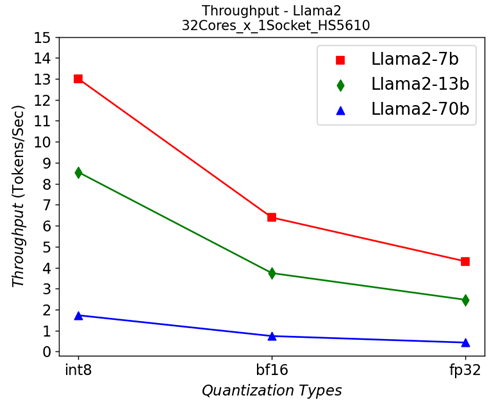
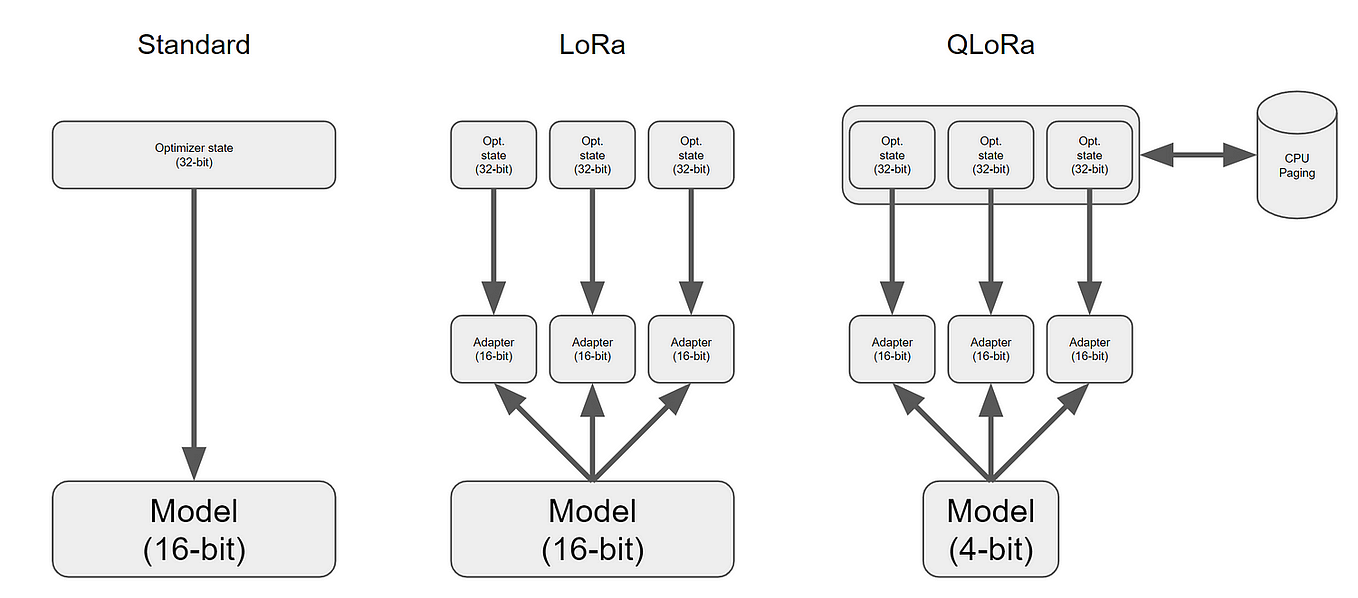
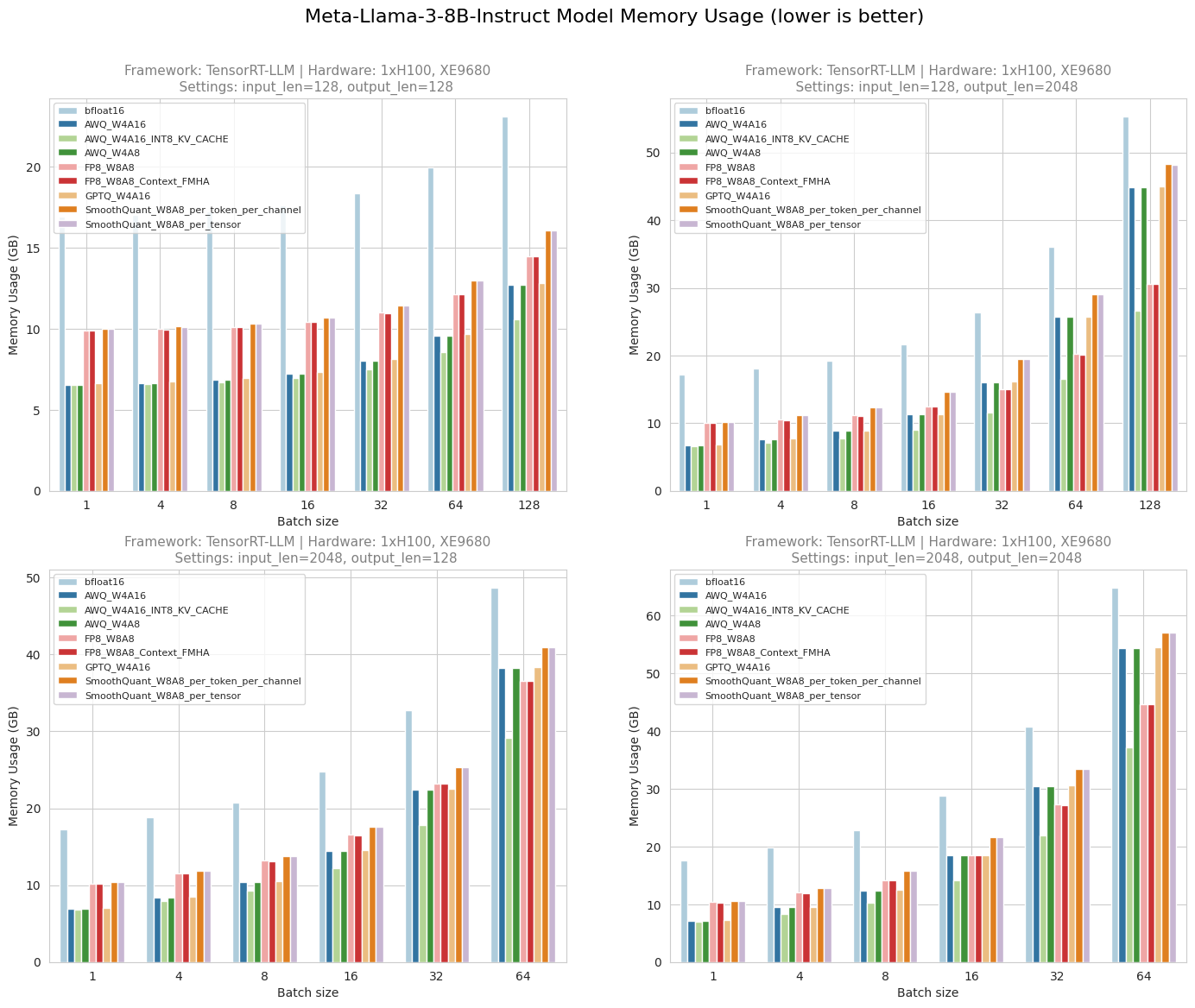
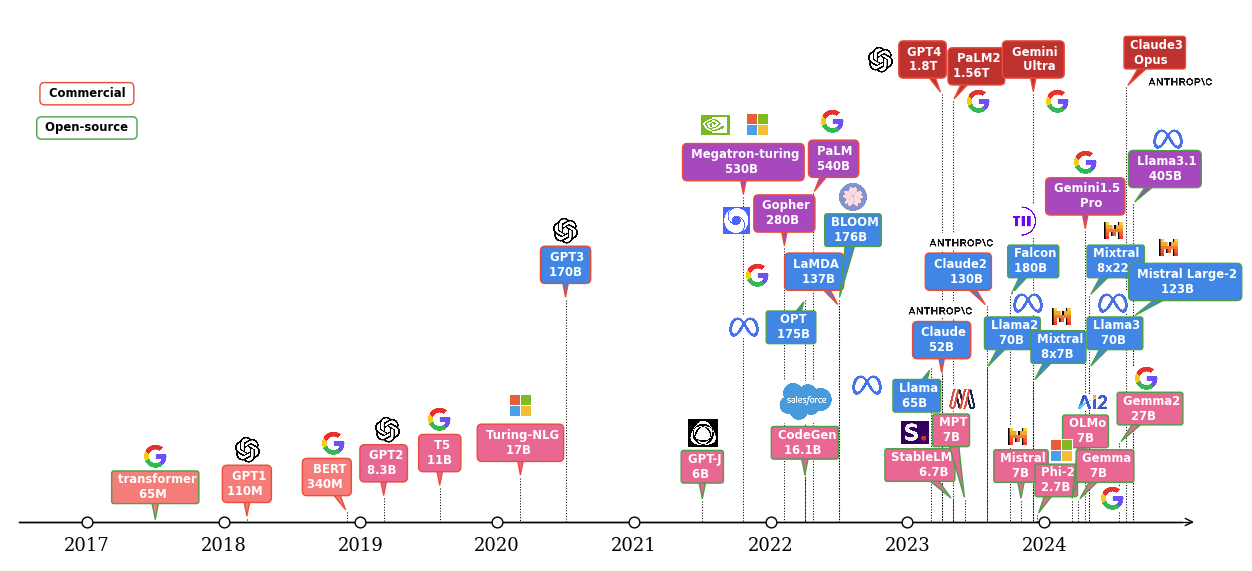
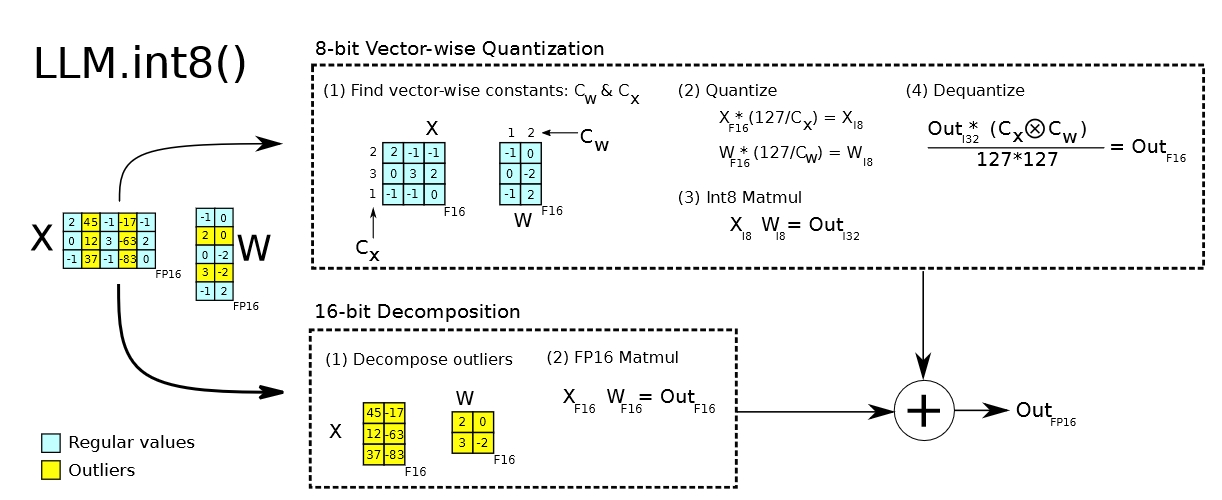
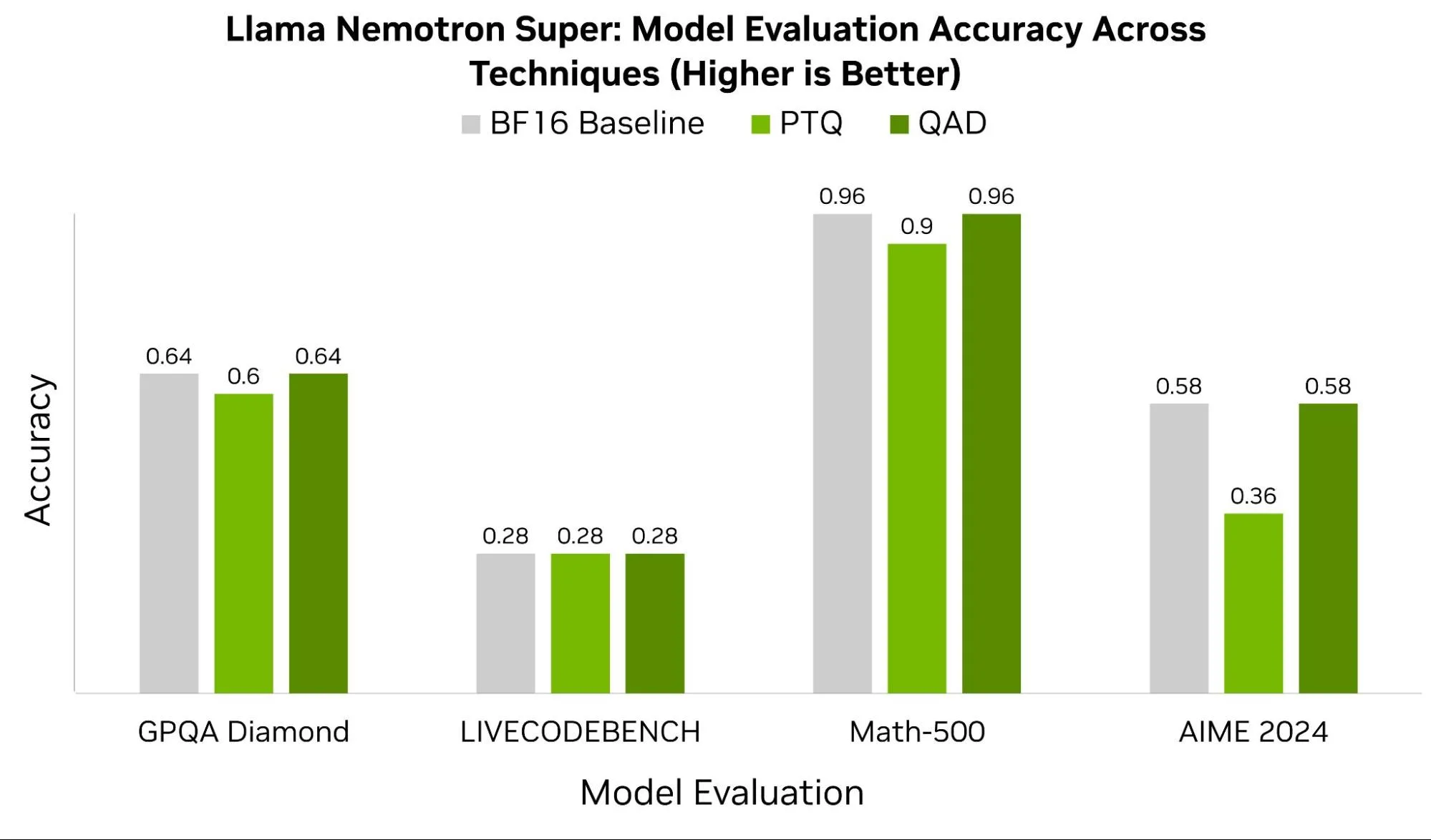
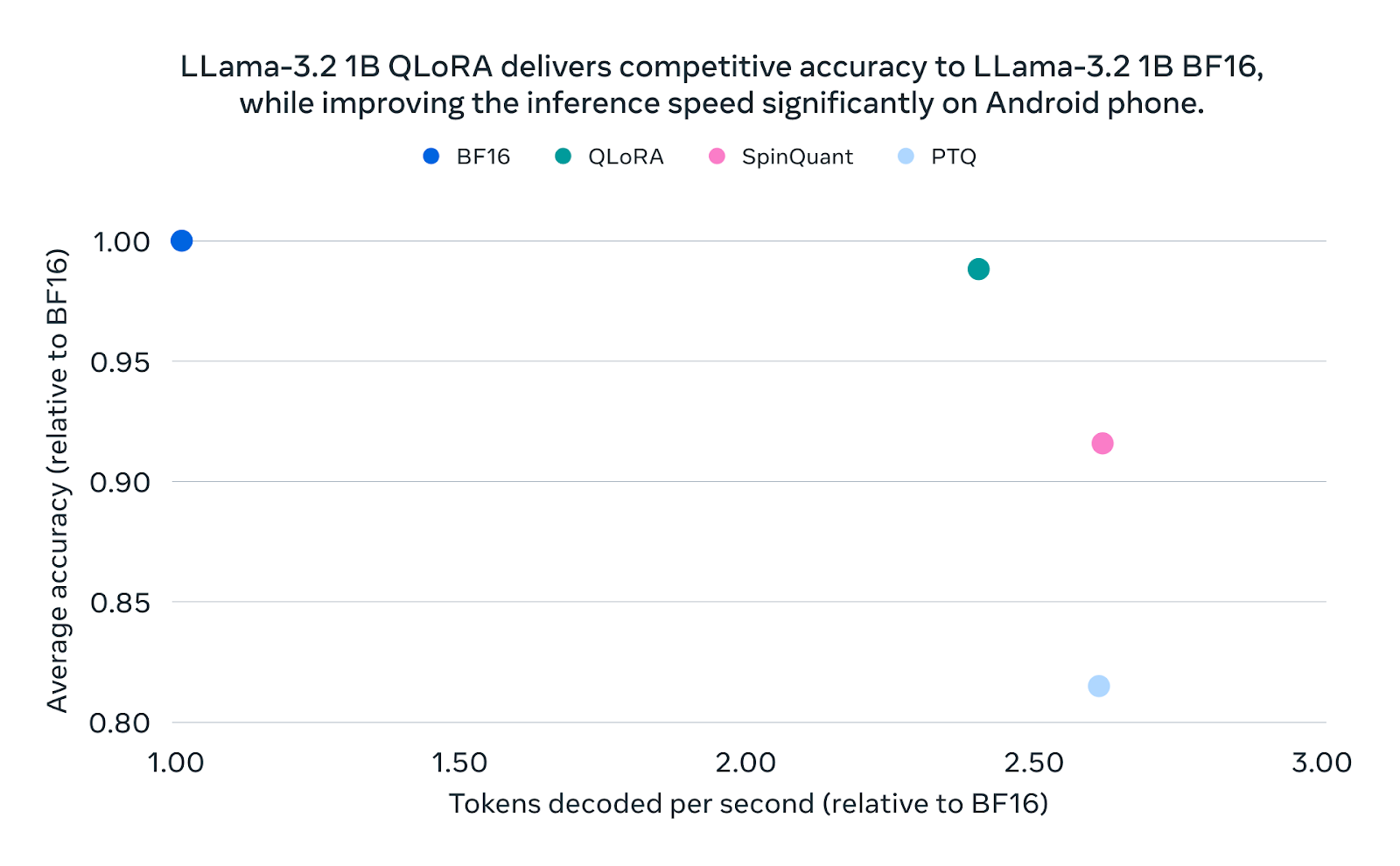
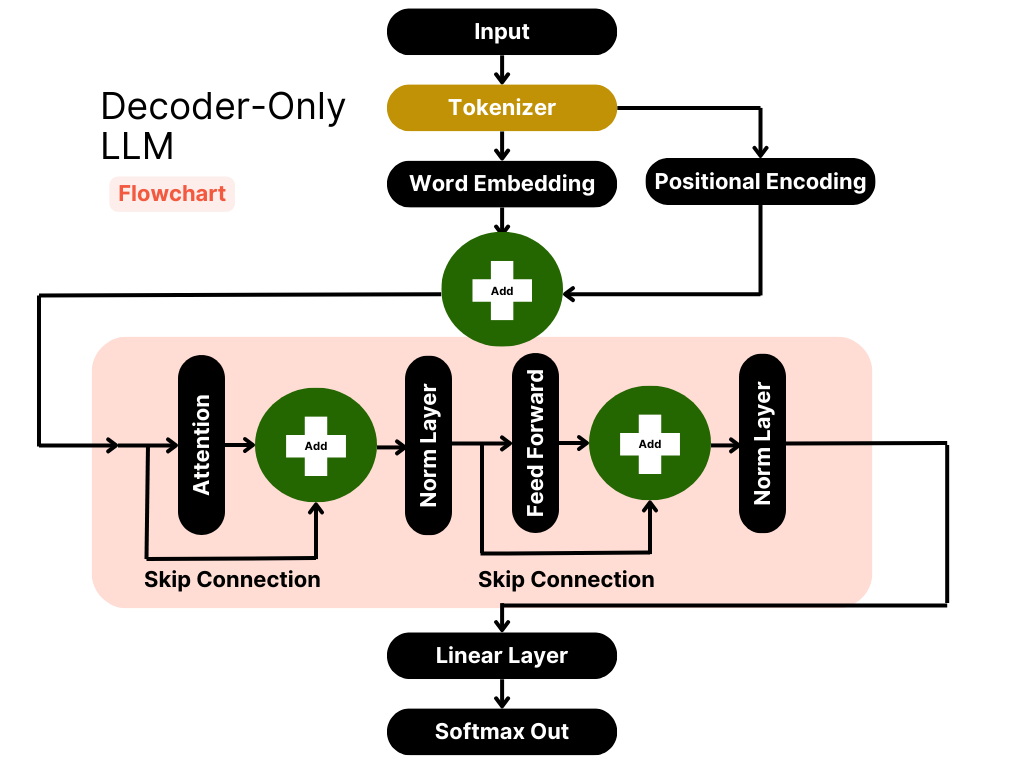
Showing 119 of 119on this page. Filters & sort apply to loaded results; URL updates for sharing.119 of 119 on this page
Deploying Llama 7B Model with Advanced Quantization Techniques on Dell ...
Quantization of Llama 2 with GTPQ for Fast Inference on Your Computer ...
Run LLaMA on small GPUs: LLM Quantization in Python - YouTube
Deploying Llama 8B Model with Advanced Quantization Techniques on Dell ...
LLM Quantization with llama.cpp on Free Google Colab | Llama 3.1 | GGUF ...
Qwen2 vs. Llama 3: QLoRA Learning Curves and Quantization Performance
How to Use the LLaMA 65B Model with AWQ Quantization fxis.ai
Building Llama 3 ChatBot Part 1: Quantization using AutoGPTQ | by ...
Fast and Small Llama 3 with Activation-Aware Quantization (AWQ)
Optimizing Llama 3.2 1B Using Quantization Techniques Usingbitsandbytes ...
Optimizing LLAMA 3.1 (70B): Harnessing Quantization for Efficient Large ...
New Tutorial on LLM Quantization w/ QLoRA, GPTQ and Llamacpp, LLama 2 ...
1-bit and 2-bit Llama 3: Quantization with HQQ and Fine-tuning with HQQ+
Llama-3 8B Model Stats. Llama-3 8B with 4-bit quantization only… | by ...
2 to 6 bit quantization coming to llama.cpp : r/LocalLLaMA
🦙 Optimize Your LLM Models and Save Costs with llama.cpp Quantization 🦙 ...
Quantize Llama models with GGUF and llama.cpp | Towards Data Science
Step-by-Step Model Merging and GGUF imatrix Quantization | K4YT3X
GitHub - Lightning-AI/lit-llama: Implementation of the LLaMA language ...
LLaMa 量化部署 - 知乎
How Quantization Aware Training Enables Low-Precision Accuracy Recovery ...
How Does Meta's Llama 3.2 Improve Mobile AI Performance? | Analytics ...
meta-llama/Llama-3.2-1B · llama-3.2-1B model with quantization
Quantize Llama models with GGML and llama.cpp | Towards Data Science
Tutorial: Quantizing Llama 3+ Models for Efficient Deployment
Introducing quantized Llama models with increased speed and a reduced ...
Llama-3.1 Quantization - a neuralmagic Collection
Unsloth - Dynamic 4-bit Quantization
“Mastering Llama Math (Part-1): A Step-by-Step Guide to Counting ...
Evaluating Quantized Llama 2 Models for IoT Privacy Policy Language ...
Model Quantization - A Lazy Data Science Guide
Neural Magic Releases Fully Quantized FP8 Version of Meta’s Llama 3.1 ...
LLaMa 量化部署常用方案总结! - 知乎
Resolving ModuleNotFoundError: No Module Named ‘llama_index.readers ...
Meta Llama 3 Optimized CPU Inference with Hugging Face and PyTorch ...
The Complete Guide to Meta’s Quantized LLaMA Models: Making AI ...
Fine-tuning LLMs to 1.58bit: extreme quantization made easy
LLaMa GPTQ 4-Bit Quantization. Billions of Parameters Made Smaller and ...
Unleashing the Power of AI on Mobile: LLM Inference for Llama 3.2 ...
Llama 4 Scout: Running 17B AI Locally Step by Step
Quantizing Llama 70B for Production - Lattice Blog
LLM Quantization Made Easy: Essential Tips for Success
Post-Training Quantization of LLMs with NVIDIA NeMo and NVIDIA TensorRT ...
LLaMA - A Lazy Data Science Guide
[논문 리뷰] The Uniqueness of LLaMA3-70B Series with Per-Channel Quantization
How Minor Adjustments to Popular 1.5-bit Quantization Technique Lowers ...
Effective Weight-Only Quantization for Large Language Models with Intel ...
How to use LLama2 locally with Python, quantization and LoRA
Accelerating LLaMA with Fabric: A Comprehensive Guide to Training and ...
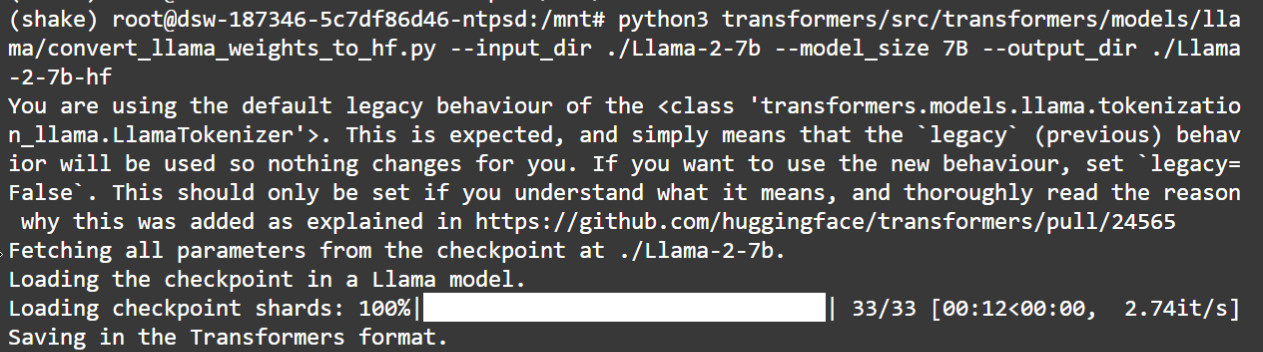
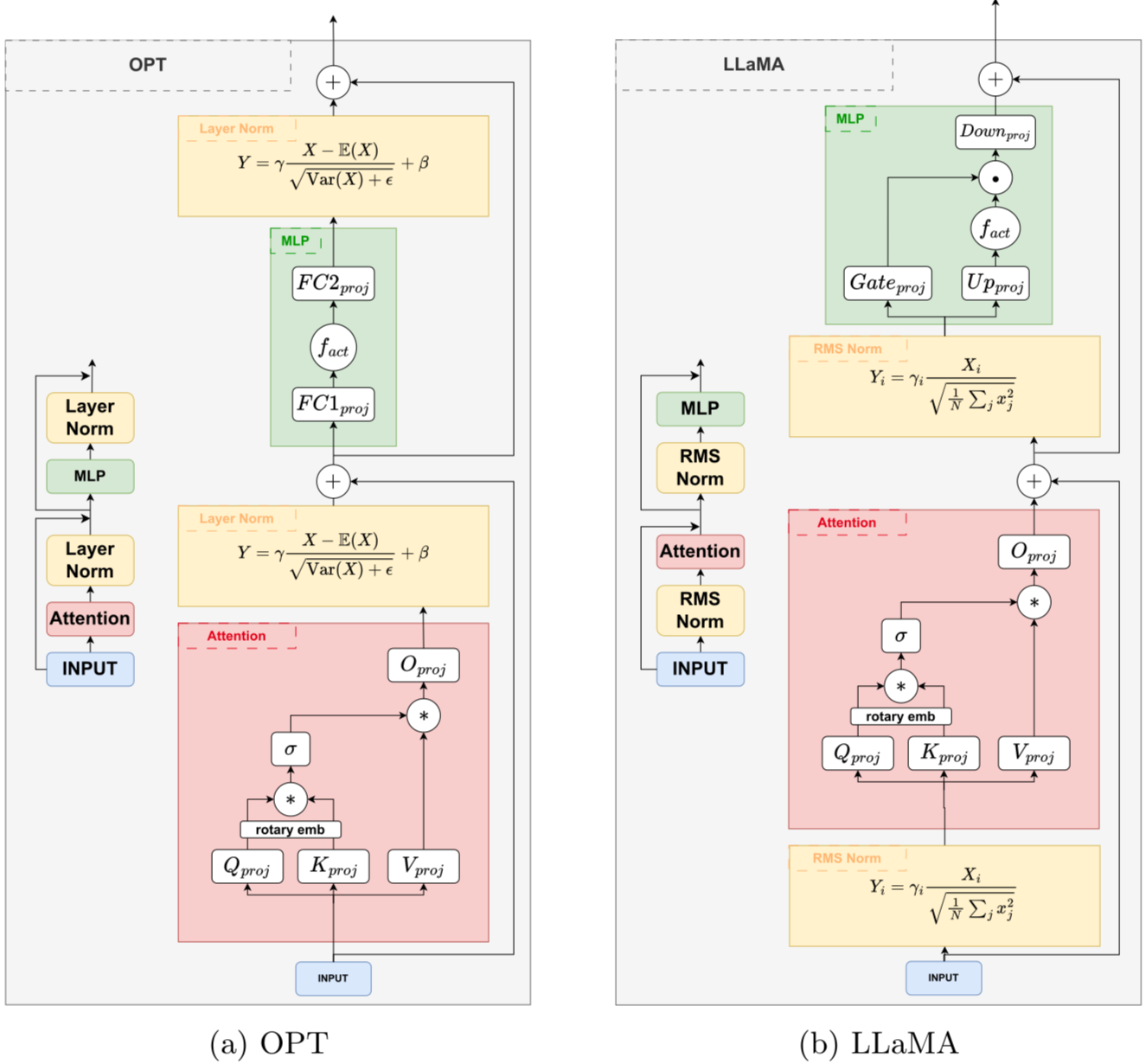
LLama2-7B Models Quantization Method - 陈沙克日志 | shake Blog
2024 LA Guide: Optimize AI with llama.cpp Quantization » Bee Techy, LLC.
3 Ways to Quantize Llama 3.1 With Minimal Accuracy Loss - YouTube
메타, 속도 향상 및 메모리 사용량 감소된 양자화(Quantized) Llama 모델 공개 | GeekNews
How to Use the 4-bit Quantized Llama 3 Model - fxis.ai
How to Use Llama-3.1-70B-Instruct Model with Quantization fxis.ai
量化 - LLaMA Factory
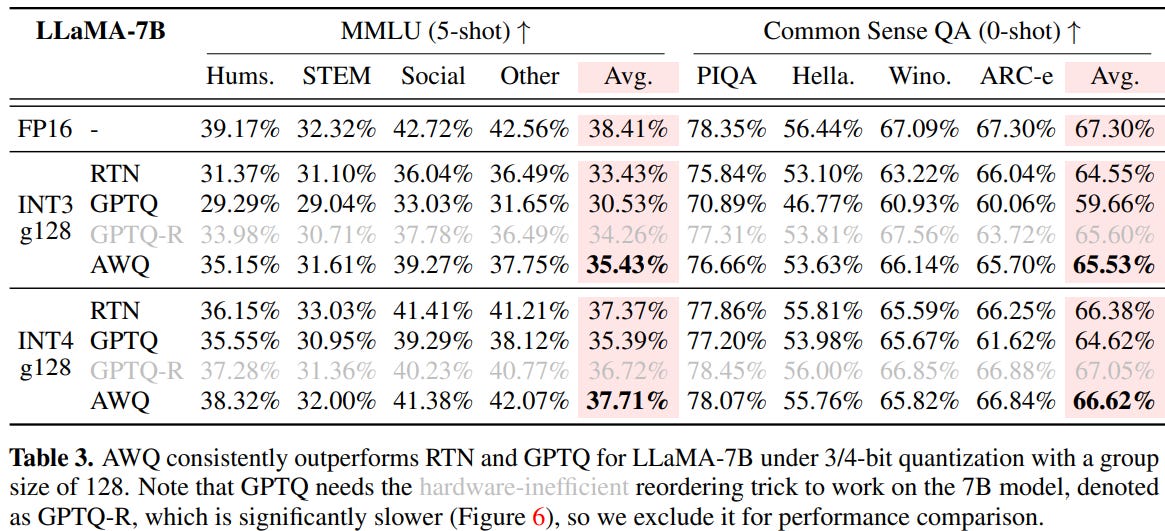
GitHub - Macaronlin/LLaMA3-Quantization: A repository dedicated to ...
[論文レビュー] Precision Where It Matters: A Novel Spike Aware Mixed ...
Quantizing Large Language Models: A step by step example with Meta ...
Run LLama-3.1 8B Instruct Quantized Model on CPU | by Muhammad Faizan ...
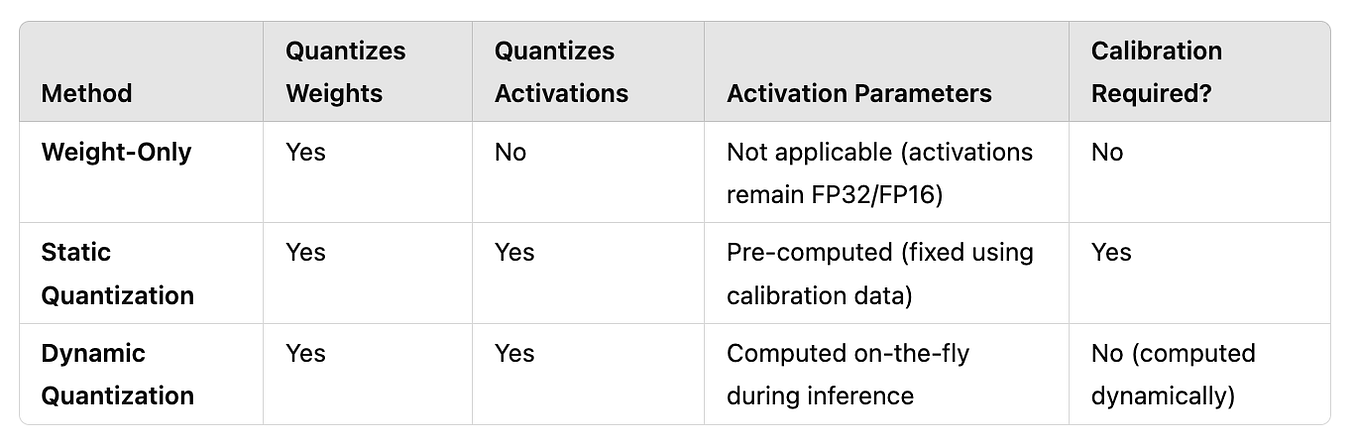
What are Quantized LLMs?
Running Large Language Models Privately | Towards Data Science
llama4
Introducing LLama.cpp: An Open-Source Machine Learning Library for ...
Meta Developers
LLaMA3-Quantization - a Efficient-ML Collection
Meet LLama.cpp: An Open-Source Machine Learning Library to Run the ...
(PDF) Benchmarking quantized LLaMa-based models on the Brazilian ...
meta-llama/Llama-3.2-1B Quantized - a HF-Quantization Collection
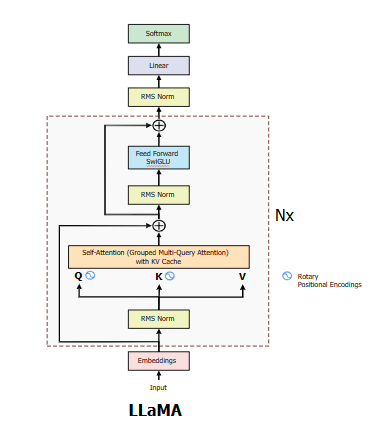
Understand How Llama3.1 Works — A Deep Dive Into the Model Flow | by ...
Quantized Models: Model Comparison Examples :: LLM optimization and ...
Breaking News: Run Large LLMs Locally with Less RAM and Higher Speed ...
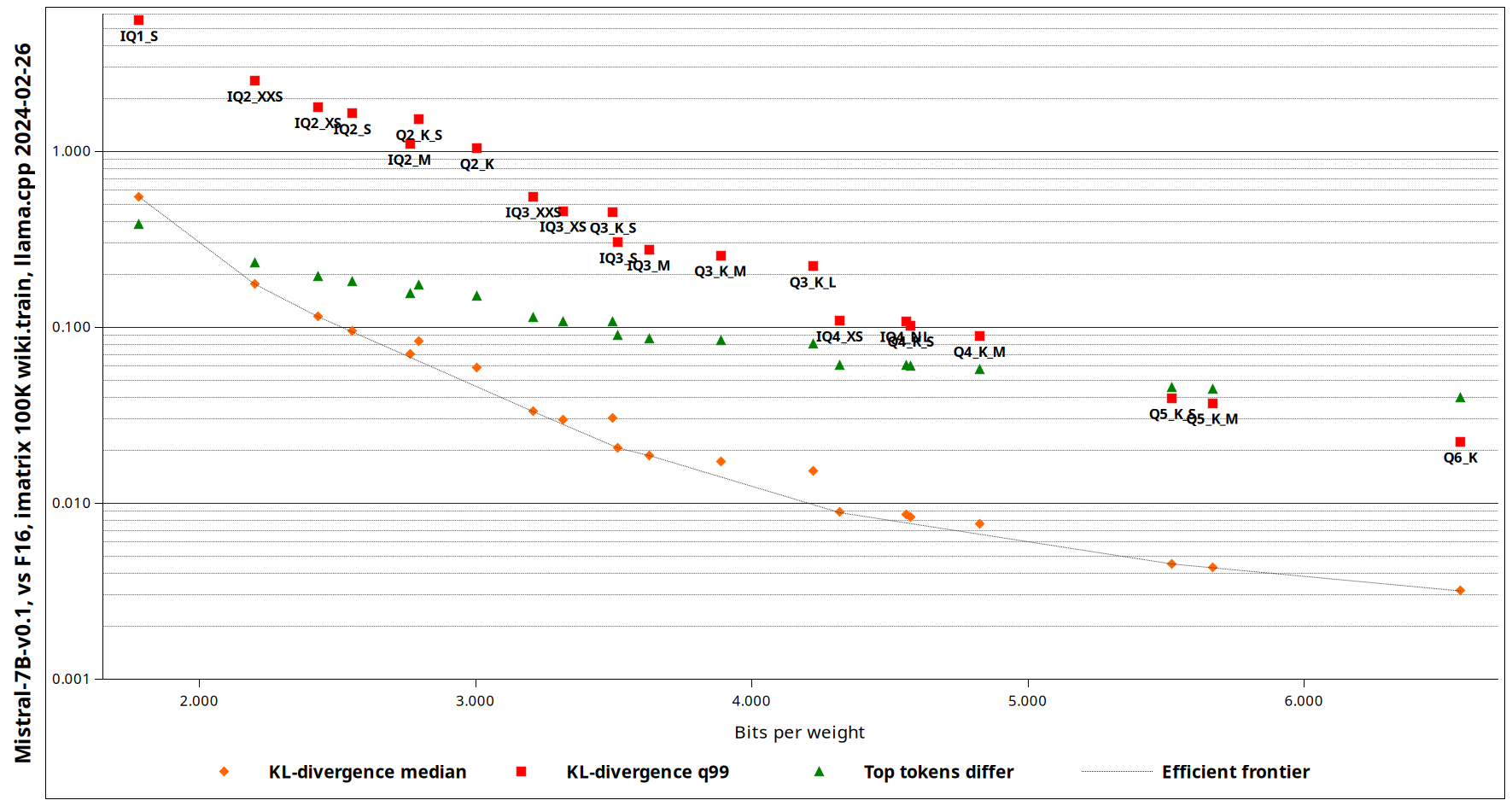
GitHub - matt-c1/llama-3-quant-comparison: Comparison of the output ...
Figure 1 from Benchmarking quantized LLaMa-based models on the ...
Quantizing Large Language Models With llama.cpp: A Clean Guide for 2024 ...
大模型入门指南 - Quantization:小白也能看懂的“模型量化”全解析 - 知乎
GitHub - GURPREETKAURJETHRA/LLaMA3-Quantization: LLaMA3-Quantization
How to eval based quant model? · Issue #8 · Macaronlin/LLaMA3 ...
llama.cpp 推理教程 - RWKV 中国
Quantized Models for meta-llama/Llama-3.2-1B – Hugging Face
Quantized Fine-tuning on LLaMa-2 for RAG | by tybens | Towards ...
meta-llama/Llama-3.2-11B-Vision-Instruct · Can I apply 4-Bit ...
GitHub - Green-Halo/Quantized-LLaMA: Tool for the automatic ...
Simple Tutorial to Quantize Models using llama.cpp from safetensors to ...
Table IV from Benchmarking quantized LLaMa-based models on the ...
config.json · neuralmagic/Meta-Llama-3.1-70B-Instruct-quantized.w4a16 ...
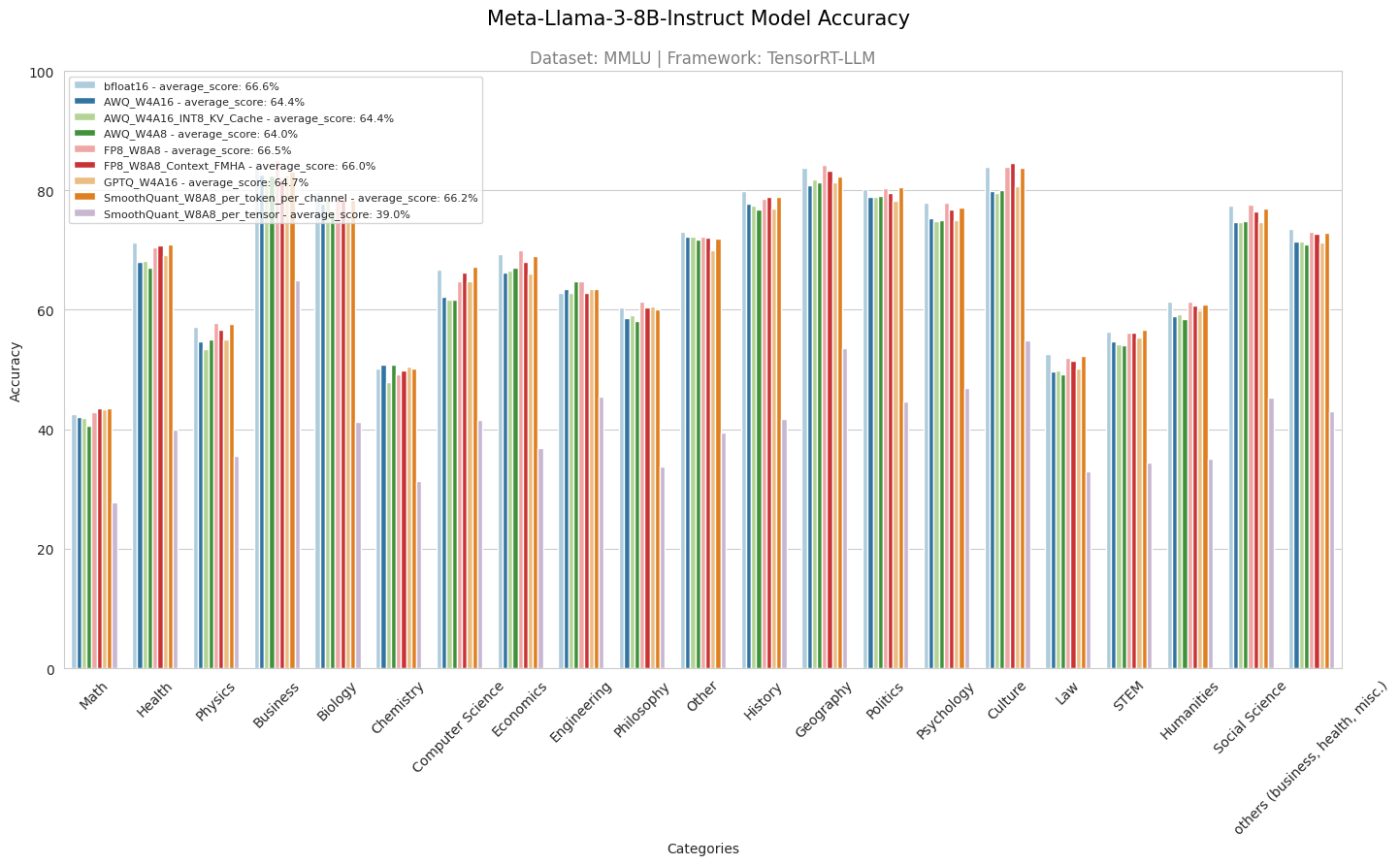
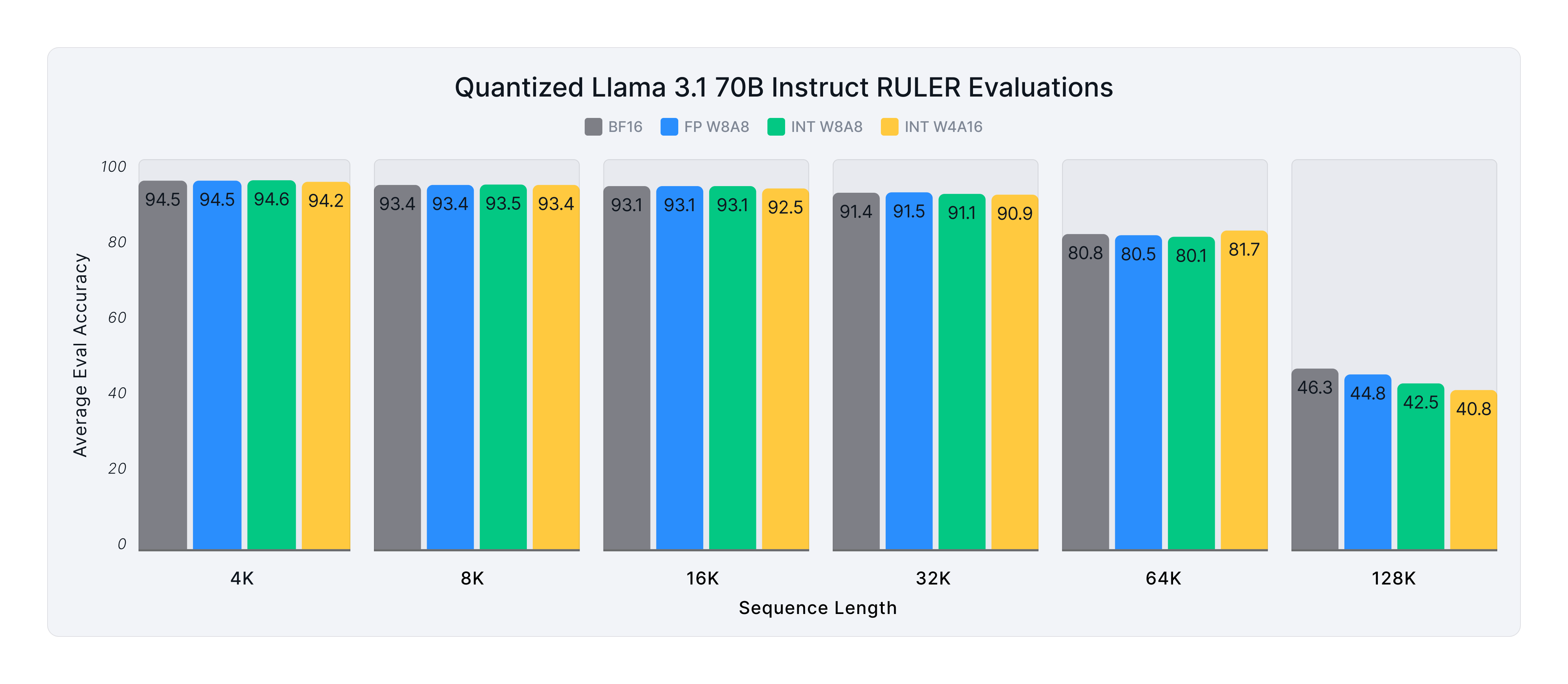
How well do quantized models handle long-context tasks? | Red Hat Developer
devatar/quantized_Llama-3.1-8B-Instruct · Hugging Face
Neural Magic has launched a fully quantized FP8 iteration of Meta's ...