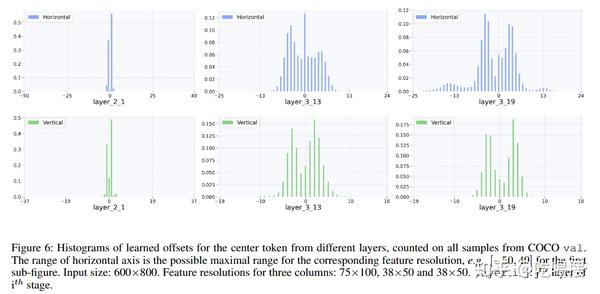
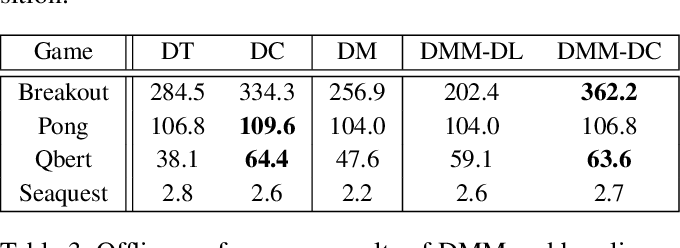
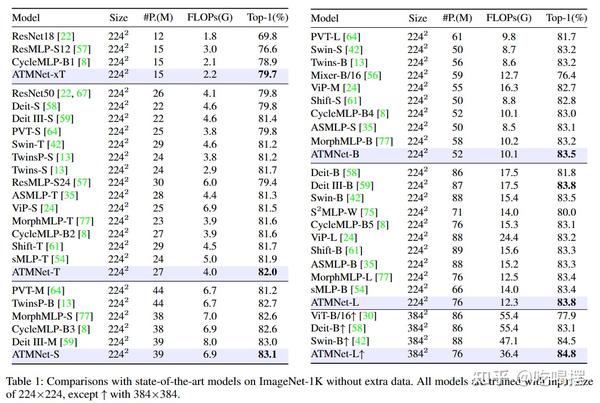
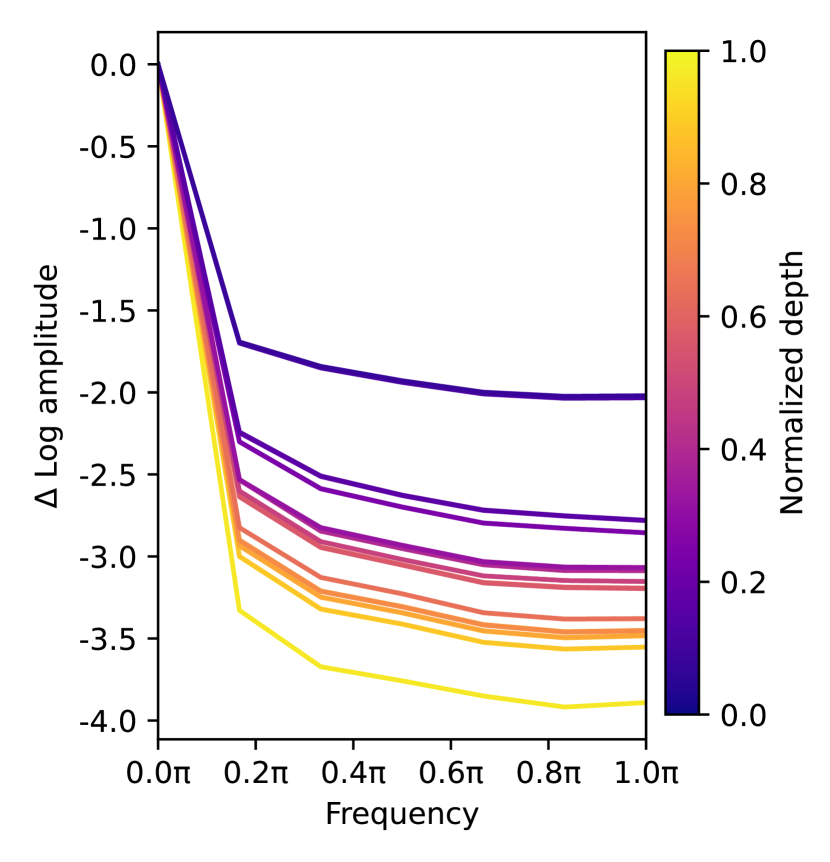
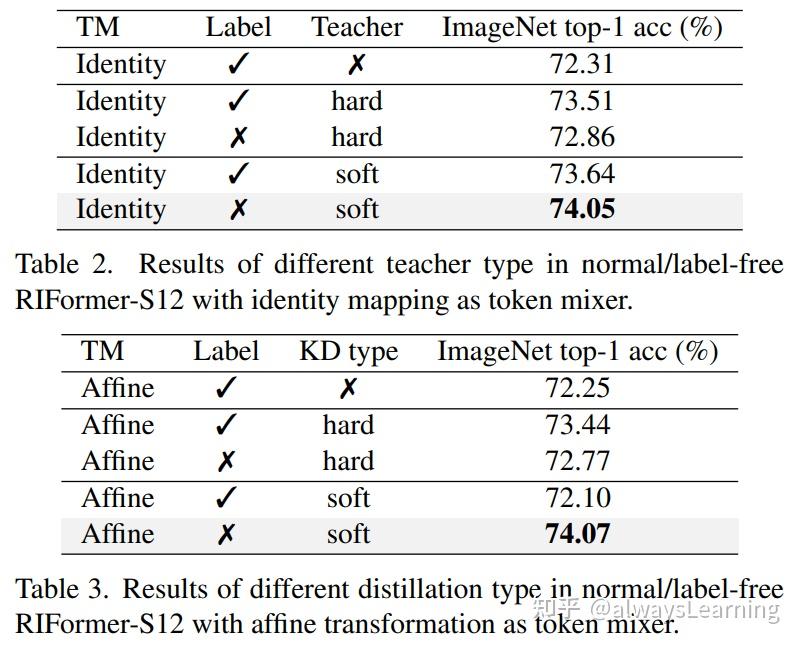
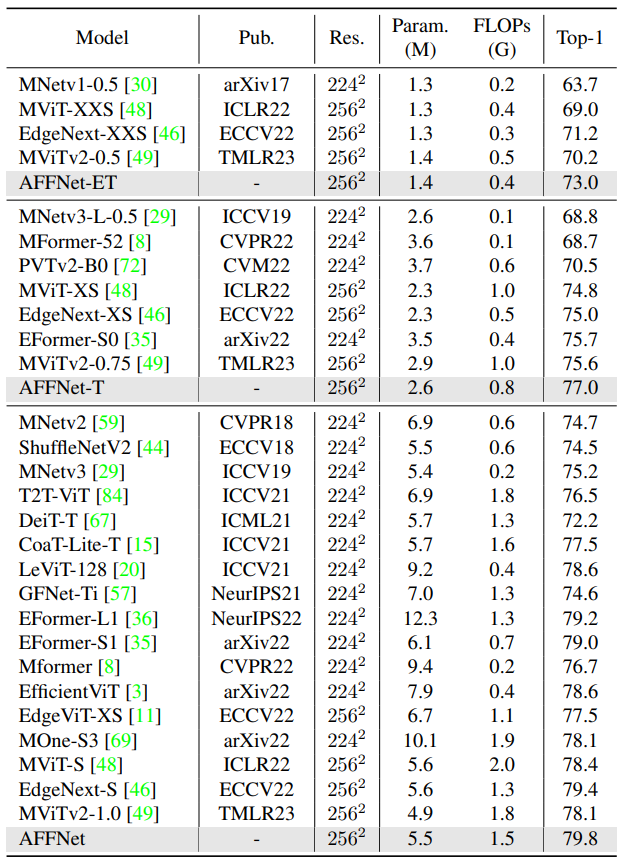
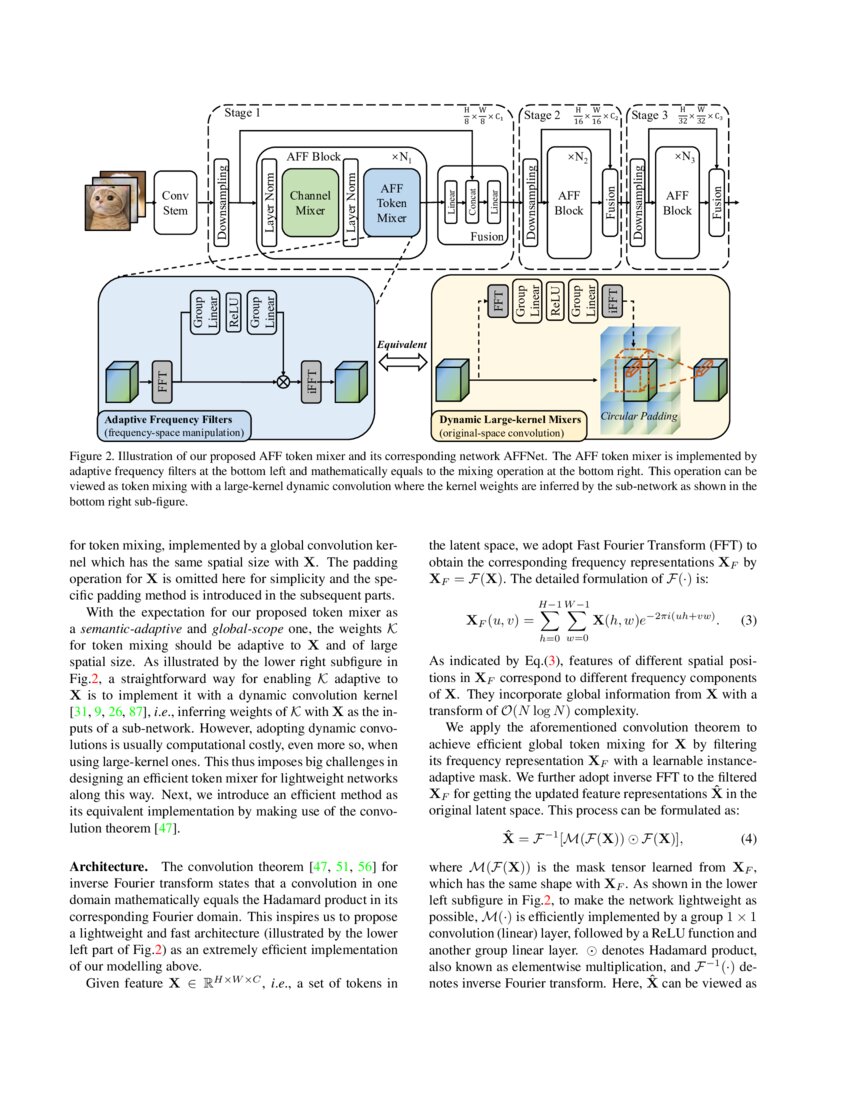
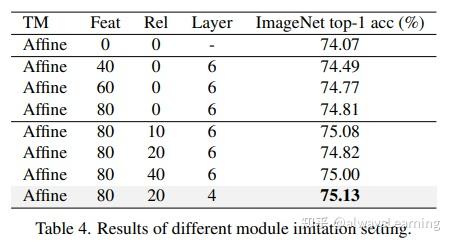
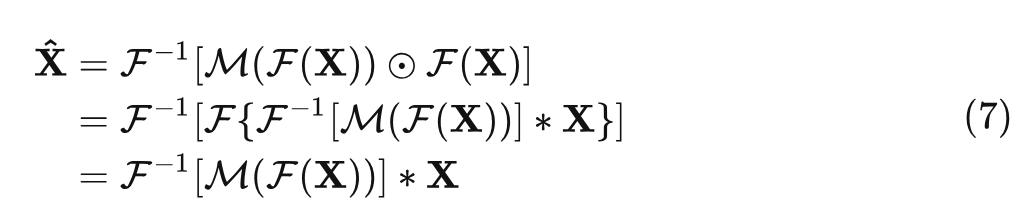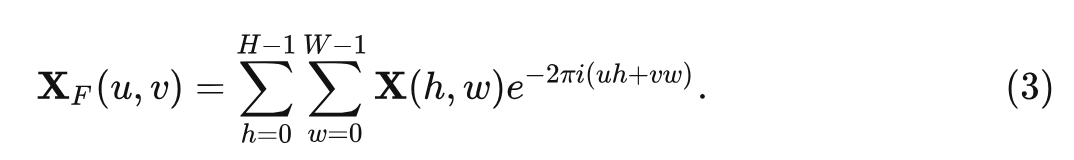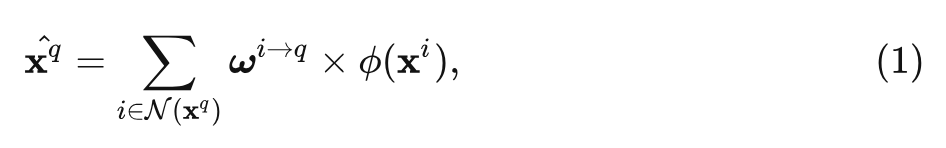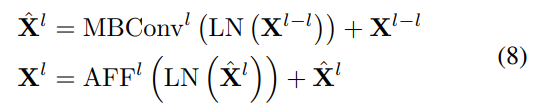Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
RIFormer: Keep Your Vision Backbone Effective But Removing Token Mixer - 知乎
Figure 2 from An Efficient Token Mixer Model for Sheet Metal Defect ...
Resampling mixer to replace transformer token mixer and channel mixer - 知乎
SWAT Mixer Block: In both token mixing and channel mixing, we first ...
Figure 1 from An Efficient Token Mixer Model for Sheet Metal Defect ...
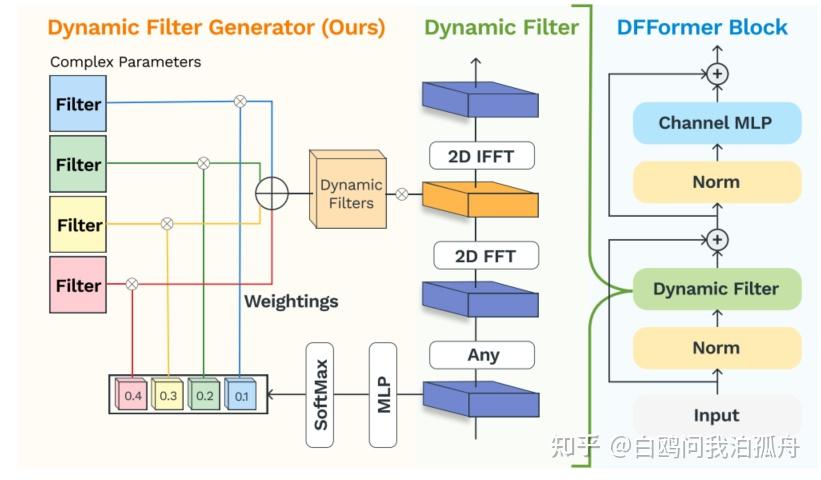
FFT-based Dynamic Token Mixer for Vision - 知乎
FFT-Based Dynamic Token Mixer for Vision | Underline
(PDF) EBTNet: Efficient Bilateral Token Mixer Network for Fetal Cardiac ...
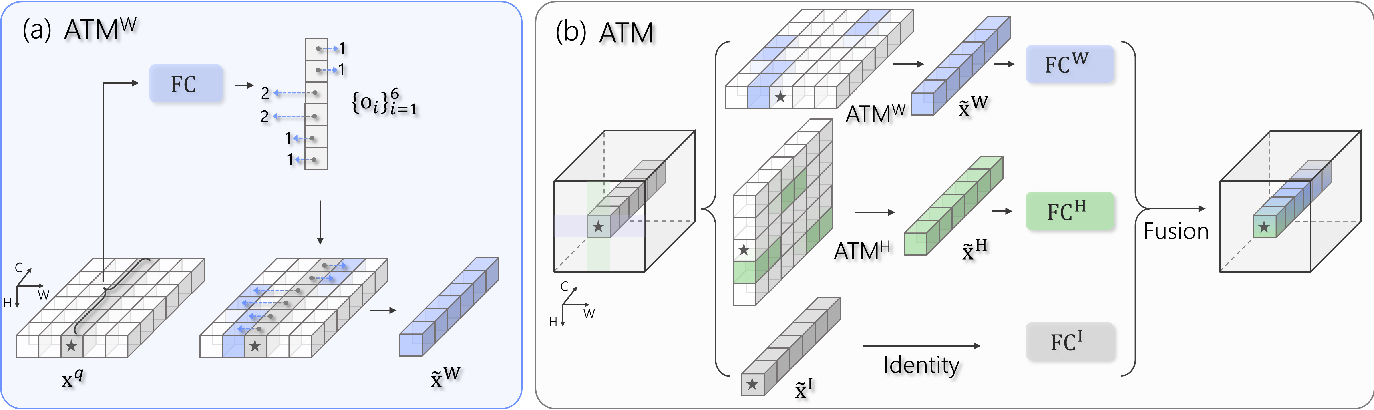
Active Token Mixer | Underline
FFT-based Dynamic Token Mixer for Vision-CSDN博客
Figure 1 from Active Token Mixer | Semantic Scholar
Process of token exchange module | Download Scientific Diagram
500-series Mixer module - 24 推子以上 - 传新科技有限公司
Comparison of different spatial token mixer designs. | Download ...
Figure 1 from FFT-based Dynamic Token Mixer for Vision | Semantic Scholar
Figure 3 from FFT-based Dynamic Token Mixer for Vision | Semantic Scholar
【AAAI 2023 Oral】 Active Token Mixer - 知乎
(aaai2024) FFT-based Dynamic Token Mixer for Vision - 知乎
Token Module
Table 3 from Integrating Multi-Modal Input Token Mixer Into Mamba-Based ...
Amazon.com: 4 Channel Passive Mixer Module 1 in 4 Out Mini Stereo Audio ...
Intellijel Aux Mix 1U 3-Channel Stereo Mixer Module
Mixer Scalable App Token 67196702 Vector Art at Vecteezy
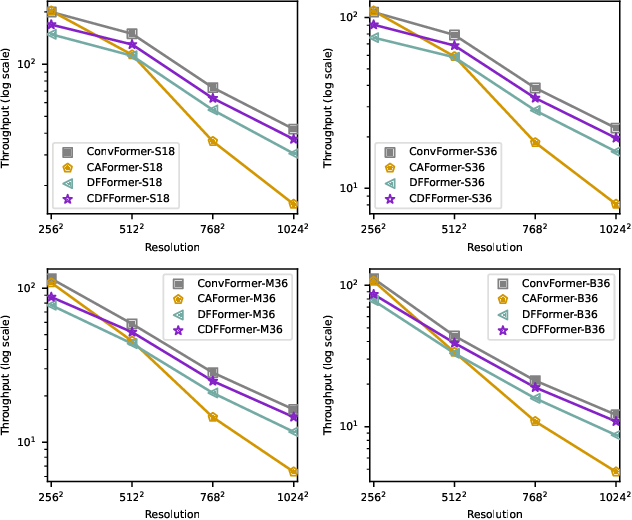
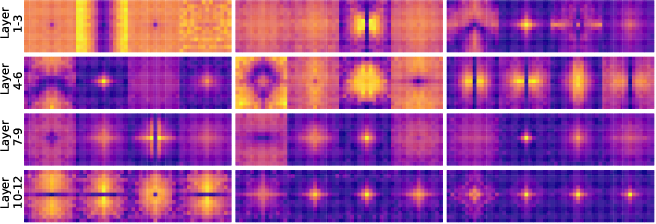
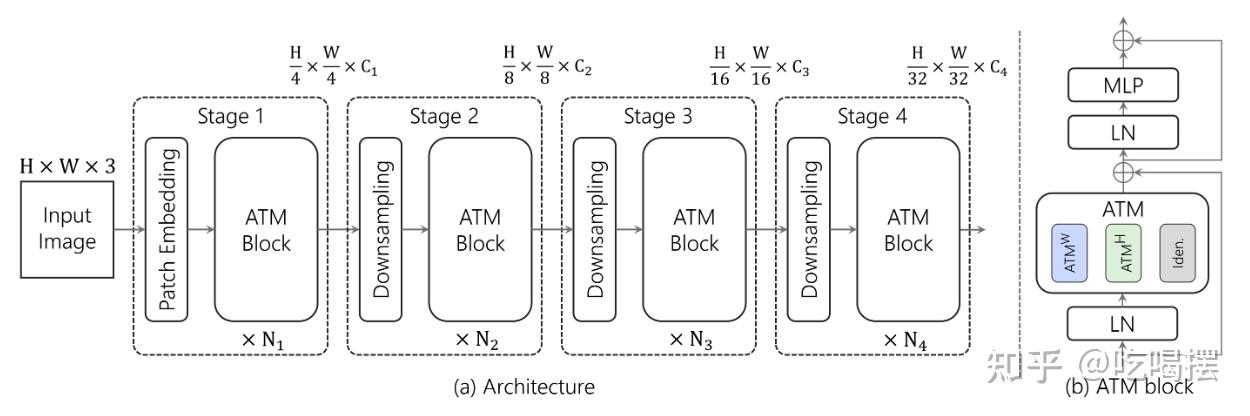
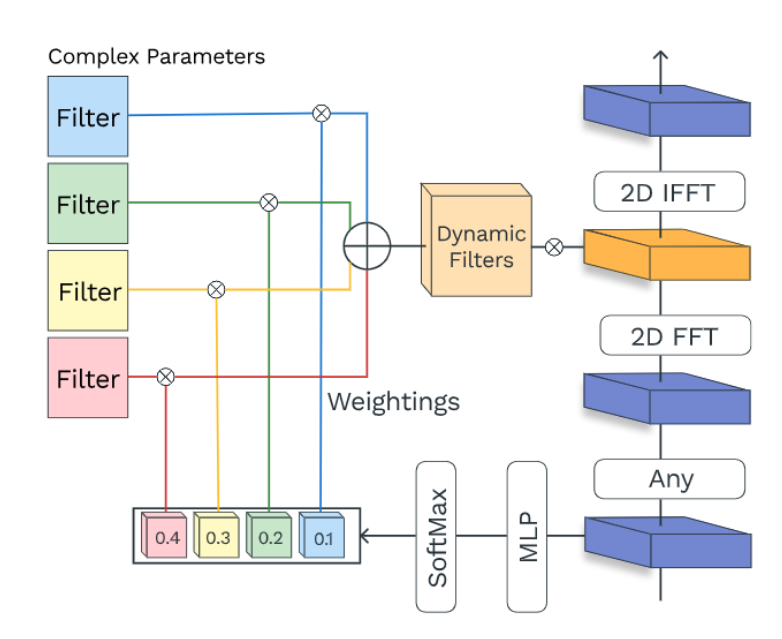
[2303.03932] FFT-based Dynamic Token Mixer for Vision
MambaMixer: Efficient Selective State Space Models with Dual Token and ...
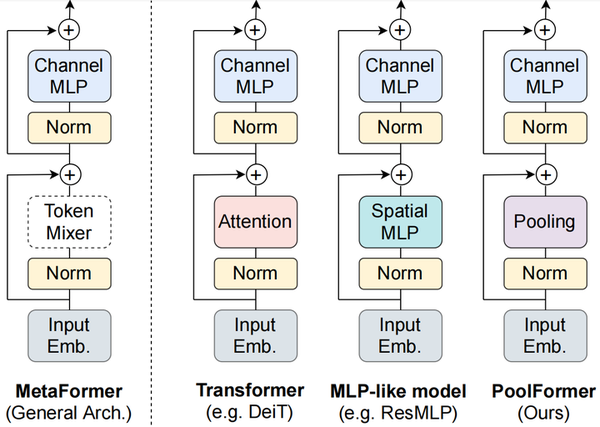
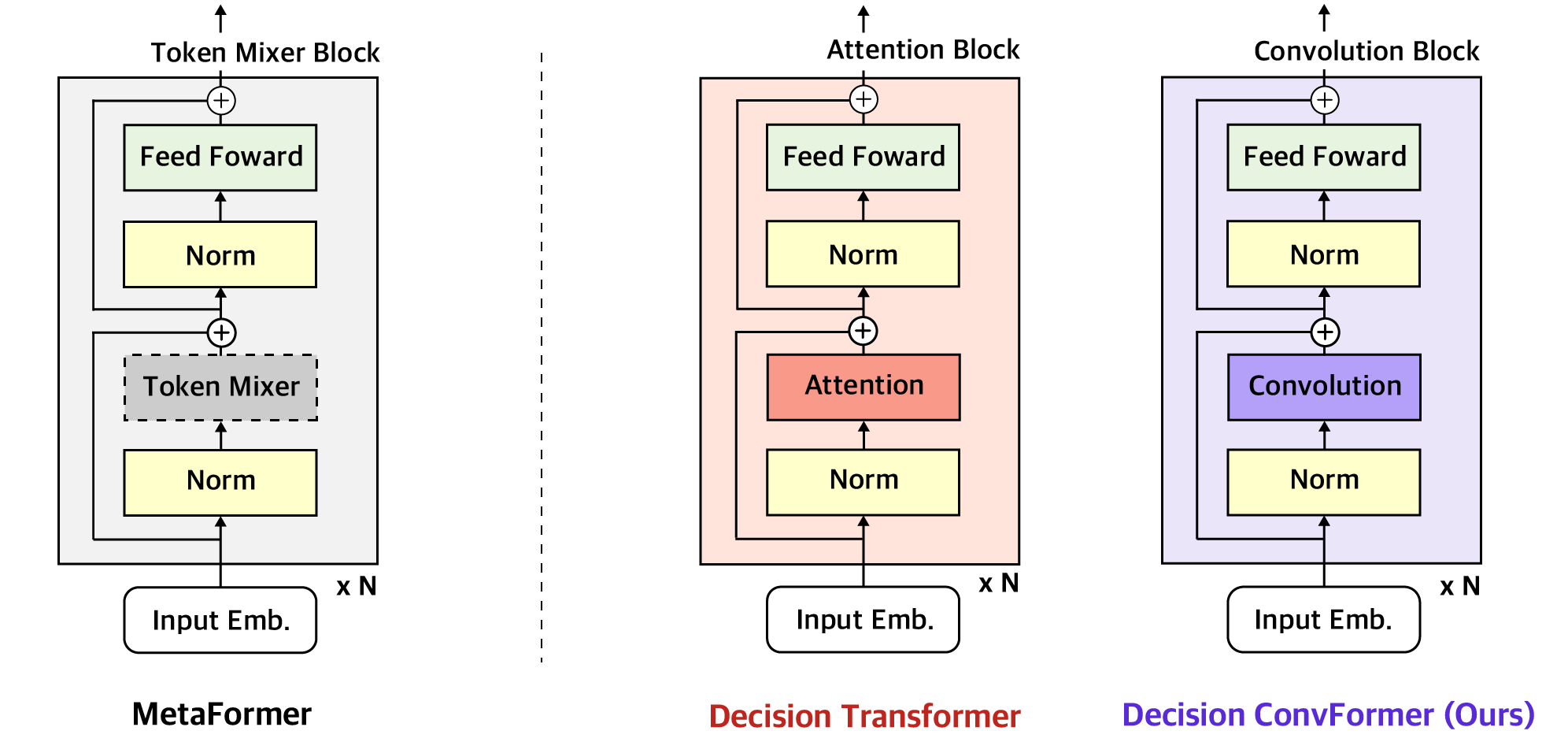
如何评价颜水成团队的MetaFormer: token mixers并不重要? - 知乎
EmbedFormer: Embedded Depth-Wise Convolution Layer for Token Mixing
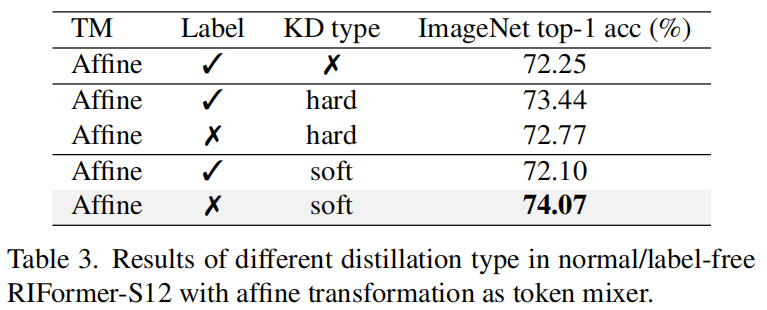
无自注意力照样高效!RIFormer: 开启token mixer free transformer结构新篇章! - 知乎
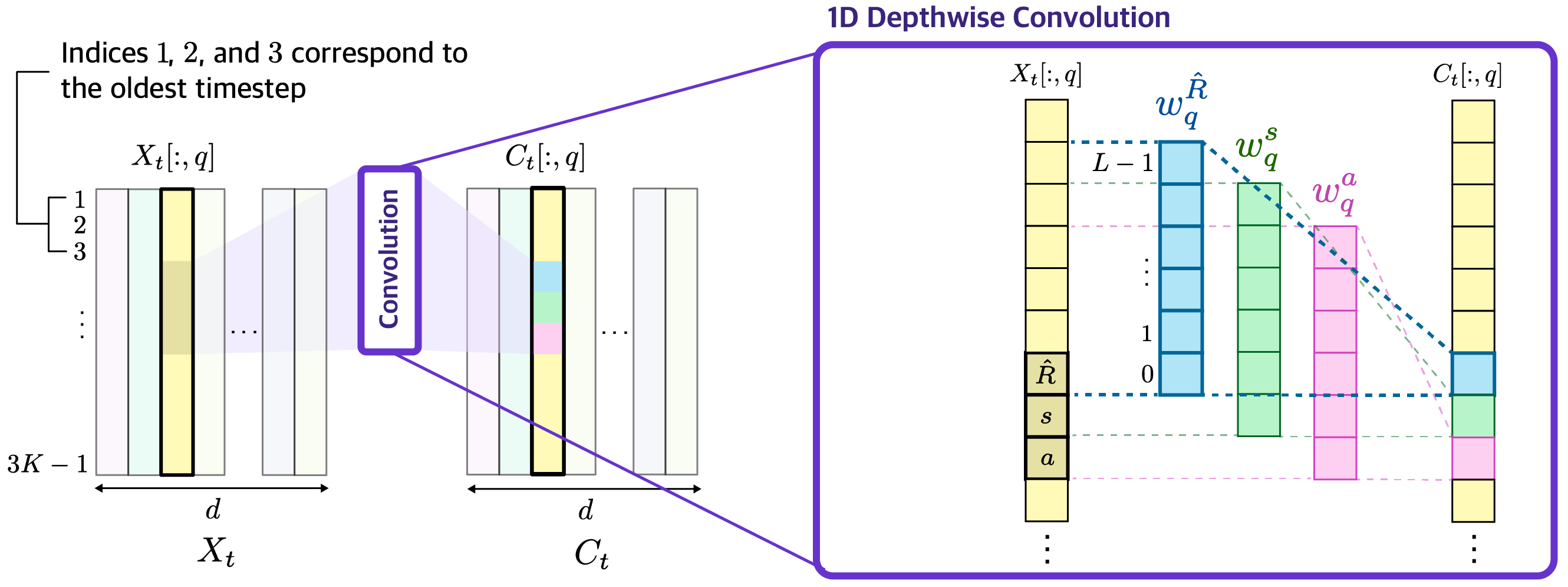
Temporal Scale Mixer Module. The output tokens Fn of stage n is resized ...
MVFormer: Diversifying Feature Normalization and Token Mixing for ...
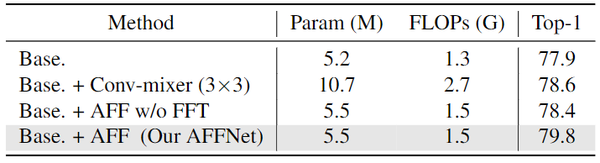
【ICCV2023】Adaptive Frequency Filters As Efficient Global Token Mixers ...
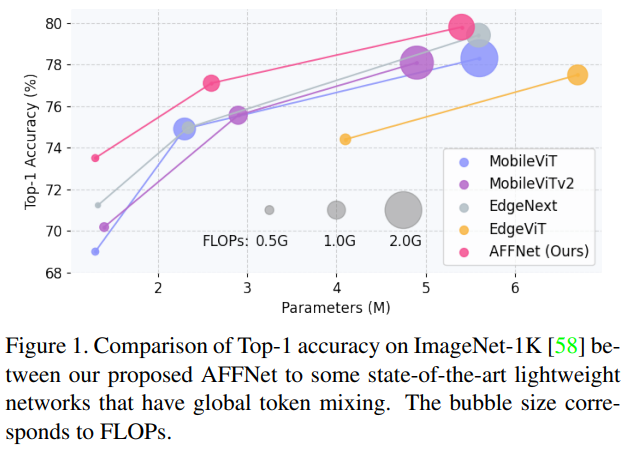
[2307.14008] Adaptive Frequency Filters As Efficient Global Token Mixers
Modular Audio Mixer at Matthew Boston blog
Adaptive Frequency Filters As Efficient Global Token Mixers | DeepAI
Token Logic Modules Introduction | Pocket Network Docs 2025
Any Idea why the tokenizer module keeps adding frames? Every time I ...
(PDF) Adaptive Fourier Neural Operators: Efficient Token Mixers for ...
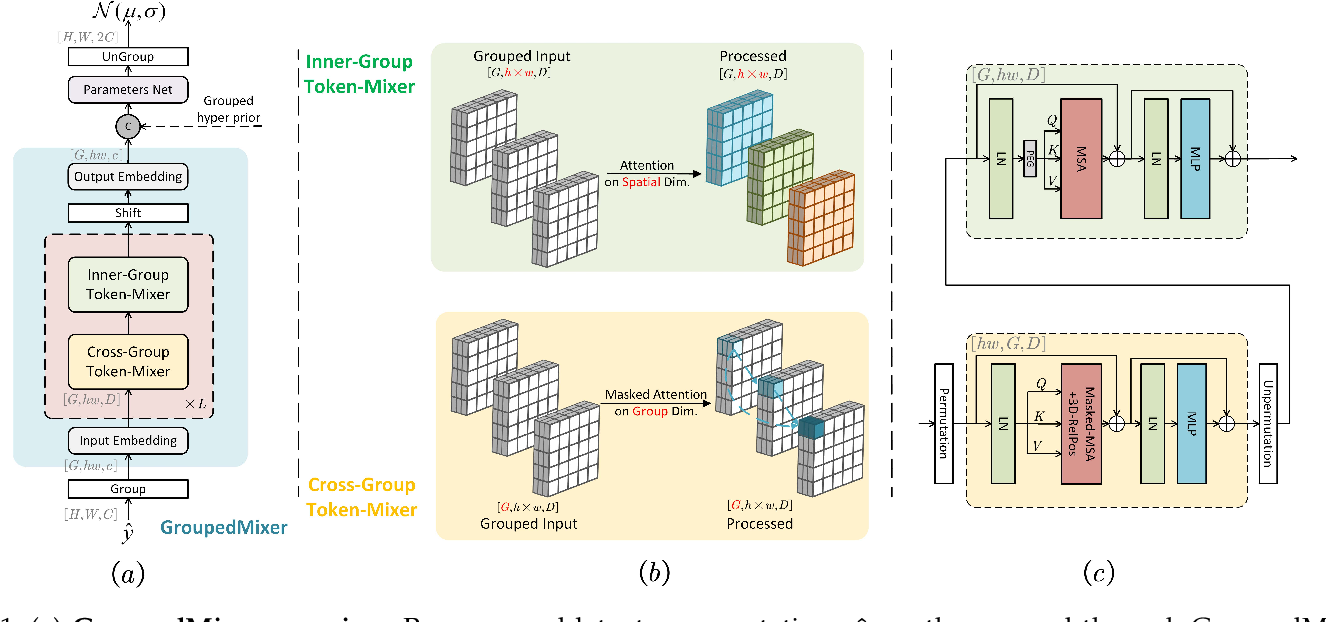
Figure 1 from GroupedMixer: An Entropy Model With Group-Wise Token ...
Understanding Attention Token Mixers and Exploring Attention-Free ...
(a) The overall architecture of the Super Token Transformer (STT). The ...
NANO Modules Performance Mixer – Thomann France
Mixer 4 from David Haillant's Electronic stuff on Tindie
How to Create the Tokenfactory Module
ammoon 4-Channel Line Stereo Mixer Audio Mixer 4-in-1-out Passive Mixer ...
Adaptive Fourier Neural Operators: Efficient Token Mixers for Transformers
Spectral clustering of tokens for different token mixers. From top to ...
Spiking Token Mixer: A event-driven friendly Former structure for ...
Adaptive Frequency Filters As Efficient Global Token Mixers - YouTube
The MLP-based blocks with the convolutional token-mixing modules: (a ...
Jeonghye Kim
[2307.00407] WavePaint: Resource-efficient Token-mixer for Self ...
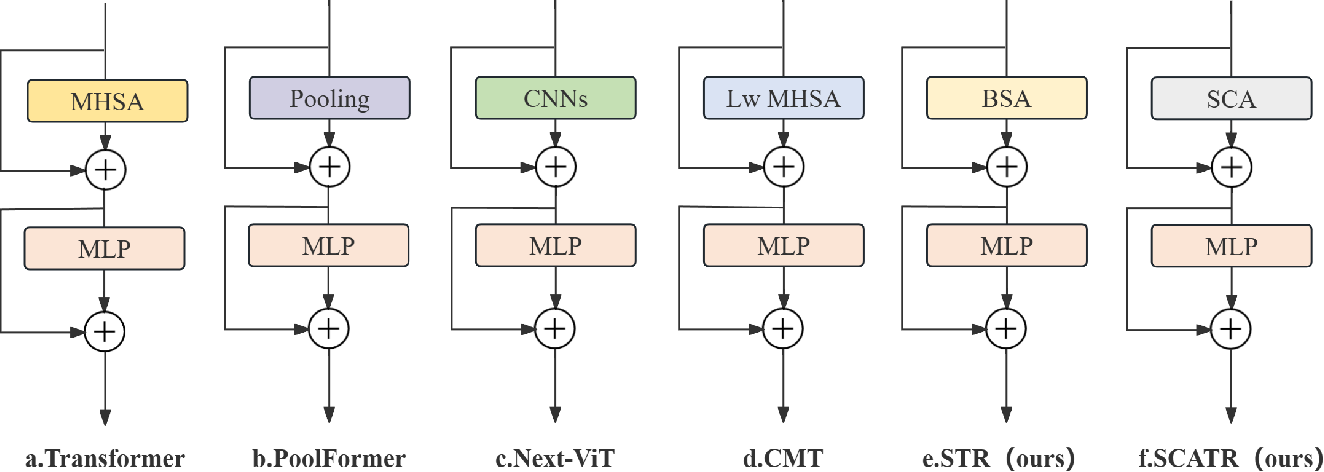
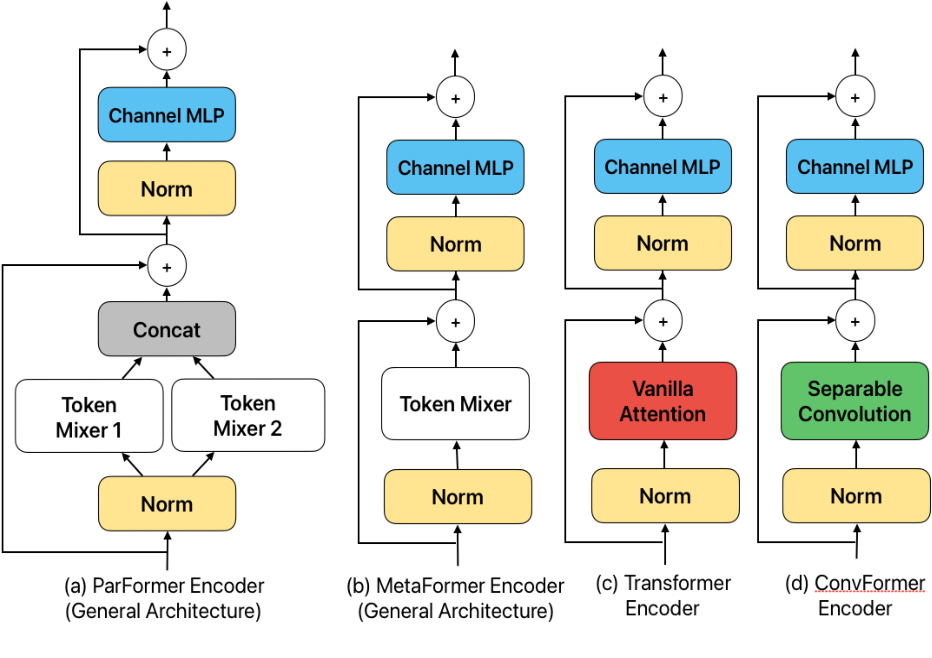
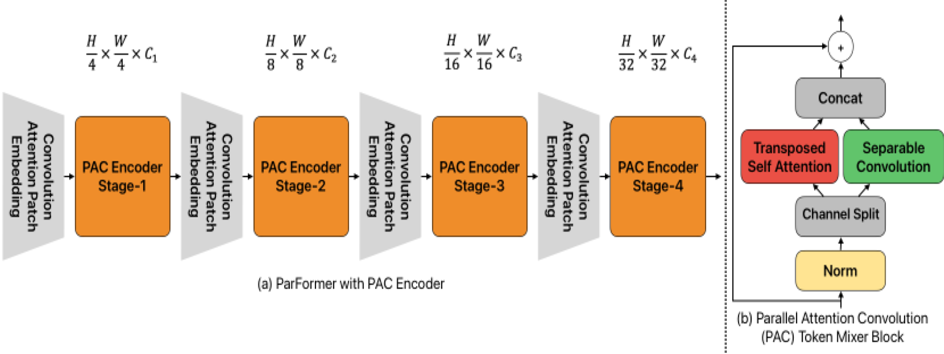
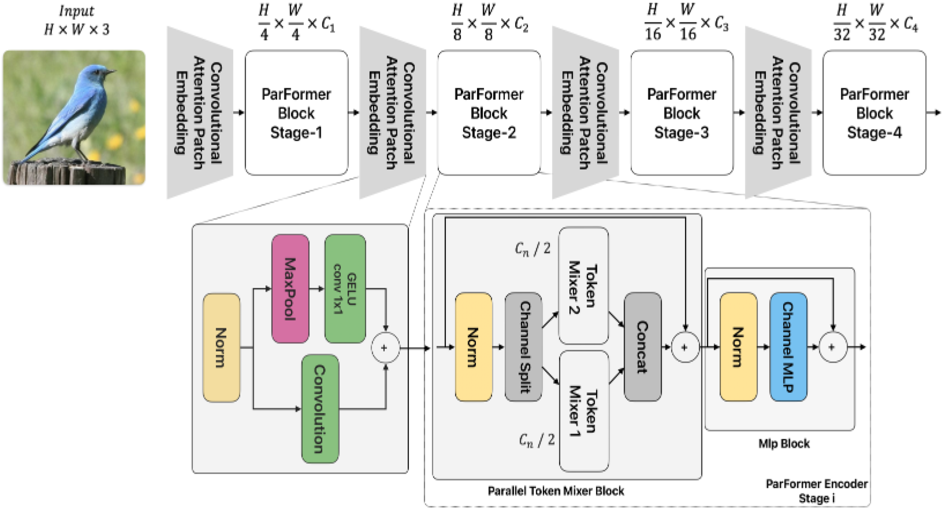
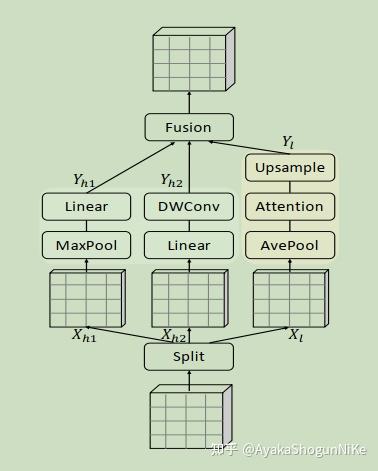
Figure 1 from ParFormer: Vision Transformer Baseline with Parallel ...
Next-ViT论文学习笔记_token mixer-CSDN博客
HyperTransXNet: Learning Both Global and Local Dynamics with a Dual ...
GitHub - Nekos4Lyfe/TokenMixer: An A1111 extension for interpolating ...
GitHub - microsoft/TokenMixers
GitHub - lyupengju/MetaUNETR · GitHub
Token-Mixer/README.md at main · yangyan22/Token-Mixer · GitHub
(PDF) TransXNet: Learning Both Global and Local Dynamics With a Dual ...
(PDF) WavePaint: Resource-efficient Token-mixer for Self-supervised ...
ICCV 2023 | 傅里叶算子高效Token Mixer:轻量级视觉网络新主干 - 知乎
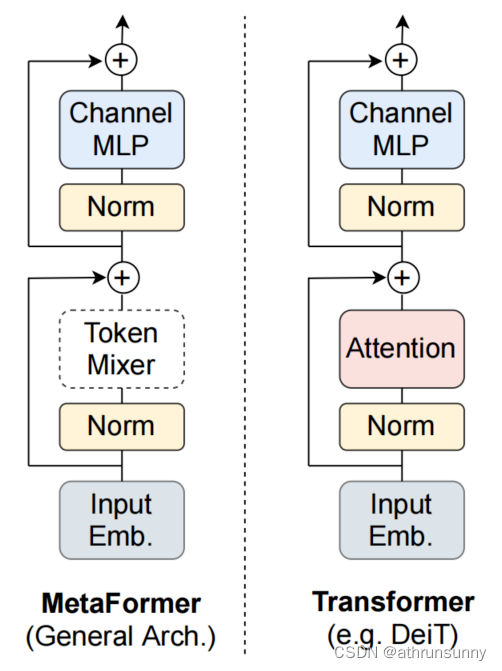
无需新型token mixer就能SOTA:MetaFormer视觉基线模型开源,刷新ImageNet记录 - 知乎
An Introductory Guide to MetaFormers in Computer Vision
Spatial Resolution Enhancement Framework Using Convolutional Attention ...
Mezclador de rendimiento MKII – WMD
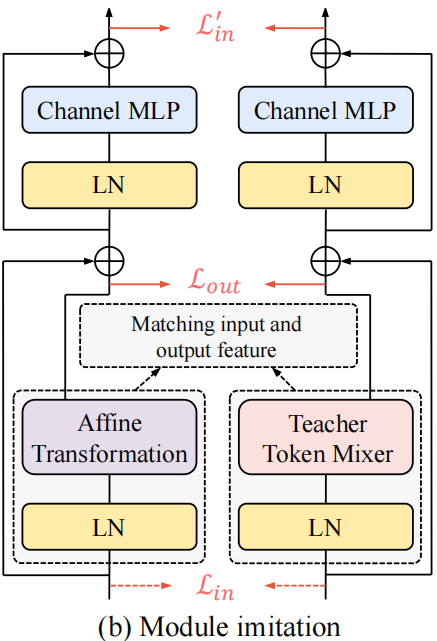
(PDF) RIFormer: Keep Your Vision Backbone Effective While Removing ...
[ FastViT ] 2. prerequisite.
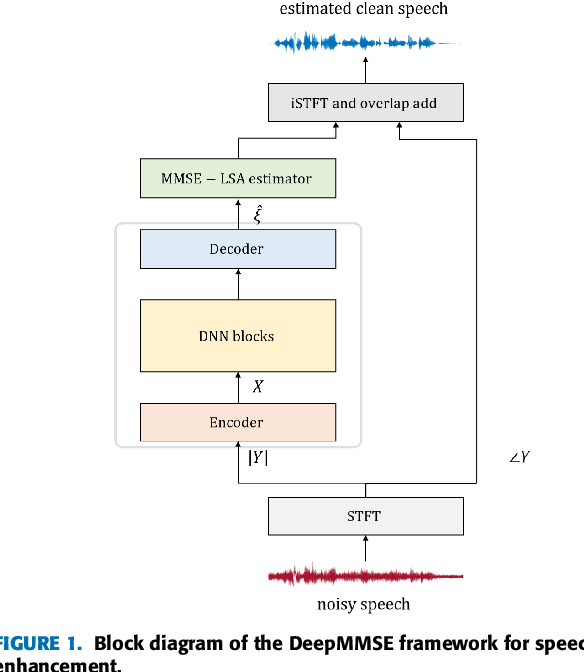
(PDF) Speech Enhancement Using MLP-Based Architecture With ...
Figure 1 from Speech Enhancement Using MLP-Based Architecture With ...
GitHub - LMMMEng/TransXNet: TransXNet: Learning Both Global and Local ...
Hint-AD | Project Page
A token-mixer architecture for CAD-RADS classification of coronary ...
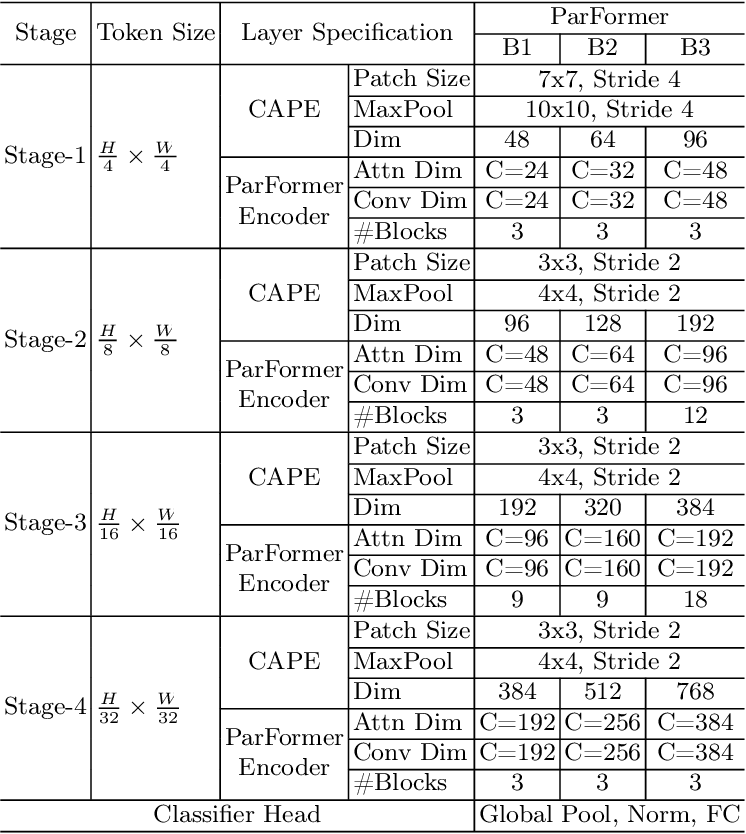
Table 1 from ParFormer: Vision Transformer Baseline with Parallel Local ...
RTDETR融合[CVPR2025]BHViT中的token_mixer模块-CSDN博客
高速な深層学習モデルアーキテクチャ2023 - Speaker Deck
无需新型token mixer就能SOTA:MetaFormer视觉基线模型开源,刷新ImageNet记录-腾讯云开发者社区-腾讯云
Inception Transformer - 知乎
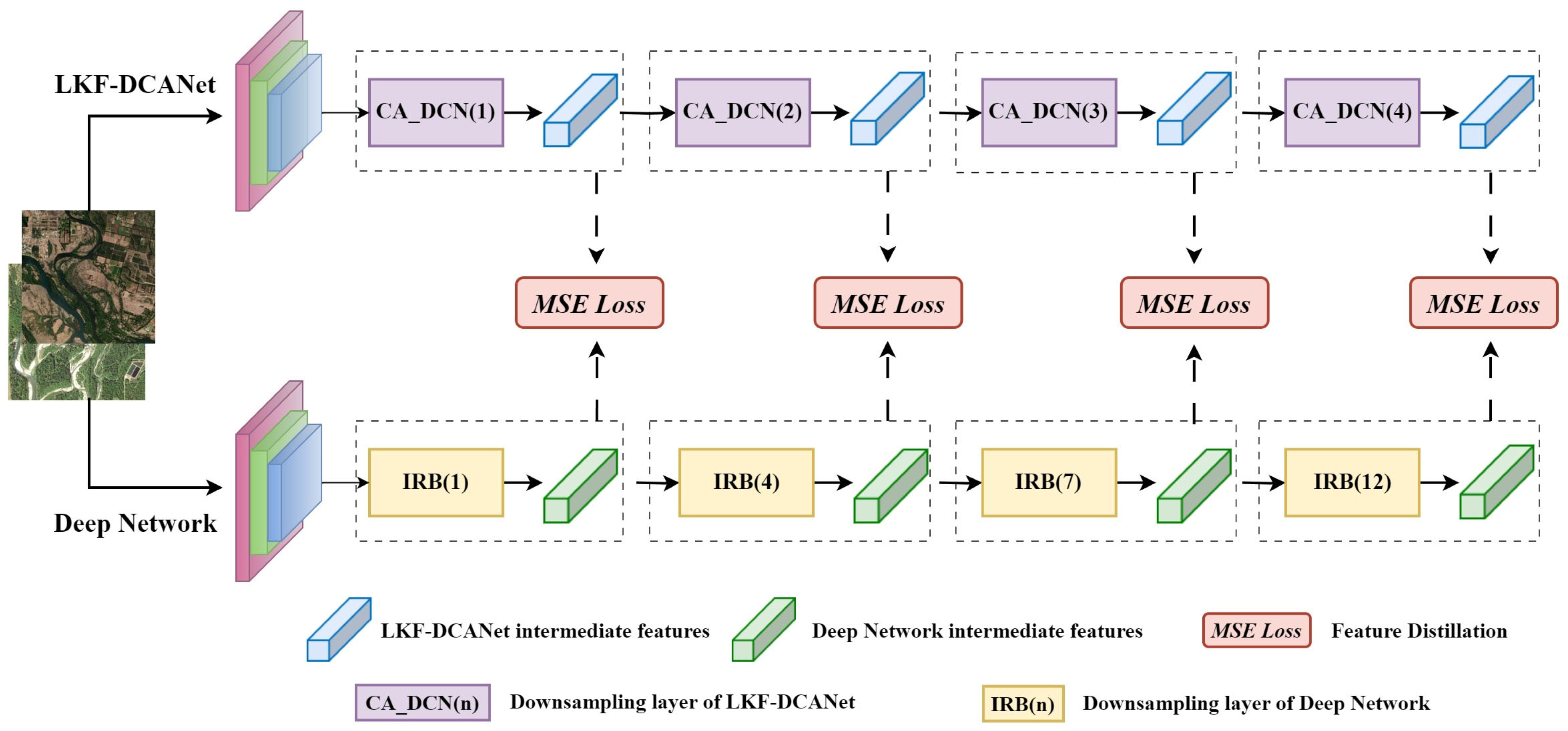
A Lightweight Network for Water Body Segmentation in Agricultural ...