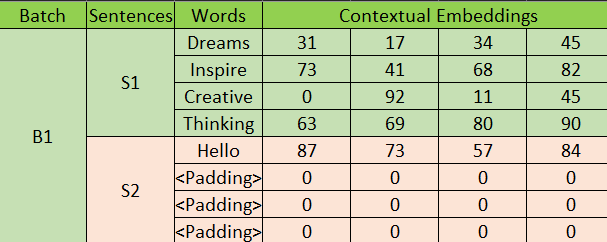
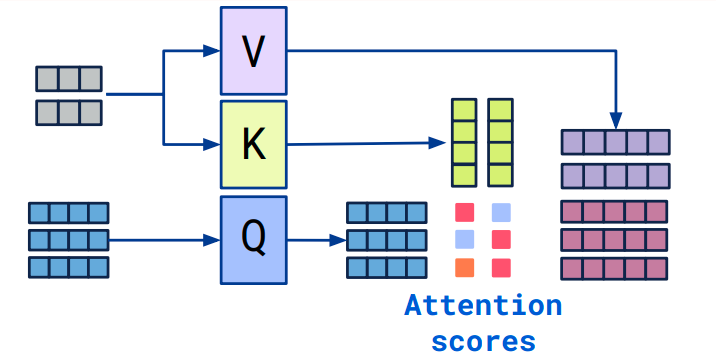
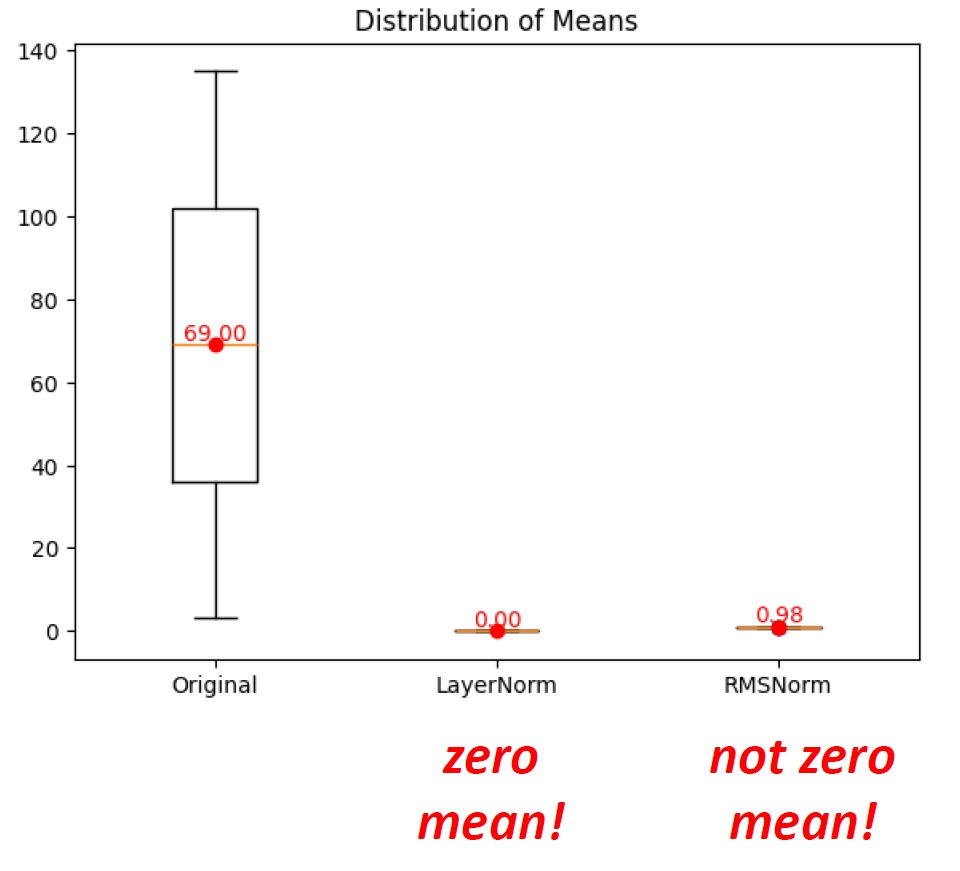
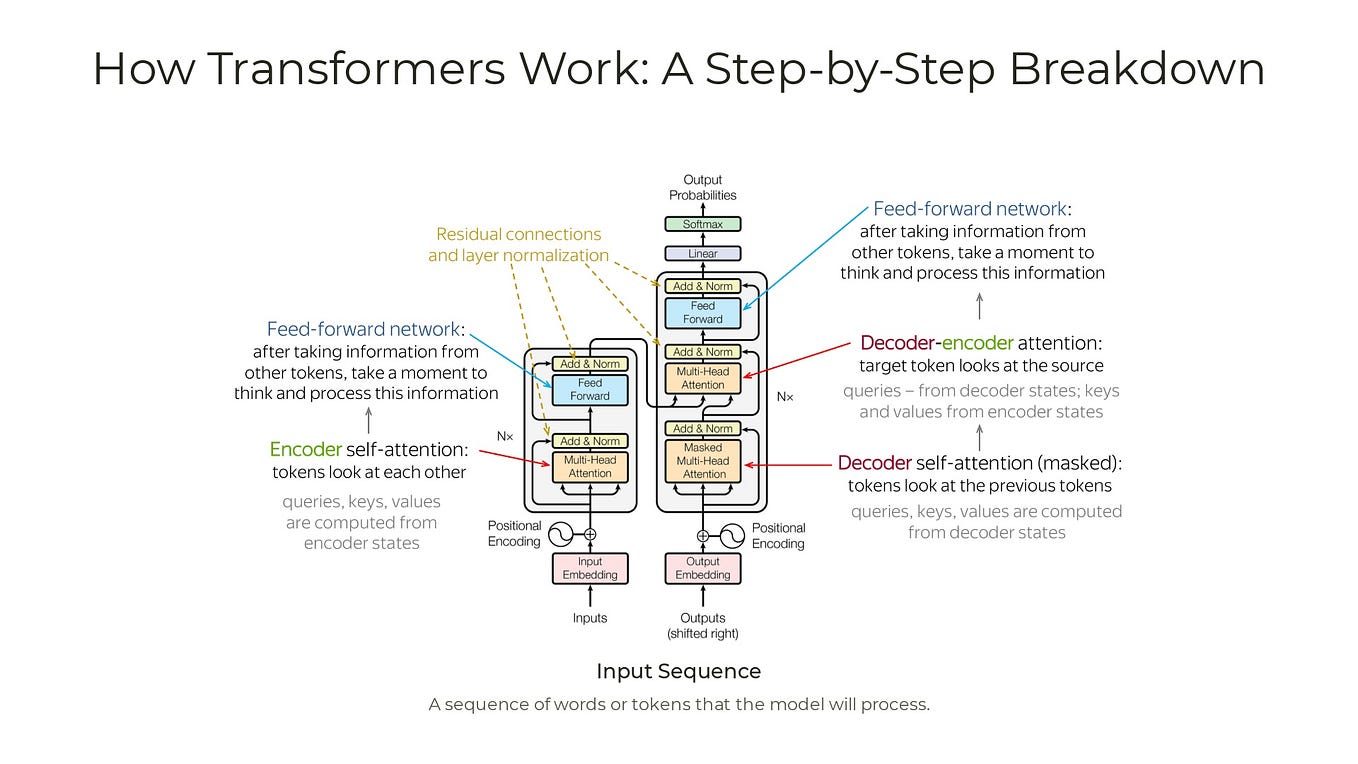
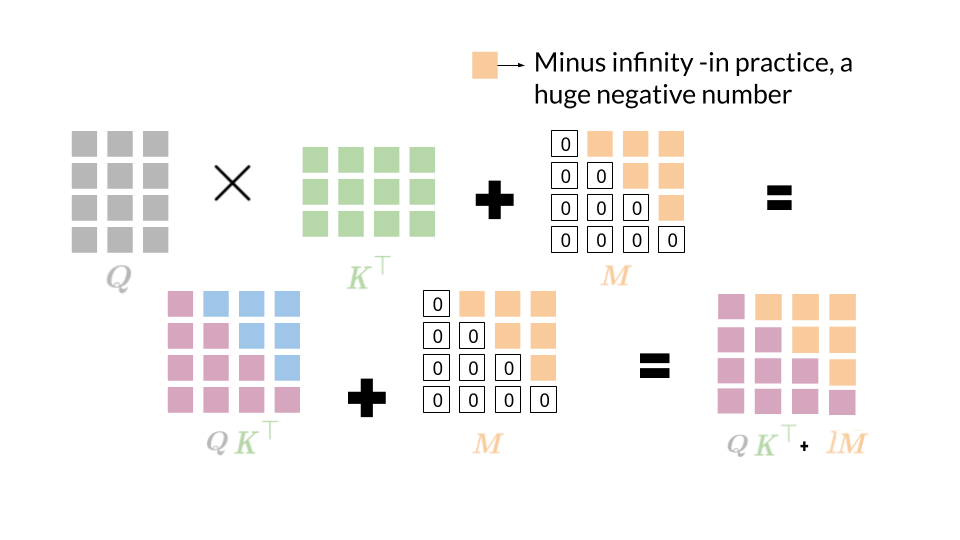Showing 119 of 119on this page. Filters & sort apply to loaded results; URL updates for sharing.119 of 119 on this page
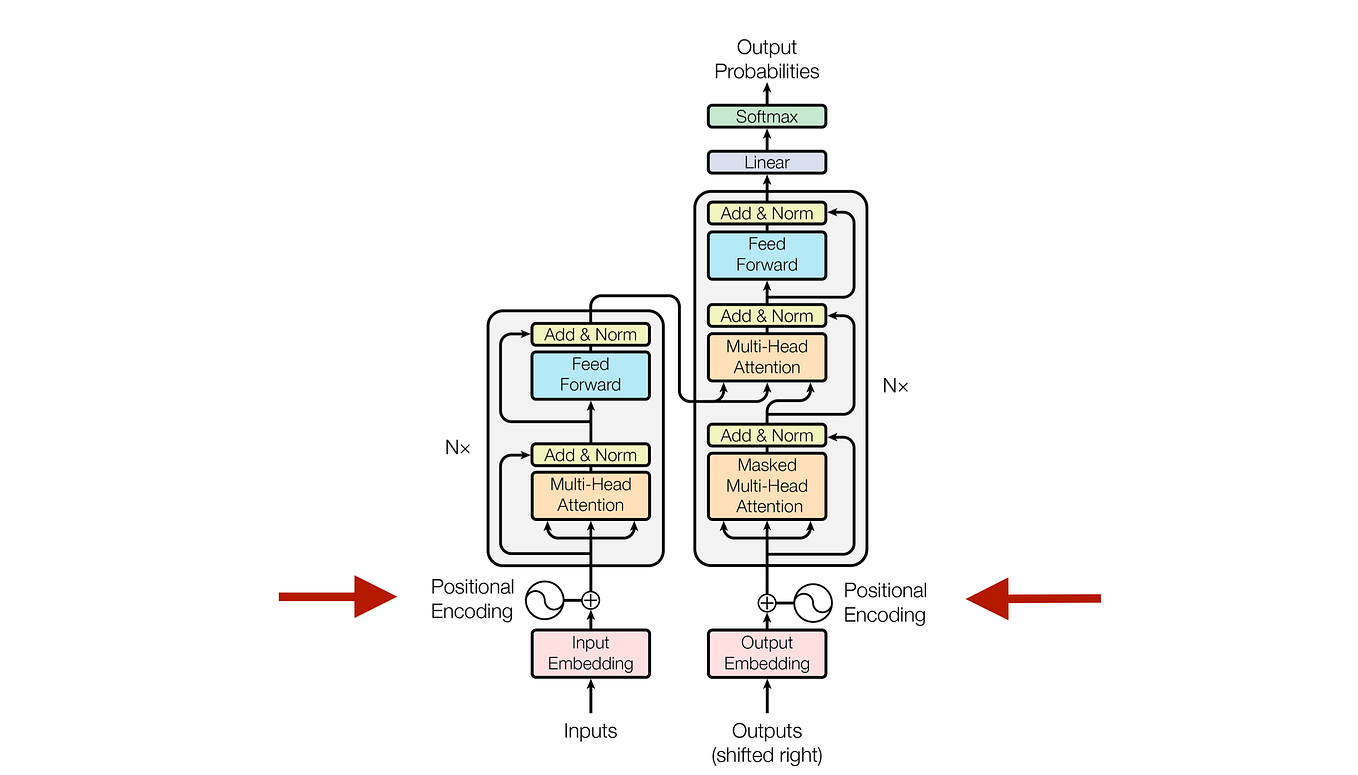
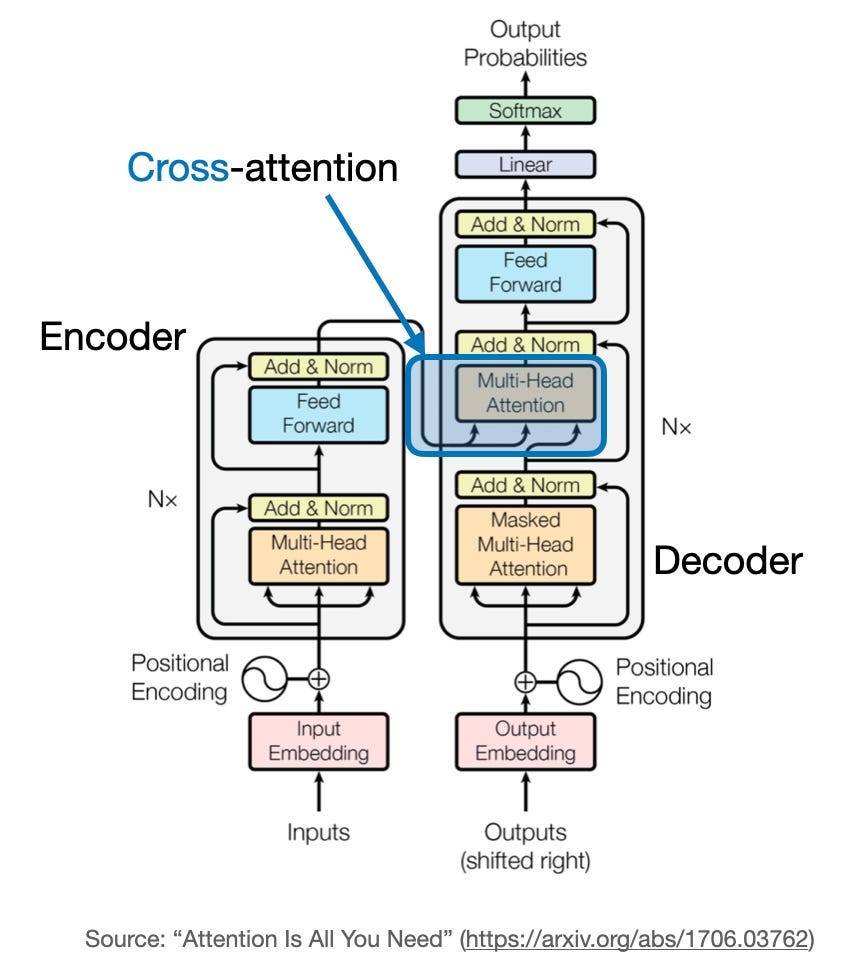
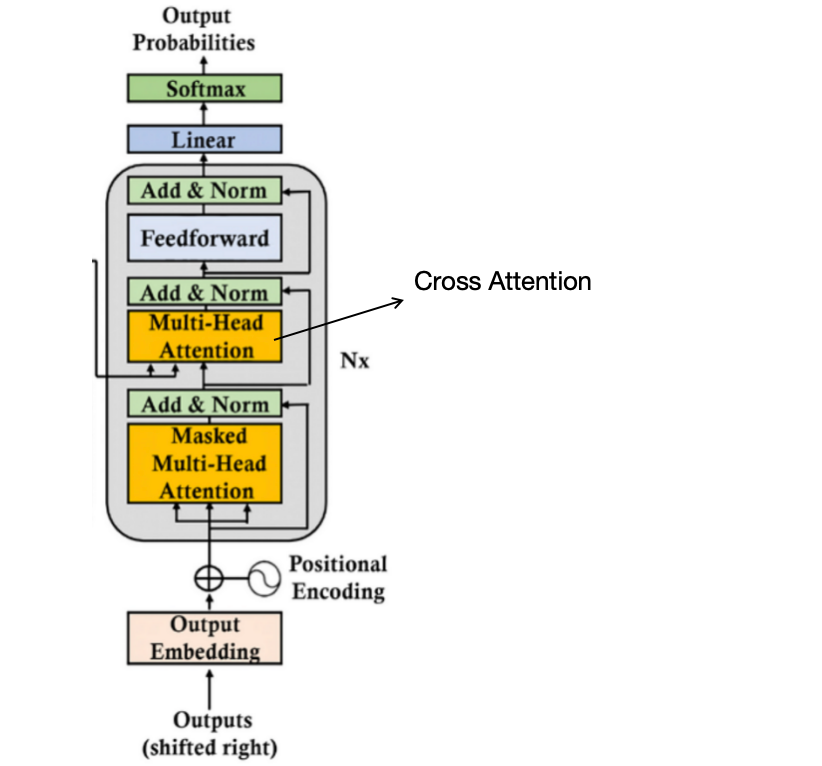
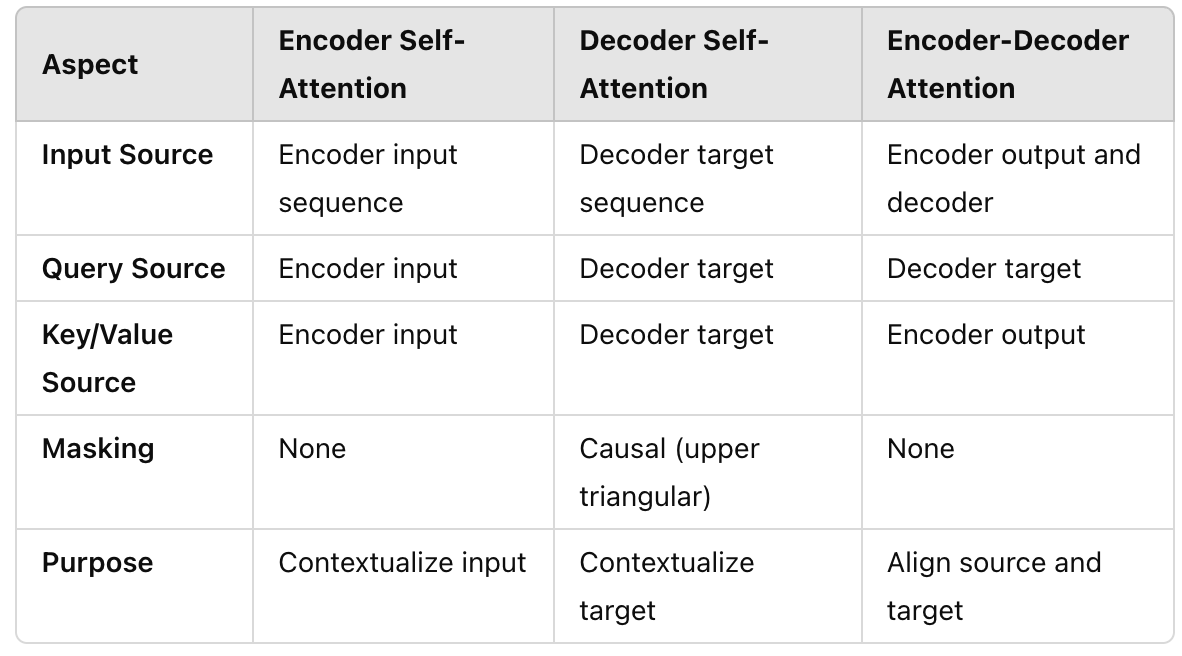
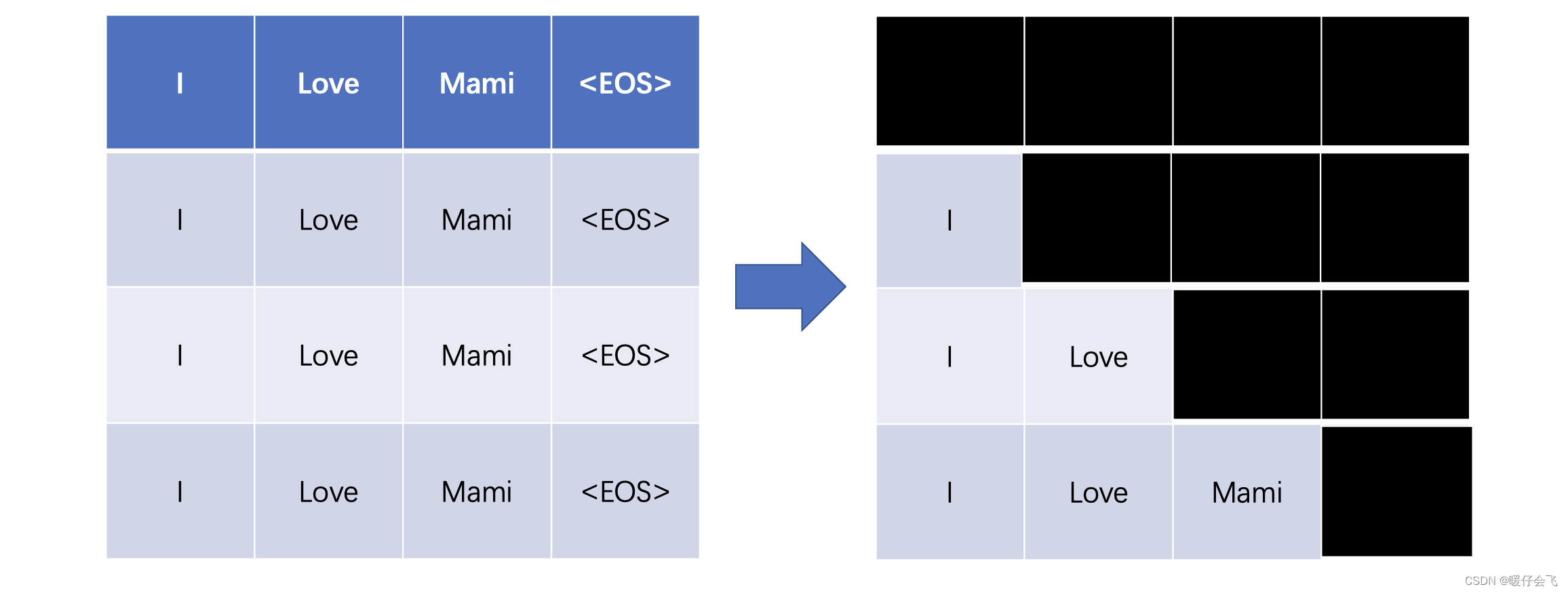
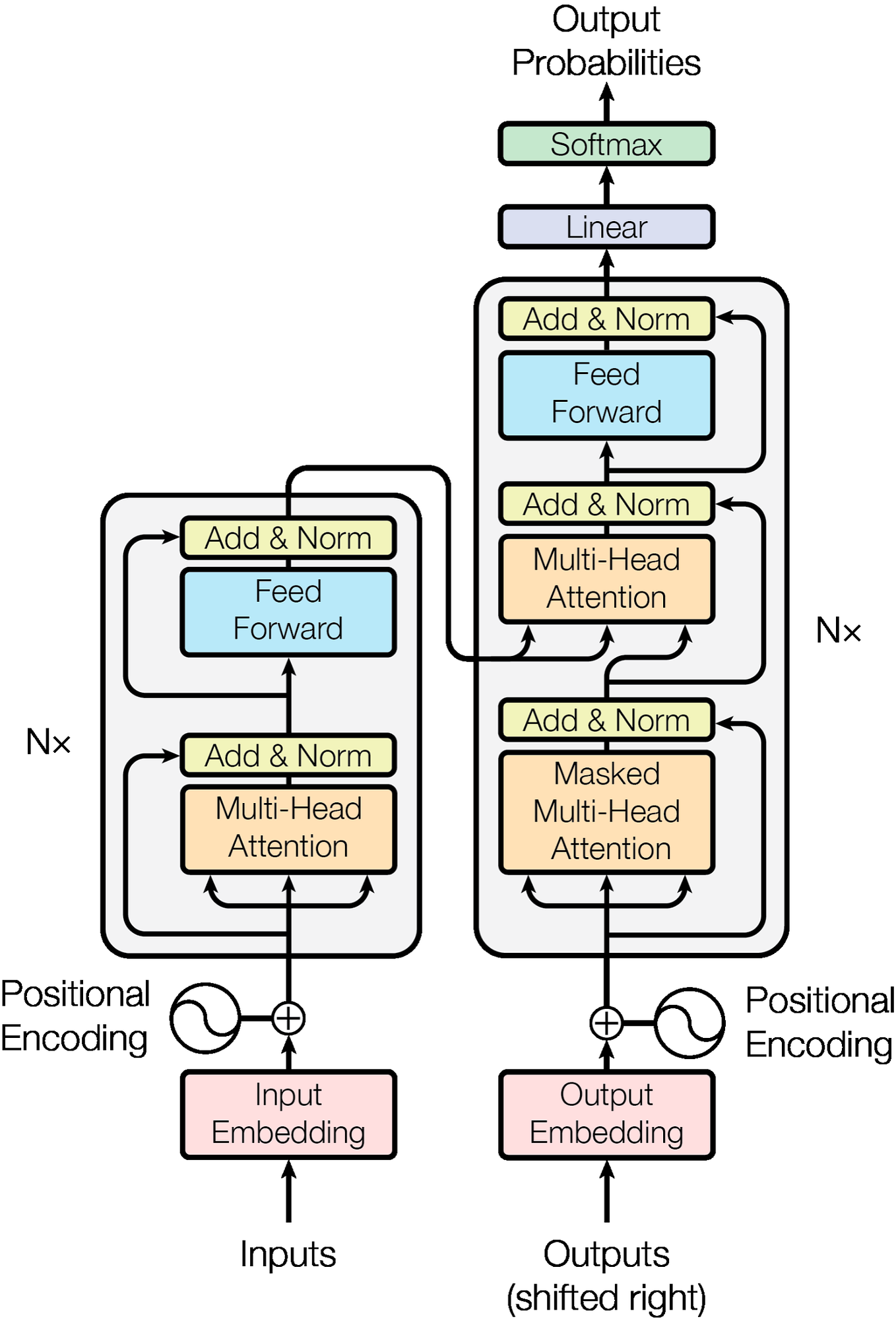
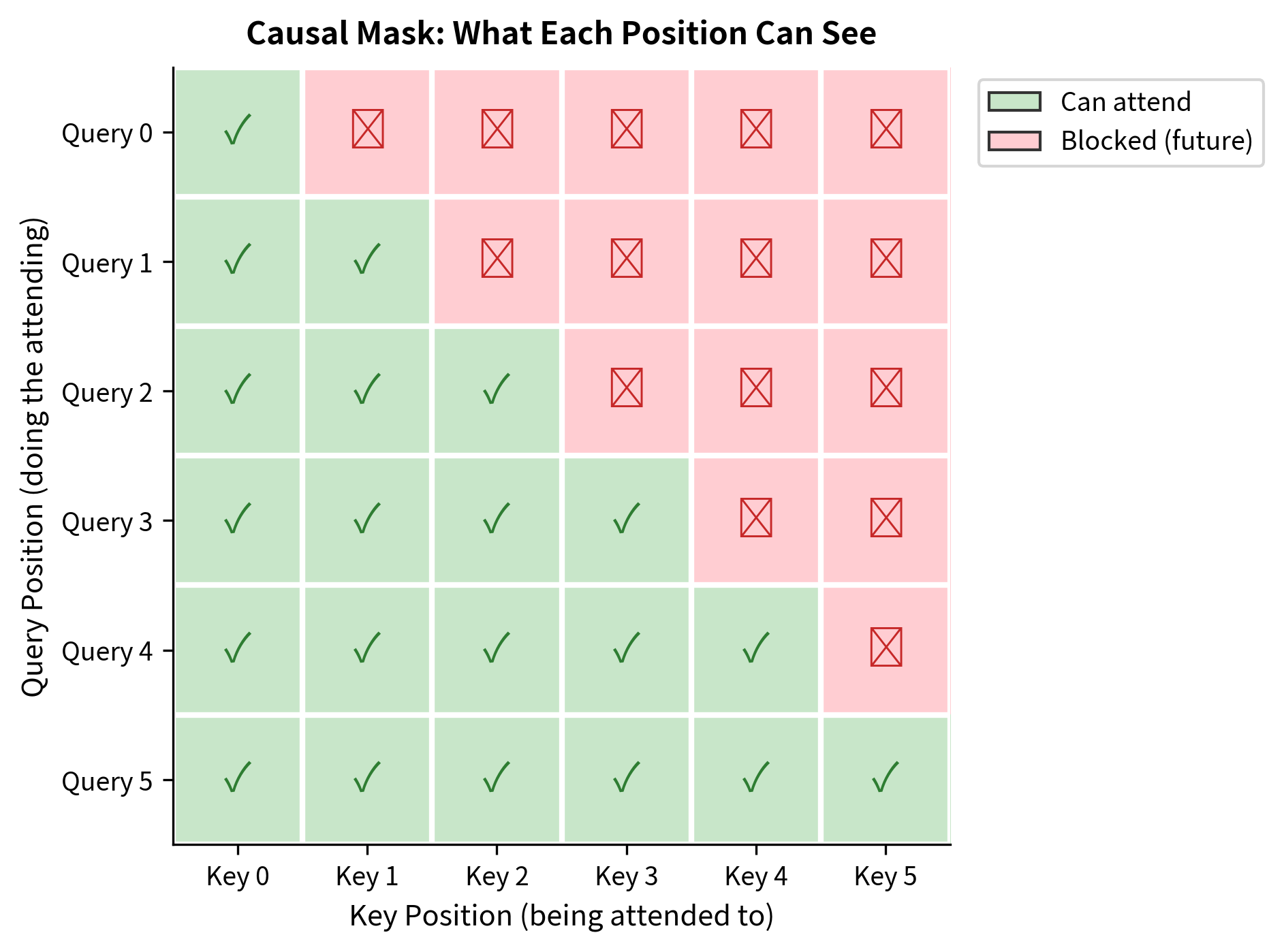
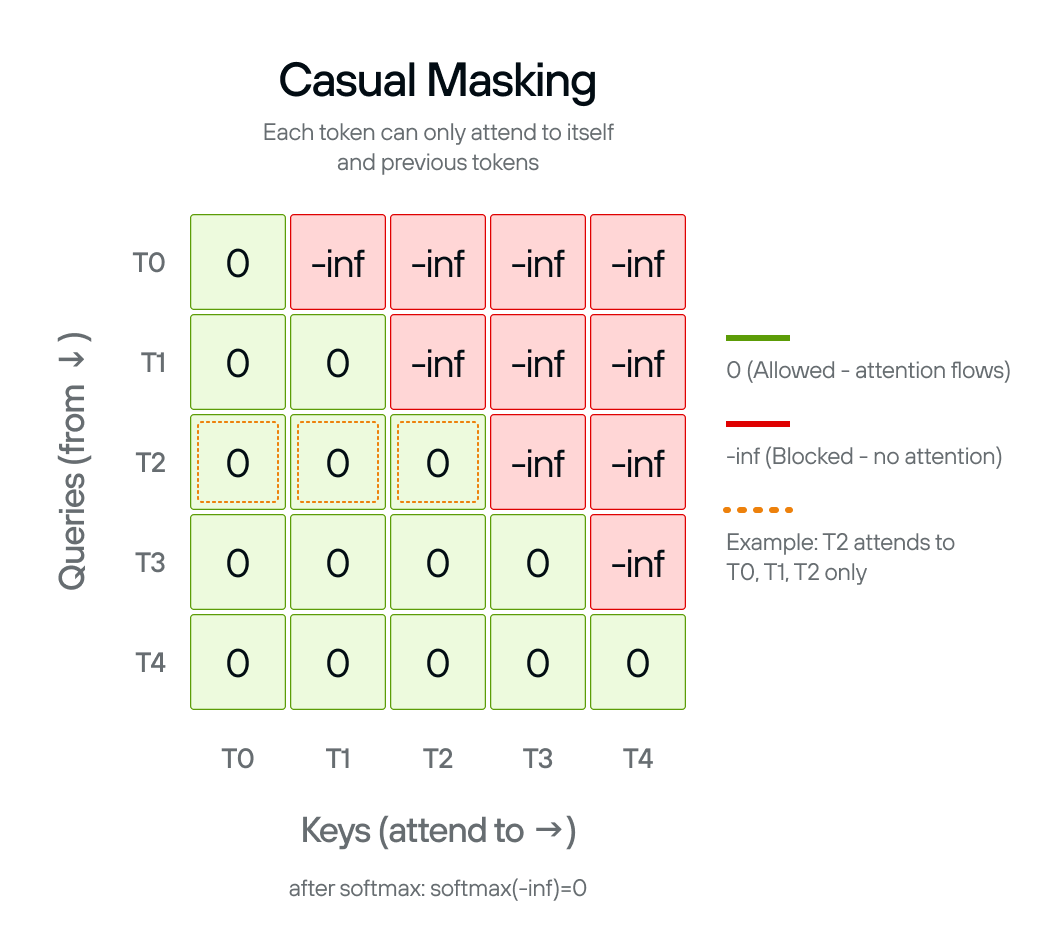
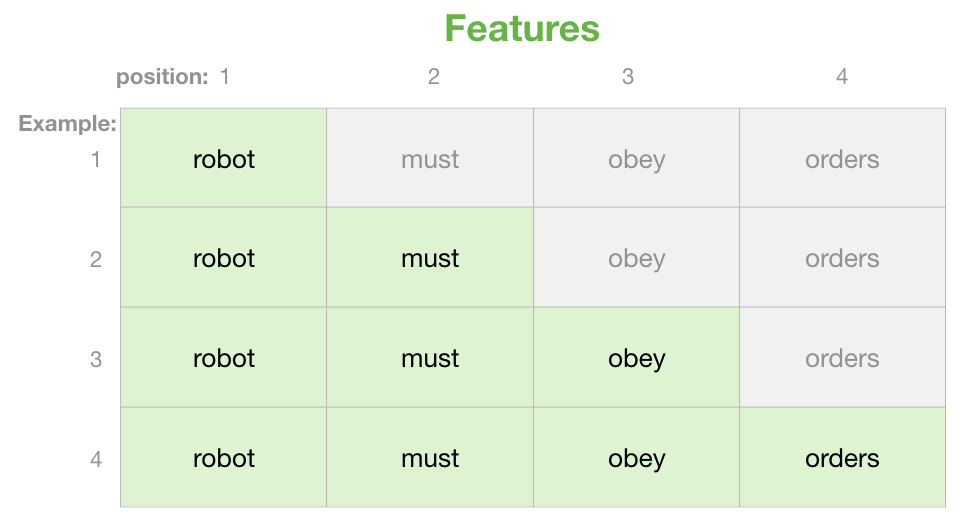
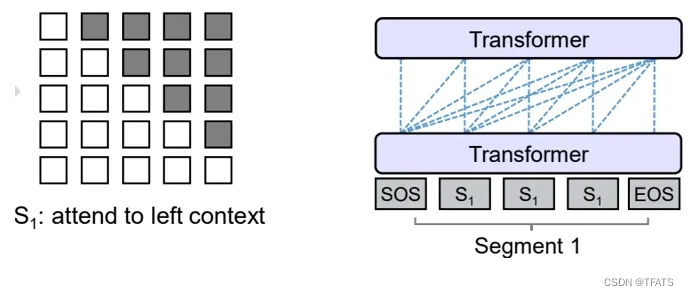
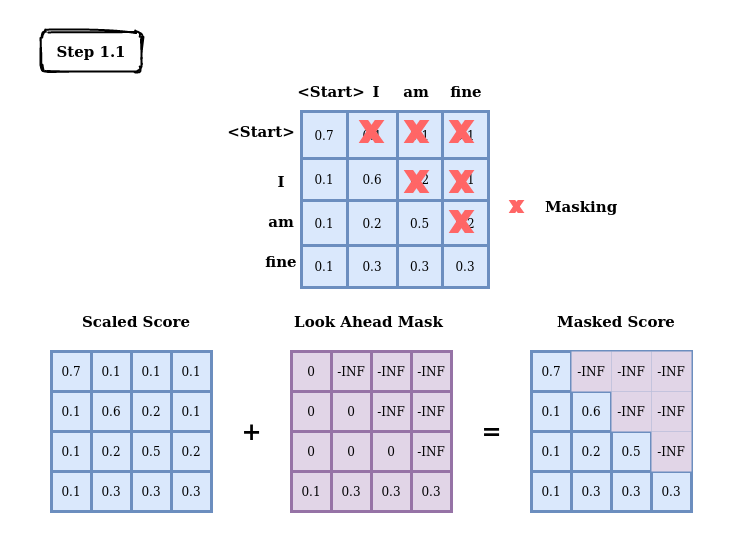
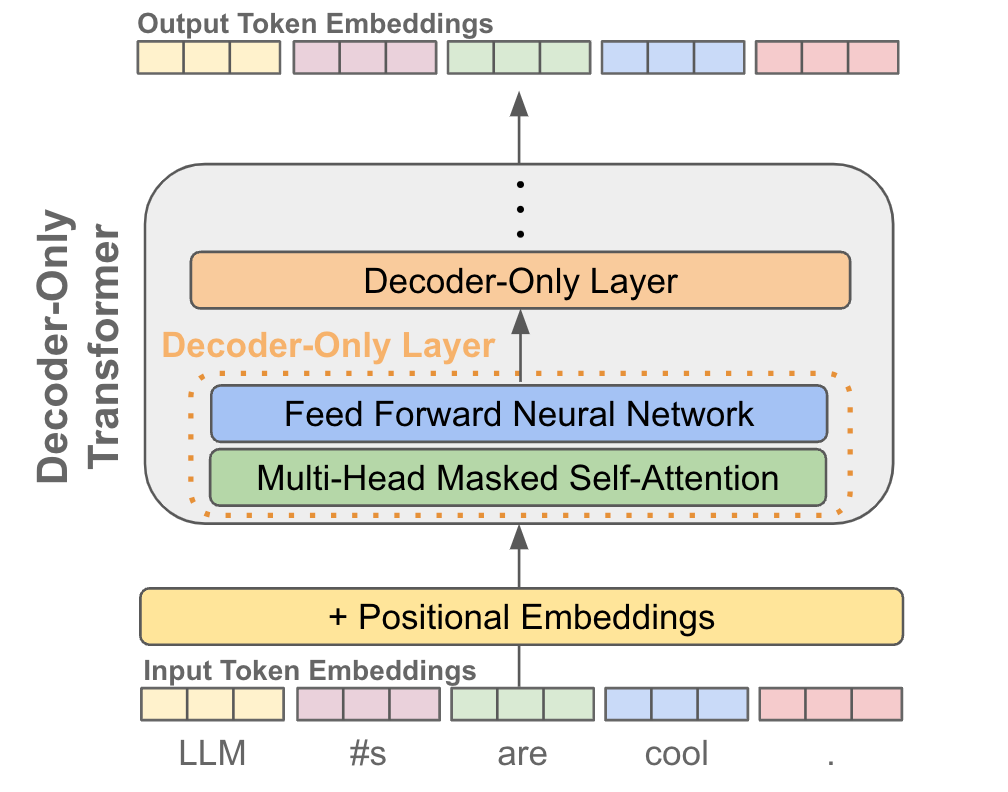
A Simple Example of Causal Attention Masking in Transformer Decoder ...
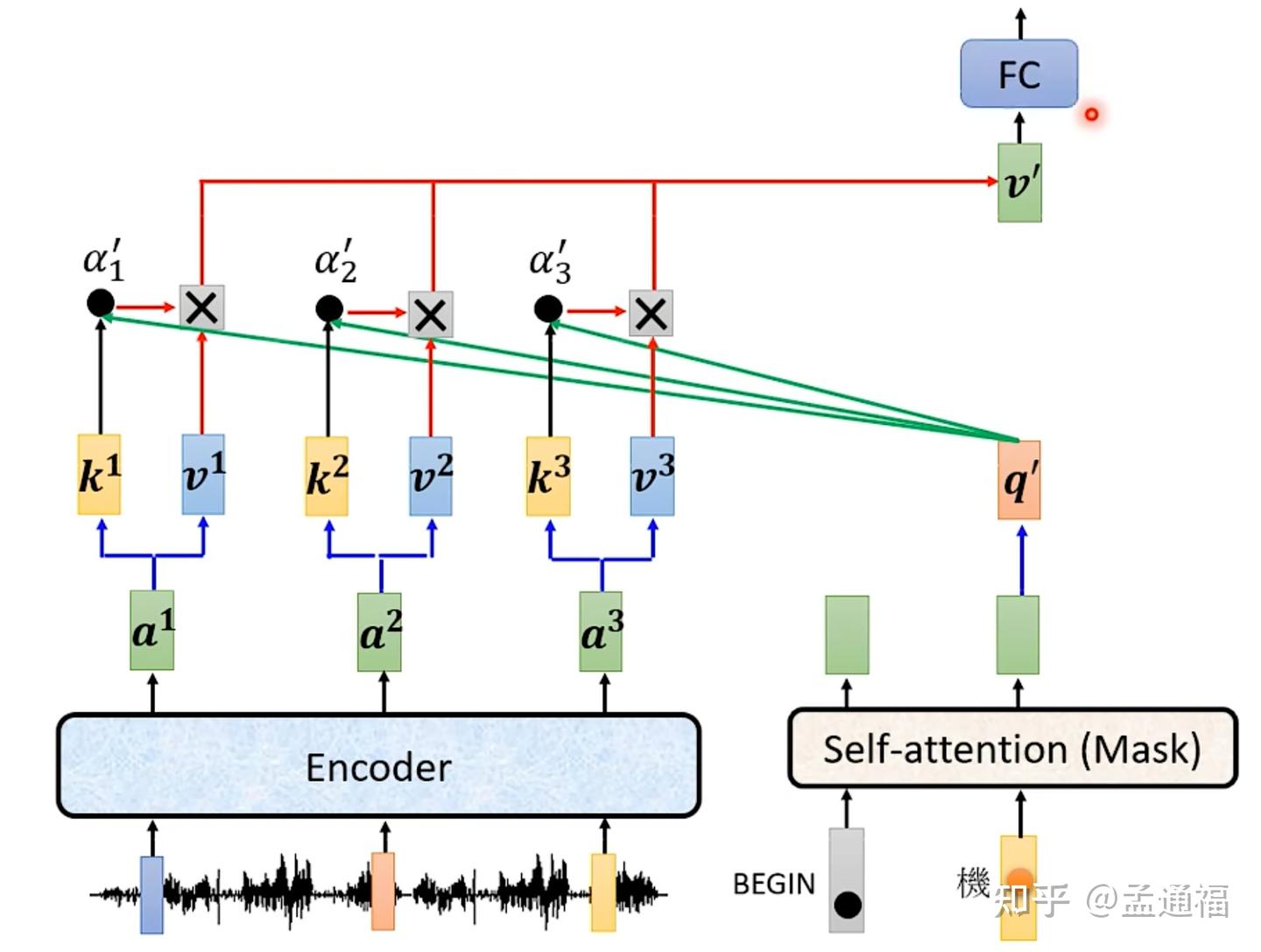
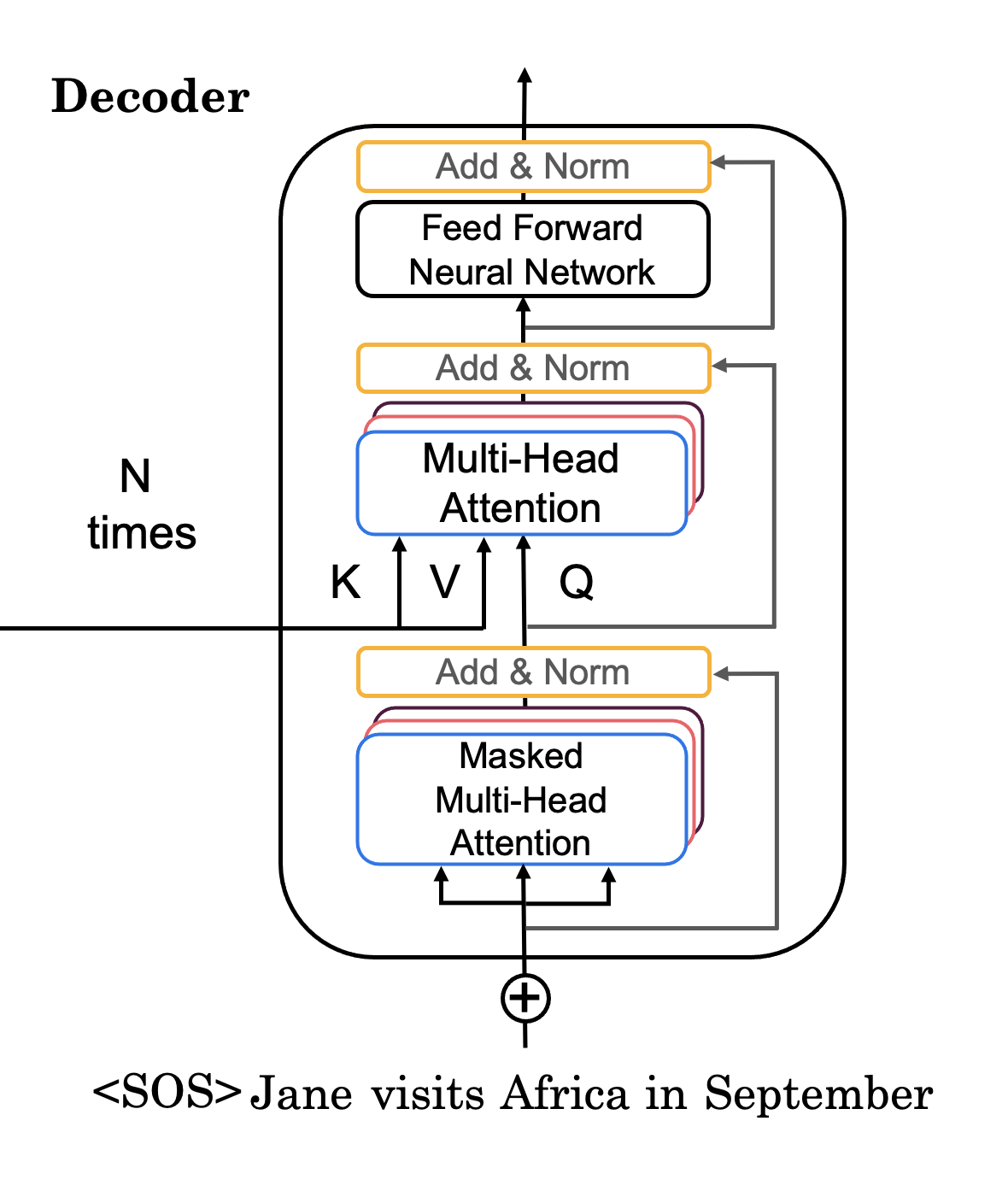
Transformer 解读之:用一个小故事轻松掌握 Decoder 端的 Masked Attention,为什么要使用 Mask ...
Decoder Architecture: Causal Masking & Autoregressive Generation ...
machine learning - Why do we mask input tokens for the decoder in a ...
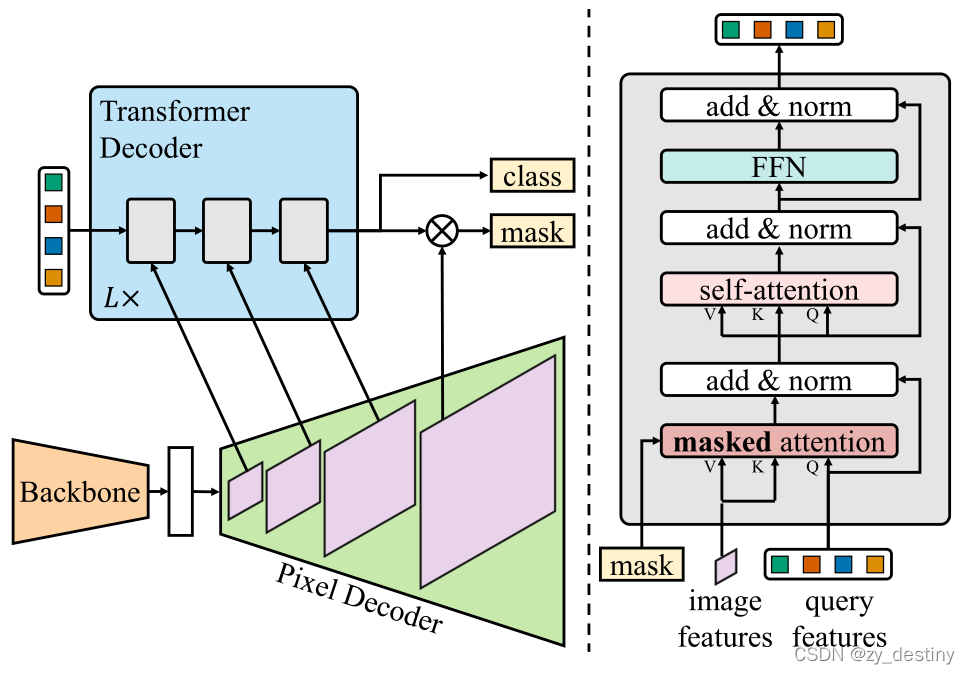
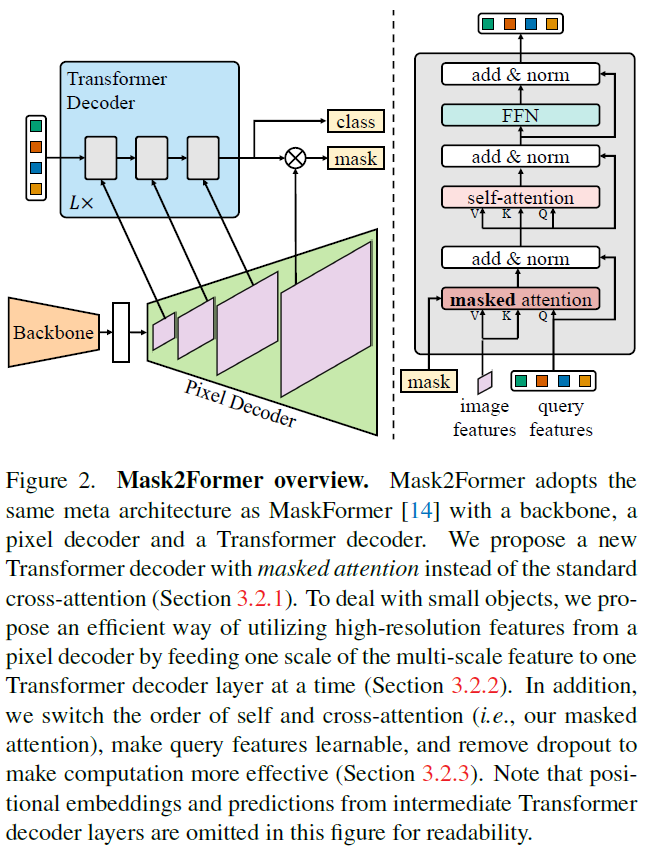
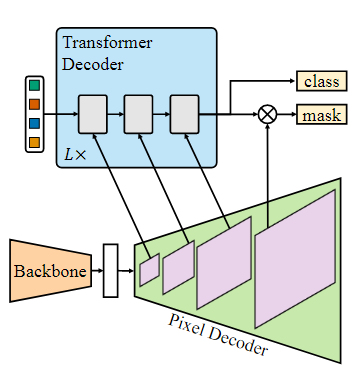
【Mask2Former】Masked-attention Mask Transformer for Universal Image ...
Mask2Former architecture. Each grey block in the transformer decoder ...
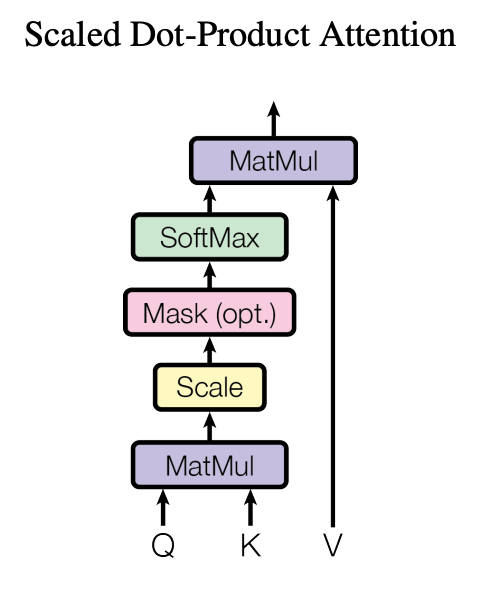
deep learning - How does the mask work in the Transformer if it ...
(a) Sparse transformer architecture (b) Decoder based full attention ...
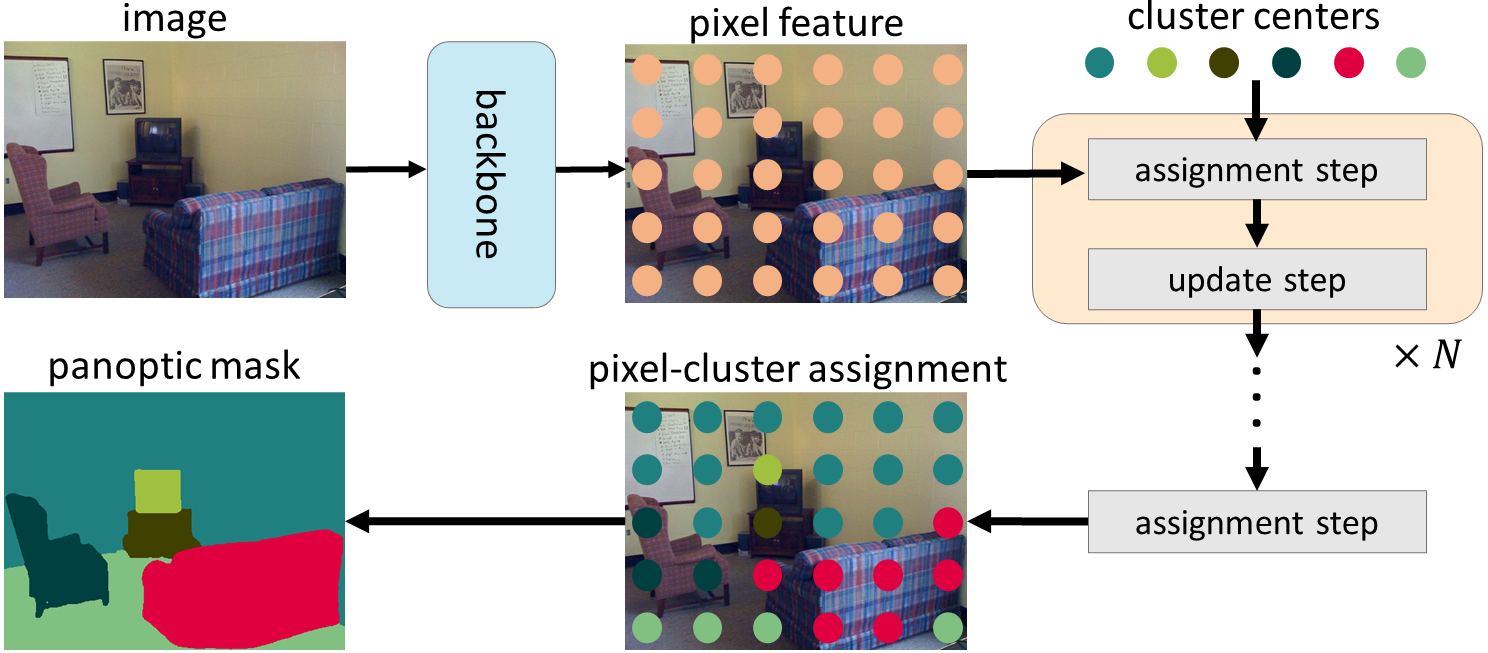
Revisiting Mask Transformer from a Clustering Perspective
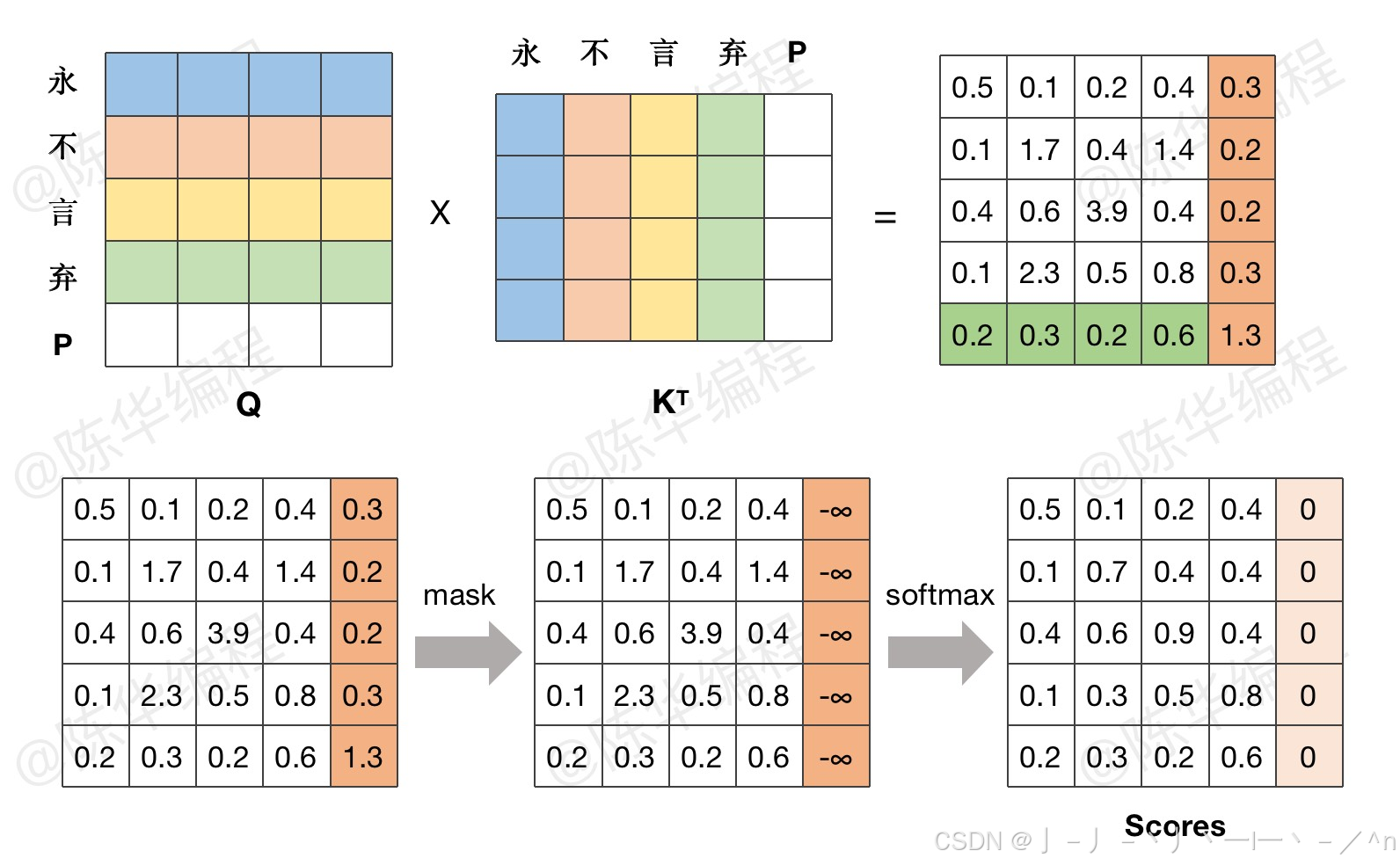
LLM - Make Causal Mask 构造因果关系掩码-CSDN博客
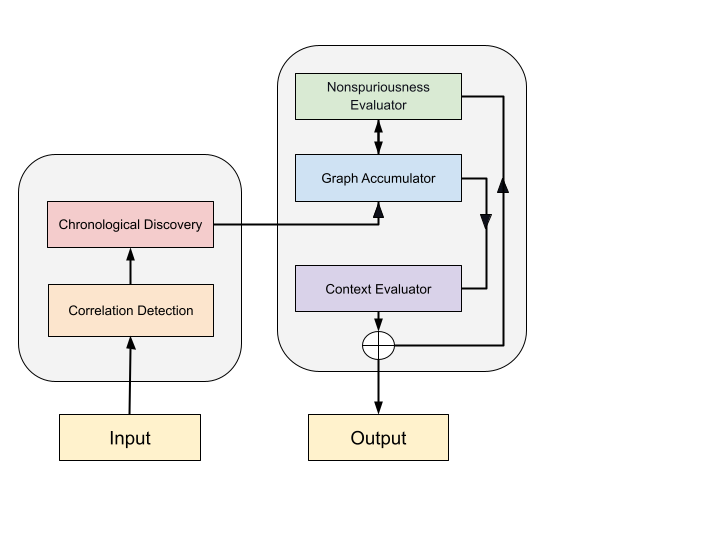
Causal LMs are language models that use a causal mask Figure 1: A ...
pytorch - Training torch.TransformerDecoder with causal mask - Stack ...
STUDY: Socially aware temporally causal decoder recommender systems
LLM - Make Causal Mask 构造因果关系掩码
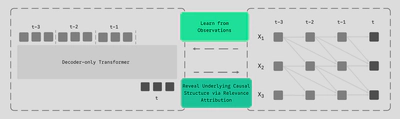
Transformer Is Inherently a Causal Learner | Xinyue Wang
Causal masking - Build an LLM from scratch with MAX
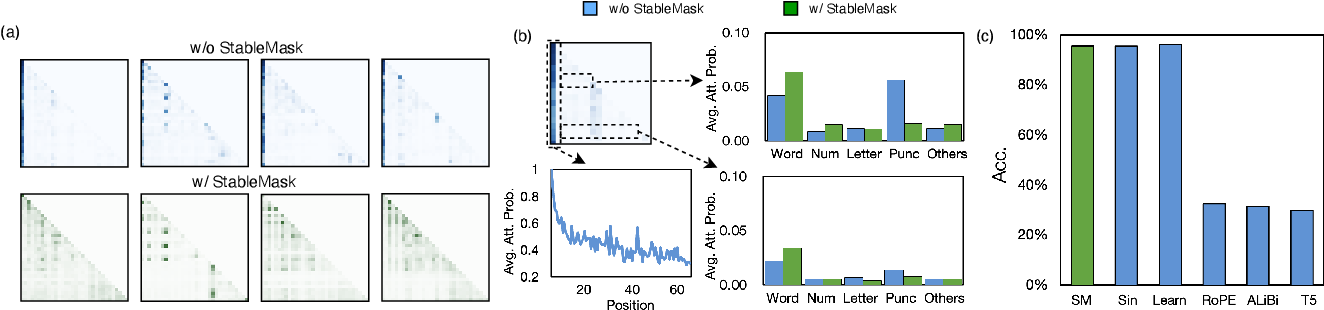
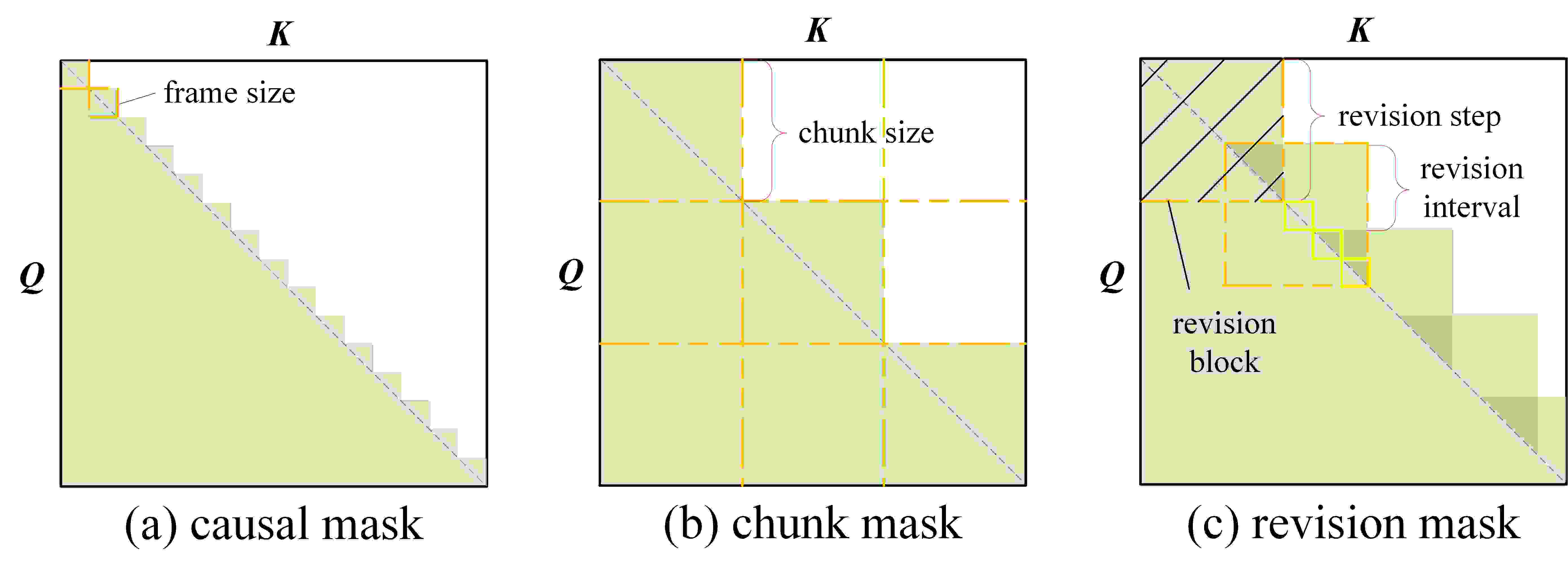
Figure 1 from StableMask: Refining Causal Masking in Decoder-only ...
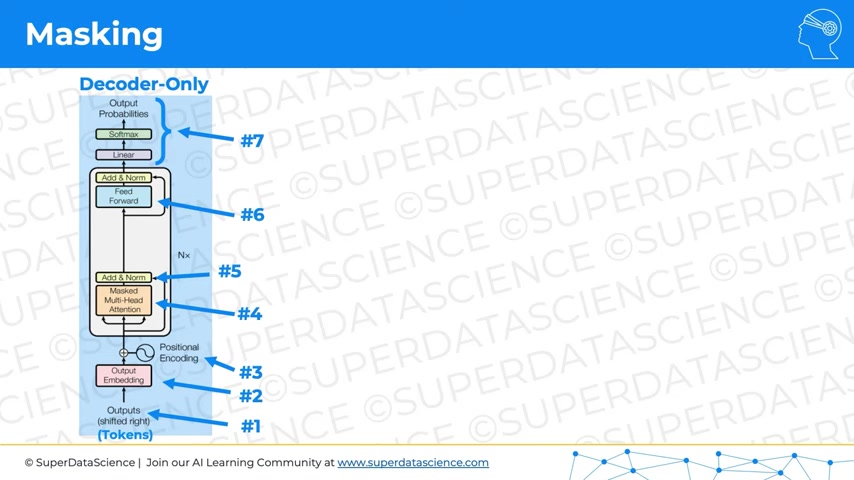
Masking in Transformer Encoder/Decoder Models - Sanjaya’s Blog
Design choices of the decoder. (a) Generating a mask by directly using ...
Creating a Transformer From Scratch - Part One: The Attention Mechanism ...
Transformers - Part 7 - Decoder (2): masked self-attention - YouTube
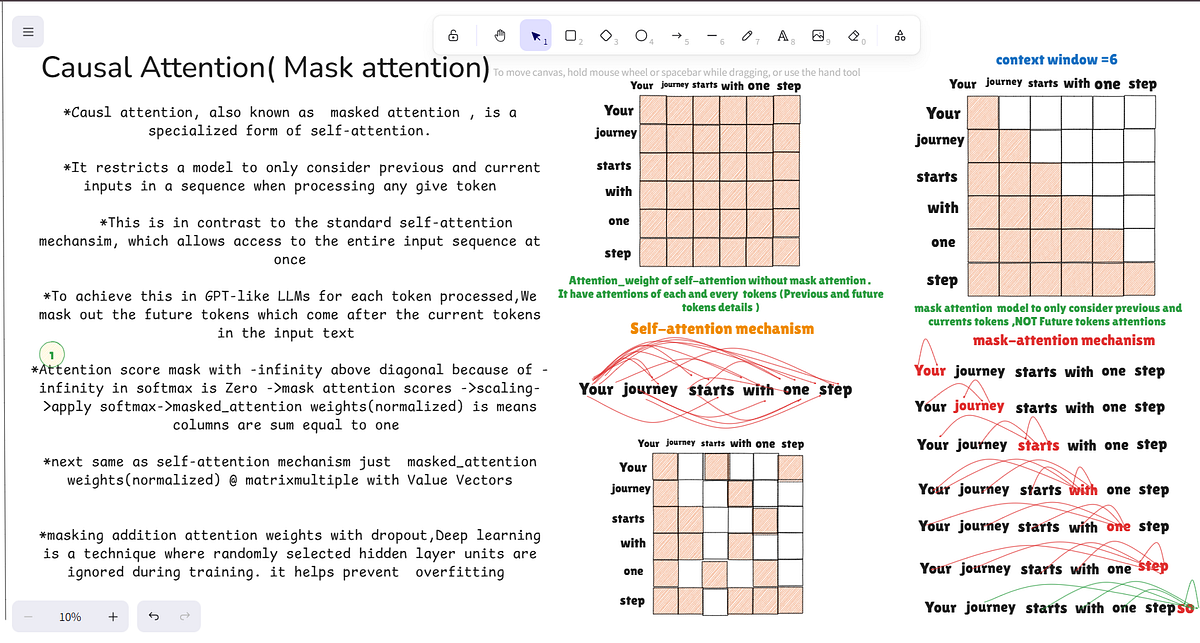
Causal-Attention (Mask Attention) Decoder Magic (GPT) from scratch in ...
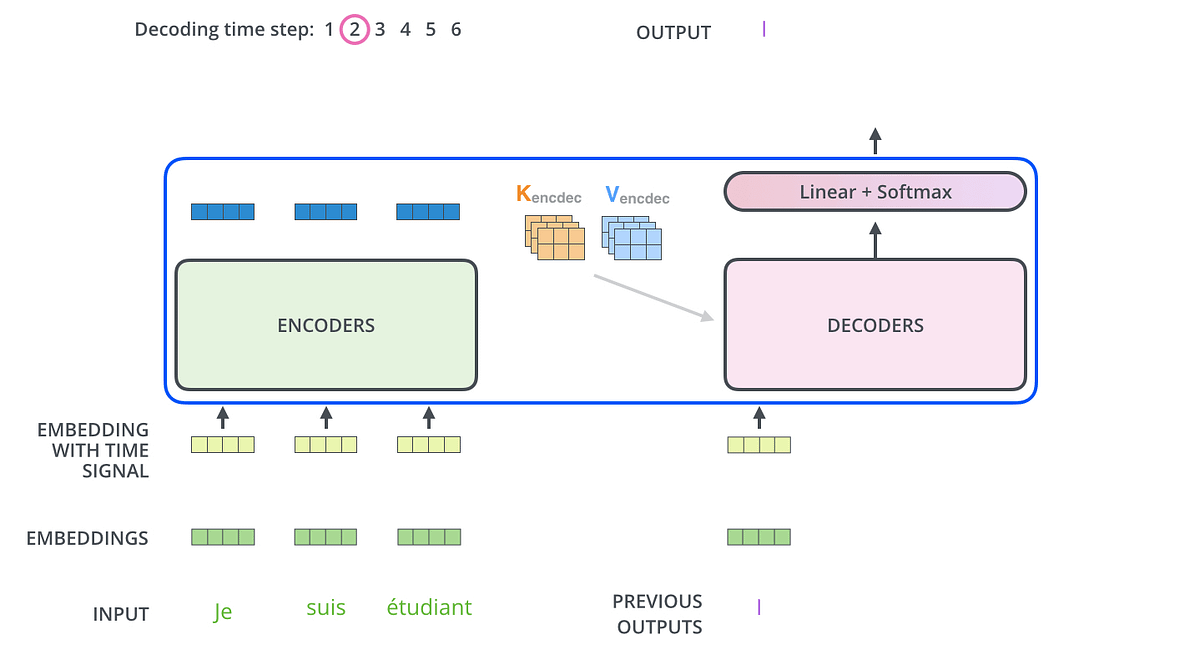
Illustration of the Transformer based encoder-decoder model. | Download ...
causal_mask of the decoder · Issue #16 · tatp22/linformer-pytorch · GitHub
Description of the casual mask method in transformer. | Download ...
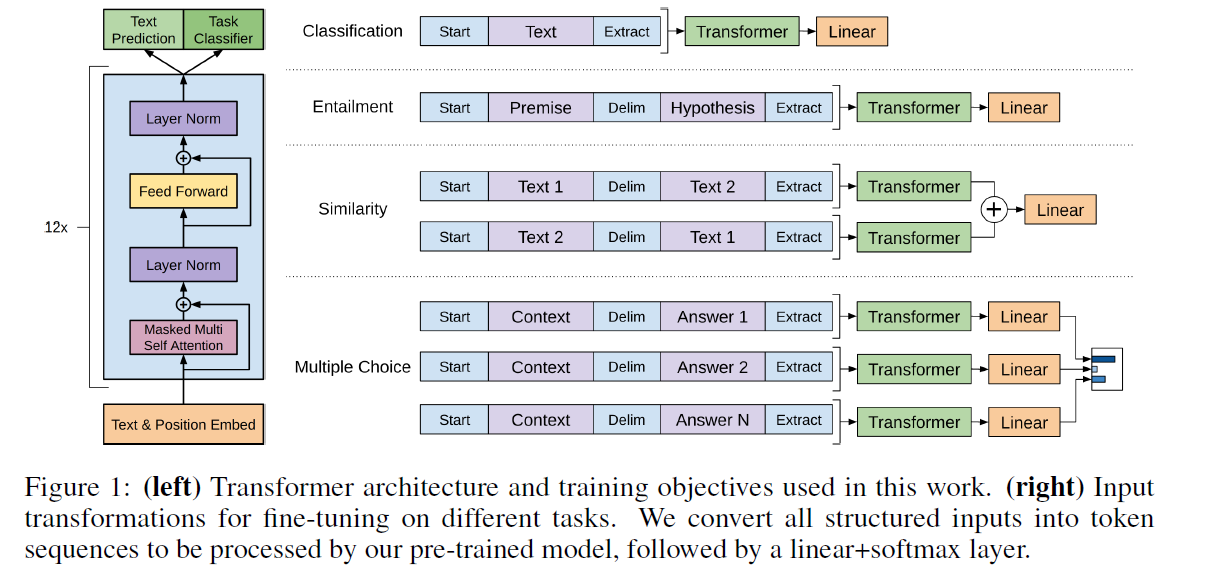
GPT-2 model architecture. The GPT-2 model contains N Transformer ...
Improving Streaming End-to-End ASR on Transformer-based Causal Models ...
Causal Transformers: Automated Causal Detection | by Todd Moses | Medium
[D] Causal attention masking in GPT-like models : r/MachineLearning
Transformer - murtaza
Learning JAX by Building Flexible Transformer Attention Masks: From ...
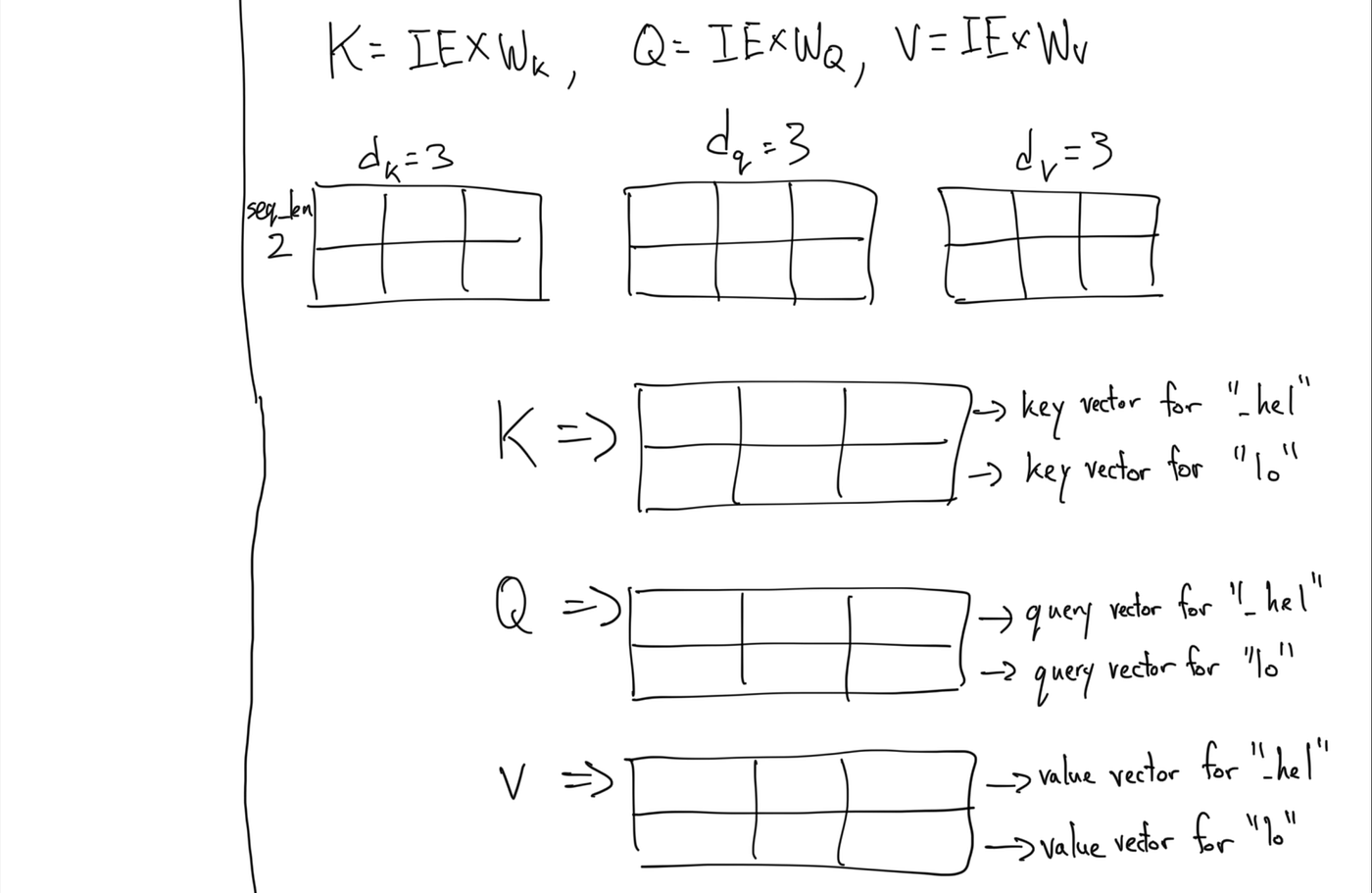
Understanding and Coding Self-Attention, Multi-Head Attention, Causal ...
Transformer -decoder mask篇. 接續上篇的Transformer -encoder mask篇… | by 任書瑋 ...
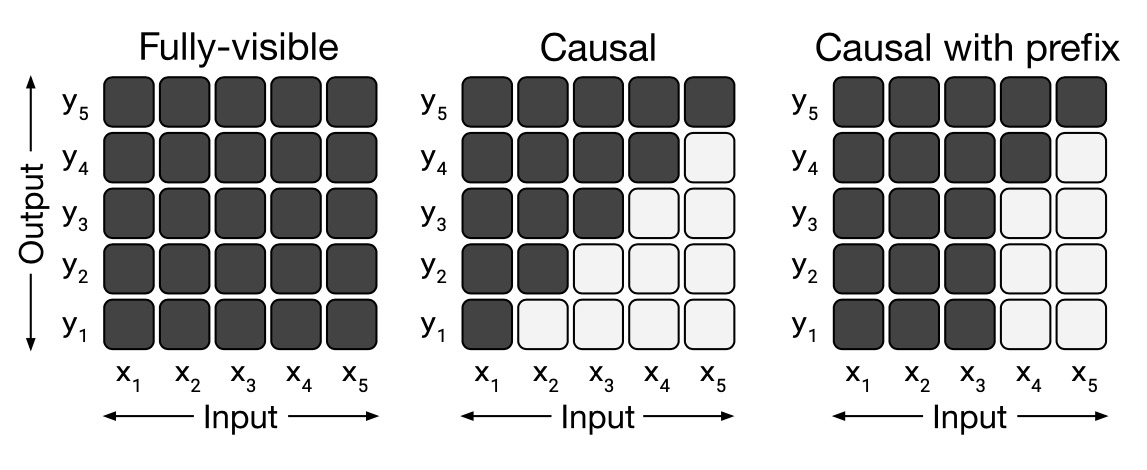
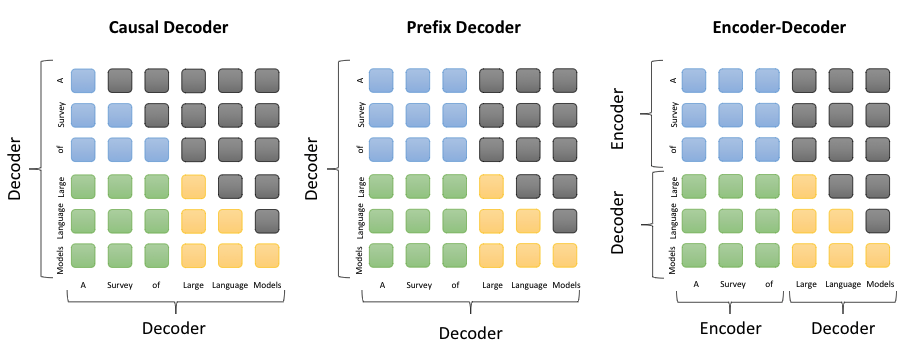
比较Causal decoder、Prefix decoder和encoder-decoder-CSDN博客
02 transformer:encoder结构和decoder结构 - 知乎
MaskFormer, Mask2Former
Mask2Former阅读笔记-CSDN博客
Transformer39~-CSDN博客
LLM主流框架:Causal Decoder、Prefix Decoder和Encoder-Decoder-CSDN博客
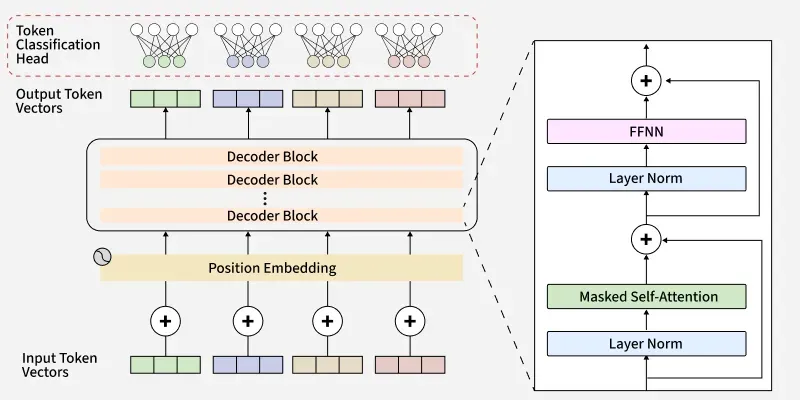
Working of Decoders in Transformers - GeeksforGeeks
(五)nlp学习之Transformer模型讲解 - 知乎
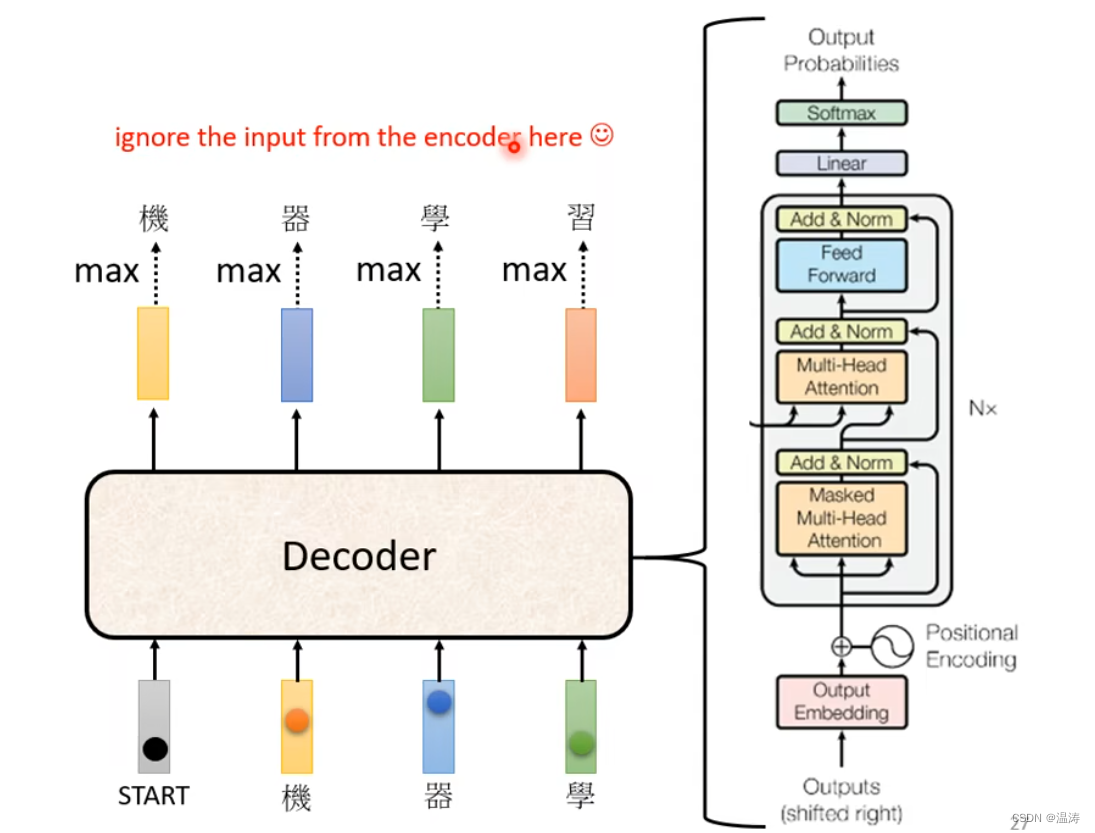
P11机器学习--李宏毅笔记(Transformer Decoder)Testing部分-EW帮帮网
PyLessons
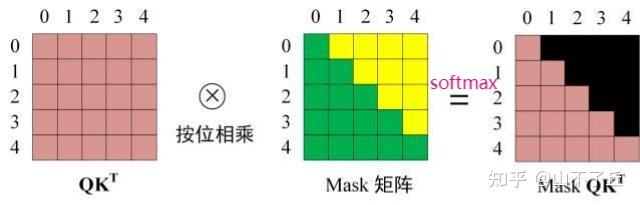
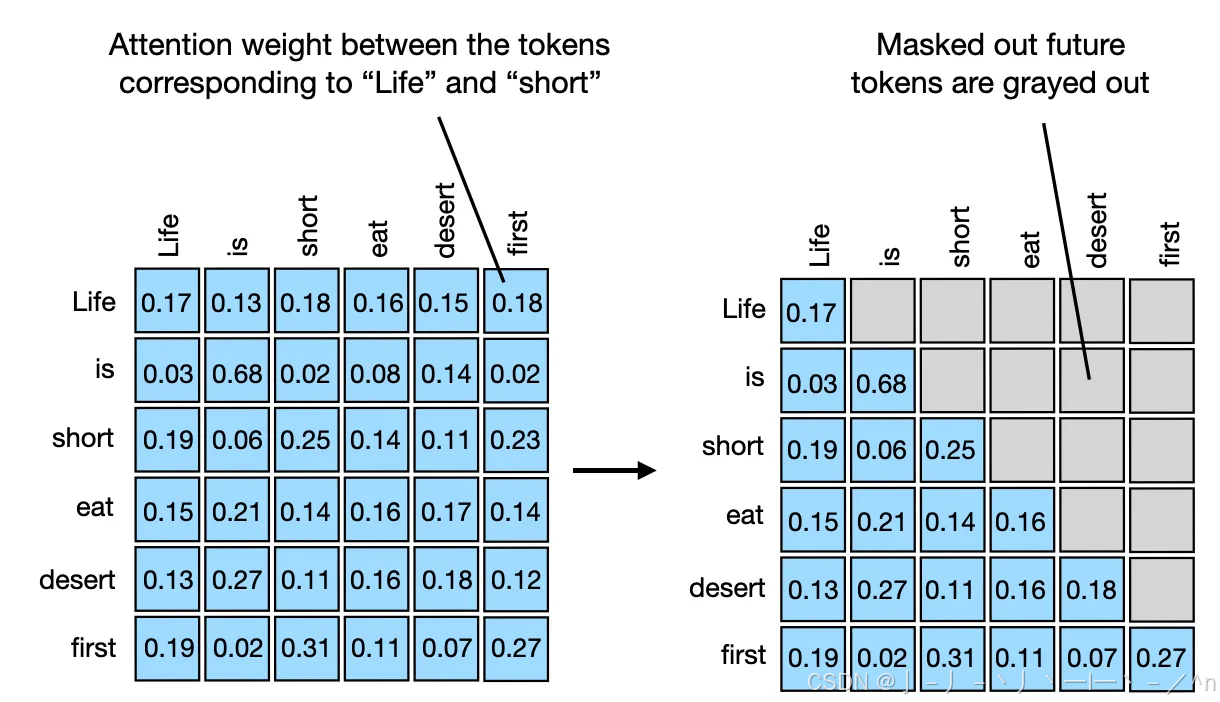
模型结构|解读transformer模型中三种attention和mask(一)_casual mask-CSDN博客
Transformer相关——(7)Mask机制 | 冬于的博客
GitHub - alex-matton/causal-transformer-decoder
从EncoderDecoder到Transformer
Understanding_Transformers
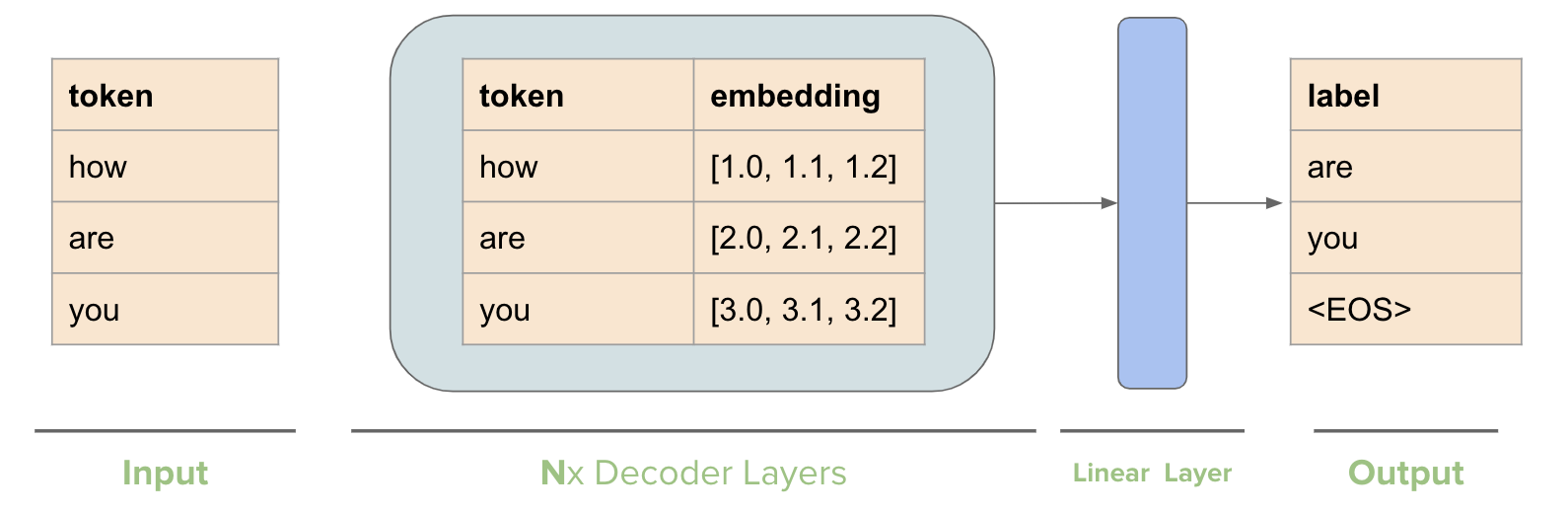
Transformers — Visual Guide
Language Model Training and Inference: From Concept to Code
史上最详细Transformer讲解以及transformer实现中文版完形填空(掩蔽字训练MASK) 内容详细易懂且附有全部代码 ...
Transformer模型中的Masking机制:原理、应用与重要性
深入理解Transformer中的解码器原理(Decoder)与掩码机制 - 技术栈
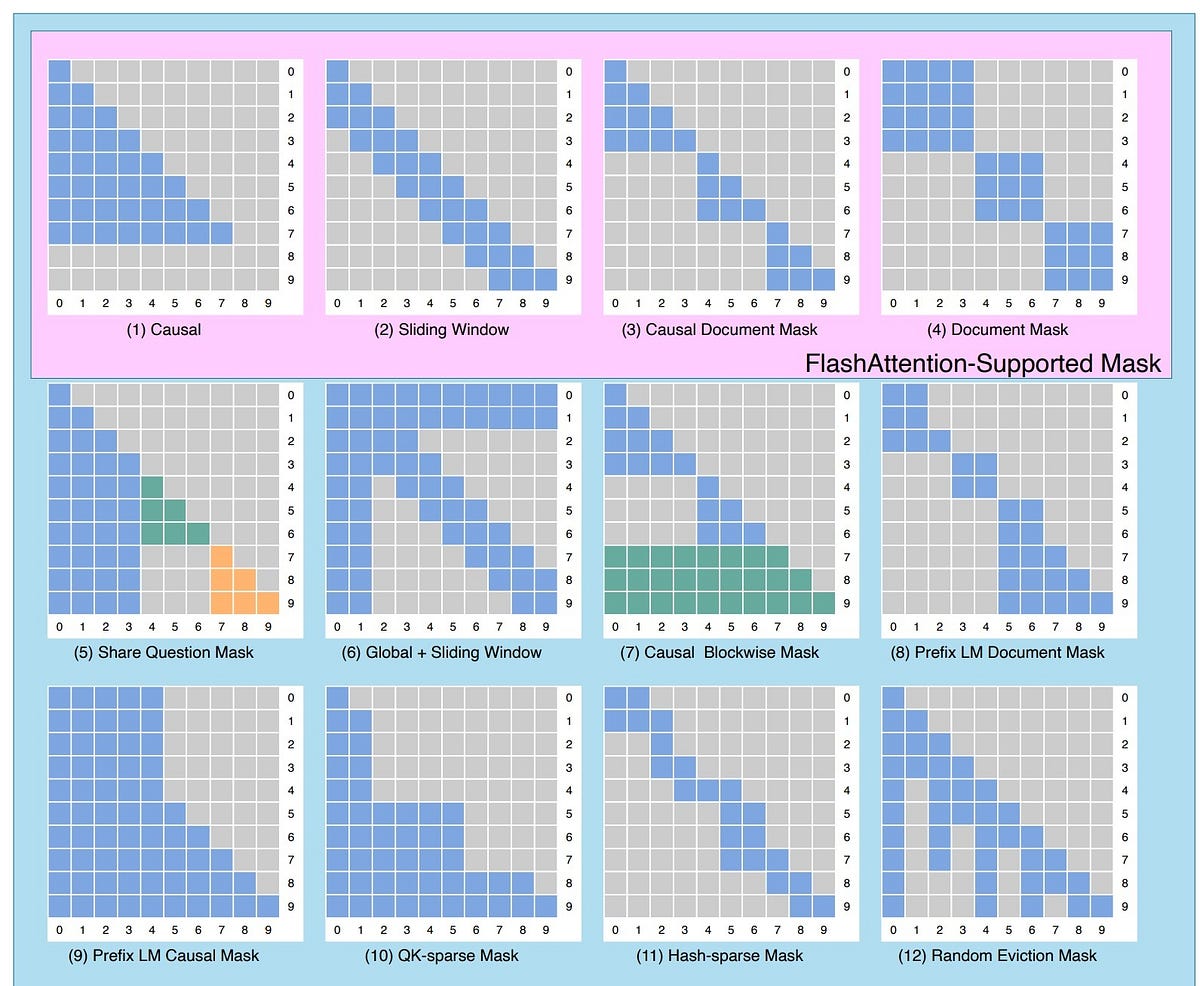
4D masks support in Transformers
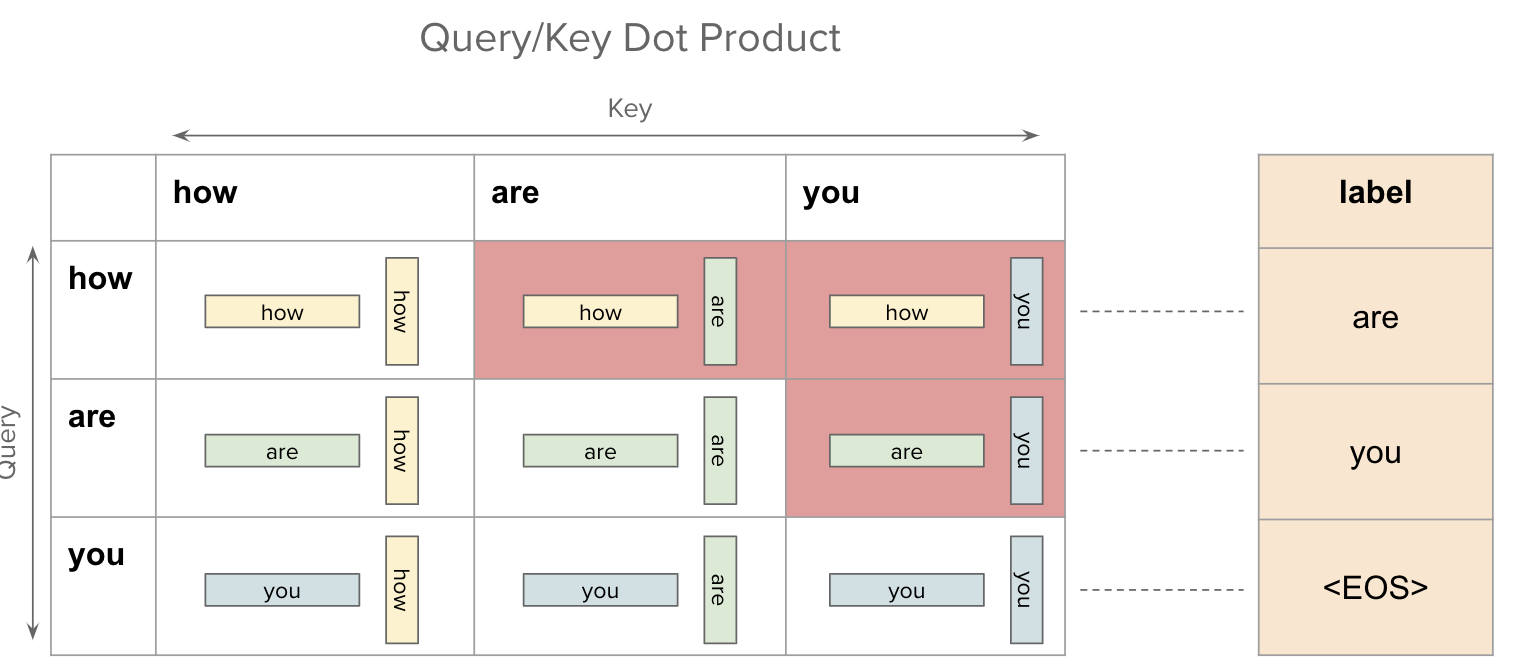
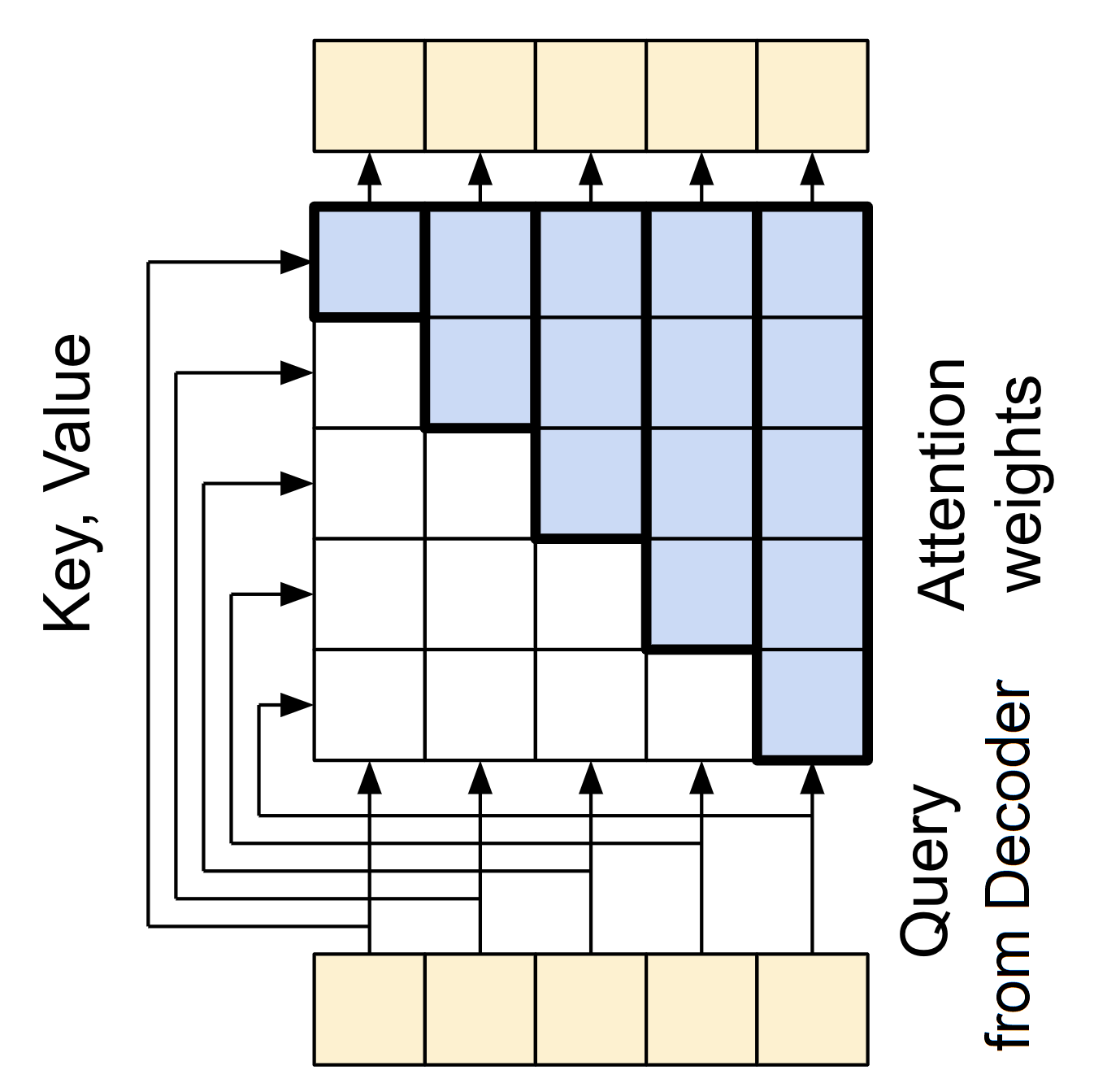
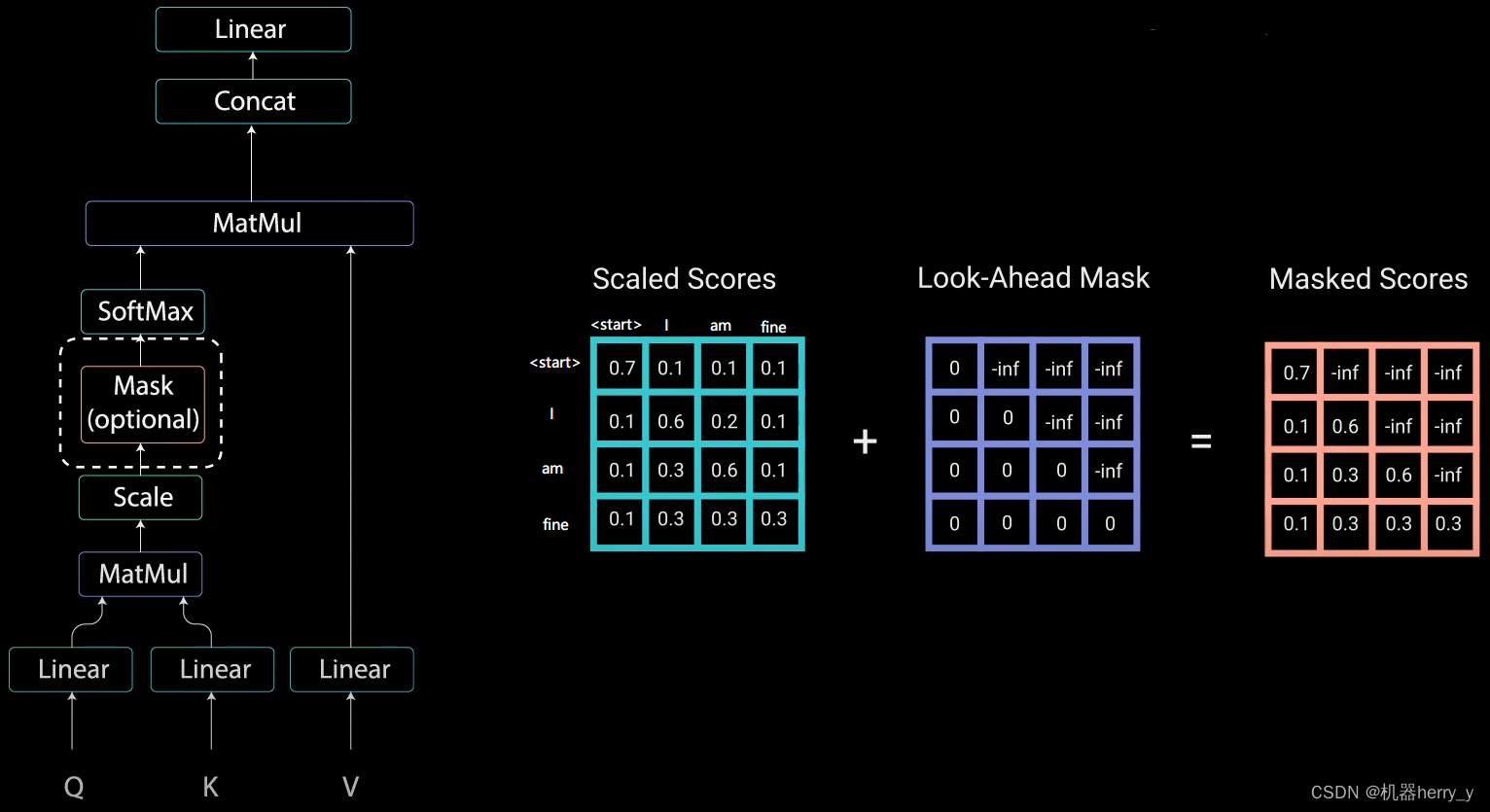
Intuition about the application of padding masks and look-ahead masks ...
Transformer推理结构简析(Decoder + MHA)_transformer mha-CSDN博客
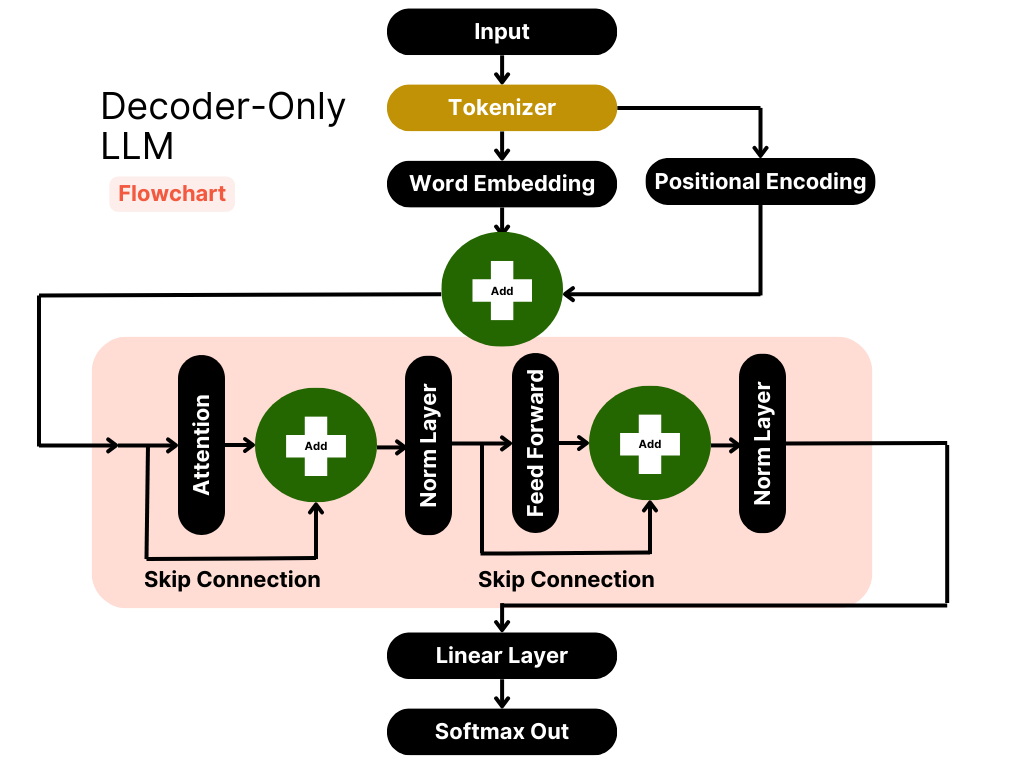
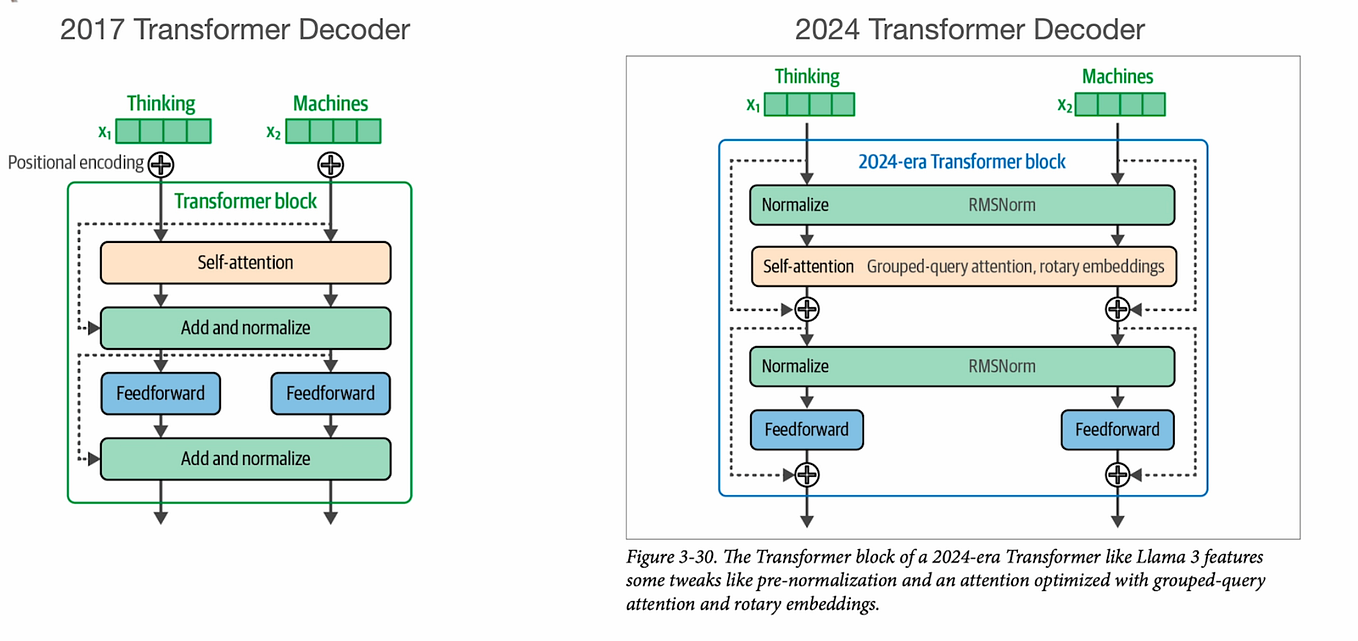
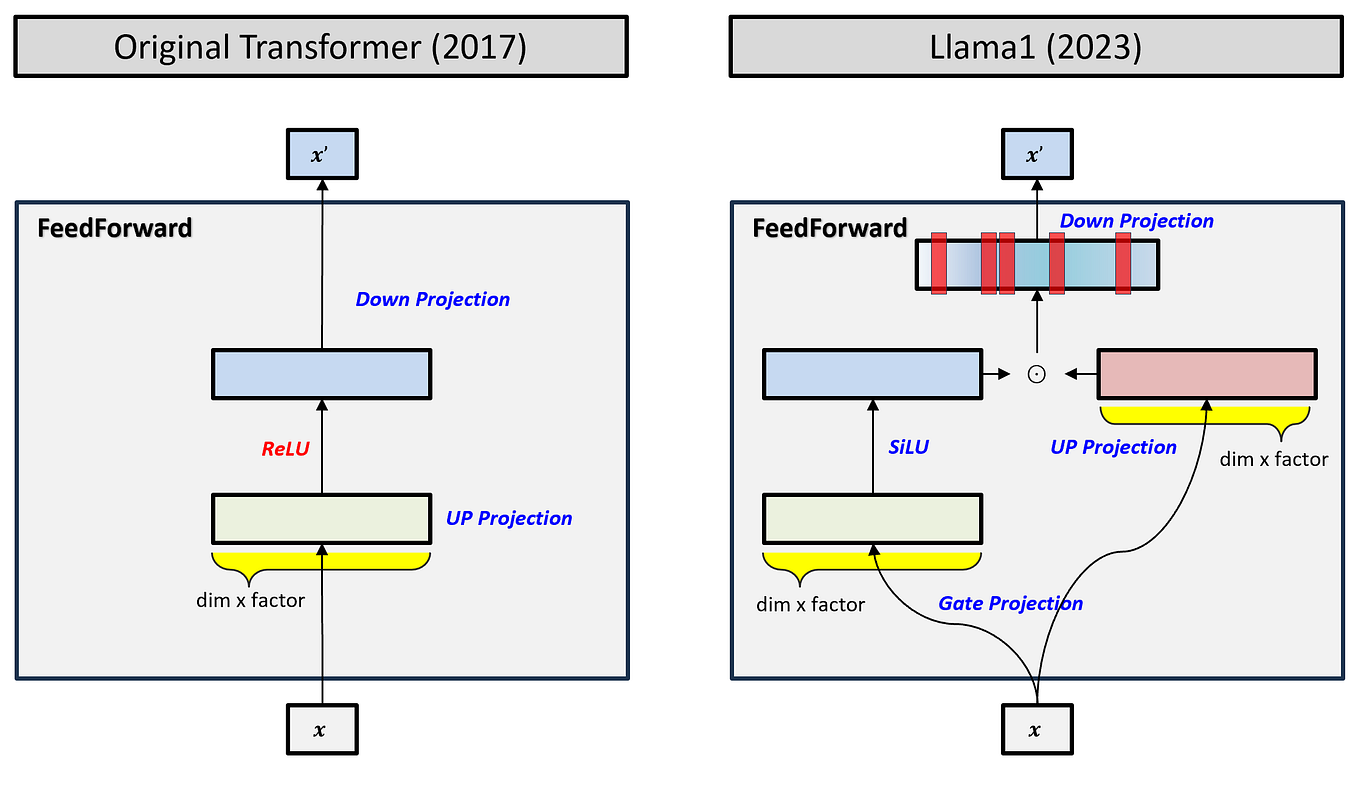
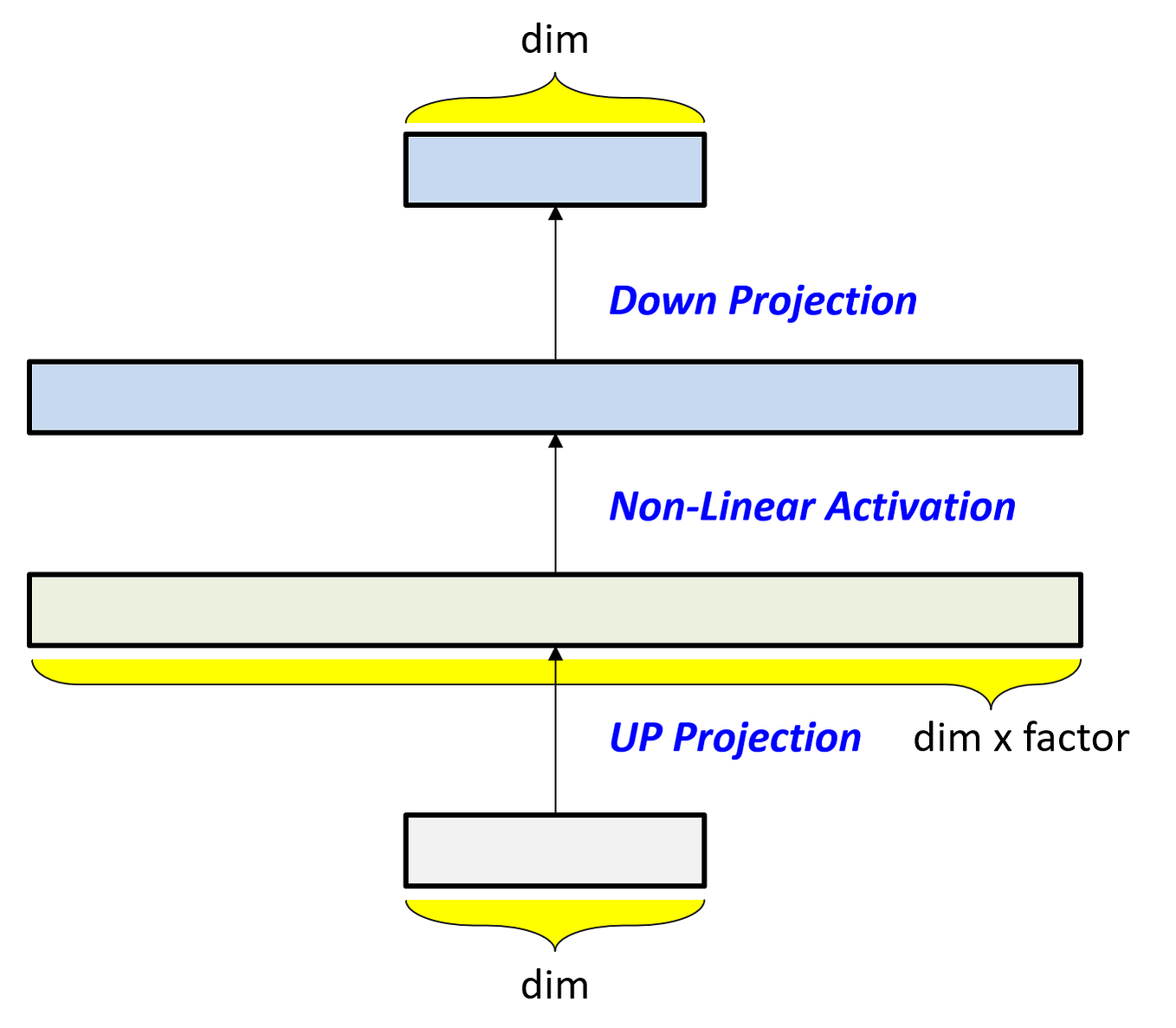
Chapter 17 | Sebastian Raschka, PhD
(a) The illustration of Spectrum Encoder. (b) The illustration of the ...
第五章第四周习题: Transformers Architecture with TensorFlow - xingye_z - 博客园
The Foundation Models Reshaping Computer Vision - Edge AI and Vision ...