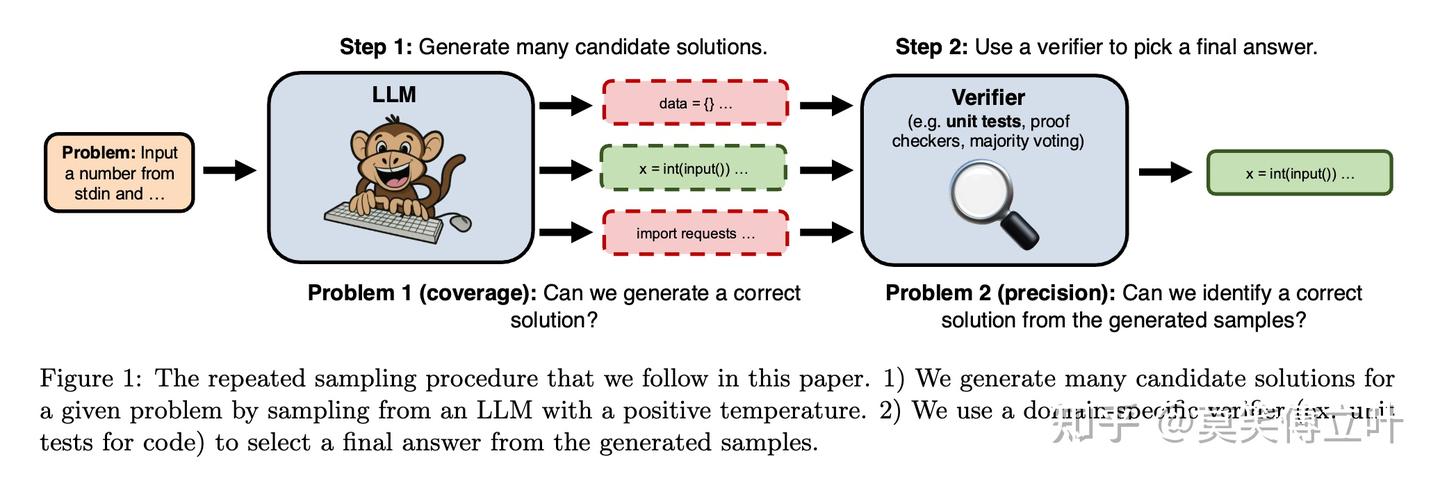
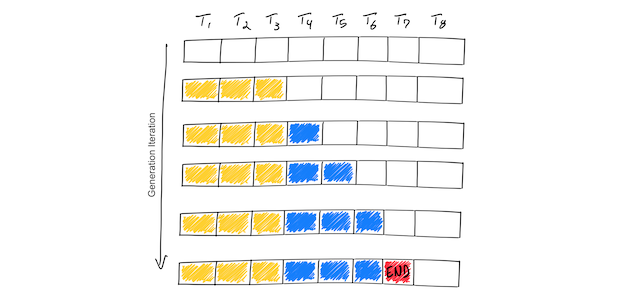
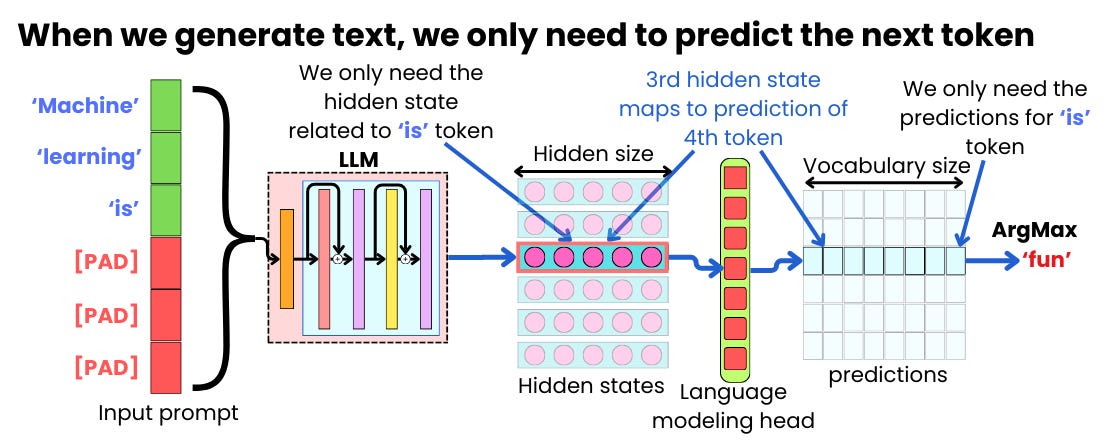
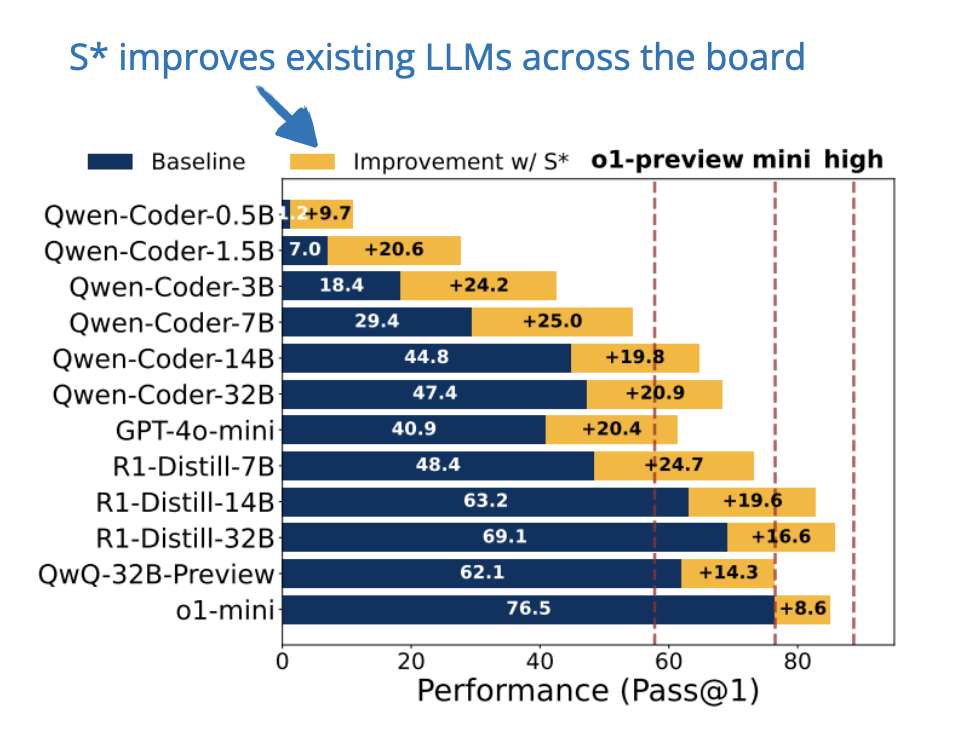
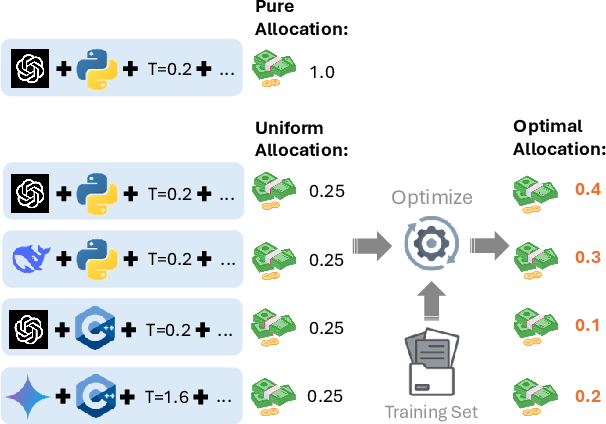
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
(PDF) Diversified Sampling Improves Scaling LLM inference
Paper page - Diversified Sampling Improves Scaling LLM inference
🚀 Day 3: Decoding the LLM Inference complexities 🚀 Speculative Sampling ...
What Is An LLM | PDF | Sampling (Statistics) | Statistical Inference
Free Video: Common Sampling Methods for Modern NLP - CMU LLM Inference ...
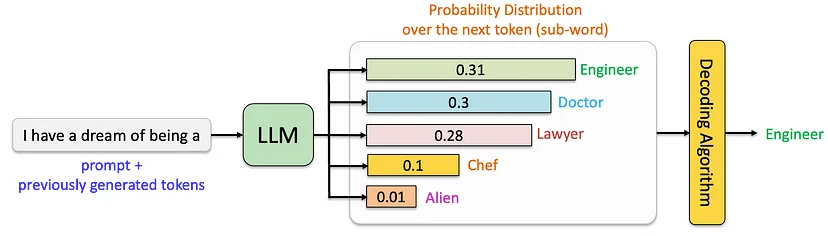
LLM inference does a sampling at the end This is based on parameters ...
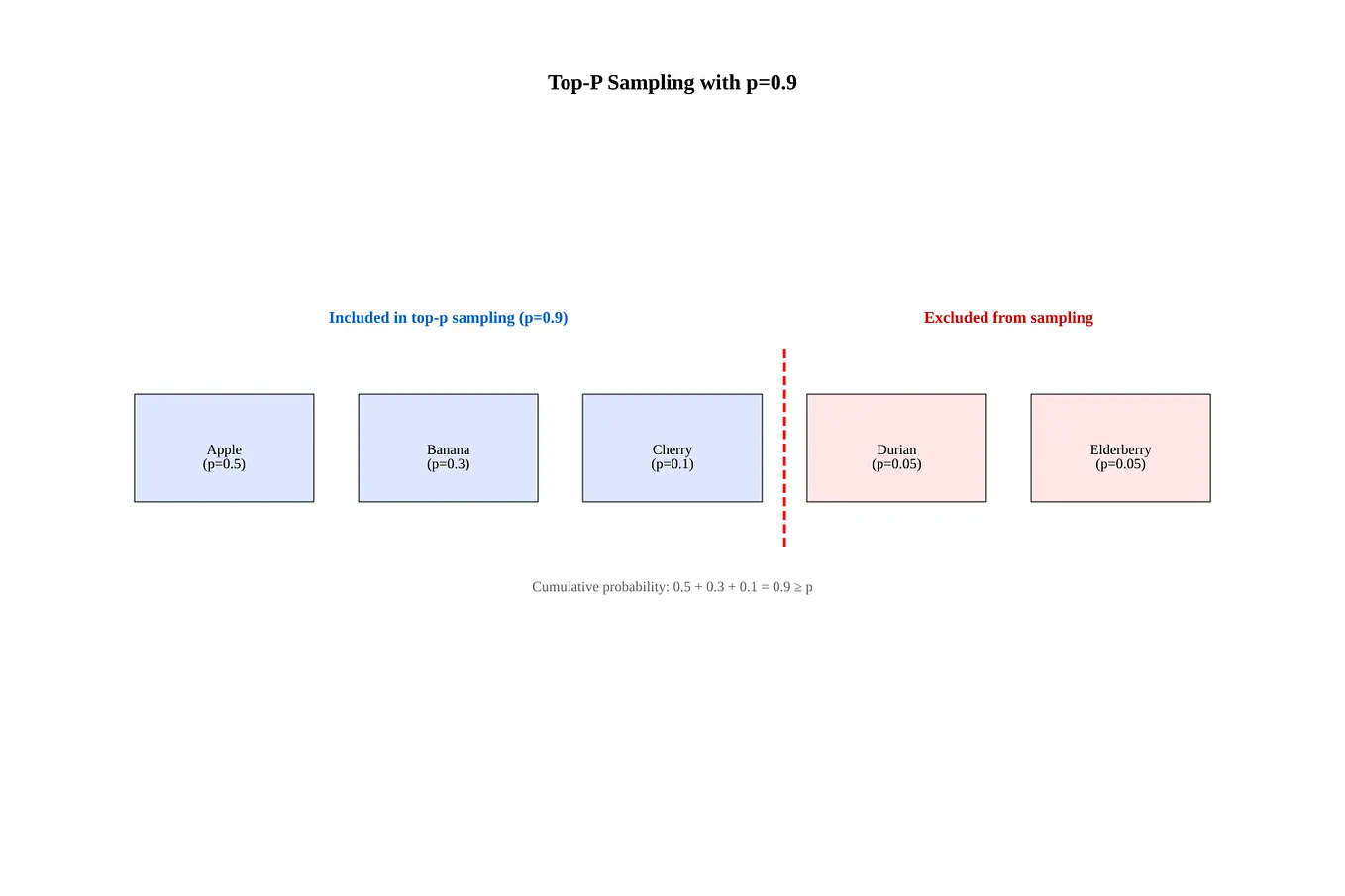
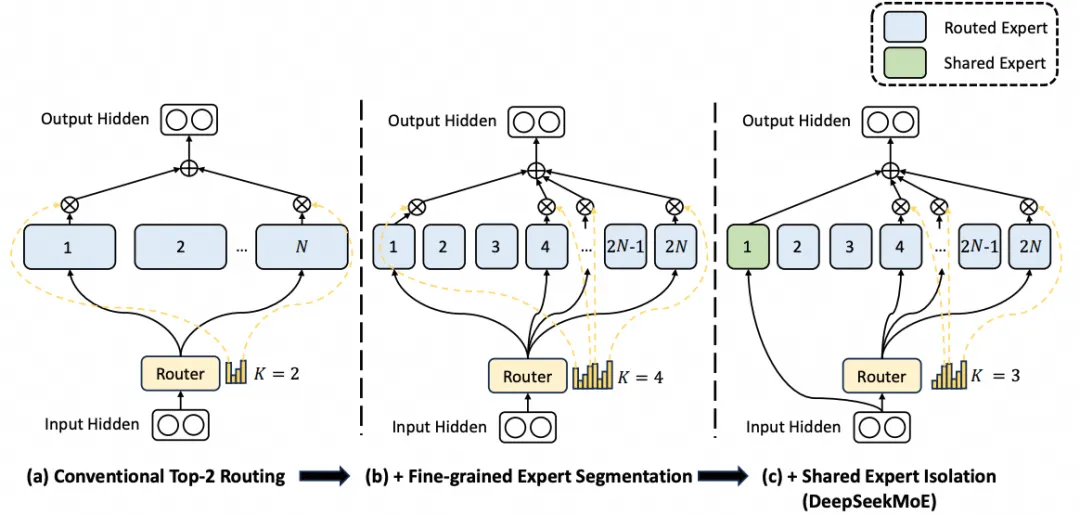
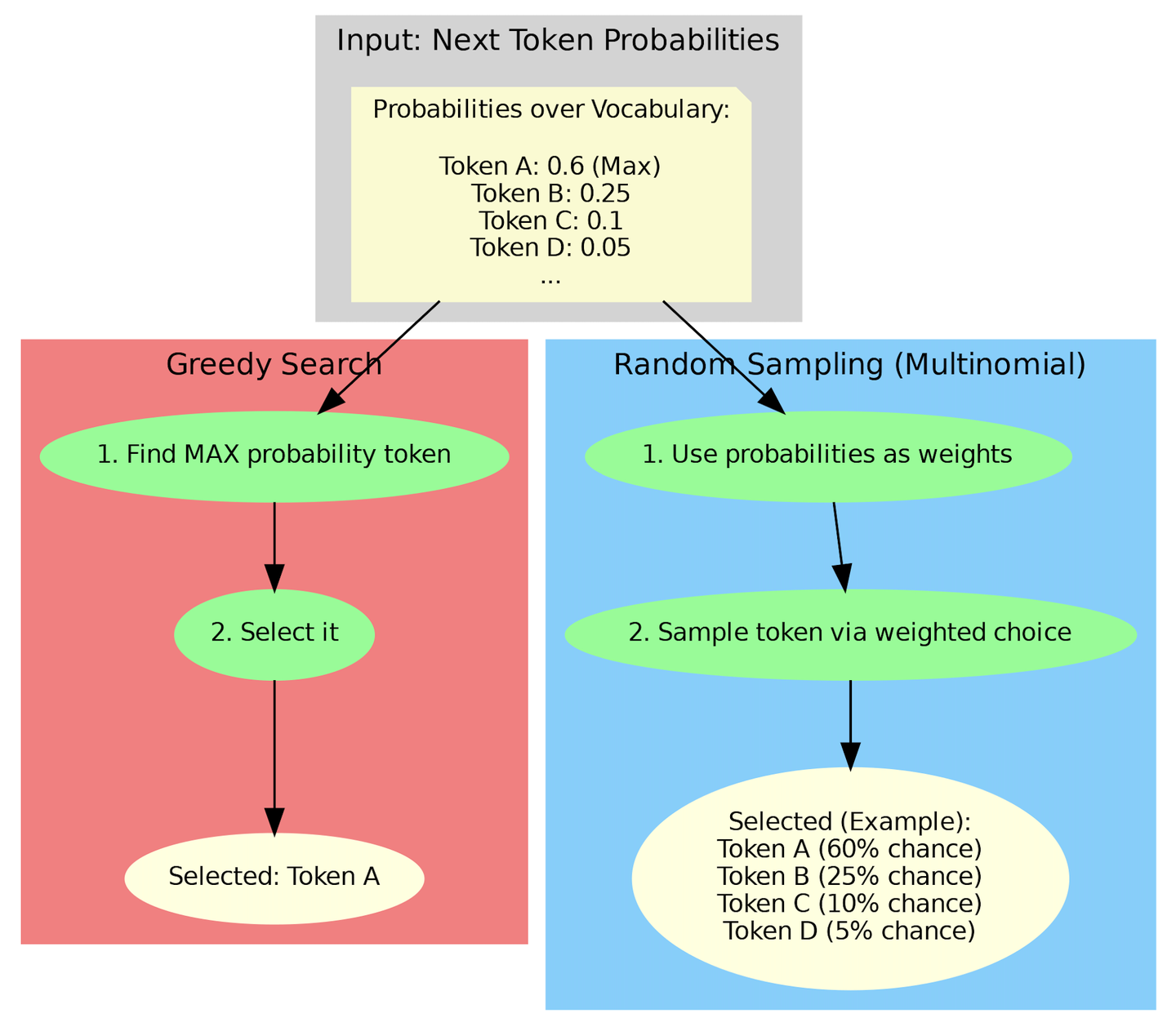
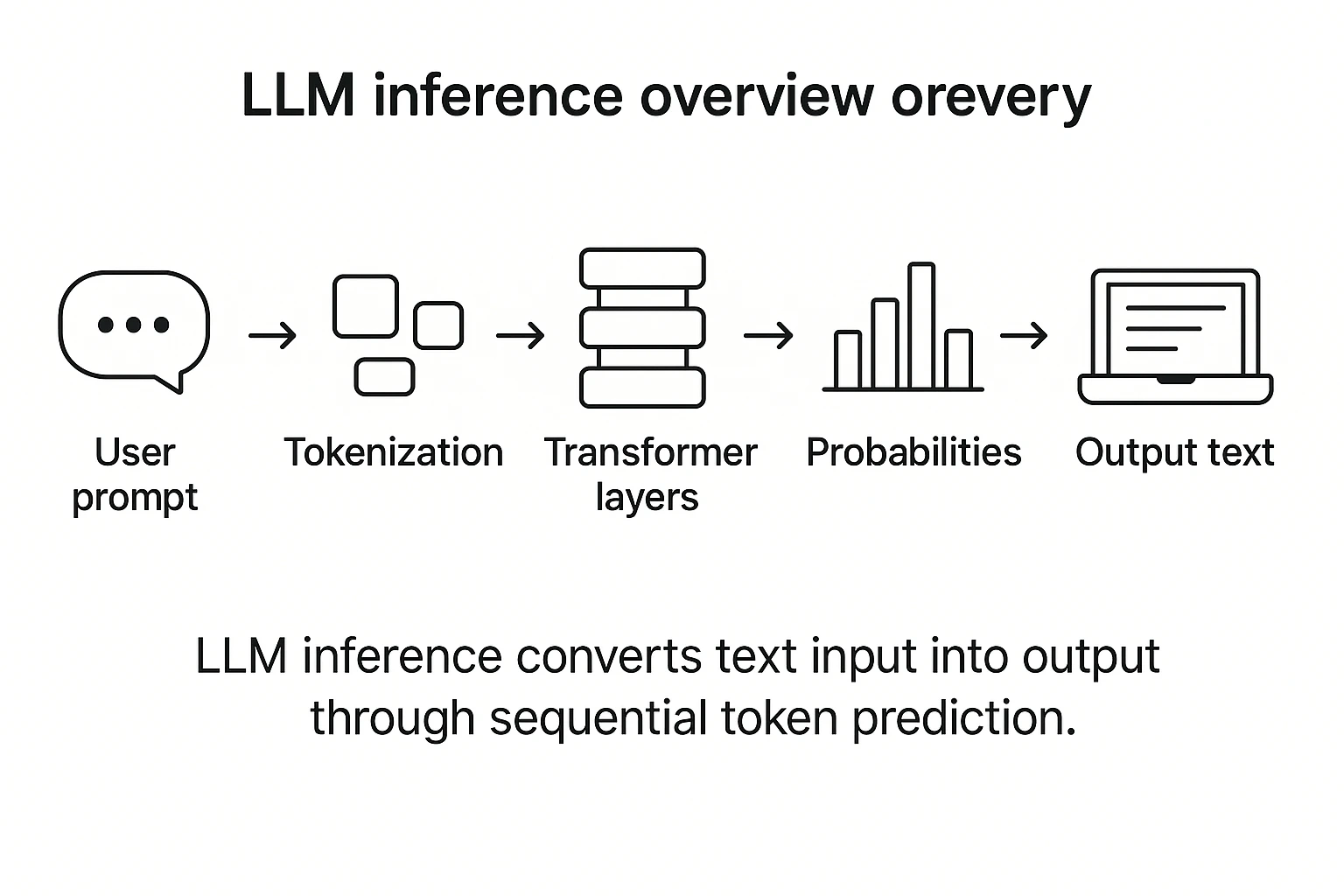
LLM Inference Sampling Methods
Scaling Inference Time: Enhancing LLM Performance with Sampling ...
EAGLE: the fastest speculative sampling method speed up LLM inference 3 ...
The State of LLM Reasoning Model Inference
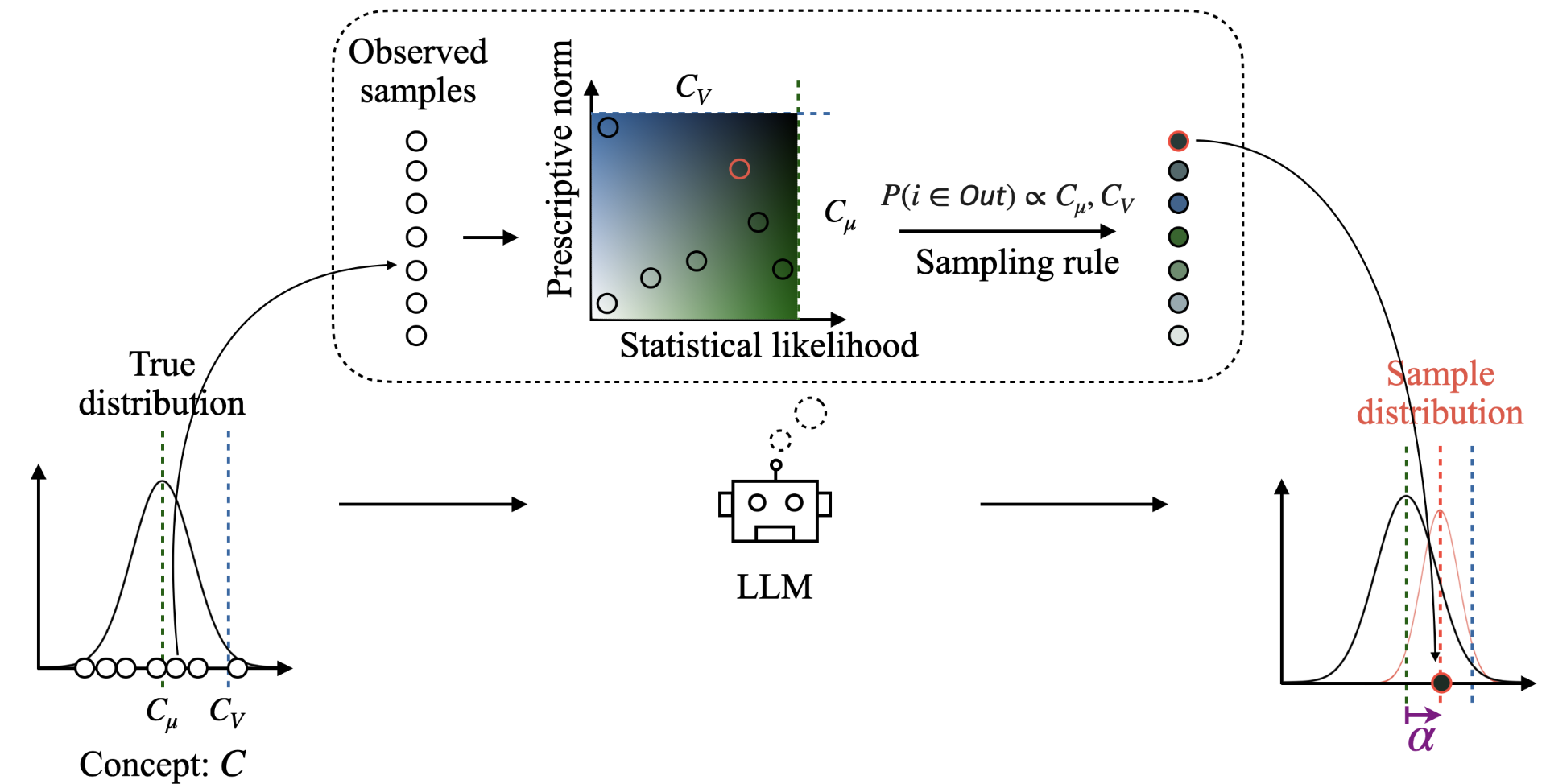
A Theory of LLM Sampling
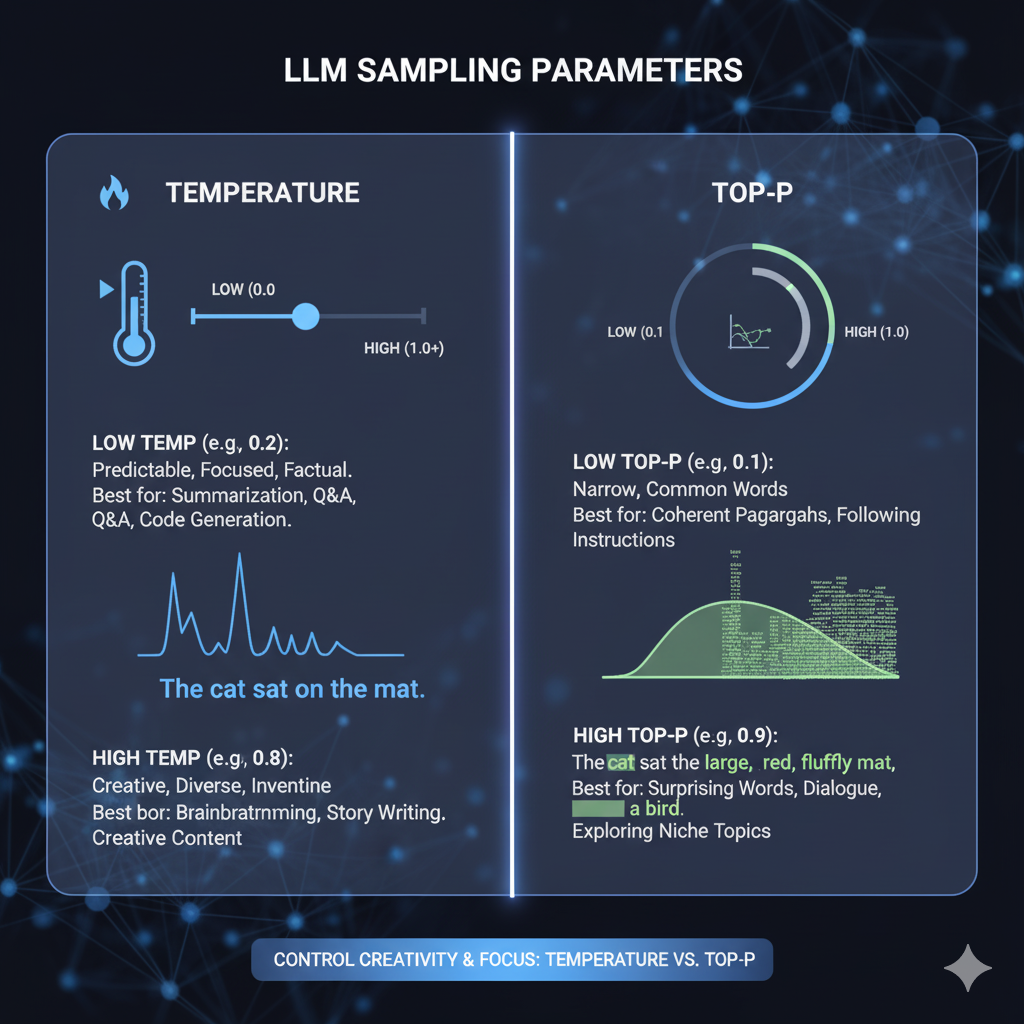
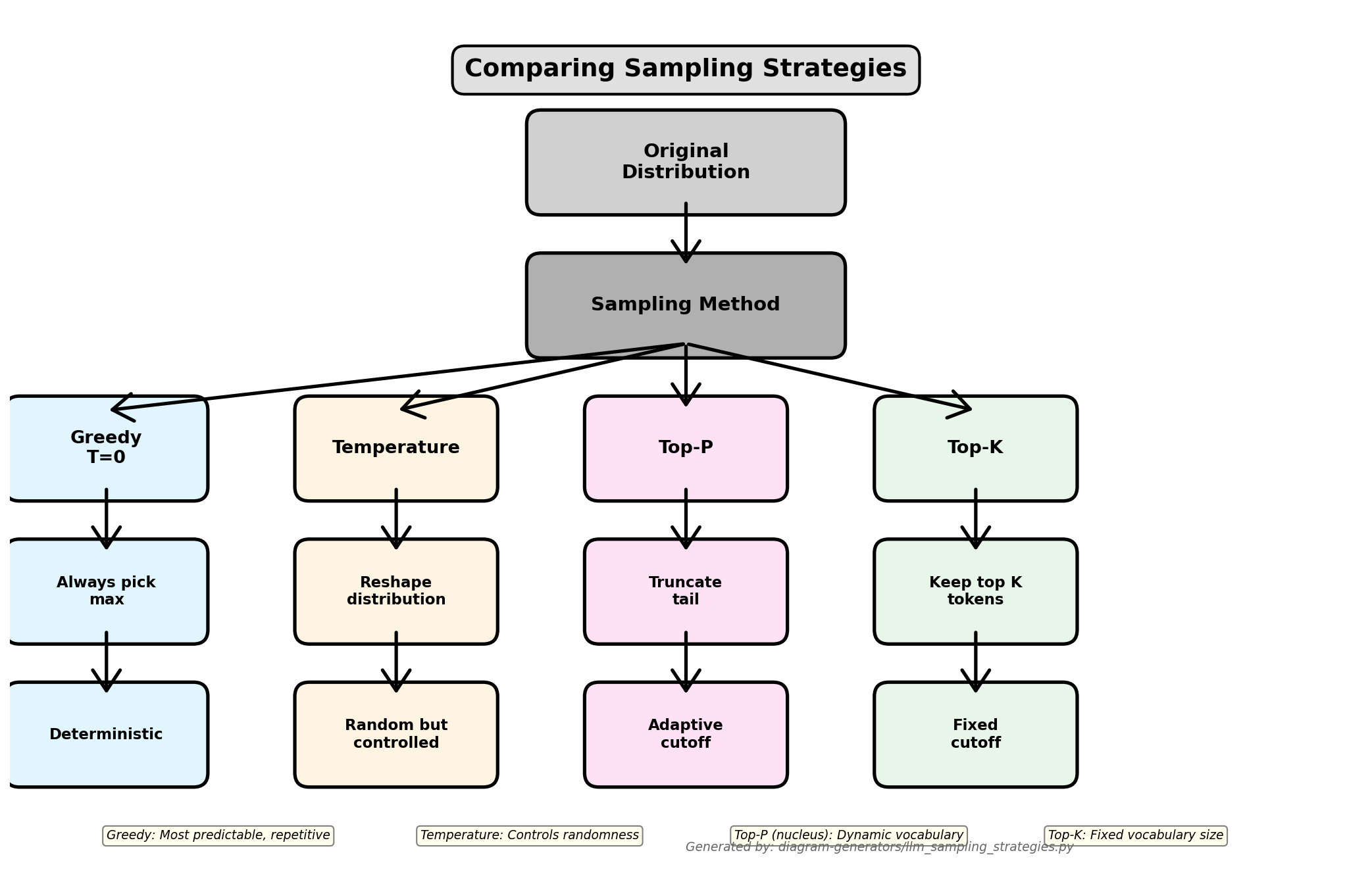
Temperature vs Top-p: LLM Sampling Guide (2025)
(PDF) Scaling LLM Inference with Optimized Sample Compute Allocation
LLM Sampling Explained: Selecting the Next Token | Thinking Sand
[论文评述] Scaling LLM Inference with Optimized Sample Compute Allocation
【LLM推理智能】Scaling Inference Compute with Repeated Sampling - 知乎
Understanding LLM Batch Inference | Adaline
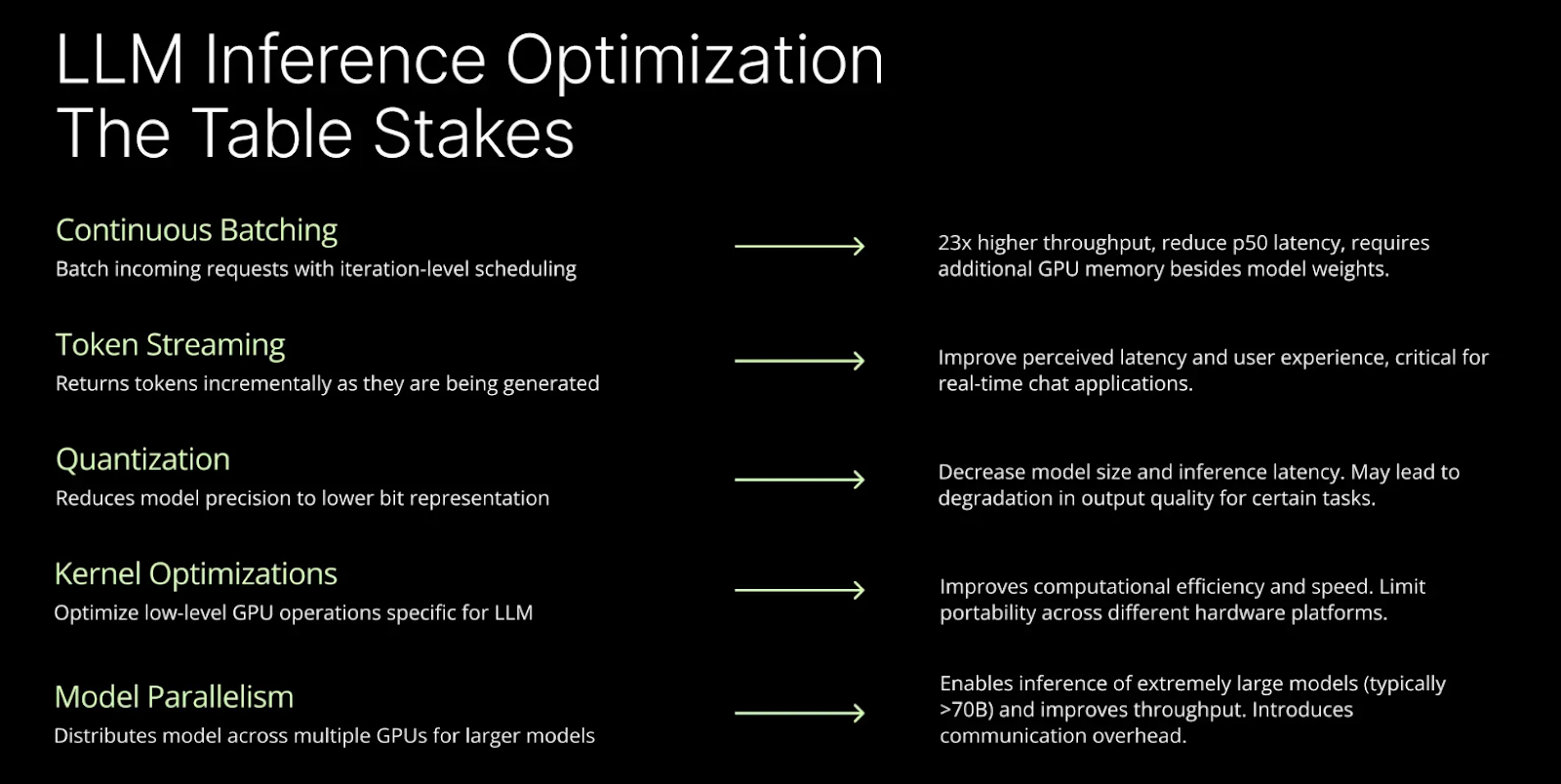
LLM Inference Optimization Techniques: A Comprehensive Analysis | by ...
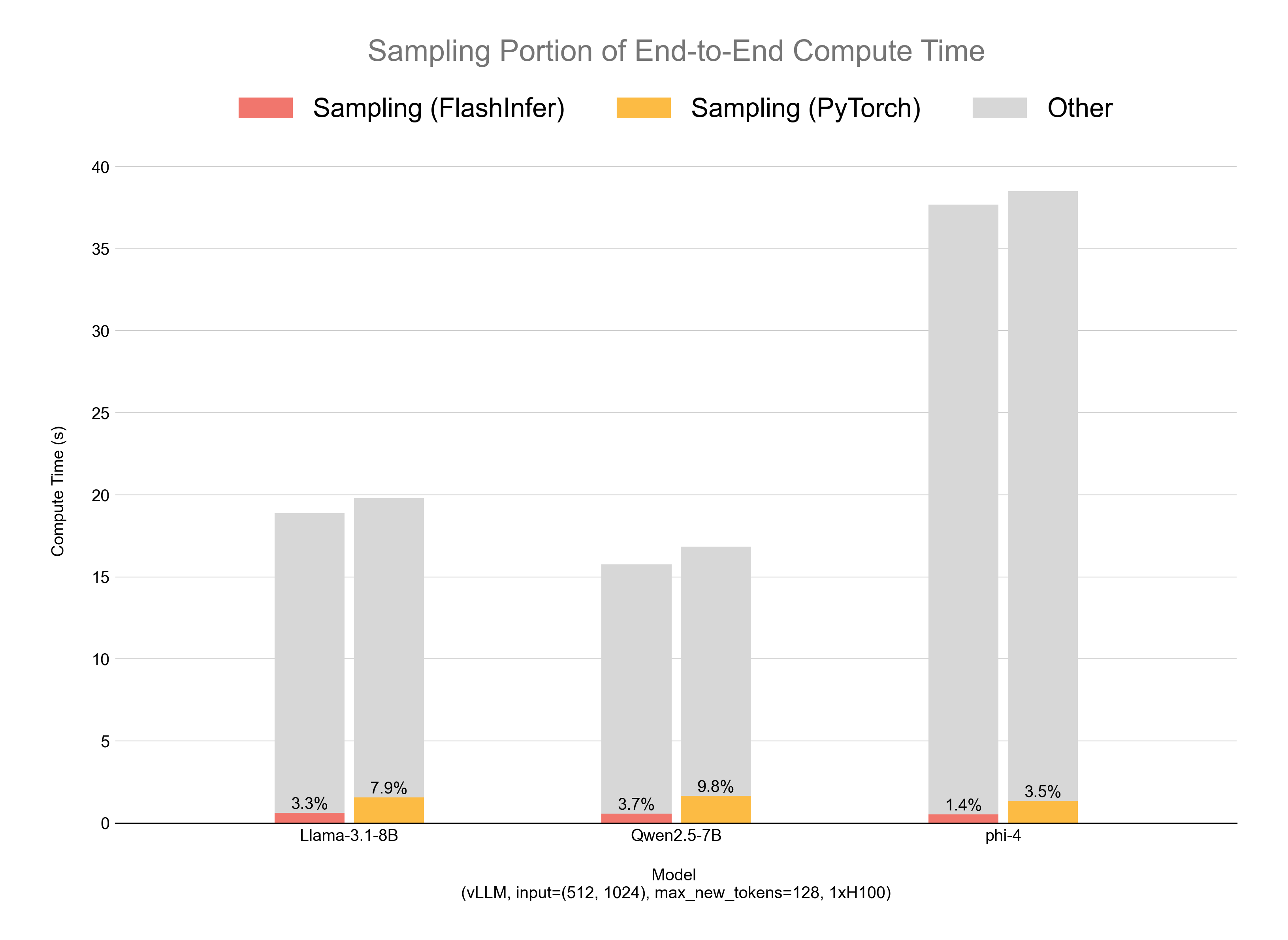
Sorting-Free GPU Kernels for LLM Sampling | FlashInfer
Illustration of the proposed method. (a) LLM inference comprises two ...
LLM Inference Stages Diagram | Stable Diffusion Online
LLM 生成式配置的推理参数温度 top k tokens等 Generative configuration inference ...
Accelerating LLM Inference: Fast Sampling with Gumbel-Max Trick
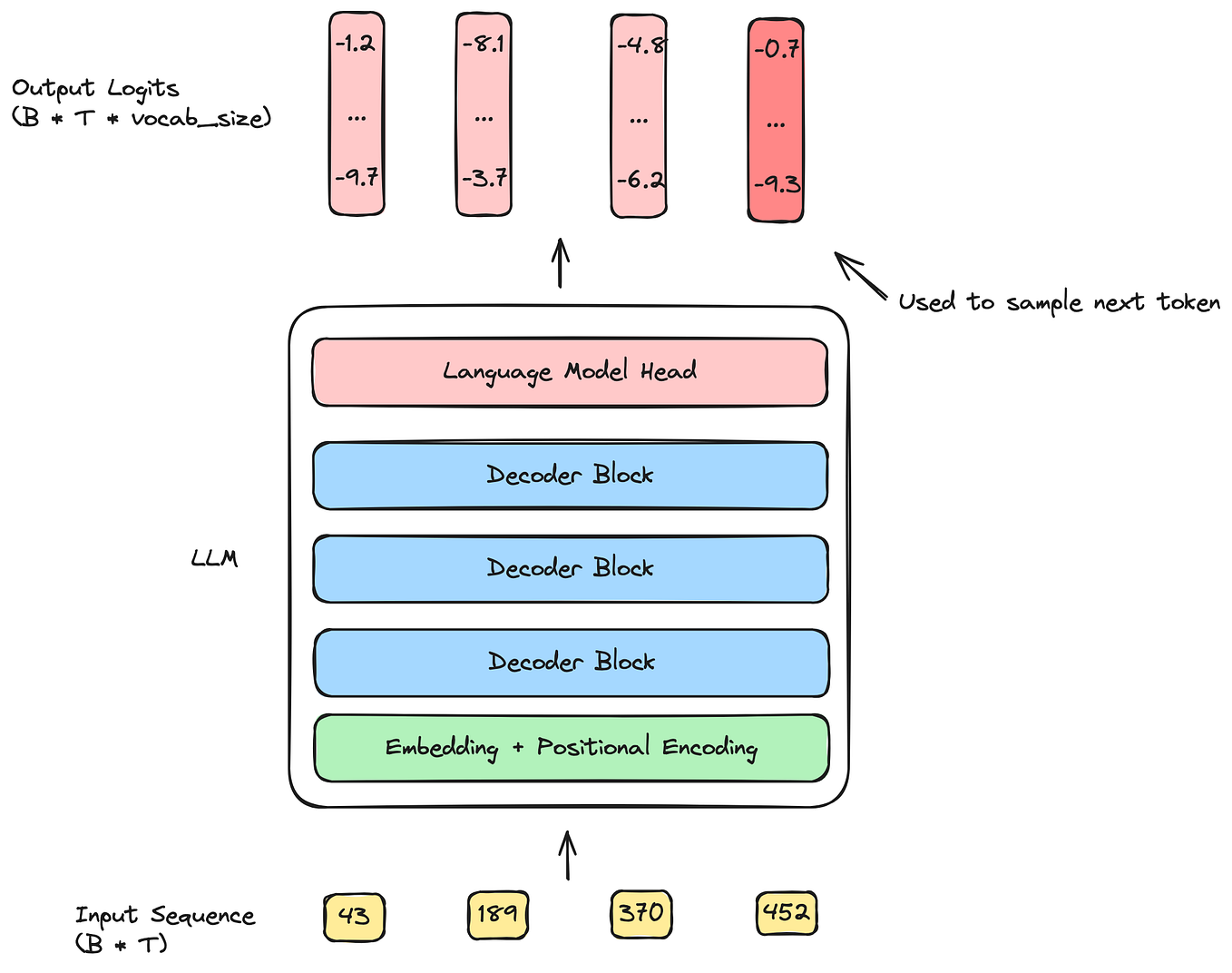
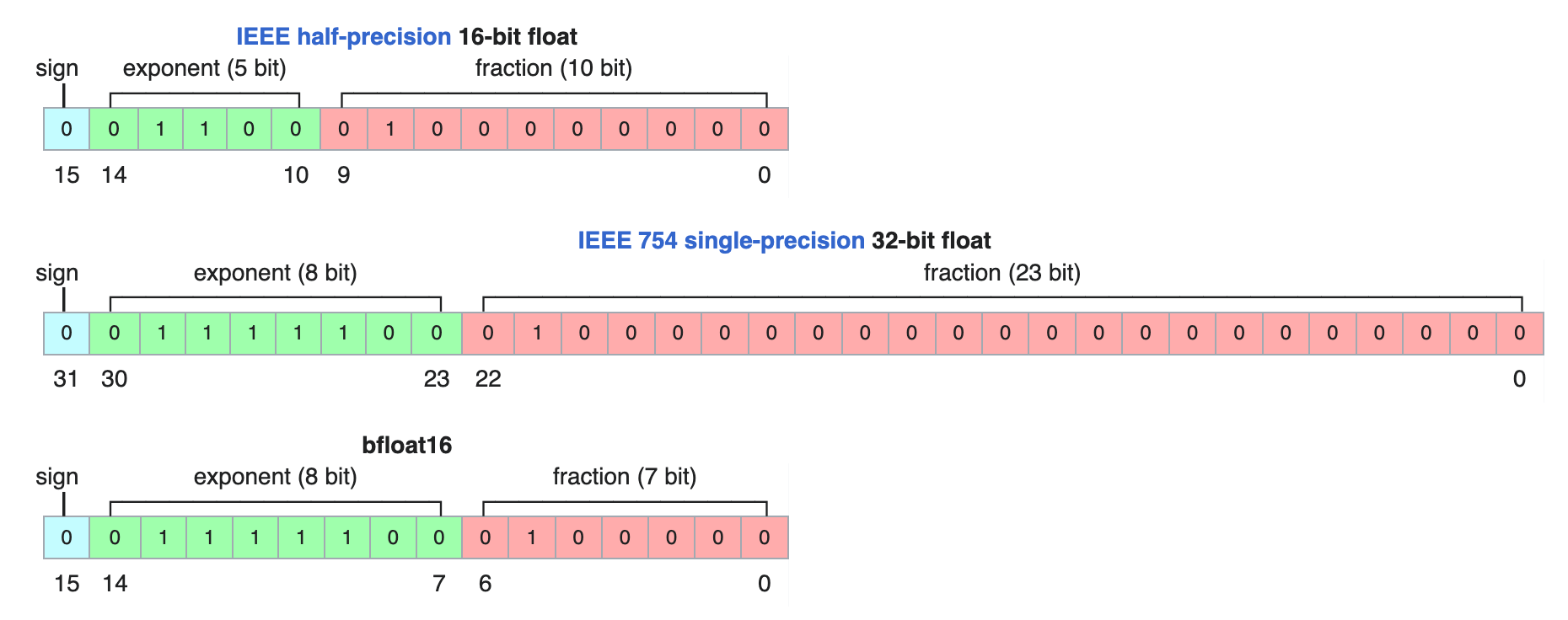
LLM Inference — A Detailed Breakdown of Transformer Architecture and ...
LLM Inference Benchmarking: How Much Does Your LLM Inference Cost ...
Understanding how LLM inference works with llama.cpp
LLM Sampling with FastMCP: Using Client LLMs for Scalable AI Workflows ...
LLM Inference Optimization for NLP Applications
Speculative Decoding via Early-exiting for Faster LLM Inference with ...
LLM Inference - Hw-Sw Optimizations
Reasoning under Uncertainty: Efficient LLM Inference via Unsupervised ...
LLM inference optimization: Model Quantization and Distillation - YouTube
Achieve 23x LLM Inference Throughput & Reduce p50 Latency
How to Scale LLM Inference - by Damien Benveniste
Key metrics for LLM inference | LLM Inference Handbook
Figure 2 from Scaling LLM Inference with Optimized Sample Compute ...
LLM Inference Optimization Overview - From Data to System Architecture
LLM Inference
A Survey of LLM Inference Systems | alphaXiv
AI Speculative Sampling Boost LLM Speeds Without Losing Quality - Geeky ...
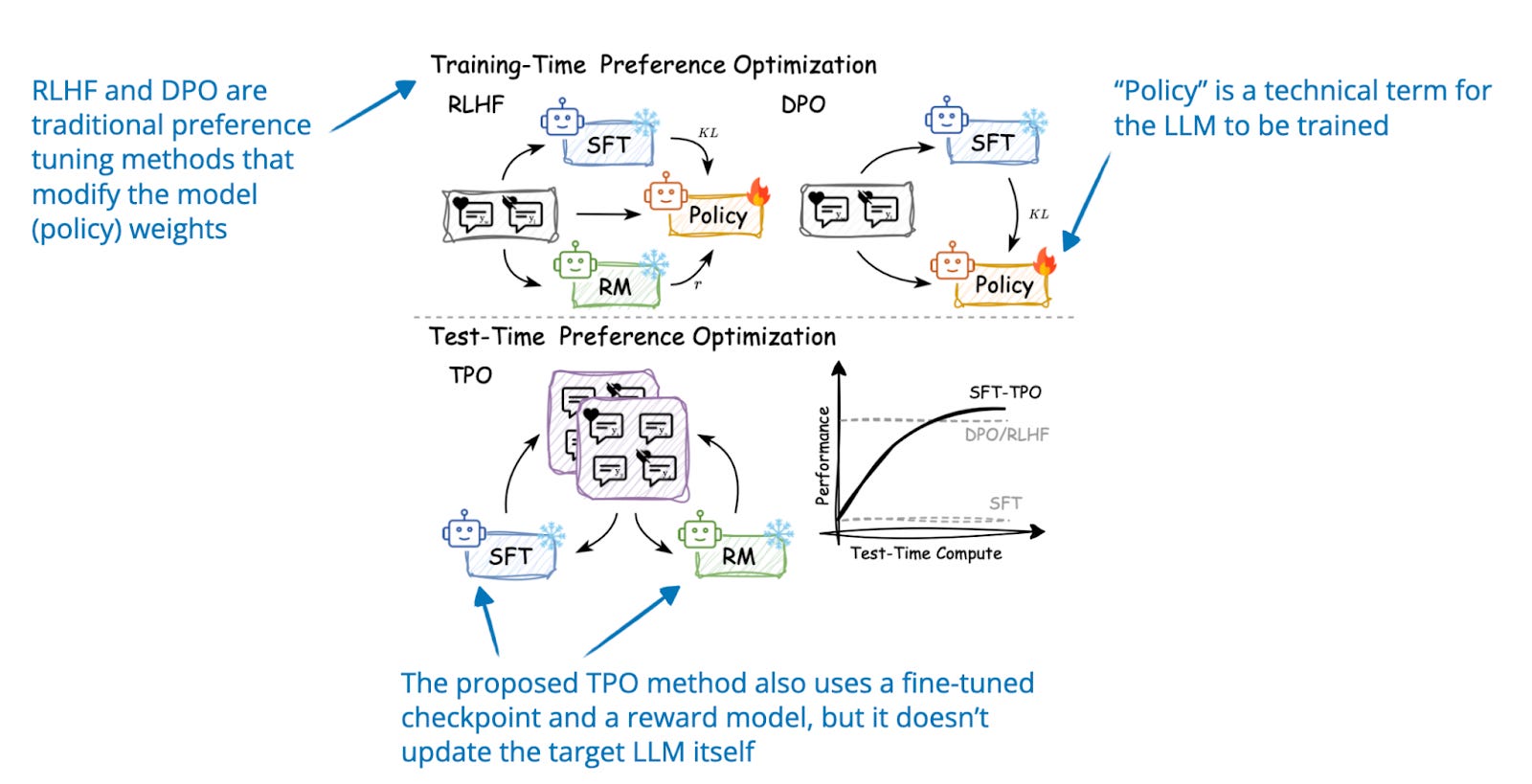
Defeating Nondeterminism in LLM Inference - Thinking Machines Lab
A Survey of Efficient LLM Inference Serving | PDF | Scheduling ...
LLM Inference Optimization Techniques
LLM Inference - a zzzac Collection
LLM Inference Archives | Uplatz Blog
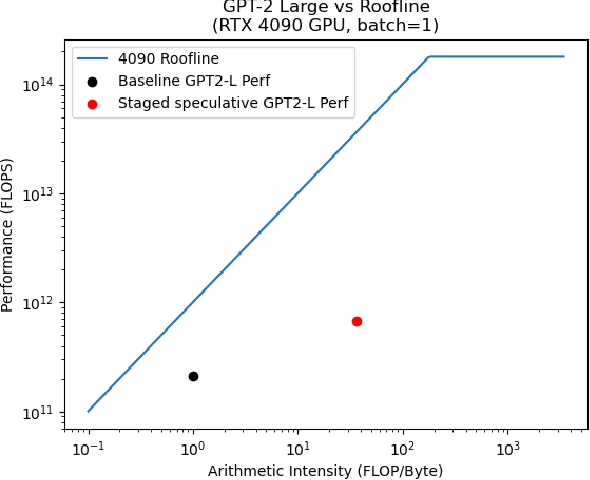
Accelerating LLM Inference with Staged Speculative Decoding | DeepAI
Paper page - LLM Inference Unveiled: Survey and Roofline Model Insights
LLM Inference Hardware: Emerging from Nvidia's Shadow
Dummy's Guide to Modern LLM Sampling Intro Knowledge | MONA
Advanced LLM Sampling Methods to Transform AI Outputs
LLM Sampling Parameters Guide | smcleod.net
LLM Inference Series: 5. Dissecting model performance | by Pierre ...
vLLM: PagedAttention for 24x Faster LLM Inference
[2402.16363] LLM Inference Unveiled: Survey and Roofline Model Insights
LLM Inference Series: 4. KV caching, a deeper look | by Pierre Lienhart ...
How to benchmark and optimize LLM inference performance (for data ...
LLM Inference Series: 1. Introduction | by Pierre Lienhart | Medium
Best LLM Inference Engines and Servers to Deploy LLMs in Production - Koyeb
BEACON: Smarter LLM Sampling - ByteTrending
Efficient LLM inference - Artificial Fintelligence
Efficient LLM inference - by Finbarr Timbers
Figure 1 from Accelerating LLM Inference with Staged Speculative ...
LLM / vLLM : Sampling / 采样介绍 - 知乎
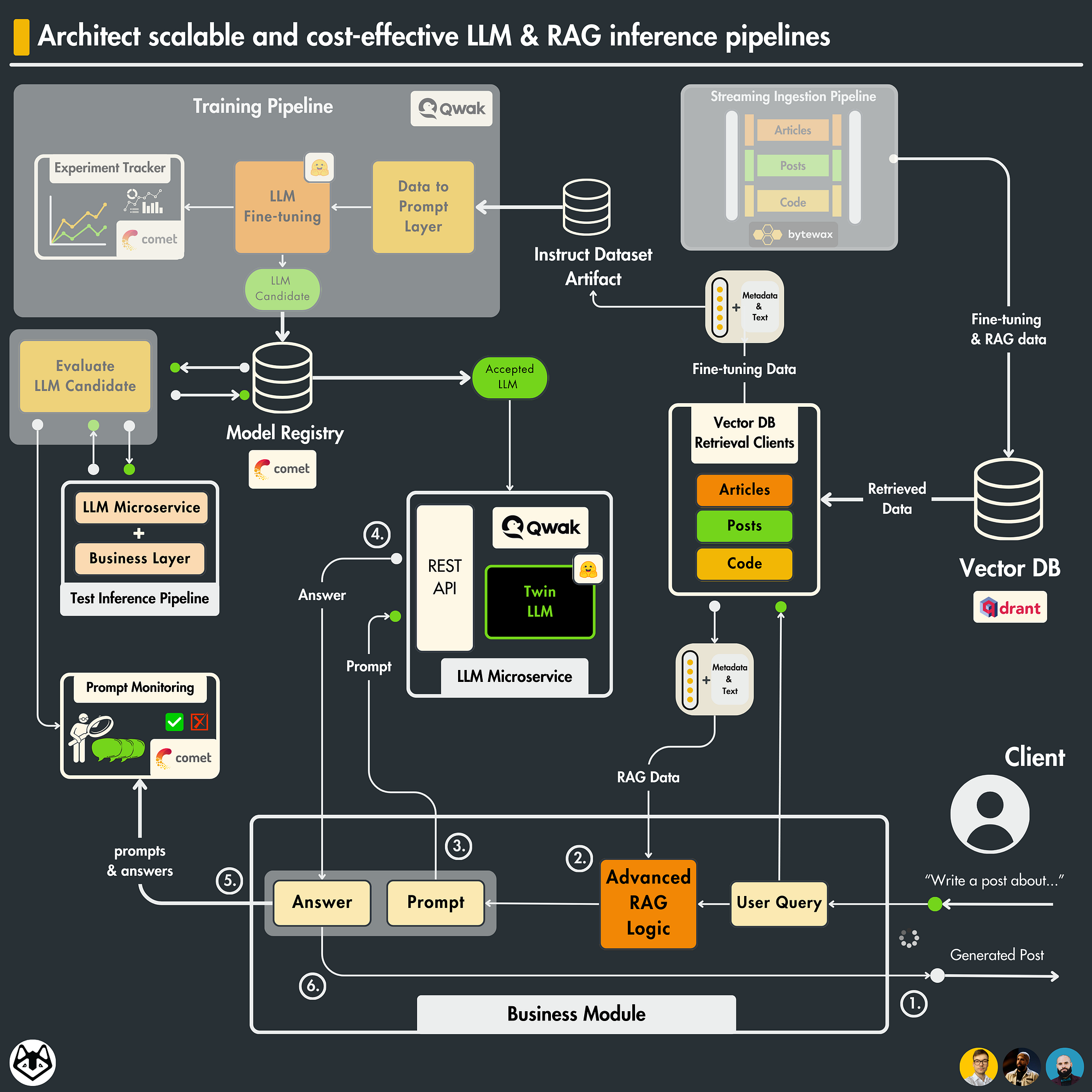
How to Architect Scalable LLM & RAG Inference Pipelines
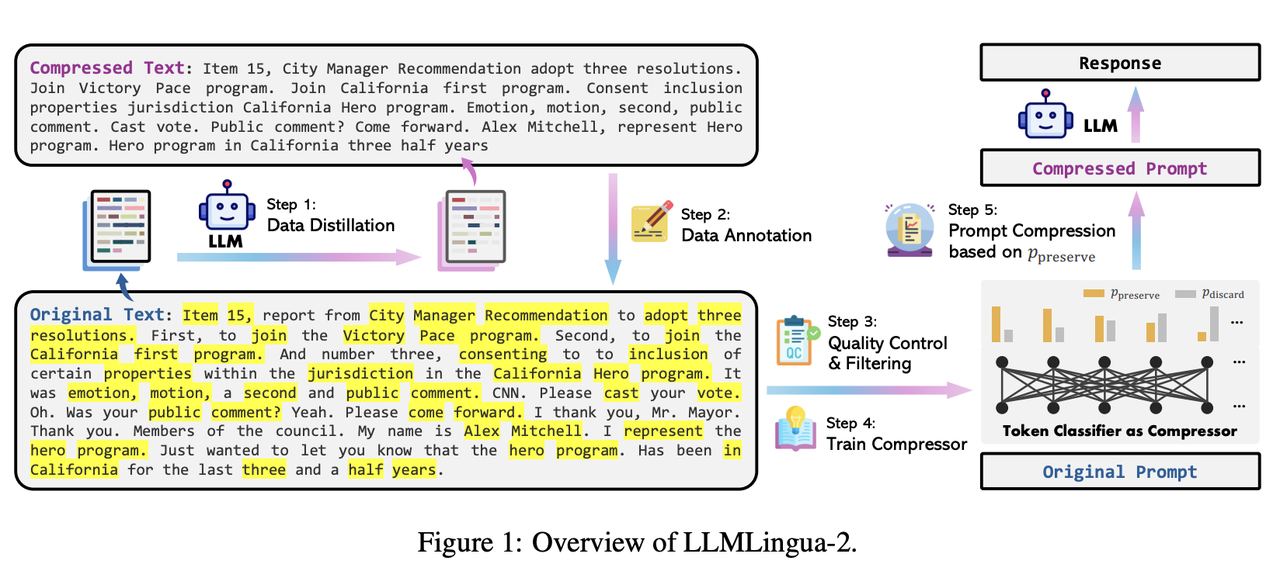
LLMLingua: Revolutionizing LLM Inference Performance through 20X Prompt ...
What Is LLM Inference? Process, Latency & Examples Explained (2026)
7 LLM Decoding Strategies: Top-P vs Temperature vs Beam Search (2025 ...
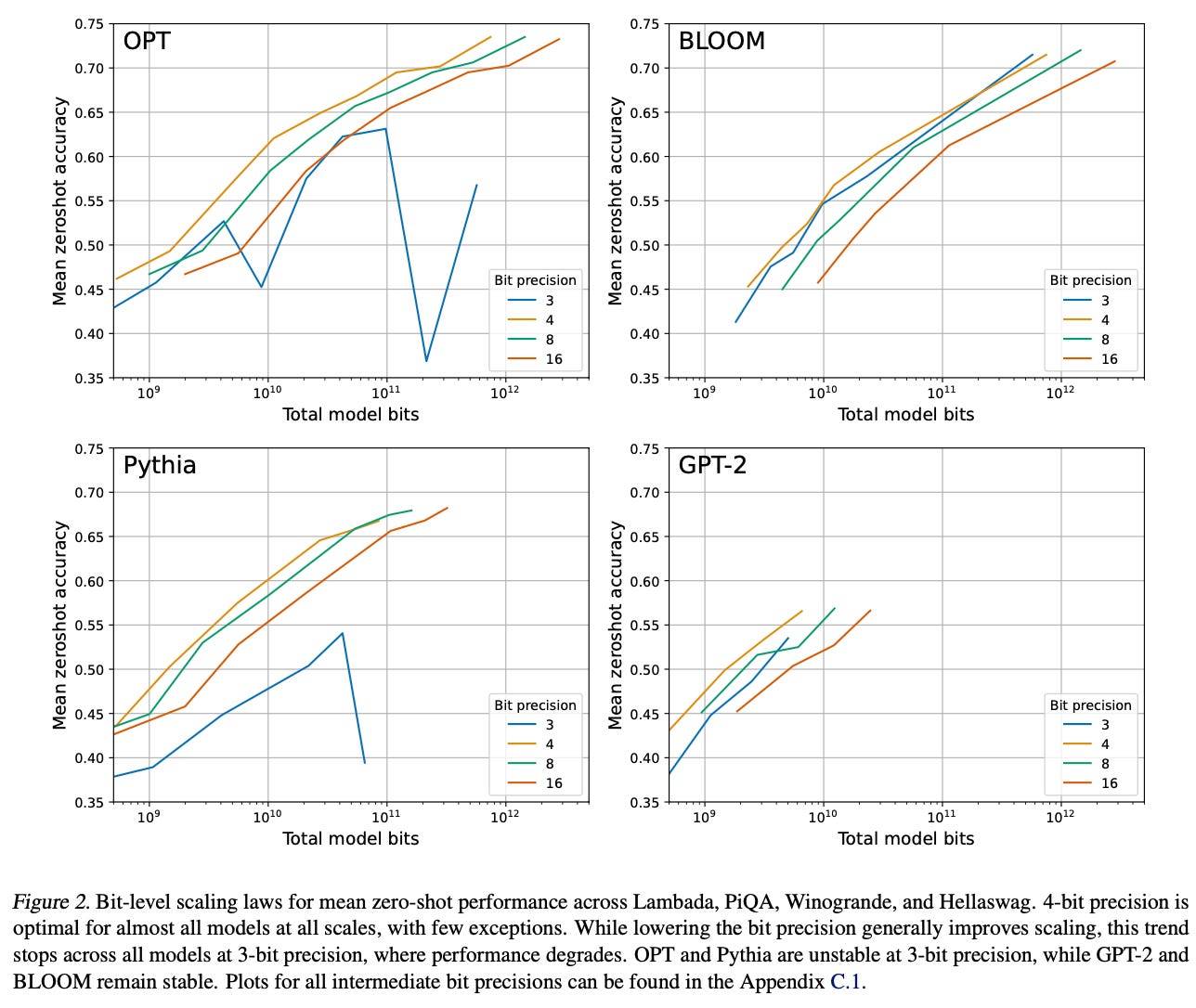
Smaller, Weaker, Yet Better: Training LLM Reasoners Via Compute-Optimal ...
Paper page - Speculative Decoding via Early-exiting for Faster LLM ...
Understanding LLM Generation (Decoder) Parameters (Sample/Inference ...
[vLLM vs TensorRT-LLM] #3. Understanding Sampling Methods and Their ...
The Shift to Distributed LLM Inference: 3 Key Technologies Breaking ...
[논문 리뷰] Wider or Deeper? Scaling LLM Inference-Time Compute with ...
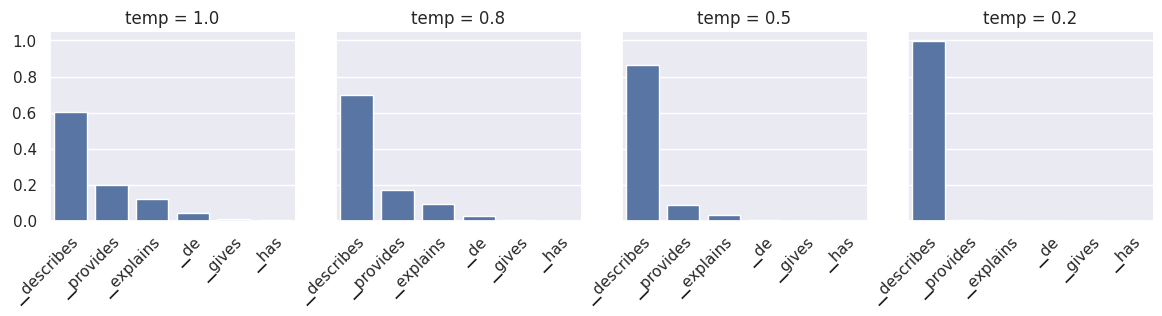
Understanding LLM Sampling: How Temperature, Top-K, and Top-P Shape ...
Understanding LLM Context Window and Working | MatterAI Blog
Guide to Self-hosting LLM Systems - Zilliz blog
A Guide to Efficient LLM Deployment | Datadance
LLM APIs & Prompt Engineering
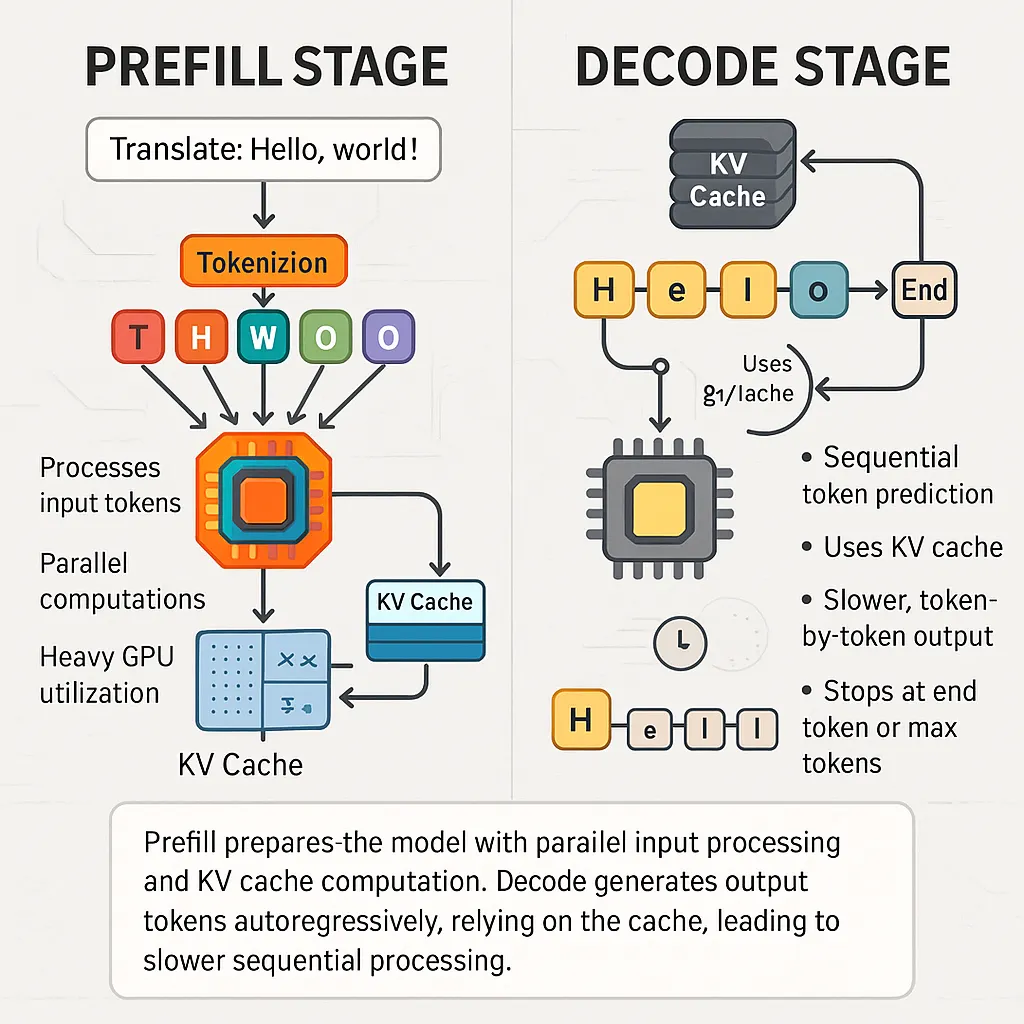
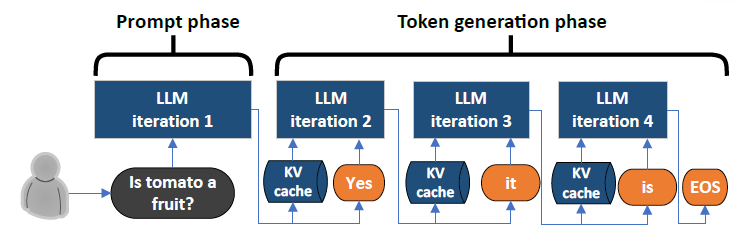
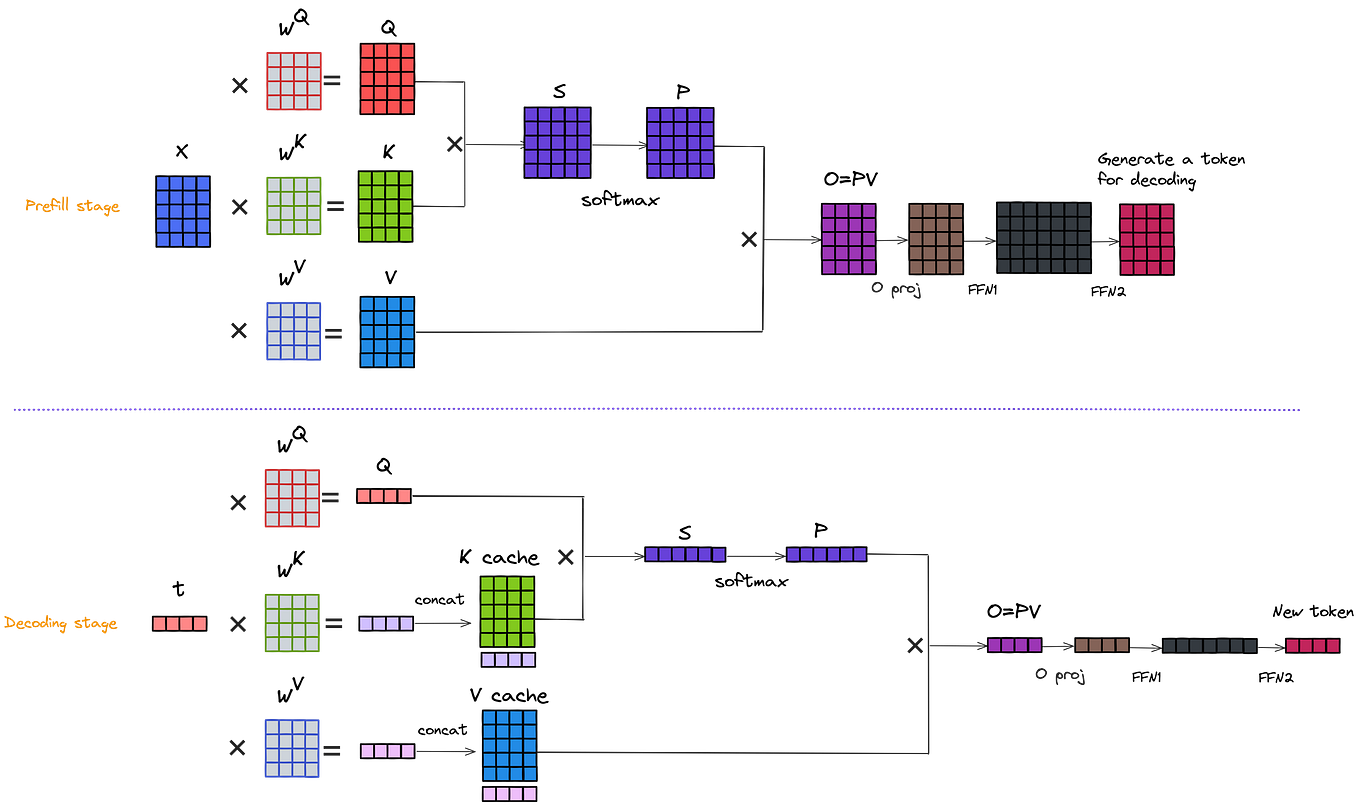
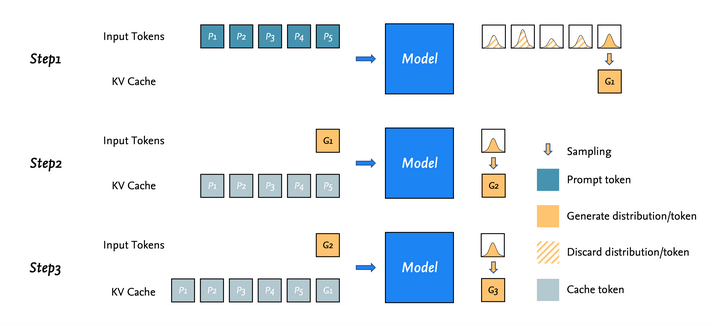
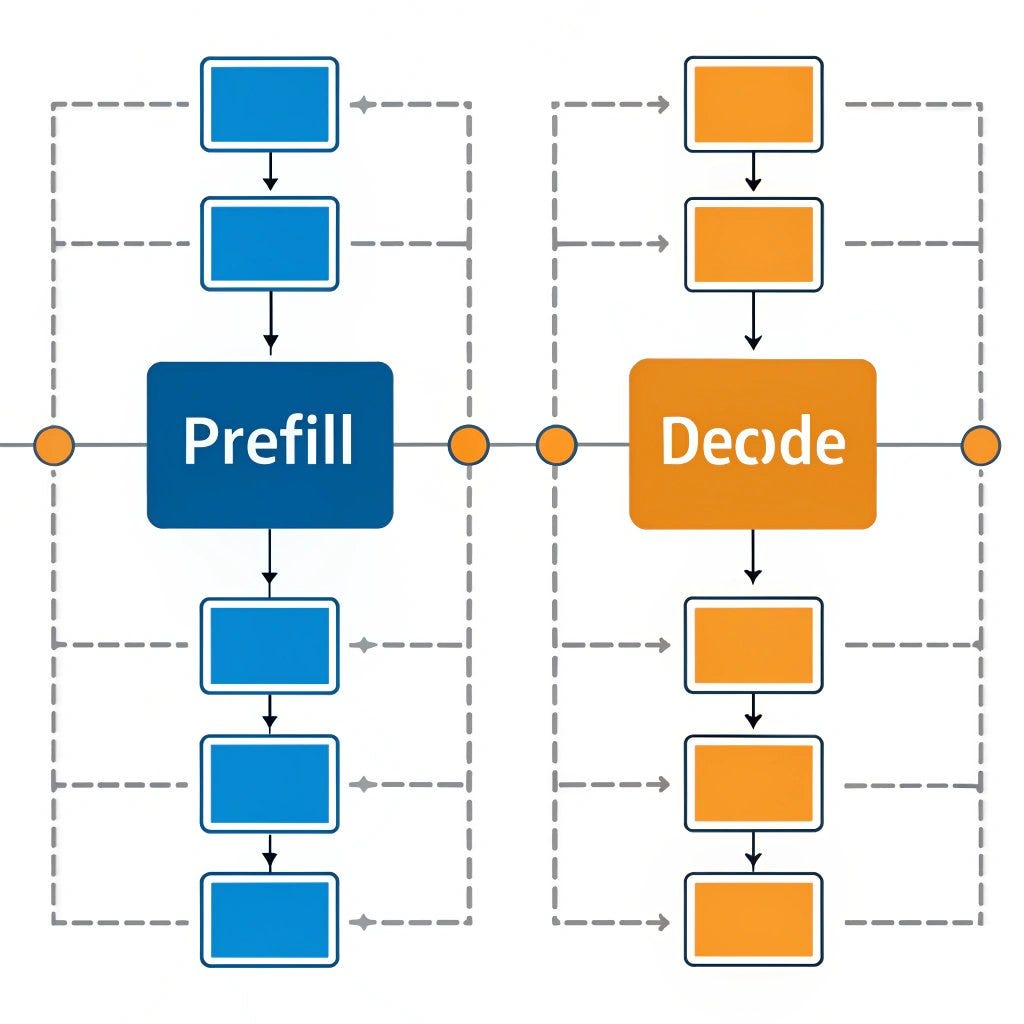
Understanding the Two Key Stages of LLM Inference: Prefill and Decode ...
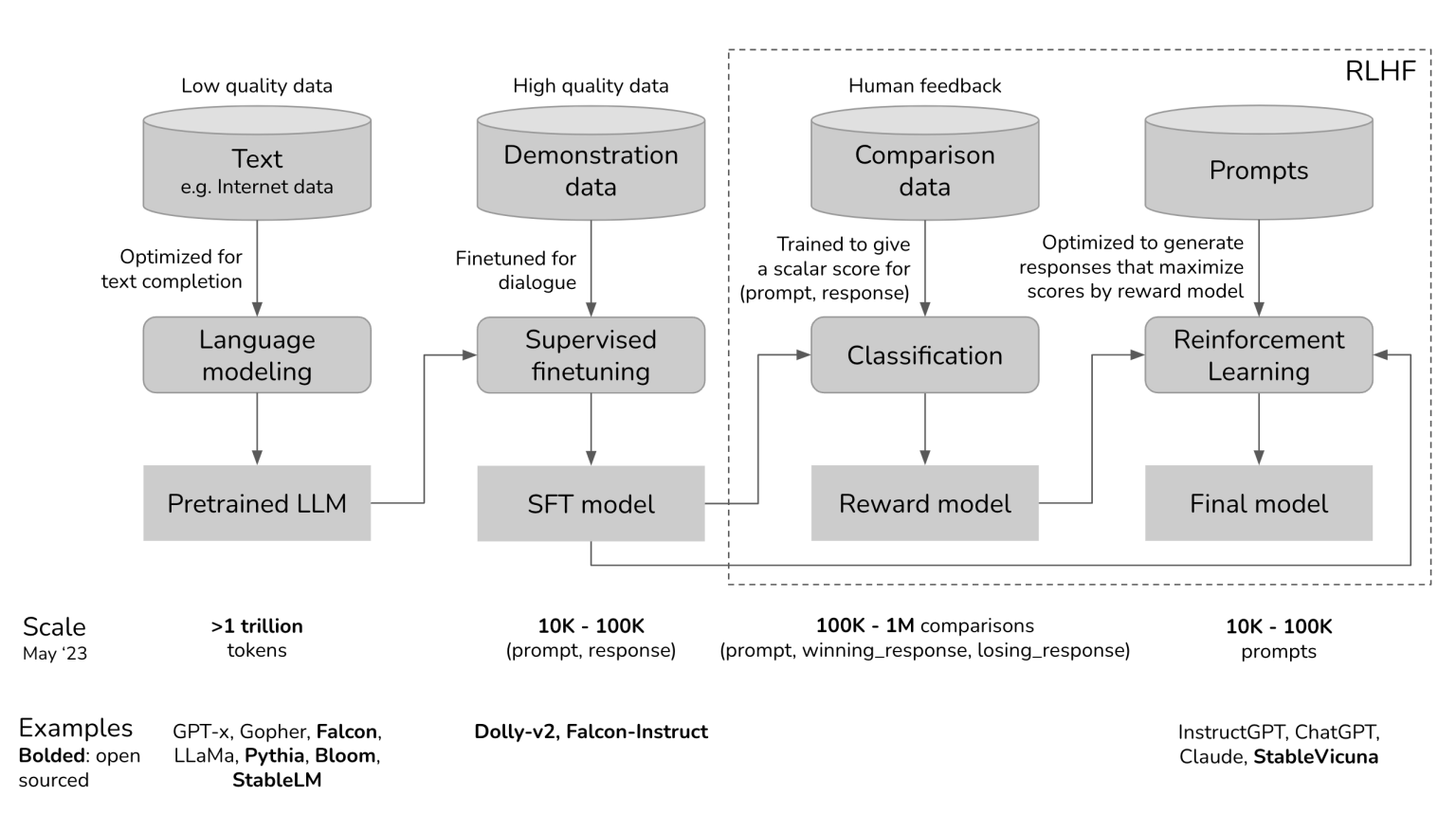
LLM Training Pipeline Overview | AI Tutorial | Next Electronics
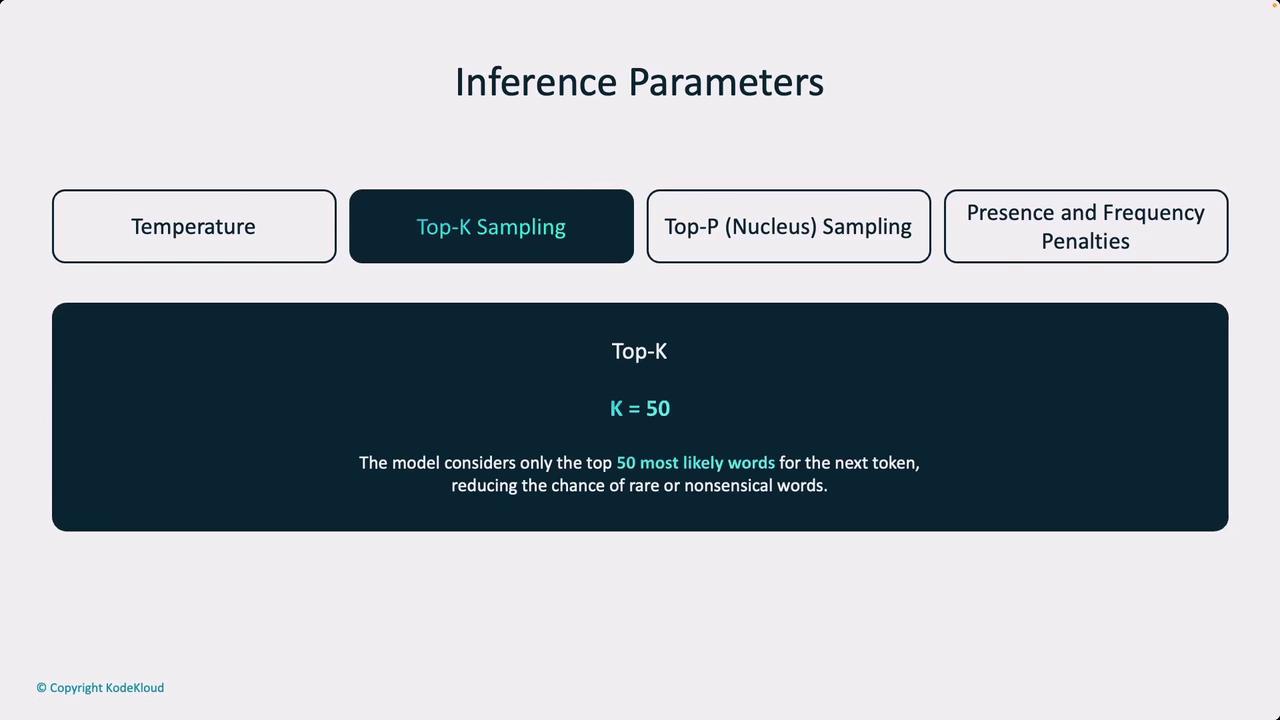
Inference Parameters - KodeKloud
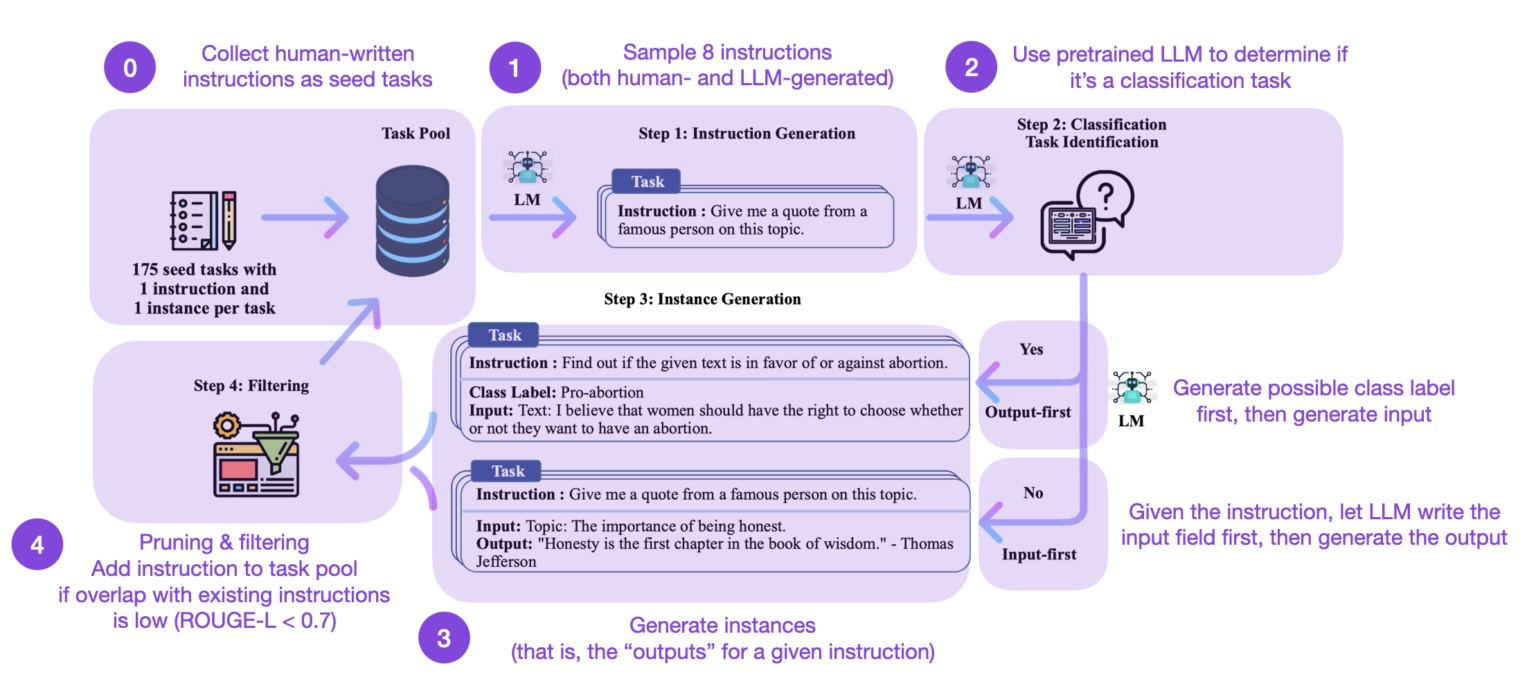
How To Build LLM (Large Language Models): A Definitive Guide
Exploring LLM Visualization: Techniques, Tools, and Insights | by ...
Basic LLM Inference/Generation,一篇就够了。 - 知乎
Parameter-Efficient LLM Finetuning With Low-Rank Adaptation (LoRA ...
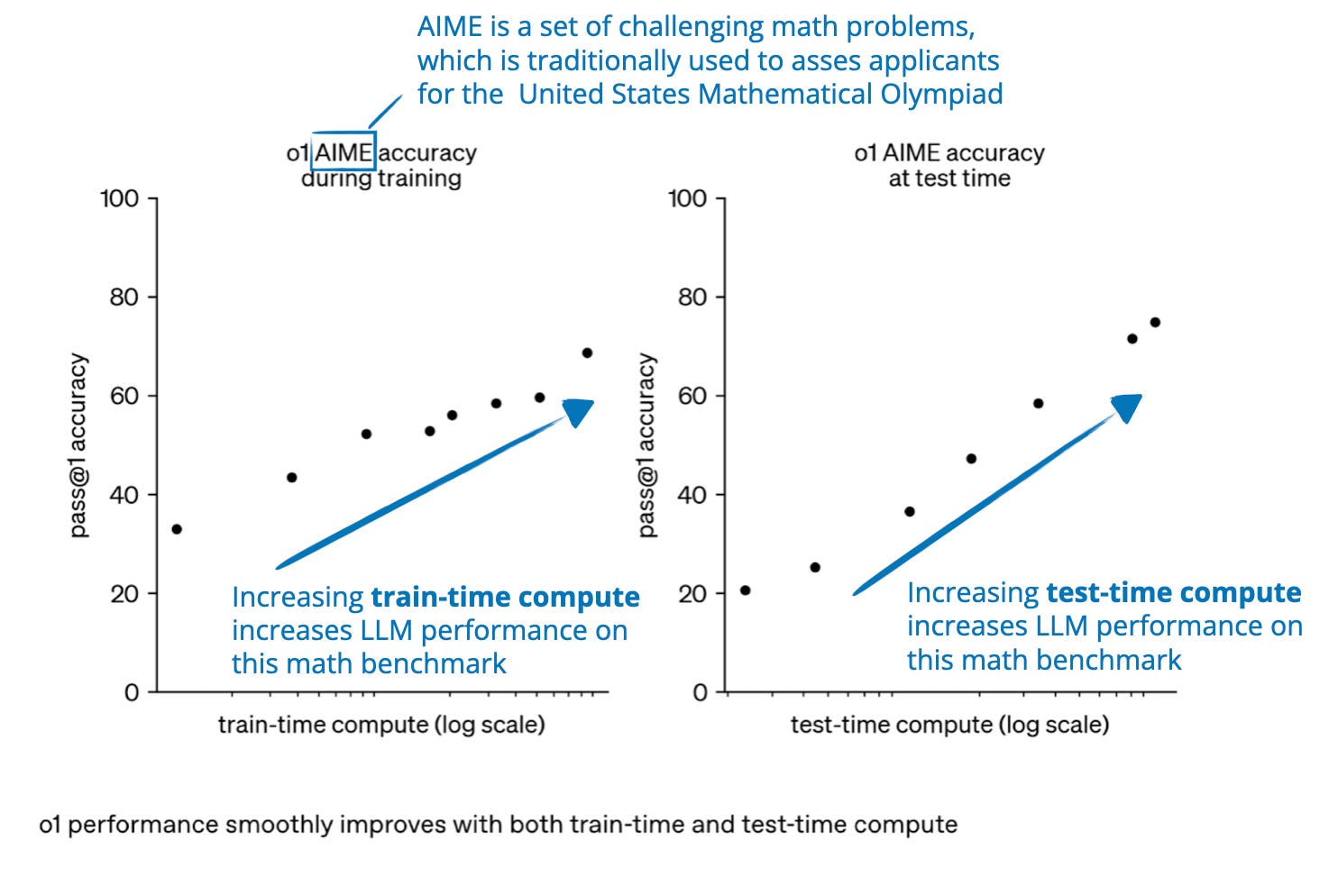
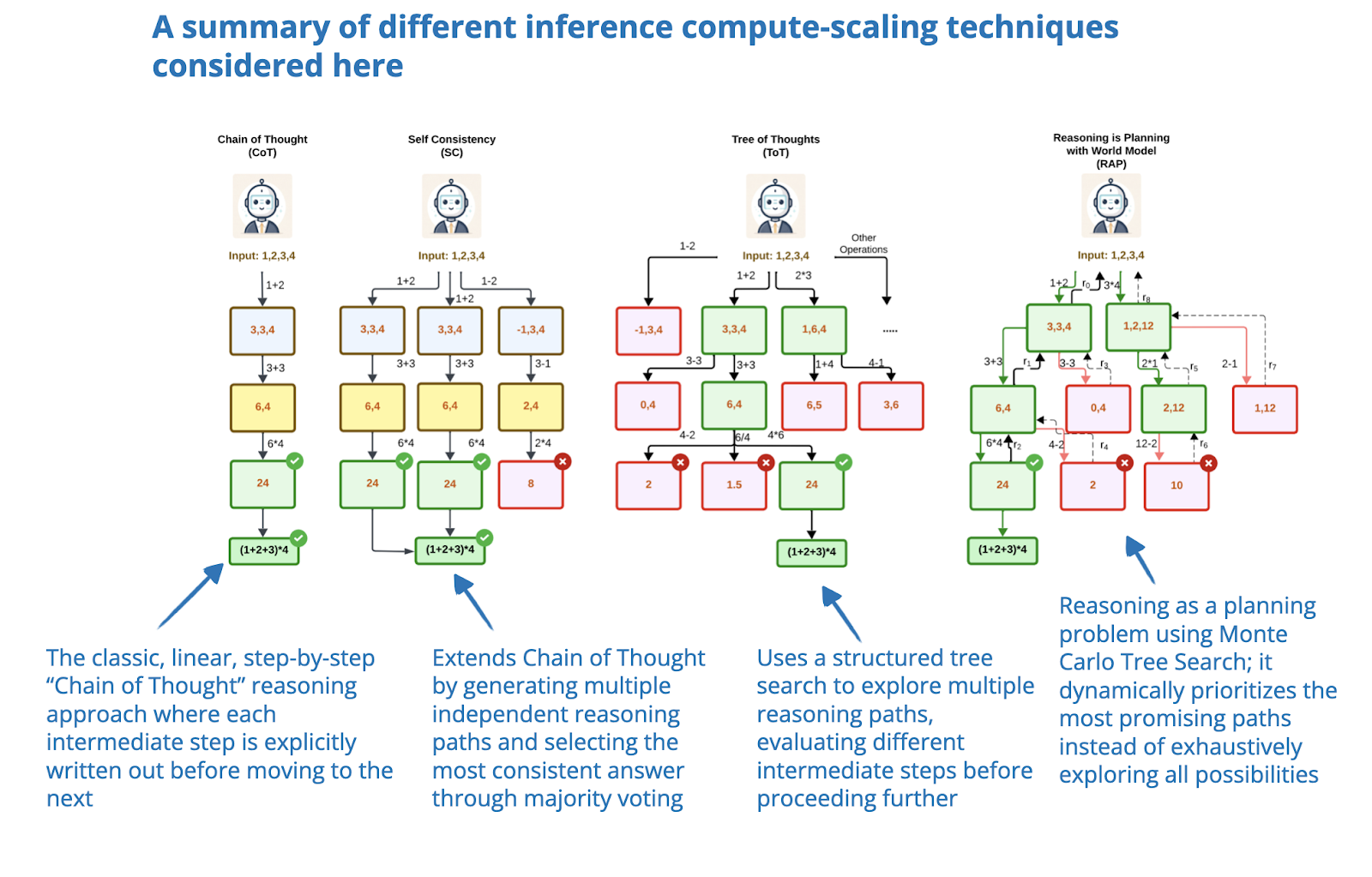
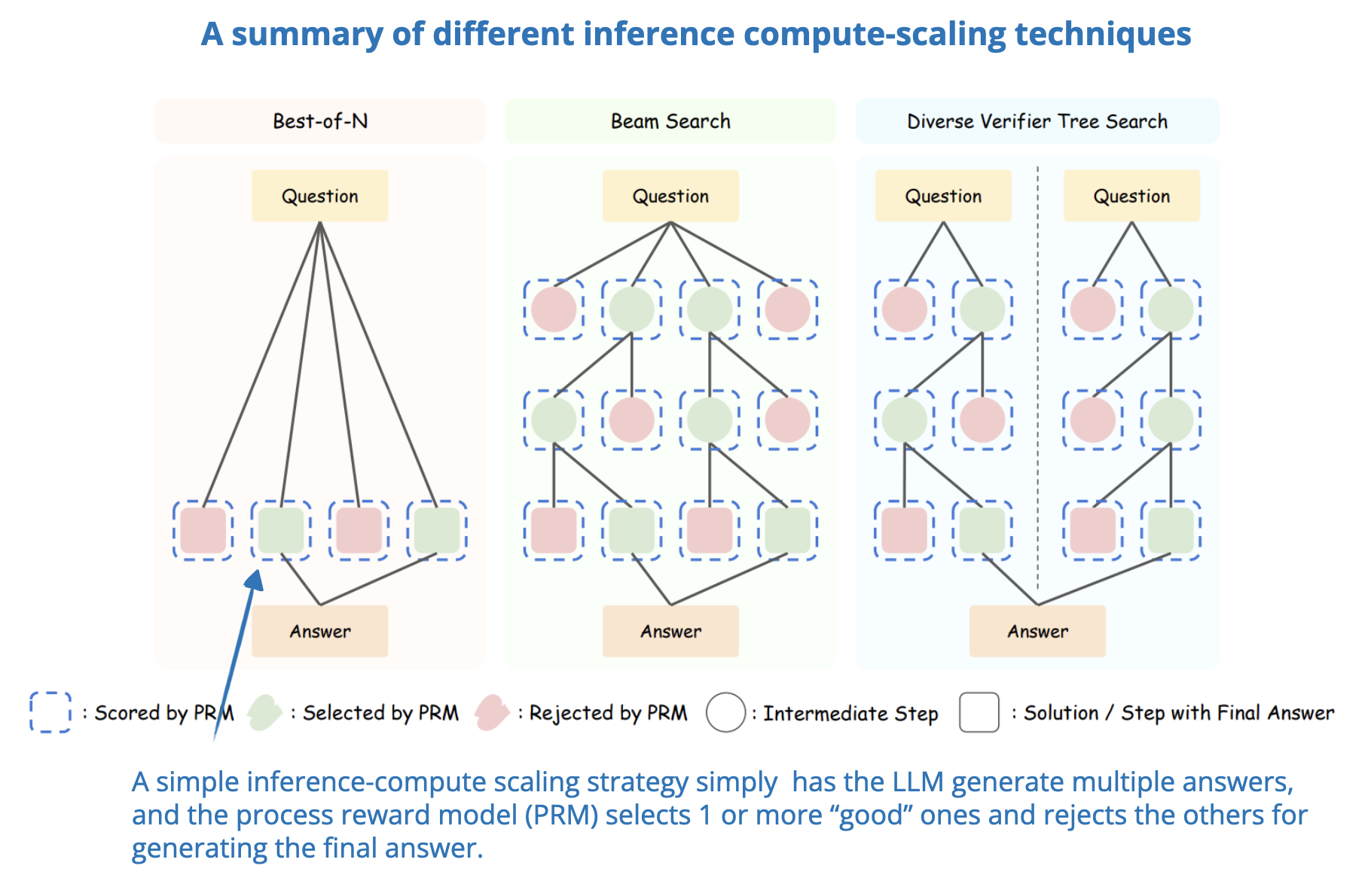
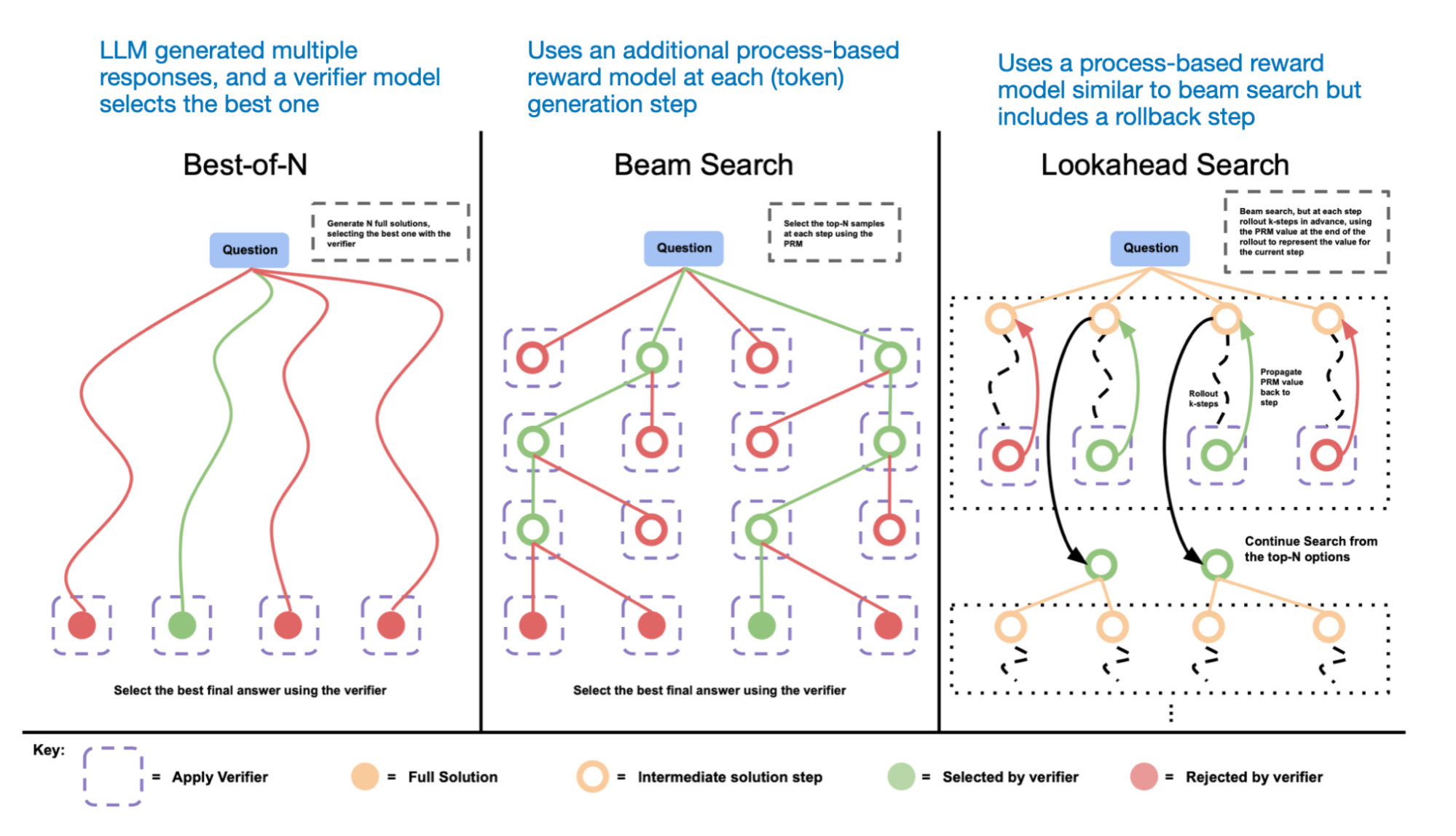
Inference-Time Compute Scaling Methods to Improve Reasoning Models ...
LLM-Inference-Acceleration/attention-mechanism/lisa--layerwise ...
sample-for-secure-medical-llm-inference-with-nitro-enclaves/CODE_OF ...
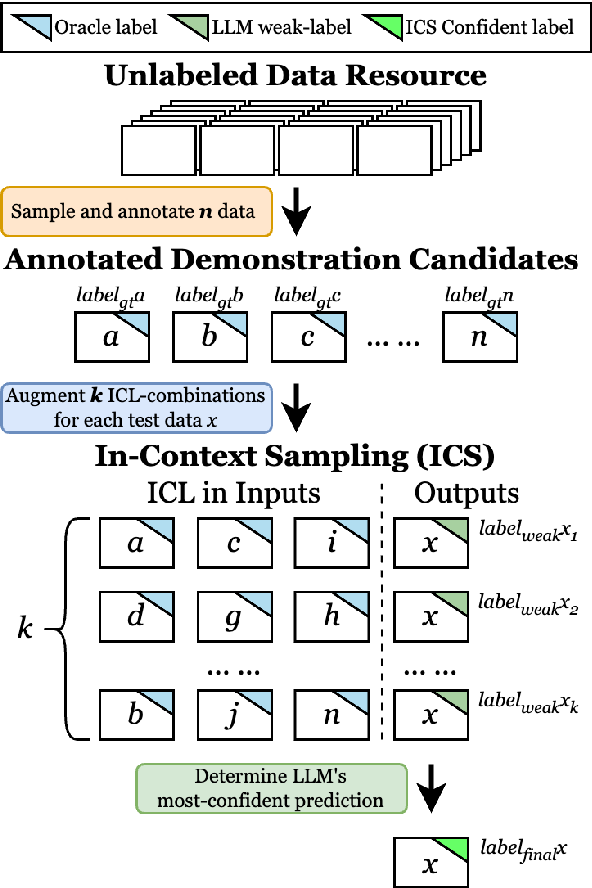
Figure 1 from More Samples or More Prompts? Exploring Effective In ...
一起理解下LLM的推理流程_llm推理过程-CSDN博客
You've Changed: Detecting Modification of Black-Box Large Language ...
Inference-Time Optimizations - TensorZero Docs
Patterns for Building LLM-based Systems & Products
GitHub - modelize-ai/LLM-Inference-Deployment-Tutorial: Tutorial for ...
GitHub - Artefact2/llm-sampling: A very simple interactive demo to ...