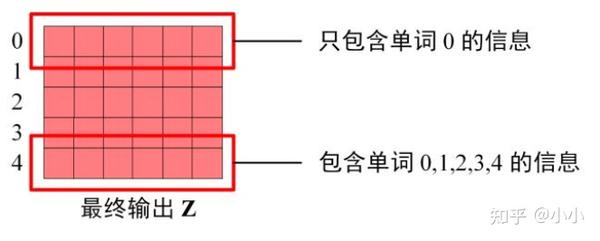
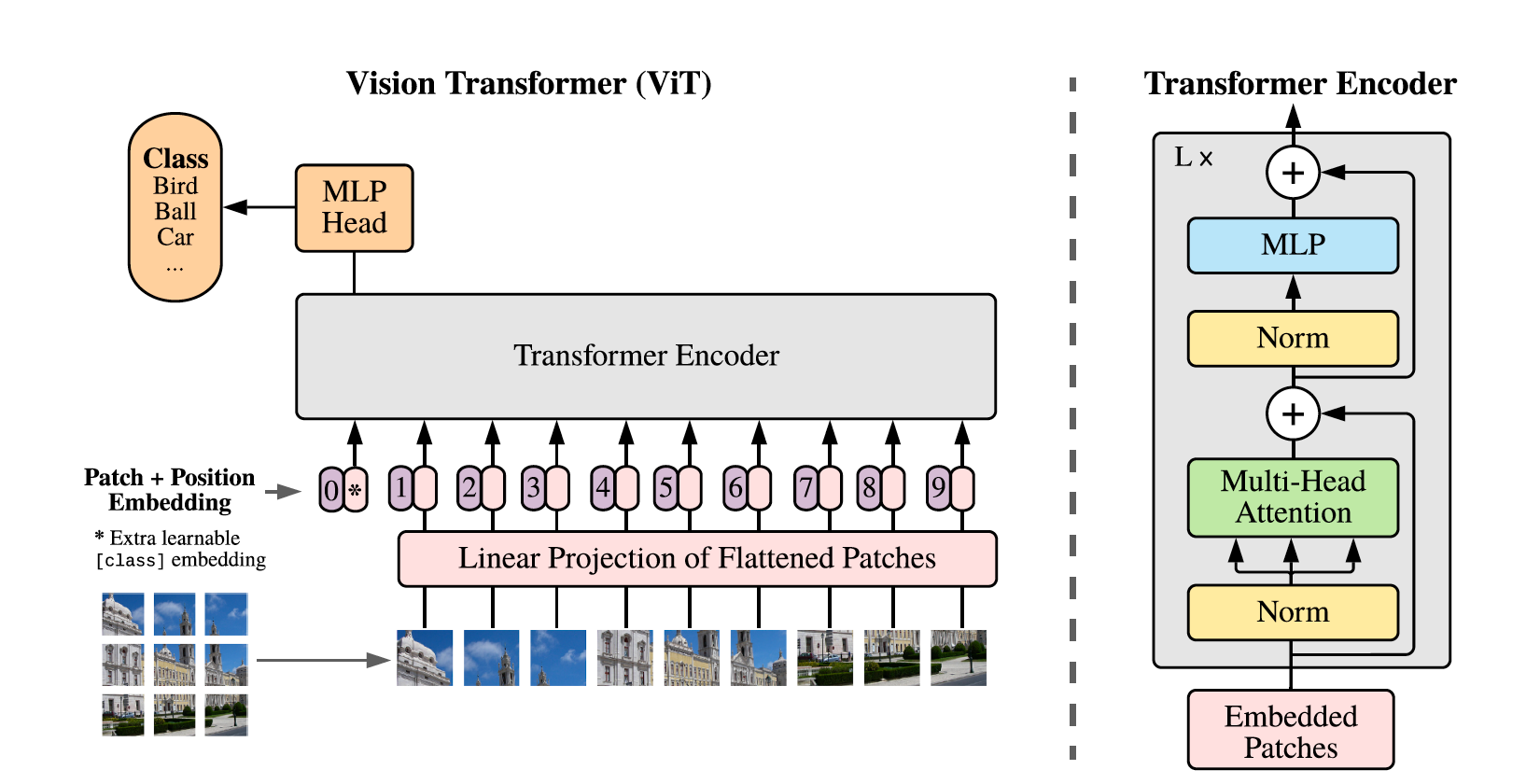
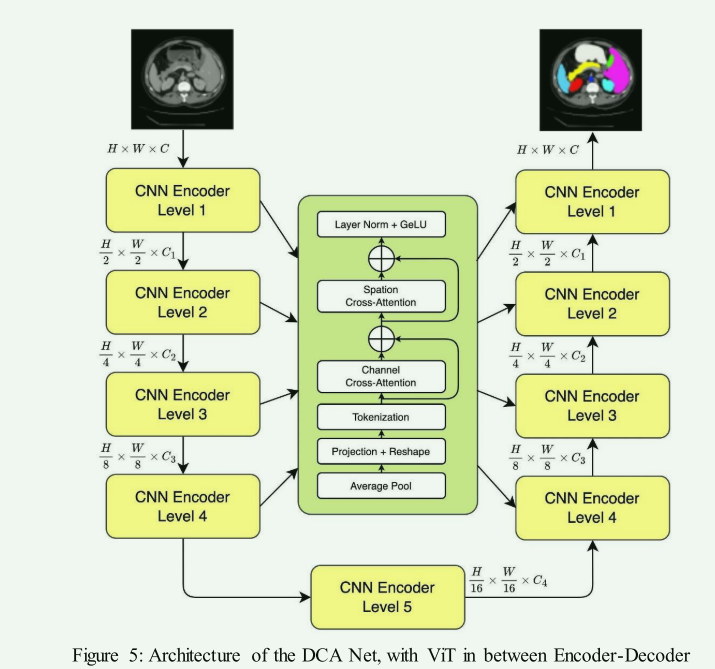
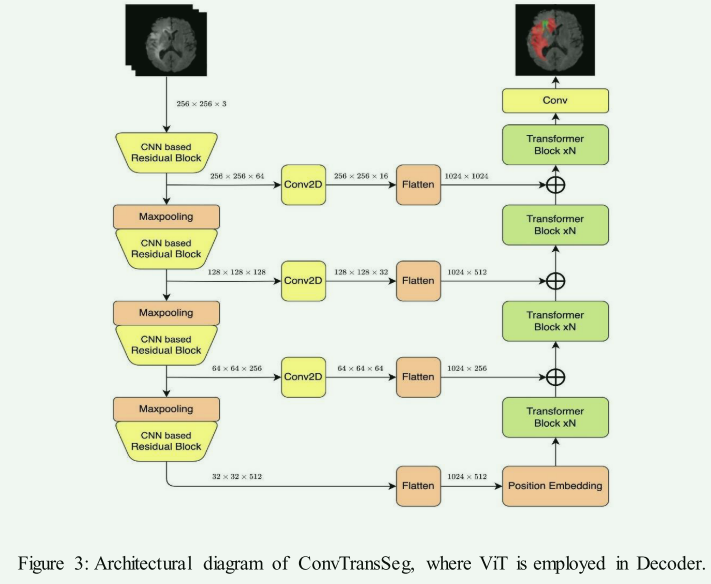
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
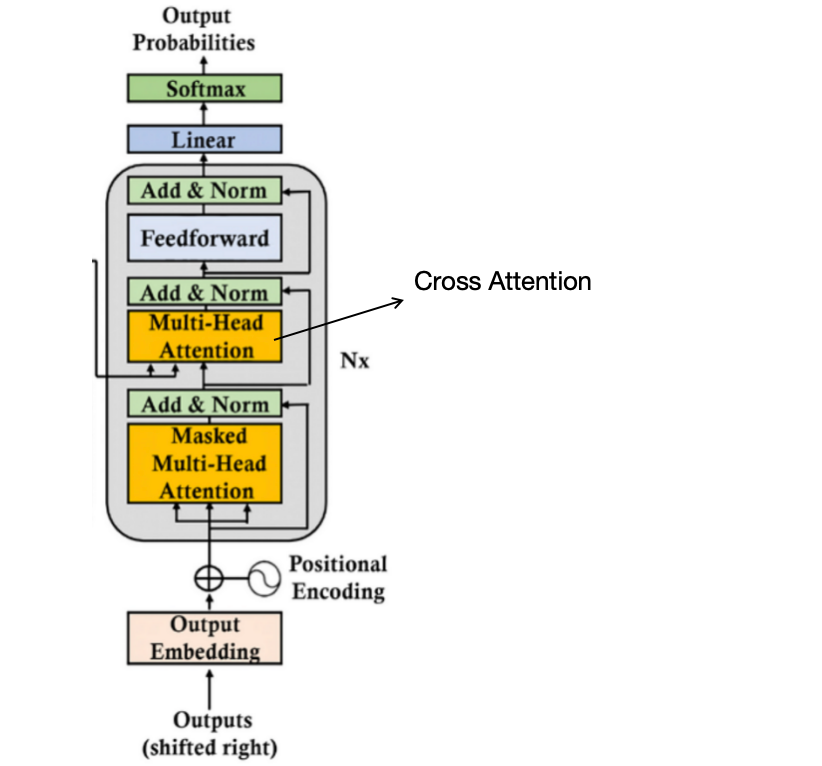
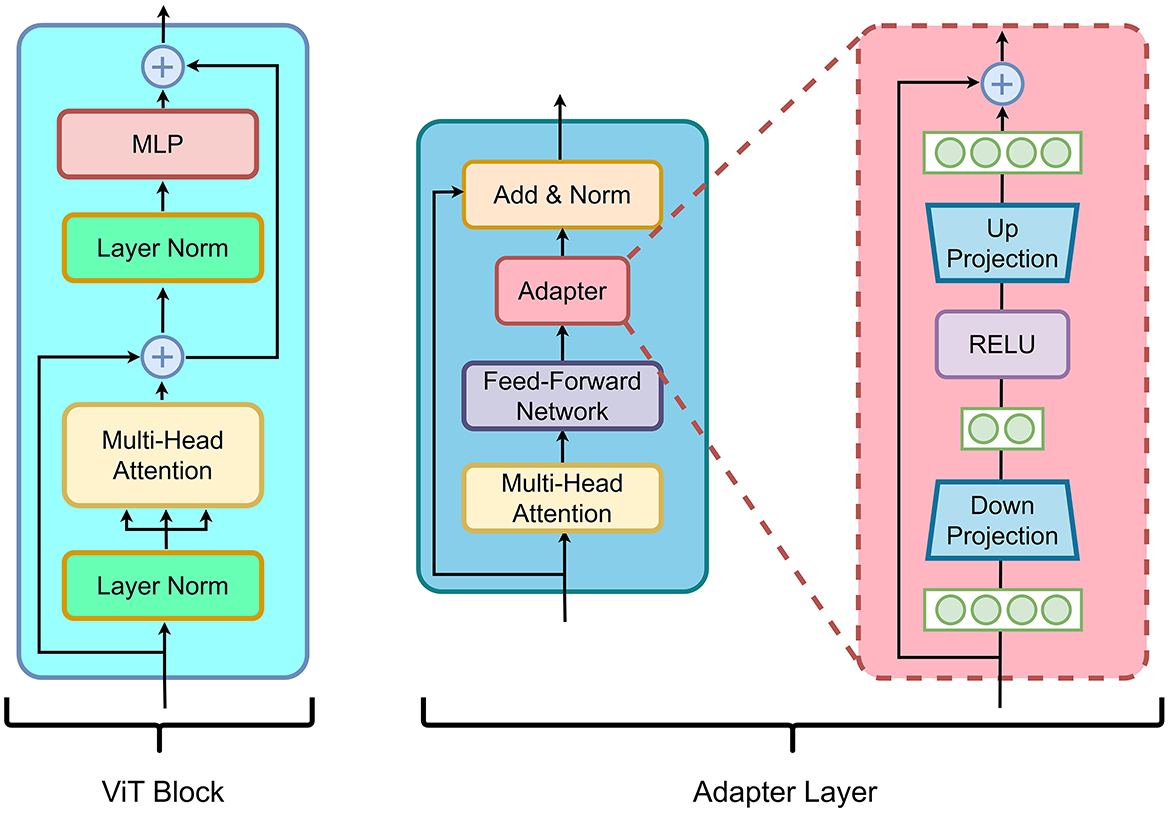
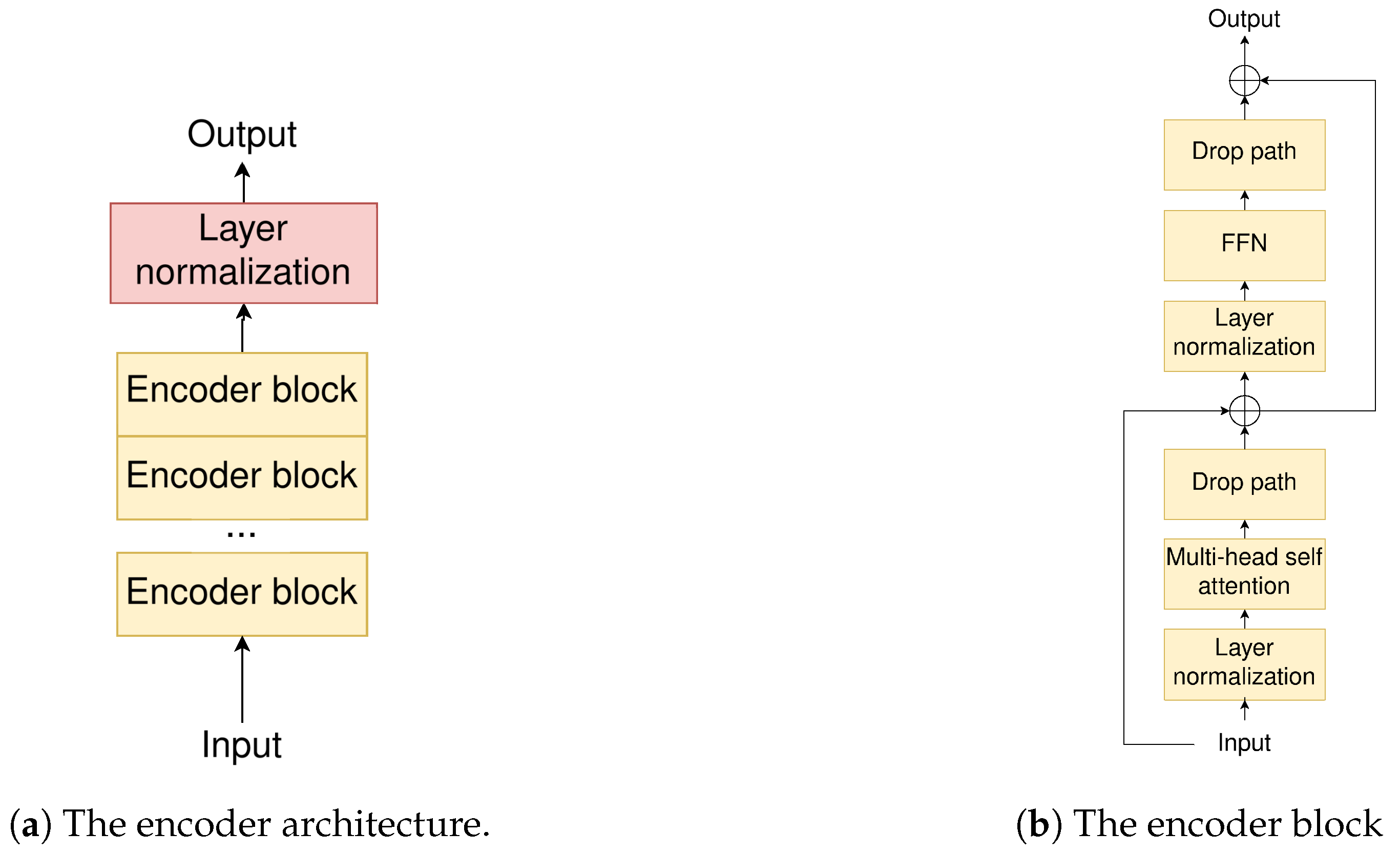
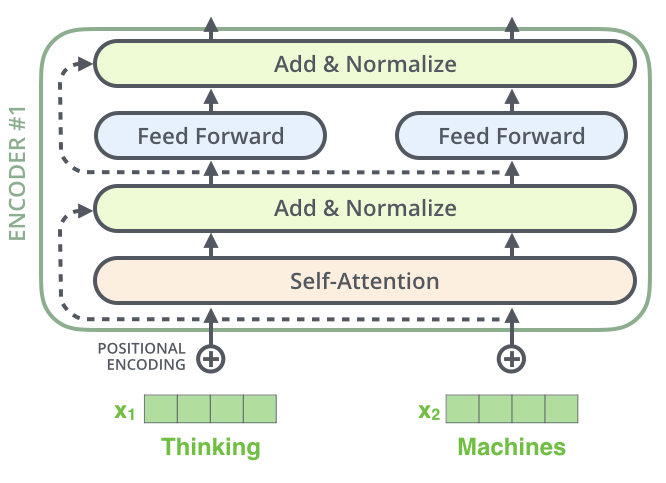
Architecture of the ViT encoder block and the segmentation decoder ...
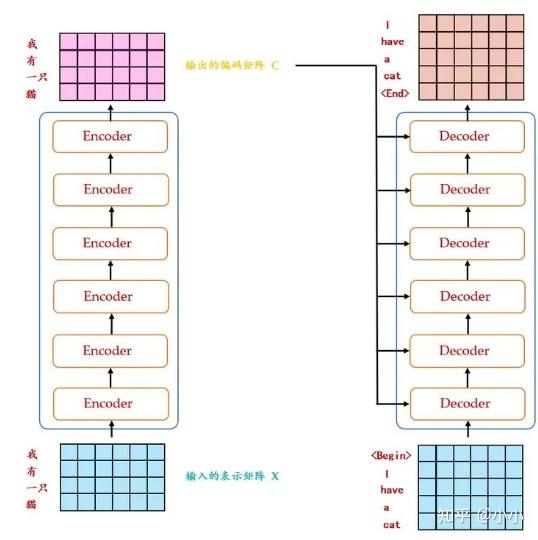
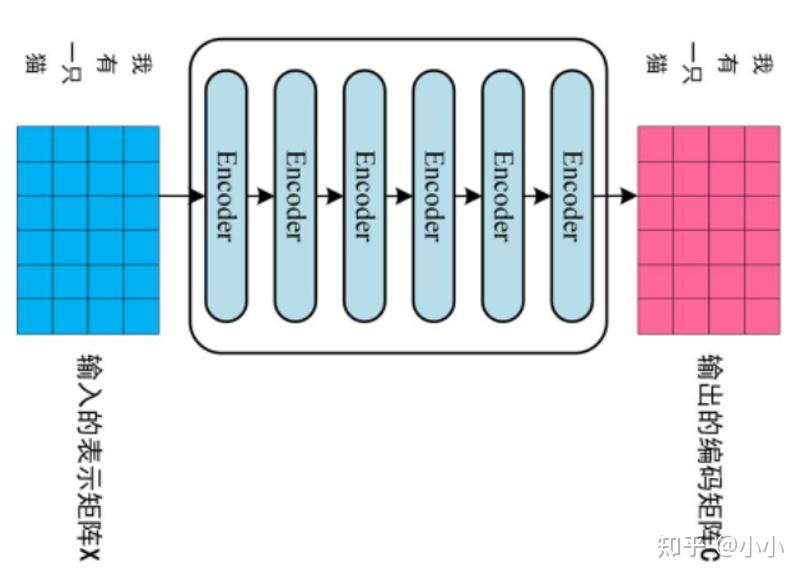
Paper page - Your ViT is Secretly an Image Segmentation Model
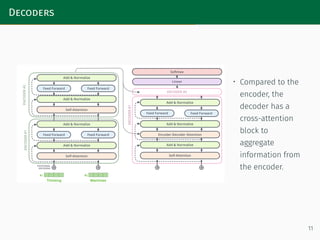
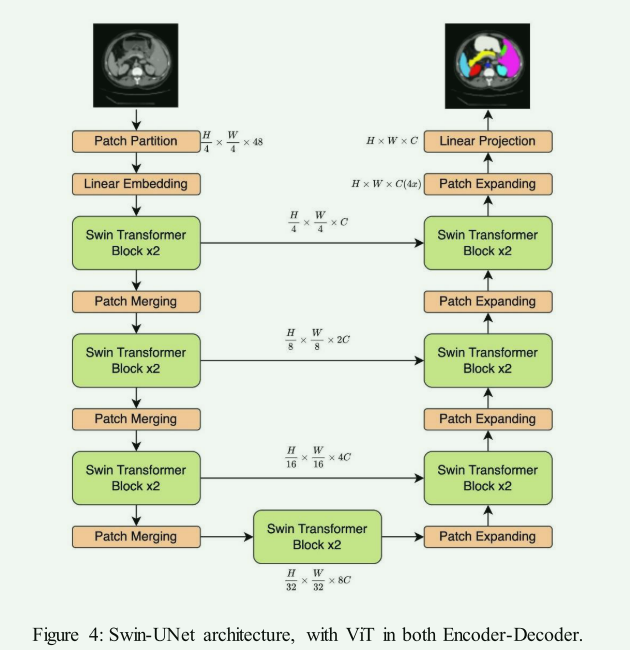
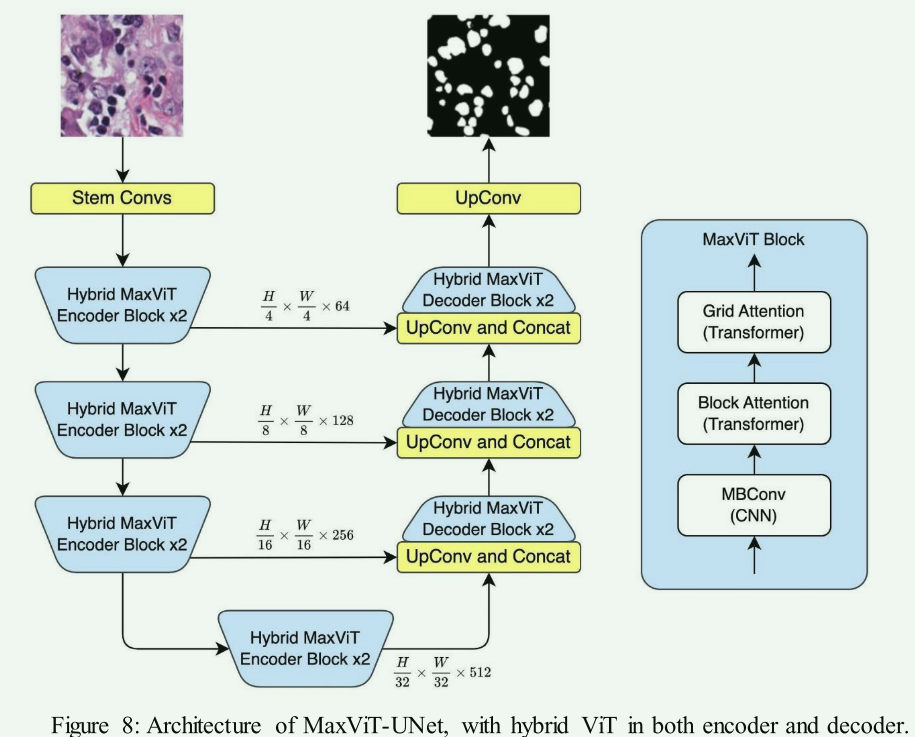
The proposed MResTNet architecture uses a ViT encoder and decoder ...
实用指南:Your ViT is Secretly an Image Segmentation Model - yxysuanfa - 博客园
List: ViT Segmentation | Curated by Martinc | Medium
语义分割中的 ViT decoder · Blog of C.P.F.
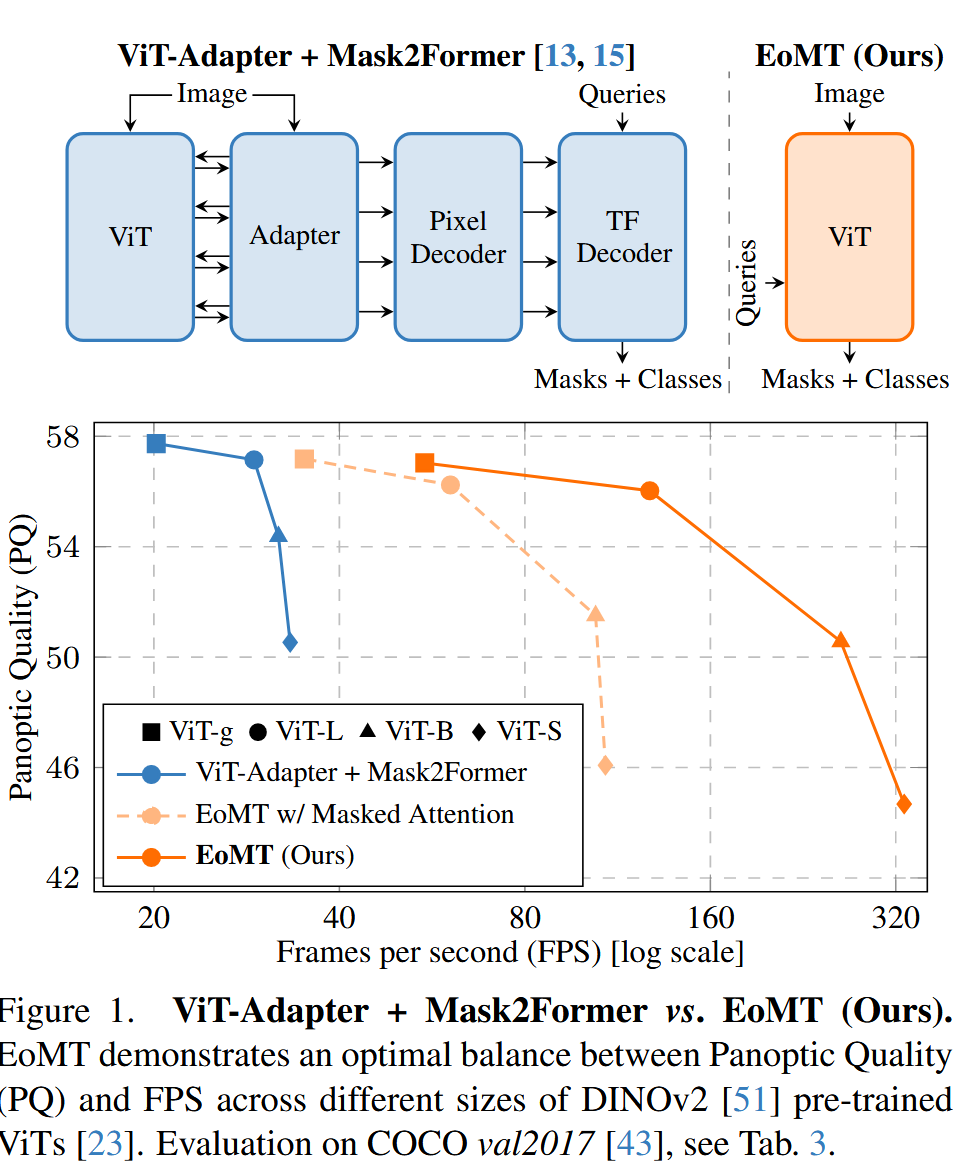
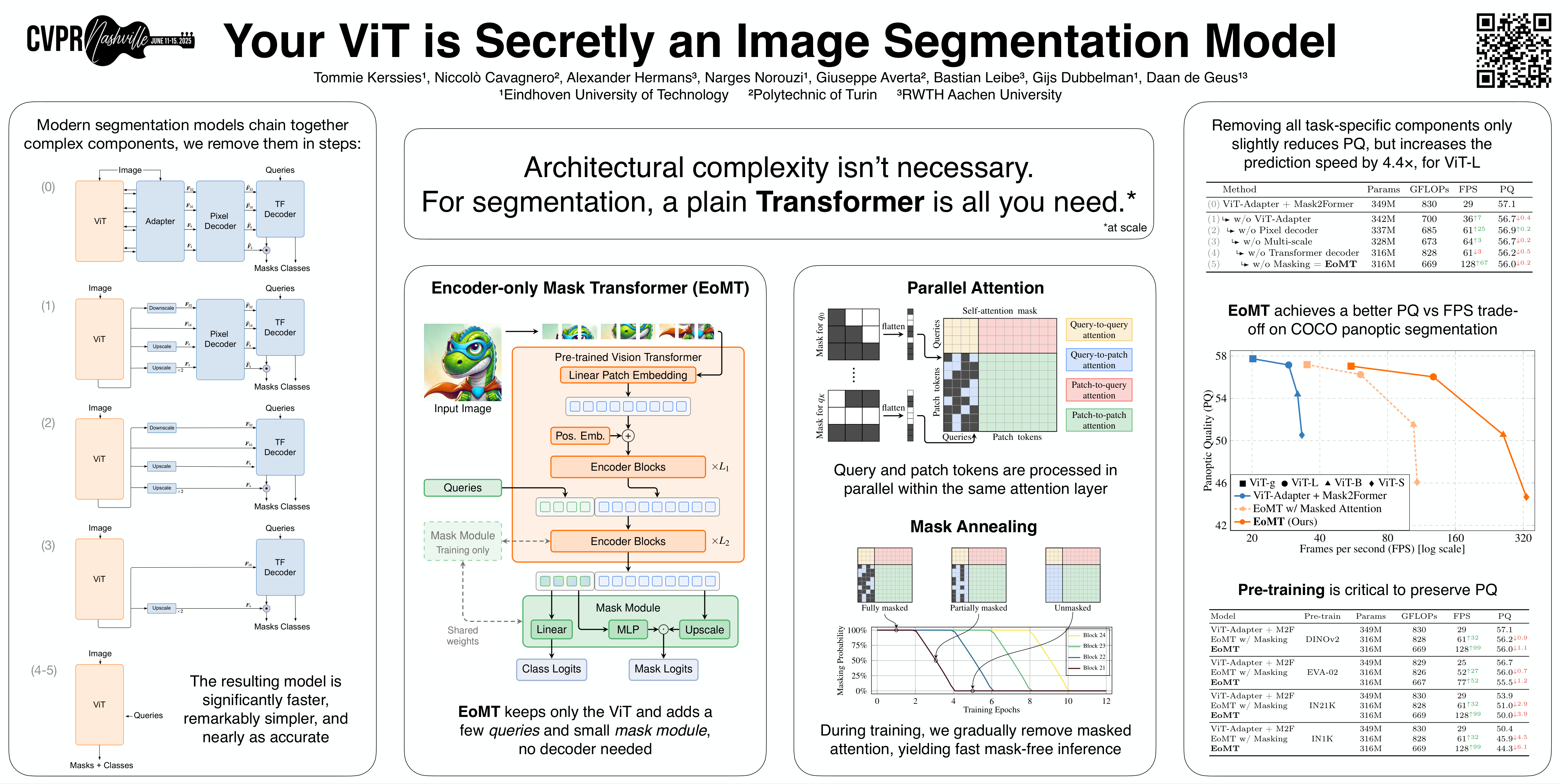
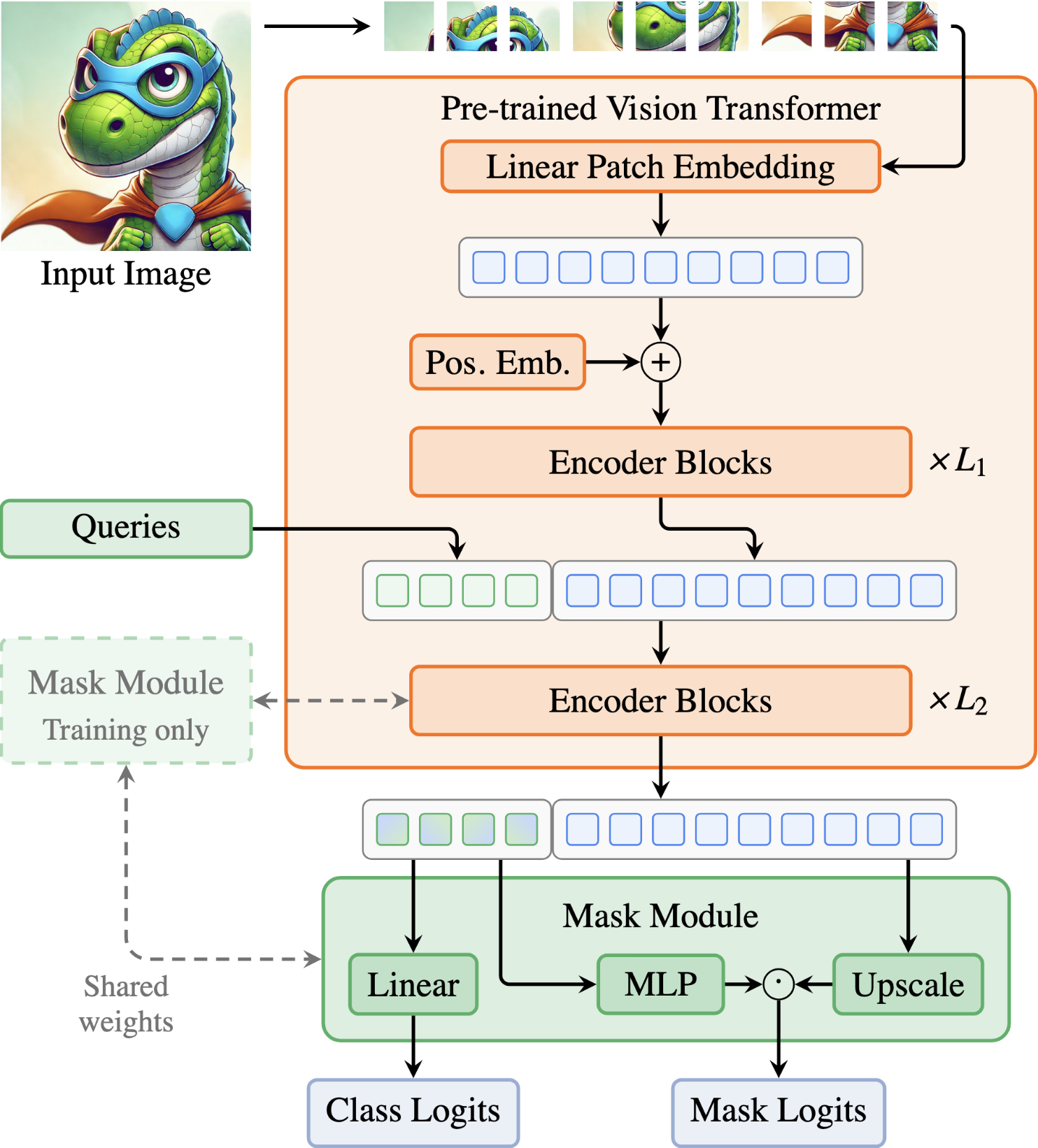
CVPR Poster Your ViT is Secretly an Image Segmentation Model
LViT: A Lightweight ViT for Stroke Lesion Segmentation | Springer ...
[논문 리뷰] Applying ViT in Generalized Few-shot Semantic Segmentation
Your ViT is Secretly an Image Segmentation Model - Visual Computing ...
(PDF) Your ViT is Secretly an Image Segmentation Model
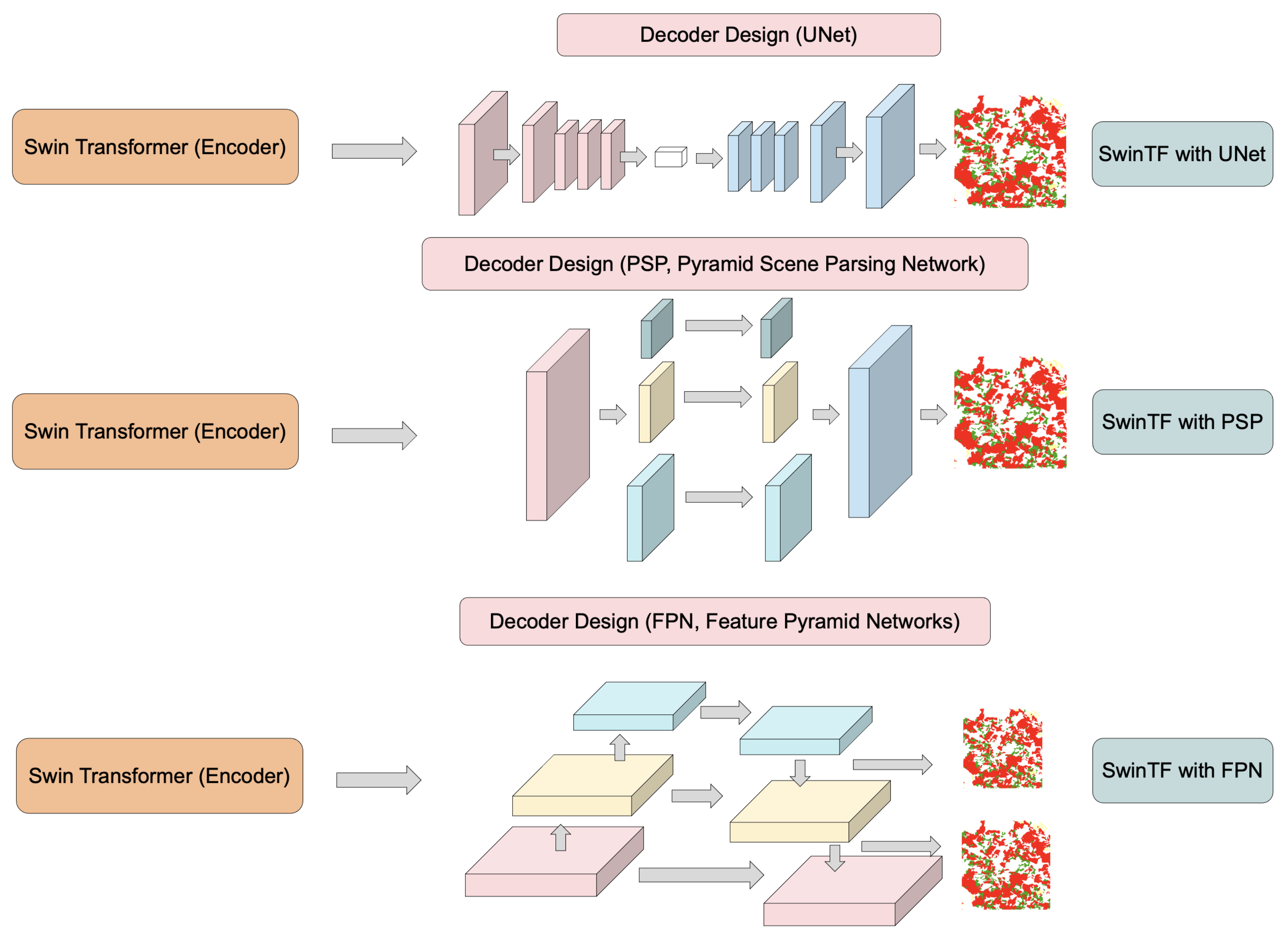
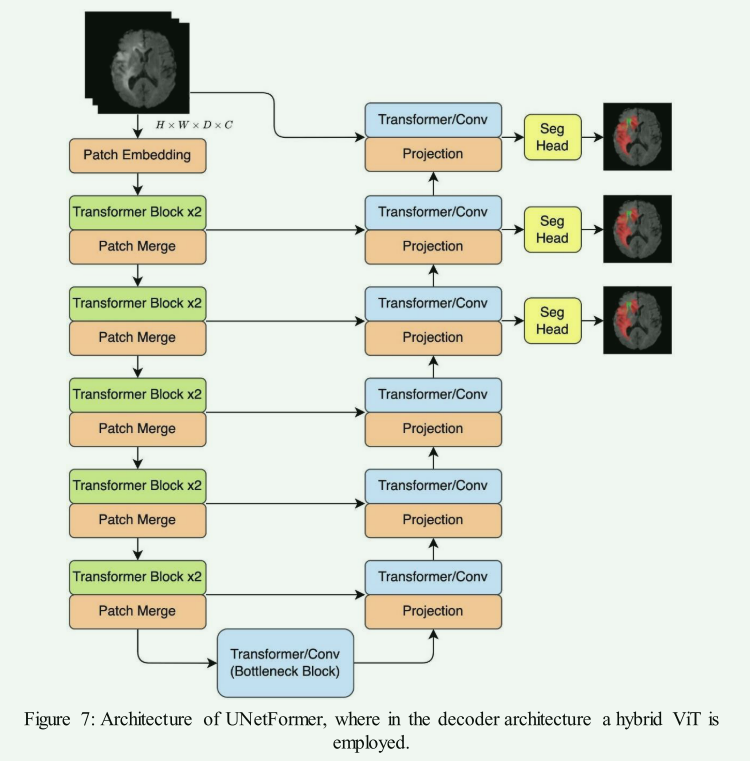
Transformer-Based Decoder Designs for Semantic Segmentation on Remotely ...
Examples of ViT applications in medical image segmentation | Download ...
ViT for segmentation - vision - PyTorch Forums
Pipeline for Segmentation with MAE Self Pre-training. In the first ...
computer vision transformers: ViT does not have a decoder? - Data ...
Segmenter architecture adapted from [11]. It basically has a ViT ...
(PDF) A Recent Survey of Vision Transformers for Medical Image Segmentation
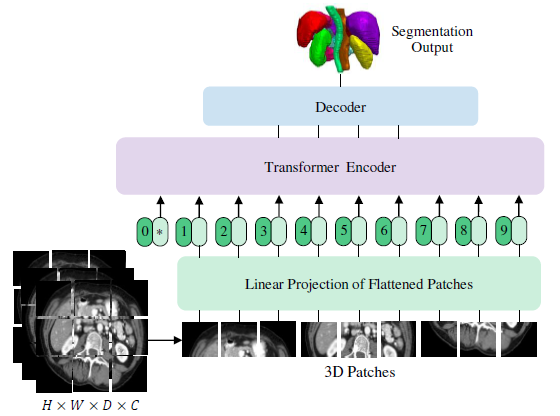
Overview of the proposed encoder-decoder architecture using a ViT ...
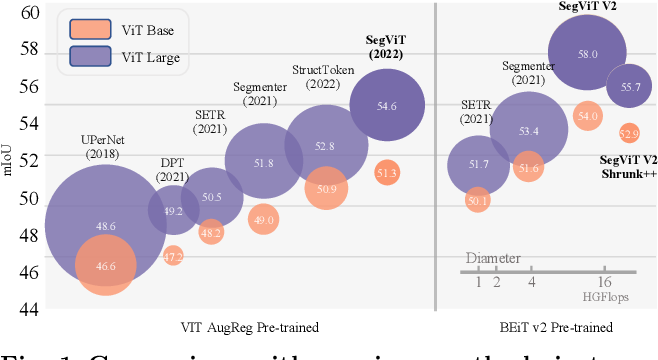
SegViTv2: Exploring Efficient and Continual Semantic Segmentation with ...
The encoder and decoder configurations. ViT-series refers to three ...
Transformer(三)ViT decoder - 知乎
(PDF) GIVTED-Net: GhostNet-Mobile Involution ViT Encoder-Decoder ...
[2406.09167] Vision Transformer Segmentation for Visual Bird Sound ...
What Is Encoder Decoder Model at Qiana Flowers blog
Image Segmentation Using Vision Transformers (ViT): A Deep Dive with ...
Review — UNETR: Transformers for 3D Medical Image Segmentation | by Sik ...
(PDF) A Novel Encoder Decoder Architecture with Vision Transformer for ...
ViT Model explanation and example how to appied | PDF
Vision Transformer for semantic segmentation on medical images ...
Segmentation of a road scene image using convolutional encoder-decoder ...
Segmentation results of ViT-based UNETR (left 3D images in first column ...
Distance Matters: A Distance-Aware Medical Image Segmentation Algorithm
The ViT Encoder Architecture | Download Scientific Diagram
Mobile U-ViT: Revisiting large kernel and U-shaped ViT for efficient ...
Vision transformers (ViT) - segmentation - a Kalray Collection
Semantic Segmentation with Vision Transformer - YouTube
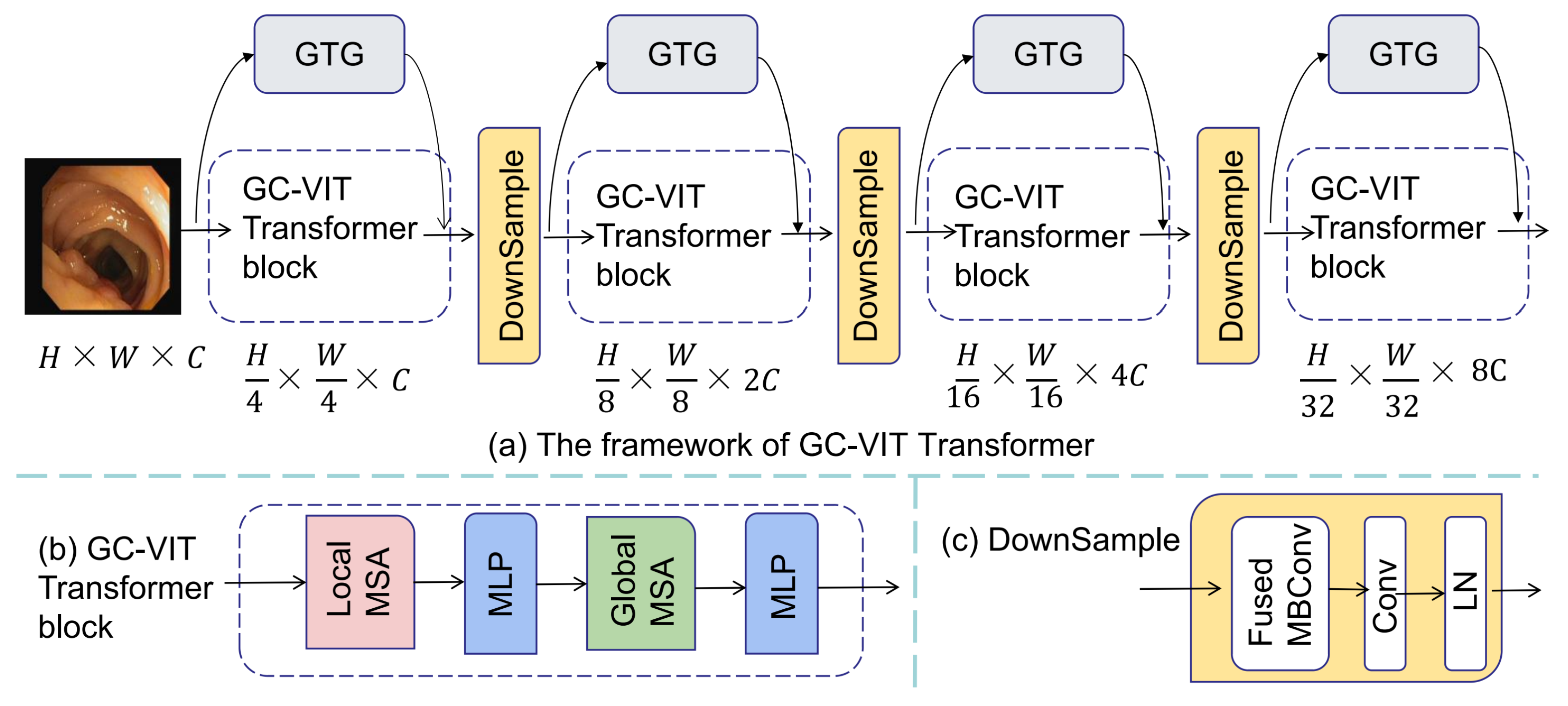
Multi-Beam Sonar Target Segmentation Algorithm Based on BS-Unet
(PDF) A Foundation Model for Cell Segmentation
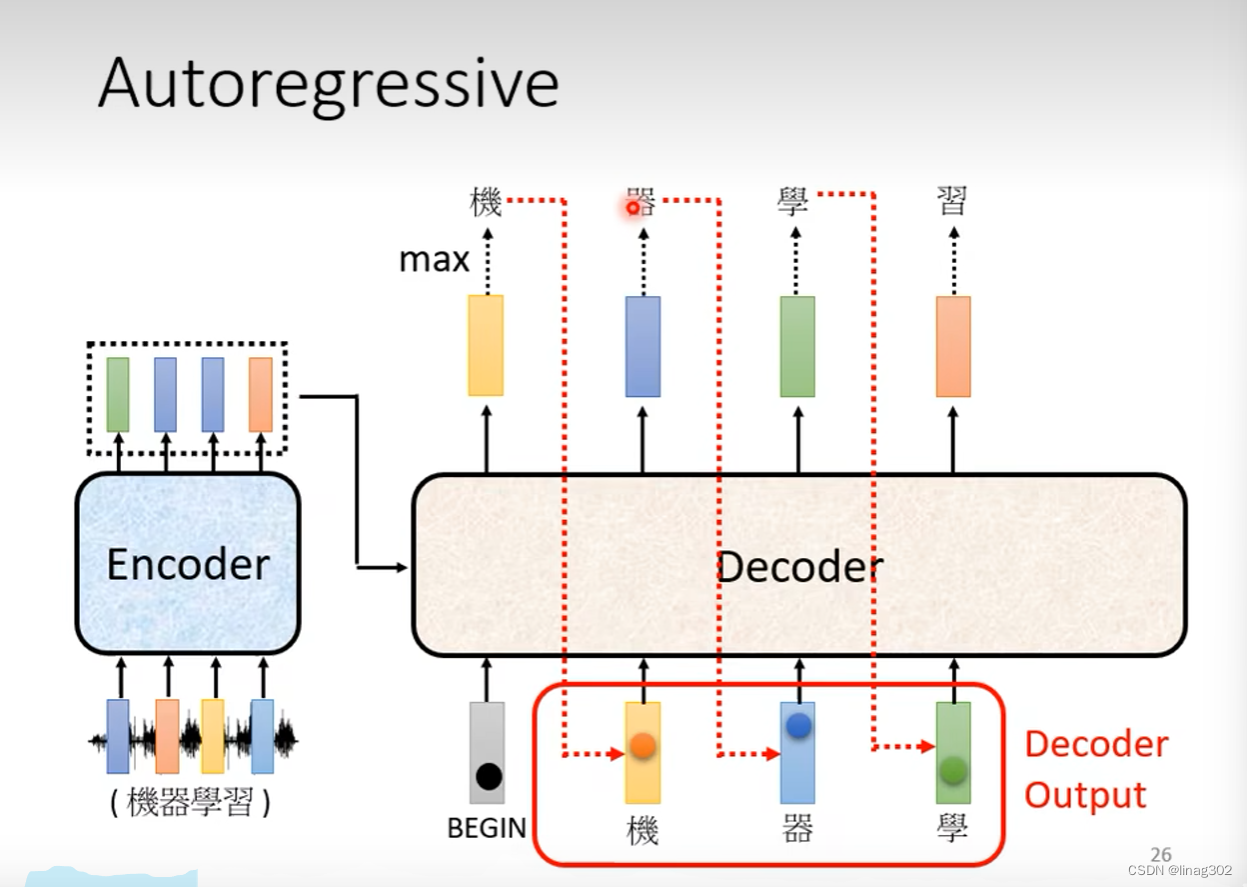
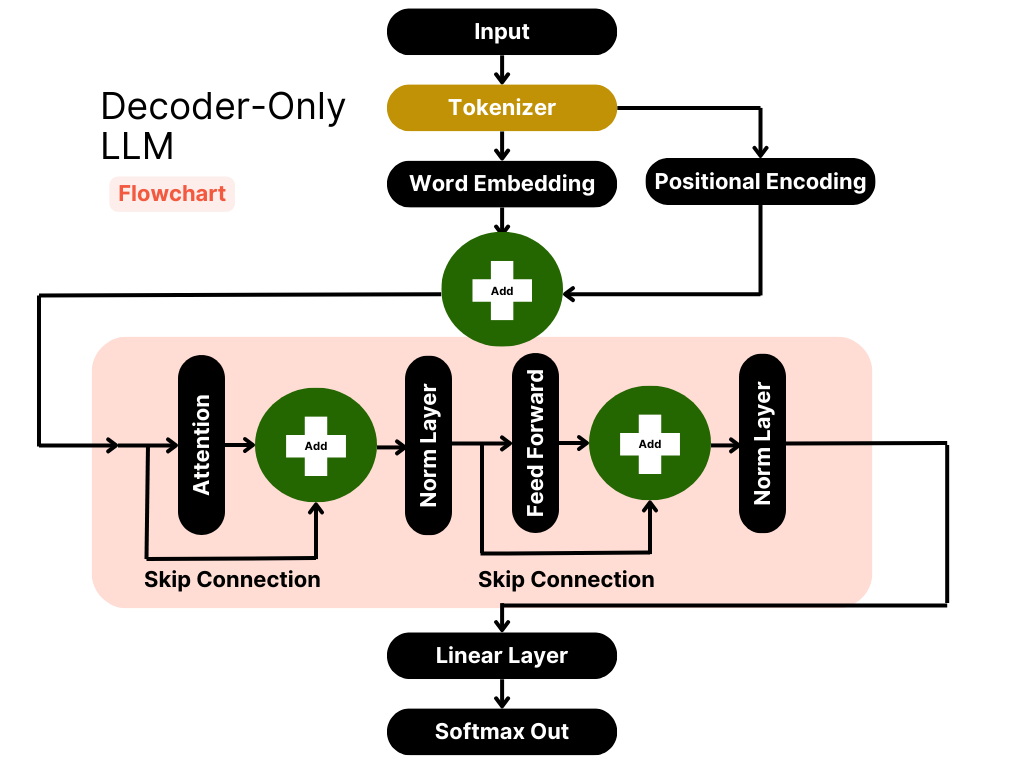
LLM(5) | Encoder 和 Decoder 架构_encoder+projector+llm架构-CSDN博客
Bcd 7 segment decoder datasheet - Everything you need to know
Deep ViT Features as Dense Visual Descriptors
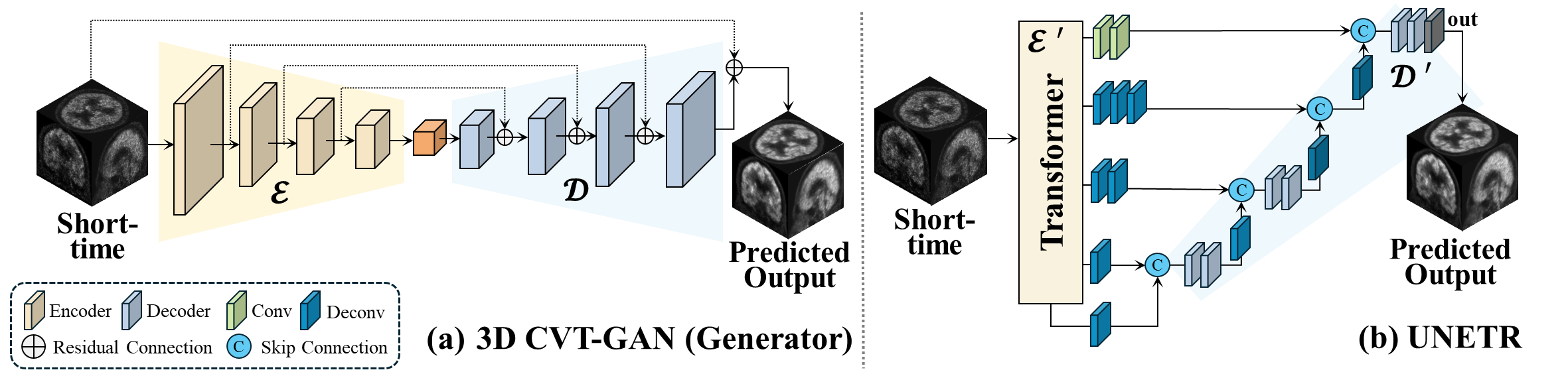
Architecture of ViT-based UNETR directly connected to a CNN-based ...
[Segmentation] 05. swin (+ ViT)
MResTNet: A Multi-Resolution Transformer Framework with CNN Extensions ...
【论文阅读笔记】A Recent Survey of Vision Transformers for Medical Image ...
The architecture of the ViT-based encoder and decoder, where both ...
MCV-UNet: a modified convolution & transformer hybrid encoder-decoder ...
The framework of the proposed NR-UNet. (a) The U-shaped encoder-decoder ...
Introduction to Vision Transformers (ViT) - Analytics Vidhya
Convolutional Neural Networks for Computer Vision - ppt download
Transformer(四)ViT and SimpleViT - 知乎
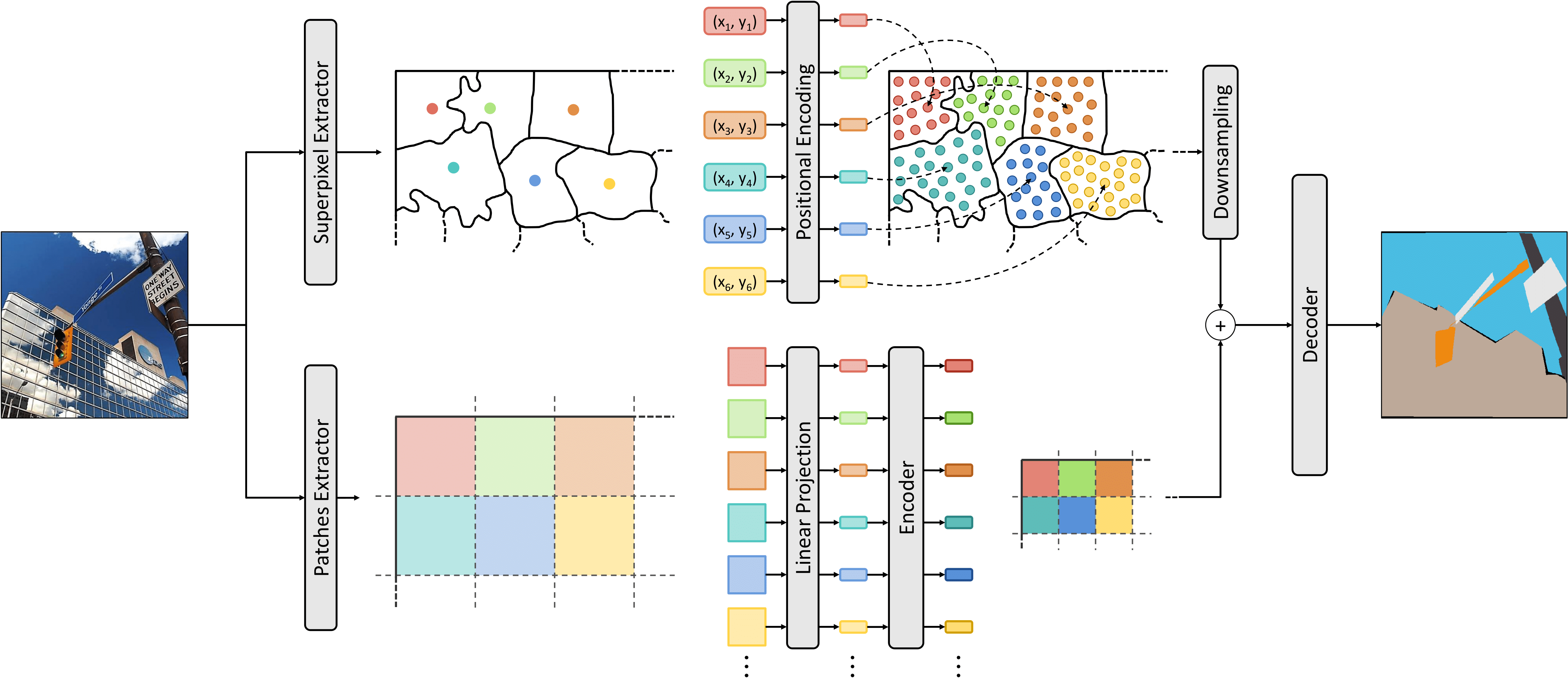
Superpixel Positional Encoding to Improve ViT-based Semantic ...
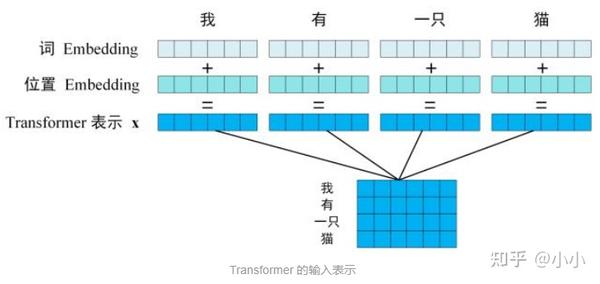
一文搞懂 ViT(Vision Transformer)-CSDN博客
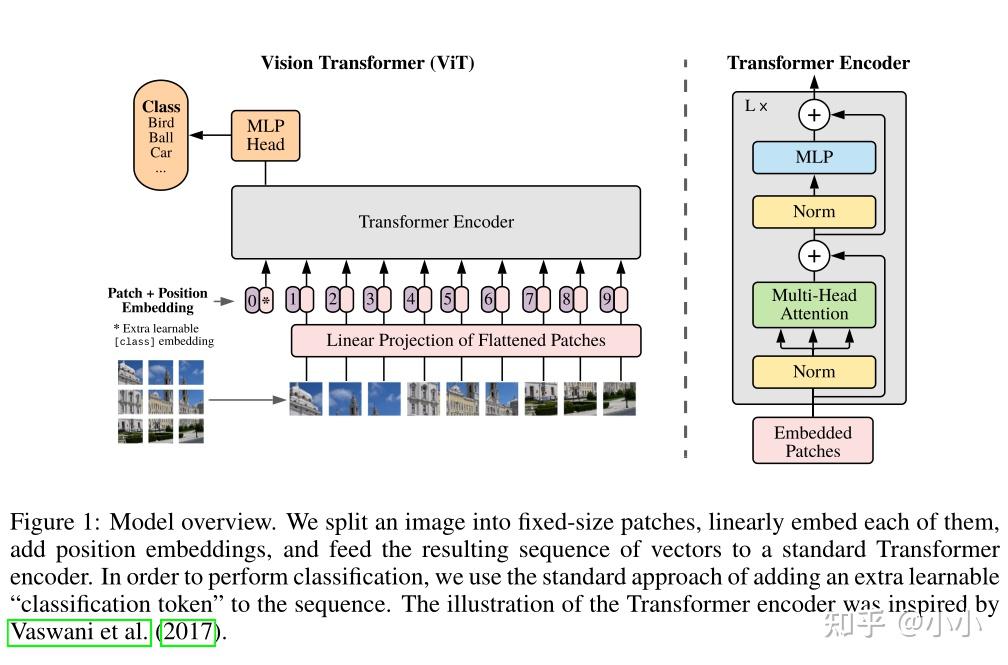
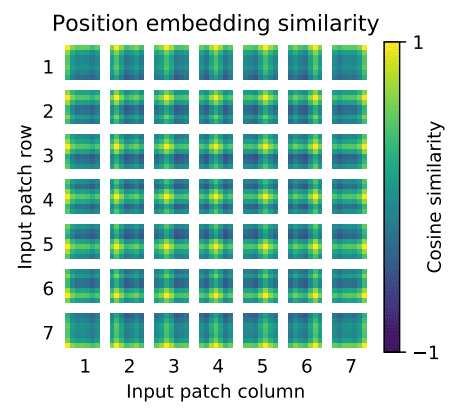
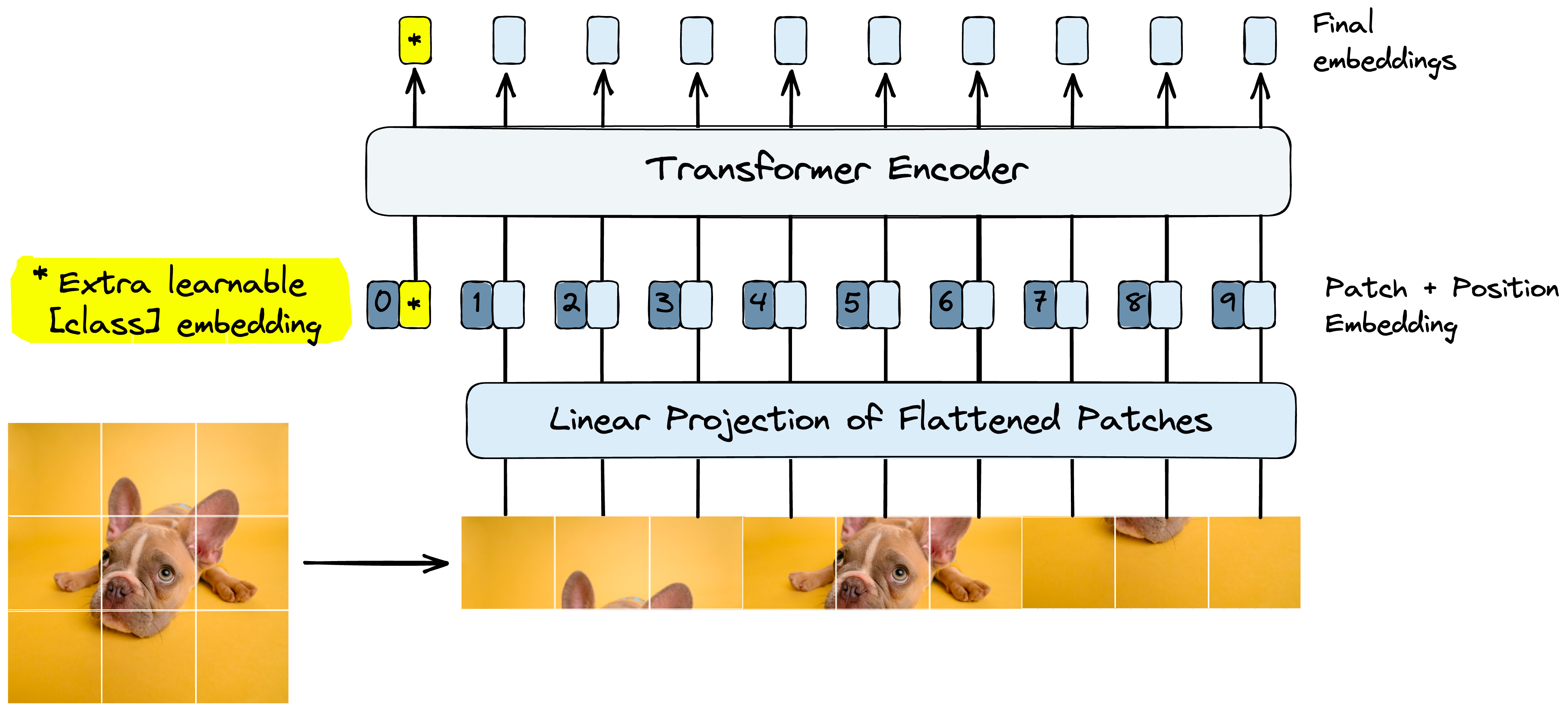
Detail architecture of ViT. Input image is at first divided into ...
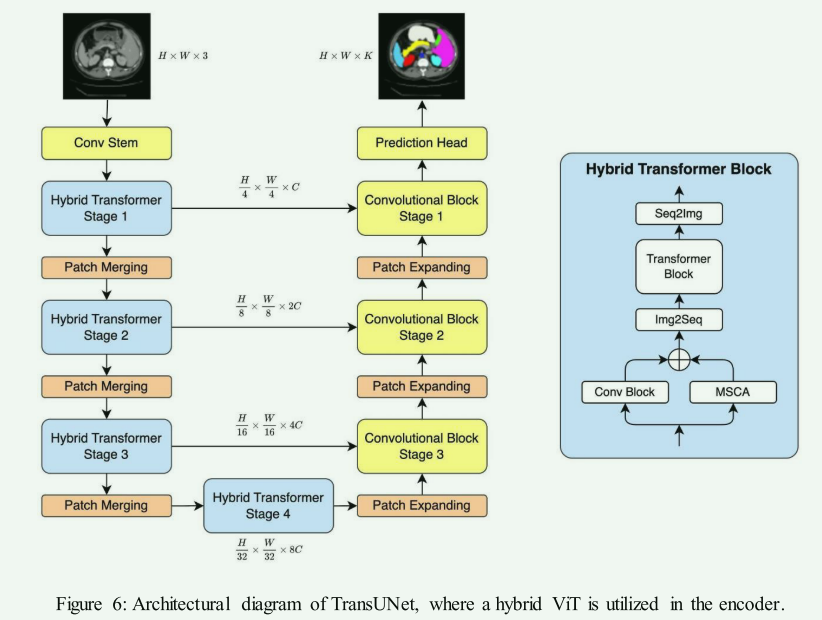
Overview of the TransUNet for medical image segmentation. (a) Schematic ...
Full article: Large multimodal model for open vocabulary semantic ...
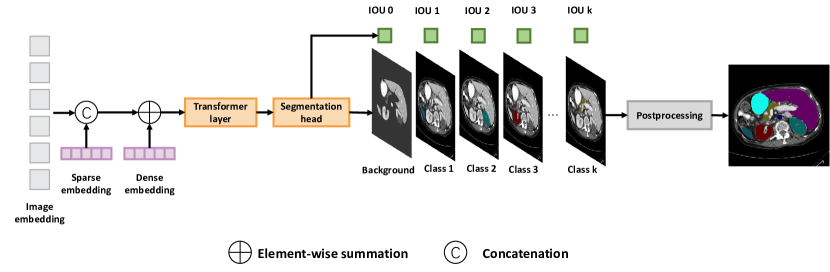
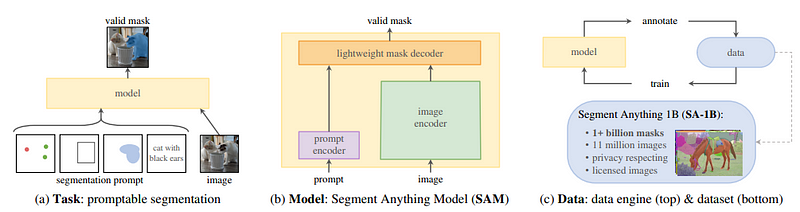
Architecture of Segment-Anything Model SAM consists of three core ...
MICV
ViT解读_vit decoder-CSDN博客
Frontiers | Leveraging advanced feature extraction for improved kidney ...
Applications of Decoders - GeeksforGeeks
vit.._vit多头注意力机制-CSDN博客
Vision Transformer Image Classification | MindSpore 2.4.0 Tutorials ...
How is a Vision Transformer (ViT) model built and implemented? | PDF
GitHub - siyttyis/VIT-Transformer-decoder: 视觉Transformer+Transformer ...
When RNN Meets CNN and ViT: The Development of a Hybrid U-Net for ...
Paper page - I-Segmenter: Integer-Only Vision Transformer for Efficient ...
Vision Transformer (ViT)初识:原理详解及代码_vit encoder和block-CSDN博客
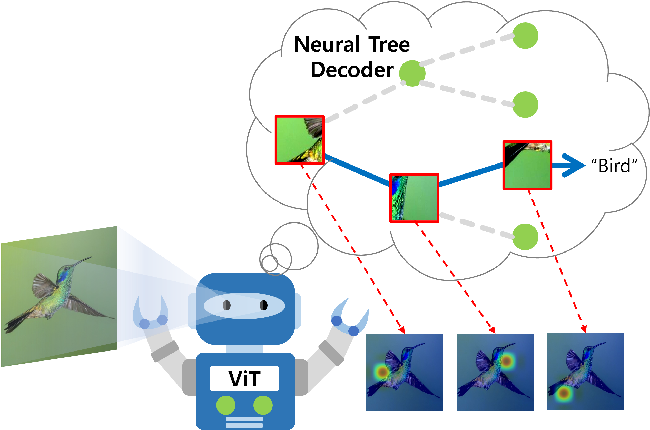
Figure 1 from ViT-NeT: Interpretable Vision Transformers with Neural ...
[2304.13785] Customized Segment Anything Model for Medical Image ...
SAM for Medical Imaging - PYCAD - Your Medical Imaging Partner
An Enhanced Encoder-Decoder Network Architecture for Reducing ...
I-Segmenter: Integer-Only Vision Transformer for Efficient Semantic ...
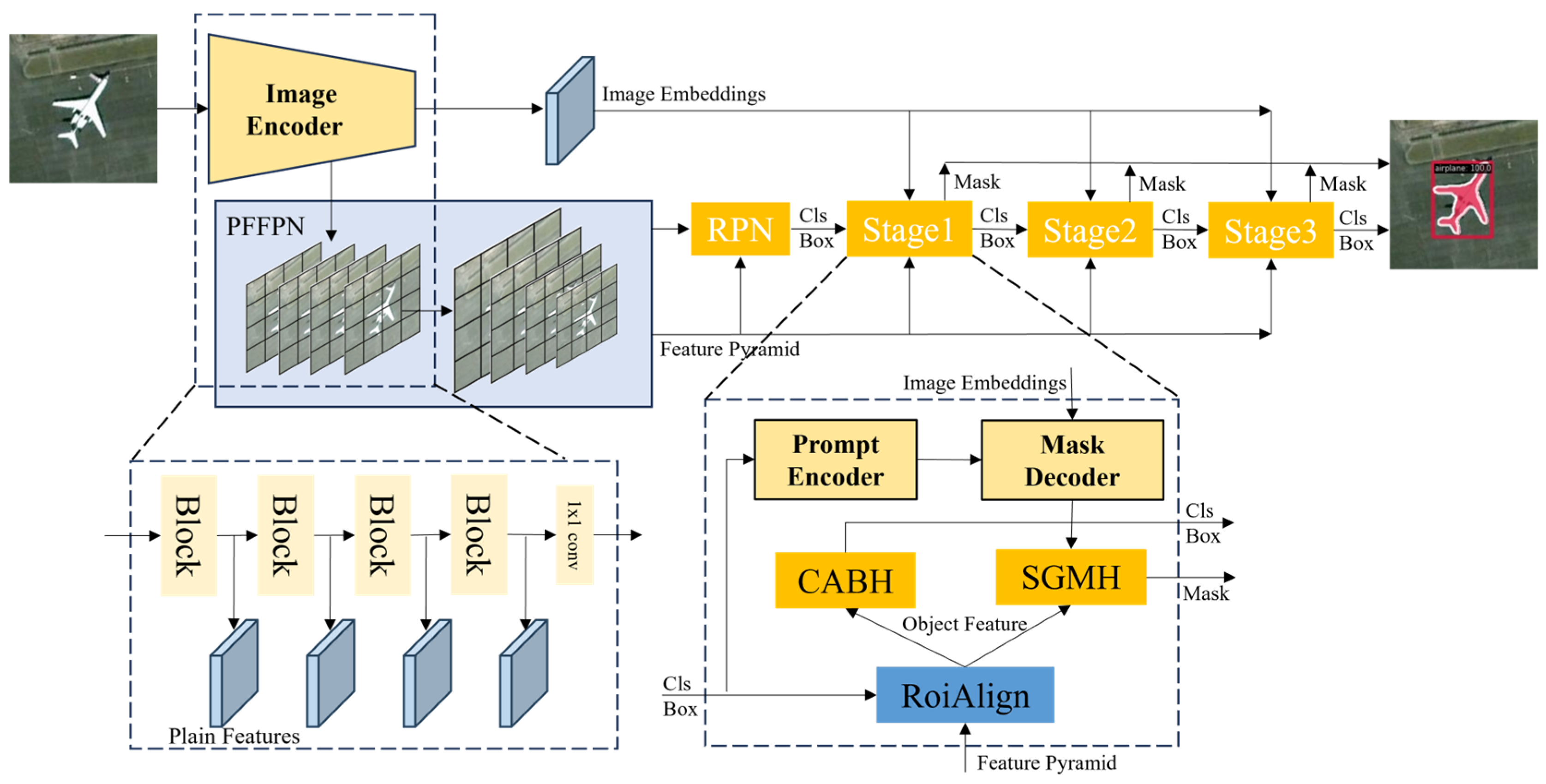
Context-Aggregated and SAM-Guided Network for ViT-Based Instance ...
Overview of the proposed ViT-DAE framework. Training: In Stage-1, an ...
Vision-Transformer-Segmentation/hubmap-pytorch-vit-segmentation ...
全网最强ViT (Vision Transformer)原理及代码解析 - 知乎
yuanzhoulvpi/vit-gpt2-image-chinese-captioning · Hugging Face
How the Vision Transformer (ViT) works in 10 minutes: an image is worth ...
Implementing Google/ViT-Base-Patch16–224 for Image Analysis | by Joshua ...
Lec 7 Trans (Decoder) +ViT | PDF | Algorithms | Learning
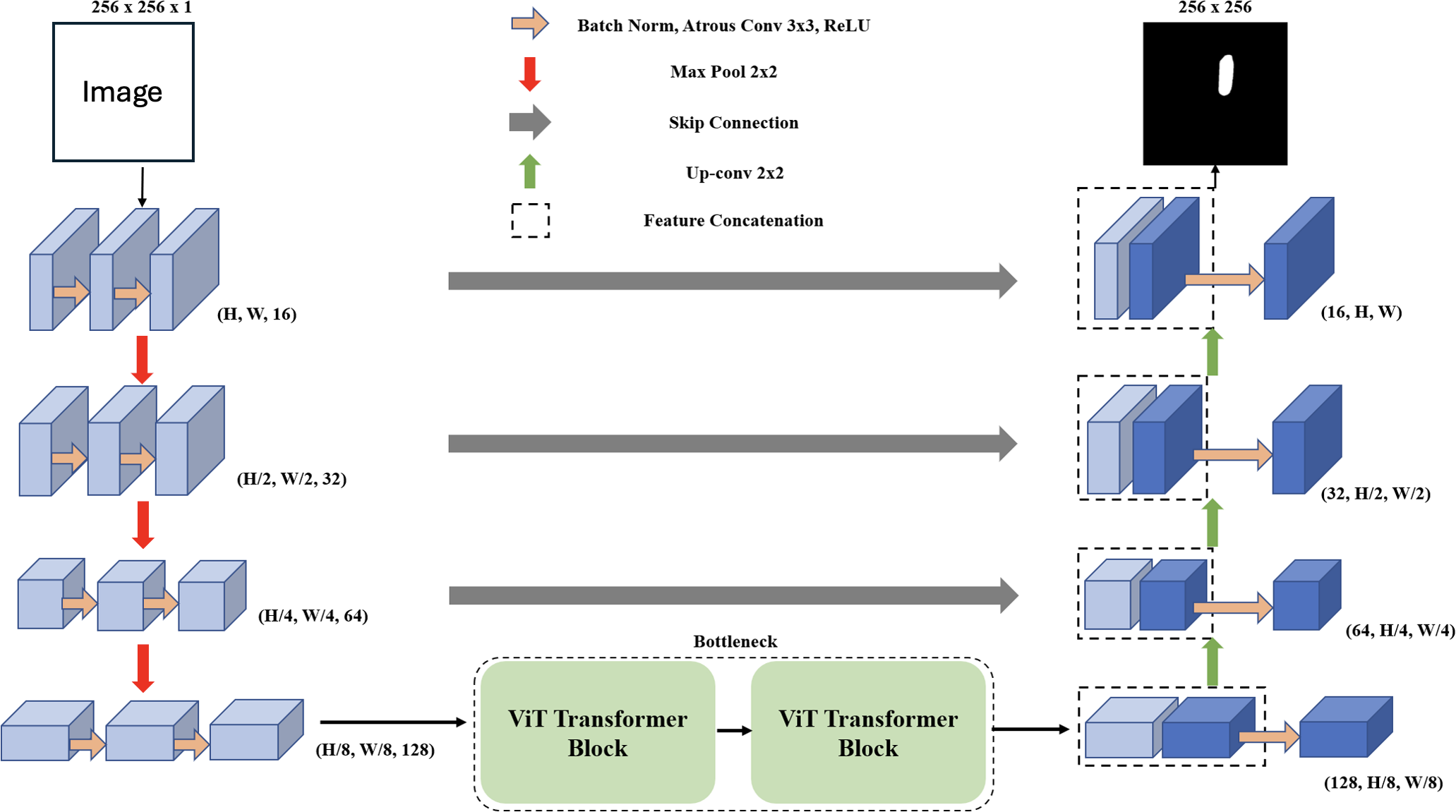
The proposed encoder-decoder model to segment the patch images consists ...
Vision Transformers (ViT) Explained | Pinecone