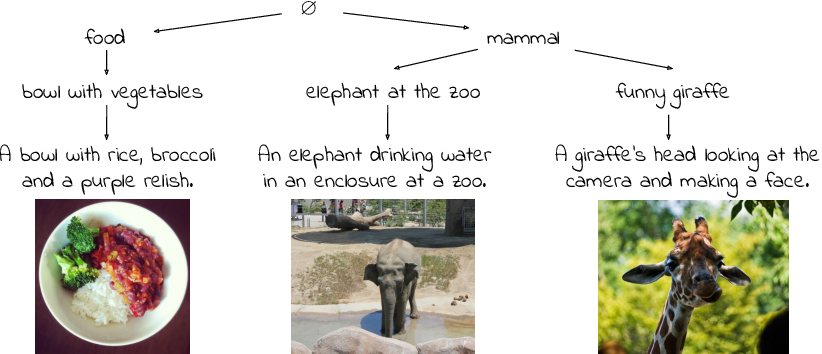
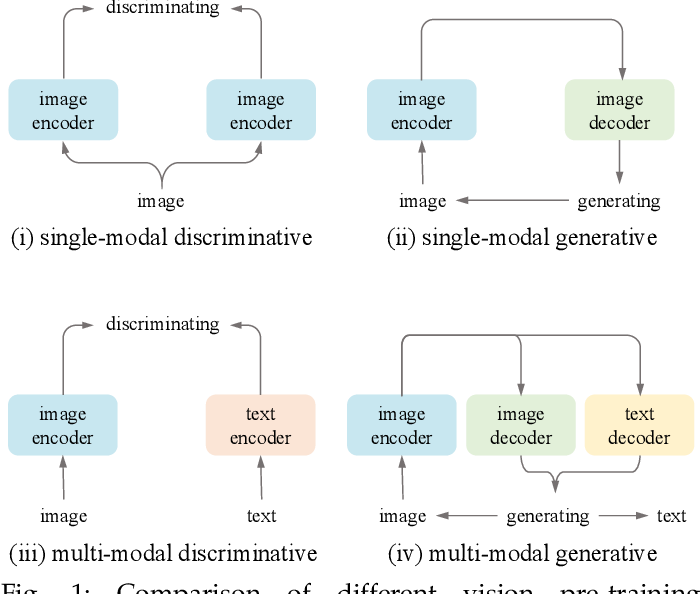
Text-Conditional JEPA for Learning Semantically Rich Visual Representations
JEPA as a Neural Tokenizer: Learning Robust Speech Representations with ...
Learning Navigational Visual Representations with Semantic Map ...
[PDF] Decoding Visual Neural Representations by Multimodal Learning of ...
Visual representations with texts domain generalization for semantic ...
Figure 2 from Multimodal Visual-Semantic Representations Learning for ...
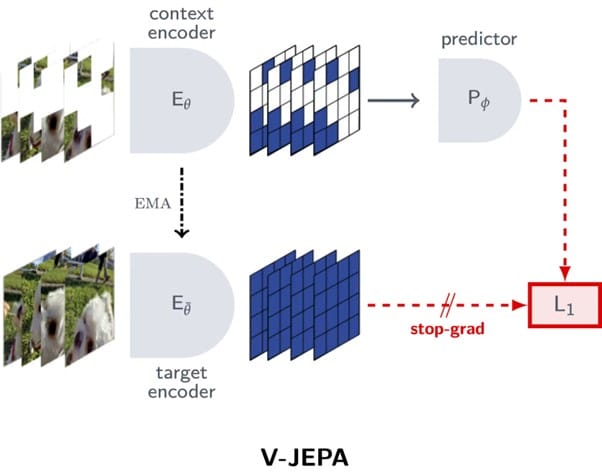
V-JEPA: Revisiting Feature Prediction for Learning Visual ...
AI/ Paper/ Revisiting Feature Prediction for Learning Visual ...
Three visual representation learning paradigms for text-to-video ...
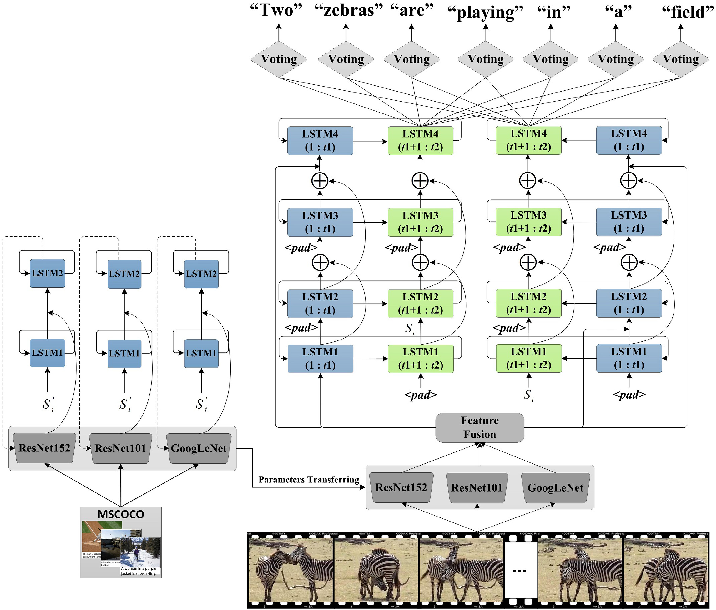
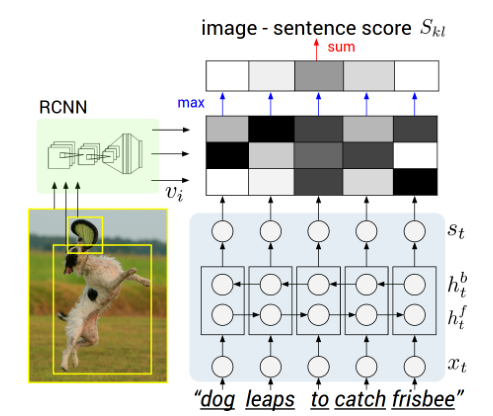
Learning a Recurrent Visual Representation for Image Caption G.docx
(PDF) Joint Learning of Words and Meaning Representations for Open-Text ...
Figure 2-1 from Interpretable representation learning for visual ...
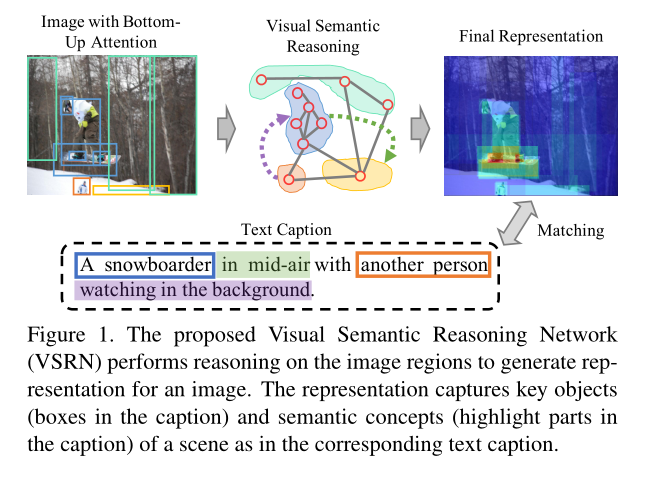
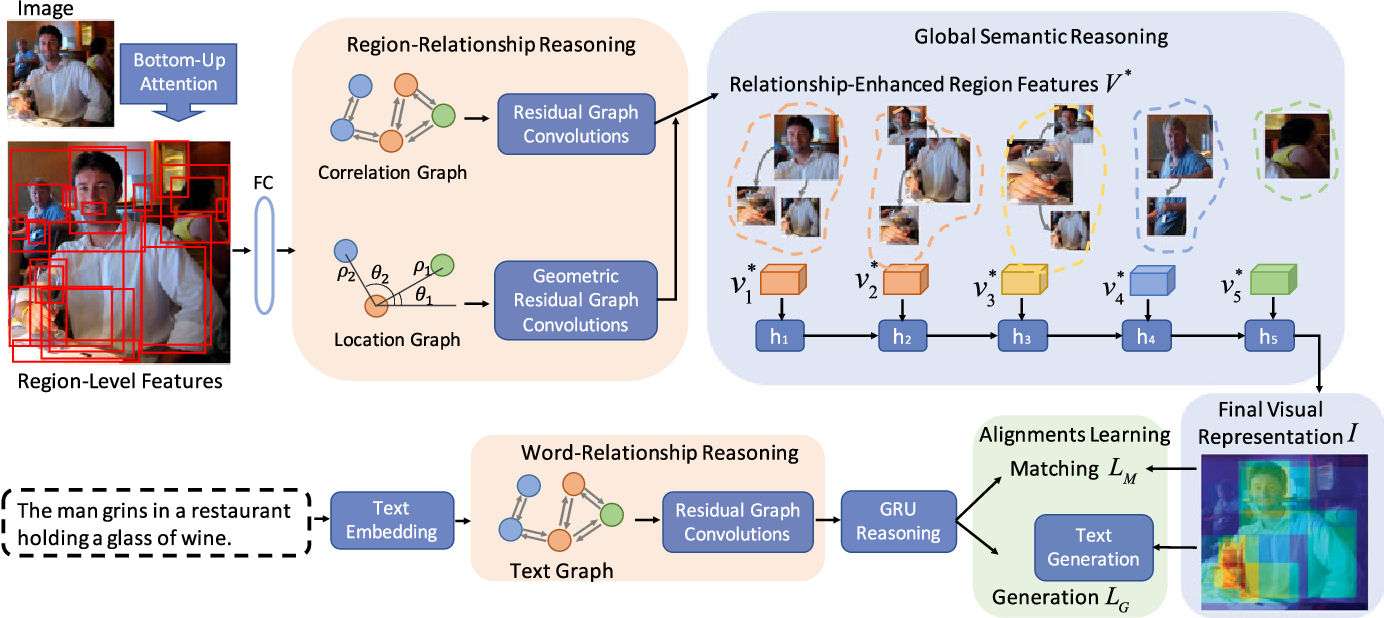
Visual Semantic Reasoning for Image-Text Matching - AHU-WangXiao - 博客园
Semantics-Guided Representation Learning with Applications to Visual ...
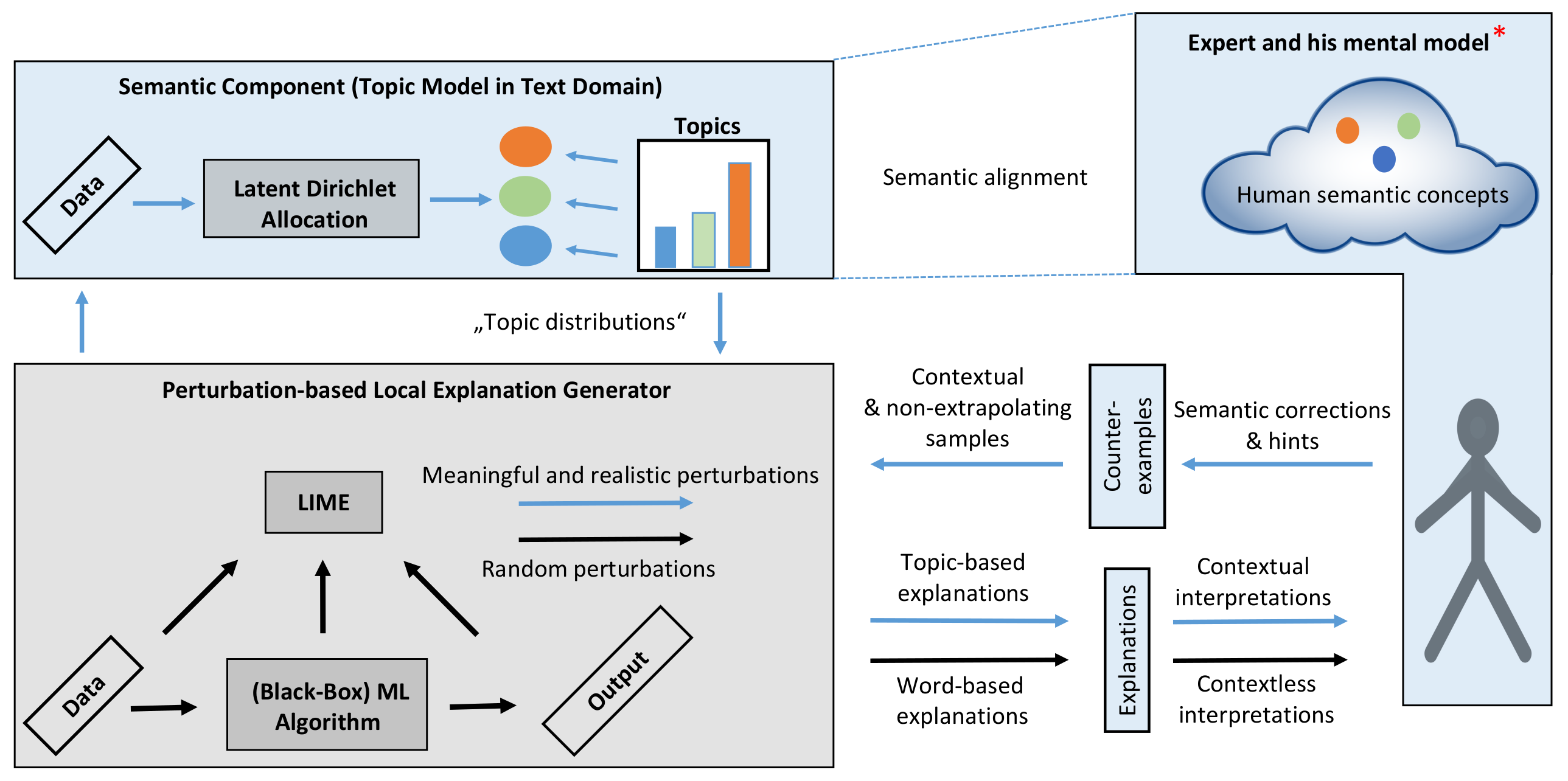
Semantic Interactive Learning for Text Classification: A Constructive ...
[PDF] Scaling Up Visual and Vision-Language Representation Learning ...
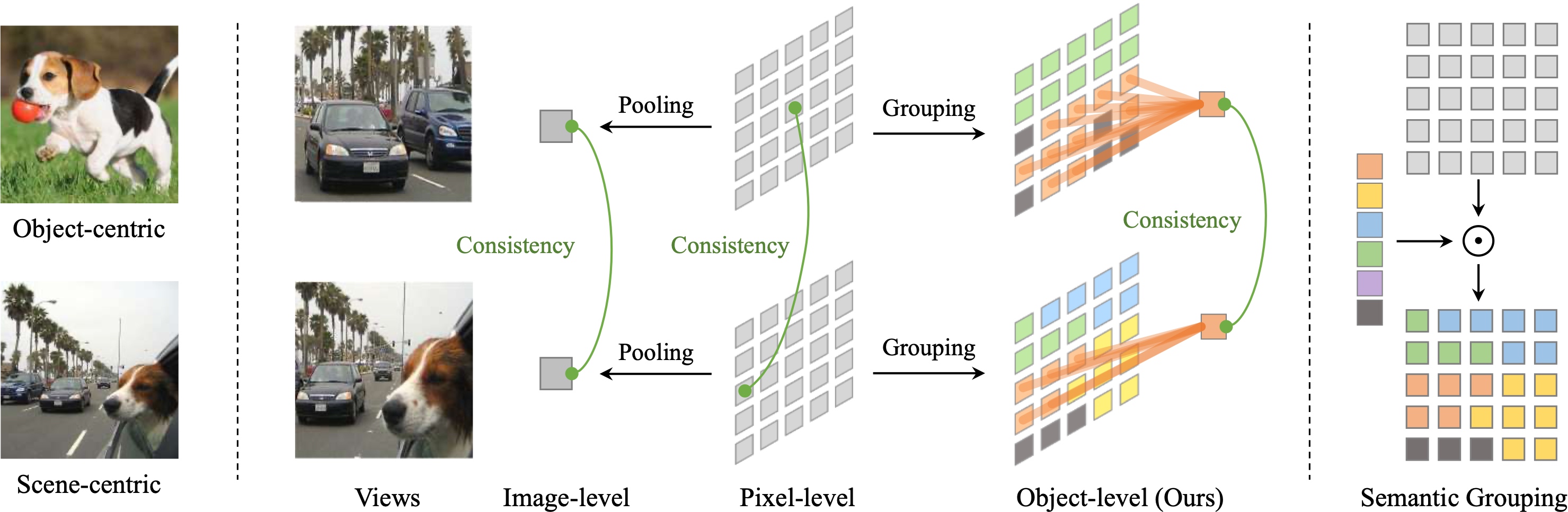
Self-Supervised Visual Representation Learning with Semantic Grouping
(PDF) Representation Learning for Semantic Scene Understanding
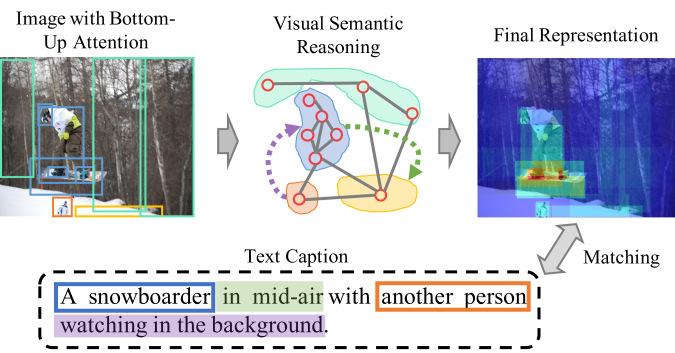
Visual Semantic Reasoning for Image-Text Matching | DeepAI
Figure 2 from Image-Text Embedding Learning via Visual and Textual ...
(PDF) Semantic representation for visual reasoning
(PDF) Neural Text Generation from Rich Semantic Representations
Figure 1 from Rich Visual and Language Representation with ...
Illustration of the proposed constraints for learning visual-semantic ...
Neural Text Generation from Rich Semantic Representations - ACL Anthology
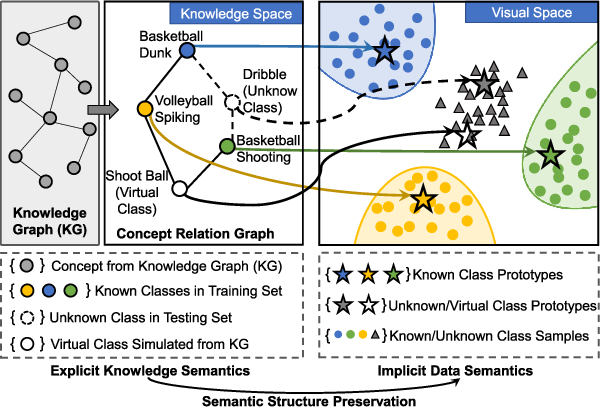
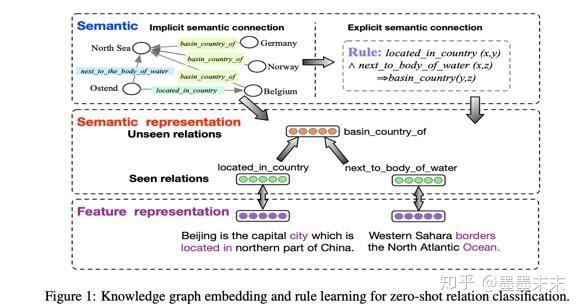
Semantic-visual shared knowledge graph for zero-shot learning [PeerJ]
Brief Review — Conditional Prompt Learning for Vision-Language Models ...
Representation Learning 101 for Software Engineers
Paper page - Learning Interpretable Representations Leads to ...
(PDF) Visual content representation using semantically similar visual words
Figure 1 from Learning the Visual Interpretation of Sentences ...
(PDF) Seeing Colors: Learning Semantic Text Encoding for Classification
(PDF) Learning Semantic-Specific Graph Representation for Multi-Label ...
Figure 1 from Exploring Rich Semantics for Open-Set Action Recognition ...
Visual Semantic Reasoning for Image-Text Matching | PDF | Art | Computers
Figure 1 from Learning Visual Representation from Modality-Shared ...
Augmenting Vision Language Pretraining by Learning Codebook with Visual ...
Figure 3 from Boosting Discriminative Visual Representation Learning ...
V-JEPA - Unsupervised Learning in Computer Vision
Figure 5 from Scaling Up Visual and Vision-Language Representation ...
(PDF) Multi-Level Visual Representation with Semantic-Reinforced ...
[论文评述] Understanding the Effect of using Semantically Meaningful Tokens ...
Unveiling Meta's V-JEPA: Advancing self-supervised Learning in AI
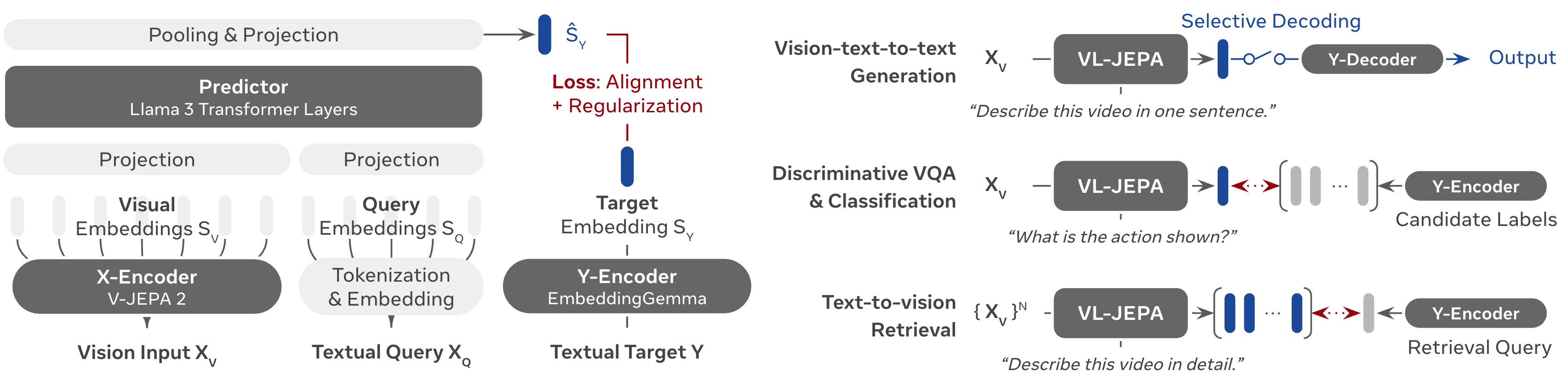
VL-JEPA: Why Predicting Embeddings Beats Generating Tokens for Vision ...
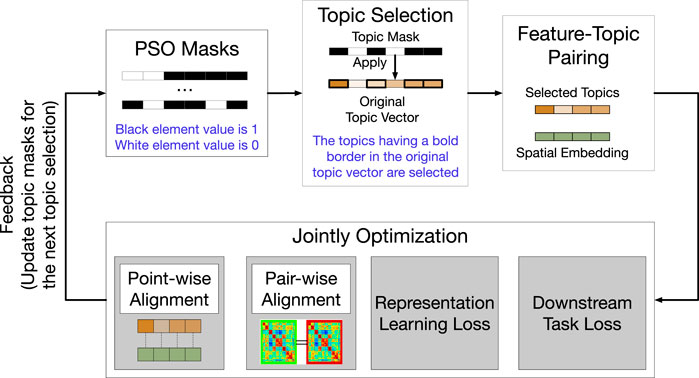
(PDF) Understanding the Effect of using Semantically Meaningful Tokens ...
VL-JEPA: Joint Embedding Predictive Architecture for Vision-language
Semantic Representations during Language Comprehension Are Affected by ...
(PDF) Visual place recognition from end-to-end semantic scene text features
Figure 1 from Learning Hierarchical Visual-Semantic Representation with ...
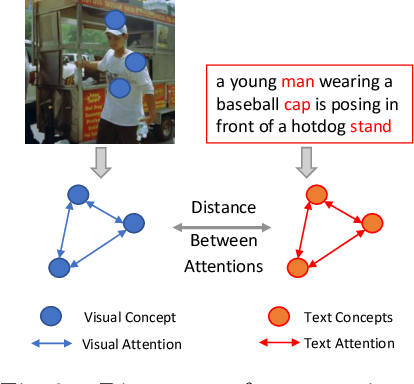
Figure 3 from Modeling visual and word-conditional semantic attention ...
Text-Image Retrieval | Deep Visual-Semantic Alignments for Generating ...
Mapping framework between visual and semantic spaces | Download ...
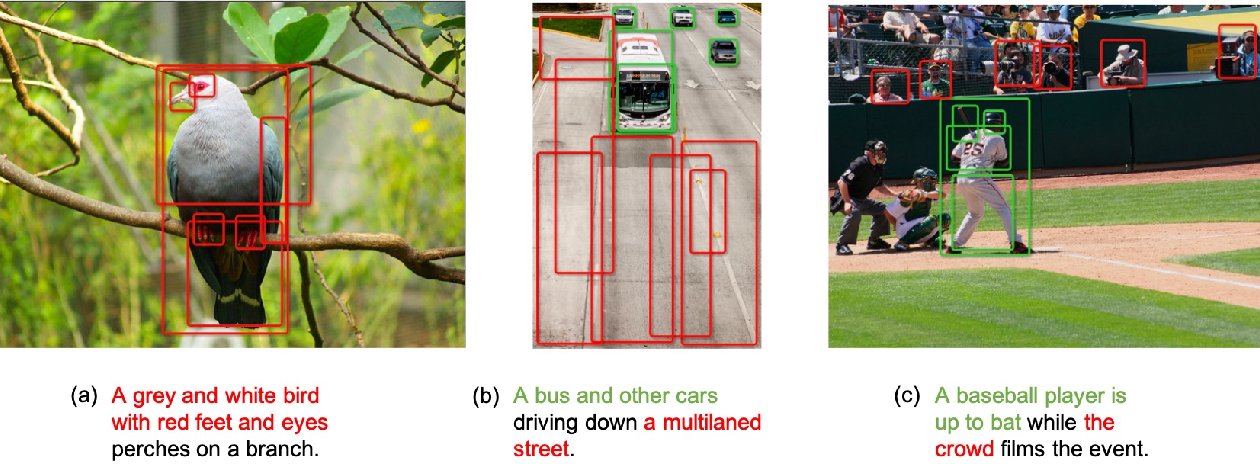
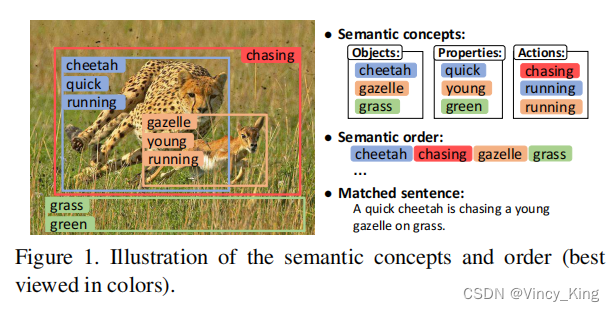
【Image Text Matching】Learning Semantic Concepts and Order for Image and ...
Figure 7 from Image Caption Generation with Text-Conditional Semantic ...
Figure 1 from Modeling visual and word-conditional semantic attention ...
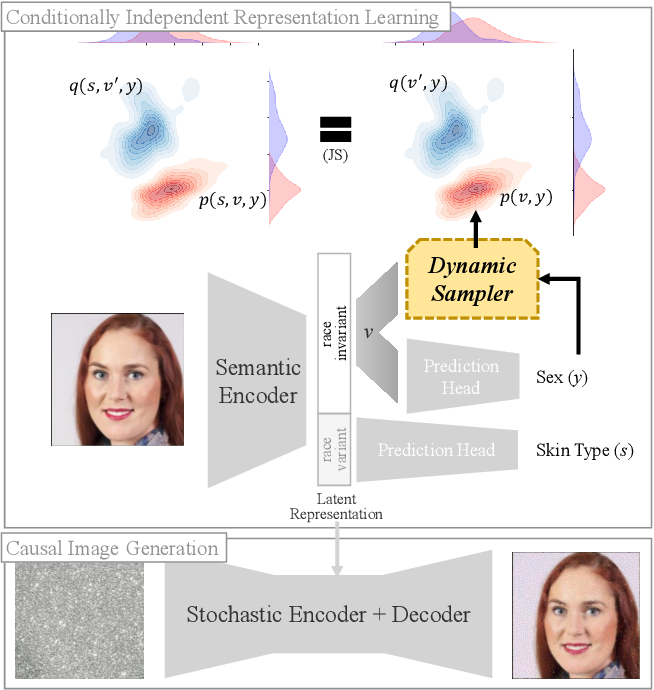
Figure 1 from Enforcing Conditional Independence for Fair ...
Emergent Visual-Semantic Hierarchies in Image-Text Representations ...
(PDF) Visual Reasoning through Semantic Representation: A Comprehensive ...
Logic-guided Semantic Representation Learning - 知乎
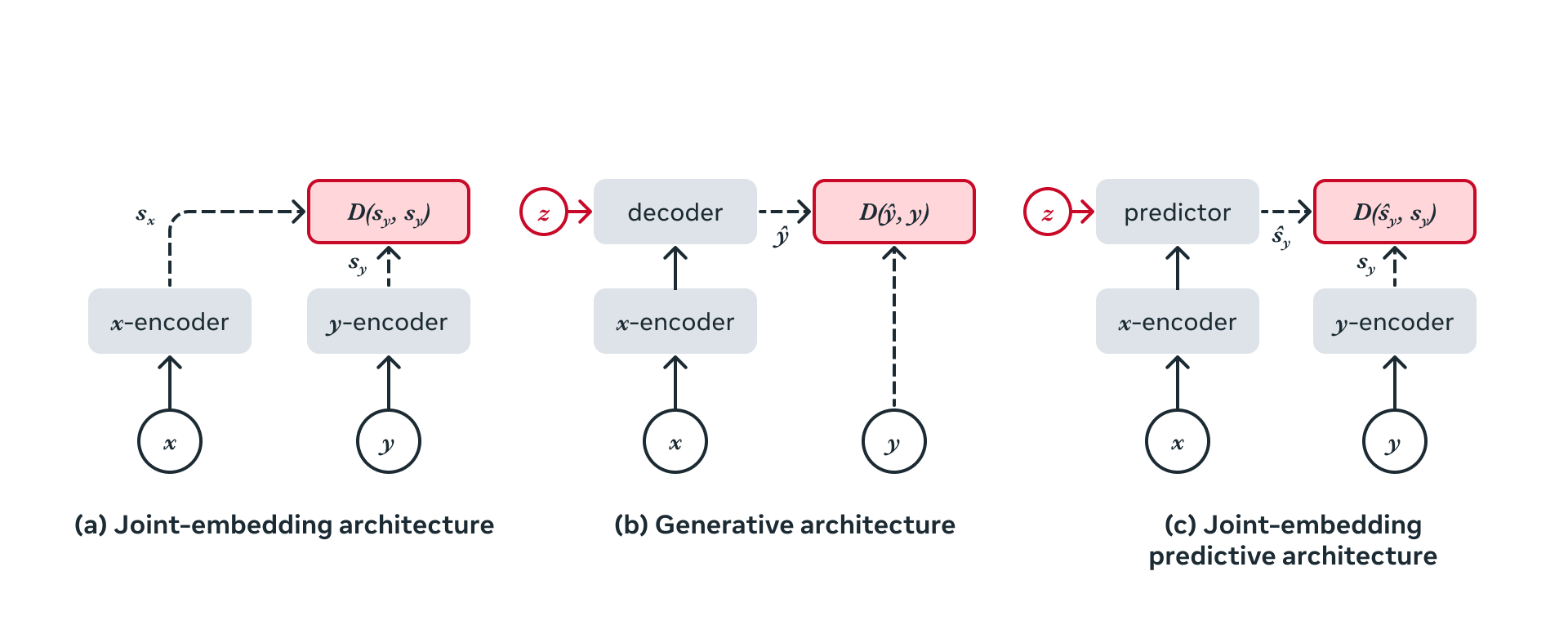
[Paper Review] Self-Supervised Learning from Images with a Joint ...
Paper page - Hierarchical Text-Conditional Image Generation with CLIP ...
Figure 2 from Enhancing Visual Representation with Textual Semantics ...
(PDF) The Impact of Deep Learning on Document Classification Using ...
Jia Et Al. - 2021 - Scaling Up Visual and Vision-Language Representati ...
| The progress of learning of the semantic-visual and lexical ...
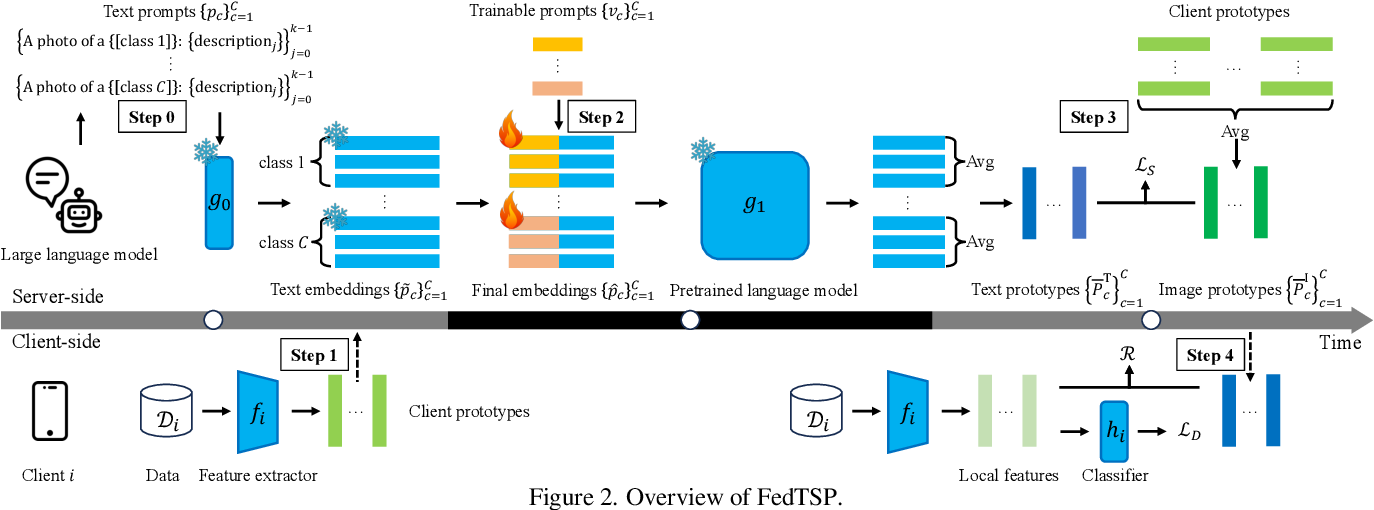
GitHub - justin-herry/JEPA-T: This is the official repository for the ...
A Visual Exploration of Semantic Text Chunking | by Robert Martin-Short ...
Hierarchical Text-Conditional Image Generation with CLIP Latents
Hierarchical text-conditional image generation with CLIP latents | OpenAI
【Image Caption】Deep Visual-Semantic Alignments for Generating Image ...
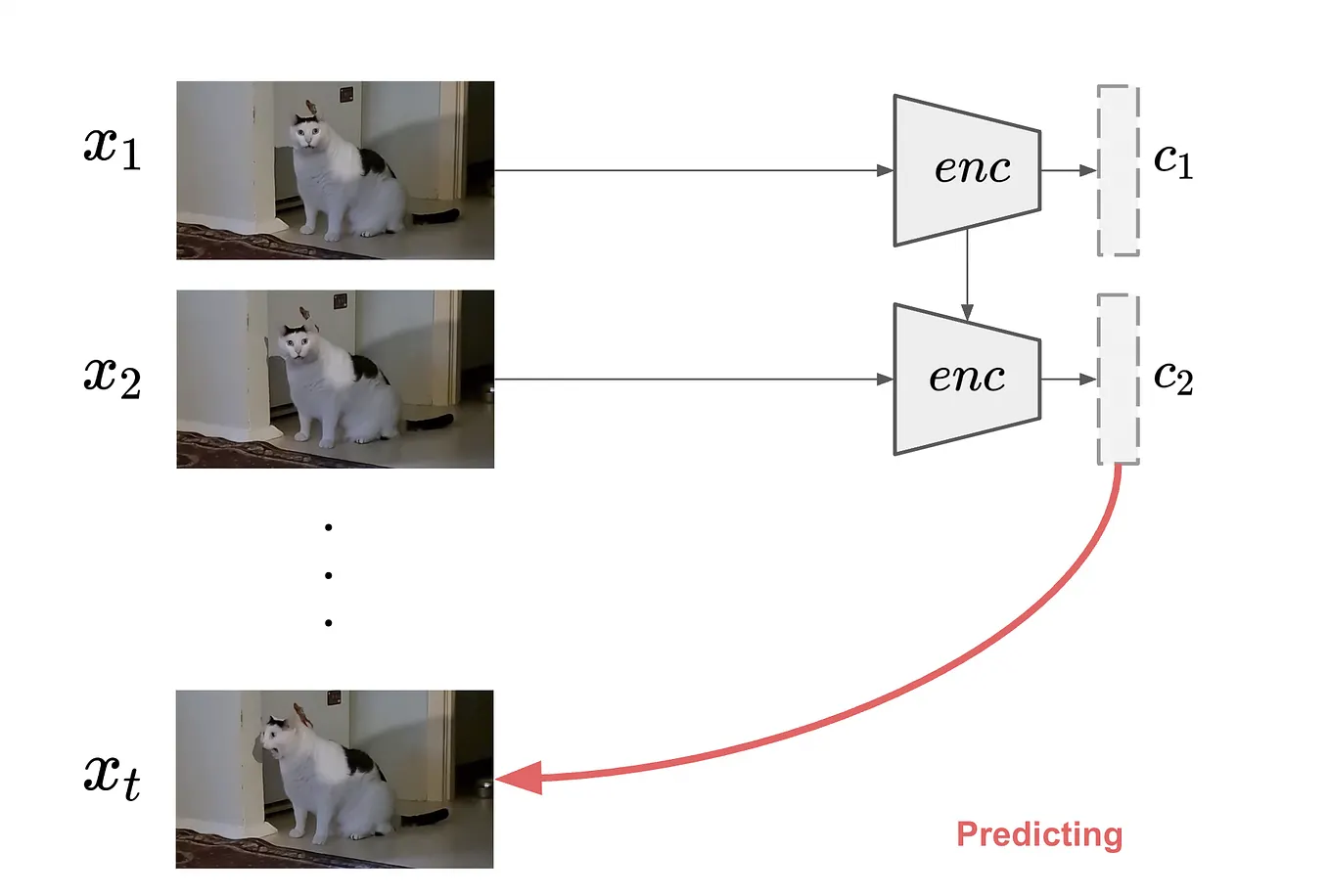
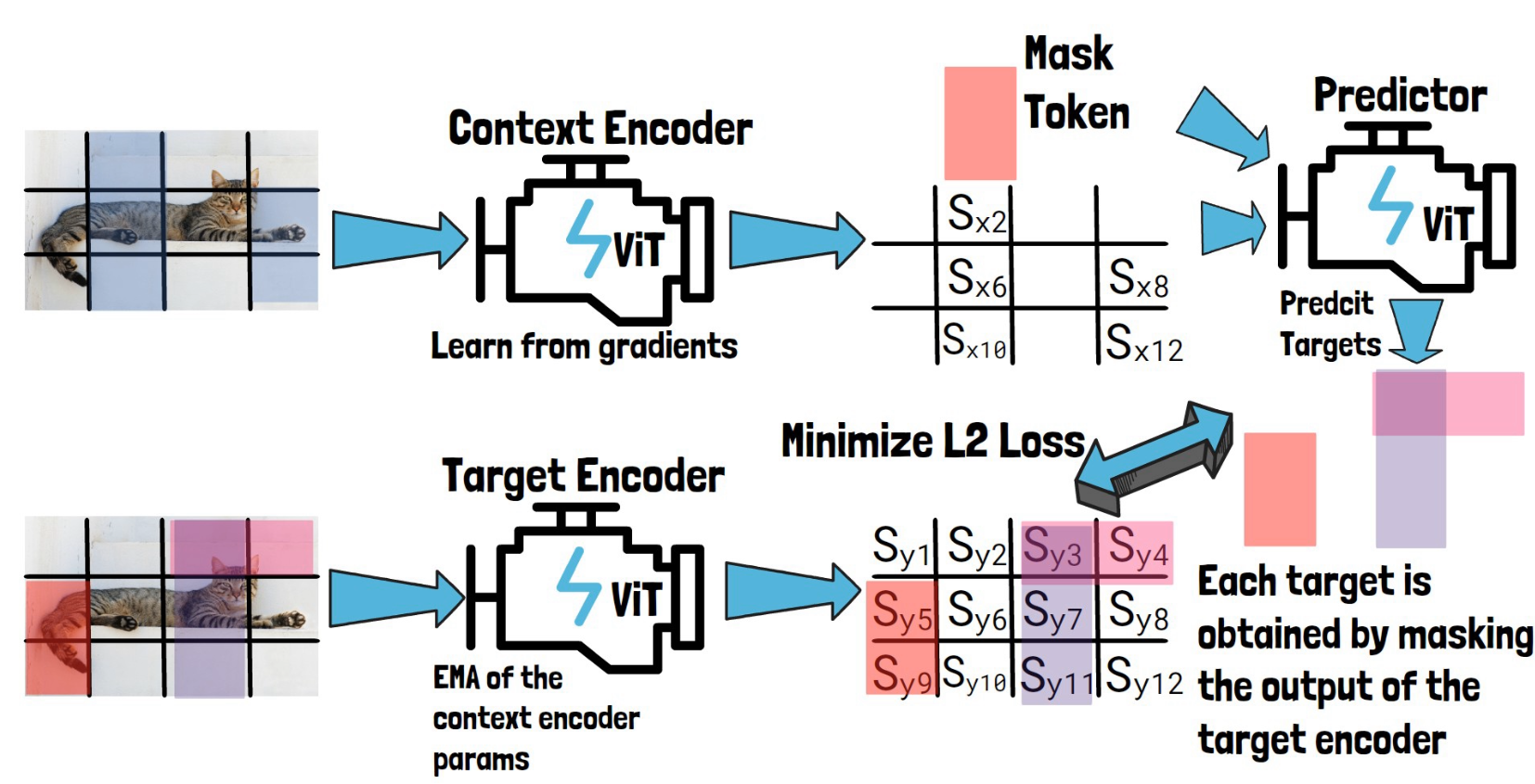
I-JEPA: Explained. JEPA is a new architecture for… | by Utkarsh Doshi ...
VL-SAT: Visual-Linguistic Semantics Assisted Training for 3D Semantic ...
V-JEPA: Teaching AI to Think, Not Just See
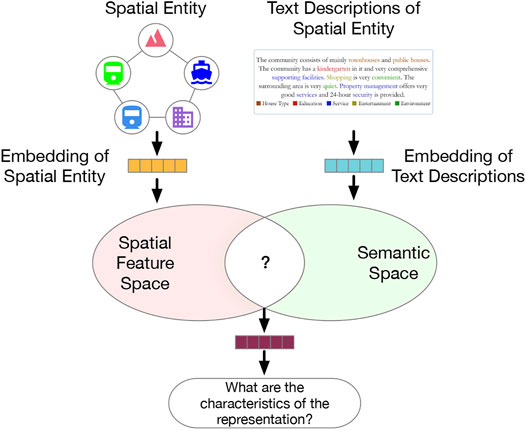
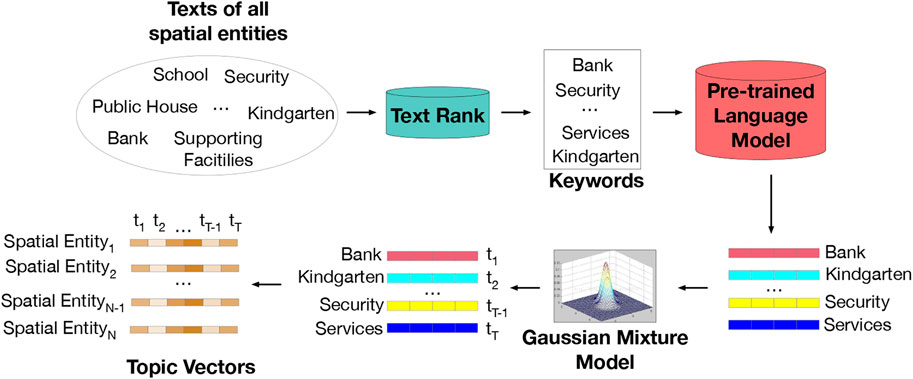
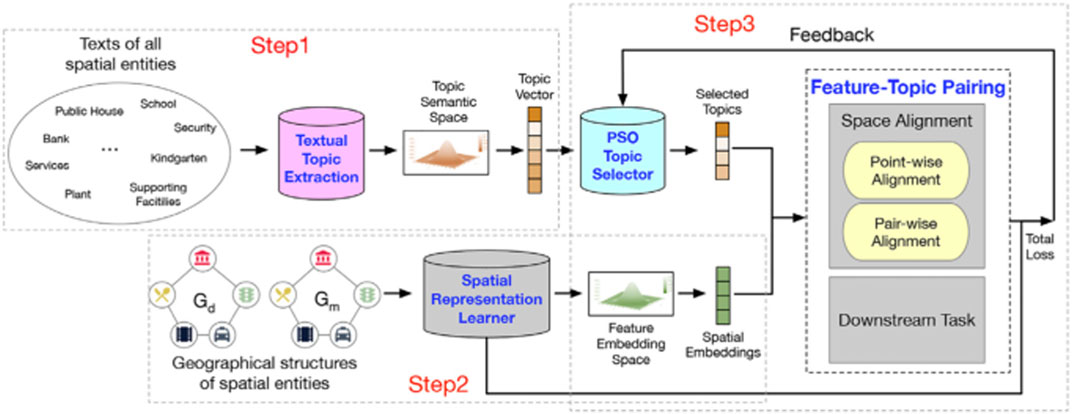
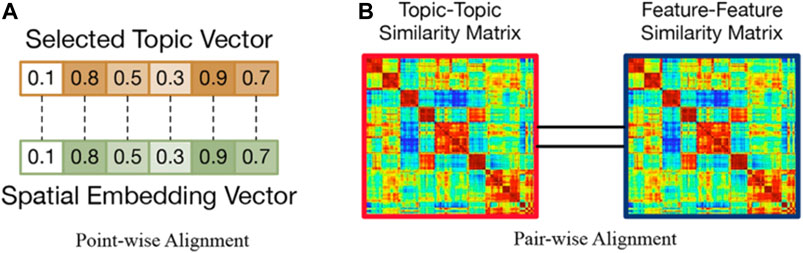
Frontiers | Towards Semantically-Rich Spatial Network Representation ...
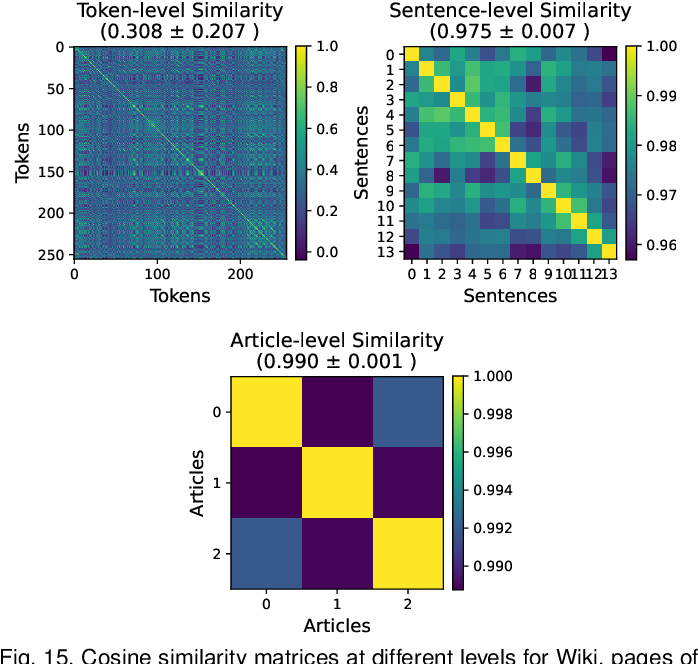
Advances in Semantic Textual Similarity
What is Semantic Mapping and When to Use it? Complete Guide
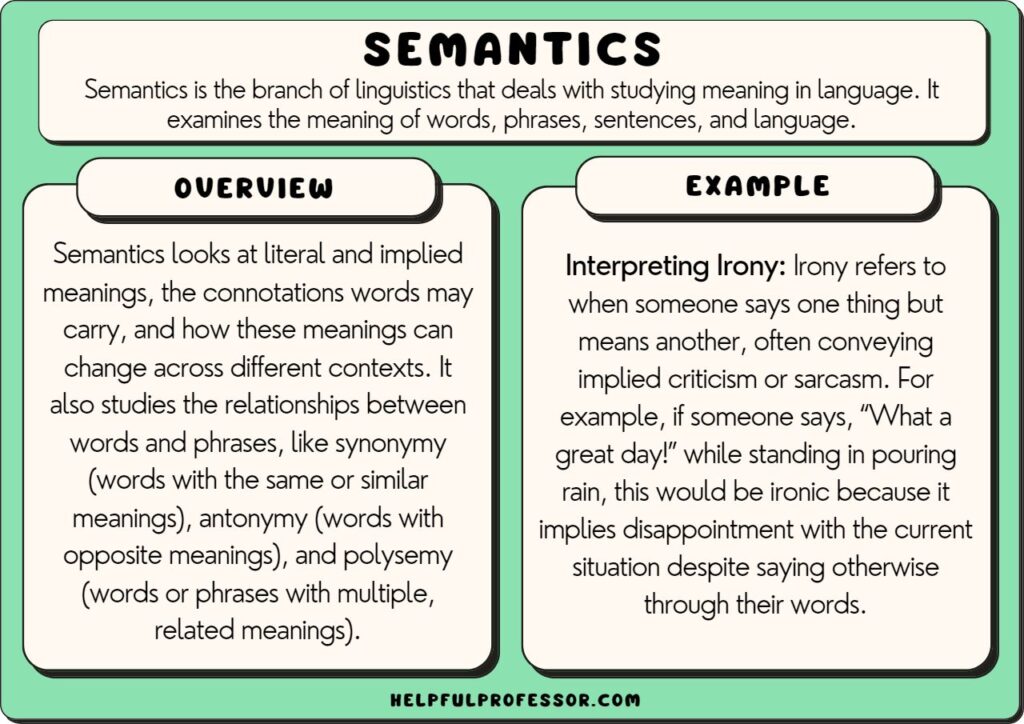
Semantics in Linguistics: Understanding the Basics
Figure 4 from Conditional Text Image Generation with Diffusion Models ...
I-JEPA: The First Human-Like Computer Vision Model
Meta AI Unveils Revolutionary I-JEPA: A Groundbreaking Leap in Computer ...
Text Representation Techniques. The Complete NLP Guide: Text to Context ...
Figure 1 from Emergent Visual-Semantic Hierarchies in Image-Text ...
18 Semantics Examples (2025)
Semantic Feature Analysis Picture Cards - Twinkl
Semantic Mapping to Build Vocabulary - Literacy Learn
Conditional Semantic Textual Similarity via Conditional Contrastive ...
Visual-semantic representations: Comparisons of the learned ...
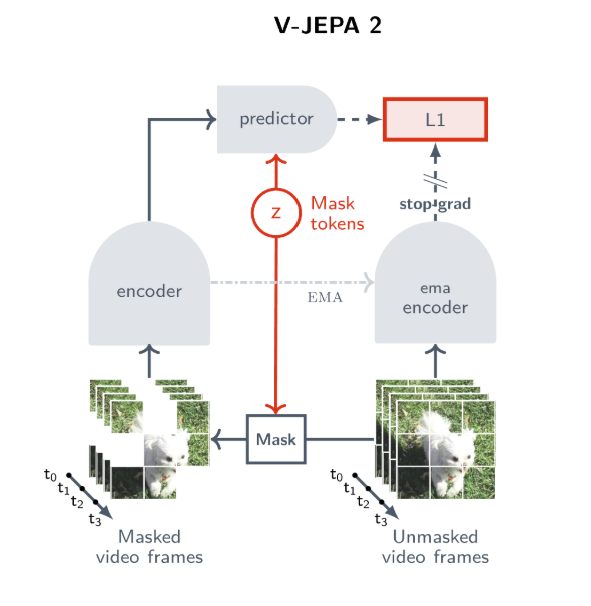
The Sequence #668: Inside V-JEPA 2: Meta AI's Breakthrough in Self ...
GitHub - cvjena/semantic-embeddings: Hierarchy-based Image Embeddings ...
NLP Based Text Summarization Using Semantic Analysis | PDF
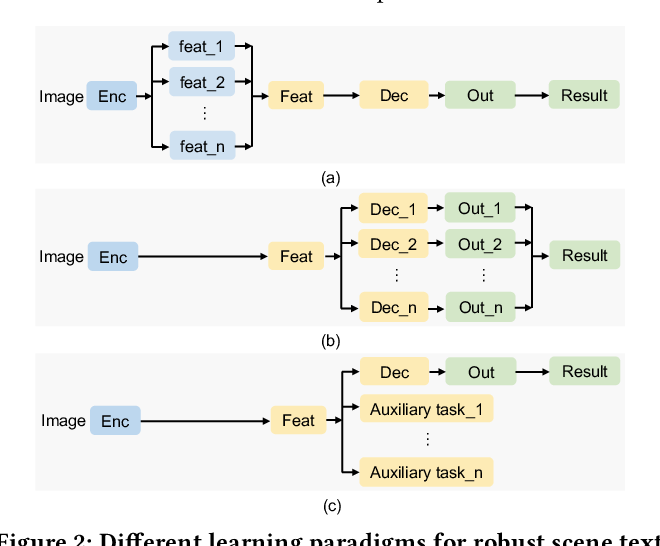
Towards Robust Real-Time Scene Text Detection: From Semantic to ...
(PDF) Semantic representation in text classification using topic ...
MinD-Vis
High-resolution image synthesis with latent diffusion models | MYRIAD
A Combination of Visual-Semantic Reasoning and Text Entailment-based ...
Accessible Visualization via Natural Language Descriptions: A Four ...
Figure 1 from Vision Learners Meet Web Image-Text Pairs | Semantic Scholar
Conditional Encoder-Based Adaptive Deep Image Compression with ...
Free Video: High-Resolution Image Synthesis and Semantic Manipulation ...
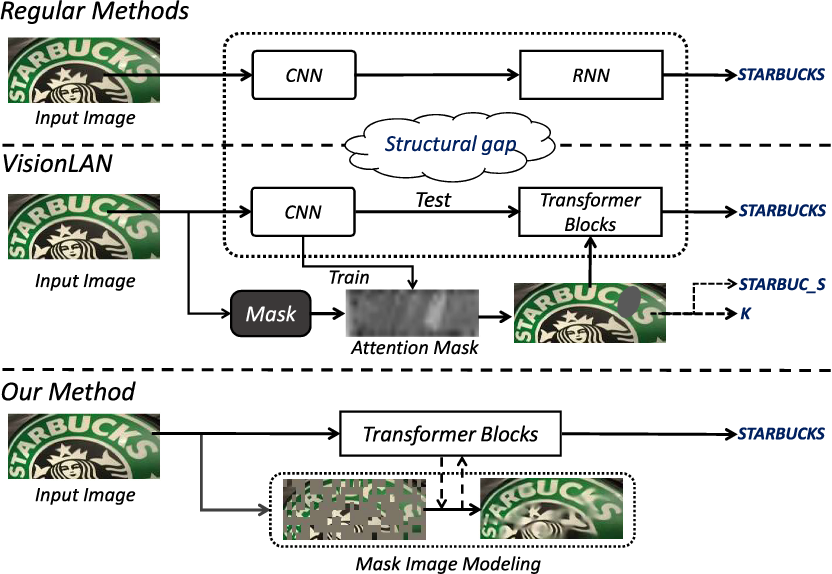
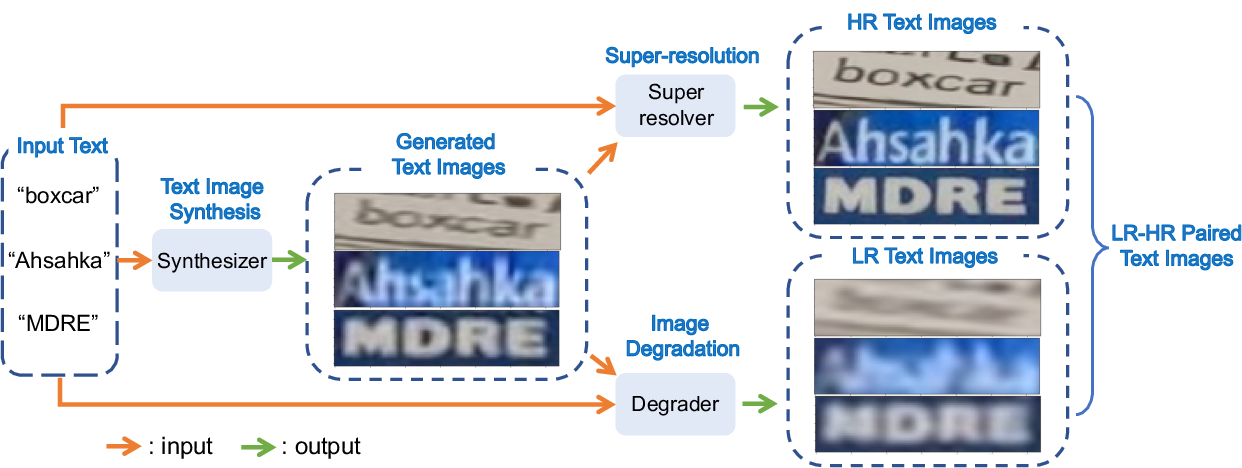
Figure 2 from Scene Text Image Super-resolution based on Text ...
PR-065 : High-Resolution Image Synthesis and Semantic Manipulation with ...
I-JEPA, or How Vision Models Understand the Relationship Between Parts ...