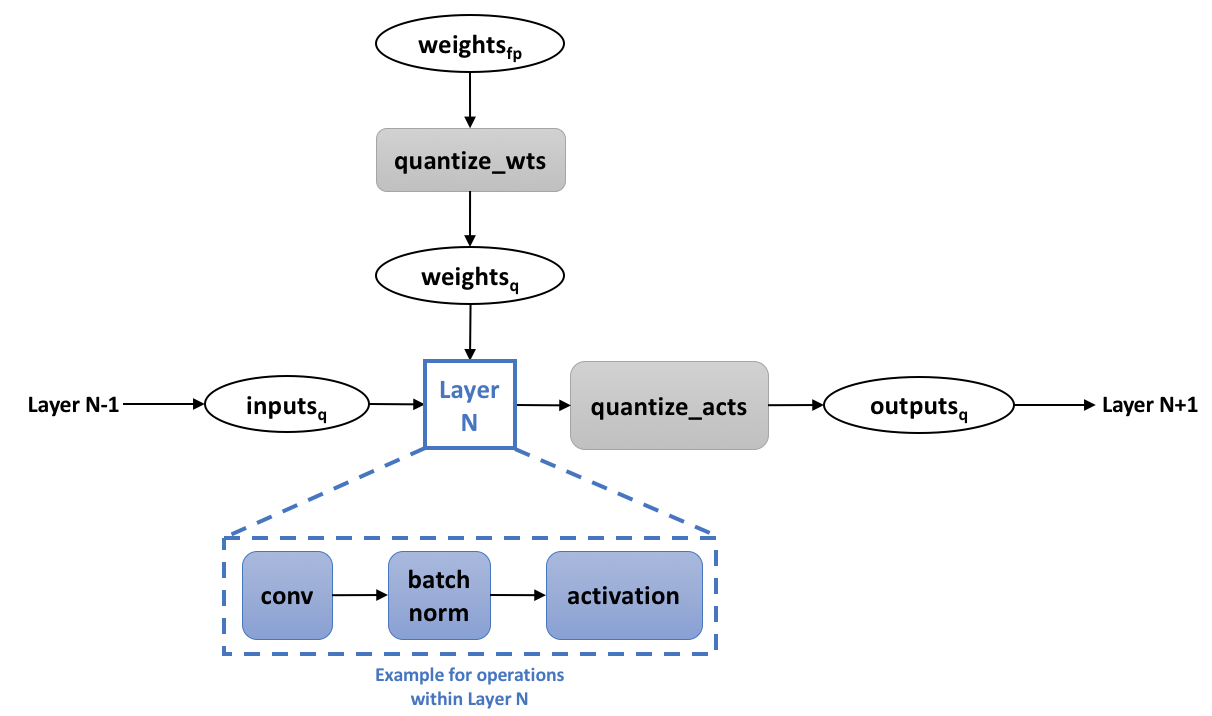
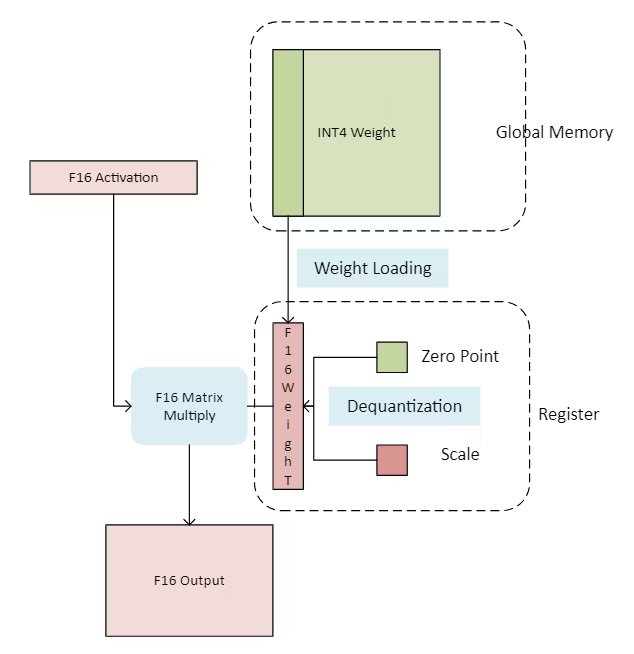
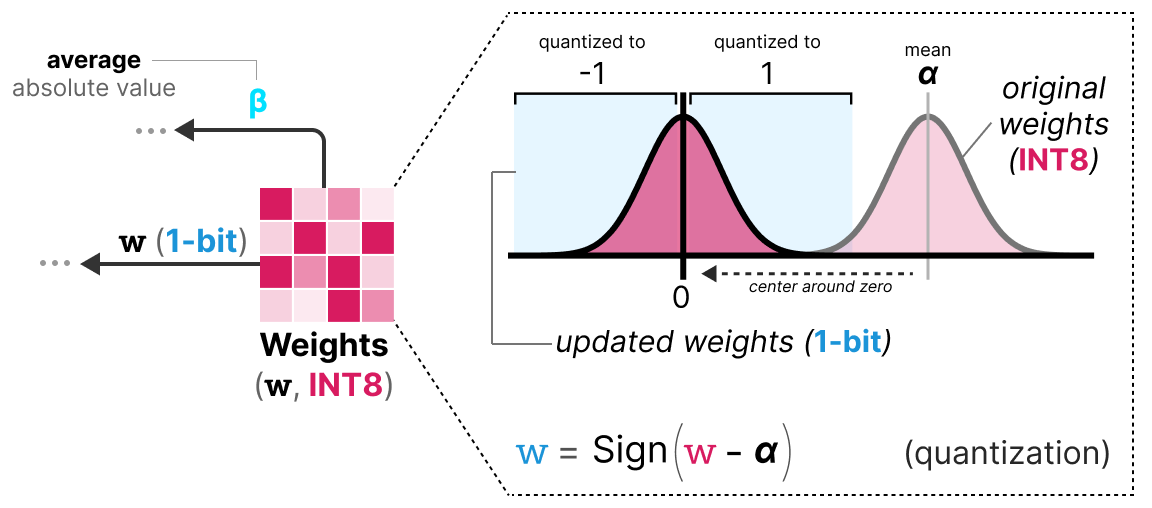
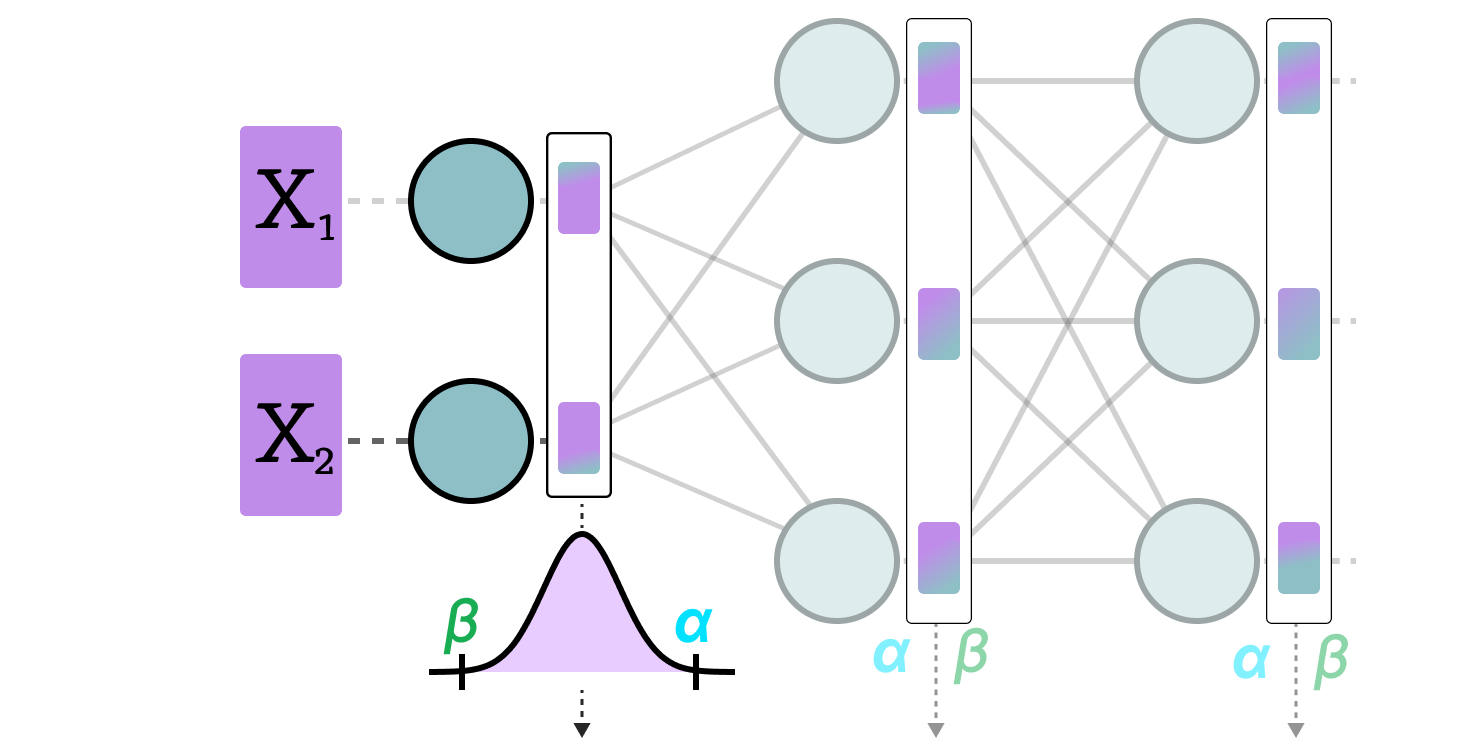
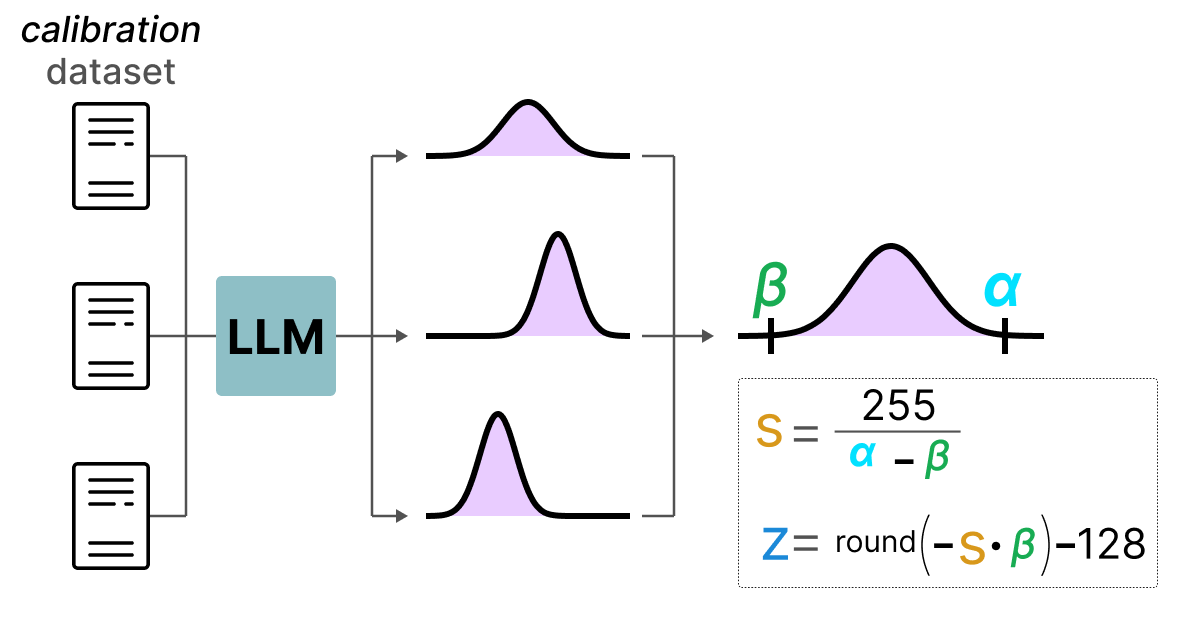
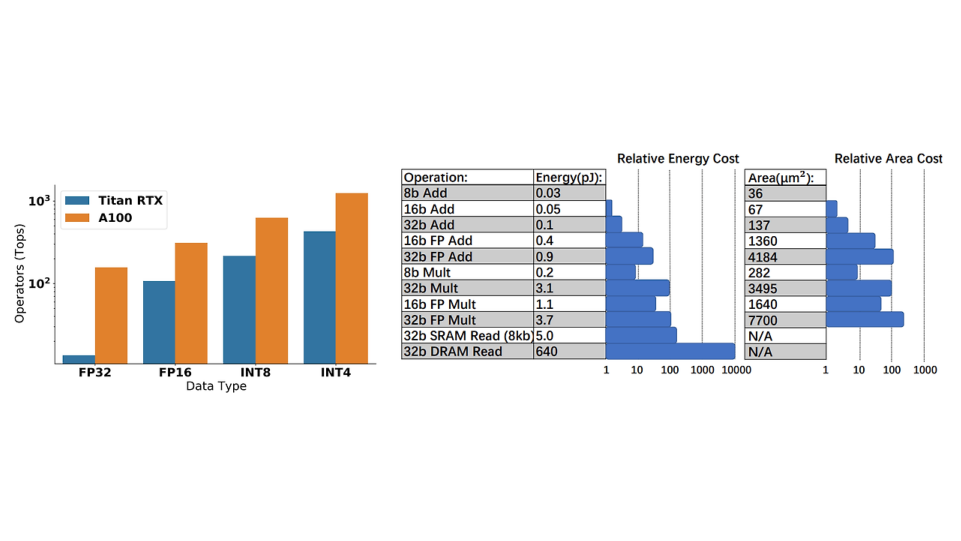
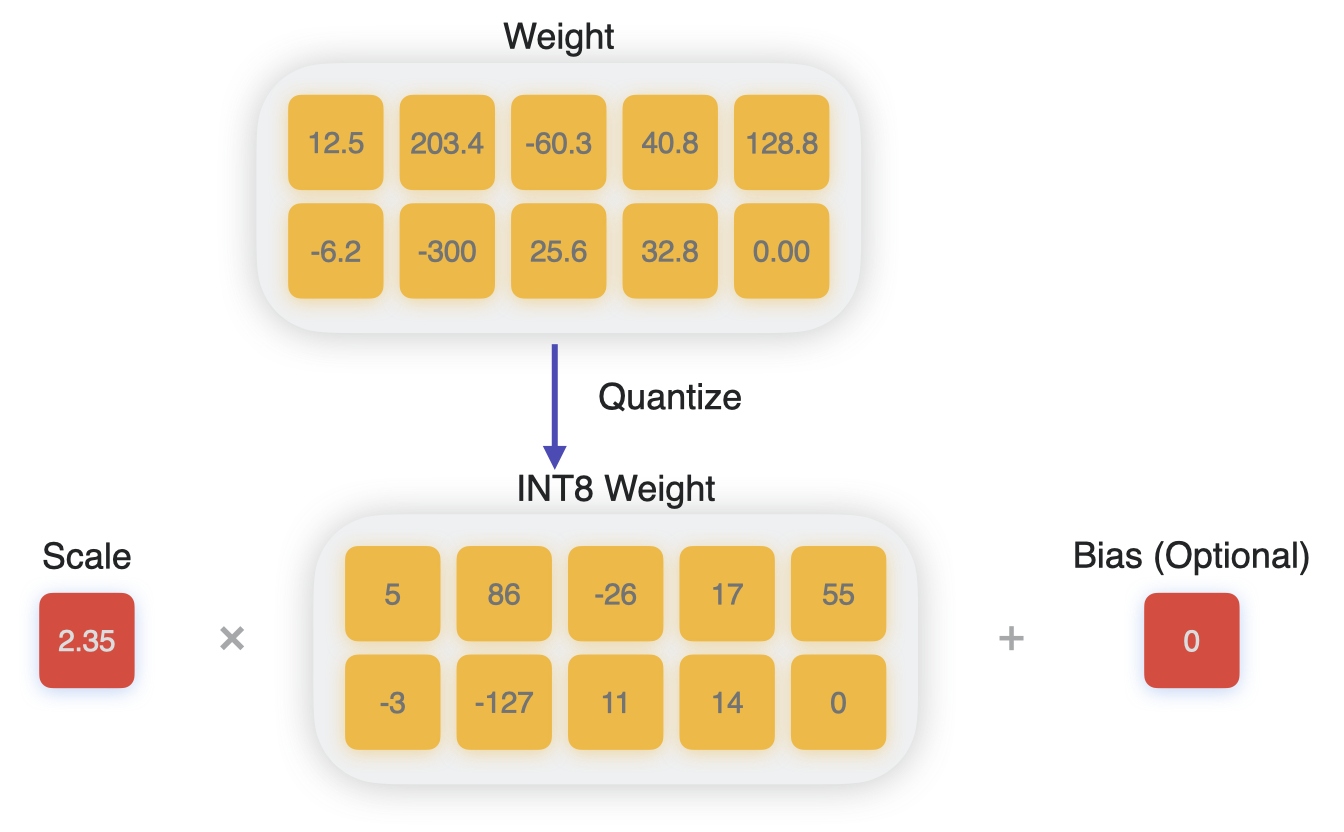
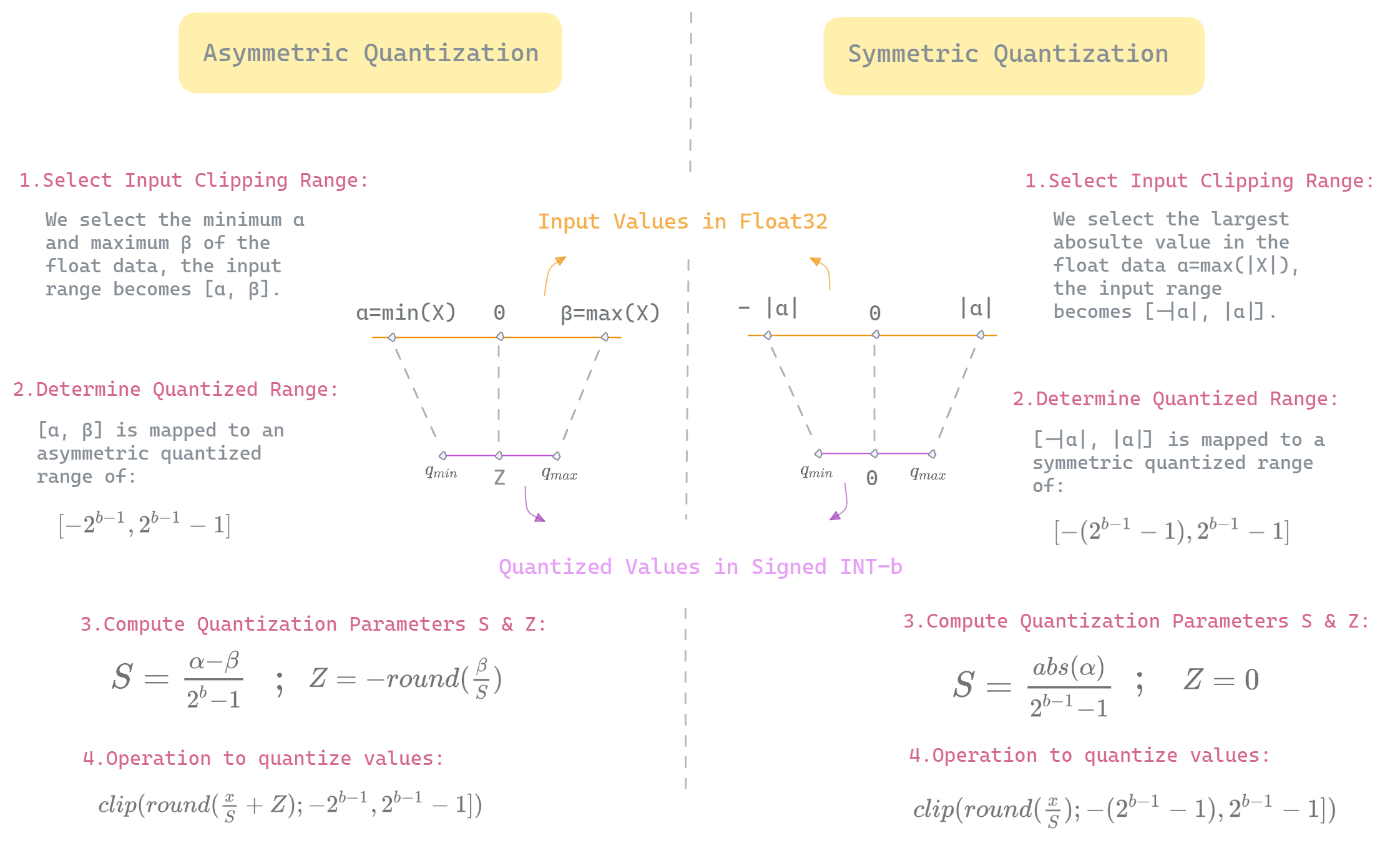
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
[2301.12017] Understanding INT4 Quantization for Language Models ...
(PDF) Understanding INT4 Quantization for Transformer Models: Latency ...
ICML Poster Understanding Int4 Quantization for Language Models ...
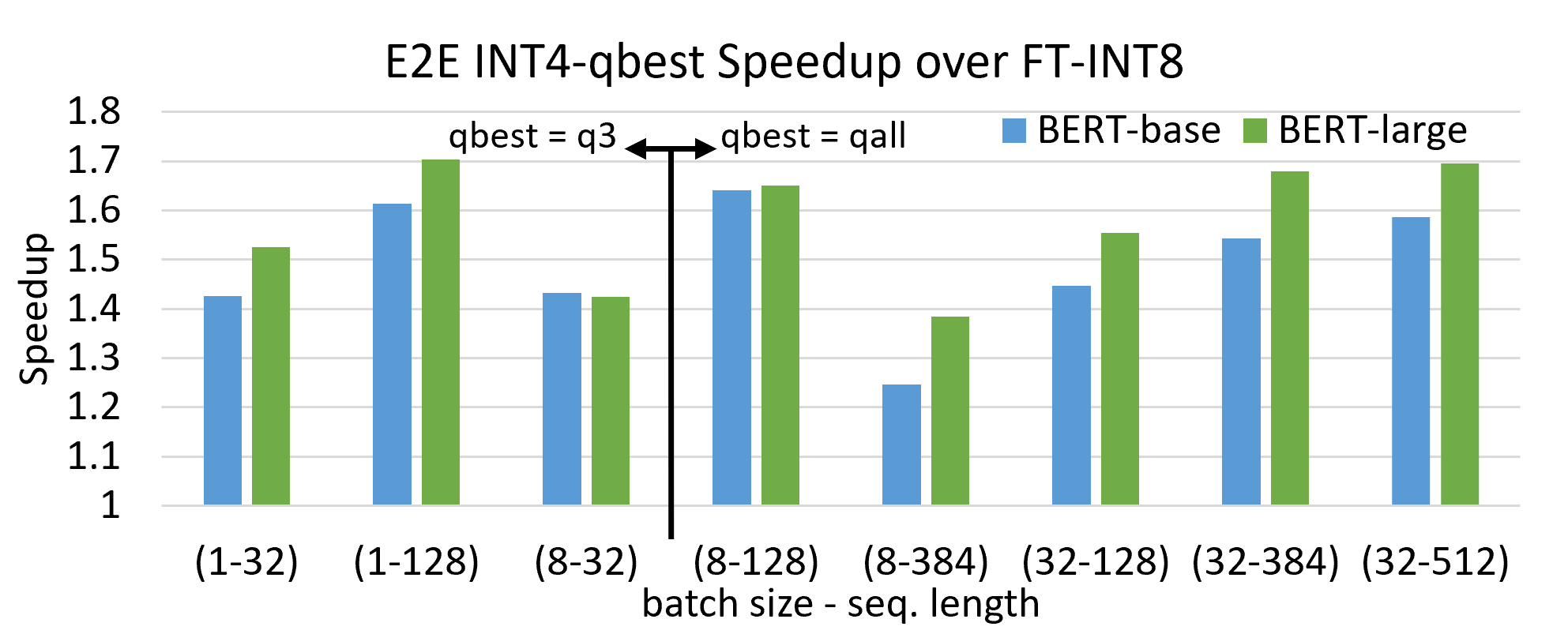
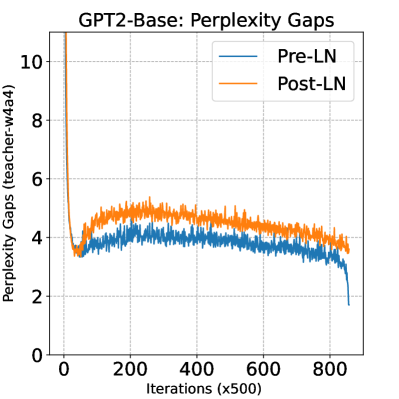
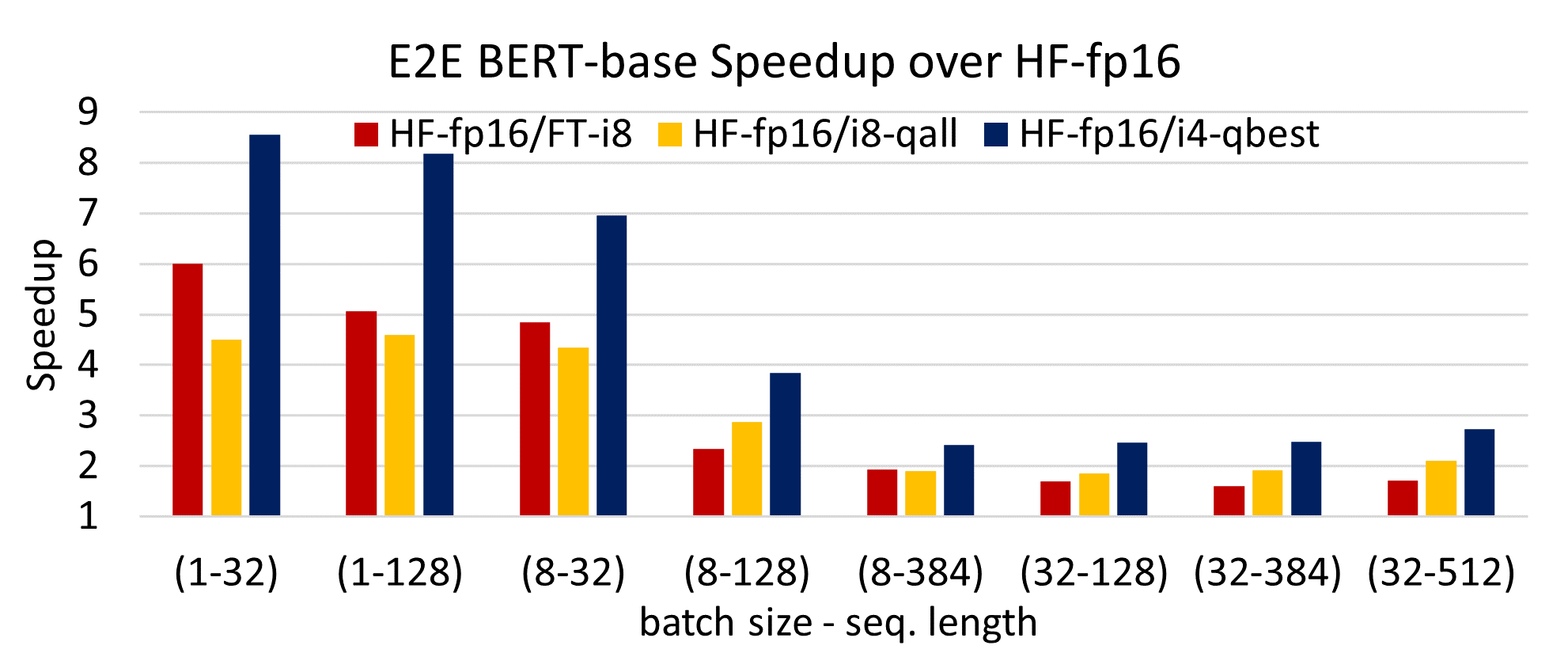
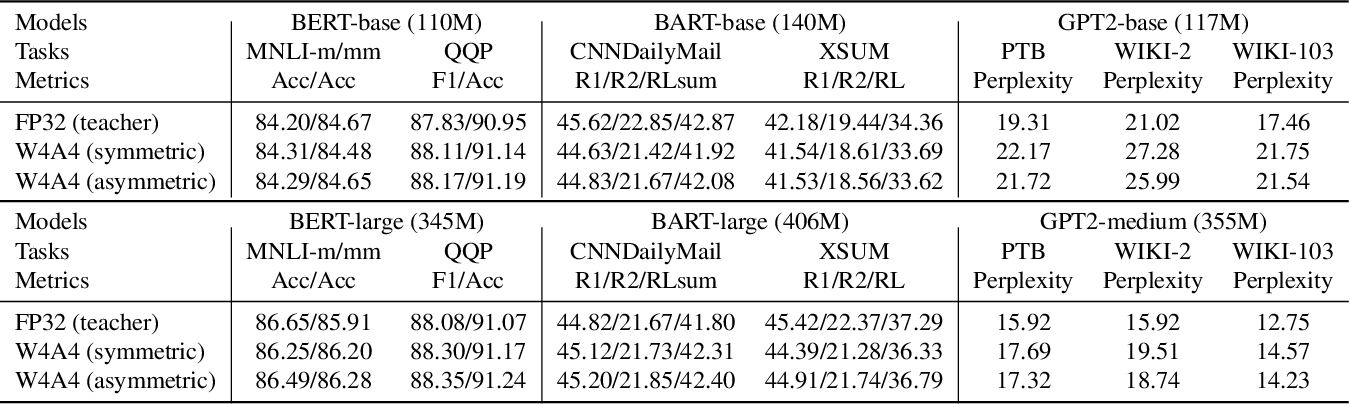
INT4 quantization only delievers 20%~35% faster inference performance ...
Understanding INT4 Quantization for Transformer Models: Latency Speedup ...
How I optimized an LLM with INT4 quantization and distillation | Shyam ...
Shrink LLMs, Boost Inference: INT4 Quantization on AMD GPUs with ...
Left: Unsigned INT4 quantization compared to unsigned FP4 2M2E ...
INT4 Quantization (with code demonstration)
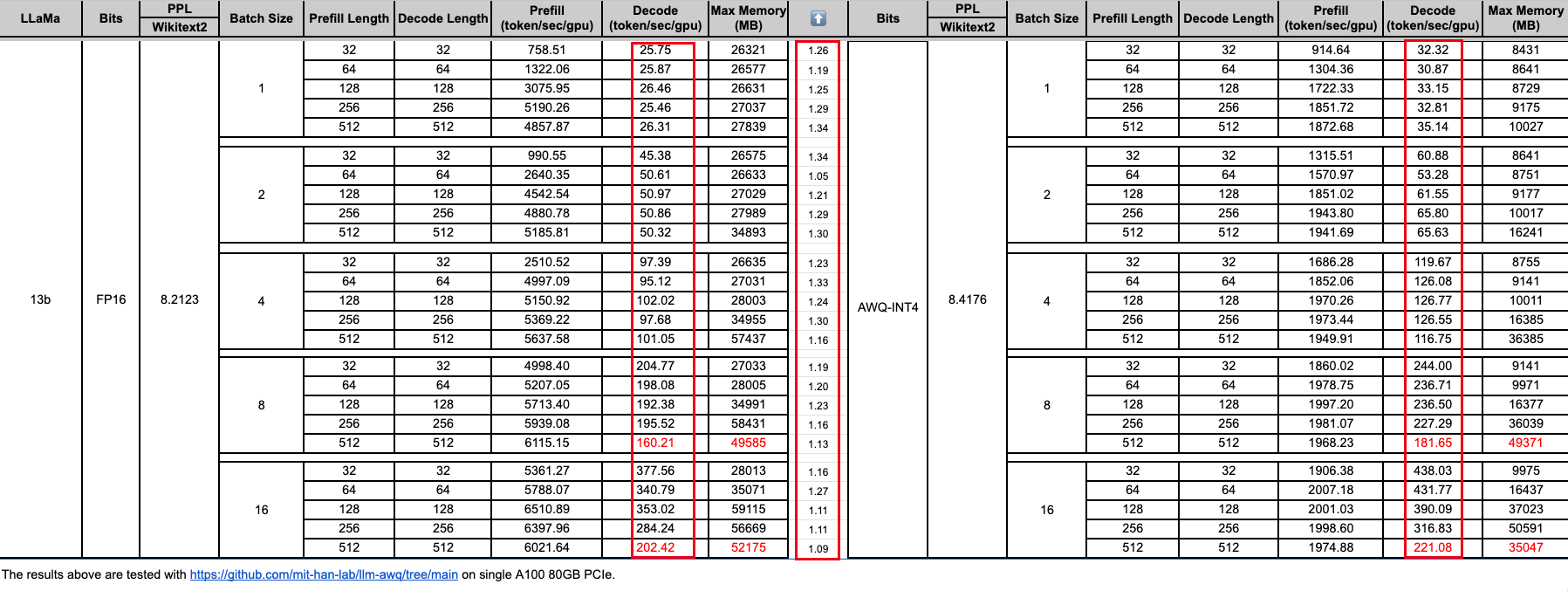
Table 1 from Understanding Int4 Quantization for Language Models ...
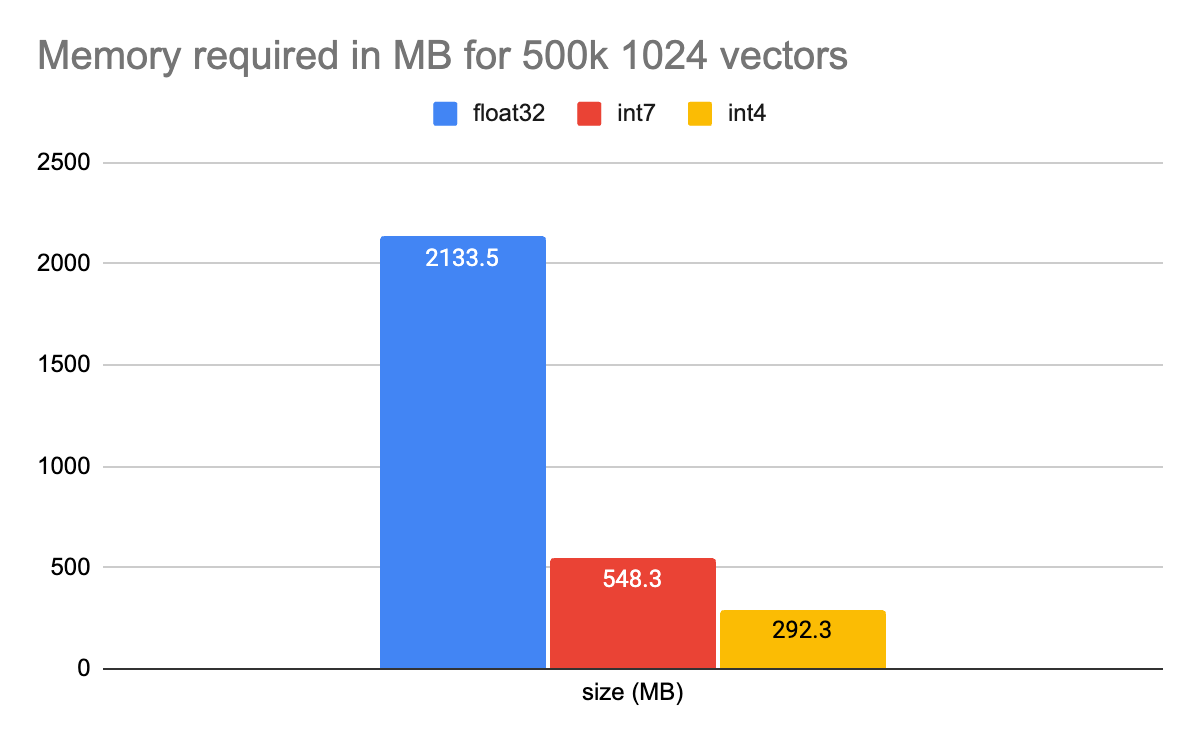
Understanding Int4 scalar quantization in Lucene - Search Labs
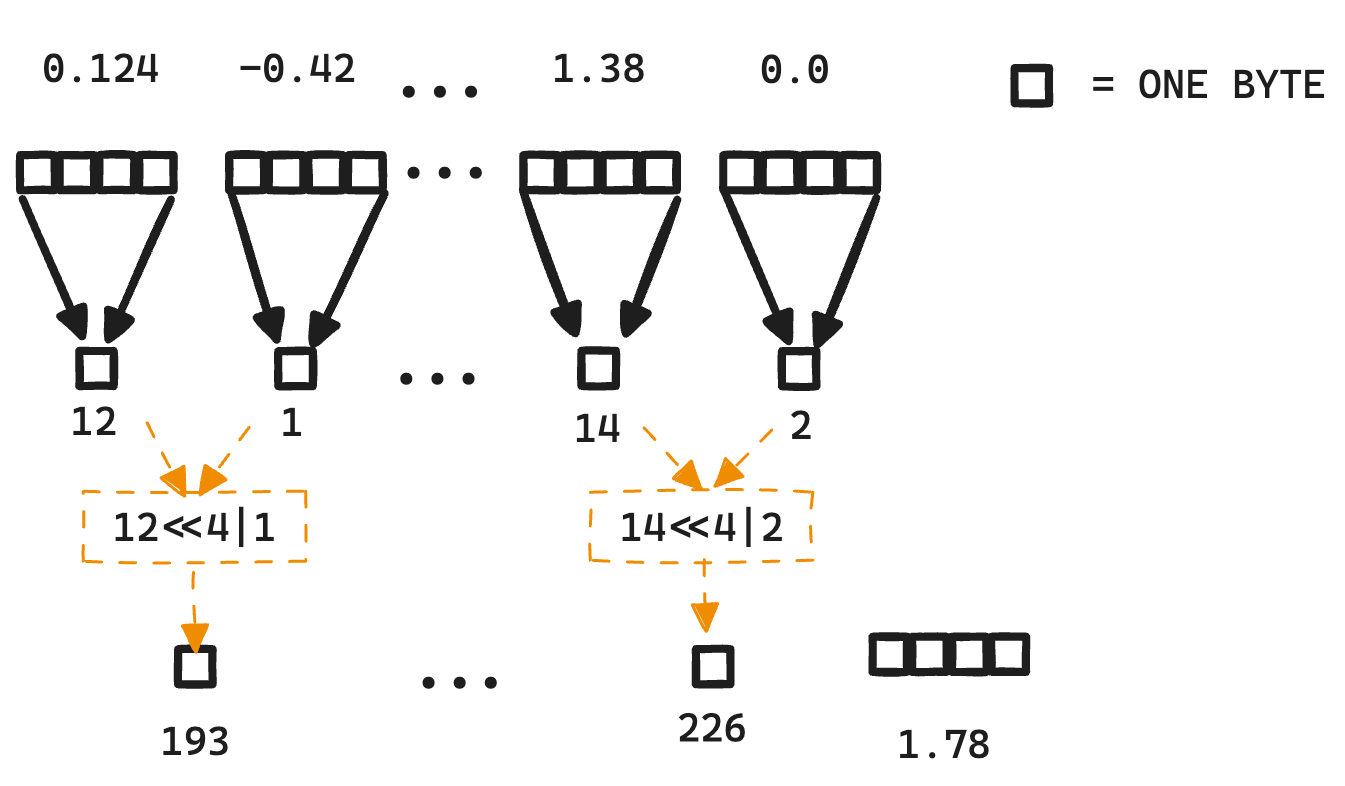
INT8, INT4 and Other Integer Types for Quantization
How LLMs run faster with INT4 quantization | Borys Nadykto posted on ...
INT4 Quantization · Issue #461 · intel/intel-extension-for-pytorch · GitHub
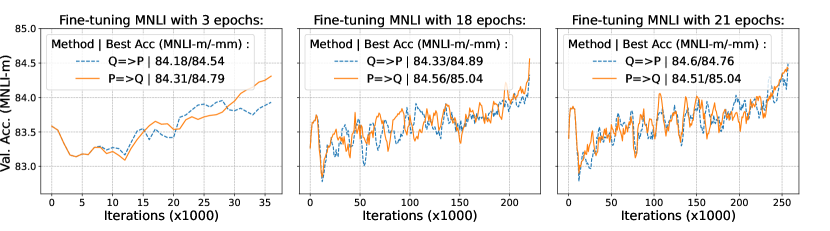
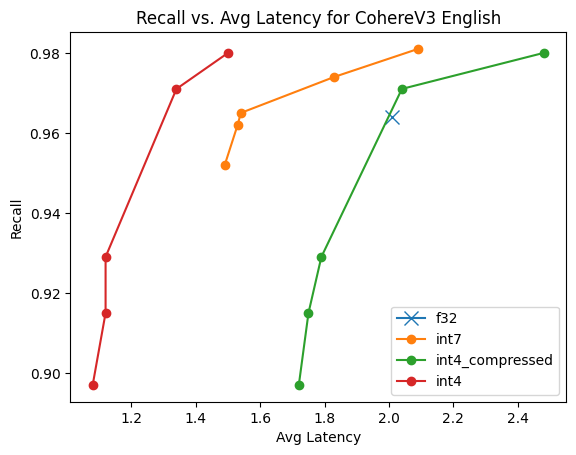
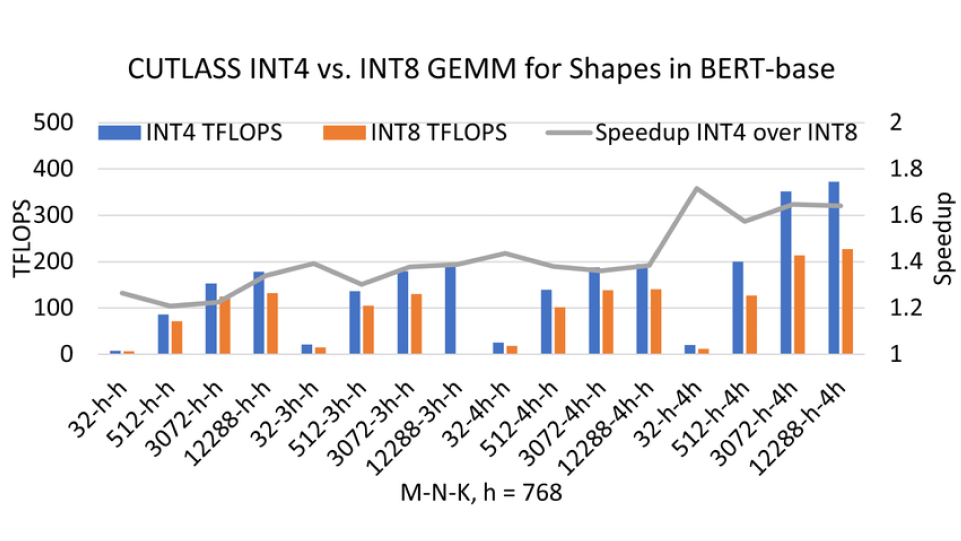
Figure 2 from Understanding INT4 Quantization for Transformer Models ...
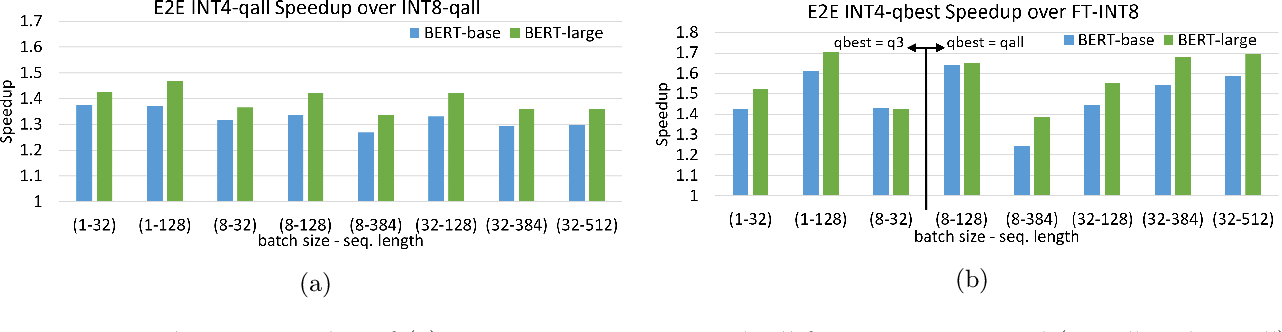
Figure 3 from Understanding INT4 Quantization for Transformer Models ...
Understanding Int4 scalar quantization in Lucene — Search Labs ...
🔢 INT4 vs FP4: The Future of 4-Bit Quantization
Using INT4 Quantization to Save VRAM with ollama · Issue #3114 · ollama ...
How to set model quantization to int4 when calling the api interface ...
Day 62/75 Why INT1 INT4 not used in LLM Quantization | What are ...
[Feature] Can you please do INT4 Quantization for InternVL2-26B and ...
Alpha-VLLM/Lumina-Next-T2I · Can you add an fp8 or int4 quantization ...
INT8 and INT4 Quantization ValueError · Issue #35 · moojink/openvla-oft ...
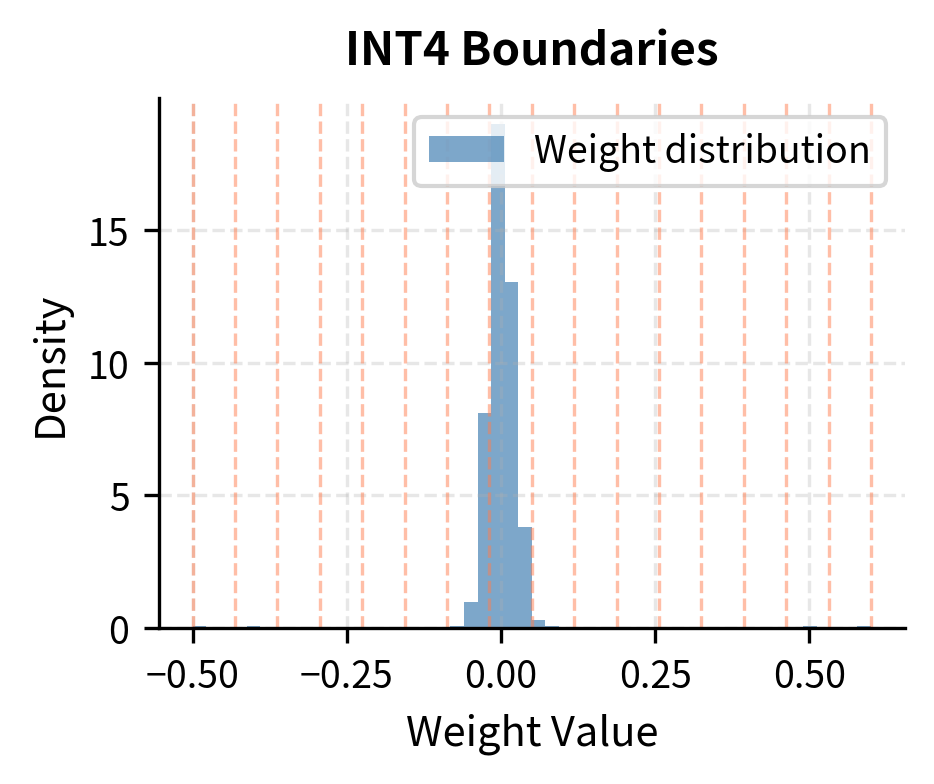
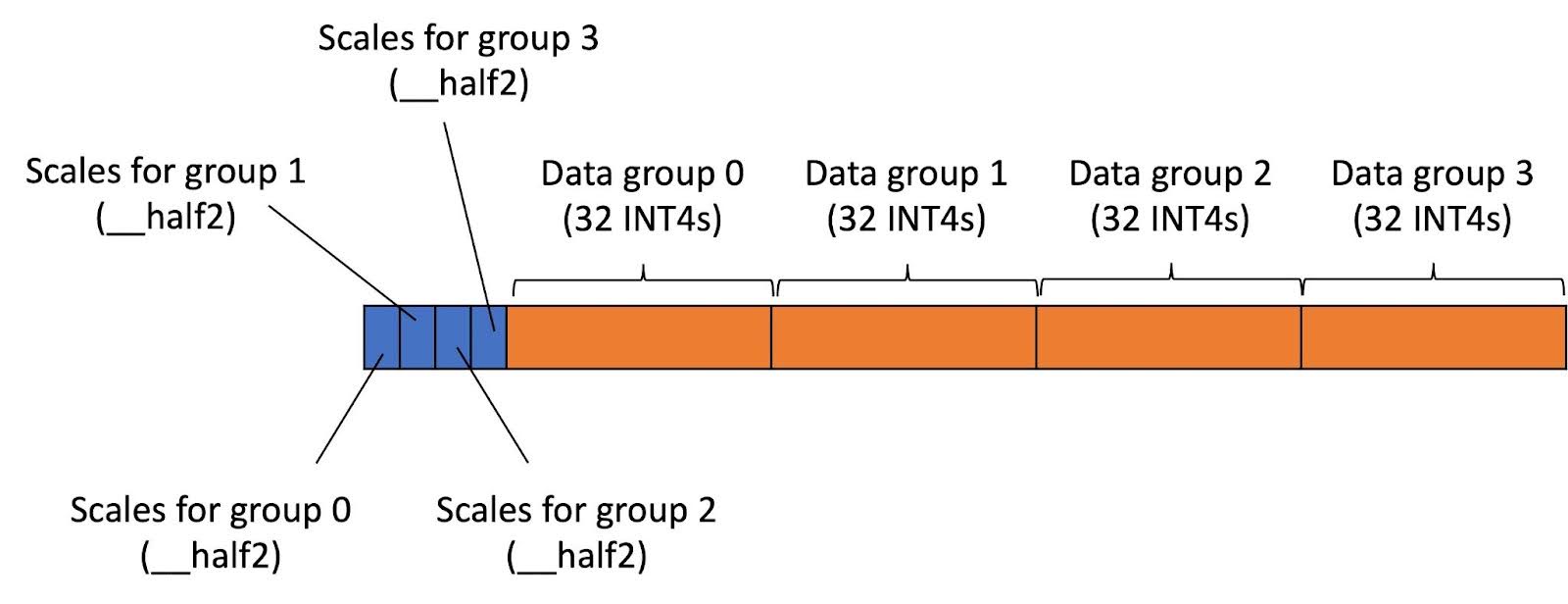
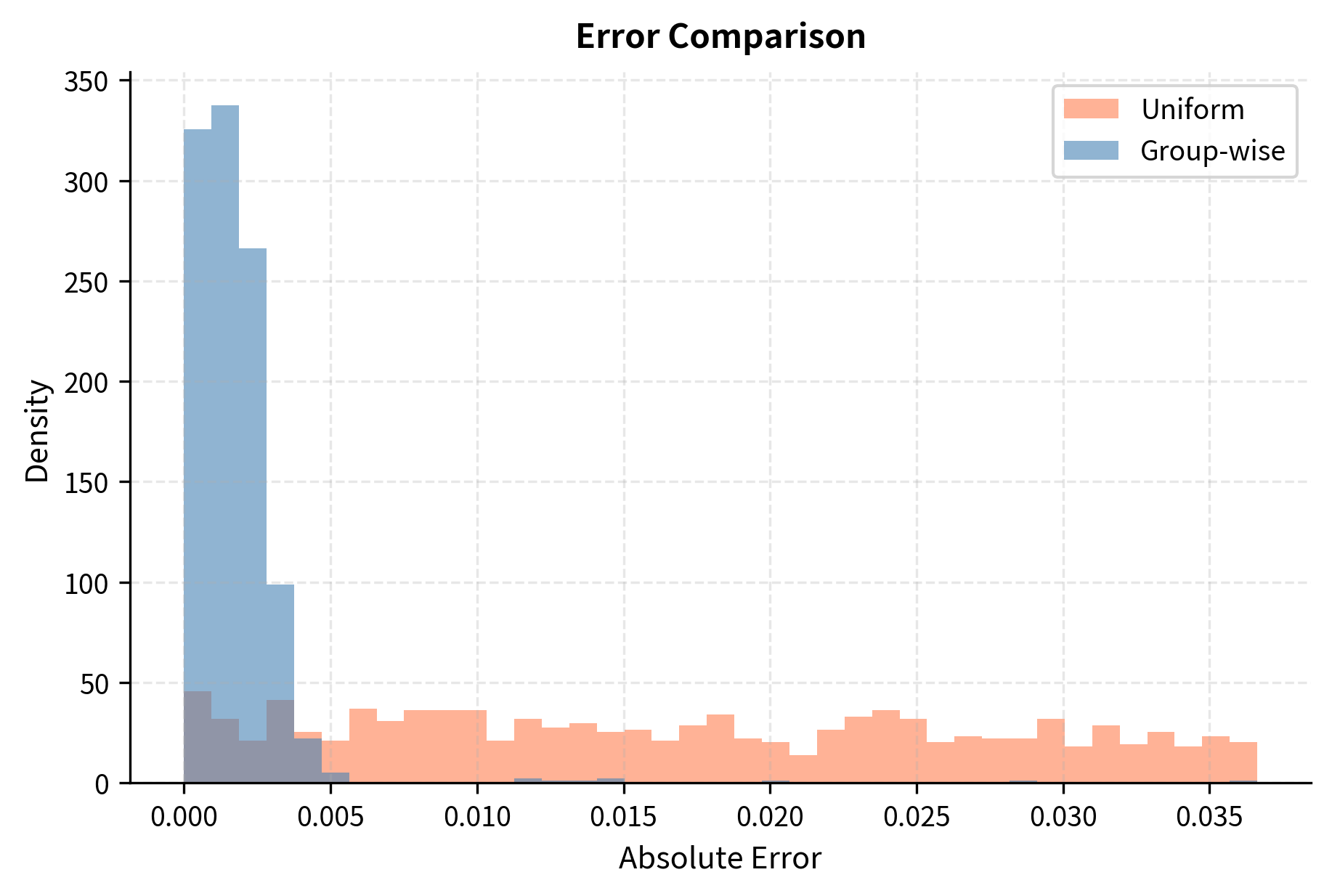
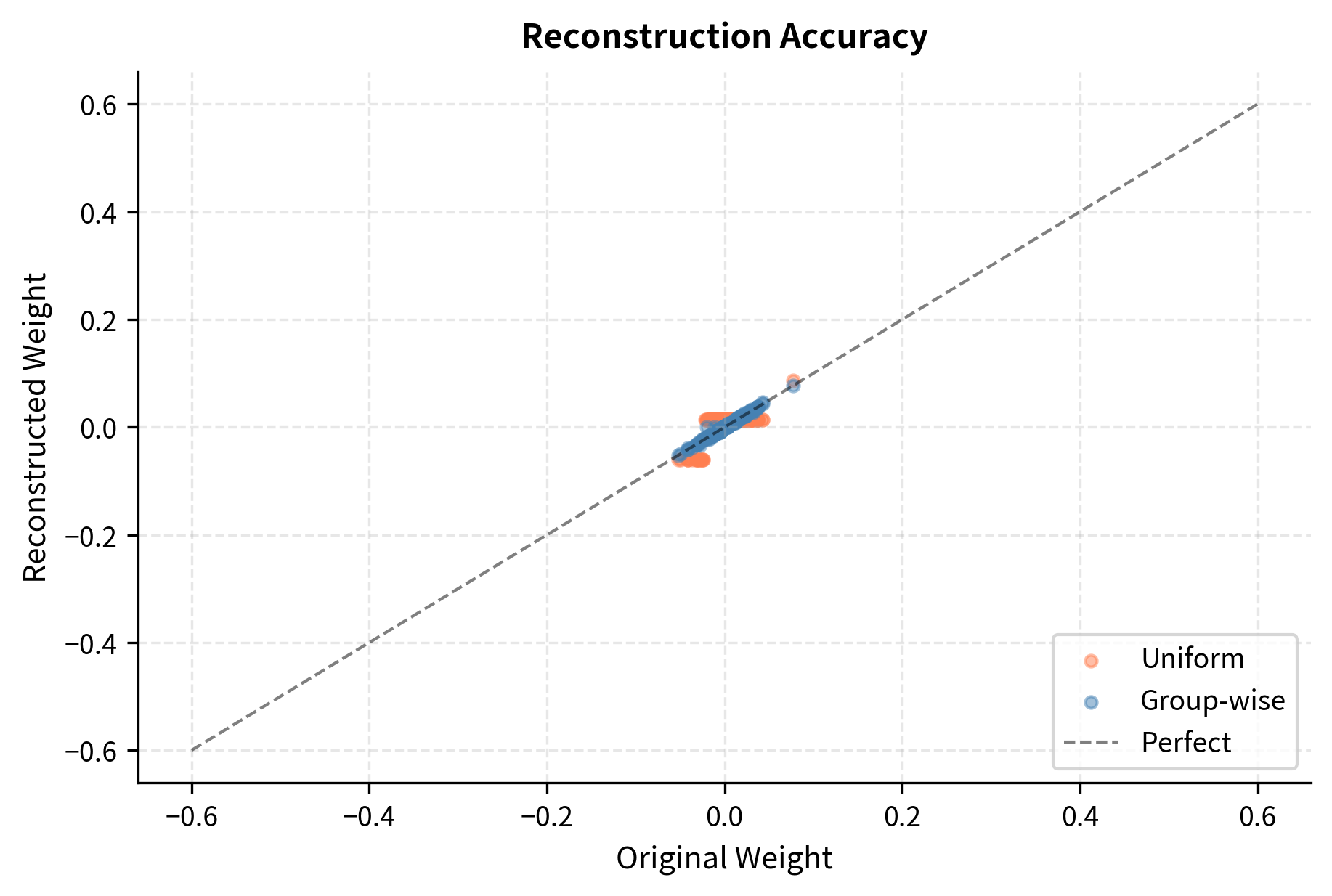
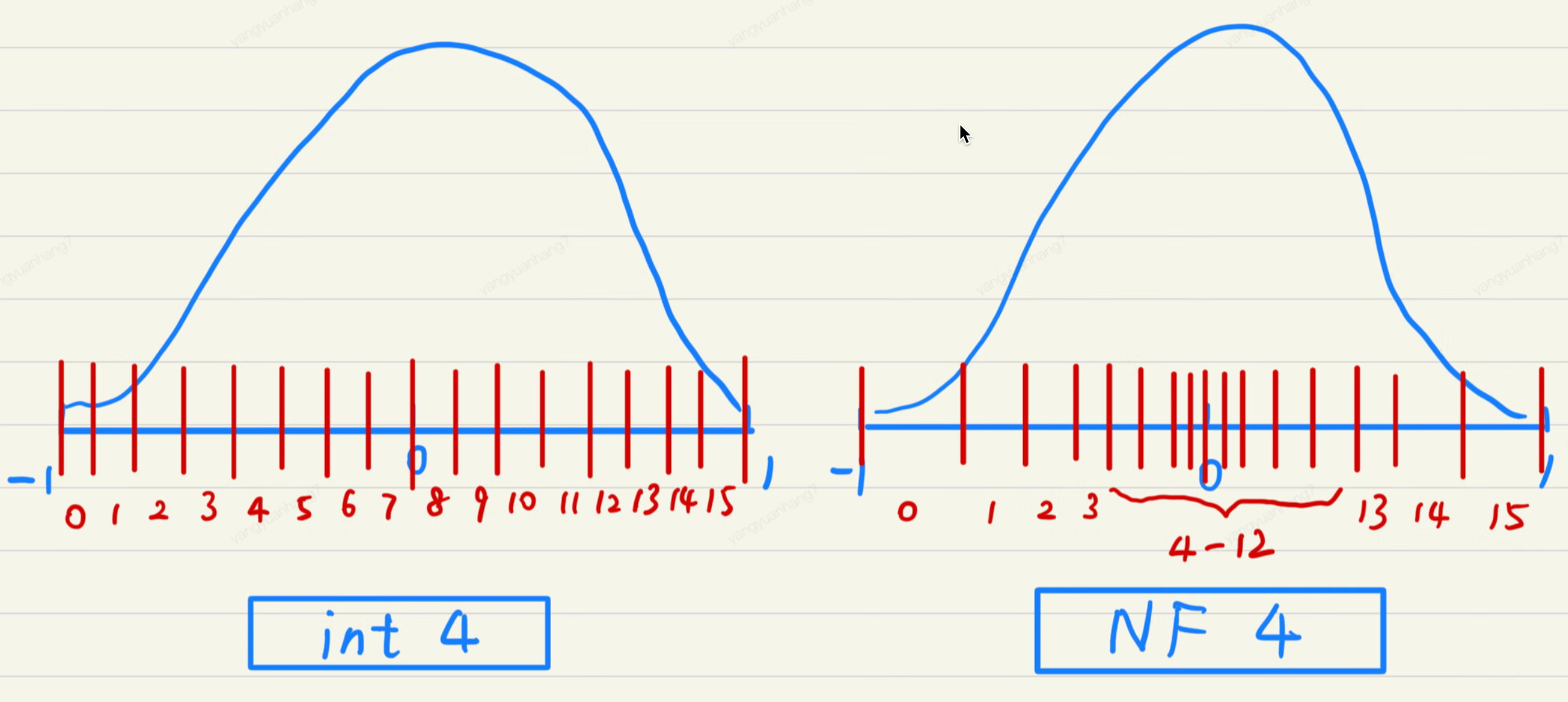
INT4 Quantization: Group-wise Methods & NF4 Format for LLMs ...
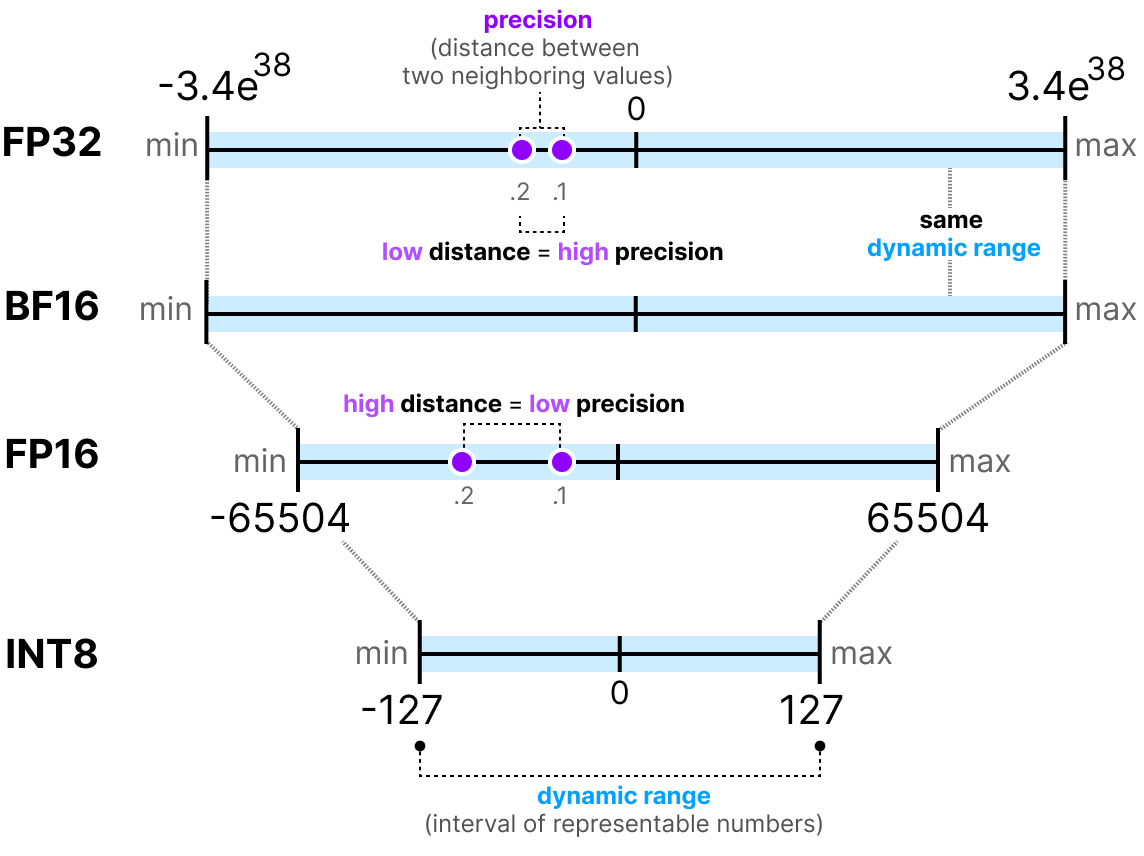
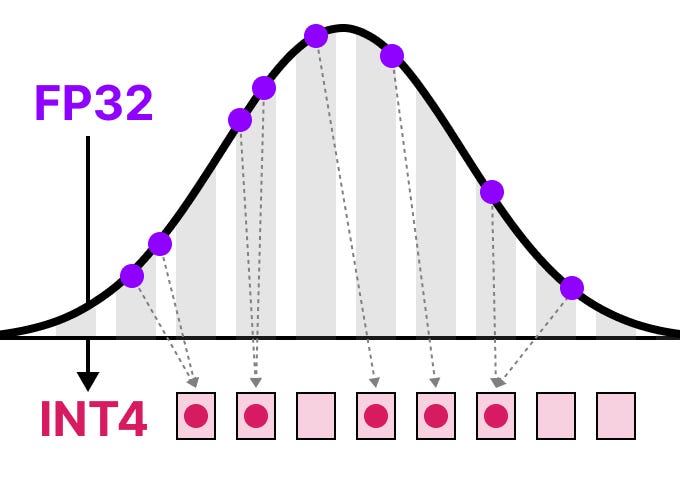
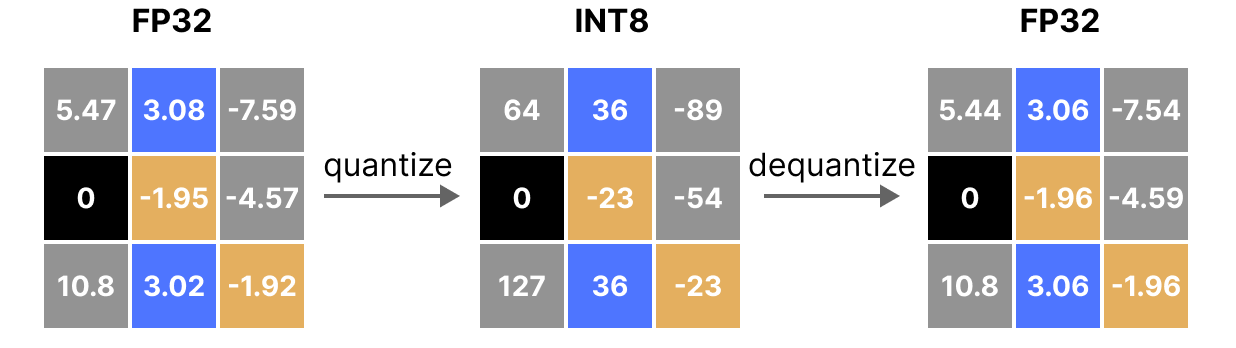
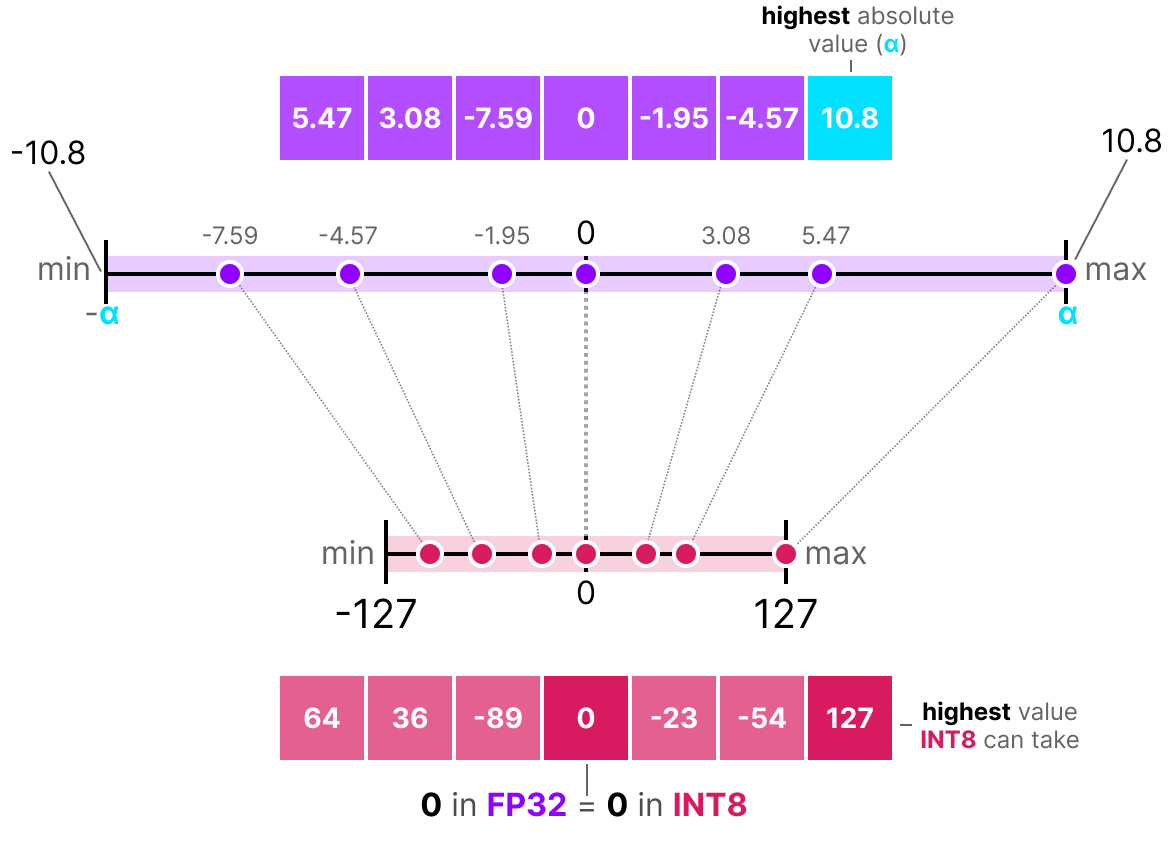
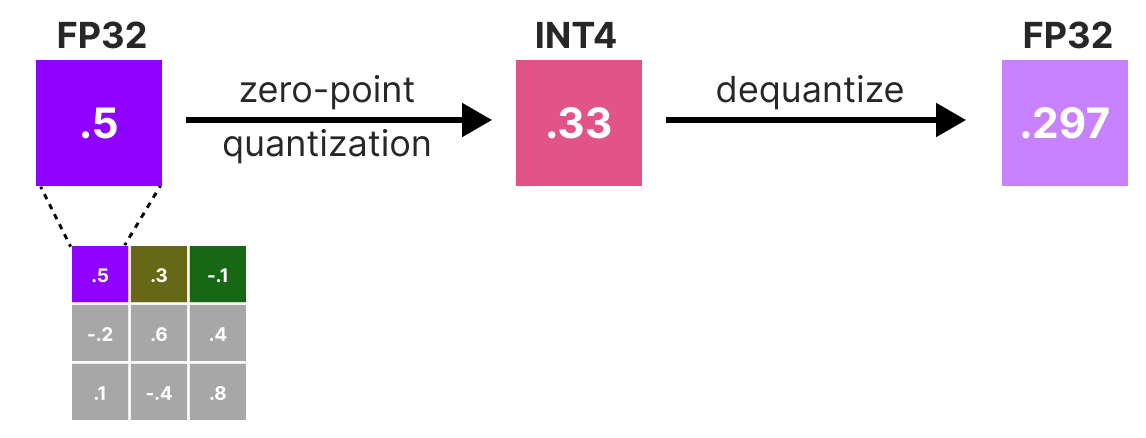
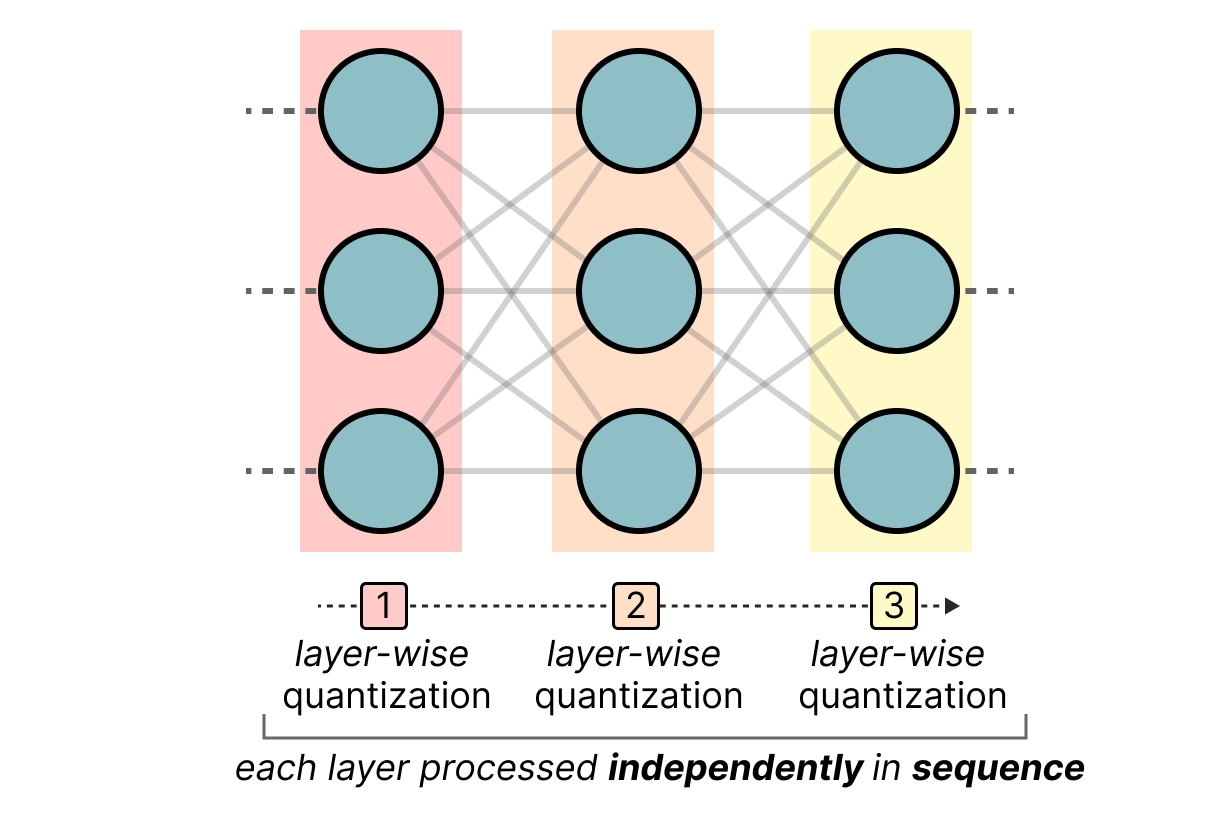
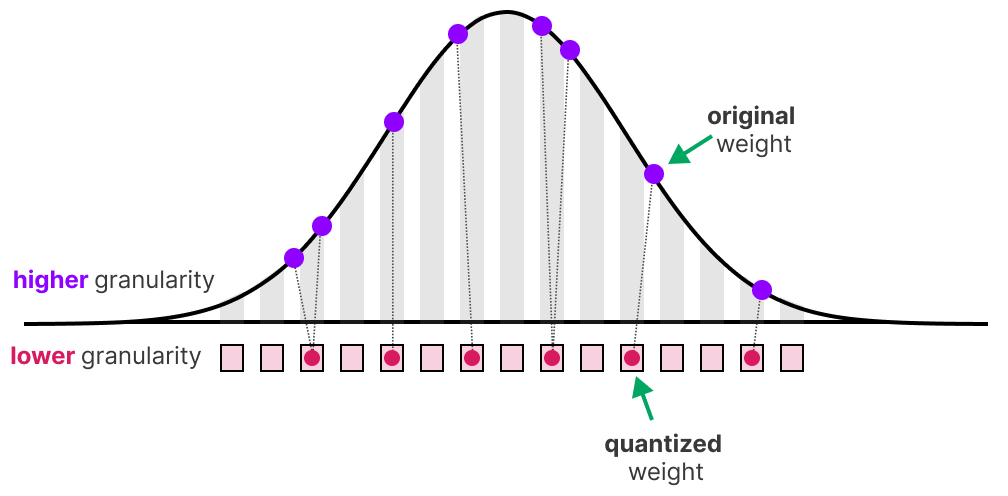
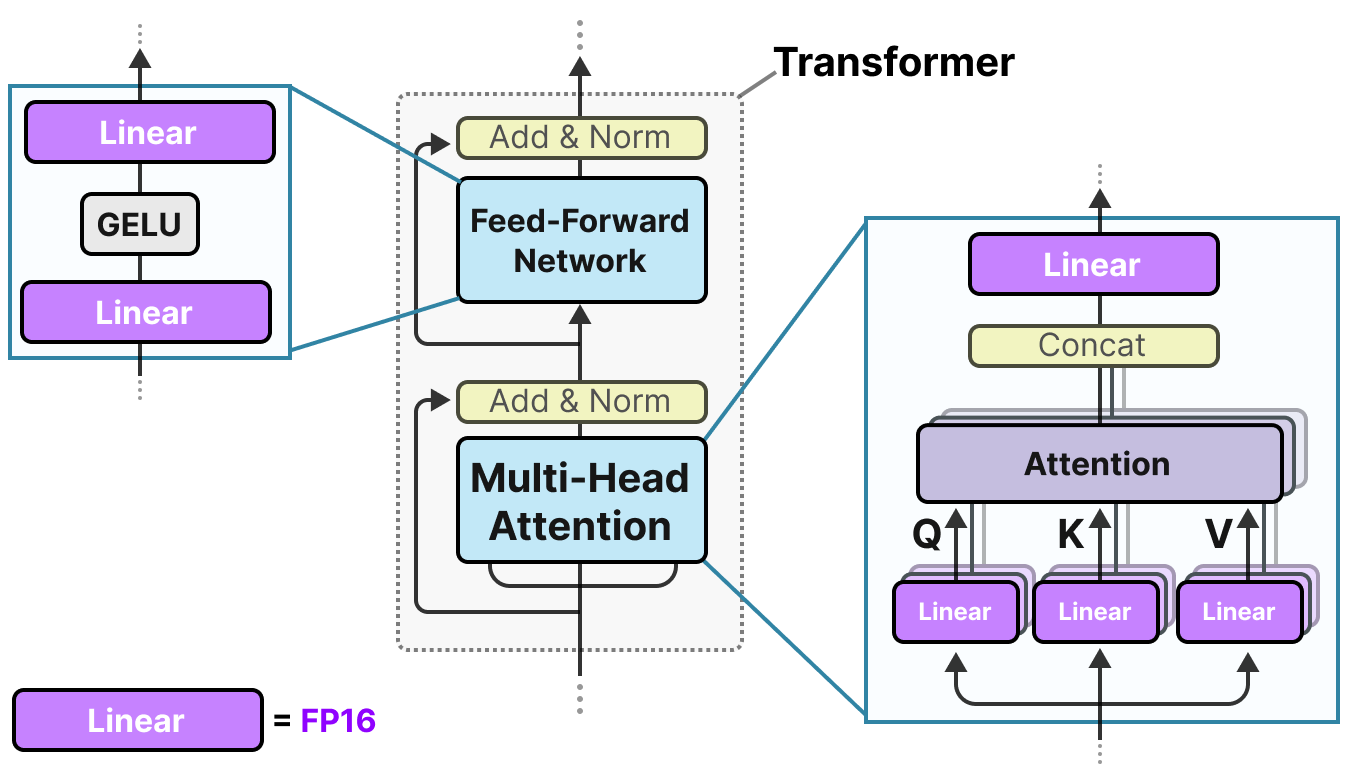
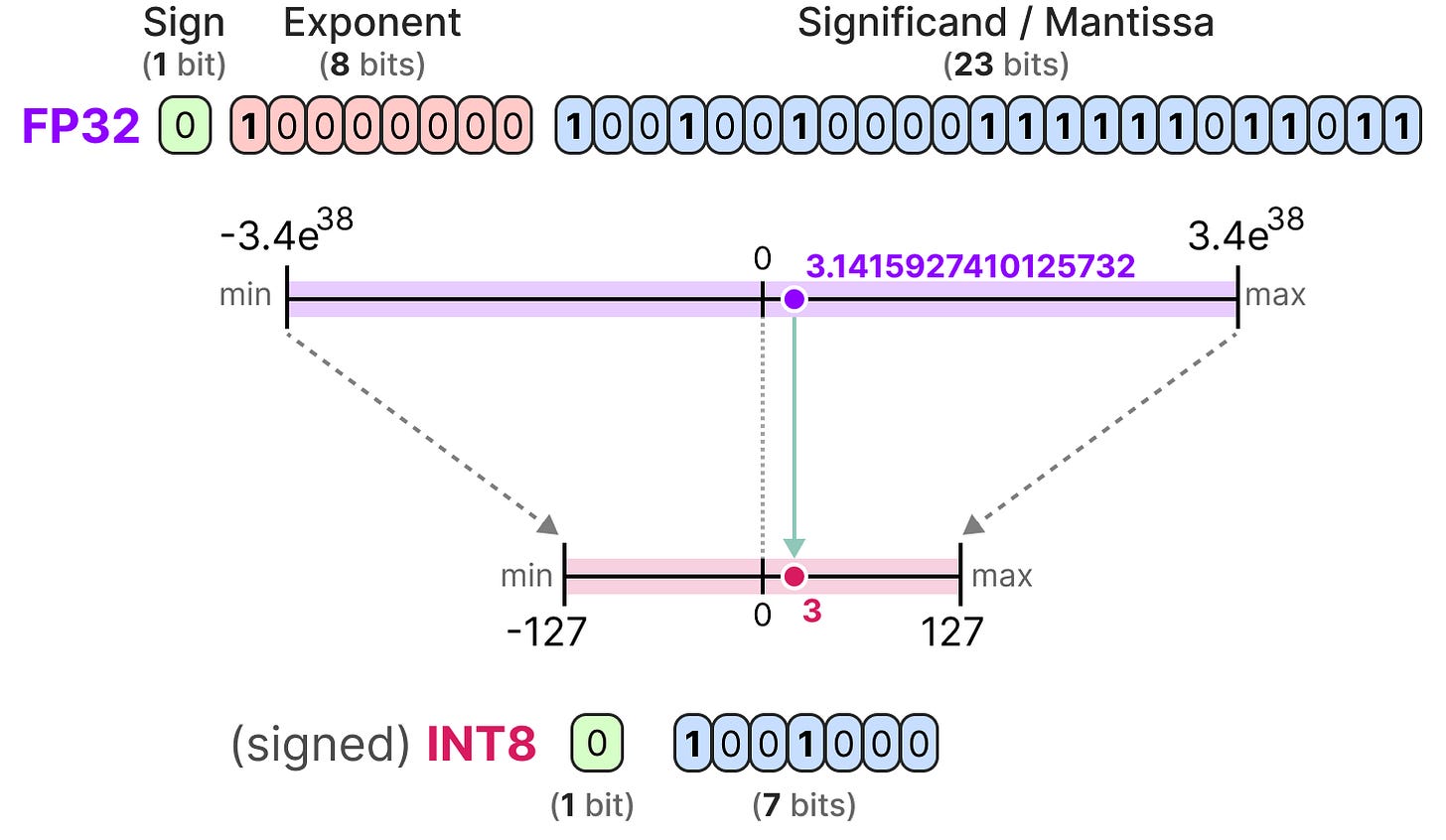
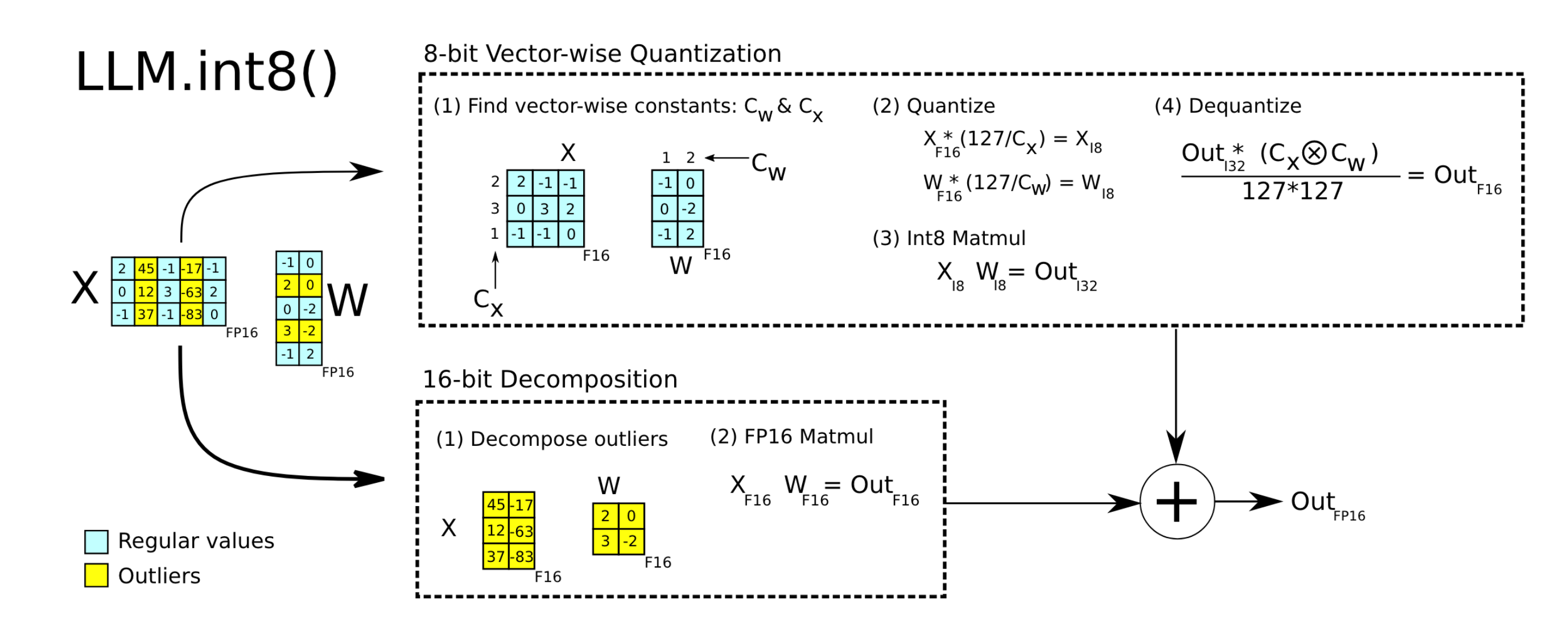
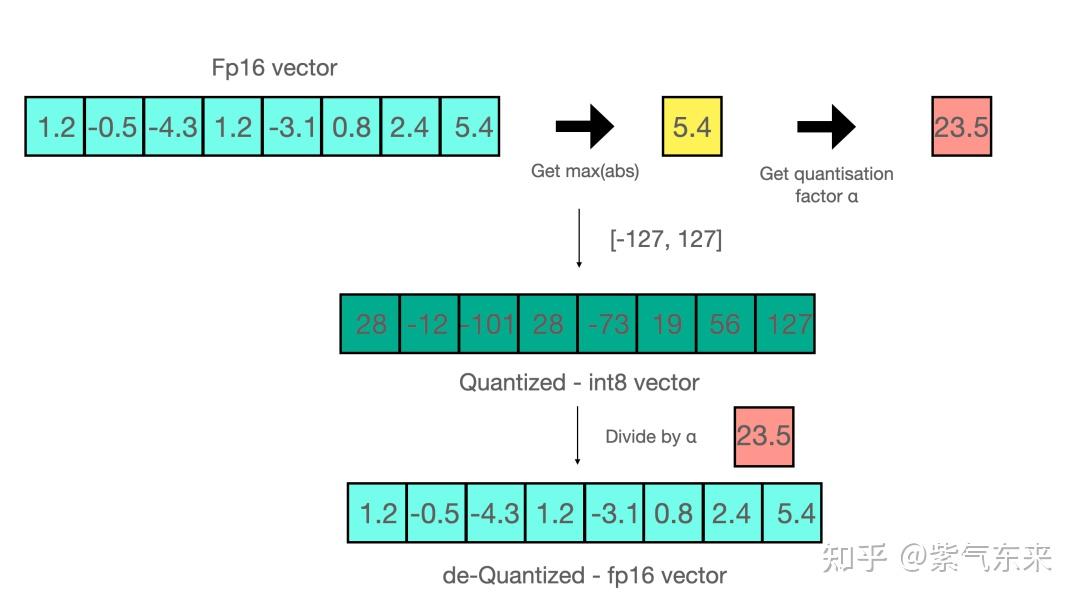
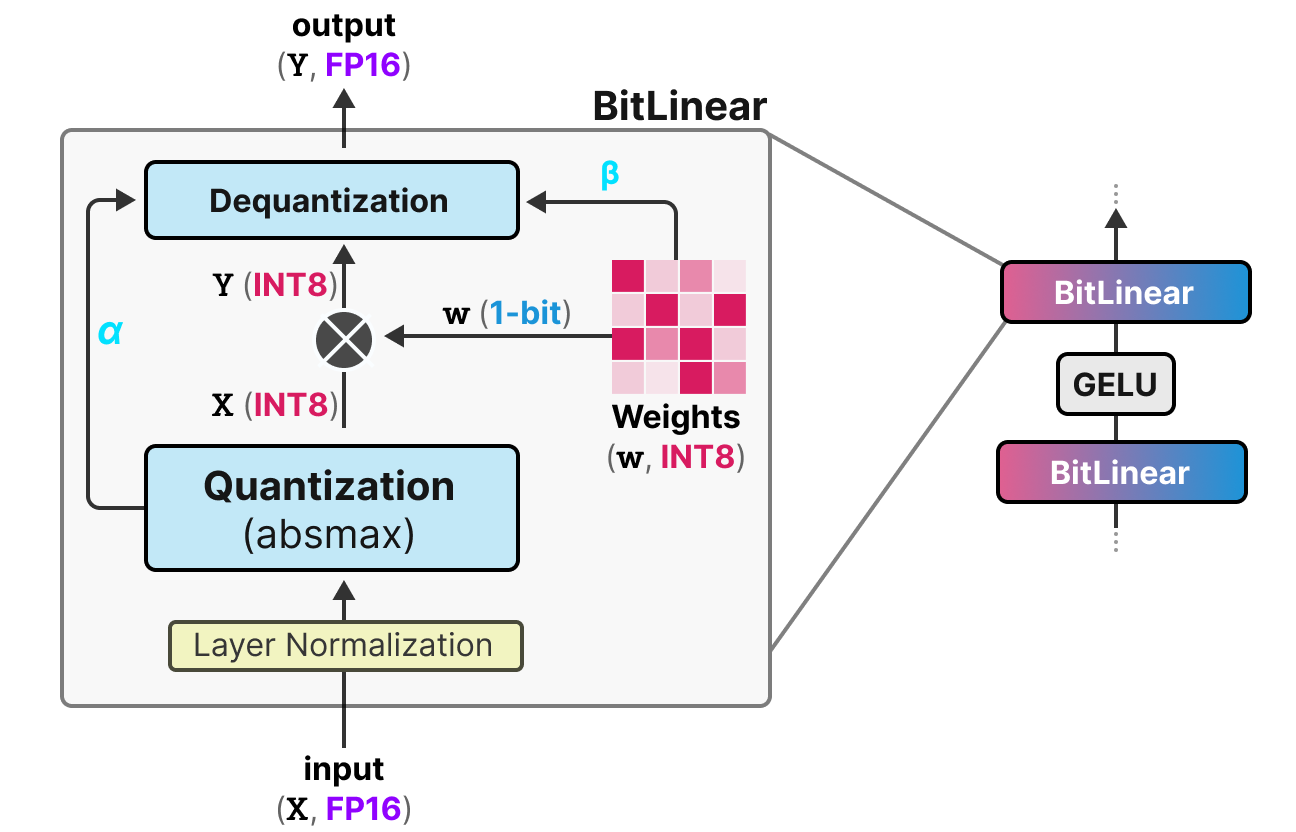
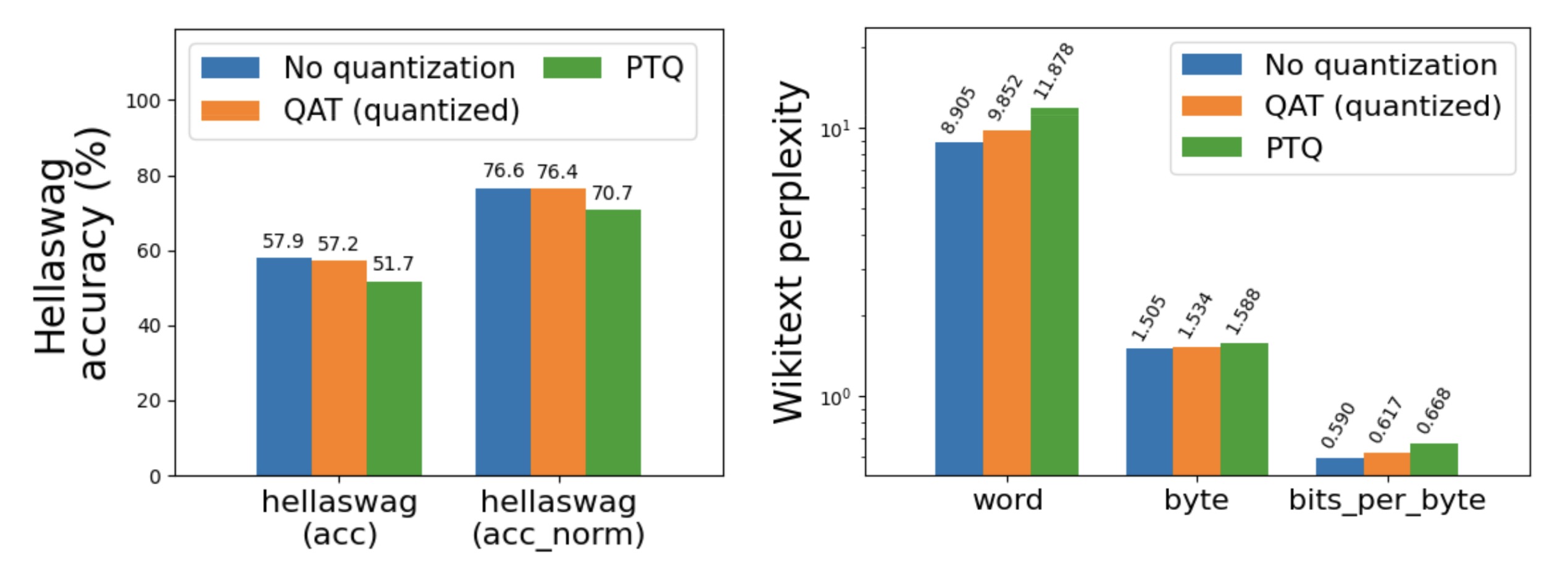
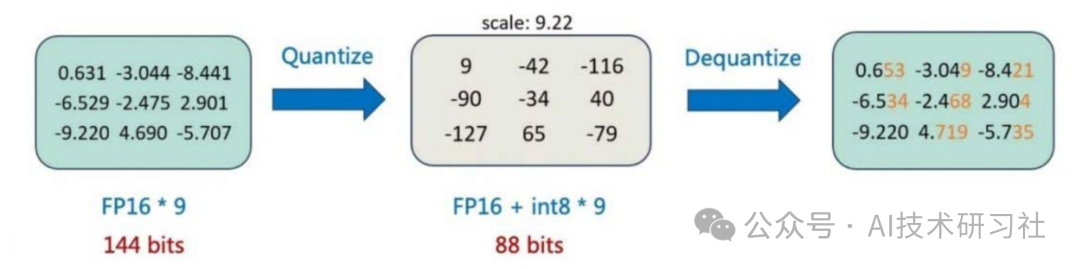
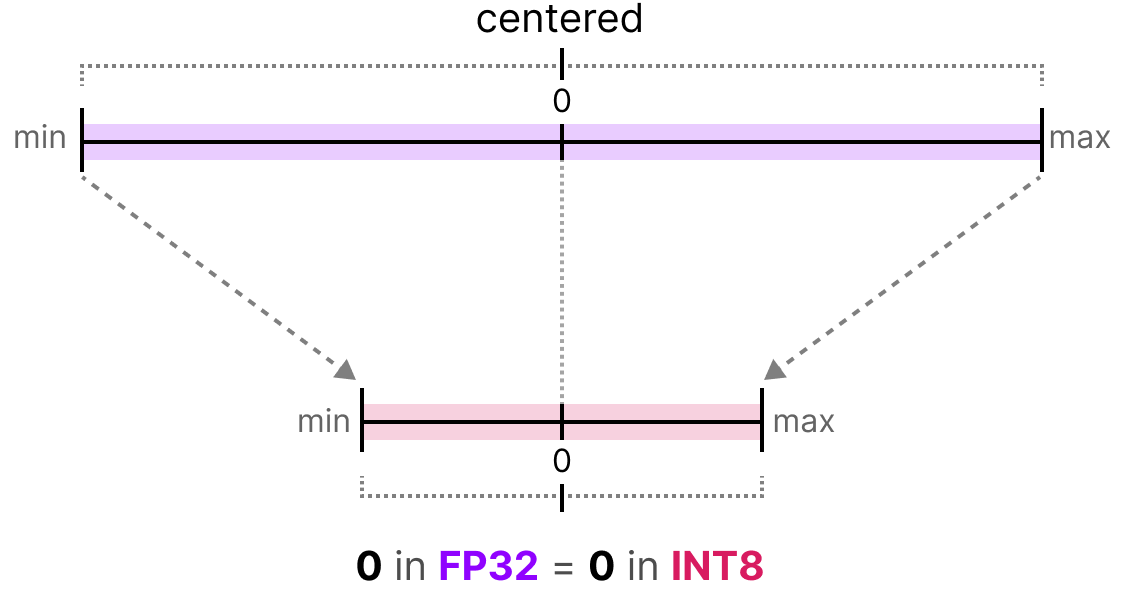
A Visual Guide to Quantization - by Maarten Grootendorst
LLM 모델 파인튜닝을 위한 Quantization | 패스트캠퍼스
A Hands-On Walkthrough on Model Quantization - Medoid AI
INT4 Decoding GQA CUDA Optimizations for LLM Inference | PyTorch
A Visual Guide to LLM Quantization | Devtalk
Exploring Model Quantization for LLMs | by Snehal | Medium
Improving LLM Inference Latency on CPUs with Model Quantization ...
Quantization
Microsoft announces ZeroQuant(4+2): Redefining LLMs Quantization with a ...
Post-Training Quantization of LLMs with NVIDIA NeMo and NVIDIA TensorRT ...
A Practical Guide to LLM Quantization (int8/int4) | Hivenet
Quantization Techniques for LLM Inference: INT8, INT4, GPTQ, and AWQ ...
The Quantization Horizon: Navigating the Transition to INT4, FP4, and ...
[Quantization] int4 vs fp4 which to choose?
How Quantization Works: From a Matrix Multiplication Perspective ...
Mastering Quantization for Large Language Models: A Comprehensive Guide ...
zai-org/glm-4v-9b · How to run the Int4 quantized model?
Quantization - Neural Network Distiller
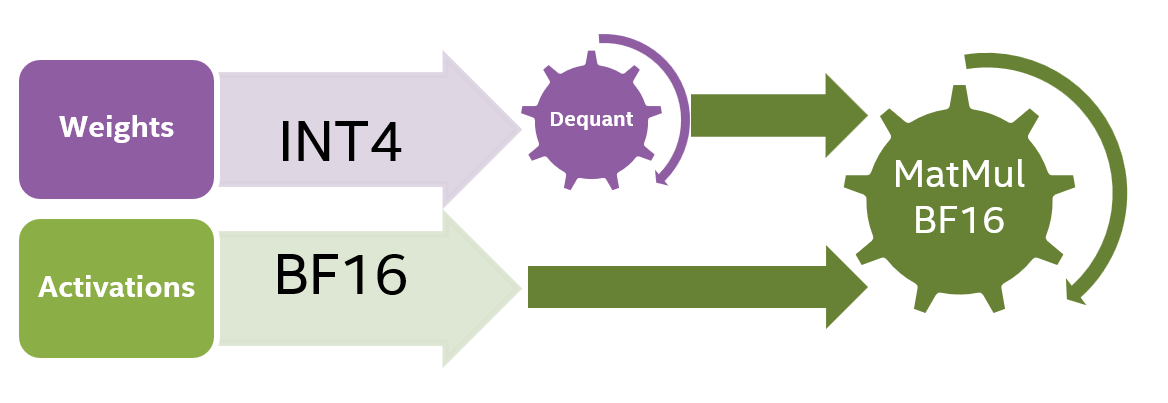
Weight-only Quantization to Improve LLM Inference
GitHub - intel/neural-compressor: SOTA low-bit LLM quantization (INT8 ...
Quantization concepts
14. Quantization — ECE 386
A Survey of Quantization Methods for Efficient Neural Network Inference ...
HAWQ-V3: Dyadic Neural Network Quantization | PDF
What is Quantization in LLM. Large Language Models comes in all… | by ...
LLM Quantization: BF16 vs FP8 vs INT4
Quantization Techniques in Deep Learning | by Anay Dongre | Jan, 2025 ...
LLM Series - Quantization Overview | by Abonia Sojasingarayar | Medium
Extremely Low Bit Transformer Quantization for On-Device NMT | PDF
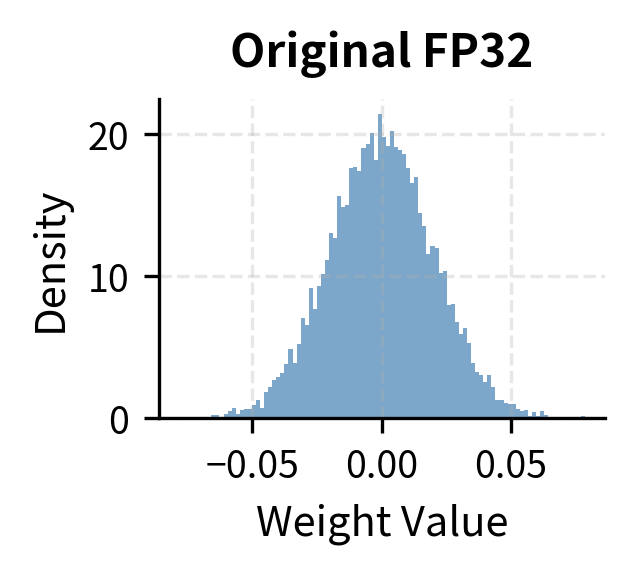
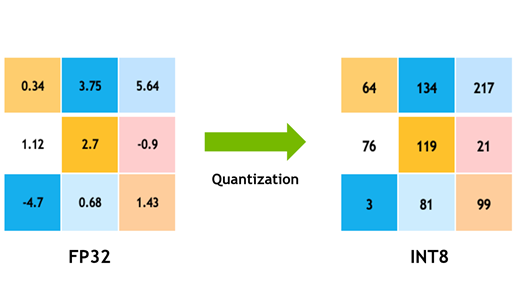
Quantization from FP32 to INT8. | Download Scientific Diagram
Quantization Overview — Guide to Core ML Tools
Mastering QLoRa : A Deep Dive into 4-Bit Quantization and LoRa ...
Quark Quantized INT4 Models - a amd Collection
LLM(11):大语言模型的模型量化(INT8/INT4)技术 - 知乎
LLMs之Quantization:LLM中量化技术的可视化指南之量化技术的简介、常用数据类型、校准权重和激活值的量化方法(PTQ/QAT ...
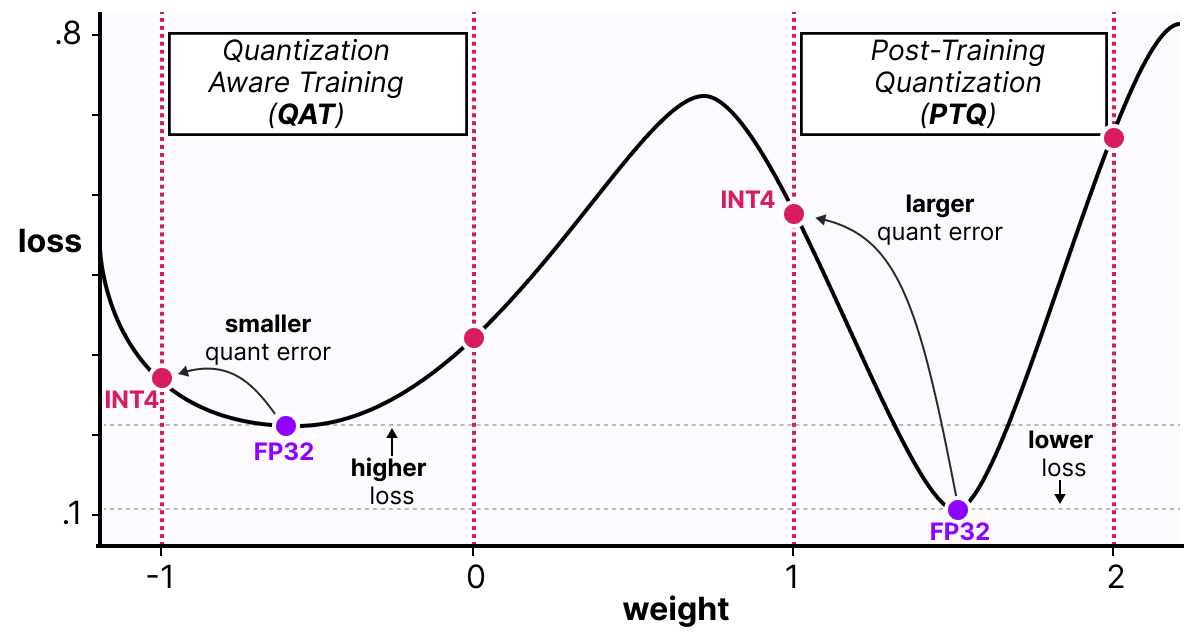
Quantization-Aware Training for Large Language Models with PyTorch ...
Serving Quantized LLMs on NVIDIA H100 Tensor Core GPUs | Databricks
LLM Quantization: Making models faster and smaller | MatterAI Blog
[2307.09782] ZeroQuant-FP: A Leap Forward in LLMs Post-Training W4A8 ...
LLM(十一):大语言模型的模型量化(INT8/INT4)技术 - 知乎
Quantize Hugging Face model to AWQ int4: A Step-by-Step Guide with ...
Quantized 8-bit LLM training and inference using bitsandbytes on AMD ...
Accelerate StarCoder with 🤗 Optimum Intel on Xeon: Q8/Q4 and ...
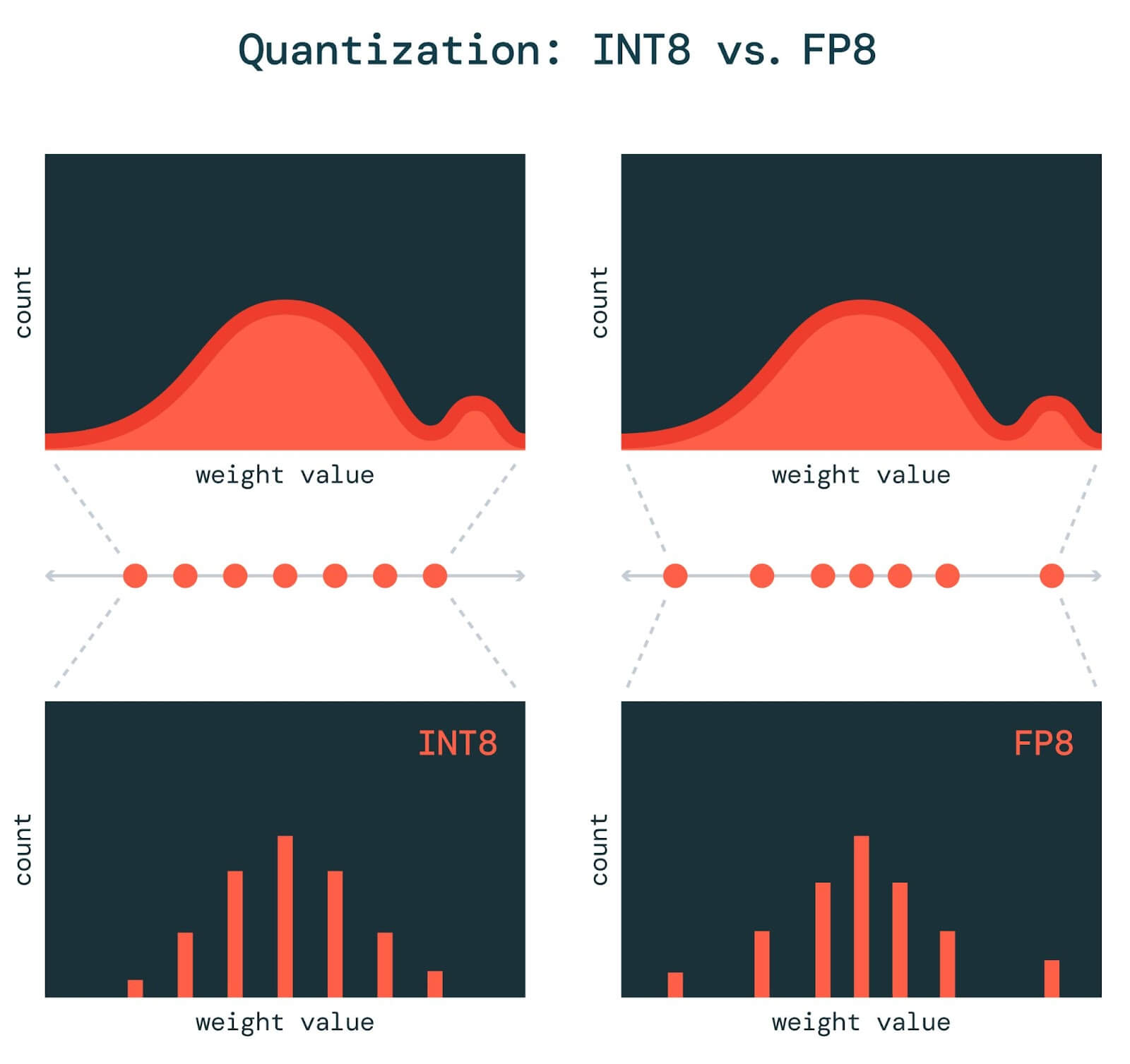
[2303.17951] FP8 versus INT8 for efficient deep learning inference
【科普】大模型量化技术大揭秘:INT4、INT8、FP32、FP16的差异与应用解析 - 墨天轮
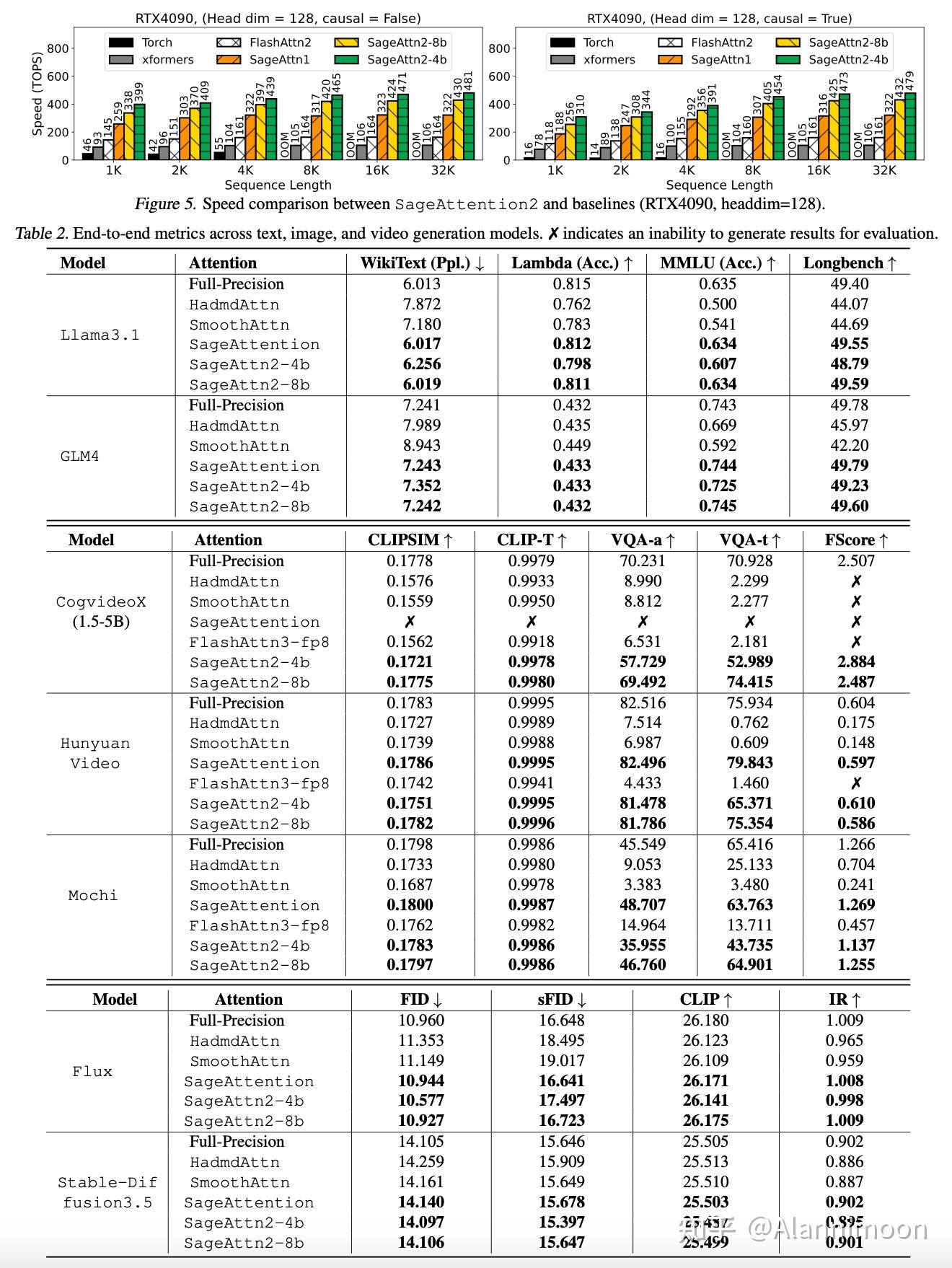
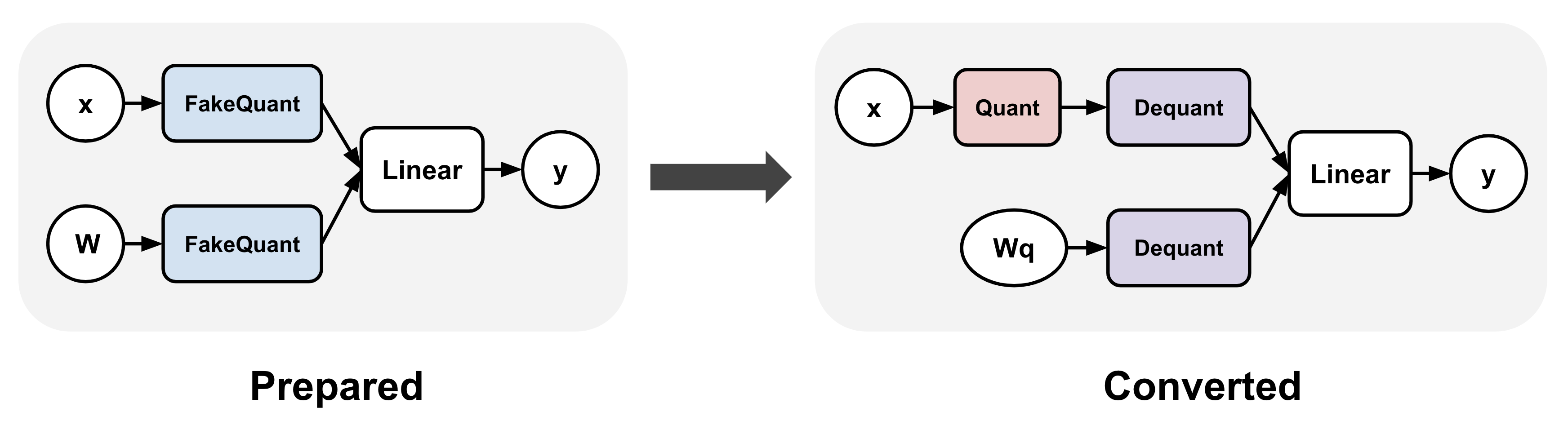
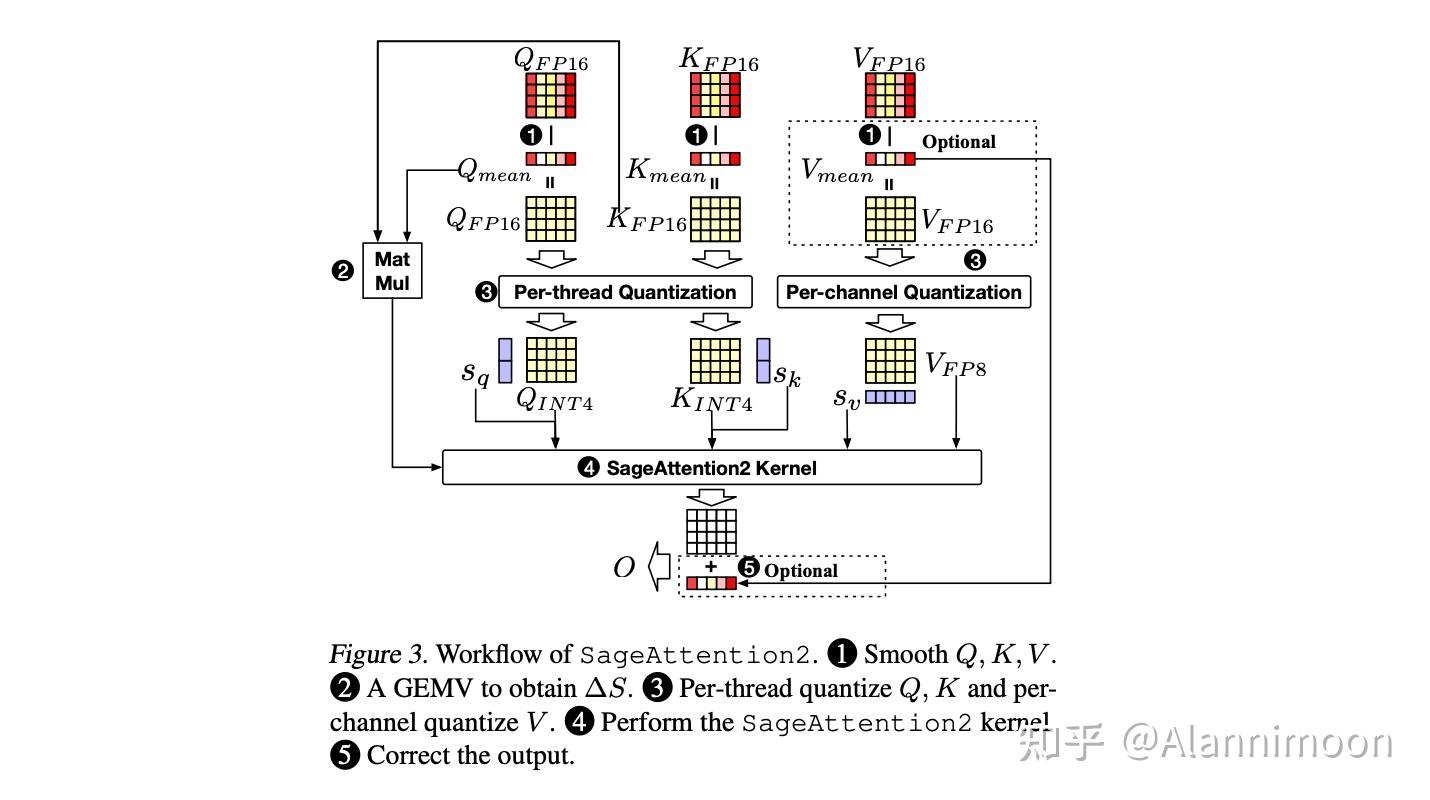
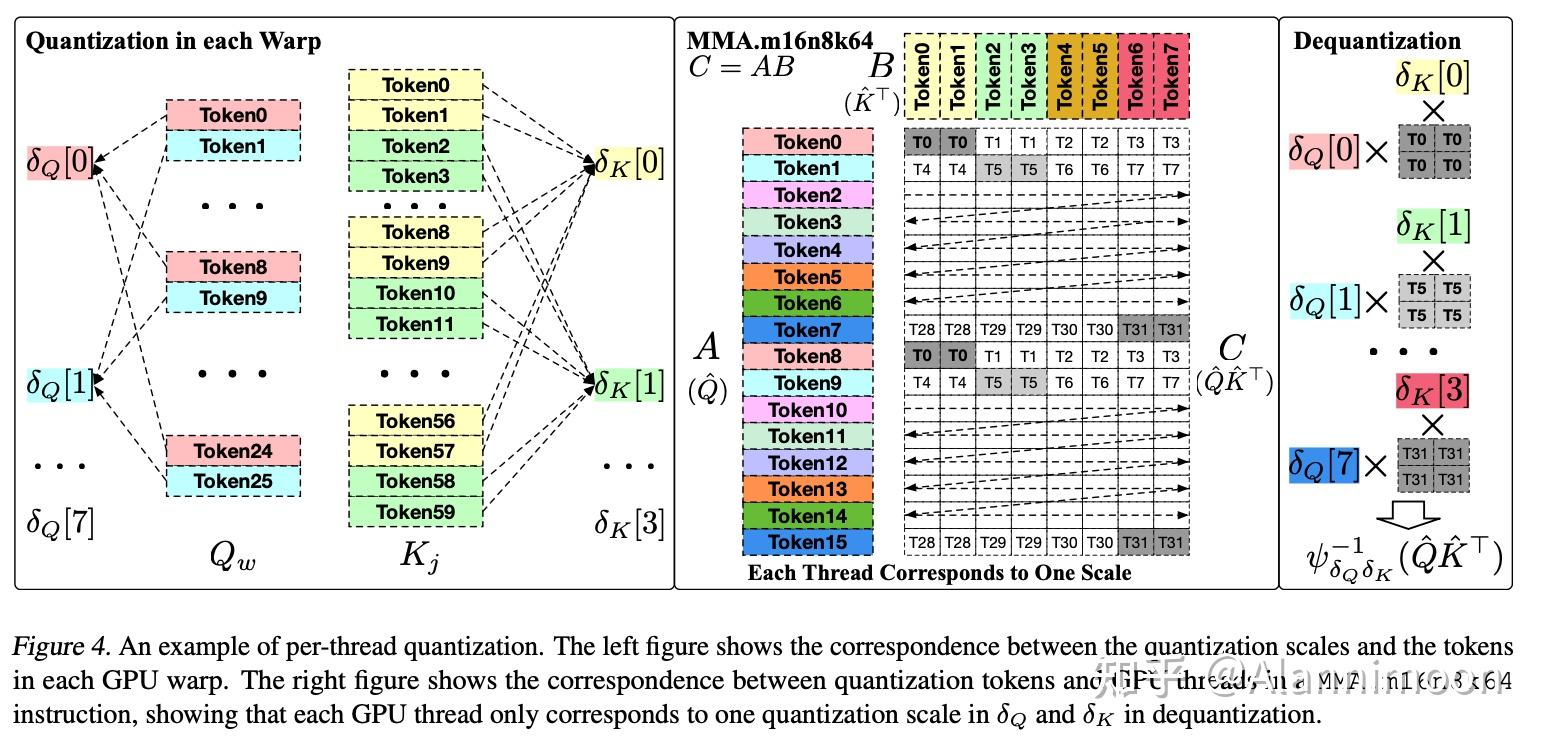
SageAttention2: Efficient Attention with Thorough Outlier Smoothing and ...
top-1 accuracy of fp32, Tensorflow's INT4-8 and AB INT4- 4 ...
QLoRA、GPTQ:模型量化概述 - 知乎
QM-ToT: A Medical Tree of Thoughts Reasoning Framework for Quantized ...
50张图解密大模型量化技术:INT4、INT8、FP32、FP16、GPTQ、GGUF、BitNet_gptq量化-CSDN博客
Full Integer Quantization. | Download Scientific Diagram
Introducing NVFP4 for Efficient and Accurate Low-Precision Inference ...