Showing 96 of 96on this page. Filters & sort apply to loaded results; URL updates for sharing.96 of 96 on this page
BLIP Model Explained: How It’s Revolutionizing Vision-Language Models ...
Image and text features extraction with BLIP and BLIP-2: how to build a ...
BLIP Bootstrapping Language-Image Pre-training for Unified Vision ...
Introduction to BLIP Model: Unlocking the Future of Image-Text ...
BLIP-2: BLIP with Frozen Image Encoders and Large Language Models论文笔记 - 知乎
hysts/InstructBLIP at main
InstructBLIP - a Hugging Face Space by shivangibithel
X-InstructBLIP
AvisC
多模态的相关模型(BLIP、BLIP-2 、Instruct-BLIP) - 知乎
Giải quyết bài toán Vision-Language với BLIP-2 và InstructBLIP
InstructBLIP analysis
InstructBLIP models - a Salesforce Collection
26. Vision Language Pretraining — LLM Foundations
CLIP models used in experiments. | Download Scientific Diagram
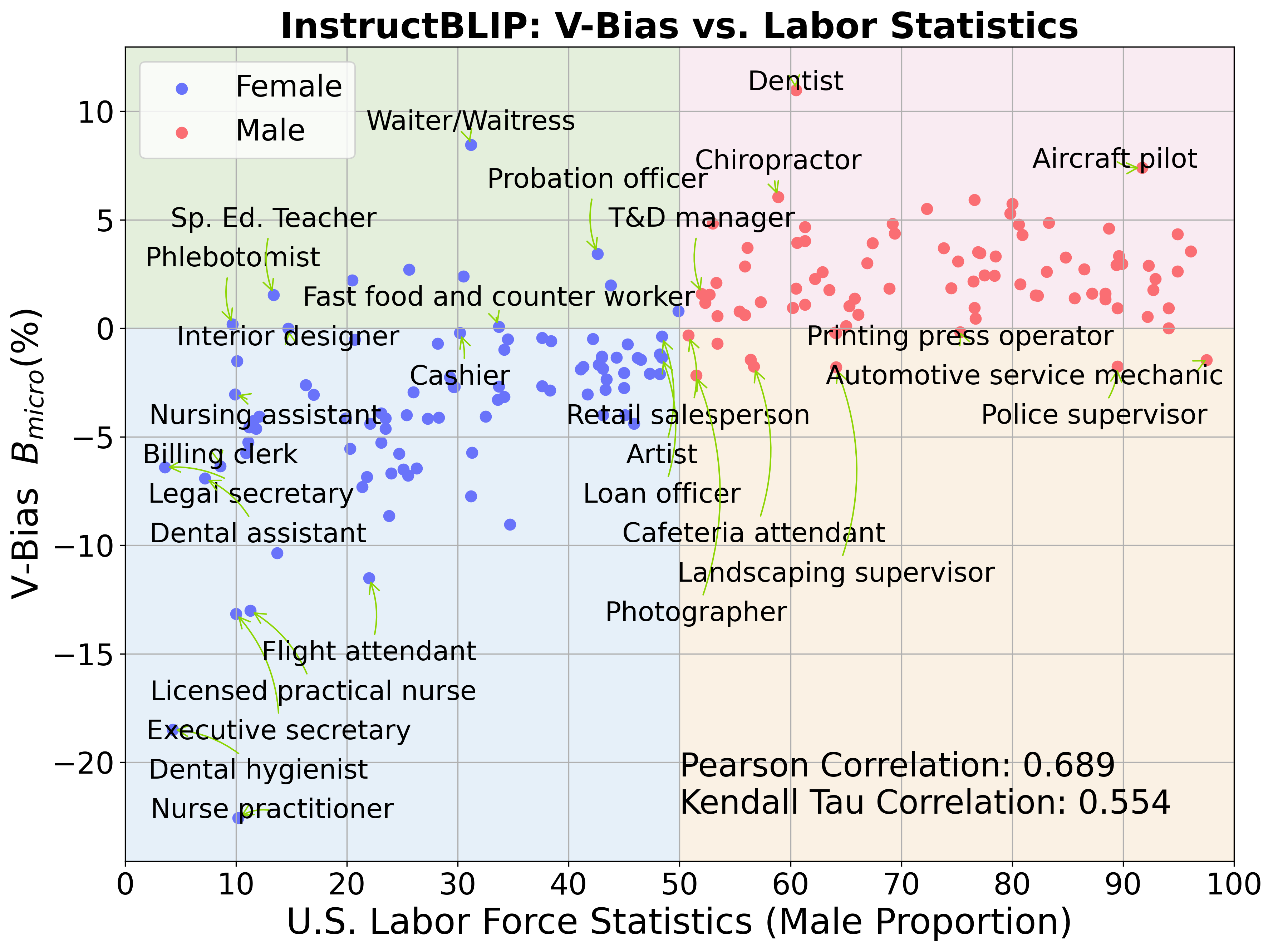
InstructBLIP: Towards General-purpose Vision-Language Models with ...
The response from InstructBLIP is more comprehensive than GPT-4, more ...
[阅读笔记10][instructBLIP]Towards General-purpose Vision-Language Models ...
Cách giải quyết bài toán Vision-Language với BLIP-2 và InstructBLIP
(PDF) InstructBLIP: Towards General-purpose Vision-Language Models with ...
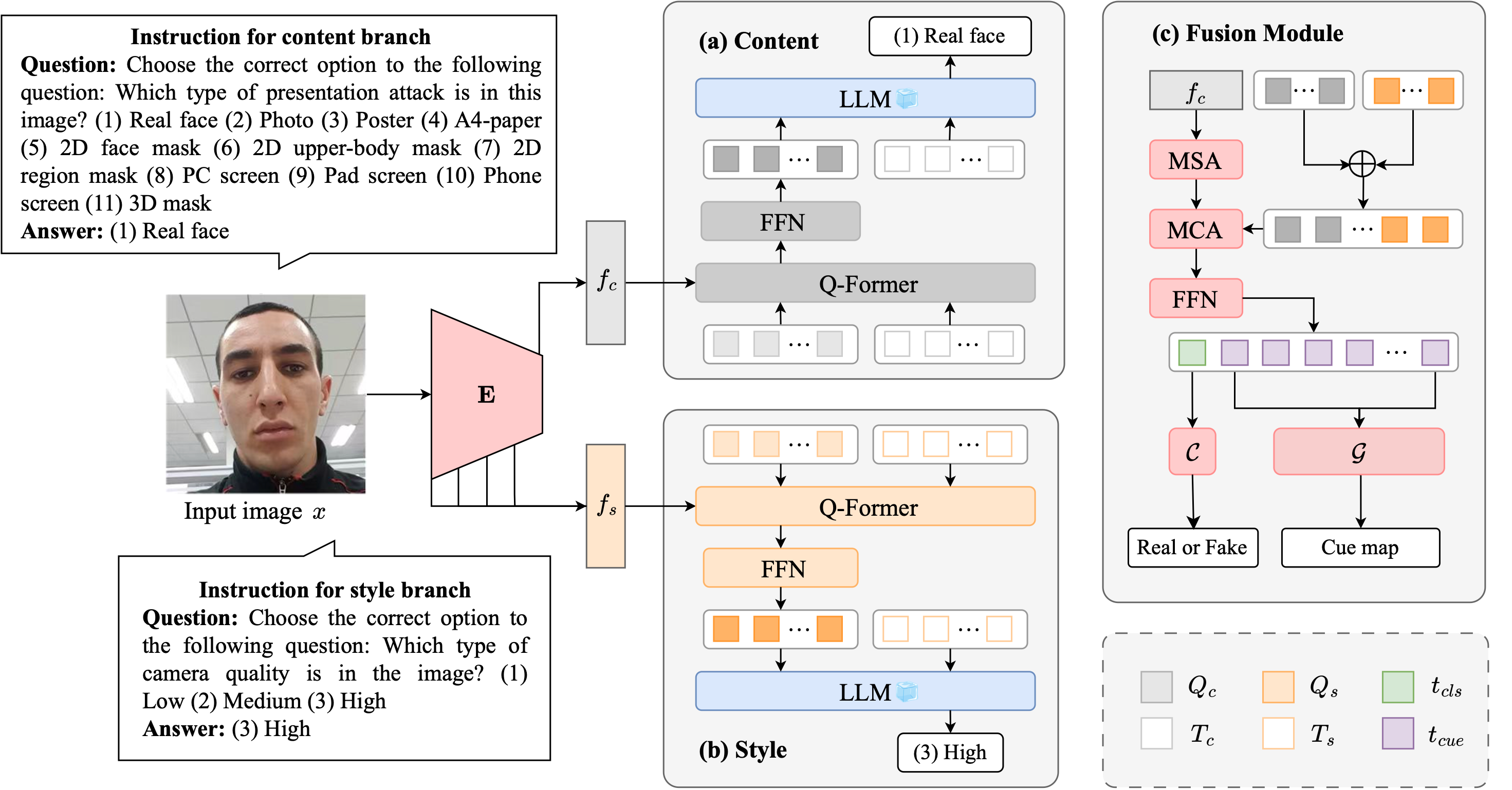
InstructFLIP: Exploring Unified Vision-Language Model for Face Anti ...
Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video ...
Delve into Visual Contrastive Decoding for Hallucination Mitigation of ...
[BLIP/BLIP2/InstructBLIP] 图文多模态理解与生成 - 知乎
文献阅读:InstructBLIP: Towards General-purpose Vision-Language Models with ...
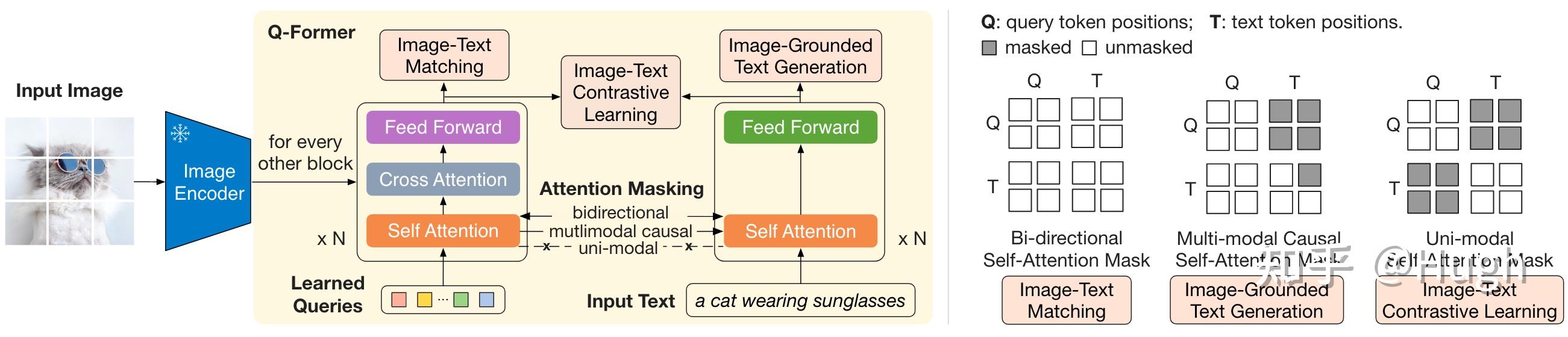
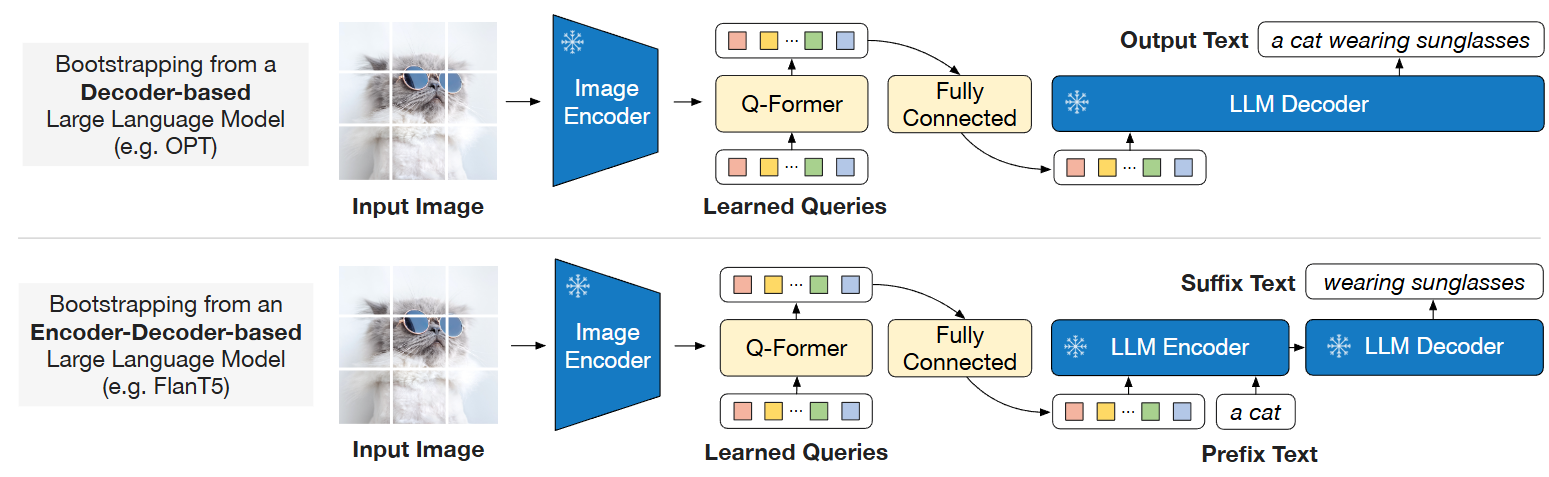
BLIP-2: A new Visual Language Model by Salesforce | BLIP-2 – Weights ...
GitHub - dxli94/InstructBLIP-demo
Japanese InstructBLIP Alpha vision-language model by Stability AI ...
InstructBLIP: Enhancing Vision-Language Models with Instruction ...
LLaVa and Visual Instruction Tuning Explained - Zilliz blog
BLIP-2: A Breakthrough Approach in Vision-Language Pre-training | by ...
[MM] MMICL: EMPOWERING VISION-LANGUAGE MODEL WITH MULTI-MODAL IN ...
华人团队开源指令调优的InstructBLIP多模态大模型 | 横扫多项SOTA,看图&推理&问答&对话样样通! - 知乎
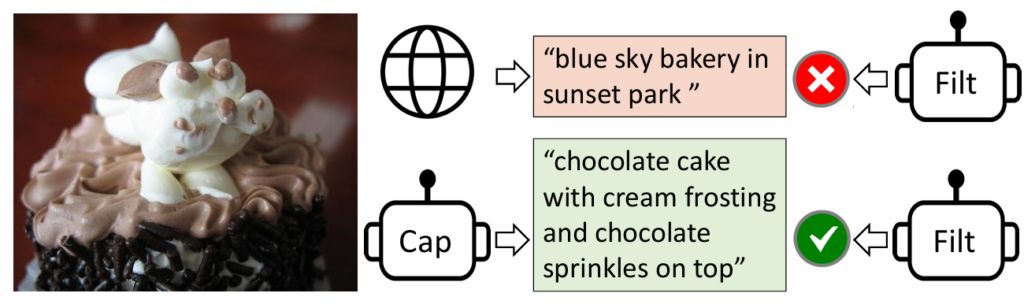
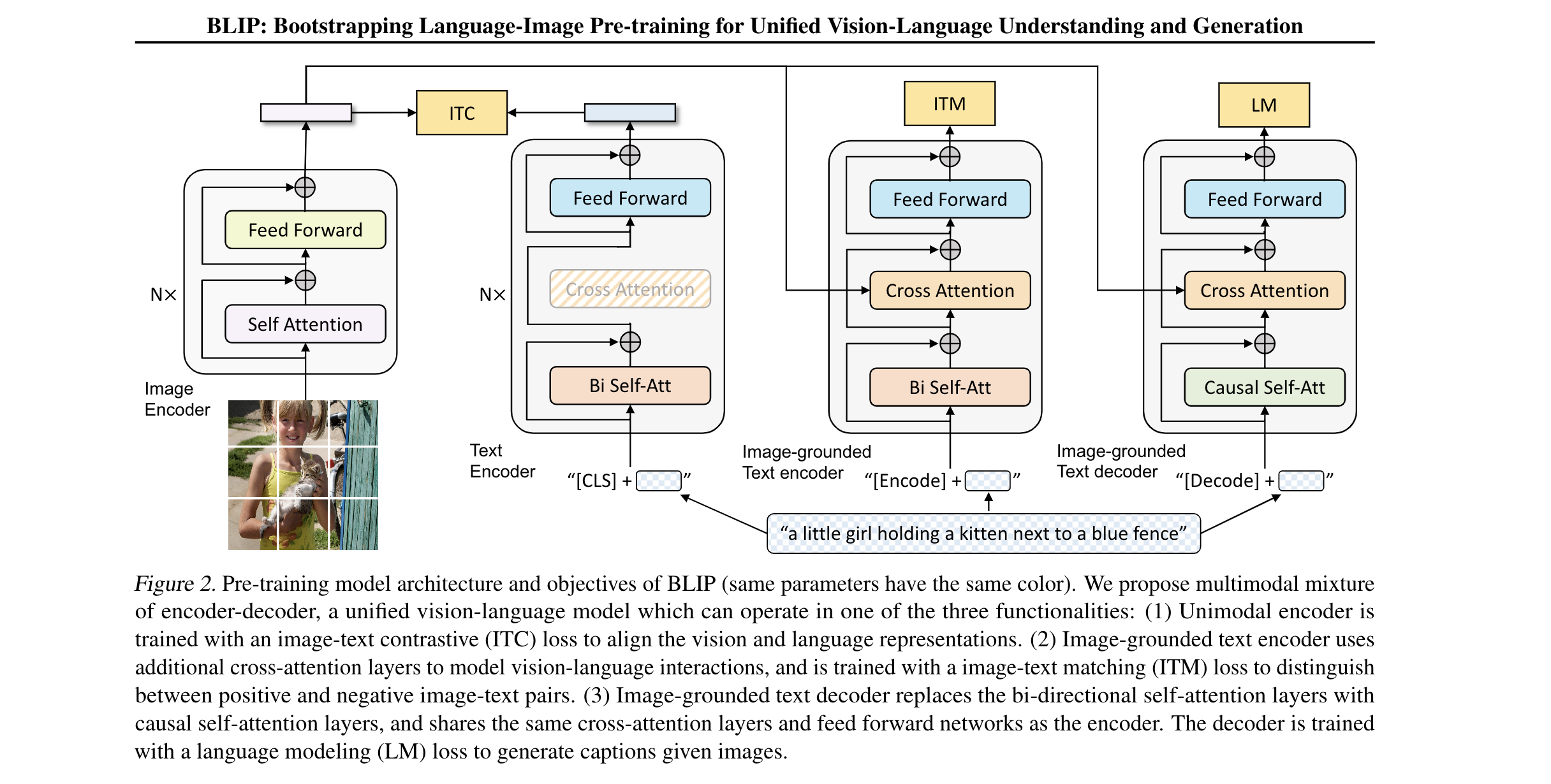
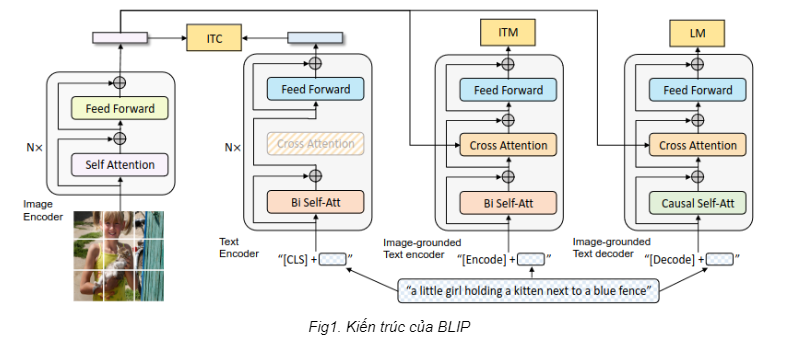
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision ...
视觉语言大模型之BLIP、BLIP2、InstrucBLIP (paper quickly reading) - 知乎
BLIP系列——BLIP、BLIP-2、InstructBLIP、BLIP-3 - 知乎
(PDF) BLIP-2: Bootstrapping Language-Image Pre-training with Frozen ...
GitHub - fitzpchao/Chinese_InstructBLIP: Adding a Randeng translation ...
Introduction to LLaVA: A Multimodal AI Model | by Uddeshya Singh | Medium
GitHub - AttentionX/InstructBLIP_PEFT
[2305.06500] InstructBLIP: Towards General-purpose Vision-Language ...
Salesforce/instructblip-flan-t5-xl at main
“Unveiling the Power of Multimodal Large Language Models ...
多模态大模型 CLIP, BLIP, BLIP2, LLaVA, miniGPT4, InstructBLIP 系列解读 - 知乎
[2201.12086] BLIP: Bootstrapping Language-Image Pre-training for ...
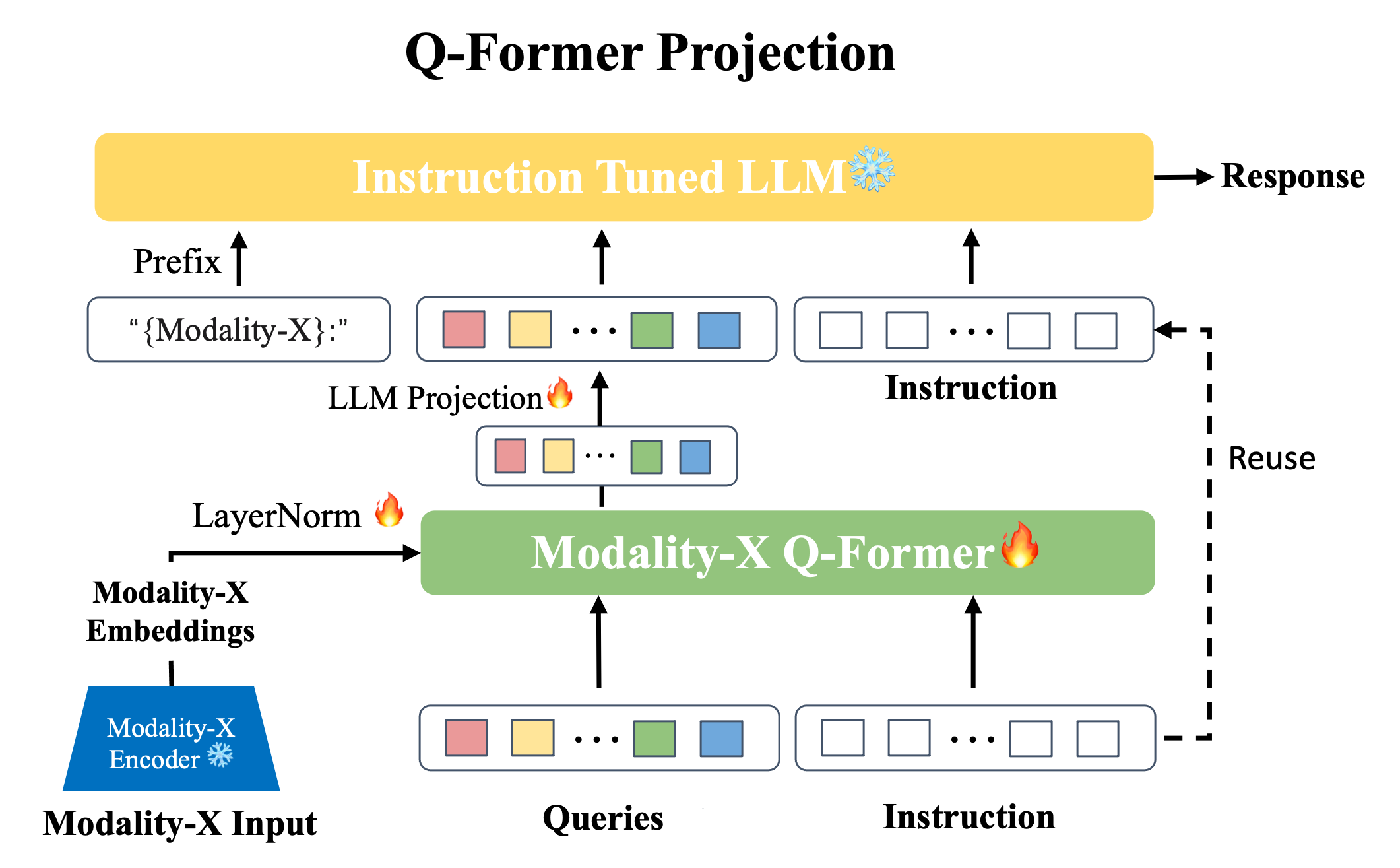
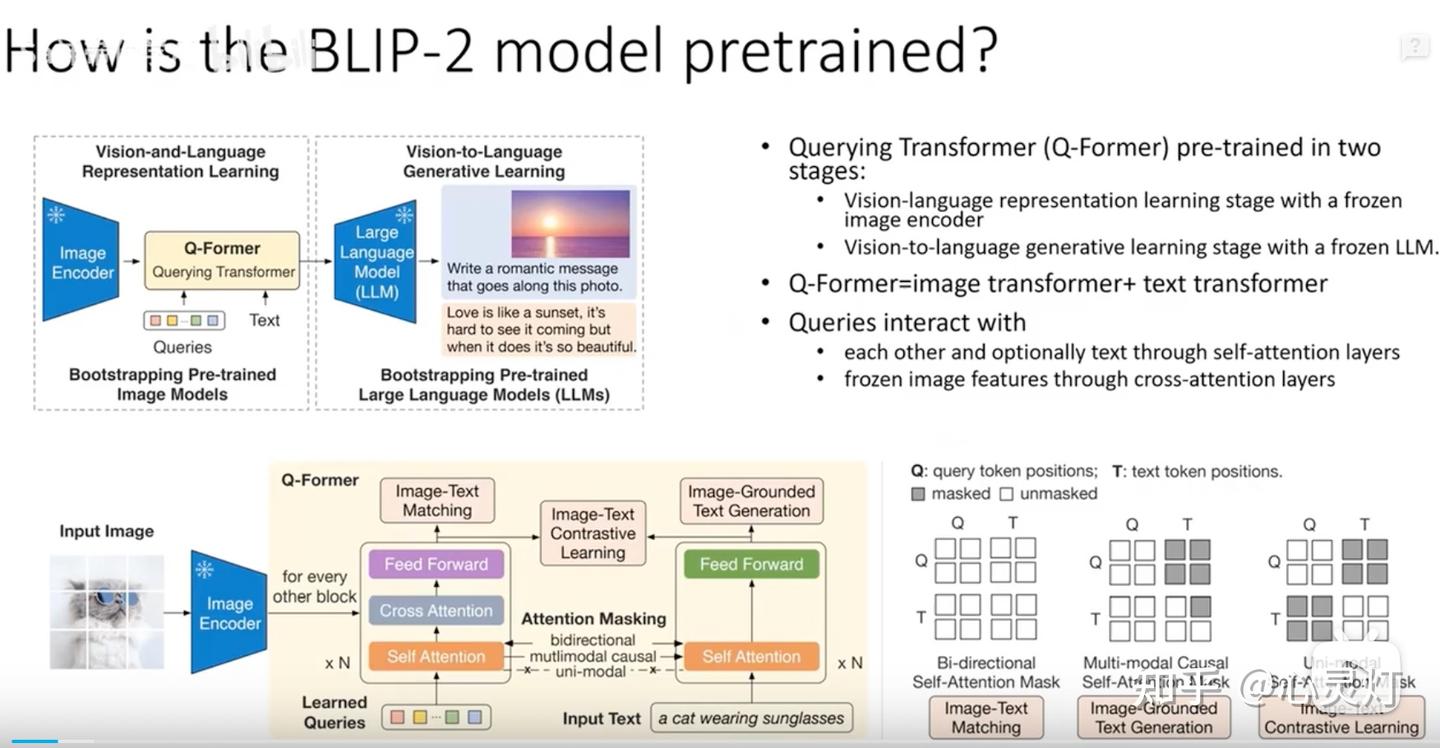
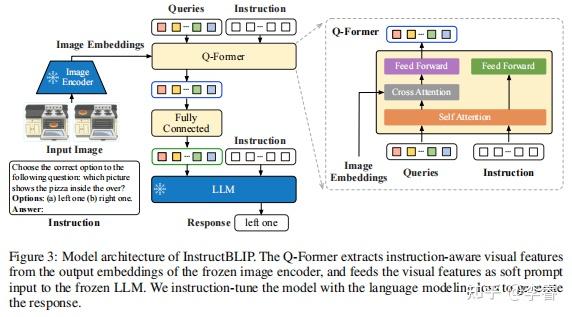
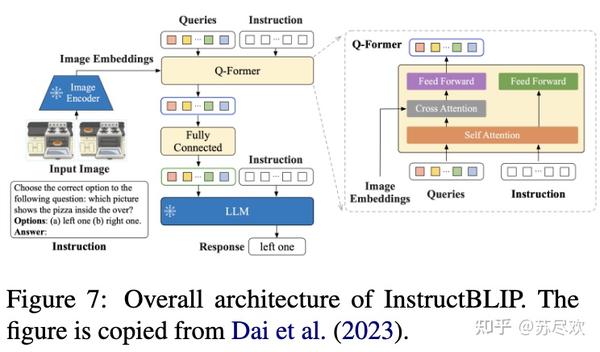
Overall architecture of InstructBLIP. The figure is copied from Dai et ...
Instructblip - a Hugging Face Space by thyaa10
[PDF] BLIP: Bootstrapping Language-Image Pre-training for Unified ...
GitHub - kjerk/instructblip-pipeline: A multimodal inference pipeline ...
【やってみた】Japanese InstructBLIP Alpha、Stability AIの日本語画像言語モデル | WEEL
Salesforce/instructblip-vicuna-7b · Can instructBlip process videos
InstructBLIP API | Run InstructBLIP with an API
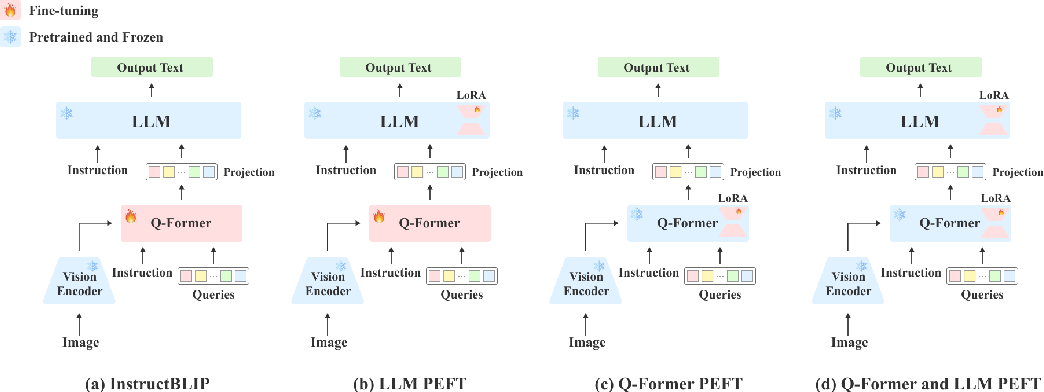
Figure 1 from Parameter-Efficient Fine-tuning of InstructBLIP for ...
Chinese InstructBLIP - a Hugging Face Space by FitzPC
Stability AI Unveils First Japanese Vision-Language Model
[论文]大语言模型指令调优综述 - 知乎
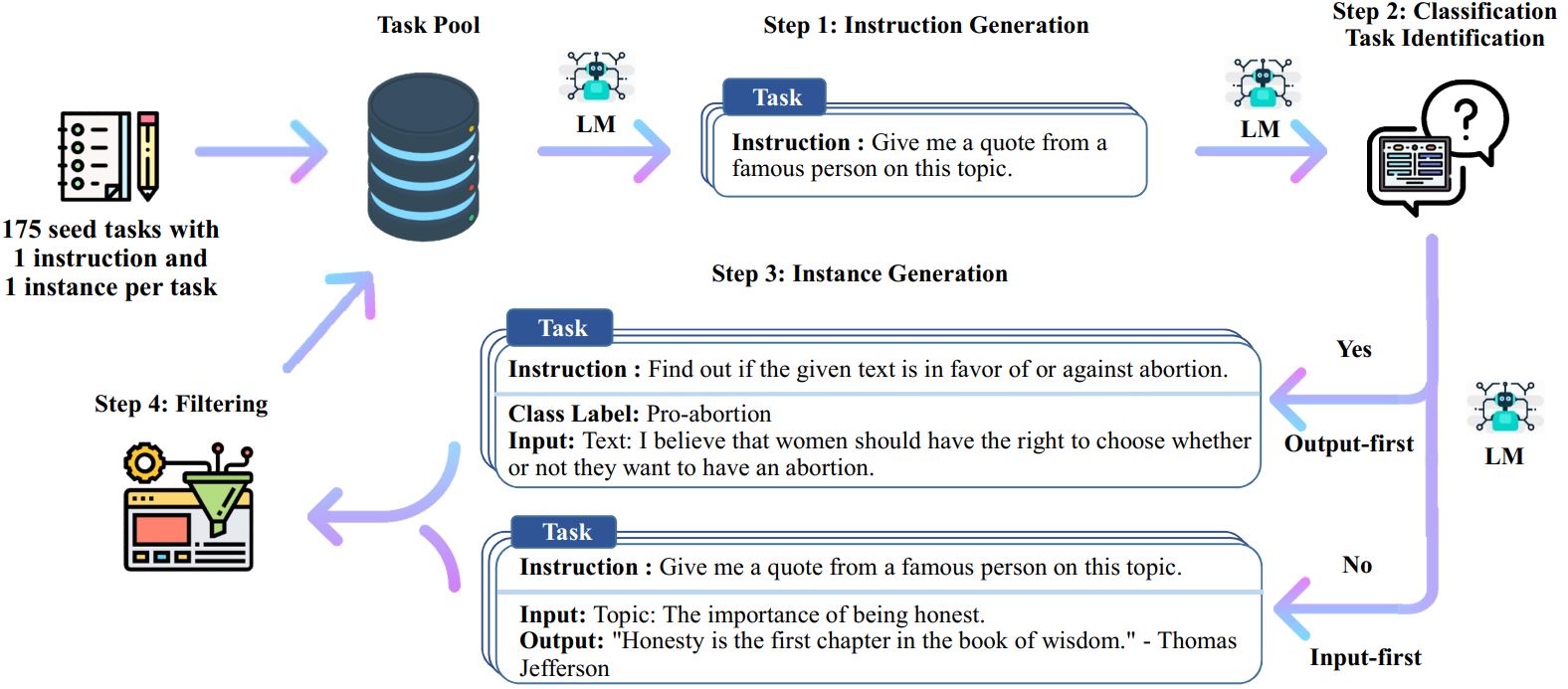
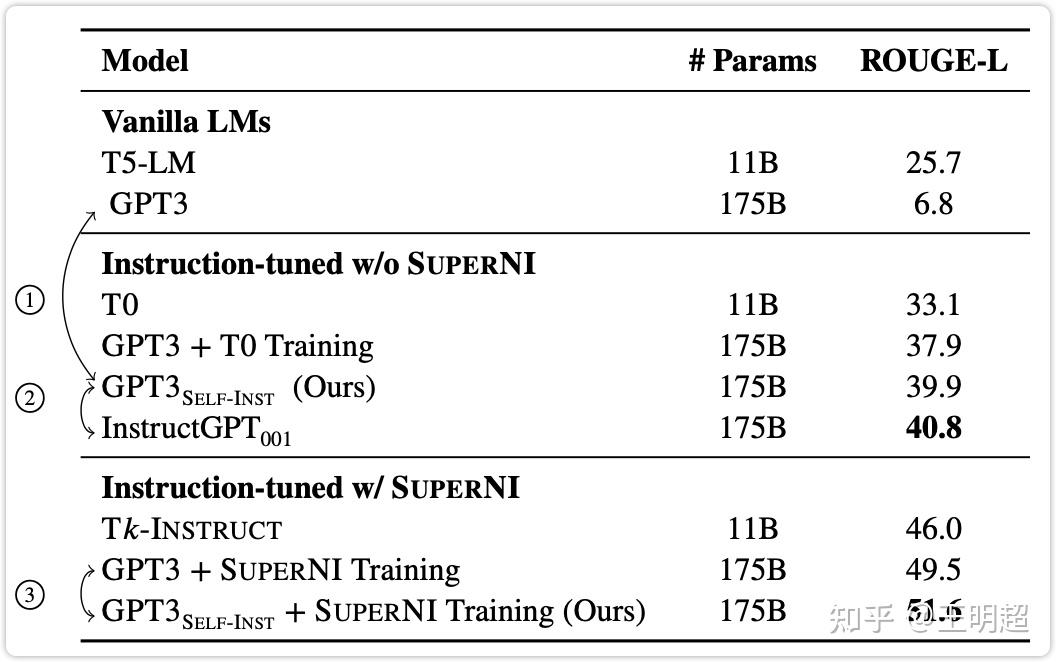
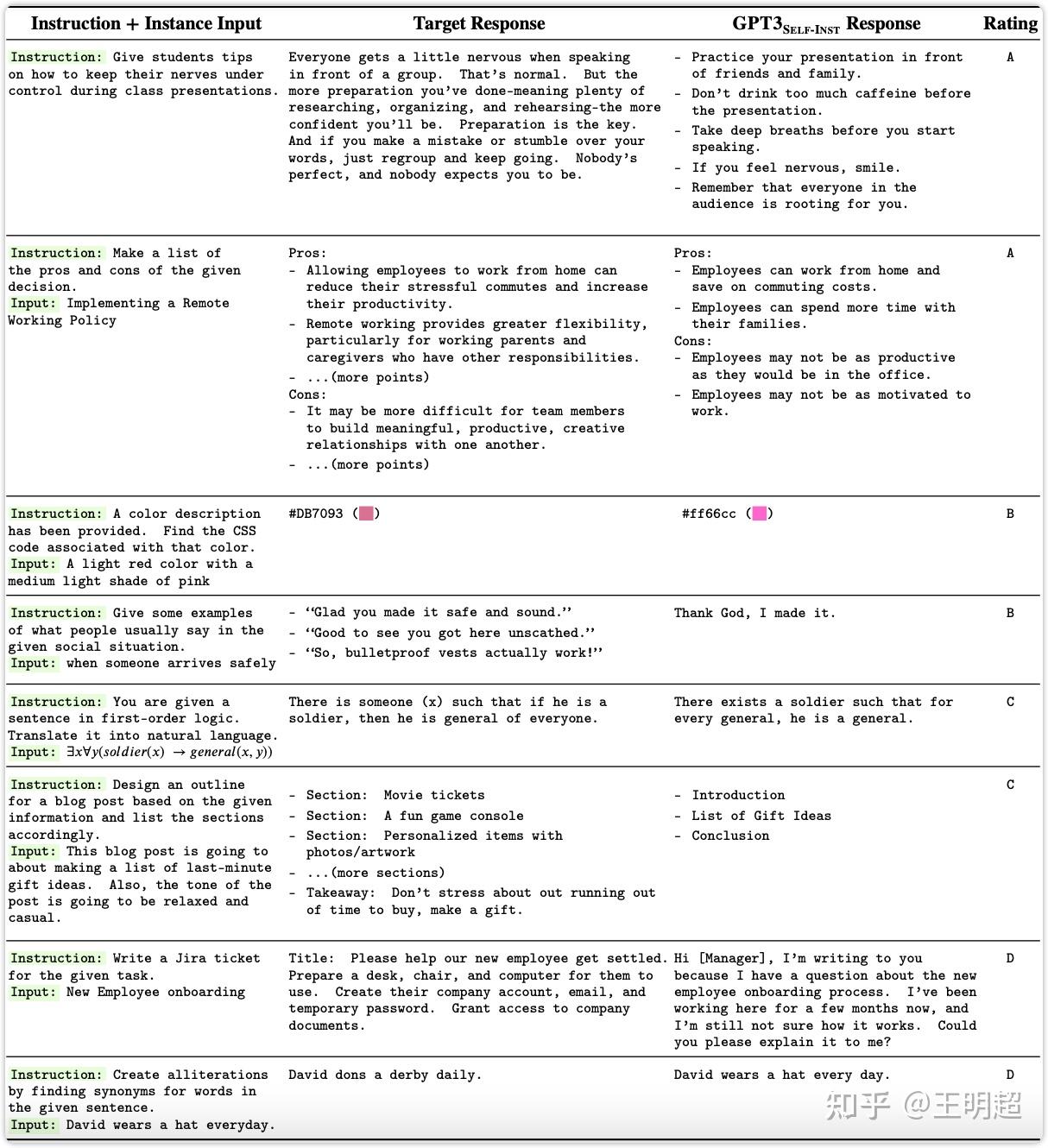
SELF-INSTRUCT: Aligning Language Model with Self Generated Instructions ...
Self-Instruct: Aligning Language Model with Self Generated Instructions ...
Stability AIが画像を認識して日本語で回答してくれるAIモデル「Japanese InstructBLIP Alpha」をリリース ...
NoyHanan/InstructBlip_Vicuna7B_Prompt_Optimizer · Hugging Face
BLIPというモデルについて調べてみた | IIJ Engineers Blog
多模态统一框架BLIP系列工作,从BLIP到InstructBLIP-腾讯云开发者社区-腾讯云
【论文极速读】 指令微调BLIP, 一种对指令微调敏感的Q-Former设计 | 机器学习杂货铺总店
Instructblip Vicuna 13b 4bit Image Qa - a Hugging Face Space by austinmw
Win rates comparison between PointLLM and human annotations or ...
多模态超详细解读 (八):InstructBLIP: 指令微调训练通用视觉语言模型 - 知乎


















































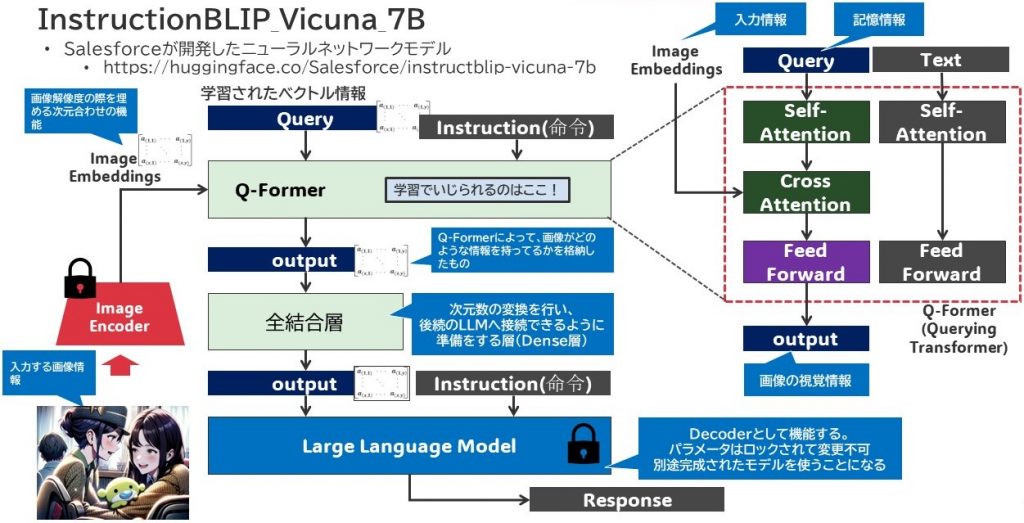

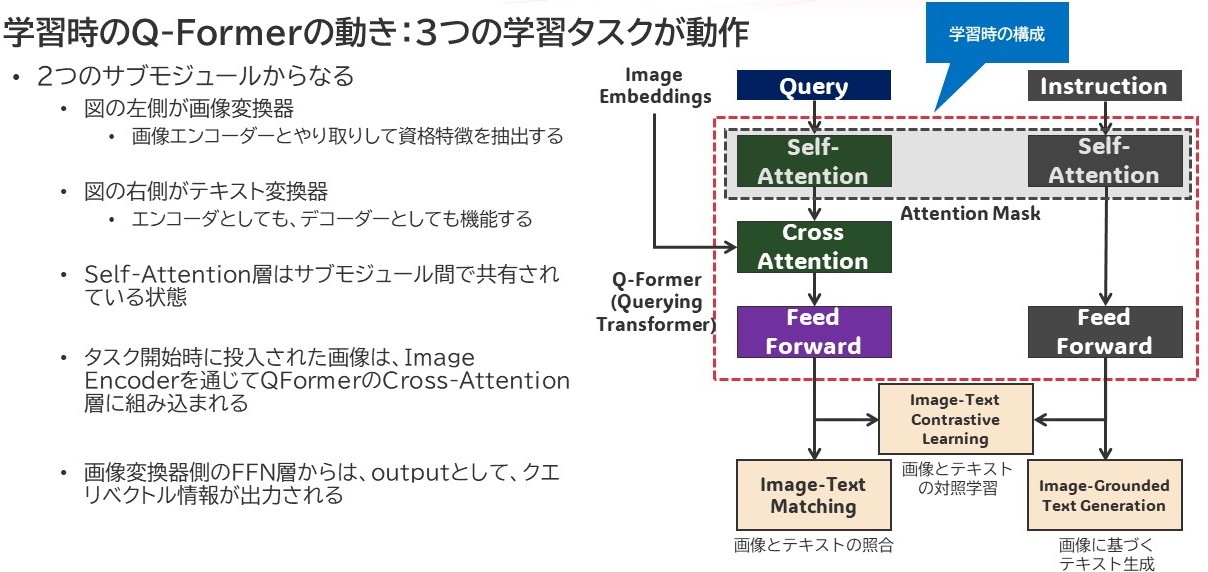




{kind=link}