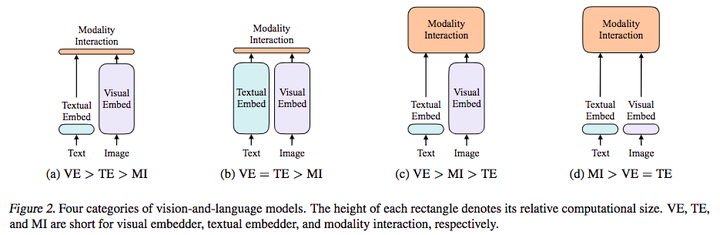
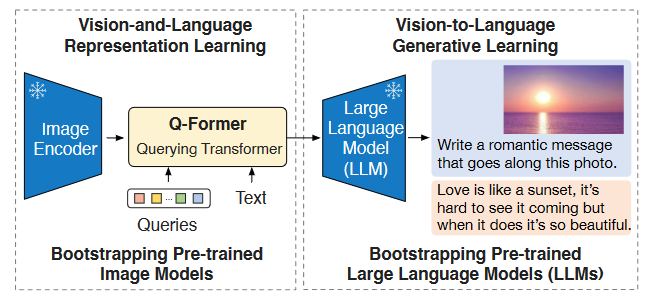
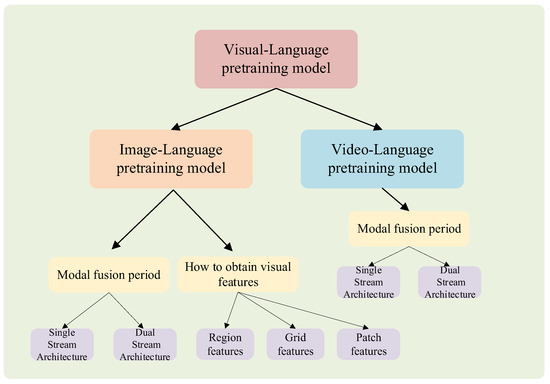
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
Expanding scene and language understanding with large-scale pre ...
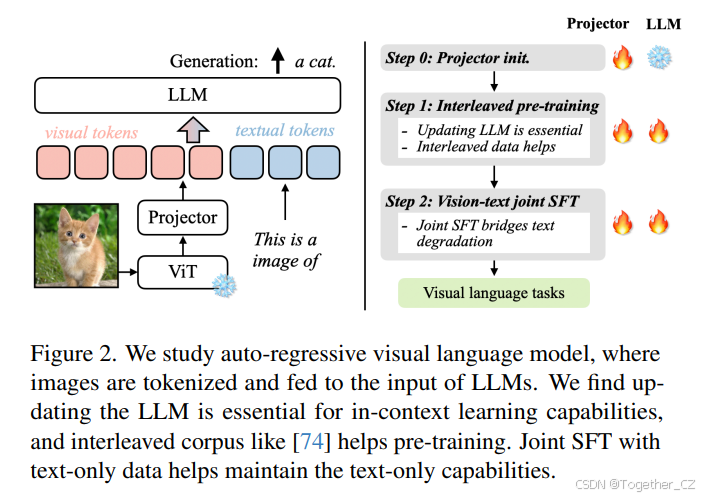
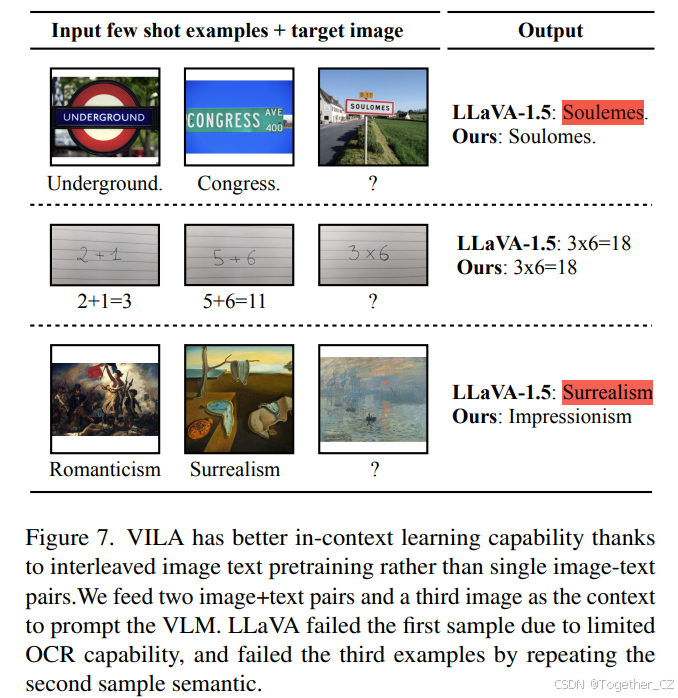
Paper page - VILA: On Pre-training for Visual Language Models
VILA: On Pre-training for Visual Language Models——视觉语言模型的预训练研究-CSDN博客
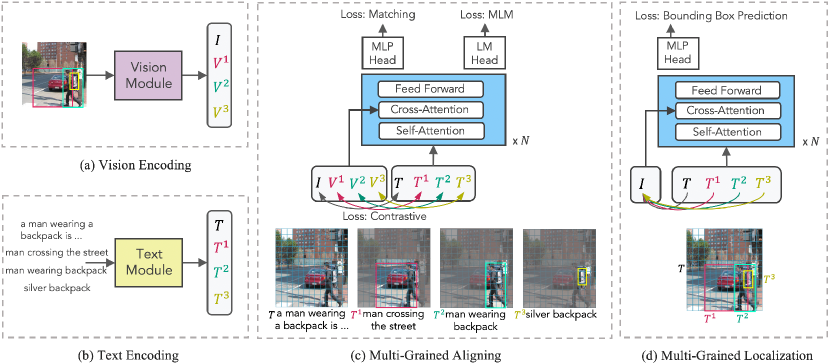
Multi-Grained Vision Language Pre-Training: Aligning Texts with Visual ...
VILA: On Pre-training for Visual Language Models: Paper and Code
VILA: On Pre-training for Visual Language Models, Ji Lin+, N/A, arXiv ...
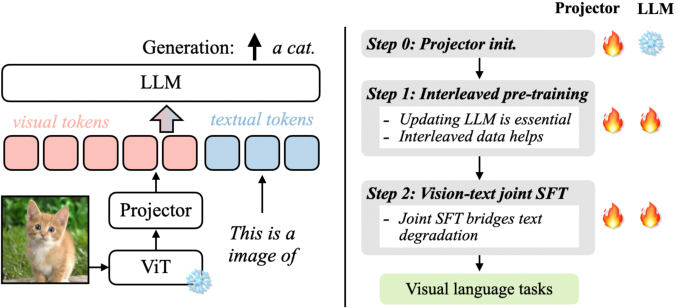
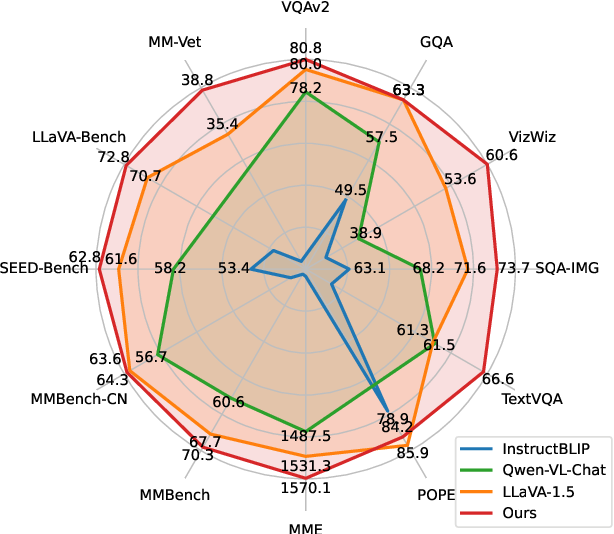
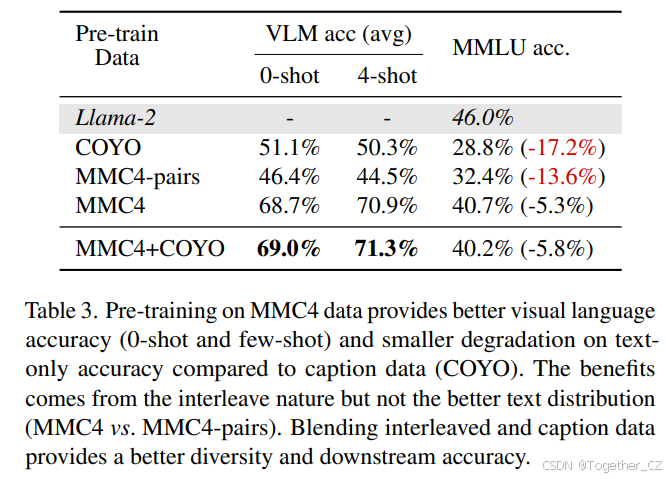
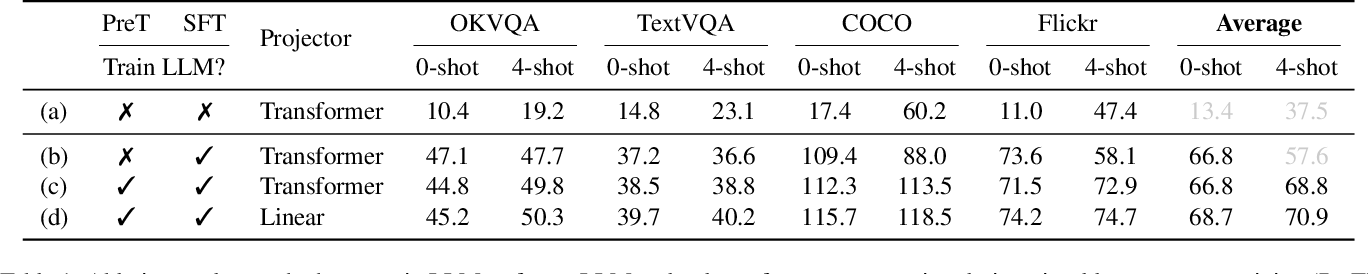
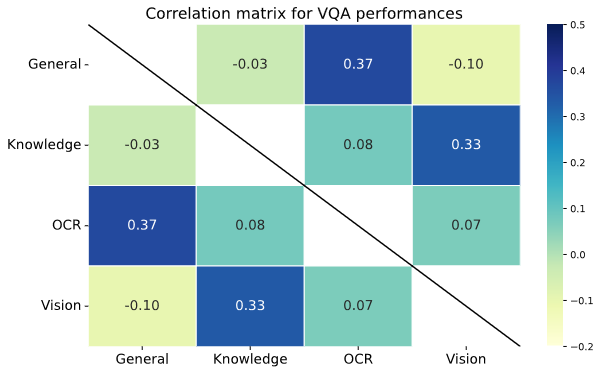
Figure 1 from VILA: On Pre-training for Visual Language Models ...
VILA: On Pre-training for Visual Language Models - 智源社区论文
[2312.07533] VILA: On Pre-training for Visual Language Models
Pre trained language model | PPTX
Paper page - Can Pre-trained Vision and Language Models Answer Visual ...
VILA: On Pre-training for Visual Language Models: Paper and Code ...
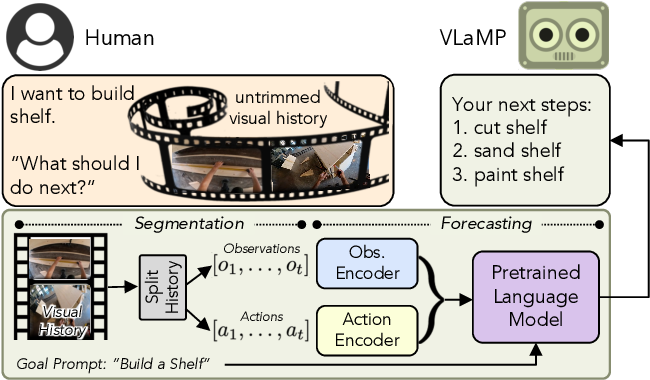
Figure 1 from Pretrained Language Models as Visual Planners for Human ...
Enhanced Chart Understanding via Visual Language Pre-training on Plot ...
VILA: On Pre-training for Visual Language Models - DEV Community
Underline | Can Pre-trained Vision and Language Models Answer Visual ...
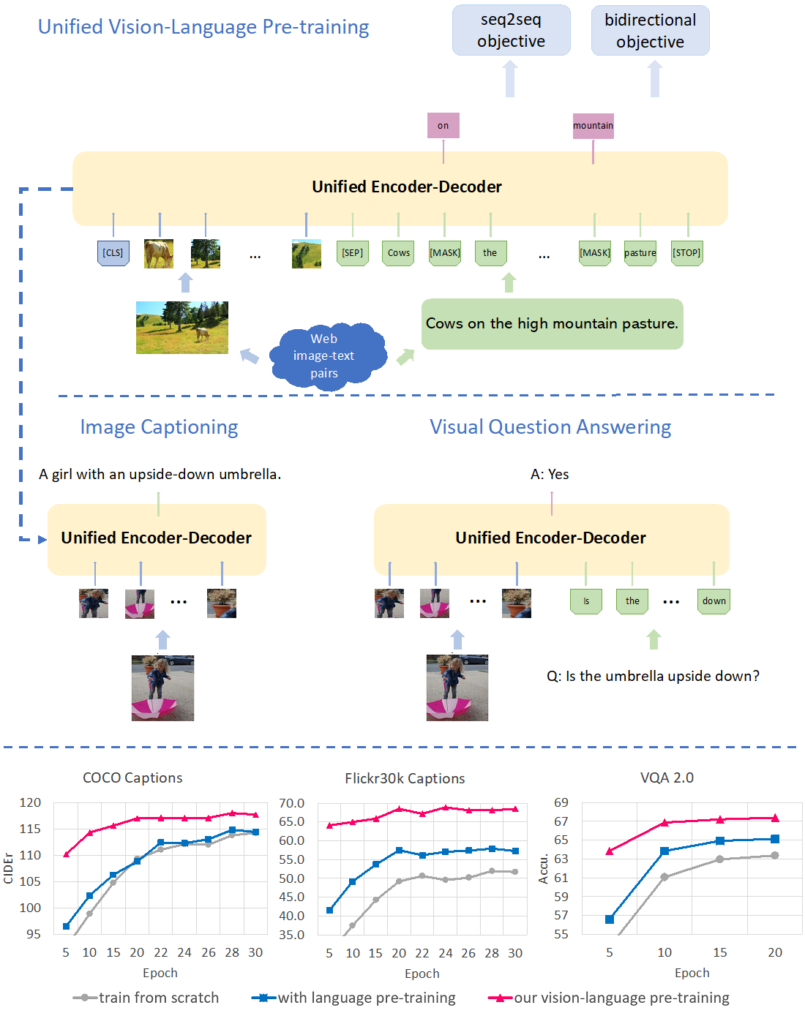
Paper Review. Unified Vision Language Pre-Training for Image Captioning ...
Vision and language pre-training(Image/Video Bert) - 知乎
Vision Language Pre-training Model
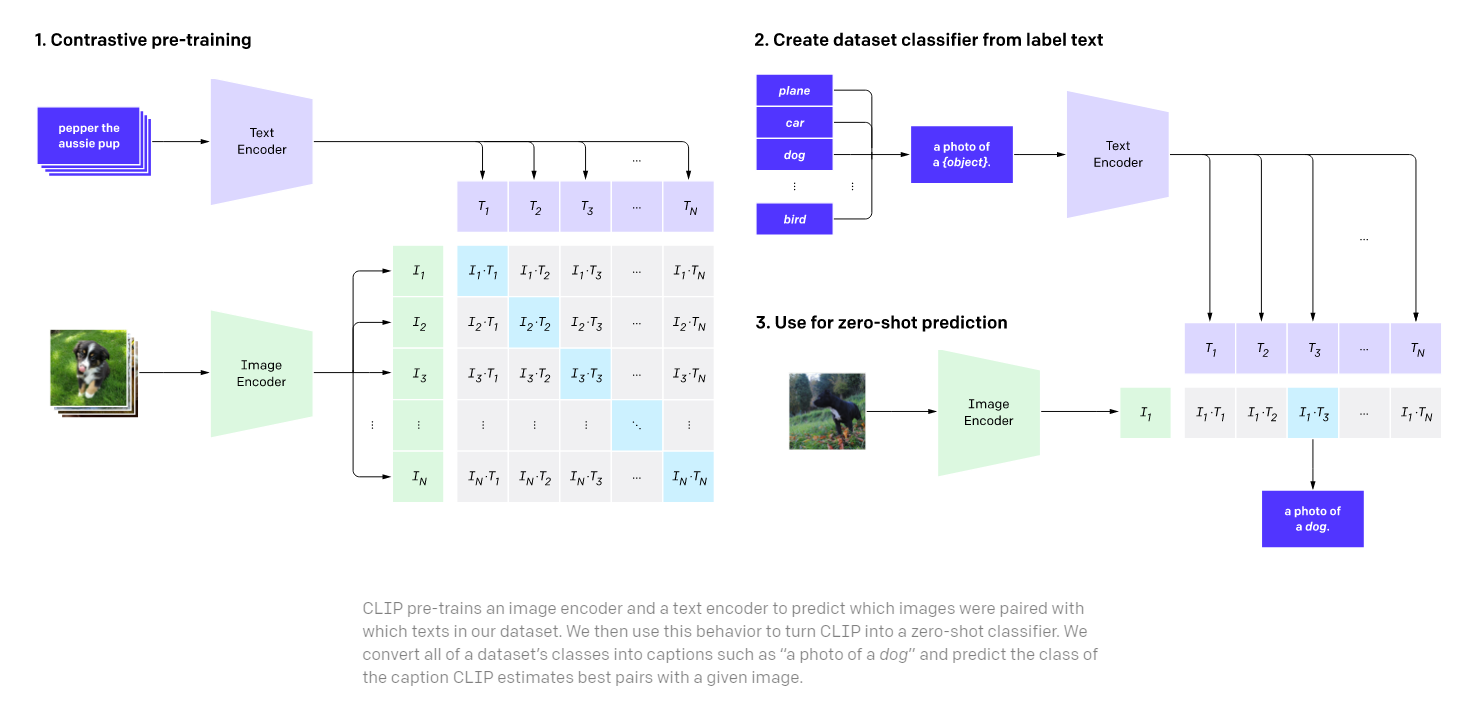
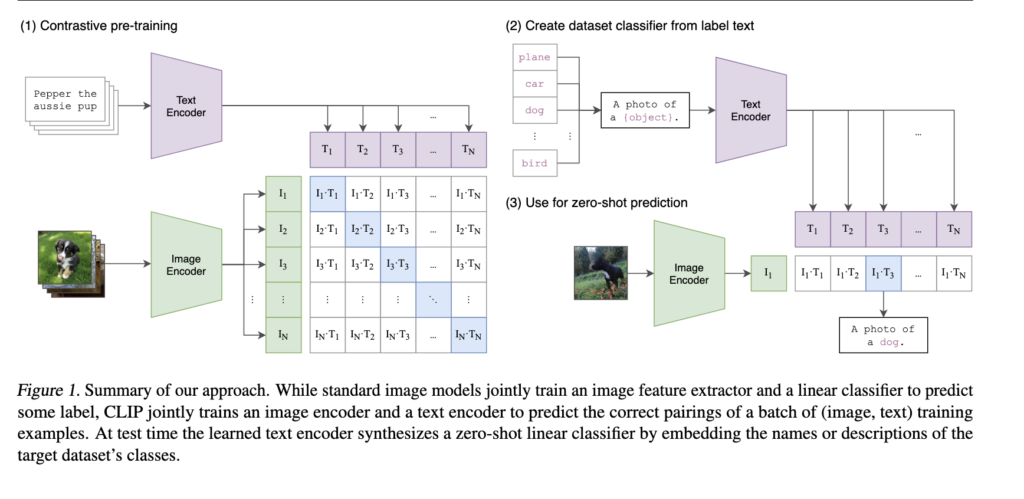
Understand CLIP (Contrastive Language-Image Pre-Training) — Visual ...
What are Pre-training Methods of Vision Language Models?
E2E-VLP: End-to-End Vision-Language Pre-training Enhanced by Visual ...
Paper page - Learning to See Before Seeing: Demystifying LLM Visual ...
Cross-lingual Visual Pre-training for Multimodal Machine | S-Logix
Learning to See Before Seeing: Demystifying LLM Visual Priors from ...
Paper page - Double Visual Defense: Adversarial Pre-training and ...
(PDF) Cross-Modal Self-Supervised Vision Language Pre-training with ...
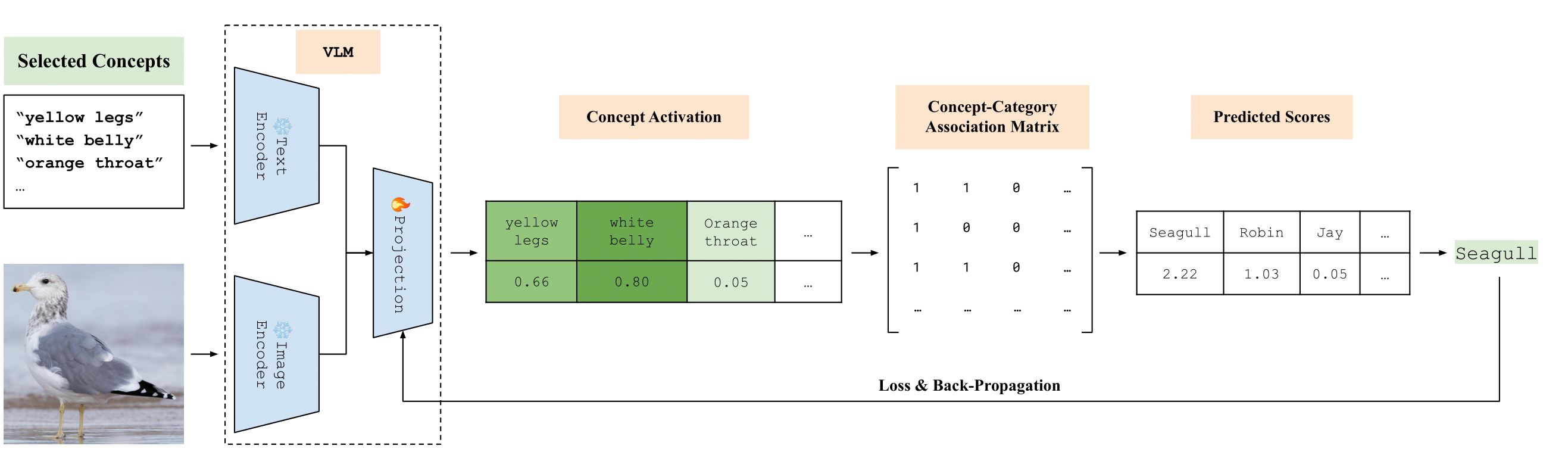
Pre-trained Vision-Language Models Learn Discoverable Visual Concepts
26. Vision Language Pretraining — LLM Foundations
Vision Language Pretraining
Figure 1 from Efficient Vision-Language Pretraining with Visual ...
Underline | GroundVLP: Harnessing Zero-Shot Visual Grounding from ...
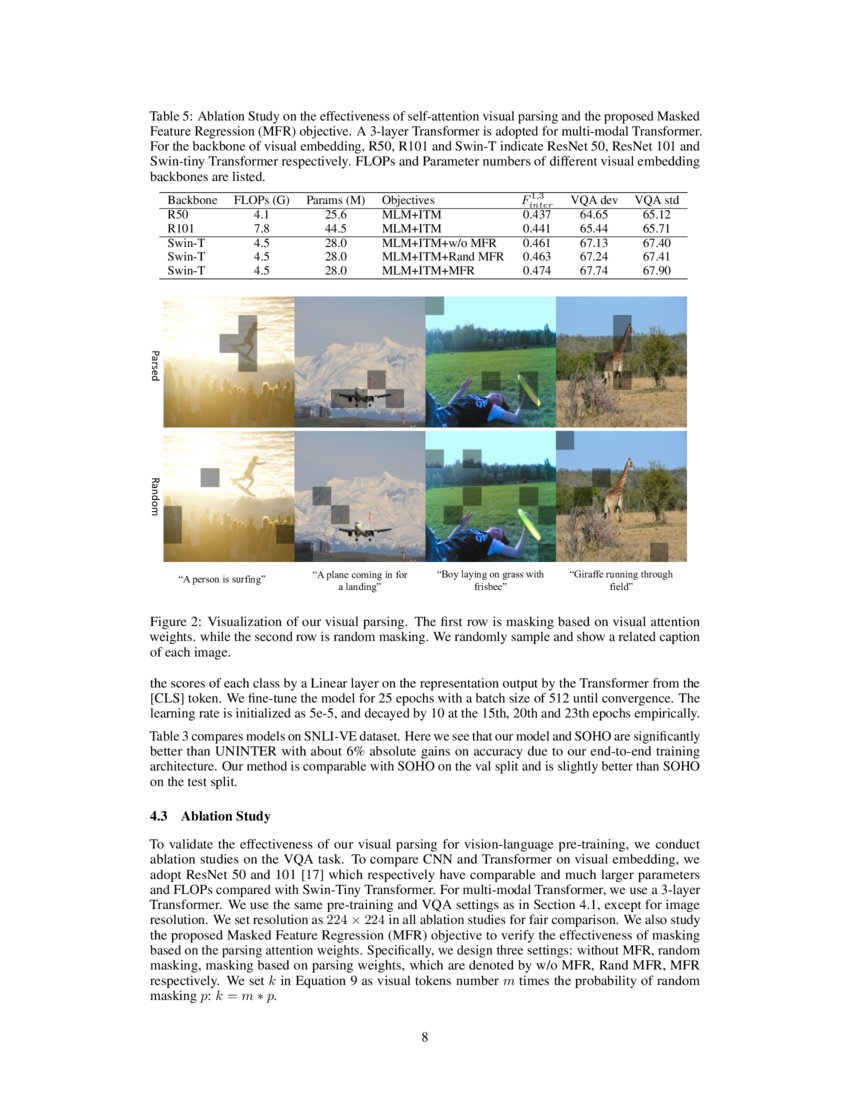
Probing Inter-modality: Visual Parsing with Self-Attention for Vision ...
[论文评述] Double Visual Defense: Adversarial Pre-training and Instruction ...
Adapting Pre-trained Language Models to Vision-Language Tasks via ...
VC-GPT: Visual Conditioned GPT for End-to-End Generative Vision-and ...
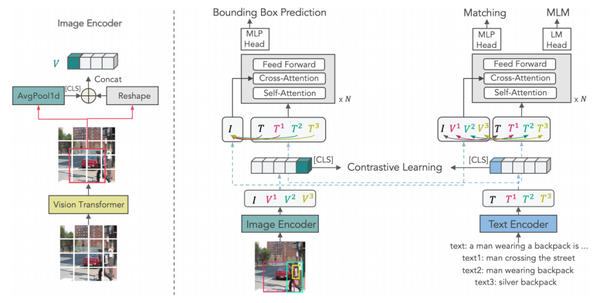
[ICML2022] Multi-Grained Vision Language Pre-Training: Aligning Texts ...
VLP (Vision Language Pre-training) 梳理 - 知乎
Vision & Language Pretrained Model 总结 | DaNing的博客
Research Progress on Vision–Language Multimodal Pretraining Model ...
Results comparison with super large-scale visual-language pre-trained ...
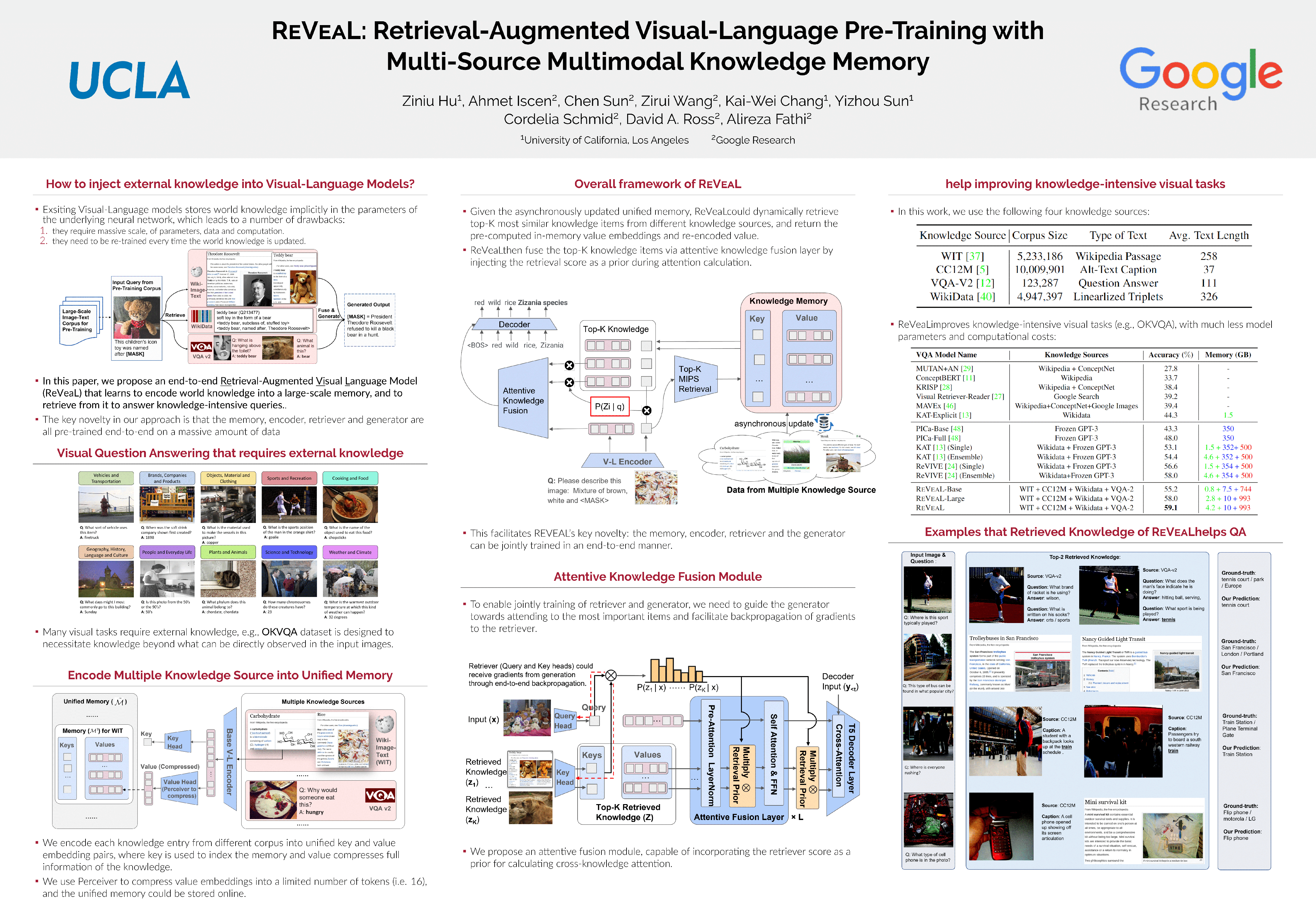
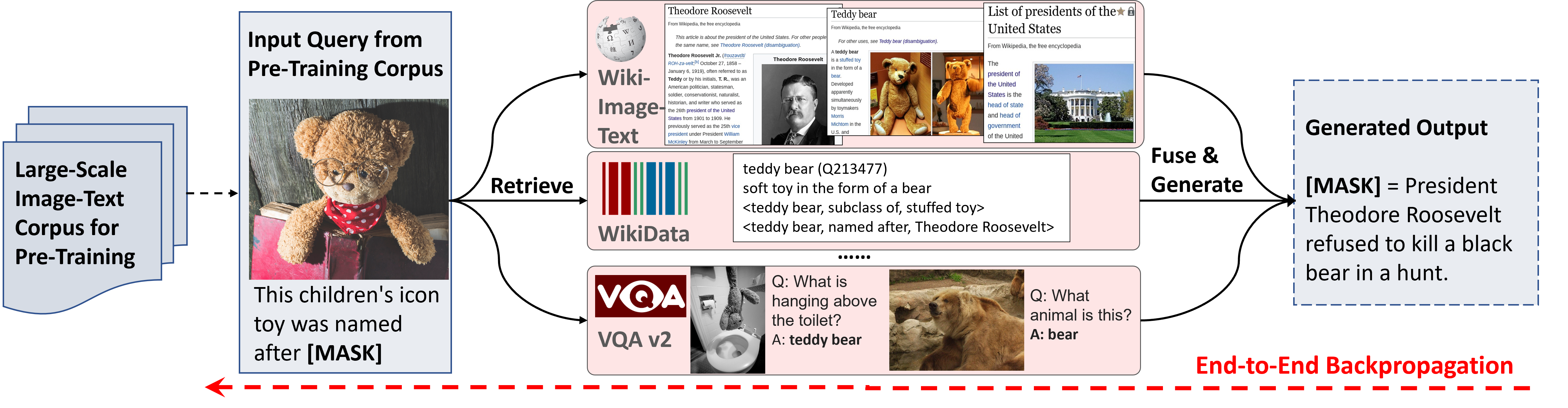
REVEAL: Retrieval-Augmented Visual-Language Pre-Training with Multi ...
CVPR Poster REVEAL: Retrieval-Augmented Visual-Language Pre-Training ...
Retrieval-augmented visual-language pre-training - Robotic Content
Retrieval-Augmented Visual-Language Pre-Training withMulti-Source ...
Retrieval-augmented visual-language pre-training
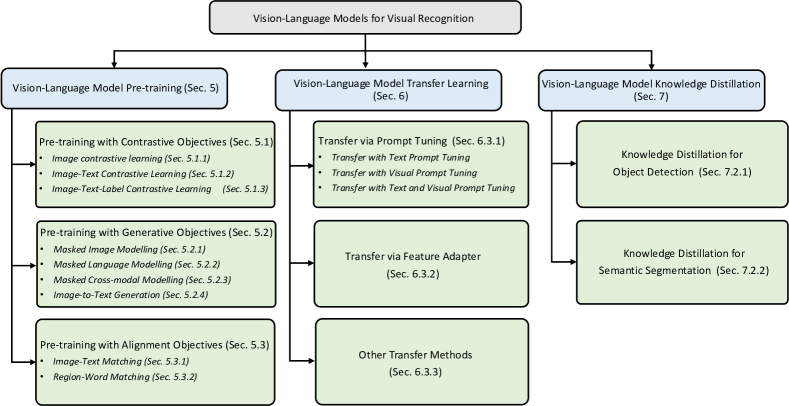
[2304.00685] Vision-Language Models for Vision Tasks: A Survey
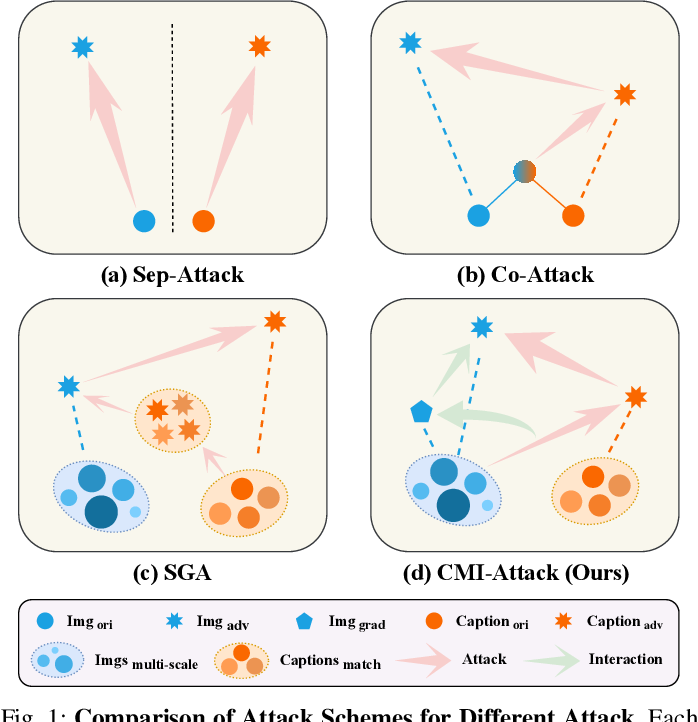
Figure 5 from Improving Adversarial Transferability of Visual-Language ...
Stop Pre-Training: Adapt Visual-Language Models to Unseen Languages ...
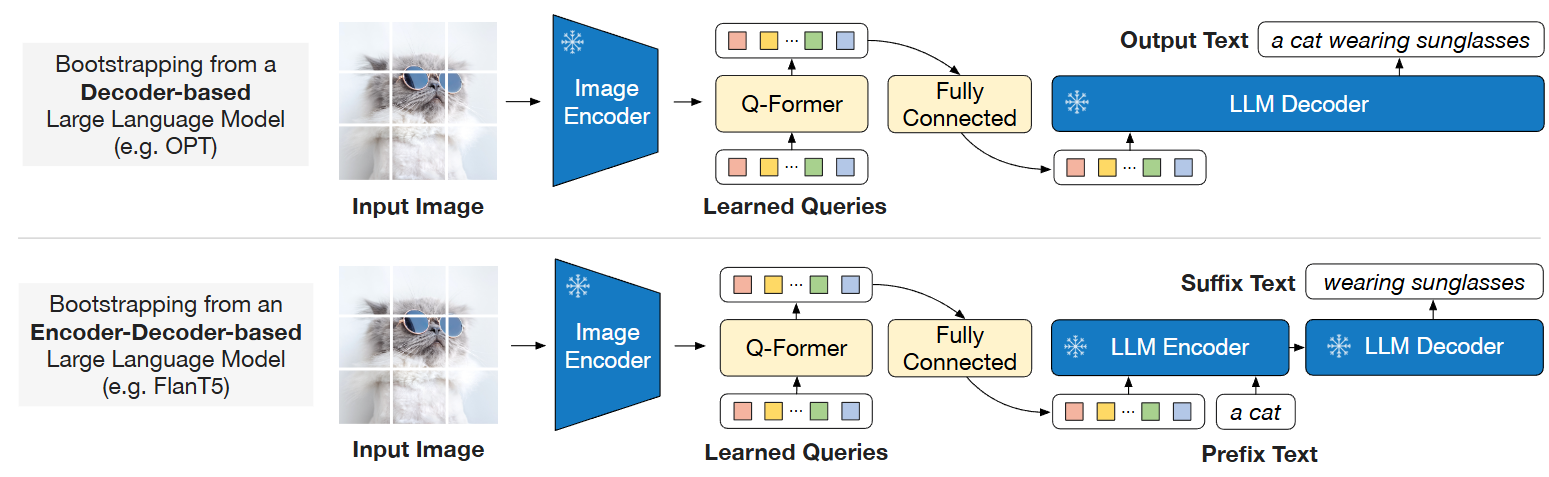
BLIP-2: A Breakthrough Approach in Vision-Language Pre-training | by ...
[Paper Review] REVEAL: Retrieval-Augmented Visual-Language Pre-Training ...
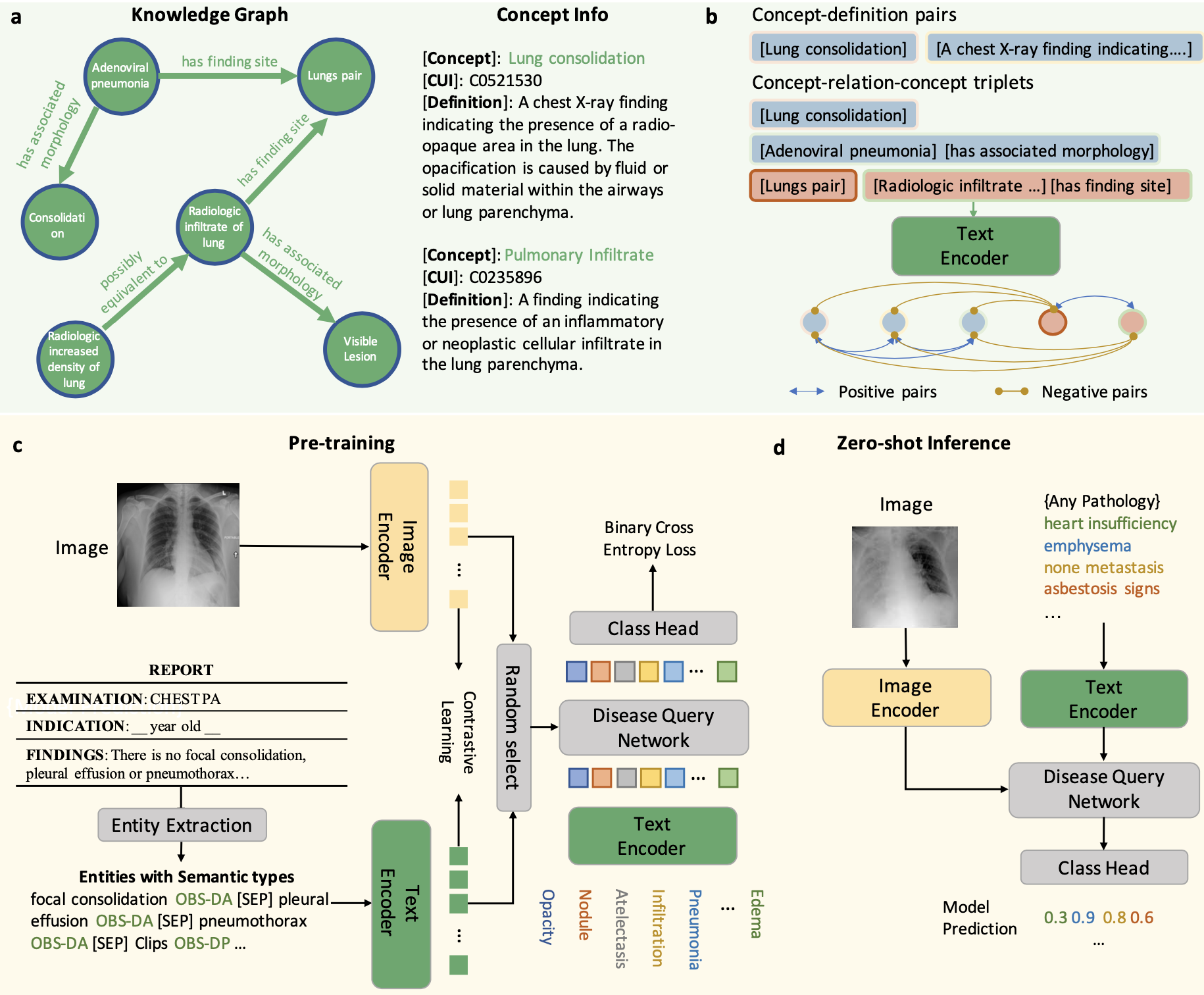
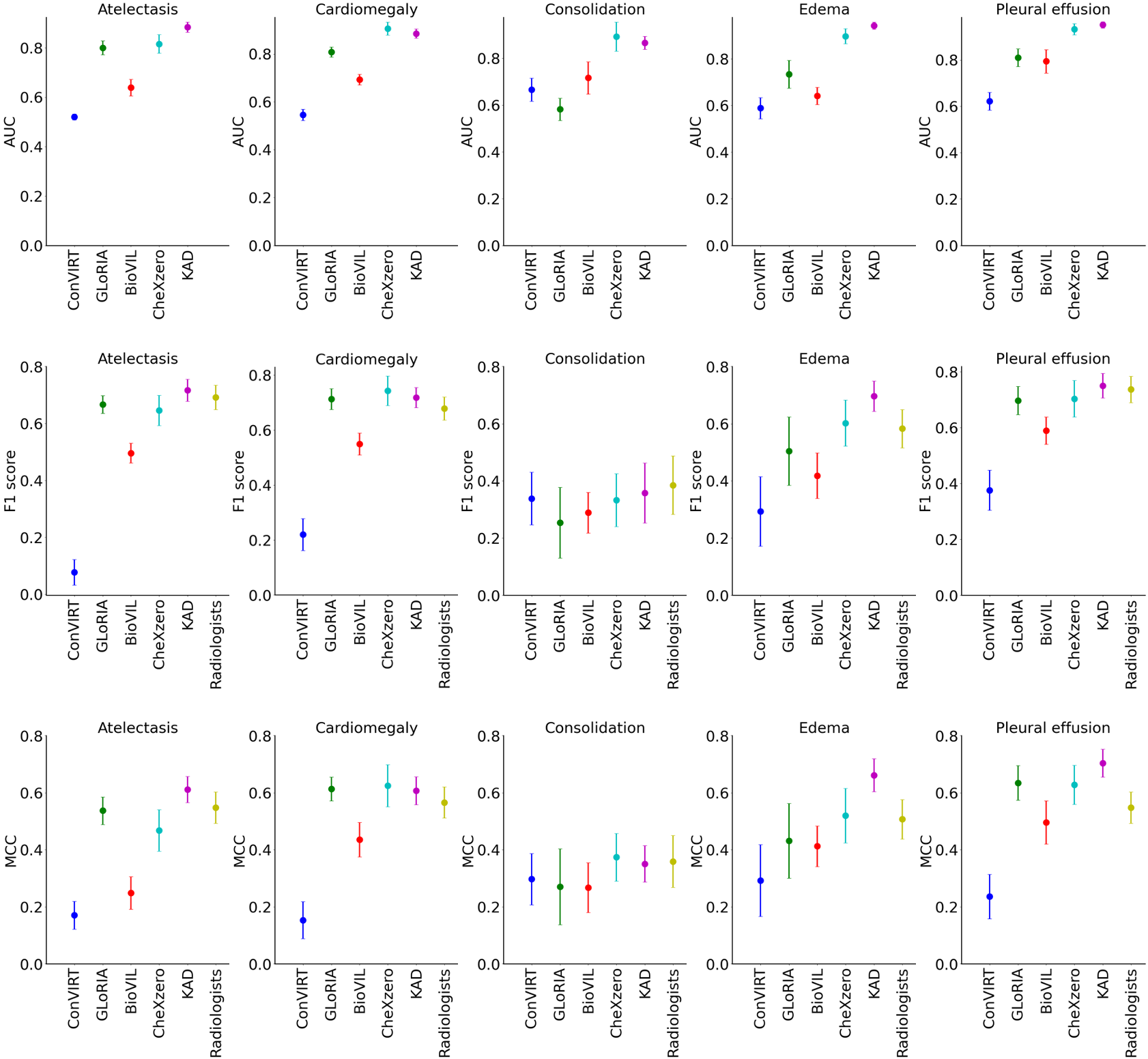
Knowledge-enhanced visual-language pre-training on chest radiology ...
Retrieval-augmented visual-language pre-training | Smart Recognition
GitHub - Zi-hao-Wei/Efficient-Vision-Language-Pre-training-by-Cluster ...
(PDF) Hierarchical Vision–Language Pre-Training with Freezing Strategy ...
Pre-Training In A Nutshell - FourWeekMBA
(PDF) ViLTA: Enhancing Vision-Language Pre-training through Textual ...
CLIP-Guided Vision-Language Pre-training for Question Answering in 3D ...
Multi-View and Multi-Scale Alignment (MaMA): Advancing Mammography with ...
Vision-Language Pretrain Review and the Potential in 3D [Part 1] | by ...
Knowledge-enhanced Visual-Language Pre-training on Chest Radiology Images
Enhancing Adversarial Transferability in Visual-Language Pre-training ...
Exploiting the Textual Potential from Vision-Language Pre-training for ...
Stop Pre-Training: Adapt Visual-Language Models to Unseen Languages
Figure 1 from Enhancing Vision-Language Pre-Training with Jointly ...
Table 1 from Stop Pre-Training: Adapt Visual-Language Models to Unseen ...
Large Vision-Language Models: Pre-training, Prompting, and Applications ...
[2211.12402] X2-VLM: All-In-One Pre-trained Model For Vision-Language Tasks
A Dive into Vision-Language Models
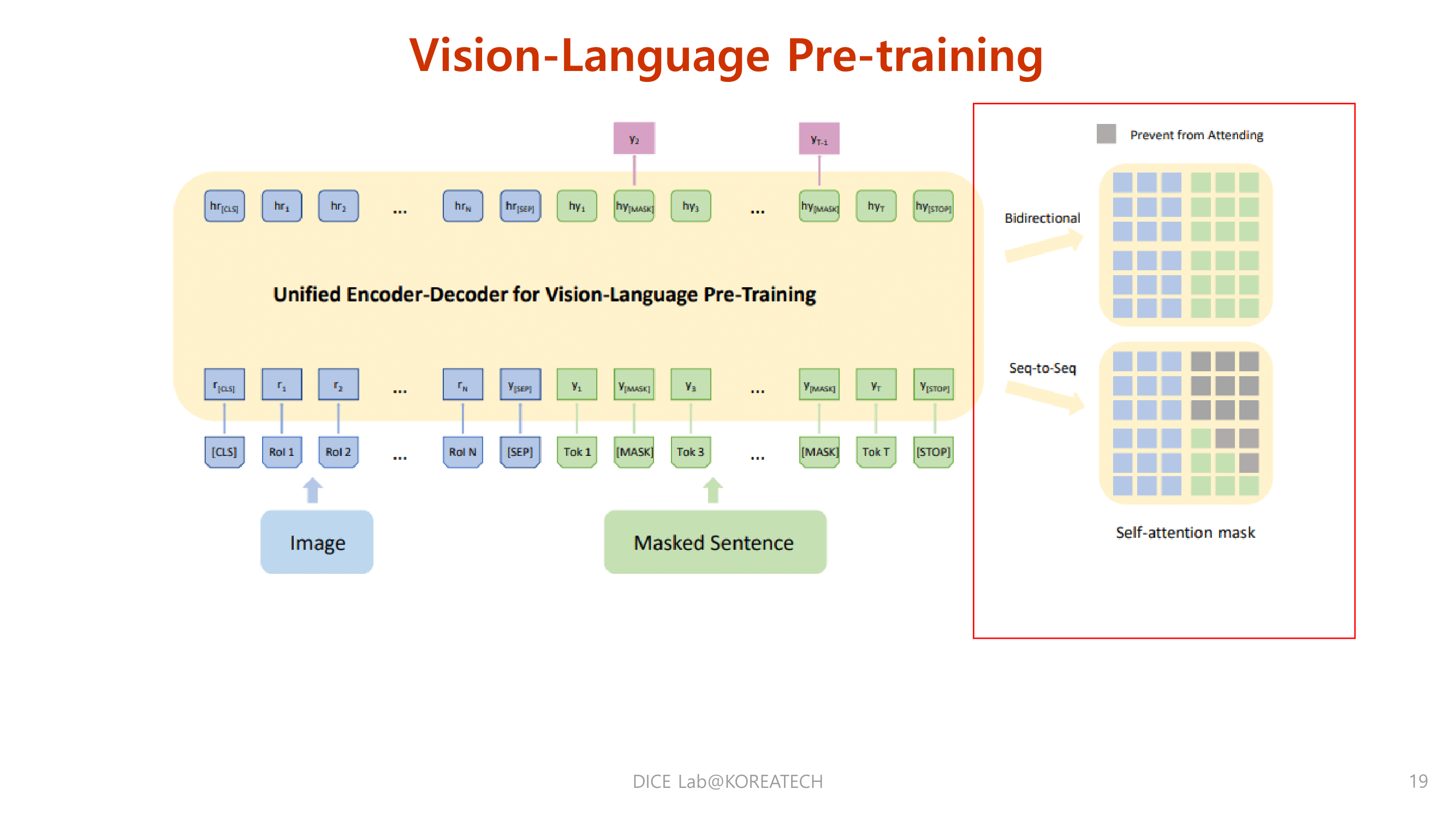
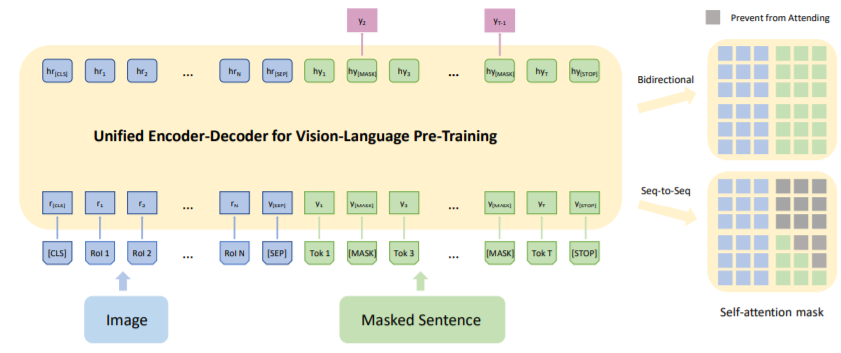
Figure 1 from Vision-and-Language Pretraining | Semantic Scholar
论文笔记7:Knowledge-enhanced visual-language pre-training on chest ...
Vision-Language的几篇工作:向更简便更scale的路 - 知乎
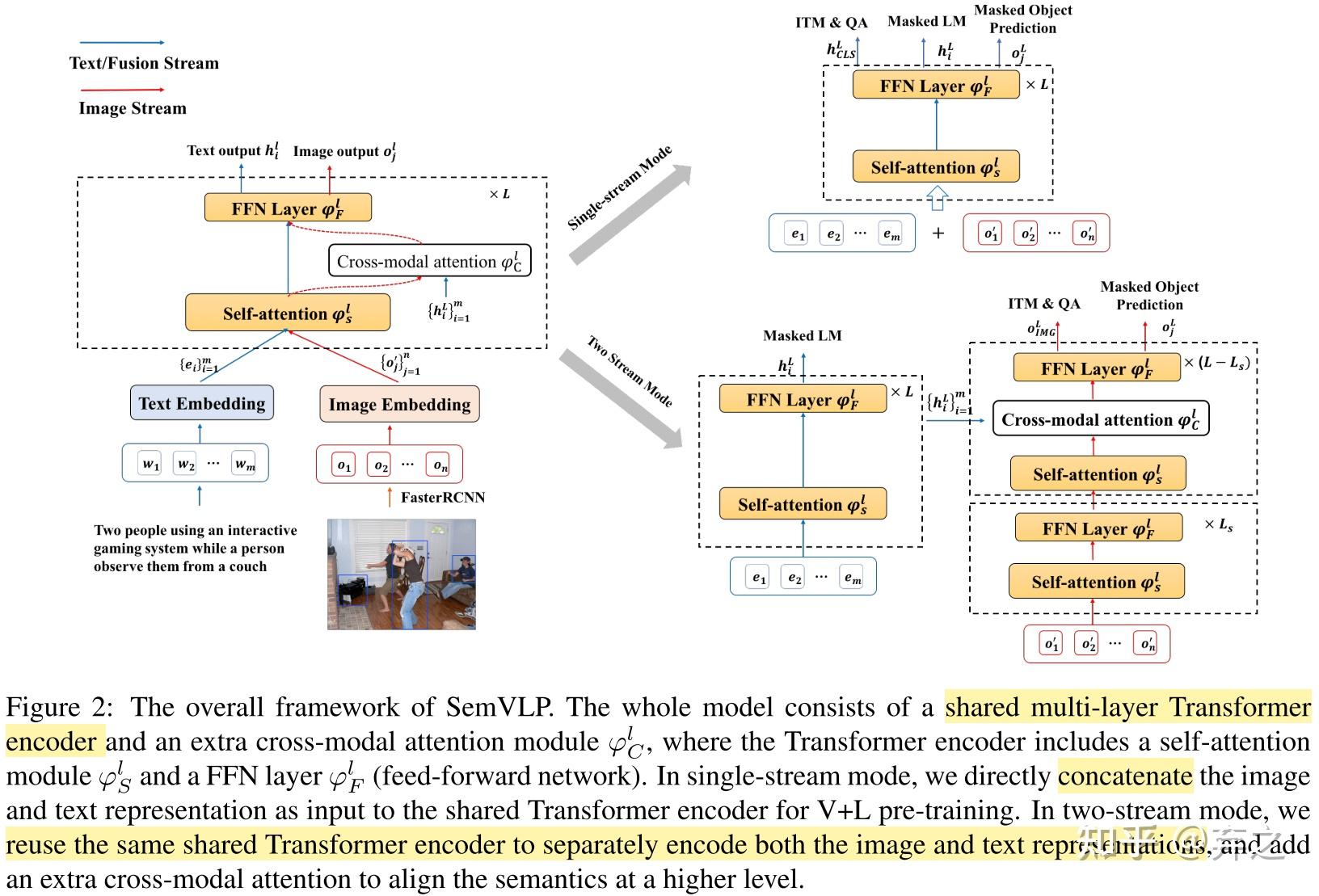
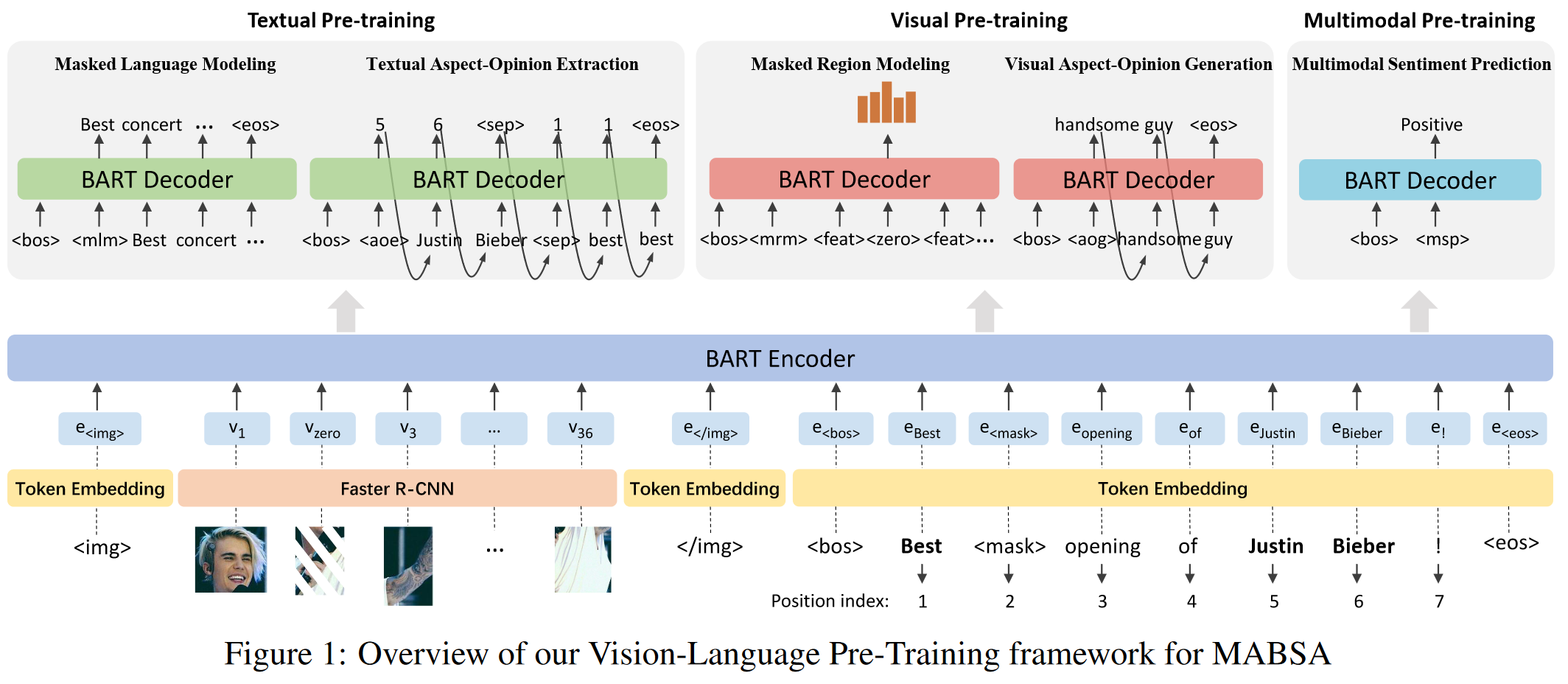
2.1 Vision-Language Pre-Training for Multimodal Aspect-Based Sentiment ...
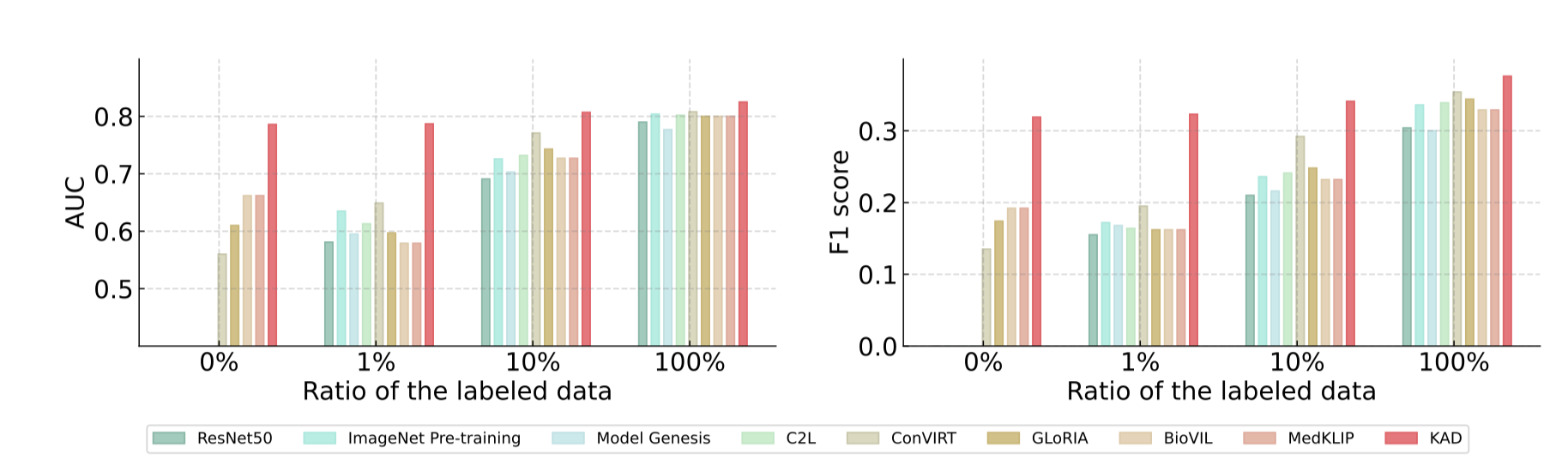
[2302.14042] Knowledge-enhanced Visual-Language Pre-training on Chest ...
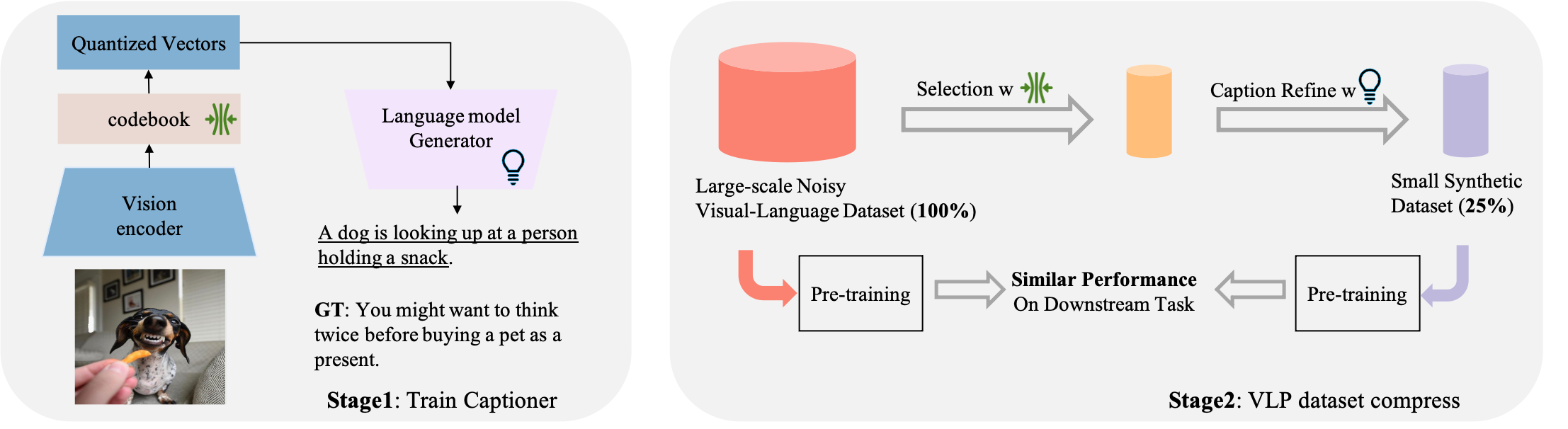
[2305.20087] 𝒯oo ℒarge; 𝒟ata ℛeduction for Vision-Language Pre-Training
This AI Paper from China Introduces Video-LaVIT: Unified Video-Language ...
Figure 1 from A Vision-Language Pre-training model based on Cross ...
Multi-CLIP: Contrastive Vision-Language Pre-training for Question ...
Figure 2 from Improving Adversarial Transferability of Visual-Language ...
Figure 1 from Improving Adversarial Transferability of Visual-Language ...
Multi-Resolution Pathology-Language Pre-training Model with Text-Guided ...
Vision-Language Pre-training: Basics, Recent Advances, and Future ...
X2-VLM: All-In-One Pre-trained Model For Vision-Language Tasks | 오상진의 ...