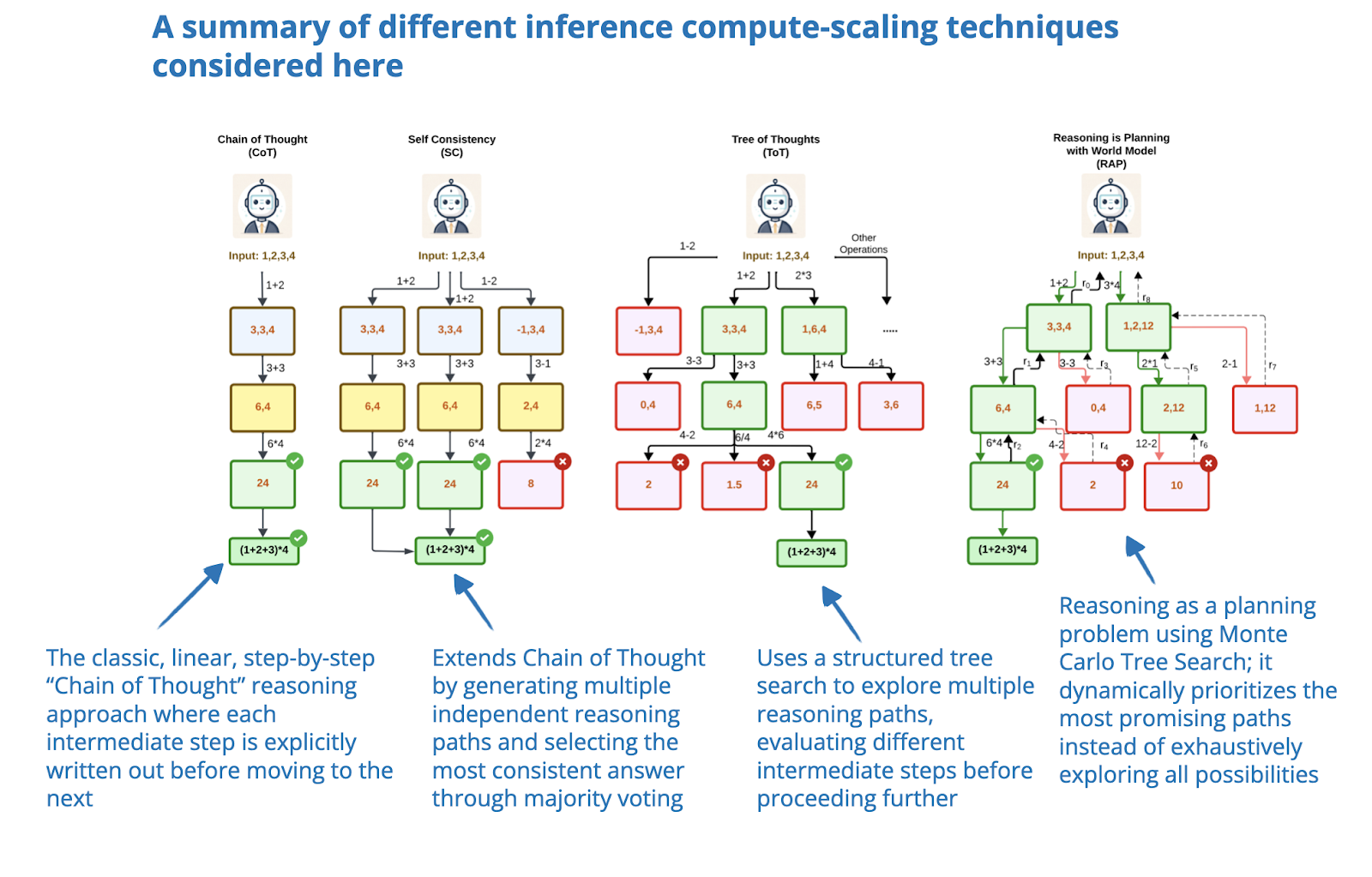
The State of LLM Reasoning Model Inference
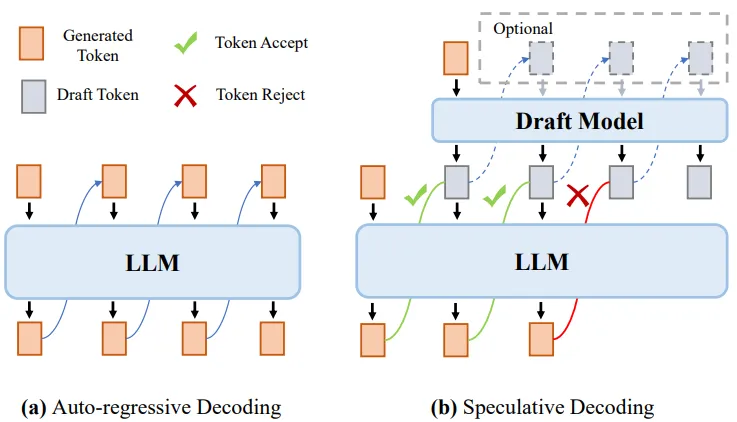
Speculative Decoding — Make LLM Inference Faster | Medium | AI Science
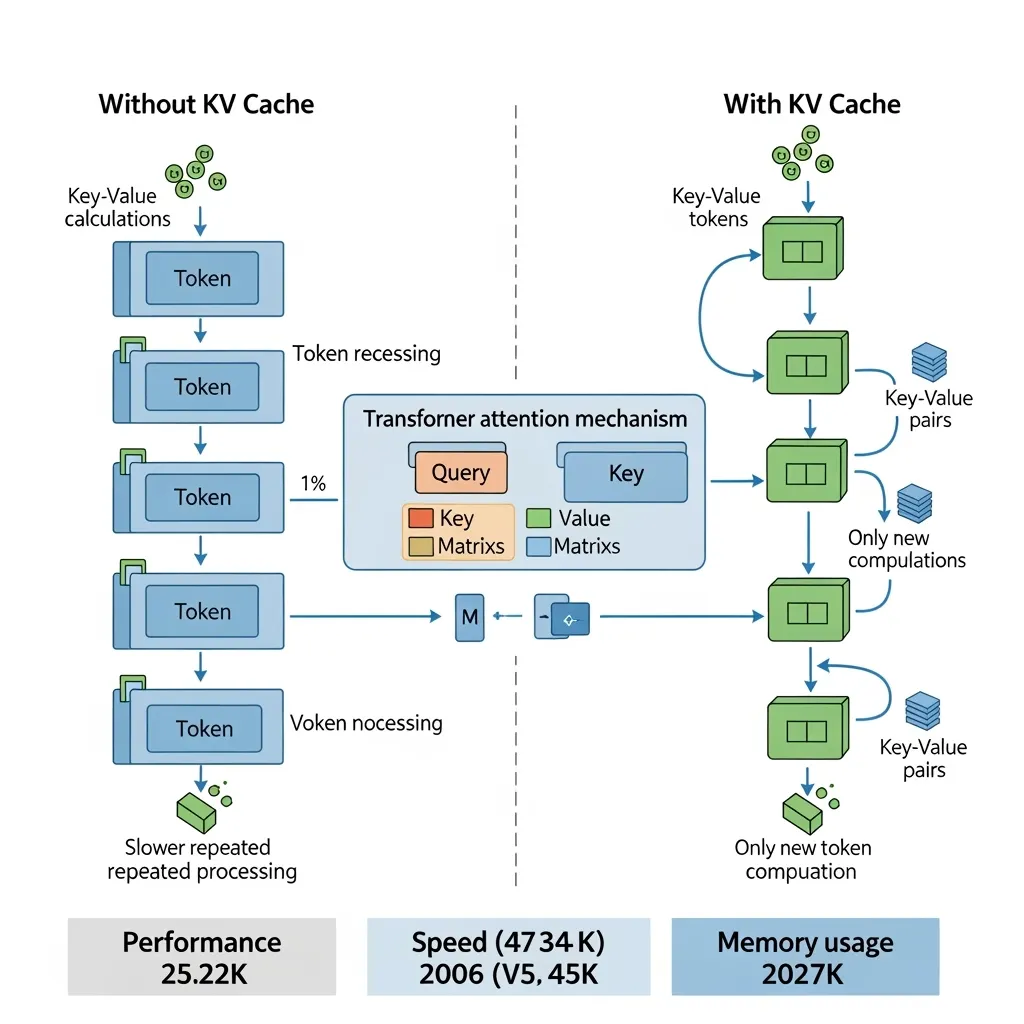
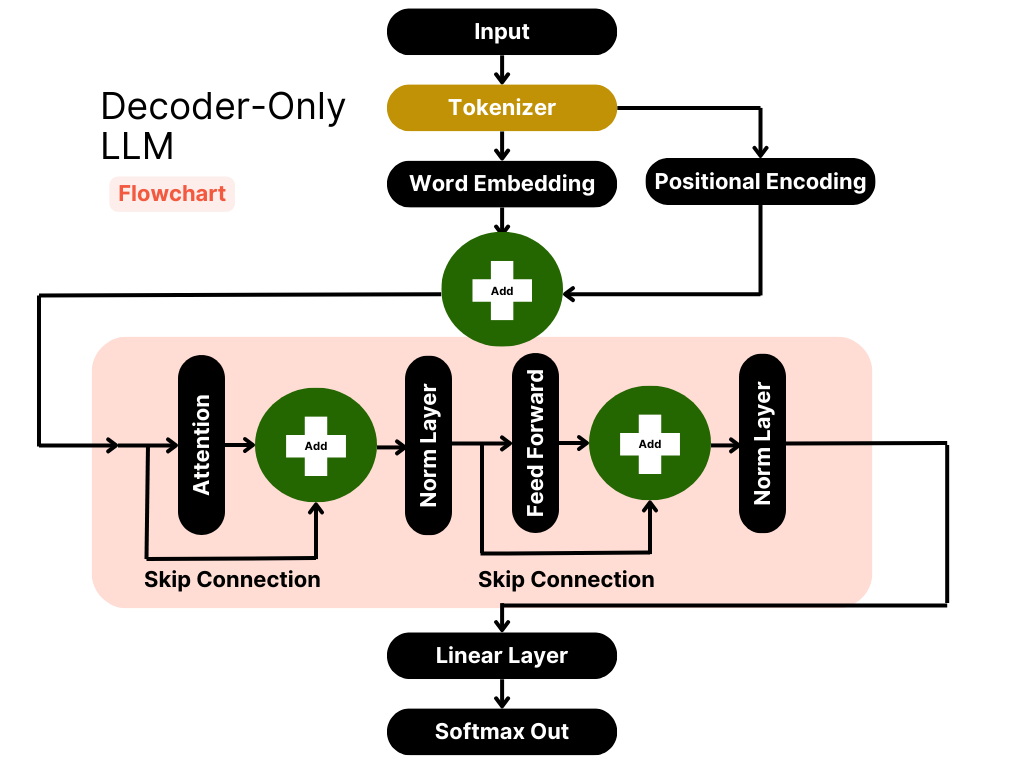
LLM Inference — A Detailed Breakdown of Transformer Architecture and ...
Illustration of the privacy-preserving LLM inference. The LLM inference ...
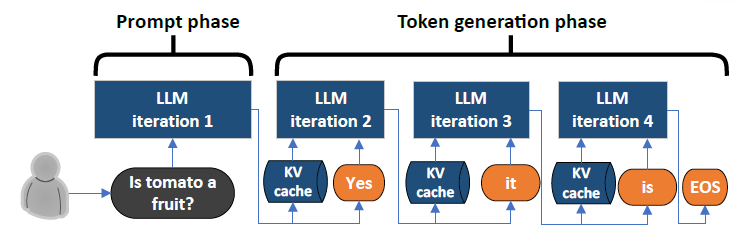
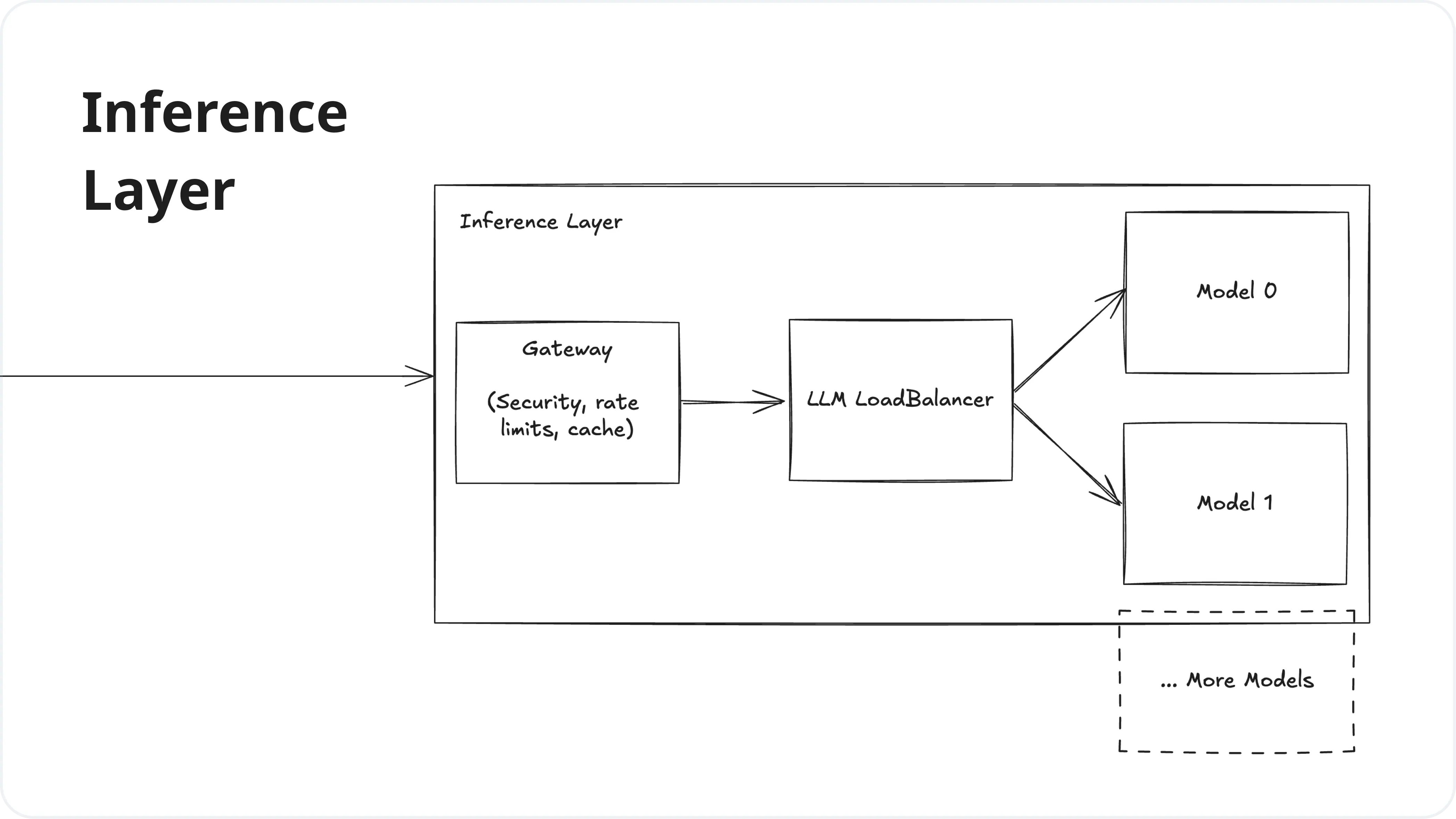
LLM Inference Stages Diagram | Stable Diffusion Online
Illustration of the proposed method. (a) LLM inference comprises two ...
LLM inference optimization: Model Quantization and Distillation - YouTube
Understanding LLM Batch Inference | Adaline
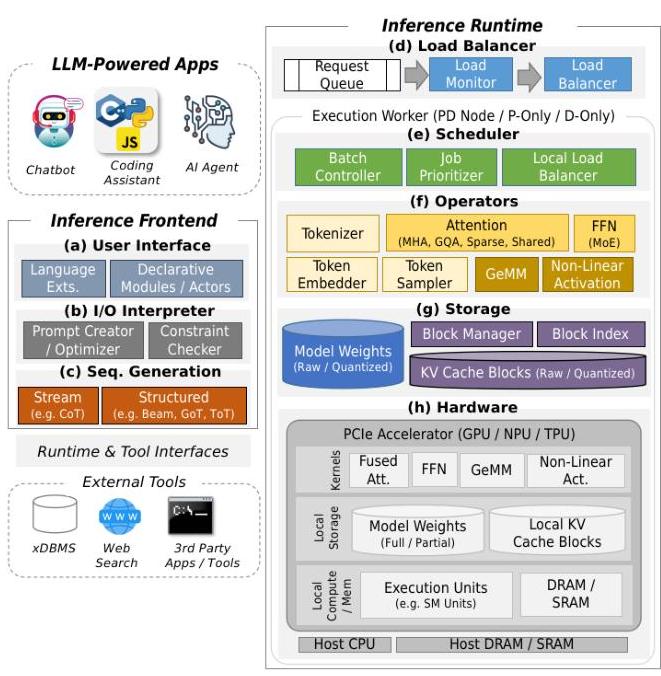
LLM Inference Optimization Overview - From Data to System Architecture
LLM Inference - Hw-Sw Optimizations
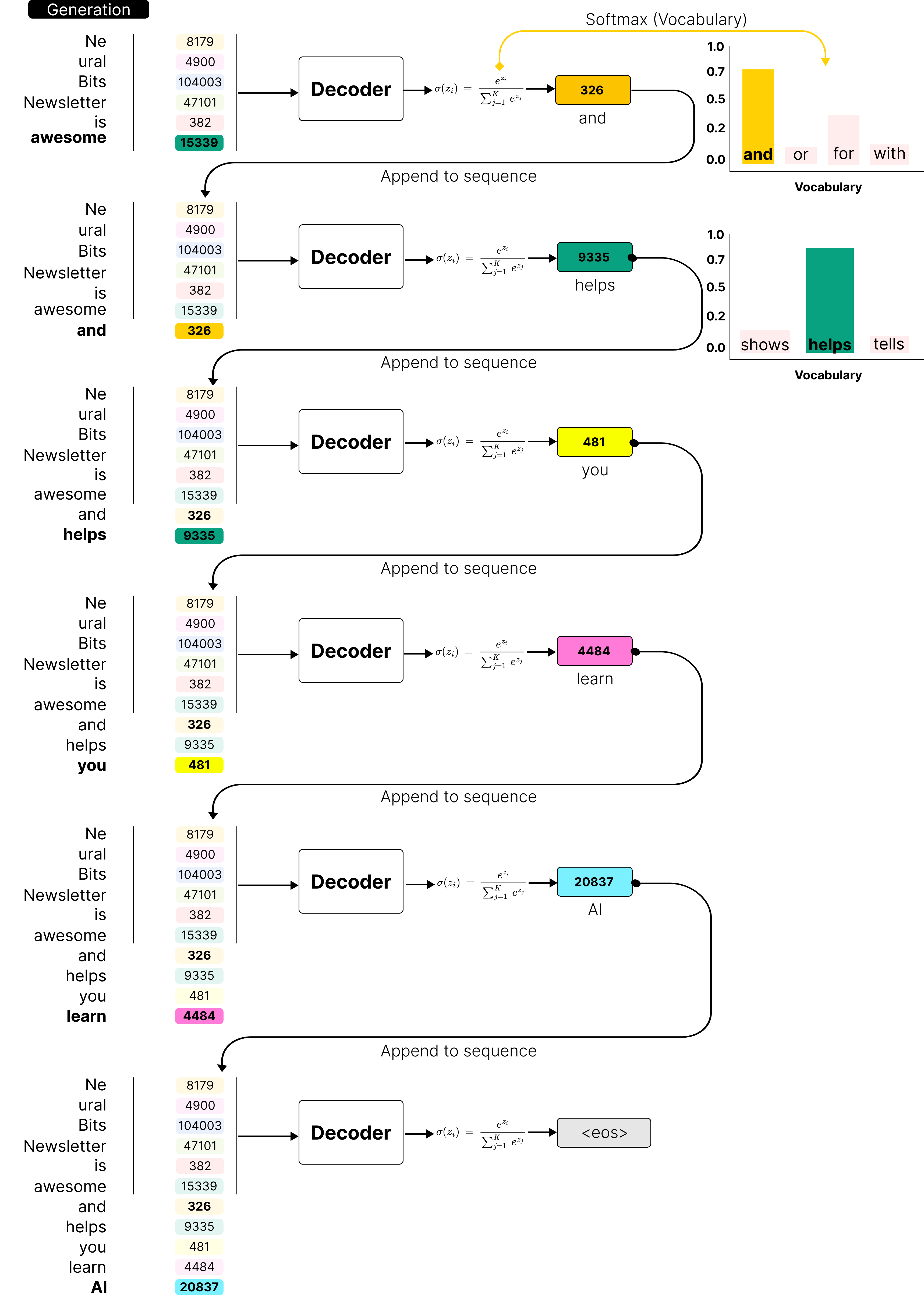
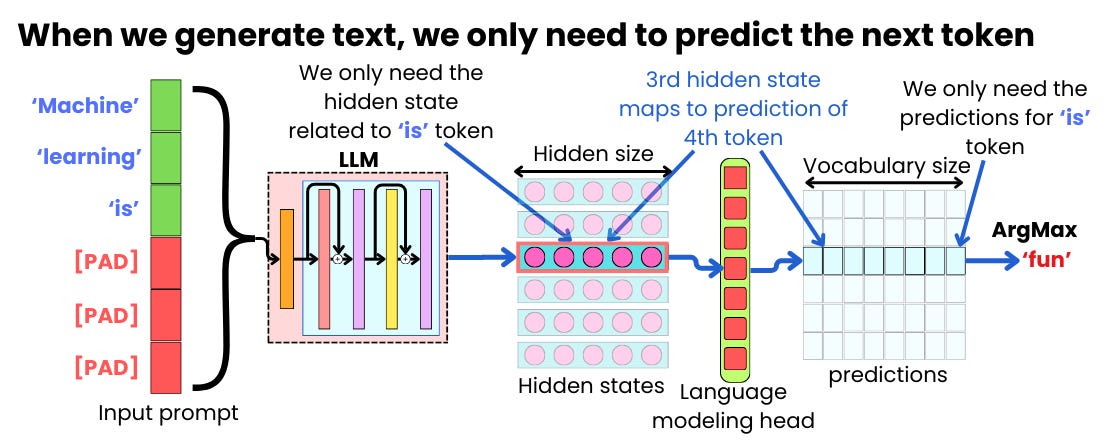
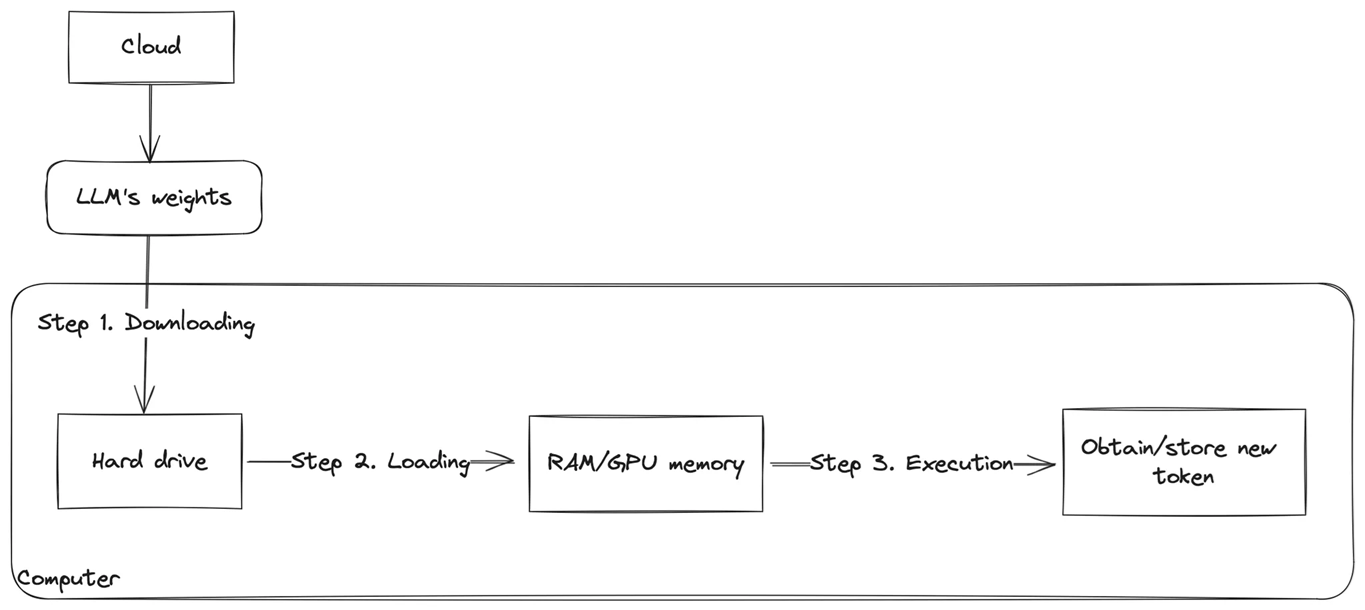
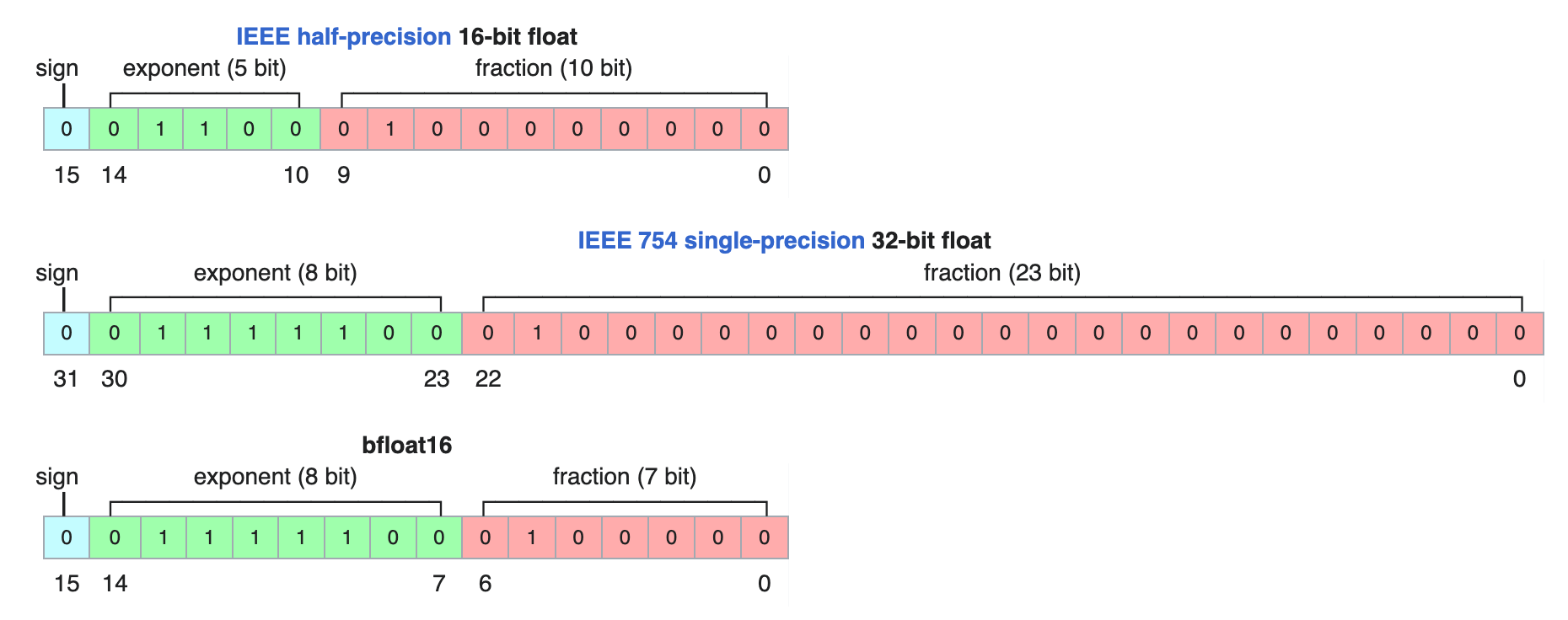
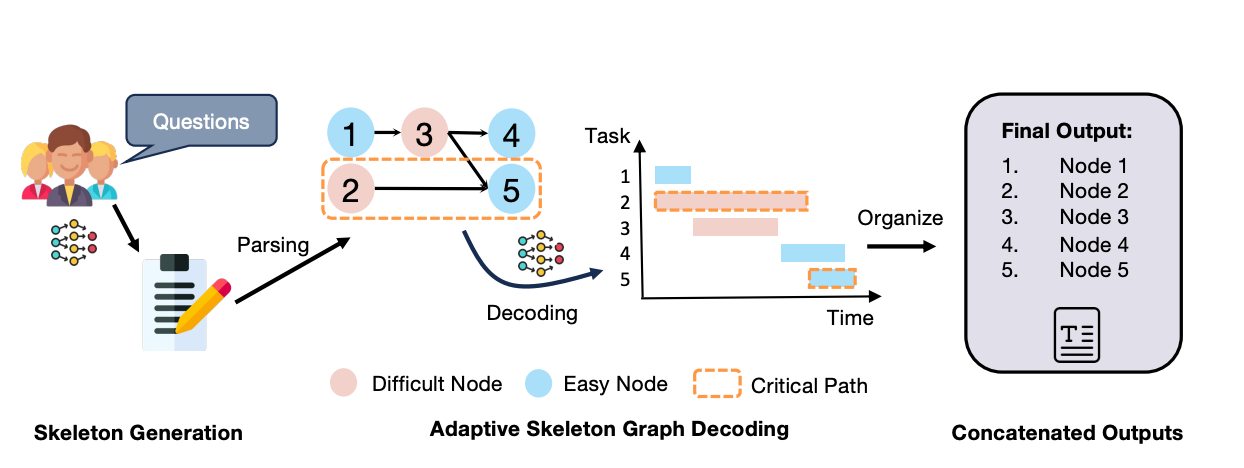
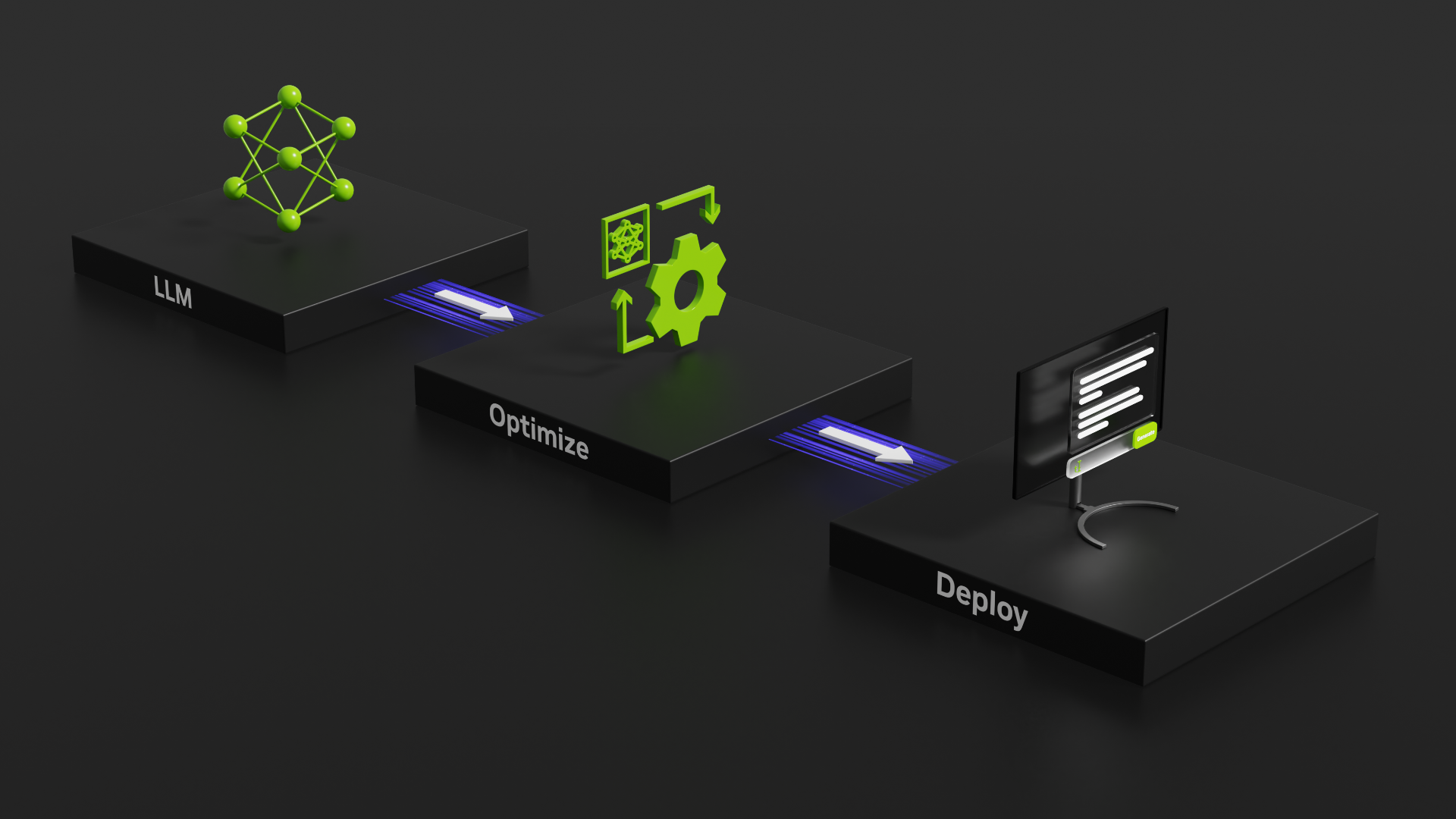
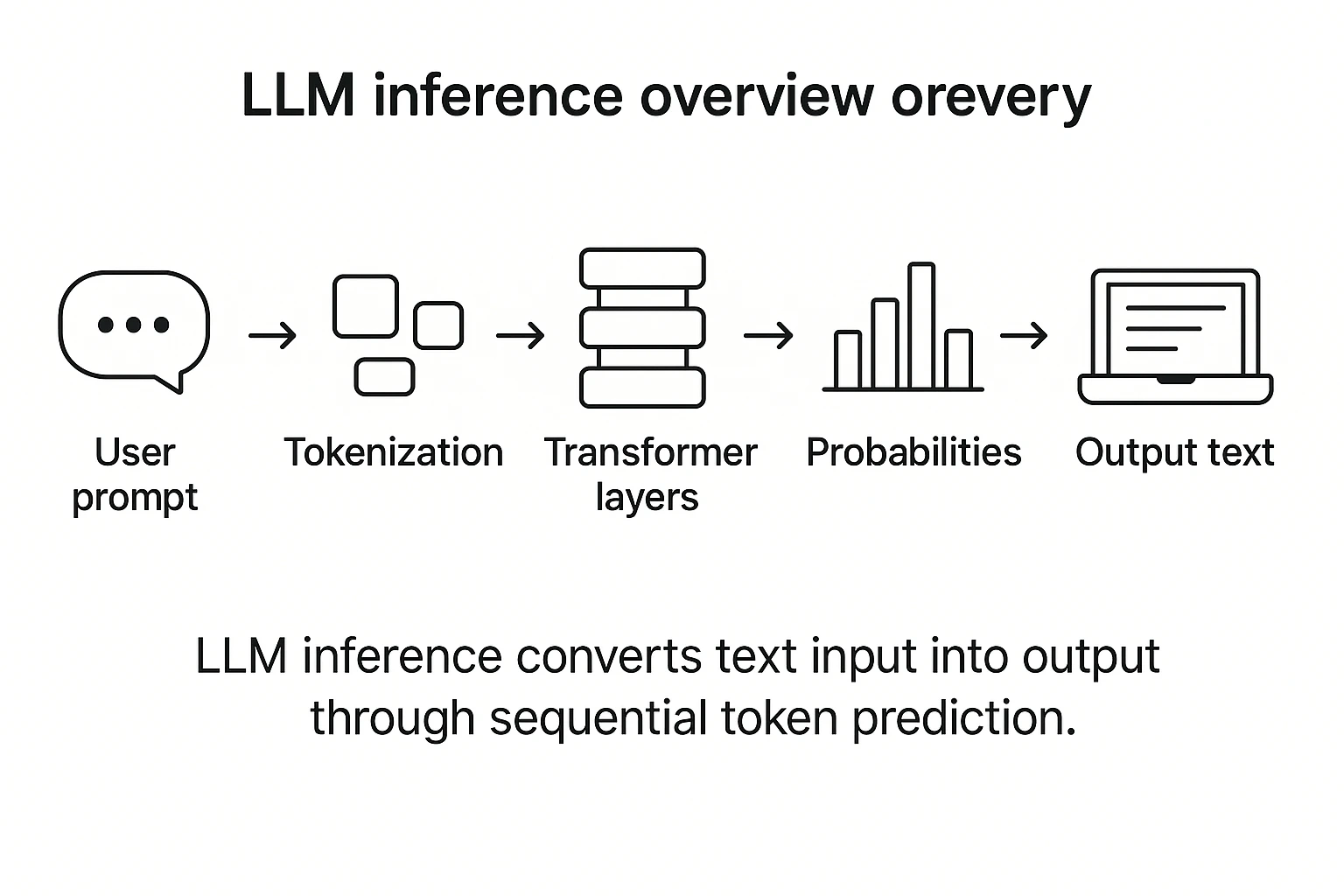
How does LLM inference work? | LLM Inference Handbook
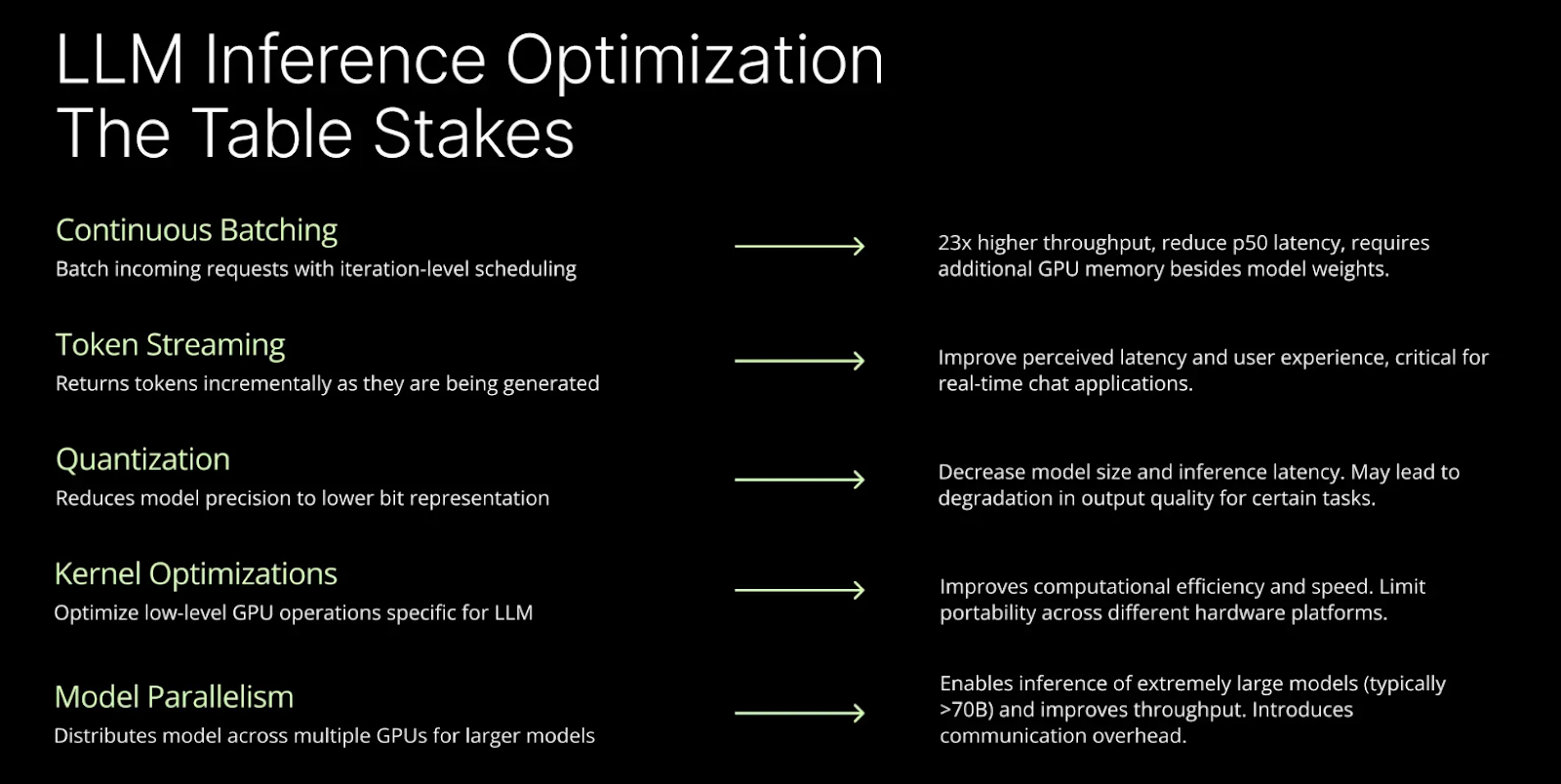
How continuous batching enables 23x throughput in LLM inference ...
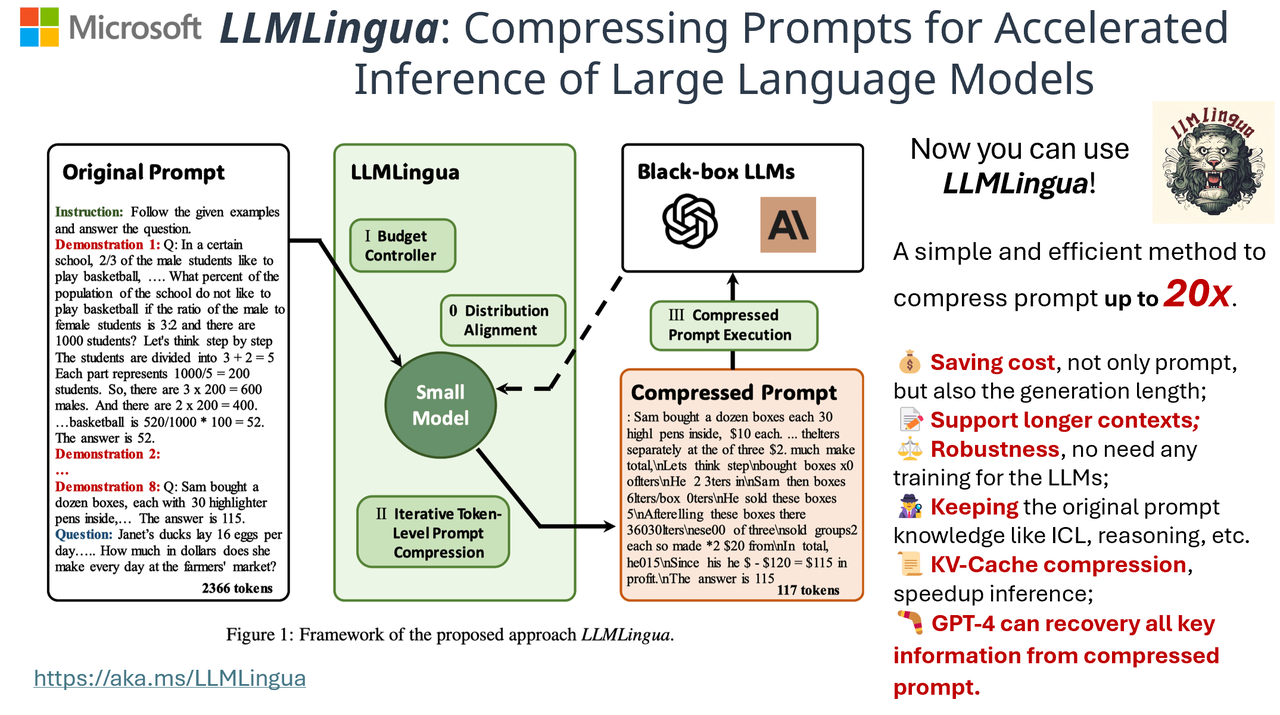
LLM Inference Optimization Techniques: A Comprehensive Analysis | by ...
Achieve 23x LLM Inference Throughput & Reduce p50 Latency
Choosing the right inference framework | LLM Inference Handbook
LLM Inference Parameters Explained Visually
Introduction to LLM Inference Benchmarking | Yu-Chen Cheng's Blog
A guide to LLM inference and performance | Baseten Blog
High-performance LLM inference | Modal Docs
(PDF) Improving the inference performance of LLM with code
LLM Inference
How to Scale LLM Inference - by Damien Benveniste
LLM Inference Essentials
Efficient LLM inference - by Finbarr Timbers
LLM Inference Benchmarking: Performance Tuning with TensorRT-LLM ...
LLM Inference Unveiled: Survey and Roofline Model Insights
A guide to open-source LLM inference and performance - Bens Bites
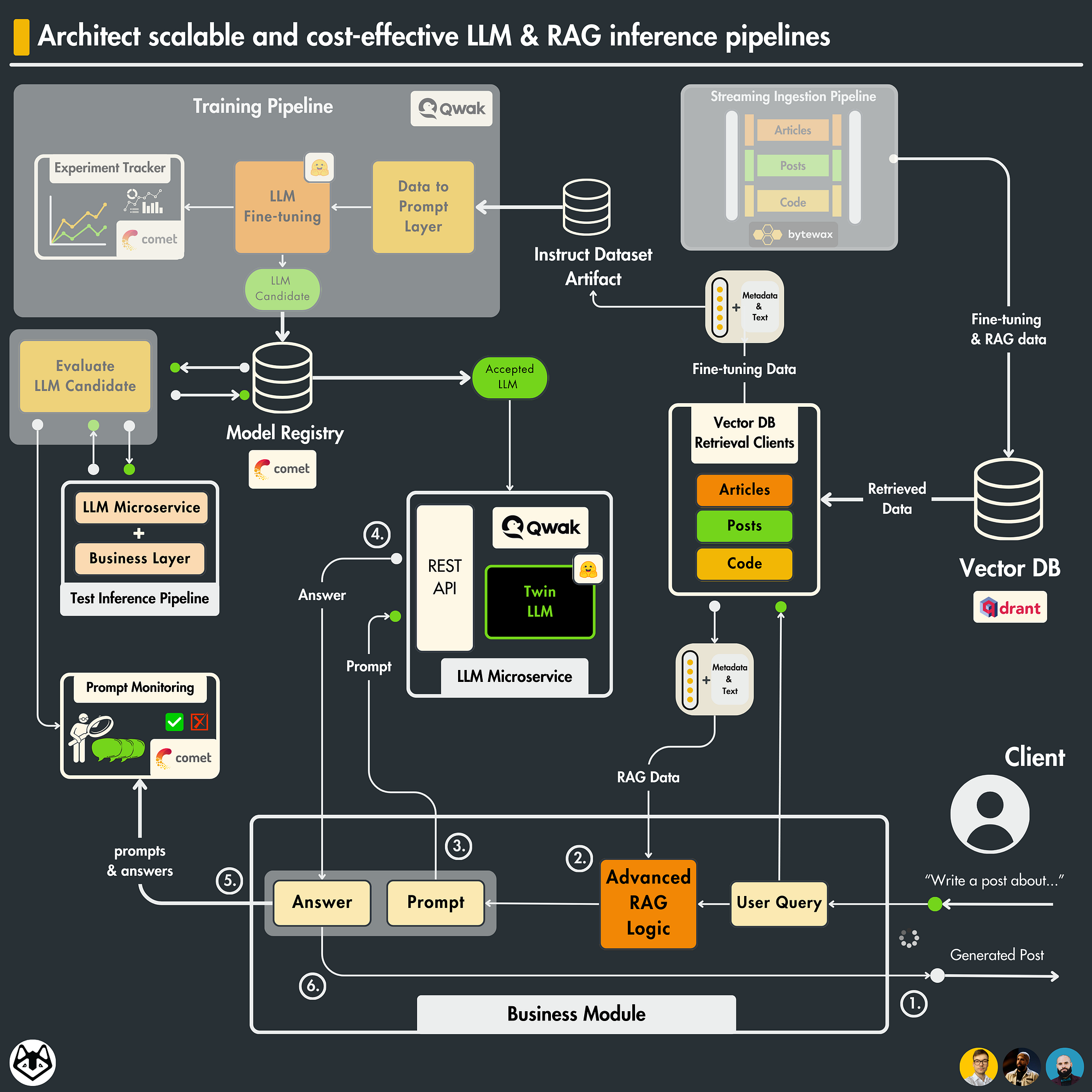
How to Architect Scalable LLM & RAG Inference Pipelines
Understanding the LLM Inference Workload: Key Insights
LLM in a flash: Efficient LLM Inference with Limited Memory
LLM Inference ( vLLM , TGI, TensorRT ) | by Pratik | Medium
Overview of an Example LLM Inference Setup - YouTube
LLM Inference v_s Fine-Tuning | PDF | Cognitive Science | Computational ...
A Survey of LLM Inference Systems | alphaXiv
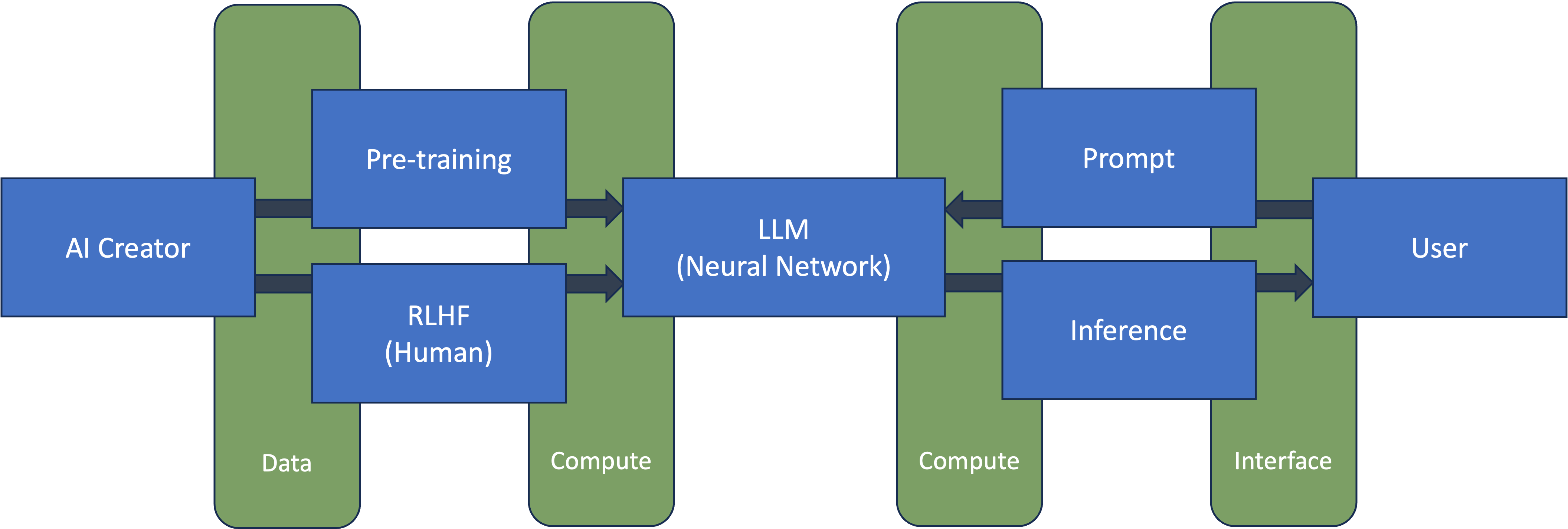
How LLM really works: From Training to Talking – The Power of Inference
LLM Inference Hardware: An Enterprise Guide to Key Players | IntuitionLabs
LLM Inference Series: 1. Introduction | by Pierre Lienhart | Medium
Does Model and Inference Parameter Matter in LLM Applications? - A Case ...
LLM Inference Hardware: Emerging from Nvidia's Shadow
Understanding LLM Inference | NVIDIA Experts Deconstruct How AI Works ...
A Guide to LLM Inference Performance Monitoring | Symbl.ai
Deep Dive: Optimizing LLM inference - YouTube
LLM Inference Series: 5. Dissecting model performance | by Pierre ...
LLM inference optimization: Tutorial & Best Practices | LaunchDarkly
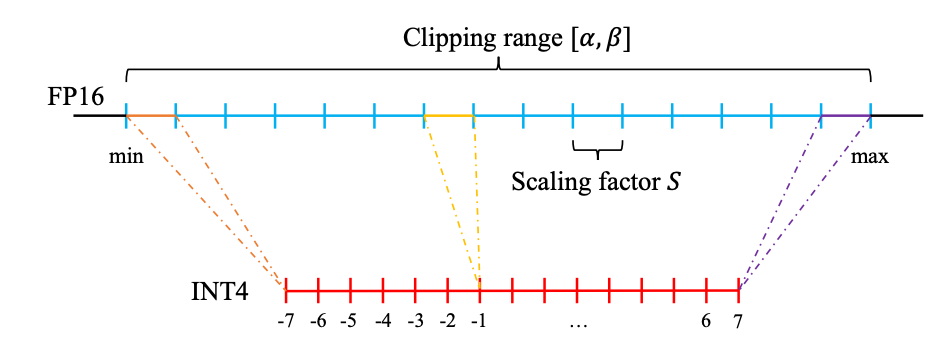
(PDF) Sustainable LLM Inference for Edge AI: Evaluating Quantized LLMs ...
[2402.16363] LLM Inference Unveiled: Survey and Roofline Model Insights
LLM Inference Archives | Uplatz Blog
Fault-Tolerance for LLM Inference | IIJ Engineers Blog
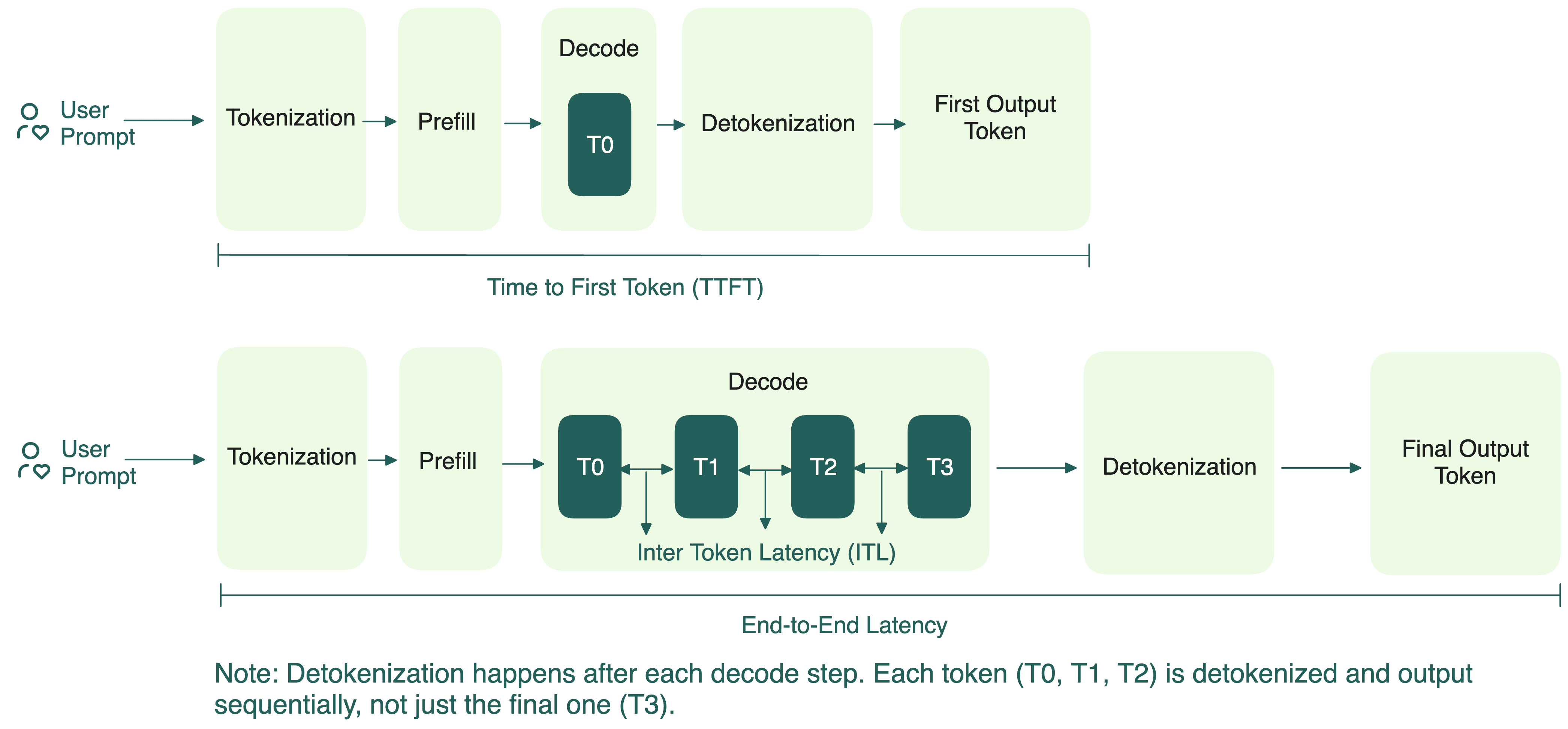
LLM Inference Benchmarking: Fundamental Concepts | NVIDIA Technical Blog
What Is LLM Inference? Process, Latency & Examples Explained (2026)
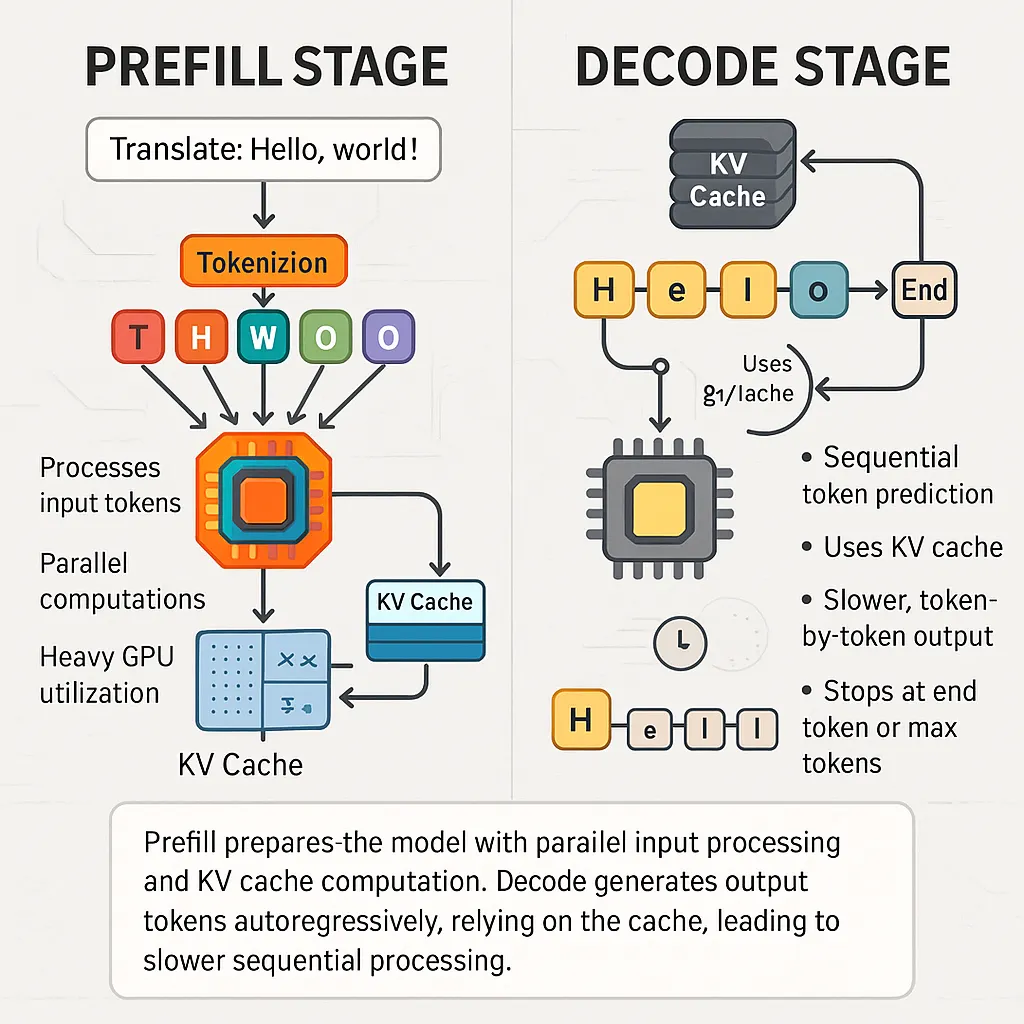
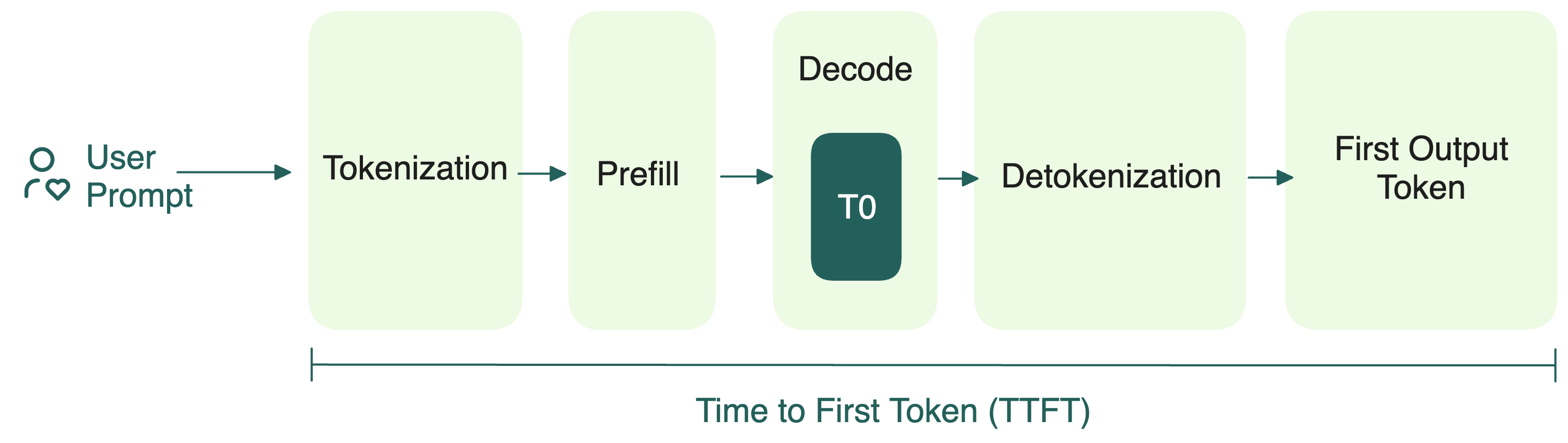
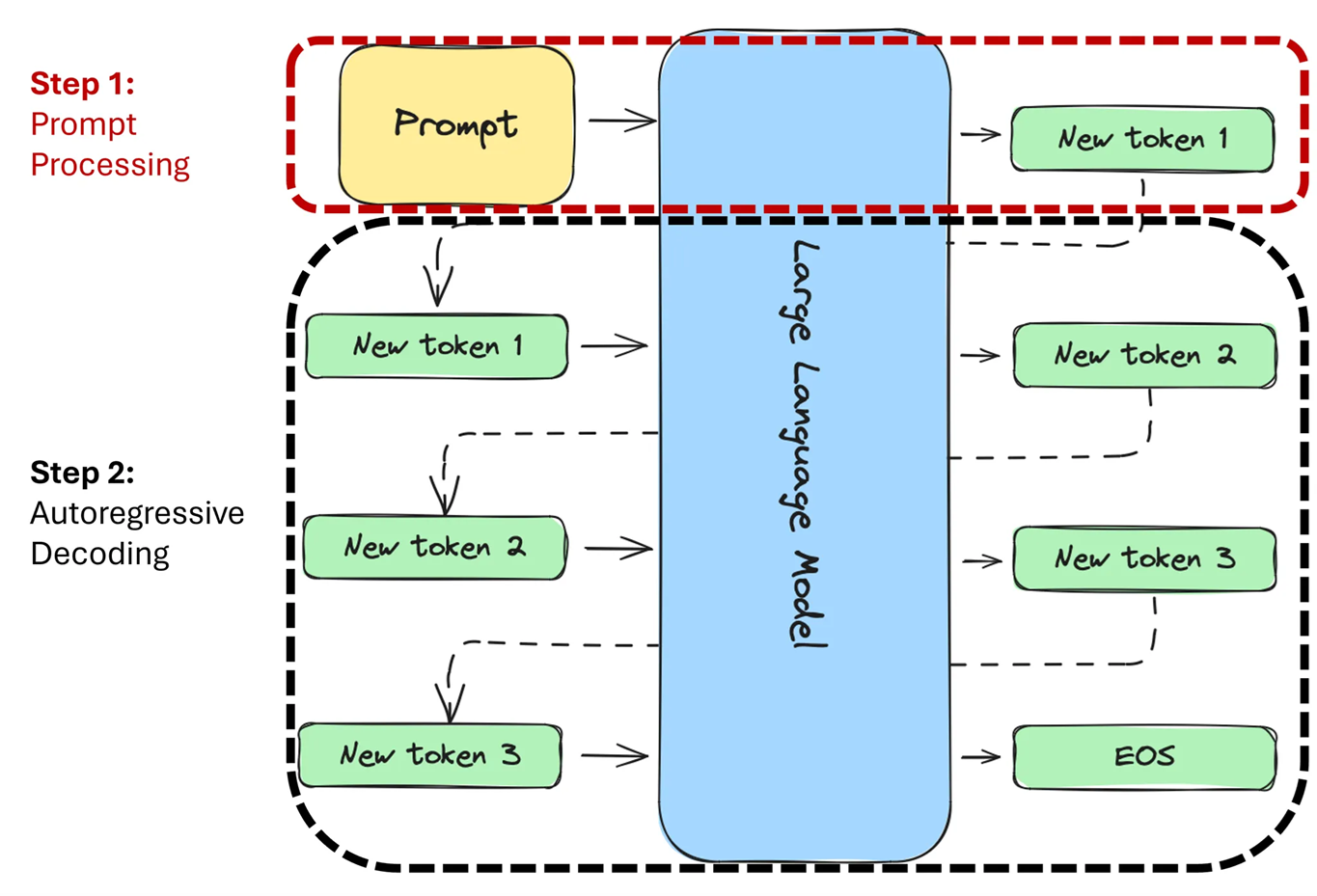
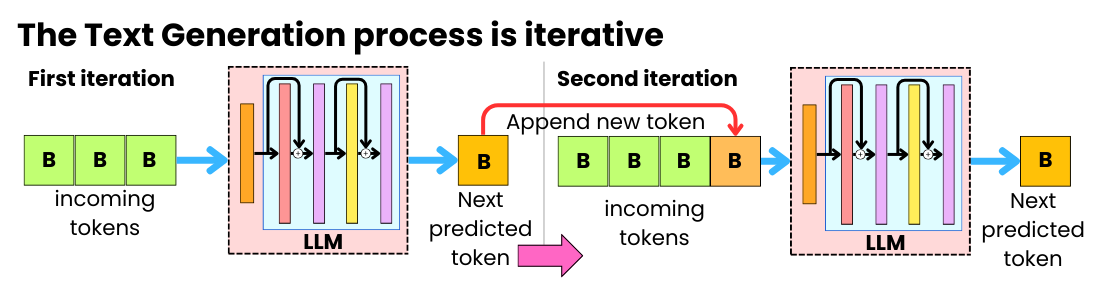
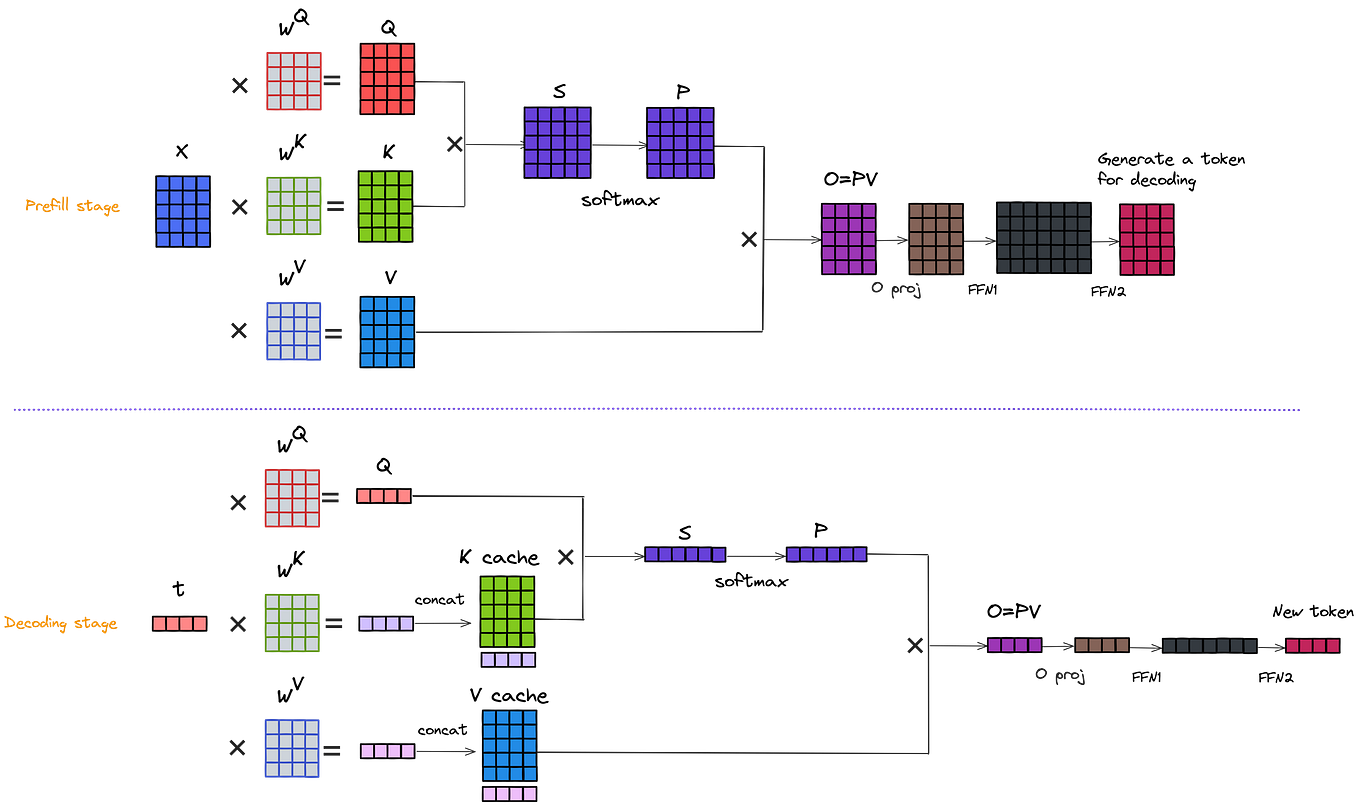
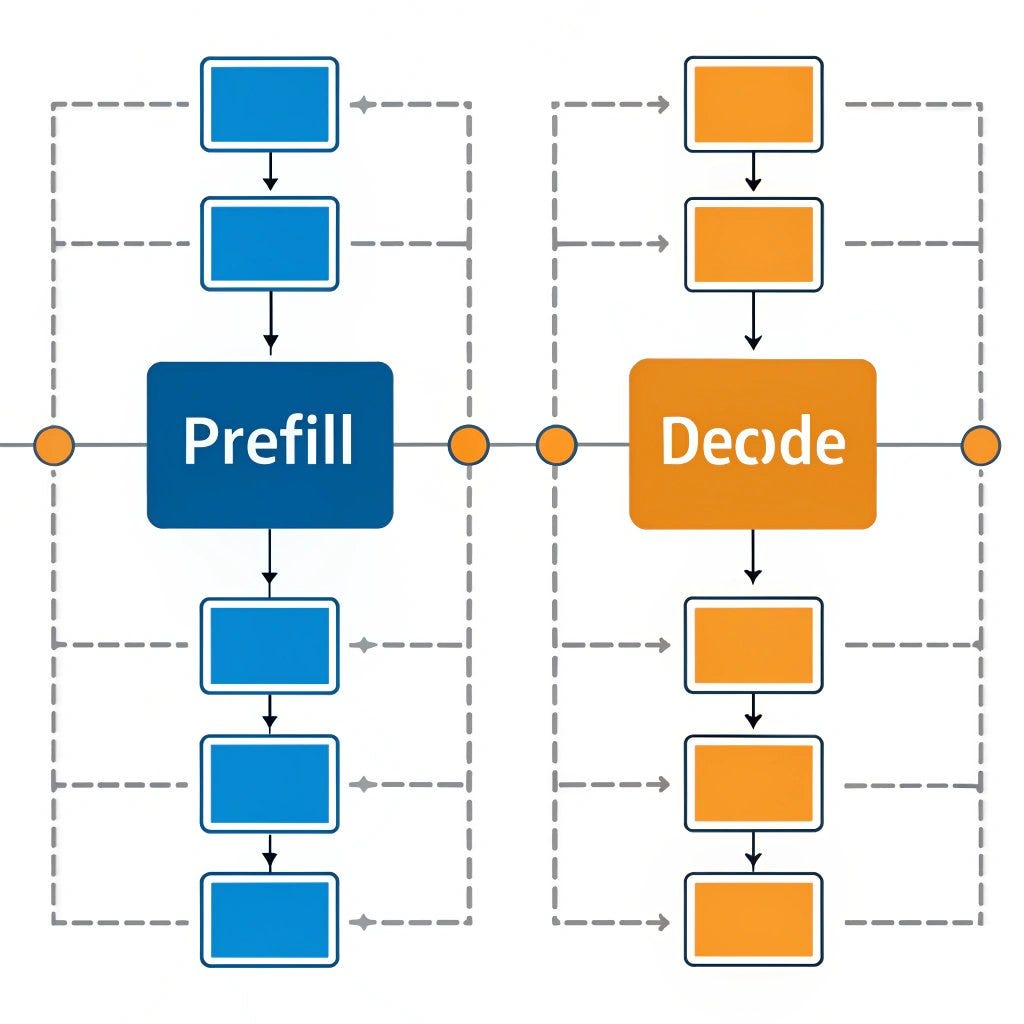
Understanding the Two Key Stages of LLM Inference: Prefill and Decode ...
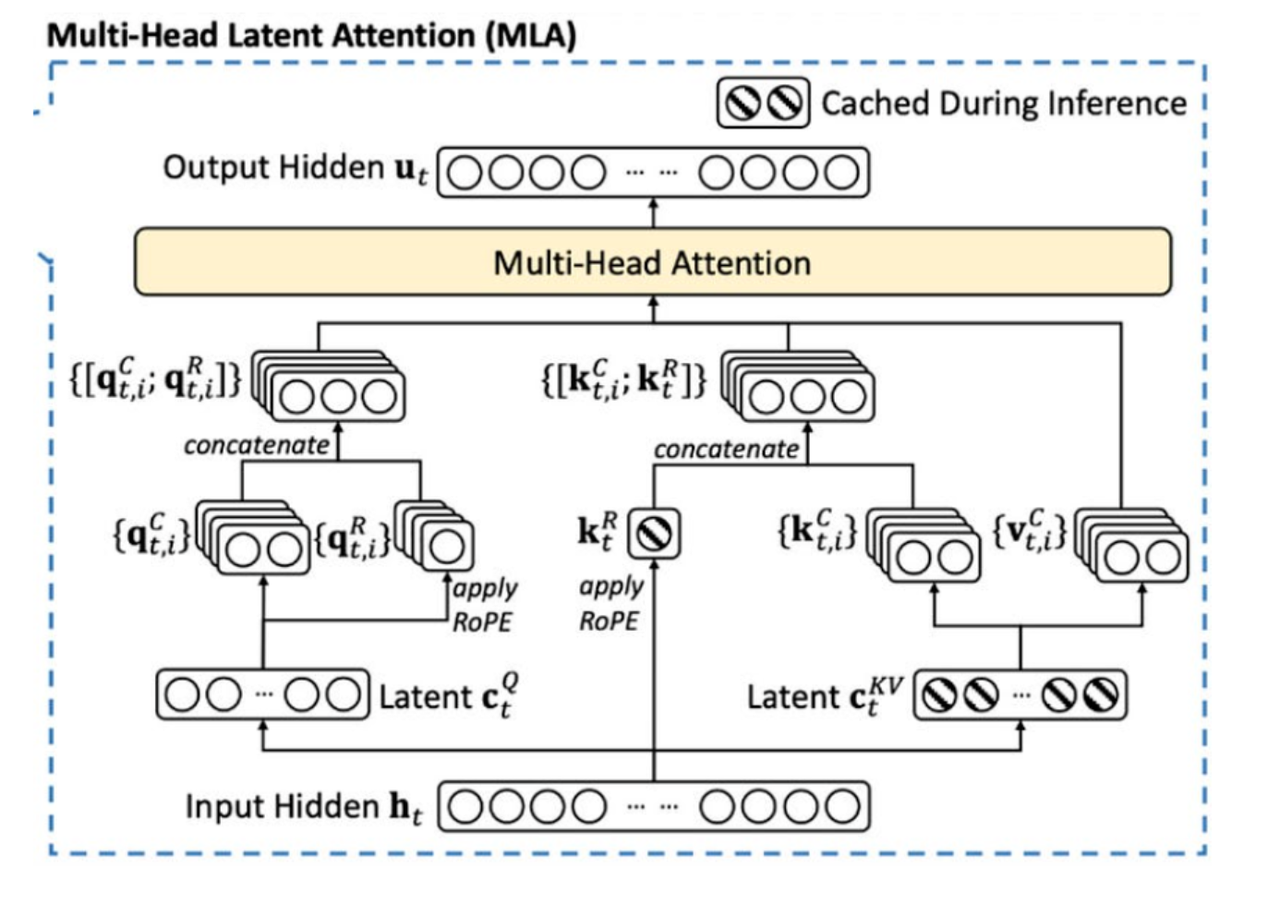
The Shift to Distributed LLM Inference: 3 Key Technologies Breaking ...
A Guide to Efficient LLM Deployment | Datadance
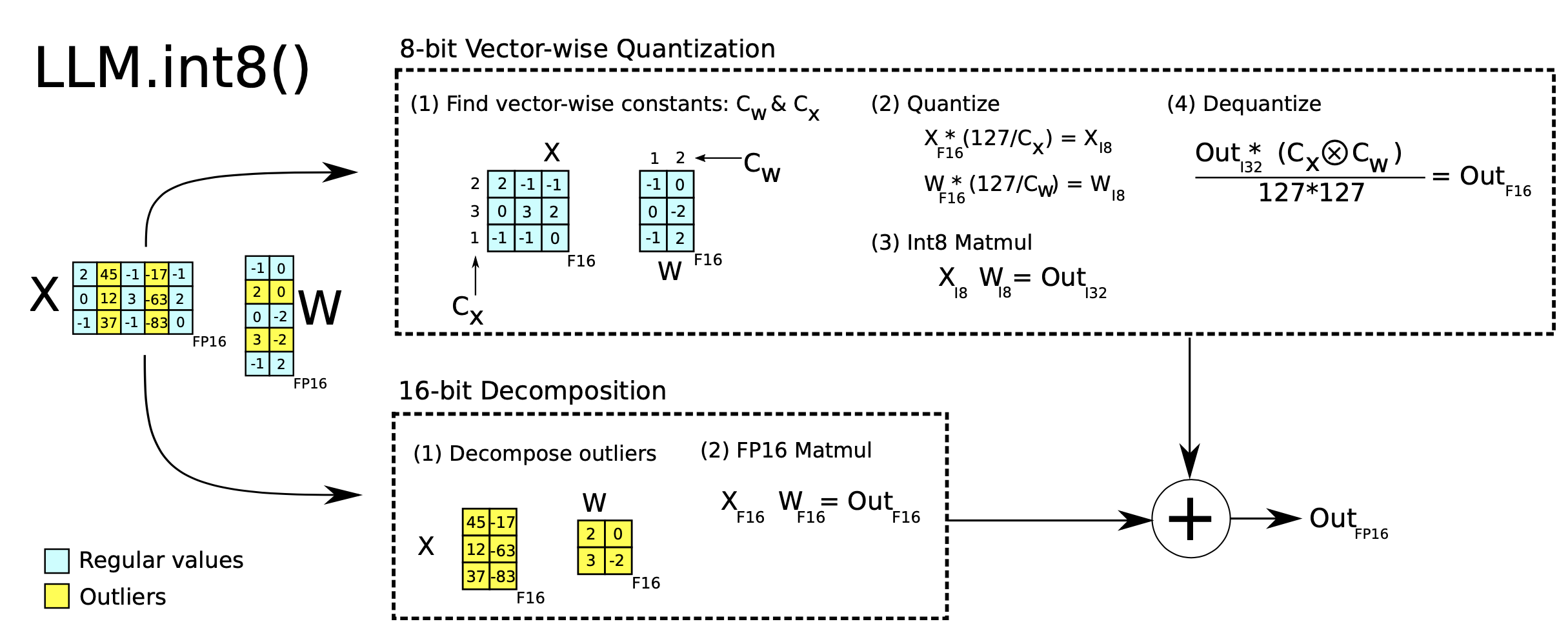
Large Transformer Model Inference Optimization | Lil'Log
Guide to Self-hosting LLM Systems - Zilliz blog
Large Language Models LLMs Distributed Inference Serving System ...
What is LLM Inference? • luminary.blog
The 4 Must-Know LLM Parameters and the Intuitive Math Behind Them - YouTube
What is LLM Model Inference?
The New World of LLM Functions: Integrating LLM Technology into the ...
The Emerging LLM Stack: A Comprehensive Guide for Developers - Helicone
LLM Inference: Techniques for Optimized Deployment in 2025 | Label Your ...
Understanding AI: LLM Basics for Investors
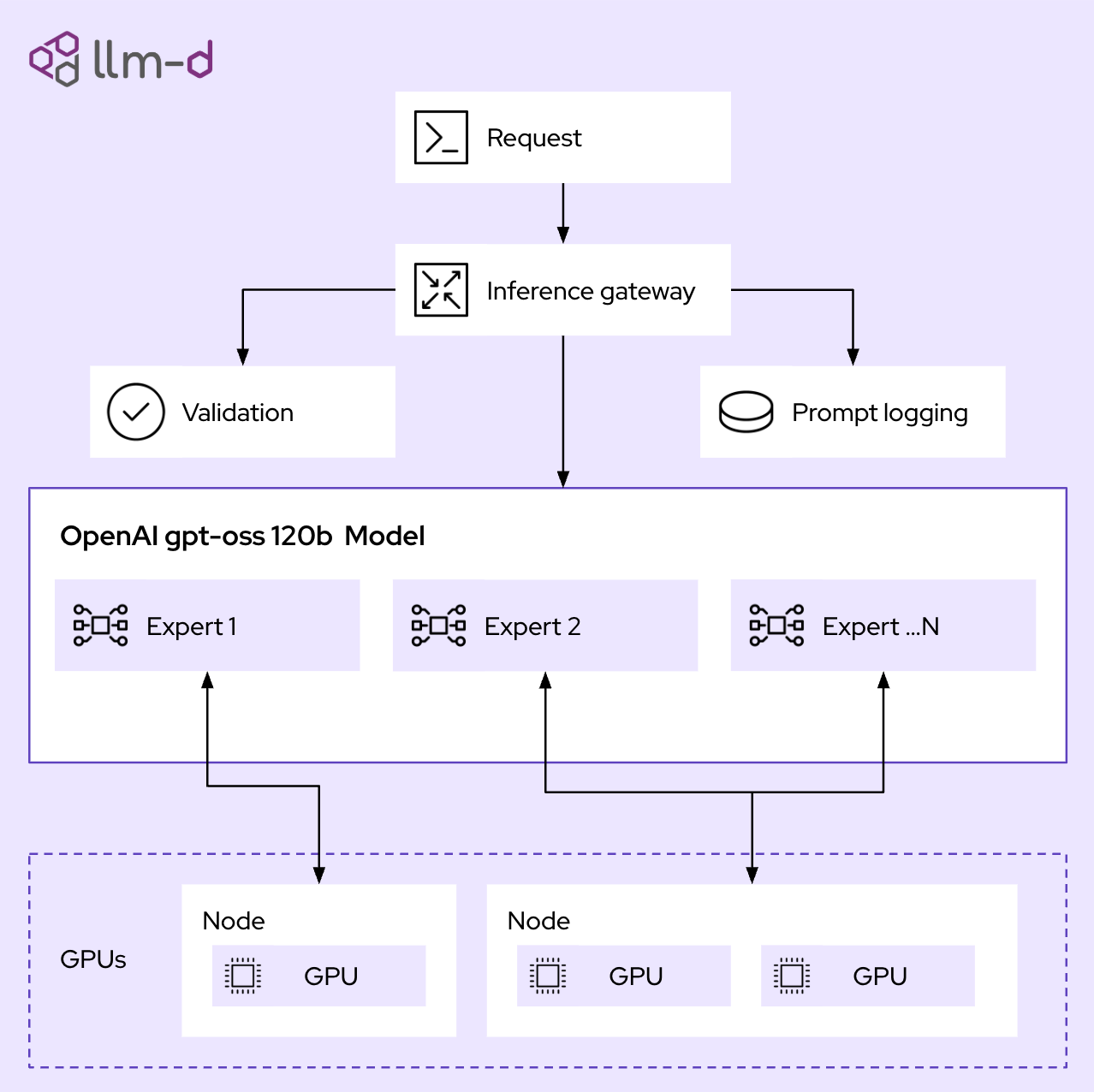
Introduction to distributed inference with llm-d | Red Hat Developer
LLM Inference: how different it is from traditional ML?
Journey LLM 8: Activation Functions | by Akshay Jain | Medium
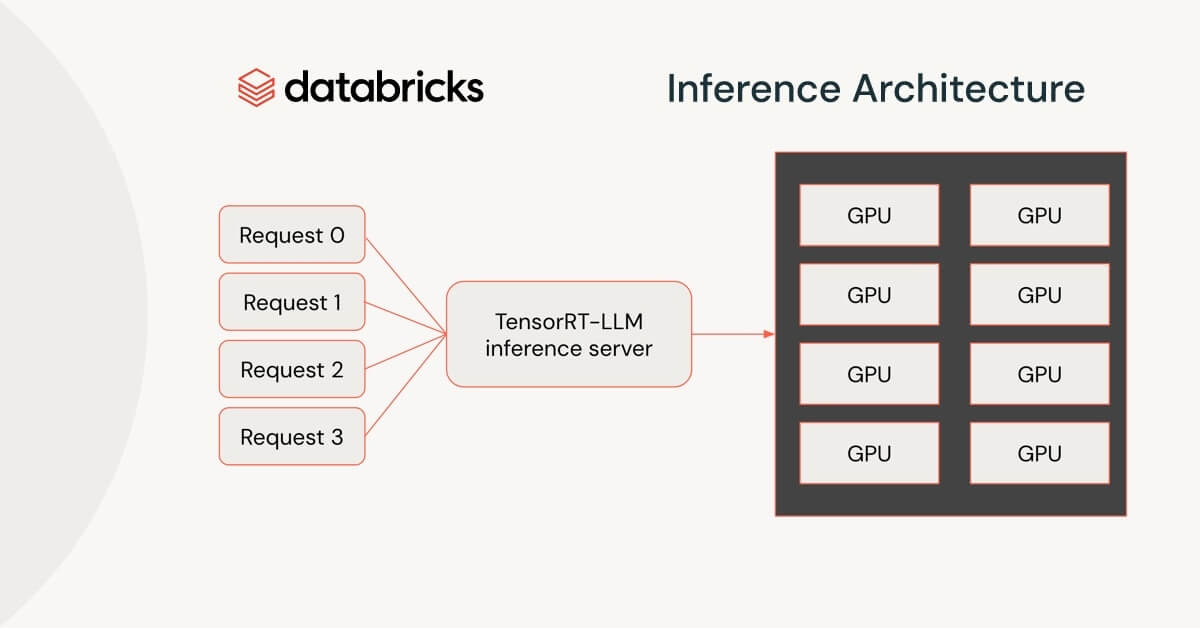
Integrating NVIDIA TensorRT-LLM with the Databricks Inference Stack ...
Optimizing LLM Inference. Optimization begins where architectures… | by ...
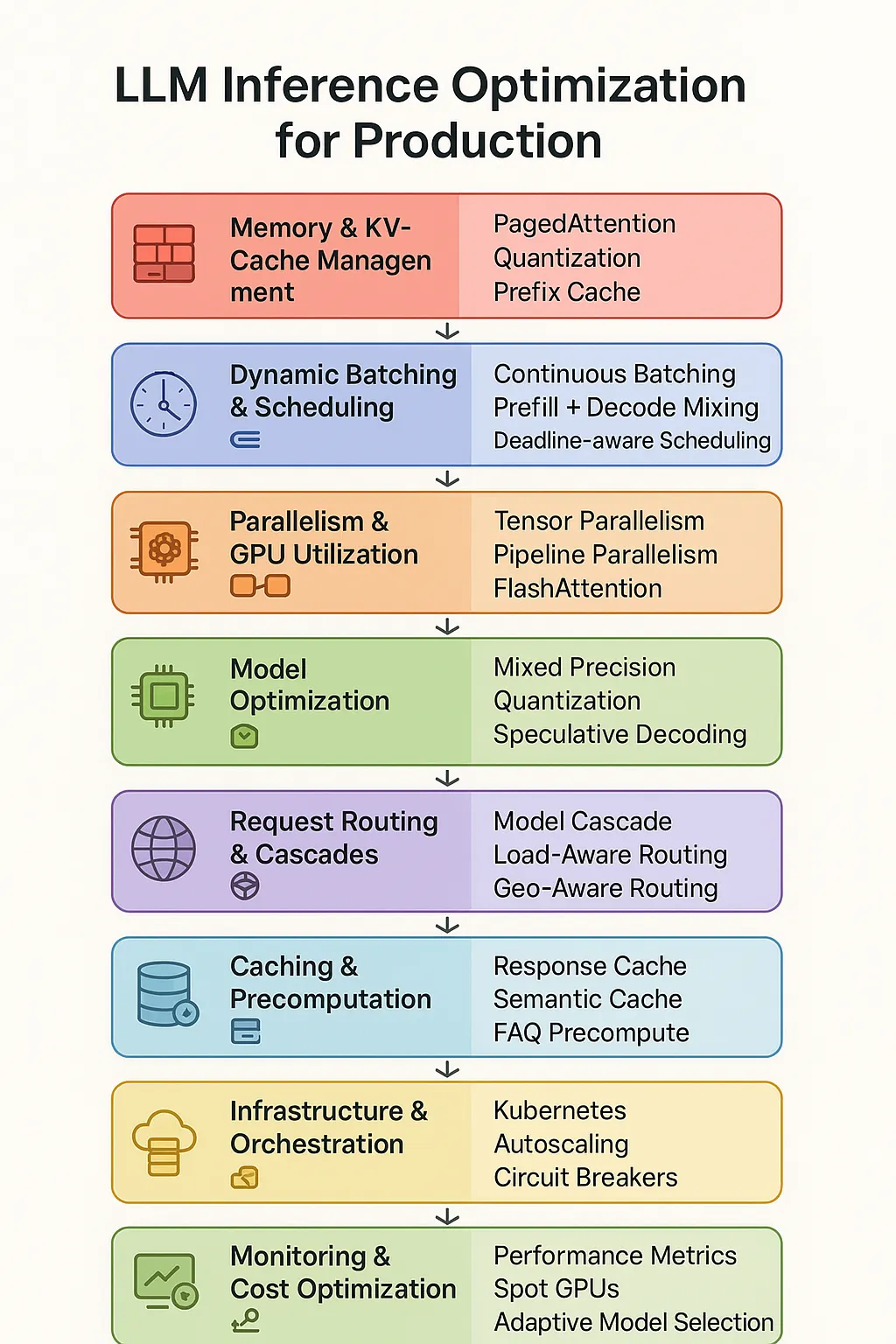
Ways to Optimize LLM Inference: Boost Response Time, Amplify Throughput ...
Basic Understanding of Loss Functions and Evaluation Metrics in AI ...
LightLLM: A Lightweight, Scalable, and High-Speed Python Framework for ...
一起理解下LLM的推理流程_llm推理过程-CSDN博客
GitHub - modelize-ai/LLM-Inference-Deployment-Tutorial: Tutorial for ...
【LLM】LangChain入门:构建LLM驱动的应用程序入门指南 | AI开发者中心
From Text to Action: How LLMs Became AI Agents
Optimizing Large Language Model Inference: A Deep Dive into Continuous
图文详解LLM inference:LLM模型架构详解 - 知乎
GitHub - UranusSeven/Effective-LLM-Inference-Evaluation: A project ...
(PDF) Towards Efficient Multi-LLM Inference: Characterization and ...
GitHub - Yiyi-philosophy/LLM-inference: LLM-inference code
GitHub - graphcore-research/llm-inference-research: An experimentation ...