Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
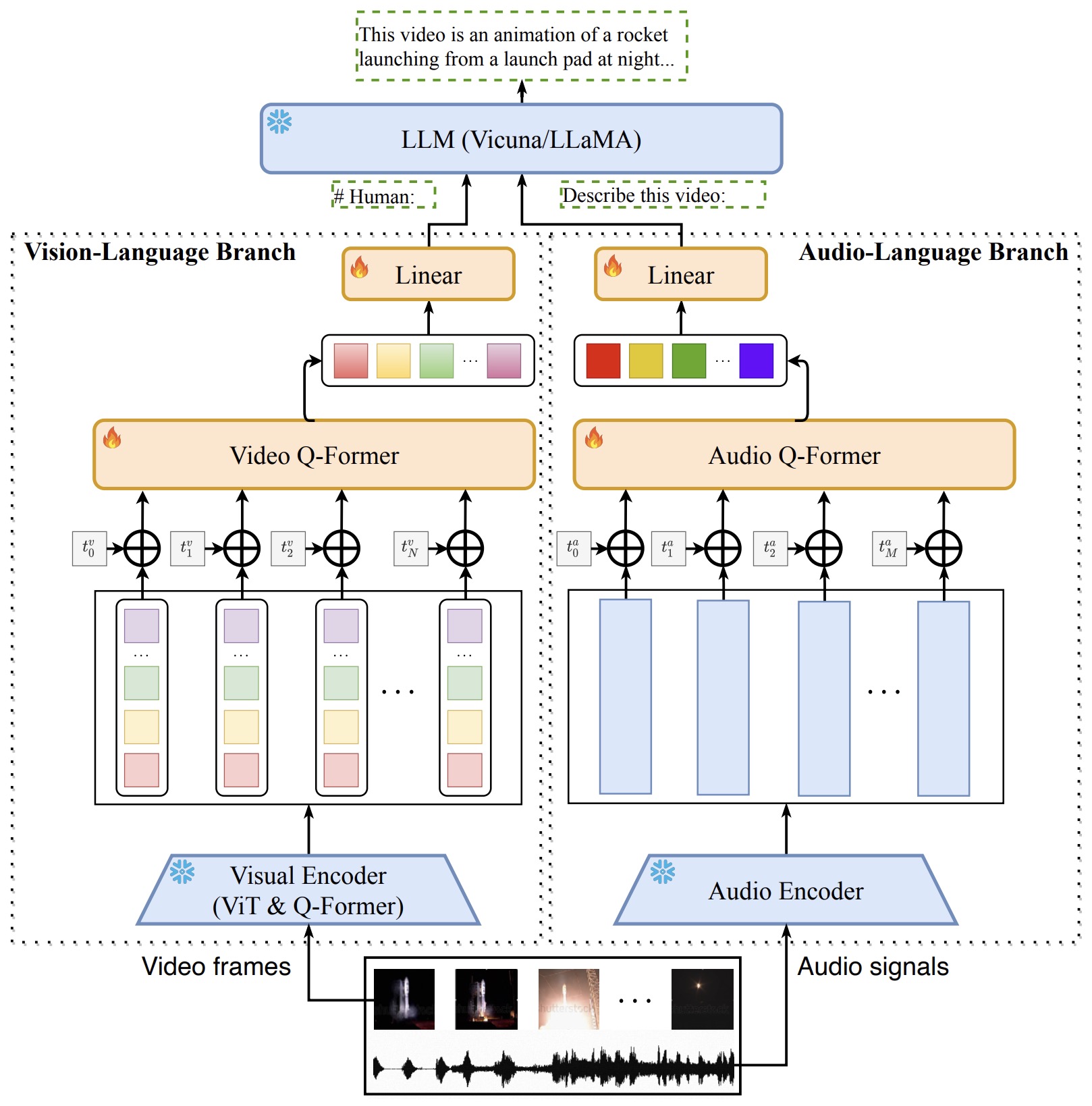
Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video ...
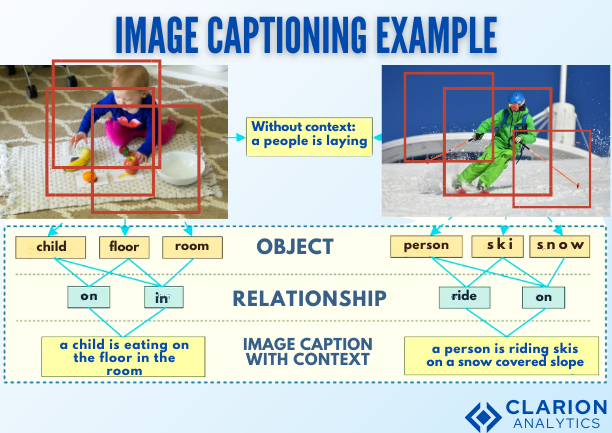
Vision Language Model (VLM) based Information Extraction | Firstsource
[ML Story] Fine-tune Vision Language Model on custom dataset | by Nitin ...
Rise of Vision Language Model (VLM) and CogAgent - DATUMO
[논문 리뷰] Mitigating Hallucination for Large Vision Language Model by ...
Building A Simple Custom Vision Language Model with Hugging Face🤗 | by ...
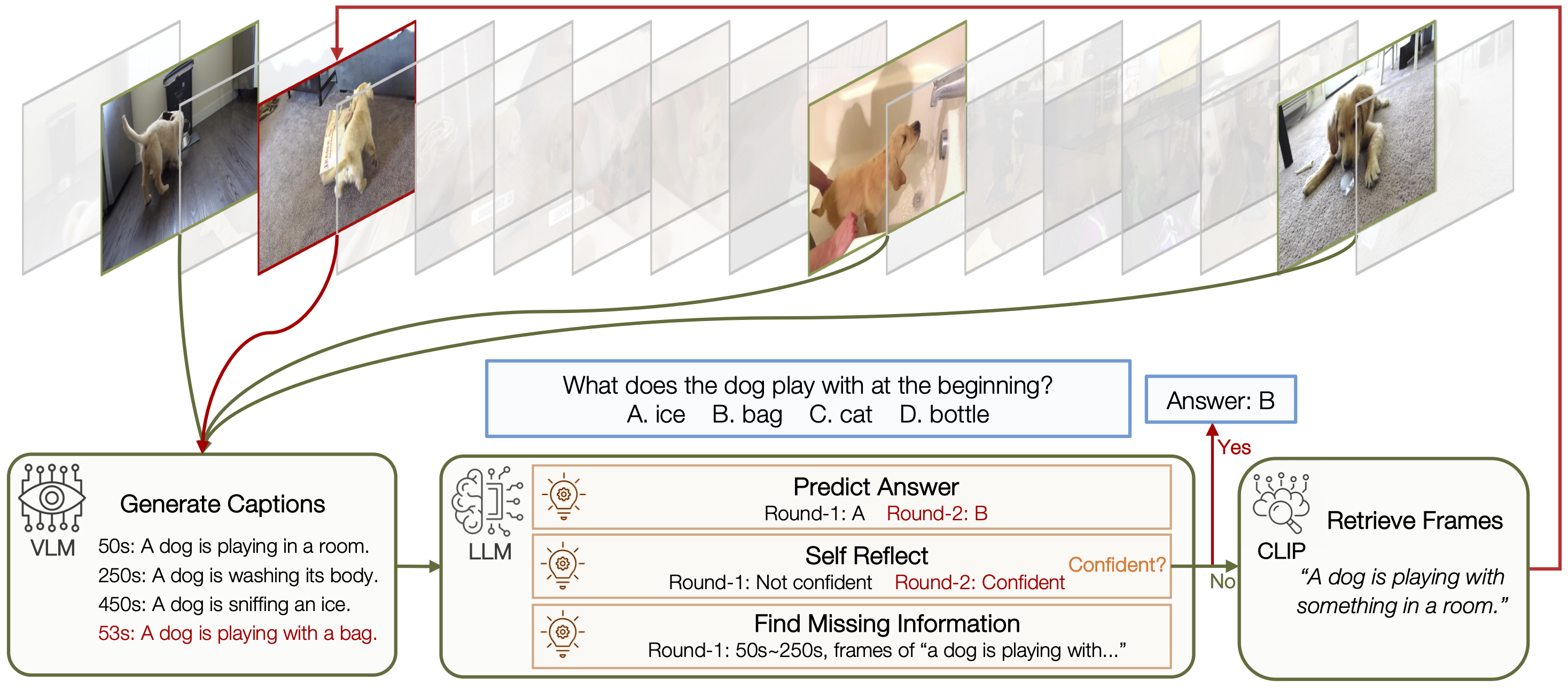
VideoAgent: Long-form Video Understanding with Large Language Model as ...
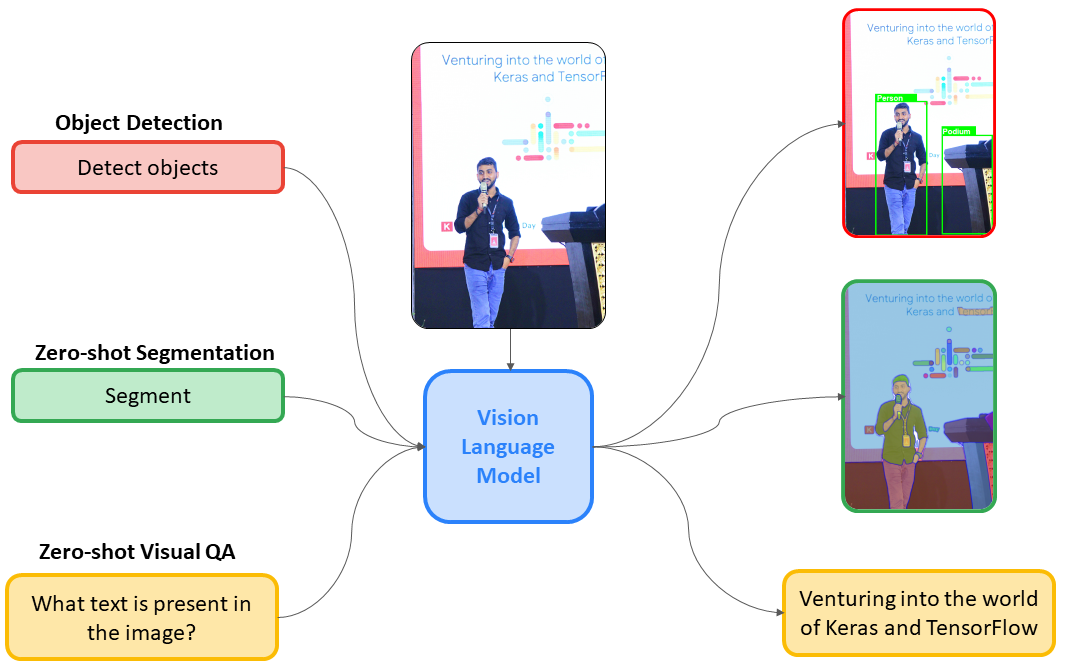
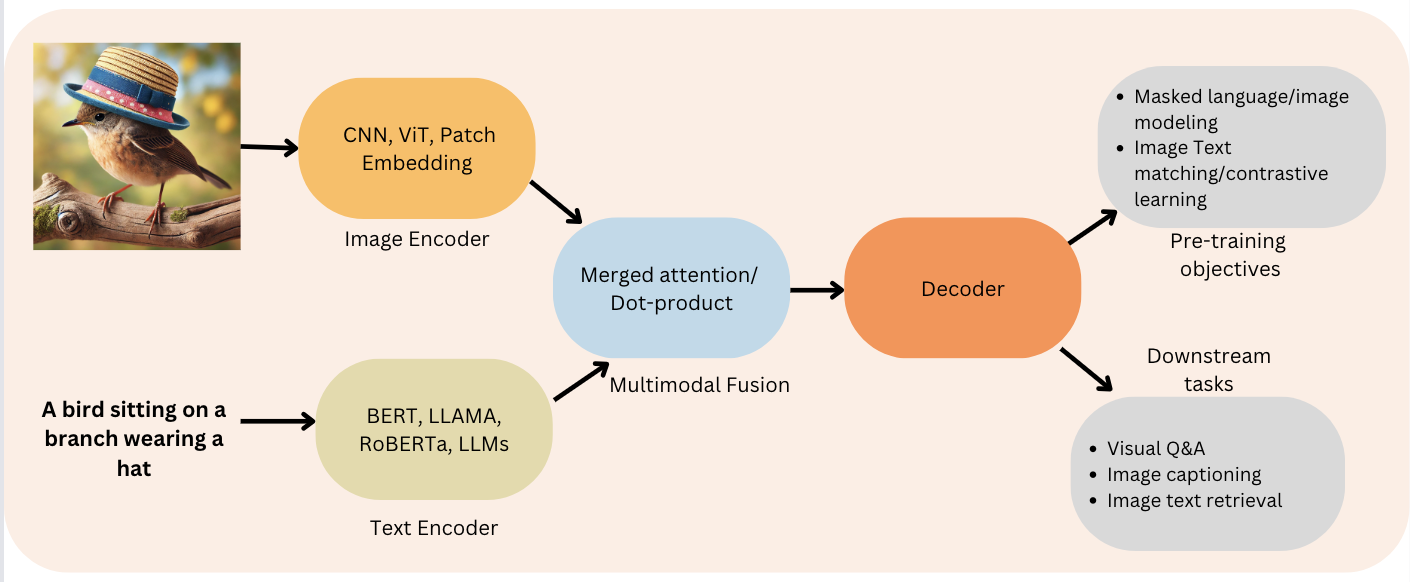
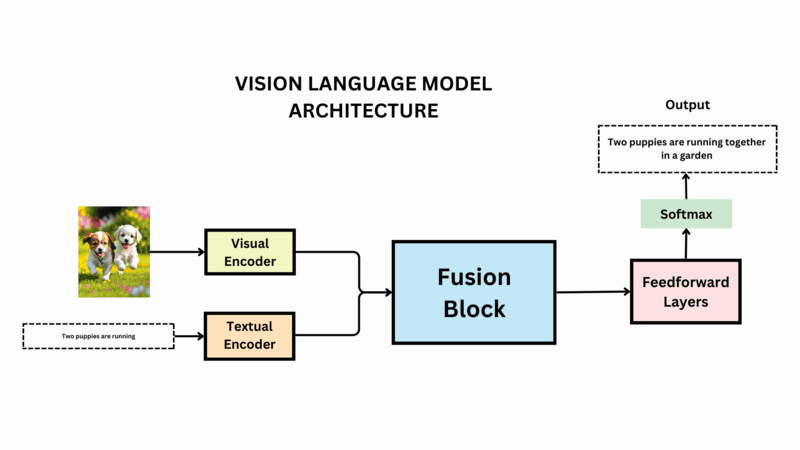
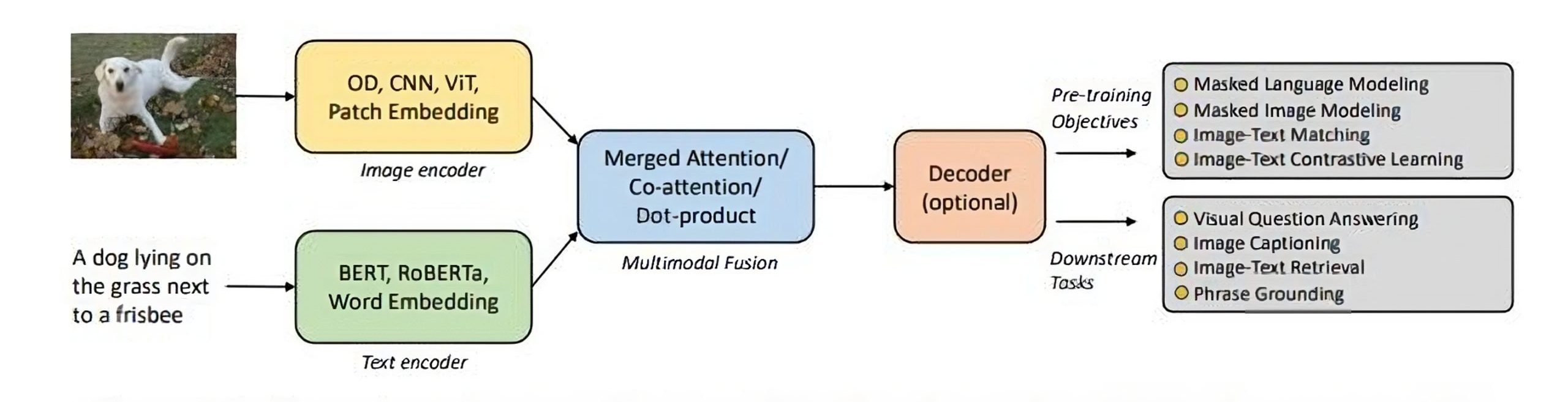
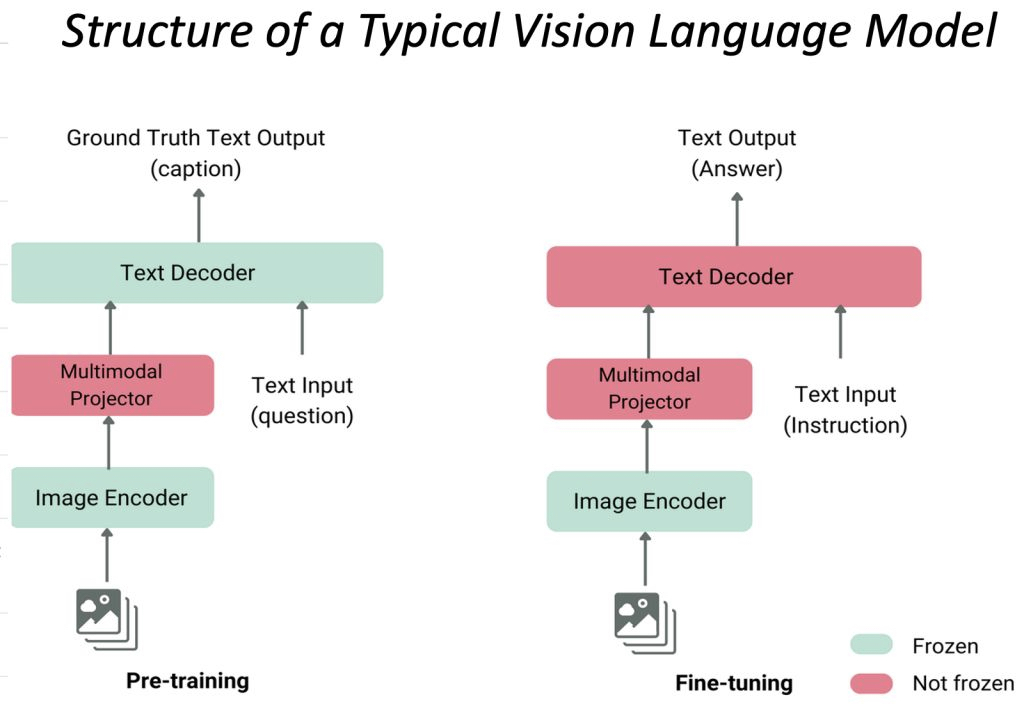
A Comprehensive Guide to Vision Language Models (VLMs)
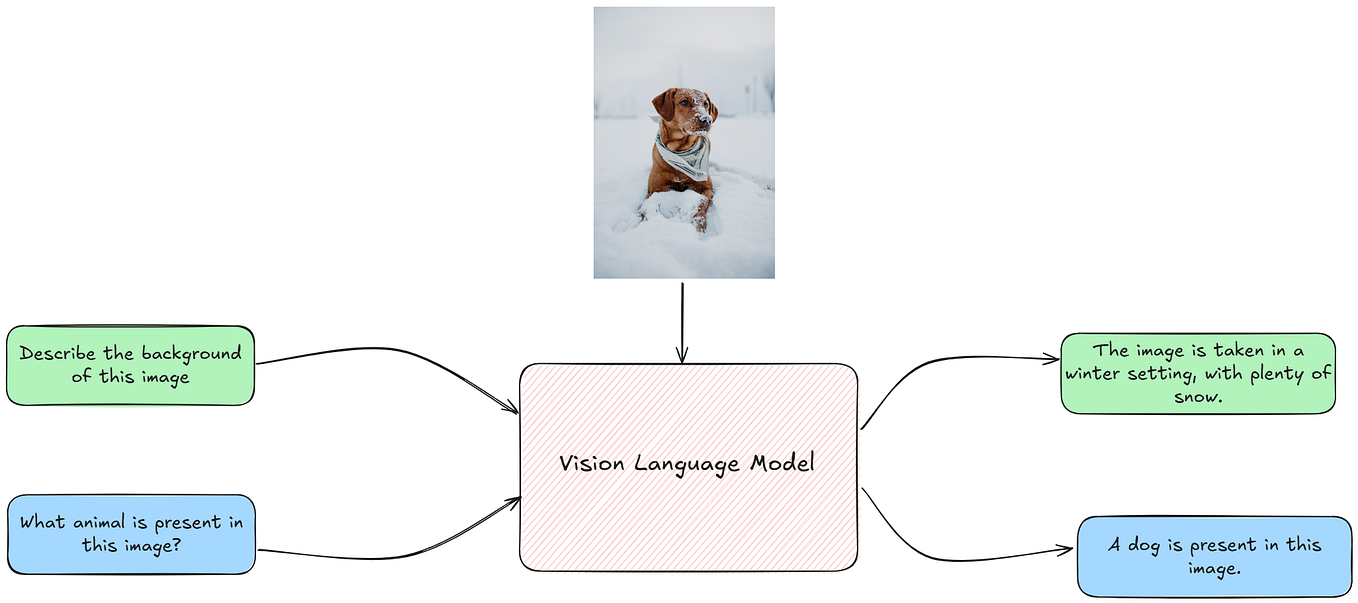
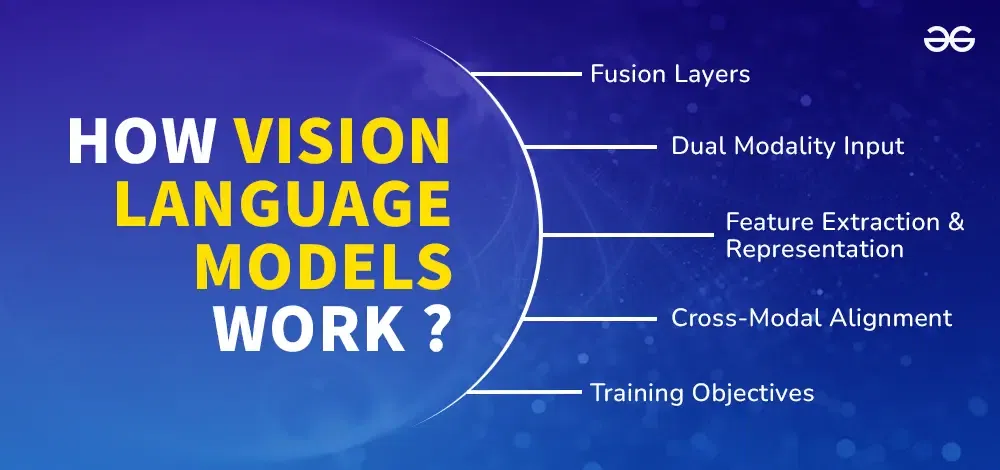
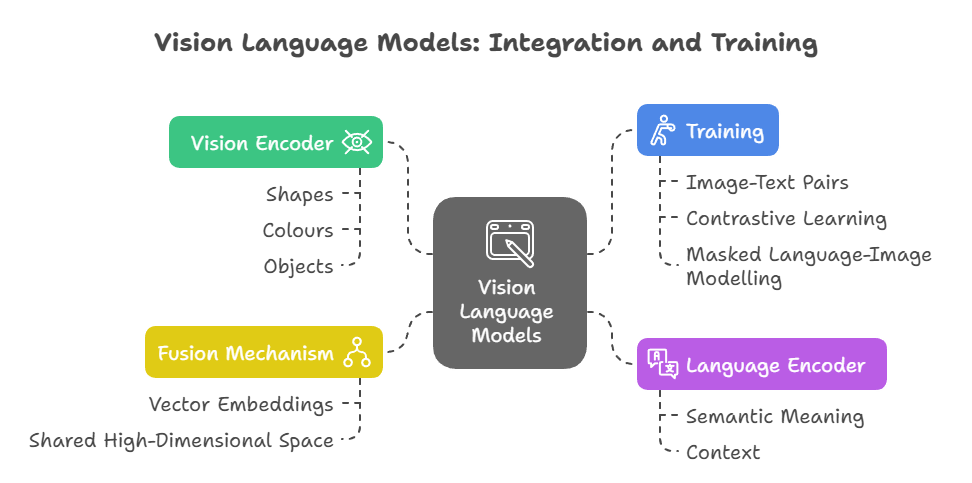
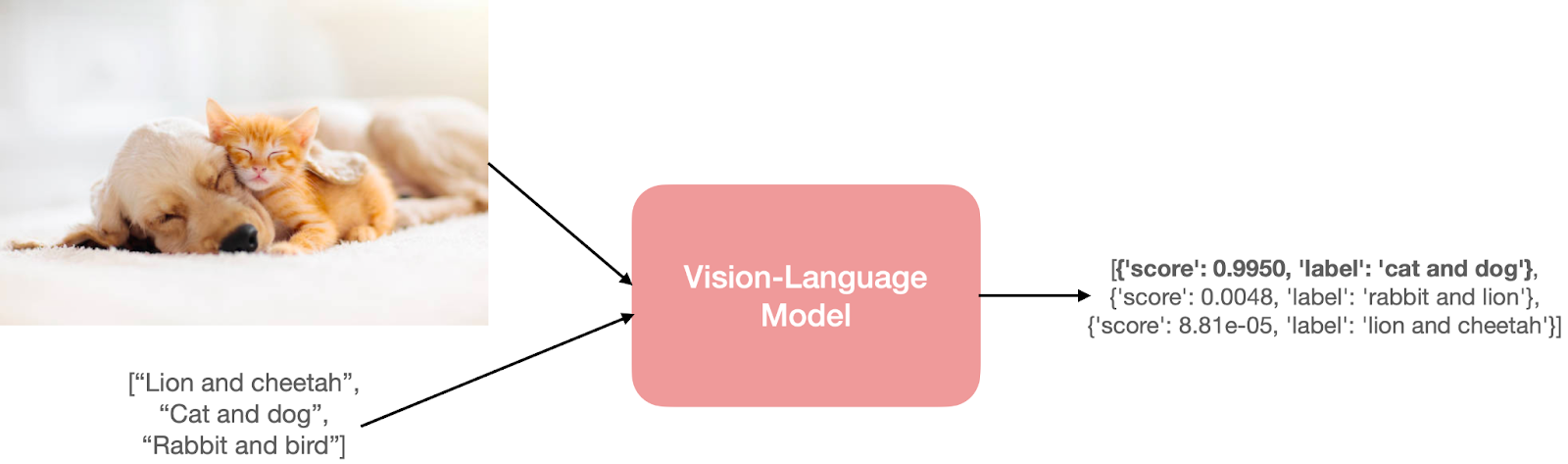
Vision Language Models (VLMs) Explained - GeeksforGeeks
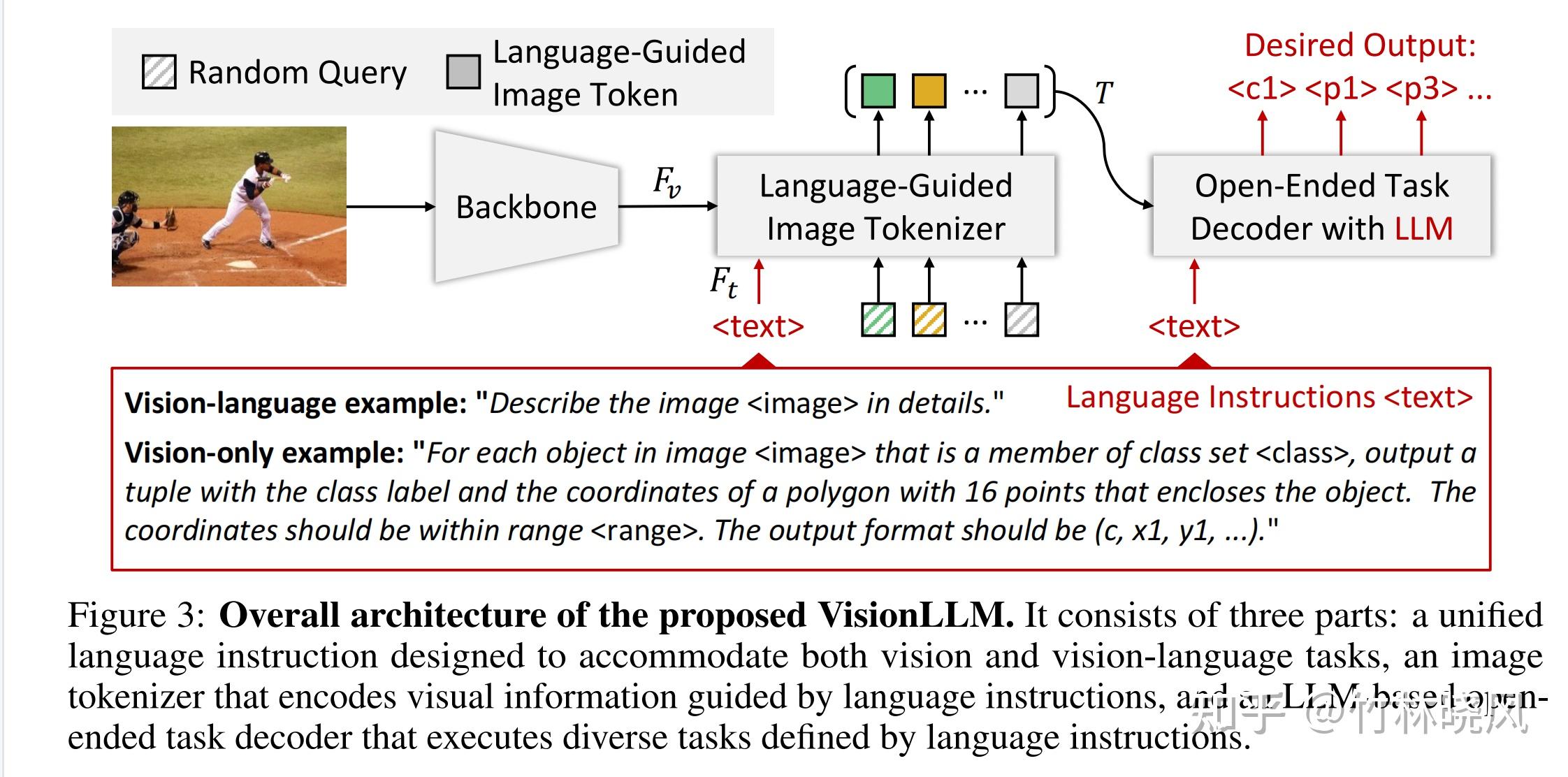
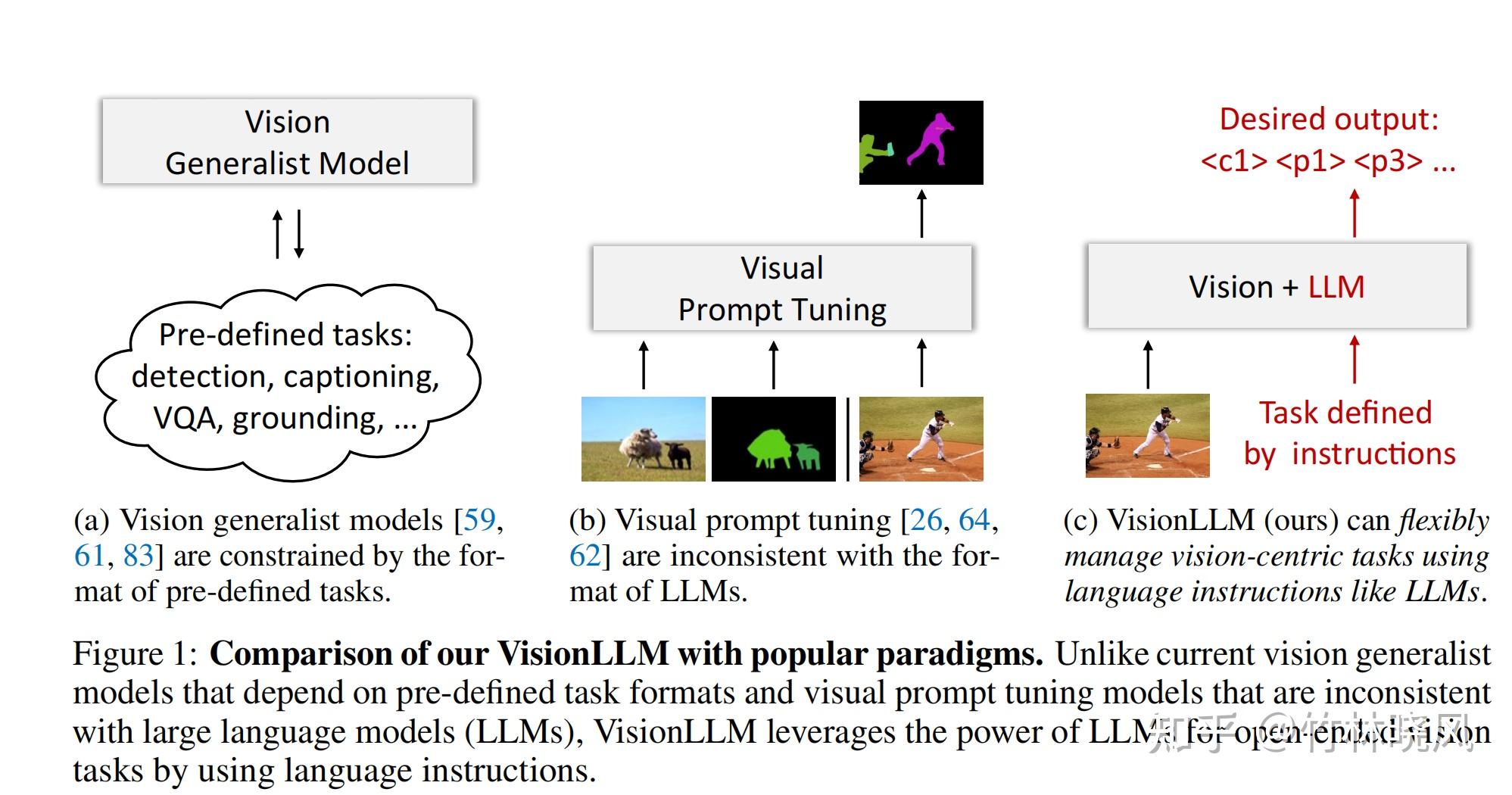
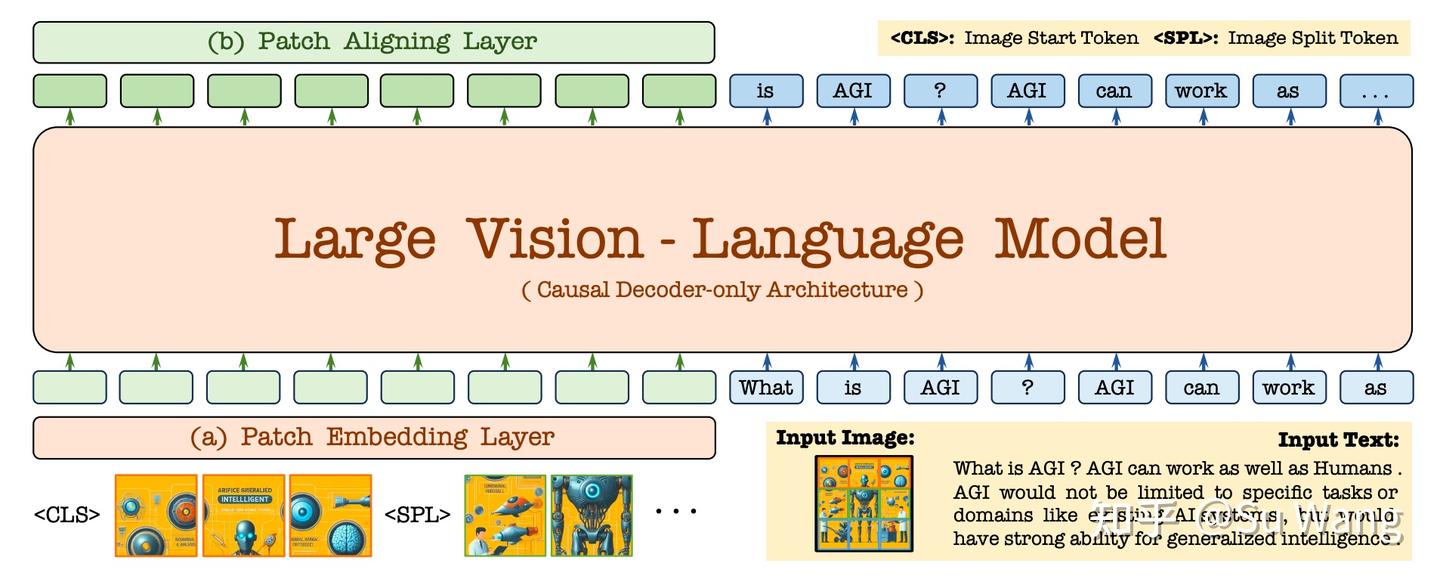
VisionLLM: Large Language Model is also an Open-Ended Decoder for ...
Understanding Vision Language Models
Vision Language Models (VLMs) Explained | DataCamp
Demystifying Vision Language Models (VLMs): The Core of Multimodal AI
Vision Language Models Là Gì? GPT 4o Có Phải Là VLMs Không?
What Are Vision Language Models and How Do They Work? | Definition from ...
Unlock AI Potential with Vision Language Models
Vision Language models: towards multi-modal deep learning | AI Summer
Vision Language Models | Multi Modality, Image Captioning, Text-to ...
Vision Language Models Explained
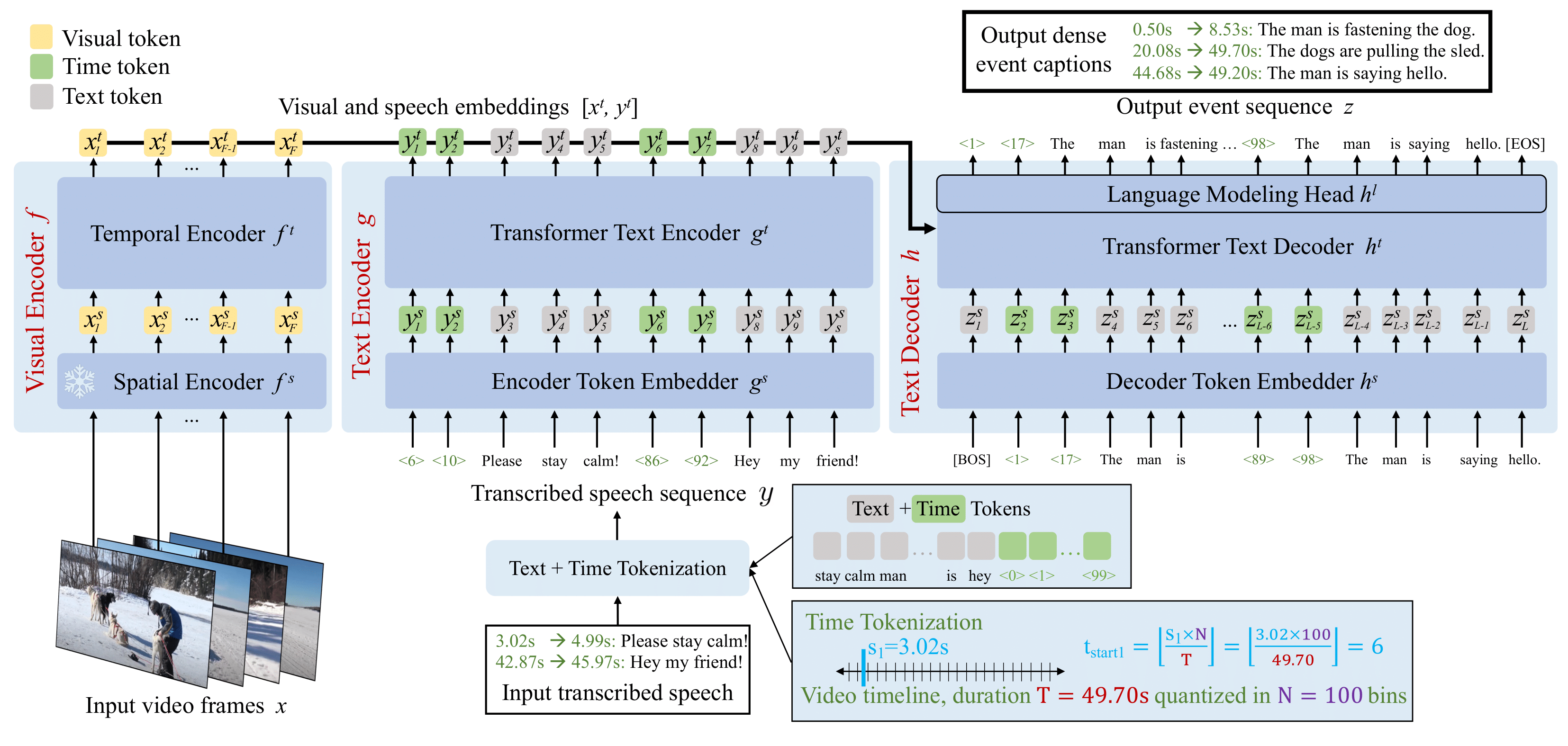
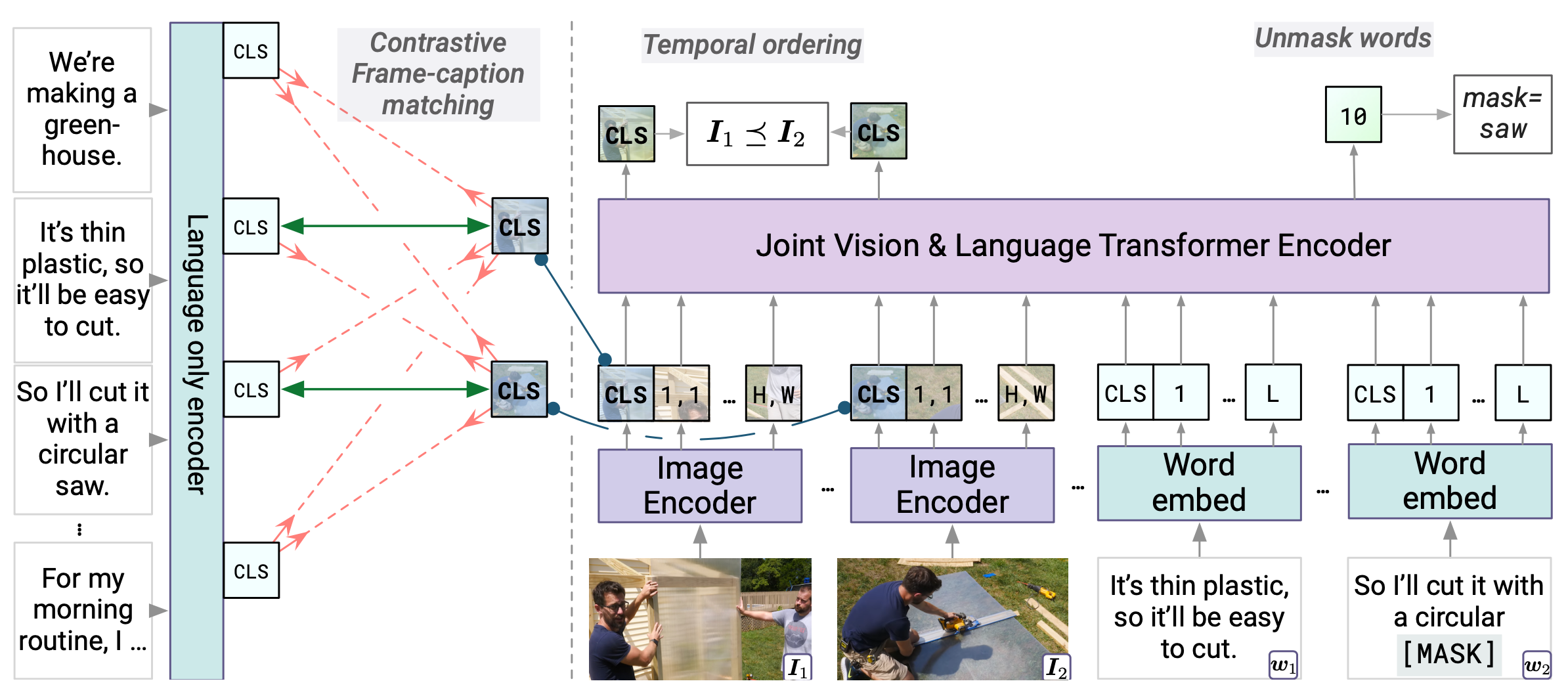
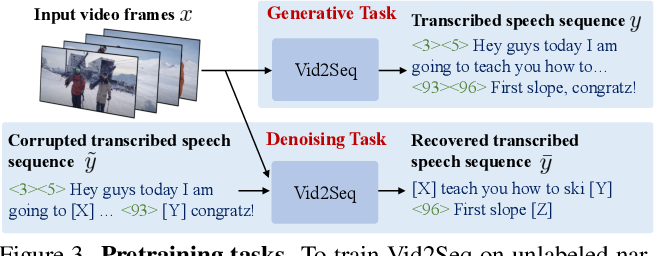
Vid2Seq: a pretrained visual language model for describing multi-event ...
Paper page - VisionLLM: Large Language Model is also an Open-Ended ...
Vision Language Modeling. Can machines truly understand what they… | by ...
Vid2Seq: Large-Scale Pretraining of a Visual Language Model for Dense ...
Revolutionize Technology with Vision Language Models Leading the Way
Decoding SmolVLA: A Vision-Language-Action Model for Efficient and ...
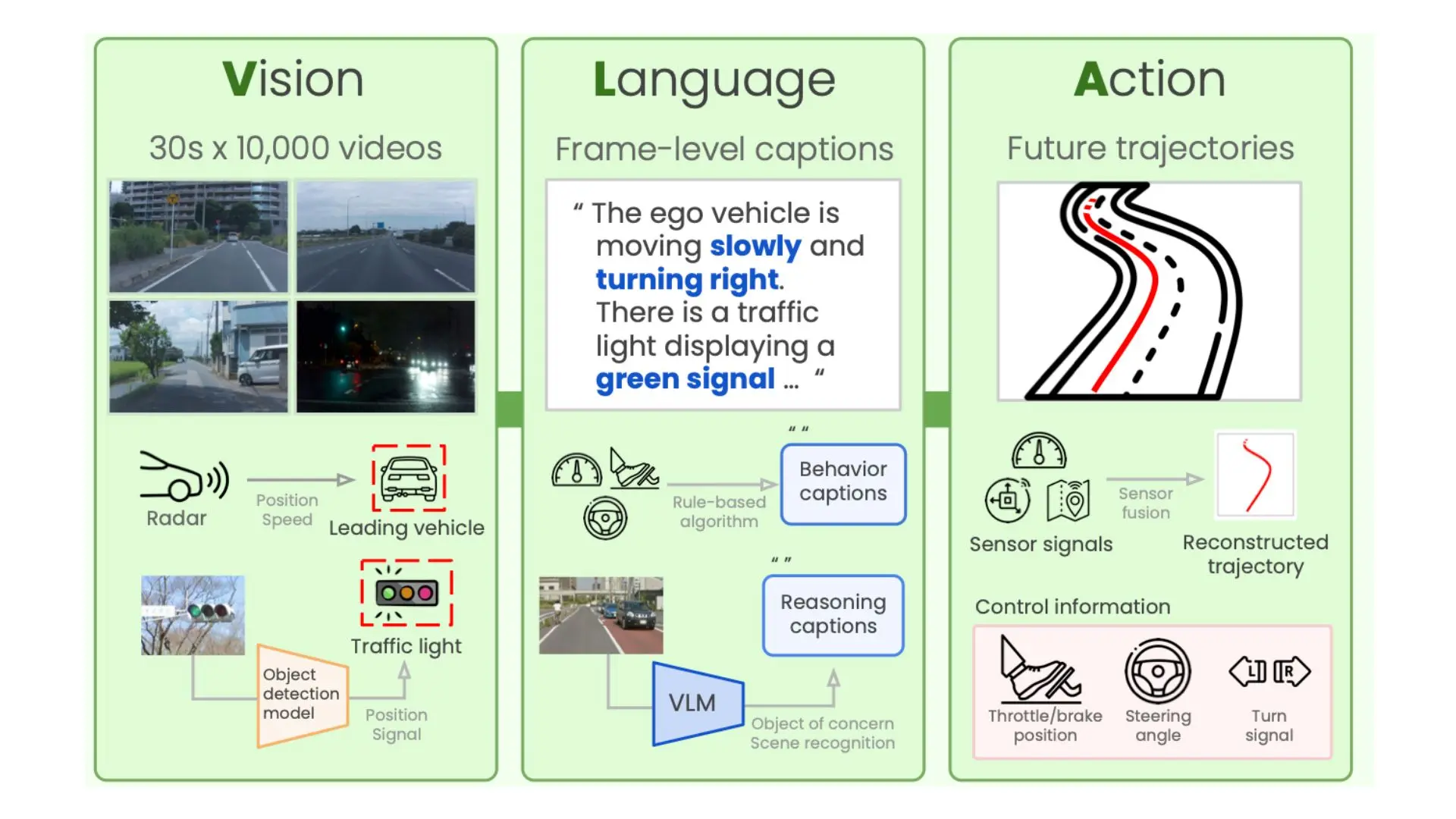
(PDF) Vision Language Models in Autonomous Driving: A Survey and Outlook
A Comparative Evaluation of Open-Source Vision Language Models | QBurst ...
BLIP-2: A new Visual Language Model by Salesforce | BLIP-2 – Weights ...
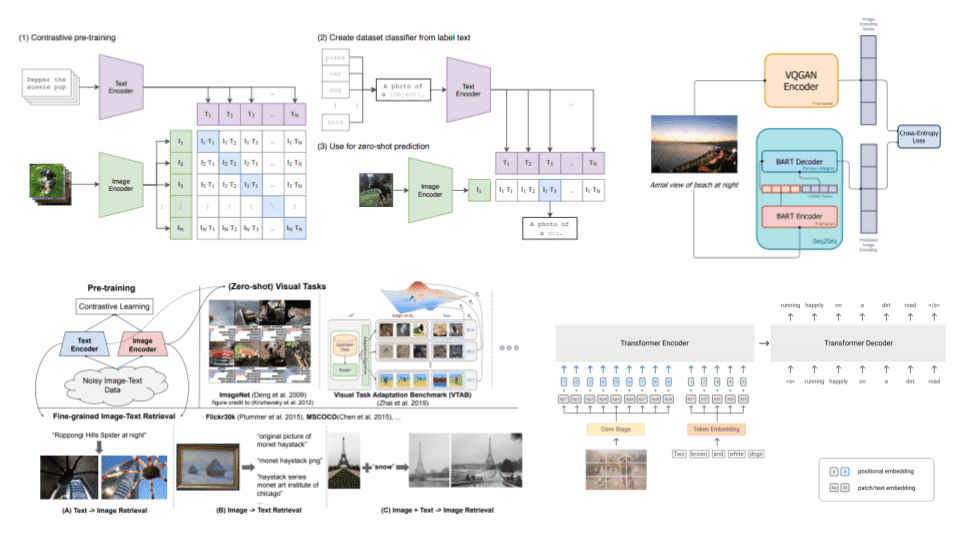
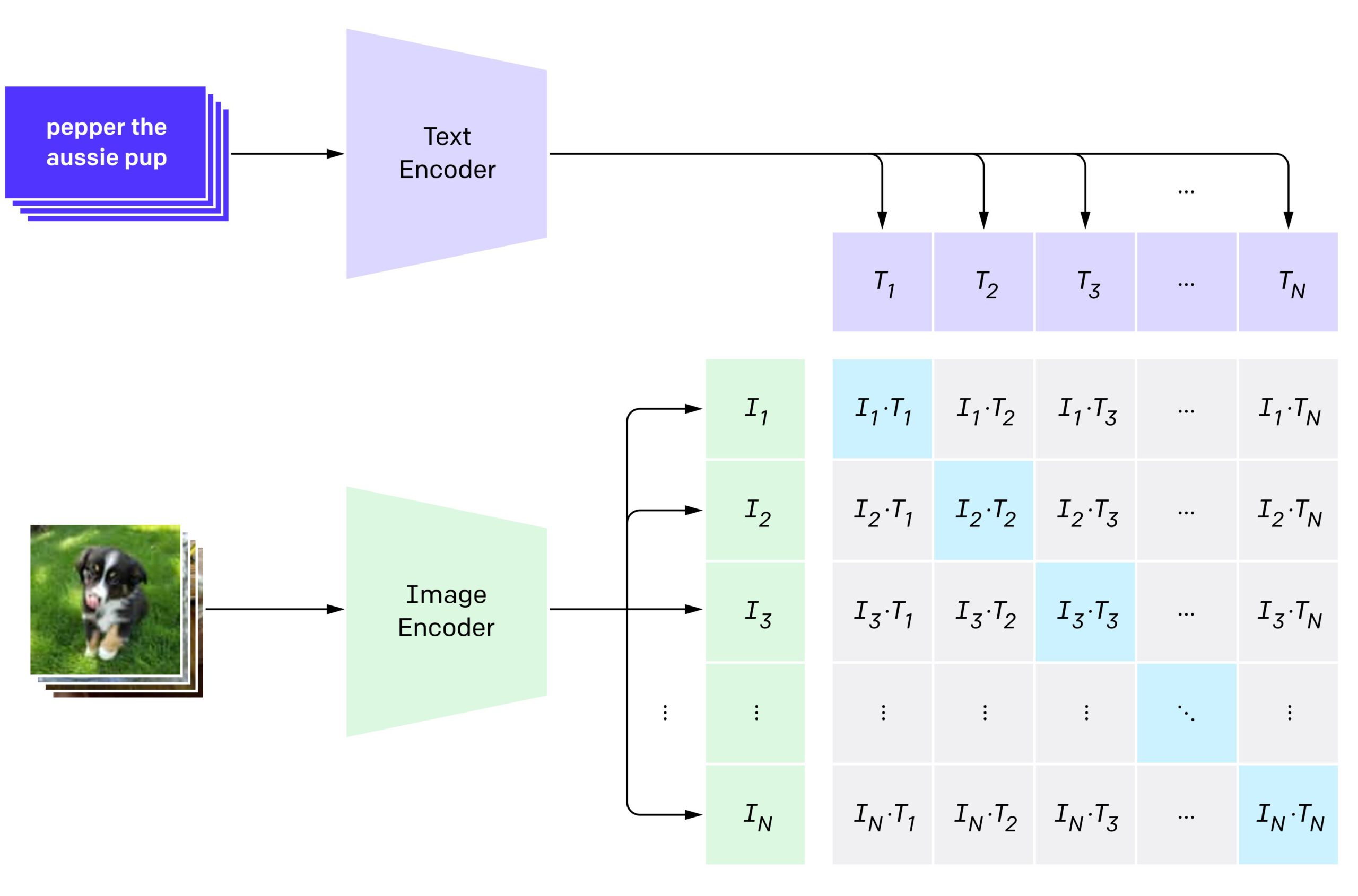
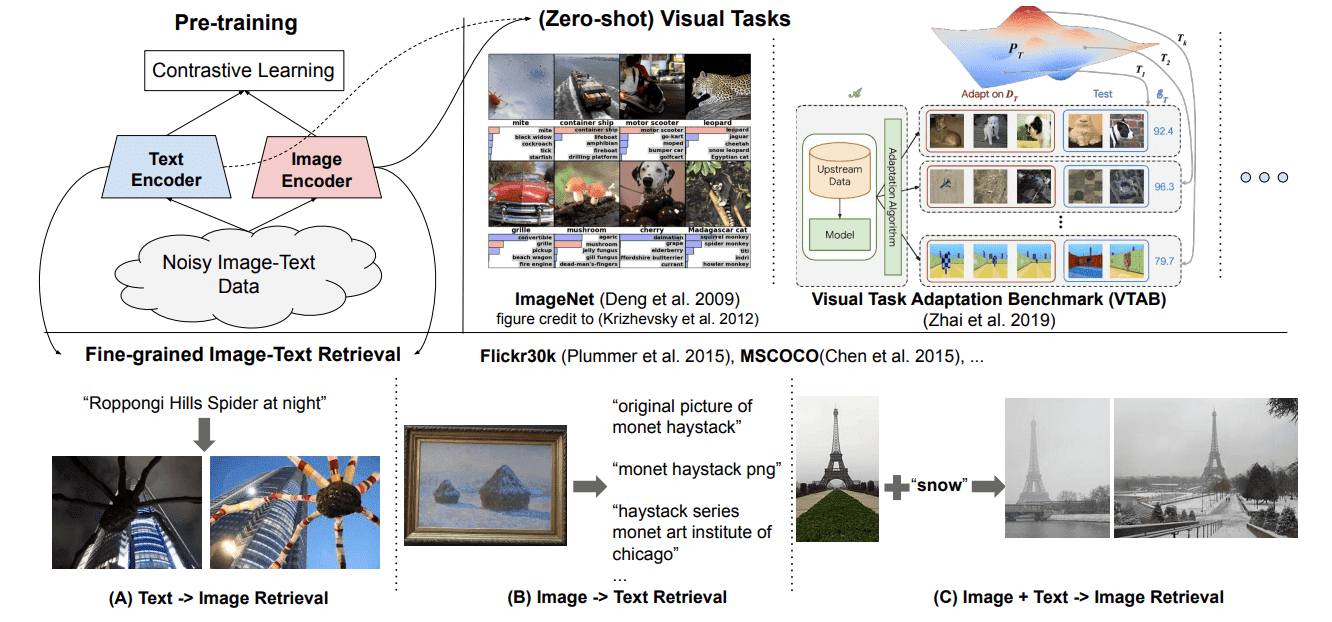
Vision Language Models (Better, faster, stronger)
BrainChat: Decoding Semantic Information from fMRI using Vision ...
Decoding Vision-Language Models: A Developer's Guide
Introduction to Visual-Language Model | by Navendu Brajesh | Medium
Vision AI Agents: How They Work & Real-World Examples
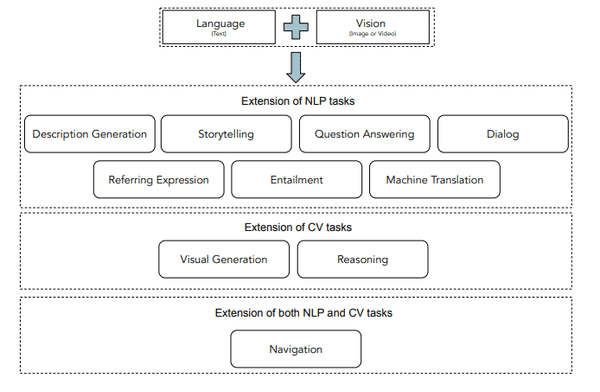
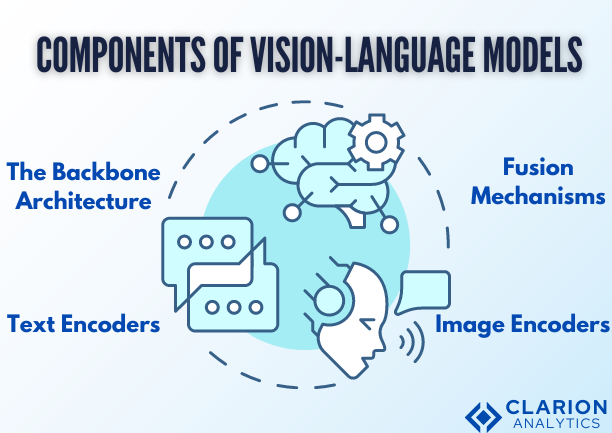
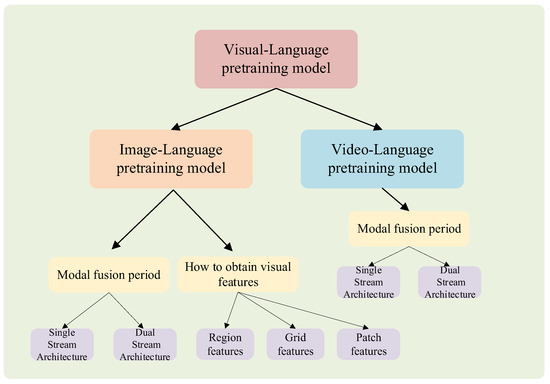
Research Progress on Vision–Language Multimodal Pretraining Model ...
Generalized Visual Language Models | Lil'Log
VLM (Vision Language Model) Explained
VLM (Vision Language Model) Nedir? - OpenZeka Blog
SpecVLM: Fast Speculative Decoding in Vision-Language Models | alphaXiv
“Bridging Vision and Language: Designing, Training and Deploying ...
What Are Visual Language models (VLMs) And How Do They Work? - TopDailyBlog
Vision-Language Model - a hllj Collection
Decoding Vision-Language Models: A Comprehensive Examination - Only AI ...
Vision-Language Models for Vision Tasks: A Survey - 知乎
NVIDIA PRISMER A Vision-Language Model with An Ensemble of Experts High ...
Alibaba Cloud Releases Qwen2-VL, an Advanced Vision-Language Model for ...
A Guide to Implement the Vision Encoder for LLaVA | Medium
[2211.12402] X2-VLM: All-In-One Pre-trained Model For Vision-Language Tasks
Bridging Vision and Language: Exploring CLIP, BLIP, and OWL-ViT | by ...
Expanding scene and language understanding with large-scale pre ...
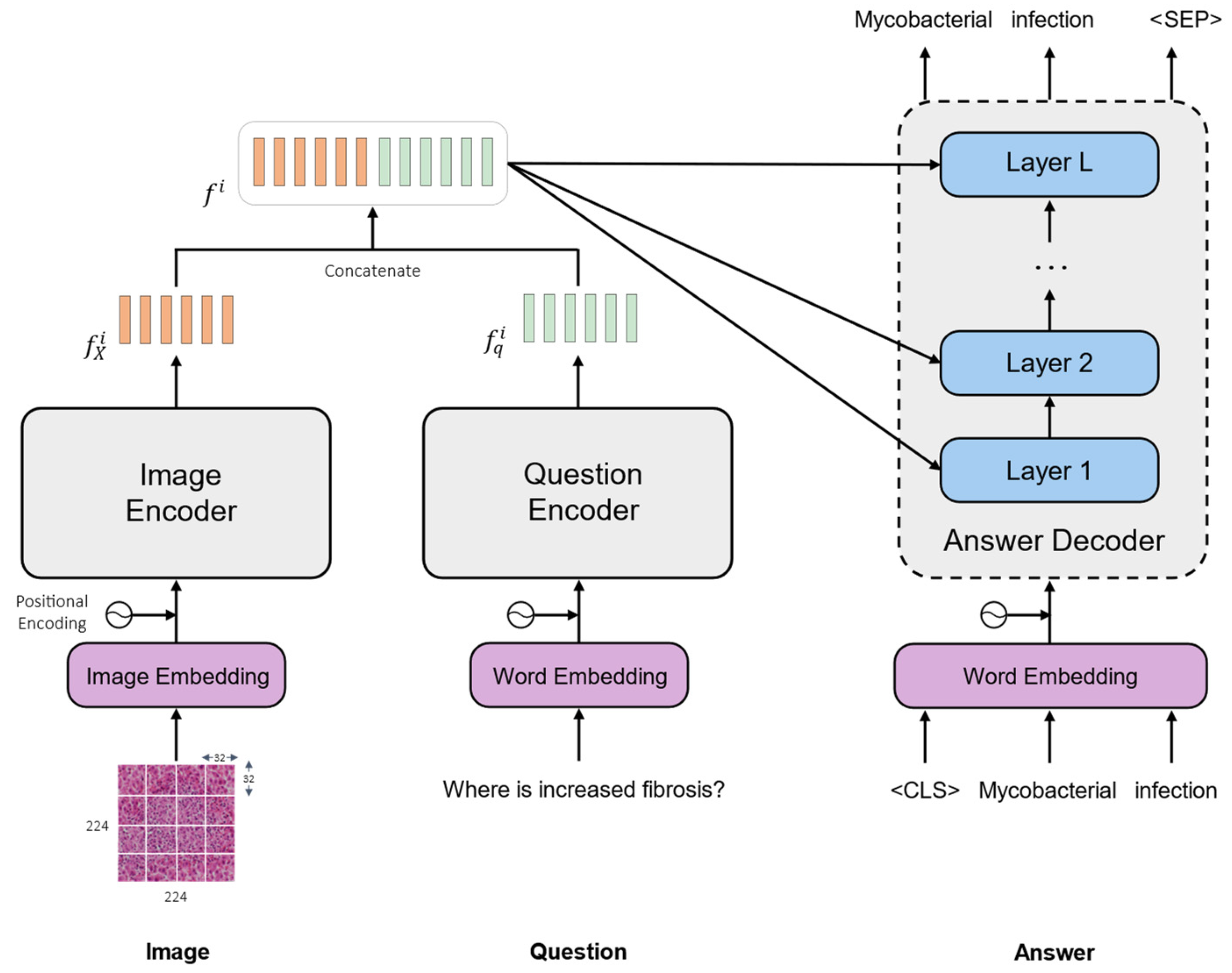
Vision–Language Model for Visual Question Answering in Medical Imagery
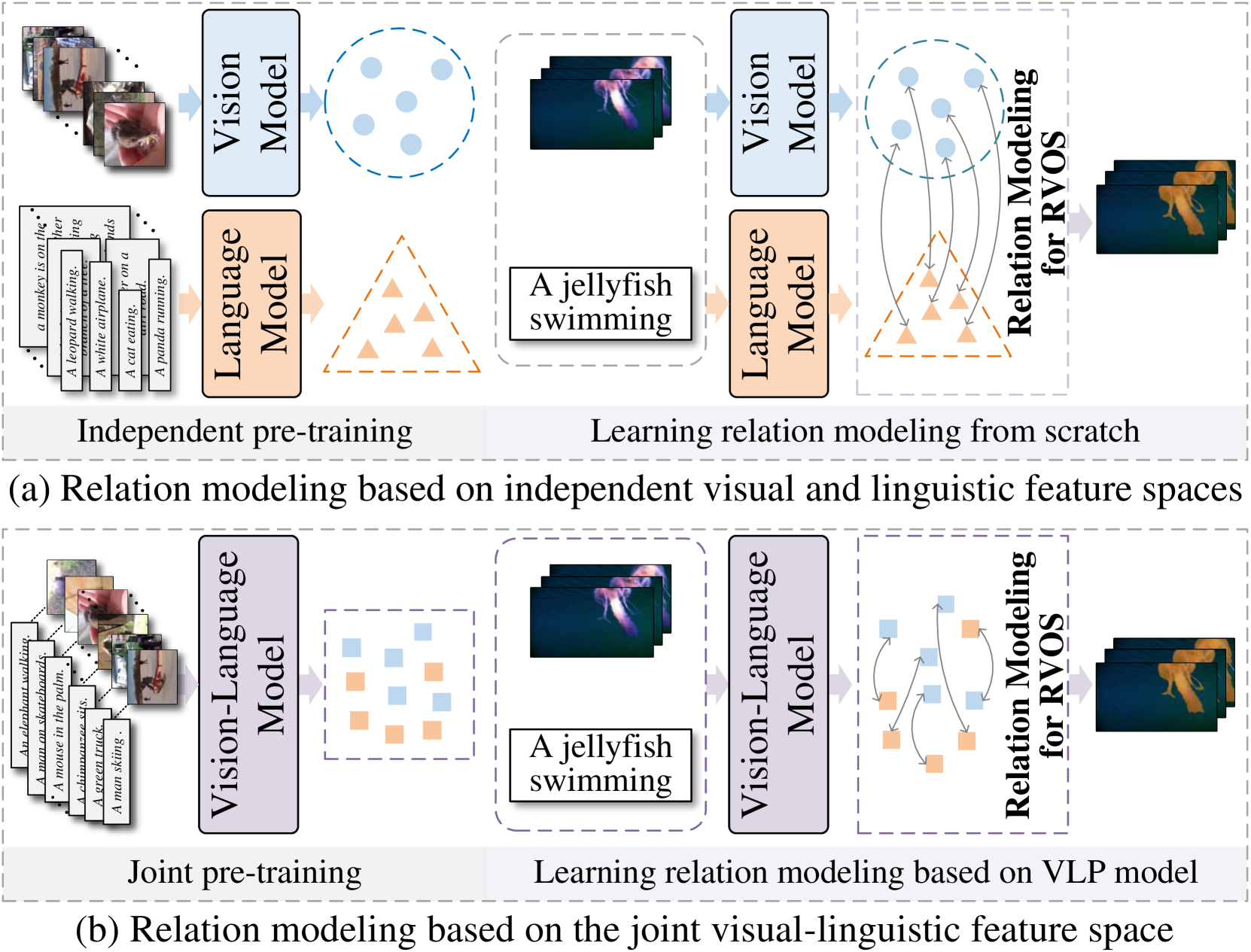
Driving Referring Video Object Segmentation with Vision-Language Pre ...
Exploring Multimodal Large Language Models: A Step Forward in AI | by ...
What is Visual Language Model? - Tech Blogger
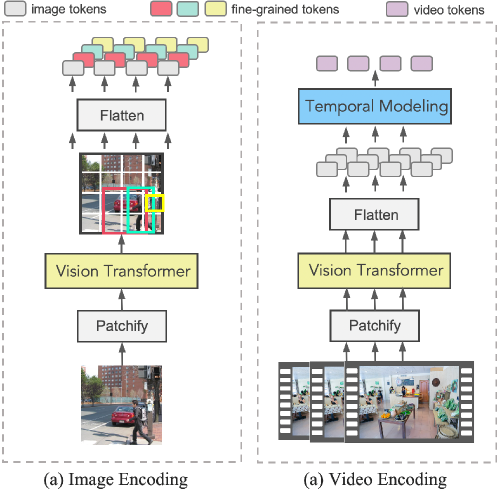
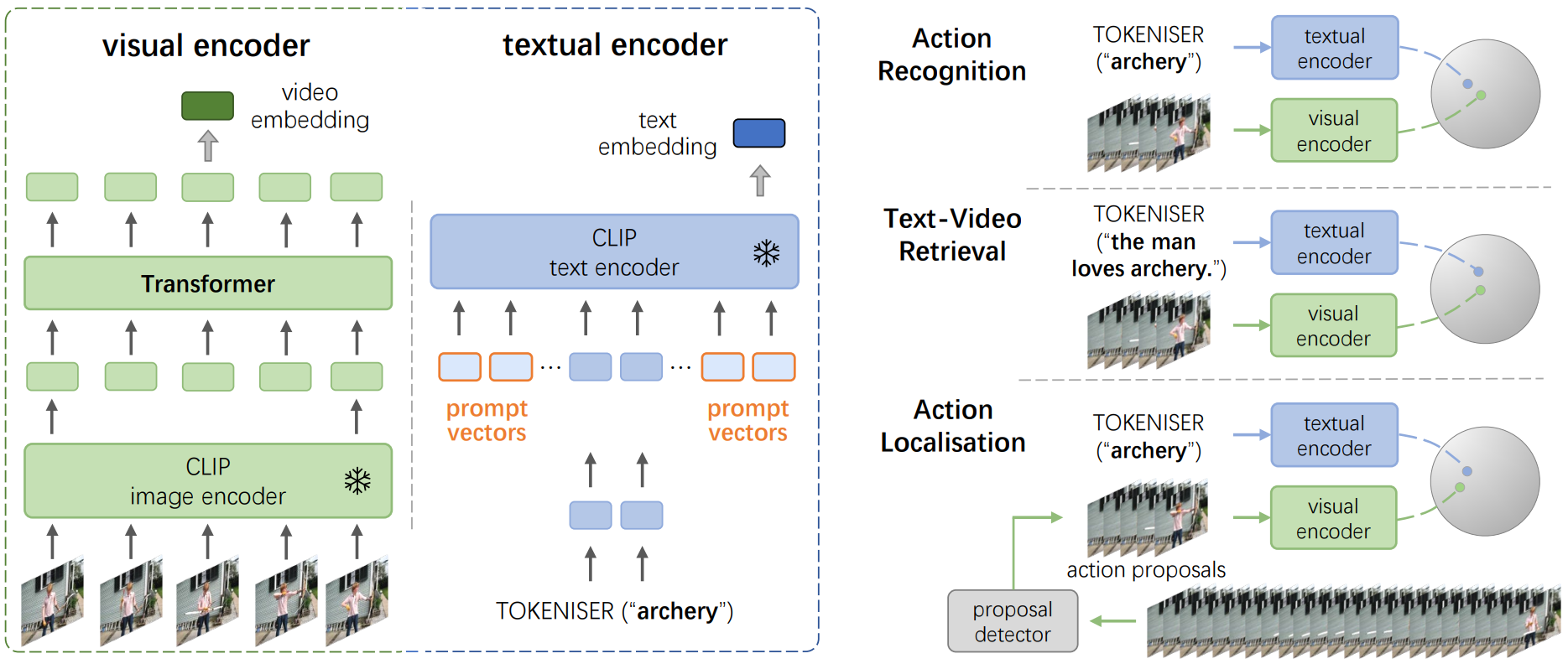
Prompting Visual-Language Models for Efficient Video Understanding
An overview of the language decoding. It consists of three parts: (1 ...
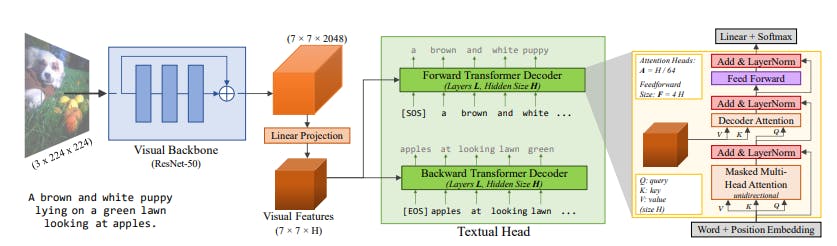
Figure 3 from Vid2Seq: Large-Scale Pretraining of a Visual Language ...
Aman's AI Journal • Primers • Overview of Vision-Language Models
Integrating Image-To-Text And Text-To-Speech Models (Part 1) — Smashing ...
A Dive into Vision-Language Models
Vision-Language-Action Models for Robotics: A Review Towards Real-World ...
How Vision-Language-Action Models Powering Humanoid Robots
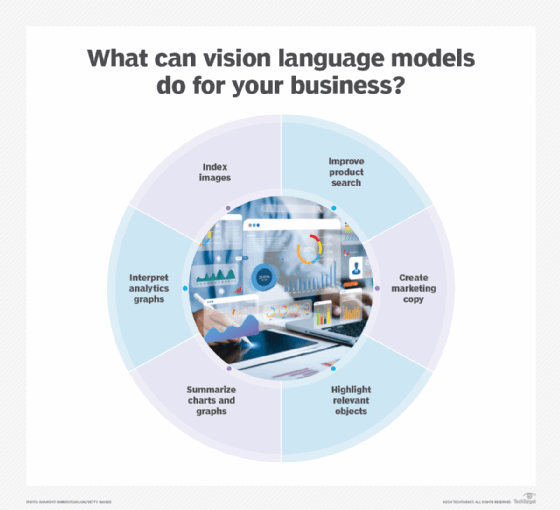
Applications of Vision-Language Models - Real World Use Cases
Learning the Visualness of Text Using Large Vision-Language Models ...
What Is Vision-Language Model: A-to-Z Guide for Beginners!
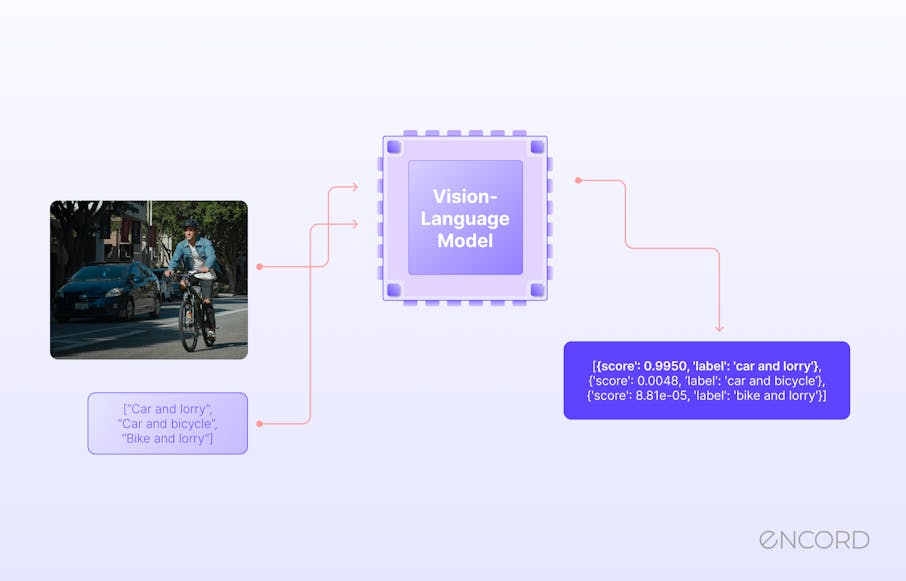
Vision-Language Models: How They Work & Overcoming Key Challenges | Encord
Paper page - Vision-Language-Action Models: Concepts, Progress ...
Mitigating Object Hallucinations in Large Vision-Language Models ...
[paper reading] Unveiling Encoder-Free Vision-Language Models(无编码器视觉语言 ...
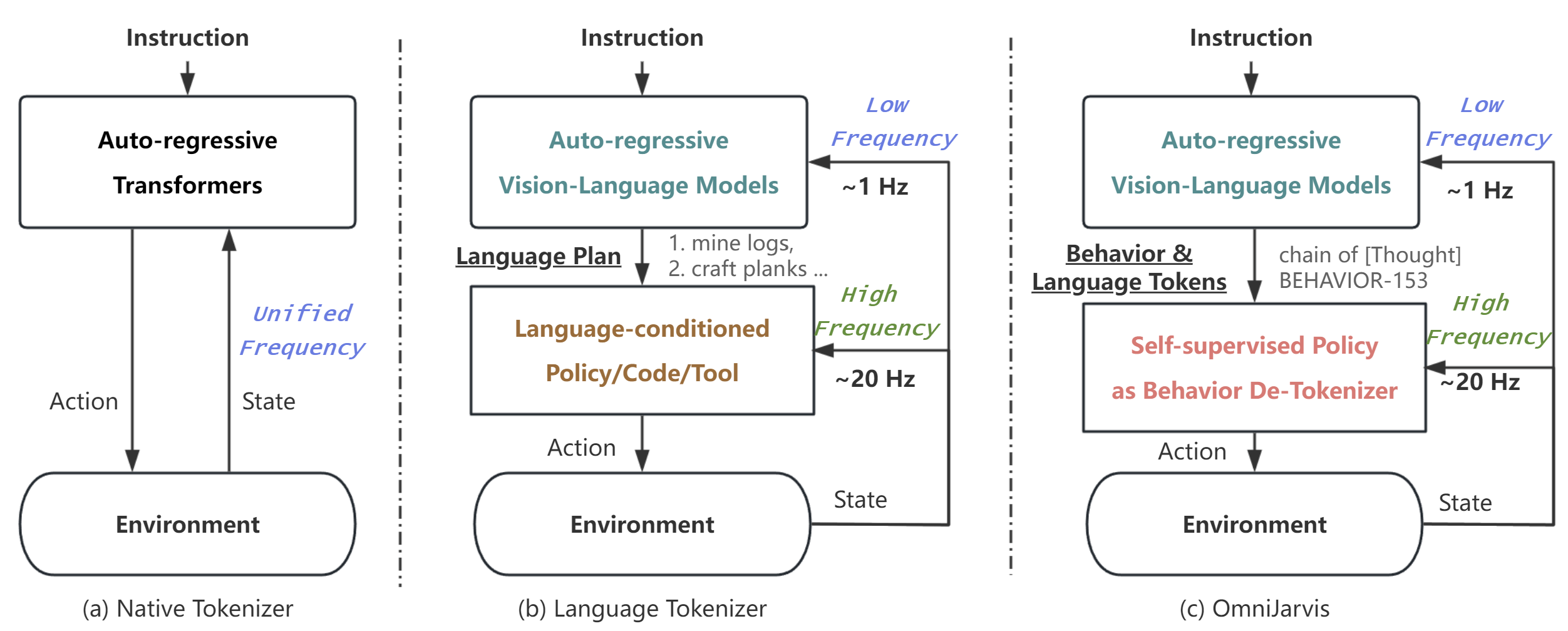
OmniJARVIS: Unified Vision-Language-Action Tokenization Enables Open ...
Vision-language models for medical report generation and visual ...
(PDF) Controlling Vision-Language Models for Universal Image Restoration
A Survey on Vision-Language-Action Models for Embodied AI: Paper and Code
What are Vision-Language Models? | NVIDIA Glossary
Vision-language models from scratch in colab | by Nate Nethercott | Medium
DeepSeek-AI Introduces DeepSeek-VL: An Open-Source Vision-Language (VL ...
Mitigating Hallucinations in Large Vision-Language Models with ...
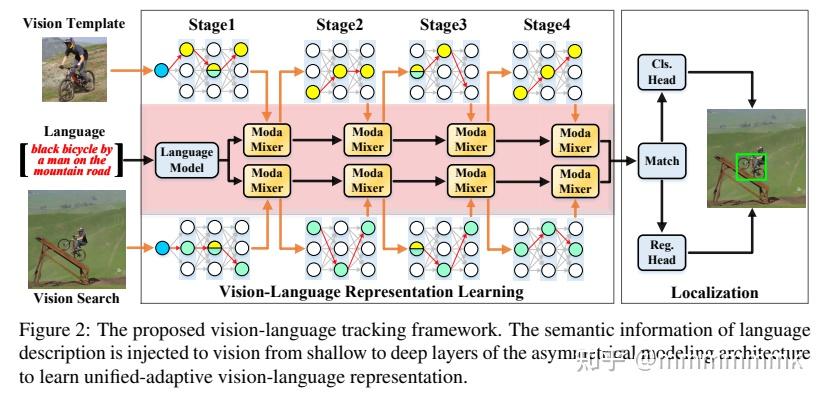
Divert More Attention to Vision-Language Tracking - 知乎
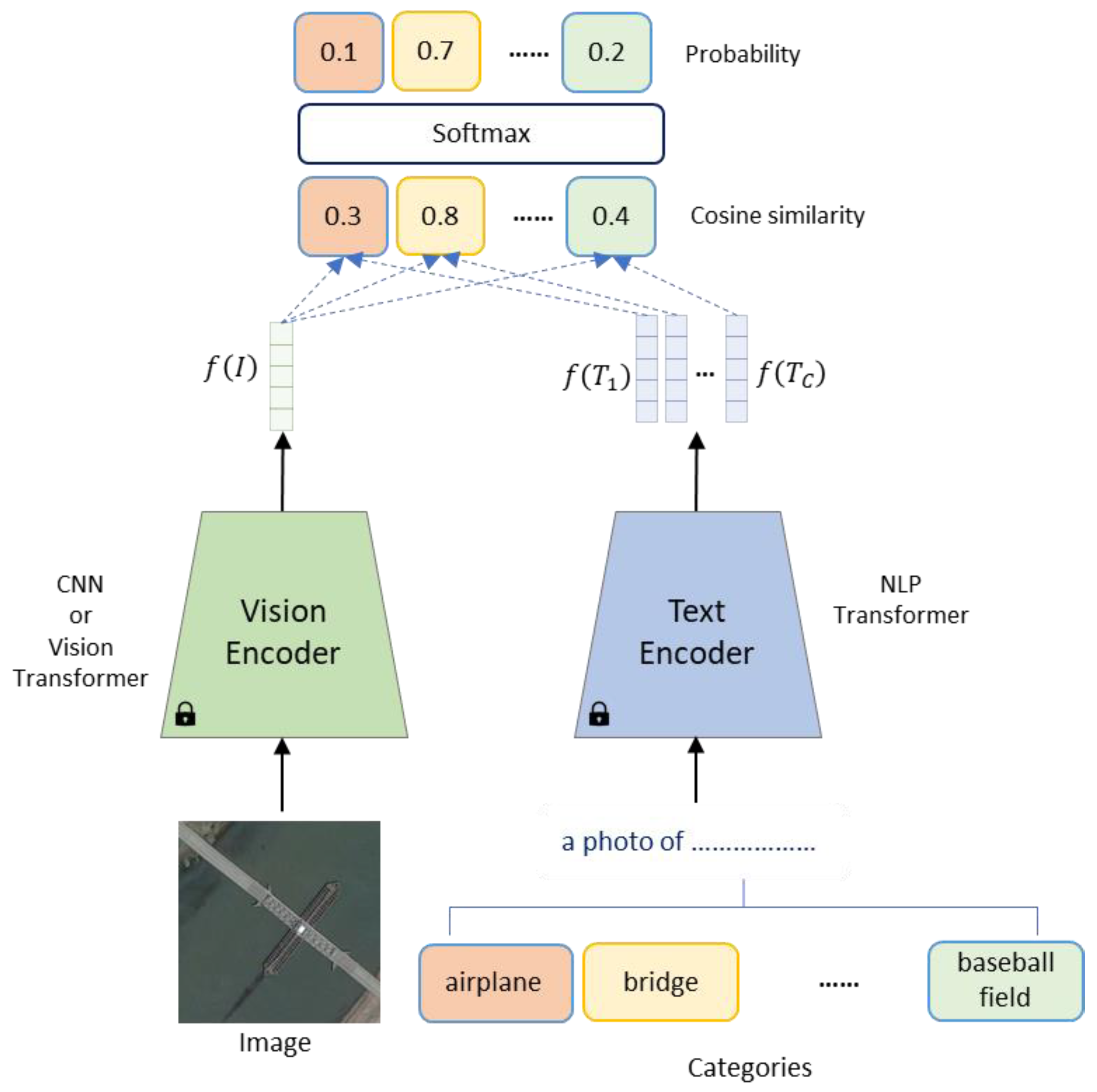
Advancements in Vision–Language Models for Remote Sensing: Datasets ...
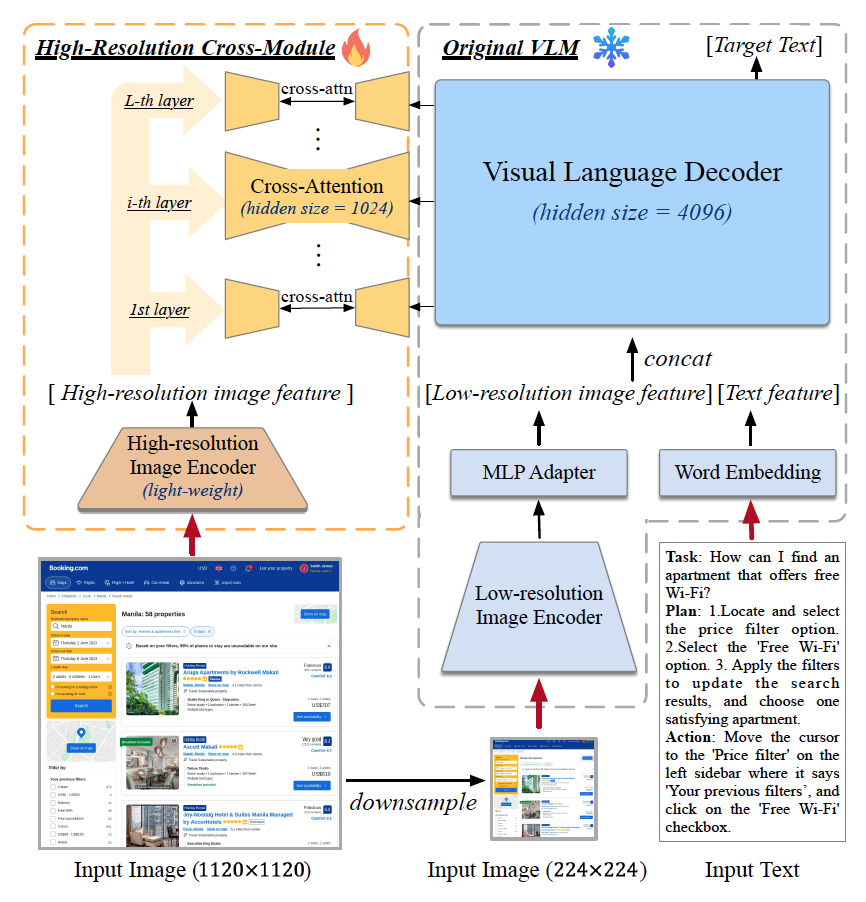
Breaking resolution curse of vision-language models
Mitigating Hallucination in Visual-Language Models via Re-Balancing ...
Vision-Language Models for Medical Report Generation and Visual ...
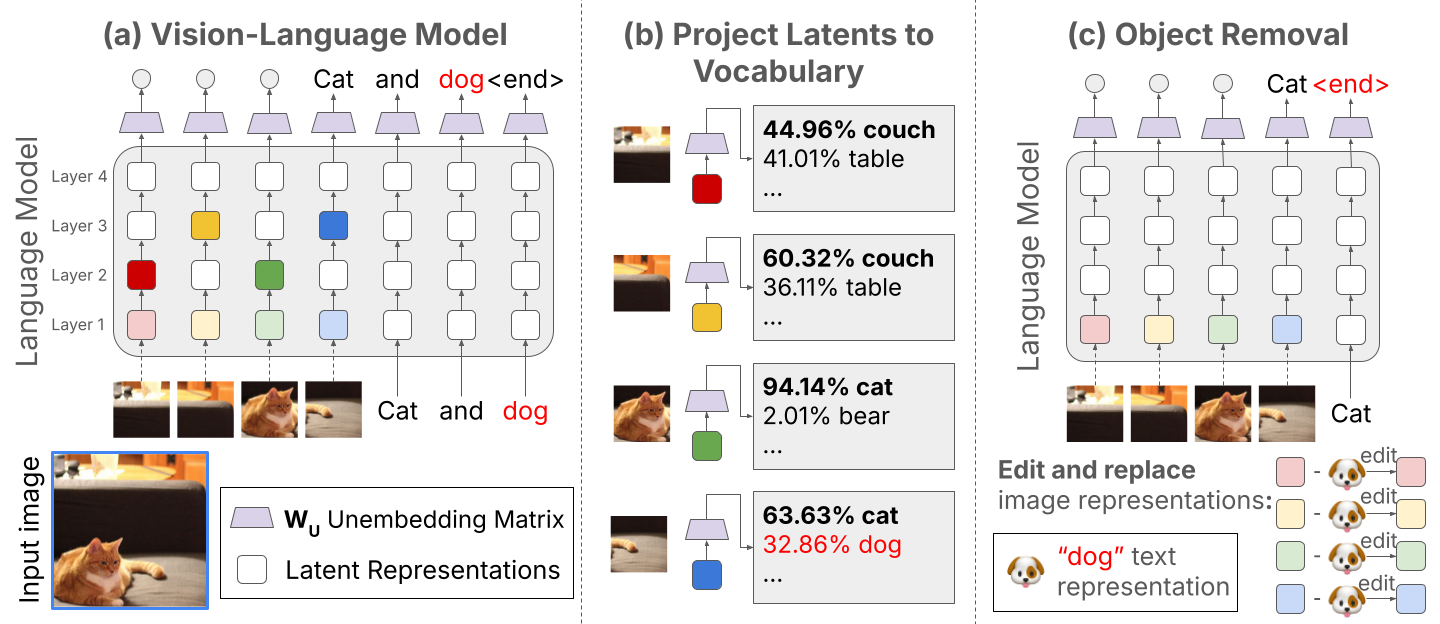
Interpreting and Editing Vision-Language Representations to Mitigate ...
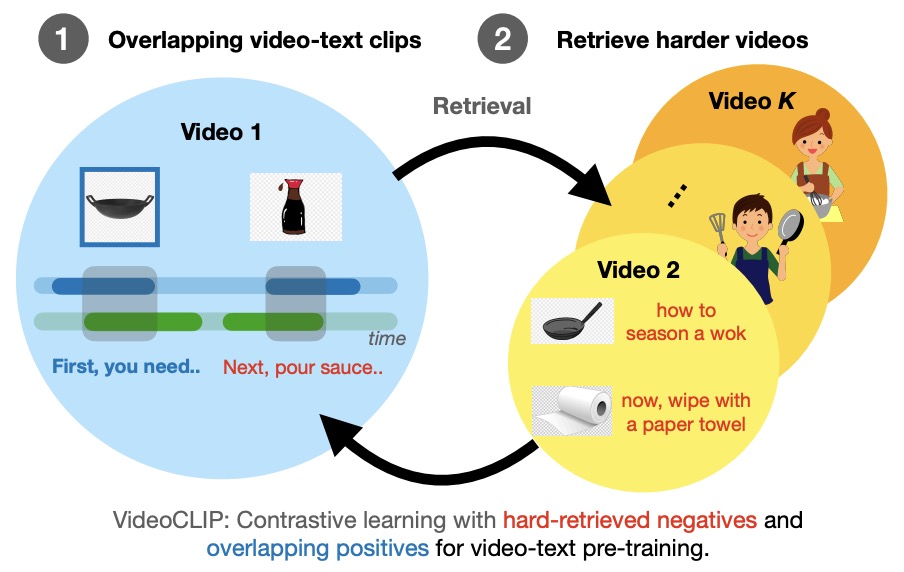
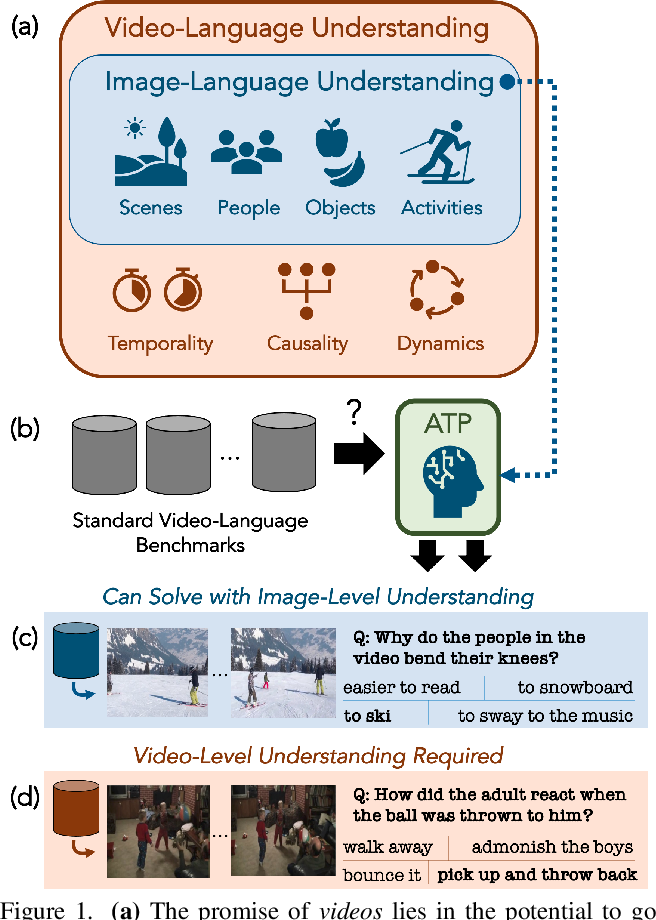
Figure 1 from Revisiting the “Video” in Video-Language Understanding ...
视觉语言模型 (更好、更快、更强)
Vision-Language Models for Zero-Shot Classification of Remote Sensing ...
Google DeepMind Researchers Utilize Vision-Language Models to Transform ...
Florence-2: Revolutionizing Vision-Language Models with Lightweight ...
Introduction to Vision-Language Modeling: Challenges and Applications ...
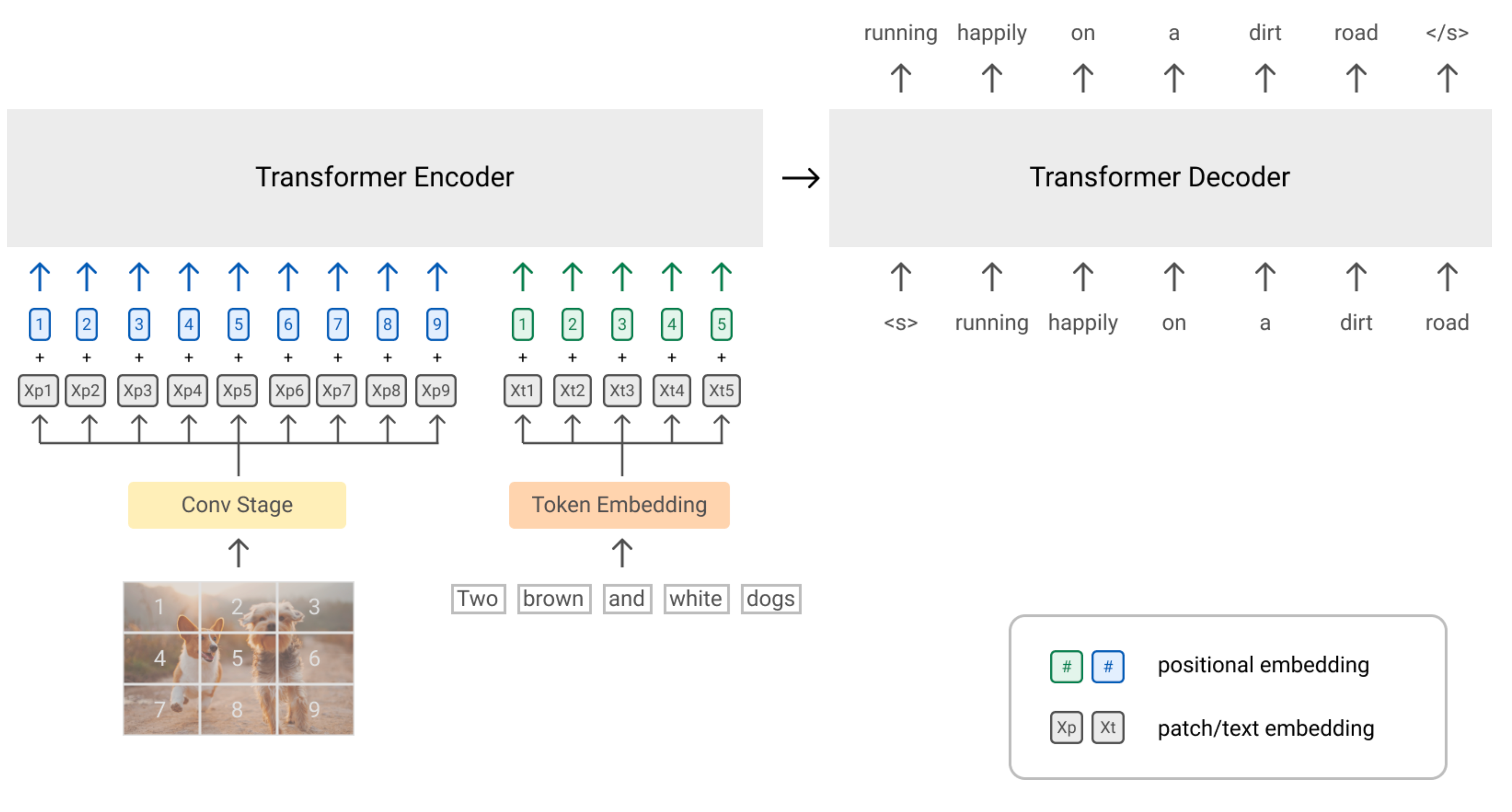
Vision-Language-Model-from-scratch-in-Pytorch/VLMfrom scratch.py at ...
Fine-tuning Vision-Language Models with LoRA: A Practical Guide | by ...
A Deep Dive into VLMs: Vision-Language Models | by Sunidhi Ashtekar ...
BRAVE: Broadening the visual encoding of vision-language models [ECCV ...
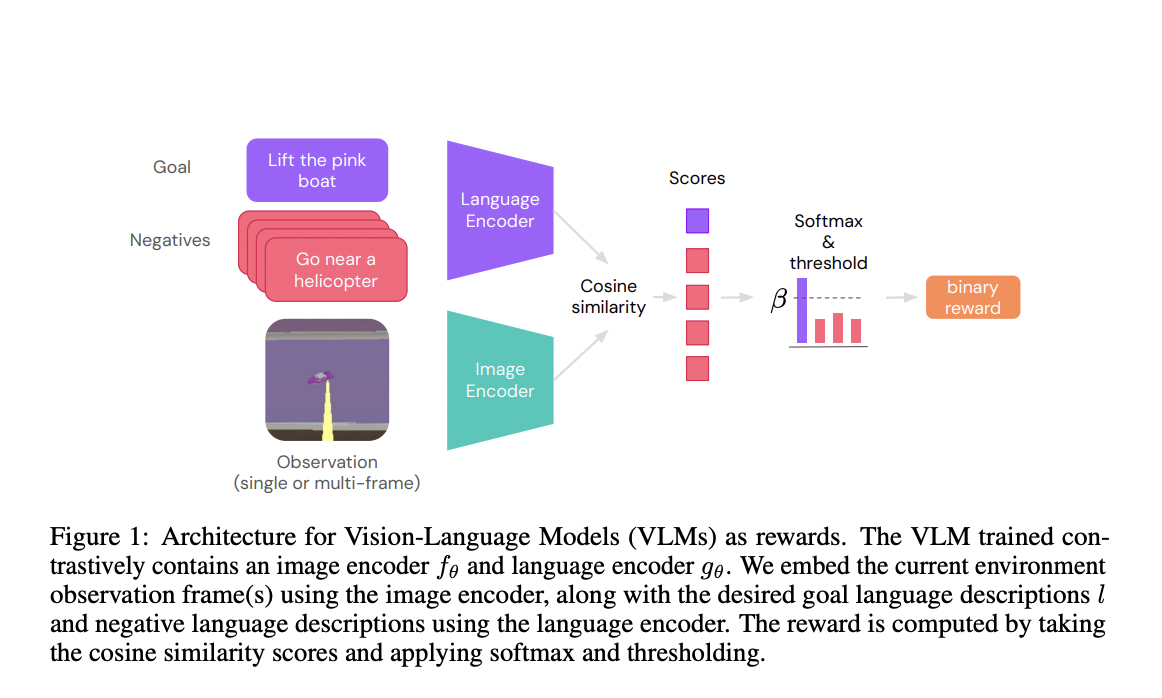
Vision-language models that can handle multi-image inputs - Amazon Science