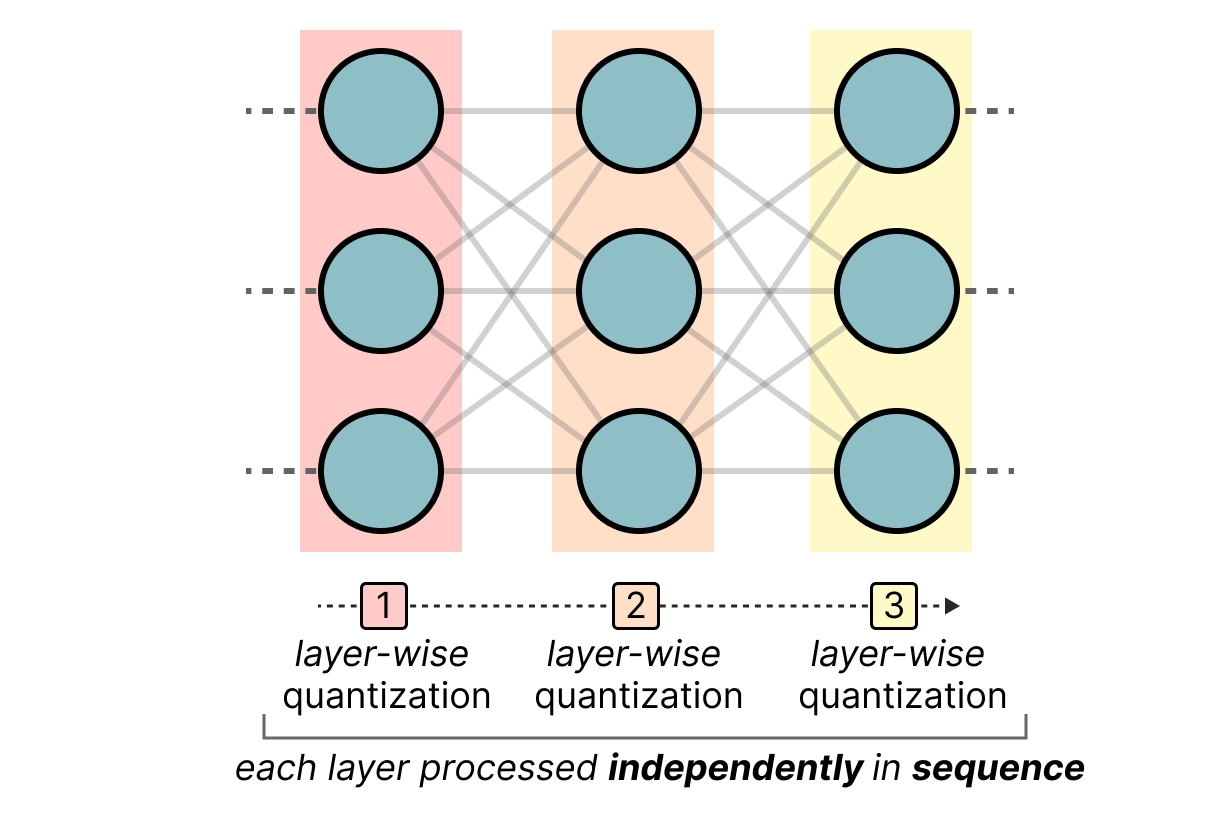
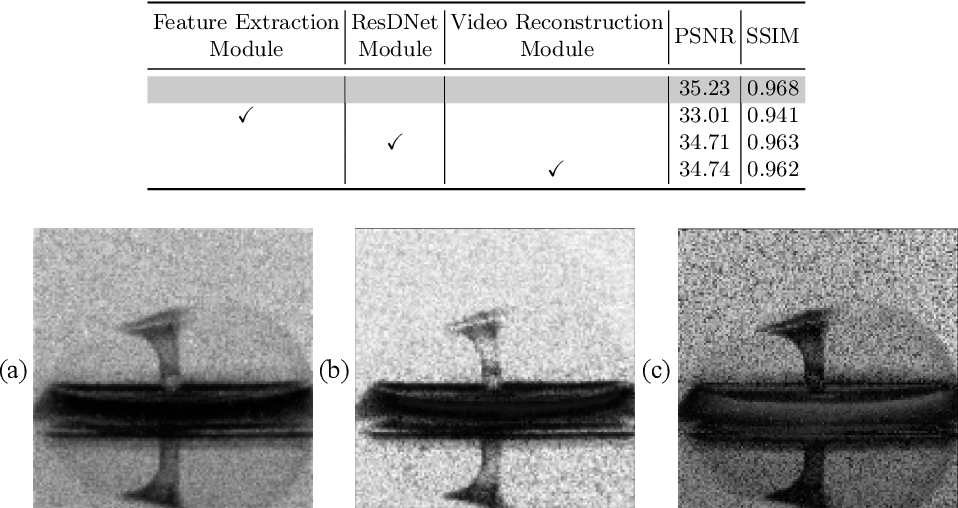
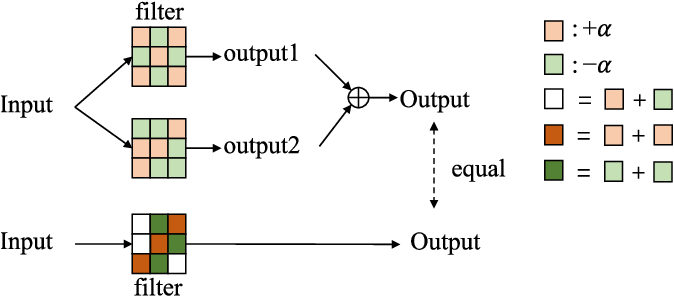
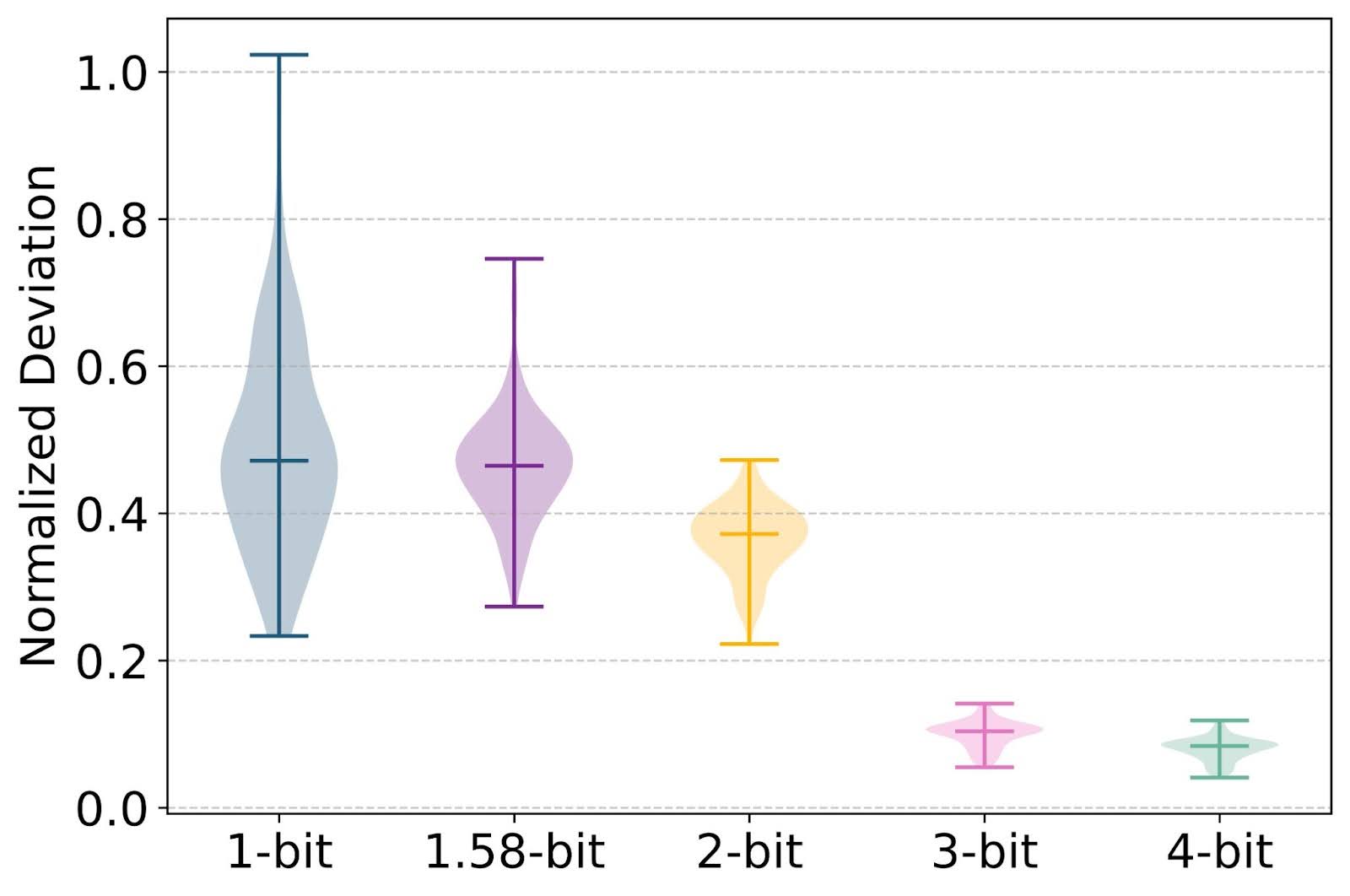
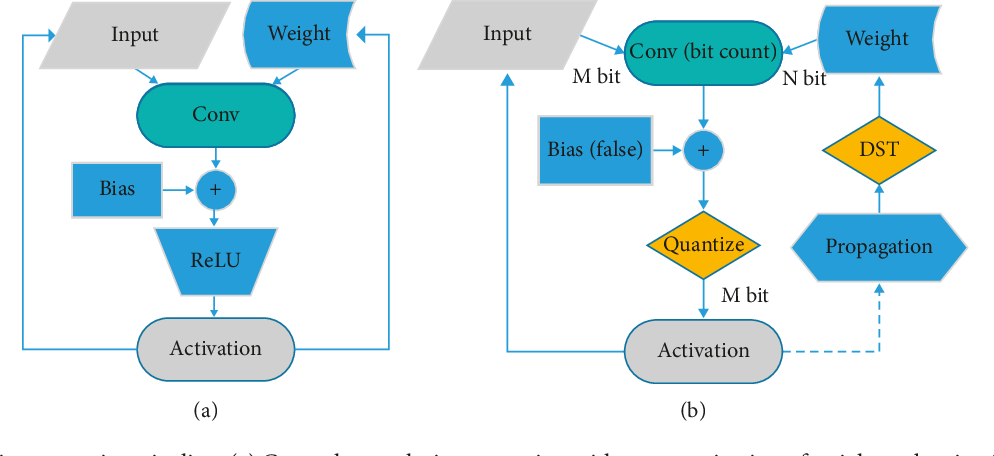
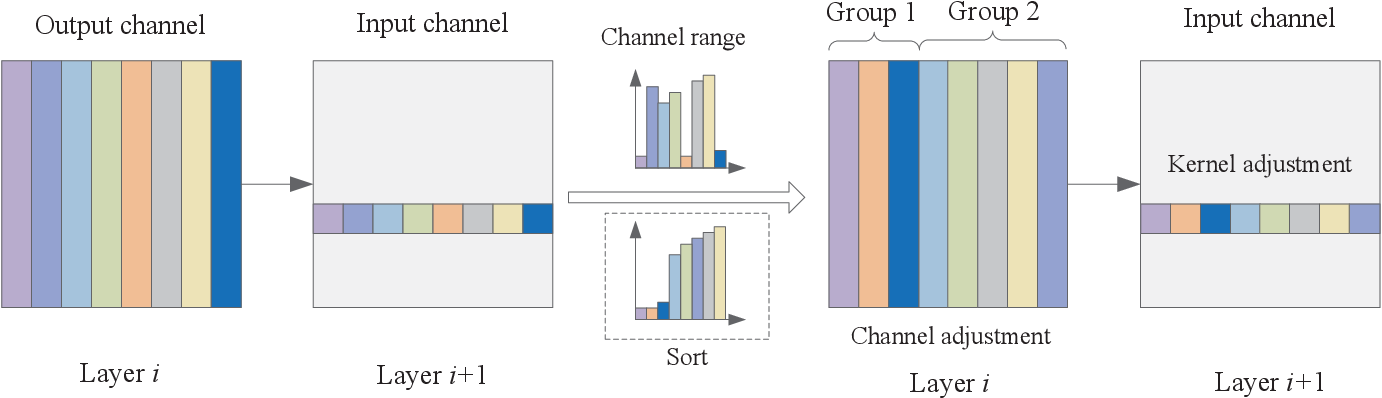
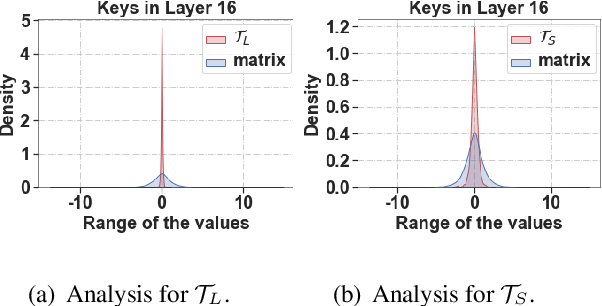
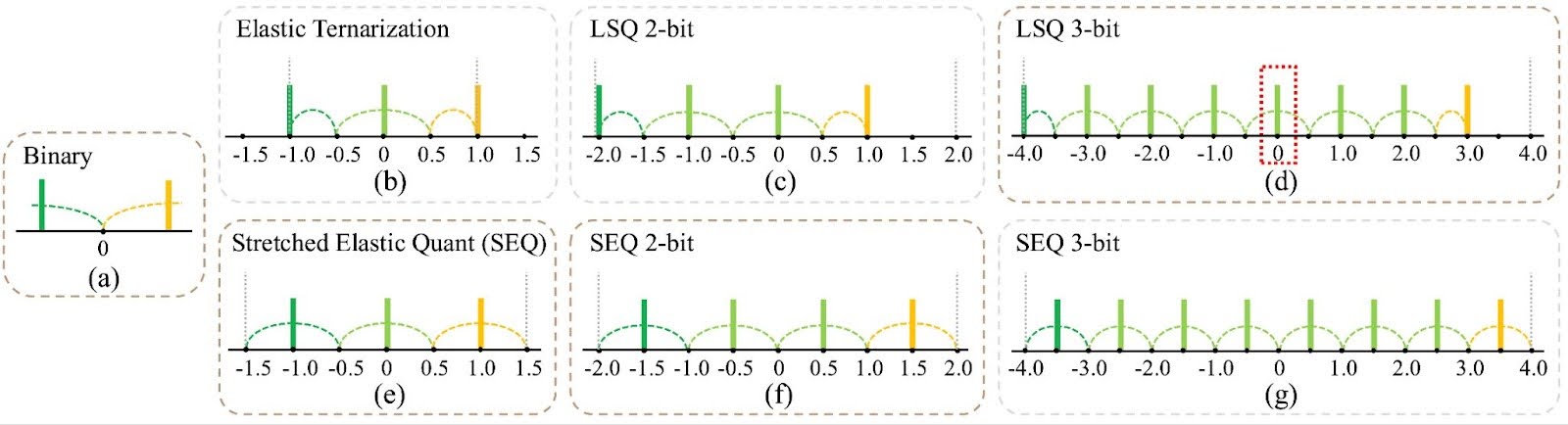
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
Advancing Low Bit Quantization for LLMs: AutoRound x LLM Compressor ...
Extremely Low Bit Transformer Quantization for On-Device NMT | PDF
Paper page - Mixed-Precision Graph Neural Quantization for Low Bit ...
Mixed-Precision Graph Neural Quantization for Low Bit Large Language Models
[논문 리뷰] Mixed-Precision Graph Neural Quantization for Low Bit Large ...
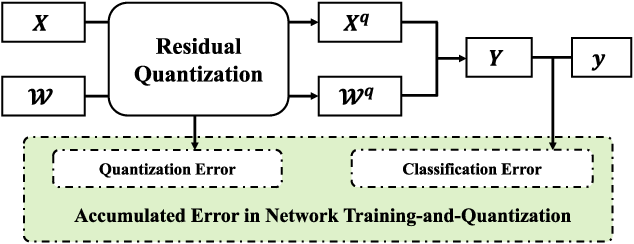
Figure 1 from Residual Quantization for Low Bit-Width Neural Networks ...
Figure 2 from Residual Quantization for Low Bit-Width Neural Networks ...
(PDF) Pitch quantization in low bit-rate speech coding
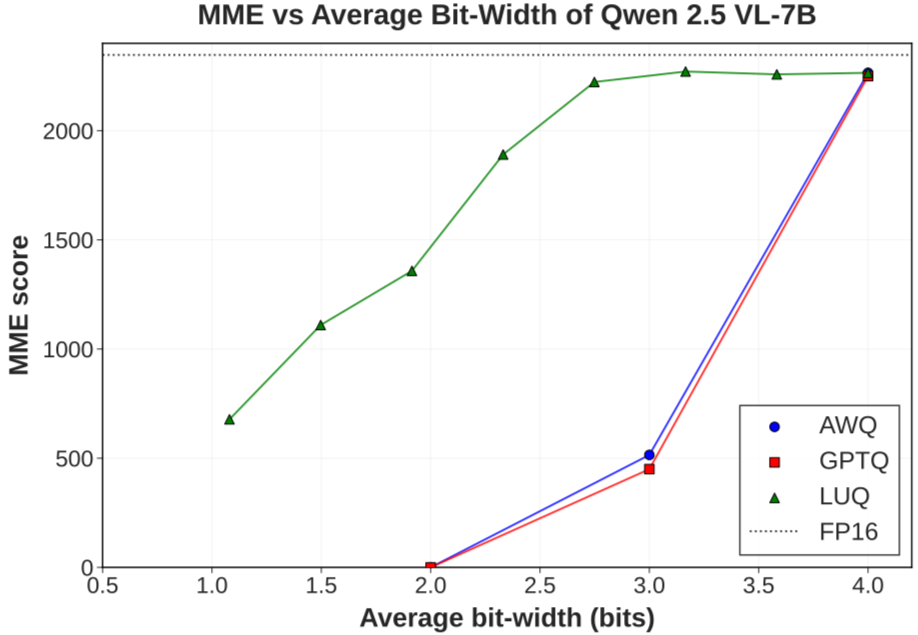
[논문 리뷰] LUQ: Layerwise Ultra-Low Bit Quantization for Multimodal Large ...
Figure 5 from Residual Quantization for Low Bit-Width Neural Networks ...
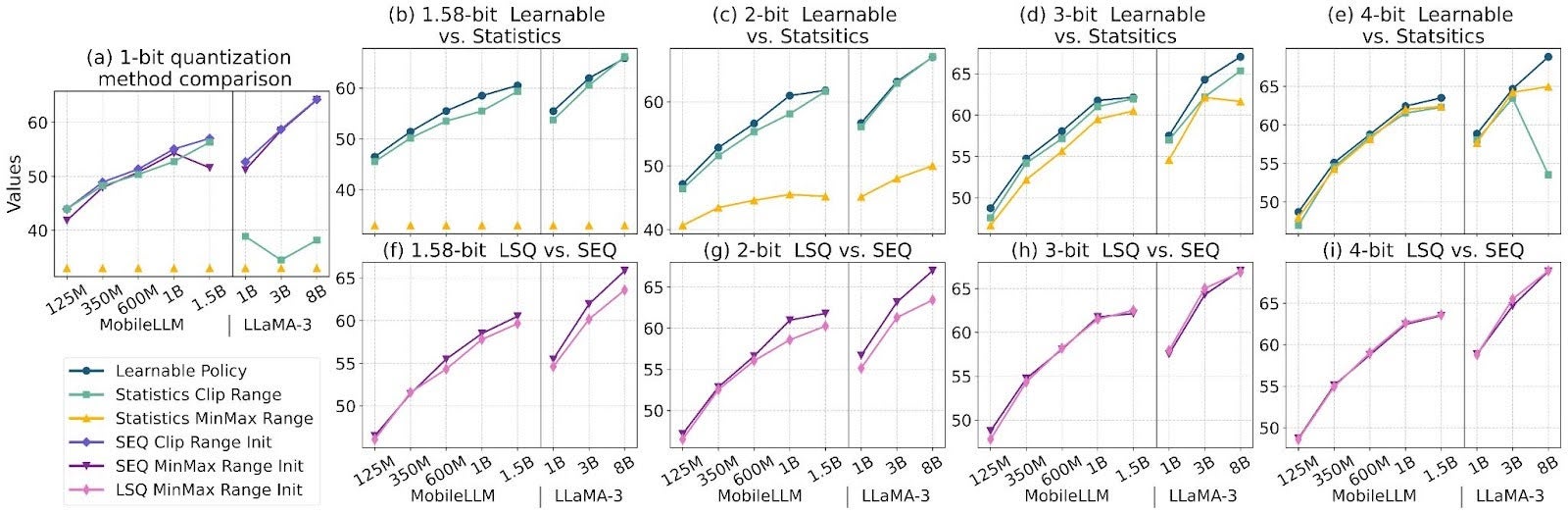
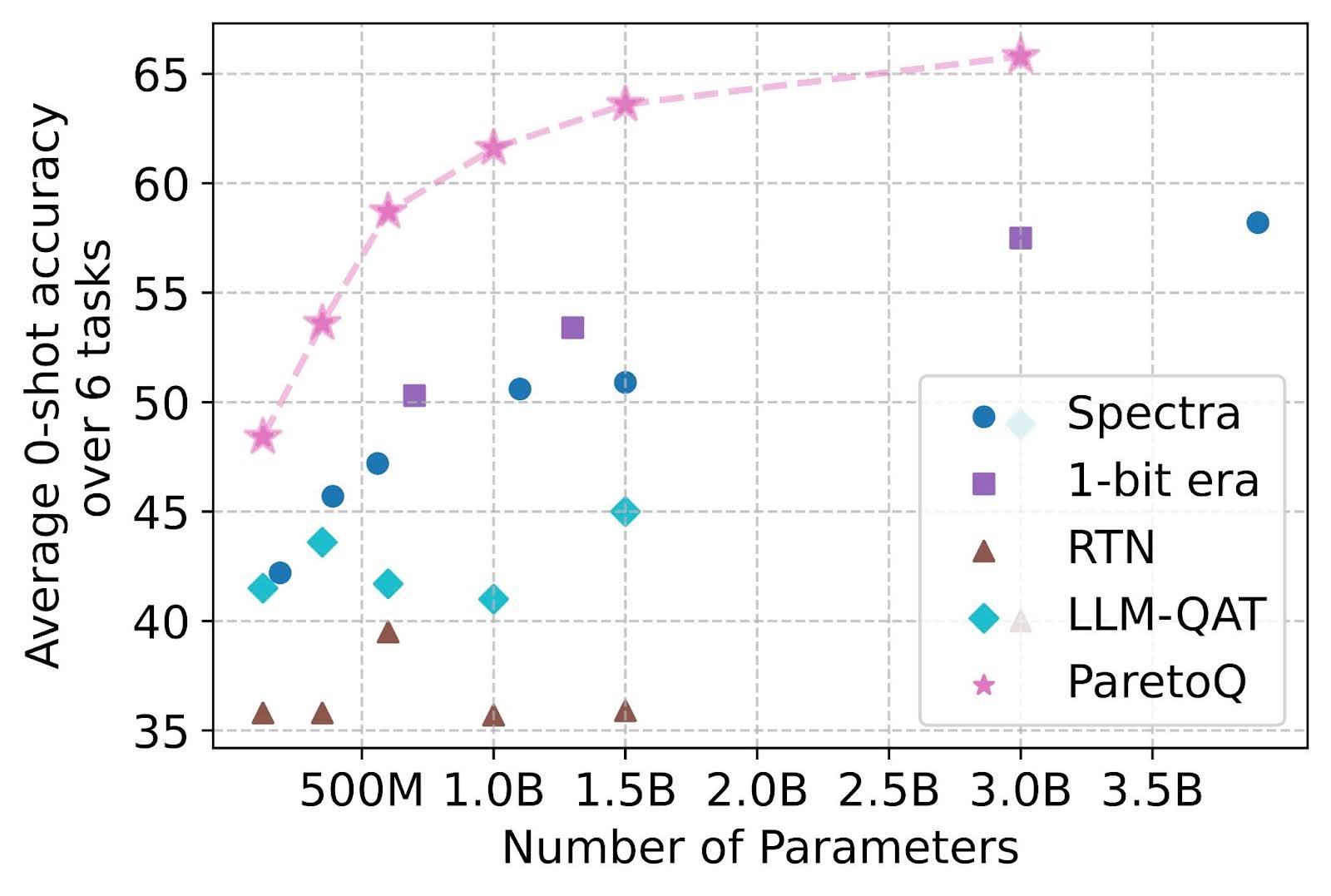
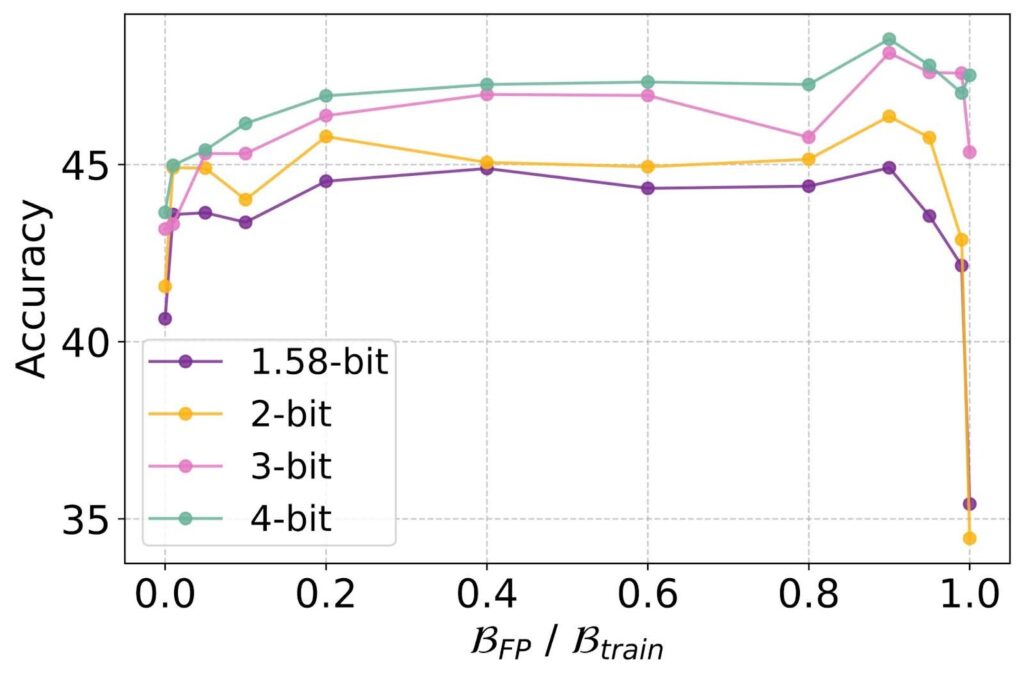
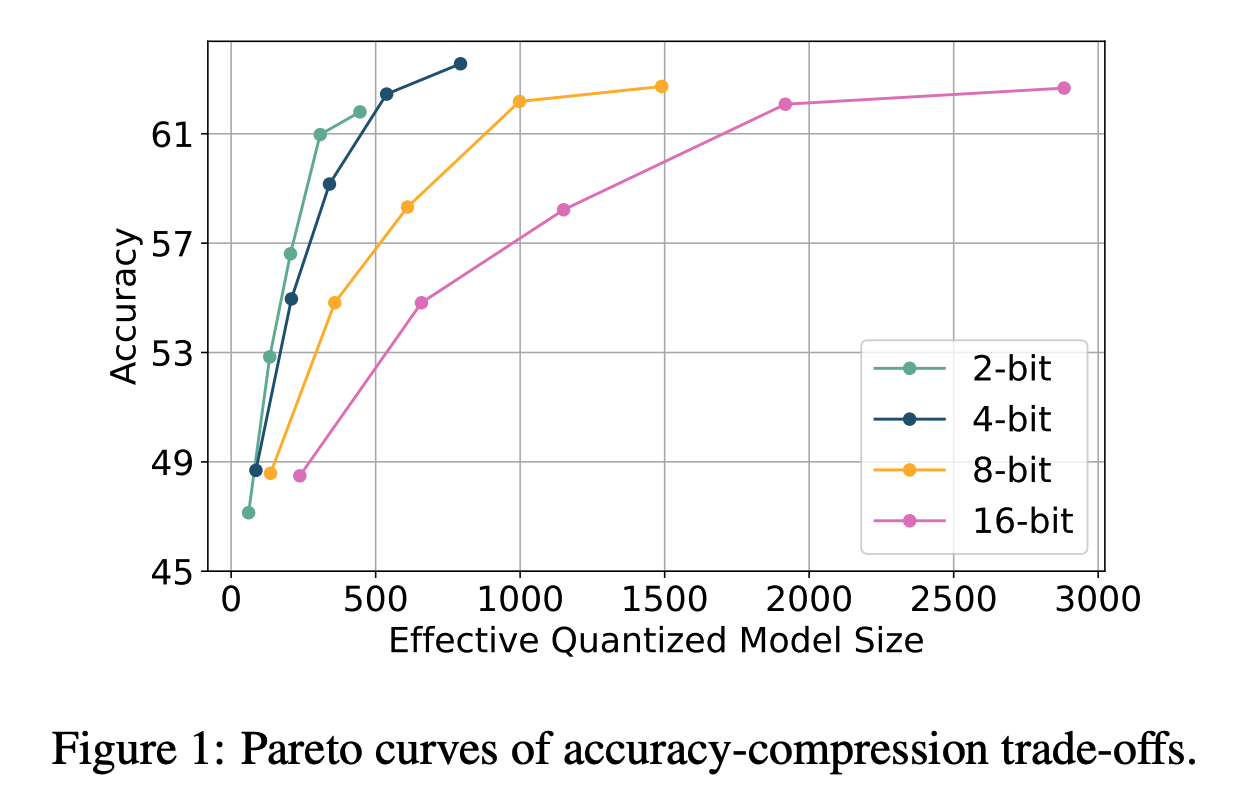
ParetoQ: Scaling Laws in Extremely Low-bit LLM Quantization | Hung-Yueh ...
QuantSR: Accurate Low-bit Quantization for Efficient Image Super ...
Figure 1 from Low-bit Quantization for Deep Graph Neural Networks with ...
ParetoQ: Scaling Laws in Extremely Low-bit LLM Quantization – PyTorch
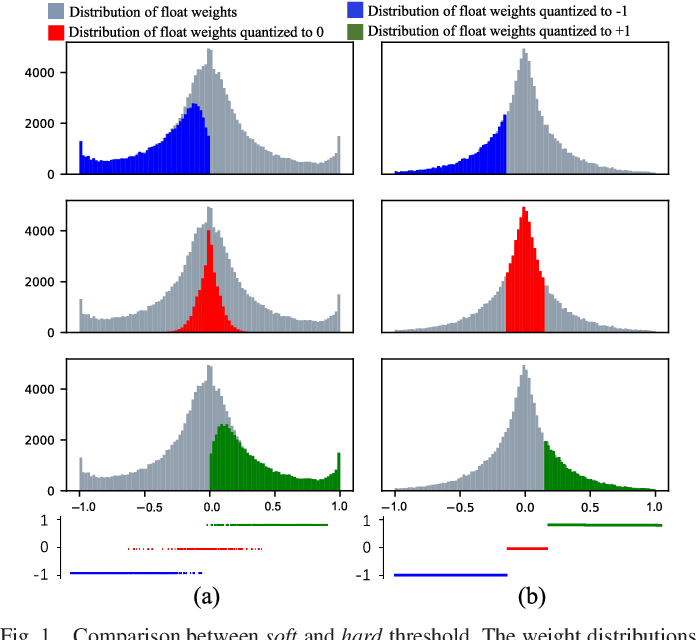
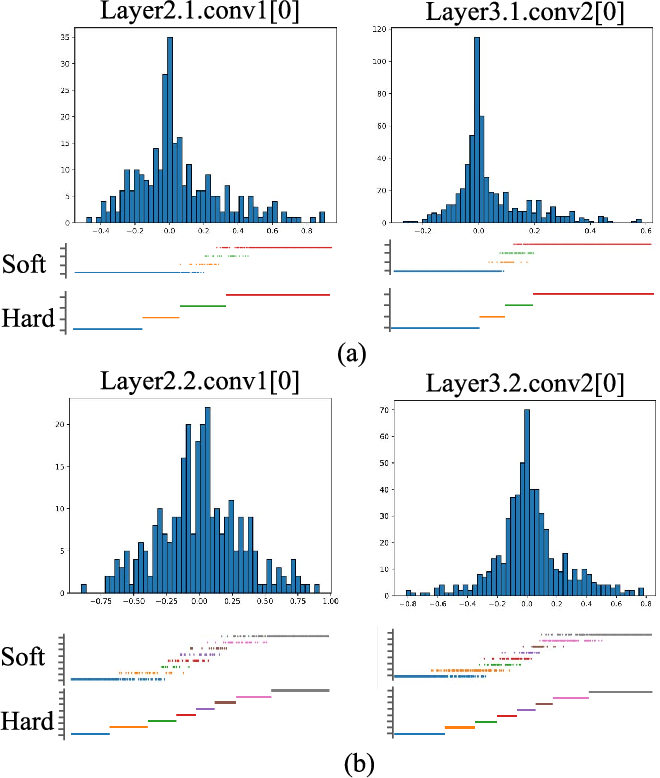
Figure 1 from Improving Extreme Low-Bit Quantization With Soft ...
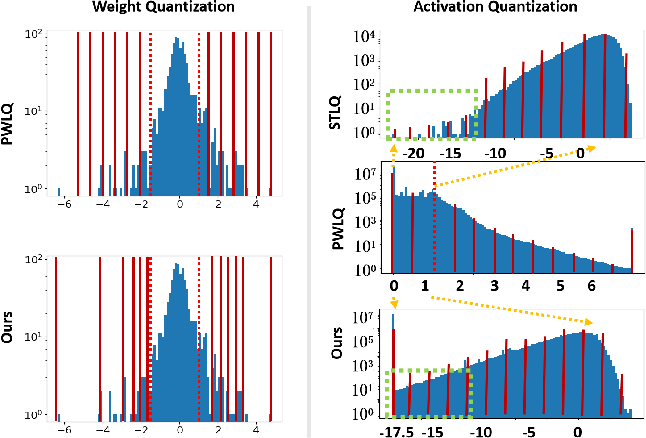
Figure 1 from Distribution Matched Low-bit Post-Training Quantization ...
Advances to low-bit quantization enable LLMs on edge devices ...
Figure 2 from Improving Extreme Low-Bit Quantization With Soft ...
How to Achieve Extreme Low-bit Quantization for LLMs - YouTube
Figure 1 from Atom: Low-bit Quantization for Efficient and Accurate LLM ...
Figure 4 from Improving Extreme Low-Bit Quantization With Soft ...
ButterflyQuant: Ultra-low-bit LLM Quantization through Learnable ...
Figure 1 from A Simple Low-bit Quantization Framework for Video ...
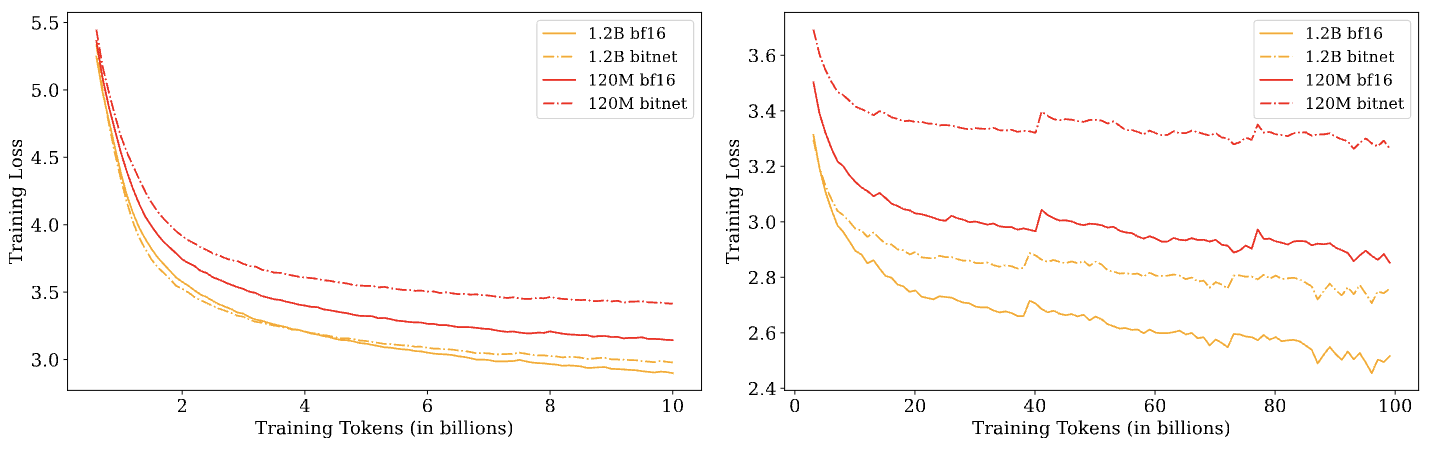
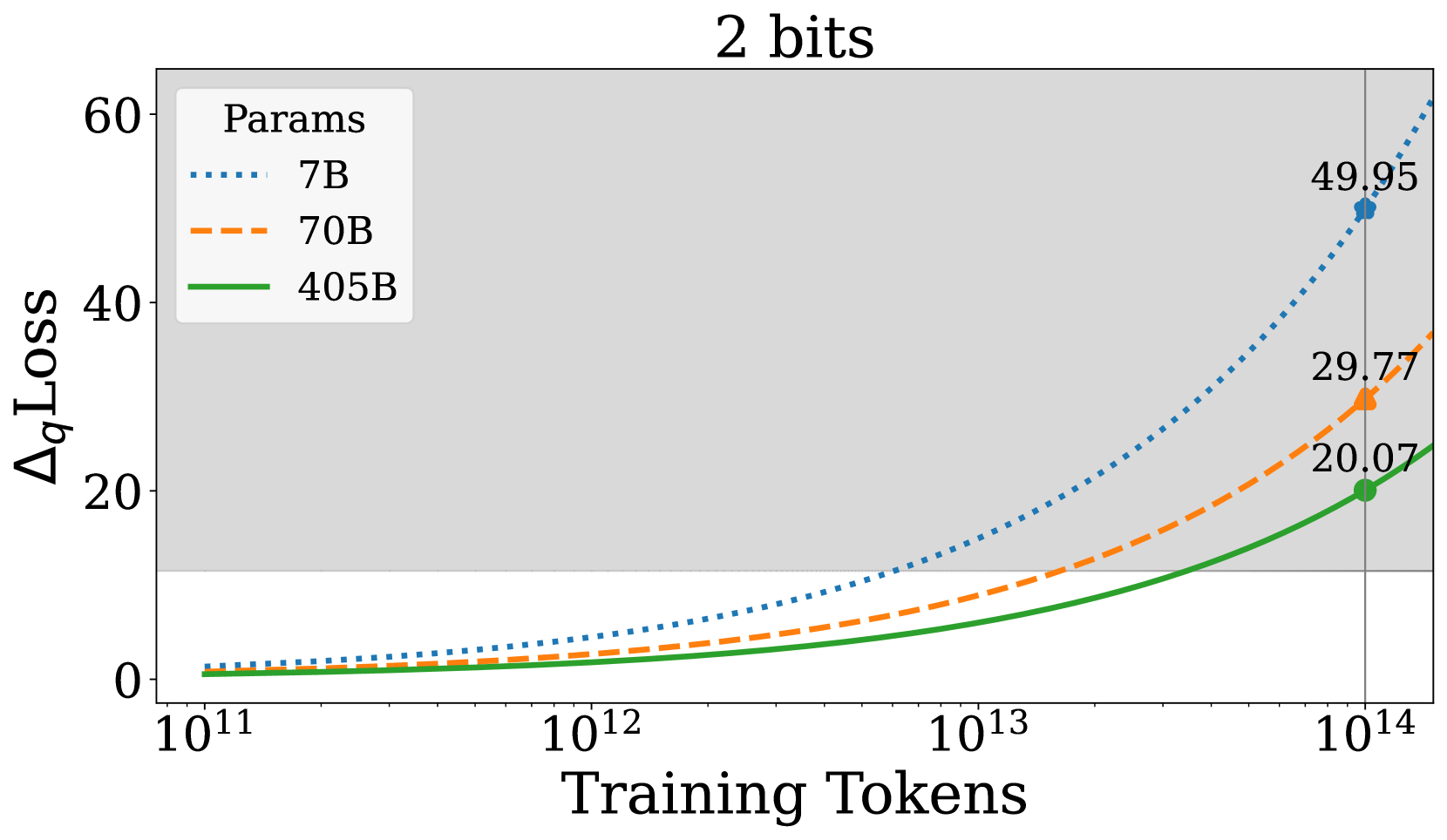
Low-Bit Quantization Favors Undertrained LLMs: Scaling Laws for ...
[论文评述] CondiQuant: Condition Number Based Low-Bit Quantization for ...
(PDF) Low-bit Model Quantization for Deep Neural Networks: A Survey
Honey, I shrunk the LLM! A beginner’s guide to quantization | News For ...
Figure 2 from Low-Bit Quantization and Quantization-Aware Training for ...
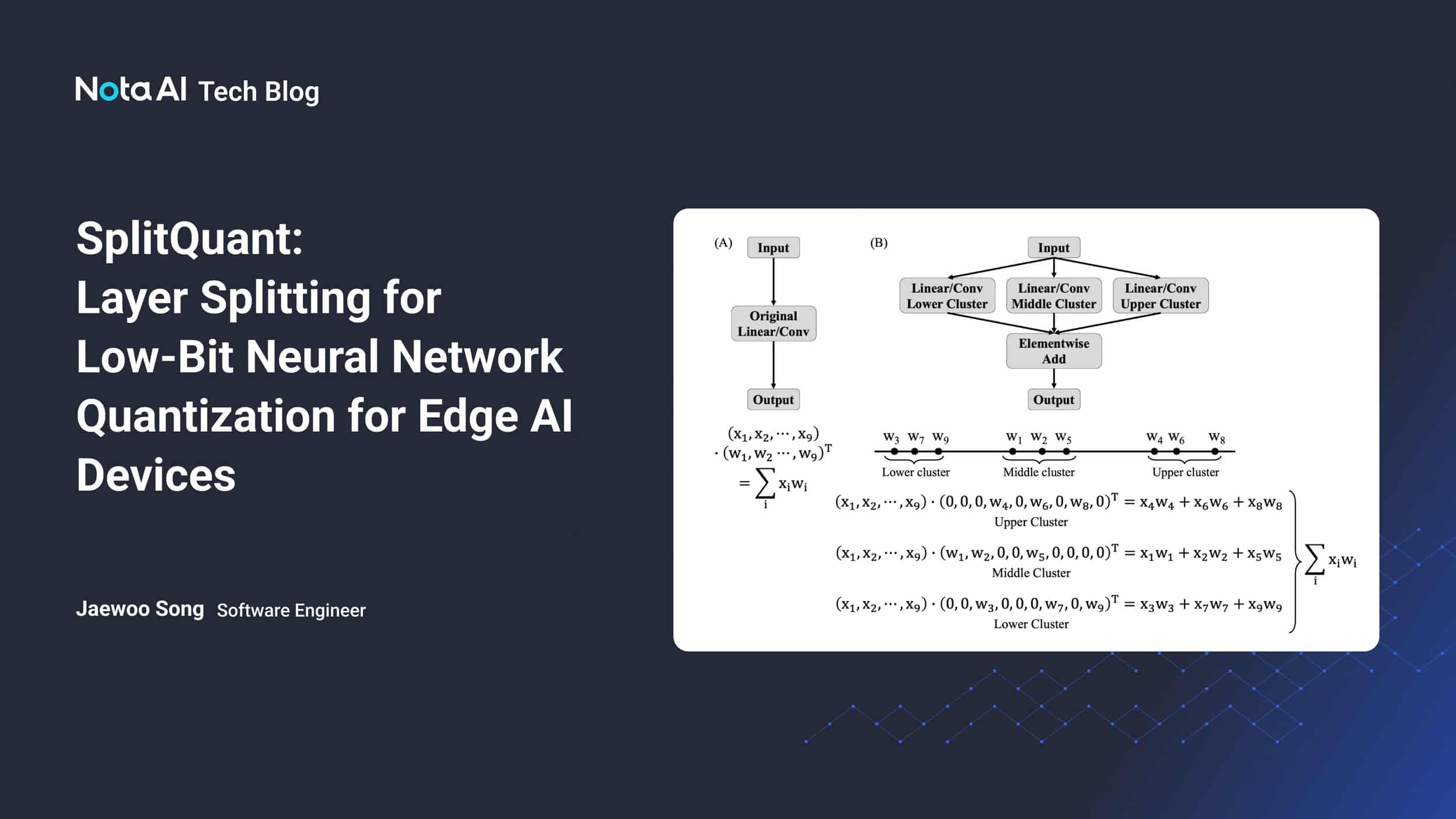
SplitQuant: Layer Splitting for Low-bit Neural Network Quantization for ...
Low-bit Quantization for Deep Graph Neural Networks with Smoothness ...
🎉 Quantization process. compression. 2019-01-14
(PDF) Low-Bit Quantization Methods for Modulated Wideband Converter ...
Low-Bit Quantization Favors Undertrained LLMs
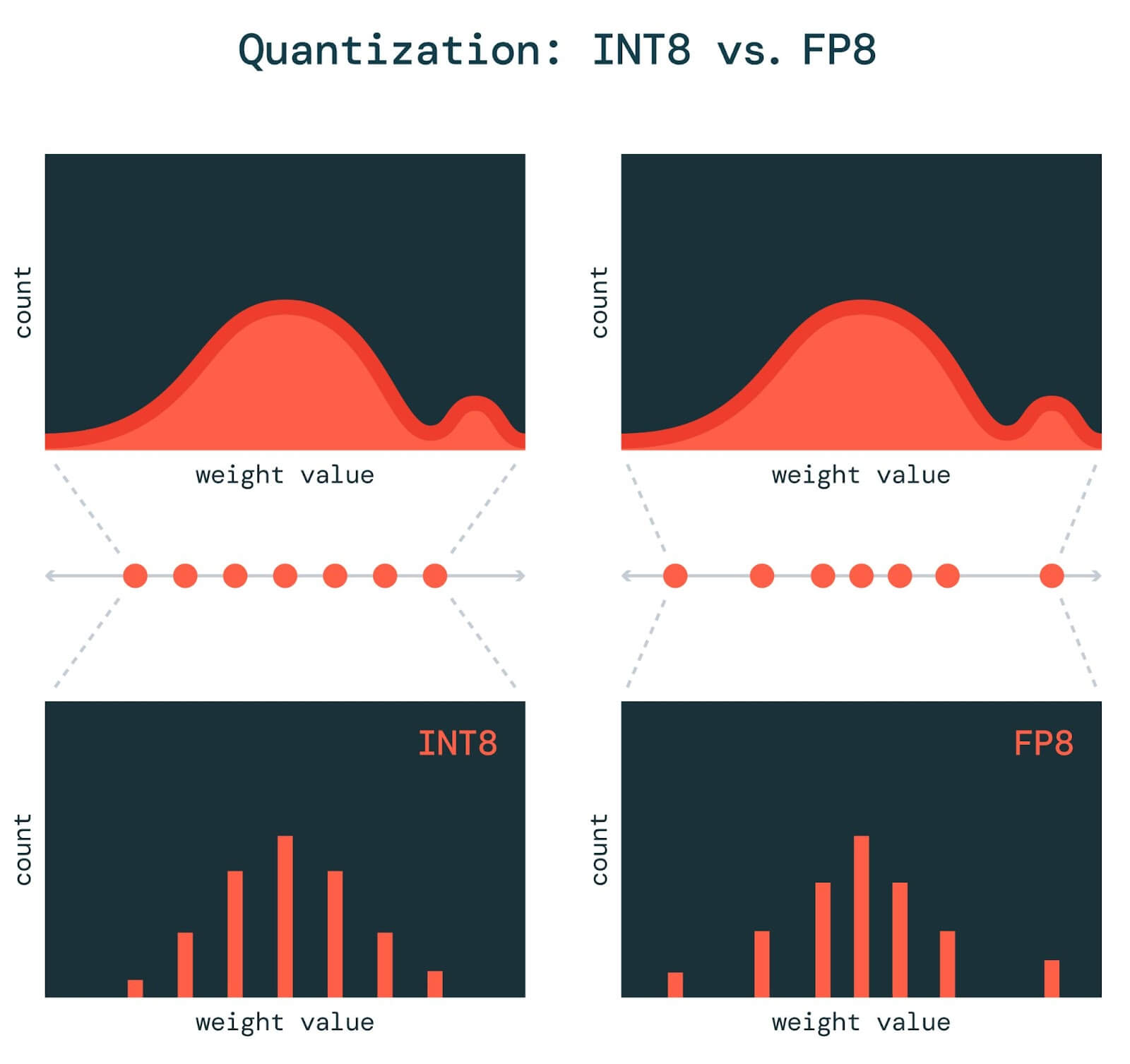
A Visual Guide to Quantization - by Maarten Grootendorst
Low-Bit Quantization Favors Undertrained LLMs - ACL Anthology
PB-LLM: a cutting-edge technique for extreme low-bit quantization in ...
(PDF) A Novel Low-Bit Quantization Strategy for Compressing Deep Neural ...
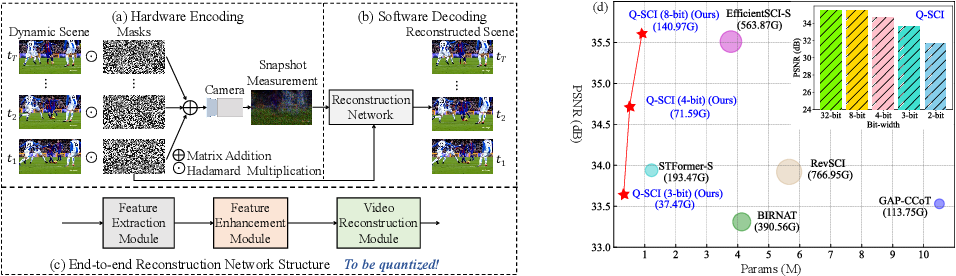
A Simple Low-bit Quantization Framework for Video Snapshot Compressive ...
Figure 3 from Improving Extreme Low-Bit Quantization With Soft ...
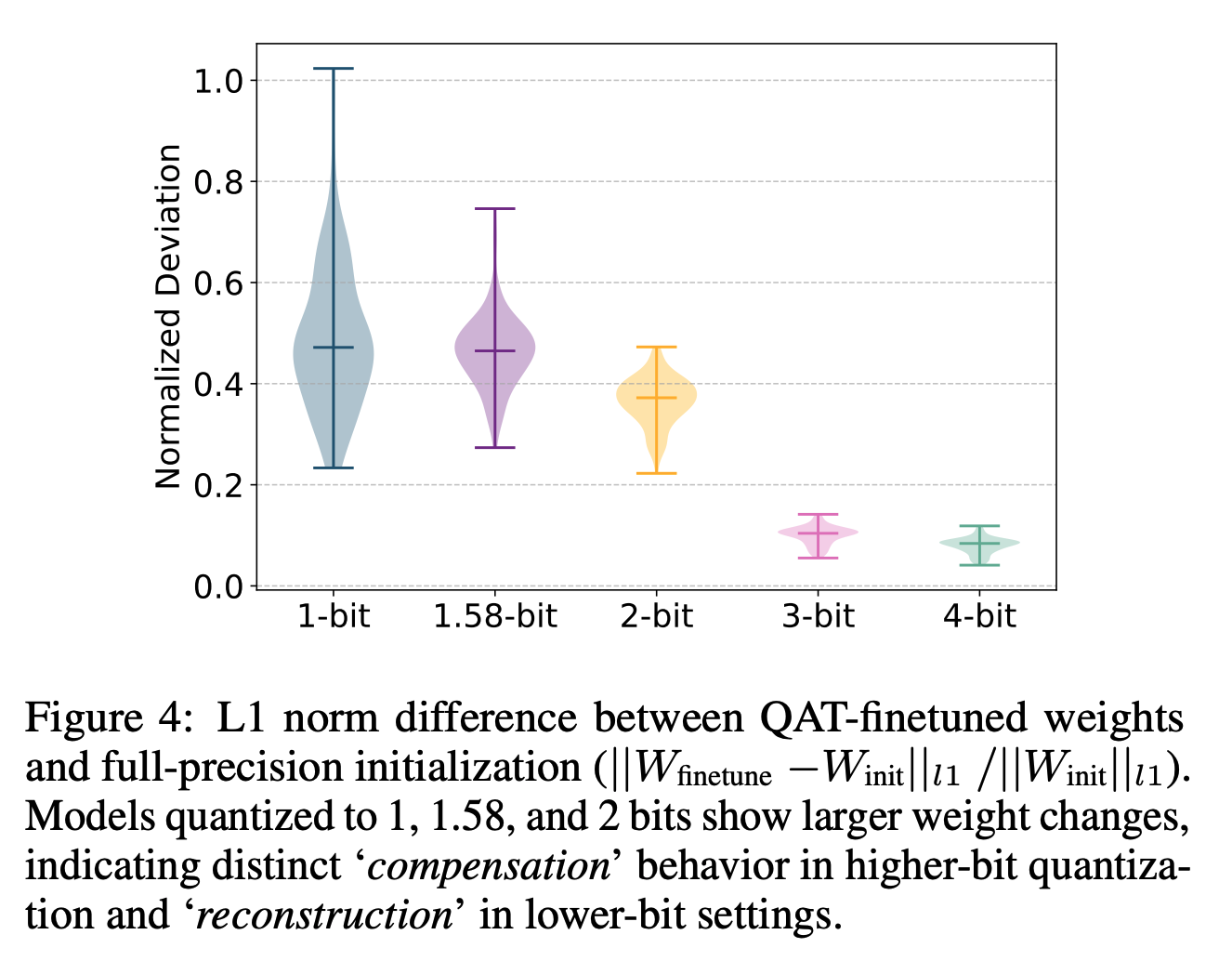
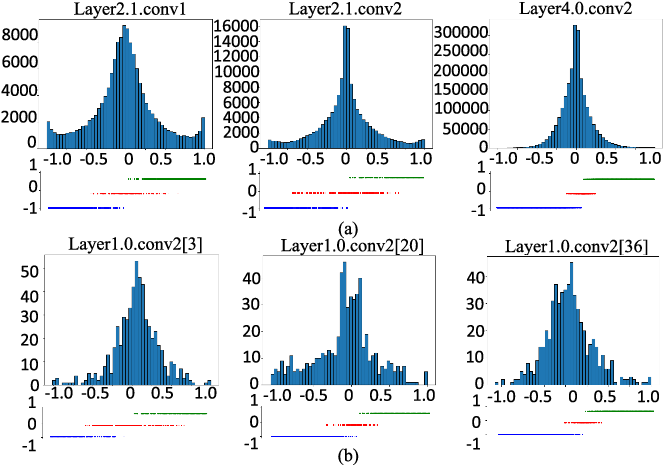
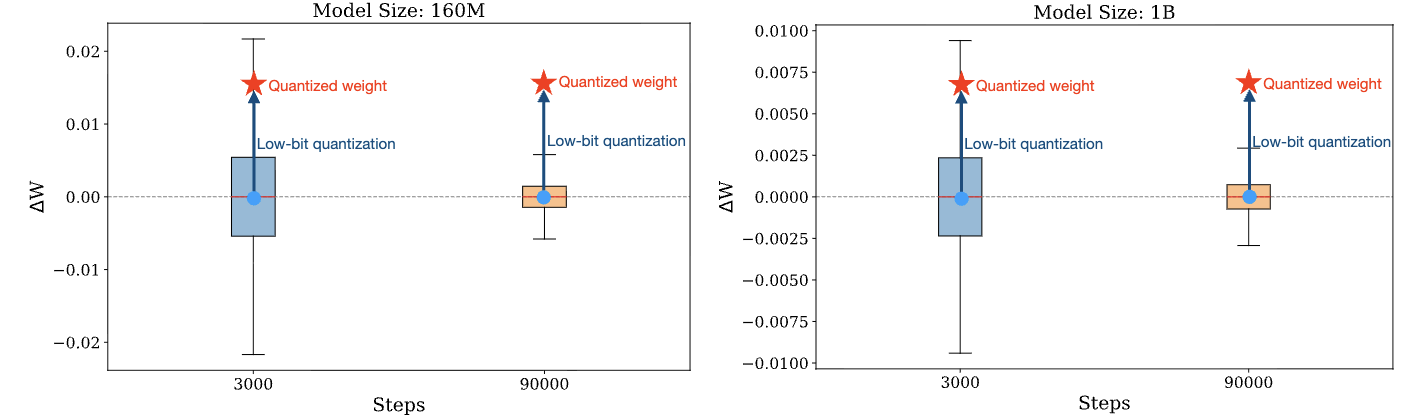
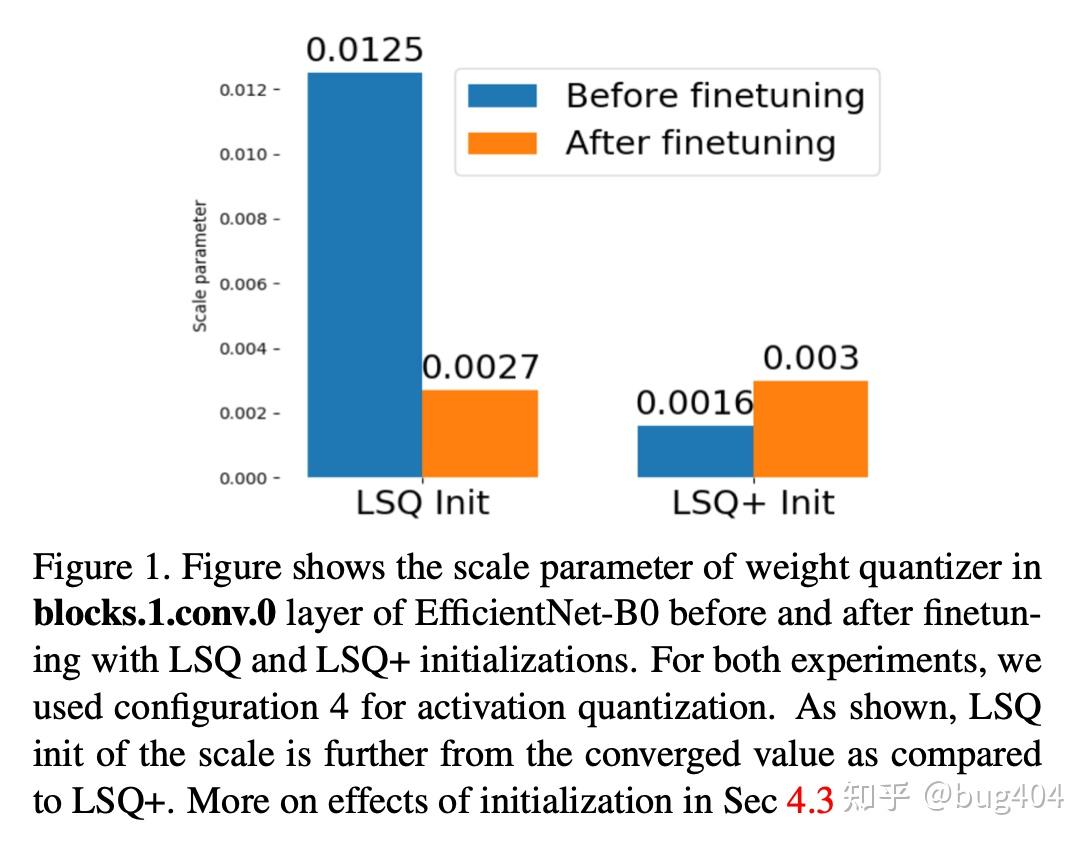
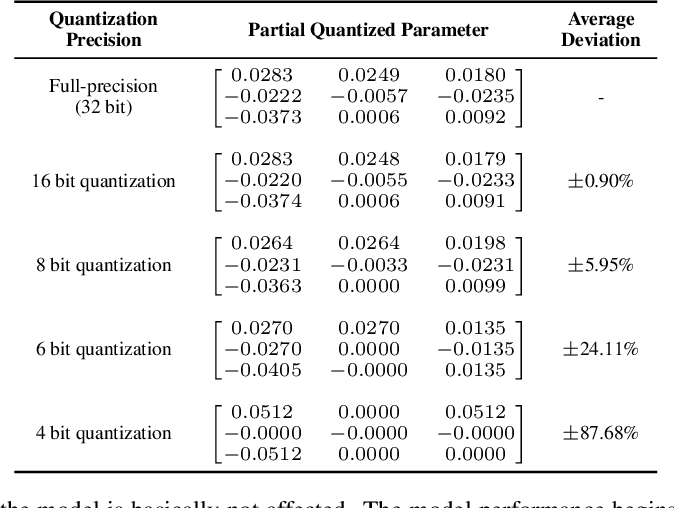
a Result of the weight quantization. After the weight quantization ...
Navigating the Quantization Frontier: Achieving Ultra-Low-Bit Model ...
MBCQ: Mixed-bias compensation quantization for extremely low-bit post ...
LSQ+: Improving low-bit quantization through learnable offsets and ...
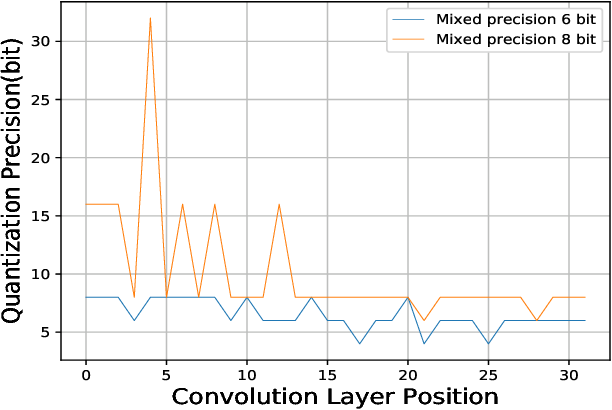
(PDF) Mixed Precision Low-bit Quantization of Neural Network Language ...
[논문 리뷰] ButterflyQuant: Ultra-low-bit LLM Quantization through ...
A Hardware-Friendly Low-Bit Power-of-Two Quantization Method for CNNs ...
This AI Research Introduces Atom: A Low-Bit Quantization Technique ...
Low-bit Quantization of Neural Networks for Efficient Inference | DeepAI
Table I from Improving Extreme Low-Bit Quantization With Soft Threshold ...
2DQuant: Low-bit Post-Training Quantization for Image Super-Resolution ...
Table 1 from Lowbit Neural Network Quantization for Speaker ...
(PDF) Direct Target Localization With Low-Bit Quantization in Wireless ...
(PDF) Low-bit Quantization of Recurrent Neural Network Language Models ...
(PDF) A Hardware-Friendly Low-Bit Power-of-Two Quantization Method for ...
Atom: Low-bit Quantization for Efficient and Accurate LLM Serving ...
Figure 1 from A Novel Low-Bit Quantization Strategy for Compressing ...
Figure 1 from Towards Low-Bit Quantization of Deep Neural Networks with ...
Neuron-by-Neuron Quantization for Efficient Low-Bit QNN Training
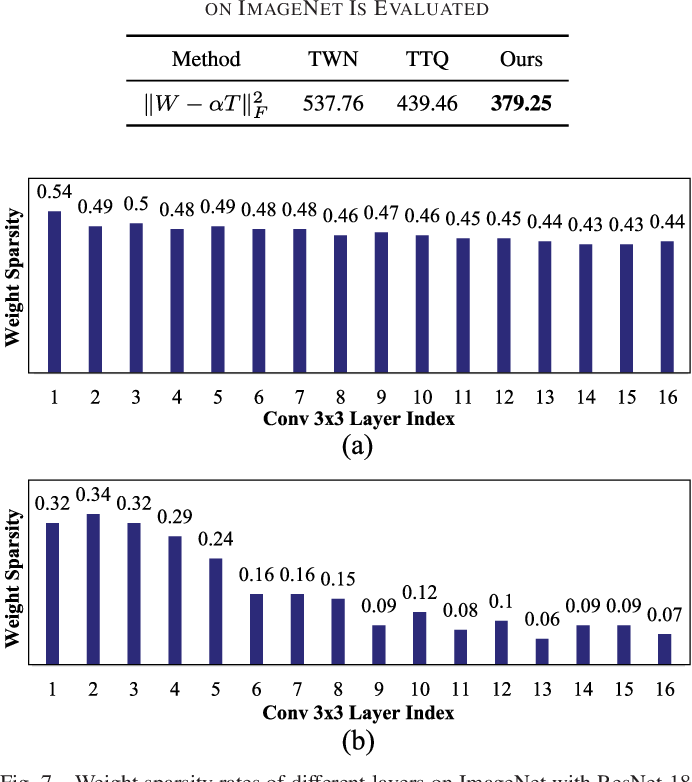
Comparison with the state-of-the-art low-bit quantization methods on ...
Figure 1 from Unlocking Data-free Low-bit Quantization with Matrix ...
VPTQ: Extreme Low-bit Vector Post-Training Quantization for Large ...
A Novel Low‐Bit Quantization Strategy for Compressing Deep Neural ...
Paper page - Low-Bit Quantization Favors Undertrained LLMs: Scaling ...
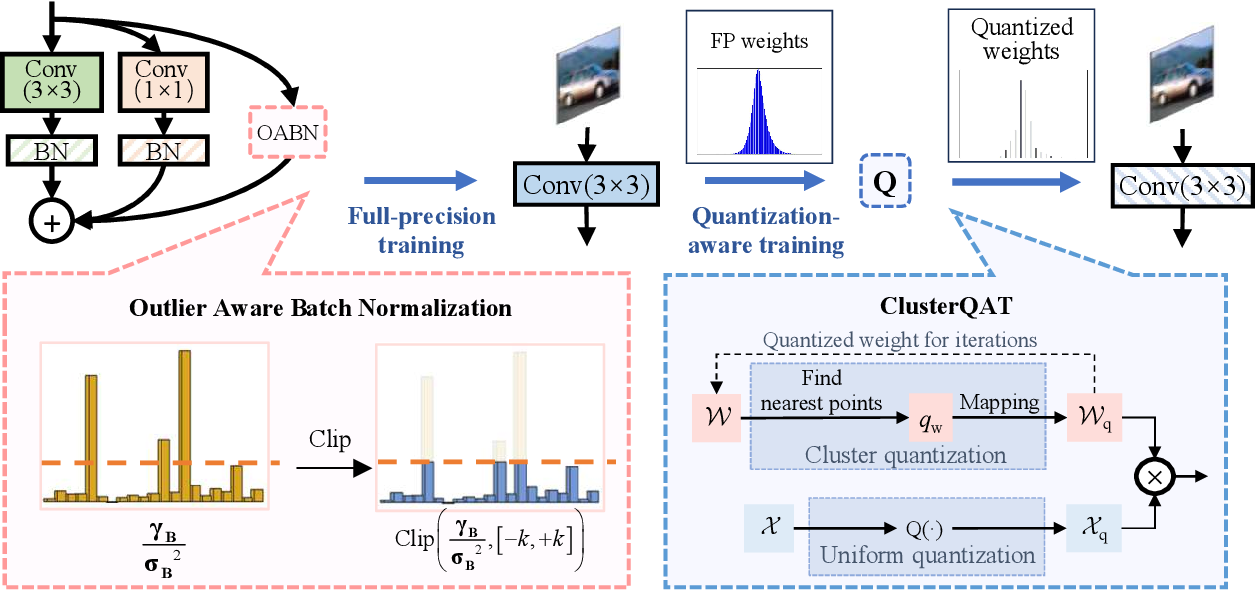
Table 1 from Outlier-Aware Training for Low-Bit Quantization of ...
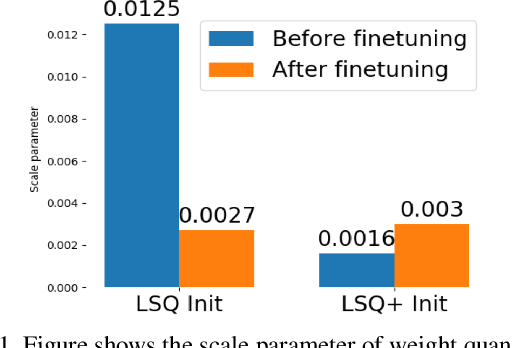
(PDF) LSQ+: Improving low-bit quantization through learnable offsets ...
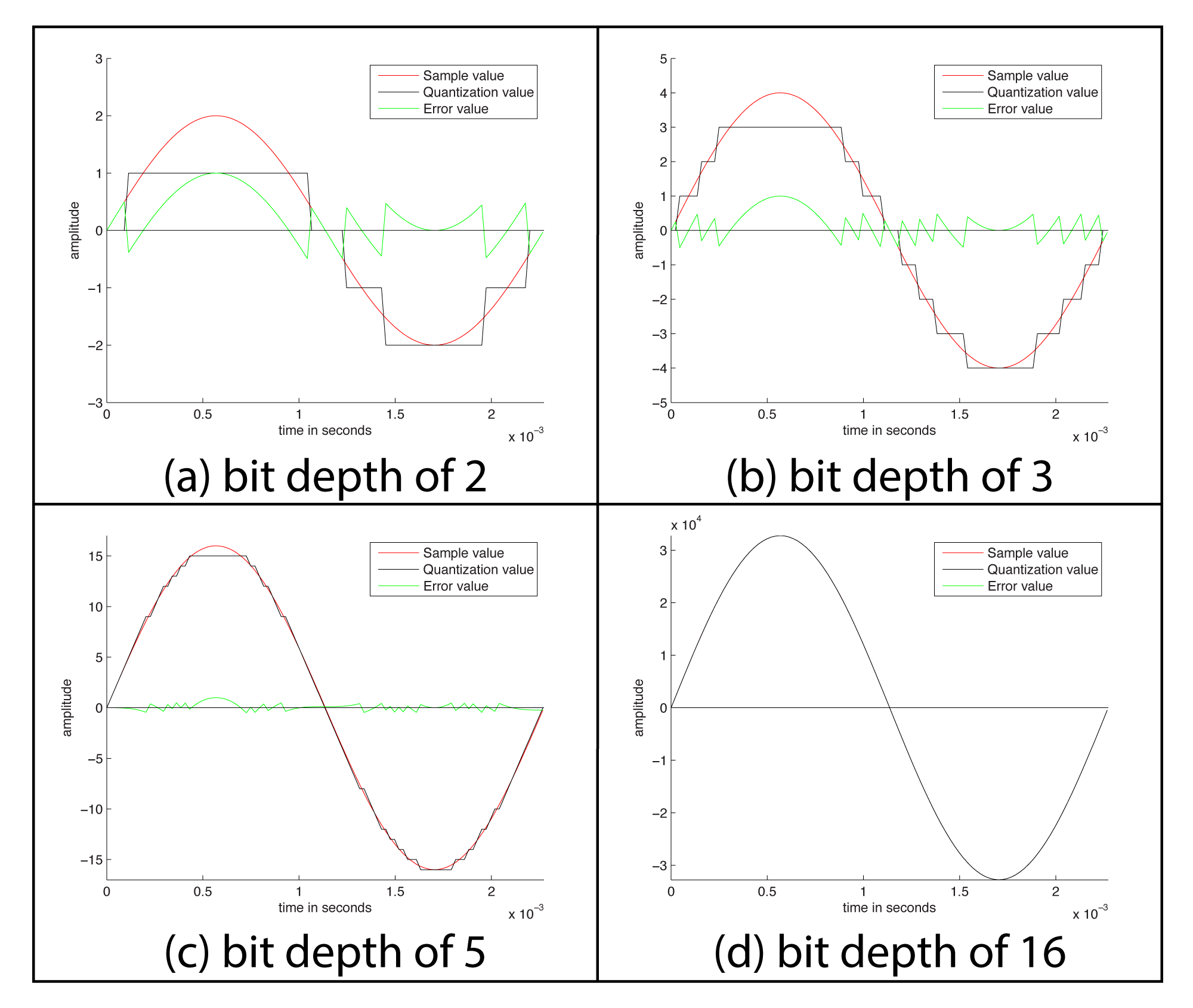
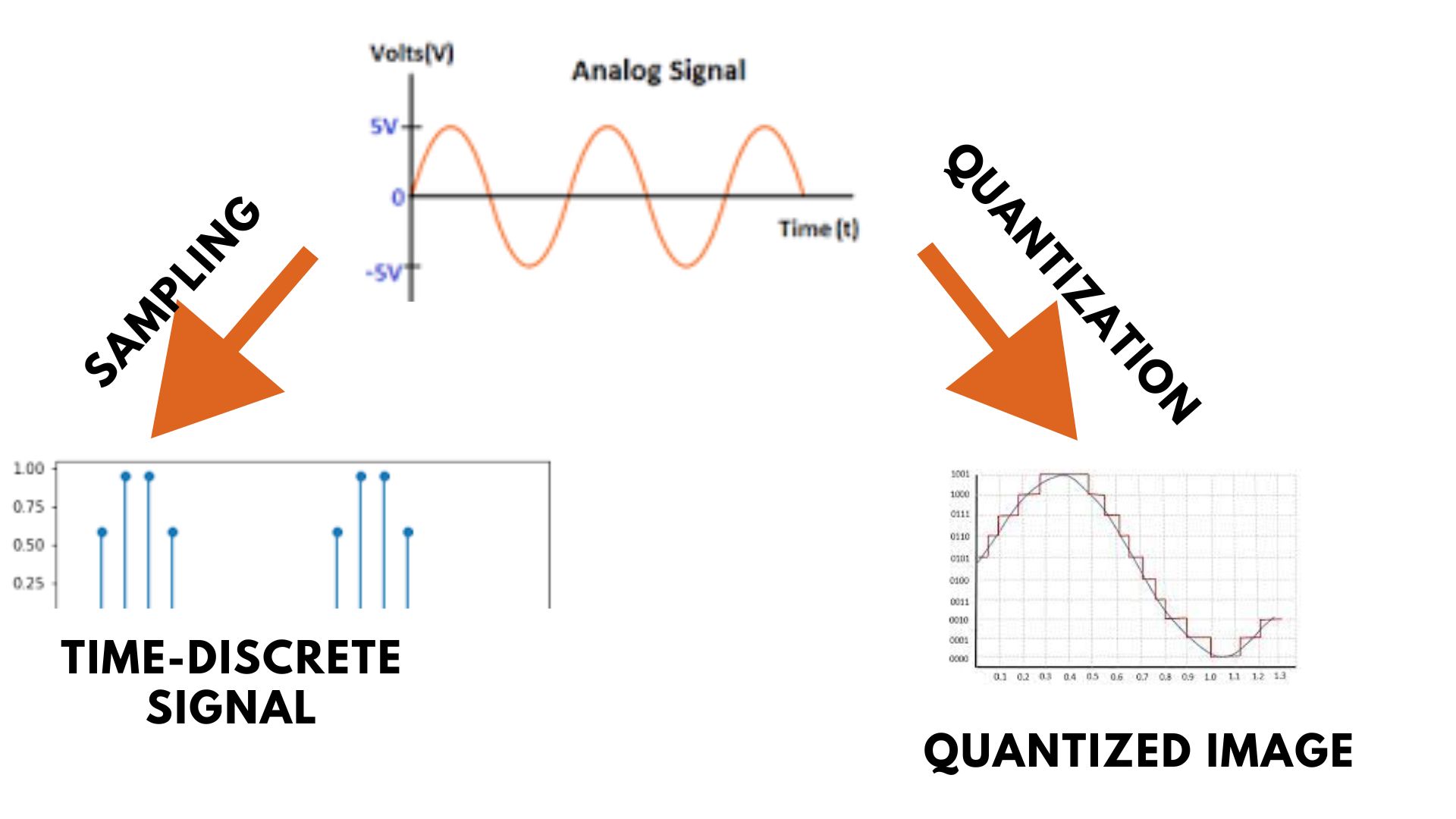
What Is Quantization In Analog To Digital Conversion at Henry Numbers blog
Figure 1 from LSQ+: Improving low-bit quantization through learnable ...
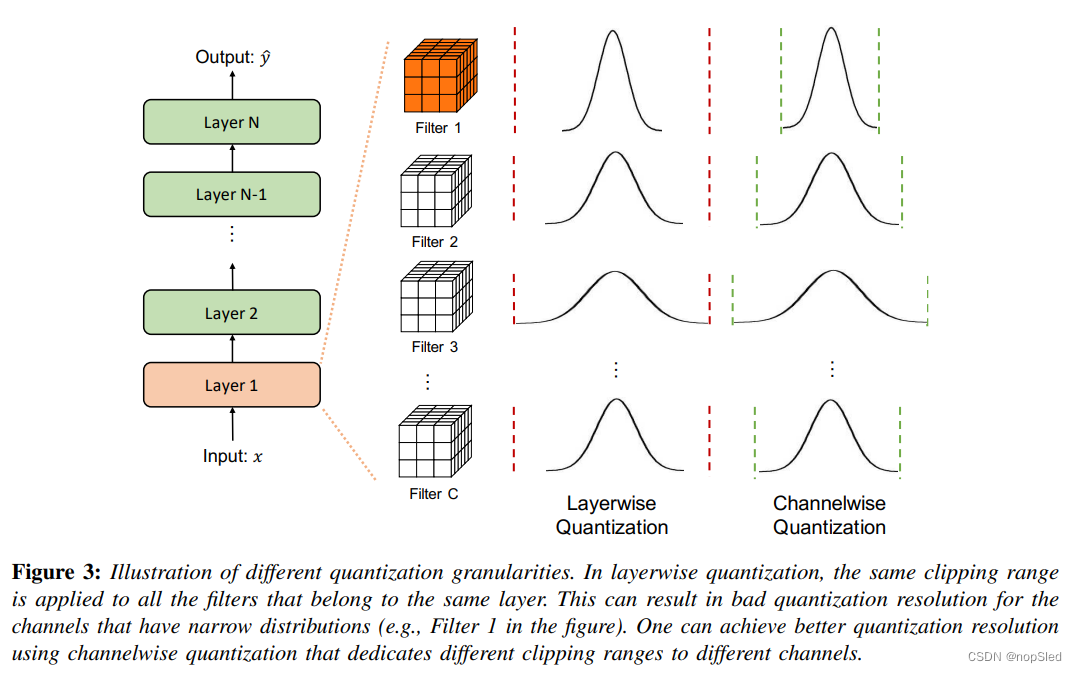
A Survey of Quantization Methods for Efficient Neural Network Inference ...
Figure 1 from Low-Bit Quantization and Quantization-Aware Training for ...
Figure 1 from QuantSR: Accurate Low-bit Quantization for Efficient ...
[論文レビュー] Quantization Meets Reasoning: Exploring LLM Low-Bit ...
Paper page - Atom: Low-bit Quantization for Efficient and Accurate LLM ...
GitHub - efeslab/Atom: [MLSys'24] Atom: Low-bit Quantization for ...
(PDF) Low-bit Quantization of Neural Networks for Efficient Inference
Figure 1 from Two-Step Quantization for Low-bit Neural Networks ...
Table 1 from Why Do Some Inputs Break Low-Bit LLM Quantization ...
Paper page - Low-bit Model Quantization for Deep Neural Networks: A Survey
A Visual Guide to Quantization - Maarten Grootendorst
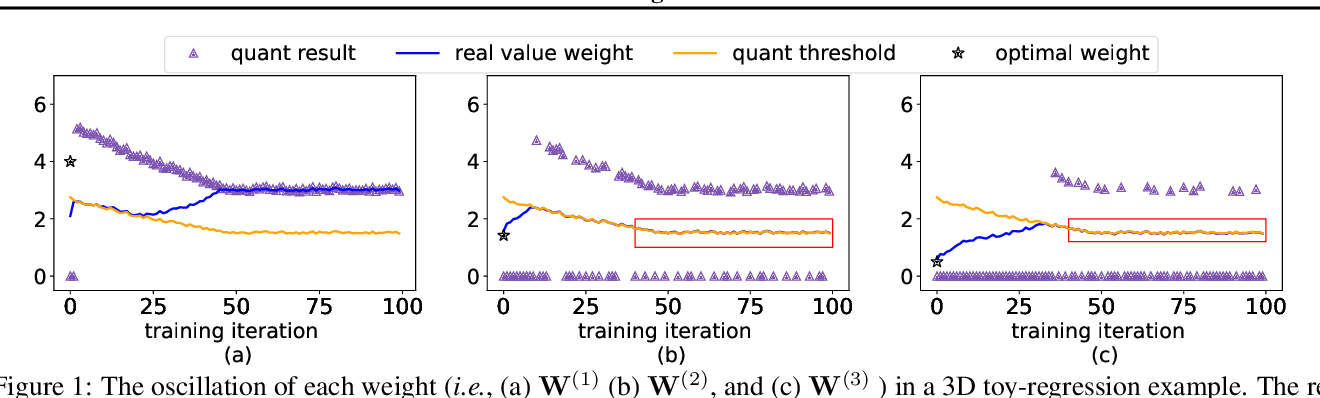
Figure 1 from Oscillation-free Quantization for Low-bit Vision ...
GitHub - pksvision/Low-Bit-Quantization-Pytorch
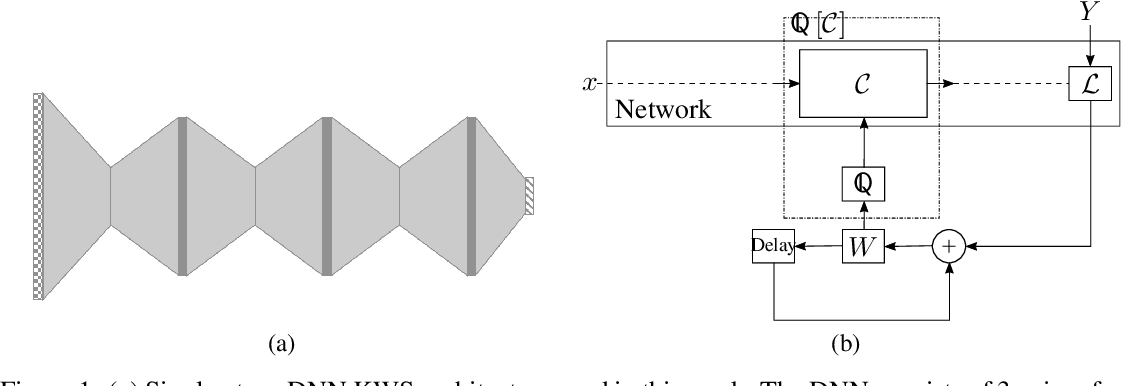
Quantify and fine-tune shared weights 4.2 Low-bit representation A ...
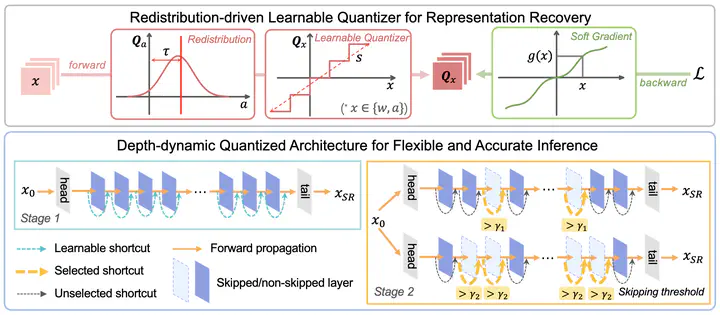
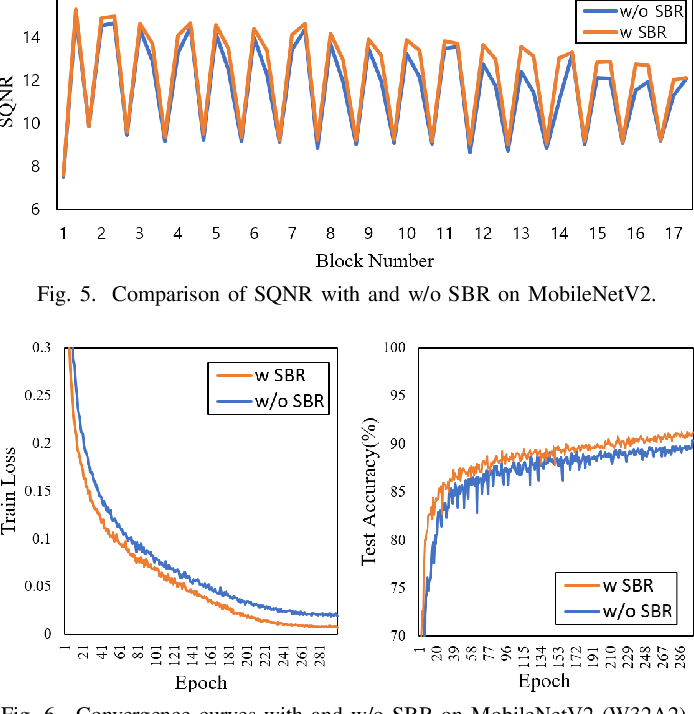
Figure 5 from Regularizing Activation Distribution for Ultra Low-bit ...
Learning Accurate Low-Bit Deep Neural Networks with Stochastic ...
Advances in the Neural Network Quantization: A Comprehensive Review
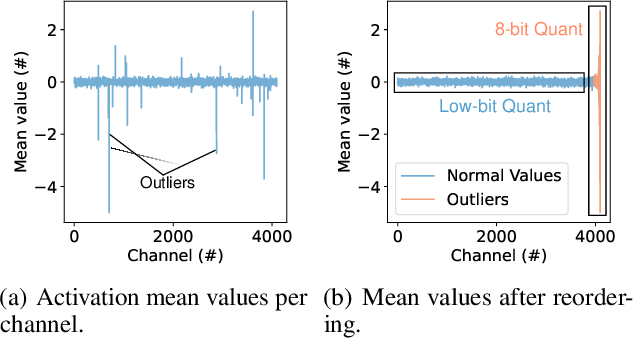
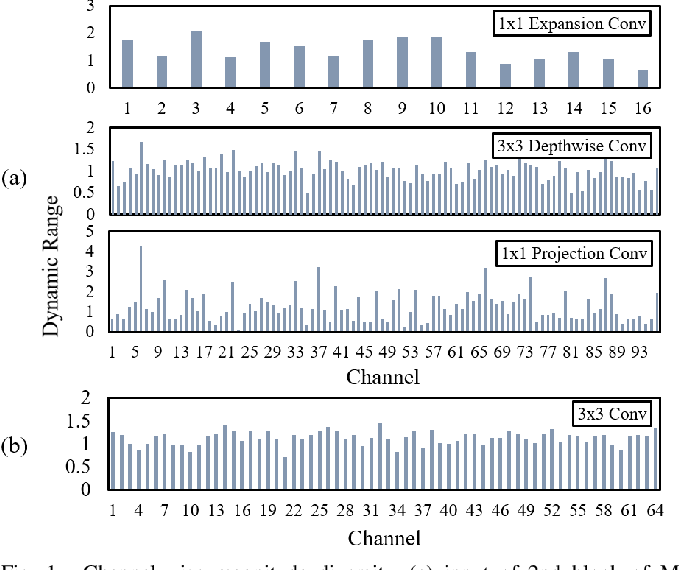
Rethinking Channel Dimensions to Isolate Outliers for Low-bit Weight ...
(PDF) INT v.s. FP: A Comprehensive Study of Fine-Grained Low-bit ...
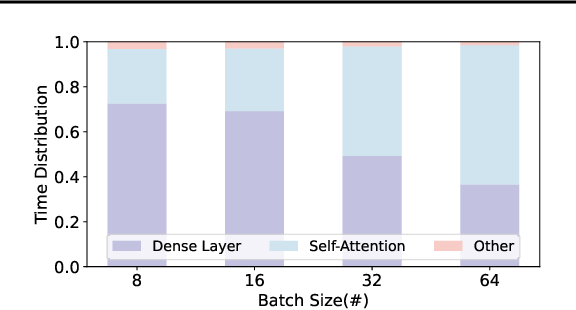
(PDF) Metis: Training Large Language Models with Advanced Low-Bit ...
Progressive 2-Bit Quantization: A Breakthrough for On-Device
Serving Quantized LLMs on NVIDIA H100 Tensor Core GPUs | Databricks
(PDF) QuantFace: Towards Lightweight Face Recognition by Synthetic Data ...
(PDF) Q-DETR: An Efficient Low-Bit Quantized Detection Transformer
(PDF) NSNQuant: A Double Normalization Approach for Calibration-Free ...
Why Do Some Inputs Break Low-Bit LLM Quantization? - ACL Anthology
Figure 1 from Regularizing Activation Distribution for Ultra Low-bit ...
Figure 3 from Learning Accurate Low-Bit Deep Neural Networks with ...