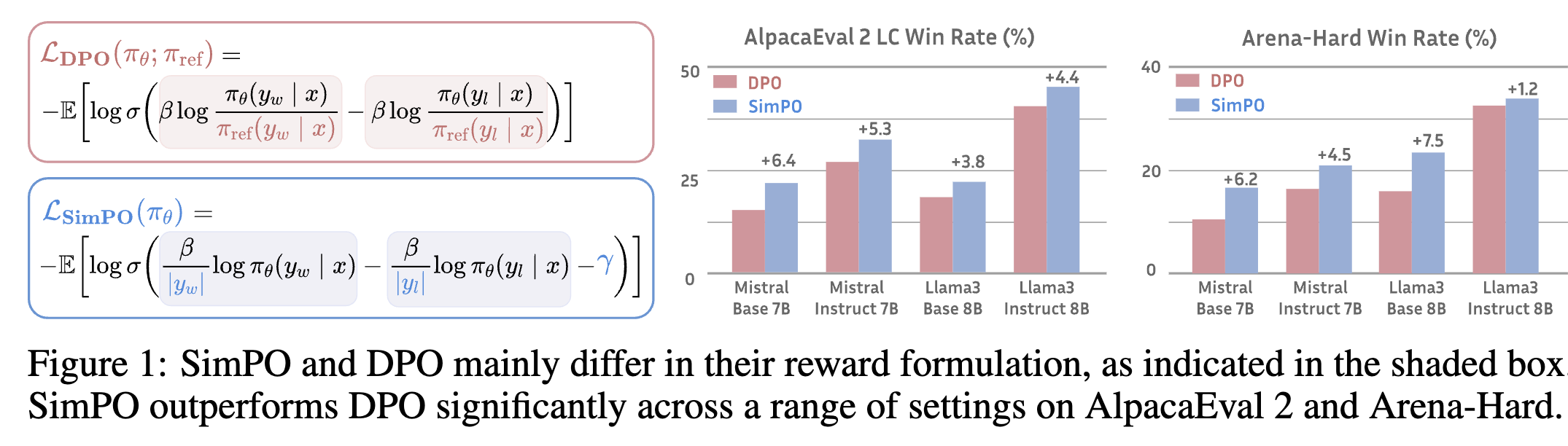
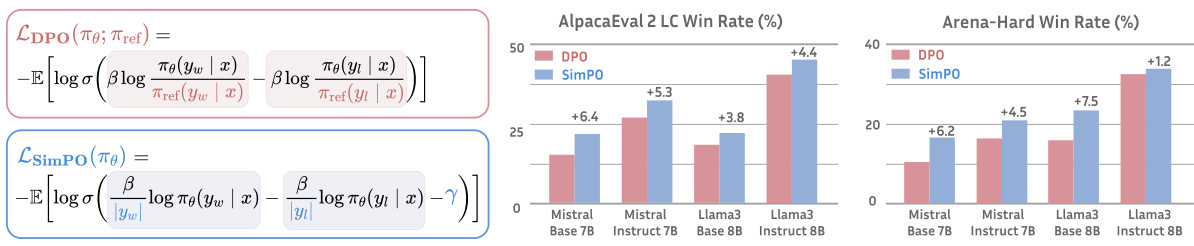
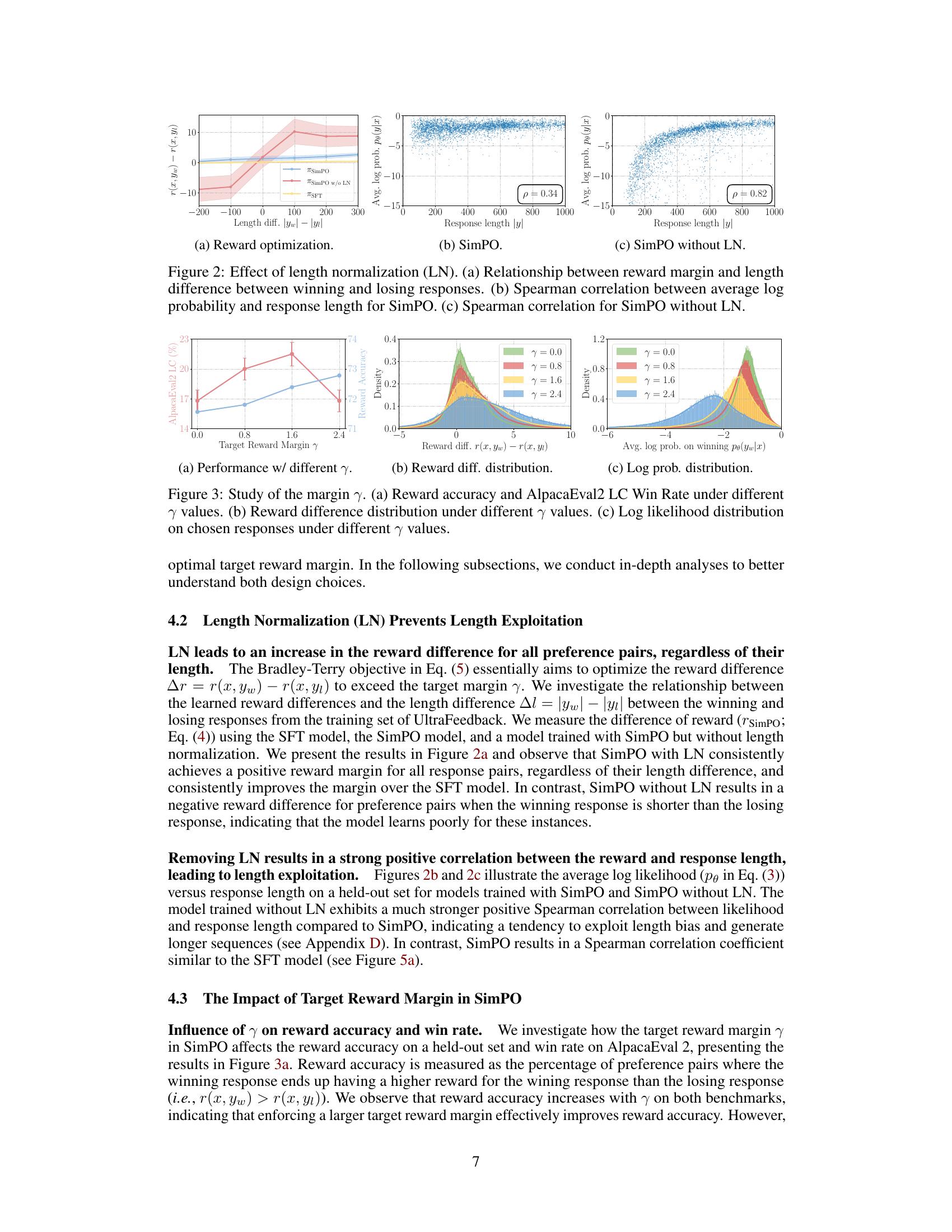
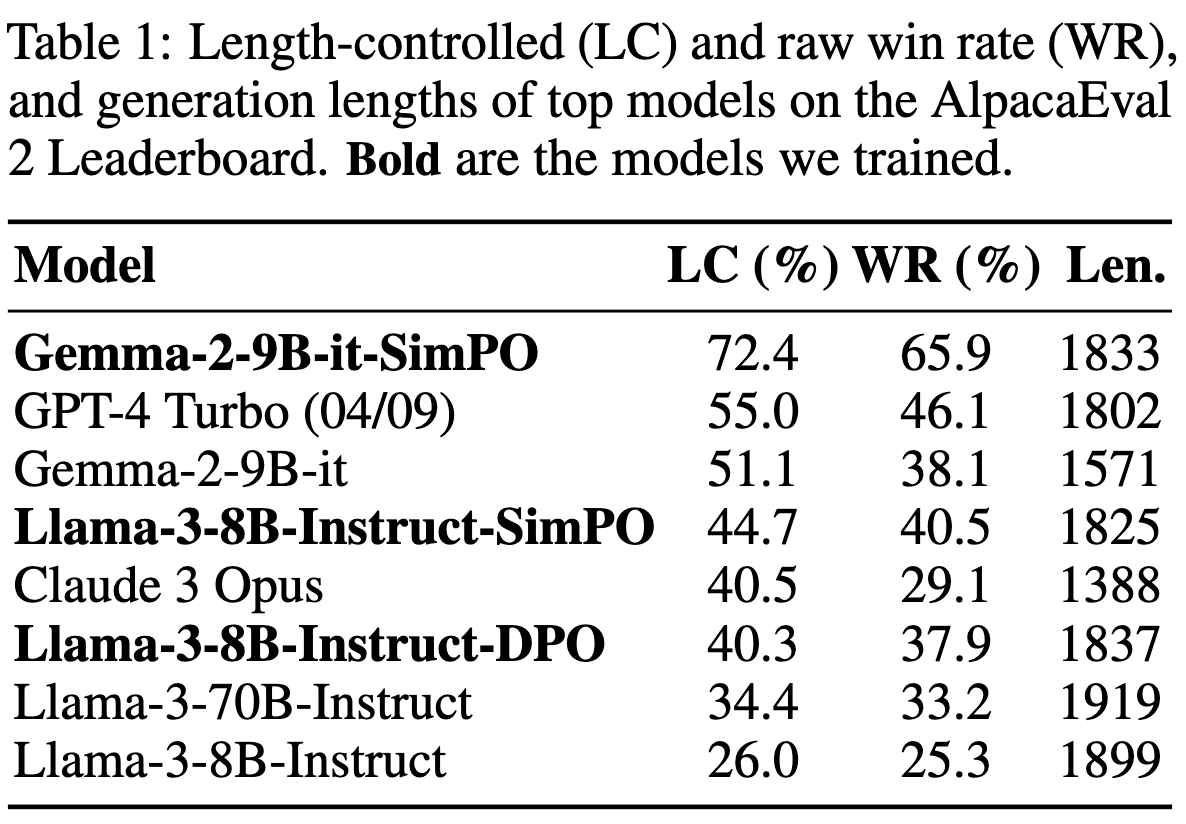
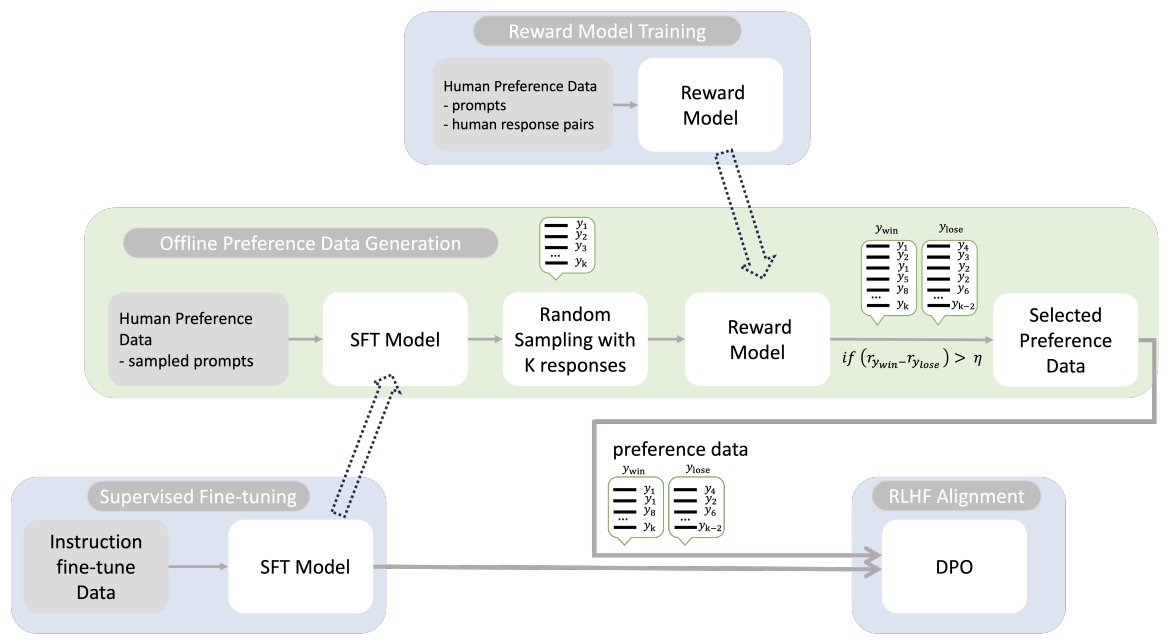
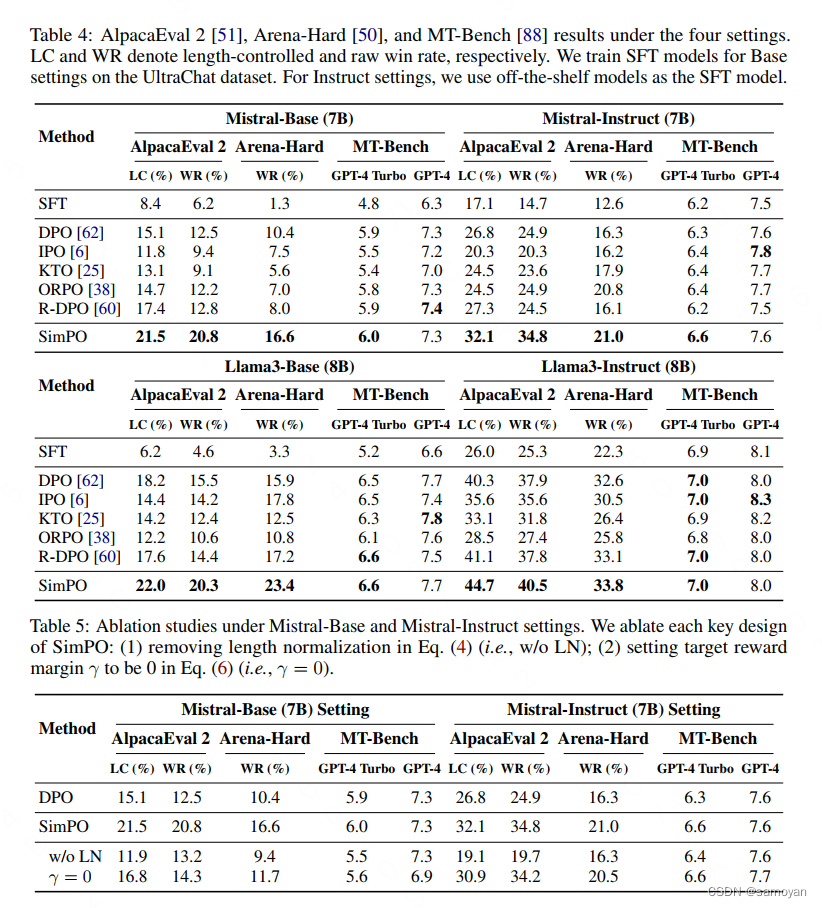
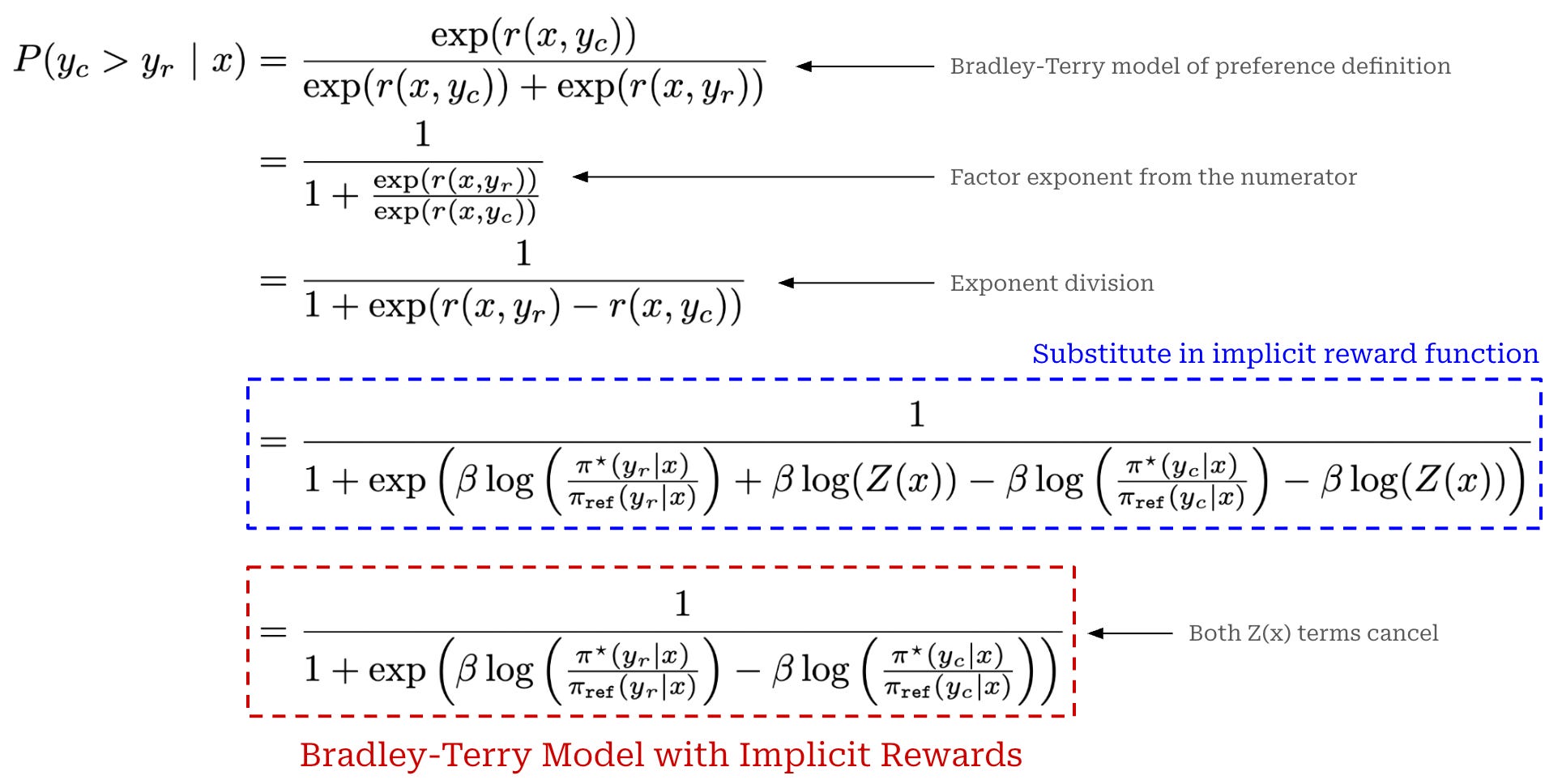
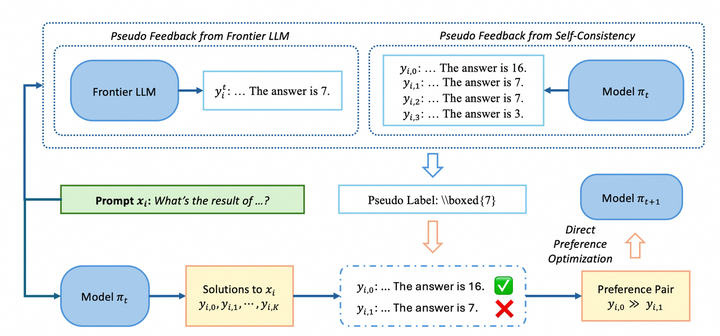
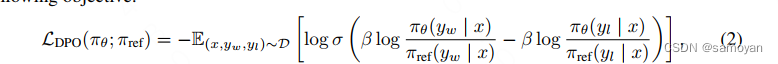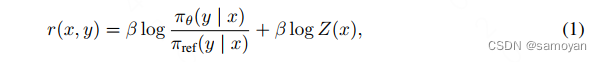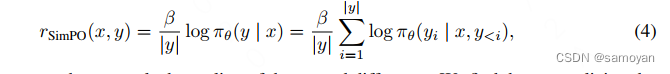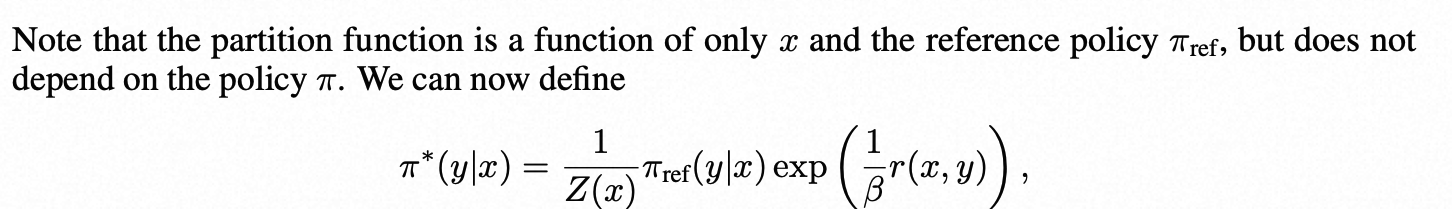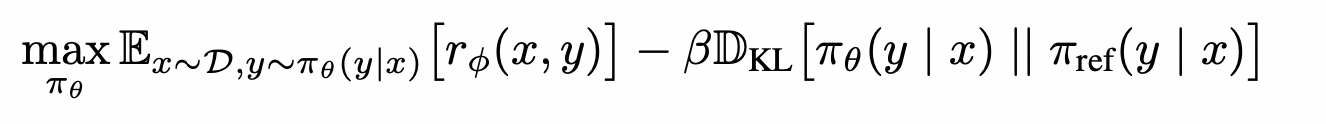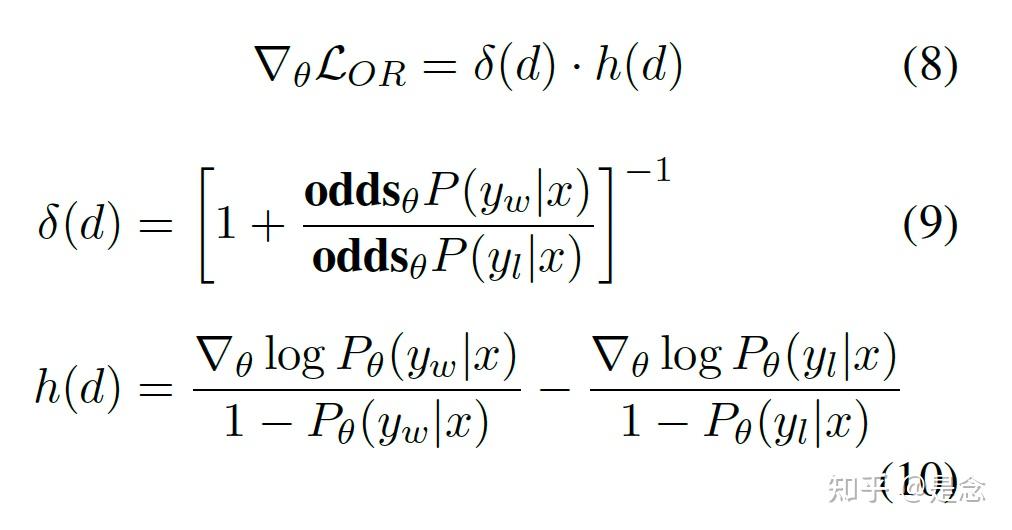Showing 118 of 118on this page. Filters & sort apply to loaded results; URL updates for sharing.118 of 118 on this page
SimPO: Simple Preference Optimization with Reference-Free Reward ...
SimPO: Simple Preference Optimization with a Reference-Free Reward ...
[RL] SimPO: Simple Preference Optimization with a Reference-Free Reward ...
Table 3 from SimPO: Simple Preference Optimization with a Reference ...
🤓 Simple Preference Optimization (SimPO) is a new algorithm for ...
SimPO Simple Preference Optimization with a Reference Free Reward ...
SimPO: Simple Preference Optimization with a Reference-Free Reward - 知乎
NeurIPS Poster SimPO: Simple Preference Optimization with a Reference ...
[논문 리뷰] SafeDPO: A Simple Approach to Direct Preference Optimization ...
SimPO - Simple Preference Optimization - New RLHF Method - YouTube
[PDF] SimPO: Simple Preference Optimization with a Reference-Free ...
SimPO: Simple Preference Optimization with a Reference-Free Reward - 智源社区论文
[2024 Best AI Paper] SimPO: Simple Preference Optimization with a ...
GitHub - RAY2L/SimPOW: SimPOW: Simple Preference Optimization with WEIGHTS
Paper page - SimPO: Simple Preference Optimization with a Reference ...
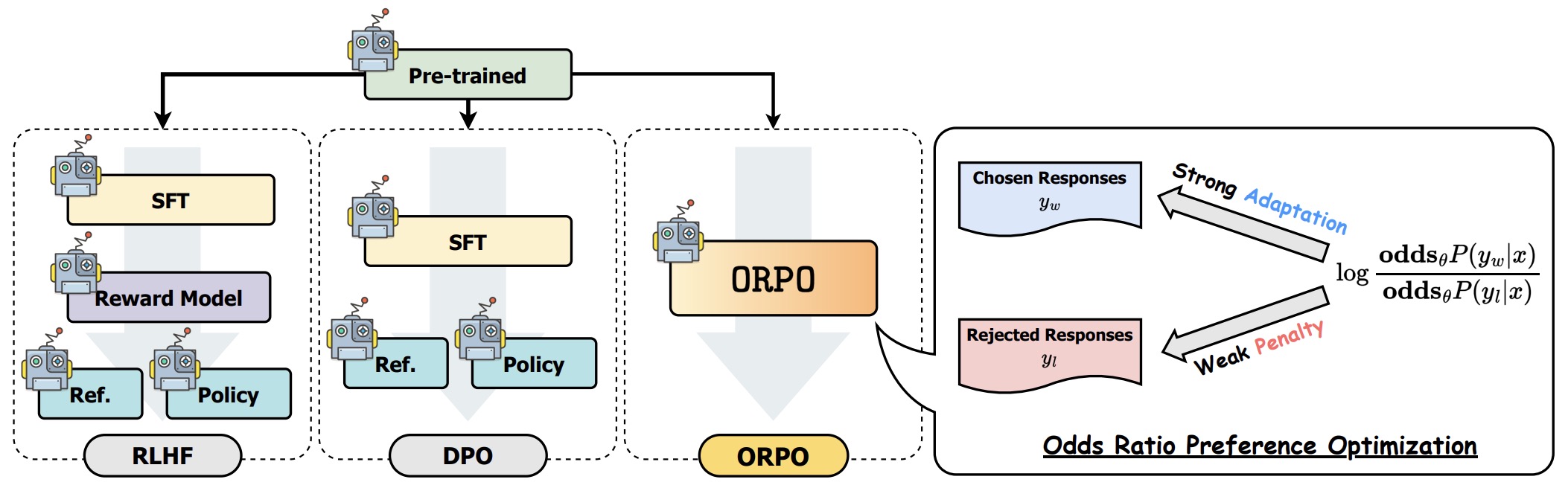
Direct Preference Optimization (DPO): A simple and straightforward ...
Walber Cardoso on LinkedIn: SimPO (Simple Preference Optimization ...
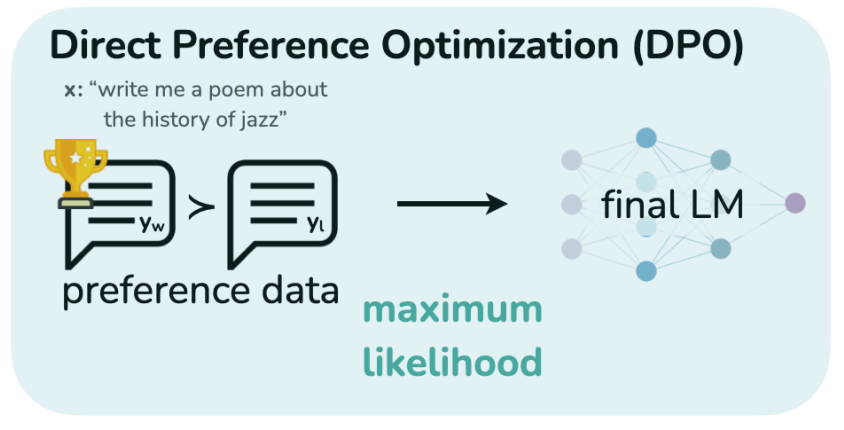
Direct Preference Optimization (DPO)
Understanding Direct Preference Optimization (DPO) for LLMs | Cameron R ...
What is direct preference optimization (DPO)? | SuperAnnotate
Direct Preference Optimization (DPO): Your Language Model is Secretly a ...
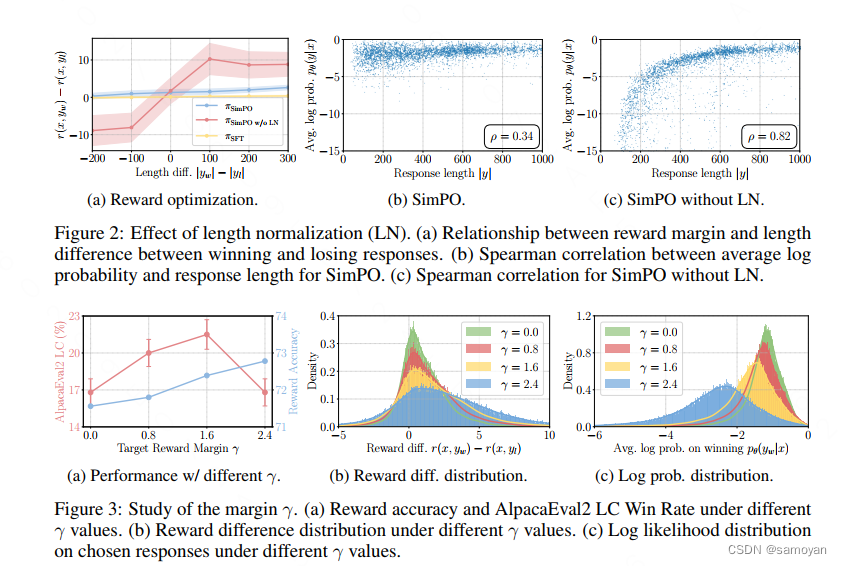
SimPO:一个不需要reward model 的对齐优化方法:有跟DPO 进行对比_simpo: simple preference ...
Direct Preference Optimization Using Sparse Feature-Level Constraints ...
GitHub - princeton-nlp/SimPO: [NeurIPS 2024] SimPO: Simple Preference ...
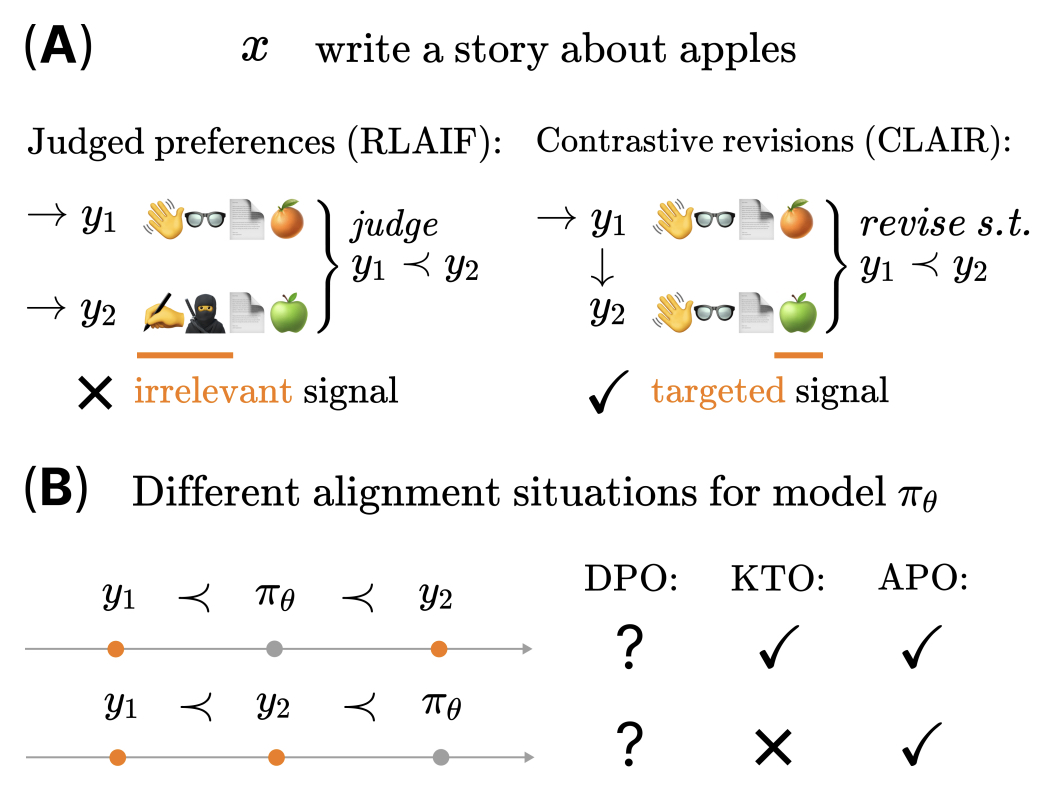
GitHub - ContextualAI/CLAIR_and_APO: Anchored Preference Optimization ...
Aman's AI Journal • Primers • Preference Optimization
(PDF) Preference Optimization by Estimating the Ratio of the Data ...
Preference Card Optimization 101: The Basics
Understanding Direct Preference Optimization | by Matthew Gunton ...
Understanding Direct Preference Optimization | Towards Data Science
Direct Preference Optimization (DPO) - How to fine-tune LLMs directly ...
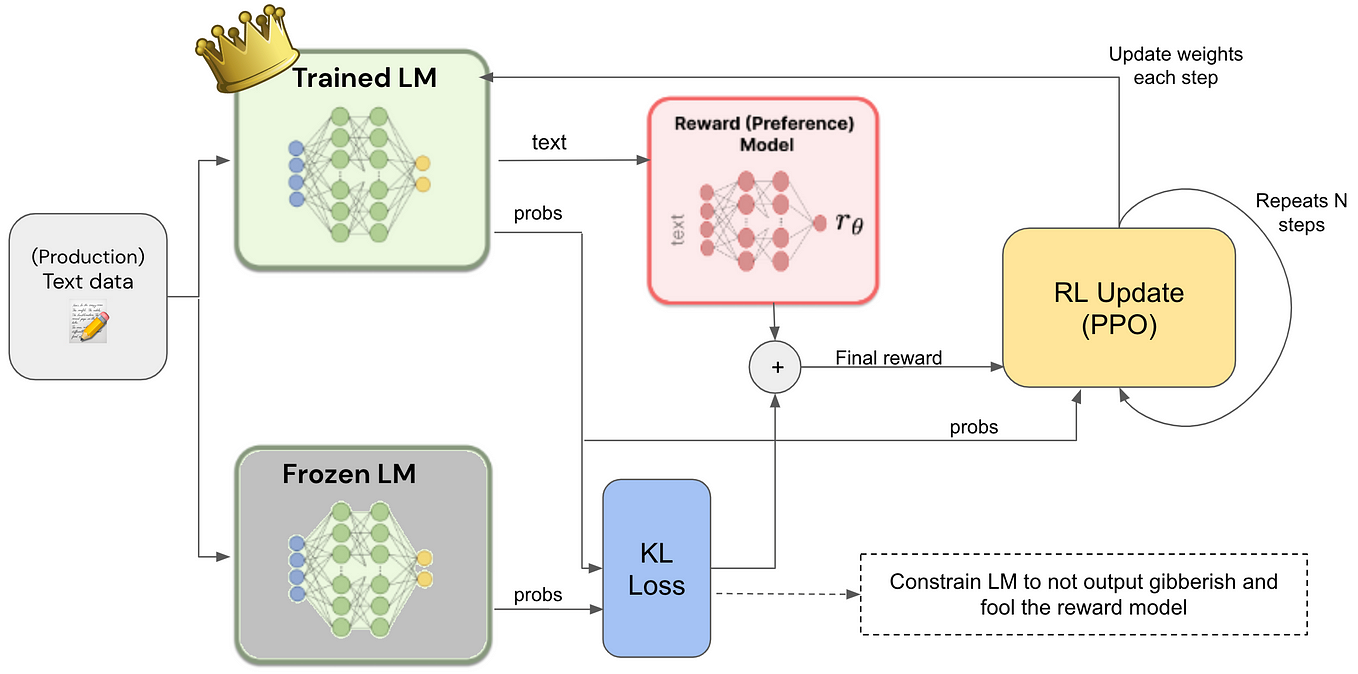
Direct Preference Optimization (DPO) vs RLHF/PPO (Reinforcement ...
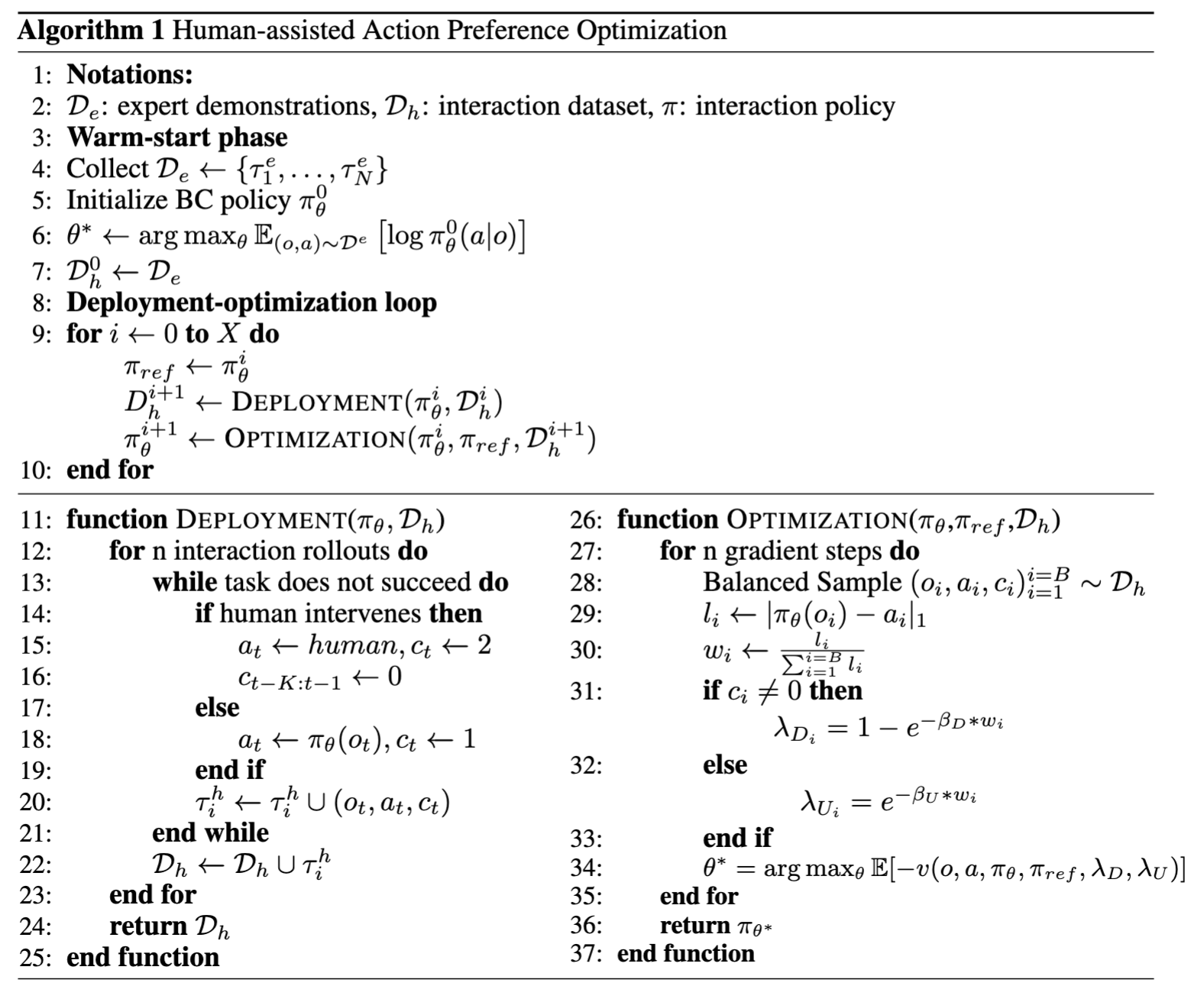
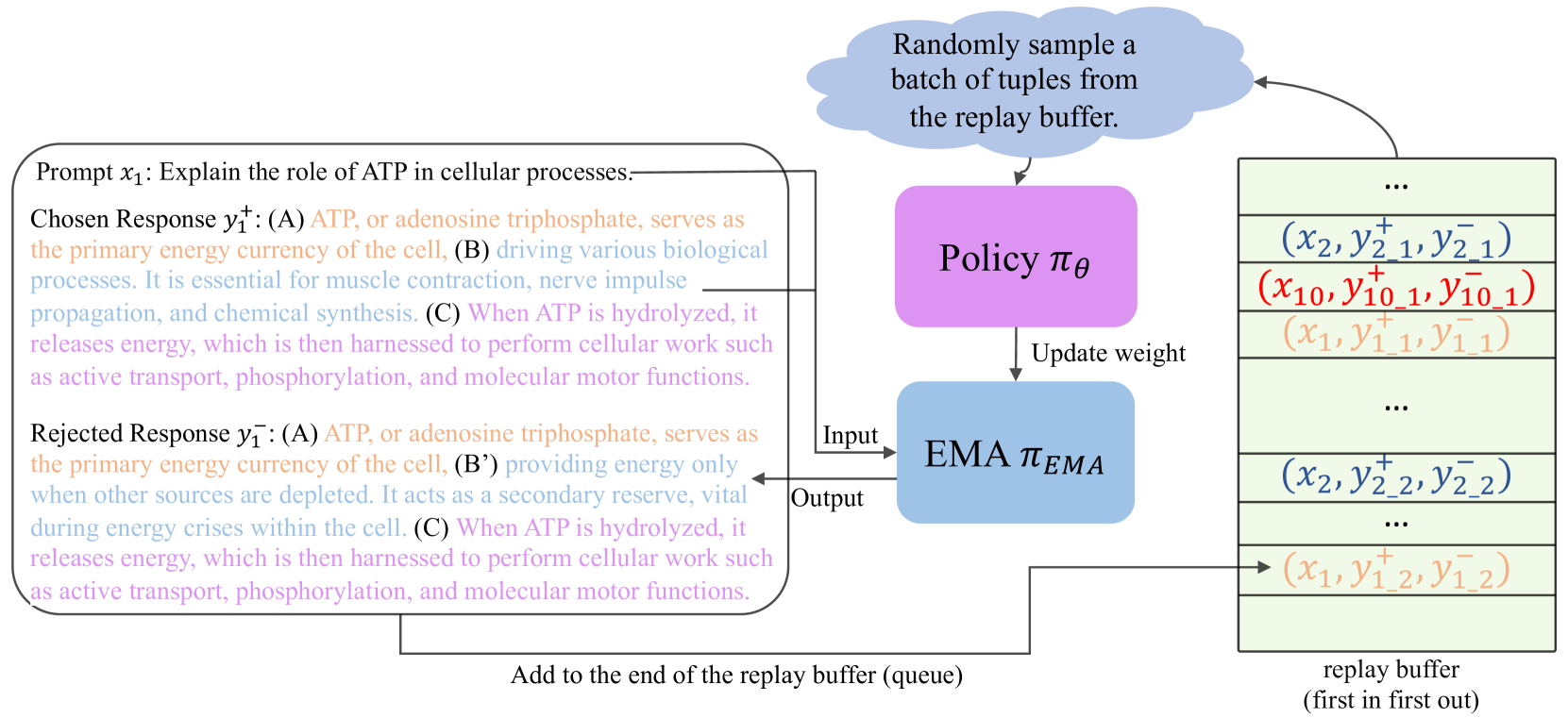
Robotic Policy Learning via Human-assisted Action Preference Optimization
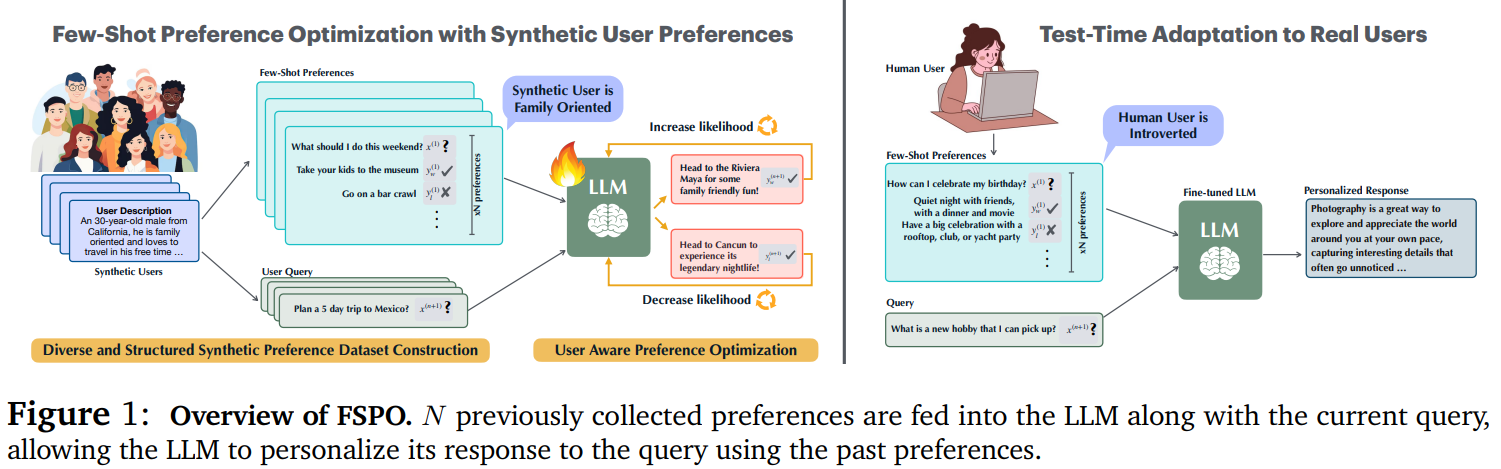
Few-Shot Preference Optimization (FSPO): A Novel Machine Learning ...
Direct Preference Optimization of Video Large Multimodal Models from ...
Direct Preference Optimization (DPO) | by João Lages | Medium
Fine-tune Llama 3 using Direct Preference Optimization
Preference Tuning LLMs with Direct Preference Optimization Methods
A recent paper shows that Direct Preference Optimization (𝐃𝐏𝐎) is ...
Self-Play Preference Optimization for Language Model Alignment
Preference Optimization for Reasoning with Pseudo Feedback(模型自迭代方法) - 知乎
Direct Preference Optimization for Large Language Models: A Look at Its ...
Self-Play Preference Optimization (SPPO): Innovating Machine Learning ...
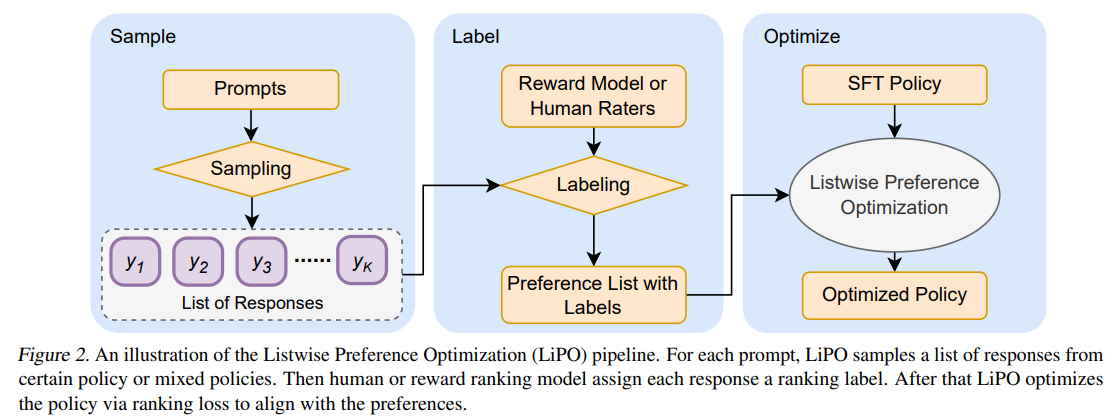
Google AI Research Introduces Listwise Preference Optimization (LiPO ...
Direct Preference Optimization (DPO) explained: Bradley-Terry model ...
Annotation-Efficient Preference Optimization for Language Model ...
Dual Caption Preference Optimization for Diffusion Models - AI for ...
Accelerated Preference Optimization for Large Language Model Alignment ...
Preference Training for LLMs in a Nutshell
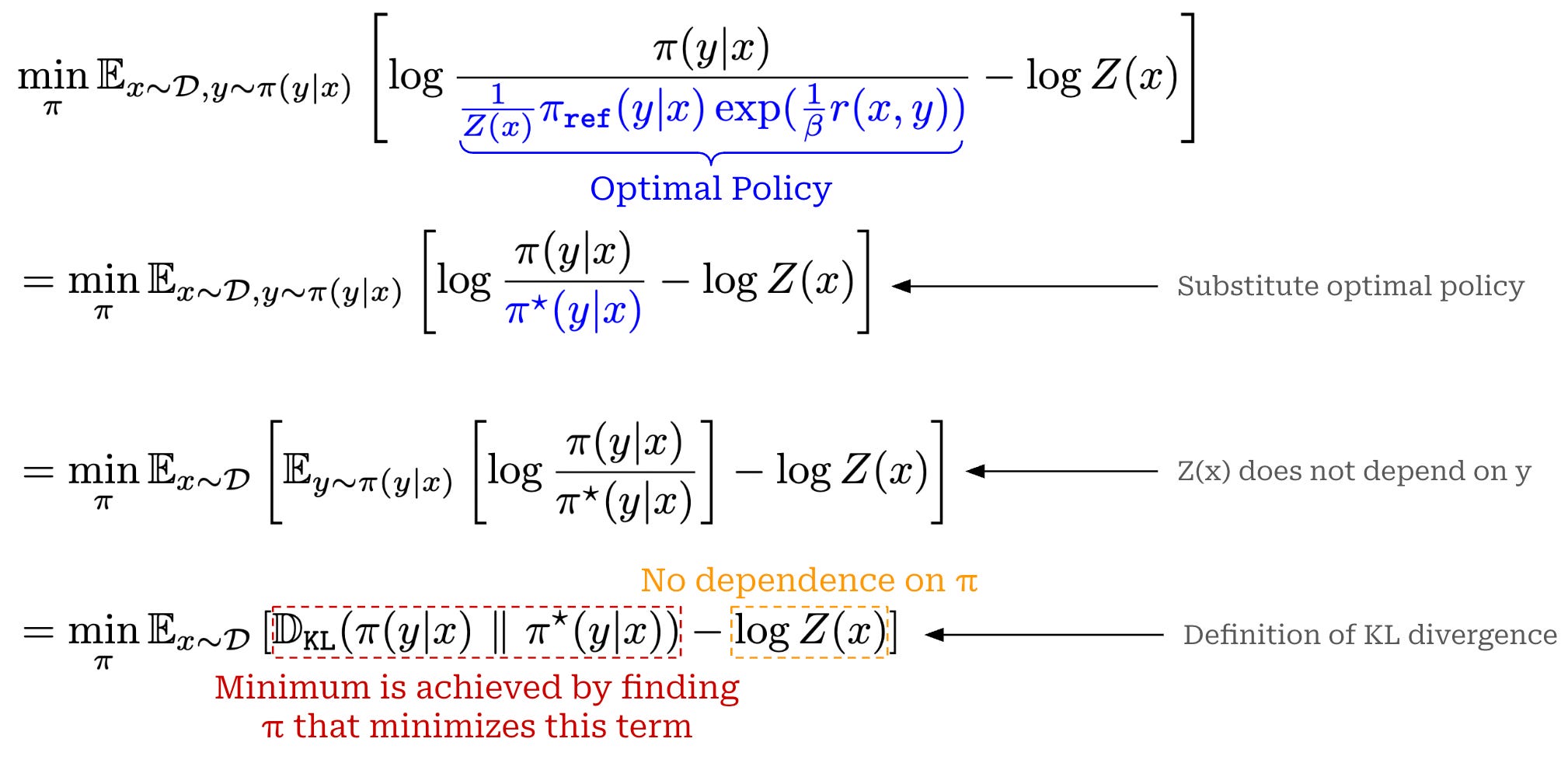
SimPO算法-Simple Preference Optimizationwith a Reference-Free Reward -CSDN博客
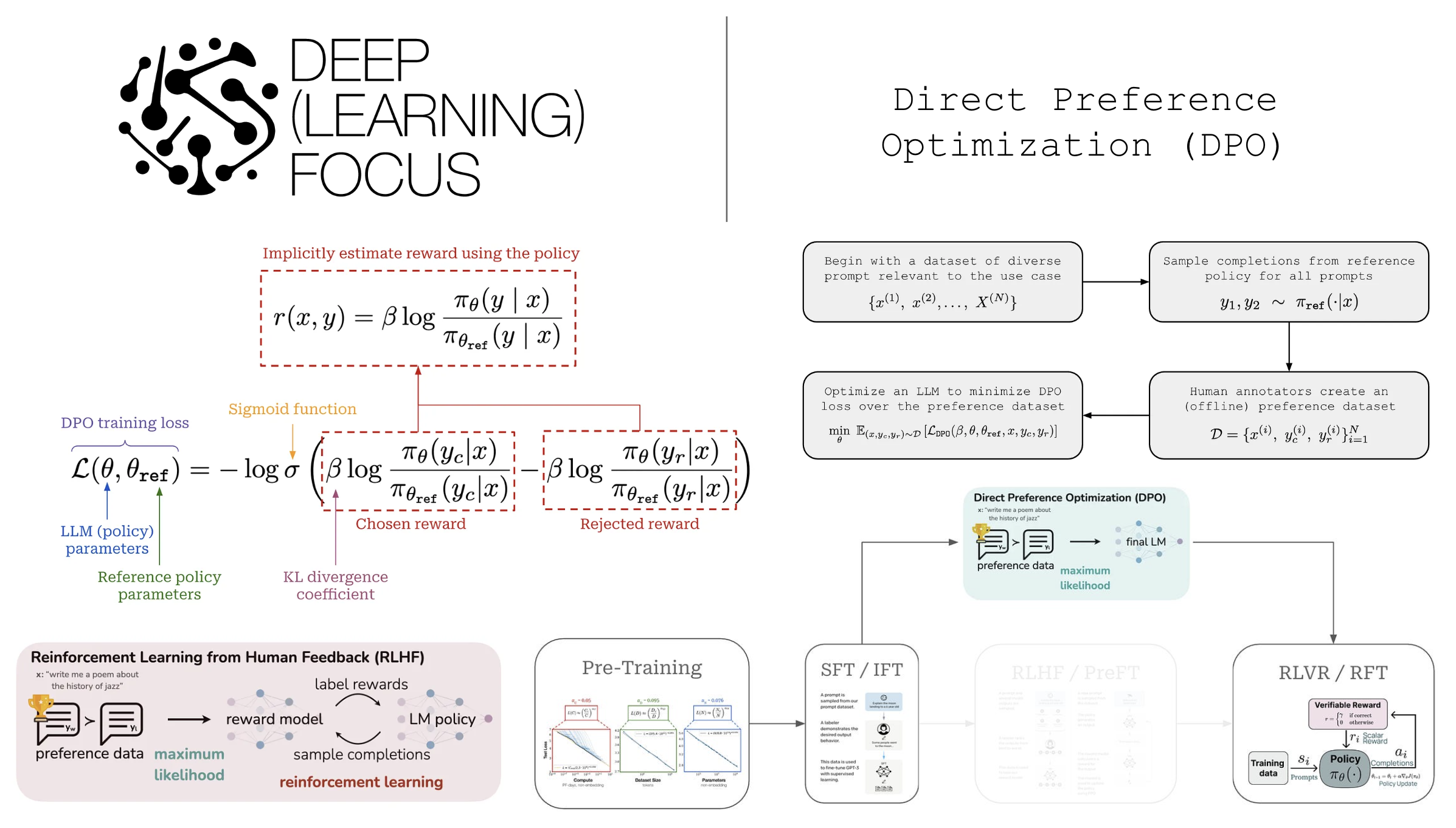
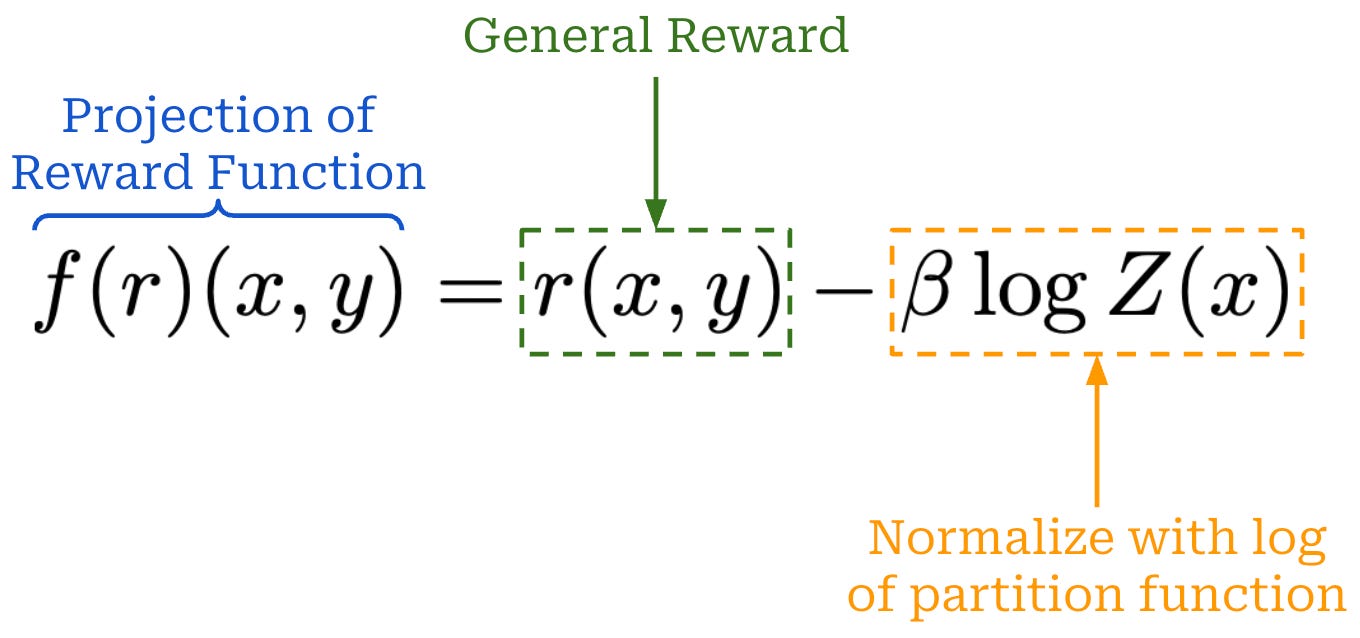
Direct Preference Optimization: Your Language Model is Secretly a ...
Free Video: Aligning Language Models with LESS Data and Simple ...
DPO(Direct Preference Optimization):LLM的直接偏好优化 - 知乎
What is Direct Preference Optimization? | Deepchecks
Paper page - Pre-DPO: Improving Data Utilization in Direct Preference ...
Paper page - Direct Preference Optimization: Your Language Model is ...
Direct Preference Optimization: Your Language Model Is Secretly A ...
[论文评述] Chain of Preference Optimization: Improving Chain-of-Thought ...
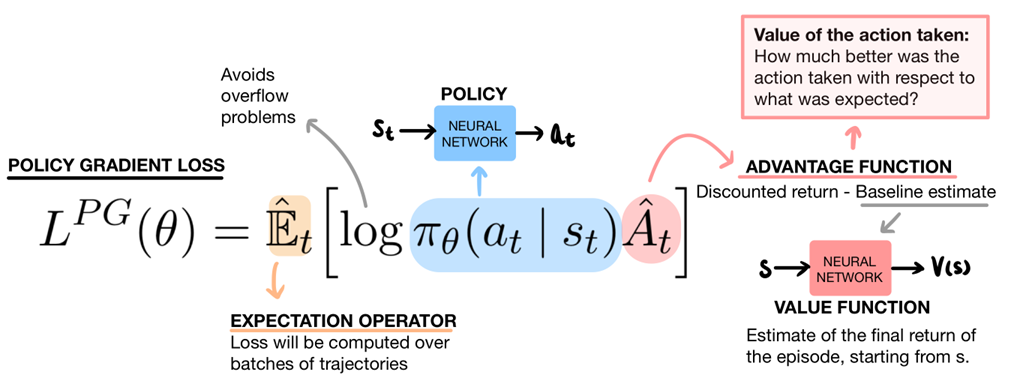
Proximal Policy Optimization (PPO): The Key to LLM Alignment
Paper page - Simplicity Prevails: Rethinking Negative Preference ...
Preference model based on reference points | Download Scientific Diagram
Boost Your Own Human Image Generation Model via Direct Preference ...
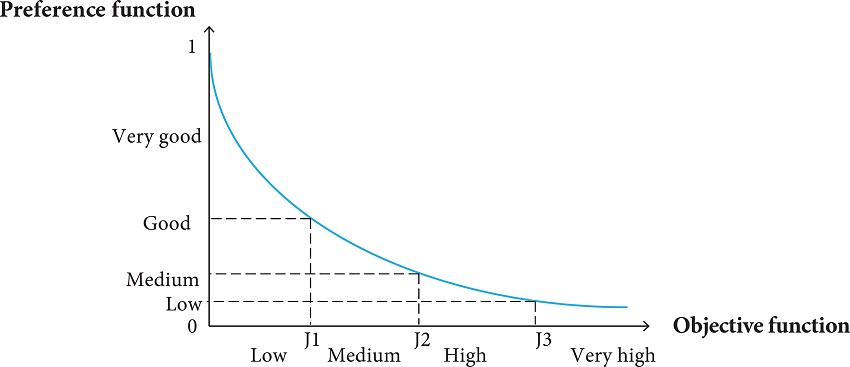
A New Approach for Robust Design Optimization Based on the Concepts of ...
[논문 리뷰] Explicit Preference Optimization: No Need for an Implicit ...
Soft Preference Optimization: Aligning Language Models to Expert ...
[论文笔记]DPO:Direct Preference Optimization: Your Language Model is ...
Direct Preference Optimization(DPO)学习笔记 - 知乎
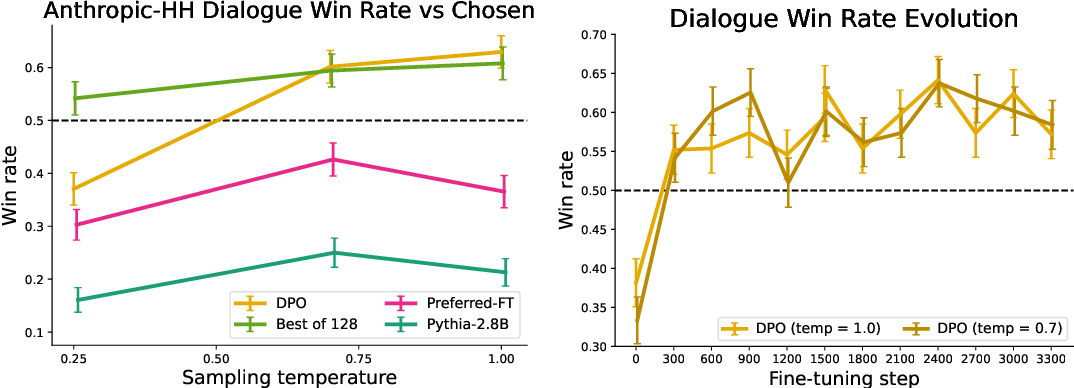
Figure 3 from Direct Preference Optimization: Your Language Model is ...
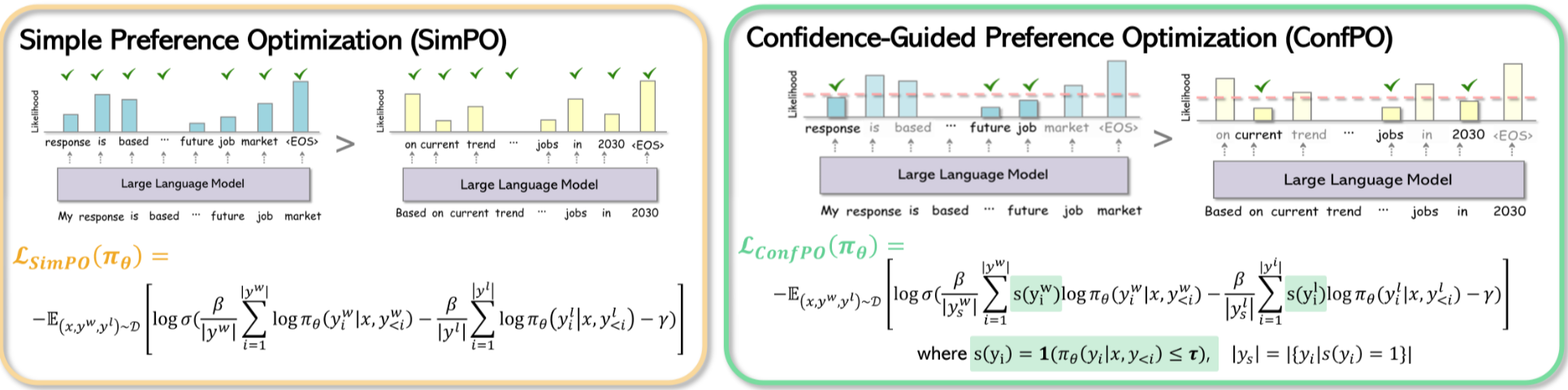
[论文评述] ConfPO: Exploiting Policy Model Confidence for Critical Token ...
Do You Really Need Reinforcement Learning (RL) in RLHF? A New Stanford ...
[大模型 13] 偏好学习新作,ODPO 和 SimPO - 知乎
LLM Alignments [Part 8: SimPO]. Today, we discuss another alignment ...
GitHub - eric-mitchell/direct-preference-optimization: Reference ...
2024年大模型Alignment偏好优化技术PPO,DPO, SimPO,KTO,Step-DPO, MCTS-DPO,SPO - 知乎
RLHF and alternatives: DOVE
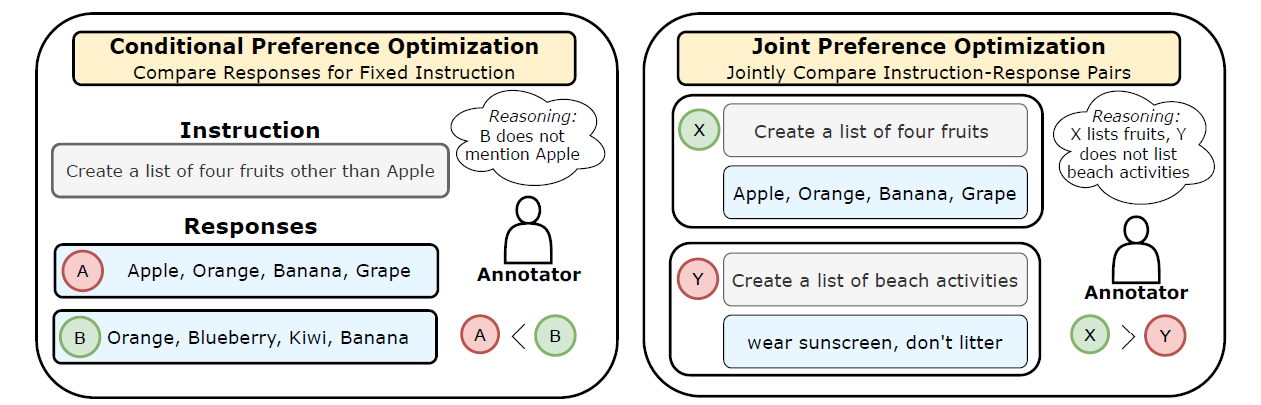
IOPO: Empowering LLMs with Complex Instruction Following via Input ...