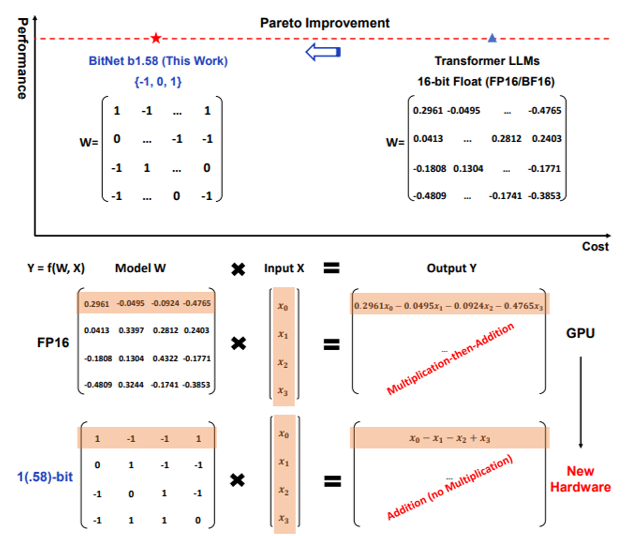
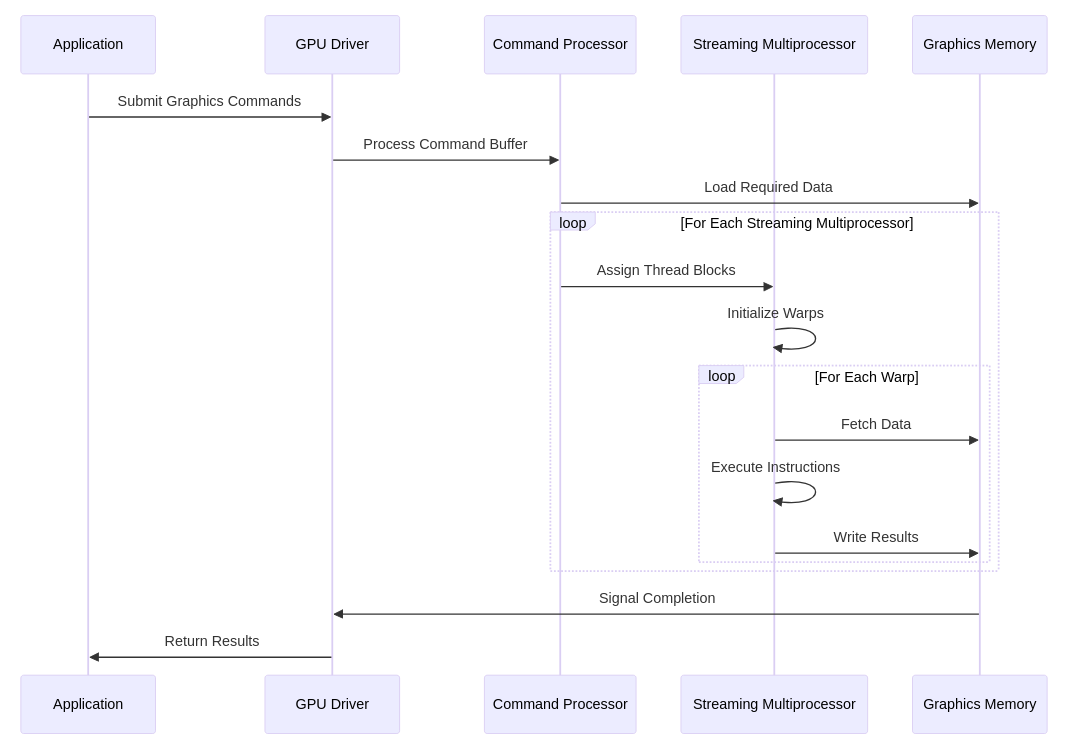
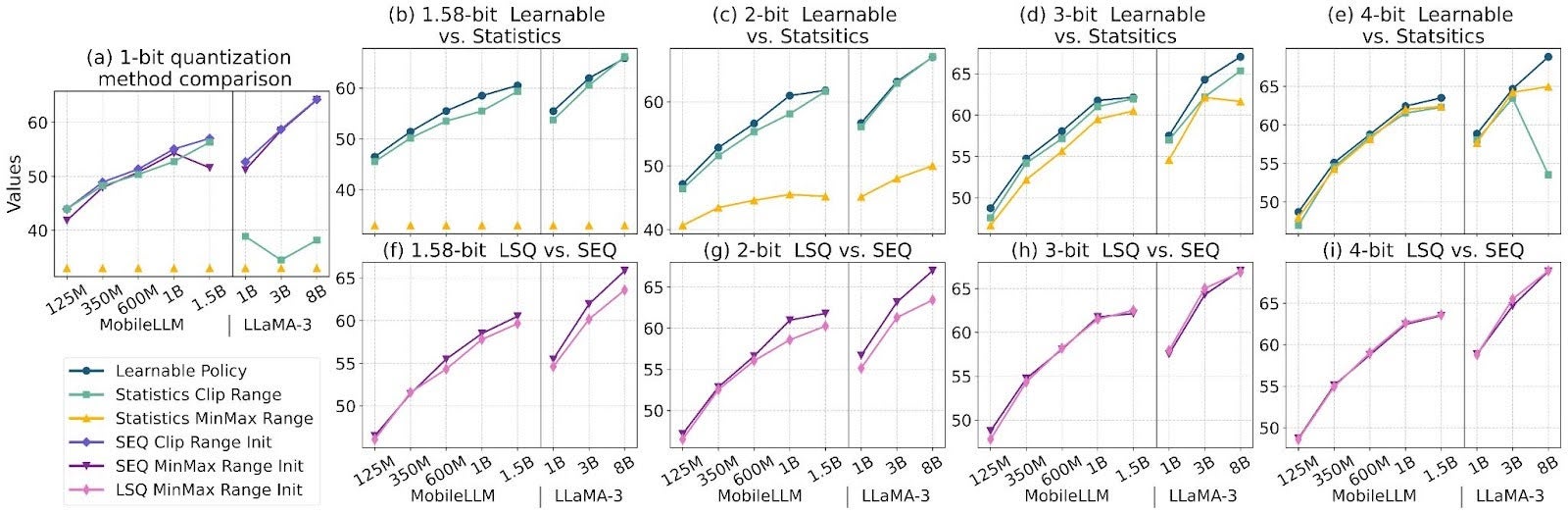
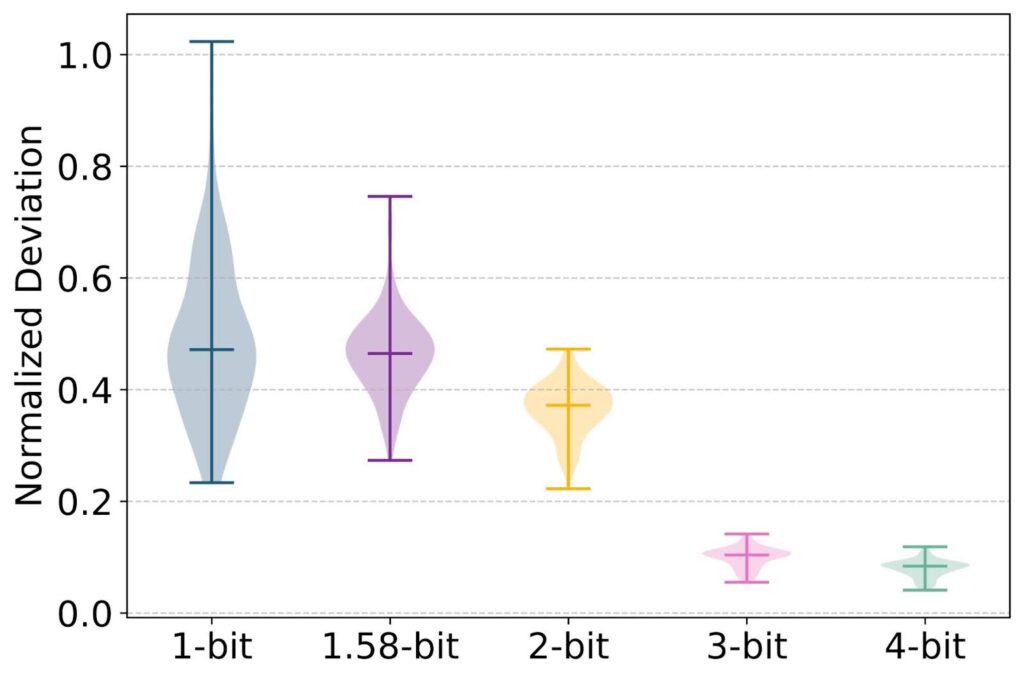
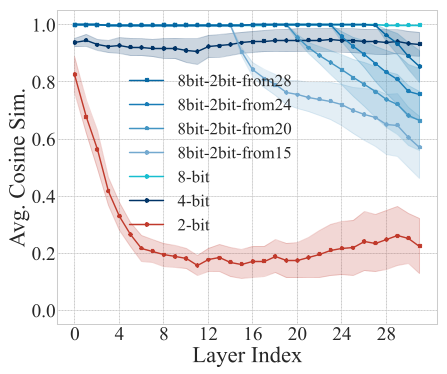
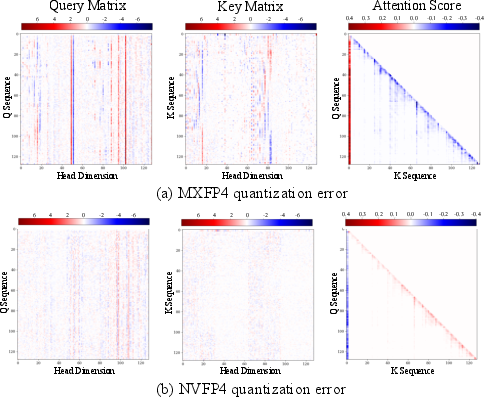
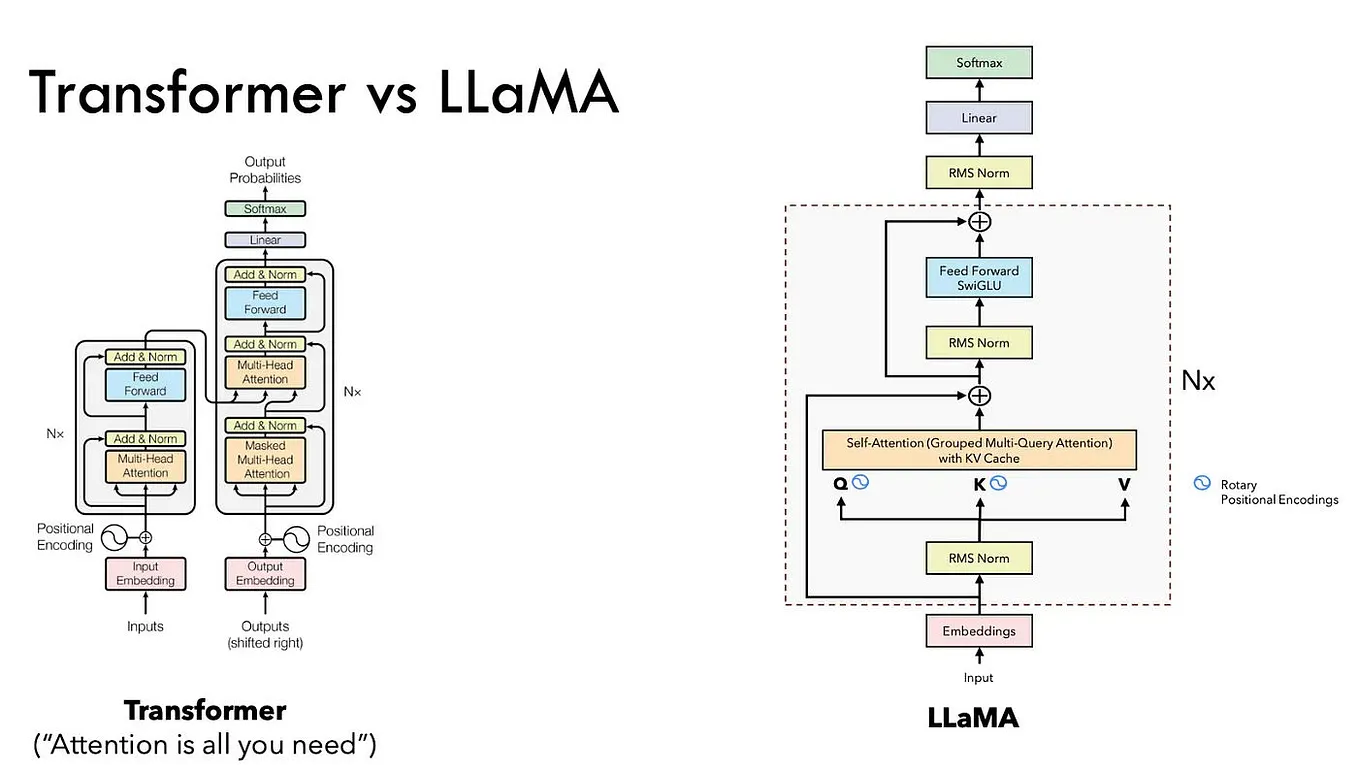
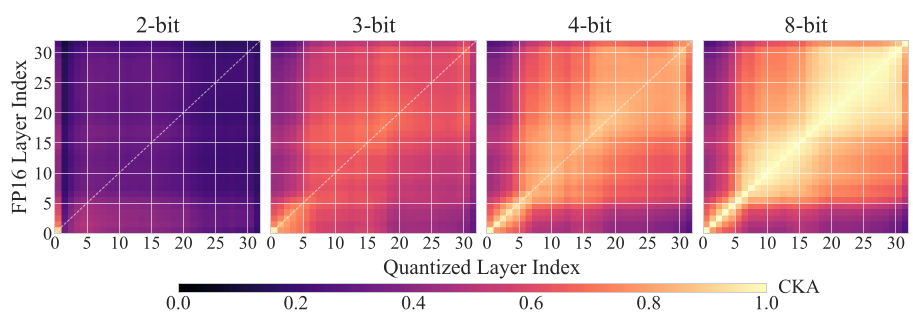
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
1-Bit LLM and the 1.58 Bit LLM- The Magic of Model Quantization | by Dr ...
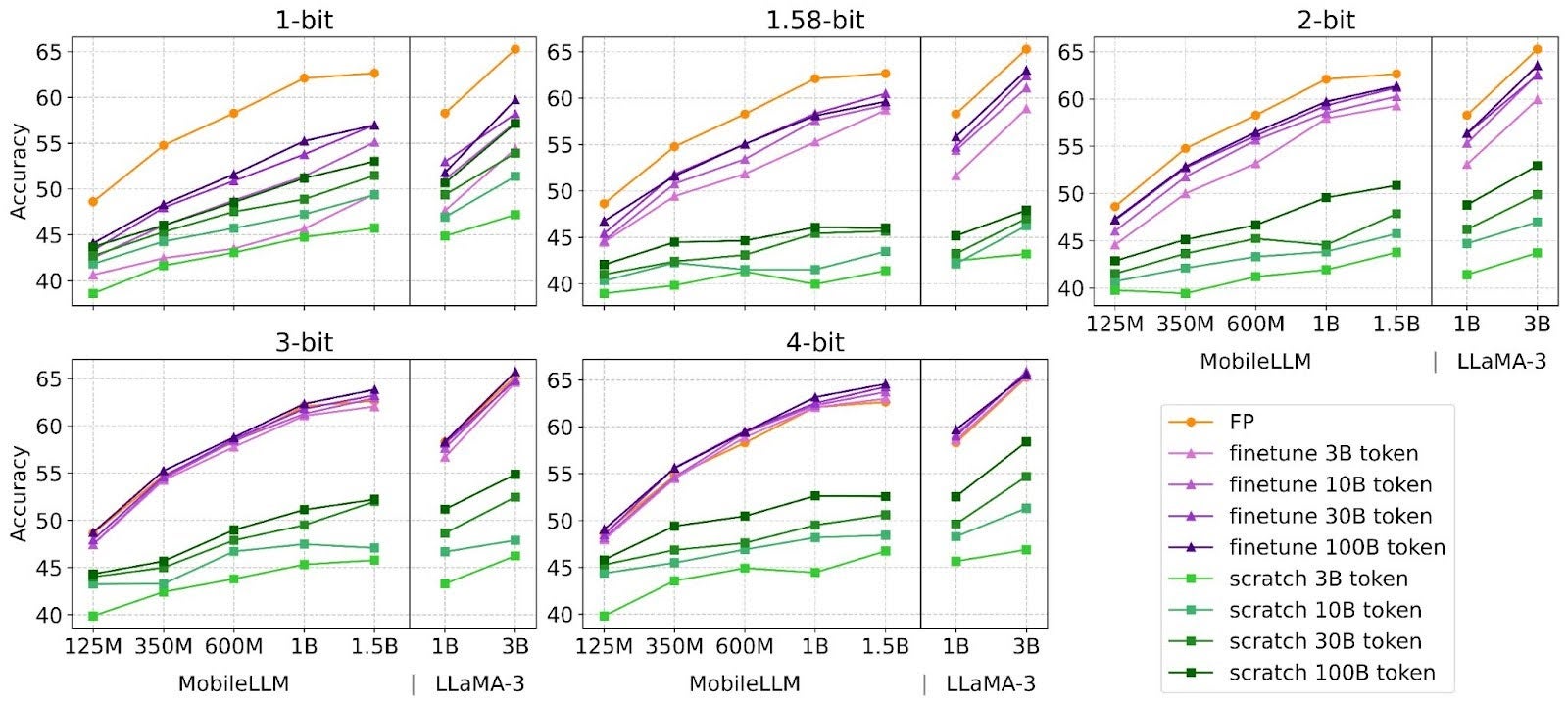
ParetoQ: Scaling Laws in Extremely Low-bit LLM Quantization – PyTorch
Advances to low-bit quantization enable LLMs on edge devices ...
How to optimize large deep learning models using quantization
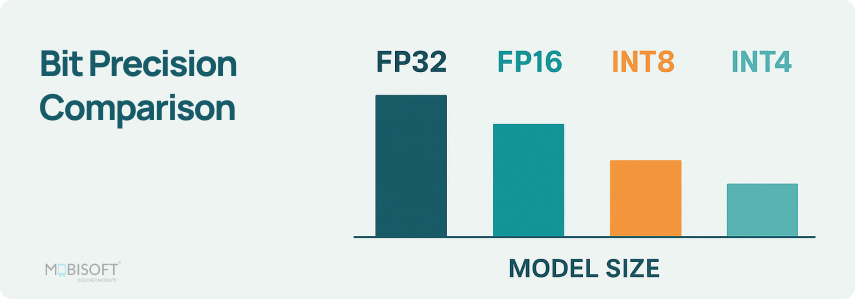
What is Quantization in LLM? A Complete Guide to Optimizing AI
Top LLM Quantization Methods and Their Impact on Model Quality
A Comprehensive Guide On LLM Quantization And Use Cases
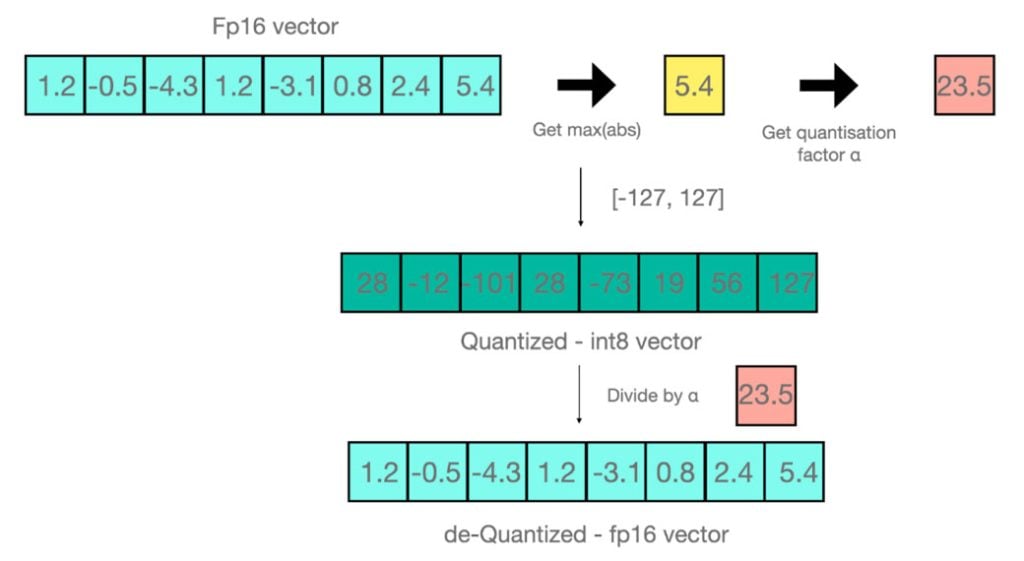
A Visual Guide to LLM Quantization by Maarten Grootendorst | Shivanand ...
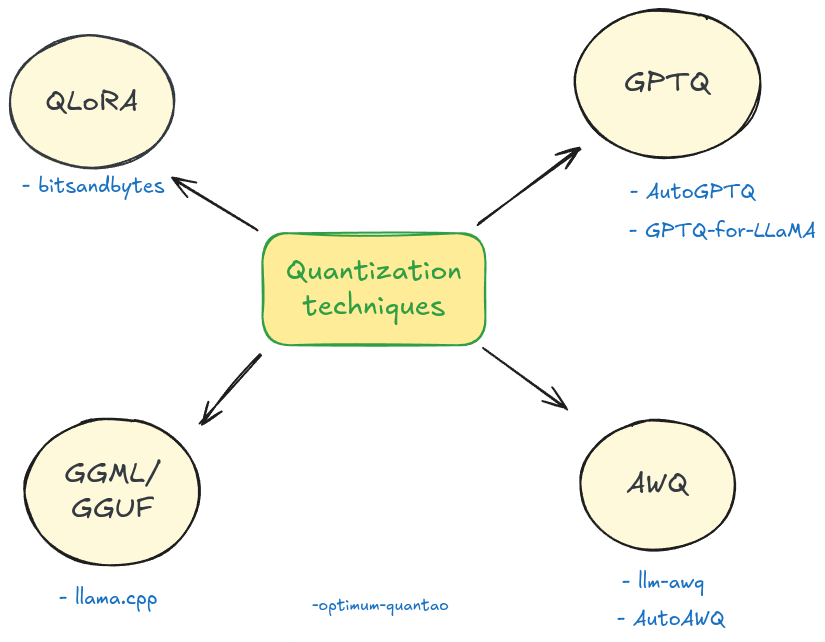
Practical Guide to LLM Quantization Methods - Cast AI
QLLM: Accurate and Efficient Low-Bitwidth Quantization for Large ...
PB-LLM: a cutting-edge technique for extreme low-bit quantization in ...
Microsoft AI Researchers Introduce Advanced Low-Bit Quantization ...
Understanding Quantization for LLMs | by LM Po | Medium
Figure 1 from Atom: Low-bit Quantization for Efficient and Accurate LLM ...
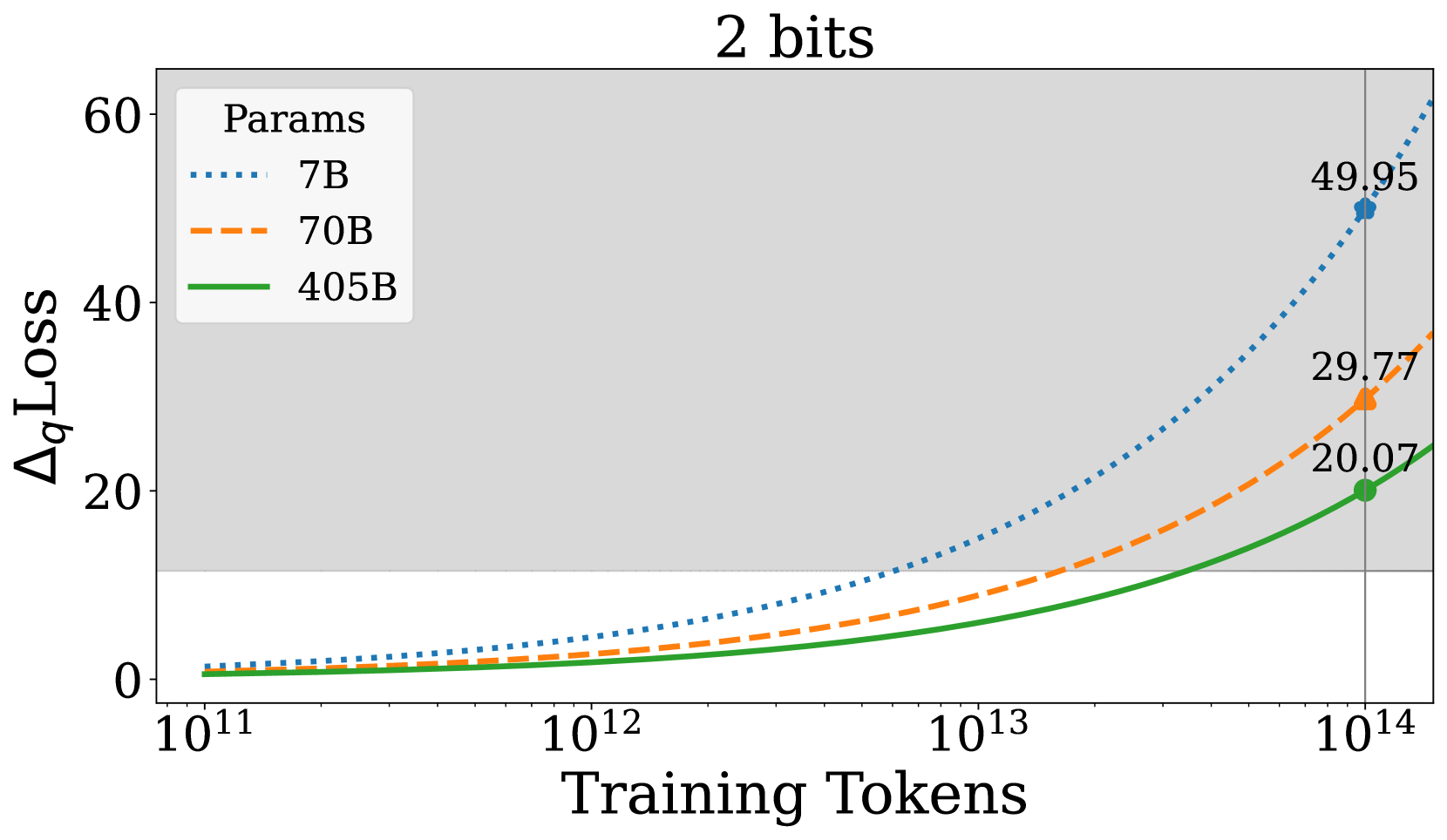
Low-Bit Quantization Favors Undertrained LLMs: Scaling Laws for ...
Democratizing LLMs: 4-bit Quantization for Optimal LLM Inference | by ...
[論文レビュー] Quantization Meets Reasoning: Exploring LLM Low-Bit ...
The Ultimate Handbook for LLM Quantization | Towards Data Science
A Comprehensive Guide on LLM Quantization and Use Cases
Democratizing LLMs: 4-bit Quantization for Optimal LLM Inference ...
4-bit Quantization with GPTQ | Towards Data Science
Exploring Model Quantization for LLMs | by Snehal | Medium
BitsAndBytesConfig: Simplifying Quantization for Efficient Large ...
Making LLMs even more accessible with bitsandbytes, 4-bit quantization ...
4-bit LLM Quantization with GPTQ - Origins AI
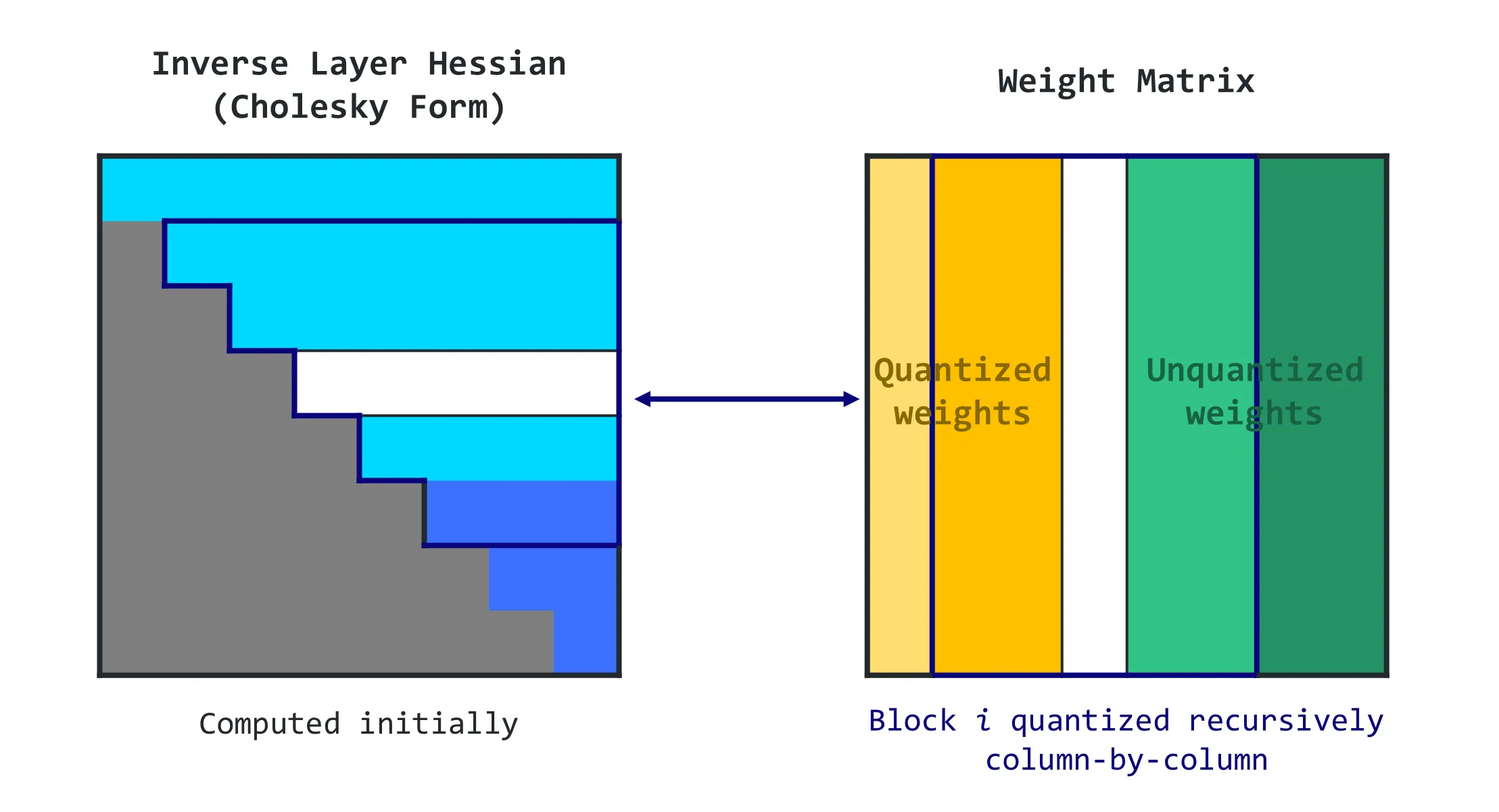
Atom: Low-bit Quantization for Efficient and Accurate LLM Serving ...
Quantization for Local LLMs: How It Works and Which Formats Fit Your Setup
Advances to low-bit quantization enable LLMs on edge devices - 智源社区
A Beginner's Guide to LLM Quantization
Quantization in LLMs: Why Does It Matter? | by Aimee Coelho | data from ...
GLM-130B LLM demonstrates 4-bit quantization loss shrinks as model ...
Quantization Techniques to Reduce LLM Model Size and Memory: A Complete ...
Model Quantization for Neural Networks: Tools, Methods, & More
What is Quantization in LLM. Large Language Models comes in all… | by ...
[LG] BiLLM: Pushing the Limit of Post-Training Quantization for LLMs ...
What LLM quantization works best for you? Q4_K_S or Q4_K_M | by Michael ...
Postmortem: How a Quantization Error in Llama 3.2 7B Caused Incorrect ...
Using Gemma-4-26B-A4B at 4-bit quantization seems to degrade tool ...
Navigating the Complexities of LLM Quantization : r/programming
Table 1 from Towards Joint Quantization and Token Pruning of Vision ...
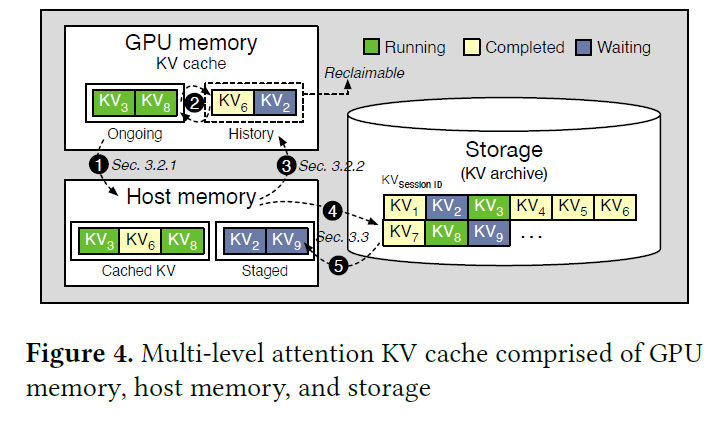
Dropping a paper. Since we're doing vector quantization on KV now, I ...
Figure 1 from Compensation of Coarse Quantization Effects on Channel ...
Exploiting LLM Quantization - 智源社区论文
LLM Quantization-Build and Optimize AI Models Efficiently
Maximizing Business Potential with Large Language Models (LLMs)
Parameter-Efficient LLM Finetuning With Low-Rank Adaptation (LoRA ...
[vLLM — Quantization] bitsandbytes: 8-bit Optimizers, LLM.int8(), QLoRA ...
Introduction to llm-finetuning and Quantization. Refining Generative ...
LLM Quantization: Making models faster and smaller | MatterAI Blog
Faster and More Efficient 4-bit quantized LLM Model Inference | by ...
How to run new 1-bit LLM on your CPU Machine using microsoft’s BitNet ...
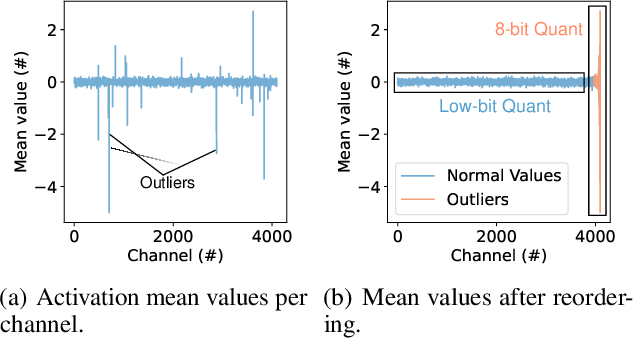
(PDF) Why Do Some Inputs Break Low-Bit LLM Quantization?
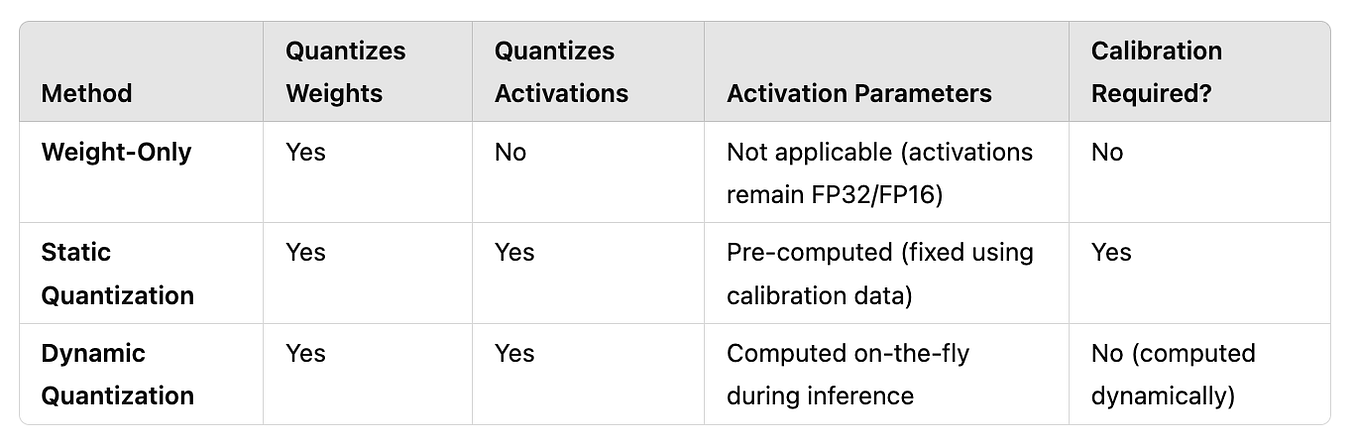
LLM Quantization: Weight-Only? Static? Dynamic? | by hebiao064 | Medium
LLM量化对效果的影响 - How Good Are Low-bit Quantized LLAMA3 Models? An ...
Crusadersk/mistral-7b-awq-4bit · Hugging Face
From Signal Degradation to Computation Collapse: Uncovering the Two ...
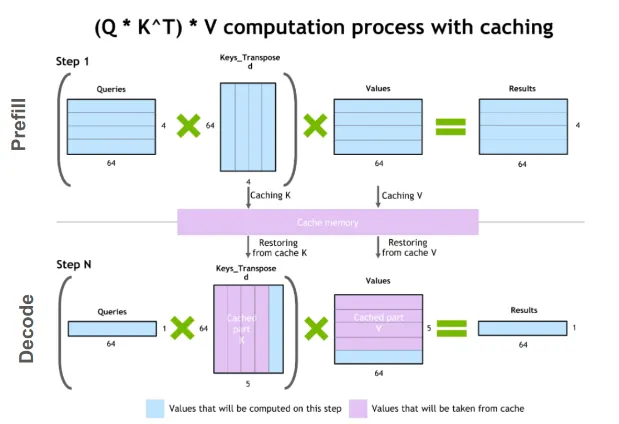
Diagonal-Tiled Mixed-Precision Attention for LLMs
rdtand/Qwen3.6-27B-PrismaQuant-5.5bit-vllm · Hugging Face
4bit-Quantization in Vector-Embedding for RAG Proposes 4-bit ...
Understanding LLM Quantization. With the surge in applications using ...
Google Introduces TurboQuant: A New Compression Algorithm that Reduces ...
LLM Quantization: A Comprehensive Guide to Model Compression for ...
ใครจะเชื่อว่า Model 2-bit ไฟล์แค่... - AI ย่อยง่าย by New | Facebook
GreenTune: Energy-Efficient Low-Rank Tuning of LLMs with ThreeE ...
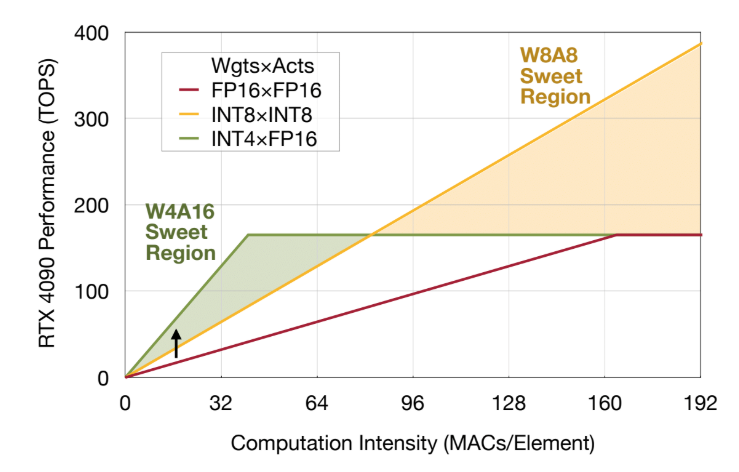
7+ main precision formats used in AI ️ FP32 ️ FP16 ️ BF16 ️ FP8 (E4M3 ...
Anyone telling me context is the problem. It’s limited but not ...
config.json · mlx-community/Huihui-Qwen3.6-35B-A3B-Claude-4.7-Opus ...
AI Infra Brief|AI Ethics Debate, 1-Bit LLMs, Browser Agents ...
Geek - Qwen 3.6 : 27B เปิด opensource แล้วใช้งานบน local ได้แล้ว ...
Samsung and SK hynix Unlikely to Face Another 'Plunge'... Google ...
ruygar/gemma-4-E4B-it-BB · Hugging Face
How Much VRAM Do You Need for Local LLMs? | PCPartGuide
Paul B. (@PaulBalanca) / Posts / X
The numbers: - 5.02x compression (3 bits/coordinate) ~0.985 cosine ...
🦥 Just posted by @UnslothAI: DeepSeek-V4 is here! 🔥 DeepSeek-V4-Pro (1 ...
What are the best AI models you can fit on disks? Here are my guesses ...
athanor-ai/DeepSeek-Prover-V2-7B-GPTQ-4bit · Hugging Face
FHE-Enabled Llama-3 Inference
vixhaℓ (@TheVixhal) on X
When I was consulting for @HBO Silicon Valley, zero-loss compression ...
Small Language Models: The Decentralized AI Revolution - Alabia ...
Bonsai 8B Model 2026: Complete Guide to the Efficient 1-Bit Language Model
A Qwen 3.5 9B AI model now runs on just ~4–6GB VRAM. Here’s the trick ...