Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
NVIDIA TF32 Tensor Core을 통한 AI training 가속화 (Ampere GPU 아키텍처) : 네이버 블로그
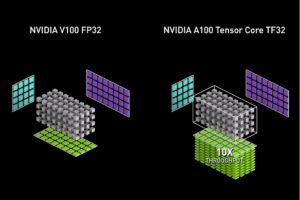
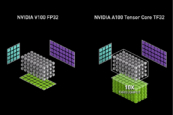
Accelerating AI Training with NVIDIA TF32 Tensor Cores | NVIDIA ...
How to use TF32 in Tensorrt · Issue #1824 · NVIDIA/TensorRT · GitHub
Tensor Core TF32 Support (Assignments 8 & 9) | vortexgpgpu/vortex ...
利用 NVIDIA TF32 Tensor 核心加快人工智慧訓練 - NVIDIA 台灣官方部落格
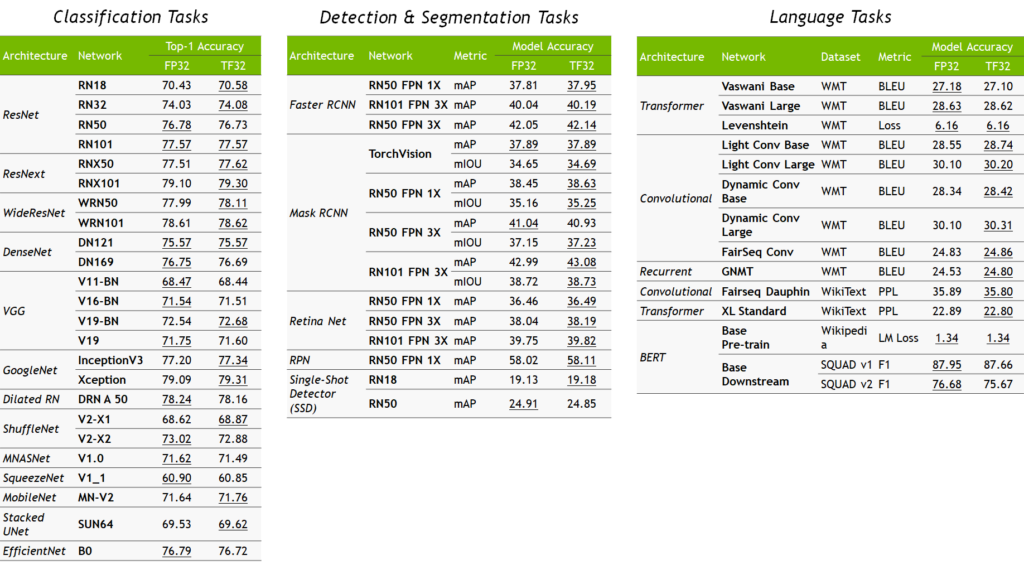
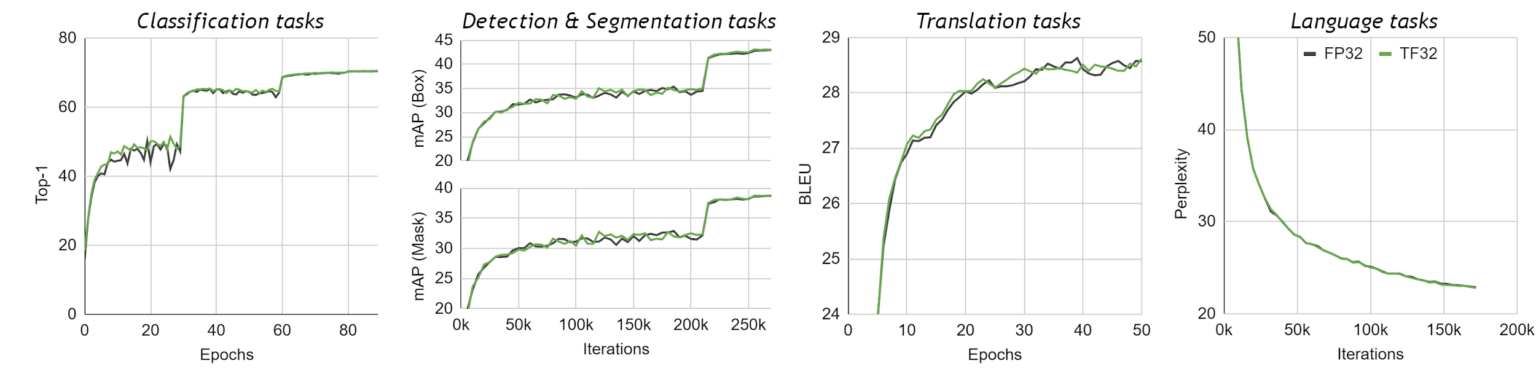
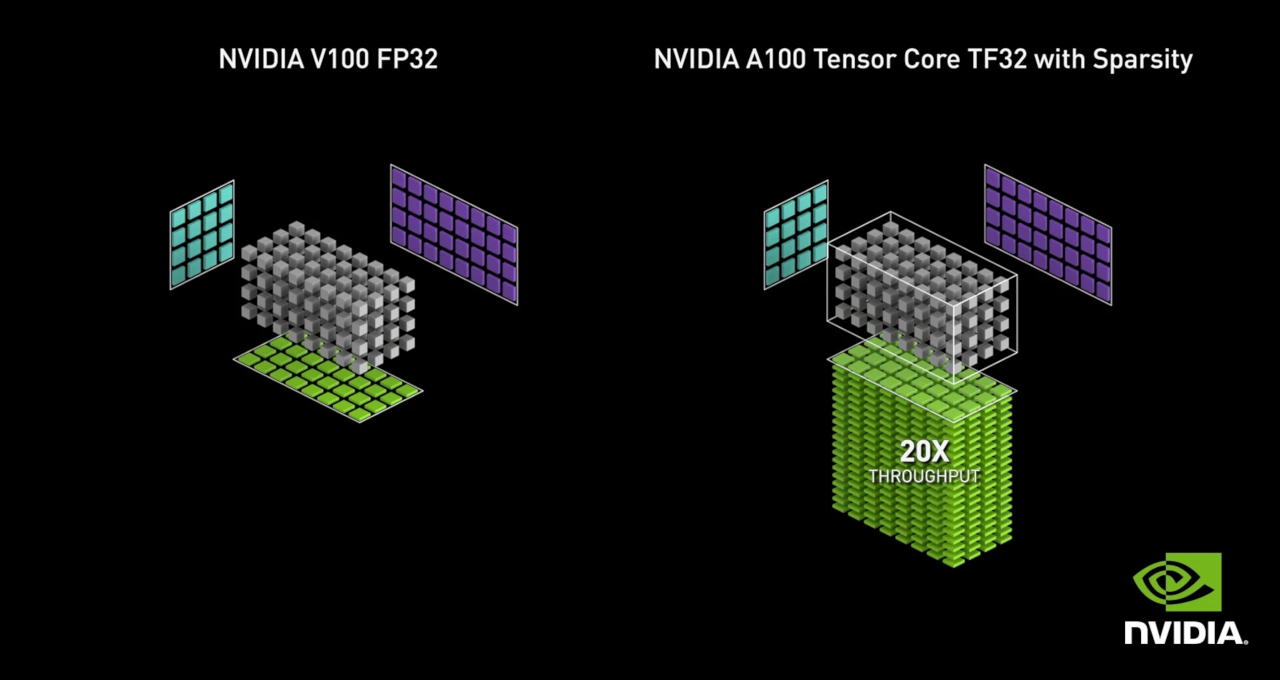
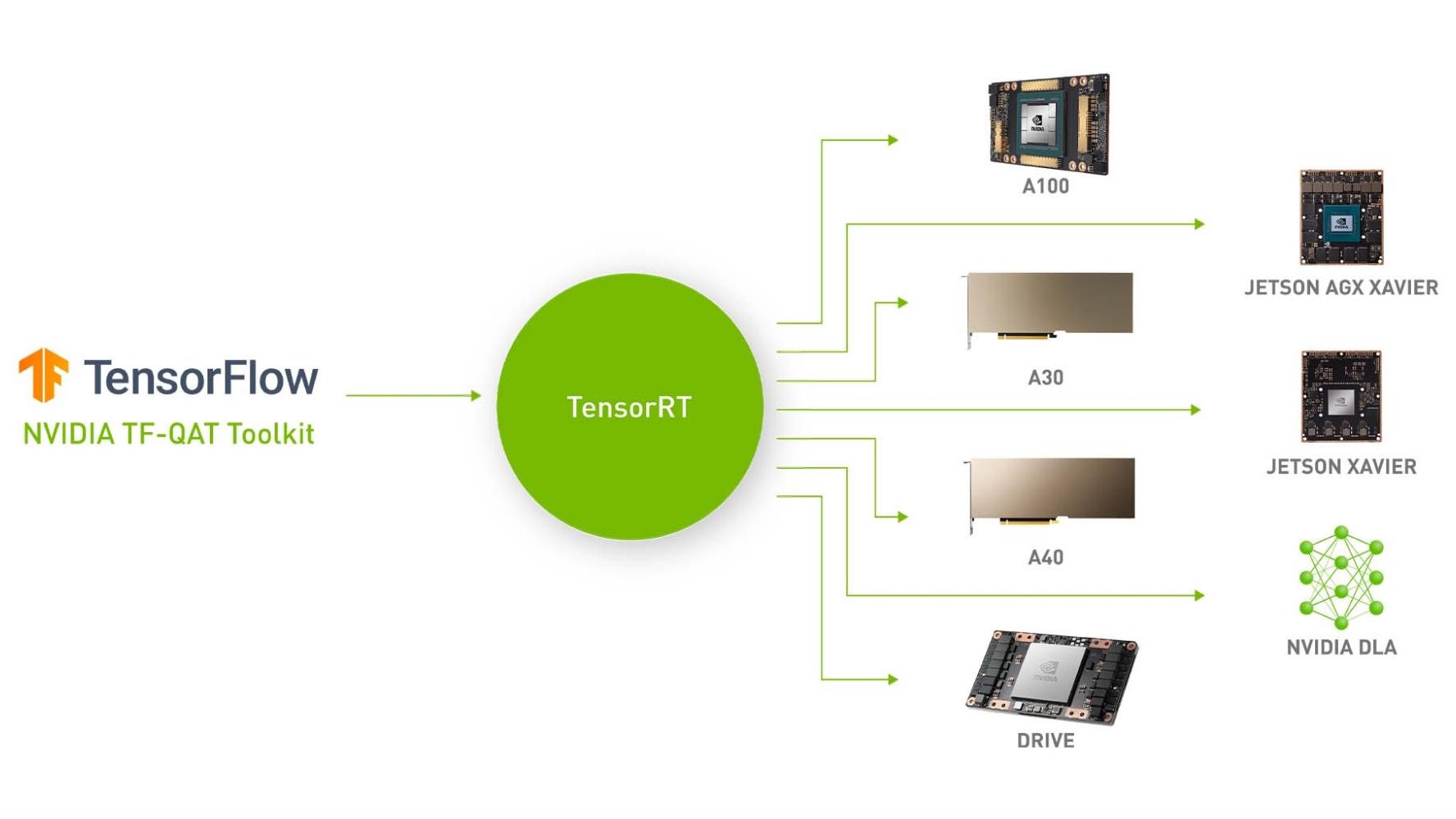
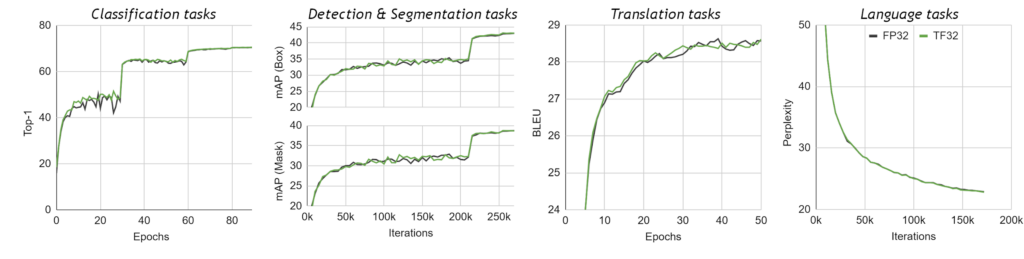
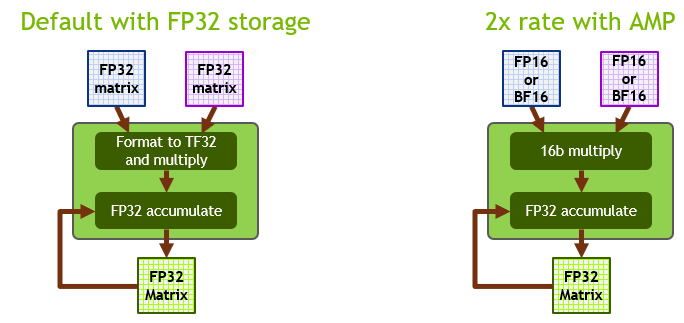
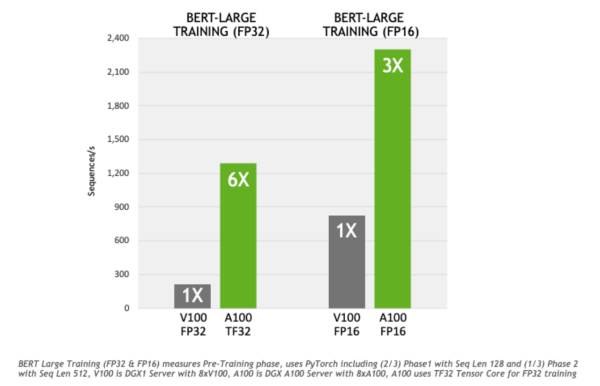
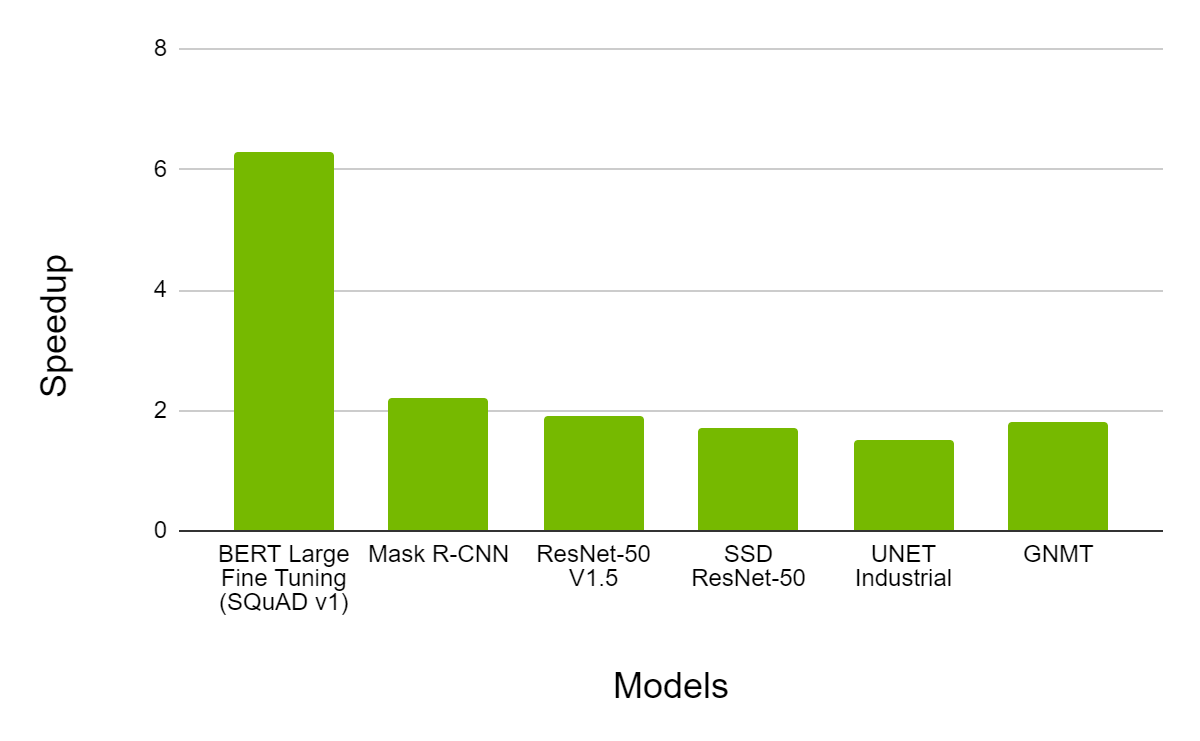
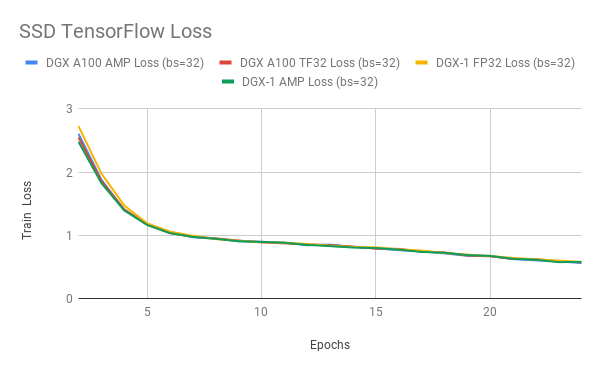
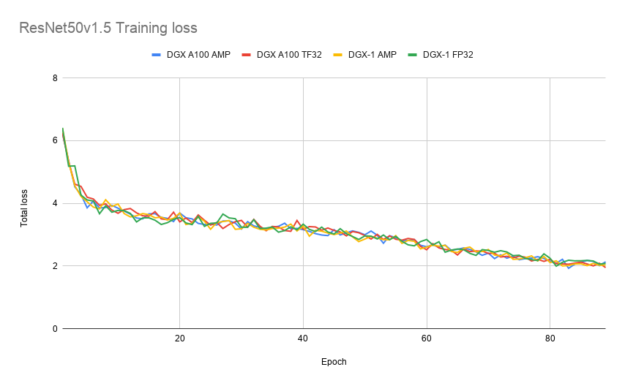
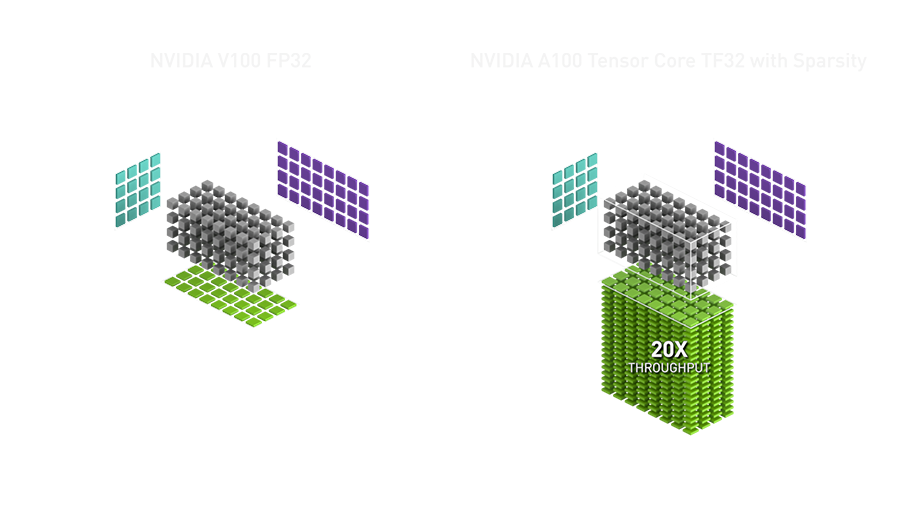
Getting Immediate Speedups with NVIDIA A100 TF32 | NVIDIA Technical Blog
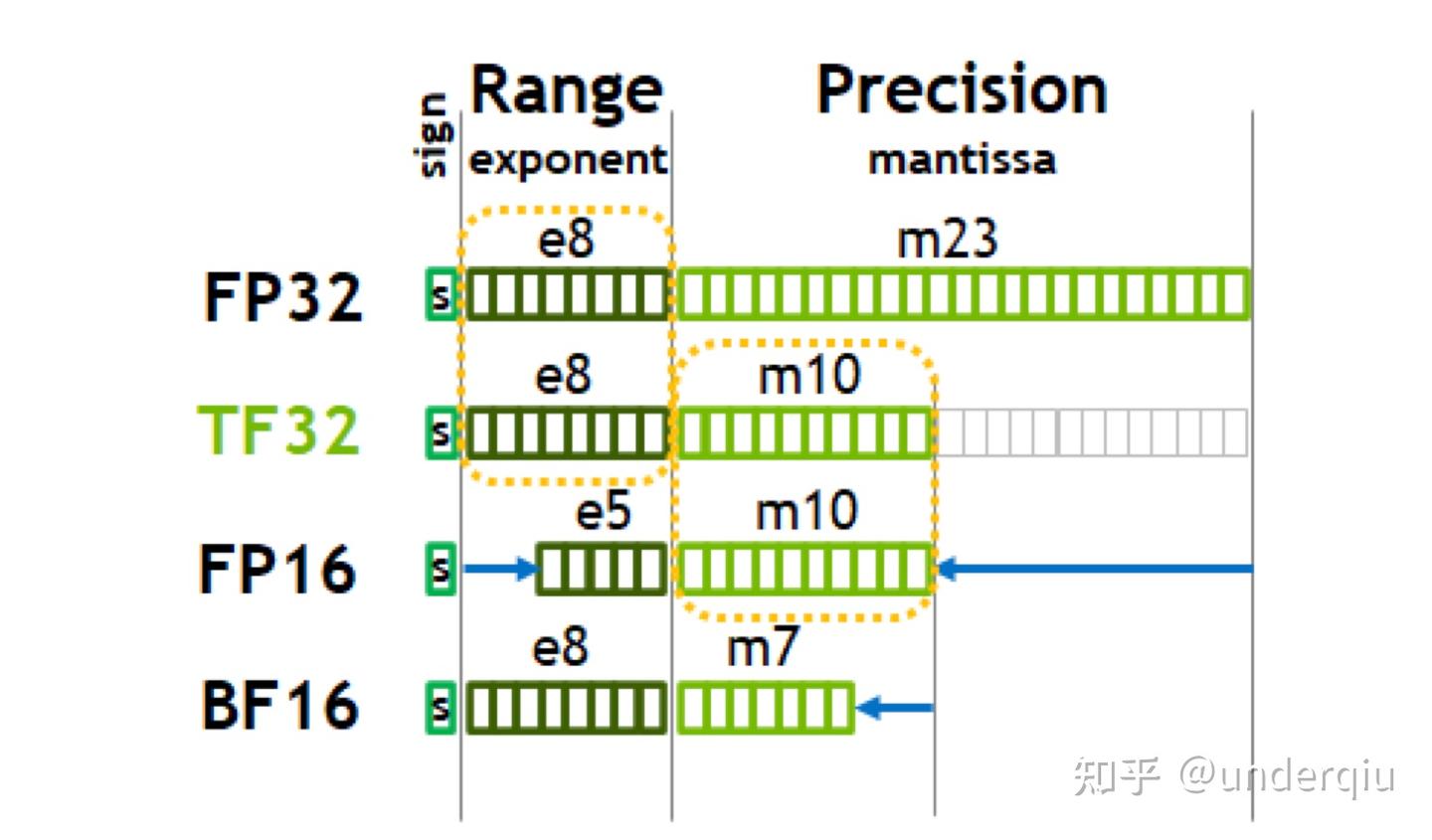
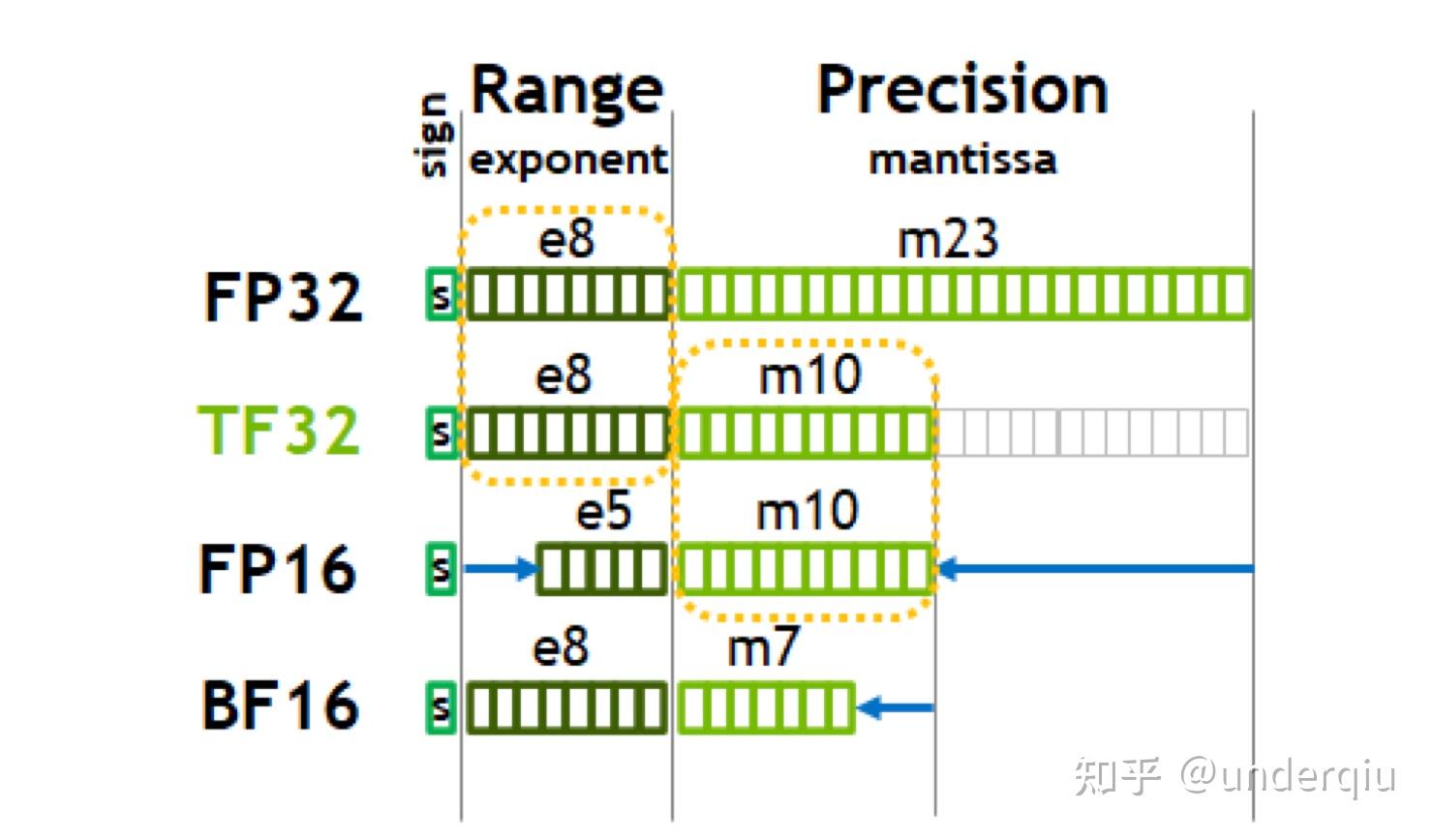
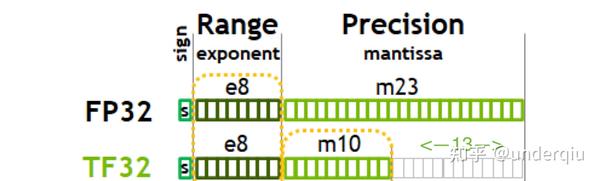
FP32 versus TF32 Precision in Deep Learning | by Umair Akbar | Medium
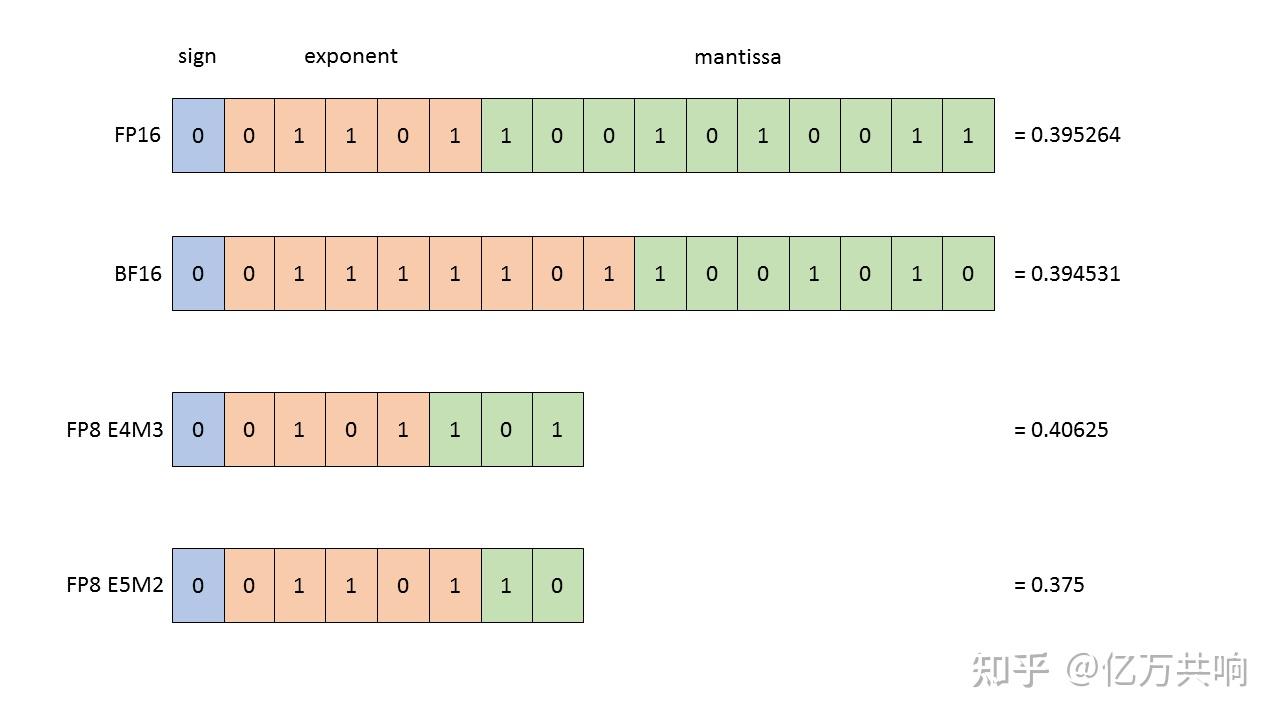
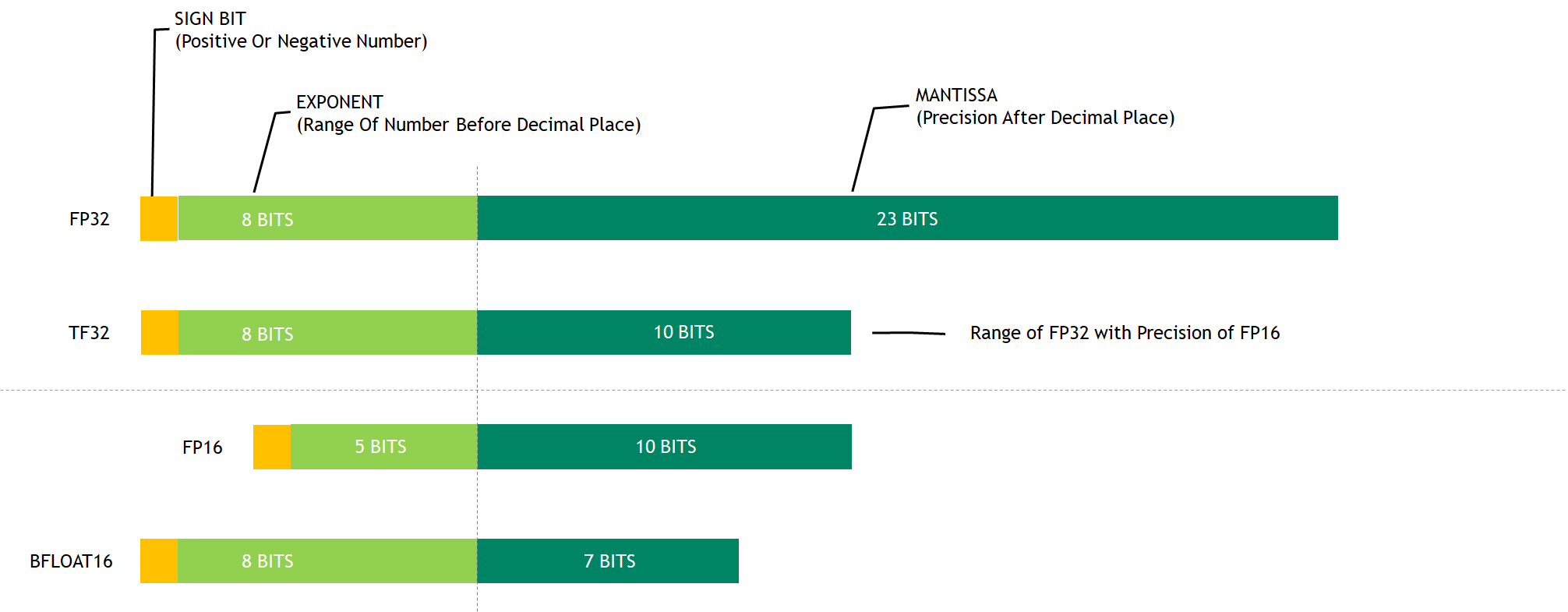
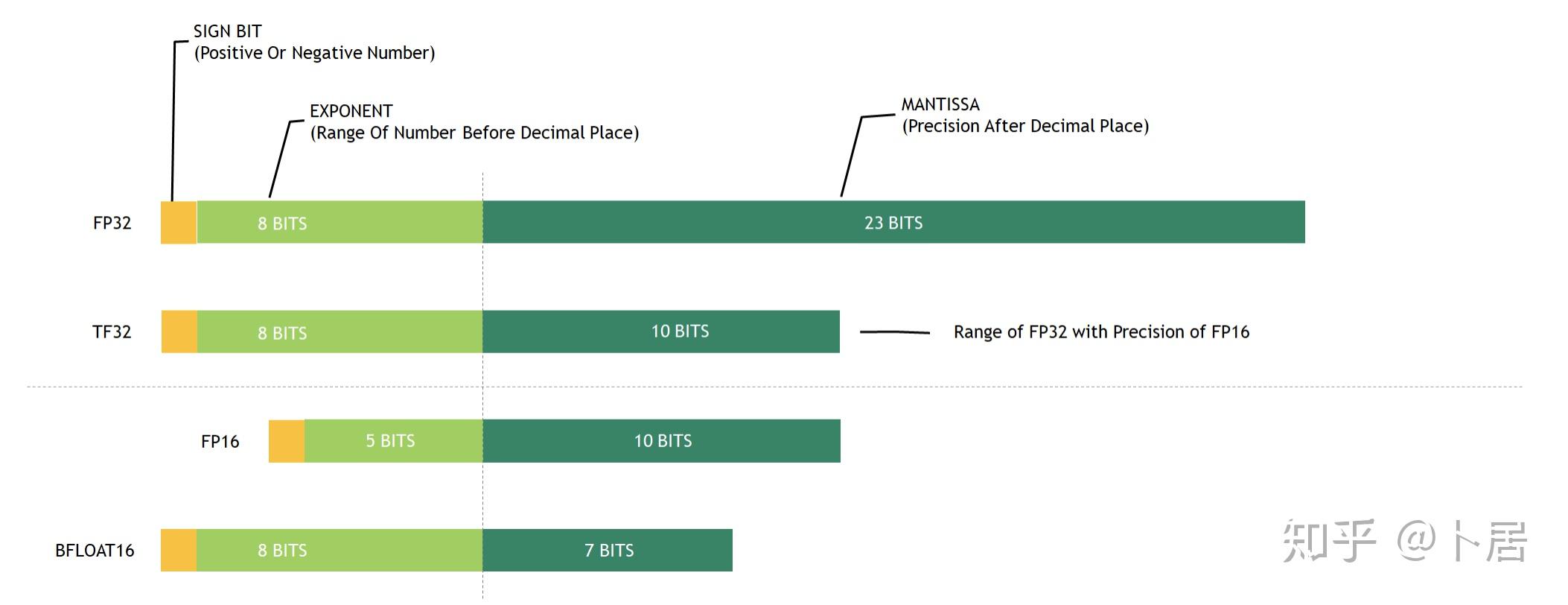
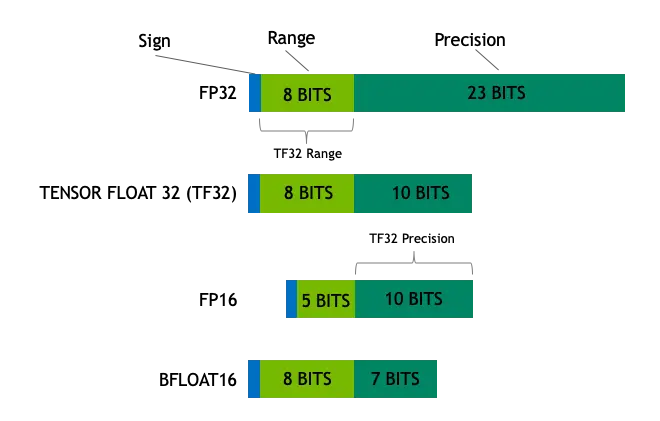
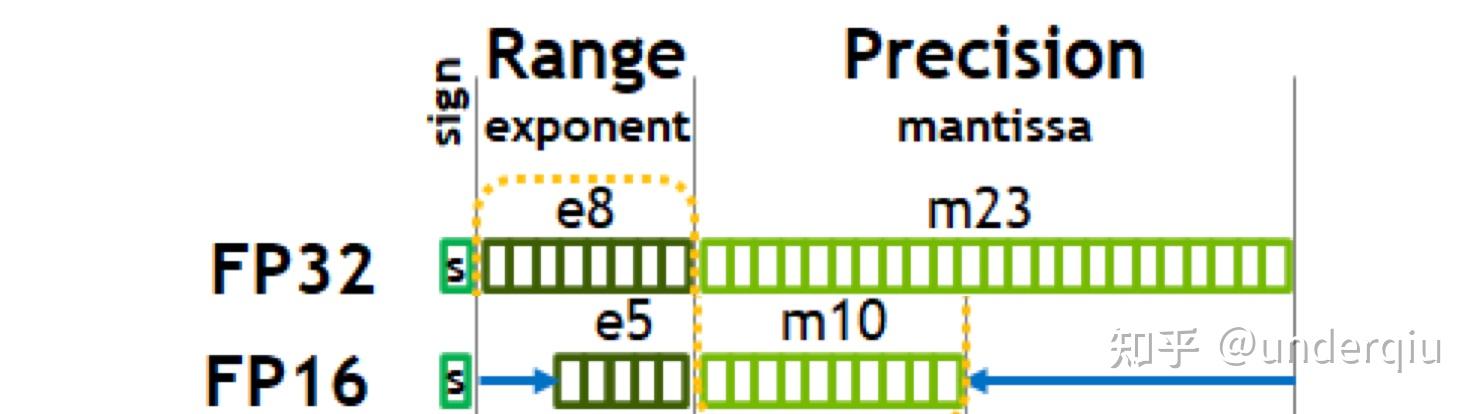
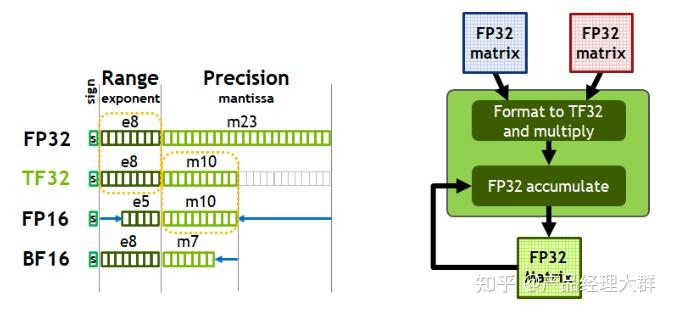
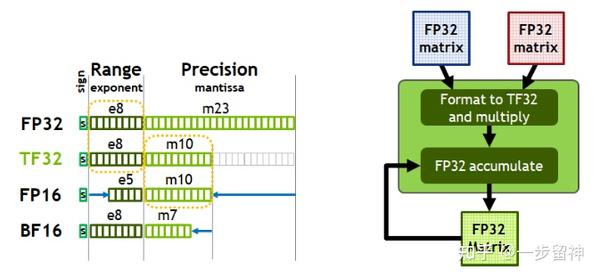
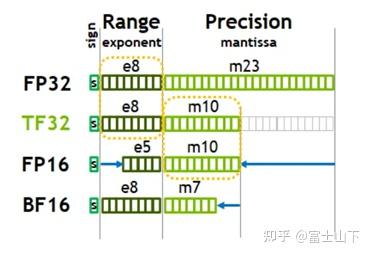
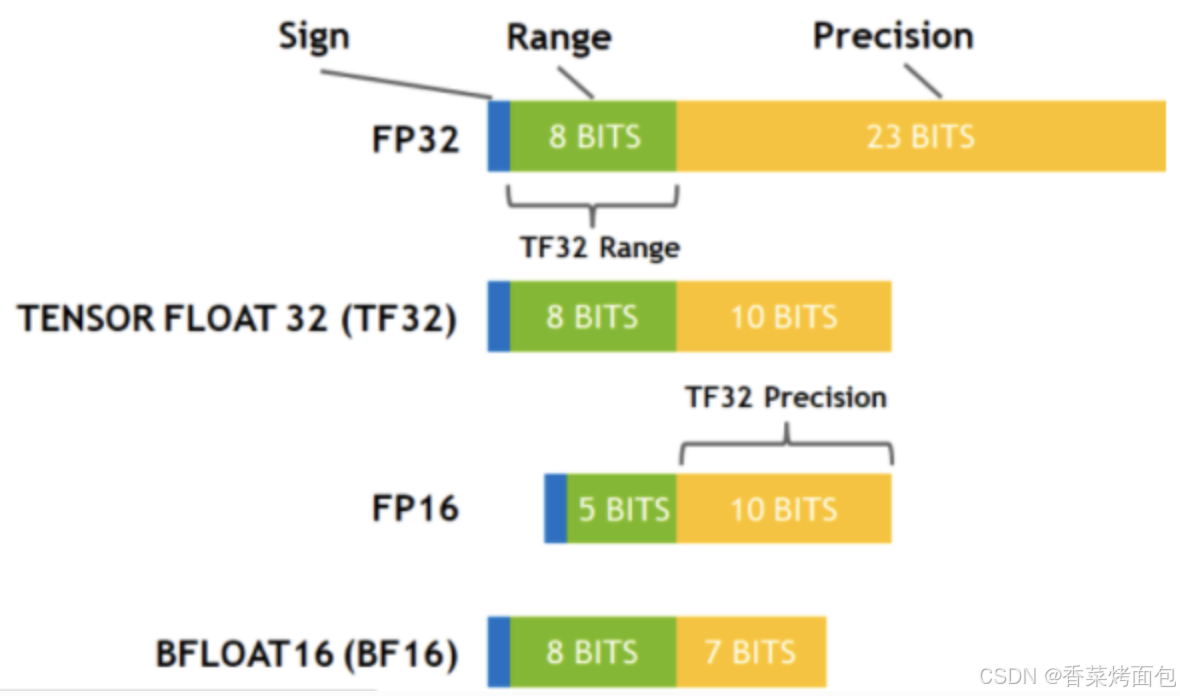
计算精度对比:FP64, FP32, FP16, BFLOAT16, TF32 - 知乎
Andrej Karpathy explains Tensor Cores and TF32 precision 💎🔥 Just ...
Performance comparison of our method in TF32 and FP16, cuBLAS SGEMM and ...
简单理解TensorFloat32_tensor float-CSDN博客
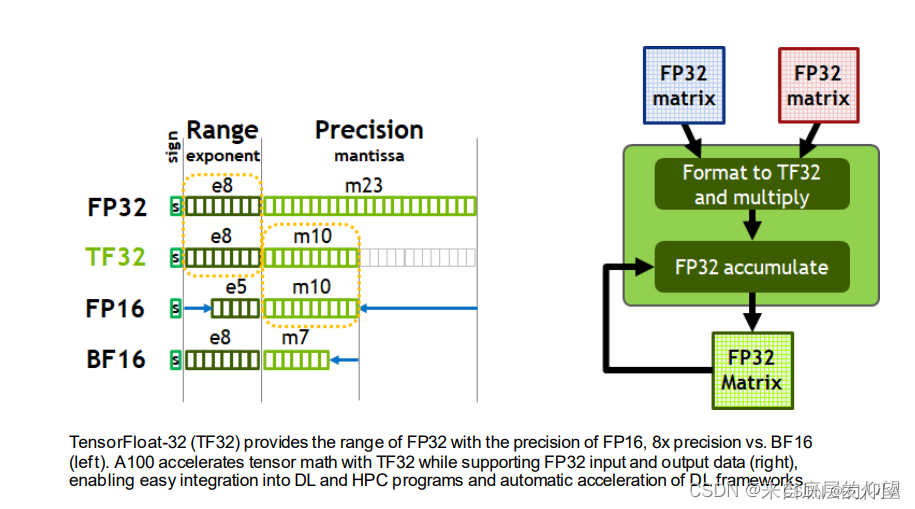
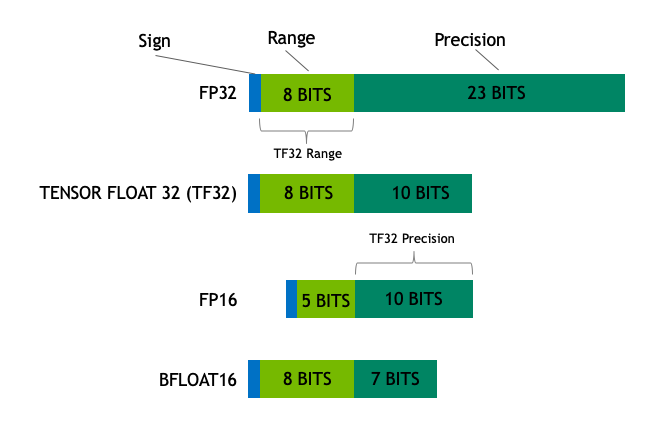
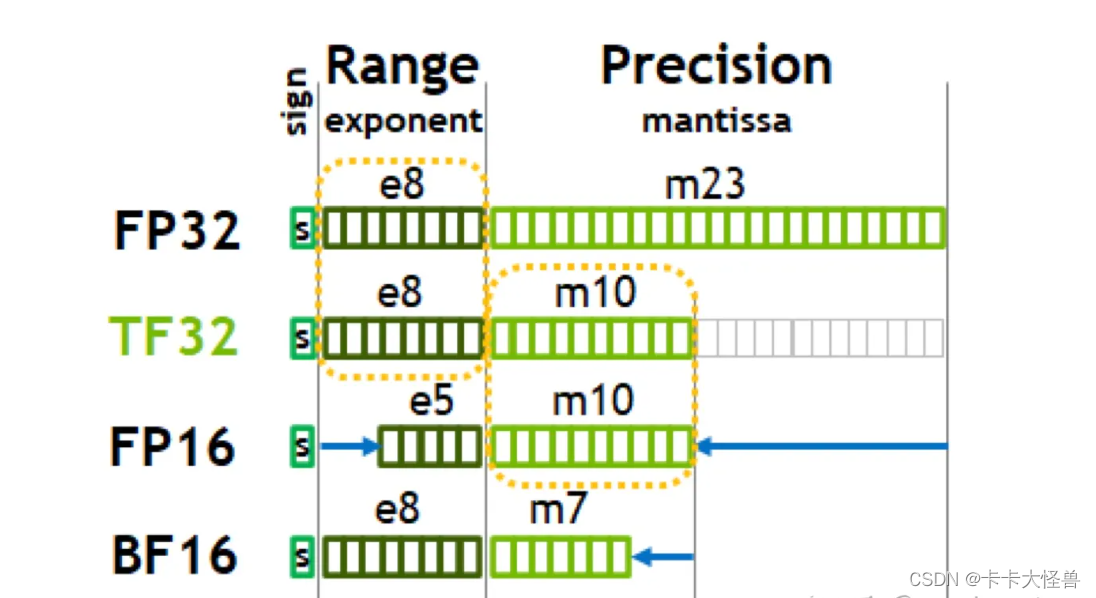
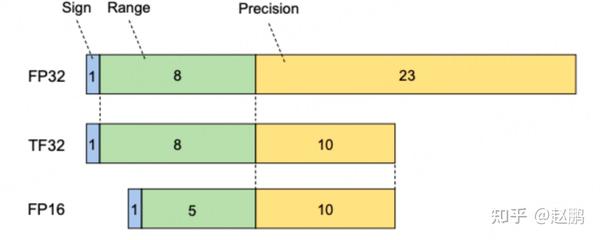
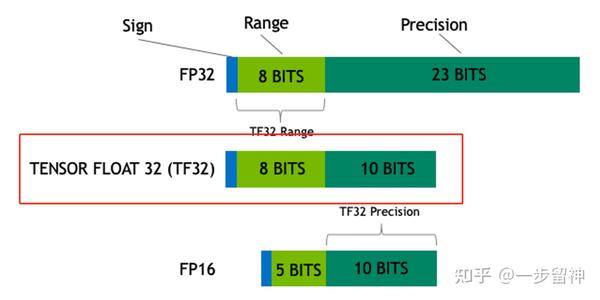
What is the TensorFloat-32 Precision Format? | NVIDIA Blog
FP32,TF32,FP16,BF16介绍_tf32和fp32-CSDN博客
Accelerating TensorFlow on NVIDIA A100 GPUs | NVIDIA Technical Blog
TF32格式下矩阵乘(SGEMM)运算 - 知乎
A100 GPUの TensorFloat-32 が AI の学習と HPC を最大 20 倍高速化
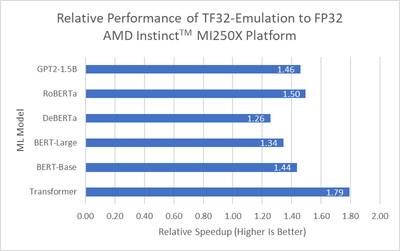
Application-Transparent Emulation of TensorFloat32^1 using BFloat16 on ...
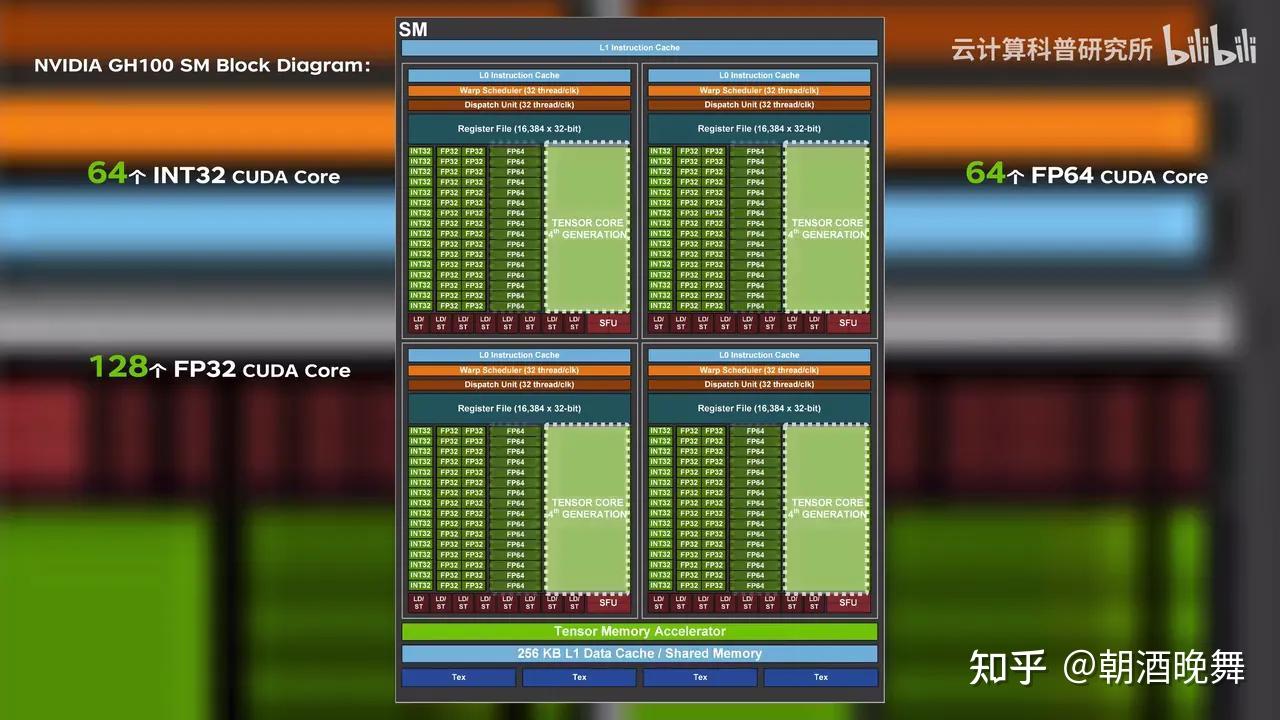
【GPU算力进化史】从CUDA Core到Tensor Core,FP32到TF32的双重变革——AI性能大爆发! - 知乎
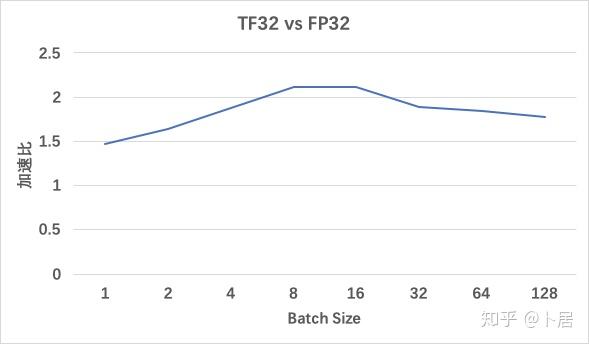
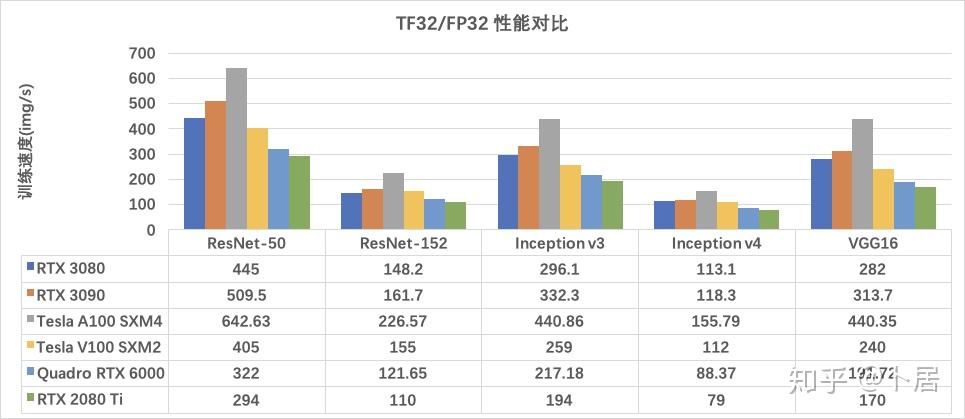
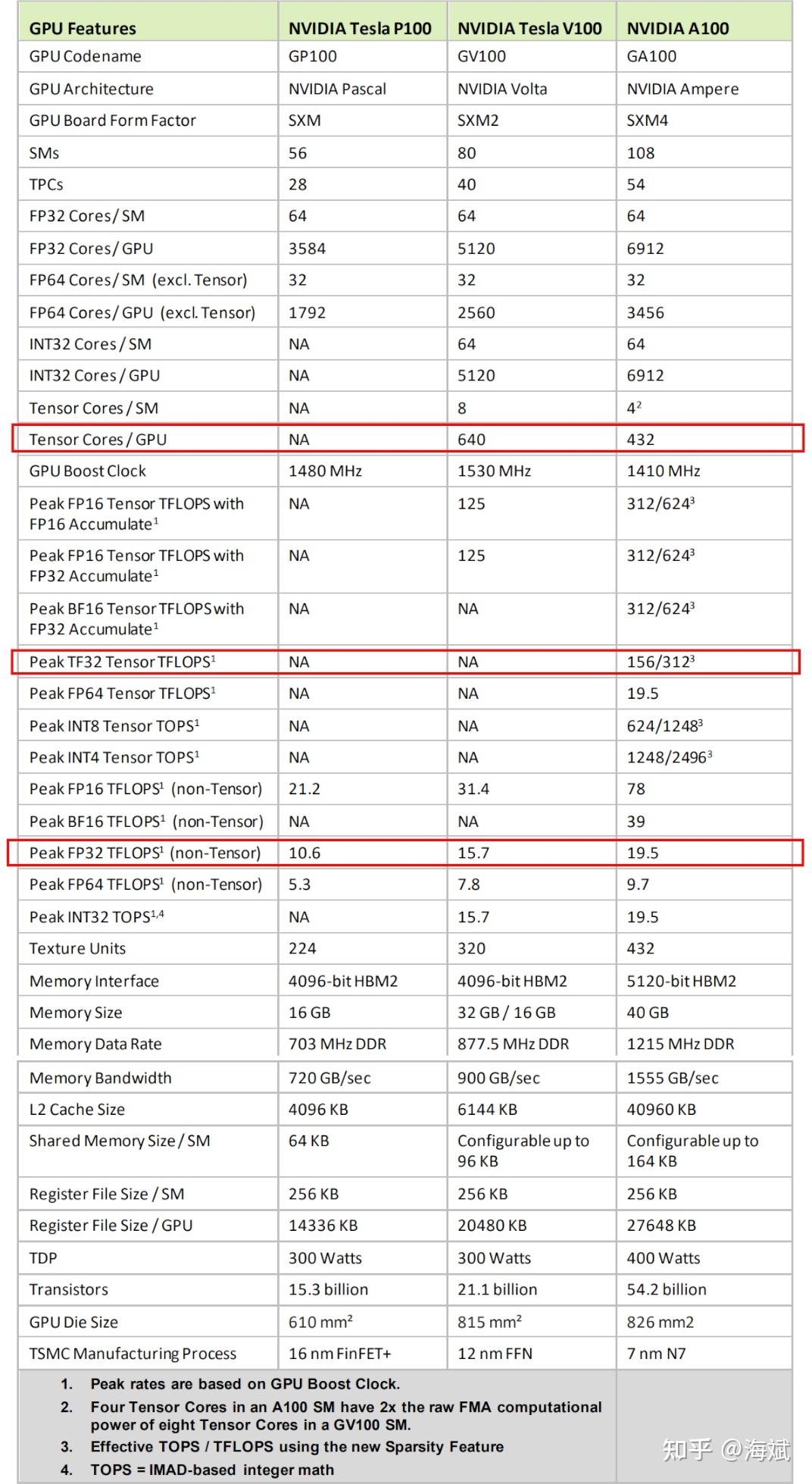
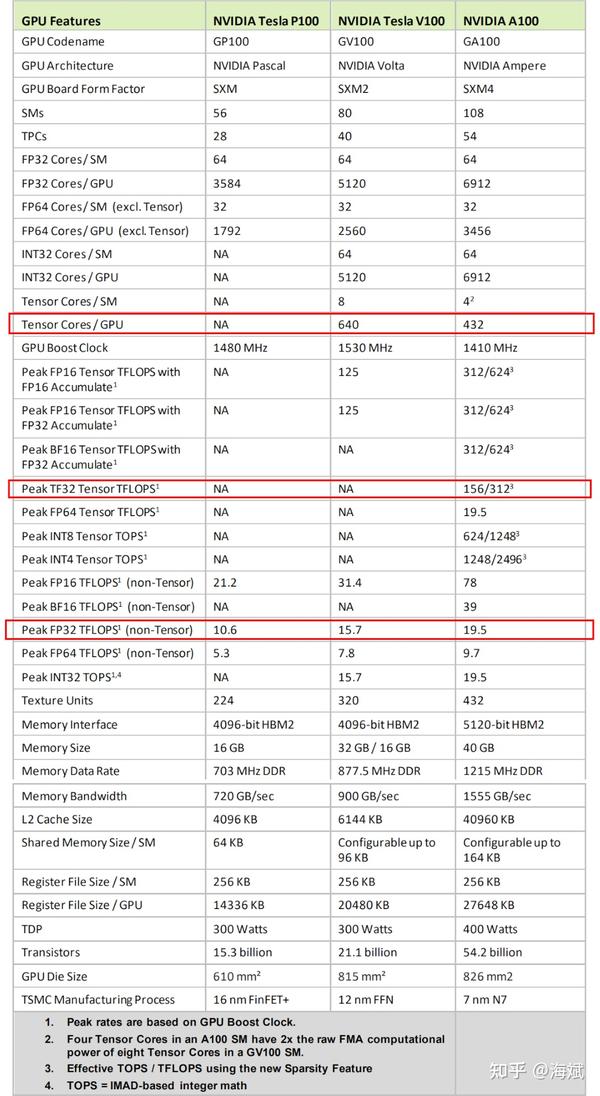
A100 Tensor Float 32 性能实测 - 知乎
什么是TF32(TensorFloat-32) | AIUG
深度学习中的TF32和BF16格式 | unvs
【大模型实战篇】大模型显存资源计算以及GPU如何选择-CSDN博客
Accelerating TensorFlow on NVIDIA A100 GPUs - Edge AI and Vision Alliance
Line-By-Line, Let's Reproduce GPT-2: Section 2 - Hardware Optimization ...
从一次面试搞懂 FP16、BF16、TF32、FP32 - 知乎
Intel Panther Lake處理器GPU詳解,12組Xe 3核心帶來50%效能成長 | T客邦
大模型涉及到的精度有多少种?FP32、TF32、FP16、BF16、FP8、FP4、NF4、INT8都有什么关联,一文讲清楚 - 知乎
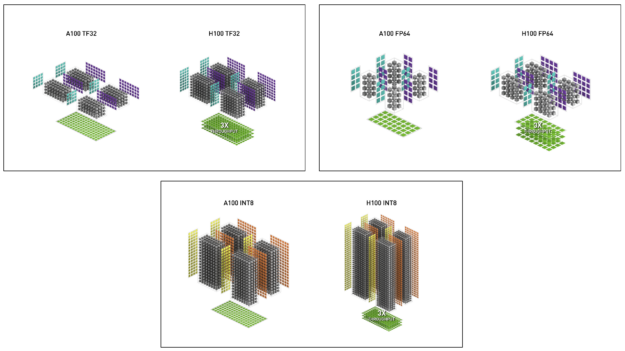
英伟达A100 Tensor Core GPU架构深度讲解-腾讯云开发者社区-腾讯云
Mixed Precision Training — InternEvo 0.5.3 documentation
大模型涉及到的精度是啥?FP32、TF32、FP16、BF16、FP8、FP4、NF4、INT8区别_fp4和fp8-CSDN博客
大模型精度:FP32、TF32、FP16、BF16、FP8、FP4、NF4、INT8 - 知乎
彻底理解系列之:FP32、FP16、TF32、BF16、混合精度 - 53AI-AI知识库|企业AI知识库|大模型知识库|AIHub
FP32 & TF32-腾讯云开发者社区-腾讯云
显卡的一些总结_tf32-CSDN博客
彻底理解系列之:FP32、FP16、TF32、BF16、混合精度 - 知乎
Mixed Precision — InternEvo 0.5.3 documentation
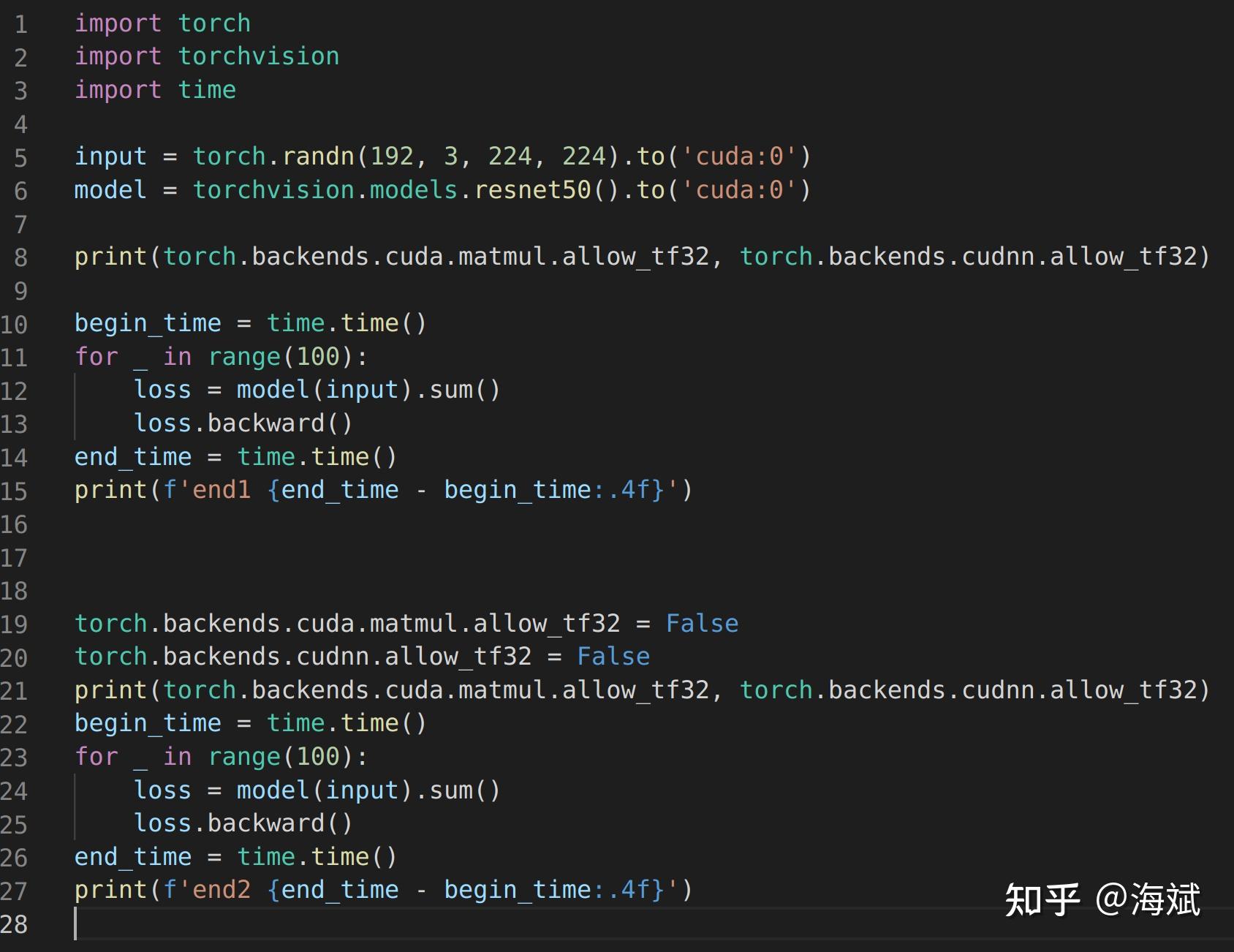
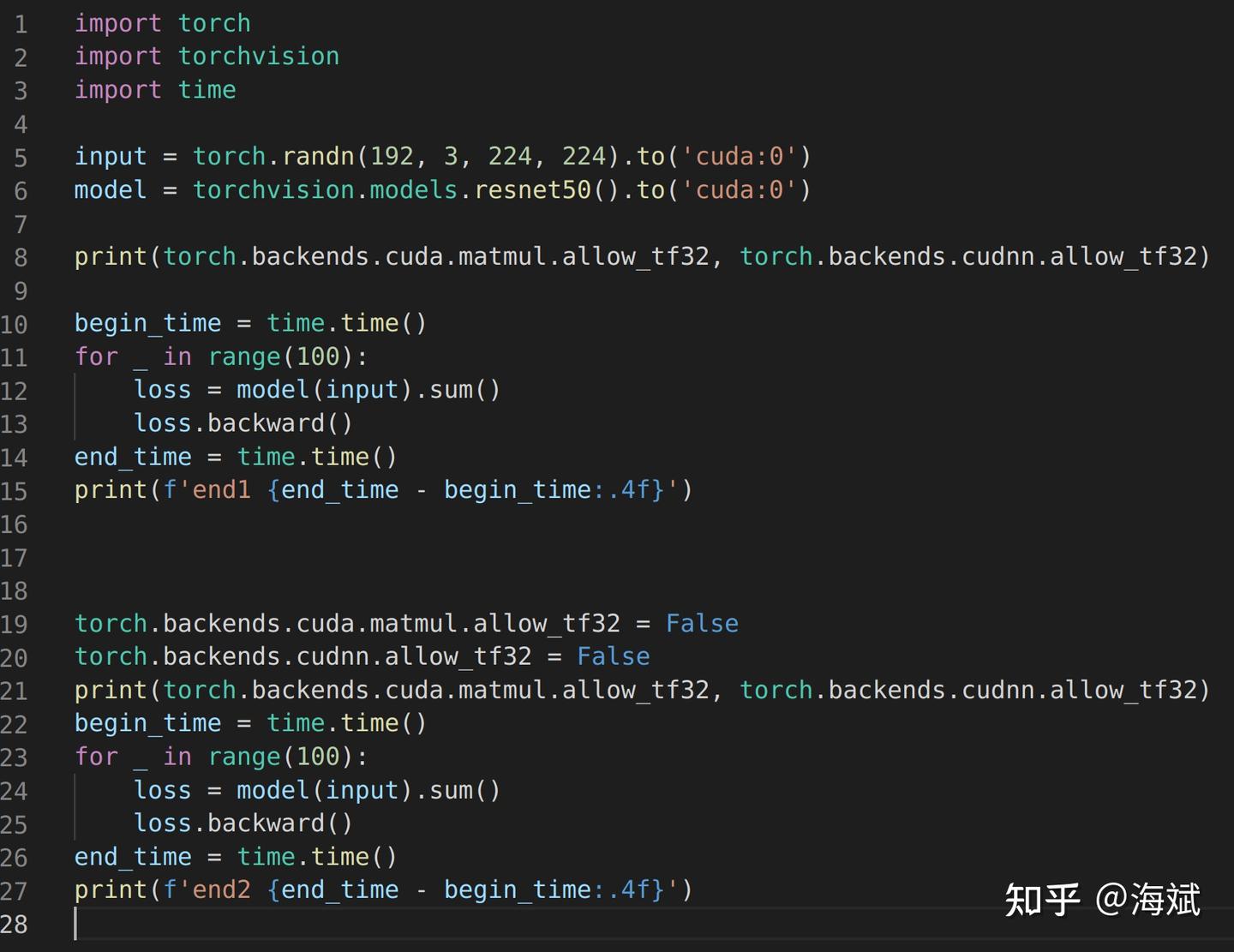
在pytorch上实测TF32性能(3090、A100) - 知乎
Efficient Quantum Circuit Simulation by Tensor Network Methods on ...
大模型常用精度_bfloat16-CSDN博客
de:code 2020 聴講ノート(AI・機械学習関連のみ) - いっしきまさひこBLOG
NVIDIA 技术博客:NVIDIA Hopper 深入研究架构-CSDN社区
Tensor Cores: Versatility for HPC & AI | NVIDIA
FP32,TF32,FP16,BF16介绍-CSDN博客