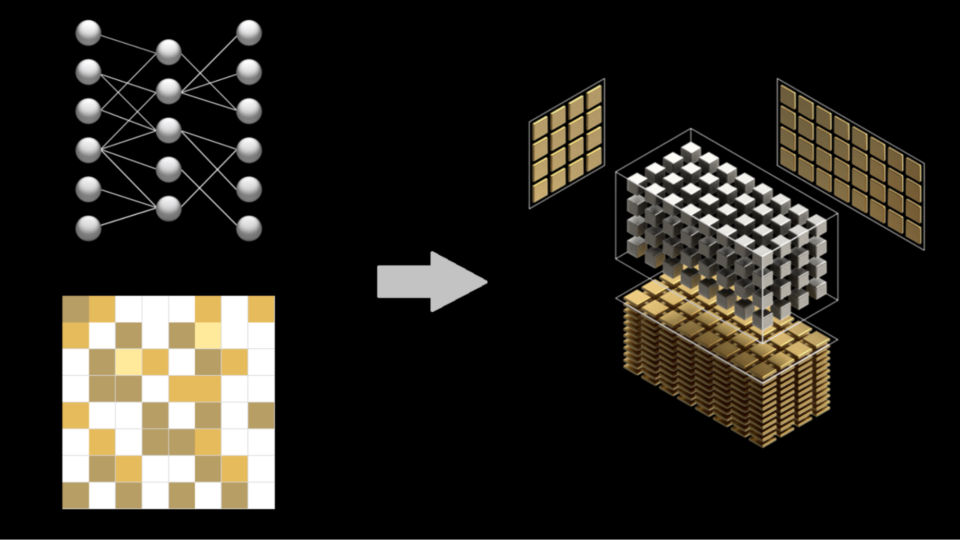
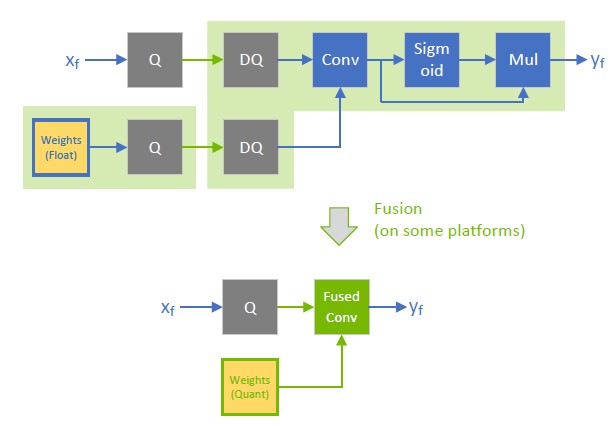
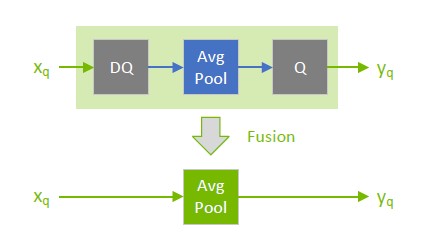
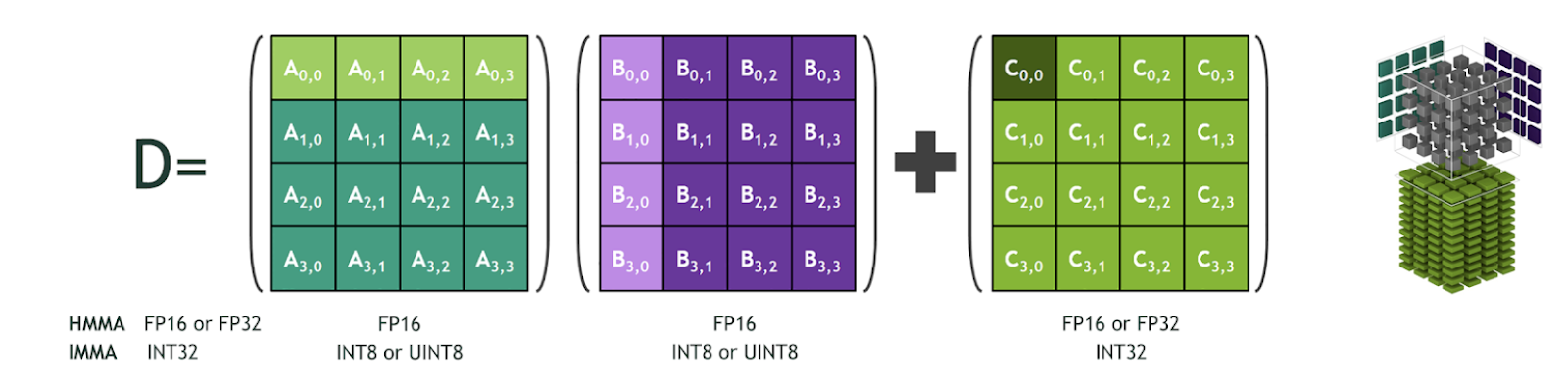
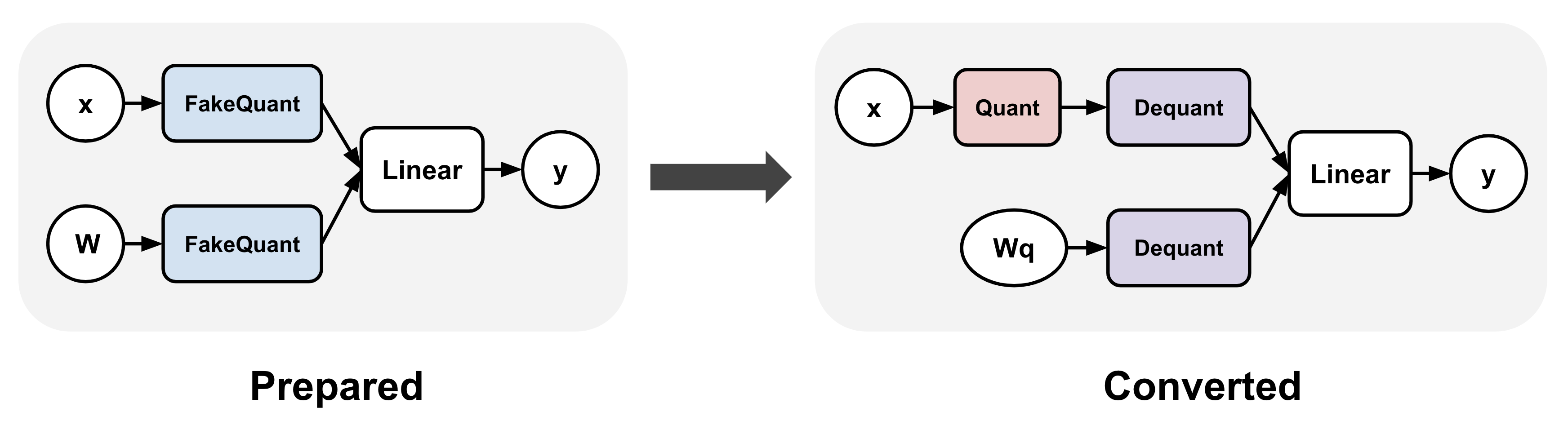
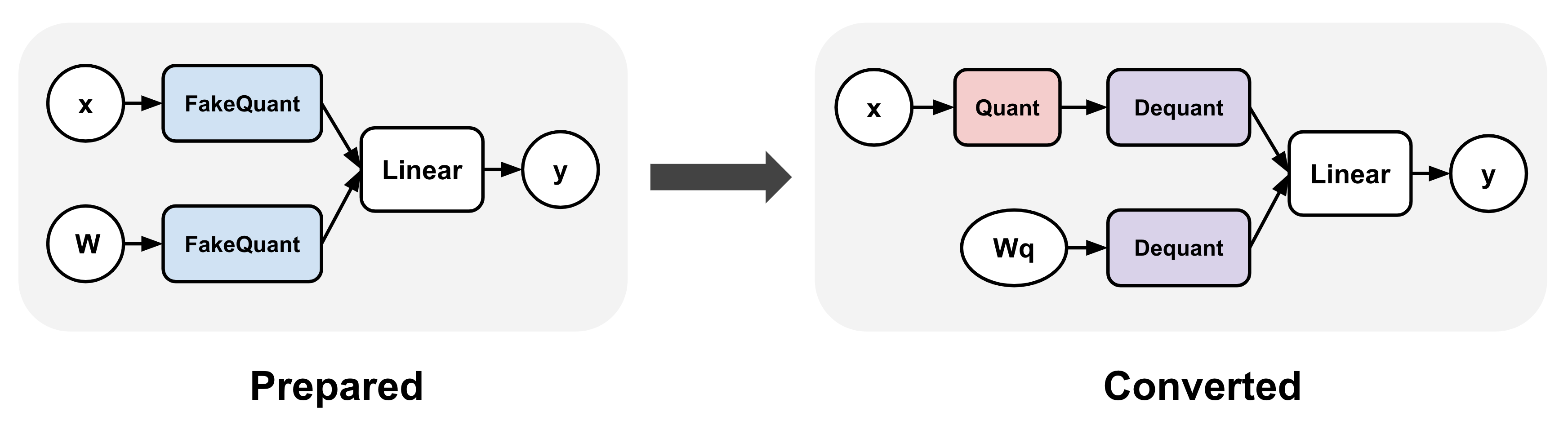
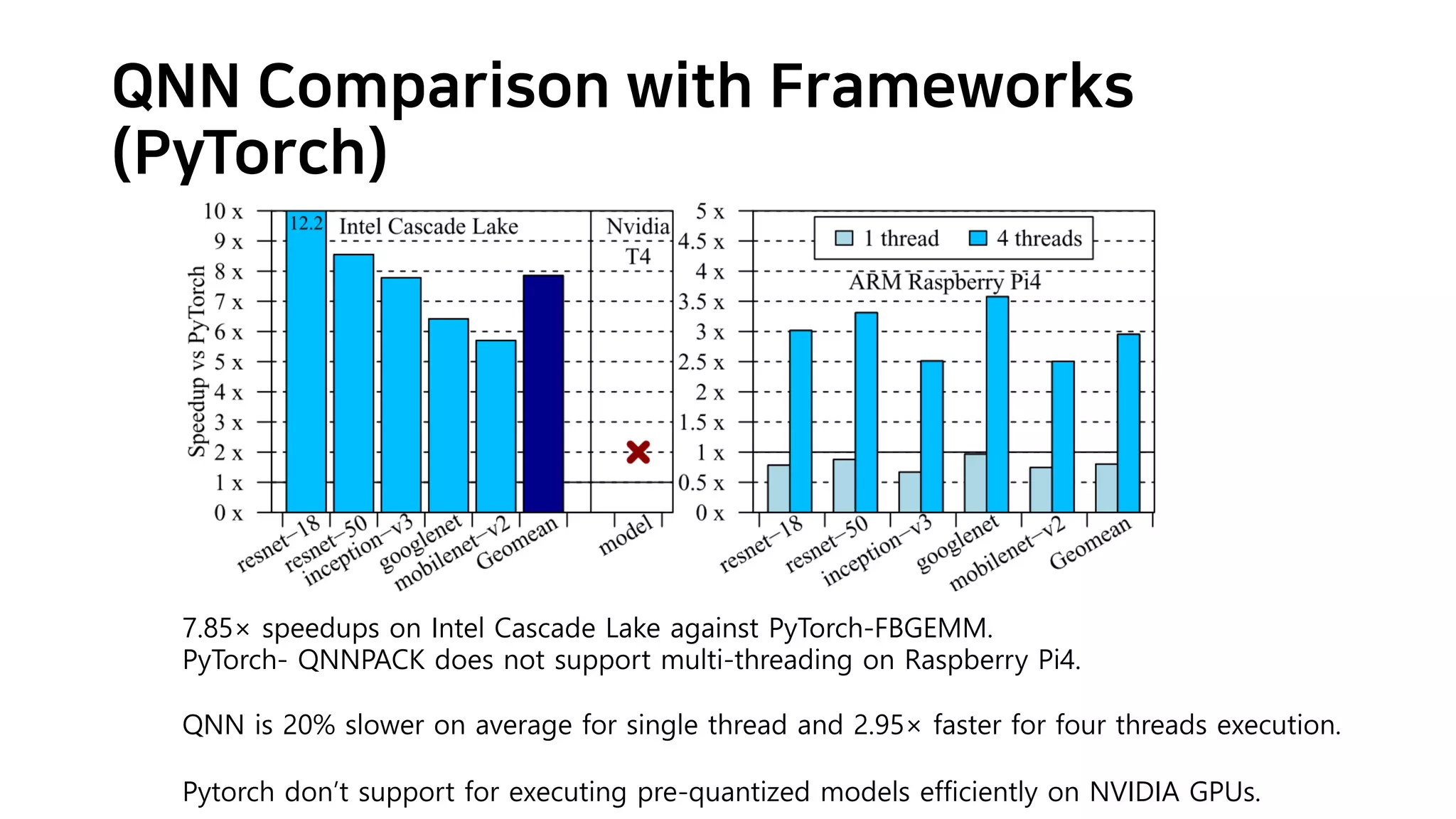
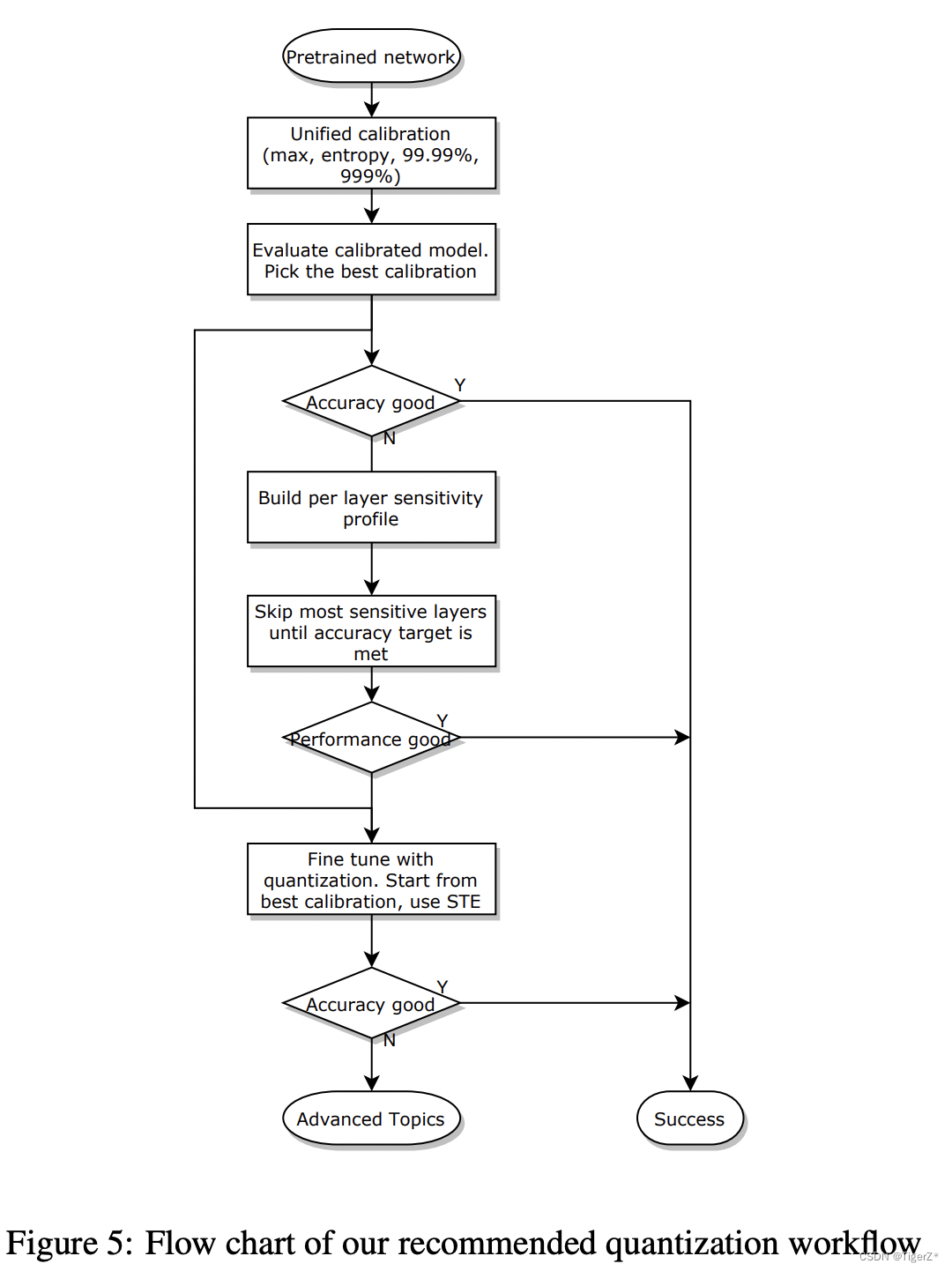
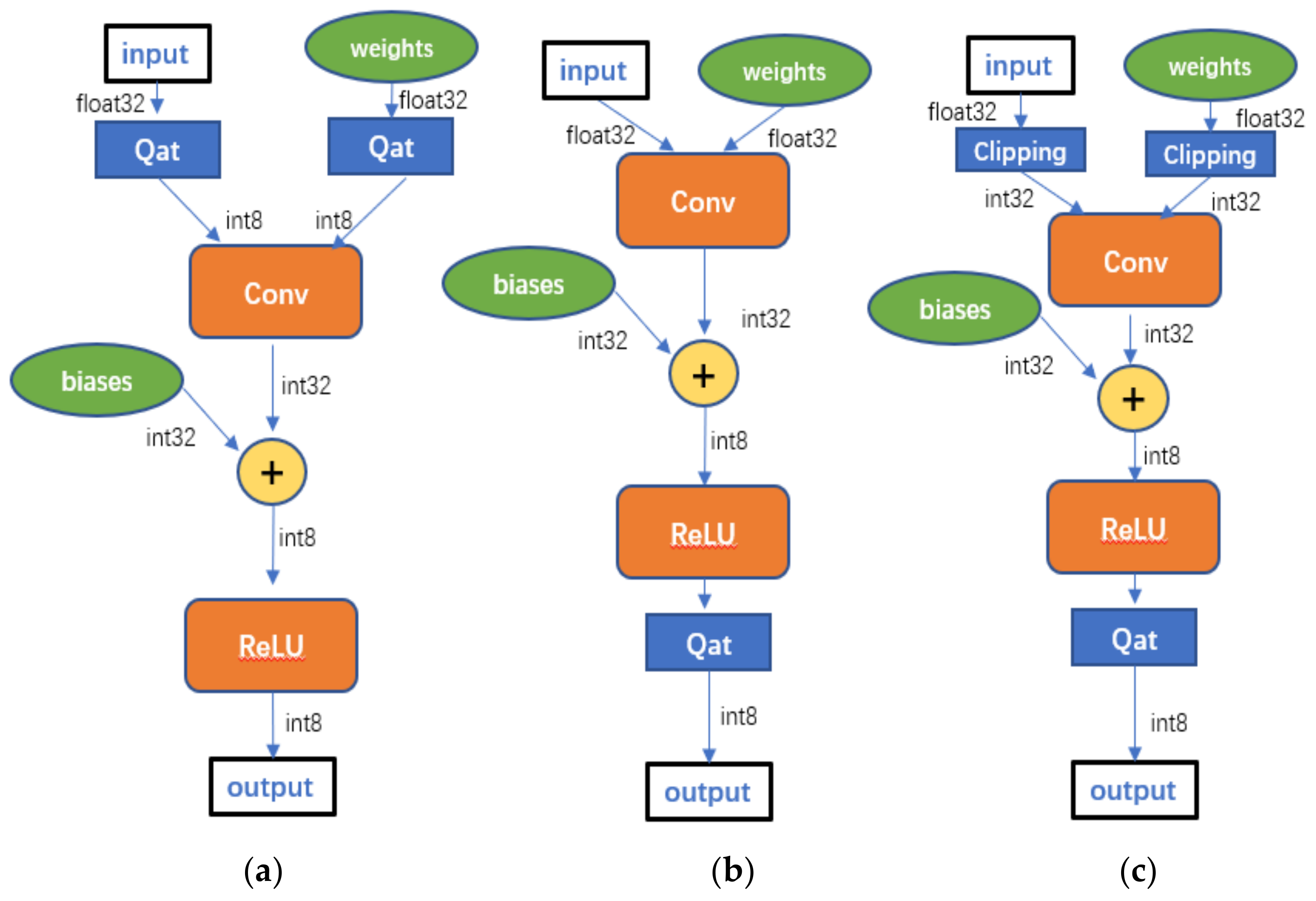
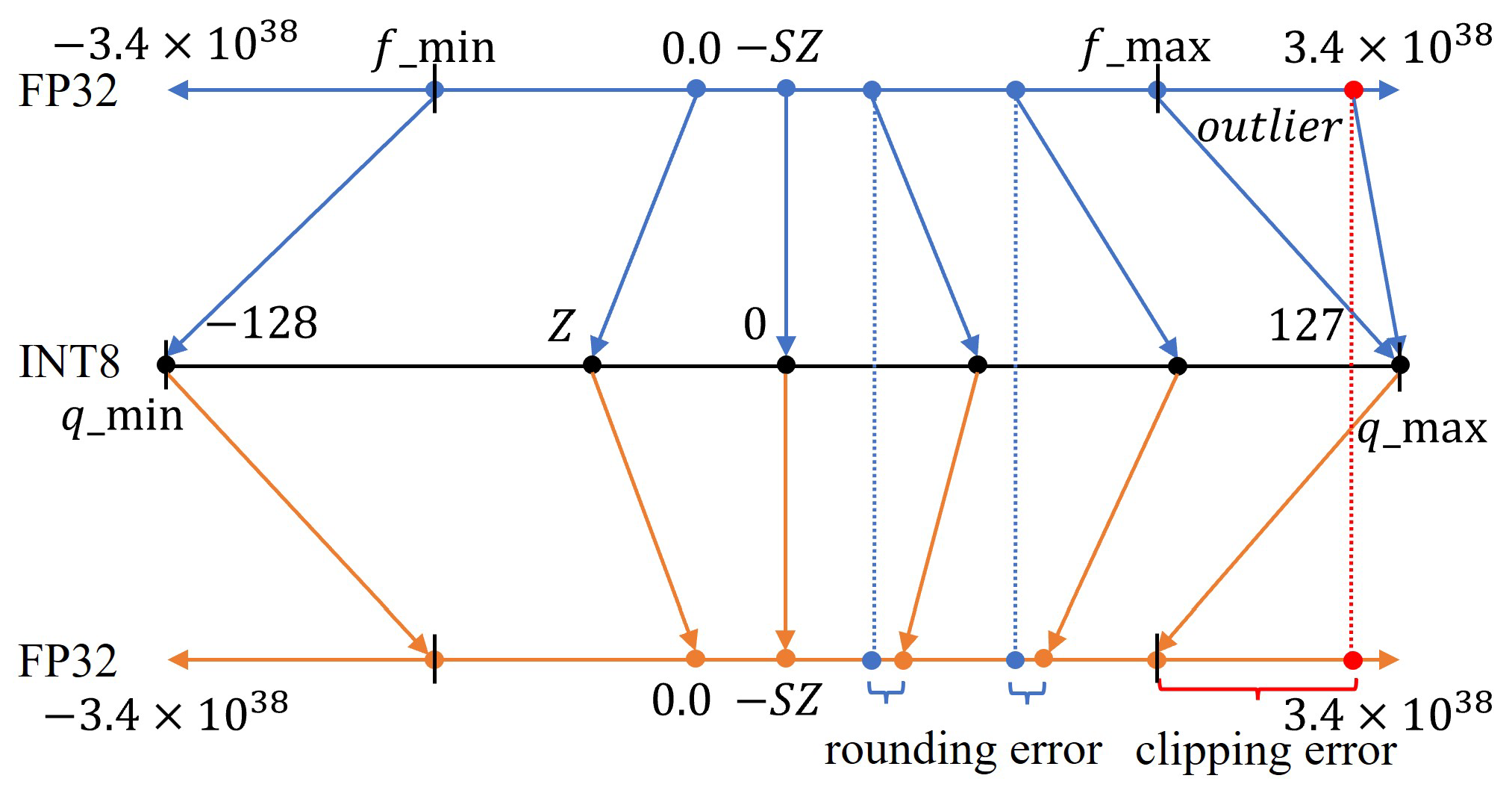
Showing 114 of 114on this page. Filters & sort apply to loaded results; URL updates for sharing.114 of 114 on this page
NVIDIA TensorRT INT8 & FP8 quantization accelerating SD inference : r ...
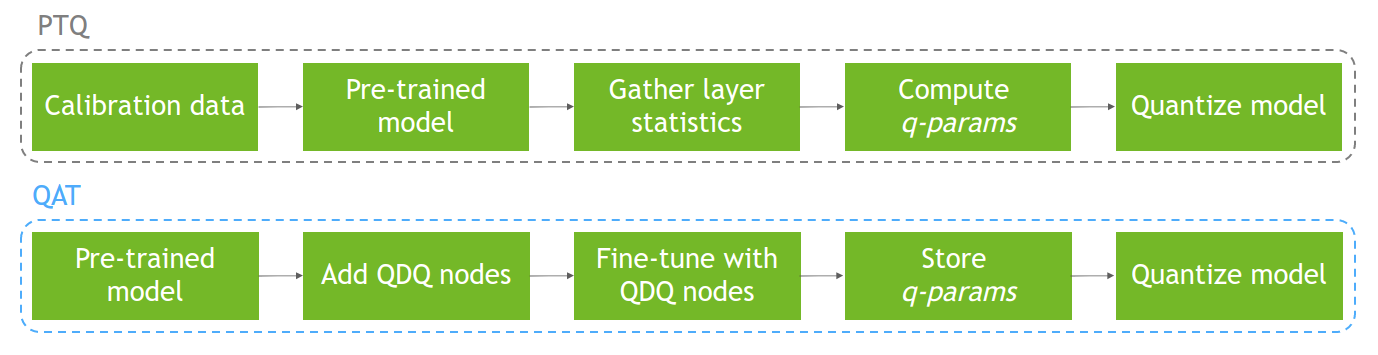
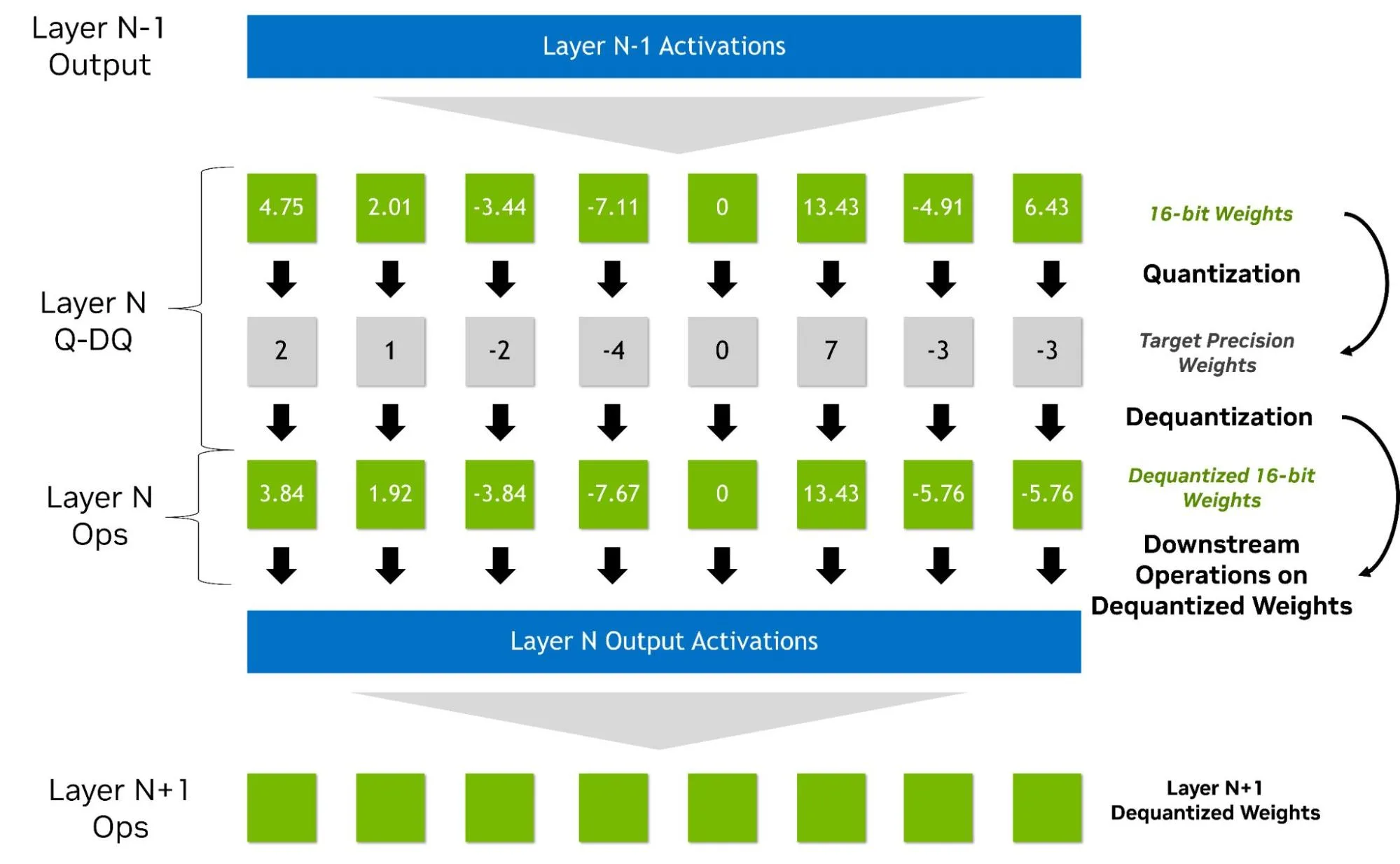
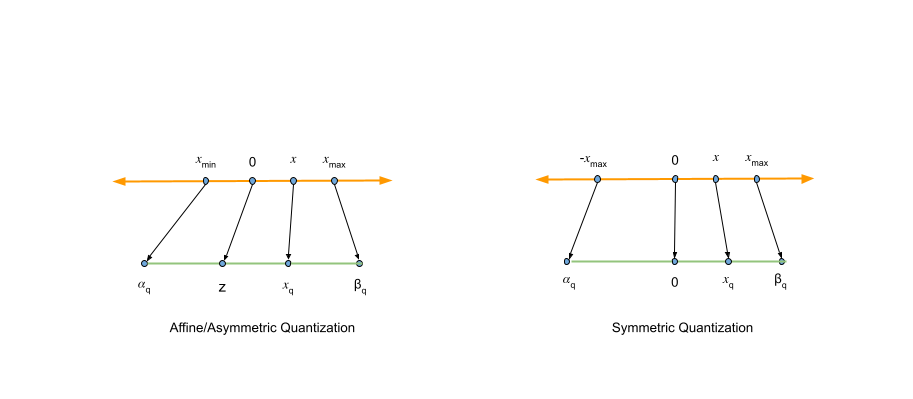
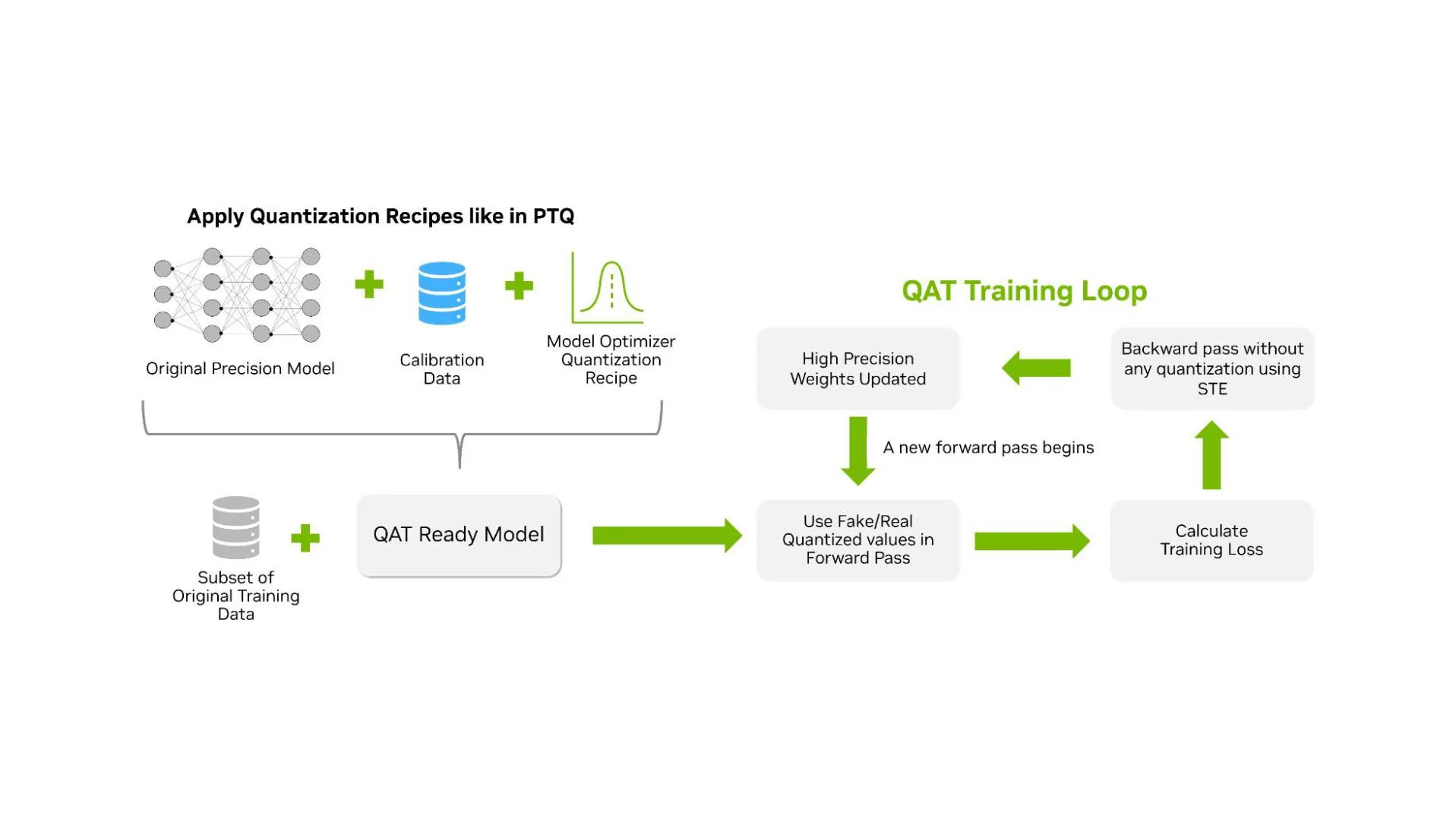
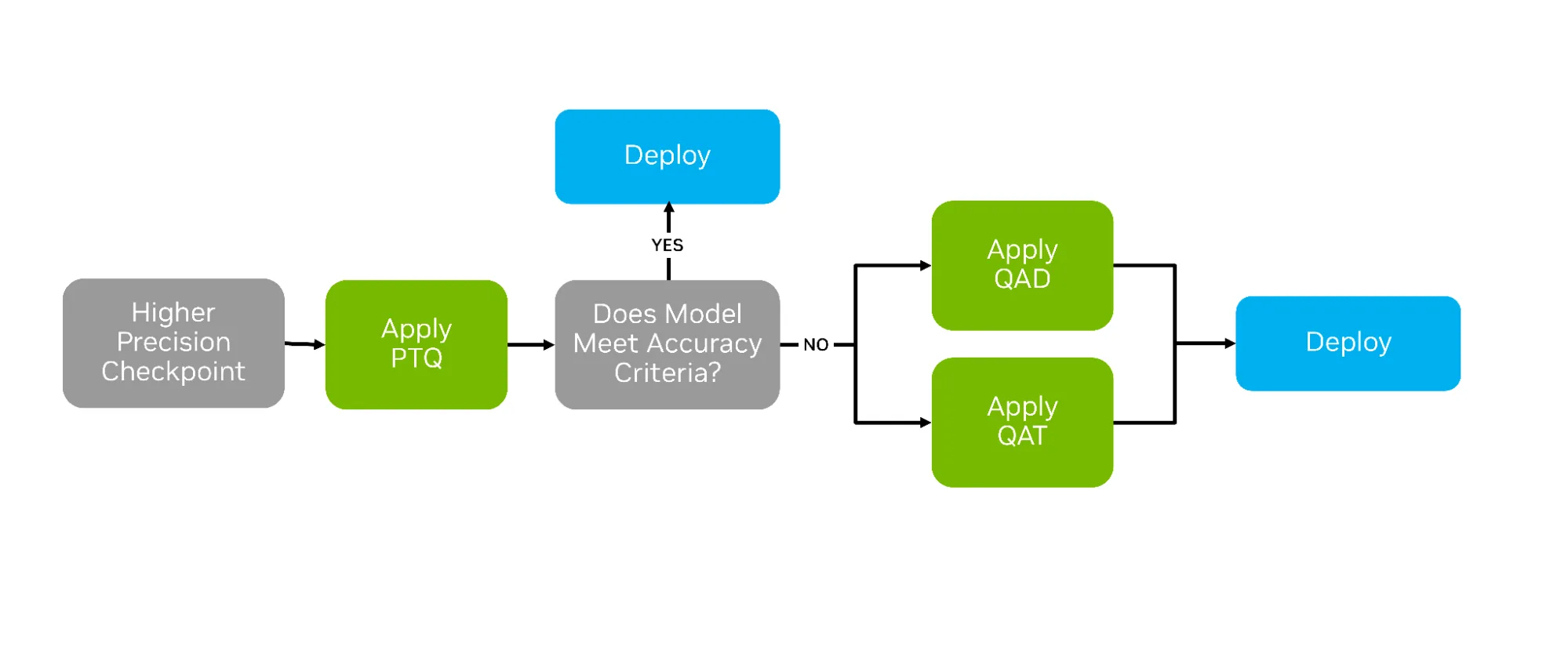
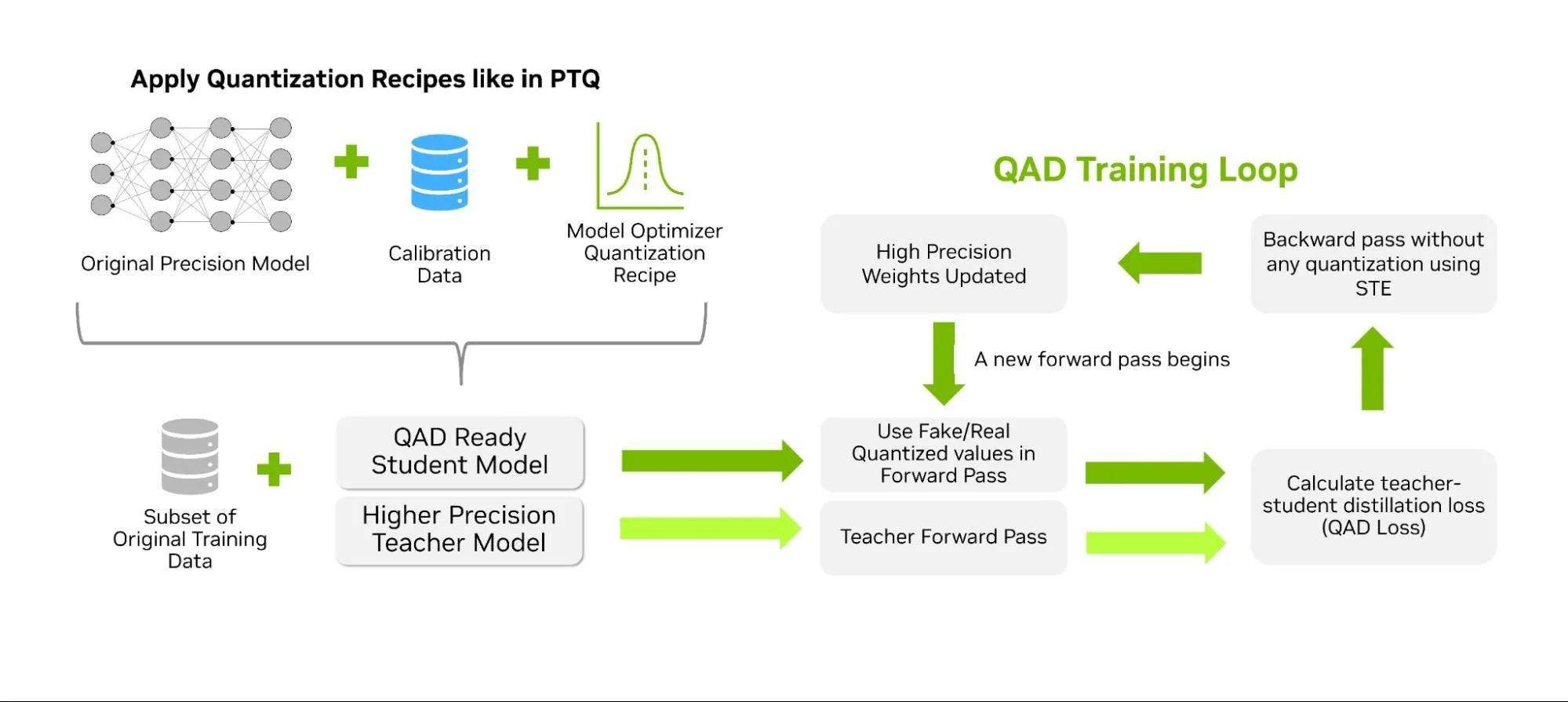
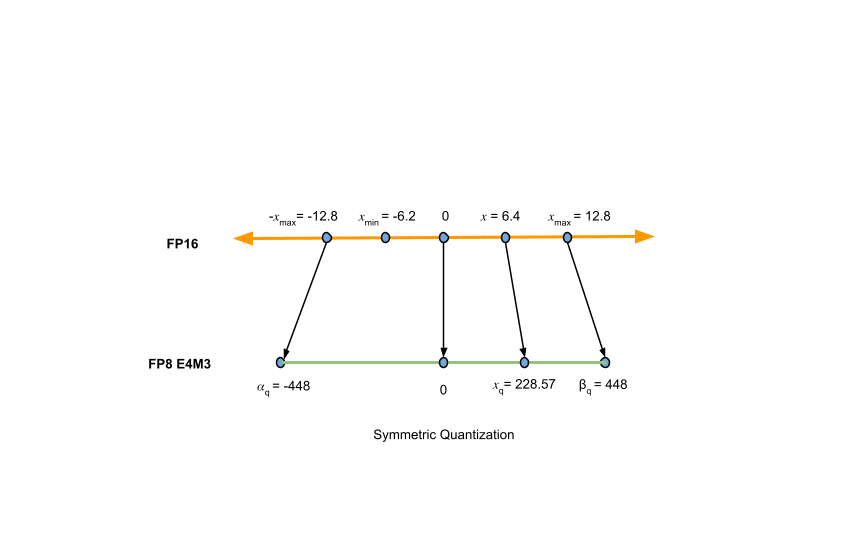
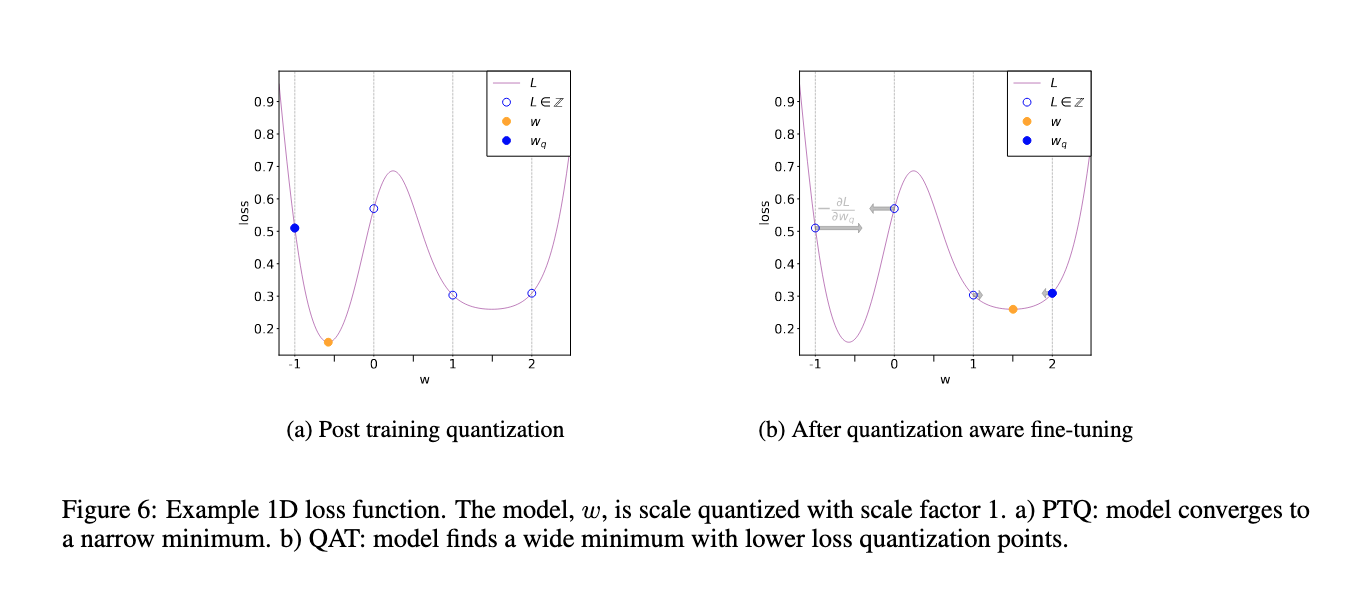
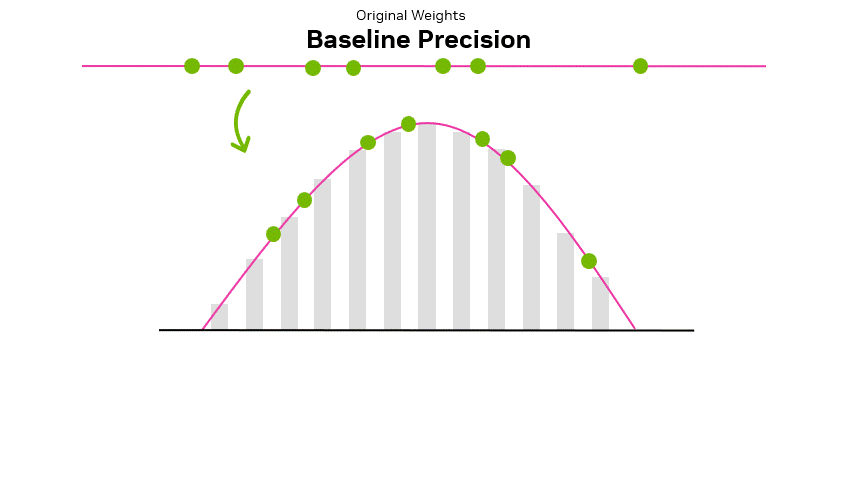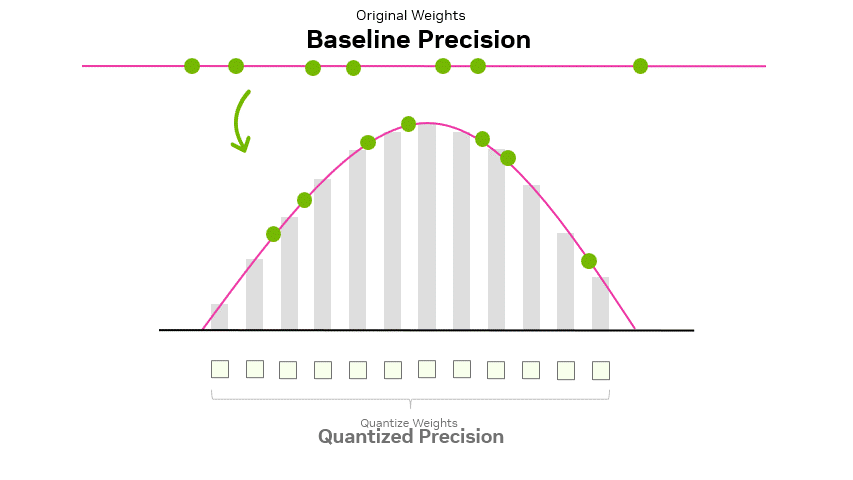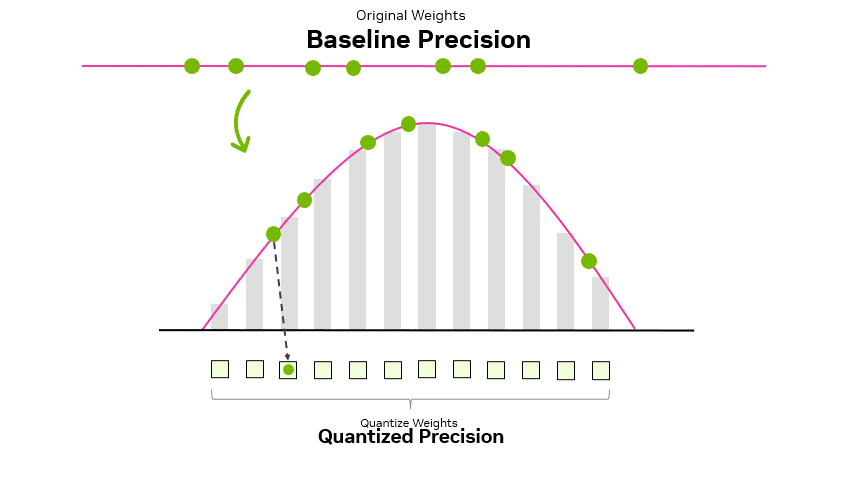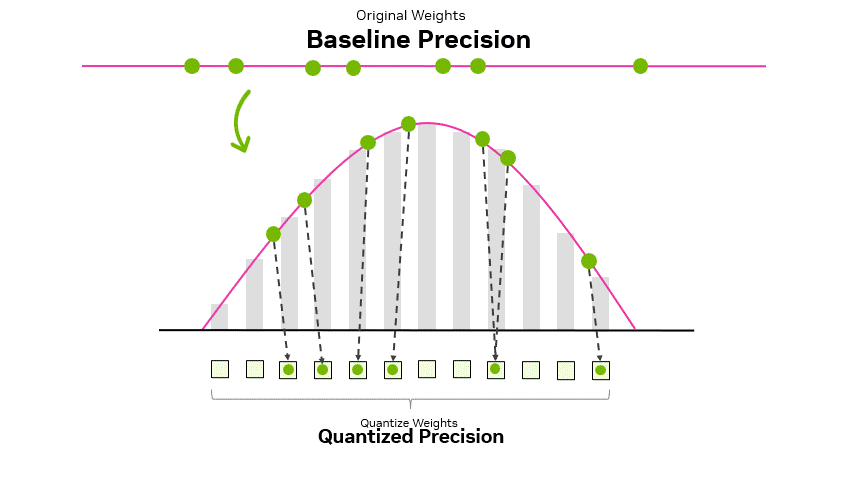
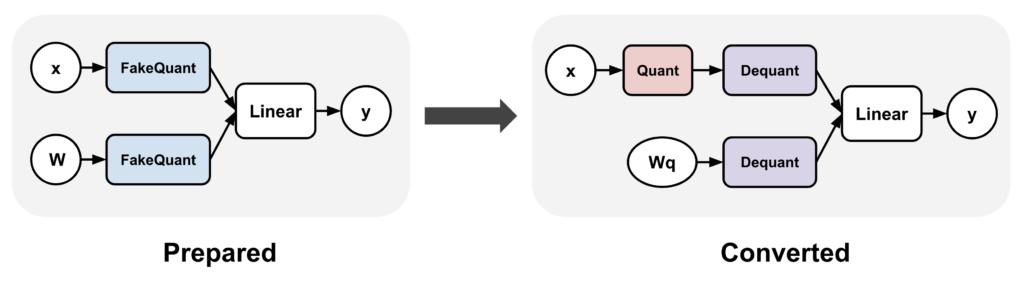
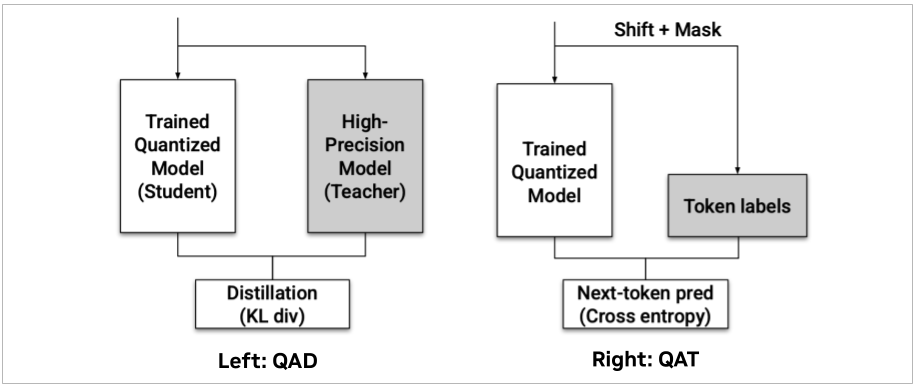
How Quantization Aware Training Enables Low-Precision Accuracy Recovery ...
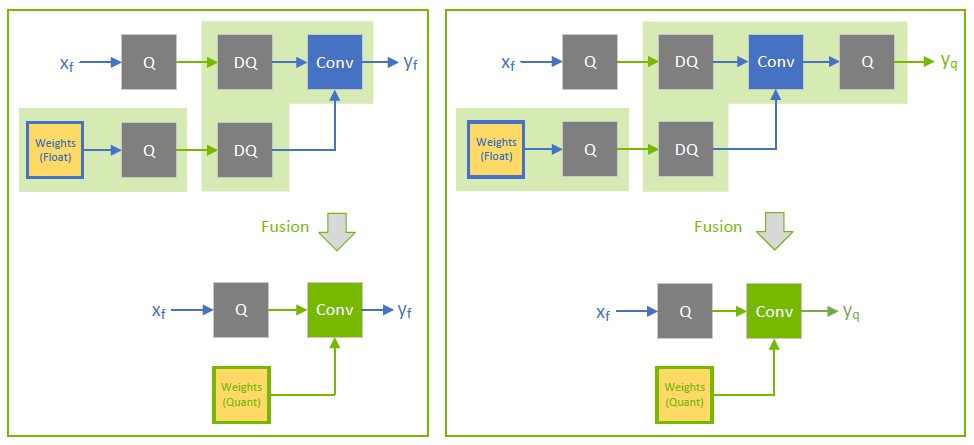
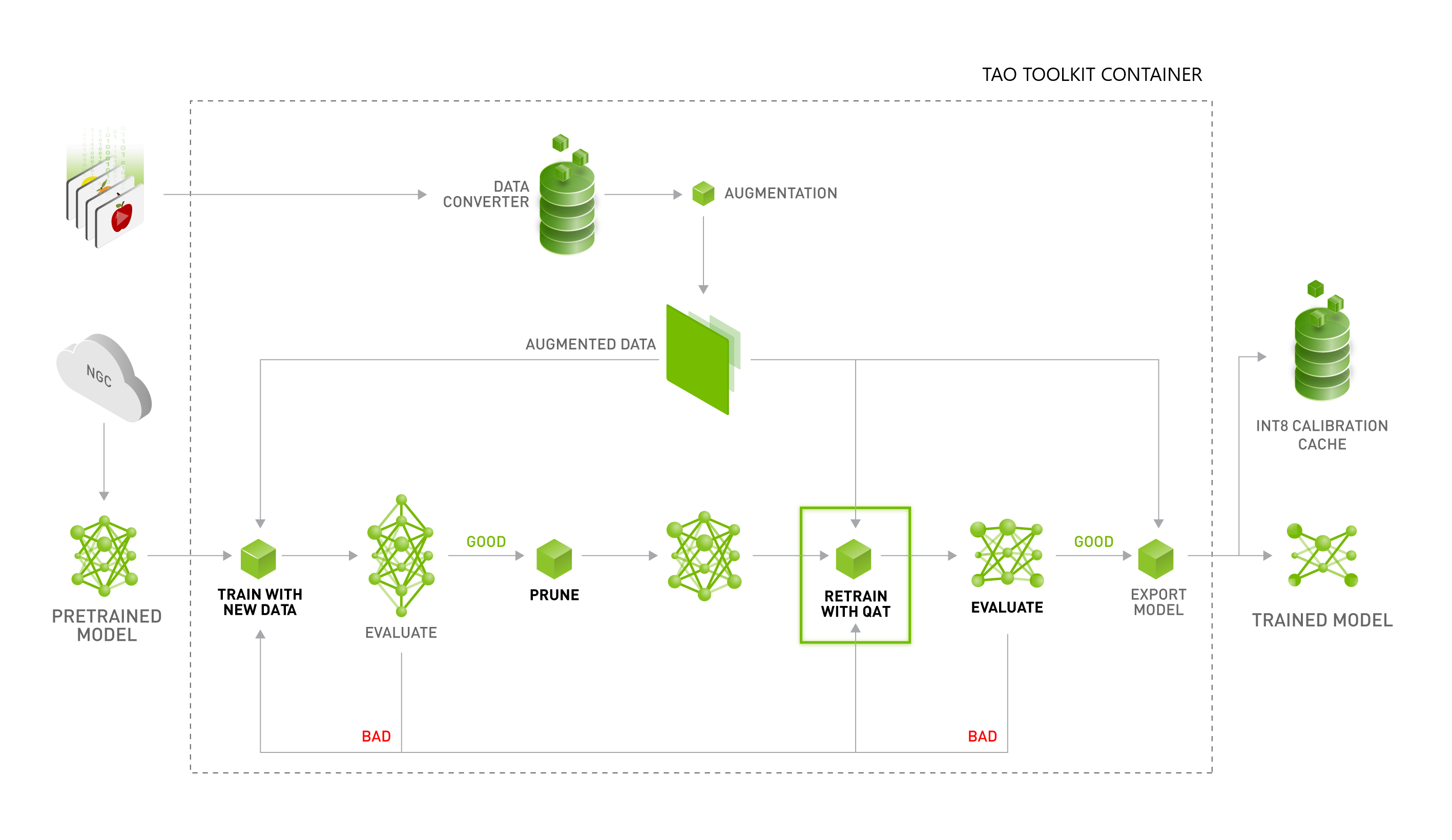
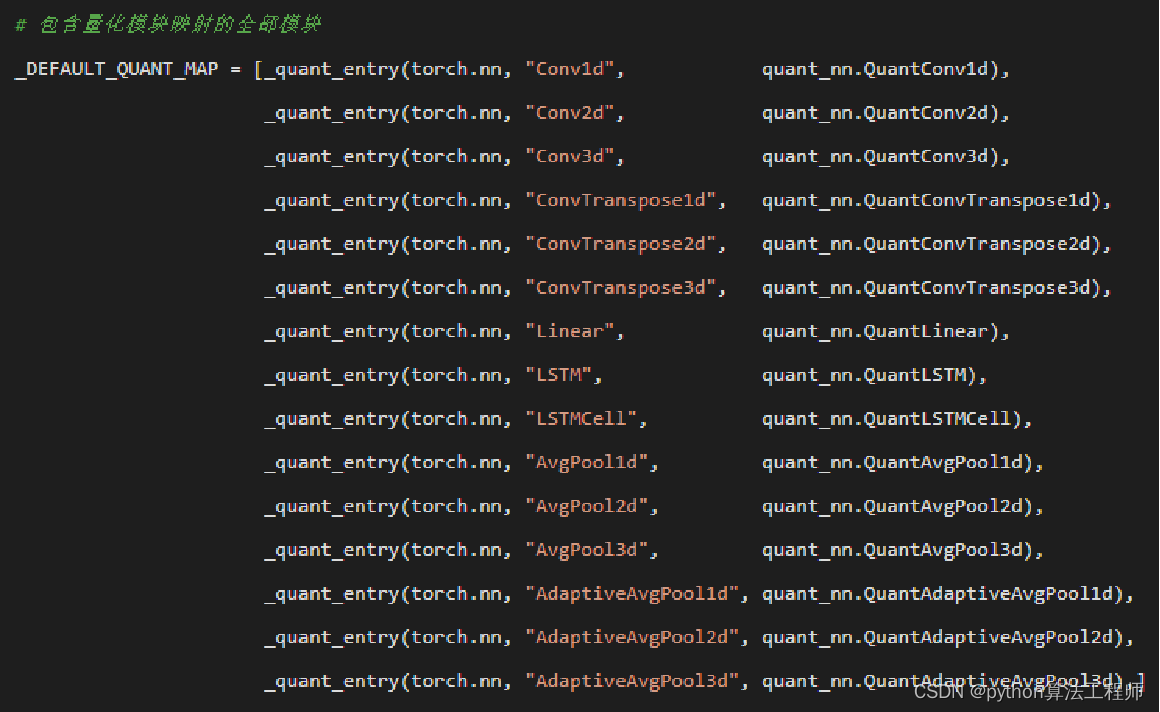
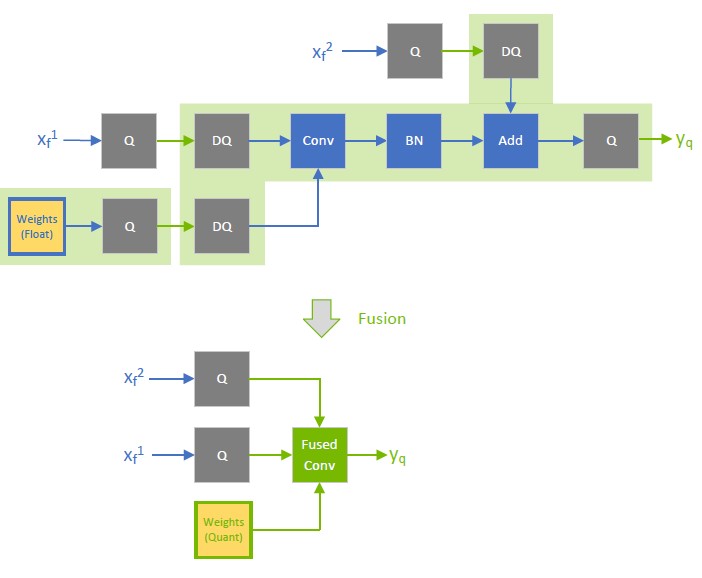
Accelerating Quantized Networks with the NVIDIA QAT Toolkit for ...
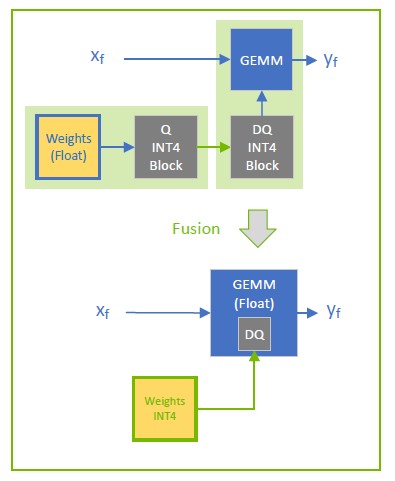
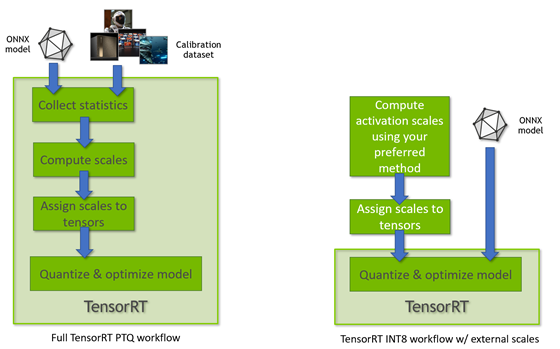
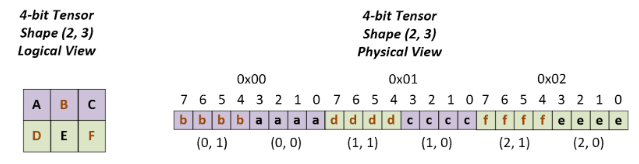
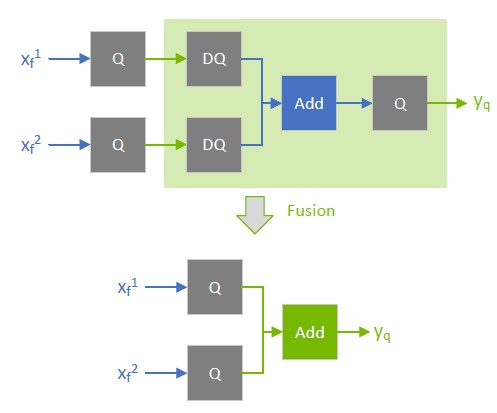
Working with Quantized Types — NVIDIA TensorRT
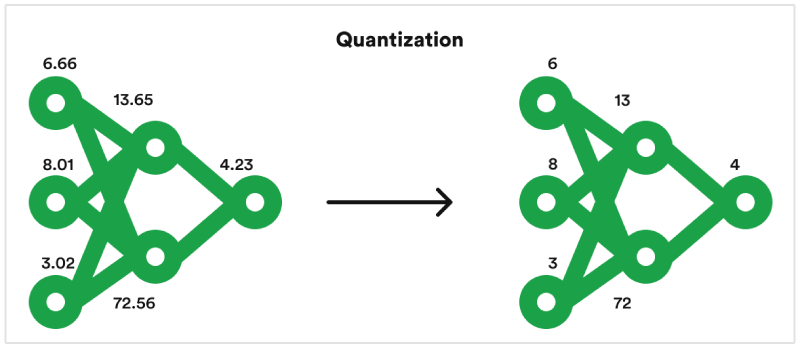
Model Quantization: Concepts, Methods, and Why It Matters | NVIDIA ...
模型量化——NVIDIA——QAT_pytorch quantization toolkit-CSDN博客
Achieving FP32 Accuracy for INT8 Inference Using Quantization Aware ...
NVIDIA 技术博客:使用 NVIDIA QAT 工具包为 TensorFlow 和 NVIDIA TensorRT 加速量化网络-CSDN社区
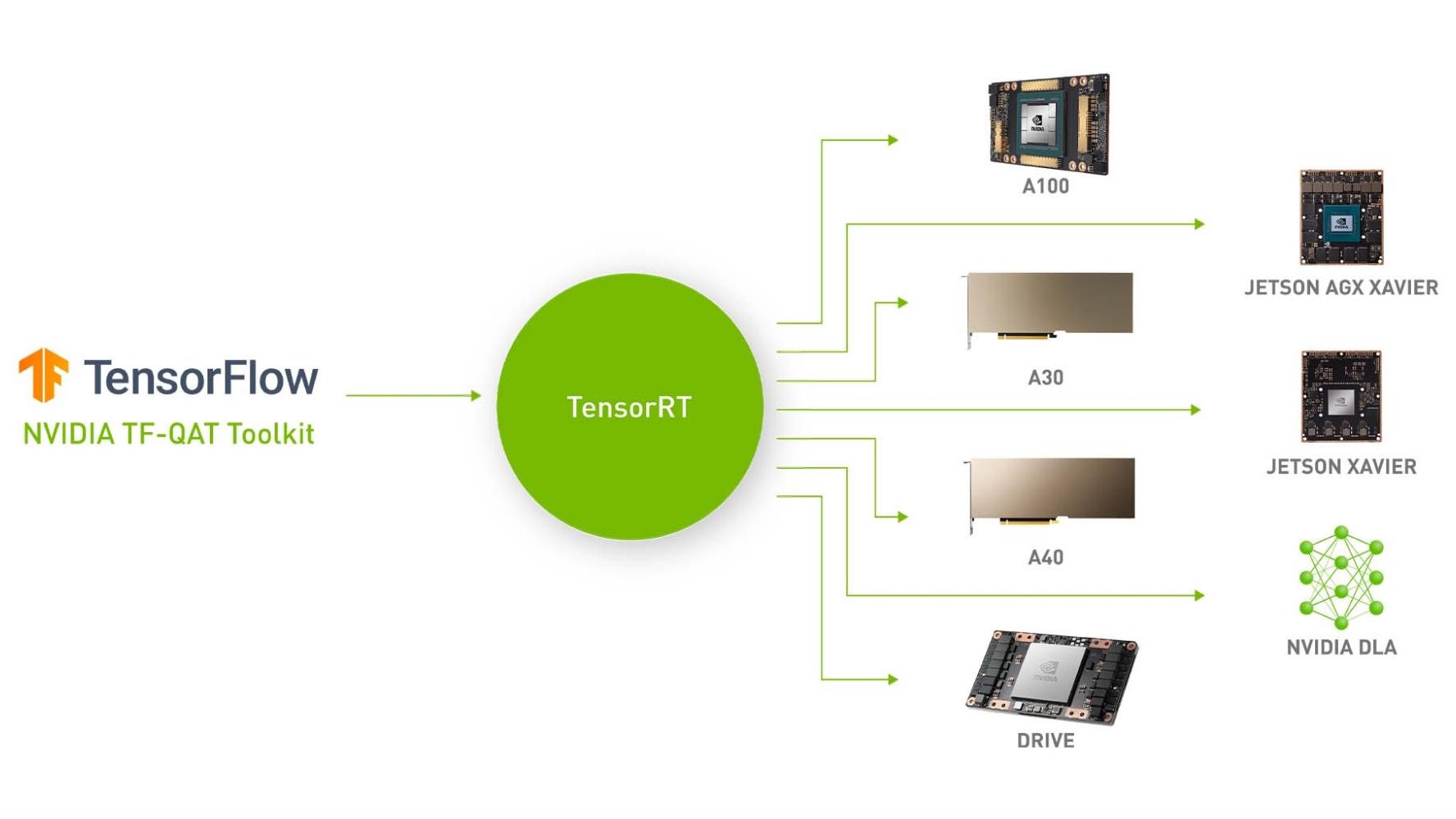
Improving INT8 Accuracy Using Quantization Aware Training and the ...
量化感知训练如何实现低精度恢复 - NVIDIA 技术博客
NVIDIA - Optimizing AI Deployments with NVIDIA TensorRT Model Optimizer ...
Quantization FP16 model using pytorch_quantization and TensorRT · Issue ...
Recommended Torch Quantization Library to Use -- Modelopt v.s. Pytorch ...
Neural Network Quantization in PyTorch | by Arik Poznanski | Medium
Fine-Tuning gpt-oss for Accuracy and Performance with Quantization ...
How is quantization of activations handled in pytorch after QAT ...
Deploying YOLOv5 on NVIDIA Jetson Orin with cuDLA: Quantization-Aware ...
Boost SGLang Inference: Native NVIDIA Model Optimizer Integration for ...
Practical Quantization in PyTorch – PyTorch
Optimize Generative AI inference with Quantization in TensorRT-LLM and ...
Quantization Explained: Why the Same LLM Gives Better Results on High ...
PyTorch Quantization简介_pytorch quantization simulation-CSDN博客
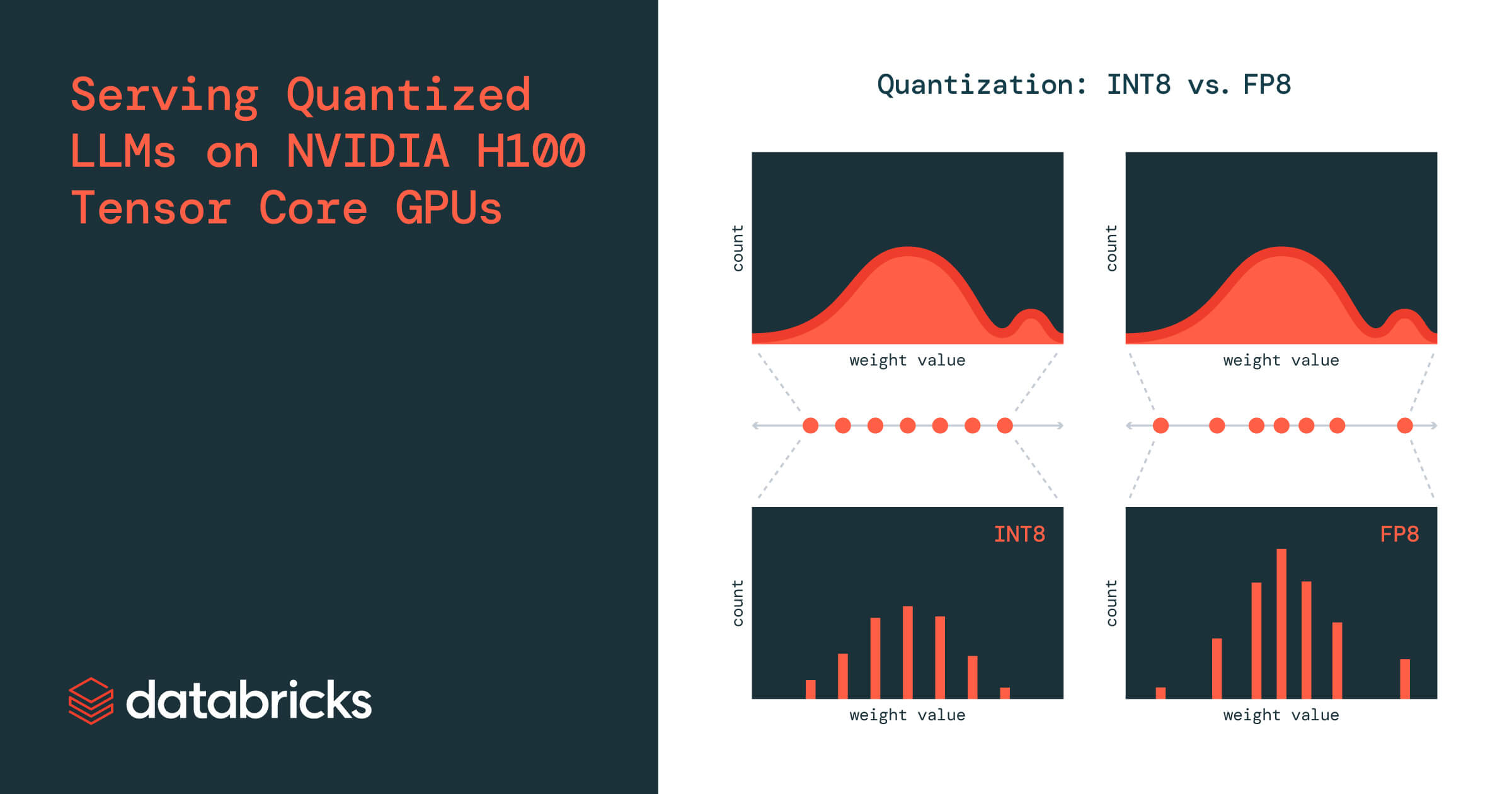
Serving Quantized LLMs on NVIDIA H100 Tensor Core GPUs | Databricks Blog
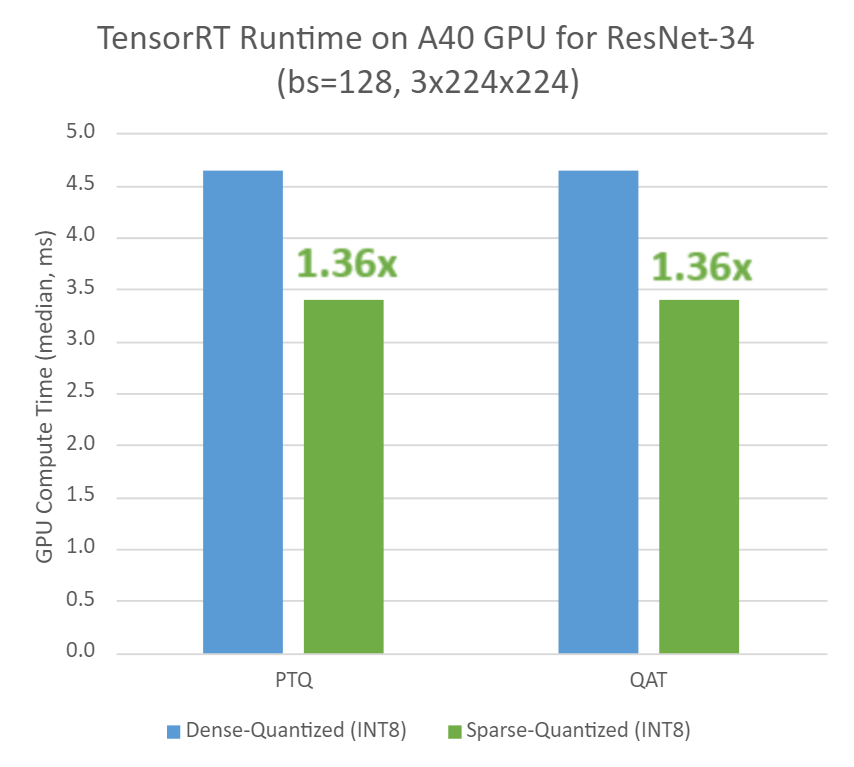
Sparsity in INT8: Training Workflow and Best Practices for NVIDIA ...
Fast and Accurate GPU Quantization for Transformers
Overview of natively supported quantization schemes in 🤗 Transformers
Optimizing LLMs for Performance and Accuracy with Post-Training ...
GTC 2020: Toward INT8 Inference: Deploying Quantization-Aware Trained ...
PyTorch-Quantization Toolkit · Issue #981 · NVIDIA/TensorRT · GitHub
pytorch_quantization QAT on centerpoint · Issue #2447 · NVIDIA/TensorRT ...
TensorRT/tools/pytorch-quantization/examples/calibrate_quant_resnet50 ...
Quantization-Aware Training for Large Language Models with PyTorch ...
[Hugging Face transformer models + pytorch_quantization] PTQ ...
Manually load int8 weight from QAT model (quantized with pytorch ...
LSQ using pytorch_quantization · Issue #3076 · NVIDIA/TensorRT · GitHub
Quantized model has different output between pytorch and onnx · Issue ...
using pytorch_quantization to quantize mmdetection3d model · Issue ...
Efficient execution of quantized deep learning models a compiler ...
模型量化——NVIDIA——方案选择(PTQ、 partialPTQ、 QAT)_nvidia pytorch quantization-CSDN博客
pytorch-quantization example classfication_flow.py has incorrect import ...
pytorch-quantization 2.1.1 Problem. · Issue #1685 · NVIDIA/TensorRT ...
YOLOv5 QAT model inference empty && pytorch-quantization-toolkit ...
What is TensorRT? Overview & Use Case
use nvidia's pytorch_quantization for int8 QAT · Issue #1944 · open ...
is there any more detailed doc about pytorch_quantization? · Issue ...
TensorRT is encountering issues with models quantized using pytorch ...
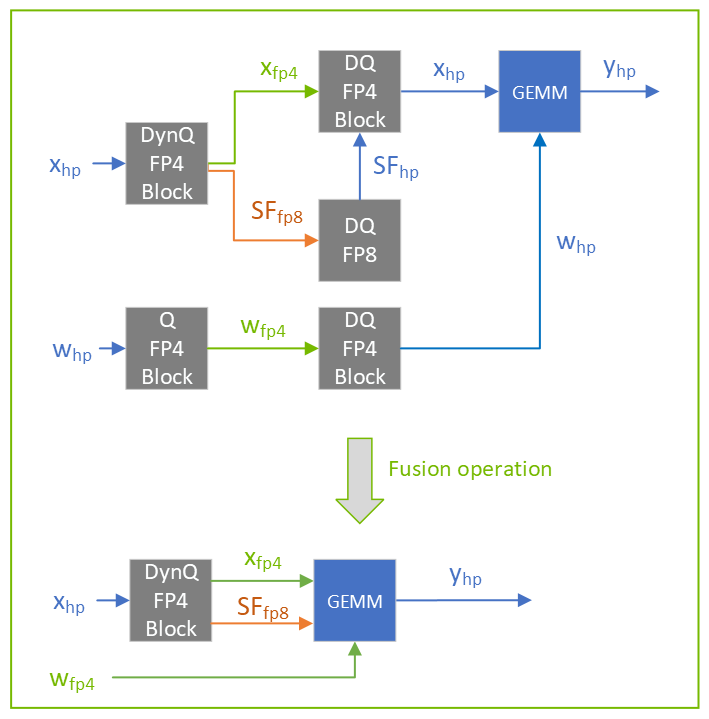
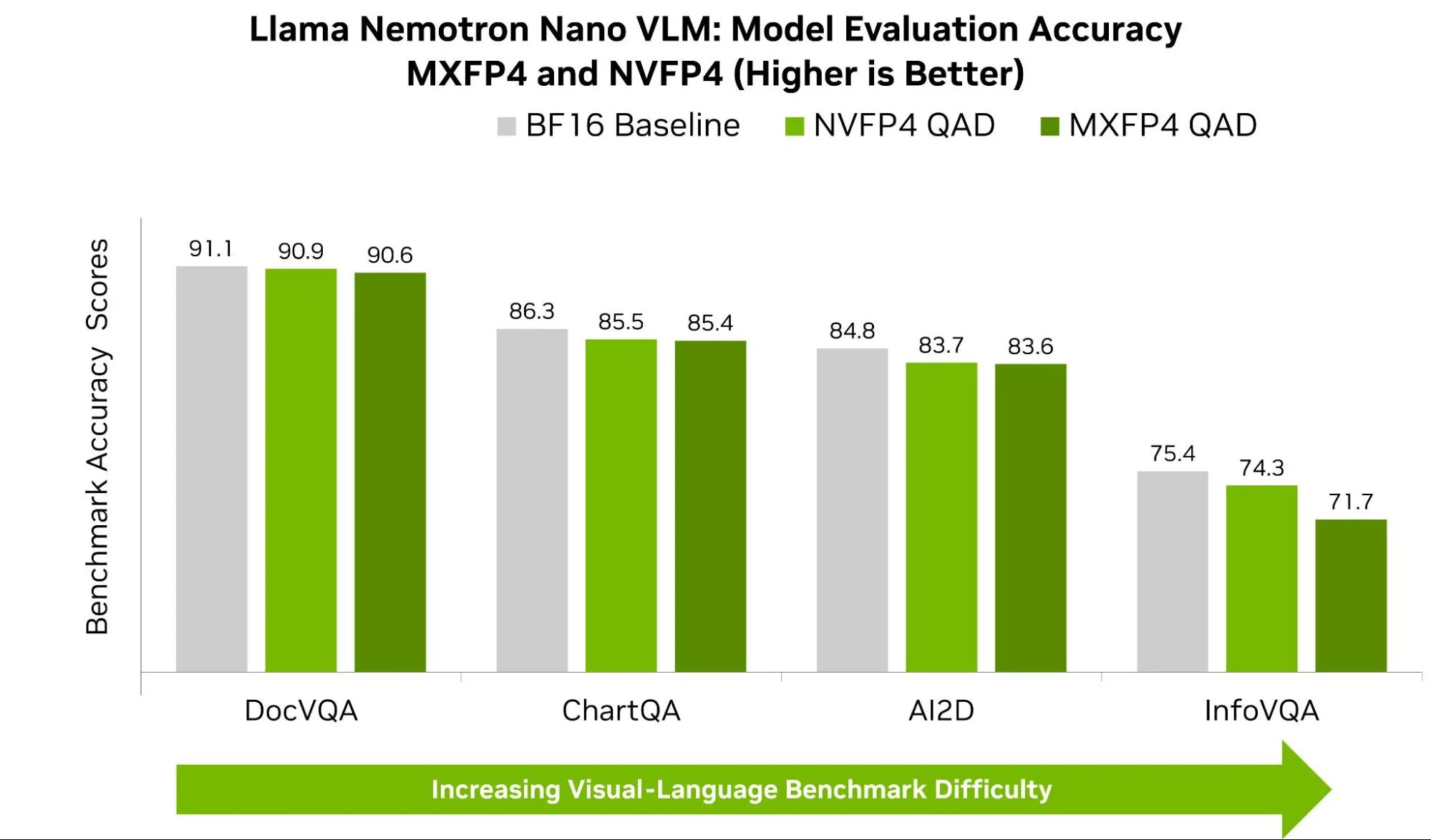
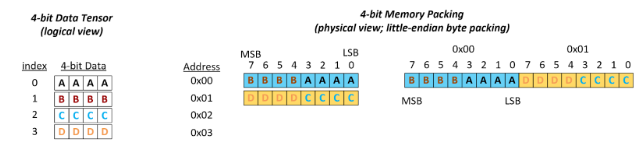
Enable NVFP4 Inference for Nemotron with Quantization-Aware ...
Quantized Model Pytorch at Brayden Woodd blog
Deep Learning Performance Characterization on GPUs for Various ...