Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
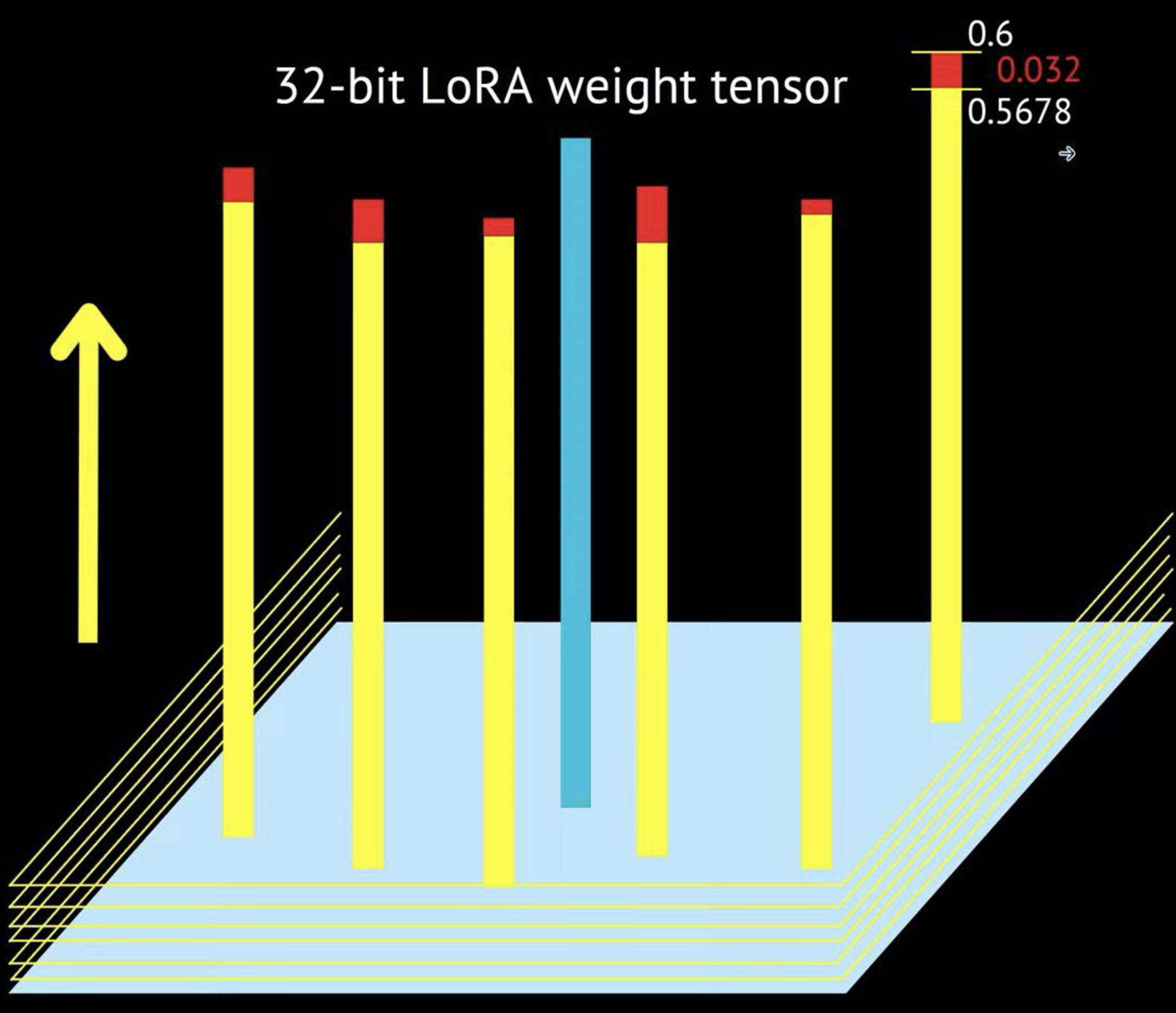
LLMs for your iPhone: Whole-Tensor 4 Bit Quantization
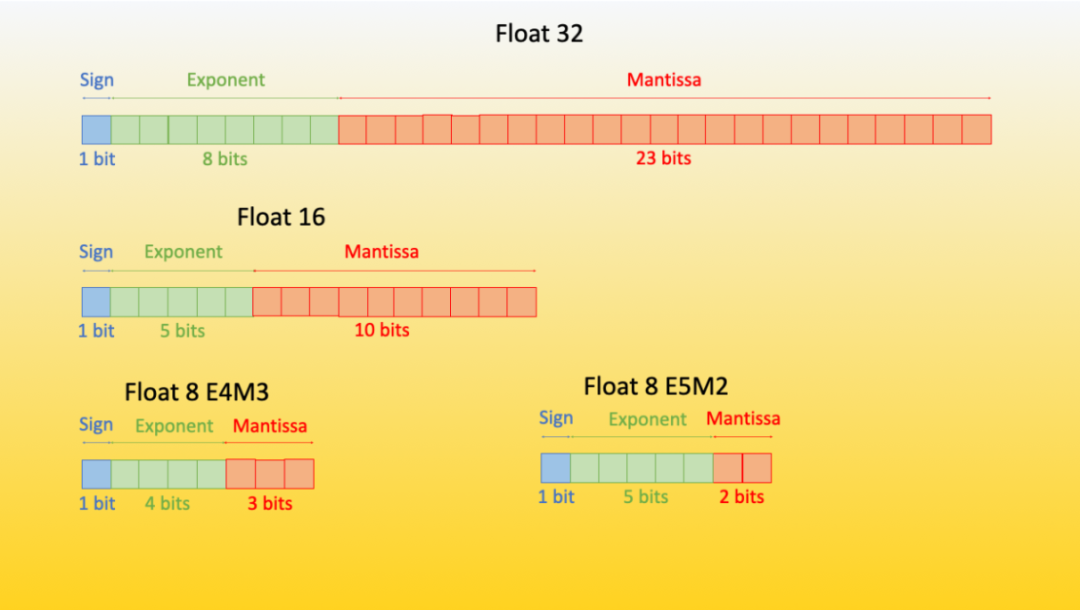
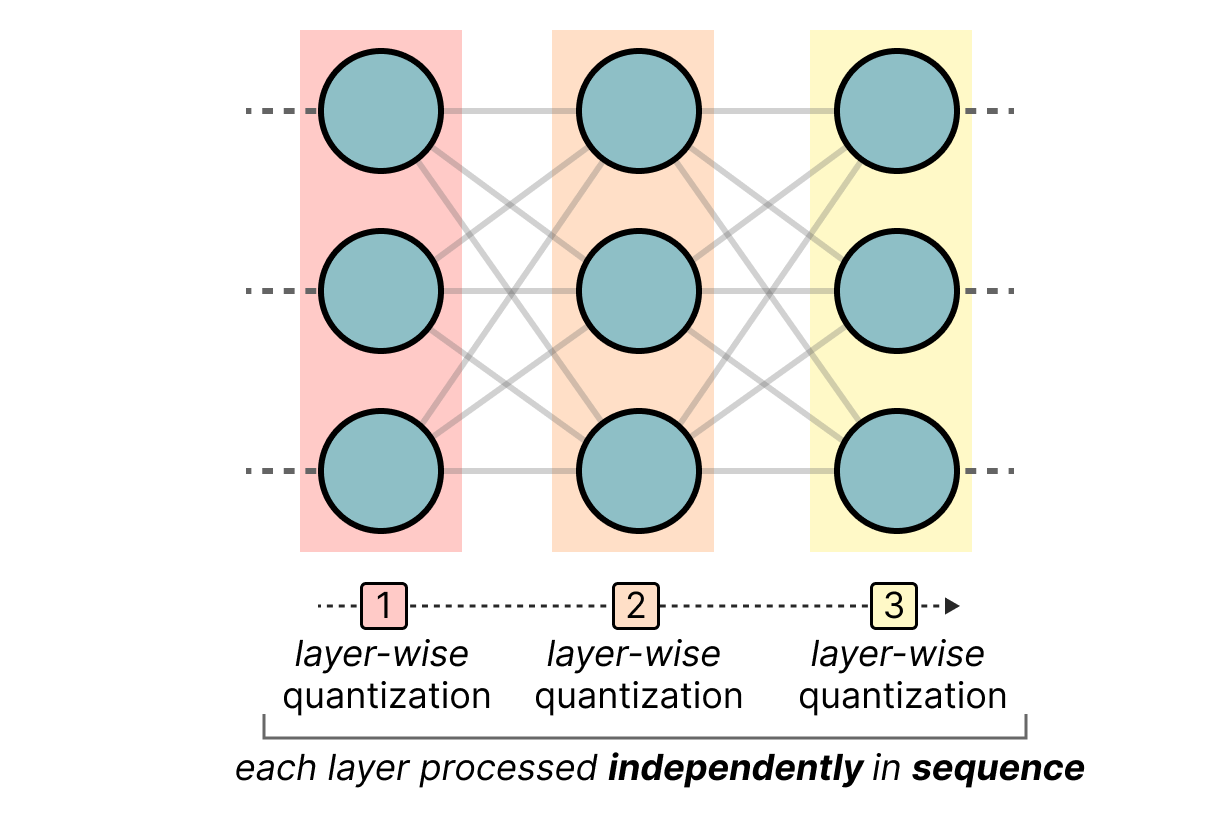
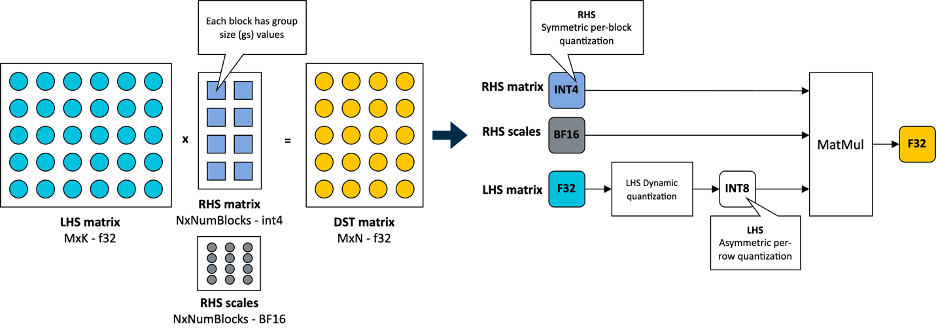
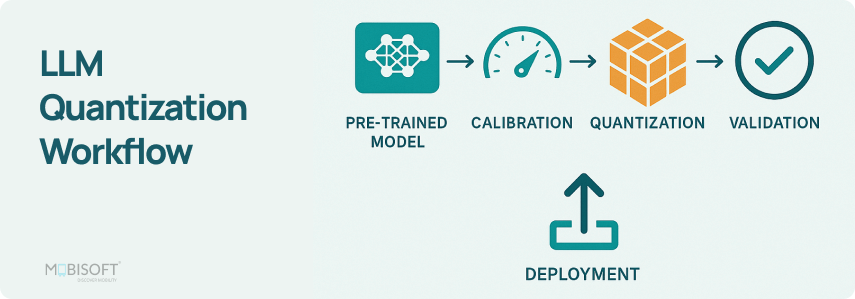
4-bit LLM training and Primer on Precision, data types & Quantization
[논문 리뷰] BCQ: Block Clustered Quantization for 4-bit (W4A4) LLM Inference
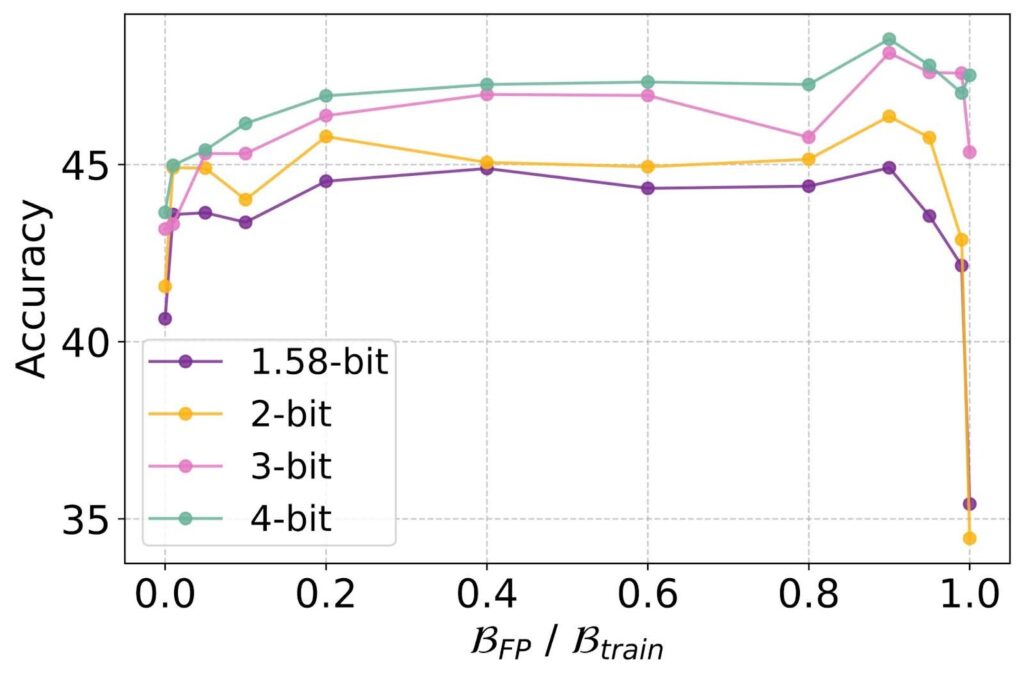
ParetoQ: Scaling Laws in Extremely Low-bit LLM Quantization – PyTorch
Practical Guide to LLM Quantization Methods - Cast AI
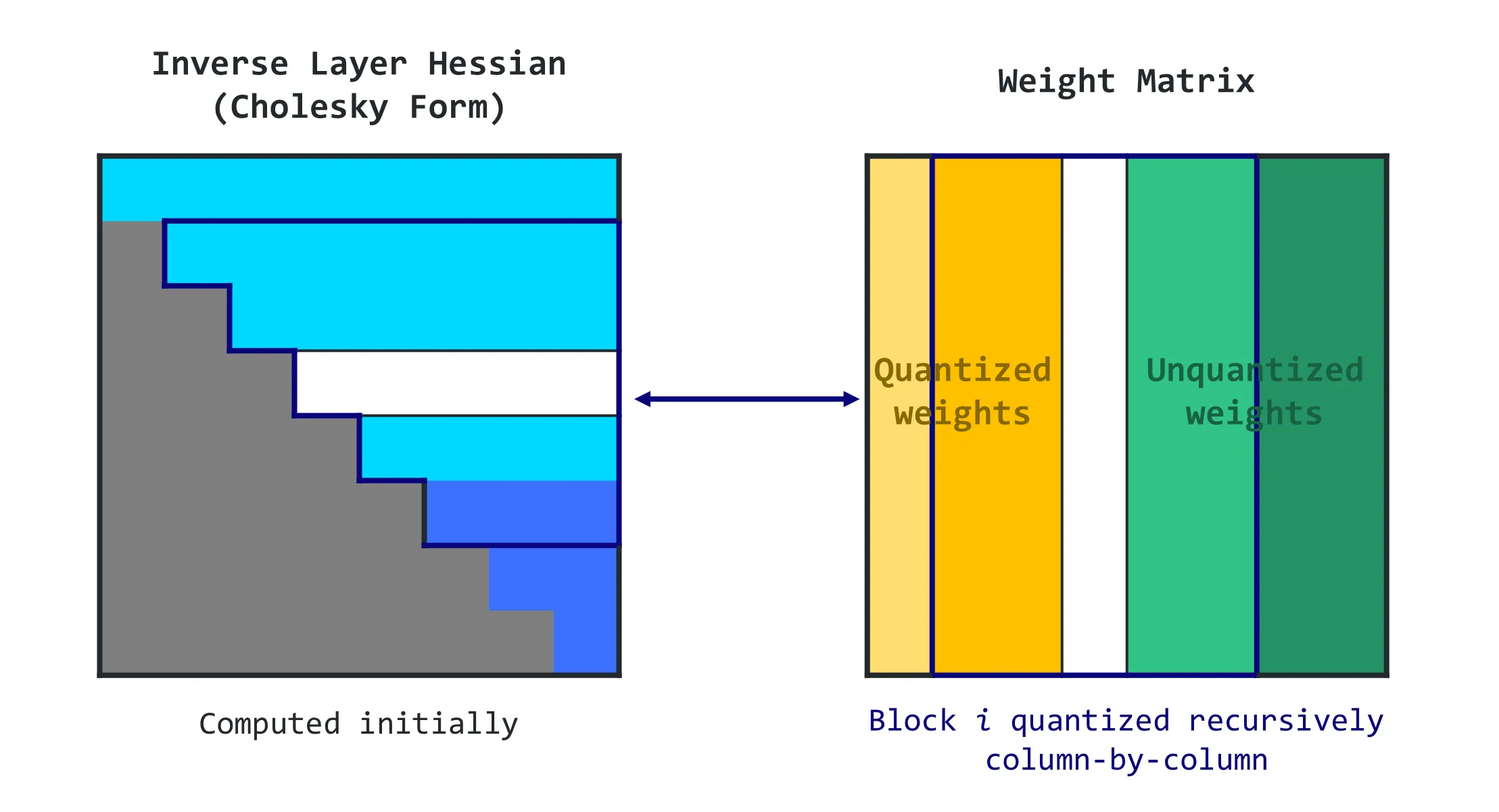
4-bit LLM Quantization with GPTQ - Origins AI
Democratizing LLMs: 4-bit Quantization for Optimal LLM Inference ...
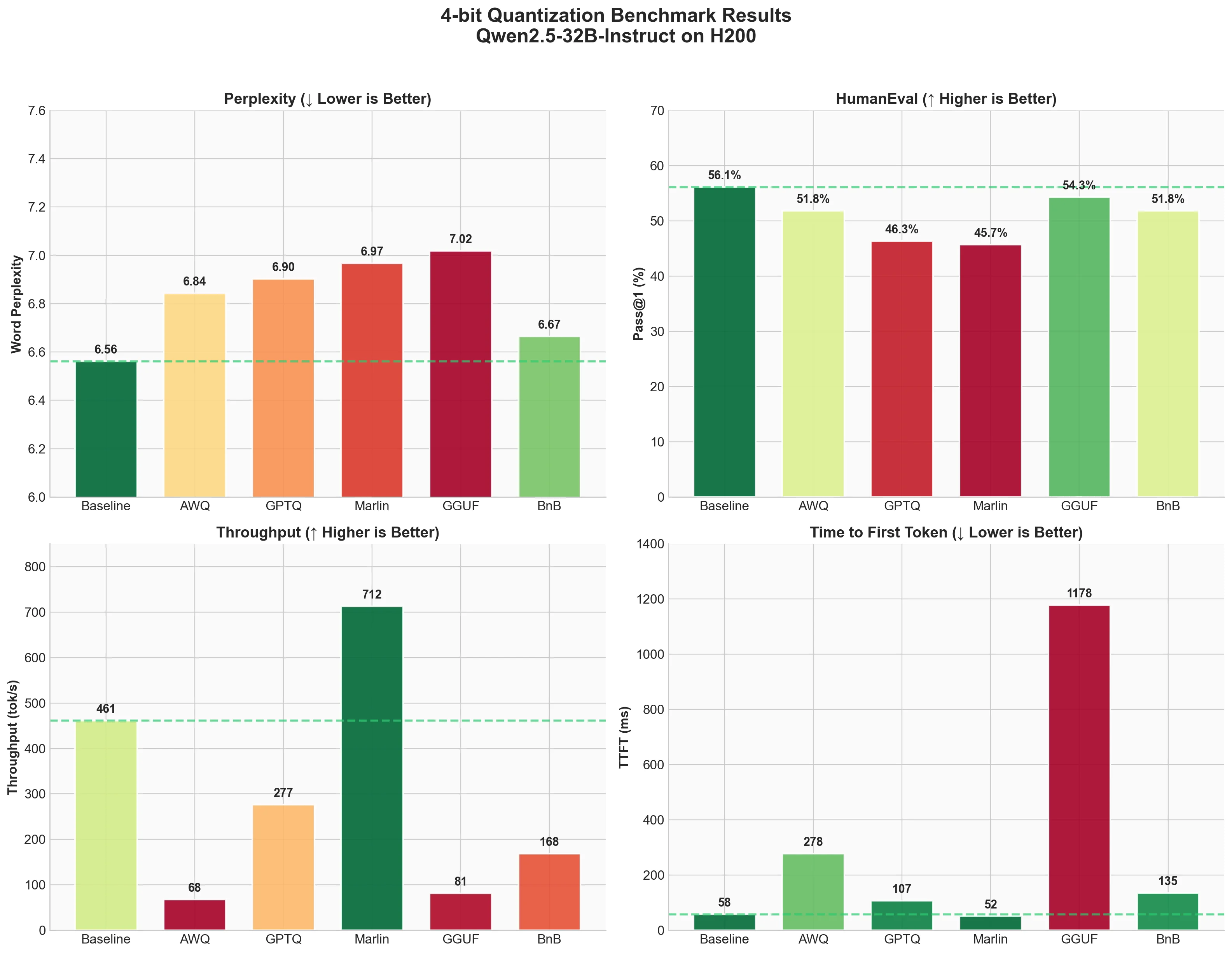
The Complete Guide to LLM Quantization with vLLM: Benchmarks & Best ...
Top LLM Quantization Methods and Their Impact on Model Quality
The Ultimate Handbook for LLM Quantization | Towards Data Science
(PDF) BCQ: Block Clustered Quantization for 4-bit (W4A4) LLM Inference
LLM Series - Quantization Overview | by Abonia Sojasingarayar | Medium
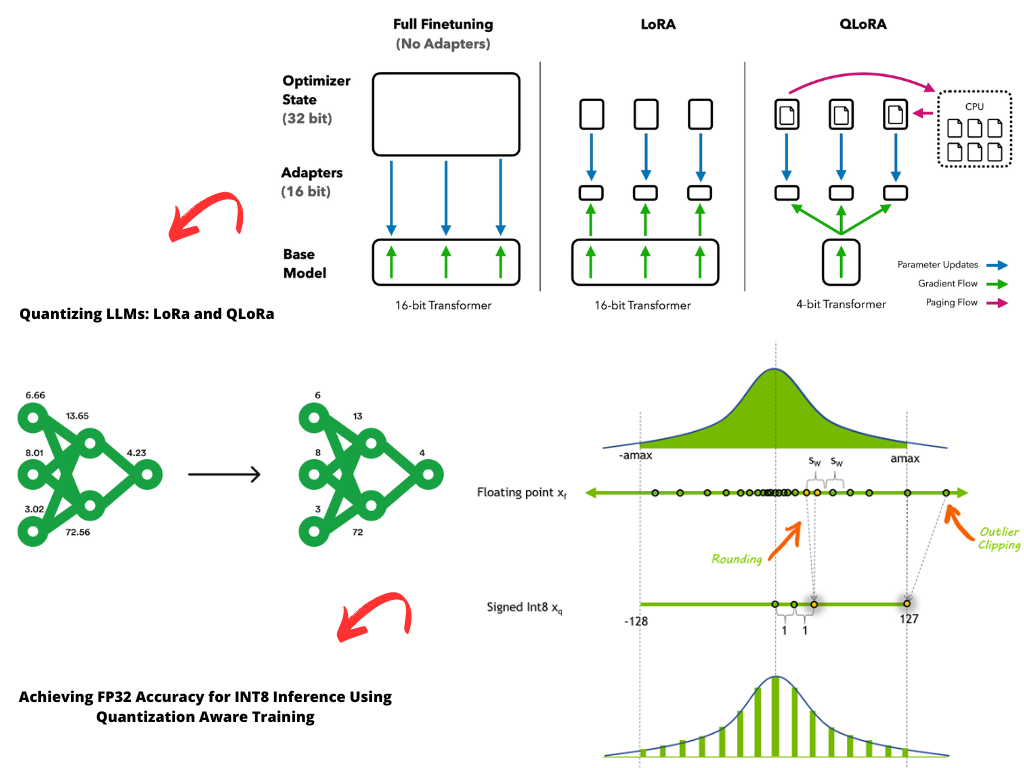
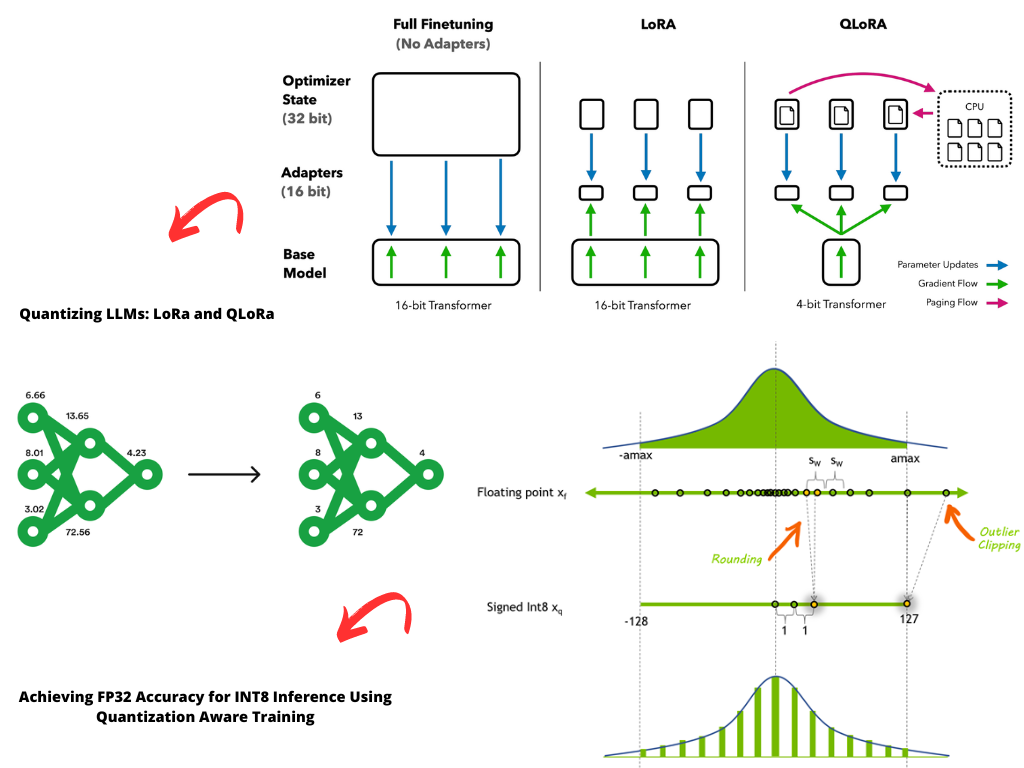
QLoRA: 4-Bit Quantization for Memory-Efficient LLM Fine-Tuning ...
Democratizing LLMs: 4-bit Quantization for Optimal LLM Inference | by ...
ParetoQ: Scaling Laws in Extremely Low-bit LLM Quantization | Zechun Liu
LLM Quantization Explained. Shrinking AI models from feast to fit… | by ...
Quantization of LLM Models: Model Compression Strategies for Reducing ...
GLM-130B LLM demonstrates 4-bit quantization loss shrinks as model ...
Efficient LLM Inference Achieves Speedup With 4-bit Quantization And ...
QLoRA:4-bit level quantization and fine-tuning method for LLM with 33B ...
Figure 1 from Atom: Low-bit Quantization for Efficient and Accurate LLM ...
The Complete Guide to LLM Quantization | LocalLLM.in
The LLM Revolution: Boosting Computing Capacity with Quantization ...
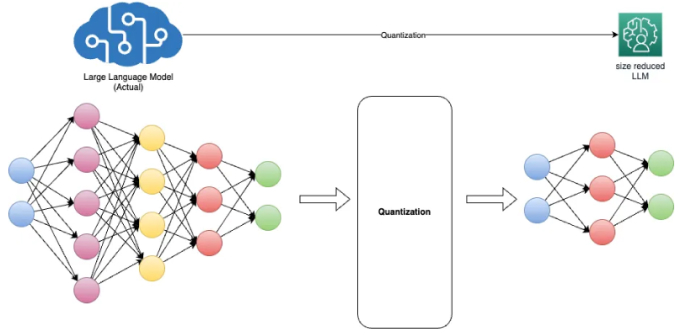
Optimizing LLM Model using Quantization
Implementing LLM Quantization with bitsandbytes
WTH is LLM quantization? 4bit GPTQ? | by Dharani J | Medium
What is Quantization in LLM? A Complete Guide to Optimizing AI
LLM Quantization: Quantize Model with GPTQ, AWQ, and Bitsandbytes ...
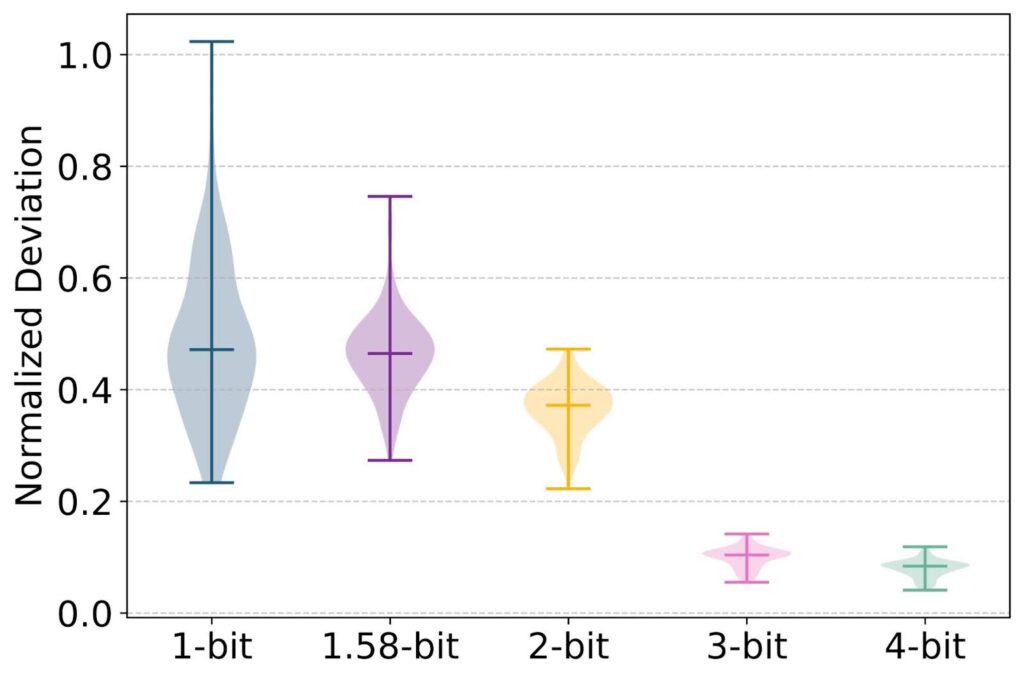
Quantization of unsigned data to 3-bit or 4-bit (α = 1.0) using three ...
Honey, I shrunk the LLM! A beginner's guide to quantization • The Register
Faster and More Efficient 4-bit quantized LLM Model Inference | by ...
LLM Quantization-Build and Optimize AI Models Efficiently
LLM Quantization: Making models faster and smaller | MatterAI Blog
4-bit Quantization with GPTQ | Towards Data Science
Researchers Accelerate LLM Inference With LiquidGEMM, Achieving 4.94x ...
Mastering QLoRa : A Deep Dive into 4-Bit Quantization and LoRa ...
用 bitsandbytes、4 比特量化和 QLoRA 打造亲民的 LLM - 智源社区
Advances to low-bit quantization enable LLMs on edge devices ...
Lets Finetune LLM - Speaker Deck
enhancement: Add 4-bit quantization / inference support · Issue #181 ...
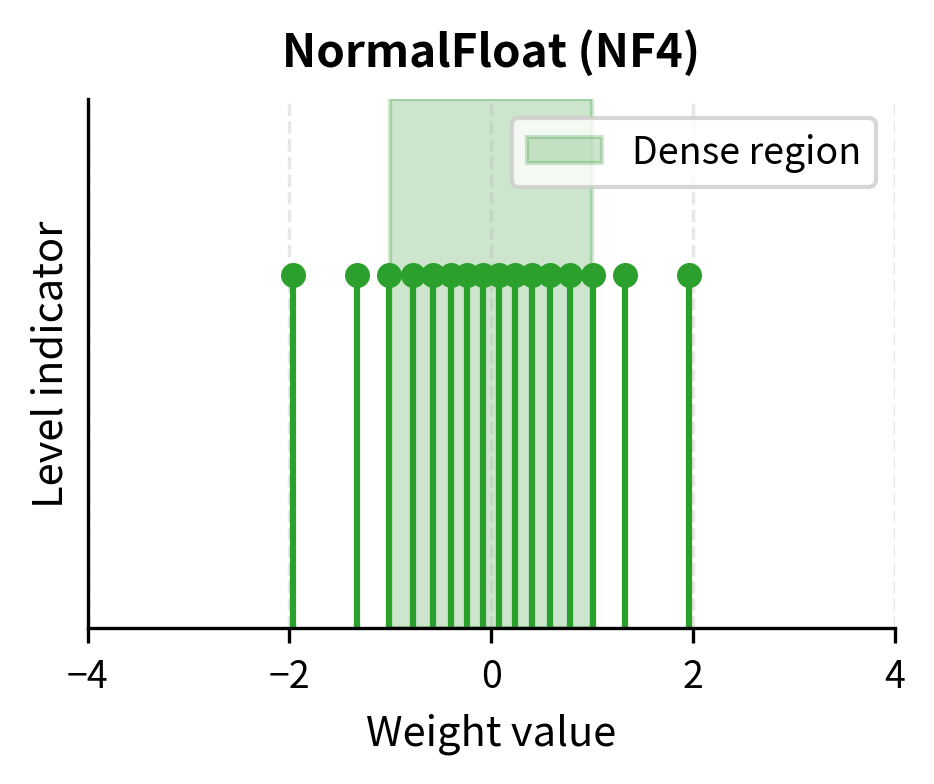
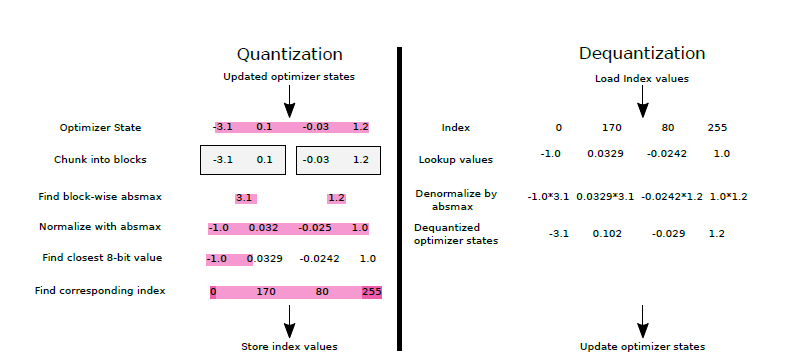
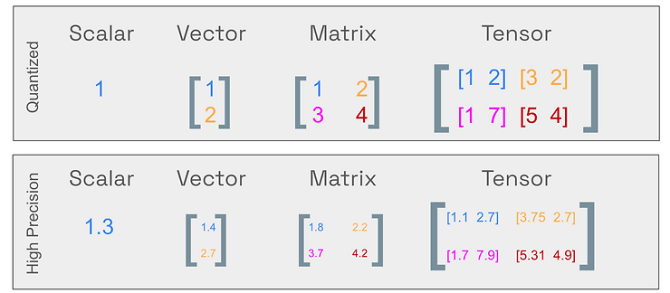
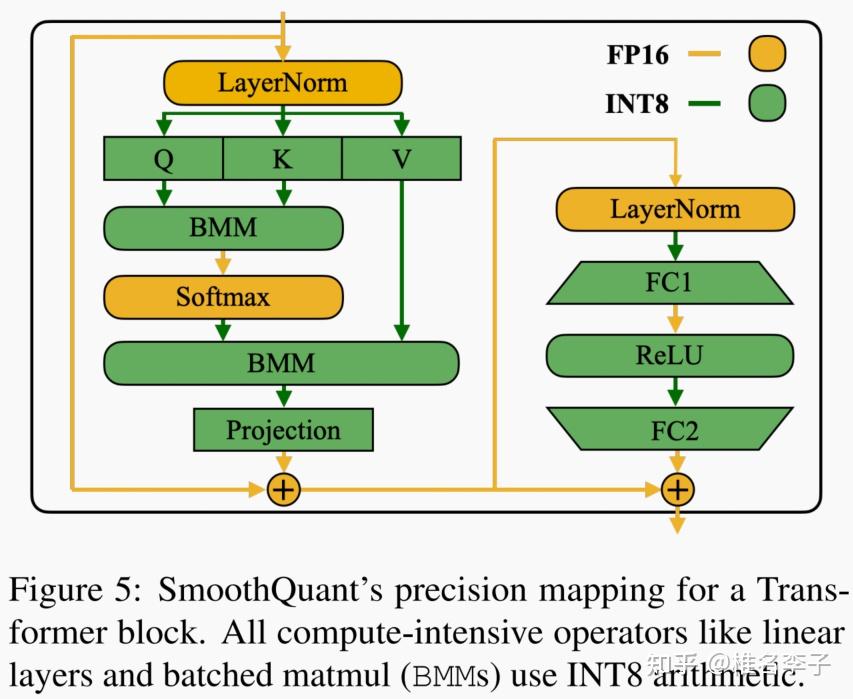
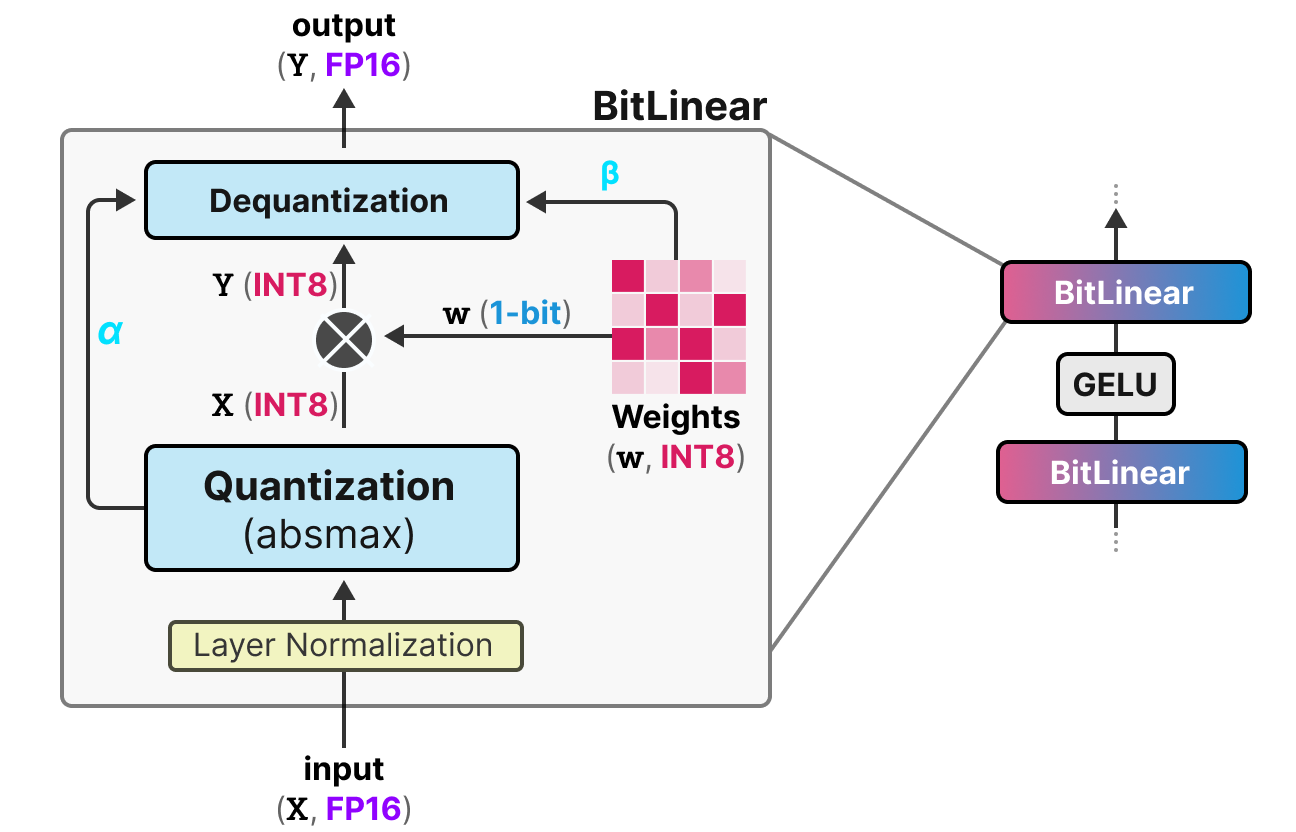
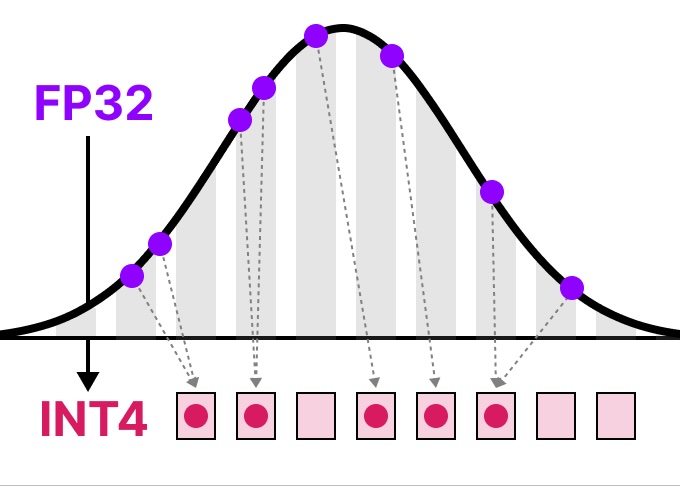
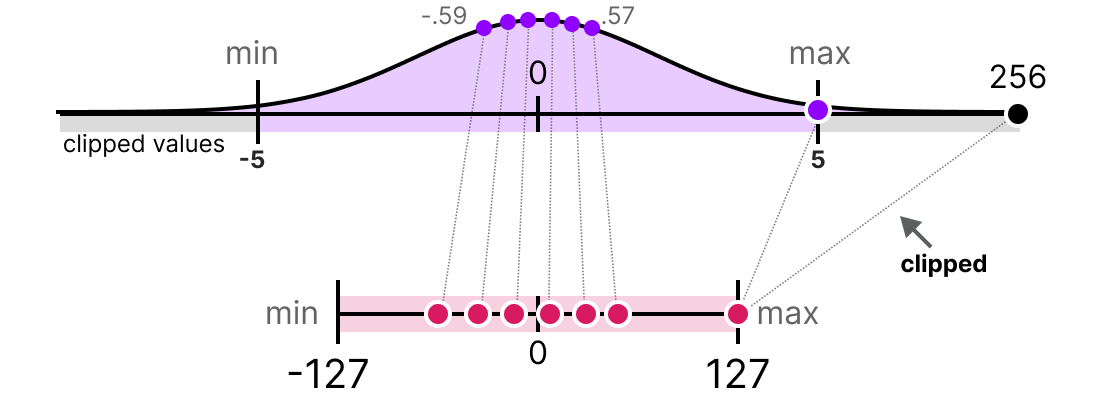
A Visual Guide to Quantization - Maarten Grootendorst
SDP4Bit: Toward 4-bit Communication Quantization in Sharded Data ...
Unleashing the Power of AI on Mobile: LLM Inference for Llama 3.2 ...
We compare different ways to achieve 4-bit quantization using three ...
Understanding Quantization for LLMs | by LM Po | Medium
Shrinking Giants: The Quantization Mathematics Making LLMs Accessible
LLM Quantization: Weight-Only? Static? Dynamic? | by hebiao064 | Medium
Optimize Your LLM with Quantization: Save Memory and Boost Performance ...
Quantizing Giants: How a 4-Bit LLM Saved Lives in a Real-World Hospital ...
Quantized 8-bit LLM training and inference using bitsandbytes on AMD ...
Exploring Model Quantization for LLMs | by Snehal | Medium
GPTQ Quantization (3-bit and 4-bit) · Issue #9 · ggml-org/llama.cpp ...
Quantization using bitsandbytes. ‘bitsandbytes’ is a tool to reduce ...
Quantization trong LLM: Tối ưu hóa tốc độ Mô hình Ngôn ngữ Lớn - Blog ...
MSU AI Club
🌟 Dynamic 4-bit Quantization: A Smarter Solution! Quantizing models to ...
模型量化-llm量化 - 知乎
What are Quantized LLMs?
Introduction to llm-finetuning and Quantization. Refining Generative ...
LLMs之Quantization:LLM中量化技术的可视化指南之量化技术的简介、常用数据类型、校准权重和激活值的量化方法(PTQ/QAT ...
模型量化1-概述1:量化的过程就是选取合适量化参数(scale factor,zero point,clipping value)以及数据映射 ...
Custom build on-premise Large Language Model — Fine-tuning models on ...
LLaMa GPTQ 4-Bit Quantization. Billions of Parameters Made Smaller and ...
LLM-FP4: 4-Bit Floating-Point Quantized Transformers - ACL Anthology
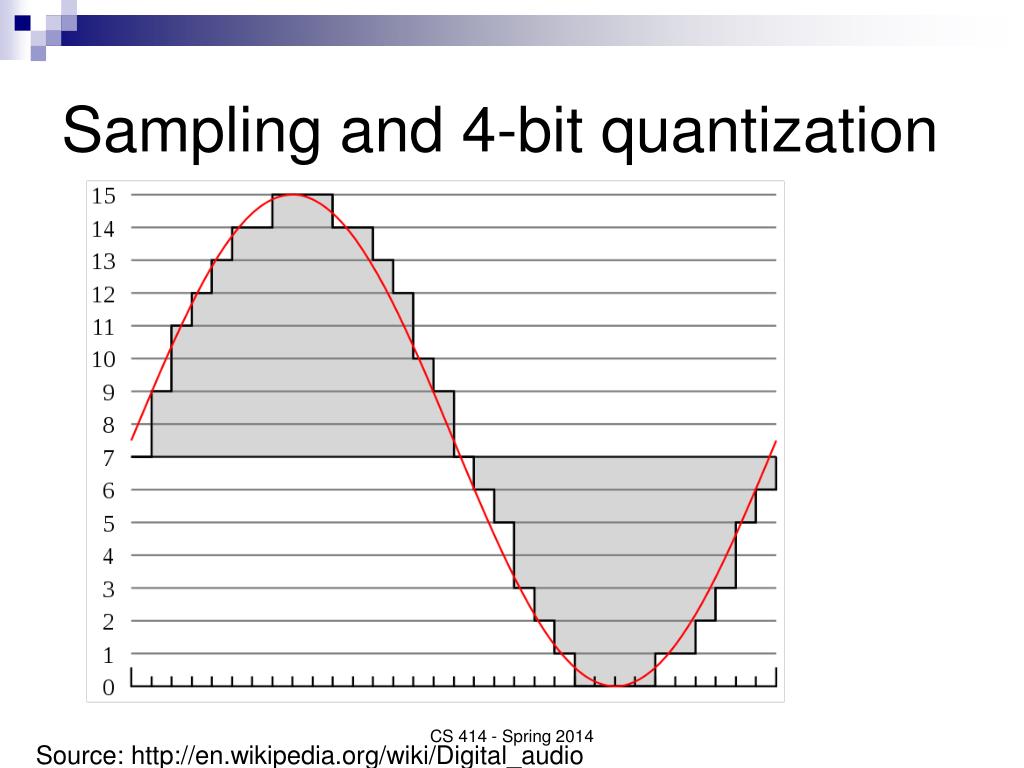
PPT - CS 414 – Multimedia Systems Design Lecture 3 – Digital Audio ...
From Precision to Quantization: A Practical Guide to Faster, Cheaper LLMs
Paper page - LLM-FP4: 4-Bit Floating-Point Quantized Transformers
大模型入门指南 - Quantization:小白也能看懂的“模型量化”全解析_大模型量化-CSDN博客
Publications | VSDL