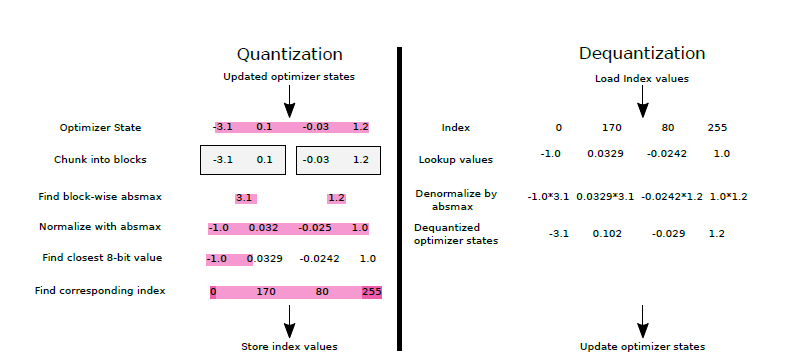
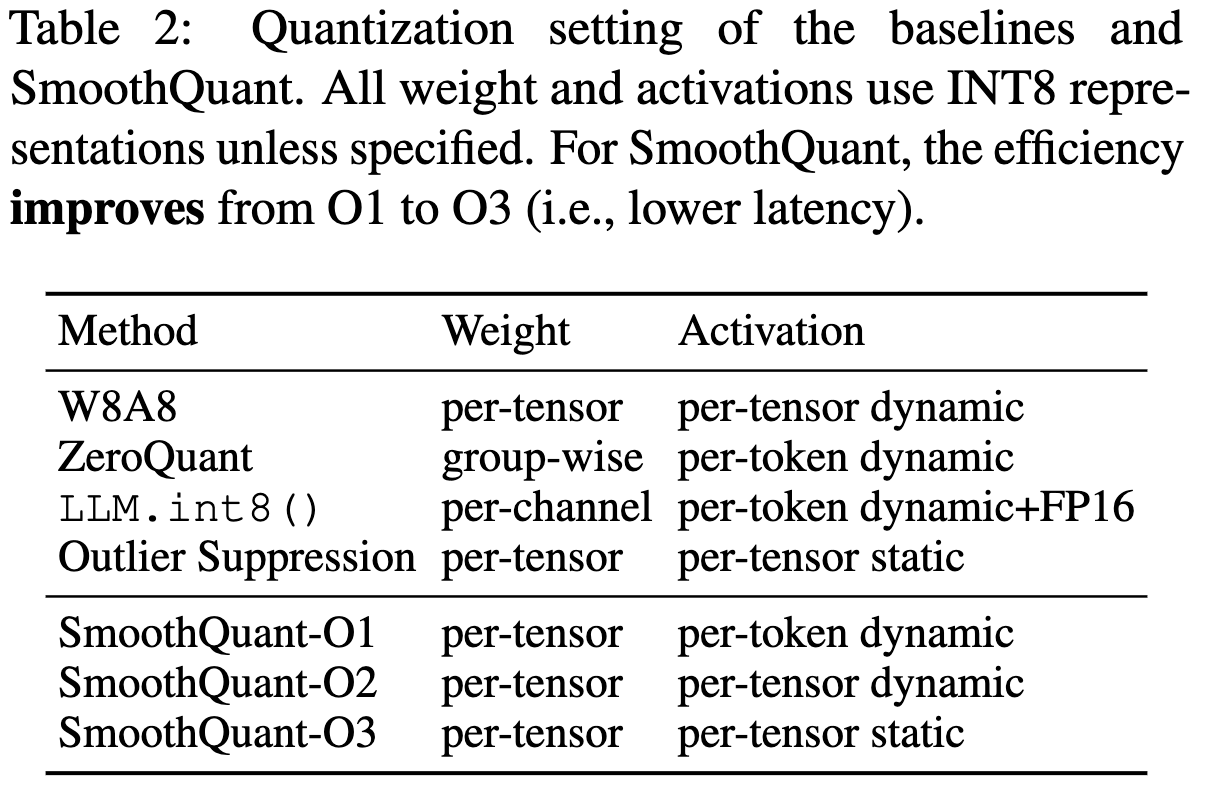
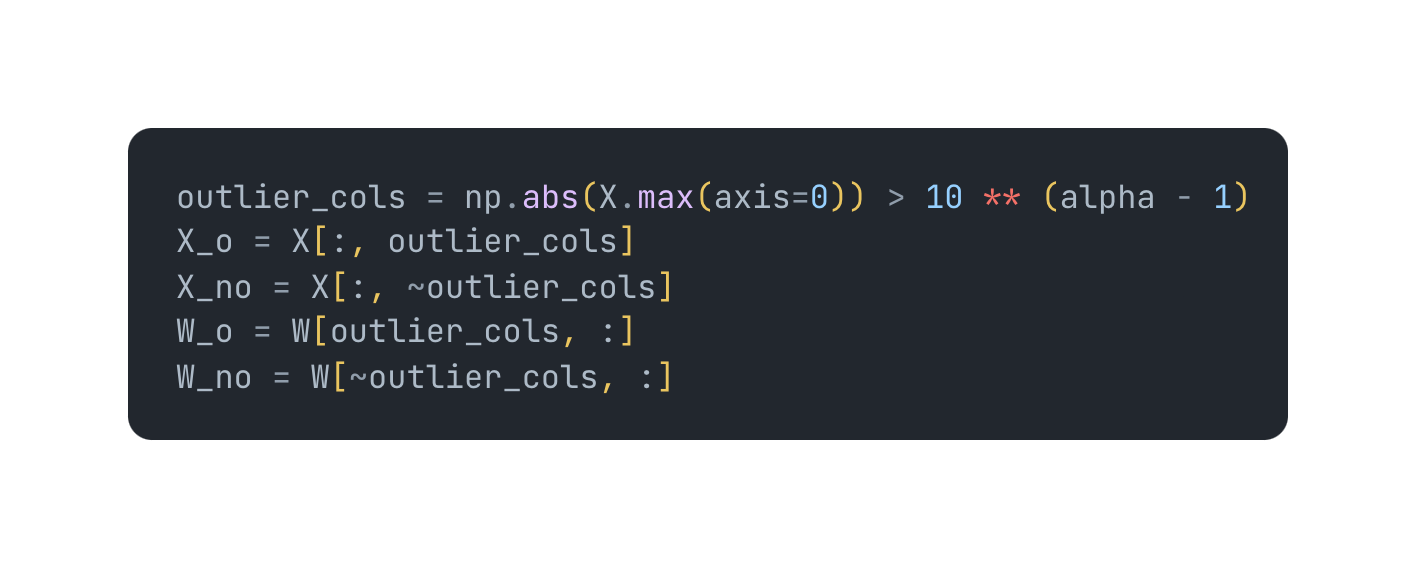
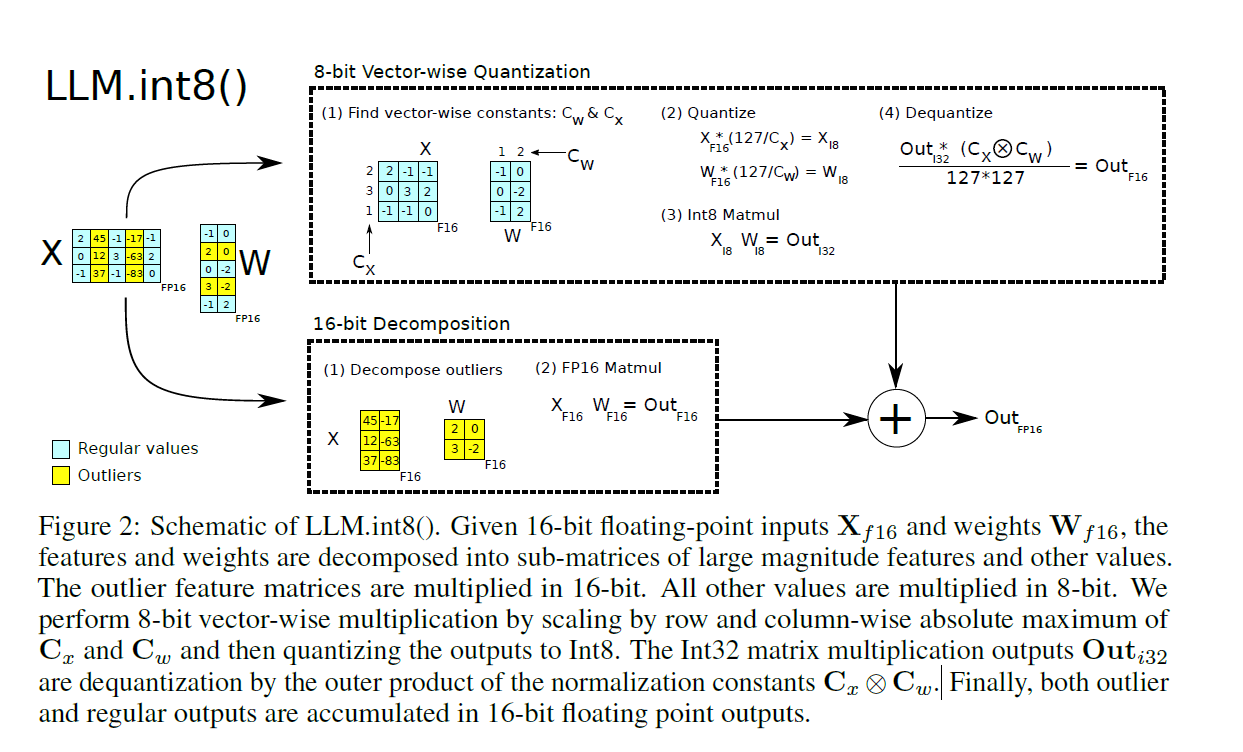
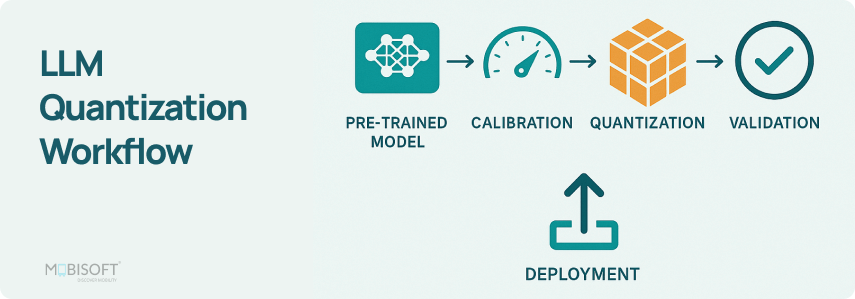
Showing 95 of 95on this page. Filters & sort apply to loaded results; URL updates for sharing.95 of 95 on this page
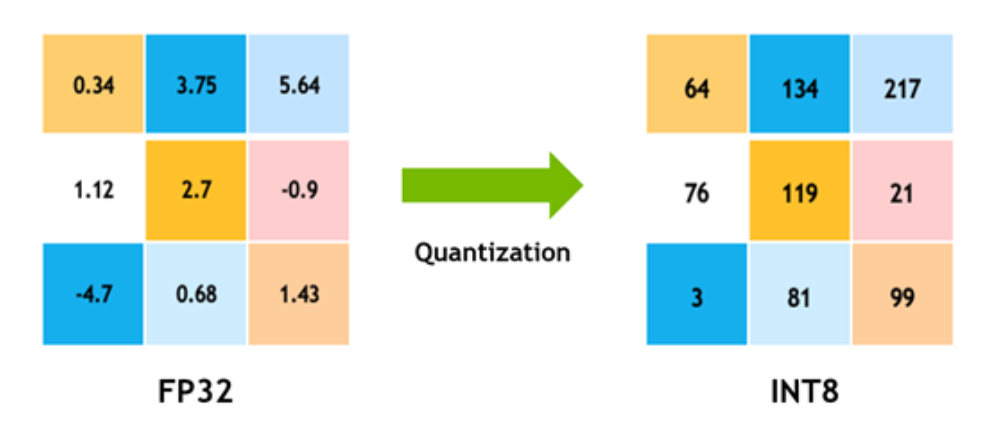
Day 60/75 LLM Quantization to Convert Float32 to Int8 | LLM Evaluation ...
Leaner LLM Inference with INT8 Quantization on AMD GPUs using PyTorch ...
LLM Decoding Attention-KV Cache Int8 Quantization | by Bruce-Lee-LY ...
The Ultimate Handbook for LLM Quantization | Towards Data Science
Unlocking LLM Performance: Advanced Quantization Techniques on Dell ...
LLM Series - Quantization Overview | by Abonia Sojasingarayar | Medium
Improving LLM Inference Latency on CPUs with Model Quantization ...
LLM Quantization Explained - YouTube
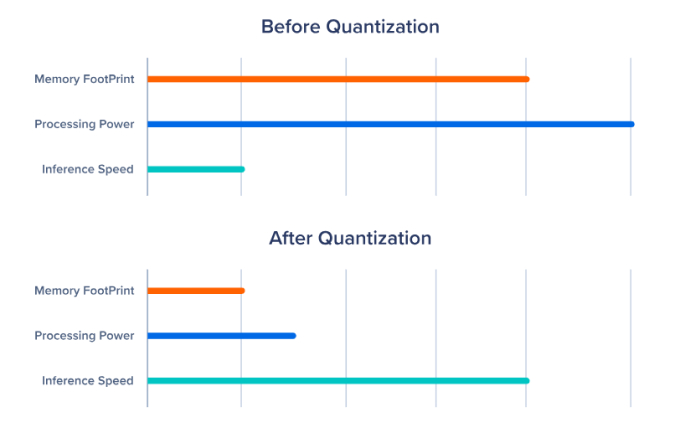
Top LLM Quantization Methods and Their Impact on Model Quality
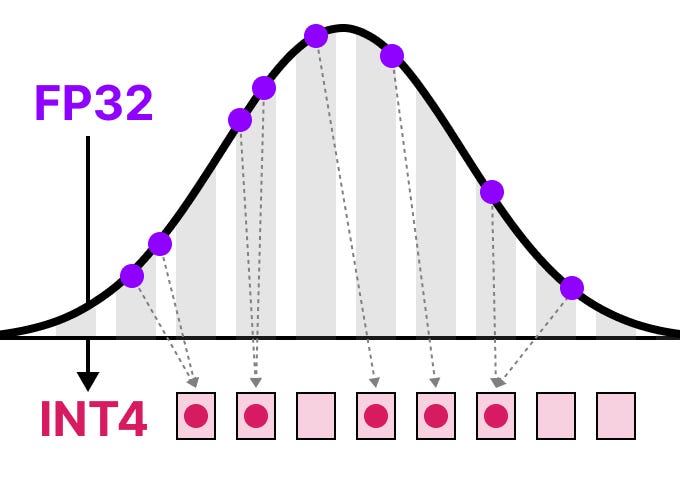
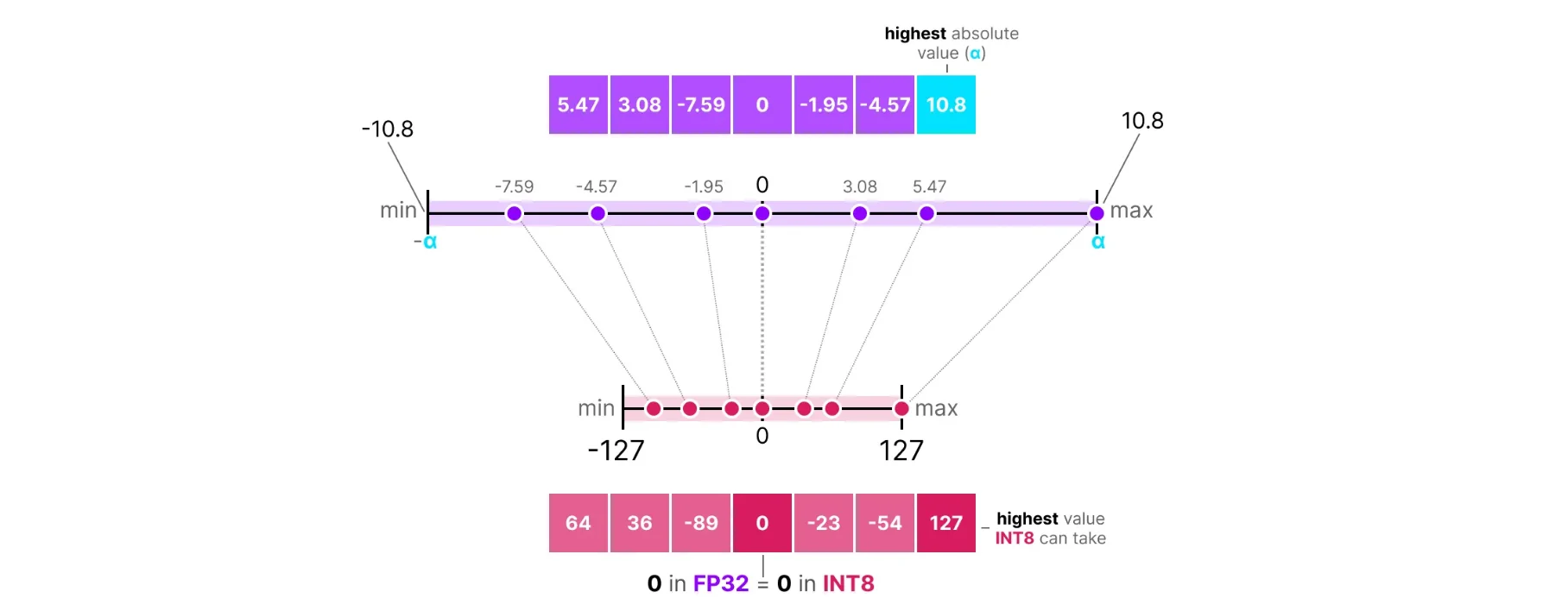
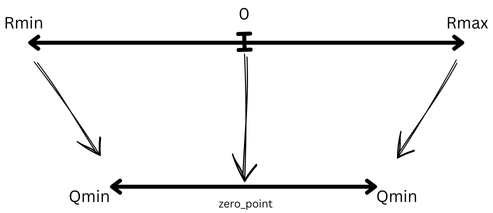
A Visual Guide to LLM Quantization | Devtalk
8 LLM Quantization Moves for 60% Cheaper Inference | by Hash Block ...
5 Essential LLM Quantization Techniques Explained
A Practical Guide to LLM Quantization (int8/int4) | Hivenet
An Introduction to LLM Quantization - TextMine
The Complete Guide to LLM Quantization with vLLM: Benchmarks & Best ...
Data Types in LLM Quantization
Practical Guide to LLM Quantization Methods - Cast AI
Deep Learning INT8 Quantization MATLAB Simulink, 42% OFF
INT8 KV cache + per-channel weight-only quantization leading to wired ...
The Complete Guide to LLM Quantization | LocalLLM.in
Exploiting LLM Quantization
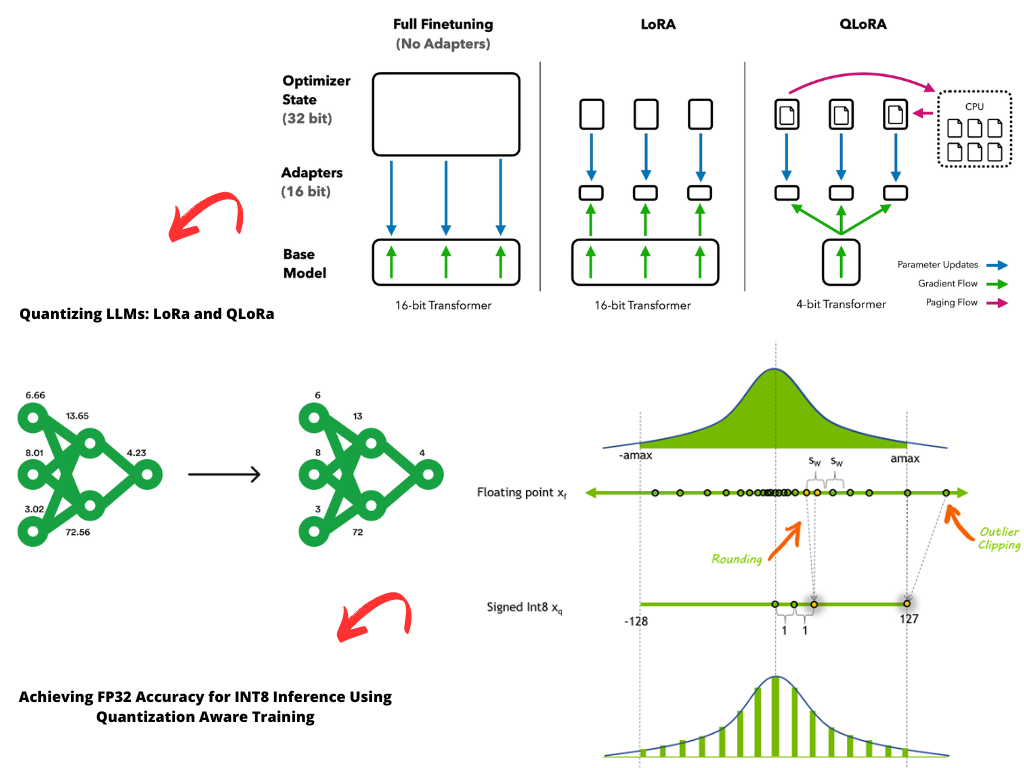
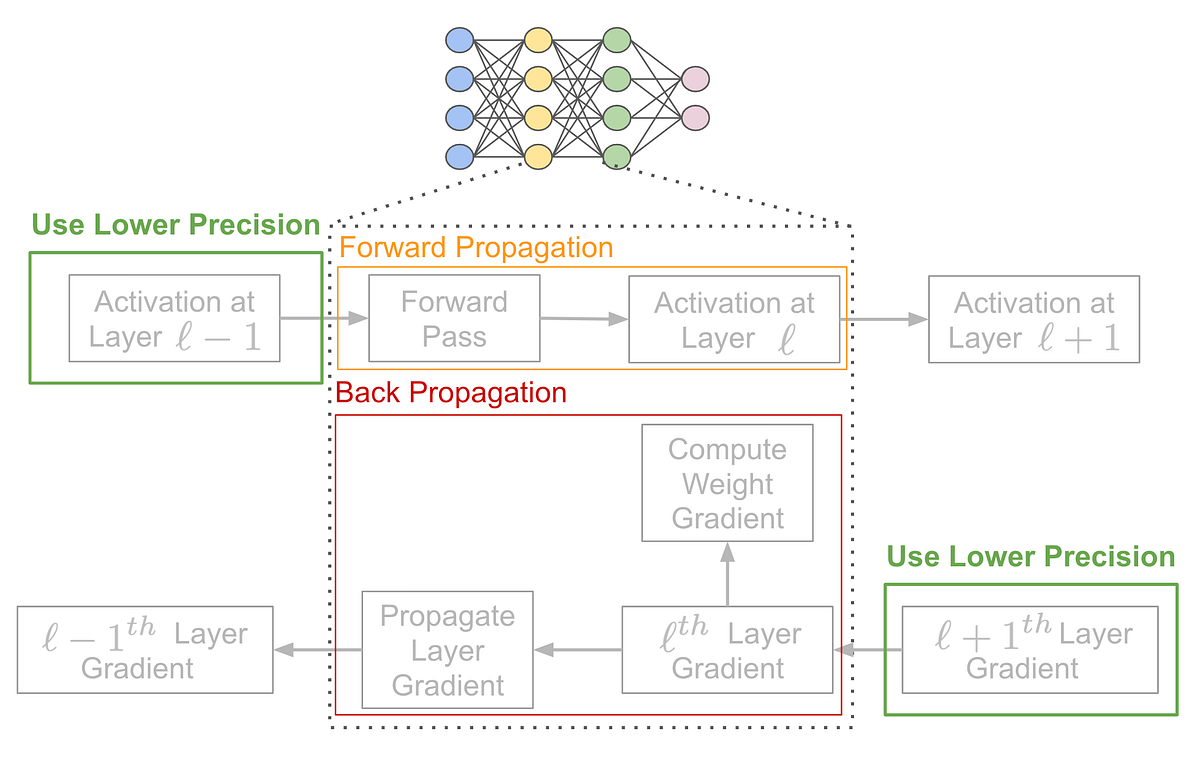
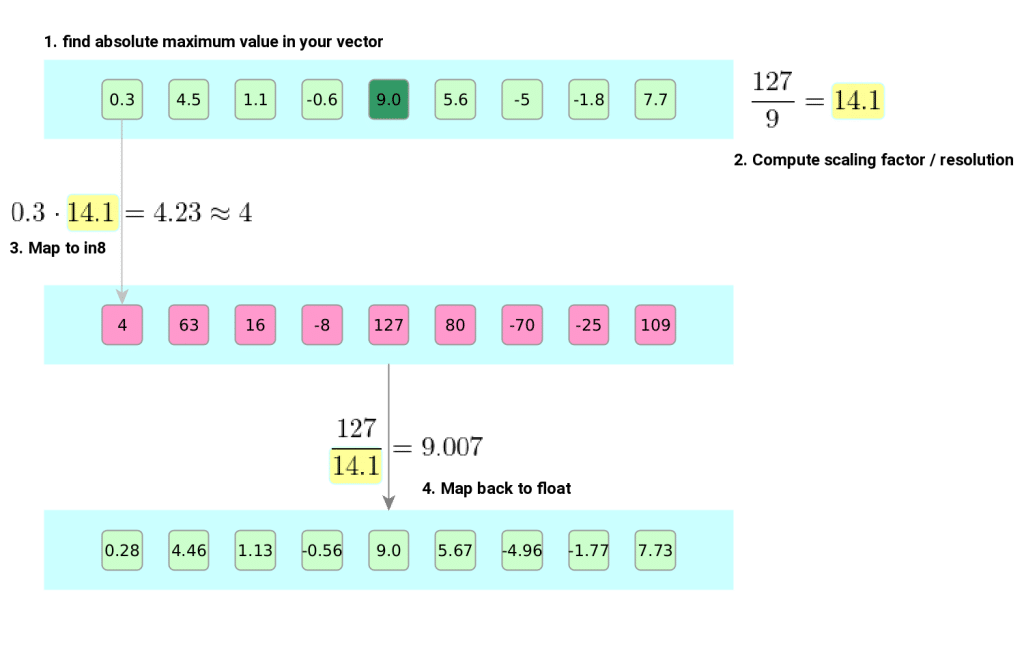
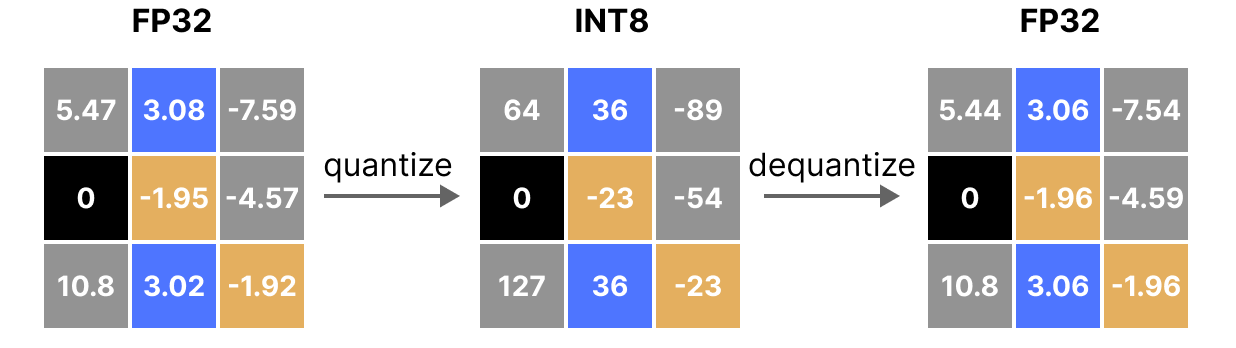
Day 61/75 LLM Quantization | How Accuracy is maintained? | How FP32 and ...
Quantization Techniques for LLM Inference: INT8, INT4, GPTQ, and AWQ ...
Simplify LLM Quantization Process for Success | by Novita AI | Jul ...
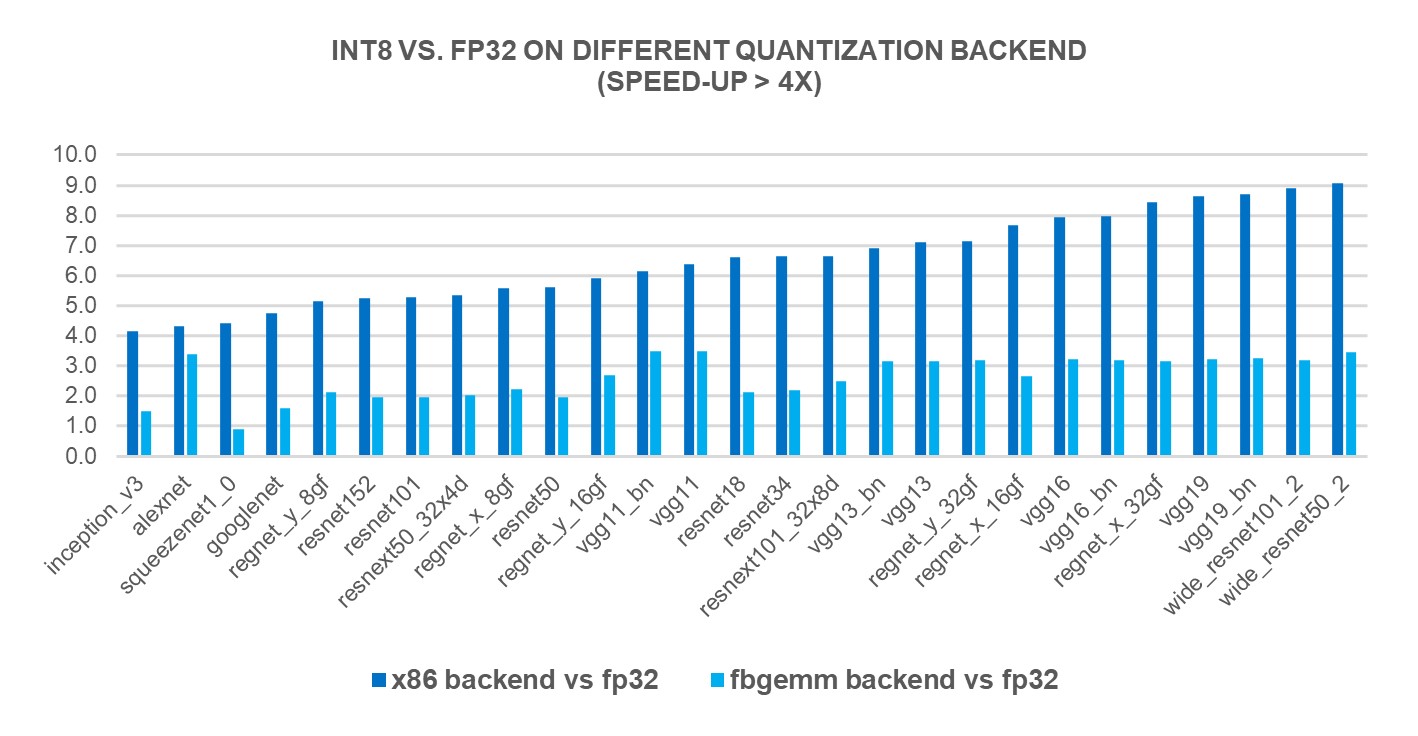
INT8 Quantization for x86 CPU in PyTorch | PyTorch
Quantization Methods for 100X Speedup in Large Language Model Inference
LLM Quantization-Build and Optimize AI Models Efficiently
Local Large Language Models | Int8
[Ep3] LLM Quantization: LLM.int8(), QLoRA, GPTQ, ... - YouTube
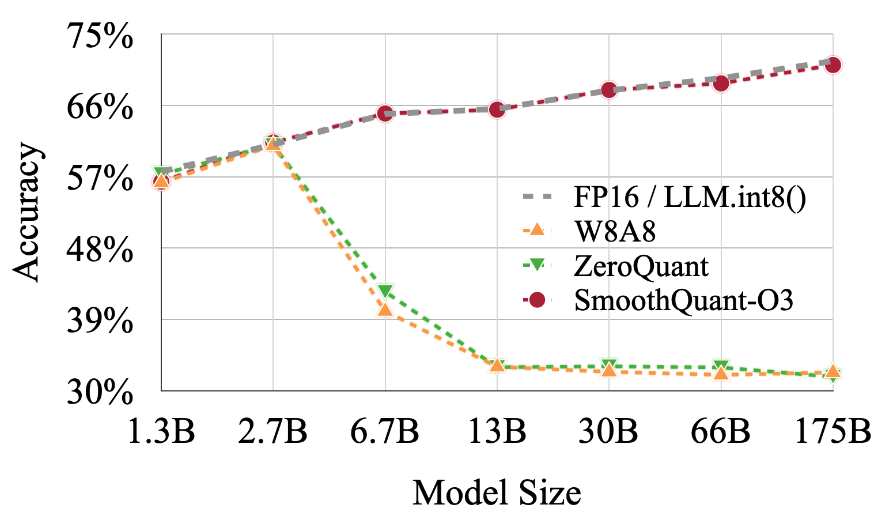
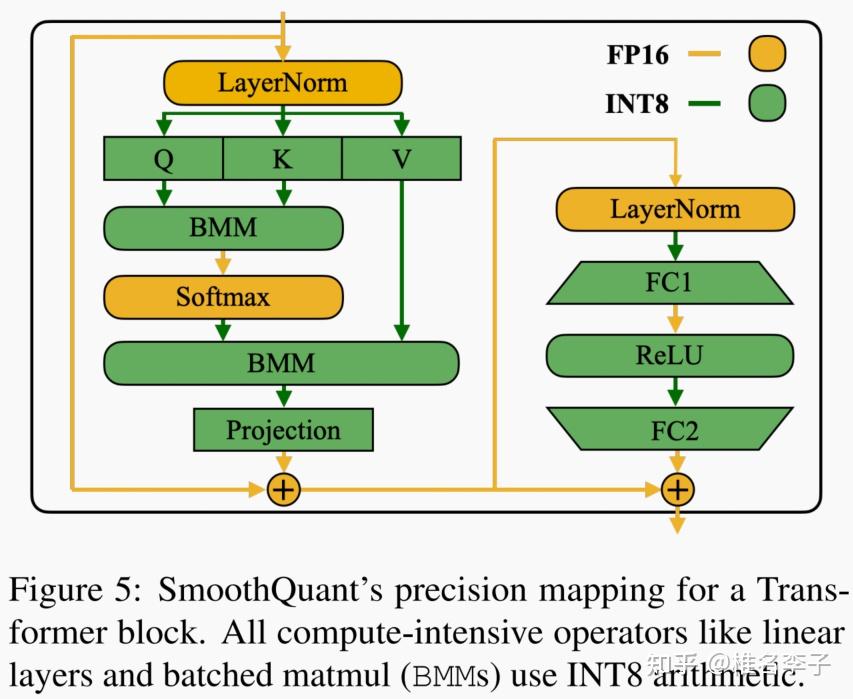
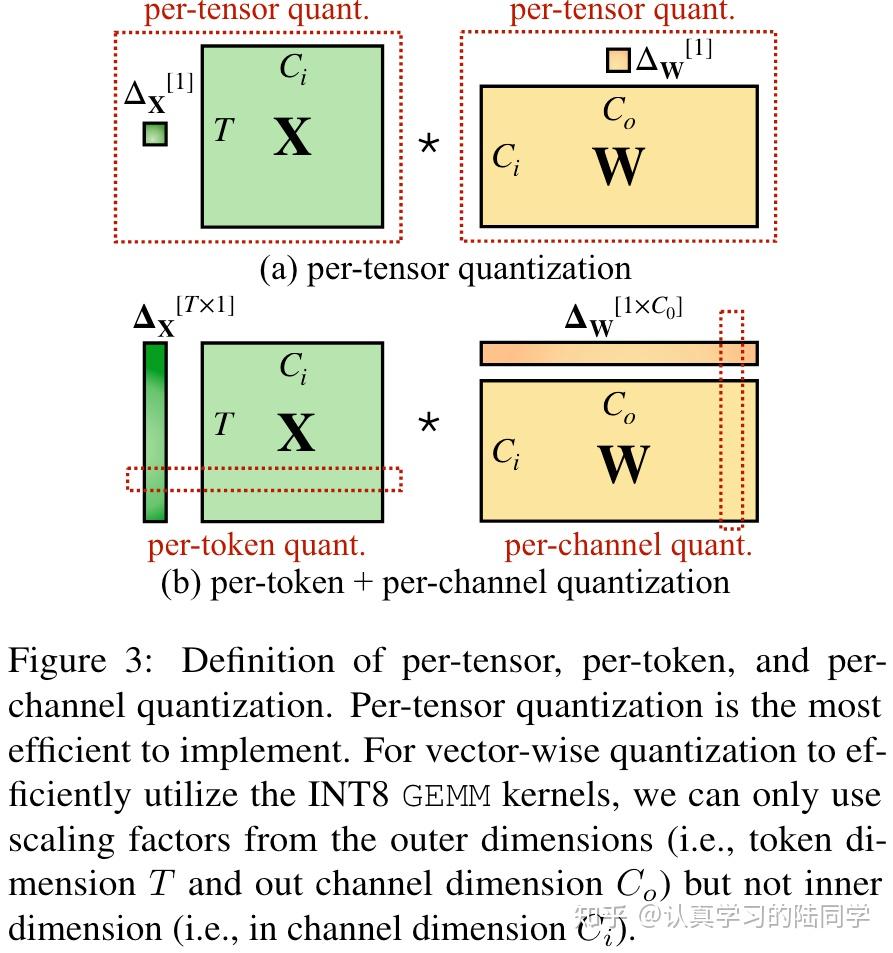
SmoothQuant: Accurate and Efficient Post-Training Quantization for ...
Exploring quantization in Large Language Models (LLMs): Concepts and ...
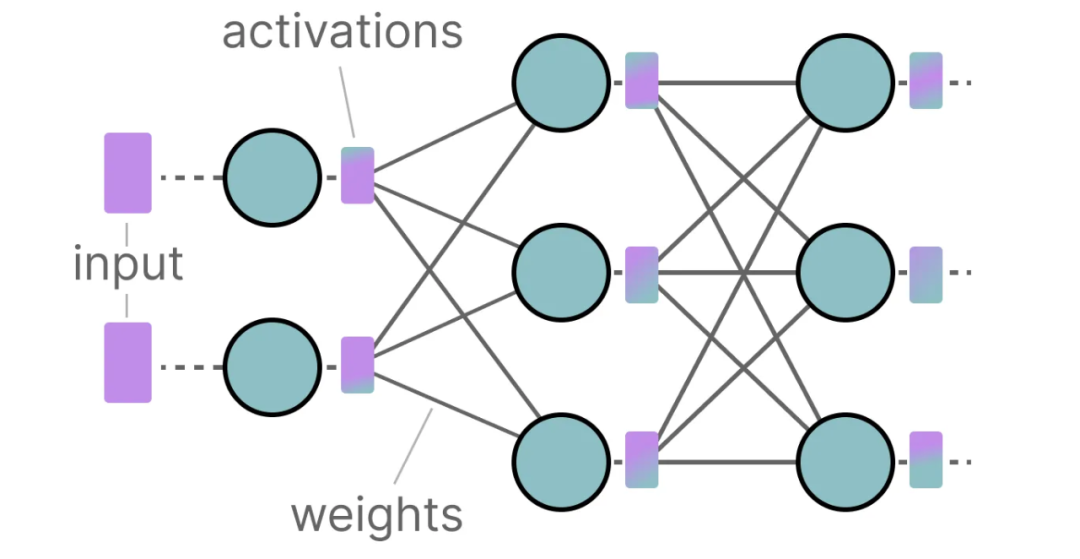
Introduction to Weight Quantization | Towards Data Science
Quantized 8-bit LLM training and inference using bitsandbytes on AMD ...
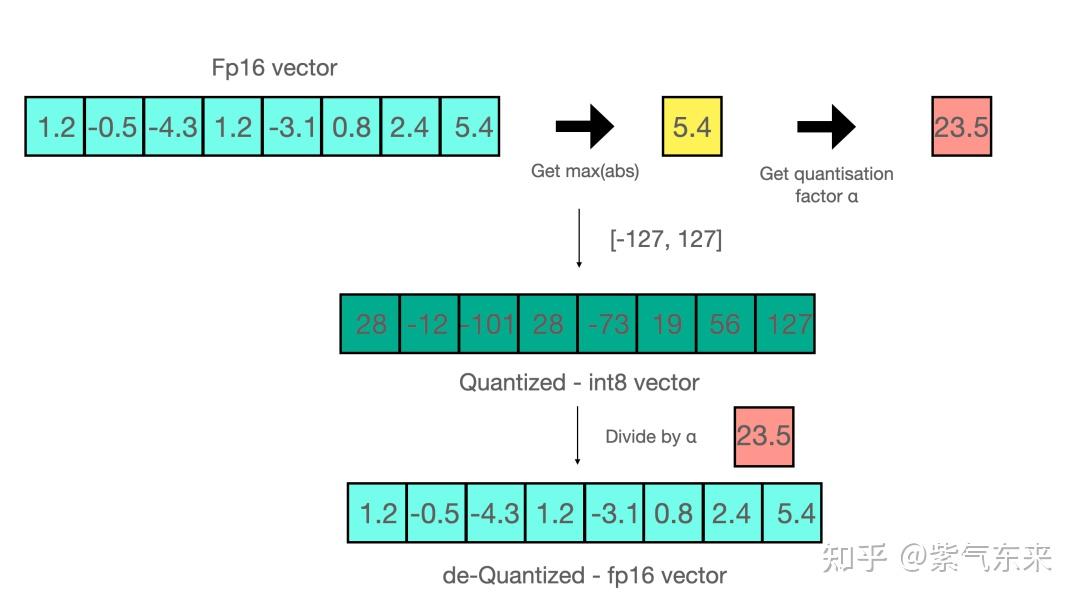
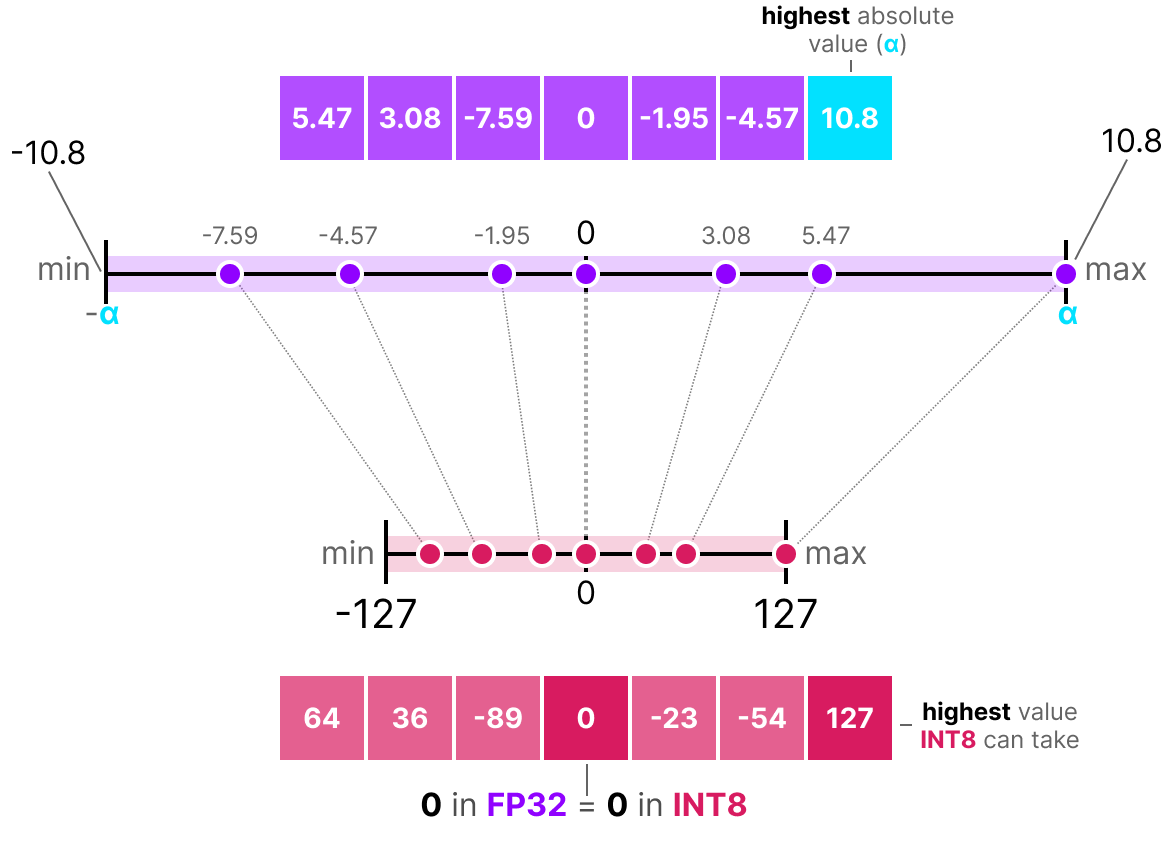
Understanding LLM.int8() Quantization — Picovoice
LLM Quantization: Making models faster and smaller | MatterAI Blog
[LLM] SmoothQuant: Accurate and Efficient Post-Training Quantization ...
How Quantization Works & Quantizing SAM
Introduction to Weight Quantization - Origins AI
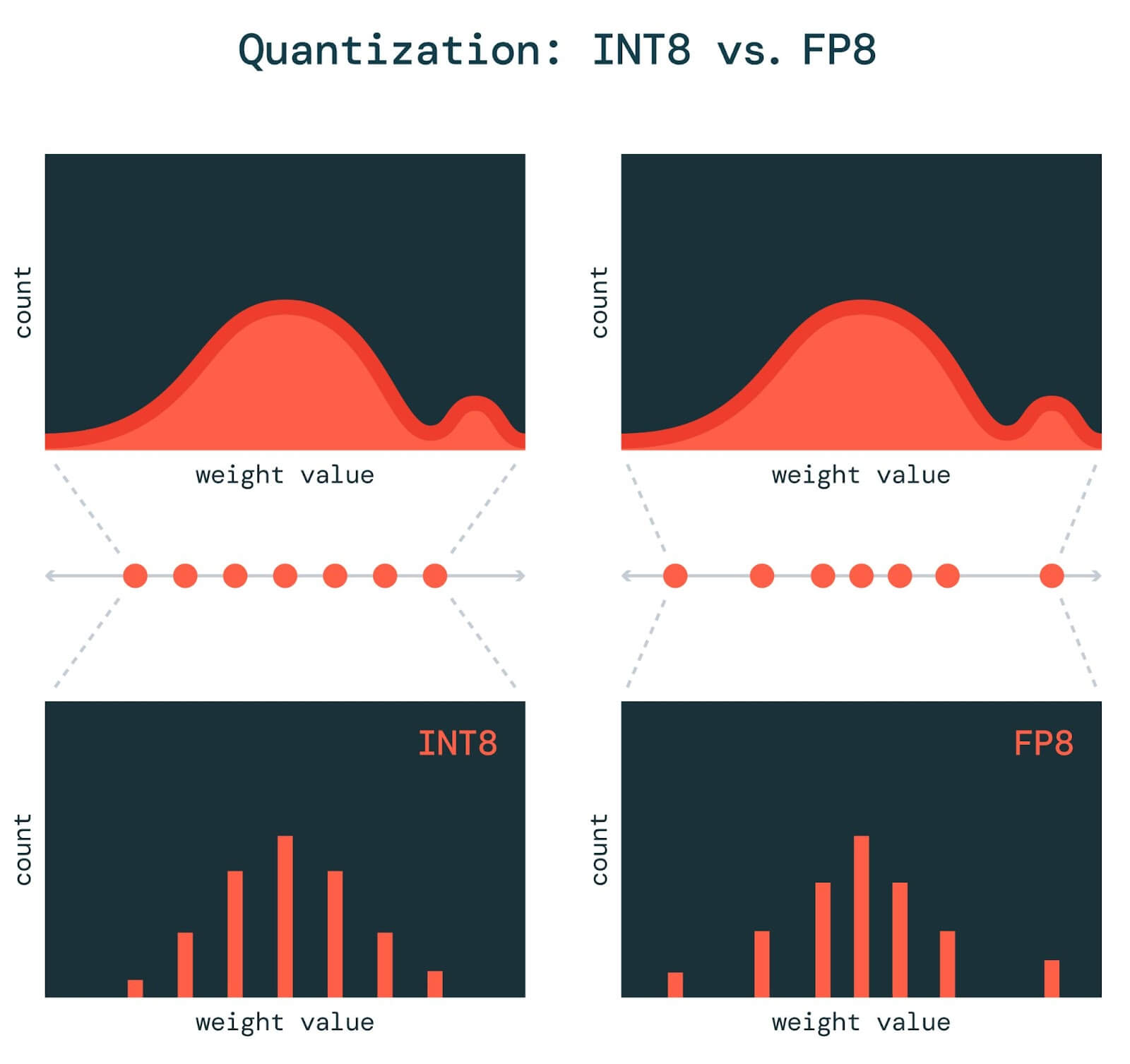
[2303.17951] FP8 versus INT8 for efficient deep learning inference
LLM 量化技术小结 - 知乎
Mastering LLM Techniques: Inference Optimization – GIXtools
Quantization Overview — Guide to Core ML Tools
Support weight only quantization from bfloat16 to int8? · Issue #110 ...
7 ML Quantization Wins (INT8/FP8) Without Quality Freefall | by ...
Shrinking Giants: The Quantization Mathematics Making LLMs Accessible
LLM Compressor is here: Faster inference with vLLM | Red Hat Developer
What is Quantization in LLM? A Complete Guide to Optimizing AI
Serving Quantized LLMs on NVIDIA H100 Tensor Core GPUs | Databricks
LLM(11):大语言模型的模型量化(INT8/INT4)技术 - 知乎
LLMs之Quantization:LLM中量化技术的可视化指南之量化技术的简介、常用数据类型、校准权重和激活值的量化方法(PTQ/QAT ...
大模型 LLM.int8() 量化技术原理与代码实现-51CTO.COM
Sparsity in INT8: Training Workflow and Best Practices for NVIDIA ...
[vLLM — Quantization] bitsandbytes: 8-bit Optimizers, LLM.int8(), QLoRA ...
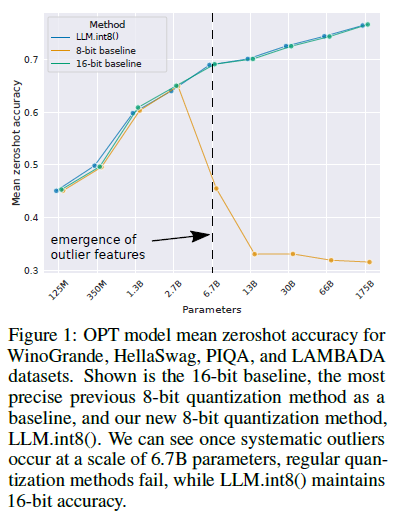
LLM.int8() and Emergent Features — Tim Dettmers
模型量化-llm量化 - 知乎
[핵심][22.08]LLM.int8()
大模型LLM.int8()量化技术原理与代码实现-CSDN博客
Lê Ngọc Thạch on LinkedIn: LLM.int8() This technique identifies ...
[LLM量化] LLM.int8(), GPTQ, SmoothQuant, AWQ, SqueezeLLM, ATOM, OmniQuant ...
INT8模型量化:LLM.int8 - 知乎
【LLM】vLLM部署与int8量化-CSDN博客
[R] LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale ...
aashush/quantized-local-llm-int8 at main
What are Quantized LLMs?
(PDF) LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale