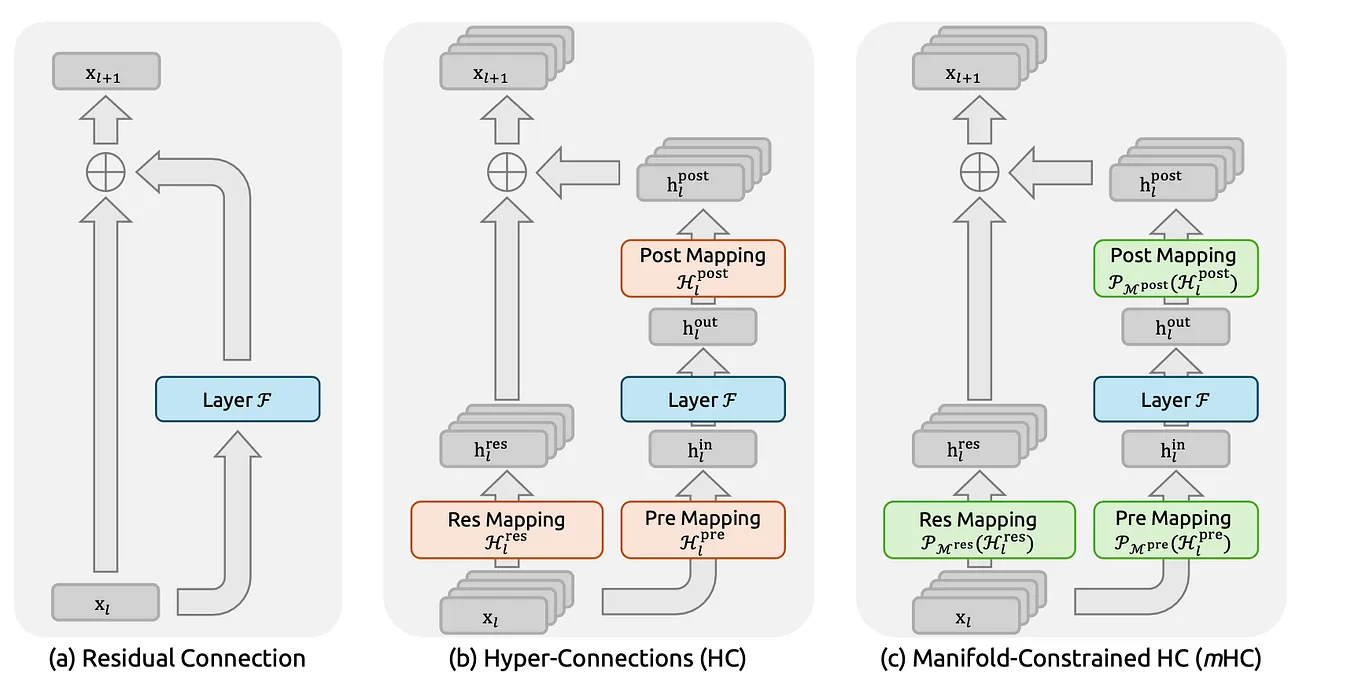
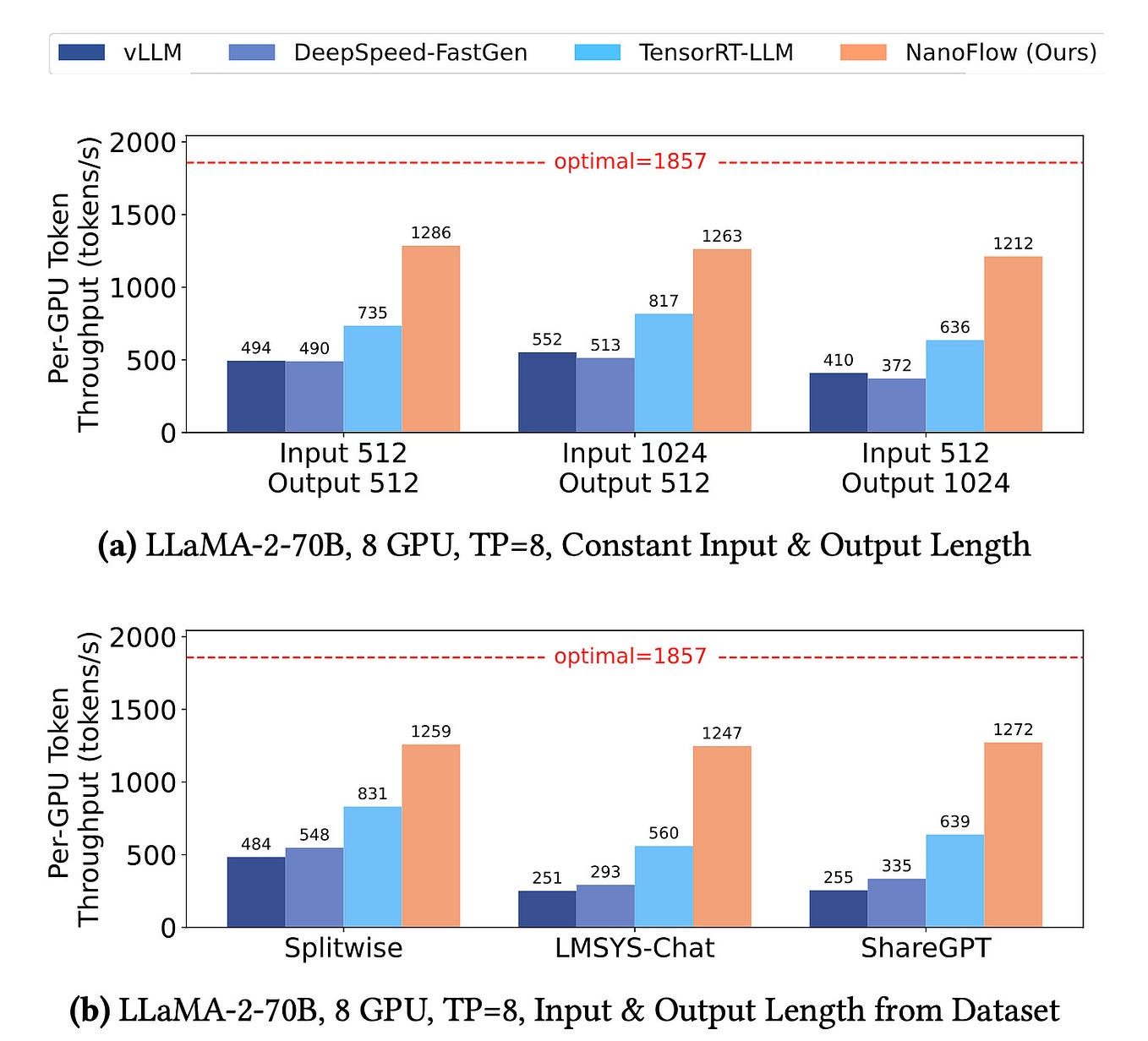
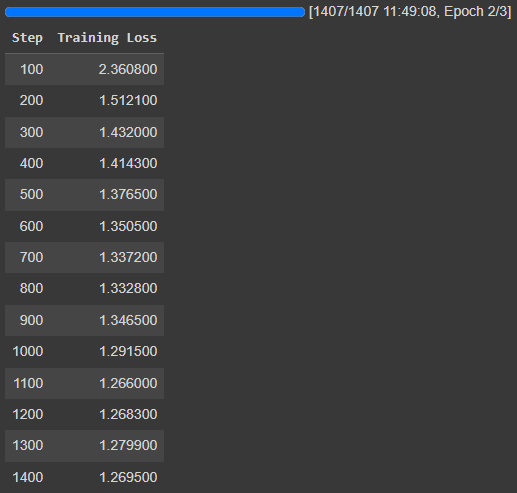
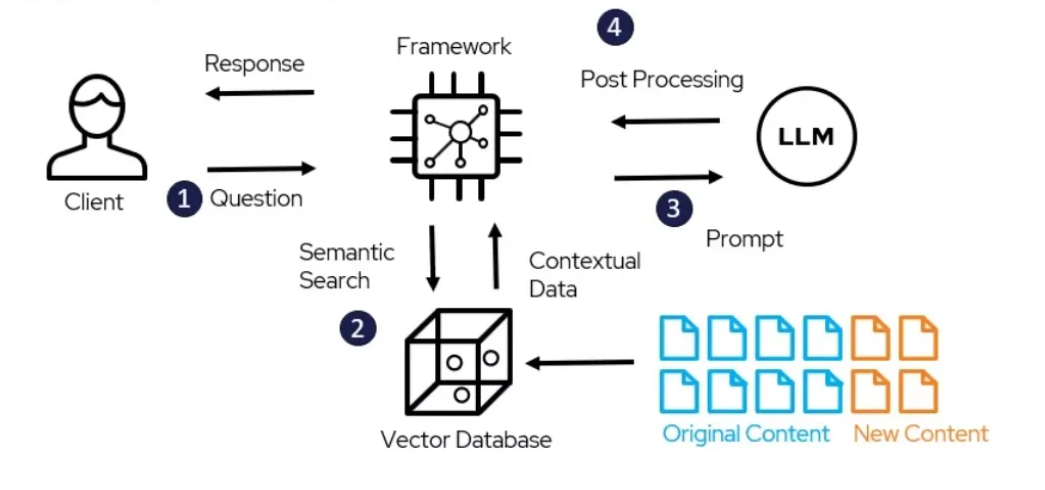
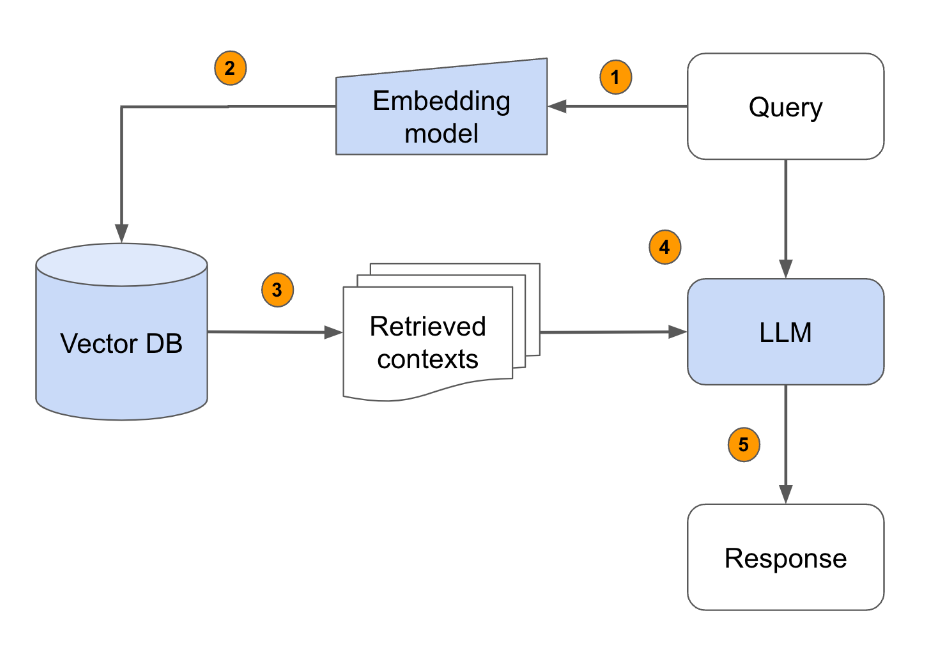
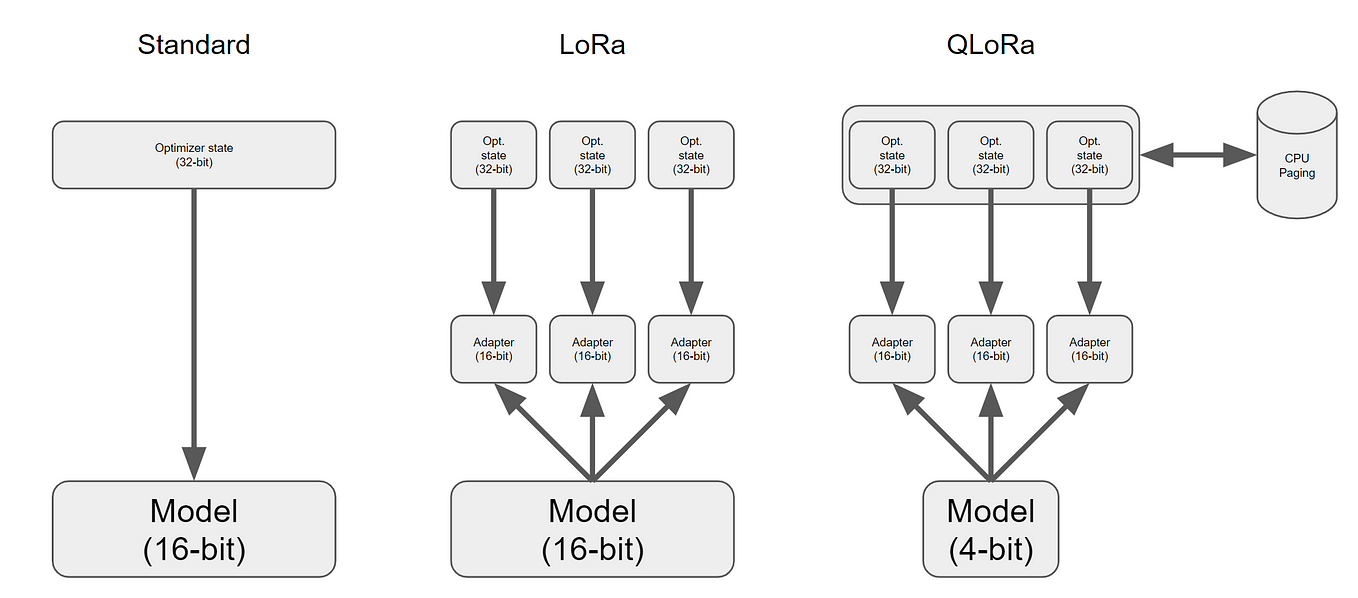
AirLLM: Layered Inference for Low-Memory Hardware | by Benjamin Marie ...
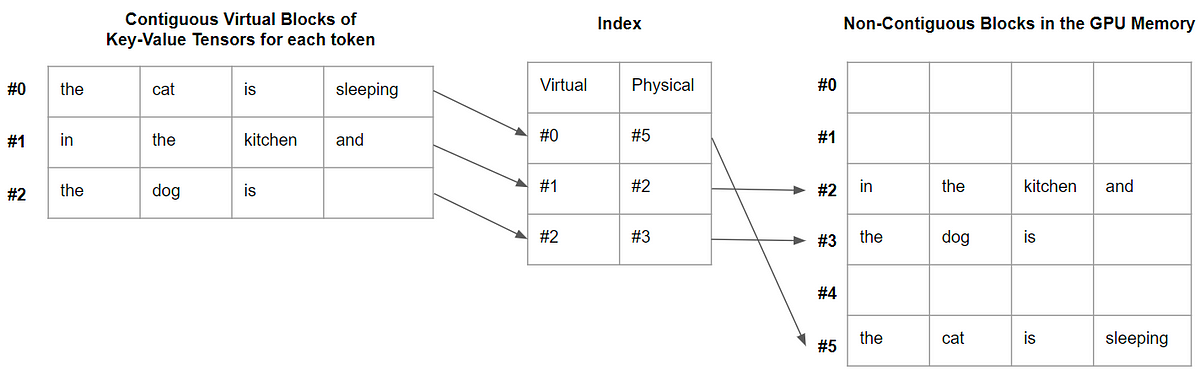
vLLM: PagedAttention for 24x Faster LLM Inference | by Benjamin Marie ...
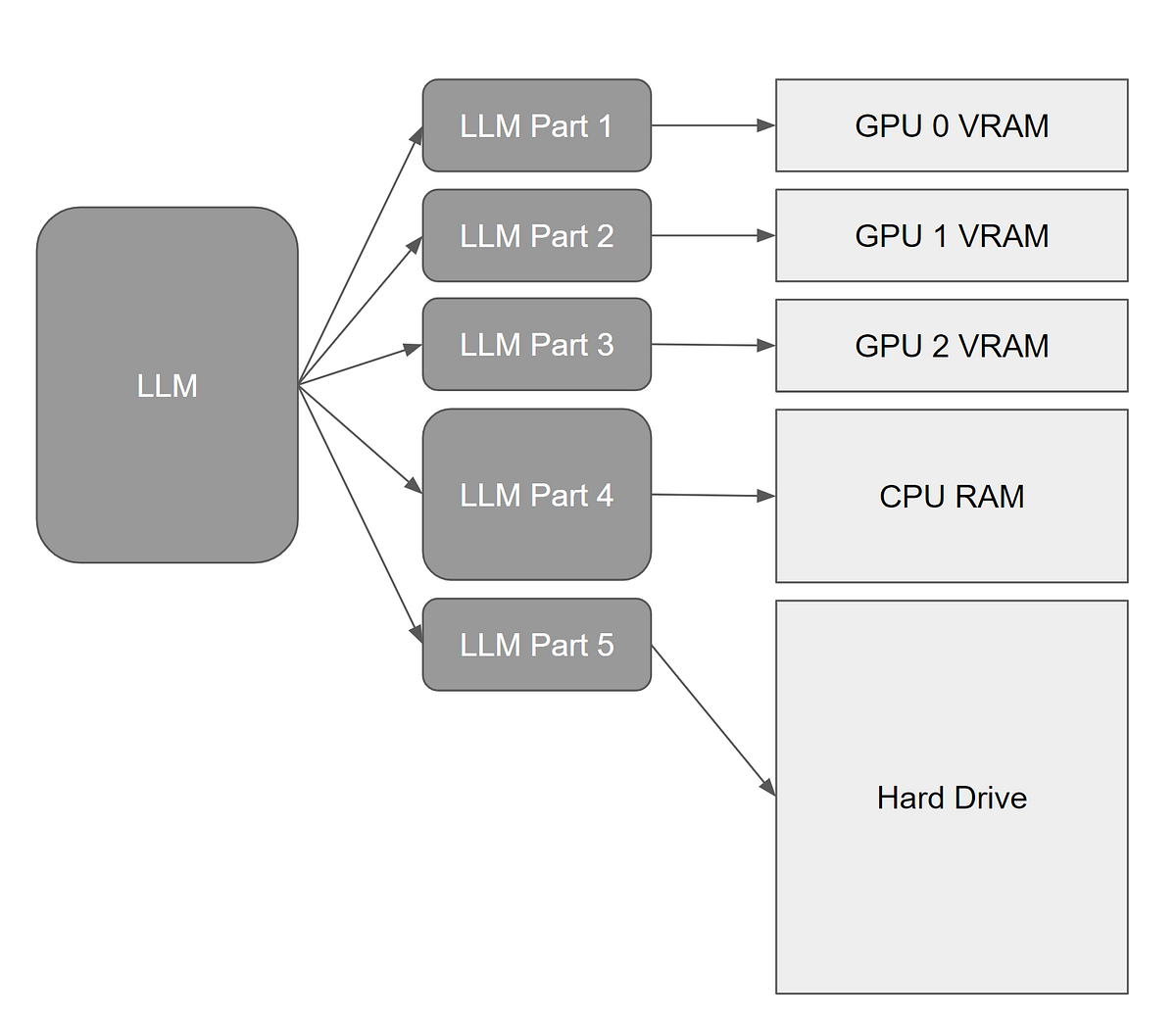
AirLLM: Layered Inference for Low-Memory Hardware
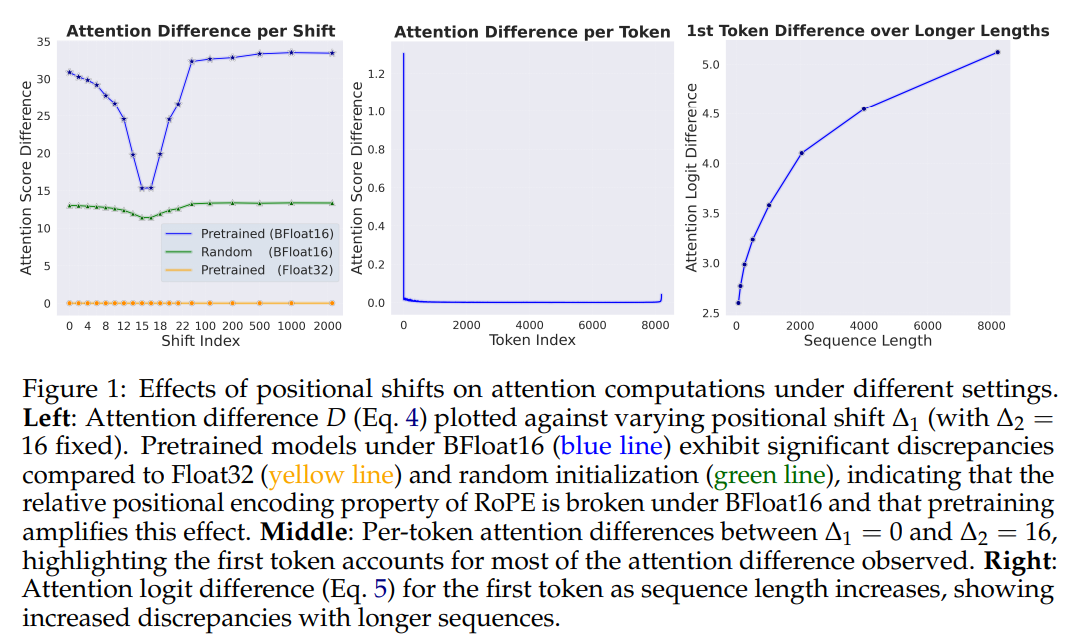
Is BFloat16’s Precision Not Good Enough for RoPE? | by Benjamin Marie ...
Fine-tune Falcon-7B on Your GPU with TRL and QLoRA | by Benjamin Marie ...
Phi-2: A Small Model Easy to Fine-tune on Your GPU | by Benjamin Marie ...
Fine-tune Falcon-7B on Your GPU with TRL and QLoRa | by Benjamin Marie ...
DeepSeekMoE: MoE with Segmented and Shared Experts | by Benjamin Marie ...
QuTLASS: Efficient Inference with 4-bit Models for Blackwell GPUs | by ...
Instruct LLMs: West-of-N for Better RHLF | by Benjamin Marie | Medium
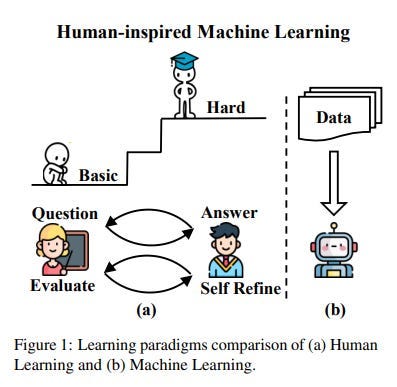
YODA: Progressive Learning for LLMs | by Benjamin Marie | Medium
Freeze and Prune to Fine-tune Your LLM with APT | by Benjamin Marie ...
URIAL: Towards the End of Fine-tuning for LLM Alignment? | by Benjamin ...
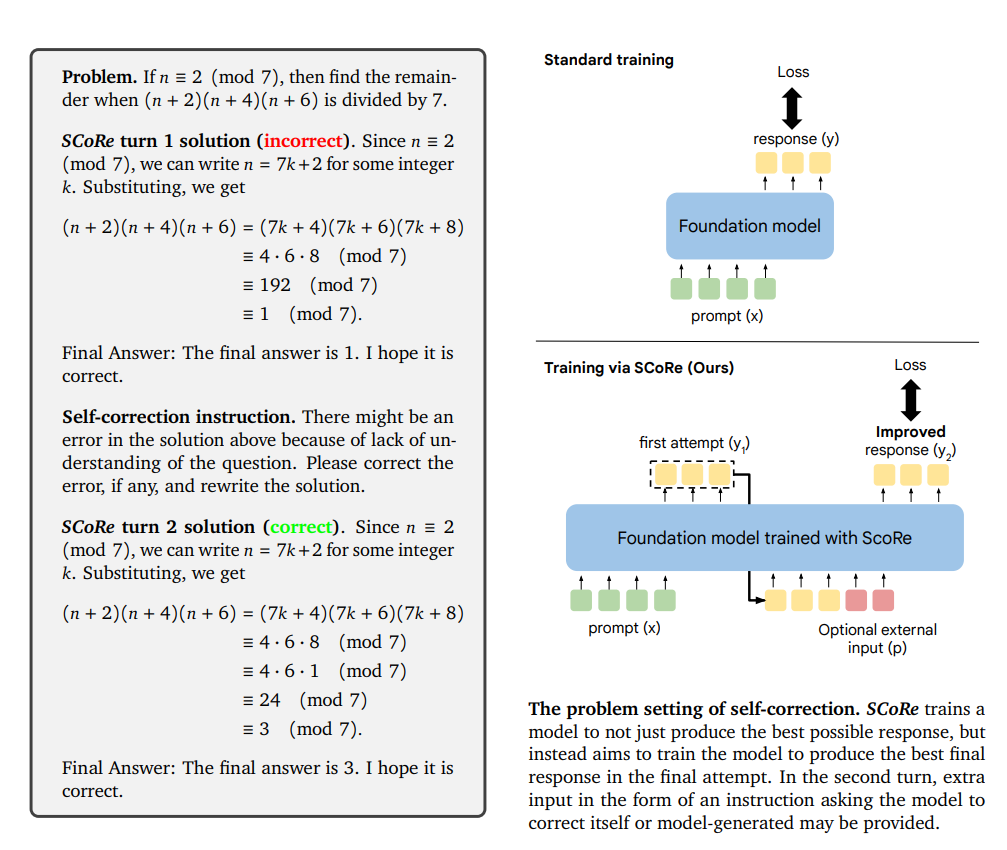
Reinforced Self-Training (ReST) for LLMs | by Benjamin Marie | Medium
Meta MMS Better than OpenAI Whisper? Not So Sure… | by Benjamin Marie ...
Learn about GGUF quantization by Benjamin Marie | Towards Data Science ...
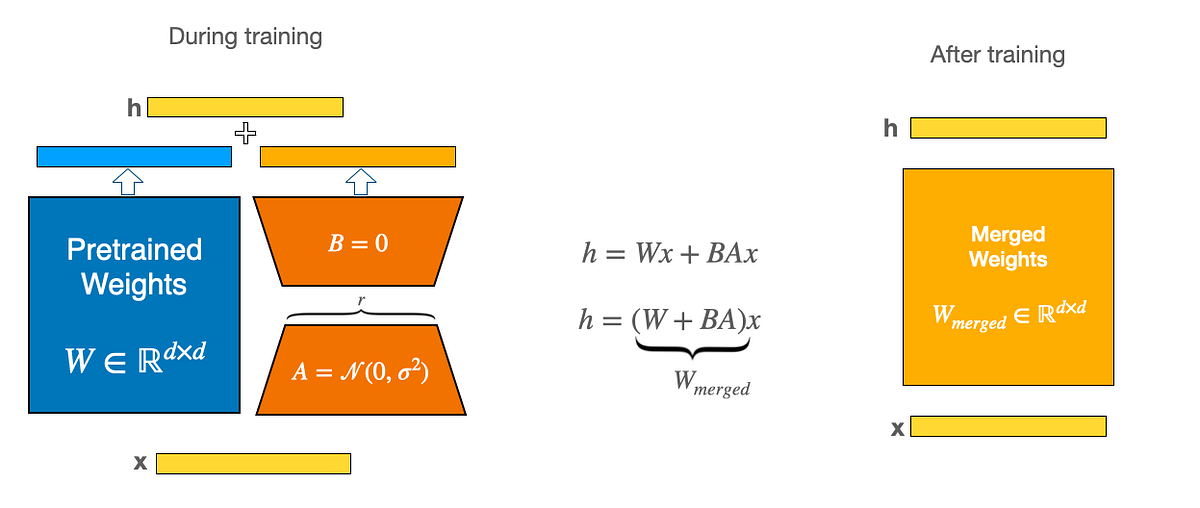
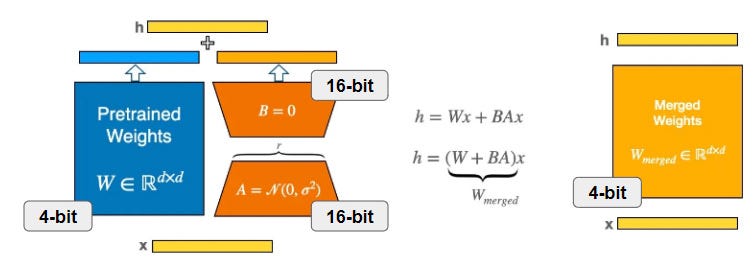
LoRA: Load and Merge Your Adapters with Care | by Benjamin Marie | Medium
NVFP4: Same Accuracy with 2.3x Higher Throughput for 4-Bit LLMs | by ...
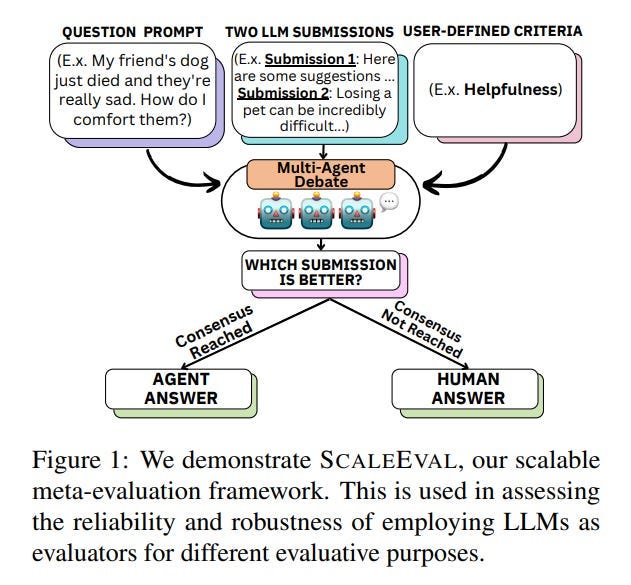
Can We Trust LLMs to Evaluate LLMs? | by Benjamin Marie | Medium
How Well Does Qwen3 Handle 4-bit and 2-bit Quantization? | by Benjamin ...
Llama 3.2: Small and Vision Language Models | by Benjamin Marie | Medium
List: Questionable Evaluation in AI | Curated by Benjamin Marie | Medium
How to Fine-tune, Quantize, and Run Microsoft phi-1.5 | by Benjamin ...
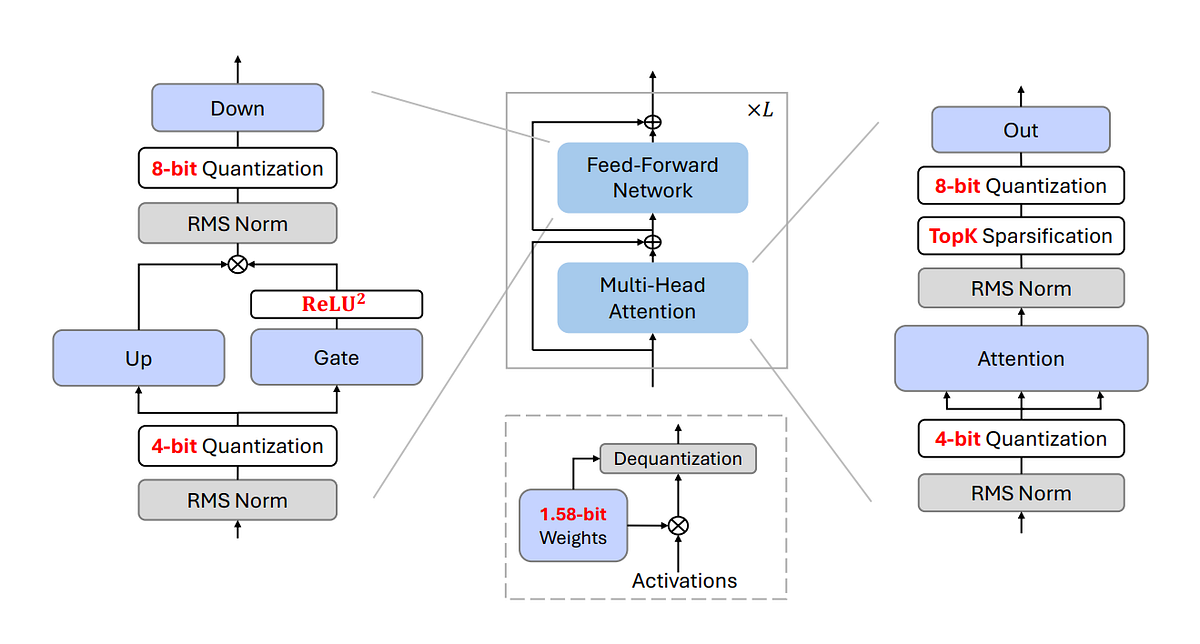
BitNet a4.8: Memory-Efficient Inference with 4-bit Activations for 1 ...
The Weekly Kaitchup #35 - by Benjamin Marie
Safe, Fast, and Memory Efficient Loading of LLMs with Safetensors | by ...
The Weekly Kaitchup #6 - by Benjamin Marie
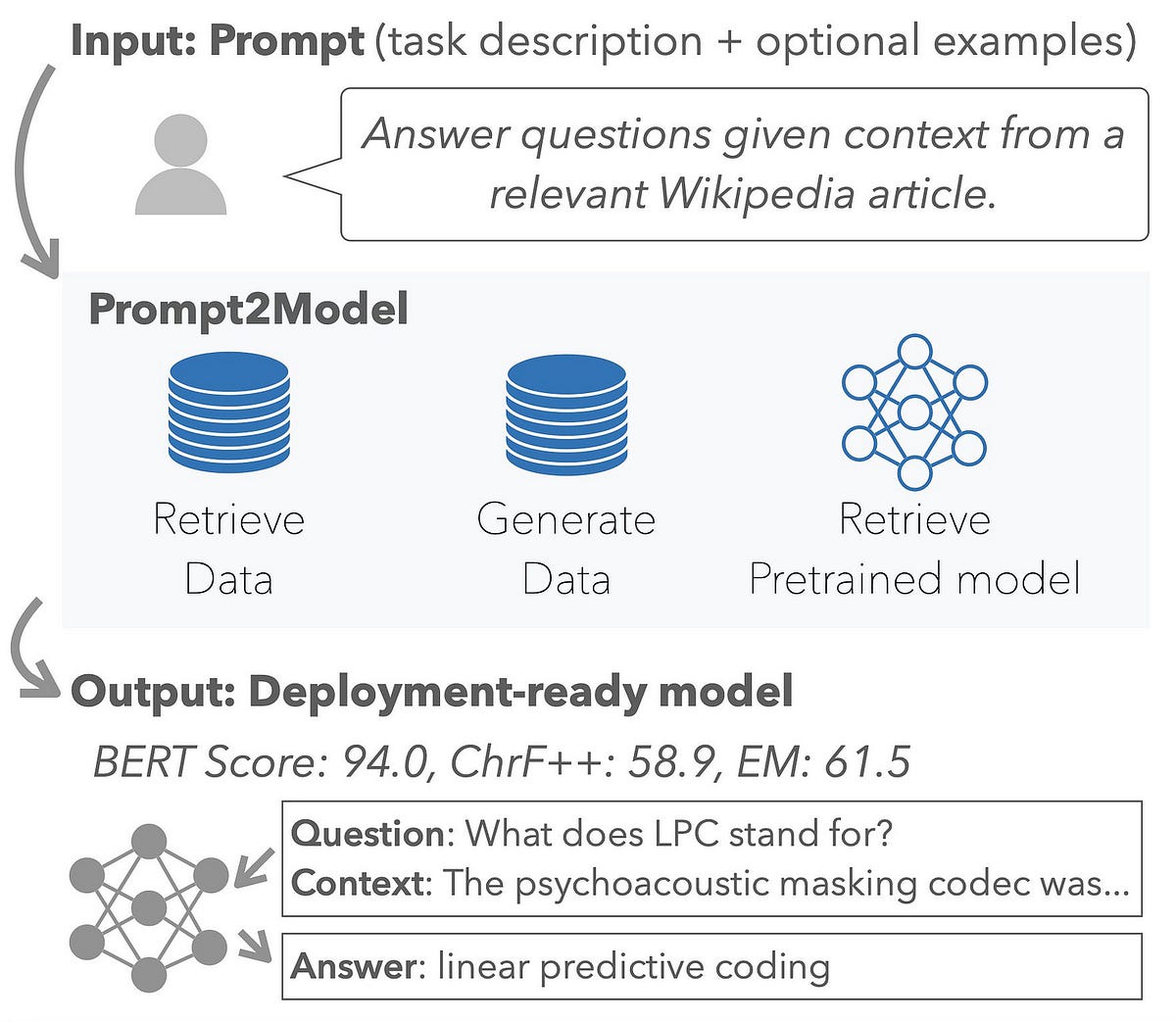
Prompt2model: Create a Large Language Model With Just a Prompt | by ...
Qwen2-VL: How Does It Work? - by Benjamin Marie
Quantization of Llama 2 with GTPQ for Fast Inference on Your Computer ...
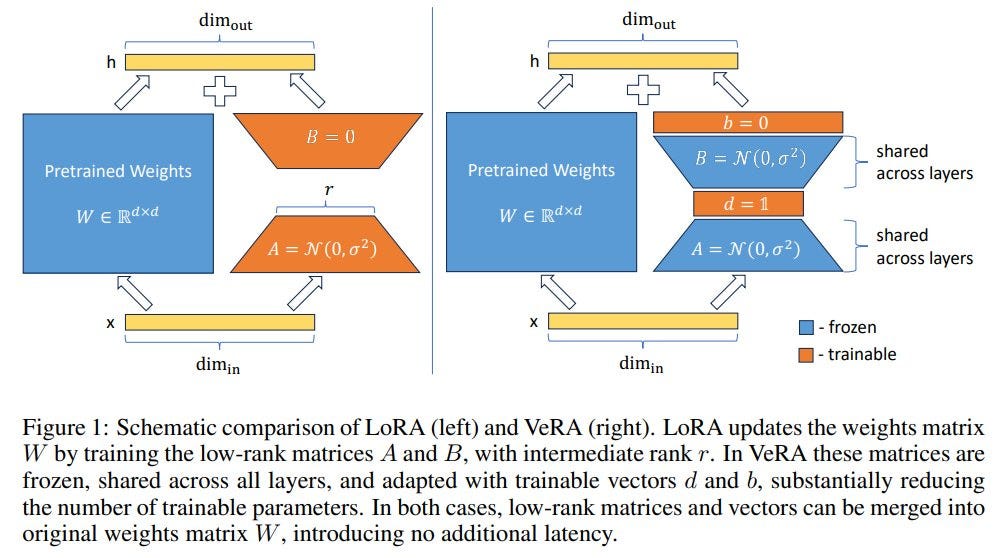
VeRA: LoRA but 10x Smaller. Frozen random matrices are useful | by ...
The Weekly Kaitchup #15 - by Benjamin Marie
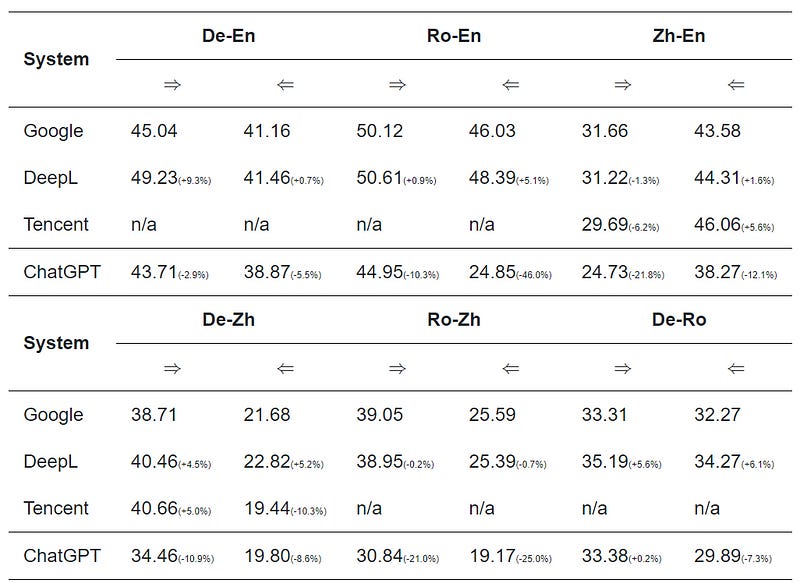
Translate with ChatGPT - by Benjamin Marie
Fine-tune Llama 3 on Your Computer - by Benjamin Marie
Fine-tuning LLMs with a Chat Template - by Benjamin Marie
How to run Llama 3.2 locally with OpenVINO™ | by OpenVINO™ toolkit ...
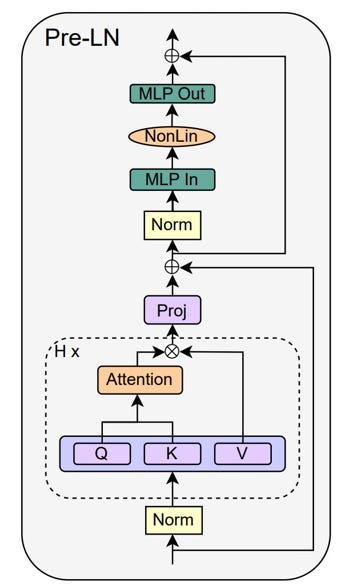
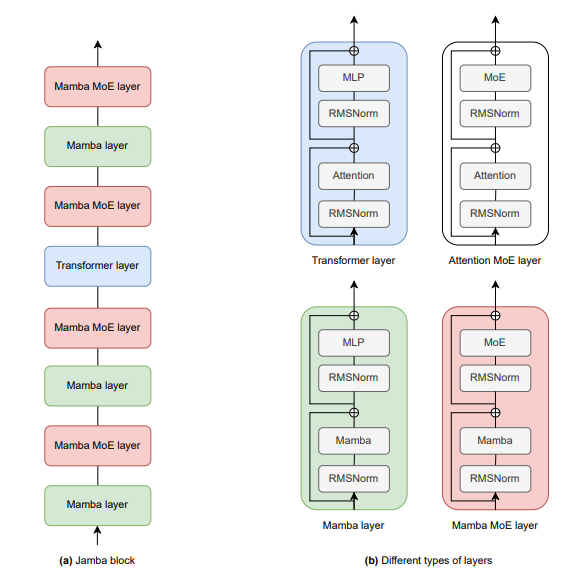
Jamba: The New Hybrid Transformer/Mamba - by Benjamin Marie
Padding Large Language Models - by Benjamin Marie
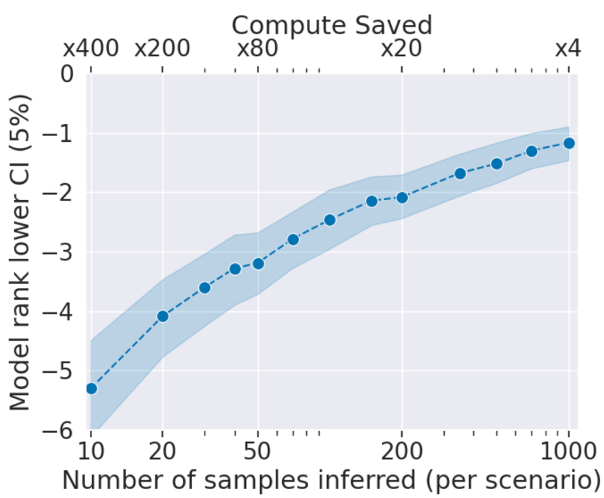
Running LLama 3 70B on a Single 4GB GPU with AirLLM and Layered ...
Thanks! That's a list I'll keep near my keyboard. - Benjamin Marie - Medium
Ollama vs vLLM: which framework is better for inference? 👊 (Part I ...
What Is AI Inference and How Does It Work? | Gcore
Onnx Model Quantization | by Nashrakhan | Medium
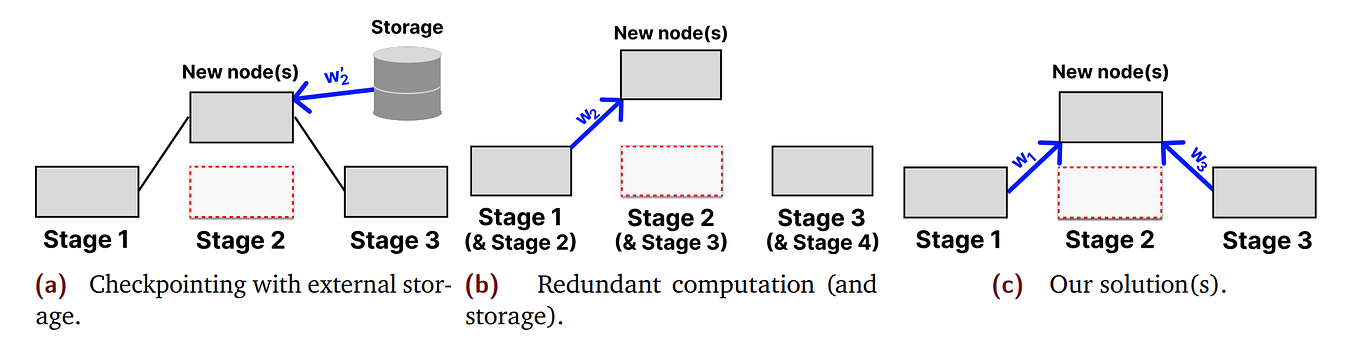
PyTorch Activation Checkpointing: Complete Guide | by Hey Amit | Medium
Mistral 7B: Recipes for Fine-tuning and Quantization on Your Computer ...
How to Set Up a PEFT LoraConfig. Fine-tuning large language models ...
Device Map: Avoid Out-of-Memory Errors When Running Large Language ...
Train Instruct LLMs On Your GPU with DeepSpeed Chat — Step #1 ...
LLM Inference Hardware: Emerging from Nvidia's Shadow
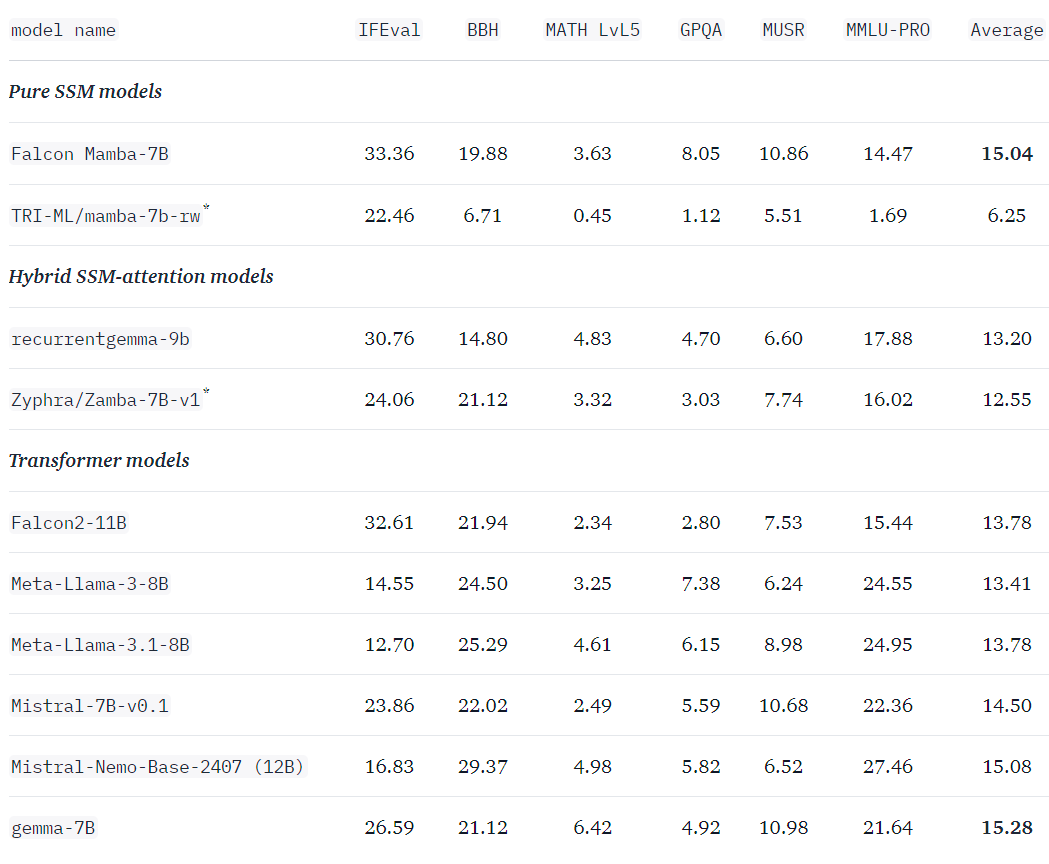
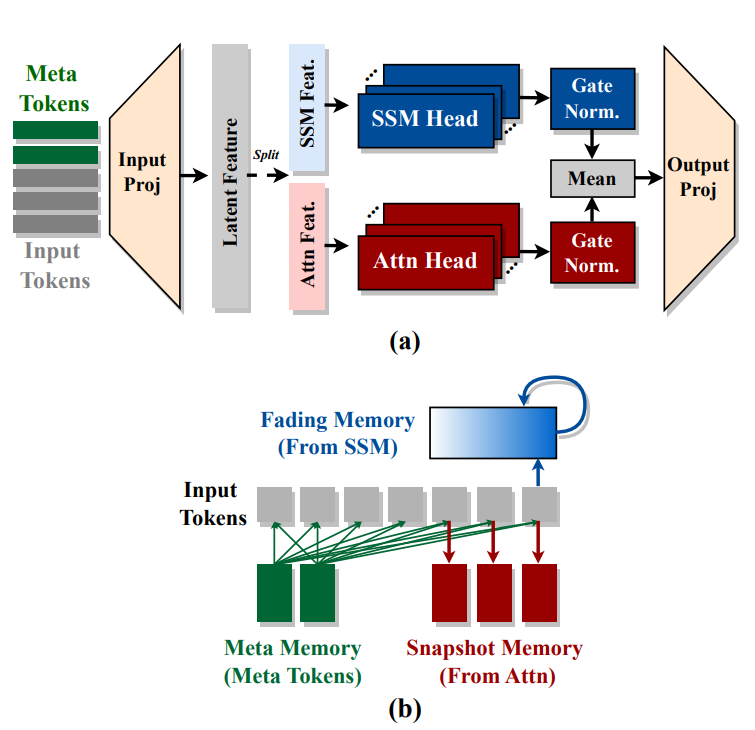
Hymba: Combining Attention Heads and SSM Heads within the Same Layer ...
Quantization for parameters, activations, and KV cache
Self-Rewarding Language Models. One more alternative to reinforcement ...
Breaking the Speed Barrier in Self-Attention: GQA, MQA, and MLA ...
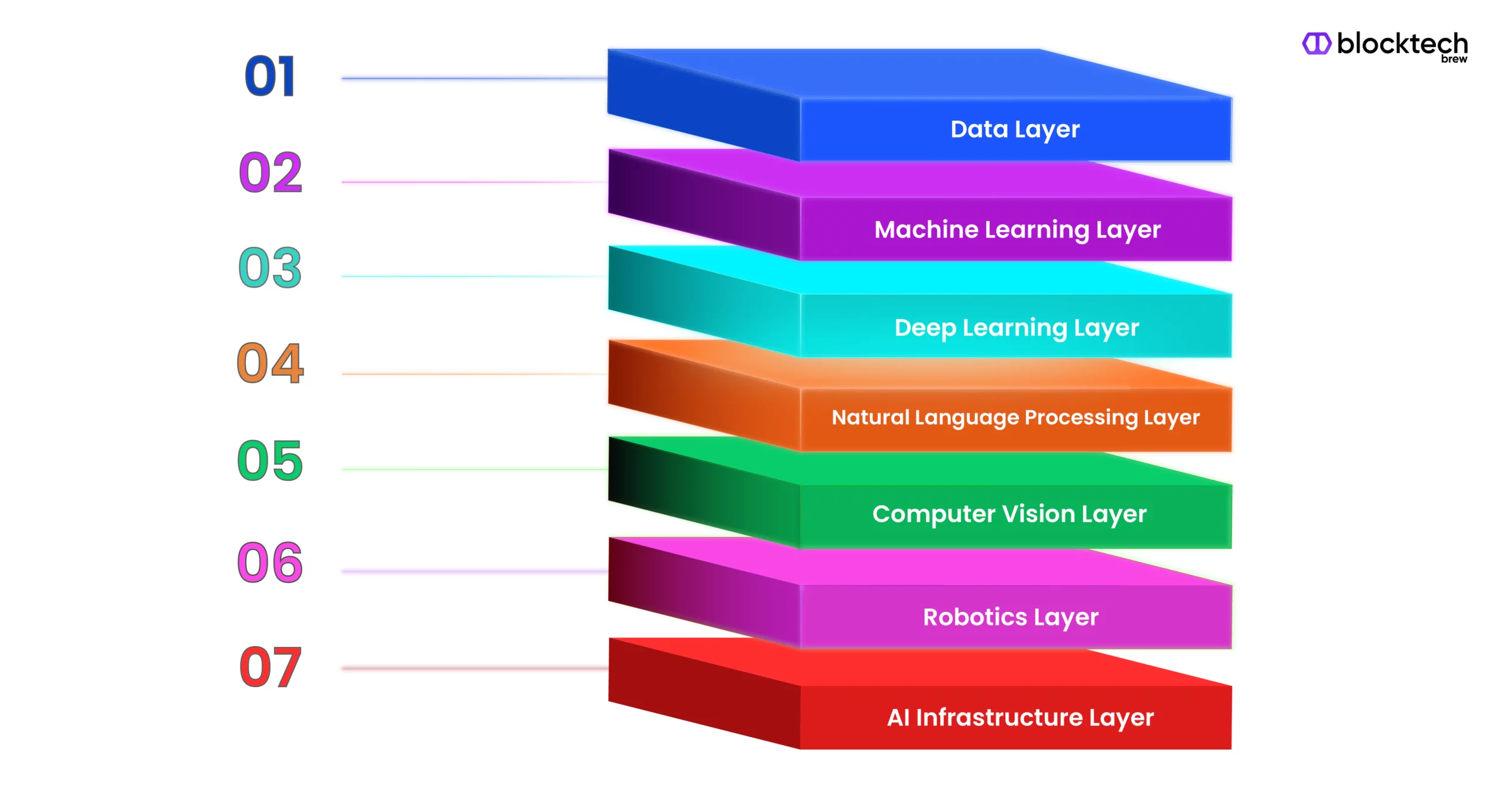
An Explained Guide to the Artificial Intelligence Stack | Blocktech Brew
Resolving-“RuntimeError: CUDA Out of memory” error, and Other ...
Multi-GPU Training in PyTorch with Code (Part 3): Distributed Data ...
[vLLM — Quantization] bitsandbytes: 8-bit Optimizers, LLM.int8(), QLoRA ...
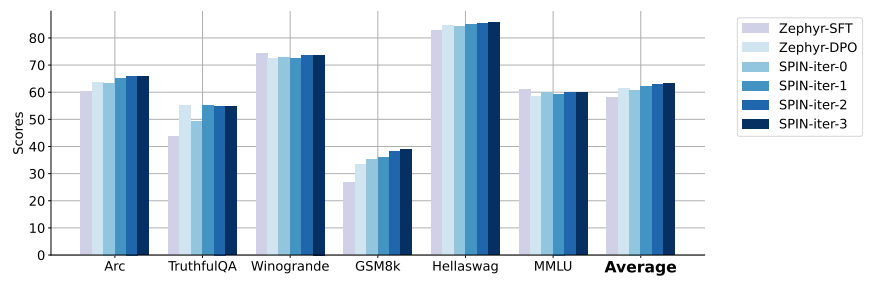
SPIN: Self-play Fine-tuning to Improve LLMs without Additional Data ...
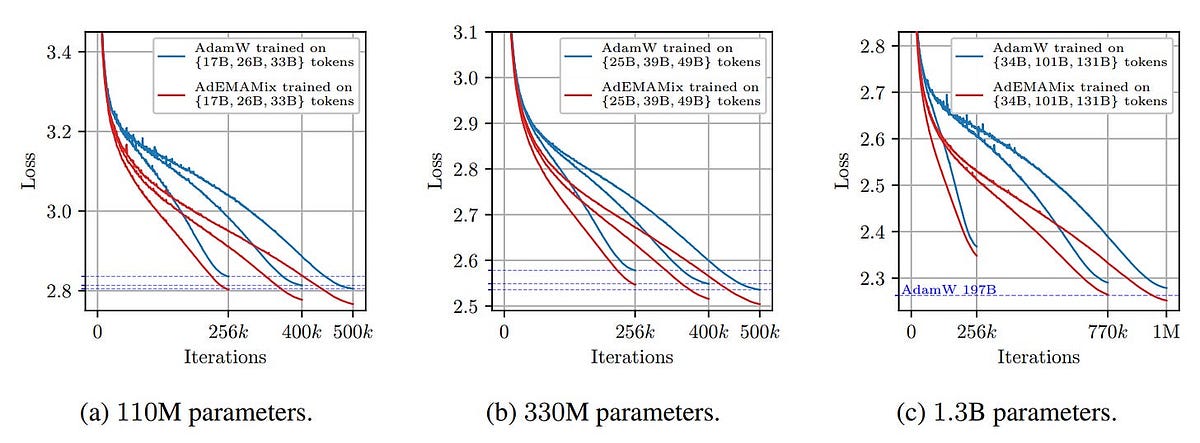
AdEMAMix: Achieve the Same Results as with AdamW Using Only Half as ...
Fine-Tuning a Pre-Trained GPT-2 Model and Performing Inference: A Hands ...
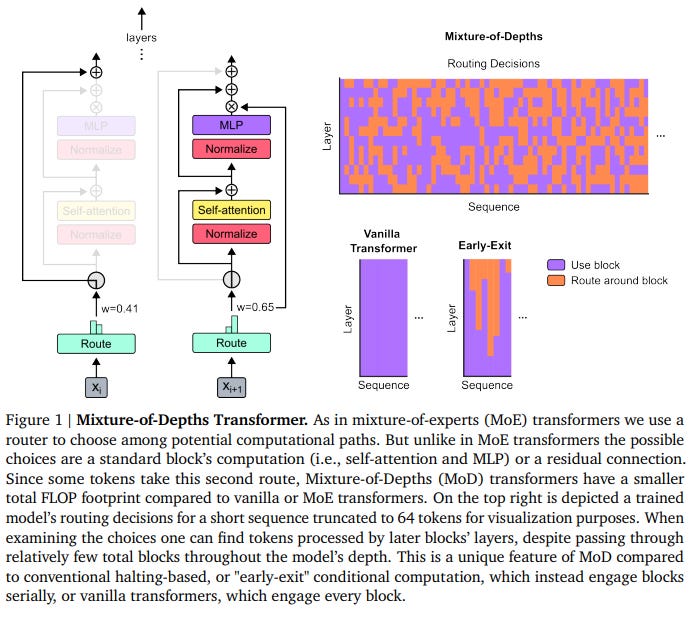
From 16-bit to 2-bit: Finding the Best Trade-off Between Memory ...
Aligning LLMs with Direct Preference Optimization (DPO)— background ...
An evaluation of the very popular DPO
Understanding Repository Pattern In Laravel – peerdh.com
5 ขั้นตอน: จดสิทธิบัตร AI ให้สำเร็จได้อย่างไร?