Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
OpenCL matrix-multiplication SGEMM tutorial
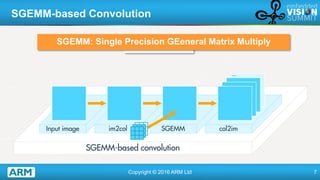
"Using SGEMM and FFTs to Accelerate Deep Learning," a Presentation from ...
GitHub - ScaleMP/SEG_SGEMM: This SGEMM workload demonstrates the ...
SGEMM Tutorial | Keeneland
SGEMM in WebGL2-compute
The performance of 3 SGEMM NT kernels: matplotlib bar plot with error ...
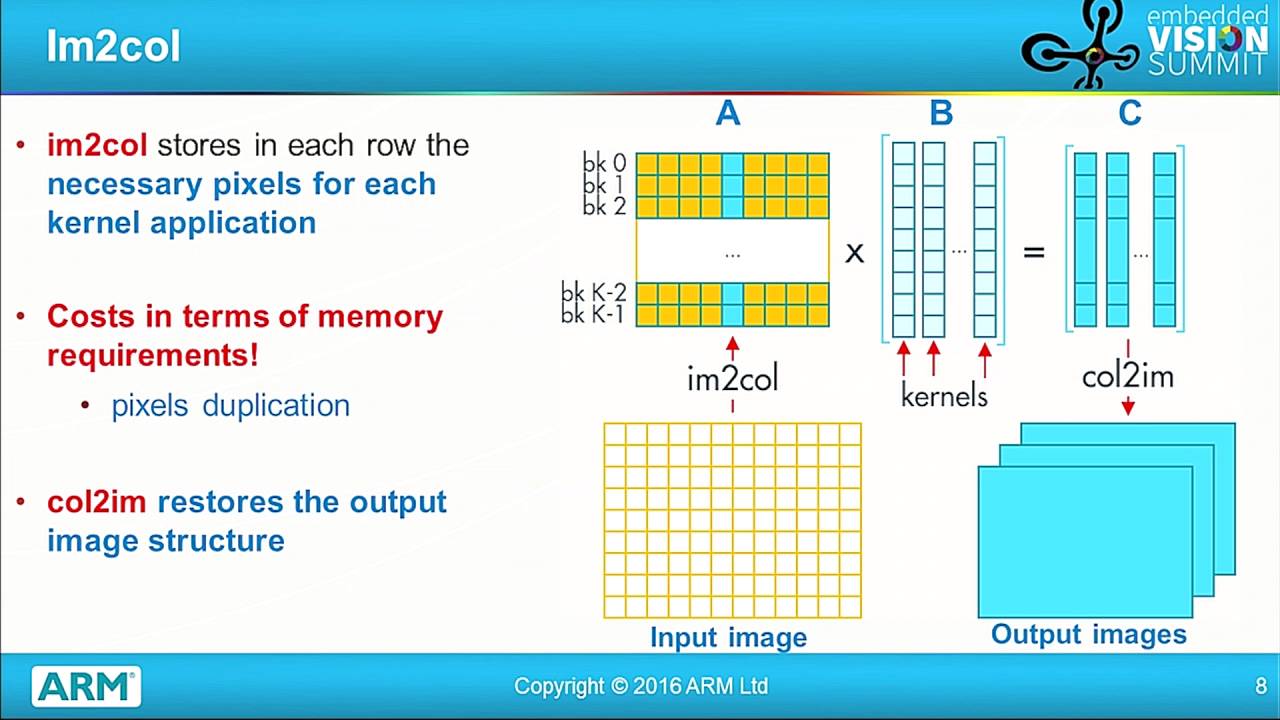
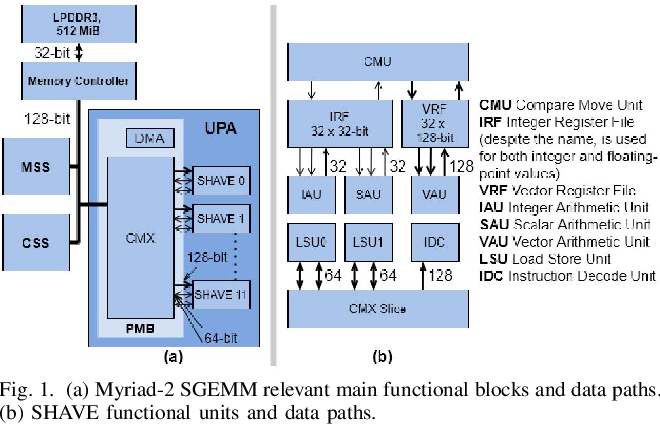
A Highly Efficient SGEMM Implementation using DMA on the Intel/Movidius ...
Relative performance of each BLAS3 routine to SGEMM routine | Download ...
矩阵乘法 SGEMM - 知乎
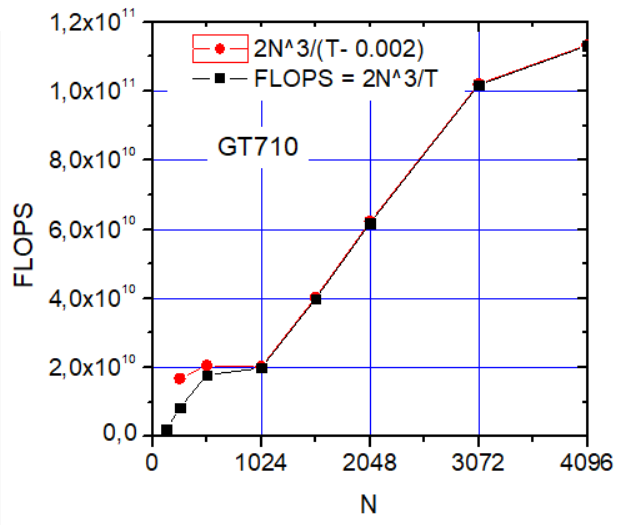
Measured SGEMM performance and power for GPU frequencies 575MHz and ...
Figure 1 from A Highly Efficient SGEMM Implementation using DMA on the ...
ARM's Gian Marco Iodice Explains How SGEMM and FFTs Can Accelerate Deep ...
What is a SGEMM
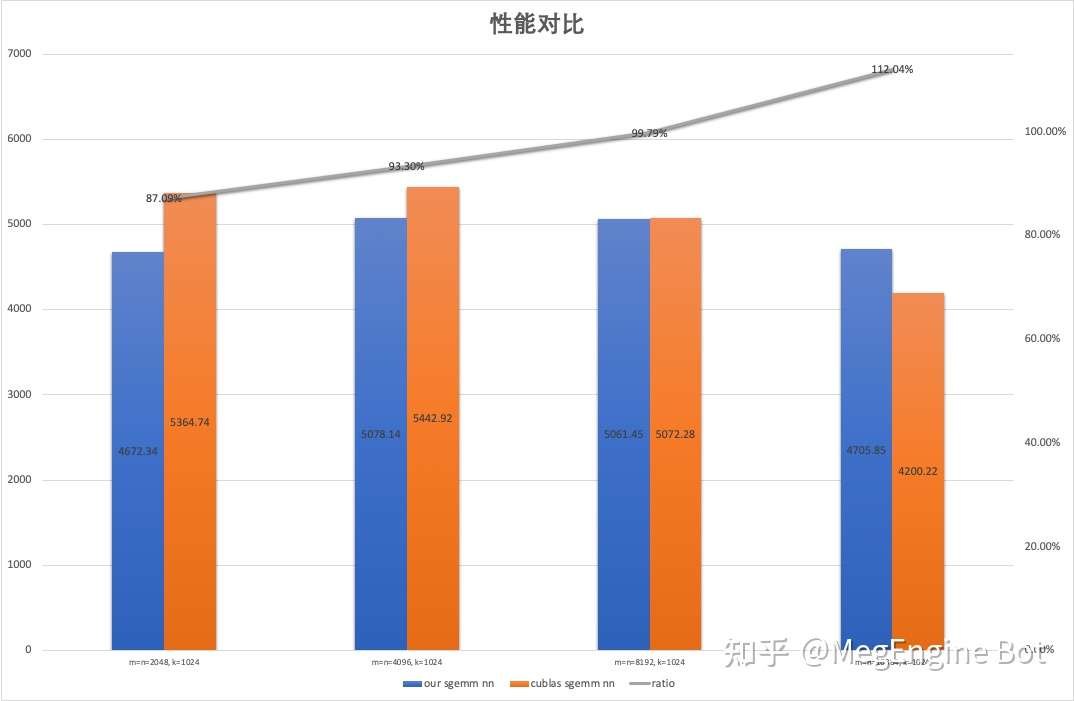
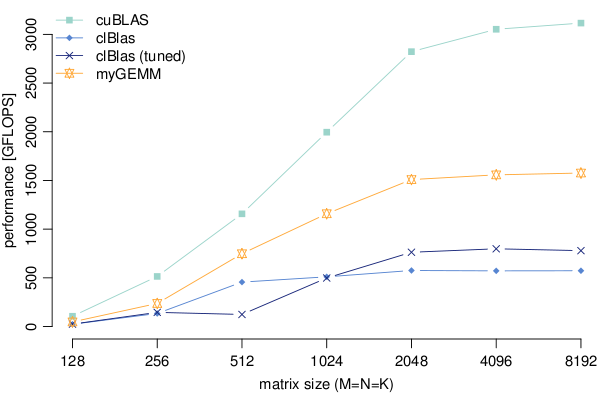
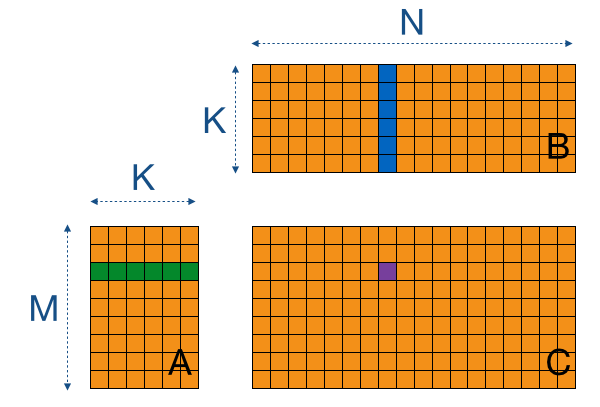
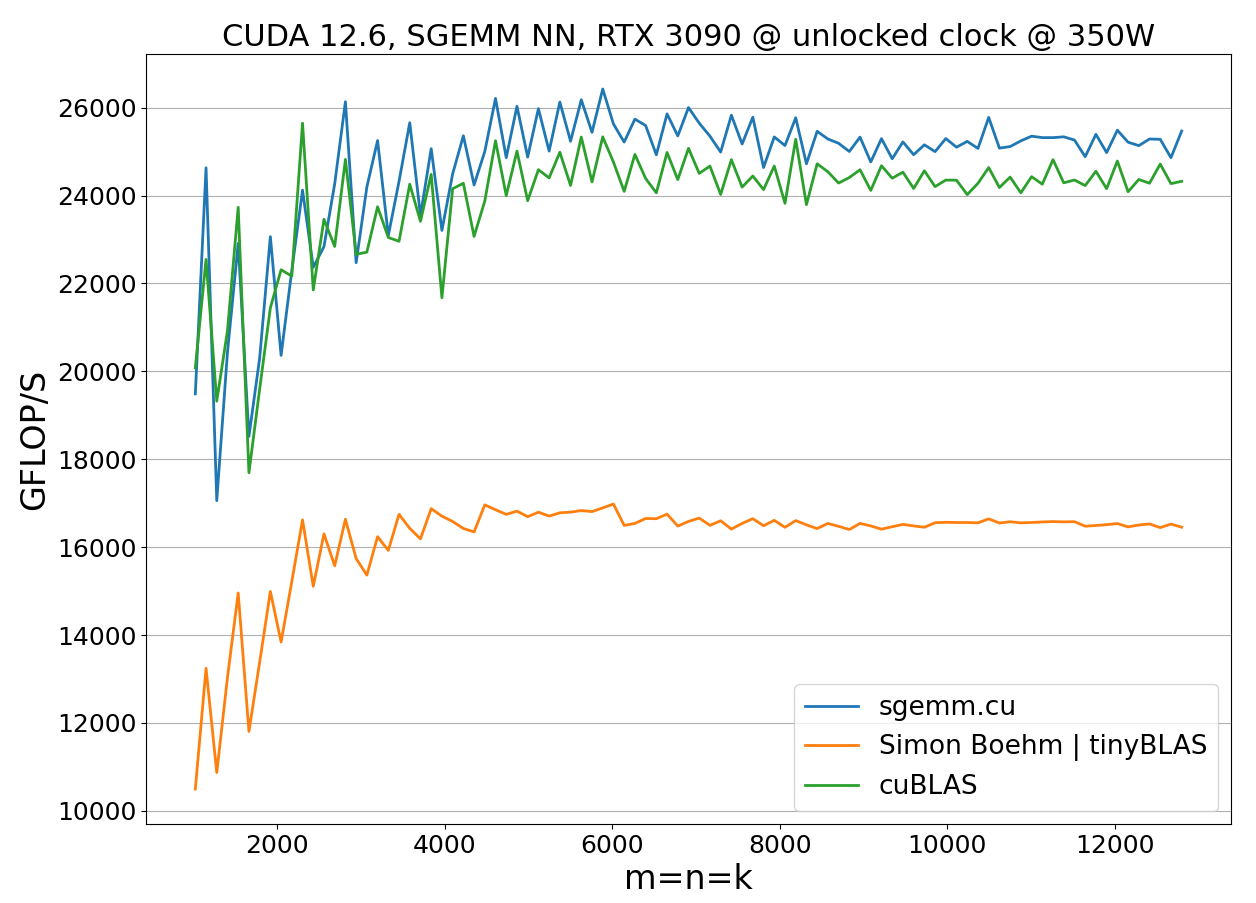
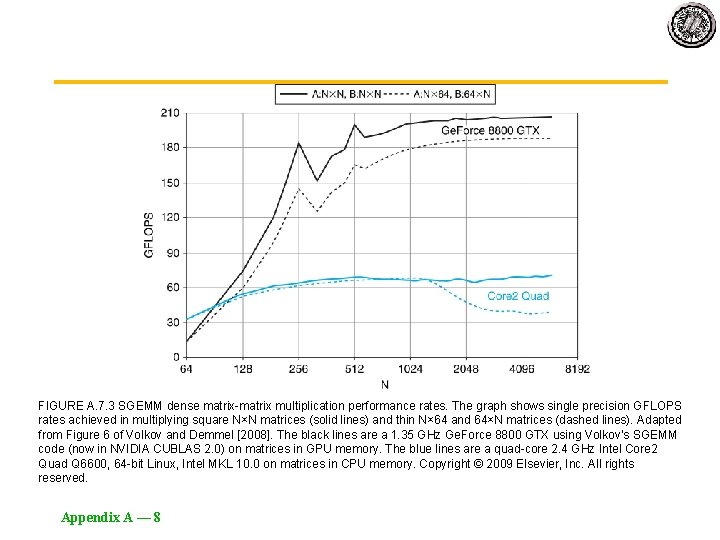
Beating cuBLAS in Single-Precision General Matrix Multiplication
The simple-precision general matrix multiplication (SGEMM). | Download ...
SGEMM(单核通用矩阵乘法加速) - 知乎
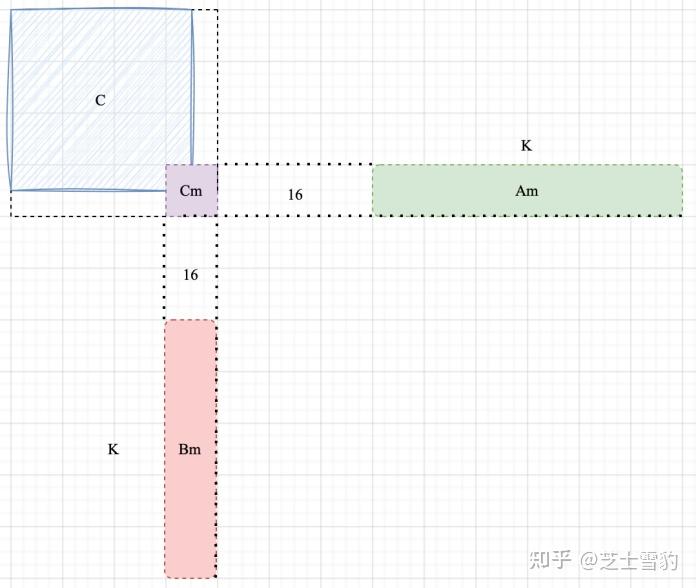
CUDA SGEMM矩阵乘法优化笔记——从入门到cublas - 知乎
CUDA单精度矩阵乘法(sgemm)优化笔记 - 知乎
MKL (s/d/c/z)GEMM: how we can improve their performance
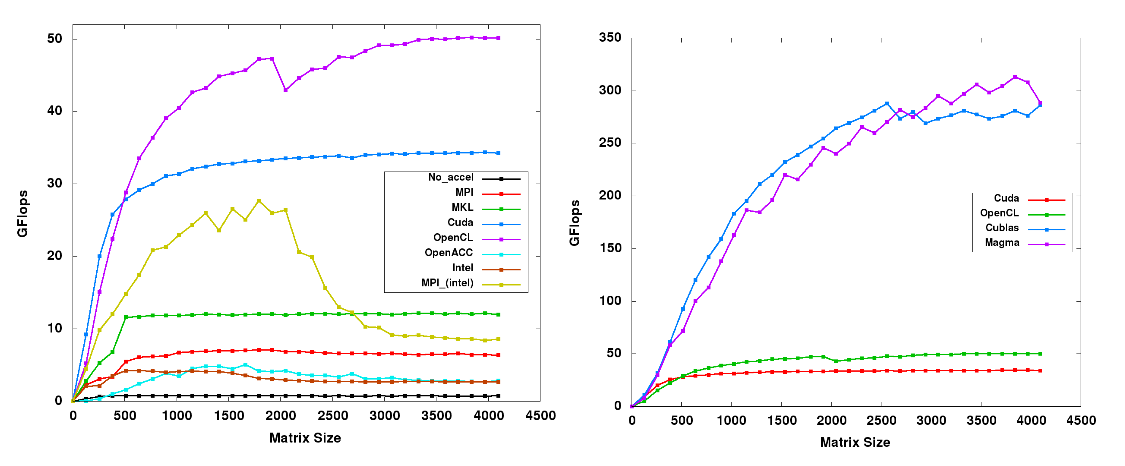
High-Performance and Power-Efficient Emulation of Matrix Multiplication ...
GitHub - zongy17/sgemm-serial: An single-precision dense matrix ...
GitHub - zhangkai0425/SGEMM-HPC: Implementation and optimization of ...
Speedup of Hybrid Matrix Multiplication with 1-Level Recursion over ...
Matrix-multiplication(sgemm) division:Divide matrix-multiplication task ...
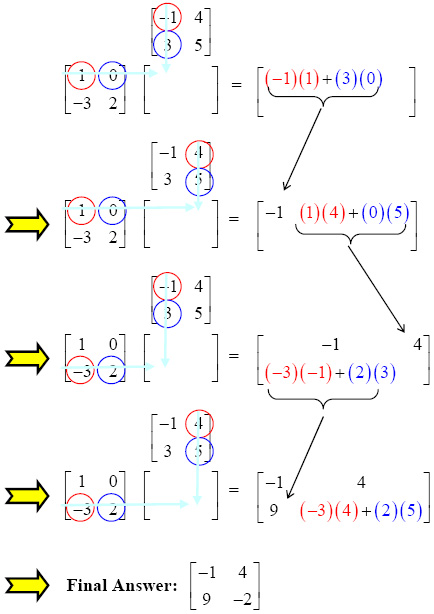
How to Multiply Matrices - USE The Matrix Scheme Trick - YouTube
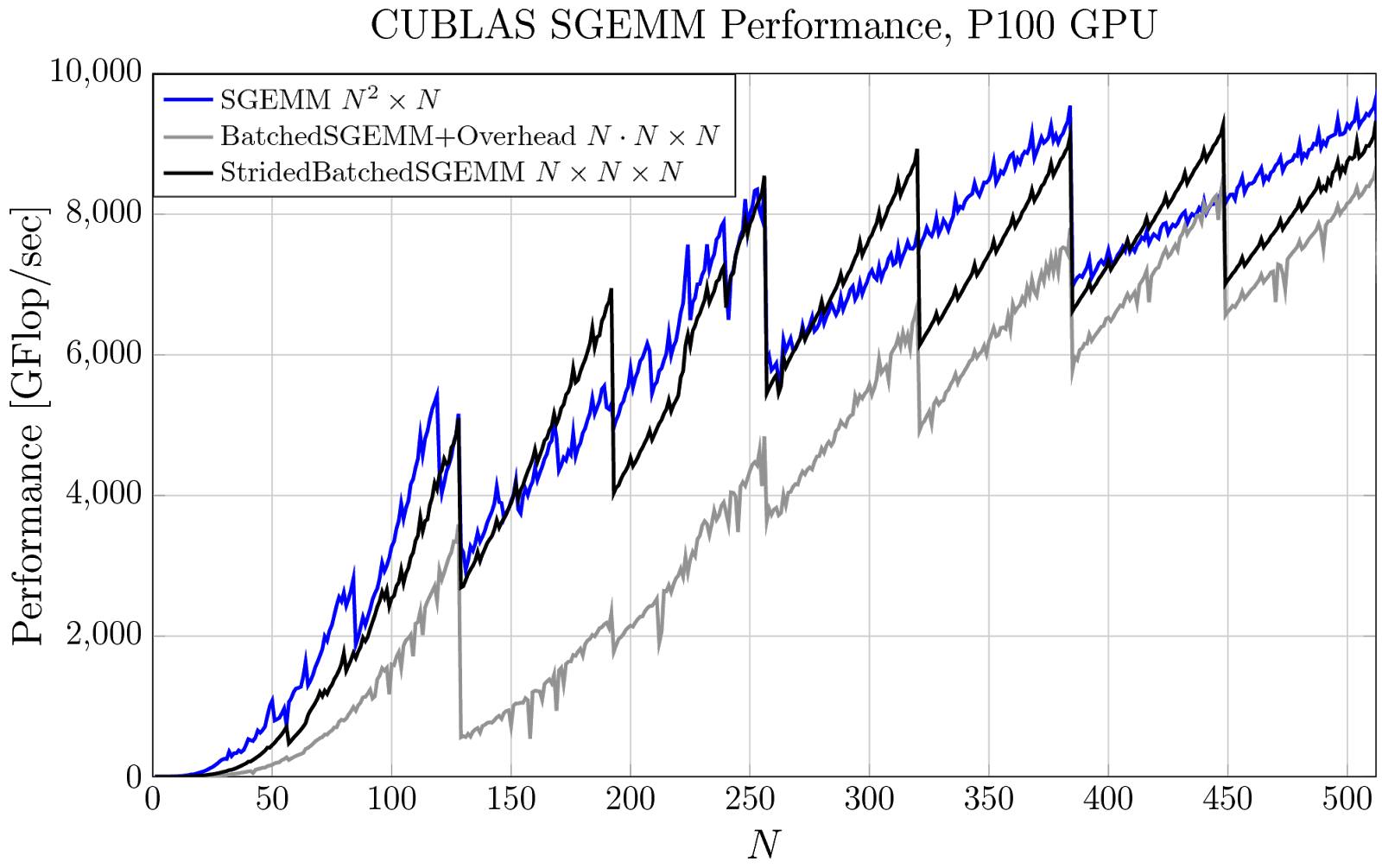
Pro Tip: cuBLAS Strided Batched Matrix Multiply | NVIDIA Technical Blog
GitHub - waterzxj/SGEMM: 矩阵相乘算法
GitHub - manikandan1408/SGEMM-Kernel-Performance-using-Linear-and ...
【CUDA】Sgemm单精度矩阵乘法(上)_gemv-CSDN博客
Comparison with other implementations of matrix multiplication. These ...
PPT - Linear Algebra on GPUs PowerPoint Presentation, free download ...
矩阵乘法(SGEMM)在CPU端优化实践记录 - 知乎
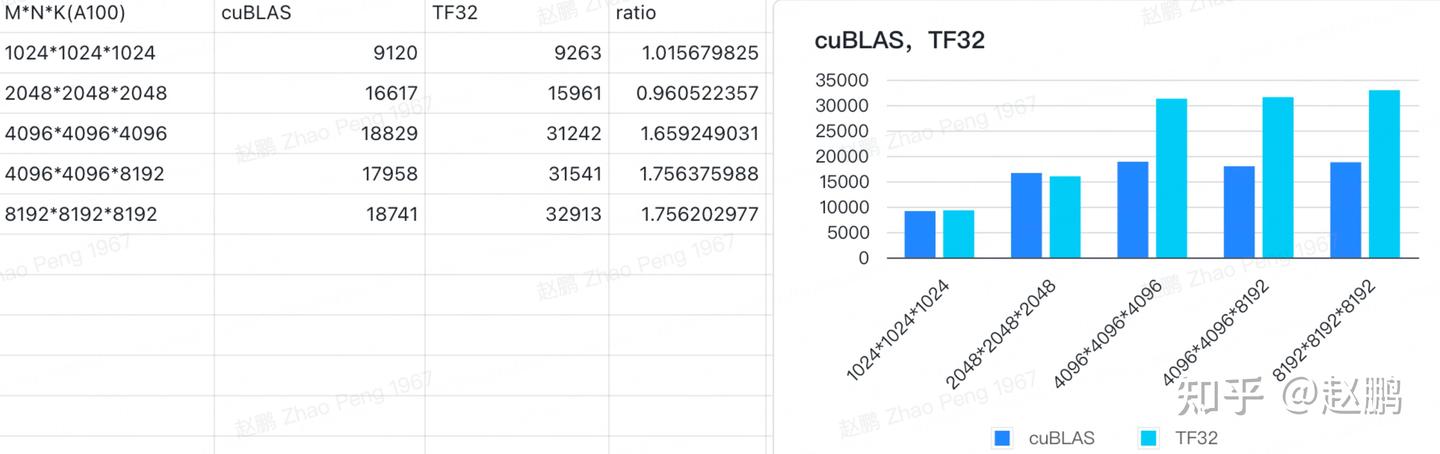
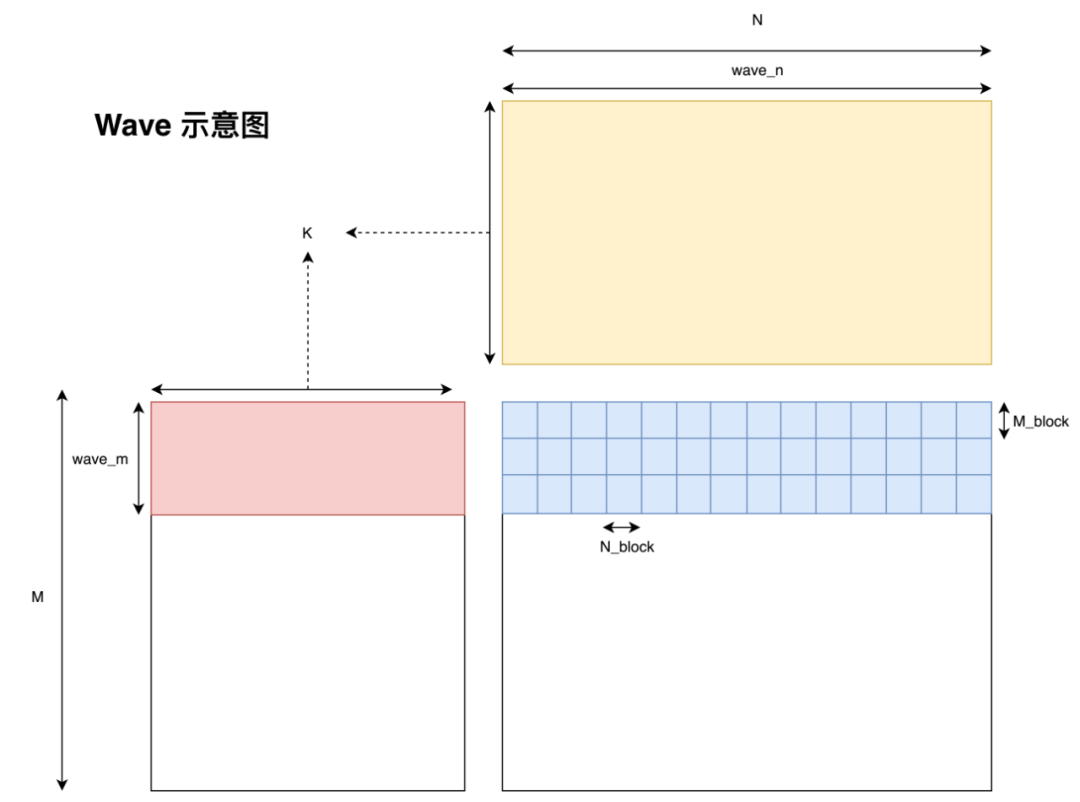
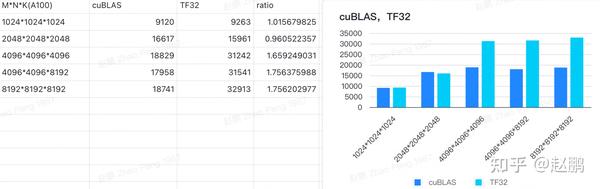
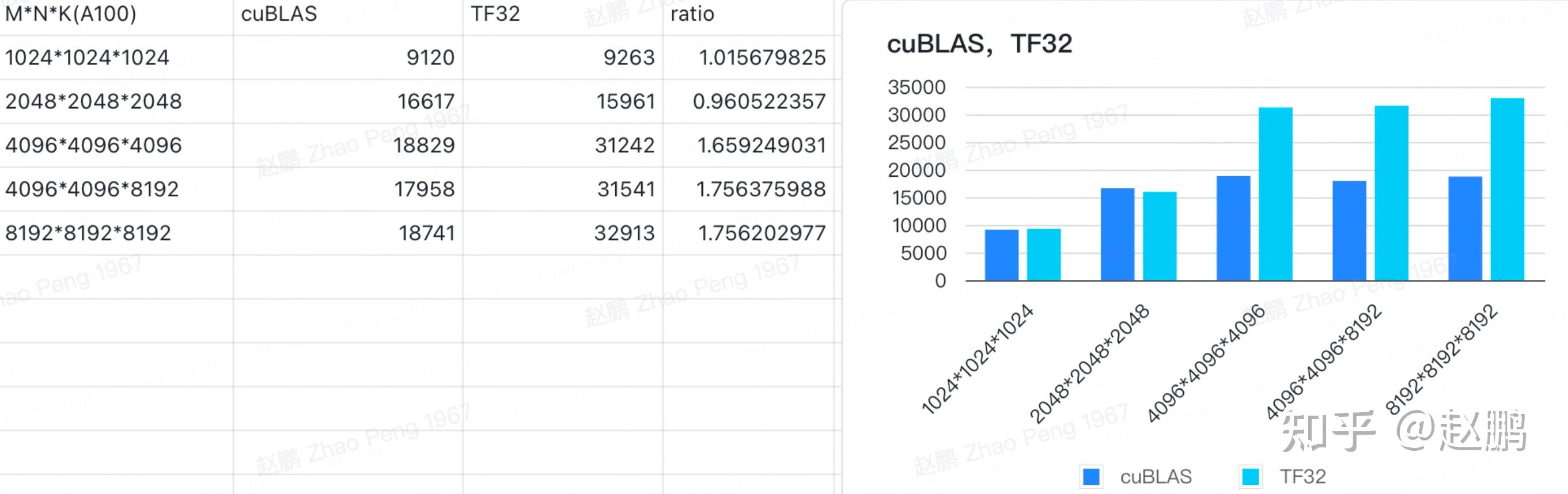
TF32格式下矩阵乘(SGEMM)运算 - 知乎
GitHub - TheAIFellow/SGEMM-GPU-Kernel-Performance: Predicting the ...
GitHub - siboehm/SGEMM_CUDA: Fast CUDA matrix multiplication from ...
Fast matrix multiplication via compiler‐only layered data ...
Fast Multidimensional Matrix Multiplication on CPU from Scratch
General Matrix Multiply (GeMM) — Spatial
Performance Issue: sparse matrix-matrix multiplication · Issue #3 · ARM ...
GitHub - Zhao-Dongyu/sgemm_riscv: This project records the process of ...
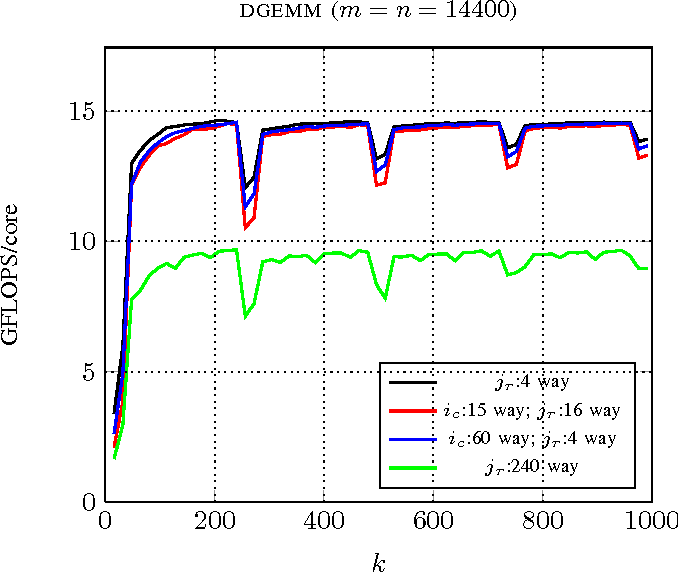
Matrix size N vs. Loop Count for SGEMM. | Download Scientific Diagram
Matrix Multiplication Example · Issue #495 · riscvarchive/riscv-v-spec ...
CUDA学习:Sgemm算子(1) - 知乎
General matrix-matrix multiplication (GEMM) kernel written in Go ...
Mini Project: GPU Accelerated Matrix Multiplication (almost) like cuBLAS
Graphics Processing Unit FIGURE A 2 2 Contemporary
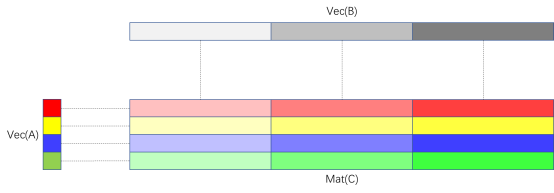
Matrix Multiplication Made Easy
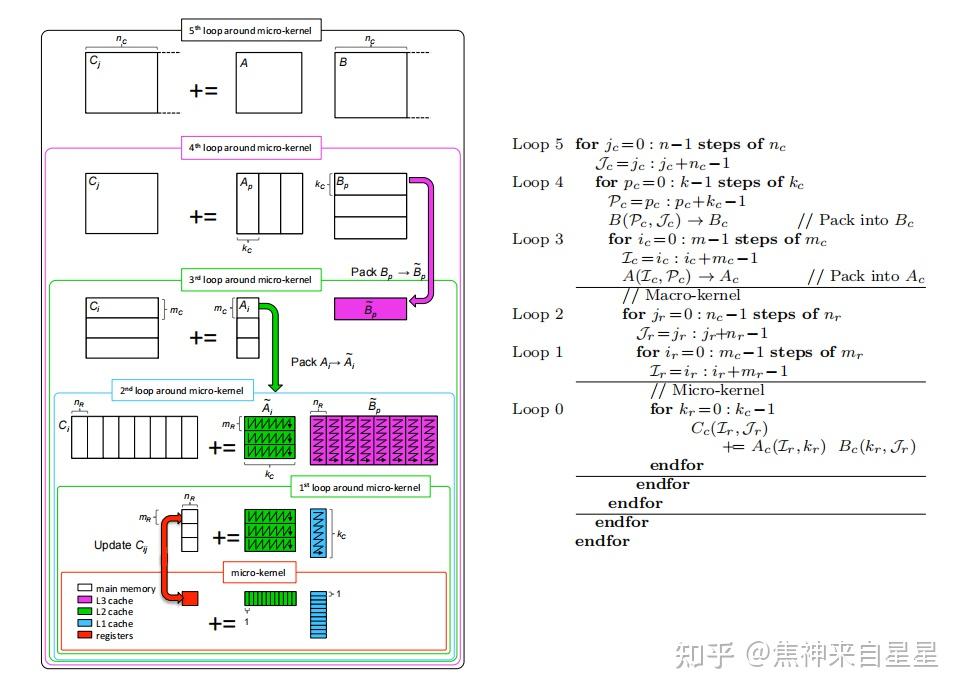
Figure 8 from Anatomy of High-Performance Many-Threaded Matrix ...
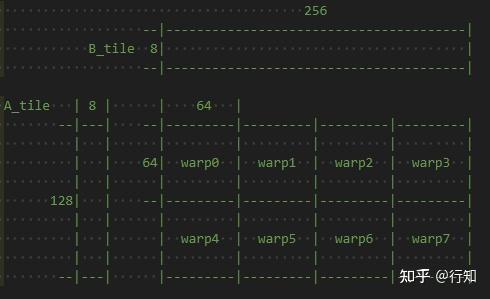
关于sgemm_hsw的一点解释说明 - 知乎
Workload of The Pre-Pack Module | Download Scientific Diagram
GPU优化:深入探究矩阵乘算法SGEMM的实现及优化_猿代码-超算人才智造局
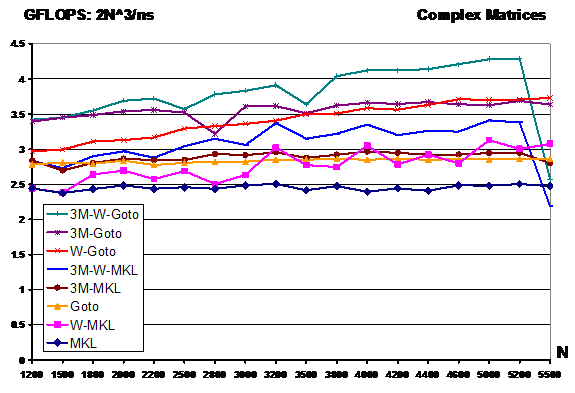
PPT - BLIS Matrix Multiplication: from Real to Complex PowerPoint ...
如何高效实现矩阵乘?万文长字带你从CUDA初学者的角度入门-腾讯云开发者社区-腾讯云
GitHub - alex-xia-xia/armv8_sgemm · GitHub
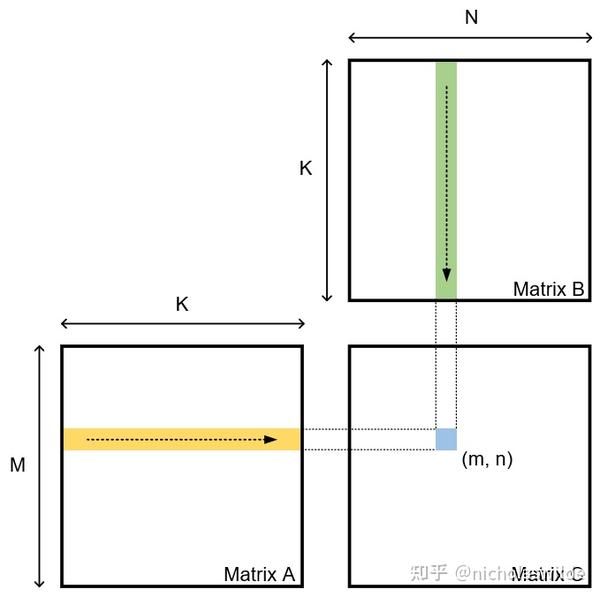
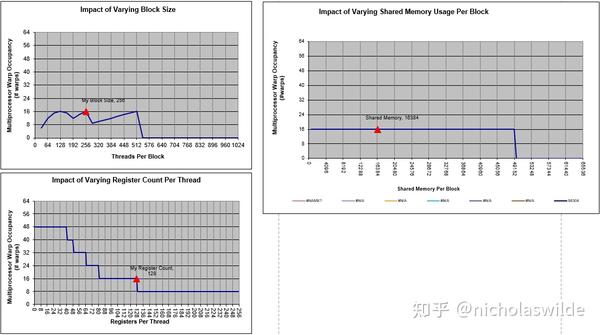
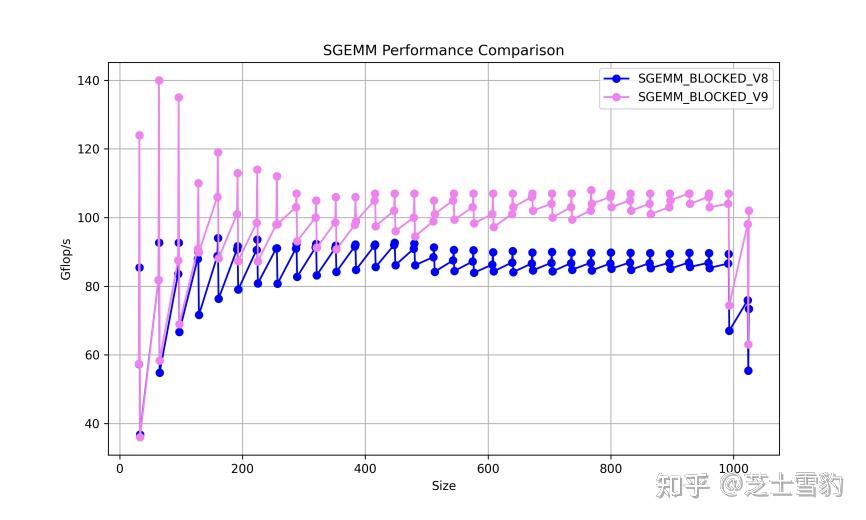
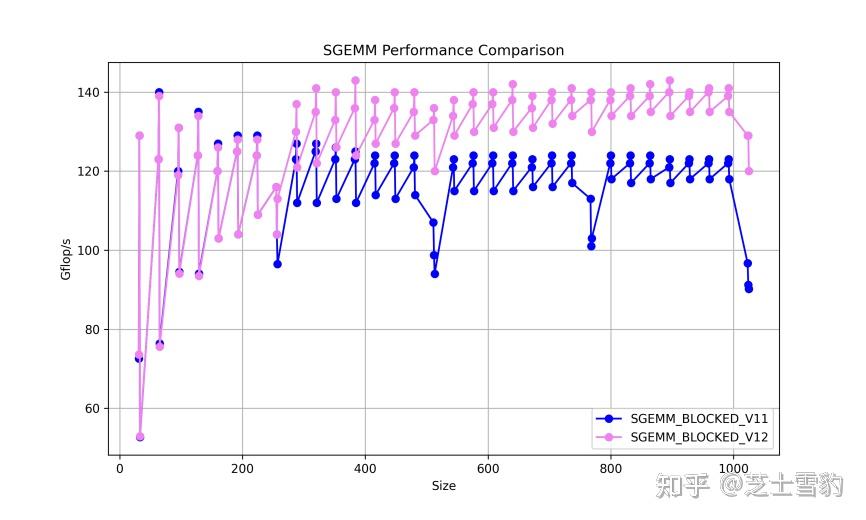
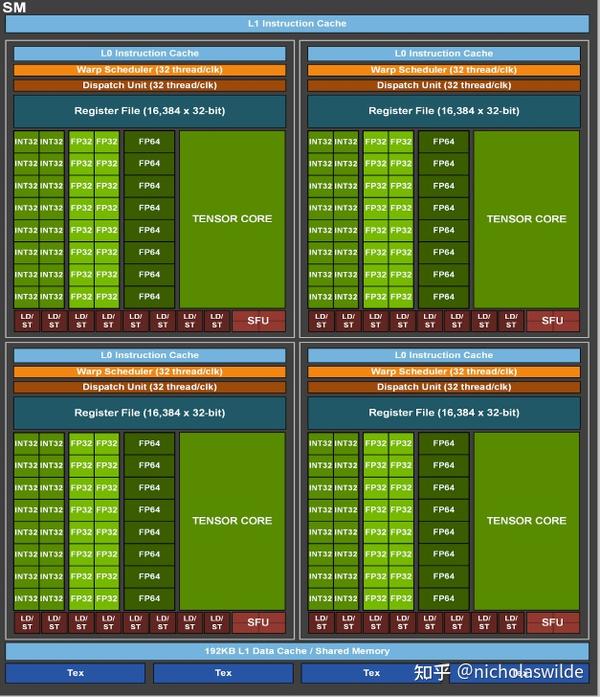
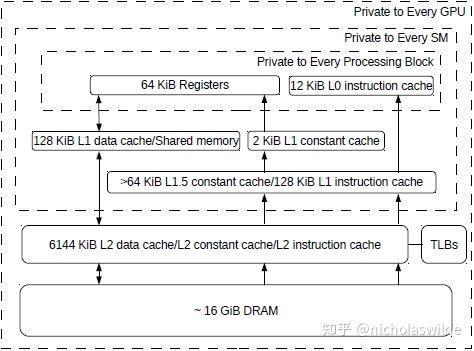
GitHub - nicolaswilde/cuda-sgemm
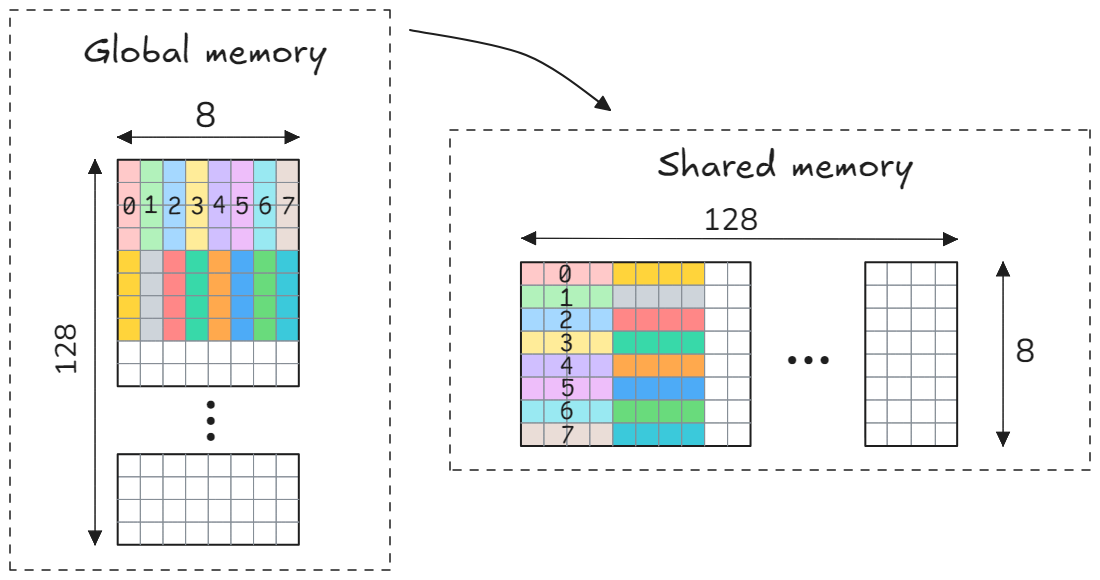
Matrix multiply on Adreno GPUs – Part 1: OpenCL optimization | Qualcomm
CUDA 矩阵乘法终极优化指南 - 网络文件共享
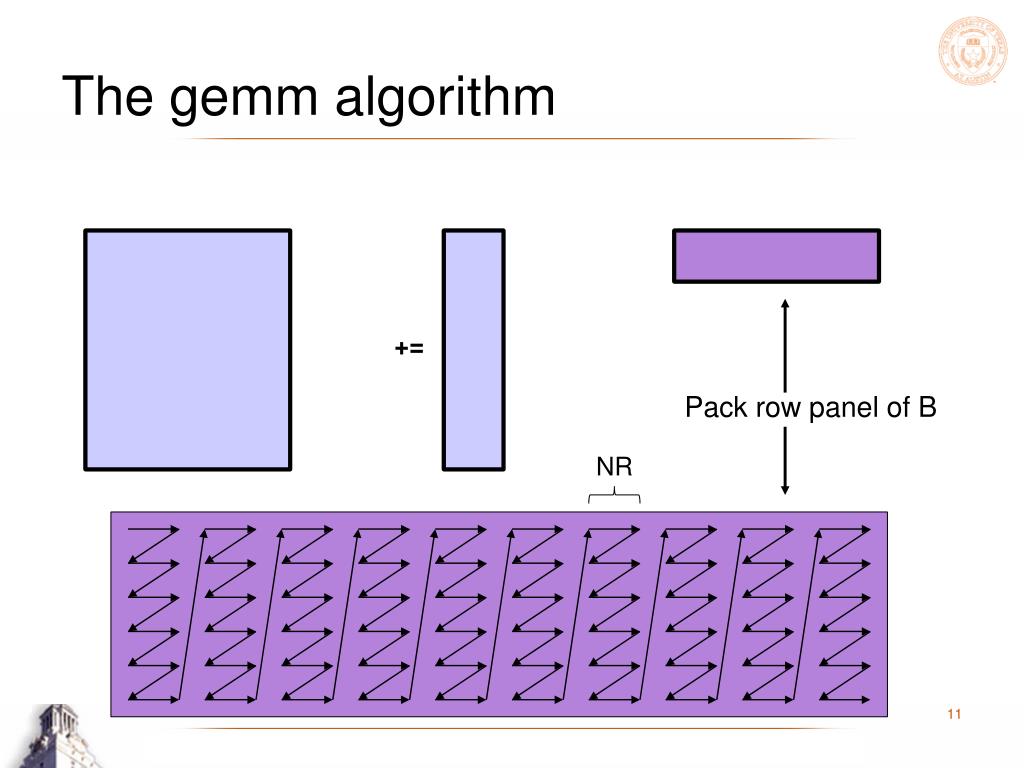
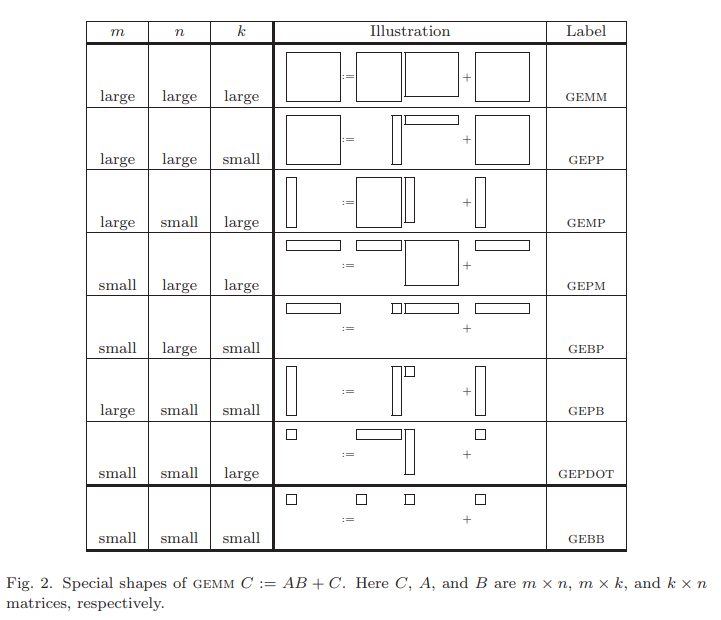
Anatomy Of High Performance Matrix Multiplication 高性能矩阵乘法剖析 | zzz

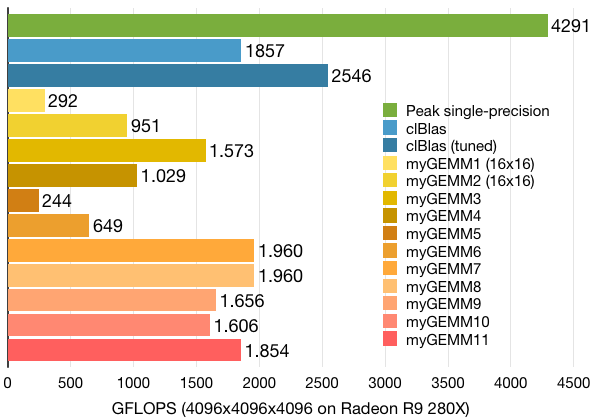
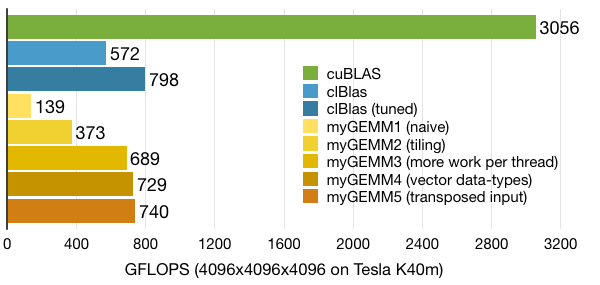
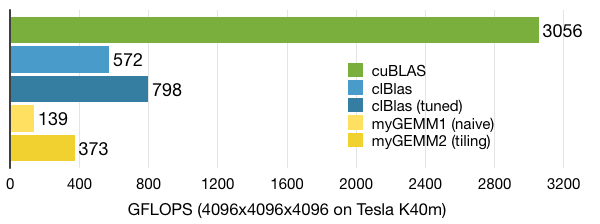
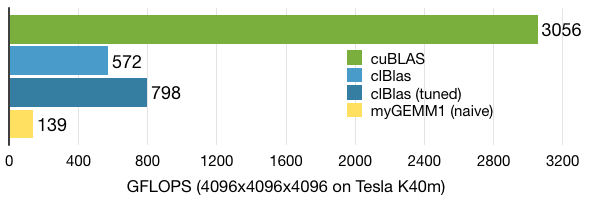
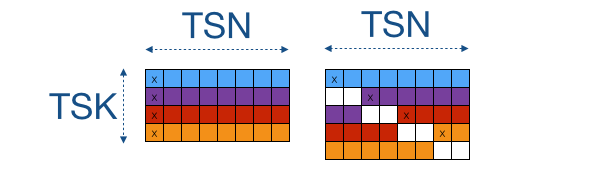
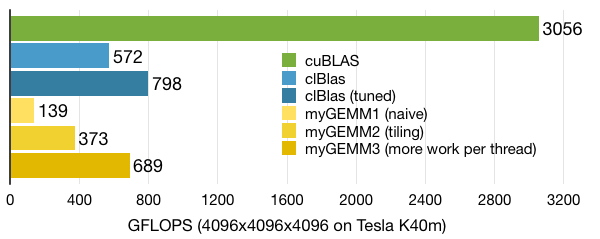
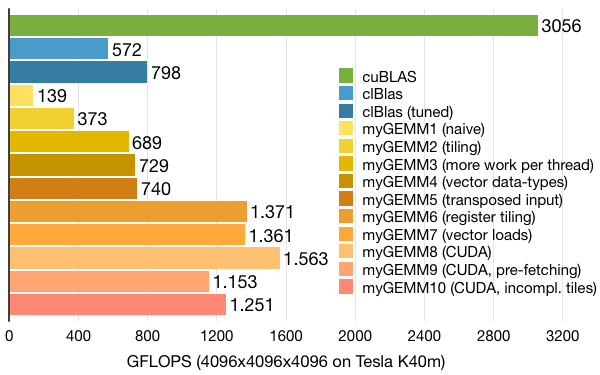
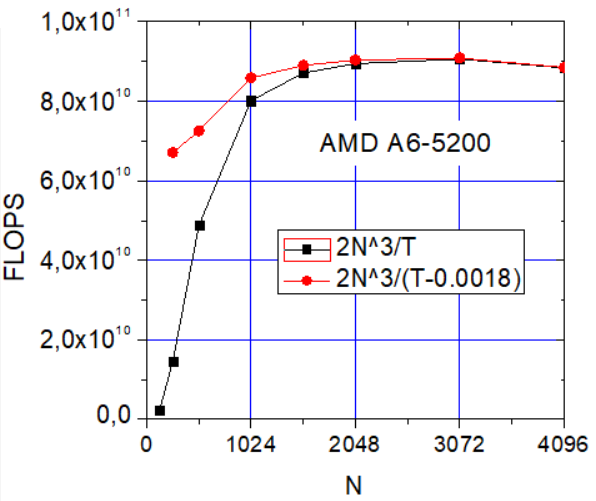








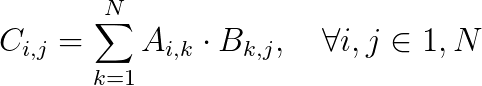

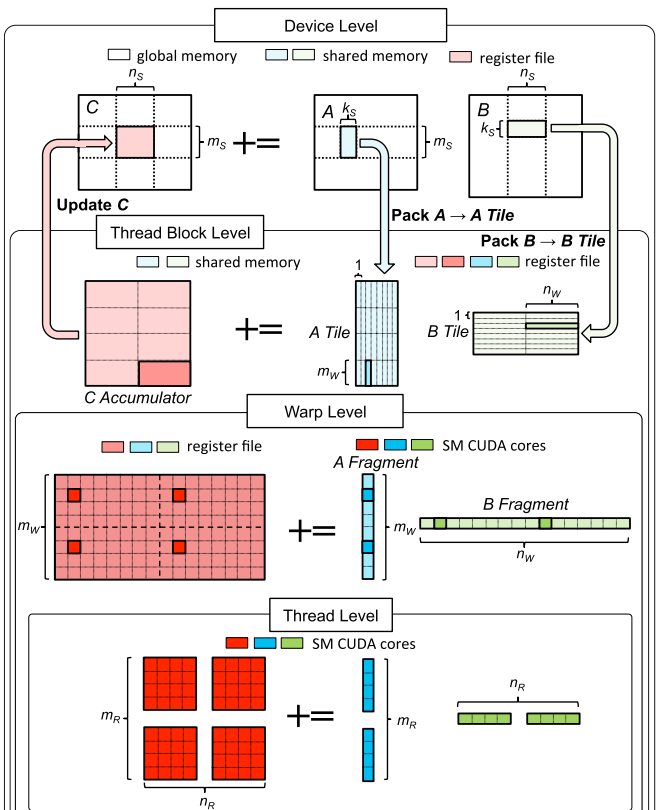

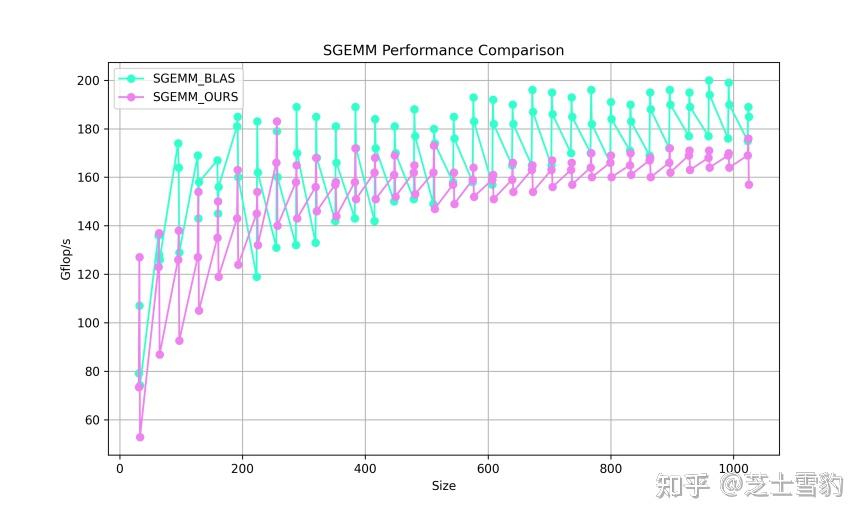
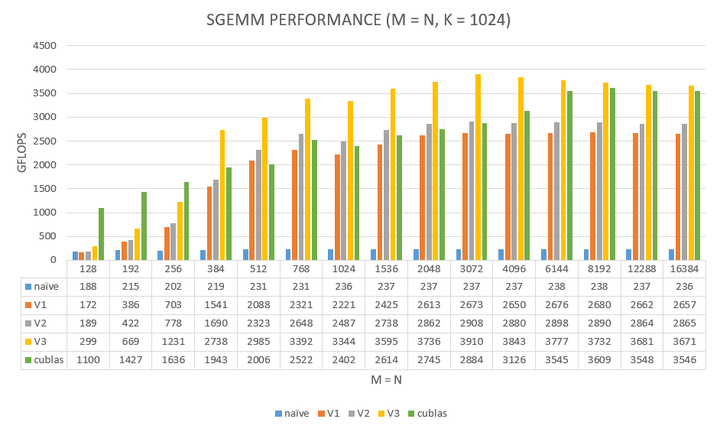
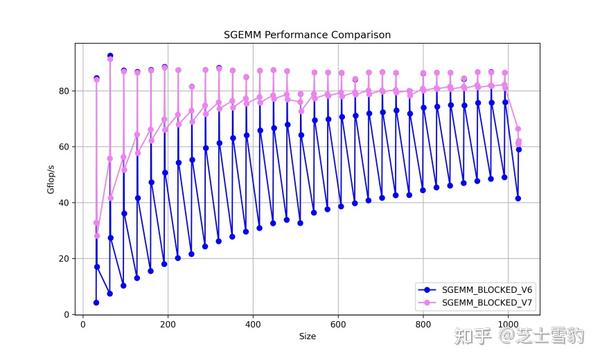
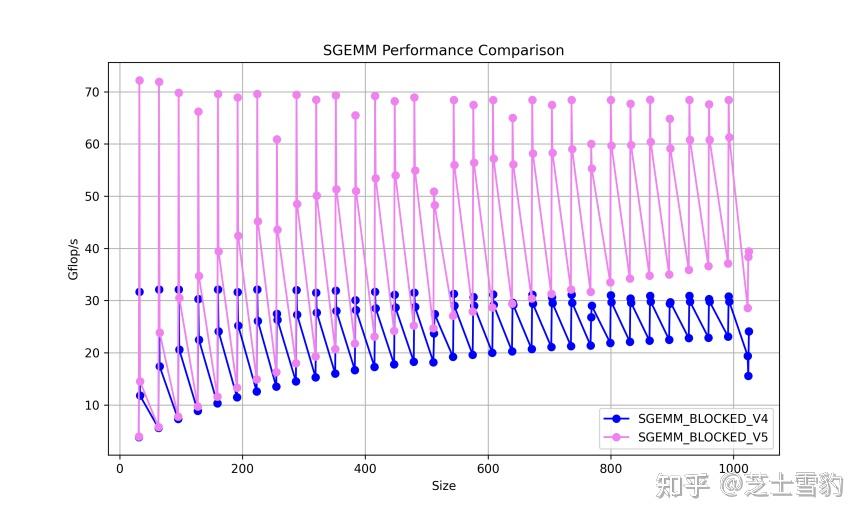
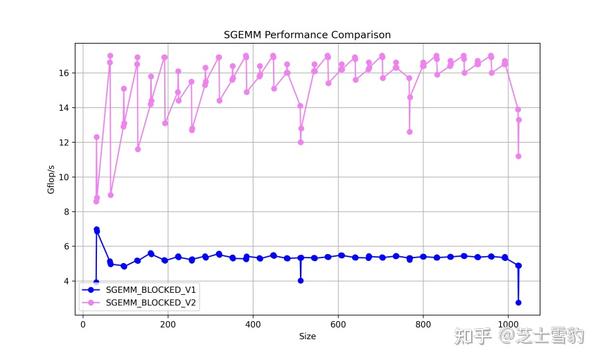
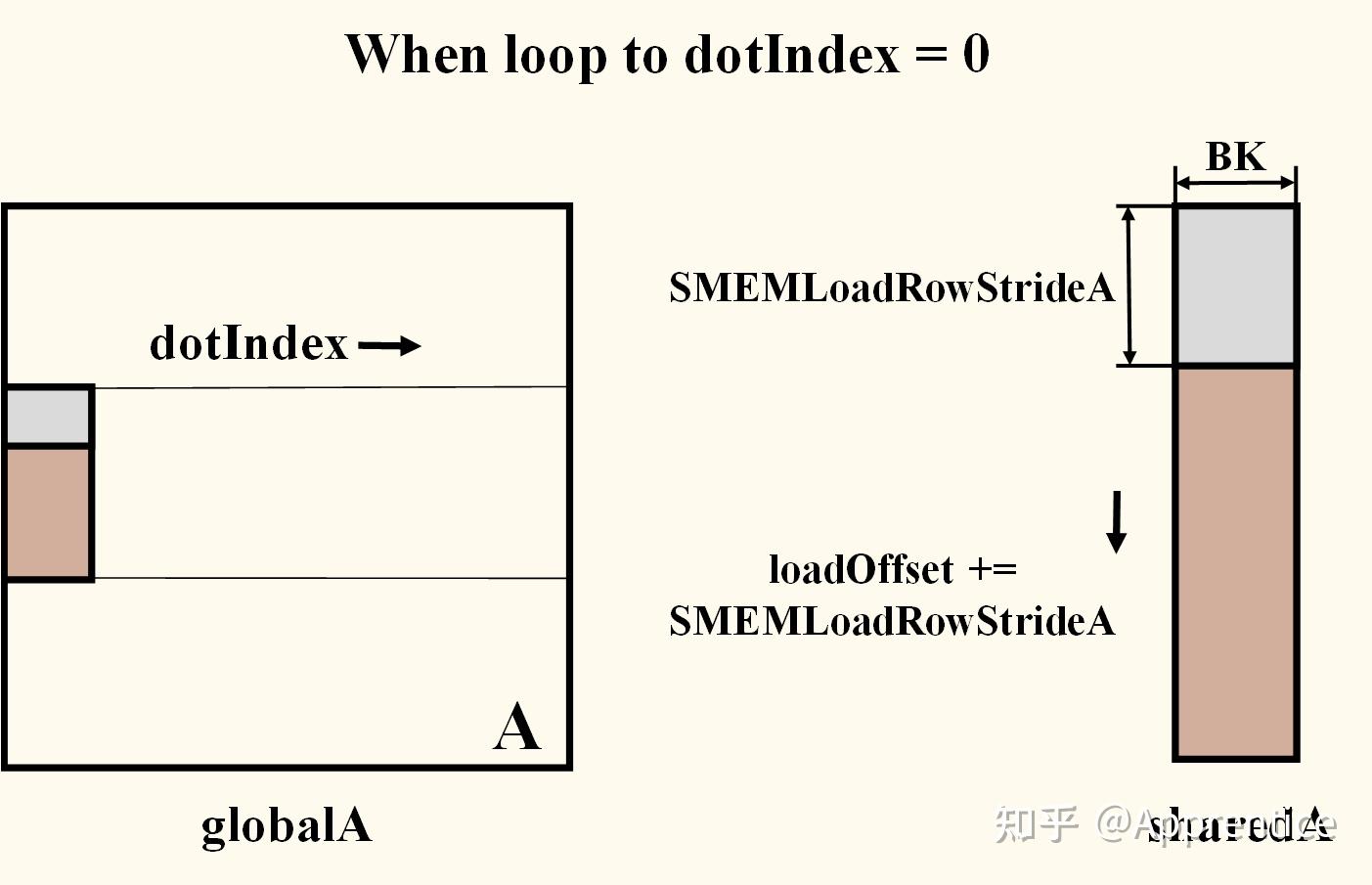
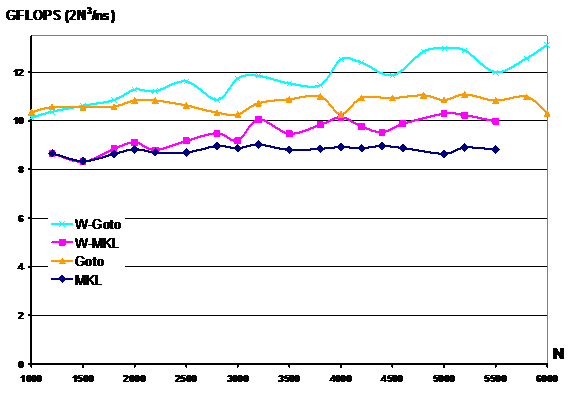
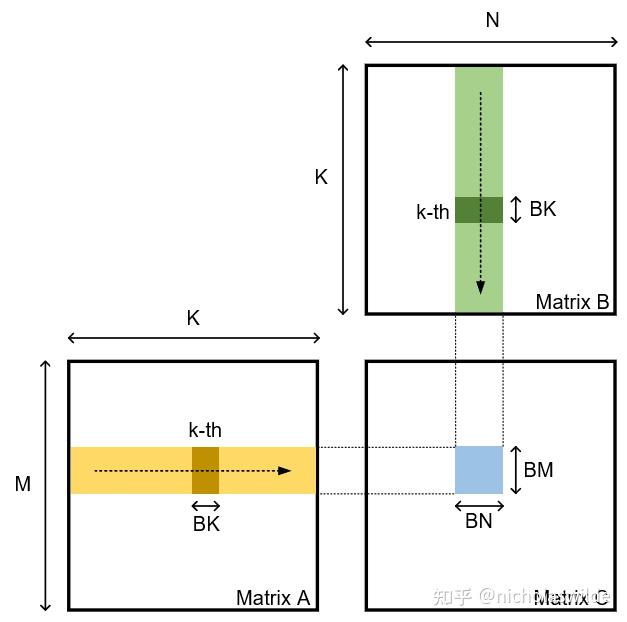

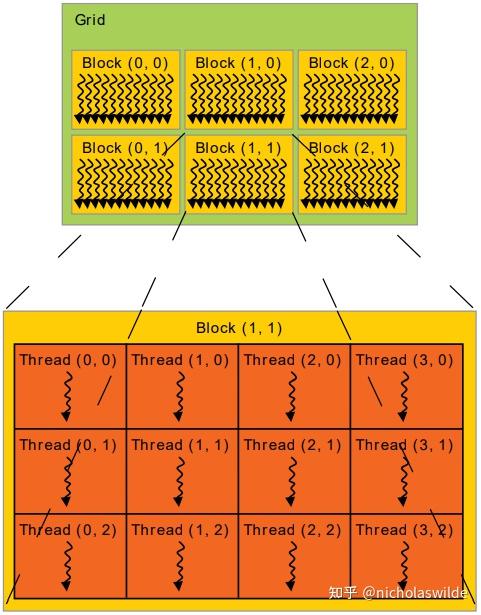
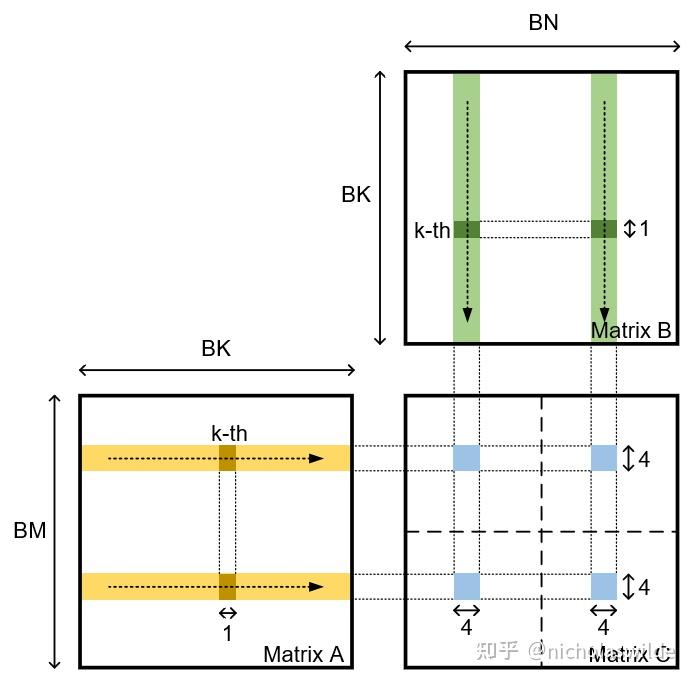









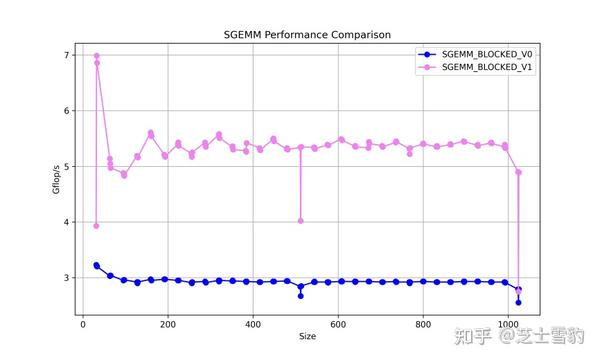
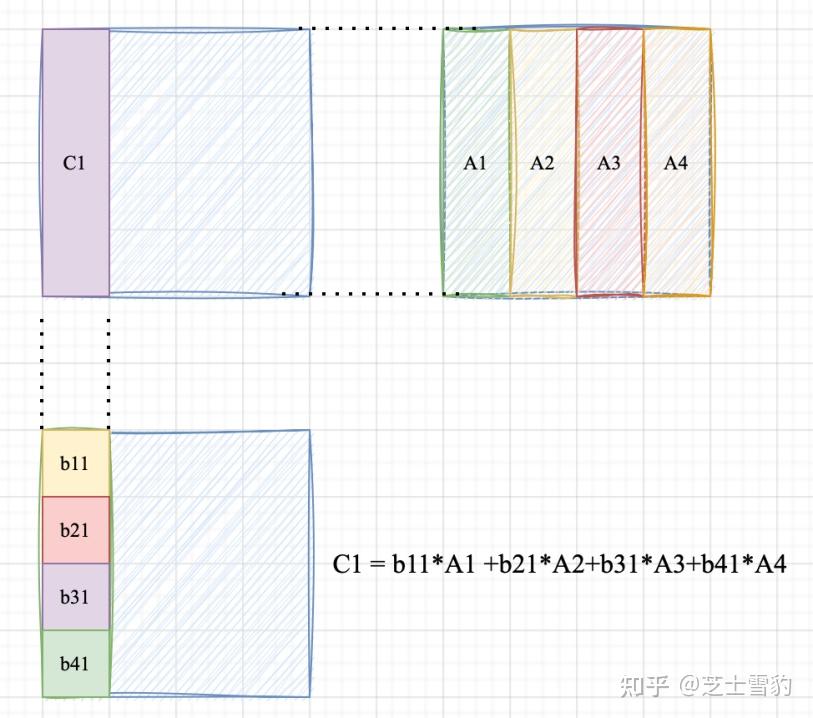


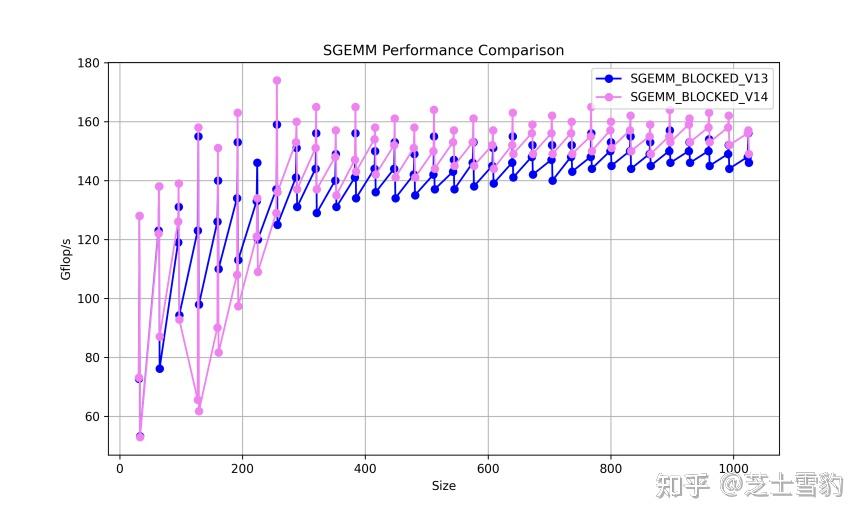

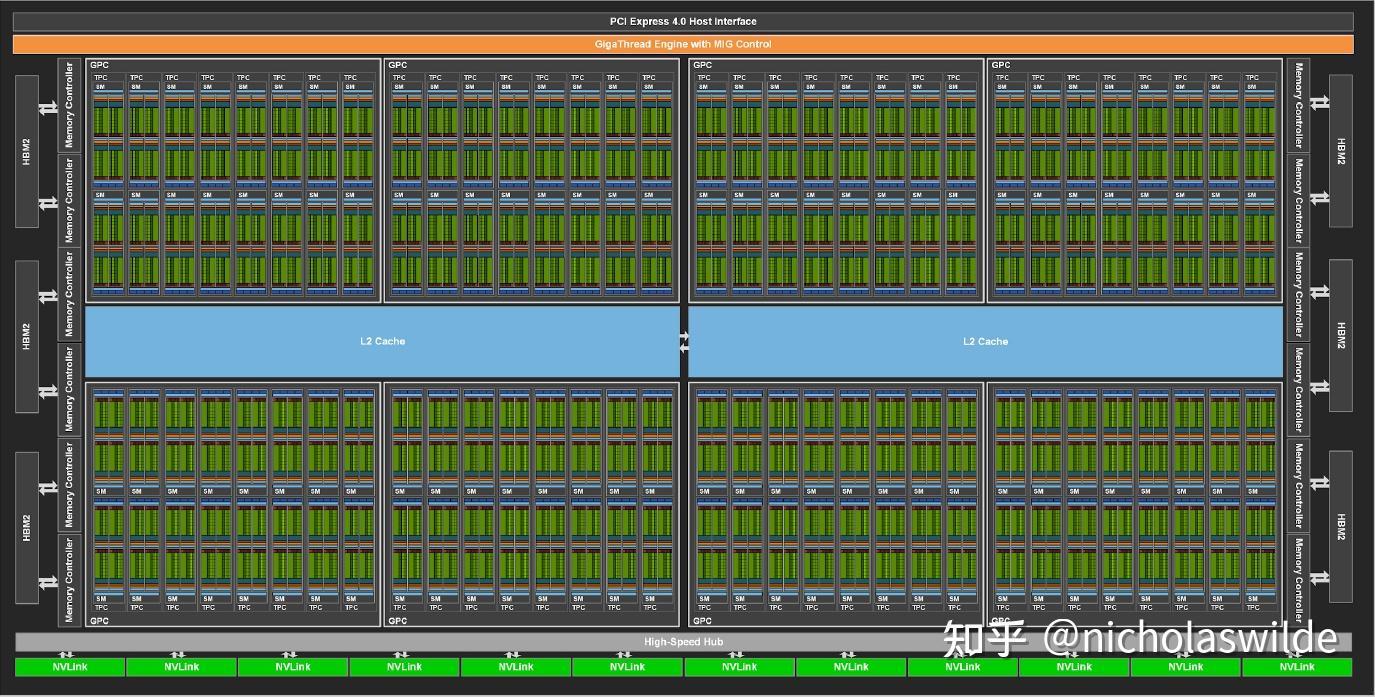
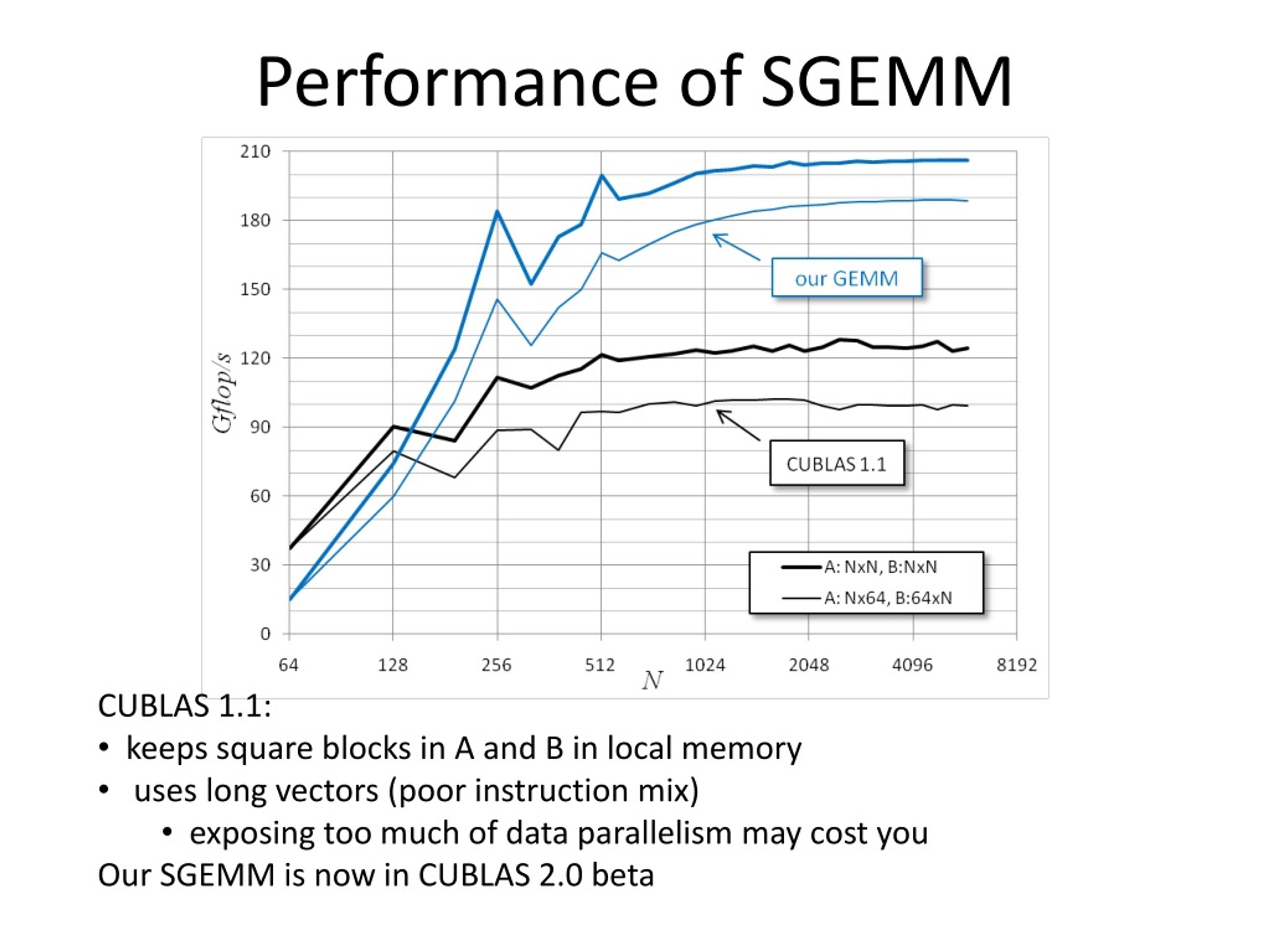
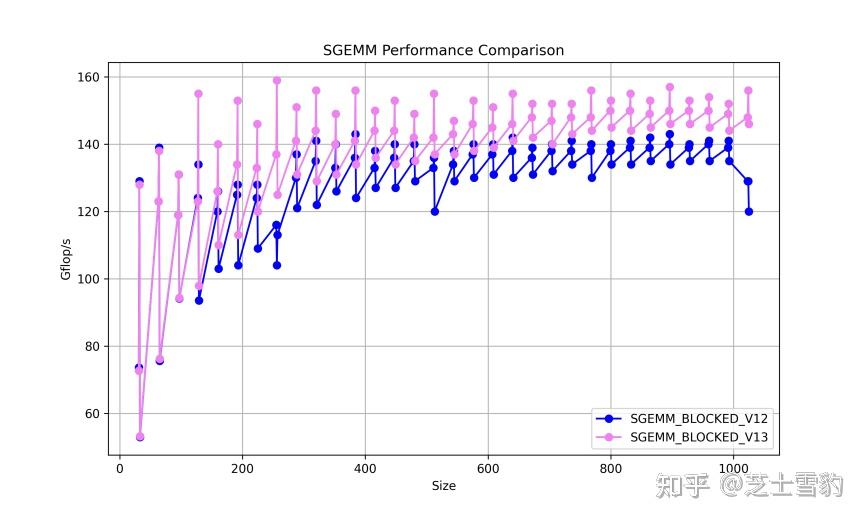
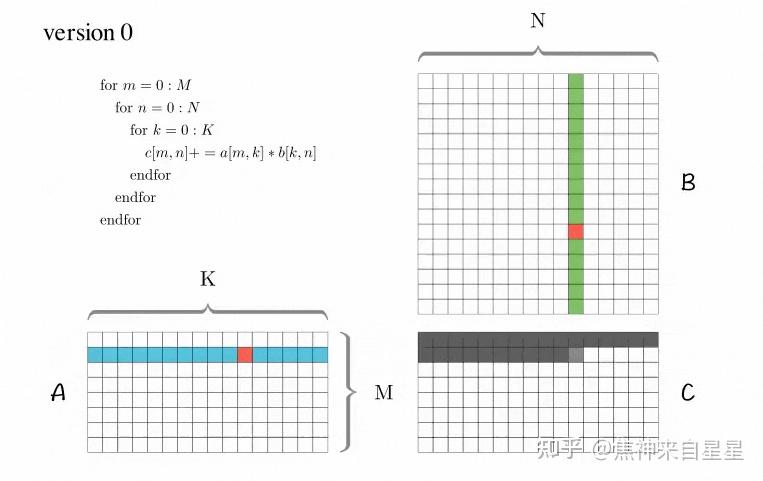
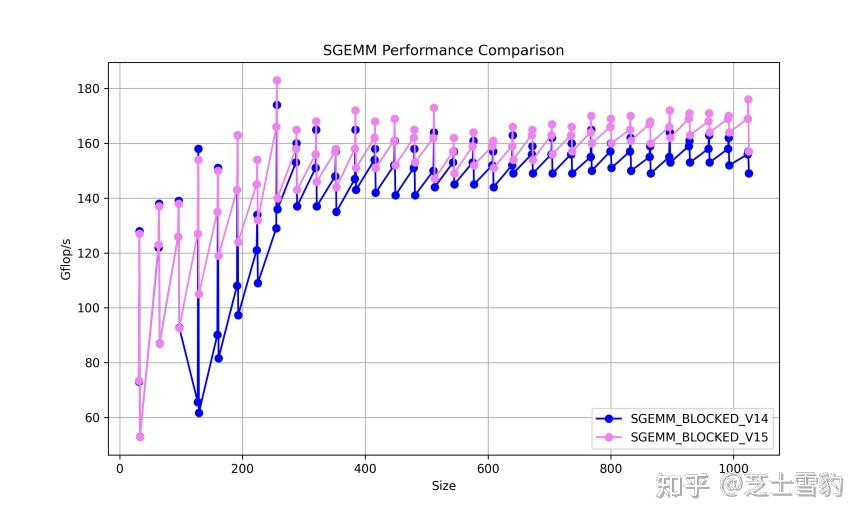
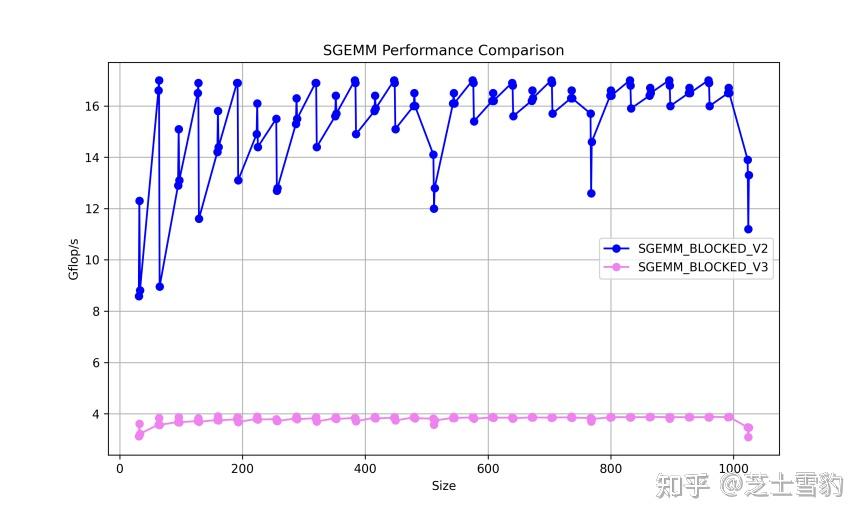
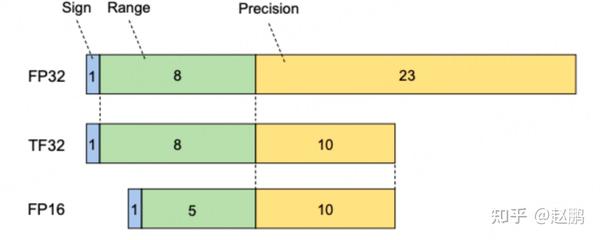
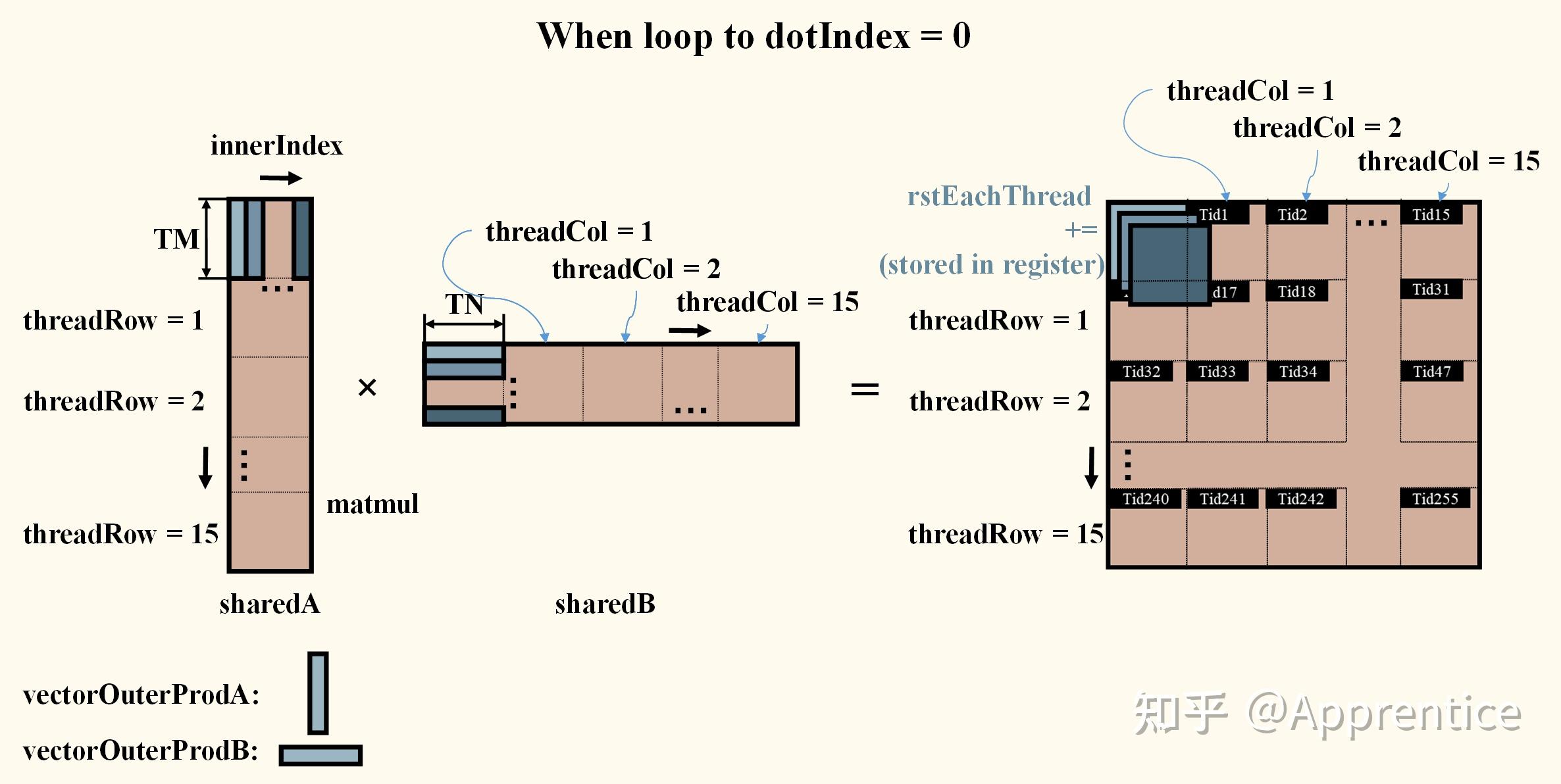
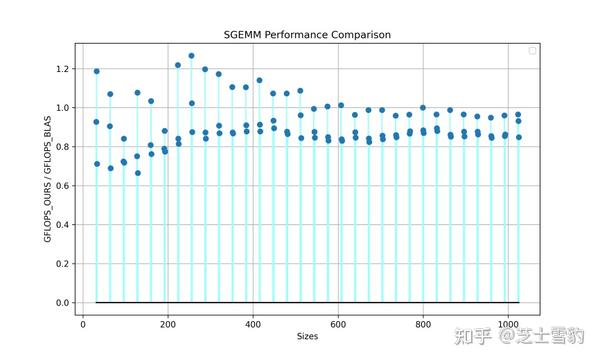


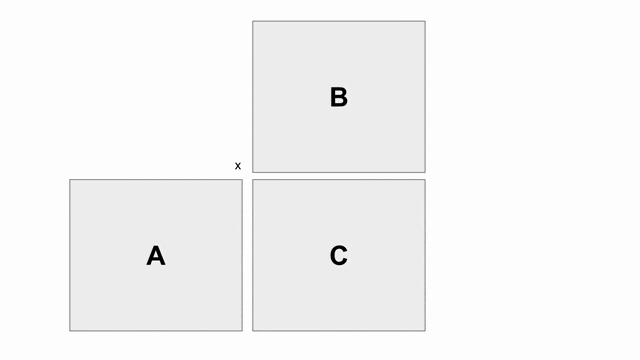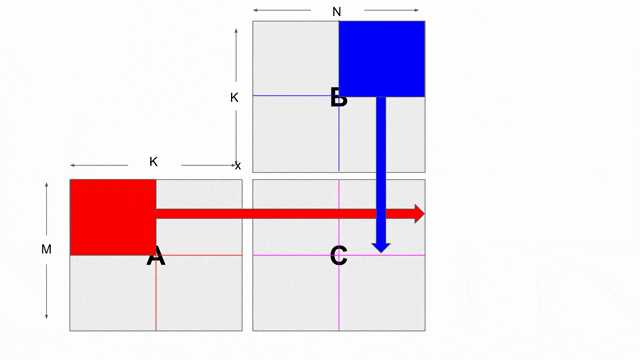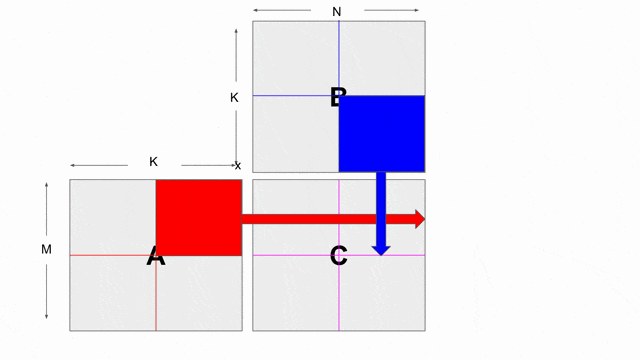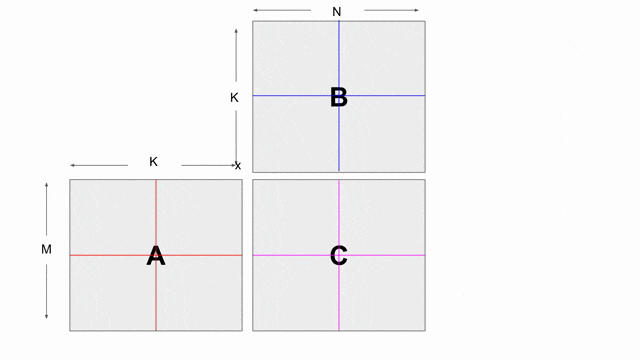.gif)
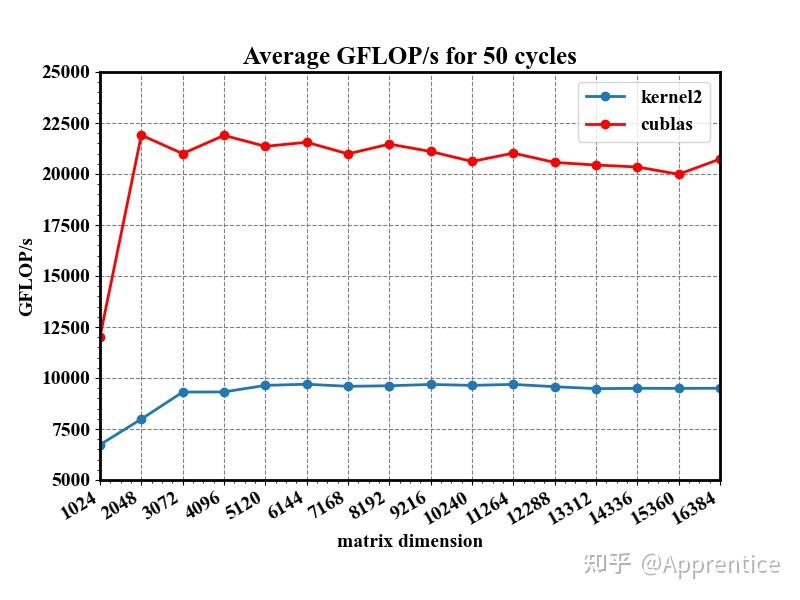

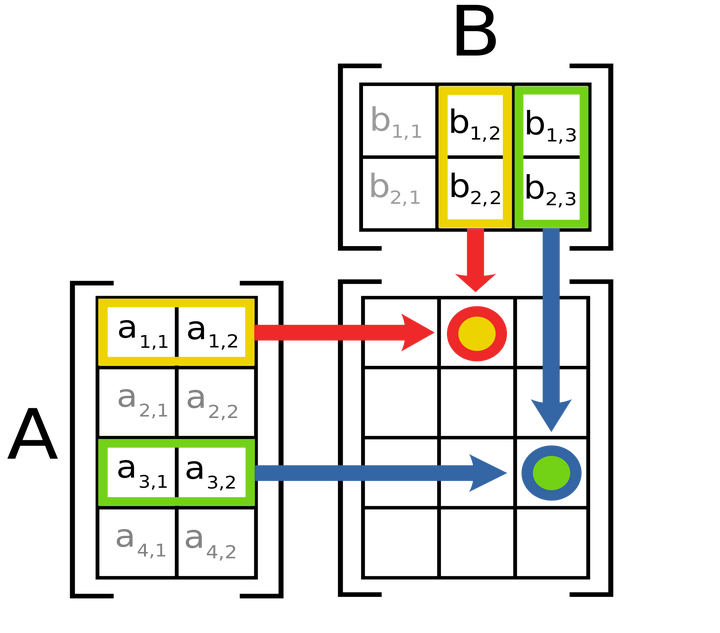

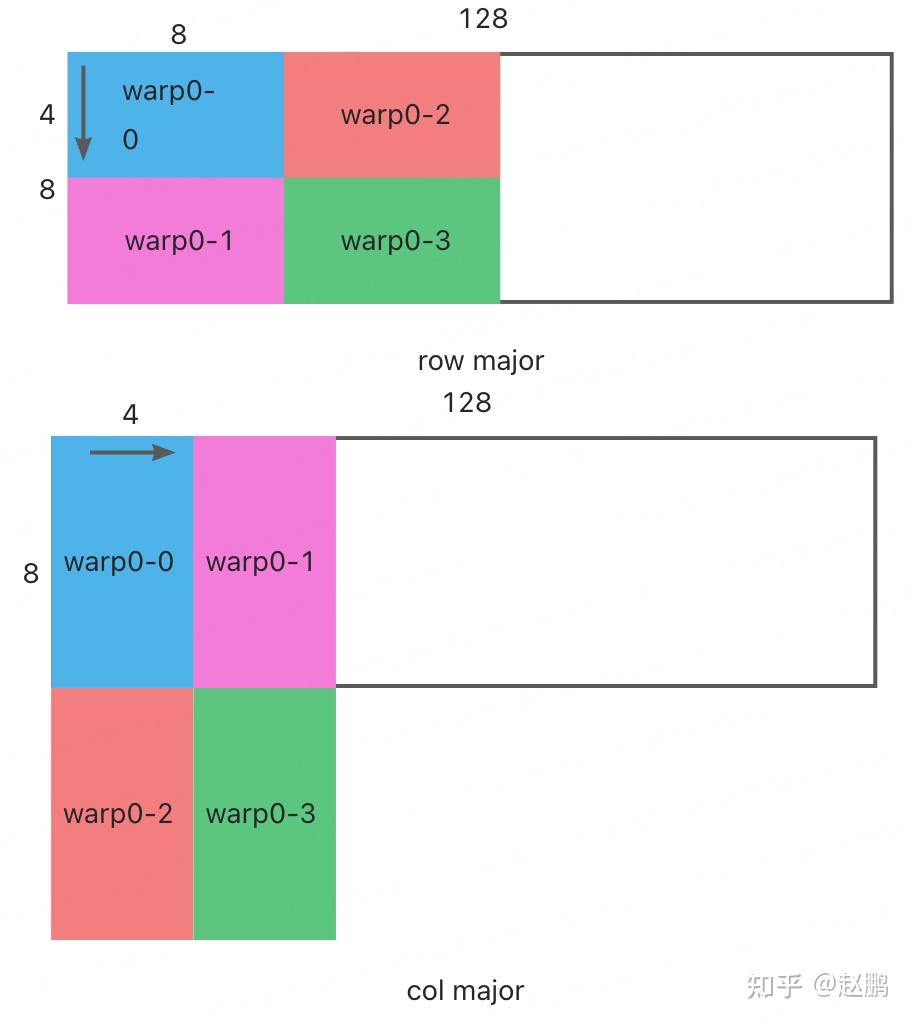
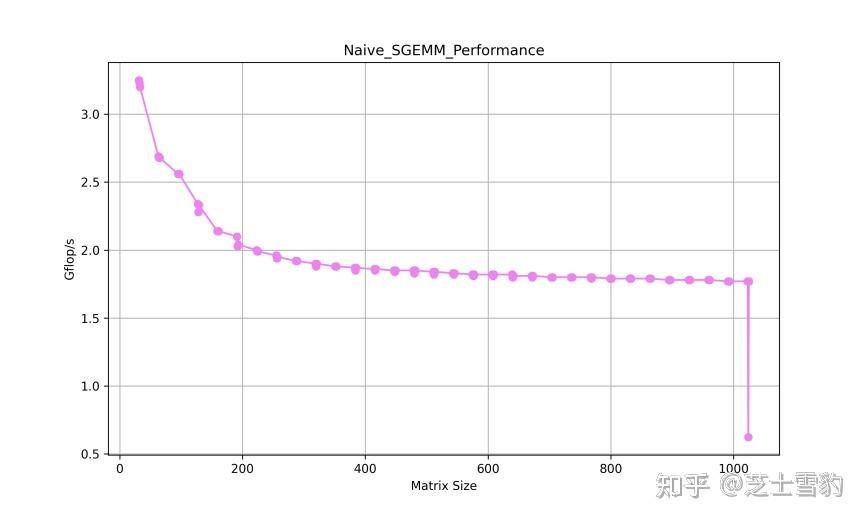


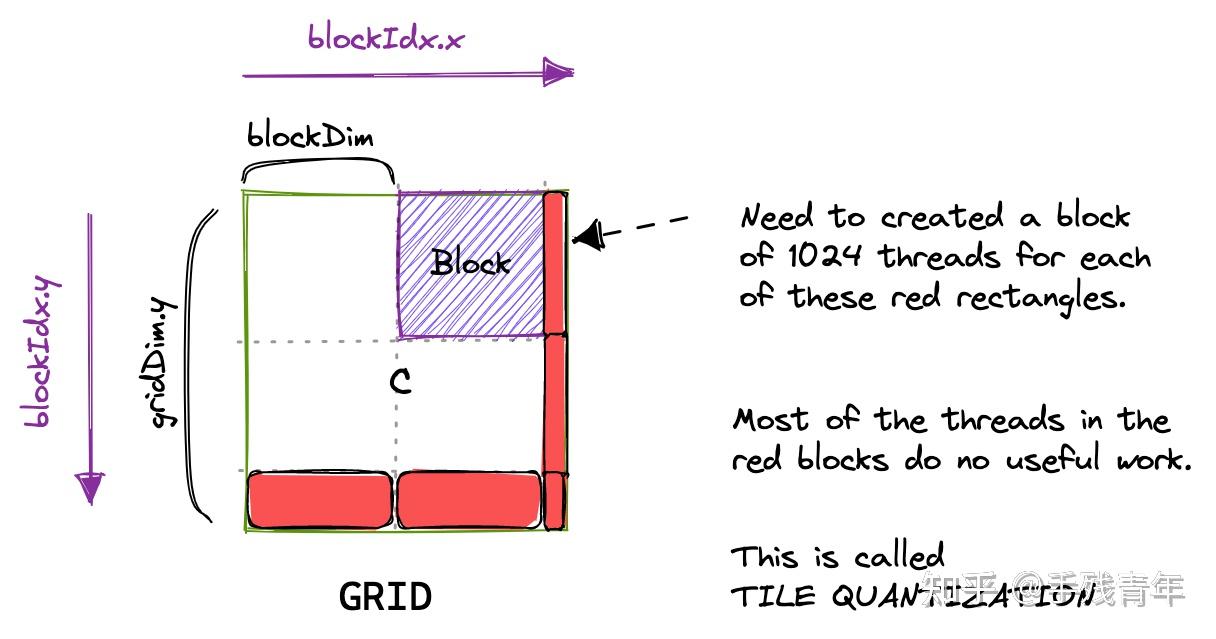

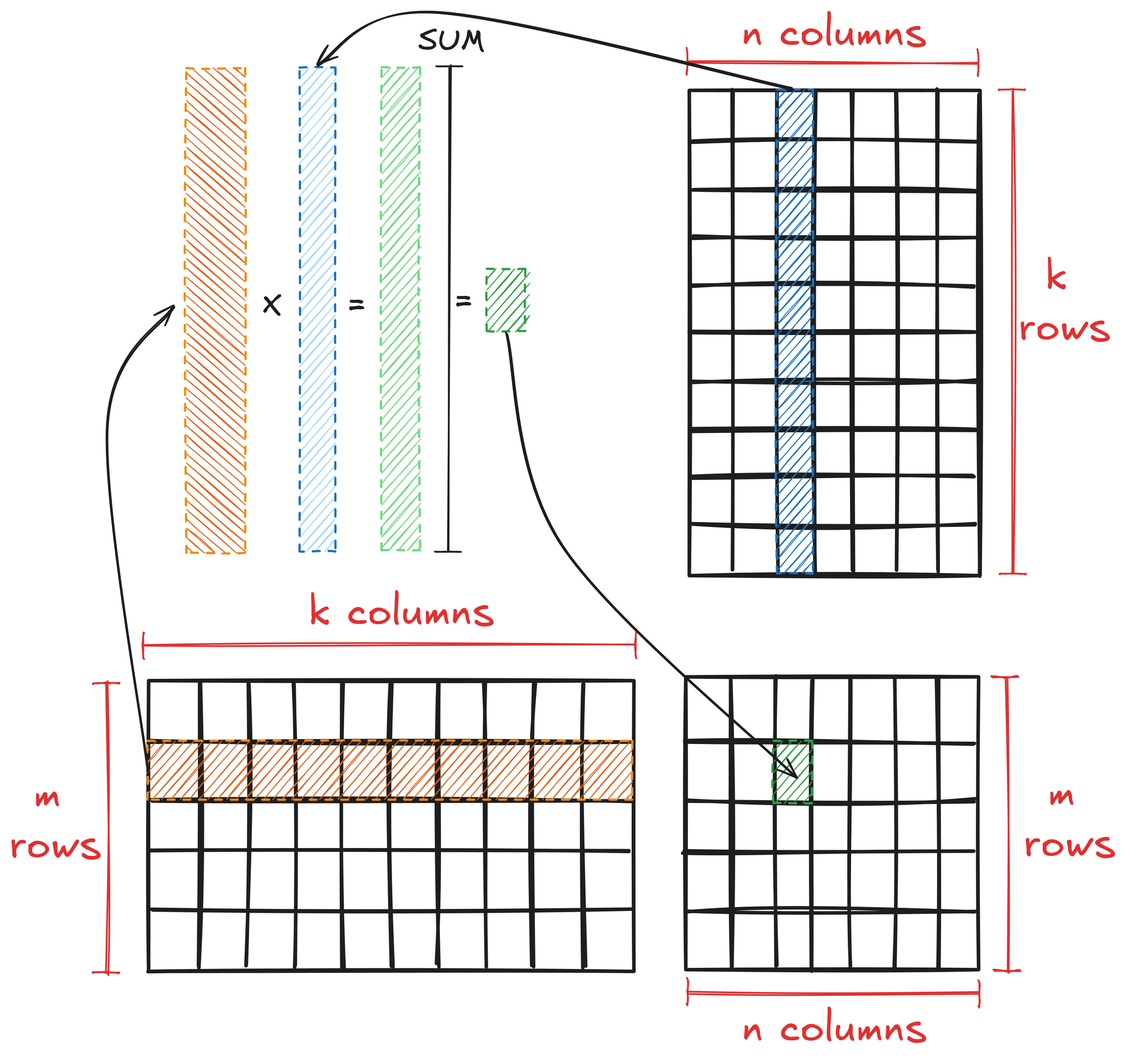
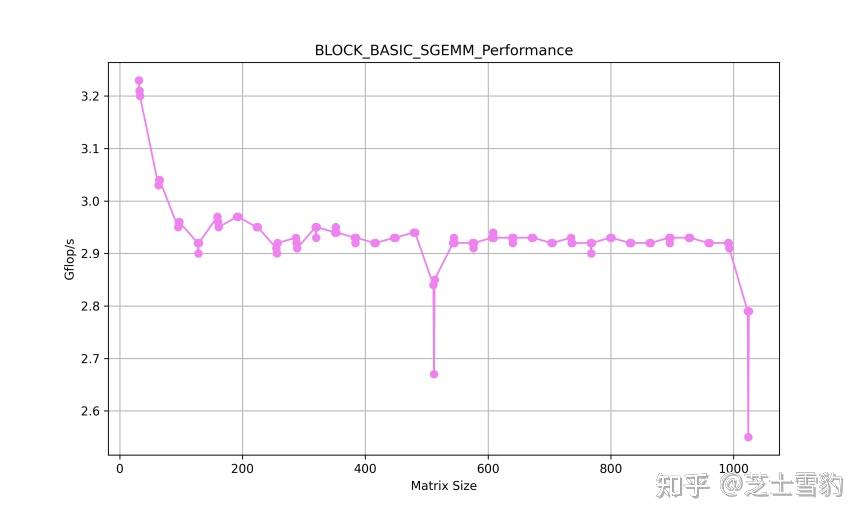
.gif?format=500w)


.gif?format=100w)