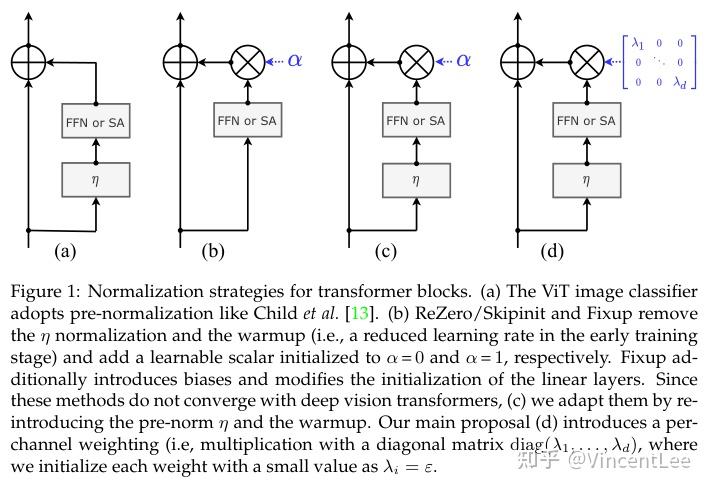
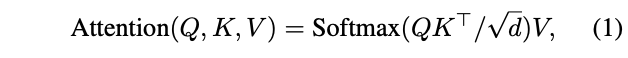Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
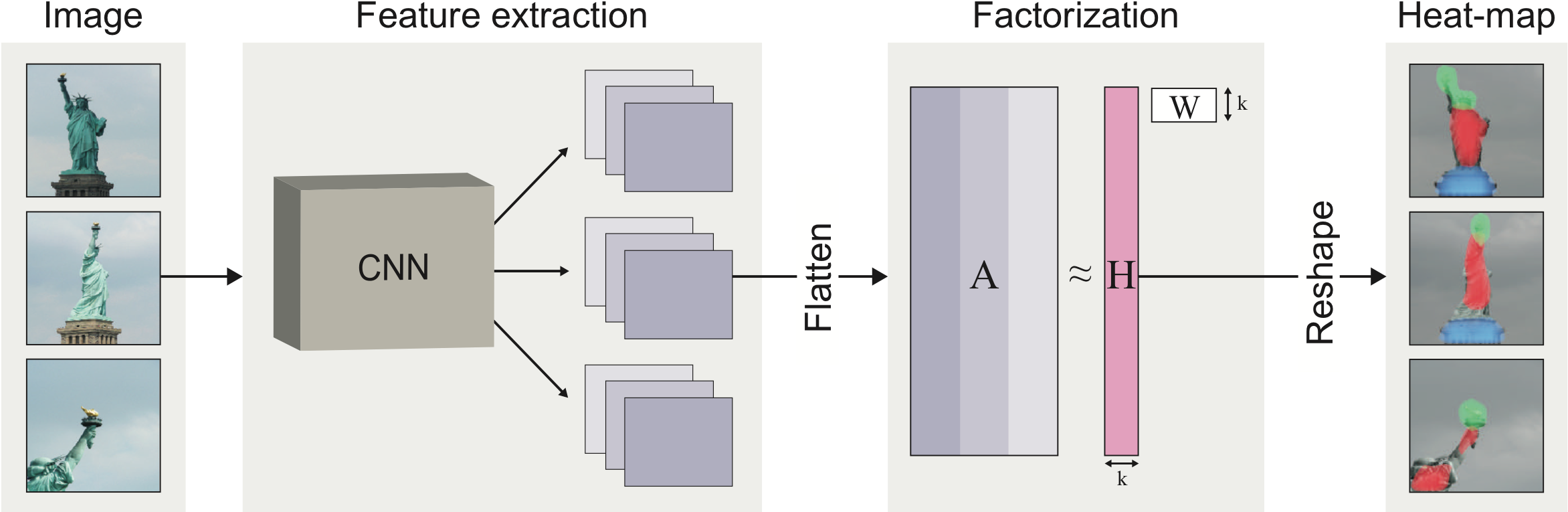
Deep Feature Factorization For Concept Discovery
Deep Feature Factorization For Concept Discovery | DeepAI
[P] Better AI Explainability with Deep Feature Factorization : r ...
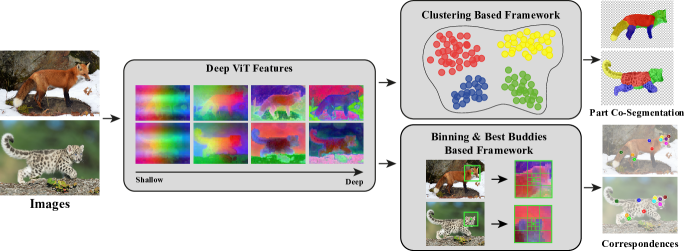
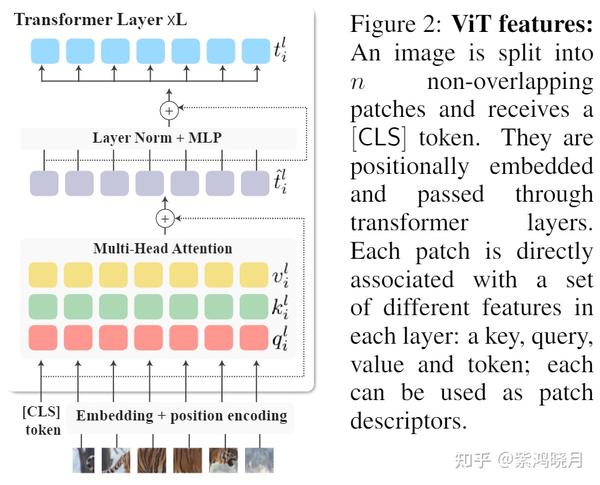
[2112.05814] Deep ViT Features as Dense Visual Descriptors
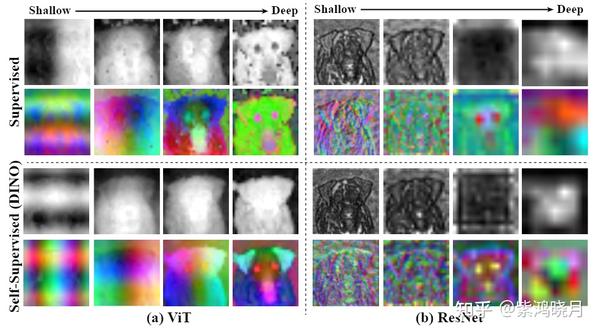
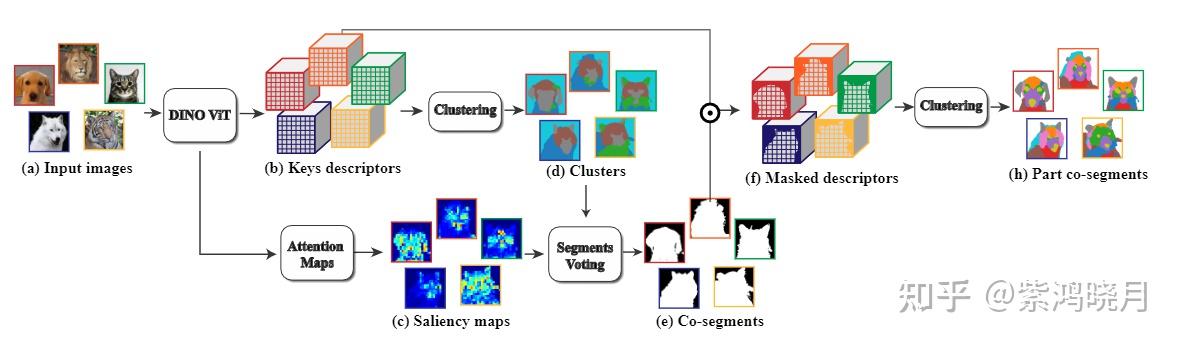
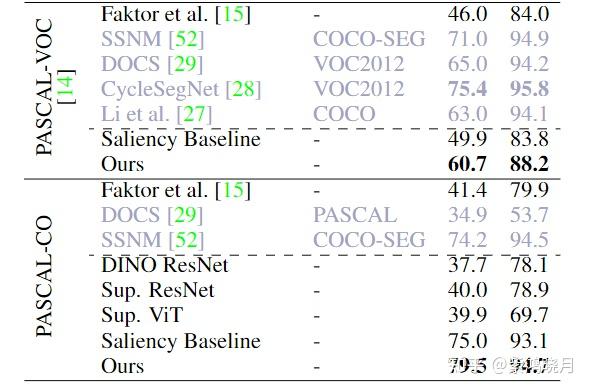
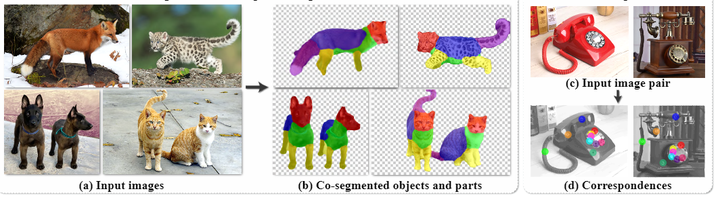
Deep ViT Features as Dense Visual Descriptors - 知乎
[PDF] Deep ViT Features as Dense Visual Descriptors | Semantic Scholar
(PDF) Deep ViT Features as Dense Visual Descriptors
Deep ViT Features as Dense Visual Descriptors
Figure 11 from Deep ViT Features as Dense Visual Descriptors | Semantic ...
Deep Feature Pyramid Hashing for Efficient Image Retrieval
Figure 9 from Deep ViT Features as Dense Visual Descriptors | Semantic ...
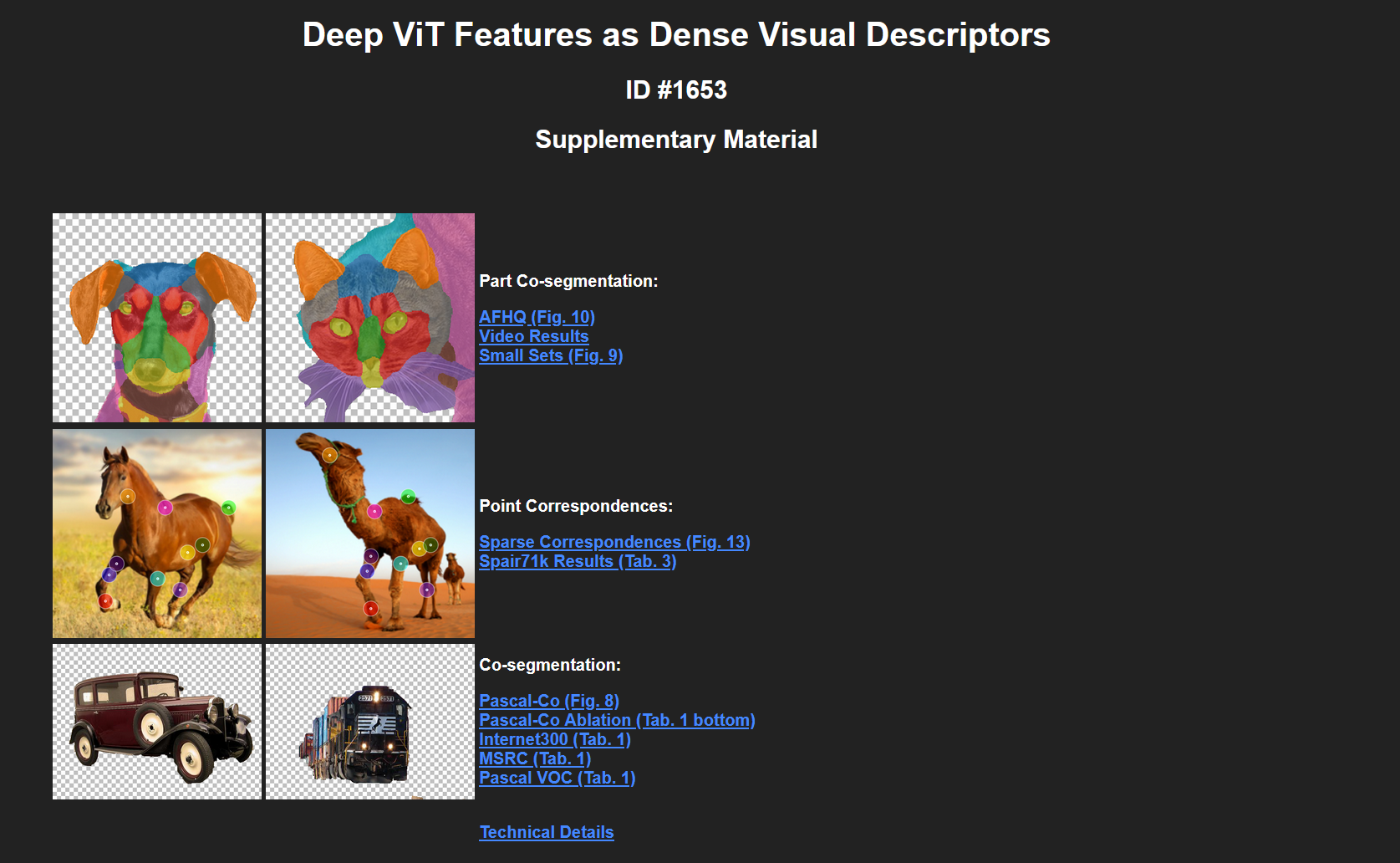
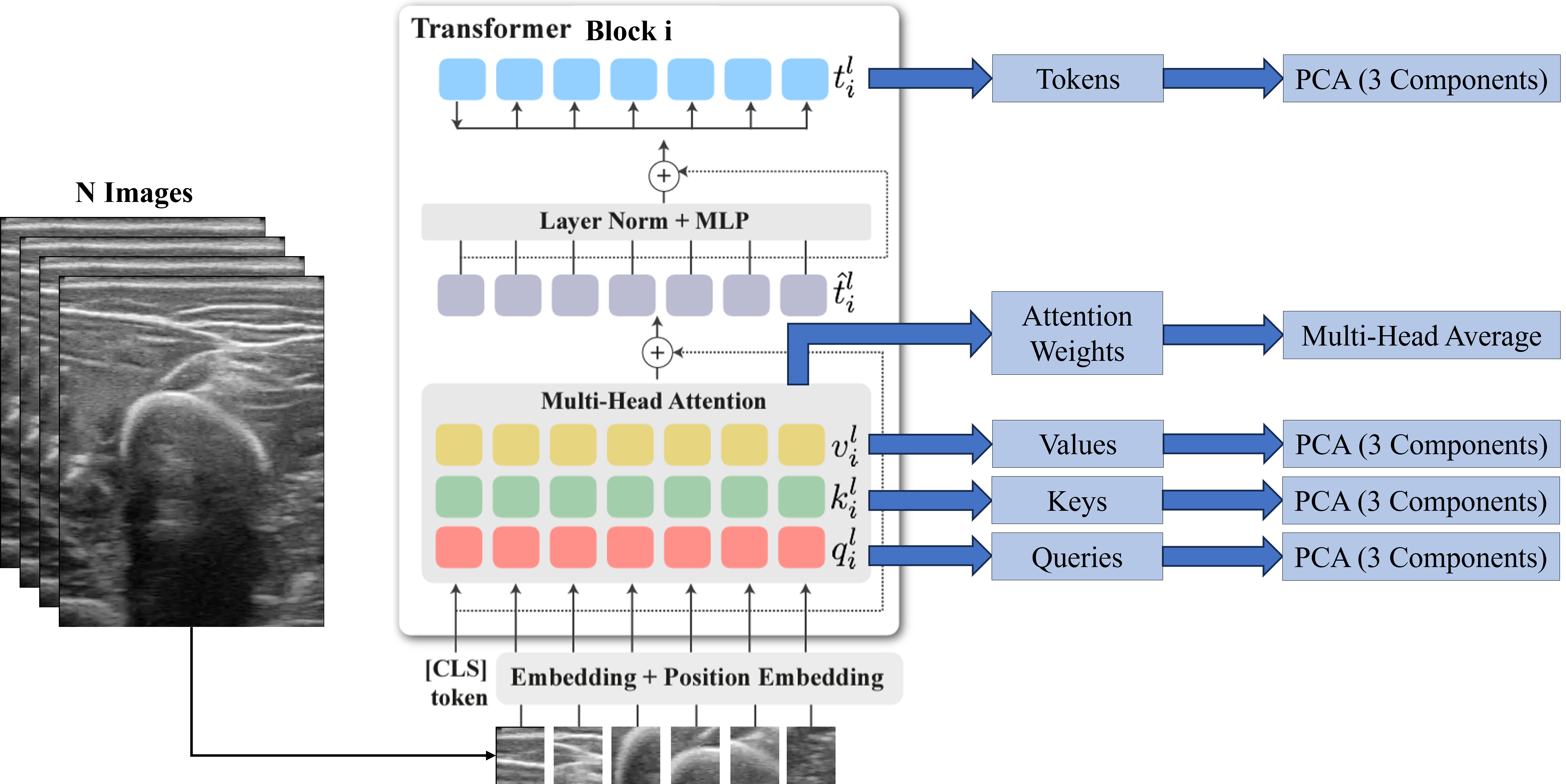
Deep ViT Features as Dense Visual Descriptors: Supplementary Material
Figure 8 from Deep ViT Features as Dense Visual Descriptors | Semantic ...
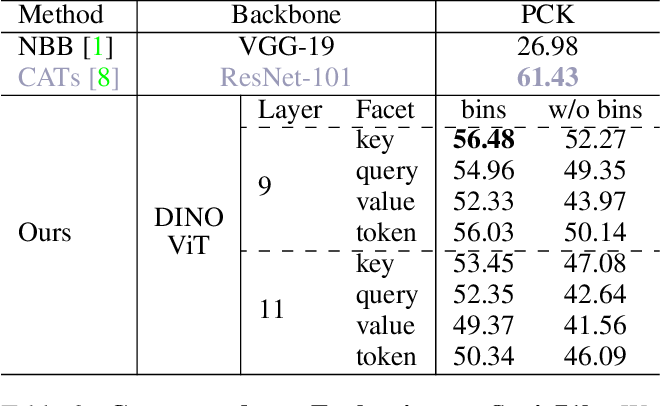
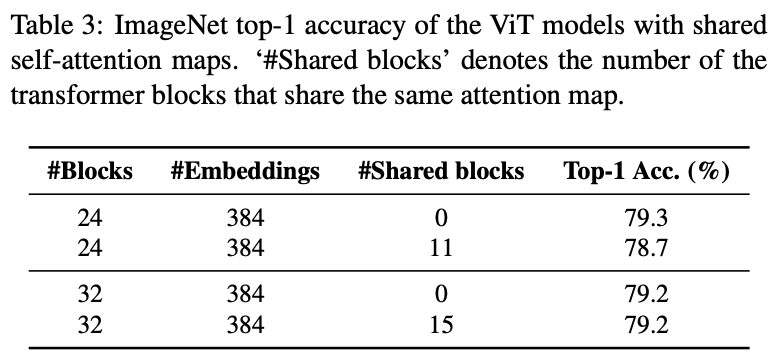
Table 3 from Deep ViT Features as Dense Visual Descriptors | Semantic ...
Deep learning image classification strategy. (a) ViT model architecture ...
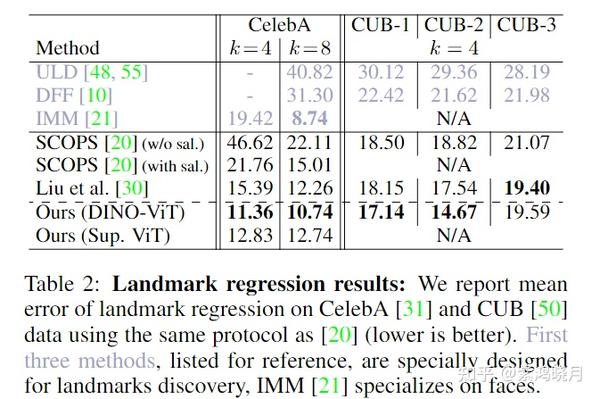
Table 1 from Deep ViT Features as Dense Visual Descriptors | Semantic ...
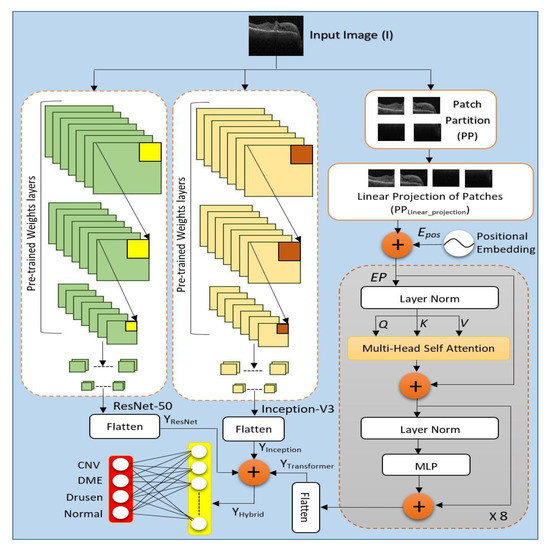
(PDF) A Hybrid Deep Learning-ViT Model and A Meta-Heuristic Feature ...
[2209.02432] ViTKD: Practical Guidelines for ViT feature knowledge ...
Proposed architecture of ViT for feature extraction. | Download ...
Performance of fusing three types of ViT-based deep features extracted ...
Deep features visualization via PCA: Applied on (a) ViTs and (b ...
Vision transformer (ViT)-based deep learning model for diagnosis of ...
Conv-ViT: A Convolution and Vision Transformer-Based Hybrid Feature ...
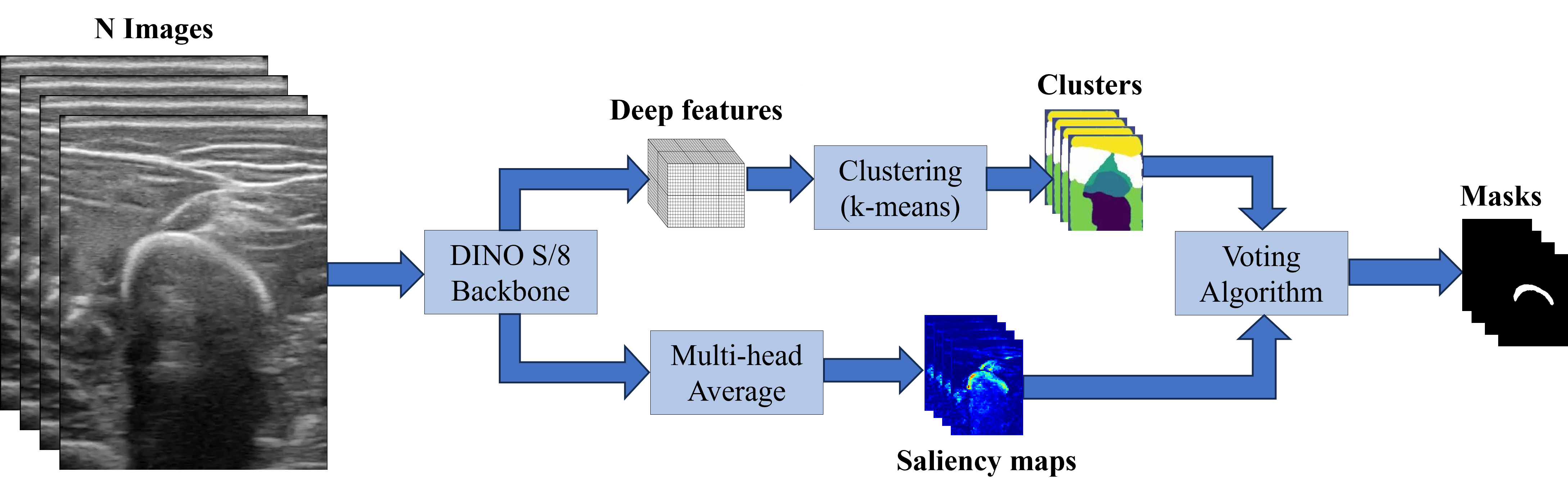
The pipeline of FORMULA. To enhance ViT features for unsupervised ...
Vit model overview As seen in Fig. 3, We start by dividing the image ...
Robustness of self-supervised ViT features in b-mode images | 6.S898 ...
Transformers in computer vision: ViT architectures, tips, tricks and ...
Similarity visualization of different ViT features on the image ...
The three basic ViT architectures, namely ViT-Base, ViT-Large and ...
GitHub - SehwanMoon/Vision-segmentaiont-Deep-feature-factorization ...
Detail architecture of ViT. Input image is at first divided into ...
GitHub - ShirAmir/dino-vit-features: Official implementation for the ...
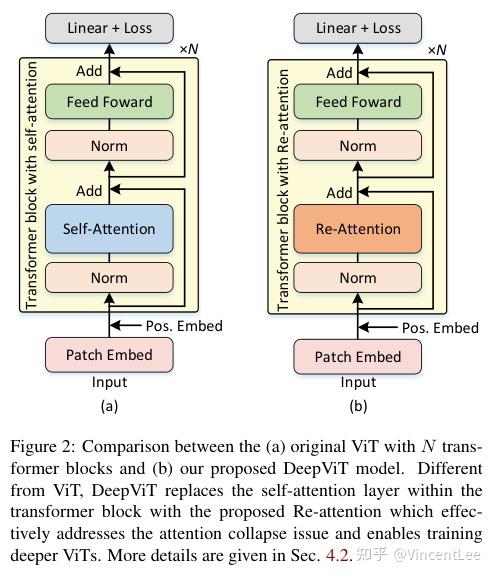
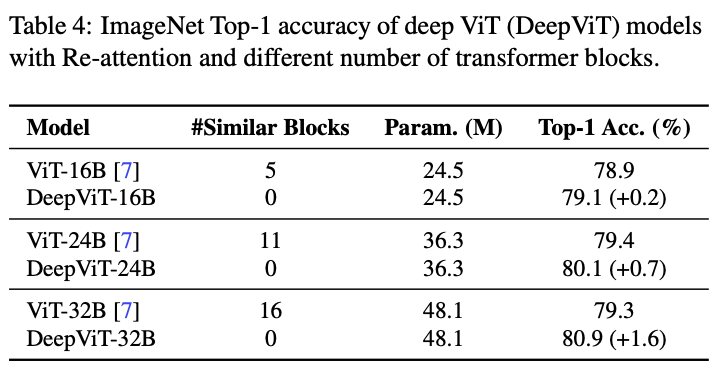
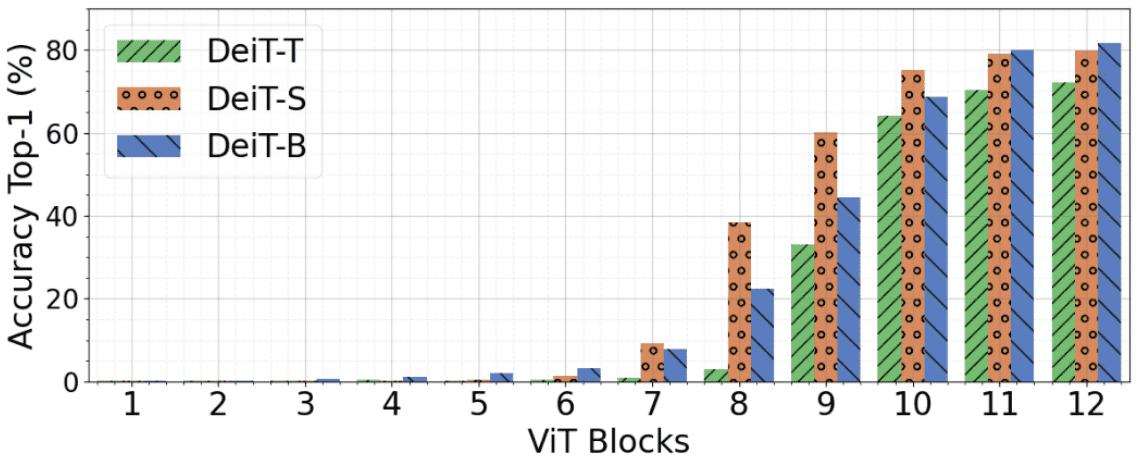
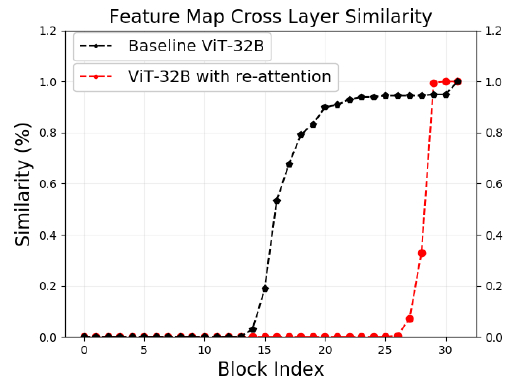
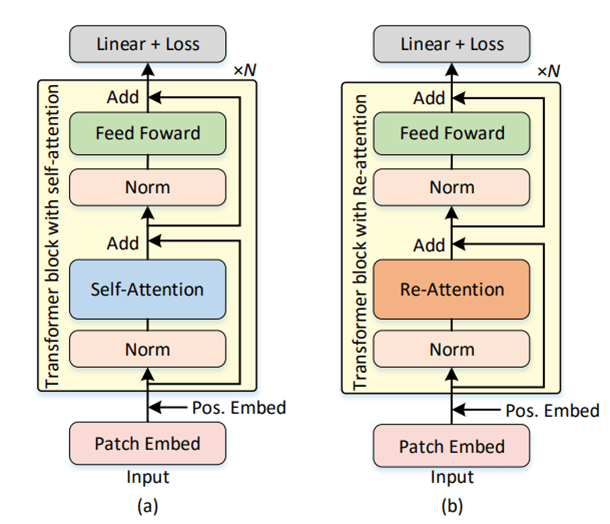
DeepViT:字节提出深层ViT的训练策略 | 2021 arxiv - 知乎
Vision Transformer (ViT) Architecture - GeeksforGeeks
DeepViT:字节提出深层ViT的训练策略 | 2021 arxiv - 晓飞的算法工程笔记 - 博客园
Analysis of the overall structure of ViT. | Download Scientific Diagram
Understanding Vision Transformers (ViTs): Hidden properties, insights ...
Vision Transformer 超详细解读 (原理分析+代码解读) (八) - 知乎
深層学習を利用した画像処理・ 画像認識と必要なGPU性能 | GDEP Solutions
IAML Distill Blog: Transformers in Vision
Vgg-ViT: A Framework for Deepfakes Images Detection | Springer Nature Link
DeepViT:字节提出深层ViT的训练策略 | 2021 arxiv-腾讯云开发者社区-腾讯云
Illustration of our contribution. In short, we propose a ViT-based ...
Expression-relevant vision transformer (ViT)-latent vector extraction ...
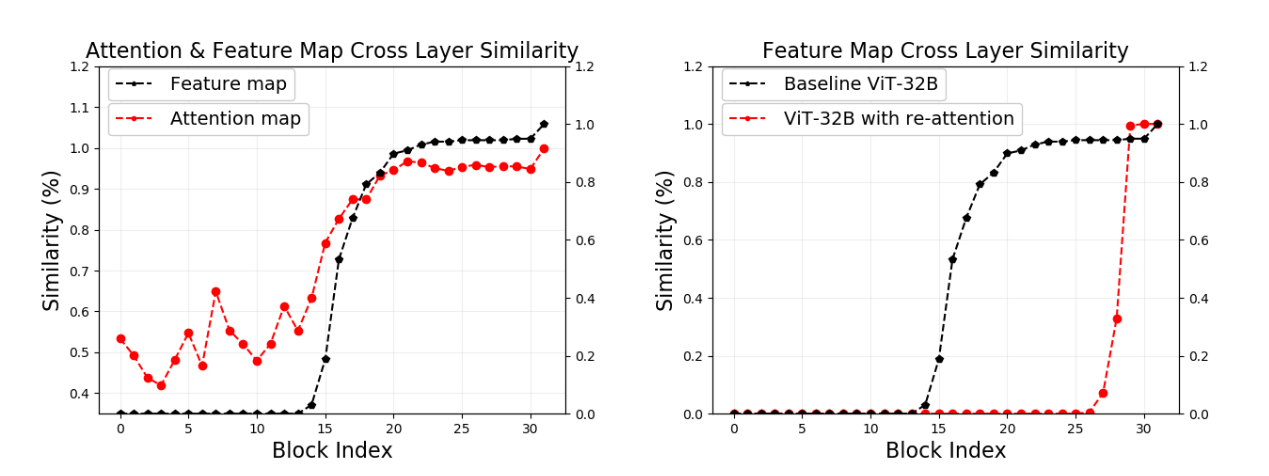
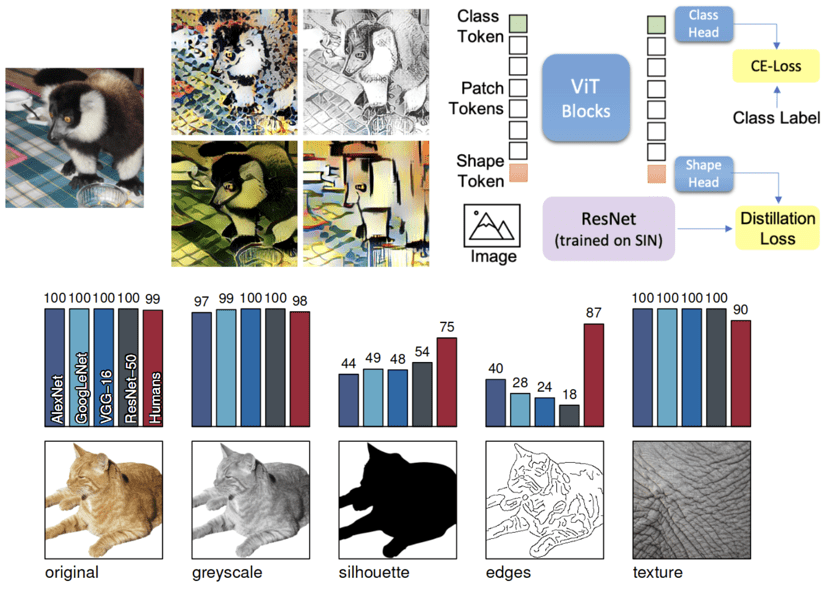
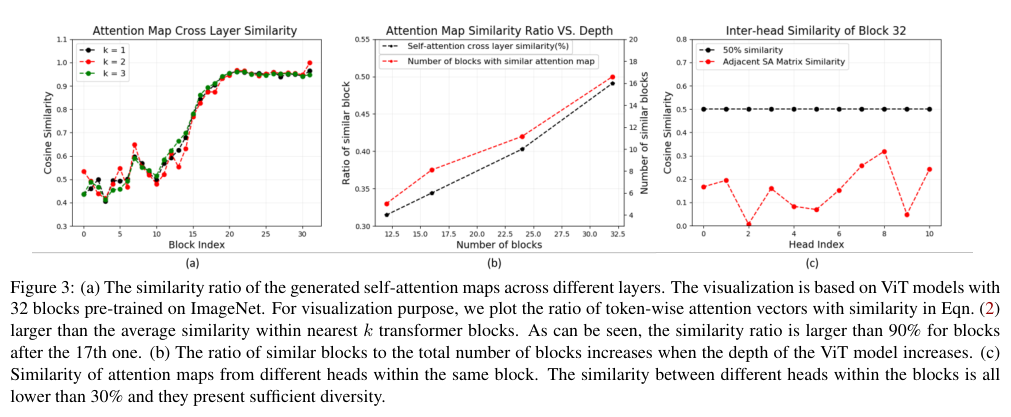
WHAT DO VISION TRANSFORMERS LEARN A VISUAL EXPLORATION.pdf
Experimenting with Vision Transformer | DeepDetect
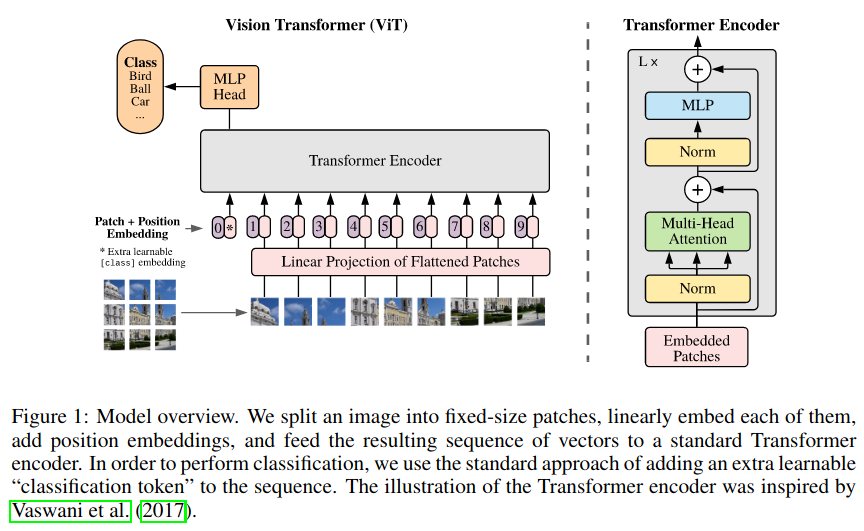
The Vision Transformer Model - MachineLearningMastery.com
How the Vision Transformer (ViT) works in 10 minutes: an image is worth ...
CaiT:Facebook提出高性能深度ViT结构 | ICCV 2021 - 知乎
Vision Transformers (ViT) Explained | Pinecone
Vision Transformers Part 4. — Let's understand different ViT… | by ...