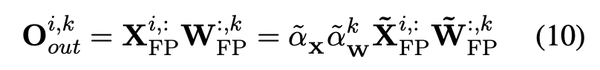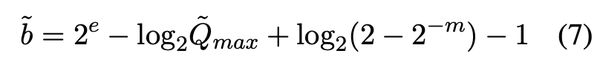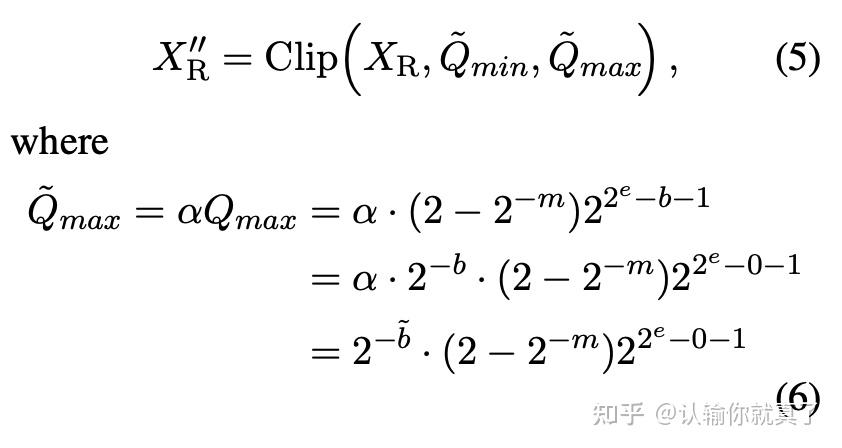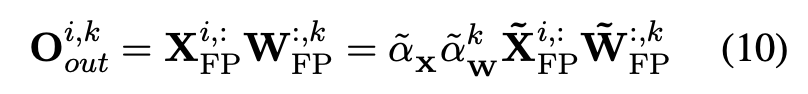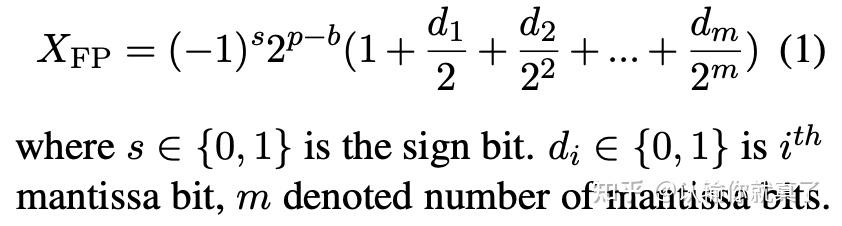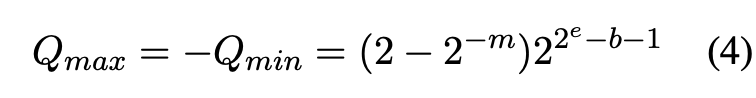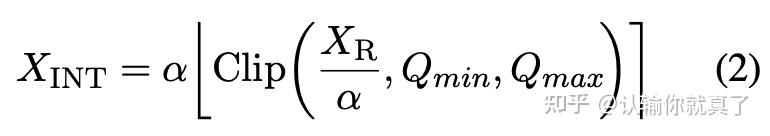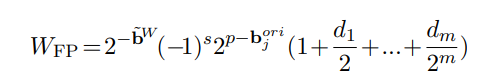Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
fp4 Quantization - LLM Compressor Docs
Will a LLM trained with FP4 have frontier-level performance before 2028 ...
Will a LLM trained with FP4 have competitive performance in 2 years ...
Accurate LLM Training with FP4 Quantization, Coming Soon?
unable to run fp4 format using LLM API code, reported error:[TensorRT ...
SageAttention3 Cracks the Code with FP4 | Embedded LLM posted on the ...
fp4 量化 - LLM Compressor 文档 - vLLM 文档
[논문 리뷰] Towards Efficient Pre-training: Exploring FP4 Precision in ...
Optimization Using FP4 Quantization For Ultra-Low Precision Language ...
使用bitsandbytes、4 位量化和 QLoRA 使 LLM 更易于访问 - 知乎
4 LLM Compression Techniques That You Can't Miss
Accelerate Your AI Workflow with FP4 Quantization on Lambda
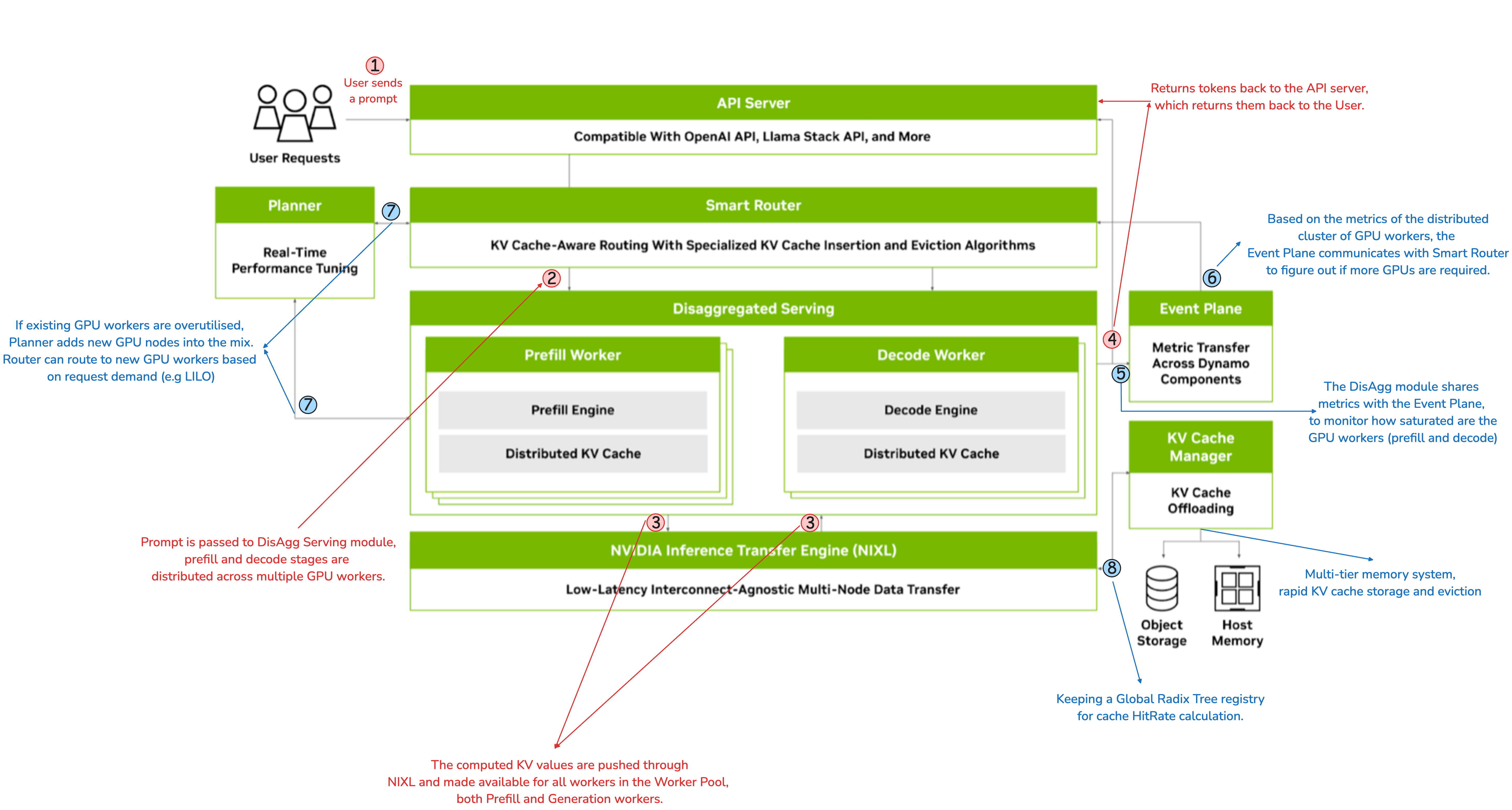
What is NVIDIA Dynamo LLM Inference Framework
GitHub - intel/ipex-llm-tutorial: Accelerate LLM with low-bit (FP4 ...
A guide to LLM inference and performance | Baseten Blog
SageAttention3: 5x Faster LLM Inference on Blackwell GPUs with Plug-and ...
LLM Compressor 0.7.0: Optimizing LLMs with QuIP, FP4, and DeepSeek ...
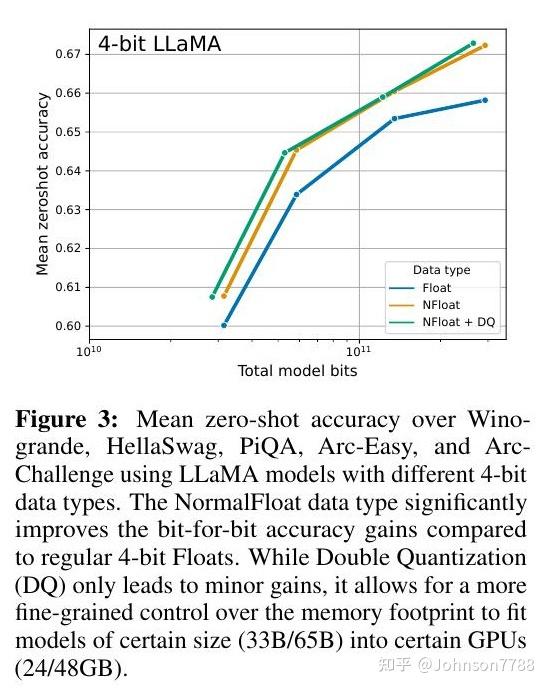
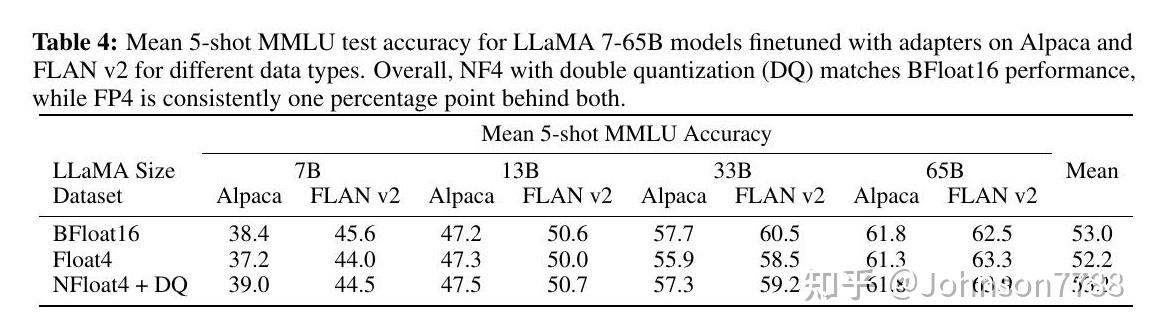
4-bit LLM training and Primer on Precision, data types & Quantization
扩散模型解读 (十四):HQ-DiT:高效的 FP4 混合精度量化 DiT - 知乎
GitHub - intel/neural-compressor: SOTA low-bit LLM quantization (INT8 ...
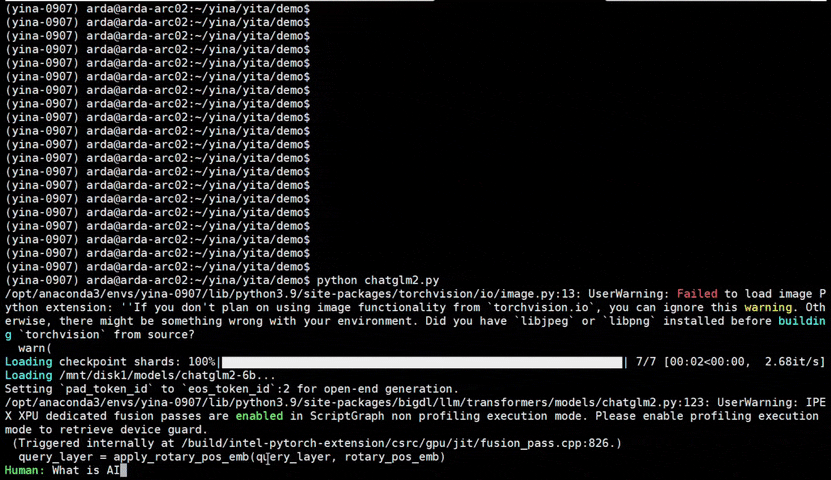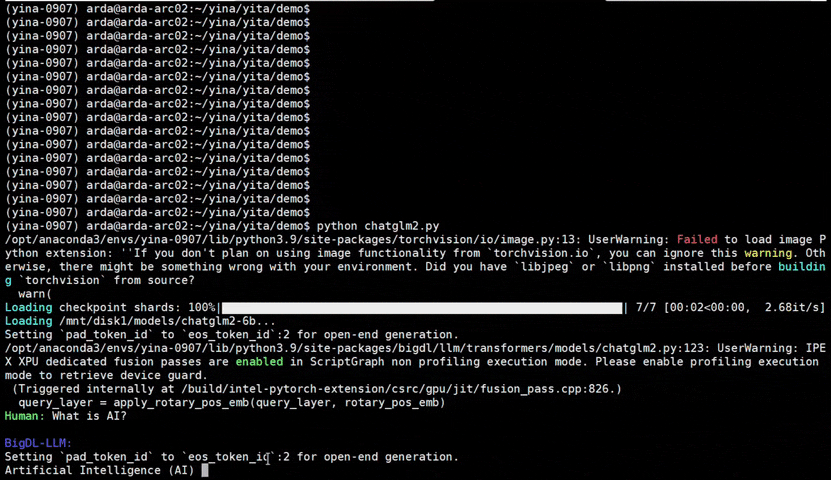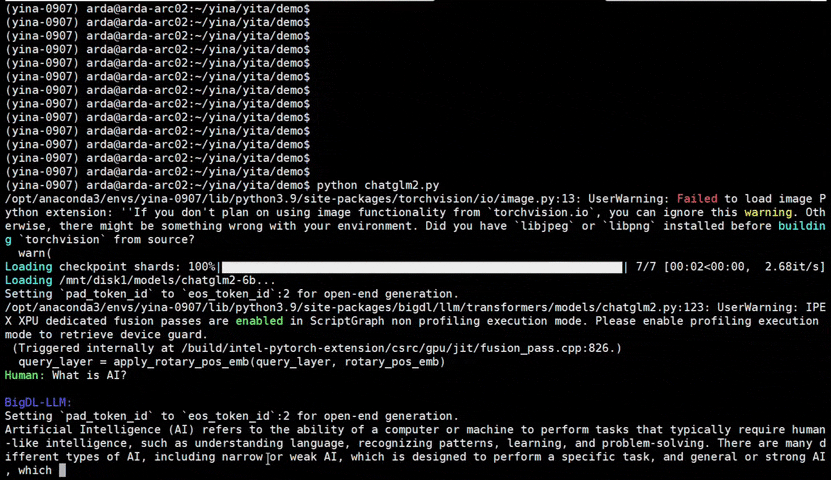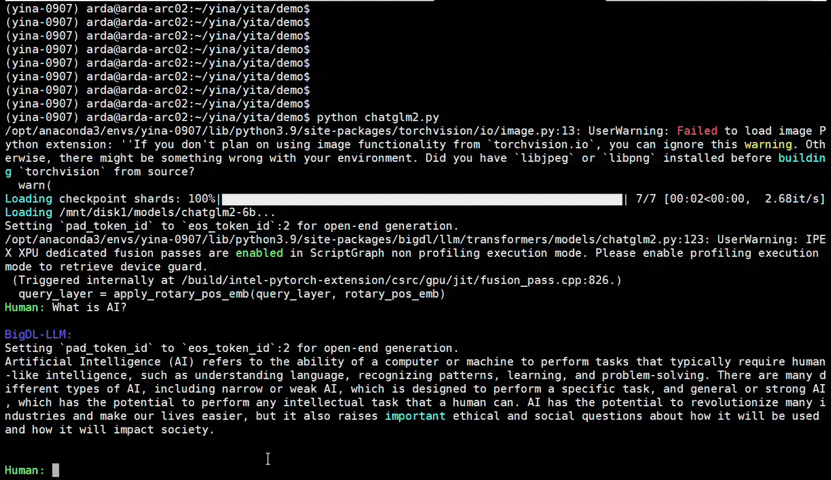
GitHub - dopyutarou/BigDL: Accelerate LLM with low-bit (FP4 / INT4 ...
FireAttention V4: Industry-Leading Latency and Cost Efficiency with FP4
GitHub - jinghong123/BigDL: Accelerate LLM with low-bit (FP4 / INT4 ...
[Quantization] int4 vs fp4 which to choose?
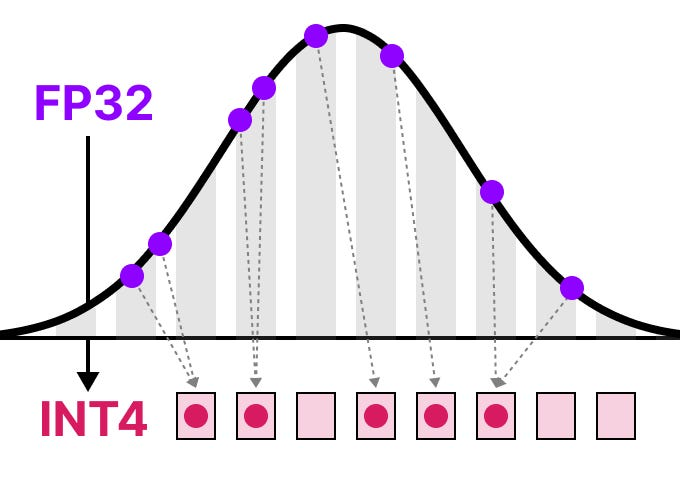
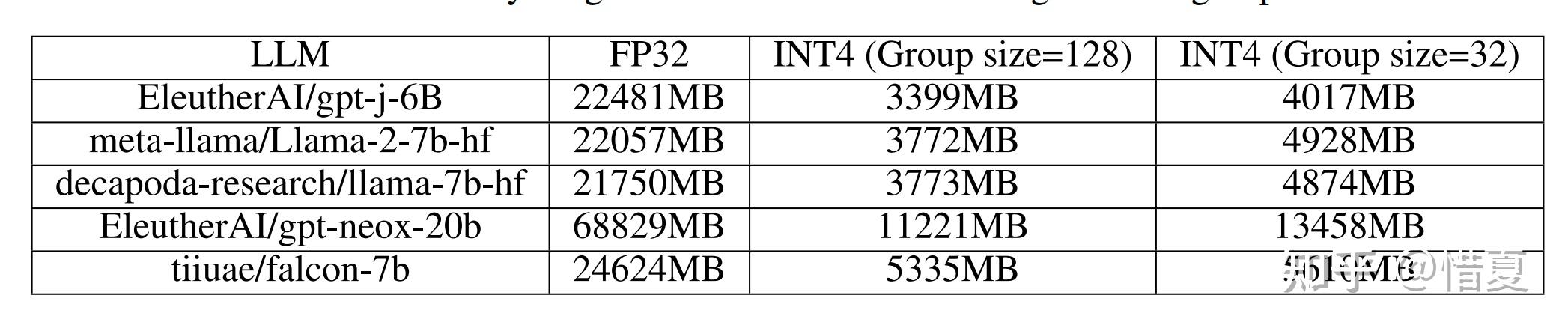
Low-Bit LLM Quantization (INT4, NF4, FP4)
FP4 trtllm-build failed on 5090 · Issue #3259 · NVIDIA/TensorRT-LLM ...
GitHub - Proj-Odin/BigDL: Accelerate LLM with low-bit (FP4 / INT4 / FP8 ...
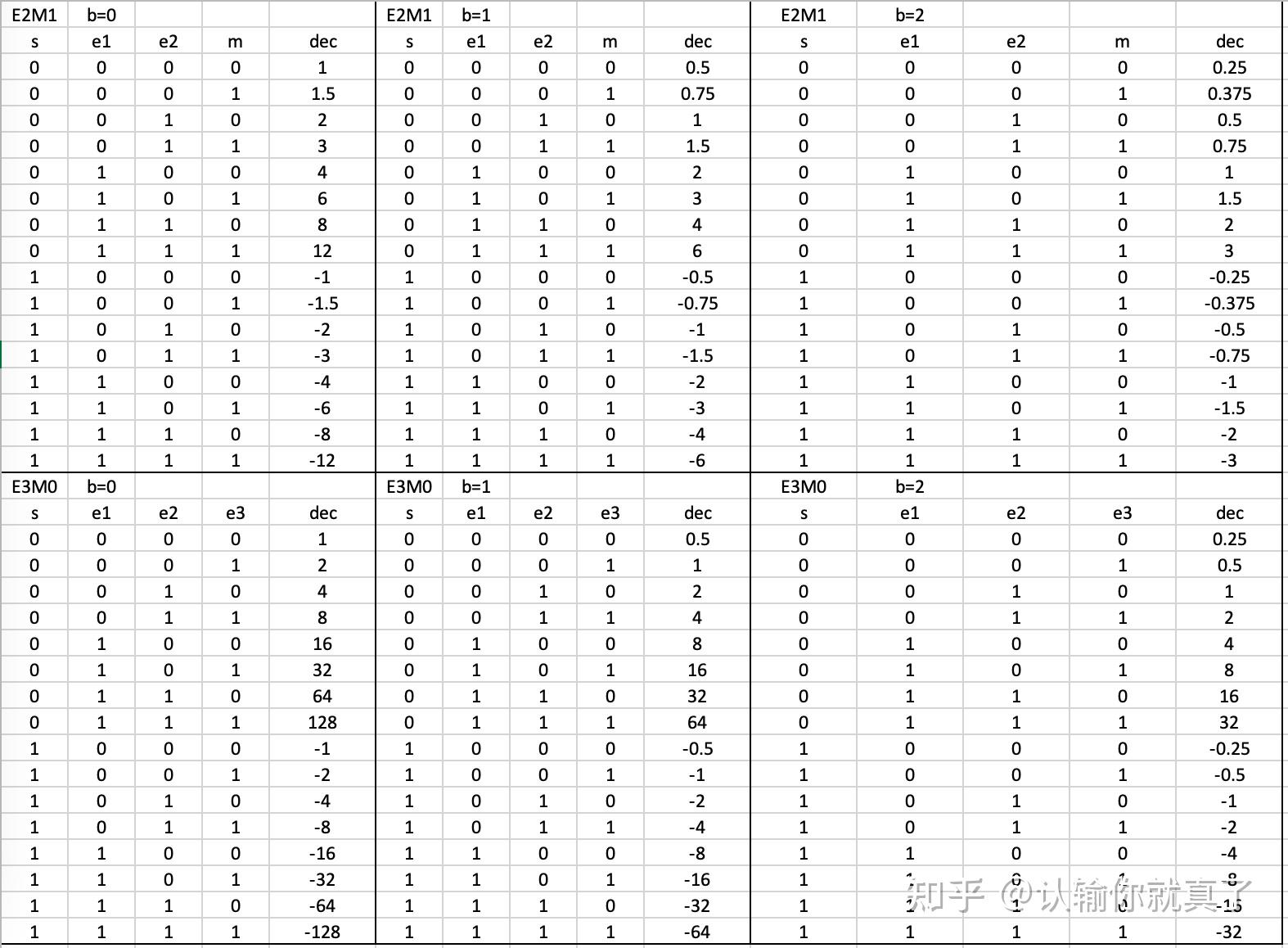
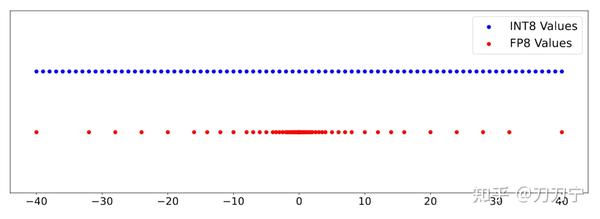
Left: Unsigned INT4 quantization compared to unsigned FP4 2M2E ...
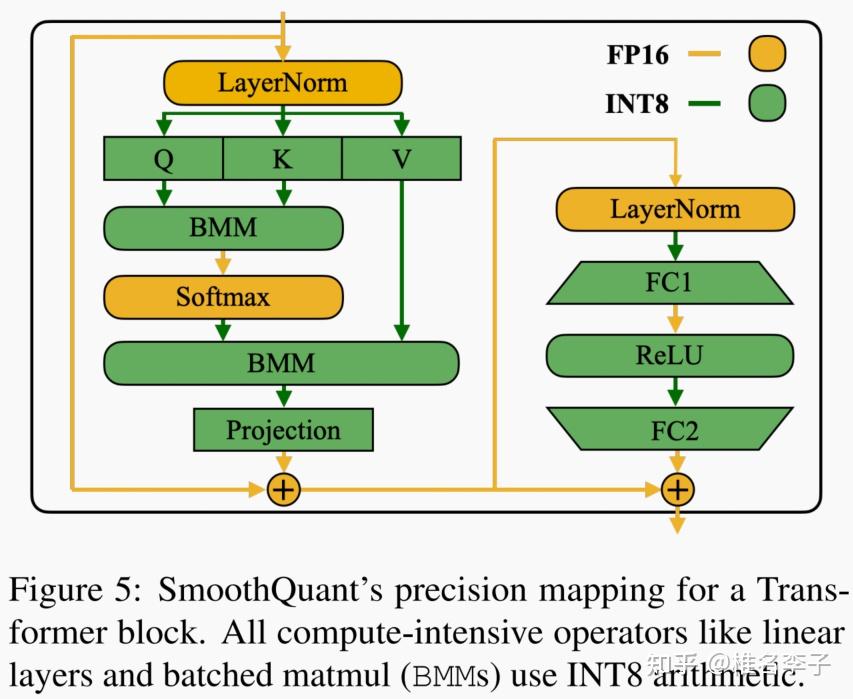
量化那些事之FP8与LLM-FP4 - 知乎
LLM.fp4 低精度浮点量化大模型 - 知乎
FP4低精度LLM训练框架 - 知乎
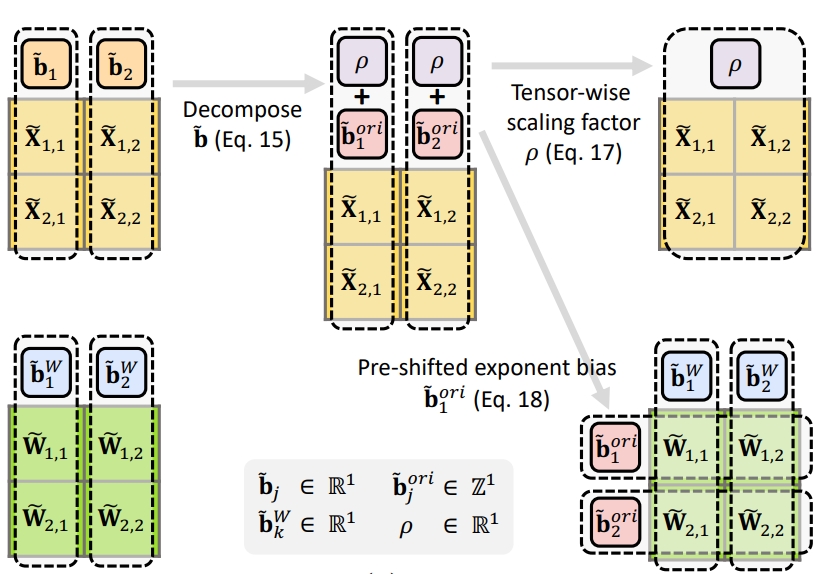
微软:FP4量化方法训练LLM_optimizing large language model training using fp4-CSDN博客
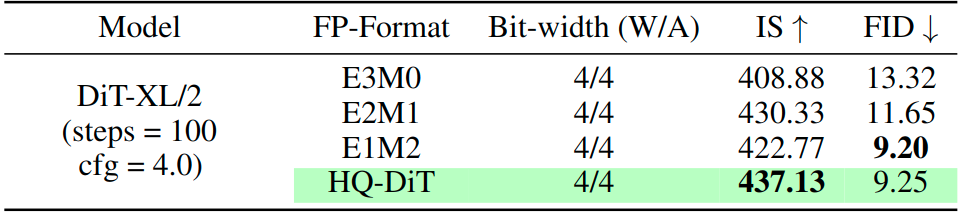
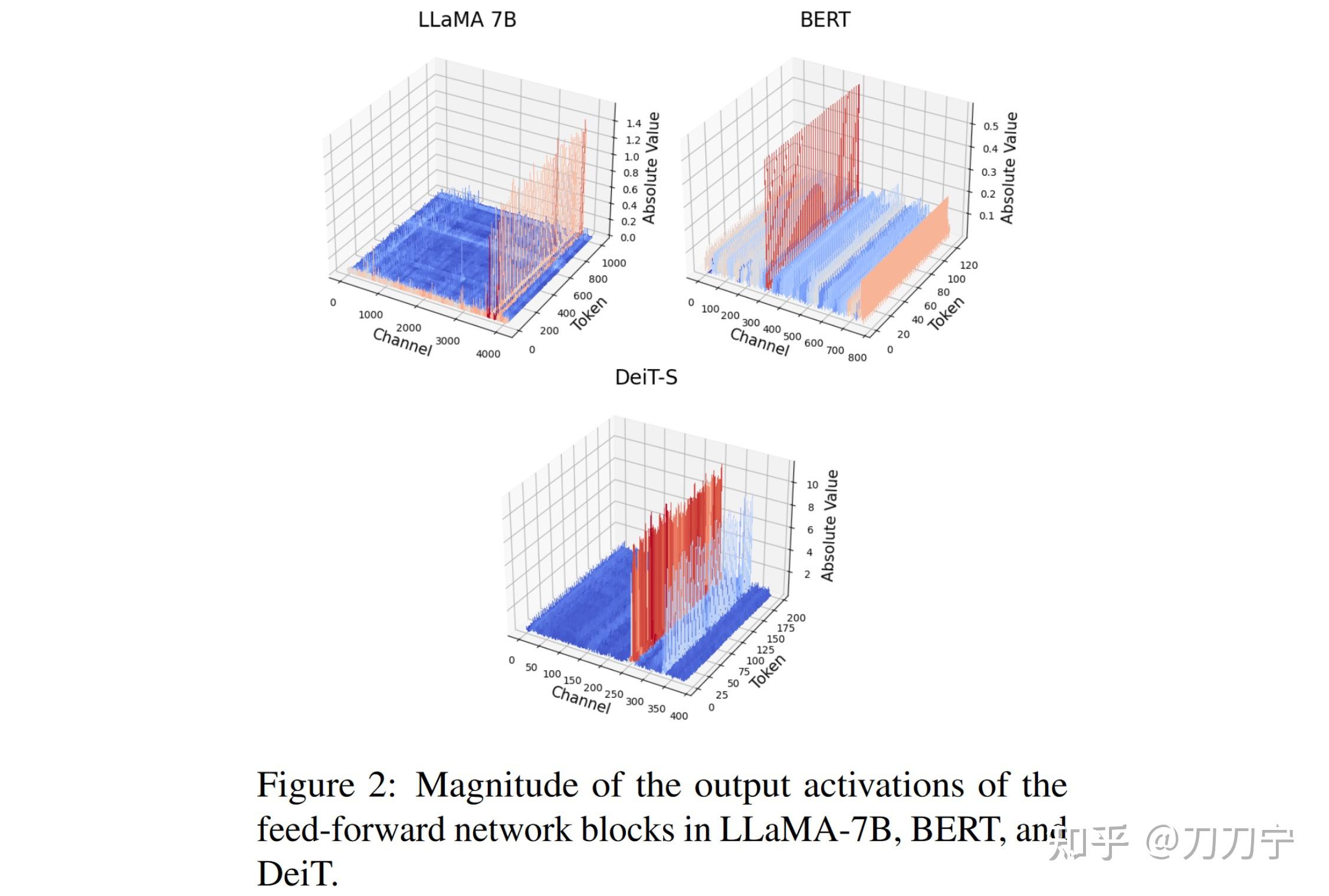
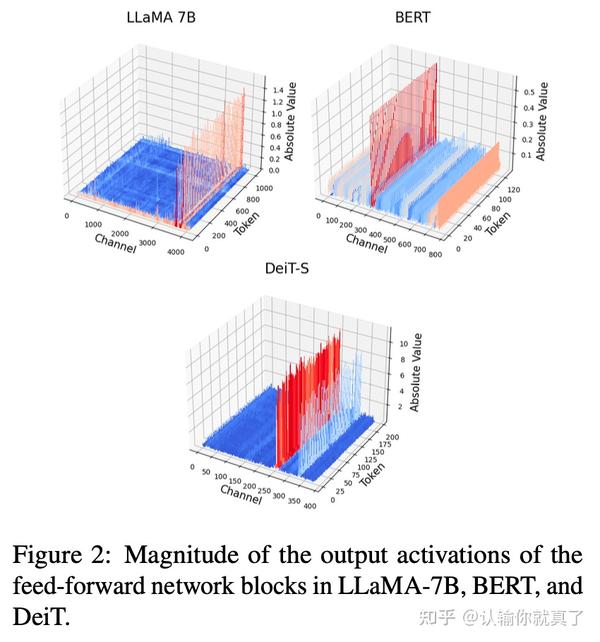
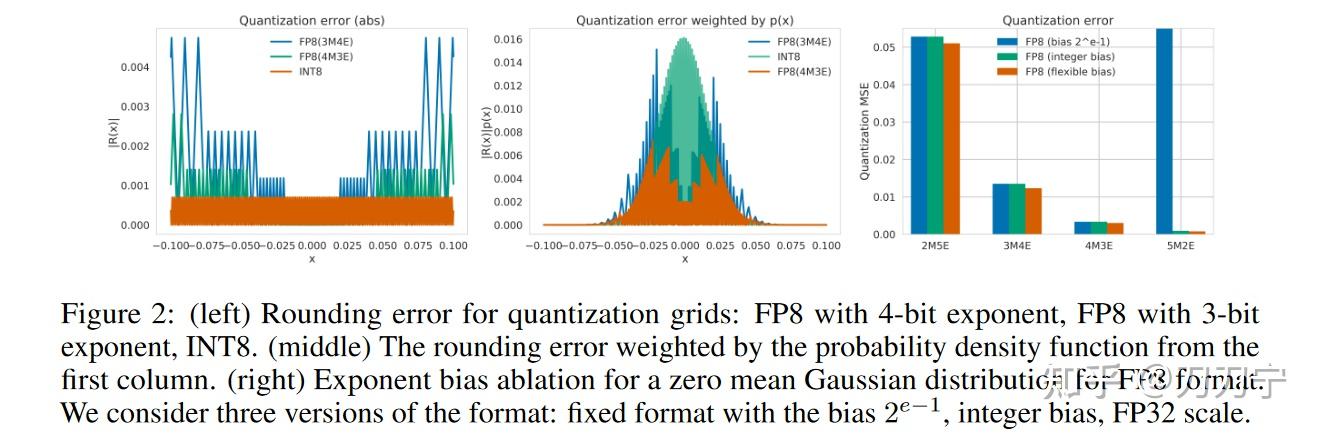
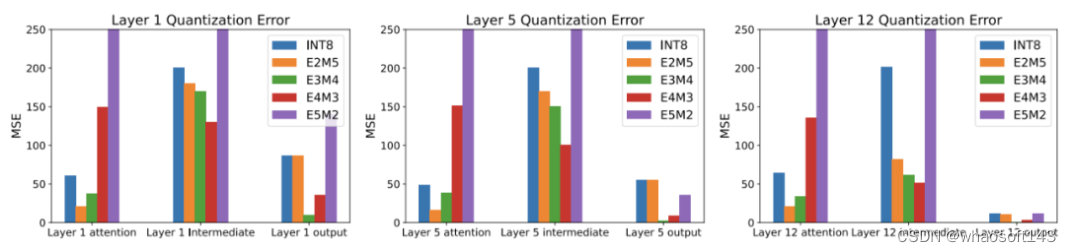
Figure 7 from LLM-FP4: 4-Bit Floating-Point Quantized Transformers ...
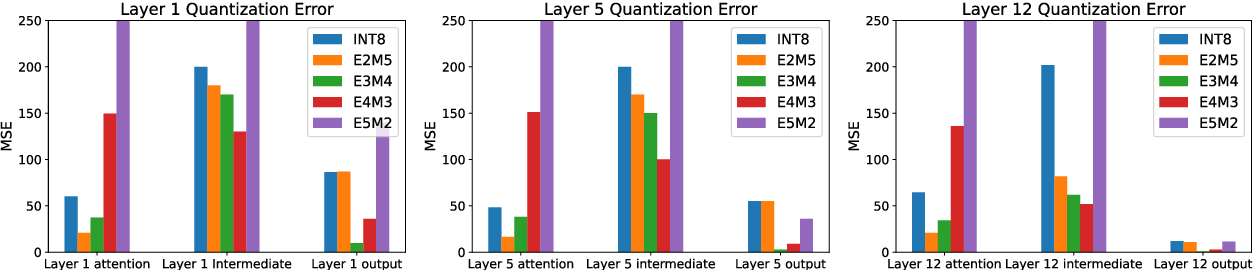
Figure 3 from LLM-FP4: 4-Bit Floating-Point Quantized Transformers ...
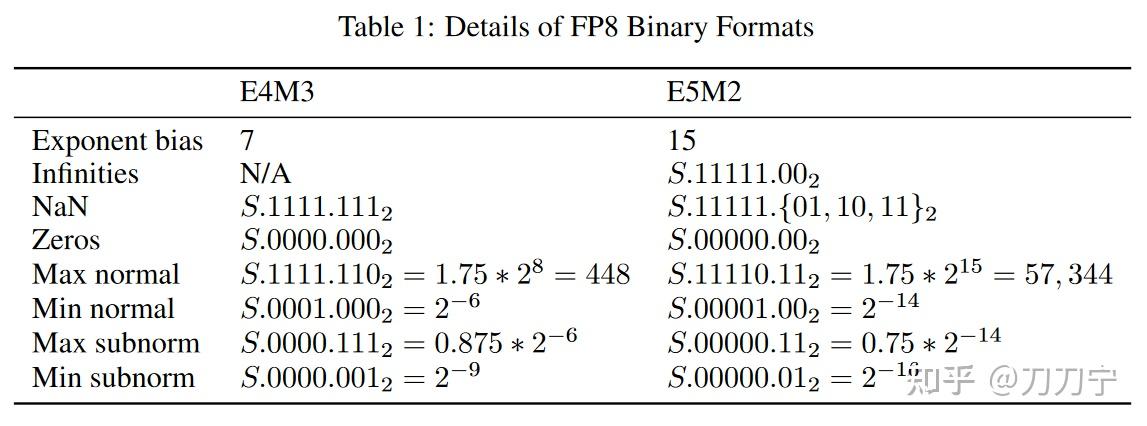
LLM-FP4: 4-Bit Floating-Point Quantized Transformers - ACL Anthology
Optimizing LLMs for Performance and Accuracy with Post-Training ...
[PDF] LLM-FP4: 4-Bit Floating-Point Quantized Transformers | Semantic ...
Paper page - LLM-FP4: 4-Bit Floating-Point Quantized Transformers
[IDSL Paper Review] LLM-FP4 - YouTube
低比特LLM量化(INT4, NF4, FP4)
LLM-FP4 model inference problem · Issue #8 · nbasyl/LLM-FP4 · GitHub
Table 6 from LLM-FP4: 4-Bit Floating-Point Quantized Transformers ...
GitHub - nbasyl/LLM-FP4: The official implementation of the EMNLP 2023 ...
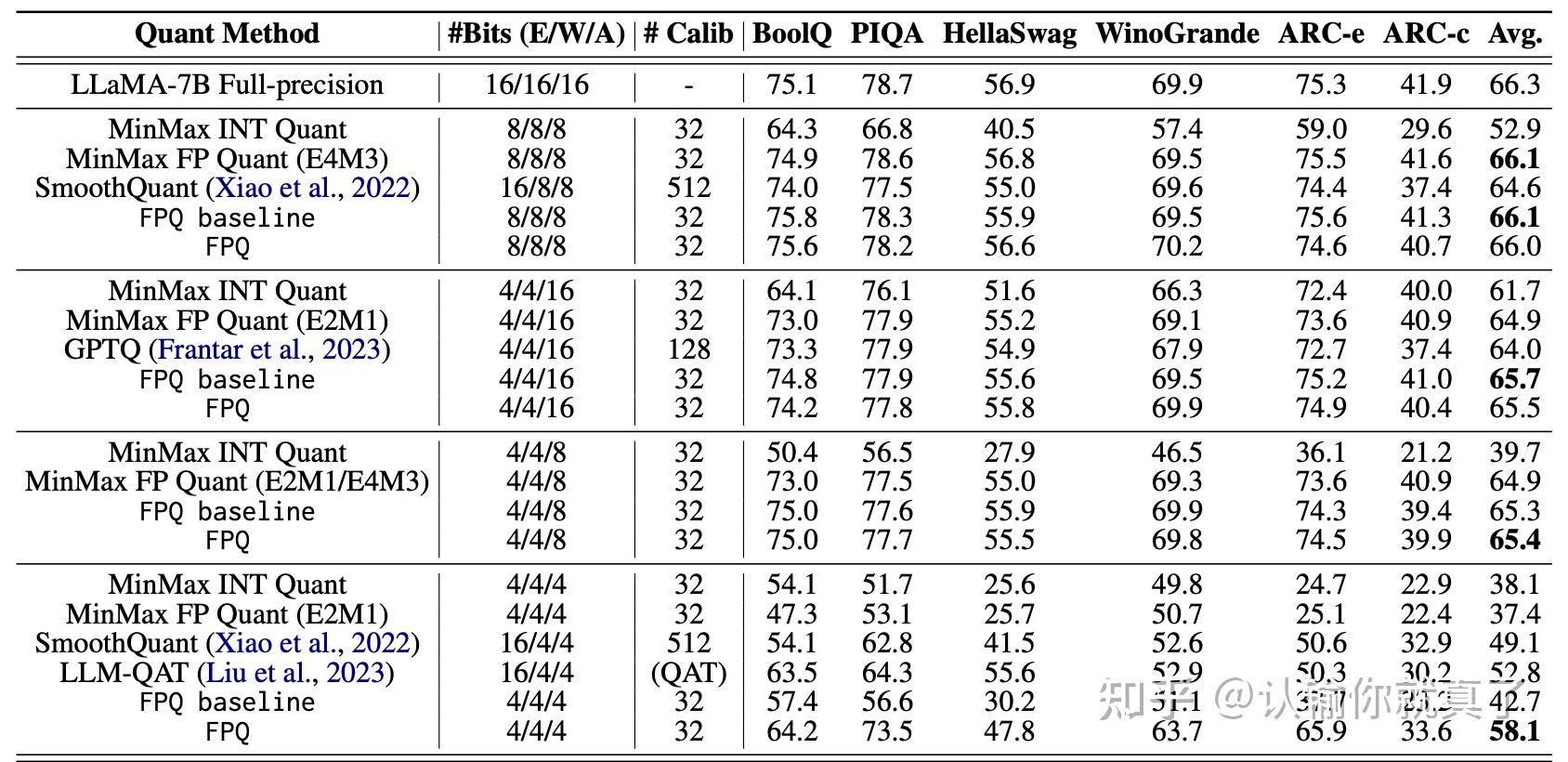
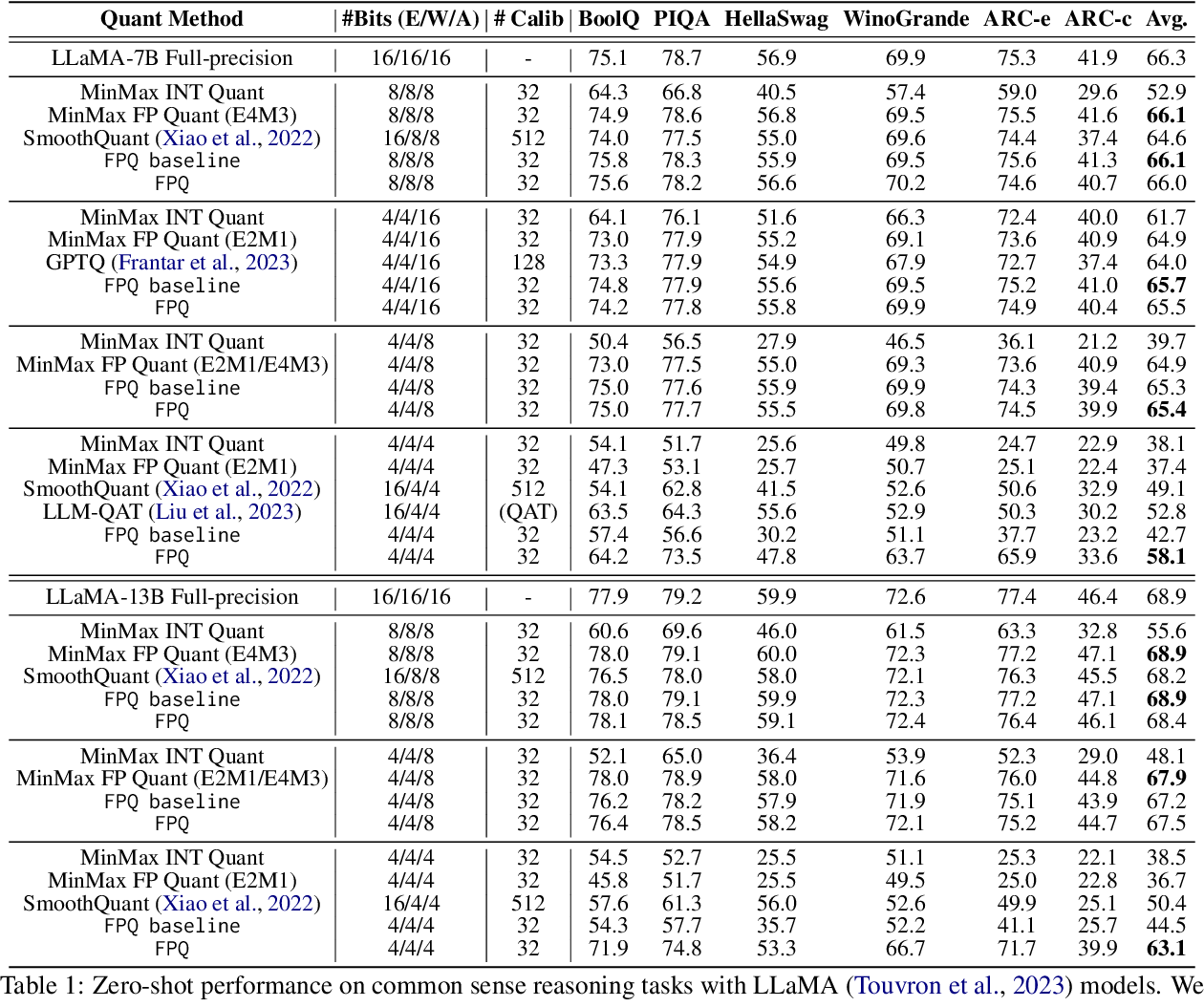
Table 1 from LLM-FP4: 4-Bit Floating-Point Quantized Transformers ...
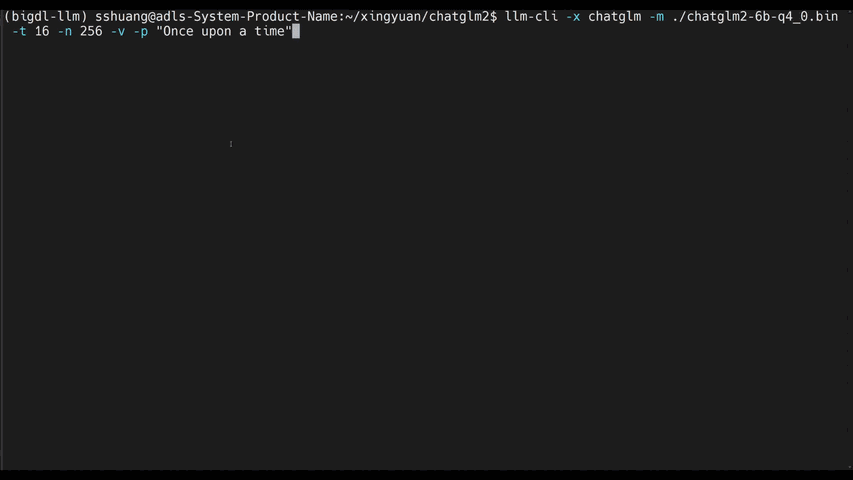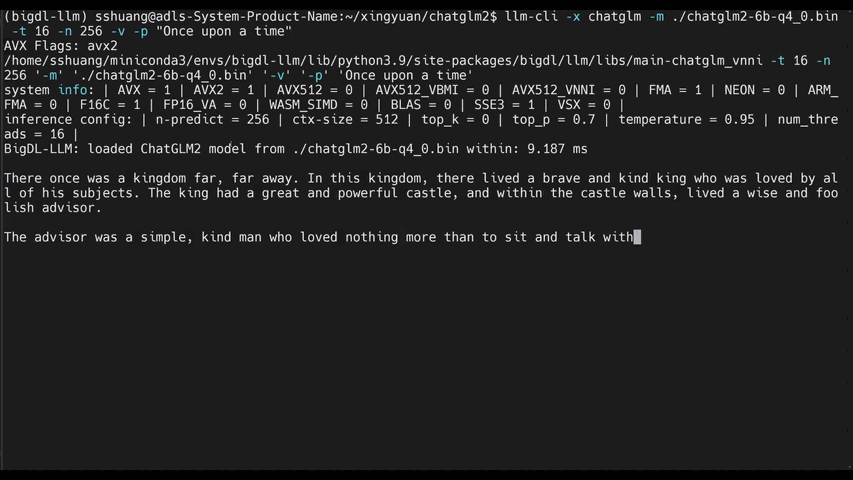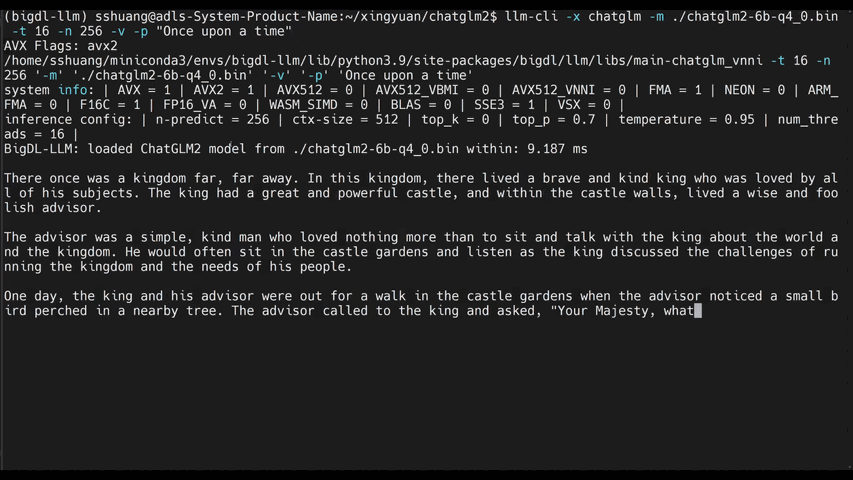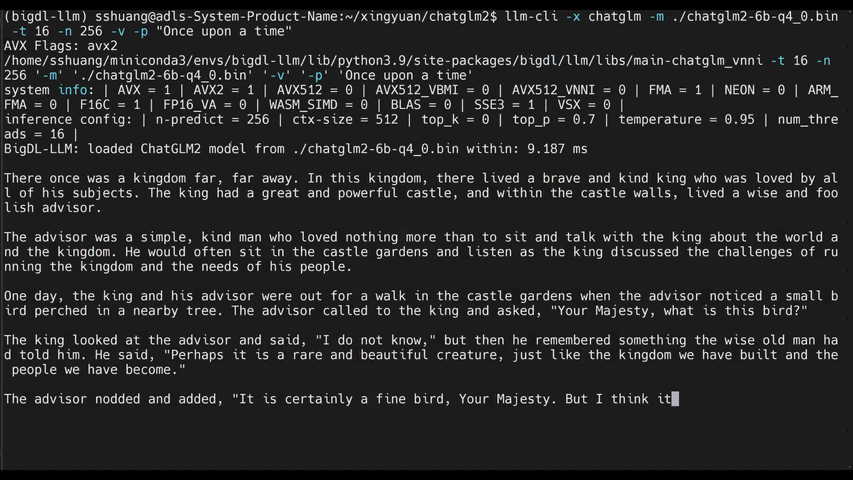
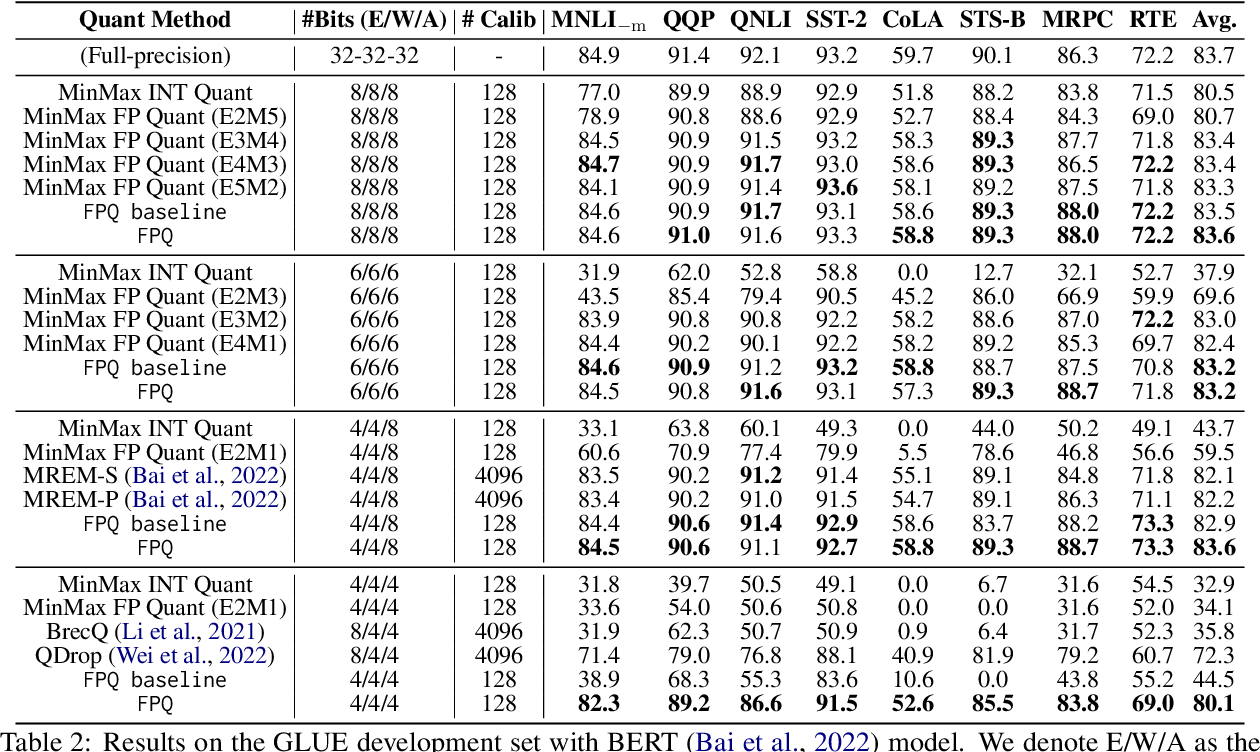
Table 5 from LLM-FP4: 4-Bit Floating-Point Quantized Transformers ...
LLM-FP4: 4-Bit Floating-Point Quantized Transformers: Paper and Code
LLM-FP4-CSDN博客
LLM을 소비자 하드웨어에서 학습 위한 검토-FP4와 양자화 @자료실 - (사)경남ICT협회
Publications | VSDL
LLM-FP4 Transformer极低bit量化论文简析 - 知乎
LLM百倍推理加速之量化篇 - 知乎
量化那些事之FP8与LLM-FP4 - 53AI-AI知识库|企业AI知识库|大模型知识库|AIHub
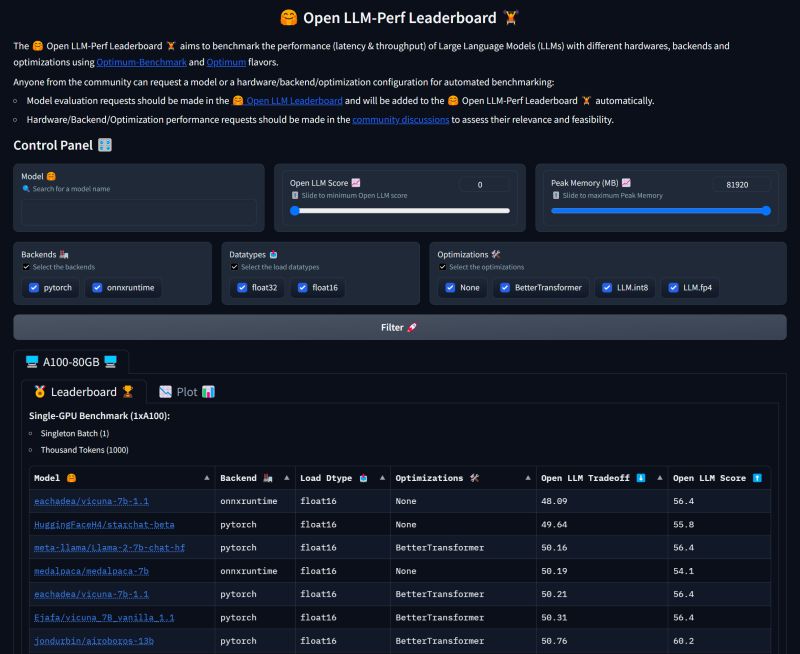
🤗 Open LLM-Perf updates 🦙: - Llama-2 benchmarks with memory and latency ...
open-llm-leaderboard/ehristoforu__fp4-14b-v1-fix-details · Datasets at ...
QLORA:LLM的高效量化微调 - 知乎
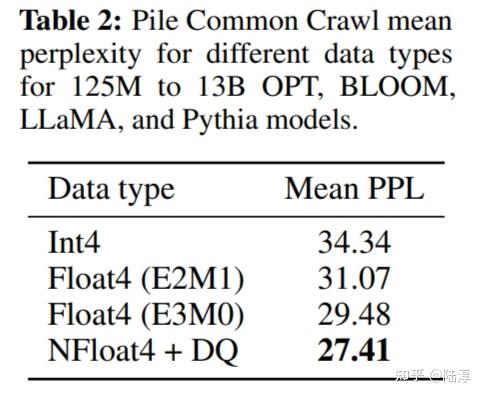
【手撕LLM-QLoRA】NF4与双量化-源码解析 - 知乎
nvidia/DeepSeek-R1-FP4 · Request for Detailed Benchmarking Setup with ...
EMNLP 2023 | 解决LLaMA、BERT等部署难题:首个4-bit浮点量化LLM来了-CSDN博客
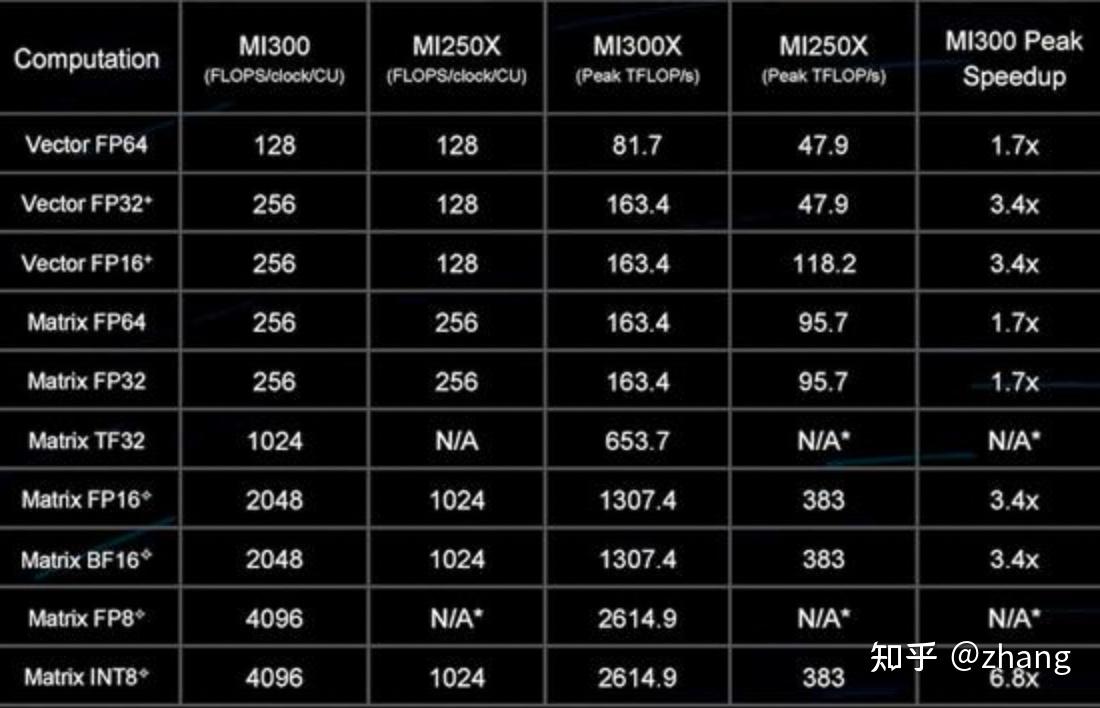
NVIDIA Blackwell Up To 2.2x Faster Than Hopper In MLPerf v4.1 AI ...
Advantech Unveils “Edge AI-Powered Robotics in - Advantech
模型量化-llm量化 - 知乎
[Awesome-LLM-Inference]🔥第三期:30篇,LLM推理论文集-500页PDF💡 - 知乎
LLM微调方法(Efficient-Tuning)六大主流方法:思路讲解&优缺点对比[P-tuning、Lora、等]_llms大模型 ...
Entwickelt für hohe Leistung und Effizienz beim KI-Reasoning | NVIDIA ...
LLM-CPUs上的高效LLM推理 - 知乎
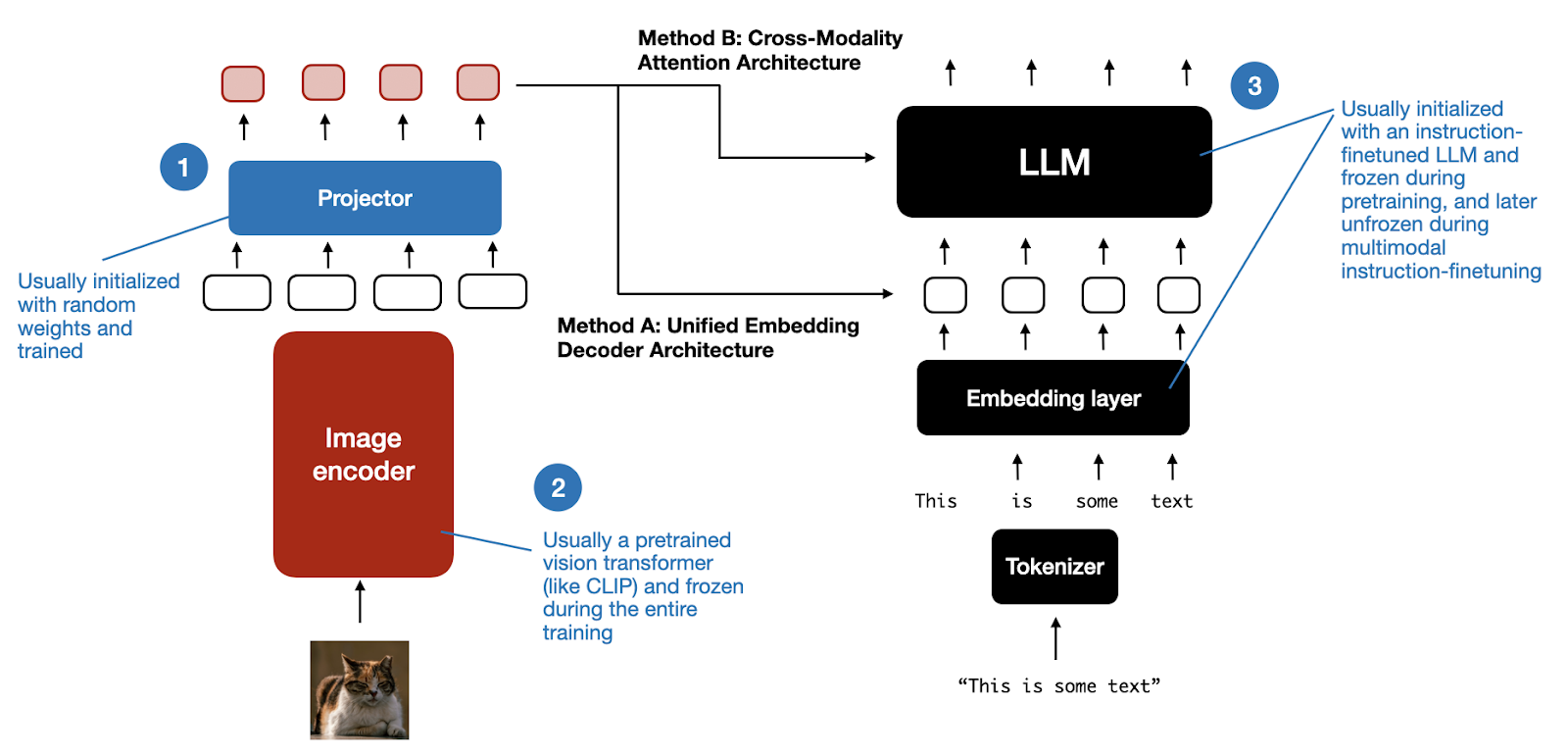
Understanding Multimodal LLMs - Avinash Barnwal, Ph.D.
TensorRT-LLMによるRTX 5090でのLLMのNVFP4量子化・推論
QLoRA:4-bit级别的量化+LoRA方法,用3090在DB-GPT上打造基于33B LLM的个人知识库 - 知乎
LLM(十八):LLM 的推理优化技术纵览_vllm与fastertransformer对比-CSDN博客
Driver crash during warmup of DeepSeek-R1-FP4 · Issue #4816 · NVIDIA ...
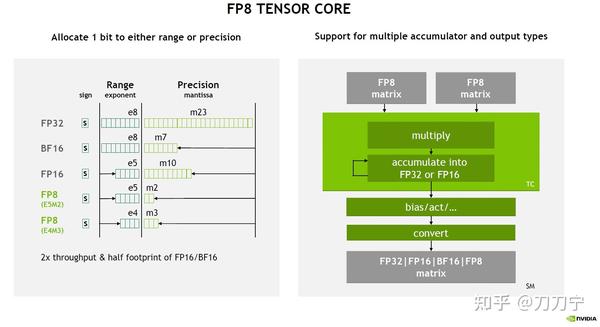
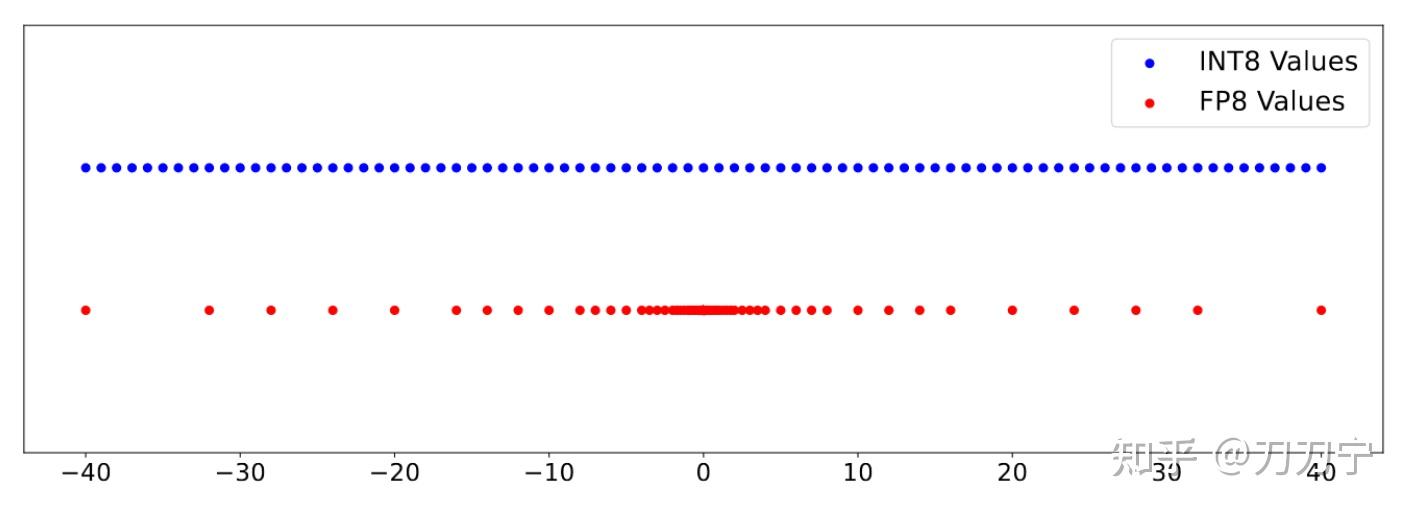
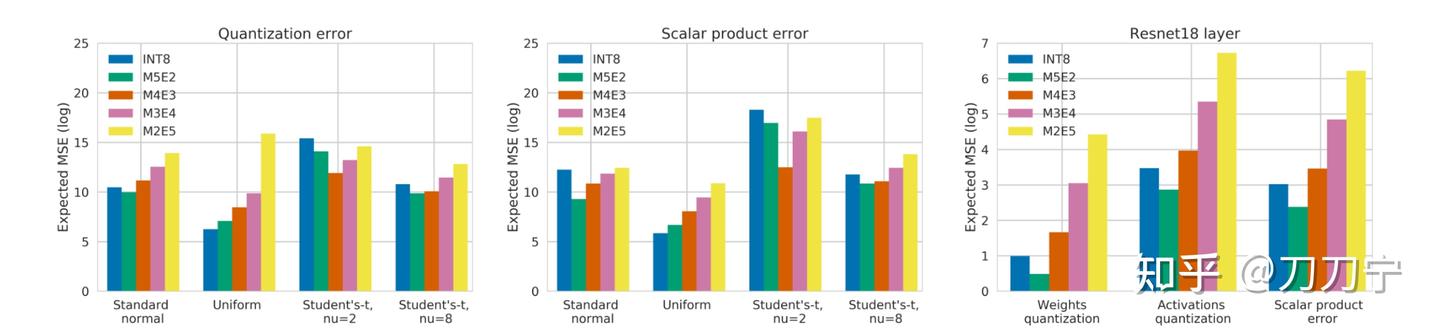
FP8 量化:原理、实现与误差分析-轻识
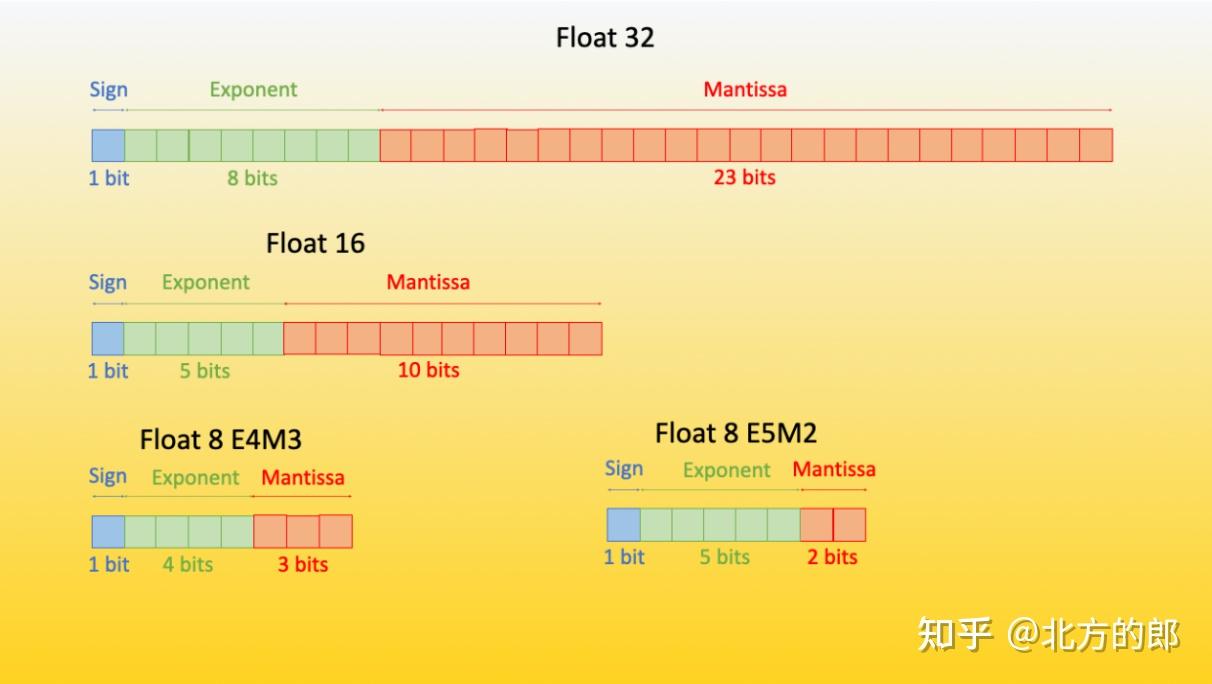
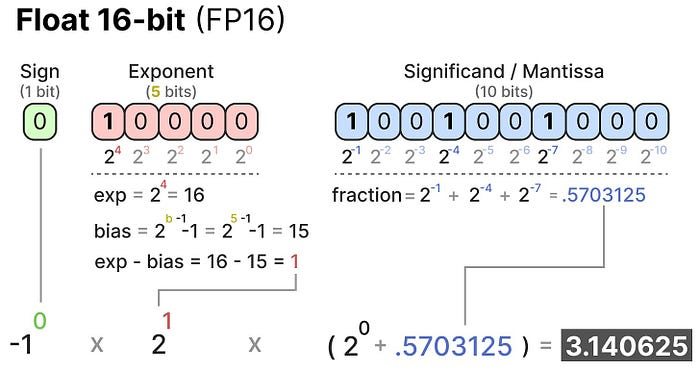
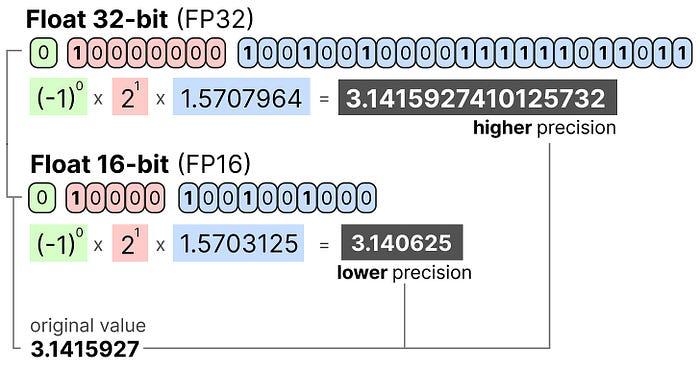
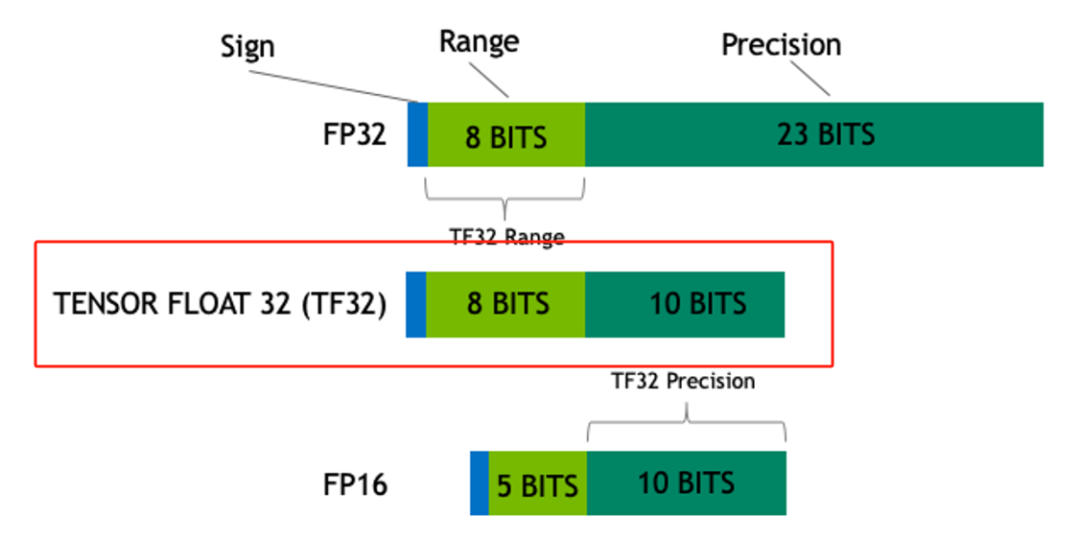
一文讲清楚大模型涉及到的精度:FP32、TF32、FP16、BF16、FP8、FP4、NF4、INT8-CSDN博客
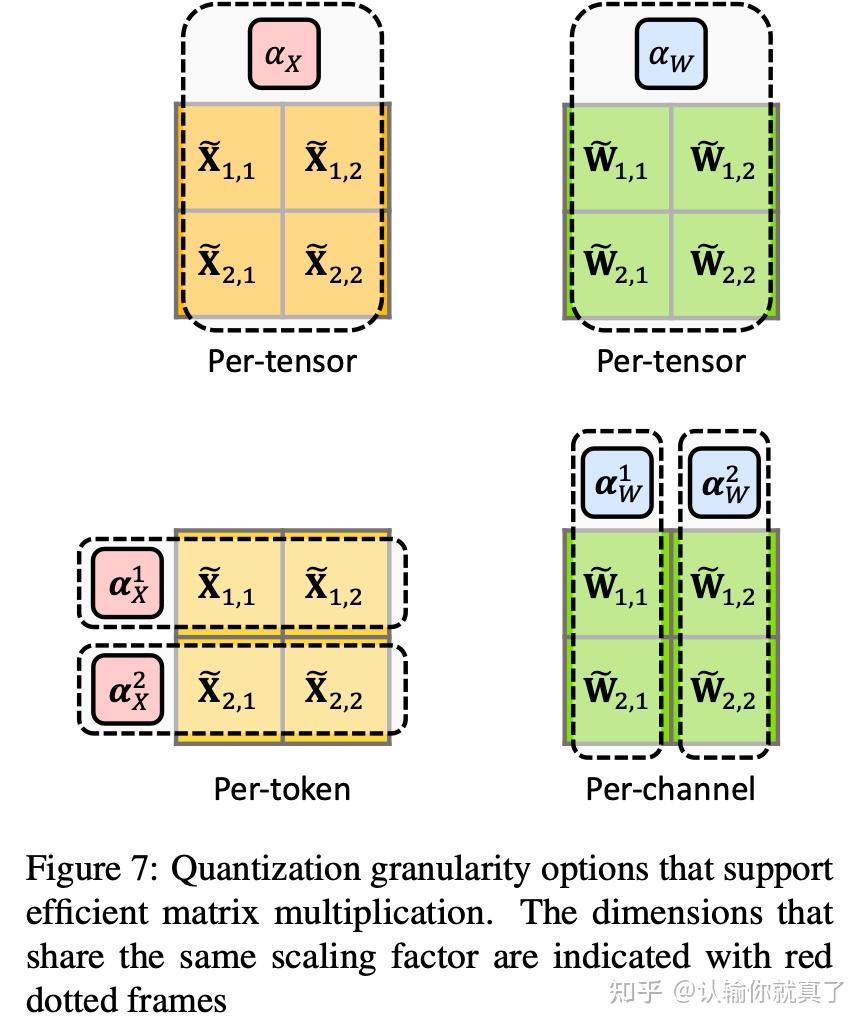
LLMs之Quantization:LLM中量化技术的可视化指南之量化技术的简介、常用数据类型、校准权重和激活值的量化方法(PTQ/QAT ...
DeepLearning.AI | Researchers showed that LLMs can be trained using 4 ...