Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
FP8 Quantization for Ultra-Low Latency AI | AI Tutorial | Next Electronics
[2309.14592] Efficient Post-training Quantization with FP8 Formats
DeepSeek V3 FP8 QUANTIZATION Explained - 4x Less Memory - YouTube
Bits and Business: FP8 quantization deepdive into DeepSeek’s High ...
fp8 Weight and Activation Quantization - LLM Compressor Docs
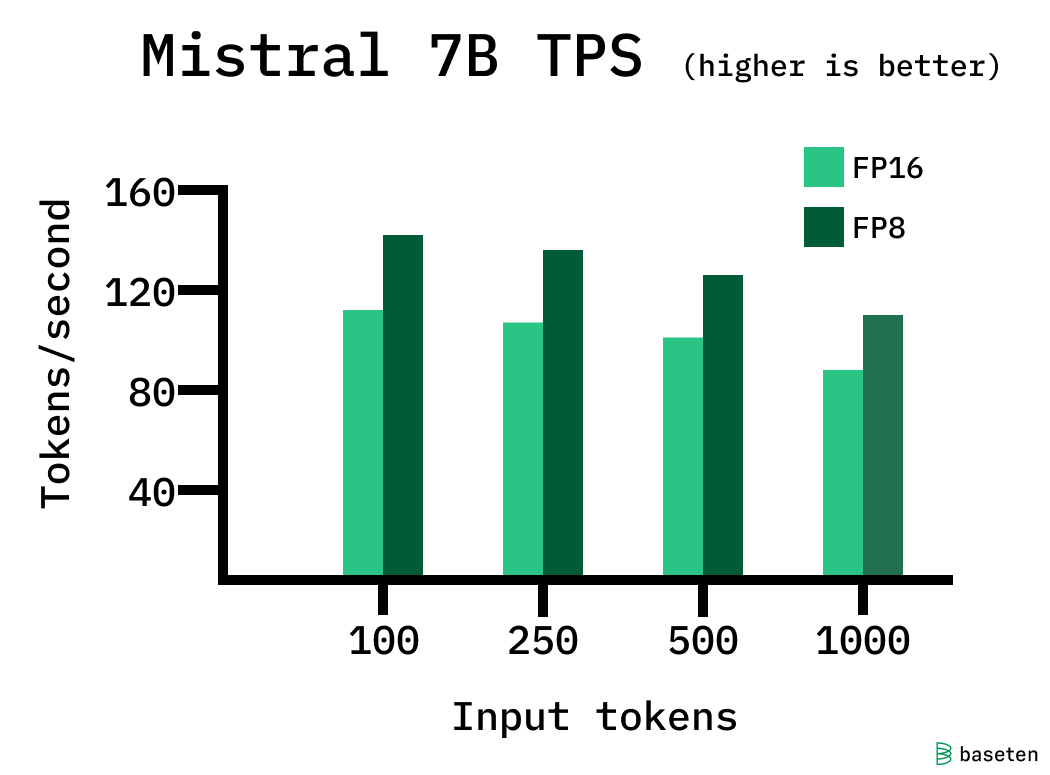
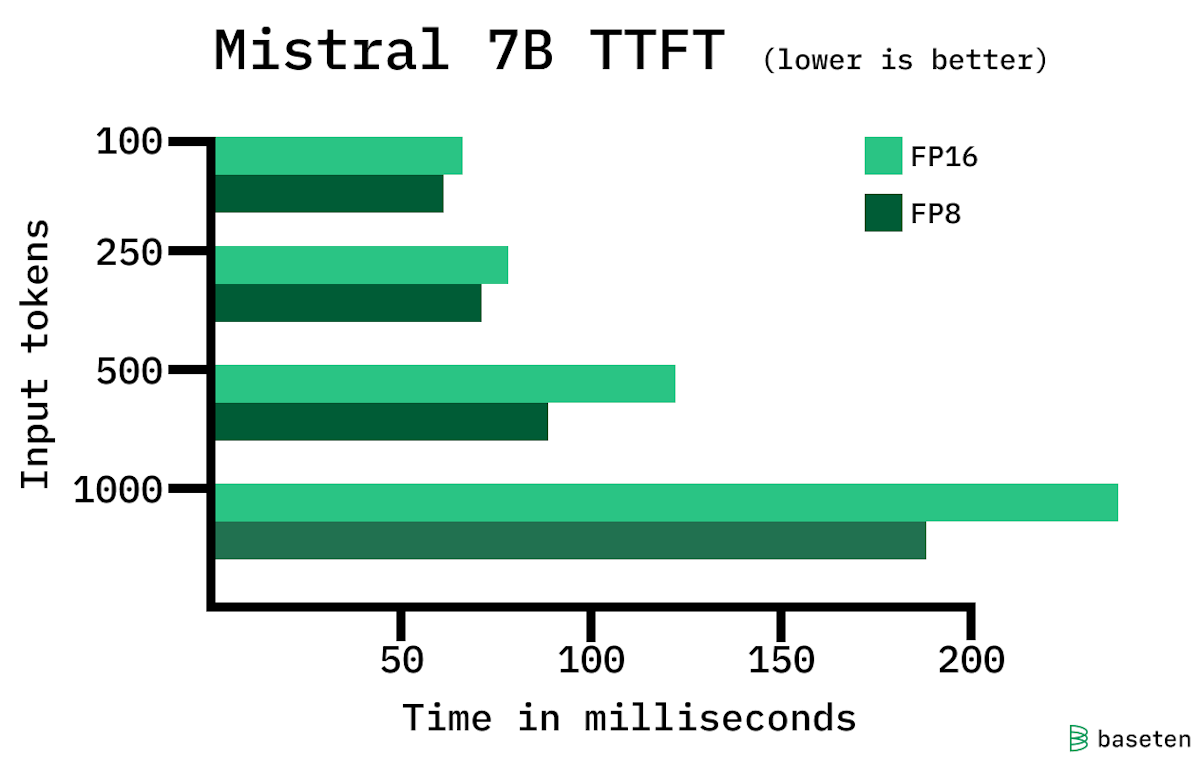
33% faster LLM inference with FP8 quantization | Baseten Blog
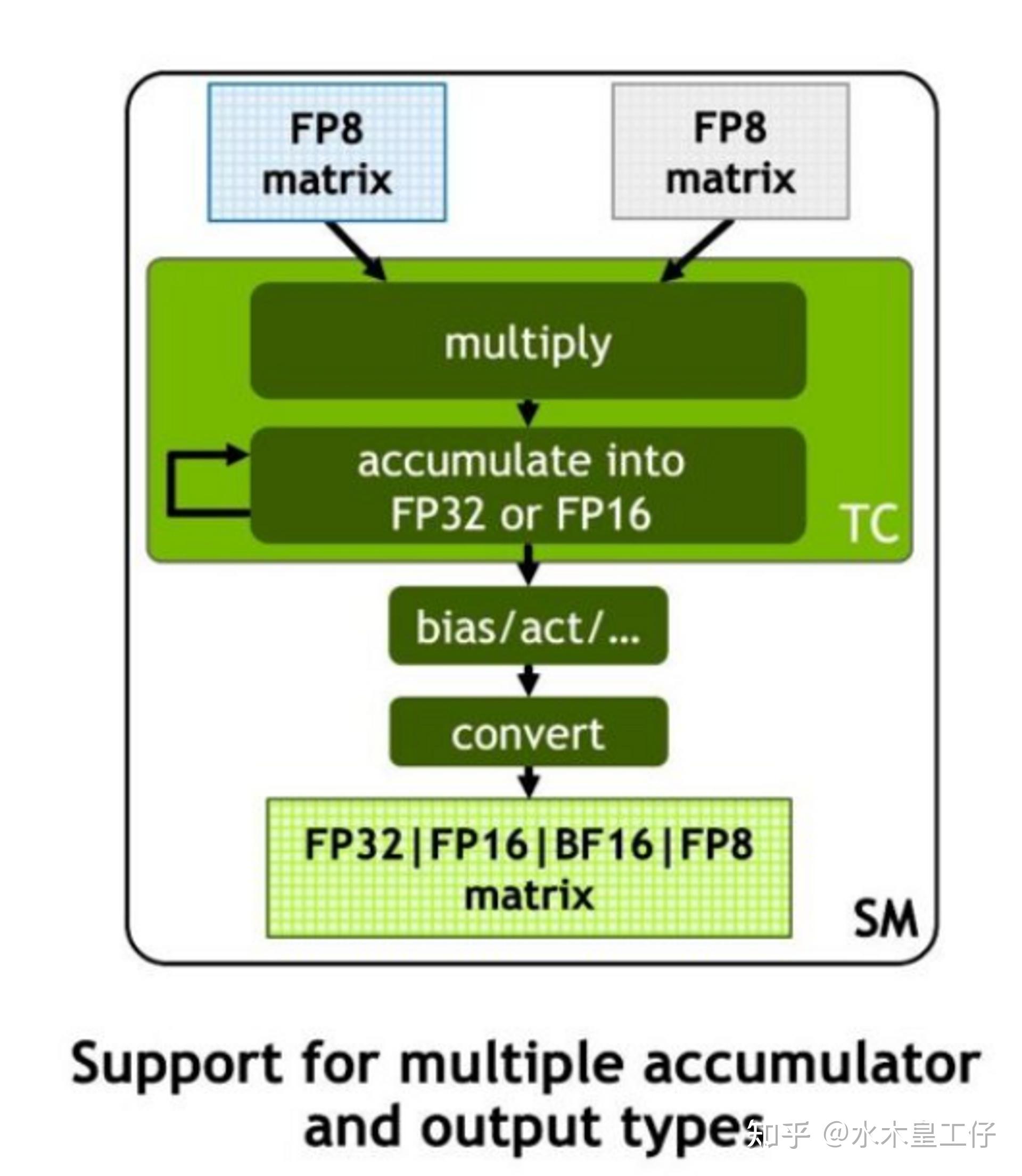
FP8 Quantization | hpcaitech/ColossalAI | DeepWiki
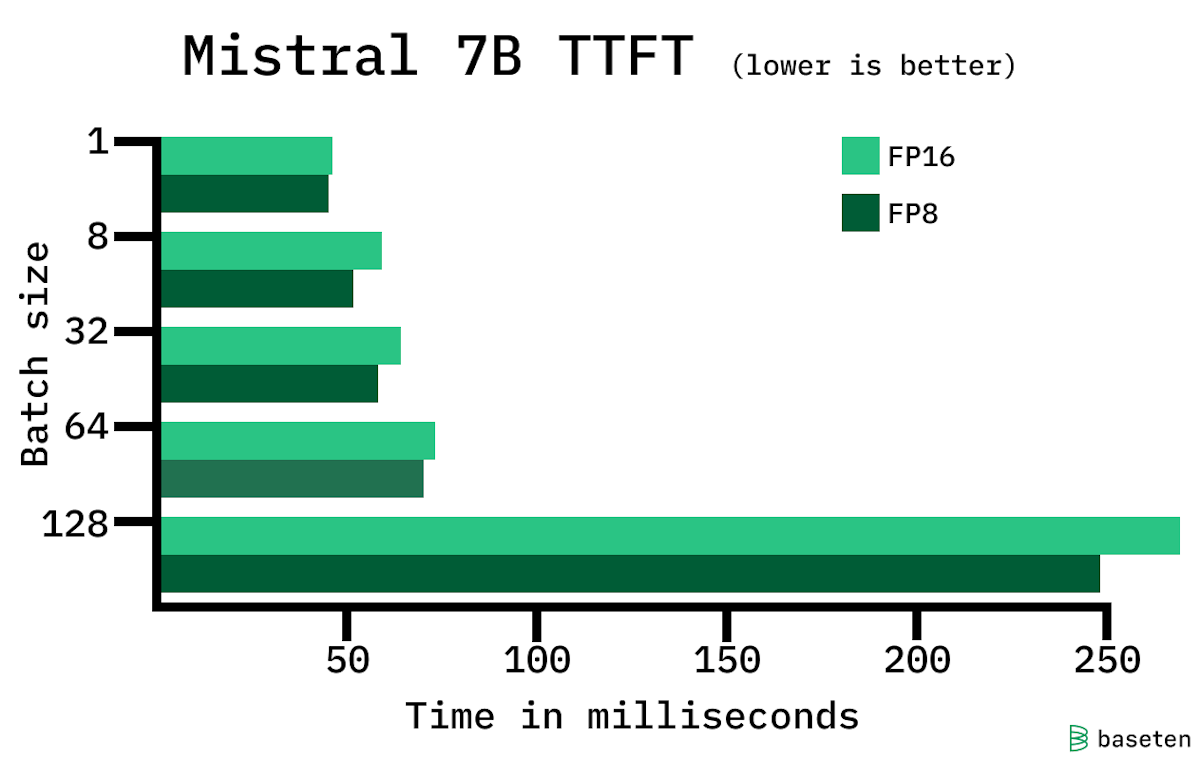
33% faster LLM inference with FP8 quantization
RFC: FP8 Quantization Schema in vLLM update · vllm-project vllm ...
FP8 Quantization | Parasail
Paper page - Efficient Post-training Quantization with FP8 Formats
[Bug]: FP8 Quantization (static and dynamic) incompatible with `--cpu ...
Plans for block-wise FP8 quantization during training? · Issue #1411 ...
FP8 quantization with AMD Quark for vLLM — Tutorials for AI developers 12.0
Comfy-Org/flux1-dev · May I ask how FP8 quantization is implemented ...
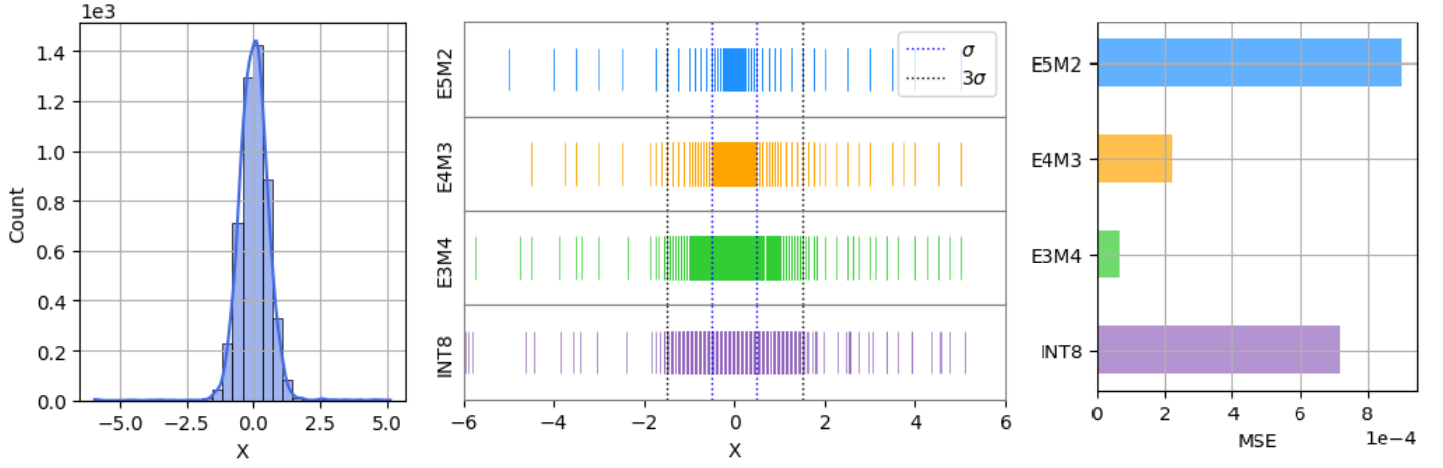
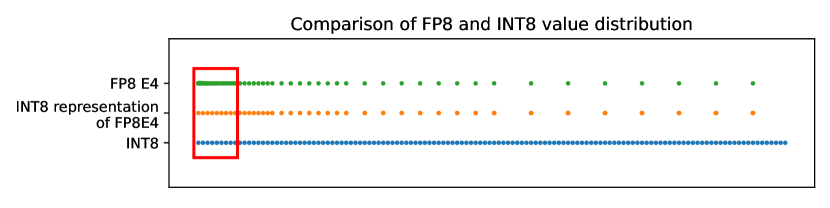
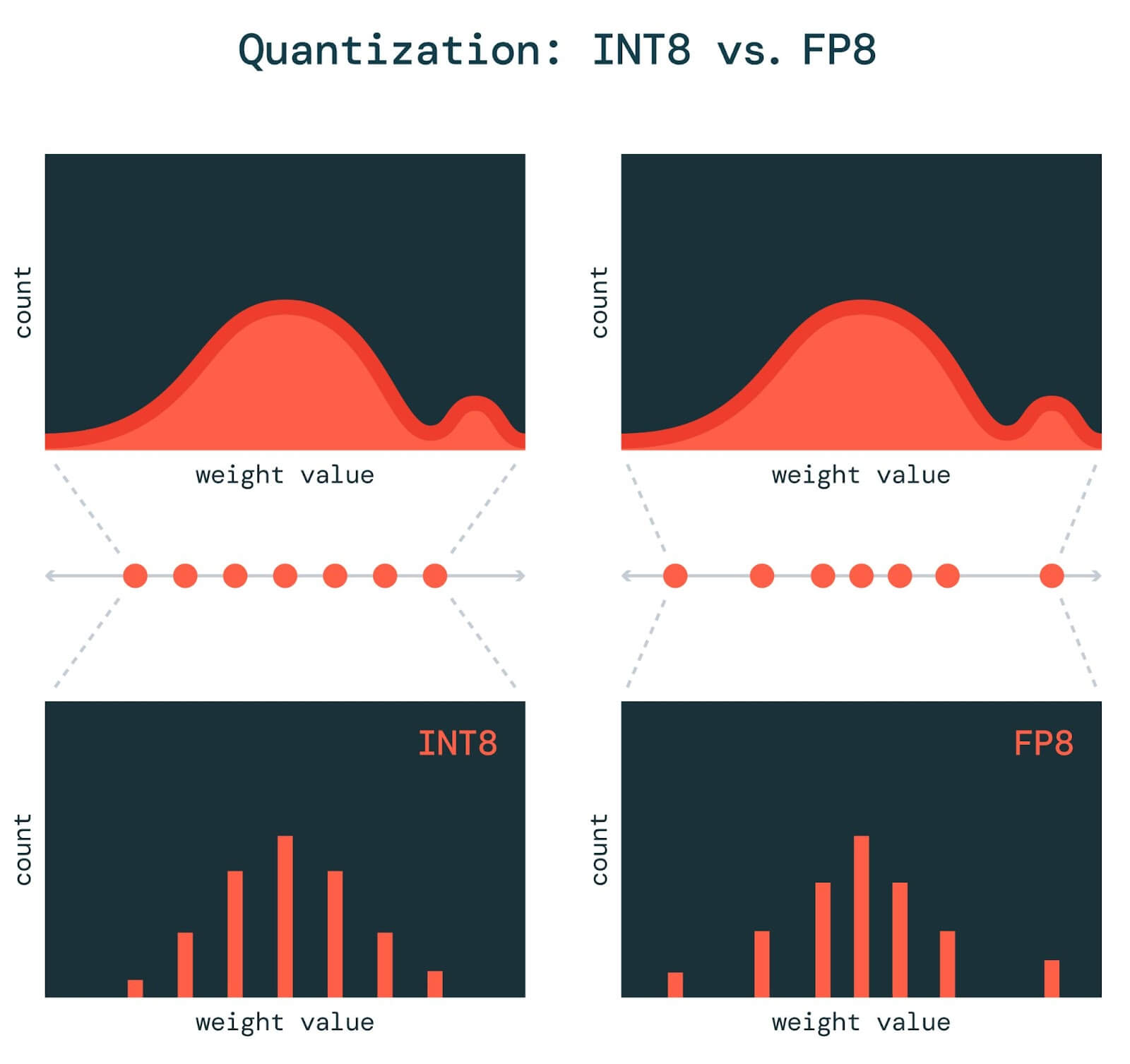
A Contrast between INT8 and FP8 Quantization Methods. The top row ...
fp8 quantization with FSDP2 error · Issue #1929 · pytorch/ao · GitHub
Have you considered FP8 quantization with block size 64 · QwenLM Qwen3 ...
[Intel Gaudi] #4. FP8 Quantization - The official SqueezeBits Tech blog
FP8 Quantization in NeMo RL — NeMo-RL
FP8 quantization for LLM by vLLM | Neural Magic (Acquired by Red Hat ...
[Intel Gaudi] #4. FP8 Quantization - SqueezeBits
Inquiry on FP8 Quantization for Query in masked_multihead_attention ...
vLLM Office Hours - FP8 Quantization Deep Dive - July 9, 2024 - YouTube
Why dose fp8 quantization use multiplication by scale ? · Issue #477 ...
Unknown quantization type, got fp8 · Issue #35471 · huggingface ...
[Doc]: Why is FP8 static quantization marked as deprecated? · Issue ...
[KR] OwLite와 함께하는 FP8 Quantization | SqueezeBits
[Bug]: ValueError: The quantization method fp8 is not supported for the ...
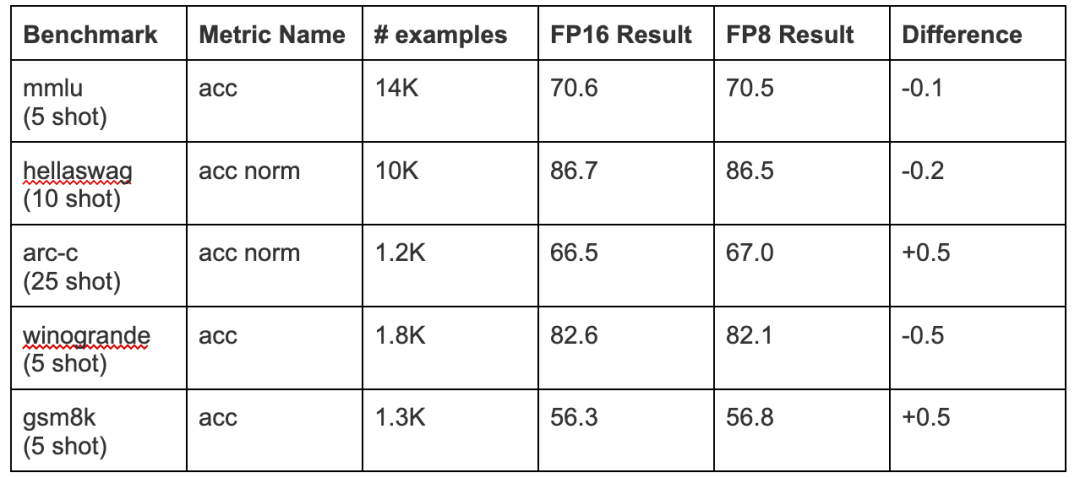
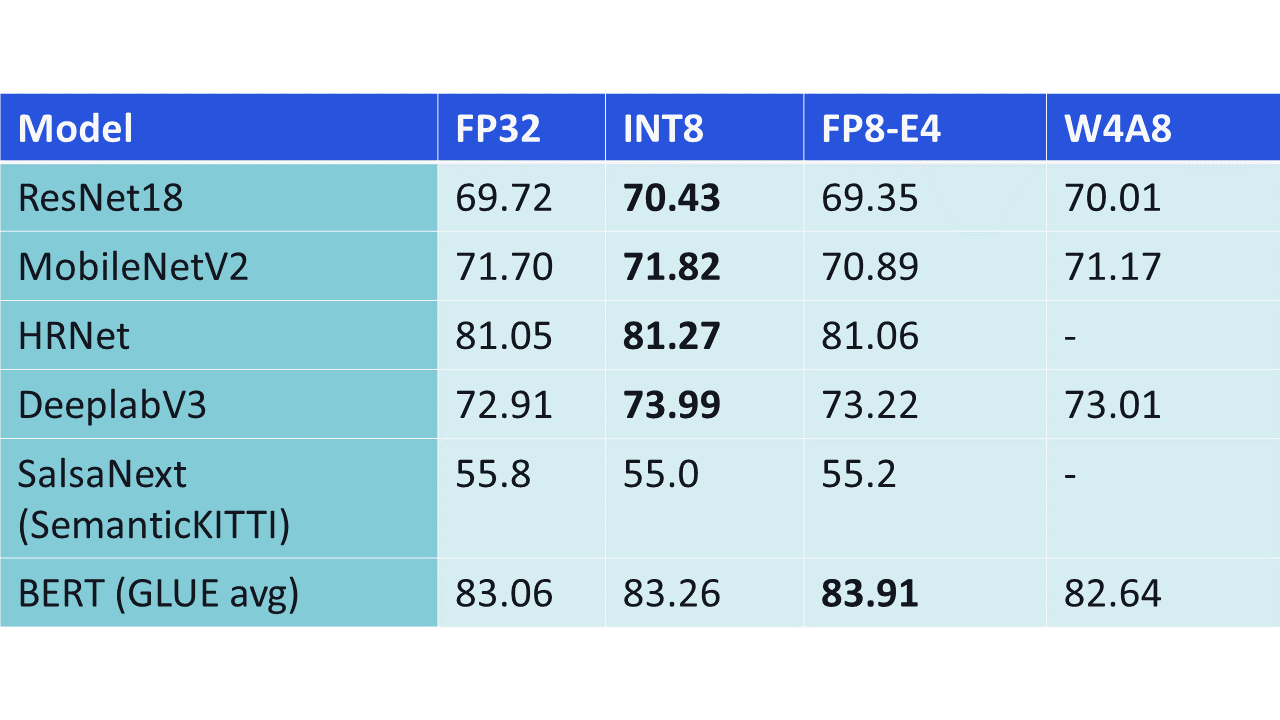
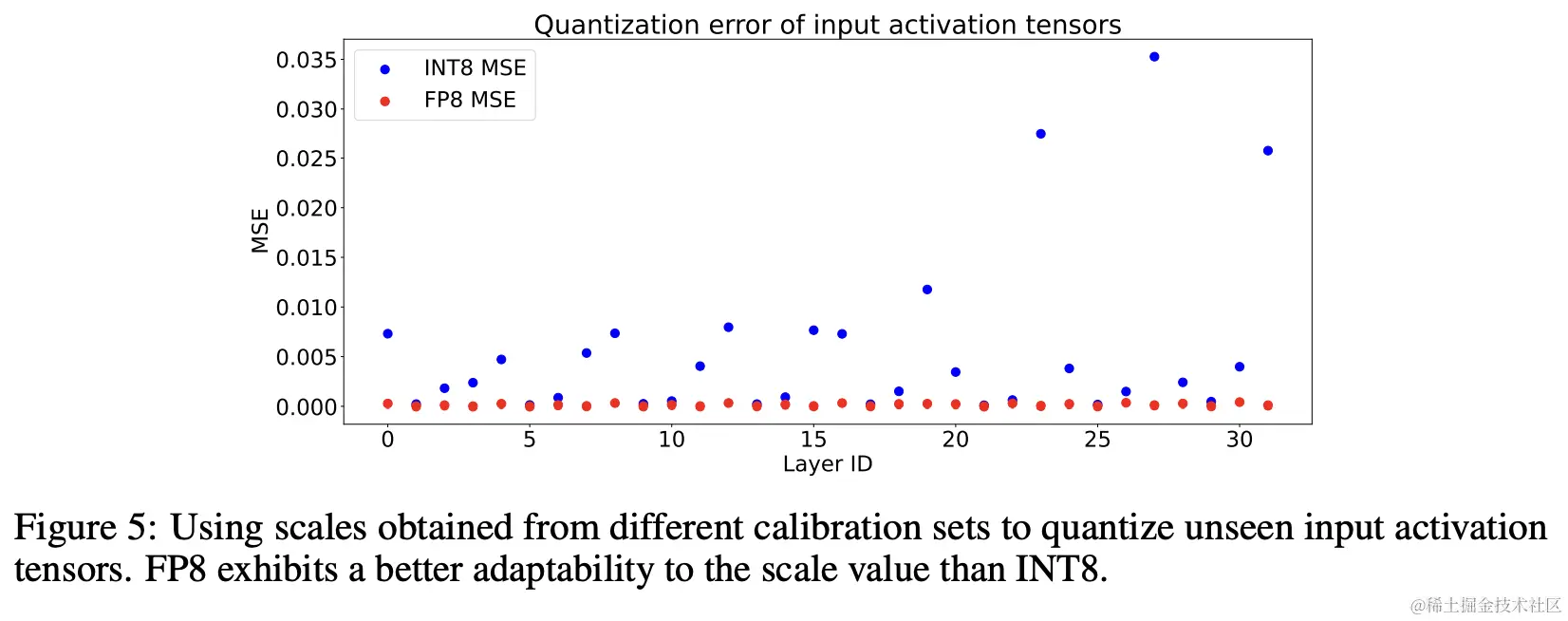
Table 2 from Efficient Post-training Quantization with FP8 Formats ...
[Bug]: FP8 Quantization with enforce_eager=False Causes Gibberish ...
NVIDIA TensorRT INT8 & FP8 quantization accelerating SD inference : r ...
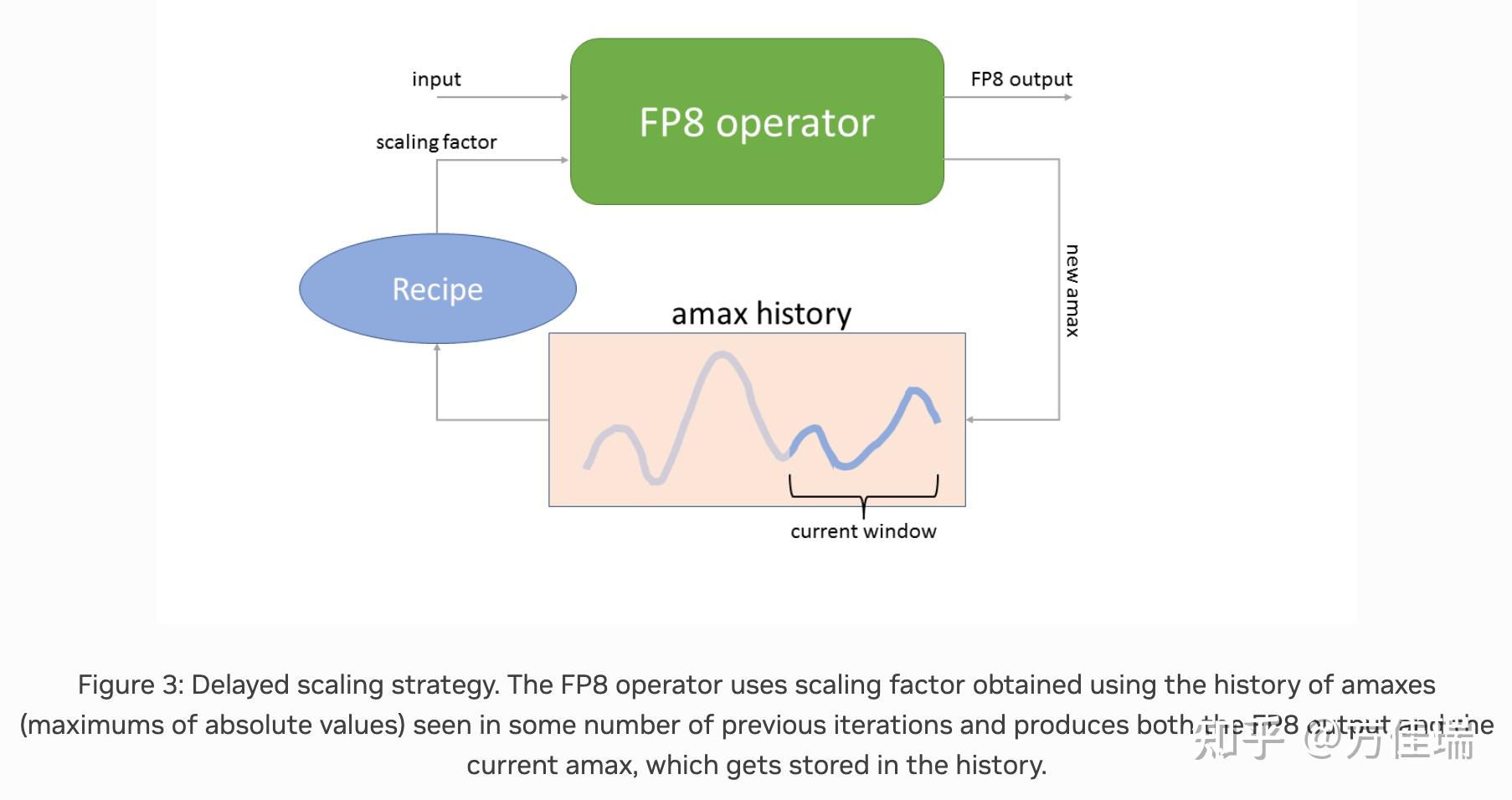
Figure 3 from Efficient Post-training Quantization with FP8 Formats ...
Quantization Methods for 100X Speedup in Large Language Model Inference
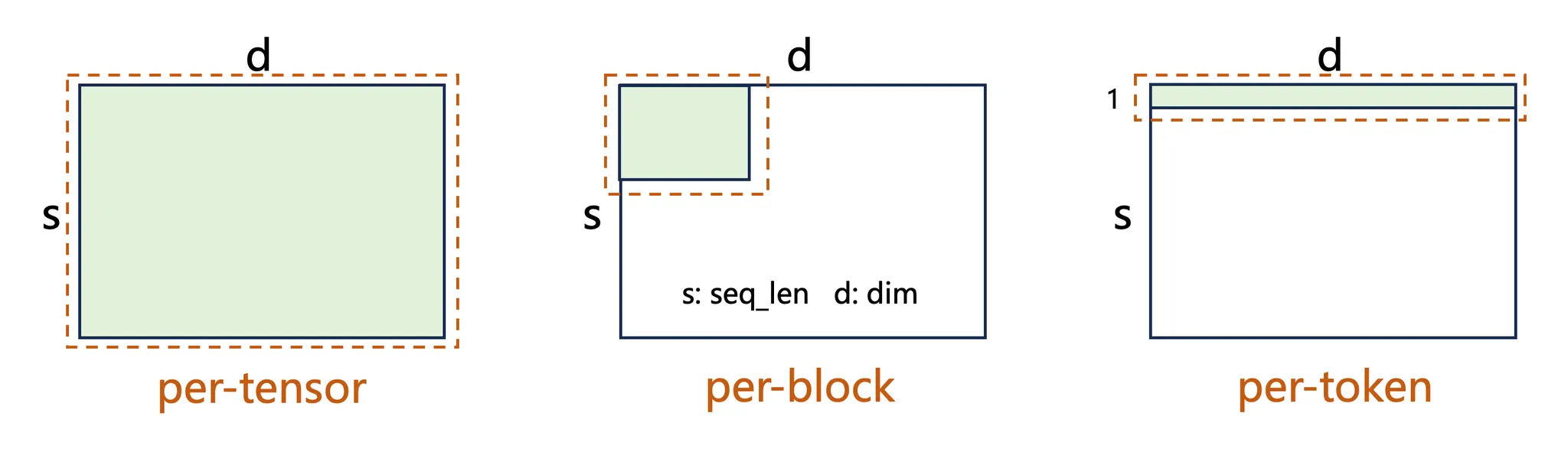
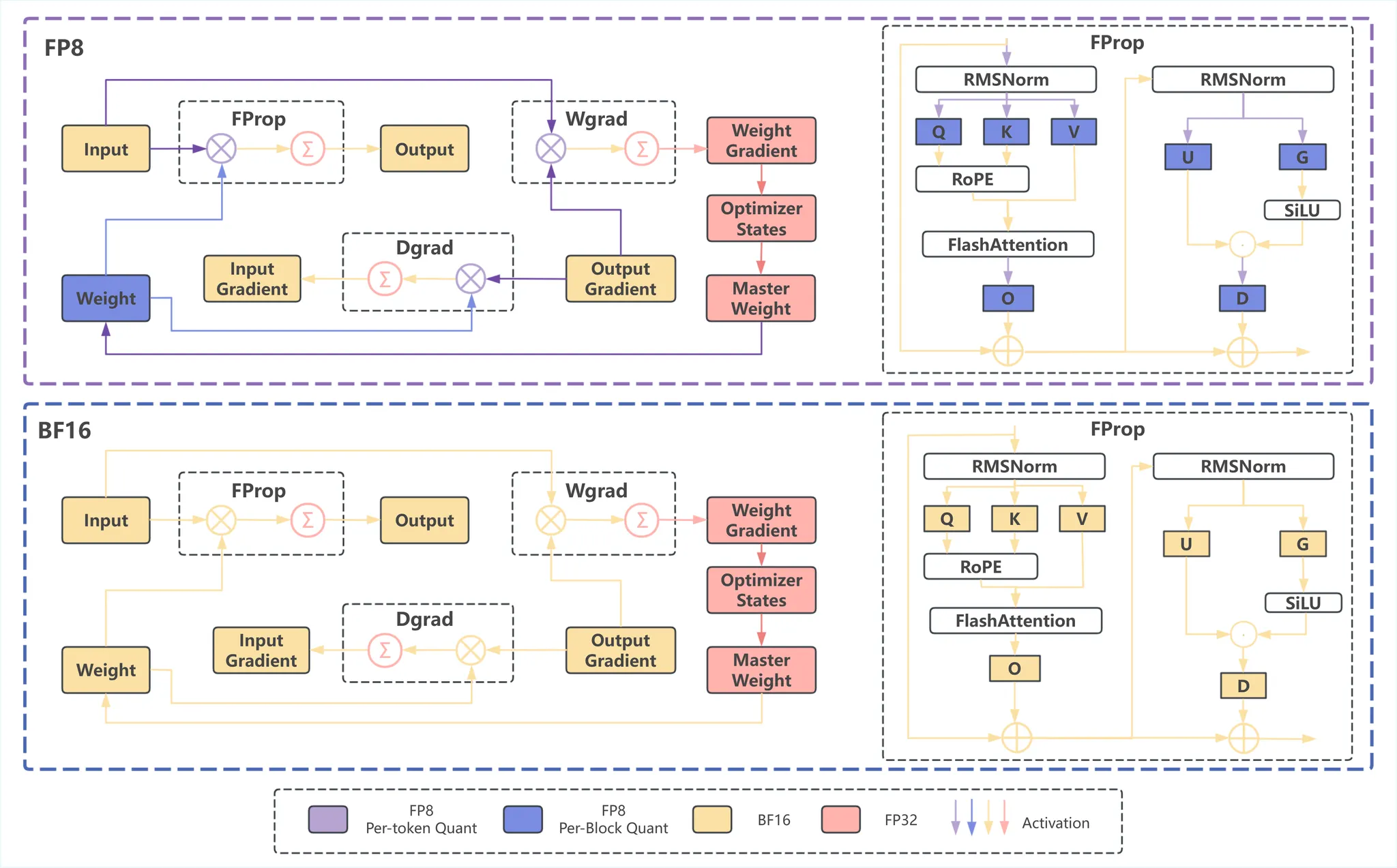
Fine-grained FP8
7 ML Quantization Wins (INT8/FP8) Without Quality Freefall | by ...
Using FP8 and FP4 with Transformer Engine — Transformer Engine 2.13.0 ...
Improve Latency and Throughput with Weight-Activation Quantization in ...
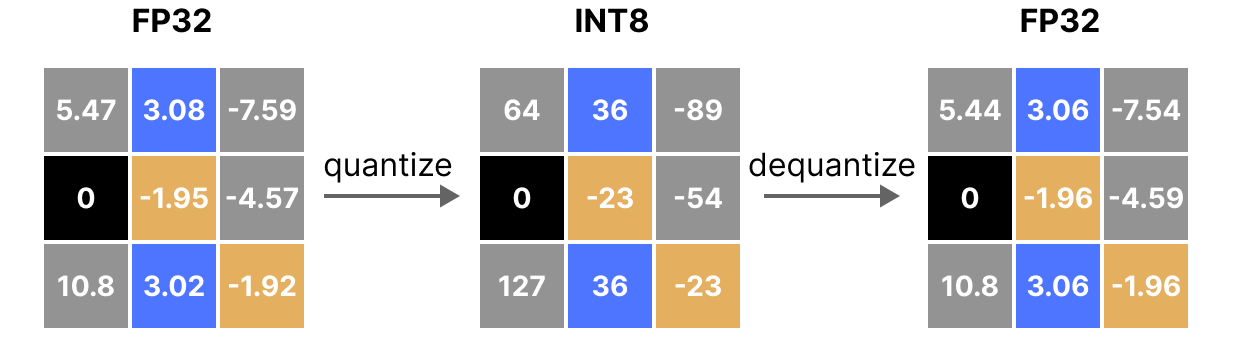
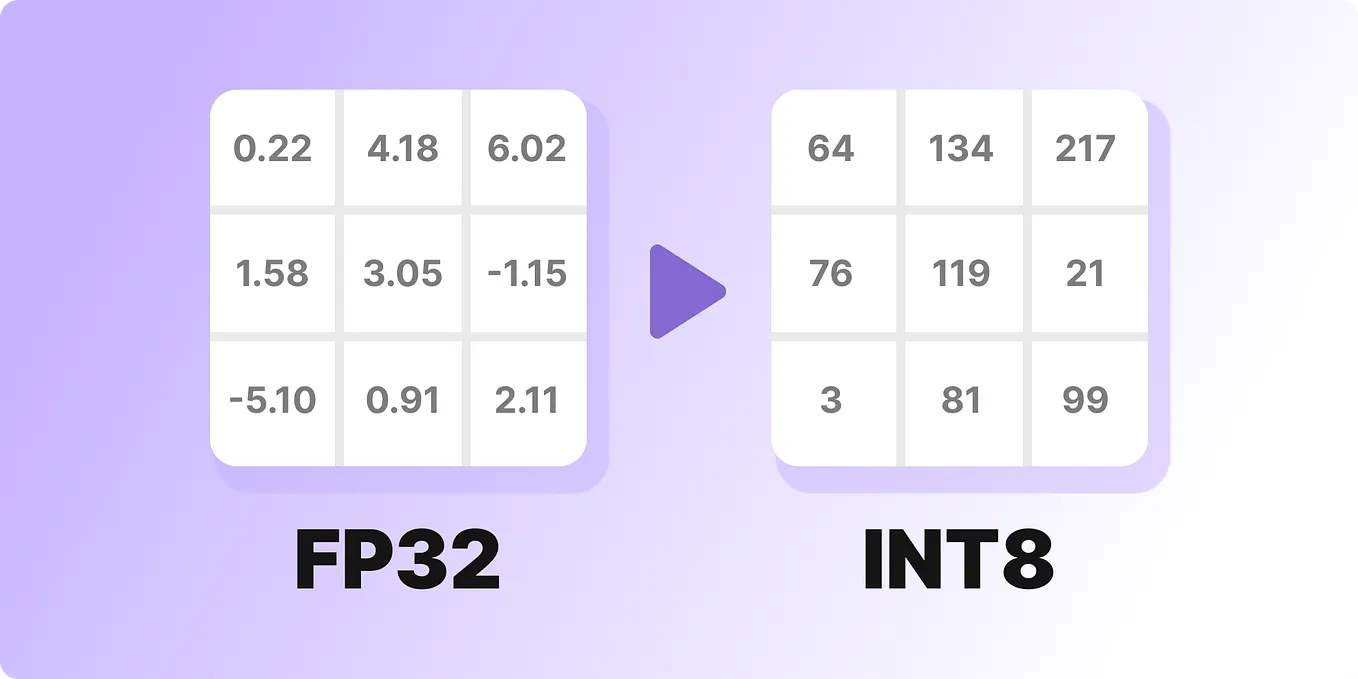
A Visual Guide to Quantization - by Maarten Grootendorst
(PDF) FP8 Quantization: The Power of the Exponent
Quark Quantized OCP FP8 Models - a amd Collection
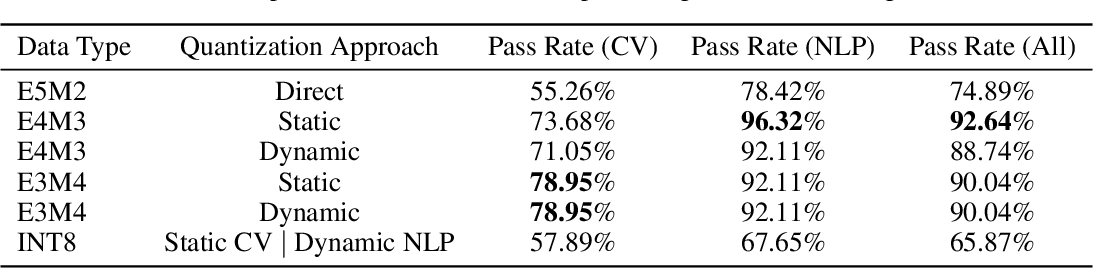
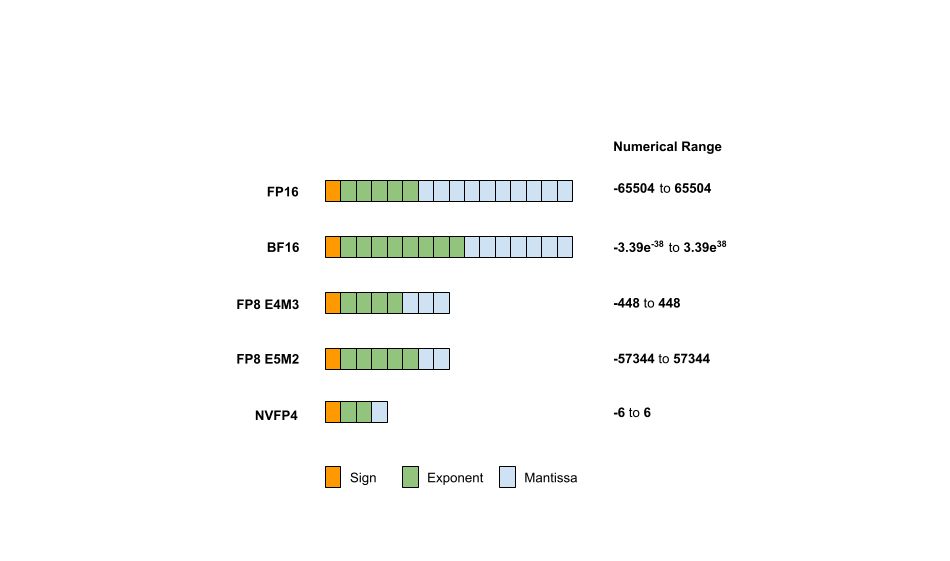
[2303.17951] FP8 versus INT8 for efficient deep learning inference
Kijai/flux-fp8 · Quantization Method?
w8a8_fp8 quantization · Issue #958 · vllm-project/llm-compressor · GitHub
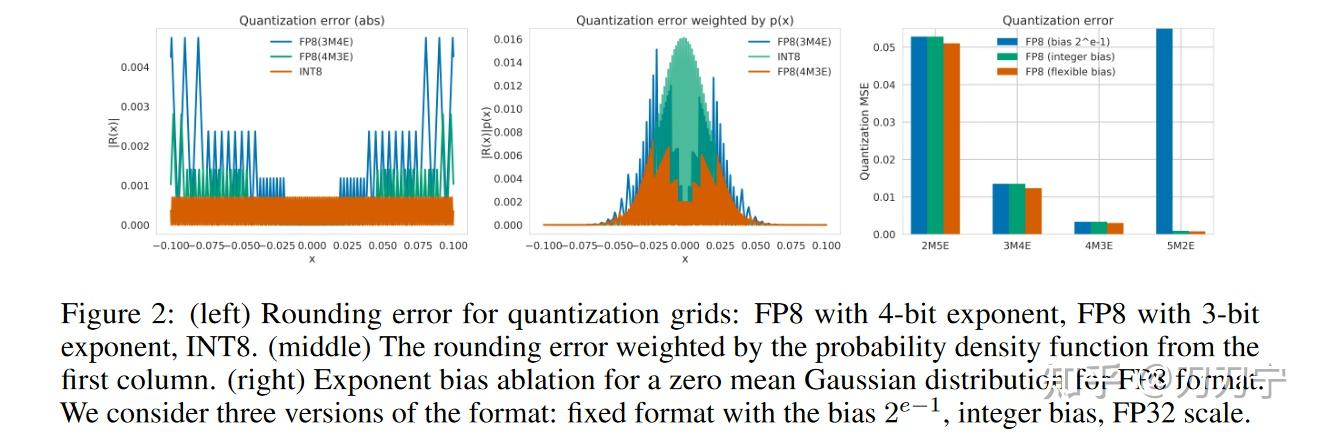
[2208.09225] FP8 Quantization: The Power of the Exponent
Z-Image Turbo - Quantized for low VRAM | Text encoder fp8 scaled ...
Quark Quantized PTPC FP8 Models - a amd Collection
yachty66/8-bit-quantized-catvton-flux · Is this model the fp8 quantized ...
(PDF) FP8 versus INT8 for efficient deep learning inference
Neural Magic has launched a fully quantized FP8 iteration of Meta's ...
万字综述:全面梳理 FP8 训练和推理技术-CSDN博客
FP8 量化:原理、实现与误差分析-轻识
Achieving FP32 Accuracy for INT8 Inference Using Quantization Aware ...
2022-9-18 arXiv roundup: Reliable fp8 training, Better scaling laws ...
Sage Attention with WAN FP8 model (or FP8 quantization) causes black ...
Float8 (FP8) Quantized LightGlue in TensorRT with NVIDIA Model ...
Serving Quantized LLMs on NVIDIA H100 Tensor Core GPUs | Databricks
Model Quantization: Concepts, Methods, and Why It Matters | NVIDIA ...
大模型量化技术原理:FP8_e4m3-CSDN博客
Optimizing LLMs for Performance and Accuracy with Post-Training ...
Unified FP8: Moving Beyond Mixed Precision for Stable and Accelerated ...
FP8格式理解解析-CSDN博客
GitHub - Qualcomm-AI-research/FP8-quantization
FP8-quantization-of-ResNet18/resnet18_cifar10_update_quantization.ipynb ...
Snowflake AI Research Optimizes Llama 3.1 405B for Efficient AI Deployment
GitHub - Neurone/flux.1-dev-fp8: Inference app for a FP8-quantized ...
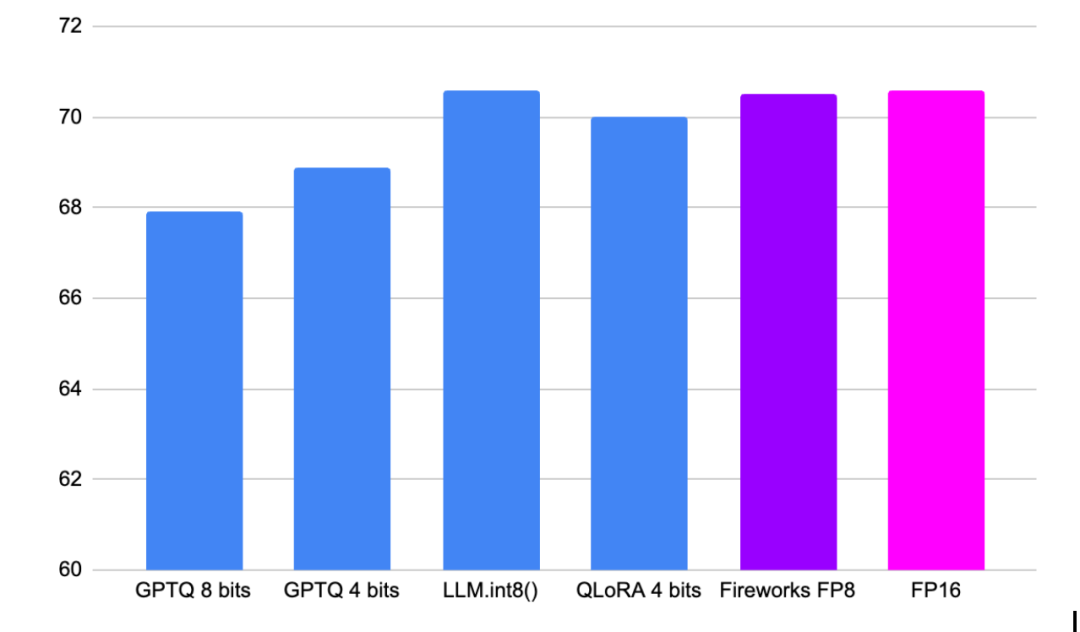
LLM推理部署(七):FireAttention——通过无损量化比vLLM快4倍_fp8 quantization: the power of ...
rkfg/Ovi-fp8_quantized · Hugging Face
“DNN Quantization: Theory to Practice,” a Presentation from AMD | PDF
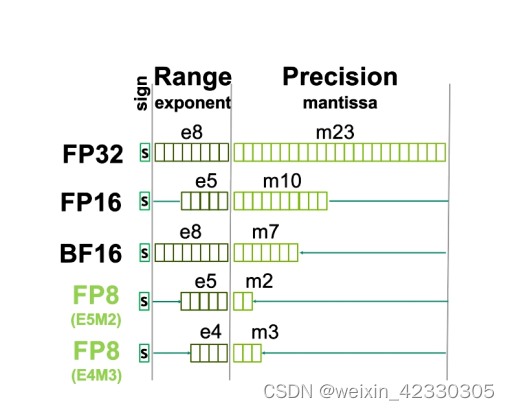
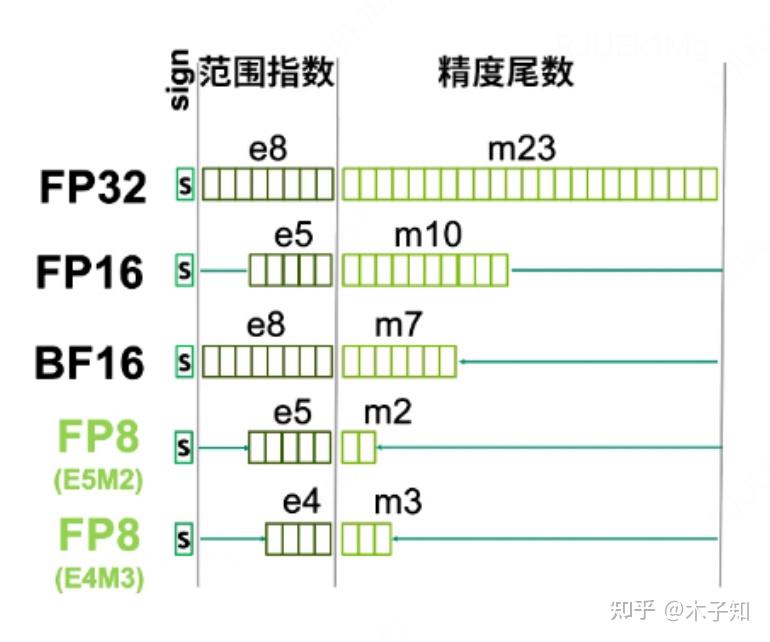
FP64、FP32、FP16、FP8简介-CSDN博客
Floating-point Arithmetic for AI Inference: Hit or Miss? - Edge AI and ...
本地手动量化模型FP8(fp8 quantization),Qwen-Image-Lightning-4steps-V1.0-fp8-e4m3 ...
LLM推理量化:FP8 versus INT8 - 知乎
GitHub - aredden/flux-fp8-api: Flux diffusion model implementation ...
【小白学习笔记】FP8 量化基础 - 英伟达 - 知乎
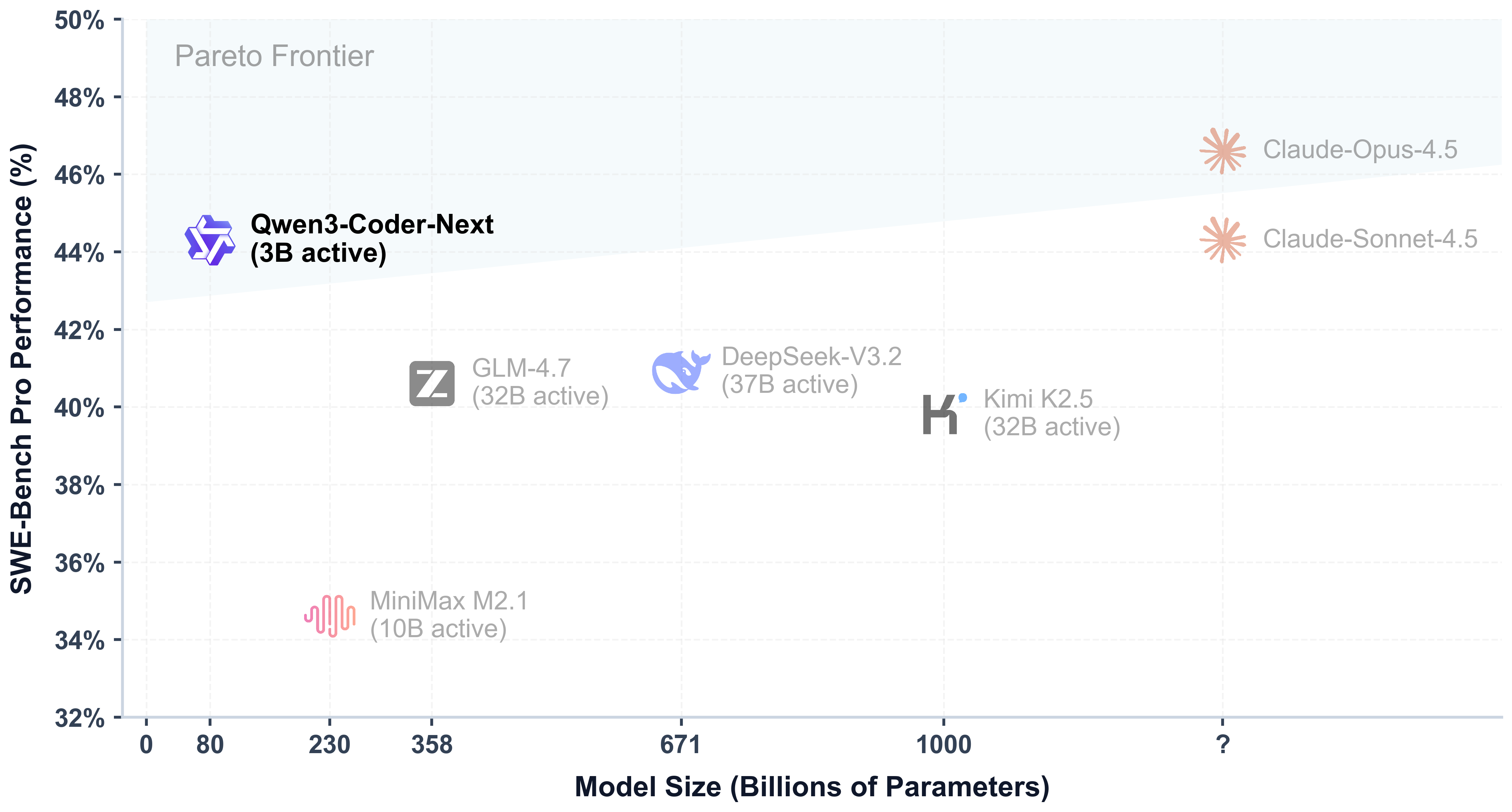
Qwen/Qwen3-Coder-Next-FP8 · Hugging Face
nm-testing/Mixtral-8x7B-Instruct-v0.1-FP8-quantized at main
Optimizing FLUX.1 Kontext for Image Editing with Low-Precision ...
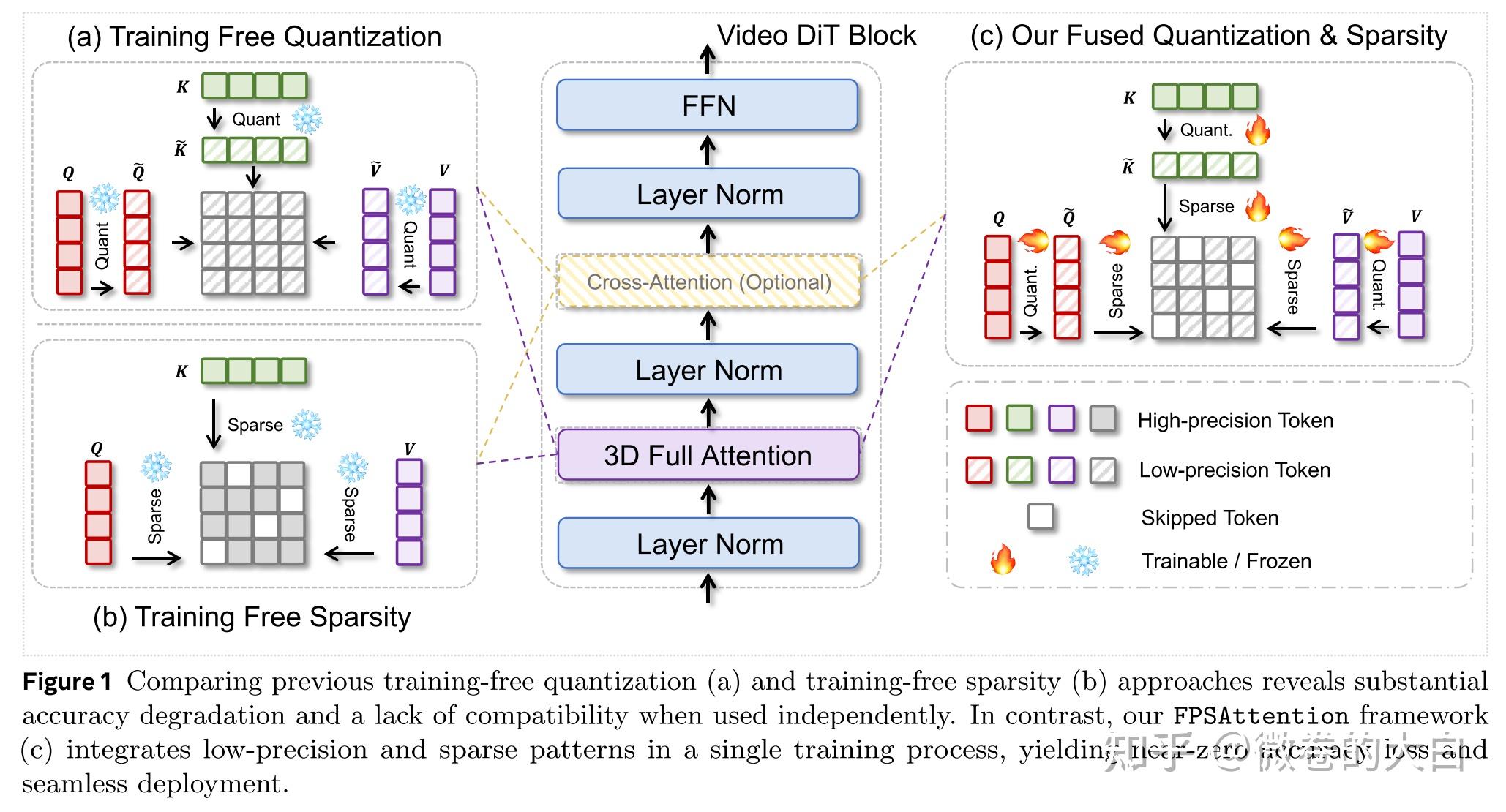
FPSAttention:量化+稀疏组合加速 Diffusion 视频生成 - 知乎
量化那些事之FP8与LLM-FP4 - 知乎
SRPO-Refine-Quantized - v1.0-fp8 | Flux Checkpoint | Civitai
大模型训练之FP8-LLM别让你的H卡白买了:H800的正确打开方式 - 知乎
FP8: Efficient model inference with 8-bit floating point numbers
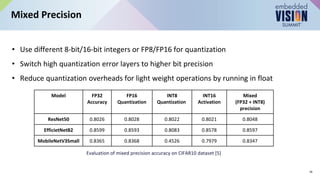
Mixed Precision Training in LLMs: FP16, BF16, FP8, and Beyond | by ...
Ran Golan on LinkedIn: #machinelearning #quantization #fp8 #datascience ...
When it comes to efficiently serving LLMs, we often hear about ...
Thread by @jphme on Thread Reader App – Thread Reader App
使用FP8进行大模型量化原理及实践 - 53AI-AI知识库|企业AI知识库|大模型知识库|AIHub
Amazon SageMaker launches the updated inference optimization toolkit ...