Showing 99 of 99on this page. Filters & sort apply to loaded results; URL updates for sharing.99 of 99 on this page
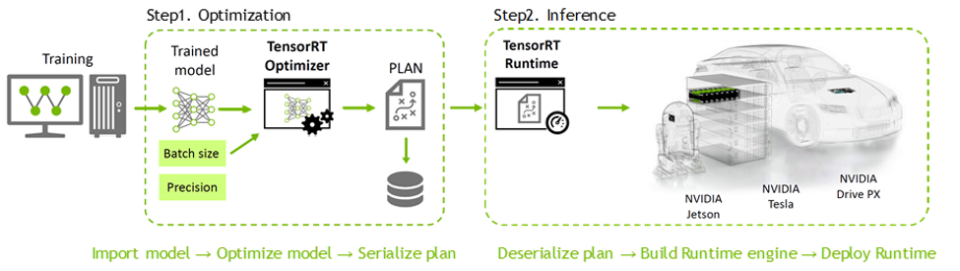
Deployment workflow for inference using TensorRT | Download Scientific ...
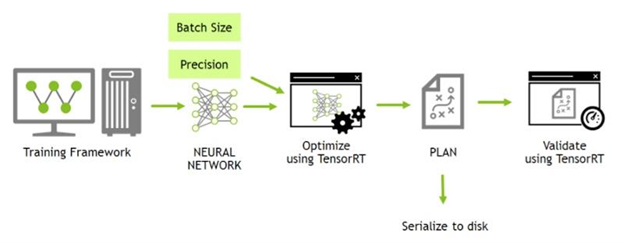
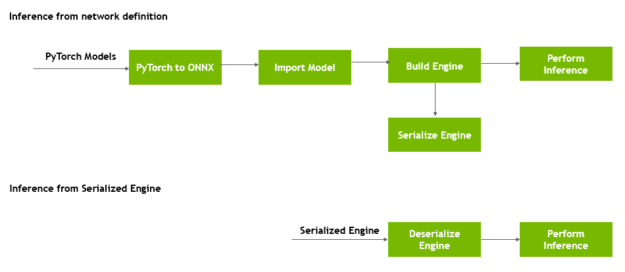
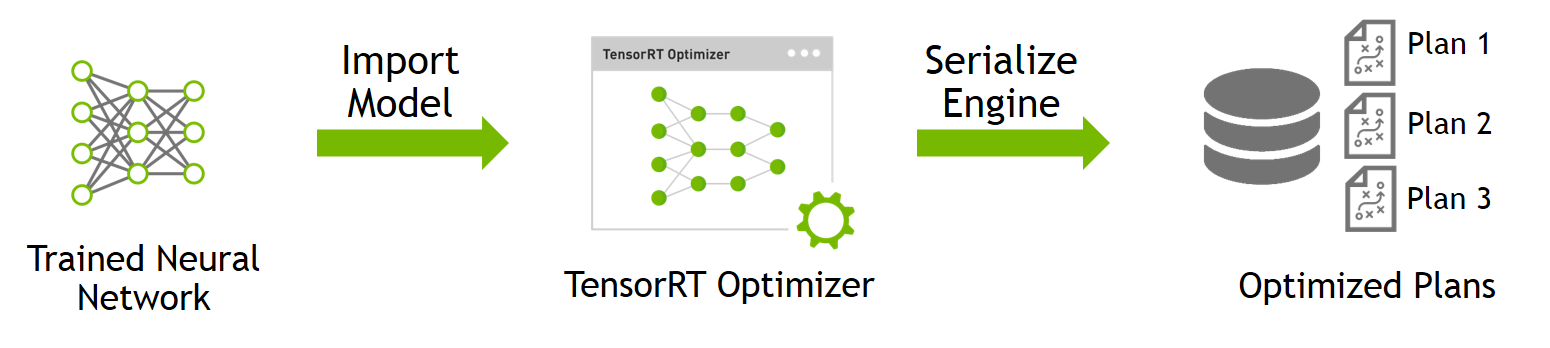
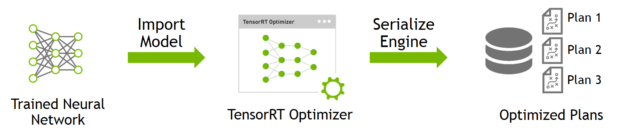
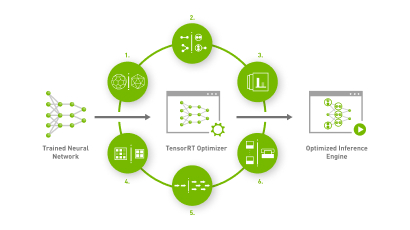
Quick Start Guide — NVIDIA TensorRT
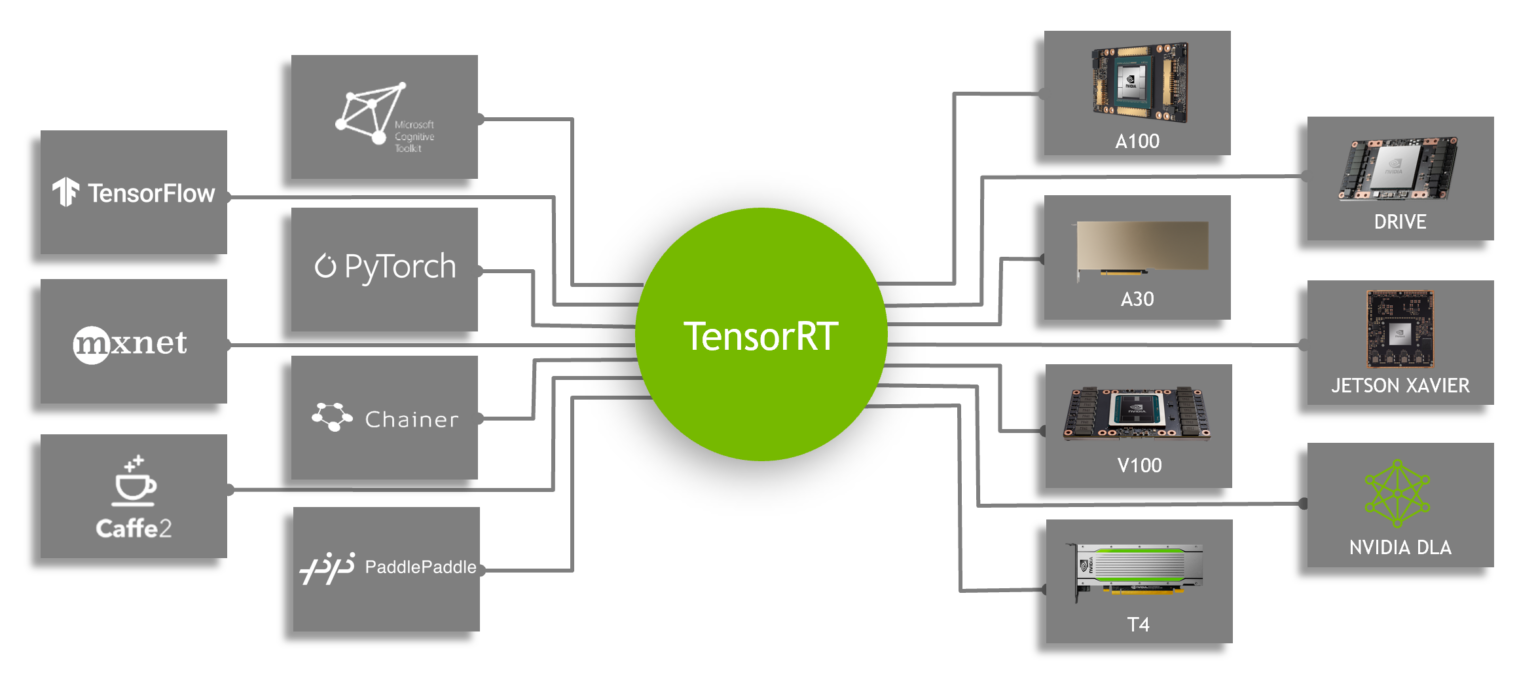
TensorRT SDK | NVIDIA Developer
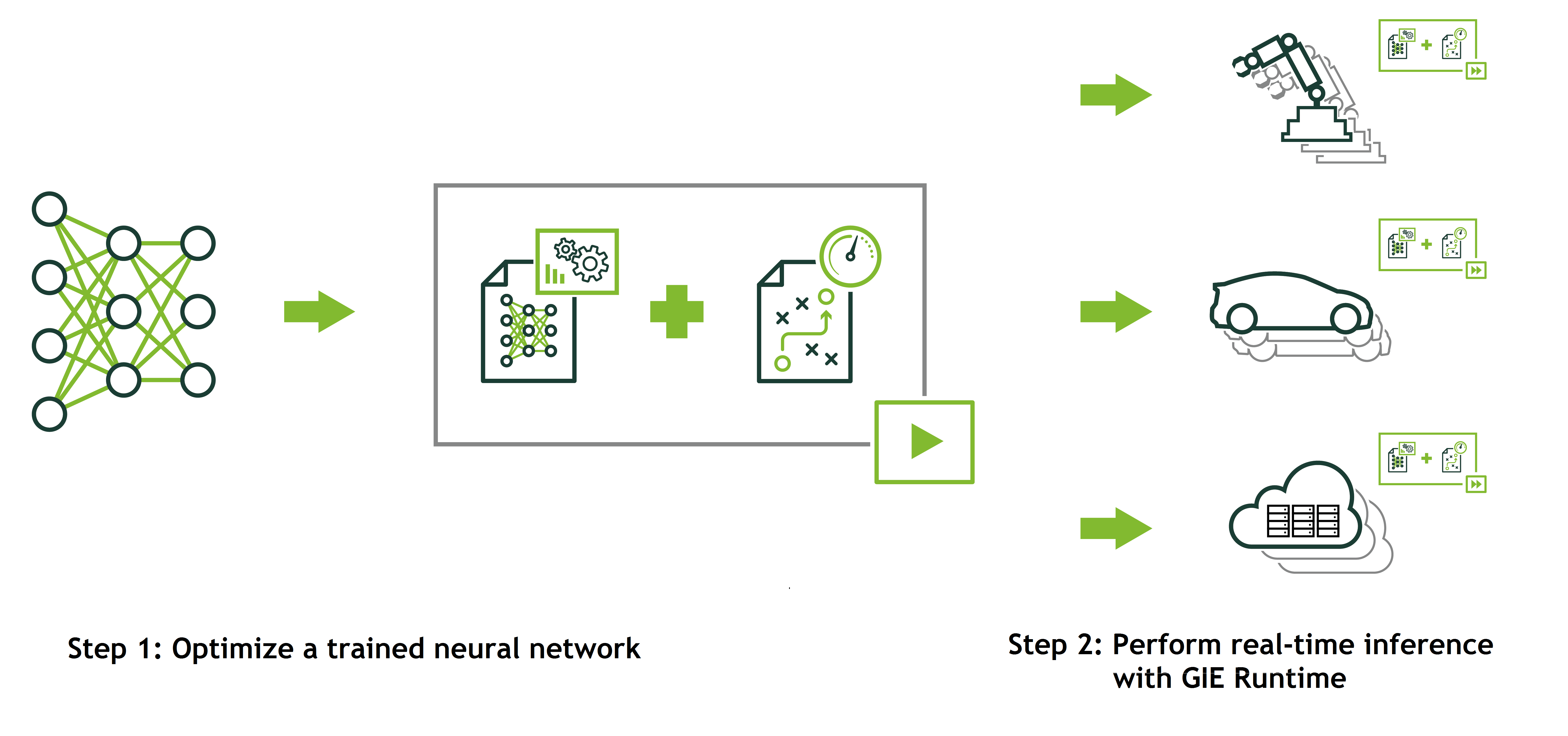
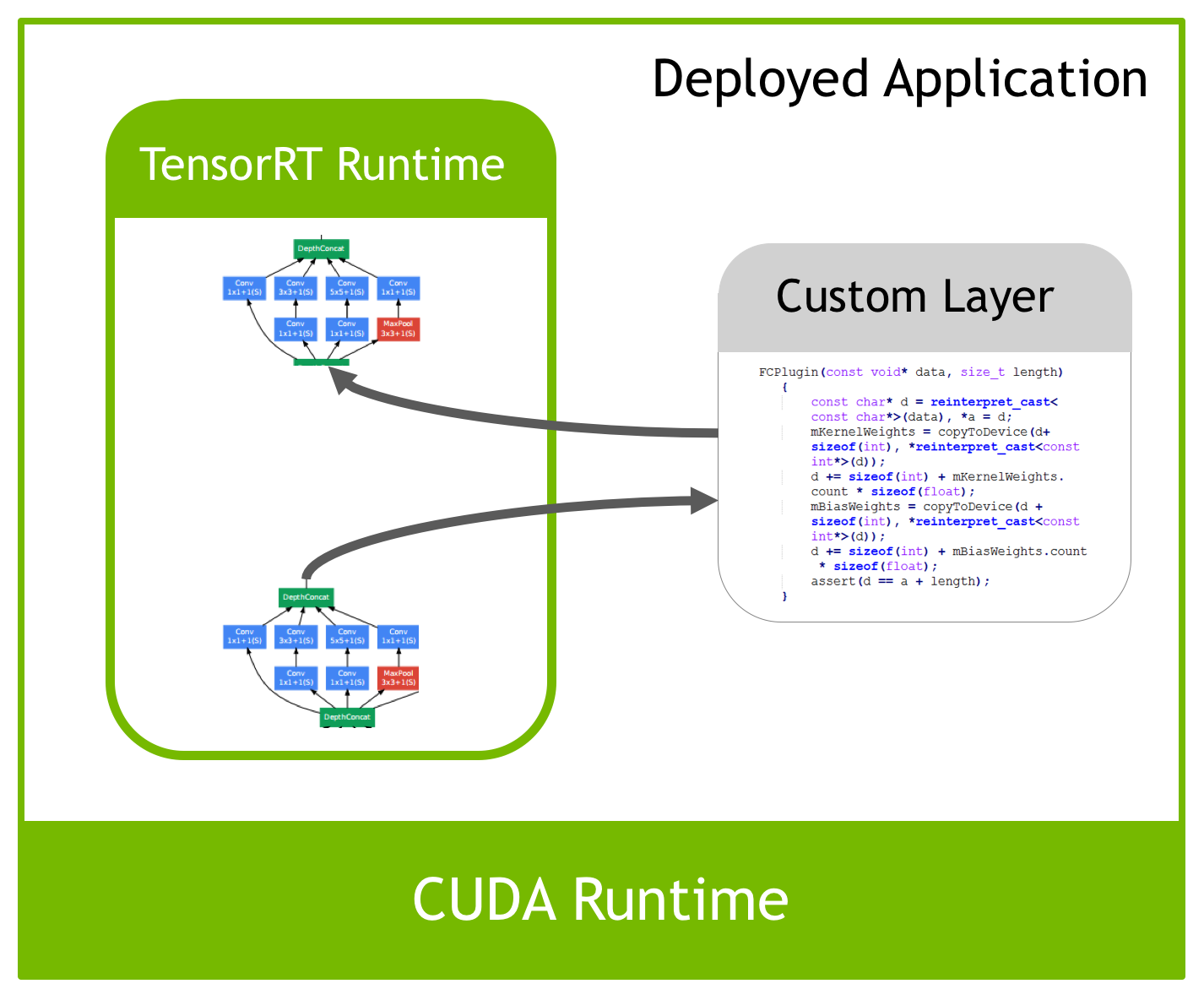
Deploying Deep Neural Networks with NVIDIA TensorRT | NVIDIA Technical Blog
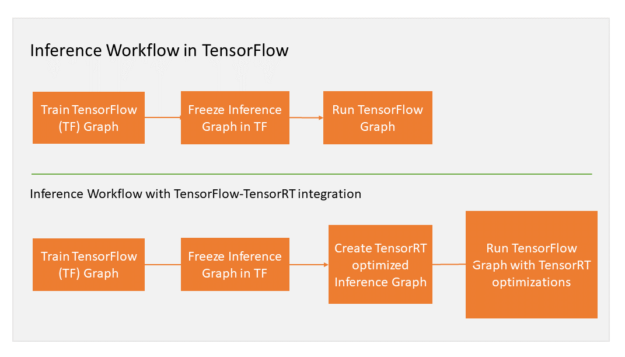
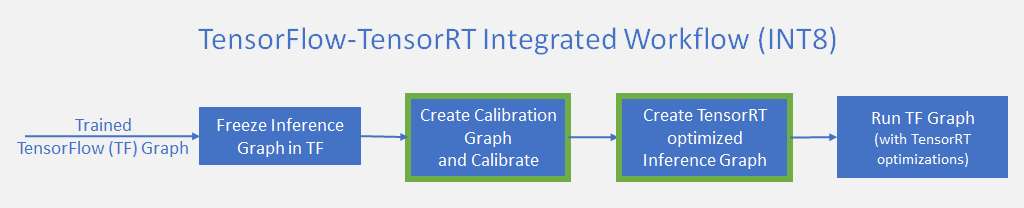
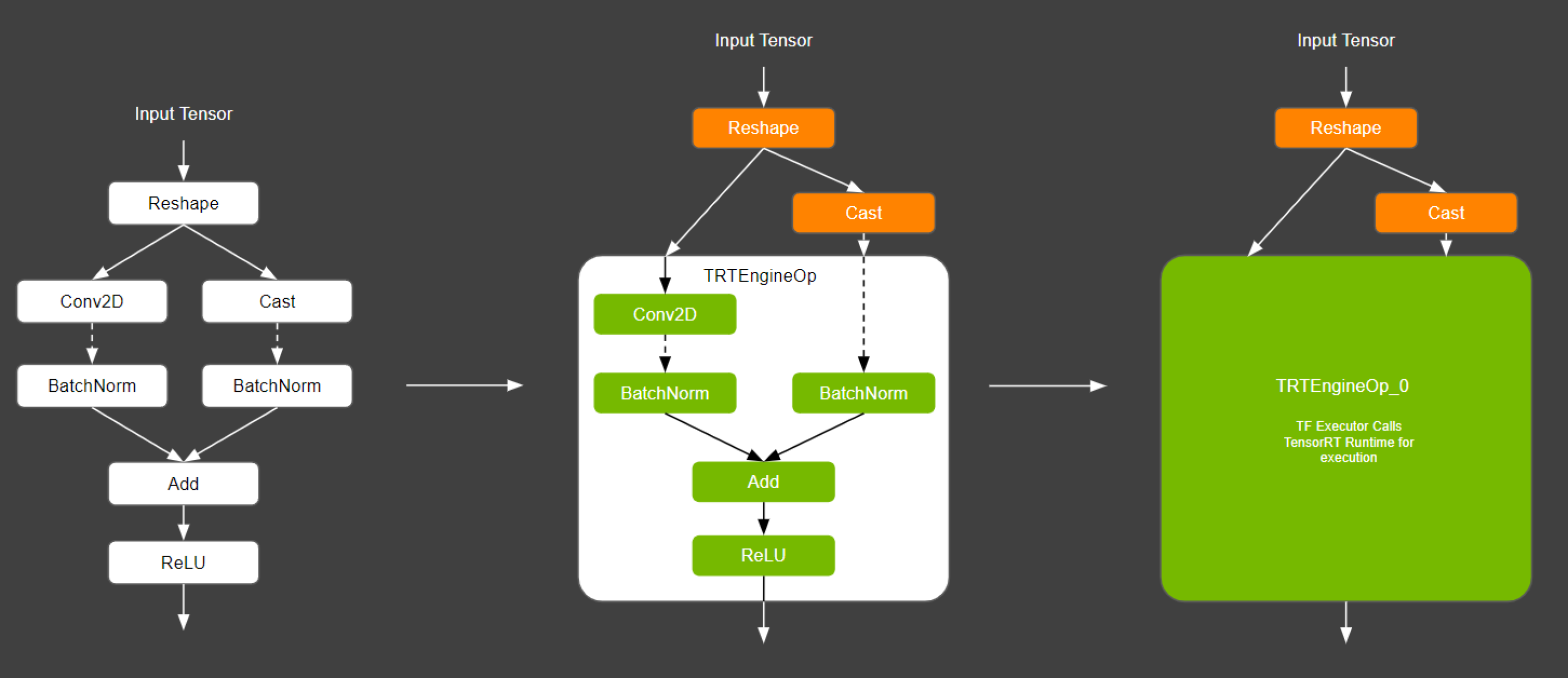
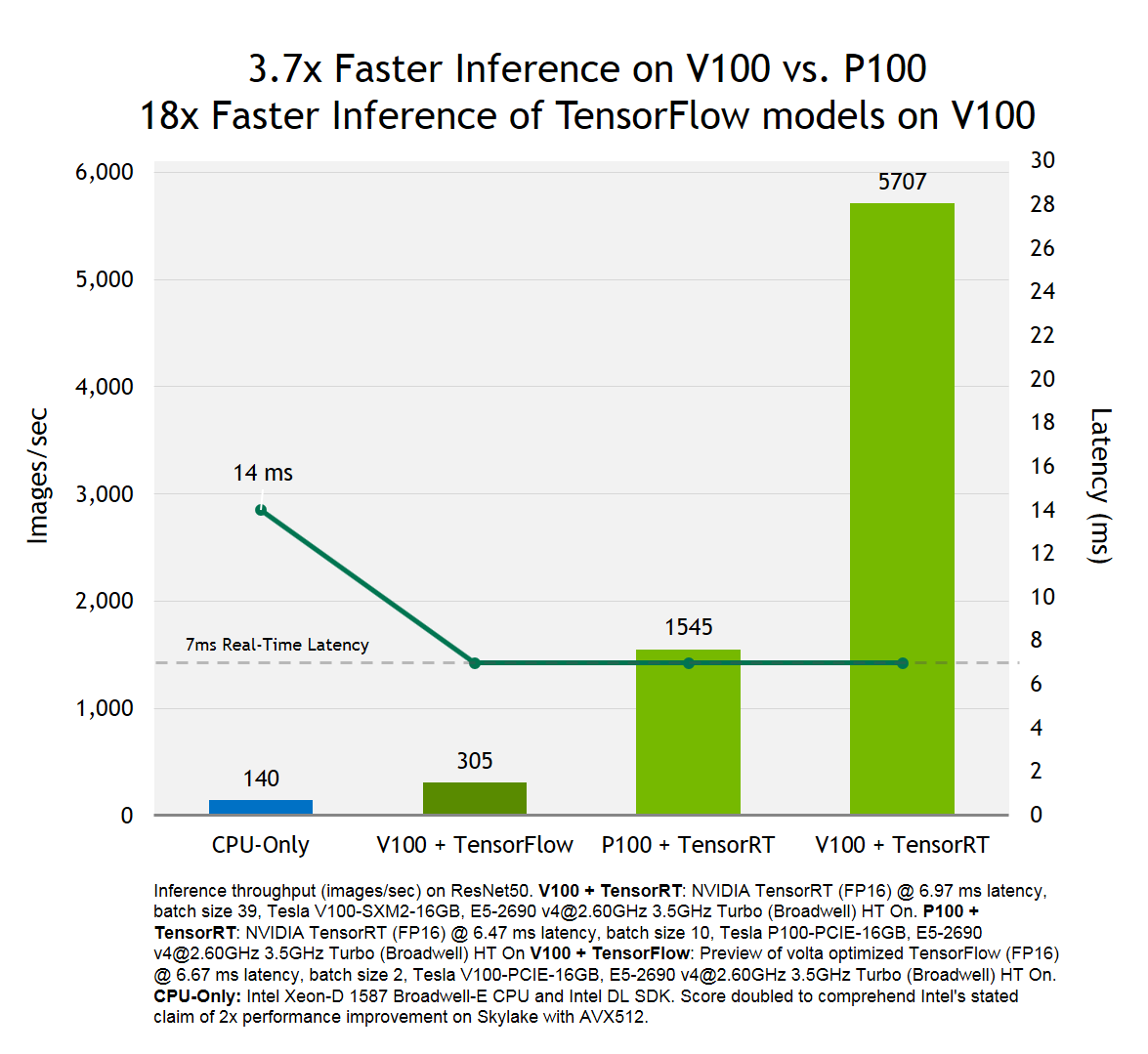
TensorRT Integration Speeds Up TensorFlow Inference | NVIDIA Technical Blog
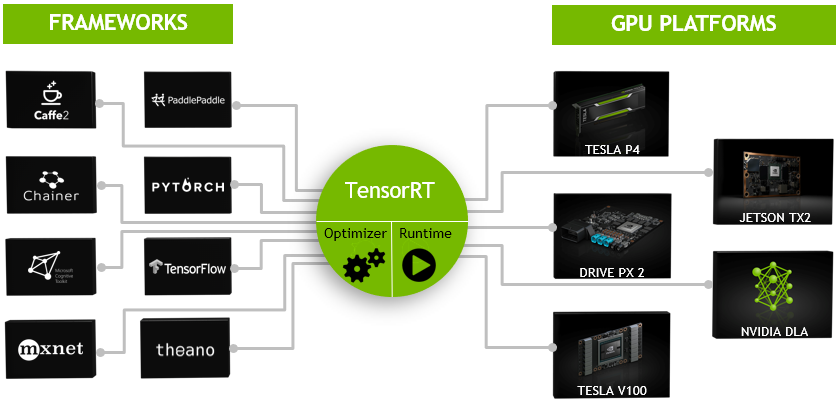
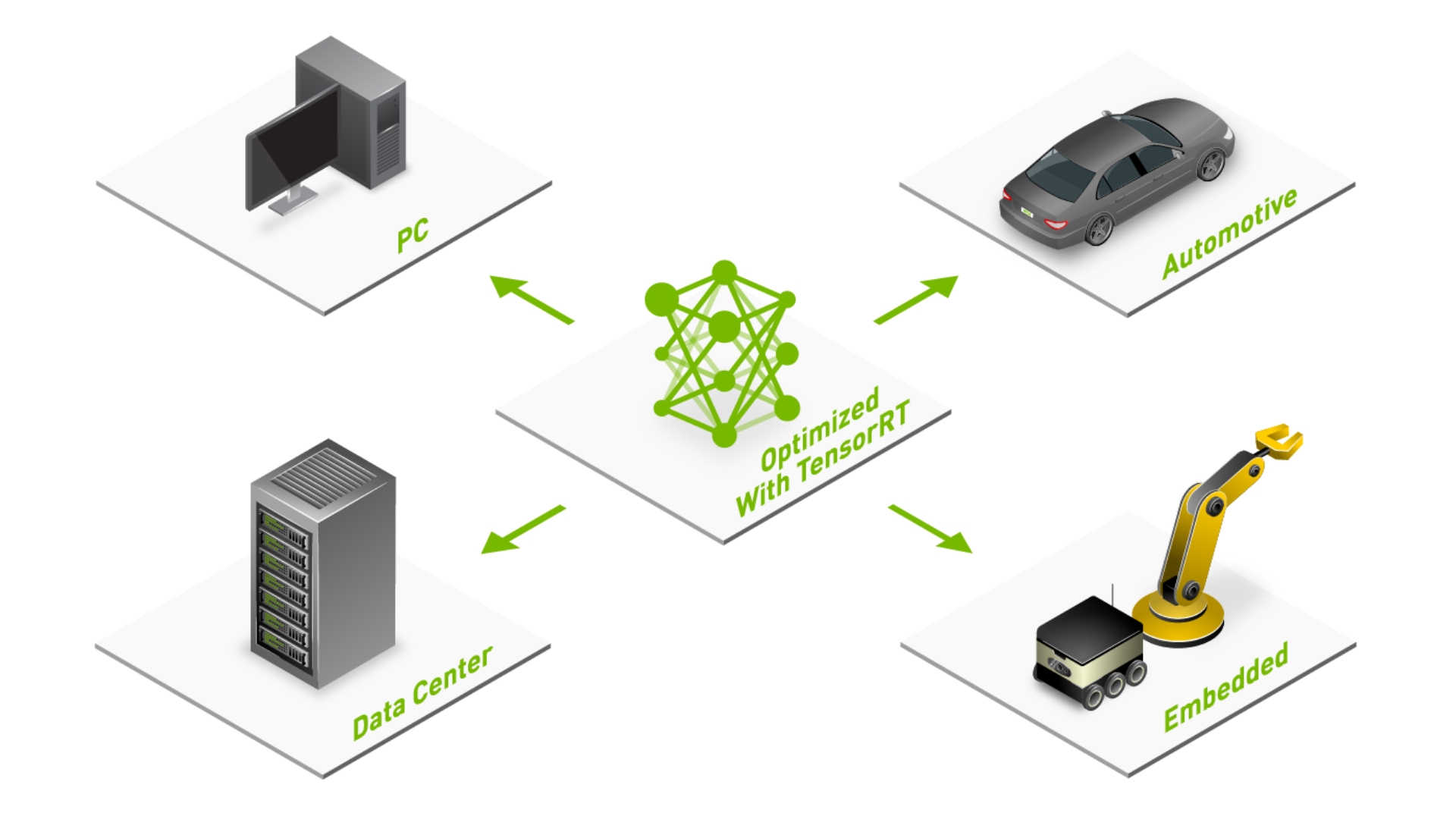
NVIDIA TensorRT | NVIDIA Developer
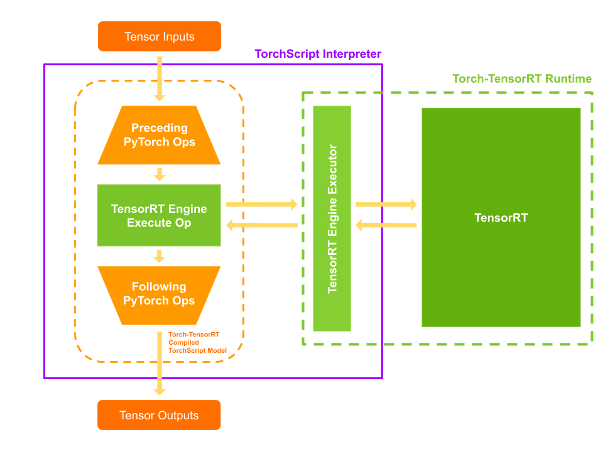
使用 Torch TensorRT 将 PyTorch 的推理速度提高6倍 - NVIDIA 技术博客
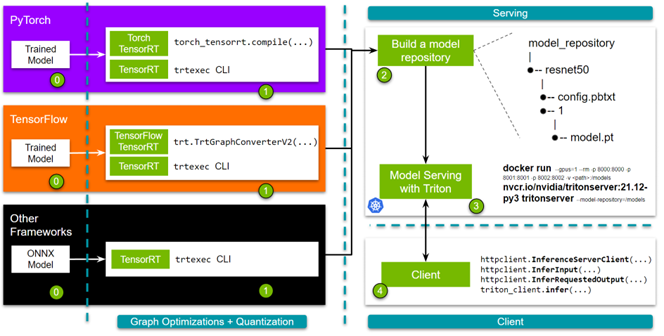
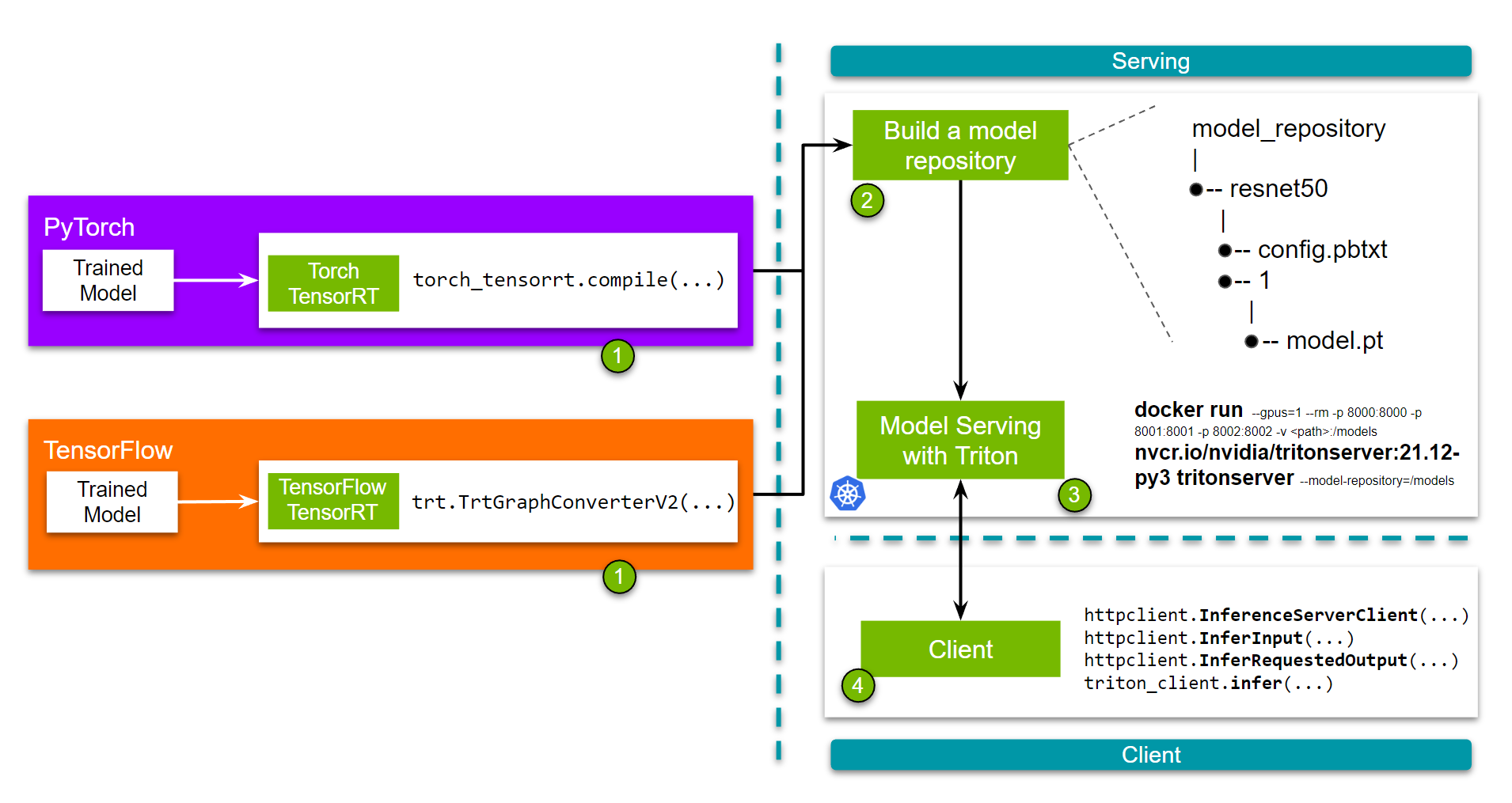
Optimizing and Serving Models with NVIDIA TensorRT and NVIDIA Triton ...
Inference Optimization using TensorRT – DEVSTACK
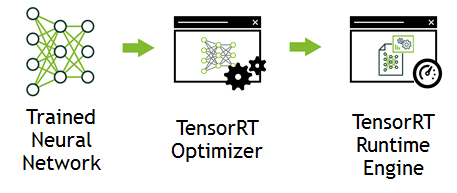
The TensorRT Workflow. [6] | Download Scientific Diagram
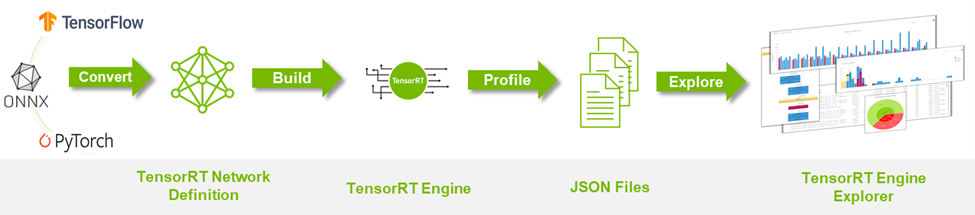
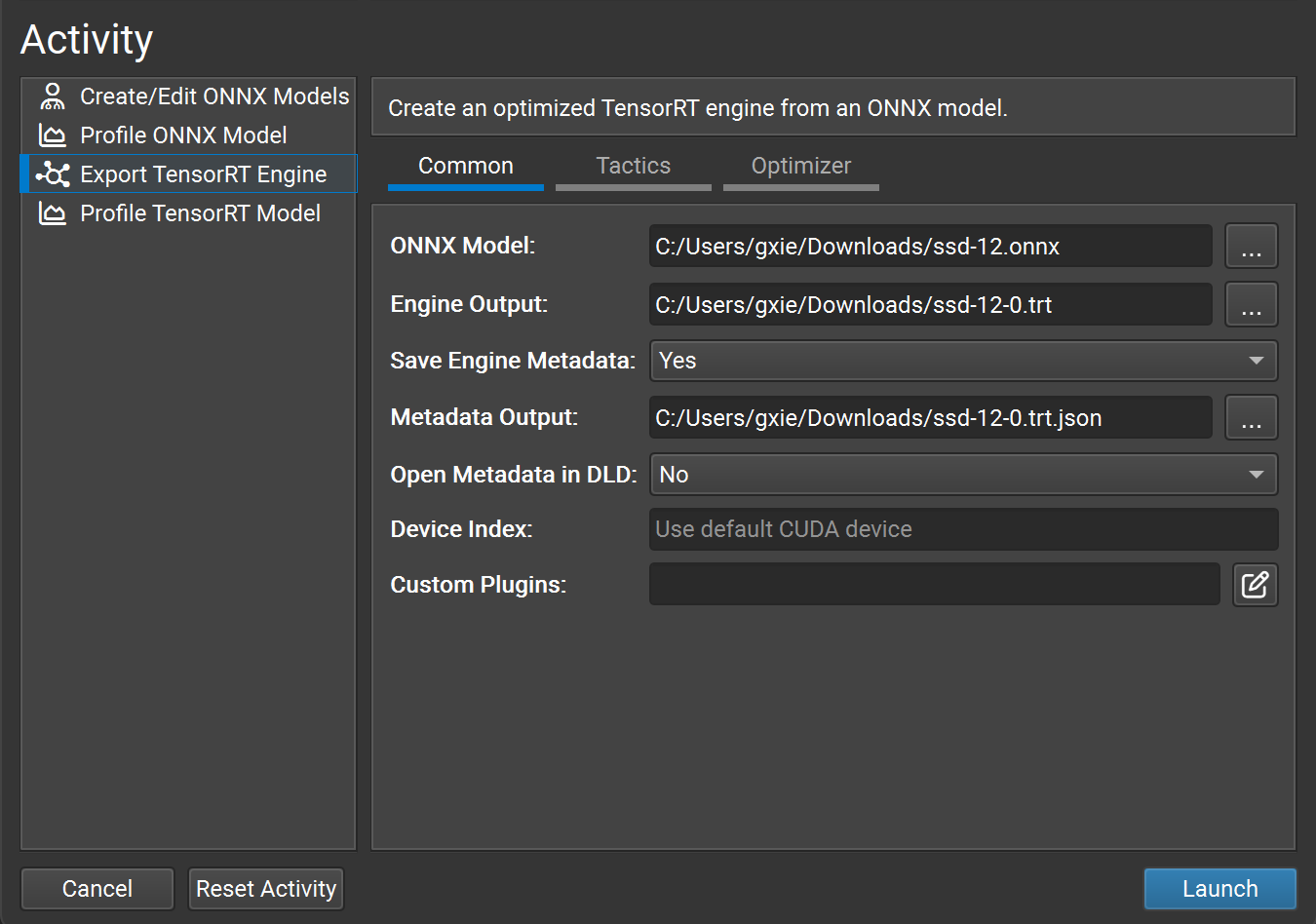
TREx で NVIDIA TensorRT Engines を探る - NVIDIA 技術ブログ
TensorRT 3: Faster TensorFlow Inference and Volta Support | NVIDIA ...
ComfyUI: nVidia TensorRT (Workflow Tutorial) - YouTube
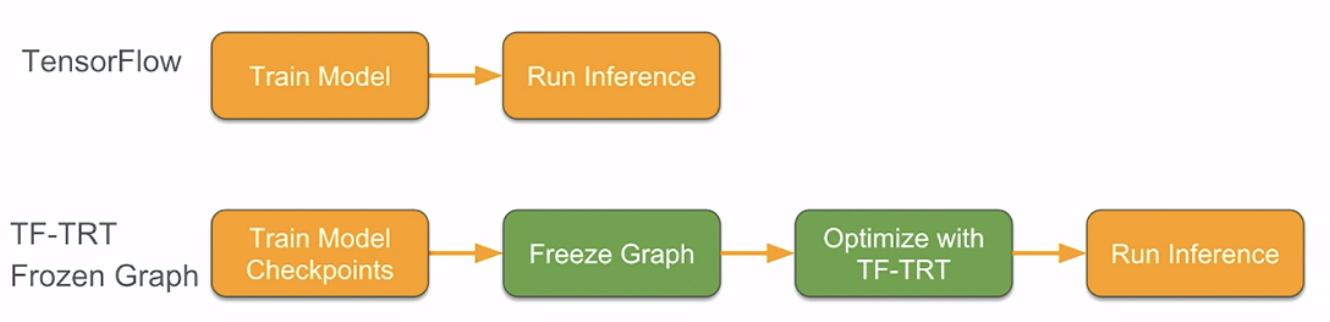
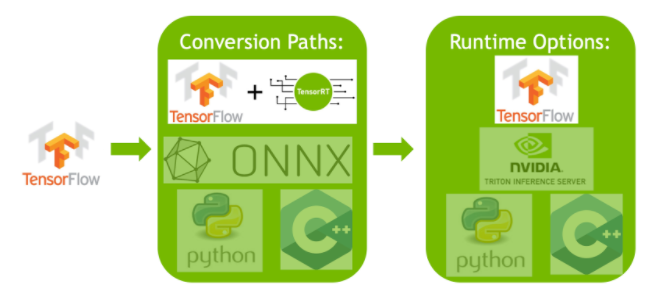
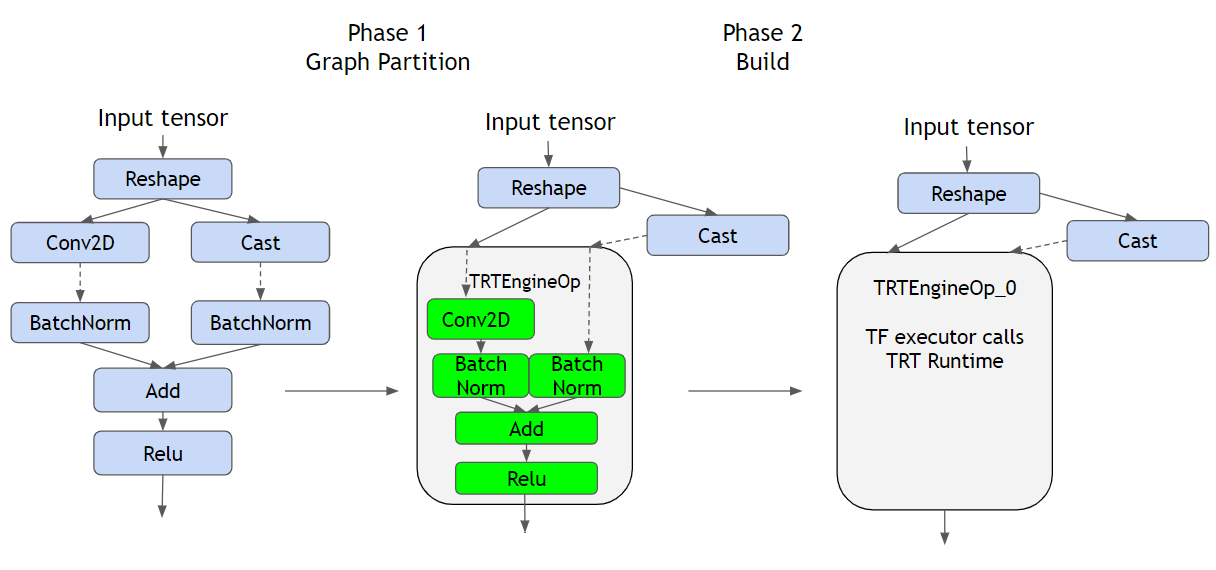
Speed up TensorFlow Inference on GPUs with TensorRT — The TensorFlow Blog
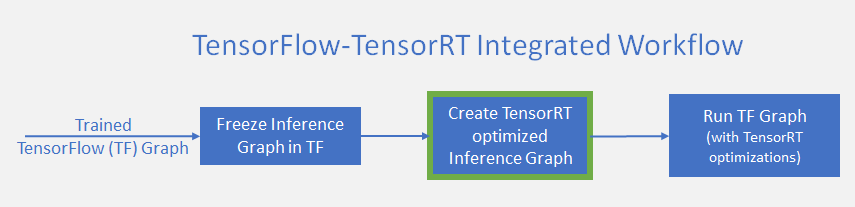
High performance inference with TensorRT Integration — The TensorFlow Blog
Optimzed Workflow to perform inference using TensorFlow-TensorRT via ...
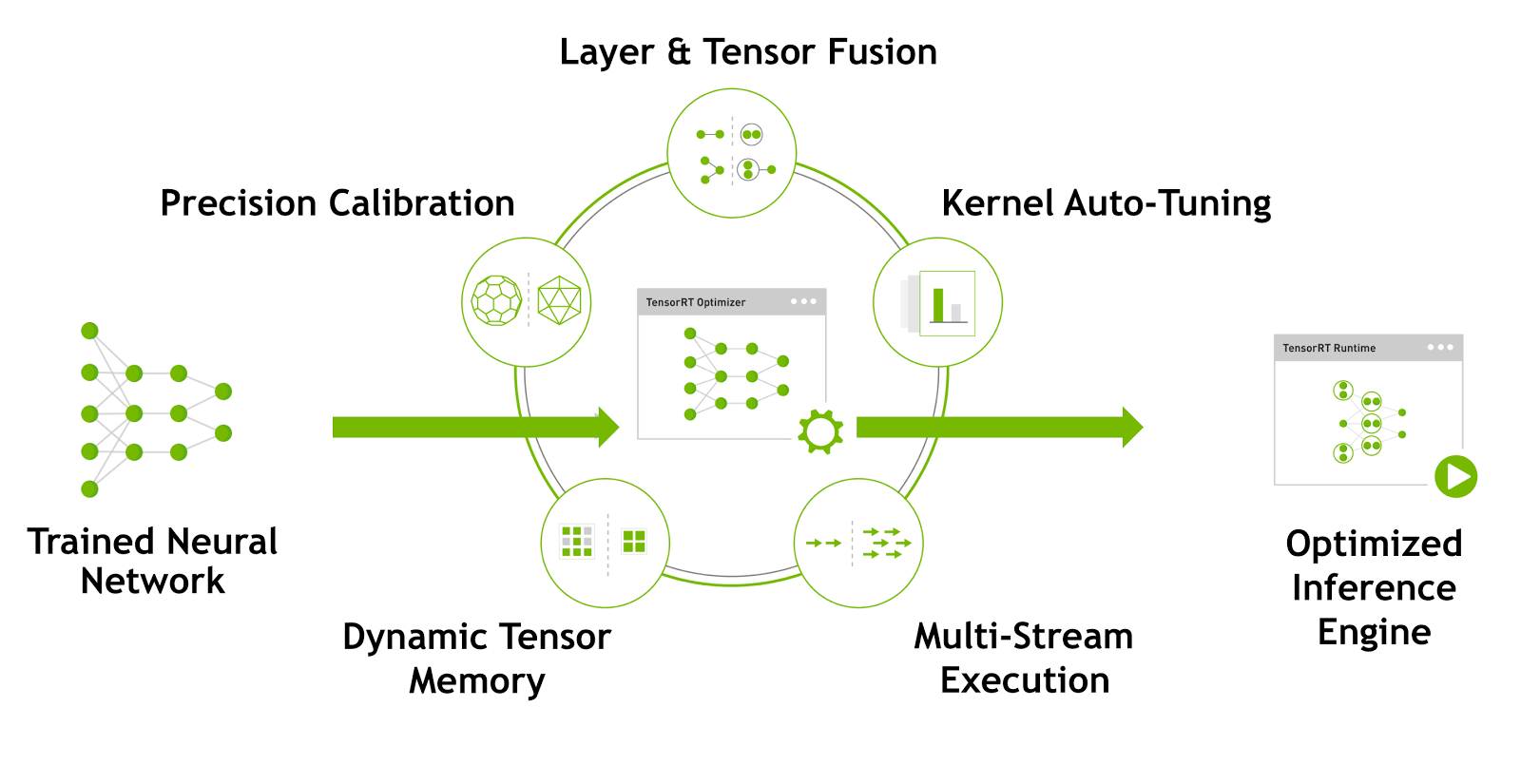
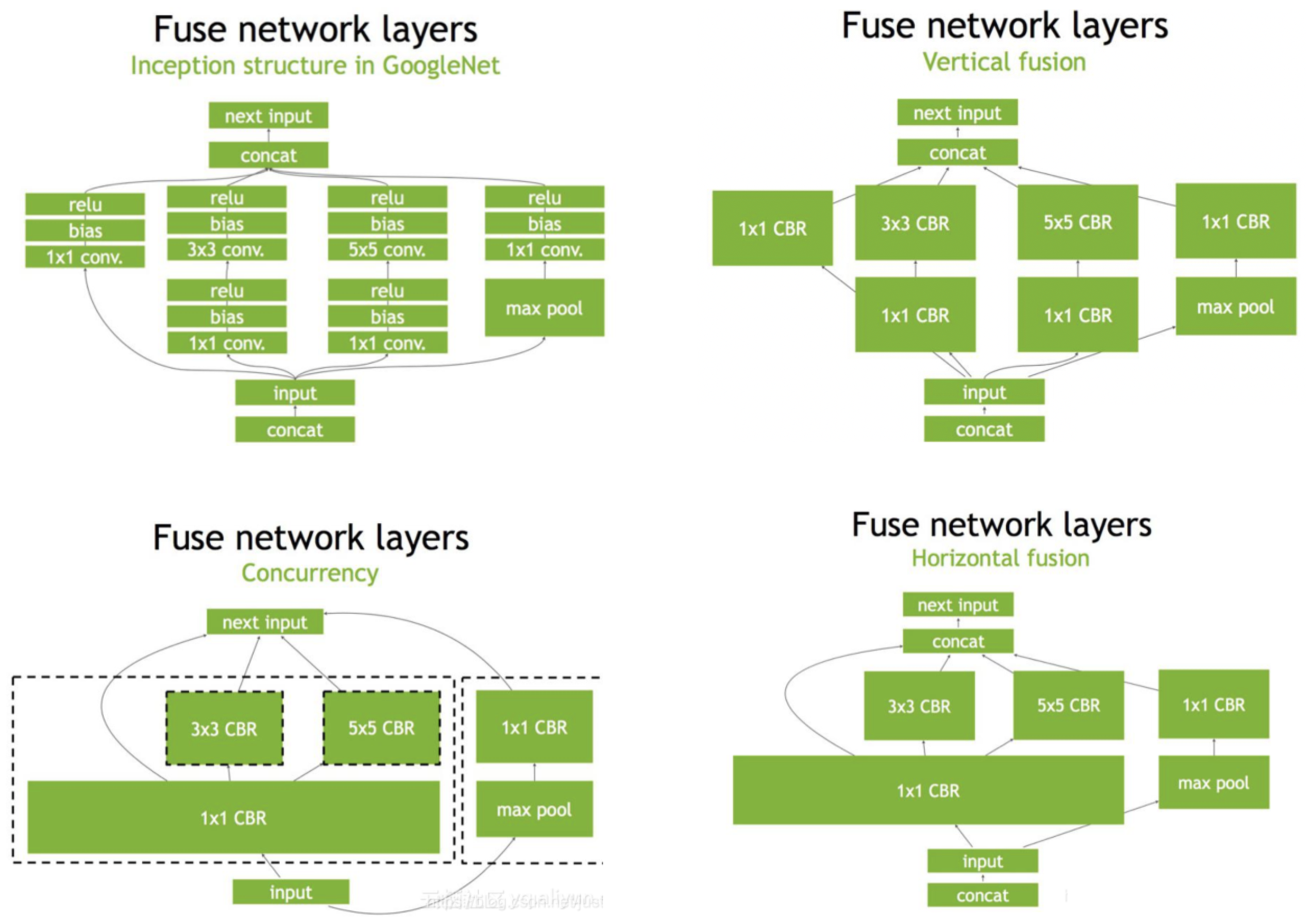
Speeding Up Deep Learning Inference Using TensorRT | NVIDIA Technical Blog
Quick Start Guide :: NVIDIA Deep Learning TensorRT Documentation
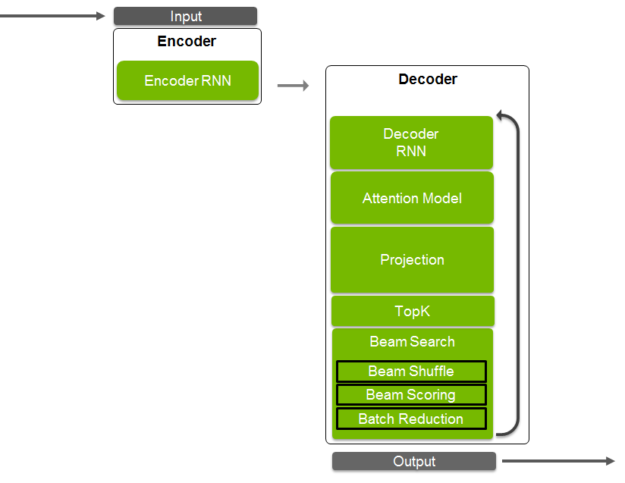
Neural Machine Translation Inference with TensorRT 4 | NVIDIA Technical ...
Tutorial de instalación y uso de TensorRT - programador clic
How to use TensorRT C++ API for high performance GPU inference by Cyrus ...
Accelerating Inference in TensorFlow with TensorRT User Guide - NVIDIA Docs
How to Speed Up Deep Learning Inference Using TensorRT | NVIDIA ...
NVIDIA TensorRT – Inference 최적화 및 가속화를 위한 NVIDIA의 Toolkit - NVIDIA Blog ...
Real-Time Natural Language Processing with BERT Using NVIDIA TensorRT ...
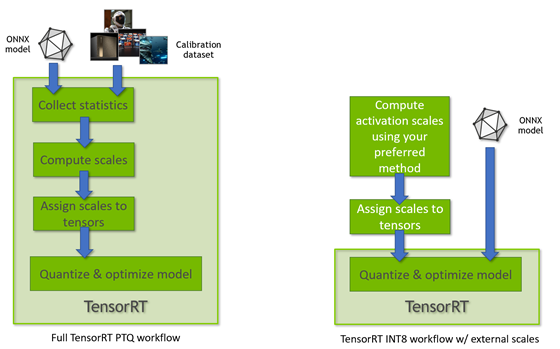
Post-Training Quantization of LLMs with NVIDIA NeMo and NVIDIA TensorRT ...
Sparsity in INT8: Training Workflow and Best Practices for NVIDIA ...
Real-Time Natural Language Understanding with BERT Using TensorRT ...
Developer Guide :: NVIDIA Deep Learning TensorRT Documentation
Optimzed workflow to perform inference using TensorFlow-TensorRT via ...
【大模型部署】利用 TensorRT 实现深度学习模型的构建与加速 - 知乎
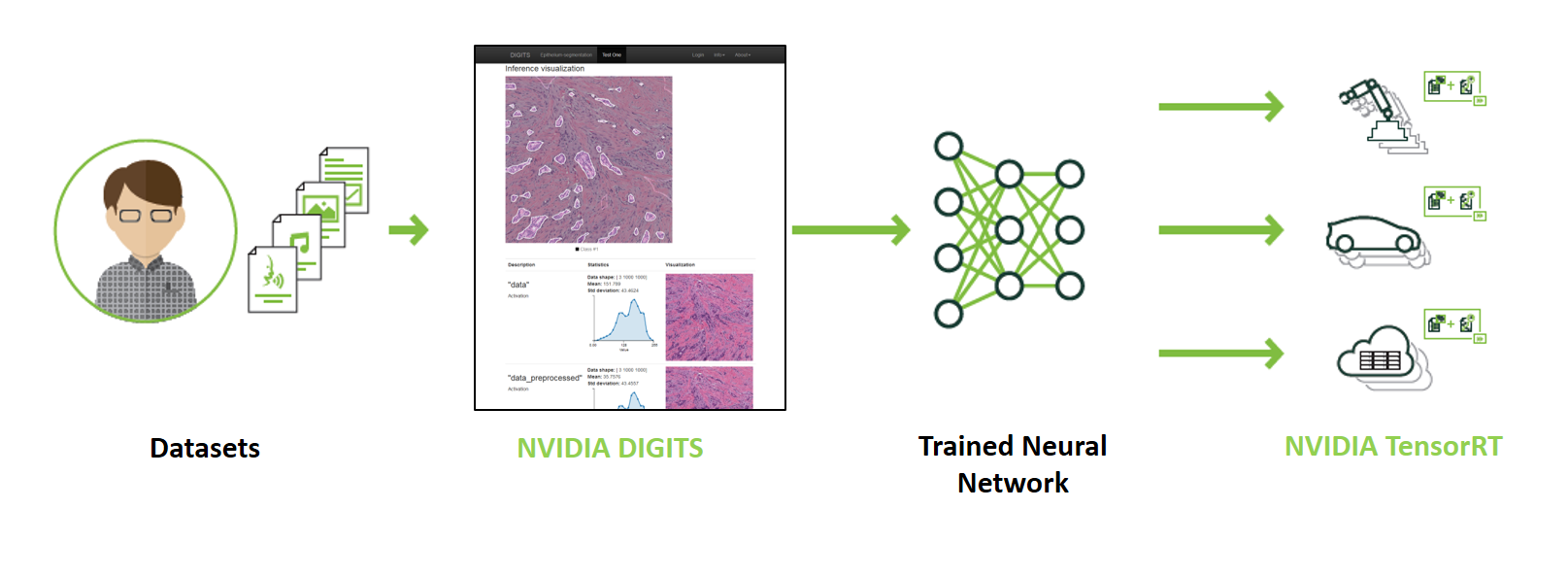
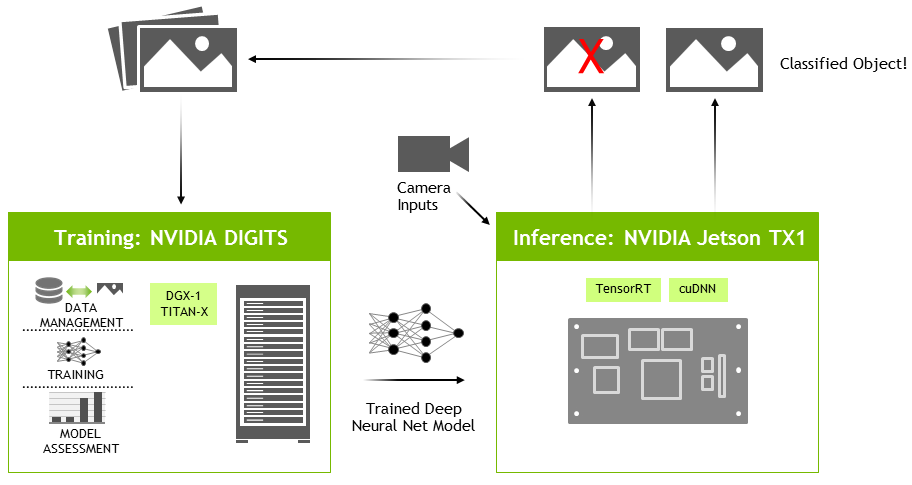
JetPack 2.3 with TensorRT Doubles Jetson TX1 Deep Learning Inference ...
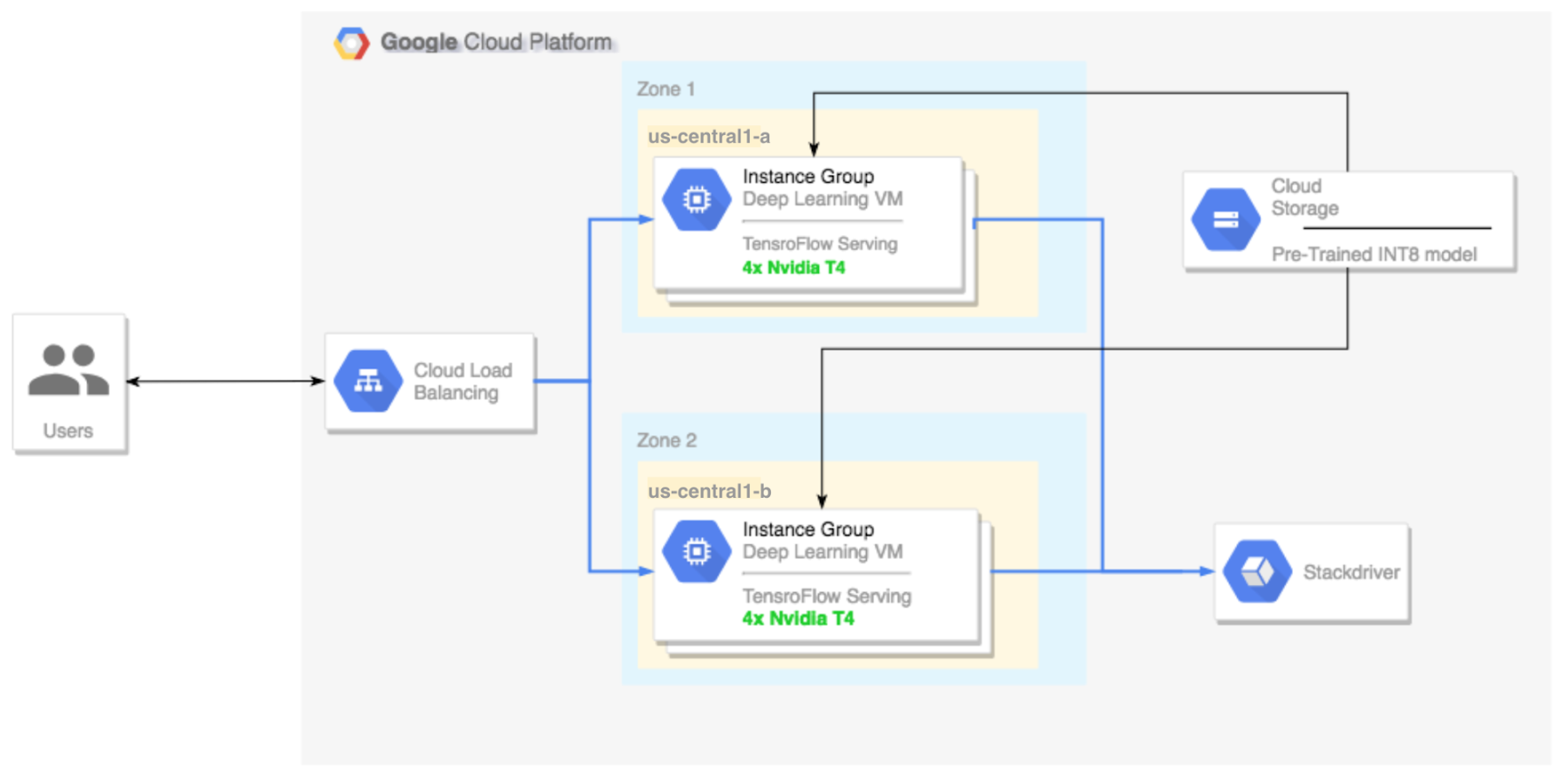
Running TensorFlow inference workloads at scale with TensorRT 5 and ...
Optimizing NVIDIA TensorRT Conversion for Real-time Inference on ...
使用 NVIDIA TensorRT 進行 BERT 即時自然語言處理 - NVIDIA 台灣官方部落格
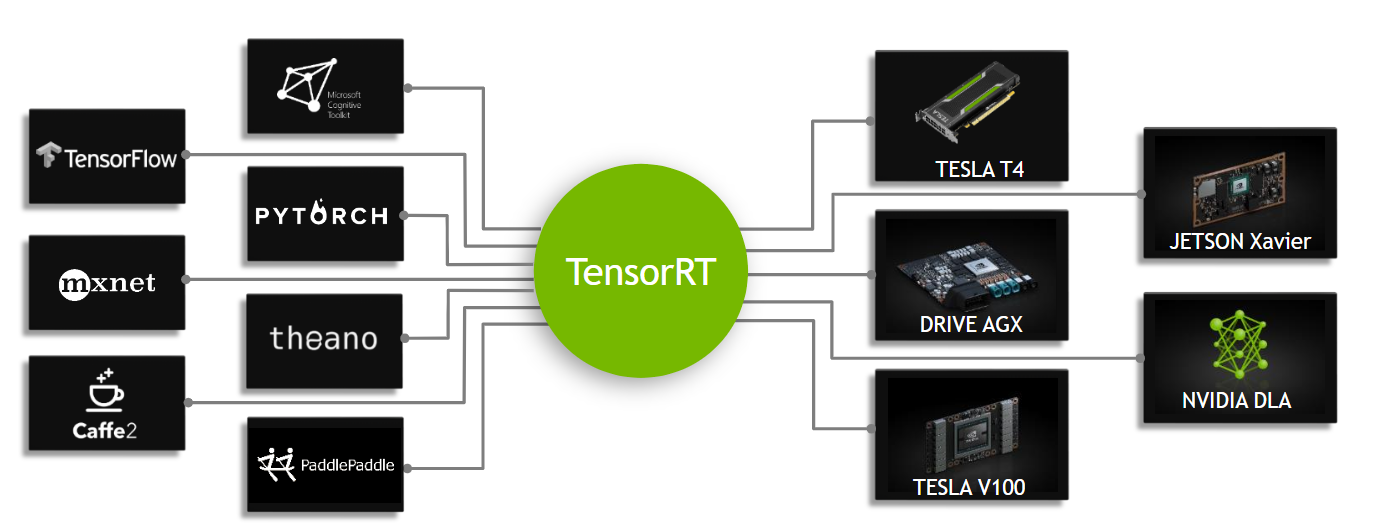
TensorRT : High-performance deep learning inference
NVIDIA TensorRT Accelerates Stable Diffusion Nearly 2x Faster with 8 ...
Understanding Nvidia TensorRT for deep learning model optimization | by ...
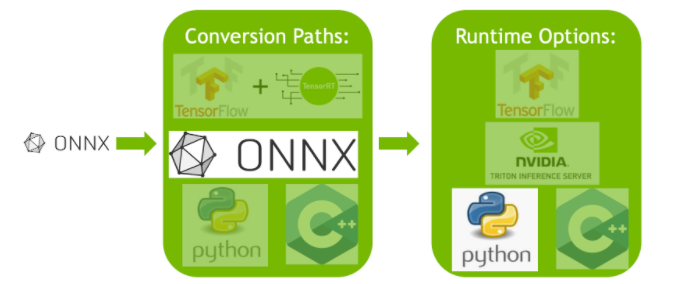
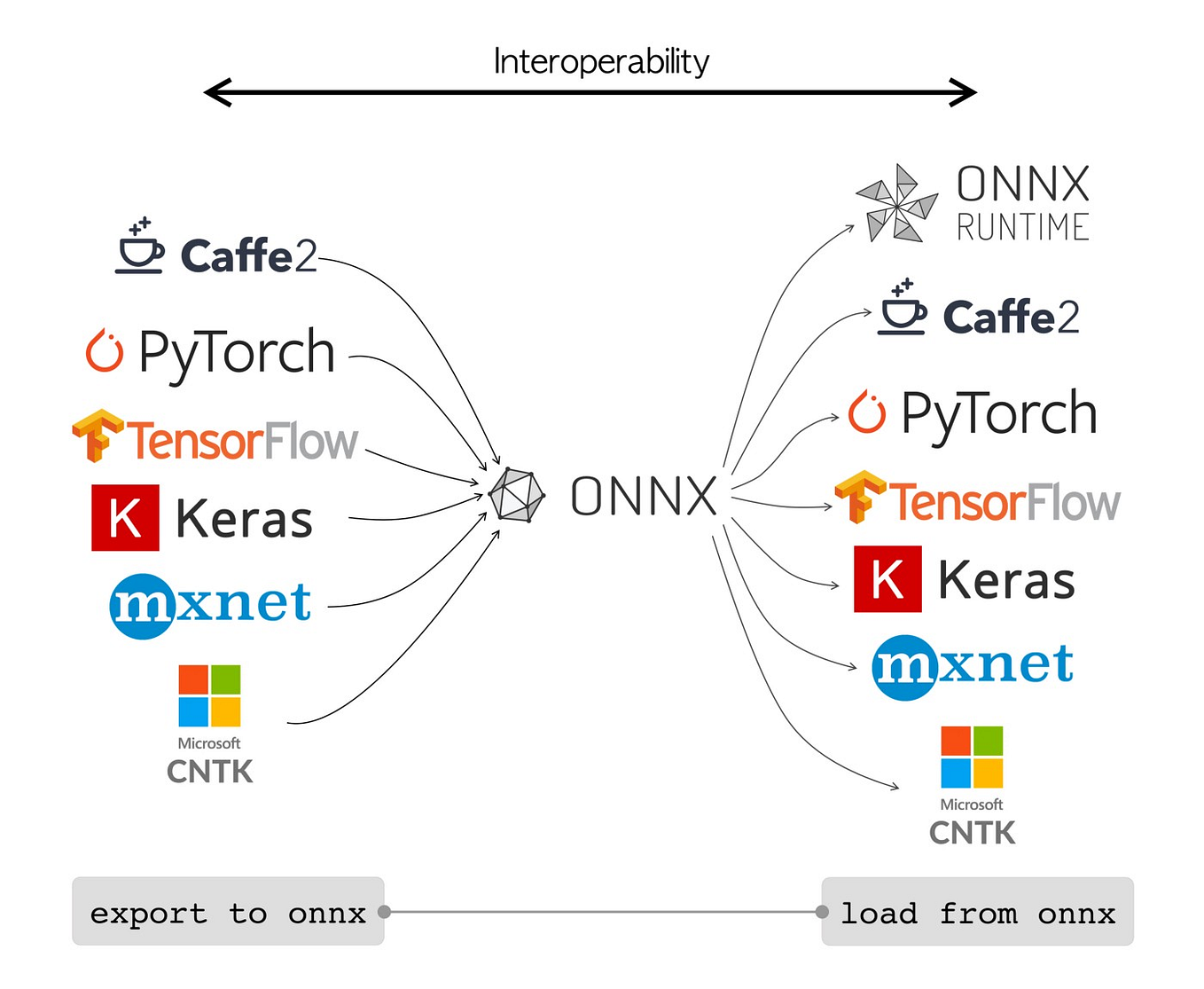
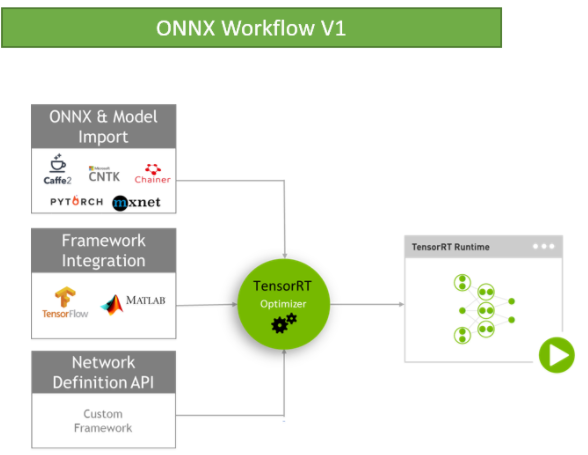
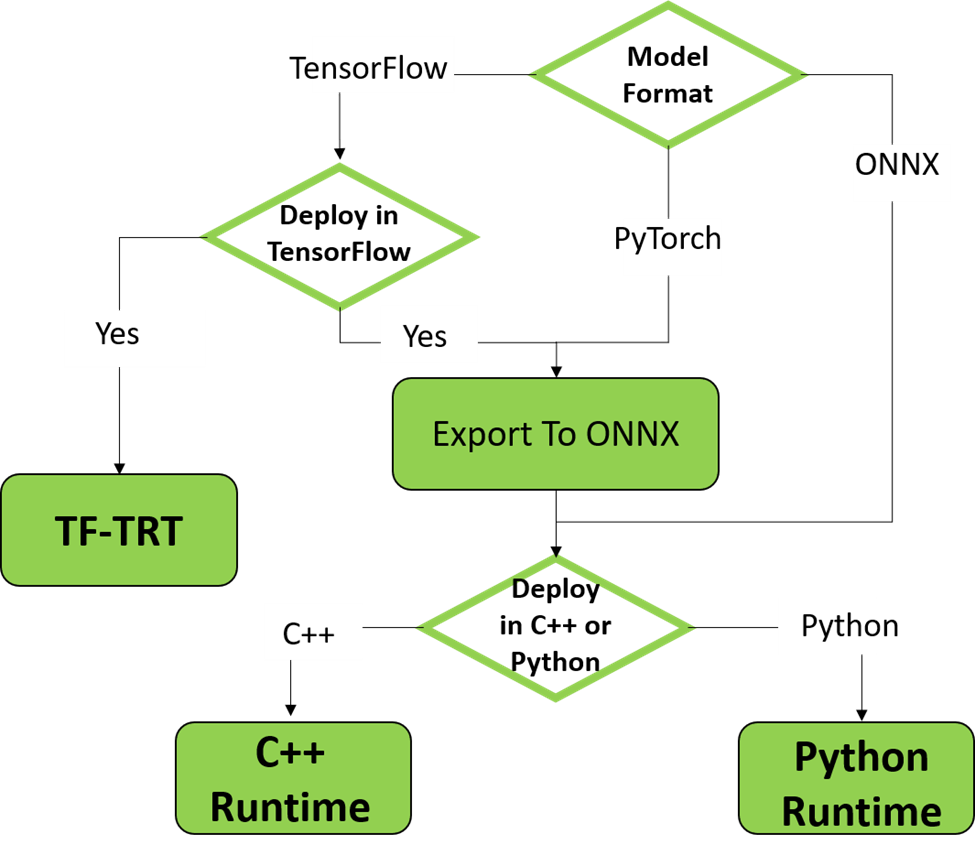
Speeding Up Deep Learning Inference Using TensorFlow, ONNX, and NVIDIA ...
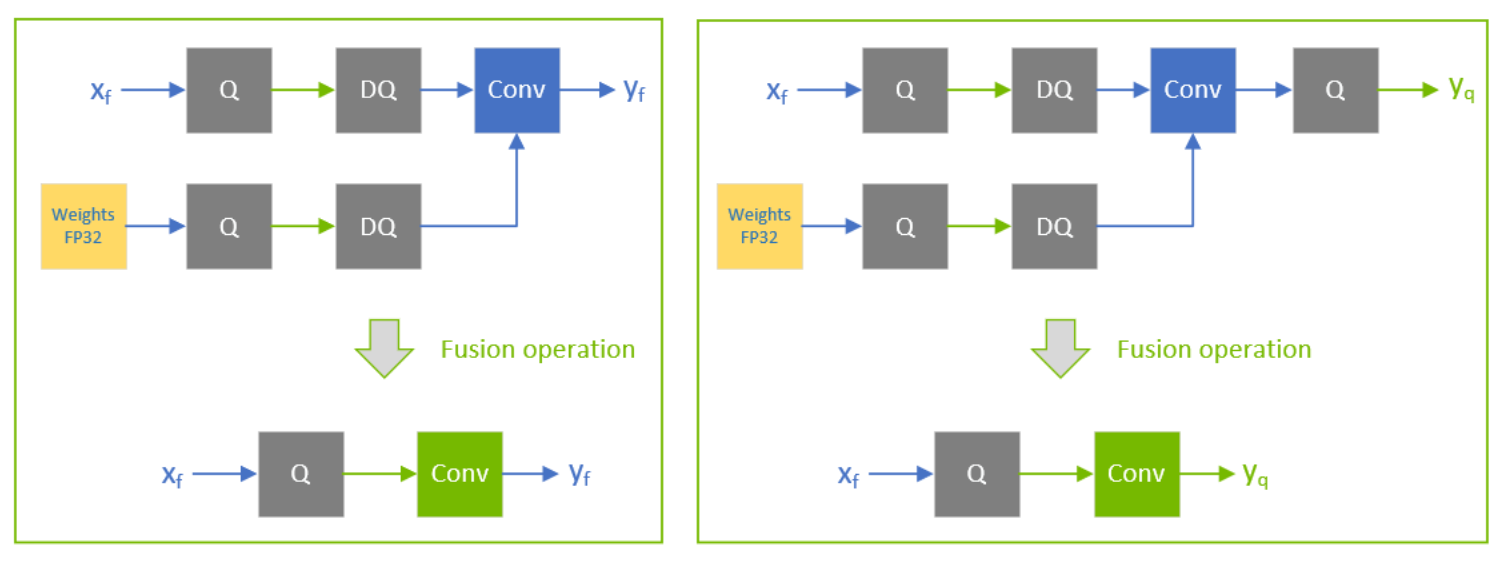
Achieving FP32 Accuracy for INT8 Inference Using Quantization Aware ...
Leveraging TensorFlow-TensorRT integration for Low latency Inference ...
Accelerating LLM and VLM Inference for Automotive and Robotics with ...
TensorRT(1)-介绍-使用-安装 | arleyzhang
NVIDIA TensorRT----Quick Start Guide | NVIDIA Docs_tensorrt quickstart ...
Speeding Up Deep Learning Inference Using TensorFlow, ONNX, and ...
Accelerating Quantized Networks with the NVIDIA QAT Toolkit for ...
TensorRT-LLM Speculative Decoding Boosts Inference Throughput by up to ...
NVIDIA TensorRT-LLM Now Supports Recurrent Drafting for Optimizing LLM ...
Accelerating Inference for Deep Learning Models — NVIDIA Triton ...
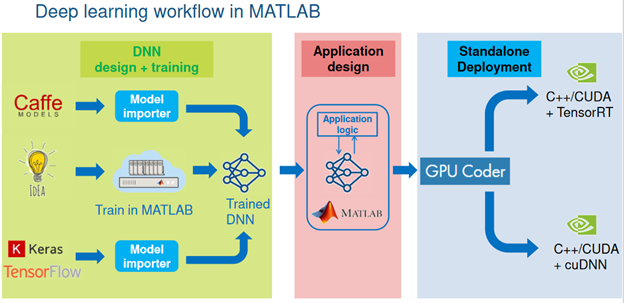
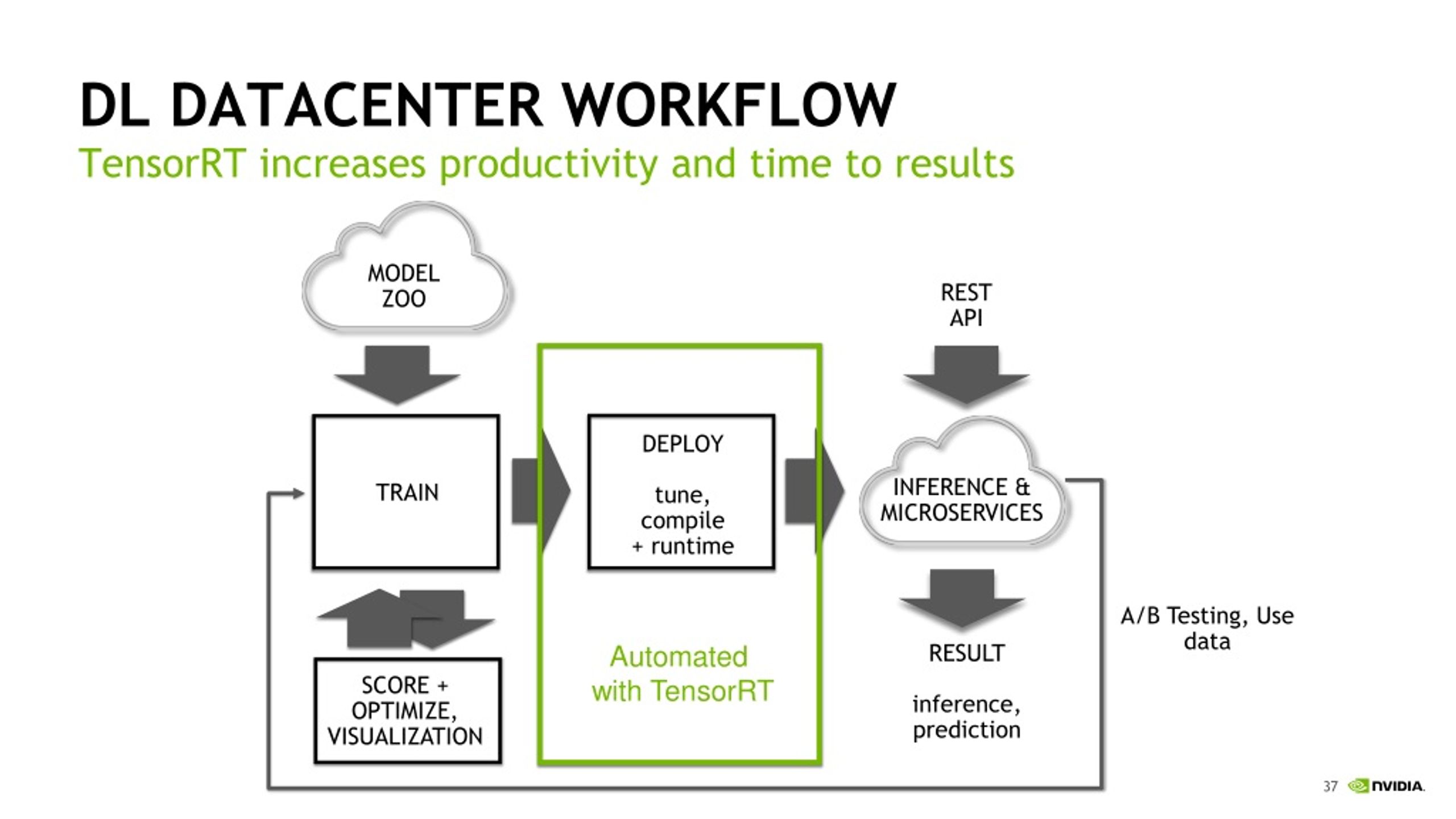
PPT - Deep Learning Workflows: Training and Inference PowerPoint ...
TensorRT模型转换及部署,FP32/FP16/INT8精度区分_tensorrt engine in fp16-CSDN博客
深度学习模型部署(八)TensorRT完整推理流程_tensorrt 多进程推理-CSDN博客
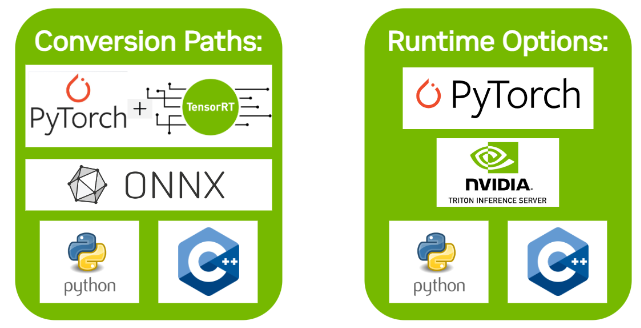
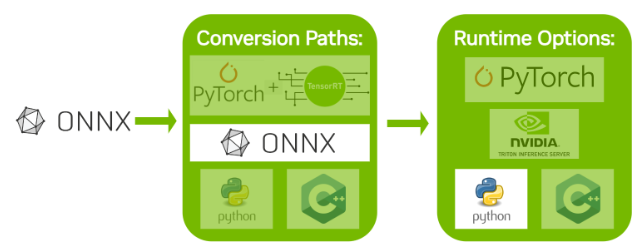
Streamlining AI Inference Performance and Deployment with NVIDIA ...
Resources for Media and Entertainment Industry | NVIDIA Developer
Platform Tensorrt_Plan at Alex Cruz blog
Simplifying and Accelerating Machine Learning Predictions in Apache ...
TensorRT详细入门指北,如果你还不了解TensorRT,过来看看吧_tensor drt-CSDN博客