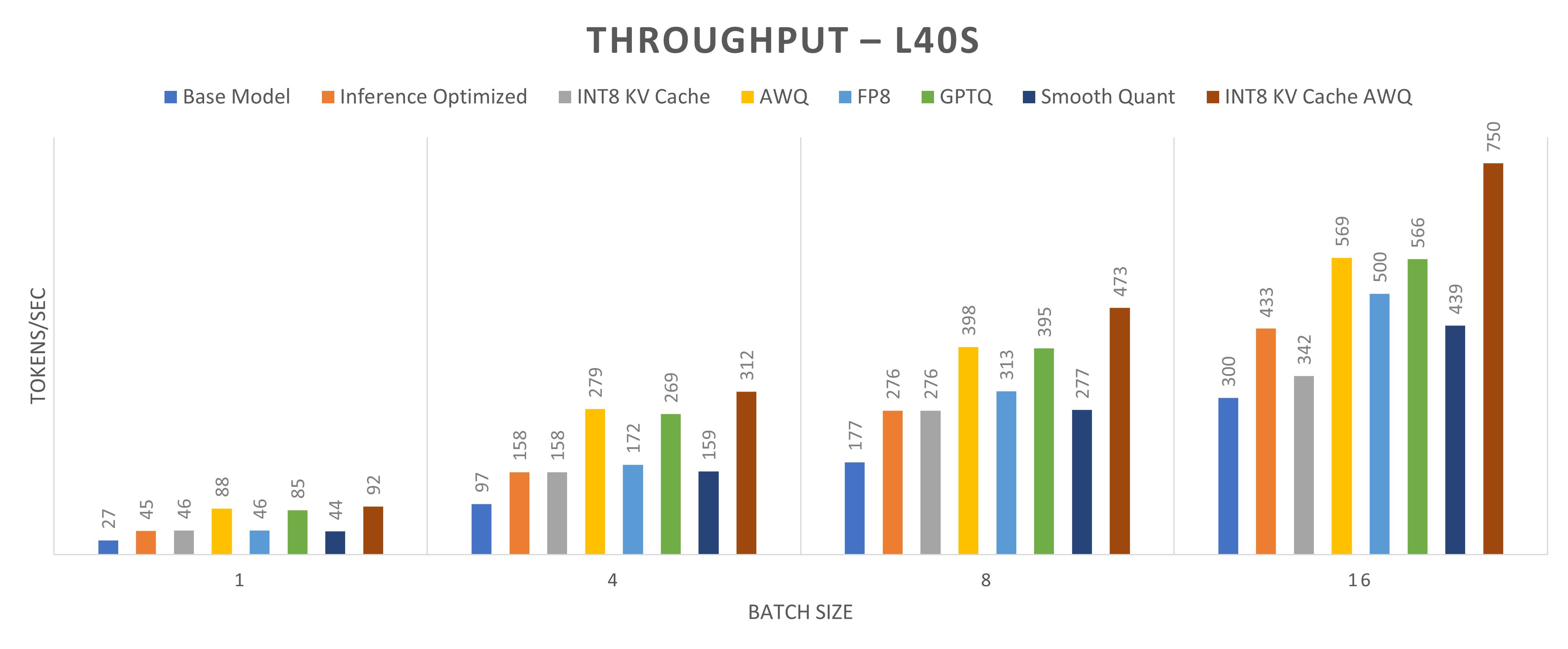
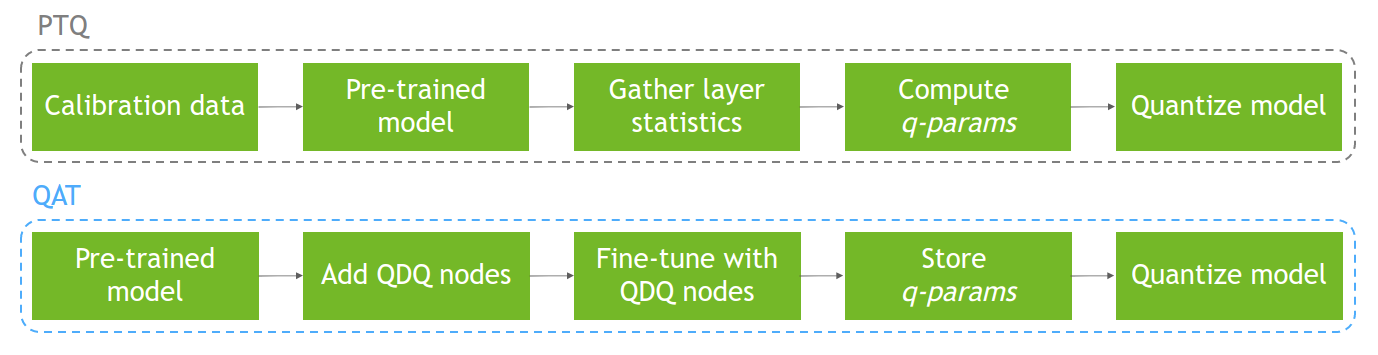
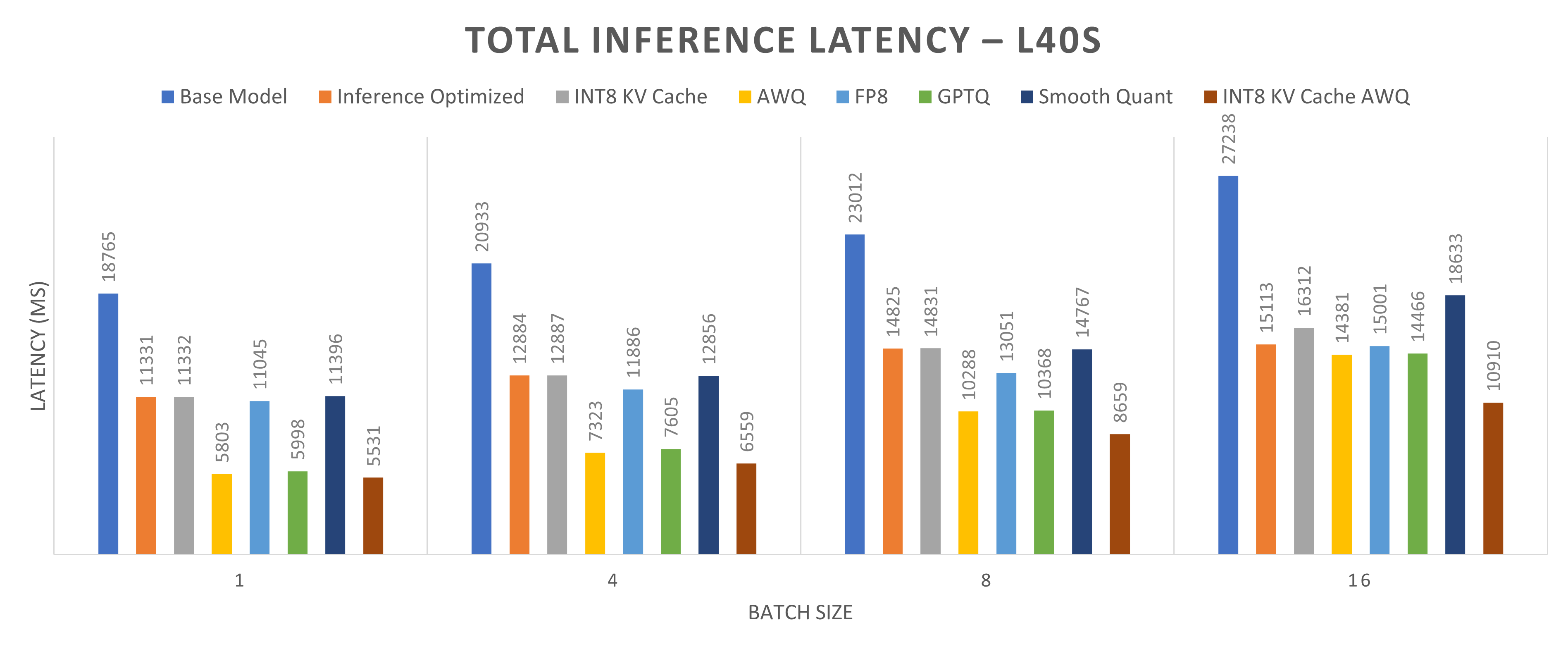
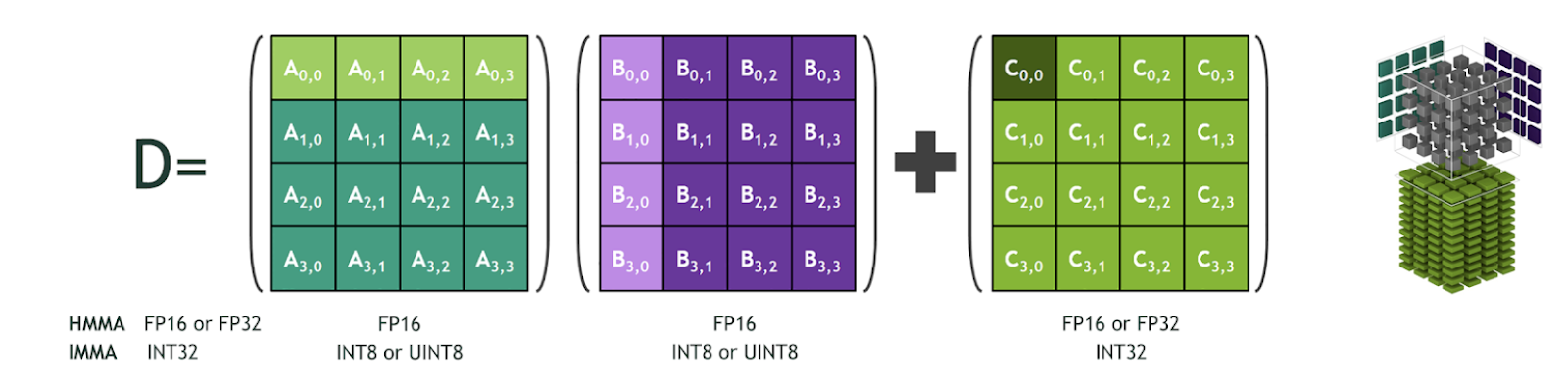
Showing 107 of 107on this page. Filters & sort apply to loaded results; URL updates for sharing.107 of 107 on this page
How tensorRT load a quantization onnx model · Issue #2685 · NVIDIA ...
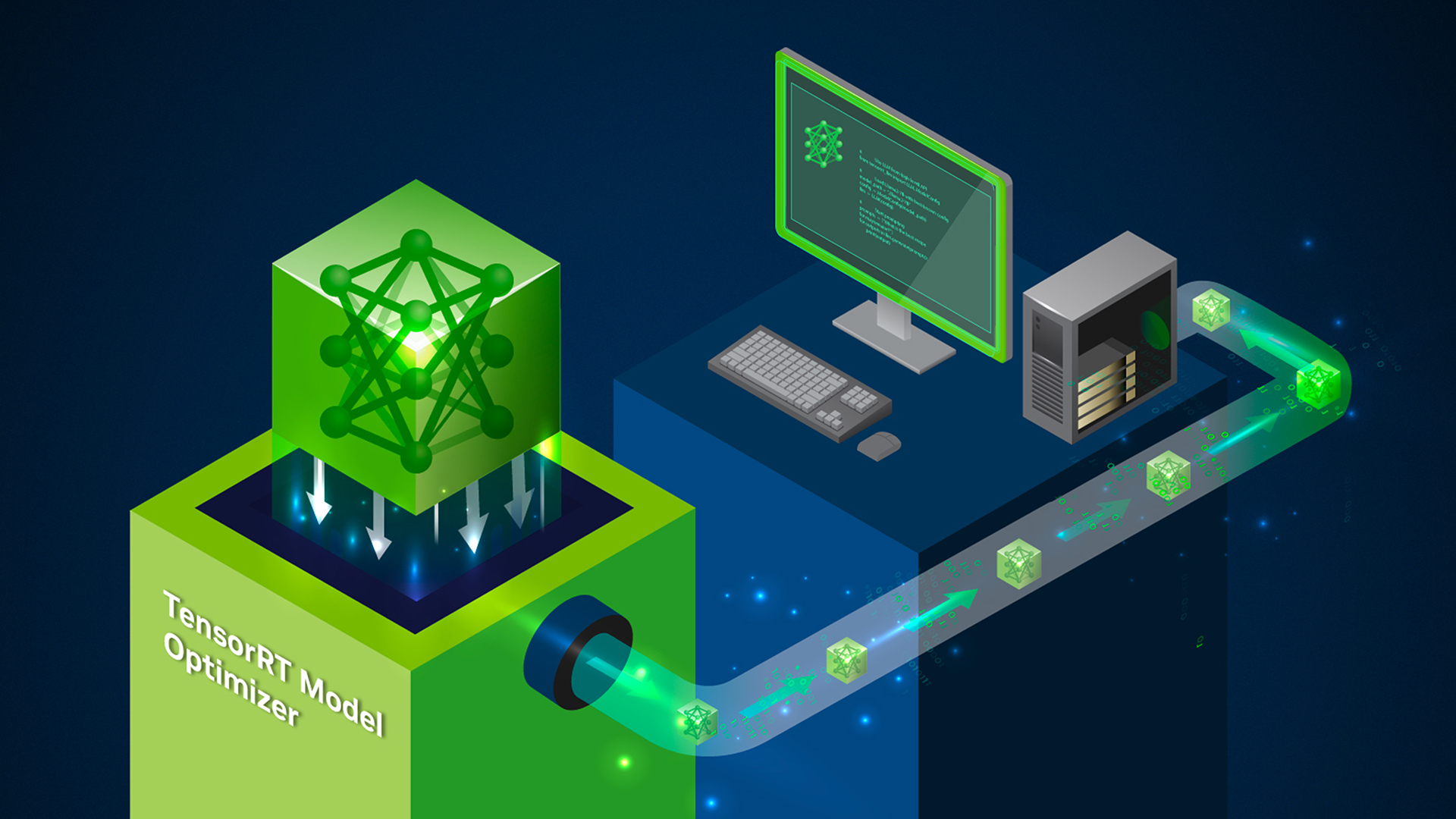
Model Quantization: Concepts, Methods, and Why It Matters | NVIDIA ...
Boost SGLang Inference: Native NVIDIA Model Optimizer Integration for ...
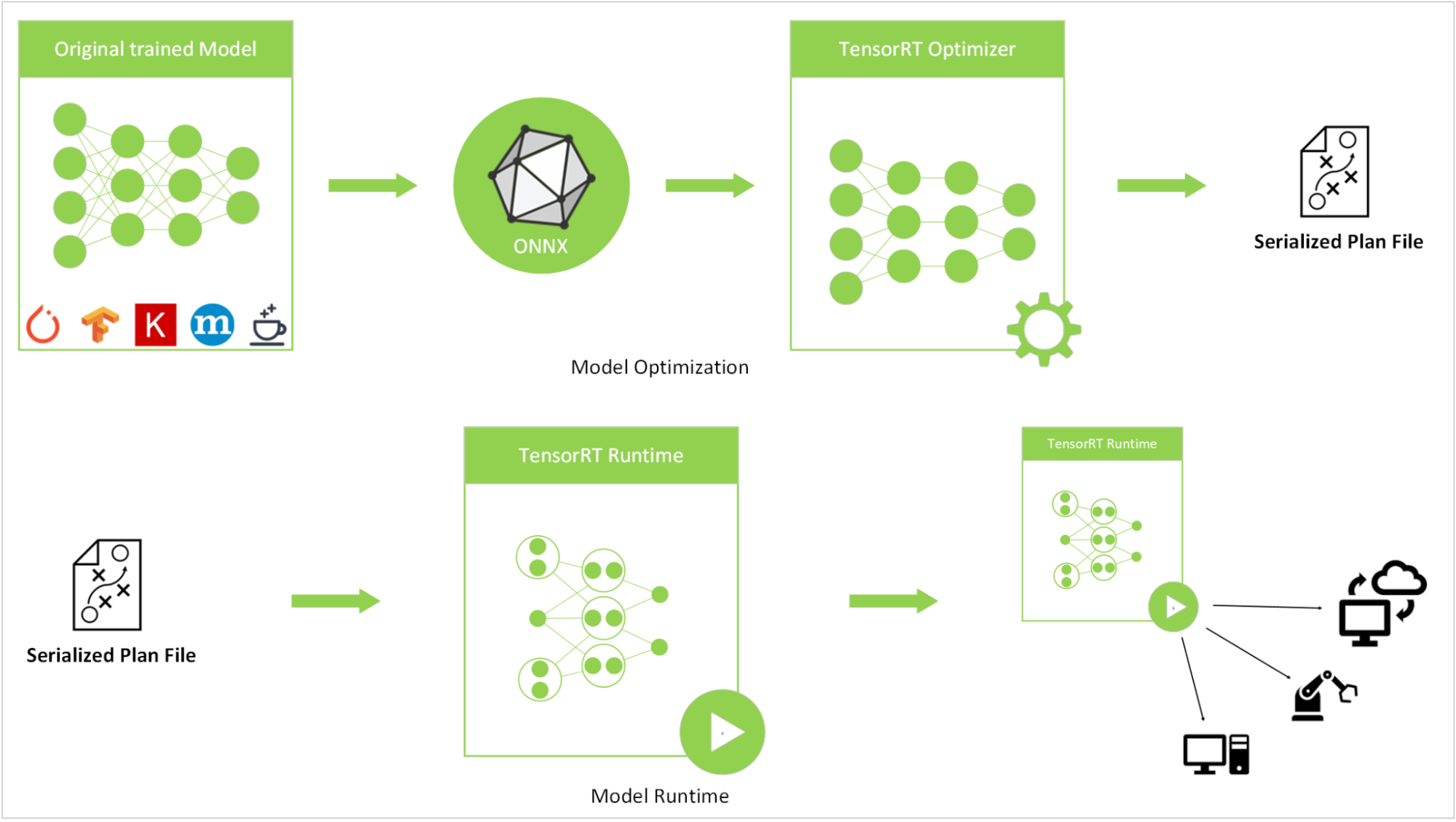
NVIDIA - Optimizing AI Deployments with NVIDIA TensorRT Model Optimizer ...
Post-Training Quantization of LLMs with NVIDIA NeMo and NVIDIA TensorRT ...
Mastering Generative AI with Model Quantization
Quantization FP16 model using pytorch_quantization and TensorRT · Issue ...
⚡️ Quick Guide: What Model Quantization Really Does Quantization is one ...
As AI Grows More Complex, Model Builders Rely on NVIDIA | NVIDIA Blog
A Deep Dive into Model Quantization for Large-Scale Deployment ...
Free Video: Inference and Quantization for AI - Session 3 from Nvidia ...
Quantization of Convolutional Neural Networks: Model Quantization ...
Model Quantization - A Lazy Data Science Guide
NVIDIA TensorRT Model Optimizer_modelopt-CSDN博客
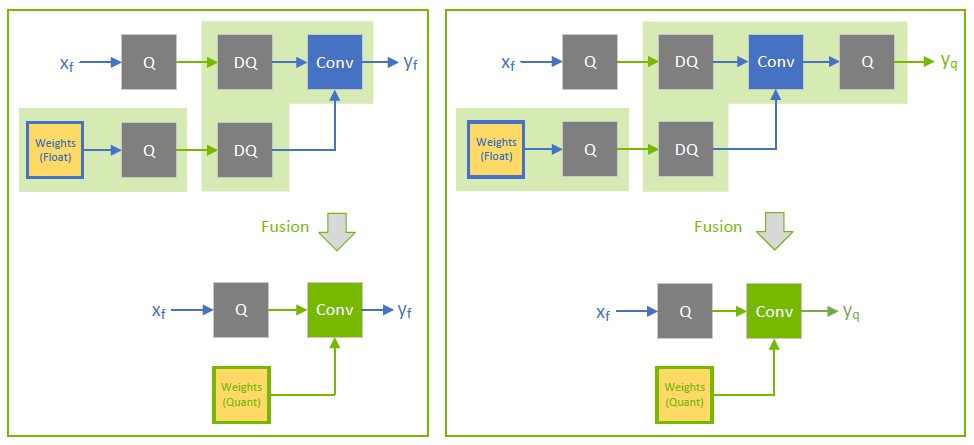
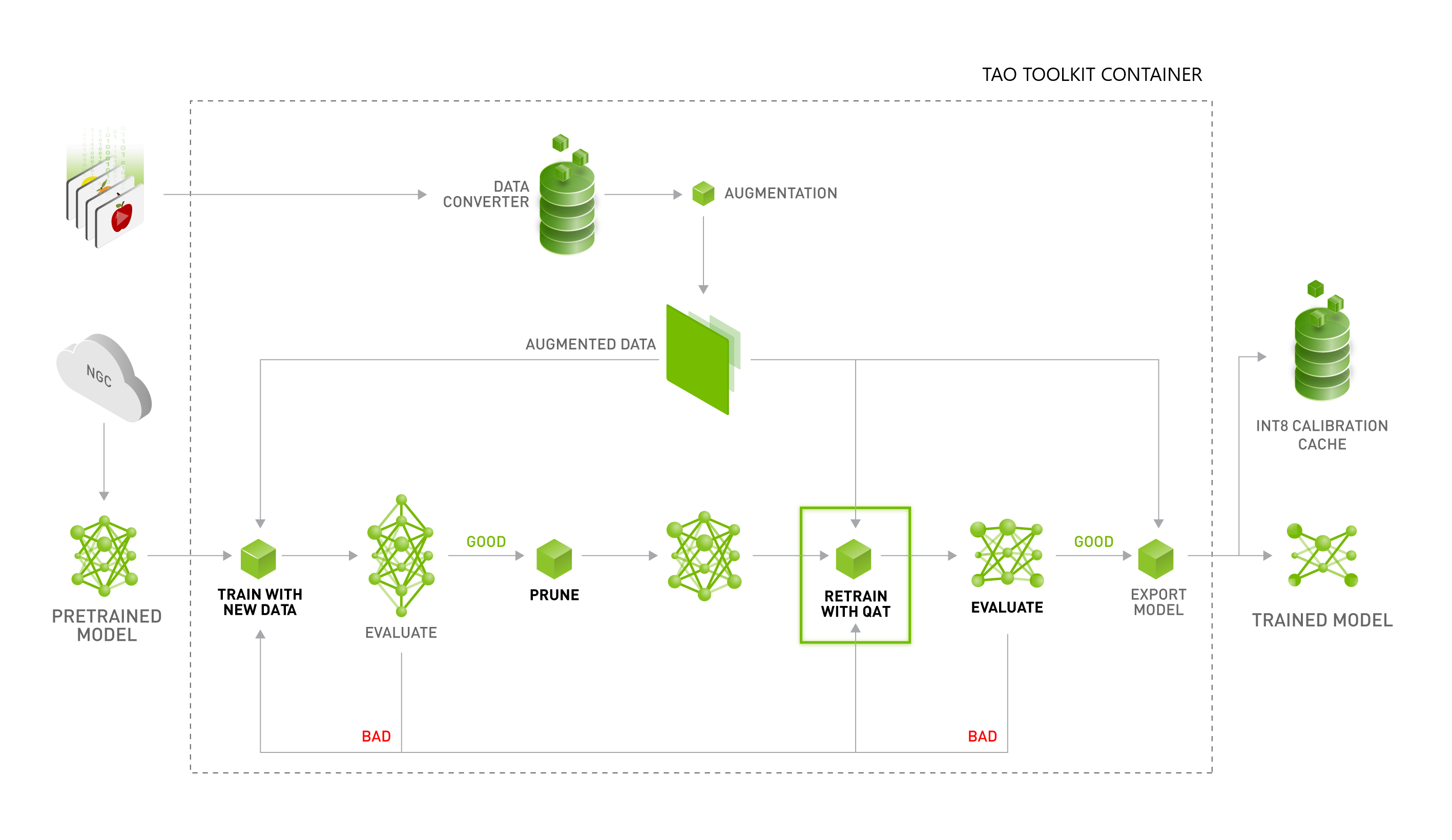
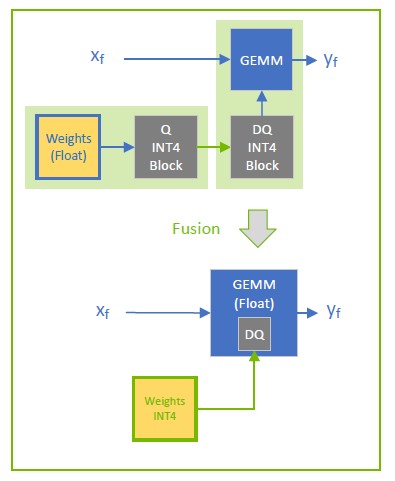
Accelerating Quantized Networks with the NVIDIA QAT Toolkit for ...
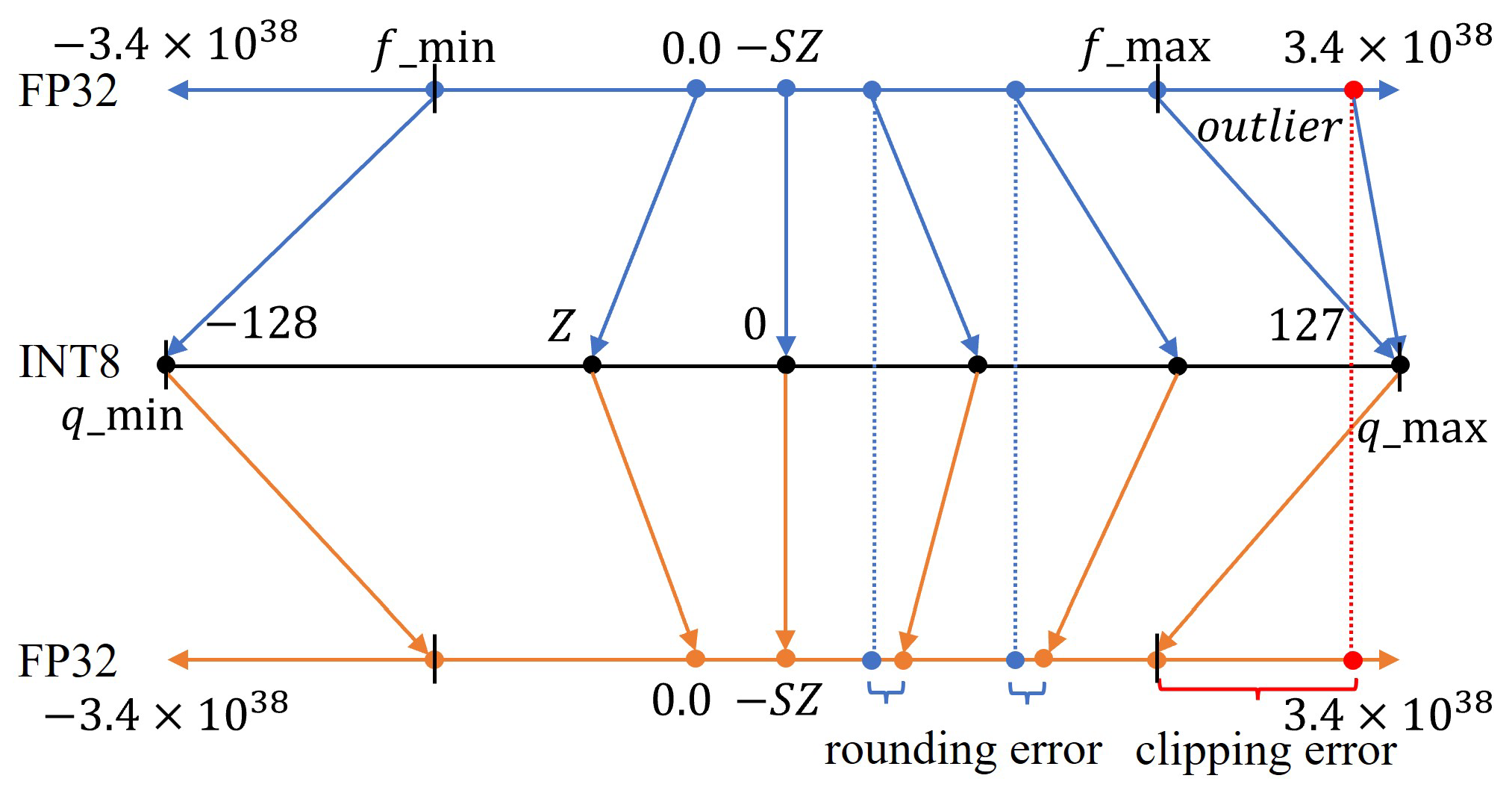
Working with Quantized Types — NVIDIA TensorRT
Improving INT8 Accuracy Using Quantization Aware Training and the ...
Model-Optimizer/modelopt/torch/quantization/calib at main · NVIDIA ...
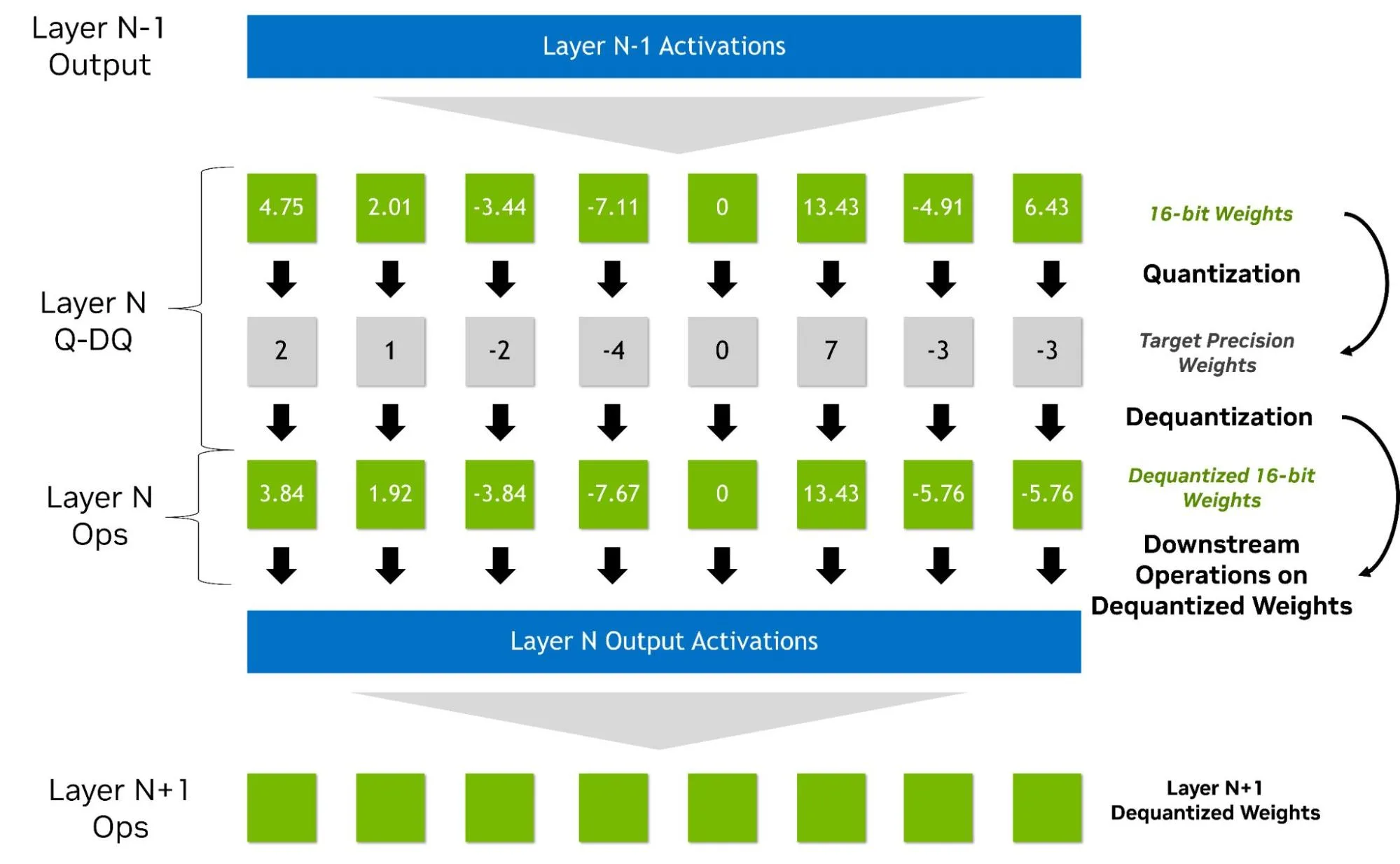
量化感知训练如何实现低精度恢复 - NVIDIA 技术博客
How Quantization Aware Training Enables Low-Precision Accuracy Recovery ...
4-bit quantization for Gemma3ForConditionalGeneration · Issue #380 ...
[Doc - Guidance] Proper MoE quantization · Issue #732 · NVIDIA/Model ...
Accelerate Generative AI Inference Performance with NVIDIA TensorRT ...
Fine-Tuning gpt-oss for Accuracy and Performance with Quantization ...
Serving Quantized LLMs on NVIDIA H100 Tensor Core GPUs | Databricks
NVIDIA Accelerated Quantum Research Center to Bring Quantum Computing ...
模型量化:核心概念、实现方法与关键作用 - NVIDIA 技术博客
What is Quantization and how to use it with TensorFlow
Model Quantization: Meaning, Benefits & Techniques
NVIDIA - Easily speed up your LLMs by up to 3x⚡️while preserving over ...
Model Quantization: Run Large AI Models on Limited Hardware
Deploying YOLOv5 on NVIDIA Jetson Orin with cuDLA: Quantization-Aware ...
Quantized Model Runs Very Slow (Unable to load extension modelopt_cuda ...
Quantized model has different output between pytorch and onnx · Issue ...
Problem with structured sparsity and explicit quantization (PTQ) on ...
using pytorch_quantization to quantize mmdetection3d model · Issue ...
Serving Quantized LLMs on NVIDIA H100 Tensor Core GPUs | Databricks Blog
模型量化——NVIDIA——QAT_pytorch quantization toolkit-CSDN博客
Serving Quantized LLMs on NVIDIA H100 Tensor Core GPUs | Audrey Cain
Overview of natively supported quantization schemes in 🤗 Transformers
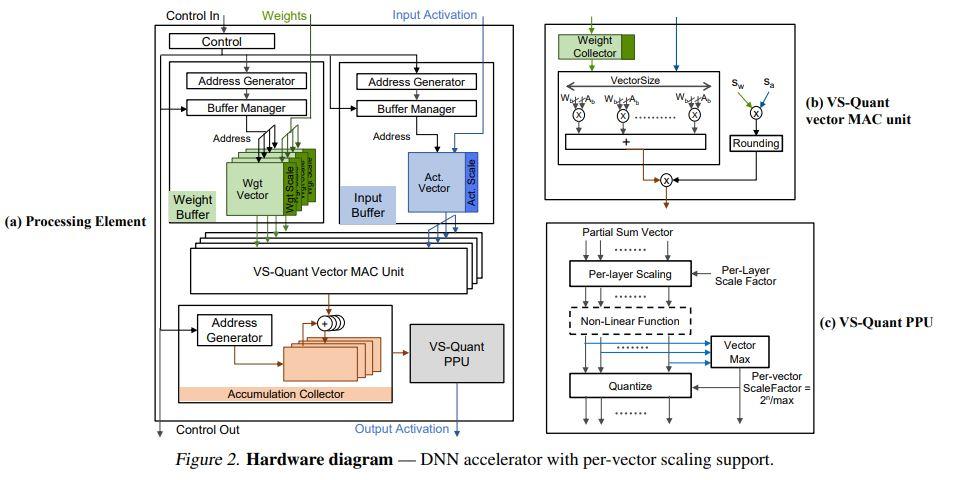
VS-QUANT: Per-Vector Scaled Quantization for Accurate Low-Precision ...
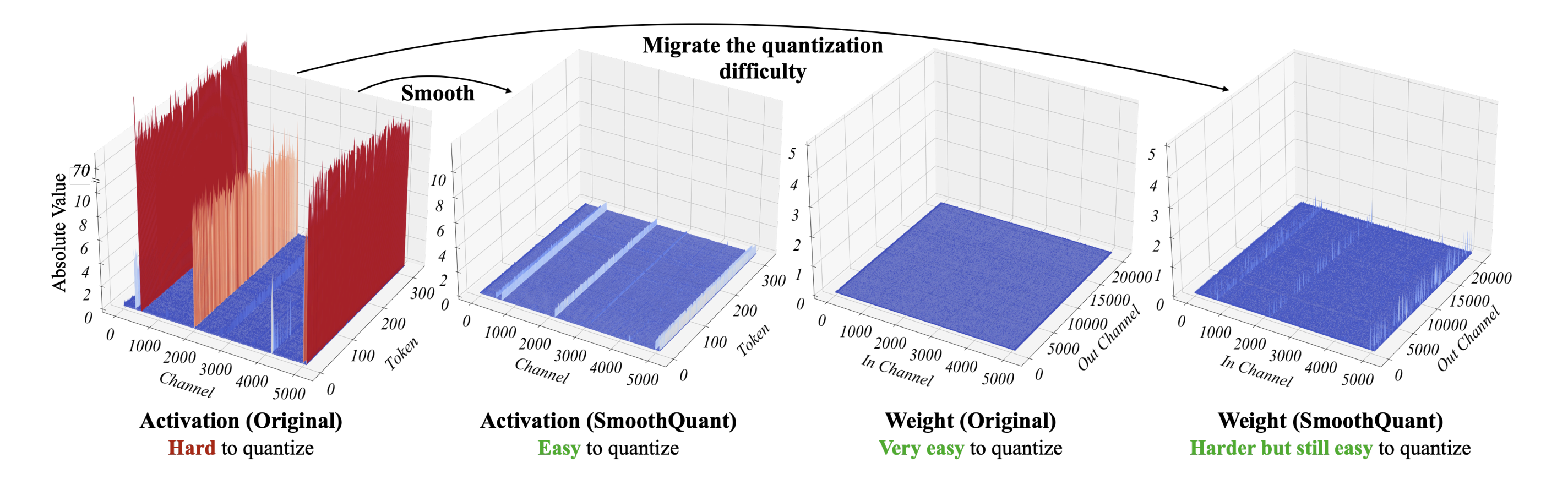
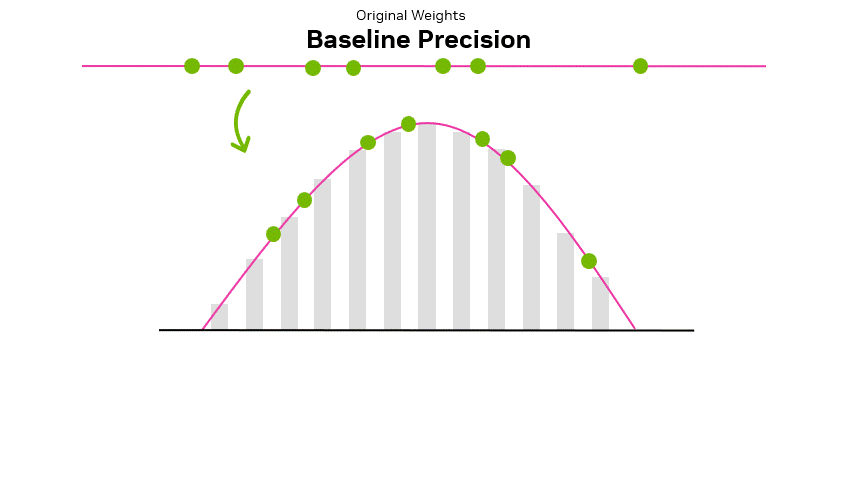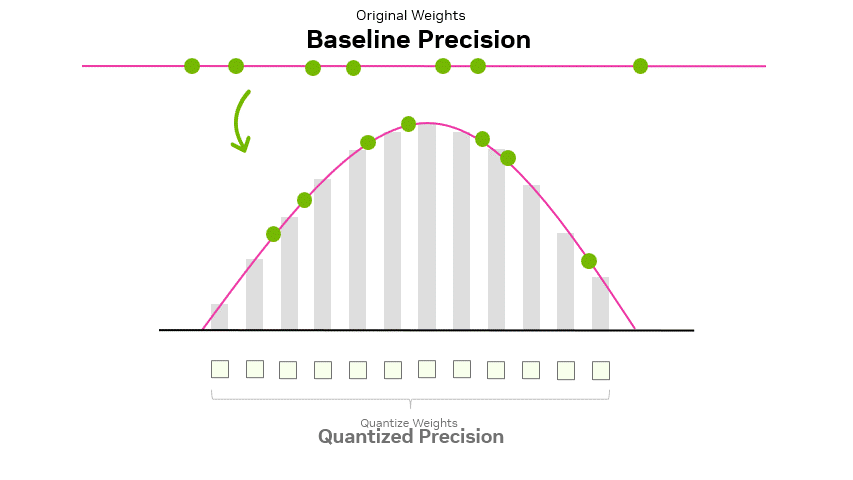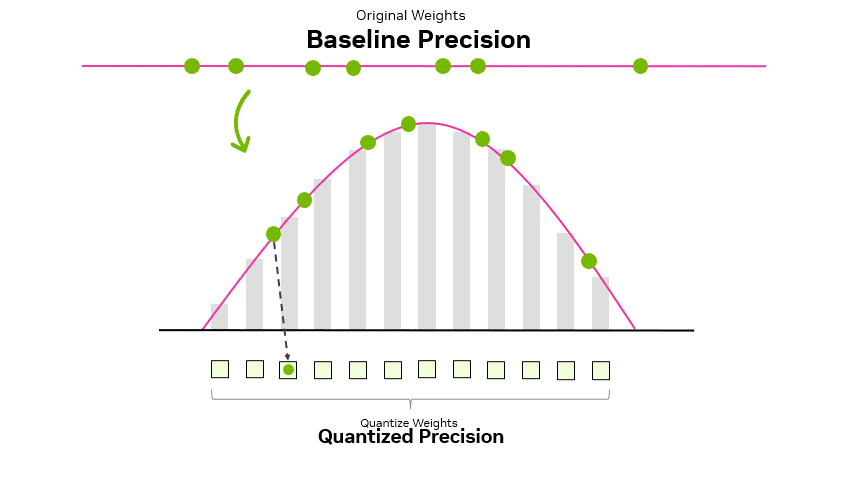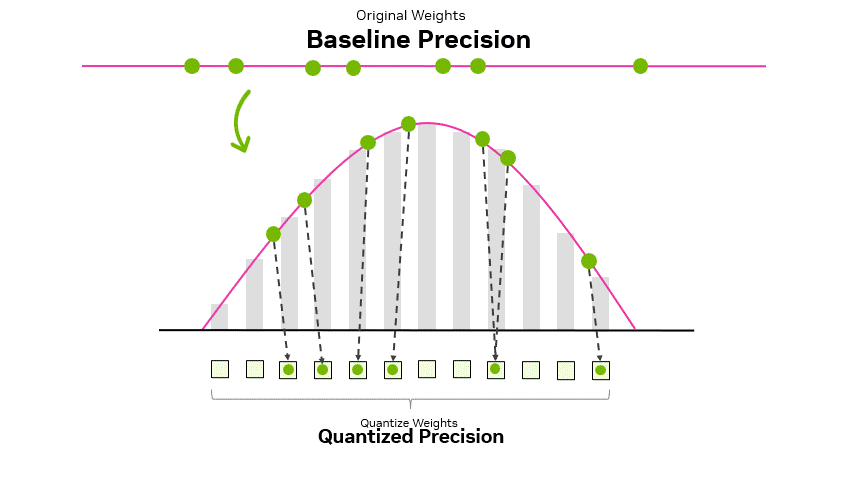
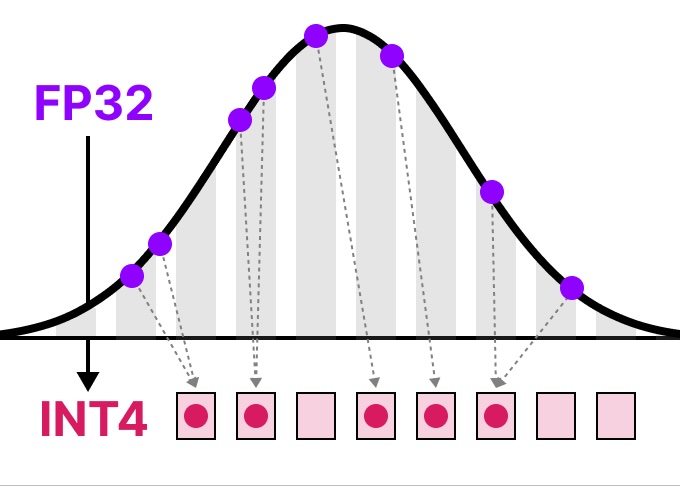
A Visual Guide to Quantization - by Maarten Grootendorst
AI Model Optimization: Maximizing Performance and Efficiency | IT-Magic
Unlocking Model Quantization: Why Precision Matters in Deep Learning ...
Fast and Accurate GPU Quantization for Transformers | Speechmatics
Unlocking LLM Performance: Advanced Quantization Techniques on Dell ...
NVIDIA 技术博客:使用 NVIDIA QAT 工具包为 TensorFlow 和 NVIDIA TensorRT 加速量化网络-CSDN社区
Quantization for Neural Networks - Lei Mao's Log Book
Optimizing LLMs for Performance and Accuracy with Post-Training ...
Robust Scene Text Detection and Recognition: Inference Optimization ...
Deep Learning Performance Characterization on GPUs for Various ...
GPU memory requirements for serving Large Language Models | UnfoldAI
大模型入门指南 - Quantization:小白也能看懂的“模型量化”全解析_大模型量化-CSDN博客
MSU AI Club
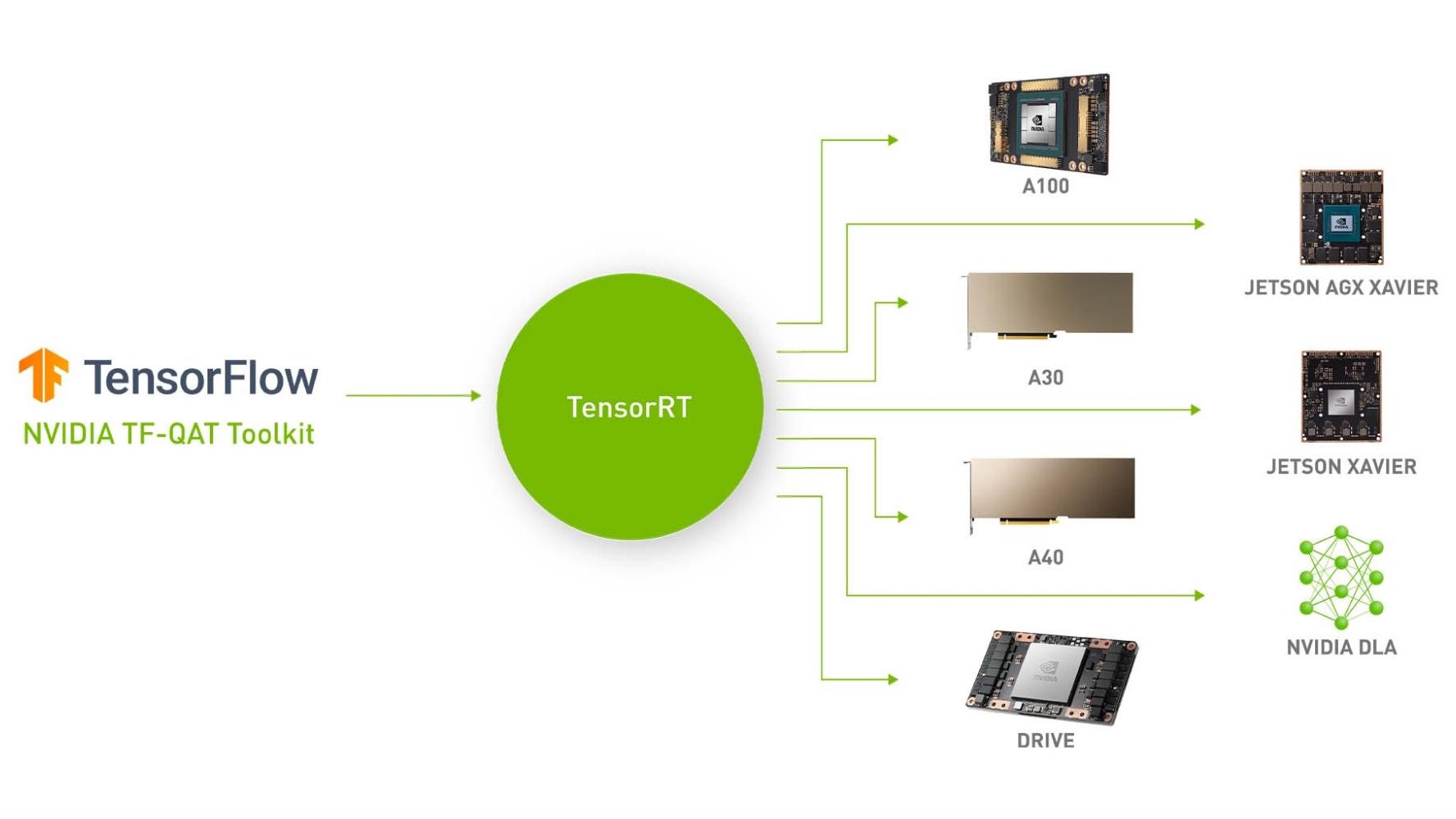



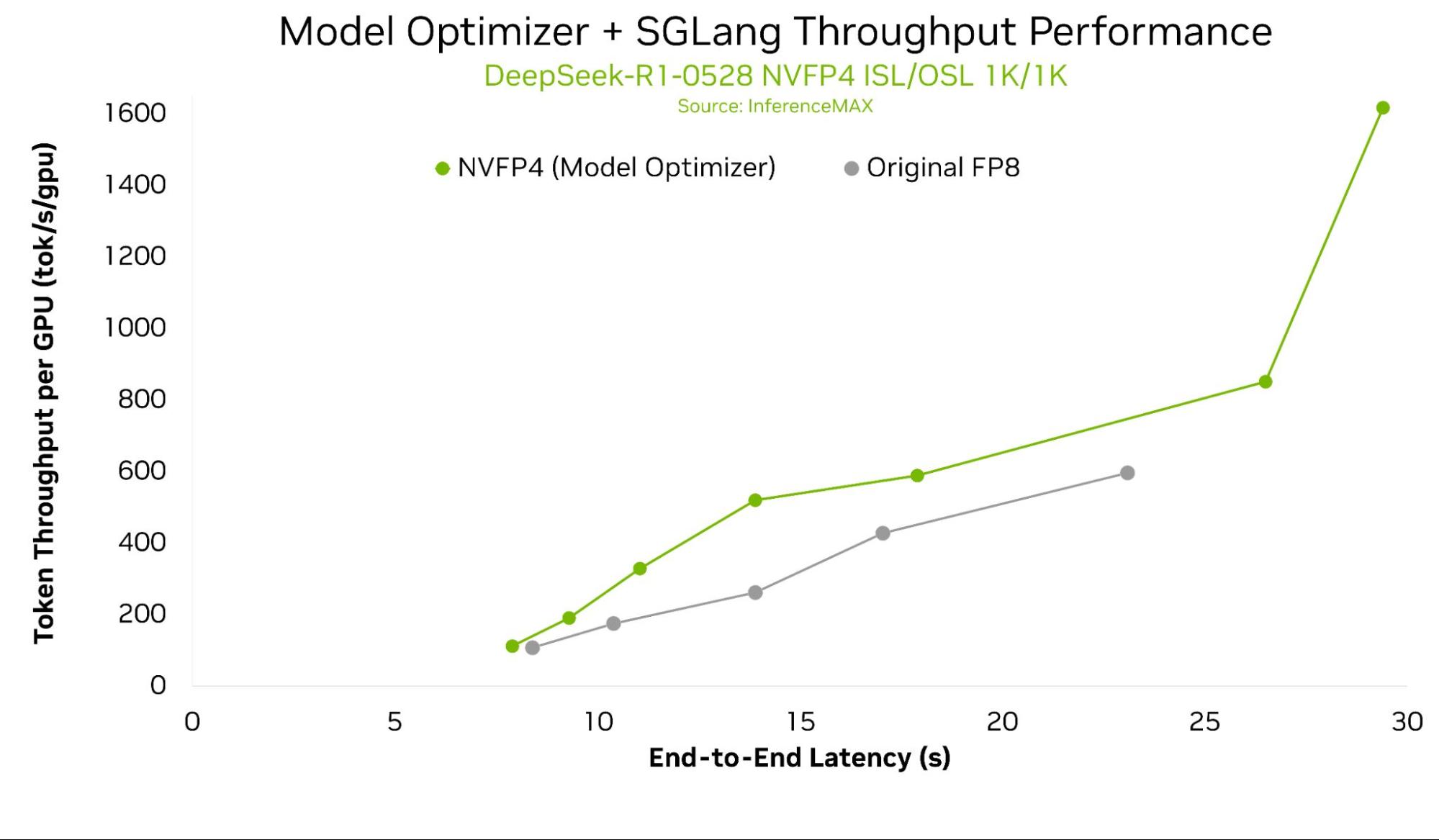
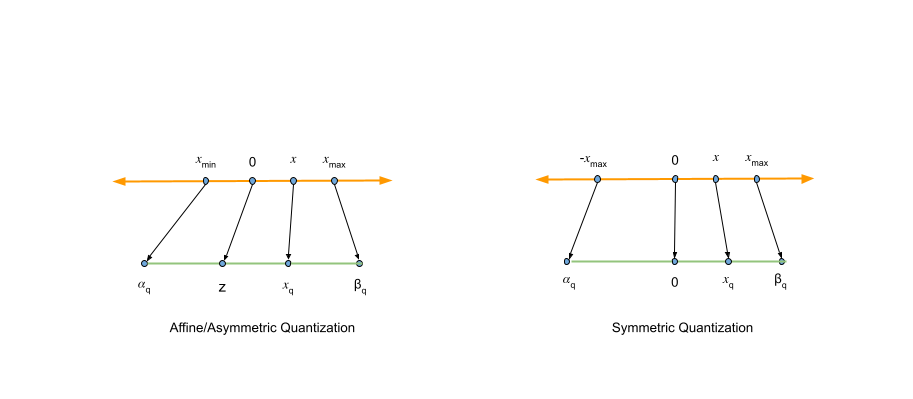



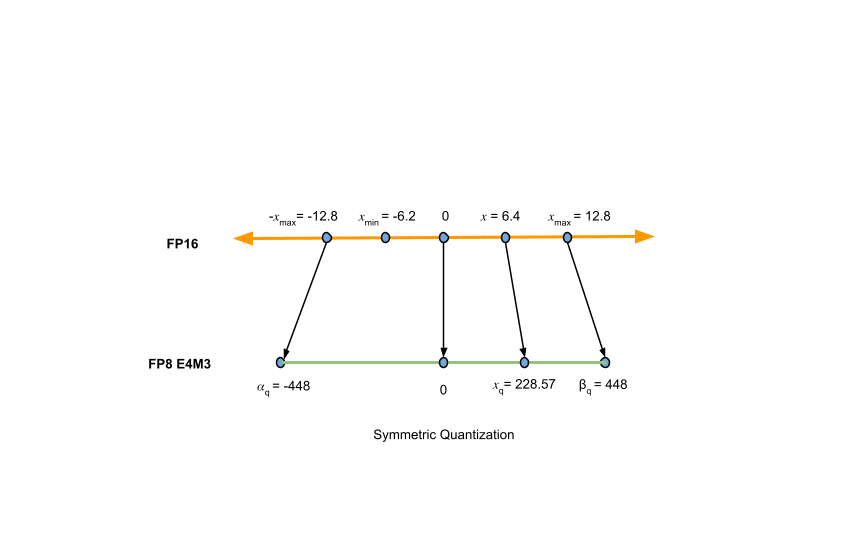









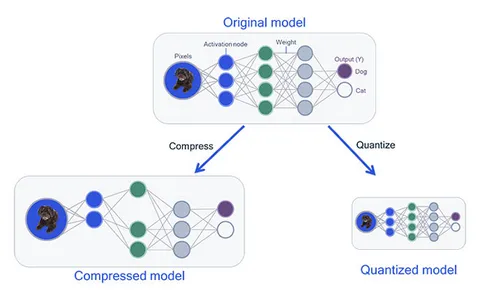
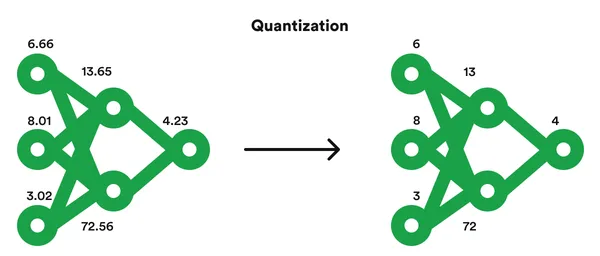

















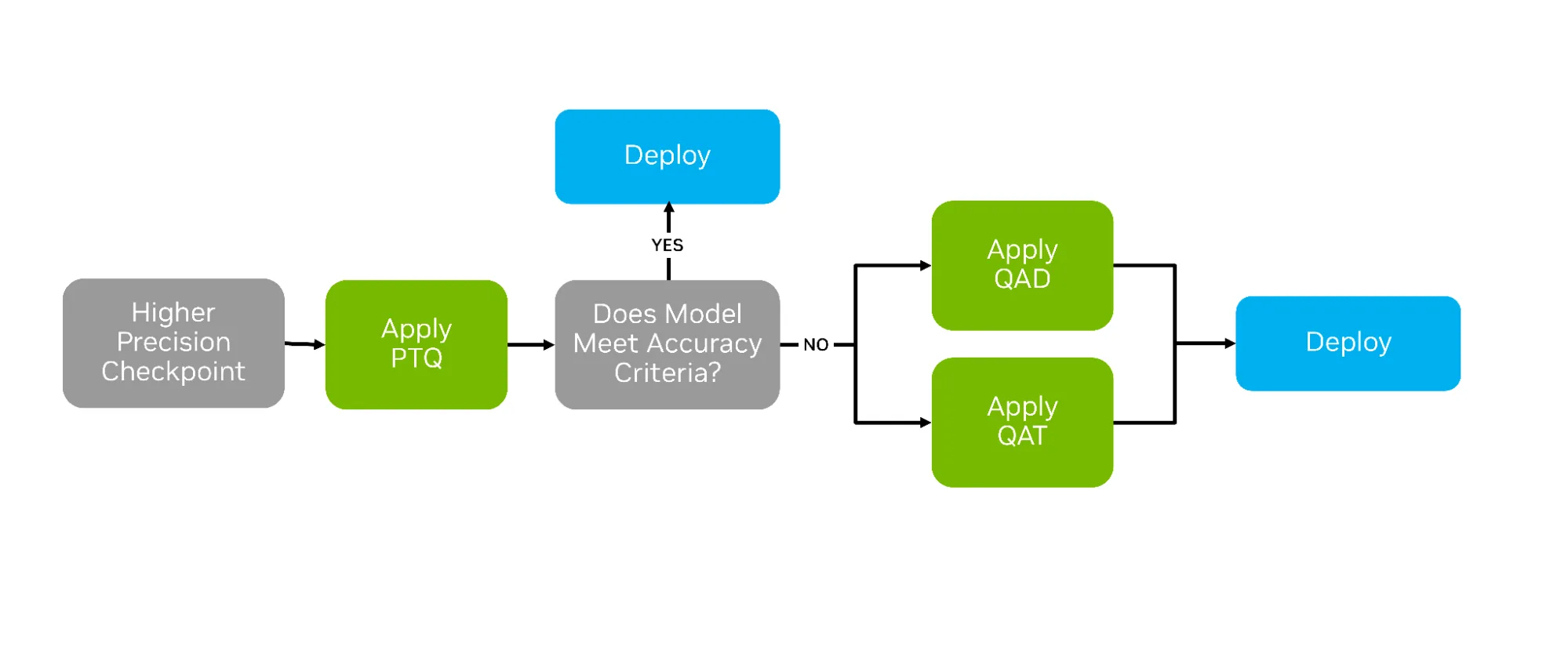

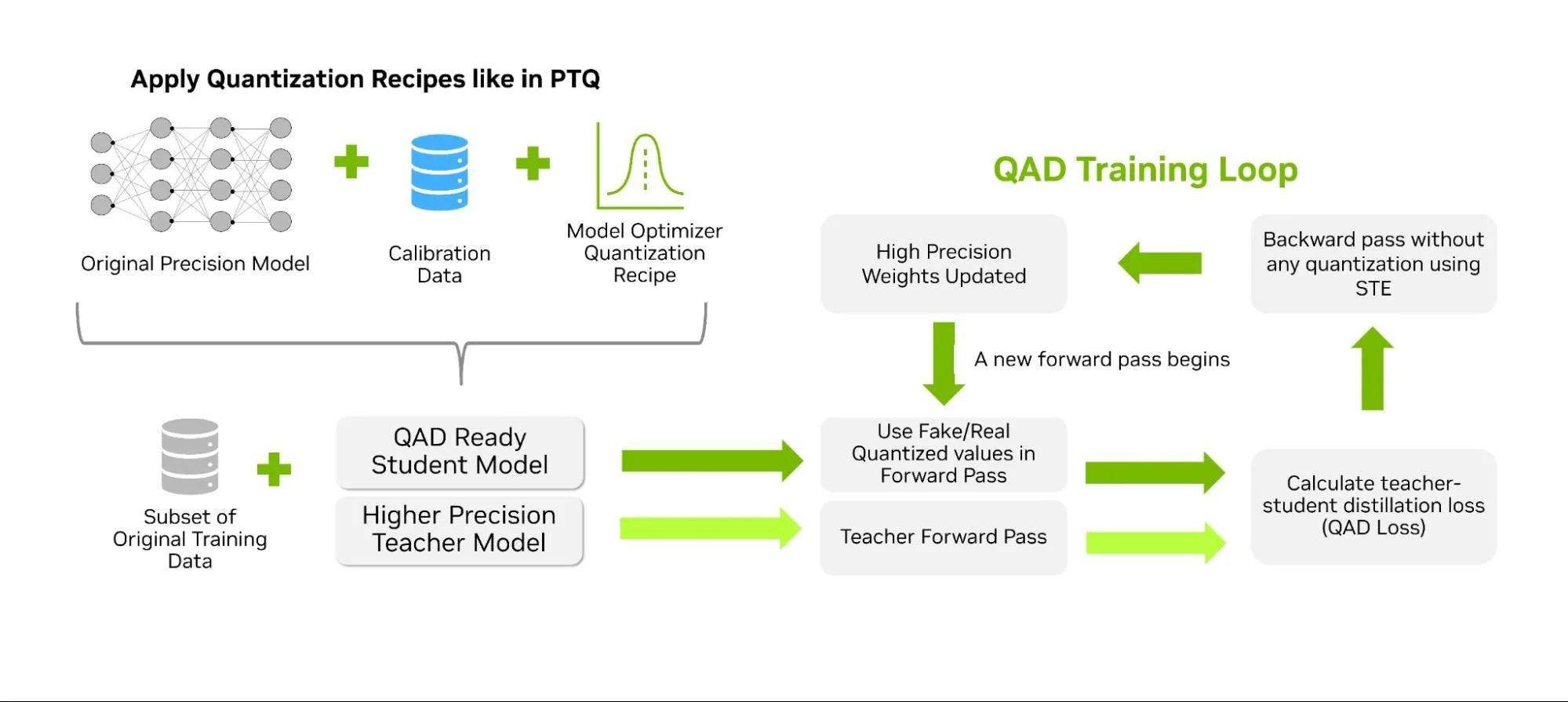


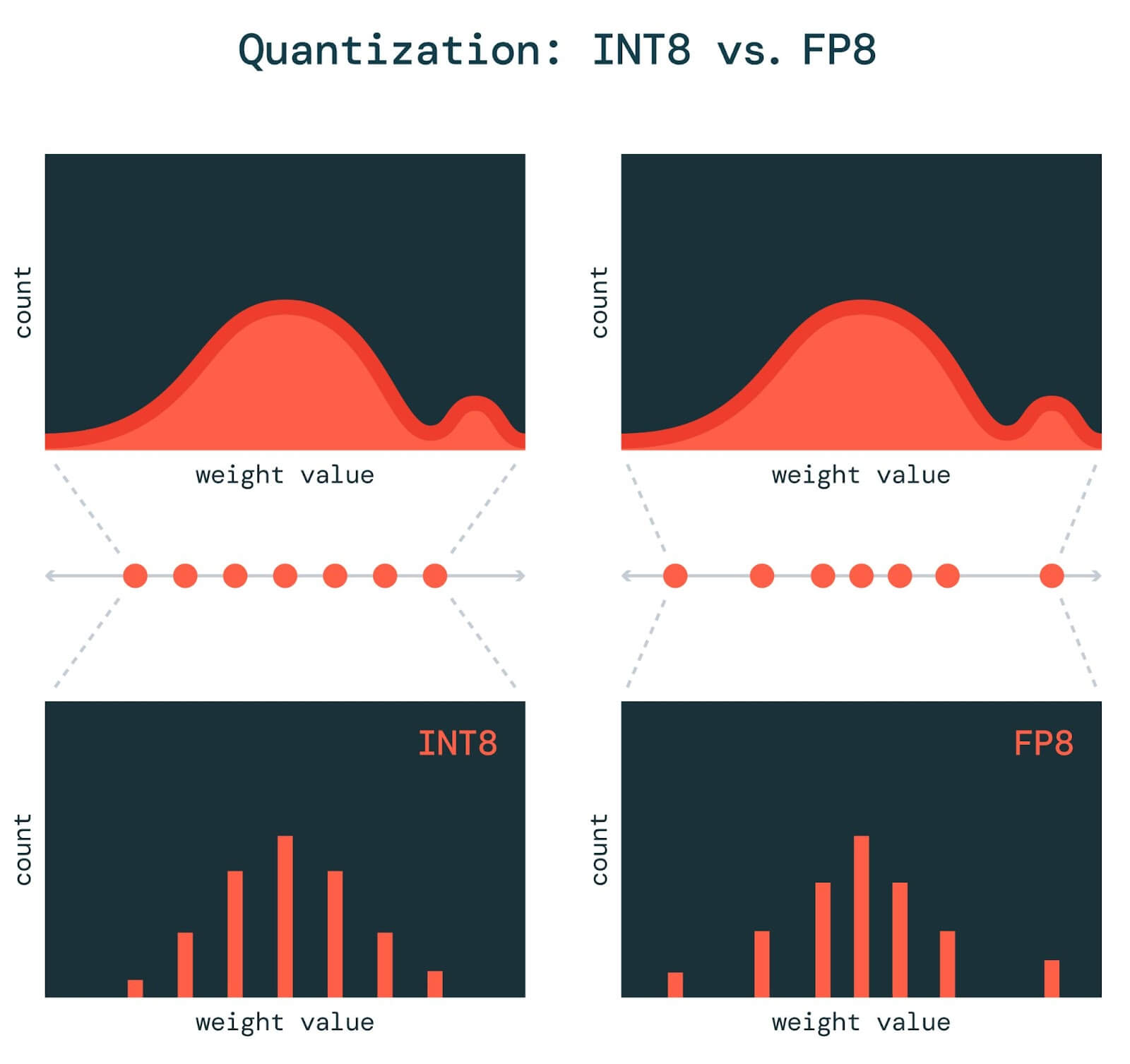
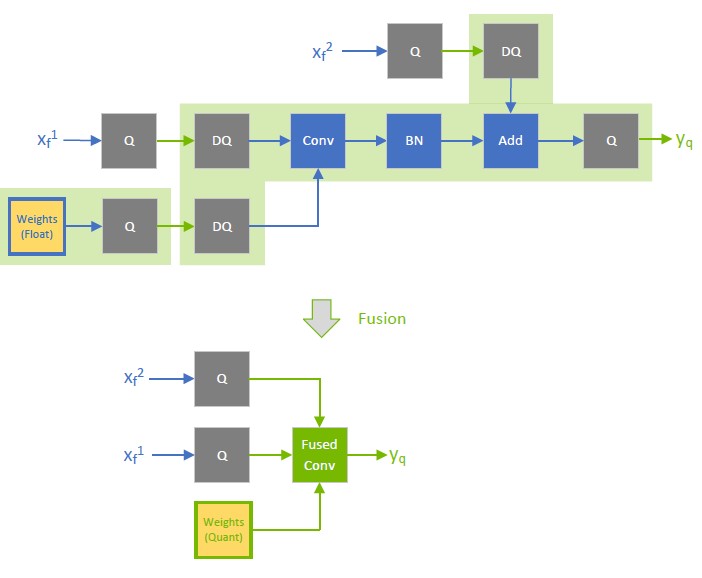
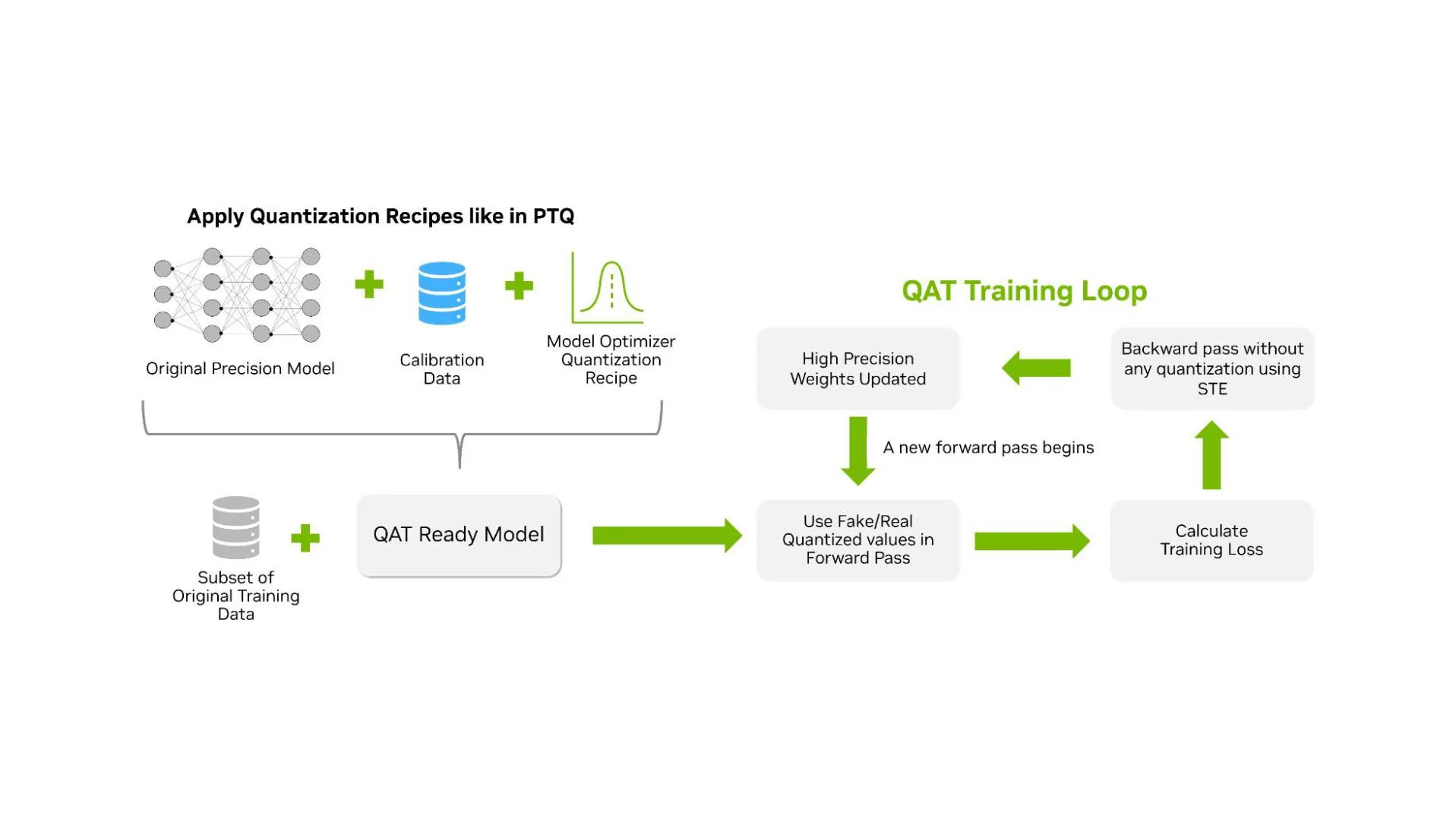
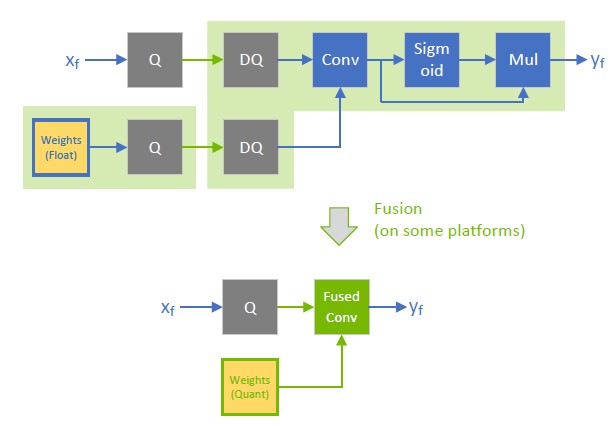
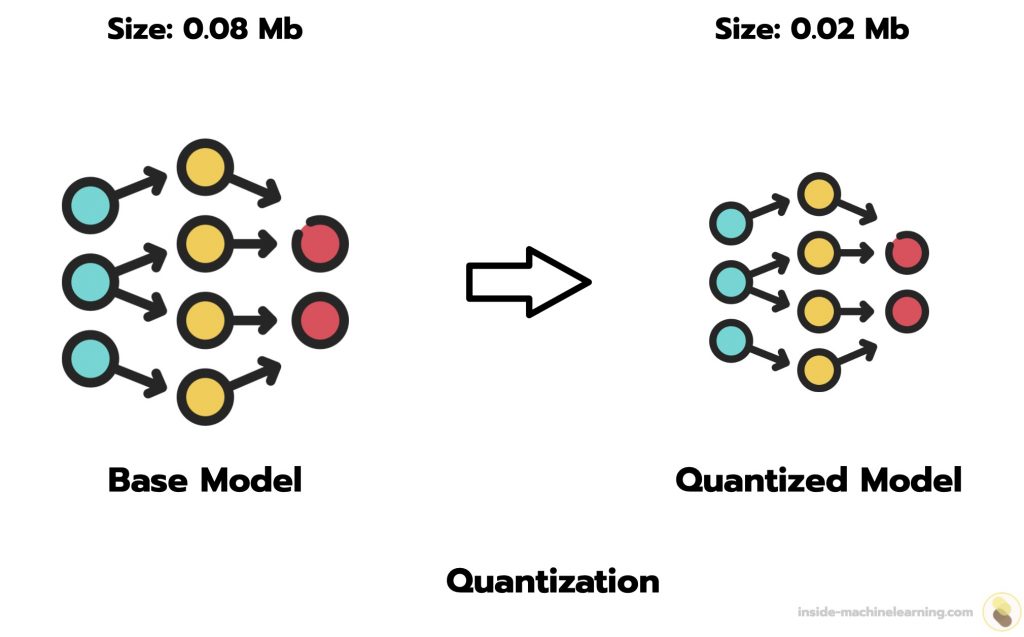
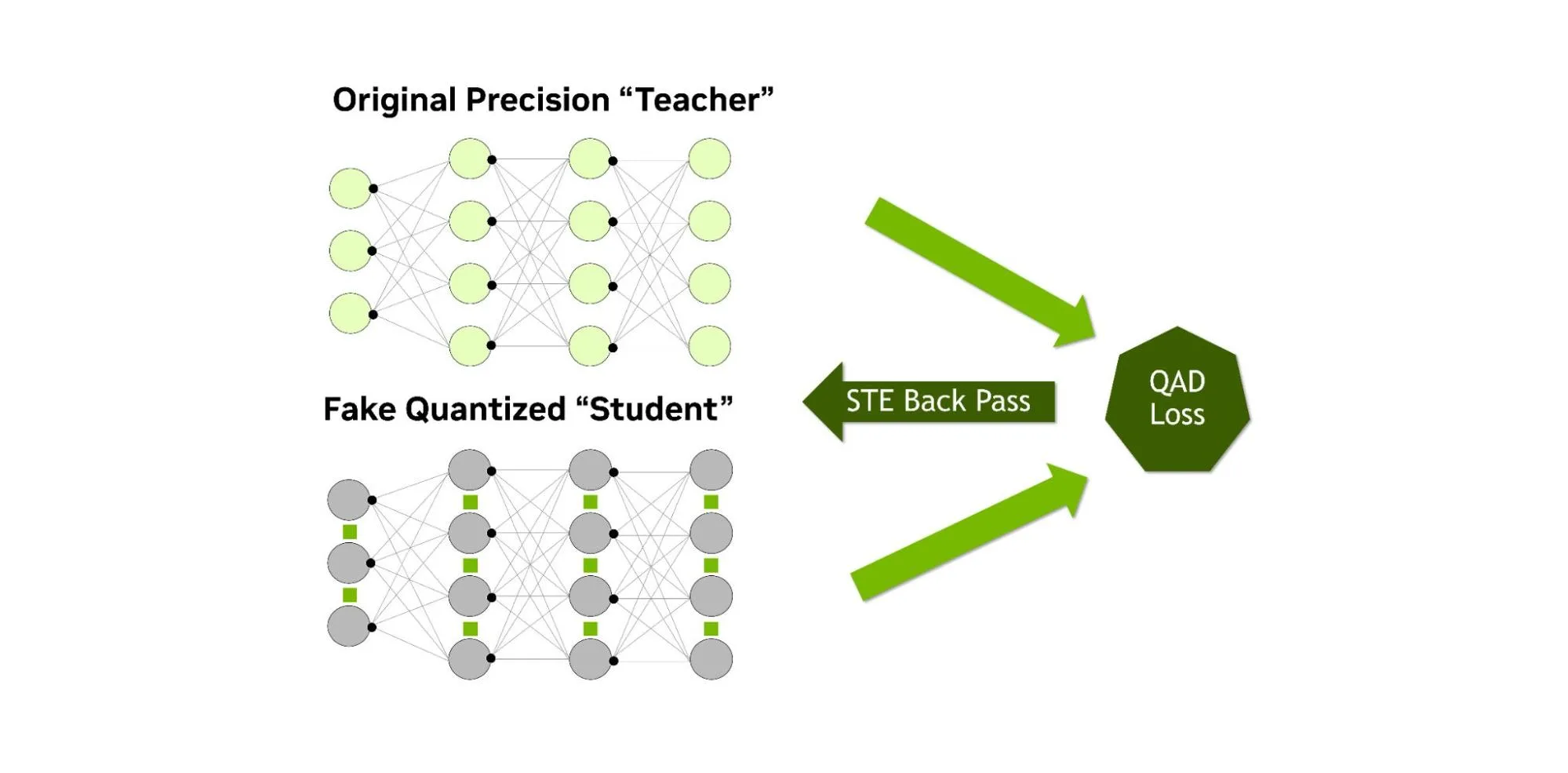
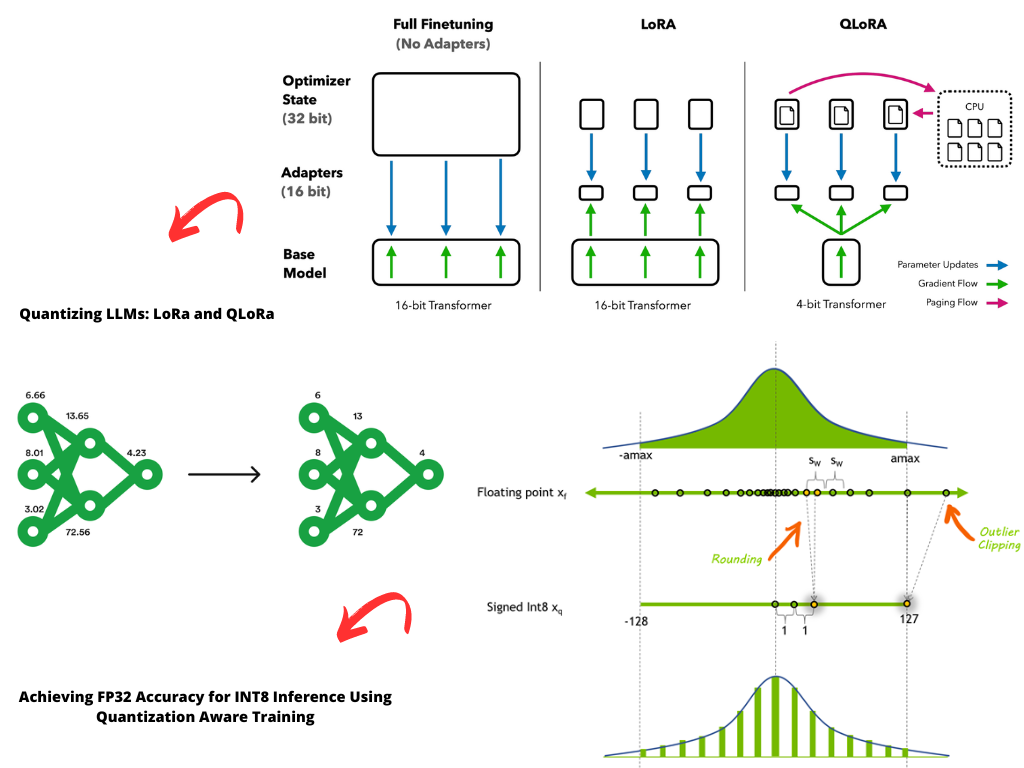
%20(1)-png.png?width=2880&height=1440&name=Top%20AI%20Infrastructure%20(1)%20(1)-png.png)