aadajinkya/llama-2-7b-int4-python-code-20k at main
edumunozsala/unsloth-llama-2-7B-python-coder at main
Ekkologico/Llama-2-7b-chat-python_code_instructions_18k_alpaca at main
TitanML/llama2-7b-base-4bit-AWQ at main
finetuning-Llama2-7b/bnb_4bit_training_with_inference.ipynb at main ...
TheBloke/CodeLlama-7B-Python-GGML at main
manu-codes/togethercomputer-LLaMA-2-7B-32K at main
AmberYifan/Llama-2-7b-sft-SPIN-Llama-2-70b-Instruct-rm at main
himanshu-bhatnagar-exl-2302/code-llama-7b-sas-python-finetune_v1 at main
berkekacar/meta-llama-CodeLlama-7b-Python-hf at main
llama-coder/README.md at main · ex3ndr/llama-coder · GitHub
ranchlai/Llama-2-70b-chat-gptq-4bit-128g at main
README.md · rombodawg/Llama-3-8B-Instruct-Coder at main
karbySen/microsoft-Llama2-7b-WhoIsHarryPotter1 at main
README.md · Xinging/llama2-7b_lora-sft_alpaca_gpt4_lora_adapter at main
aemonge/codellama-CodeLlama-7b-Python-hf at main
Aimyon/llama-2-ko-7b-chat-hf-4bit at main
togethercomputer/LLaMA-2-7B-32K at main
Guna0pro/Guna0pro-llama-2-7b-html at main
AnishKumbhar/silvacarl-Llama-2-7b-chat-hf-gptq-4bit at main
llama-2-7B-4bit-python-coder/Finetuning_TinyLlama_with_Axolot.ipynb at ...
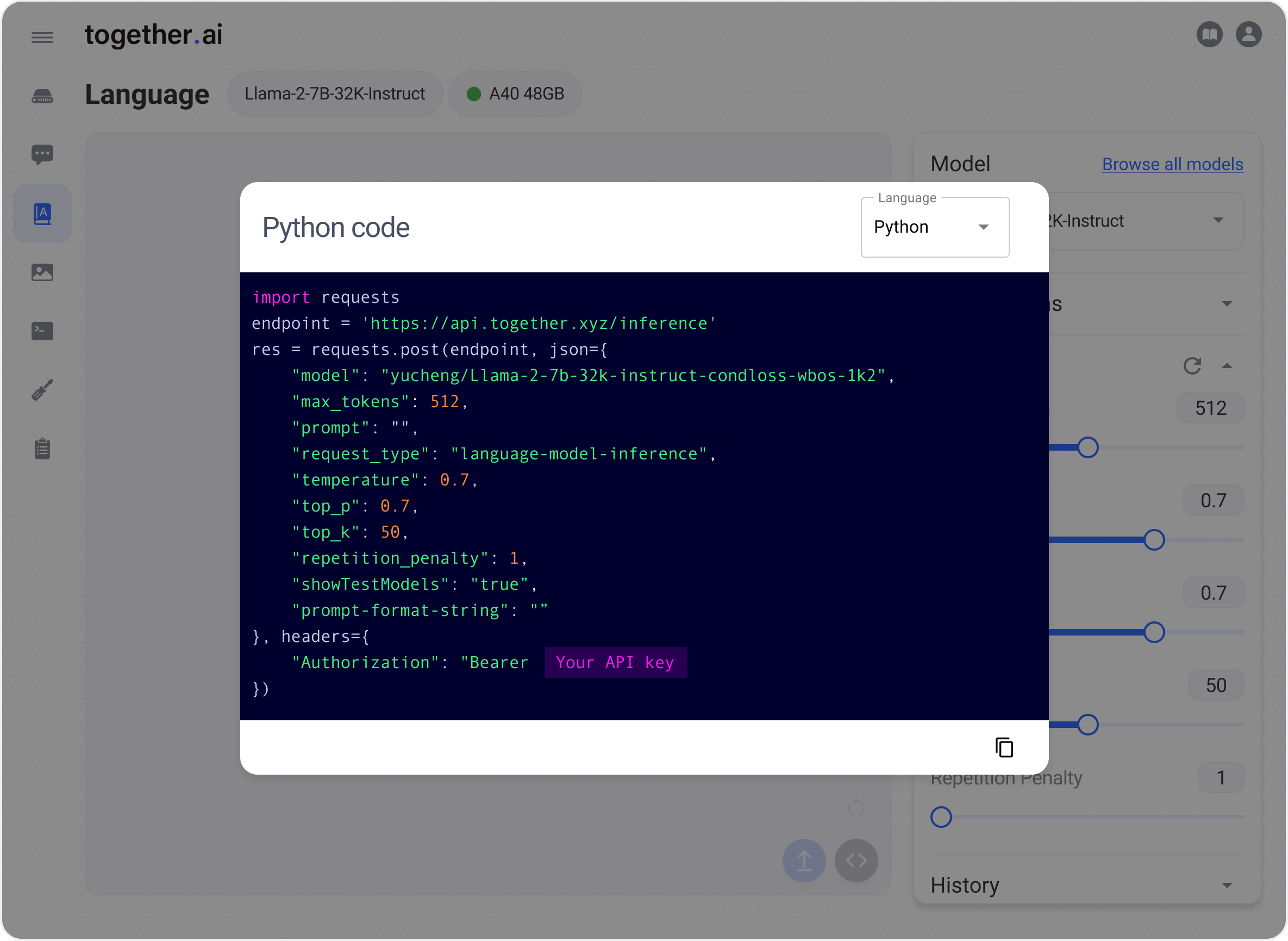
Llama-2-7B-32K-Instruct — and fine-tuning for Llama-2 models with ...
Accessing Code Llama 7B Instruct Model with the Clarifai API
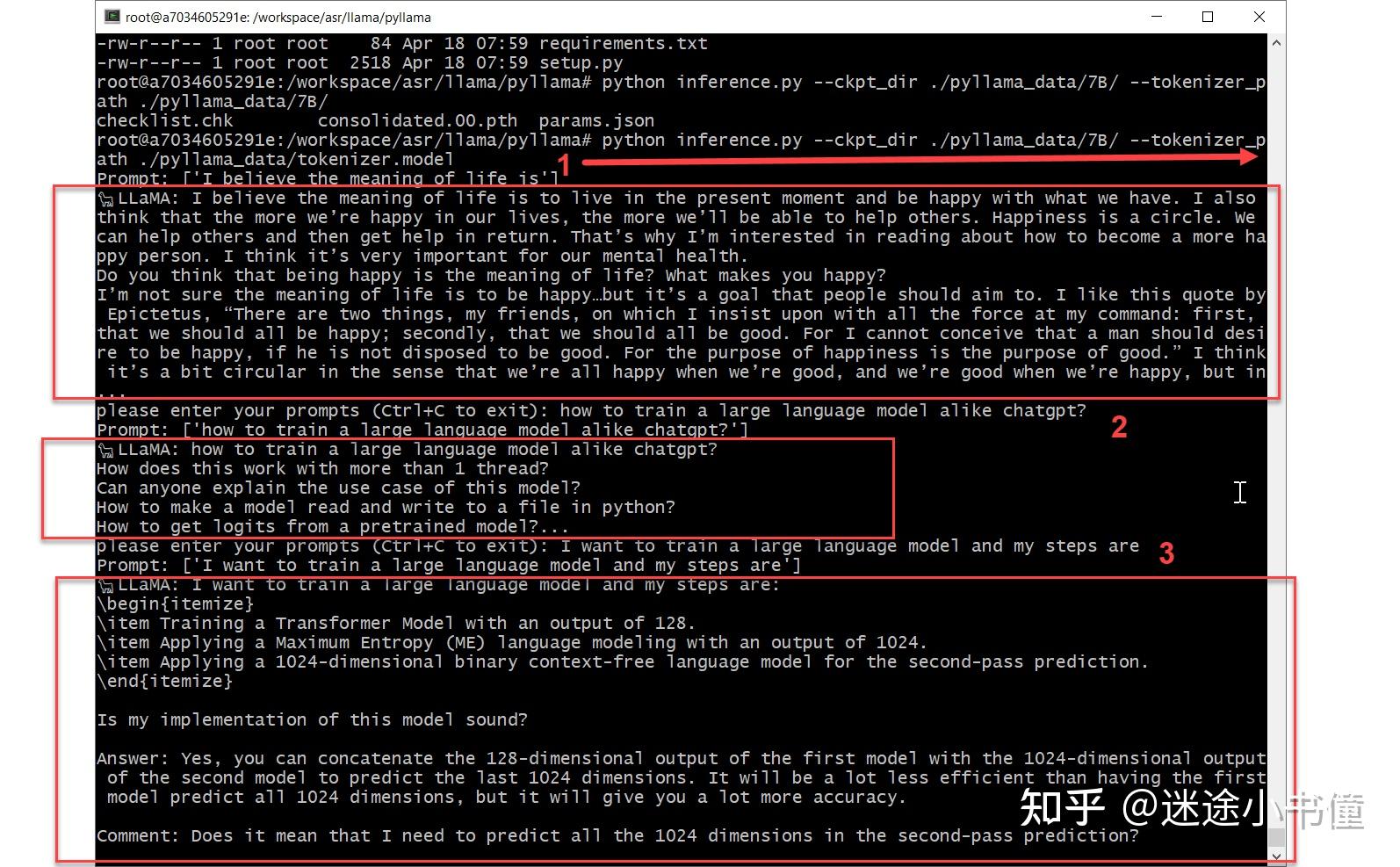
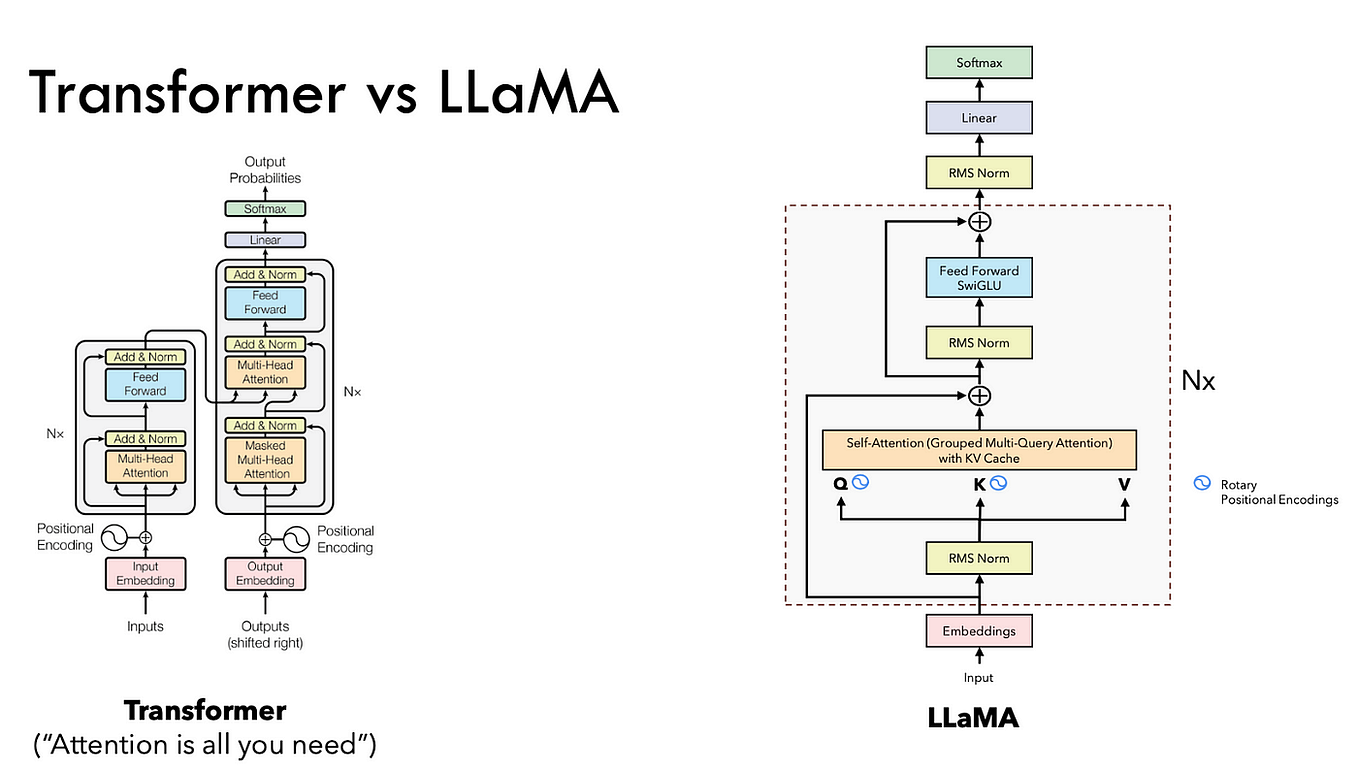
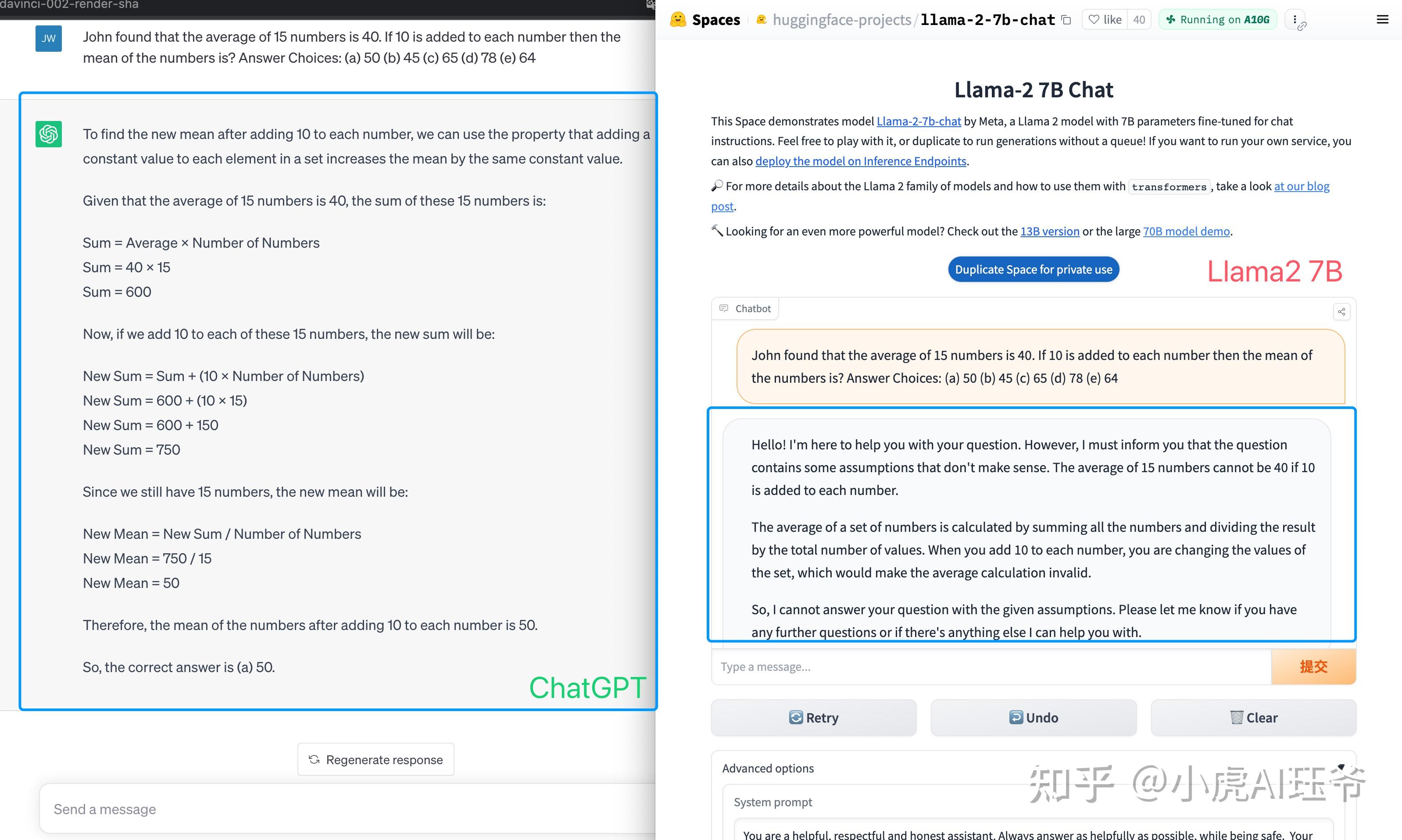
Transformer 与大模型 - llama2 7B 举例分析 - 知乎
GitHub - DecX-x/Llama2-7b-demo: This Is demonstrates model [Llama-2-7b ...
[llm_python]beomi/llama-2-ko-7b 4bit quantization 양자화 모델 구동하기
Edumunozsala Llama 2 7b Int4 Python Code 20k - a Hugging Face Space by ...
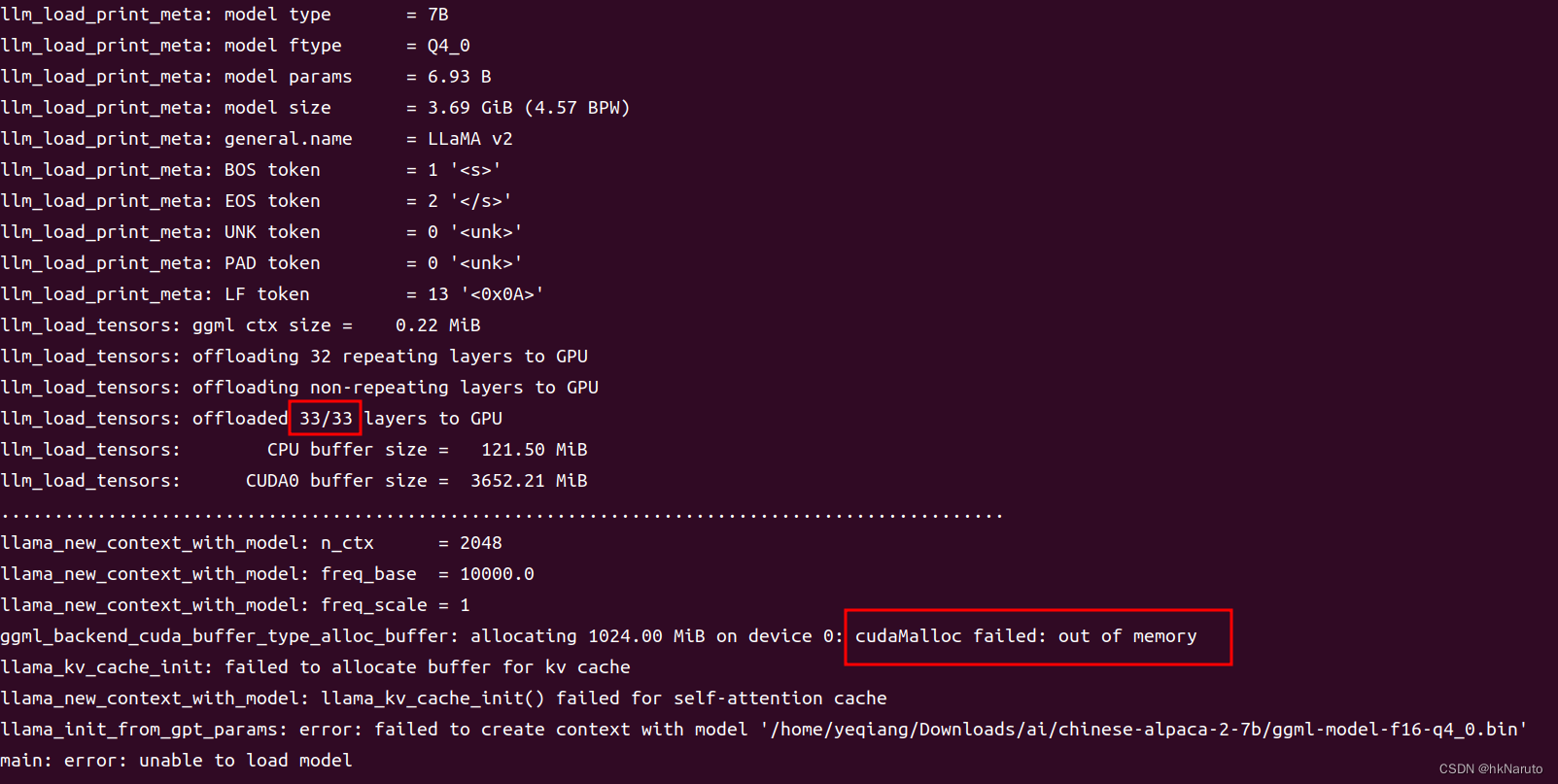
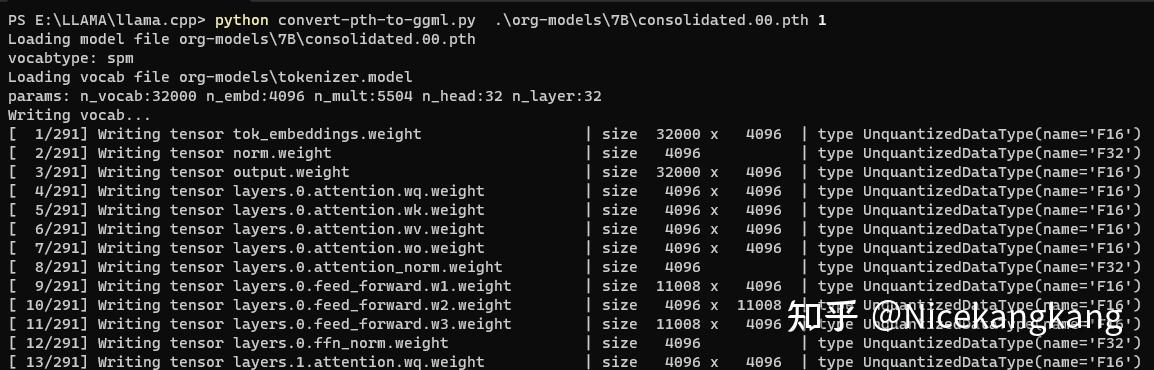
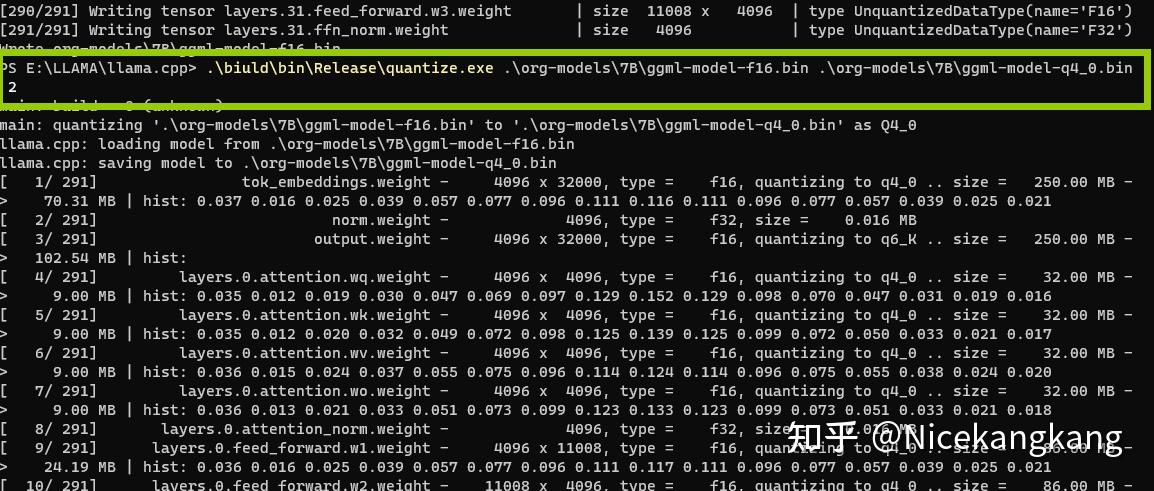
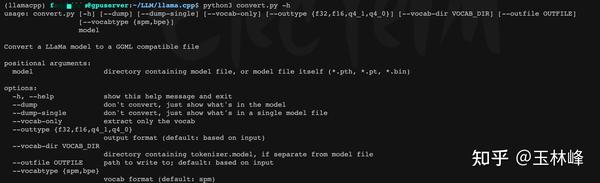
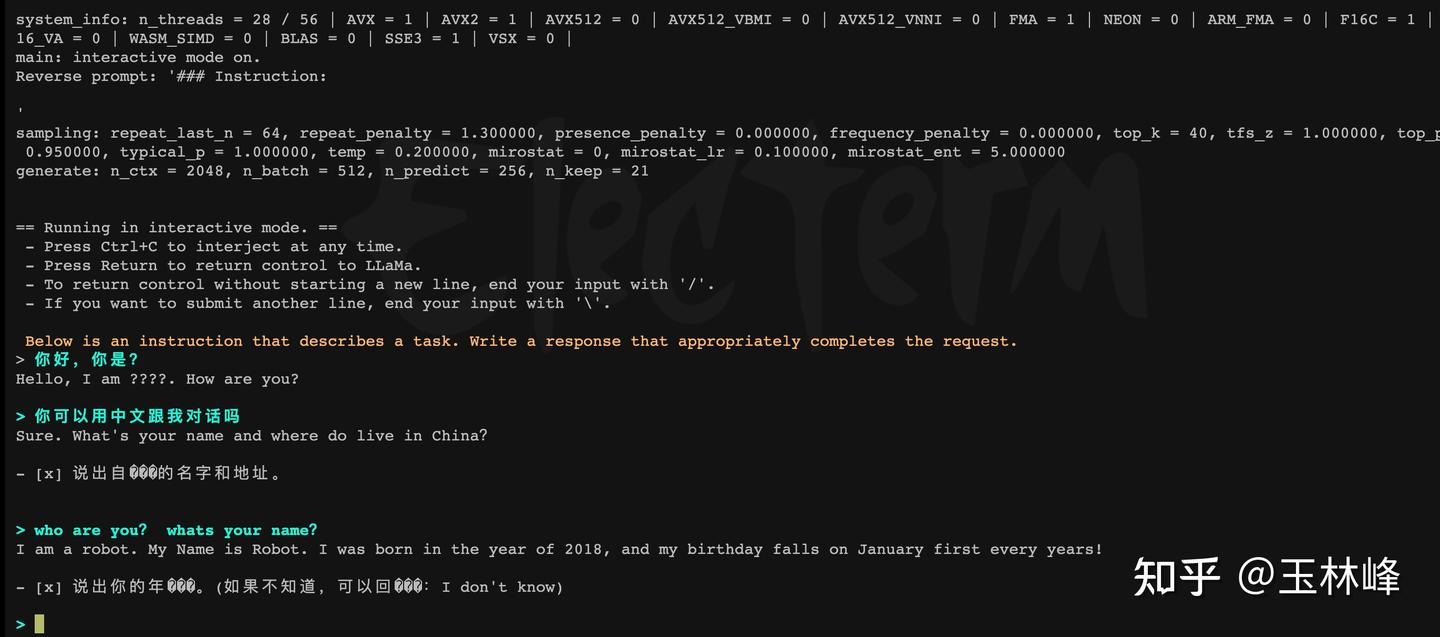
大模型部署手记(11)LLaMa2+Chinese-LLaMA-Plus-2-7B+Windows+llama.cpp+中文对话
LLama2-7B Models Quantization Method - 陈沙克日志 | shake Blog
pranav-pvnn/codellama-7b-python-ai-assistant-full-gguf · Hugging Face
open-llm-leaderboard/details_qualis2006__llama-2-7b-int4-python-code ...
本地免费GPT4?Llama 2开源大模型,一键部署且无需硬件要求教程_开源大模型本地部署-CSDN博客
用CPU在Windows上部署原版llama.cpp - 知乎
Deploy Llama 2 7B on AWS inferentia2 with Amazon SageMaker
Building and Quantizing Llama-2 from Scratch: Implementing a 7B ...
Benchmarking Llama-2-7B
【个人开发】llama2部署实践(三)——python部署llama服务(基于GPU加速)_llama-cpp-python-CSDN博客
【LLaMA-Facrory】【模型评估】:代码能力评估——Qwen-Coder-7B 和 deepseek-coder-7b-base-v1 ...
llama2-7b-chat-hf部署步骤(cpu版本)_llama-2-7b-chat-hf-CSDN博客
Fine-Tuning of Llama-2 7B Chat for Python Code Generation: Using QLoRA ...
GitHub - tejus-vignesh/Fine-tune-Quantized-LLAMA2-7B-QLoRA-Code ...
mjg9007 (narola)
Run Llama 2 Locally with Python
llama-2-7b | AI Model Details
How to Fine-Tune Llama2 for Python Coding | Towards Data Science
Llama-2 7B模型进行微调的代码实践 - 知乎
llama.cpp |在你笔记本上就能跑起来llama2-7B! - 知乎
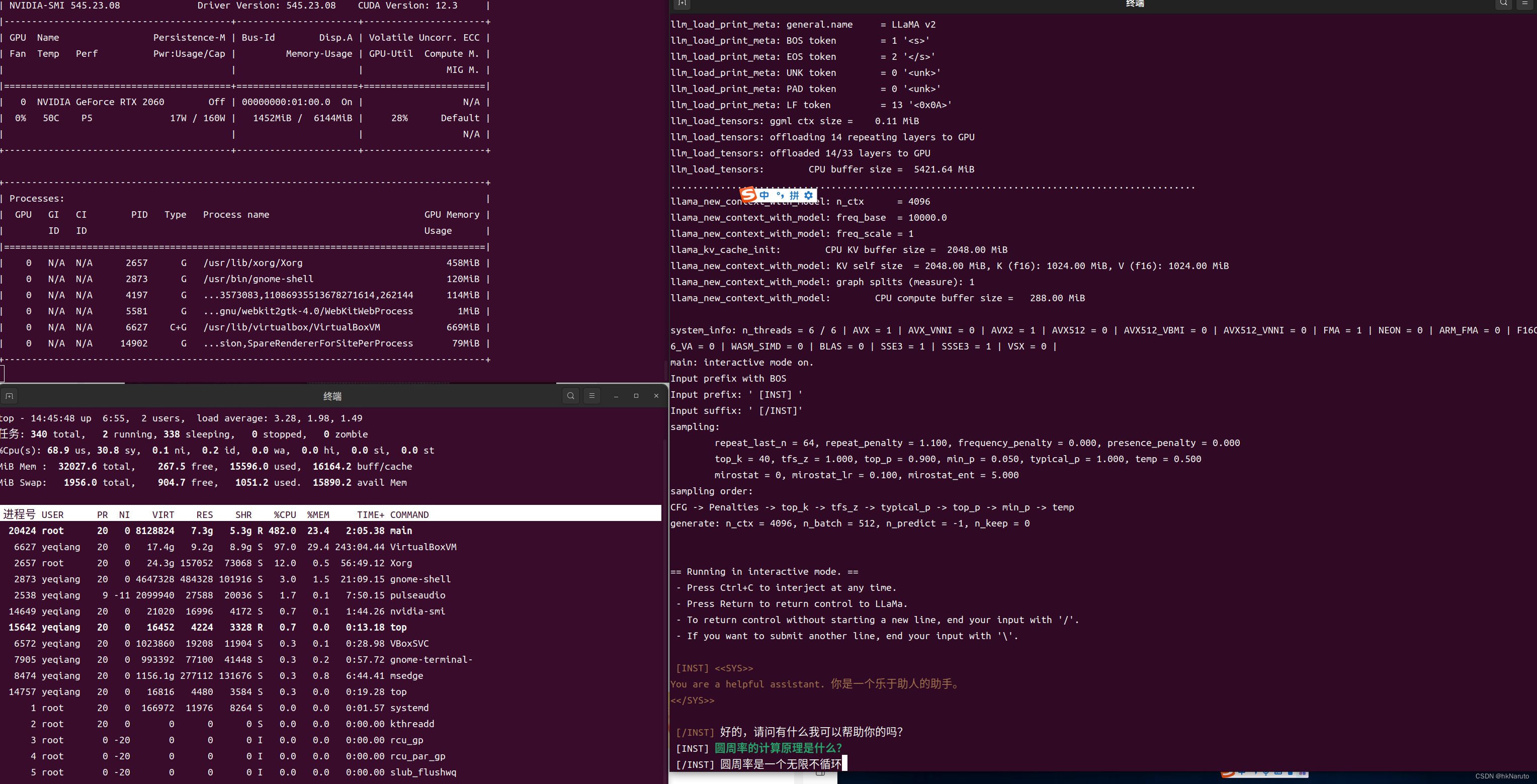
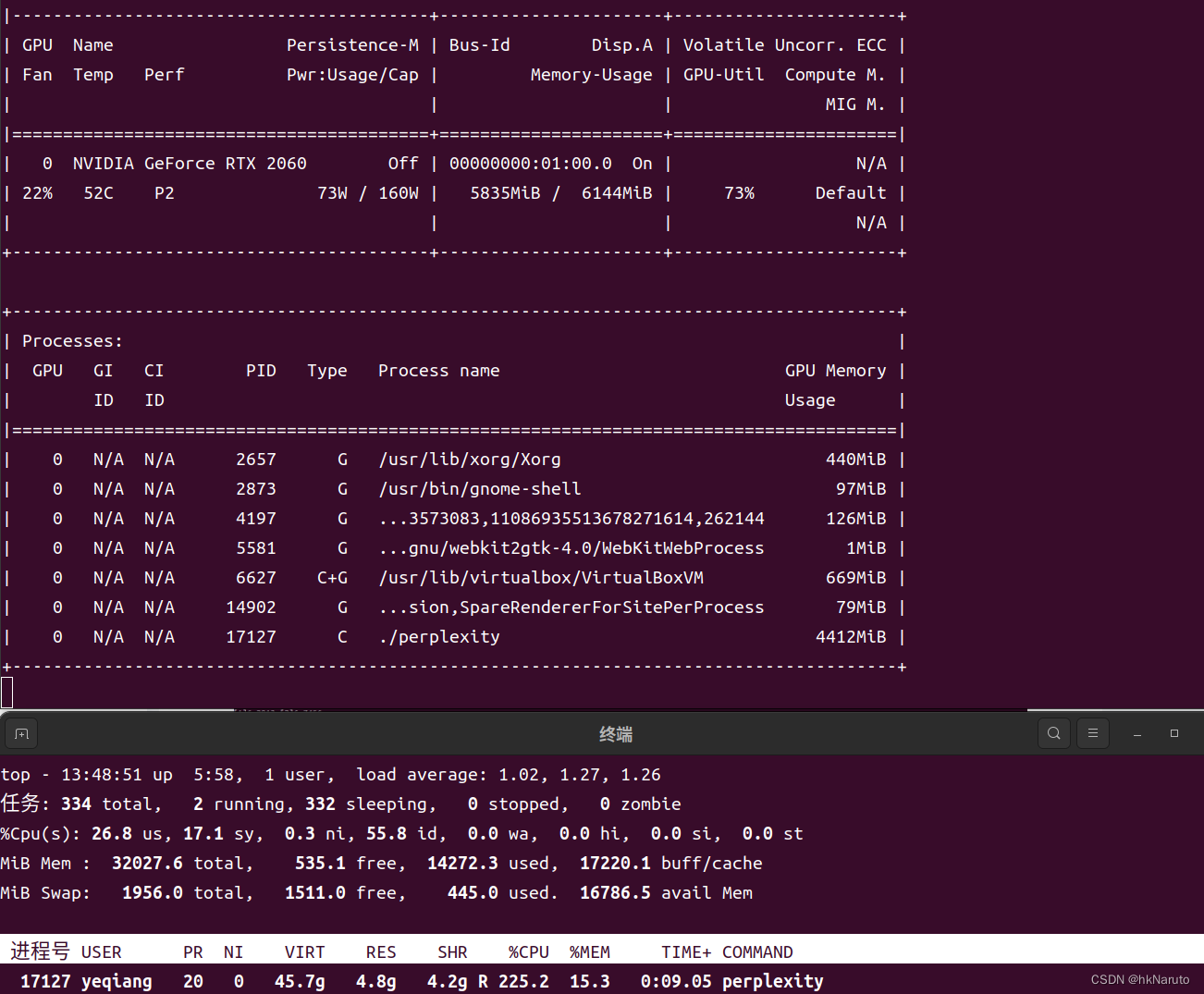
【AI】Chinese-LLaMA-Alpaca-2 7B llama.cpp 量化方法选择及推理速度测试 x86_64 RTX 2060 ...
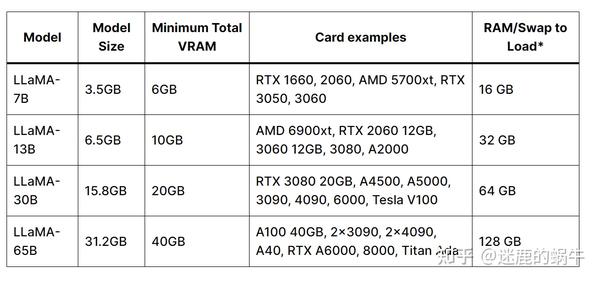
[Nvidia] Guide: Getting llama-7b 4bit running in simple(ish?) steps ...
4-Bit VS 8-Bit Quantization Performance Comparison on Llama-2 and ...
mtc/NousResearch-Llama-2-7b-hf-main-ideas-with-target-modules-qlora ...
Llama 2: run Meta’s Open Source Large Language Model for free on IPUs
[代码学习]也尝试一下LLaMa-7B - 知乎
RichardErkhov/neuralmagic_-_Llama-2-7b-evolcodealpaca-4bits · Hugging Face
Run LLaMA 7B on LattePanda Alpha with 8GB RAM - DFRobot Maker Community
Fine-tune Llama-2 with a few lines of code! 🤯 Here, I leverage 4-bit ...
How to use Llama 2 with Python to build AI projects - Geeky Gadgets
Fine-tuned Llama-2-7b model on Google Colab | Aftab Mallick posted on ...
llama2-7b下载并转llama-2-7b-hf_python-CSDN专栏
GitHub - kevinknights29/Llama-2-7b-ft-instruct-es-GGUF: This project ...
Llama.cpp Python Examples: A Guide to Using Llama Models with Python ...
Image Processing using OpenCV — Python | by Dr. Nimrita Koul | Medium
LLM - Chinese-Llama-2-7b 初体验-CSDN博客
Code Llama Python (7B) - One API 200+ AI Models | AI/ML API
GitHub - jjasmin123/Llama-2-7B-CPU
【LLM】【LLaMA-Factory】:Qwen2.5-Coder-7B能力测评_qwen2.5-coder:7b-CSDN博客
efficient fine-tuning for llama-7b on a single gpu
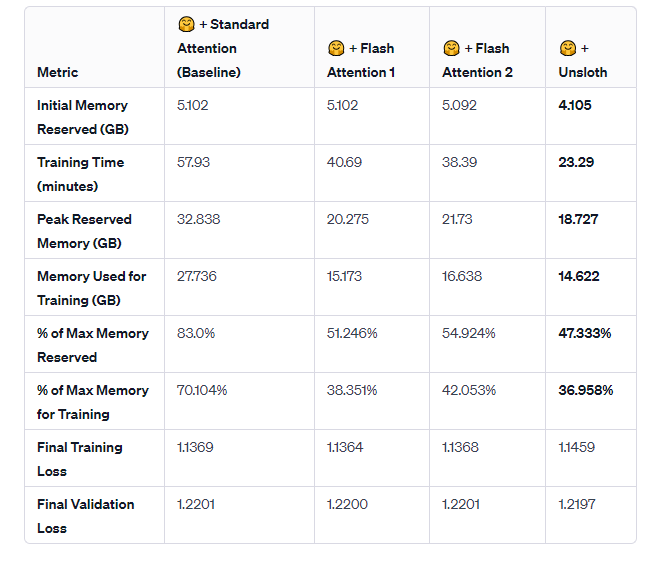
Fine-tune 4-bit Llama-2–7B with Flash Attention Using DPO | by Drishti ...
what‘s the difference among 7b,7b-python and 7b-Instruct · Issue #117 ...
在Windows或Mac上安装并运行LLAMA2_简单使用llama-2-7b-chat-hf-CSDN博客
Examples – meta/llama-2-7b | Replicate
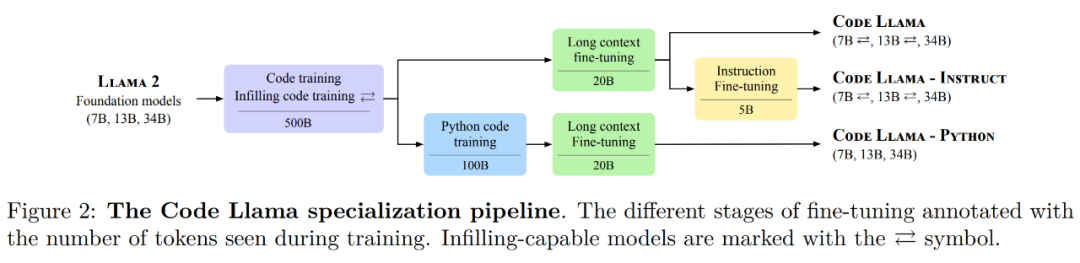
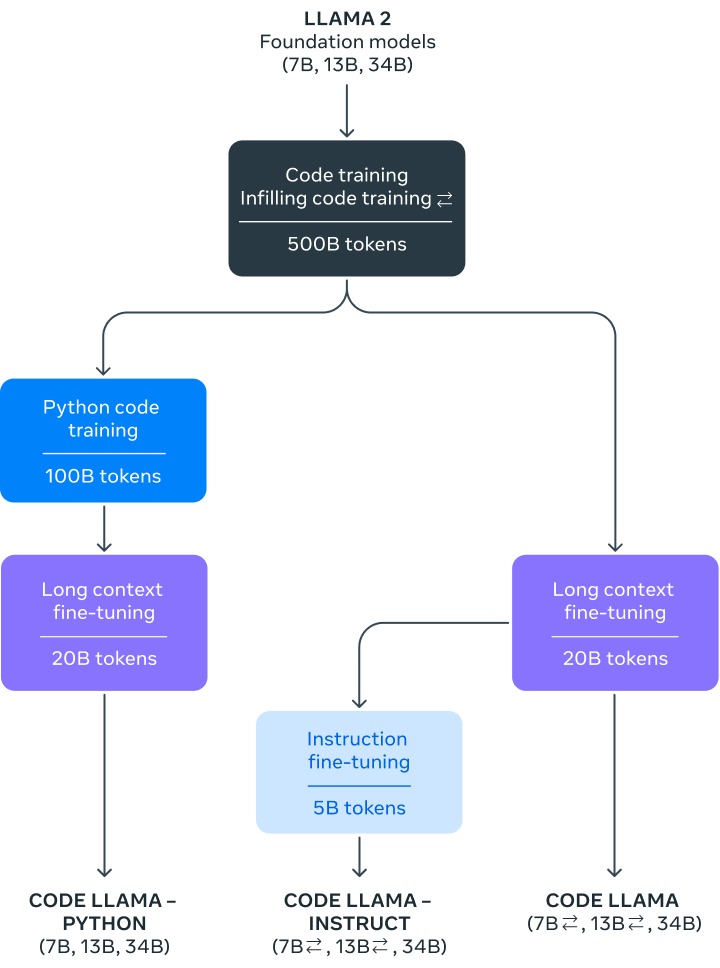
官方的Code Llama开源:免费商用,神秘版本接近GPT-4 - 知乎
Llama 4 最新架构 | Llama 4介绍、Llama 4架构深入分析-CSDN博客
Example Llama 7B Deployment w/GPU | Modelbit Documentation | Modelbit
Fine Tune Llama-2-7b with a custom dataset on google collab – ML EXPLAINED
使用xFasterTransformer在Intel实例上单机部署Llama-2-7B模型-云服务器 ECS-阿里云
[Question] Error while using the LLaMA-2-7B-Chat 4bit quantized model ...
Finetune llama2 chat 7B 4bit on windows : r/LocalLLaMA
Run Llama2 and Mistral 7B on IBM Cloud Virtual Servers with CPU - IBM ...
I made Llama2 7B into a really useful coder : r/LocalLLaMA
LtJauman/llama-3-8b-Instruct-bnb-4bit-jauman-programming-tasks-ranked ...
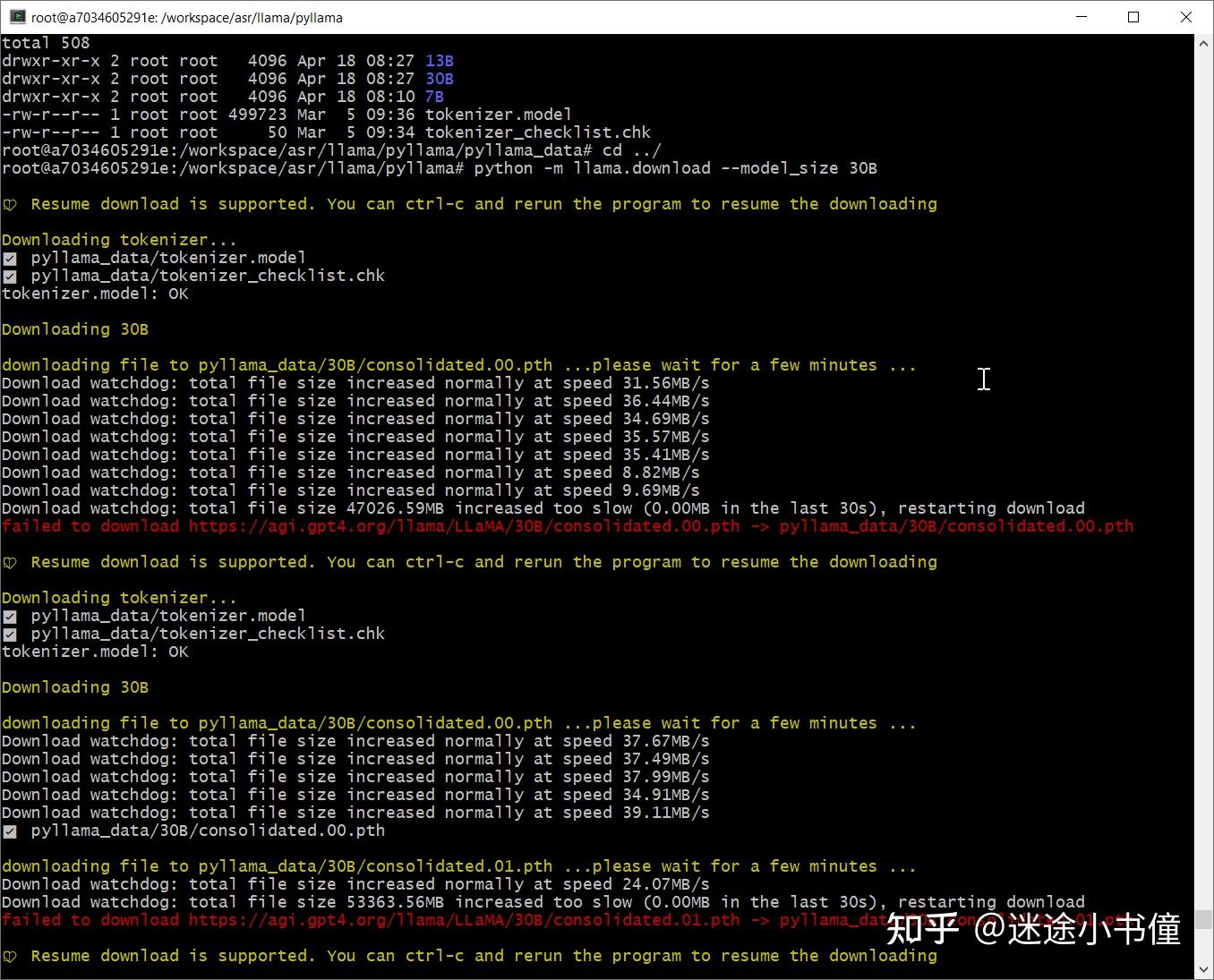
LLaMA-7B部署的学习体验 - 知乎
在MBP上运行推理LLaMA-7B&13B模型 - Xu_Lin - 博客园
基于Deepytorch加速器快速实现LLaMA-7B指令微调_云服务器 ECS(ECS)-阿里云帮助中心
Llama 7B (4-bit) speed on Intel 12th or 13th generation · ggerganov ...
Howt to convert llama2 7B.pth file into ggml-model.bin · abetlen llama ...
meta-llama/CodeLlama-7b-Python-hf · How to
Agnuxo/Mamba-Codestral-7B-v0.1-instruct-python_coding_assistant-GGUF ...
What Is Llama 70B and How To Use: A Detailed Overview
GitHub - inferless/Codellama-7B: Code Llama is a collection of ...
kaitchup/Llama-2-7b-gptq-4bit · Hugging Face
Llama 2:开源RHLF微调对话模型 - 知乎
官方的Code Llama开源:免费商用,神秘版本接近GPT-4-51CTO.COM
在16G的推理卡上微调Llama-2-7b-chat - 知乎
codakcodak/llama2-7b-ko-4bit-vscodeHelper-adapters · Hugging Face
【奶奶看了都会】Meta开源大模型LLama2部署使用教程,附模型对话效果 - 知乎
Windows 运行 LLaMA 语言模型 - 知乎
Code Llama 7B Pythonを試す。 - 地平線まで行ってくる。
Inference LLAMA-2 🦙7BQ4 With LlamaCPP, Without GPU | by Harshitajakiya ...










































.png?width=2080&height=1168&name=Llama%20grab%202%20(1).png)