Showing 94 of 94on this page. Filters & sort apply to loaded results; URL updates for sharing.94 of 94 on this page
CLIP visual encoder in VL-T5. | Download Scientific Diagram
Modified CLIP visual encoder · Issue #15 · chongzhou96/MaskCLIP · GitHub
Performance for the CLIP visual encoder using a ResNet backbone as ...
Overview of VT-CLIP where text encoder and visual encoder refers to the ...
Example showing how the CLIP text encoder and image encoders are used ...
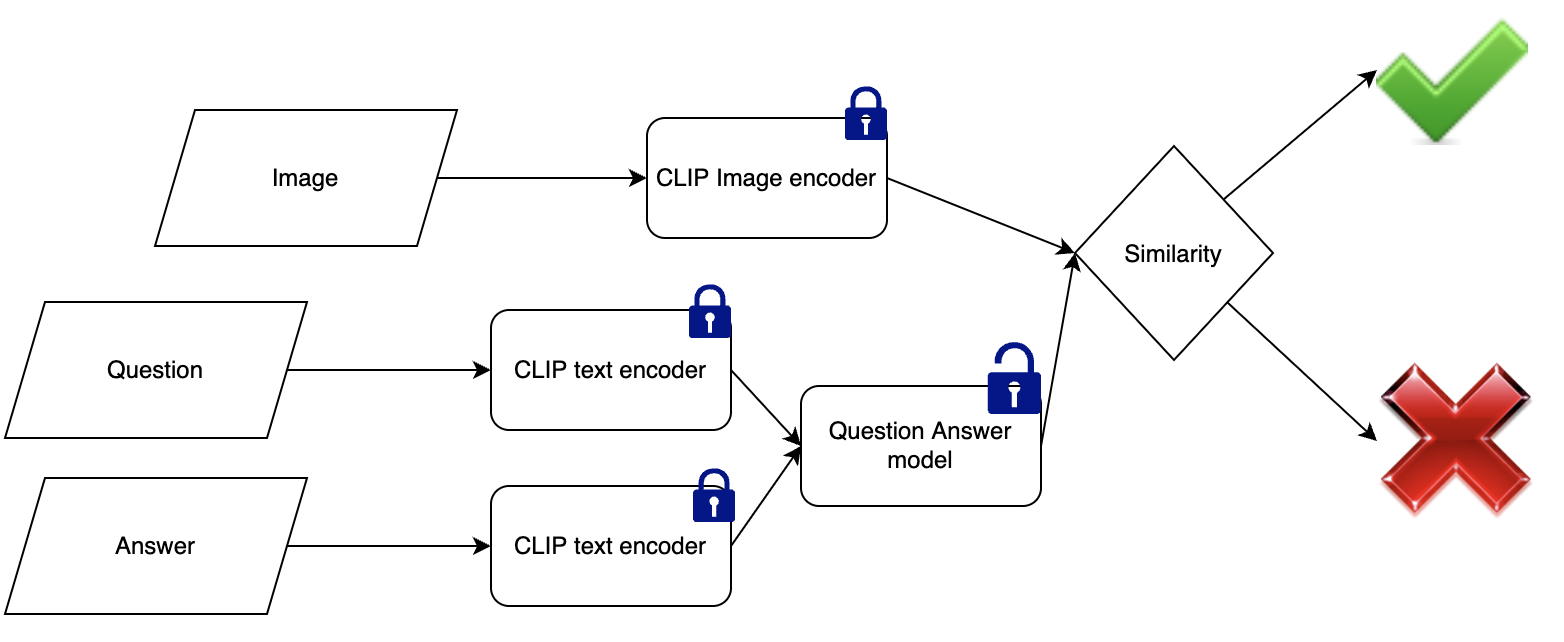
Visual Question Answering using CLIP - Ashwin’s
Leveraging CLIP for Visual Question Answering
[Survey] Visual Encoders and CLIP · Issue #11 · Nana2929/Medical-VQA ...
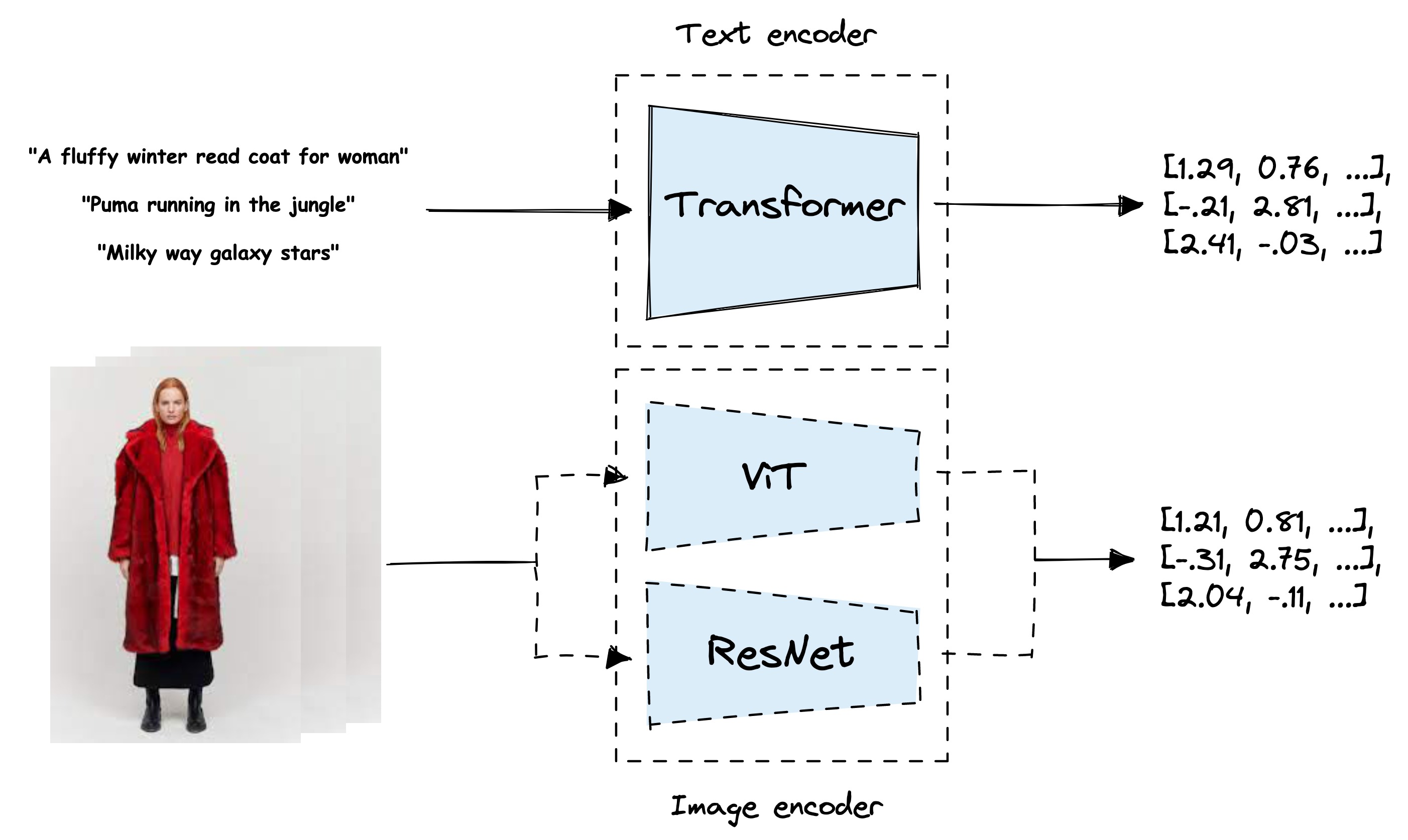
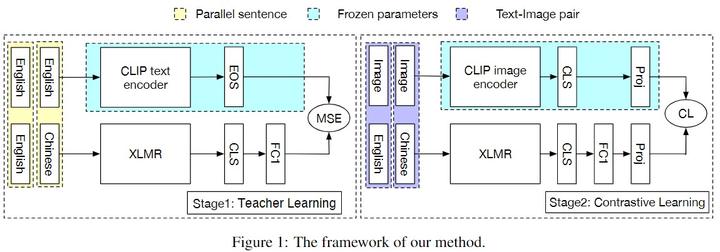
Simultaneous training of the text and image encoder to learn visual ...
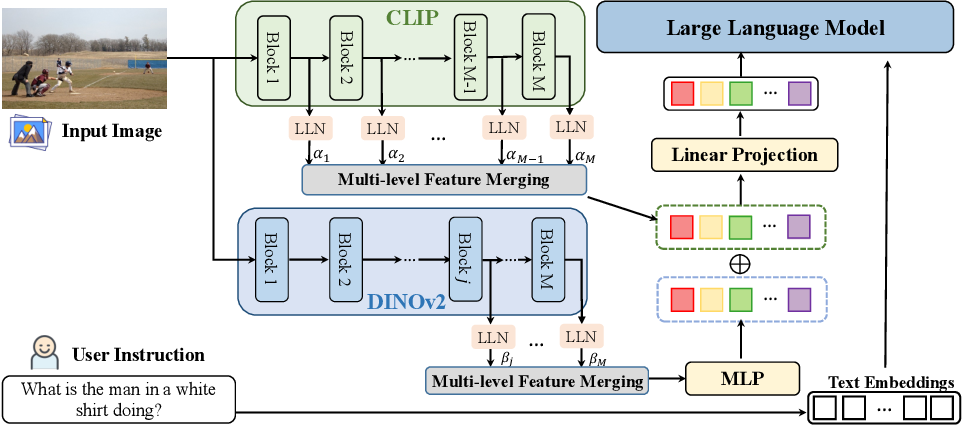
Figure 4 from From CLIP to DINO: Visual Encoders Shout in Multi-modal ...
We use CLIP image encoder for the images, with the left side ...
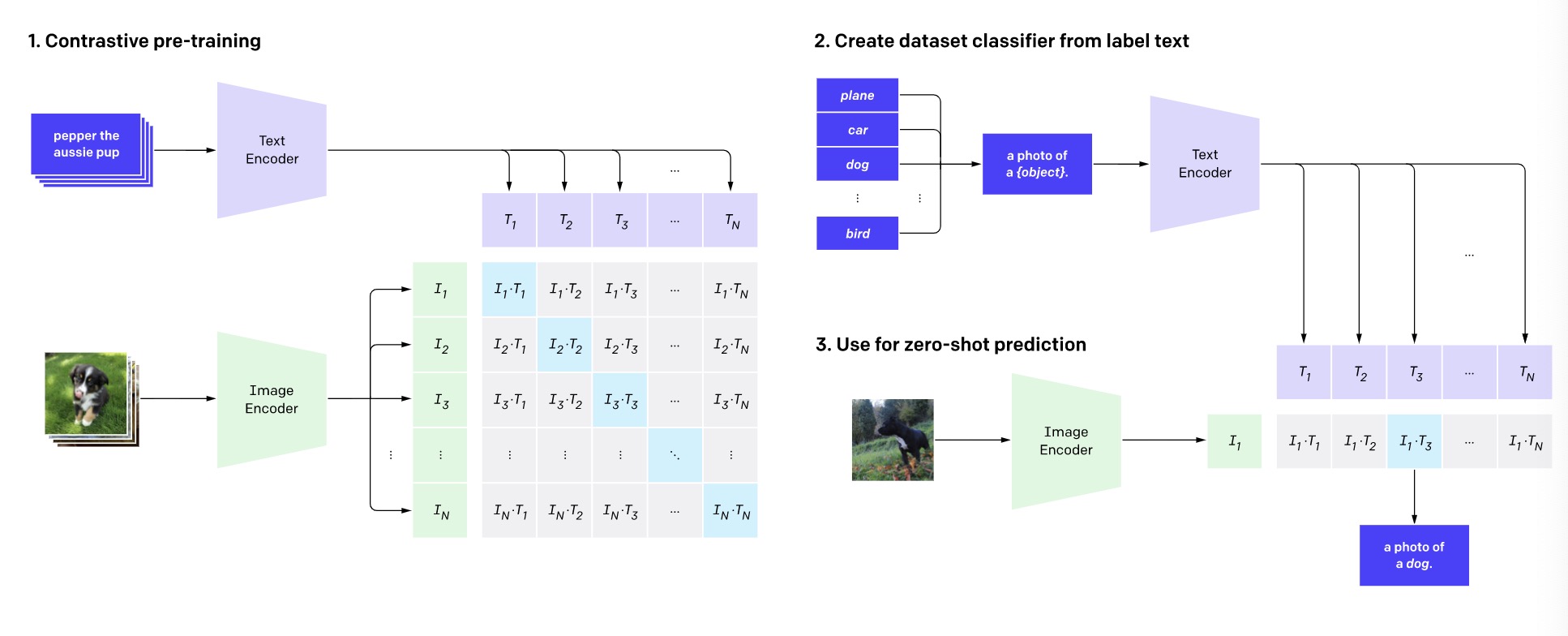
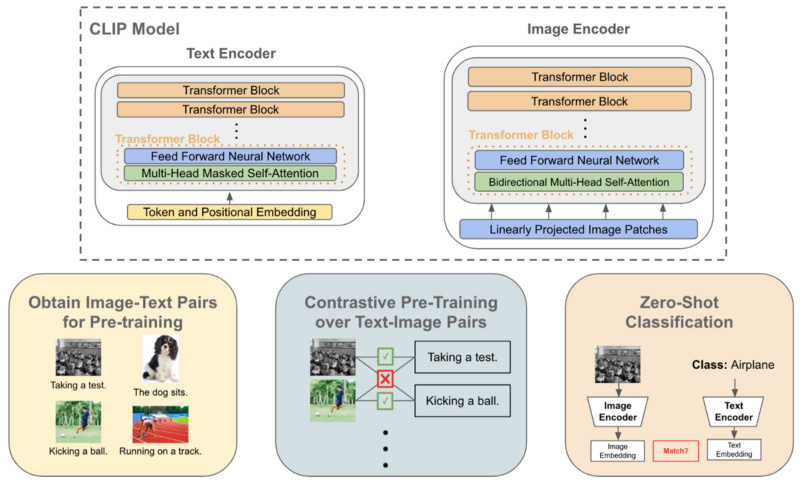
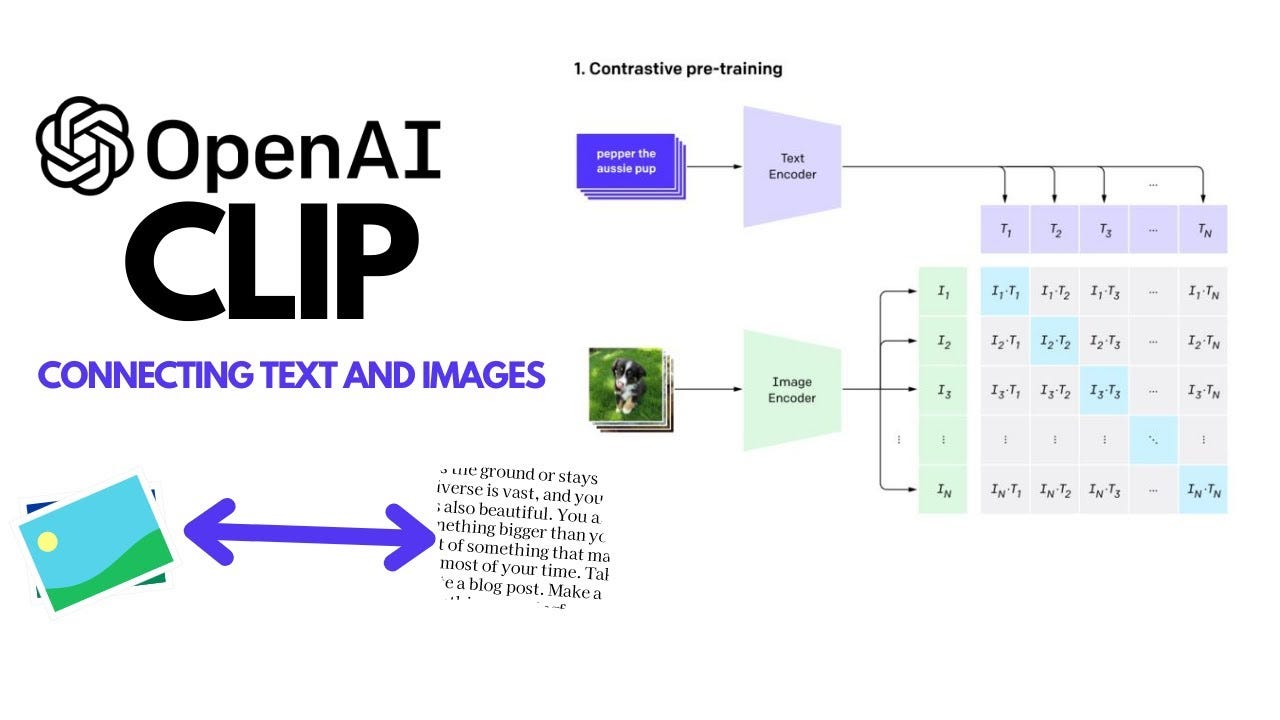
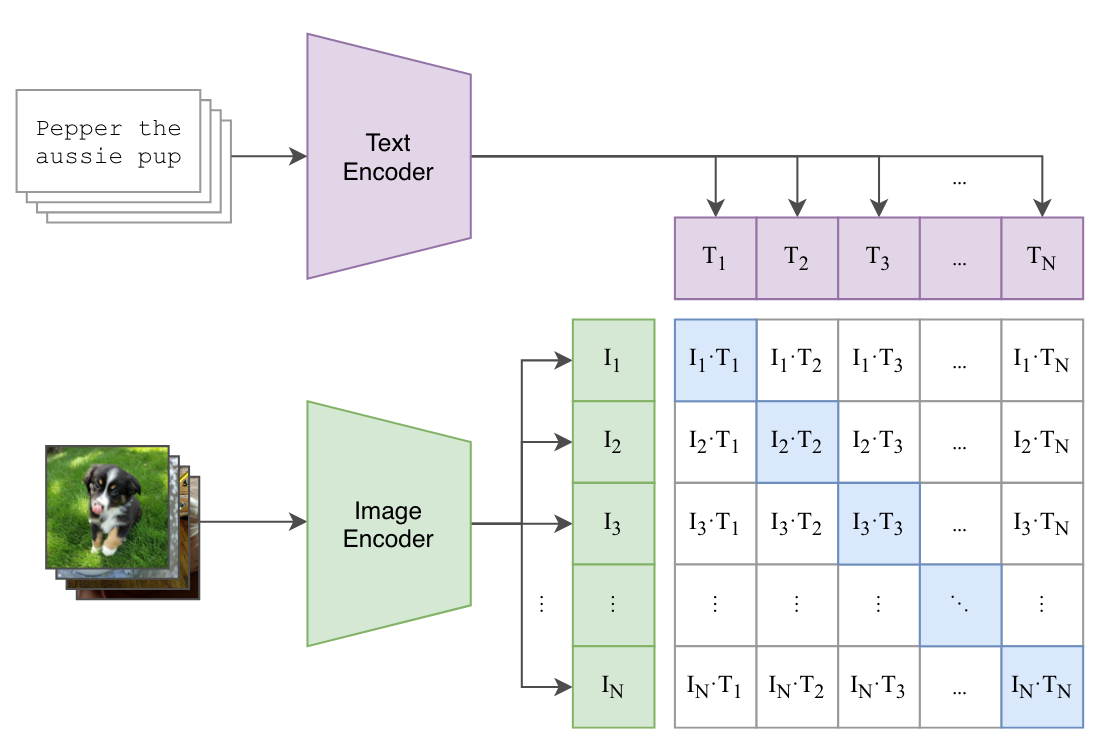
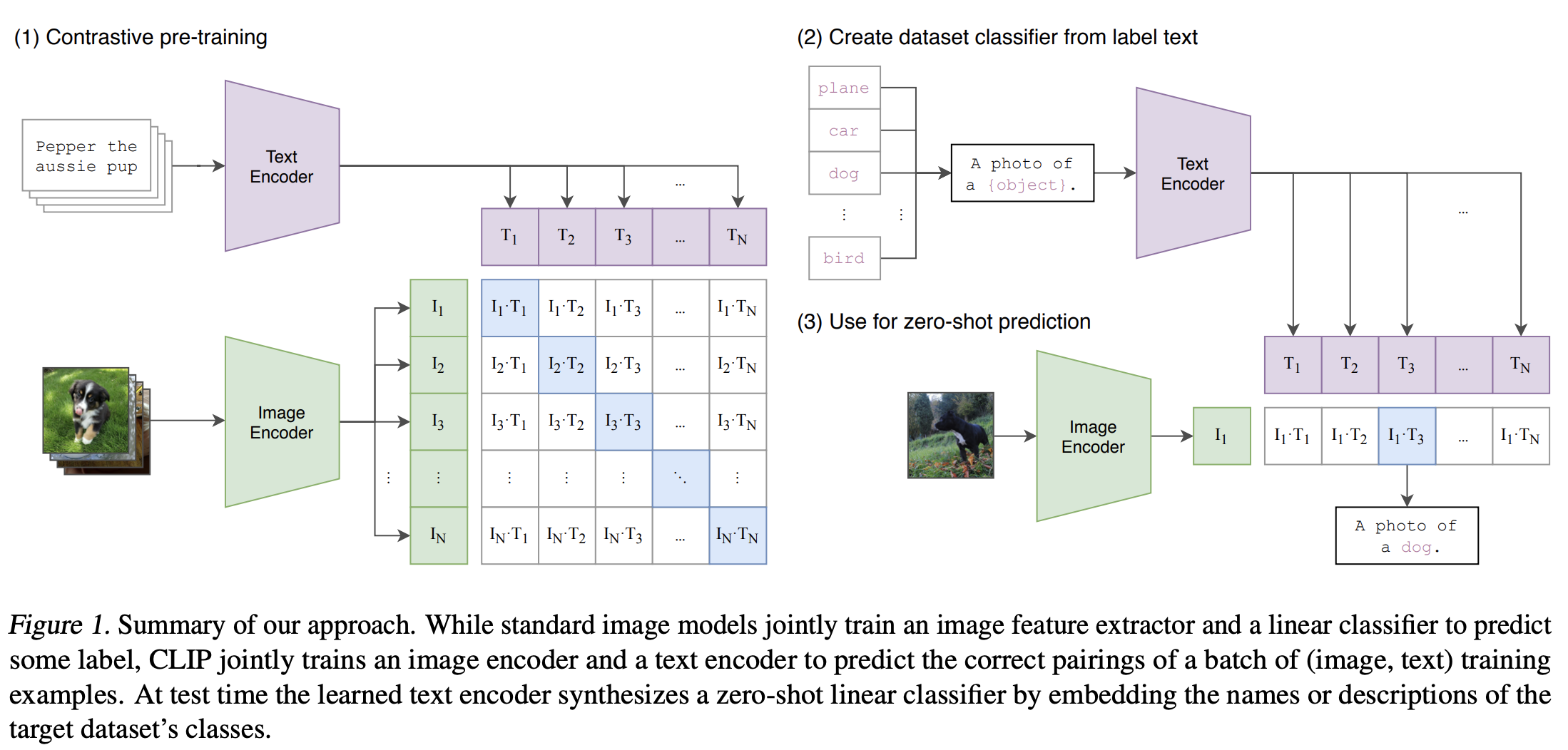
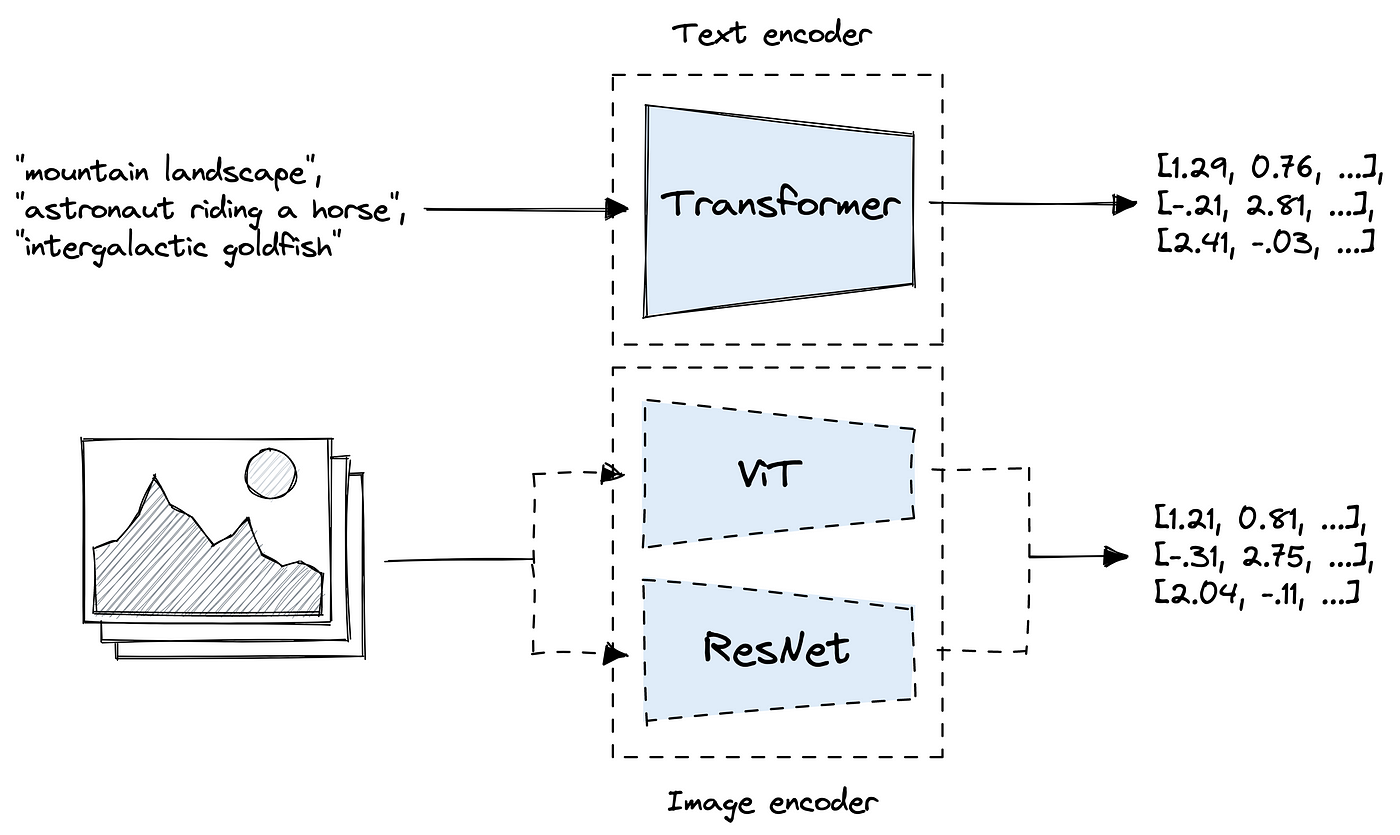
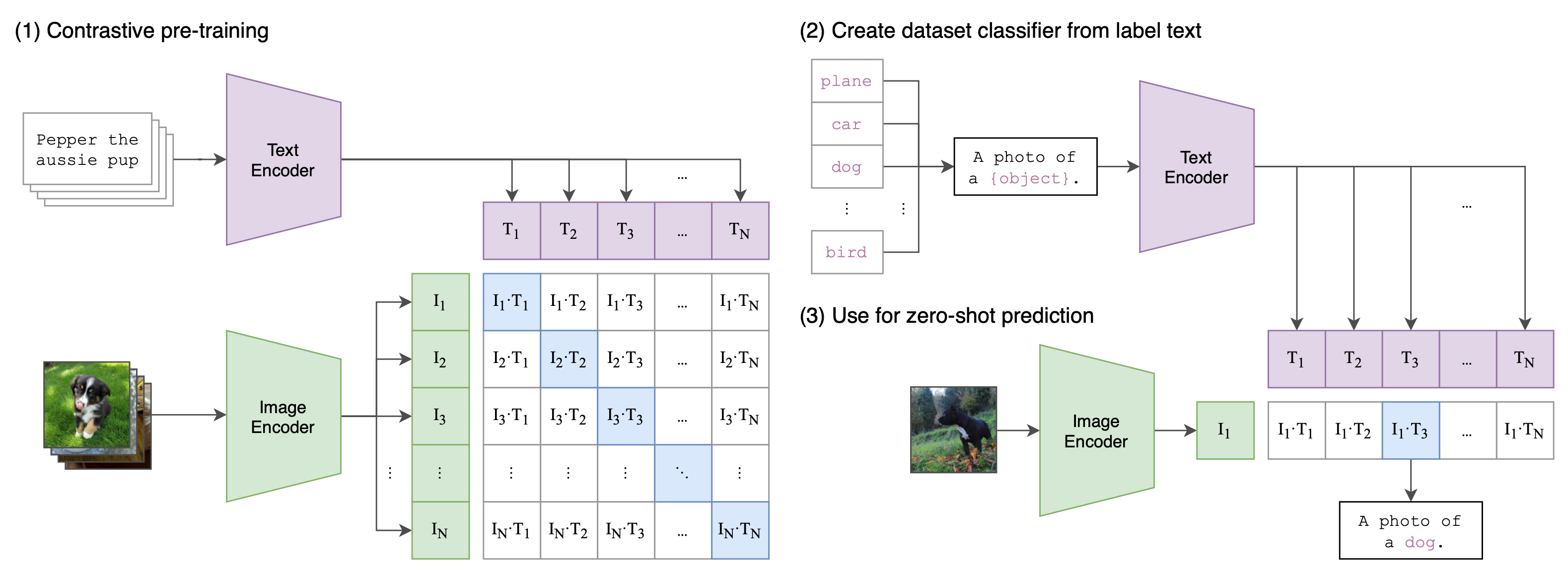
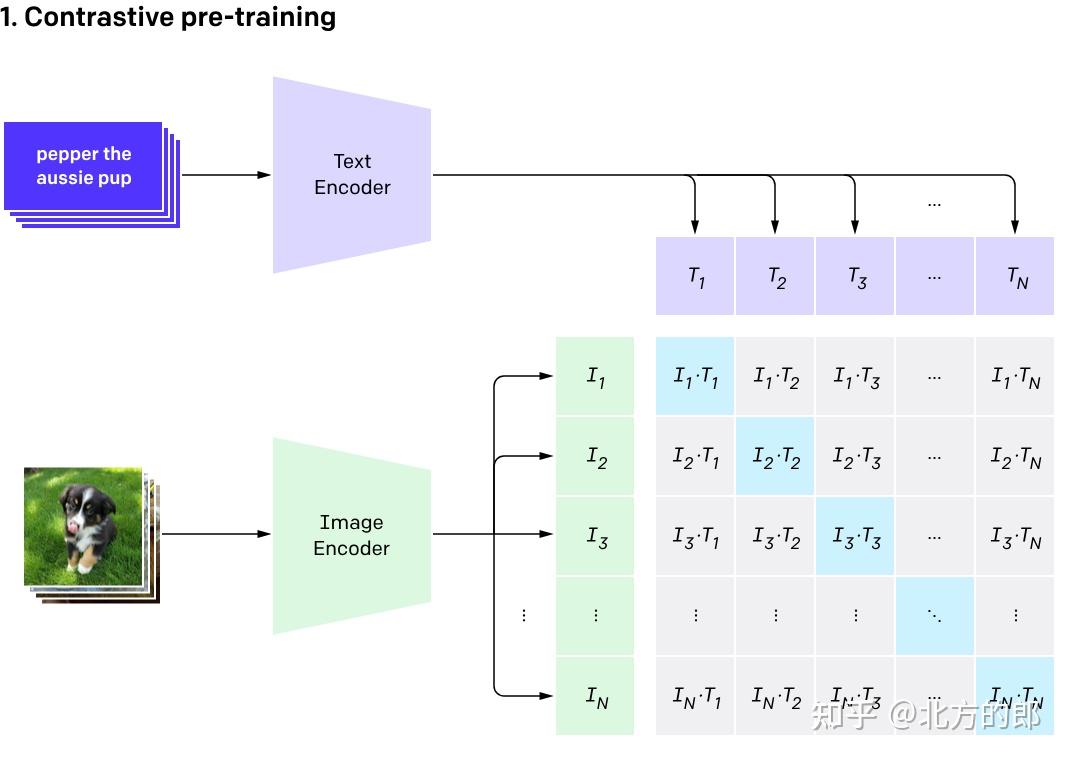
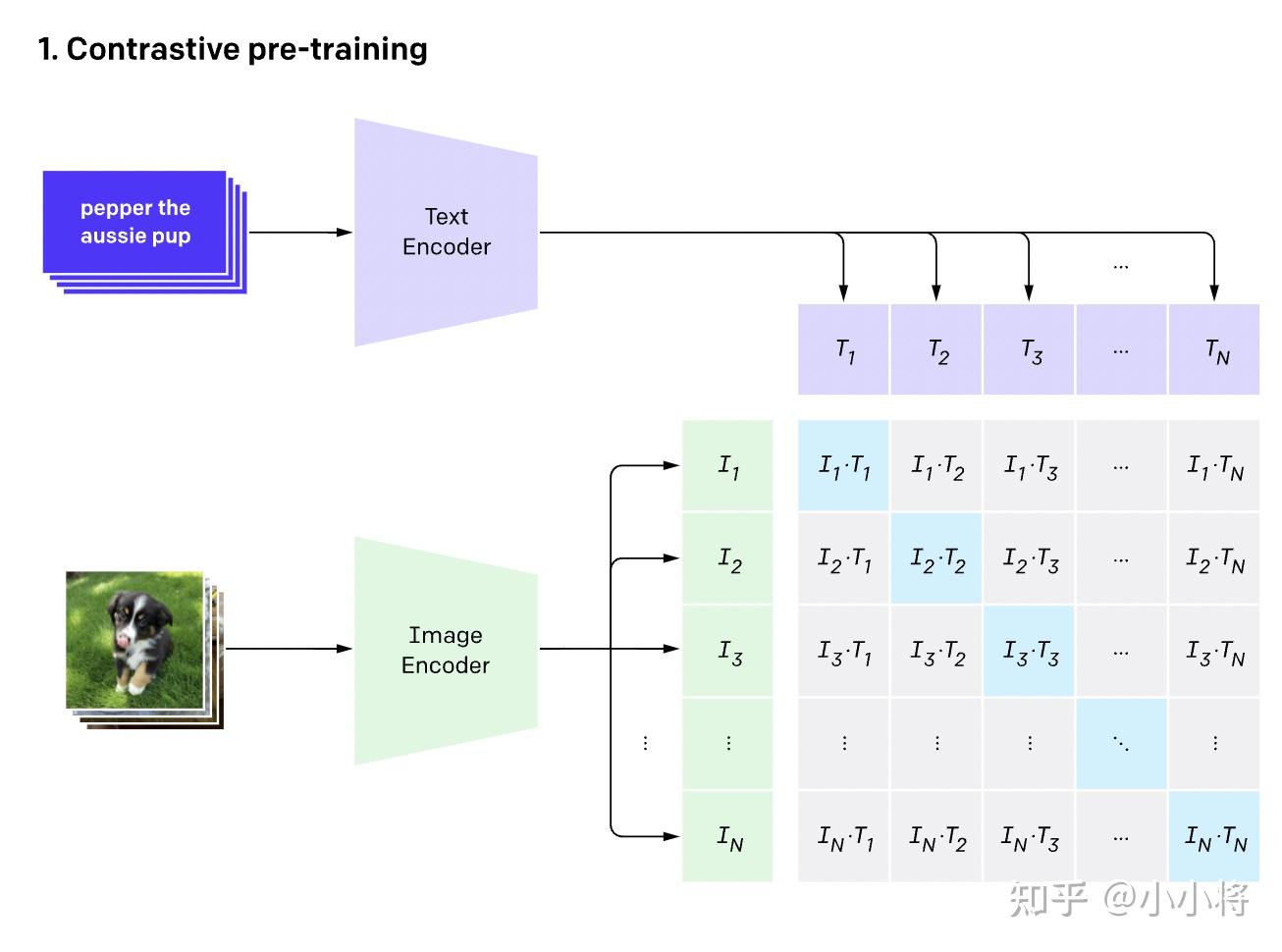
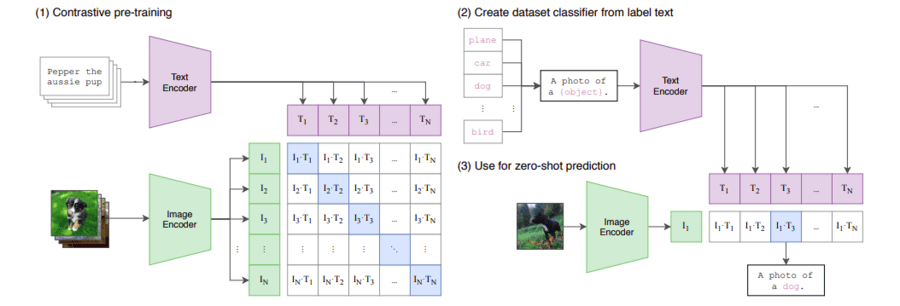
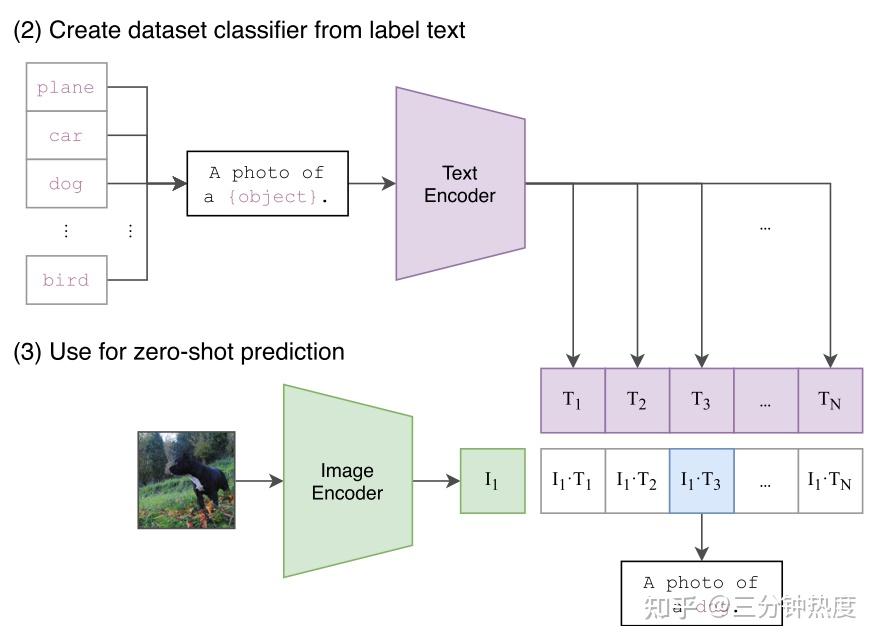
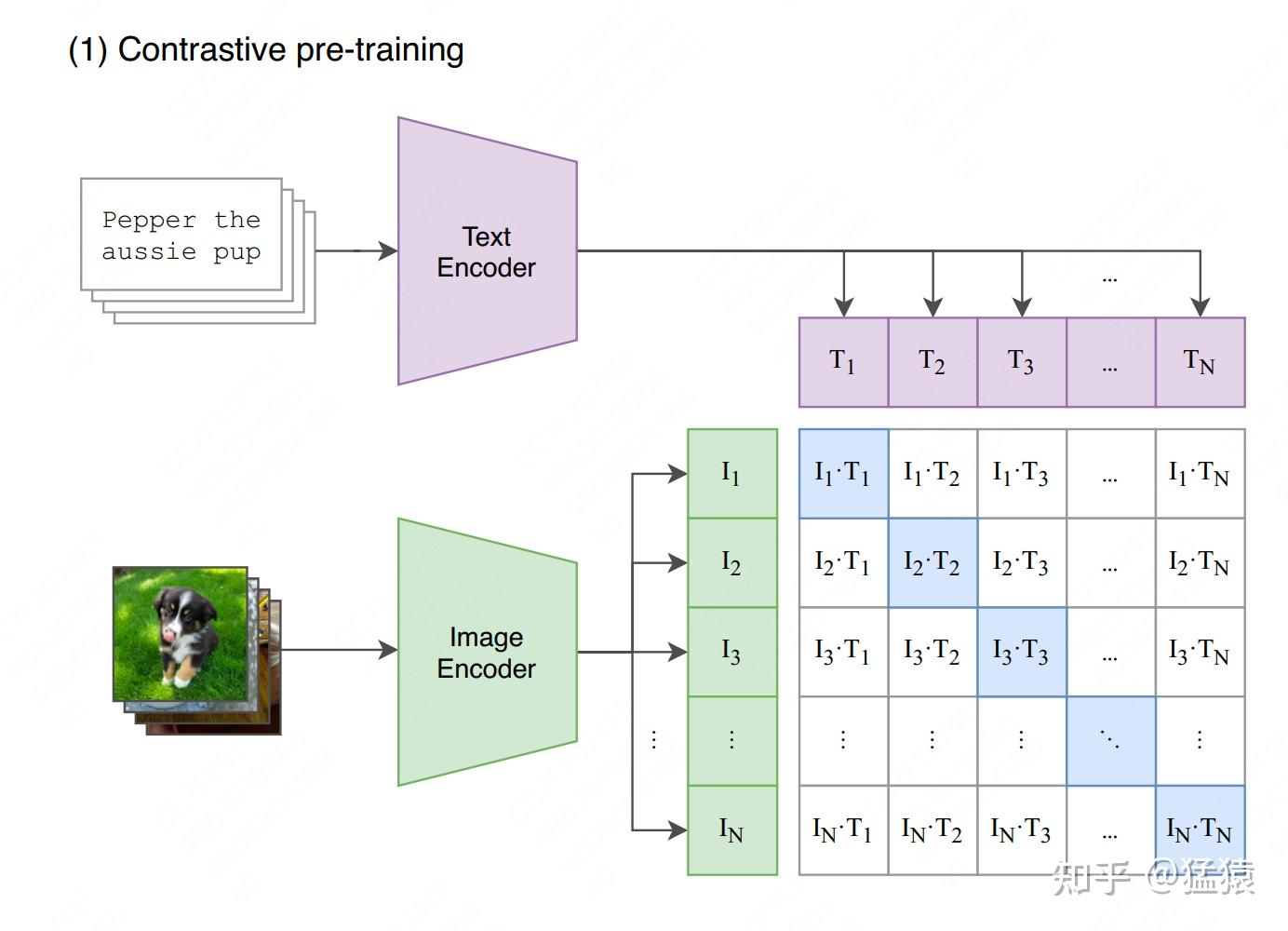
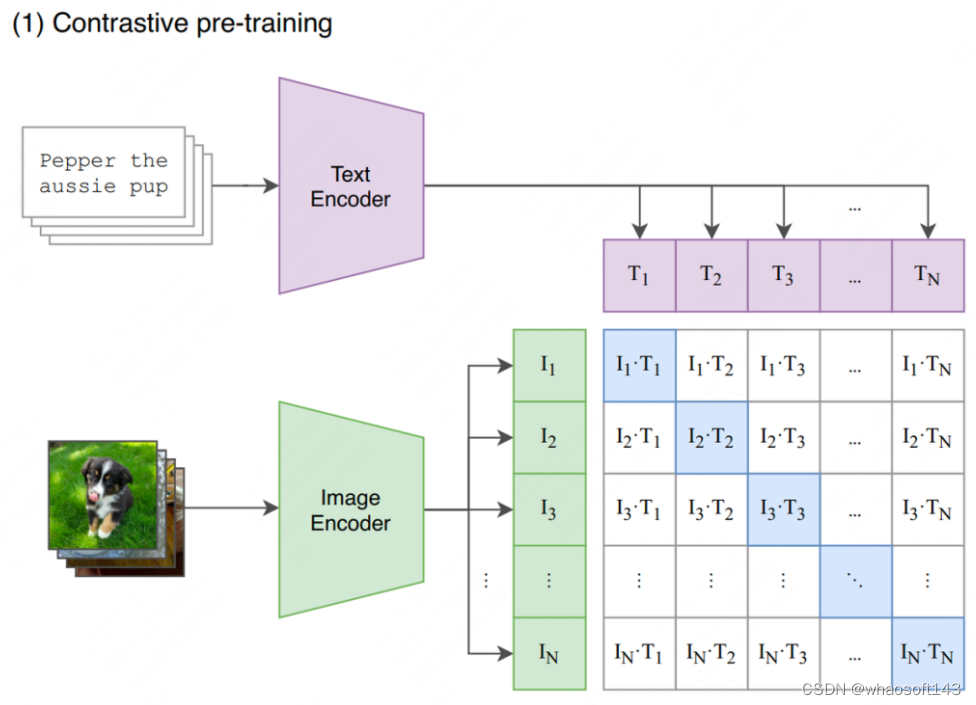
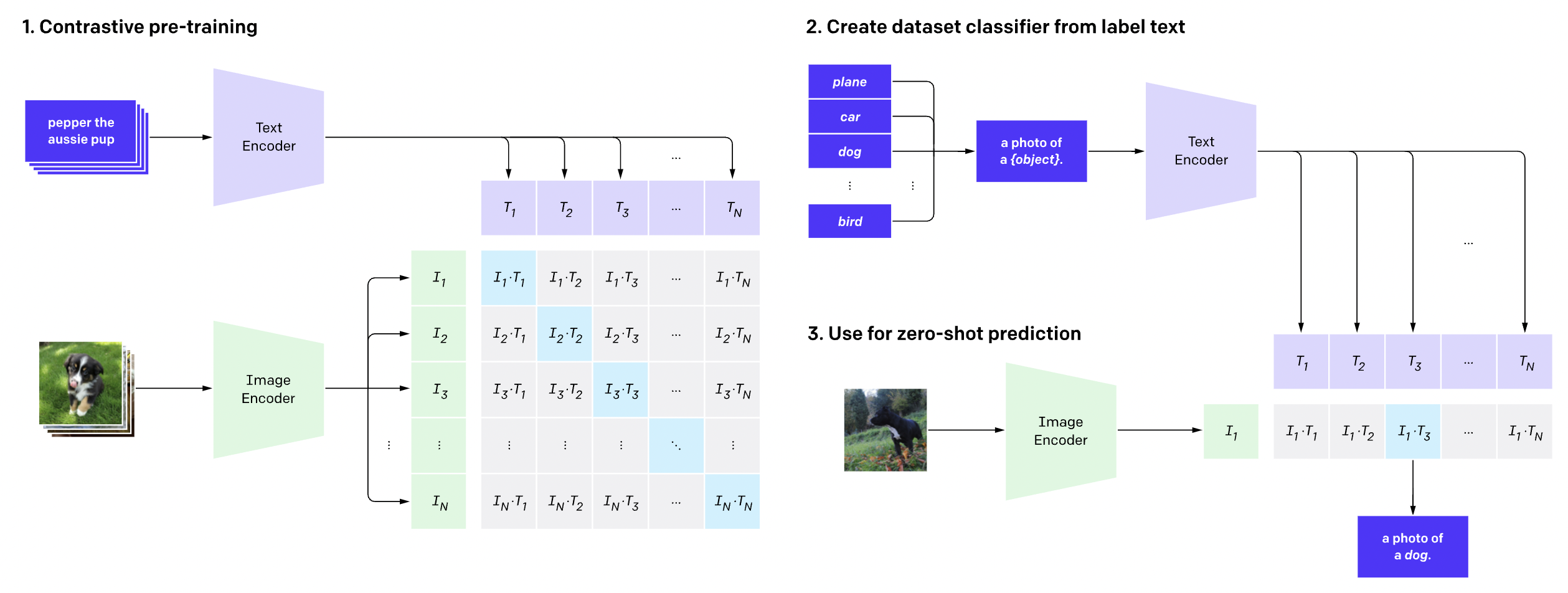
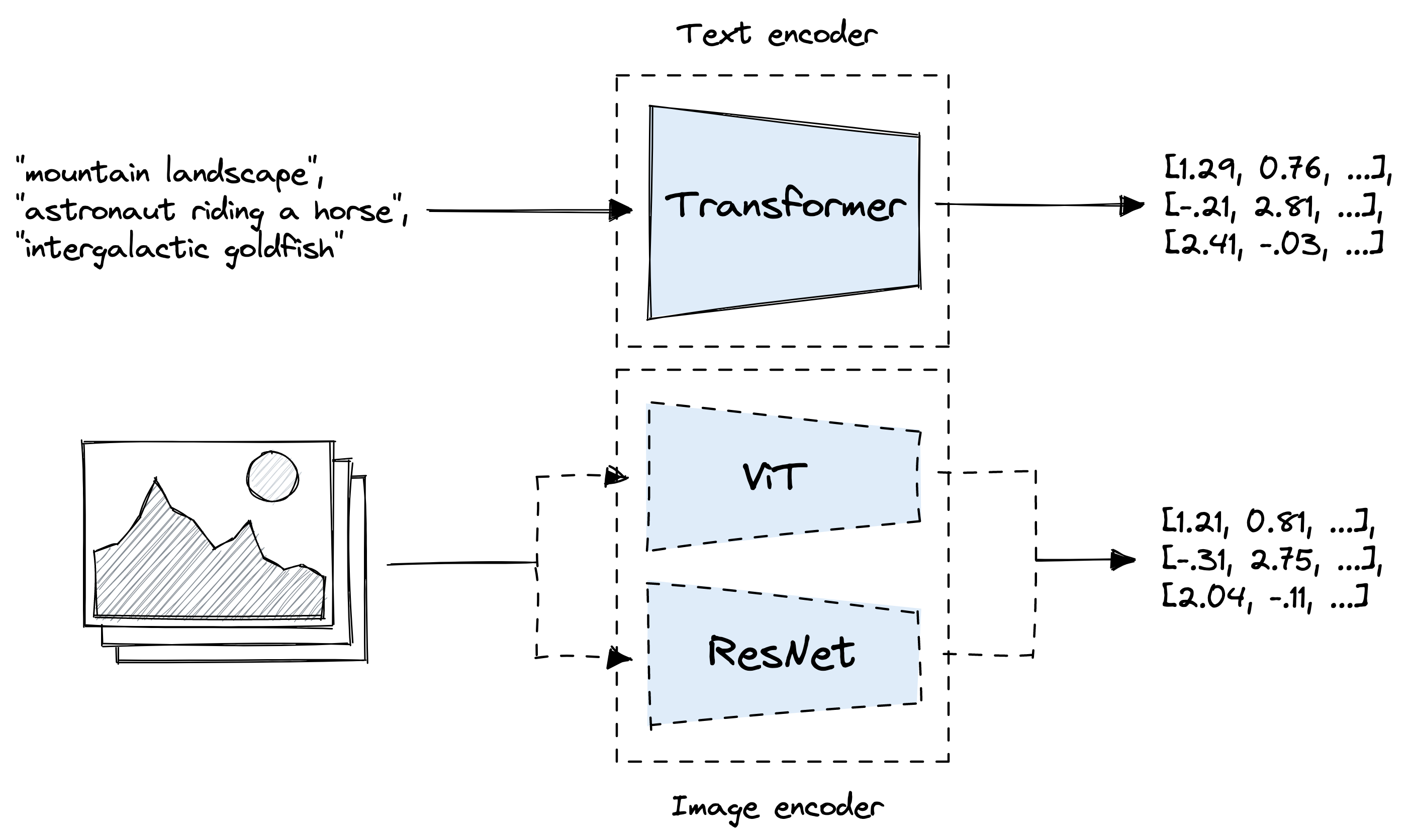
CLIP : Learning Transferable Visual Models From Natural Language ...
【论文精读04】AltCLIP: Altering the Language Encoder in CLIP for Extended ...
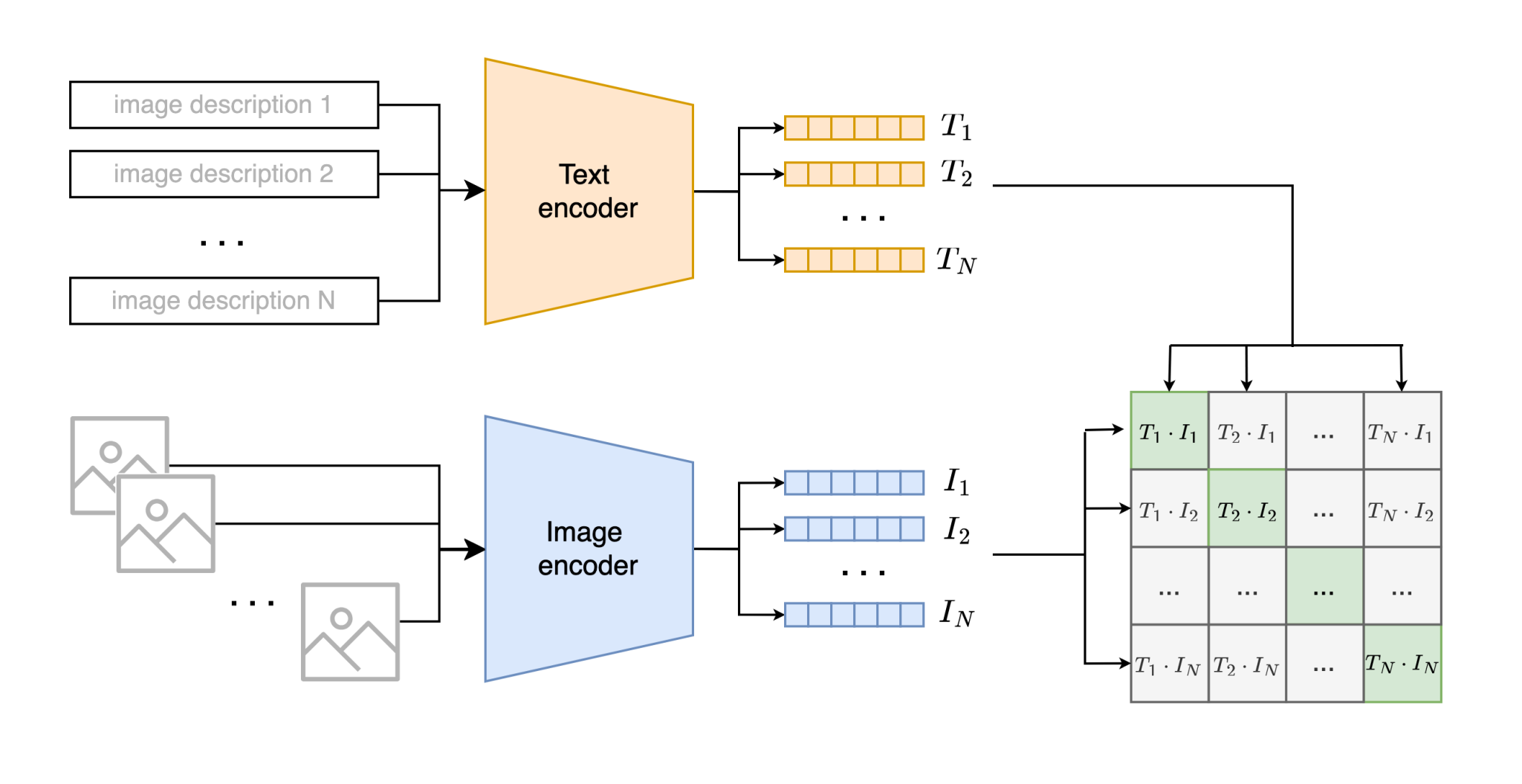
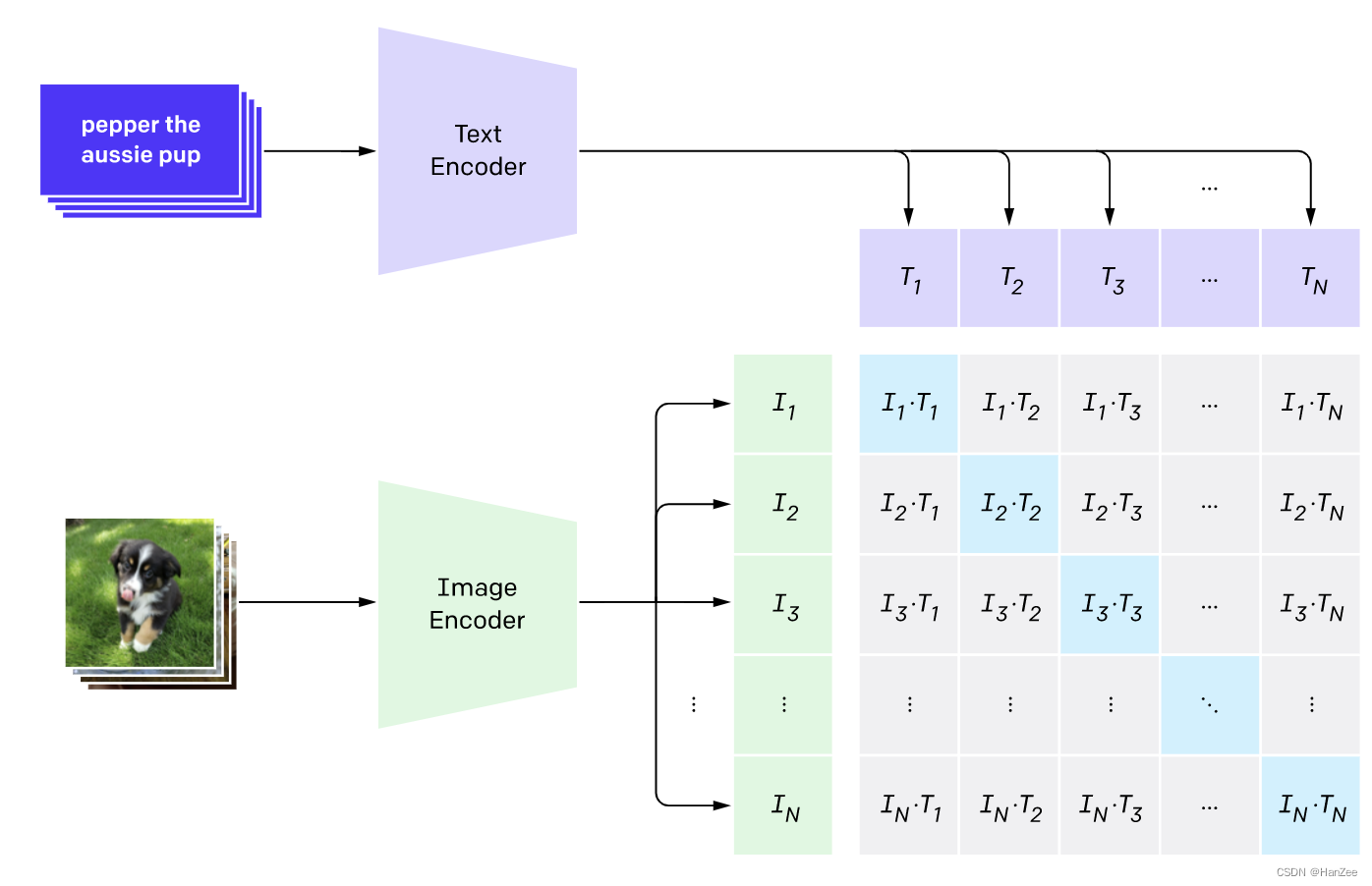
Multi-modal ML with OpenAI's CLIP | Pinecone
CLIP (Contrastive Language-Image Pretraining) - GeeksforGeeks
Image Captioning with CLIP
Figure 2 from The Unreasonable Effectiveness of CLIP Features for Image ...
Using CLIP to Classify Images without any Labels
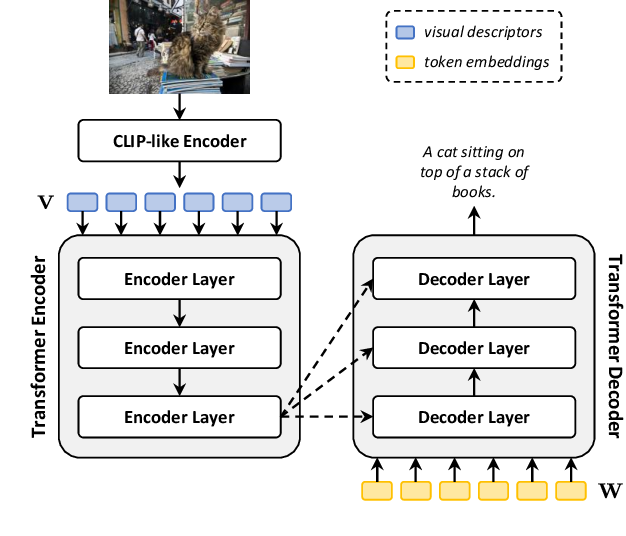
[2112.02399] VT-CLIP: Enhancing Vision-Language Models with Visual ...
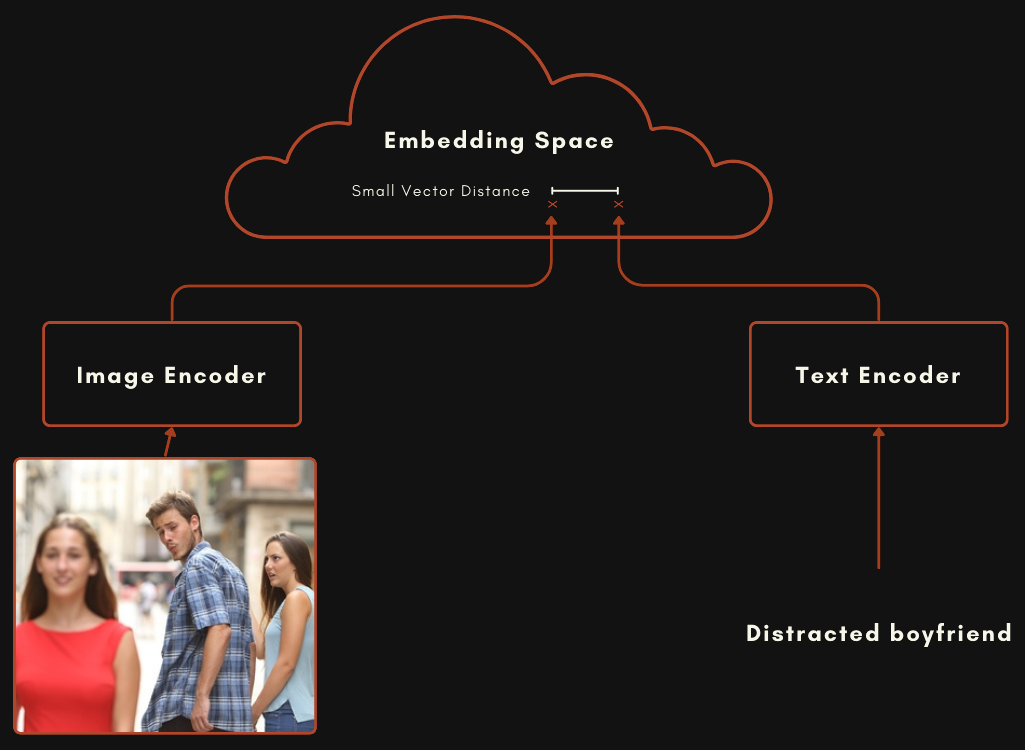
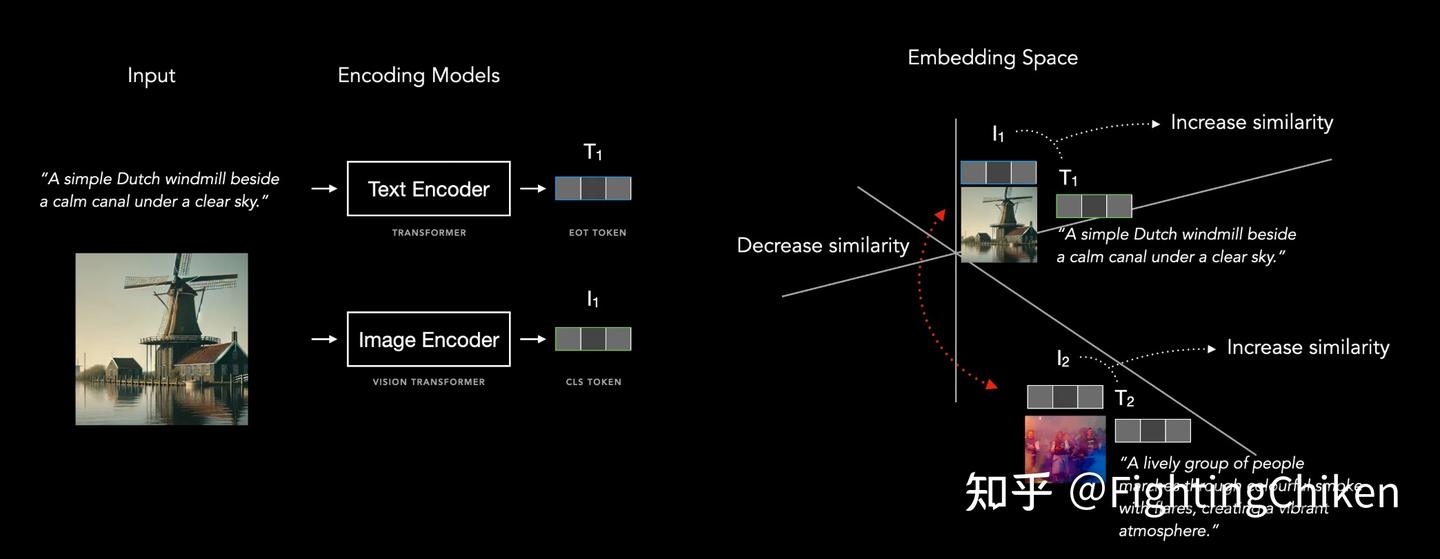
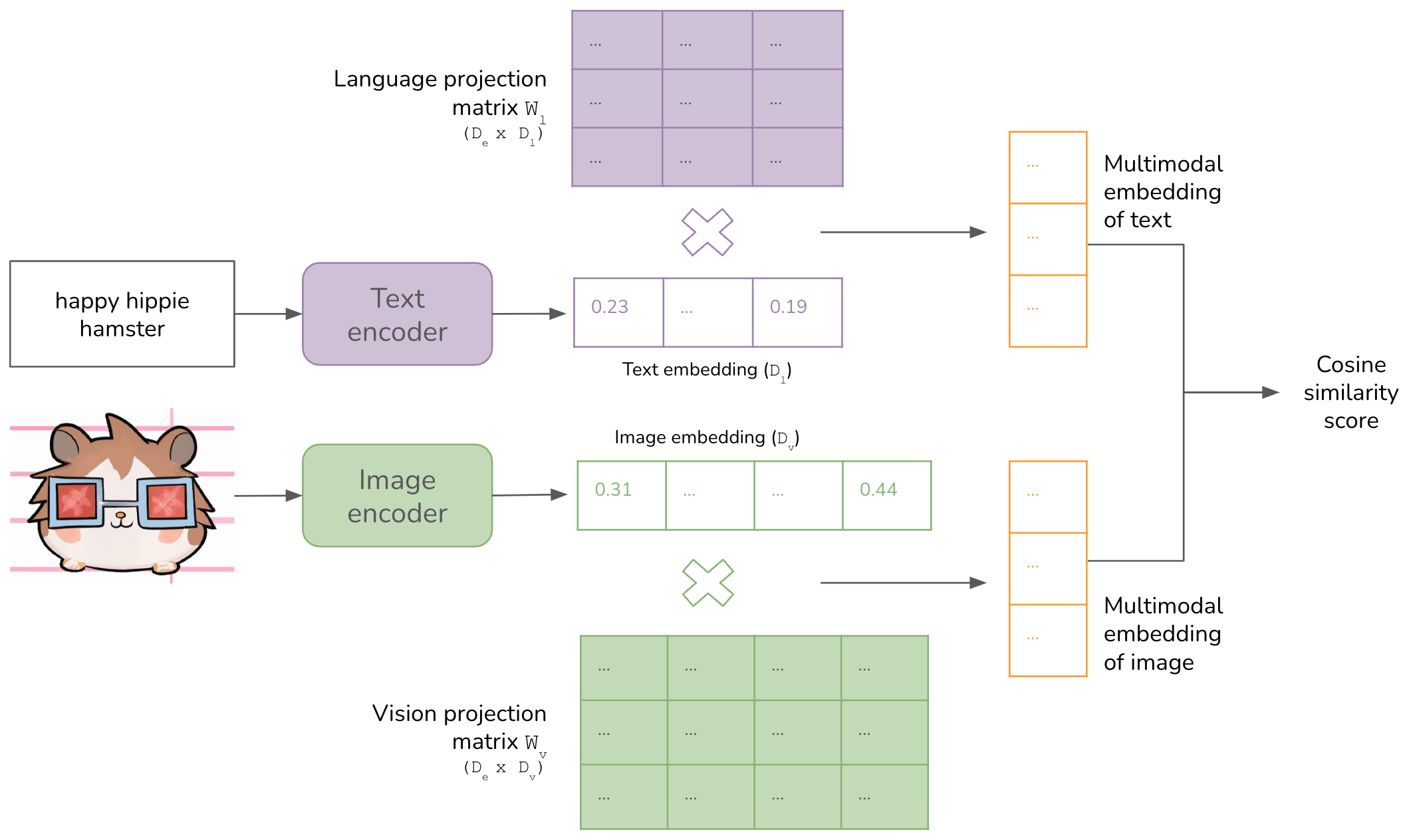
Quick tip: Visualising Similarities Between CLIP Text and Image ...
【论文笔记】Fine-tuned CLIP Models are Efficient Video Learners-CSDN博客
The Annotated CLIP (Part-2)
[CLIP] Learning Transferable Visual Models From Natural Language ...
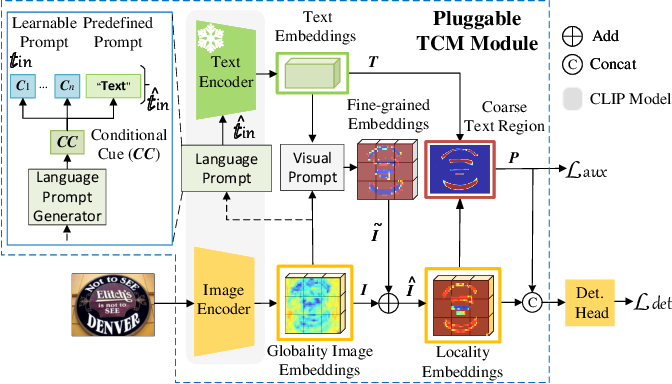
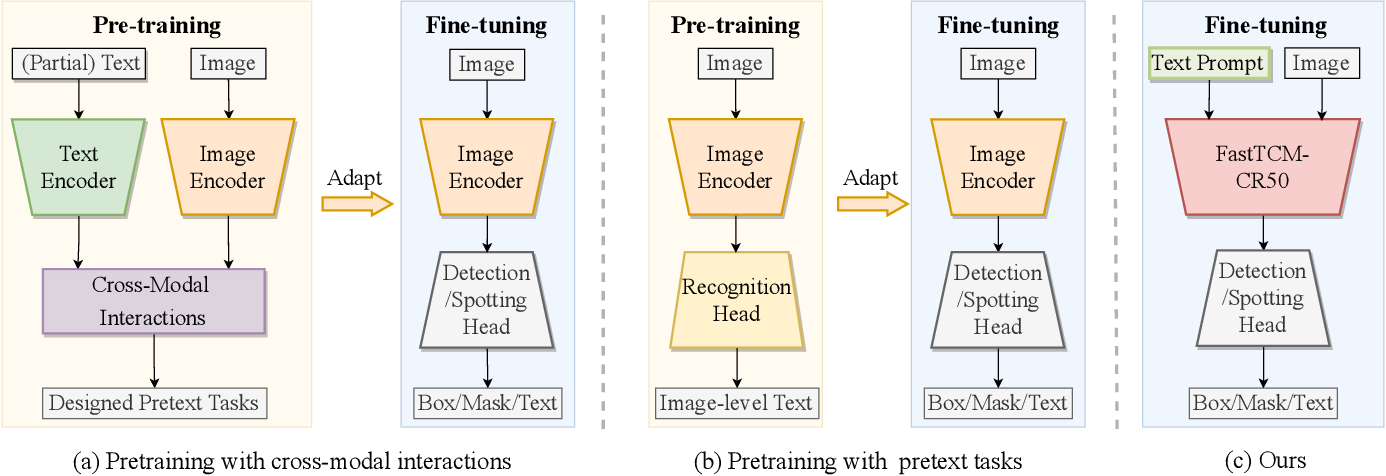
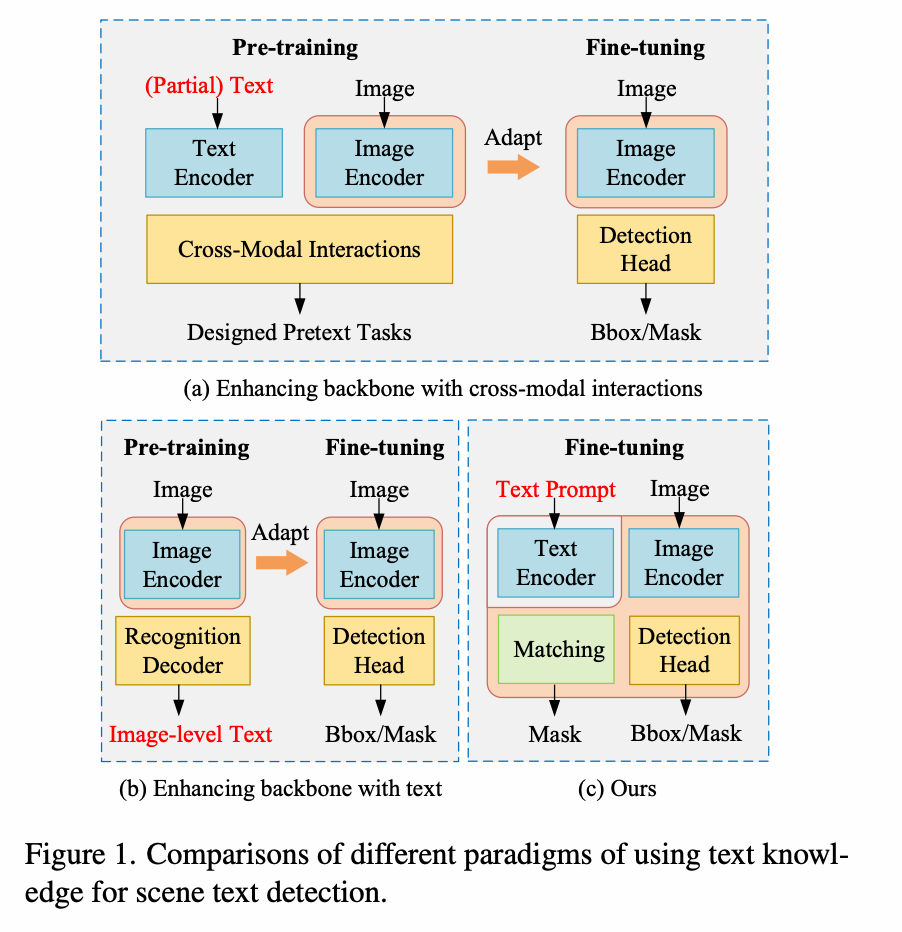
【论文阅读】Turning a CLIP Model into a Scene Text Detector-CSDN博客
The What and Why of Text-Image Modality Gap in CLIP Models
Unlocking the Power of CLIP Encoder: A Text Encoder's Impact
CLIP Text Encoder-CSDN博客
(PDF) Turning a CLIP Model into a Scene Text Spotter
Bridging the Gap Between Text and Images in Computer Vision With CLIP ...
(PDF) Turning a CLIP Model into a Scene Text Detector
【论文&模型讲解】CLIP(Learning Transferable Visual Models From Natural Language ...
CLIP原文——Learning Transferable Visual Models From Natural Language ...
Multi-modal representation learning : A deepdive and comparison of CLIP ...
CLIP & CLAP_contrastive language-audio pretraining-CSDN博客
Review — CLIP: Learning Transferable Visual Models From Natural ...
[논문 리뷰] Unifying Specialized Visual Encoders for Video Language Models
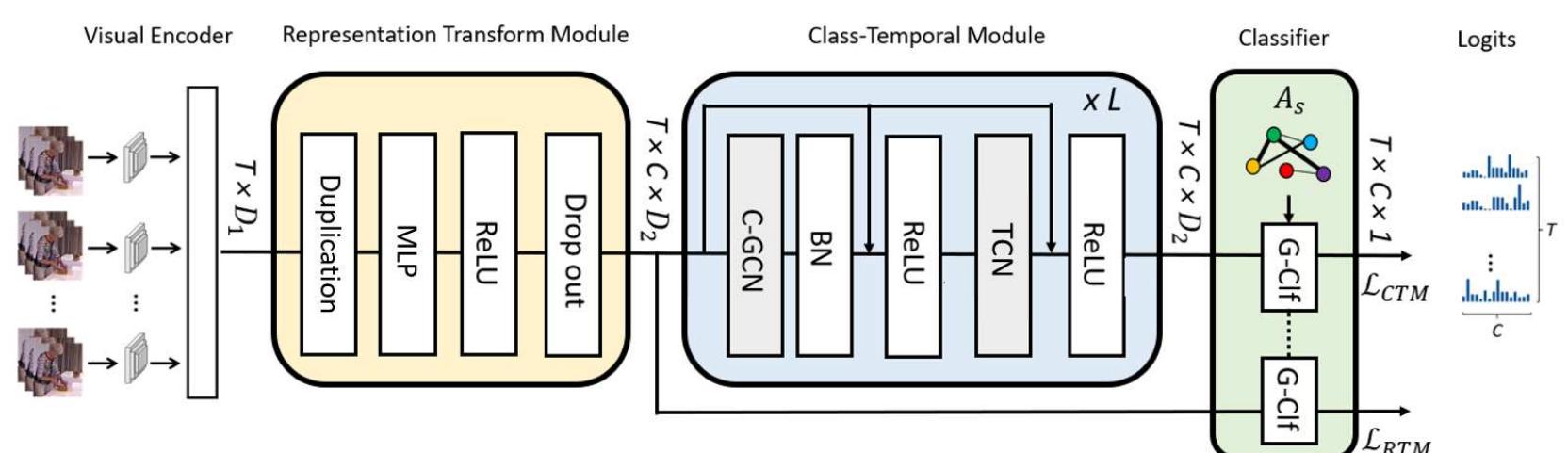
Overall structure. the model composed of a visual encoder, a
Figure 3 from Turning a CLIP Model into a Scene Text Detector ...
Do the text encoders vary between different clip models · Issue #297 ...
Overall structure. The model composed of a Visual Encoder, a ...
Building CLIP From Scratch. Open World Object Recognition on the… | by ...
Turning a CLIP Model into a Scene Text Spotter: Paper and Code
Turning a CLIP Model into a Scene Text Detector - 知乎
Examples of the two vision-language understanding tasks. For VQA ...
(PDF) VT-CLIP: Enhancing Vision-Language Models with Visual-guided Texts
Overview of our method. The image is encoded into a feature map by the ...
CLIP: Bridging Vision and Language in AI
Understanding and Fine-tuning CLIP. A Revolutionary Vision-Language ...
CLIP模型全景回顾:视觉-语言预训练模型的演进与展望 - 知乎
CLIP, LLaVA, and the Brain | Towards Data Science
[Journal club] CRIS: CLIP-Driven Referring Image Segmentation - Speaker ...
神器CLIP:连接文本和图像,打造可迁移的视觉模型 - 知乎
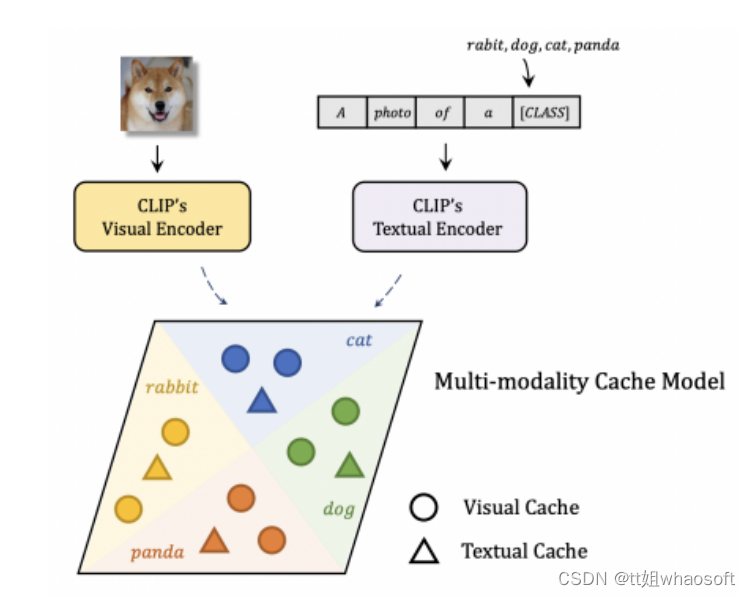
大幅提升CLIP图像分类准确率-Tip-Adapter_clip adapter-CSDN博客
CLIP, Intuitively and Exhaustively Explained | Towards Data Science
[2401.06167] Enhancing Multimodal Understanding with CLIP-Based Image ...
Image Retrieval Using CLIP: Deep Dive into Multimodal Visual-Text Matching
深度解读CLIP:打破文字与图像之间的壁垒 - 知乎
Table 1 from Switching Text-Based Image Encoders for Captioning Images ...
A Systematic Literature Review on Using the Encoder-Decoder Models for ...
The architecture of the proposed CLIP-empowered generator for ...
CLIP模型学习(Contrastive Language-Image Pre-training) - 知乎
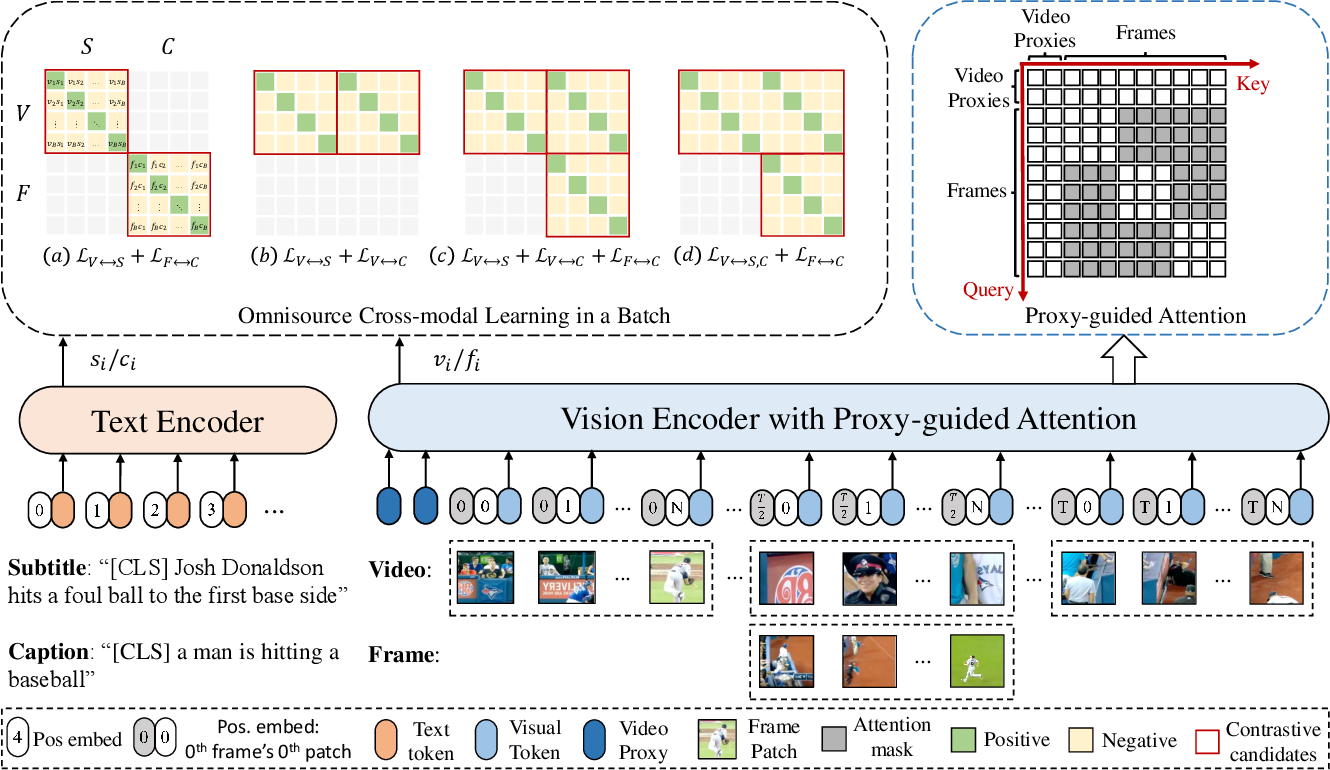
[2209.06430] CLIP-ViP: Adapting Pre-trained Image-Text Model to Video ...
关于多模态经典之作CLIP,还有哪些细节是你不知道的 - 知乎
CLIP: Multi-modality and Zero shot image classification 📸 – Ismael ...
Multimodality and Large Multimodal Models (LMMs)
CLIP6-CSDN博客
Shrinking the Impossible (Part 2): Teaching Chatbots to See with LLaVA ...
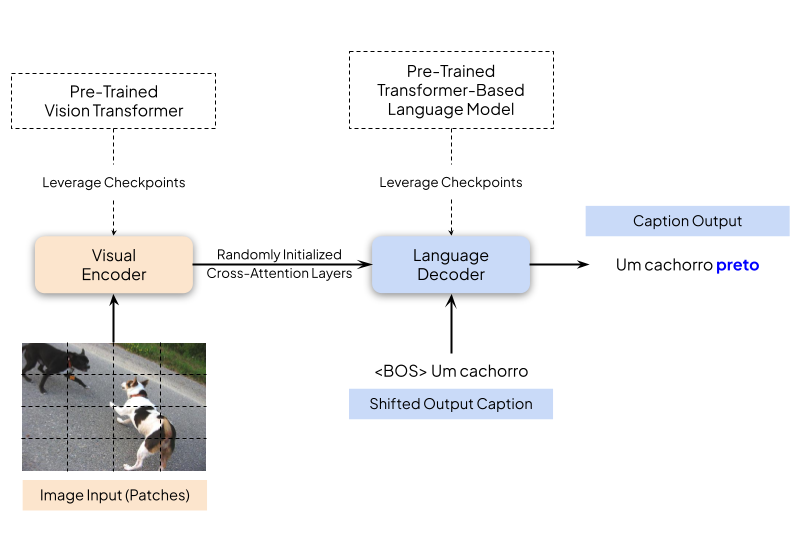
A Comparative Evaluation of Transformer-Based Vision Encoder-Decoder ...
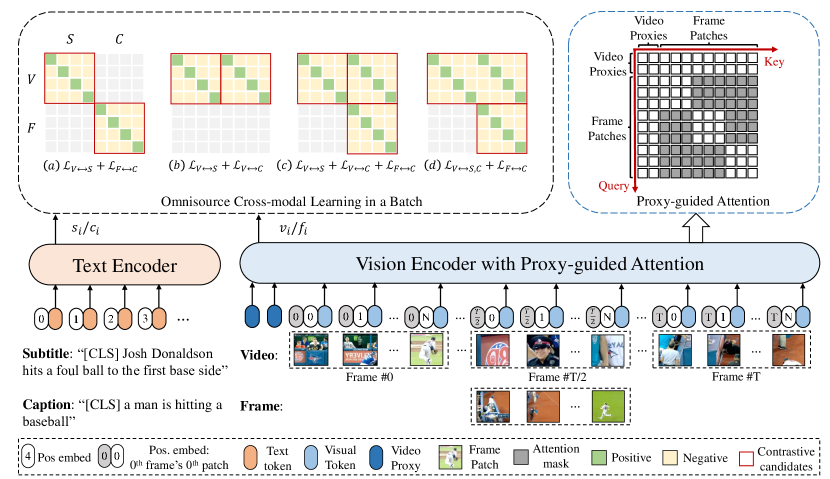
Figure 2 from CLIP-ViP: Adapting Pre-trained Image-Text Model to Video ...
《CLIP:Connecting text and images》论文学习 - 郑瀚 - 博客园
CLIP6_clip的缺点-CSDN博客
Encoders-Only Models: Workhorses of Practical Language Processing ...
SAM3 - a facebook Collection
AEmotionStudio/SCAIL-fp8 · Hugging Face
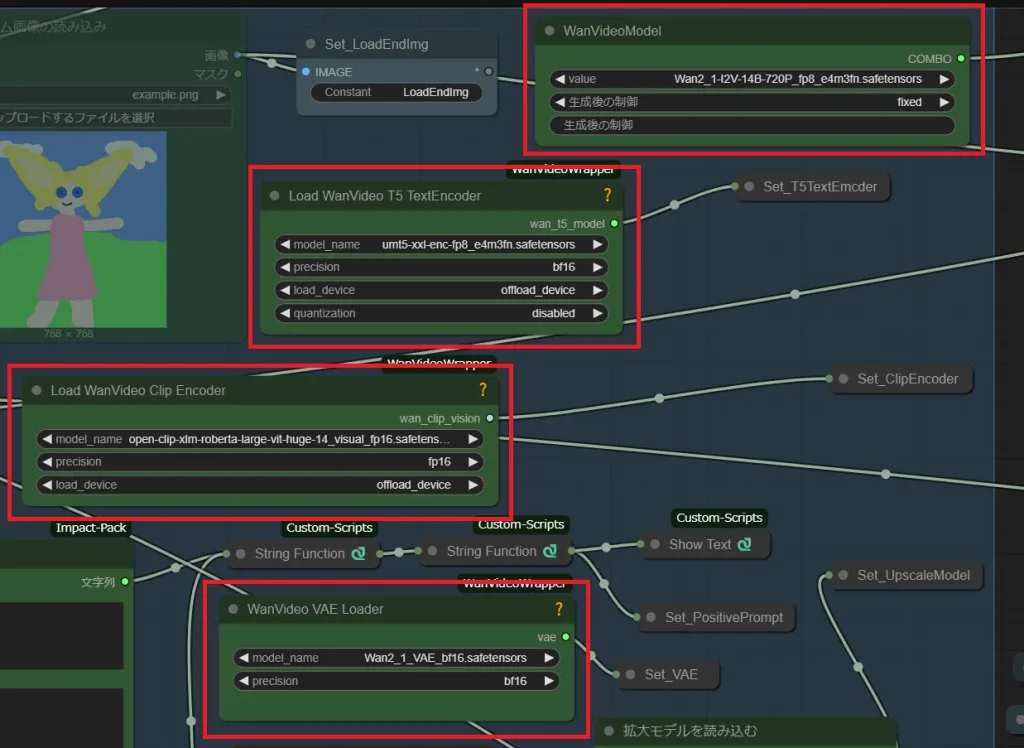
How to Run Wan 2.2 Image to Video Model in ComfyUI (FP8 Version) - Next ...
Welcome to Adobe Premiere 26.0! | Community
【動画生成AI】Wan2.1の導入方法 ComfyUI用ワークフロー配布あり【WAN2.1】 | オンラインゲーマー日記
10 Best AI Video Generators in 2026 (Tested and Ranked)
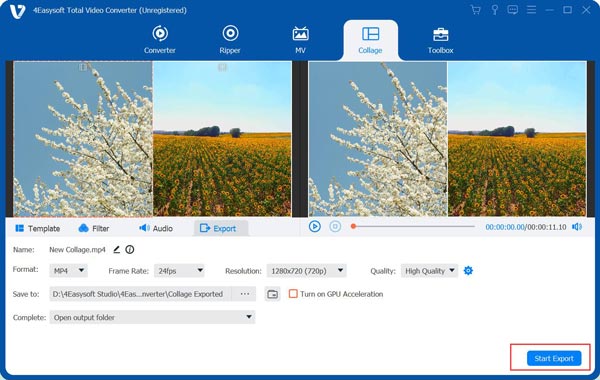
How to Make a Video Collage: 5 Tools to Try with Useful Tips
Avengers star bashes Disney for ‘disgusting’ layoffs: ‘Shame on you ...

















.png)