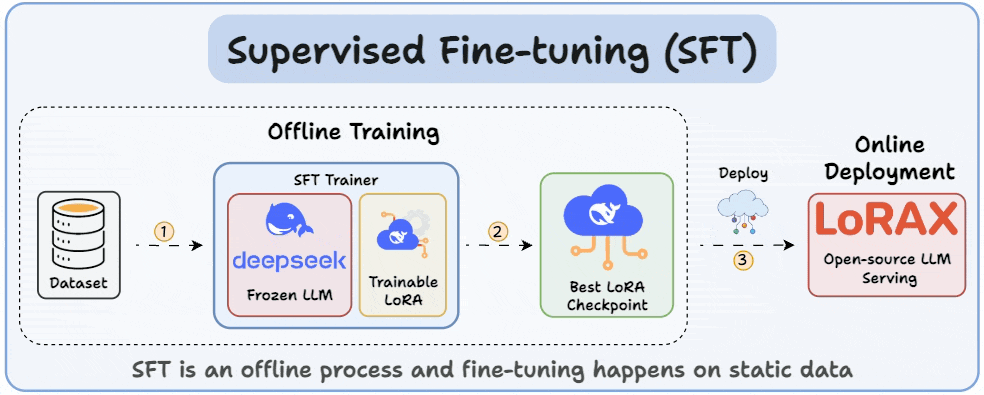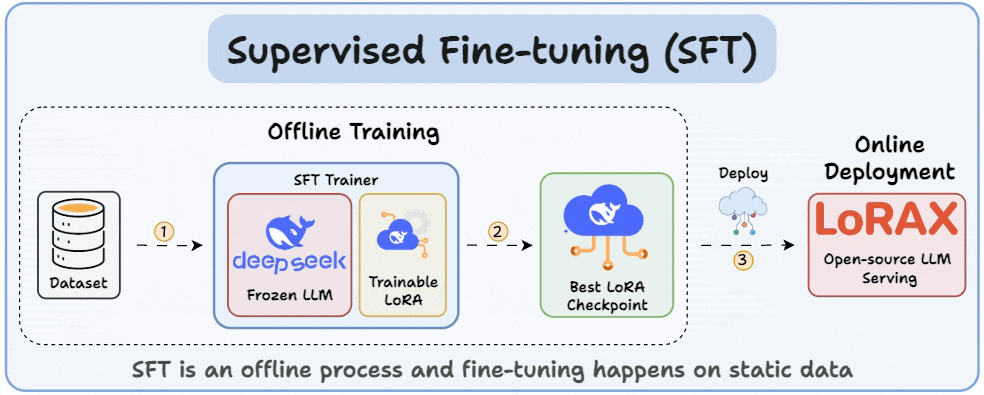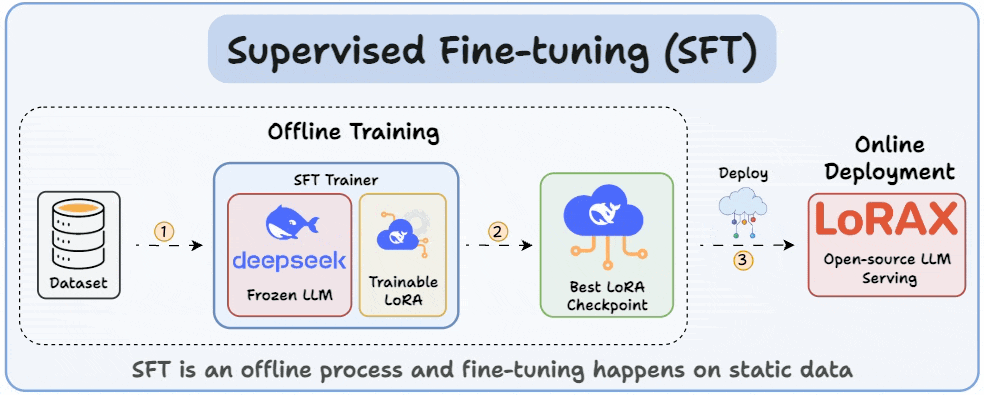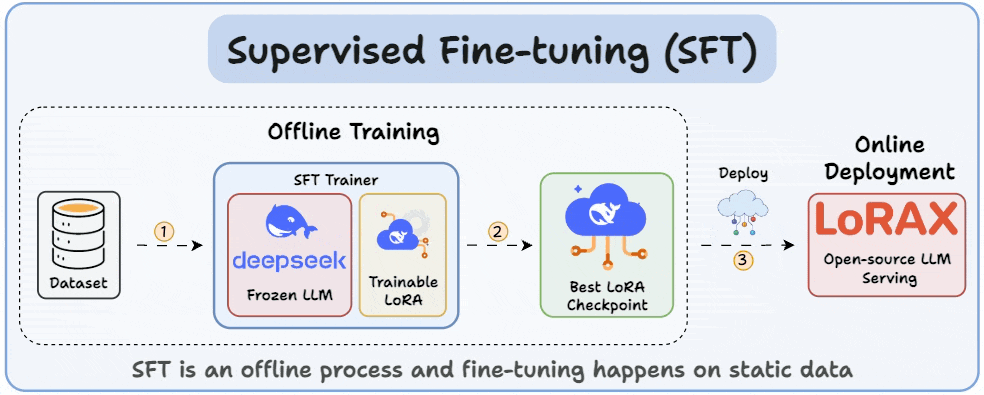
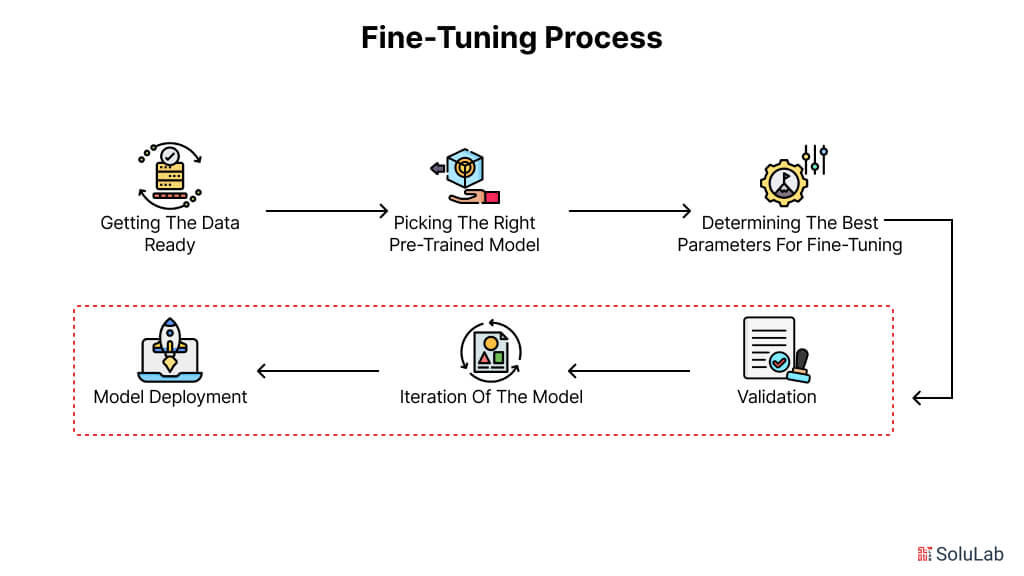
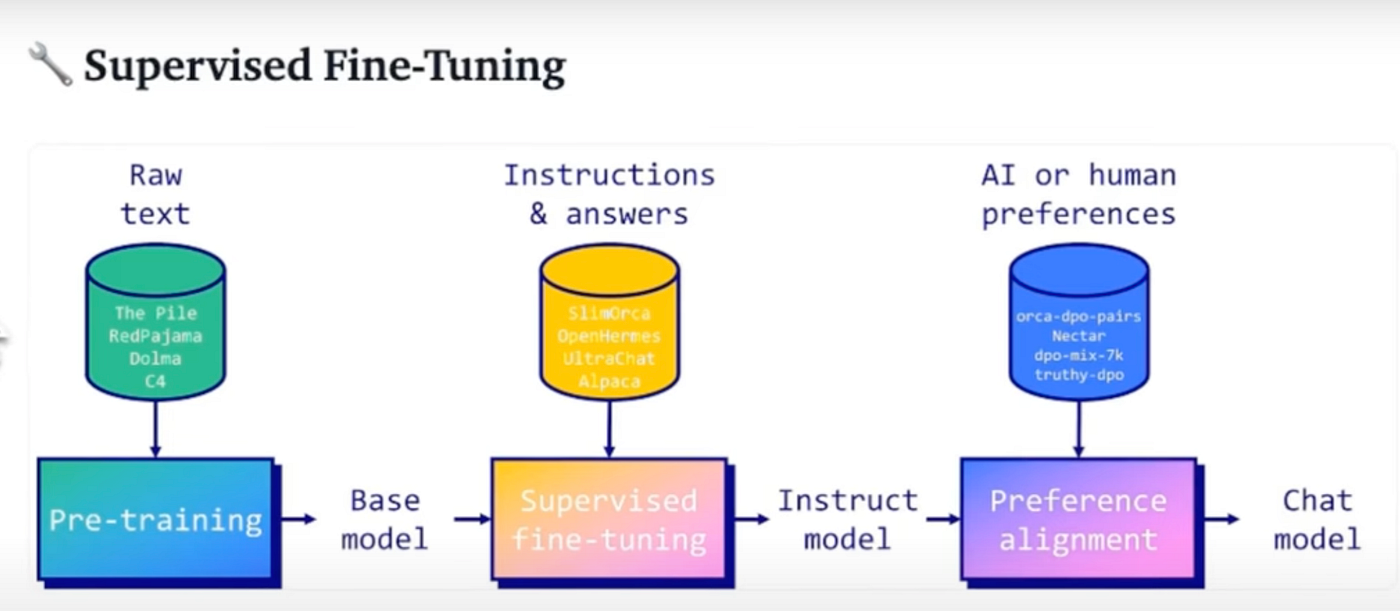
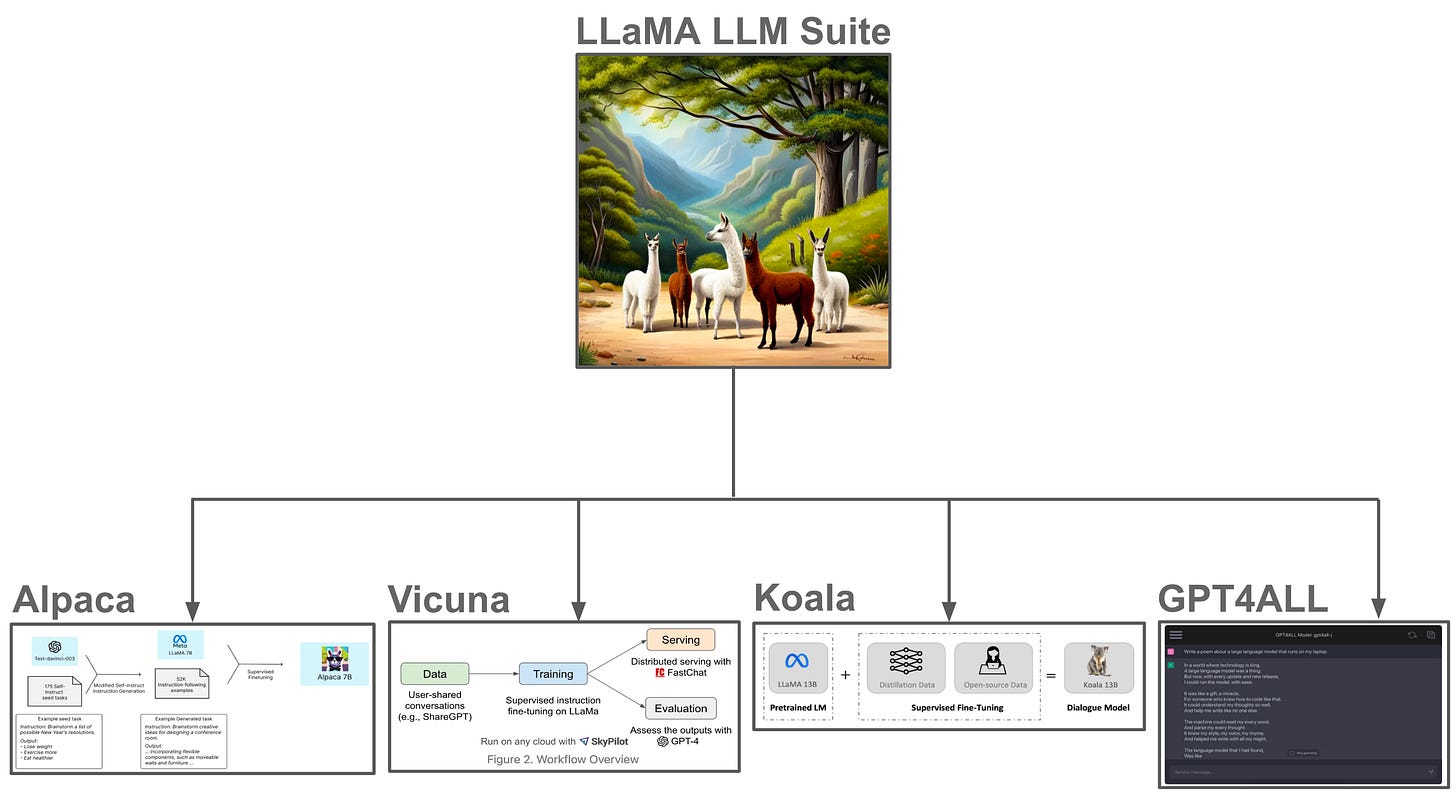
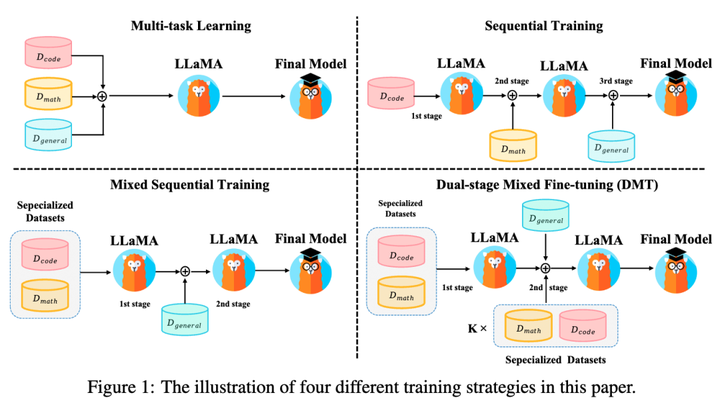
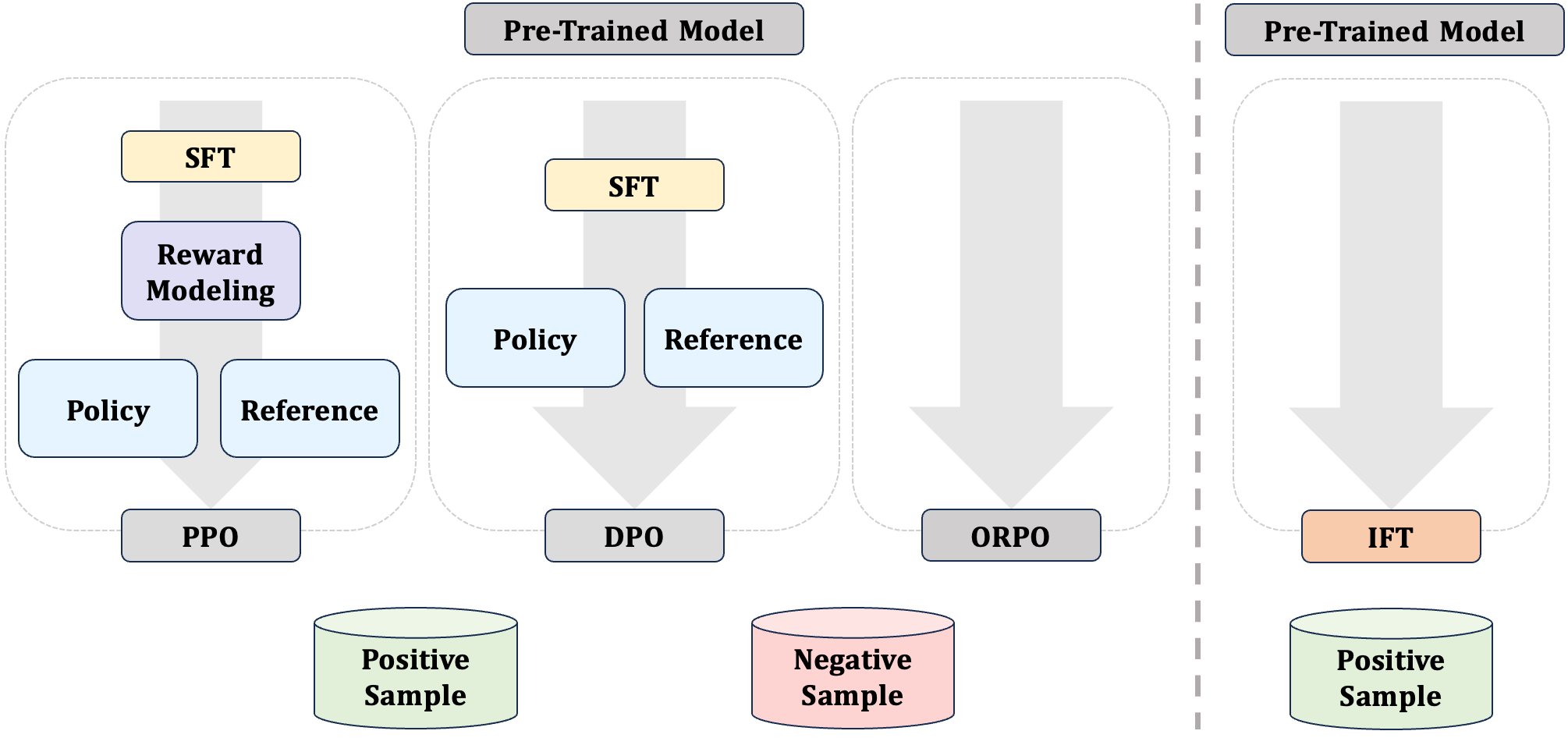
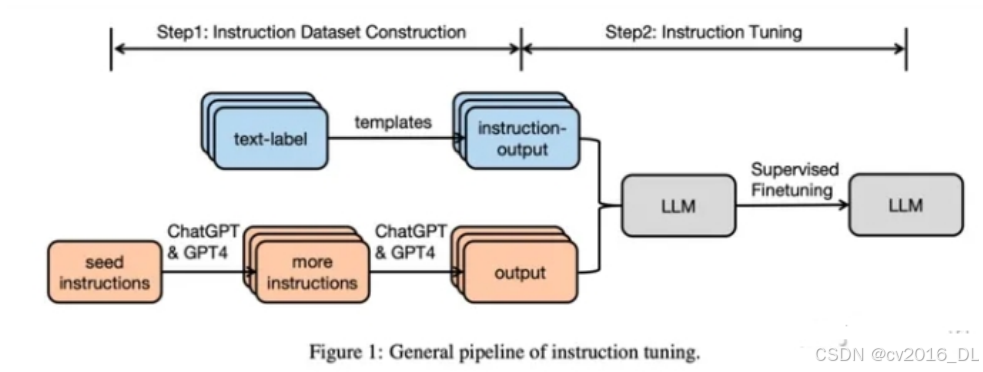
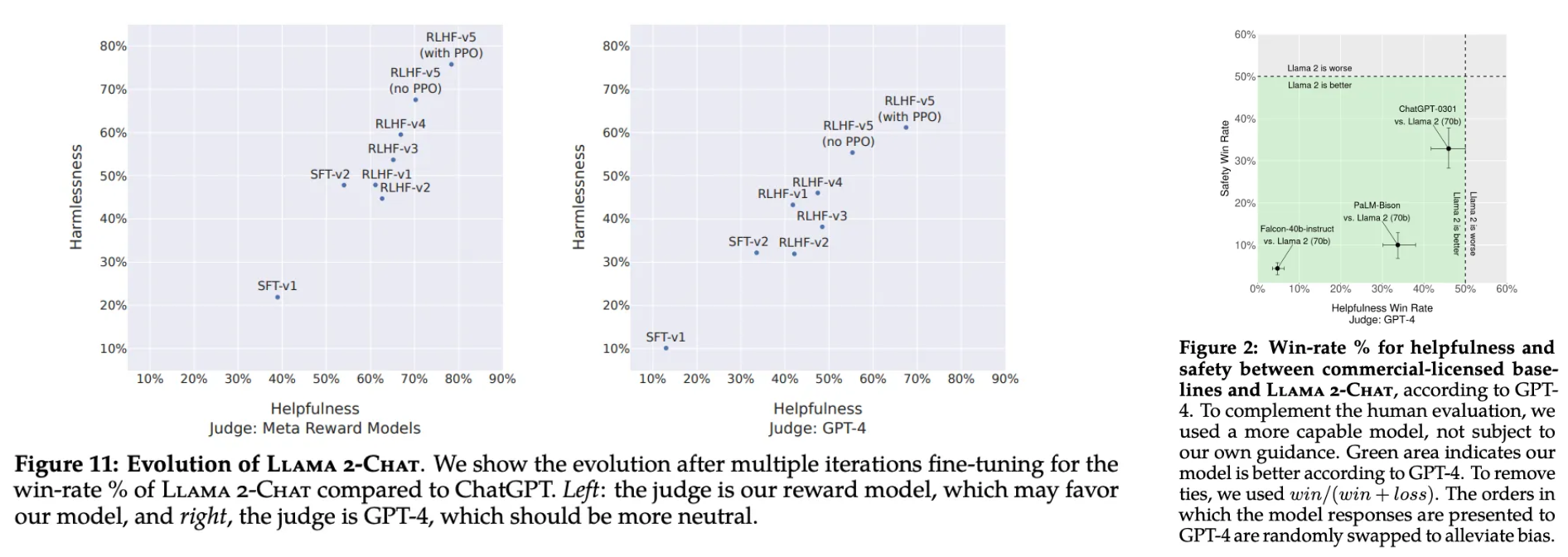
Showing 114 of 114on this page. Filters & sort apply to loaded results; URL updates for sharing.114 of 114 on this page
9 The process of gaining knowledge through SFT can be considered ...
SFT & EB Approaches emerging from Structural Tradition: Therapy Process ...
SFT process · Issue #13 · KANABOON1/MemGen · GitHub
Monitoring SOP SFT | PDF | Process (Computing) | Databases
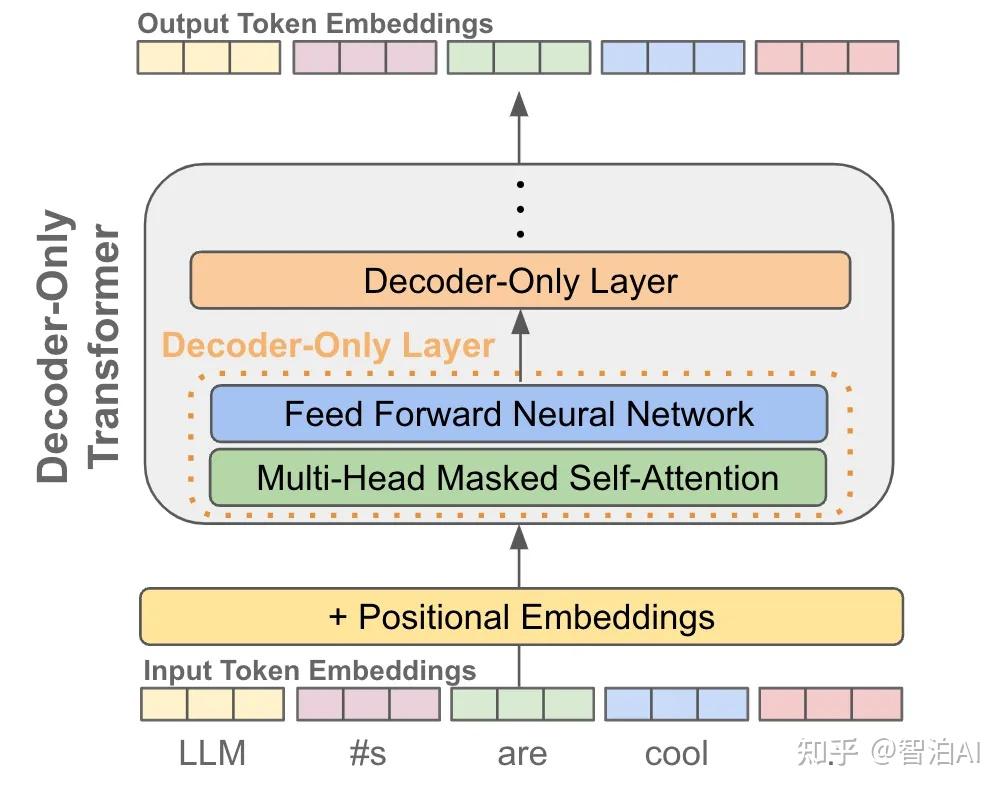
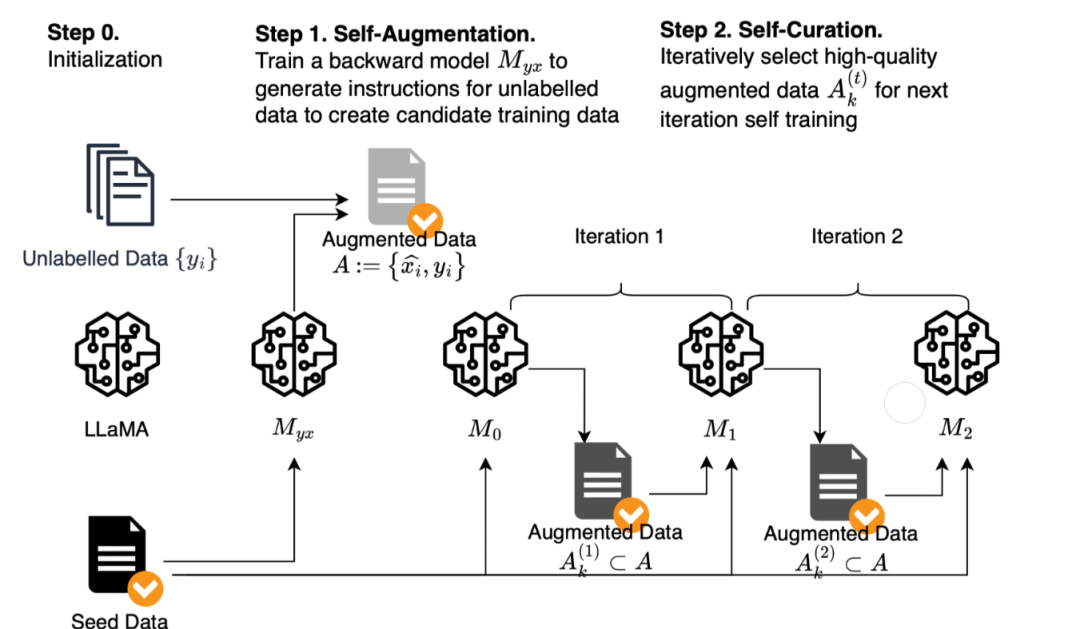
What is SFT Process How does the SFT process help to build LLM models ...
How does the SFT process help to build LLM models at a cheaper cost ...
NousResearch/Nous-Capybara-34B · More detailed on sft process or ...
Too slow sft process · Issue #3971 · modelscope/ms-swift · GitHub
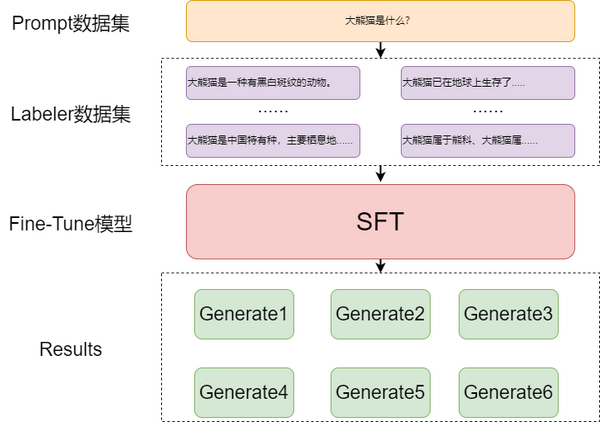
【科普】大模型中常说的 SFT 是指什么? | FisherAI
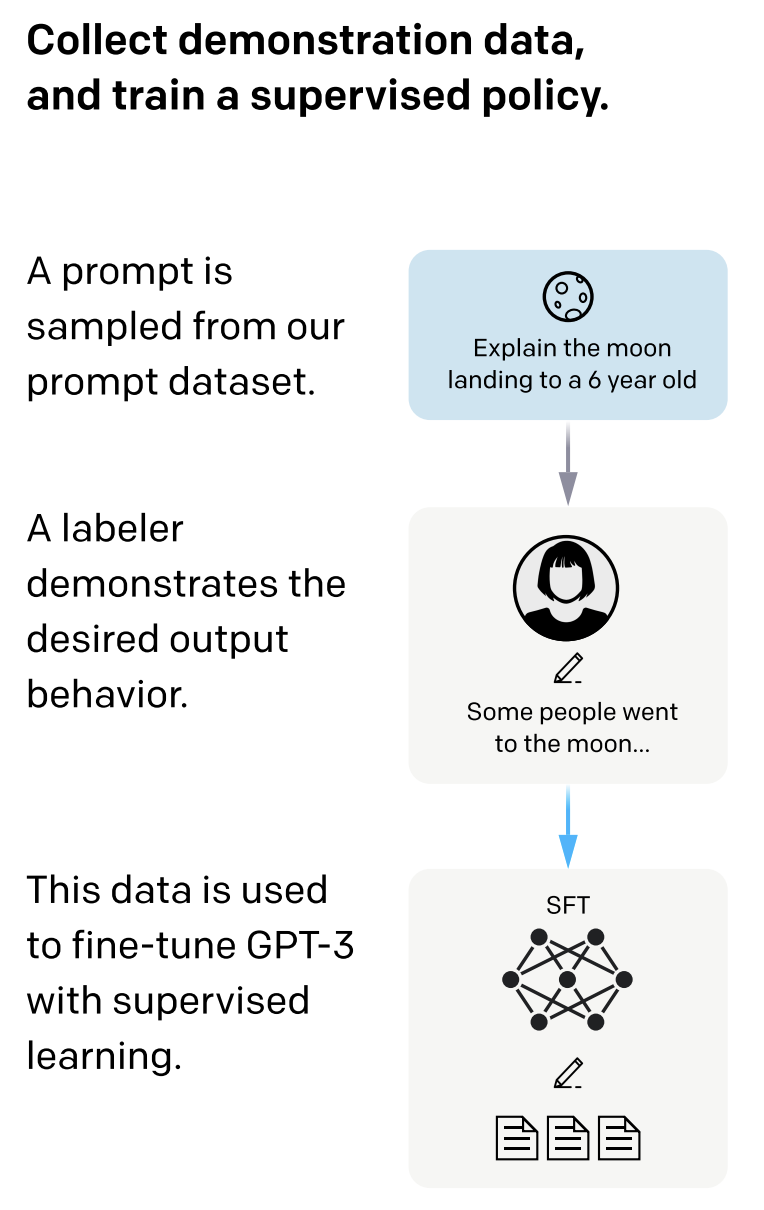
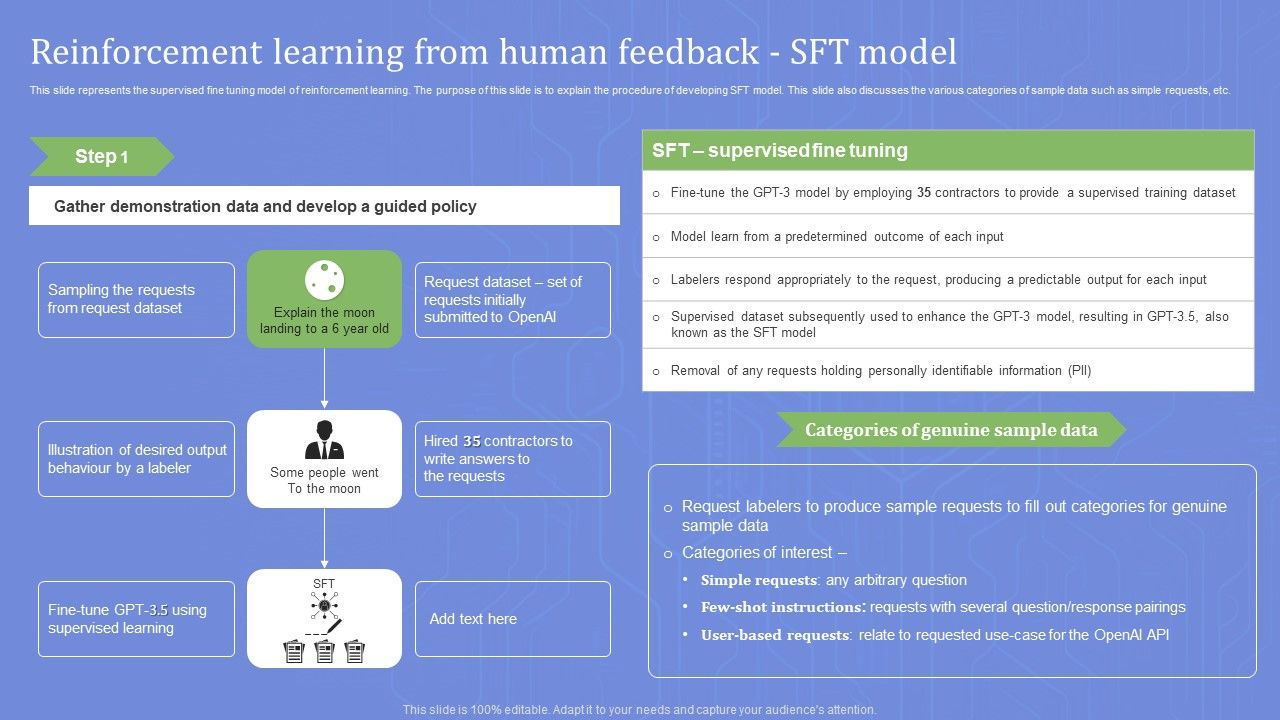
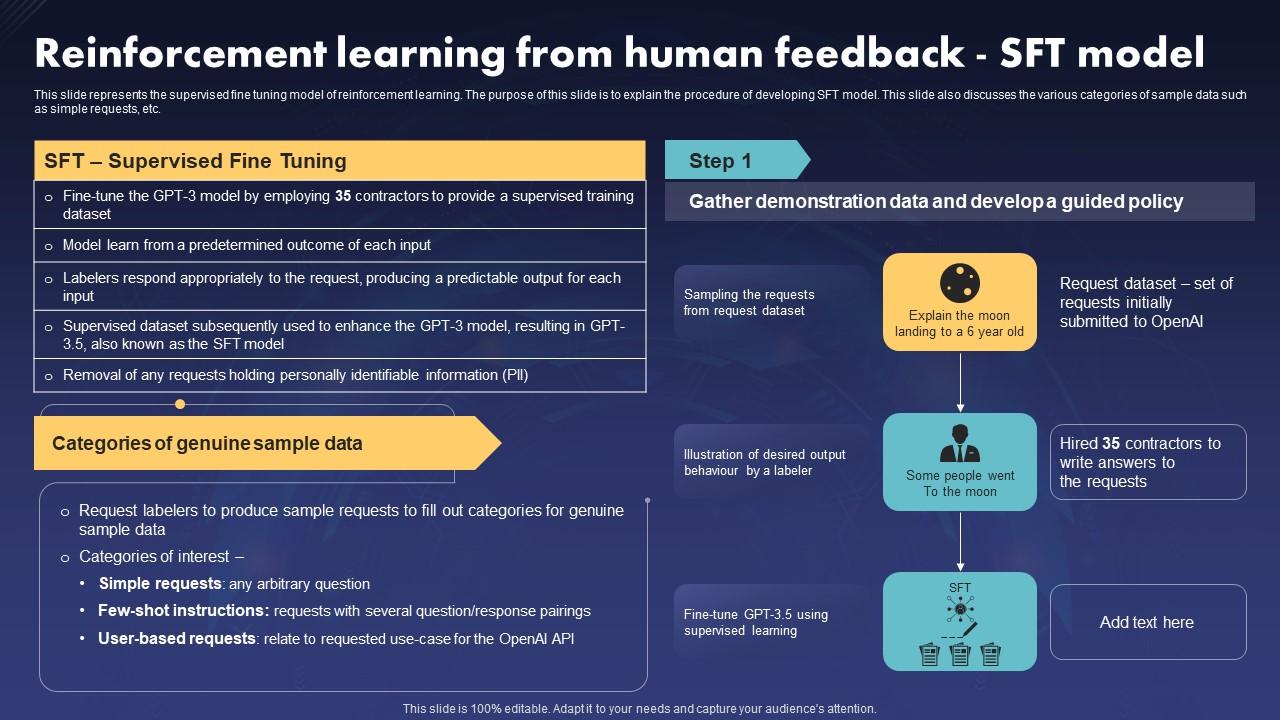
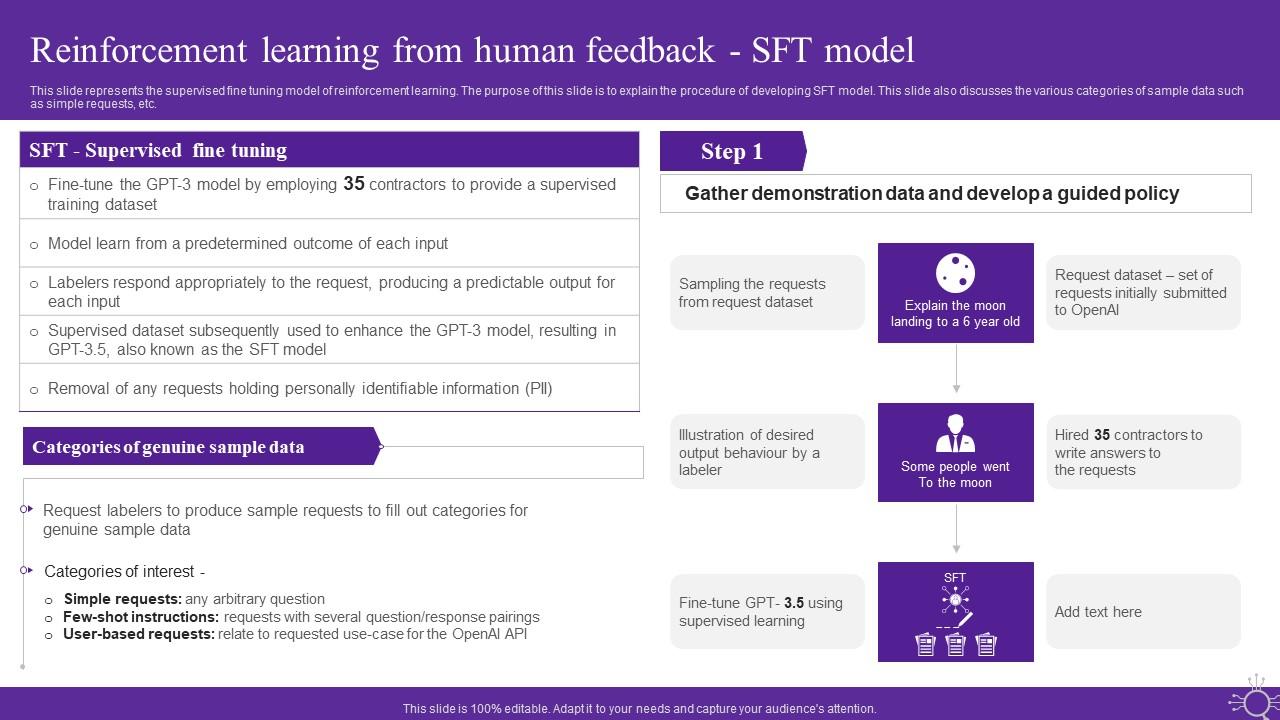
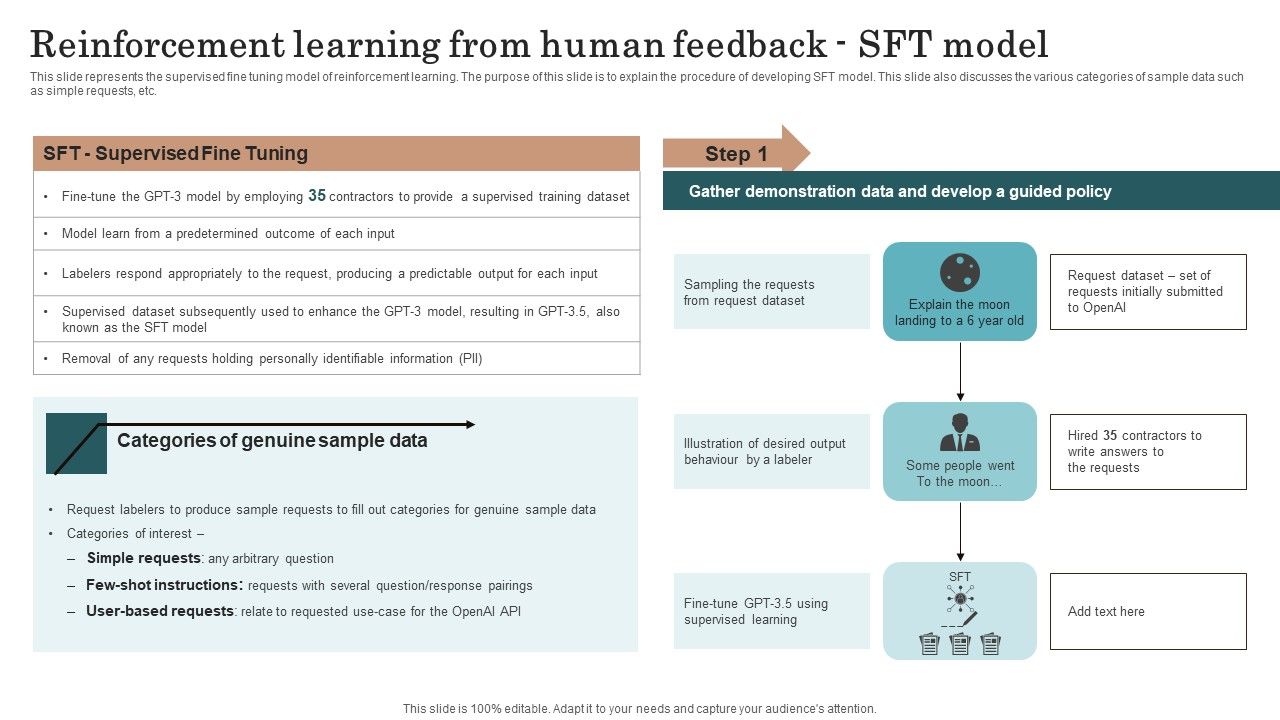
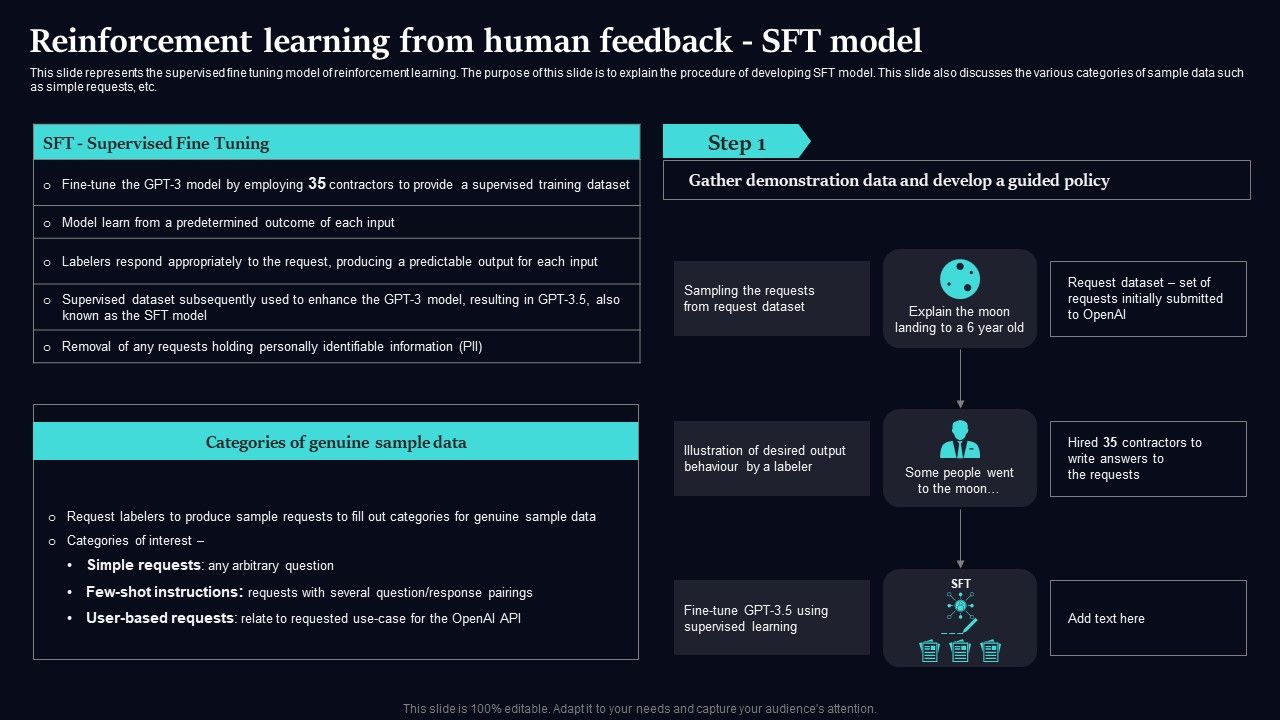
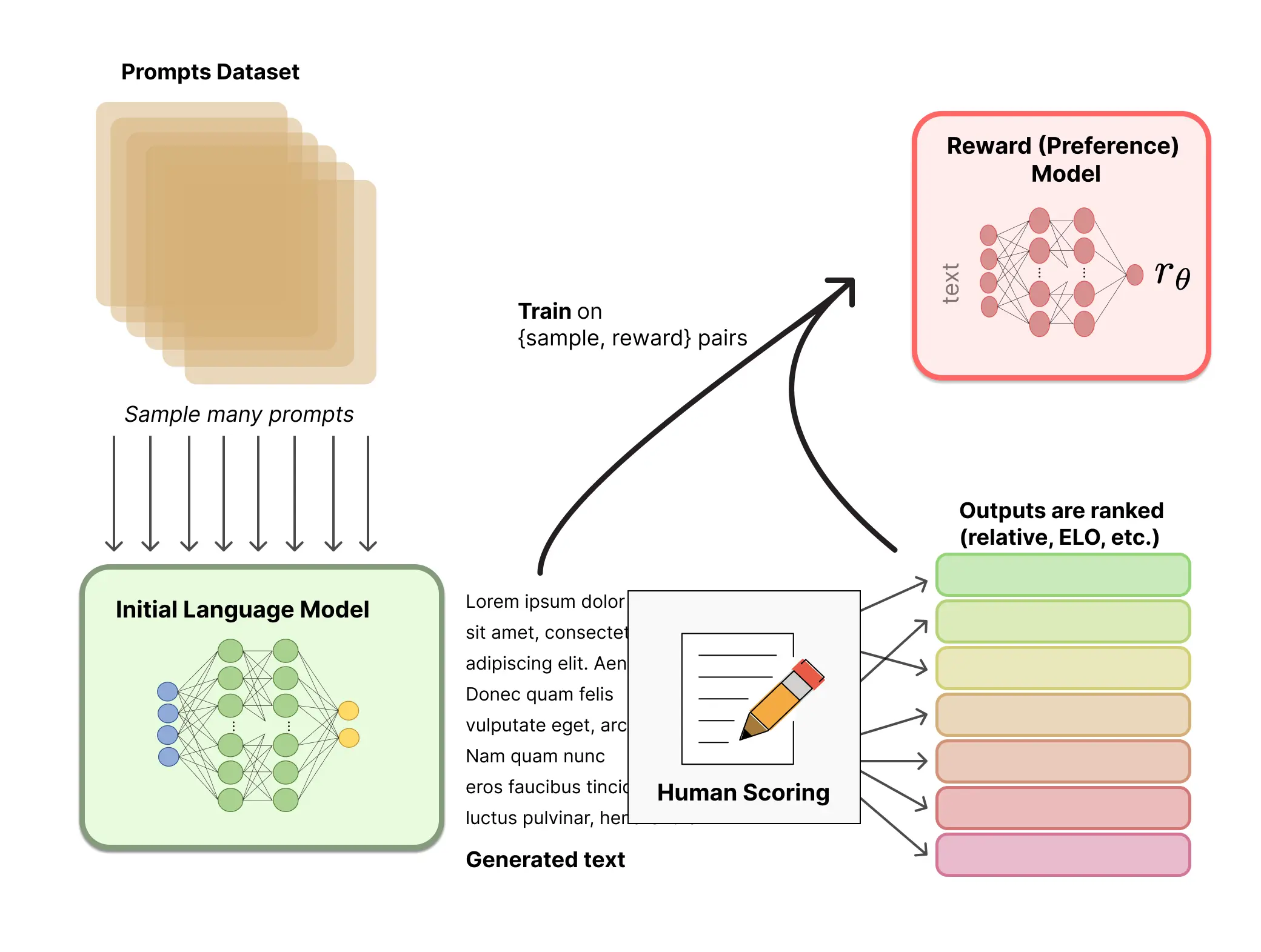
Reinforcement Learning From Human Feedback Sft Model Demonstration PDF
Reinforcement Learning Sft Model Prompt Engineering For Effective ...
Chatgpt IT Reinforcement Learning From Human Feedback SFT Model PPT Example
A) Schematic diagram demonstrating the hierarchical structure of SFT ...
Schematic representation of the solving process of the proposed method ...
大模型微调: SFT 经验分享(非常详细),零基础入门到精通,看这一篇就够了_sft 大模型-CSDN博客
SFT 是什么?大模型SFT(监督微调)该怎么做(经验技巧+分析思路) - 知乎
Schematic diagram of the functionalization of the SFT surface and the ...
Process model of student feedback on teaching (SFT, Source Own ...
Reinforcement Learning From Human Feedback Sft Model Open Ai Language ...
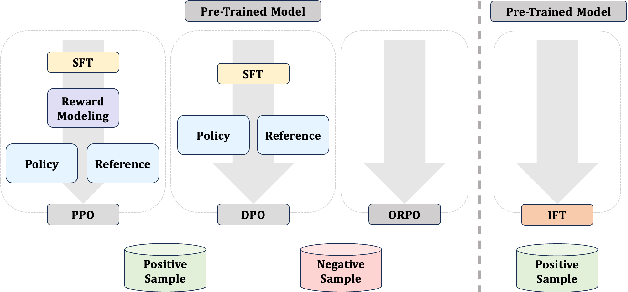
Figure 1 from Intuitive Fine-Tuning: Towards Unifying SFT and RLHF into ...
SFT 是什么?大模型SFT(监督微调)该怎么做(经验技巧+分析思路)-CSDN博客
大模型 SFT 经验分享(超全面!超详细!)收藏这一篇就够了!_sft 大模型-CSDN博客
SFT vs. RL: Cracking the Code of Foundation Model Post-Training | by ...
(PDF) The Process Model of Student Feedback on Teaching (SFT): A ...
The principle of SfT and its application to augmented reality. Results ...
Multimodal SFT data for the win: pushing model performance in the real ...
SFT Reporting Amendments - Singhi Chugh & Kumar
Fine-tuning a Multimodal Model Using SFT (Single or Multi-Image Dataset)
Complete Guide to GSTR-2B Form Process Using Gen GST Software | PDF
使用大型语言模型进行监督微调(SFT)从想法到实现的工作过程中理解SFT的工作原理..._sft 大模型-CSDN博客
Understanding and Using Supervised Fine-Tuning (SFT) for Language Models
Supervised Fine-Tuning for Text-to-Code Models
DONY Simple and Practical Algorithm sft.pptx
How it works-ARKS
Basic principle of SFT. | Download Scientific Diagram
GitHub - TheMarkL-Corp/sft-process-flow
Technical Architecture of DeepSeek v3 Explained
Exploring the Strengths and Trade-offs of Fine-tuning and RAG in ...
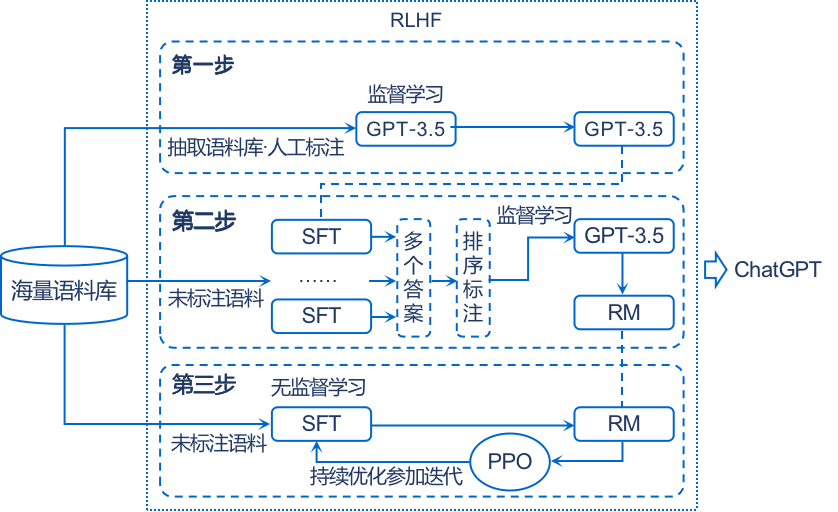
ChatGPT原理详解+实操(1)----SFT(GPT模型精调) - 知乎
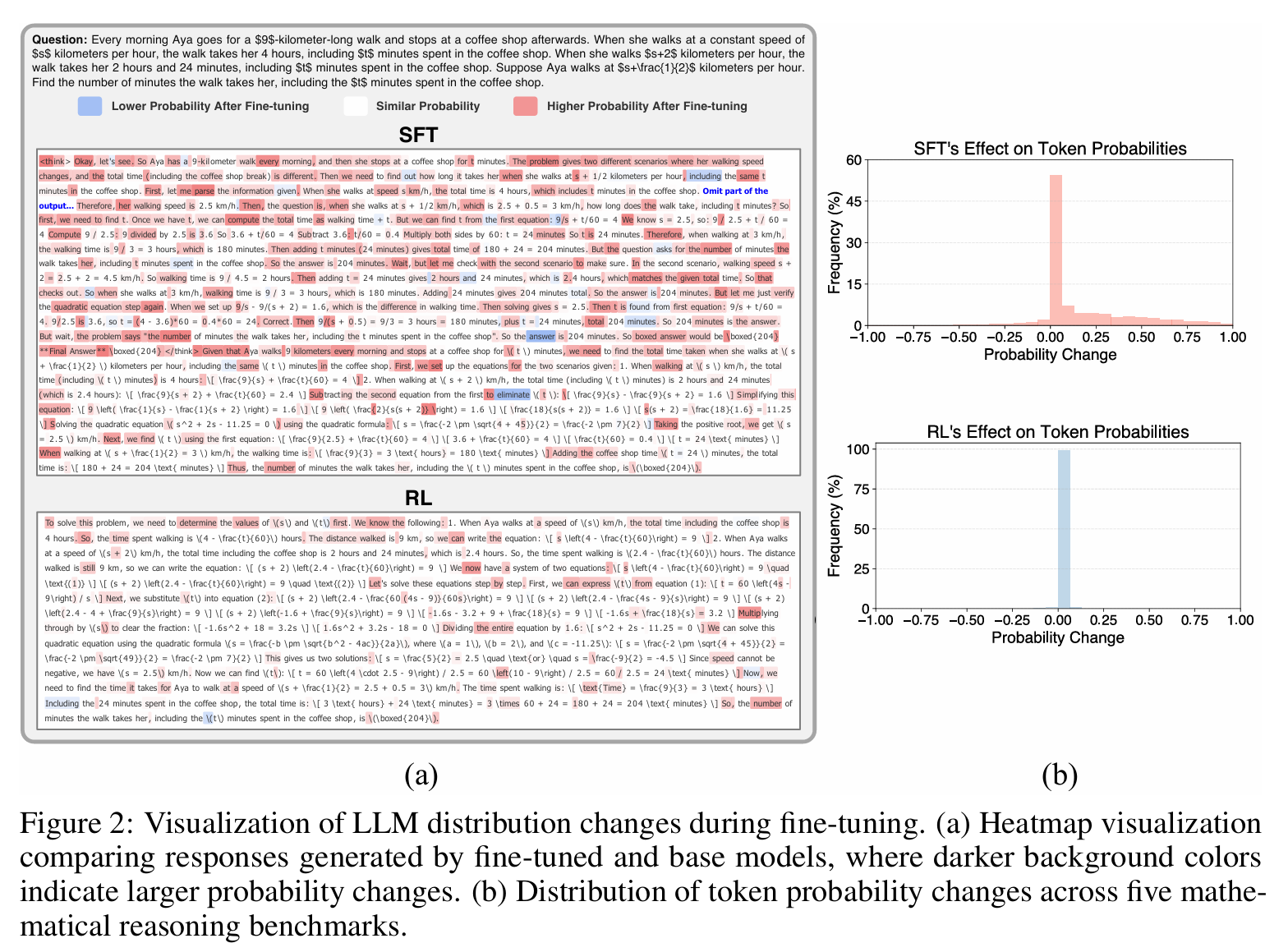
Think, Prune, Train, Improve: Scaling Reasoning without Scaling Models ...
一文详解:SFT 是什么?大模型SFT(监督微调)该怎么做(经验技巧+分析思路)-CSDN博客
【LLM】sft和pretrain数据处理和筛选方法_sft数据-CSDN博客
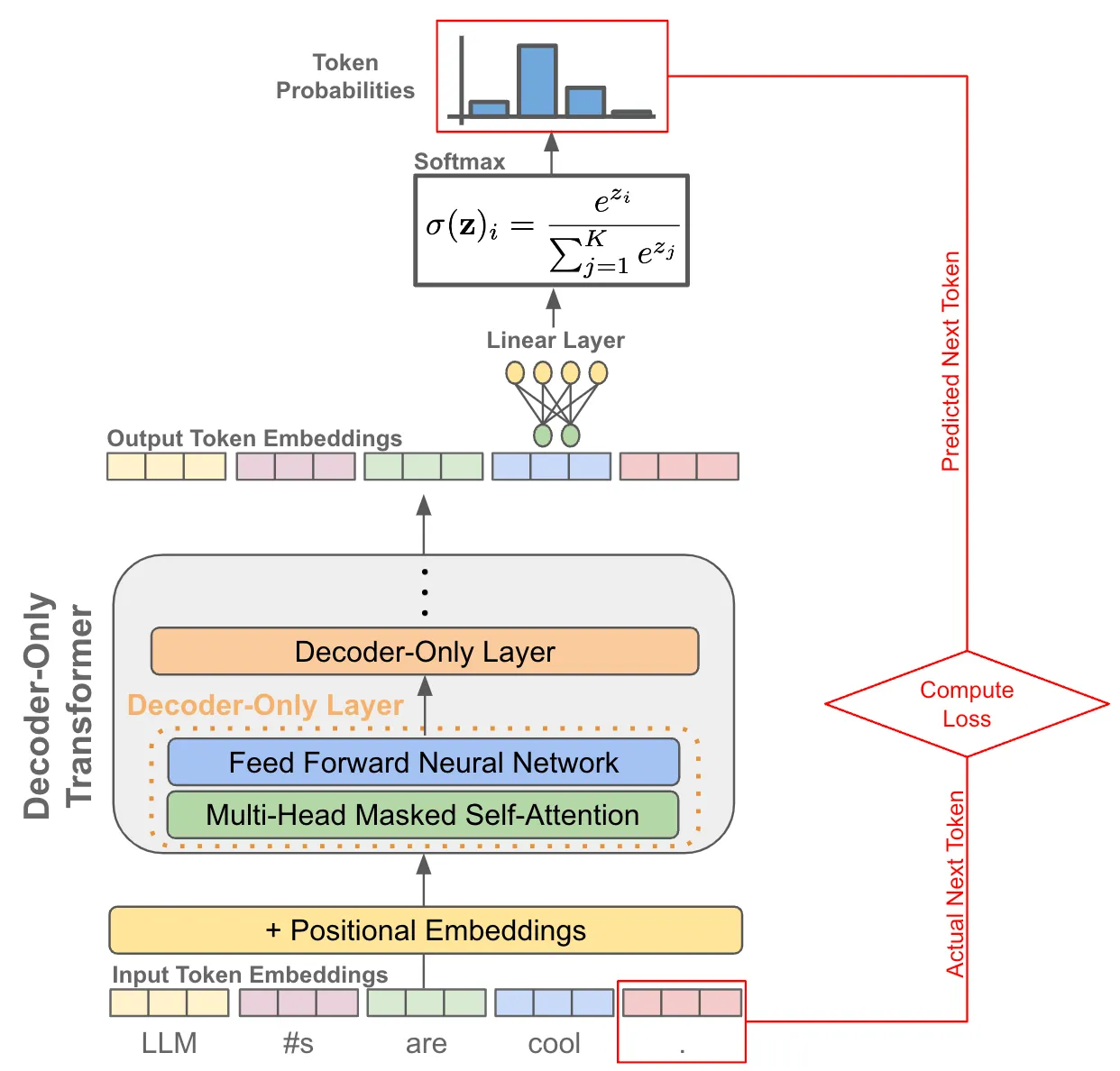
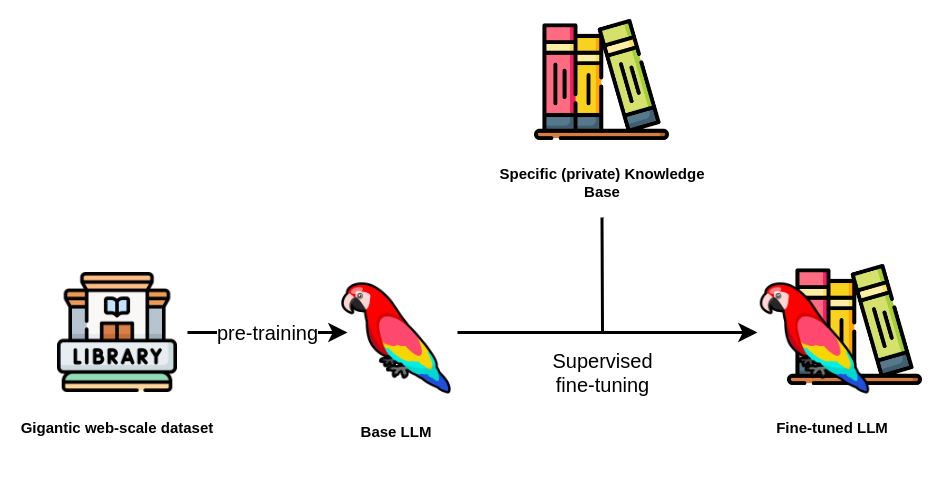
The 4 Stages of Training Large Language Models (LLMs): A Complete Guide
[Hands-on] Build Your Reasoning LLM
Processof changeresearchinsft chapter | PDF
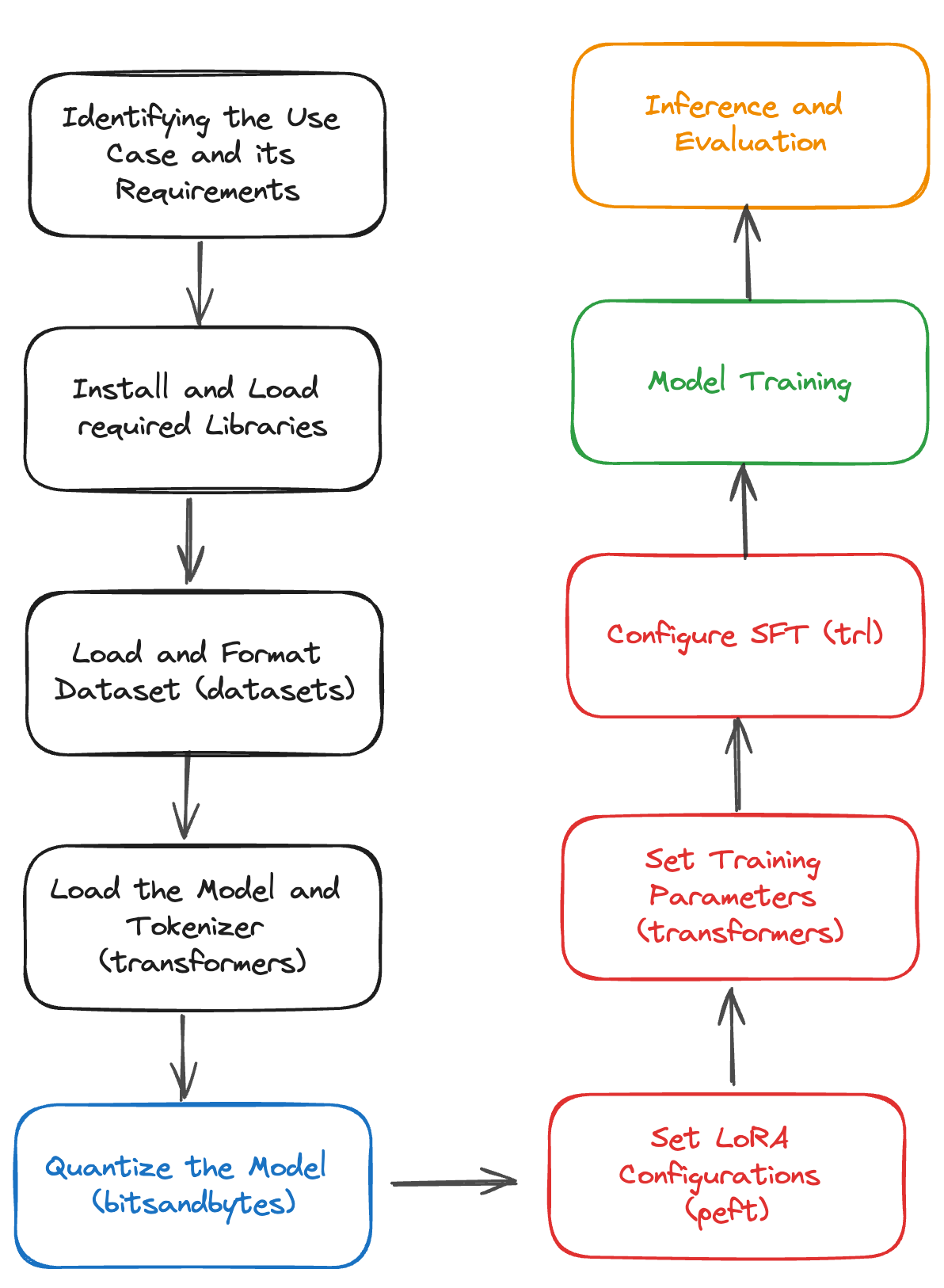
Fine-Tuning a Model Step by Step: Expert Guide
Supervised Fine-Tuning: How to Customize Your LLM?
Post-training of LLM(产品经理民科普及版) | 飞桨开源社区博客
大模型微调:SFT(Supervised Fine-Tuning)主要方式、SFT-训练参数如何调整_51CTO博客_模型微调的步骤
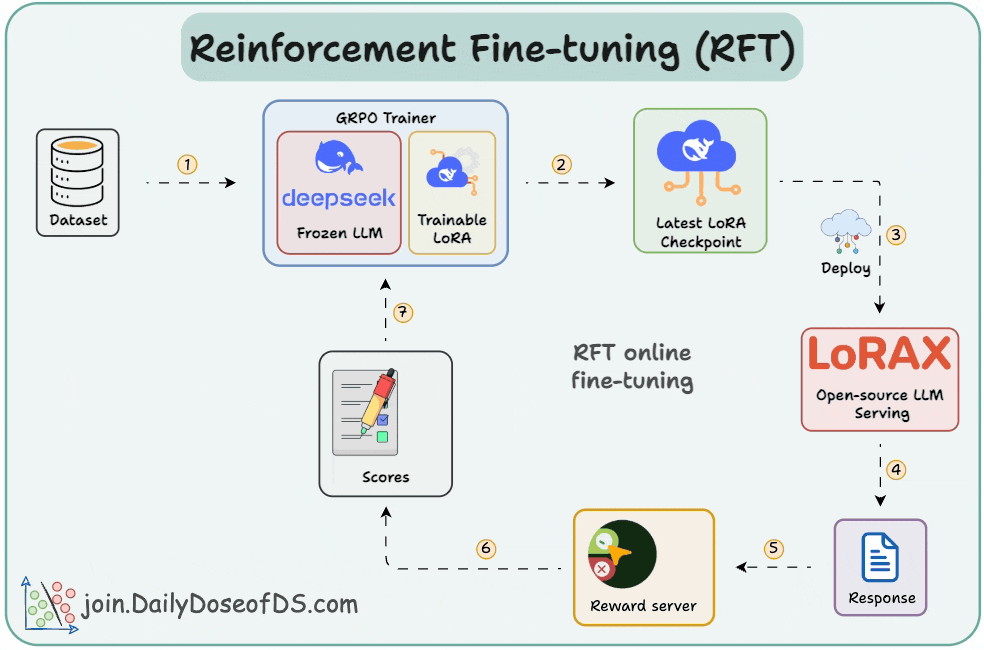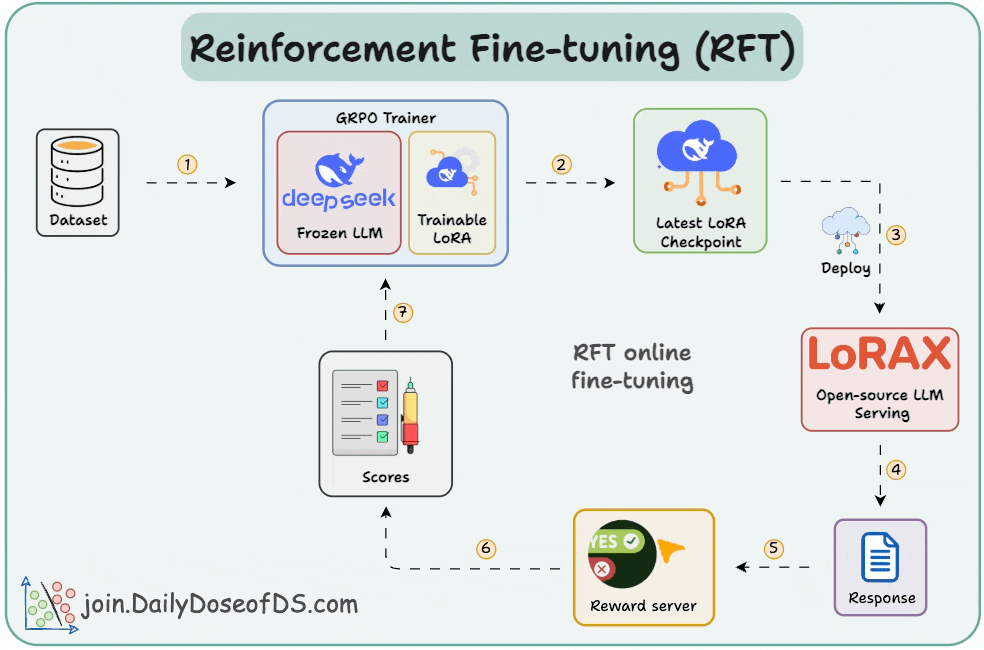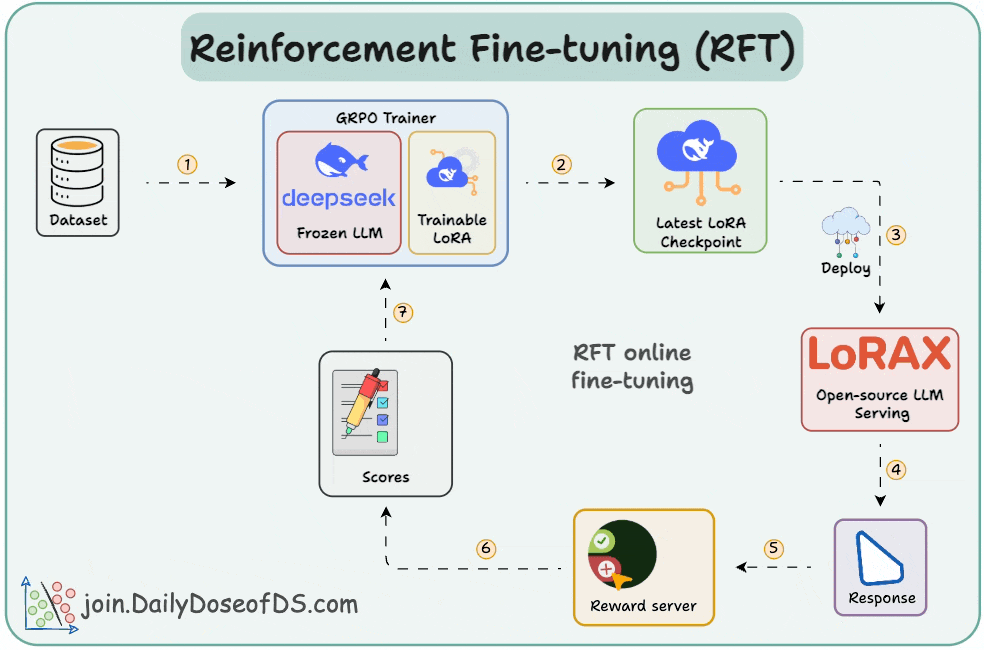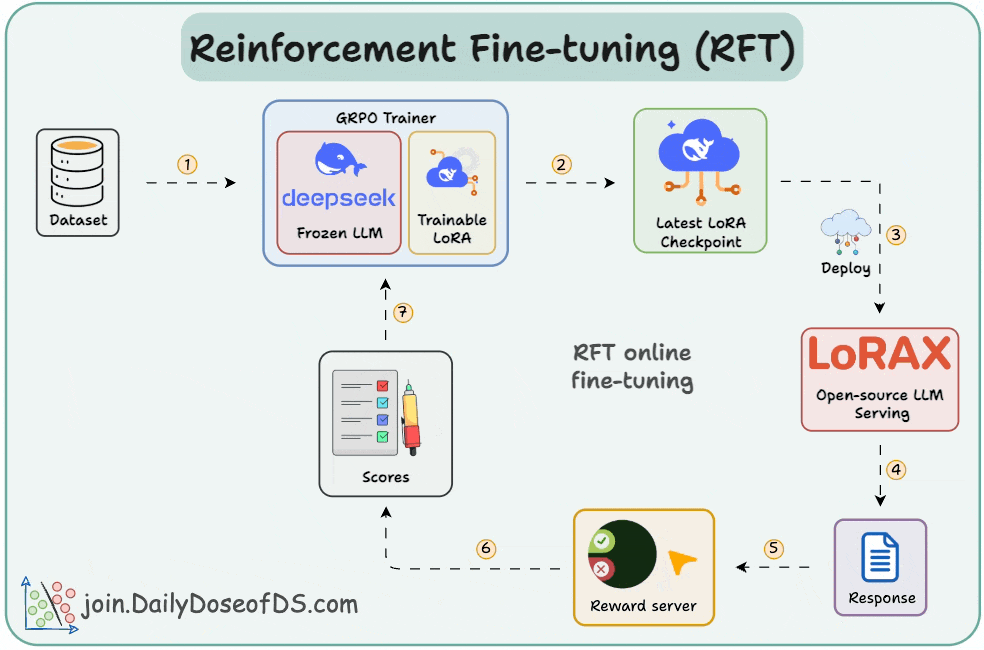
Deep Dive into OpenAI’s Reinforcement Fine-Tuning (RFT): Step-by-Step ...
大模型基础应用框架(ReACT\SFT\RAG)技术创新及零售业务落地应用-京东云开发者社区
[LLM] 大模型基础|预训练|有监督微调SFT | 推理_llm sft-CSDN博客
深入解析RFT:与SFT的对比及LLM微调范式的全面分析_rft sft-CSDN博客
讲解PSFT如何借鉴PPO机制解决SFT过拟合与熵坍塌-开发者社区-阿里云
【LLM数据篇】预训练数据集+指令生成sft数据集-CSDN博客
Chatgpt Incorporation Into Web Apps Reinforcement Learning From Human Feedb
[DRAFT1Learning to Summarize with trlX | summarize_RLHF – Weights & Biases
大模型训练四阶段从预训练SFT到增强学习RL-开发者社区-阿里云
Regenerative Artificial Intelligence Systems Reinforcement Learning From Hu
GitHub - karabenemsi/sft-lab-7-process-pairs
Front-Loading Reasoning: The Synergy between Pretraining and Post ...
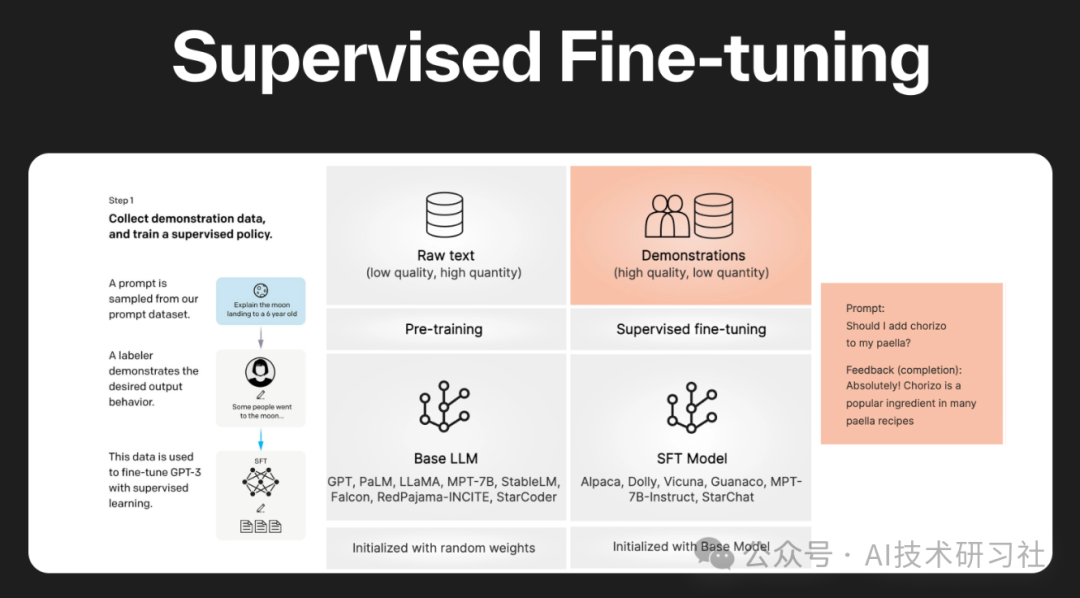
Illustration of self-supervised learning pre-training and fine-tuning ...
Supervised Fine-Tuning: What It Is and Key Techniques
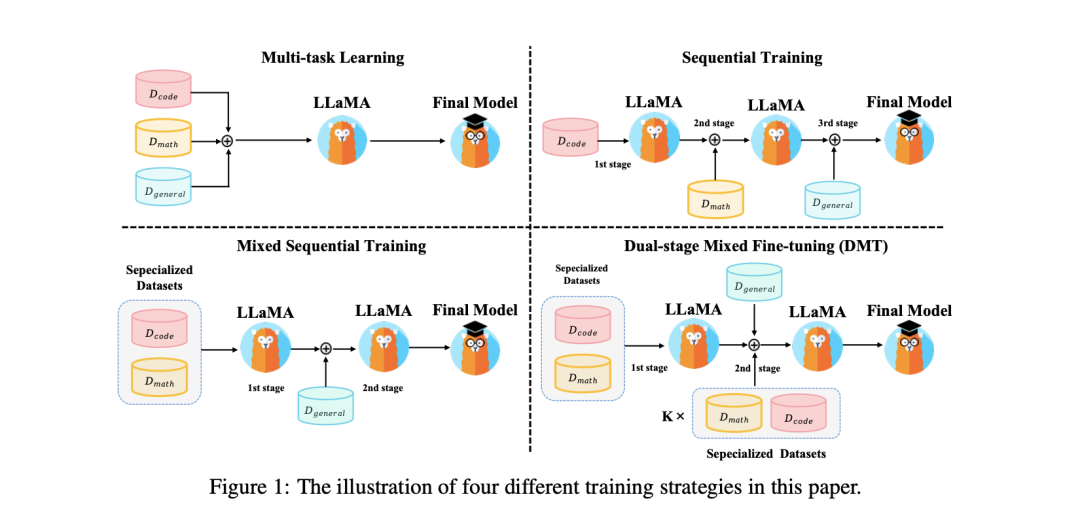
如何混合大模型SFT阶段的各能力项数据? - 知乎
HFT: Half Fine-Tuning for Large Language Models | AI Research Paper Details
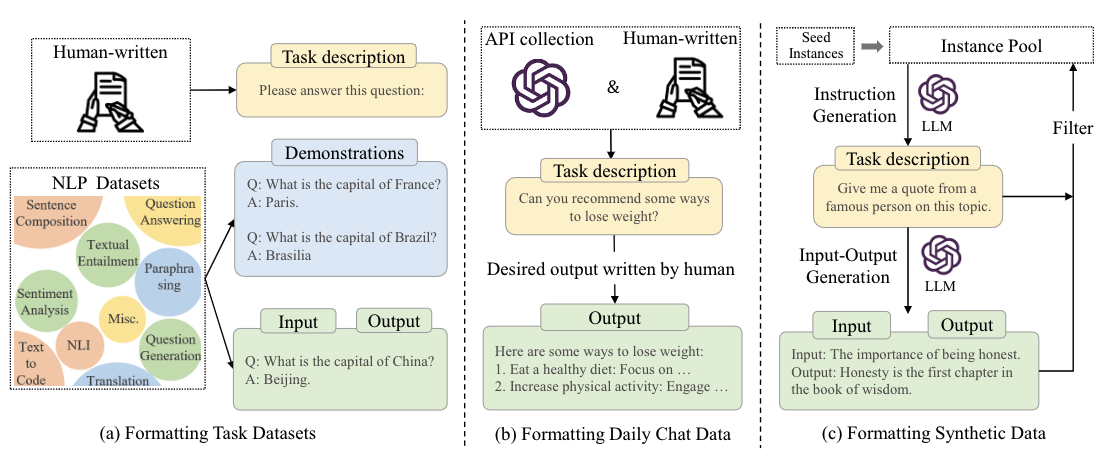
大模型(LLMs)LLM生成SFT数据方法面_sft数据集-CSDN博客
10 Ways to Opt-Out of AI Model Training on Popular Platforms - Fusion Chat
RAG vs. fine-tuning: Choosing the right method for your LLM | SuperAnnotate
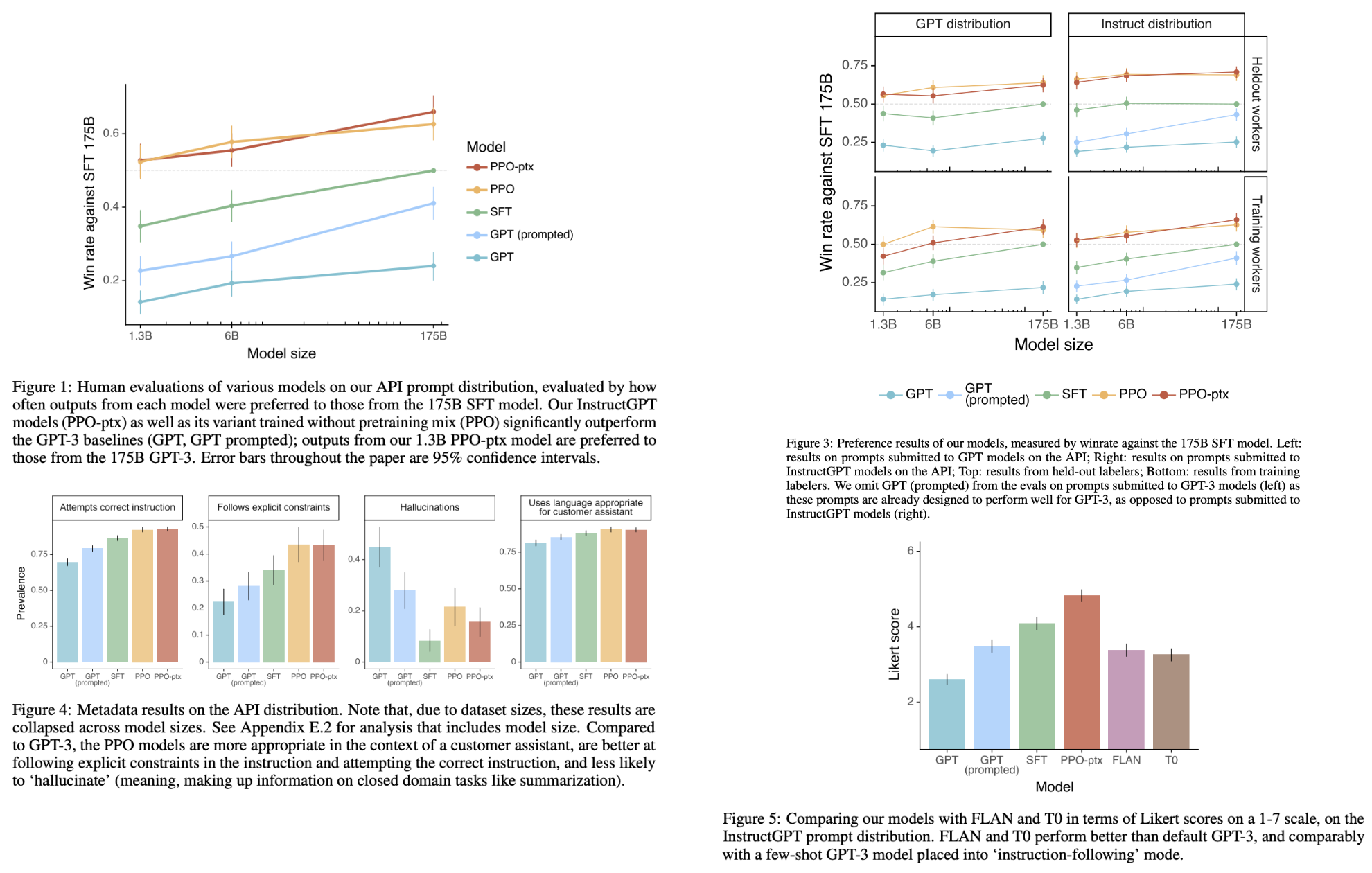
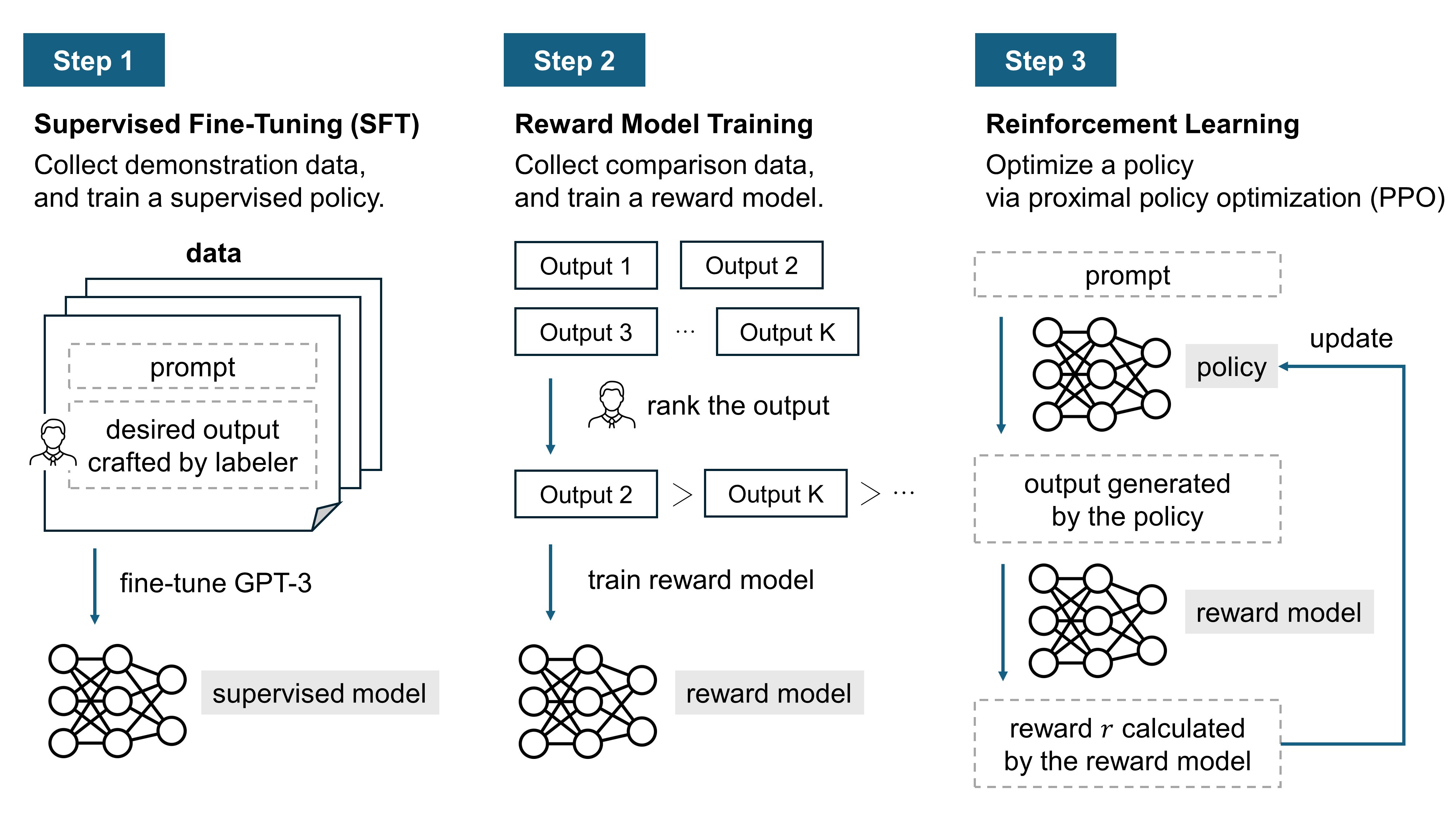
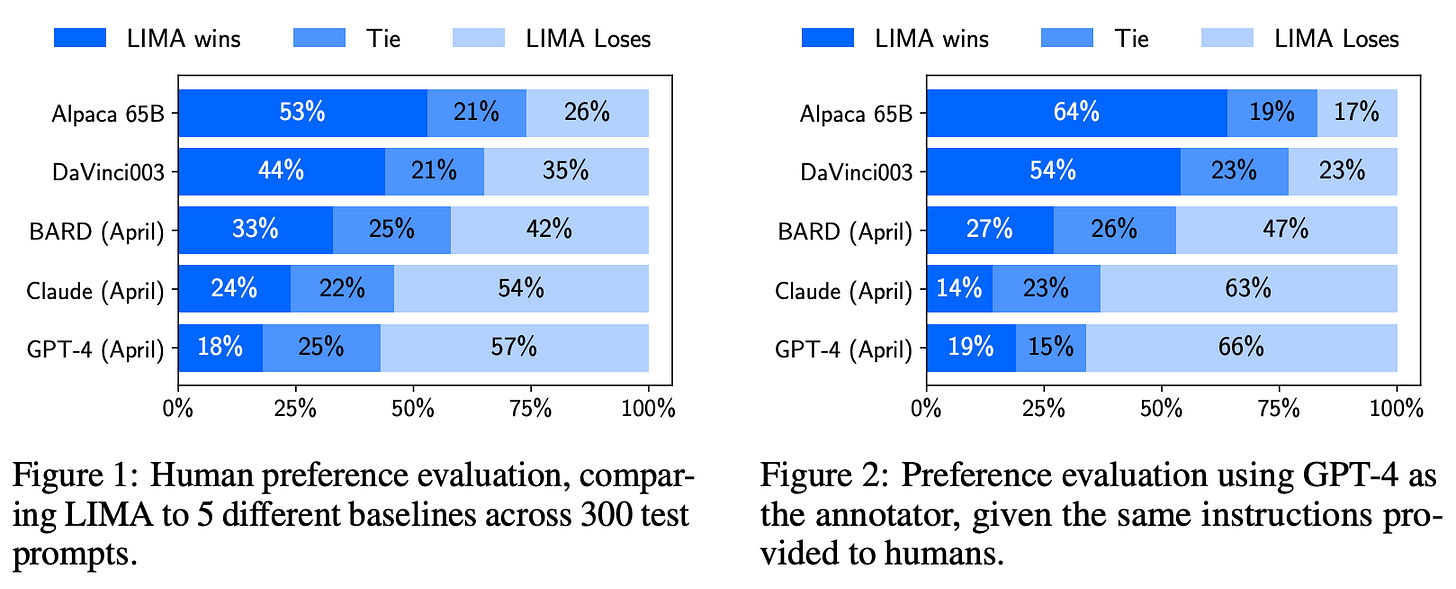
Training Language Models to Follow Instructions with Human Feedback ...
(PDF) Scaling of Search and Learning: A Roadmap to Reproduce o1 from ...
Supervised Fine-Tuning (SFT) Vs. Reinforcement Learning from Human ...
【基础】大模型的知识训练:模型训练的四个阶段 - 知乎
SFT_百度百科
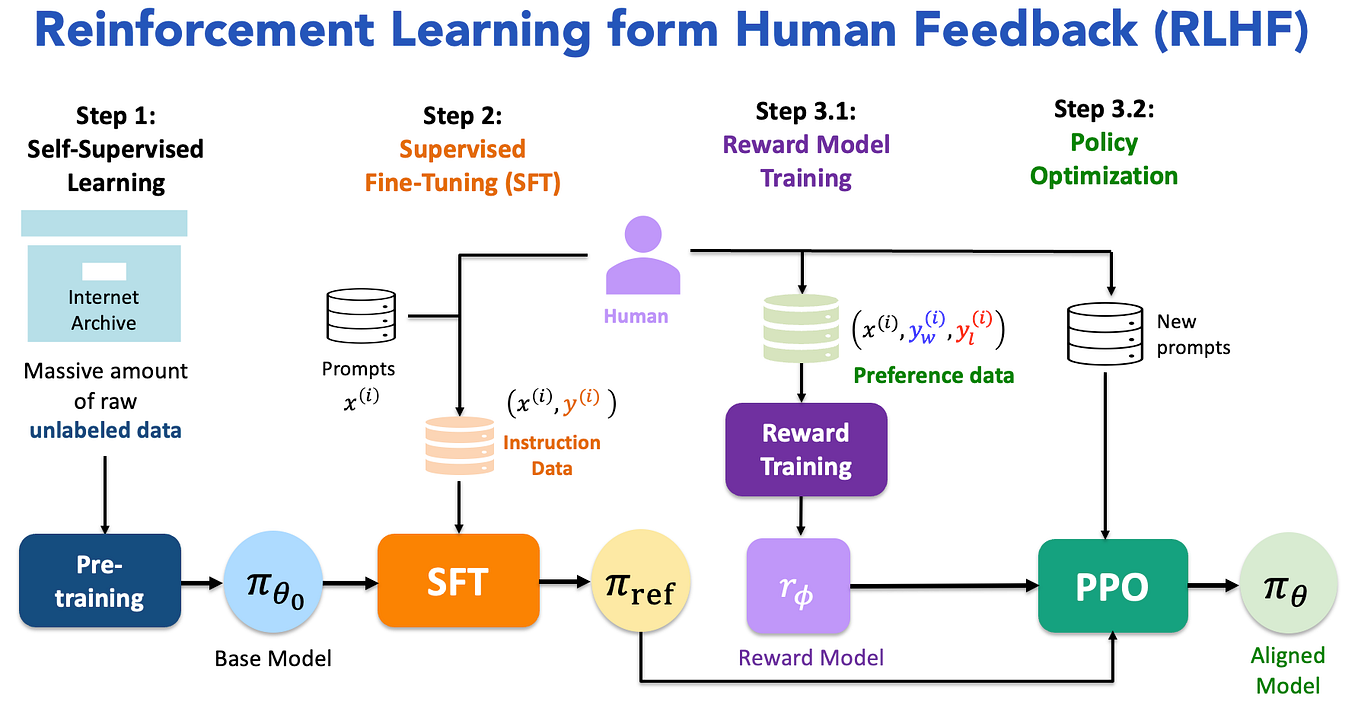
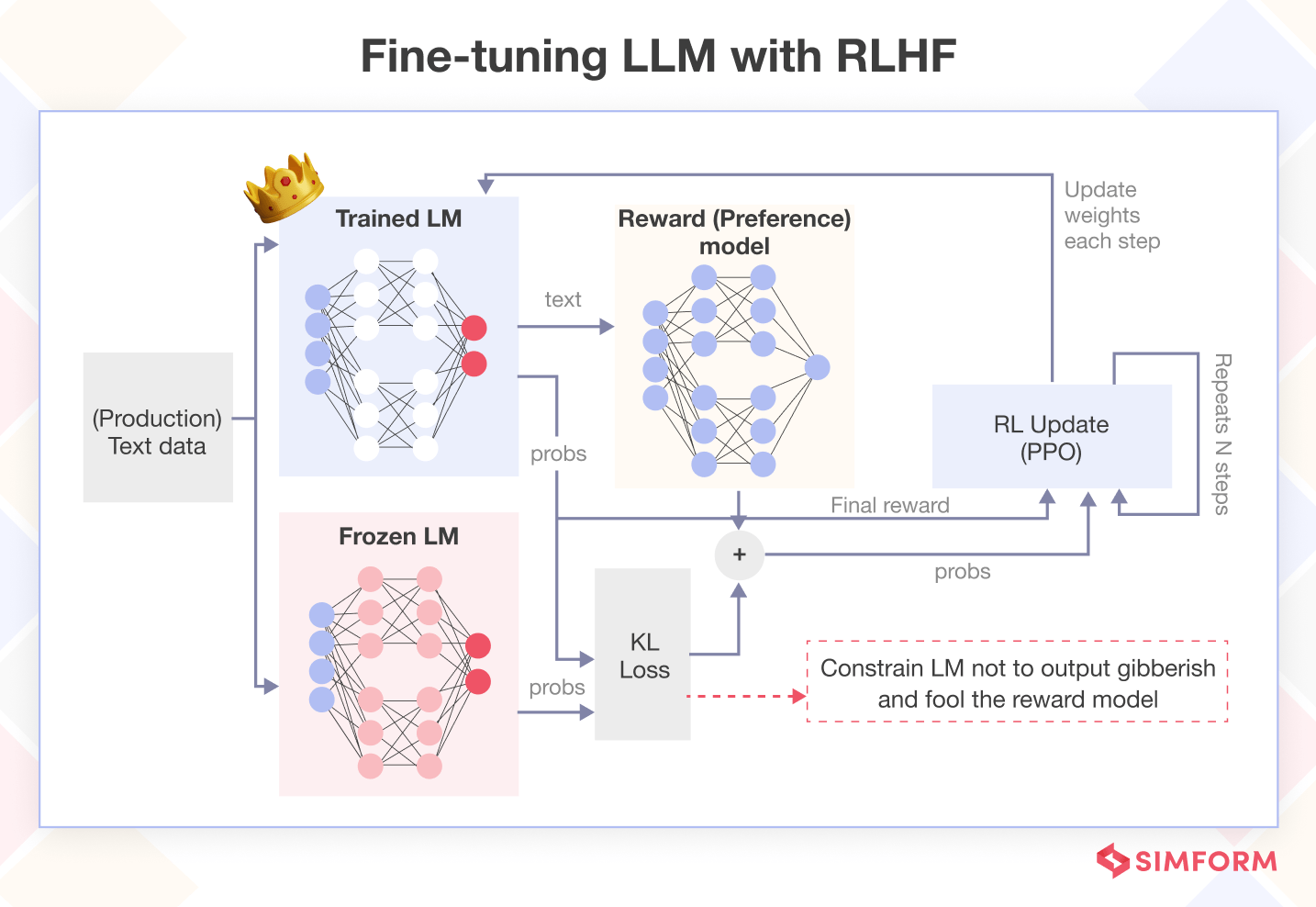
What is Reinforcement Learning from Human Feedback (RLHF)?
阿里云百炼SFT微调从数据准备到模型部署的全流程实践-开发者社区-阿里云
Guide to Reinforcement Finetuning - Analytics Vidhya
Supervised Fine-Tuning Summary | PDF | Artificial Intelligence ...
Safety Forecasting Tool
Retraining LLM: A Comprehensive Guide
Fine-Tuning vs. Retrieval Augmented Generation for LLMs
Fine-tuning Large Language Models: Complete Optimization Guide
Gas Burner归档 - SFT: Professional Solution Provider for Industrial ...
The complete guide to LLM fine-tuning - TechTalks
大语言模型参数高效微调SFT LoRA P-tuning Freeze详解-开发者社区-阿里云
How skills-first transformation can unlock a new approach to talent ...
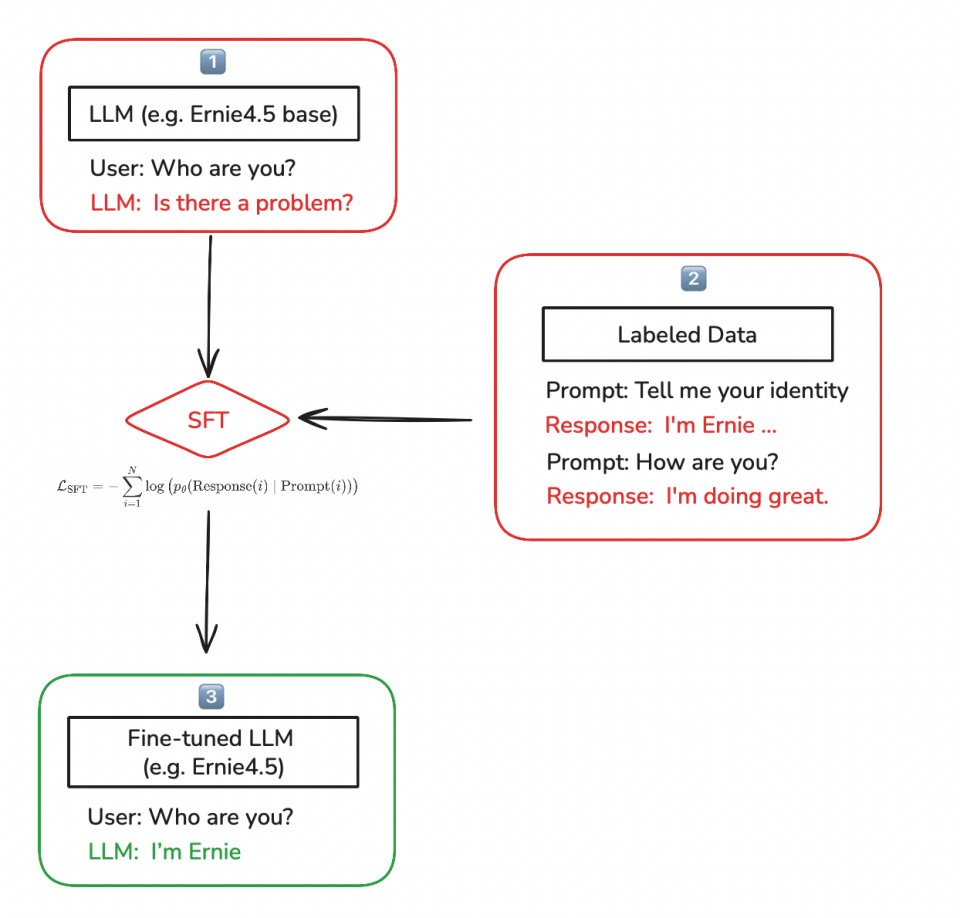
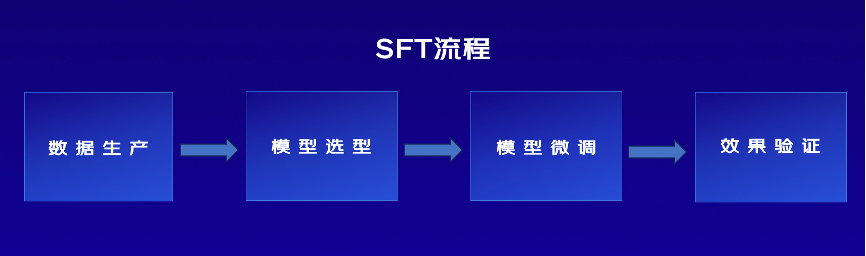
SFT最佳实践 - 千帆大模型平台 | 百度智能云文档
人工智能大语言模型微调技术:SFT 监督微调、LoRA 微调方法、P-tuning v2 微调方法、Freeze 监督微调方法_汀丶人工智能的 ...
SRFT: A Single-Stage Method with Supervised and Reinforcement Fine ...
Difference between Trainer class and SFTTrainer (Supervised Fine tuning ...
20分钟上手TRL:从SFT到DPO的完整训练流程-CSDN博客
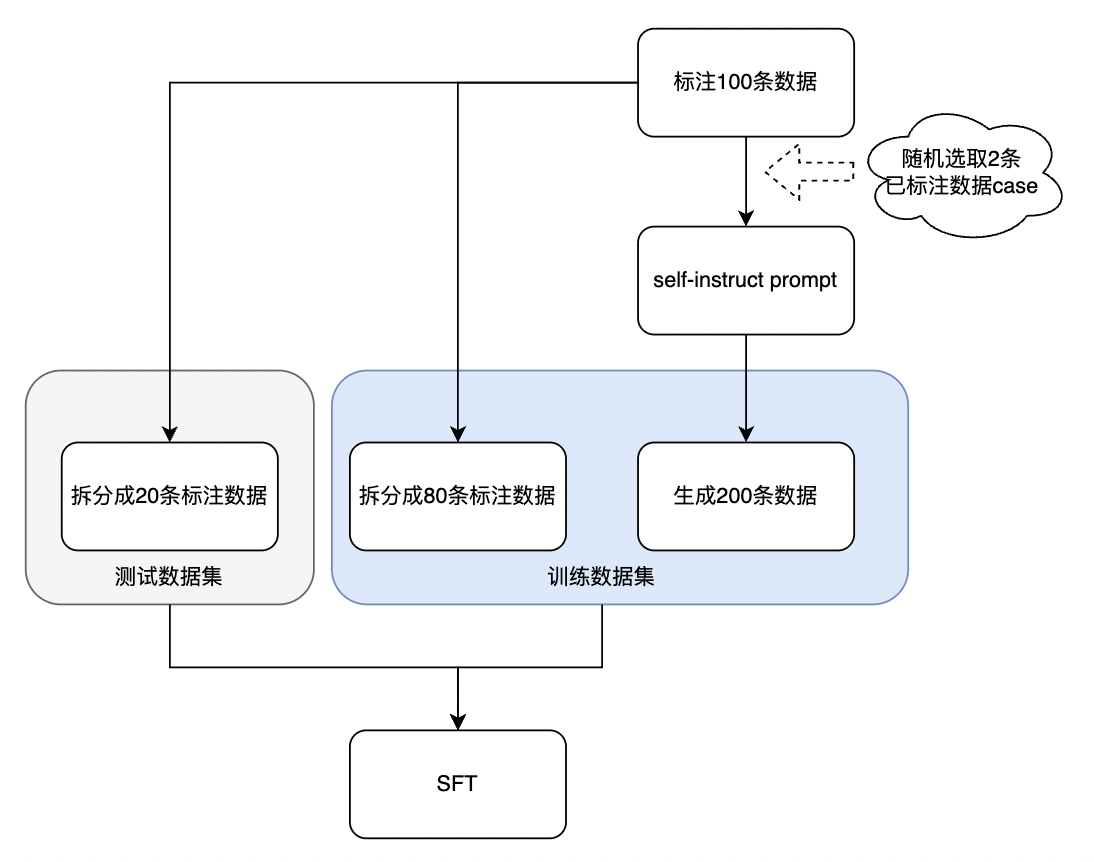
SFT微调的数据组合及训练策略如何影响大模型性能:4个经典问题及实验结论分享 - 智源社区