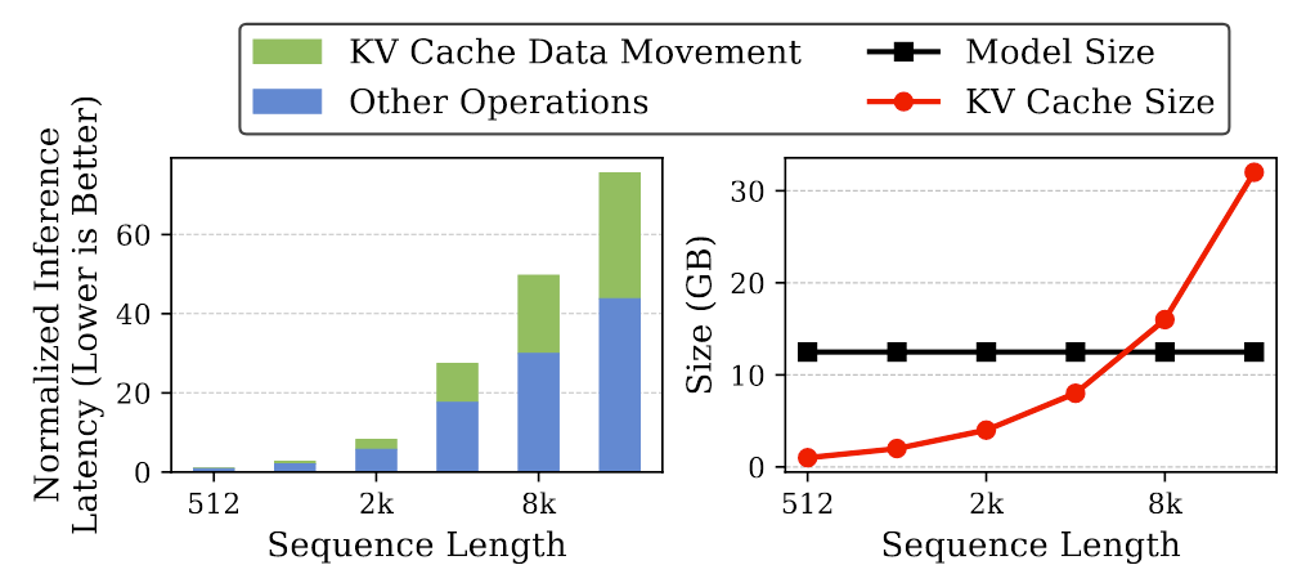
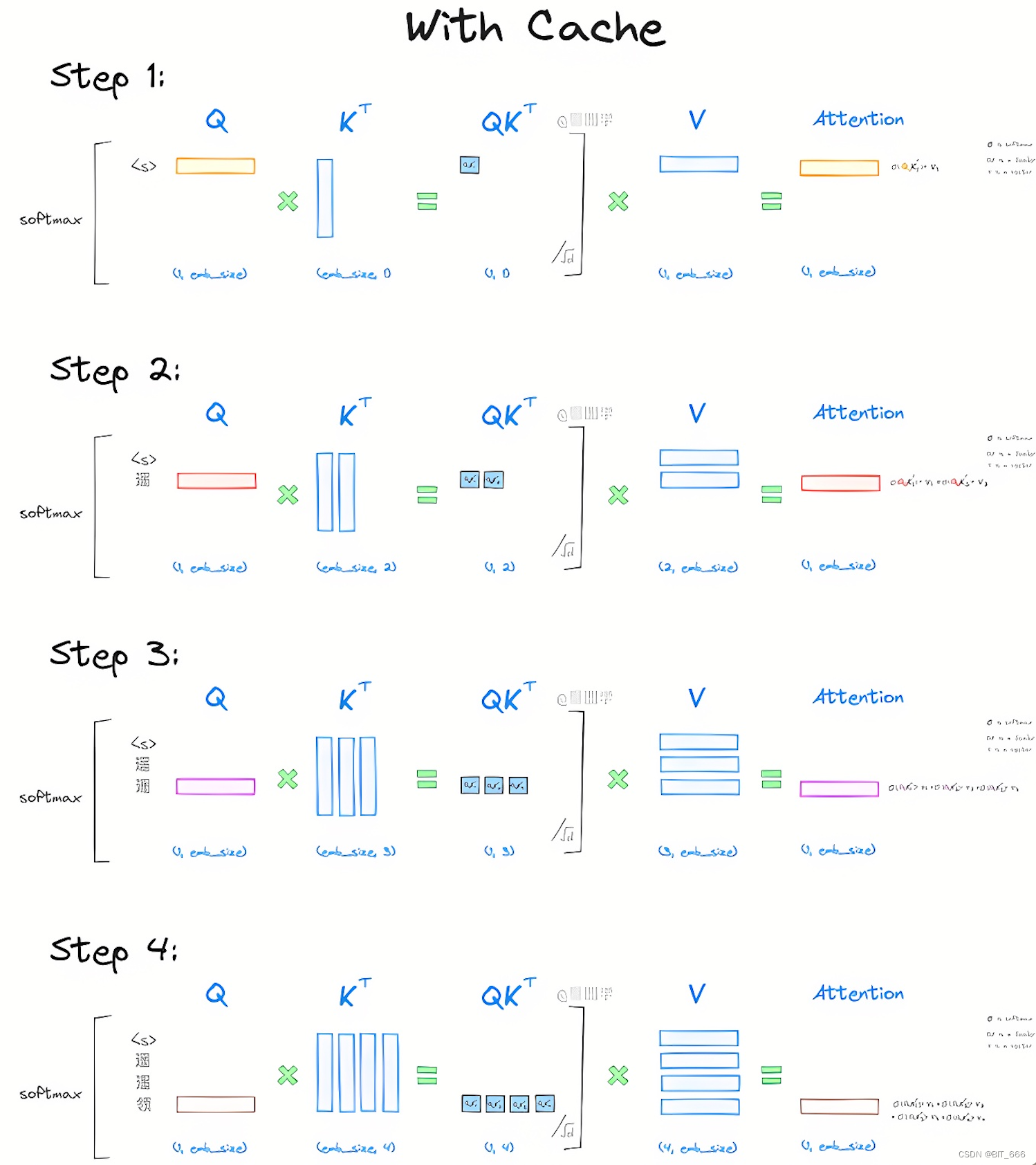
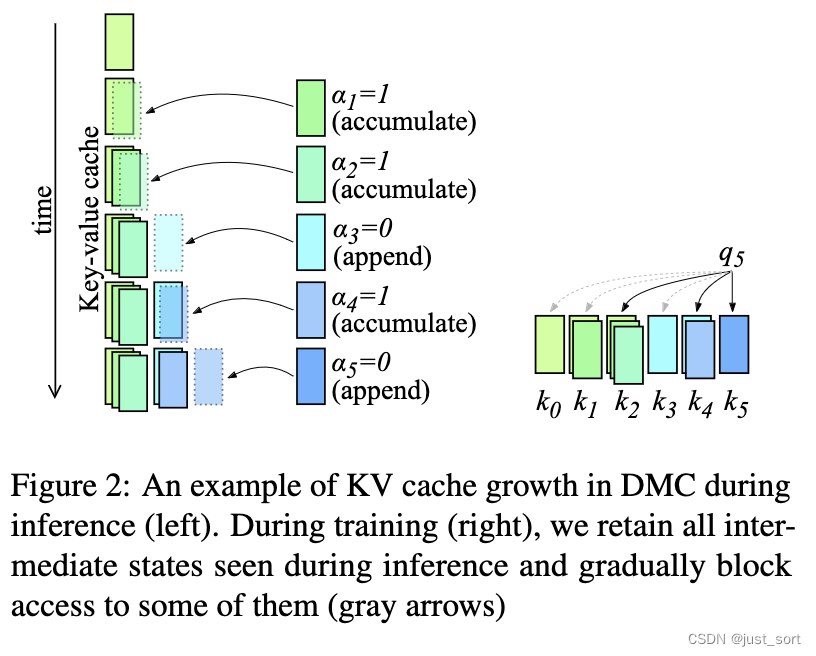
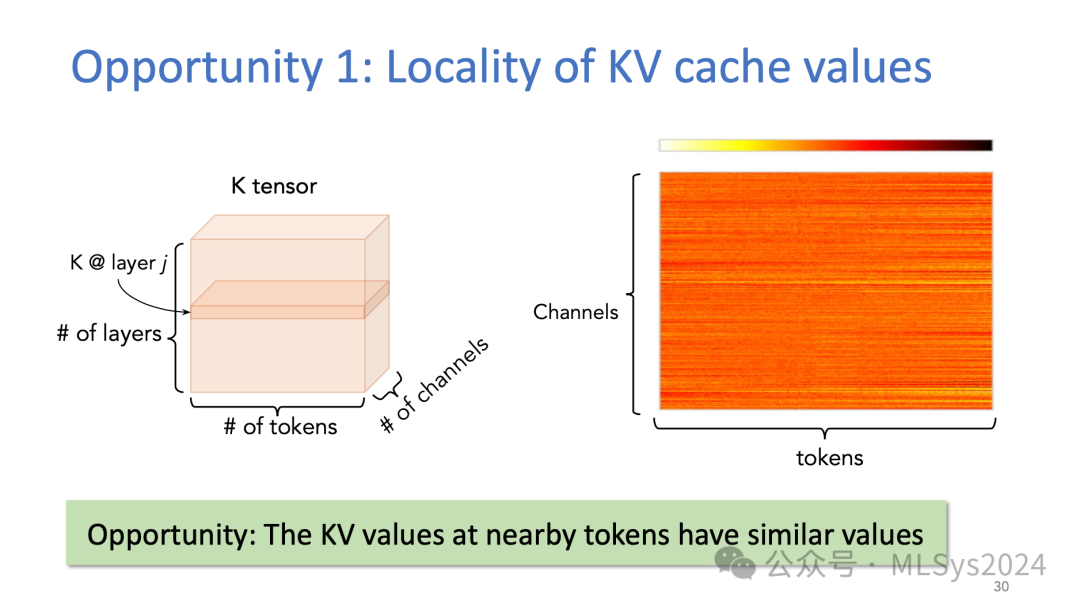
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
KV cache offloading - exploring the benefits of shared storage - NetApp ...
KV Cache Offloading - When is it Beneficial? - NetApp Community
KV Cache Offloading for LLM Inference Using CXL-UEC Fabrics (Part II)
Dell PowerScale and ObjectScale with KV Cache Offloading | ITN
KV cache SSD Offloading · Issue #159 · kvcache-ai/Mooncake · GitHub
[RFC]: KV cache offloading · Issue #19854 · vllm-project/vllm · GitHub
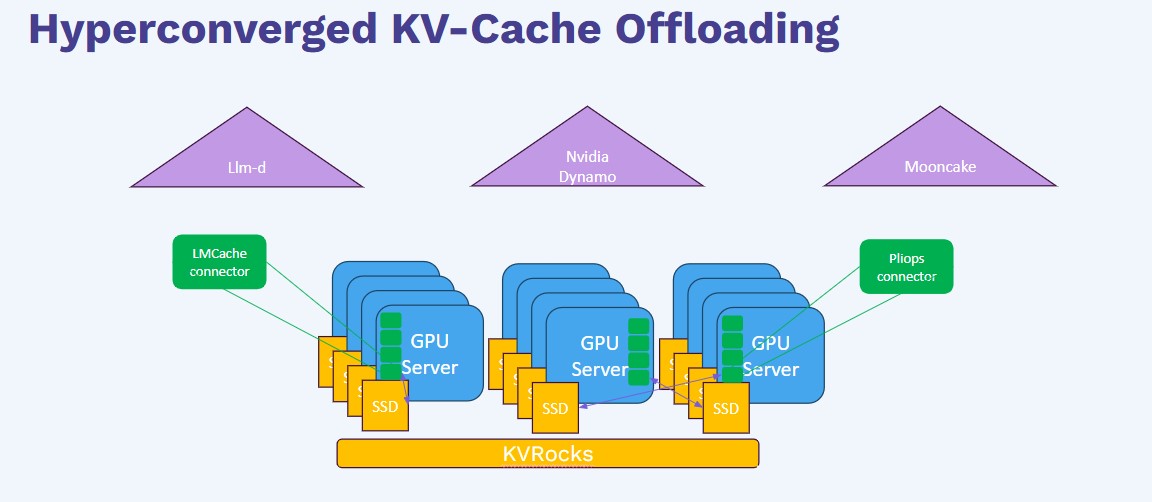
GenAI LLM KV Cache Offloading - Pliops CTO Lecture | Pliops LightningAI
From Bottleneck to Breakthrough: Scalable KV Cache Offloading with Dell ...
Any plans to support KV Cache offloading to CPU (and NVMe)? · Issue ...
Static KV cache with CPU offloading · Issue #32179 · huggingface ...
KV cache offloading | LLM Inference Handbook
KV cache offloading - CPU RAM vs. storage - NetApp Community
Instruction for running Dynamo with KV cache CPU offloading · Issue ...
GenAI LLM KV Cache Offloading - Pliops CTO Lecture - YouTube
LLM Inference: Accelerating Long Context Generation with KV Cache ...
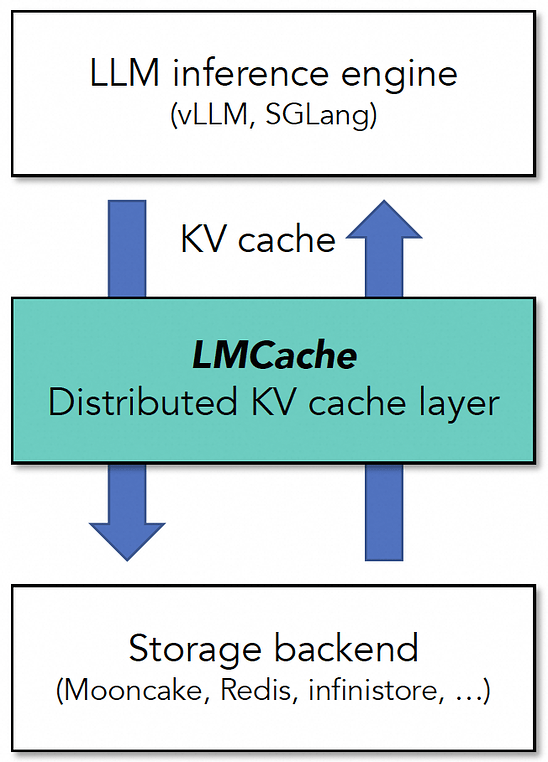
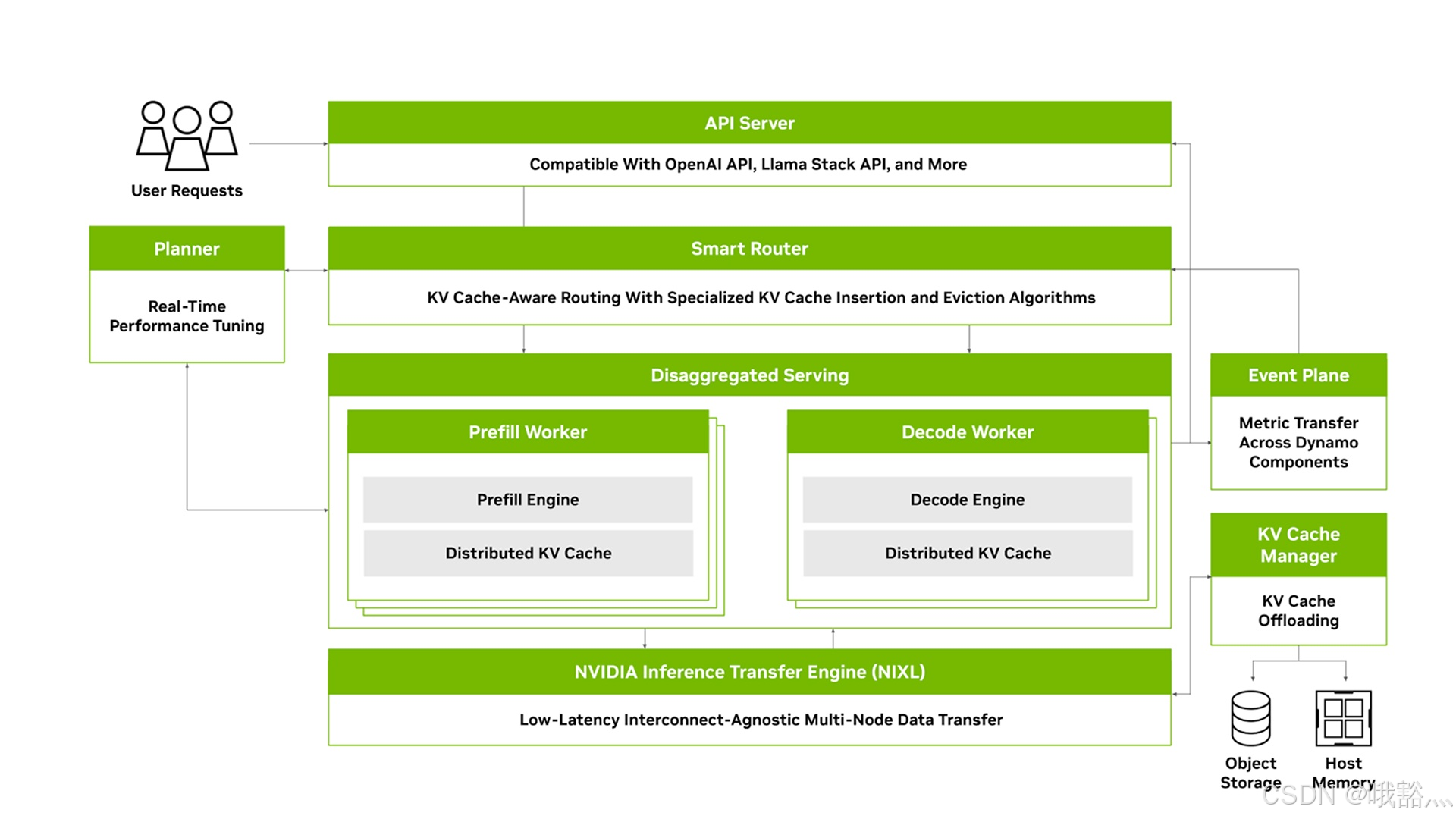
How to Reduce KV Cache Bottlenecks with NVIDIA Dynamo | NVIDIA ...
KV Cache Offload Accelerates LLM Inference - NADDOD Blog
Samsung KV Cache Offloading; +95% rapidez en inferencia IA
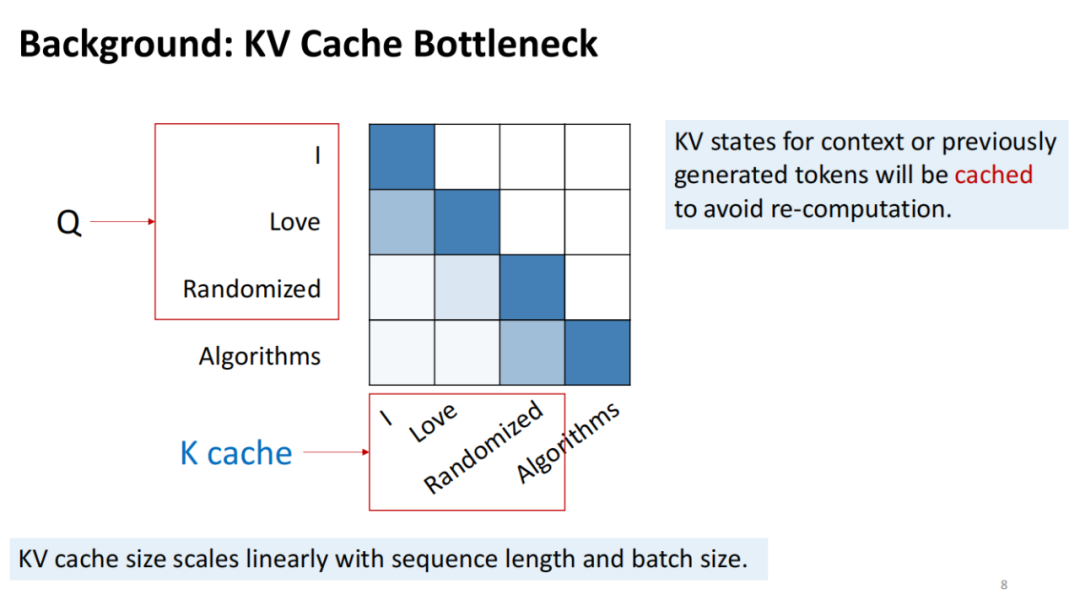
How KV Cache Works & Why It Eats Memory | by M | Foundation Models Deep ...
SGLang HiCache KV Cache offload-CSDN博客
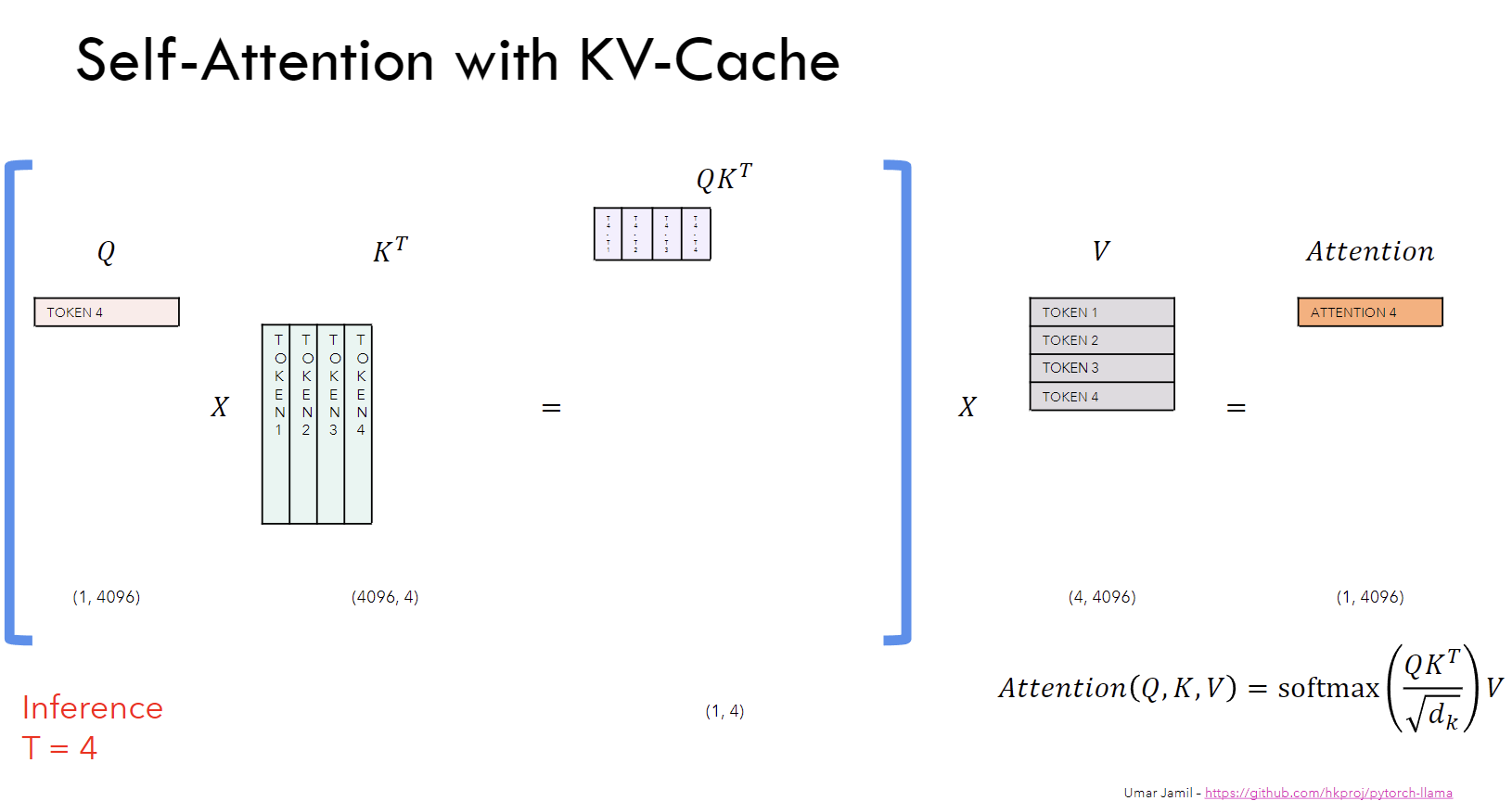
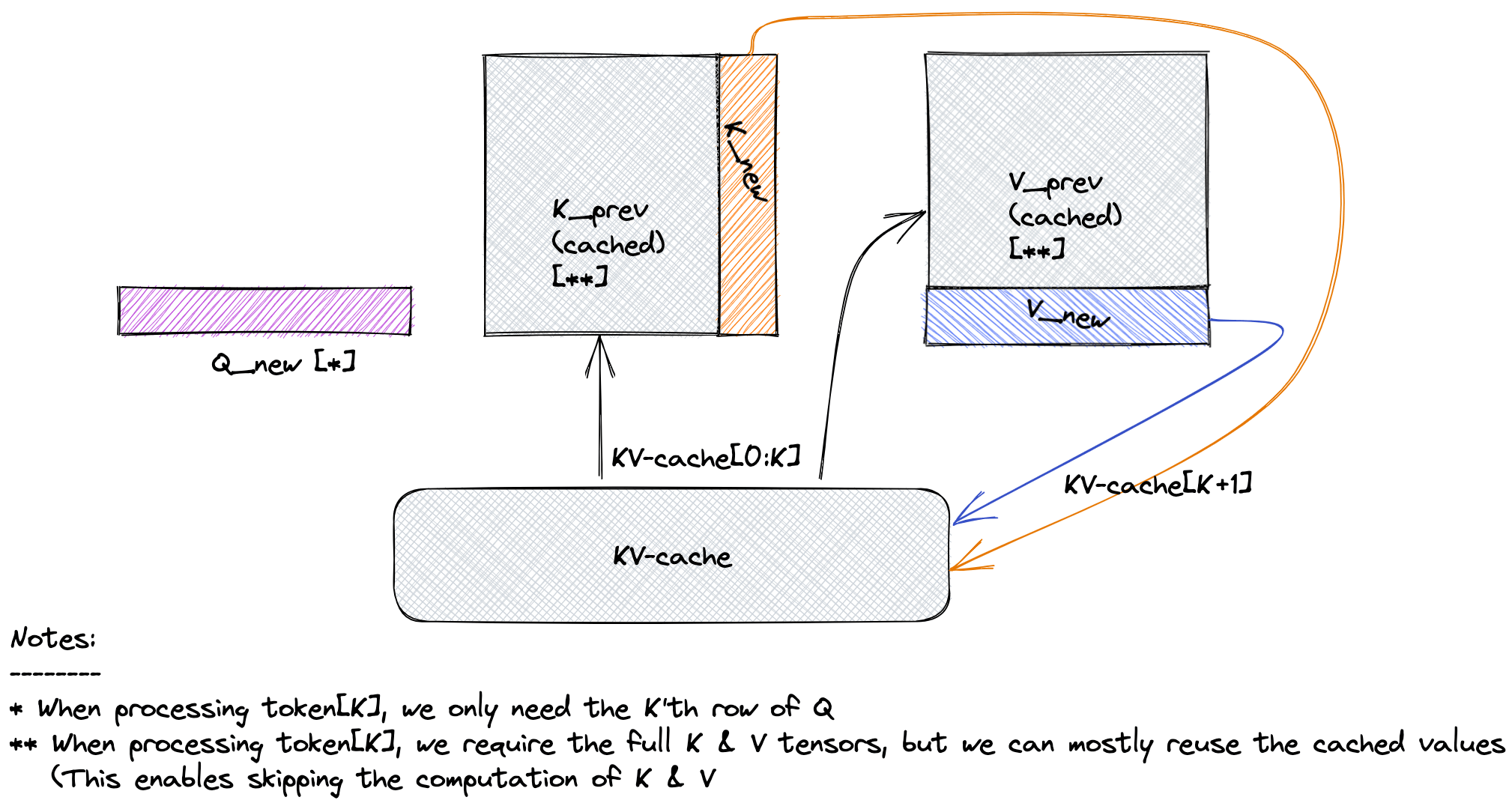
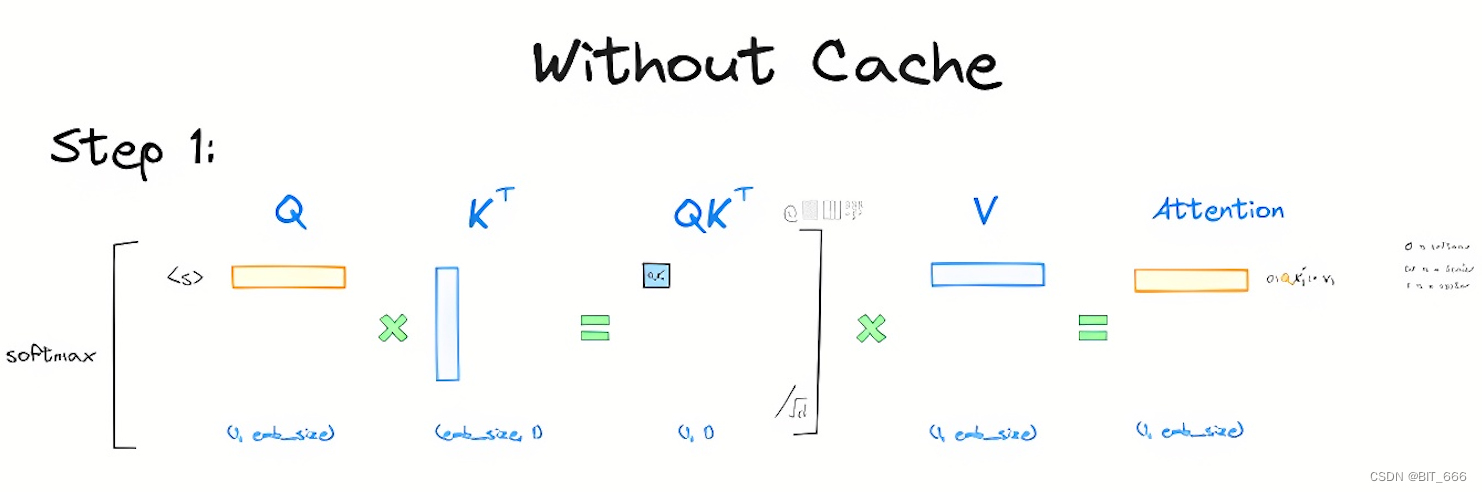
Understanding and Coding the KV Cache in LLMs from Scratch
Accelerate Large-Scale LLM Inference and KV Cache Offload with CPU-GPU ...
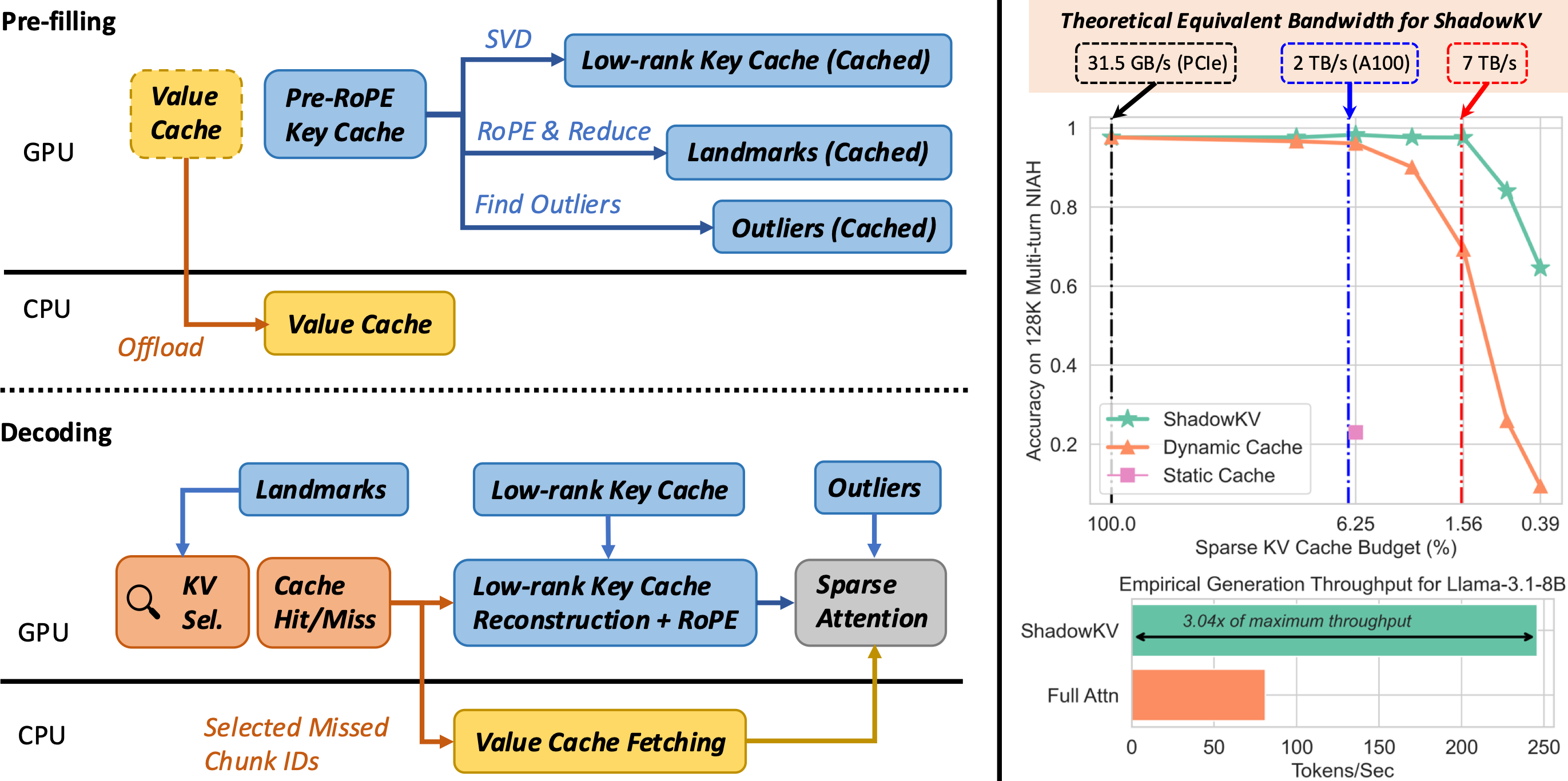
ShadowKV: KV Cache in Shadows for High-Throughput Long-Context LLM ...
Welcome to my blog! - Understanding KV Cache
KV Cache in Transformer Models - Data Magic AI Blog
LLM KV Cache Offloading: Analysis and Practical Considerations by ...
AI 推理 KV Cache 详解:Transformer 架构下的性能优化关键 - 开发技术 - 冷月清谈
GitHub - llm-d/llm-d-kv-cache: Distributed KV cache scheduling ...
How To Use KV Cache Quantization for Longer Generation by LLMs - YouTube
KV Cache Transform Coding for Compact Storage in LLM Inference ...
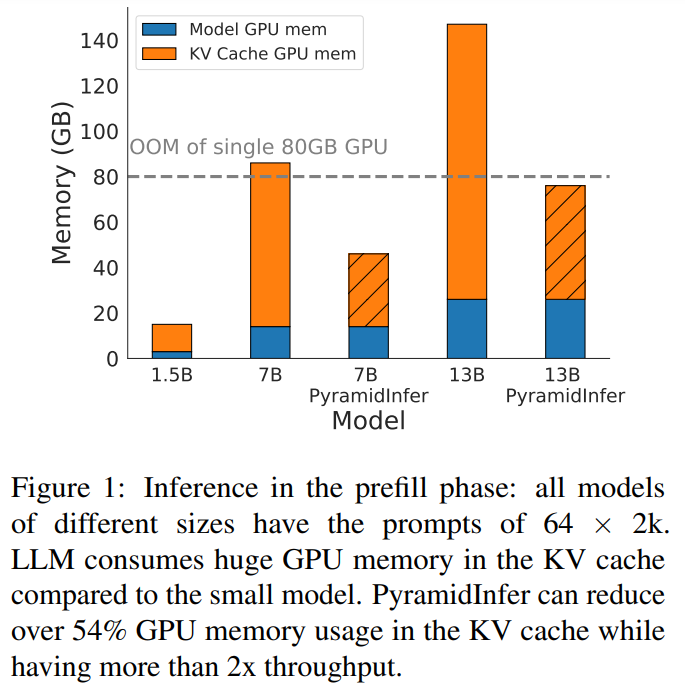
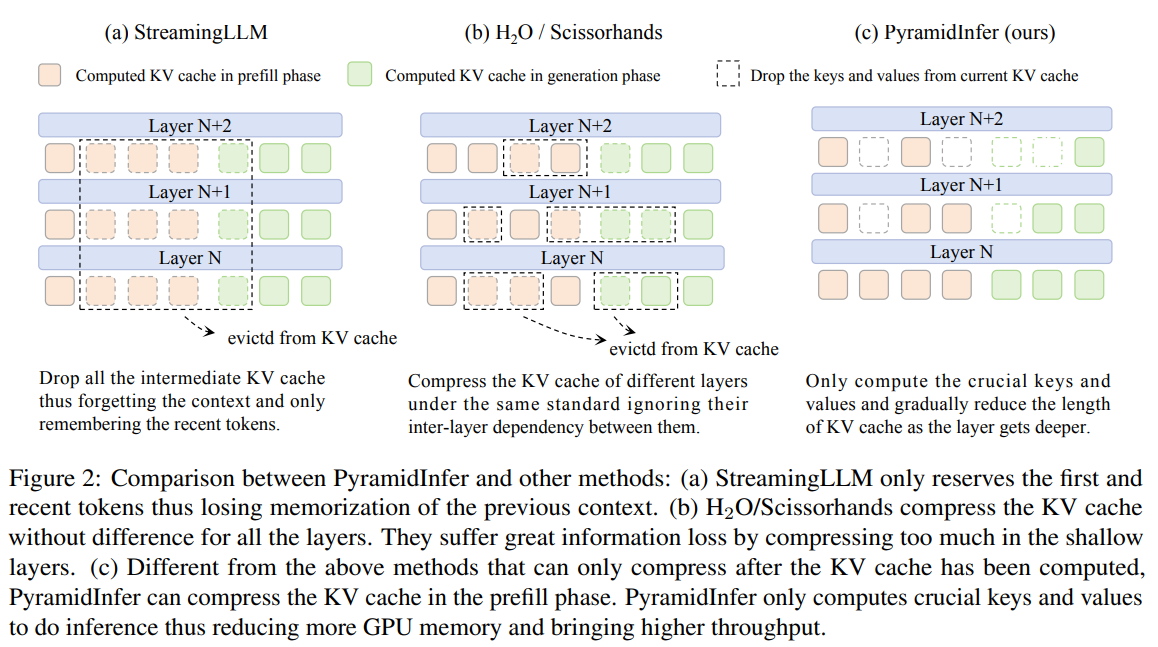
PyramidInfer: Allowing Efficient KV Cache Compression for Scalable LLM ...
5x Faster Time to First Token with NVIDIA TensorRT-LLM KV Cache Early ...
NVIDIA Dynamo 推理框架_sglang kv cache offload-CSDN博客
Understanding KV Cache and Paged Attention in LLMs: A Deep Dive into ...
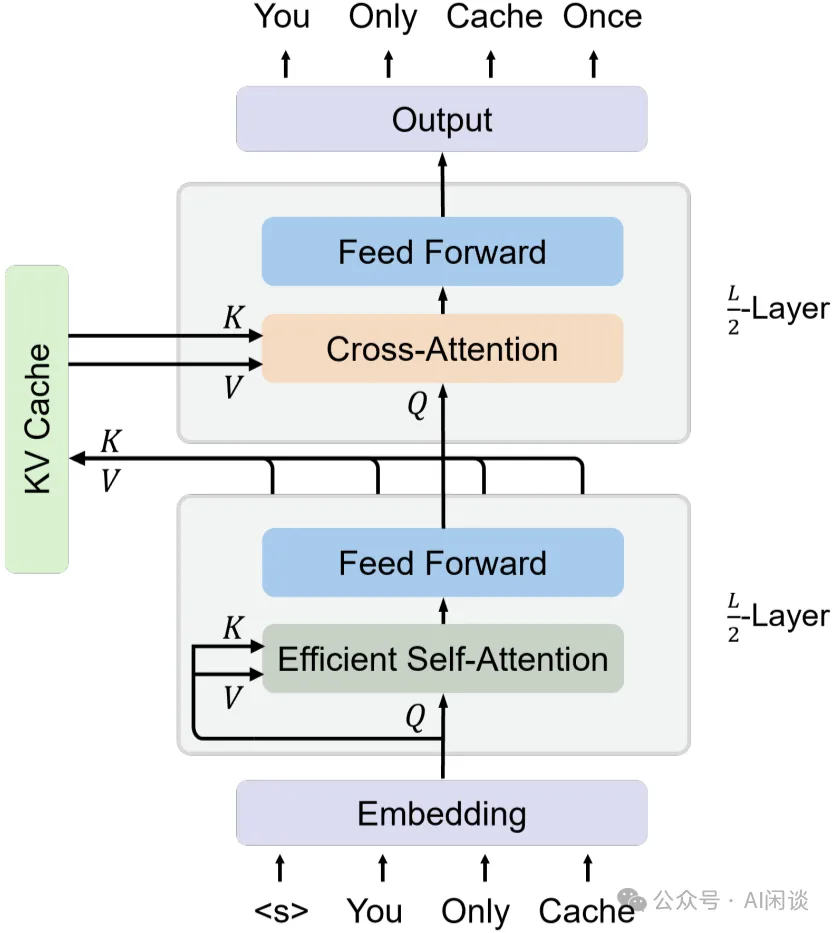
UX - SimLayerKV: An Efficient Solution to KV Cache Challenges in Large ...
[RFC]: Offload KV cache to CPU in V1 · Issue #16144 · vllm-project/vllm ...
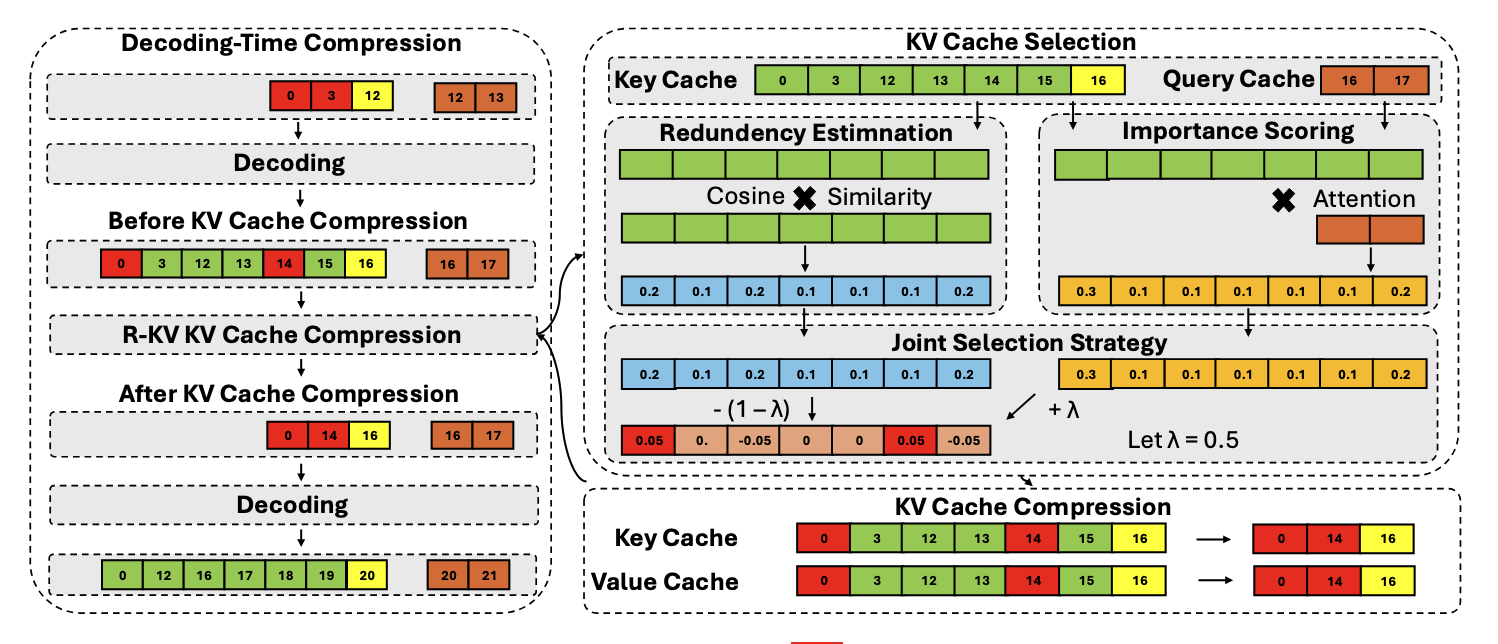
R-KV: Redundancy-aware KV Cache Compression for Reasoning Models
LLM Jargons Explained: Part 4 - KV Cache - YouTube
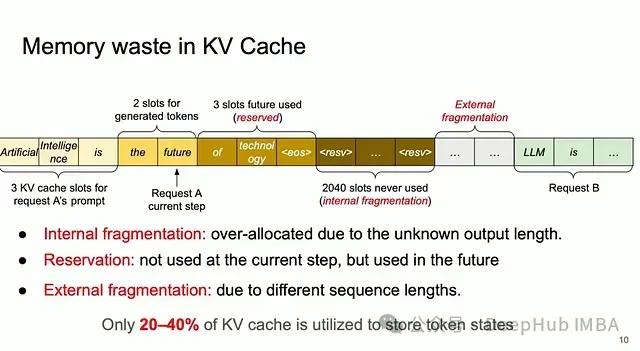
Techniques for KV Cache Optimization in Large Language Models
KV Cache Quantization Overview
并行 & 框架 & 优化(六)——Megatron-LM, KV Cache
MiniCache 和 PyramidInfer 等 6 种优化 LLM KV Cache 的最新工作-AI.x-AIGC专属社区-51CTO.COM
KIVI: A Plug-and-Play 2-bit KV Cache Quantization Algorithm without the ...
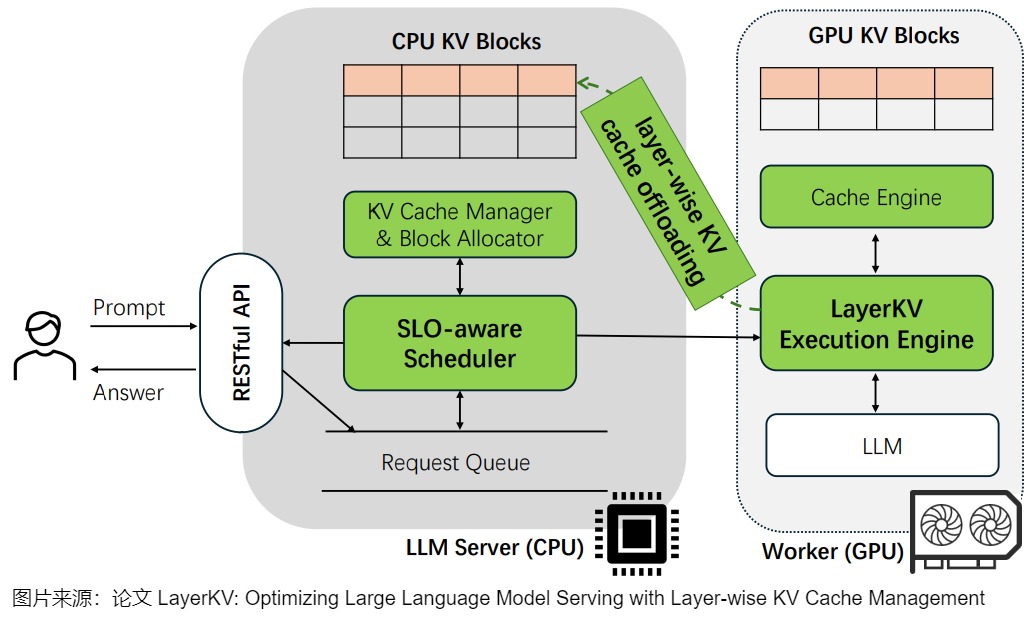
How Pliops LightningAI Redefines KV-Cache Offloading for Scalable GenAI ...
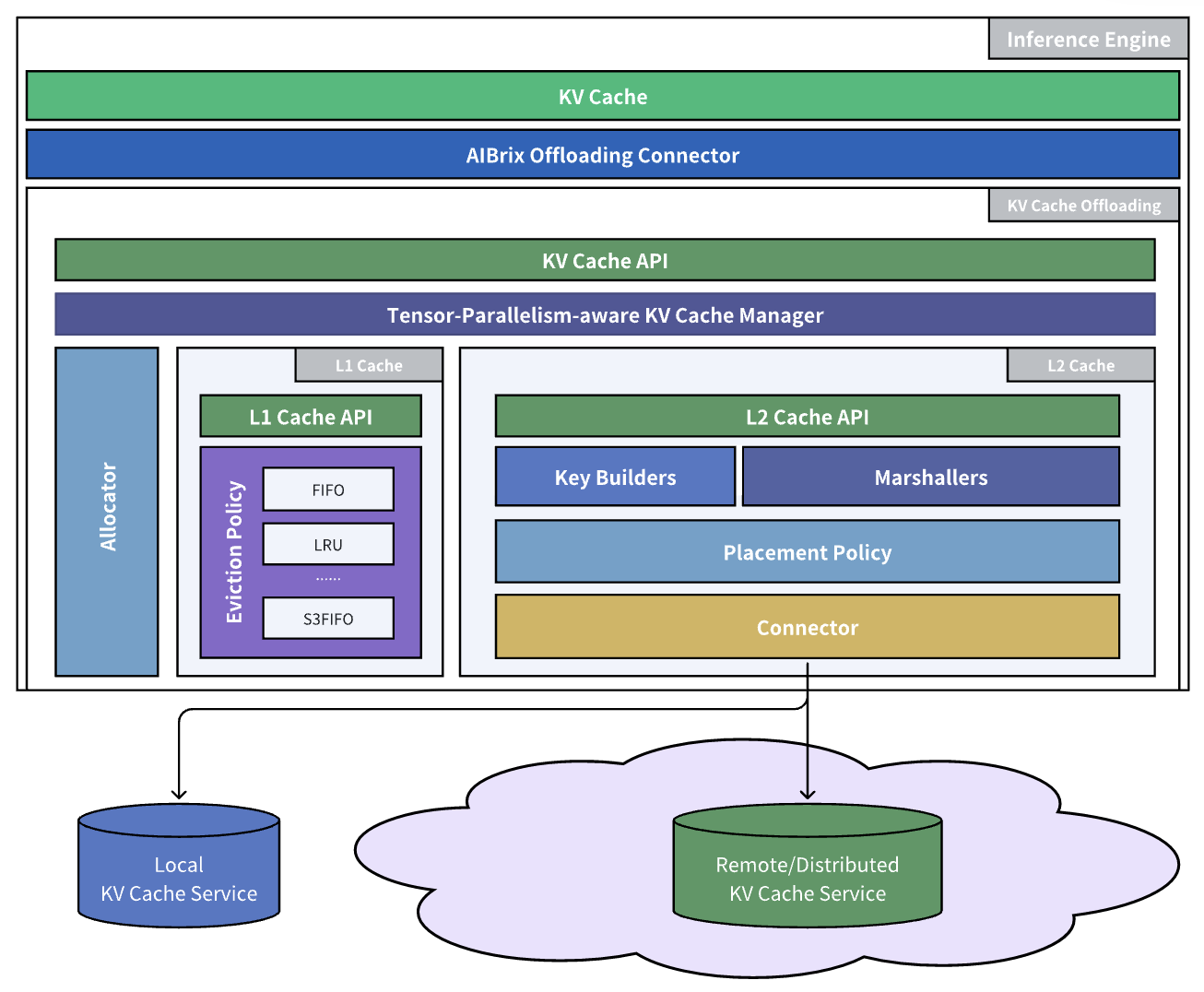
AIBrix KVCache Offloading Framework — AIBrix
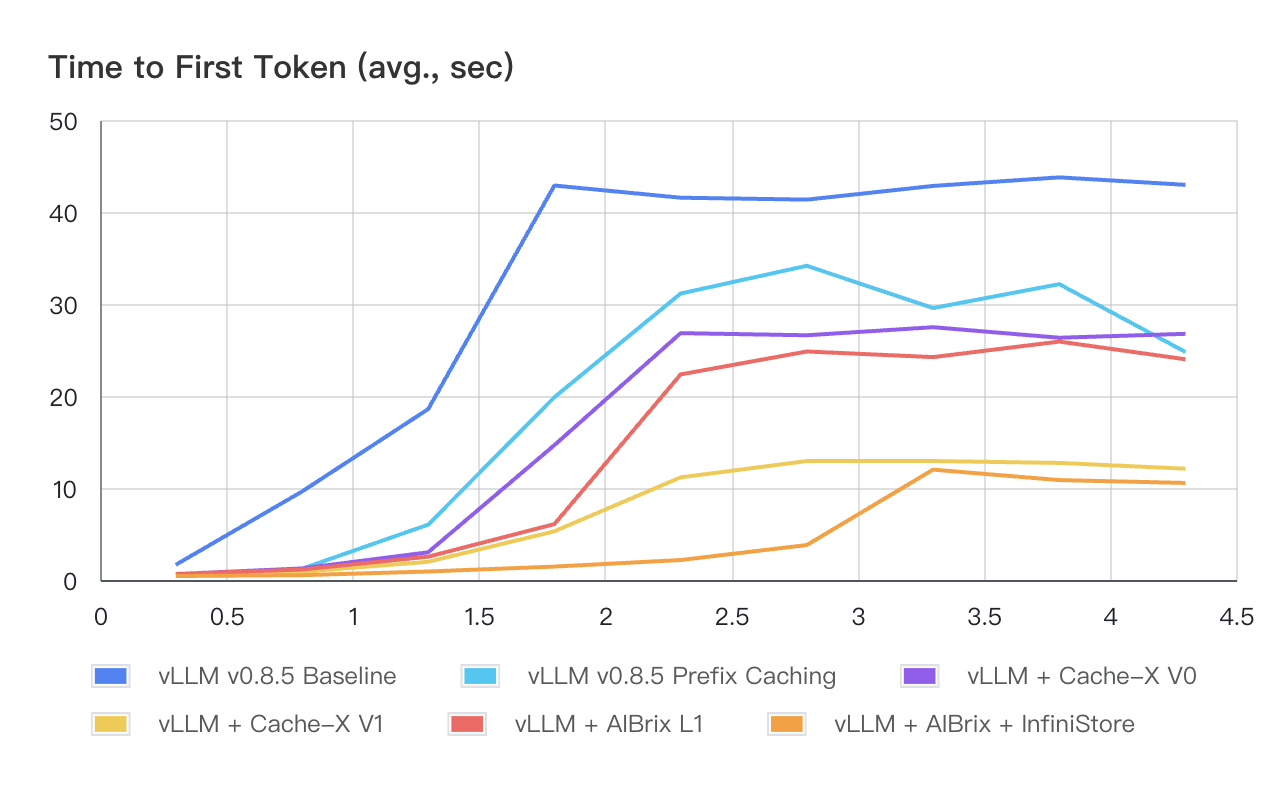
KV Caches and Time-to-First-Token: Optimizing LLM Performance
大模型推理优化实践:KV cache 复用与投机采样_kvcache-CSDN博客
探秘Transformer系列之(24)--- KV Cache优化 - 罗西的思考 - 博客园
KV Cache:图解大模型推理加速方法_kvcache图解-CSDN博客
KV Cache量化技术详解:深入理解LLM推理性能优化_ollama kv cache-CSDN博客
KV Cache量化技术详解:深入理解LLM推理性能优化-EW帮帮网
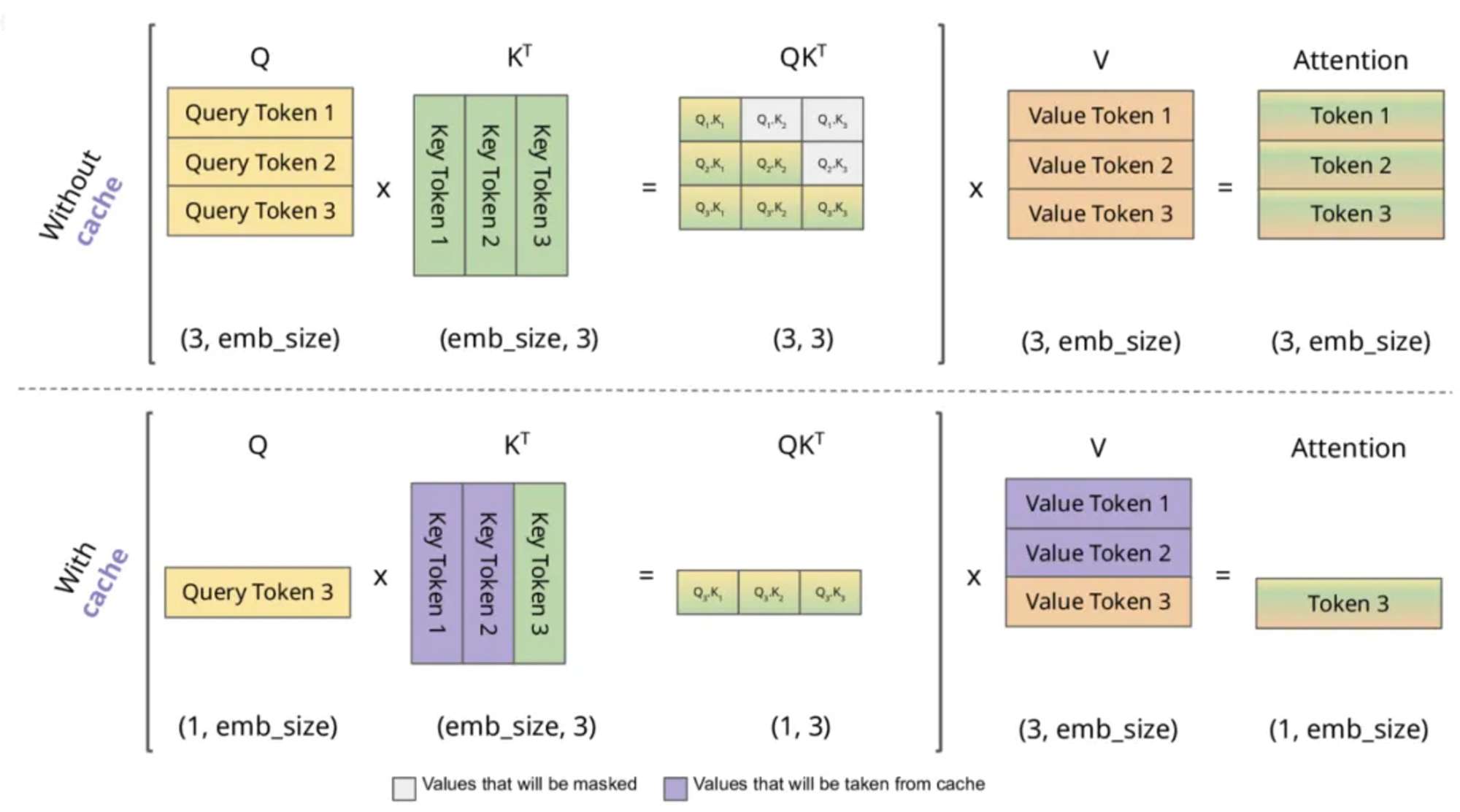
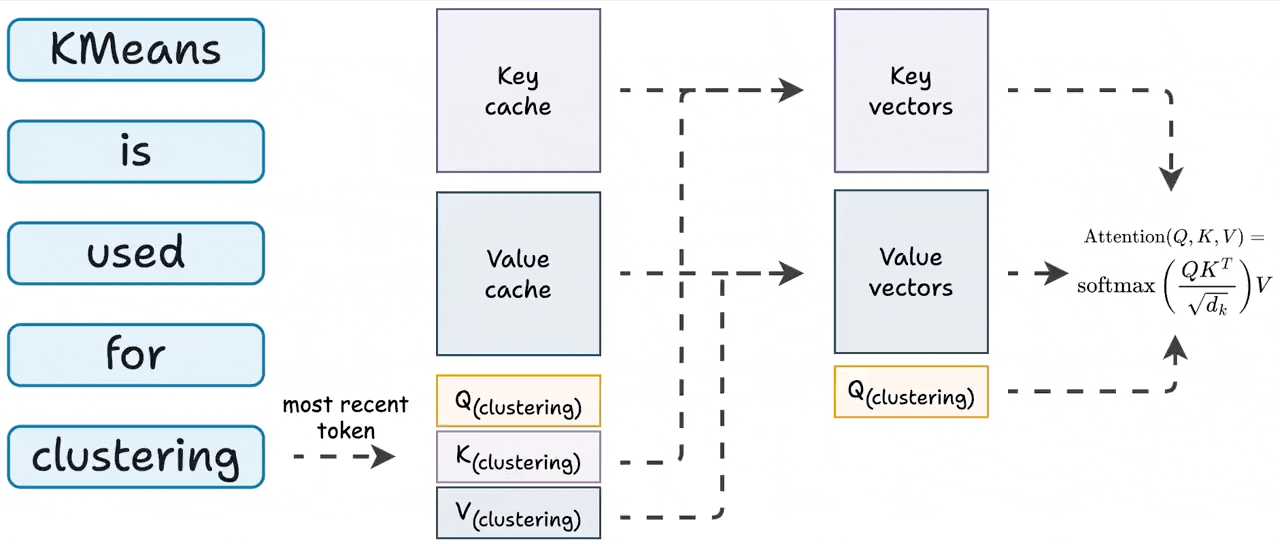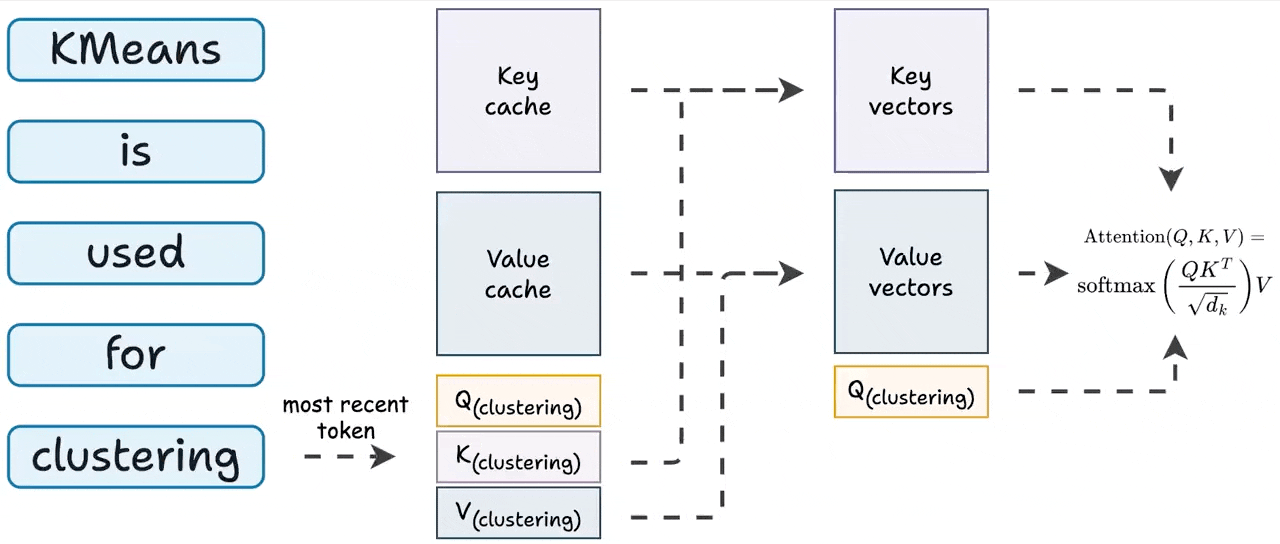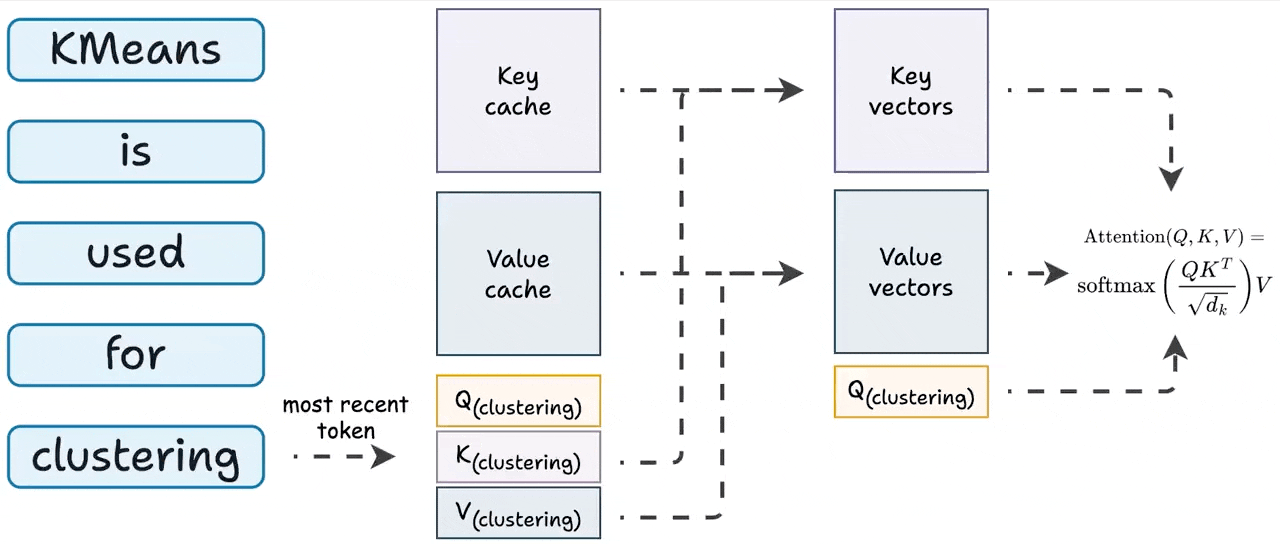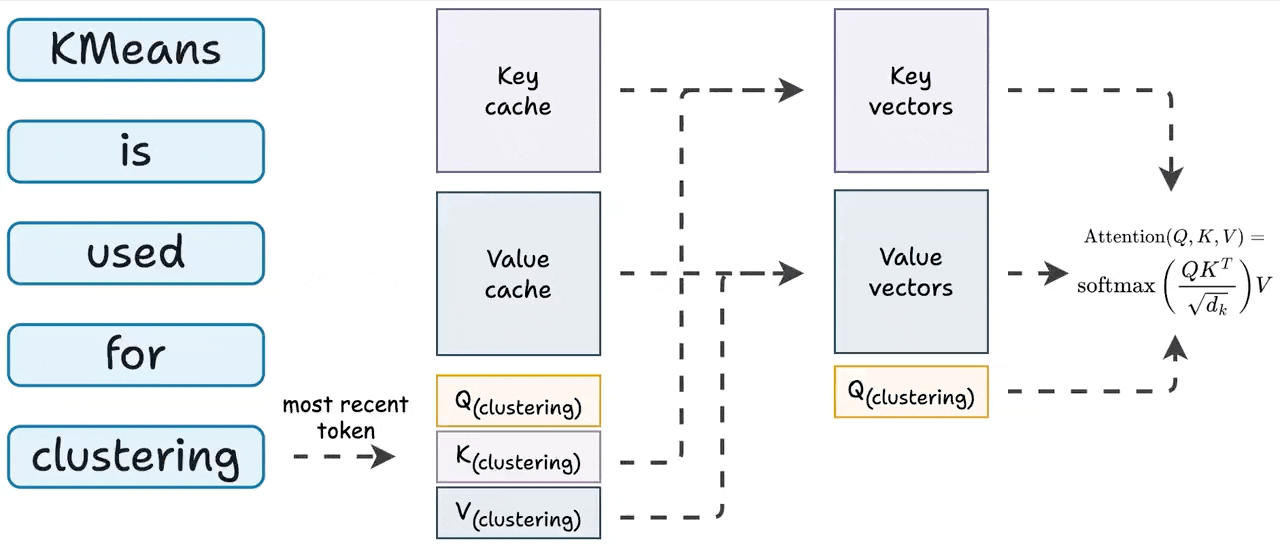
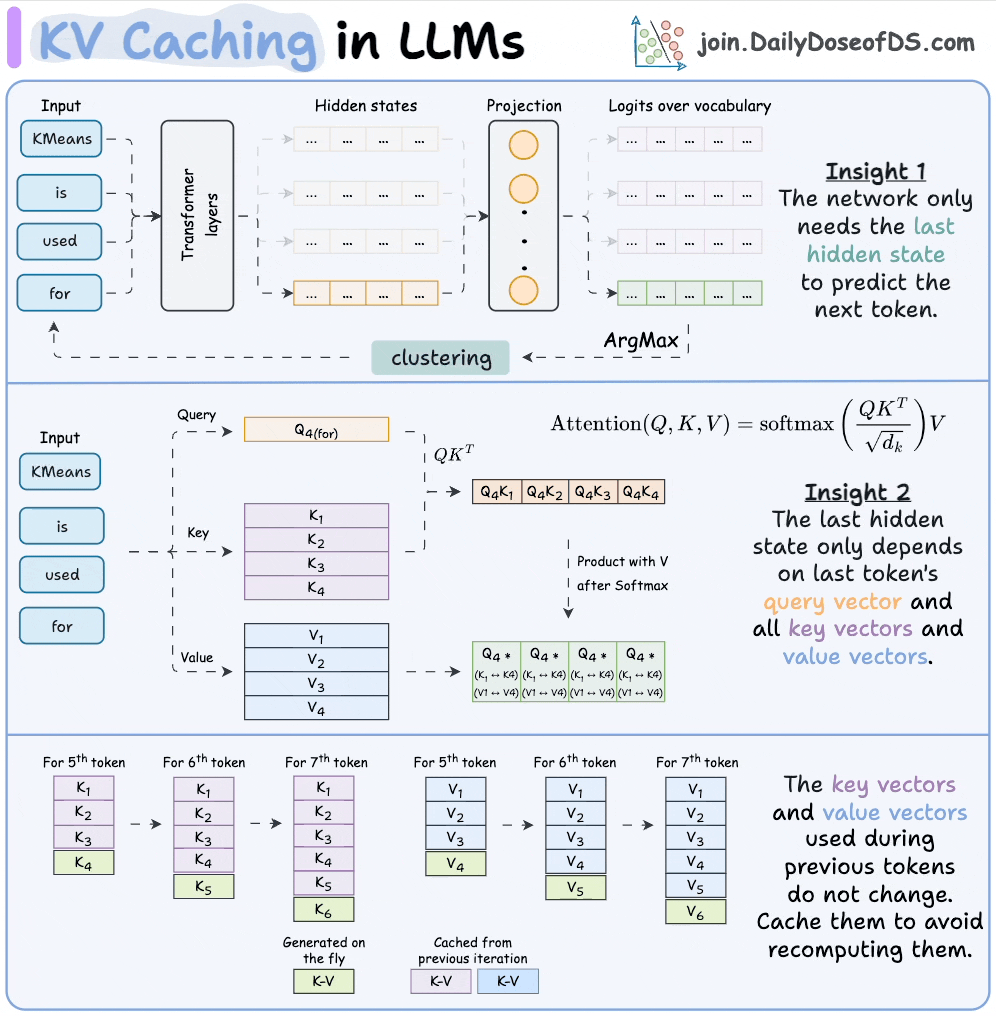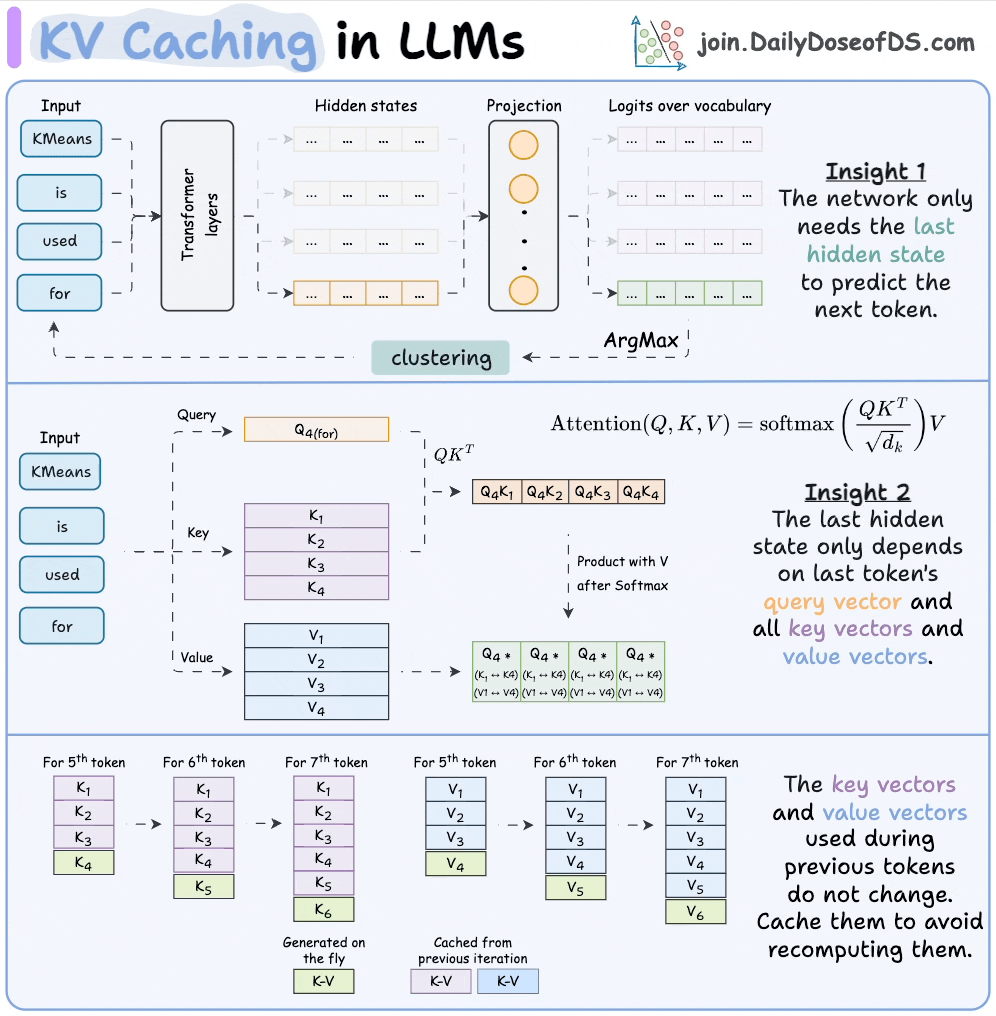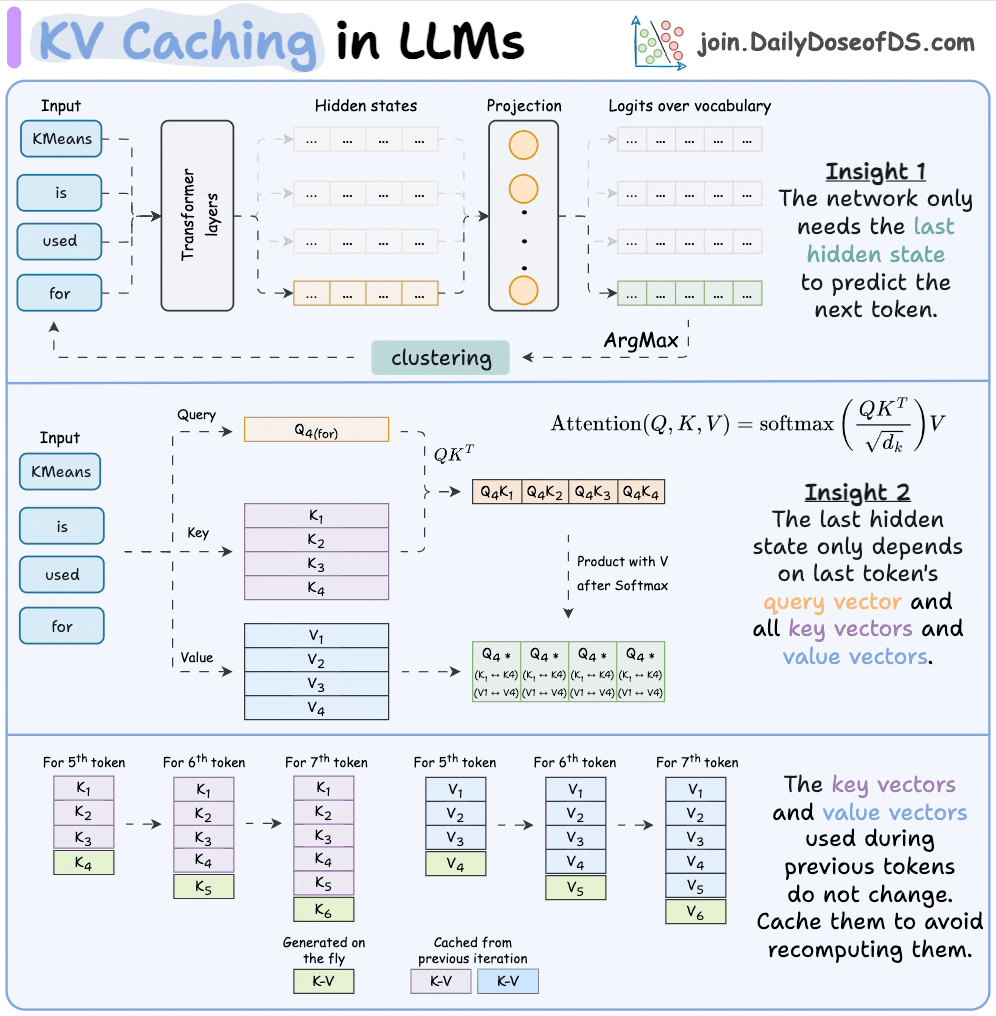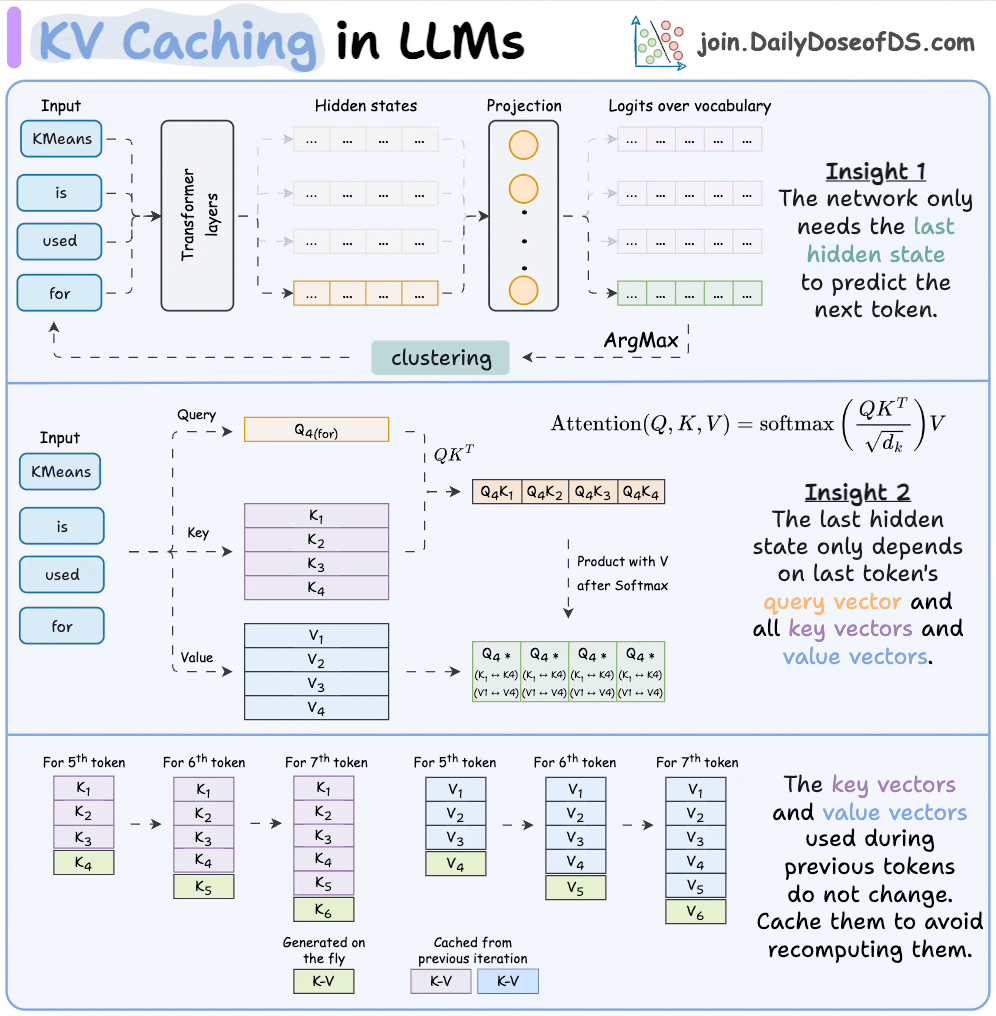
KV Caching in LLMs, explained visually
KV Caching Explained: Optimizing Transformer Inference Efficiency
LLM - Generate With KV-Cache 图解与实践 By GPT-2_llm kv cache-CSDN博客
大模型推理加速:KV Cache Sparsity(稀疏化)方法 - 知乎
GQA,MLA之外的另一种KV Cache压缩方式:动态内存压缩(DMC)_kv cache 压缩-CSDN博客
全局多级KV Cache - xLLM
KV Caching in LLMs, Explained Visually. - by Avi Chawla
KV Cache量化技术详解:深入理解LLM推理性能优化 - 知乎
探索vLLM分布式预填充与KV缓存:提升推理效率的前沿技术_vllm kv cache-CSDN博客
KV Caching Illustrated | Kapil Sharma
KV Cache传输引擎全面解析:从原理到性能对比 - 知乎
Entropy-Guided KV Caching for Efficient LLM Inference
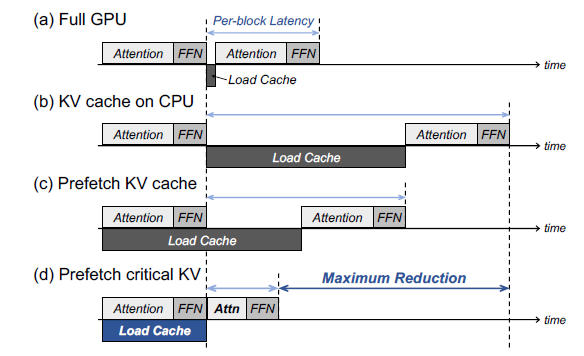
Compute Or Load KV Cache? Why Not Both? | AI Research Paper Details
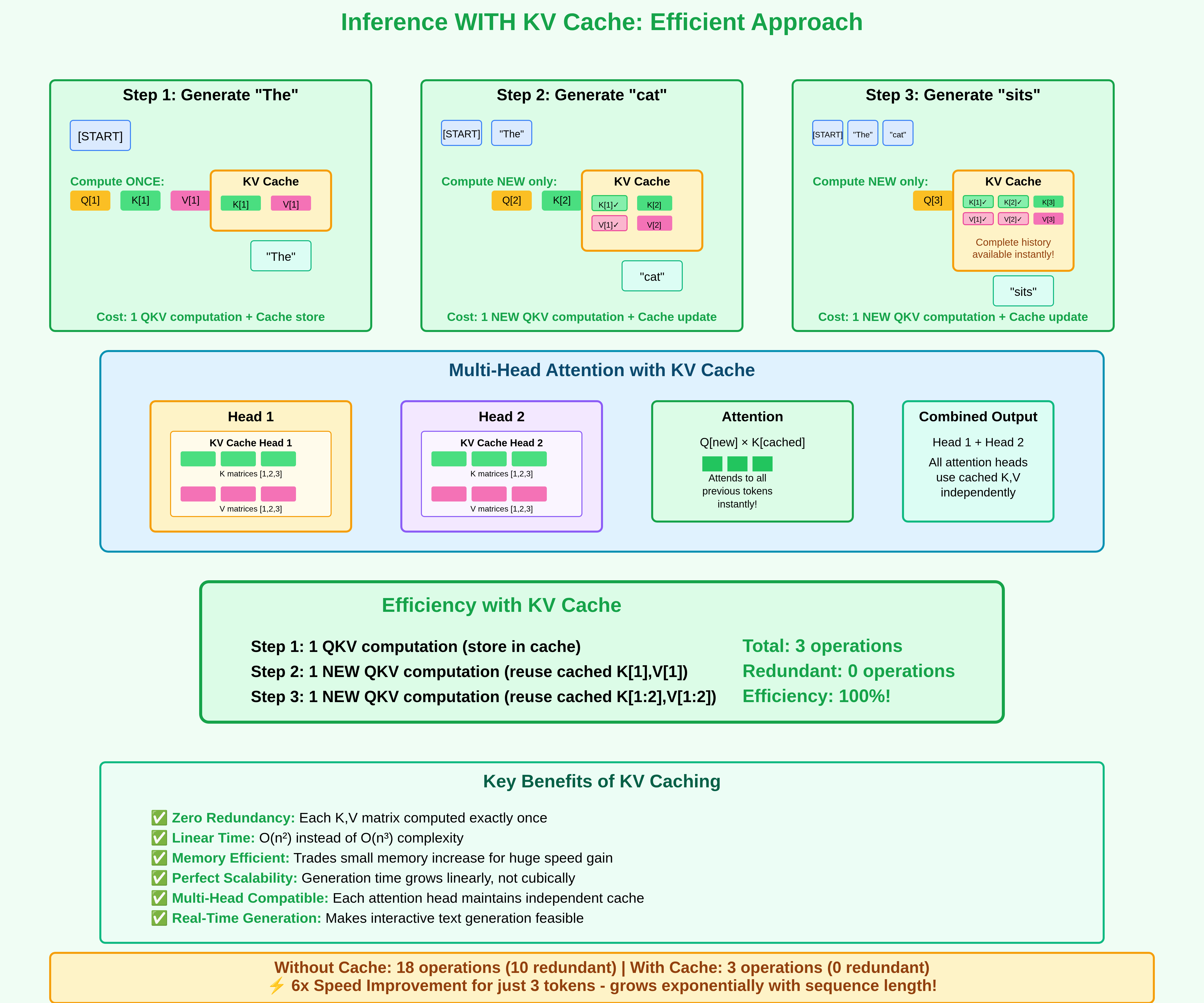
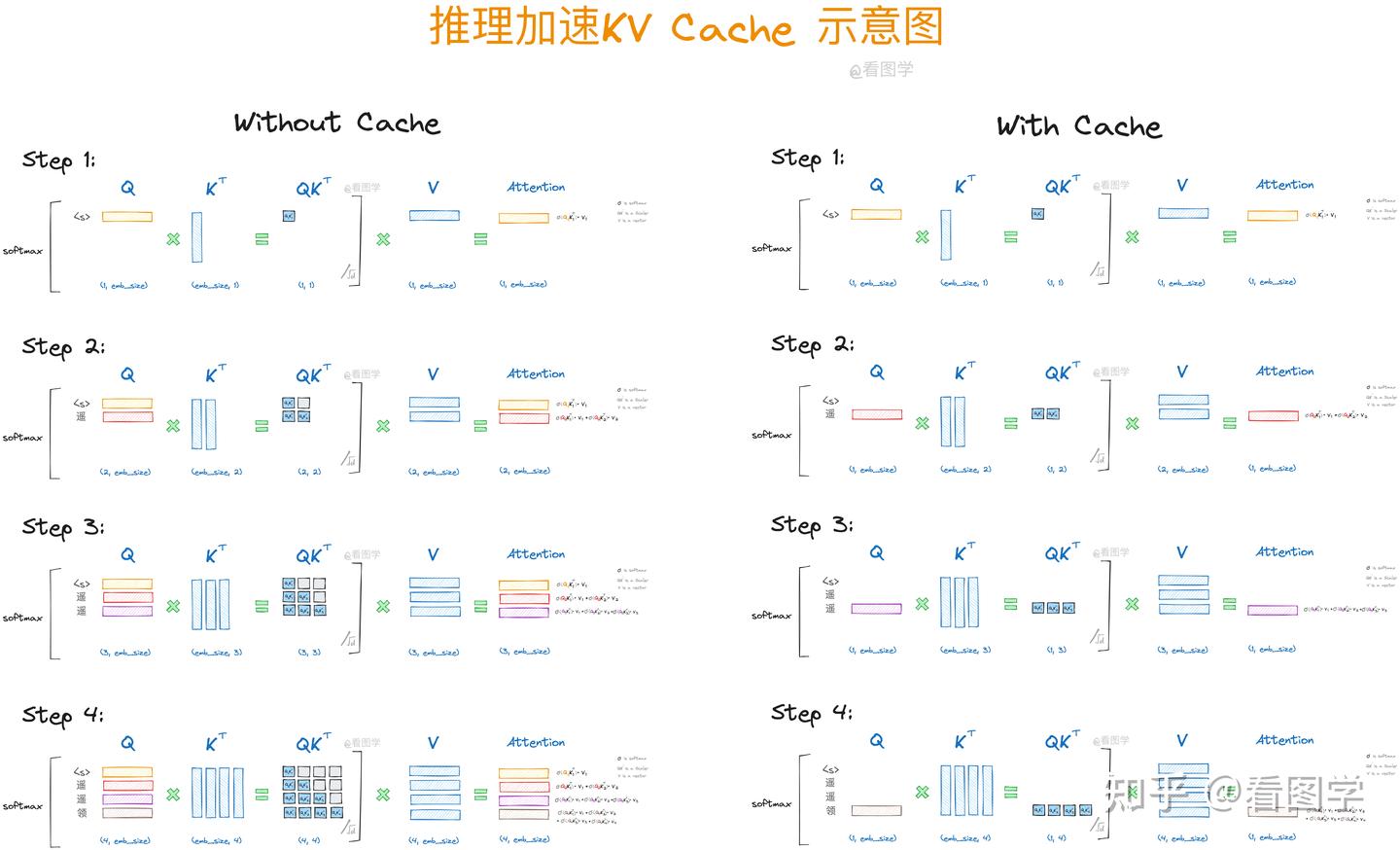
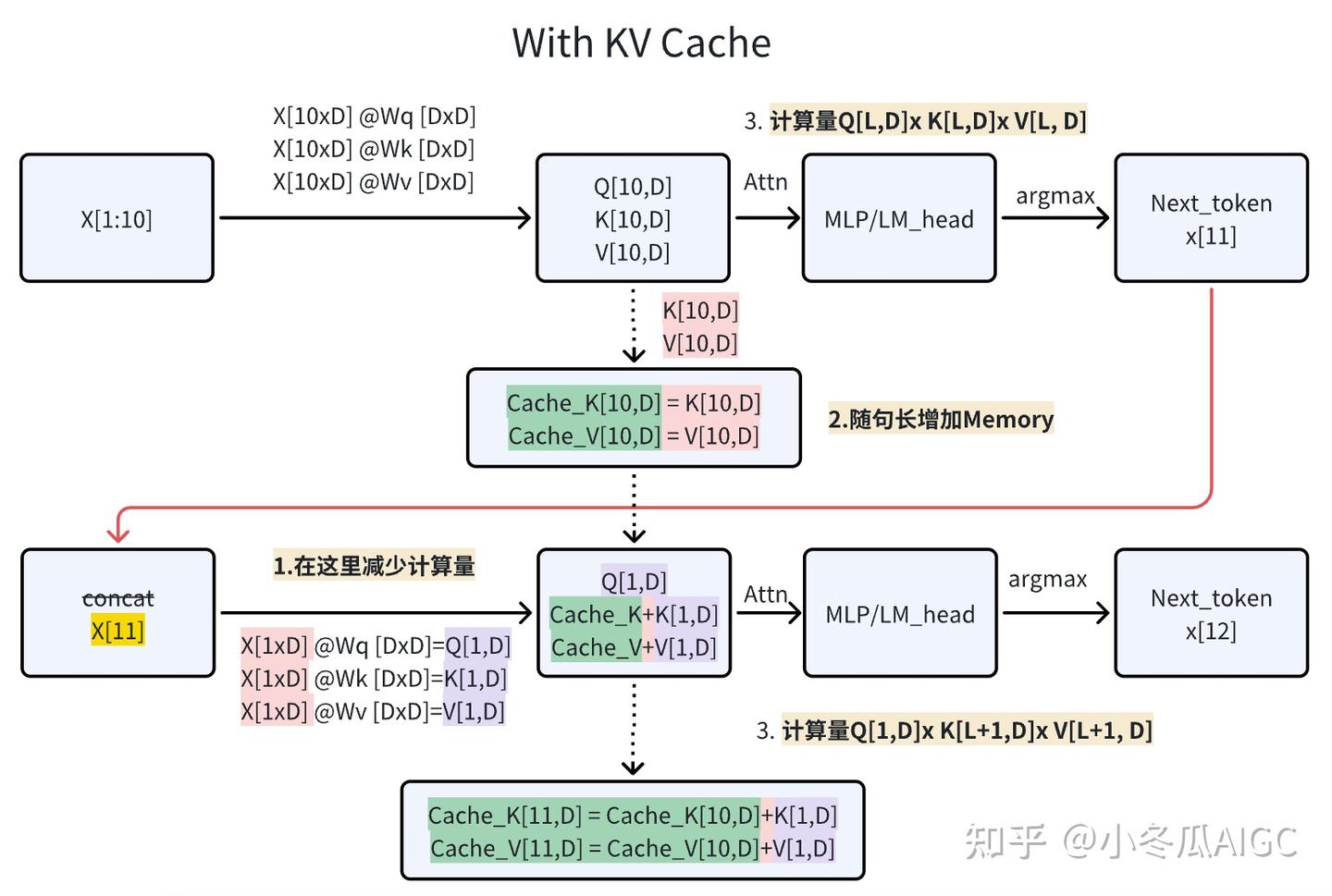
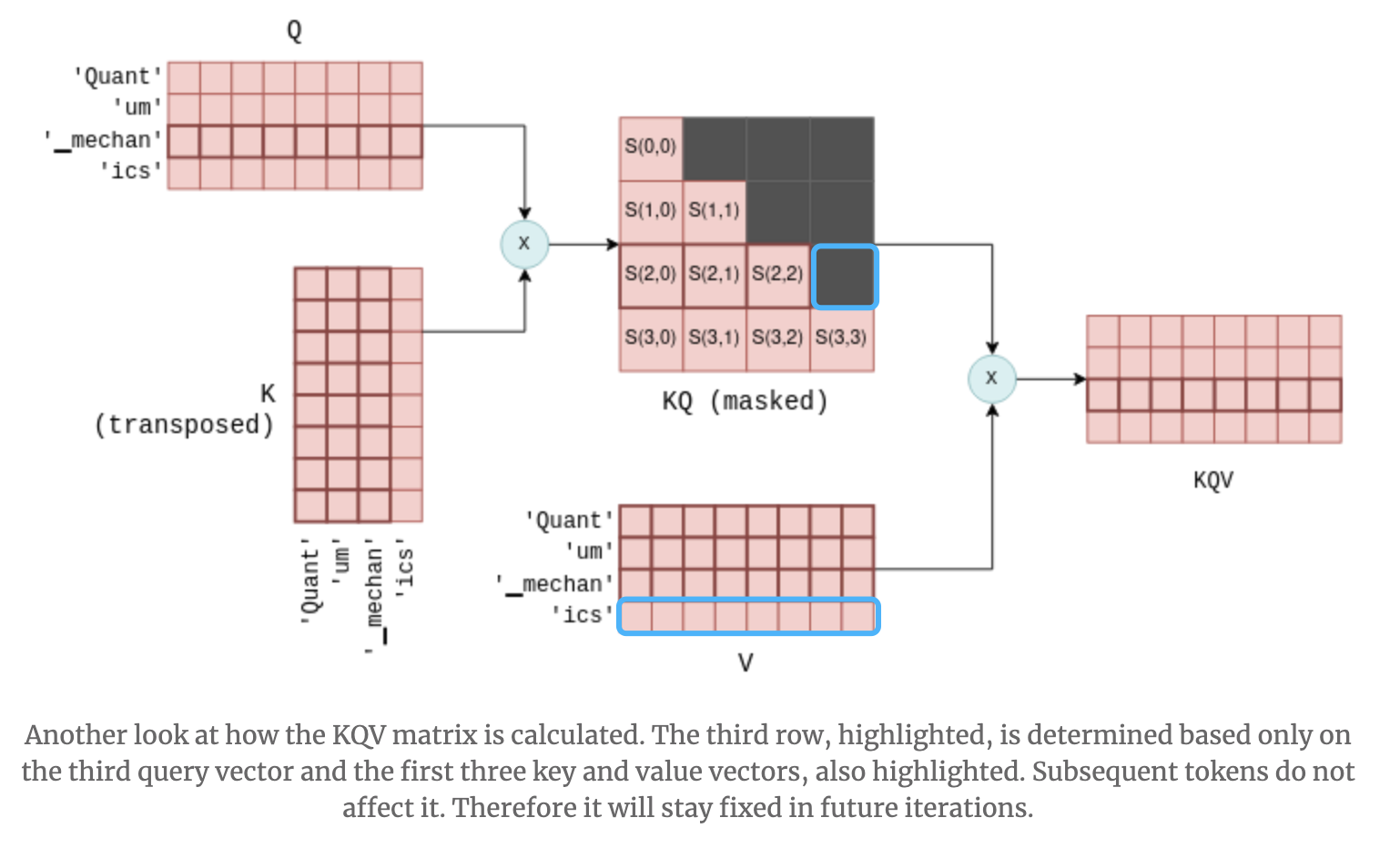
大模型推理加速:看图学KV Cache - 知乎
[vLLM — Prefix KV Caching] vLLM’s Automatic Prefix Caching vs ...
How to properly disable offloading MoE layers to CPU? · Issue #50 ...
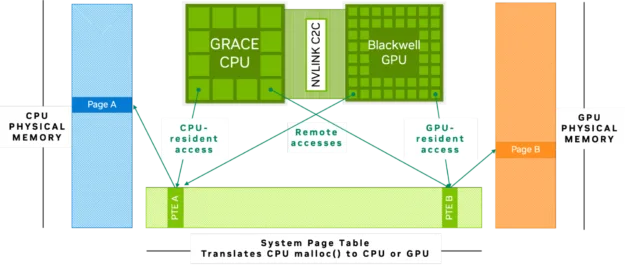
NVIDIA GH200 Superchip Accelerates Inference by 2x in Multiturn ...
AIBrix v0.3.0 Release: KVCache Offloading, Prefix Cache, Fairness ...
Llama3.1 inference memory requirement | by satojkovic | Medium
ExtraTech Bootcamps
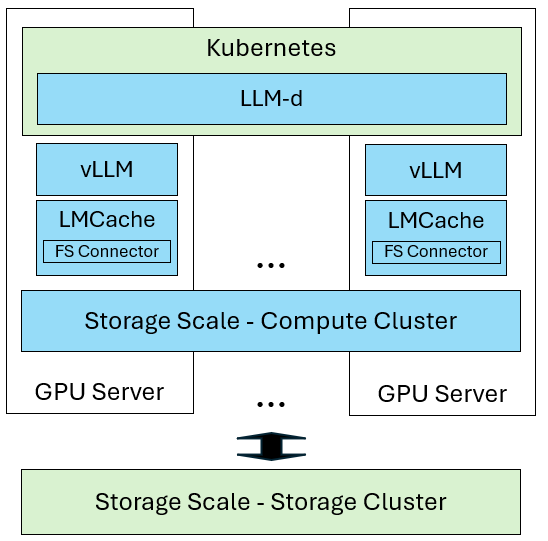
Deploying Distributed LLM Inference Service with IBM Storage Scale for ...
加速LLM大模型推理,KV缓存技术详解与PyTorch实现-CSDN博客
Mooncake:LLM服务的KVCache为中心分解架构_mooncake: a kvcache-centric disaggregated ...
GitHub - jethwa09/Local-KV-Cache-Offloading-for-Mini-LLMs
KV_cache offload · Issue #943 · deepspeedai/DeepSpeedExamples · GitHub
[Prefill优化][万字]🔥原理&图解vLLM Automatic Prefix Cache(RadixAttention): 首 ...
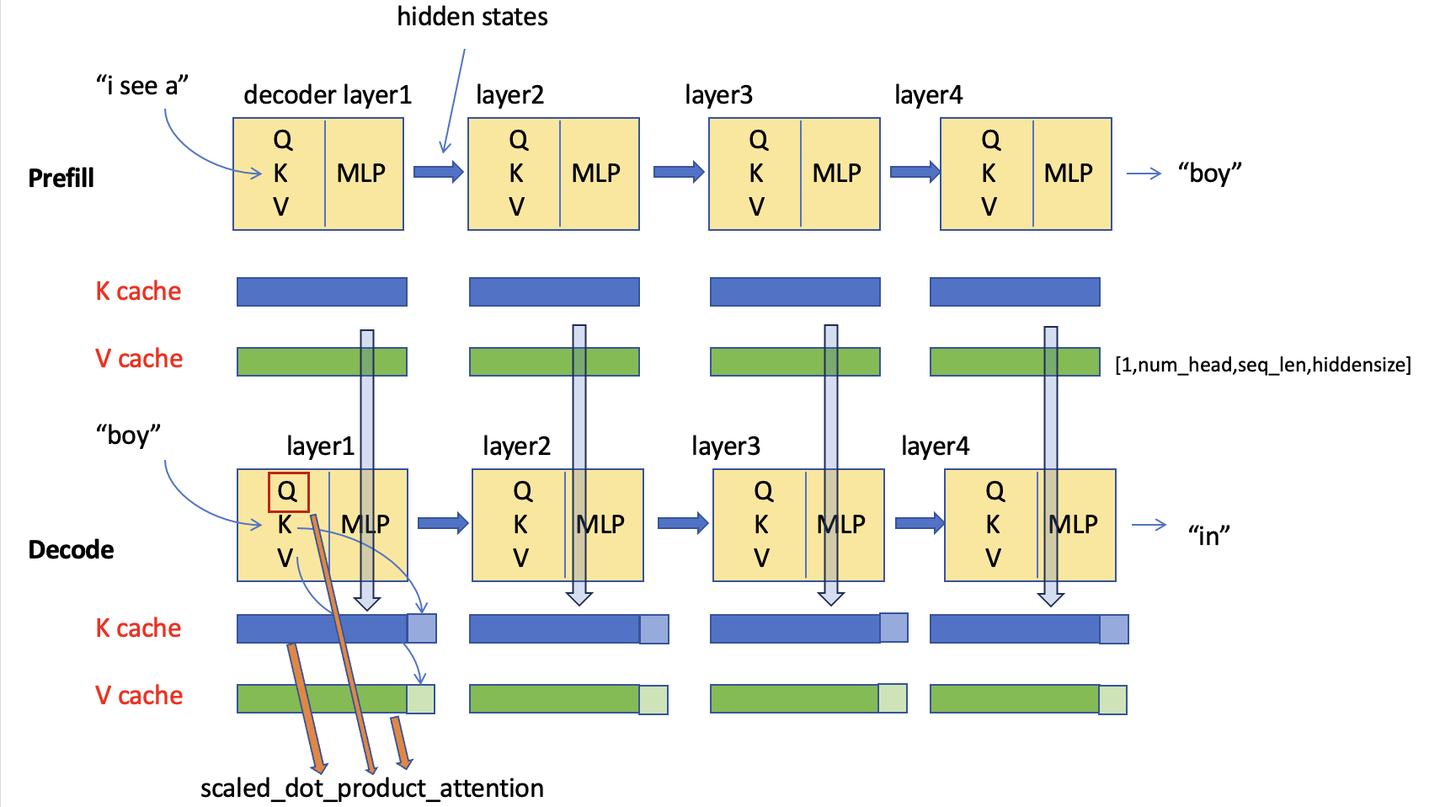
【手撕LLM-KVCache】显存刺客的前世今生--文末含代码 - 知乎
The Shift to Distributed LLM Inference: 3 Key Technologies Breaking ...
kvcache原理、参数量、代码详解_kv cache-CSDN博客
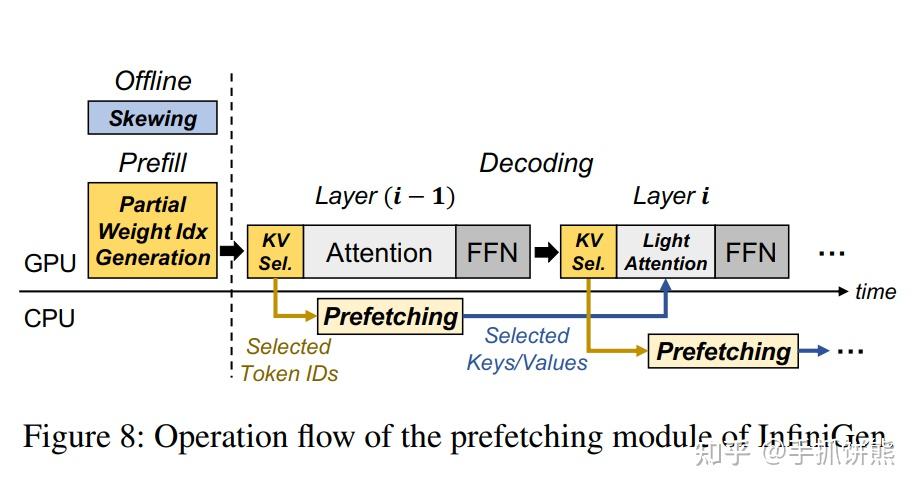
InfiniGen: Efficient Generative Inference of Large Language Models with ...
LLM - Generate With KV-Cache 图解与实践 By GPT-2_gpt2 kv缓存的使用和实现-CSDN博客
【大模型LLM基础】自回归推理生成的原理以及什么是KV Cache?_kv cache示意图-CSDN博客
可视化KV Cache的原理(代码实现的角度) - 知乎
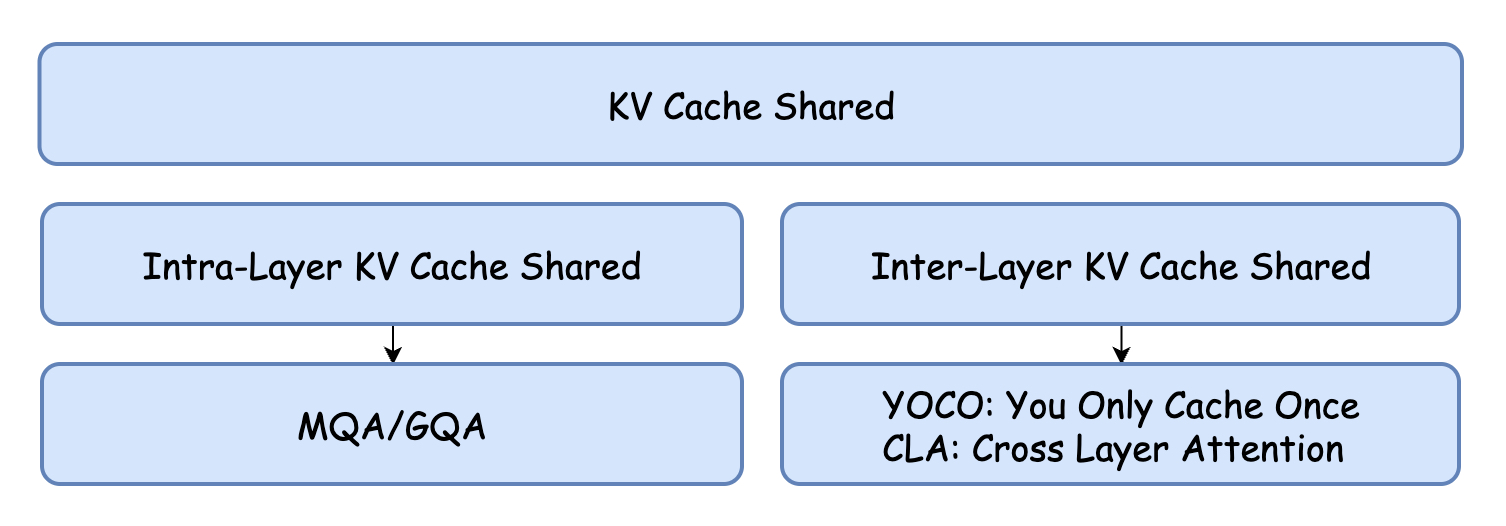
[KV Cache优化]🔥MQA/GQA/YOCO/CLA/MLKV笔记: 层内和层间KV Cache共享 - 知乎
LLM高效推理:KV缓存与分页注意力机制深度解析-51CTO.COM
NVIDIA Dynamo, A Low-Latency Distributed Inference Framework for ...
Transformer系列:图文详解KV-Cache,解码器推理加速优化_mb648c193277ba0的技术博客_51CTO博客
Optimizing Inference for Long Context and Large Batch Sizes with NVFP4 ...
Beidi Chen陈贝迪 独家 | 高效长序列生成之路:CPU & GPU —— 算法、系统与硬件的 co-design
kv-cache 原理及优化概述 - Zhang
SqueezeAttention: 2D Management of KV-Cache in LLM Inference via Layer ...
KV-Cache Wins You Can See: From Prefix Caching in vLLM to Distributed ...
Transformer推理加速方法-KV缓存(KV Cache)-CSDN博客
阿里云Tair KVCache:打造以缓存为中心的大模型Token超级工厂-阿里云开发者社区