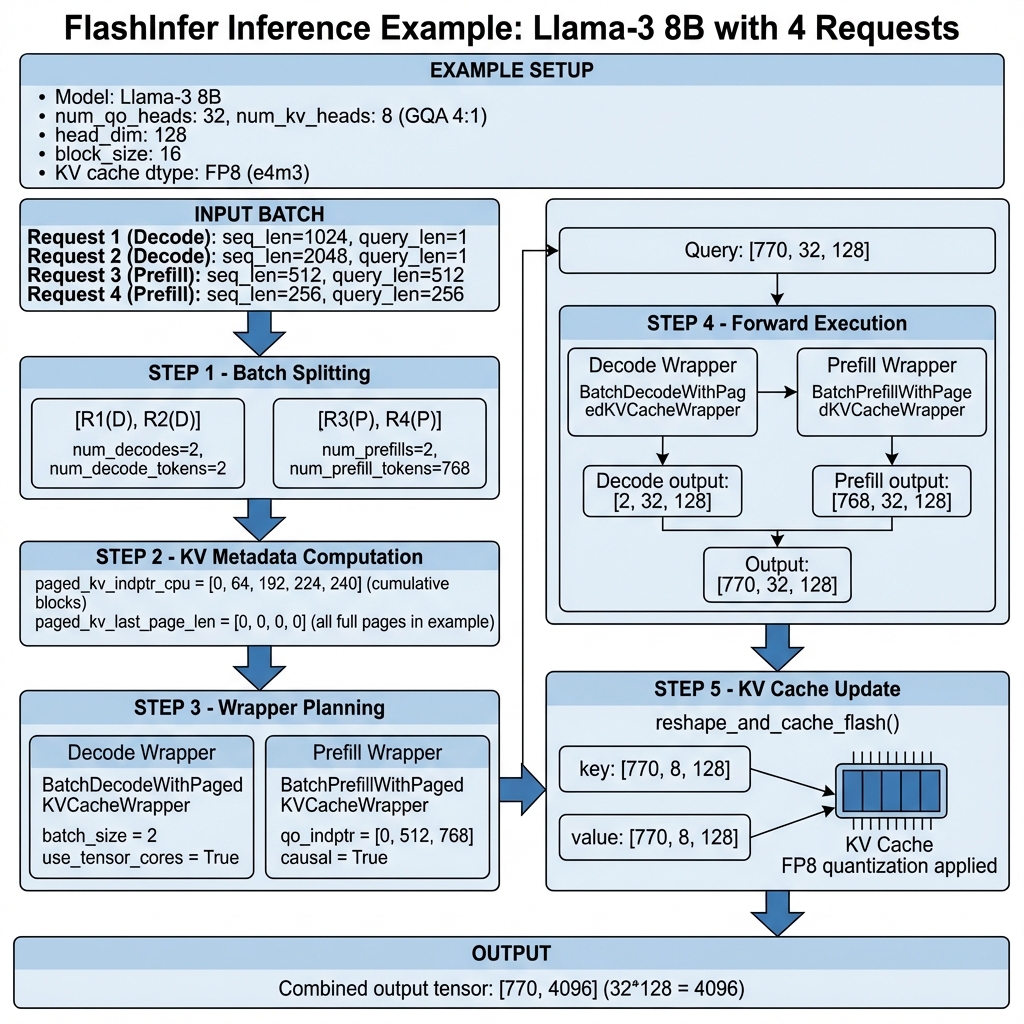
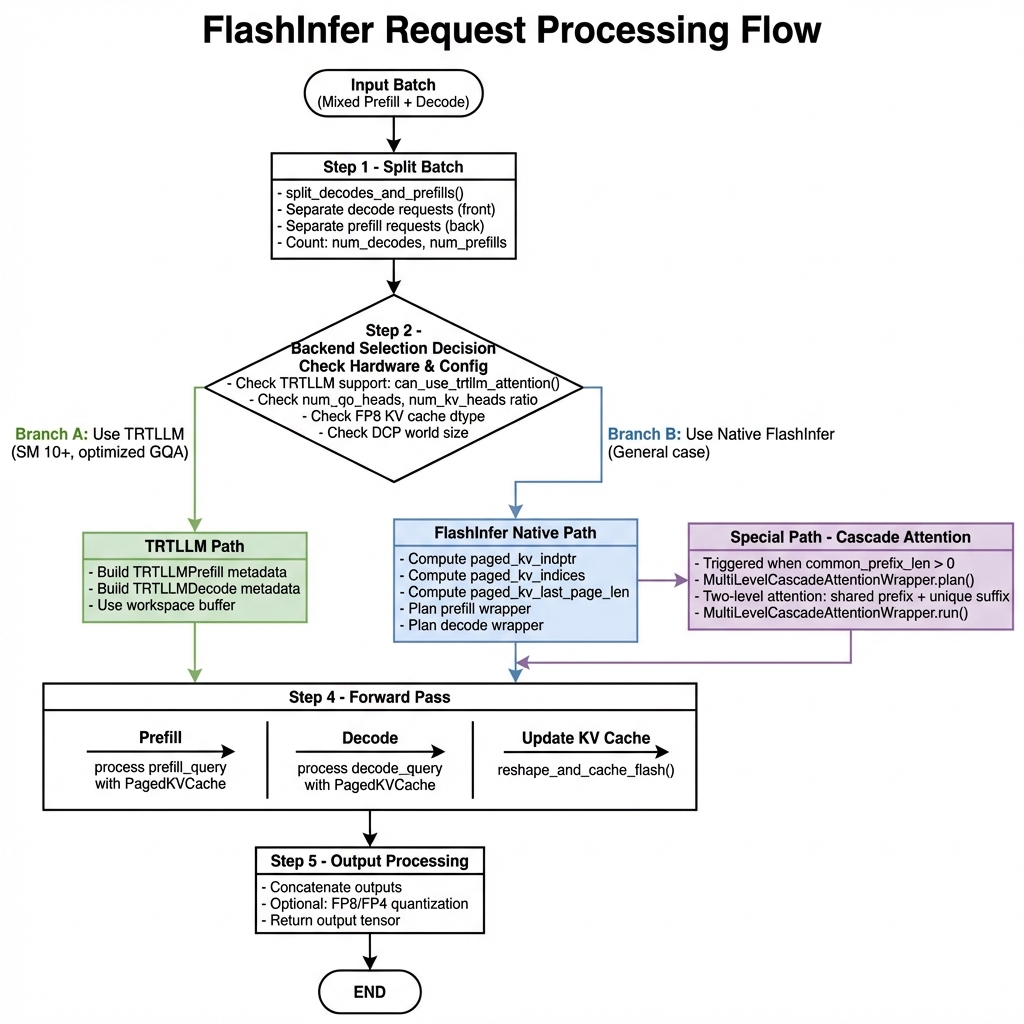
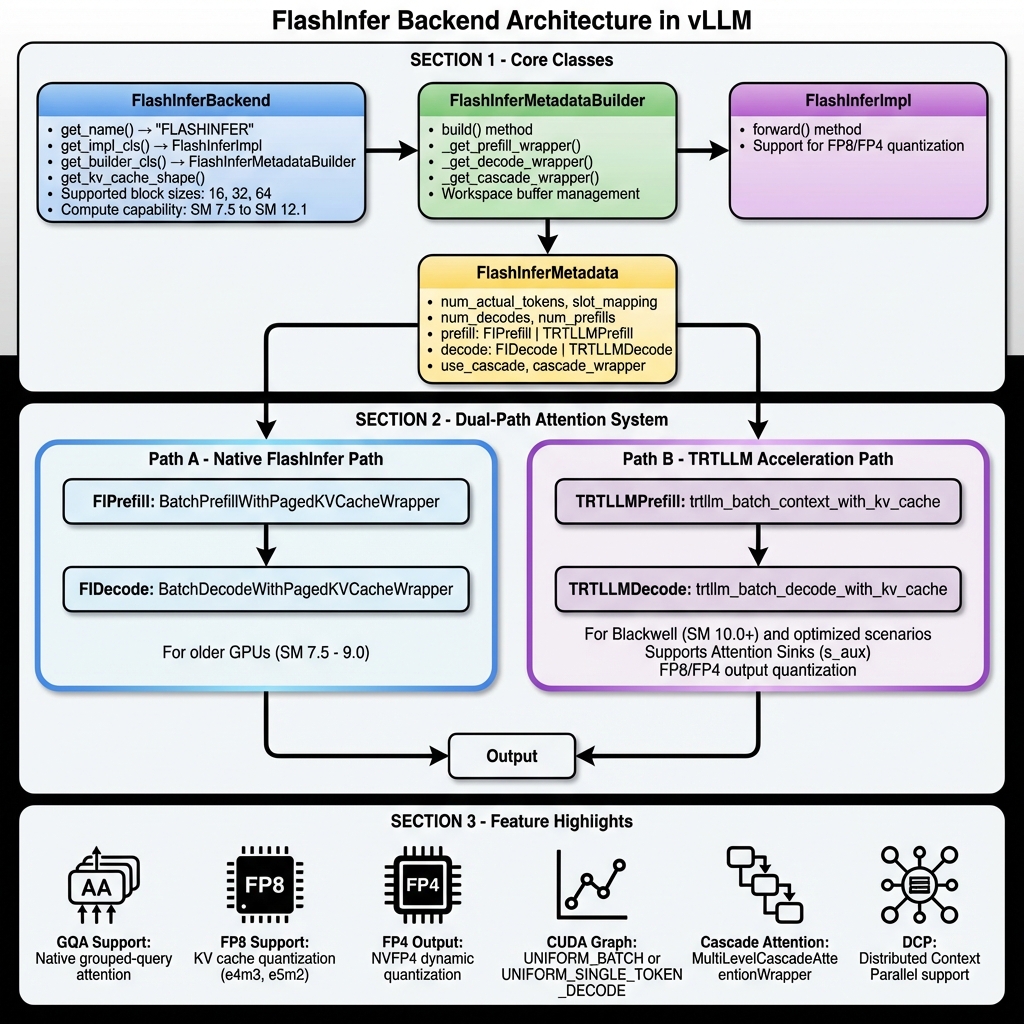
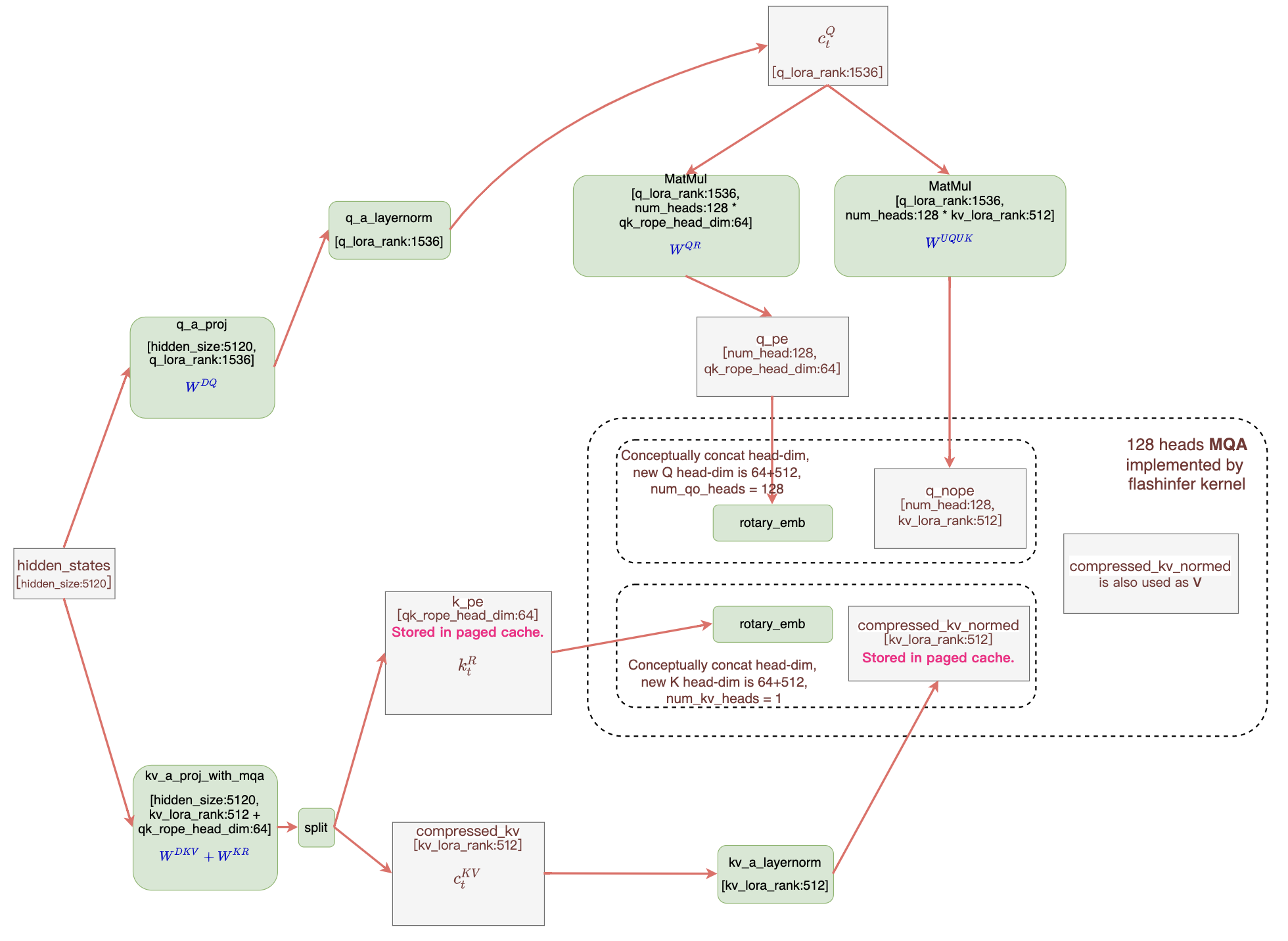
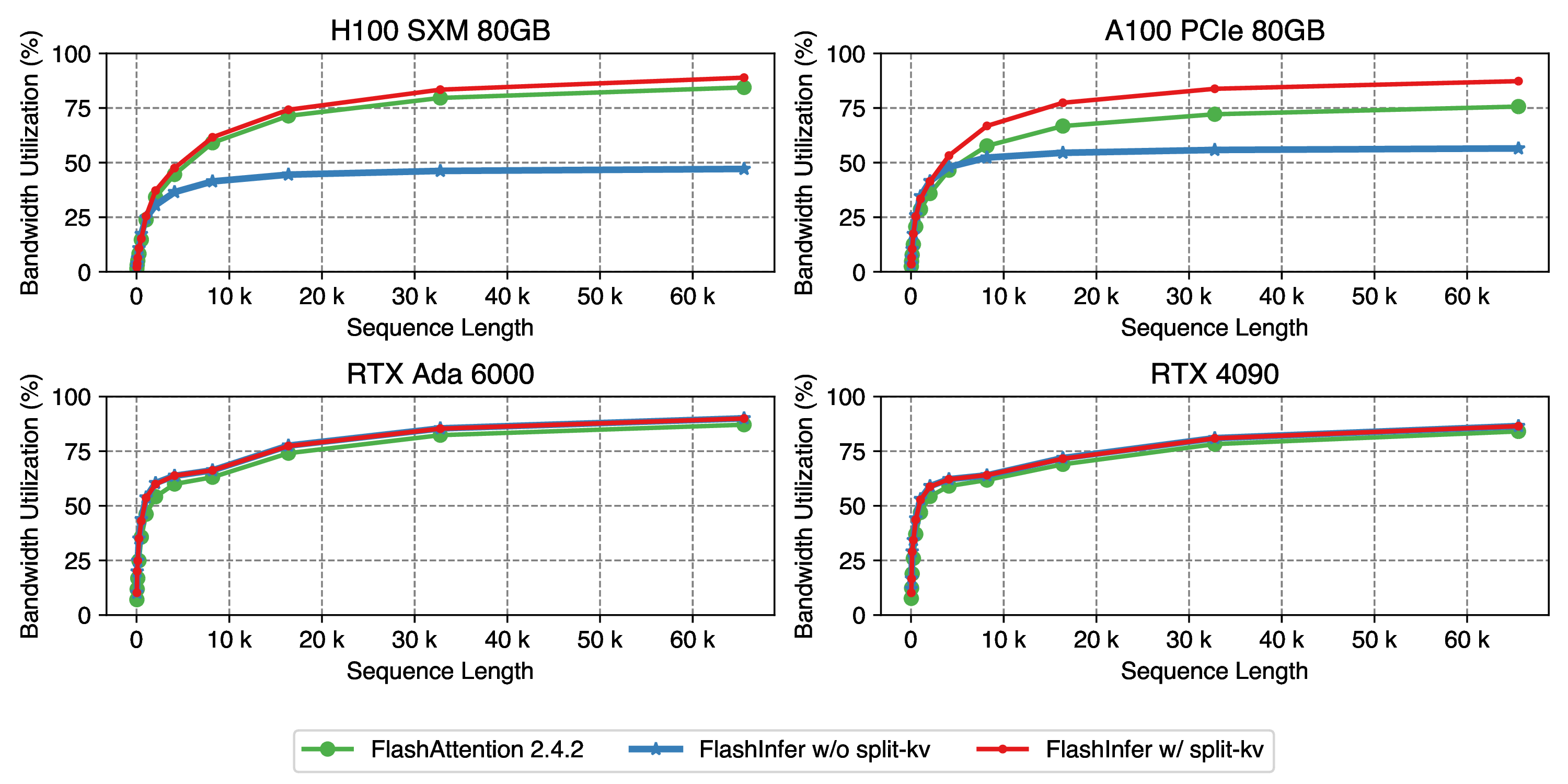
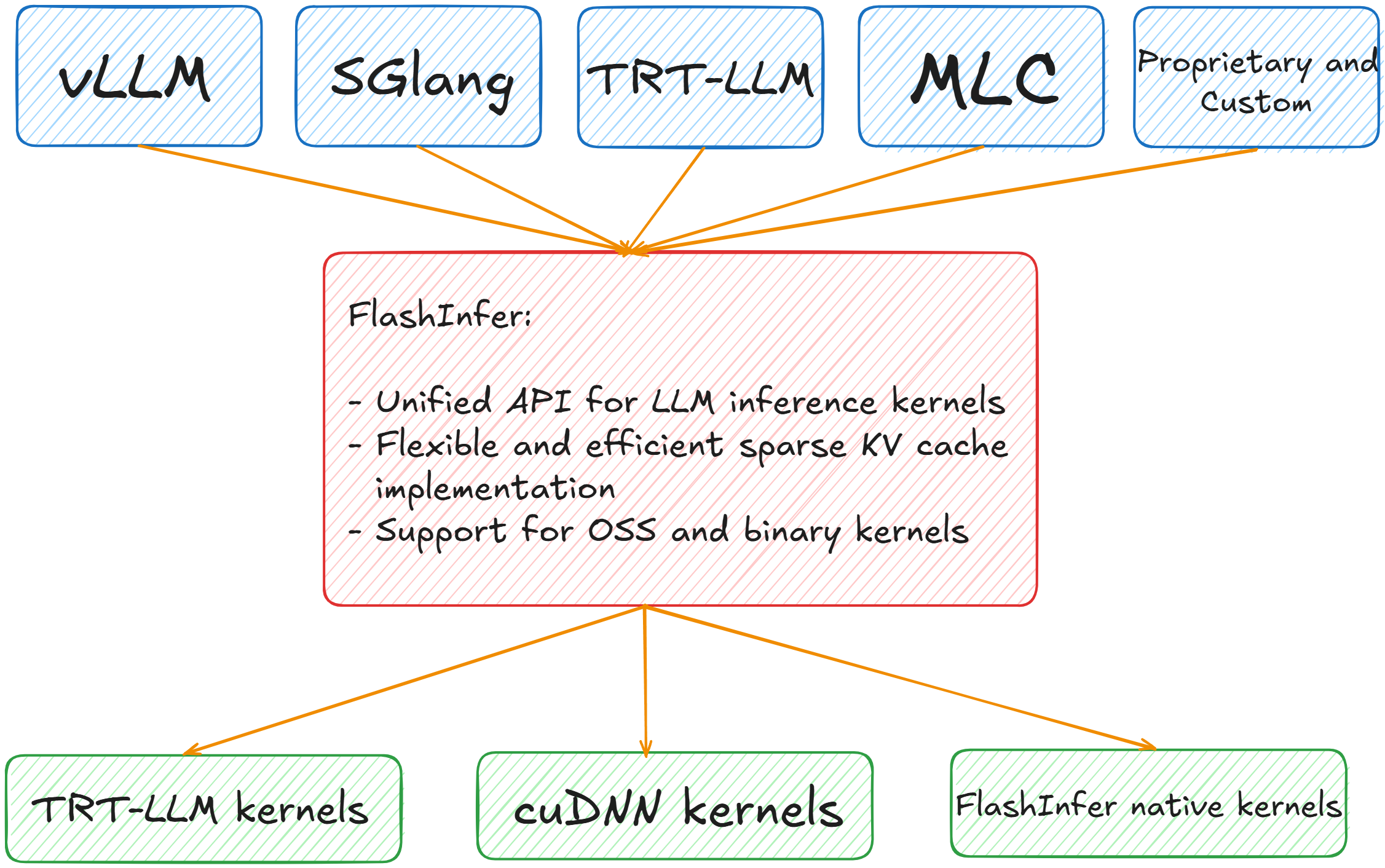
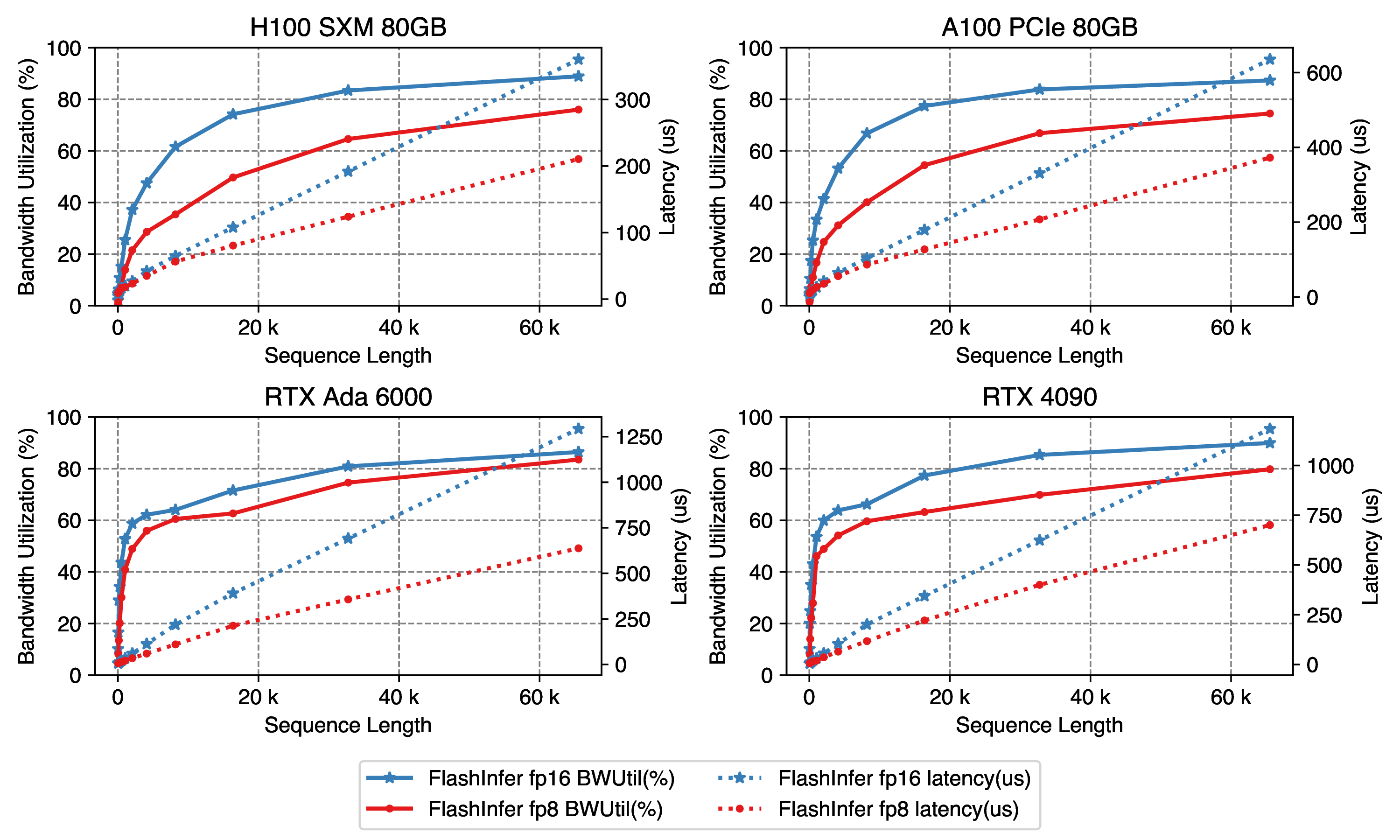
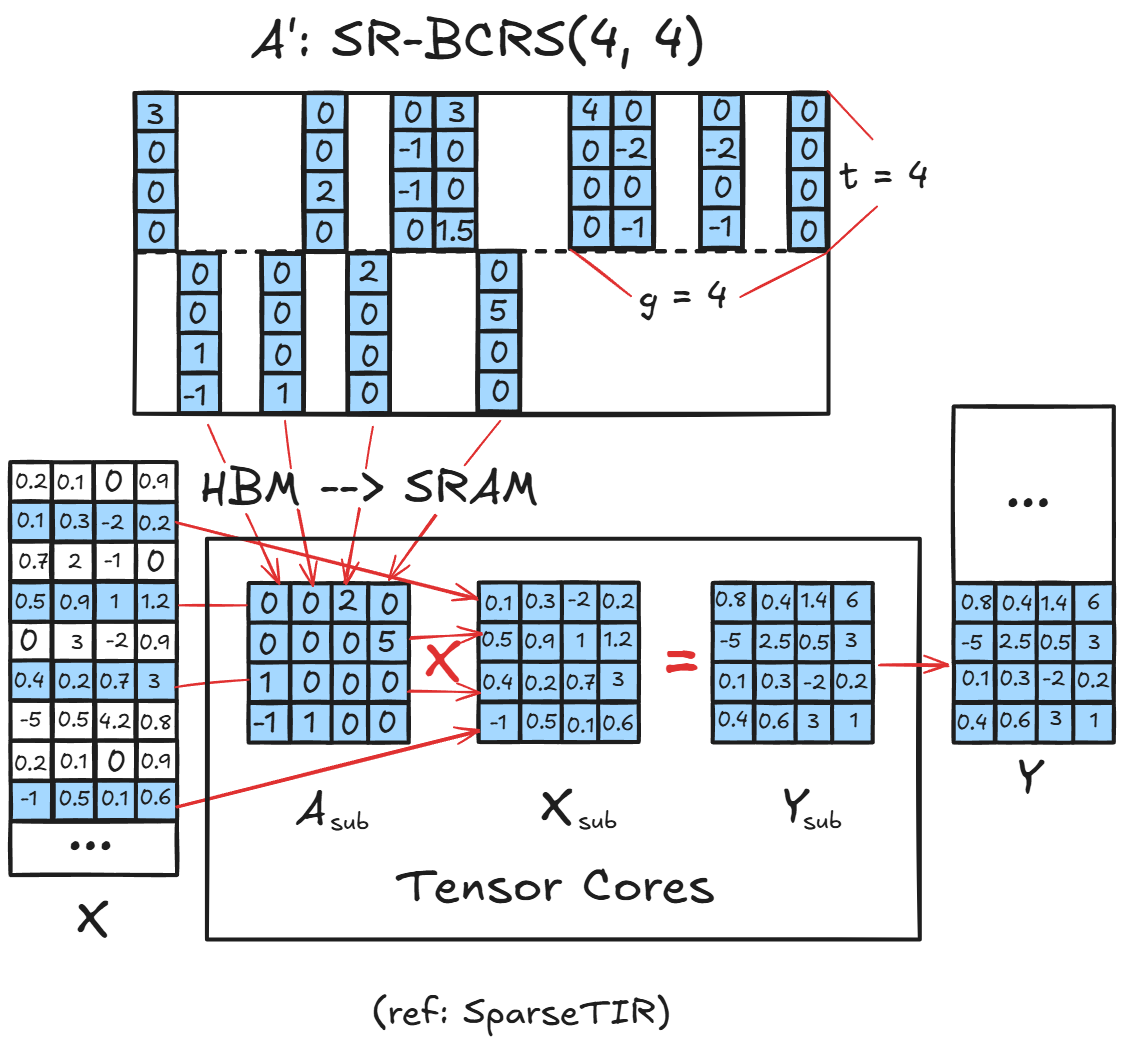
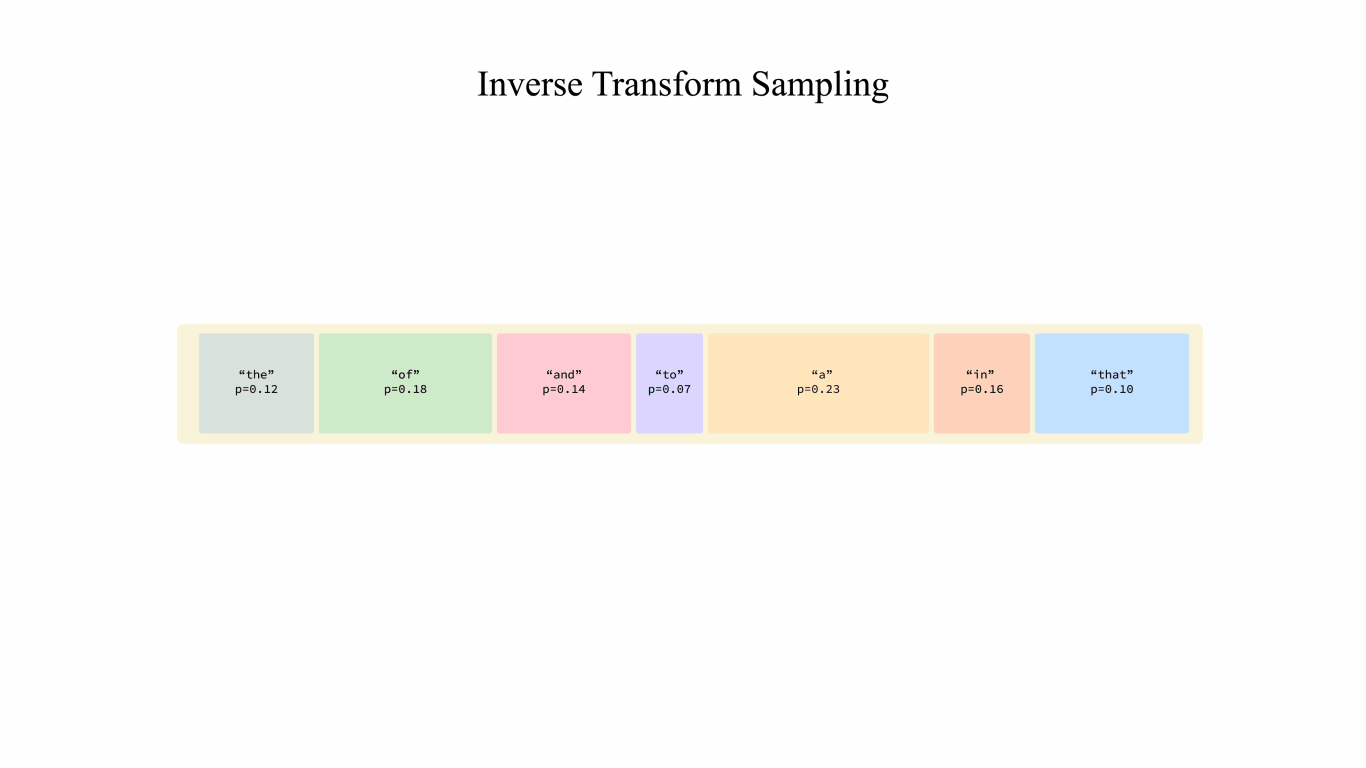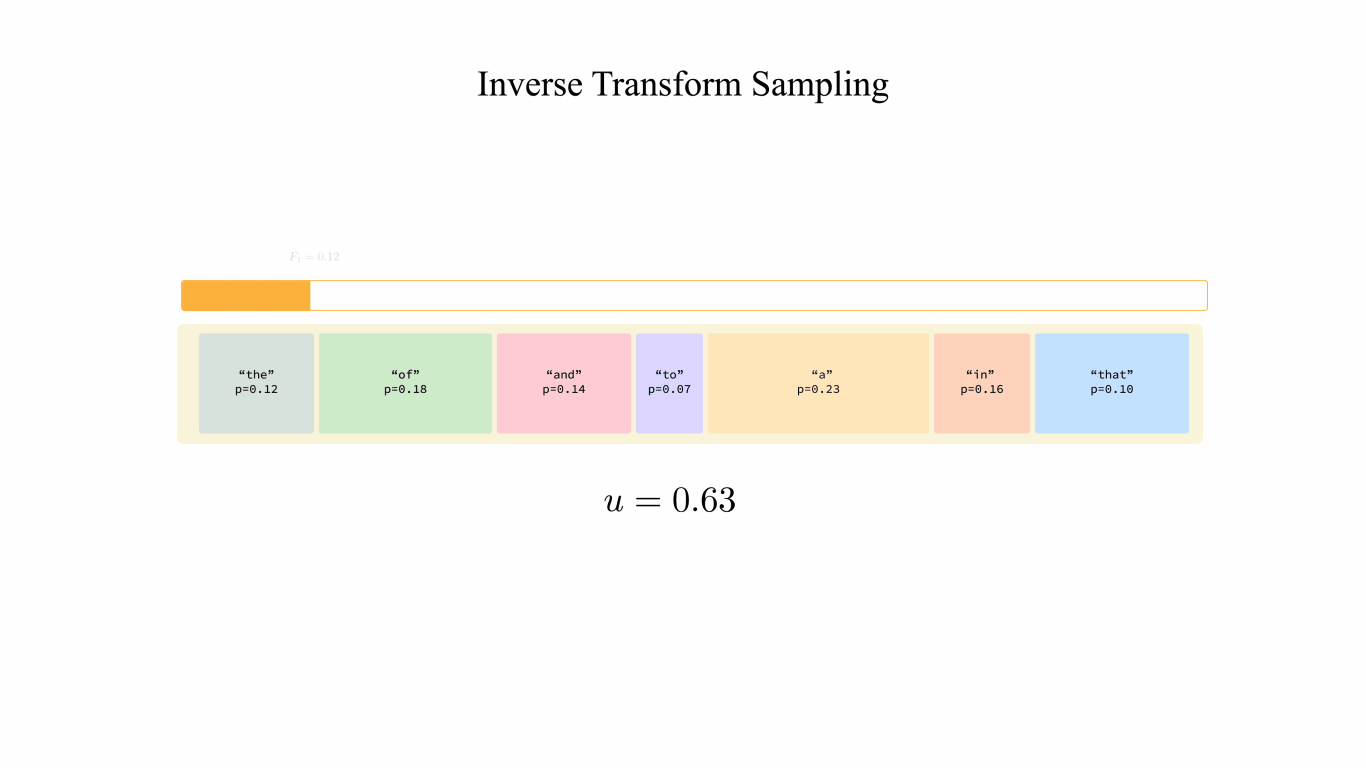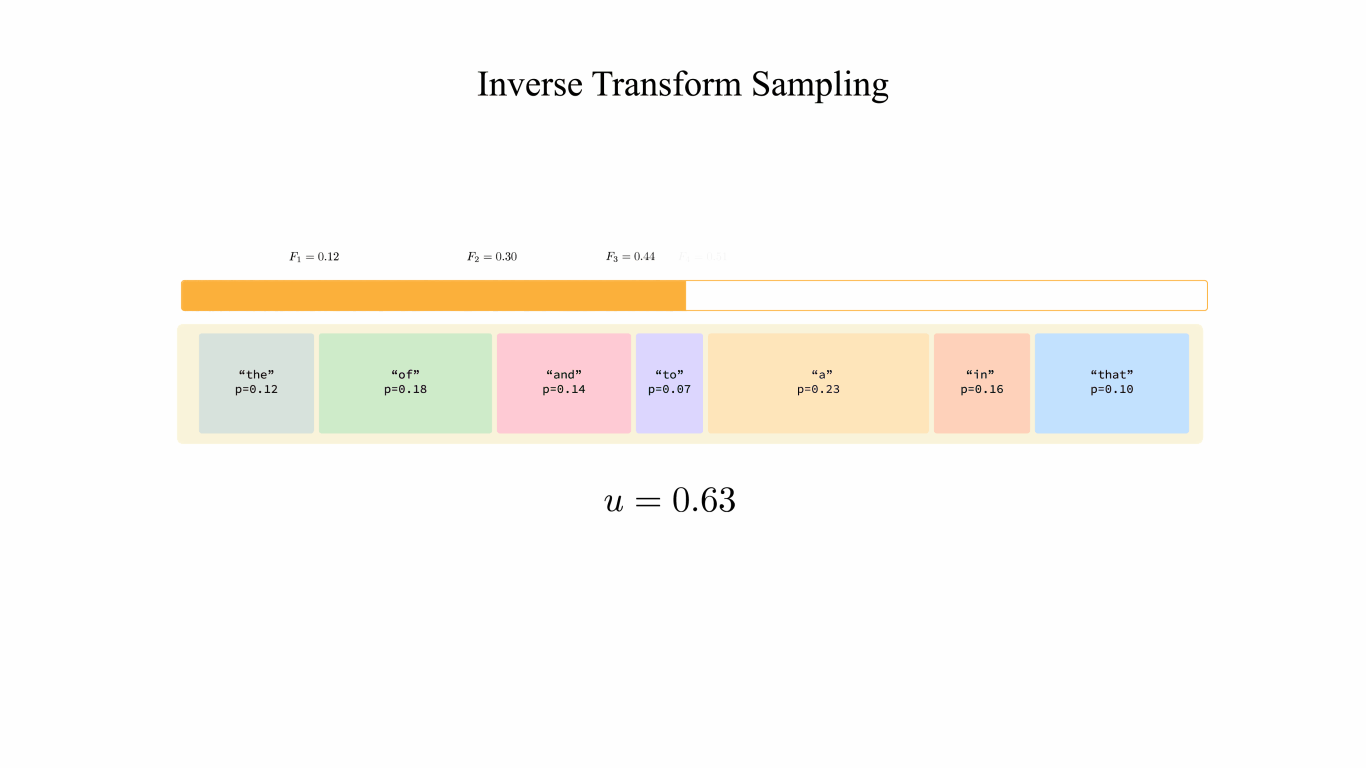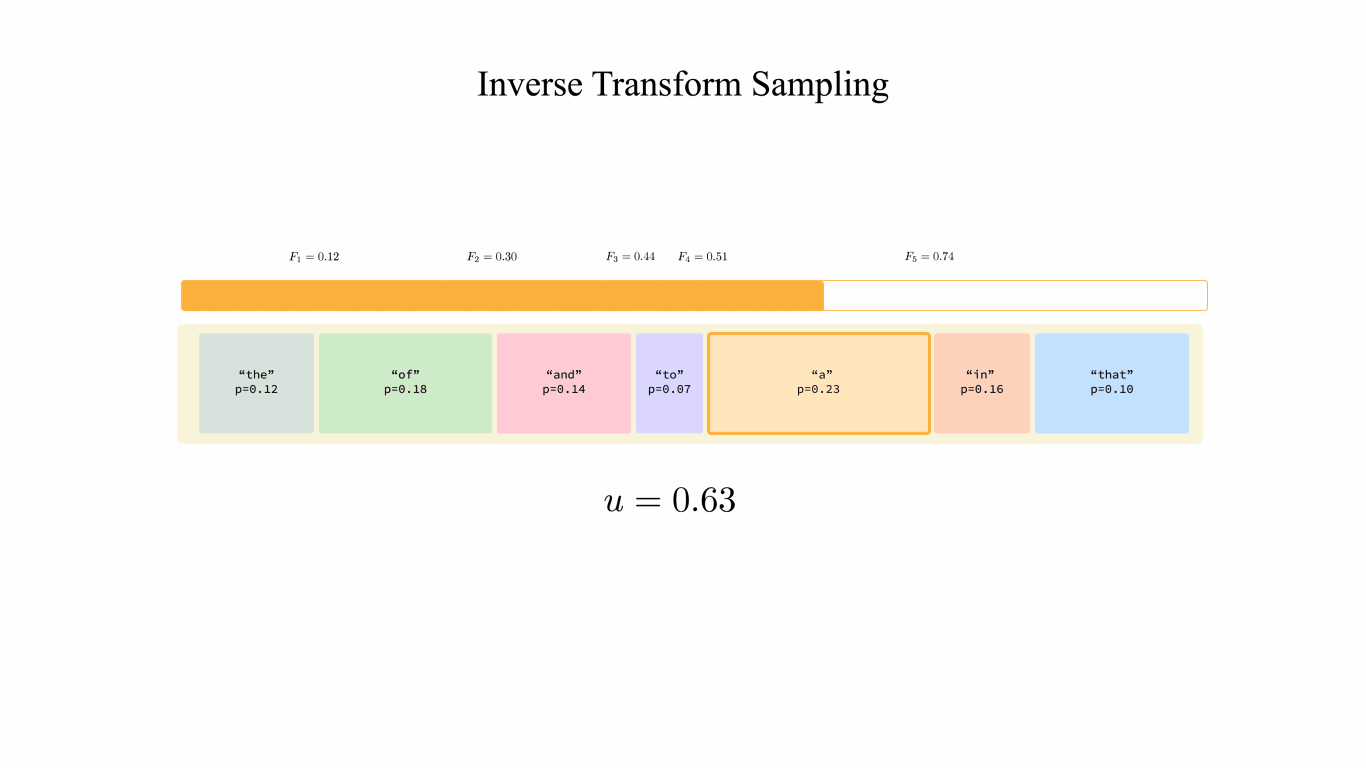
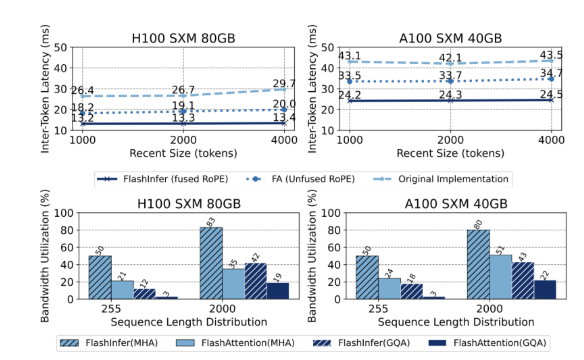
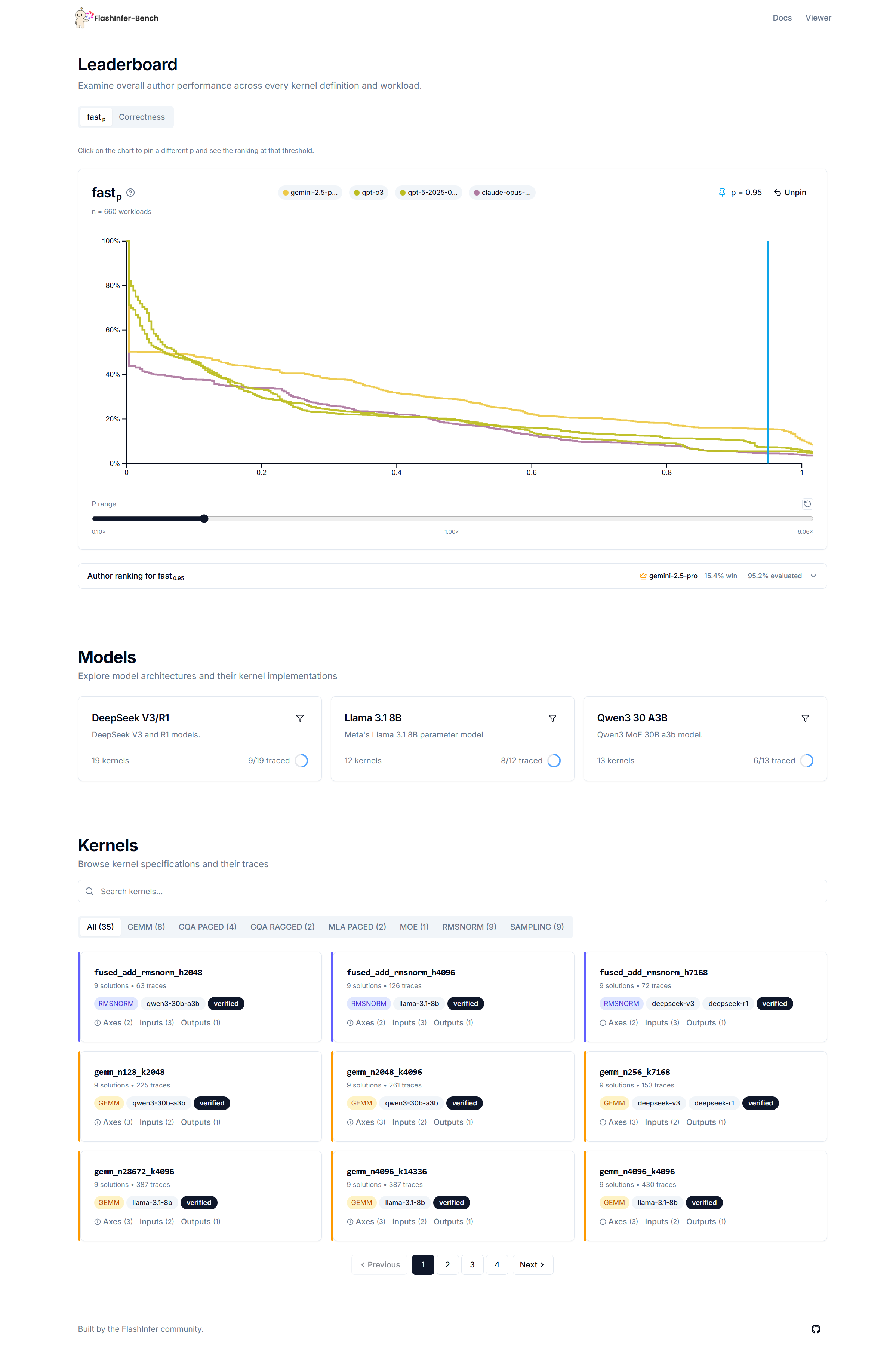
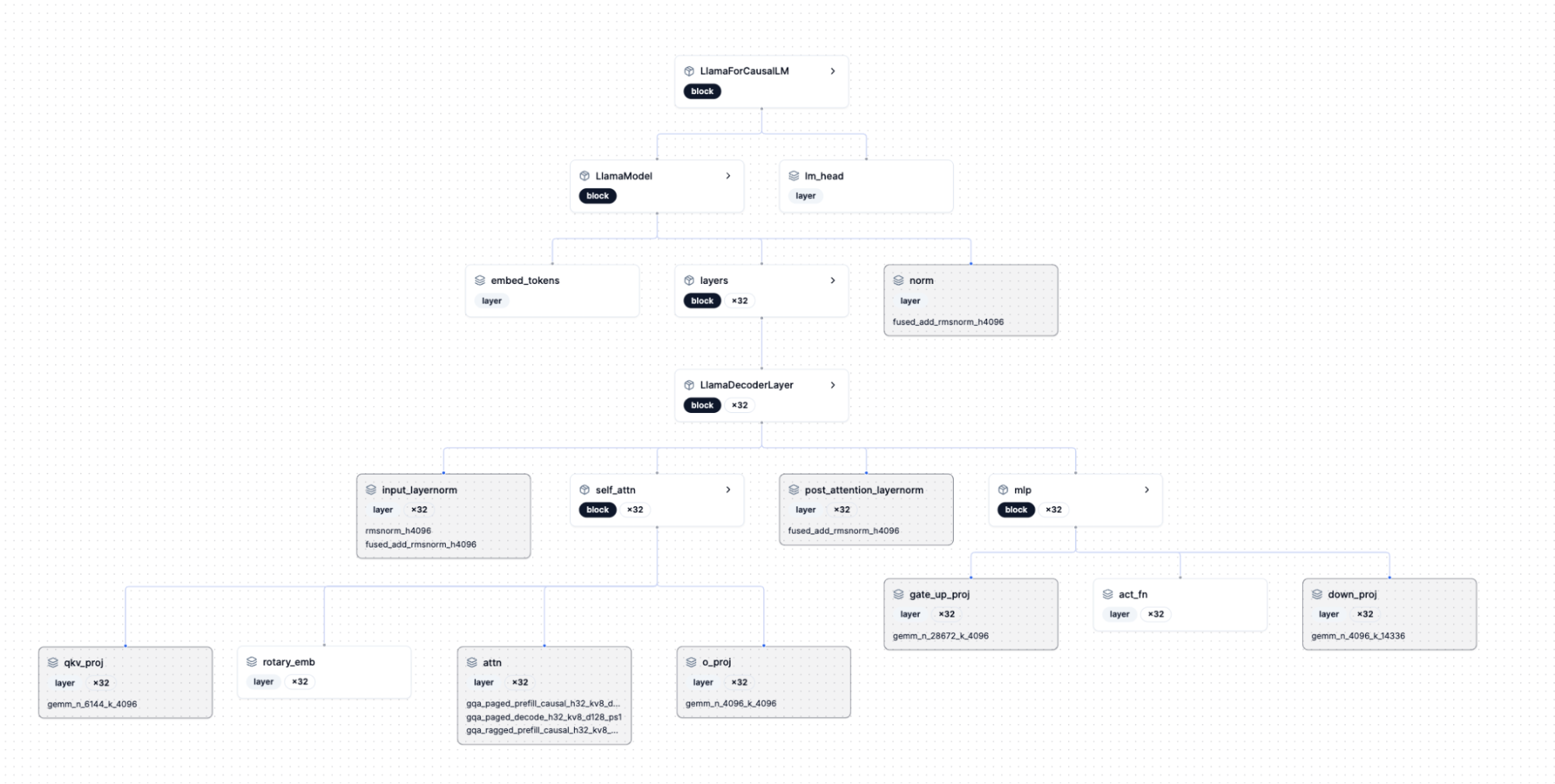
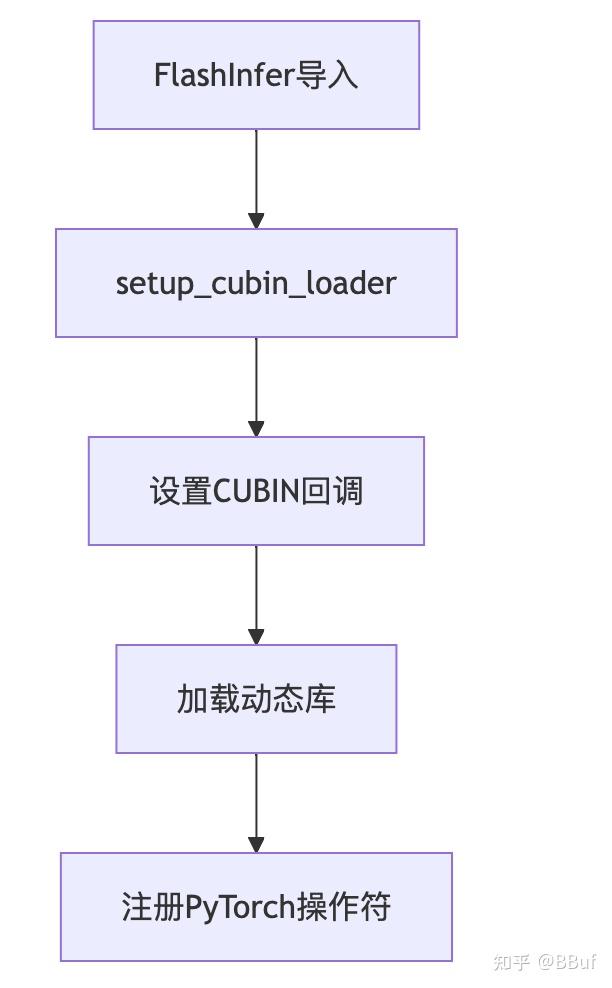
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
FlashInfer | Introduce Techniques to accelerate Large Language Model ...
FlashInfer download | SourceForge.net
NVIDIA Track | MLSys 2026 FlashInfer AI Kernel Generation Contest
FlashInfer 0.2 - Efficient and Customizable Kernels for LLM Inference ...
FlashInfer 深度解析
FlashInfer
Run High-Performance LLM Inference Kernels from NVIDIA Using FlashInfer ...
FlashInfer 0.6.6 documentation
Lecture 41: FlashInfer - YouTube
FlashInfer | 高效LLM推理引擎 - 知乎
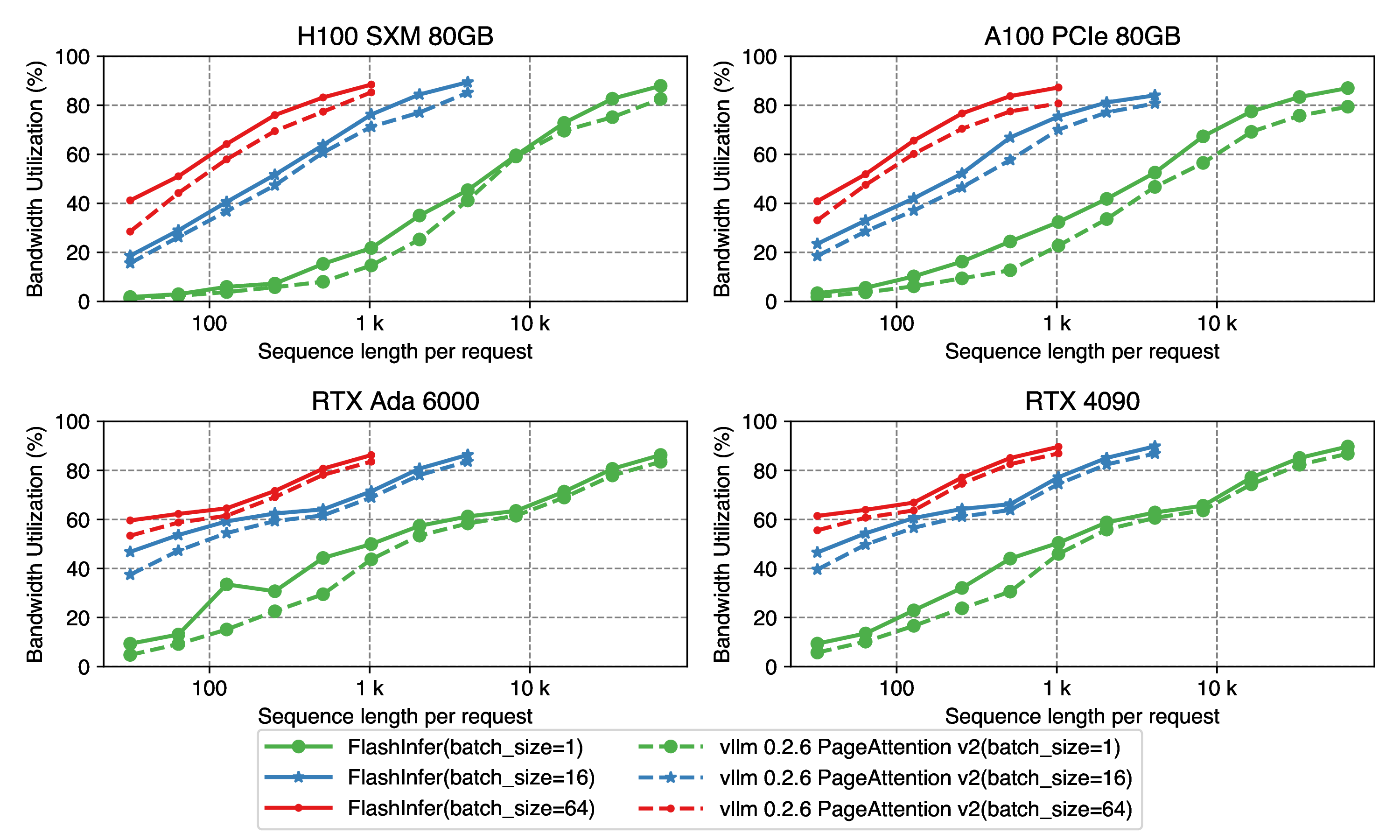
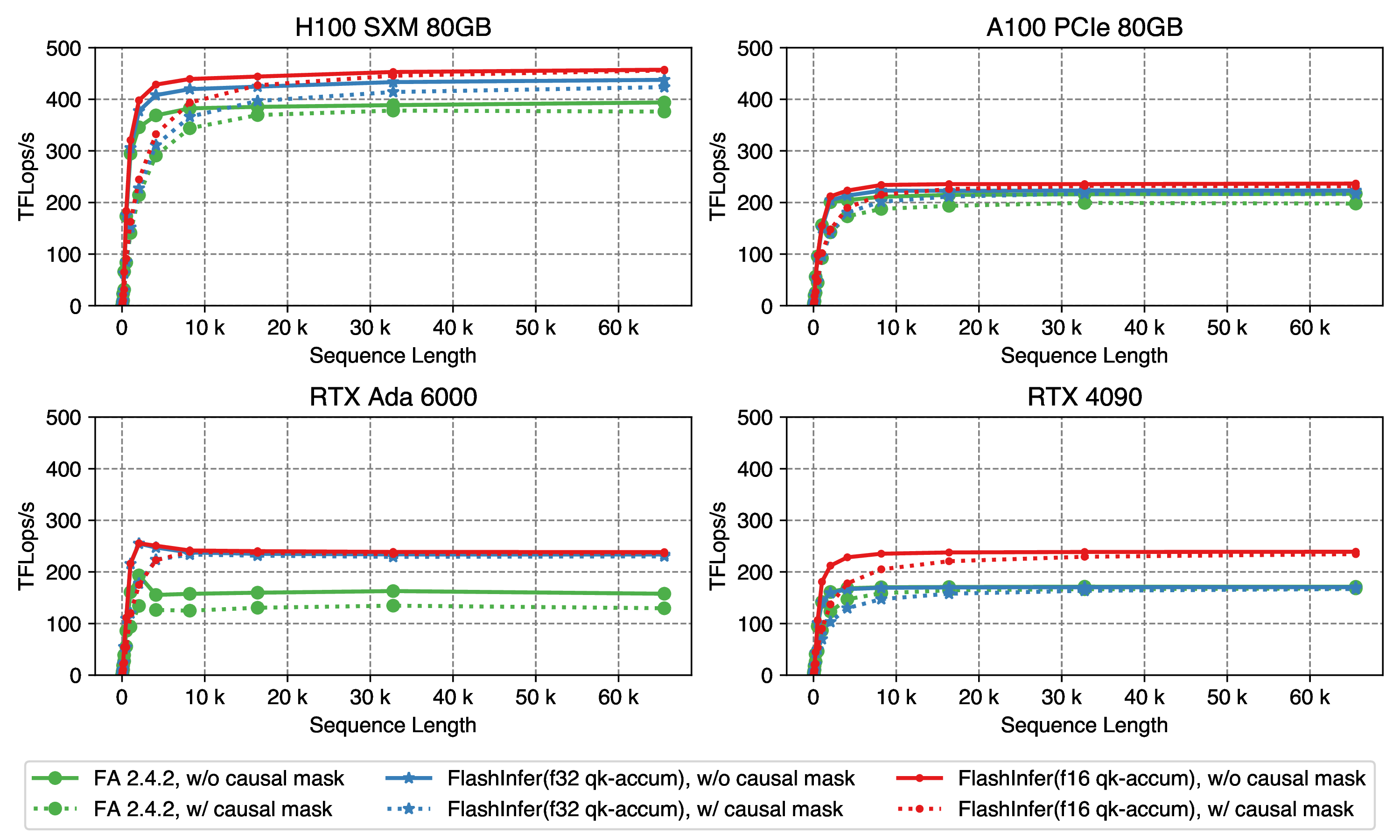
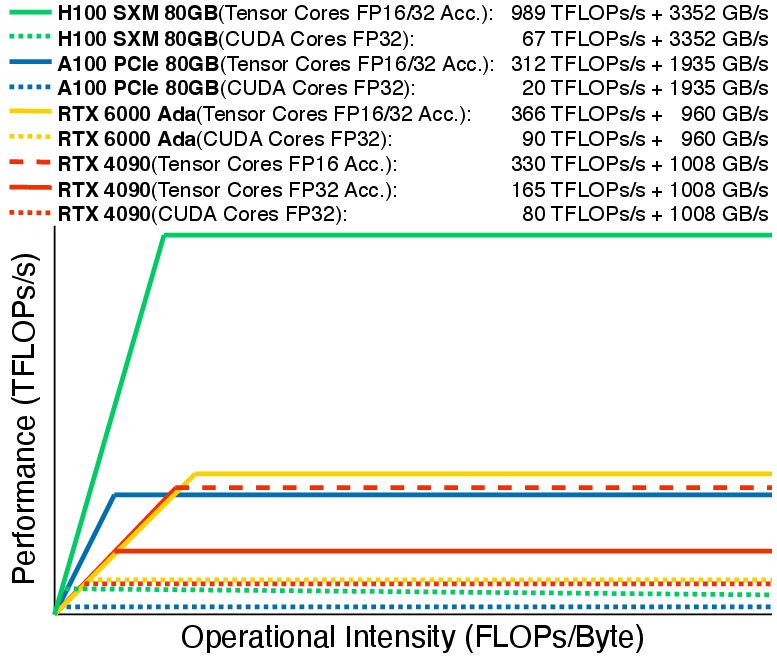
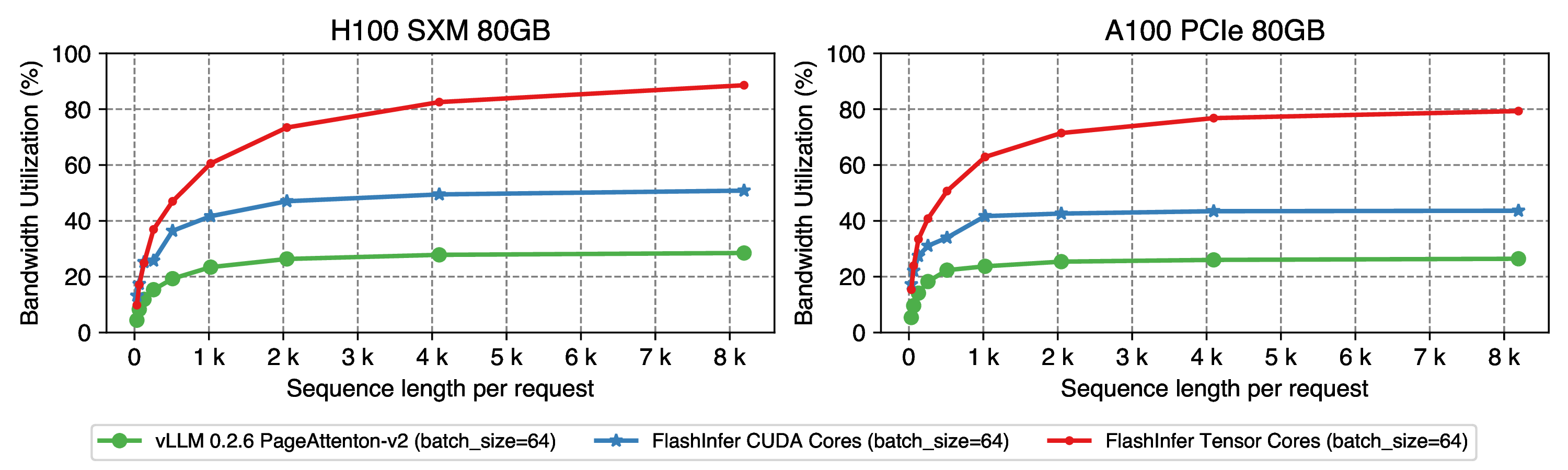
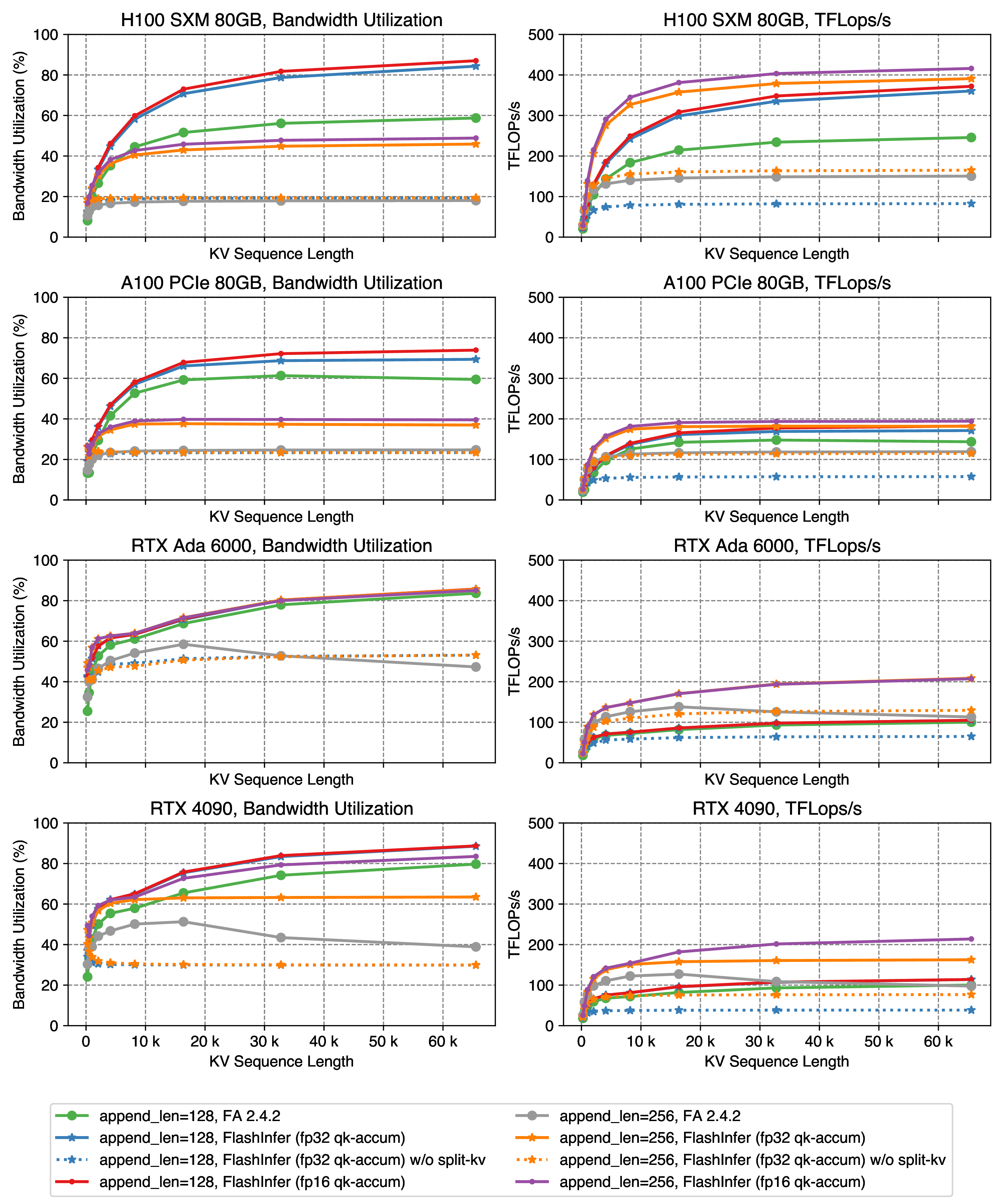
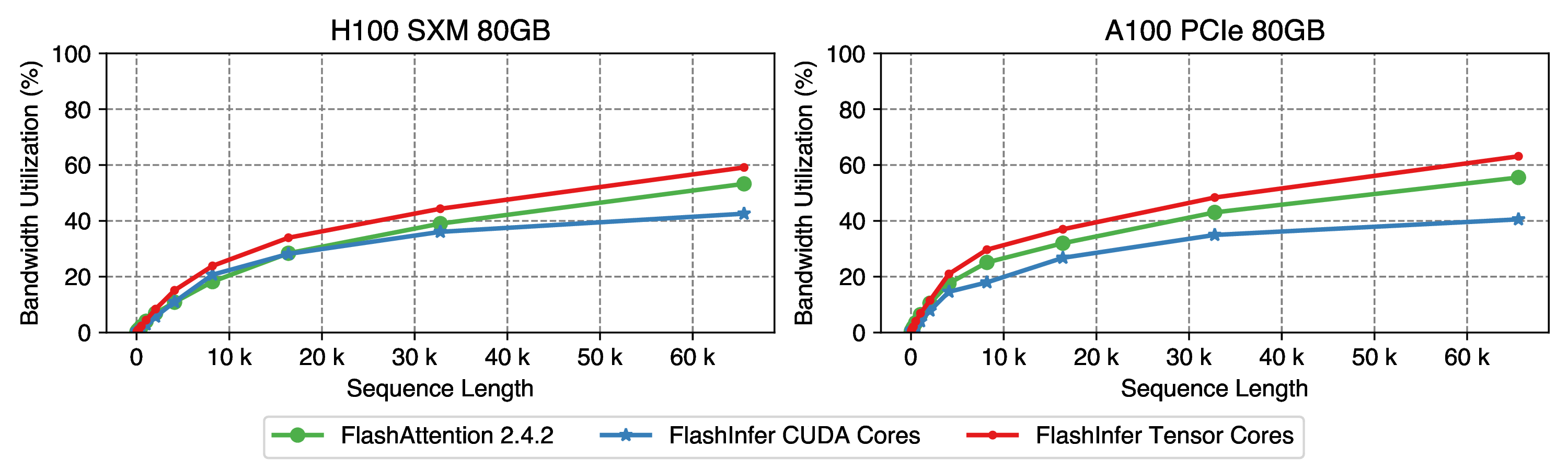
Accelerating Self-Attentions for LLM Serving with FlashInfer | FlashInfer
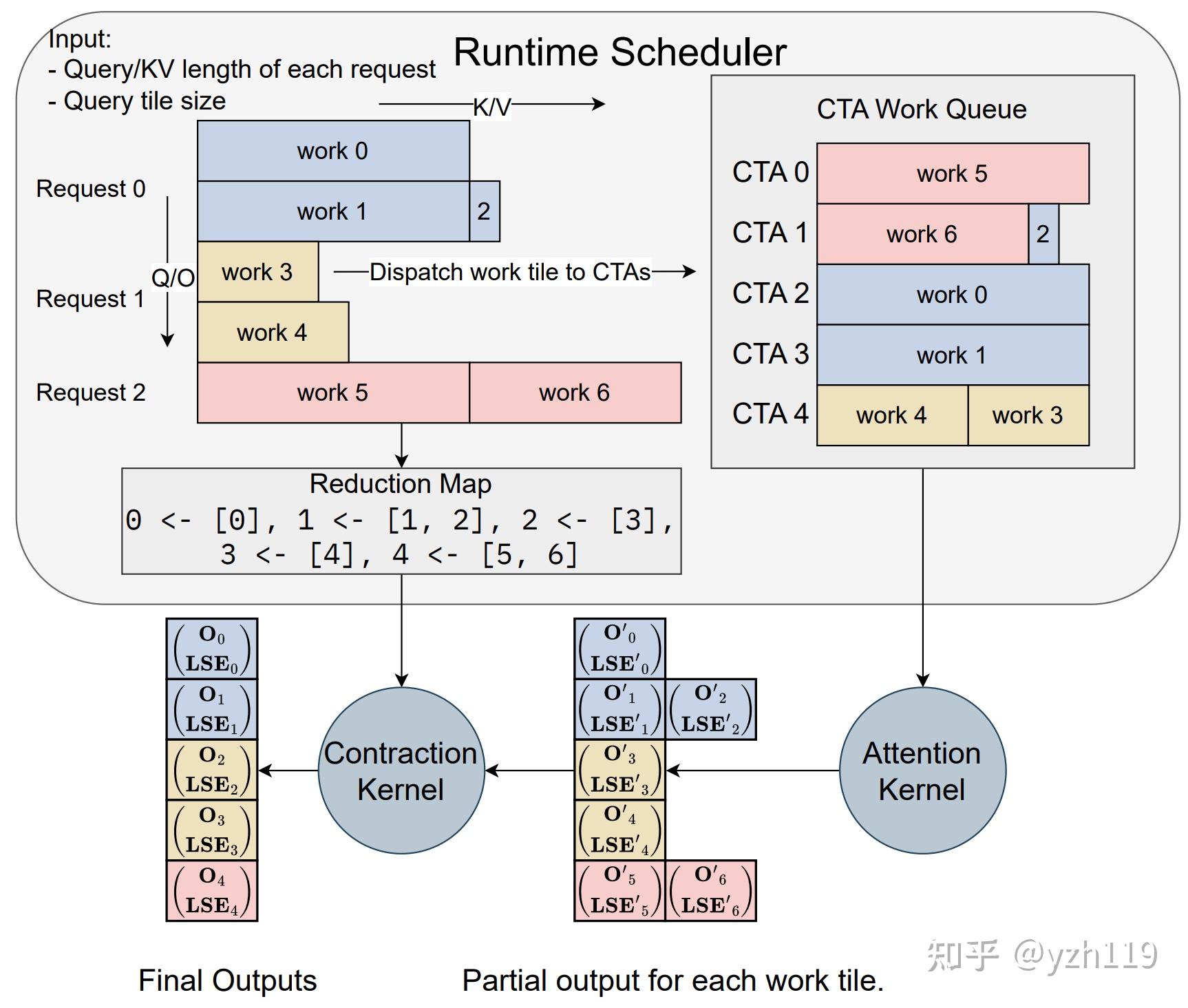
Dissecting FlashInfer - A Systems Perspective on High-Performance LLM ...
[Feature]: update to flashinfer 0.2.3 · Issue #15666 · vllm-project ...
Failed to build flashinfer from source · Issue #432 · flashinfer-ai ...
flashinfer - 专注LLM服务的高效GPU内核库 - 懂AI
[Performance]: FLASHINFER backend is slower than FLASH_ATTN on H100 ...
Does flashinfer support head_size = 576 for Ampere GPUs? · Issue #1043 ...
flashinfer not found by importlib.metadata.PackageNotFoundError · Issue ...
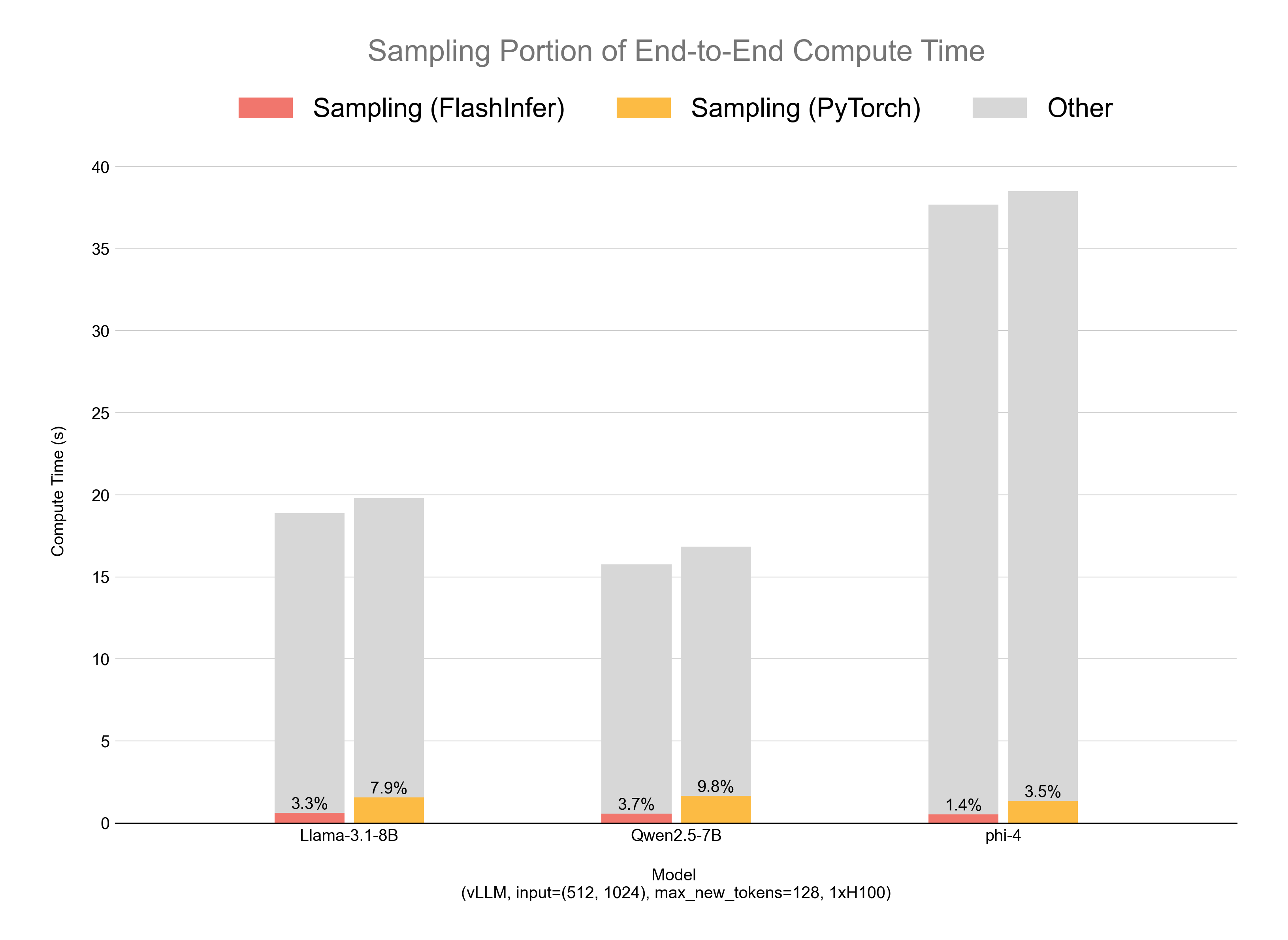
Sorting-Free GPU Kernels for LLM Sampling | FlashInfer
[Roadmap] FlashInfer v0.2 to v0.3 · Issue #675 · flashinfer-ai ...
FlashInfer 0.2.3+ does not support per-request generators · Issue #1104 ...
Support more `group_size` in Batch Decoding · Issue #996 · flashinfer ...
Prebuilt kernels not found, using JIT backend · Issue #876 · flashinfer ...
flashinfer-ai (FlashInfer AI)
高效Attention引擎是怎样炼成的?陈天奇团队FlashInfer打响新年第一枪!-腾讯云开发者社区-腾讯云
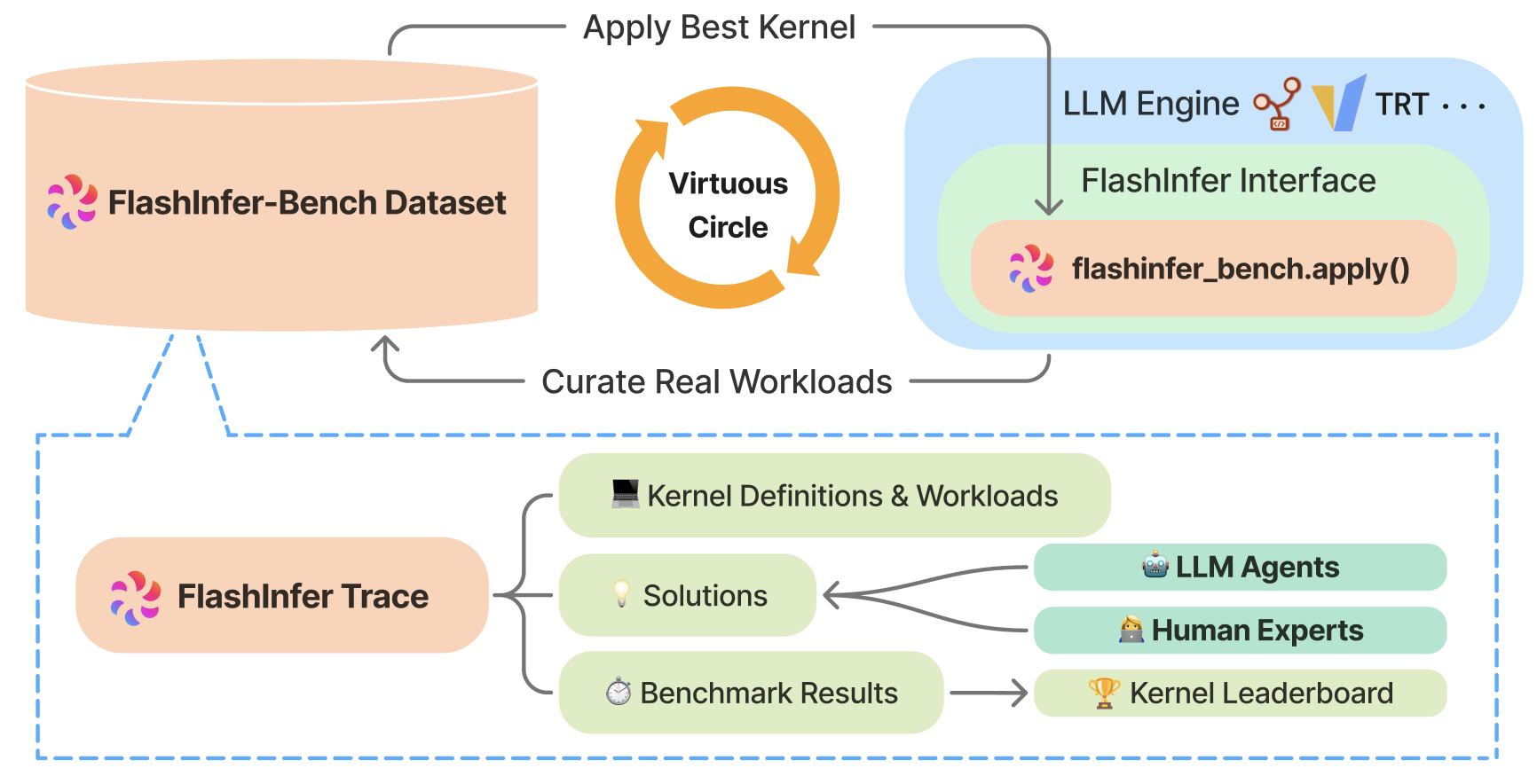
FlashInfer-Bench: Building the Virtuous Cycle for AI-driven LLM Systems ...
flashinfer-ai/flashinfer | DeepWiki
高效Attention引擎是怎样炼成的?陈天奇团队FlashInfer打响新年第一枪!_腾讯新闻
GitHub - firefly-ghs/MLA-flashinfer: FlashInfer: Kernel Library for LLM ...
[논문 리뷰] FlashInfer: Efficient and Customizable Attention Engine for LLM ...
FlashInfer-是一个用于大型语言模型服务的高性能GPU内核库。
flashinfer-ai/flashinfer-trace at main
高效Attention引擎是怎樣煉成的?陳天奇團隊FlashInfer打響新年第一槍! - 新浪香港
FlashInfer:为LLM推理服务打造的高效、可定制注意力引擎 - 知乎
NVIDIA联合高校发布 “FlashInfer”:提升大语言模型推理效率的全新内核库 - 来上云吧,企业上云一站式服务
FlashInfer: A Kernel Library Revolutionizing Large Language Model ...
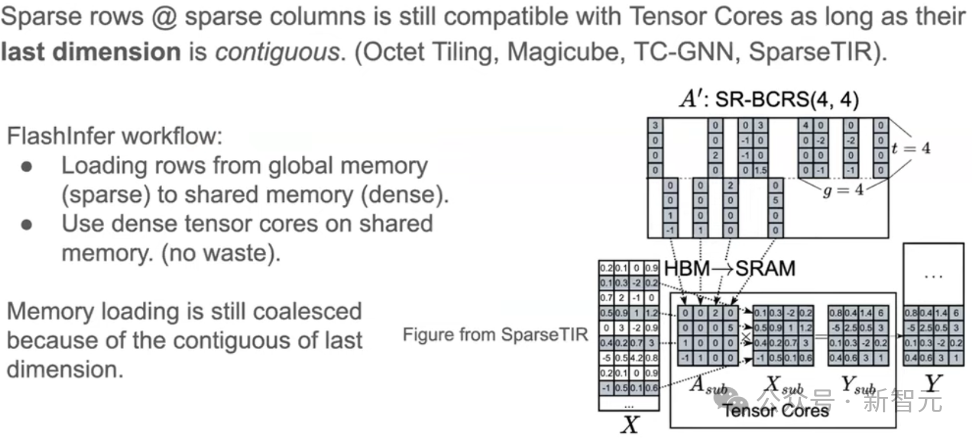
Sparse and Block-Sparse Attention | flashinfer-ai/flashinfer | DeepWiki
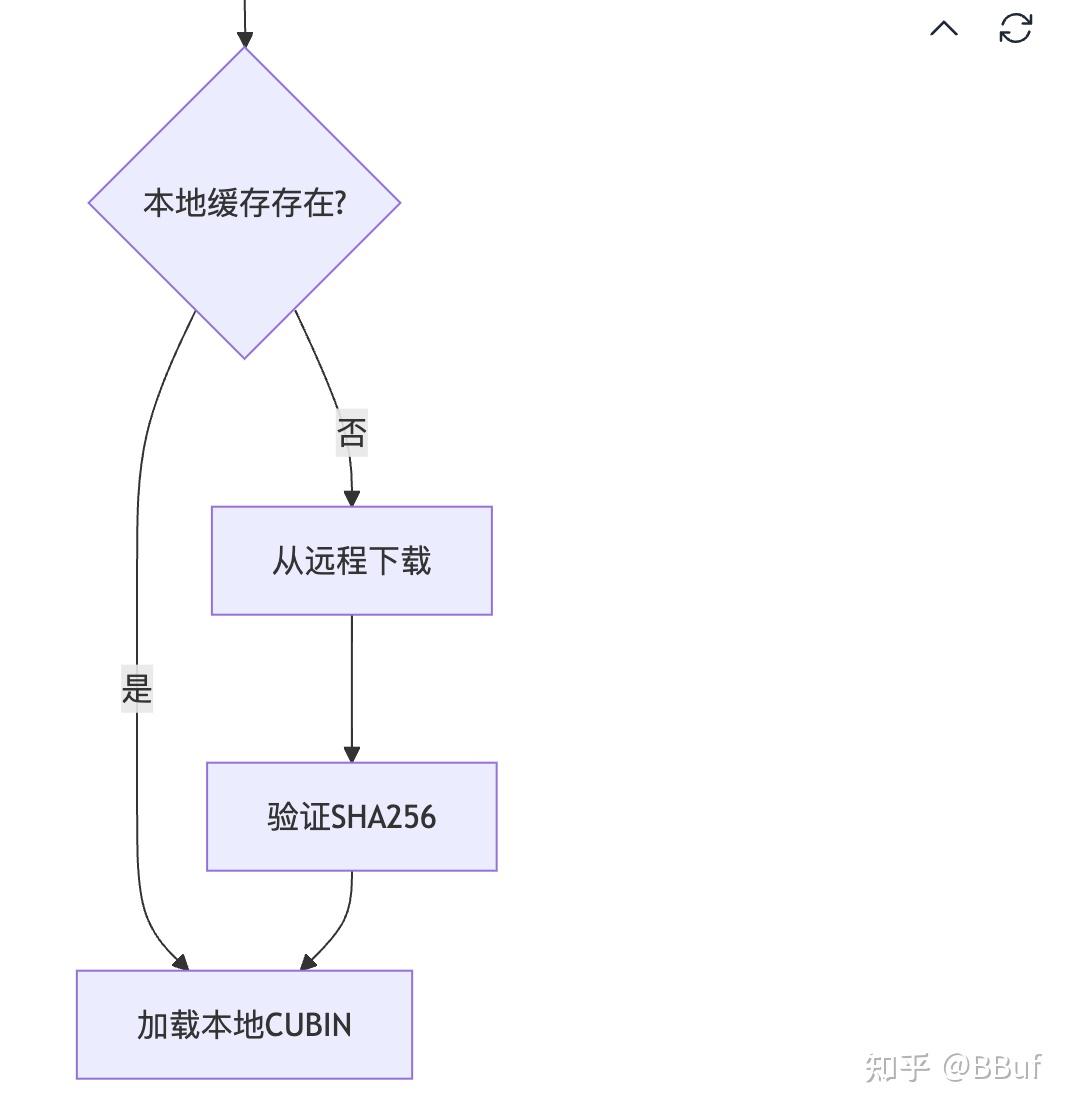
FlashInfer集成TensorRT-LLM cubin kernel技术分析 - 知乎
FlashInfer: Efficient and Customizable Attention Engine for LLM ...
Hands-On FlashAttention: Installation and Usage. Math Explained. (Feat ...
Firworks/INTELLECT-3-nvfp4 · works with vLLM, with FLASHINFER_MOE_FP4
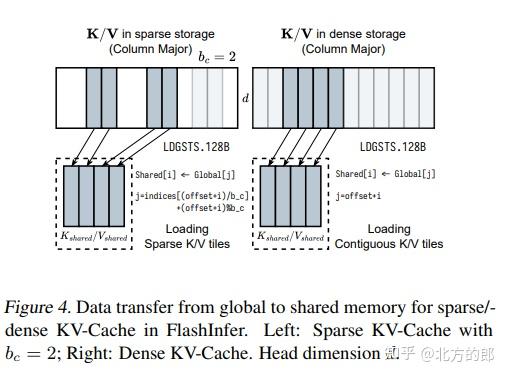
FlashInfer中DeepSeek MLA的内核设计 - 知乎
(PDF) FlashInfer: Efficient and Customizable Attention Engine for LLM ...
FlashInfer:面向 LLM 服务的可定制且高效的 GPU 注意力引擎 - 极术社区 - 连接开发者与智能计算生态
flashinfer-python was not found in the package registry · Issue #777 ...
FlashInfer集成TensorRT-LLM cubin kernel技术分析 - 每时AI
FlashInfer: 二次开发的Sweet spot - 知乎
NVIDIA FlashInfer発表、LLM推論処理を劇的高速化する新技術 - Bignite
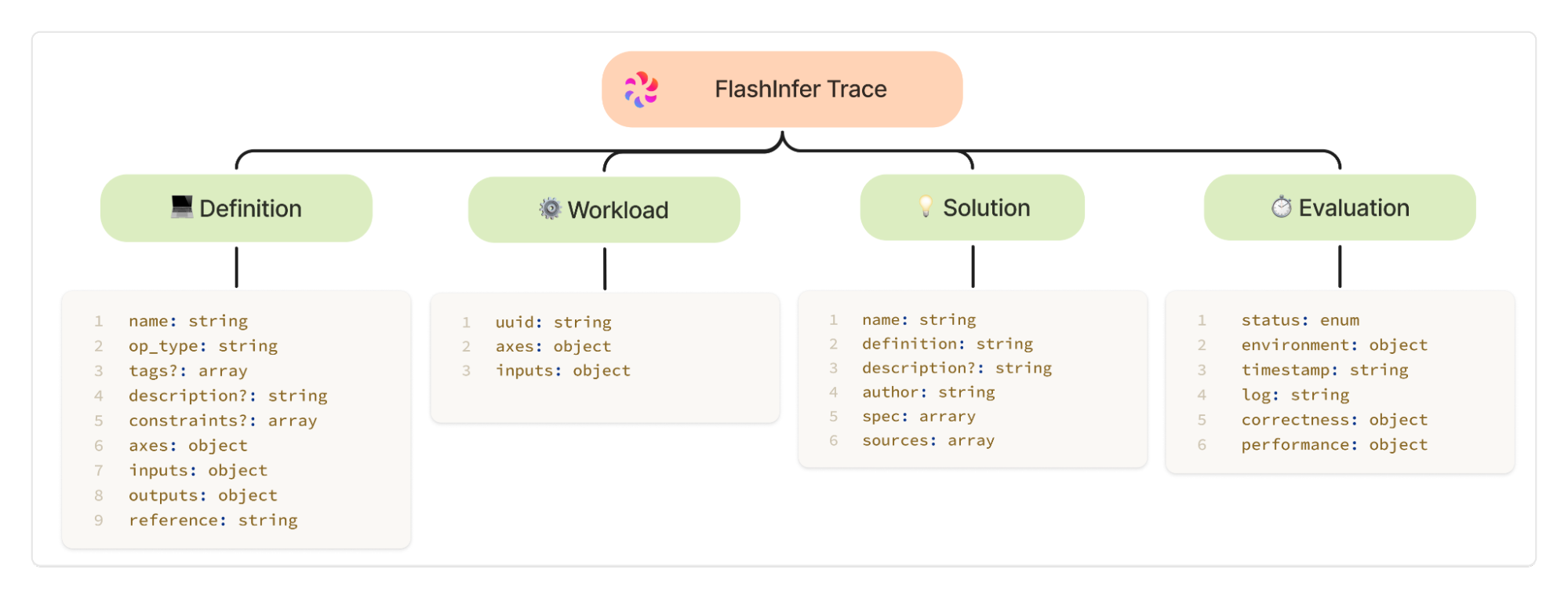
Trace and Evaluation Schema | flashinfer-ai/flashinfer-bench | DeepWiki
Inferright Flashlight, 2025 The Ultimate Survival Flashlight, LED ...
Inferright Flashlight, Inferright Flash Light That Can Start A Fire ...
[JIT] No module named 'flashinfer.jit.aot_config' when install from ...
Inferright Flashlight ,2025 The Ultimate Survival Flashlight, 2-in-1 ...
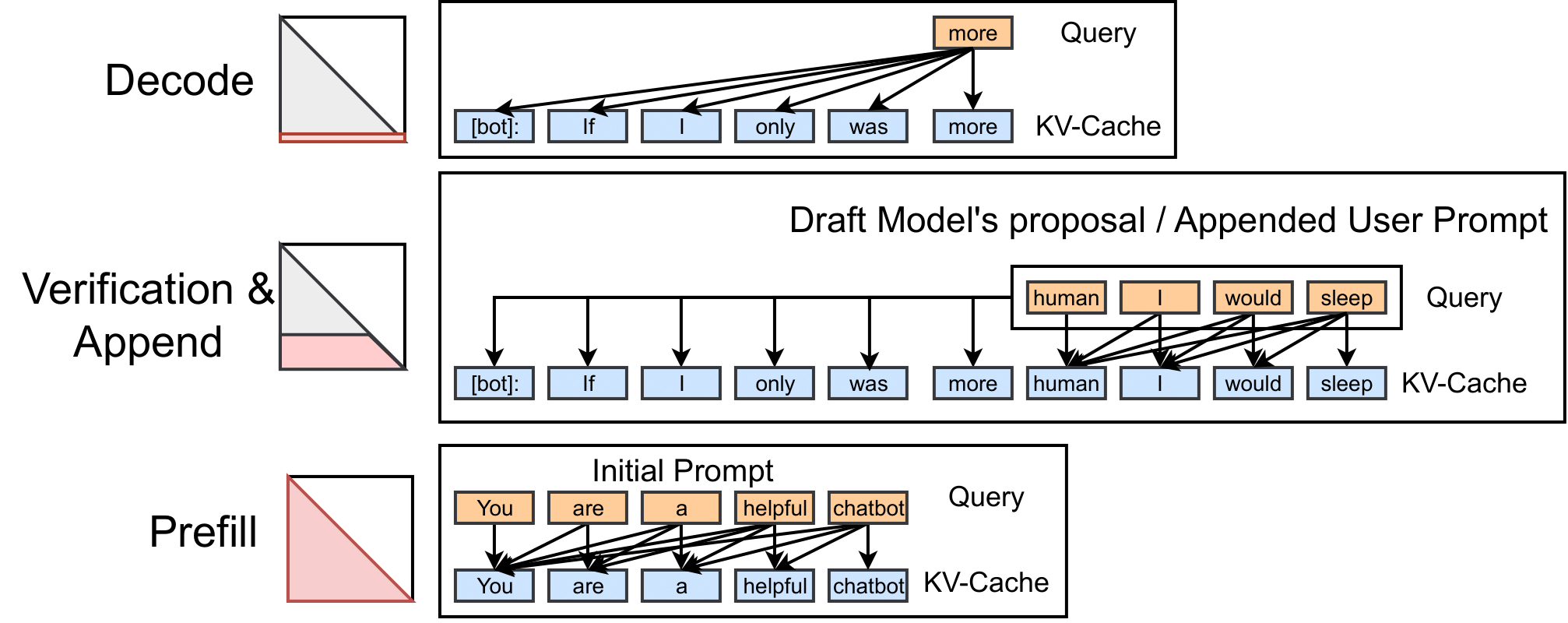
Chunked prefill support · Issue #392 · flashinfer-ai/flashinfer · GitHub
[Feature]: Integrate `flash-infer` FP8 KV Cache Chunked-Prefill (Append ...
GitHub - sumo43/vllm-flashinfer: A high-throughput and memory-efficient ...
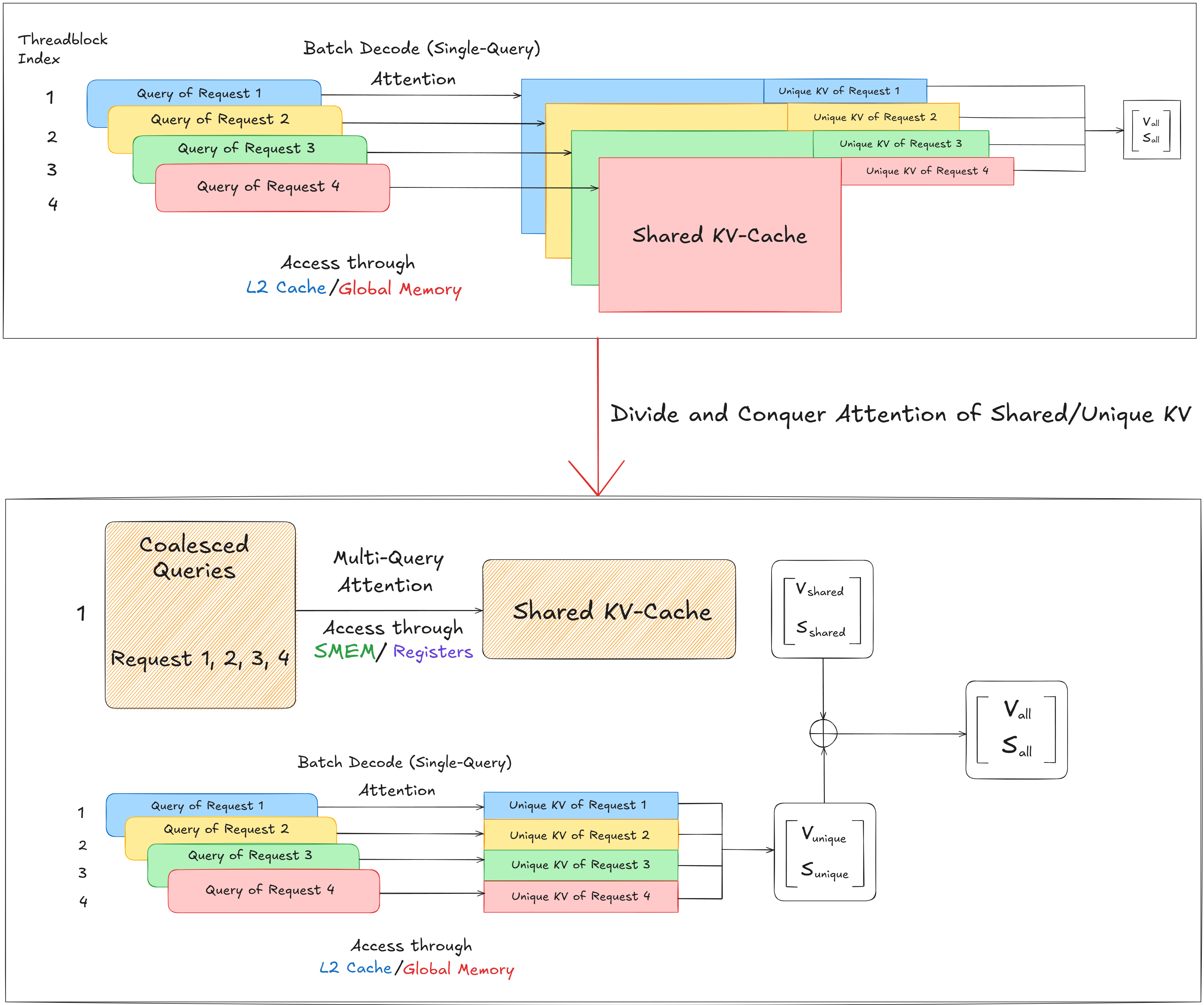
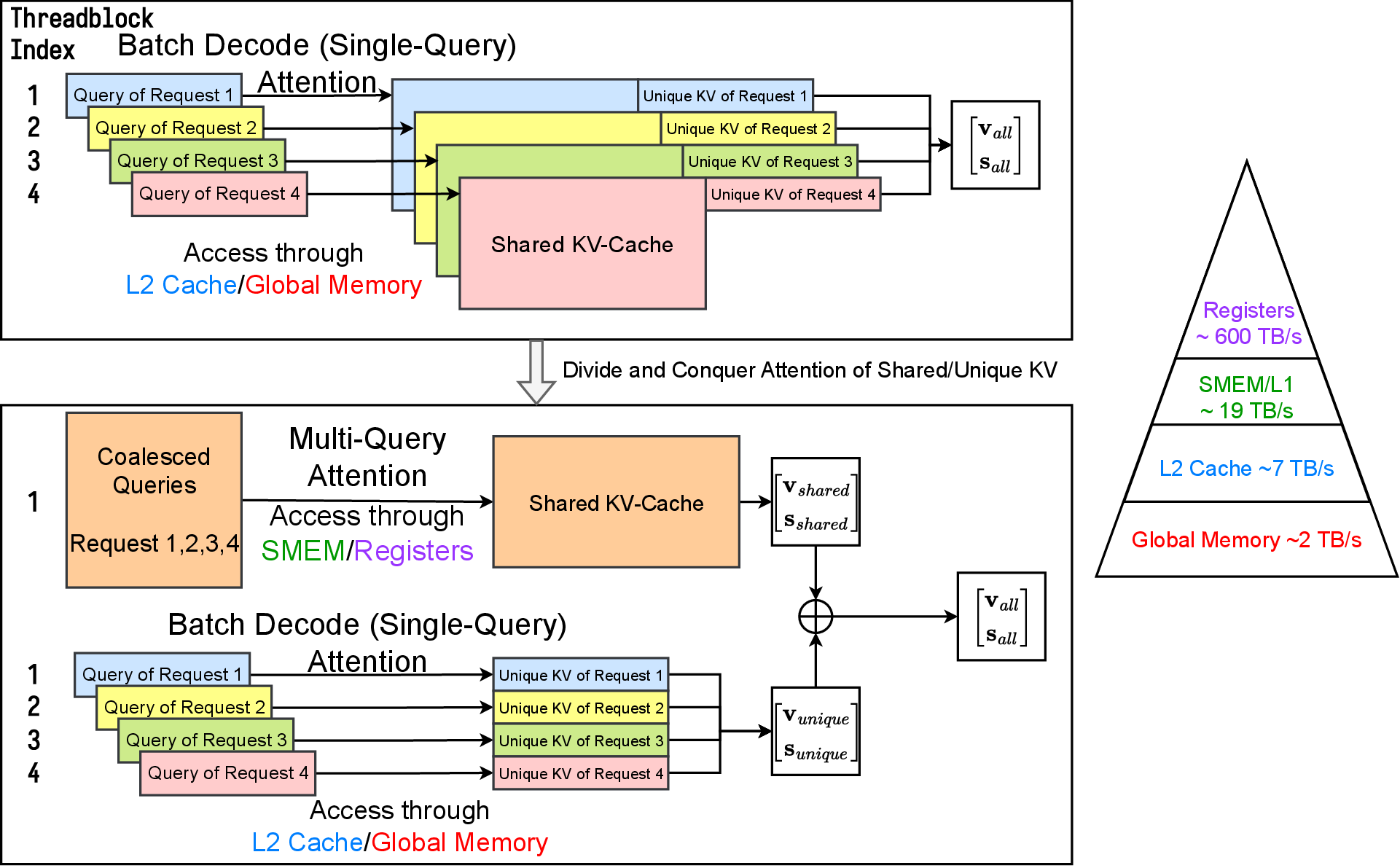
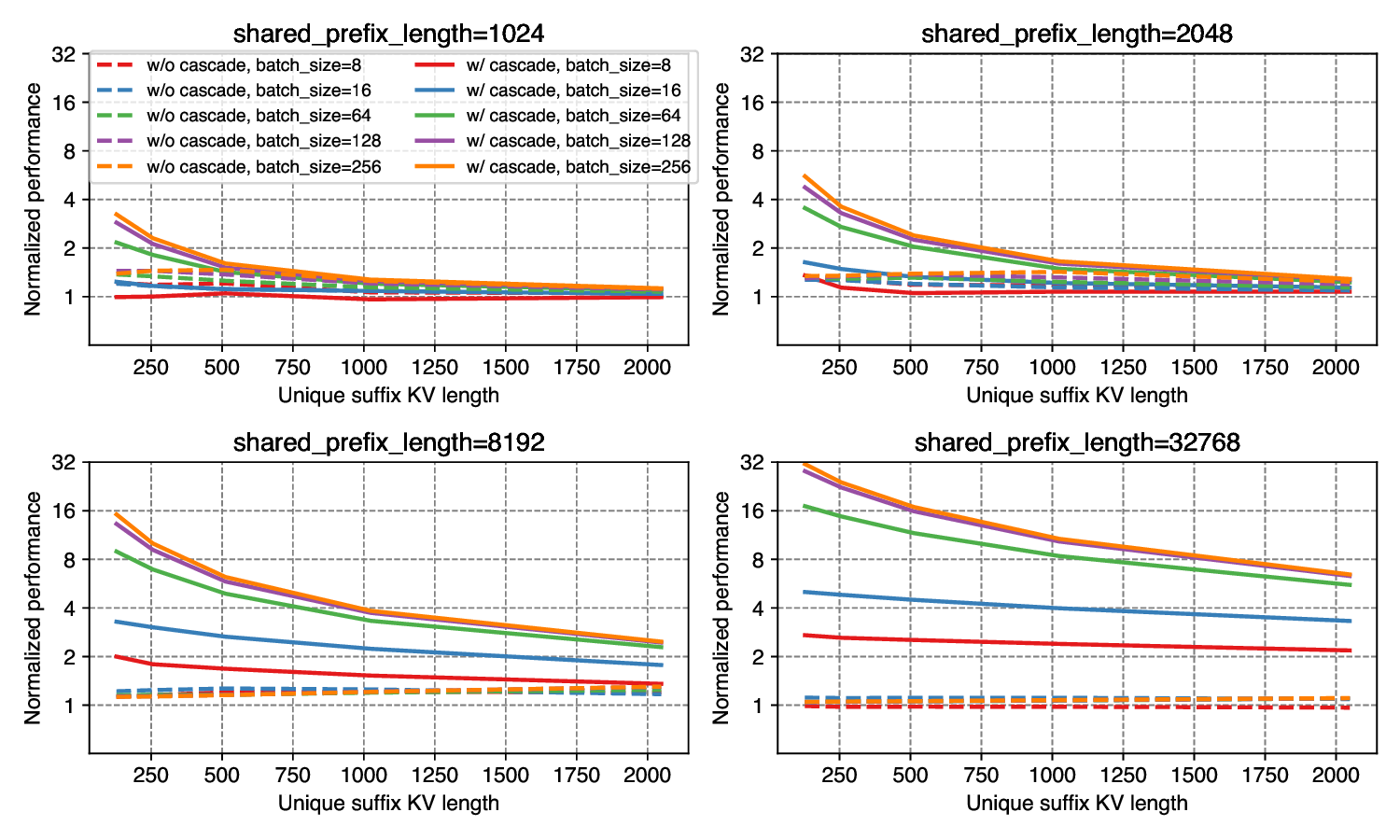
Cascade Inference: Memory Bandwidth Efficient Shared Prefix Batch ...
Allen School News » Allen School researchers receive Best Paper Award ...
Installation fails immediately: ModuleNotFoundError: No module named ...
NVIDIA Proprietary licensing · Issue #1977 · flashinfer-ai/flashinfer ...
[bug] fp4 moe not working on sm120 · Issue #1816 · flashinfer-ai ...