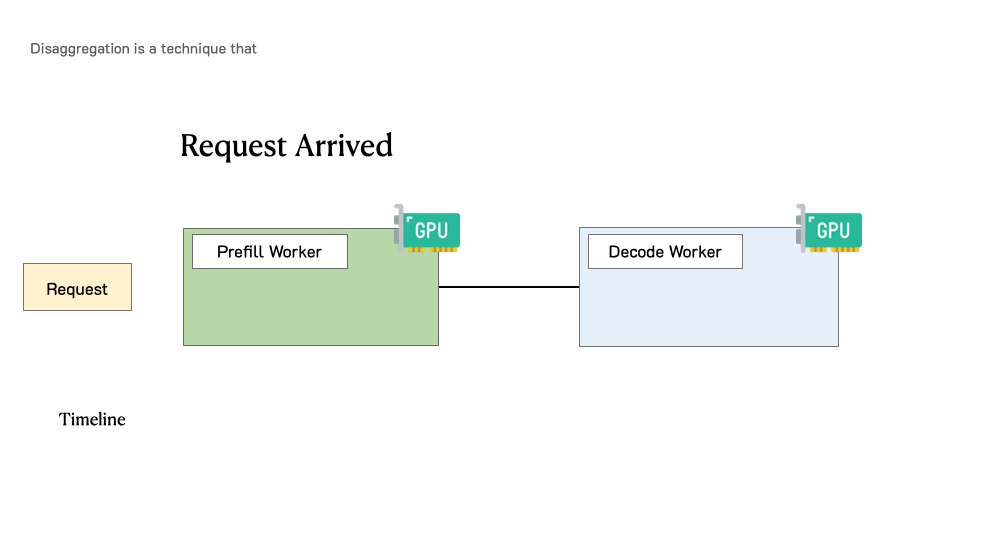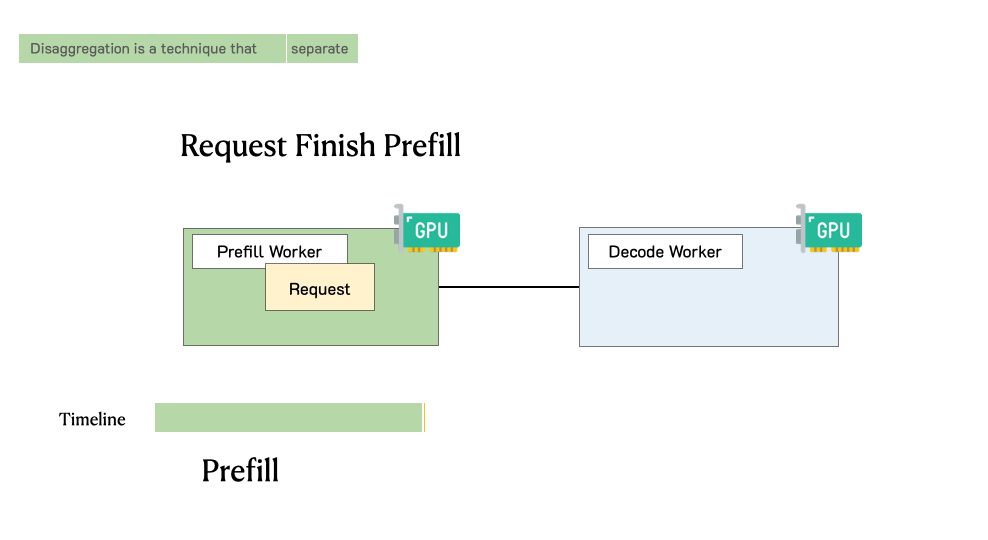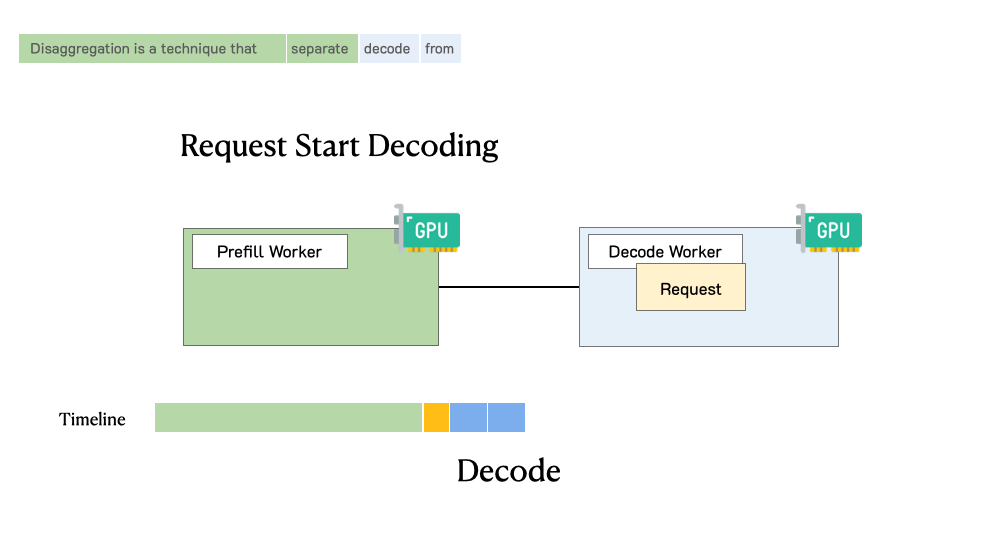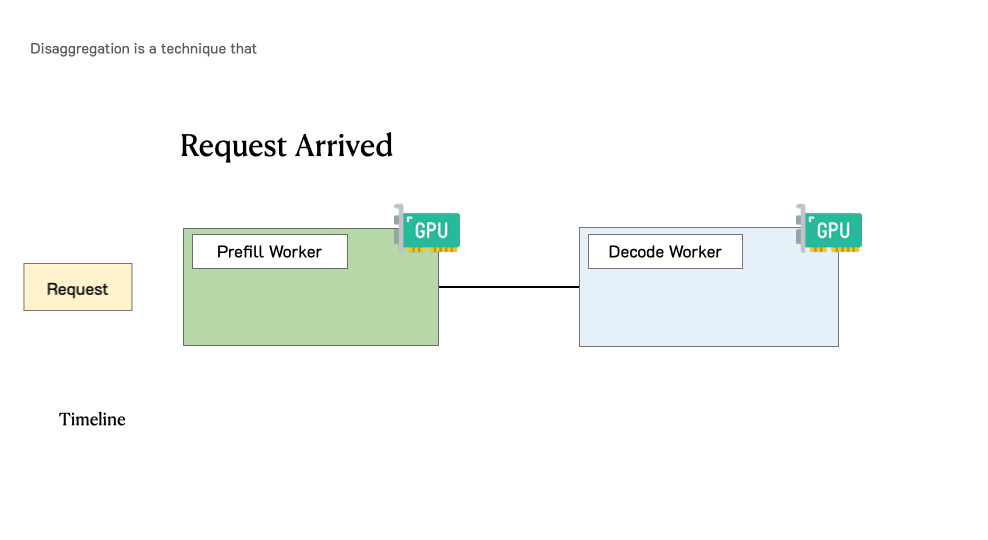
Showing 119 of 119on this page. Filters & sort apply to loaded results; URL updates for sharing.119 of 119 on this page
The LLM Serving Engine Showdown: Friendli Engine Outshines | by ...
SGLang Joins PyTorch Ecosystem: Efficient LLM Serving Engine | daily.dev
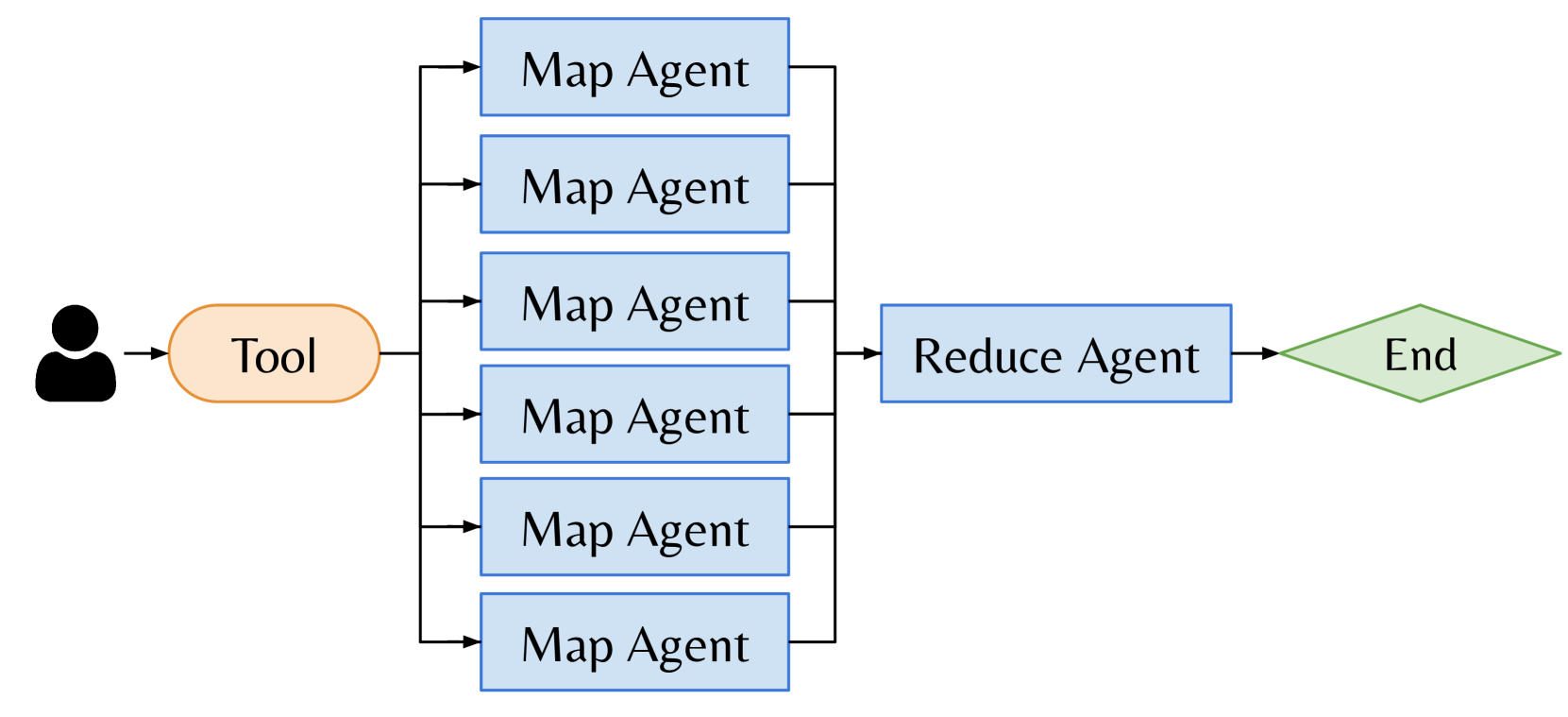
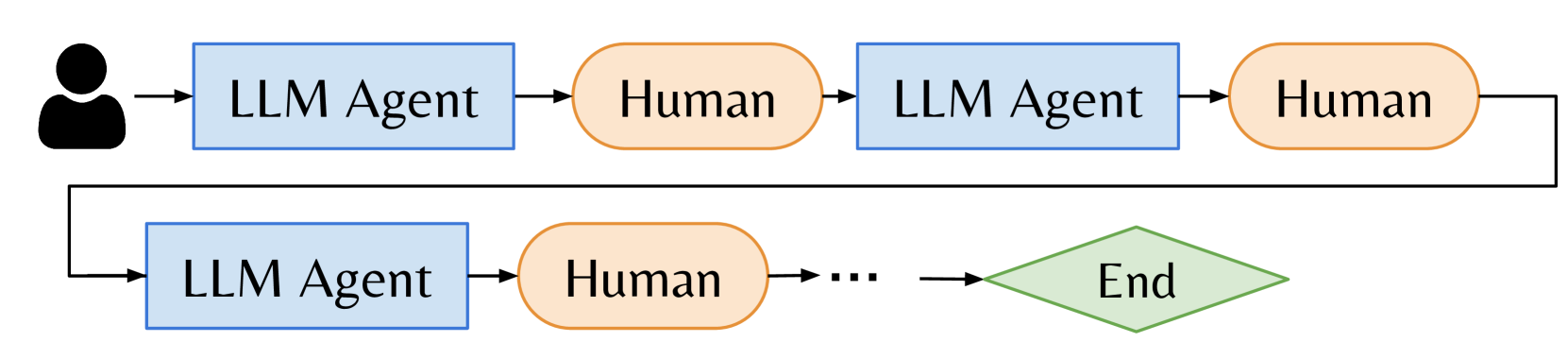
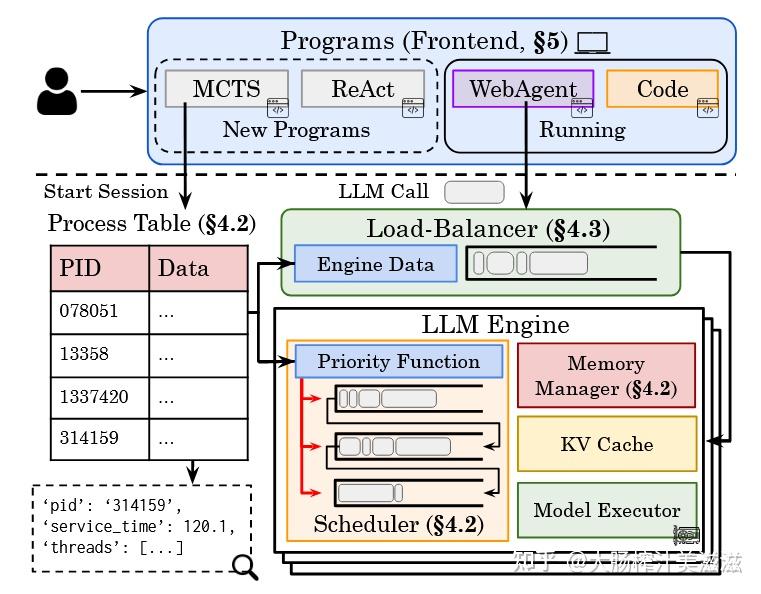
Autellix: An Efficient Serving Engine for LLM Agents as General ...
LitServe: Fast Serving Engine for AI Models | Kalyan KS posted on the ...
(PDF) Autellix: An Efficient Serving Engine for LLM Agents as General ...
Modular: Accelerating AI model serving with the Modular AI Engine
Serving Engine as a Service at Yahoo! JAPAN #SolrJP | PDF
Md - The fastest serving engine for LLMs is here (open-source)! LMCache ...
GitHub - fabigr8/LitServe-fix-oai: Lightning-fast serving engine for ...
Paper page - Autellix: An Efficient Serving Engine for LLM Agents as ...
[PDF] Autellix: An Efficient Serving Engine for LLM Agents as General ...
PeriFlow | Supercharged Generative AI Serving Engine | Futureen
Introducing LitServe: A Fast and Scalable Serving Engine for AI ...
GitHub - Lightning-AI/LitServe: High-throughput serving engine for AI ...
[QA] Autellix: An Efficient Serving Engine for LLM Agents as General ...
LitServe is the next-gen serving engine for AI models—lightning fast ⚡ ...
Buy Efficient Serving Solutions: Server Engine – PC HOME DECOR
LitServe - LLM Serving Inference Engine - Install and Test Locally ...
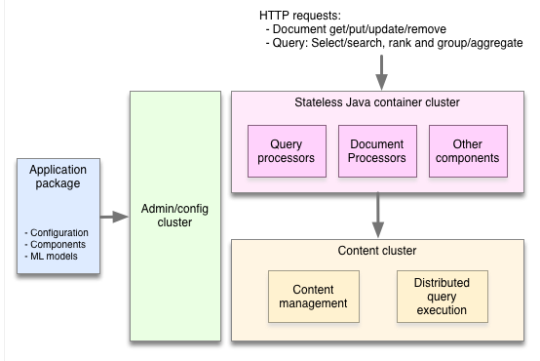
Open Sourcing Vespa, Yahoo’s Big Data Processing and Serving Engine ...
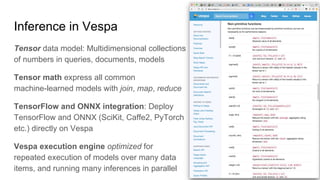
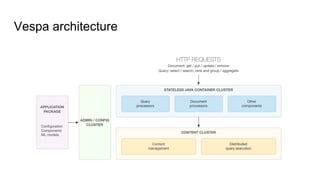
Vespa - Online Platform for Big Data serving engine & AI
Opinion: Best practices for building an AI serving engine
LitServe:Deploy AI models at scale. High-throughput serving engine for ...
[논문 리뷰] Autellix: An Efficient Serving Engine for LLM Agents as General ...
SGLang Joins PyTorch Ecosystem: Efficient LLM Serving Engine – PyTorch
LMCache: Fast LLM Serving Engine with Cache | Sumanth P posted on the ...
Serving Engine as a Service at Yahoo! JAPAN #SolrJP | PPT
I just found the fastest serving engine for LLMs: | Avi Chawla
The fastest serving engine for LLMs is here (open-source)! LMCache is ...
论文阅读笔记 Autellix: An Efficient Serving Engine for LLM Agents as General ...
Service Engine Soon Light: Meaning, Fixes & More
Nissan Service Engine Soon Light On? Causes & Fixes Explained - Nissan ...
Large Language Models LLMs Distributed Inference Serving System ...
What is Service Engine soon light & what to do when it’s on
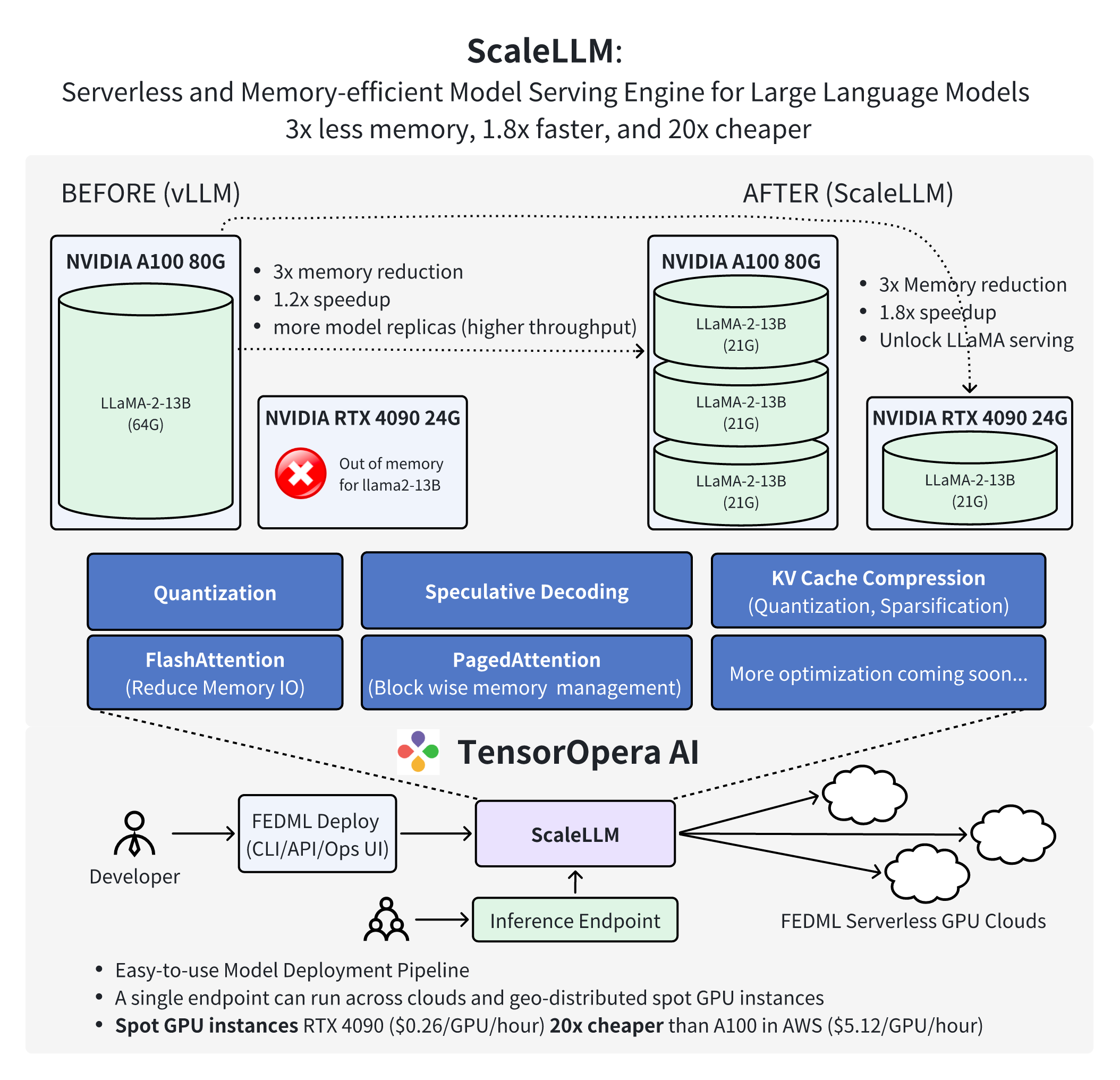
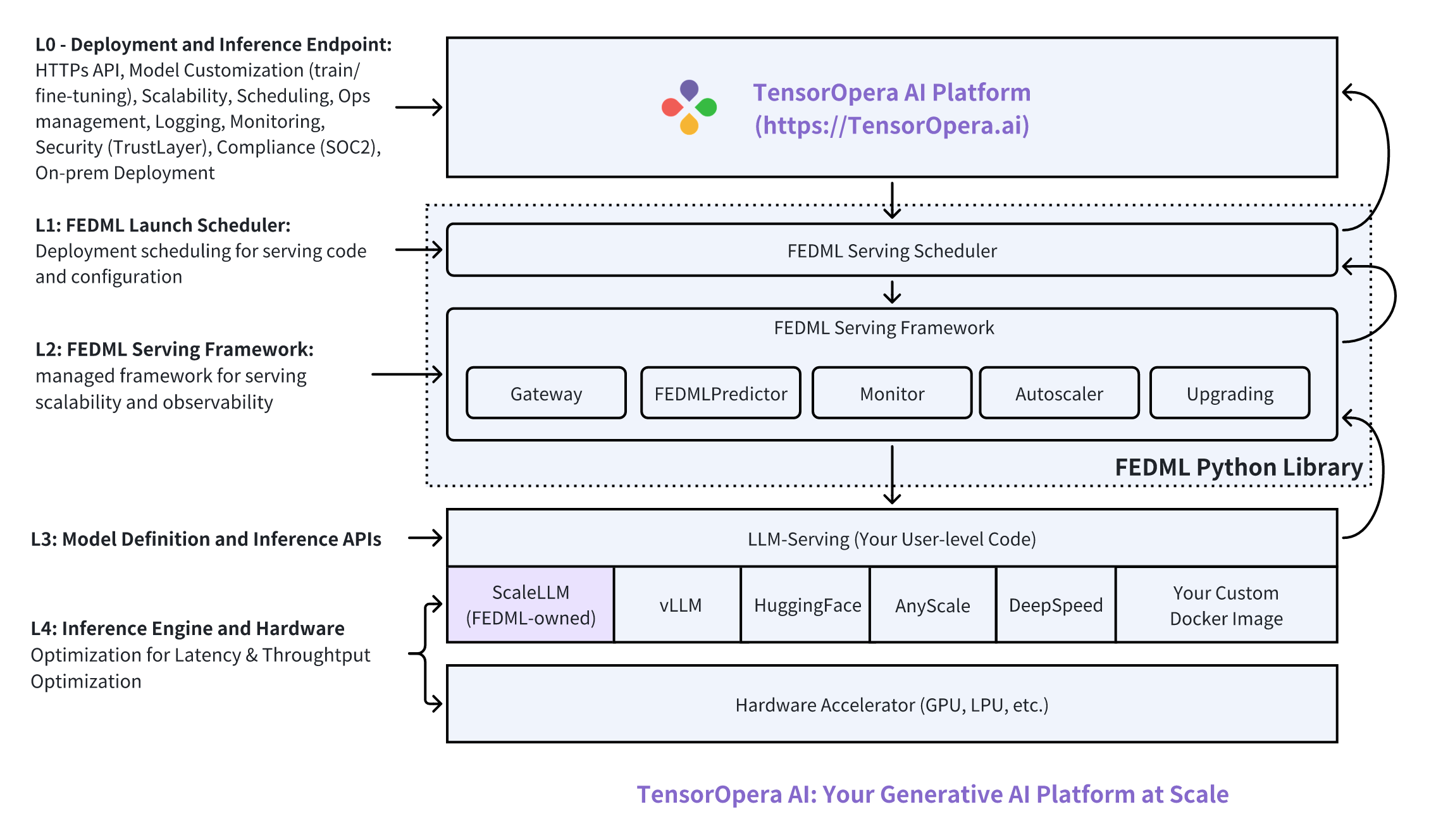
Scalable Model Deployment and Serving on TensorOpera AI
Revolutionizing LLM Serving: Automated Inference Engine Tuning for SLO ...
Service Engine - Aztekindo Services
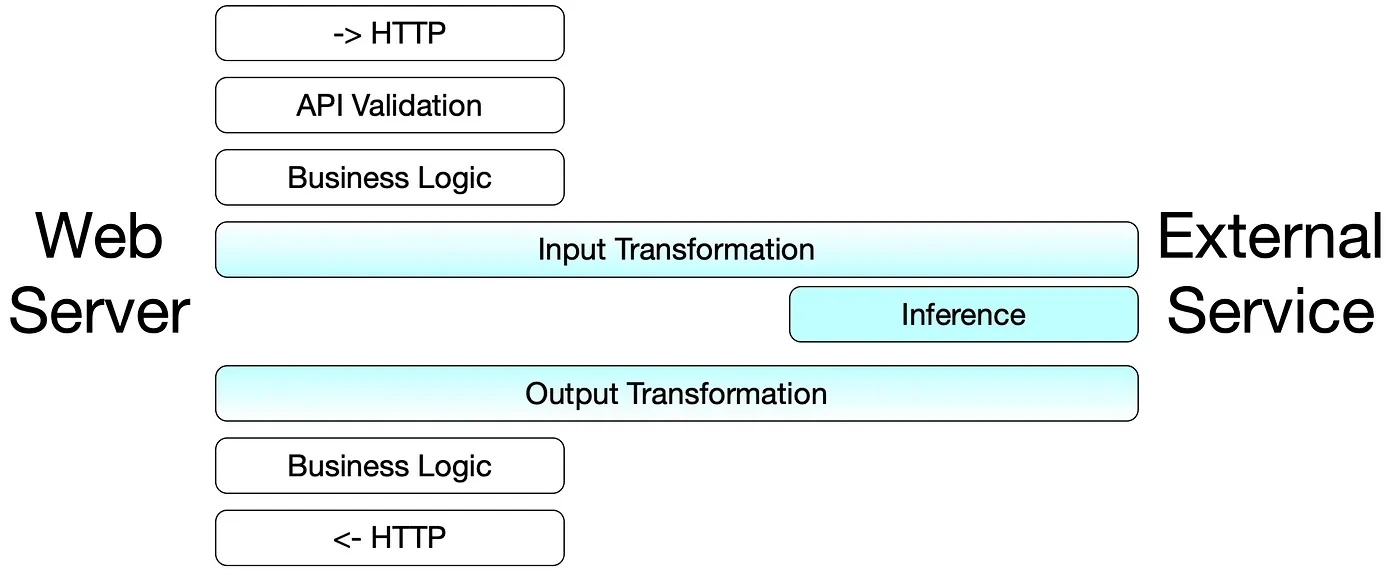
What it means to serve an LLM and which serving technology to choose from
SMP expands engine sensors - Auto Service World
Land Rover Range Rover Evoque Service Cost South Africa | Engine Finder
Ford Oil Change in Dubai - Expert Engine Protection & Maintenance ...
PM Modi says road, rail to serve as growth engine for Sikkim tourism ...
Engine Oil Becomes Costlier, Vehicle Service Costs Rise - Yamuna Nagar ...
GitHub - johnsonhk88/vllm-serving-engine-Testing-code: Vllm serving ...
Introduction to Vespa – The Open Source Big Data Serving Engine, Jon ...
Service Virtualization With The Managed Services Engine | Microsoft Learn
Engine Repair Calgary, AB | Car Engine Services
Engine Assemblies at William Shields blog
Redesigning Pinterest’s Ad Serving Systems with Zero Downtime | by ...
3ZZ-FE Engine Information, Specifications, and Offers
Jobs at Engine
How an Internal Combustion Engine Works (Step By Step)
Nokia unveils PSE-6s super-coherent optical engine for 1.2-Tbps to 2.4 ...
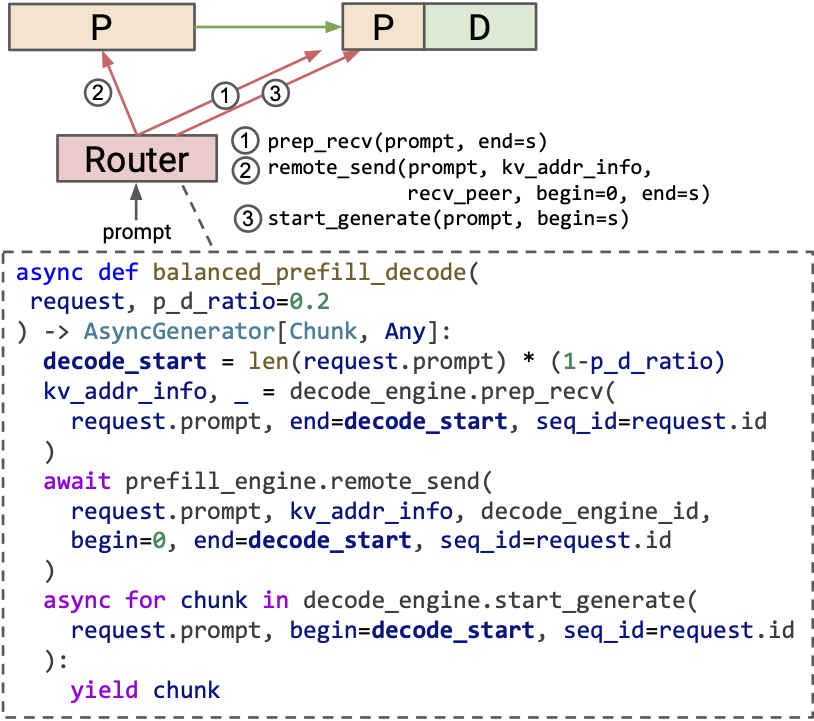
Throughput is Not All You Need: Maximizing Goodput in LLM Serving using ...
Inside vLLM: Anatomy of a High-Throughput LLM Inference System ...
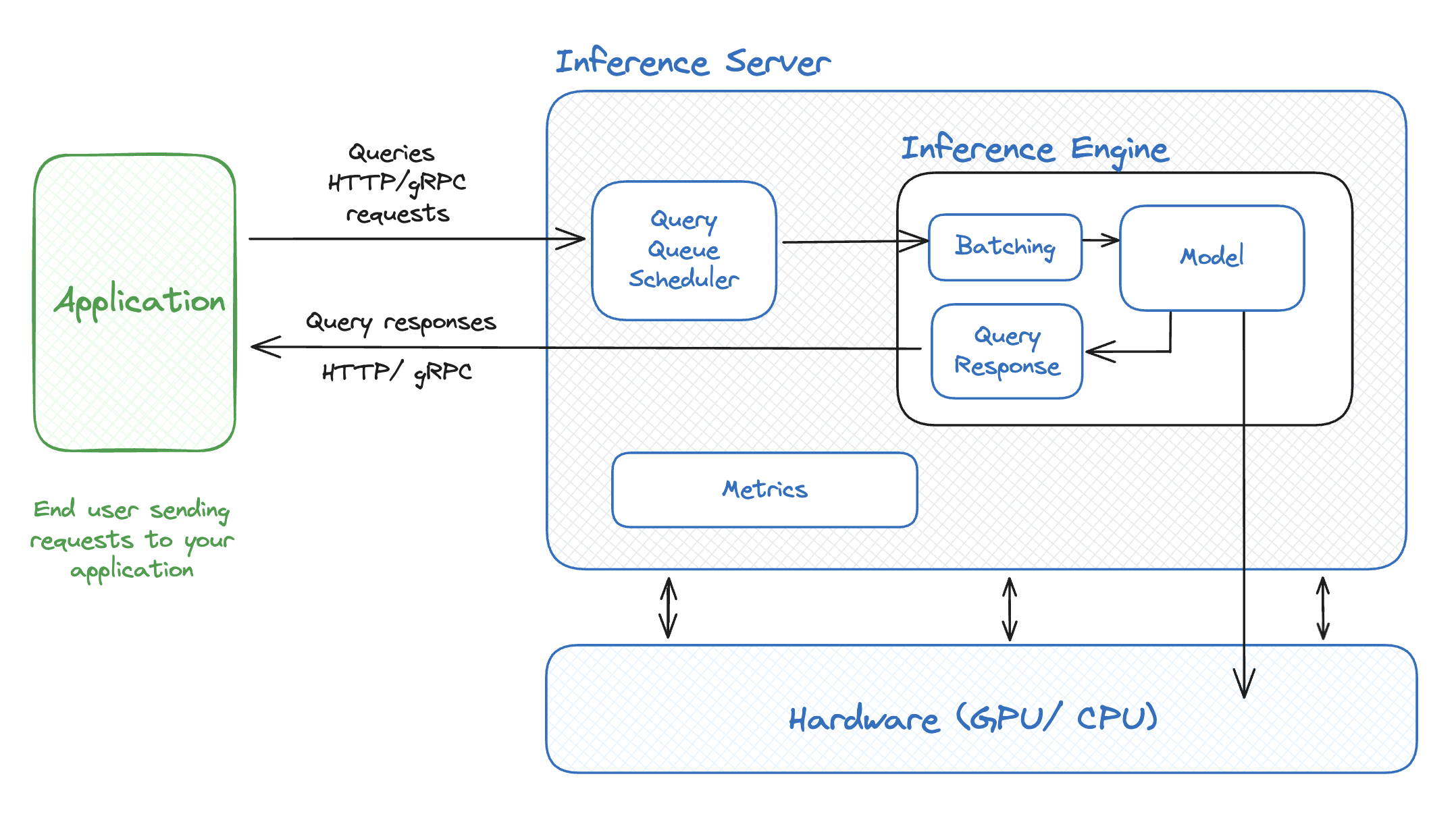
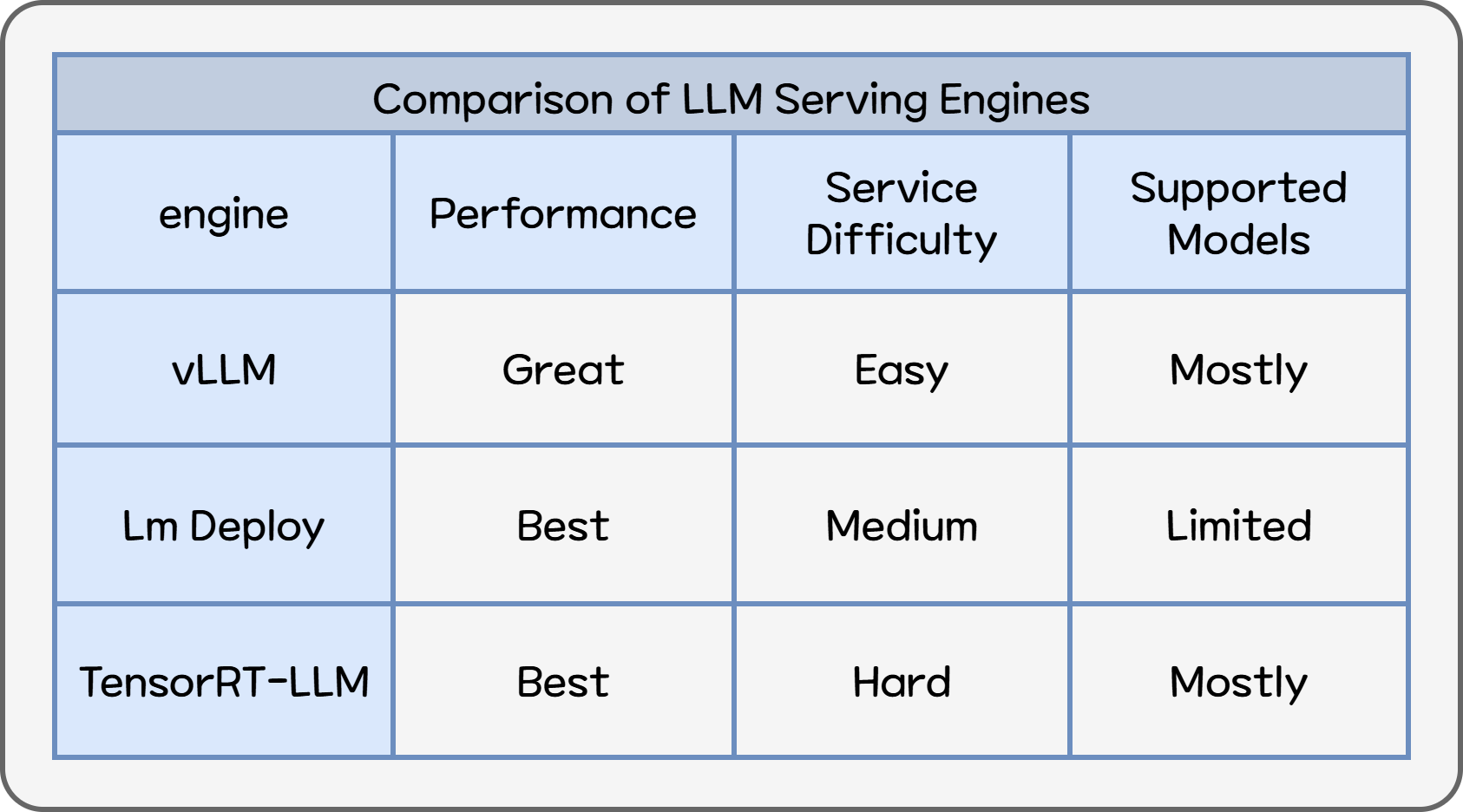
Best LLM Inference Engines and Servers to Deploy LLMs in Production - Koyeb
NSX AVI Load Balancer – Service Unit explained – CSP Blog
GitHub - microsoft/sarathi-serve: A low-latency & high-throughput ...
vLLM v0.6 | OpenLM.ai
GitHub - tenda-dev/vllm-serving-engine: A high-throughput and memory ...
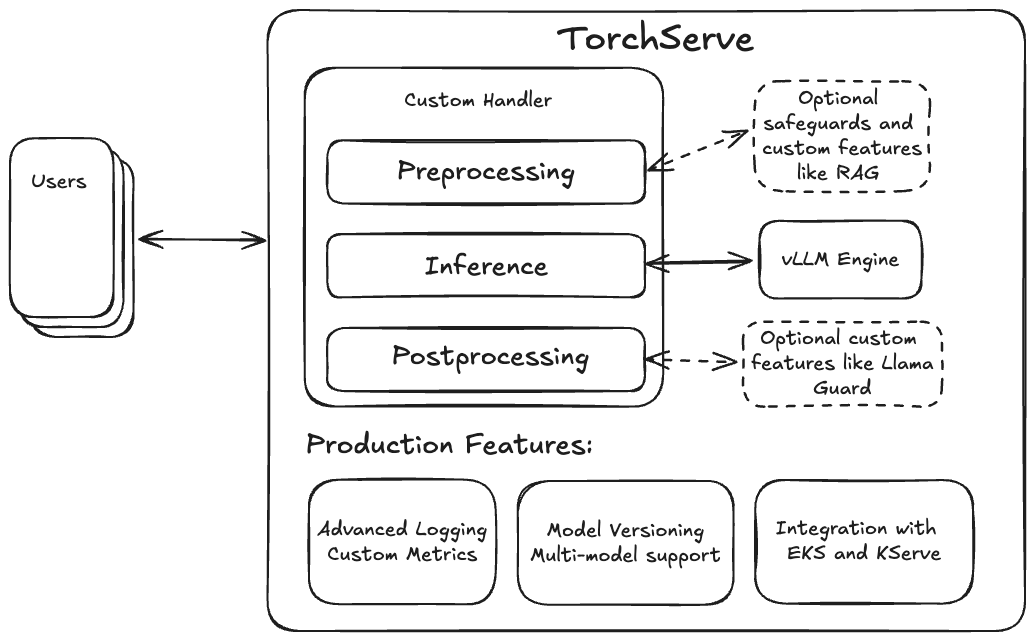
Deploying LLMs with TorchServe + vLLM – PyTorch
Why Philadelphia’s 2026 sporting events will serve as economic growth ...
What is Kserve? - Hopsworks
GitHub - MachineLearningSystem/24OSDI-sarathi-serve: A low-latency ...
Logical view of communication involving two service engines. | Download ...
Complete Mastery of vLLM: Optimization for EVA | mellerikat
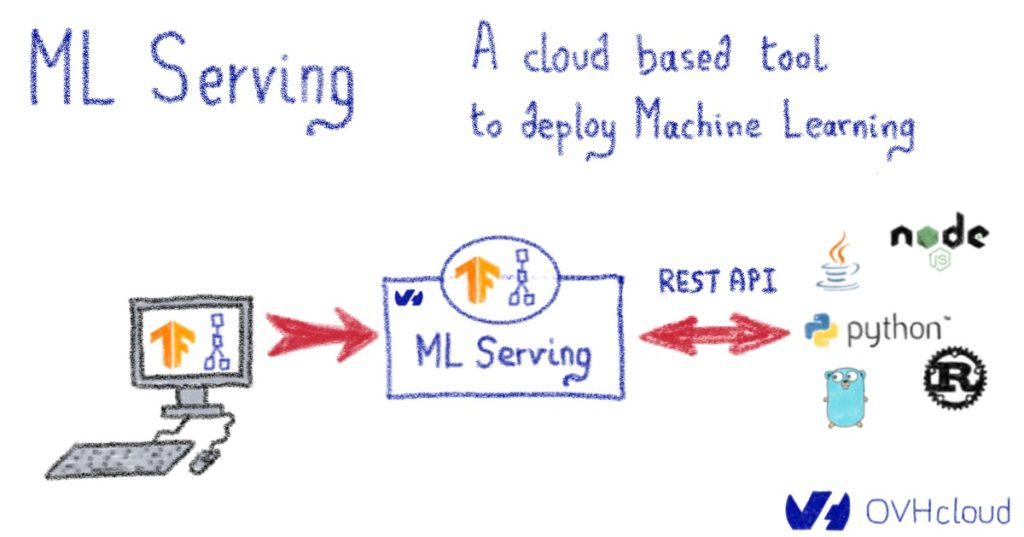
ML Serving: a cloud based tool to deploy Machine Learning - OVHcloud Blog
GitHub - neuralmagic/nm-vllm: A high-throughput and memory-efficient ...
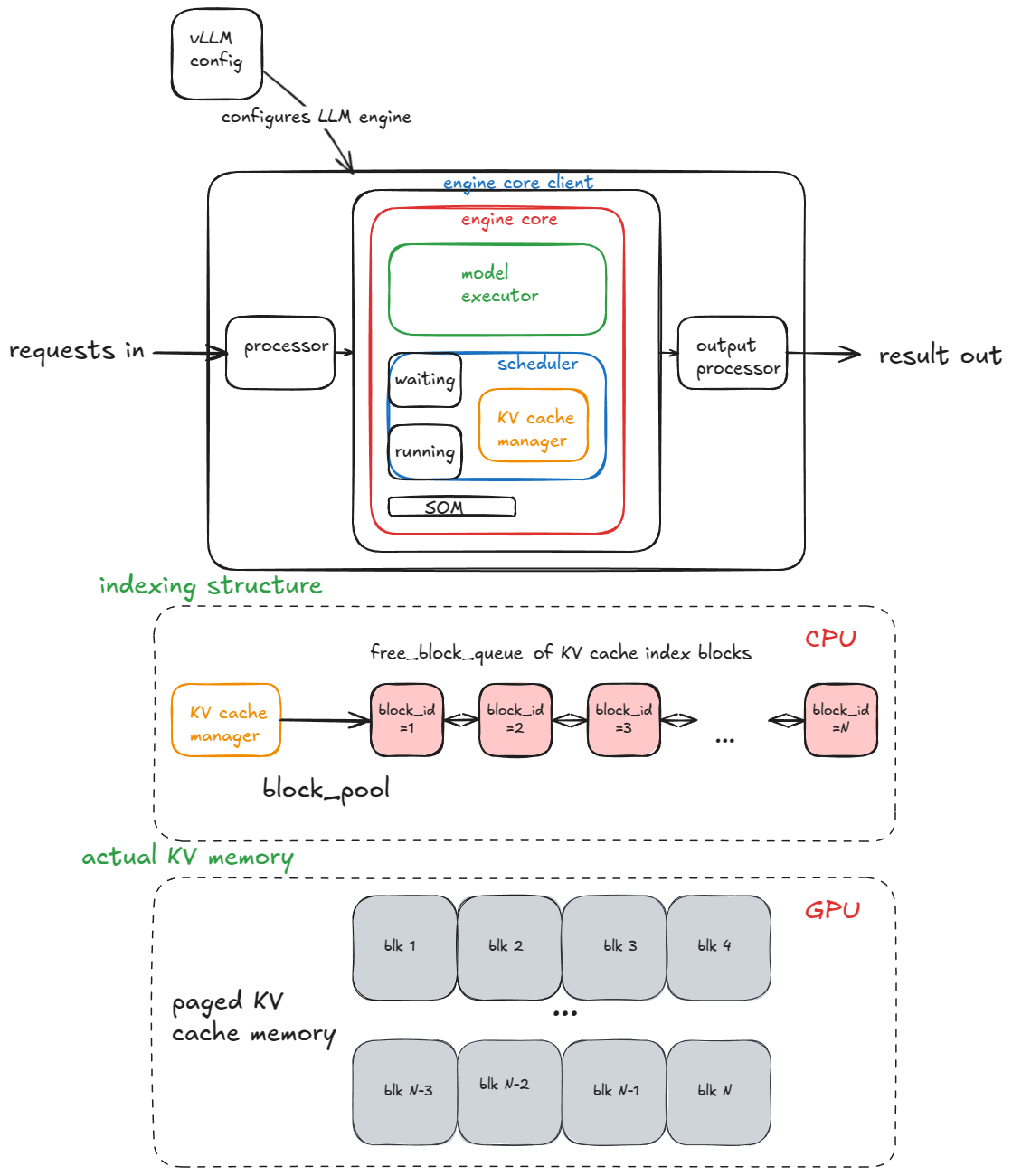
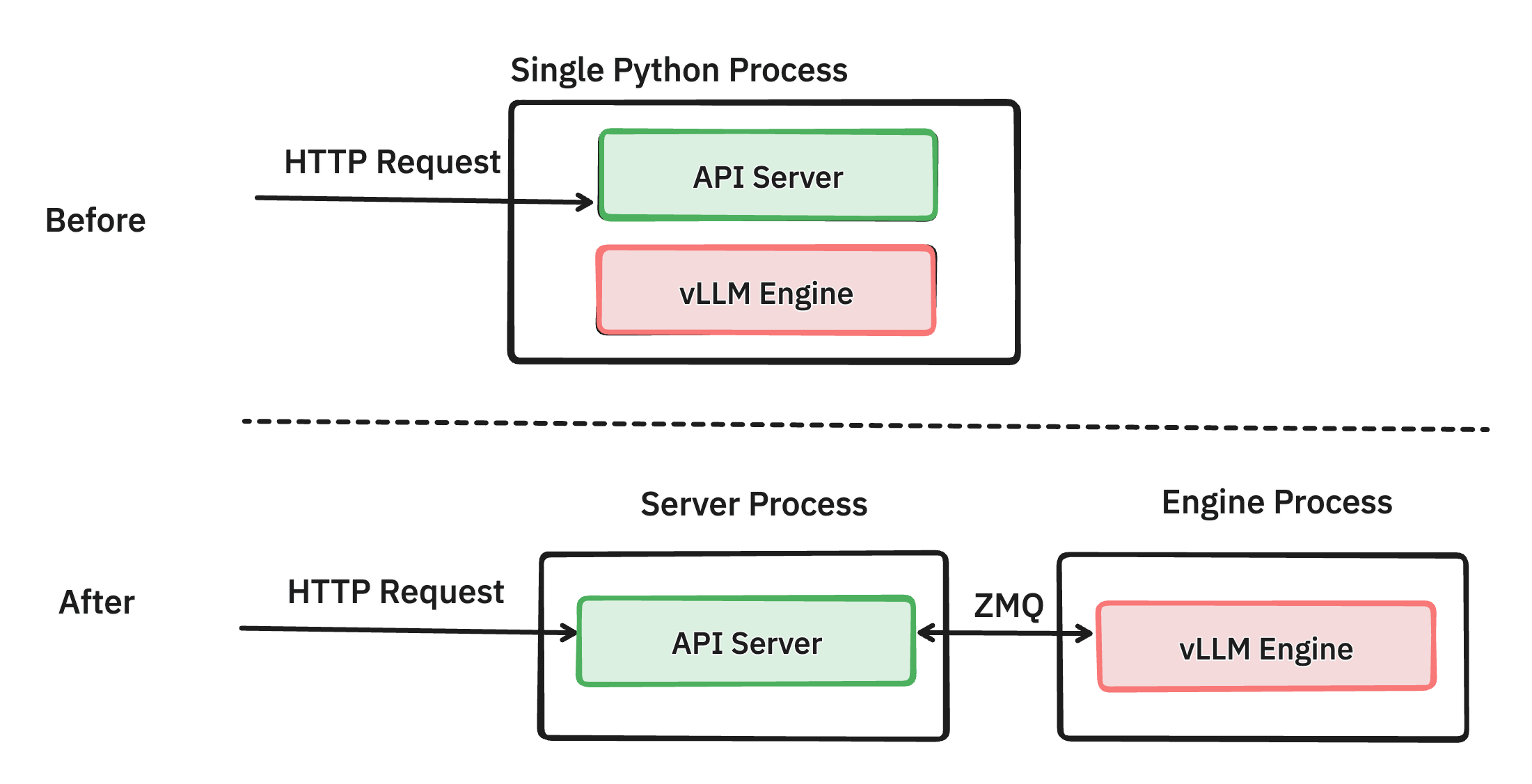
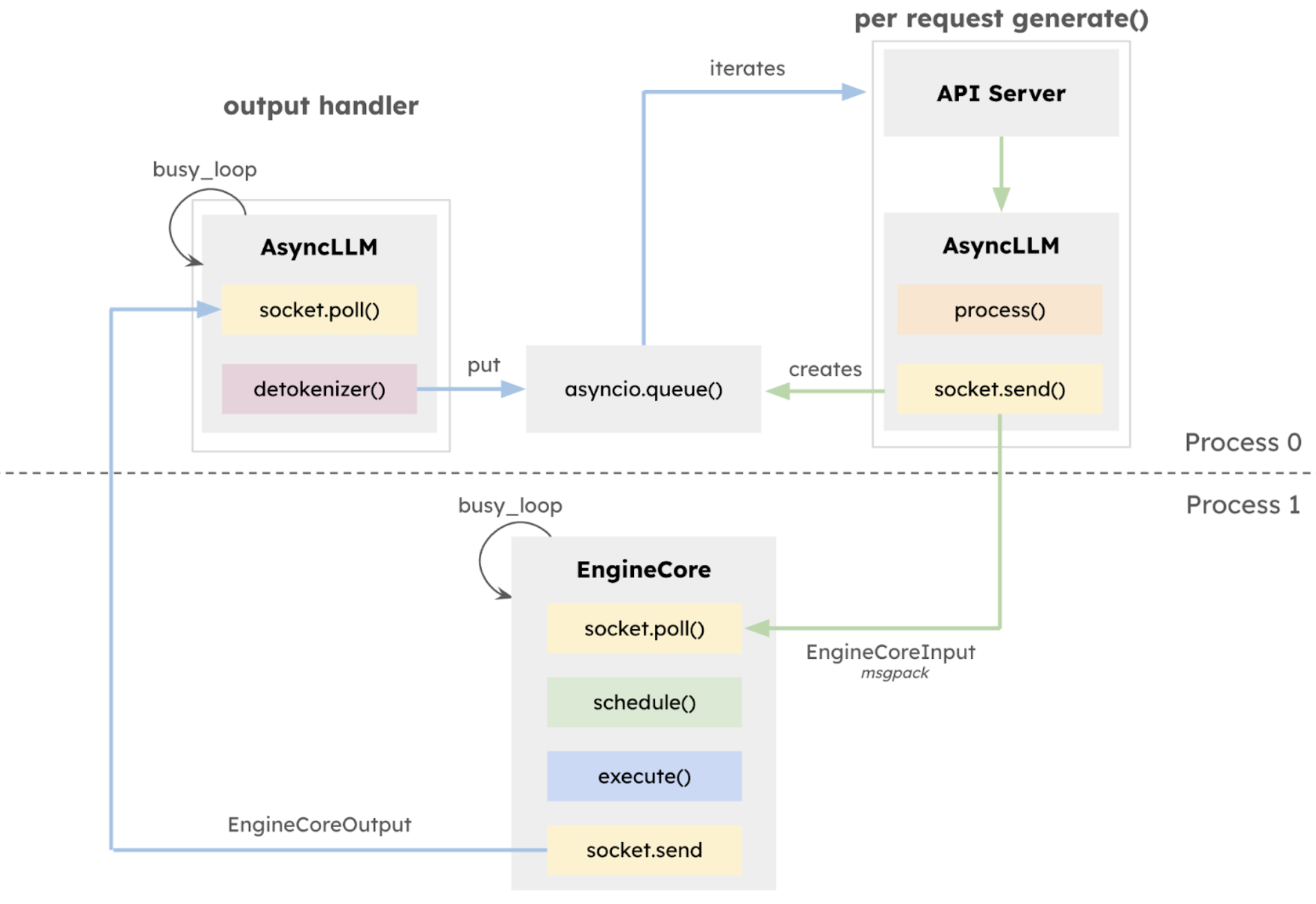
vLLM V1: A Major Upgrade to vLLM’s Core Architecture | vLLM Blog
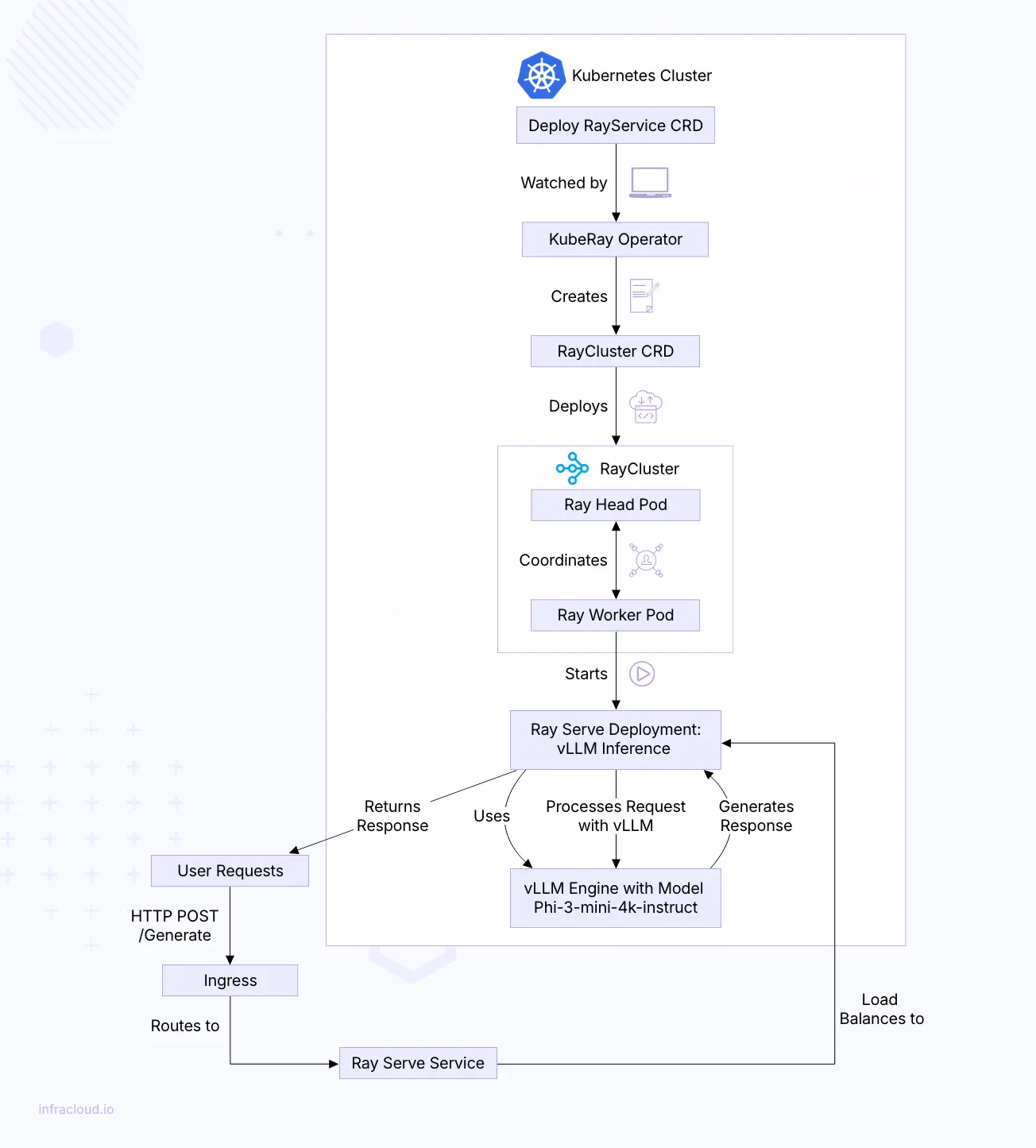
Running Phi 3 with vLLM and Ray Serve
What is vLLM? - Hopsworks
MLC | Microserving LLM engines
Aberdeen: Here be dragons… a remarkable Karoo town
Different Types of Service Engines and Servers
UpMortem - Unleashing LLM Potential with vLLM: Fast and Efficient ...
GitHub - lhf-labs/vllm-compressed: A high-throughput and memory ...
GitHub - aashaka/vllm-oss: A high-throughput and memory-efficient ...
GitHub - JLWLL/vllm-npu: A high-throughput and memory-efficient ...
GitHub - g-eoj/vllm-prompt-adapters: A high-throughput and memory ...
GitHub - SamujjwalSam/vllm-jais: A high-throughput and memory-efficient ...
GitHub - natureofnature/vllm-open-source: A high-throughput and memory ...
GitHub - derange-alembic/vllm-fork: A high-throughput and memory ...
GitHub - wamos/vllm-llama-pipeline-parallel: A high-throughput and ...
GitHub - OpenPipe/vllm-lora: A high-throughput and memory-efficient ...
GitHub - shenchouyeh/vllm-arm64: A high-throughput and memory-efficient ...
GitHub - SoheylM/vllm-localllm-cuda12: A high-throughput and memory ...
GitHub - Stability-AI/stable-vllm: A high-throughput and memory ...
GitHub - stevegrubb/vllm-fork: A high-throughput and memory-efficient ...
GitHub - mistralai/vllm-release: A high-throughput and memory-efficient ...
GitHub - ZJU-REAL/EasySteer-vllm: A high-throughput and memory ...
GitHub - leigao97/vllm-bench: A high-throughput and memory-efficient ...
GitHub - Jotschi/vllm-cuda118: A high-throughput and memory-efficient ...
GitHub - QwenLM/vllm-gptq: A high-throughput and memory-efficient ...