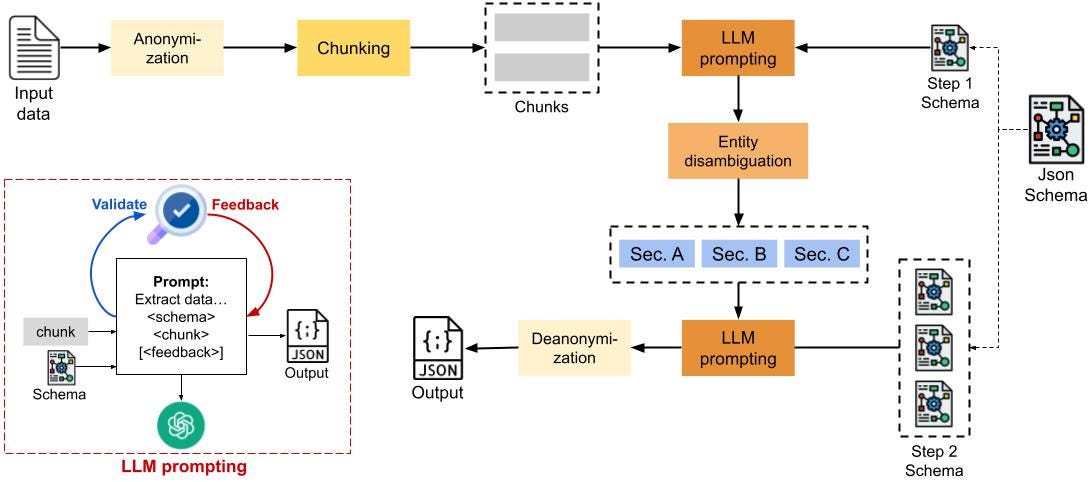
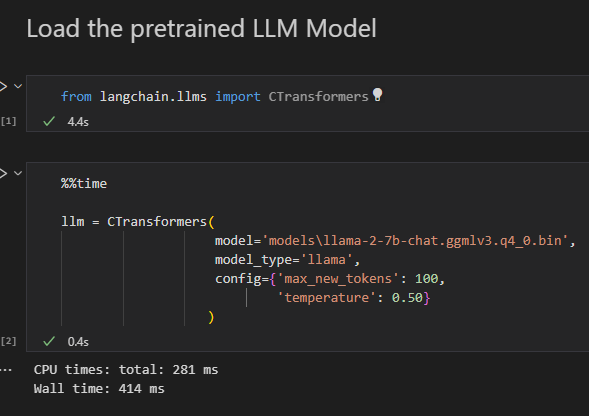
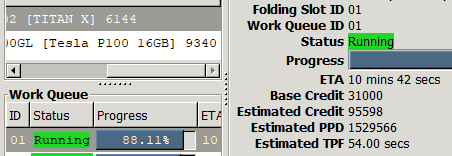
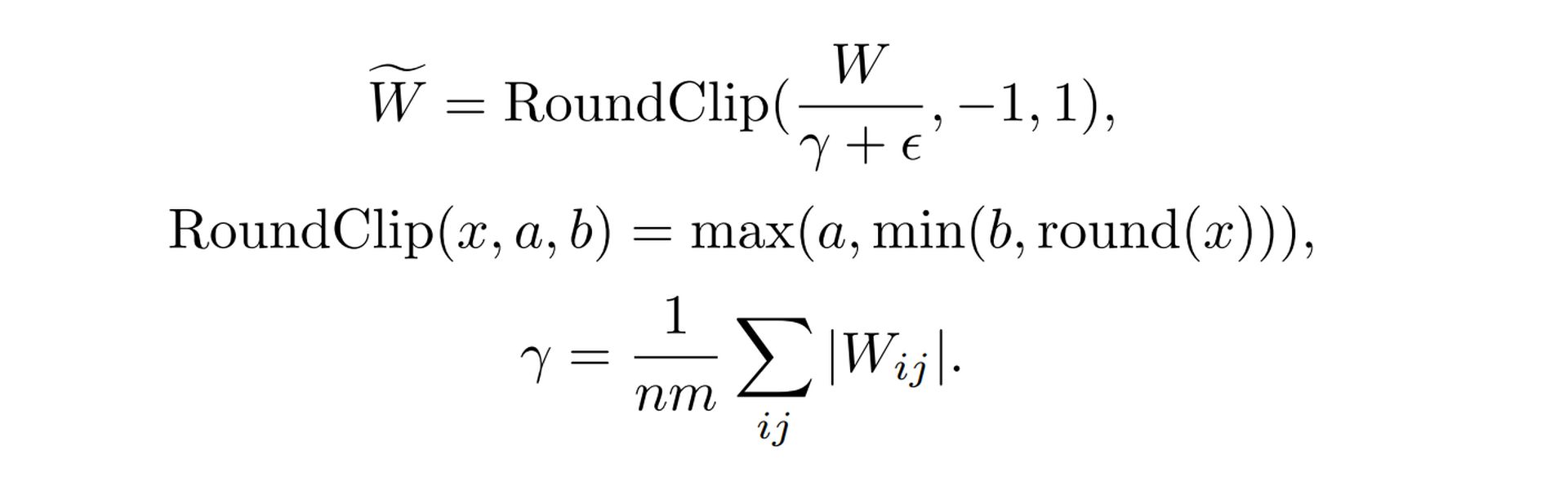Beyond Bits: Running a Native 1‑Bit LLM on Your Laptop | by Dhananjay ...
LLM Programming Made Easy: 20 Min tutorial on starting your local SLM ...
Microsoft Open-Sources bitnet.cpp: A Super-Efficient 1-bit LLM ...
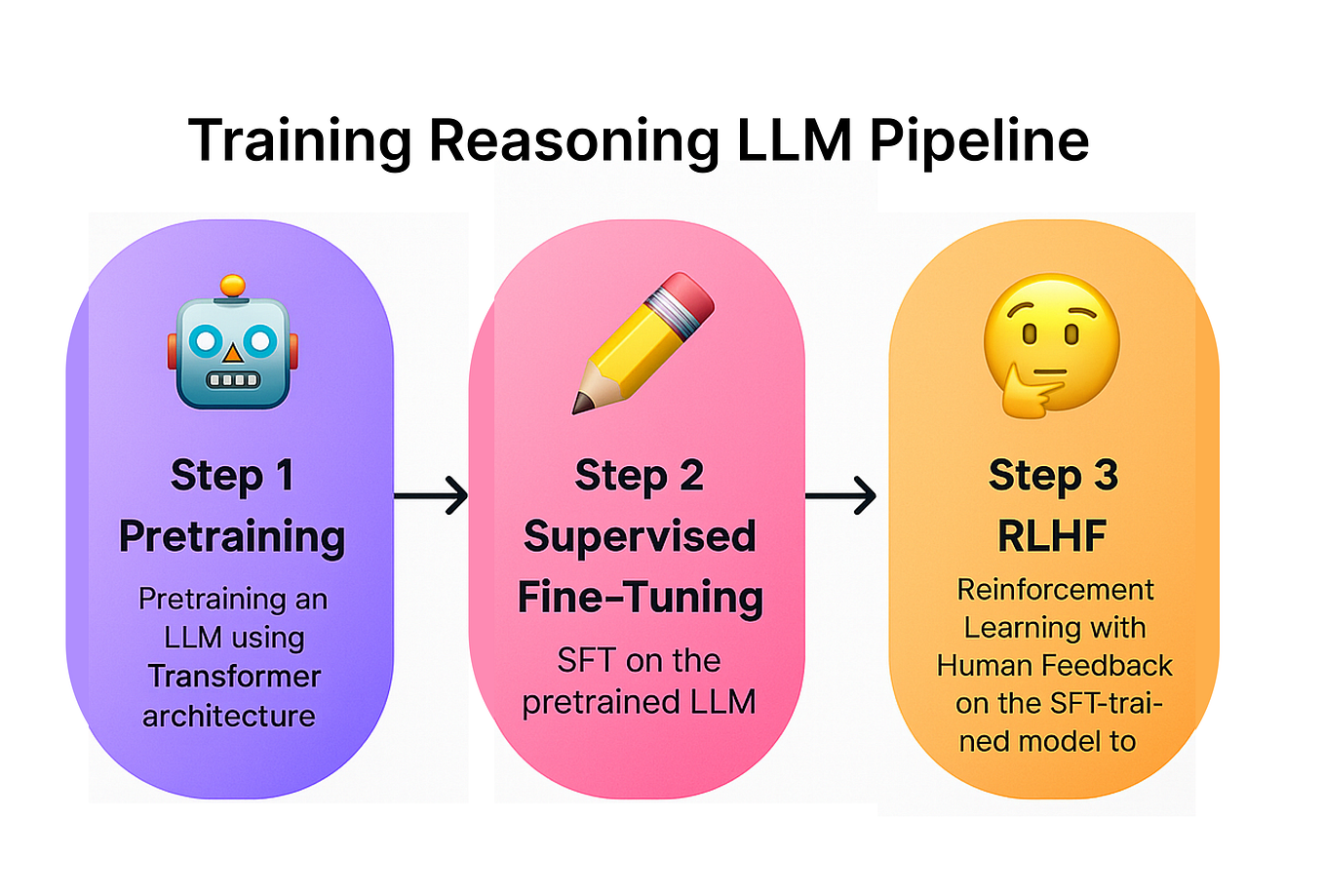
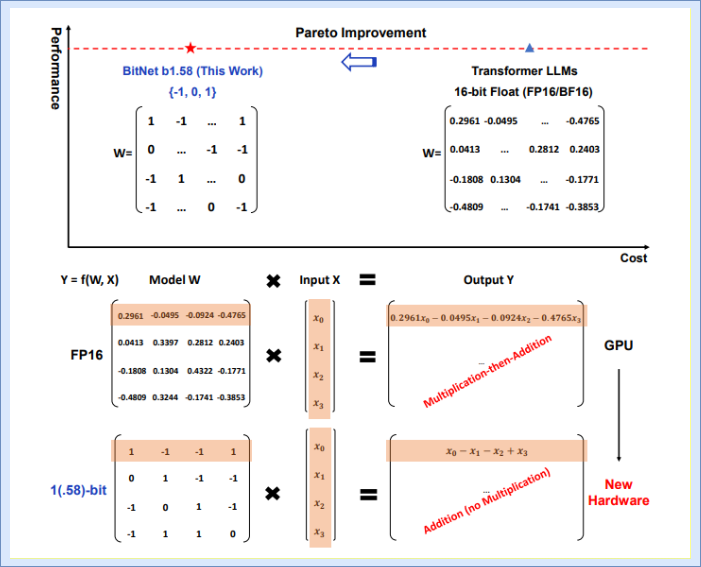
The Era of 1-bit LLMs: A New Dawn for Powerful and Efficient Language ...
FastAPI-BitNet: Running Microsoft's BitNet Inference Locally with 1-Bit ...
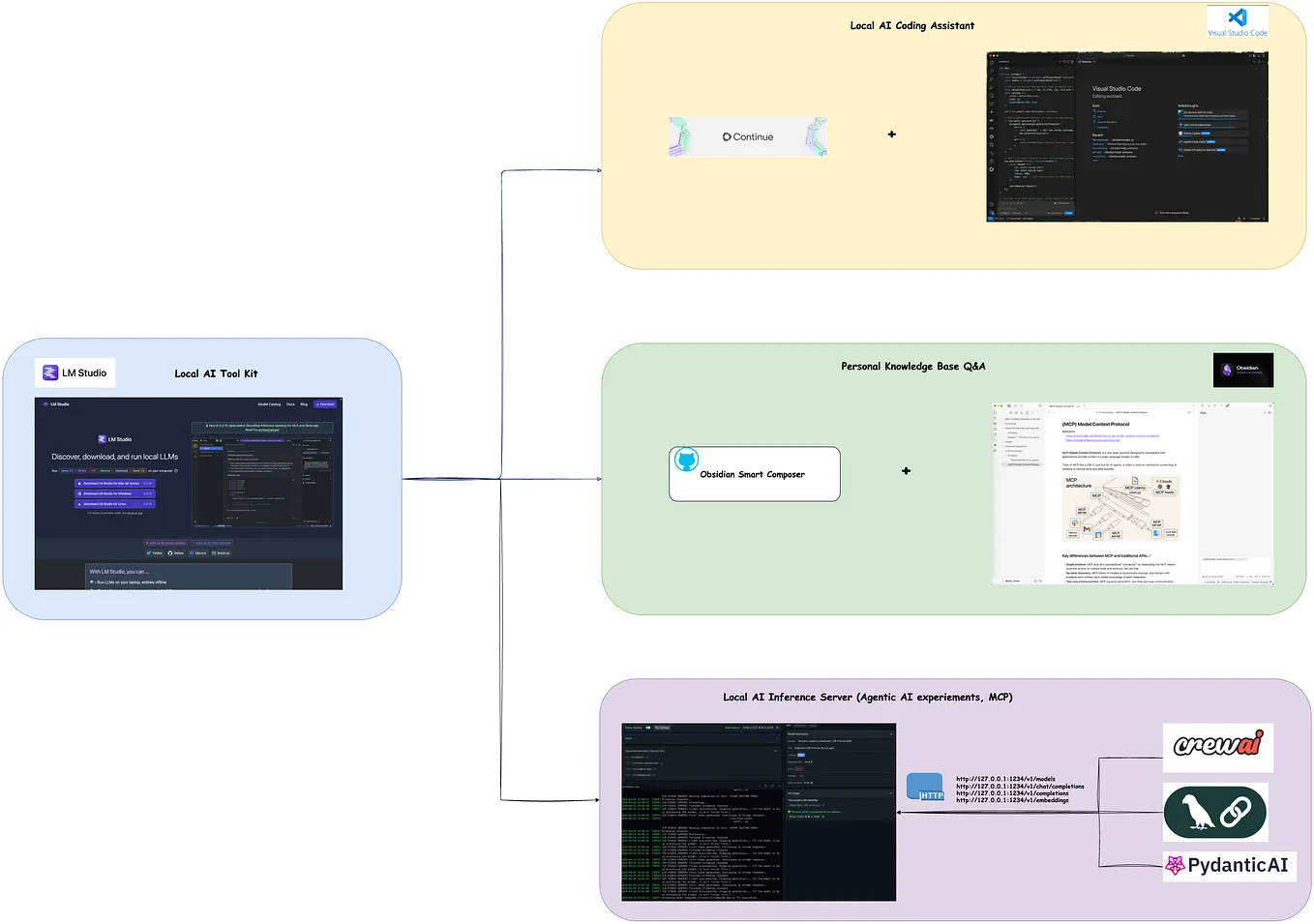
Running local LLM with LM Studio. If you want to use Ollama then follow ...
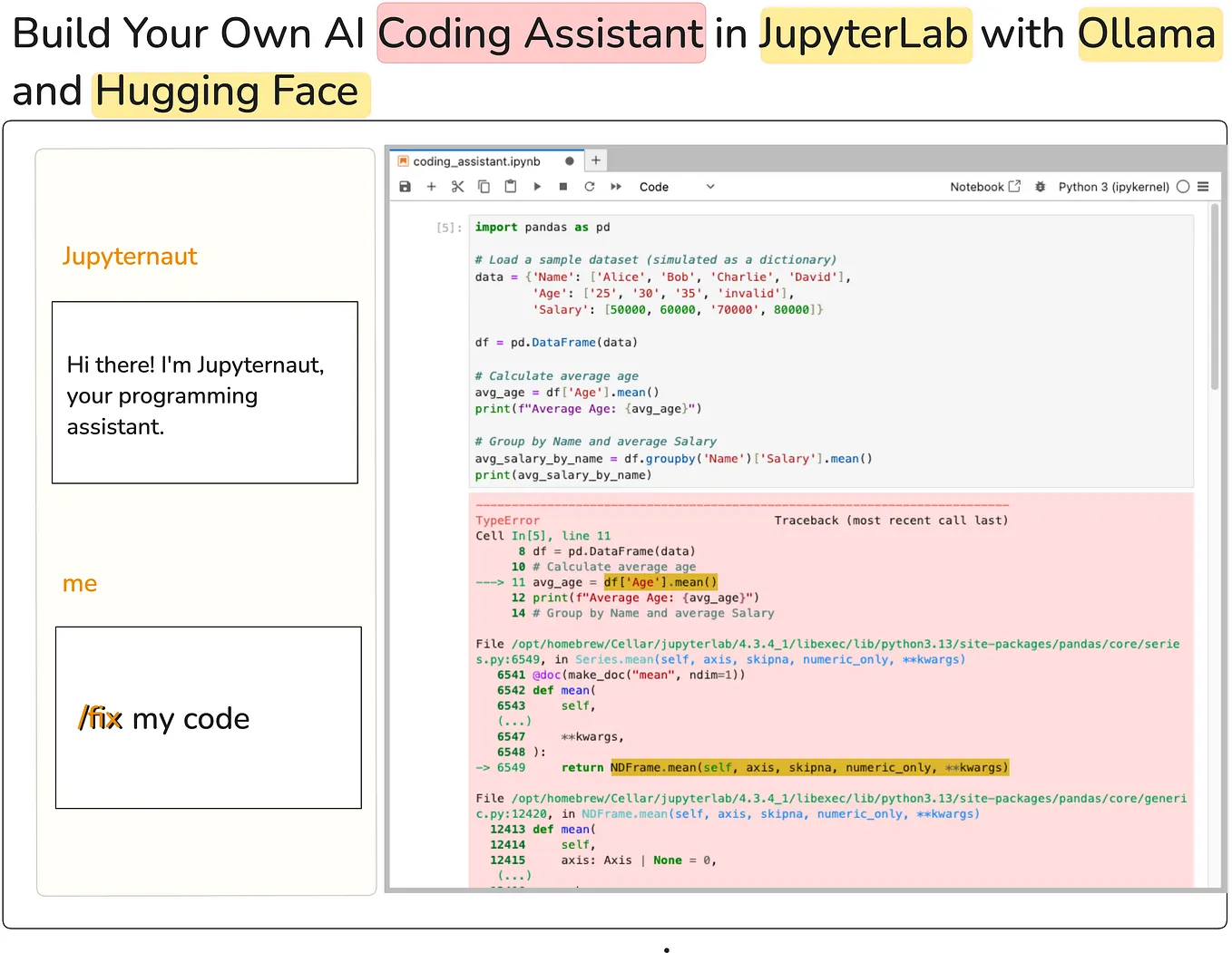
Your Private AI Code Assistant: A Beginner’s Guide to Offline LLM on ...
Microsoft researchers build 1-bit AI LLM with 2B parameters — model ...
vLLM with torch.compile: Efficient LLM inference on PyTorch | Red Hat ...
How to Run a Local LLM on Raspberry Pi: Step-by-Step Guide to Deploy AI ...
How to run new 1-bit LLM on your CPU Machine using microsoft’s BitNet ...
Microsoft Open-Sources BitNet: A 1-Bit LLM Framework Revolutionizing AI ...
A complete guide to running local LLM models | by Guodong (Troy) Zhao ...
1-Bit LLM INSTALLATION| 7B LOCAL LLMs in 1-Bit + Test Demo #ai #llm ...
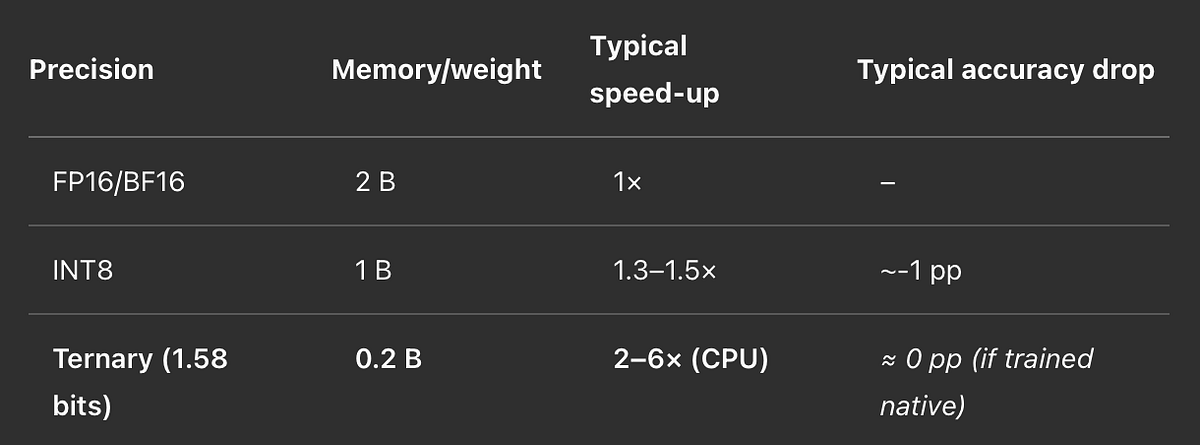
1-Bit LLM and the 1.58 Bit LLM- The Magic of Model Quantization | by Dr ...
How to Make a Bonsai from a Regular Tree + Garden Tour! | Bonsai ...
Deploy an AI Coding Assistant with NVIDIA TensorRT-LLM and NVIDIA ...
Microsoft Native 1-Bit LLM Could Bring Efficient genAI to Everyday CPUs ...
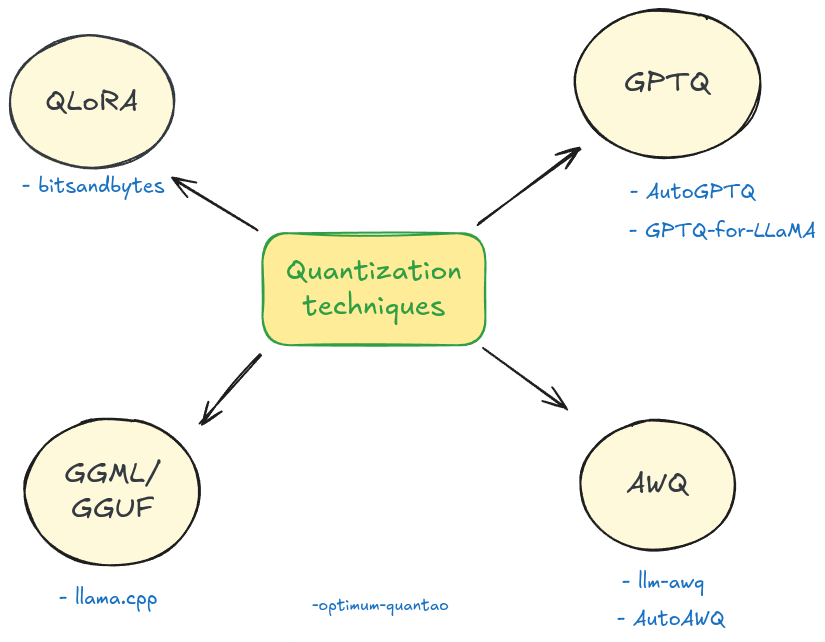
Democratizing LLMs: 4-bit Quantization for Optimal LLM Inference ...
LLM By Examples: Build Llama.cpp with GPU (CUDA) support | by MB20261 ...
VSCuda: LLM based CUDA extension for Visual Studio Code
Generative AI: LLMs: How to do LLM inference on CPU using Llama-2 1.9 ...
A Practical Guide to Train an Open Source LLM on MosaicML | Width.ai
Parameter-Efficient LLM Finetuning With Low-Rank Adaptation (LoRA ...
Unlock Your LLM Coding Potential with StarCoder2 | NVIDIA Technical Blog
Run 1 Bit LLM on Apple Silicon iPhone iPad and Macbook - MLX Bitnet ...
Phi-2: A Small Model Easy to Fine-tune on Your GPU | by Benjamin Marie ...
bitnet.cpp: Efficient Inference with 1-Bit LLMs on your CPU
Integrating Local LLM Frameworks: A Deep Dive into LM Studio and ...
Reimagining AI Efficiency: A Practical Guide to Using BitNet’s 1-Bit ...
Quantized 8-bit LLM training and inference using bitsandbytes on AMD ...
Best 1 Bit LLM Pretraining [With Source Code] | How 1 Bit LLMs Work ...
Understanding 1-Bit LLMs and How They Differ from Multi-Bit LLM Models
What is New in LM Studio? How to Control Multiple GPUs for AI Models ...
CUDA PyTorch BitsAndBytes FlashAttention2 Mixtral-8x7B Test | [“LLM ...
Don't Be Fooled By The Size Of Microsoft's 1-Bit LLM - Dataconomy
Microsoft Drops New 1-Bit LLM: Bitnet b1.58 2B-4T | Install and Test ...
GitHub - marcin-kruszynski/ipex-ollama-intel-igpu: Accelerate local LLM ...
GitHub - Universal-Invariant/AI-ipex-llm: Accelerate local LLM ...
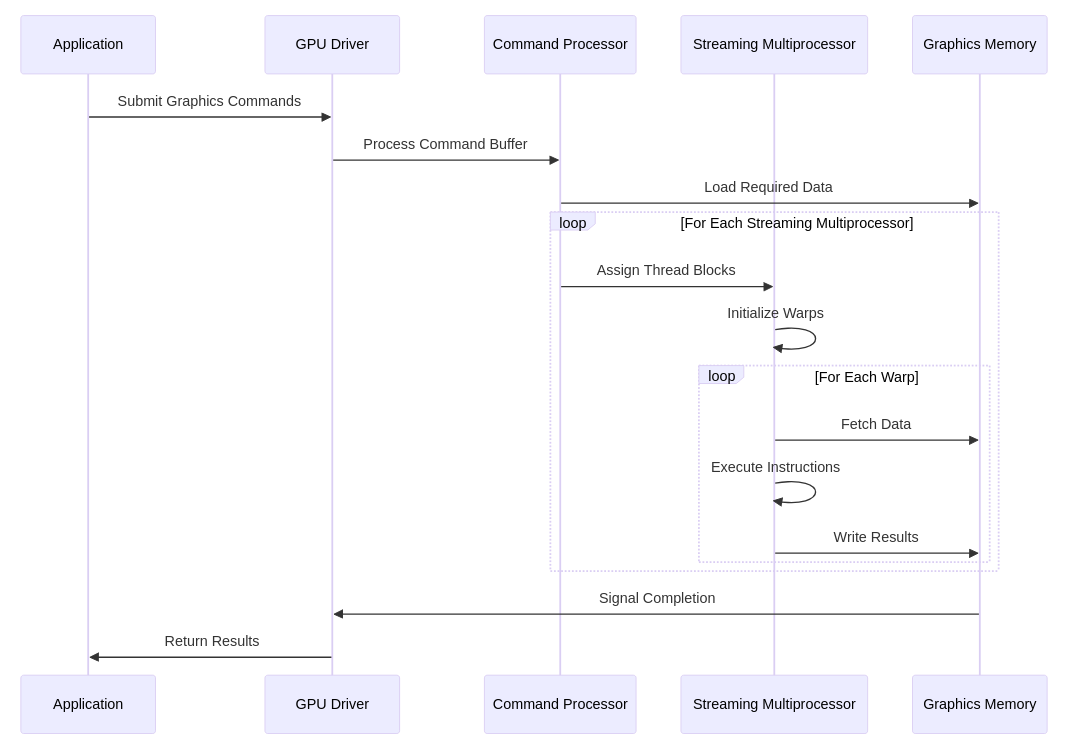
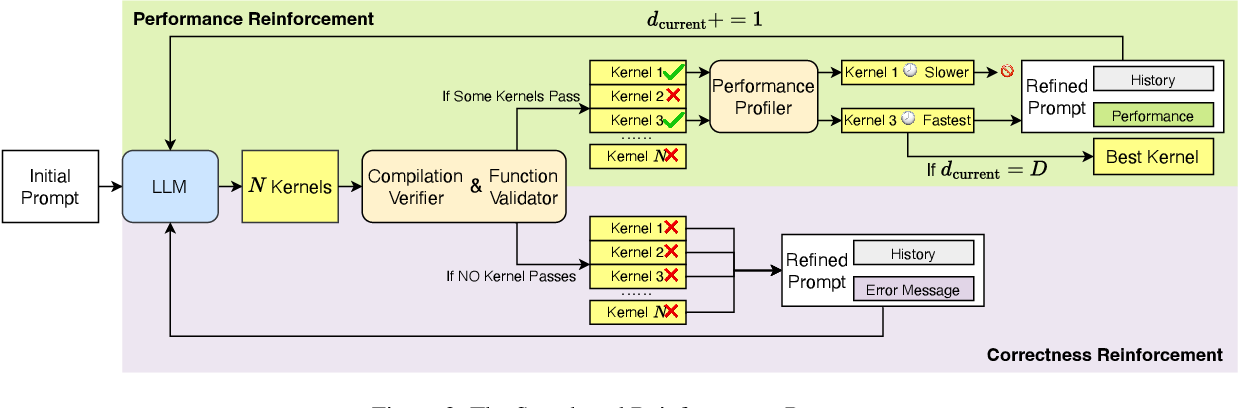
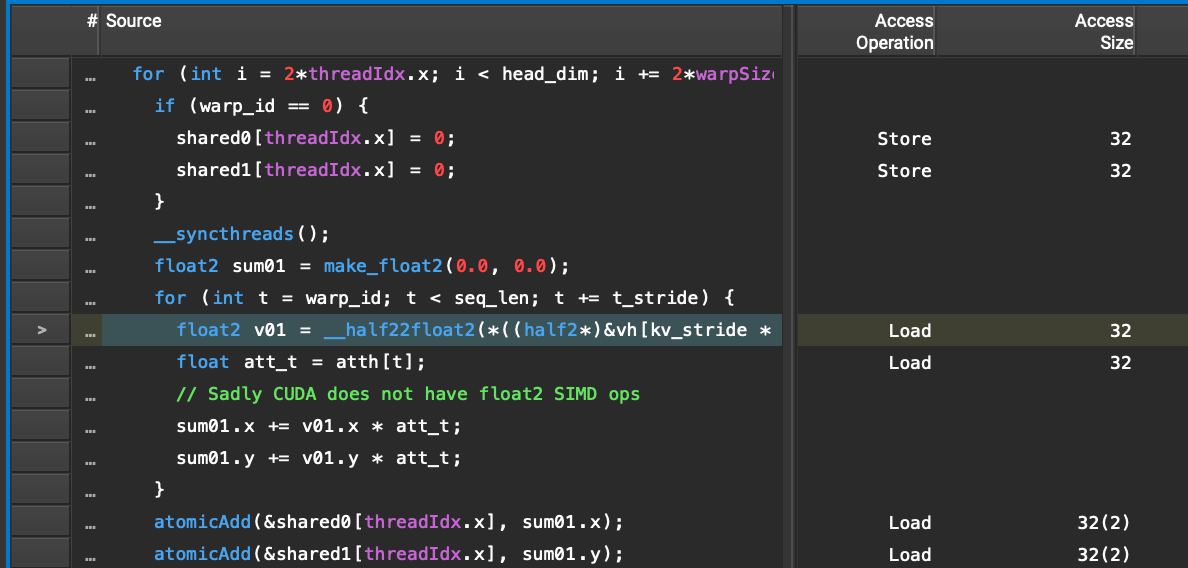
Figure 2 from CUDA-LLM: LLMs Can Write Efficient CUDA Kernels ...
GitHub - prism-em/prismatic: C++/CUDA package for parallelized ...
Make A Wire Bonsai Tree - Next Level Wire Art - YouTube
🚀 BitNet & T-MAC이 가져온 1-bit LLM 혁명 | Wellflix
TUTORIAL 6 CODING CHALLENGE 1 - Wadaef
Microsoft Open-Sources 1-bit LLMs: Run 100B Parameter Models Locally ...
Llama-Bitnet | Training a 1.58 bit LLM | by Zain ul Abideen | Medium
Understanding and Estimating GPU Memory Demands for Training LLMs in ...
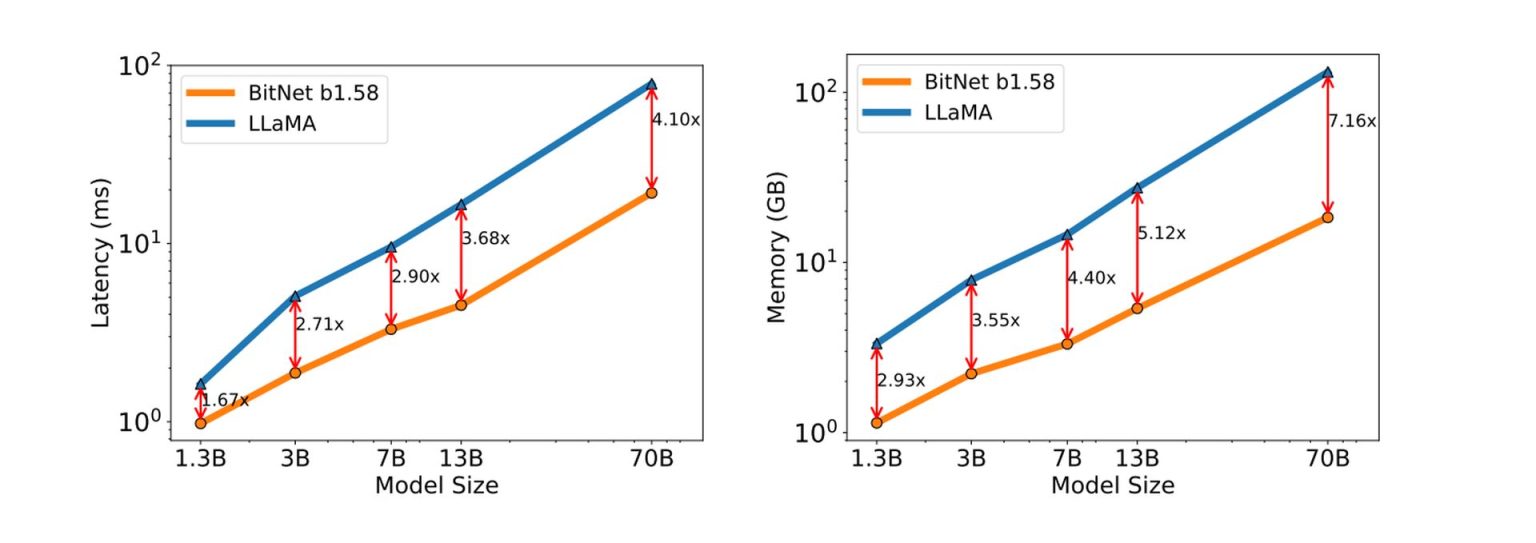
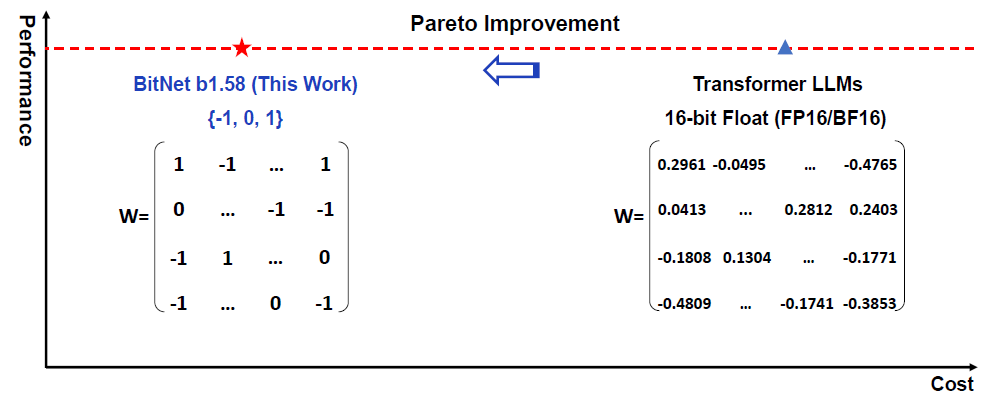
The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits and ...
LangChain tutorial #1: Build an LLM-powered app in 18 lines of code ...
Wire Bonsai Tutorial at Marjorie Lockett blog
GPU for LLM - GPU - Level1Techs Forums
Microsoft introduces its 1-bit LLM - TechBriefly
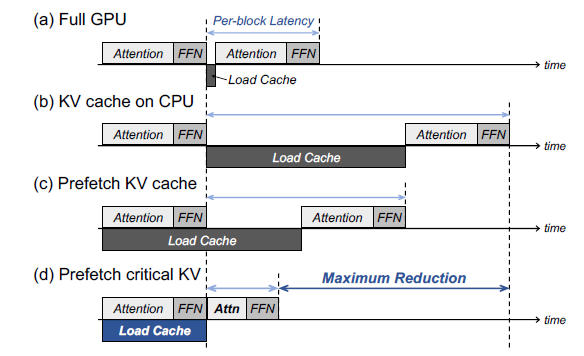
Advances to low-bit quantization enable LLMs on edge devices ...
GitHub - intel/ipex-llm: Accelerate local LLM inference and finetuning ...
How to Use GPU on LLM Studio | GPU Acceleration Guide
⭐️ Fast LLM Inference From Scratch
1-Bit LLMs: Microsoft's Groundbreaking Technology
[vLLM — Quantization] bitsandbytes: 8-bit Optimizers, LLM.int8(), QLoRA ...
What is 1-bit LLM? - YouTube
[PDF] CUDA-LLM: LLMs Can Write Efficient CUDA Kernels | Semantic Scholar
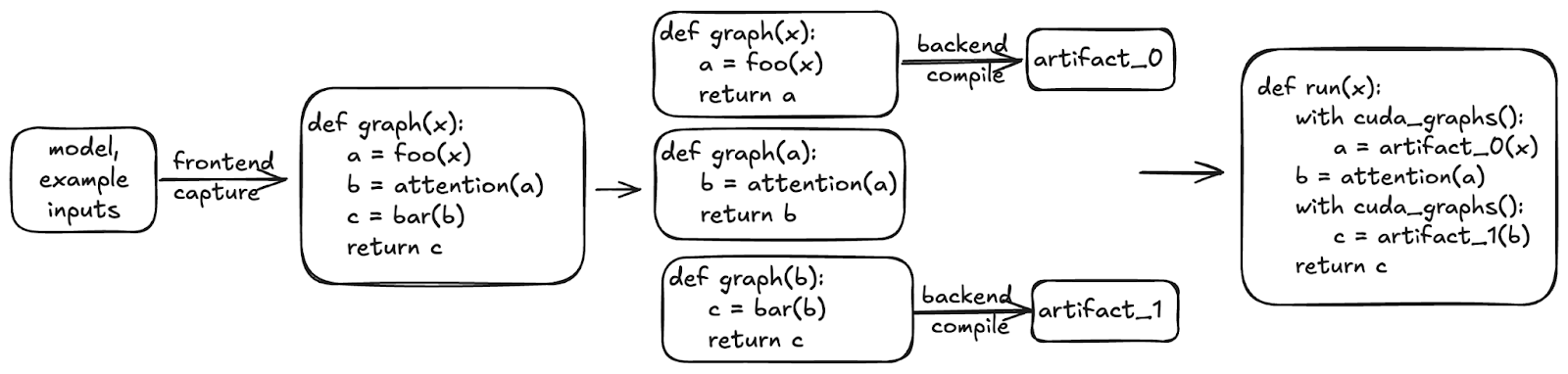
Efficiently Serving LLMs (Part 4): How CUDA Graphs make vLLM think faster
how-to-optim-algorithm-in-cuda/cutlass/TensorRT-LLM中的 Quantization GEMM ...
The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
在高版本CUDA的条件下,bitsandbytes发现低版本CUDA SETUP,完美解决方案,免费用。_welcome to ...
The Era of 1-bit LLMs-All Large Language Models are in 1.58 Bits - YouTube
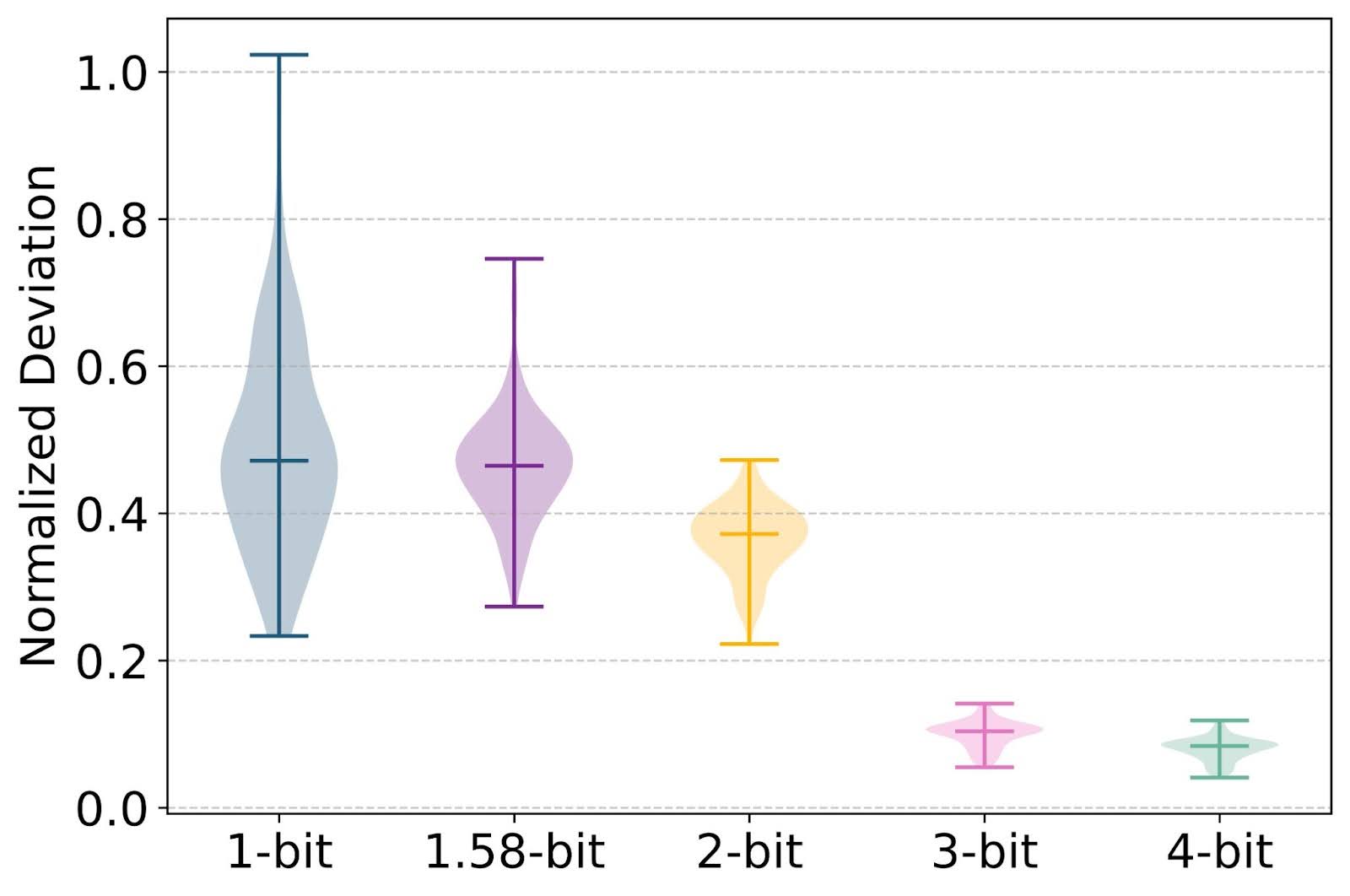
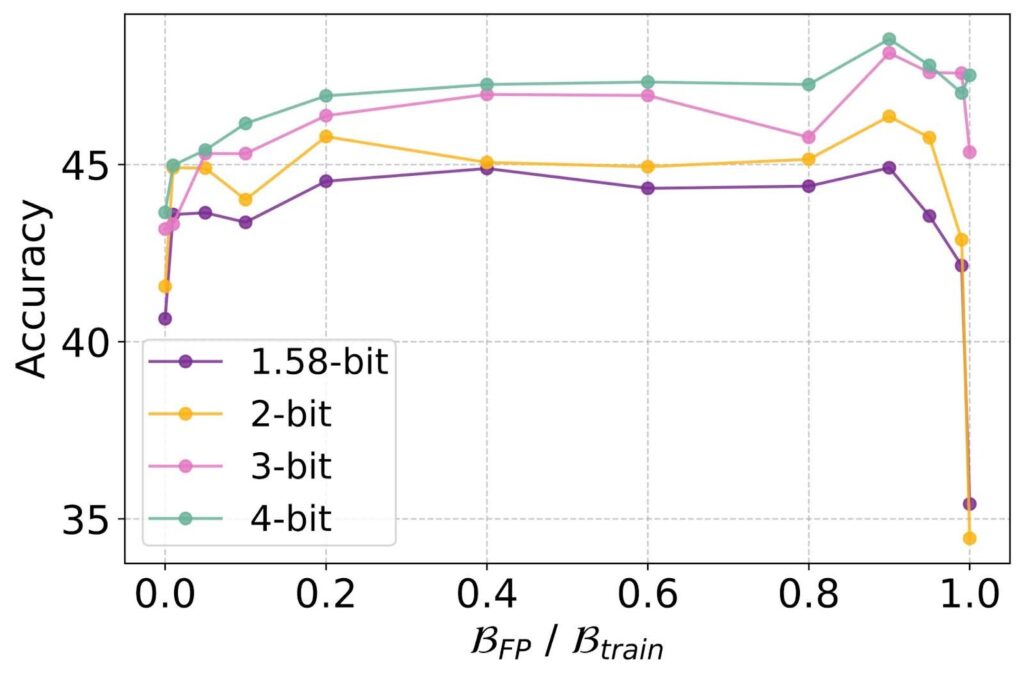
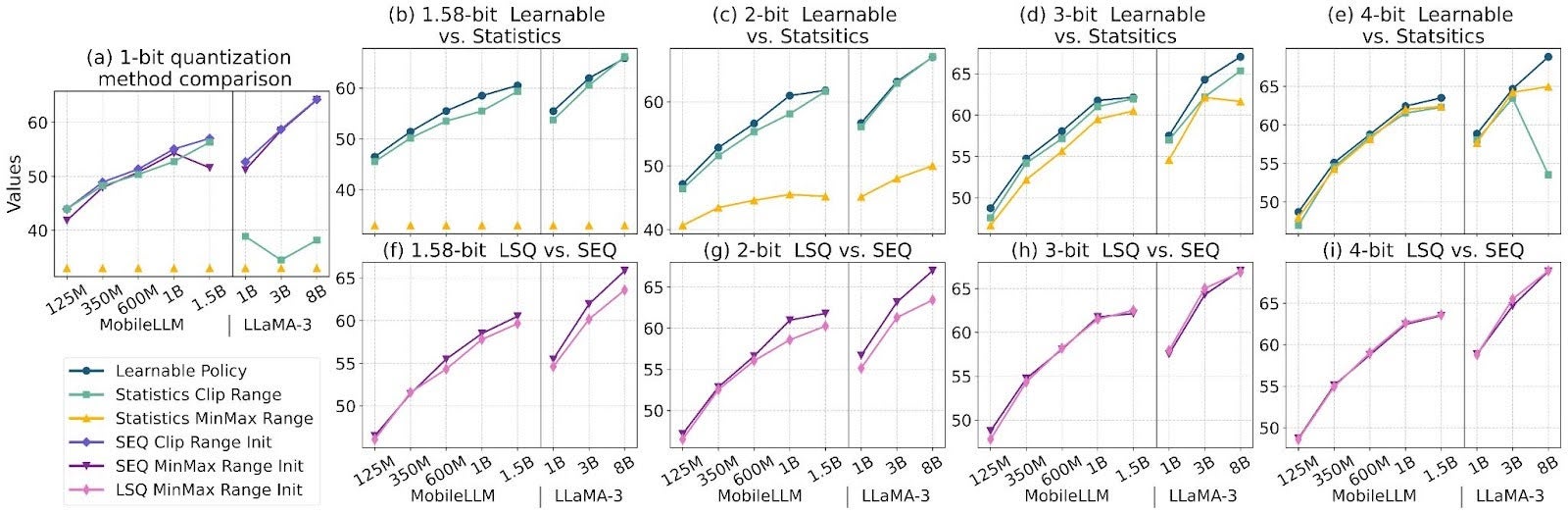
ParetoQ: Scaling Laws in Extremely Low-bit LLM Quantization – PyTorch
How to Wire Bonsai (The Basics) Part 1 | Bonsai, Basic, Propagation
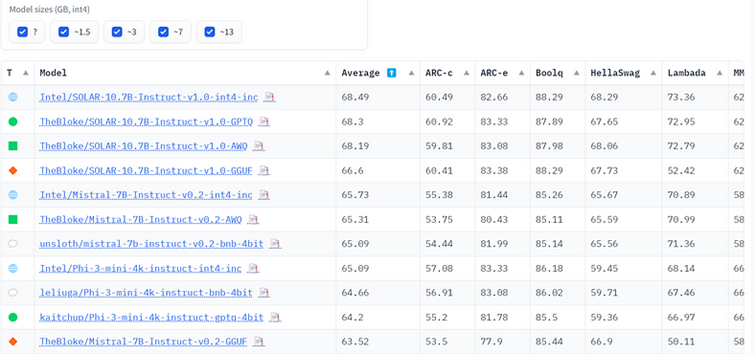
Low-Bit Quantized Open LLM Leaderboard
CUDA-Free Inference for LLMs – PyTorch
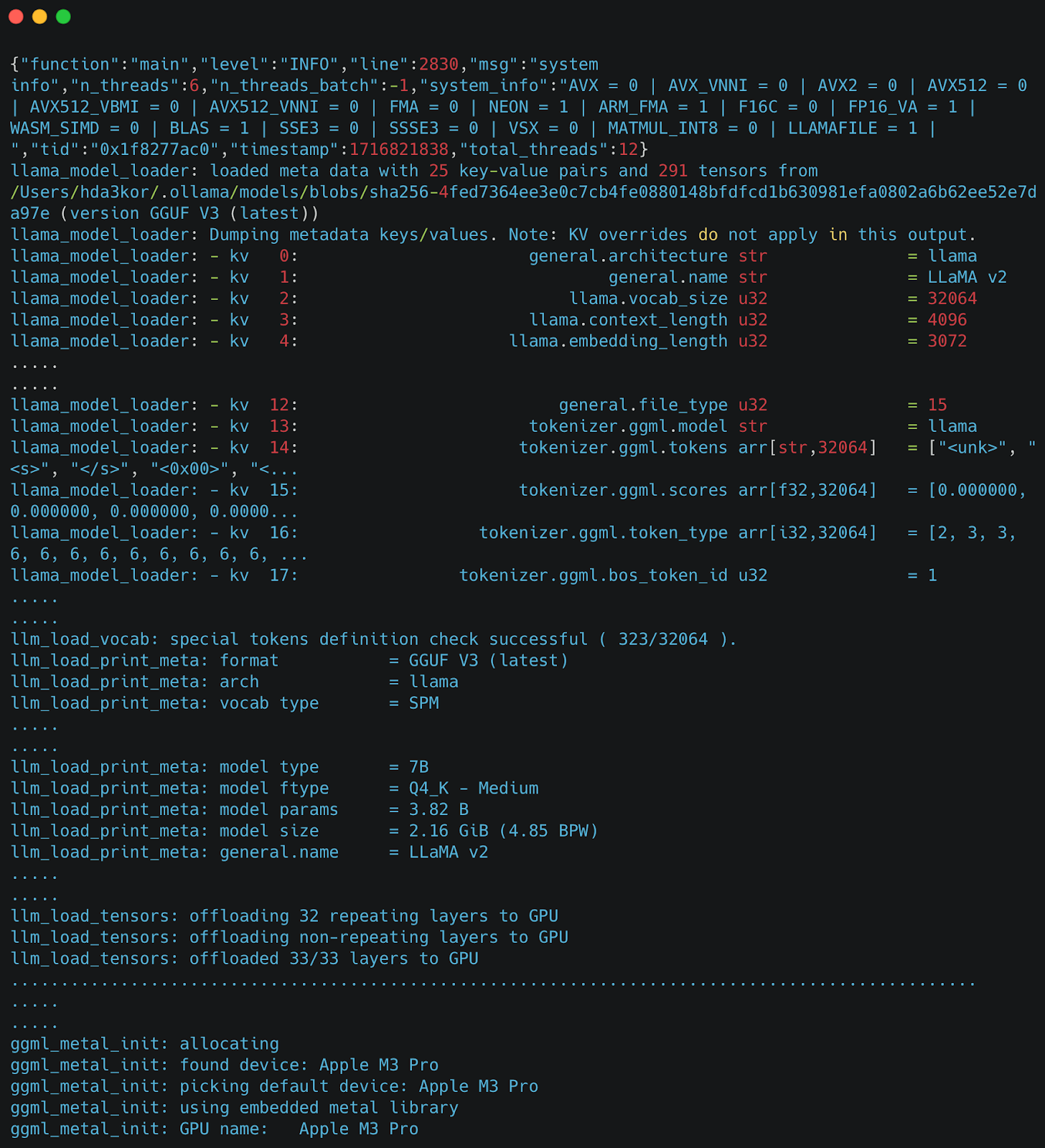
Meet LLama.cpp: An Open-Source Machine Learning Library to Run the ...
WebGPU로 나만의 LLM 만들기 | Sionic AI
Training LLMs with AMD MI250 GPUs and MosaicML | Databricks Blog
How to Compile and Build the GPU version of llama.cpp from source and ...
2025年“LLM== 编译器”:Megakernel(vLLM / TensorRT-LLM / TVM-Relax / IREE ...
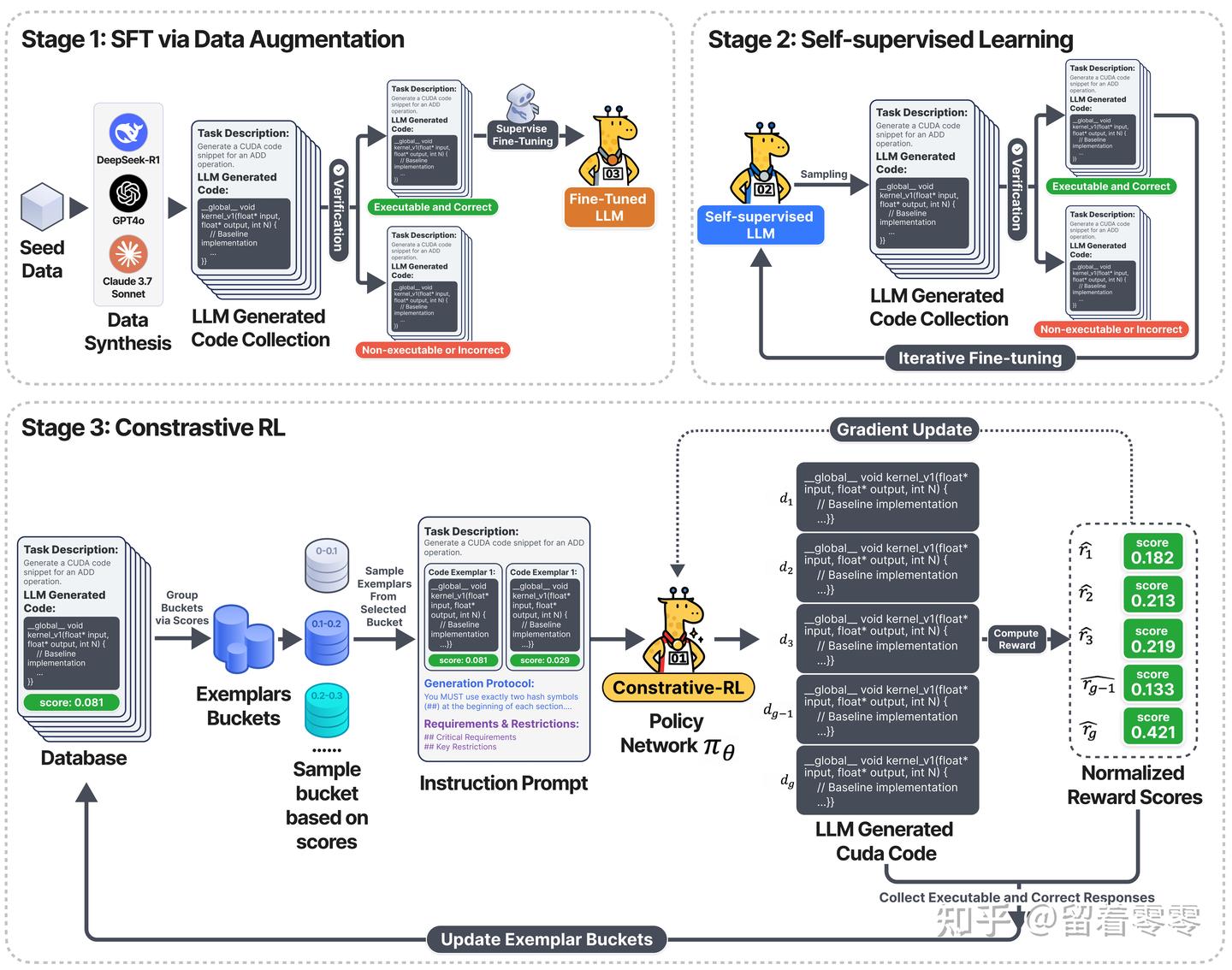
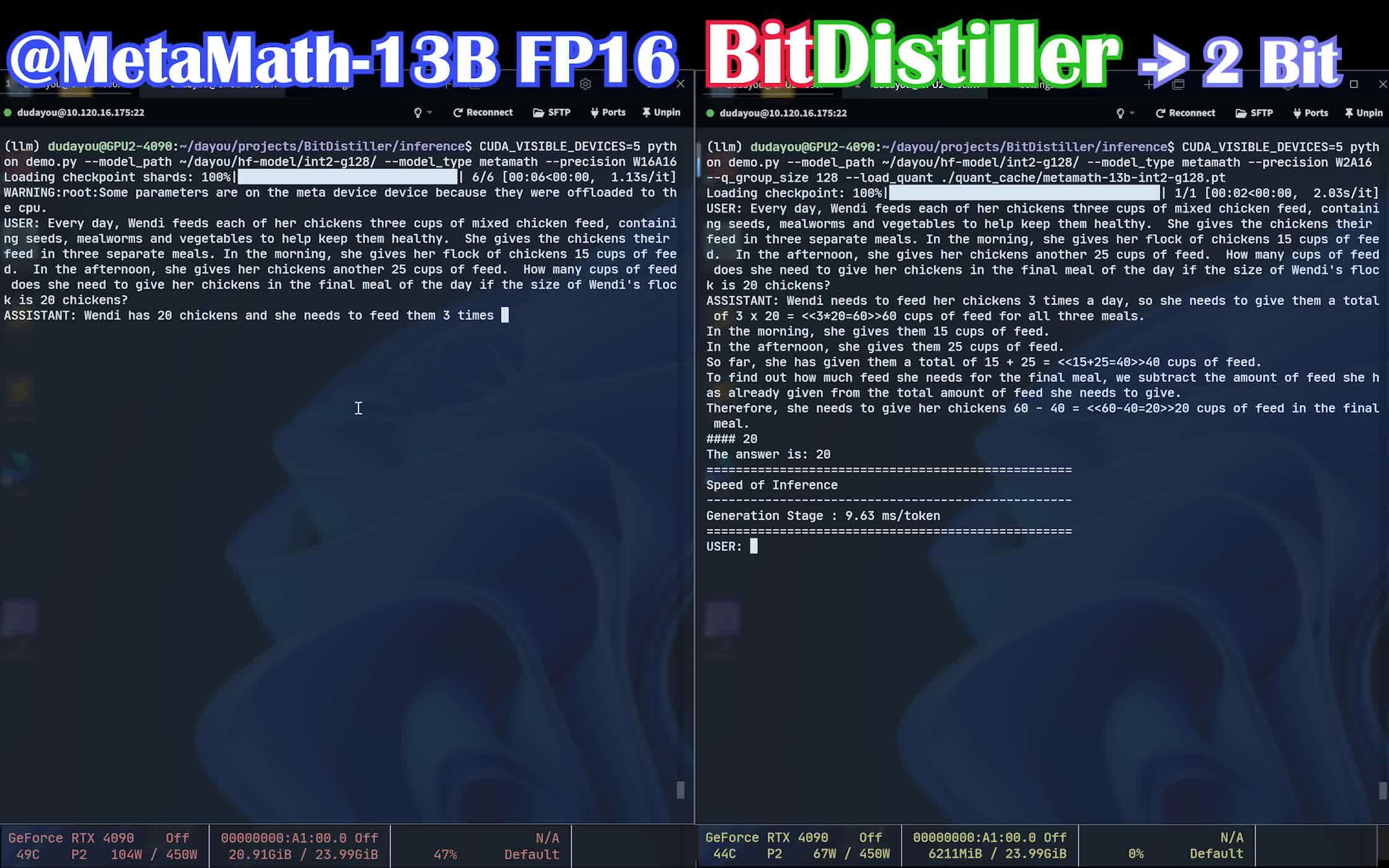
【ACL 2024】BitDistiller: LLM sub-4bit 的量化蒸馏训练,部署你的专属2-bit LLM - 知乎
How 1 Bit LLMs Work - YouTube
Fine Tuning Mistral (or ANY LLM) using LoRA | by Prakhar Saxena | Medium
How to Deploy an LLM: More Control, Better Outputs | HatchWorks AI
BitNet b1.58が1ビットLLMと呼ばれる理由は?メリット・概要・活用方法について徹底解説!
【LLM前沿技术】1 bit LLM的时代到来了~ - 知乎
PyTorch官宣:告别CUDA,GPU推理迎来Triton加速新时代 | 最新快讯_triton cuda-CSDN博客
14화 LLM을 로컬에서 실행할 수 있는 방법들















/filters:no_upscale()/news/2025/04/microsoft-bitnet-1bit-llm/en/resources/1microsoft-2-1745402359083.jpg)