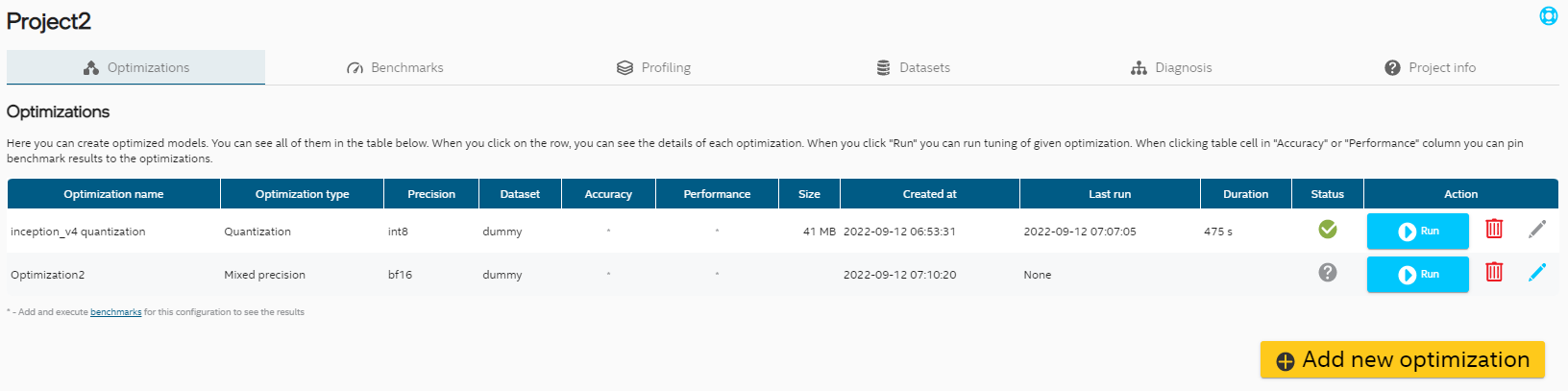
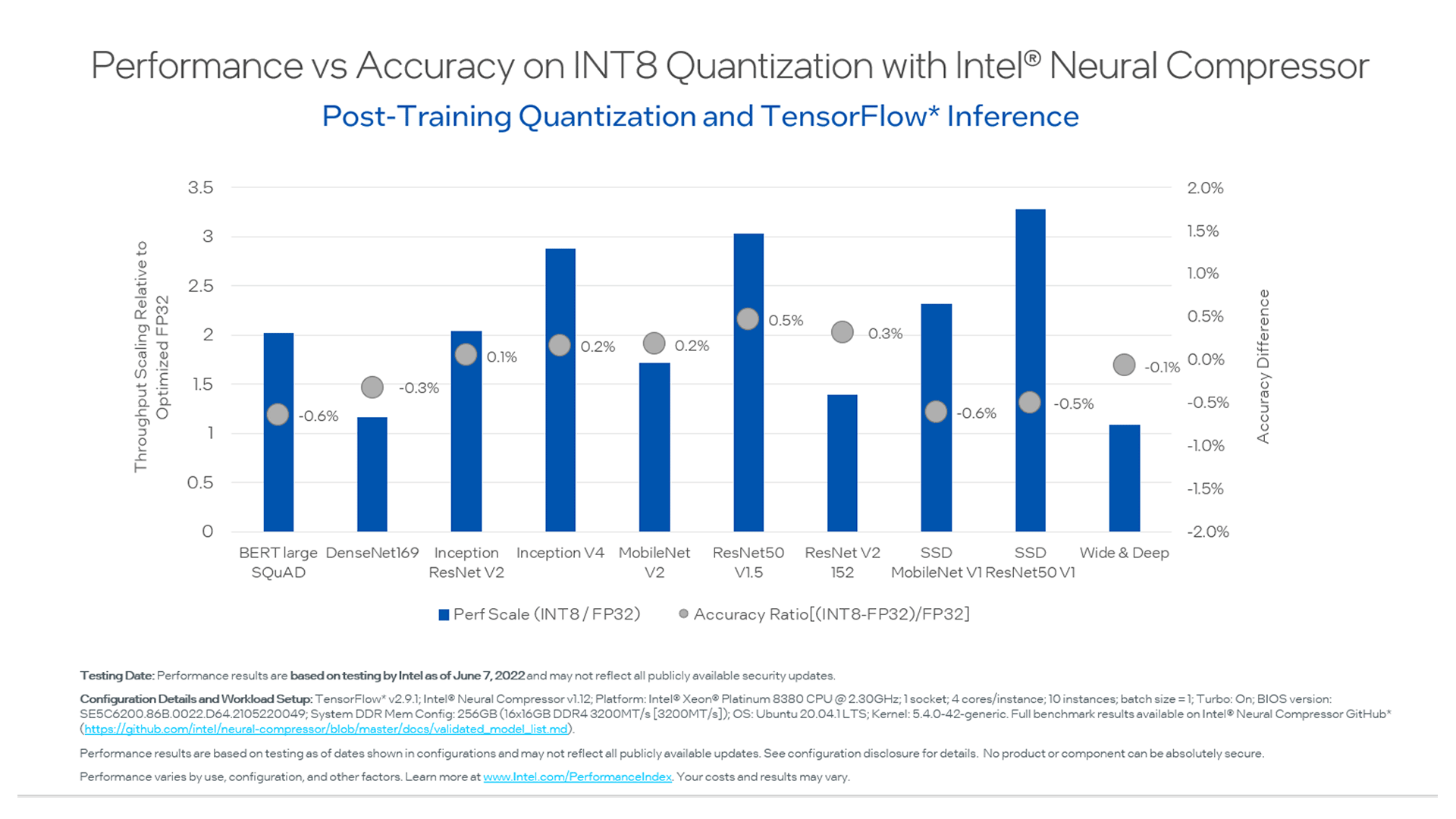
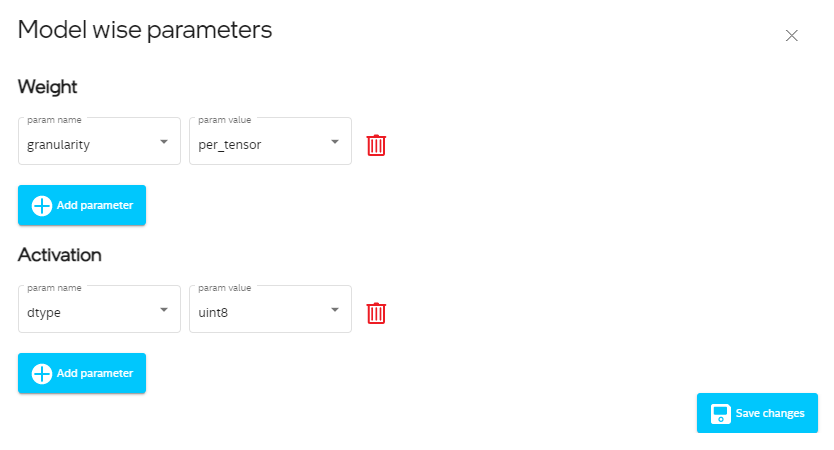
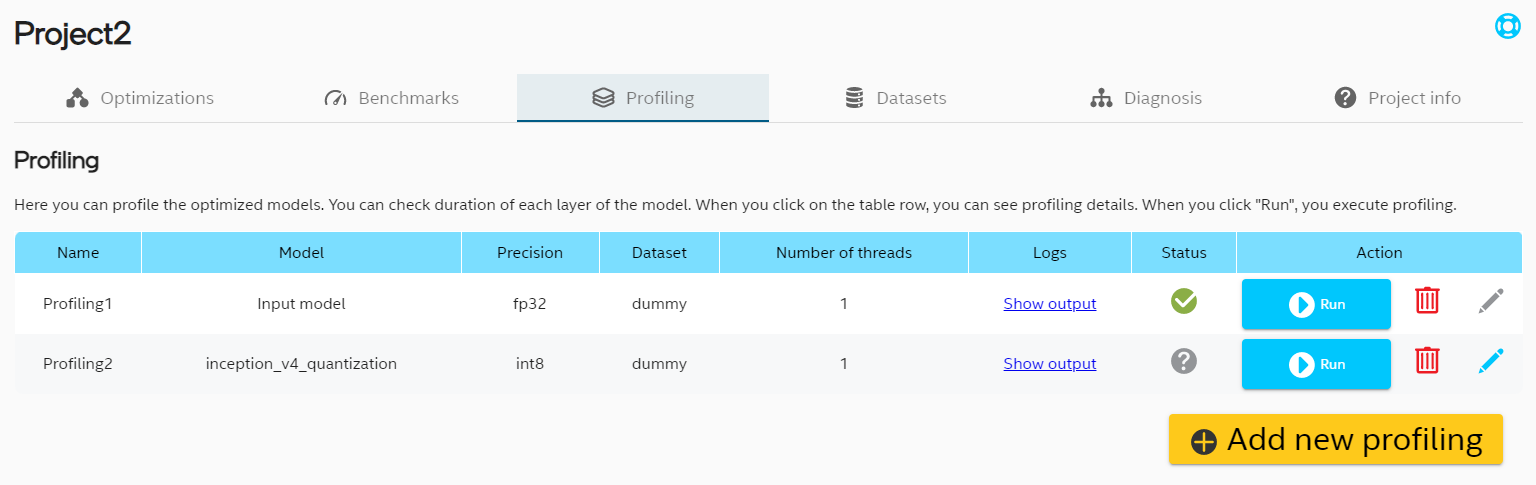
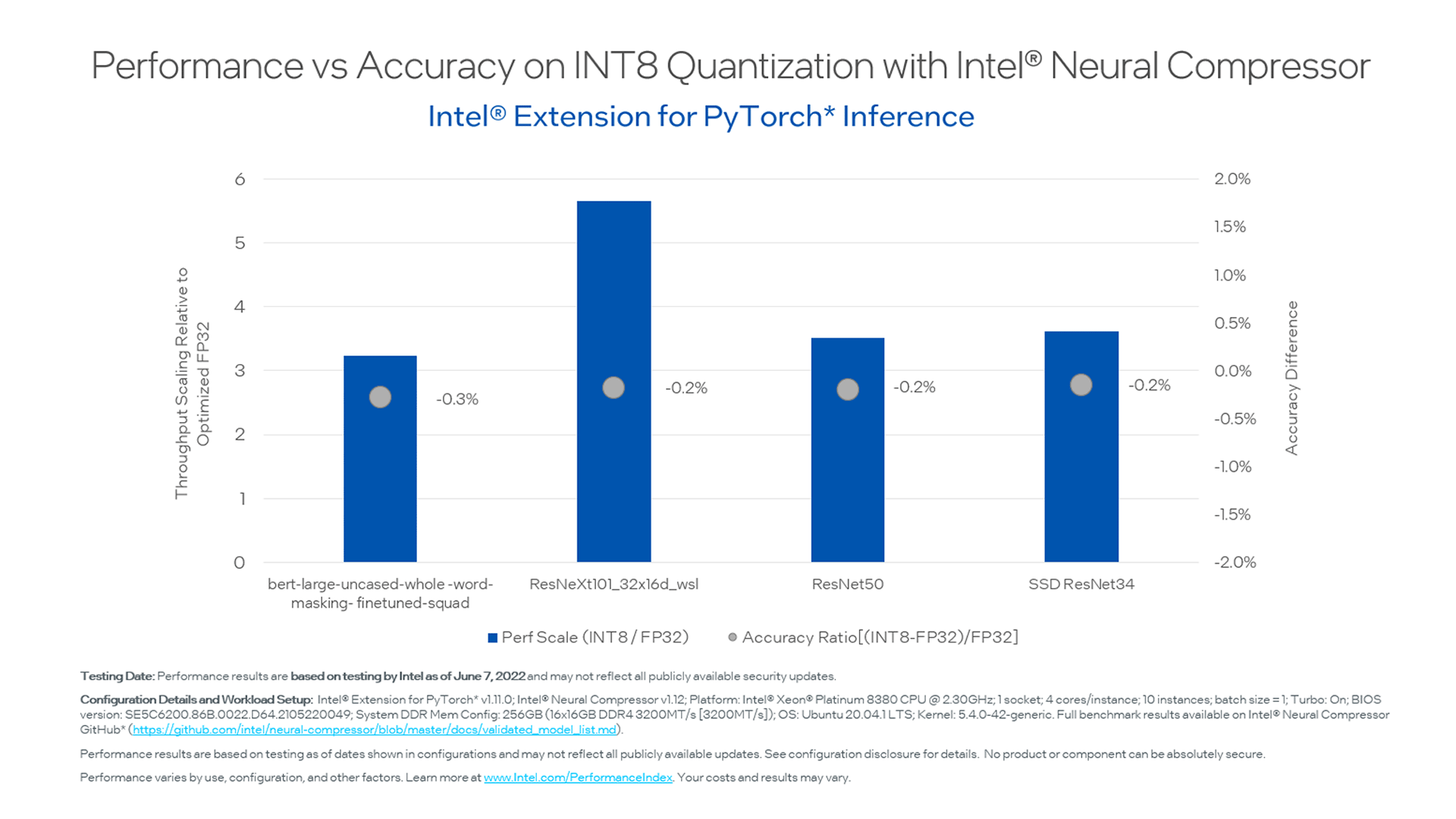
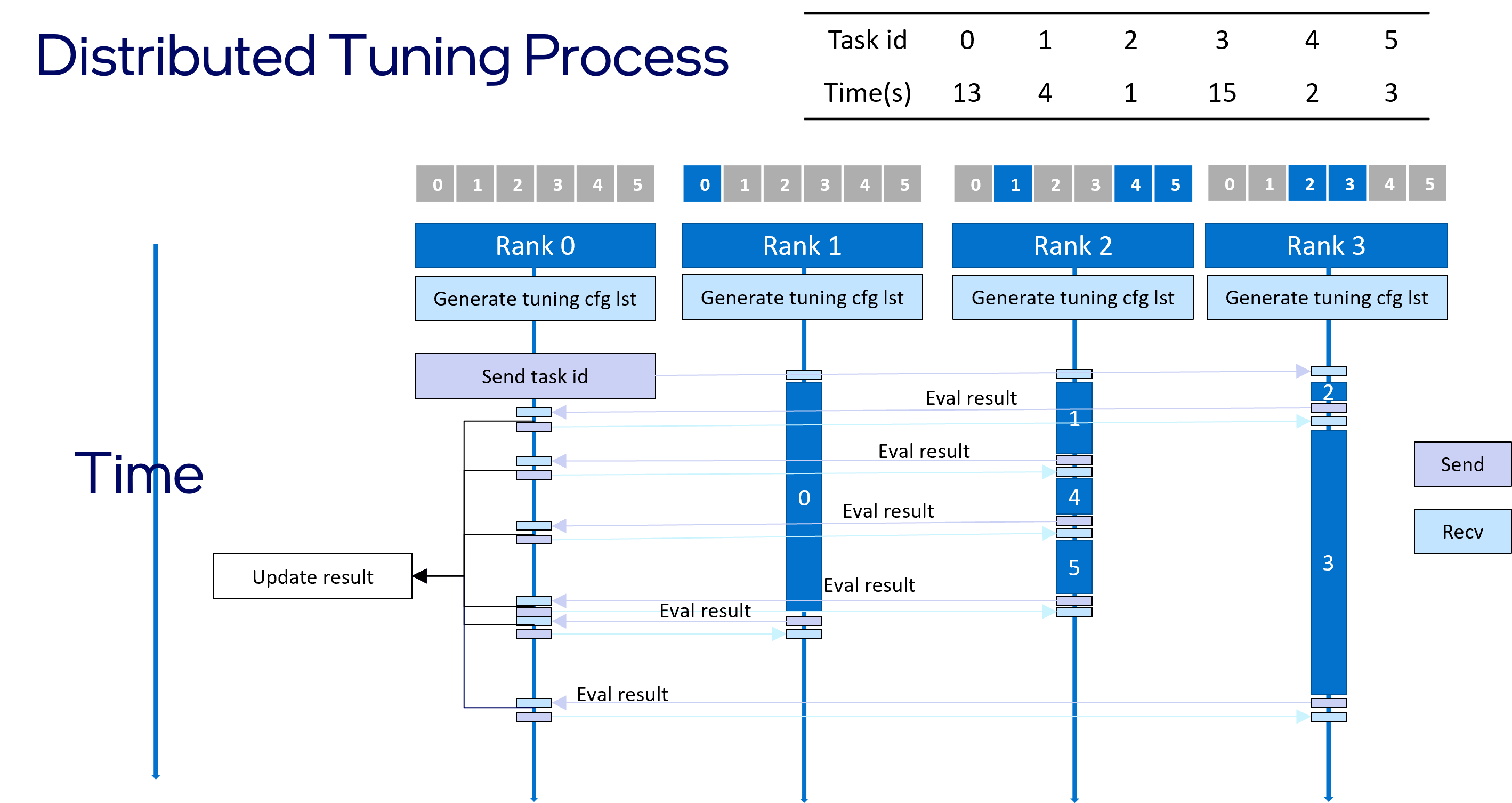
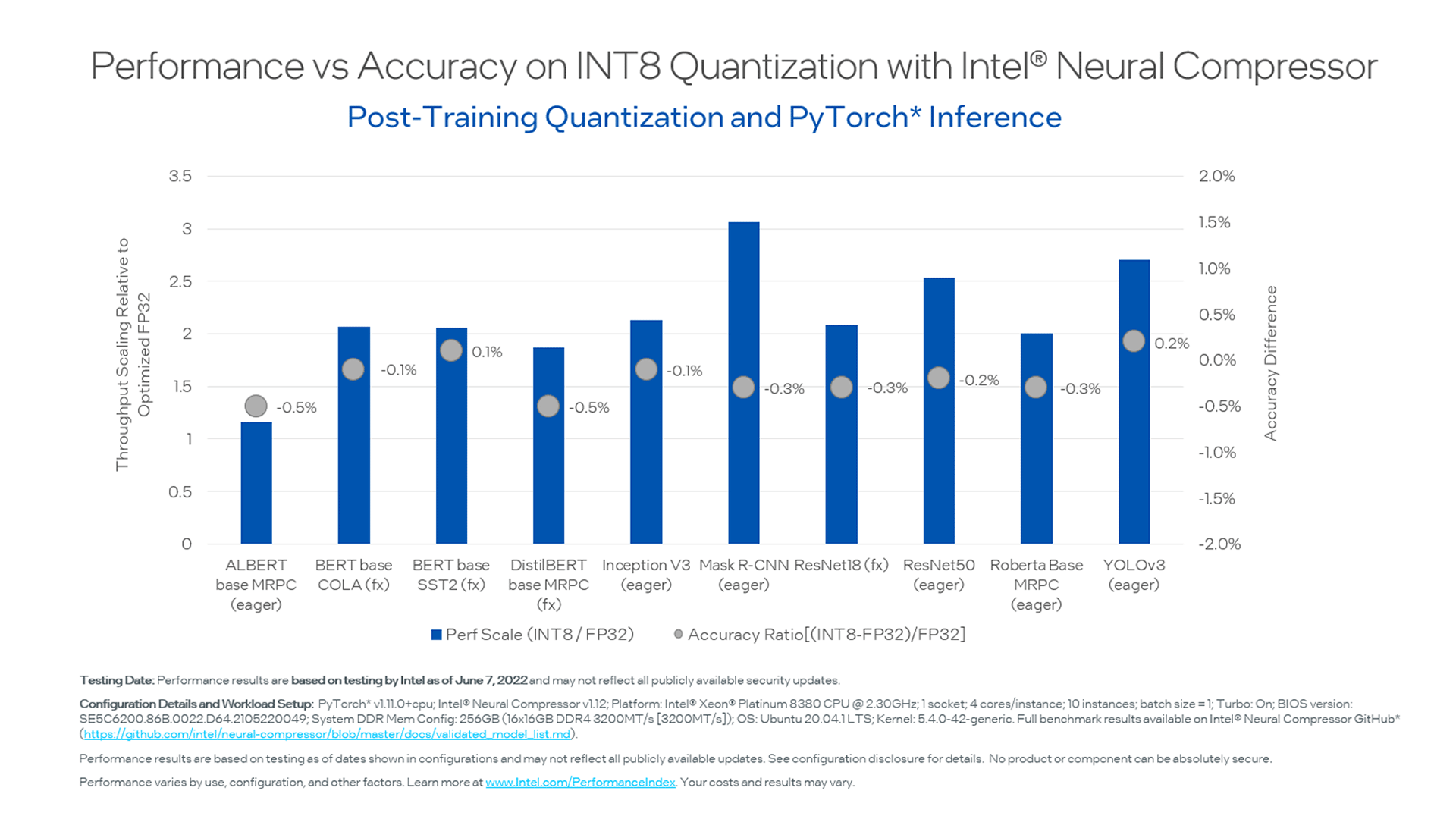
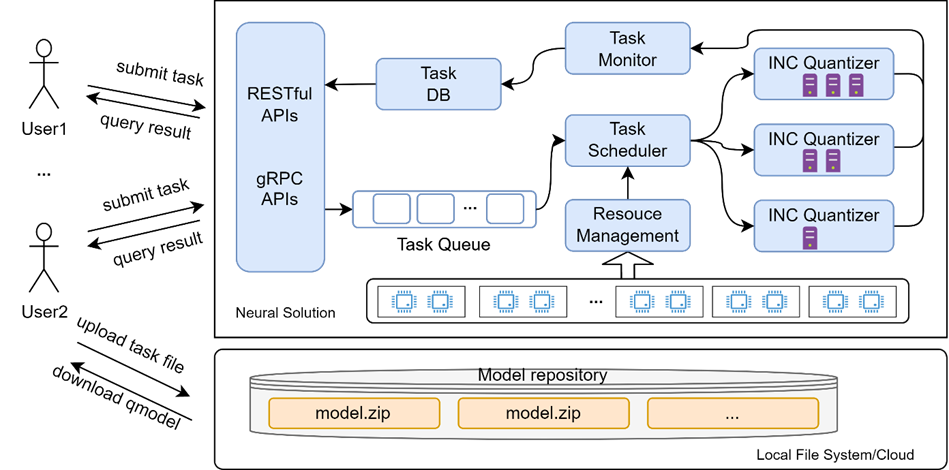
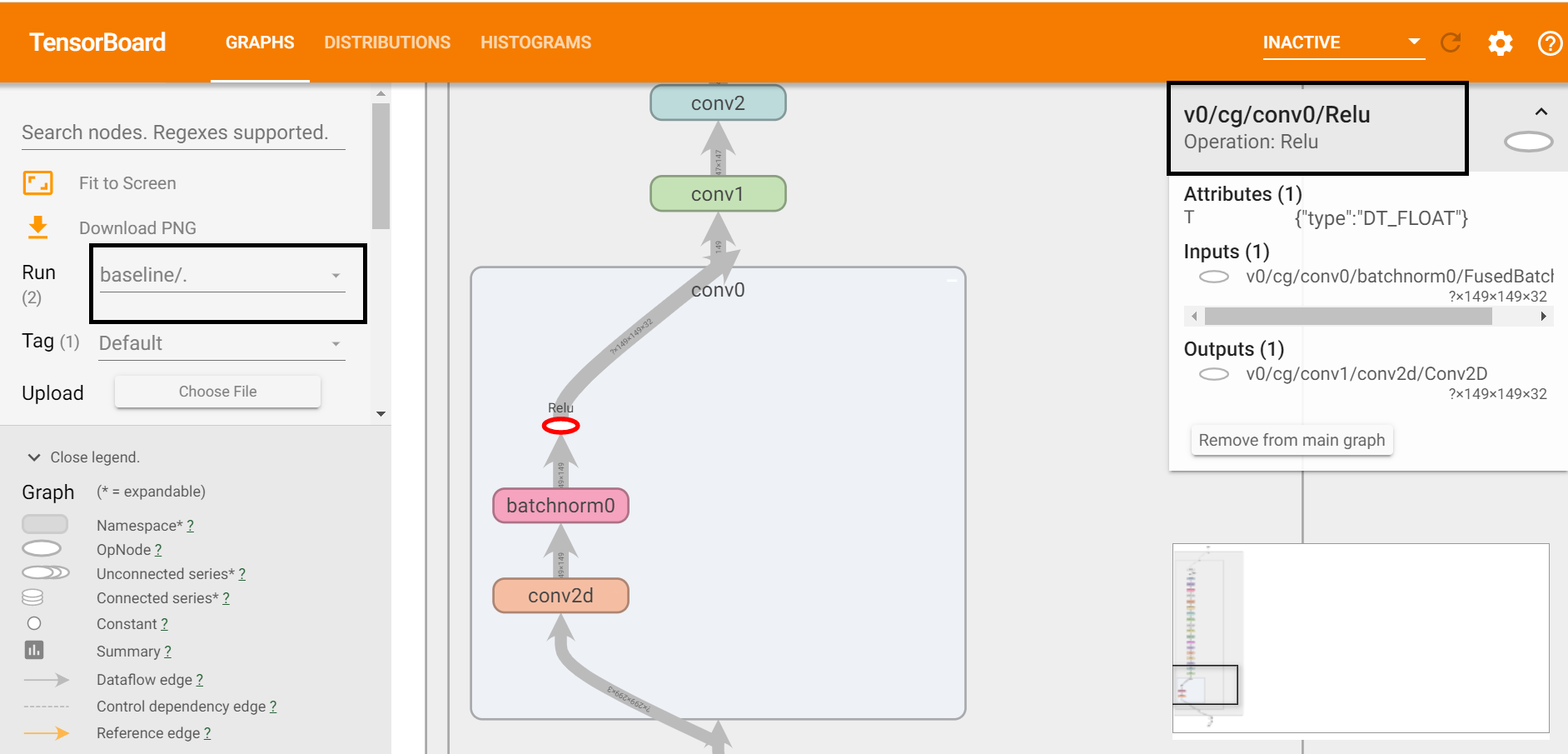
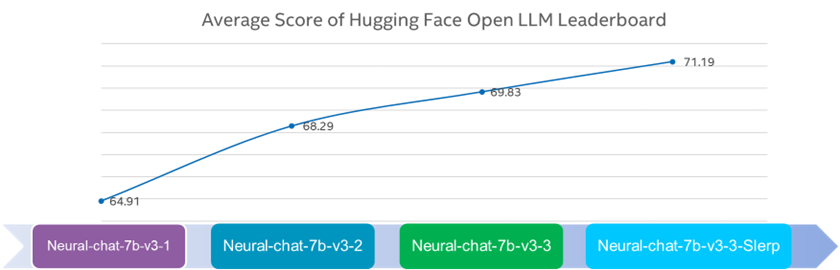
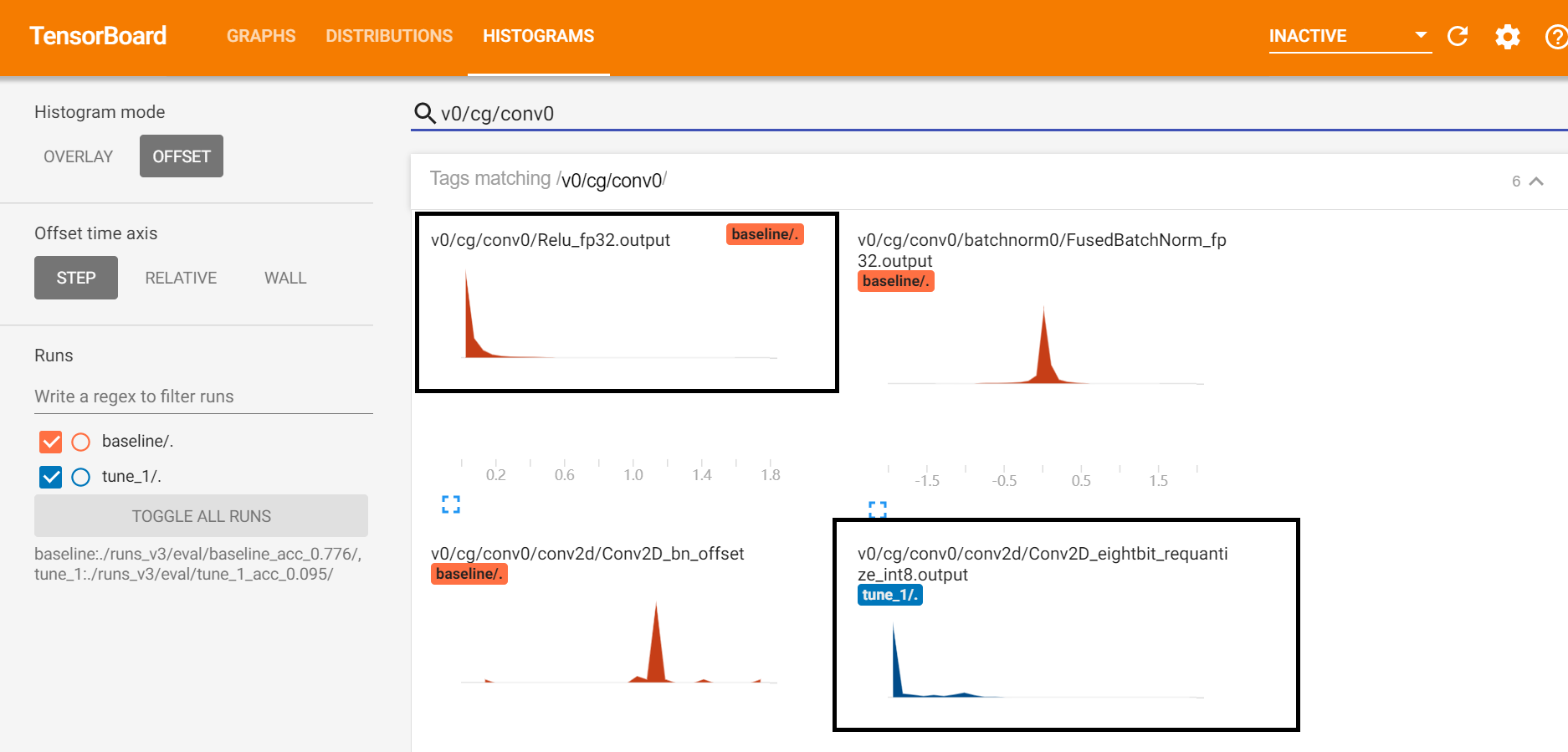
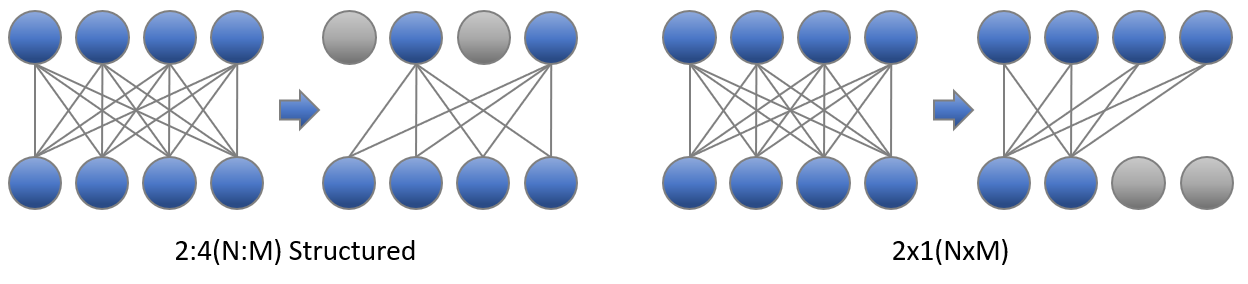
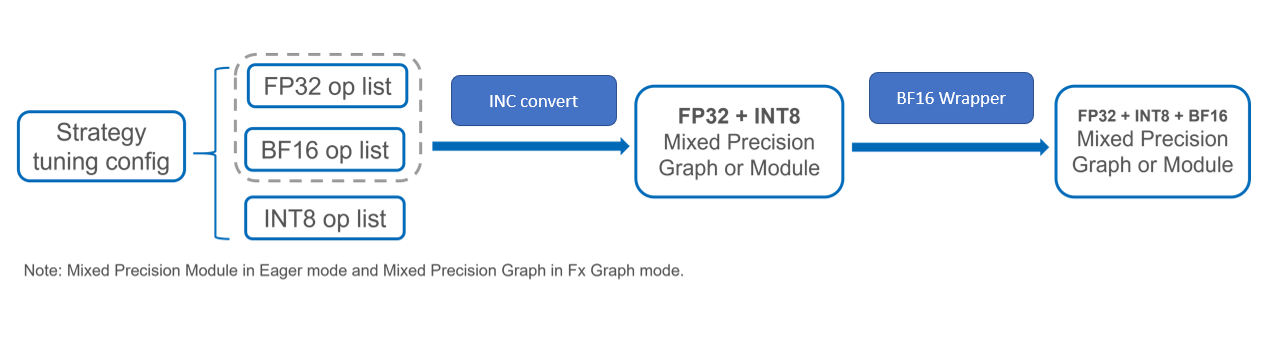
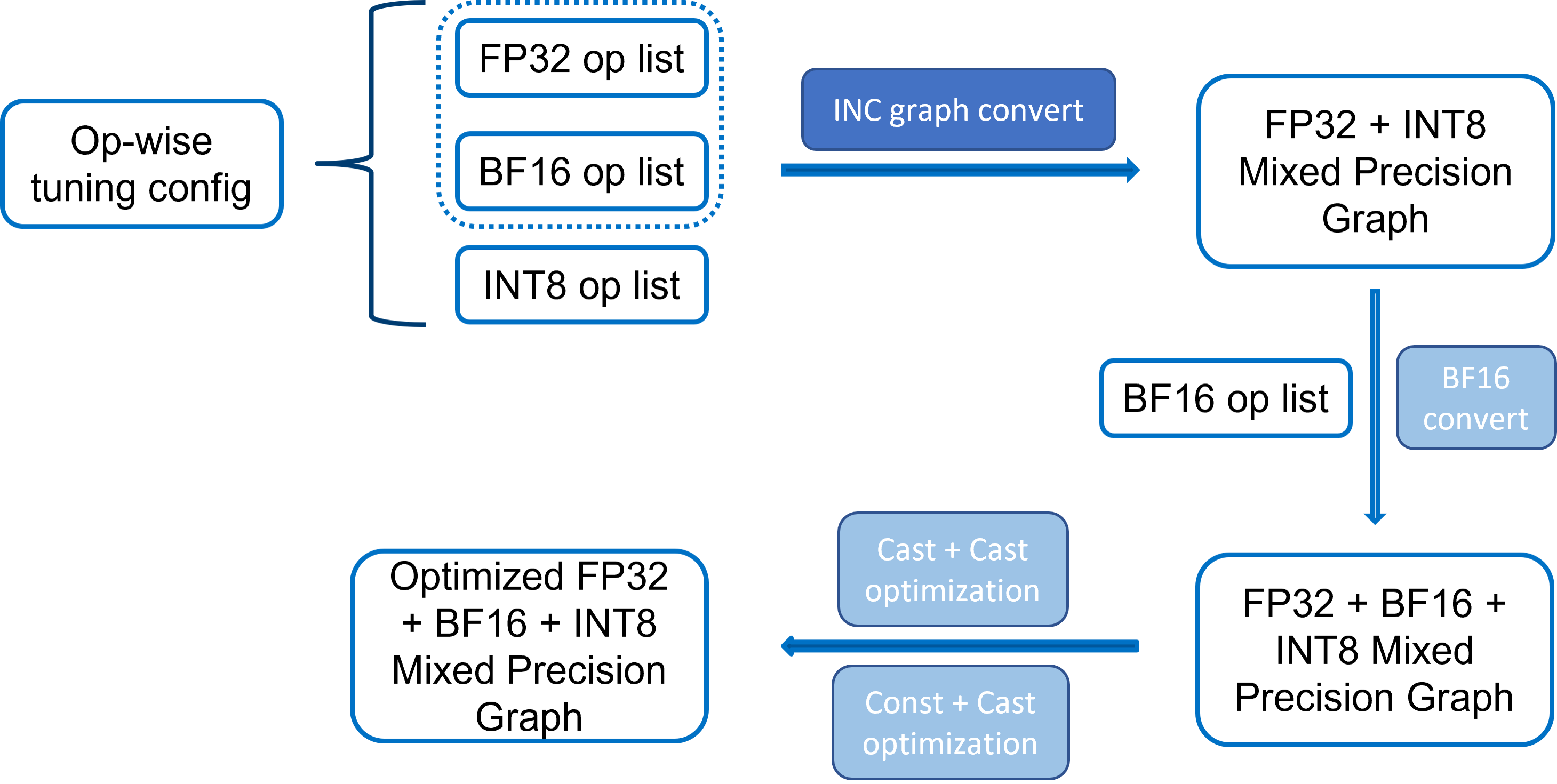
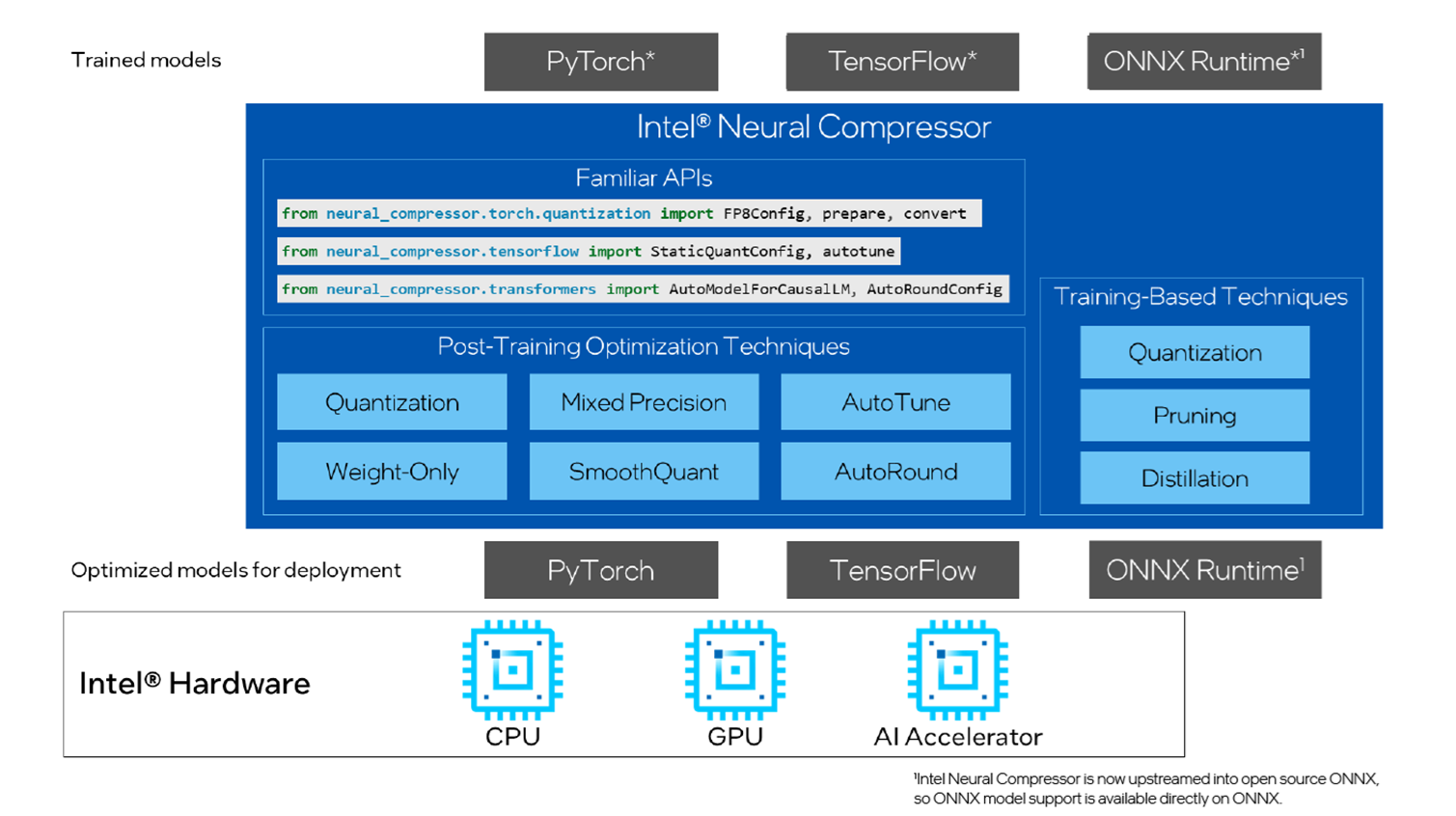
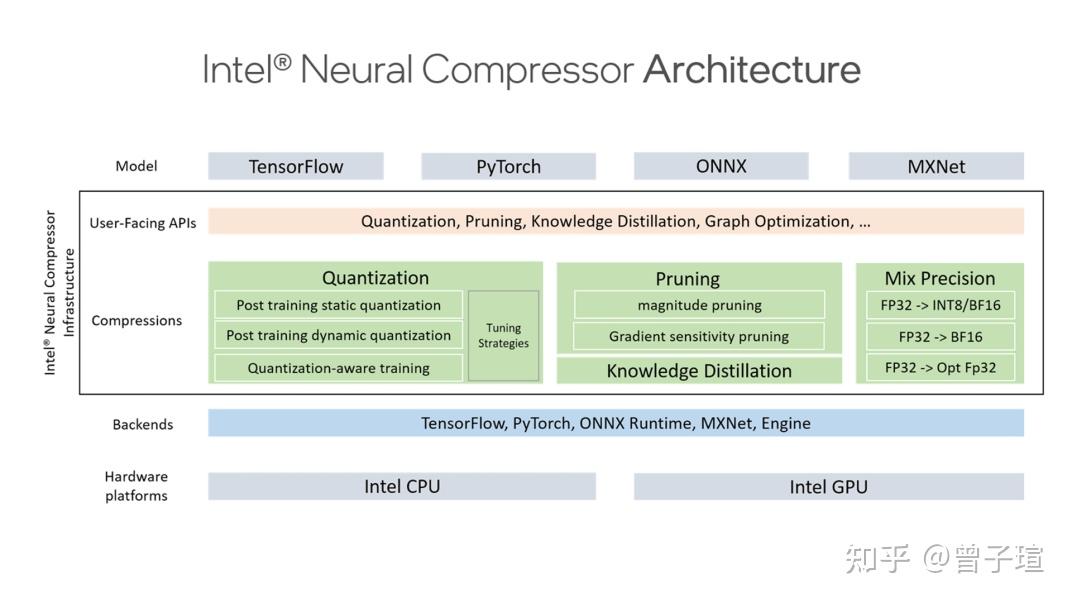
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
Faster, Easier Optimization with Intel® Neural Compressor - Intel ...
Faster, Easier Optimization with Intel® Neural Compressor - Intel Community
Quantizing ONNX Models using Intel® Neural Compressor - Intel Community
PyTorch Inference Acceleration with Intel® Neural Compressor | Intel ...
Dynamic Quantization with Intel Neural Compressor and Transformers ...
From Innovation to Ecosystem: A Journey of Intel Neural Compressor | by ...
Intel Neural Compressor v3.0: A Quantization Tool across Intel Hardware ...
Intel Innovation 2021 Demo: Intel Neural Compressor - YouTube
One-Click Enabling of Intel Neural Compressor Features in PyTorch ...
Intel Neural Compressor Joins ONNX in Open Source for AI
Dynamic Neural Architecture Search with Intel Neural Compressor | by ...
Perform Model Compression Using Intel® Neural Compressor
An Easy Introduction to Intel® Neural Compressor
Accelerate AI Inference with Intel® Neural Compressor
Perform Model Optimization Using Intel® Neural Compressor
Intel Neural Compressor: AI-Optimized Simple Quantization
Intel® Neural Compressor — Intel® Neural Compressor documentation
It's a wrap! Intel® oneAPI masterclass on Neural Compressor to ...
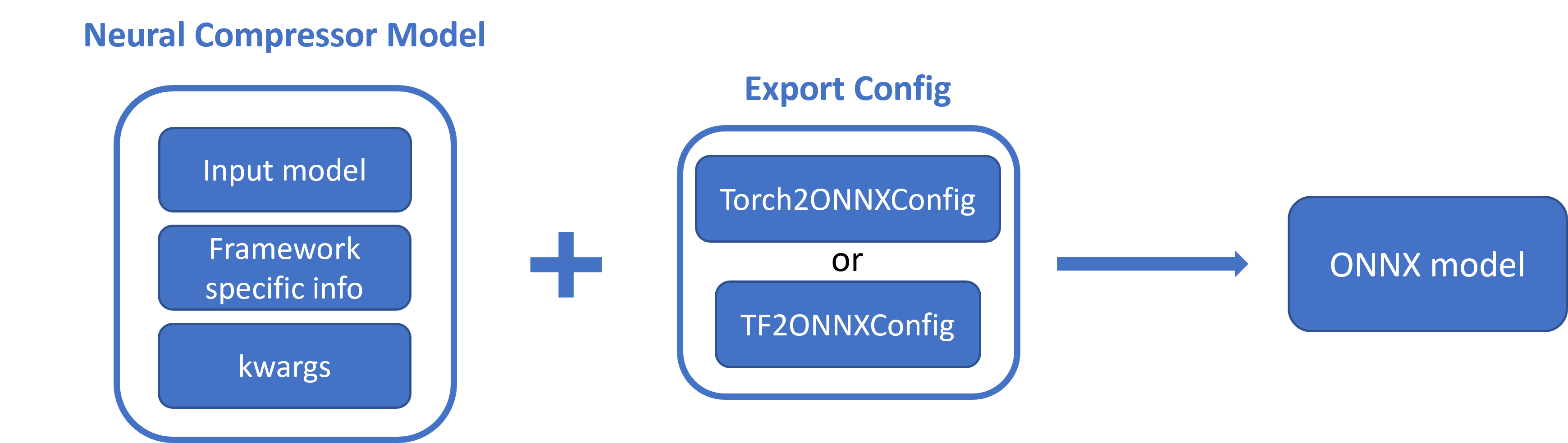
Export — Intel® Neural Compressor 3.2 documentation
Intel® Neural Compressor Bench — Intel® Neural Compressor documentation
How Intel's new Neural Compressor makes AI faster | UNICOM Engineering ...
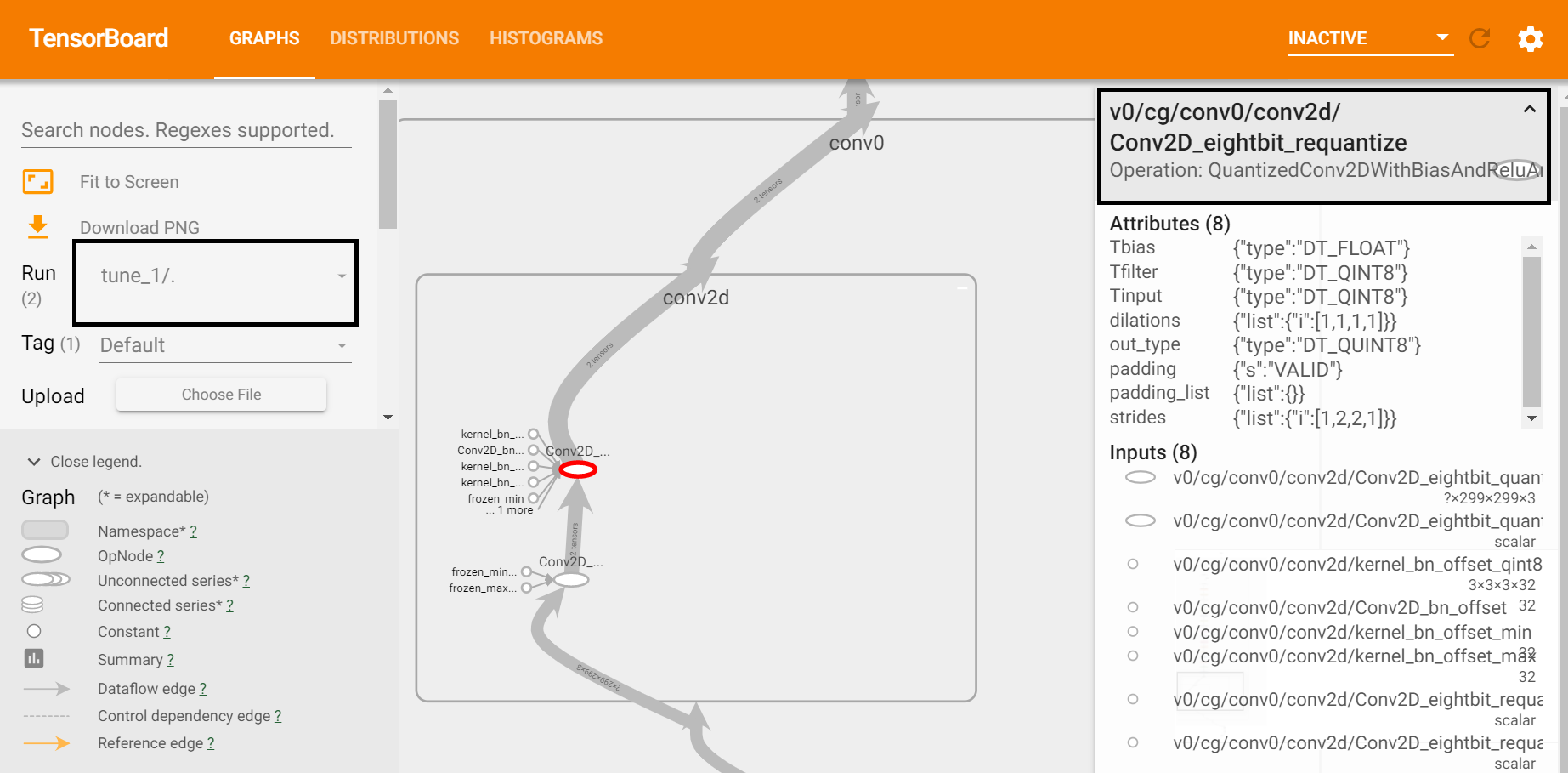
TensorBoard — Intel® Neural Compressor documentation
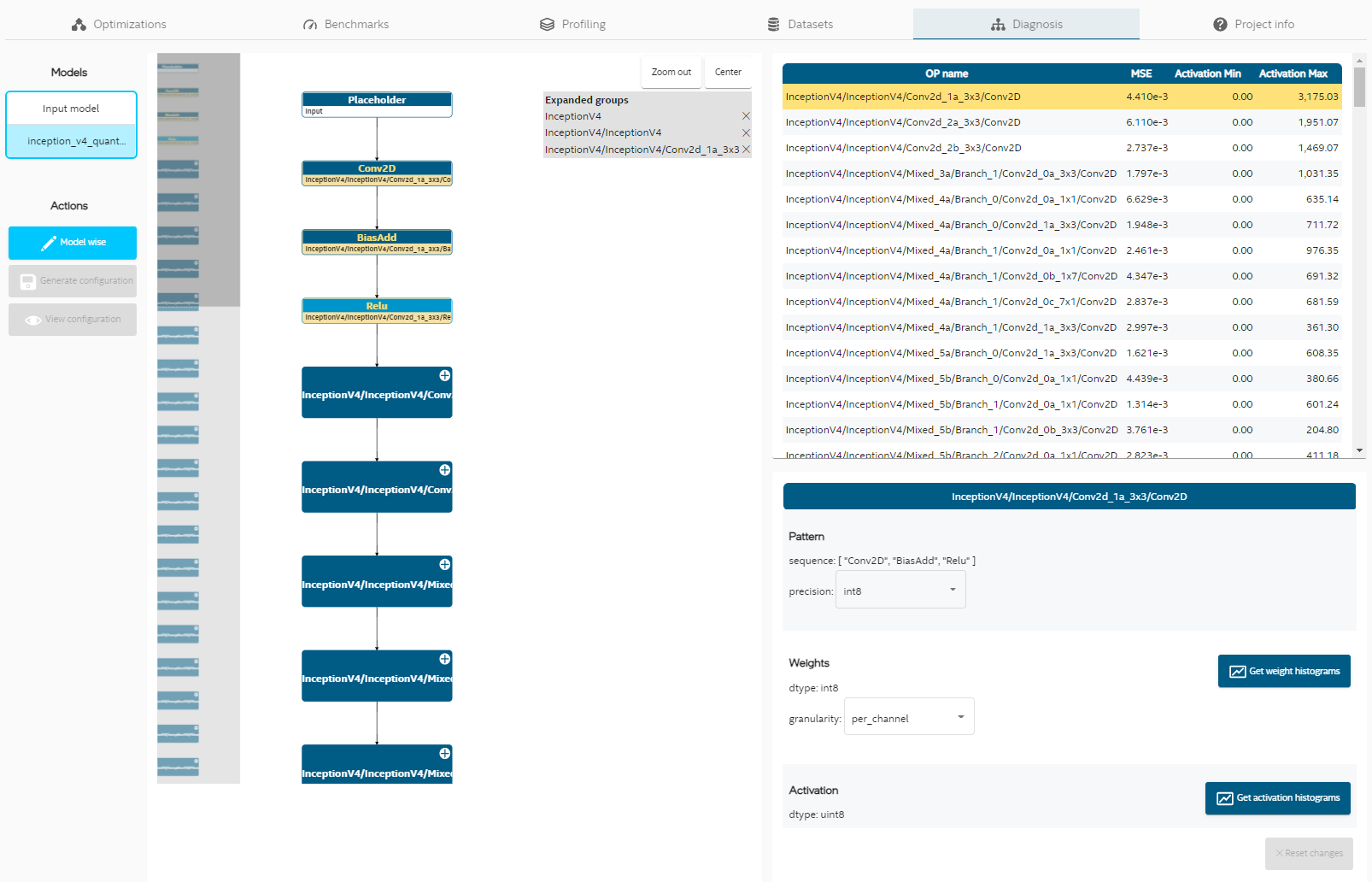
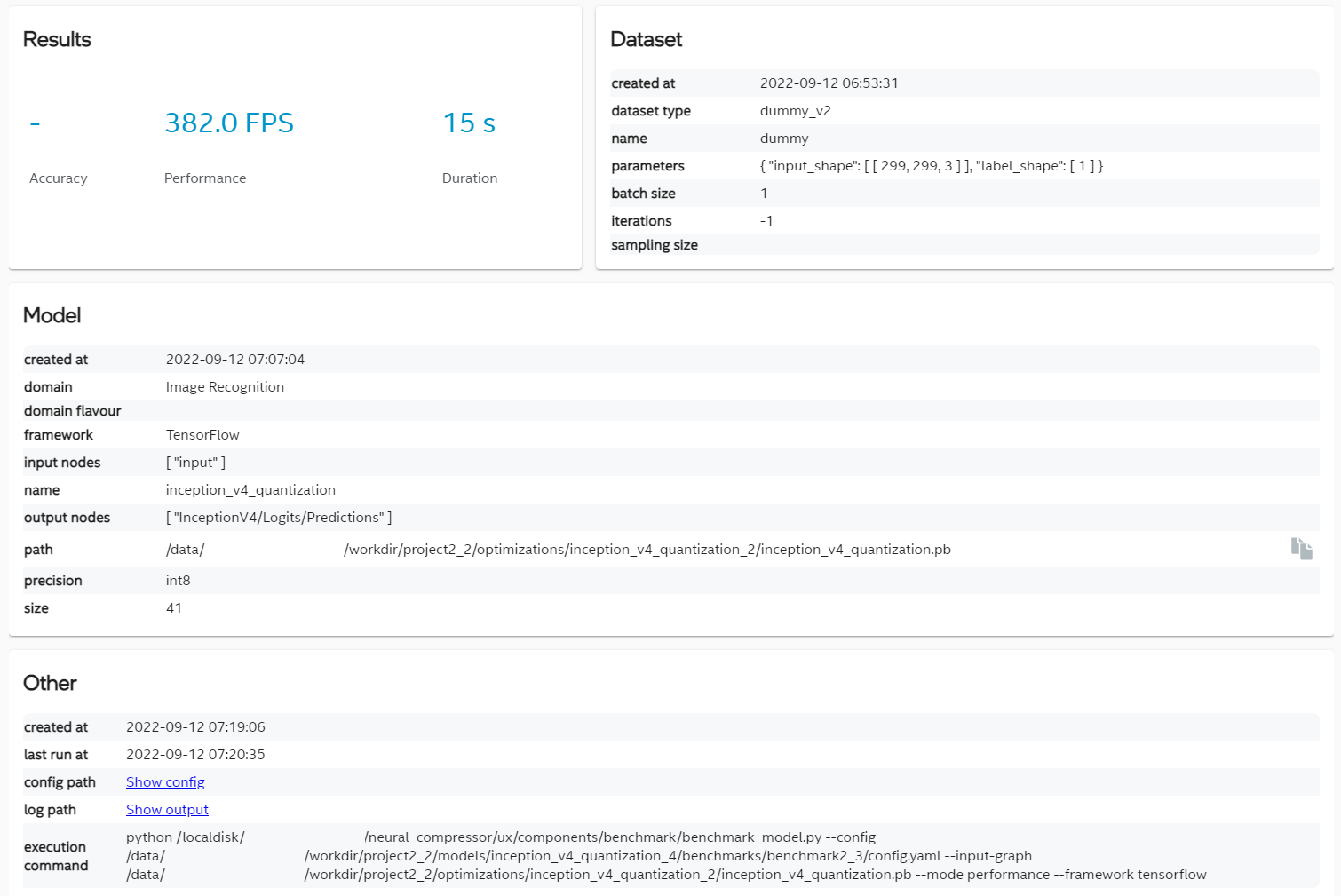
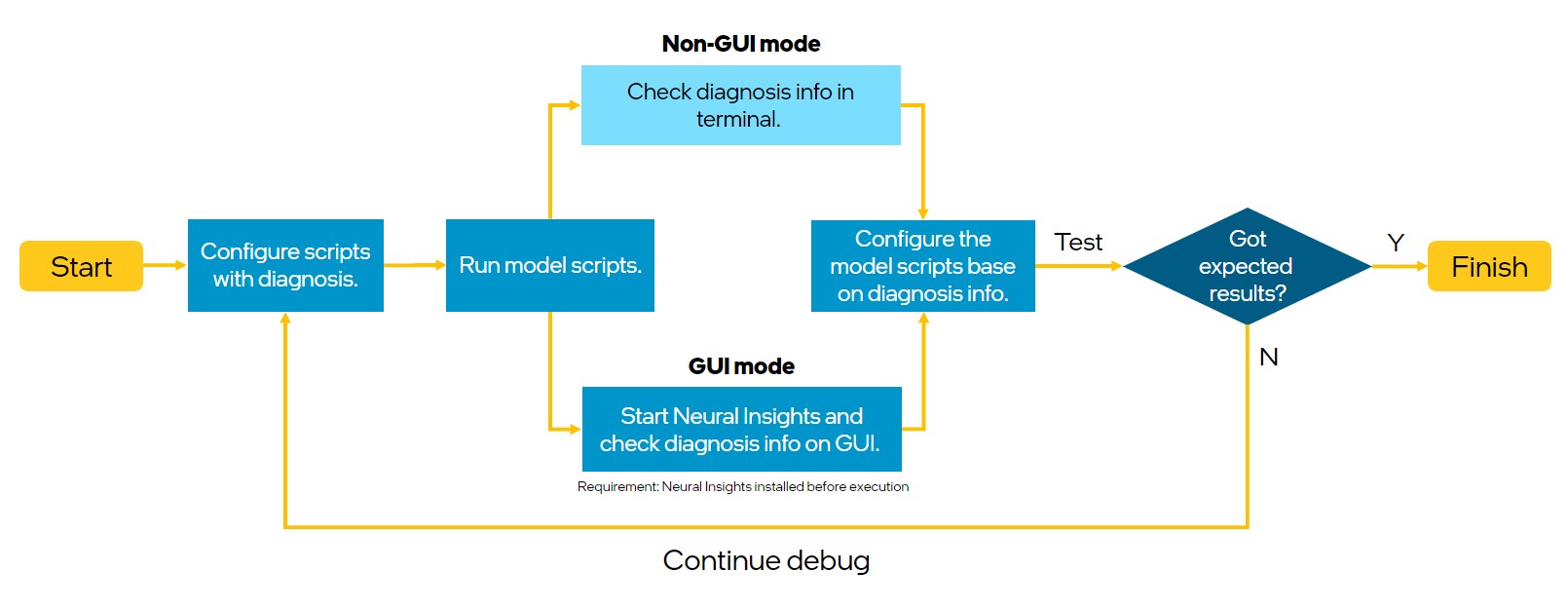
Diagnosis — Intel® Neural Compressor 3.0 documentation
Intel(R) Neural Compressor – Medium
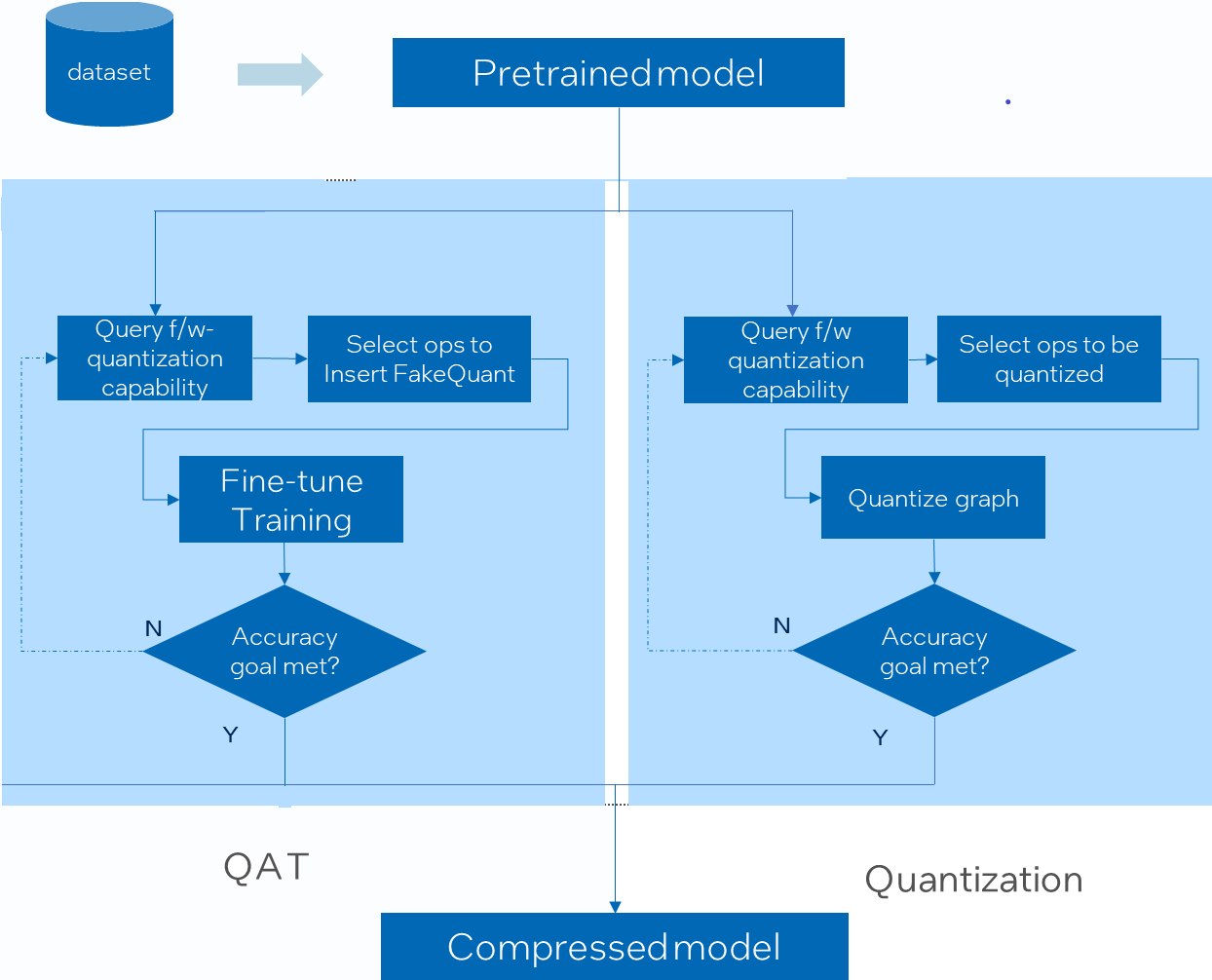
Quantization — Intel® Neural Compressor 3.6 documentation
Quantization — Intel® Neural Compressor documentation
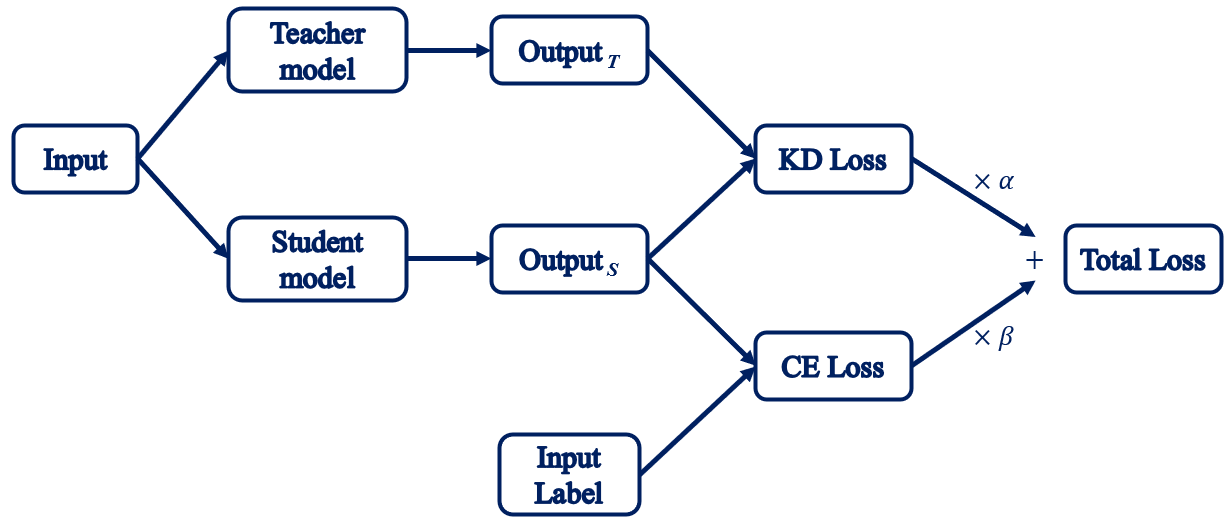
Distillation — Intel® Neural Compressor documentation
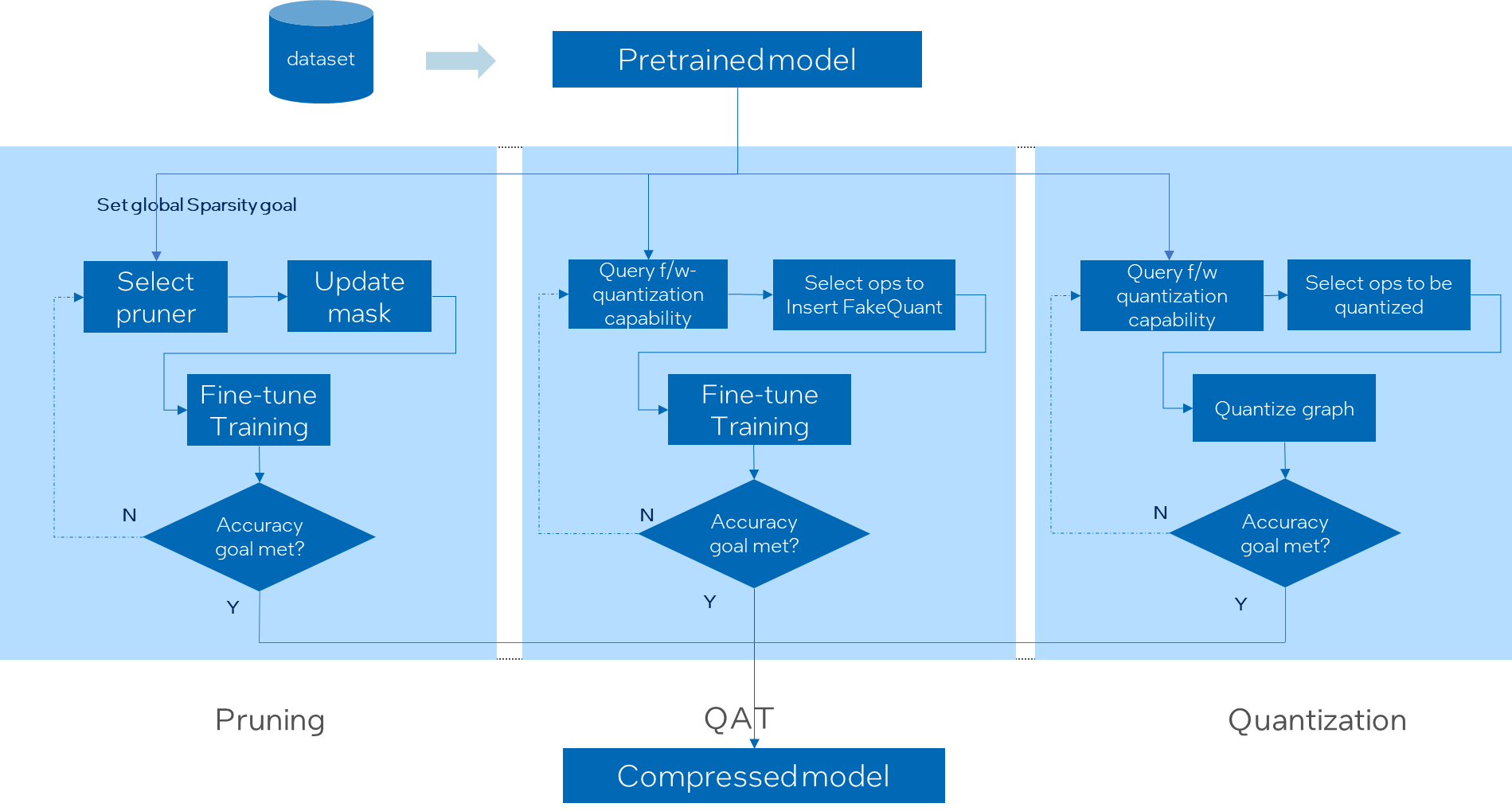
Design — Intel® Neural Compressor documentation
Découvrez Intel® Neural Compressor : une bibliothèque Python open ...
Intel Neural Compressorに深刻な脆弱性、即時アップデートを推奨
Tuning Strategies — Intel® Neural Compressor 3.6 documentation
Streamlining Model Optimization as a Service with Intel Neural ...
Smooth Quant — Intel® Neural Compressor 3.0 documentation
Want to learn about Intel Neural Compressor: A model compression tool ...
Highly-efficient LLM Inference on Intel Platforms | by Intel(R) Neural ...
Mixed Precision — Intel® Neural Compressor 3.6 documentation
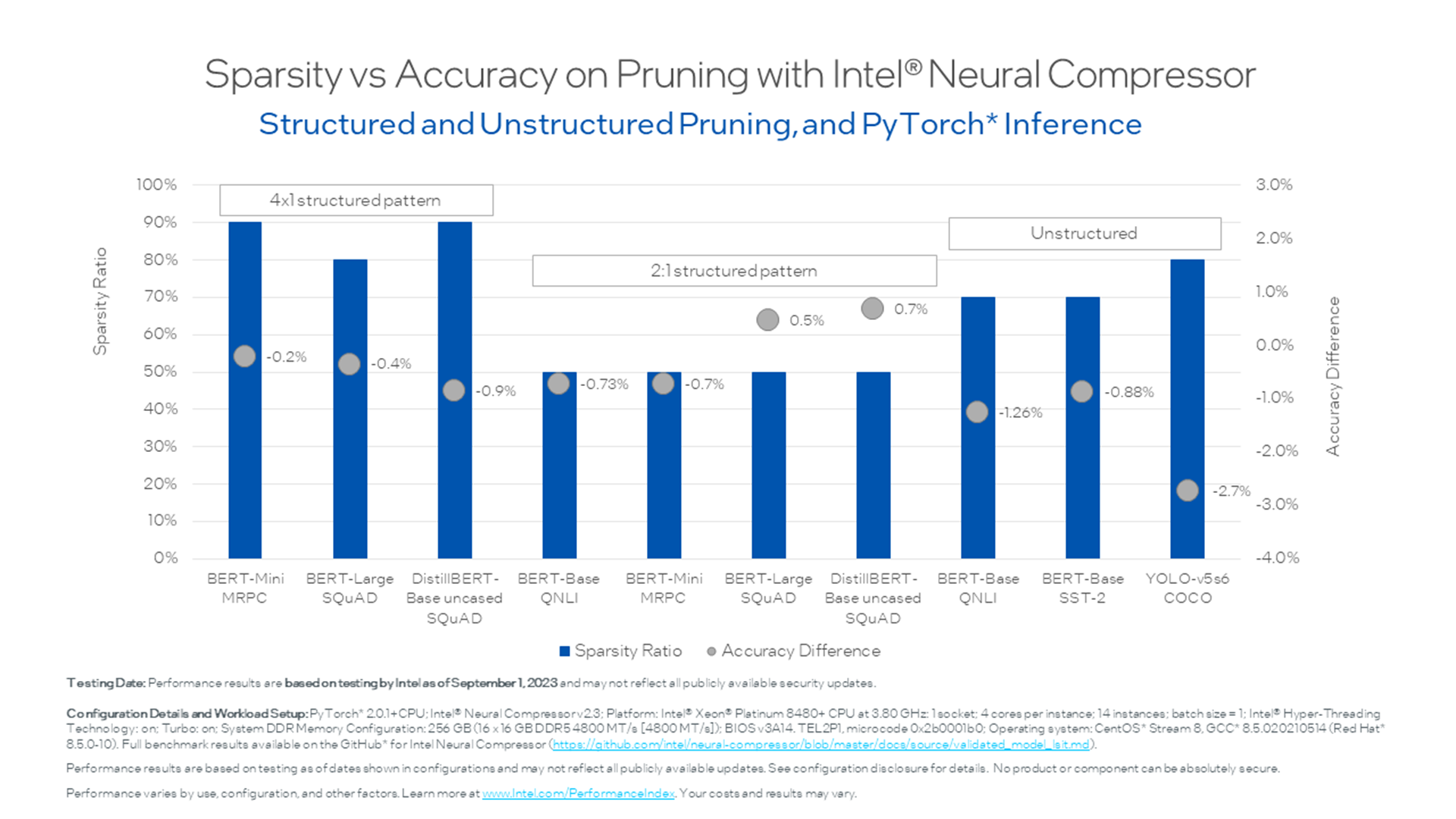
Pruning — Intel® Neural Compressor 2.3 documentation
Diagnosis — Intel® Neural Compressor 2.6 documentation
GitHub - sankalpvarshney/neural-compressor: Intel® Neural Compressor ...
Intel Neural Compressor: 加速深度学习推理的开源工具 - 懂AI
Pruning — Intel® Neural Compressor documentation
Quantization of Transformer Models with Neural Compressor
Meet Intel® Neural Compressor: An Open-Source Python Library for Model ...
Compressing the Transformer: Optimization of DistilBERT with the Intel ...
Join this masterclass on ‘Speed up deep learning inference with Intel ...
Turn ON Auto Mixed Precision during Quantization — Intel® Neural ...
One-Click Quantization of Deep Learning Models with the Neural Coder ...
GitHub - vishnumadhu365/neural-compressor-sample-update: Intel® Neural ...
Streamlining Model Optimization as a Service with Intel® Neural ...
neural-compressor/docs/source/3x/PT_SmoothQuant.md at master · intel ...
Effective Weight-Only Quantization for Large Language Models with Intel ...
How to Fine-Tune INT8 DistilBart on CNN DailyMail Using Intel® Neural ...
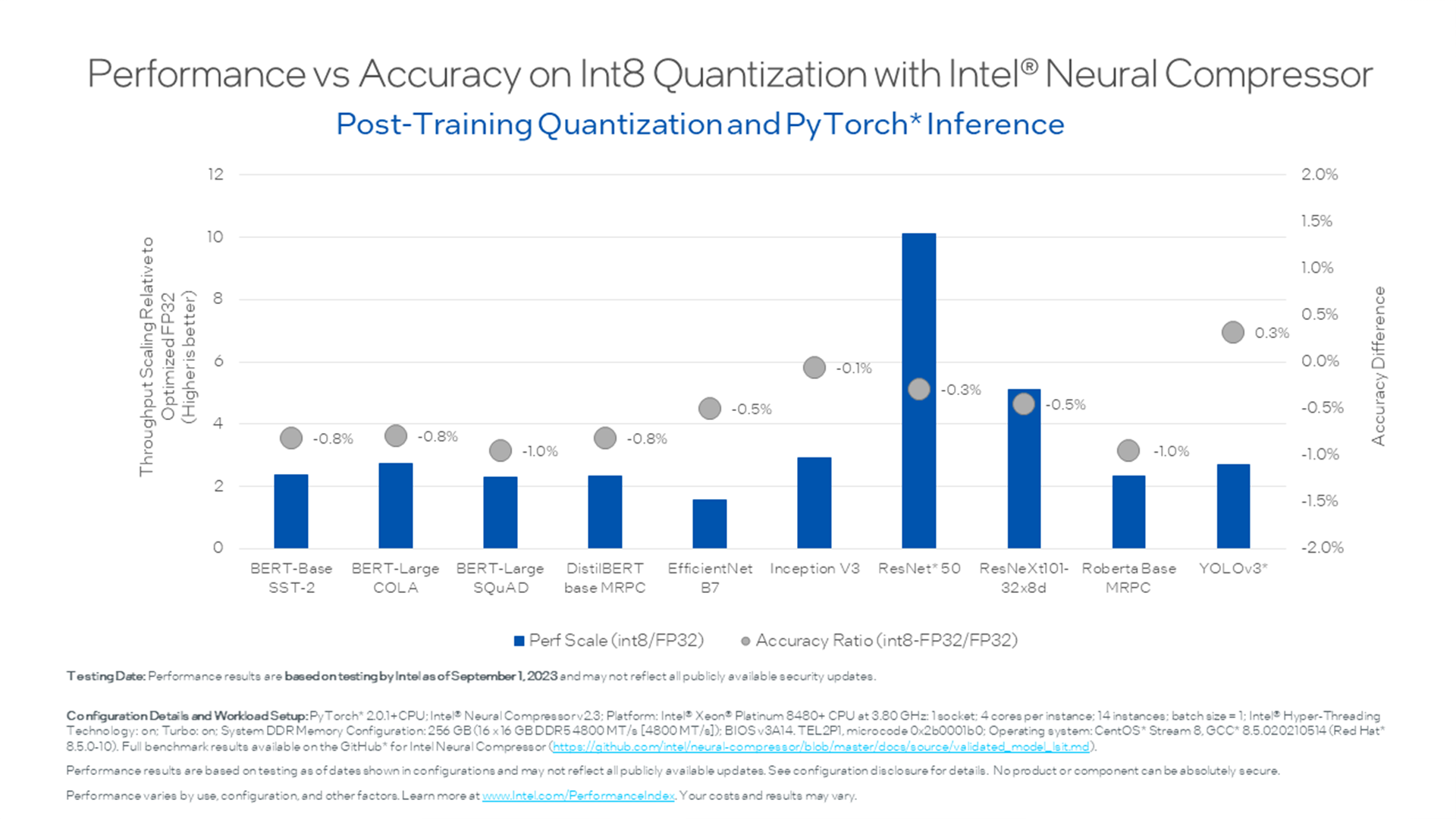
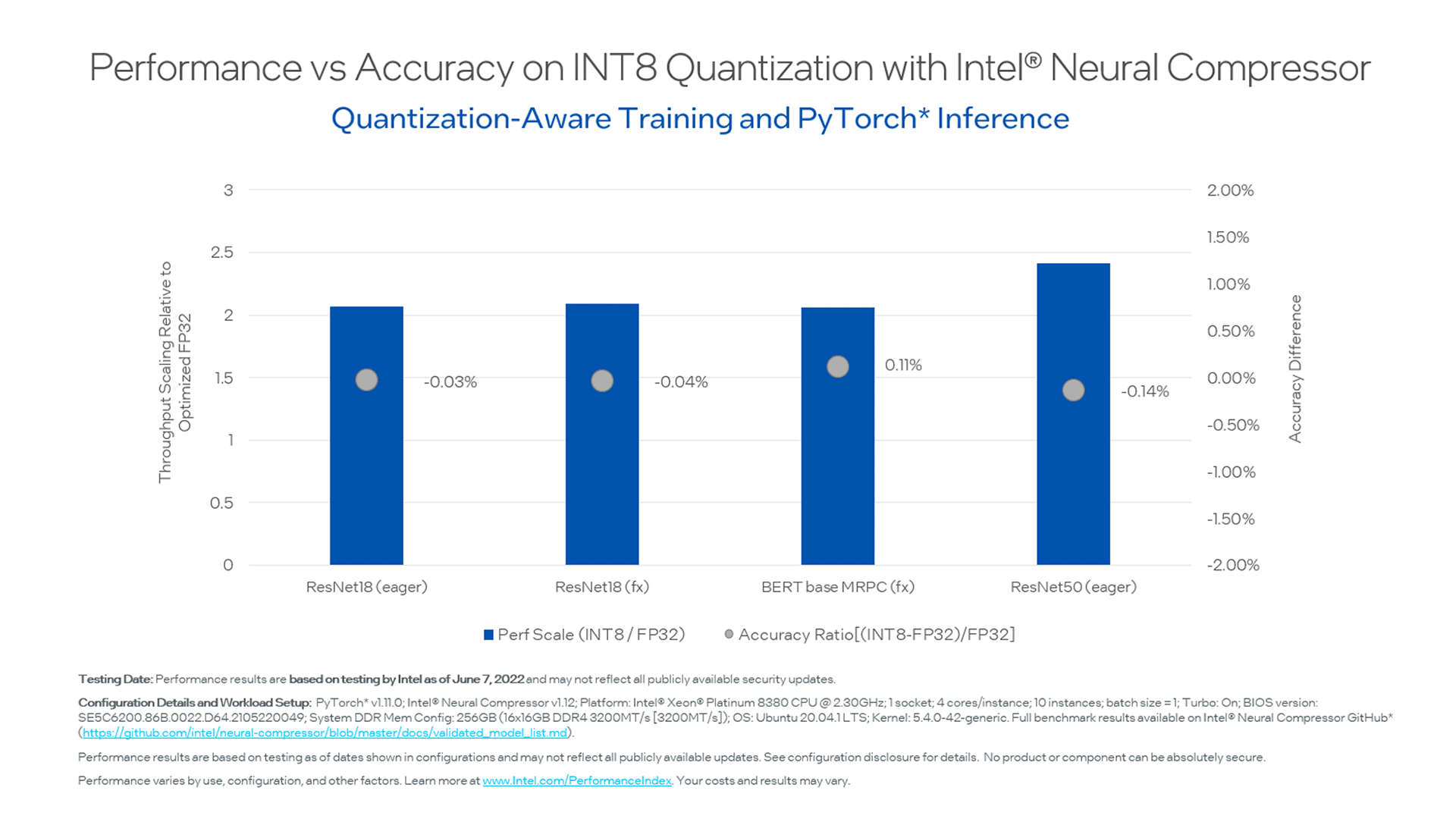
Developer Productivity & Performance 2025.1
Get Started Post-Training Dynamic Quantization | AI Model Optimization ...
GitHub - intel/neural-compressor: SOTA low-bit LLM quantization (INT8 ...
Intel(R) Neural-Compressor
Accelerating vLLM and SGLang Deployment using AutoRound | by Intel(R ...
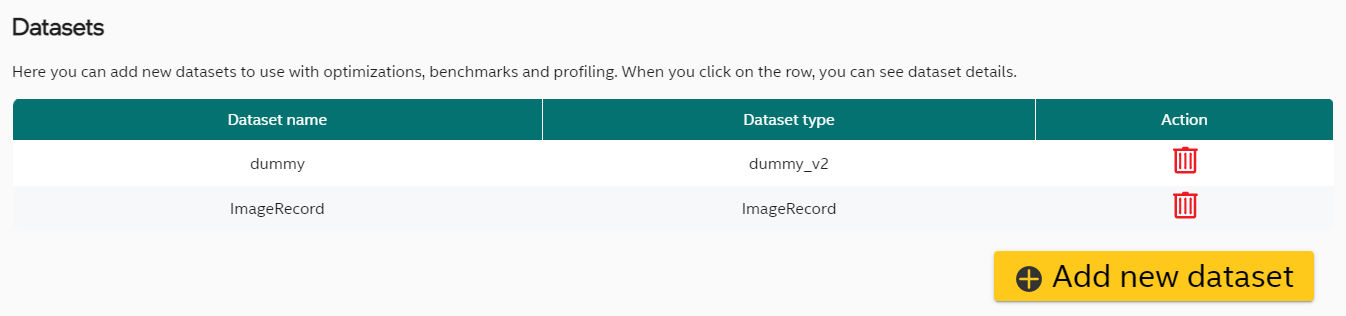
neural-compressor-modify/docs/dataset.md at master · shjiyang-intel ...
GitHub - intel/neural-compressor: SOTA low-bit LLM quantization ...
INT6/INT4 support for model optimization · Issue #1100 · intel/neural ...
用CPU做大模型推理——英特尔解决方案 - 知乎
huntr: intel/neural-compressor
How to Perform Post-Training Dynamic Quantization on T5 Large with ...