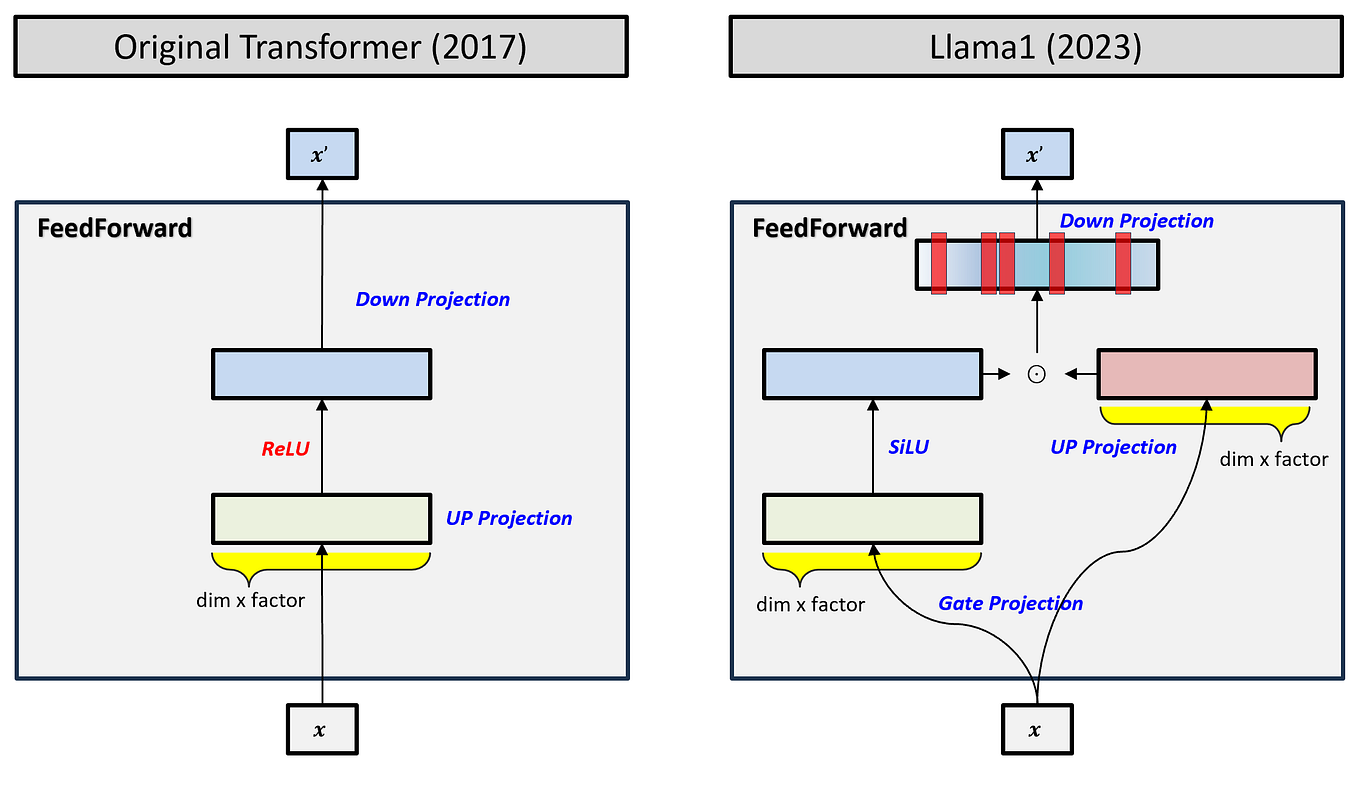
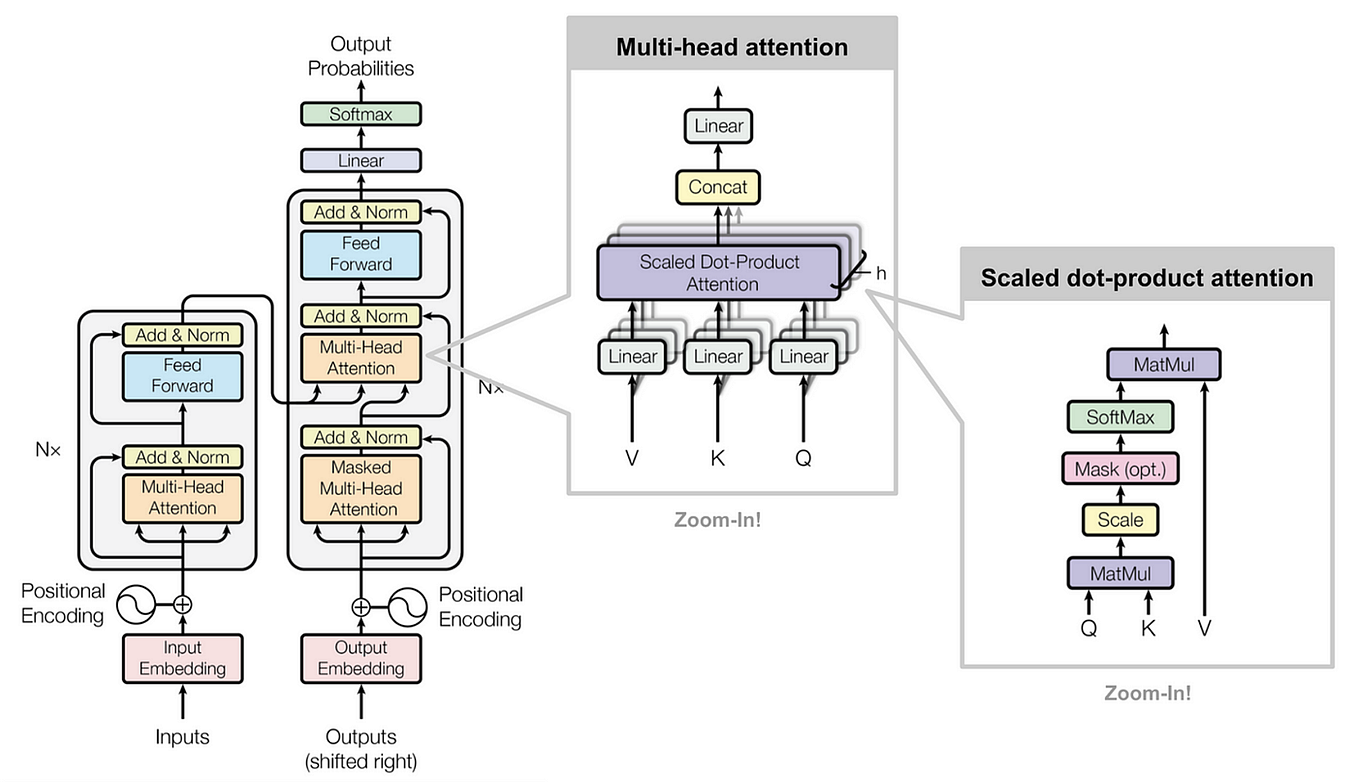
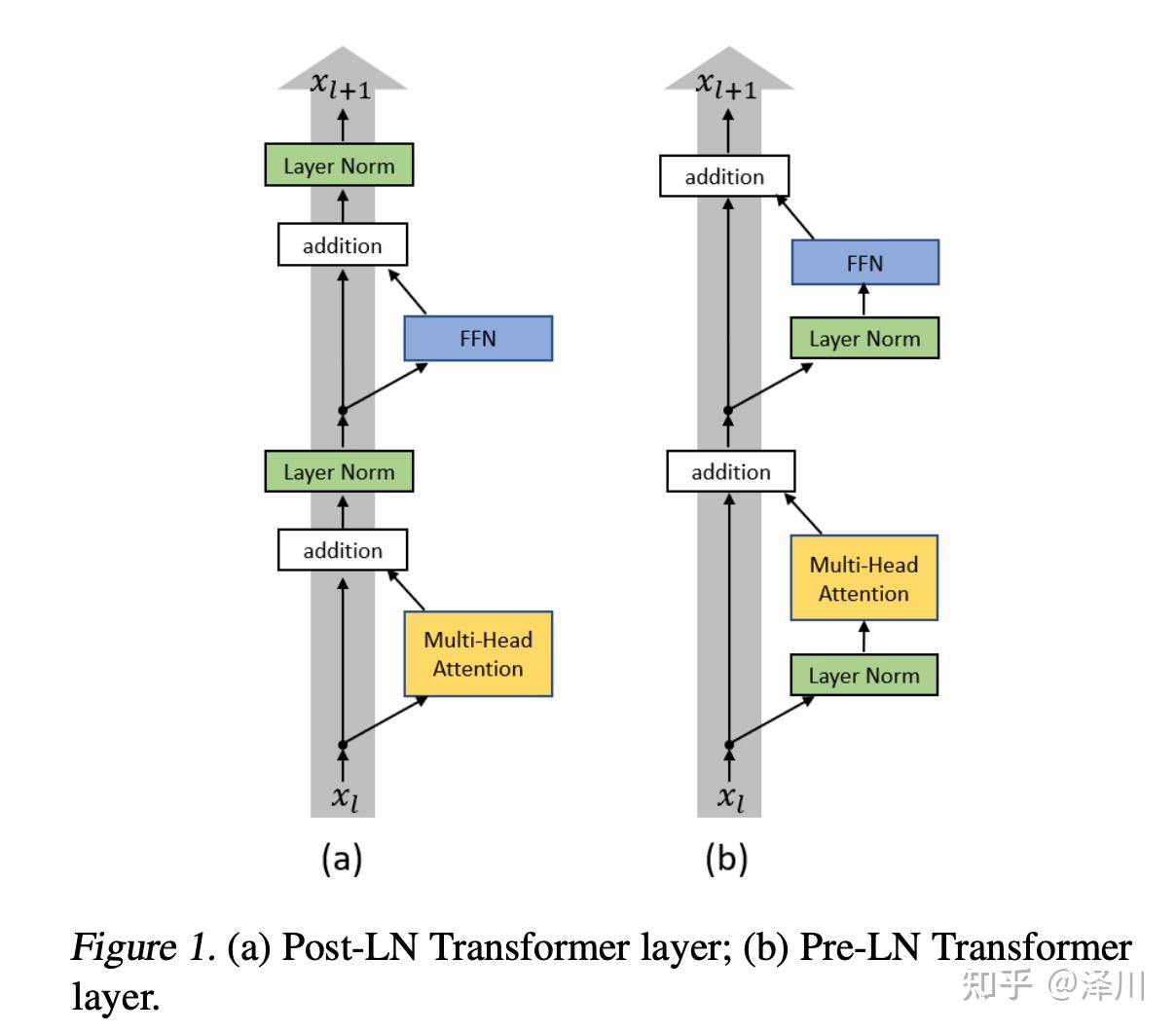
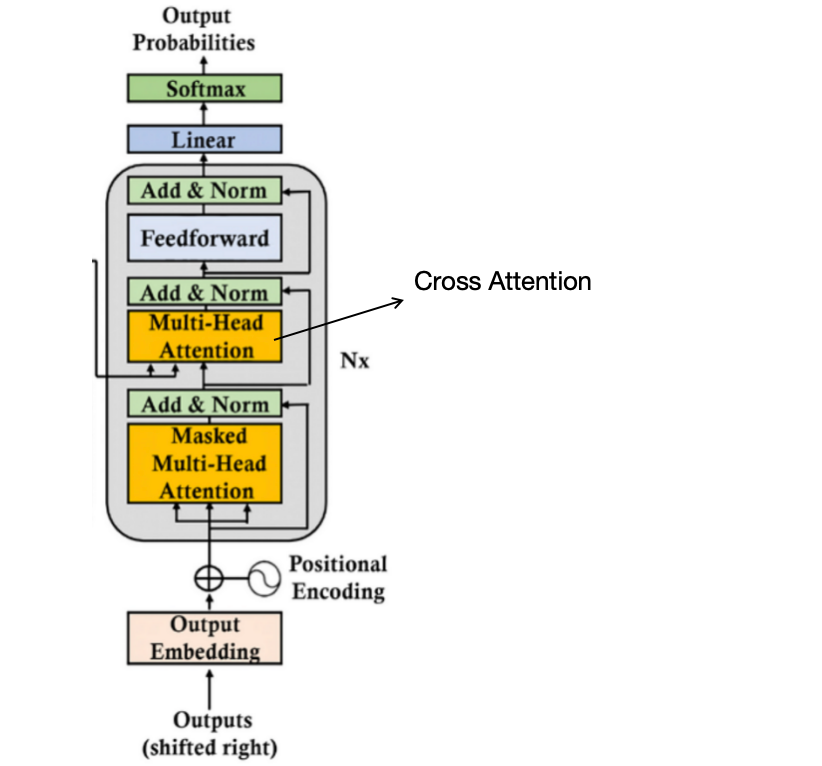
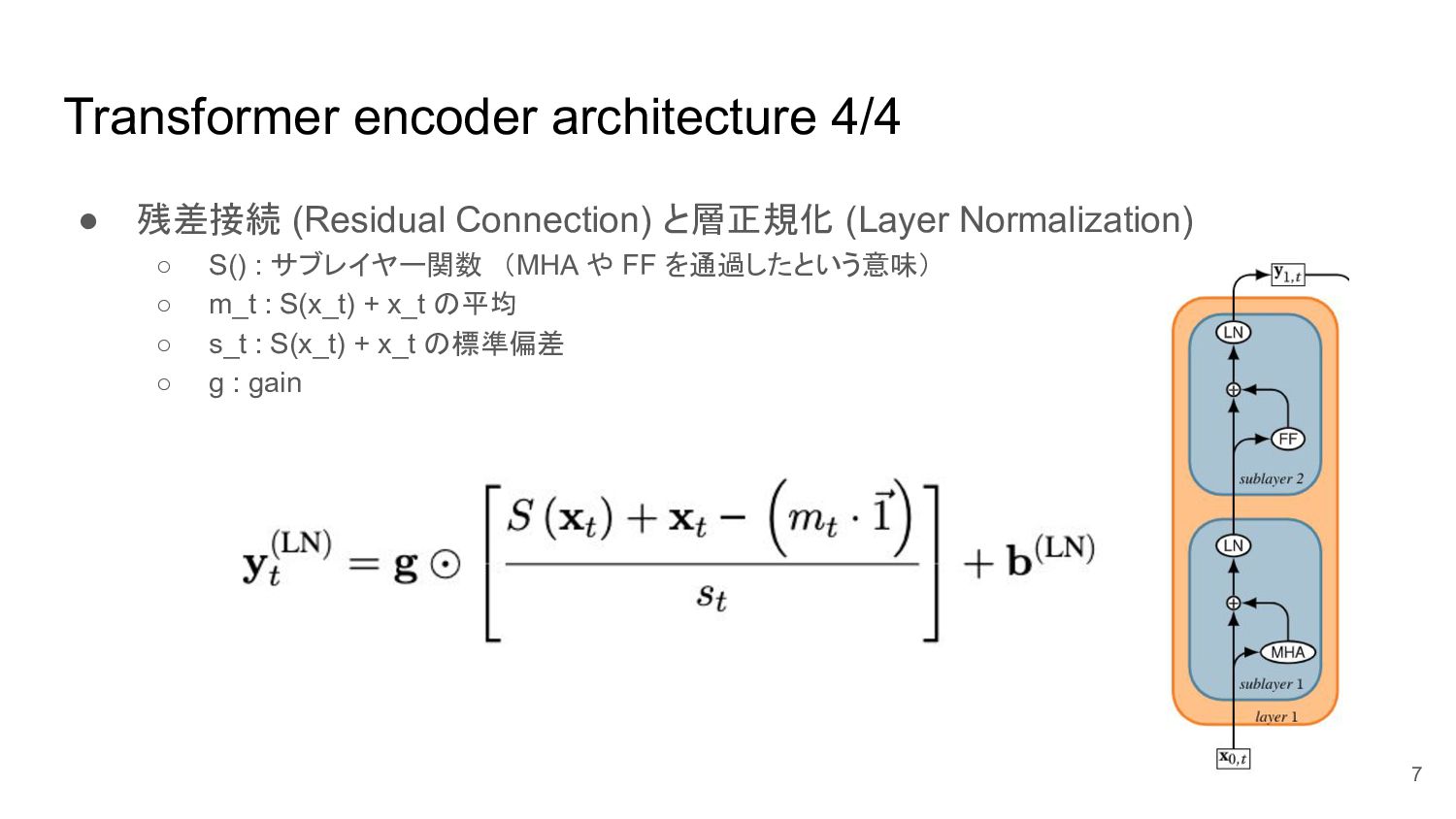
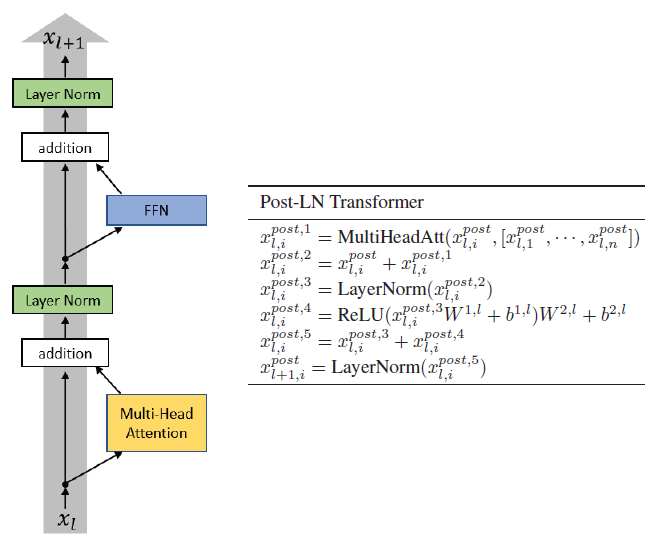
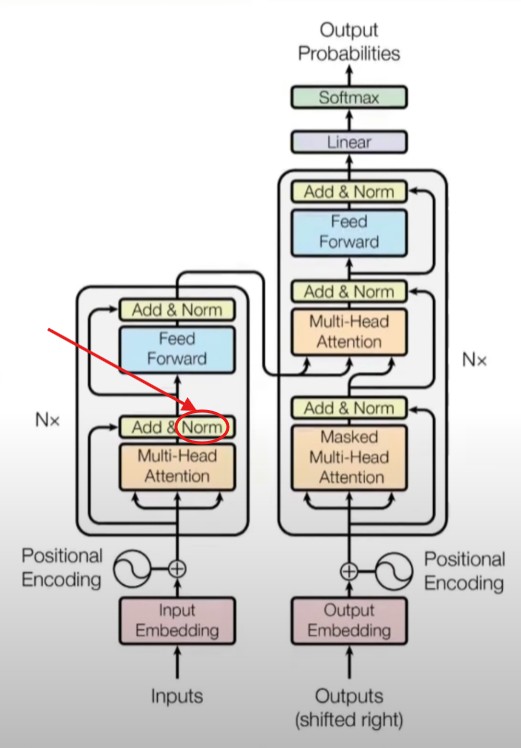
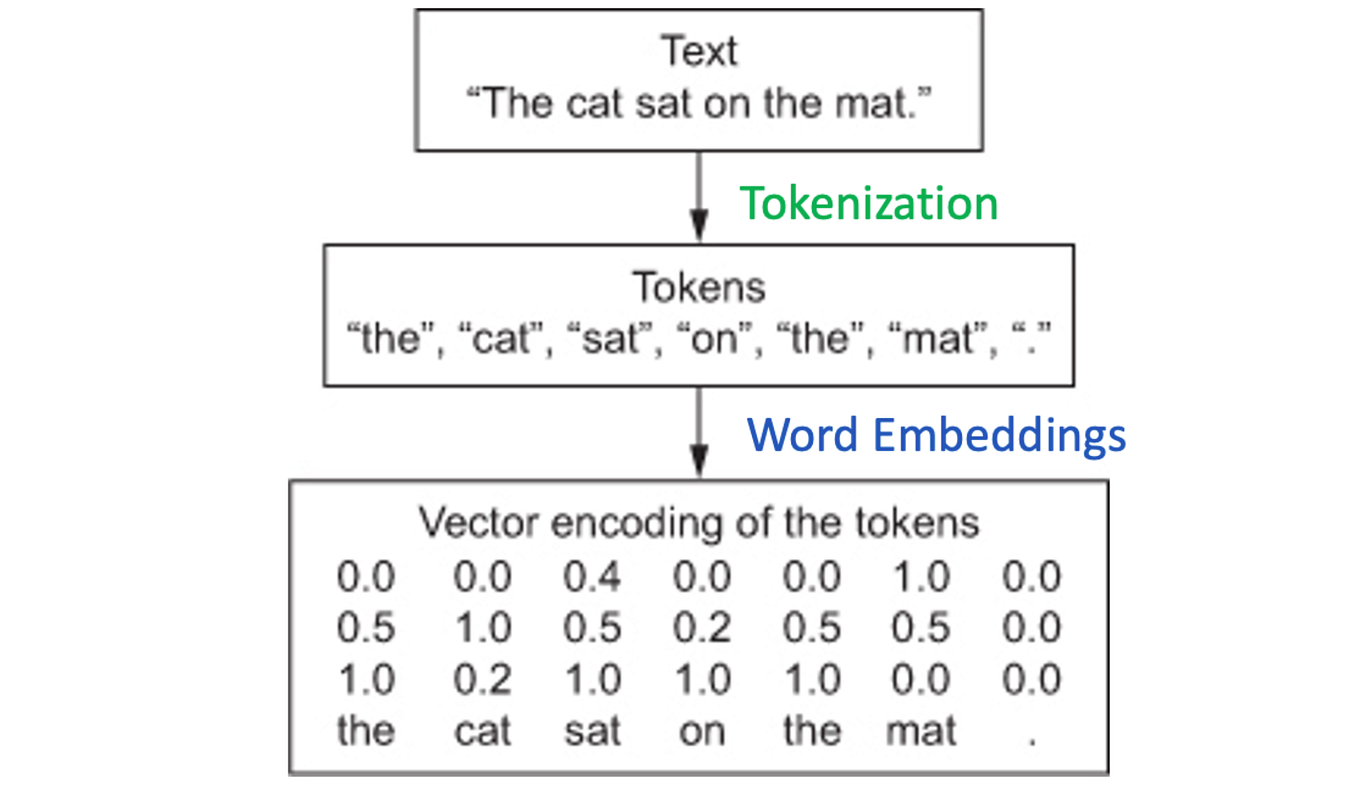
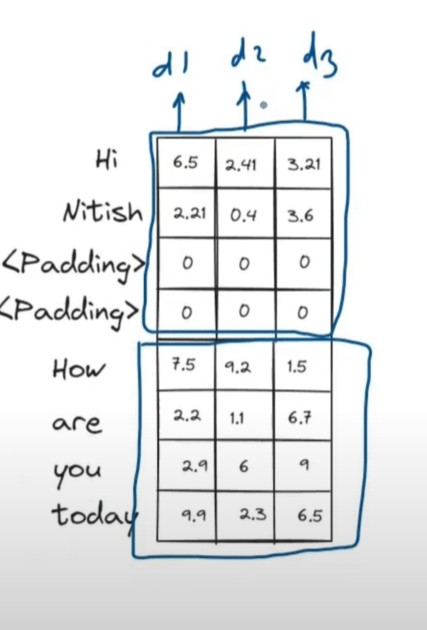
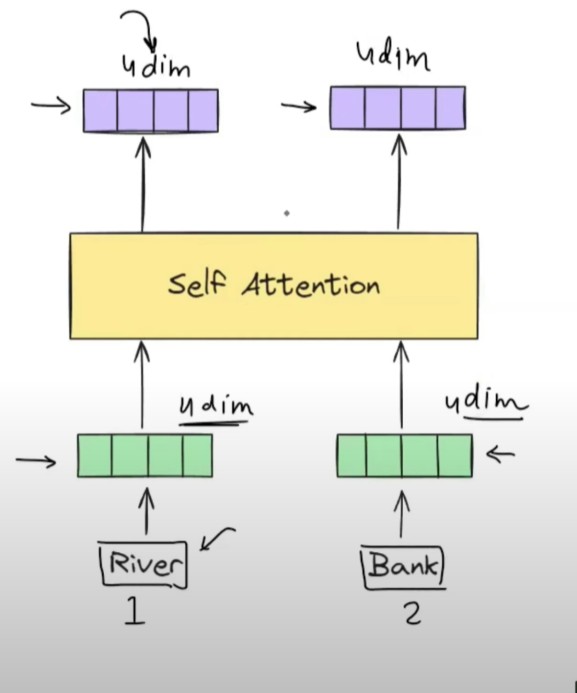
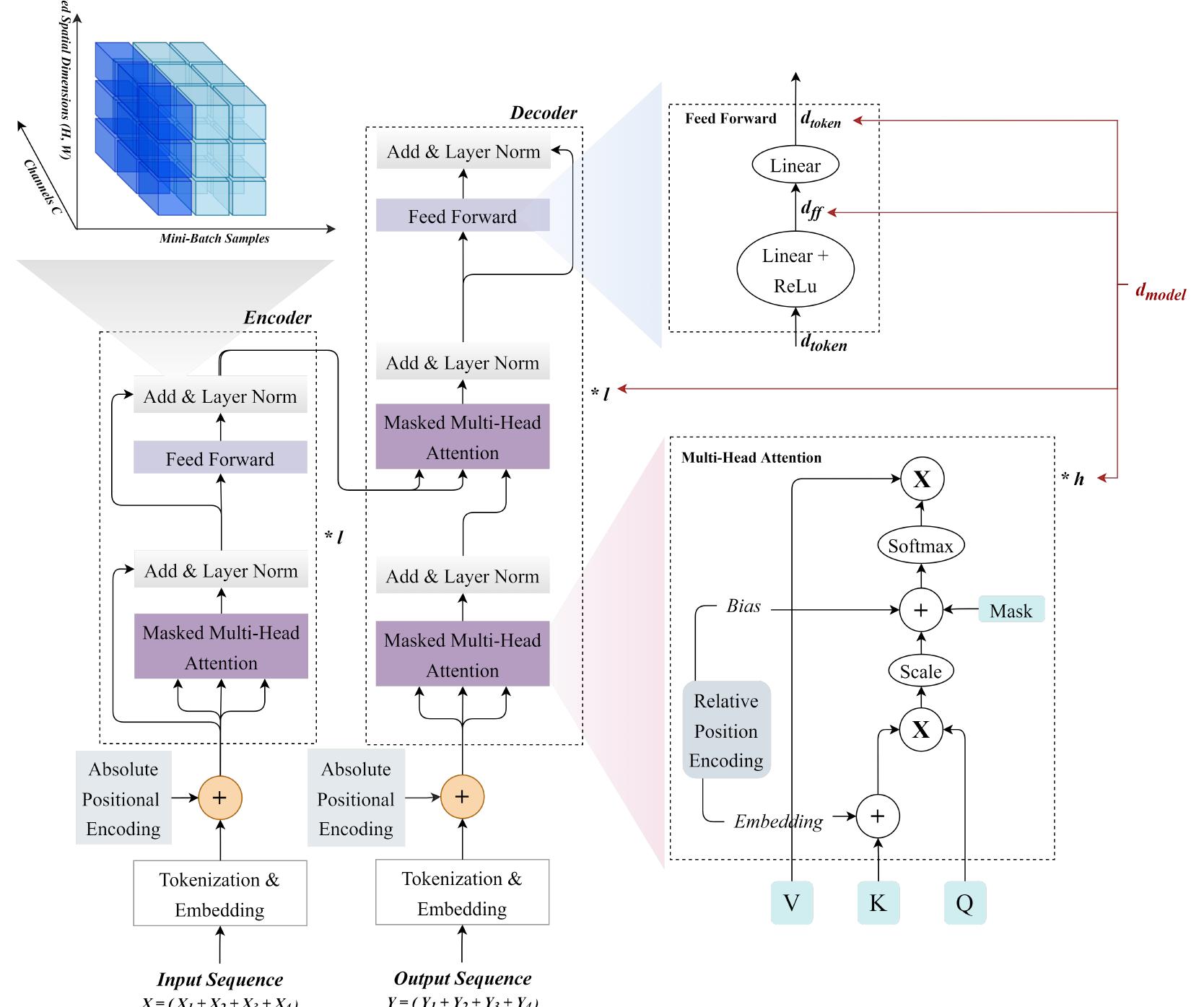
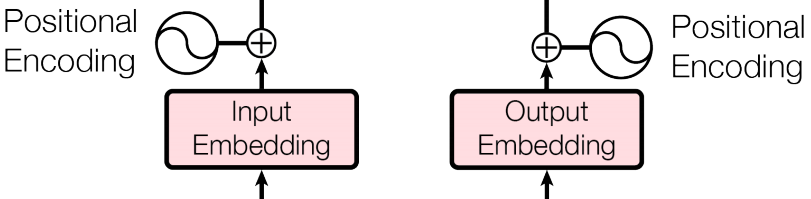
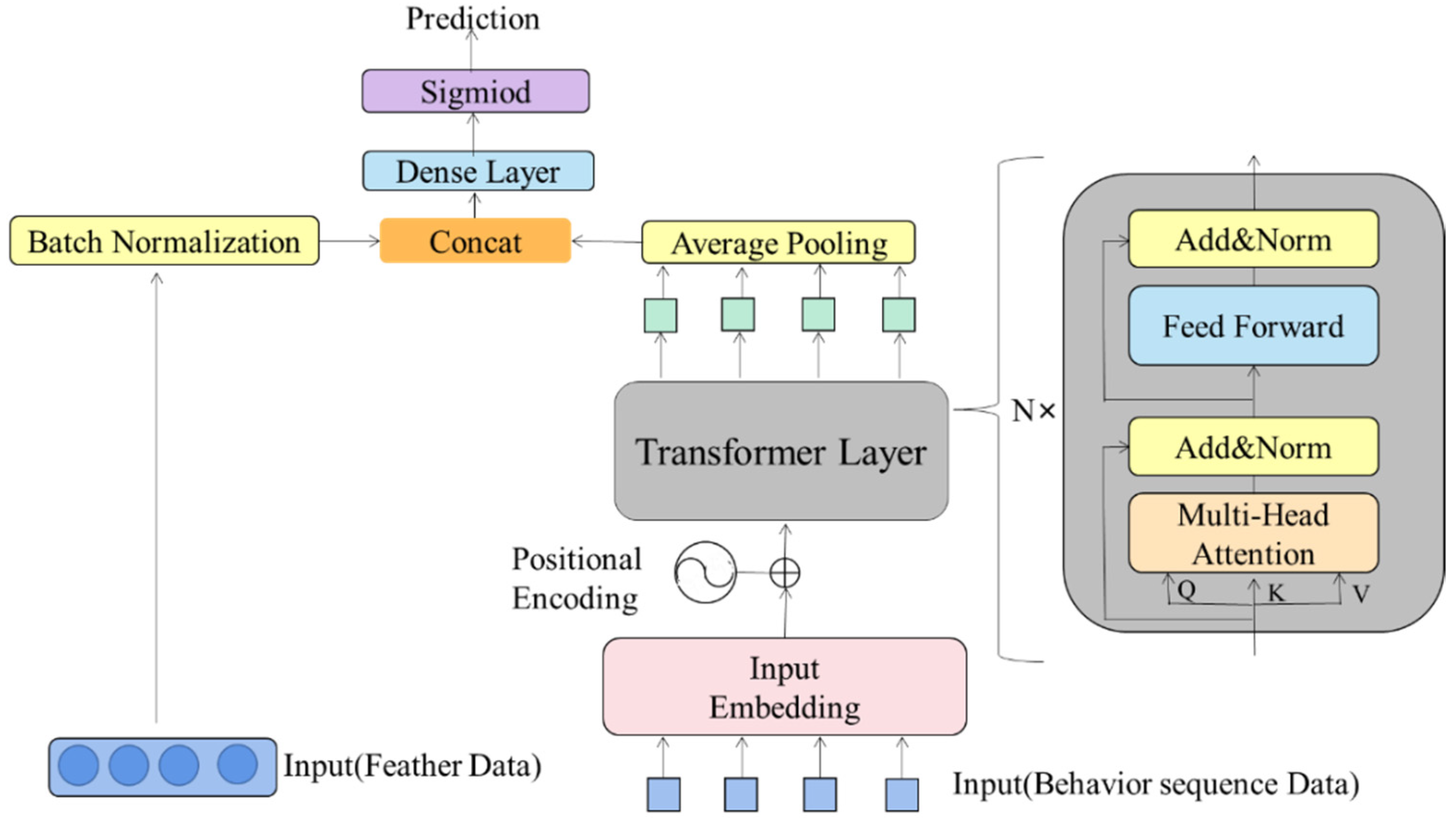
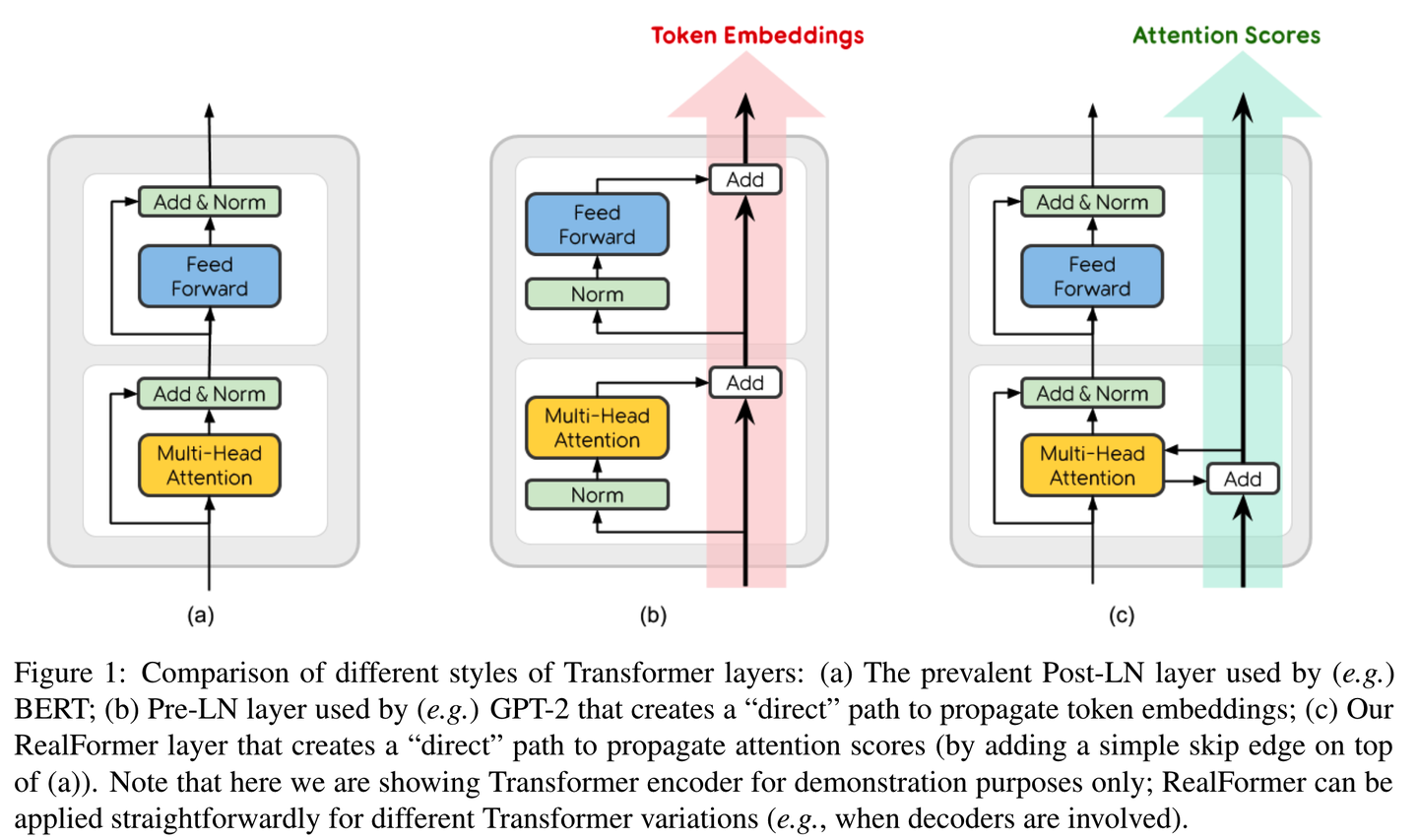
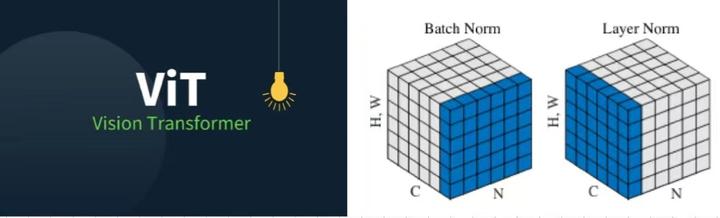
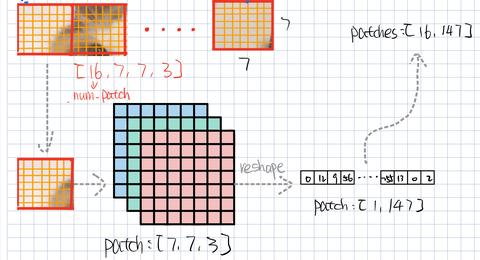
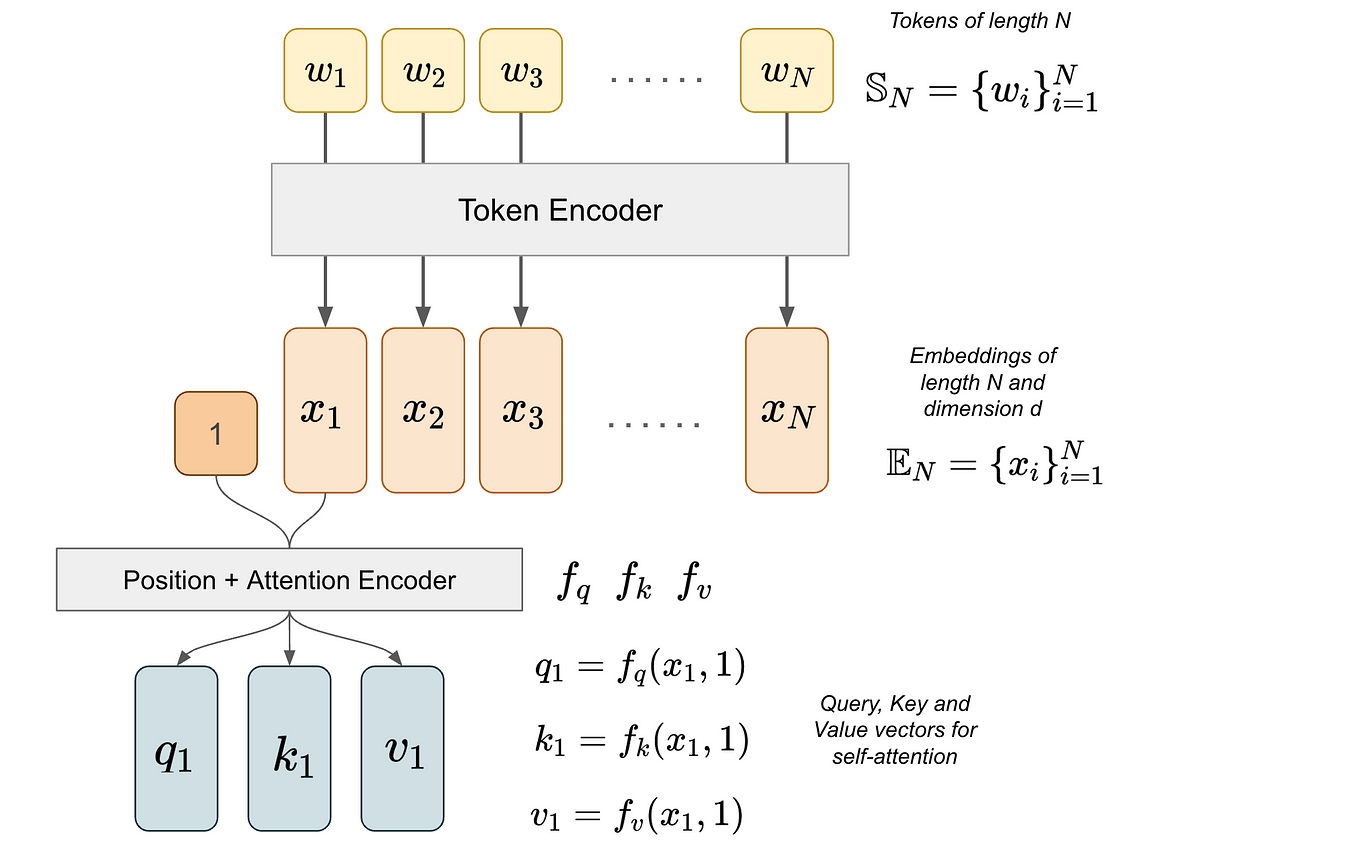
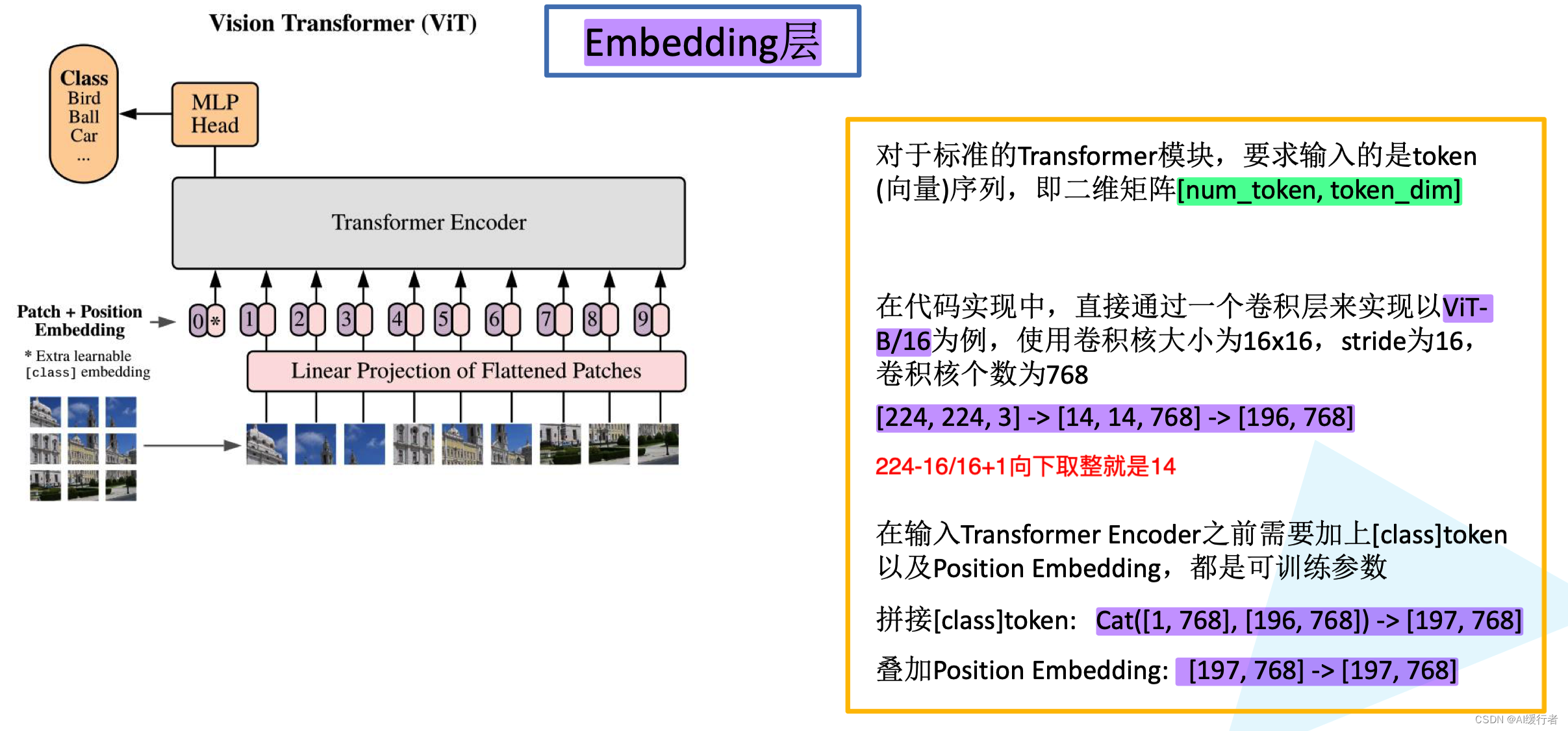
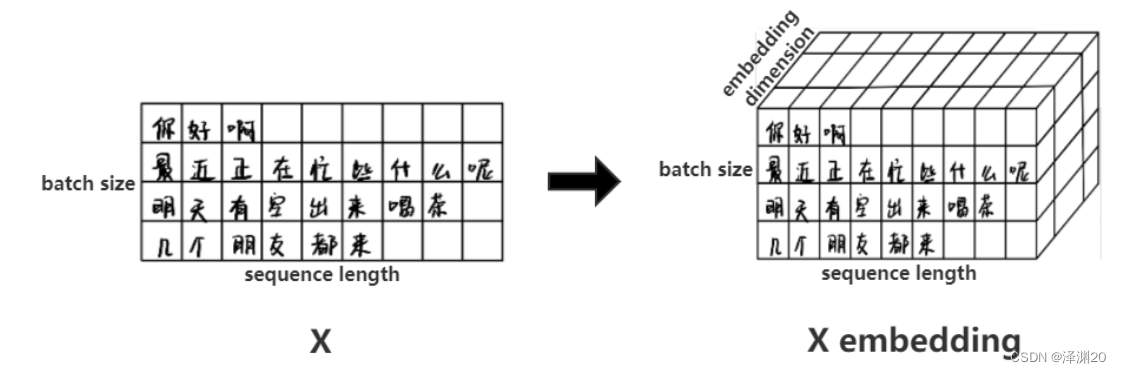
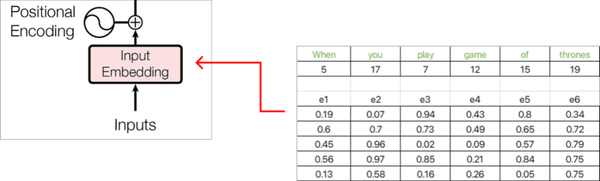
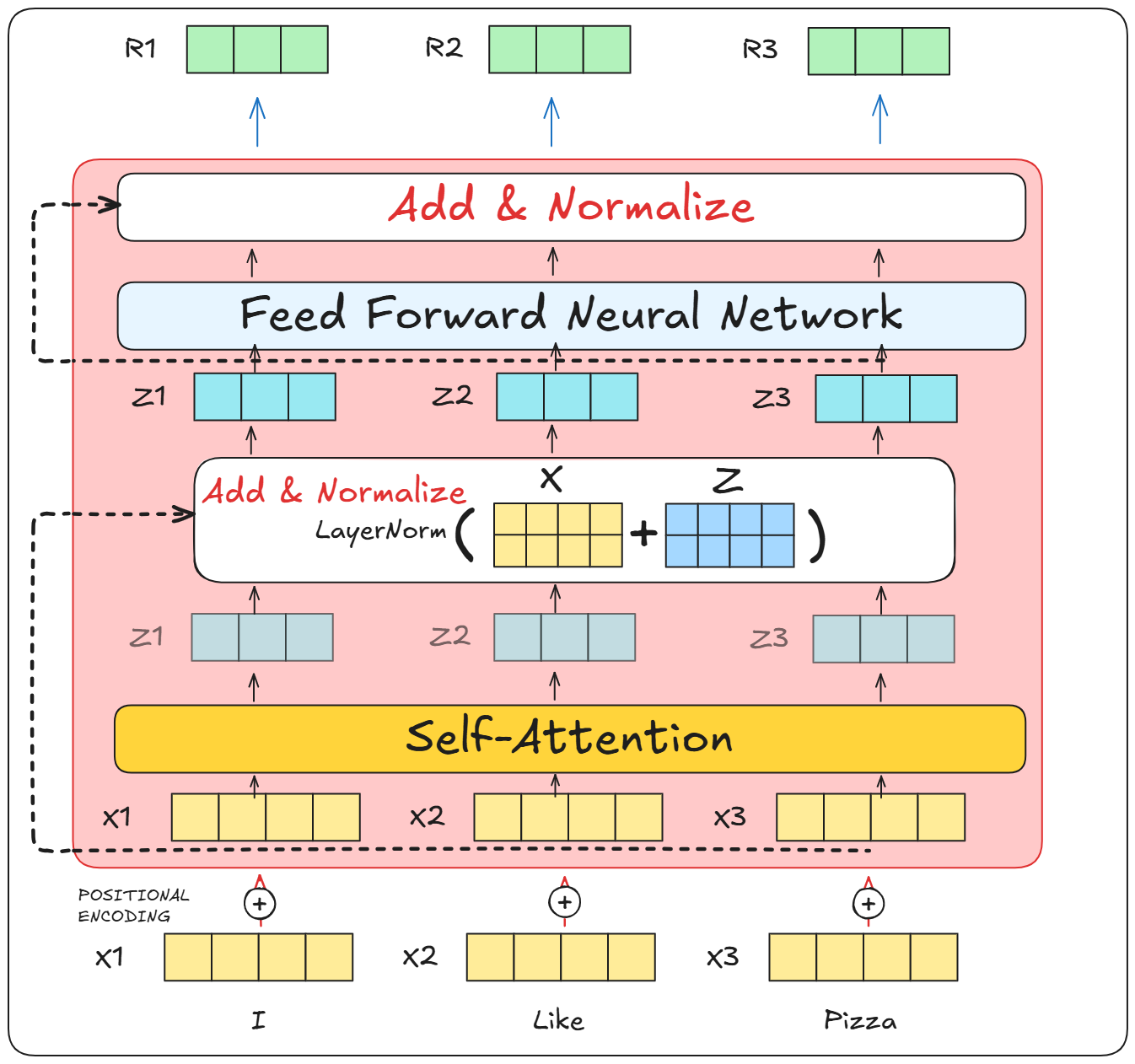
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
Layer Normalization in Transformer | by Sachinsoni | Medium
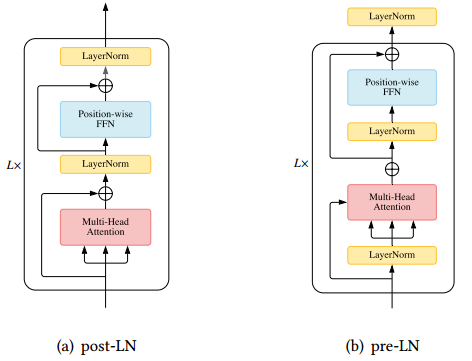
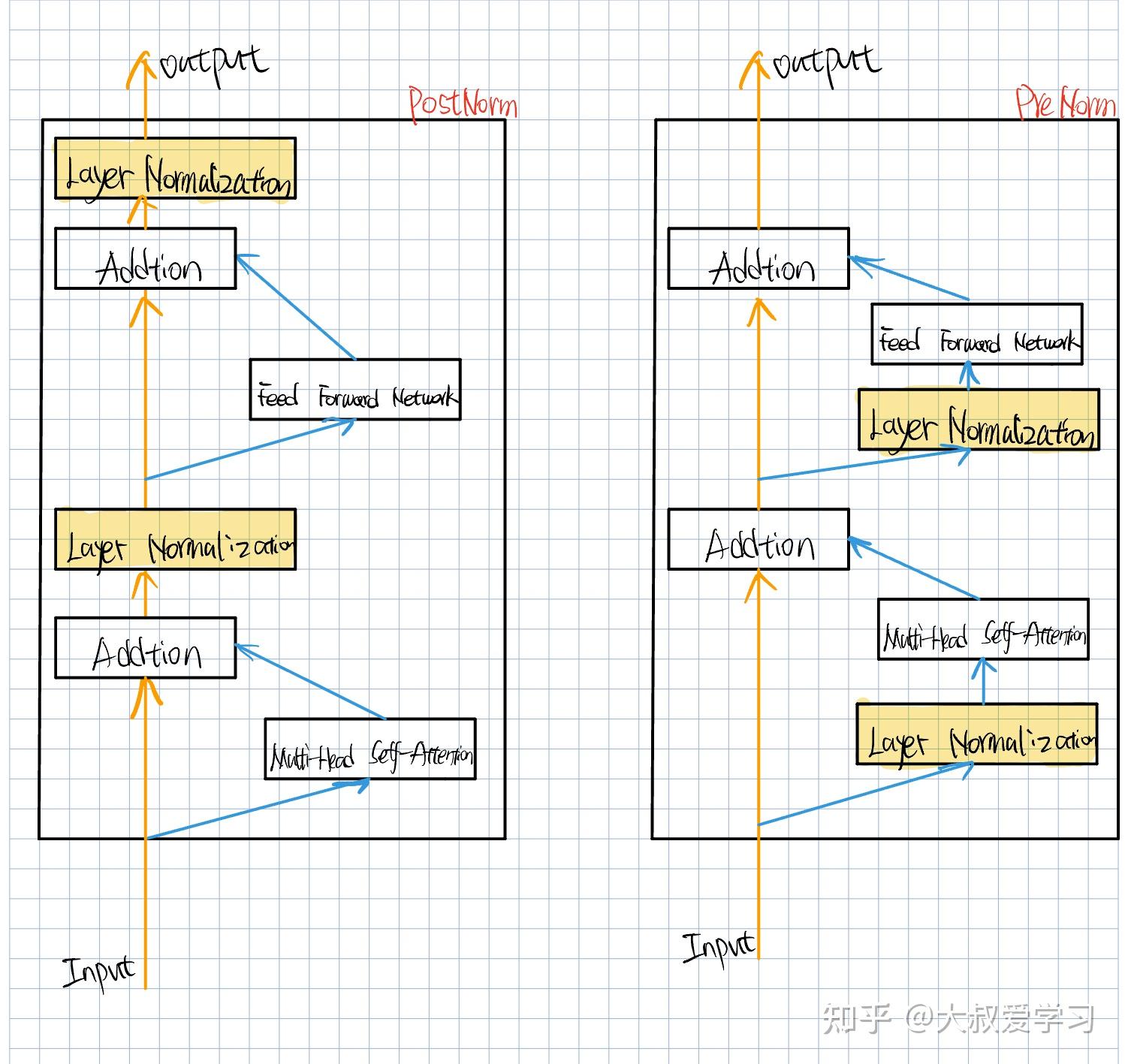
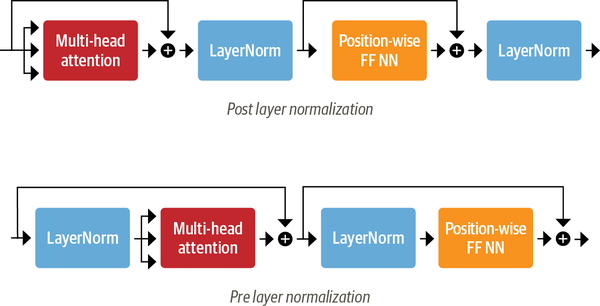
Review — Pre-LN Transformer: On Layer Normalization in the Transformer ...
Layer Normalization in Transformer - 知乎
Normalization in Transformer Neural networks with Code | Aparna Soneja
[PDF] On Layer Normalization in the Transformer Architecture | Semantic ...
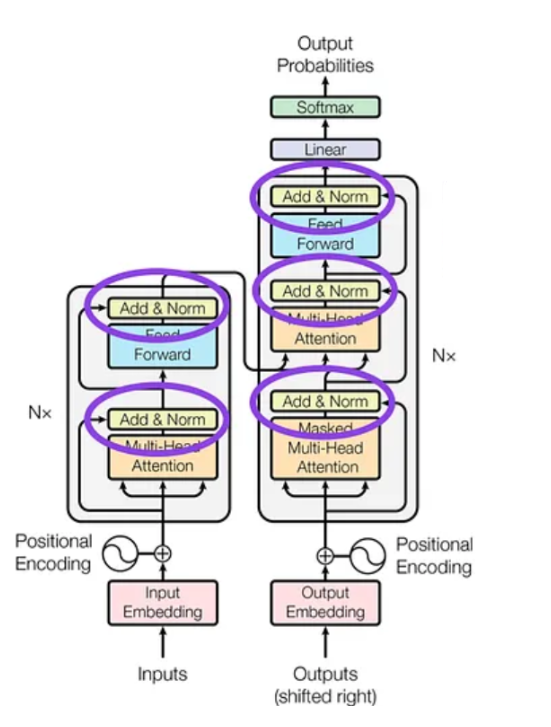
Across Transformer blocks, Layer Normalization (Ba et al. | Niccolo ...
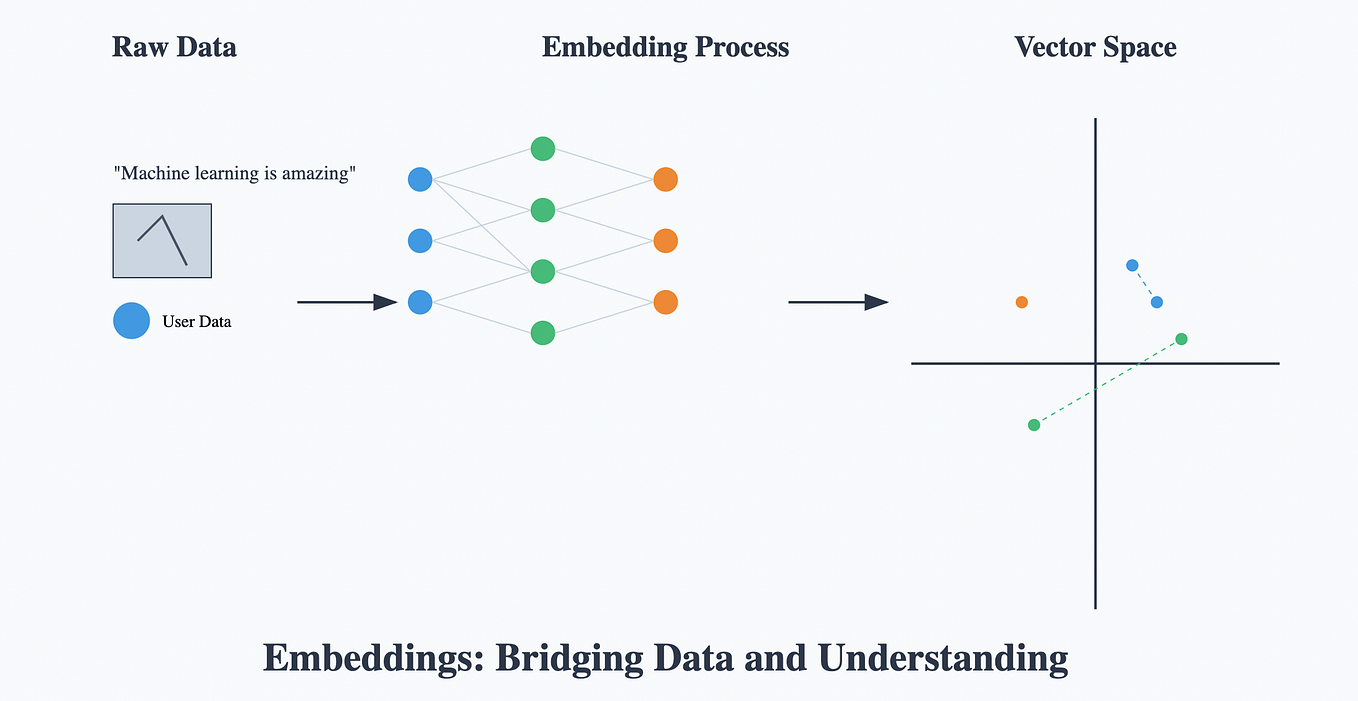
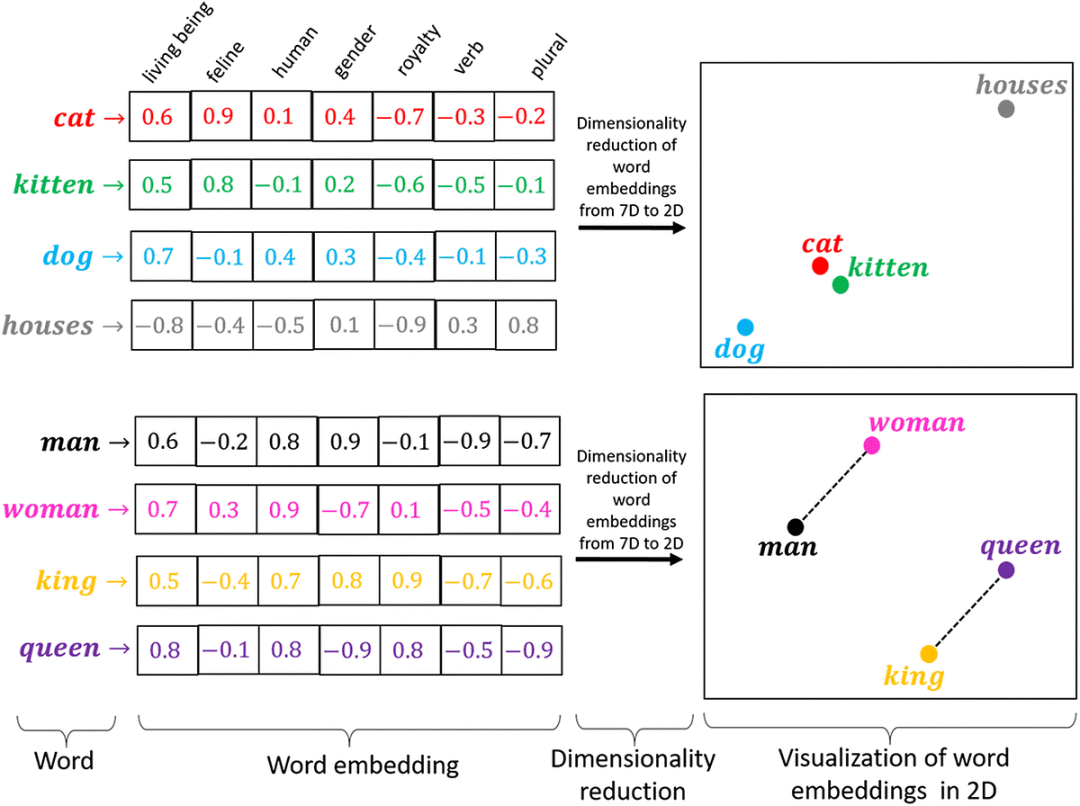
How to Dissect a Muppet: The Structure of Transformer Embedding Spaces ...
LLM Basics: Embedding Spaces - Transformer Token Vectors Are Not Points ...
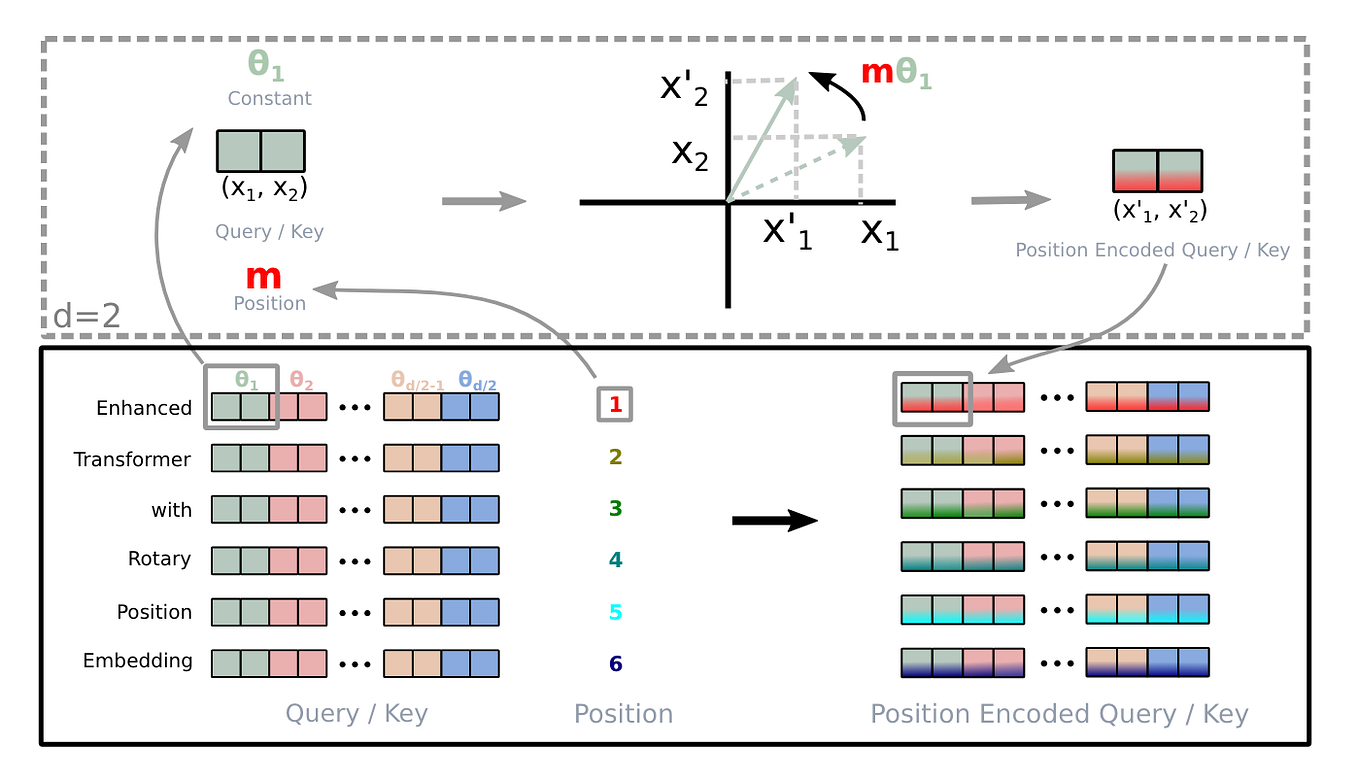
Brief Review — RoFormer: Enhanced Transformer with Rotary Position ...
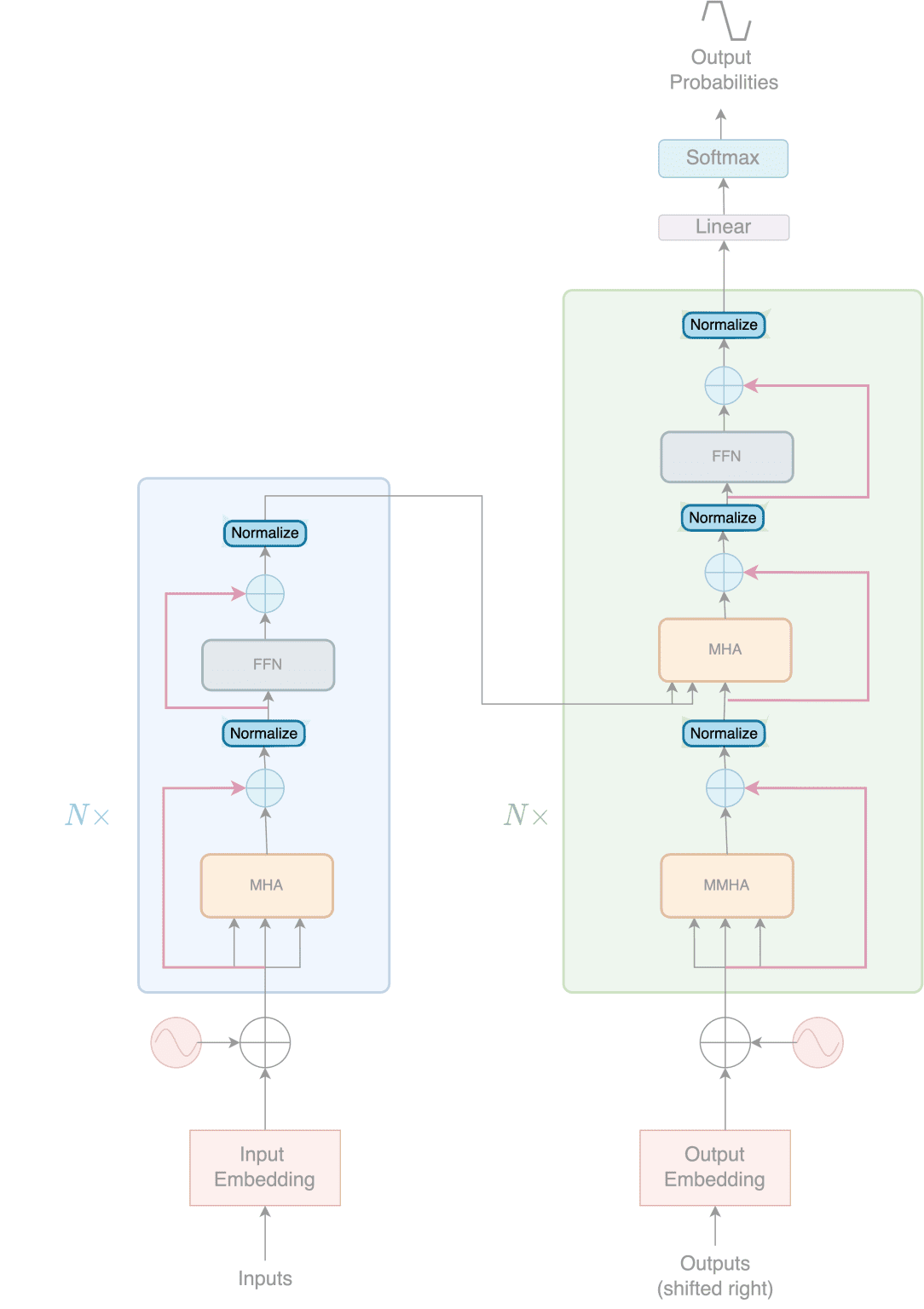
The Transformer neural network architecture
Understanding The Transformer Architecture
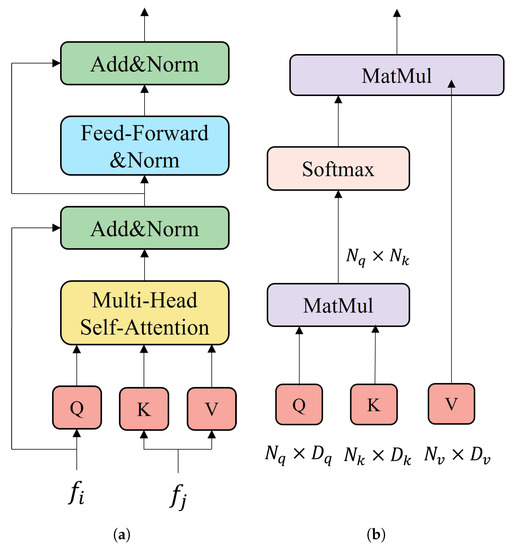
Several transformer layers will be applied in each block in ...
A Deep Dive Into the Transformer Architecture – The Development of ...
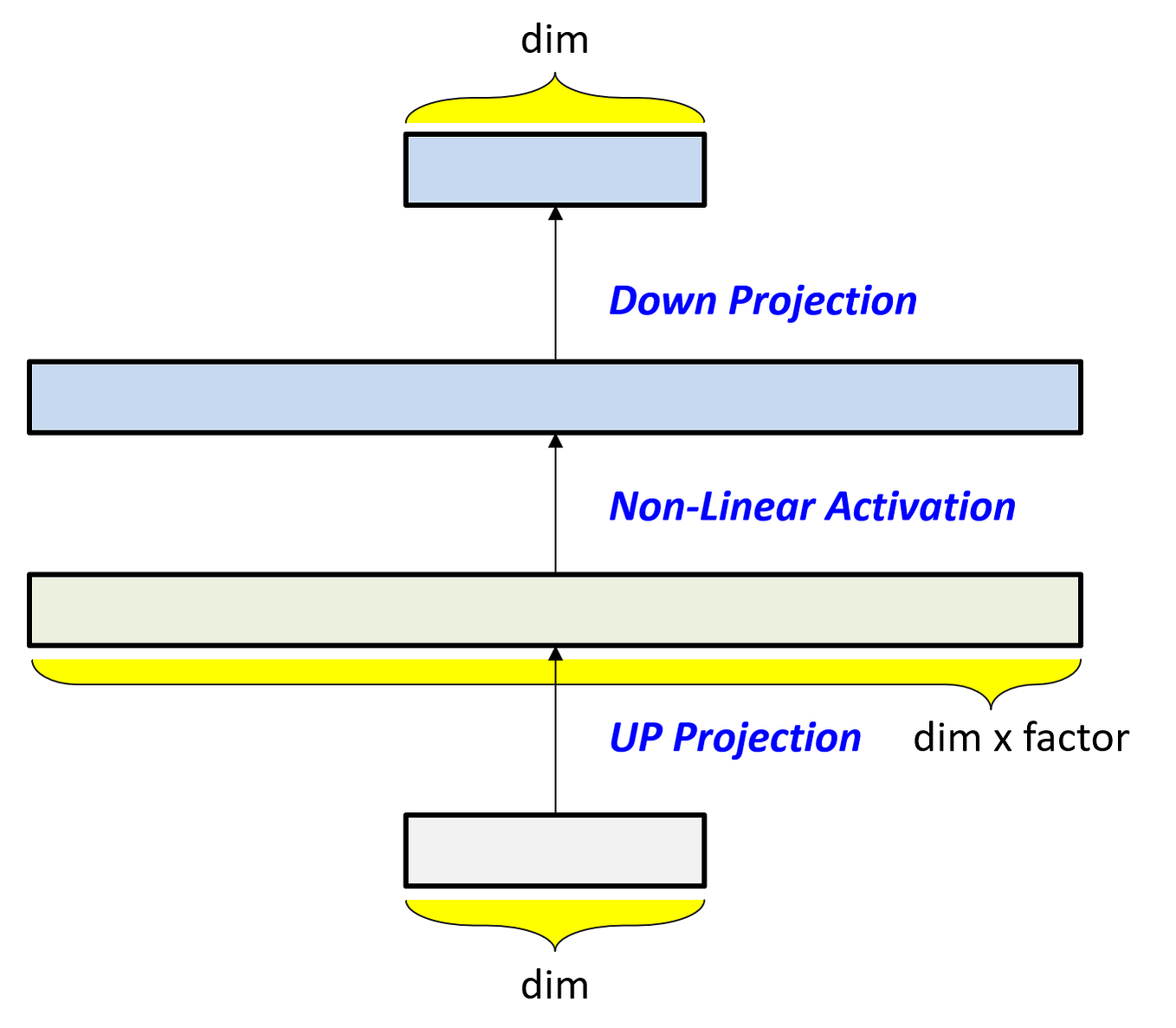
How to Estimate the Number of Parameters in Transformer models ...
Transformers – Layered Normalization – Praudyog
Inspecting Layer Normalization In Transformers | by Ryan Partridge | Medium
Learning Geometric Feature Embedding with Transformers for Image Matching
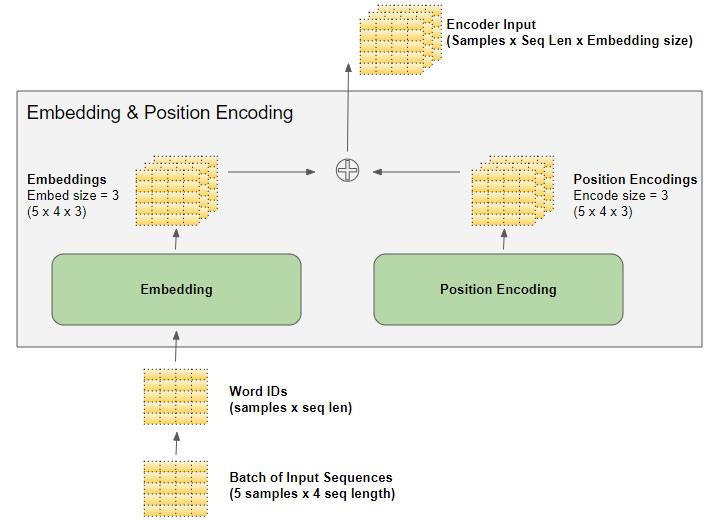
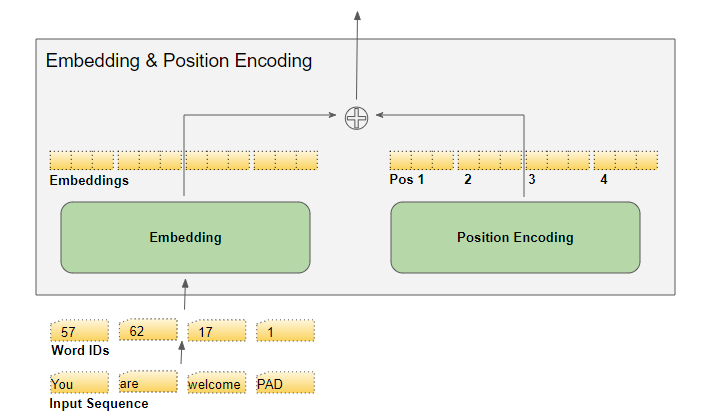
探秘Transformer系列之(7)--- embedding - 知乎
Layer Normalization in Transformers
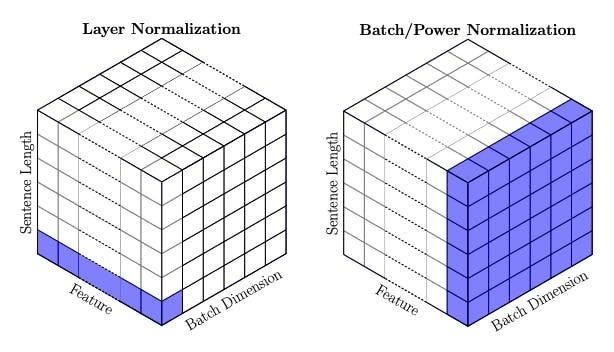
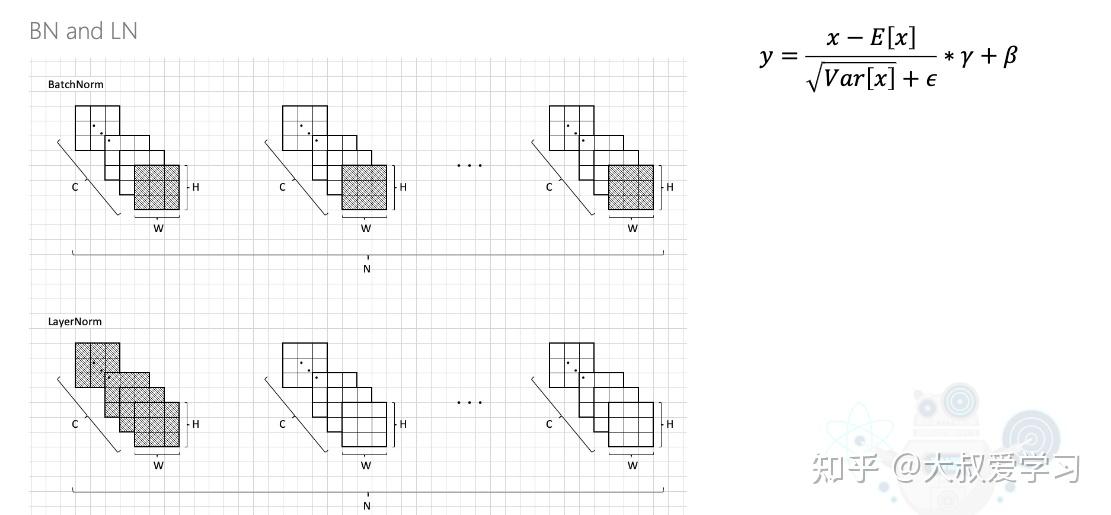
Transformer学习笔记三:Batch Normalization & Layer Normalization - 墨天轮
图解Transformer系列三:Batch Normalization & Layer Normalization (批量&层标准化) - 掘金
Layer normalization in transformers: Easy and clear explanation
11.7. The Transformer Architecture — Dive into Deep Learning 1.0.0 ...
Neural machine translation with a Transformer and Keras | Text ...
Redesigning Embedding Layers for Queries, Keys, and Values in Cross ...
Transformer Networks
A diagram explaining how a transformer works. A series of sine waves ...
Math Behind Positional Embeddings in Transformer Models | by Freedom ...
Transformer Architecture — image segmentation prompt documentation
Transformer Notes - Bo Song
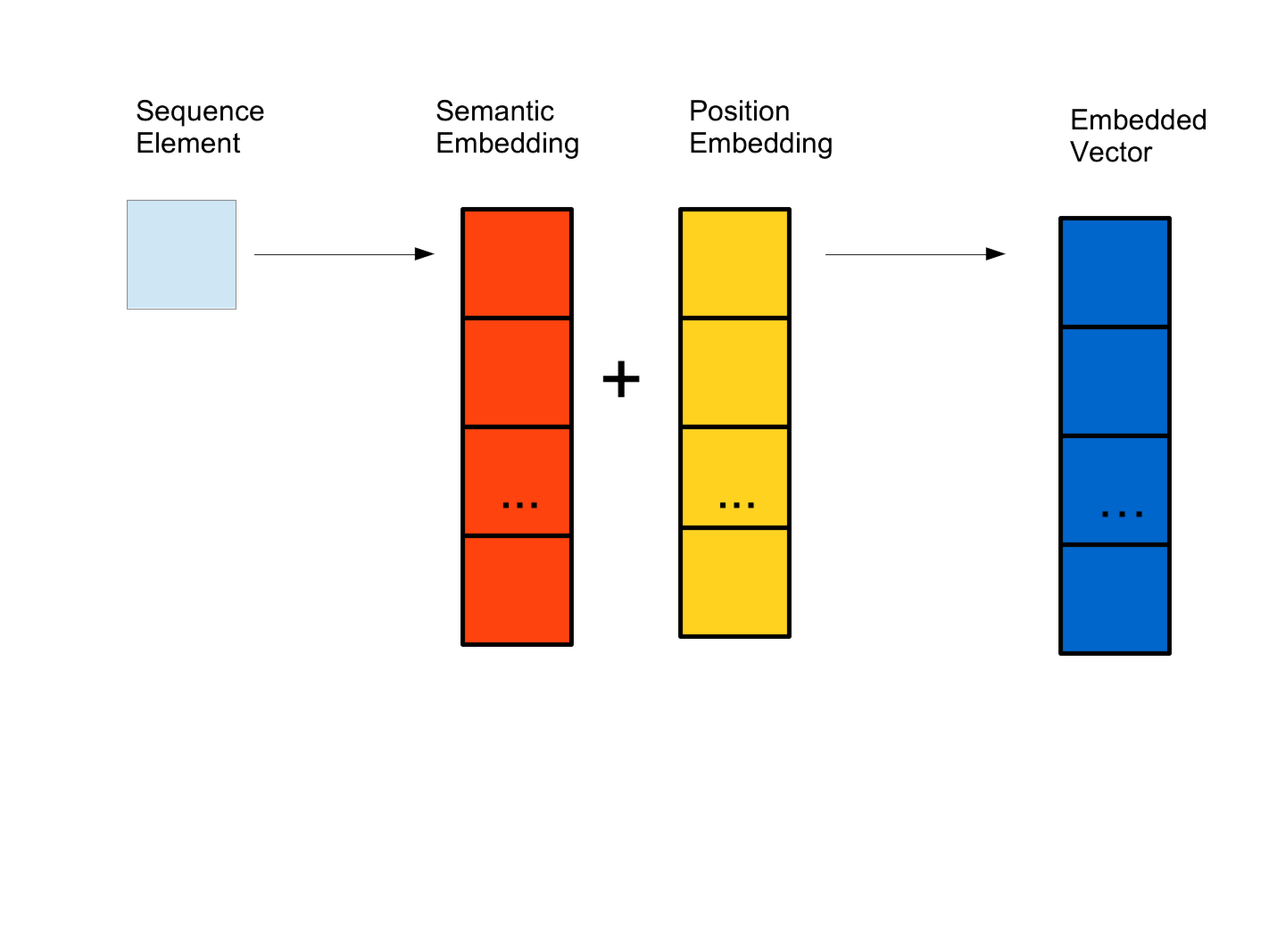
Positional Embeddings in Transformer Models: Evolution from Text to ...
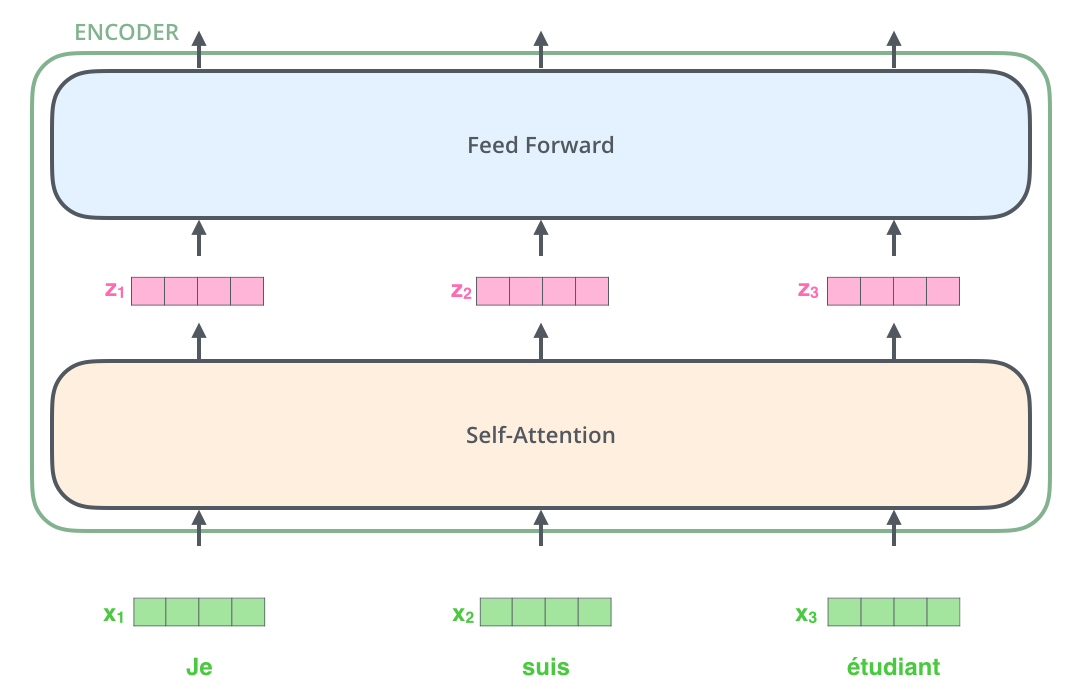
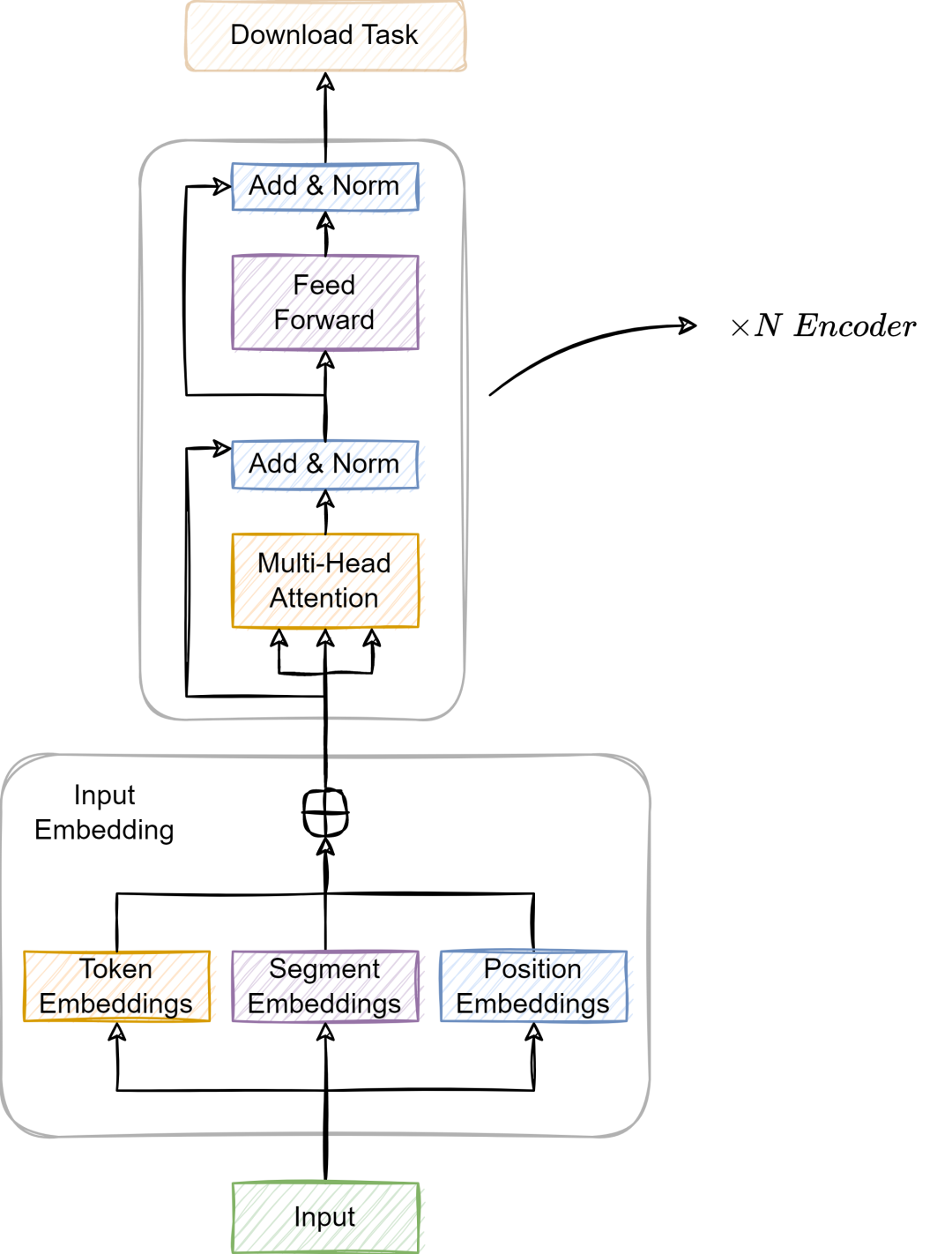
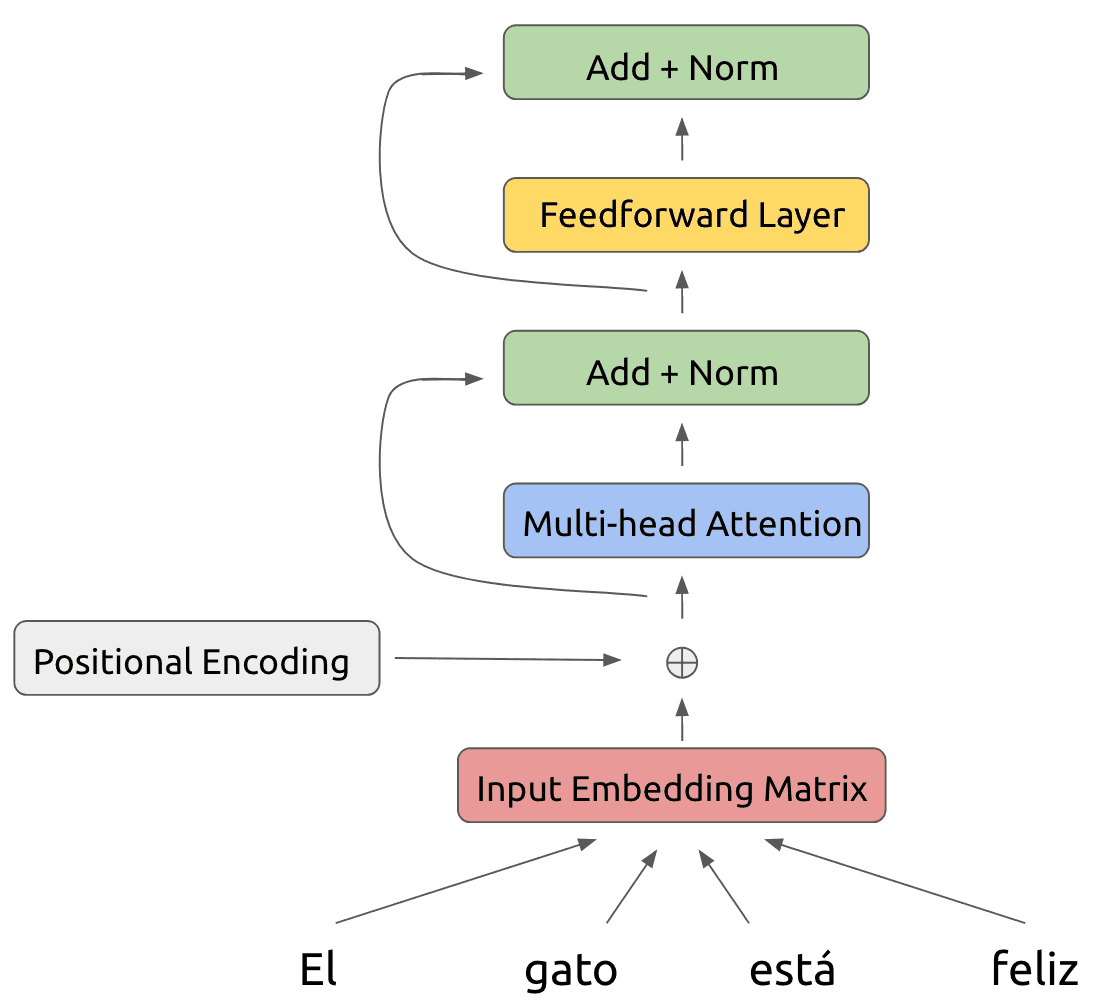
The Illustrated Transformer – Jay Alammar – Visualizing machine ...
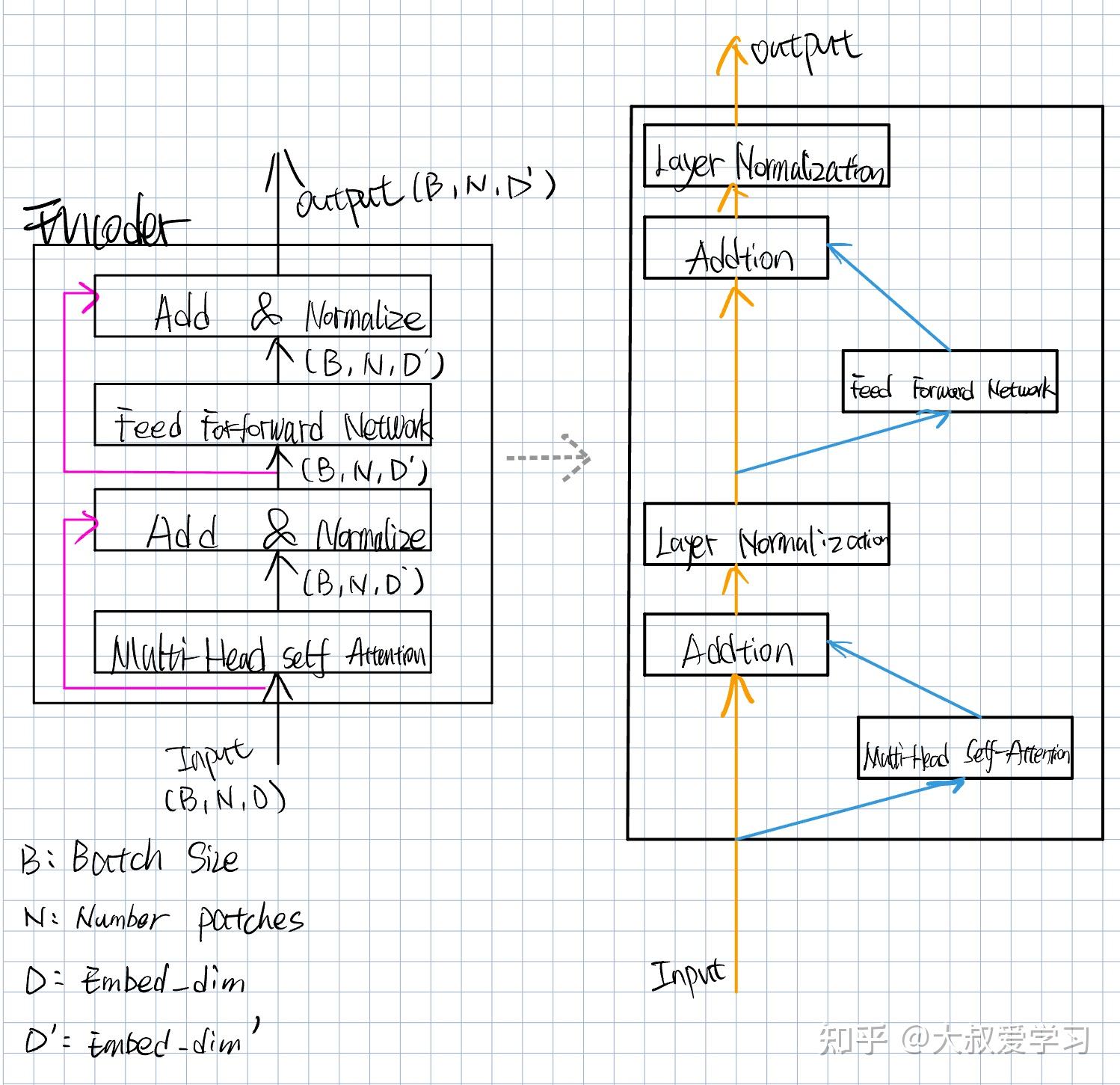
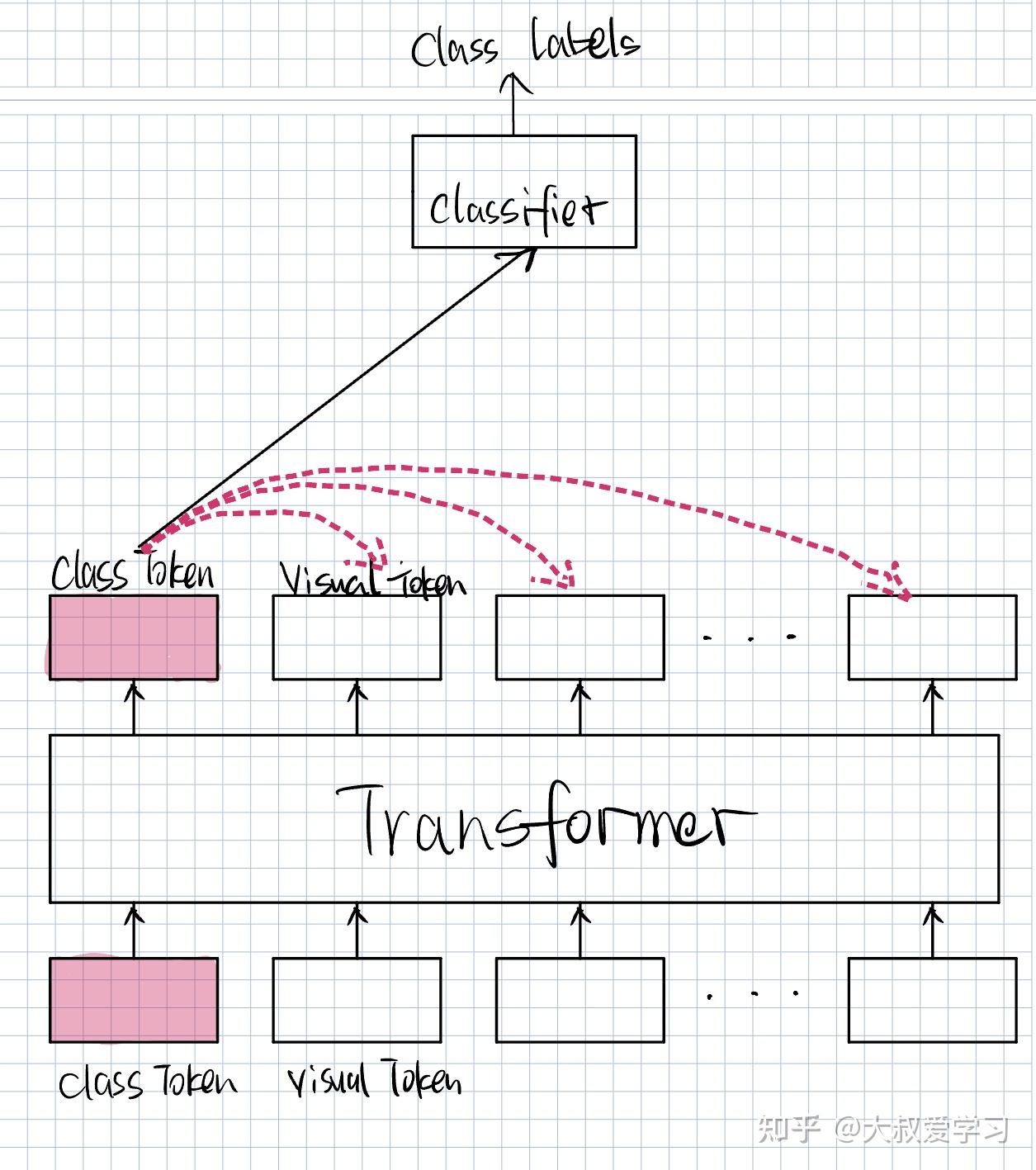
The construction of the transformer encoder. It consists of patch ...
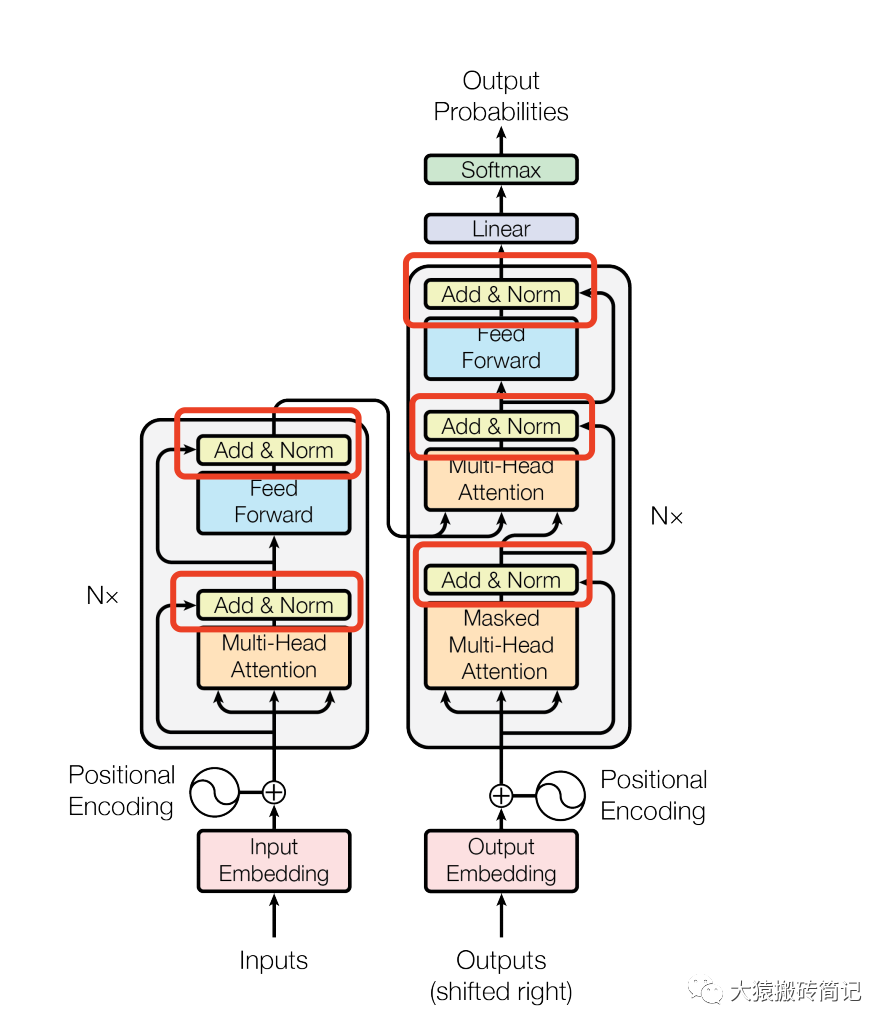
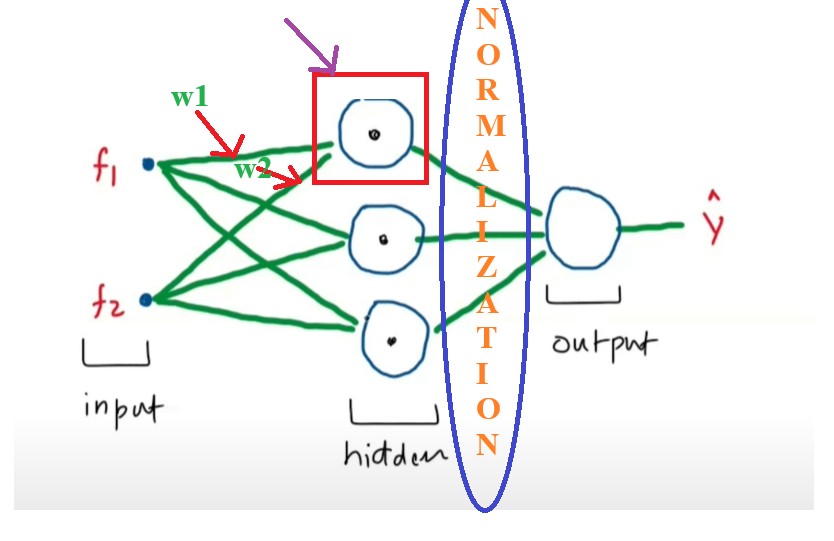
Decoding Transformers : The Layer Normalization Saga | by Himanshu Kale ...
Normalization From Non-Stationary Transformer和Embedding哪个在前 - Genspark
Mastering Transformers: A Comprehensive Guide to Transformer ...
The architecture of Transformer with reordering embeddings. | Download ...
Transformer中的Layer Normalization - 知乎
Schematic of the Feature Transformer block. (Res LN represents the ...
The overall structure of the improved transformer model. The input ...
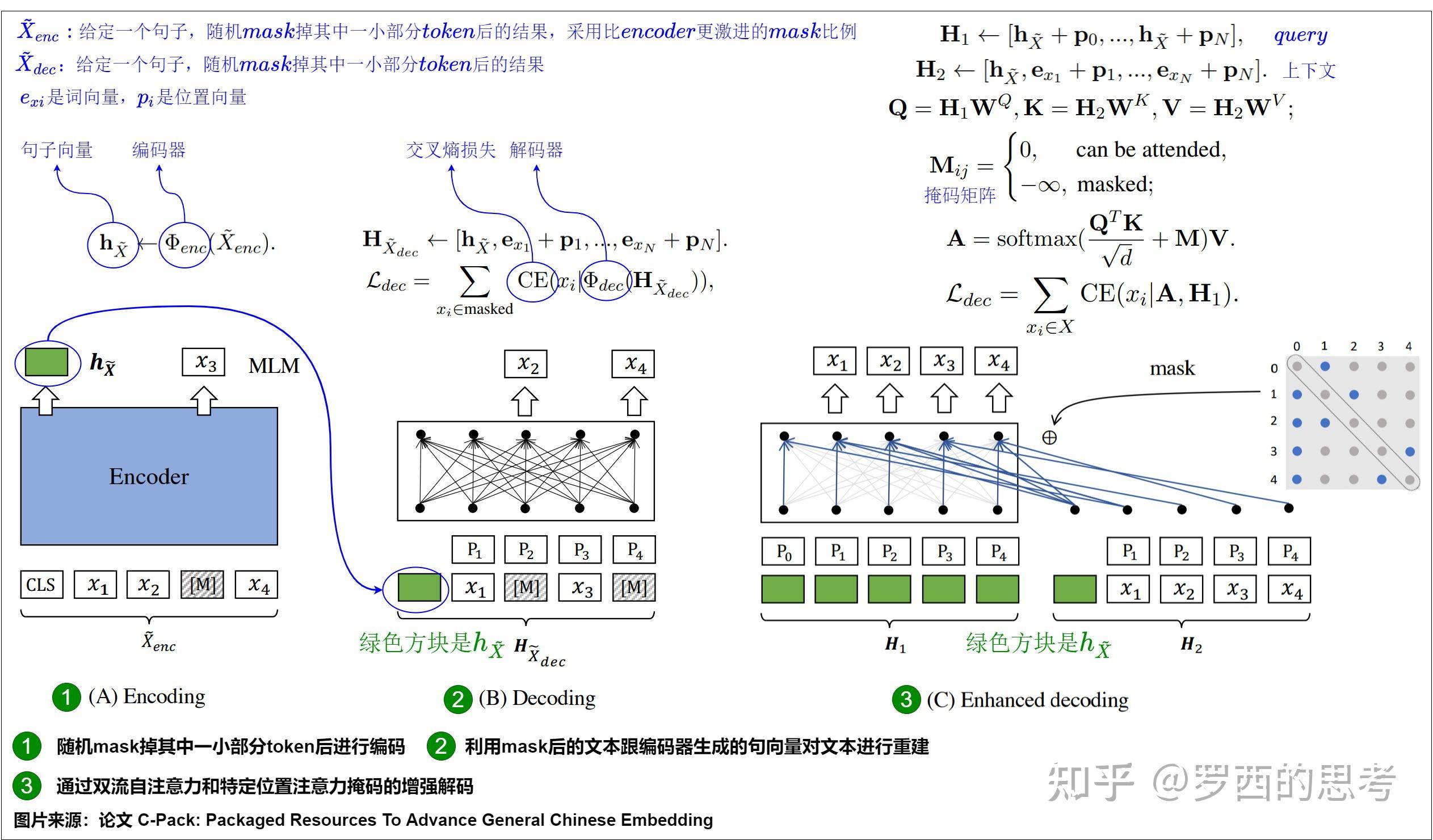
探秘Transformer系列之(7)--- embedding - 罗西的思考 - 博客园
Transformer | 一文带你了解Embedding(从传统嵌入方法到大模型Embedding) - 知乎
Transformer Architecture: Redefining Machine Learning Across NLP and Beyond
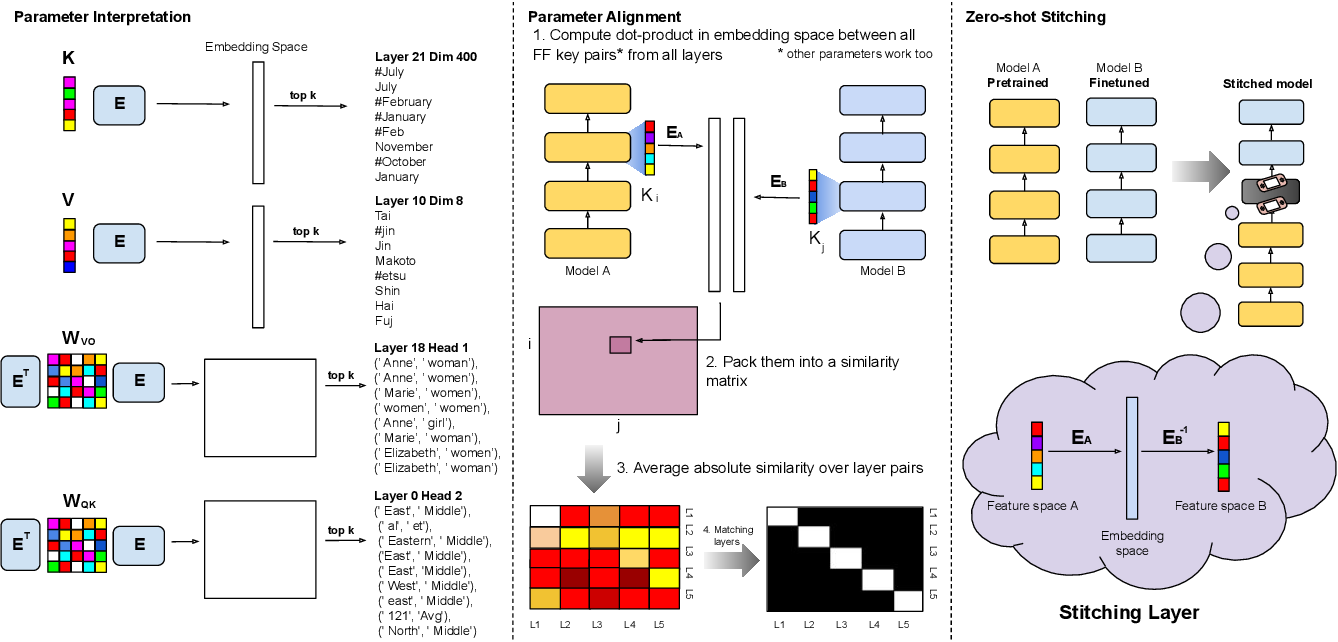
Figure 1 from Analyzing Transformers in Embedding Space | Semantic Scholar
Explain the need for Positional Encoding in Transformer models (with ...
Transformer | CSNLP学徒
A diagram showing the detailed transformer architecture,
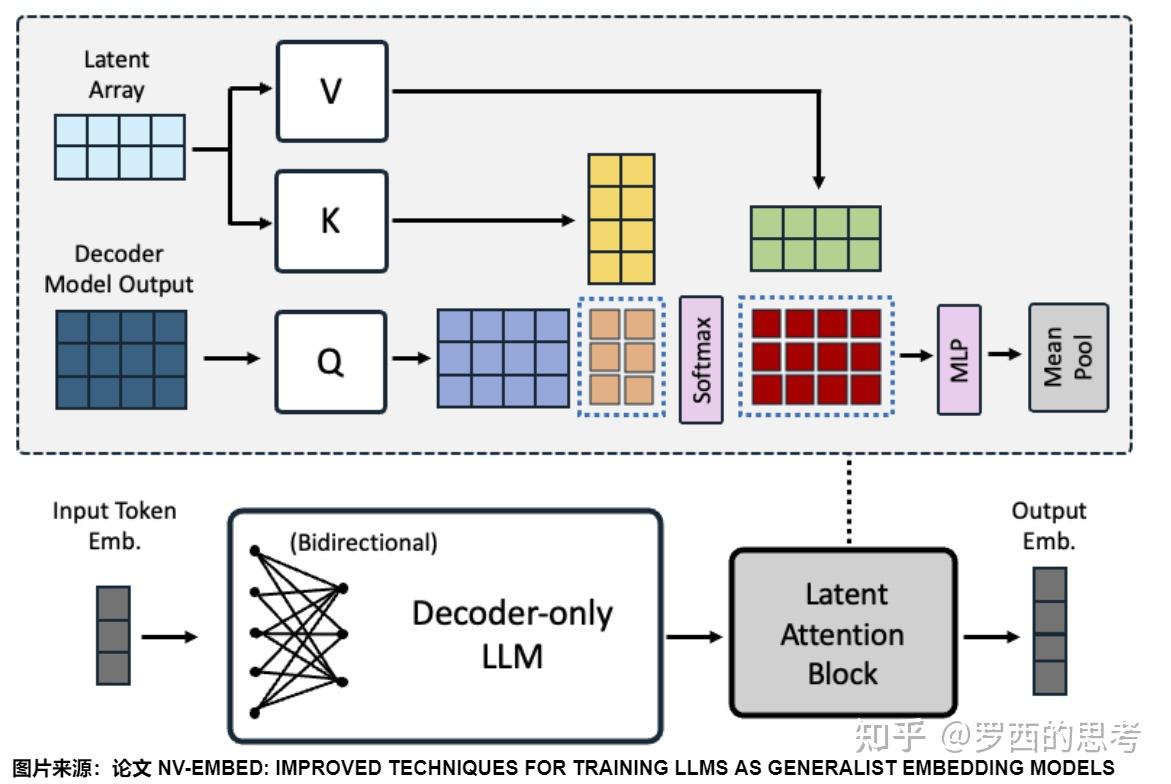
Advanced Transformer Architectures in Modern LLMs
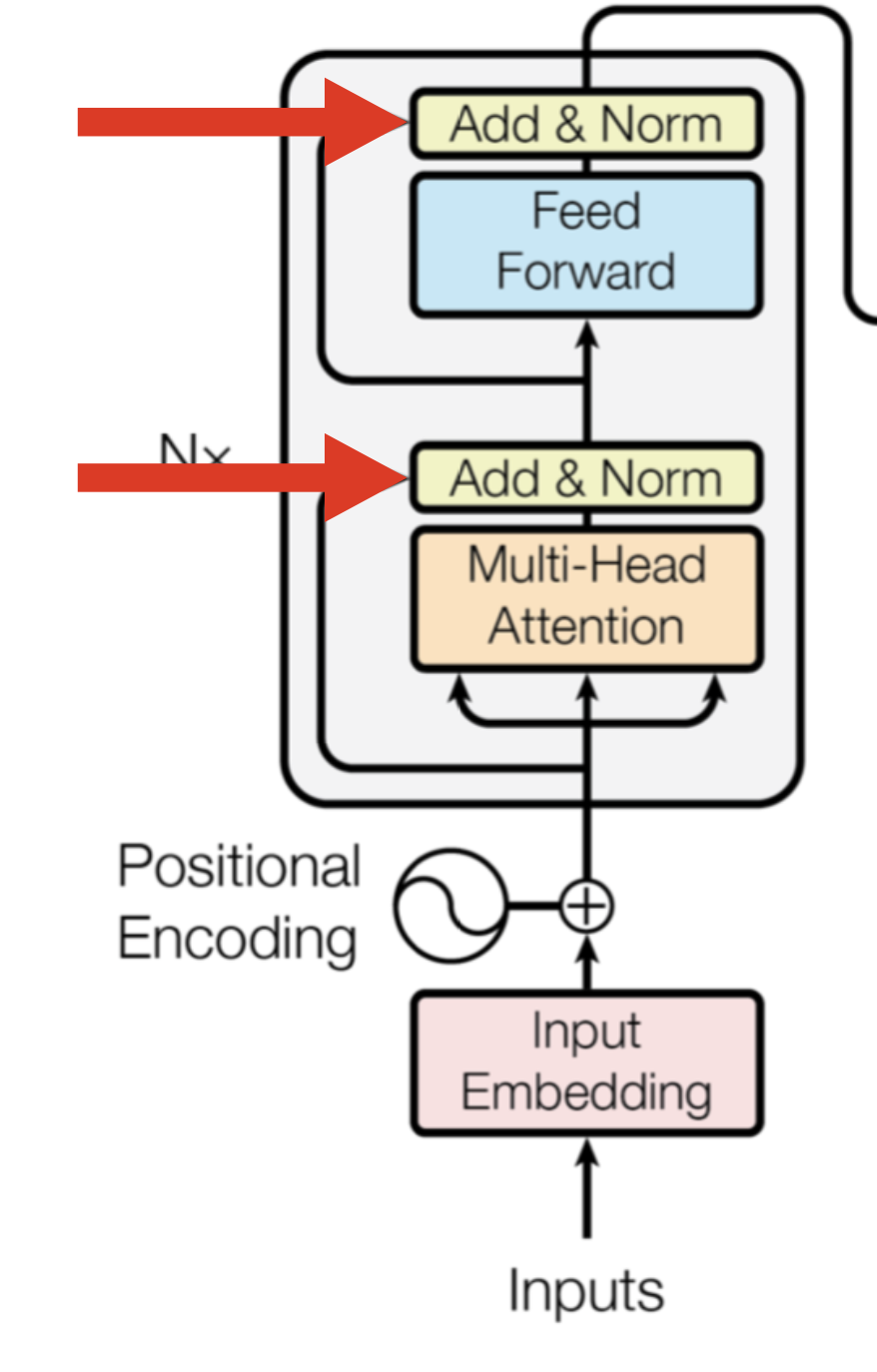
Transformers: Attention is all you need — Layer Normalization | by ...
Transformers without Normalization . | PPT
Detailed view of a transformer block which powers the dynamic state of ...
Layer Normalization. This is the fifth article in The… | by Hunter ...
Mastering t-SNE(t-distributed stochastic neighbor embedding) | by ...
机器学习笔记:Transformer_embedding dimension-CSDN博客
Mastering Embeddings: A Must-Read Guide - Markovate
Architecture of VSP transformer. Norm: normalization. CT-reconstructed ...
Transformers Explained Visually - How it works, step-by-step | Ketan ...
图解Vit 3:Vision Transformer——ViT模型全流程拆解(Layer Normalization, Position ...
一文看懂 Transformer!超级详解,小白入门必看!-CSDN博客
Lecture 7: Foundation Models - The Full Stack
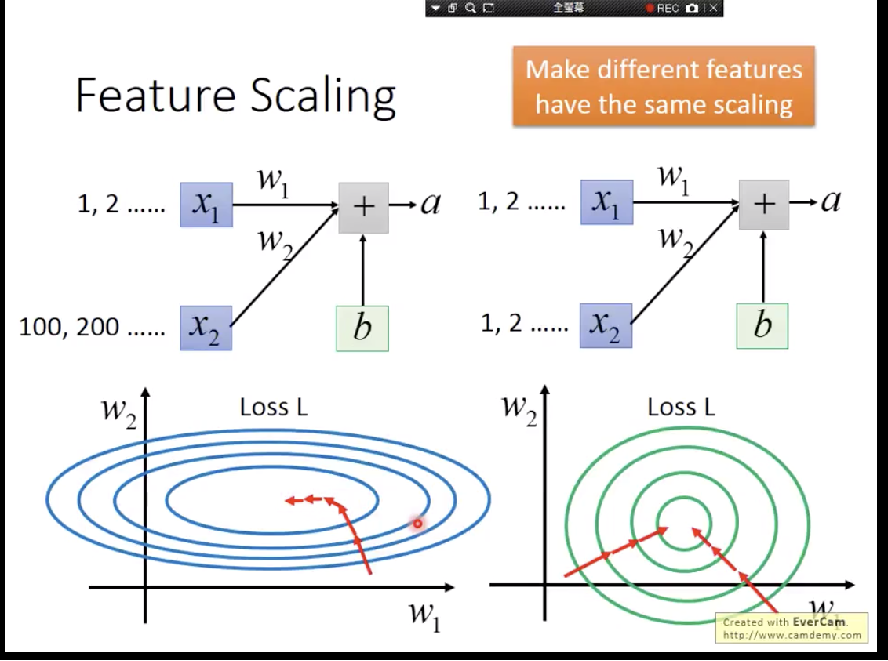
A Deep Learning Approach for Credit Scoring Using Feature Embedded ...
transformer中normalization的二三事 - 知乎
Transformer学习笔记 - Jiashi Blog
The architecture of each stage in the hierarchical overlapped small ...
Transformers: Attention in Disguise - Mihail Eric
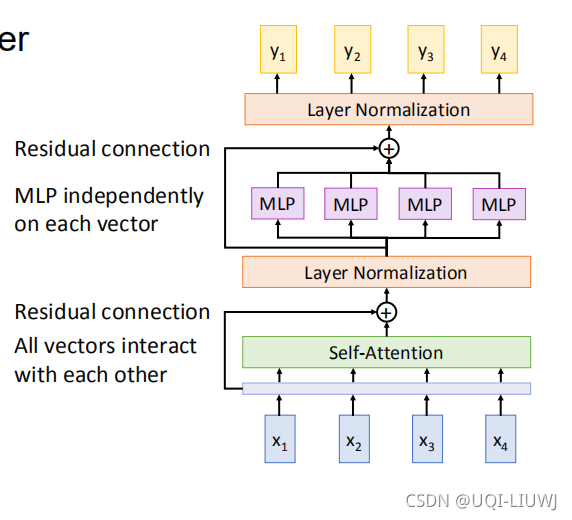
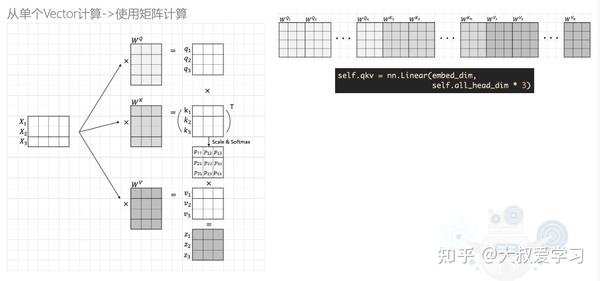
Self-Attention Explained with Code | Towards Data Science
Transformers
一文彻底搞懂Transformer - Word Embedding(词嵌入)-CSDN博客
A Deep Dive into Transformers with TensorFlow and Keras: Part 2 ...
Transformer原理及Pytorch代码实现 - 知乎
Transformer原理简明讲解 | 我的学习笔记 | 土猛的员外
How to Modify Positional Encoding in torch.nn.Transformer? | by Hey ...
Transformers Explained Visually (Part 2): How it works, step-by-step ...
Transformer之Layer Normalization与Transformer整体结构_51CTO博客_transformer ...
通过在线编程彻底搞懂transformer模型之一:embedding嵌入_transformer embedding-CSDN博客
Stronger Normalization-Free Transformers | AI Research Paper Details
『论文精读』Vision Transformer(VIT)论文解读_vit论文-CSDN博客
深度学习之Transformer模型及原理学习篇(详细!)_深度学习transformer-CSDN博客
Transformer流程解析及细节思考-CSDN博客
通俗易懂!图解 Transformers 的数学原理! - 知乎
Transformers Laid Out | Pramod’s Blog
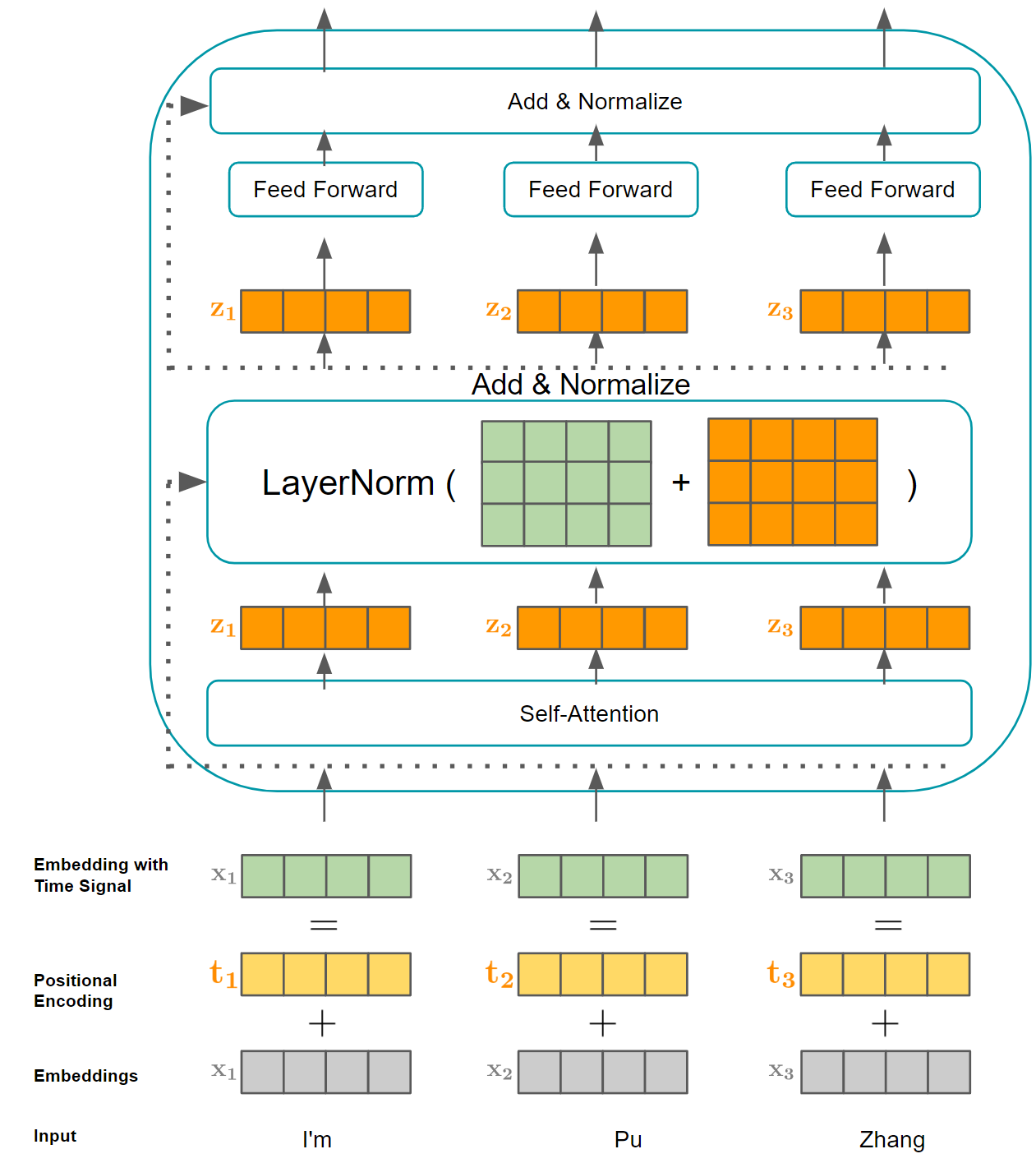
Transformers | Pu Zhang's Personal Website