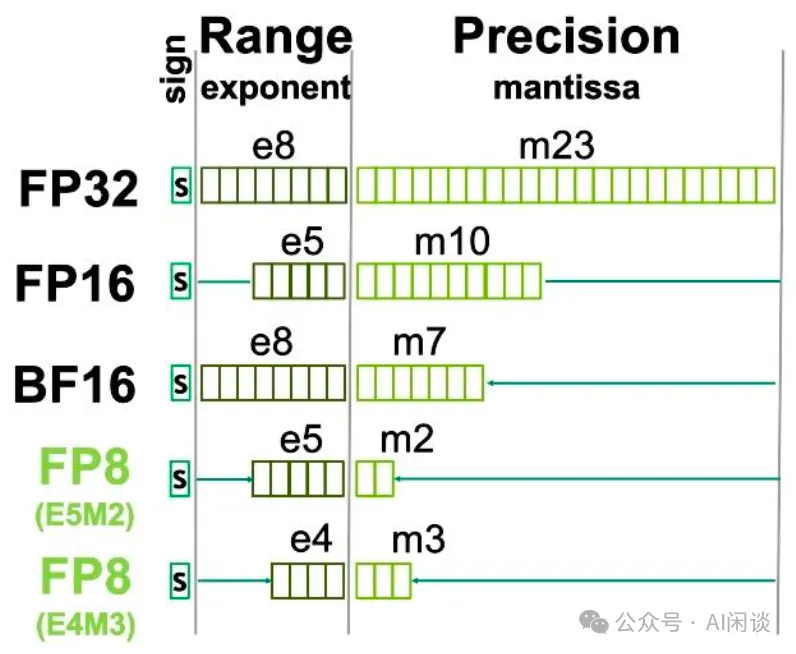
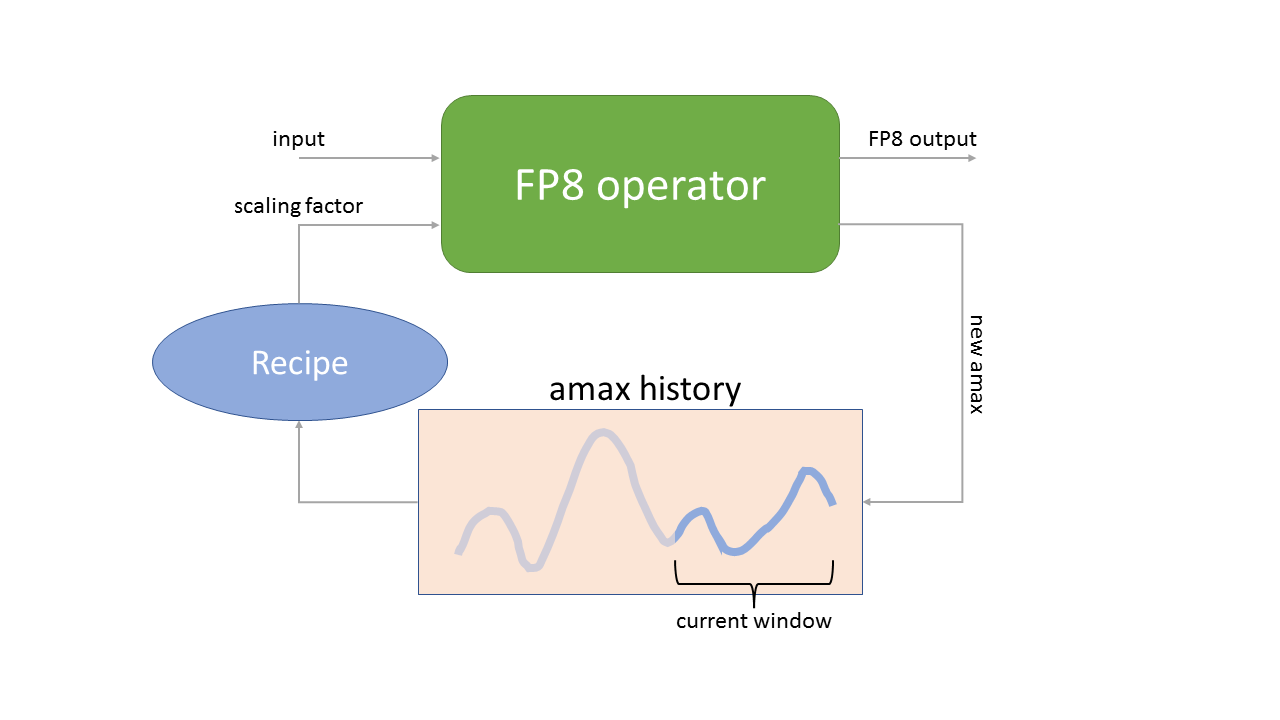
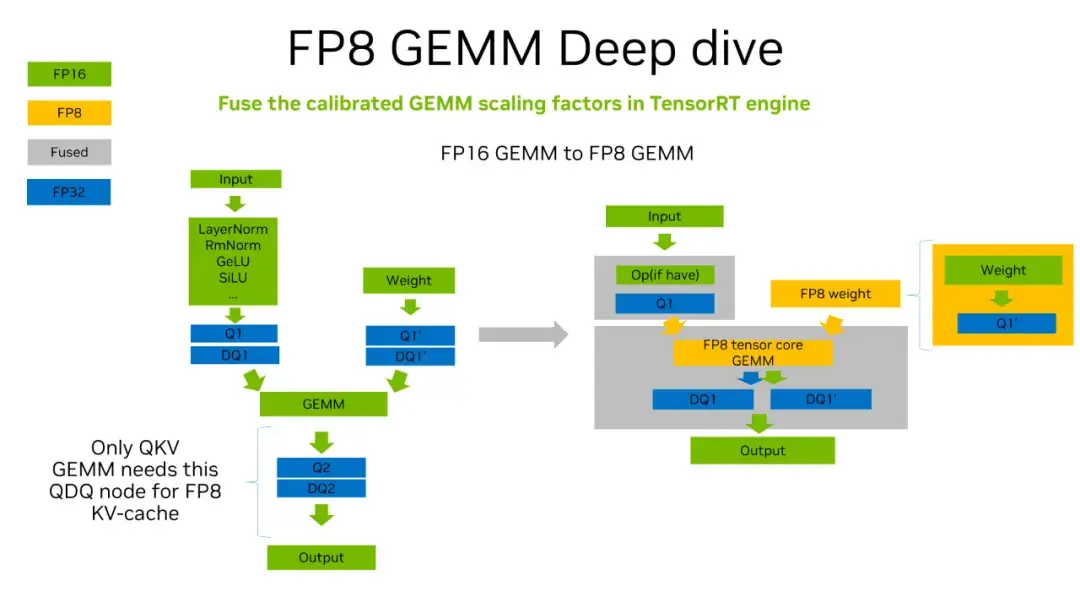
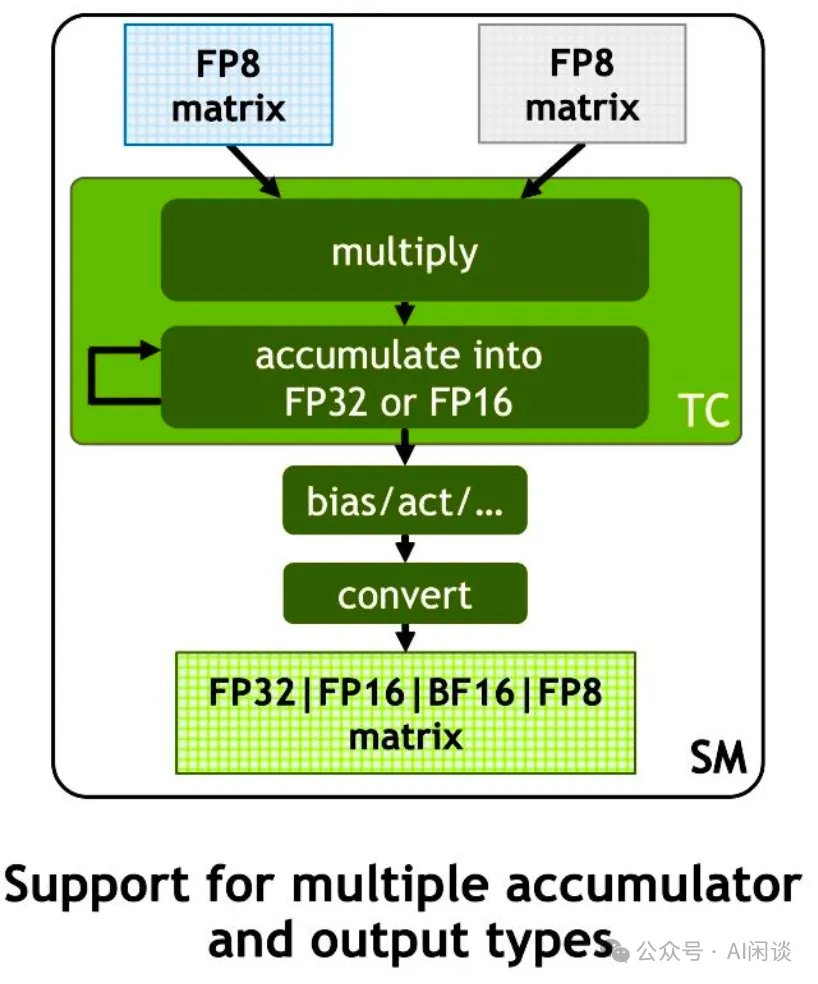
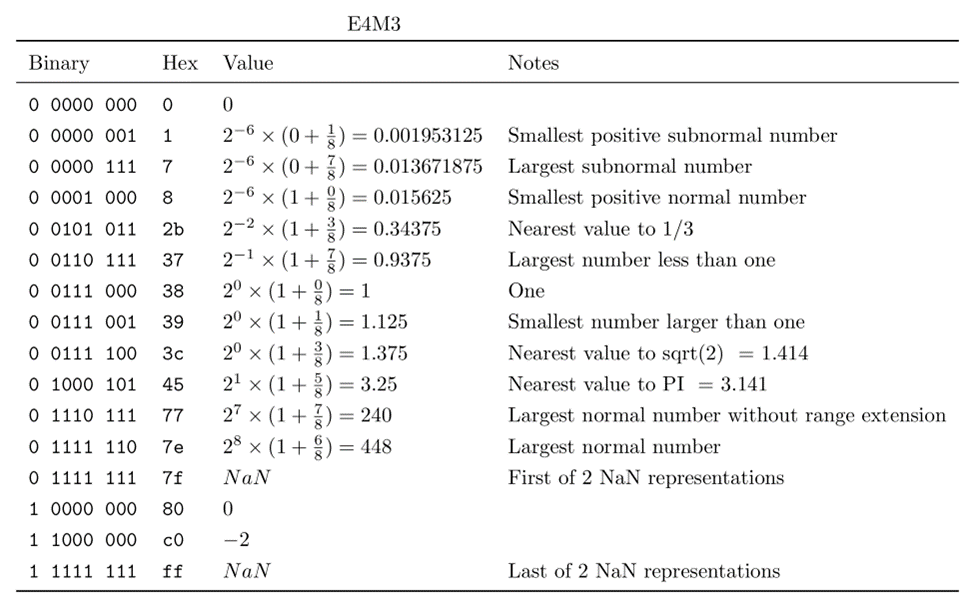
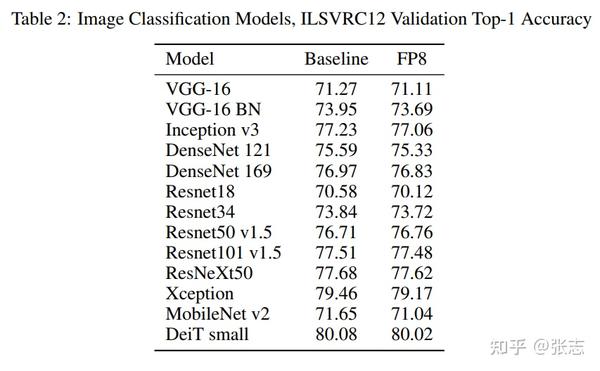
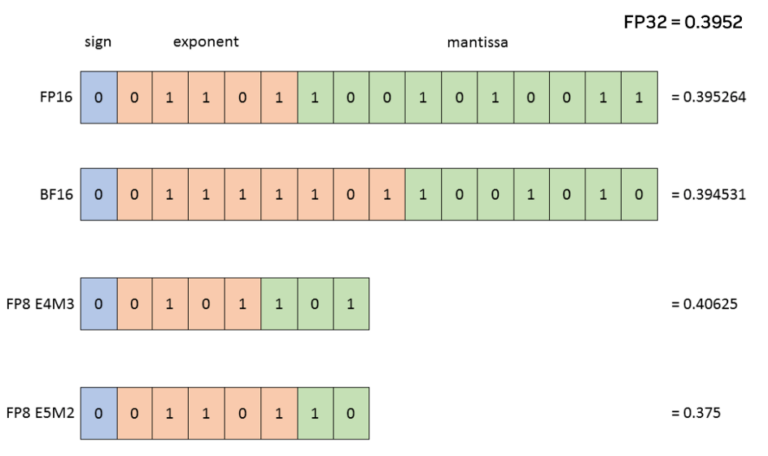
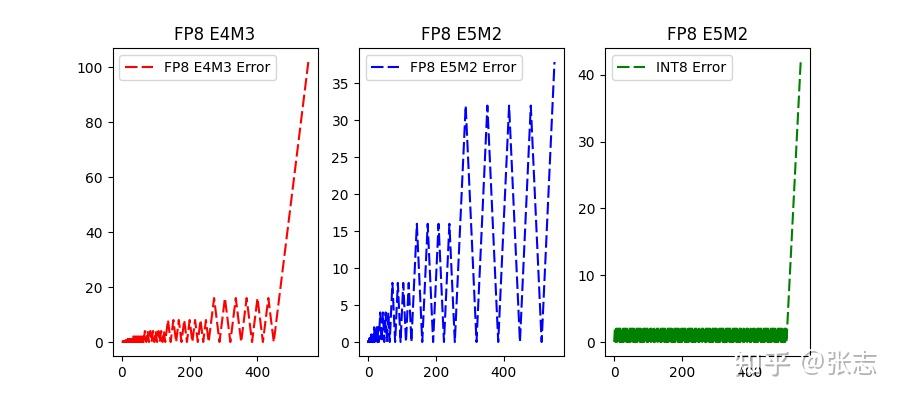
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
万字综述:全面梳理 FP8 训练和推理技术-AI.x-AIGC专属社区-51CTO.COM
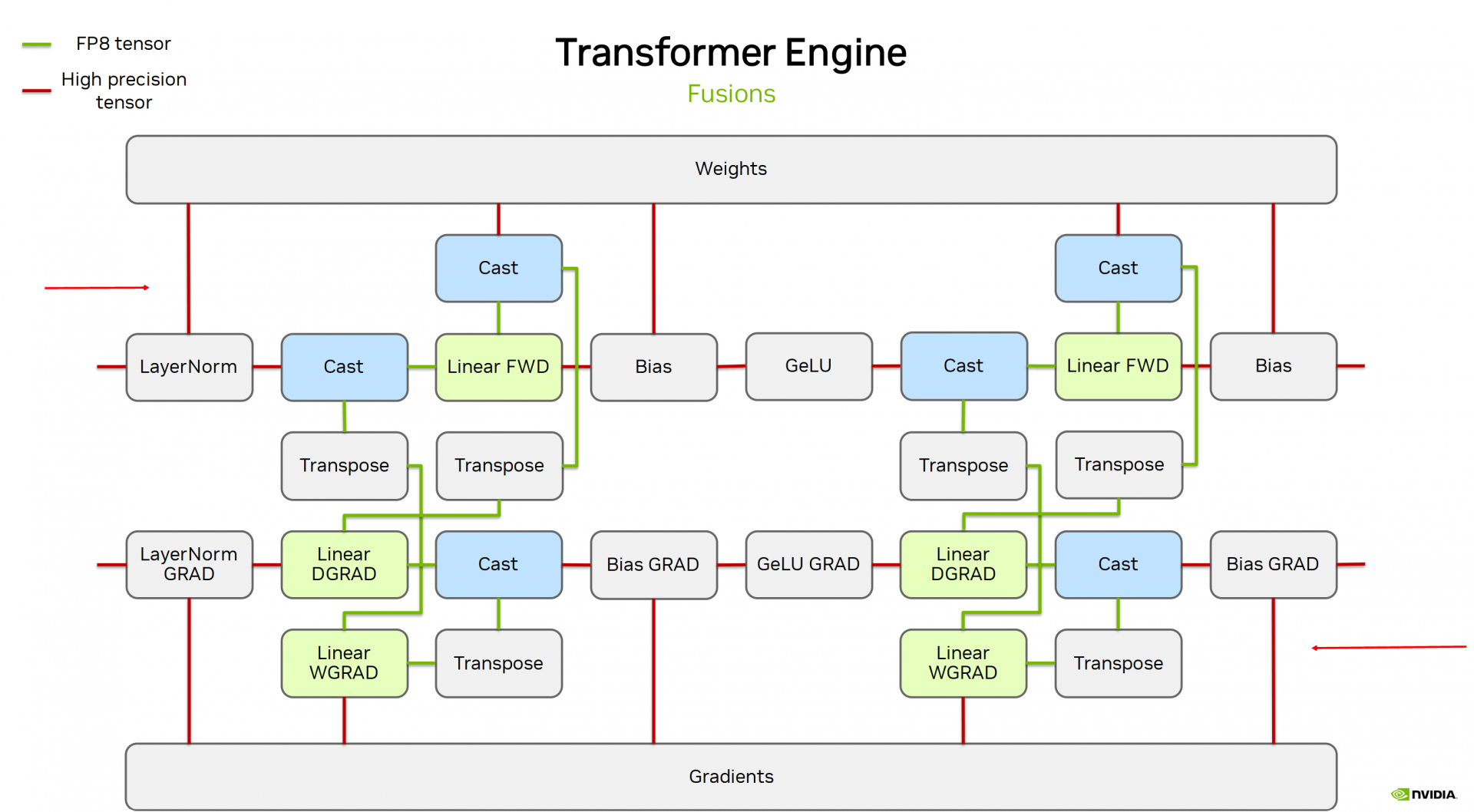
Using FP8 and FP4 with Transformer Engine — Transformer Engine 2.13.0 ...
TensorRT-LLM 低精度推理优化:从速度和精度角度的 FP8 vs INT8 的全面解析 - 知乎
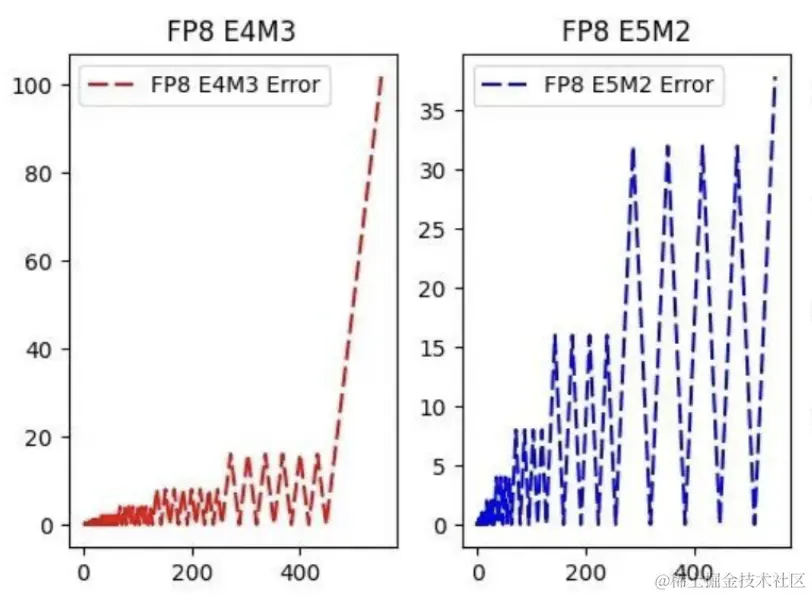
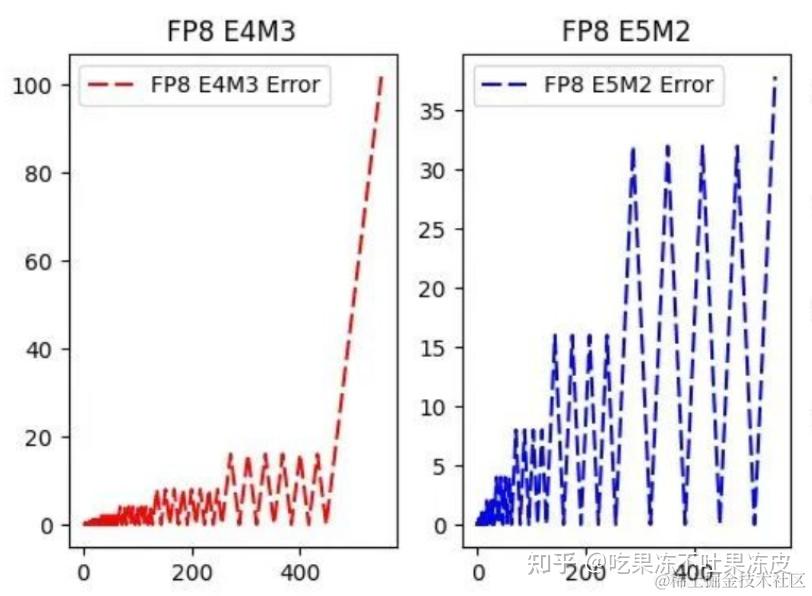
FP8 量化:原理、实现与误差分析-轻识
FP8 Quantization for Ultra-Low Latency AI | AI Tutorial | Next Electronics
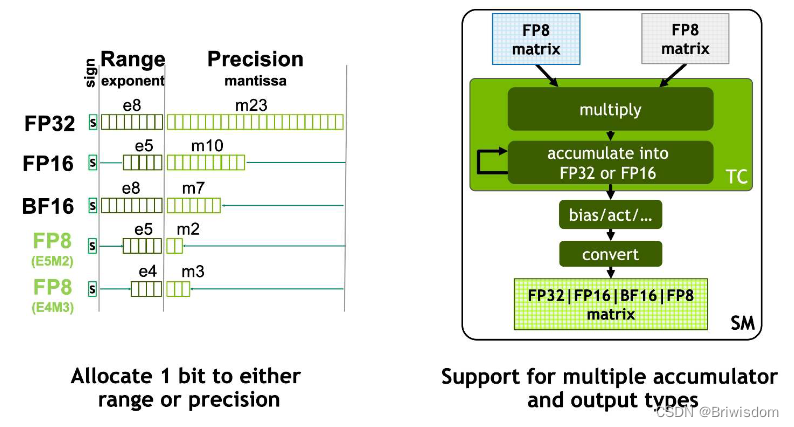
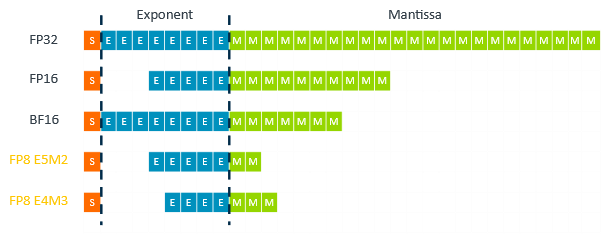
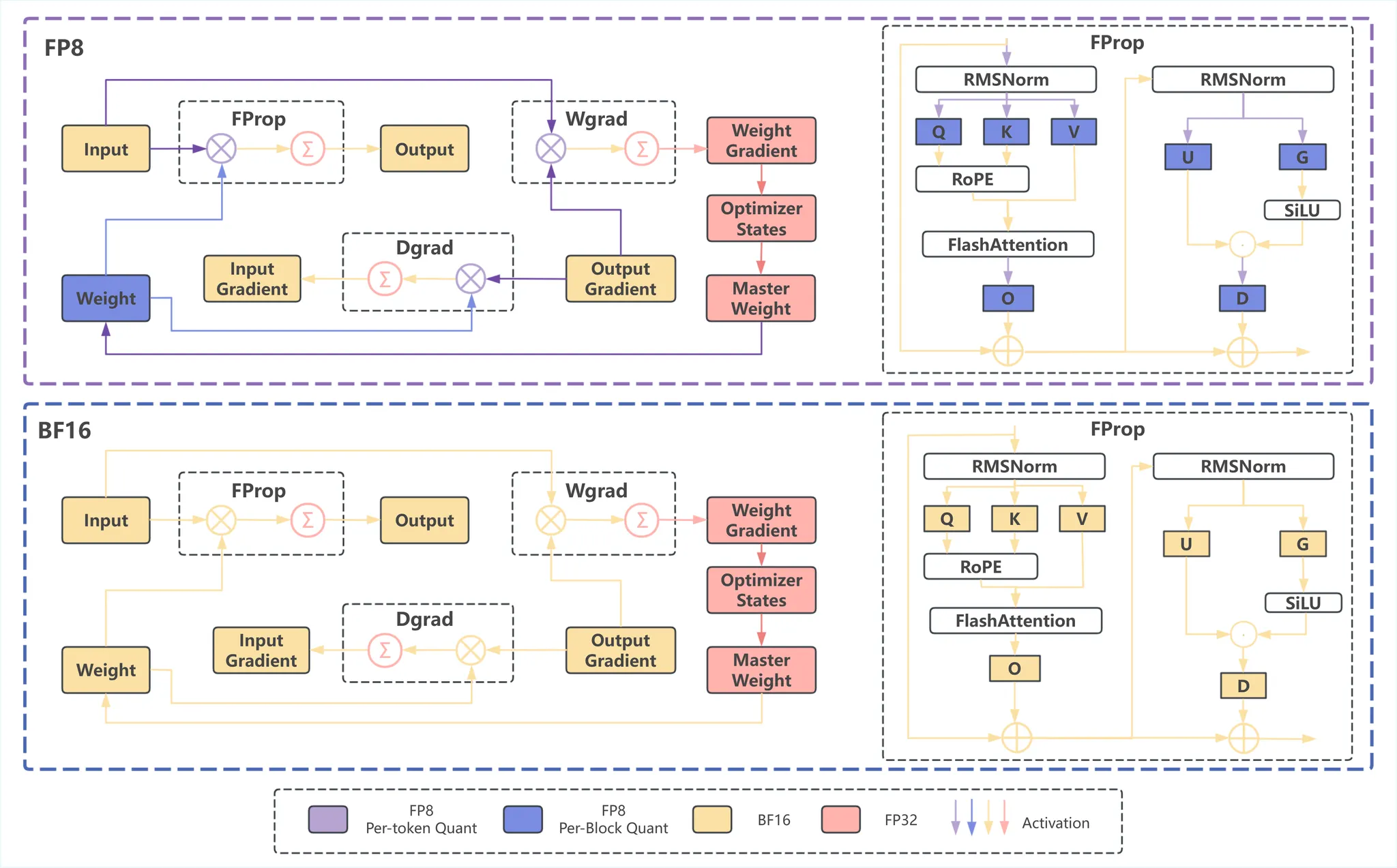
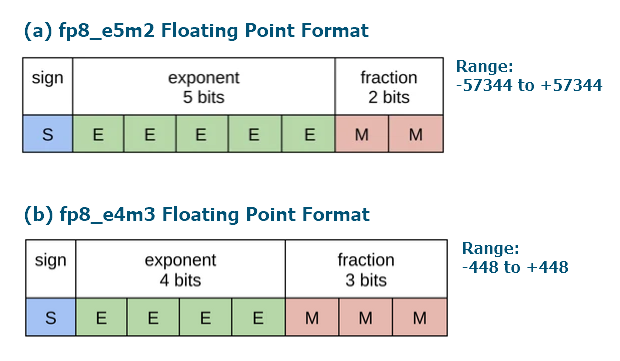
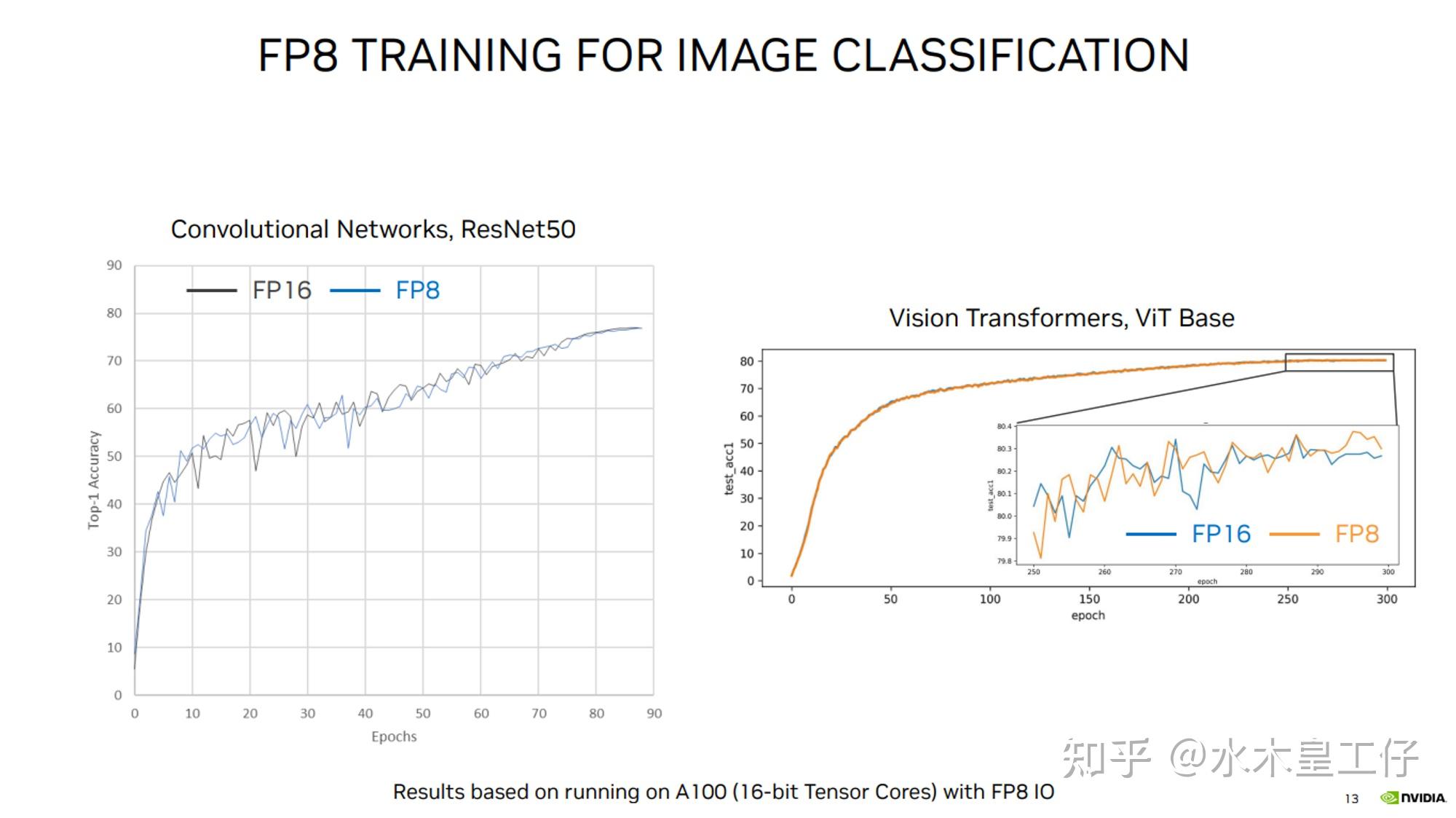
FP8 训练的挑战和最佳实践_NVIDIA AI 技术专区-NVIDIA AI 技术专区
TensorRT-LLM 低精度推理优化:从速度和精度角度的 FP8 vs INT8 的全面解析-迈络思Elite合作伙伴——中科新远网络解决 ...
How we built DeepL’s next-generation LLMs with FP8 for training and ...
[2303.17951] FP8 versus INT8 for efficient deep learning inference
NVIDIA, Arm, and Intel Publish FP8 Specification for Standardization as ...
What's New in Transformer Engine and FP8 Training S62457 | GTC 2024 ...
TensorRT-LLM 低精度推理优化:从速度和精度角度的 FP8 vs INT8 的全面解析 - NVIDIA 技术博客
Guide to FP8 & FP16: Accelerating AI - Convert FP16 to FP8?
Microsoft Researchers Unveil FP8 Mixed-Precision Training Framework ...
Using FP8 with Transformer Engine — Transformer Engine 2.0.0 documentation
FP8 量化-原理、实现与误差分析 - 知乎
Simple FP16 and FP8 training with unit scaling
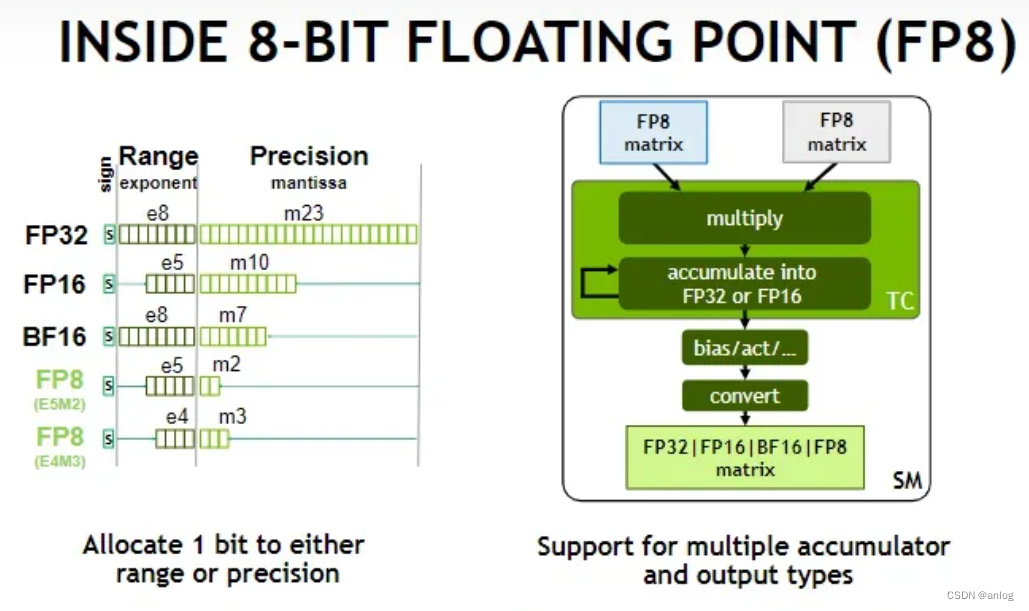
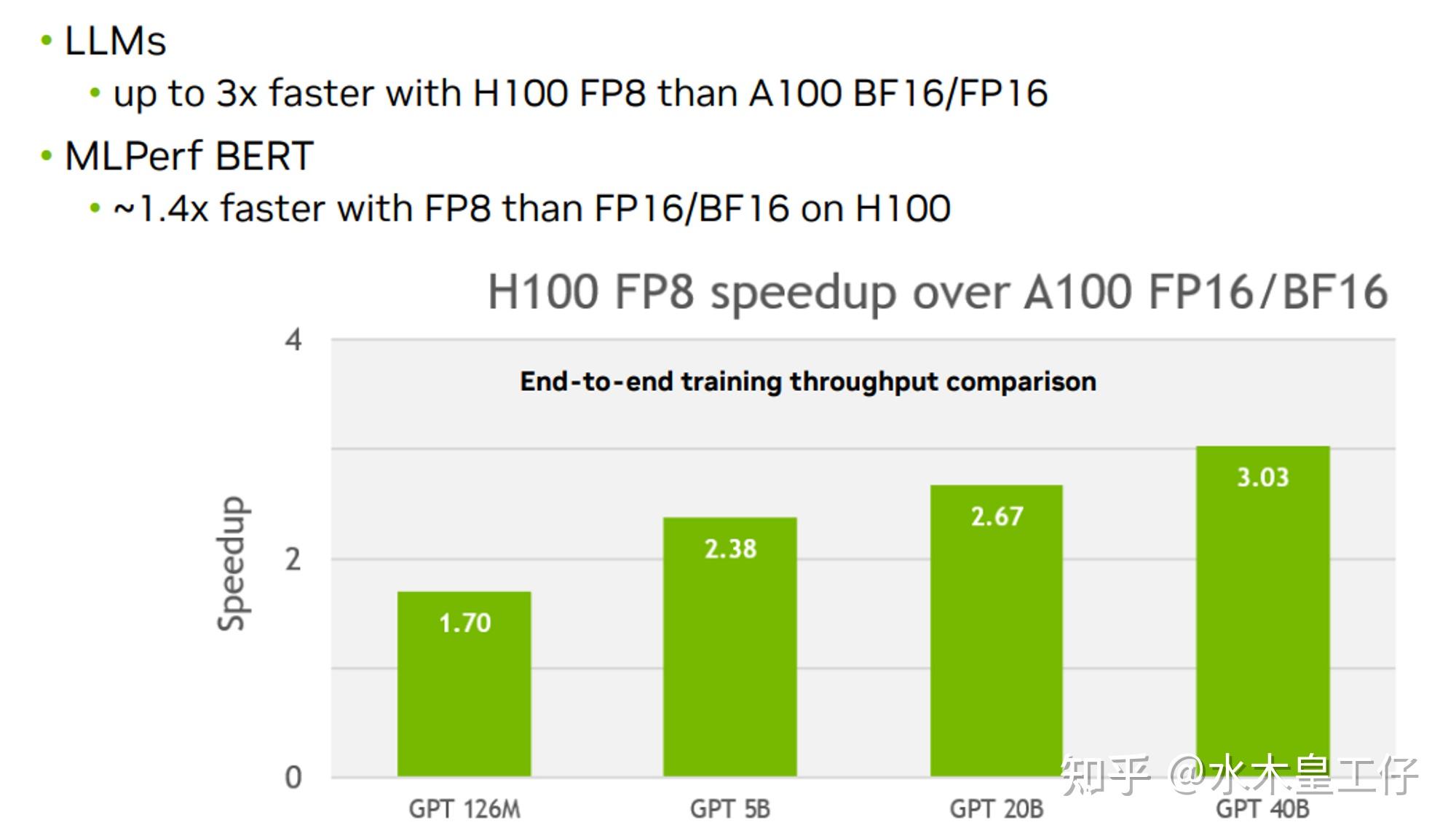
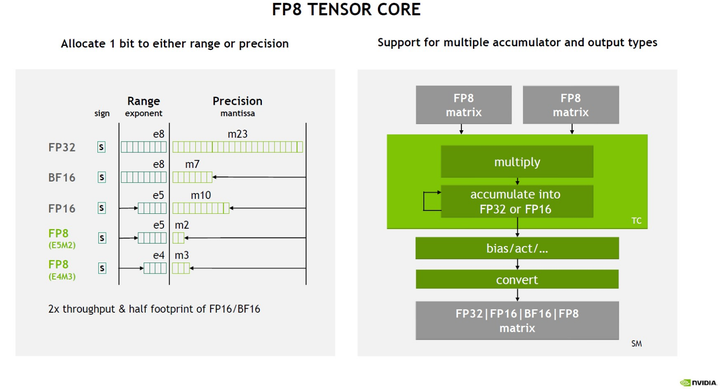
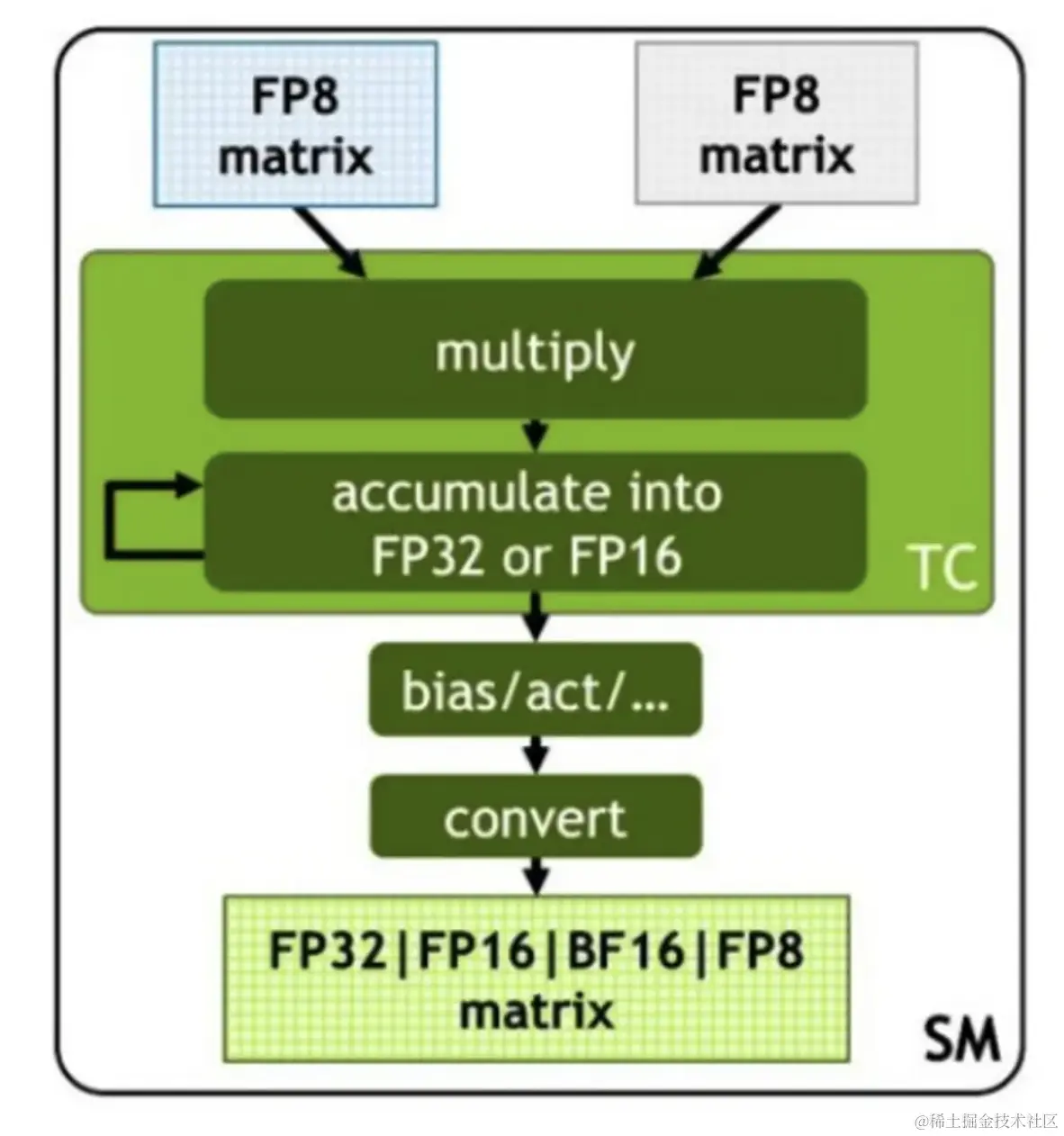
NVIDIA Hopper: H100 and FP8 Support
Qwen Edit 2511 FP8 e4m3fn - v1.0 | Qwen Checkpoint | Civitai
万字综述:全面梳理 FP8 训练和推理技术-CSDN博客
Transformer Engine ではじめる FP8 Training (導入編) - NVIDIA 技術ブログ
AMD's Zen 4 Phoenix Pictured: FP7 and FP8 CPUs Exposed | Tom's Hardware
CPUs using Socket FP8
FLUX.1 [dev] fp8 versions - Scaled fp8/fp8_e4m3fn/fp8_e5m2 - fp8_e4m3fn ...
[Intel Gaudi] #4. FP8 Quantization - SqueezeBits
微软推出 FP8 混合精度训练框架:比 BF16 快 64%,内存占用少 42%-51CTO.COM
FP8 for Deep Learning S52166 | GTC Digital Spring 2023 | NVIDIA On-Demand
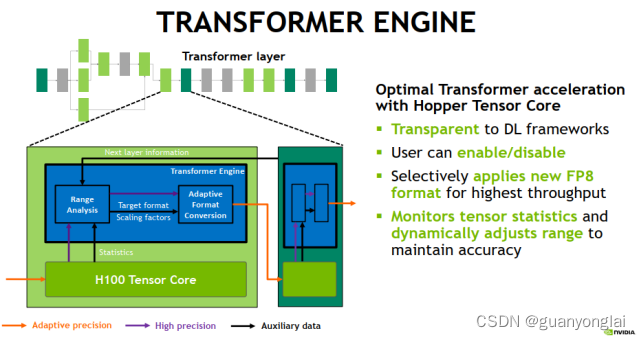
FP8 低精度训练:Transformer Engine 简析 - 知乎
lllyasviel/flux_text_encoders · what is the difference FP8 vs FP16 for ...
FP8 LM - Training FP8 Large Language Models - YouTube
FLUX.1 [dev] fp8 versions - Scaled fp8/e4m3fn/e5m2 - Scaled fp8 v2 ...
FP8 训练与AI 芯片 - 知乎
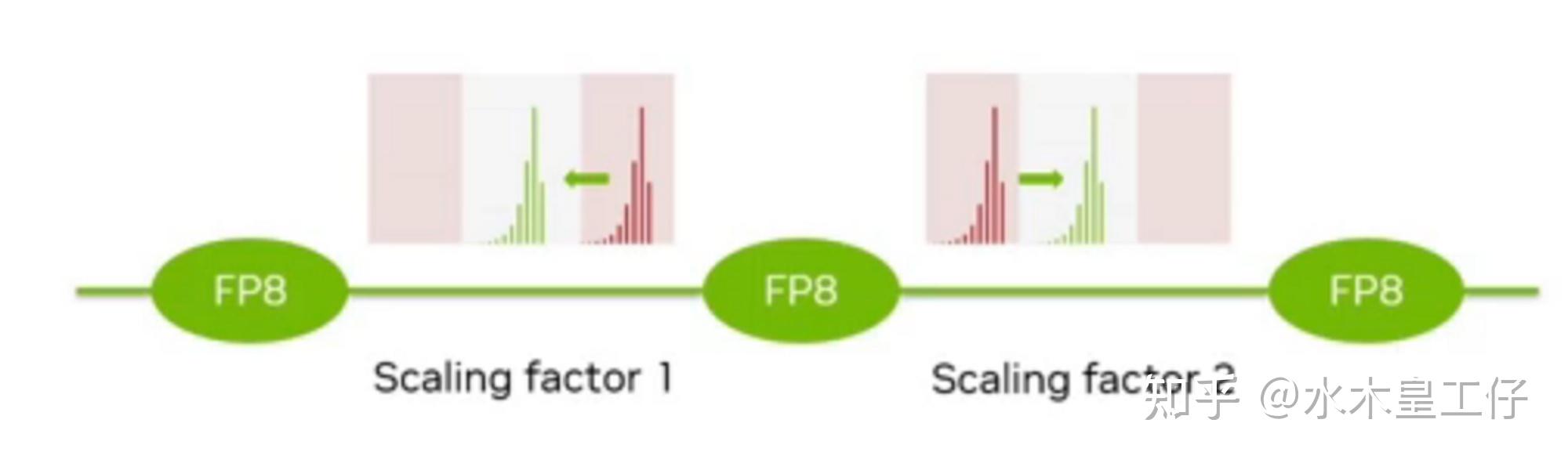
Per-Tensor and Per-Block Scaling Strategies for Effective FP8 Training ...
FP8 Training with Transformer Engine S51393 | GTC Digital Spring 2023 ...
FP8 低精度训练:Transformer Engine 简析 - 53AI-AI知识库|企业AI知识库|大模型知识库|AIHub
FlexPoint FP8 | 8" Ultra-Compact Coaxial Point Source Loudspeaker
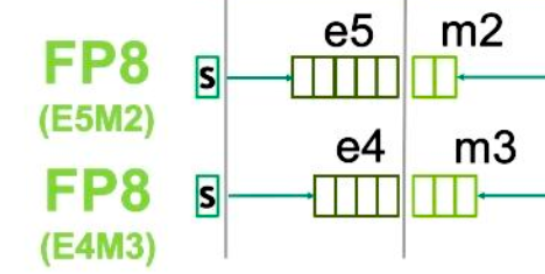
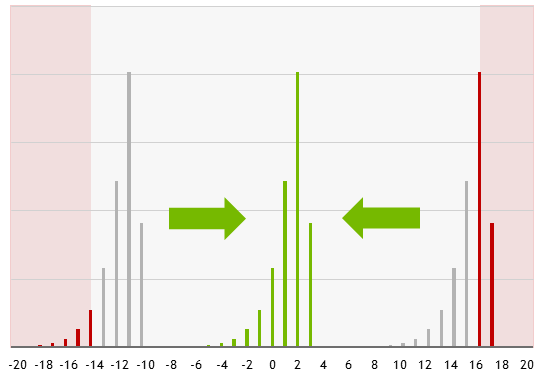
FP8 Formats for Deep Learning | DeepAI
Comfy-Org/stable-diffusion-3.5-fp8 · What means "scaled"? fp8 model only?
FP8 Format | Standardized Specification for AI - Jotrin Electronics
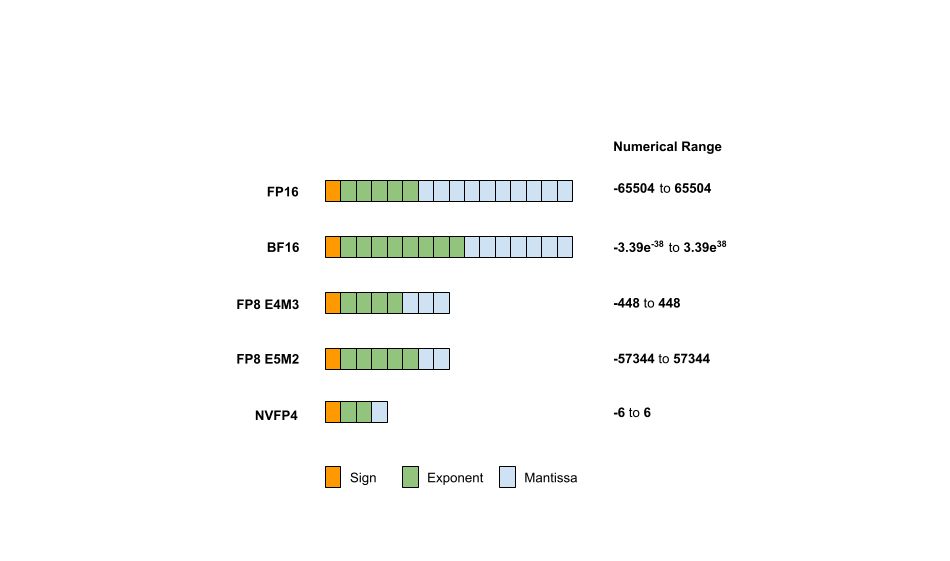
The Road to MX: The Evolution of AI Data Formats (INT8, Bfloat, FP8 ...
NVIDIA GPU 架构下的 FP8 训练与推理_汽车技术__汽车测试网
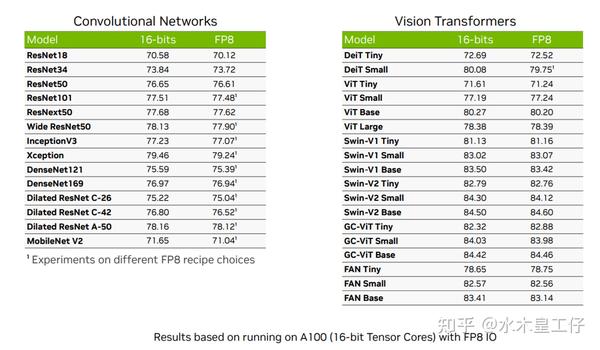
Faster Training Throughput in FP8 Precision with NVIDIA NeMo | NVIDIA ...
fp8 AdamW 探路小记 - 知乎
FP8格式理解解析-CSDN博客
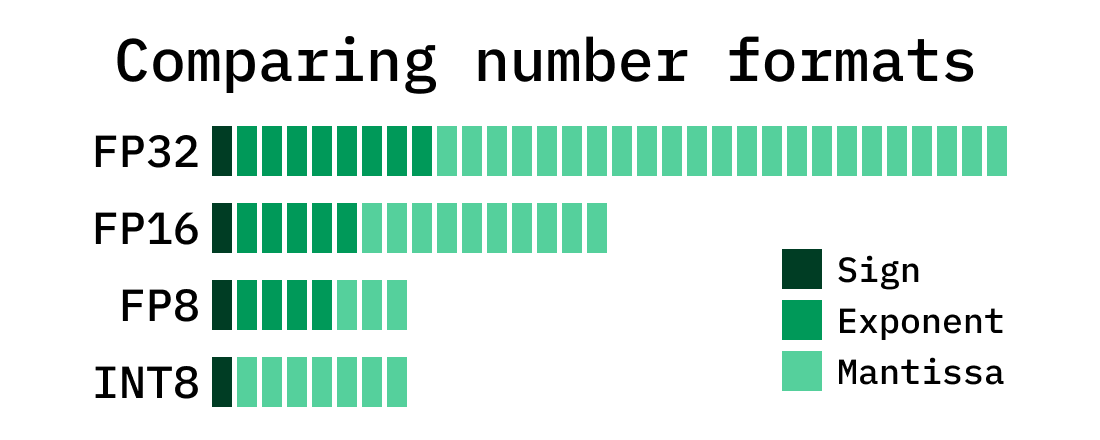
Floating-Point 8: An Introduction to Efficient, Lower-Precision AI ...
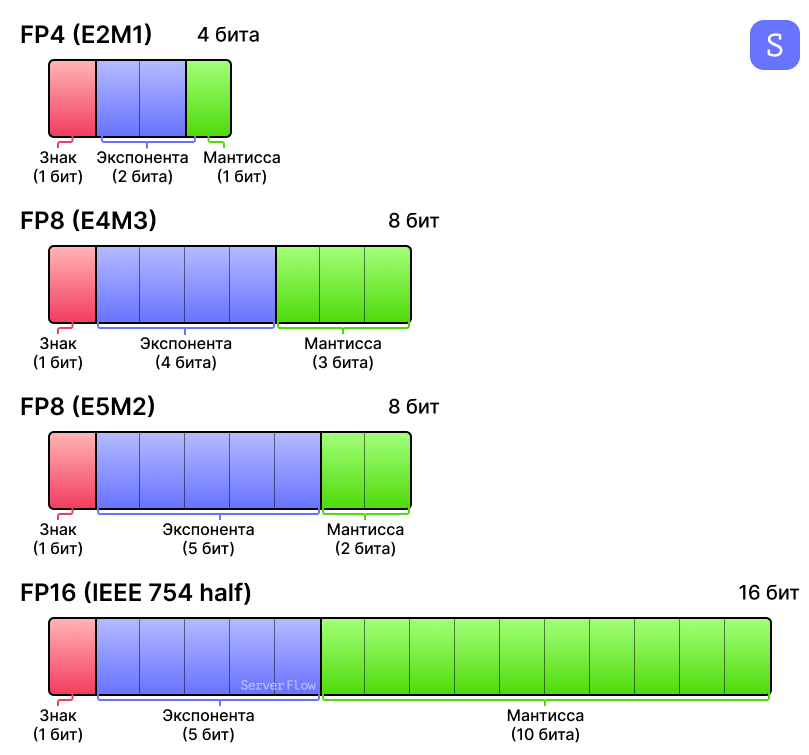
从浮点数定义到FP8: AI模型中不同的数据类型-CSDN博客
Arm Community
Unified FP8: Moving Beyond Mixed Precision for Stable and Accelerated ...
Working with ONNX models in float16 and float8 formats - MQL5 Articles
FP8训练调研-CSDN博客
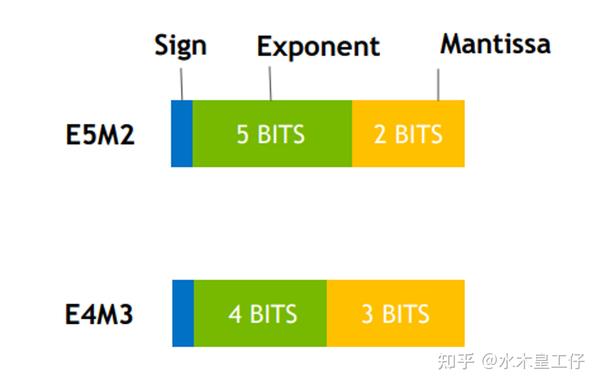
FP8: архитектура формата E4M3 и E5M2 и его роль в Mixed Precision ...
【小白学习笔记】FP8 量化基础 - 英伟达 - 知乎
量化-Fp8 和 Fp16 的性能对比 - 知乎
FP8: Efficient model inference with 8-bit floating point numbers ...
flux.1-dev-fp8/README.md at main · Neurone/flux.1-dev-fp8 · GitHub
Qwen/Qwen3-VL-4B-Instruct-FP8 · Hugging Face
FP8, BF16, and INT8: How Low-Precision Formats Are Revolutionizing Deep ...
README.md · silveroxides/FLUX.2-dev-fp8_scaled at main
大模型量化技术原理:FP8_e4m3-CSDN博客
MimicPC - Complete Guide to Flux.1 Models | Mimic PC
【小白学习笔记】FP8 训练简要流程 - Transformer Engine in H100 - 知乎
Reducing AI large model training costs by 30% requires just a single ...
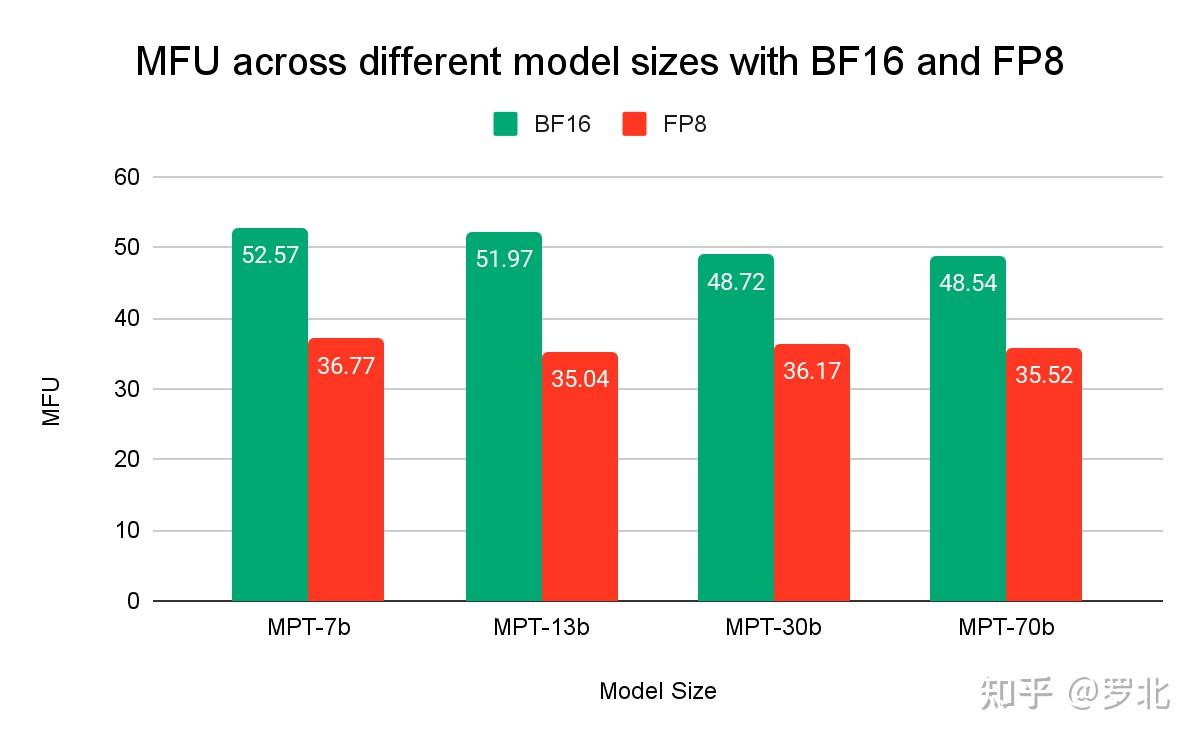
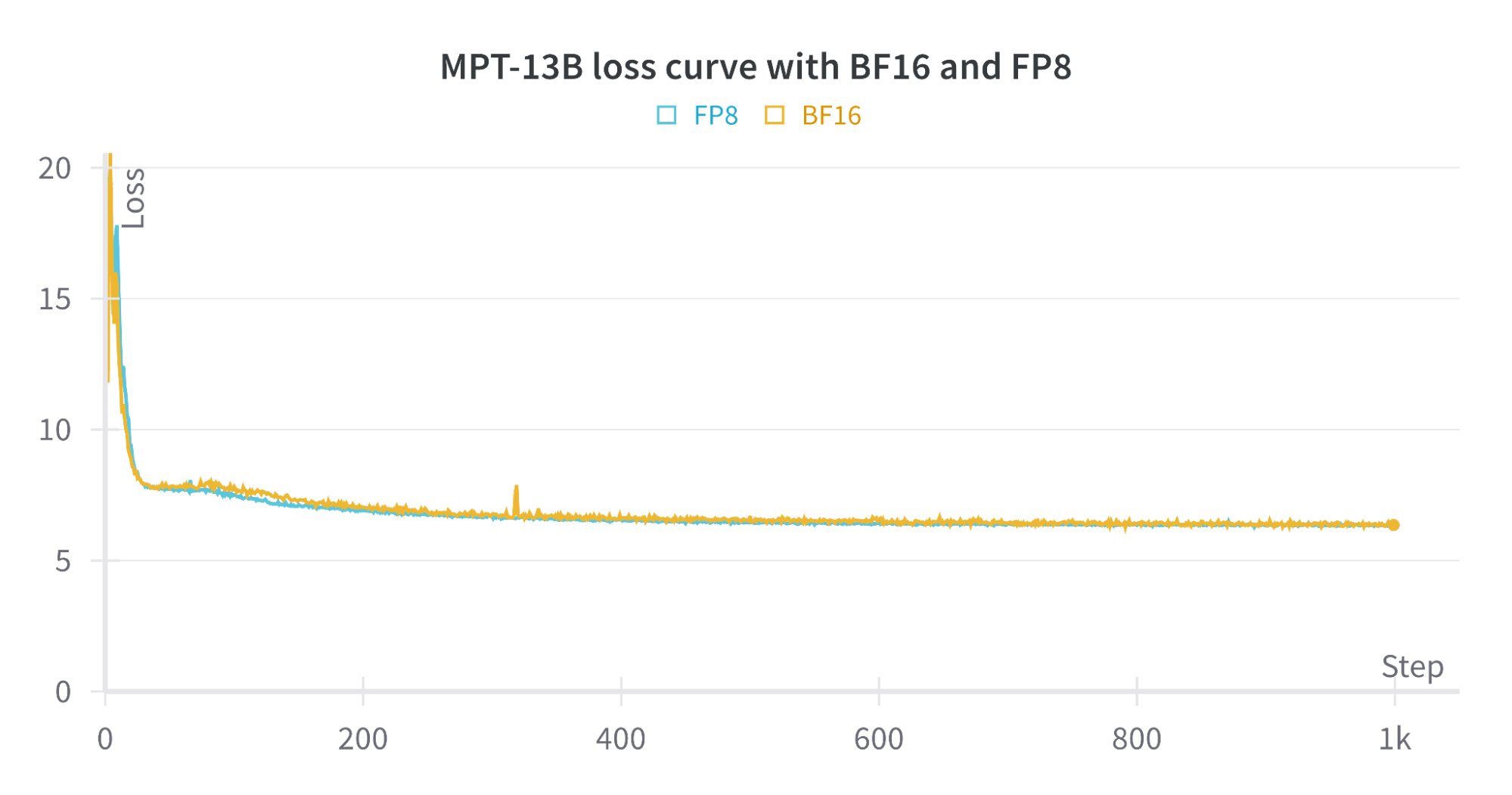
Turbocharged Training: Optimizing the Databricks Mosaic AI Stack With ...
NVIDIA, Intel & ARM Bet Their AI Future on FP8, Whitepaper For 8-Bit FP ...
FP8量化解读--8bit下最优方案?(一) - 知乎
Floating-point Arithmetic for AI Inference: Hit or Miss? - Edge AI and ...
DeepSeek技术创新深度解读:从V3与R1与MoE - 知乎
使用FP8进行大模型量化原理及实践 - 53AI-AI知识库|企业AI知识库|大模型知识库|AIHub
量化那些事之FP8与LLM-FP4 - 知乎
Nvidia、Arm與Intel公布FP8規格,企圖成為AI交換格式標準 | iThome
Optimizing LLMs for Performance and Accuracy with Post-Training ...
大模型量化技术原理:FP8-CSDN博客
flux1-dev-fp8-e4m3fn.safetensors · Kijai/flux-fp8 at main
Qwen/Qwen3-Coder-30B-A3B-Instruct-FP8 · Hugging Face
大模型量化技术原理:FP8 - 知乎
Model Quantization: Concepts, Methods, and Why It Matters | NVIDIA ...