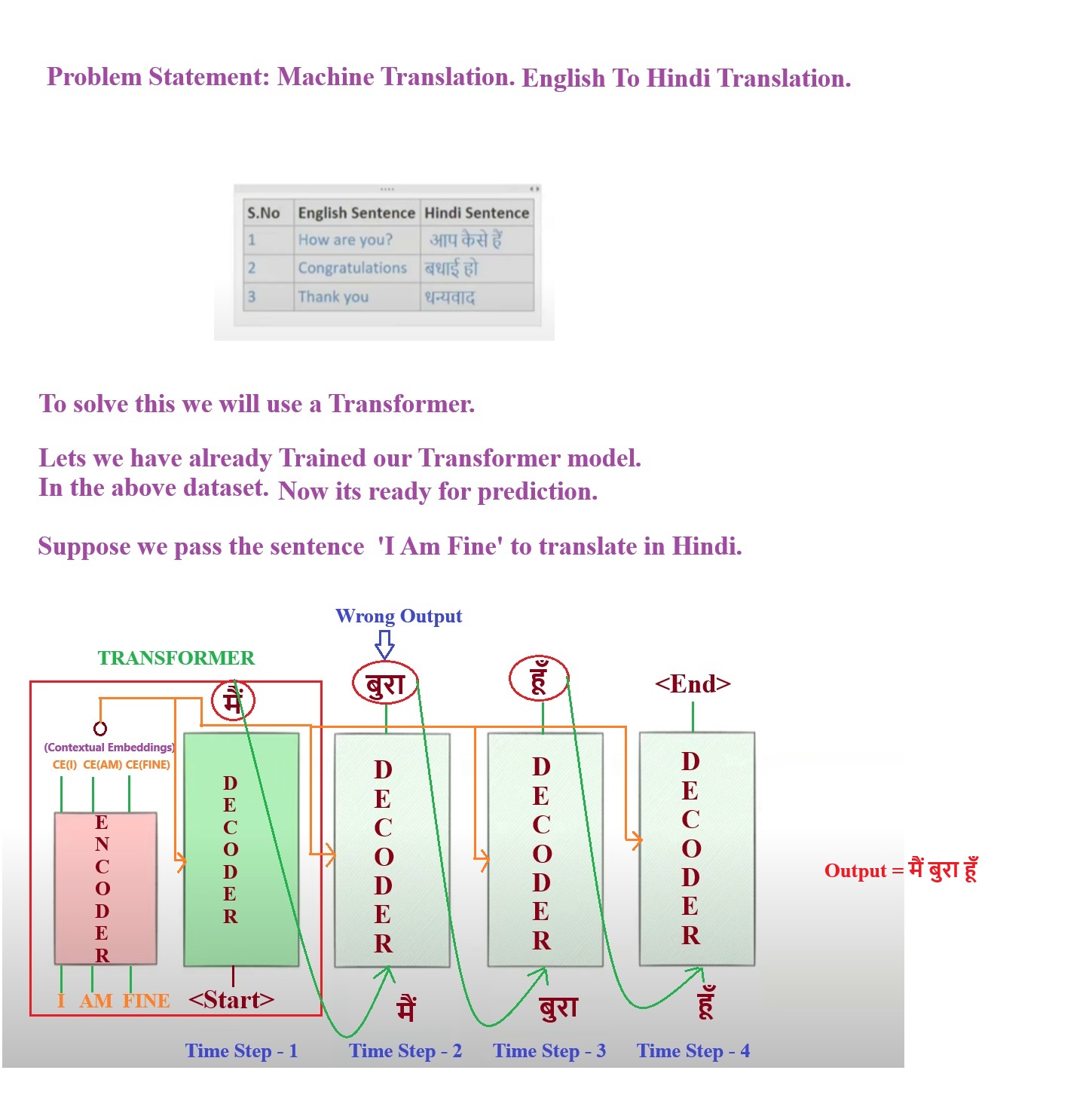
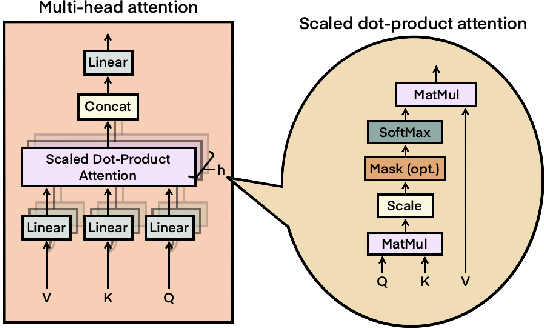
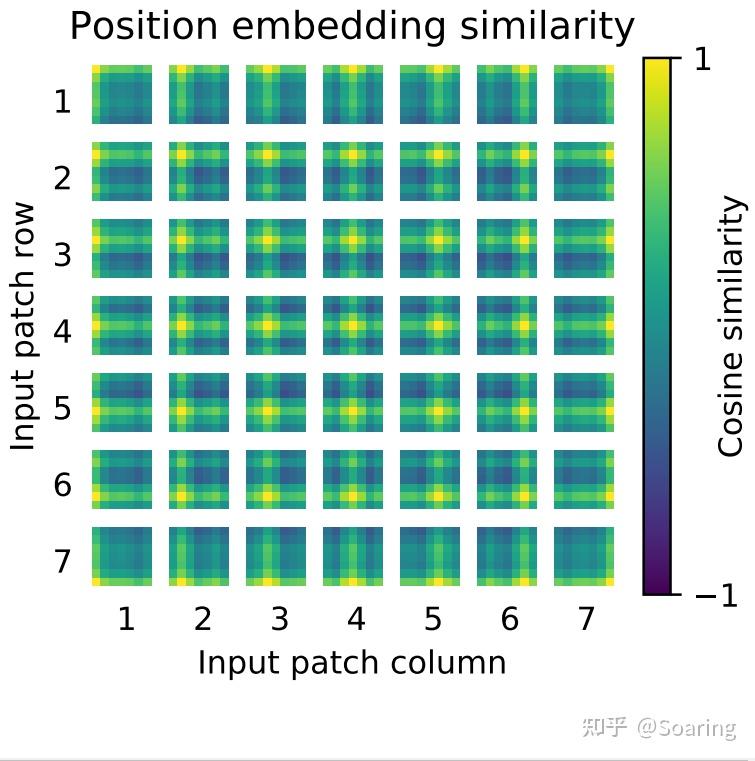
Showing 119 of 119on this page. Filters & sort apply to loaded results; URL updates for sharing.119 of 119 on this page
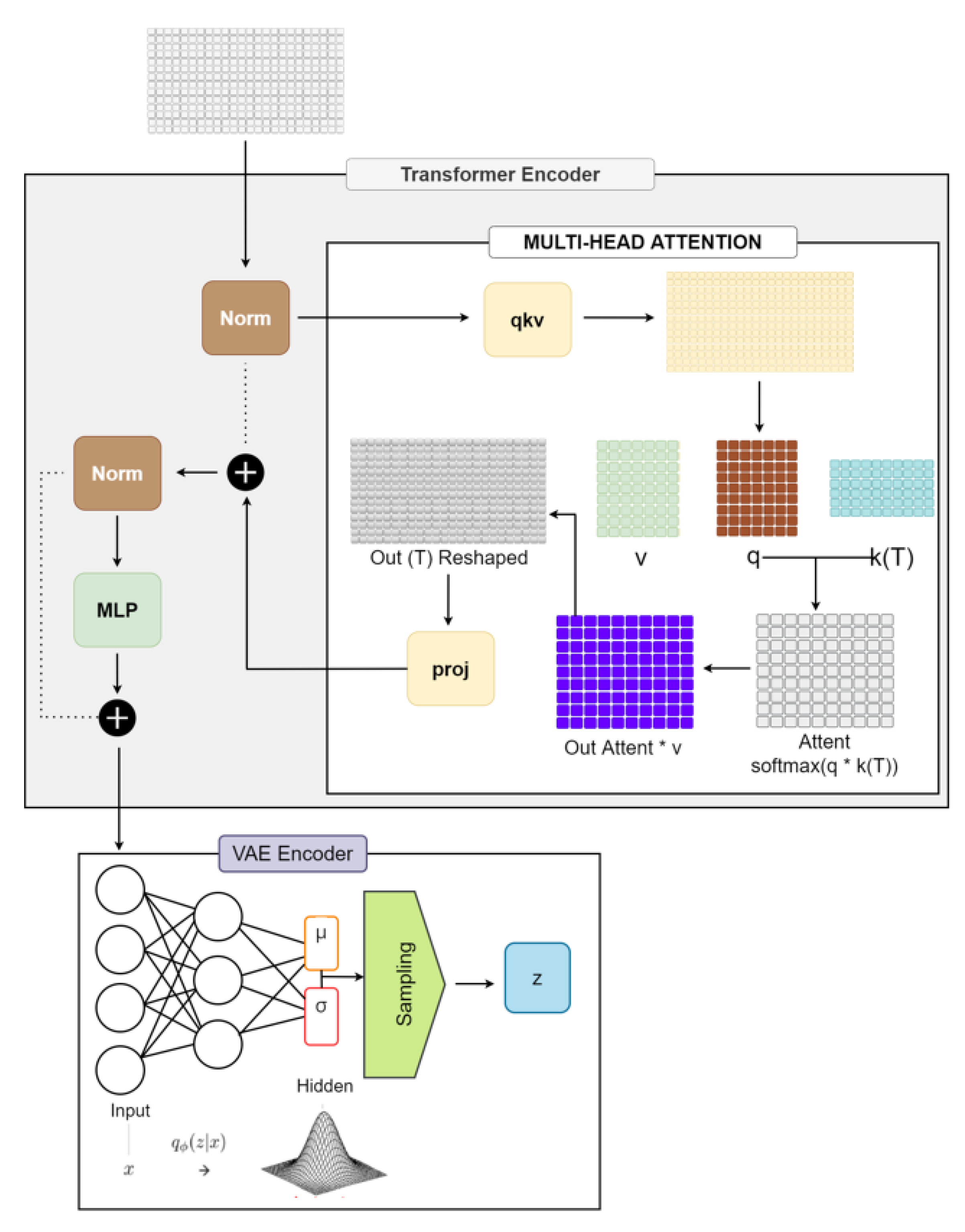
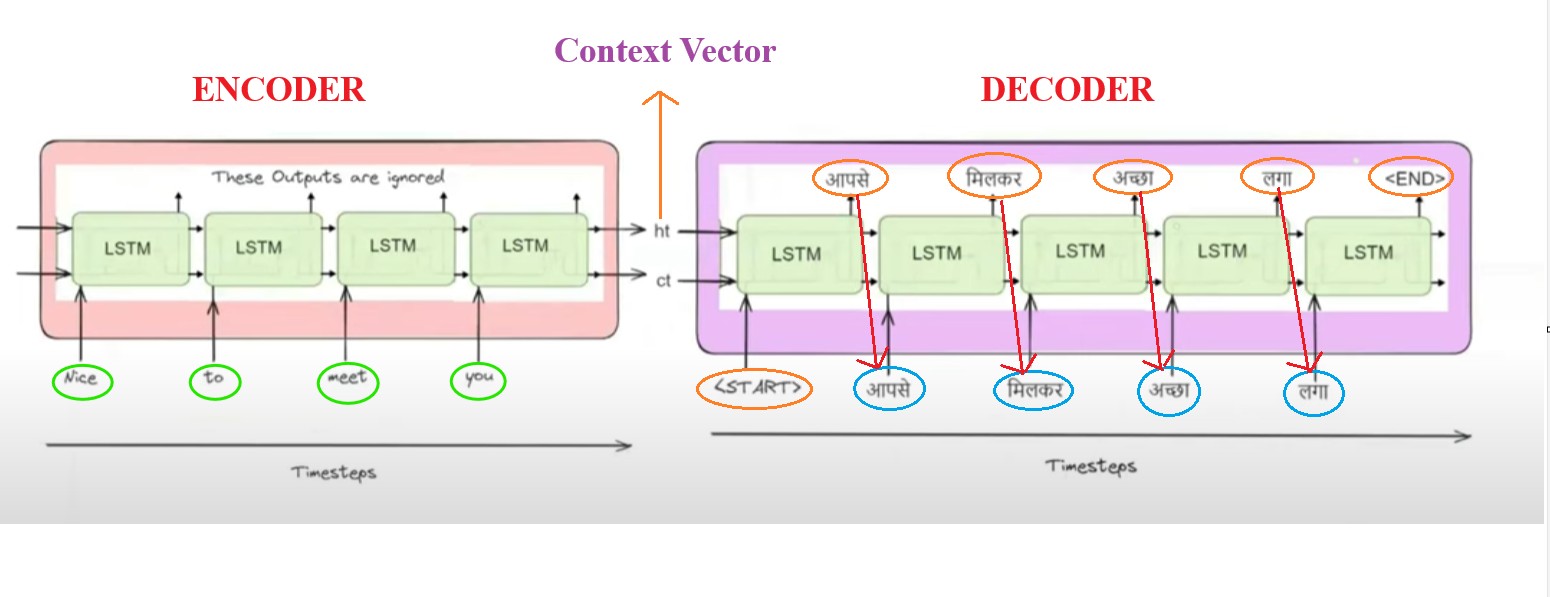
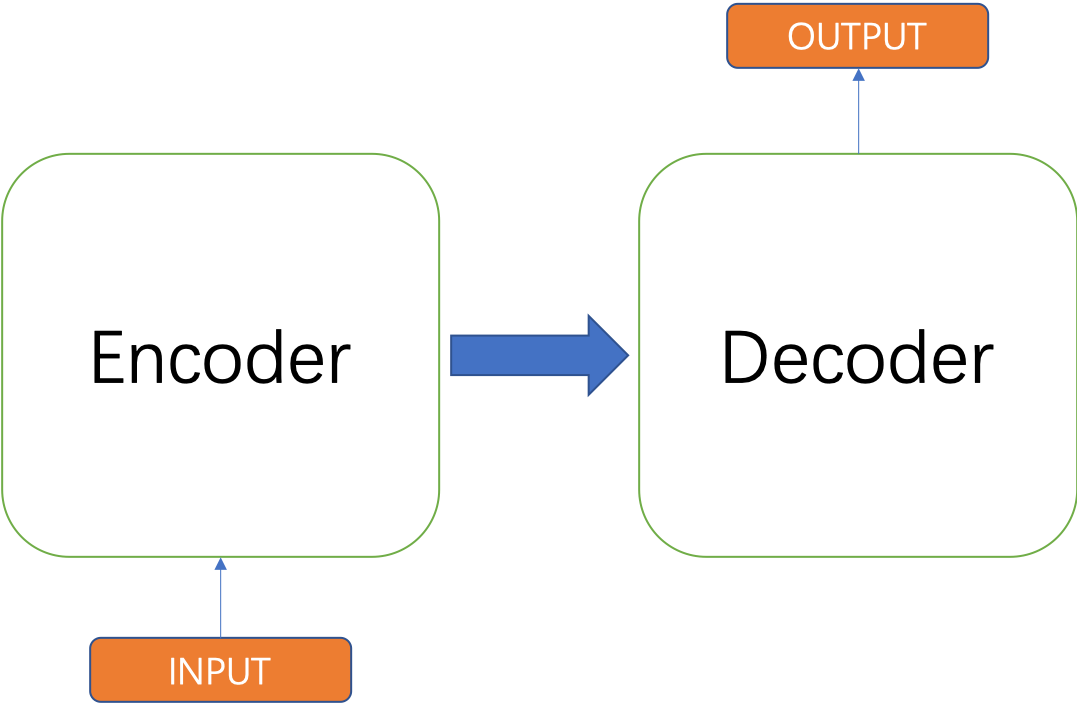
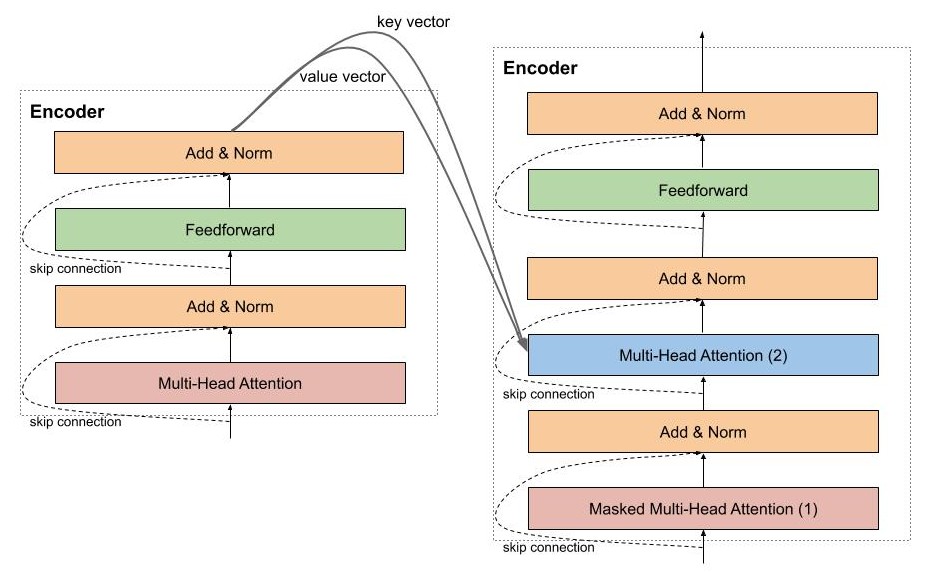
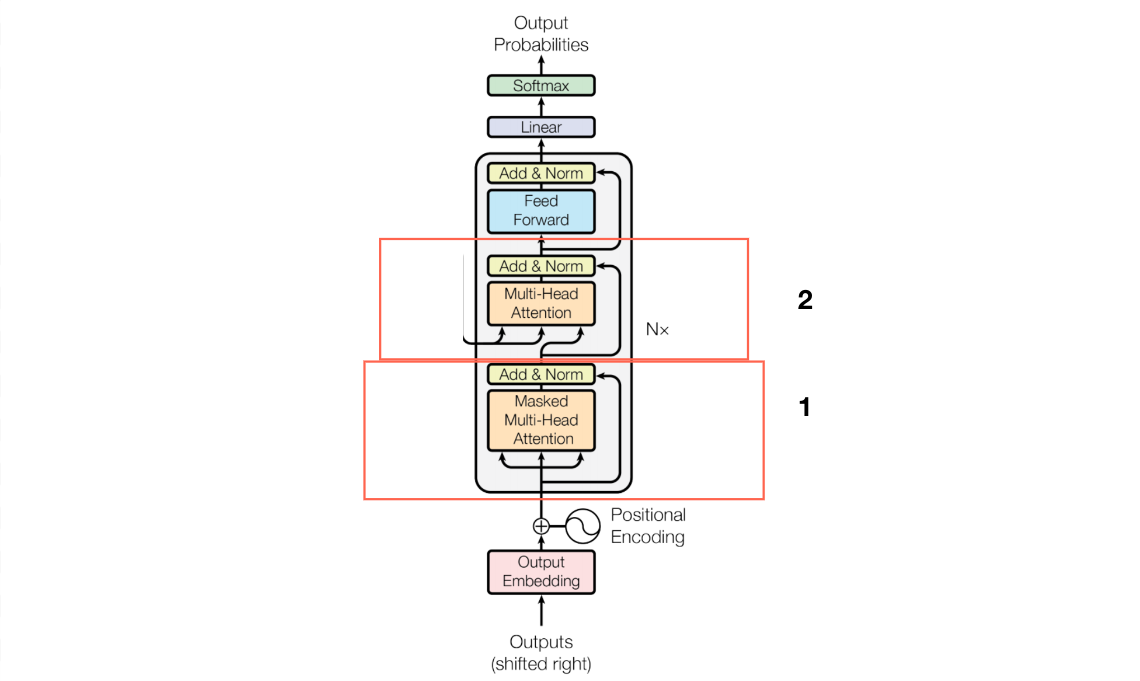
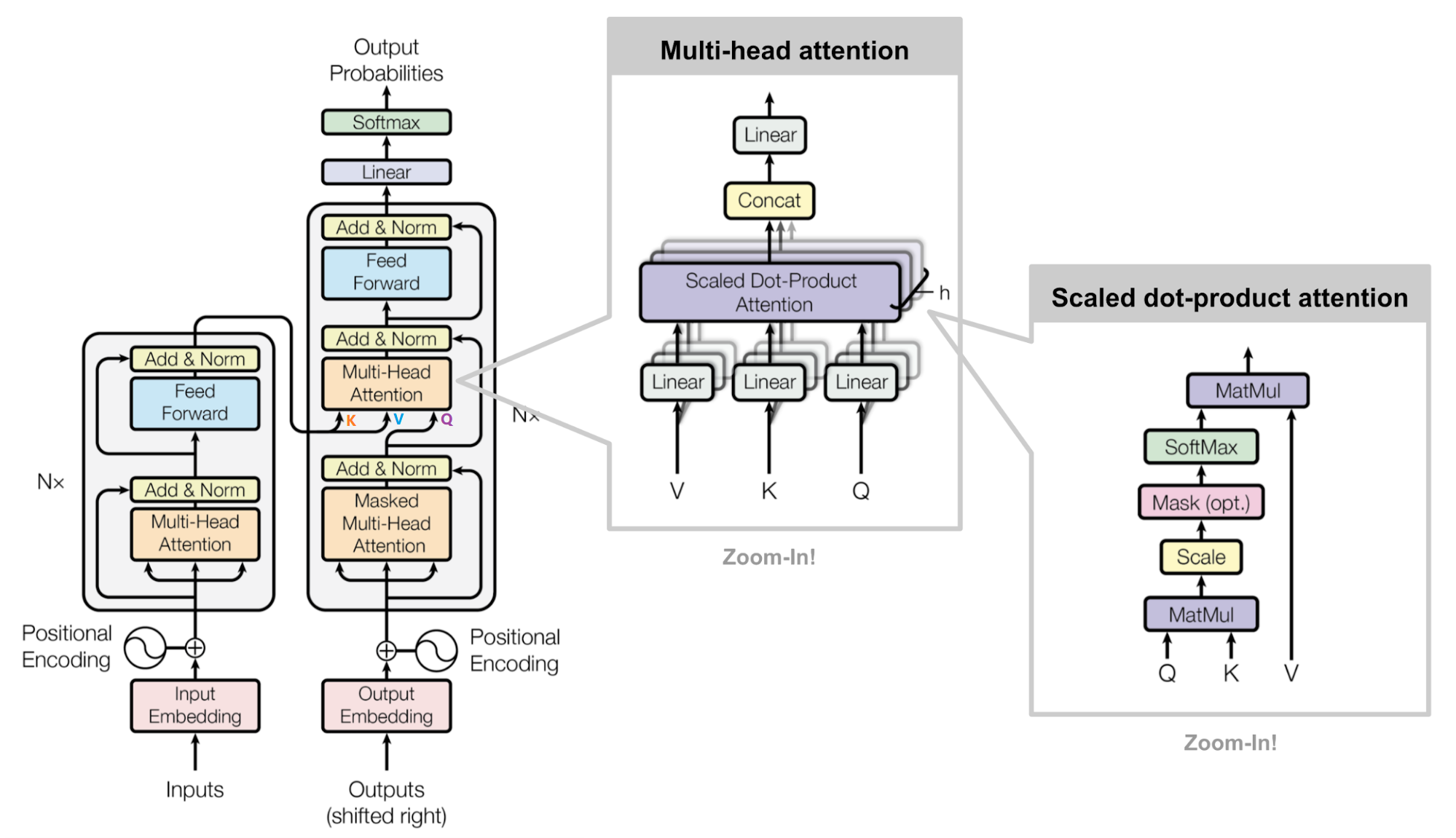
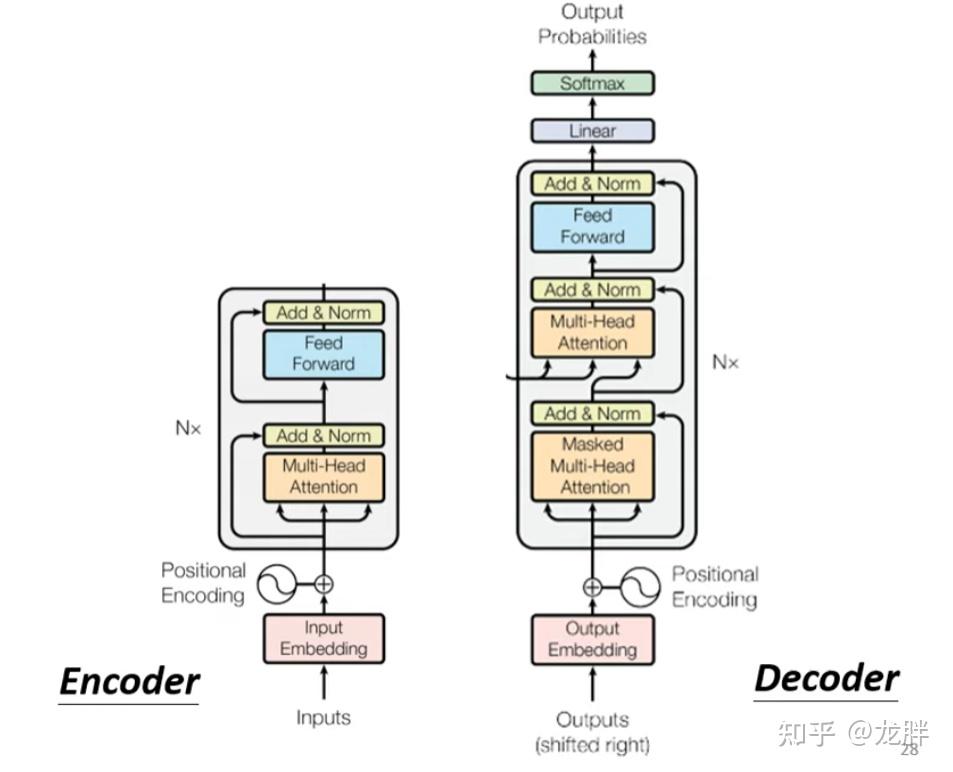
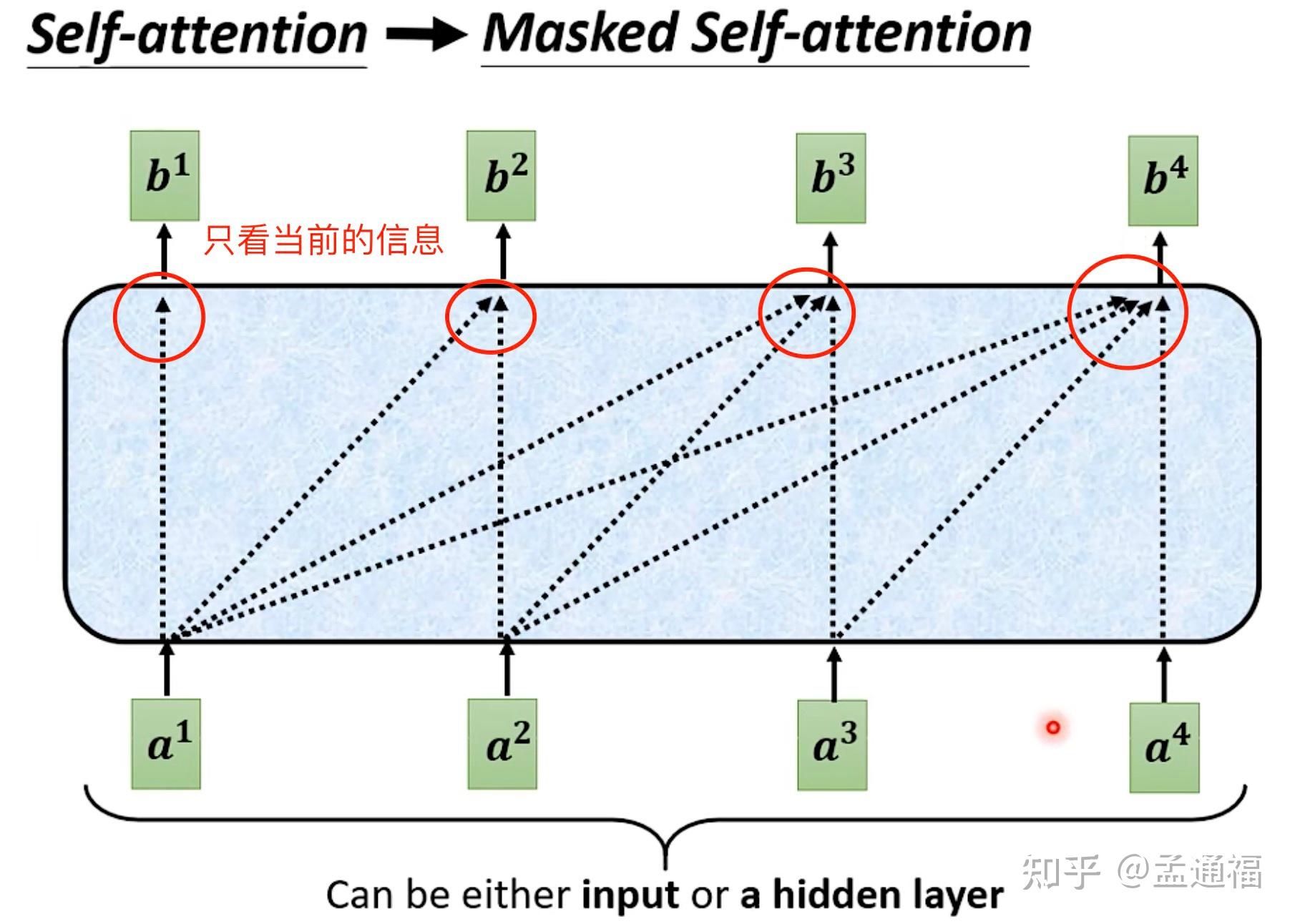
Transformer : encoder 및 decoder (Masked Self-attention)
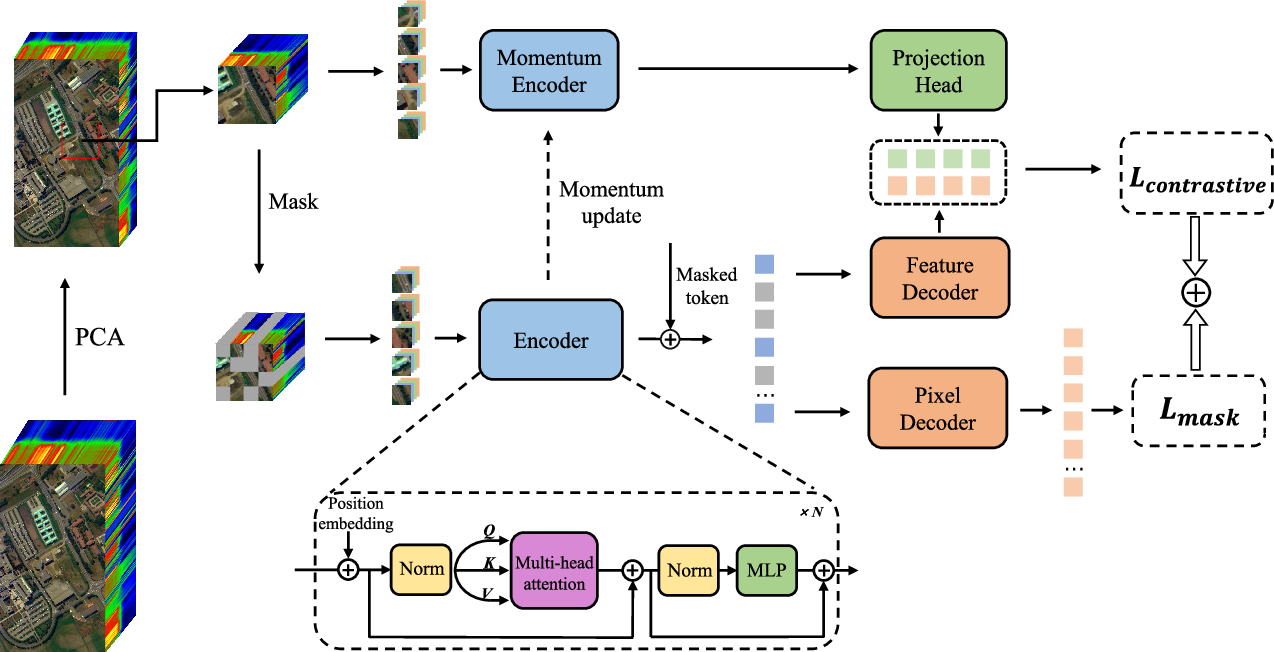
Figure 2 from Masked Auto-Encoding Spectral–Spatial Transformer for ...
Masked Autoencoder Transformer at Theresa Sotelo blog
[논문 리뷰] Masked Autoencoder with Swin Transformer Network for Mitigating ...
Masked Autoencoder Swin Transformer at Samara Smalling blog
[2401.06274] Transformer Masked Autoencoders for Next-Generation ...
Decoder vs Encoder in Transformer Models | AI Tutorial | Next Electronics
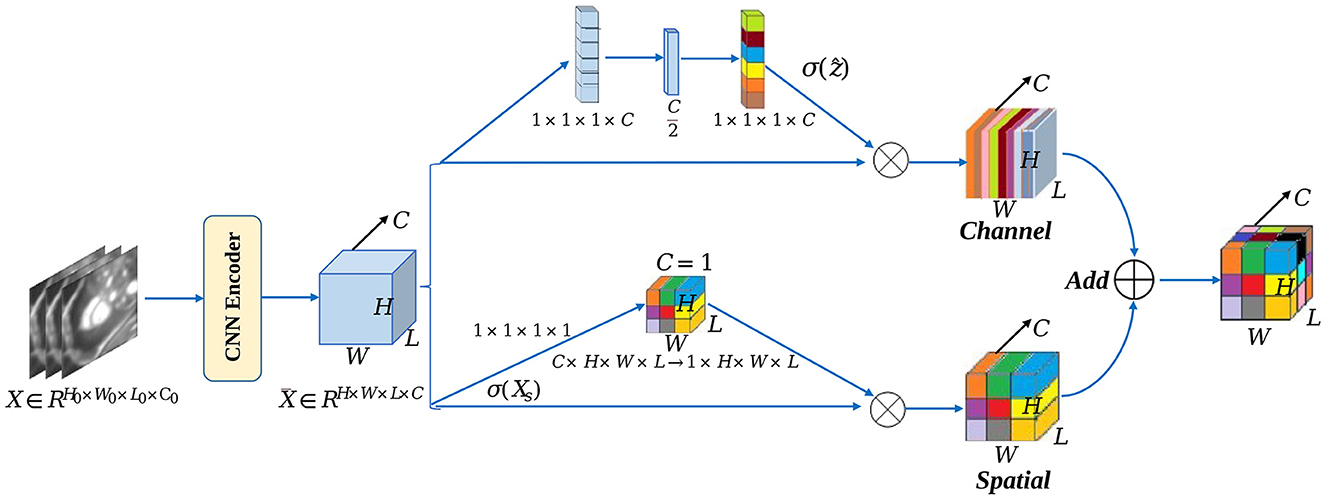
Overview of the masked auto encoder which takes masked images as input ...
9: The architecture of a transformer model. The encoder consists of í ...
(PDF) Rethinking Vision Transformer and Masked Autoencoder in ...
Transformer 模型介绍(四)——编码器 Encoder 和解码器 Decoder - 技术栈
[2005.11978] MASKED PRE-TRAINED ENCODER BASE ON JOINT CTC-TRANSFORMER
[논문 리뷰] Transformer with Leveraged Masked Autoencoder for video-based ...
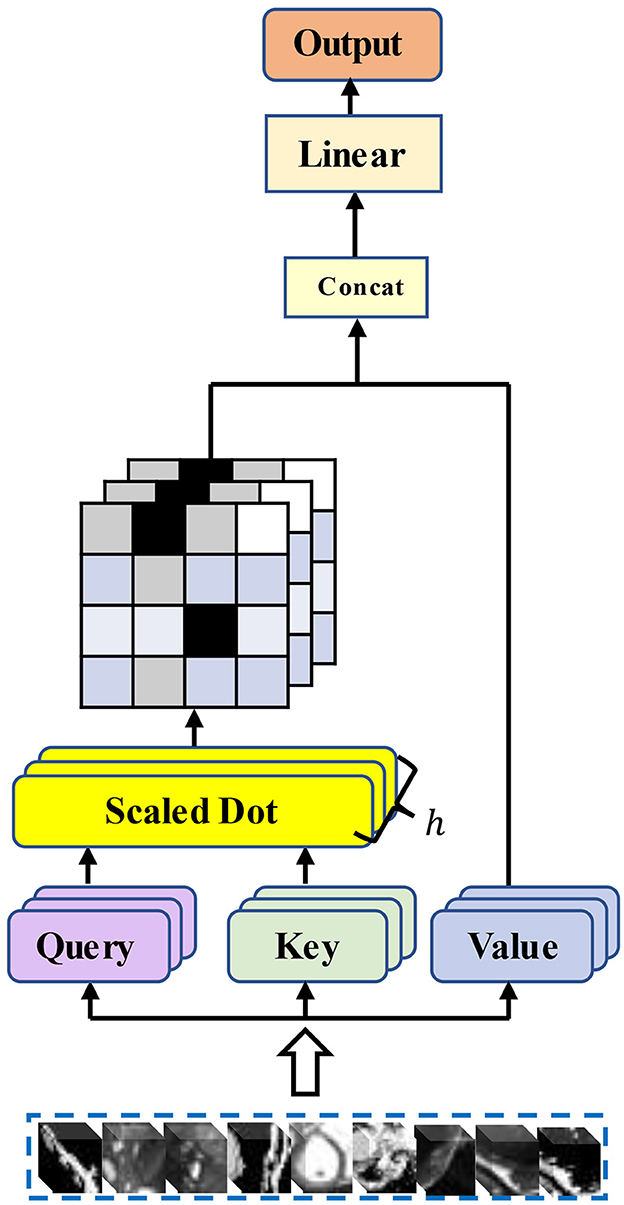
Masked Multi Head Attention in Transformer | by Sachinsoni | Medium
Transformer – Masked Self Attention – Praudyog
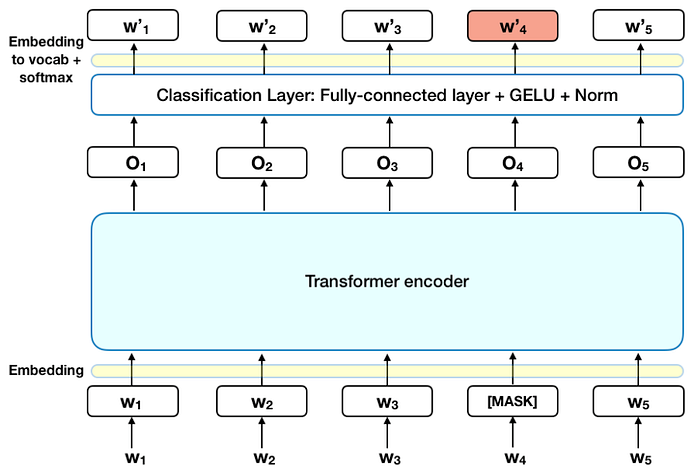
transformer - What does the outputlayer of BERT for masked language ...
The Transformer architecture. It consists of an encoder (left) and a ...
Joining the Transformer Encoder and Decoder Plus Masking ...
Transformer encoder model: ei is the embedding vector which is a 92 ...
The structure diagram of the Multimodal Transformer Encoder in MMVC ...
Figure 2 from Transformer Masked Autoencoders for Next-Generation ...
Figure 1 from Transformer Masked Autoencoders for RF Device ...
Figure 2 from Masked autoencoders are effective solution to transformer ...
Day 11 of 30 – Masked Autoencoders (MAE): Self-Supervised Transformers ...
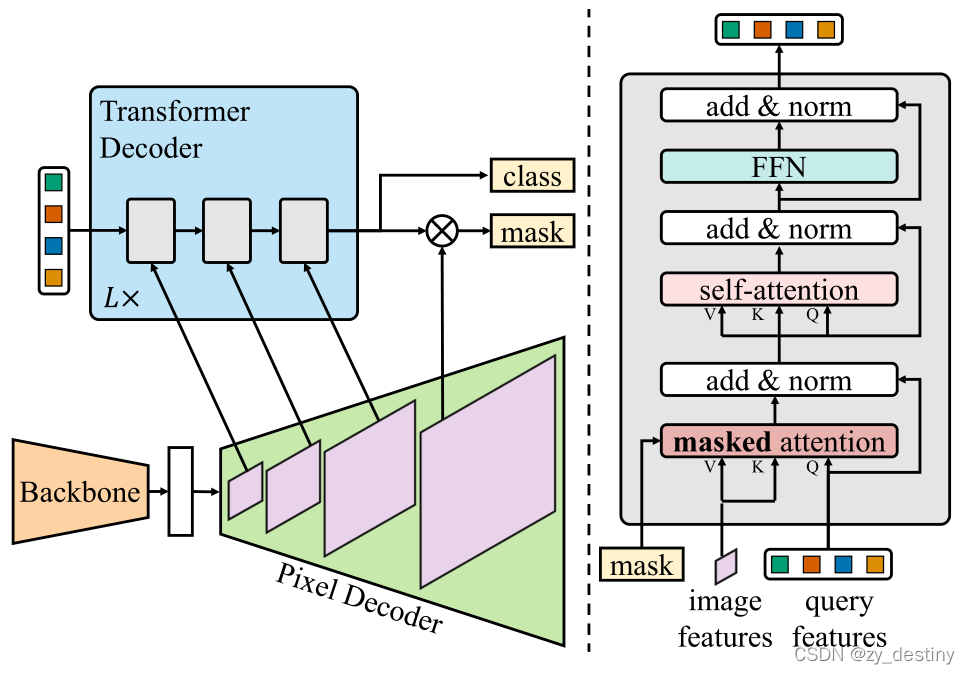
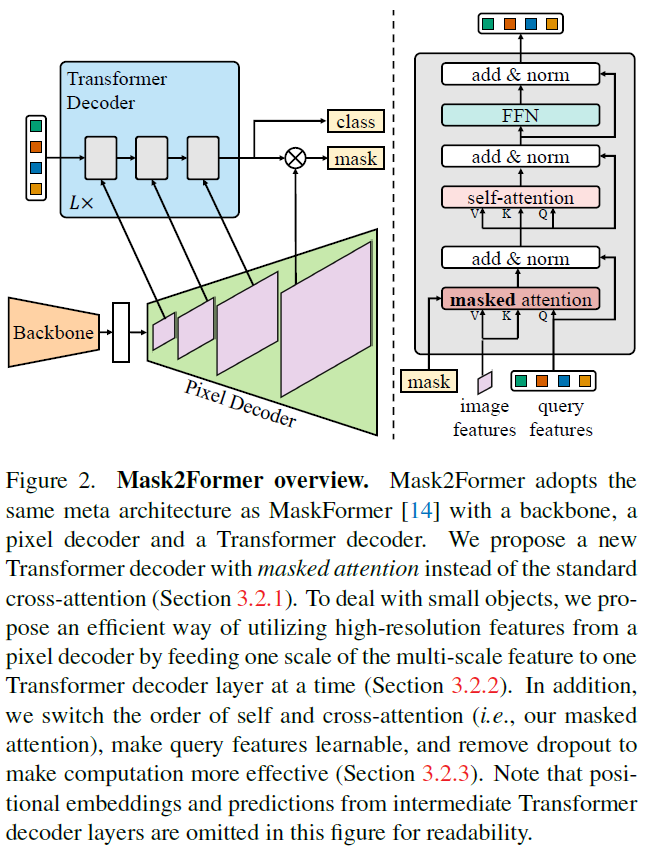
【Mask2Former】Masked-attention Mask Transformer for Universal Image ...
The graphical representation of Bidirectional encoder representations ...
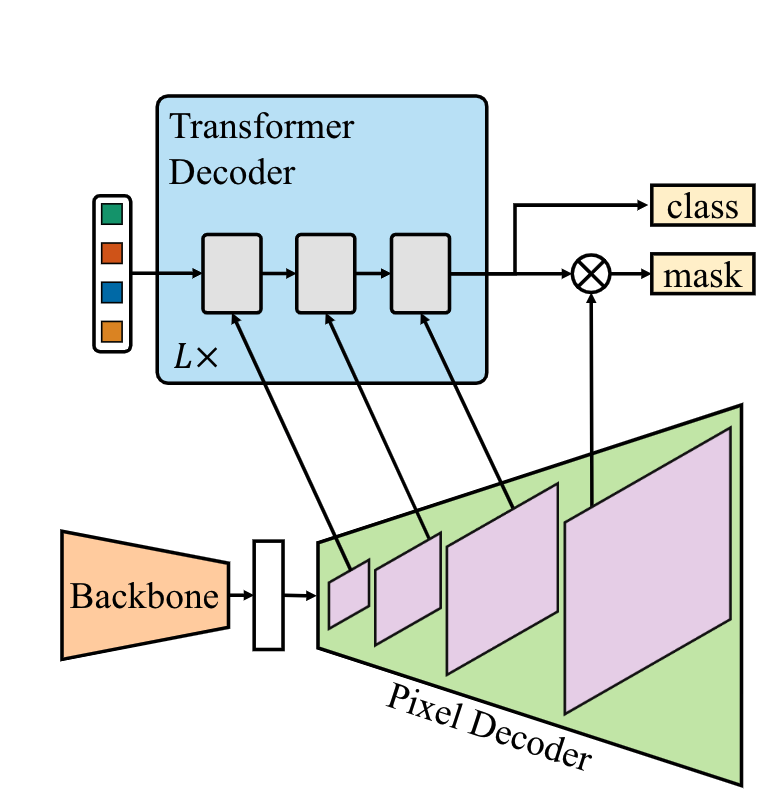
Mask2Former architecture. Each grey block in the transformer decoder ...
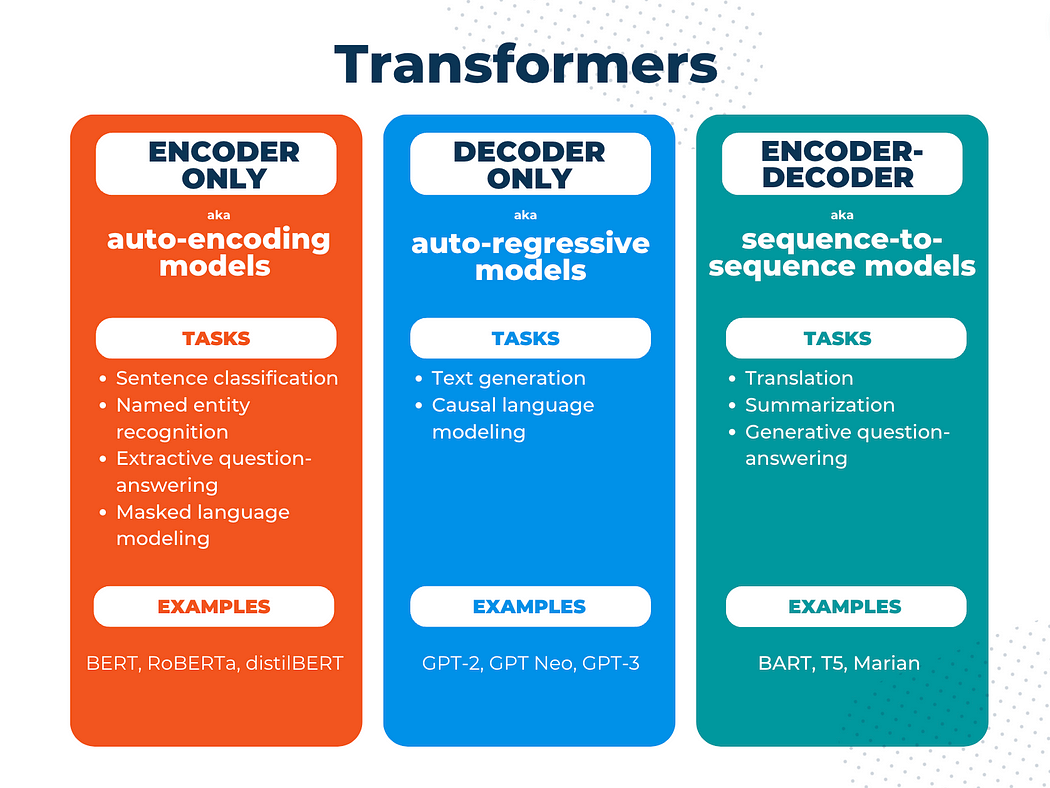
Transformers: Transformers Types: Encoder Only Models Also called as ...
Soft‐masked Bidirectional Encoder Representation from Transformers ...
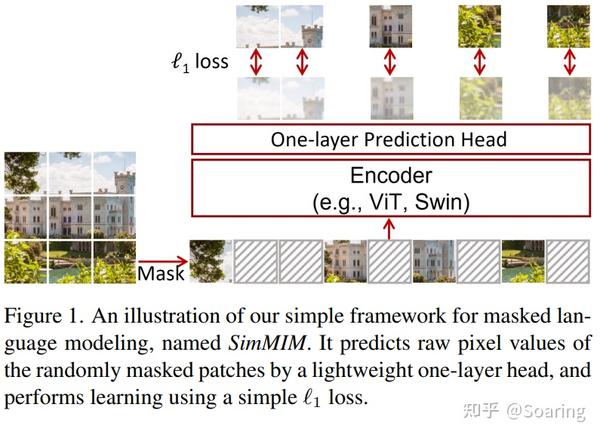
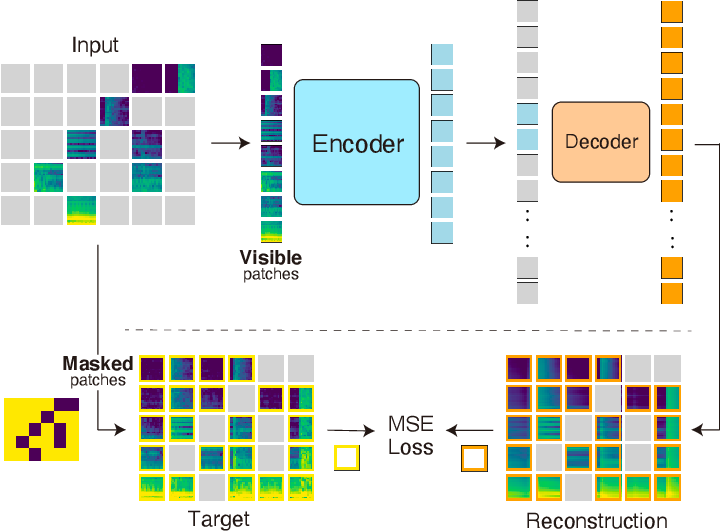
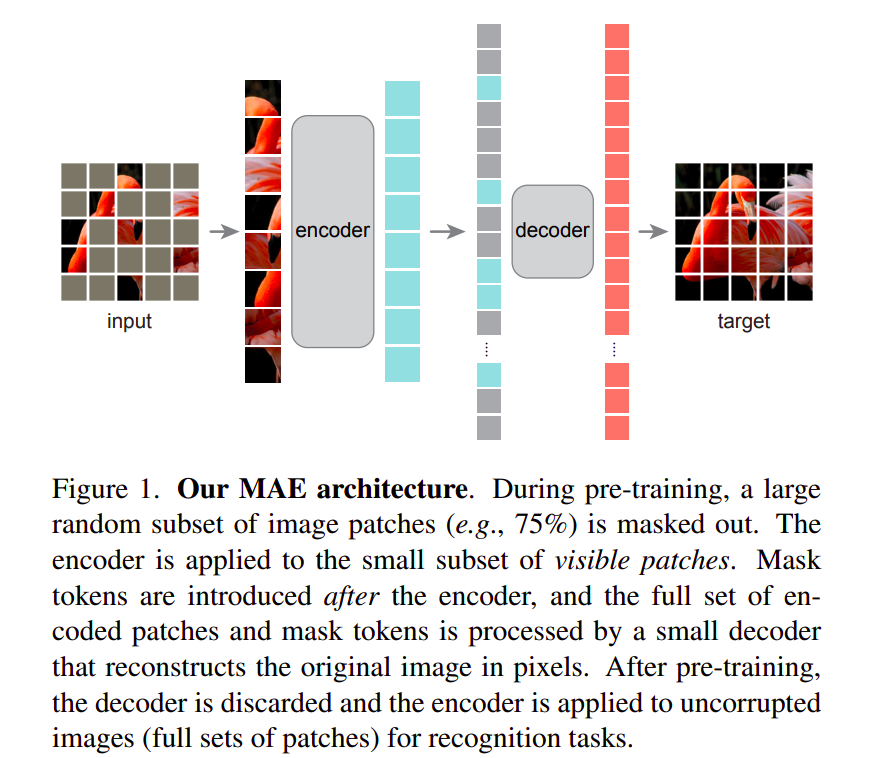
Masked Autoencoders Are Scalable Vision Learners - 知乎
Semi-MAE: Masked Autoencoders for Semi-supervised Vision Transformers ...
Bidirectional Encoder Representations from Transformers – Wikipedia
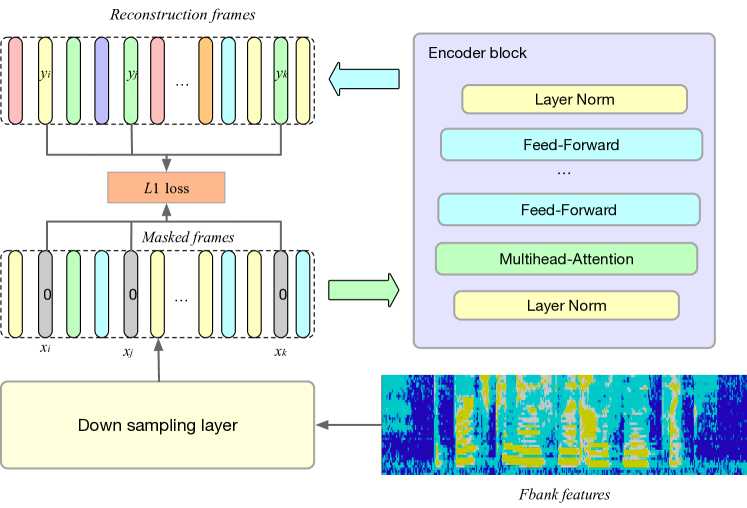
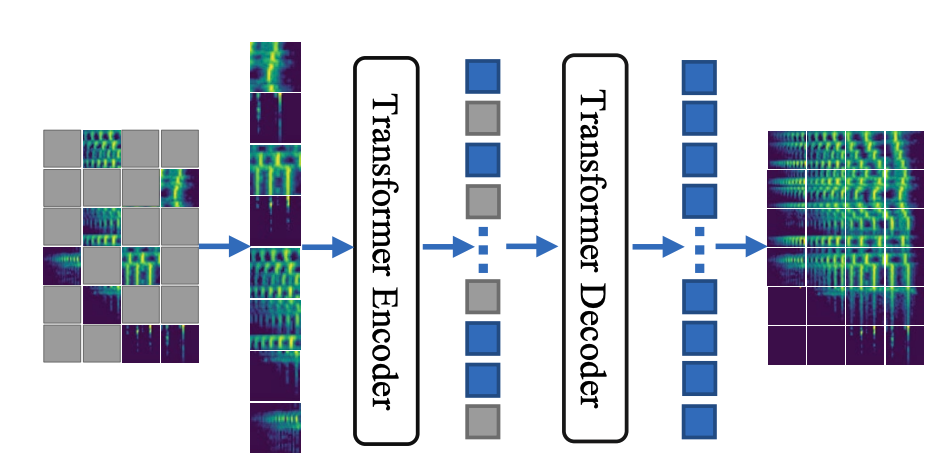
Overview of masked spectrogram autoencoders for efficient pretraining
Paper reading | VideoMAE: Masked Autoencoders are Data-Efficient ...
Transformers - Part 7 - Decoder (2): masked self-attention - YouTube
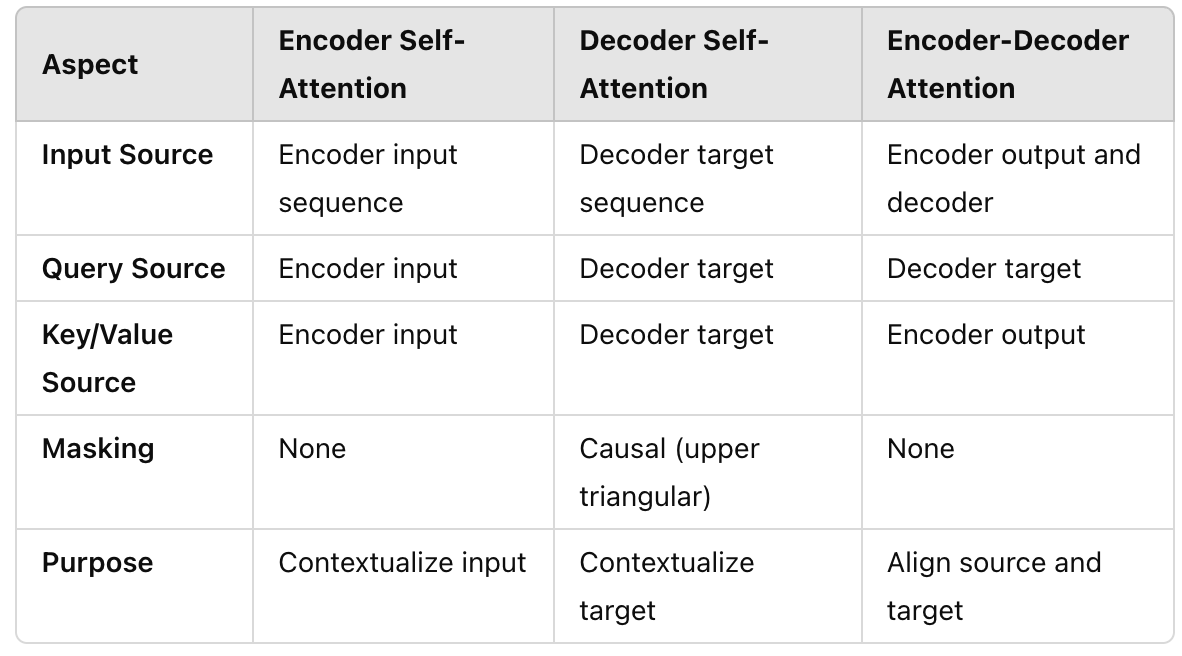
Masking in Transformer Encoder/Decoder Models - Sanjaya’s Blog
Efficient Transformer Encoders for Mask2Former-style models
Revisiting Mask Transformer from a Clustering Perspective
Explain the Transformer Architecture (with Examples and Videos) - AIML.com
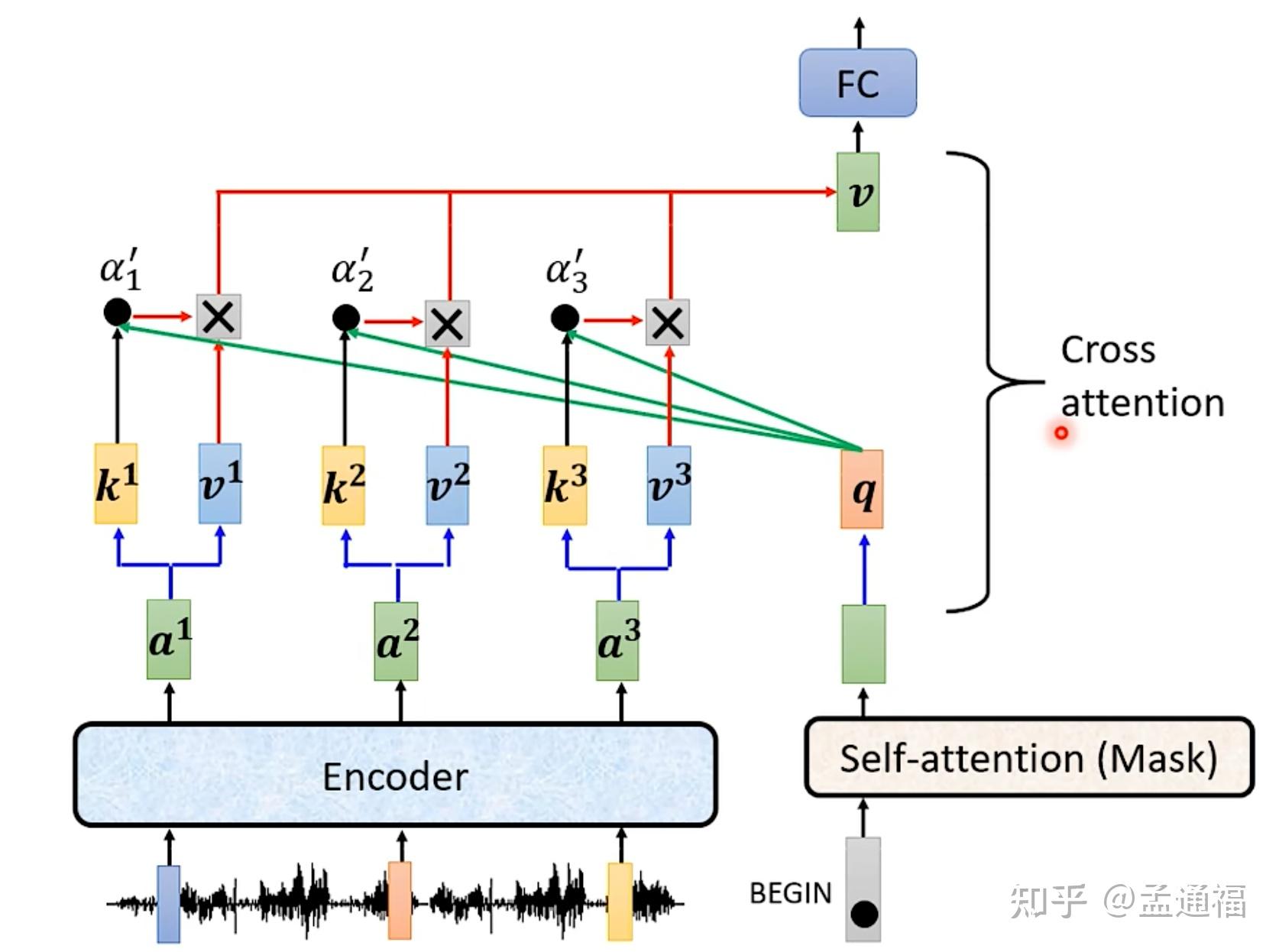
Transformer -decoder mask篇. 接續上篇的Transformer -encoder mask篇… | by 任書瑋 ...
BERT Model – Bidirectional Encoder Representations from Transformers ...
MaskFormer2 : Masked-attention Mask Transformer for Universal Image ...
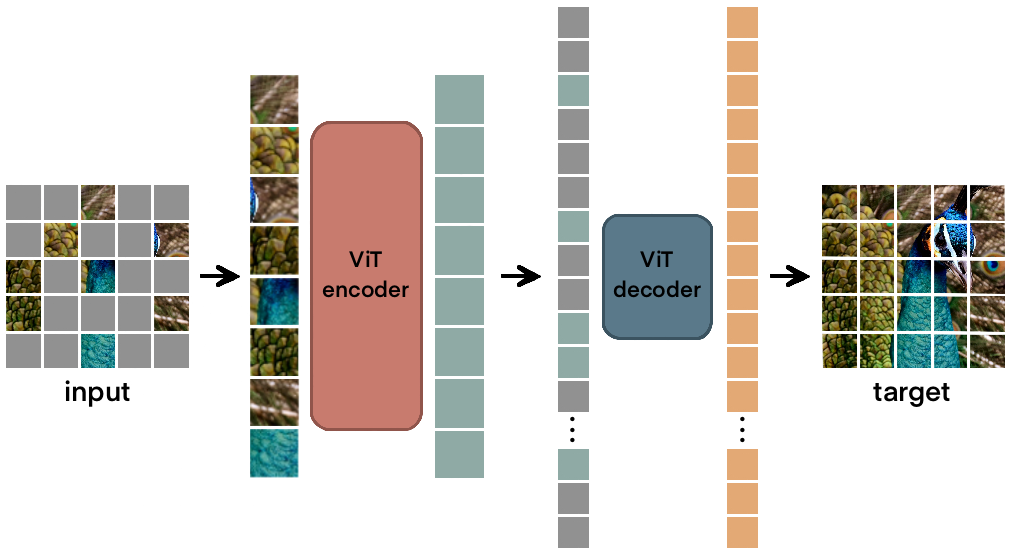
Reconstruct The Complete Image Just from a Few Patches| Building Masked ...
Transformer 解读 - Fan's Blog
The detail of the mask used in the transformer encoder. The gray square ...
Illustration of the Transformer based encoder-decoder model. | Download ...
深入理解深度学习——BERT(Bidirectional Encoder Representations from Transformers ...
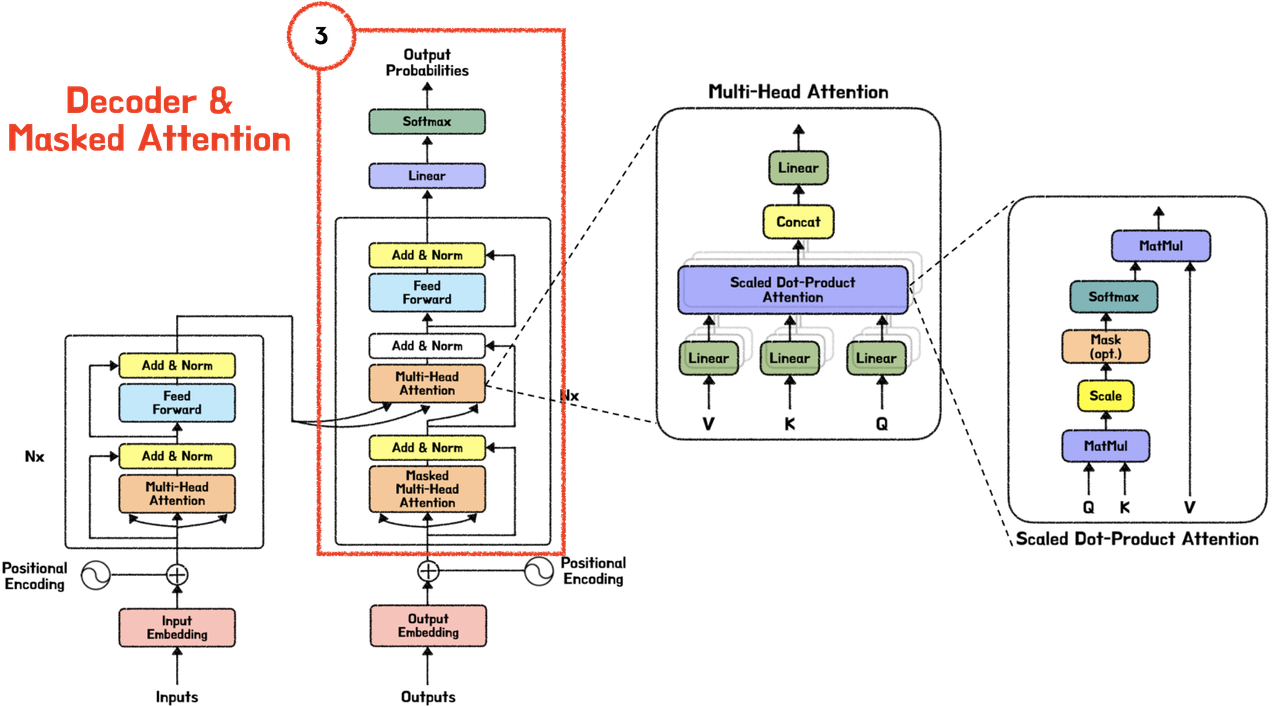
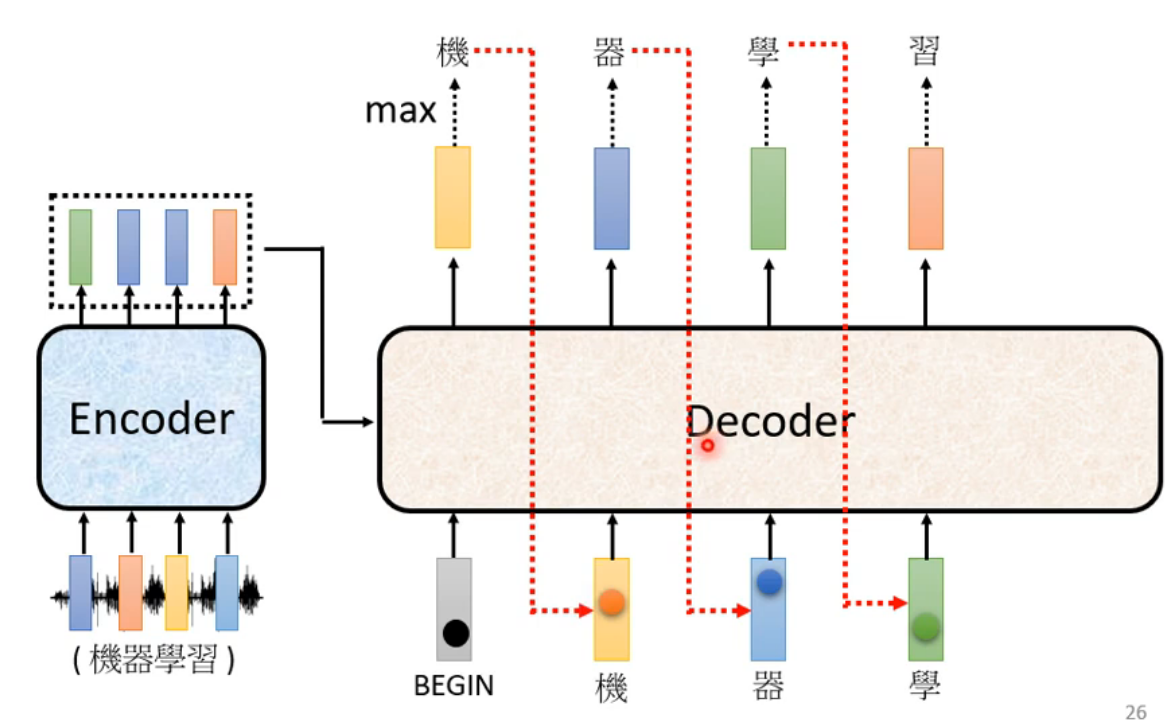
트랜스포머(Transformer) 파헤치기—3. Decoder & Masked Attention
Transformer -encoder mask篇. 這篇會著重介紹實際使用Transformer… | by 任書瑋 | Data ...
Transformer Encoder/Decoder结构中的掩码Mask介绍 - 知乎
【论文笔记】Mask2Former: Masked-attention Mask Transformer for Universal ...
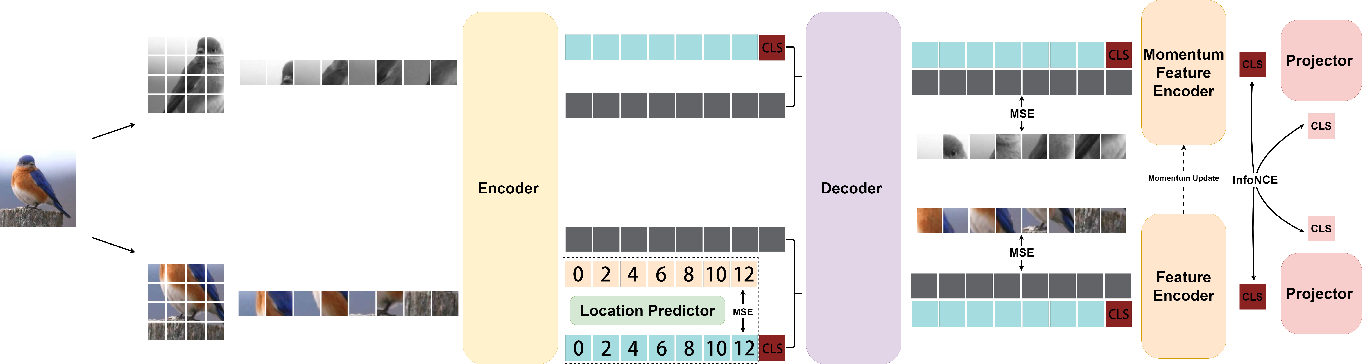
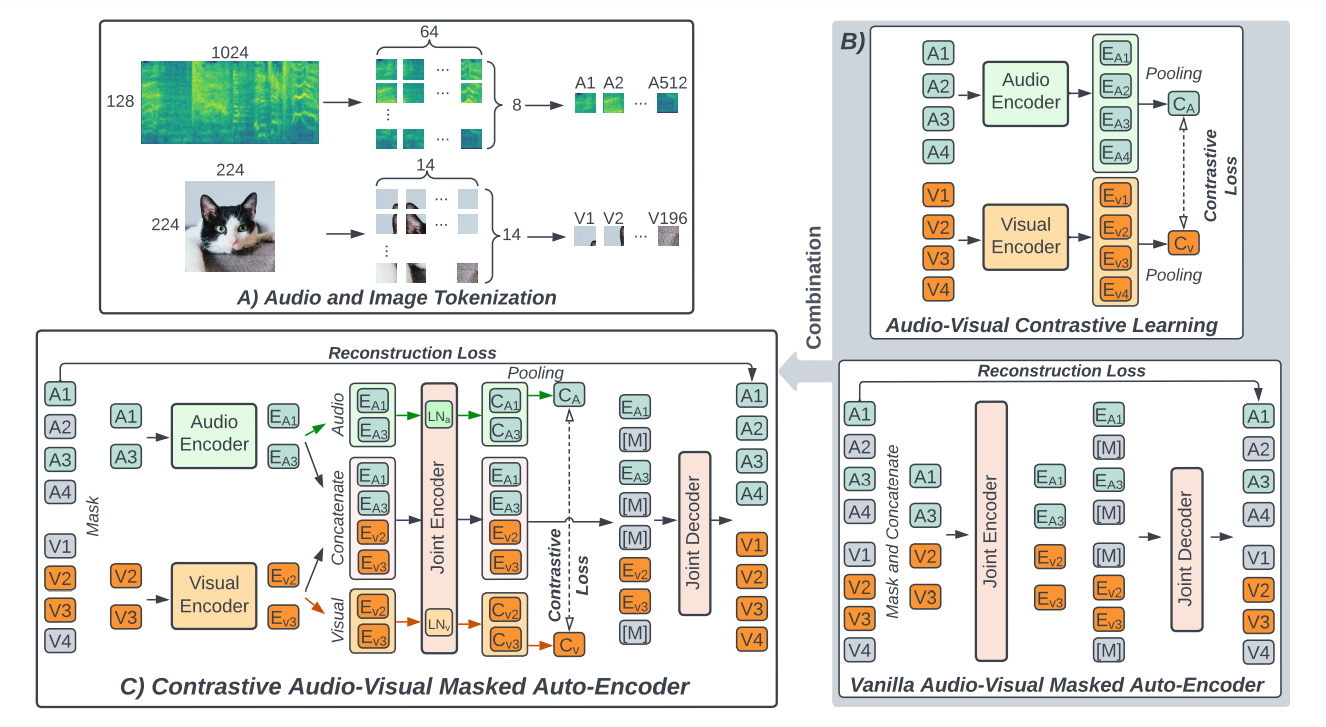
CAV-MAE : Contrastive Audio-Visual Masked AutoEncoder (2022.08)
(PDF) RetroMAE: Pre-training Retrieval-oriented Transformers via Masked ...
Tìm hiểu mô hình Transformer - Ngươi Không Phải Là Anh Hùng, Ngươi Là ...
Transformer 从零解读 - kingwzun - 博客园
Architecture of transformer-based model: encoder (on the left) and ...
Masked Language Model: All you need to Know | by Amit Yadav | Medium
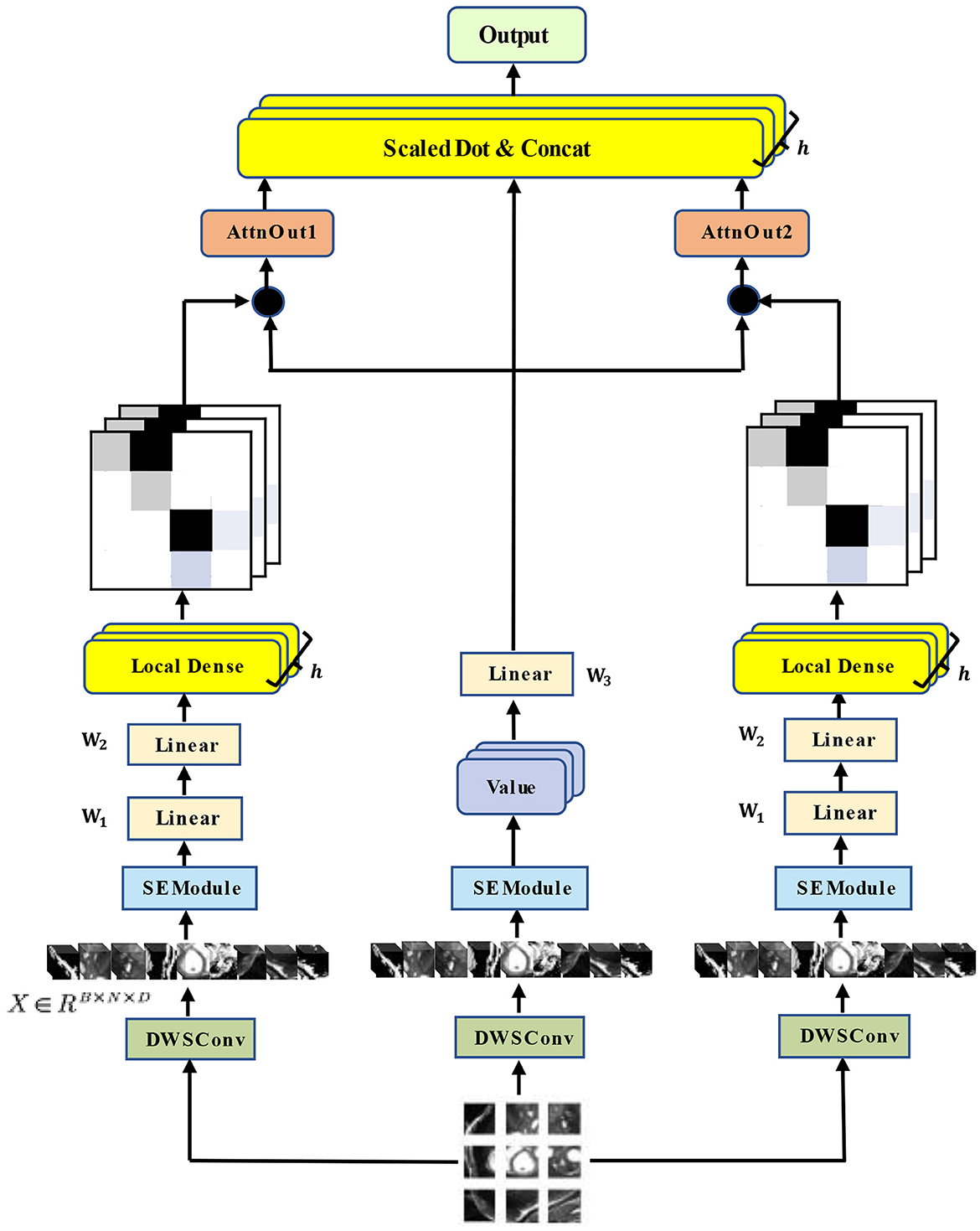
Enhancing Mask Transformer with Auxiliary Convolution Layers for ...
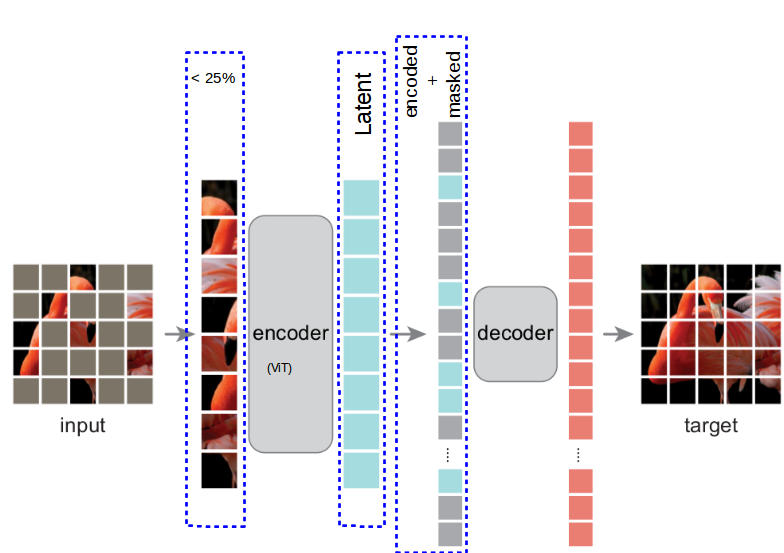
Masked autoencoder (MAE) for visual representation learning. Form the ...
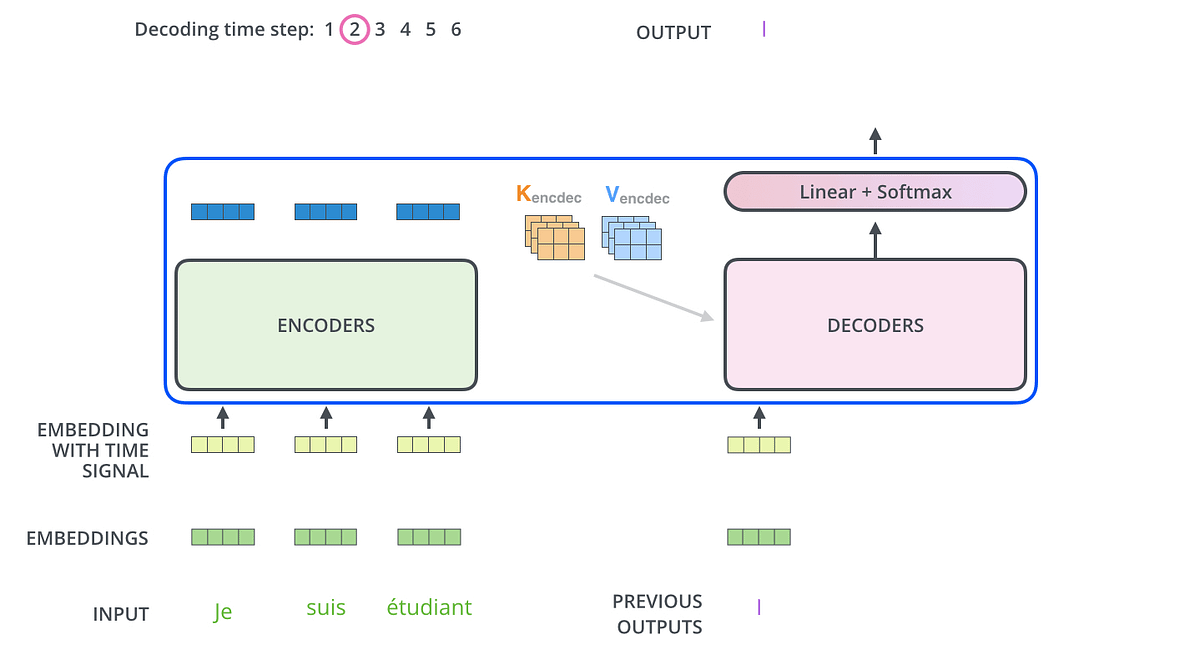
Visually Walking Through a Transformer Model
Transformer [全网最详细的Transformer讲解] - 知乎
Understanding Transformer Variants – BERT, GPT, T5, and More - Skillcurb
Exploring Masked Autoencoders in Vision Transformers - YouTube
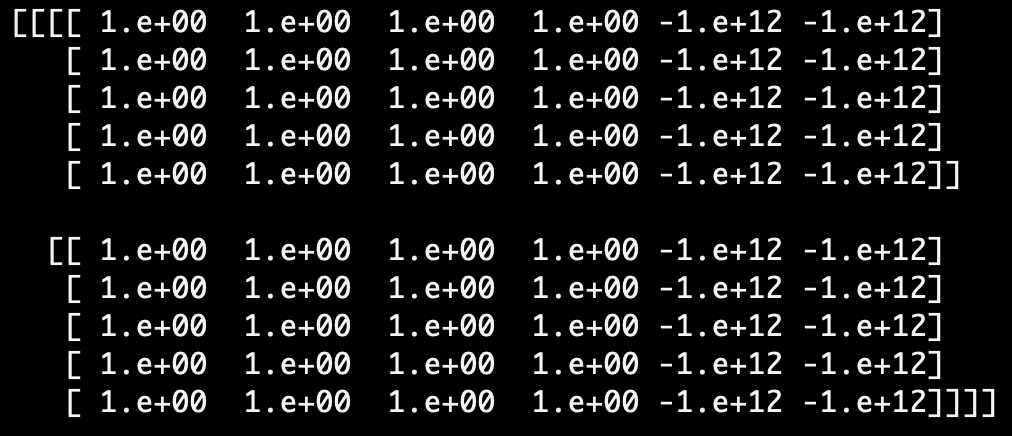
Transformer相关——(7)Mask机制 | 冬于的博客
Vision Transformers (ViT) for Self-Supervised Representation Learning ...
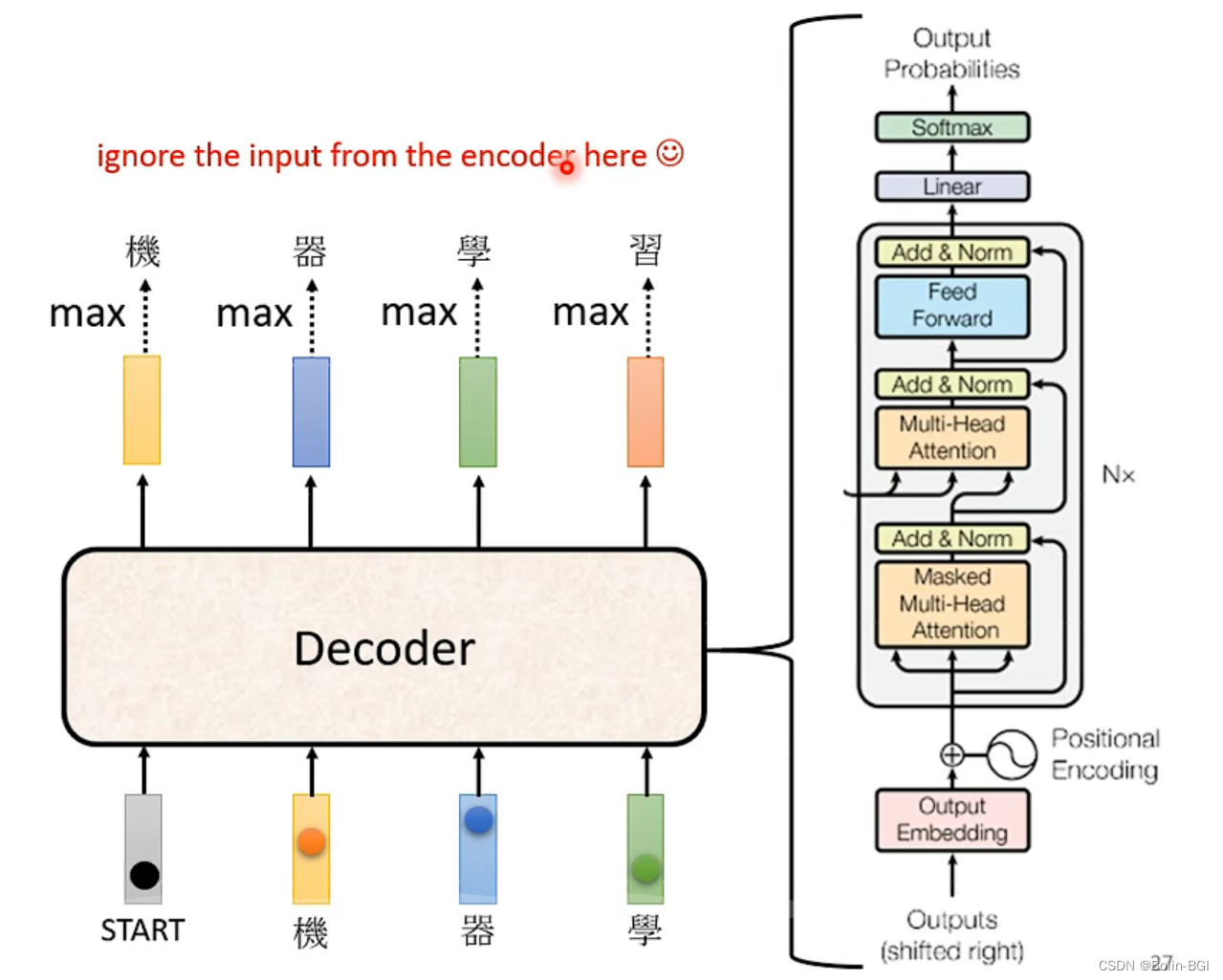
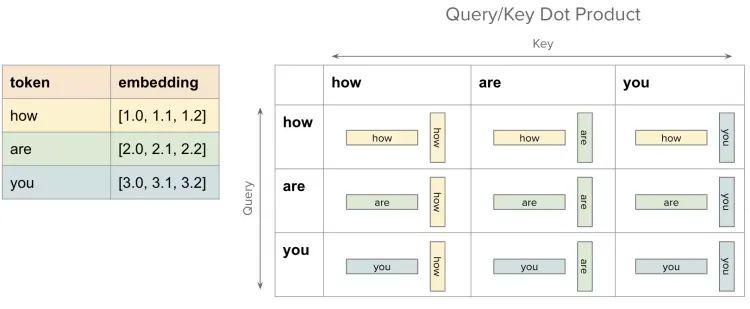
【深度学习】Transformer中的mask机制超详细讲解_transformer mask-CSDN博客
MaskFormer, Mask2Former
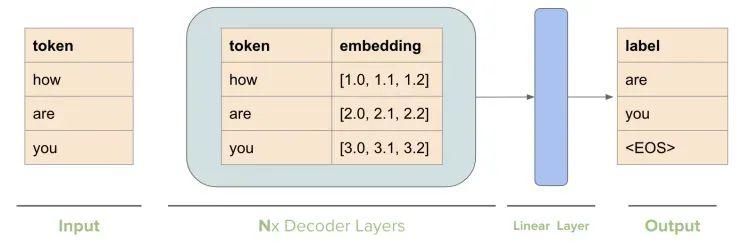
Working of Decoders in Transformers - GeeksforGeeks
深度学习进阶之Transformer - AI备忘录
🚀 Excited to share that EoMT (Encoder-only Mask Transformer) has ...
【Pytorch】Transformer中的mask - 知乎
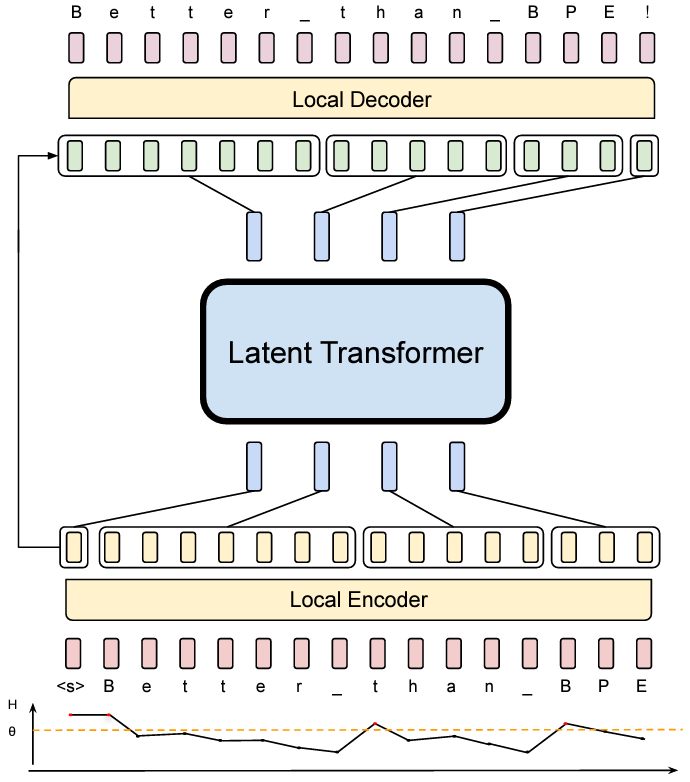
GitHub - rlucatoor/masked-transformer: A Pytorch implementation of a ...
02 transformer:encoder结构和decoder结构 - 知乎
Intuition about the application of padding masks and look-ahead masks ...
深入理解Transformer中的解码器原理(Decoder)与掩码机制_transformer掩码-CSDN博客
大模型学习笔记:Transformer - 知乎
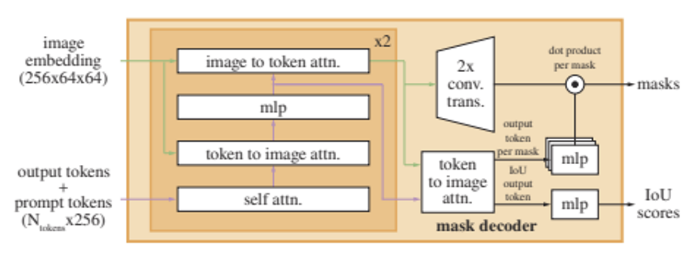
SAM
深入解析Transformer编码器解码器核心组件与代码实现-开发者社区-阿里云
Mask Autoencoder 各类变体 - 知乎
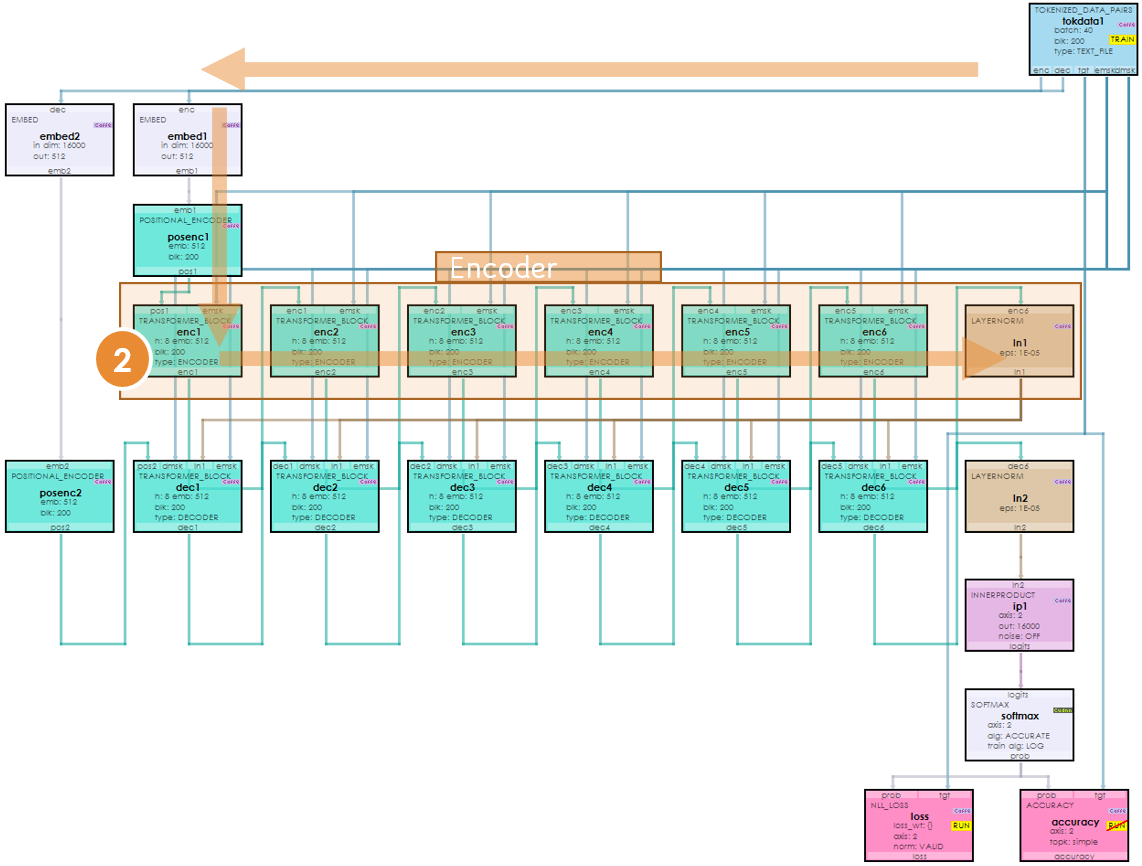
迟到的transformer encoder代码详解_transformerencoderlayer-CSDN博客
Decoder-Only Transformers: The Workhorse of Generative LLMs
从EncoderDecoder到Transformer
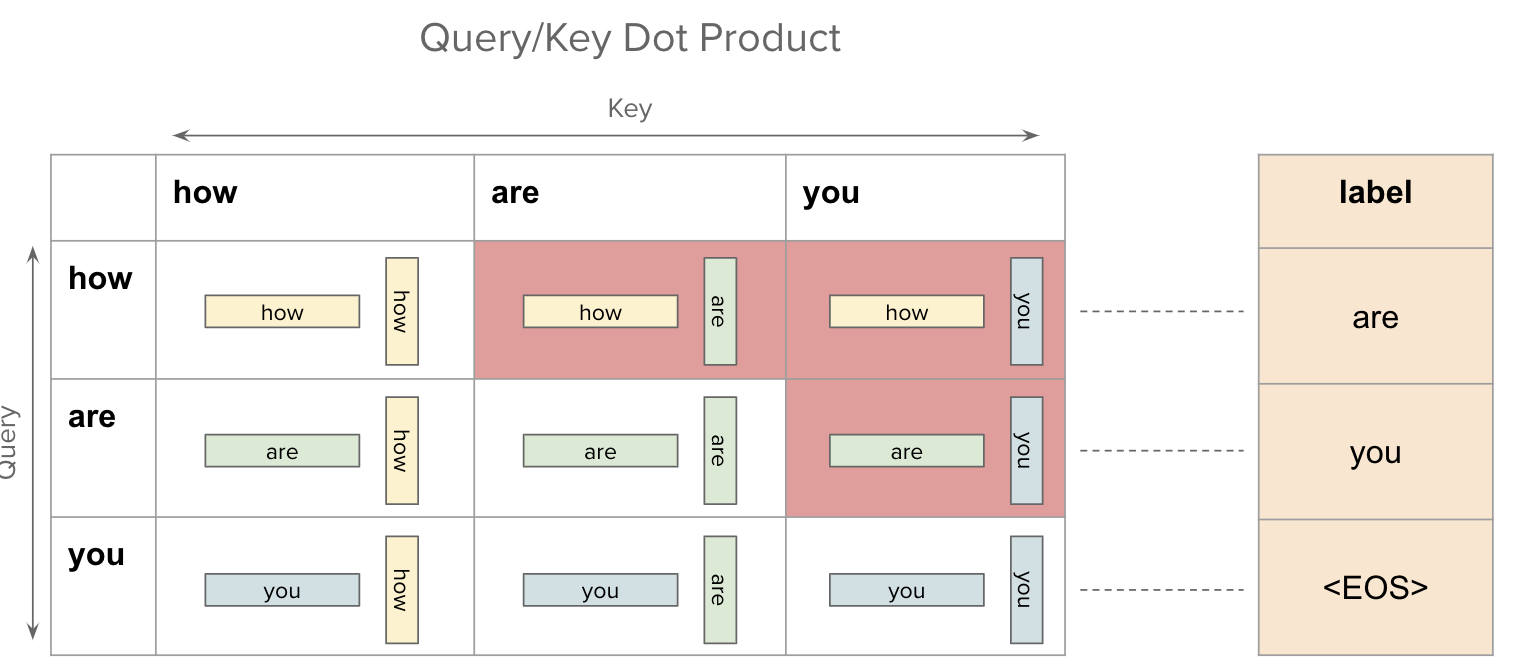
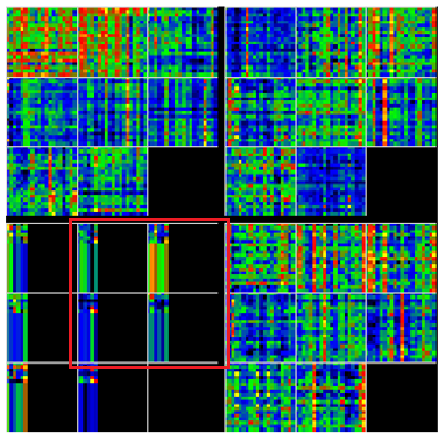
Explainable AI: Visualizing Attention in Transformers - MLOps Community
maskformer | Akshath Raghav R
Transformer_encoder传向decoder的是哪两个-CSDN博客
EoMT(Encoder-only Mask Transformer) - 知乎
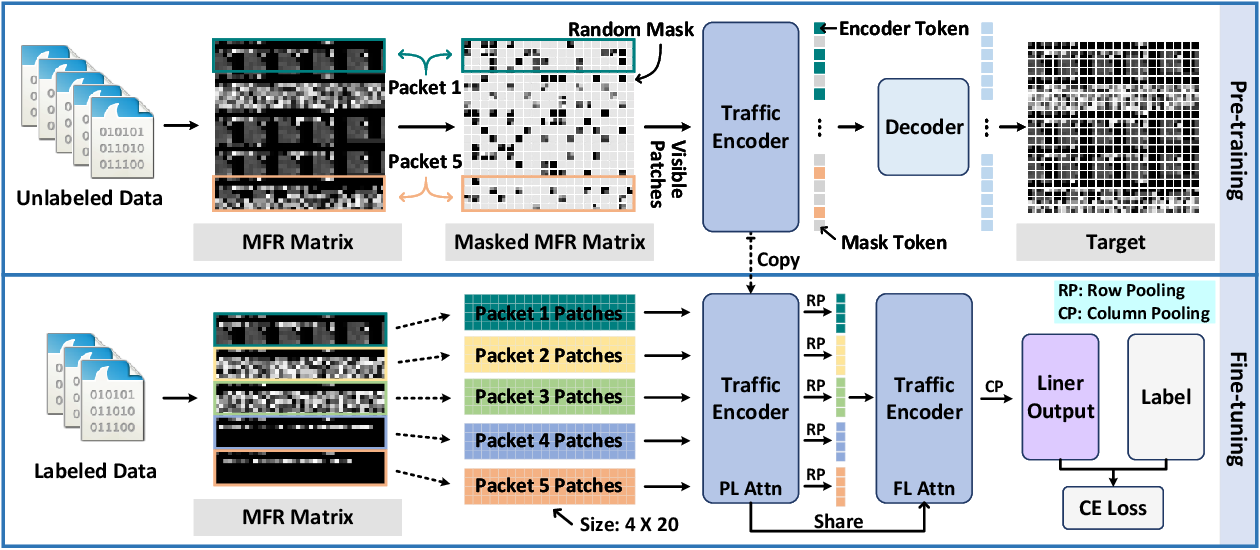
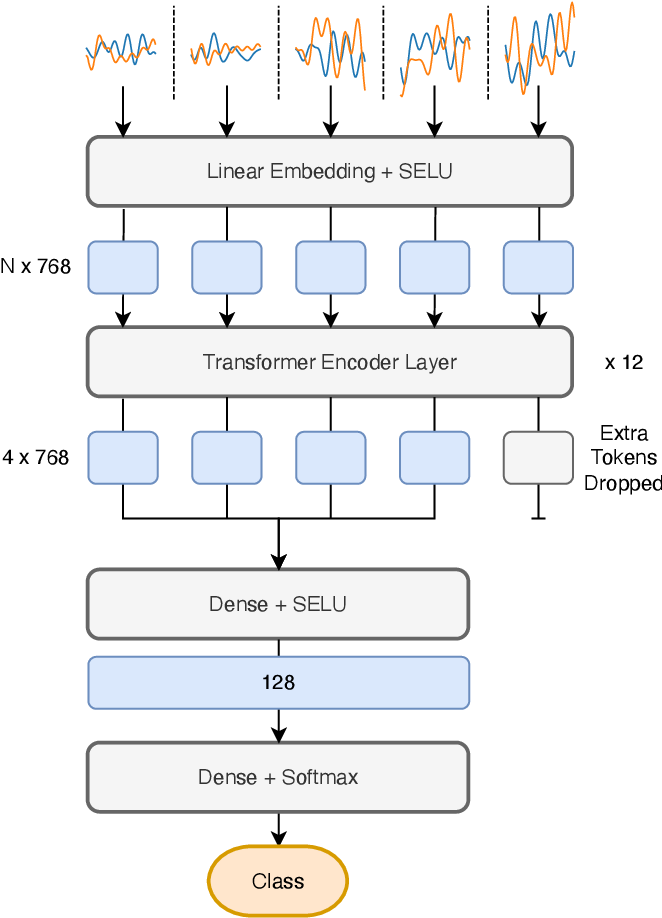
Client Time Series Model: a Multi-Target Recommender System based on ...
【Transformer系列(1)】encoder(编码器)和decoder(解码器)_encoder和decoder的区别-CSDN博客