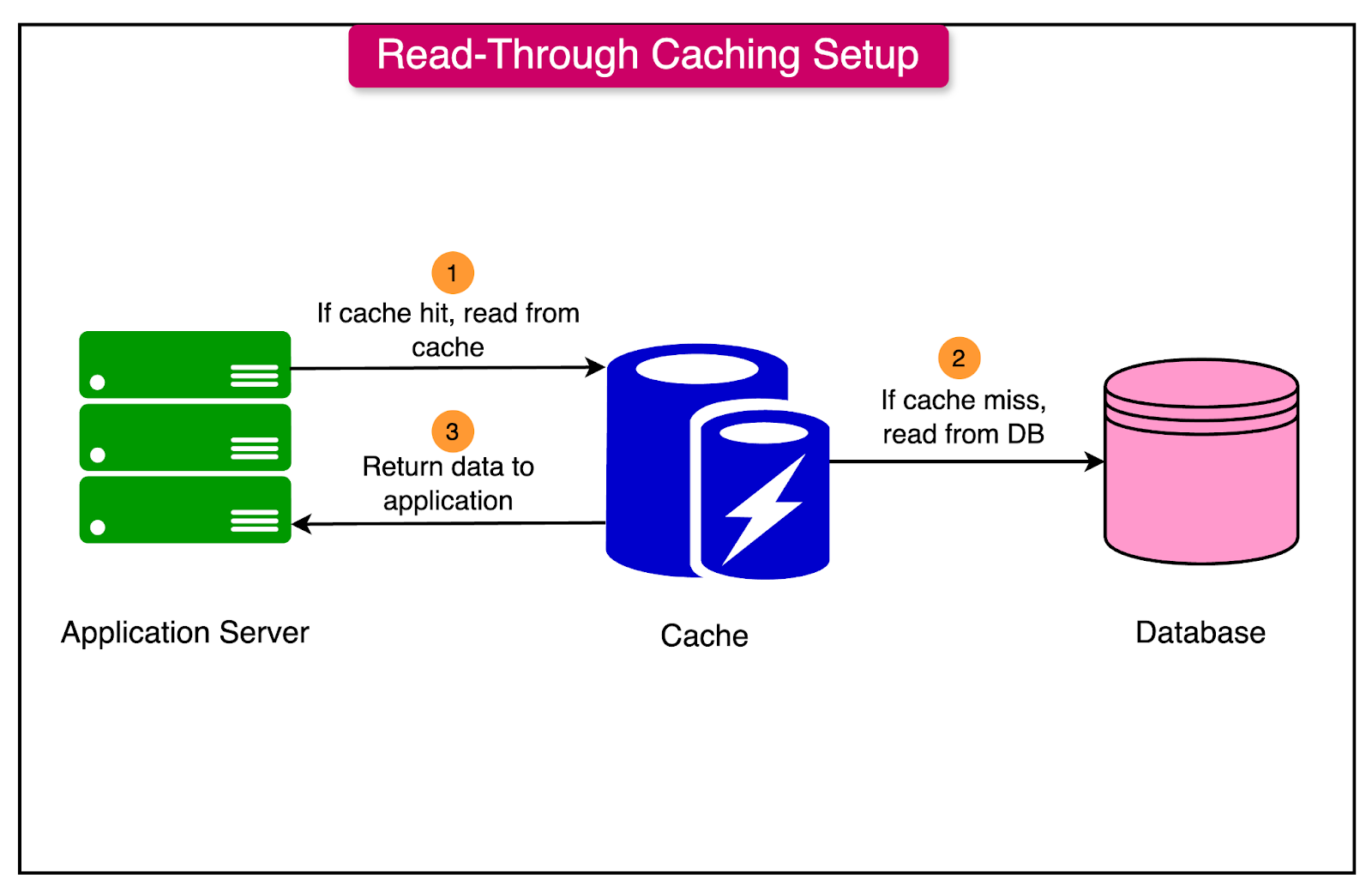
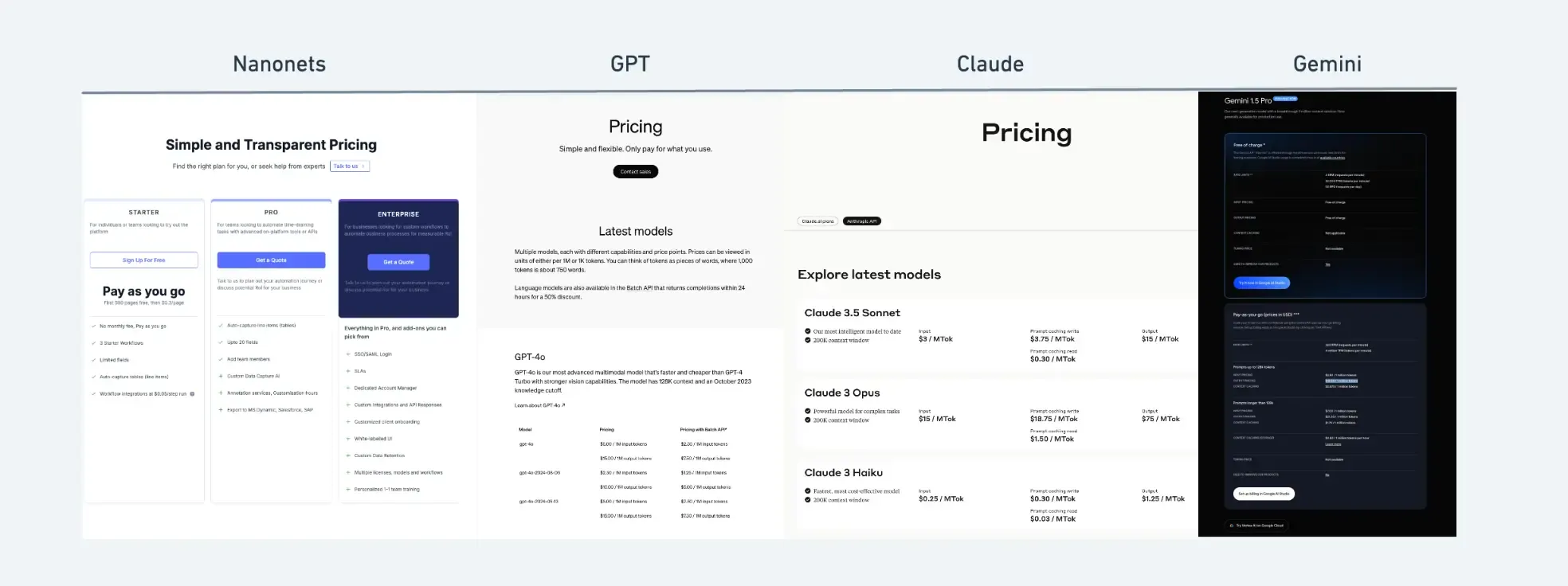
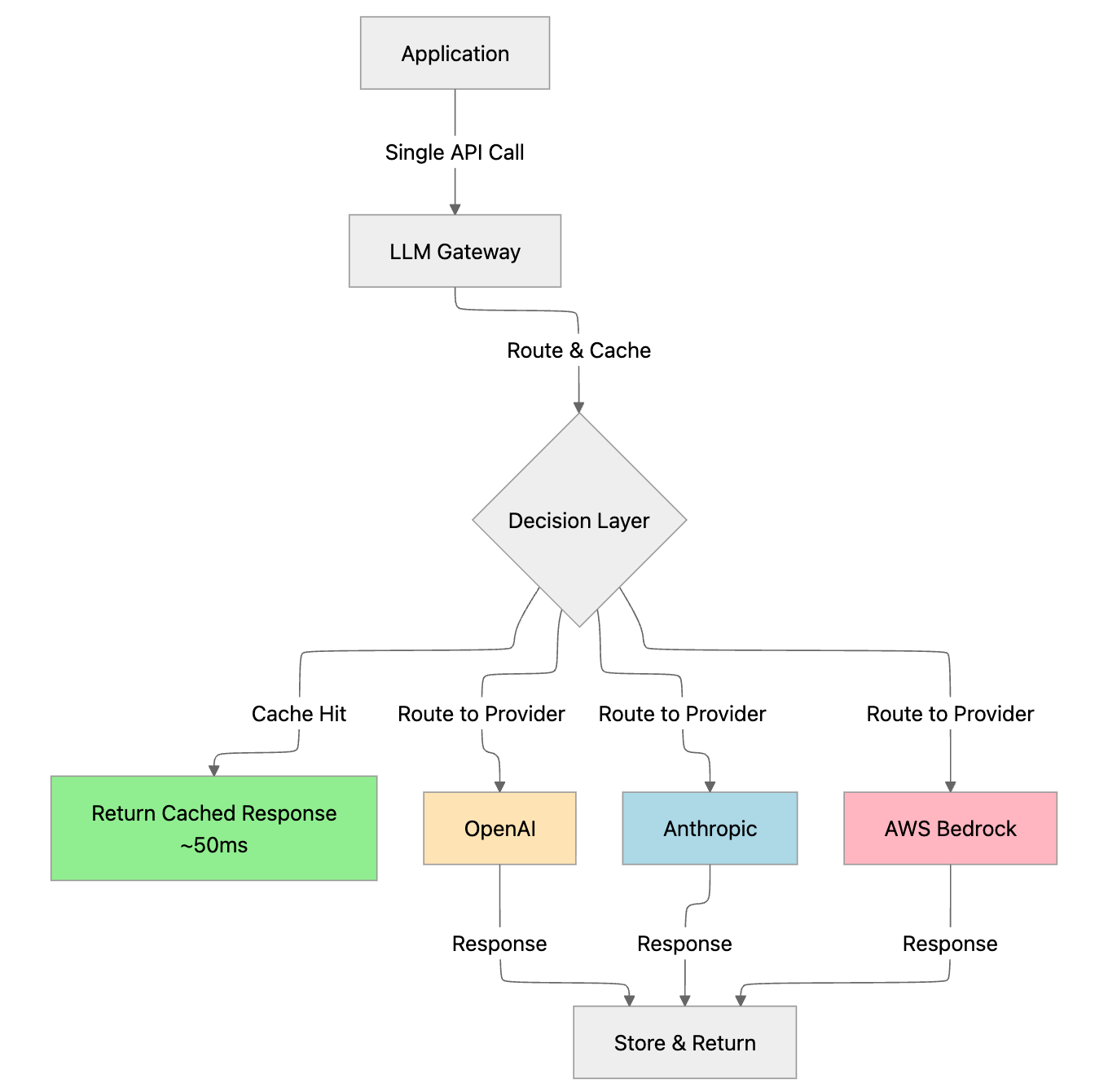
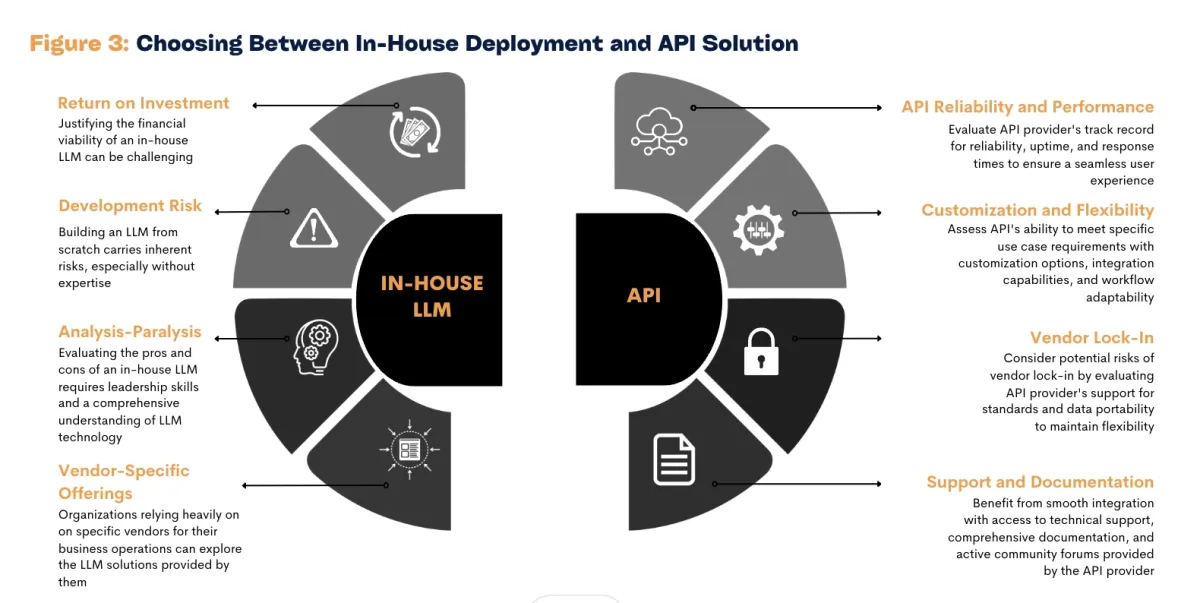
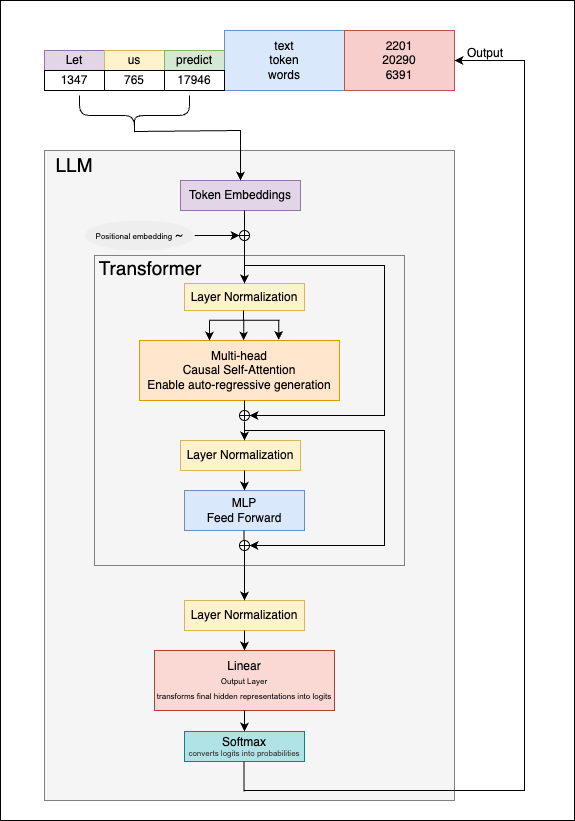
How I Cut My API Response Time by 80% with Ktor Client Caching (And You ...
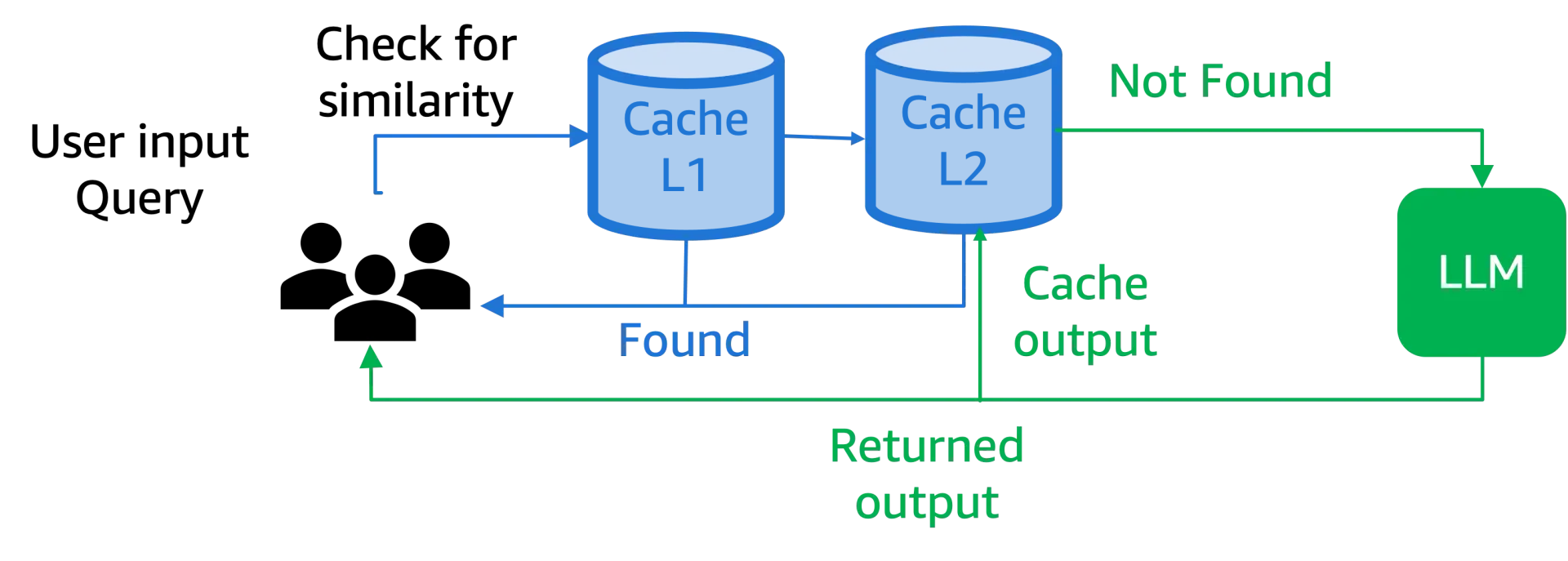
LLM Caching Isn’t Optional — Here’s How I Built It with Redis and ...
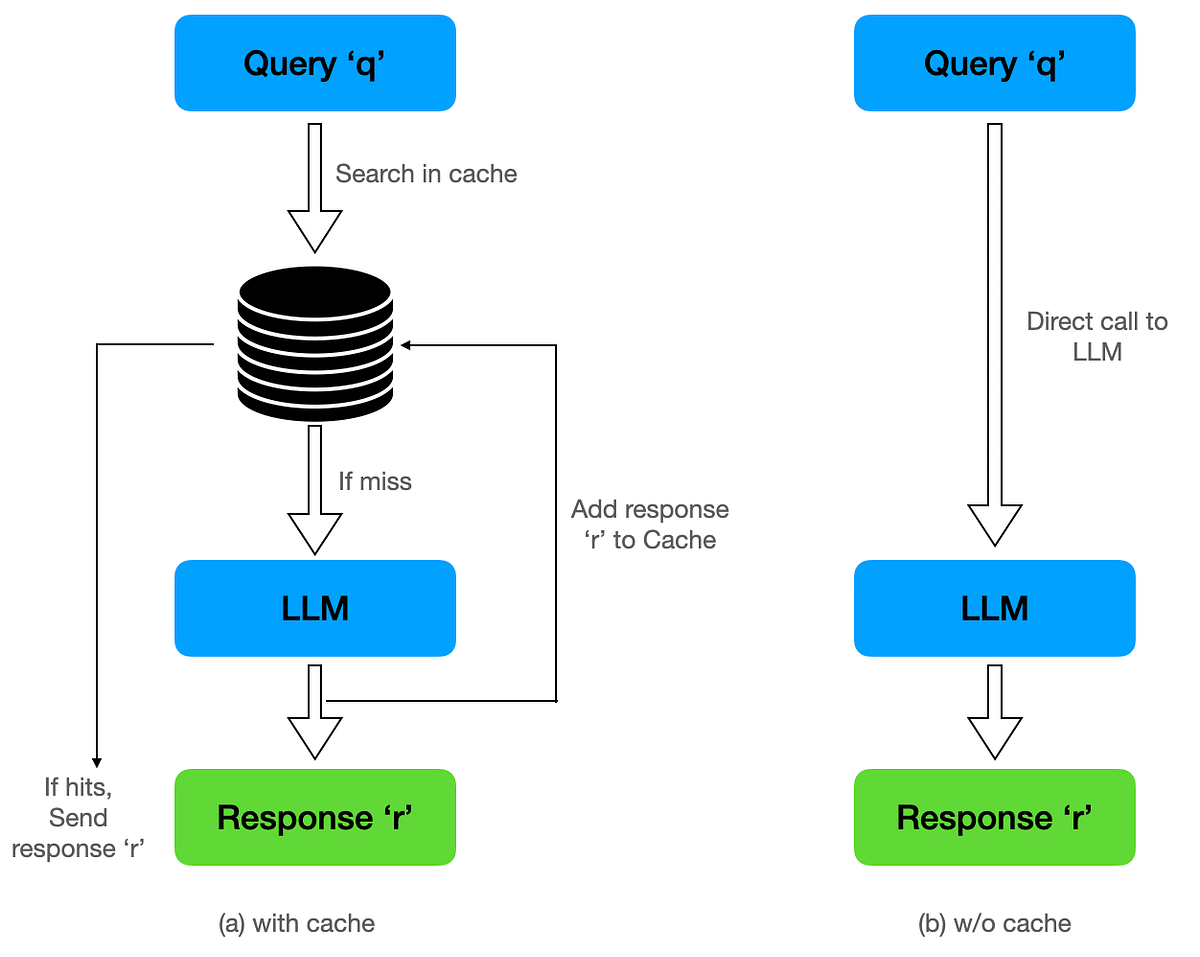
How Context Caching Can Cut Your LLM API Costs by 90% | by Samar Singh ...
Prompt Caching and Why Your LLM Bill Just Exploded | by The Accelerant ...
🔥 Don’t Miss Out: How I Slashed My Claude API Bill by 90%, Unlocked ...
How I Cut LLM Latency by 6x with Redis and Gemini | by Shubham Daraad ...
The Complete Guide to Prompt Caching: Cut LLM Costs by 90%
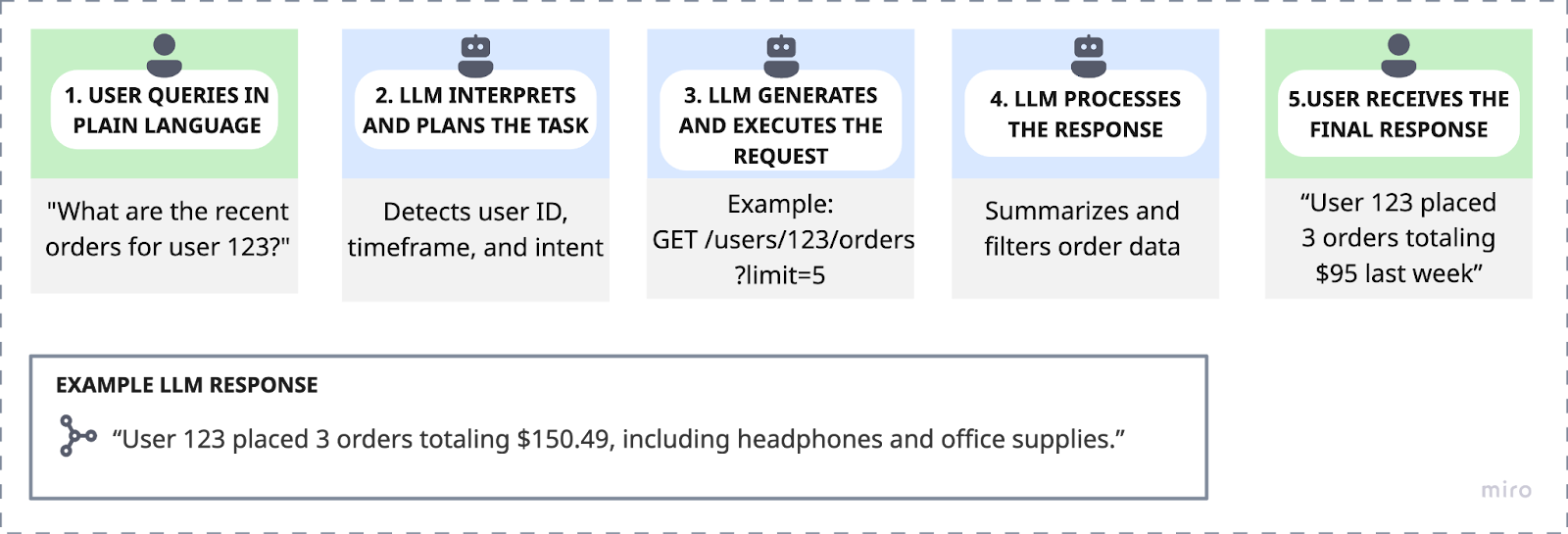
What Can LLM APIs Be Used For? A Complete Guide with Examples ...
Providing a caching layer for LLM with Langchain in AWS - DEV Community
Run-Rate Shock: How to Cut Your LLM Bill by 30–60% Without Killing UX ...
Cut LLM API Costs by 40% with TOON in .NET
How to Cut Your LLM API Costs by 90%: Caching, Routing, and Prompt ...
GitHub - devanmolsharma/cachelm: A semantic caching layer for LLM apps ...
Content caching for Gemini API — a good improvement for AI Workflows ...
How I Reduced API Response Time by up to 80% Using .NET Caching ...
Smart Caching for Fast LLM Tools — ColdStarts & HotContext, Part 1 | by ...
Providing a caching layer for LLM with Langchain in AWS
Semantic Caching for LLM Execution Plans: How We Cut Costs by 90% - DEV ...
How I Reduced LLM Costs by 75% Using Caching | by Chameera Dulanga ...
12 techniques to reduce your LLM API bill and launch blazingly fast ...
Cut LLM Costs with Smarter Prompts, Retrieval and Caching
Cut LLM Costs and Latency with ScyllaDB Semantic Caching - ScyllaDB
I tested 5 API caching techniques – here’s what actually improved ...
Comparing LLM serving frameworks — LLMOps | by Thiyagarajan ...
LMCache: Accelerating LLM Inference with Smart KV Caching (Part 1 of 2 ...
Exploring Caching Strategies to Speed Up LLM Applications | by ...
How I Built an LLM-Powered API Router with FastAPI and LangChain Agents ...
44. Optimizing API performance with caching strategies in Amazon API ...
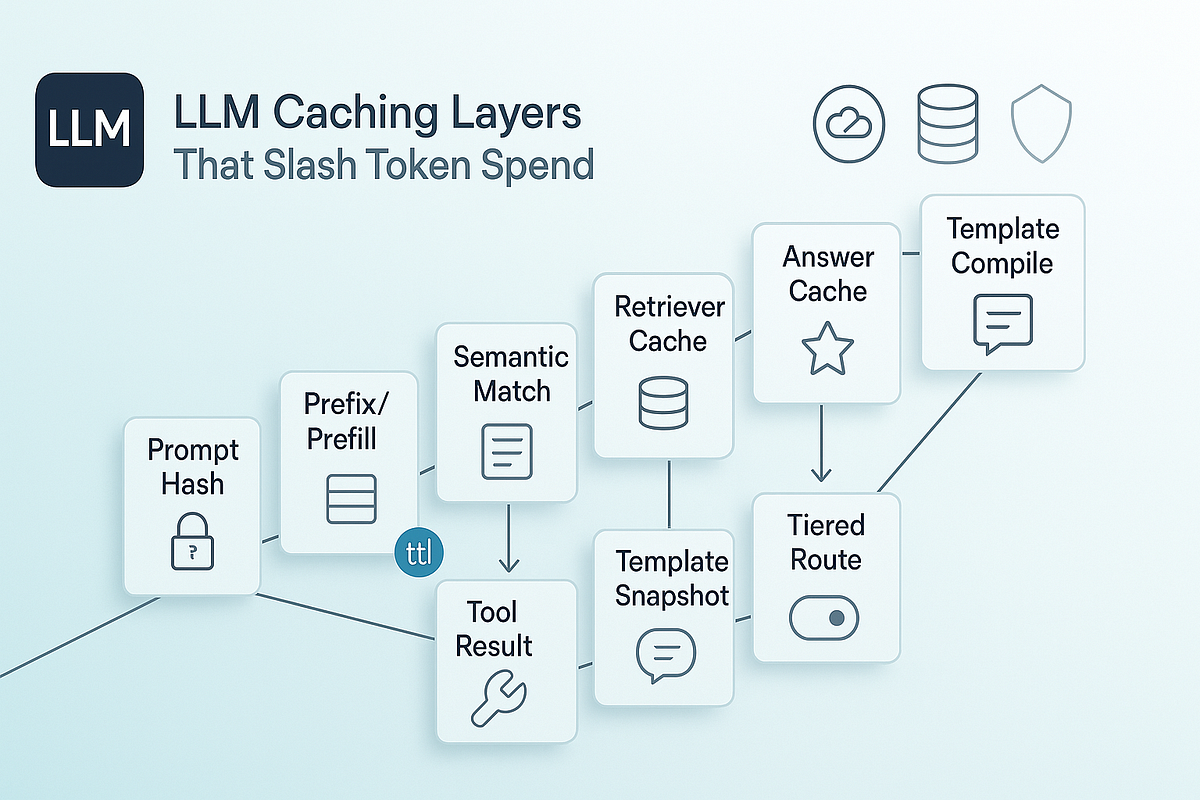
10 LLM Caching Layers That Slash Token Spend | by Syntal | Medium
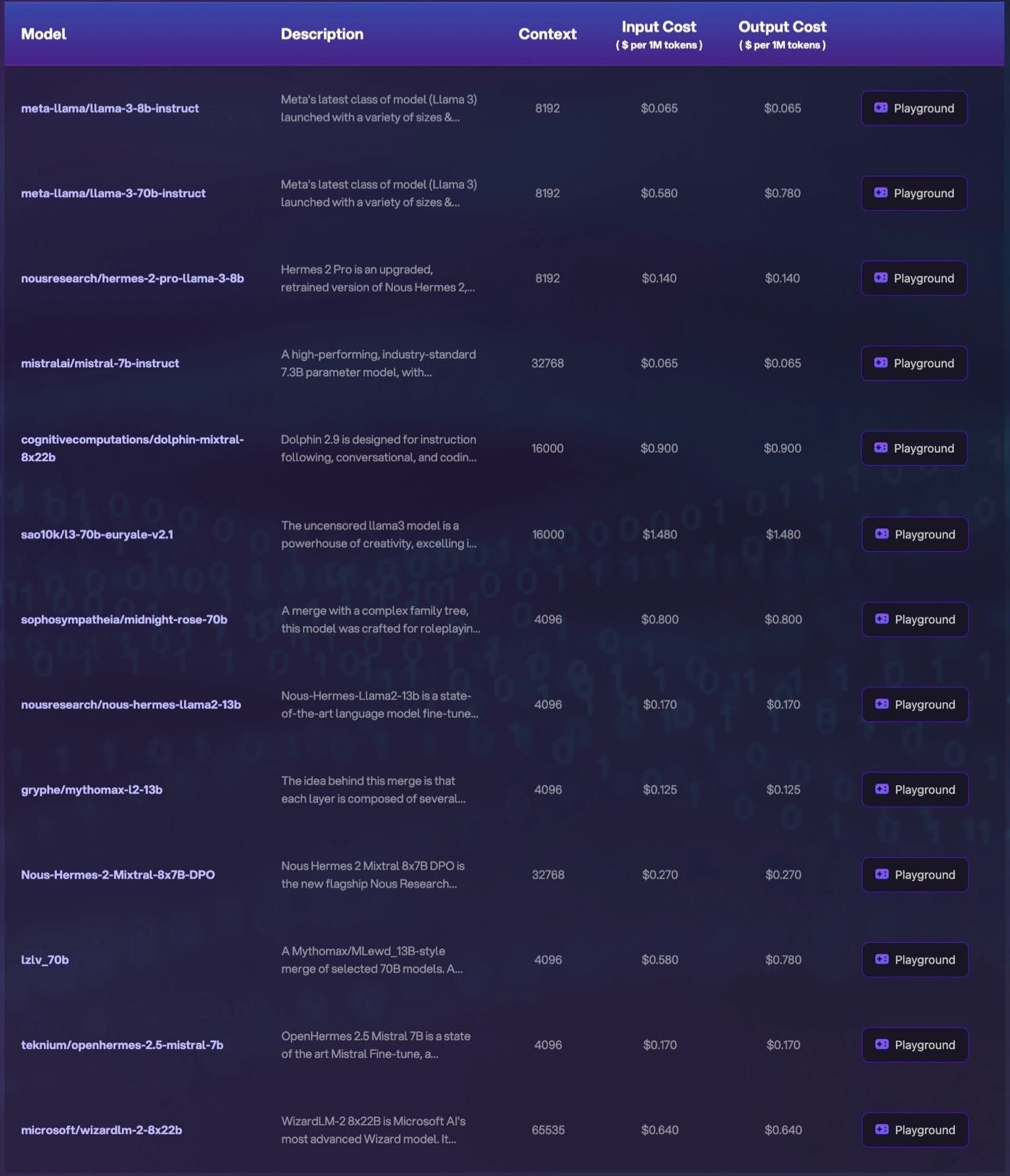
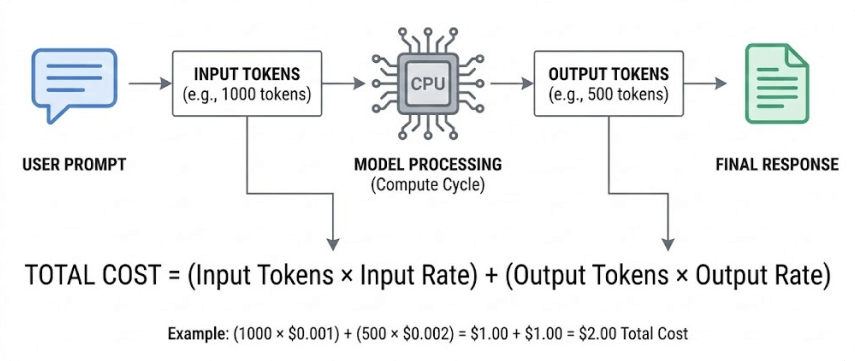
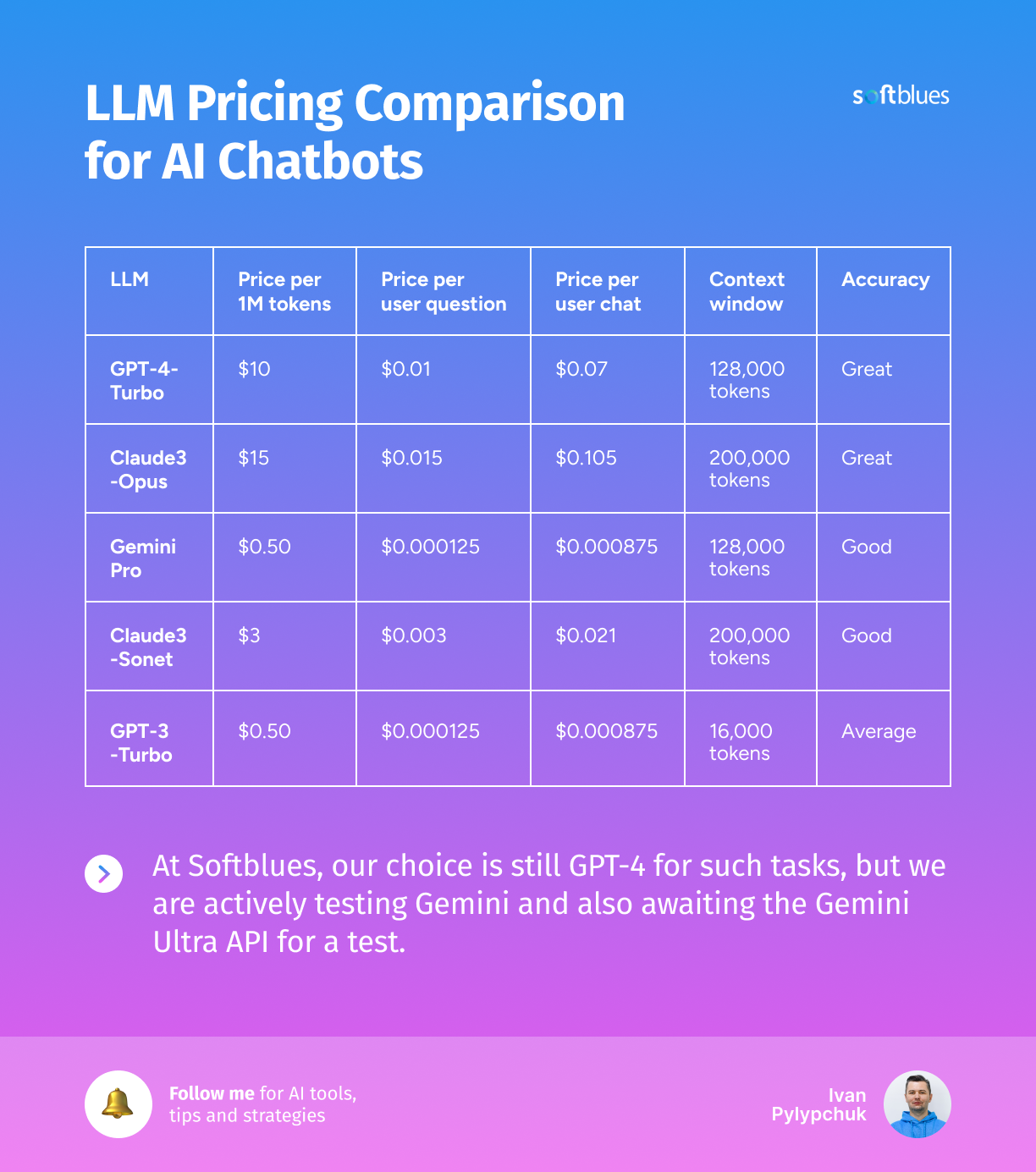
LLM API Pricing Comparison 2025: Complete Cost Analysis Guide - Binadox
How to Build a Caching Layer for High-Performance APIs - Datatas
Prompt Caching in LLM Systems. Table of Contents: - Caching Strategy ...
Reducing Latency in LLM-Based Applications with Caching: A Guide for ...
Guide to LLM API Pricing: Choose the Best for Your Needs - YouTube
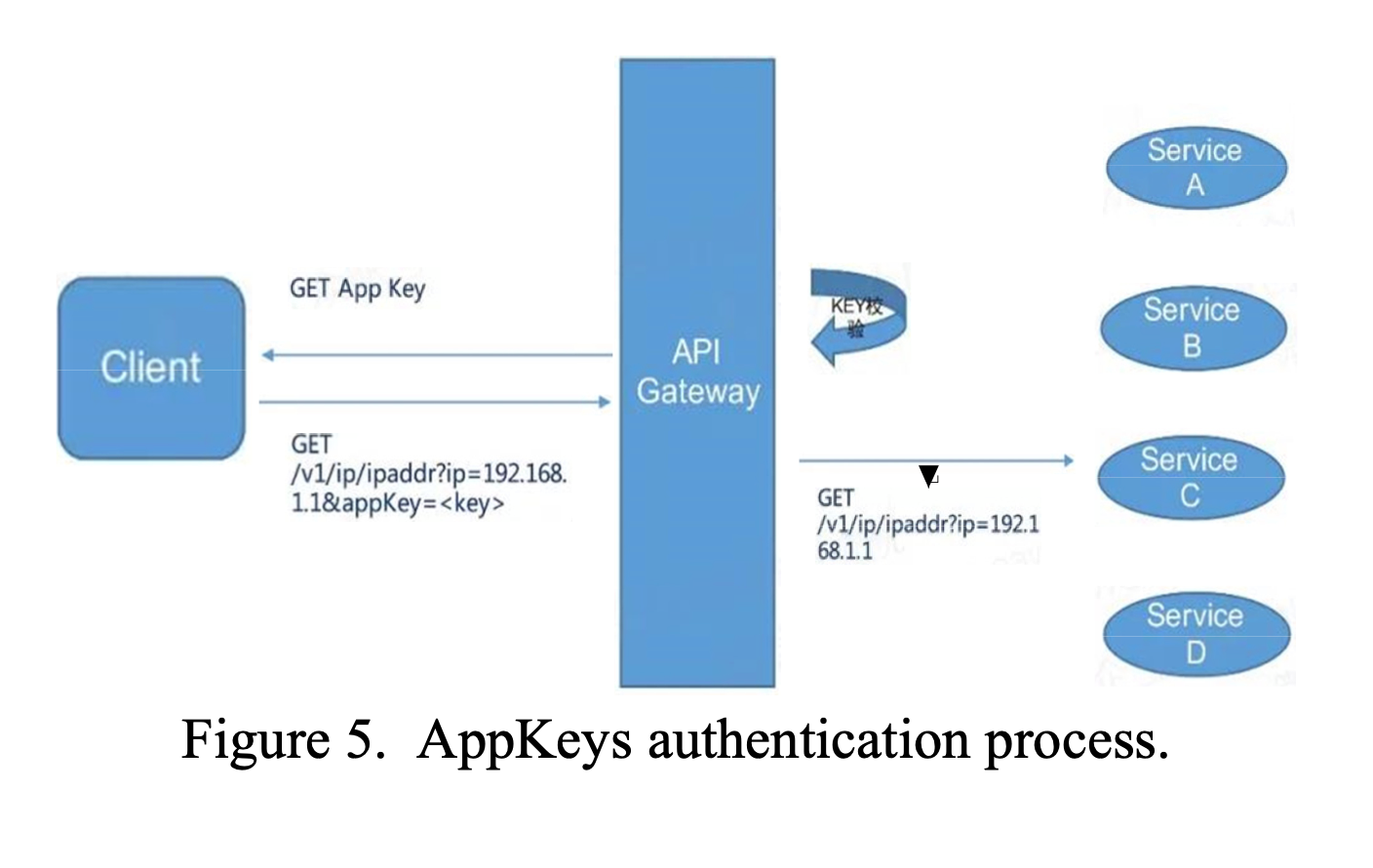
Multi-layer Caching in API Gateway Tackles High Traffic Challenges ...
Lowering Your Gemini API Bill: A Guide to Context Caching - DEV Community
Optimizing Docker Builds: Layer Caching | by Naveen V | Medium
Reframing LLM 'Chat with Data': Introducing LLM-Assisted Data Recipes ...
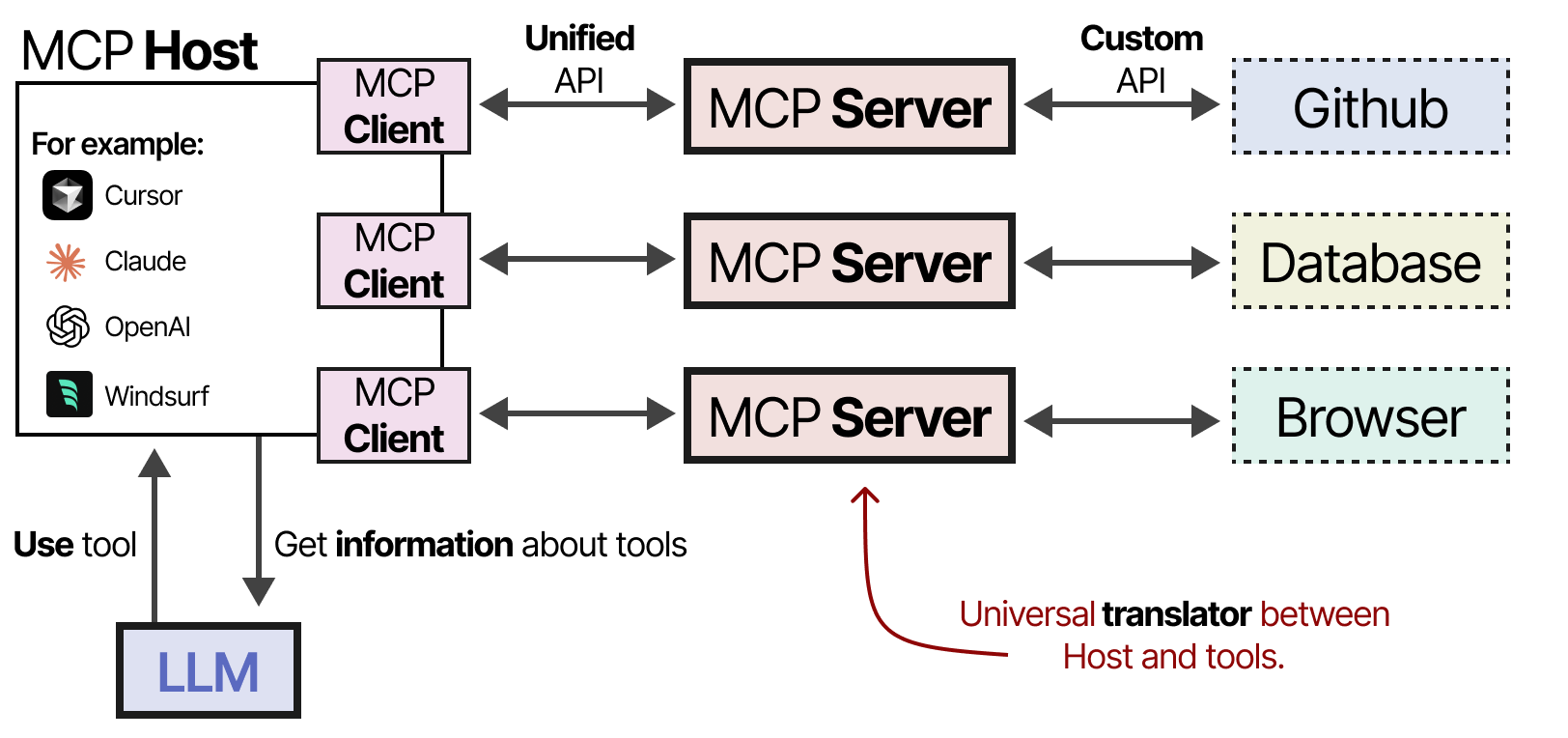
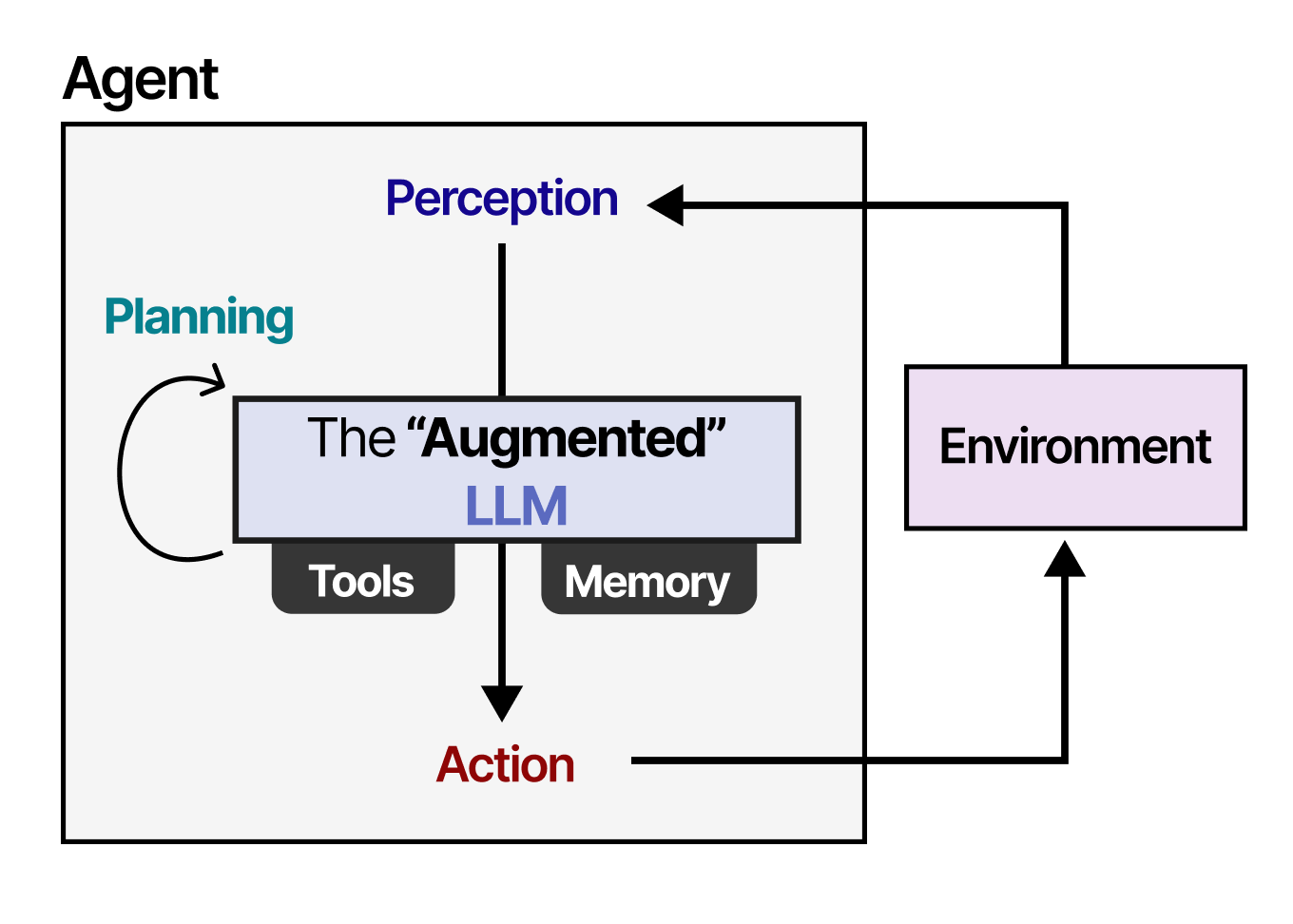
A Visual Guide to LLM Agents - by Maarten Grootendorst
PPT - Cut LLM Costs Without Compromising Performance PowerPoint ...
Slash API Costs: Mastering Caching for LLM Applications - YouTube
Comprehensive Guide to LLM API Pricing: Choose the Best for Your Needs
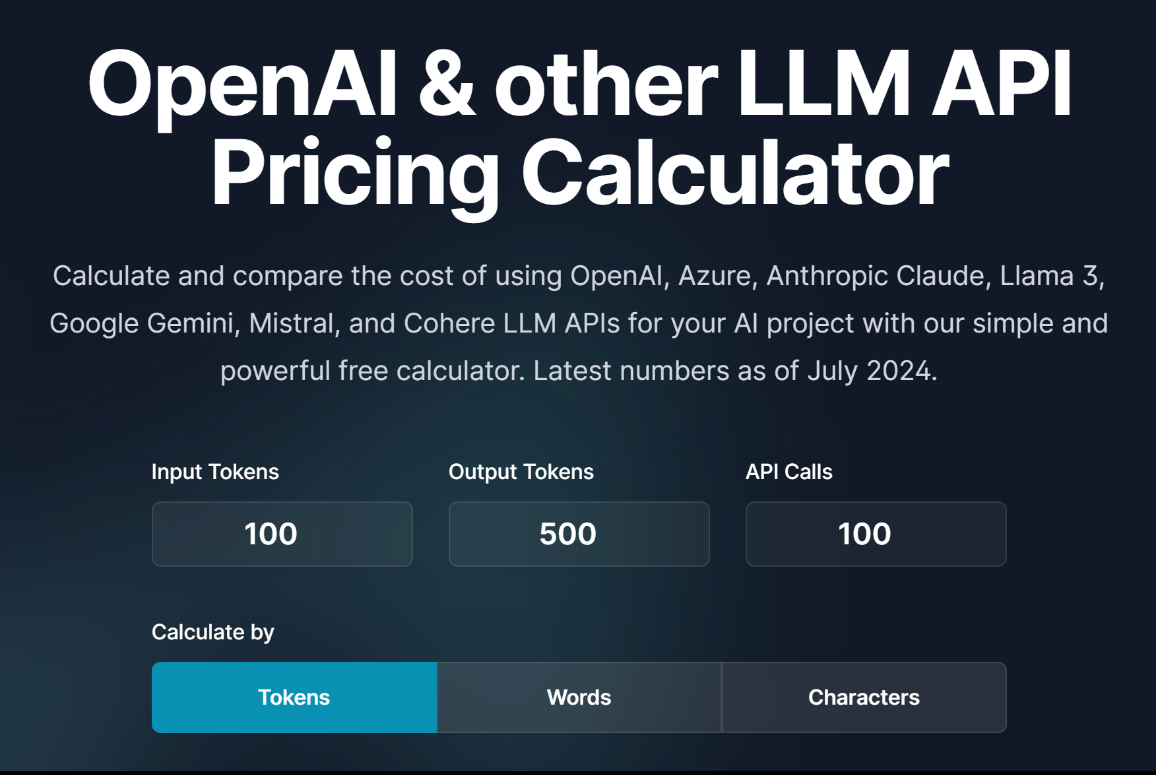
LLM API Pricing Calculator: Easily Estimate Costs Across Multiple ...
利用 Prompt Caching 优化 LLM 性能与成本的全方位指南 | 企业级大模型 LLM API 接口聚合平台 | n1n.ai
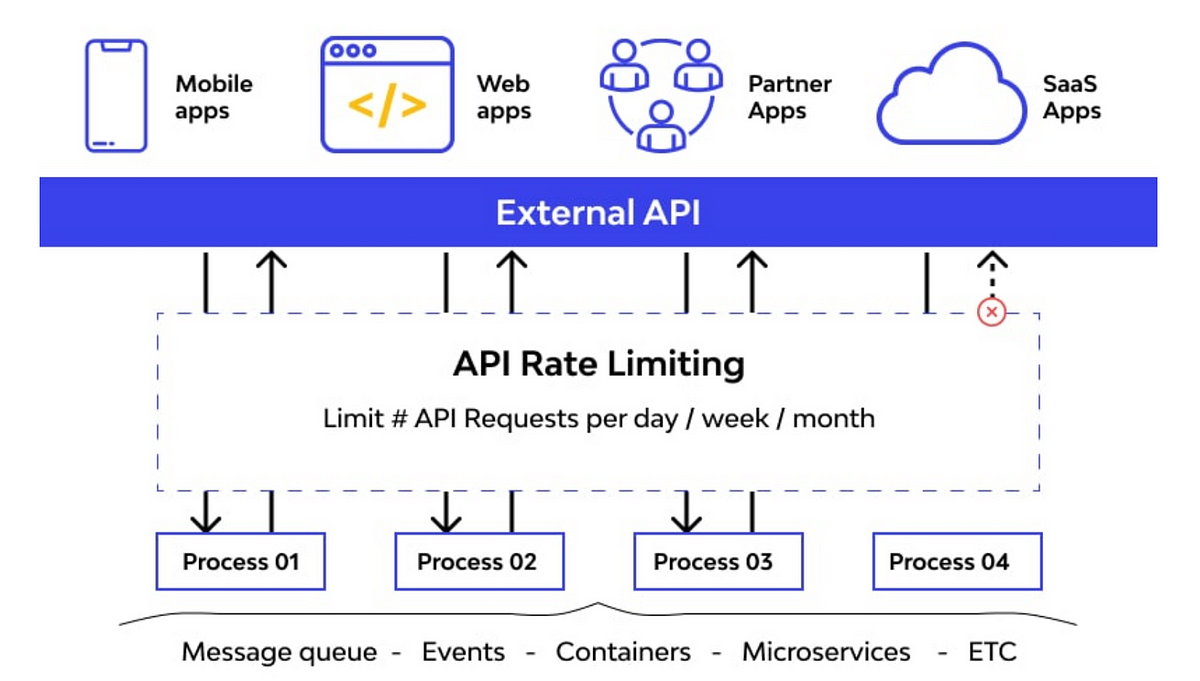
The New API Economy With LLMs
How to Host an LLM as an API (and make millions!) #fastapi #llm #ai # ...
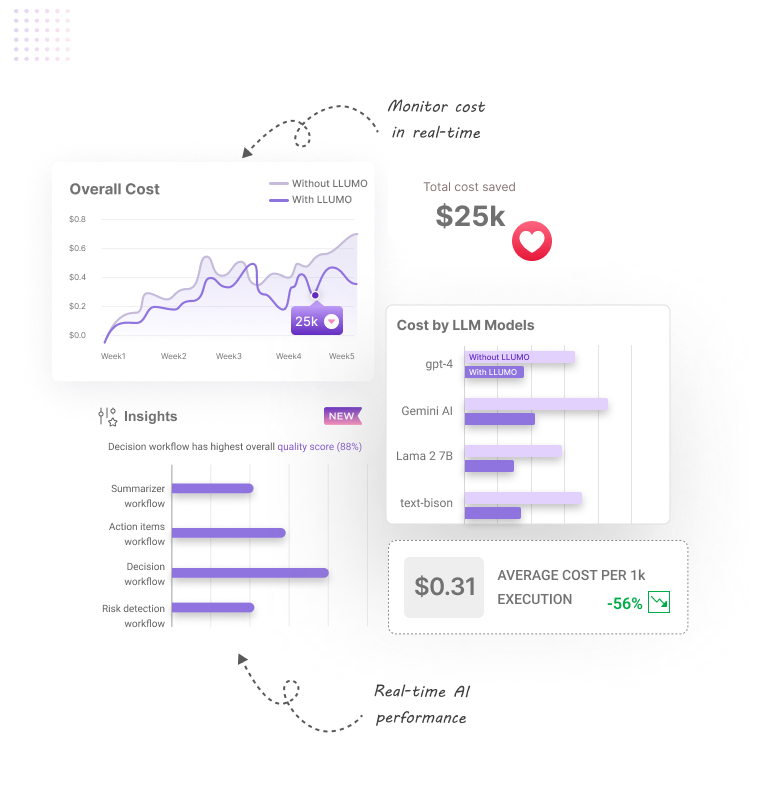
Cut LLM Cost by 80%
How to Improve Performance with API Gateway Caching Strategies
Cutting LLM Costs with MongoDB Semantic Caching - YouTube
Caching Strategies Explained: The Complete Guide - Ajit Singh
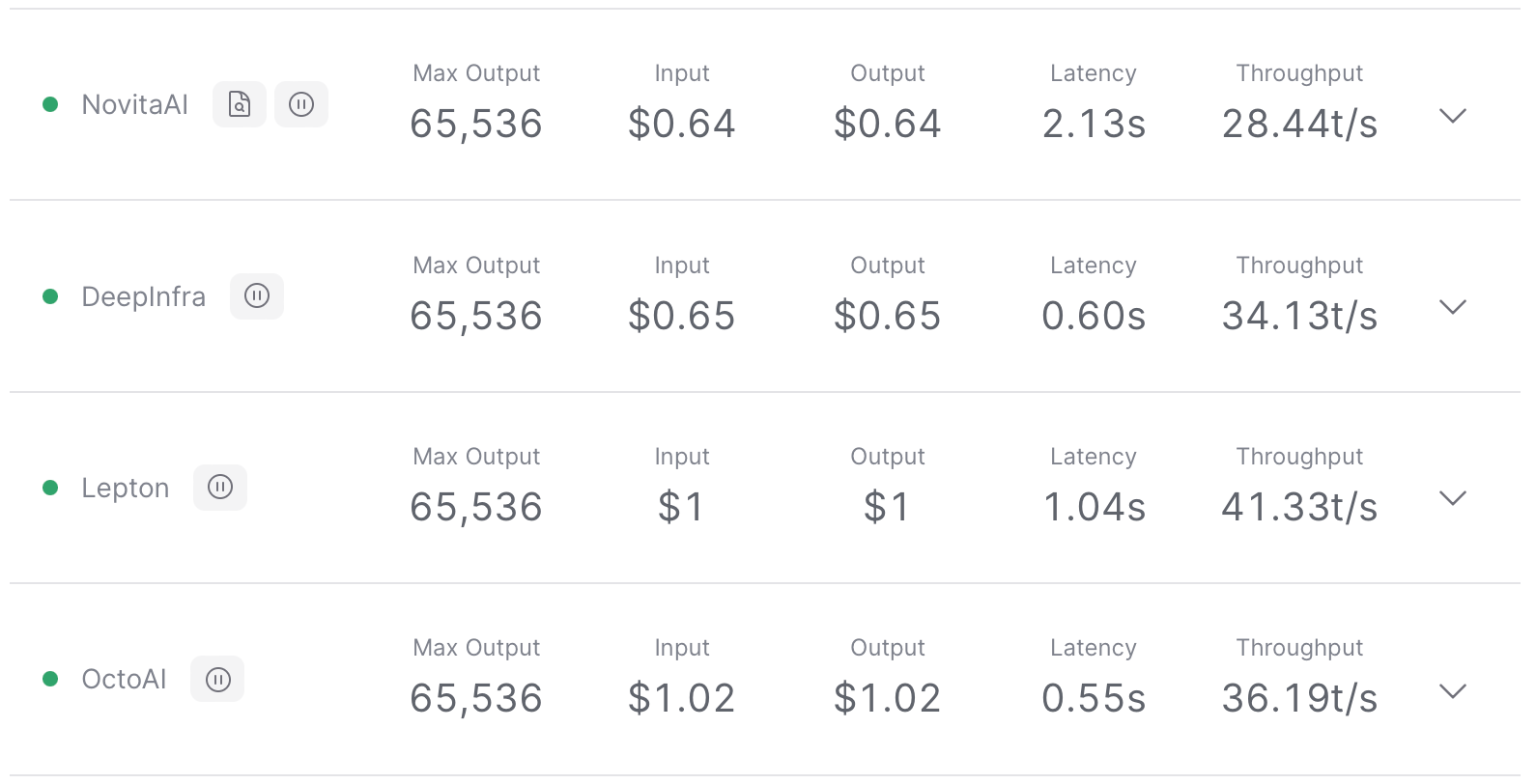
Tool To Find Cheapest or Fastest LLM API Provider - LLM API Showdown ...
A Deep Dive into LLM Prompt Caching
Self host LLM with EC2, vLLM, Langchain, FastAPI, LLM cache and ...
LLM API Pricing Calculator | Compare 300+ AI Model Costs
LLM API Pricing Calculator – Shekhar Gulati
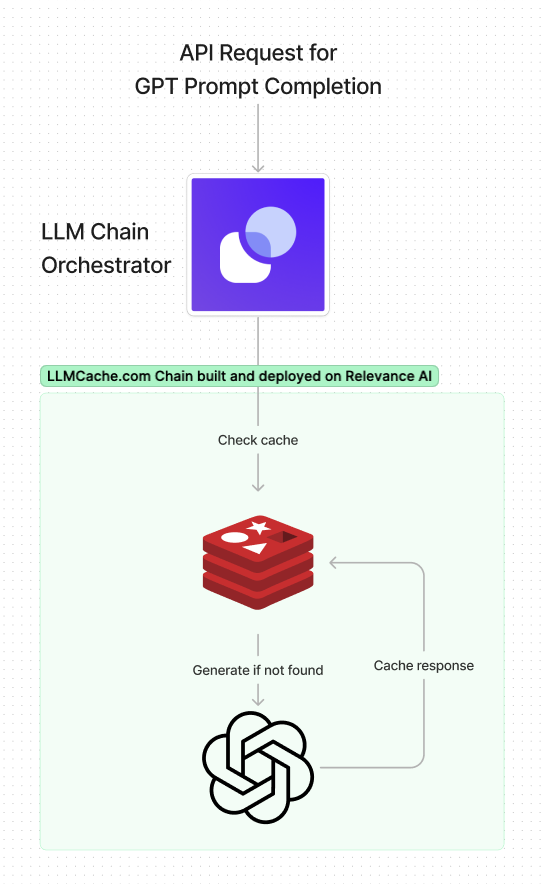
LLMCache - How to Build a Cache with Relevance AI and Redis
LLM API Pricing Calculator - TILNOTE
Estimate LLM API costs for your team
How to Implement Effective LLM Caching
The People You Need at Your Company for LLM Capabilities | In Plain English
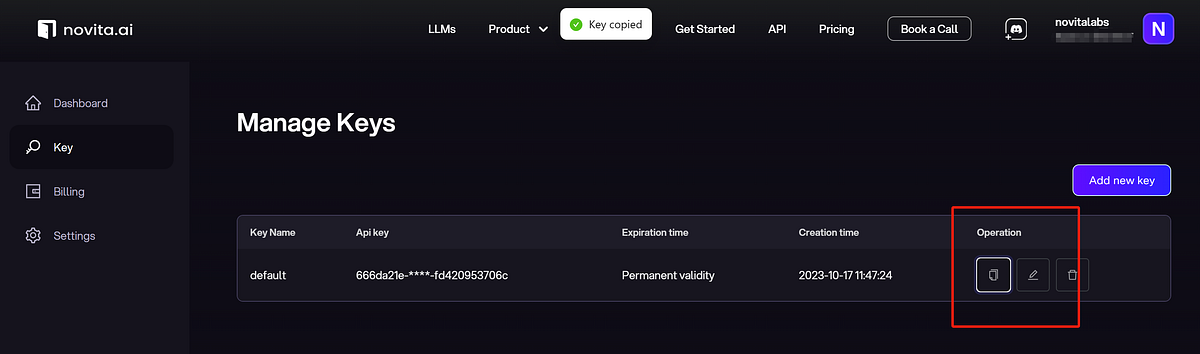
Simplified LLM API Key Using Guide
LLM integration guide: Paid & free LLM API comparison
Basic Caching Strategies for LLM Applications
Mastering LLM API Gateway: Your Ultimate Guide
What Can LLM API Be Used For? Unlock Limitless Potential
3 crucial caching choices: Where, when, and how — Momento
Caching Generative LLMs | Saving API Costs - Analytics Vidhya
LLM API Pricing Guide: Costs, Token Rates & Models
7 Strategies to reduce LLM API costs
LLM Caching Datasets
Effective Caching Techniques For Optimizing Api Performance – peerdh.com
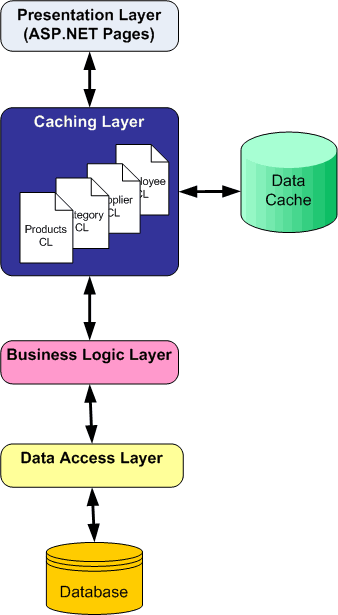
Caching Data in the Architecture (C#) | Microsoft Learn
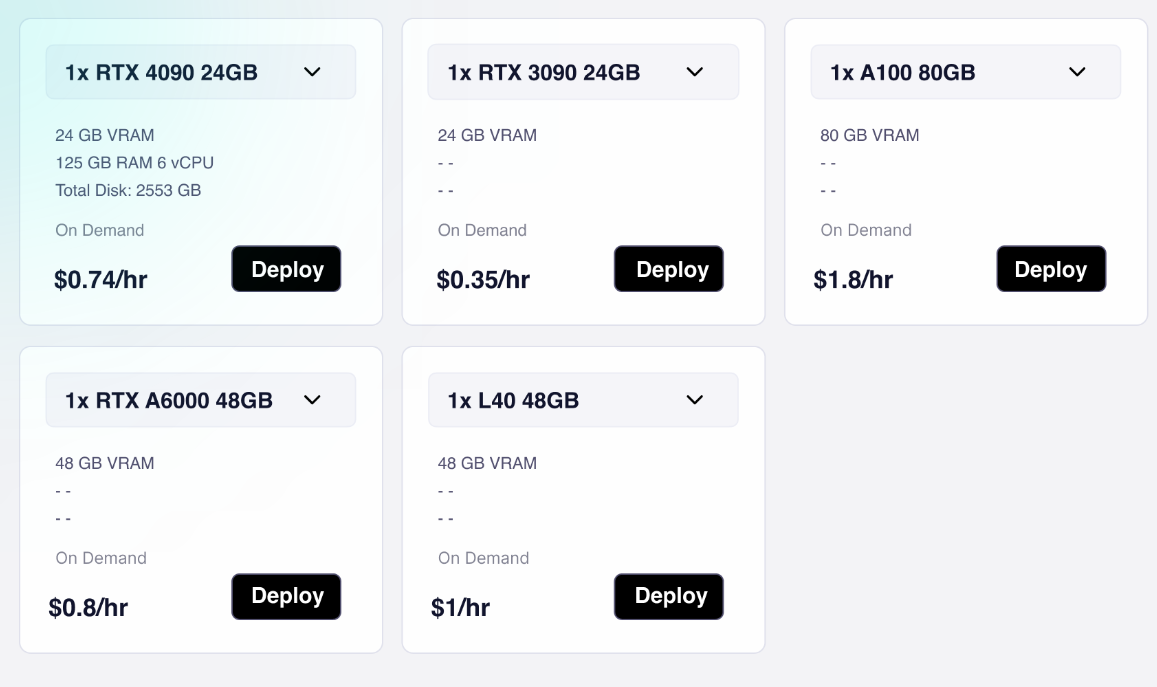
How to Scale LLM Inference - by Damien Benveniste
LLM API for AI Chatbots: Cost and Performance Breakdown
LLM API Integration Made Easy for Developers
90% Cost Reduction With Prefix Caching for LLMs
Unlock Efficiency: Slash Costs and Supercharge Performance with ...
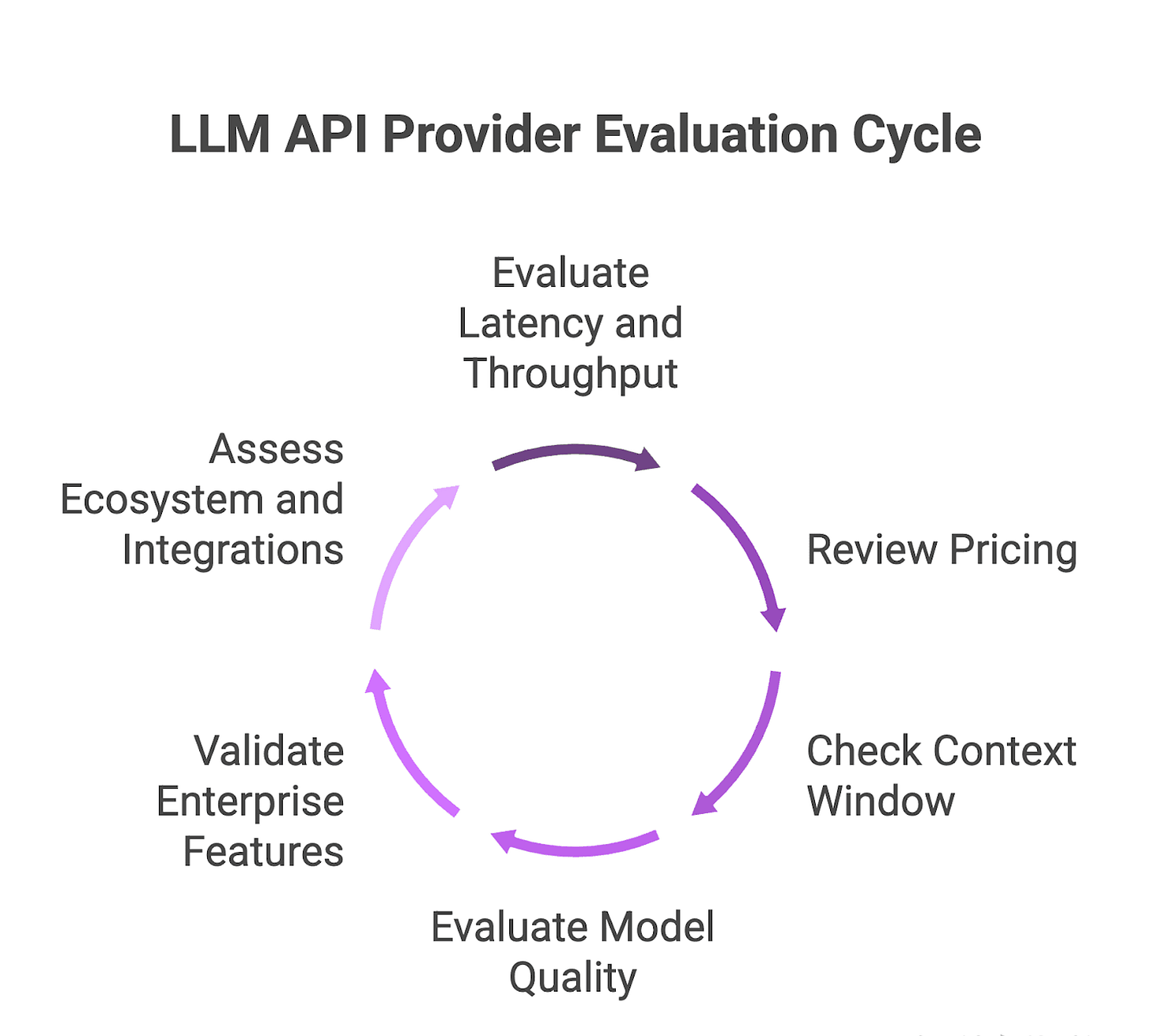
Best LLM API Providers: 2025 Comparison Guide
Les meilleurs outils LLM gratuits, API et modèles Open Source | Eden AI
Caching Strategies for API - GeeksforGeeks
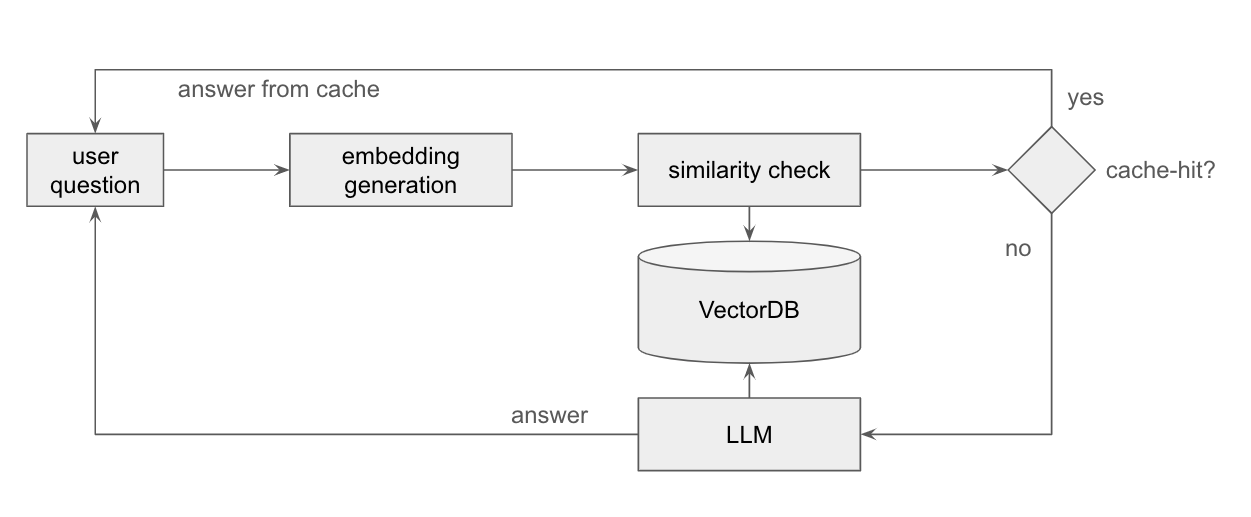
Caching in LLM-Based Applications | by Nishi Ajmera | GoPenAI
Compare AI Costs: Free LLM API Price Calculator
Understanding LLM APIs | Adaline
LLM APIの選定の観点と比較
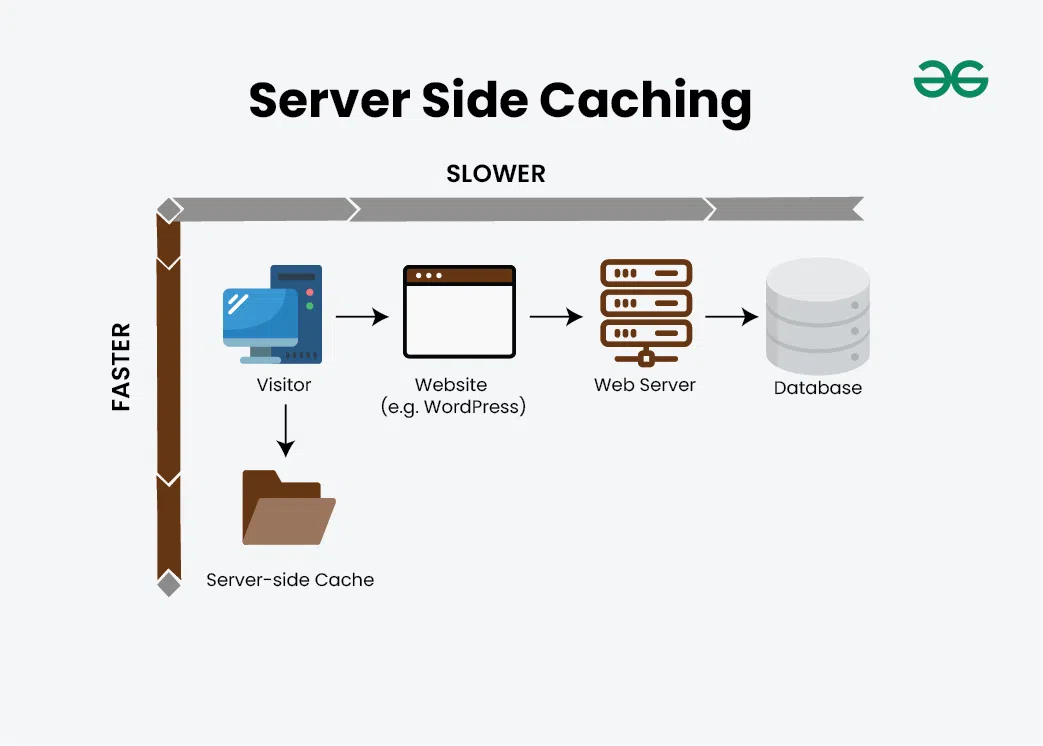
What is Caching and How it Works | AWS
Large Language Model (LLM) API Guide
LLM APIを良い感じに呼べればOKな時に便利なlitellm
Distributed Caching: The Secret to High-Performance Applications
Best LLM APIs for Document Data Extraction
Cache your way to faster LLM Application Response
LLM Systems at Scale | Biweekly Engineering - Episode 31
How to Reduce LLM Cost and Latency in AI Applications
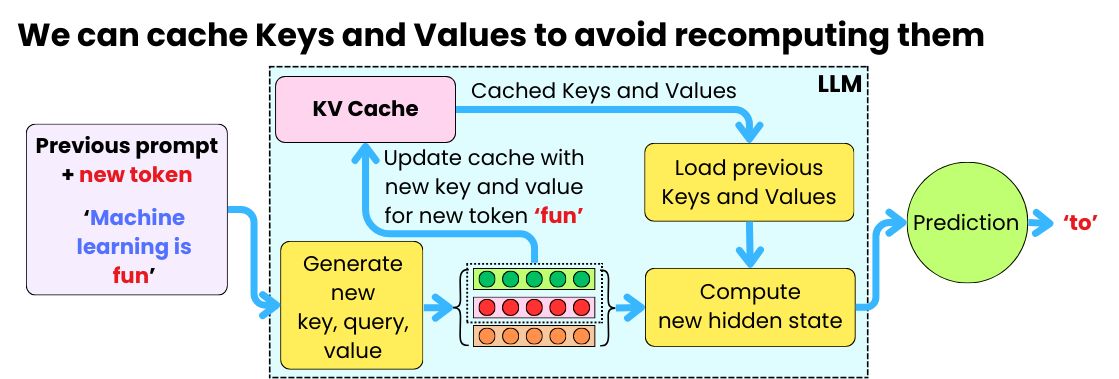
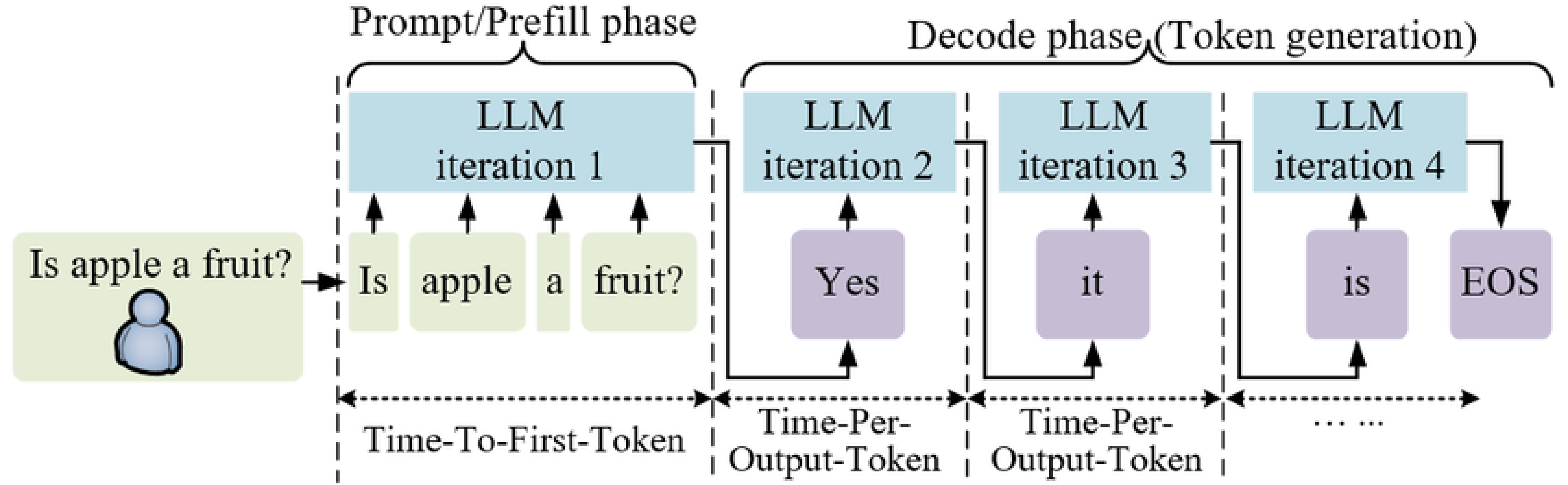
Mastering LLM Techniques: Inference Optimization | NVIDIA Technical Blog
Cloud LLM vs Local LLMs: 3 Real-Life examples & benefits
Top 5 AI Gateways for Multi-Model Routing
Top 11 Tools and Practices for Fine-Tuning Large Language Models (LLMs)
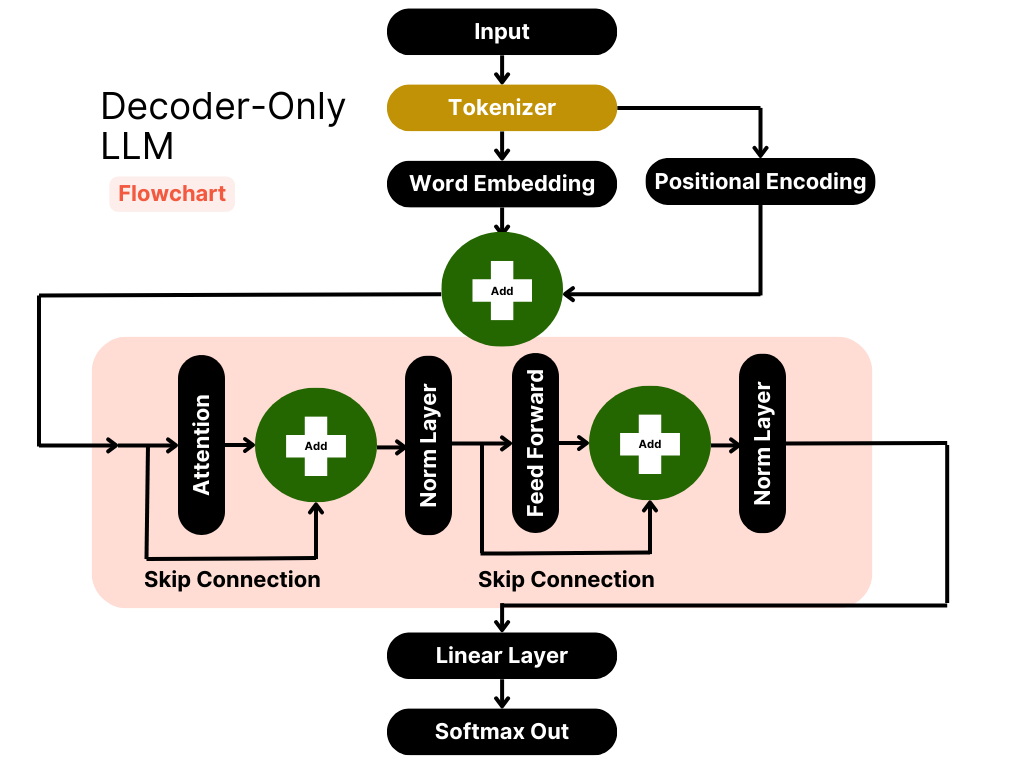
Comprehensive Guide to LLMs
What is Database Caching? Definition & FAQs | ScyllaDB


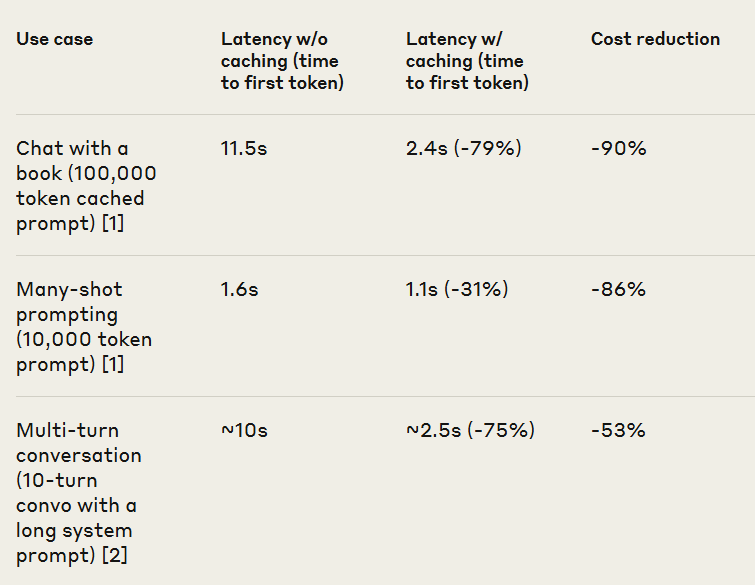





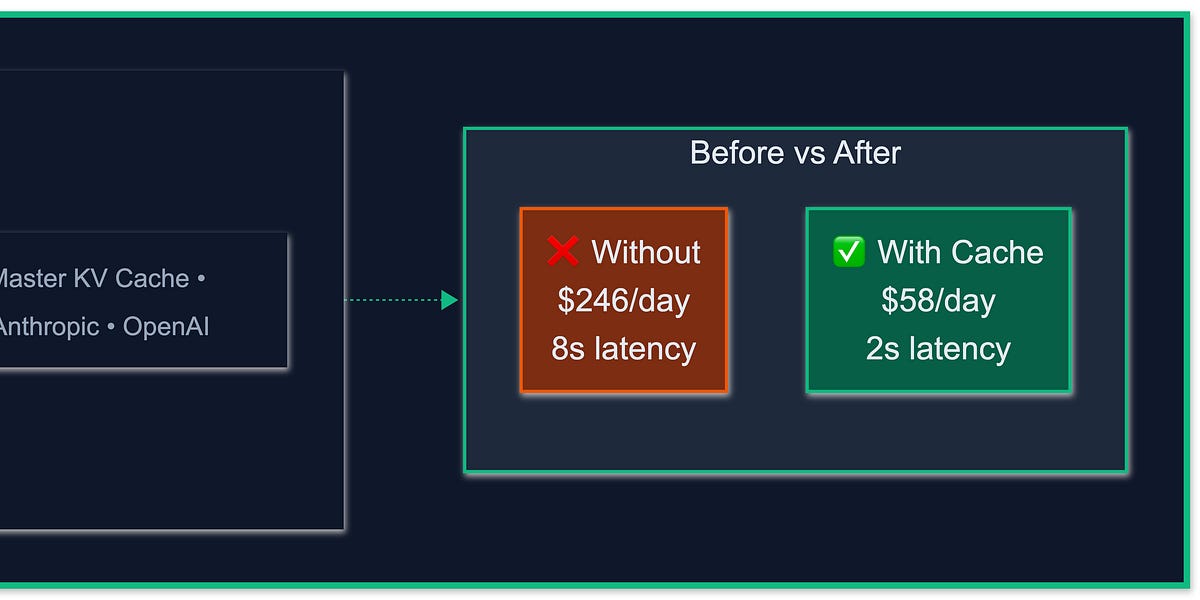












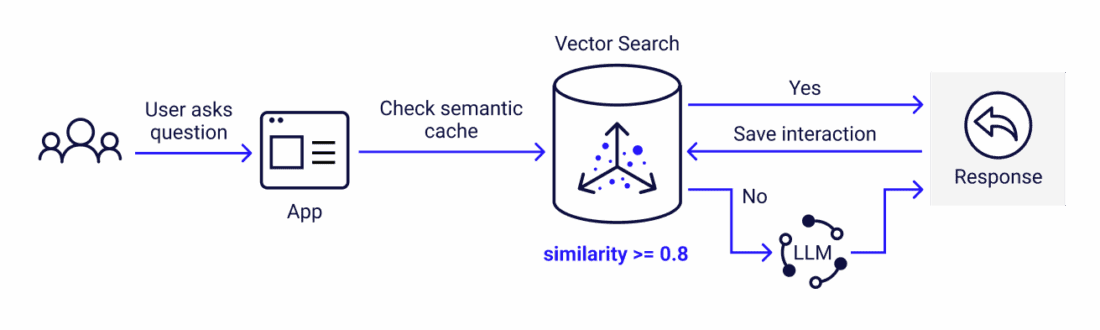



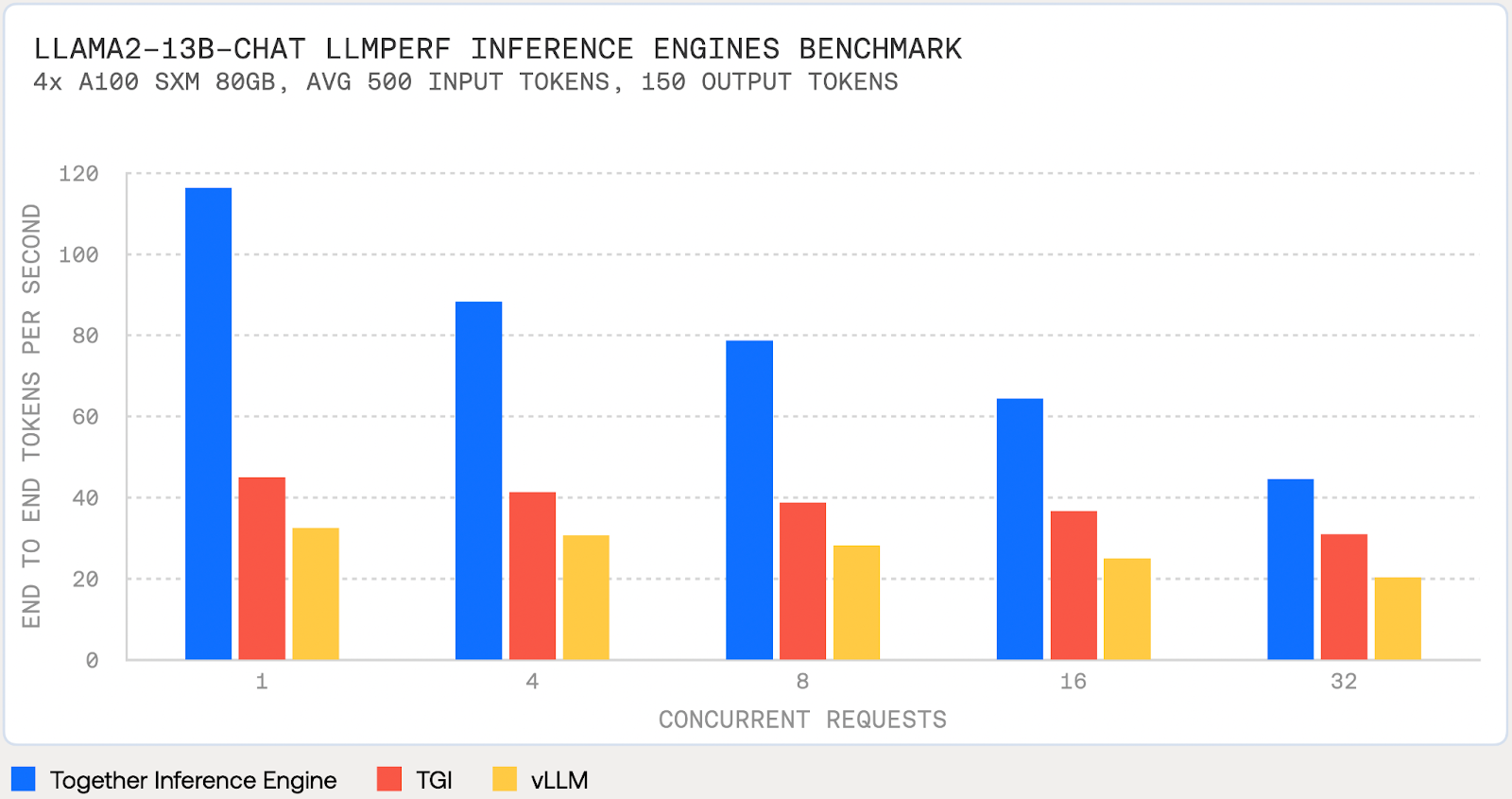



















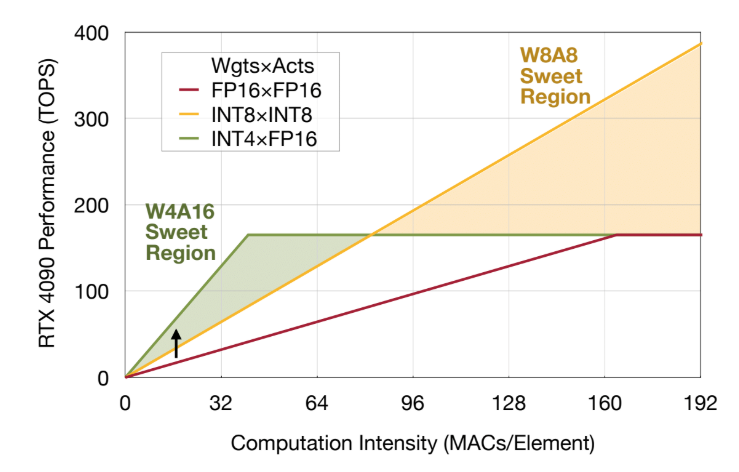



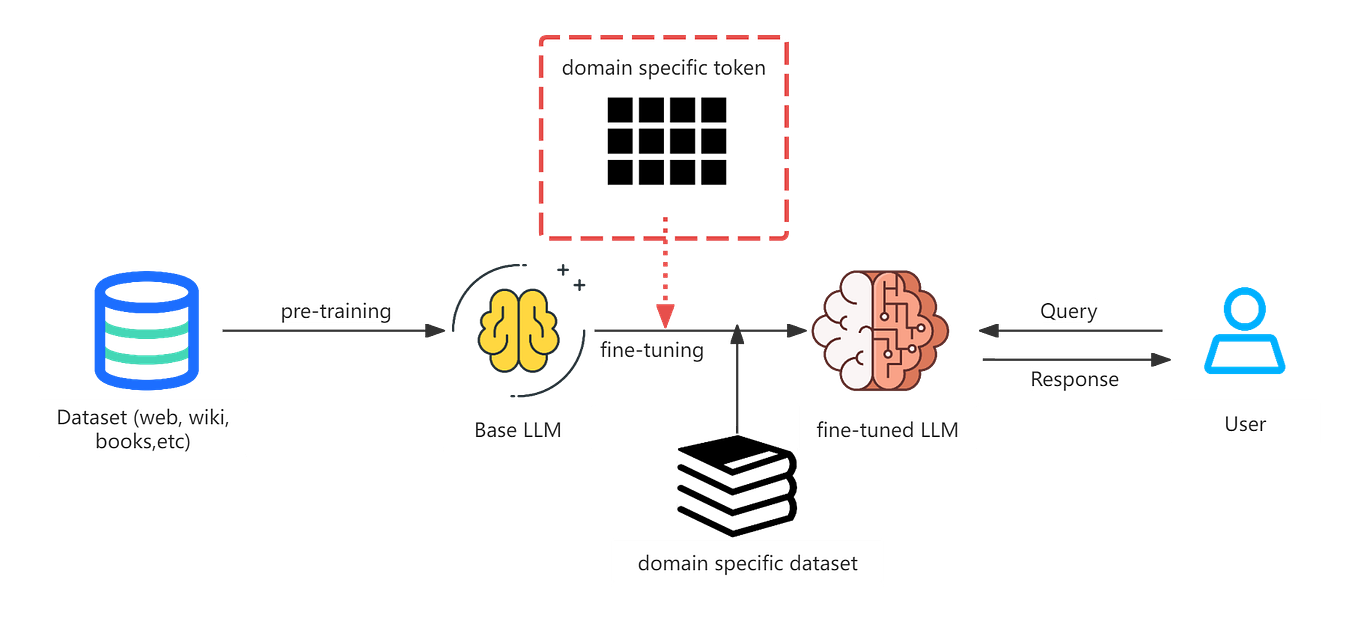
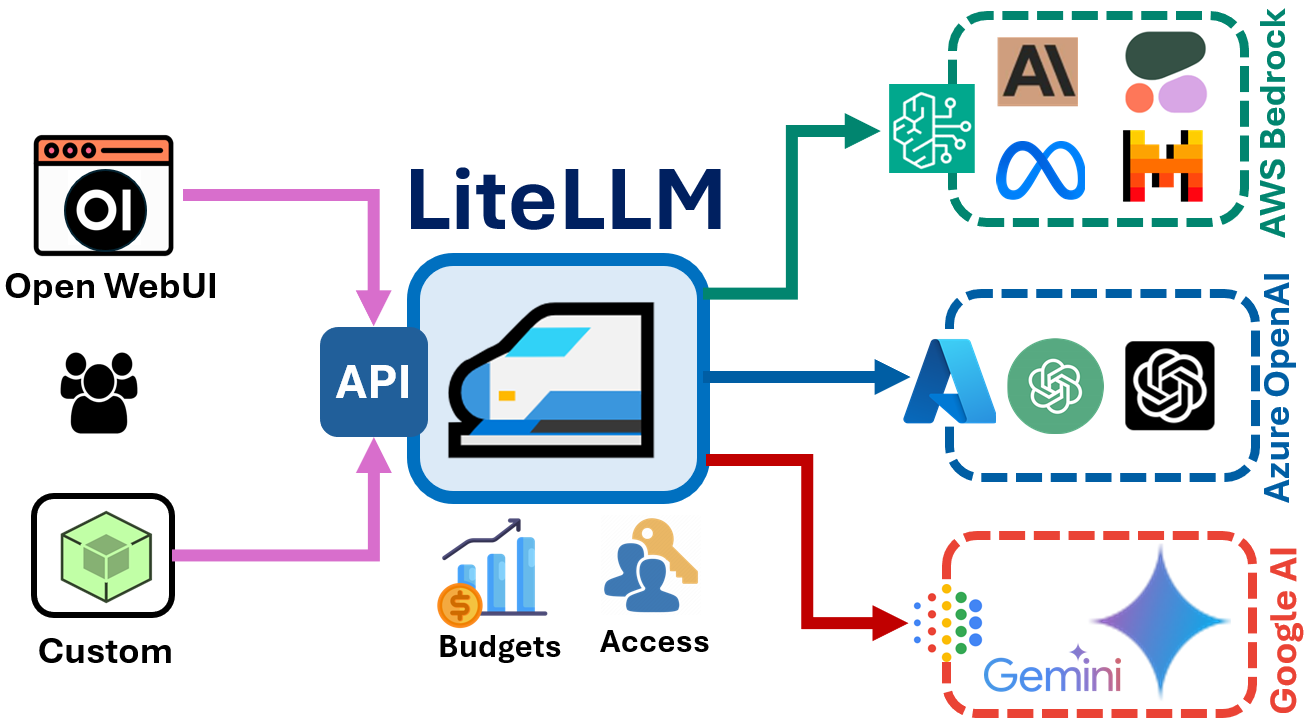

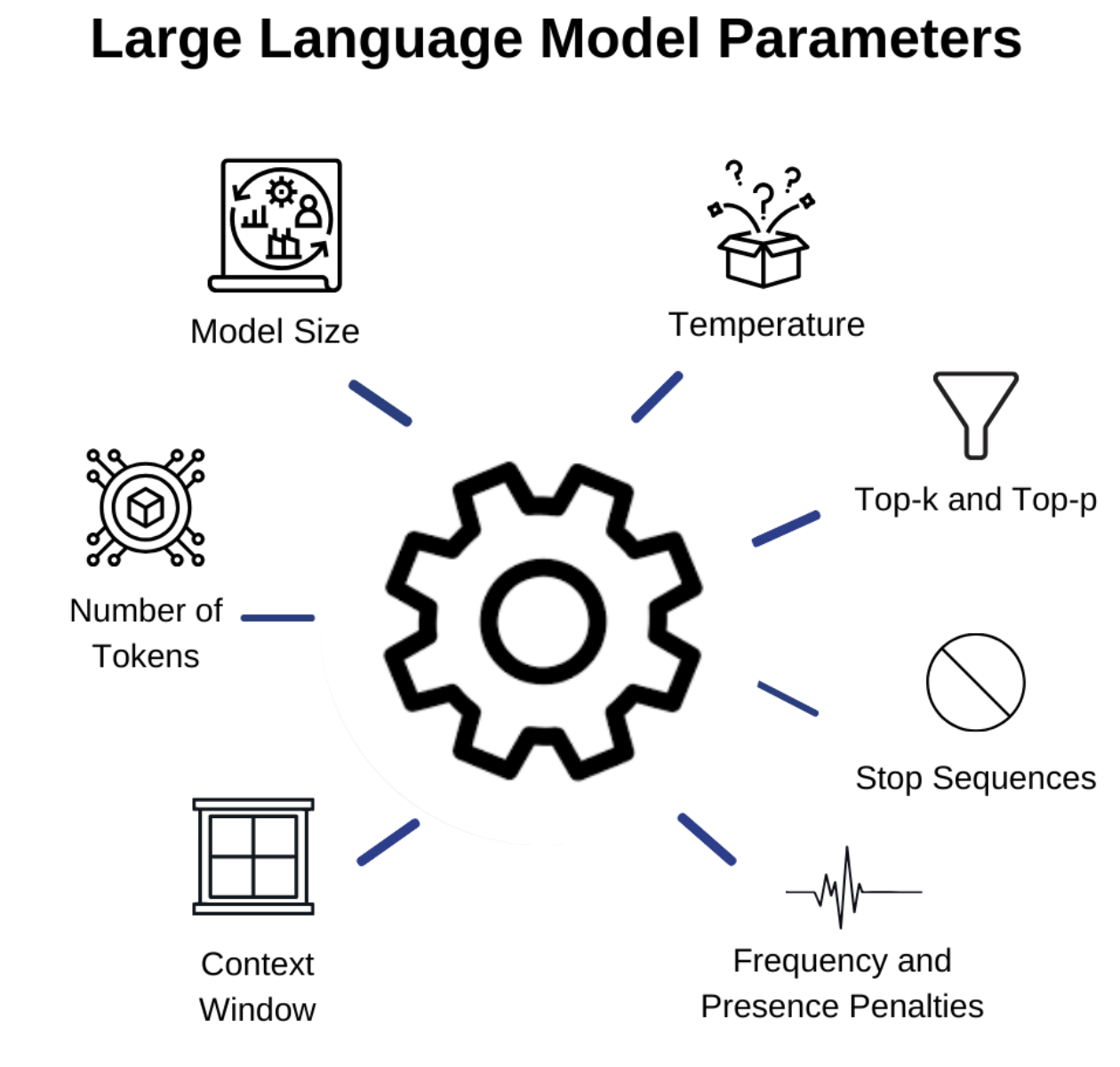



.png)








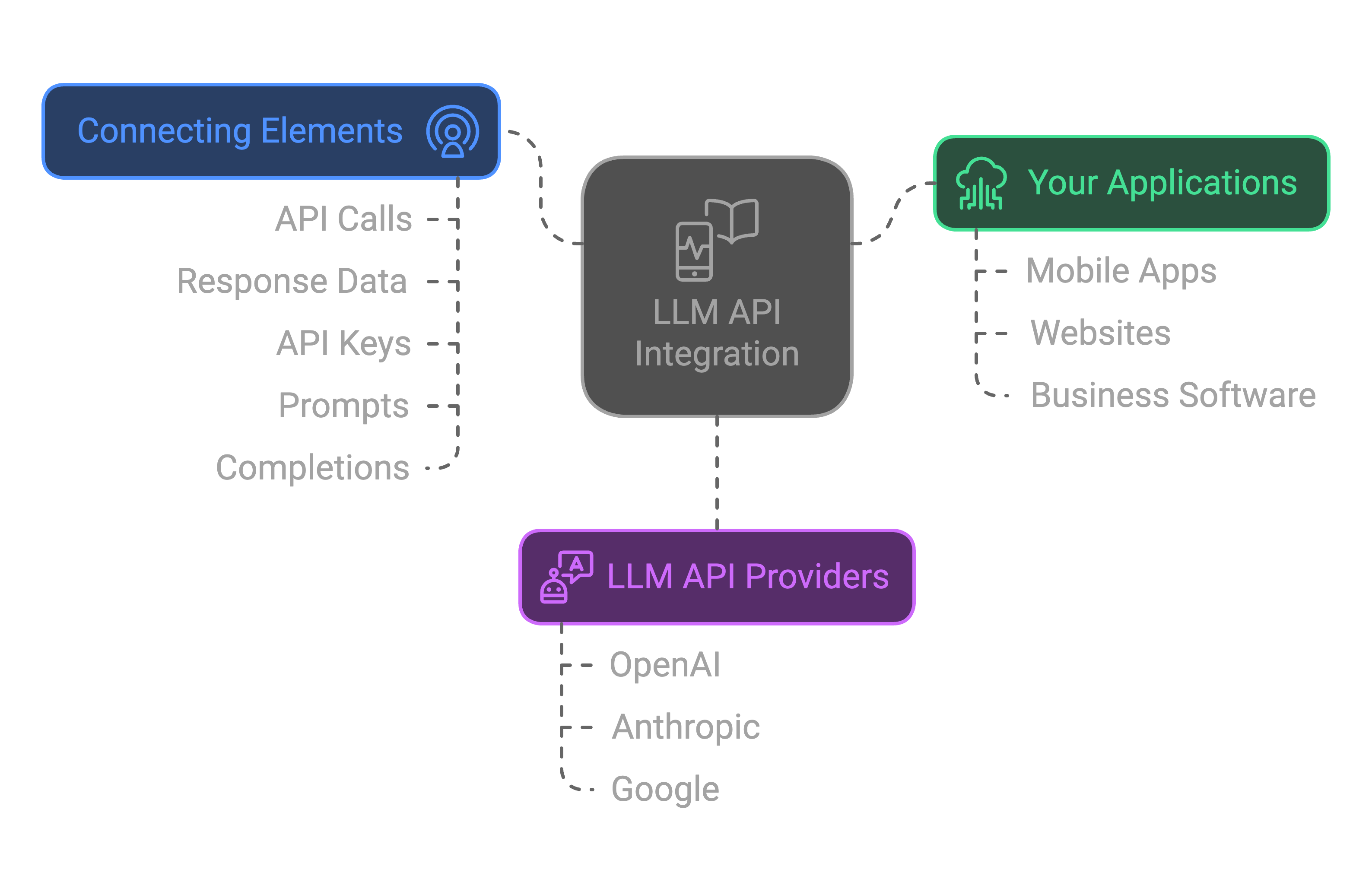
.webp)