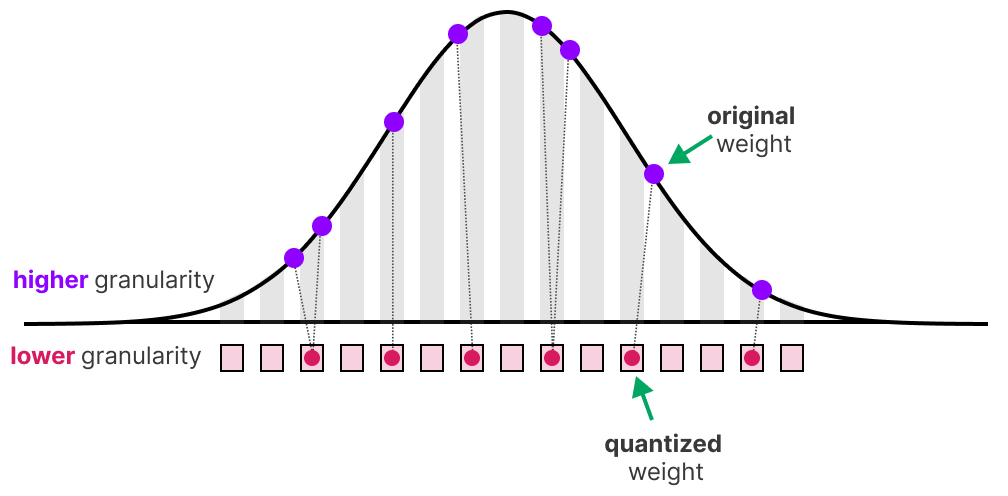
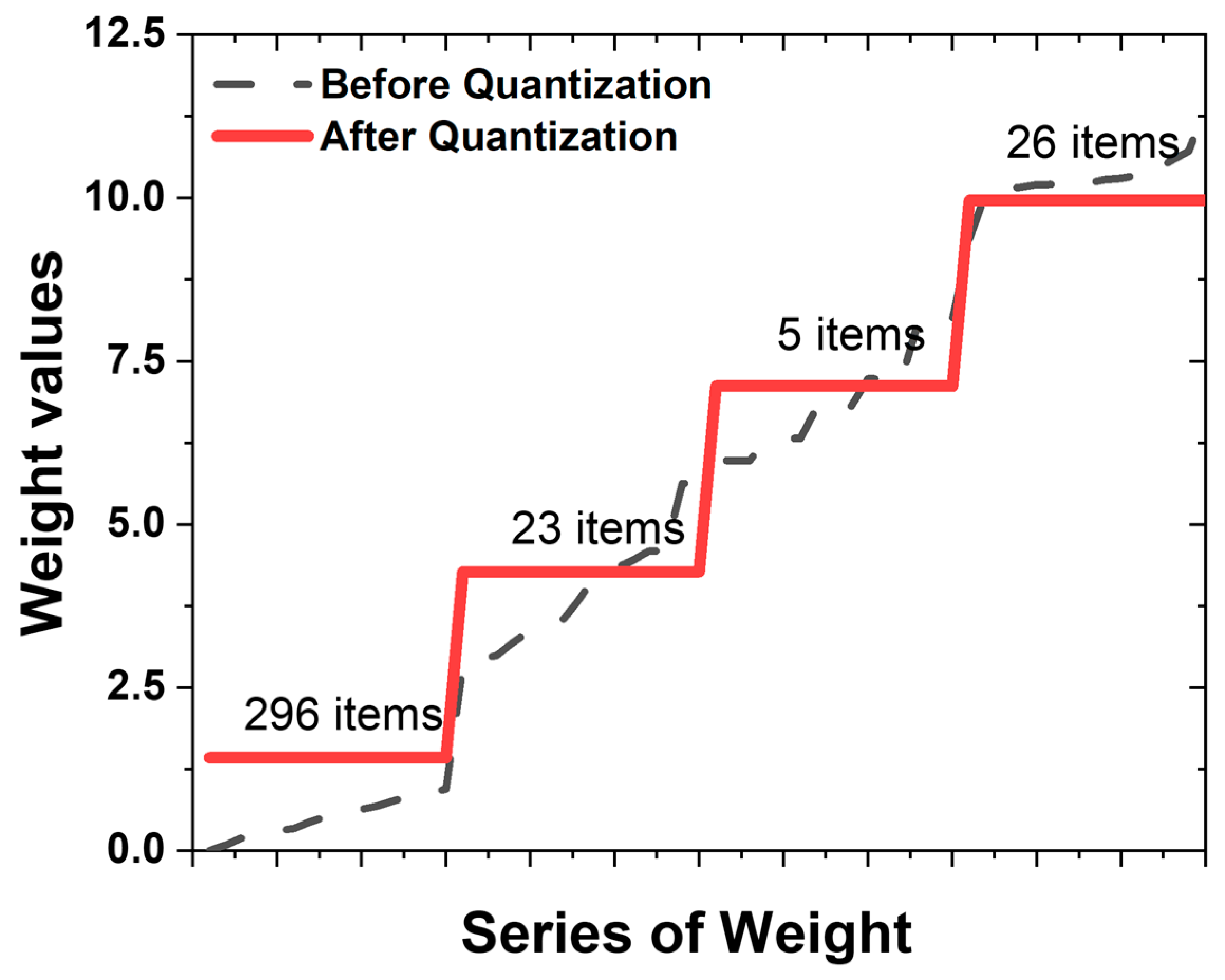
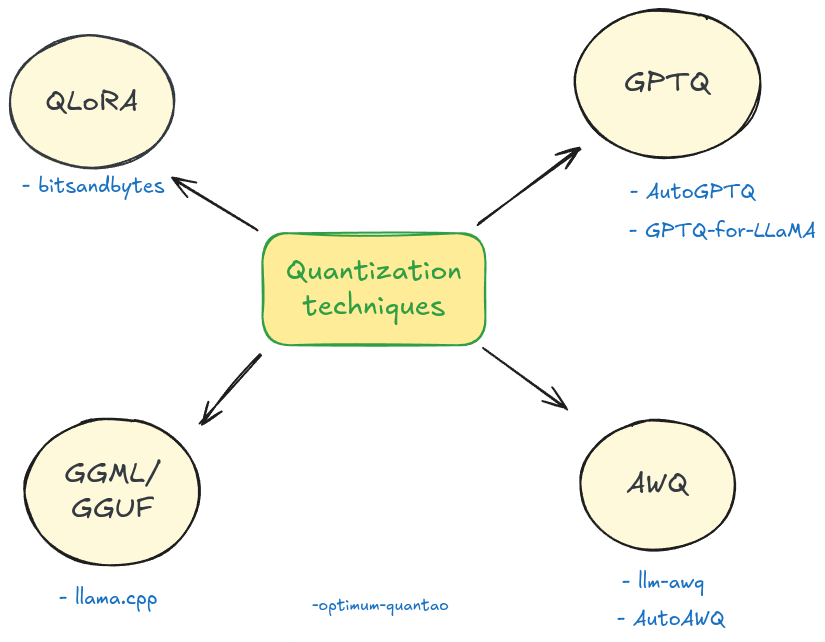
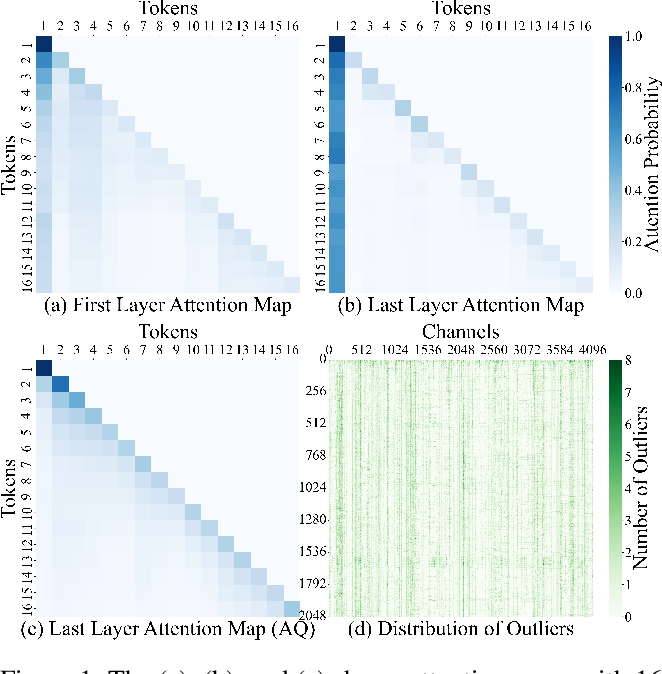
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
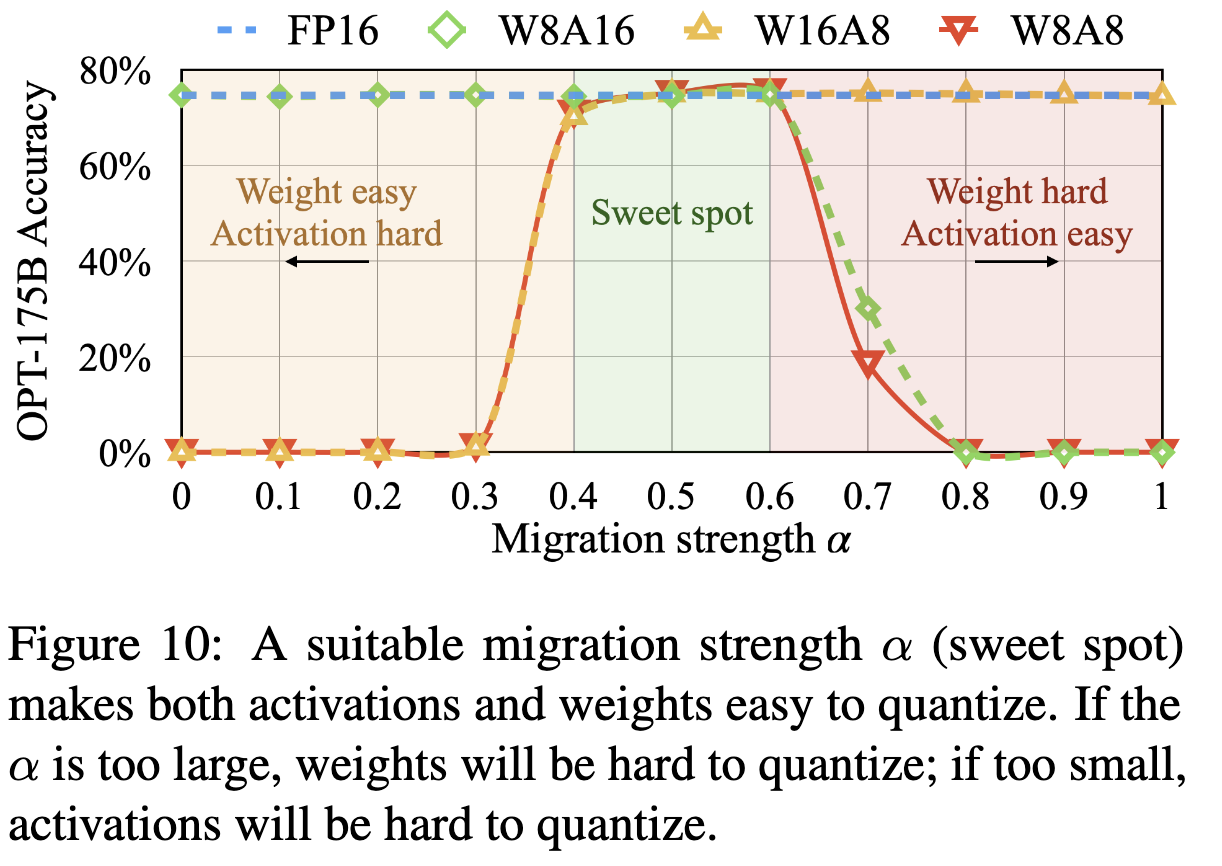
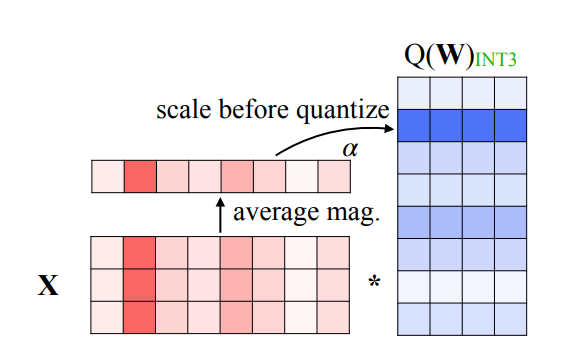
(a) Weight and activation quantization scheme, (b) Memory footprint of ...
The position of activation quantization nodes of layer l. Positions of ...
Different ways of inserting activation quantization nodes. Our method ...
CIFAR-10: Comparison of activation quantization methods (no weight ...
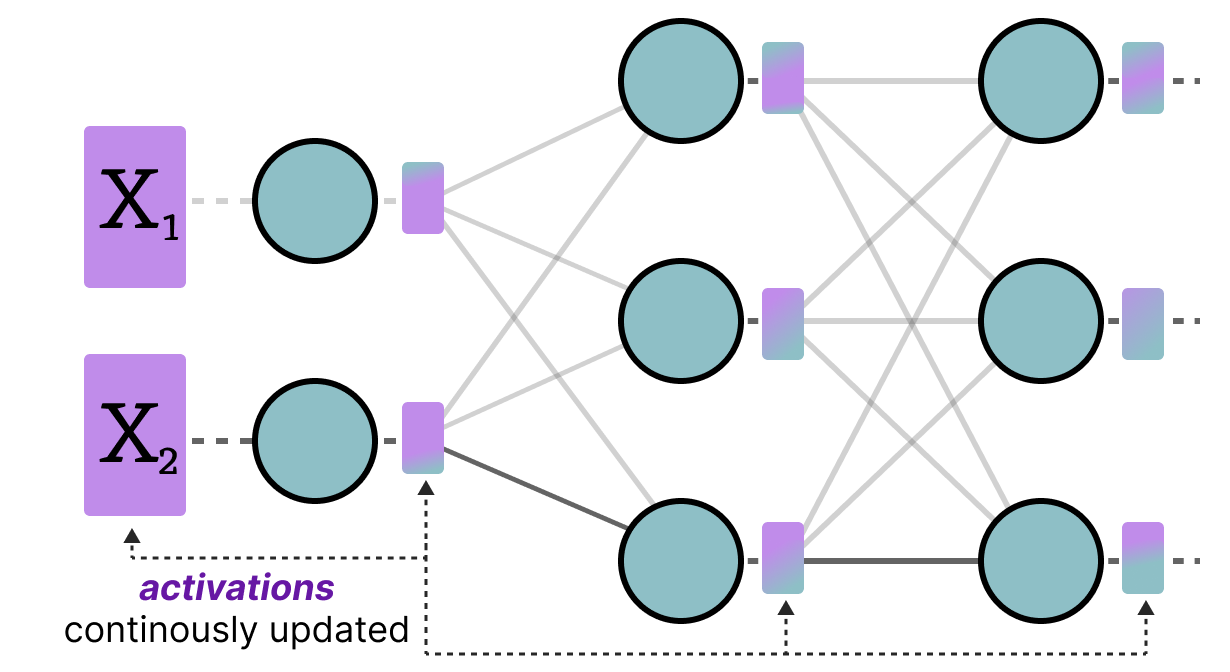
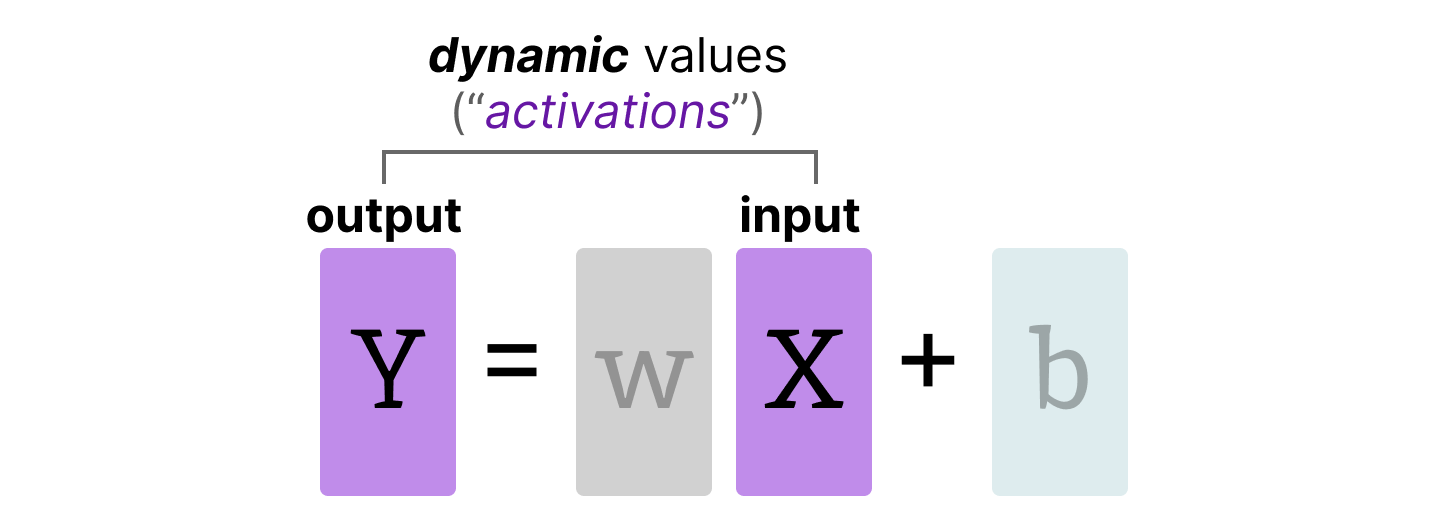
3 cases to involve activation quantization when optimizing the k th ...
Training IOU for different AP2D-Net models. A, activation quantization ...
Efficient Activation Quantization via Adaptive Rounding Border for Post ...
Two-bit activation quantization comparison. Our sparse quantization ...
Significant Accuracy Drop After "Custom" Activation Quantization ...
Figure 1 from A Case for Dynamic Activation Quantization in CNNs ...
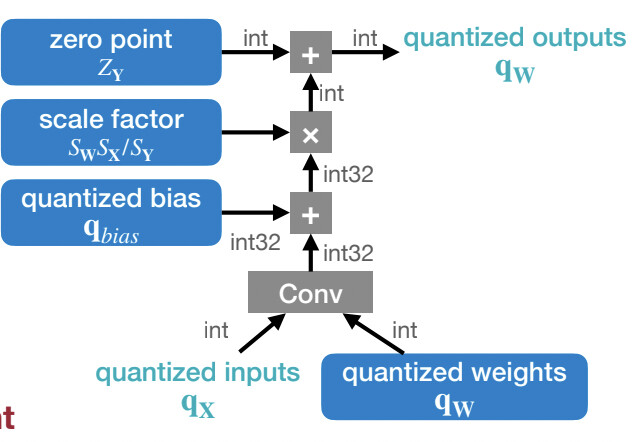
The logic implementation of Quantization (Left) and Relu Activation ...
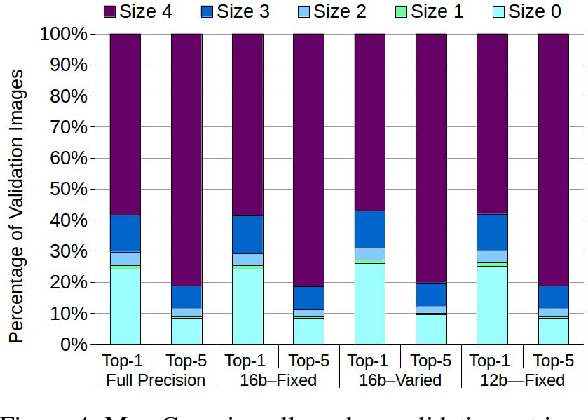
Inference accuracy of the OCNN with reduced activation quantization bit ...
Neural Network Activation Quantization with Bitwise Information Bottlenecks
Figure 4 from A Case for Dynamic Activation Quantization in CNNs ...
Data-Free Quantization with Accurate Activation Clipping and Adaptive ...
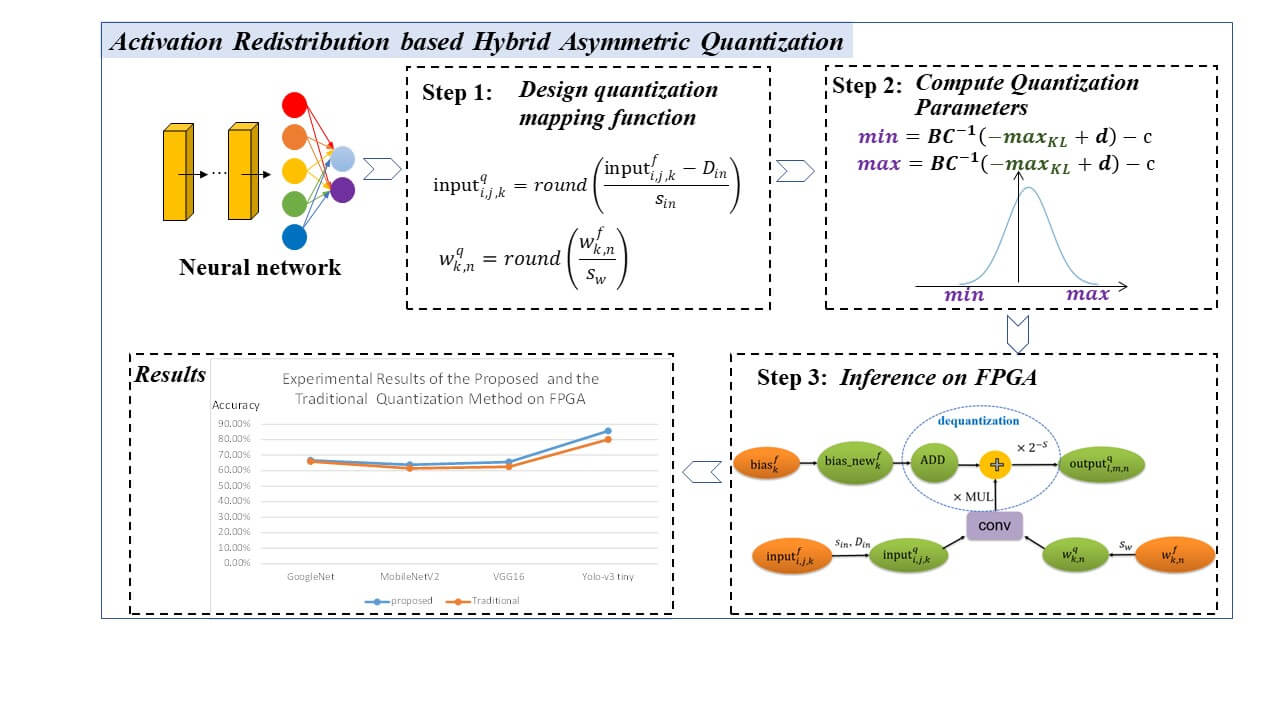
CMES | Activation Redistribution Based Hybrid Asymmetric Quantization ...
NoisyQuant: Noisy Bias-Enhanced Post-Training Activation Quantization ...
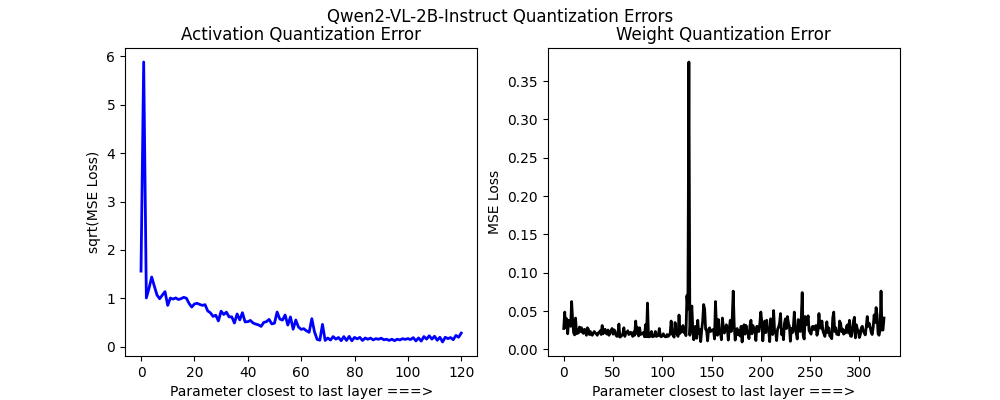
The comparison of activation quantization error measured by MSE between ...
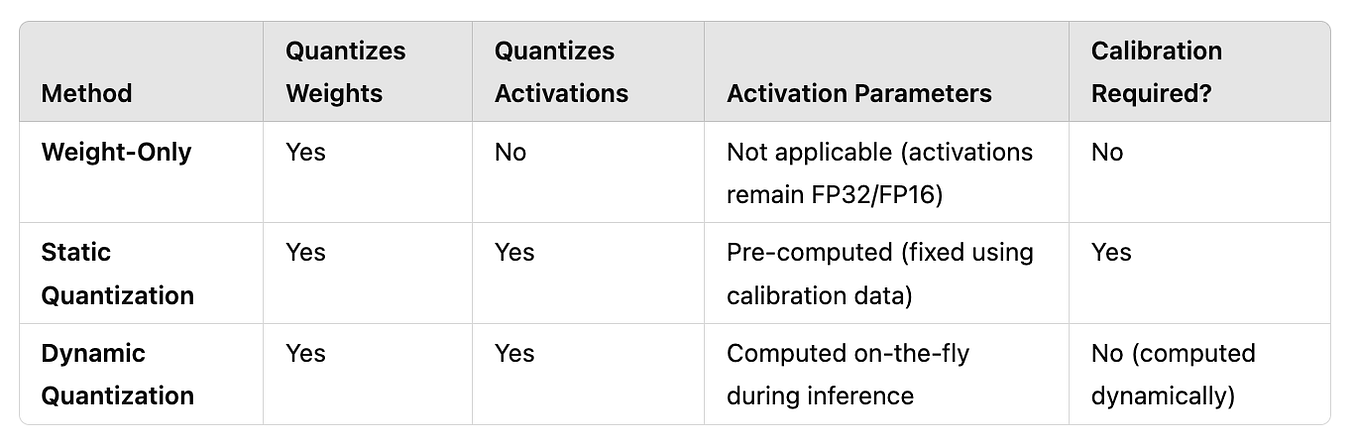
Comparison of post training weight and activation quantization ...
[RFC]: Int8 Activation Quantization · Issue #3975 · vllm-project/vllm ...
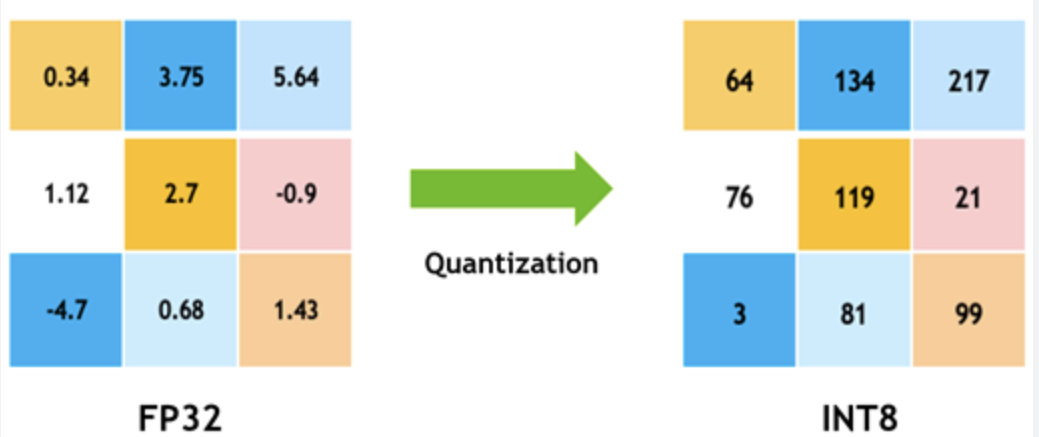
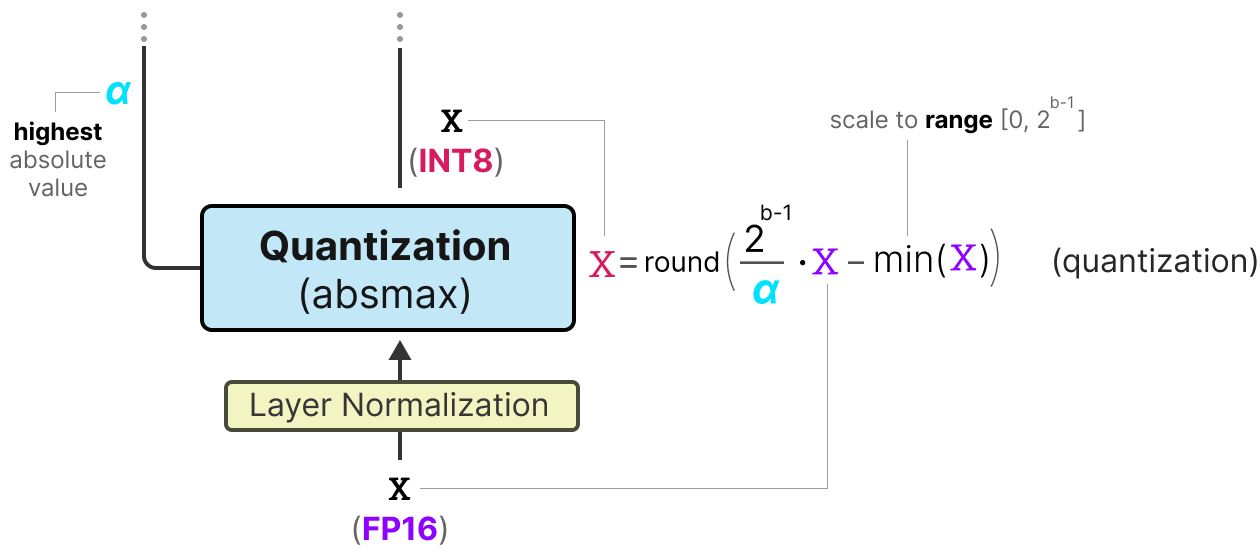
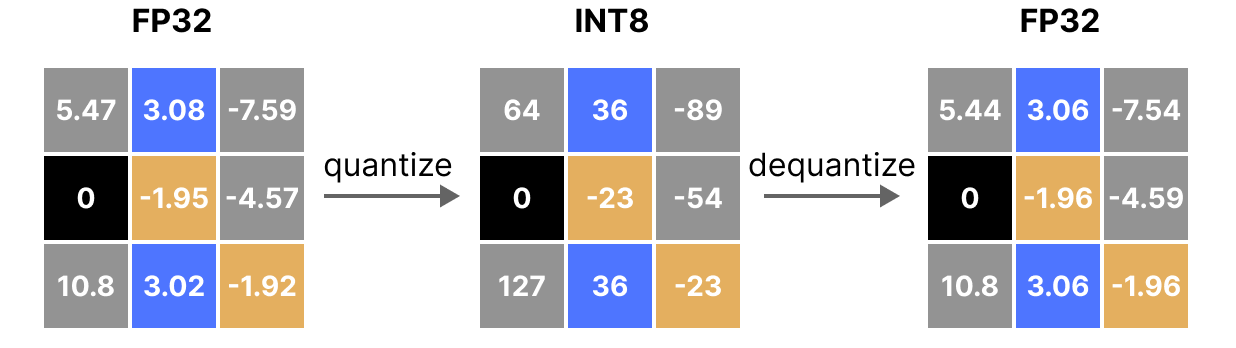
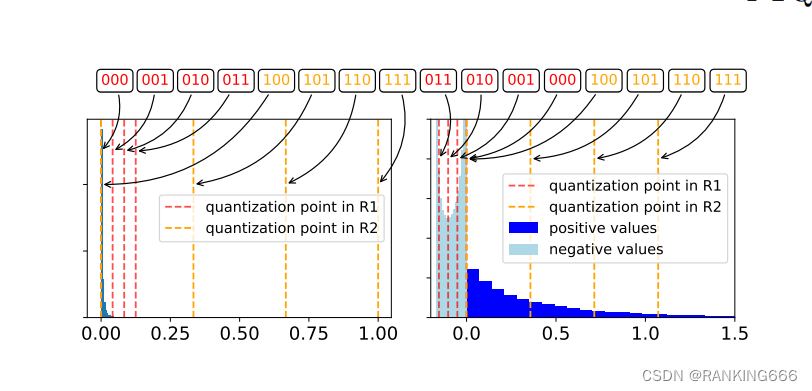
A Visual Guide to Quantization - by Maarten Grootendorst
Compressing LLMs with AWQ: Activation-Aware Quantization Explained | by ...
Prefixing Attention Sinks can Mitigate Activation Outliers for Large ...
Quantization of Convolutional Neural Networks: Model Quantization ...
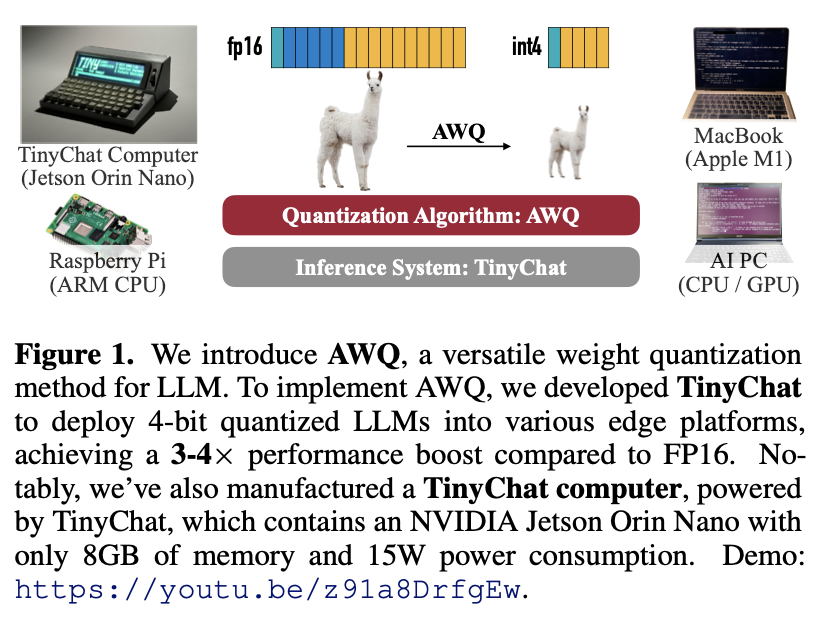
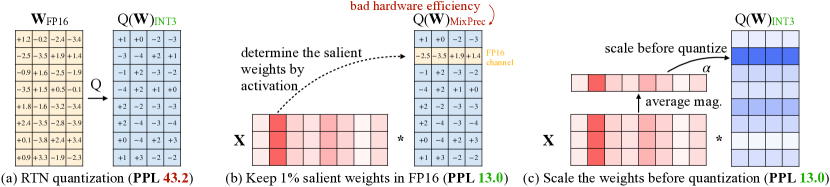
AWQ: Activation-aware Weight Quantization for LLM Compression and ...
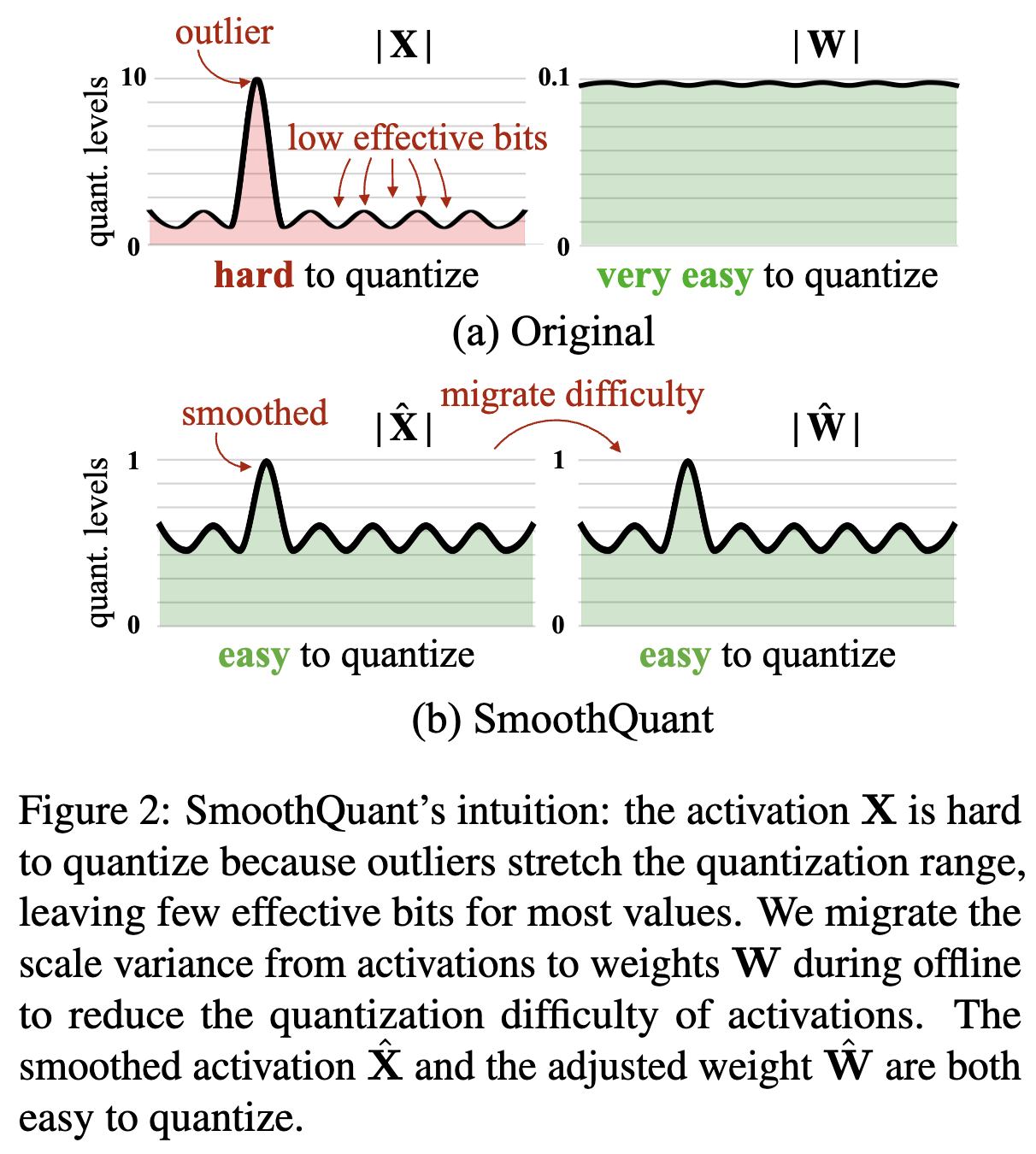
[LLM] SmoothQuant: Accurate and Efficient Post-Training Quantization ...
Fast and Small Llama 3 with Activation-Aware Quantization (AWQ)
Unsloth - Dynamic 4-bit Quantization
Understanding Activation-Aware Weight Quantization (AWQ): Boosting ...
Unlocking Efficiency on LLMs with Activation-Aware Weight Quantization ...
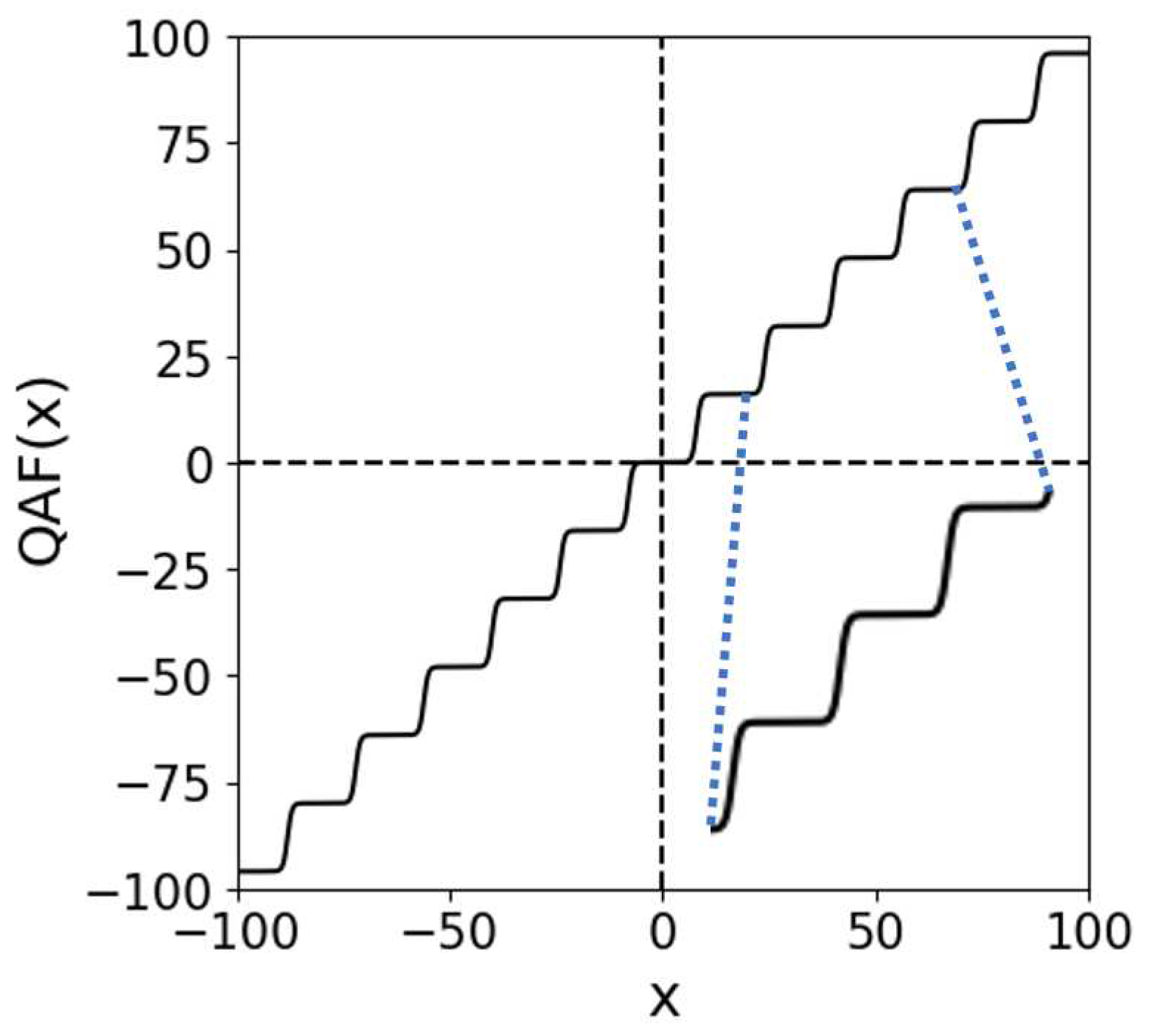
Quantized activation functions. τ is a value determined in the network ...
(PDF) GPTAQ -Activation Quantization with Cross Layer Equalization for ...
Practical Guide to LLM Quantization Methods - Cast AI
The Ultimate Handbook for LLM Quantization | Towards Data Science
[vLLM — Quantization] AWQ: Activation-aware Weight Quantization for LLM ...
Improving LLM Inference Latency on CPUs with Model Quantization ...
Awq Activation-Aware Weight Quantization | PDF | Graphics Processing ...
Study of Weight Quantization Associations over a Weight Range for ...
[vLLM vs TensorRT-LLM] #7. Weight-Activation Quantization - SqueezeBits
AWQ: Activation-aware Weight Quantization Explained
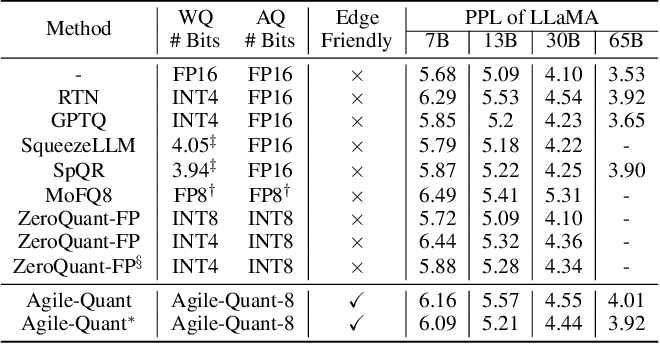
Agile-Quant: Activation-Guided Quantization for Faster Inference of ...
Quantizing Models with Activation-Aware Quantization (AWQ) - LLM ...
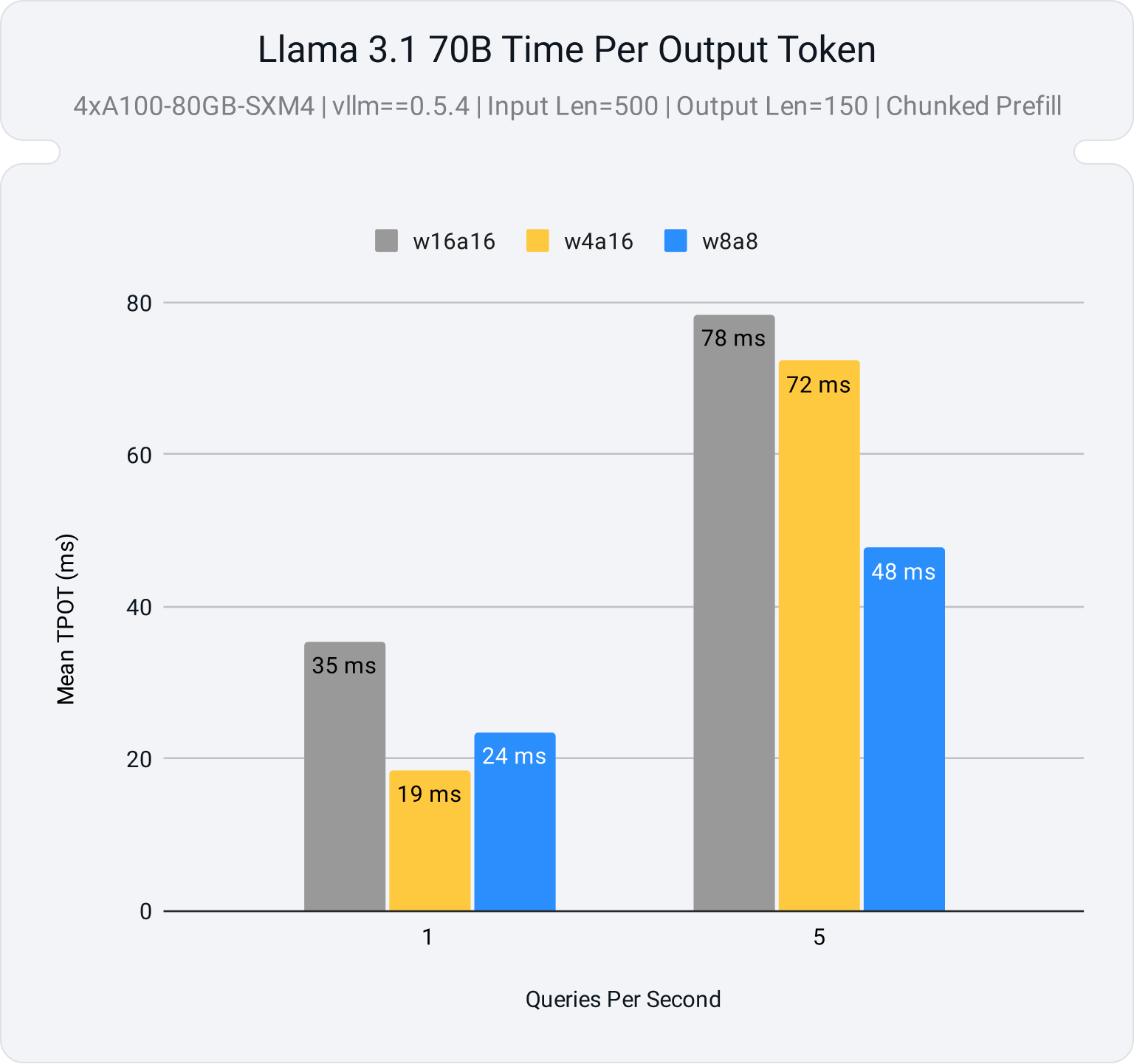
Improve Latency and Throughput with Weight-Activation Quantization in ...
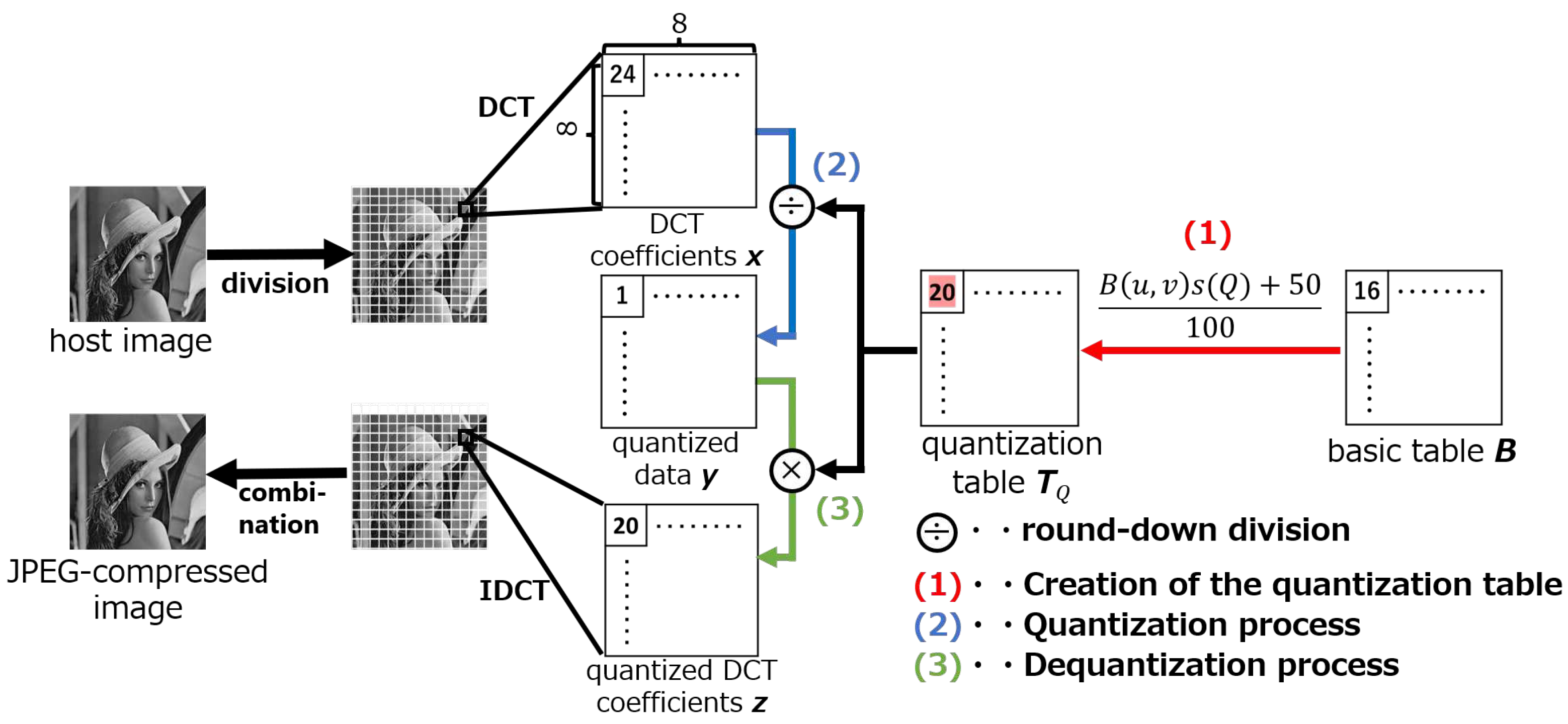
Watermarking Method Based on Neural Network with JPEG Quantization ...
Top LLM Quantization Methods and Their Impact on Model Quality
LLM Quantization Techniques- GPTQ
Paper page - Agile-Quant: Activation-Guided Quantization for Faster ...
Exploring quantization in Large Language Models (LLMs): Concepts and ...
[2306.00978] AWQ: Activation-aware Weight Quantization for LLM ...
AdaLog: Post-Training Quantization for Vision Transformers with ...
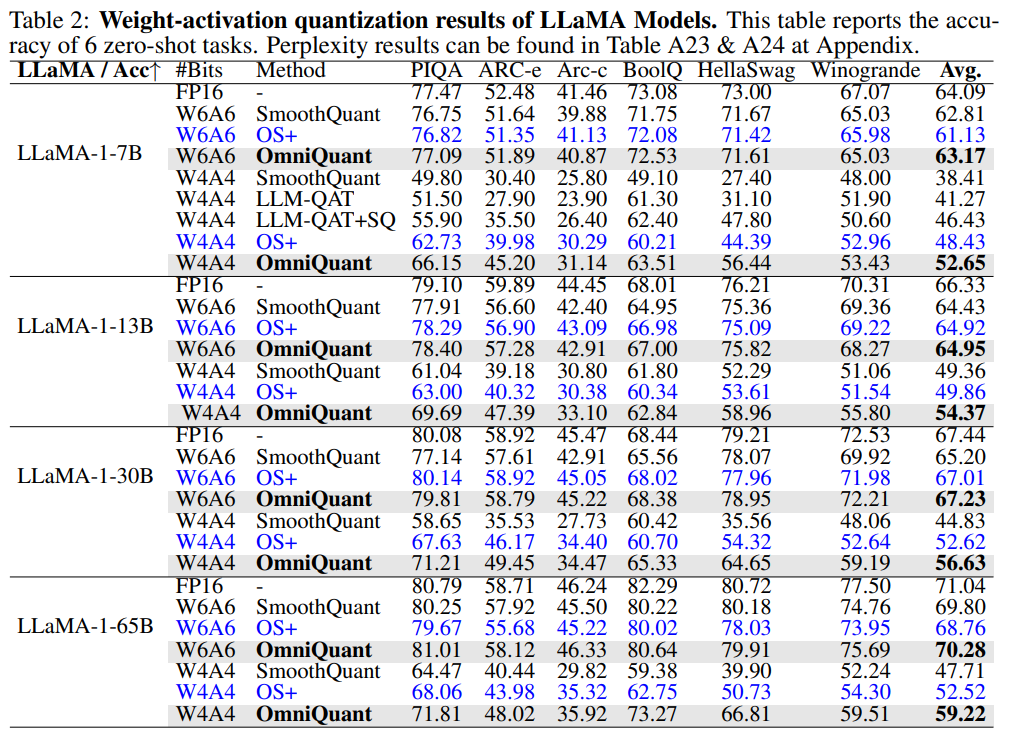
OMNIQUANT: OMNIDIRECTIONALLY CALIBRATED QUANTIZATION FOR LARGE LANGUAGE ...
| The impact of the activation precision in the output layer during ANN ...
[vLLM vs TensorRT-LLM] #6. Weight-Only Quantization - AI大模型 - 老潘的AI社区
Activation Compression of Graph Neural Networks using Block-wise ...
VIT quantization相关论文阅读_post-training quantization for vision ...
AWQ: Activation-aware Weight Quantization - In this paper, we pro- pose ...
Edge-ASR: Towards Low-Bit Quantization of Automatic Speech Recognition ...
Quick Review: AWQ: Activation-aware Weight Quantization for LLM ...
Exploring SwiGLU : The Activation Function Powering Modern LLMs | by ...
Paper page - AWQ: Activation-aware Weight Quantization for LLM ...
Illustration of Quantized activation function f (z) for an complex ...
Understanding Quantization for LLMs | by LM Po | Medium
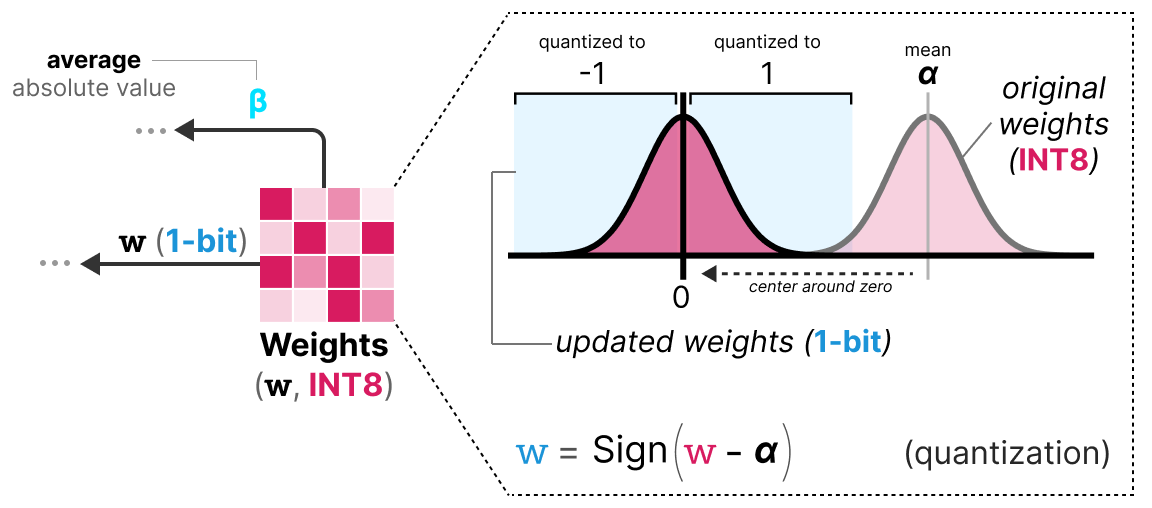
Achieving binary weight and activation for LLMs using Post-Training ...
Neural Network Quantization: What Is It and How Does It Relate to ...
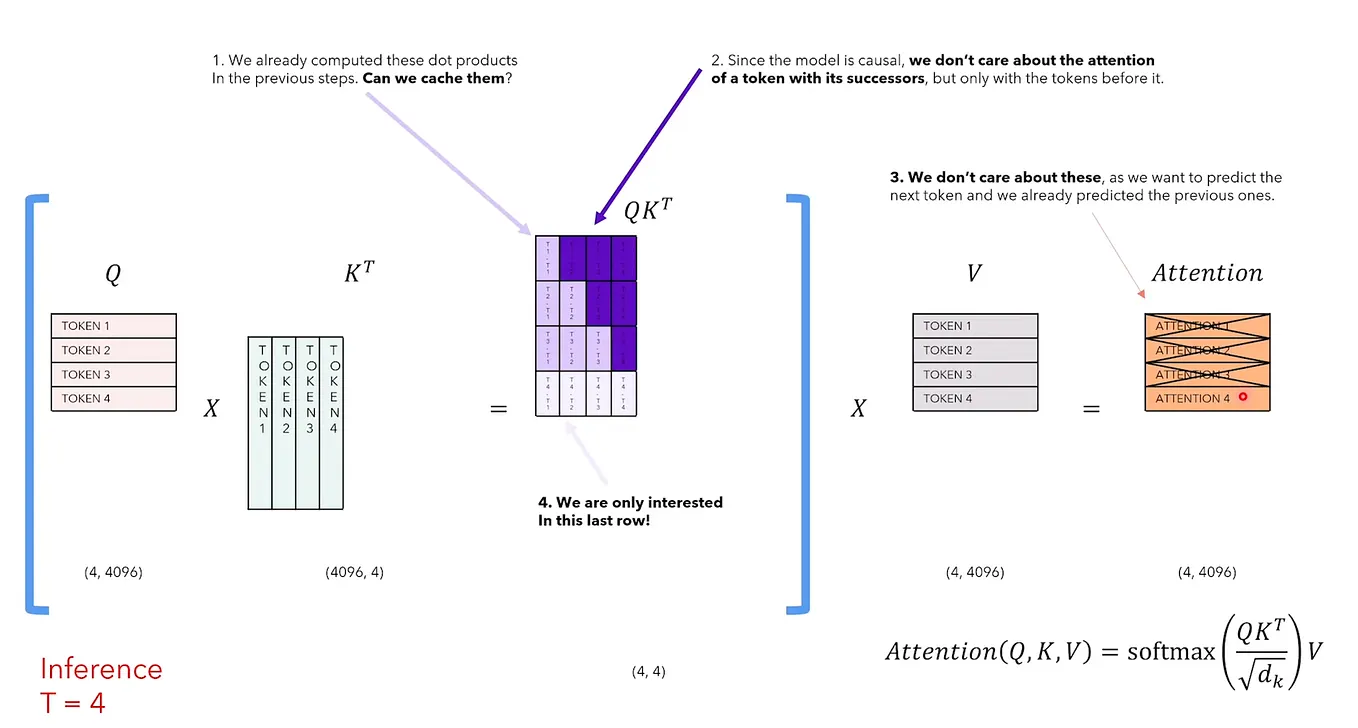
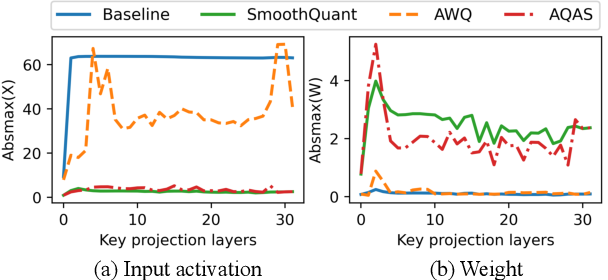
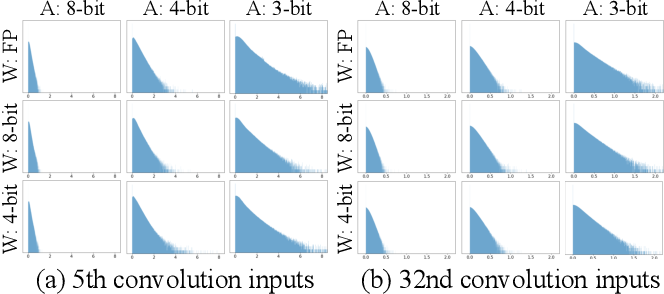
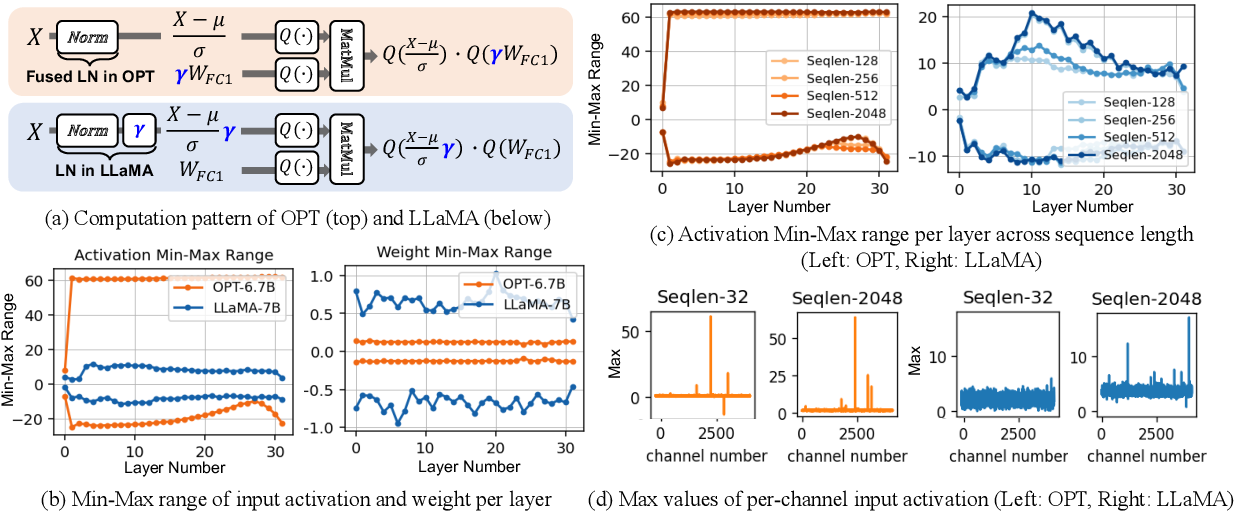
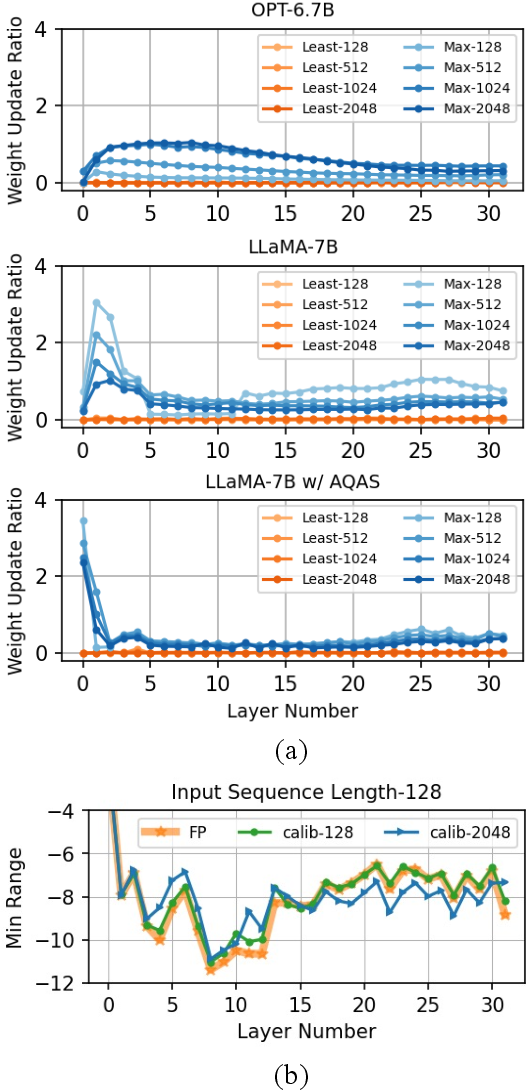
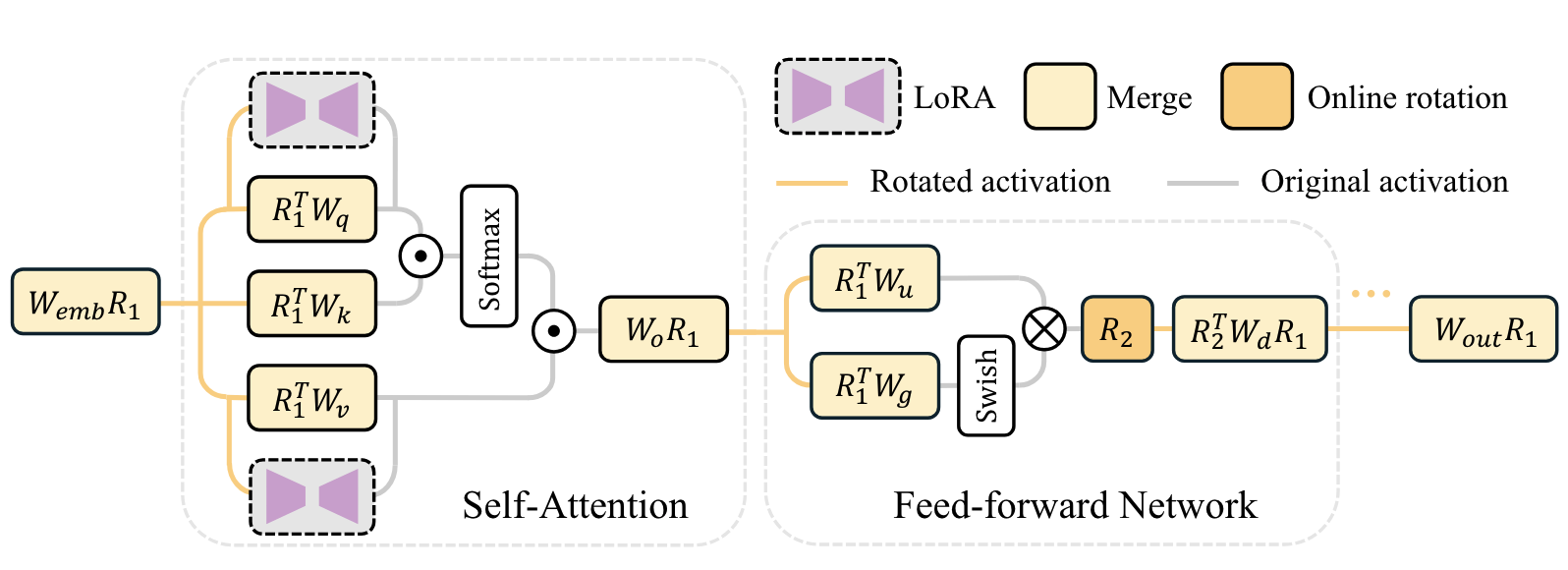
Enhancing Computation Efficiency in Large Language Models through ...
The Machine Learning Surgeon's Guide to Quantization: Precision Cuts ...
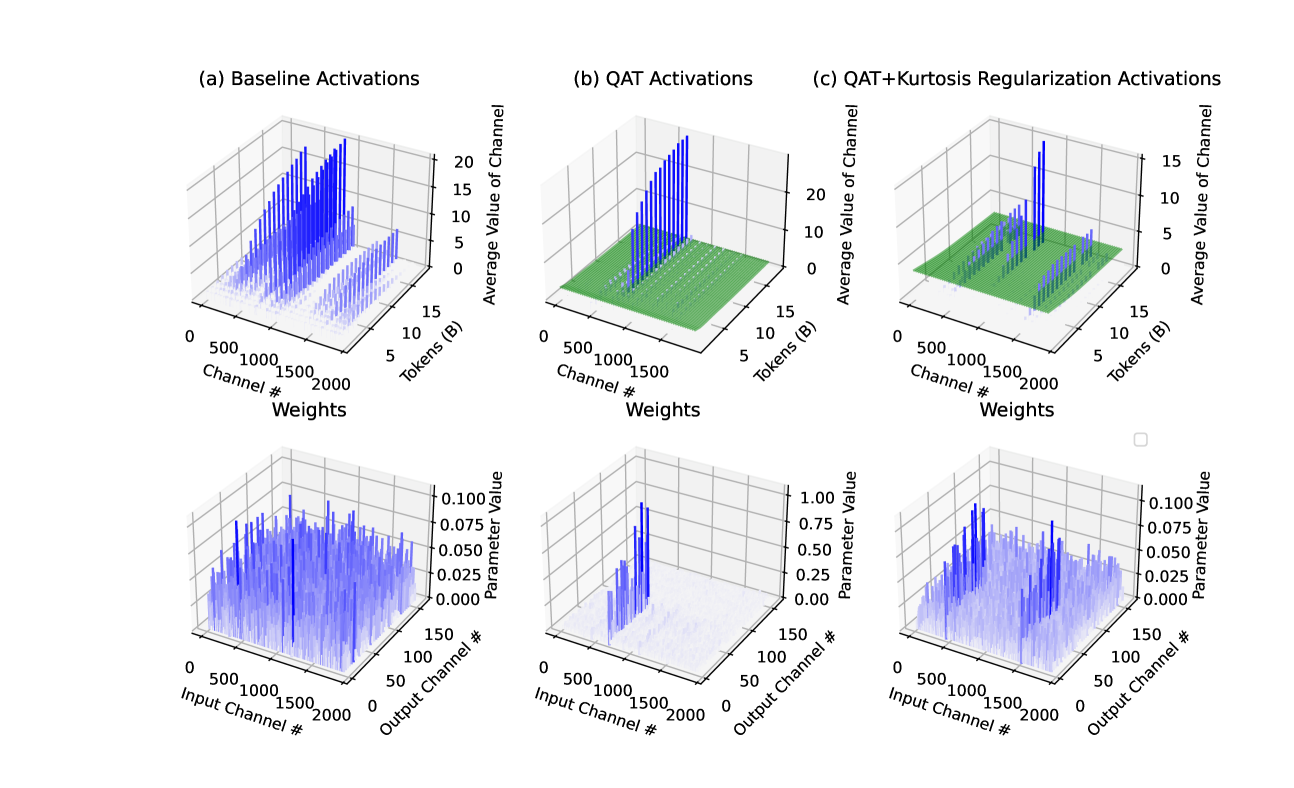
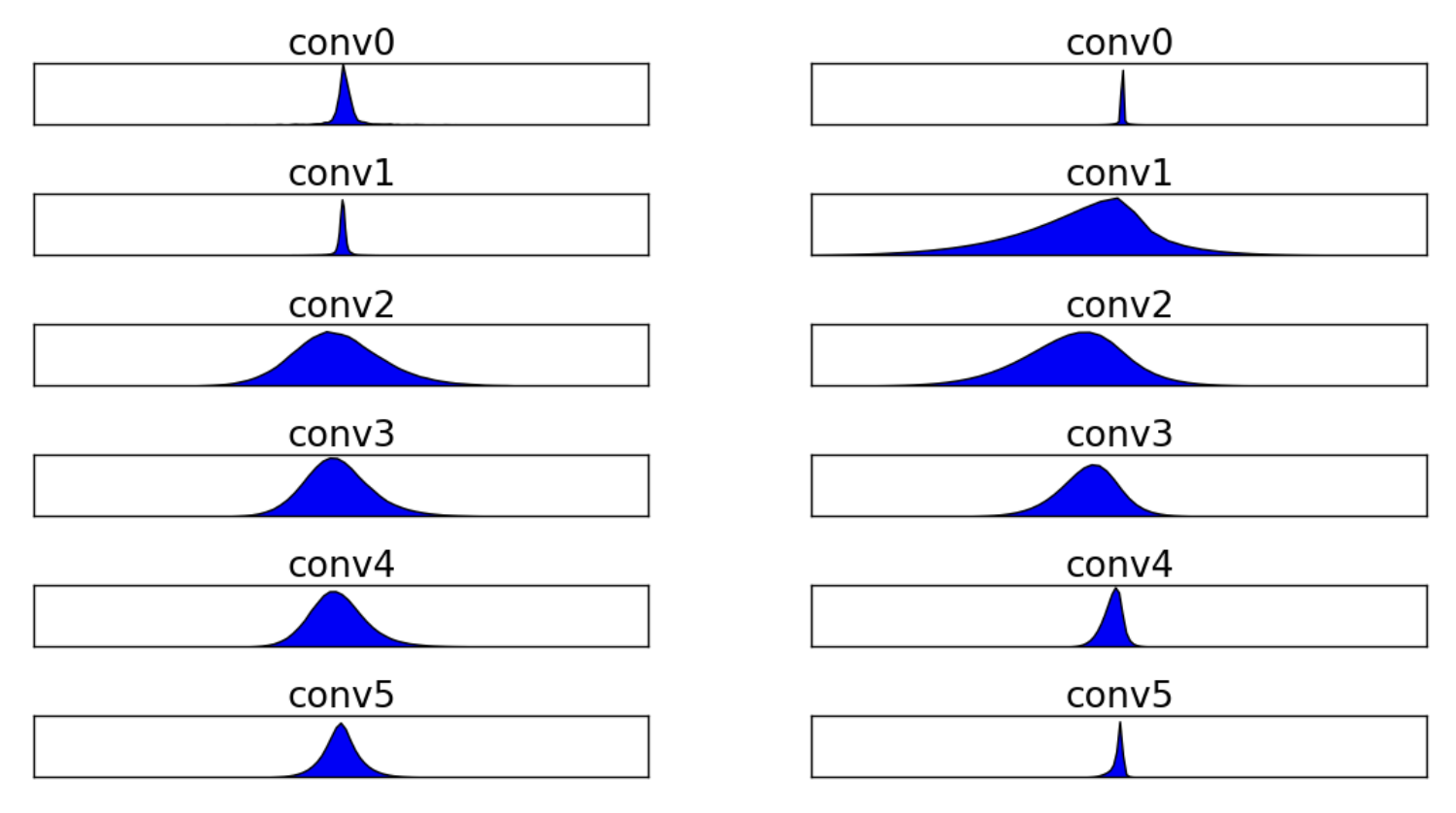
Figure 2 from Enhancing Computation Efficiency in Large Language Models ...
ZeroQuant与SmoothQuant量化总结-CSDN博客
Figure 1 from MetaMix: Meta-state Precision Searcher for Mixed ...
Figure 1 from Enhancing Computation Efficiency in Large Language Models ...
Figure 3 from Enhancing Computation Efficiency in Large Language Models ...
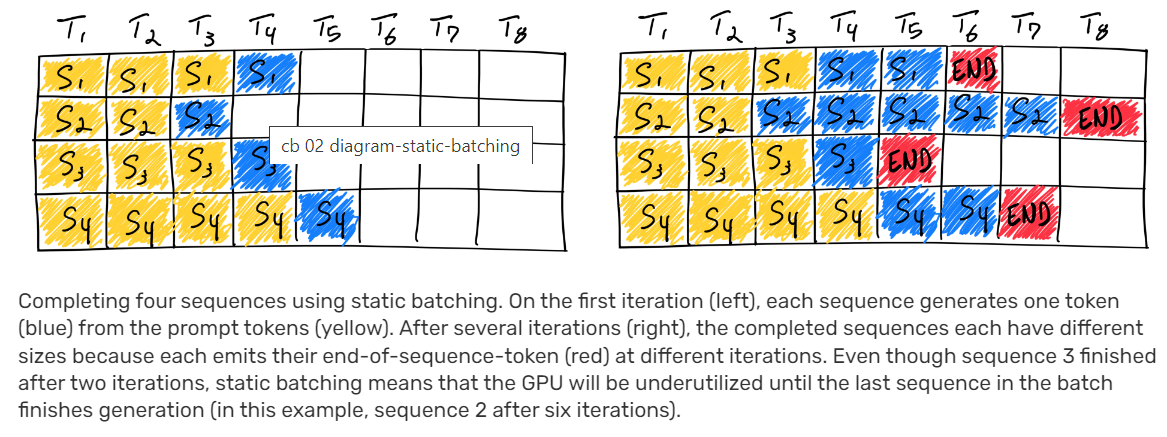
LLM Compressor is here: Faster inference with vLLM | Red Hat Developer
Publications | VSDL