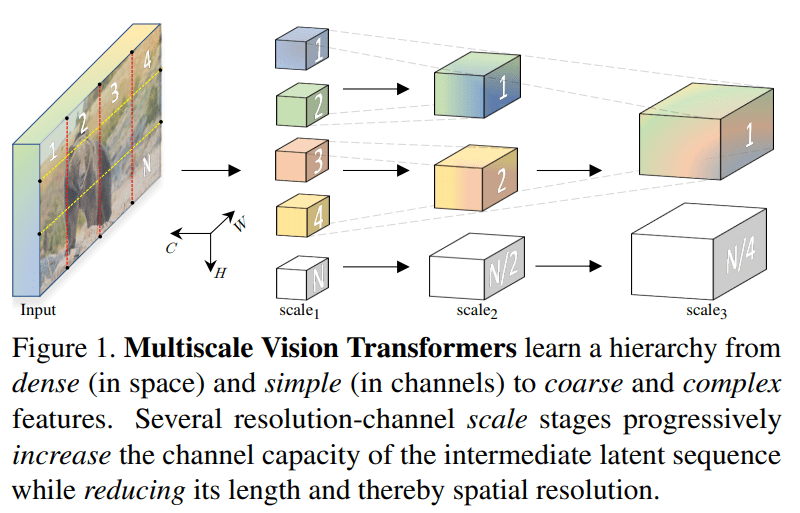
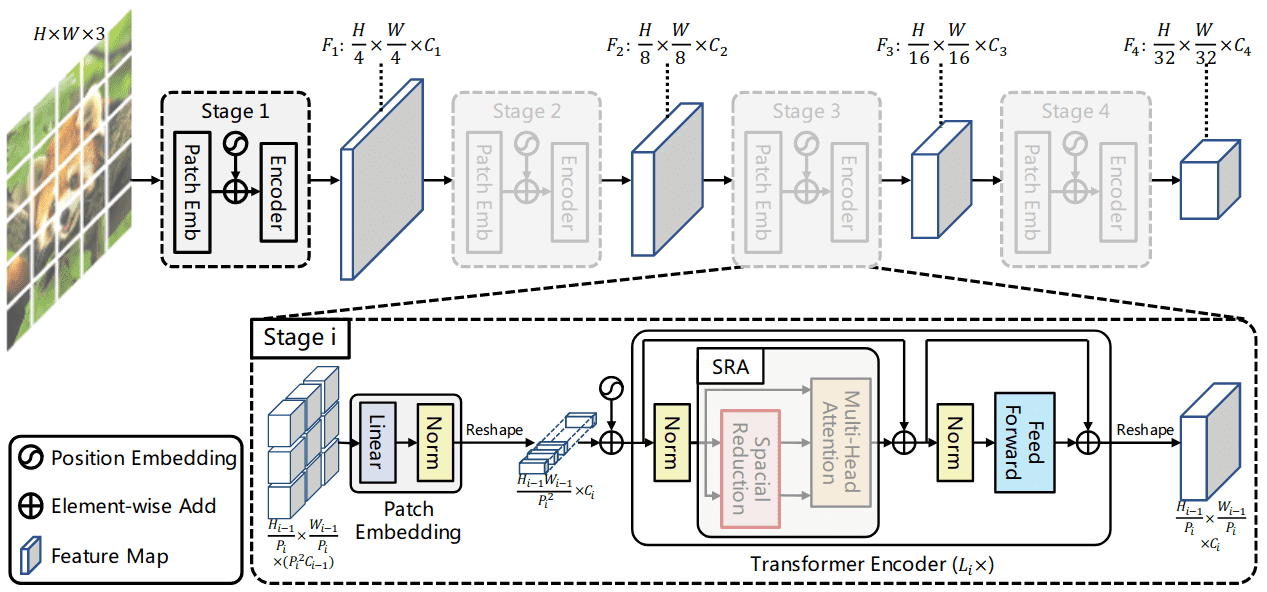
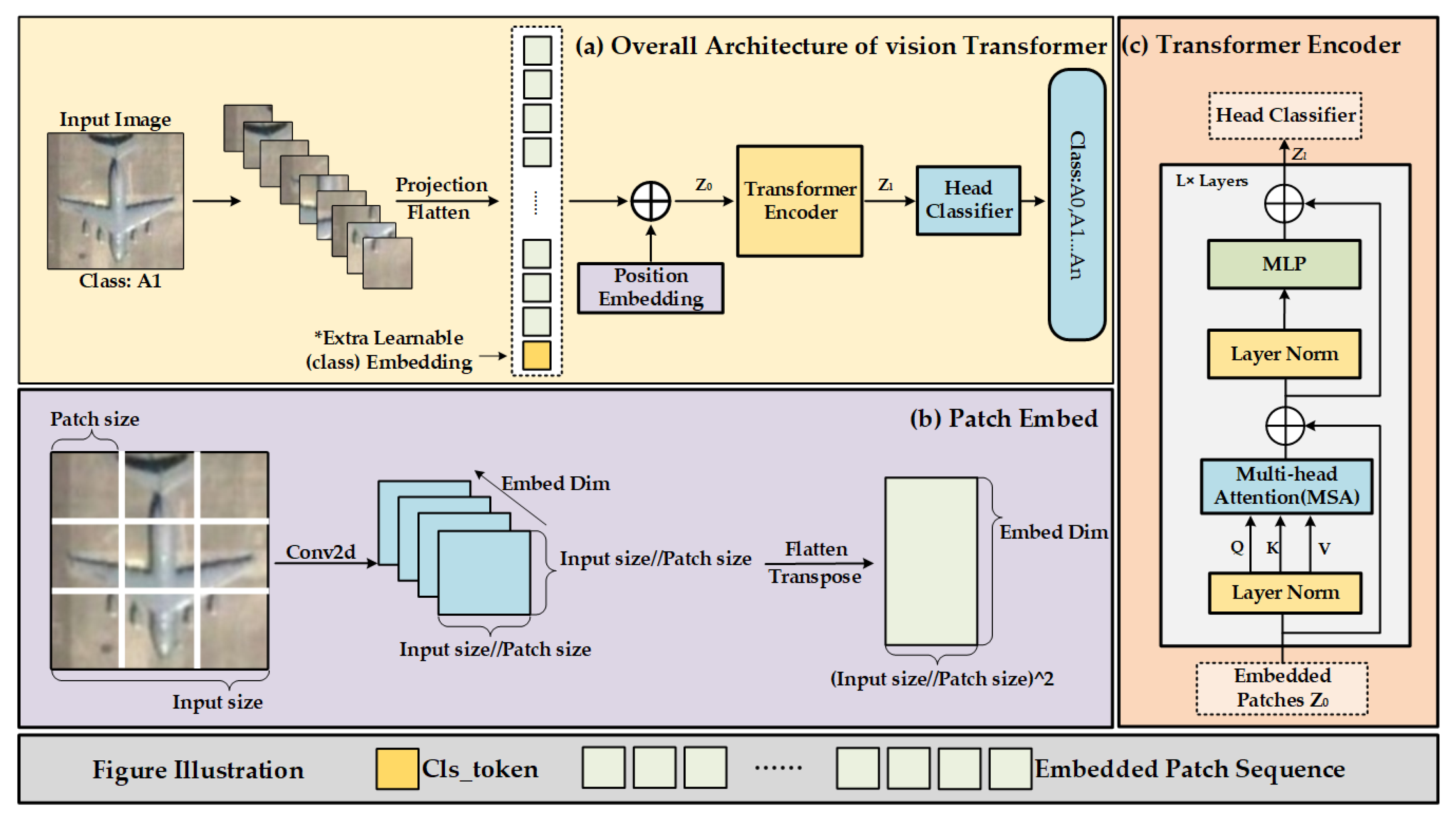
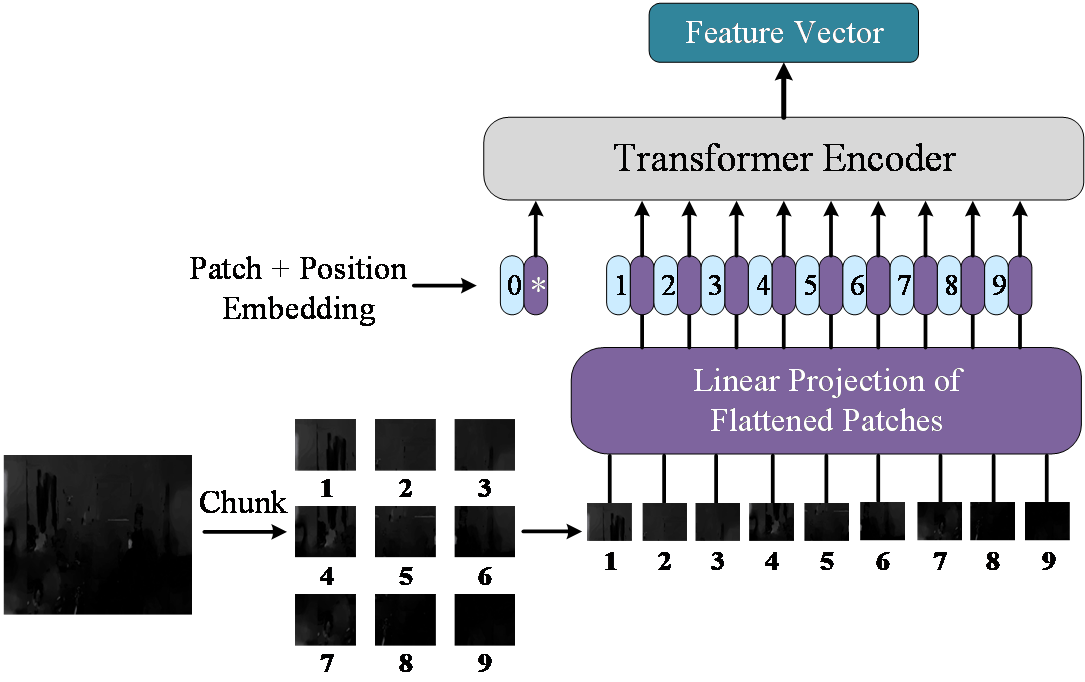
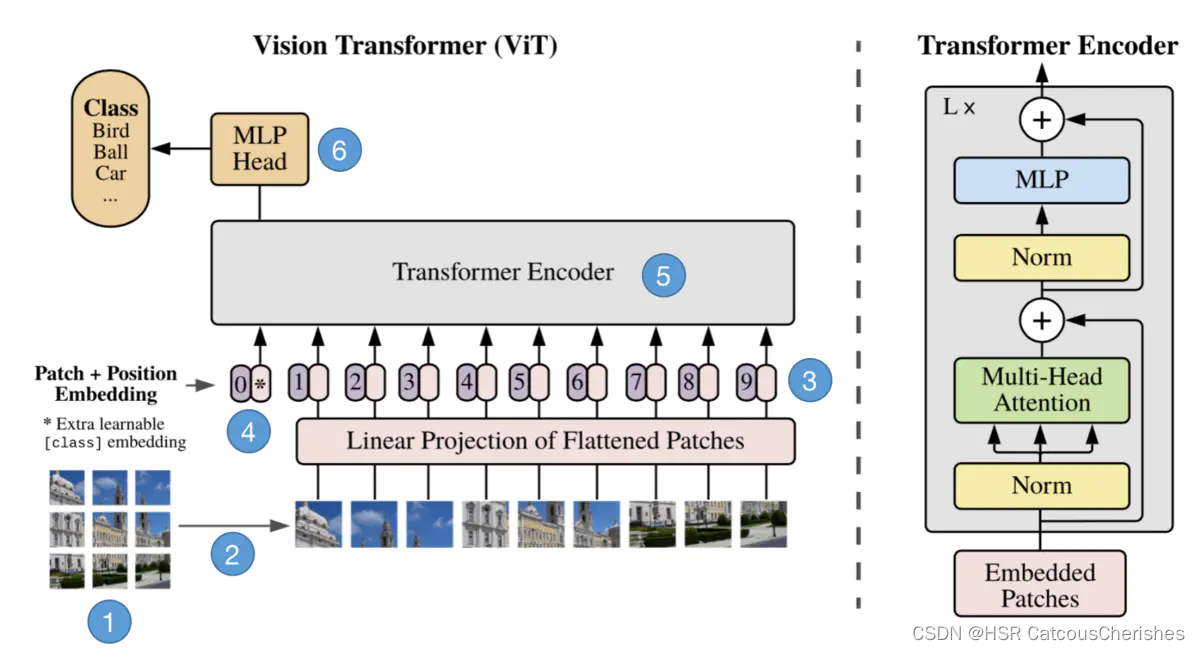
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
A Hybrid Model of Feature Extraction and Dimensionality Reduction Using ...
Getting Started with ViT Image Feature Model Using DINOv2 fxis.ai
The ViT model extracts image feature process | Download Scientific Diagram
Proposed architecture of ViT for feature extraction. | Download ...
[2302.00875] Vision Transformer-based Feature Extraction for ...
Deep learning image classification strategy. (a) ViT model architecture ...
An Enhanced Feature Extraction Framework for Cross-Modal Image–Text ...
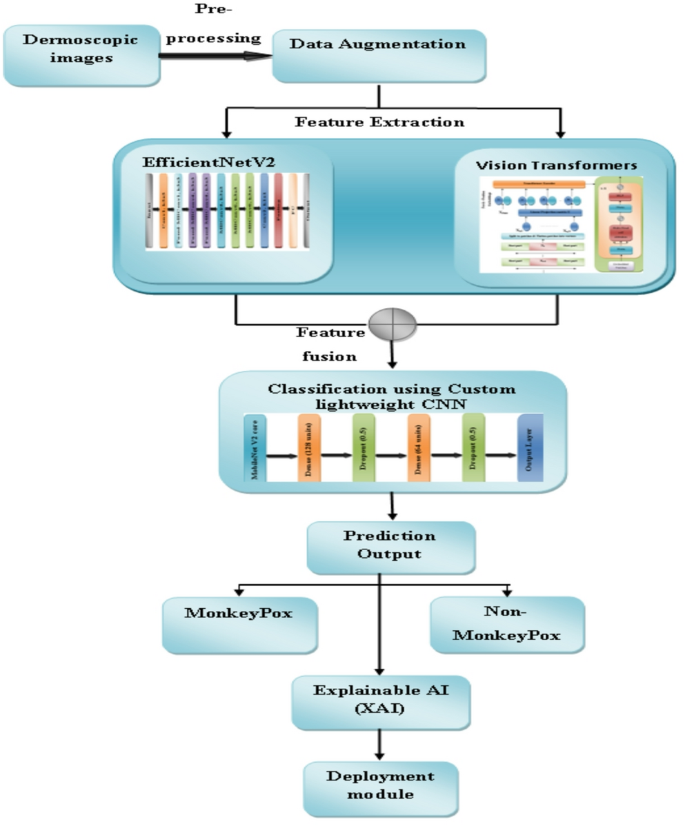
Hybrid EfficientNetV2–ViT feature extraction with lightweight CNN for ...
The overall architecture of the “VTA + HBE” model. The model uses a ViT ...
The illustration of vision Transformer for feature extraction module ...
Architecture of the proposed feature extraction backbone. The backbone ...
ViT model and transformer encoder [34] | Download Scientific Diagram
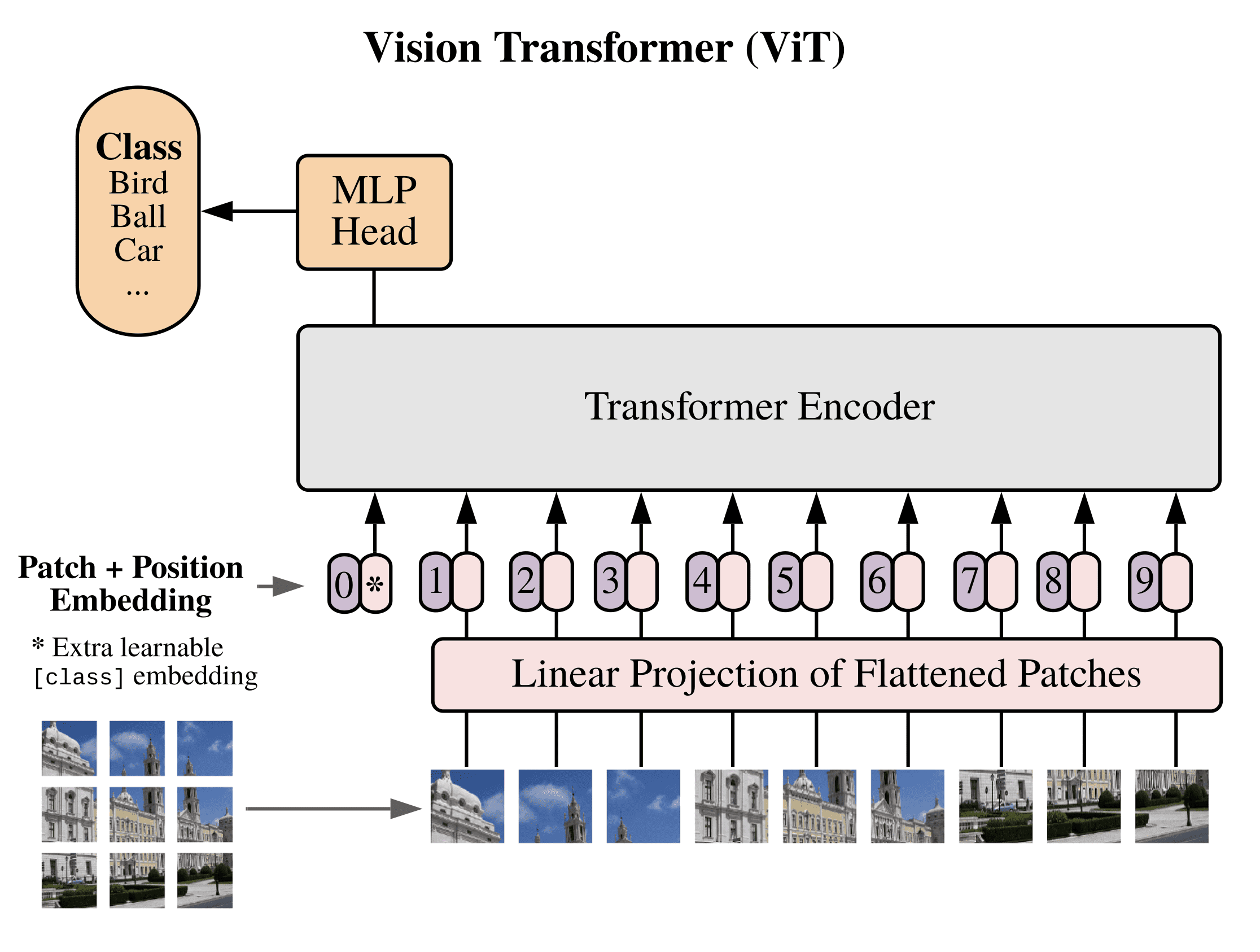
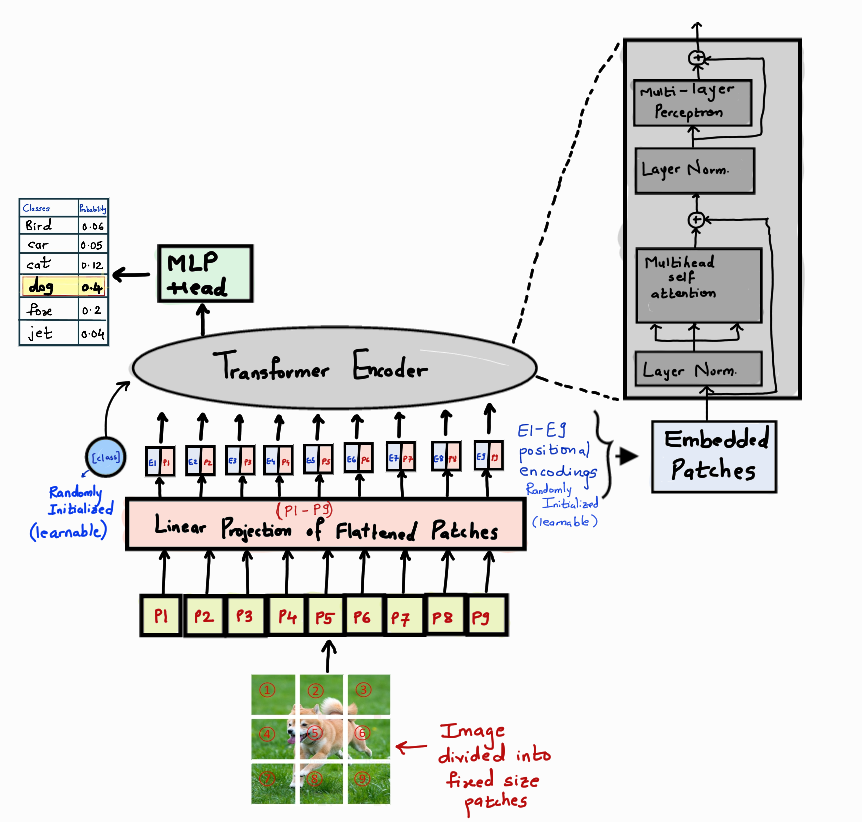
Vision Transformer (ViT) model architecture. ViT breaks the image into ...
The t-SNE visualization results of feature extraction via deep learning ...
Vision Transformers (ViTs) for Feature Extraction and Classification of ...
Issue with Inference API for ViT Model - "image-feature-extraction ...
PPT - leewayhertz.com-HOW IS A VISION TRANSFORMER MODEL ViT BUILT AND ...
ViT model structure diagram. | Download Scientific Diagram
ASK-ViT: A Model with Improved ViT Robustness through Incorporating SK ...
(PDF) A Deep Features Extraction Model Based on the Transfer Learning ...
Multi-Scale and Multi-Factor ViT Attention Model for Classification and ...
ViTs as backbones: Leveraging vision transformers for feature extraction
Build Your Own ViT Model from Scratch
Expression-relevant vision transformer (ViT)-latent vector extraction ...
Conv-ViT: A Convolution and Vision Transformer-Based Hybrid Feature ...
The working principle diagram of the multimodal Transformer feature ...
The Pre-Trained ViT Model. | Download Scientific Diagram
The Vision Transformer Model - MachineLearningMastery.com
Frontiers | Attention-enhanced hybrid deep learning model for robust ...
Compact DINO-ViT: Feature Reduction for Visual Transformer
DINO samples. Visualization of the attention matrix of ViT heads ...
How is a Vision Transformer (ViT) model built and implemented? | PDF
An Explainable Vision Transformer Model Based White Blood Cells ...
Comparison of ViT and MG-ViT classification points of interest. Among ...
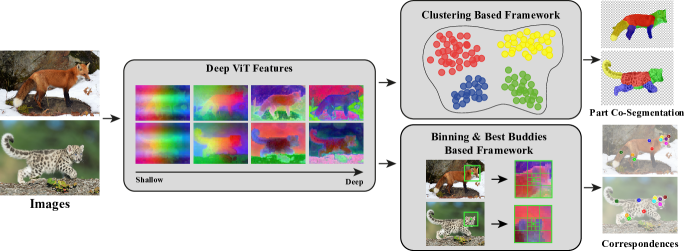
[2112.05814] Deep ViT Features as Dense Visual Descriptors
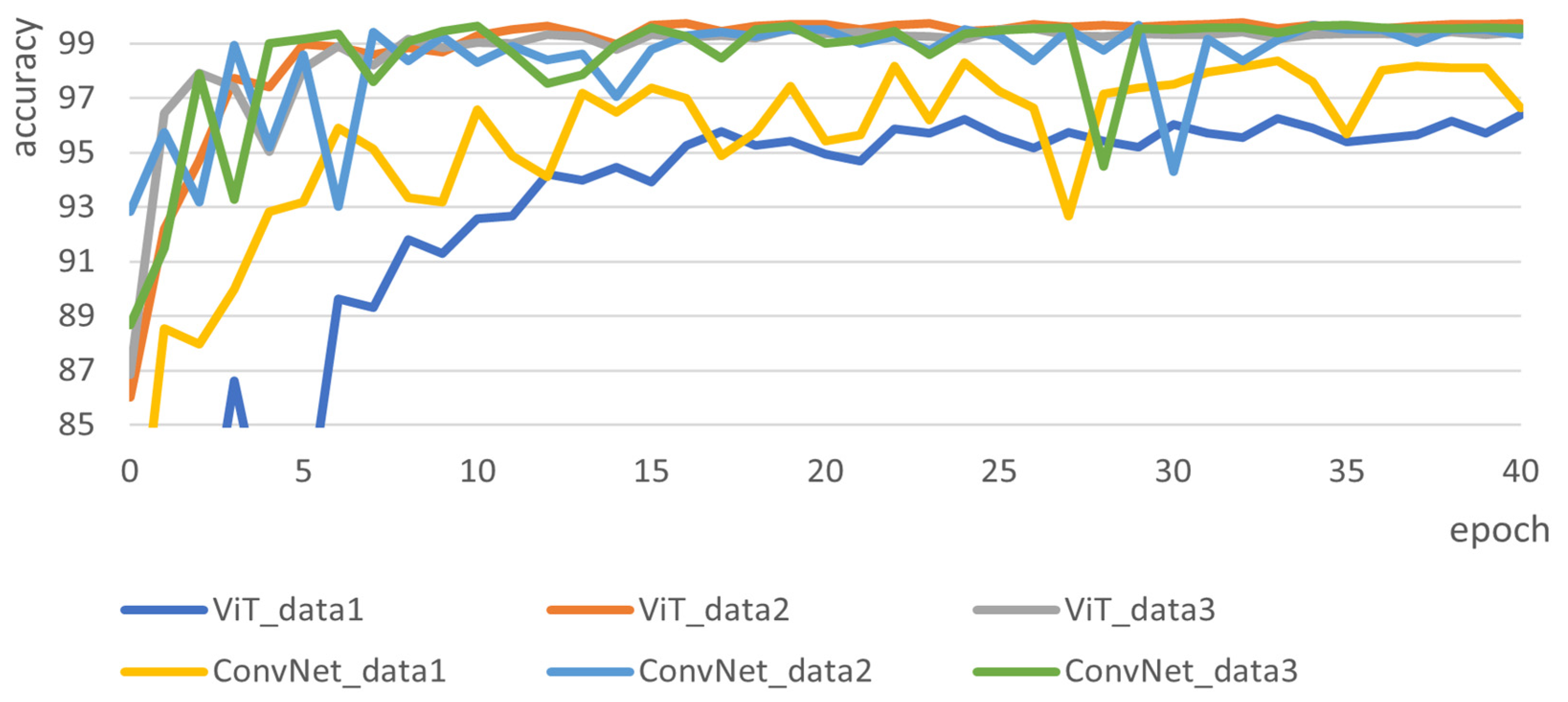
A Performance Comparison of Japanese Sign Language Recognition with ViT ...
Transformers in computer vision: ViT architectures, tips, tricks and ...
The pipeline of FORMULA. To enhance ViT features for unsupervised ...
Model structure of a VIT. | Download Scientific Diagram
P2FEViT: Plug-and-Play CNN Feature Embedded Hybrid Vision Transformer ...
(PDF) ViT-Core: Lightweight Anomaly Detection Model using Transformer ...
How is a Vision Transformer (ViT) model built and implemented? : r ...
How is a Vision Transformer (ViT) model built and implemented?
A Malware Detection and Extraction Method for the Related Information ...
(PDF) A Novel Transformer Model with Multiple Instance Learning for ...
ViT | Vision Transformer | Vision Transformer (ViT) Architecture ...
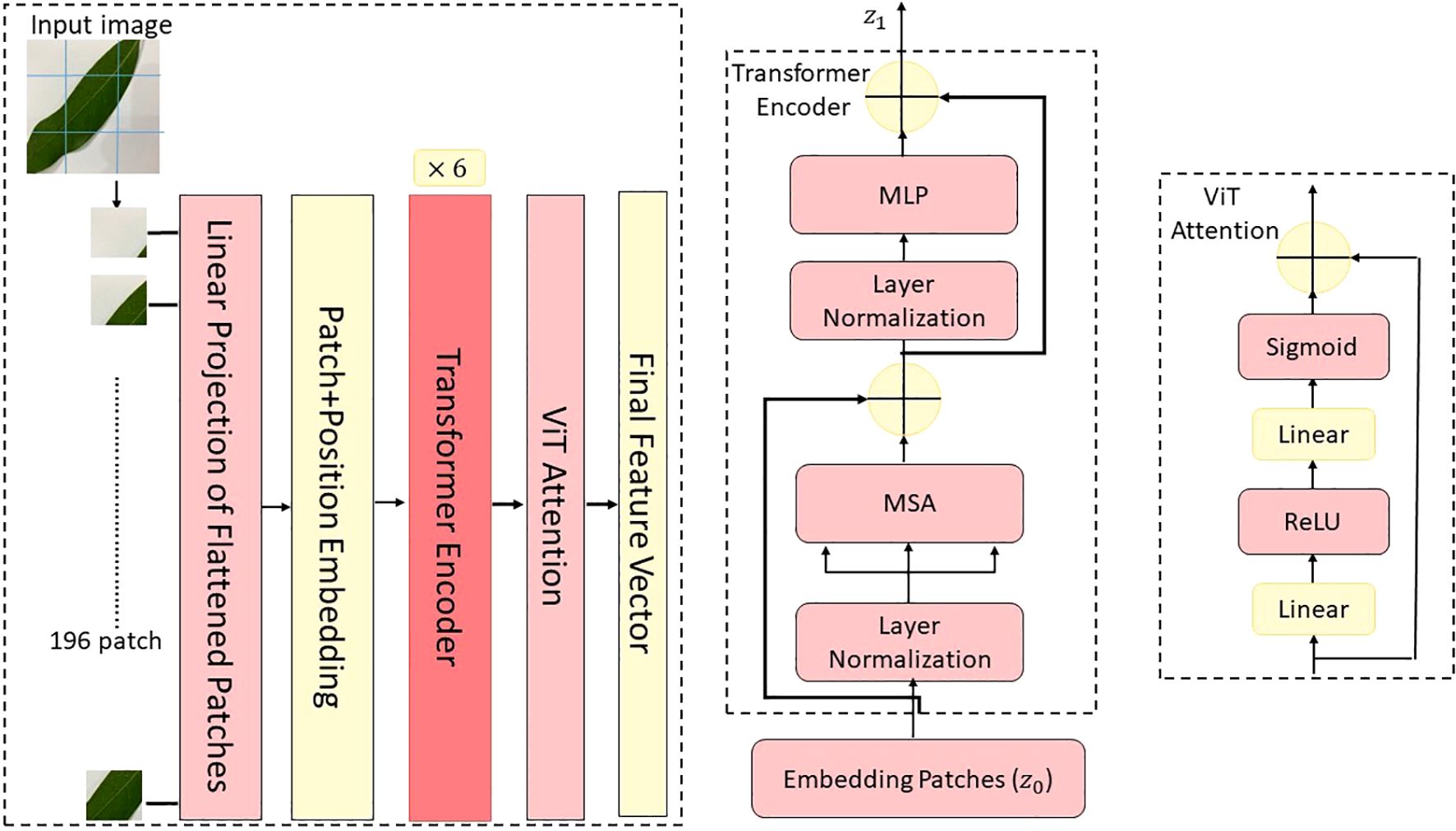
The illustration of the proposed ViT architecture. (a) The main ...
CNN Attention Enhanced ViT Network for Occluded Person Re-Identification
Overview of the proposed n-CNN-ViT architecture. The model is composed ...
(PDF) Efficient Scopeformer: Towards Scalable and Rich Feature ...
Advanced Chest X-Ray Analysis via Transformer-Based Image Descriptors ...
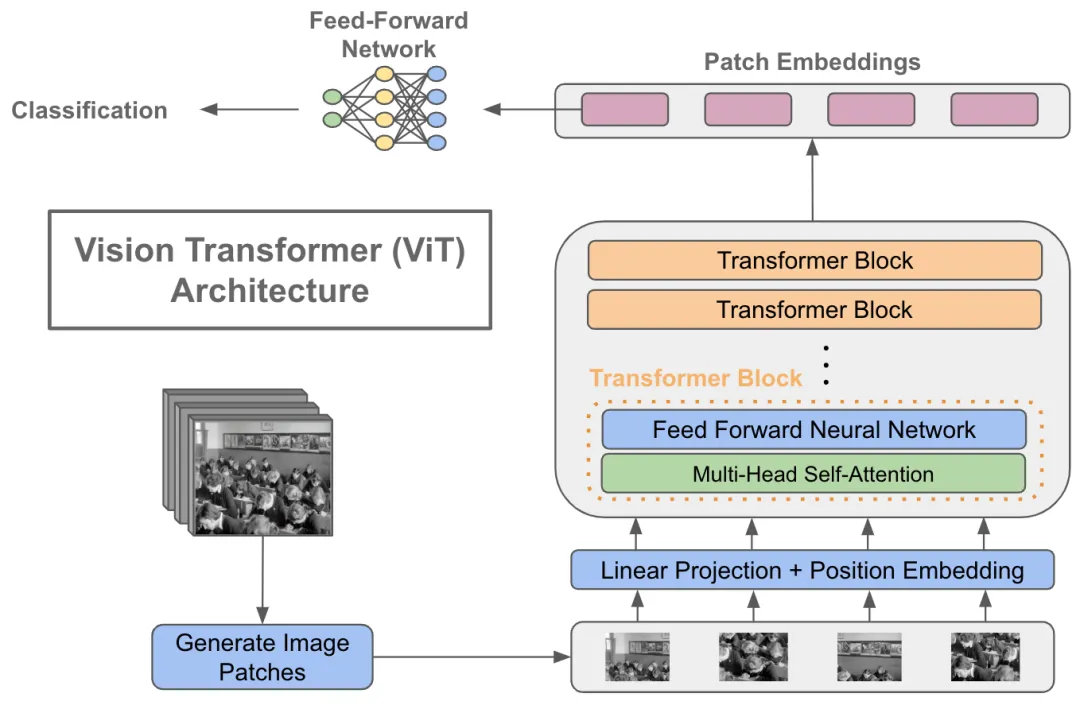
Vision Transformer (ViT) Architecture - GeeksforGeeks
Illustration of our contribution. In short, we propose a ViT-based ...
Vision Transformer:视觉Transformer对CNN的降维打击
Transformer(四)ViT and SimpleViT - 知乎
(PDF) Computer Vision Methods for the Microstructural Analysis of ...
GitHub - jeslinpjames/ViT-Video-Feature-Extraction
(PDF) Conv-ViT: A Convolution and Vision Transformer-Based Hybrid ...
Vision Transformer Model: Architecture, development and applications
(PDF) CONV-VIT: A CONVOLUTION AND VISION TRANSFORMER BASED HYBRID ...
Vision Transformers (ViT) Explained | Pinecone
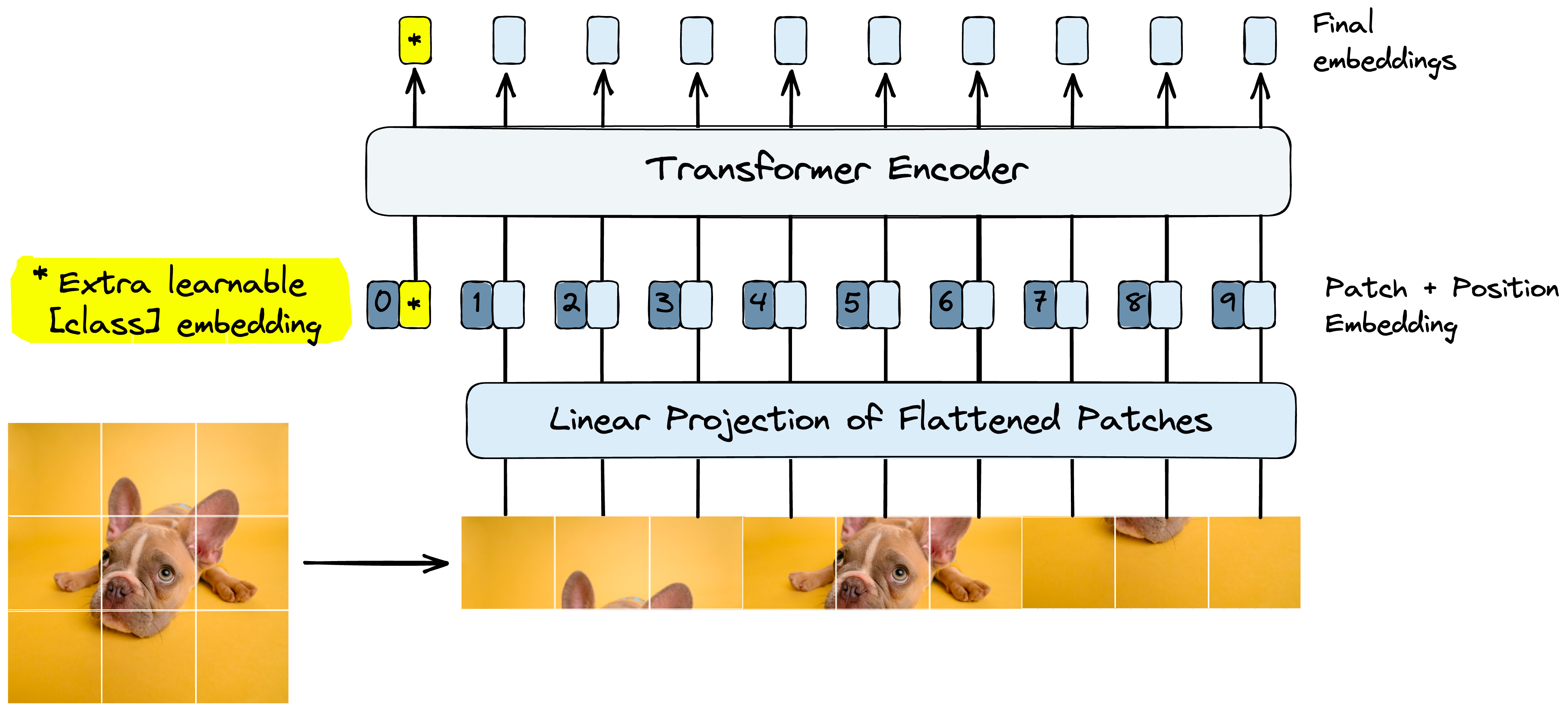
Vision Transformer (ViT) Notes | Wenwen Kong
Example of an architecture of the ViT, based on [1]. | Download ...
Vision Transformers, Explained | Towards Data Science
Vision Transformer: A New Era in Image Recognition
Vision Transformer: What It Is & How It Works [2024 Guide]
ViT: Vision Transformer. Transformers for image recognition at… | by ...
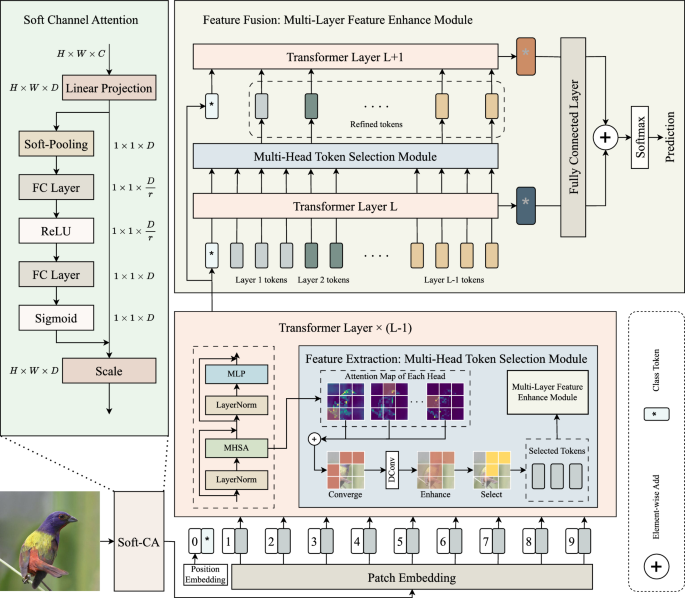
Ts-vit: feature-enhanced transformer via token selection for fine ...
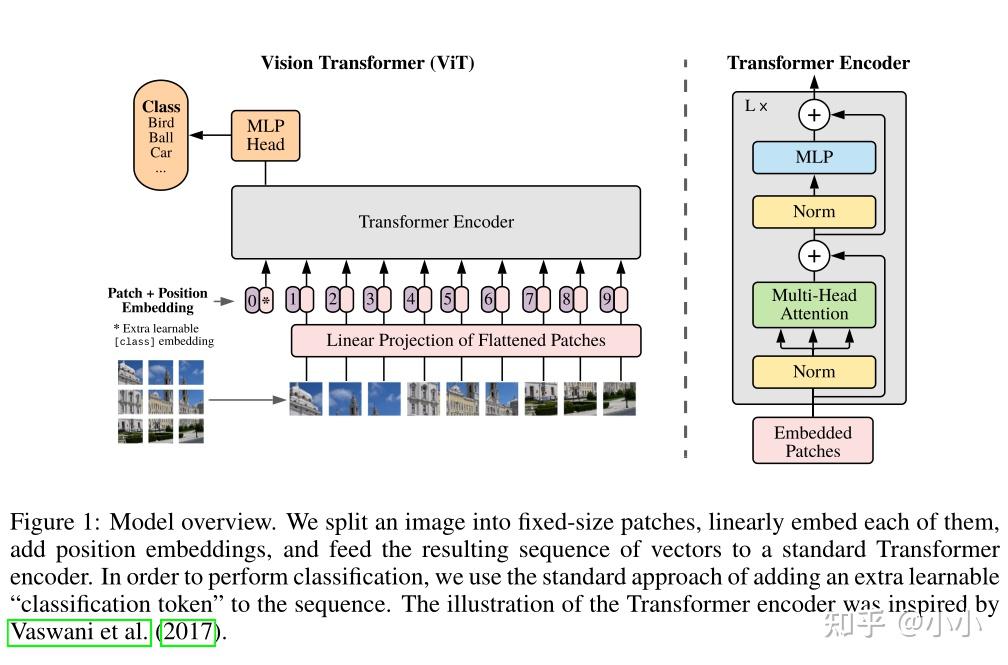
Transformers for Image Recognition at Scale
Lightweight Vision Transformer with transfer learning for interpretable ...
GitHub - PramitDutta1999/Conv-ViT-A-Convolution-and-Vision-Transformer ...
Applying vision transformer to assess multi-scale morphological ...
Transformer and Mixer Features | Form and Formula
ViTT: Vision Transformer Tracker
The vision transformer architecture. (a) The main architecture of the ...
White Blood Cell Classification: Convolutional Neural Network (CNN) and ...
Historical Manuscripts Analysis: A Deep Learning System for Writer ...
GitHub - Redcof/vit-gpt2-image-captioning: A Image to Text Captioning ...
Vision Transformers Explained at Hunter Berry blog
Vision Transformers (ViT): Revolutionizing Computer Vision
Vision Transformer (ViT) - YouTube
V-DETR: Pure Transformer for End-to-End Object Detection | SpringerLink
IEIE SPC - IEIE Transactions on Smart Processing & Computing
System Diagram of Vision Transformer (ViT). | Download Scientific Diagram
A Marine Organism Detection Framework Based on Dataset Augmentation and ...
How to use YOLOv9 for Object Detection | by Mert | Medium
Vision Transformer (ViT)模型与代码实现(PyTorch)_vit model-CSDN博客