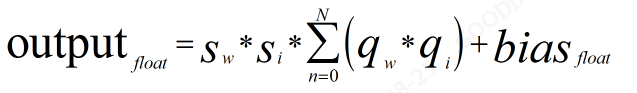Showing 96 of 96on this page. Filters & sort apply to loaded results; URL updates for sharing.96 of 96 on this page
Achieving FP32 Accuracy for INT8 Inference Using Quantization Aware ...
python - INT8 quantization for FP32 matrix multiplication - Stack Overflow
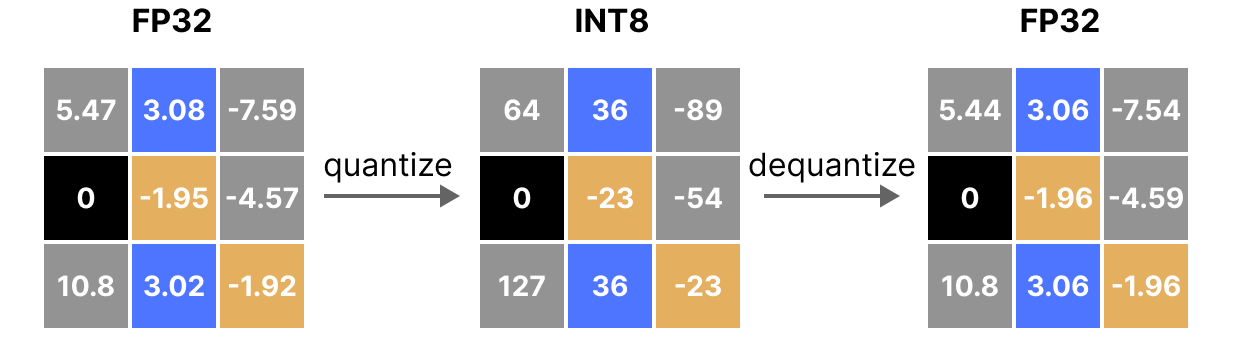
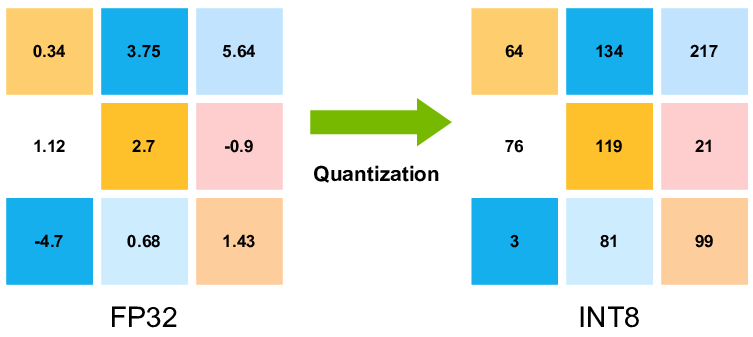
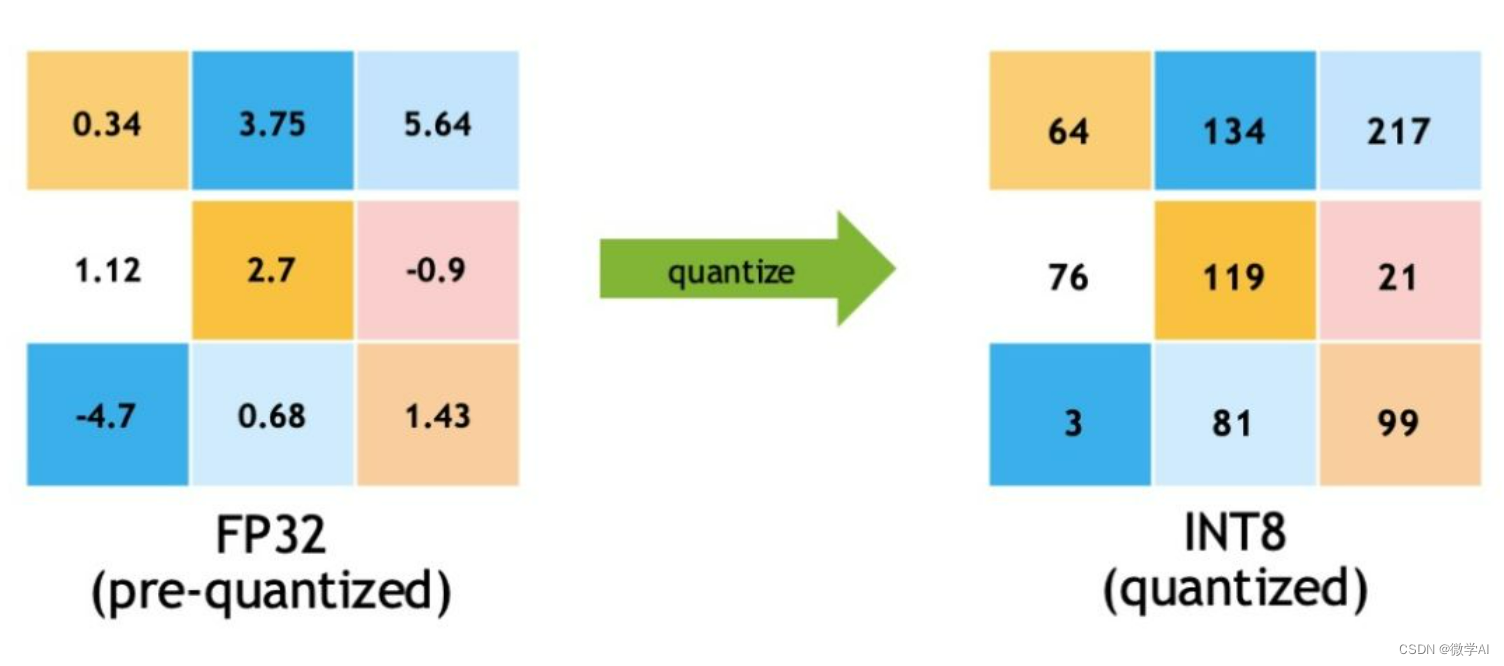
Quantization from FP32 to INT8. | Download Scientific Diagram
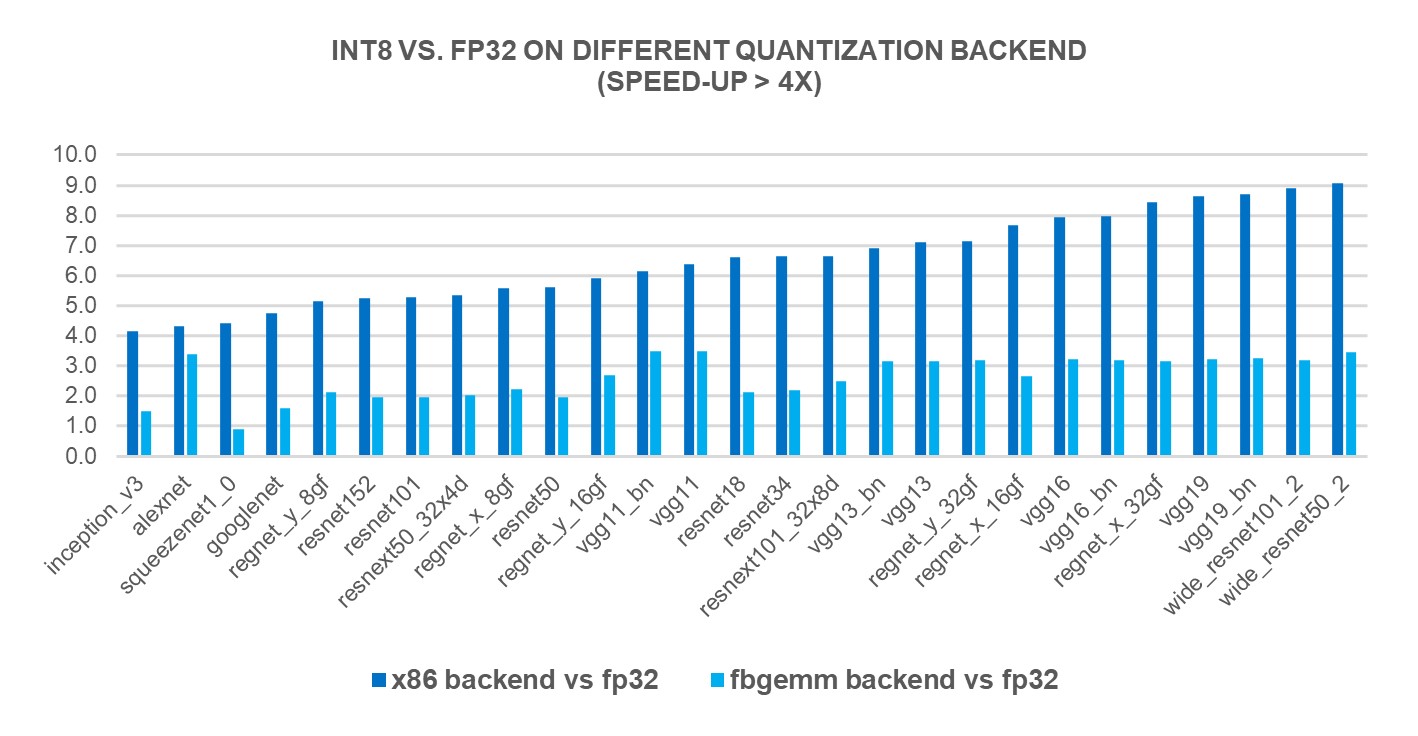
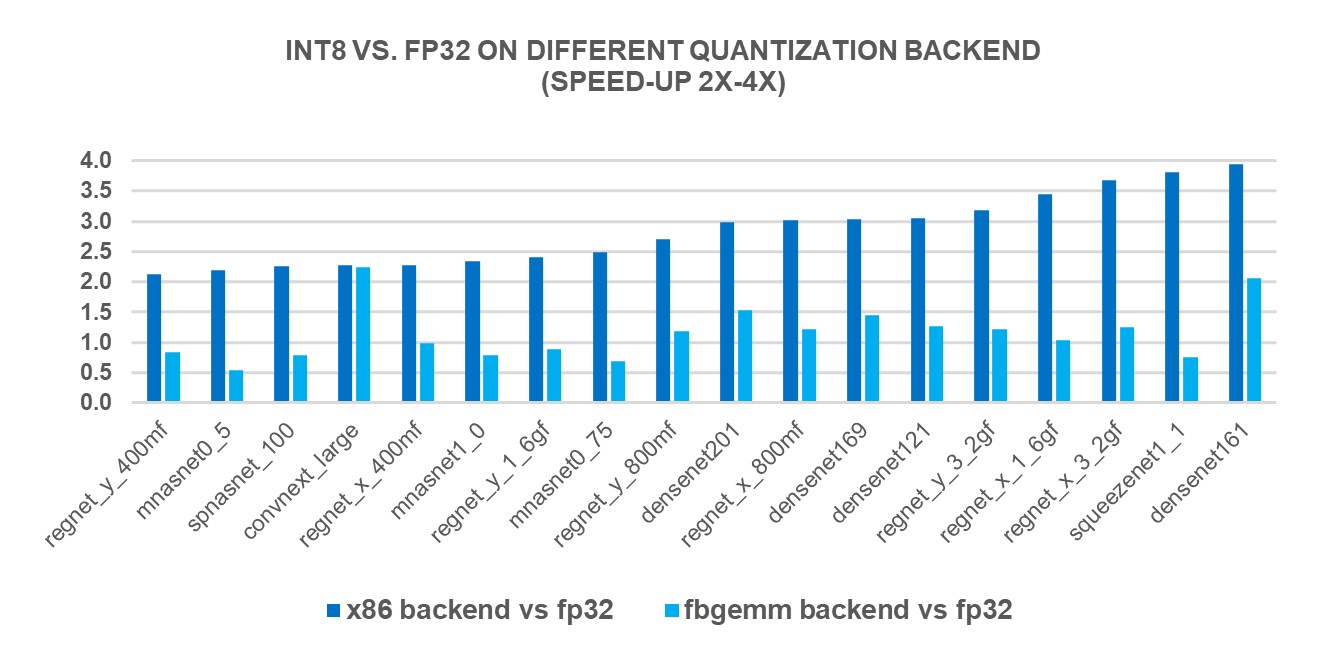
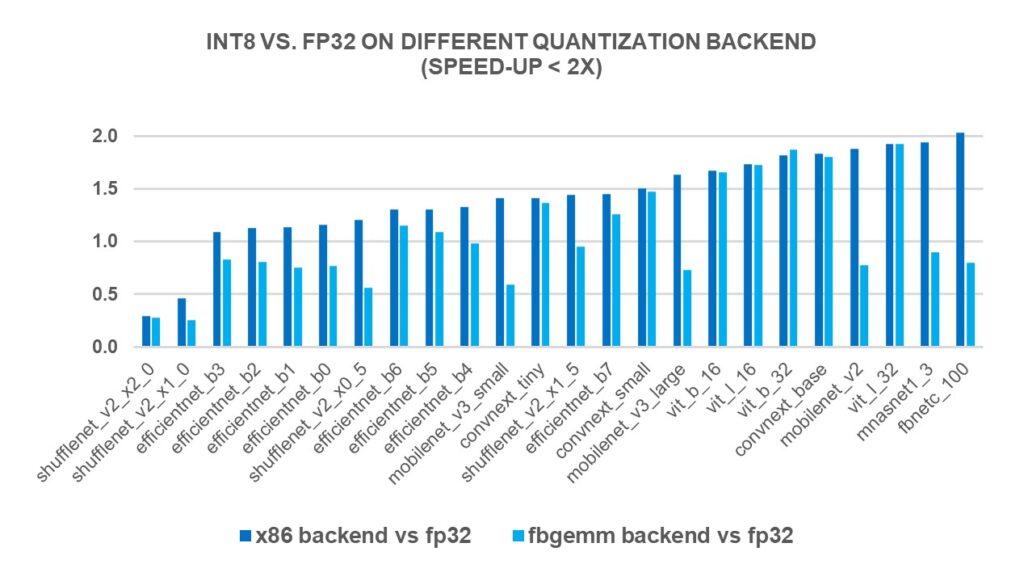
INT8 Quantization for x86 CPU in PyTorch | PyTorch
INT8 Quantization for x86 CPU in PyTorch – PyTorch
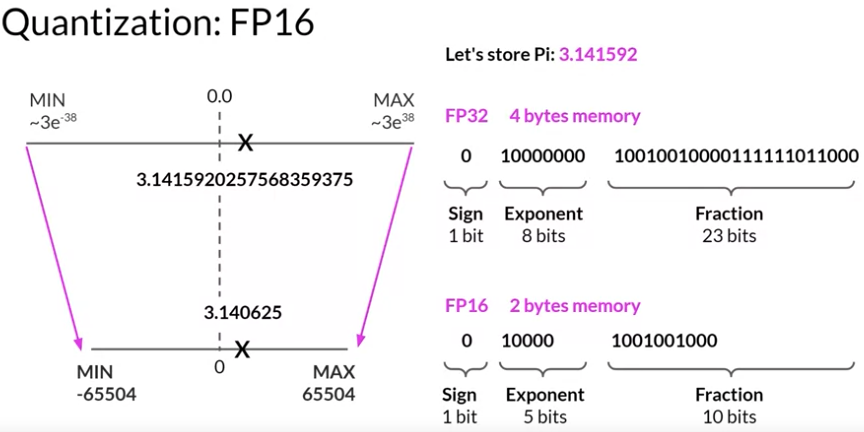
Quantization from FP32 to FP16. | Download Scientific Diagram
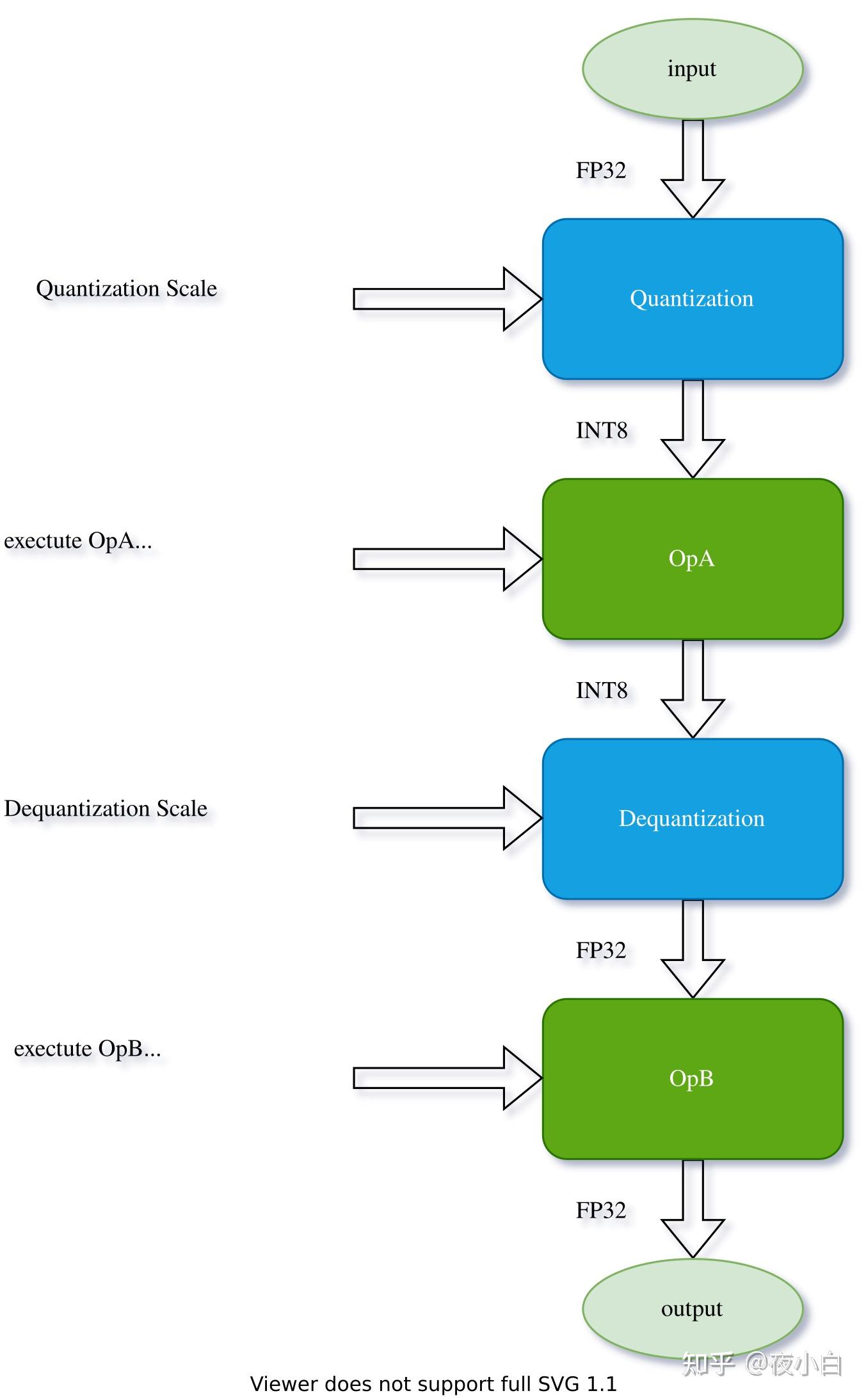
利用 NVIDIA TensorRT 量化感知训练实现 INT8 推理的 FP32 精度 - 广州市迈进信息科技有限公司/研云创服务器
Int8 quantization and tvm implementation - Programmer Sought
An overview of quantization and compilation of FP32 bits NN model ...
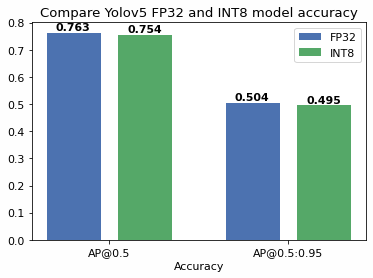
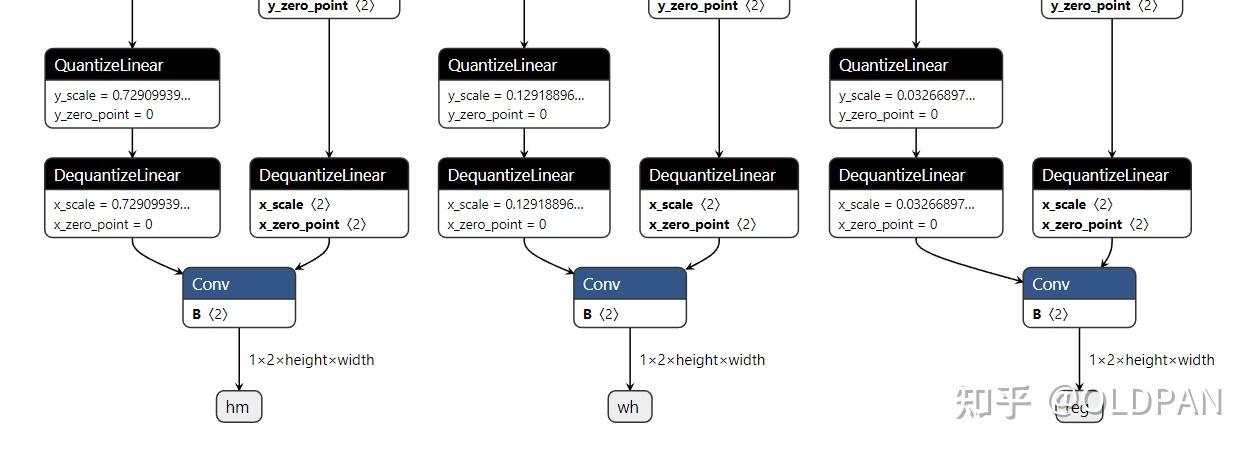
YOLOv5 Model INT8 Quantization based on OpenVINO™ 2022.1 POT API ...
Day 61/75 LLM Quantization | How Accuracy is maintained? | How FP32 and ...
Quantization Deep Dive: From FP32 to INT4 - The Complete Guide | ML ...
模型精度量化:从 FP32 到 INT8 的技术路径 - 知乎
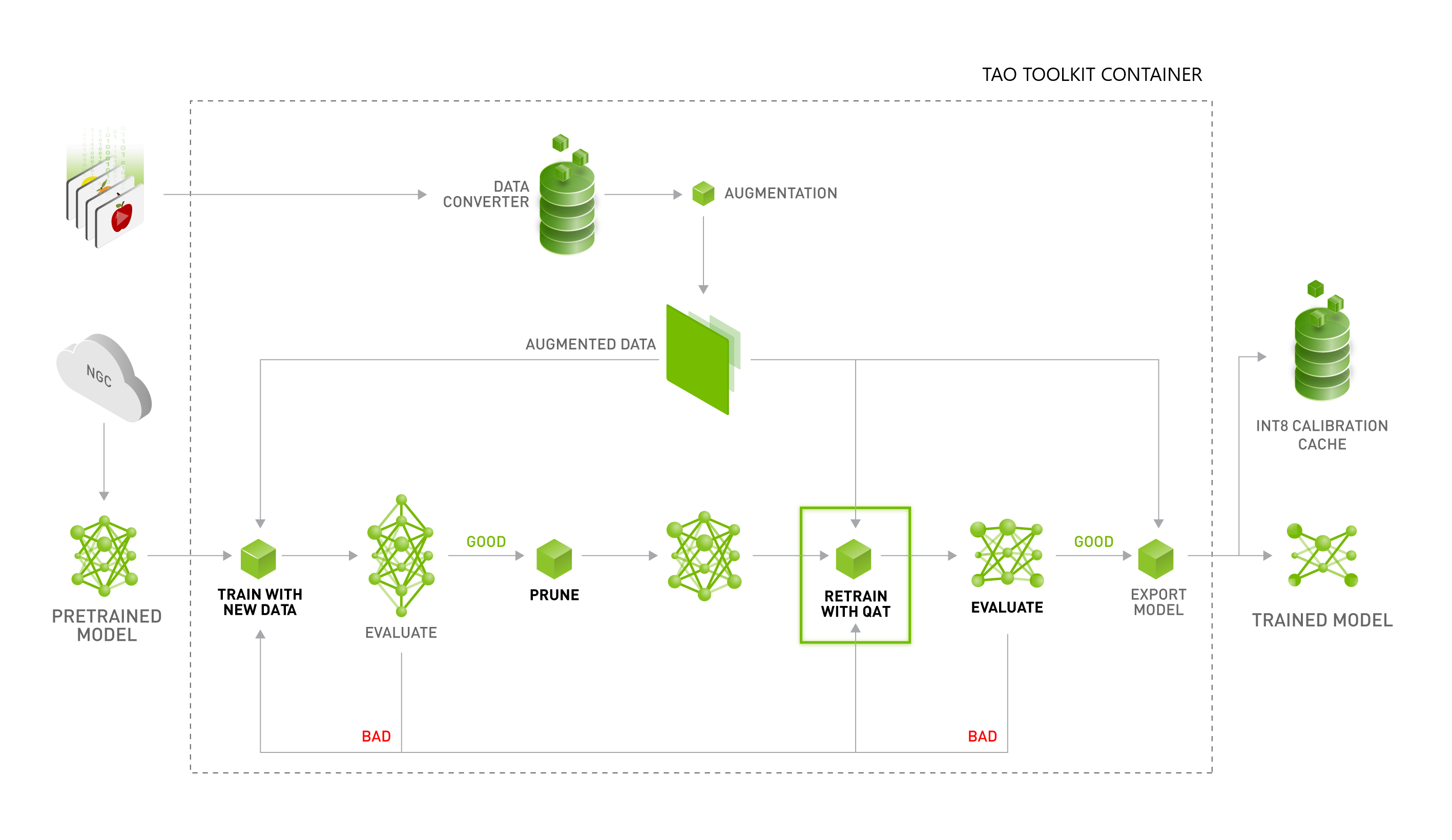
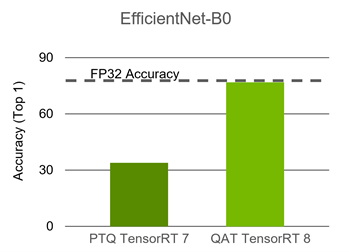
Improving INT8 Accuracy Using Quantization Aware Training and the ...
The process of converting FP32 to INT8 under TensorRT - Programmer Sought
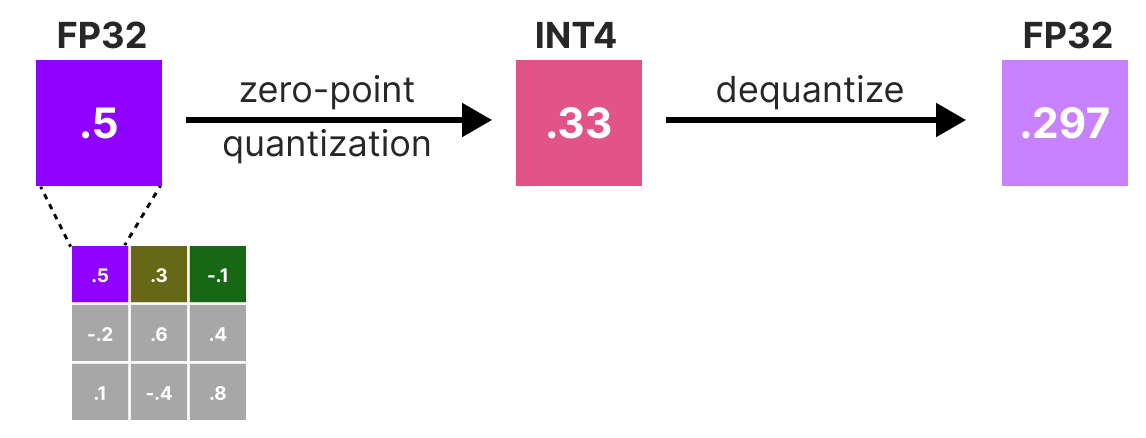
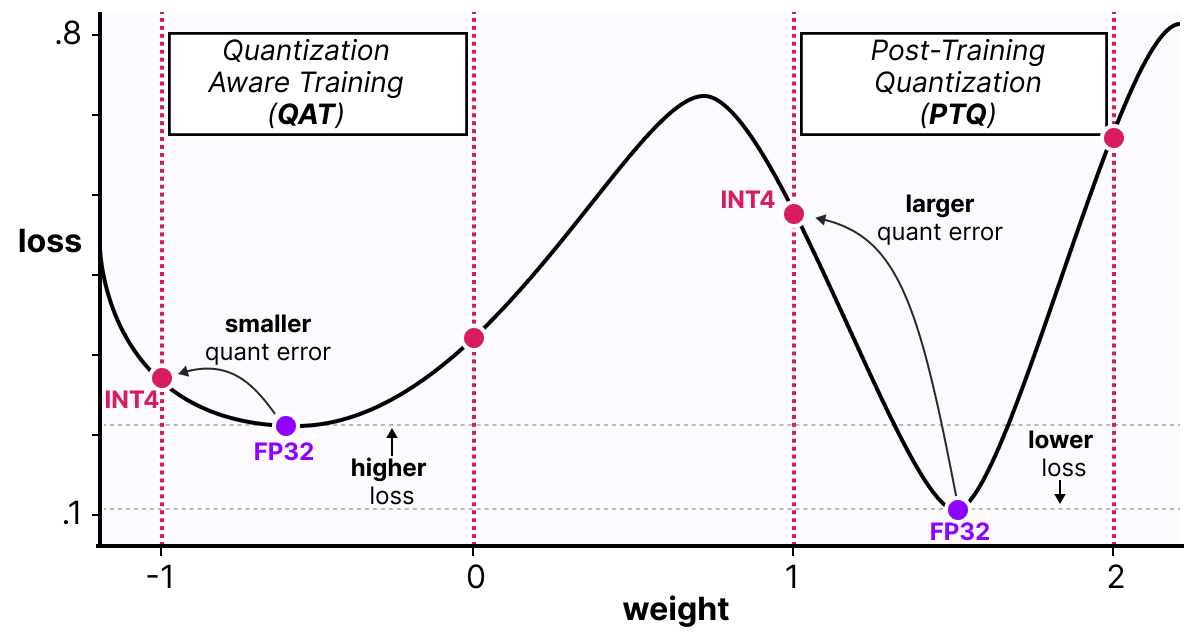
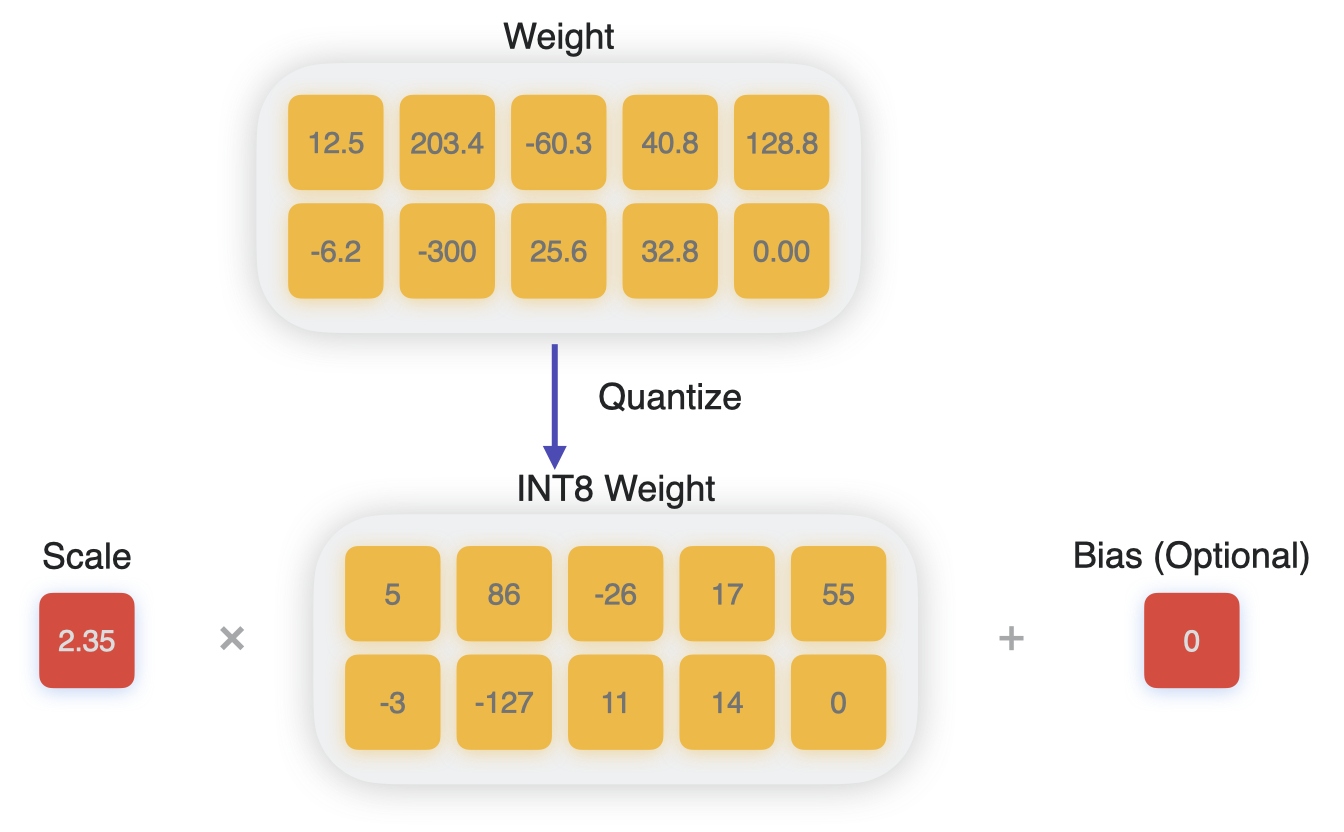
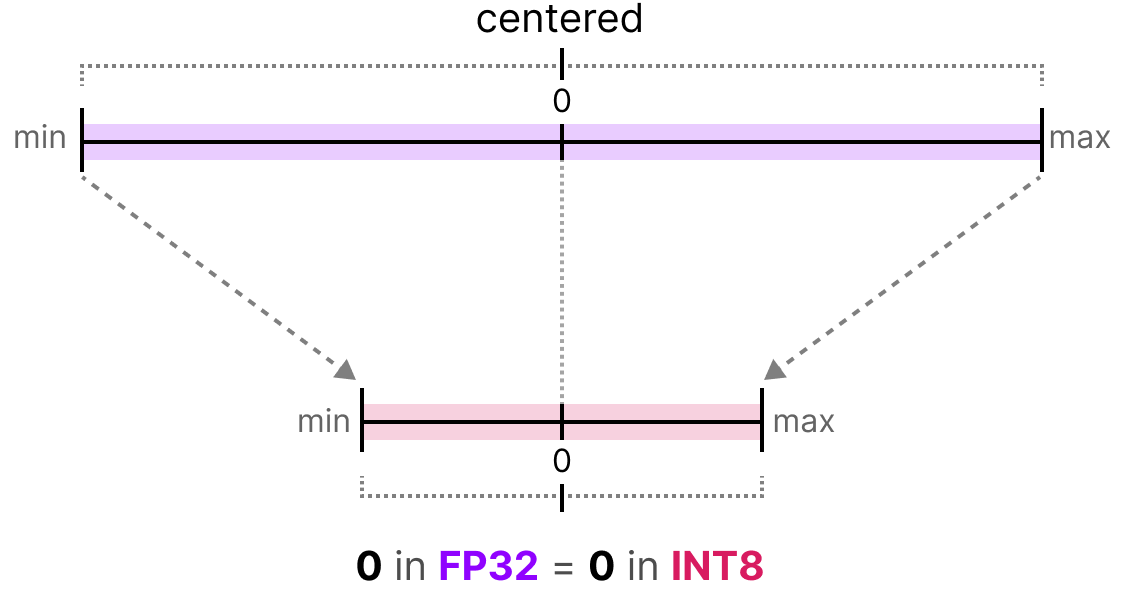
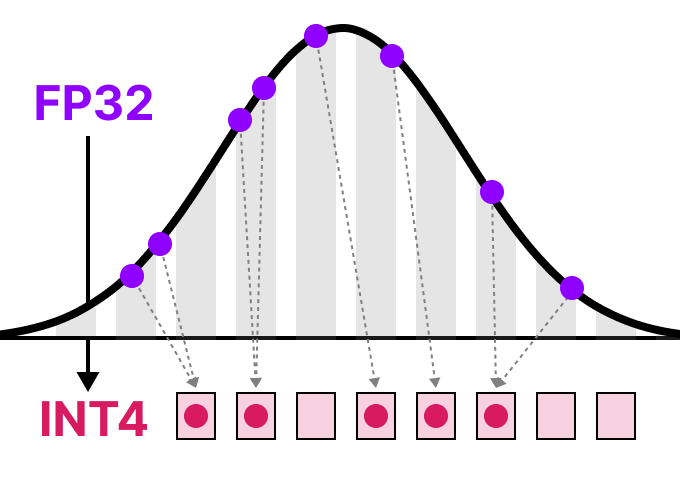
A Visual Guide to Quantization - by Maarten Grootendorst
A Hands-On Walkthrough on Model Quantization - Medoid AI
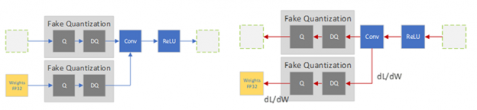
How Quantization Aware Training Enables Low-Precision Accuracy Recovery ...
Key Factors in AI's Advancement: Research Papers, Quantization ...
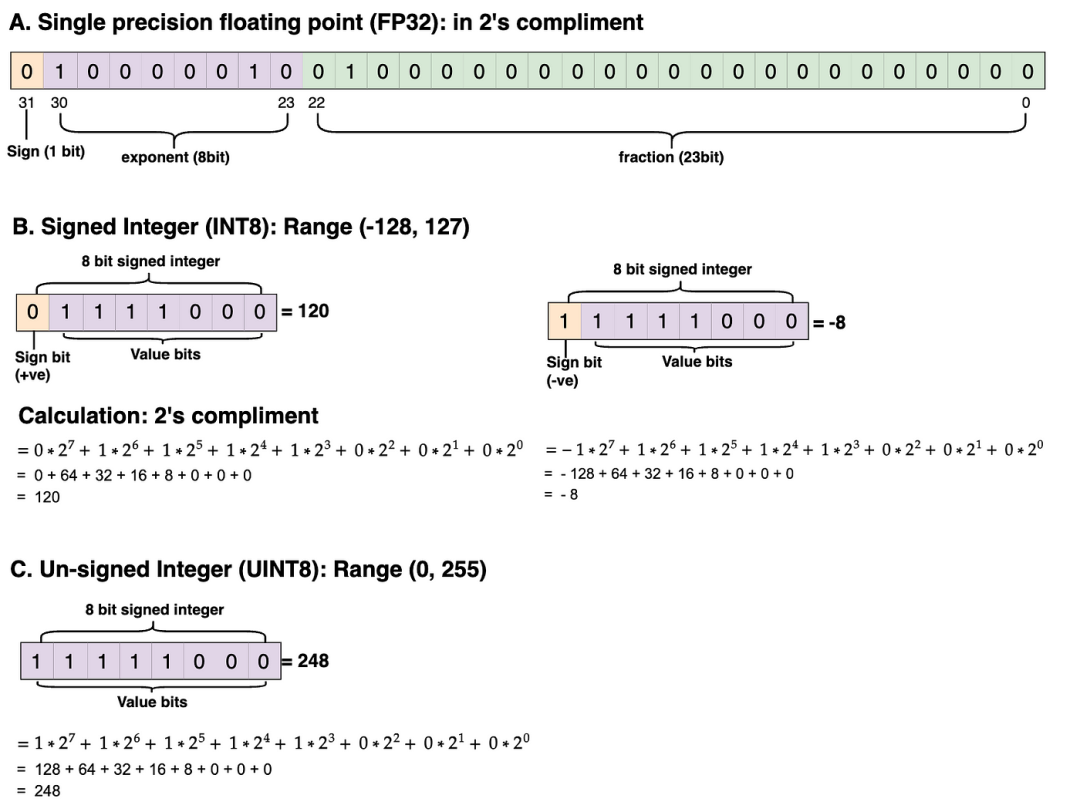
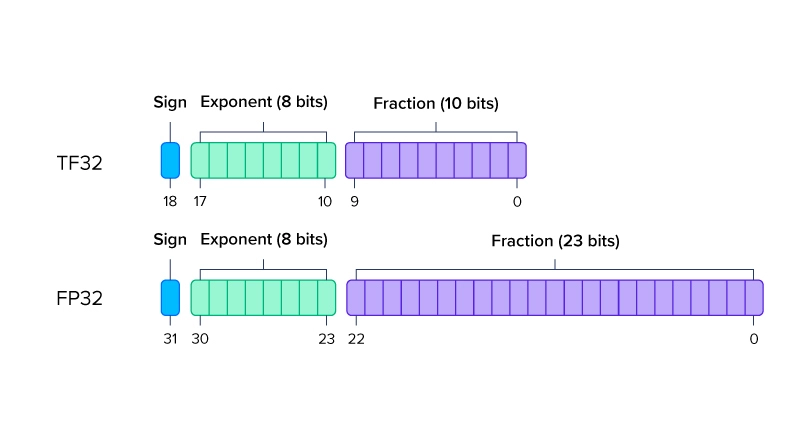
Understanding FP32, FP16, and INT8 Precision in Deep Learning Models ...
Quantization Methods for 100X Speedup in Large Language Model Inference
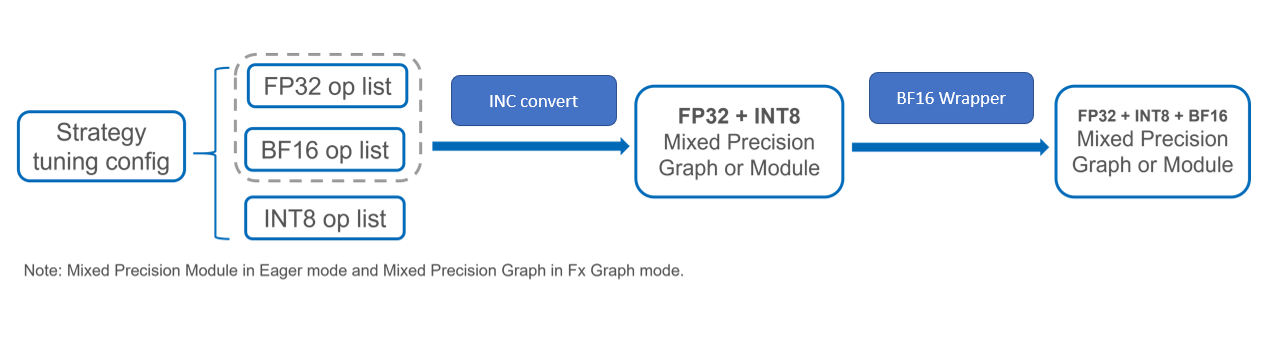
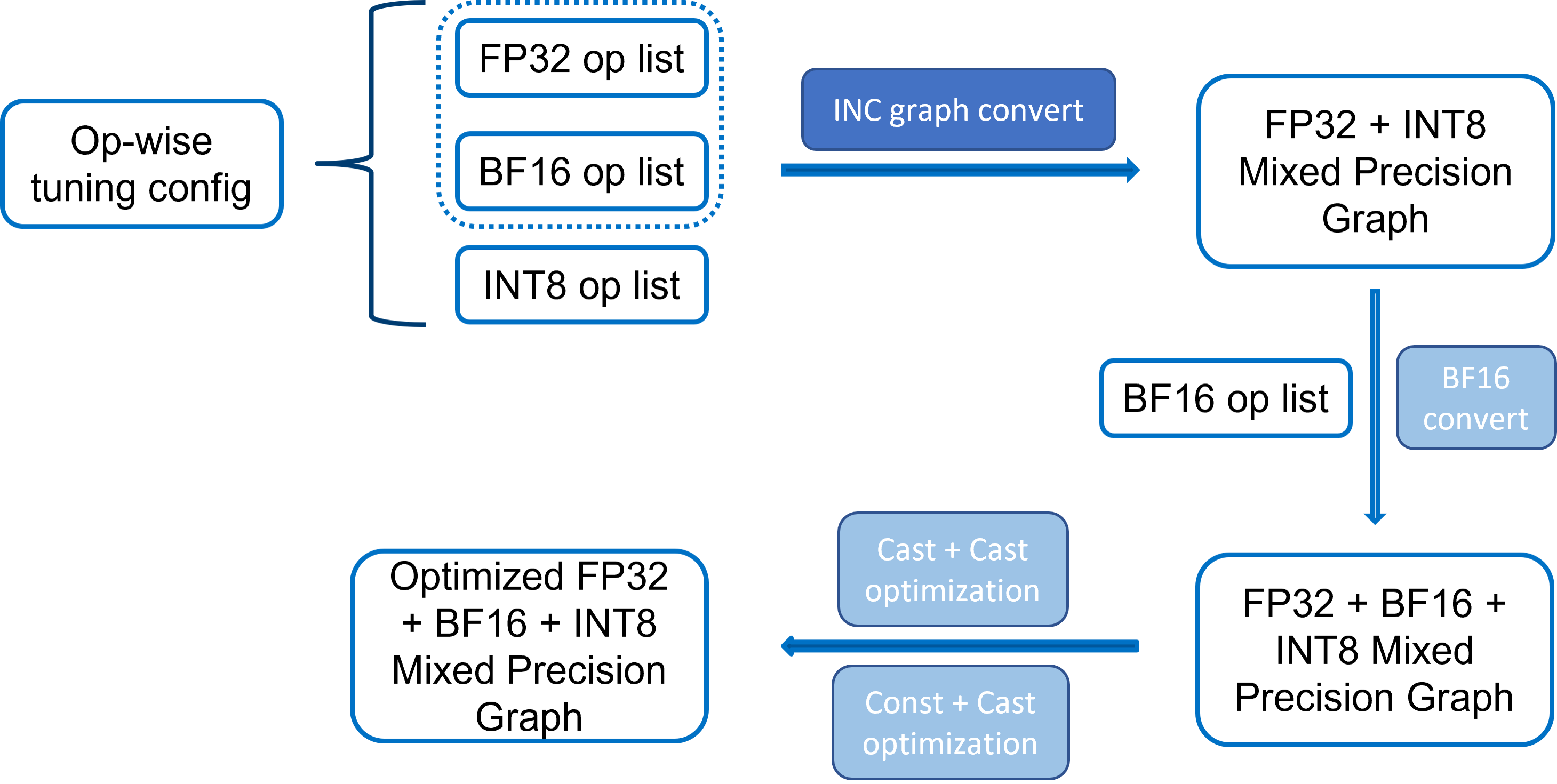
Turn ON Auto Mixed Precision during Quantization — Intel® Neural ...
A Visual Guide to Quantization - Maarten Grootendorst
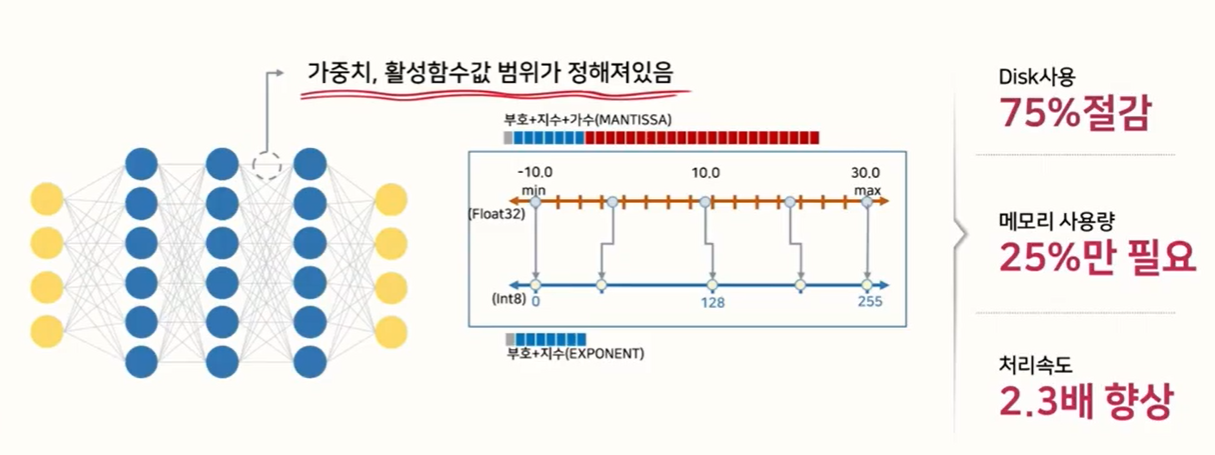
Shrinking AI Models by 75%: A Practical Guide to PyTorch INT8 ...
FP8 Quantization for Ultra-Low Latency AI | AI Tutorial | Next Electronics
Quantized model parameter after PTQ, INT8? - quantization - PyTorch Forums
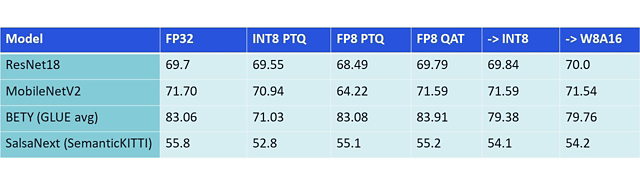
[2303.17951] FP8 versus INT8 for efficient deep learning inference
Improving LLM Inference Latency on CPUs with Model Quantization ...
Model Quantization in Deep Learning
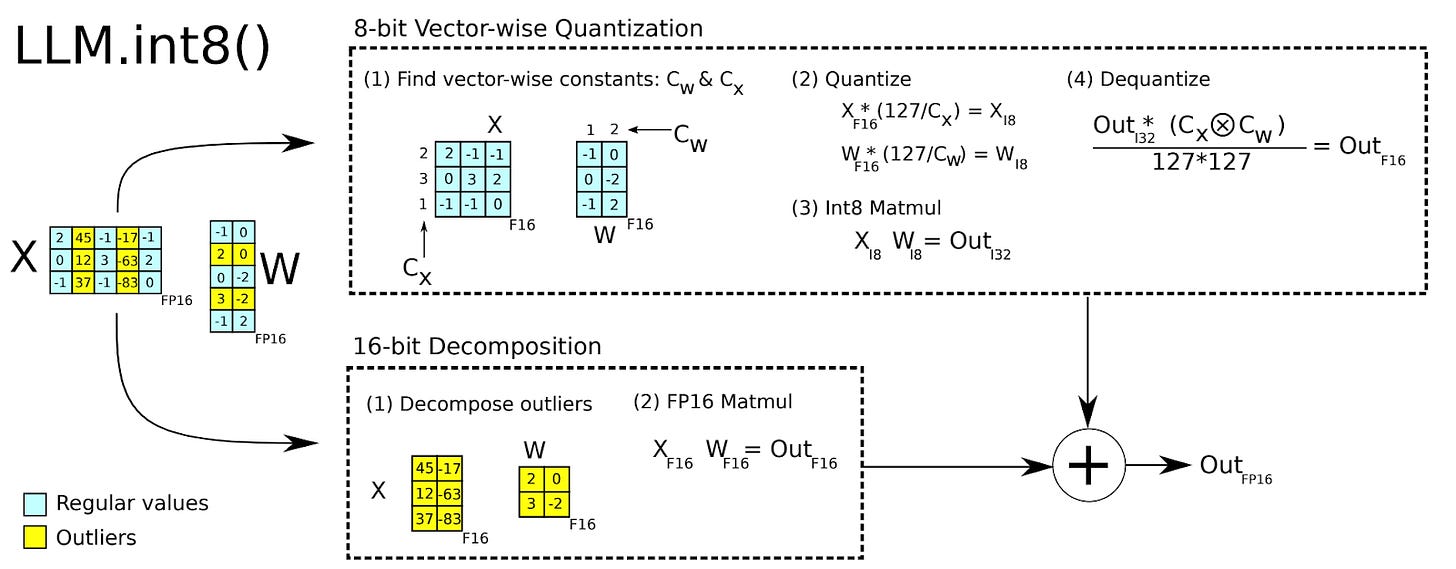
Quantization in LLMS (Part 1): LLM.int8(), NF4 | TensorTunes
딥러닝의 Quantization (양자화)와 Quantization Aware Training - gaussian37
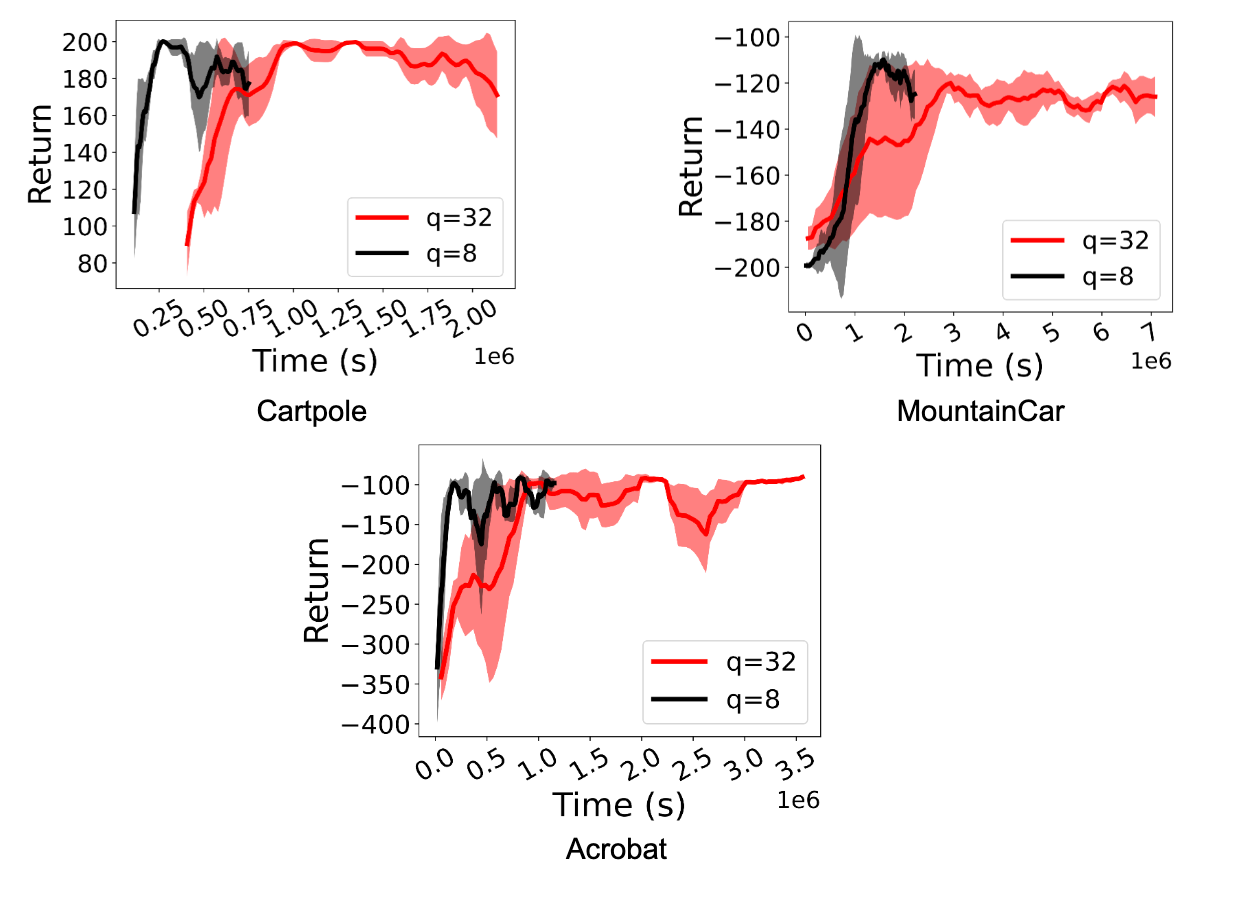
Quantization for Fast and Environmentally Sustainable Reinforcement ...
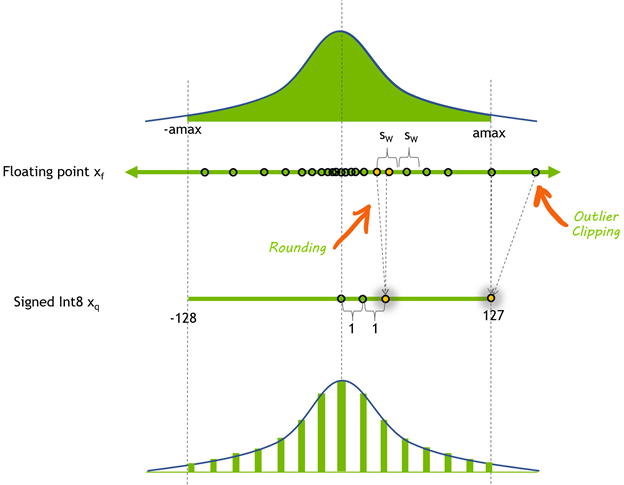
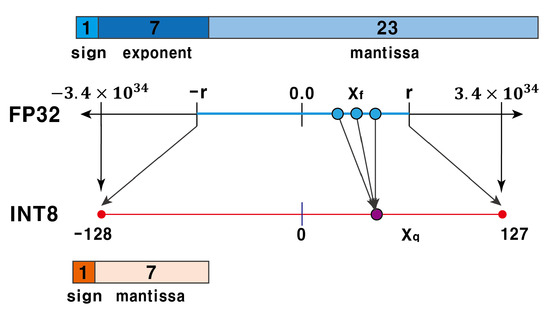
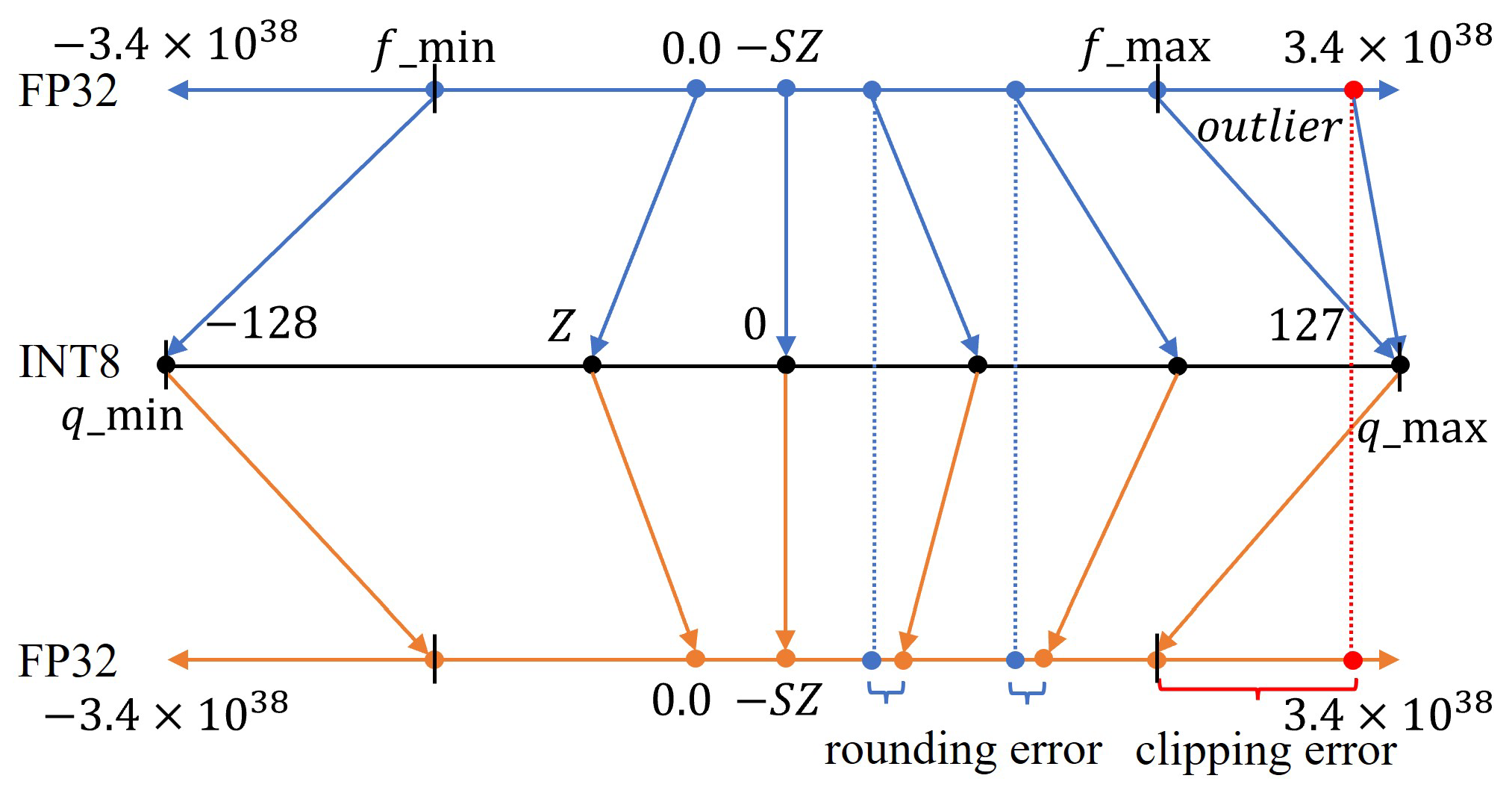
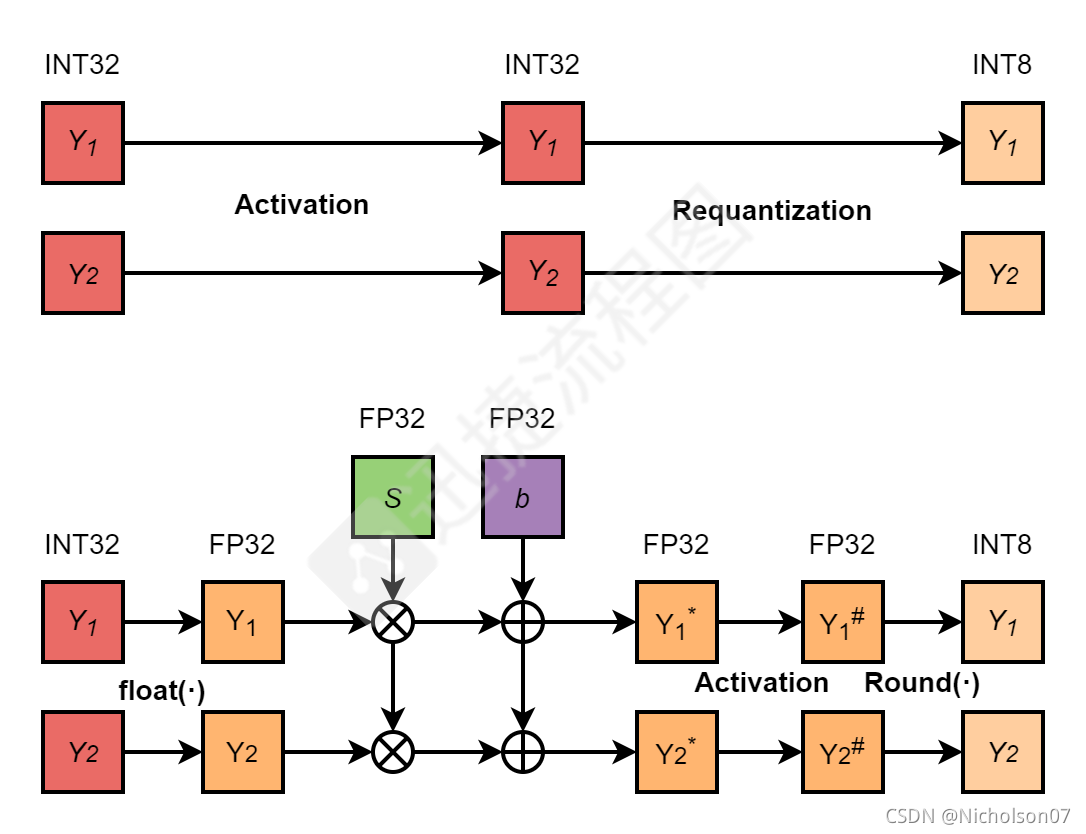
Integer quantization for deep learning inference: principles and ...
Update #31: Expectations for AI + Healthcare and 8-bit Quantization
Quantization FP16 model using pytorch_quantization and TensorRT · Issue ...
Can the output of operator QuantizedConv2d is fp32? - quantization ...
Practical tips for better quantization results - Fritz ai
TensorFlow 2.x Quantization Toolkit 1.0.0 documentation
Extremely Low Bit Transformer Quantization for On-Device NMT | PDF
Curious About Faster ML Models? Discover Model Quantization With ...
Precision-recall curves for the Darknet FP32 model, TensorRT FP16 ...
The INT quantization paradigm. | Download Scientific Diagram
A2C rewards for fp32, fp16, and int8 policies. | Download Scientific ...
Weight distribution of FP32 model, model quantized using the proposed ...
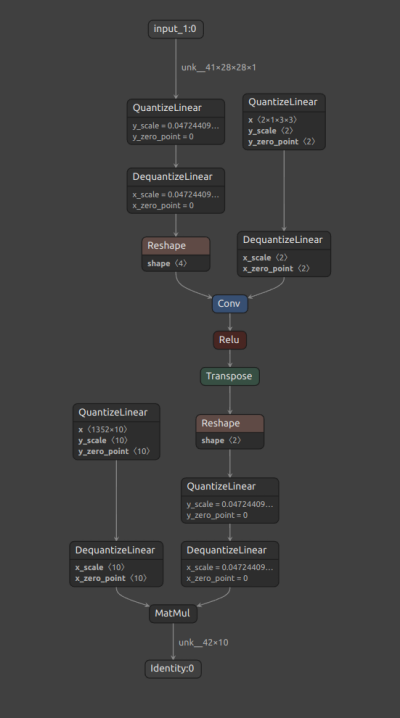
Quantization Overview — Guide to Core ML Tools
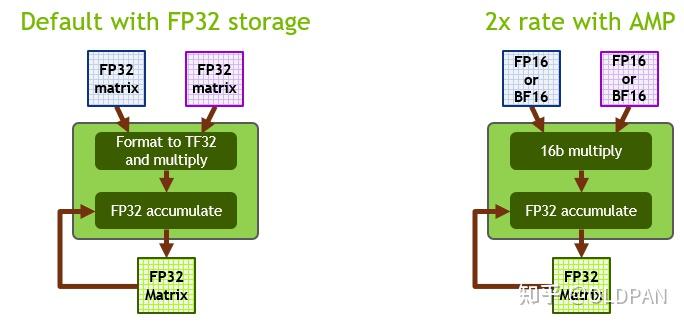
Small numbers, big opportunities: how floating point accelerates AI and ...
深度学习技巧应用17-pytorch框架下模型int8,fp32量化技巧_pytorch模型int8量化-CSDN博客
利用TensorRT实现INT8量化感知训练QAT_tensorrt int8量化-CSDN博客
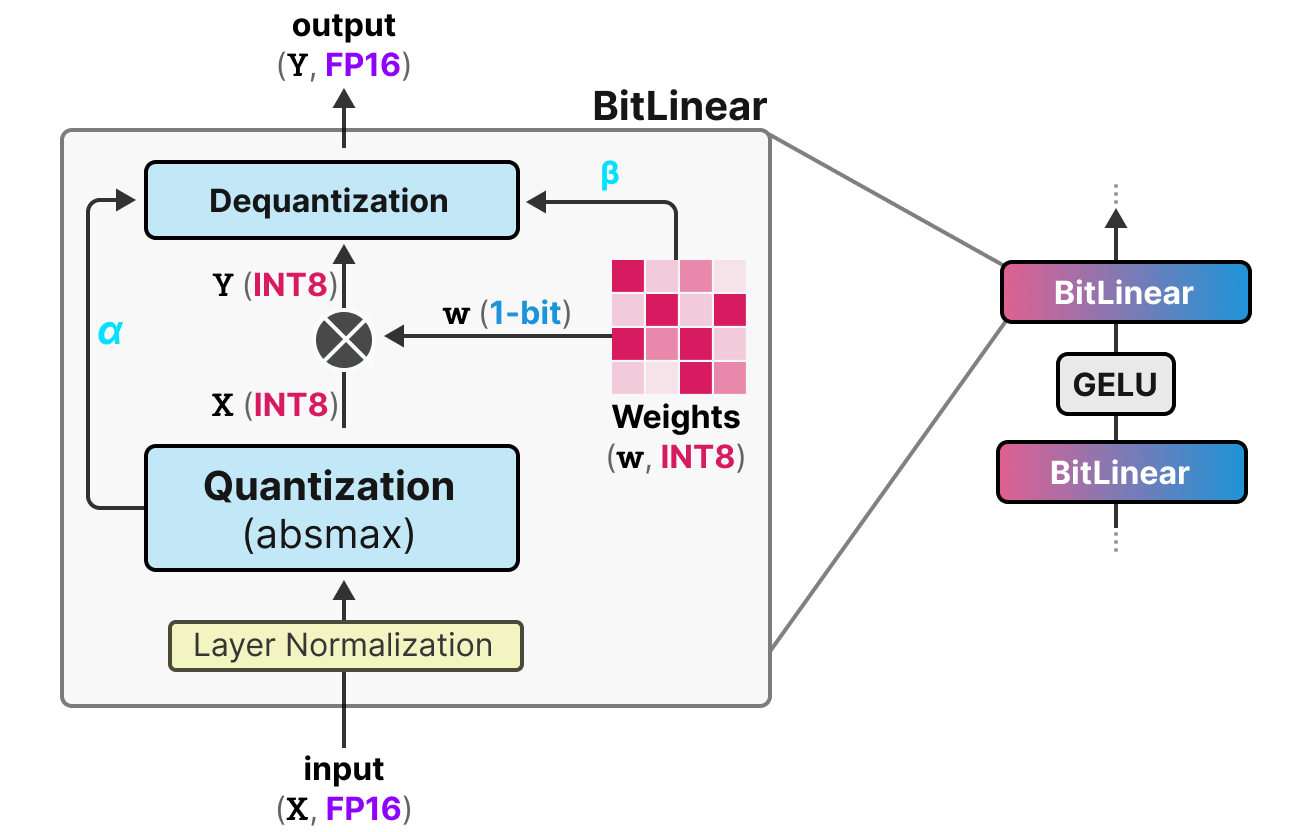
50张图解密大模型量化技术:INT4、INT8、FP32、FP16、GPTQ、GGUF、BitNet_gptq量化-CSDN博客
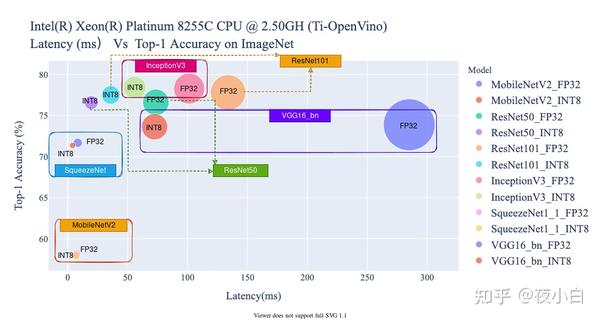
Deep Learning Performance Characterization on GPUs for Various ...
A Method of Deep Learning Model Optimization for Image Classification ...
PyTorch on Twitter: "For non-BF16 and ARM CPUs, lower precision is ...
PyTorch如何量化模型(int8)并使用GPU(训练/Inference)? - 知乎
量化算法概述 — MindSpore master 文档
[Quantization stable diffusion model sd2.1 fp into onnx int8][pytorch ...
GitHub - kentaroy47/benchmark-FP32-FP16-INT8-with-TensorRT: Benchmark ...
量化感知训练(Quantization-aware-training)探索-从原理到实践 - 知乎
部署系列——神经网络INT8量化教程第一讲! - 知乎
Floating-Point Arithmetic for AI Inference — Hit or Miss?
小白也能懂!INT4、INT8、FP8、FP16、FP32量化-CSDN博客
Floating-point Arithmetic for AI Inference: Hit or Miss? - Edge AI and ...
模型量化(Model Quantization)-CSDN博客
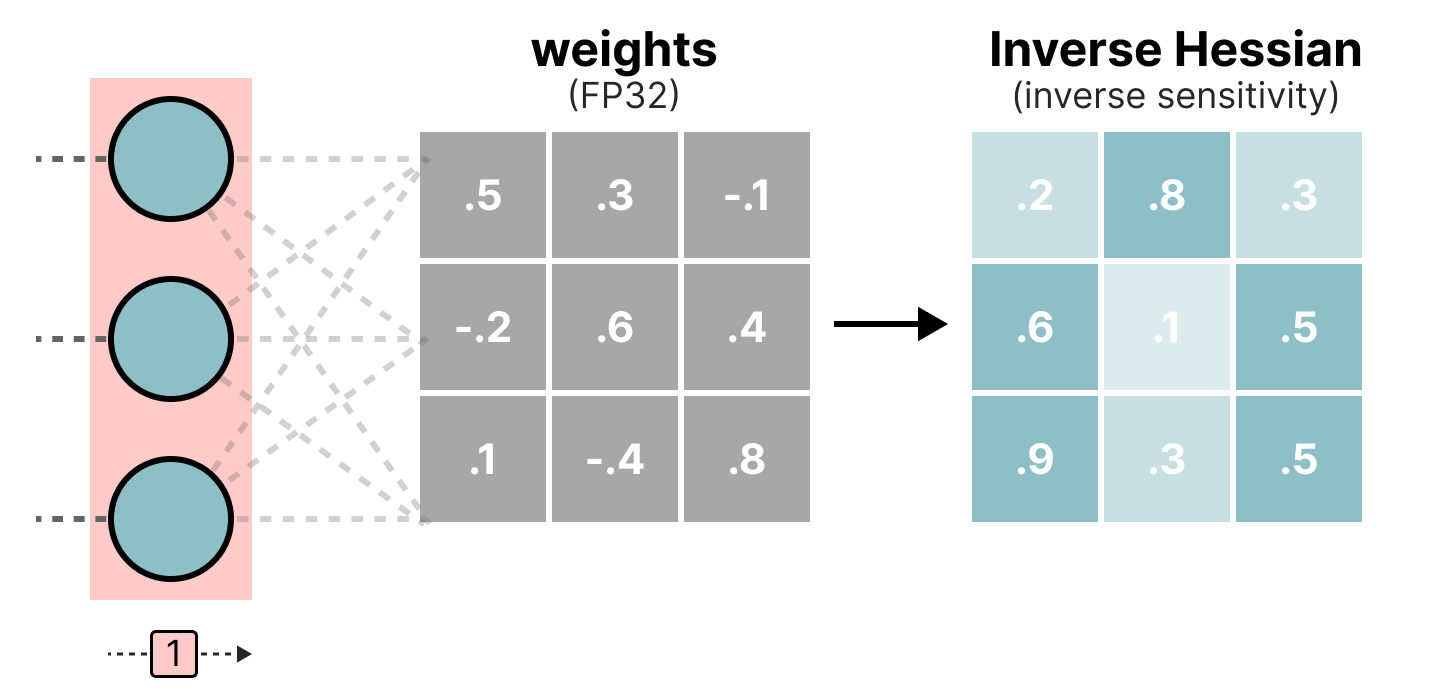
“DNN Quantization: Theory to Practice,” a Presentation from AMD | PDF
为啥大模型需要量化?如何量化_大模型里面量化学习-CSDN博客
QLoRA - How to Fine-Tune an LLM on a Single GPU | Towards Data Science
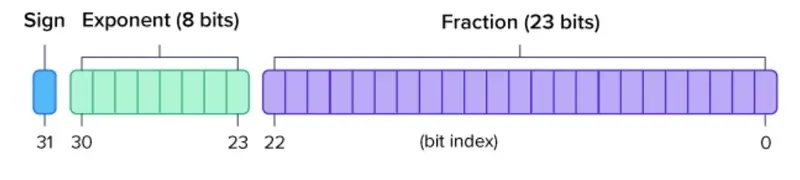
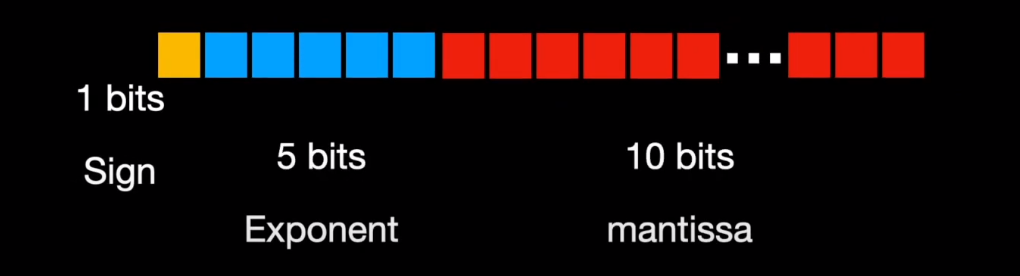
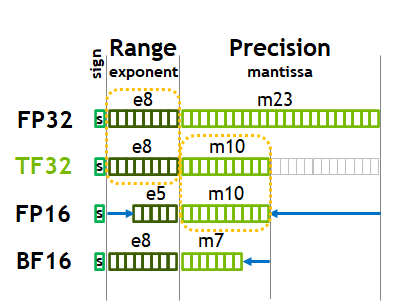
Floating Point Numbers: (FP32 and FP16) and Their Role in Large ...
What is FP64, FP32, FP16? Defining Floating Point | Exxact Blog
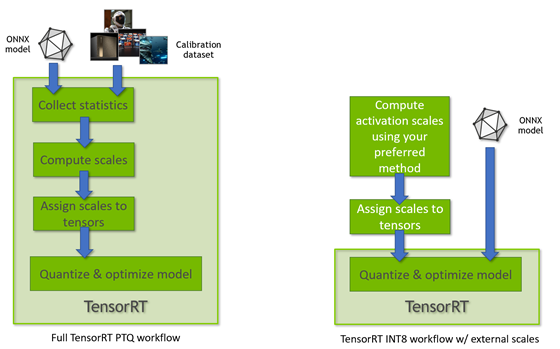
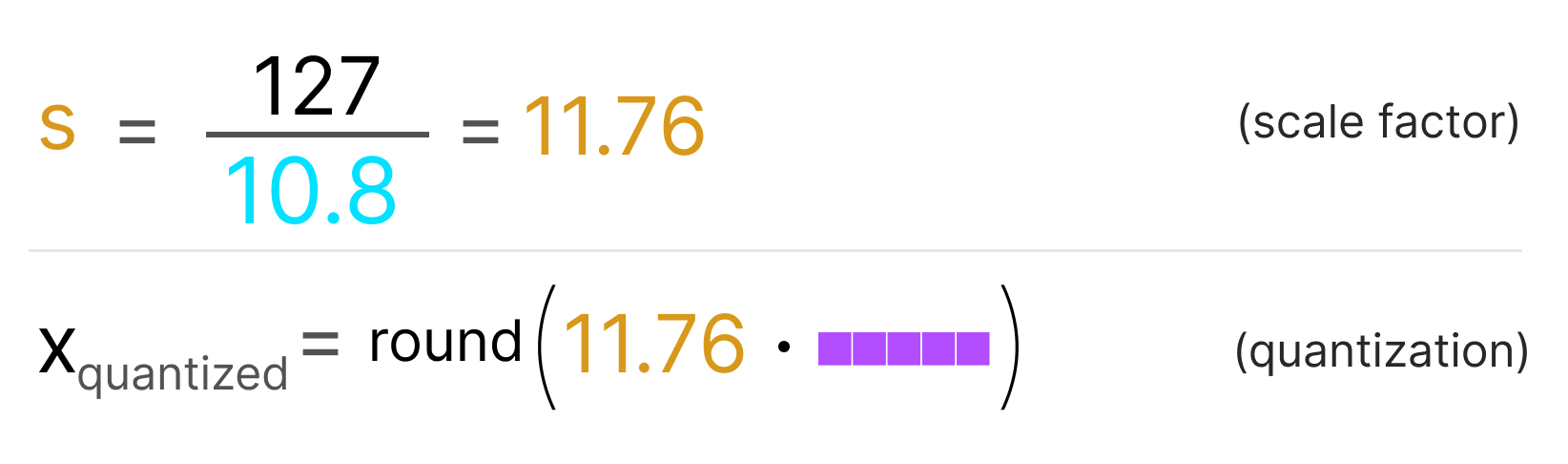
TensorRT INT8量化原理与实现(非常详细)-CSDN博客