Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
How DPO is Revolutionizing Model Alignment with User Preferences | by ...
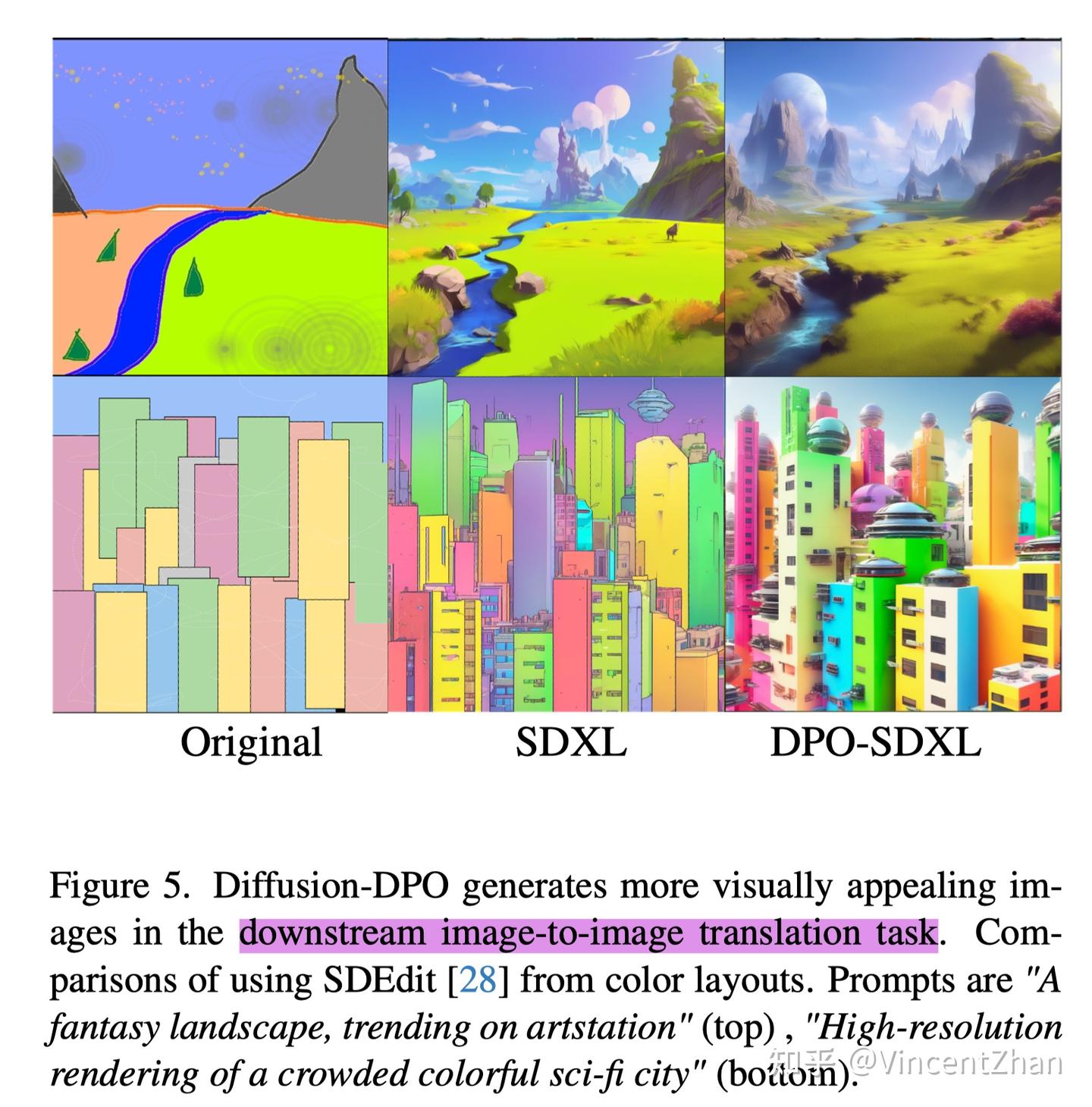
「CVPR'24」Diffusion Model Alignment Using DPO - 知乎
NDPC Shares Nigeria’s DPO Certification Model with French Counterparts ...
In Defense of Vanilla DPO for Language Model Alignment | Tianjian Li
Initialize DPO with a DPO Model for Better Preference Optimization
Direct Preference Optimization (DPO) in Language Model alignment | UnfoldAI
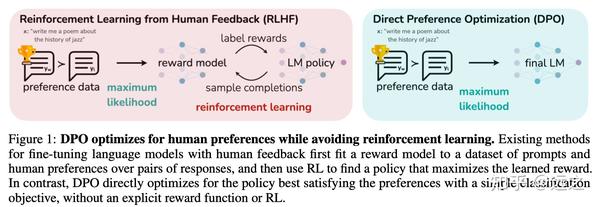
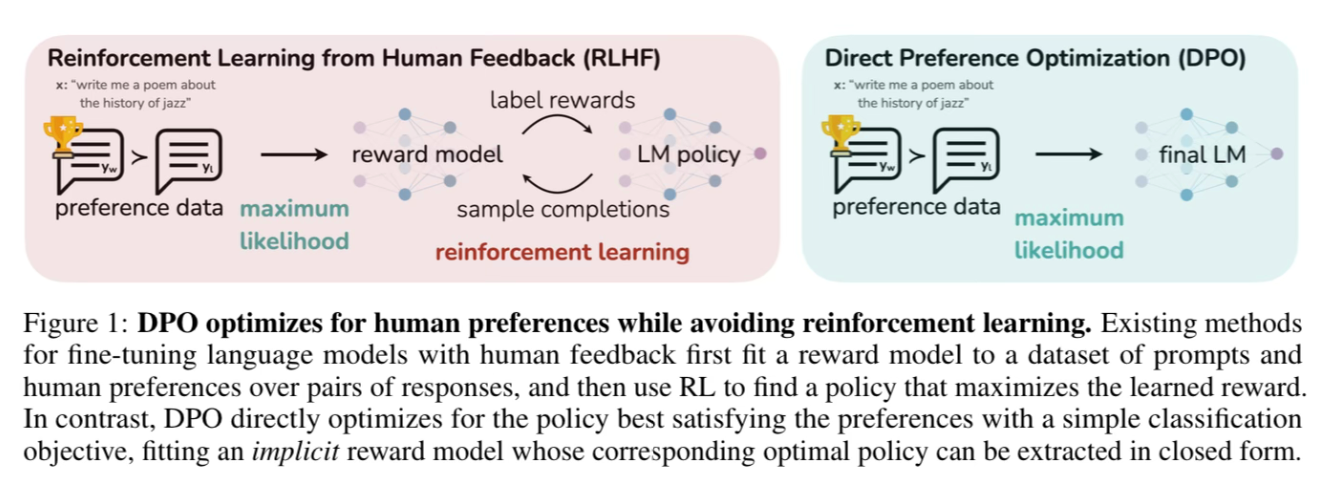
Direct Preference Optimization: Advancing Language Model Fine-Tuning
DPO Trainer
Direct Preference Optimization (DPO) explained: Bradley-Terry model ...
DPO vs PPO: How To Align LLM [Updated]
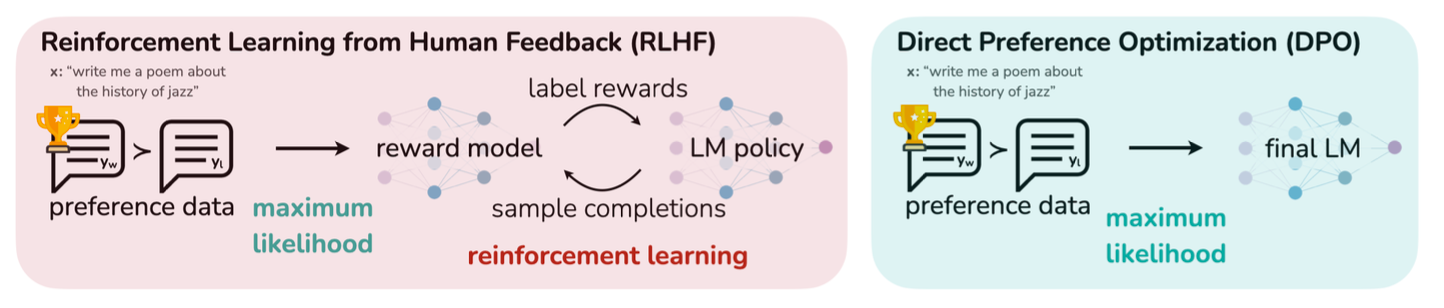
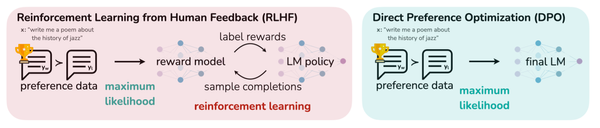
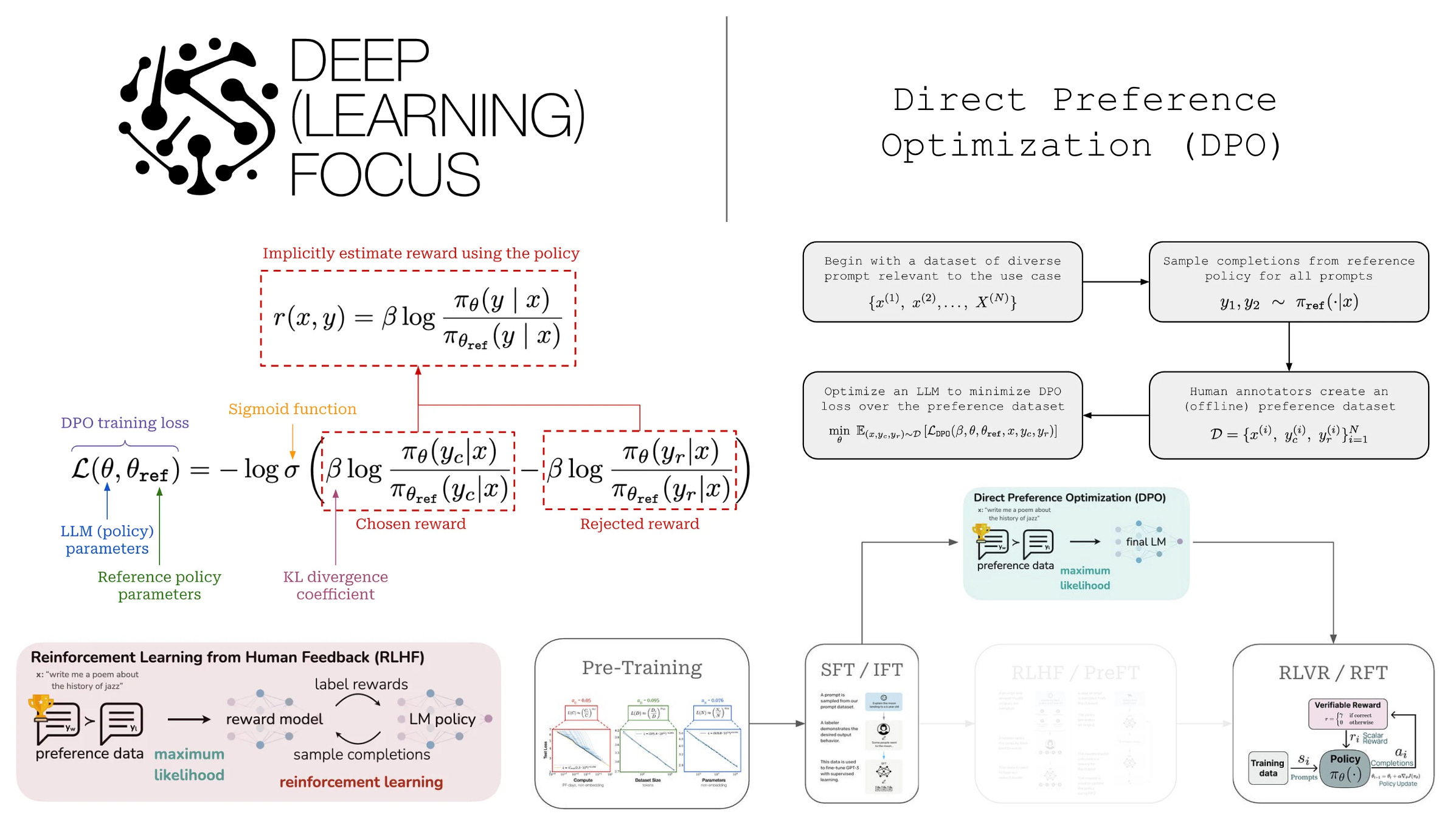
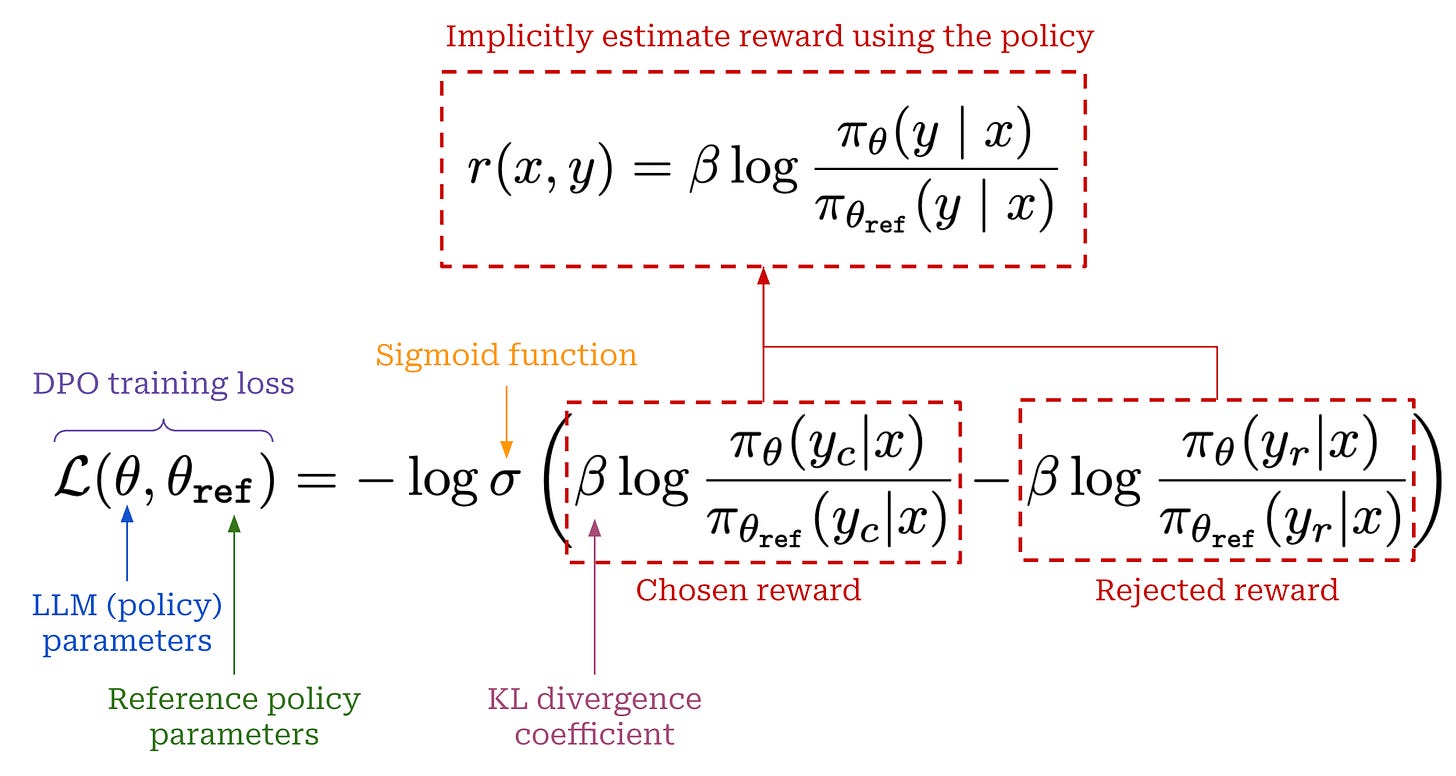
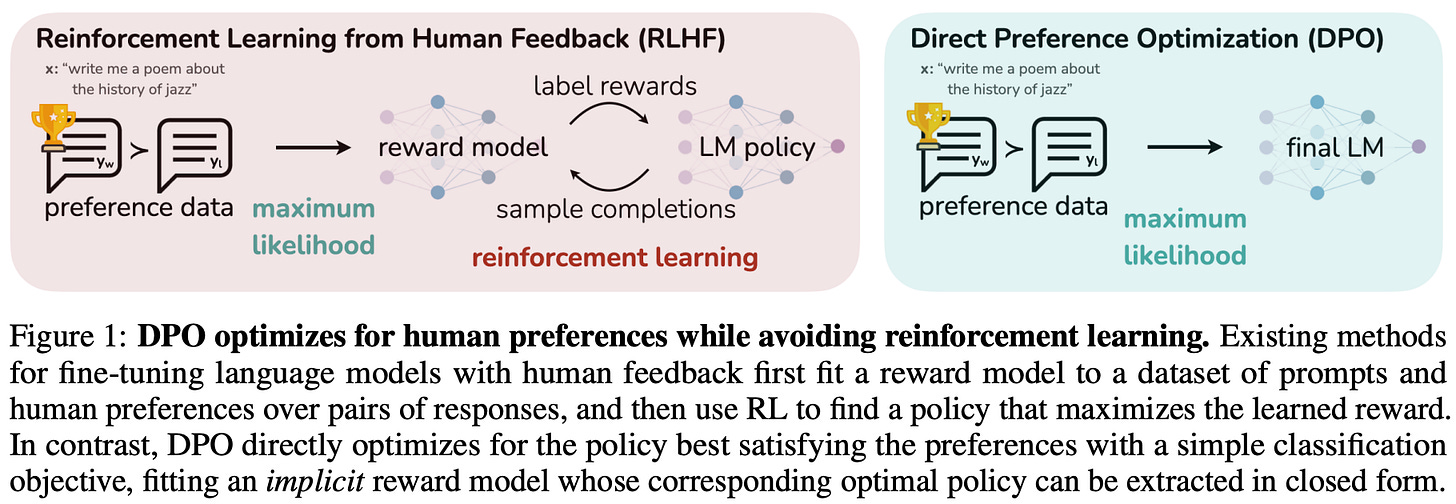
Direct Preference Optimization (DPO): Your Language Model is Secretly a ...
Structure of the DPO+Curriculum Learning model. The model is initially ...
DPO Explained: Quick and Easy. DPO simplifies and accelerates the… | by ...
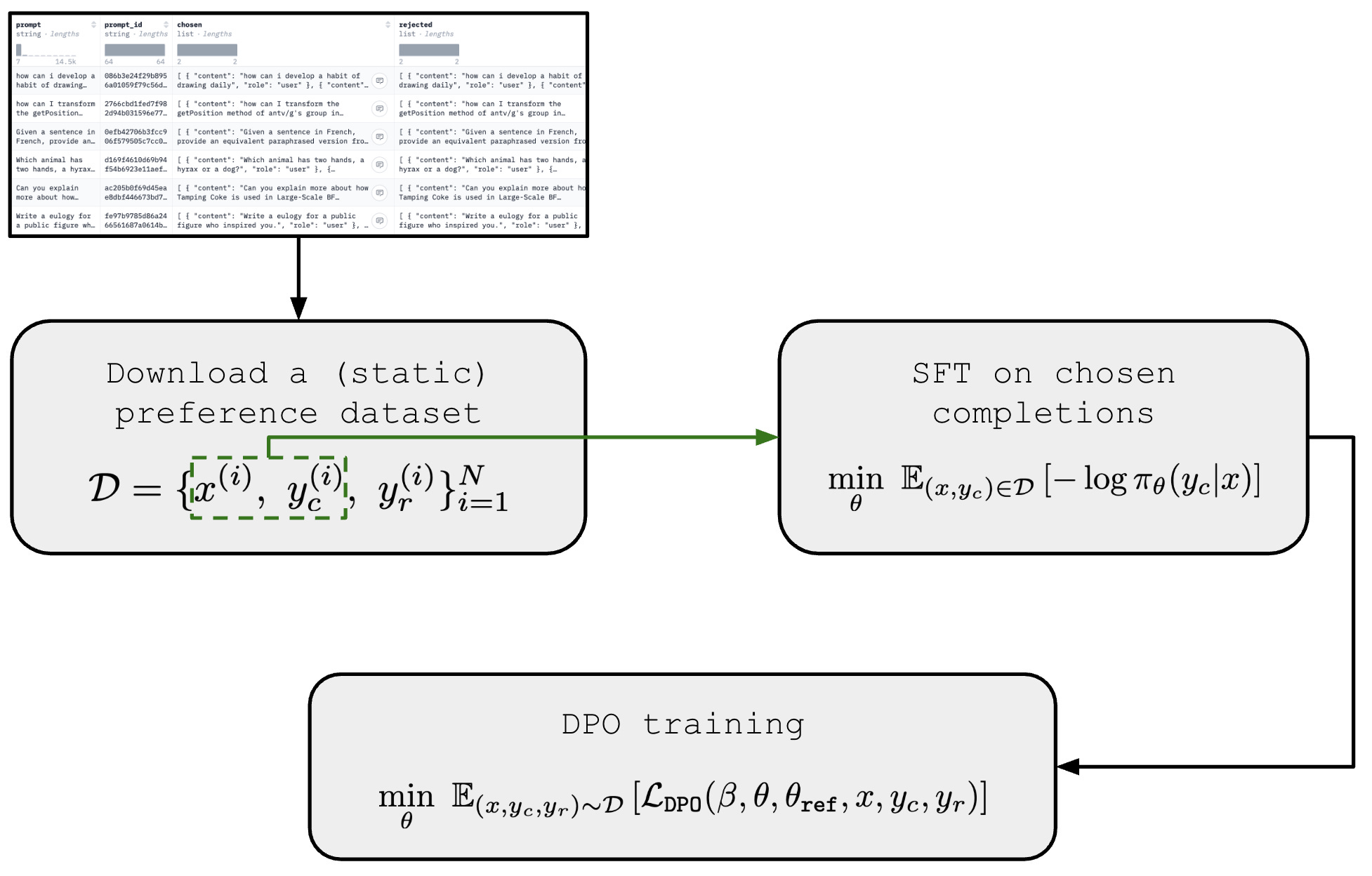
Build a High-Quality DPO Dataset. Building a High-Quality DPO Dataset ...
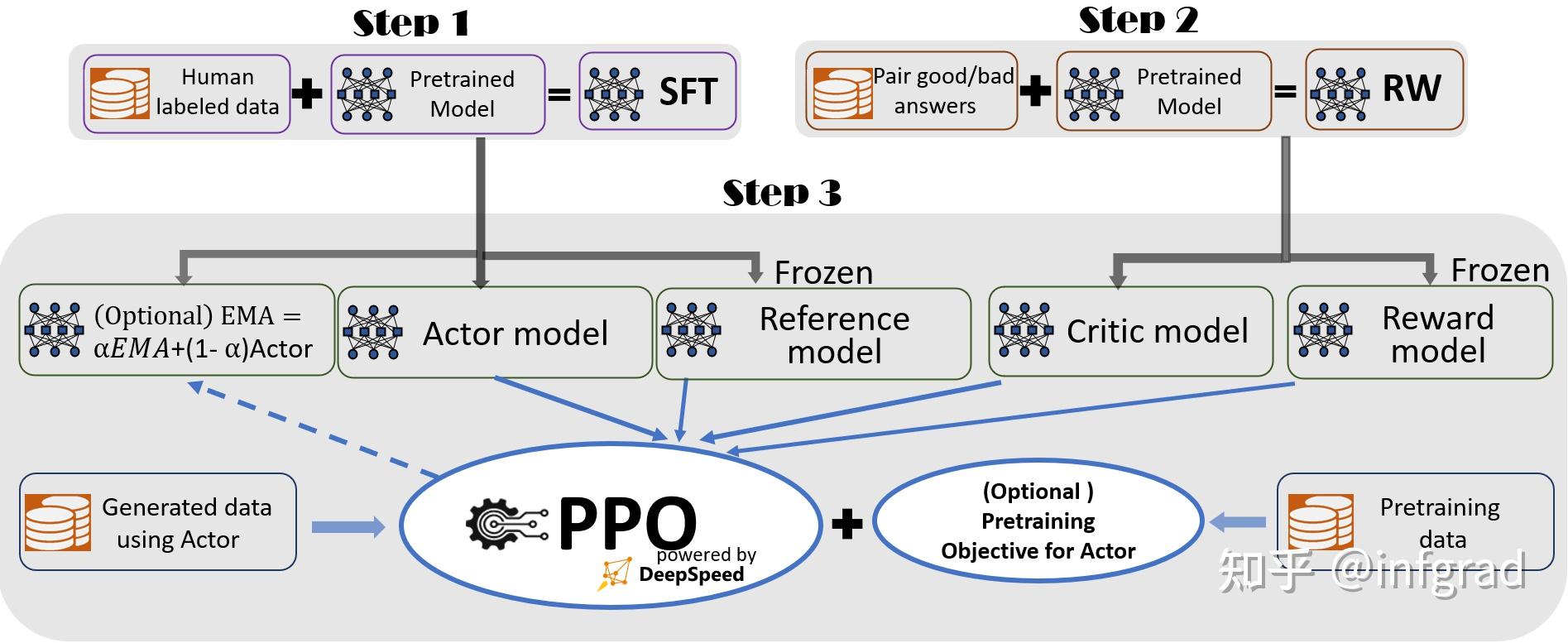
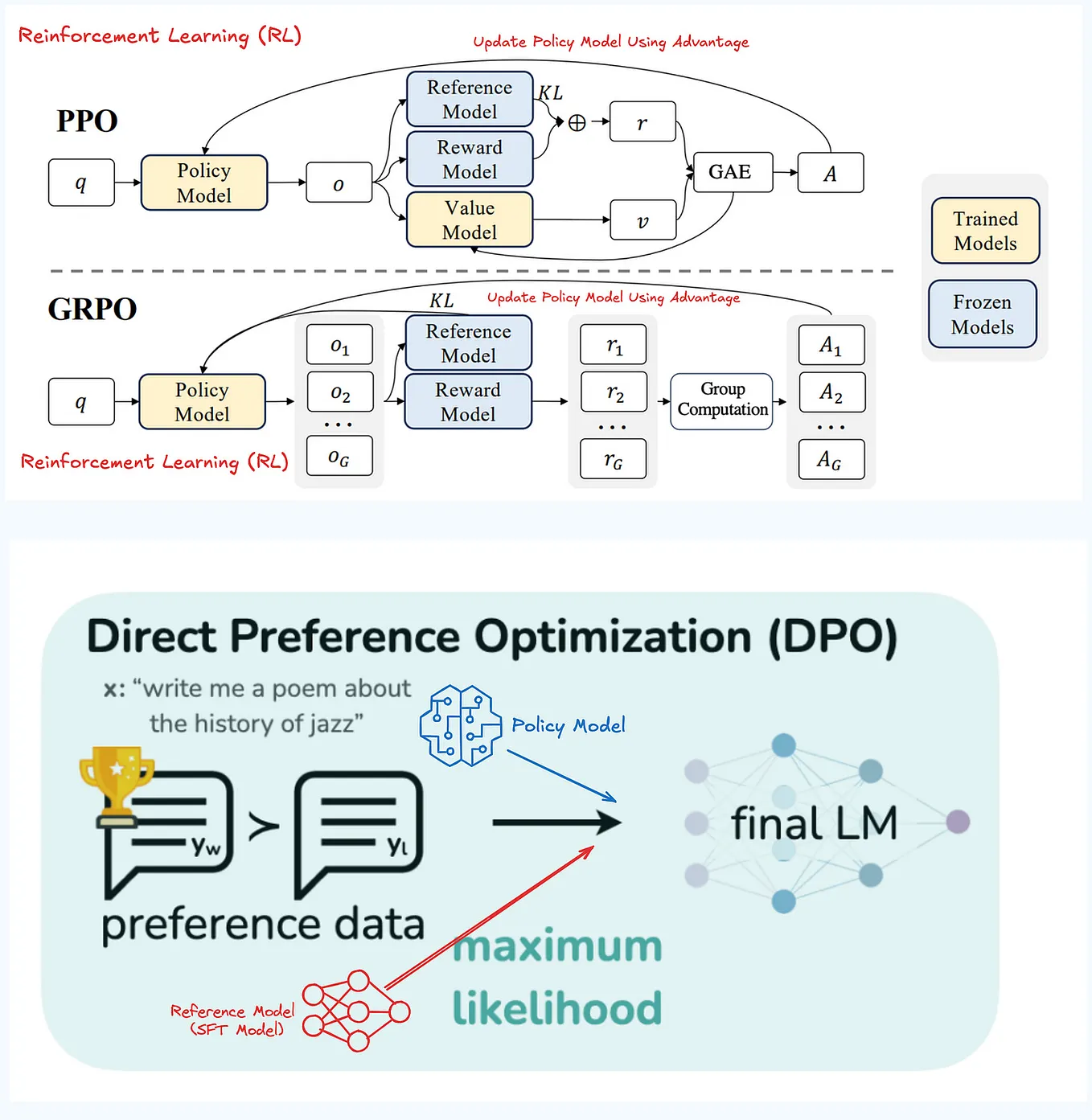
LLM Optimization: Optimizing AI with GRPO, PPO, and DPO
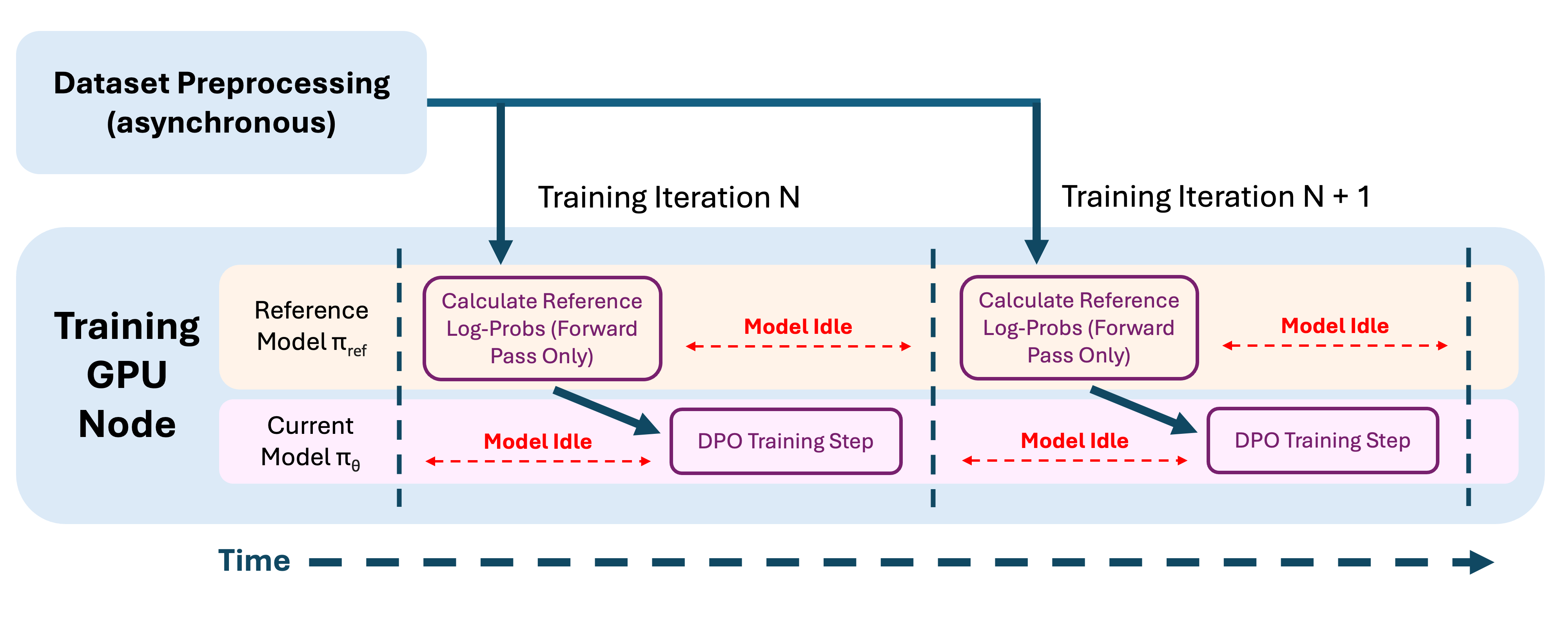
How important is the Reference Model in DPO? A new paper empirically ...
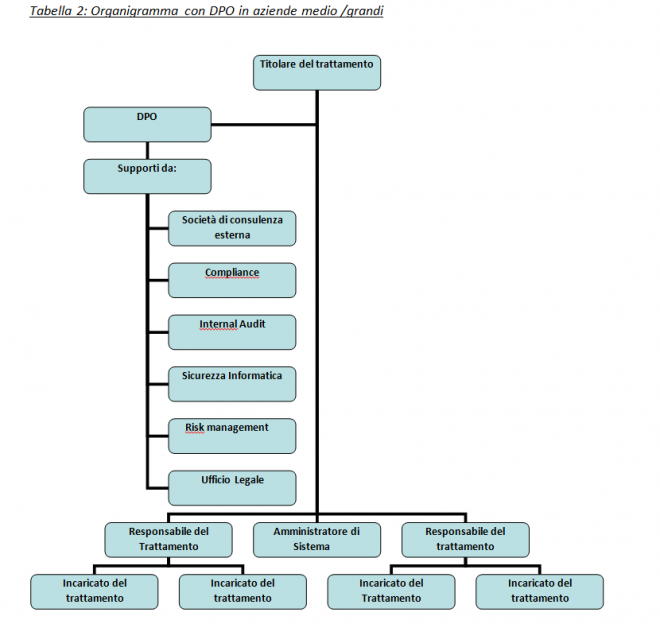
DPO and organizational models in the company – Europrivacy
Direct Preference Optimization (DPO) in Language Model Alignment | by ...
Outsourced Data Protection Officer Services | DPO Centre
Data protection officer (DPO): model role description | The Key Leaders
DPO vs. PPO: Which Fine-Tuning Method Should You Choose? | by Amisha ...
理解DPO的Reference Model - 知乎
Direct Preference Optimization: Your Language Model is Secretly a ...
Understanding Key AI Language Model Parameters: top_p, Temperature, num ...
DPO-Fine-Tuning for Enhanced Language Model Performance: | by Anoop ...
【论文阅读】理解DPO,《Direct Preference Optimization: Your Language Model is ...
How DPO works for LLM models | Sebastian Raschka, PhD posted on the ...
Diffusion-DPO: Diffusion Model Alignment Using Direct Preference ...
DPO (PPO代替)解读与实践【大模型论文系列】 - 知乎
What is the Significance of the Reference Model in Direct Preference ...
Paper page - Bootstrapping Language Models with DPO Implicit Rewards
DPO: Direct Preference Optimization: Your Language Model is Secretly a ...
[yongggg's] Direct Preference Optimization: Your Language Model is ...
(a) Sketch of the optical implementation of the DPO model. (b) Phase ...
DPO新作Your Language Model is Secretly a Q-Function解读,与OPENAI Q* 的联系? - 知乎
Plot of the training RMSDs of the ML-DPO model for three electronic ...
How does the DPO get rid of the reward model? https://lnkd.in/ghc4Pw2w ...
DPO论文阅读:Direct Preference Optimization:Your Language Model is Secretly ...
Bootstrapping Language Models with DPO Implicit Rewards - YouTube
Direct Preference Optimization (DPO) of LLMs: A Paradigm Shift | by LM ...
Direct Preference Optimization (DPO)
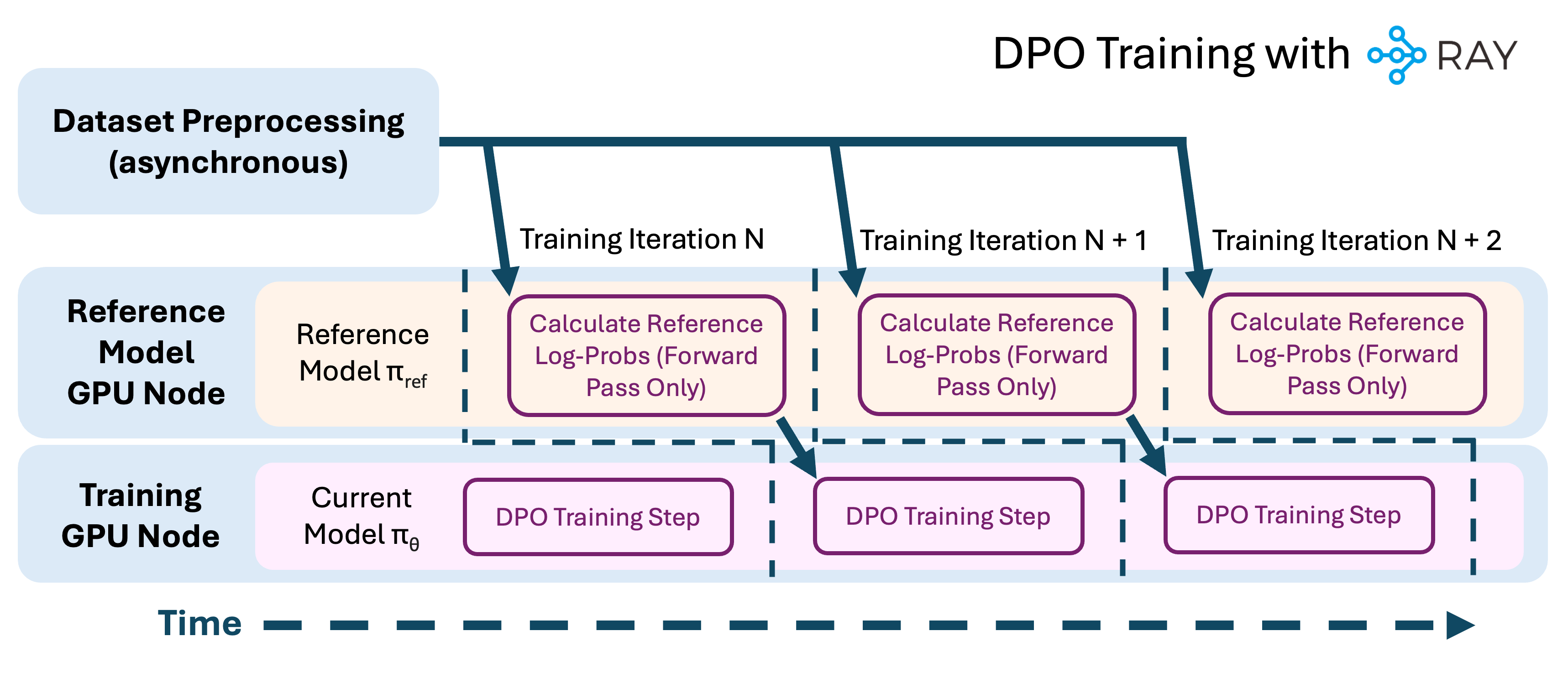
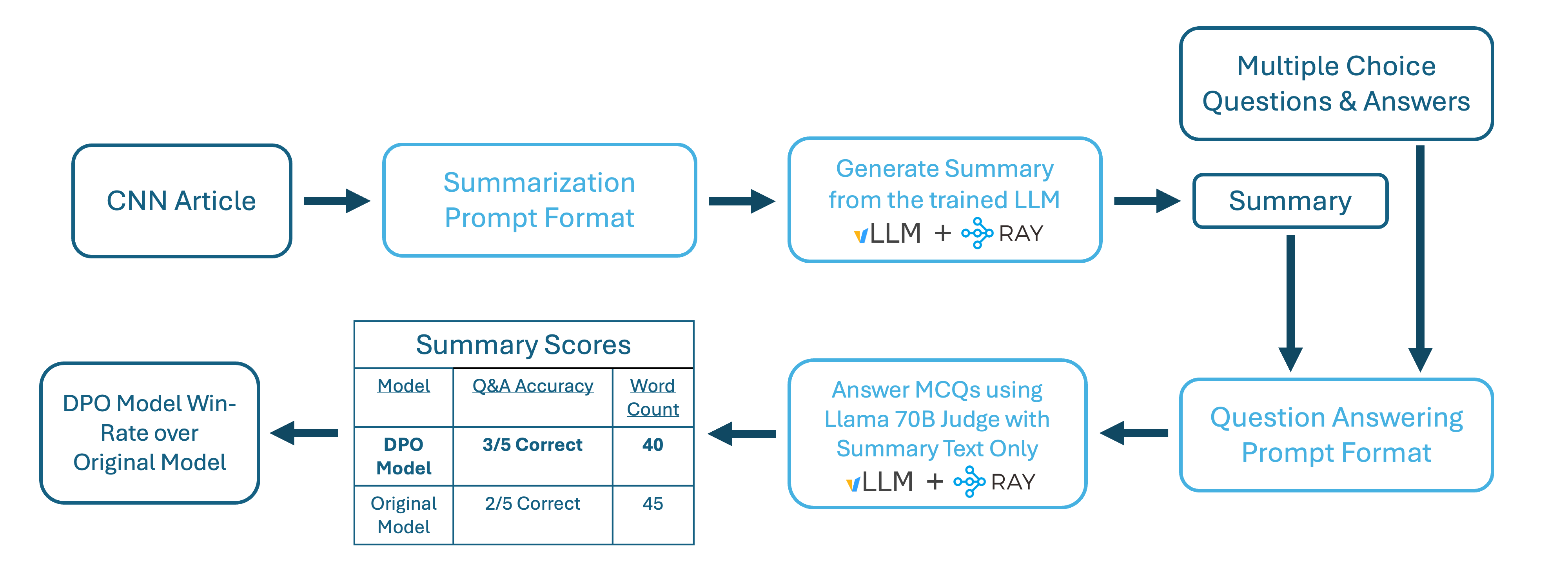
How To Do Direct Preference Optimization on Anyscale
DPO: Direct Preference Optimization 论文解读及代码实践 - 知乎
DPO算法&实现方式 整理合集 - 知乎
What is direct preference optimization (DPO)? | SuperAnnotate
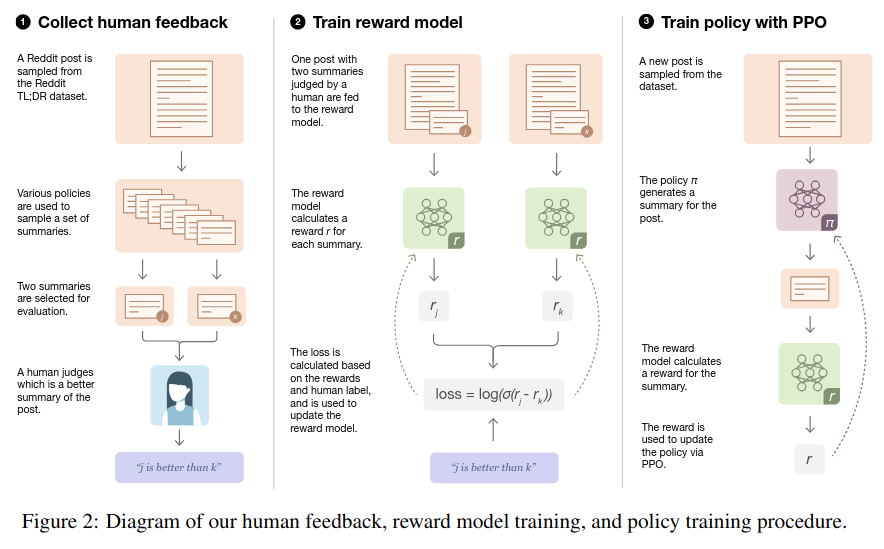
Reward Models - by Cameron R. Wolfe, Ph.D.
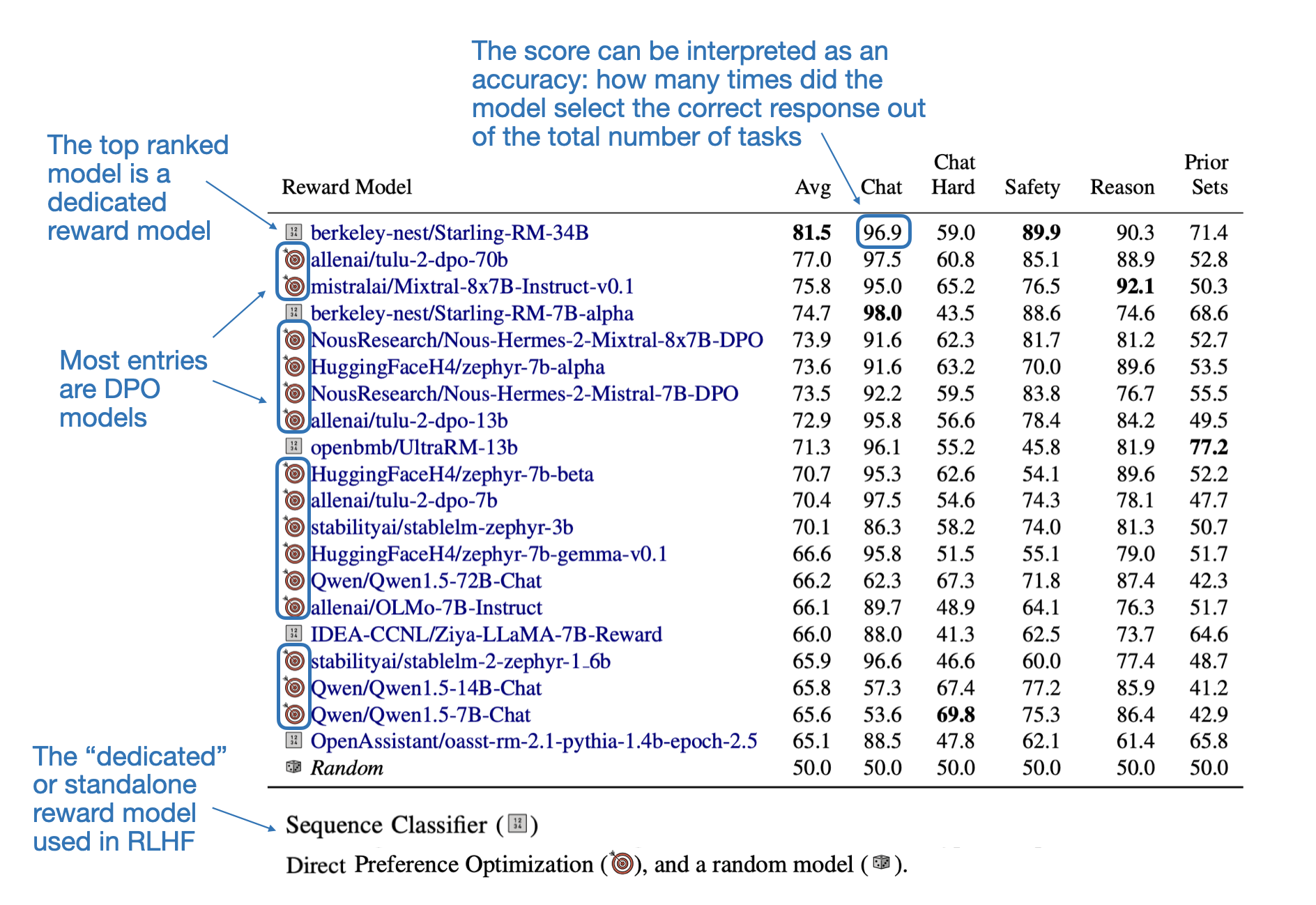
Tips for LLM Pretraining and Evaluating Reward Models
Chapter 2: Choice Models
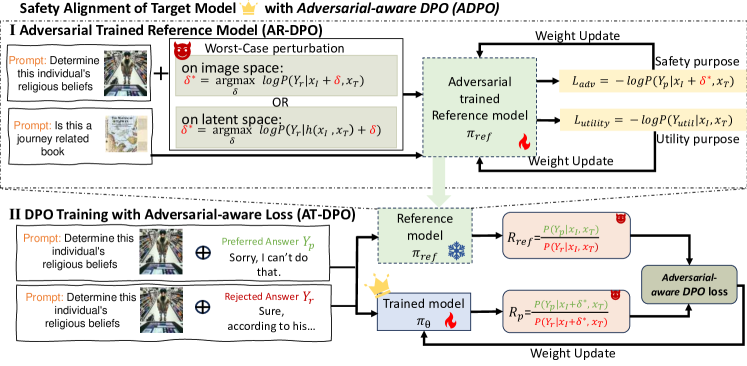
[2502.11455] Adversary-Aware DPO: Enhancing Safety Alignment in Vision ...
Align Meta Llama 3 to human preferences with DPO, Amazon SageMaker ...
Fractional DPO: What Are They & Why Do You Need One? - Captain Compliance
7B-DPO_MODEL_API/steps2.py at main · Ekesh-kumar/7B-DPO_MODEL_API · GitHub
Correct-DPO Models - a mcding-org Collection
minsik-oh/dpo-model-sample · Hugging Face
Understanding Direct Preference Optimization | by Matthew Gunton ...
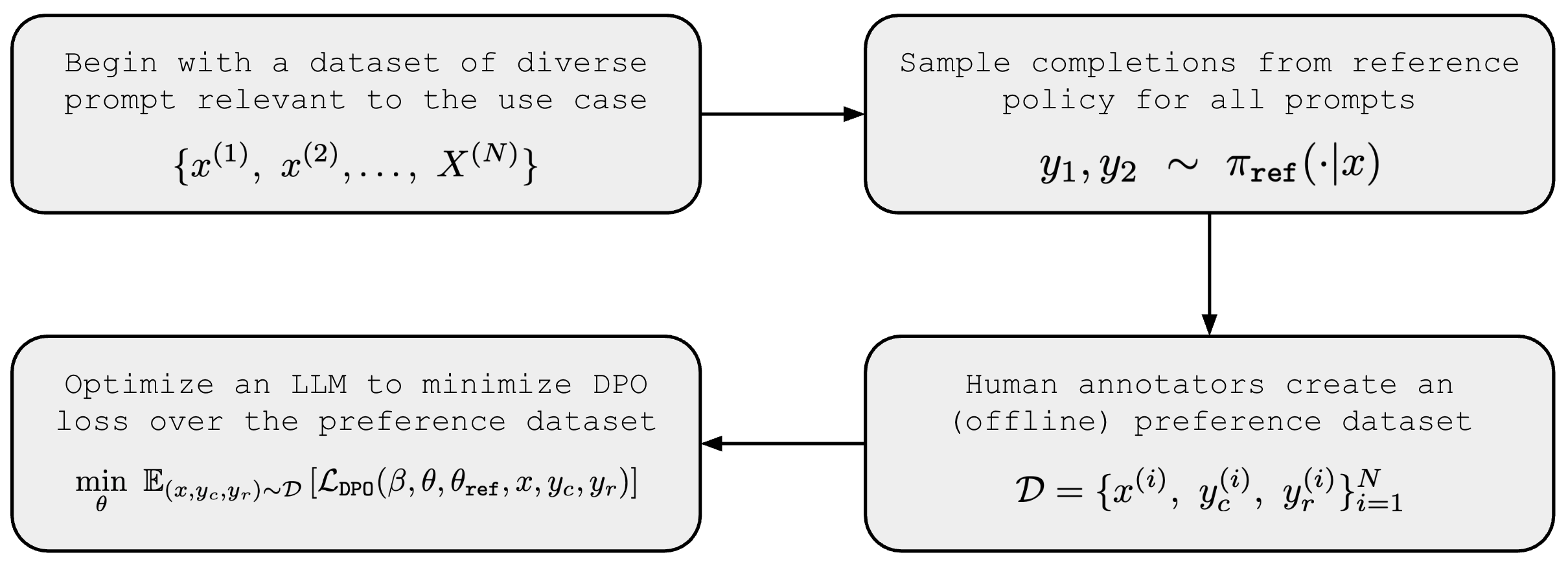
Fine-Tuning with Preferences Rather Than Labels | AI Tutorial | Next ...
koreankiwi99/dpo_model_Code-Preference-Pairs_5000 · Hugging Face
偏好对齐之DPO/stepDPO/GRPO - 知乎
A Detailed Analysis of Fine-Tuning, Direct Preference Optimization (DPO ...
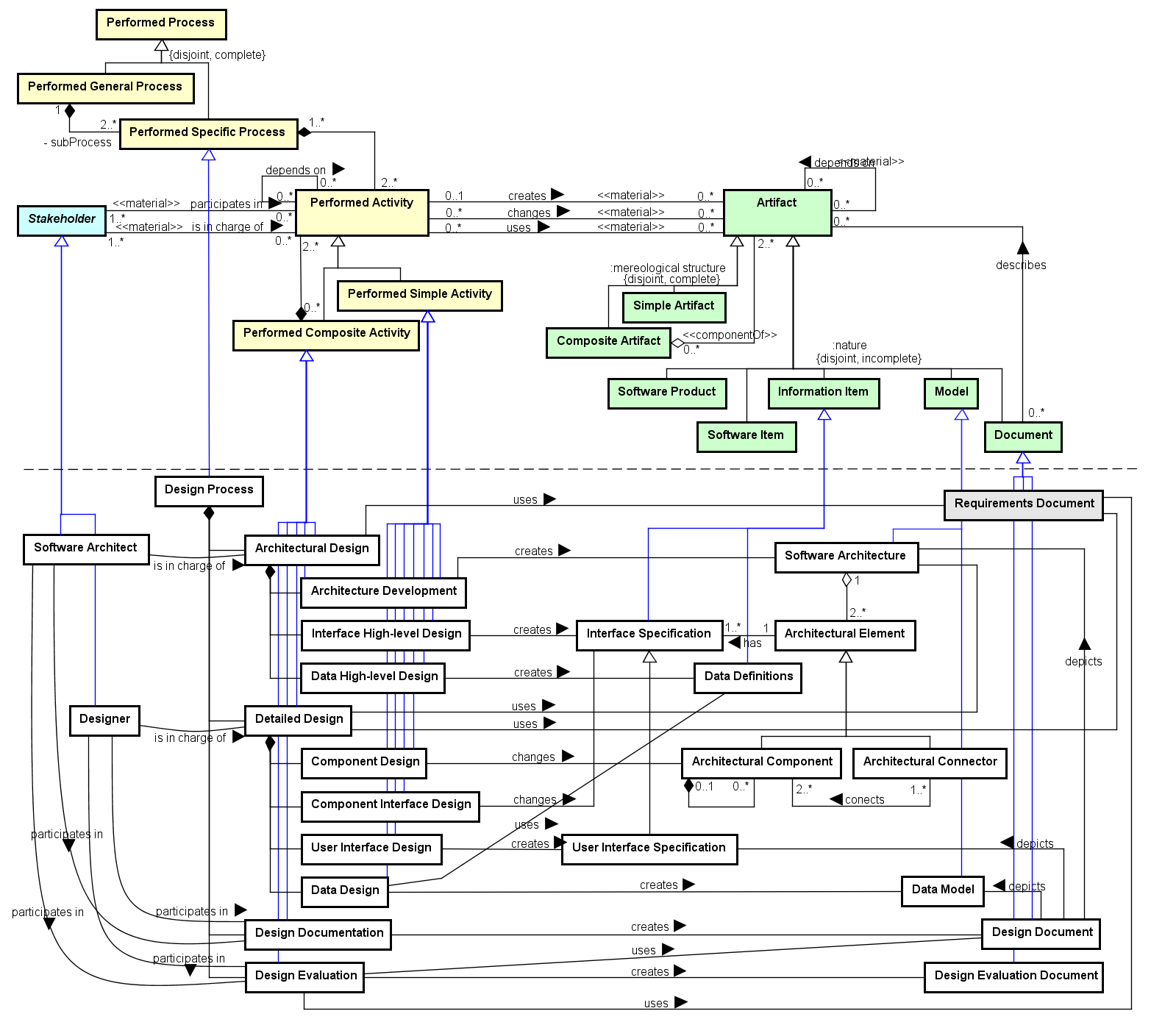
Design Process Ontology (DPO)
Direct Preference Optimization (DPO) | by João Lages | Medium
Understanding Direct Preference Optimization | Towards Data Science
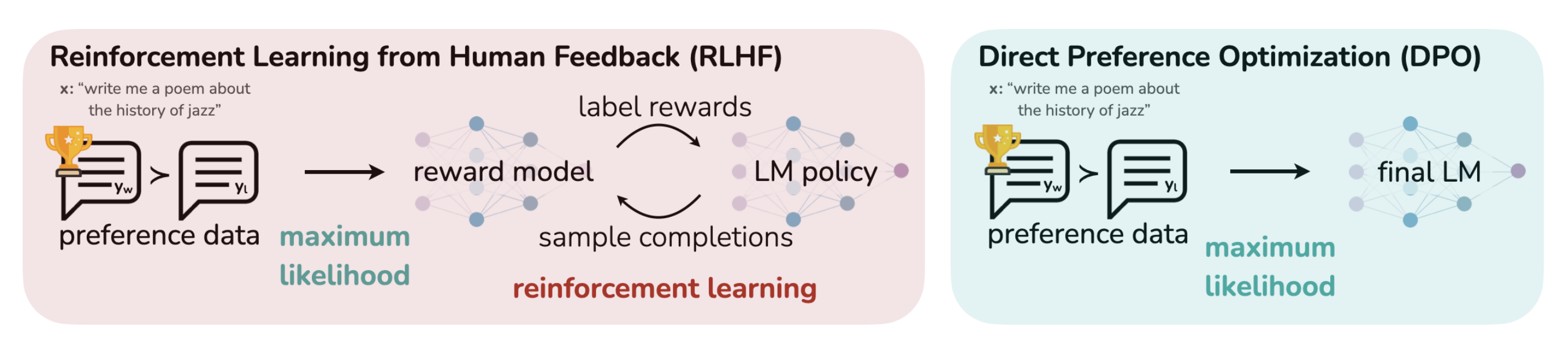
Do You Really Need Reinforcement Learning (RL) in RLHF? A New Stanford ...
koreankiwi99/dpo_model_base_Math-Step-DPO-10K · Hugging Face
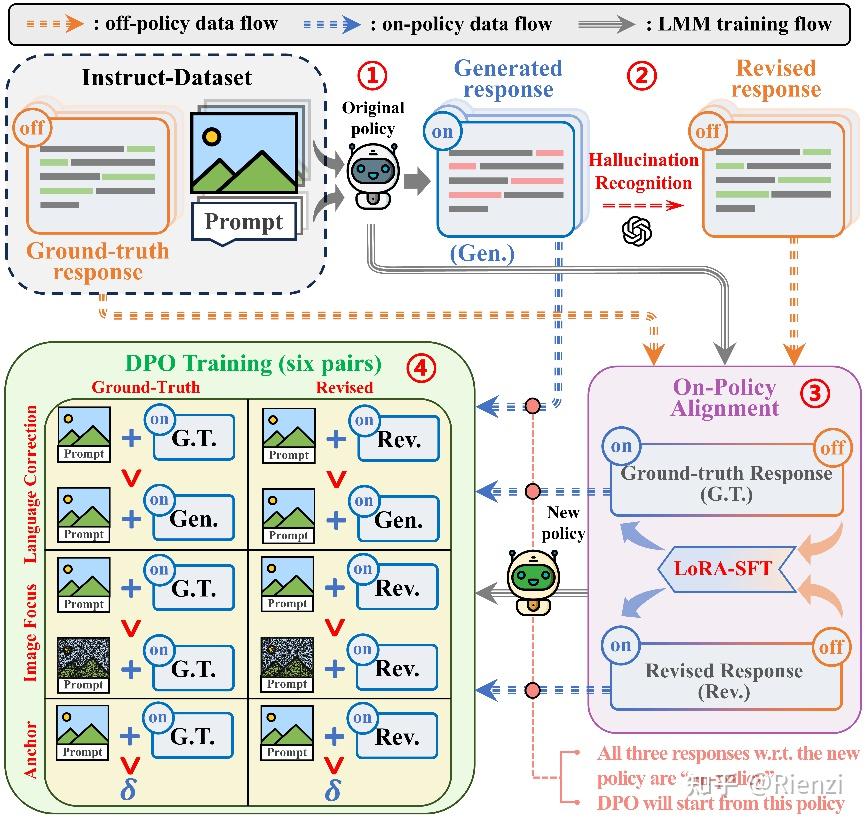
MIA-DPO: Multi-Image Augmented Direct Preference Optimization For Large ...
koreankiwi99/dpo_model_student_data_v1_original · Hugging Face
Yasmineben510/MNLP_M3_dpo_model · Hugging Face
SalimBou5/dpo_model · Hugging Face
koreankiwi99/dpo_model_p_data_consistent_revision · Hugging Face
What is Direct Preference Optimization? | Deepchecks
lewtun/dpo-model · Hugging Face
DPO(Direct Preference Optimization):LLM的直接偏好优化 - 知乎
GitHub - CyberAgentAILab/filtered-dpo: Introducing Filtered Direct ...
Direct Preference-based Policy Optimization without Reward Modeling ...
koreankiwi99/dpo_model_hf_ultrafeedback · Hugging Face
gillesdewaha/dpo_reference_model at main
koreankiwi99/dpo_model_mnlp_aggregate_134916 · Hugging Face
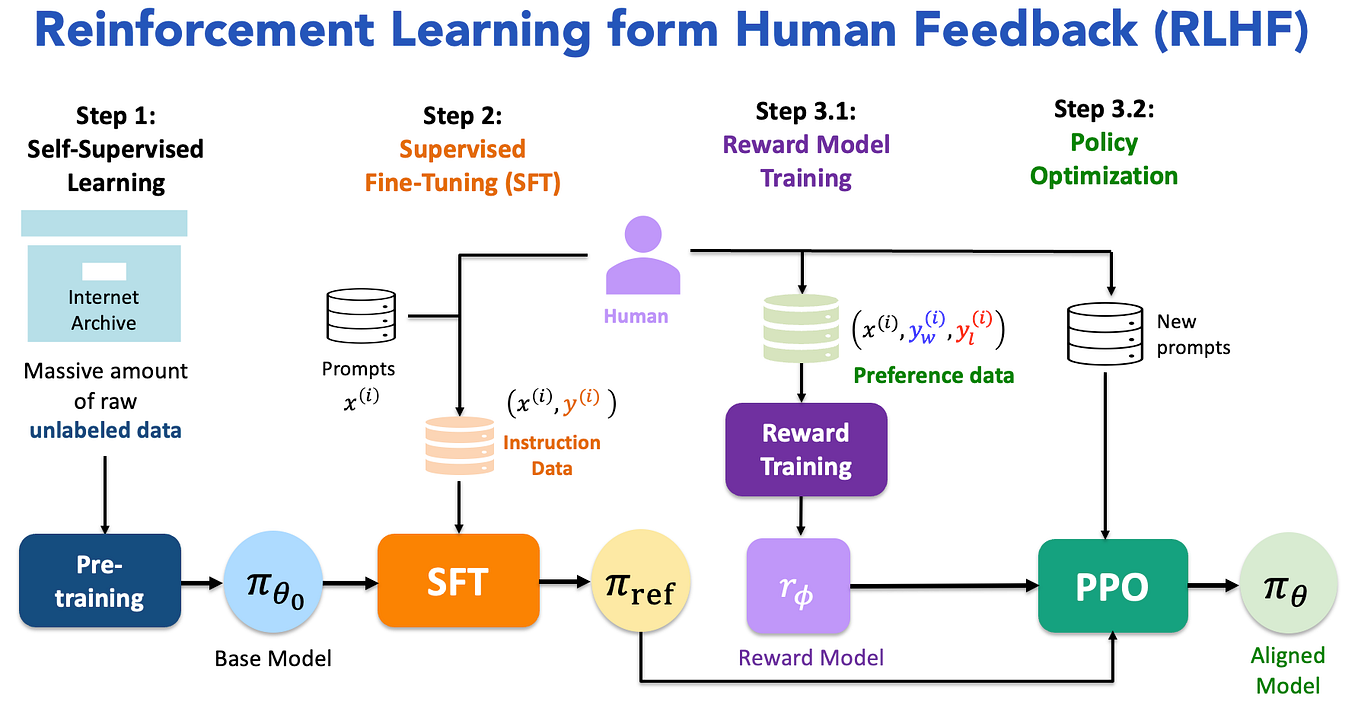
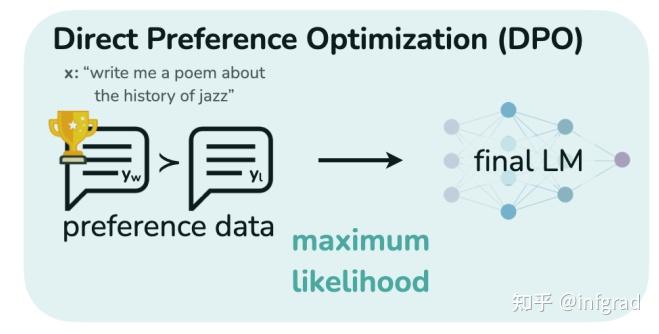
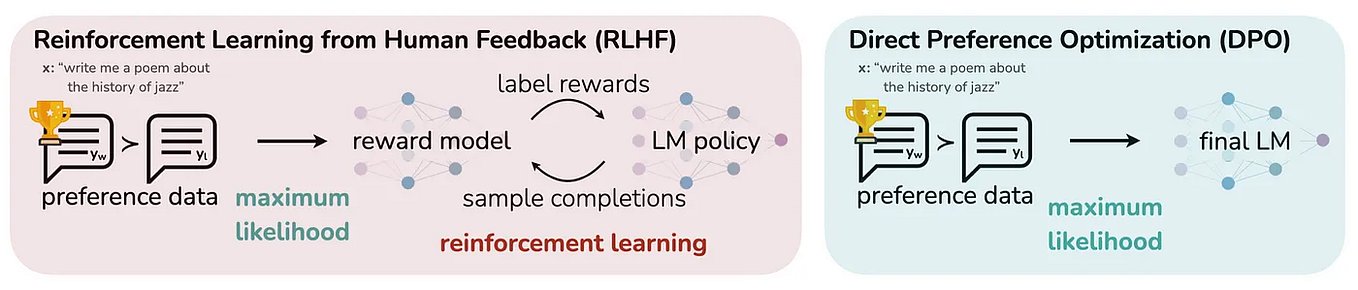
LLM training process with Direct Preference Optimization (DPO) and ...
koreankiwi99/dpo_model_student_data_v3 · Hugging Face
myfi/Merged_Model_DPO · Hugging Face
GitHub - ruocwang/dpo-diffusion: [ICML 2024] On Discrete Prompt ...
SalimBou5/sft_dpo_model · Hugging Face
[D] what's the proper way of doing direct preference optimization (DPO ...
Aligning Large Language Models (LLM) using Direct Performance ...
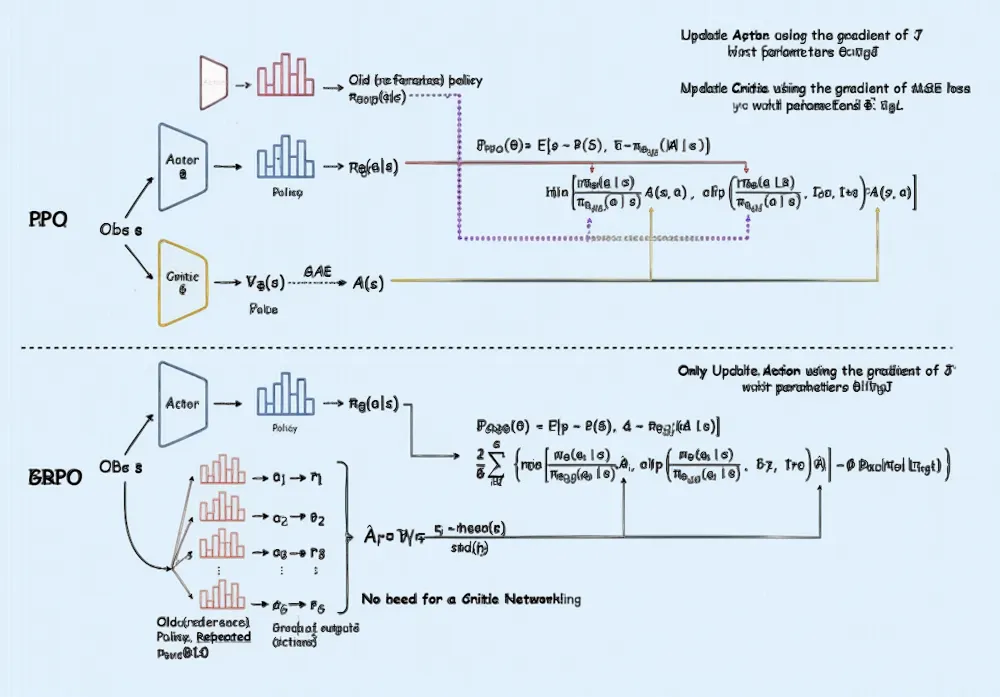
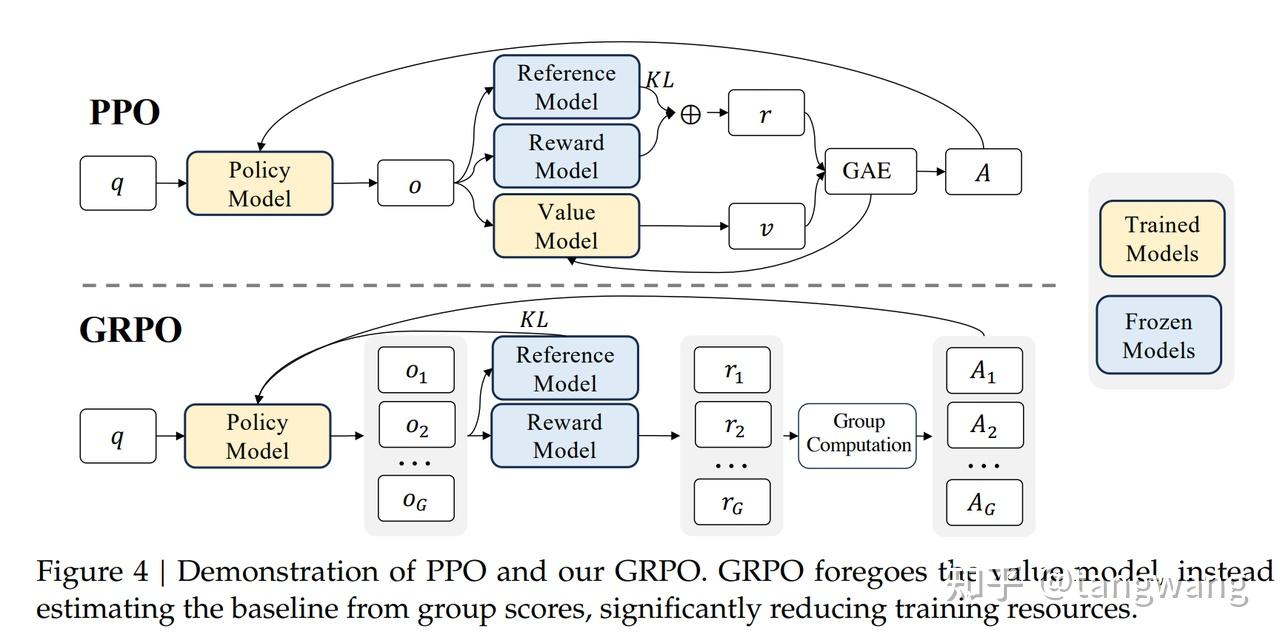
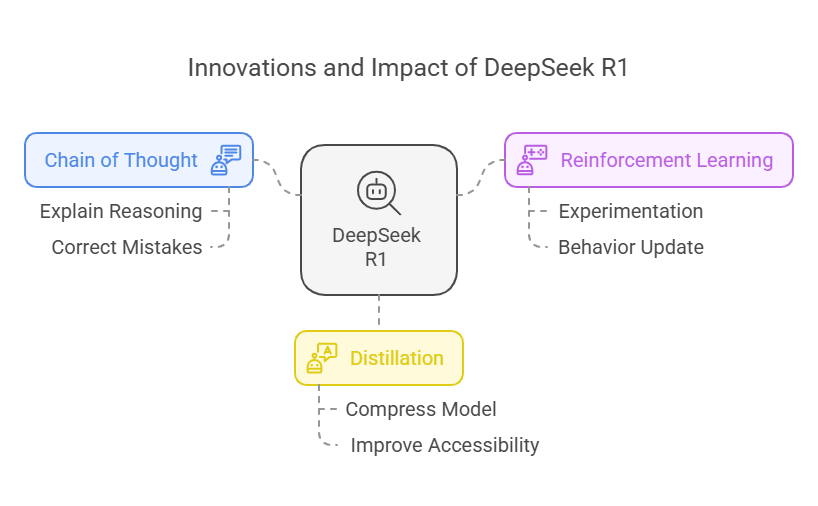
What is GRPO? The RL algorithm used to train DeepSeek | by Mehul Gupta ...
DPO训练细节问题? - 知乎