Showing 109 of 109on this page. Filters & sort apply to loaded results; URL updates for sharing.109 of 109 on this page
Int4 Precision for AI Inference | NVIDIA Technical Blog
Int4 Precision for AI Inference - Edge AI and Vision Alliance
Why INT4 is presented as performance of GPUs? - Deep Learning - fast.ai ...
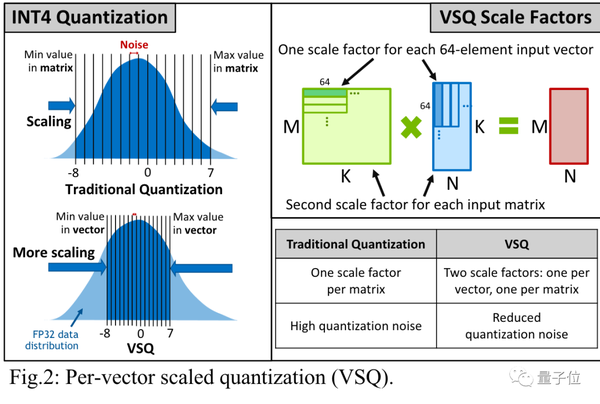
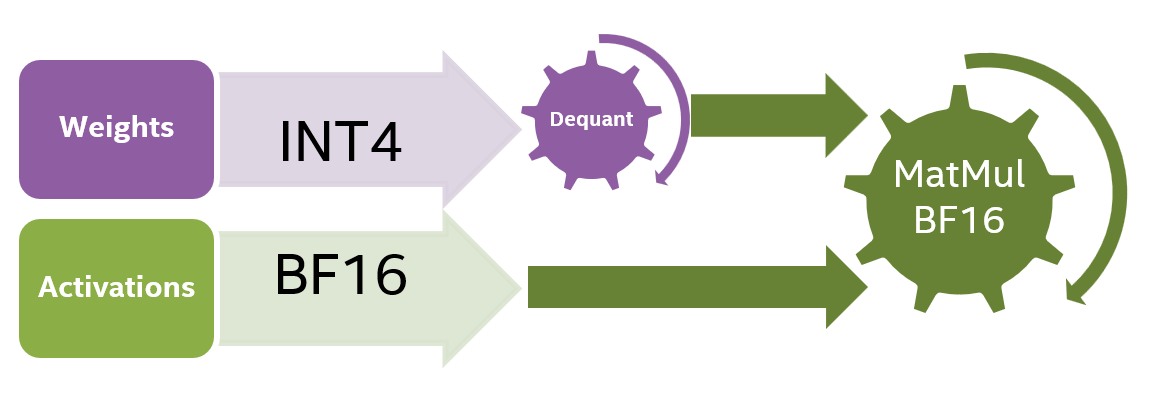
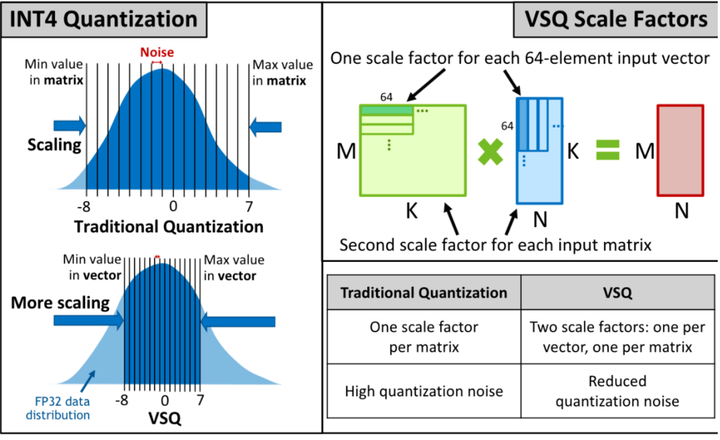
Left: Unsigned INT4 quantization compared to unsigned FP4 2M2E ...
Understanding Int4 scalar quantization in Lucene - Search Labs
(PDF) Understanding INT4 Quantization for Transformer Models: Latency ...
[2301.12017] Understanding INT4 Quantization for Language Models ...
[Quantization] int4 vs fp4 which to choose?
[RFC][Tensorcore] INT4 end-to-end inference - pre-RFC - Apache TVM Discuss
INT4 and other low-precision conversion support status · Issue #64193 ...
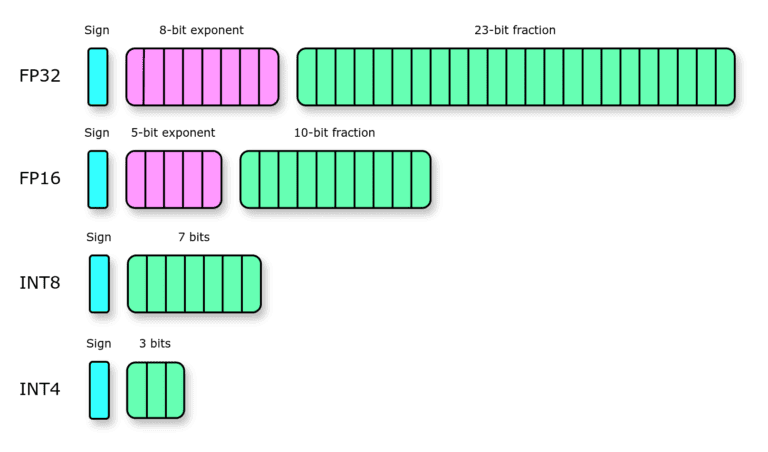
Understanding FP32, FP16, and INT8 Precision in Deep Learning Models ...
INT4 Quantization (with code demonstration)
INT4 Decoding GQA CUDA Optimizations for LLM Inference | PyTorch
INT4
Table 1 from Understanding Int4 Quantization for Language Models ...
Int4
Advanced 1746-INT4 Analog Input Module: Precision Data Collection for ...
INT4 解码 GQA CUDA 优化用于 LLM 推理 – PyTorch - PyTorch 框架
INT4 Decoding GQA CUDA Optimizations for LLM Inference – PyTorch
Method, system and device for processing int4 data type based on ...
INT4 解码 GQA CUDA 优化用于 LLM 推理 | PyTorch - PyTorch 深度学习库
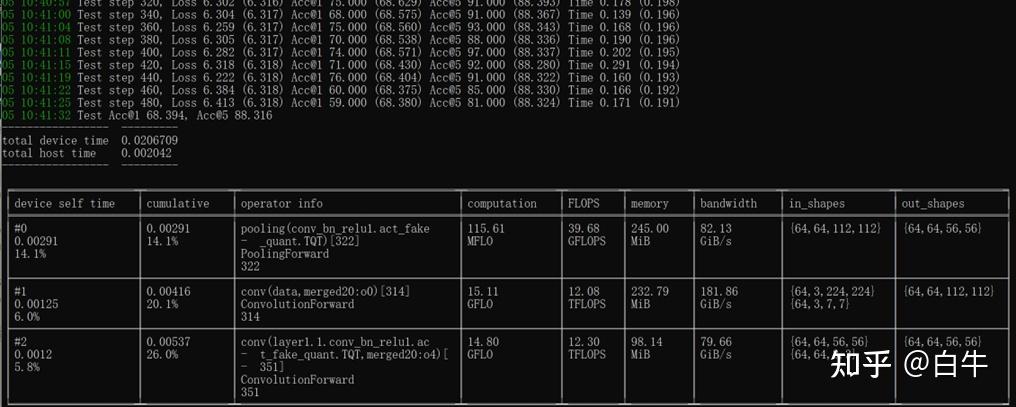
int4 炼丹要术 - 知乎
Low Precision
Precision Computing » image4
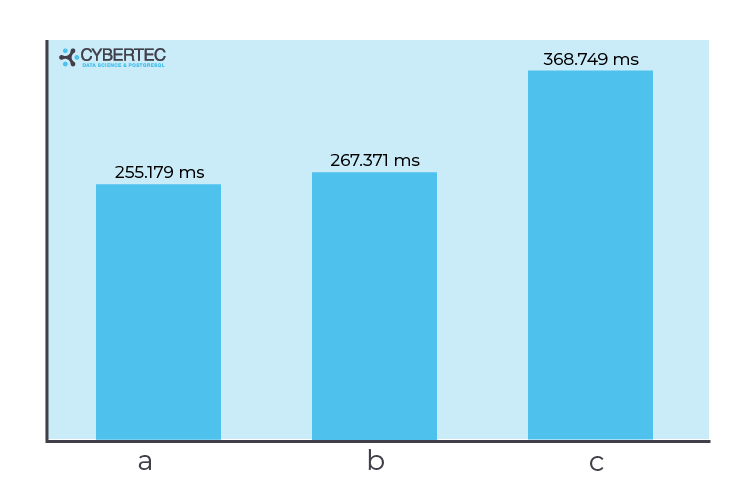
PostgreSQL: int4 vs. float4 vs. numeric | data types - CYBERTEC
Qwen3.5 quantization: INT4 vs NVFP4 vs FP8 vs BF16 I ran full ...
Precision Value Numbers at Tess Harris blog
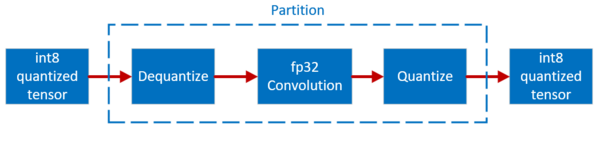
A Hands-On Walkthrough on Model Quantization - Medoid AI
英伟达首席科学家:5nm实验芯片用INT4达到INT8的精度,每瓦运算速度可达H100的十倍 - 知乎
Lunar Lake’s iGPU: Debut of Intel’s Xe2 Architecture
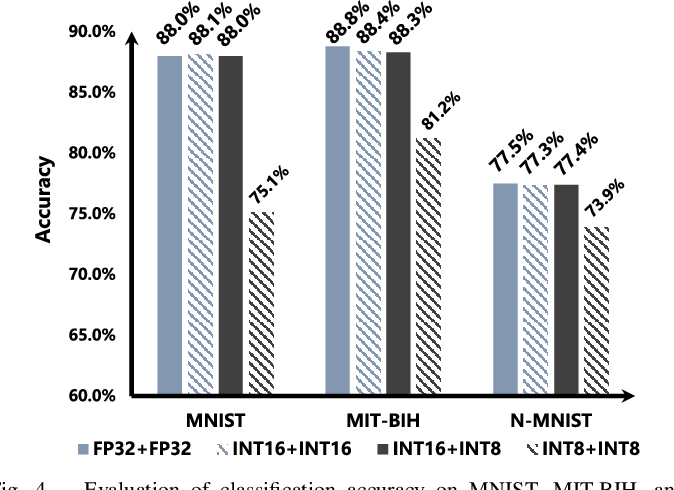
top-1 accuracy of fp32, Tensorflow's INT4-8 and AB INT4- 4 ...
大模型 LLM.int8() 量化技术原理与代码实现-51CTO.COM
使用 珞 Optimum Intel 在英特尔至强上加速 StarCoder: Q8/Q4 及投机解码 - HuggingFace - 博客园
英伟达首席科学家:5nm实验芯片用INT4达到INT8的精度_风闻
(更新中)浮点定点精度及对应运算硬件需求总结 - 知乎
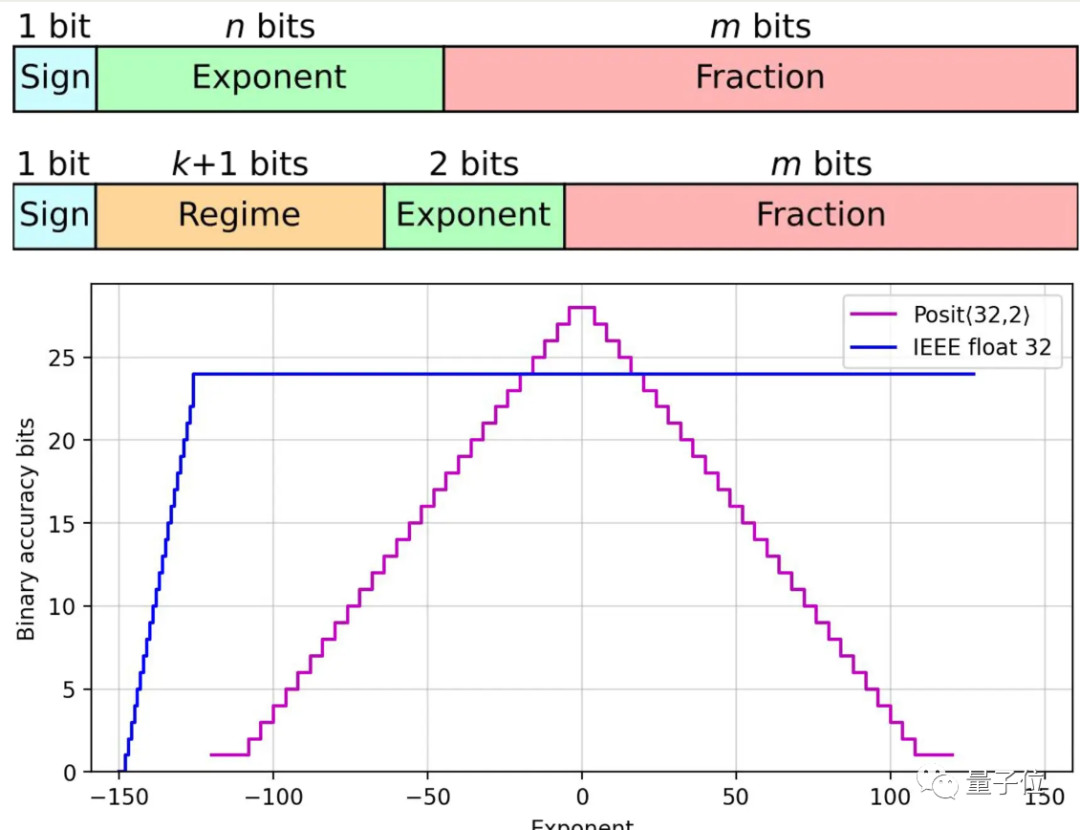
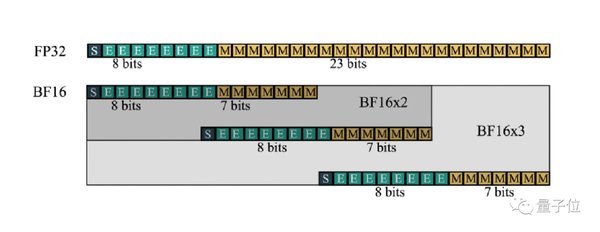
The figure is inspired from [48]. Decimal accuracy for 1) 8-bit signed ...
Figure 4 from A Low-Power Hybrid-Precision Neuromorphic Processor With ...
Model INT4-I Linear Integrator | Strainsense Signal Conditioners
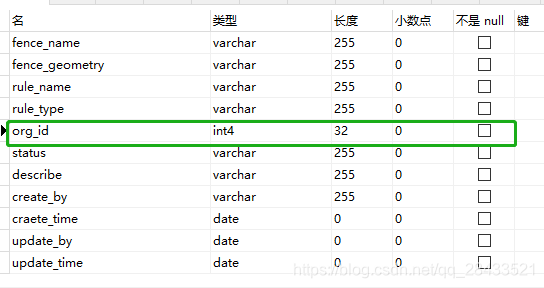
postgresql的int4类型-CSDN博客
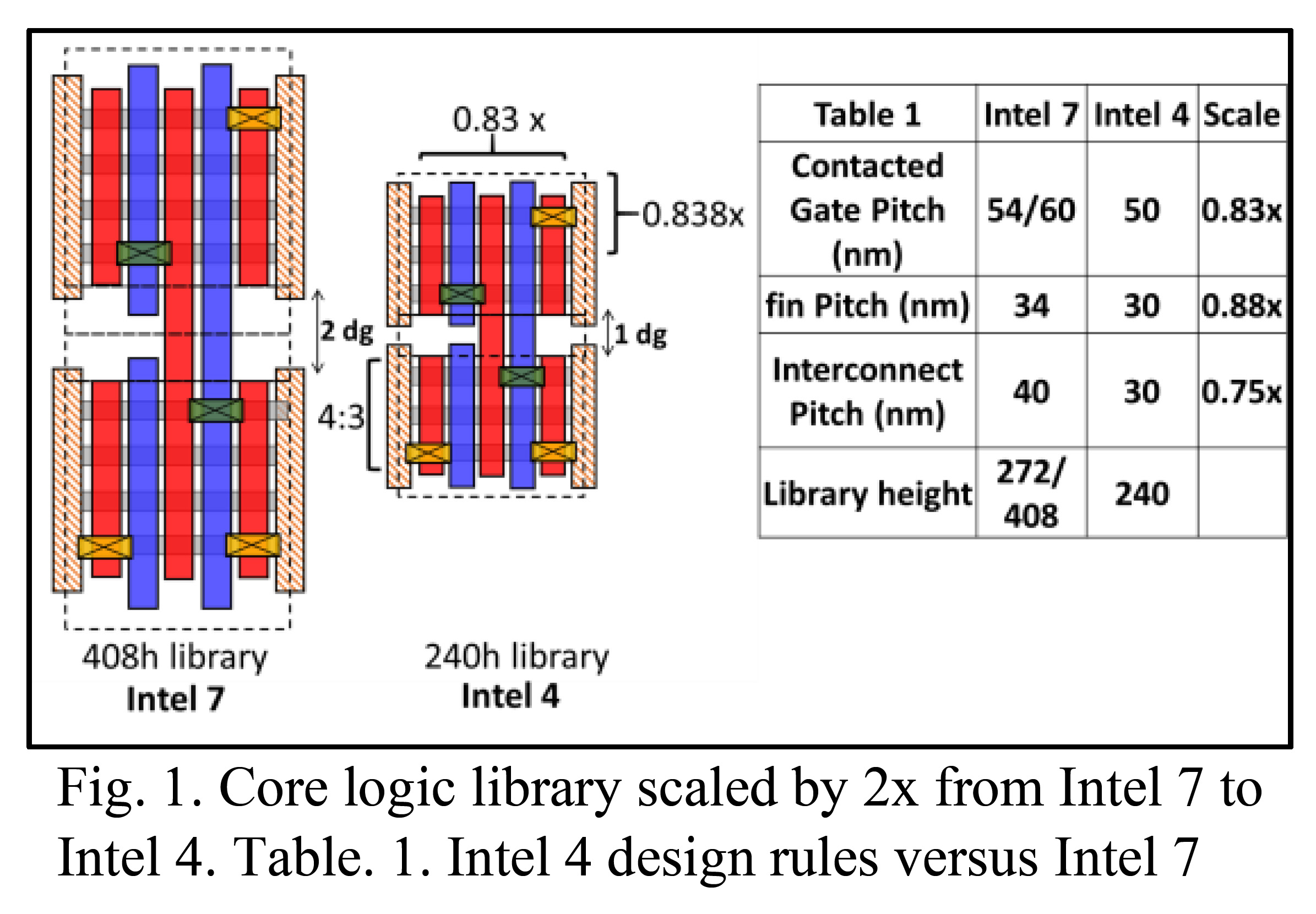
Intel 4 Deep Dive - SemiWiki
youneleex/Qwen3.5-27B-GPTQ-Int4 · Hugging Face
raydelossantos/gemma-4-26B-A4B-it-GPTQ-Int4 · Hugging Face
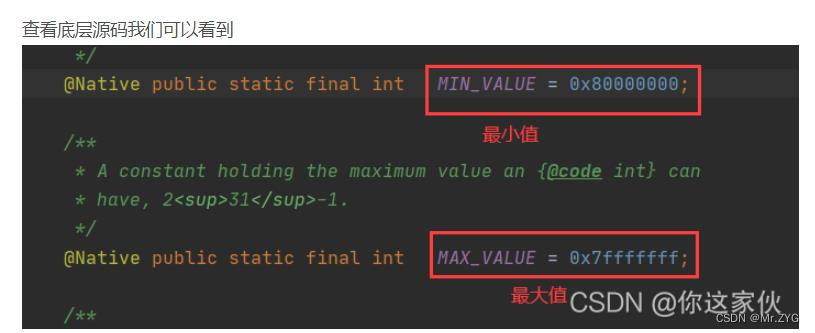
菜鸟理解int为啥是4个字节_int4个字节-CSDN博客
RK3588 Comprehensive Analysis: The Rise of a High-End Domestic SoC ...
大佬们,目前int4版本支持微调吗? · Issue #102 · ssbuild/chatglm_finetuning · GitHub
In 1969, the Apollo Guidance Computer (AGC) took humans to the Moon ...
Xingyu-Zheng/Qwopus3.5-9B-v3-INT4-FOEM · Hugging Face
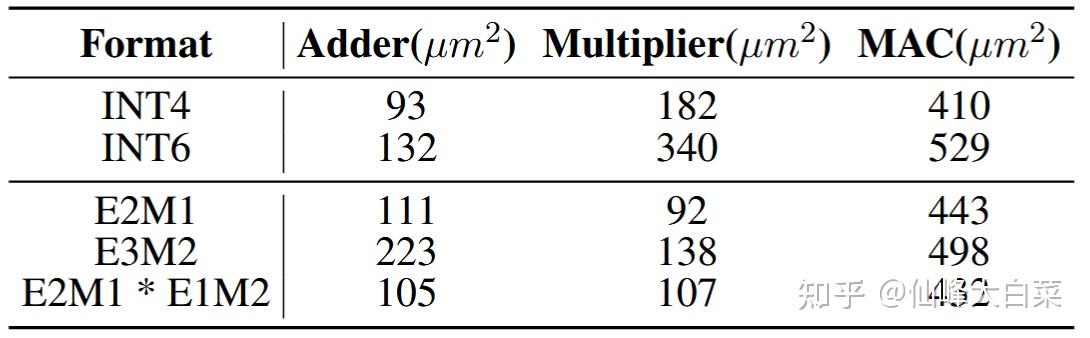
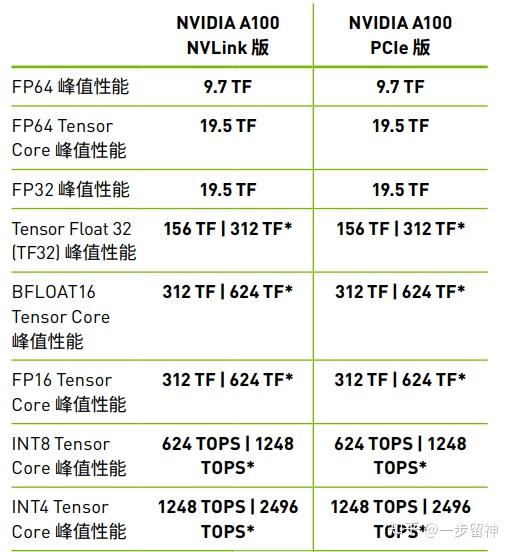
芯片算力和精度(int8、fp16、双精度、单精度等等)是怎样的关系? - 知乎
$INTC Intel’s CES 2026 product and platform narrative centered on Core ...
The DGX Spark GB19 has up 1 PFLOPS (1,000 TOPS) of FP4 Tensor ...
Ceva NeuPro™ From coin cell wearables to multi core clusters
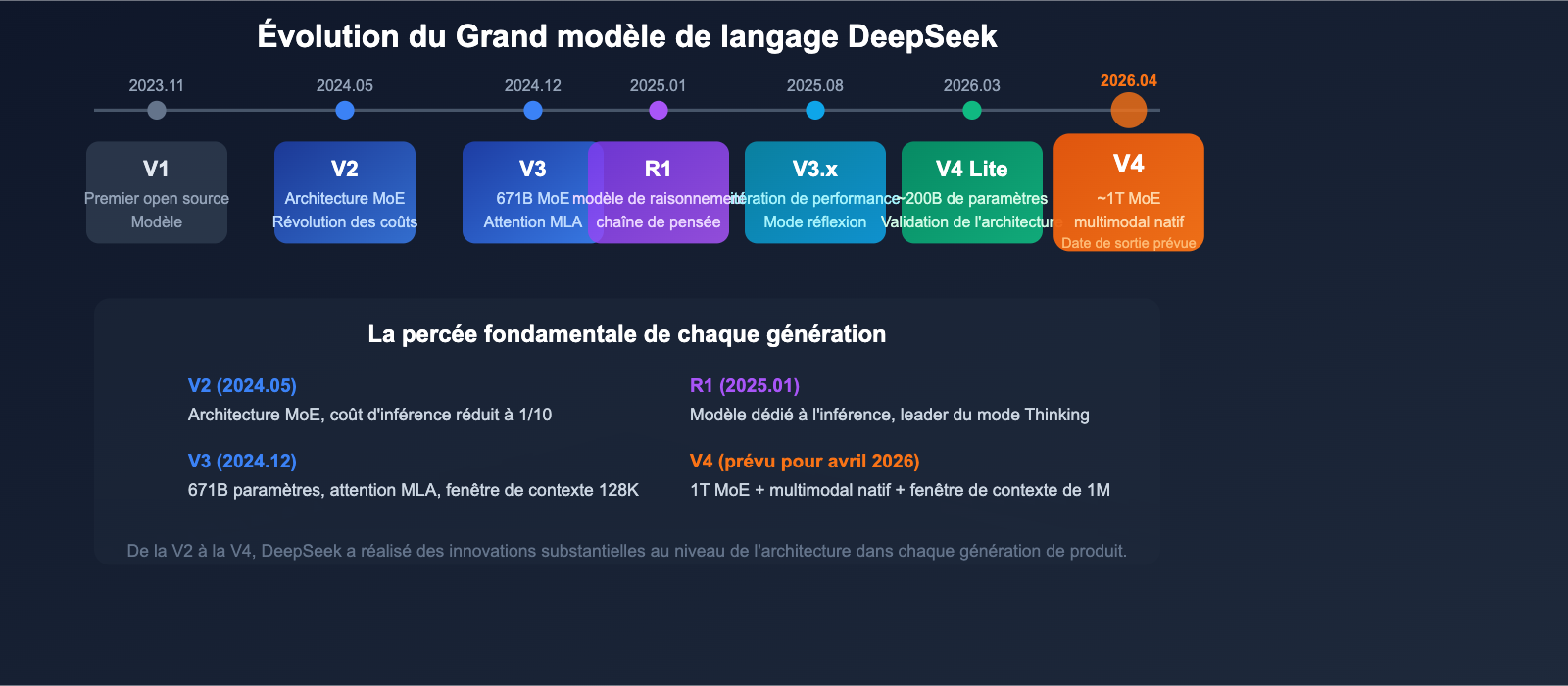
DeepSeek V4 Preview: Comprehensive Analysis of 1T Parameter MoE ...
README_CN.md · tonera/FLUX.2-klein-9B-Nunchaku at main
geoffsee/octen-embedding-0.6b-onnx-fp16 · Hugging Face
“Adaptive Block-Scaled Data Types” A lot of 4-bit LLM quantization ...
Data Types and Variables Numeral Types Text Types
Aperçu de la sortie de DeepSeek V4 : analyse complète de l’architecture ...
端侧 AI 部署实战:如何在 8GB 显存上跑通 7B 模型 - 知乎
caiovicentino1/Qwen3.5-9B-EOQ-v3 · Hugging Face
低ビットに量子化されたモデルのAIって、思考中にモヤモヤみたいなものを抱えていたりするんだろうか?
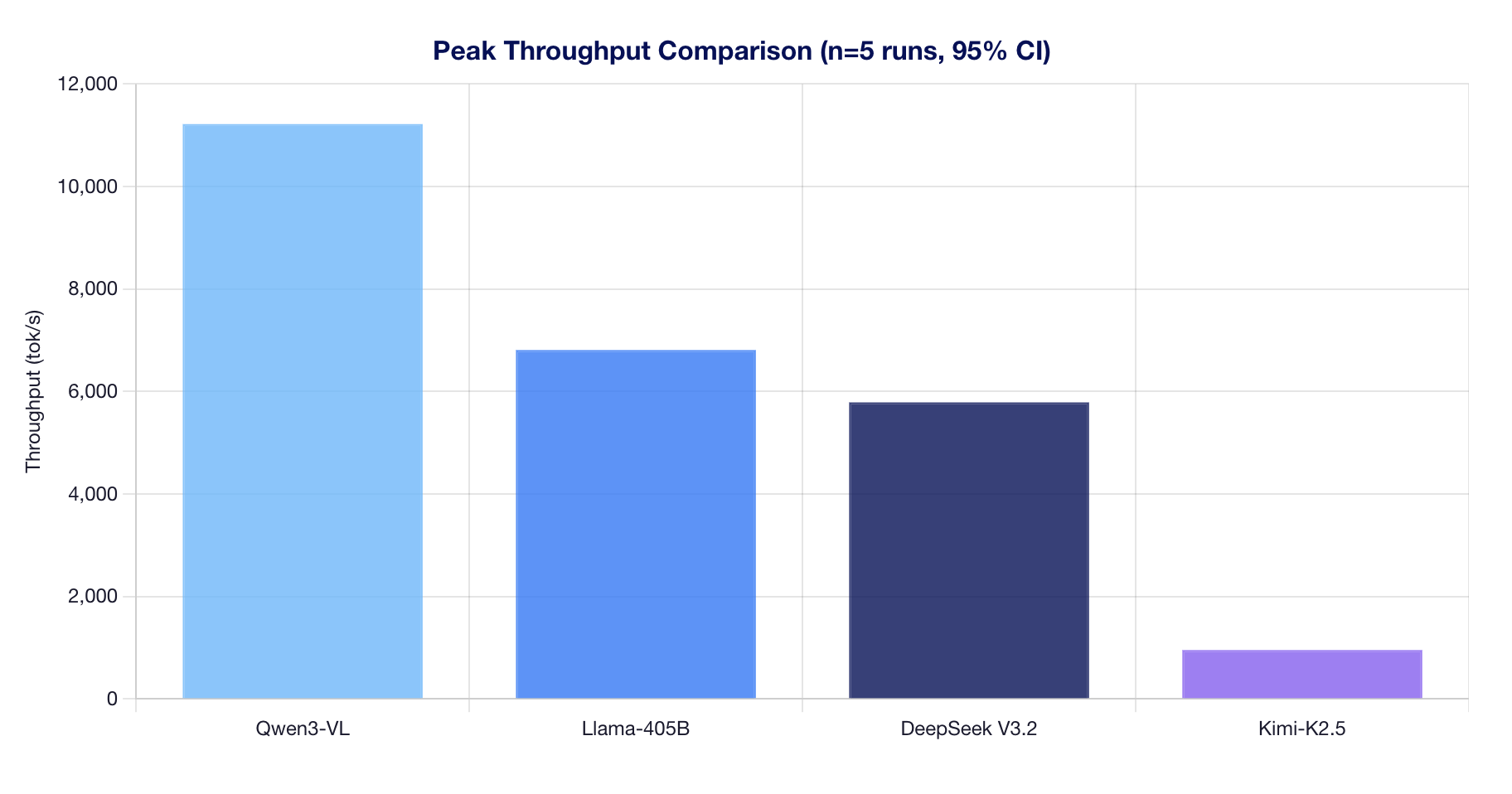
Multi-Run Statistical Analysis | Vultr Docs
UmeAiRT/ComfyUI-Auto-Installer-Assets · Hugging Face
Run Z-Image Turbo on 6GB-8GB VRAM: Quantized Models, Setup, and ...
Quantification du KV-Cache : TurboQuant et l'état de l'art en 2026
caiovicentino1/Qwen3.5-9B-Claude-Opus-PolarQuant-Q5 · Hugging Face
Paul B. (@PaulBalanca) / Posts / X
caiovicentino1/Qwopus-MoE-35B-A3B-PolarQuant-Q5 · Hugging Face
caiovicentino1/Gemma-4-31B-it-PolarQuant-Q5 · Hugging Face
FuriosaAI Secures Samsung SDS as New Client, to Deploy Renegade NPU in ...
Snapdragon 8 Gen 2: The Definitive Guide to the AI-Powered Performance ...
本地大模型:如何在内网部署 Llama/Qwen 等安全增强模型
#openai #sora #aibusiness #anthropic | Agnieszka Ole
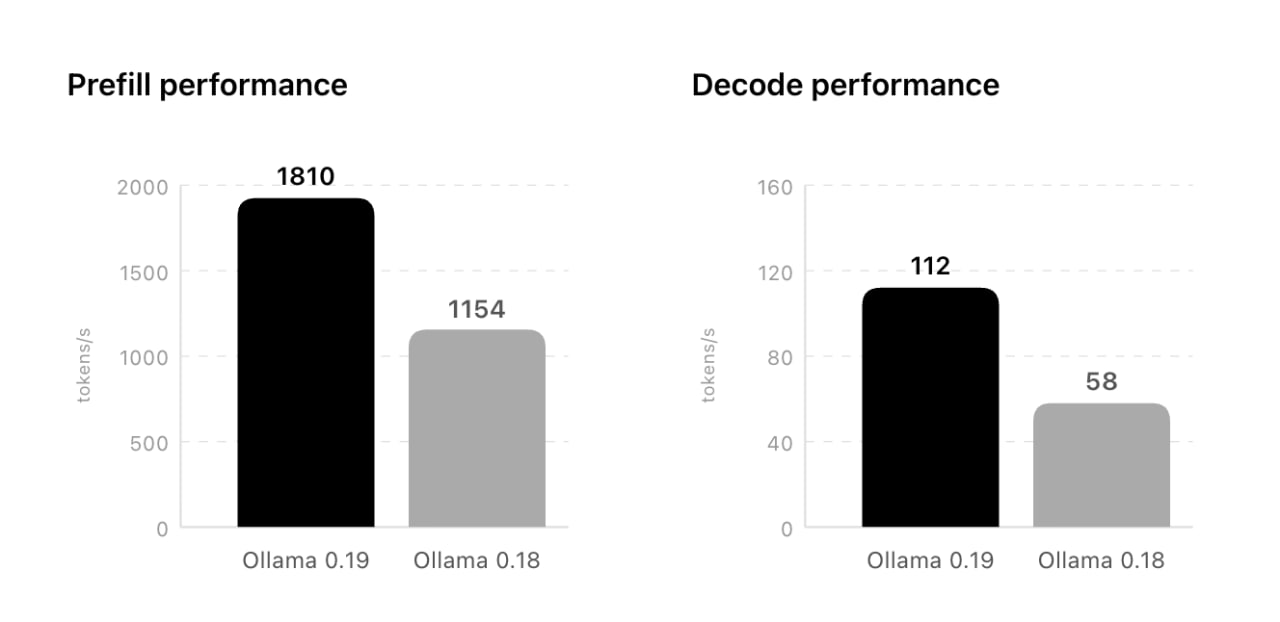
Ollama Just Got Blazing Fast on Macs: Full MLX Support Brings 2× ...
如何理解int (*(*(*p)(int *))[4]) (int*)? - 知乎
int和float精度_int精度与float精度哪个高-CSDN博客
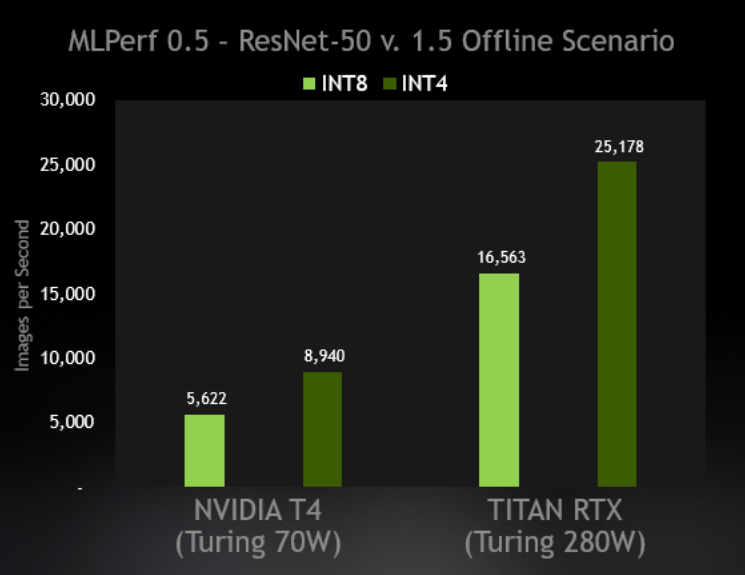
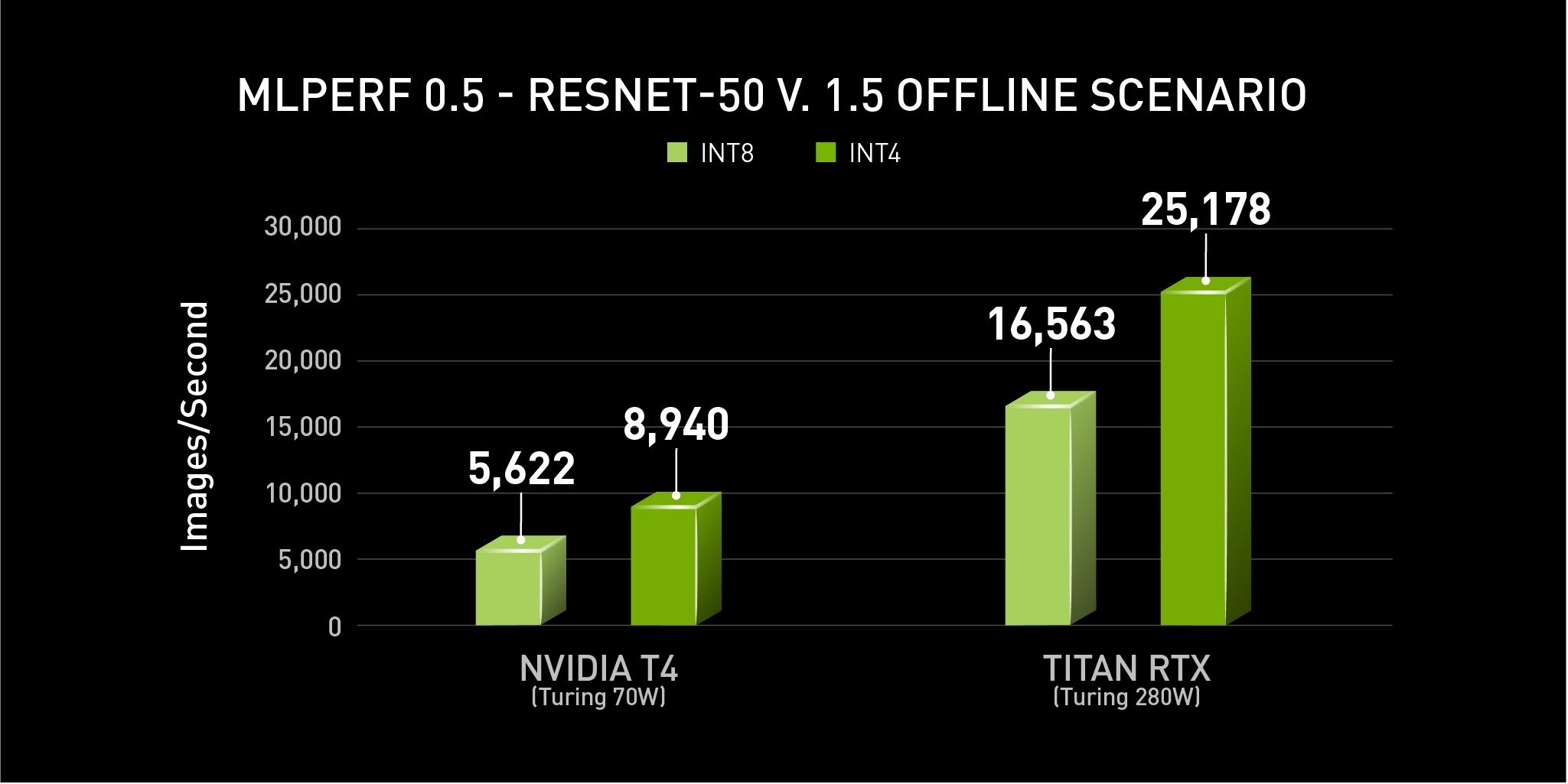

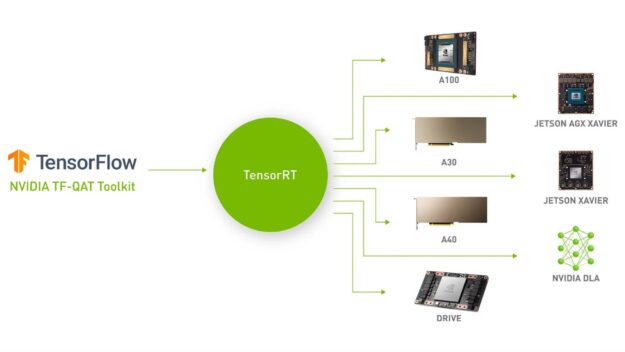


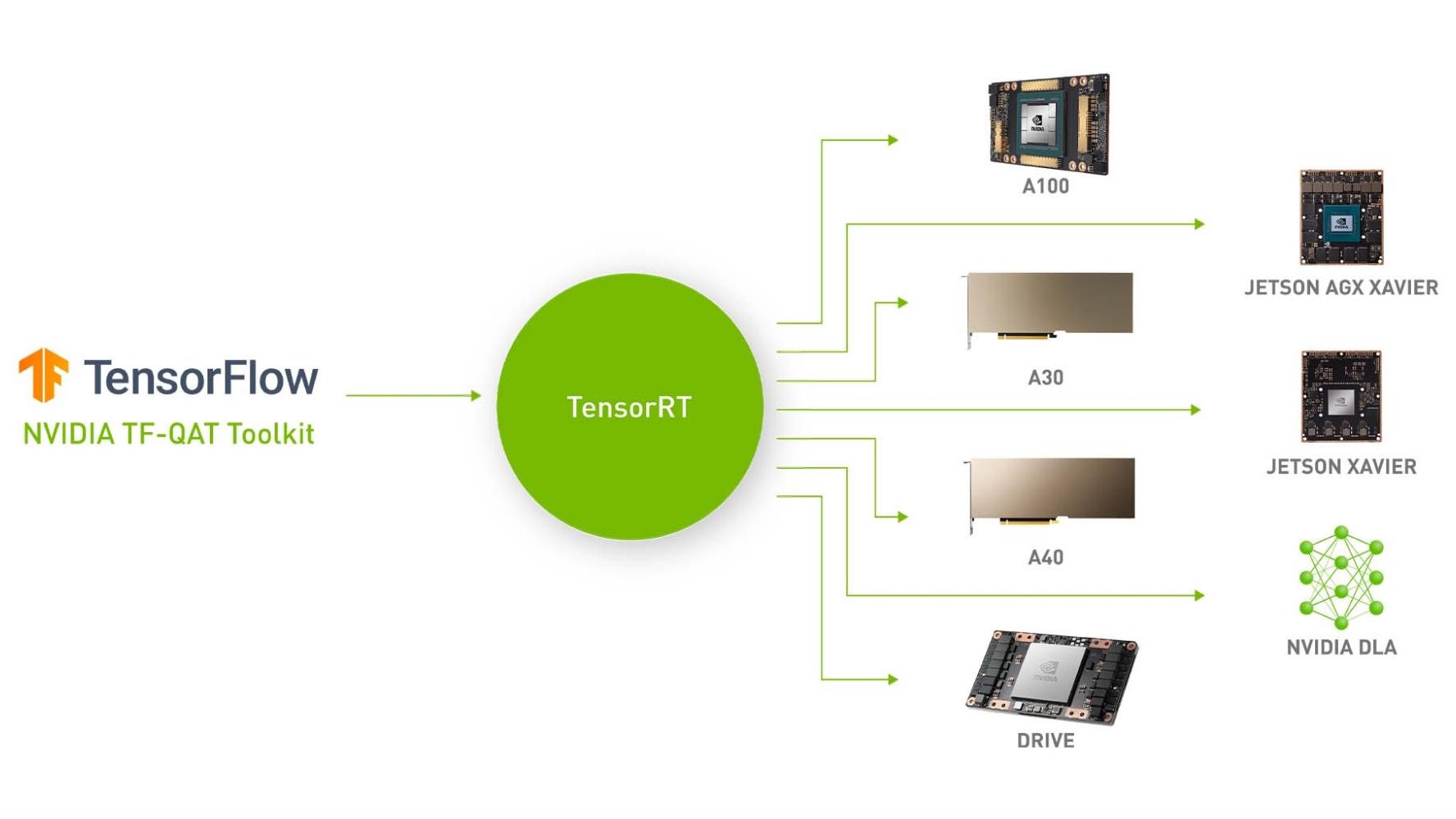












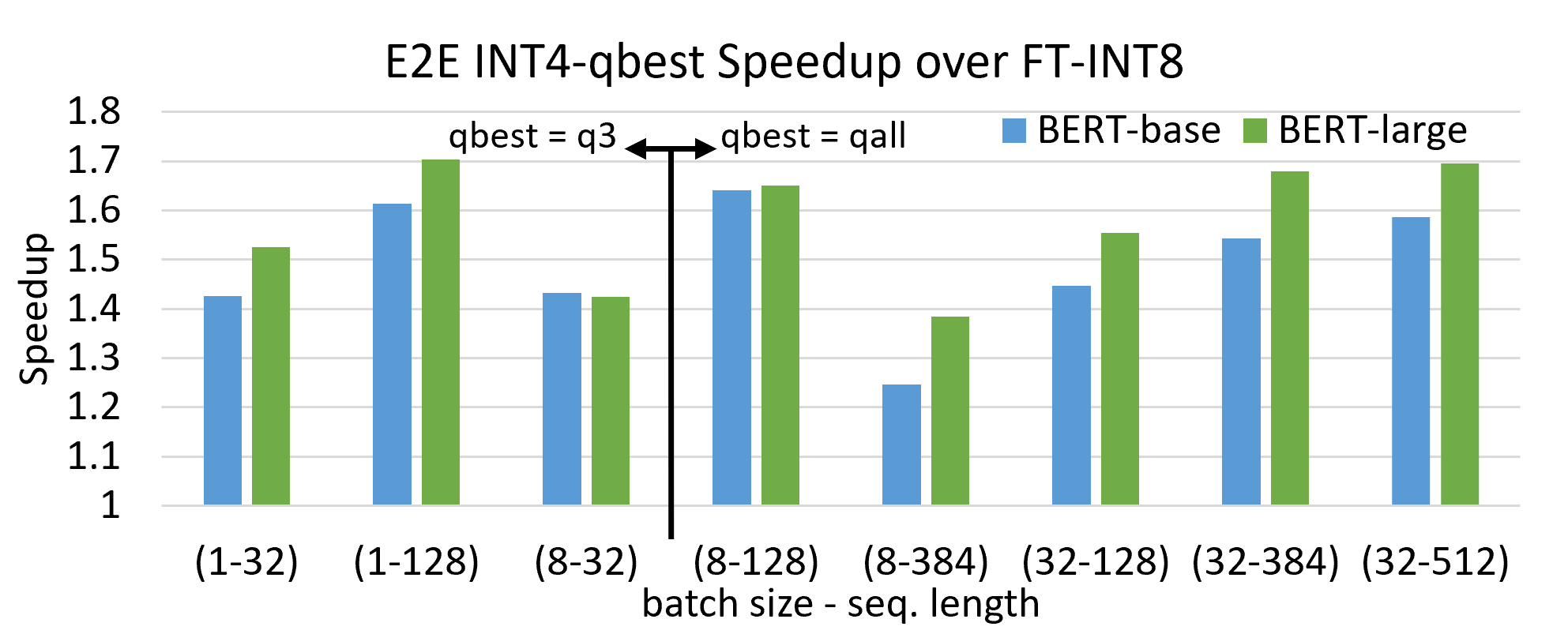

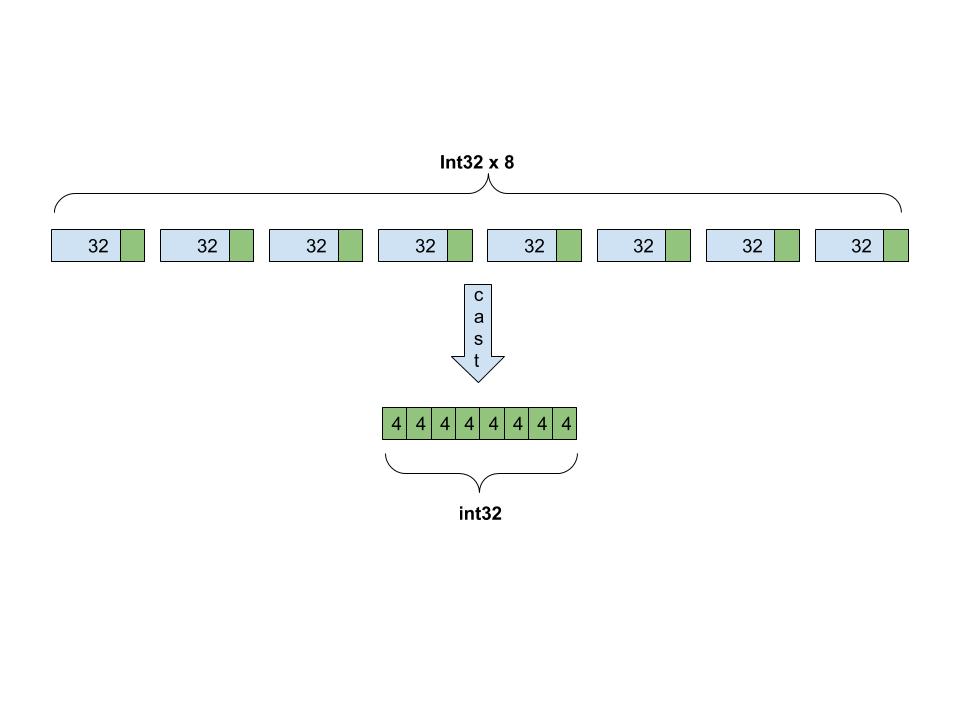



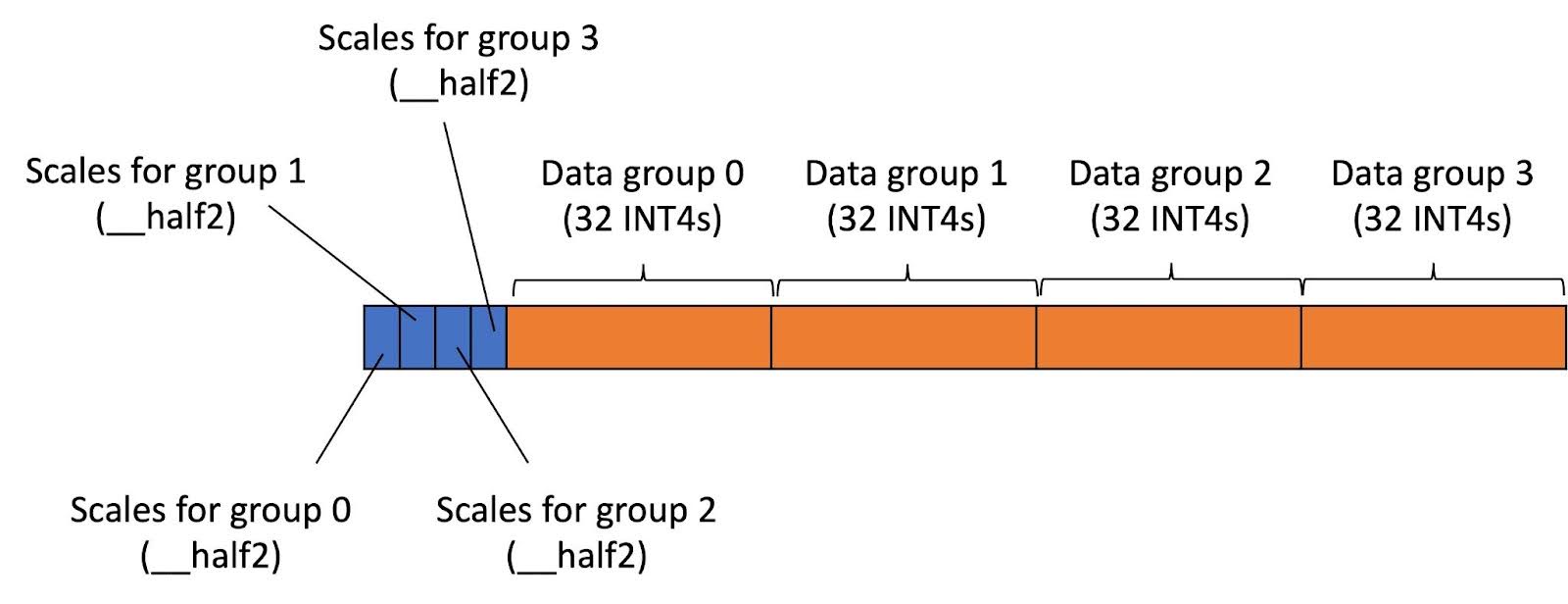


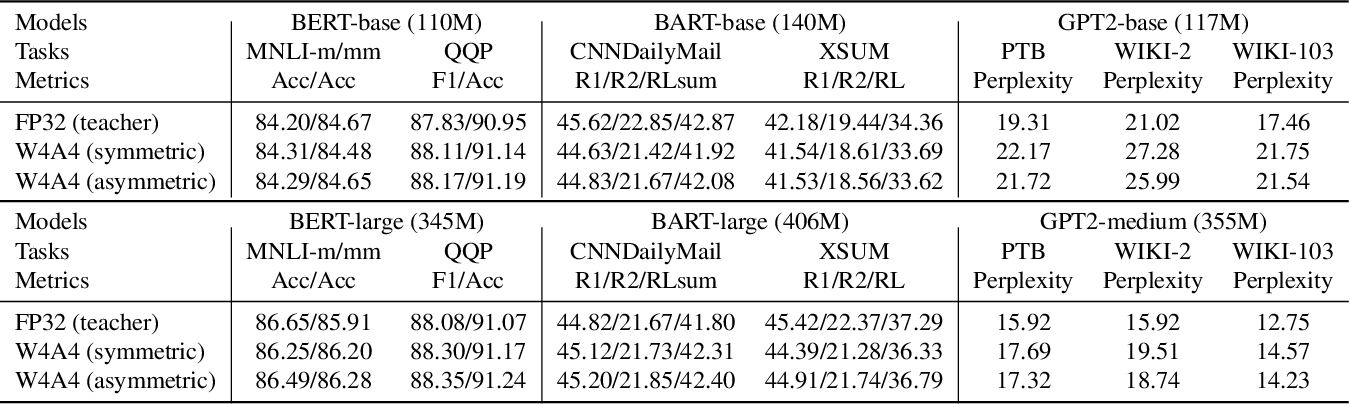
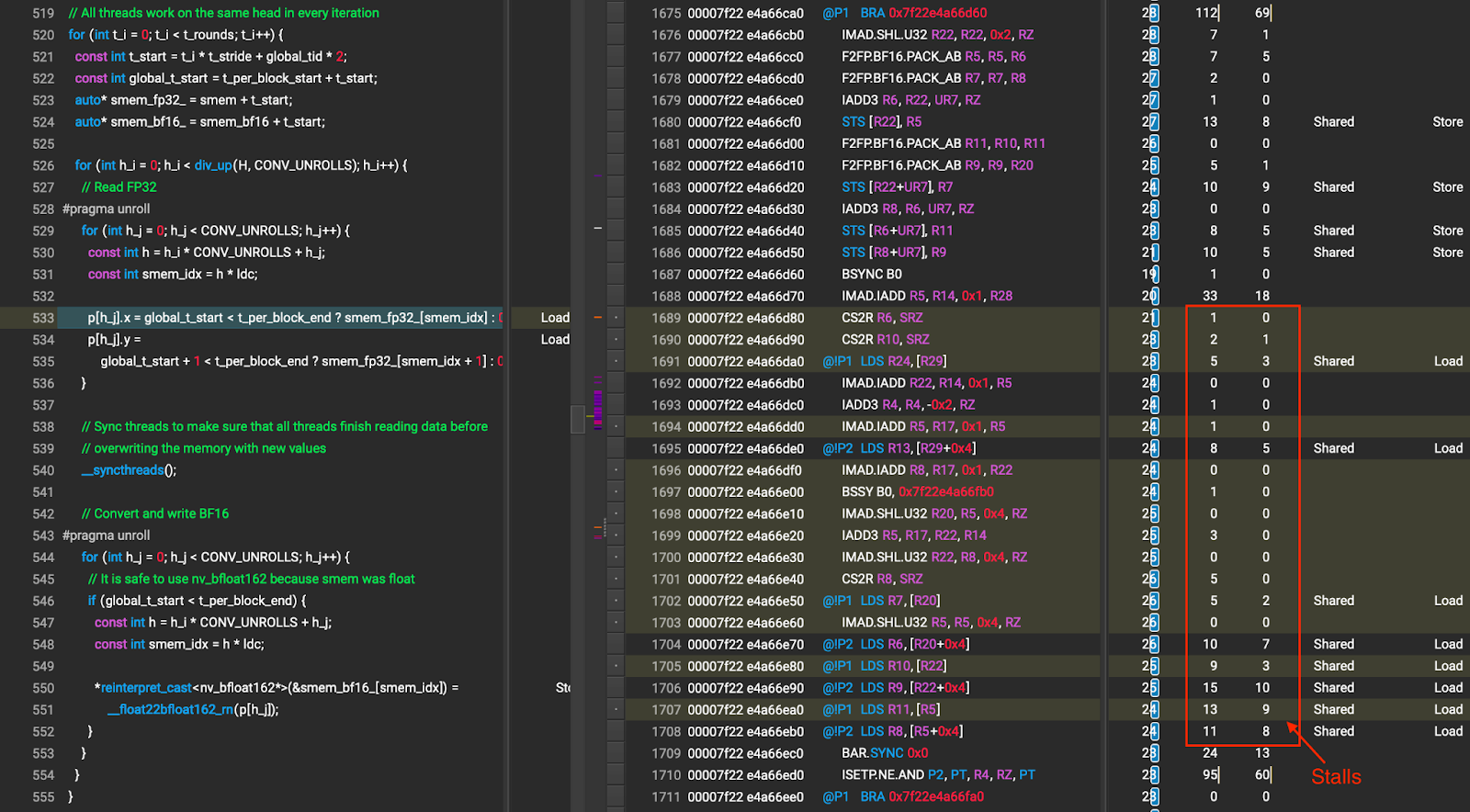





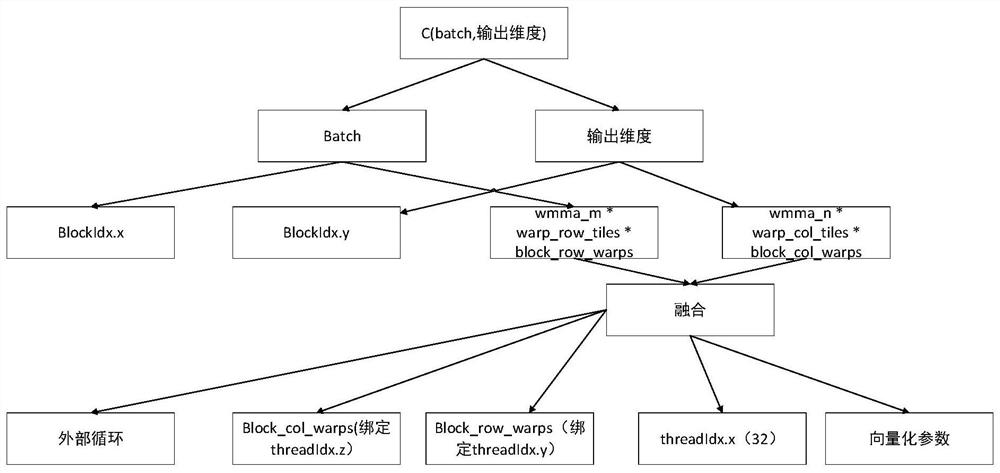
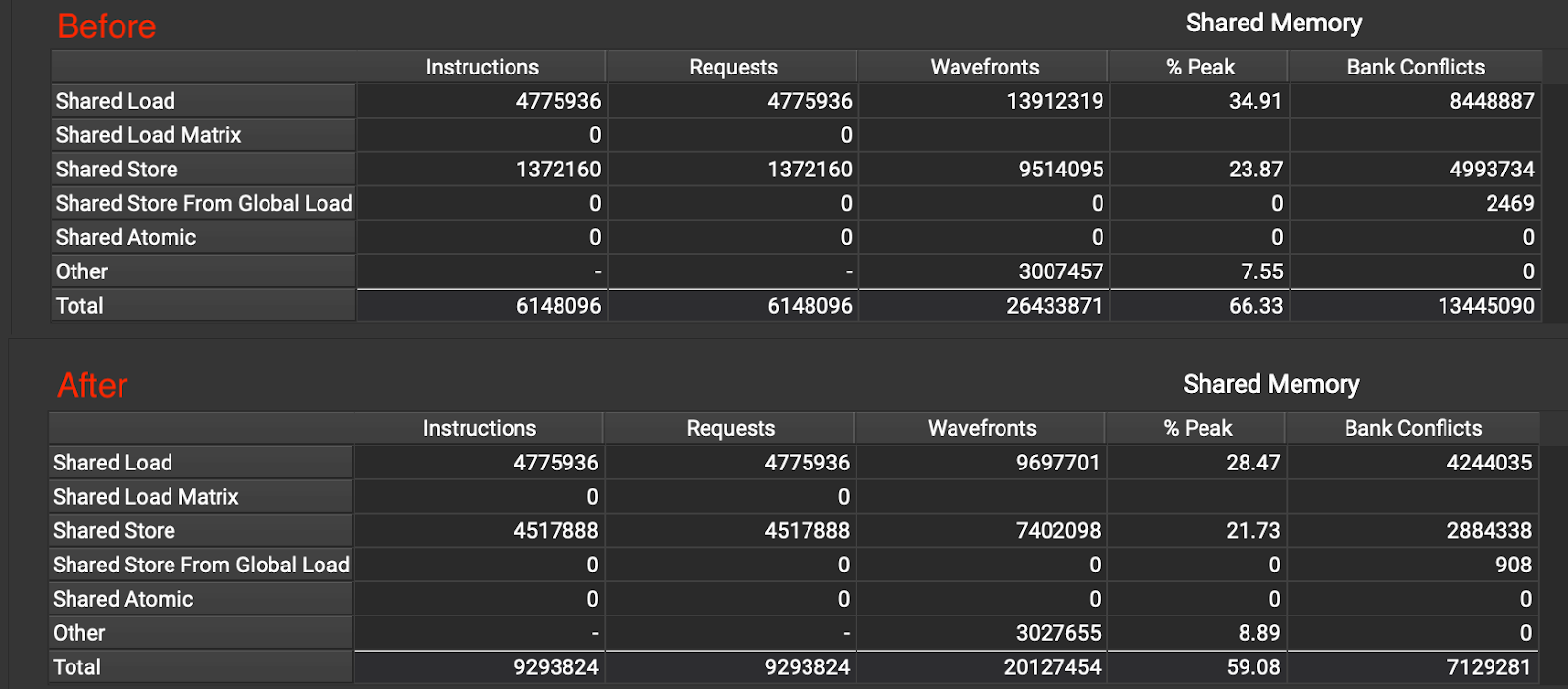
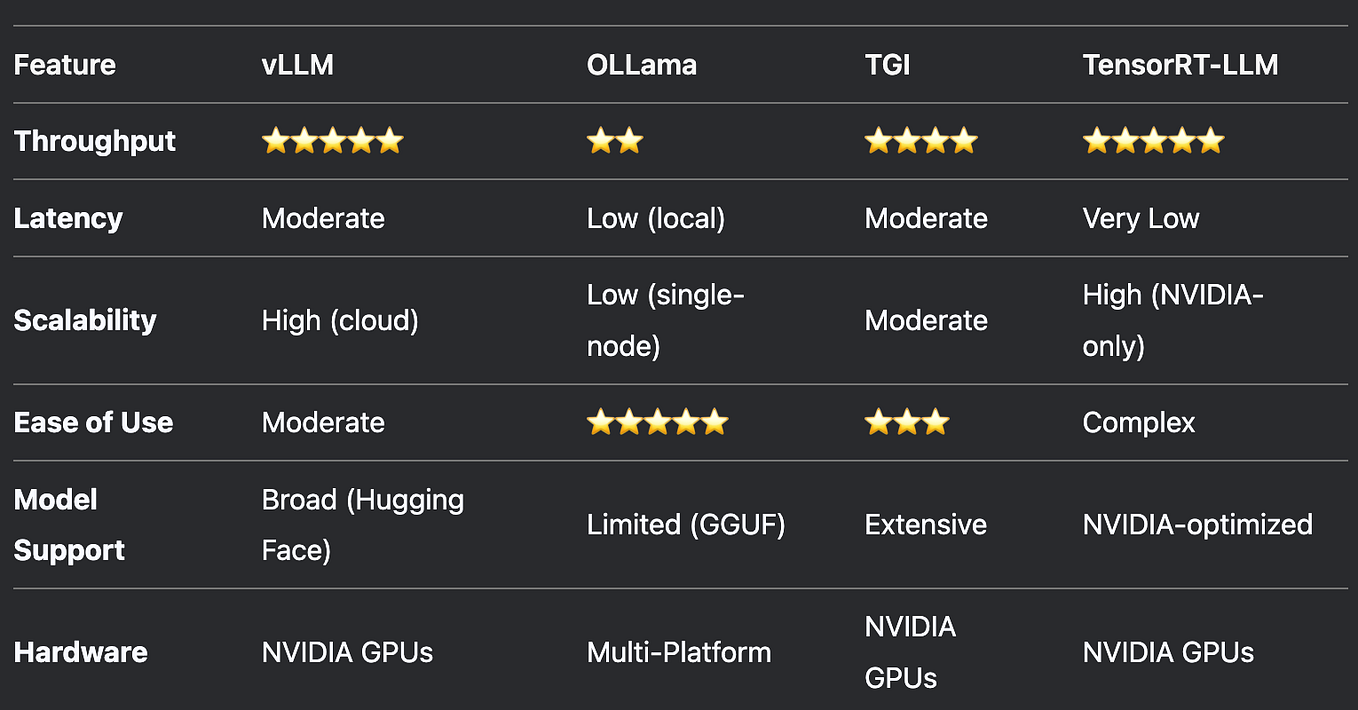









































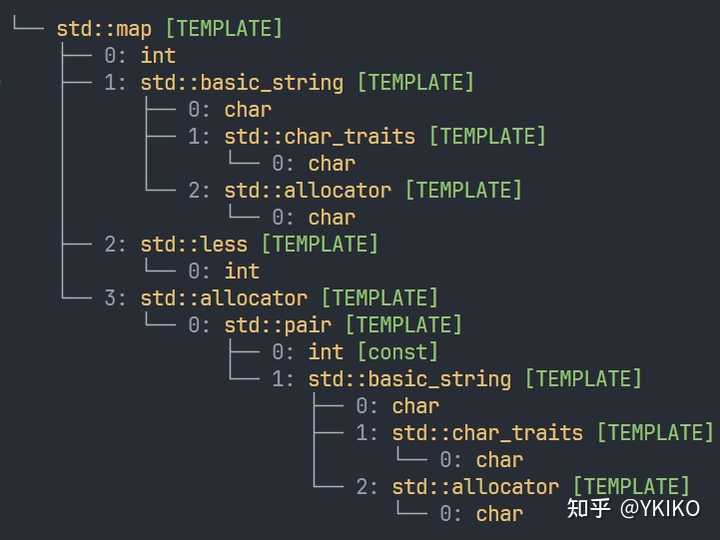
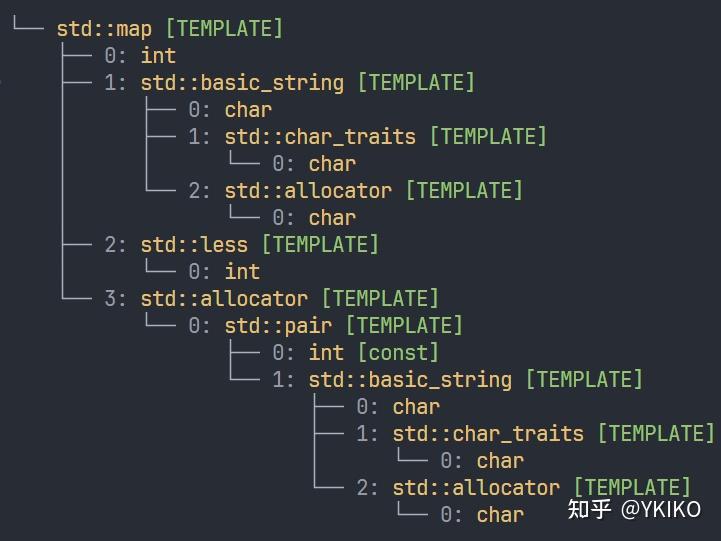

{kind=link}